| timezone |
|---|
America/Los_Angeles |
-
自我介绍: Hi, 我是Ramsay, 对新事物比较感兴趣,自认为是个喜欢学习的人,所以就来参加 Solidity 的学习.
-
你认为你会完成本次残酷学习吗? 尽力而为,不中途放弃.
课程提到的未添加 License 会导致出现编译 warning, 这个是我第一个接触会因为没有注明 License 而告警的编程语言,可能是因为区块链的透明性,所以天然就拥抱开源。
搜索了一下,发现并非 Solidity 并非一开始就有这个特性,而是在 0.6.8 引入的,只是 Release Note 里面没有注明动机
这行代码表示源文件将不允许小于 0.8.21 版本或大于等于 0.9.0 的编译器编译(第二个条件由 ^ 提供)
pragma solidity ^0.8.21;课程未说明的是,^ 机制是如何运作。在版本管理里面,以 0.8.21 为例:
- 0: major version
- 8: minor version
- 21: patch version
major version 大于0就意味着发布了稳定版本,稳定版本的意思就是起码 1.0 之后,不升级 major version 不会出现 breaking change, 算是一个 commitment, 而未发布稳定版本就意味着,当下我们还在开发,接口什么的可能会变。
而 ^version: 代表 Compatible with version, 它有两个含义。
如果发布了稳定版本,那么就意味着会自动帮你升级 minor version 和 patch version, major version 不动. 如 ^1.2.3 就意味着大于 1.2.3 小于 2.0.0
如果未发布稳定版本,例如 ^0.8.21, 他的意思就是, 可以升级,但是不要变动到版本号中最左边的非零数字, 即 ^0.8.21 is 大于等于 0.8.21, 但小于0.9, 因为升级到0.9 就意味着最左边的非零数字(left-most non-zero)变了.
类似含义的还有 ~version: 意味着 Approximately equivalent to version, 就是只升级 patch version, 不会变动 major version 和 minor version.
上面提到的其实是Javascript NPM 的规则,Solidity 直接站在 npm 的肩膀上了, 官网文档:
It is possible to specify more complex rules for the compiler version, these follow the same syntax used by npm.
(属于吹毛求疵类型,如果能改掉就更好了)
示例中的变量不要使用 _string 这样没有含义的命名
value type, reference type, enum, array, vector 这些概念在其他语言中都大同小异,比如Java 中, primitive type 就是 value type, 默认是传值, class 就是 reference type, 默认是传引用,而 C++ 是都可以有,可以自行设计。
enum 是一个比较冷门的变量,几乎没什么人用。
其实 enum 在定义有限个常量时,是非常有用,类如星期,月份等.
Address type 是 Solidity 特有的类型,我接触的编程语言都没有这个概念,所以我研读了一下官方文档。
address: Holds a 20 byte value (size of an Ethereum address).
address payable: Same as address, but with the additional members transfer and send.
The idea behind this distinction is that address payable is an address you can send Ether to, while you are not supposed to send Ether to a plain address, for example because it might be a smart contract that was not built to accept Ether.
因为 Solidity 是构建在 EVM 之上的,EVM可以说是 smart contract 的基石,而地址就是EVM这基石的每个砖块的唯一标识符,可以类比成运行在计算机的程序,每个变量都会有自己唯一的内存地址。
而 address payable 就是一串可以接收 Ethereum 的地址(我可以理解成是合法的 Ethereum 地址), address 就是一串 20byte 的字符串(或许是合法的地址)
address 只能通过 payable(<address>) 转换成 address payable, 我估计这个函数的内部会校验 address 地址的合法性.
address type 还内置了一系列的函数
By the way, Solidity 也是我接触的,第一门类型有两个以上关键词的语言,想必这样会增加编译器的解析成语法树的成本,另外可读性也不是很好:
address payable x = payable(0x123);
address myAddress = address(this);
我很容易把 payable 当作是变量名, 把 address payable 合并成 adrpay 可能更符合我的品味,并且易于编译器处理.
Contract 目前在我的理解里就是类比Java 中的Class, 就是用户定义的,包含数据与函数的,运行在虚拟机(JVM/EVM)上的最小代码单元. contract 与 address 之间可以通过 address(x) 函数进行显式转换.
如果想要把 contract 转换成 address payable, 要么 contract 定义了 receive 或 payable 回调函数,要么使用 payable(address(x)) 来作转换
A user-defined value type allows creating a zero cost abstraction over an elementary value type.
zero cost abstraction 这个是我在C++和Rust 之外, 第一次听到有语言标榜 zero cost abstraction ,只是看下来,这个 User-defined value type 就是一个 alias, 其实就是 C++ 的 typedef 或者 using
和 zero cost abstraction 并没有什么关系.
Solidity 这个函数签名方式着实是有点不习惯,可见性修饰符放在参数括号之后。
pure 和 view 是其他语言所没有的关键的,严格来说是 pure 没有, view 类似 C++ 的 const 关键字,是只读的意思。
虽然作者在教程解释得很有趣,但是 pure function 其实是来自函数式编程中的概念,有两个含义:
- 给定相同的输入,就一定会返回相同的输出,和数学中的函数一样
- 没有副作用 (side effect), 类如文件读写,或者修改变量的操作.
根据官方文档,另外一个函数有趣的点在于,两个函数类型是可以隐式转换的,只要他们的函数签名,返回类型,可见性,以及状态可变性之间存在包含关系:
A function type A is implicitly convertible to a function type B if and only if their parameter types are identical, their return types are identical, their internal/external property is identical and the state mutability of A is more restrictive than the state mutability of B. In particular:
- pure functions can be converted to view and non-payable functions
- view functions can be converted to non-payable functions
- payable functions can be converted to non-payable functions
payable 函数可以转换为 non-payable 函数,因为官方的说法是, payable 可以收,也可以不收(只收0个ETH),那么也可以看成 non-payable. 但是 non-payble 不能收就是不能收,没法转成 payable, 所以只能单向转换.
Solidity的函数声明实在是太多关键字,这次我第一个见过需要使用 returns 来标识函数返回值的语言。
既有 C++/Java 这样把函数返回值声明在参数前的,也有 Rust/Golang这样把函数返回值声明在参数之后的,Solidity 还需要个专门的关键字来声明返回值,可能是因为区块链的严谨性,需要显式声明一切。
命名式返回(named return values) 是 Golang 上也有的特性,只是我更习惯直接使用 return value 进行返回,既可以实现 early return, 也不用担心重构变量名之后,需要同步修改返回值中的变量名。
解构式赋值(Destructuring assignment), 一个很有用的特性,特别是一个函数会返回多个值的时候,可以直接对多个变量赋值。
这个是 Solidity 特有的特性,需要指定数据存储的位置。因为 Solidity 运行在EVM上,存储上链的数据 storage 需要比较多的 gas, 而存储在内存上 memory/calldata 则相对便宜,那么 Solidity 的开发人员是否和60-70年代的开发者一样,需要为节省存储空间而绞尽脑汁优化程序呢?
这肯定是个有趣的体验。
从Java的角度来理解, storage 类似存储在堆上(heap), memory/calldata 存储在栈上(stack), 所以类(合约)实例的成员变量存储在 heap 上,函数变量存储在栈上
赋值操作在C++和Rust有比较多的规则,因为他们都是给开发者足够的自由度来管理内存,决定是否 copy,或者是 move. Solidity的赋值也给我类似的感觉,因为 gas fee的原因,所以 Solidity的赋值操作要兼具性能和成本考量.
- memory 与 memory 之间的赋值是创建新的引用
- storage 与 local storage 之间的赋值也是创建引用
- 其他情况都是复制值
对 Solidity 上的动态数组的概念有些疑惑,按照官方文档:
Dynamically-sized arrays can only be resized in storage. In memory, such arrays can be of arbitrary size but the size cannot be changed once an array is allocated.
也就是只有存储在链上动态数组可以变更 size,在 memory 的数组的 size 在初始化后就无法变更,那么这是否还能叫动态数组呢?也就是意味着,对于 memory 类型的数组, push 函数无法使用。
而 bytes 和 string 都是特殊类型的数组,bytes 包含任意长度的字节数据,而 string 包含任意长度的UTF-8数据。除此之外,还 bytes1 和 bytes:
- bytes: 是动态数组,可以包含任意数量的字节
- bytes1: 是固定长度数组,只包含一个字节
不知道为什么要这么设计, 将 bytes1 从只包含一个字节的固定数组,设计成 byte 类型, 表示一个字节,不是更合理嘛, 还不需要这个奇怪的命名.
Solidity 也可能会出现野指针的问题,Solidity 只允许对引用类型声明引用(指针),所以野指针也只会出现在嵌套的引用类型上,如下:
contract C {
uint[][] s;
function f() public {
// Stores a pointer to the last array element of s.
uint[] storage ptr = s[s.length - 1];
// Removes the last array element of s.
s.pop();
// Writes to the array element that is no longer within the array.
ptr.push(0x42);
// Adding a new element to ``s`` now will not add an empty array, but
// will result in an array of length 1 with ``0x42`` as element.
s.push();
assert(s[s.length - 1][0] == 0x42);
}
}Solidity 也支持数组切片的特性,如 x[start:end], 不过目前只支持 calldata 类型的数组。 start 和 end 都不是必填的, start 默认是0,end默认是数组长度
Solidity 的 Struct 不是类似 C++/Java 的 struct, 作为数据与函数的集合,而更像是C中的struct,只作为数据的载体,不包含函数实现。
需要注意的是,Solitidy 的结构体成员不能包含结构体本身, 如:
struct Campaign {
uint fundingGoal;
Campaign self; // 不支持这样的语法
}因为Solidity 需要在编译期知道结构体的大小,如果包含自己,那么就会变成无限递归,编译器就无法推断出结构体的大小了, 进而分配内存
mapping(KeyType KeyName? => ValueType ValueName?) 这个语法不知道是否是向 Ruby 借鉴的呢? keyType 可以是内置的值类型, bytes, string, 任意的合约或者是枚举类型. 其他用户自定义的类型或复杂类型, 如 mapping, struct, array 都无法作为 key,为什么呢?
我查了一下,原因可能是以下几个方面:
- Hash function limitations: EVM 内置的hash 函数Keccak-256 对基础类型有优化, 处理复杂类型或者自定义类型效率就没有那么高
- Storage layout: 基础类型因为简单,存储和计算 hash 值就简单高效,而复杂类型因为其内存布局比较复杂,所以效率没有那么高
- Gas costs: 使用复杂类型作为Key很可能会增加 gas 费,所以直接禁用复杂类型有助于降低gas 费
Mapping 只可以当作是合约的状态变量,函数内的状态变量,不能用作函数参数或者返回值;对于包含 Mapping 的数组和结构体,也会有同样的限制.
Ethereum 基金会定义的用于发币的 ERC20 协议:
totalSupply()
balanceOf(account)
transfer(to, amount)
allowance(owner, spender)
approve(spender, amount)
transferFrom(from, to, amount)其中的 allowance 函数操作的 _allowances 就是一个 Mapping
另外一个需要注意的点是,Solidity 默认是不支持遍历 mapping 的,但是有第三方实现了可遍历的 mapping:
You cannot iterate over mappings, i.e. you cannot enumerate their keys. It is possible, though, to implement a data structure on top of them and iterate over that.
猜测还是因为 gas 费的限制, 遍历一个包含很多数据的 mapping 时间复杂度是 O(N), 而 mapping lookup 是 O(1), 前者可能需要大量的 gas fee.
在Solidity中,声明但没赋值的变量都有它的初始值或默认值, 对于不同类型的变量,Solidity 会设置不同类型的默认值。
看到Solidity默认赋值的行为时,我难免会有疑问,为什么 Rust 和 C++ 不这么做呢?所以我问了下Claude:
If it's beneficial, why doesn't Rust and C++ support default value for declared variable?
Rust:
- Zero-cost abstractions: Rust aims to provide high-level features without runtime cost. Automatic initialization would add overhead.
- Explicit is better than implicit: Rust favors explicitness to avoid subtle bugs and make code behavior clear.
- Safety through compile-time checks: Rust's borrow checker prevents use of uninitialized variables, catching potential errors at compile time rather than runtime.
- Performance: Allowing uninitialized memory can be more efficient in some cases, especially for large data structures.
- Use-case flexibility: Some algorithms benefit from working with uninitialized memory for performance reasons.
C++:
- Performance: C++ prioritizes performance, and automatic initialization could introduce unnecessary overhead.
- Backwards compatibility: C++ has a long history and changing this behavior could break existing code.
- Low-level control: C++ provides fine-grained control over memory, which includes the ability to work with uninitialized memory when needed.
- Use in systems programming: Like Rust, C++ is often used in contexts where direct memory manipulation is necessary.
- Optimization opportunities: Leaving variables uninitialized allows compilers more freedom for optimizations.
While Solidity's approach is beneficial in its context (smart contracts on a blockchain), it's not universally superior.
的确很合理,Solidity和Rust/C++定位不同,选择的策略也不同.
delete 操作符可以重置一个变量为初始化值,所以 delete 的含义应该是 reset. delete 同样支持操作动态数组,将其长度重置为0;或者是静态数组,将静态数组中每个的元素重置为初始化值。
需要注意的是, delete 同样支持只操作数组中的某个元素 delete a[x], 就重置了下标为 x 的元素,数组中的其他元素就保持不变.
另外, delete 对 mapping是没有效果的,如果一个 struct a包含 mapping, delete a 不会重置 mapping 为初始化值。但是 delete 支持删除 mapping 中的特定的 key, 如 delete a[x] 就是删除了 key=x 的值。
constant 和 immutable 都是用来声明常量的, 数值变量可以声明 constant和 immutable;string和bytes可以声明为constant,但不能为immutable.
那么两者之间有什么差别呢?什么时候应该使用哪一个关键字来声明常量呢?
总结下来,主要是赋值时机和 gas 费的差别:
constant 必须是在编译期确定,所以必须是在声明时初始化,会被直接写入到字节码中;而 immutable 修饰的变量,可以在运行时确定,即在构造器中指定,也会被写入到字节码中。
二者声明的变量都不会存储在链上,都会被写入到字节码中
读取 constant 变量是不需要任何 gas 的, 而读取 immutable 是需要一点 gas 费的,当然也比读取其他非常量便宜很多。
constant 一般用来指定编译期已知的变量,如数字或者是所有合约都一样的配置;immutable 则是用于部署后不变的值,如合约地址或者是因合约而异的配置值
Solidity 的控制流和其他语言基本是一模一样了。
既然教程用 Solidity 写了个插入排序,那么我就不写插入排序了,写个 leetcode 的起手题: twosum .
Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target. You may assume that each input would have exactly one solution, and you may not use the same element twice. You can return the answer in any order.
Example 1:
Input: nums = [2,7,11,15], target = 9 Output: [0,1] Explanation: Because nums[0] + nums[1] == 9, we return [0, 1].
Example 2: Input: nums = [3,2,4], target = 6 Output: [1,2]
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.21;
contract TwoSum {
mapping (uint32 => uint32) public num_indics;
mapping (uint32 => bool) public contains;
function twoSum(uint32[] calldata input, uint32 target) external payable returns (uint32[] memory){
for(uint32 i = 0; i < input.length; i++){
num_indics[input[i]] = i;
contains[input[i]] = true;
}
uint32[] memory result = new uint32[](2);
for(uint32 i = 0; i < input.length; i++){
if (contains[target - input[i]] && i != num_indics[target - input[i]]){
result[0] = i;
result[1] = num_indics[target - input[i]];
return result;
}
}
// not found
return result;
}
}twosum 非常简单,真正写起来的时候才意识到 Solidity 和其他编程语言的差别, Solidity 的 mapping 不像正常的 hashmap 那样,它是不支持 `contains 函数的,所以我只好用另外一个 mapping 来模拟 contains 的函数,但是这样又会增加存储的开销。
顺便推荐个 web3 的 Leetcode,用 Solidity 来解决编程题:https://dapp-world.com
0.4.22之前的构造器函数估计是向 Java 学习的,使用与合约名同名的函数作为构造函数而使用,但是Java中的构造函数是和普通函数不一样的,是没有返回值的,所以无法与普通函数混淆。
但是 Solidity 并没有这样的限制,函数并不一定要强制声明返回值,所以使得构造函数可能成普通函数,引发漏洞。
所以0.4.22版本及之后,采用了全新的 constructor 写法,这个就是向 Javascript 学习,显式声明构造函数。(感觉这个语法设计着实没有深思熟虑)
与Java/C++ 不同的是,因为 Solidity 没有函数重载的概念,所以 Solidity 最多只有一个构造函数,如果没有显式声明构造函数,就使用默认的构造函数。
Modifier 类似其他语言的装饰器,或者是切面编程,可以运行函数主体前或者运行后执行对应的操作。常见的用法是把包含 Modifier 的合约定义成库,然后通过继承来使用相应的 Modifier:
contract owned {
constructor() { owner = payable(msg.sender); }
address payable owner;
// This contract only defines a modifier but does not use
// it: it will be used in derived contracts.
// The function body is inserted where the special symbol
// `_;` in the definition of a modifier appears.
// This means that if the owner calls this function, the
// function is executed and otherwise, an exception is
// thrown.
modifier onlyOwner {
require(
msg.sender == owner,
"Only owner can call this function."
);
_;
}
}
contract priced {
// Modifiers can receive arguments:
modifier costs(uint price) {
if (msg.value >= price) {
_;
}
}
}
contract Register is priced, owned {
mapping(address => bool) registeredAddresses;
uint price;
constructor(uint initialPrice) { price = initialPrice; }
// It is important to also provide the
// `payable` keyword here, otherwise the function will
// automatically reject all Ether sent to it.
function register() public payable costs(price) {
registeredAddresses[msg.sender] = true;
}
// This contract inherits the `onlyOwner` modifier from
// the `owned` contract. As a result, calls to `changePrice` will
// only take effect if they are made by the stored owner.
function changePrice(uint price_) public onlyOwner {
price = price_;
}
}而 _ 指代的就是被修改的函数主体。
如果从存储的角度来思考事件(Event),也可以解释为什么存储在事件的gas费会比链上便宜那么多。
存储在链上的最大特点就是不可篡改,意味着有多个节点都对写入的值达成共识(可以理解成多副本冗余),而日志并不存储在链上,就是不需要网络节点达成共识,类似于单机存储,成本自然就下来。
如果所有存储的内容都需要达成共识,开销也太大了。
按照 Event 的 ABI 标准, 事件包含以下的内容:
- address: 合约地址
- topics 数组:
- topics[0]: 第一个元素的值是 "anonymous" 或者
keccak(EVENT_NAME+"("+EVENT_ARGS.map(canonical_type_of).join(",")+")"),canonical_type_of是用来获取参数类型的函数 - topics[1-3]: 保存被声明成
indexed类型的参数,最多3个参数 - 所以 topics 数组的长度最大为4,最多包含3个参数,因为第1个参数被用来标识事件了
- topics[0]: 第一个元素的值是 "anonymous" 或者
- data: 就是存储的数据,对应的就是没有被声明成
indexed的参数
indexed 可以标记值类型,枚举,静态数组和 string (如果超过256个字节,就会使用 Keccak 函数计算 hash 值,确保长度都是固定的),但不可用来标记 mapping, struct 和动态数组。
其他语言中也有事件的概念,如 Javascript 里面有许多浏览器操作的事件,如点击按钮,移动鼠标等等。我们同样可以使用 web3.js 这个库来订阅我们感兴趣的事件:
var options = {
fromBlock: 0,
address: web3.eth.defaultAccount,
topics: ["0x0000000000000000000000000000000000000000000000000000000000000000", null, null]
};
web3.eth.subscribe('logs', options, function (error, result) {
if (!error)
console.log(result);
})
.on("data", function (log) {
console.log(log);
})
.on("changed", function (log) {
});Solidity 的继承基本就是借鉴 C++的,无论是 virtual, override 关键字,还是构造函数的继承,又或者是多继承。
虽然Solidity 的继承是借鉴 C++ 的, 但是 C++ 继承的问题, Solidity 也加以限制了。如C++中的多继承,函数名冲突问题:
class A{
public:
void func();
};
class B{
private:
bool func() const;
};
class C: public A, public B{ ... };
C c;
c.func(); // 歧义!虽然B::func是私有的,但仍然会编译错, 编译器不知道 c.func() 指的是哪个类的func。而在 Solidity 中,如果继承的父类有重名函数, Solidity 编译器会要求重新,无论这个函数是否有声明成 virtual:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.21;
contract A {
uint data = 2;
function func() public {
}
}
contract B {
function func() public {
}
}
contract C is A, B {} // => 编译器报错, TypeError: Derived contract must override function "func". Two or more base classes define function with same name and parameter types.另外,如果A, B 中有相同的状态变量,如 data, C 继承自 A,B 的话,也会报错: DeclarationError: Identifier already declared., 从而规避掉 C++ 多继承情况下,同名函数或者同名变量的歧义问题。
C++的菱形继承是多继承的特例,因为存在类成员变量和函数,变成一个更复杂的问题了,而 Solidity 通过禁止在继承链上出现同名的变量和函数,规避掉这个问题。
Effective C++ 和 More Effective C++ 作者 Scott Meyers对于多继承的建议是
- 如果能不使用多继承,就不用他;
- 如果一定要多继承,尽量不在里面放数据
Java 就吸取了第二条建议,然后设计了 Interface, 不允许定义状态变量。
使用 Solidity 的时候,我也是同样的观点,如果能不使用多继承,就不用; 如果一定要多继承,就不要定义数据变量。
其实我是不理解 Solidity 都支持 Interface了,为什么还需要学C++的多继承呢,直接借鉴Java的单继承 + 多接口组合不是更清晰嘛?
C++的多继承是因为它是面向对象的先驱, 历史悠久, Python 搞多继承是因为没有 Interface 的概念,现在是 C++ 和 Java 的特点都拿过来了, 反而是复杂化了。
在面向对象中,继承通常是和多态组合发挥作用的,而 Solidity 也是支持多态的,如:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.21;
// Base contract
contract Animal {
function speak() public virtual returns (string memory) {
return "Animal sound";
}
}
// Derived contract 1
contract Dog is Animal {
function speak() public virtual override returns (string memory) {
return "Woof";
}
}
// Derived contract 2
contract Cat is Animal {
function speak() public override returns (string memory) {
return "Meow";
}
}
// Test contract
contract TestPolymorphism {
function getAnimalSound(Animal animal) public returns (string memory) {
return animal.speak();
}
}Solidity 的 Interface 和 abstract contract 基本就是参照 Java的 Interface 和 abstract class 了(准确来说,应该是Java8之前的Interface, Java8 之后, interface 也可以有默认函数实现了).
Java Interface中所有的函数默认是 public 的, Solidity Interface 中的函数默认是 external; Solidity Interface 不允许定义任何变量, 但是可以定义事件,Java Interface 允许定义常量 public static final
使用 Interface 在 Solidity 中实现多态:
interface Animal {
function makeSound() external view returns (string memory);
}
// Contract Dog implementing the Animal interface
contract Dog is Animal {
function makeSound() external pure override returns (string memory) {
return "Woof";
}
}
// Contract Cat implementing the Animal interface
contract Cat is Animal {
function makeSound() external pure override returns (string memory) {
return "Meow";
}
}
contract AnimalShelter {
function getAnimalSound(Animal animal) public view returns (string memory) {
// Polymorphic behavior: Treats both Dog and Cat as an Animal
return animal.makeSound();
}
}
课程中无聊猿(BAYC)的交互, 其实就是多态的一种应用,BAYC 就是若干个实现了代币 IERC721 接口的代币之一.
另外一个非常关键的知识点就是合约的ABI 与接口等价,RPC 接口调用的ABI,背后实际调用的是定义的各式接口。
按照官方文档的说明,Solidity使用的是 state-reverting exception,我是第一次了解 state-reverting 的异常。
它的大概含义是,如果出现异常,那么函数调用及其子函数调用导致的所有的状态变更,都需要回滚(reverted, undone), 概念理解起来和数据库的异常处理很类似,只是成功和失败两个状态,没有中间态,失败就回滚所有操作,保证原子性。
Solidity 内置的错误类型有两种 Error(string) 和 Panic(uint256). Error 就类似 Java 中的常规错误(CheckedException), 可以预期会发生的; Panic 就类似 Java 中的UncheckedException, 就是通常来表示在没有 bug 代码中就不应该出现的错误,比如数组越界,除0等等。
文档提及的 state-reverting 是通过 revert 函数来实现的,它接受一个 Error 类型作为参数,revert 回滚状态,并将传入的错误向调用方抛出,调用方也会自动向它的调用方抛出,直到遇到 try/catch 语句捕获异常。
(原来还一个 throw 的关键字,具有同样的功能,不过在 0.4.13 被废弃,后面就被移除了,估计是只强调了「向上抛出」的语义,没有强制「回滚」)
而 assert 和 require 就是两个在预期条件不满足时,分别用来抛出 Panic 和 Error 的函数,差别就是 require 还可以指定一下错误信息, 两个函数内部都会调用 revert 来回滚状态,并将异常向上抛出。
Solidity 的 try/catch 和 Java 也很类似:
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.8.1;
interface DataFeed { function getData(address token) external returns (uint value); }
contract FeedConsumer {
DataFeed feed;
uint errorCount;
function rate(address token) public returns (uint value, bool success) {
// Permanently disable the mechanism if there are
// more than 10 errors.
require(errorCount < 10);
try feed.getData(token) returns (uint v) {
return (v, true);
} catch Error(string memory /*reason*/) {
// This is executed in case
// revert was called inside getData
// and a reason string was provided.
errorCount++;
return (0, false);
} catch Panic(uint /*errorCode*/) {
// This is executed in case of a panic,
// i.e. a serious error like division by zero
// or overflow. The error code can be used
// to determine the kind of error.
errorCount++;
return (0, false);
} catch (bytes memory /*lowLevelData*/) {
// This is executed in case revert() was used.
errorCount++;
return (0, false);
}
}
}catch 语句可以用来匹配不同的错误类型,优先级从上到下,就是如果匹配到某个 catch 语句,就不会向下继续走了。
前面两个 catch 语句就是用来捕获 Solidity 内置的 Error 和 Panic 类型,而 catch(bytes memory lowLevelData) 就比较有趣,有错误数据它能 catch 到,没有错误数据它也能 catch 到, bytes memory 就是用来获取底层错误信息,相当于是用来兜底的。
所以想要 catch 住所有的错误,要不用 catch {...} (不指定错误类型),要不用 catch (byte memory lowLevelData) {...} catch 底层错误信息.
Solidity 101 课程到此结束, 耶.
函数重载的概念在C++ 和 Java 中都是非常常见且有用的功能的,可以编写多个同名但是函数签名不一样的参数。
对于课程提到的实参匹配问题:
function f(uint8 _in) public pure returns (uint8 out) {
out = _in;
}
function f(uint256 _in) public pure returns (uint256 out) {
out = _in;
}调用 f(50) 的确会报错,因为 50 既可以转换成 uint8 也可以转换成 uint256,解决方法就是显式给出类型,如uint8 number = 50;.
但是调用 f(256) 却不会报错,因为 256 只能转换 uint256, uint8 的最大值为 255.
就像所有的库一样,Solidity的库目标也是为了复用,定义一个库合约,然后被多个合约调用,减少代码冗余。
而在Solidity,库合约其实可以看作是所有合约隐式的基类,库合约不会出现在继承链里面,但是调用库合约就好像调用基类的函数一样, 通过L.f() 这样的语法, 我个人是不太喜欢用 using for指令,太隐式了,涉及到钱的东西,还是显式调用好。
而关于库合约限制,不能存储状态变量,不能继承或者被继承,以及不能接收Ether等,都是为了可以让库合约成为纯粹的库,避免引入状态导致问题。
关于合约调用合约,有三个关键的底层函数,CALL, DELEGATECALL, CALLCODE(已废弃).
CALL 是最常用的,用来调用其他合约的或者发送Ether的函数,当调用CALL的时候,他会创建自己的上下文;而 DELEGATECALL 和 CALL 类似,最大的差别是它可以保存合约调用者的状态,意味着它会使用调用方的状态,而非被调用方的状态。
而调用库合约,用的就是DELEGATECALL.
谈到库,另外一个绕不开的话题就是怎么引用第三方现成的库合约,这就需要包管理器(package manager), Java有Maven, Javascript 有NPM, Solidity 用啥呢? 下节分解.
上一个章节提到了库合约,要使用库合约,肯定是要和包管理器结合,需要一种方式来把库合约引入进来。
在 Solidity 比较流行的一种包管理方式是使用 NPM, 类似本地开发,安装 OpenZeppelin 的库:
npm install @openzeppelin/contracts// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "@openzeppelin/contracts/utils/math/SafeMath.sol";
contract MyContract {
using SafeMath for uint256;
// Your code
}
或者像Golang 那样,通过 http/https 链接来直接引入资源,但是这种方式有个缺点就是没有版本机制,也就是如果依赖的库合约文件升级了,那么你就直接引用了最新的库合约,可能引入了 breaking change, 所以使用 full url 引入库合约的时候,就要小心一些。
// 通过网址引用
import 'https://github.com/OpenZeppelin/openzeppelin-contracts/blob/master/contracts/utils/Address.sol'; // Address.sol 文件一旦更新,就会直接导入最新文件
除了NPM之外,还有其他的Solidity 包管理器,如 ethPM 和 DappTools.
在最差情况下, receive 函数只有大概2300 gas可用,没有太多余地做打日志之外的操作。按照官方文档的说法,下面的操作会消耗超过2300 gas:
- 向链上写入数据
- 创建合约
- 调用会消耗大量 gas 的外部函数
- 发送 Ether. (没错,这意味着你无法在接收 Ether 的函数里面发送 Ether, 不然你大概率会因为 out of gas 被接收失败)
虽然 receive 和 fallback 函数都可以用来接收 Ether, 但是使用 fallback 来处理接受 Ether 并不是推荐的做法,顾名思义, fallback 函数应该处理的是兜底的失败逻辑,而不是处理正常的接收逻辑。
就类似于不应该依赖 try/catch 来处理正常的逻辑分支。
上文提到,没有 receive 和 fallback 函数是无法接收 Ether, 但是凡事也有例外,也有一种特殊情况,就是作为矿工奖励的接收方(coinbase transaction), 你没有 receive 和 fallback 函数也能接收 Ether, 这是 by design 的功能,因为 EVM 的标准并没有声明应该如何处理这种转账,所以合约无法拒绝。
强塞进来的钱,想拒绝都没有办法。
按照 EVM 的规定,发送Ether时,msg.data 应该是为空的,所以这就是为什么 msg.data为空且存在 receive() 时,会触发 receive()
Solidity 有三个函数可以用来发送 Ether:
transfer: 有 2300 gas 限制, 合约的fallback()或receive()函数不能实现太复杂的逻辑; 转账失败会自动回滚.send: 有 2300 gas 限制, 合约的fallback()或receive()函数不能实现太复杂的逻辑; 转账失败不会自动回滚,需要判断转账结果call: 无gas限制, 可以支持对方合约fallback()或receive()函数实现复杂逻辑; 转账失败不会自动回滚,需要判断转账结果
推荐使用 call 来发送Ether,除了gas无限制的优点外,还有一个课程未提及的点, 就是在2019年12月的Istanbul Hardfork后, transfer 和 send 变成没有那么安全了,而 call 可搭配防重入锁来抵御重入攻击。
所谓的重入攻击,指的是有合约A(受害者)和合约B(攻击者):
- 合约A调用合约B
- 在合约A的调用完成前,合约B反过来调用合约A
- 这样就会形成递归调用,就有可能把合约A的钱耗高,或者出现预期外的情况。
以代码为例,结合前文学到的 fallback 函数:
// Vulnerable Contract A
contract VictimContract {
mapping(address => uint) public balances;
function withdraw() public {
uint balance = balances[msg.sender];
(bool success, ) = msg.sender.call{value: balance}("");
require(success);
balances[msg.sender] = 0;
}
}
// Attacker Contract B
contract AttackerContract {
VictimContract public victim;
constructor(address _victimAddress) {
victim = VictimContract(_victimAddress);
}
fallback() external payable {
if (address(victim).balance >= 1 ether) {
victim.withdraw();
}
}
function attack() external payable {
victim.withdraw();
}
}- 攻击者调用合约B的
attack函数 attack函数调用合约A的withdraw函数- 因为没有定义
receive函数,合约A给合约B转账的时候,就会调用到合约B的fallback - 当合约A调用合约B的
fallback函数,函数还没有返回,也就是合约A的withdraw还没有结束,fallback再次调用合约A的withdraw函数 - 循环调用,直到耗尽合约A的所有资金为止。
2016年导致 Ethereum 分裂成 Ethereum classic 和 Ethereum 的DAO 攻击就是重入攻击.
而在调用 call 时,配合防重入的 modifier,就能抵御这样的攻击:
bool private locked;
modifier noReentrant() {
require(!locked, "No re-entrancy");
locked = true;
_;
locked = false;
}
---
import "@openzeppelin/contracts/security/ReentrancyGuard.sol";
contract SafeEtherTransfer is ReentrancyGuard {
function sendEther(address payable _to, uint256 _amount) public nonReentrant {
(bool success, ) = _to.call{value: _amount}("");
require(success, "Transfer failed.");
}
}没有谁是一座孤岛. ——John Donn
每个人都与他人相互关联,缺一不可,合约也类似,单个的合约并不能发挥太大的作用,只有多个合约相互组合,才能构建出复杂,强大的DAPP。
在微服务的视角,想要调用微服务中某个提供特定功能的服务,只需要知道 host + port 就可以发起调用(先不考虑授权机制),而在 solidity 的世界,只需要知道合约的地址或者通过 import 引入其他合约就能发起调用,合约地址就是已部署合约的唯一标识。
contract Callee {
uint256 public x;
function setX(uint256 _x) public returns (uint256) {
x = _x;
return x;
}
}
contract Caller {
function setX(Callee _callee, uint256 _x) public {
uint256 x = _callee.setX(_x);
}
function setXFromAddress(address _addr, uint256 _x) public {
Callee callee = Callee(_addr);
callee.setX(_x);
}
}
假设合约 Callee 部署在地址 0xd9145CCE52D386f254917e481eB44e9943F39138, Caller 想要调用它,只需要 setXFromAddress(0xd9145CCE52D386f254917e481eB44e9943F39138, 256), 就能发起调用.
或者 setX(0xd9145CCE52D386f254917e481eB44e9943F39138, 256), Solidity 会把地址转换成合约 Callee 的引用,然后再发起调用。
除去通过地址或者合约引用发起调用, Solidity 还支持通过之前学过的,用来转账的 call 函数来调用其他合约,但是函数比较底层,一般不推荐用来调用其他合约.
不推荐使用 call 来调用其他合约的原因,课程并没有解释得很详细,主要是笼统地说不推荐使用,背后的原因我认为大概有以下几点:
call调用失败的回滚不会向上传递, 介绍 error-handling 的时候有提到,solidity的异常是 revert-state,也就是意味着出现异常时,会在调用栈向上回滚,而 call 在调用失败的时候并不会自动向上回滚,除非手动添加回滚操作:
(bool success, ) = targetContract.call(abi.encodeWithSignature("someFunction()"));
require(success, "Call failed");使用 call 调用跳过了编译器的类型检查,非常容易导致 bug, 比如把 targetContract.call(abi.encodeWithSignature("someFunction()"));中 someFunction 写成了 somFunction, 也能编译通过并执行, 无法检查函数是否存在或者参数类型,参数个数是否有误.
总结而言,call 就类似 Python 或者 Javascript 中的 eval 函数,可以直接将字符串当作代码来执行, 并返回执行结果.
delegatecall 的确非常神奇,我这次是没有想到在其他语言中的类似的功能, 使用 delegatecall 有个非常强大的功能,意味着它可以在运行时从其他合约地址动态加载代码,但是仍然使用本合约的上下文,也就意味着可以只把代码拿过来用,无需关心状态变化。
智能合约一旦部署,就无法修改。如果重新部署一个新合约,既会导致旧合约所有内部数据的丢失,也会导致合约地址的变更,这对于用户来说是不可接受的。
为了解决这个问题,人们提出了基于 Proxy 的合约升级方案。这种方案的核心思想是, 将合约的代码和数据分离,面向客户的是负责保存数据的 Proxy 合约, 但是 Proxy 中不包含任何逻辑代码,只是将所有的请求,都转发给实现业务代码的 Implementation 合约。
当需要升级时,只需要部署一个新的 Implementation 合约,然后将 Proxy 合约的指针更新为新的 Implementation 合约地址即可.
假如有一个代理合约,可以理解成课程中的合约B, 还有一个具体实现的合约,可以理解成合约C.
// Proxy contract
contract Proxy {
address public implementation;
constructor(address _implementation) {
implementation = _implementation;
}
function upgradeTo(address _newImplementation) public {
implementation = _newImplementation;
}
fallback() external payable {
(bool success, ) = implementation.delegatecall(msg.data);
require(success, "Delegatecall failed");
}
}
// Implementation contract
contract ImplementationV1 {
uint public value;
function setValue(uint _value) public {
value = _value;
}
}用户A通过合约B(代理合约)来调用合约C(具体的实现合约), 当合约C 升级之后,只需要调用 upgradeTo 接口,传入新合约D的地址,就可以让合约B 把请求转发给新合约D, 用户也不需要变成合约地址,因为用户只需要知道合约B的地址即可。
因为合约B调用合约C或者合约D 使用的都是 delegatecall, 所以在合约C或者D看来,就和用户A直接调用他们没有差别,通过 delegatecall 就实现了合约的平滑升级,类似CI/CD中的灰度发布了.
创建合约有两种用法, 本节提及的是 create
Contract x = new Contract{value: _value}(params);
乍看之下,觉得就是Java的类实例化,Java程序员自然是非常熟悉。的确如此,但是背后还有个本质的区别,Java程序是运行在Java virtual machine 上的,创建的类实例自然是分配在堆内存上。
如果想要部署某个服务,并且让用户可以访问,无论使用 docker 之类的容器化技术,或者使用 Lambda/Cloudflare worker 之类的 serverless 服务,都需要将代码打包,然后部署成服务器或者Serverless 平台,提供一个Ip地址或者域名供用户进行调用。
而合约的美妙便捷之处在于,智能合约是运行在EVM之上的,新创建的合约就是直接对全世界用户可见的, new 相当于是Java视角的实例化+打包+部署,或者理解成全世界的用户都可以使用你Java程序的内存地址来访问你的JVM堆分配的对象.
这种天生的分布式让我想起的Erlang的进程设计, 创建的进程也是默认分布式的, 但是相比之下,智能合约更强大。
Create2 对比 create 最大的变化或者说是优点就是地址可以是固定的,因为计算地址的四个参数都是确定的,所以生成出来的地址自然就是确定的, 而 create 用的创建者的地址 + nonce (该地址发送的交易总数) 来生成新地址, nonce 会随时间变化而变化, 地址就可能发生变化.
除了文中提到的优点外,create2 还有一些额外的优点,我觉得比较有用的就是:
上文提到,create 创建的合约地址与 nonce 相关,那么在删除合约后,重新部署合约,合约地址就有可用发生改变。而如果使用 create2, 只要使用相同的部署者地址,相同的 salt 和相同的 initcode, 就能保证部署后的合约地址不变,那么合约的删除与重新部署对于客户来说就是无感的.
在某些情况下,CREATE2 可以通过允许在部署前对合约地址进行操作来节省 Gas 费用。例如,用户可以将资金发送到尚未部署的合约地址,而后在需要时部署该合约。这样可以避免不必要的多次部署或地址查找操作。
理论虽然可行,但是往没有部署的合约打钱,难免会虚的.
凡事有利就有弊, create2 也不例外,如果不同的合约使用相同的 salt 和 initcode, 且由同一个地址部署,那么就会出现地址冲突的问题,所以需要确保 salt 的唯一.
selfdestruct 是用来删除合约,如果从Web2的视角来理解,创建合约就相当将代码部署上线,而删除合约就相当于是将代码下线,正常业务肯定是希望业务7x24小时运行,100%可用的,需要将网站下线的情况一般都比较极端,比如遭受攻击,例如曾经的索尼,或者是提桶跑路。
DAO 指的是Decentralized Autonomous Organization,去中心化的投资资金, 而课程中的提到的The DAO攻击原理就是我在笔记中提到的重入攻击:
- 用户可以在DAO提现,正常情况下,用户想要提现,那么就会向指定合约打钱,然后合约再更新余额
- 而重入攻击就是黑客调用提现功能,在合约更新余额前再递归调用,就可以在一次交易中实现多次提现,以耗尽DAO的钱.
而2016年那次攻击,黑客通过重入攻击转走了当时价值3.6 M的资金,但是被盗资金因为DAO的机制,需要先被锁定28天,就给了Ethereum 基金会反应的时间,当时有3个选项:
- 啥都不干
- Soft Fork: 修改代码,冻结被盗奖金
- Hark Fork: 将区块链回滚到被盗前的状态
最后基金会选择了选项3,回滚。
这个决定引发了极大的争议,也导致了社区的分裂,毕竟区块链标榜的就是不可窜改,现在创始人带头回滚改状态,相当于与设计初衷相背了, Ethereum 就分裂成 Ethereum(ETH) 和 Ethereum(ETC)
言归正传, selfdestruct 就可以理解成一键清空余额并删库的操作,现在 Remix 都给出编译警告了:
Warning: "selfdestruct" has been deprecated. Note that, starting from the Cancun hard fork, the underlying opcode no longer deletes the code and data associated with an account and only transfers its Ether to the beneficiary, unless executed in the same transaction in which the contract was created (see EIP-6780). Any use in newly deployed contracts is strongly discouraged even if the new behavior is taken into account. Future changes to the EVM might further reduce the functionality of the opcode.
--> contracts/DeleteContract.sol:10:9:
|
10 | selfdestruct(payable(msg.sender));
| ^^^^^^^^^^^^
而 selfdestruct(_addr) 中的 _addr 是接收合约中剩余 ETH 的地址, _addr 地址不需要有 receive 或 fallback 也能接收 ETH(这个就种coinbase 地址一样了), 也就是没有拒收的余地.
利用这个自毁并且强制转账的功能, 也可以实现某种攻击手段.
例如有这么个游戏,每次只能转入1个ETH,当你是第7个转入者,合约余额累计到7ETH的时候,你就可以把钱给领走:
contract EtherGame {
uint256 public targetAmount = 7 ether;
address public winner;
function deposit() public payable {
require(msg.value == 1 ether, "You can only send 1 Ether");
uint256 balance = address(this).balance;
require(balance <= targetAmount, "Game is over");
if (balance == targetAmount) {
winner = msg.sender;
}
}
function claimReward() public {
require(msg.sender == winner, "Not winner");
(bool sent,) = msg.sender.call{value: address(this).balance}("");
require(sent, "Failed to send Ether");
}
}
上面的代码作了限制,如果转入的金额不是1ETH,转出就会失败,最后比较余额是否等于7,但是作为攻击者,就可以利用 selfdestruct 的强制转账的机制,可以直接把游戏给搞挂:
contract Attack {
EtherGame etherGame;
constructor(EtherGame _etherGame) {
etherGame = EtherGame(_etherGame);
}
function attack() public payable {
address payable addr = payable(address(etherGame));
selfdestruct(addr);
}
}假如我合约余额是 0.00000324 ETH, 强制转账就能绕过 require(msg.value==1) 的限制,那么这个游戏就永远不会有赢家,因为它每次只能转入1ETH,没法实现 balance==targetAmount, 除非你用类似的攻击手段,再转入个 0.99999676, 湊够 1ETH.
更进一步,这里的预防手段是不要依赖 address(this).blanace, 而是要用自定义的变量:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.26;
contract EtherGame {
uint256 public targetAmount = 3 ether;
uint256 public balance;
address public winner;
function deposit() public payable {
require(msg.value == 1 ether, "You can only send 1 Ether");
balance += msg.value;
require(balance <= targetAmount, "Game is over");
if (balance == targetAmount) {
winner = msg.sender;
}
}
function claimReward() public {
require(msg.sender == winner, "Not winner");
(bool sent,) = msg.sender.call{value: balance}("");
require(sent, "Failed to send Ether");
}
}在理解ABI 编码之前,首先要了解什么ABI.
在其他编程语言的语境下(主要是C),ABI(Application Binary Interface)指的是应用程序或操作系统中的二进制接口,定义了不同程序模块(例如函数,库,操作系统内核用户究竟程序)在编译后的二进制是如何交互的, 包括函数调用方式,参数传递方式,返回值的处理,系统调用,内存布局等等。
而智能合约的ABI(Application Binary Interface), 是智能合约在以太坊等区块链网络中与外部应用程序(类如其他合约或前端应用)通信的标准.
例如有这样的ABI 部署在地址 0xC1666a11E5Ac3feAE09388f31AEff1ac014f9900:
erc_20_abi = [
{
"constant": False,
"inputs": [
{
"name": "_to",
"type": "address"
},
{
"name": "_value",
"type": "uint256"
}
],
"name": "transfer",
"outputs": [
{
"name": "",
"type": "bool"
}
],
"type": "function"
}
]就可以通过Python 脚本来调用这个合约,完成Web2与Web3的交互.
w3 = Web3()
my_contract = w3.eth.contract(address=0xC1666a11E5Ac3feAE09388f31AEff1ac014f9900, abi=erc_20_abi)
my_contract.functions.transfer(_to=other_account.address,_value=420202020).call()而所谓的ABI编码就是把数据编码成十六进制(或者二进制, 其实都可以), 例如 0x7a58c0be72be218b41c608b7fe7c5bb630736c71000000, 编码的方式多种多样, 比如有数据 uint a = 1, string b = "string", 你可以把它们都转换成对应的十六进制,然后拼接起来
a = 1 的十六进制就是 0x1, 但是uint是uint256, 是256位长度的, 换成十六进制, 就是有64位长, 补0之后变成: 0x1000000000000000000000000000000000000000000000000000000000000000
所以 abi.encode 就是补0版本的, 而 abi.encodePacked 就是不补0版本的, 可以直观看到 abi.encode 更耗费存储空间,但是如果是合约相互调用, 你使用 abi.encodePacked 来编码,使用abi.decode 解码就会报错,因为decode uint256, 它就是按照256个bit 来解码的,但是你说应该只取一个1bit,那么它就解不出正确的数值了.
而abi.encodeWithSignature() 就是配合 call 使用的, 其实参数类型 abi.encode 和 abi.encodePacked 都可以通过传入参数推断出来,而 abi.encodeWithSignature 特别之处在于它还传入了调用的函数名.
abi.encodeWithSelector 与 abi.encodeWithSignature功能类似,只不过第一个参数为函数选择器,为函数签名Keccak哈希的前4个字节
function encodeWithSelector() public view returns(bytes memory result) {
result = abi.encodeWithSelector(bytes4(keccak256("foo(uint256,address,string,uint256[2])")), x, addr, name, array);
}
但是任何哈希相关的操作,尤其是截取部分hash的情况,都需要注意可能会出现的哈希冲突,我没有深挖到 keccak256 的实现原理,但是如果有两个函数生成的hash 如下:
0x5467872.... 0x5467087....
他们的前4个字节就是一样的,当然这个只是存在理论冲突的可能,总不能无限地创建函数.
abi解码就是把对应的十六进制/二进制数据翻译成原来正常的参数,因为标准的解码就是按照参数类型解码,你是uint256, 就把256个bit 转换成数字, 所以就只有一种解码方式.
Hash 这个概念在编程中就非常常见了,在Java和C++中就有不同的Hash函数实现,而整个区块链技术都可以说是在构建在 hash function 之上的。
所谓的区块链,不同之间的区块(block) 就是通过每个区块自身的 hash 以及记录前一个区块的 hash 串连起来,成为「链」的。
生成钱包地址,交易的唯一标识,这些都和 hash function 息息相关。谈起好的 hash function, 最关键的是它是否能尽量降低 hash 碰撞的函数,即两个不同的参数,生成了相同的 hash 值。
不过按照已知技术(2024)年,想要碰撞出相同值的 hash 也是非常难的.
另外一个关于 keccak hash function 的趣事是, keccak hash function 是赢得了美国国家标准与技术研究院(National Institute of Standards and Technology)的 hash function 大赛,然后被选为SHA3的标准.
要理解什么是 selector, 就要先了解 method_id 与函数签名。
所谓的函数签名,是指函数的名称和参数类型的组合,用来唯一标识一个函数,不包含返回类型。例如有函数:
function transfer(address recipient, uint256 amount) public returns (bool)
那么它的函数签名就是 transfer(address,uint256),而 method id 就是函数签名的 keccak256 hash 之后的前4个字节, 如 transfer 函数的 method id 就是:
bytes4(keccak256("transfer(address,uint256)"))
当我们调用智能合约时,本质是向目标合约发送一段 calldata, 发送的 calldata 的前4个字节就是 selector,当 selector 和 method id 相匹配时,即表示调用对应的函数.
讲 abi encode/decode 的时候提到的第4个函数就是, abi.encodeWithSelector,知道目标合约函数的 selector 和地址,就可以直接调用目标函数了.
address targetAddress = ''
targetAddress.call(abi.encodeWithSelector(0x3ec37834, 1, 0));
所谓知其然知其所以然,为什么Solidity会使用 selector 和 method id 这样的机制呢,而不是像C++那样搞编译期解析呢?
追根溯源,还是要回到EVM的Blockchain架构上,使用 selector和 method id比直接使用函数签约最大的好处就是可以节省 gas fee.
因为无法预测开发者可能会给一个函数定义多长的名字,或者定义多少个参数,如果传递函数签名的话,那么gas fee就会随着函数名的变长或者参数数量的变多而线性增加。
使用 method_id 就能把函数签名的结果固定在4个字节,既可以节省gas,也避免了gas fee会随函数签名的长度增加而增加.
说起 try/catch, 也不是所有的现代语言都会有,像 Rust/Golang 都选择了不使用 try/catch, 一个是判断返回值,一个是处理 Result。
我在前面讲异常处理的笔记中,也预先提到了 try/catch 的内容.
在 Solidity 中, try/catch 只能被用于 external 函数或创建合约时的 constructor(被视为 external 函数调用)
try externalContract.f() {
// call成功的情况下 运行一些代码
} catch {
// call失败的情况下 运行一些代码
}如果调用的函数有返回值,那么必须在try之后声明 returns(returnType val),并且在try模块中可以使用返回的变量(这个时候, 命名式返回就派上用场了);如果是创建合约,那么返回值是新创建的合约变量。
try externalContract.f() returns(returnType){
// call成功的情况下 运行一些代码
} catch Error(string memory /*reason*/) {
// 捕获revert("reasonString") 和 require(false, "reasonString")
} catch Panic(uint /*errorCode*/) {
// 捕获Panic导致的错误 例如assert失败 溢出 除零 数组访问越界
} catch (bytes memory /*lowLevelData*/) {
// 如果发生了revert且上面2个异常类型匹配都失败了 会进入该分支
// 例如revert() require(false) revert自定义类型的error
}如果想要确保能 catch 到异常, catch 最后的分支要不是 catch (bytes memory), 要不是 catch {}
问题就来了,为什么只支持 external function呢? 个人猜测是因为:
external 调用不确定性更高,可能出来 gas 不够,或者是其他异常,所以需要引入 try/catch 来作异常处理; 而对于合约内的调用,因为 Solidity 的异常模型是 state-revert exception, 所以当内部调用出现问题了(require 或者 assert),状态就自动回滚了,无须 try/catch 处理
WTF Solidity 102 is done, I should pat myself on the back for completing this project.
为了方便交互,Ethereum 基金会定义了 ERC-20 标准,只要你的合约包含如下 methods,那么你的 token 就可以作为一种标准 ERC-20 FT 被其他的钱包和交易所所支持.
totalSupply()
balanceOf(account)
transfer(to, amount)
allowance(owner, spender)
approve(spender, amount)
transferFrom(from, to, amount)代码非常简单易懂,没有并行和并发,不需要考虑任何数据冲突。 所谓的挖矿,就是调用一下合约的 mint 方法,然后编辑账本,给某个地址增加一点余额。 所谓的转账,就是调用一下合约的 transfer 方法,然后编辑账本,给一个地址减少一点余额,给另一个地址增加一点余额。
只要你的 contract 符合 ERC-20 标准,就可以将合约地址作为一个 FT Token,登记到任何支持 ERC-20 的平台或钱包。
通过以下代码就创建了一个符合ERC20标准的Token:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.4;
import "@openzeppelin/contracts/token/ERC20/IERC20.sol";
contract ERC20Token is IERC20 {
mapping(address => uint256) public override balanceOf;
mapping(address => mapping(address => uint256)) public override allowance;
uint256 public override totalSupply;
string public name;
string public symbol;
uint8 public decimals = 18;
constructor(string memory name_, string memory symbol_) {
name = name_;
symbol = symbol_;
}
function transfer(address recipient, uint amount) public override returns (bool){
balanceOf[msg.sender] -= amount;
balanceOf[recipient] += amount;
emit Transfer(msg.sender, recipient, amount);
return true;
}
function approve(address spender, uint amount) public override returns (bool) {
allowance[msg.sender][spender] = amount;
emit Approval(msg.sender, spender, amount);
return true ;
}
function transferFrom(address sender, address recipient, uint amount) public override returns (bool) {
allowance[sender][msg.sender] -= amount;
balanceOf[sender] -= amount;
balanceOf[recipient] += amount;
emit Transfer(sender, recipient, amount);
return true;
}
function mint(uint amount) external {
balanceOf[msg.sender] += amount;
totalSupply += amount;
emit Transfer(address(0), msg.sender, amount);
}
function burn(uint amount) external {
balanceOf[msg.sender] -= amount;
totalSupply -= amount;
emit Transfer(msg.sender, address(0), amount);
}
}本来打算上线测试网的,但是一直报错 gas required exceeds allowance (85717), 我的 Sepolia ETH又不多,只好作罢.
虽然可以通过智能合约实现一个 ERC20 的Token, 但是 openzeppelin 甚至把 ERC20 Token的代码都写好了,只需要继承 ERC20.sol 即可, 网页点击下就可以一键发币.
通过继承 ERC20 来发行一个貔貅币(PIXIU Token)
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.4;
import "@openzeppelin/contracts/token/ERC20/ERC20.sol";
contract PIXIU is ERC20 {
constructor(uint256 initialSupply) public ERC20("PIXIU", "PX") {
_mint(msg.sender, initialSupply);
}
}通过智能合约来实现简易版本的 ERC20 水龙头:
pragma solidity ^0.8.4;
import "@openzeppelin/contracts/token/ERC20/IERC20.sol";
contract Facuet {
uint256 public amountAllowed = 100;
address public tokenContract;
mapping(address => bool) public requestedAddress;
event SendToken(address indexed Receiver, uint256 indexed Amount);
constructor (address _tokenContract) {
tokenContract = _tokenContract;
}
function requestTokens() external {
require(!requestedAddress[msg.sender], "Can't request multiple times!");
IERC20 token = IERC20(tokenContract);
require(token.balanceOf(address(this))>= amountAllowed, "Faucet Empty!");
token.transfer(msg.sender, amountAllowed);
requestedAddress[msg.sender] = true;
emit SendToken(msg.sender, amountAllowed);
}
}但实际的水龙头肯定会比这个复杂,因为代币数量有限,会限制每个地址领取的时间间隔(假设能重复领取的话); 为了避免被爬虫直接把水龙头给薅光,还会加上类似 Google 的 Recaptcha 或者是 Cloudflare 的 Turnstile 人机校验服务; 更严格的还会接入链上 passport 服务,超过一定分数才能领水。
这让我意识到, 即使领水是 Web3 的概念,但是水龙头的实现不能是单纯的 Solidity 智能合约,更进一步地说,如果把区块链理解成分布式的数据库,那么 Solidity 是否就算是数据库的存储过程呢?
我们当然可以把逻辑计算放到存储过程,但是鉴于其成本较高(数据库的存储过程成本就是维护成本,存储成本,而区块链就是 gas fee), 部分逻辑适合放到逻辑层(Web2),部分逻辑可以放到存储层(智能合约)
课程提到最早的代币水龙头是BTC水龙头,但是那个时候还没有智能合约,所以肯定是使用 Web2 的技术栈实现的.
通过智能合约来发送空投,其实就是一个 for 循环来给符合条件的地址列表打固定金额的钱,转账前做参数校验:
// 数组求和函数
function getSum(uint256[] calldata _arr) public pure returns(uint sum){
for(uint i = 0; i < _arr.length; i++)
sum = sum + _arr[i];
}
/// @notice 向多个地址转账ERC20代币,使用前需要先授权
///
/// @param _token 转账的ERC20代币地址
/// @param _addresses 空投地址数组
/// @param _amounts 代币数量数组(每个地址的空投数量)
function multiTransferToken(
address _token,
address[] calldata _addresses,
uint256[] calldata _amounts
) external {
// 检查:_addresses和_amounts数组的长度相等
require(_addresses.length == _amounts.length, "Lengths of Addresses and Amounts NOT EQUAL");
IERC20 token = IERC20(_token); // 声明IERC合约变量
uint _amountSum = getSum(_amounts); // 计算空投代币总量
// 检查:授权代币数量 >= 空投代币总量
require(token.allowance(msg.sender, address(this)) >= _amountSum, "Need Approve ERC20 token");
// for循环,利用transferFrom函数发送空投
for (uint8 i; i < _addresses.length; i++) {
token.transferFrom(msg.sender, _addresses[i], _amounts[i]);
}
}上面的空投代码的 gas fee 会随着地址列表的增多而线性增加, 关于 gas fee, 我现在觉得是一个相当巧妙的设计:
矿工(节点)的算力是相当宝贵的,但是你的代码运行在节点上,并不能像云上的虚拟机一样提供一个沙箱环境,那么对于恶意的代码,可能一个死循环就把矿工的算力给耗尽了,但是在程序运行之前,并没有办法判断代码是否可以及时返回的,可穷尽的。
而引入 gas fee 就相当于把金融手段解决工程问题,死循环的代码你可以写,只要你付对应的 gas fee 就可以了,相当于每个人都用钱包为其写的代码负责。
不过上面的空投代码没有做余额的检查,例如地址列表有100个,转账到99个的时候余额不足,然后回滚,但是回滚前的 gas fee 还是要照付,毕竟前面的转账矿工也干活了,不能让人家白干。
我撸空投收获最大的一次是ENS空投,你们呢?
还没有撸到过 :(
ERC20 本质上就只是一个 mapping, 记录了每一个地址的余额,仅此而已。它的缺点是,每一个 Token 都是一样的,没有任何区别。
为了能更好的和独特的资产建立联系,Ethereum基金会定义了ERC-721标准,用来定义一种独特的 token, 也就是 NFT(Non-Fungible Token)
NFT能证明某个数字资产是正版,但是无法阻止别人使用盗版,这是两个不同的问题.
而课程中反复提及的 ERC165 其实就是一个类型检查,判断合约是否实现了指定的接口, 以Rust 的代码为例:
// Define a trait
trait MyTrait {
fn my_method(&self);
}
// Implement the trait for a struct
struct MyStruct;
impl MyTrait for MyStruct {
fn my_method(&self) {
println!("MyStruct implements MyTrait");
}
}
// Function that requires the struct to implement MyTrait
fn requires_trait<T: MyTrait>(item: T) {
item.my_method();
}
fn main() {
let my_struct = MyStruct;
requires_trait(my_struct); // Will compile, because MyStruct implements MyTrait
}用 Solidity 的话来理解上面的代码,MyTrait 就类似是 ERC721 这样的接口, MyStruct 就类似合约,只有合约实现了某个指定的接口,功能才能正常运行.
强类型的编程语言编译器一般都实现了这样的能力,而因为 Solidity 编译器或者是 EVM 的限制,就需要额外提出一个 ERC 来实现这个功能, 相当于是把编译器搬到分布式环境上来了.
按照 EIP165, interface id是某个接口所有函数 selector 异或的结果, 代码示例如下:
pragma solidity ^0.4.20;
interface Solidity101 {
function hello() external pure;
function world(int) external pure;
}
contract Selector {
function calculateSelector() public pure returns (bytes4) {
Solidity101 i;
return i.hello.selector ^ i.world.selector;
}
}
如果某个接口只有一个函数,那么这个接口的接口ID自然就是函数的 selector。
我看课程中的 ERC165 和 ERC721 内容看得头疼,后面对照着 OpenZeppelin 的源码,我终于明白了我为什么头疼,同样的名词在不同语境下表达的是不过的意思.
ERC: 全称 Ethereum Request For Comment (以太坊意见征求稿), 用以记录以太坊上应用级的各种开发标准和协议, 就是正常的RFC, 各种标准和修正方案.
我们可以看下ERC721是如何实现supportsInterface()函数的:
function supportsInterface(bytes4 interfaceId) external pure override returns (bool)
{
return
interfaceId == type(IERC721).interfaceId ||
interfaceId == type(IERC165).interfaceId;
}
看到这里,我非常费解,为什么 ERC721 提案要实现 ERC165, 看了源码才意识到 ERC721 是实现了 IERC721 接口和 IERC165 接口的抽象合约:
abstract contract ERC721 is Context, ERC165, IERC721, IERC721Metadata, IERC721Errors {
...
}ERC721 要实现 supportsInterface 的函数,恰好就是 IERC165 接口中的函数, 而一个合约所支持的接口,自然包含它所实现的接口,所以 ERC721 是支持 IERC165 和 IERC721.
看到这个函数的时候,我又疑惑了,这个非常关键的条件:retval != IERC721Receiver.onERC721Received.selector 究竟是什么意思:
function _checkOnERC721Received(
address operator,
address from,
address to,
uint256 tokenId,
bytes memory data
) internal {
if (to.code.length > 0) {
try IERC721Receiver(to).onERC721Received(operator, from, tokenId, data) returns (bytes4 retval) {
if (retval != IERC721Receiver.onERC721Received.selector) {
// Token rejected
revert IERC721Errors.ERC721InvalidReceiver(to);
}
} catch (bytes memory reason) {
if (reason.length == 0) {
// non-IERC721Receiver implementer
revert IERC721Errors.ERC721InvalidReceiver(to);
} else {
/// @solidity memory-safe-assembly
assembly {
revert(add(32, reason), mload(reason))
}
}
}
}
}阅读 IERC721Receiver 接口的代码注释,我才终于理解是什么意思:
interface IERC721Receiver {
/**
* @dev Whenever an {IERC721} `tokenId` token is transferred to this contract via {IERC721-safeTransferFrom}
* by `operator` from `from`, this function is called.
*
* It must return its Solidity selector to confirm the token transfer.
* If any other value is returned or the interface is not implemented by the recipient, the transfer will be
* reverted.
*
* The selector can be obtained in Solidity with `IERC721Receiver.onERC721Received.selector`.
*/
function onERC721Received(
address operator,
address from,
uint256 tokenId,
bytes calldata data
) external returns (bytes4);
}课程完全没有提及, 为了确认 token 转账,IERC721Receiver.onERC721Received 规定,必须返回 onERC721Received 这个函数的 selector, 返回其他值或者接口未实现都会导致转账被回滚.
但是课程完全没有提及这个关键信息, 遇事不决看源码好了.
另外, ERC721 的示例代码是有问题的:
ERC721主合约实现了IERC721,IERC165和IERC721Metadata定义的所有功能,包含4个状态变量和17个函数。
但是实际的示例代码并没有实现 IERC165 接口:
contract ERC721 is IERC721, IERC721Metadata{
// 实现IERC165接口supportsInterface
function supportsInterface(bytes4 interfaceId)
external
pure
override
returns (bool)
{
return
interfaceId == type(IERC721).interfaceId ||
interfaceId == type(IERC165).interfaceId ||
interfaceId == type(IERC721Metadata).interfaceId;
}
}
我创建了一个 PR 来修复我所遇到的问题.
荷兰拍卖是指,拍卖人先将价格设定在足以阻止所有竞拍者的水平,然后由高价往低价喊,第一个应价的竞拍者获胜,并支付当时所喊到的价格。
拍卖合约继承了 Owner 合约,我看了 Owner 合约的文档, 权限控制在智能合约非常关键,最常见和最基本的权限抽近就是只有合约的所有者才有权限做管理操作,而每个合约只拥有一个所有者就是件理所当然的事了。
默认的情况,继承Owner合约的所有者就是部署合约的地址,只有它才有权限进行操作, 比如课程中的设置拍卖开始时间和提款操作.
虽然荷兰拍卖的原理是每过 AUCTION_DROP_INTERVAL 价格就衰减一次,但是并没有一个定时器或者 crontab 不停的更新时间并且广播,而是当有竞拍者调用 getAuctionPrice 时函数,根据已经过去的时间,再根据时间动态算出价格.
function getAuctionPrice()
public
view
returns (uint256)
{
if (block.timestamp < auctionStartTime) {
return AUCTION_START_PRICE;
}else if (block.timestamp - auctionStartTime >= AUCTION_TIME) {
return AUCTION_END_PRICE;
} else {
uint256 steps = (block.timestamp - auctionStartTime) /
AUCTION_DROP_INTERVAL;
return AUCTION_START_PRICE - (steps * AUCTION_DROP_PER_STEP);
}
} // 拍卖mint函数
function auctionMint(uint256 quantity) external payable{
uint256 _saleStartTime = uint256(auctionStartTime); // 建立local变量,减少gas花费
require(
_saleStartTime != 0 && block.timestamp >= _saleStartTime,
"sale has not started yet"
); // 检查是否设置起拍时间,拍卖是否开始
require(
totalSupply() + quantity <= COLLECTOIN_SIZE,
"not enough remaining reserved for auction to support desired mint amount"
); // 检查是否超过NFT上限
uint256 totalCost = getAuctionPrice() * quantity; // 计算mint成本
require(msg.value >= totalCost, "Need to send more ETH."); // 检查用户是否支付足够ETH
// Mint NFT
for(uint256 i = 0; i < quantity; i++) {
uint256 mintIndex = totalSupply();
_mint(msg.sender, mintIndex);
_addTokenToAllTokensEnumeration(mintIndex);
}
// 多余ETH退款
if (msg.value > totalCost) {
payable(msg.sender).transfer(msg.value - totalCost); //注意一下这里是否有重入的风险
}
}现实中的拍卖可能是把藏品给到竞拍者,而上面的拍卖函数是通过合约收你钱,然后「现场」铸造出来,即产即销了.
这里"建立local变量,减少gas花费", 类似于 caching 的技巧,相当于把多次访问并且只读的状态变量缓存起来,以减少 gas fee, 减少一次 SLOAD 指令,大概能节省 2100 gas fee.
荷兰拍卖中,直接和价格关联的就是 block.timestamp, 我在想,是否有可能控制 block.timestamp,比如直接把区块链时间戳直接改到起始时间+拍卖时长之后,那么不就可以直接以最低价/地板价拍到手了嘛?
不过看起来,validator 只有几秒的空间来调整,时间戳应该不存在被利用的漏洞.
我写了一篇博客来梳理这一课的内容,深入浅出地分析了Merkle Tree:区块链的完整性校验方案: Merkle Tree
文章内容
最近通过 Solidity-103 课程在学习 Solidity, 看到第36课 Merkle Tree 的时候着实头疼, 即使我已经了解 Merkle Tree 这数据结构,但是课程还是看得不明所以。
所以写下这篇文章,梳理我所理解的 Merkle Tree 及其用途,既加深自己的理解,又践行了费曼学习法
关于区块链的资料有非常多,我也不赘述了.
简单理解,区块链是由一个一个区块构成的有序链表,每一个区块都记录了一系列交易,并且,每个区块都指向前一个区块,从而形成一个链条。区块链听起来很高级,其实就是个单链表。

每个区块都会保存对应的交易信息,也会包含元数据信息在头部,包括前一个区块的 hash, 包含的交易数,merkle tree 的根节点 hash,时间戳等信息.

我们总说区块链是不可窜改,那么它究竟是怎么不可窜改的?
如果用户想要验证某个区块的某笔交易是否被窜改,他要怎么做?
最简单的方式自然是把整个区块的交易都下载下来,平均每个区块有1M的数据,验证起来肯定很费时间.
是否有一个验证方案,可以使用很小的数据集就完成验证?
有的,那就是 Merkle Tree.
那什么是 Merkle Tree?
假如我们有8笔交易被包含在区块中, 每笔交易都可以通过 hash 函数计算出一个 hash 值:
哈希值也可以看做数据,所以可以把 h1 和 h2 拼起来, h3 和 h4 拼起来, 依此类推,再计算出哈希值 b1 和 b2

递归计算下去,直到计算结果只有一个 hash 值,这个就是所谓的 merkle root, 而 h1-h8 就是所谓的 leaf node, 两者之间的就是 non-leaf node.
交易数量恰好是偶数能这么算,如果是奇数,那要怎么算呢?这个时侯,只需要把最后一个 hash 值复制一份,也能算出最终的 merkle root:

现在有了 Merkle Tree, 如果我们要验证区块中的交易是否被修改,要怎么算呢?
最简单粗暴的方式肯定是把区块所有的交易下载下来,从头重组整棵 Merkle Tree, 8笔交易计算起来还可以,如果是几千笔呢?几百万笔呢?甚至几亿笔交易呢?
重组 Merkle Tree 的时间复杂度是 O(N), 如果是1亿笔交易,这意味着你要计算1亿次,太慢了。
但是,如果我们利用 Merkle Tree 的特性,从数学的角度,我们只需要少量的Merkle Proof(你可以理解成需要提供的验证数据集), 就可以完成验证.
回到上文的 Merkle Tree, 假如我们要验证 tx2 是否被窜改,我们需要有 Merkle Tree Root 和 Merkle Proof:

假设现在我们有 tx2 的交易数据,我们只需要 Merkle Proof 提供3个hash 值(图中的绿色部分),然后我们只计算4次(橙色部分),就会算出 Merkle Root Tree 的值,用来和区块头部的 Merkle root 值进行比对。
通过 Merkle Proof 提供的数据集,我们就可以把下载8笔交易,计算15次hash,优化成只需3个 hash 值,以及计算4次hash,时间复杂度从O(N)降低成O(logN).
这个比对似乎不明显,但是以1亿交易为例的话,log(1_000_000_000) ~= 27, 也就是只需要 Merkle Proof 提供27个 hash 值即可, 巨大的性能提升.
通过Merkle tree root可以保证交易的不可窜改性,而区块 hash 又能保证区块头部的元数据不被窜改.
因为每个区块都有区块 hash, 区块hash是通过计算头部元数据信息计算出来的:

只要修改了其中一个元数据值,那么 block hash 就会发生变化,而区块链就是一个单链表,通过后一个区块通过 prev_hash 指向前一个区块,如果 block hash 发生变化,那么后一个区块就无法正确指向前一个区块了,这个链就断了.
如果一个恶意的攻击者修改了一个区块中的某个交易,那么Merkle Hash验证就不会通过。
所以,他只能重新计算Merkle Hash,然后把区块头的Merkle Hash也修改了。
这时,我们就会发现,这个区块本身的Block Hash就变了,所以,下一个区块指向它的链接就断掉了, 他就要把后续所有区块全部重新计算并且伪造出来,才能够修改整个区块链;
而要修改后续所有区块,这个攻击者必须掌握全网51%以上的算力才行。
理论上可行,但是实操难度非常非常非常大.
除去区块链,Merkle Tree还被应用于类似 Git 和 Mercurial 这样的版本管理系统中,以Git为例, 假如我们Git项目内有4个文件:

当你push 代码到远程分支或者从远程分支 pull 代码的时候,Git就计算你的Merkle Tree Root 的值, 比较远程分支的Merkle Tree Root和本地分支的Merkle Tree Root 是否相同:
如果相同,那就不用更新了;如果不同的话它就会检查左节点或者右节点,并且递归下去,
直到找到是哪些文件发生了修改,只通过网络传输修改部分的内容, 以提高传输效率.
不过Git实际用的是Merkle Tree的变体,并不是直接使用Merkle Tree.
除些之外, Merkle Tree 还在 Cassandra, DynamoDB 这样的NoSQL数据库中被用于检查不同节点数据的一致性, 细节可以看下这个 Stackoverflow 问题。
再回头来看第36课,我也终于明白Merkle Tree是用来干什么的?把整个白名单存储在智能合约上非常费 gas fee, 所以通过Merkle Tree通过验证某个地址是否在白名单上,而不需要把整个白名单列举存储在链上,只存储 Merkle Tree Root.
但是让我现在还没有理清楚的是某个地址的 proof 是怎么得出来的:
通过网站,我们可以得到地址0的proof如下,即图2中蓝色结点的哈希值:
[
"0x999bf57501565dbd2fdcea36efa2b9aef8340a8901e3459f4a4c926275d36cdb",
"0x4726e4102af77216b09ccd94f40daa10531c87c4d60bba7f3b3faf5ff9f19b3c"
]
地址0本身就是Merkle Tree的叶子节点,所以它自然会给出Merkle Proof,但是当你要计算某个地址是否在白名单内,说明这个地址是未知的,它可能在白名单内也可能不在,那么怎么知道它的Merkle Proof是什么?
假如我想计算我ETH地址 0x5B38Da6a701c568545dCfcB03FcB875f56beddC4 是否在白名单内,这个地址的Proof要怎么生成?
另外一个问题是,这种将白名单的Merkle Tree Root存在合约的方式有点不灵活,这意味着白名单不能动态变化,毕竟只要白名单变化了,Merkle Tree Root 和 Proof 都得变.
在阅读第37课的时候发现了个问题, 讲解到「步骤4通过签名和消息恢复公钥」和「步骤5 对比公钥并验证签名」, 通过截图展示了在Remix IDE 上 调用 recoverSigner 函数和 verify 函数的过程:
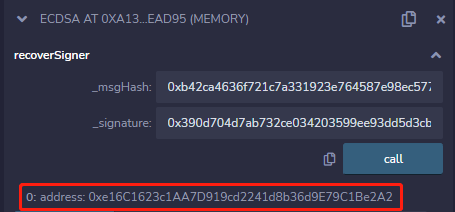
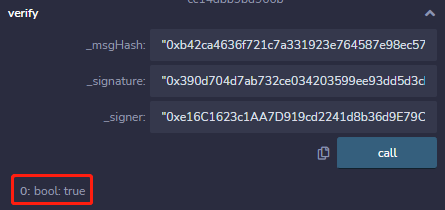
但是 recoverSigner 和 verify 函数都被声明成 internal 函数,internal 函数是无论从合约外被调用的,即使是使用 Remix IDE进行调试
// @dev 从_msgHash和签名_signature中恢复signer地址
function recoverSigner(bytes32 _msgHash, bytes memory _signature) internal pure returns (address){
}
/**
* @dev 通过ECDSA,验证签名地址是否正确,如果正确则返回true
* _msgHash为消息的hash
* _signature为签名
* _signer为签名地址
*/
function verify(bytes32 _msgHash, bytes memory _signature, address _signer) internal pure returns (bool) {
return recoverSigner(_msgHash, _signature) == _signer;
}我顺便提了个PR来修复这个问题, 关于 Solidity external 和 public 的差别, Ethereum StackExchange 的这个回答讲得非常好.
而签名中的包含的 r,s,v 信息,是 ECDSA(椭圆曲线数字签名算法)签名的三个组成部分。
- r:一个32字节的值,代表签名的第一部分,通常对应于签名过程中随机选取点的x坐标。
- s:另一个32字节的值,与 r 共同用于验证签名的唯一性和有效性。
- v:1字节的值,通常为27或28,表示 recovery id,帮助确定签名使用的两个可能的公钥中的哪一个,从而可以恢复出签名者的地址。
因为对非对称加密算法研究不深, 只能理解是3个关键要素了.
我很喜欢这种通过签名来下发NFT的方式,相当于它把白名单管理和领取的逻辑给分离出来,项目方只要给白名单内的地址进行签名,白名单内的地址就可以拿着签名来领取NFT了, 还能节省 gas fee, 既灵活也经济, 智能合约在这里的作用相当是白名单验证+Token下发.
由于签名是链下的,不需要gas,因此这种白名单发放模式比Merkle Tree模式还要经济; 但由于用户要请求中心化接口去获取签名,不可避免的牺牲了一部分去中心化;
但是即使使用 Merkle Tree 模式,还是要向中心化接口请求,获取Merkle Proof。
我觉得还是要看清楚技术的价值所在,去中心化是手段,而不是目的, 更何况现在虽然有Web3 的概念,但是现在绝大多数的项目还是跑在Web2上的,各个项目的官网不还是要跑在服务器上嘛.
作为用户,既不会关心你的网站是用Java写的,还是用PHP写的,只会关心网站的体验好不好。
同理,用户也不会关心你是用Web2或者是Web3方案做的,也只关心这个东西好不好用,区块链的确通过不可变性解决了信任问题,但是就好像EVM 可以通过gas fee经济模型来处理计算成本的问题,会有多种方案来解决同一个问题的,比如也可以通过法律来解决信任问题。
技术终究是手段,能解决问题才是目的.
生成随机数的方式有两种:
方式一:链上通过 block.timestamp, msg.sender, blockhash(block.number - 1) 变量生成随机数:
/**
* 链上伪随机数生成
* 利用keccak256()打包一些链上的全局变量/自定义变量
* 返回时转换成uint256类型
*/
function getRandomOnchain() public view returns(uint256){
// remix运行blockhash会报错
bytes32 randomBytes = keccak256(abi.encodePacked(block.timestamp, msg.sender, blockhash(block.number-1)));
return uint256(randomBytes);
}但是这些变量连伪随机数都不算,就更用说能生成安全随机数了(SecureRandom)了.
方式二:线下生成随机数,再通过通过预言机上传到链上,我对这个机制就比较感兴趣, 就去了解了一下预言机(Oracle).
预言机,名字很玄乎,实际上就是同步链外数据到链上,从而让智能合约拥有了获取链外数据的能力。
简而言之就是智能合约不能请求外部数据,所以需要找到一种方式让链外数据能够被保存到链上,这个解决方案就是 Oracle。
Oracle 的代码逻辑就是一个存储 + 异步任务引擎,接口定义如下:
// 这是一个很标准的异步任务流程,发起任务,拿到 taskID,然后轮询 taskID 直到任务完成。
//
// 当某个 consumer(其他的智能合约)需要 offchain 数据时,就请求 Oracle 的 request 接口,
// 创建一个异步任务,拿到 requestID。Oracle 本身也就是一个智能合约,也不能请求外部,
// 所以不可能实时处理请求,只能等链外的组件喂数据,所以只能以异步任务的模式来实现。
//
// 一般一个 Oracle 只负责某一类的任务,比如获取当前币价,或者获取一个随机数。
// 任务创建后会 emit 一个 Event,链外的基础设施监听到这个事件后就可以开始喂数据。
function request() external onlyOwner returns (uint256 requestId)
// fulfill 函数就是给 offchain 的基础设施喂数据用的,
// offchain 通过 Event 事件了解到有新的任务被创建了,然后准备好所需的数据,
// 用 fulfill 函数把数据喂给 Oracle,Oracle 再把数据和 requestID 一起保存到内部的一个 mapping 变量里,
// 这就实现了将链外数据保存到链上。
function fulfill(uint256 _requestId, uint256[] memory _randomWords) internal override
// consumer 在创建完任务后,轮询该接口获取任务的执行结果,也就是所请求的 offchain data
function getRequestStatus(uint256 _requestId) external view returns (uint256 paid, bool fulfilled, uint256[] memory result)这个就是标准的异步操作流程了,画个流程图就很清晰了:
sequenceDiagram
ConsumerContract ->> Oracle: 调用[request]接口,创建获取随机数任务
Oracle -->> ConsumerContract: requestId
loop SubscribeEvent
OffChainService ->> Oracle: 监听Event 事件
end
Oracle->>OffChainService: emit 事件, 触发OffChainService
OffChainService ->> OffChainService: 执行对应的链下逻辑
OffChainService ->> Oracle: 调用fullfill 接口填充数据
loop TaskStatusCheck
ConsumerContract->>Oracle: 通过[requestId]查询任务执行结果
end
Note right of ConsumerContract: [optional]Consumer可以通过查询接口轮询任务状态
Oracle ->> ConsumerContract: 拿到链下数据后,执行consumer中的回调函数[fulfillRandomWords]
- Consumer 调用 Oracle
request函数创建任务 - Oracle 创建任务后,返回requestId 作为任务标识符, 并 emit 事件
- 订阅了Oracle 事件的链下服务被新事件触发,执行任务(比如生成随机数)
- 链下服务调用
fullfill函数填充指定任务的数据 - 当任务完成之后,Consumer 智能合约有两种方式可以获取到指定的数据,通过
getRequestStatus接口轮询,或者等 Oracle 回调(如果Oracle 支持的话). 课程生成随机数的 Chainlink 预言机支持回调接口,所以课程用的就是回调(这个也的确更费心)
整套流程下来,就实现了链下数据向链上数据的转移, 而课程中提到的生成随机数,就是其中一个预言机的应用场景了。
但这么大费周章,目的只是为了生成个随机数,成本着实有点高。