SOD 数据库
 +
+
+
+++截至 2023 年
+
| 数据库 | +使用的论文 | +创建的论文 | +规模 | +标注类型 | +建库过程 | +其它 | +
|---|---|---|---|---|---|---|
| 360SOD | +Multi-Stage Salient Object Detection in 360° Omnidirectional Image Using Complementary Object-Level Semantic Information ETCI 2023 |
+Distortion-adaptive salient object detection in 360° omnidirectional images TVCG 2020 |
+500张(400张训练图像、100张测试图像) 分辨率512 × 1024 |
+object-level、human fixation | ++ | 第一个全景 SOD 数据集 | +
| F-360iSOD | ++ | A FIXATION-BASED 360◦ BENCHMARK DATASET FOR SALIENT OBJECT DETECTION ICIP 2020 |
+107张 1165个显著物体 分辨率512 × 1024 |
+object+instance level | ++ | Jun-Pu/F-360iSOD: A dataset for fixation-based salient object segmentation in 360° images (github.com) | +
| 360SSOD | +Multi-Stage Salient Object Detection in 360° Omnidirectional Image Using Complementary Object-Level Semantic Information ETCI 2023 |
+Stage-wise salient object detection in 360° omnidirectional image via object-level semantical saliency ranking TVCG 2020 |
+1105张(850张训练图像、255张测试图像) 分辨率546 × 1024 |
+object level | ++ | 360-SSOD/download (github.com) | +
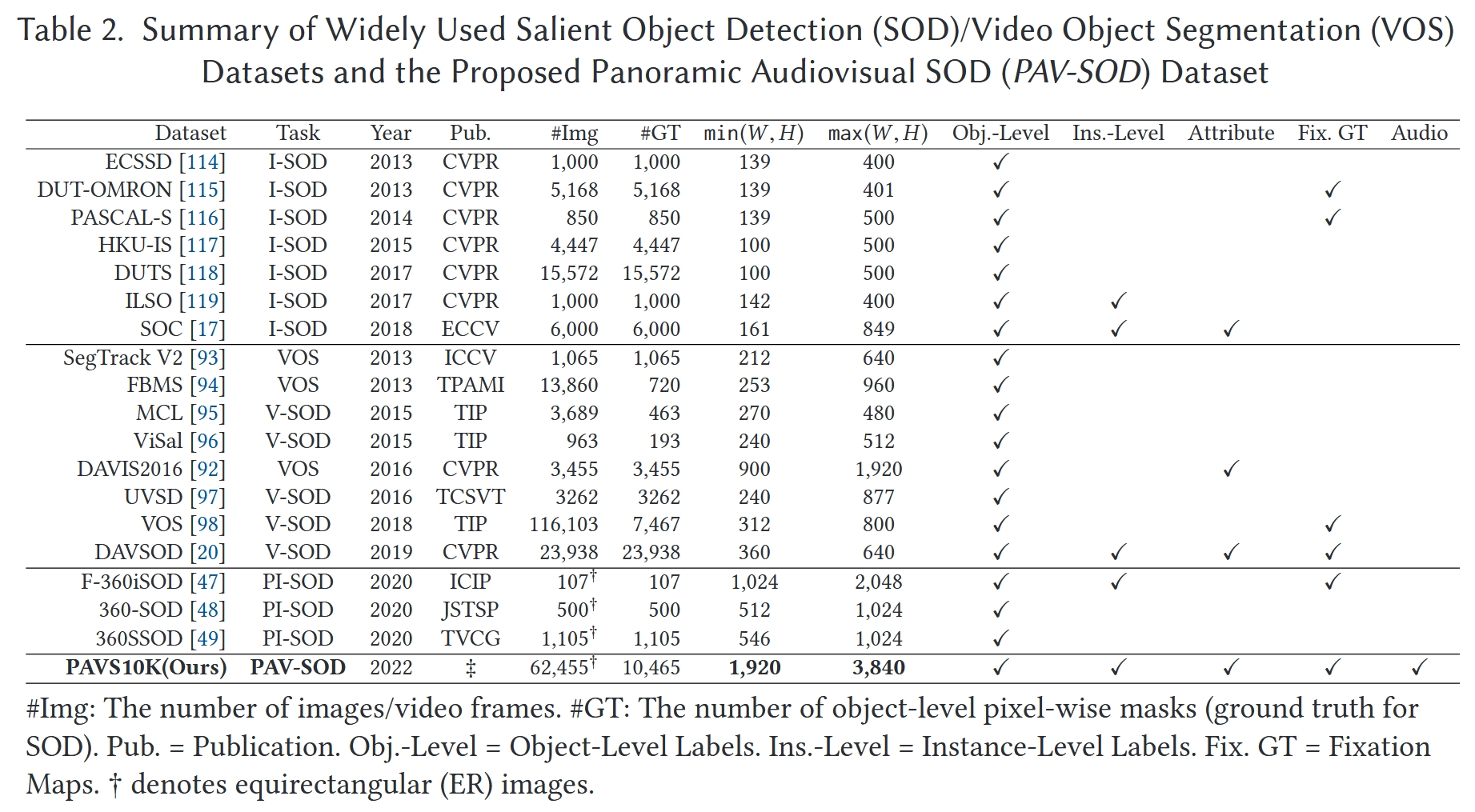
| ASOD60K (全景视频) PAVS10K的前身 |
+ASOD60K: An Audio-Induced Salient Object Detection Dataset for Panoramic Videos Arxiv 2021 |
+ASOD60K: An Audio-Induced Salient Object Detection Dataset for Panoramic Videos Arxiv 2021 |
+来自67个全景视频的62,455视频帧,其中10,465个关键帧被赋予了标签 分辨率4K |
+head movement (HM) and eye fixations, bounding boxes, object-level masks, and instance-level labels | ++ | https://github.com/PanoAsh/ASOD60K 视频具有超类和子类 花费一年建立数据集 |
+
| ODI-SOD | +View-Aware Salient Object Detection for 360∘ Omnidirectional Image TM 2022 |
+View-Aware Salient Object Detection for 360∘ Omnidirectional Image TM 2022 |
+6263张分辨率不低于2K的RP图像 (从Flickr网站收集的1,151张图片和从YouTube精选的5,112帧视频) 2,000张图片的测试集 4,263张图片的训练集 分辨率不低于2K |
+object level | +1. 使用不同的对象类别关键词(例如,人类、狗、建筑)在Flickr和YouTube上搜索全景资源,参考MS-COCO类别以涵盖各种真实世界场景。收集了8,896张图片和998个视频,包括不同的场景(例如,室内、室外)、不同的场合(例如,旅行、体育)、不同的运动模式(例如,移动、静态)和不同的视角。然后,所有视频都被采样成关键帧,并将不令人满意的图片或帧(例如,没有显著对象、质量低)剔除。 3. 首先,我们要求五位研究人员通过投票来判断对象的显著性,并选择显著的对象。其次,注释方面手动根据选定的显著对象标记二进制遮罩。最后,五位研究人员交叉检查二进制遮罩,以确保准确的像素级对象级注释。 |
+iCVTEAM/ODI-SOD: A 360° omnidirectional image-based salient object detection (SOD) dataset referred to as ODI-SOD with object-level pixel-wise annotation on equirectangular projection (ERP). (github.com) 所选图像的显着区域数量从一个到十个以上,显着区域的面积比从小于0.02%到大于65%,分辨率从2K到8K,一半以上的场景很复杂并且包含不同的对象 |
+
| PAVS10K (全景视频) |
+PAV-SOD: A New Task towards Panoramic Audiovisual Saliency Detection ACMMCC 2023 |
+PAV-SOD: A New Task towards Panoramic Audiovisual Saliency Detection ACMMCC 2023 |
+训练视频:40个,共5796帧 测试视频:27个共4669帧 |
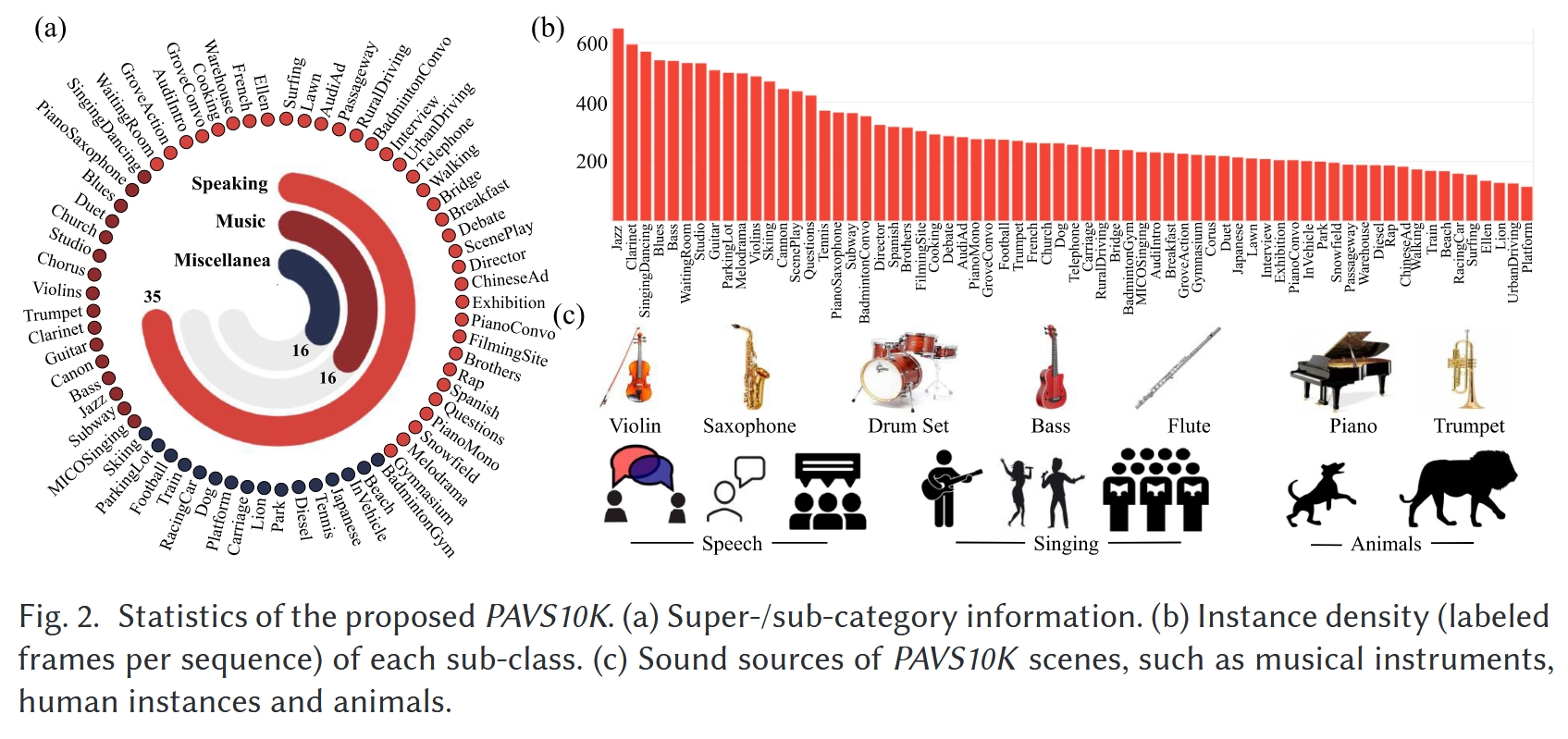
+instance level、眼动数据 | +1. 通过使用多个搜索关键词(例如,360°/全景/全向视频,空间音频,环境声学)从YouTube获取,涵盖了各种真实世界动态场景(例如,室内/室外场景)、多种场合(例如,体育、旅行、音乐会、采访、戏剧)、不同的运动模式(例如,静态/移动摄像机)以及多样化的对象类别(例如,人类、乐器、动物) 2. 获得了67个高质量的4K视频序列,手动将视频剪辑成小片段(平均29.6秒),以避免在收集眼动注视点时产生疲劳,总共有62,455帧,记录了62,455 × 40个眼动注视点 3. 所有的视频片段都是通过内置有120 Hz采样率的Tobii眼动追踪器的HTC Vive头戴式显示器(HMD)来展示,并收集眼动注视点。观察者。我们招募了40名参与者(8名女性和32名男性),年龄在18到34岁之间,他们报告说视力正常或矫正到正常。20名参与者被随机选中观看单声道声音的视频(第一组),而其他参与者观看没有声音的视频(第二组) 4. 这67个子类别可以根据主要声源的线索被归类为三个超类别,即说话(例如,对话、独白)、音乐(例如,唱歌、演奏乐器)和杂项(例如,街道上汽车引擎和喇叭的声音、露天环境中的人群噪音) 5. 从总共62,455帧中以1/6的采样率统一提取了10,465帧,用于像素级注释,使用CVAT工具箱进行手动标记 6. 3位资深研究人员参与了基于注视的显著对象的10,465帧的手动注释,最终获得了19,904个实例级显著对象标签 |
+https://github.com/ZHANG-Jun-Pu/PAV-SOD 第一个用于全景视频SOD的数据集 |
+
| 未发布 (全景视频,SOR) |
+Instance-Level Panoramic Audio-Visual Saliency Detection and Ranking ACMMM 2024 |
+Instance-Level Panoramic Audio-Visual Saliency Detection and Ranking ACMMM 2024 |
++ | instance level | +根据多个观察者的注意力转移为PAVS10K数据集提供了真实的显著性排名 | +未公开 第一个用于全景视频SOR的数据集 |
+
- - + + @@ -1270,11 +1282,211 @@
疑惑与想法
+全景图/视频 —— SOD
Distortion-Adaptive Salient Object Detection in $360^{\circ}$ Omnidirectional Images
+- TVCG 2020
+- 北航, 虚拟现实技术与系统国家重点实验室,Jia Li, Jinming Su, Changqun Xia
+- 背景
+- 基于图像的显著对象检测(SOD)在过去几十年中已被广泛研究
+- 由于缺乏具有像素级注释的数据集,360°全景图像上的SOD研究较少
+
+
+- 本文提出了一个基于360°图像的SOD数据集(360SOD),该数据集包含500张高分辨率的等矩形图像
+- 我们从五个主流的360°视频数据集中收集了具有代表性的等矩形图像,并以自由视点的方式手动为这些图像上的所有对象和区域注释了精确的遮罩
+- 这是第一个公开可用的360°场景显著对象检测数据集
+- 通过观察这个数据集,我们发现投影失真、大规模复杂场景和小尺寸显著对象是最突出的特征
+
+
+- 受此启发,本文提出了一个基于等矩形图像的SOD基线模型
+- 我们构建了一个失真适应模块来处理等矩形投影引起的失真
+- 引入了一个多尺度上下文集成块,用于感知和区分全景场景中的丰富场景和对象
+- 整个网络以深度监督的方式组织成渐进式
+
+
+- 验结果表明,所提出的基线方法在360°SOD数据集上超越了表现最佳的现有方法
+- 所提出的基线方法和其他方法在360°SOD数据集上的基准测试结果表明,所提出的数据集非常具有挑战性
+
+ +
+
+
+A FIXATION-BASED 360◦ BENCHMARK DATASET FOR SALIENT OBJECT DETECTION
+- ICIP 2020
+- 背景
+- 全景内容中的注视点预测(Fixation Prediction, FP)随着虚拟现实(Virtual Reality, VR)应用的蓬勃发展而得到了广泛的研究
+- 视觉显著性领域的另一个问题——显著对象检测(Salient Object Detection, SOD)——在360°(或全向)图像中的探索却相对较少
+- 缺乏具有像素级注释的真实场景数据集
+
+
+- 为了解决这一问题
+- 我们收集了107幅具有挑战性场景和多个对象类别的等矩形全景图
+- 基于注视点预测与显式显著性判断之间的一致性,我们在真实人类眼动追踪图的指导下,进一步手动标注了1,165个显著对象,并为这些对象在收集到的图像上提供了精确的遮罩
+- 接着,我们采用了基于多重立方体投影的微调方法,对六种最先进的SOD模型在提出的基于注视点的360°图像数据集(F-360iSOD)上进行了基准测试
+
+
+- 实验结果表明,现有方法在全景图像的SOD应用中存在局限性,这表明所提出的数据集具有挑战性
+
+ +
+
+
+
+
+FANet: Features Adaptation Network for 360 Omnidirectional Salient Object Detection
+- SPL 2020
+- 背景
+- 显著对象检测(SOD)在360°全景图像中已成为一个引人注目的问题,这得益于价格合理的360°相机的普及
+
+
+- 我们提出了一种特征适应网络(FANet),以可靠地突出显示360°全景图像中的显著对象
+- 为了利用卷积神经网络的特征提取能力并捕获全局对象信息,我们同时将等矩形360°图像和相应的立方图360°图像输入到特征提取网络(FENet),以获得多级等矩形和立方图特征
+- 此外,我们通过投影特征适应(PFA)模块在FENet的每个级别融合这两种特征,以自适应地选择这两种特征
+- 后,我们通过多级特征适应(MLFA)模块将不同级别的初步适应特征结合起来,该模块自适应地加权这些不同级别的特征,并产生最终的显著性图
+
+
+- 实验表明,我们的FANet在360°全景SOD数据集(360−SOD, F-360iSOD)上超越了最先进的方法
+
+Stage-wise salient object detection in 360° omnidirectional image via object-level semantical saliency ranking
+- TVCG 2020
+- 北航, 虚拟现实技术与系统国家重点实验室,Guangxiao Ma, Shuai Li
+- 背景
+- 二维图像的显著对象检测(SOD)已经被广泛研究,而基于360°全景图像的SOD得到的关注度较少,并且存在三个主要的瓶颈限制了其性能
+- 首先,目前可用的训练数据不足以训练360°SOD深度模型
+- 其次,360°全景图像中的视觉失真通常导致360°图像和二维图像之间的特征差异很大;因此,分阶段训练——一种广泛使用的解决训练数据短缺问题的方案,在进行360°全景图像的SOD时变得不可行
+- 第三,现有的360°SOD方法采用了多任务方法,同时执行显著对象定位和类似分割的显著性细化,面对着极其大的问题领域,使得训练数据短缺的困境更加严重
+
+
+
+
+- 为了解决所有这些问题,本文将360°SOD划分为多阶段任务,其关键理念是将原始复杂的问题领域分解为顺序的简单子问题,这些子问题只需要小规模的训练数据
+- 同时,我们学习如何对“object level 语义显著性”进行排名,以准确定位显著的视点和对象
+- 为了缓解训练数据短缺问题,我们发布了一个名为360-SSOD的新数据集
+- 包含1,105张360°全景图像,并手动标注了对象级显著性真实情况,其语义分布比现有数据集更加平衡
+
+
+- 已经将提出的方法与13种最先进方法进行了比较,所有定量结果都证明了性能的优越性
+
+
+
+ +
+
+
+ASOD60K: An Audio-Induced Salient Object Detection Dataset for Panoramic Videos
+- Arxiv 2021
+- 背景
+- 探索人类在动态全景场景中关注的内容对于许多基础应用非常有用,包括零售业中的增强现实(AR)、AR支持的招聘和视觉语言导航
+
+
+- 我们提出了PV-SOD,这是一项新任务,旨在从全景视频中分割显著对象
+- 与现有的注视点/对象级显著性检测任务不同,我们专注于声音诱发的显著对象检测(SOD),其中显著对象是根据声音诱发的眼动进行标记的
+- 我们收集了第一个大规模数据集,名为ASOD60K,其中包含带有六级层级注释的4K分辨率视频帧
+- 每个序列都标有其超类/子类,每个子类中的对象进一步用人类眼动注视点、边界框、对象级/实例级遮罩和相关属性(例如,几何失真)进行了注释
+
+
+- 我们系统地在ASOD60K上对11种代表性方法进行了基准测试,并得出了几个有趣的发现
+
+View-Aware Salient Object Detection for 360∘ Omnidirectional Image
+- TM 2022
+- 北航, 虚拟现实技术与系统国家重点实验室,Junjie Wu , Changqun Xia
+- 背景
+- 360◦场景中基于图像的显著目标检测对于理解和应用全景信息具有重要意义
+- 然而,由于缺乏大型、复杂、高分辨率和良好标记的数据集,360◦isod的研究还没有得到广泛的探索
+
+
+- 我们构建了一个大规模的360◦等值域数据集,该数据集包含了不低于2K分辨率的丰富全景场景,是目前已知的最大的360◦等值域数据集
+- 通过对数据的观察,我们发现现有的方法在全景场景中面临着三个显著的挑战:不同的失真程度、不连续的边缘效应和可变的对象比例
+
+
+- 受人类观察过程的启发,我们提出了一种基于样本自适应视图转换器(SAVT)模块的视点感知显著目标检测方法
+- 子模块视图转换器(VT)包含三个基于不同类型变换的变换分支,以学习不同视图下的各种特征,并提高模型对变形、边缘效果和对象尺度的特征容忍度
+- 子模块样本自适应融合(SAF)是根据不同的样本特征调整不同变换支路的权重,使变换后的增强特征融合得更好
+
+
+- 20种最先进的isod方法的基准测试结果表明,所构建的数据集是非常具有挑战性的
+- 详尽的实验验证了所提出的方法是实用的,并且优于目前最先进的方法
+
+ +
+
+
+Multi-Stage Salient Object Detection in 360° Omnidirectional Image Using Complementary Object-Level Semantic Information
+- ETCI 2023
+- 背景
+- 近年来,针对二维图像的显著目标检测技术得到了广泛的研究
+- 然而,由于场景的复杂性和几何失真的存在,360°超视场的研究在大视场范围内还很欠缺
+
+
+- 本文提出了一种360°全方位图像目标定位的分阶段解决方案,该方案综合考虑了RGB图像和互补的对象级语义(OLS)信息对目标定位的影响
+- 为了有效地连接两种类型的特征,提出了一种新颖的多层特征融合和渐进聚集网络(MFFPANet),用于准确检测360°全方位图像中的显著目标
+- 该网络主要由动态互补特征融合(DCFF)模块和渐进多尺度特征聚集(PMFA)模块组成
+- 首先,OLS和RGB图像共享同一个主干网络进行联合学习,DCFF模块动态整合主干网络的层次特征
+- 此外,PMFA模块包括多个级联的特征集成模块,这些模块通过深度监管逐步地集成多尺度的特征
+
+
+
+
+- 实验结果表明,该算法在两个360°SOD数据库(360SOD、360SSOD)上取得了较好的性能
+
+PAV-SOD: A New Task towards Panoramic Audiovisual Saliency Detection
+- ACMMCC 2023
+- 首篇全景视频SOD
+- 背景
+- 在360°全景真实动态场景中进行目标级视听显著检测,对于探索和建模沉浸式环境中的人的感知,以及在教育、社交网络、娱乐和培训等领域的虚拟、增强和混合现实应用的开发具有重要意义
+
+
+- 提出了一项新的任务–全景视听显著目标检测(PAV-SOD),旨在从反映现实生活场景的360°全景视频中分割出最能抓住人类注意力的目标
+- 我们收集了PAVS10K,这是第一个用于视听显著对象检测的全景视频数据集
+- 包括67个4K分辨率的等长方形视频,每个视频带有分层的场景类别和相关属性,这些标签描述了进行PAV-SOD的具体挑战
+- 10,465个均匀采样的视频帧,其中包含手动注释的对象级和实例级像素掩码
+- 从粗到细的注释允许对PAV-SOD建模进行多角度分析
+
+
+
+
+- 基于我们的PAVS10K,我们进一步系统地基准了13种最先进的显著对象检测(SOD)/视频对象分割(VOS)方法
+- 还提出了一种新的基线网络,该网络利用了360°视频帧的视觉和音频线索,并使用了一种新的条件变分自动编码器(CVAE)
+- 基于CVAE的视听网络CAV-Net由时空视频分割网络、卷积音频编码网络和视听分布估计模块组成。因此,我们的CAV-Net优于所有竞争模型,并能够估计PAVS10K中的任意不确定性
+
+
+- 通过广泛的实验结果,我们获得了一些关于PAV-SOD挑战的发现和对PAV-SOD模型可解释性的见解
+
+ +
+
+
+ +
+
+
+Panoramic Video Salient Object Detection with Ambisonic Audio Guidance
+- AAAI 2023
+- 背景
+- 视频显著目标检测作为计算机视觉的一个基本问题,在过去的十年中得到了广泛的研究
+- 现有的所有工作都集中在解决二维场景中的VSOD问题
+- 随着VR设备的快速发展,全景视频已经成为2D视频的一种有前途的替代方案,可以提供对现实世界的身临其境的感觉
+
+
+- 在本文中,我们的目标是解决全景视频及其相应的音频的视频显著目标检测问题
+- 了有效地进行视听交互,提出了一种配备两个pseudo-siamese视听上下文融合(ACF)块的多模式融合模块
+- 配备球面位置编码的ACF块使得3D环境中的融合能够从等长方形帧和双音音频中捕捉像素和声源之间的空间对应
+
+
+- 实验结果验证了我们提出的组件的有效性,并证明了我们的方法在ASOD60K数据集上取得了最好的性能
+
+Instance-Level Panoramic Audio-Visual Saliency Detection and Ranking
+- ACMMM 2024
+- 首篇全景视频SOR
+- 背景
+- 全景视听显著性检测是在360°含有声音的全景视频中分割最吸引注意力的区域
+- 为了精确地界定检测到的显著区域并有效模拟人类注意力的转移,我们将这项任务扩展到更细致的实例场景:识别显著对象实例并推断它们的显著性等级
+
+
+- 在本文中,我们提出了第一个实例级框架,可以同时应用于全景视频中多个显著对象的分割和排序
+- 包括一个感知失真的像素解码器来克服全景失真
+- 一个顺序视听融合模块来整合视听信息
+- 一个时空对象解码器来分离单个实例并预测它们的显著性分数
+
+
+- 由于缺乏此类注释,我们为PAVS10K基准创建了真实显著性等级
+- 实验表明,我们的模型能够在PAVS10K上实现显著性检测和排序任务的最先进性能
+- 其他细节
+- 声音不是查询,而是作为辅助信息嵌入到视觉特征中
+- 另外,由于缺乏排名注释,我们根据多个观察者的注意力转移为PAVS10K数据集提供了真实的显著性排名
+
+
+
+疑惑与想法
- SOR 一定需要 full segmentation 数据吗?—— 不是
- 所谓“显著”,应该是下意识的(因此最好用眼动数据定义)
- 输出是 saliency map,然后比较得出排序结果吗?
-- SOR领域论文大致分为四类(及其组合)
+- SOR领域论文大致分为五类(及其组合)
- 数据集创新
- 真值创新(如何考虑相对显著性)
- 注视点(离散)
@@ -1283,6 +1495,7 @@
-
+
diff --git a/css/main.css b/css/main.css
index 16ec069..b069e4b 100644
--- a/css/main.css
+++ b/css/main.css
@@ -1167,7 +1167,7 @@ pre .javascript .function {
}
.links-of-author a::before,
.links-of-author span.exturl::before {
- background: #ff21ff;
+ background: #5effff;
border-radius: 50%;
content: ' ';
display: inline-block;
diff --git a/index.html b/index.html
index 412191a..242d886 100644
--- a/index.html
+++ b/index.html
@@ -217,10 +217,16 @@
-
-
+
+
+
全景图/视频 —— SOD
Distortion-Adaptive Salient Object Detection in $360^{\circ}$ Omnidirectional Images
-
+
- TVCG 2020 +
- 北航, 虚拟现实技术与系统国家重点实验室,Jia Li, Jinming Su, Changqun Xia +
- 背景
-
+
- 基于图像的显著对象检测(SOD)在过去几十年中已被广泛研究 +
- 由于缺乏具有像素级注释的数据集,360°全景图像上的SOD研究较少 +
+ - 本文提出了一个基于360°图像的SOD数据集(360SOD),该数据集包含500张高分辨率的等矩形图像
-
+
- 我们从五个主流的360°视频数据集中收集了具有代表性的等矩形图像,并以自由视点的方式手动为这些图像上的所有对象和区域注释了精确的遮罩 +
- 这是第一个公开可用的360°场景显著对象检测数据集 +
- 通过观察这个数据集,我们发现投影失真、大规模复杂场景和小尺寸显著对象是最突出的特征 +
+ - 受此启发,本文提出了一个基于等矩形图像的SOD基线模型
-
+
- 我们构建了一个失真适应模块来处理等矩形投影引起的失真 +
- 引入了一个多尺度上下文集成块,用于感知和区分全景场景中的丰富场景和对象 +
- 整个网络以深度监督的方式组织成渐进式 +
+ - 验结果表明,所提出的基线方法在360°SOD数据集上超越了表现最佳的现有方法 +
- 所提出的基线方法和其他方法在360°SOD数据集上的基准测试结果表明,所提出的数据集非常具有挑战性 +
+
+A FIXATION-BASED 360◦ BENCHMARK DATASET FOR SALIENT OBJECT DETECTION
-
+
- ICIP 2020 +
- 背景
-
+
- 全景内容中的注视点预测(Fixation Prediction, FP)随着虚拟现实(Virtual Reality, VR)应用的蓬勃发展而得到了广泛的研究 +
- 视觉显著性领域的另一个问题——显著对象检测(Salient Object Detection, SOD)——在360°(或全向)图像中的探索却相对较少 +
- 缺乏具有像素级注释的真实场景数据集 +
+ - 为了解决这一问题
-
+
- 我们收集了107幅具有挑战性场景和多个对象类别的等矩形全景图 +
- 基于注视点预测与显式显著性判断之间的一致性,我们在真实人类眼动追踪图的指导下,进一步手动标注了1,165个显著对象,并为这些对象在收集到的图像上提供了精确的遮罩 +
- 接着,我们采用了基于多重立方体投影的微调方法,对六种最先进的SOD模型在提出的基于注视点的360°图像数据集(F-360iSOD)上进行了基准测试 +
+ - 实验结果表明,现有方法在全景图像的SOD应用中存在局限性,这表明所提出的数据集具有挑战性 +
+
+
+FANet: Features Adaptation Network for 360 Omnidirectional Salient Object Detection
-
+
- SPL 2020 +
- 背景
-
+
- 显著对象检测(SOD)在360°全景图像中已成为一个引人注目的问题,这得益于价格合理的360°相机的普及 +
+ - 我们提出了一种特征适应网络(FANet),以可靠地突出显示360°全景图像中的显著对象
-
+
- 为了利用卷积神经网络的特征提取能力并捕获全局对象信息,我们同时将等矩形360°图像和相应的立方图360°图像输入到特征提取网络(FENet),以获得多级等矩形和立方图特征 +
- 此外,我们通过投影特征适应(PFA)模块在FENet的每个级别融合这两种特征,以自适应地选择这两种特征 +
- 后,我们通过多级特征适应(MLFA)模块将不同级别的初步适应特征结合起来,该模块自适应地加权这些不同级别的特征,并产生最终的显著性图 +
+ - 实验表明,我们的FANet在360°全景SOD数据集(360−SOD, F-360iSOD)上超越了最先进的方法 +
Stage-wise salient object detection in 360° omnidirectional image via object-level semantical saliency ranking
-
+
- TVCG 2020 +
- 北航, 虚拟现实技术与系统国家重点实验室,Guangxiao Ma, Shuai Li +
- 背景
-
+
- 二维图像的显著对象检测(SOD)已经被广泛研究,而基于360°全景图像的SOD得到的关注度较少,并且存在三个主要的瓶颈限制了其性能
-
+
- 首先,目前可用的训练数据不足以训练360°SOD深度模型 +
- 其次,360°全景图像中的视觉失真通常导致360°图像和二维图像之间的特征差异很大;因此,分阶段训练——一种广泛使用的解决训练数据短缺问题的方案,在进行360°全景图像的SOD时变得不可行 +
- 第三,现有的360°SOD方法采用了多任务方法,同时执行显著对象定位和类似分割的显著性细化,面对着极其大的问题领域,使得训练数据短缺的困境更加严重 +
+
+ - 二维图像的显著对象检测(SOD)已经被广泛研究,而基于360°全景图像的SOD得到的关注度较少,并且存在三个主要的瓶颈限制了其性能
- 为了解决所有这些问题,本文将360°SOD划分为多阶段任务,其关键理念是将原始复杂的问题领域分解为顺序的简单子问题,这些子问题只需要小规模的训练数据 +
- 同时,我们学习如何对“object level 语义显著性”进行排名,以准确定位显著的视点和对象
-
+
- 为了缓解训练数据短缺问题,我们发布了一个名为360-SSOD的新数据集
-
+
- 包含1,105张360°全景图像,并手动标注了对象级显著性真实情况,其语义分布比现有数据集更加平衡 +
+ - 已经将提出的方法与13种最先进方法进行了比较,所有定量结果都证明了性能的优越性 +
+ - 为了缓解训练数据短缺问题,我们发布了一个名为360-SSOD的新数据集
+
+ASOD60K: An Audio-Induced Salient Object Detection Dataset for Panoramic Videos
-
+
- Arxiv 2021 +
- 背景
-
+
- 探索人类在动态全景场景中关注的内容对于许多基础应用非常有用,包括零售业中的增强现实(AR)、AR支持的招聘和视觉语言导航 +
+ - 我们提出了PV-SOD,这是一项新任务,旨在从全景视频中分割显著对象
-
+
- 与现有的注视点/对象级显著性检测任务不同,我们专注于声音诱发的显著对象检测(SOD),其中显著对象是根据声音诱发的眼动进行标记的 +
- 我们收集了第一个大规模数据集,名为ASOD60K,其中包含带有六级层级注释的4K分辨率视频帧 +
- 每个序列都标有其超类/子类,每个子类中的对象进一步用人类眼动注视点、边界框、对象级/实例级遮罩和相关属性(例如,几何失真)进行了注释 +
+ - 我们系统地在ASOD60K上对11种代表性方法进行了基准测试,并得出了几个有趣的发现 +
View-Aware Salient Object Detection for 360∘ Omnidirectional Image
-
+
- TM 2022 +
- 北航, 虚拟现实技术与系统国家重点实验室,Junjie Wu , Changqun Xia +
- 背景
-
+
- 360◦场景中基于图像的显著目标检测对于理解和应用全景信息具有重要意义 +
- 然而,由于缺乏大型、复杂、高分辨率和良好标记的数据集,360◦isod的研究还没有得到广泛的探索 +
+ - 我们构建了一个大规模的360◦等值域数据集,该数据集包含了不低于2K分辨率的丰富全景场景,是目前已知的最大的360◦等值域数据集
-
+
- 通过对数据的观察,我们发现现有的方法在全景场景中面临着三个显著的挑战:不同的失真程度、不连续的边缘效应和可变的对象比例 +
+ - 受人类观察过程的启发,我们提出了一种基于样本自适应视图转换器(SAVT)模块的视点感知显著目标检测方法
-
+
- 子模块视图转换器(VT)包含三个基于不同类型变换的变换分支,以学习不同视图下的各种特征,并提高模型对变形、边缘效果和对象尺度的特征容忍度 +
- 子模块样本自适应融合(SAF)是根据不同的样本特征调整不同变换支路的权重,使变换后的增强特征融合得更好 +
+ - 20种最先进的isod方法的基准测试结果表明,所构建的数据集是非常具有挑战性的 +
- 详尽的实验验证了所提出的方法是实用的,并且优于目前最先进的方法 +
+
+Multi-Stage Salient Object Detection in 360° Omnidirectional Image Using Complementary Object-Level Semantic Information
-
+
- ETCI 2023 +
- 背景
-
+
- 近年来,针对二维图像的显著目标检测技术得到了广泛的研究 +
- 然而,由于场景的复杂性和几何失真的存在,360°超视场的研究在大视场范围内还很欠缺 +
+ - 本文提出了一种360°全方位图像目标定位的分阶段解决方案,该方案综合考虑了RGB图像和互补的对象级语义(OLS)信息对目标定位的影响
-
+
- 为了有效地连接两种类型的特征,提出了一种新颖的多层特征融合和渐进聚集网络(MFFPANet),用于准确检测360°全方位图像中的显著目标
-
+
- 该网络主要由动态互补特征融合(DCFF)模块和渐进多尺度特征聚集(PMFA)模块组成 +
- 首先,OLS和RGB图像共享同一个主干网络进行联合学习,DCFF模块动态整合主干网络的层次特征 +
- 此外,PMFA模块包括多个级联的特征集成模块,这些模块通过深度监管逐步地集成多尺度的特征 +
+
+ - 为了有效地连接两种类型的特征,提出了一种新颖的多层特征融合和渐进聚集网络(MFFPANet),用于准确检测360°全方位图像中的显著目标
- 实验结果表明,该算法在两个360°SOD数据库(360SOD、360SSOD)上取得了较好的性能 +
PAV-SOD: A New Task towards Panoramic Audiovisual Saliency Detection
-
+
- ACMMCC 2023 +
- 首篇全景视频SOD +
- 背景
-
+
- 在360°全景真实动态场景中进行目标级视听显著检测,对于探索和建模沉浸式环境中的人的感知,以及在教育、社交网络、娱乐和培训等领域的虚拟、增强和混合现实应用的开发具有重要意义 +
+ - 提出了一项新的任务–全景视听显著目标检测(PAV-SOD),旨在从反映现实生活场景的360°全景视频中分割出最能抓住人类注意力的目标
-
+
- 我们收集了PAVS10K,这是第一个用于视听显著对象检测的全景视频数据集
-
+
- 包括67个4K分辨率的等长方形视频,每个视频带有分层的场景类别和相关属性,这些标签描述了进行PAV-SOD的具体挑战 +
- 10,465个均匀采样的视频帧,其中包含手动注释的对象级和实例级像素掩码 +
- 从粗到细的注释允许对PAV-SOD建模进行多角度分析 +
+
+ - 我们收集了PAVS10K,这是第一个用于视听显著对象检测的全景视频数据集
- 基于我们的PAVS10K,我们进一步系统地基准了13种最先进的显著对象检测(SOD)/视频对象分割(VOS)方法 +
- 还提出了一种新的基线网络,该网络利用了360°视频帧的视觉和音频线索,并使用了一种新的条件变分自动编码器(CVAE)
-
+
- 基于CVAE的视听网络CAV-Net由时空视频分割网络、卷积音频编码网络和视听分布估计模块组成。因此,我们的CAV-Net优于所有竞争模型,并能够估计PAVS10K中的任意不确定性 +
+ - 通过广泛的实验结果,我们获得了一些关于PAV-SOD挑战的发现和对PAV-SOD模型可解释性的见解 +
+
+
+
+Panoramic Video Salient Object Detection with Ambisonic Audio Guidance
-
+
- AAAI 2023 +
- 背景
-
+
- 视频显著目标检测作为计算机视觉的一个基本问题,在过去的十年中得到了广泛的研究 +
- 现有的所有工作都集中在解决二维场景中的VSOD问题 +
- 随着VR设备的快速发展,全景视频已经成为2D视频的一种有前途的替代方案,可以提供对现实世界的身临其境的感觉 +
+ - 在本文中,我们的目标是解决全景视频及其相应的音频的视频显著目标检测问题
-
+
- 了有效地进行视听交互,提出了一种配备两个pseudo-siamese视听上下文融合(ACF)块的多模式融合模块 +
- 配备球面位置编码的ACF块使得3D环境中的融合能够从等长方形帧和双音音频中捕捉像素和声源之间的空间对应 +
+ - 实验结果验证了我们提出的组件的有效性,并证明了我们的方法在ASOD60K数据集上取得了最好的性能 +
Instance-Level Panoramic Audio-Visual Saliency Detection and Ranking
-
+
- ACMMM 2024 +
- 首篇全景视频SOR +
- 背景
-
+
- 全景视听显著性检测是在360°含有声音的全景视频中分割最吸引注意力的区域 +
- 为了精确地界定检测到的显著区域并有效模拟人类注意力的转移,我们将这项任务扩展到更细致的实例场景:识别显著对象实例并推断它们的显著性等级 +
+ - 在本文中,我们提出了第一个实例级框架,可以同时应用于全景视频中多个显著对象的分割和排序
-
+
- 包括一个感知失真的像素解码器来克服全景失真 +
- 一个顺序视听融合模块来整合视听信息 +
- 一个时空对象解码器来分离单个实例并预测它们的显著性分数 +
+ - 由于缺乏此类注释,我们为PAVS10K基准创建了真实显著性等级 +
- 实验表明,我们的模型能够在PAVS10K上实现显著性检测和排序任务的最先进性能 +
- 其他细节
-
+
- 声音不是查询,而是作为辅助信息嵌入到视觉特征中 +
- 另外,由于缺乏排名注释,我们根据多个观察者的注意力转移为PAVS10K数据集提供了真实的显著性排名 +
+
疑惑与想法
- SOR 一定需要 full segmentation 数据吗?—— 不是
- 所谓“显著”,应该是下意识的(因此最好用眼动数据定义)
- 输出是 saliency map,然后比较得出排序结果吗? -
- SOR领域论文大致分为四类(及其组合)
-
+
- SOR领域论文大致分为五类(及其组合)
- 数据集创新
- 真值创新(如何考虑相对显著性)
- 注视点(离散) @@ -1283,6 +1495,7 @@
-
+diff --git a/css/main.css b/css/main.css index 16ec069..b069e4b 100644 --- a/css/main.css +++ b/css/main.css @@ -1167,7 +1167,7 @@ pre .javascript .function { } .links-of-author a::before, .links-of-author span.exturl::before { - background: #ff21ff; + background: #5effff; border-radius: 50%; content: ' '; display: inline-block; diff --git a/index.html b/index.html index 412191a..242d886 100644 --- a/index.html +++ b/index.html @@ -217,10 +217,16 @@
- SOR领域论文大致分为五类(及其组合)