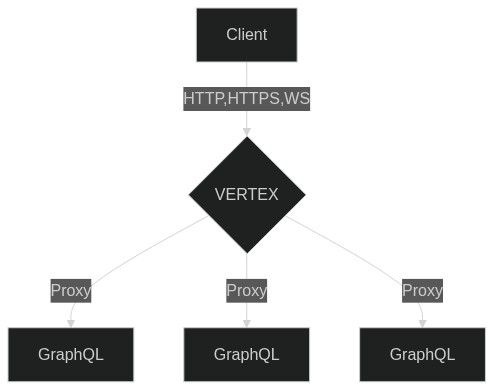
This Project is inspired by current pitfalls that I have come across at work with monolithic graphql schemas. Vertex aims to solve this issue by allowing a single graphql endpoint to many downstream services by parsing the query body and matching the query to a service.
Vertex is designed to be a serverless Graphql api gateway that can run on the AWS Lambda platform. All the proxy logic is called by the vertex handler. All the handler needs is the context to a vertex config (service query map, introspection schema, fasthttp client)
package main
import (
_ "embed"
"github.com/joshpauline/vertex/internal/clients"
"github.com/joshpauline/vertex/pkg/vertex"
"github.com/aws/aws-lambda-go/lambda"
)
//go:embed schema.graphql
var schema string
func main() {
exampleMap := map[string]string{
"countries": "countries.trevorblades.com/graphql",
"allFilms": "swapi-graphql.netlify.app/.netlify/functions/index",
}
vert := vertex.NewVertex(exampleMap, schema, clients.FHTTP())
lambda.Start(vert.Handler)
}
A CLI tool that generates a JSON file to be used with the Vertex Graphql Proxy
The generate command accepts 4 flags
- --schema || -s
- --output || -o
- --name || -n
- --url || -u
It will generate the following JSON file
{
"serviceName": "example-service-name",
"serviceUrl": "service.com/graphql",
"schema": "*** graphql schema definition",
"queryMap": {
"exampleQuery": "service.com/graphql"
}
}
- requests can be parsed within 0.01-0.1ms which will only get faster after I implement request caching
- There cannot be overlapping types throughout the graphql schemas (Might be an option for query polymorphism based on different variables)
- Services must have introspection turned on at the API level (I am working around this using a ci tool to publish schemas)
- This project is still early days so do not use in production
- Create cli tool to publish schemas from service CI current tool only for generation
- create cli tool to deploy schemas from service ci to remove need for introspection
- Load all graphs into one schema for playground introspection
- Add Web socket functionality for subsriptions
- cache full introspection graph in memory for fast retrieval
- Cache hash of request body for faster proxying
- Load and save services from DynamoDB
- Logging
- Load services from CLI