二分查找又称折半搜索算法。 狭义地来讲,二分查找是一种在有序数组查找某一特定元
素的搜索算法。这同时也是大多数人所知道的一种说法。实际上, 广义的二分查找是将问
题的规模缩小到原有的一半。类似的,三分法就是将问题规模缩小为原来的 1/3。
本文给大家带来的内容则是狭义地二分查找,如果想了解其他广义上的二分查找可以查看
我之前写的一篇博文
从老鼠试毒问题来看二分法
尽管二分查找的基本思想相对简单,但细节可以令人难以招架 ... — 高德纳
当乔恩·本特利将二分搜索问题布置给专业编程课的学生时,百分之 90 的学生在花费数小 时后还是无法给出正确的解答,主要因为这些错误程序在面对边界值的时候无法运行,或返 回错误结果。1988 年开展的一项研究显示,20 本教科书里只有 5 本正确实现了二分搜索 。不仅如此,本特利自己 1986 年出版的《编程珠玑》一书中的二分搜索算法存在整数溢出 的问题,二十多年来无人发现。Java 语言的库所实现的二分搜索算法中同样的溢出问题存 在了九年多才被修复。
可见二分查找并不简单, 本文就试图带你走近 ta,明白 ta 的底层逻辑,并提供模板帮助 大家写书 bug free 的二分查找代码。
大家可以看完讲义结合 LeetCode Book 二分查找练习一下
给定一个由数字组成的有序数组 nums,并给你一个数字 target。问 nums 中是否存在 target。如果存在, 则返回其在 nums 中的索引。如果不存在,则返回 - 1。
这是二分查找中最简单的一种形式。当然二分查找也有很多的变形,这也是二分查找容易出 错,难以掌握的原因。
常见变体有:
- 如果存在多个满足条件的元素,返回最左边满足条件的索引。
- 如果存在多个满足条件的元素,返回最右边满足条件的索引。
- 数组不是整体有序的。 比如先升序再降序,或者先降序再升序。
- 将一维数组变成二维数组。
- 。。。
接下来,我们逐个进行查看。
- 数组是有序的(如果无序,我们也可以考虑排序,不过要注意排序的复杂度)
二分查找中使用的术语:
- target —— 要查找的值
- index —— 当前位置
- l 和 r —— 左右指针
- mid —— 左右指针的中点,用来确定我们应该向左查找还是向右查找的索引
算法描述:
- 先从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;
- 如果目标元素大于中间元素,则在数组大于中间元素的那一半中查找,而且跟开始一样从 中间元素开始比较。
- 如果目标元素小于中间元素,则在数组小于中间元素的那一半中查找,而且跟开始一样从 中间元素开始比较。
- 如果在某一步骤数组为空,则代表找不到。
复杂度分析
- 平均时间复杂度:
$O(logN)$ - 最坏时间复杂度:
$O(logN)$ - 最优时间复杂度:
$O(1)$ - 空间复杂度
- 迭代:
$O(1)$ - 递归:
$O(logN)$ (无尾调用消除)
- 迭代:
后面的复杂度也是类似的,不再赘述。
这种搜索算法每一次比较都使搜索范围缩小一半,是典型的二分查找。
这个是二分查找中最简答的一种类型了,我们先来搞定它。 我们来一个具体的例子, 这样
方便大家增加代入感。假设 nums 为 [1,3,4,6,7,8,10,13,14], target 为 4·。
- 刚开始数组中间的元素为 7
- 7 > 4 ,由于 7 右边的数字都大于 7 ,因此不可能是答案。我们将范围缩写到了 7 的 左侧。
- 此时中间元素为 3
- 3 < 4,由于 3 左边的数字都小于 3 ,因此不可能是答案。我们将范围缩写到了 3 的右 侧。
- 此时中间元素为 4,正好是我们要找的,返回其索引 2 即可。
如何将上面的算法转换为容易理解的可执行代码呢?就算是这样一个简简单单,朴实无华的 二分查找, 不同的人写出来的差别也是很大的。 如果没有一个思维框架指导你,那么你在 不同的时间可能会写出差异很大的代码。这样的话,你犯错的几率会大大增加。
这里给大家介绍一个我经常使用的思维框架和代码模板。
** 首先定义搜索区间为 [left, right],注意是左右都闭合,之后会用到这个点 **
你可以定义别的搜索区间形式,不过后面的代码也相应要调整,感兴趣的可以试试别的搜 索区间。
- 由于定义的搜索区间为 [left, right],因此当 left <= right 的时候,搜索区间都不 为空,此时我们都需要继续搜索。 也就是说终止搜索条件应该为 left <= right。
举个例子容易明白一点。 比如对于区间 [4,4],其包含了一个元素 4,因此搜索区间不 为空,需要继续搜索(试想 4 恰好是我们要找的 target,如果不继续搜索, 会错过正 确答案)。而当搜索区间为 [left, right) 的时候,同样对于 [4,4],这个时候搜索区 间却是空的,因为这样的一个区间不存在任何数字·。
- 循环体内,我们不断计算 mid ,并将 nums[mid] 与 目标值比对。
- 如果 nums[mid] 等于目标值, 则提前返回 mid(只需要找到一个满足条件的即可)
- 如果 nums[mid] 小于目标值, 说明目标值在 mid 右侧,这个时候搜索区间可缩小为 [mid + 1, right] (mid 以及 mid 左侧的数字被我们排除在外)
- 如果 nums[mid] 大于目标值, 说明目标值在 mid 左侧,这个时候搜索区间可缩小为 [left, mid - 1] (mid 以及 mid 右侧的数字被我们排除在外)
- 循环结束都没有找到,则说明找不到,返回 -1 表示未找到。
public int binarySearch(int[] nums, int target) {
// 左右都闭合的区间 [l, r]
int left = 0;
int right = nums.length - 1;
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target)
return mid;
if (nums[mid] < target)
// 搜索区间变为 [mid+1, right]
left = mid + 1;
if (nums[mid] > target)
// 搜索区间变为 [left, mid - 1]
right = mid - 1;
}
return -1;
}def binarySearch(nums, target):
# 左右都闭合的区间 [l, r]
l, r = 0, len(nums) - 1
while l <= r:
mid = (left + right) >> 1
if nums[mid] == target: return mid
# 搜索区间变为 [mid+1, right]
if nums[mid] < target: l = mid + 1
# 搜索区间变为 [left, mid - 1]
if nums[mid] > target: r = mid - 1
return -1function binarySearch(nums, target) {
let left = 0;
let right = nums.length - 1;
while (left <= right) {
const mid = Math.floor(left + (right - left) / 2);
if (nums[mid] == target) return mid;
if (nums[mid] < target)
// 搜索区间变为 [mid+1, right]
left = mid + 1;
if (nums[mid] > target)
// 搜索区间变为 [left, mid - 1]
right = mid - 1;
}
return -1;
}int binarySearch(vector<int>& nums, int target){
if(nums.size() == 0)
return -1;
int left = 0, right = nums.size() - 1;
while(left <= right){
int mid = left + ((right - left) >> 1);
if(nums[mid] == target){ return mid; }
// 搜索区间变为 [mid+1, right]
else if(nums[mid] < target)
left = mid + 1;
// 搜索区间变为 [left, mid - 1]
else
right = mid - 1;
}
return -1;
}和查找一个数类似, 我们仍然套用查找一个数的思维框架和代码模板。
- 首先定义搜索区间为 [left, right],注意是左右都闭合,之后会用到这个点。
- 终止搜索条件为 left <= right。
- 循环体内,我们不断计算 mid ,并将 nums[mid] 与 目标值比对。
- 如果 nums[mid] 等于目标值, 则收缩右边界,我们找到了一个备胎,继续看看左边还 有没有了(注意这里不一样)
- 如果 nums[mid] 小于目标值, 说明目标值在 mid 右侧,这个时候搜索区间可缩小为 [mid + 1, right]
- 如果 nums[mid] 大于目标值, 说明目标值在 mid 左侧,这个时候搜索区间可缩小为 [left, mid - 1]
- 由于不会提前返回,因此我们需要检查最终的 left,看 nums[left]是否等于 target。
- 如果不等于 target,或者 left 出了右边边界了,说明至死都没有找到一个备胎,则 返回 -1.
- 否则返回 left 即可,备胎转正。
实际上 nums[mid] > target 和 nums[mid] == target 是可以合并的。我这里为了清晰 ,就没有合并,大家熟悉之后合并起来即可。
public int binarySearchLeft(int[] nums, int target) {
// 搜索区间为 [left, right]
int left = 0;
int right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
}
if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
}
if (nums[mid] == target) {
// 收缩右边界
right = mid - 1;
}
}
// 检查是否越界
if (left >= nums.length || nums[left] != target)
return -1;
return left;
}def binarySearchLeft(nums, target):
# 左右都闭合的区间 [l, r]
l, r = 0, len(nums) - 1
while l <= r:
mid = (l + r) >> 1
if nums[mid] == target:
# 收缩右边界
r = mid - 1;
# 搜索区间变为 [mid+1, right]
if nums[mid] < target: l = mid + 1
# 搜索区间变为 [left, mid - 1]
if nums[mid] > target: r = mid - 1
if l >= len(nums) or nums[l] != target: return -1
return lfunction binarySearchLeft(nums, target) {
let left = 0;
let right = nums.length - 1;
while (left <= right) {
const mid = Math.floor(left + (right - left) / 2);
if (nums[mid] == target)
// 收缩右边界
right = mid - 1;
if (nums[mid] < target)
// 搜索区间变为 [mid+1, right]
left = mid + 1;
if (nums[mid] > target)
// 搜索区间变为 [left, mid - 1]
right = mid - 1;
}
// 检查是否越界
if (left >= nums.length || nums[left] != target) return -1;
return left;
}int binarySearchLeft(vector<int>& nums, int target) {
// 搜索区间为 [left, right]
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + ((right - left) >> 1);
if (nums[mid] == target) {
// 收缩右边界
right = mid - 1;
}
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
}
if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
}
}
// 检查是否越界
if (left >= nums.size() || nums[left] != target)
return -1;
return left;
}给你一个严格递增的数组 nums ,让你找到第一个满足 nums[i] == i 的索引,如果没有这 样的索引,返回 -1。(你的算法需要有 logN 的复杂度)。
首先我们做一个小小的变换,将原数组 nums 转换为 A,其中 A[i] = nums[i] - i。这样 新的数组 A 就是一个不严格递增的数组。这样原问题转换为 在一个不严格递增的数组 A 中找第一个等于 0 的索引。接下来,我们就可以使用最左满足模板,找到最左满足 nums[i] == i 的索引。
代码:
class Solution:
def solve(self, nums):
l, r = 0, len(nums) - 1
while l <= r:
mid = (l + r) // 2
if nums[mid] >= mid:
r = mid - 1
else:
l = mid + 1
return l if l < len(nums) and nums[l] == l else -1和查找一个数类似, 我们仍然套用查找一个数的思维框架和代码模板。
有没有感受到框架和模板的力量?
- 首先定义搜索区间为 [left, right],注意是左右都闭合,之后会用到这个点。
你可以定义别的搜索区间形式,不过后面的代码也相应要调整,感兴趣的可以试试别的搜 索区间。
- 由于我们定义的搜索区间为 [left, right],因此当 left <= right 的时候,搜索区间 都不为空。 也就是说我们的终止搜索条件为 left <= right。
举个例子容易明白一点。 比如对于区间 [4,4],其包含了一个元素 4,因此搜索区间不 为空。而当搜索区间为 [left, right) 的时候,同样对于 [4,4],这个时候搜索区间却 是空的。
- 循环体内,我们不断计算 mid ,并将 nums[mid] 与 目标值比对。
- 如果 nums[mid] 等于目标值, 则收缩左边界,我们找到了一个备胎,继续看看右边还 有没有了
- 如果 nums[mid] 小于目标值, 说明目标值在 mid 右侧,这个时候搜索区间可缩小为 [mid + 1, right]
- 如果 nums[mid] 大于目标值, 说明目标值在 mid 左侧,这个时候搜索区间可缩小为 [left, mid - 1]
- 由于不会提前返回,因此我们需要检查最终的 right,看 nums[right]是否等于
target。
- 如果不等于 target,或者 right 出了左边边界了,说明至死都没有找到一个备胎,则 返回 -1.
- 否则返回 right 即可,备胎转正。
实际上 nums[mid] < target 和 nums[mid] == target 是可以合并的。我这里为了清晰 ,就没有合并,大家熟悉之后合并起来即可。
public int binarySearchRight(int[] nums, int target) {
// 搜索区间为 [left, right]
int left = 0
int right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
}
if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
}
if (nums[mid] == target) {
// 收缩左边界
left = mid + 1;
}
}
// 检查是否越界
if (right < 0 || nums[right] != target)
return -1;
return right;
}def binarySearchRight(nums, target):
# 左右都闭合的区间 [l, r]
l, r = 0, len(nums) - 1
while l <= r:
mid = (l + r) >> 1
if nums[mid] == target:
# 收缩左边界
l = mid + 1;
# 搜索区间变为 [mid+1, right]
if nums[mid] < target: l = mid + 1
# 搜索区间变为 [left, mid - 1]
if nums[mid] > target: r = mid - 1
if r < 0 or nums[r] != target: return -1
return rfunction binarySearchRight(nums, target) {
let left = 0;
let right = nums.length - 1;
while (left <= right) {
const mid = Math.floor(left + (right - left) / 2);
if (nums[mid] == target)
// 收缩左边界
left = mid + 1;
if (nums[mid] < target)
// 搜索区间变为 [mid+1, right]
left = mid + 1;
if (nums[mid] > target)
// 搜索区间变为 [left, mid - 1]
right = mid - 1;
}
// 检查是否越界
if (right < 0 || nums[right] != target) return -1;
return right;
}int binarySearchRight(vector<int>& nums, int target) {
// 搜索区间为 [left, right]
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + ((right - left) >> 1);
if (nums[mid] == target) {
// 收缩左边界
left = mid + 1;
}
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
}
if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
}
}
// 检查是否越界
if (right < 0 || nums[right] != target)
return -1;
return right;
}上面我们讲了寻找最左满足条件的值。如果找不到,就返回 -1。那如果我想让你找不到
不是返回 -1,而是应该插入的位置,使得插入之后列表仍然有序呢?
比如一个数组 nums: [1,3,4],target 是 2。我们应该将其插入(注意不是真的插入)的
位置是索引 1 的位置,即 [1,2,3,4]。因此寻找最左插入位置应该返回 1,
而寻找最左满足条件 应该返回-1。
另外如果有多个满足条件的值,我们返回最左侧的。 比如一个数组 nums: [1,2,2,2,3,4],target 是 2,我们应该插入的位置是 1。
如果你将寻找最左插入位置看成是寻找最左满足大于等于 x 的值,那就可以和前 面的知识产生联系,使得代码更加统一。唯一的区别点在于前面是最左满足等于 x,这 里是最左满足大于等于 x。
具体算法:
- 首先定义搜索区间为 [left, right],注意是左右都闭合,之后会用到这个点。
你可以定义别的搜索区间形式,不过后面的代码也相应要调整,感兴趣的可以试试别的搜 索区间。
-
由于我们定义的搜索区间为 [left, right],因此当 left <= right 的时候,搜索区间 都不为空。 也就是说我们的终止搜索条件为 left <= right。
-
当 A[mid] >= x,说明找到一个备胎,我们令 r = mid - 1 将 mid 从搜索区间排除,继 续看看有没有更好的备胎。
-
当 A[mid] < x,说明 mid 根本就不是答案,直接更新 l = mid + 1,从而将 mid 从搜 索区间排除。
-
最后搜索区间的 l 就是最好的备胎,备胎转正。
def bisect_left(A, x):
# 内置 api
bisect.bisect_left(A, x)
# 手写
l, r = 0, len(A) - 1
while l <= r:
mid = (l + r) // 2
if A[mid] >= x: r = mid - 1
else: l = mid + 1
return limport java.util.*;
public class BinarySearch {
public int getPos(int[] A, int val) {
int low=0,high=A.lenght-1;
while (low <= high){
int mid = (low + high)/2;
if (A[mid] >= val) {
high = mid-1;
} else {
low = mid+1;
}
}
return low;
}
}public:
int binarySearch(int* arr, int arrLen,int a) {
int left = 0;
int right = arrLen - 1;
while(left<=right)
{
int mid = (left+right)/2;
if(arr[mid]>=a)
right = mid - 1;
else
left = mid + 1;
}
return left;
}function binarySearch(nums, target) {
let left = 0;
let right = nums.length - 1;
while (left <= right) {
const mid = Math.floor(left + (right - left) / 2);
if (nums[mid] >= target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
}
else {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
}
}
return left;
}其他语言暂时空缺,欢迎 PR
如果你将寻找最右插入位置看成是寻找最右满足大于 x 的值,那就可以和前面的 知识产生联系,使得代码更加统一。唯一的区别点在于前面是最左满足等于 x,这里 是最左满足大于 x。
具体算法:
- 首先定义搜索区间为 [left, right],注意是左右都闭合,之后会用到这个点。
你可以定义别的搜索区间形式,不过后面的代码也相应要调整,感兴趣的可以试试别的搜 索区间。
-
由于我们定义的搜索区间为 [left, right],因此当 left <= right 的时候,搜索区间 都不为空。 也就是说我们的终止搜索条件为 left <= right。
-
当 A[mid] > x,说明找到一个备胎,我们令 r = mid - 1 将 mid 从搜索区间排除,继 续看看有没有更好的备胎。
-
当 A[mid] <= x,说明 mid 根本就不是答案,直接更新 l = mid + 1,从而将 mid 从搜 索区间排除。
-
最后搜索区间的 l 就是最好的备胎,备胎转正。
def bisect_right(A, x):
# 内置 api
bisect.bisect_right(A, x)
# 手写
l, r = 0, len(A) - 1
while l <= r:
mid = (l + r) // 2
if A[mid] <= x: l = mid + 1
else: r = mid - 1
return l # 或者返回 r + 1import java.util.*;
public class BinarySearch {
public int getPos(int[] A, int val) {
int low=0,high=A.lenght-1;
while (low <= high){
int mid = (low + high)/2;
if (A[mid] <= val) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return low;
}
}public:
int binarySearch(int* arr, int arrLen,int a) {
int left = 0;
int right = arrLen - 1;
while(left<=right)
{
int mid = (left+right)/2;
if(arr[mid]<=a)
// 搜索区间变为 [mid+1, right]
left = mid + 1;
else
// 搜索区间变为 [left, mid-1]
right = mid - 1;
}
return left;
}function binarySearch(nums, target) {
let left = 0;
let right = nums.length - 1;
while (left <= right) {
const mid = Math.floor(left + (right - left) / 2);
if (nums[mid] <= target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
}
else {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
}
}
return left;
}其他语言暂时空缺,欢迎 PR
LeetCode 有原题 33. 搜索旋转排序数组 和 81. 搜索旋转排序数组 II, 我们直接拿过来讲解好了。
其中 81 题是在 33 题的基础上增加了包含重复元素的可能,实际上 33 题的进阶就是
81 题。通过这道题,大家可以感受到”包含重复与否对我们算法的影响“。 我们直接上最复
杂的 81 题,这个会了,可以直接 AC 第 33 题。
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。
编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。
示例 1:
输入: nums = [2,5,6,0,0,1,2], target = 0
输出: true
示例 2:
输入: nums = [2,5,6,0,0,1,2], target = 3
输出: false
进阶:
这是 搜索旋转排序数组 的延伸题目,本题中的 nums 可能包含重复元素。
这会影响到程序的时间复杂度吗?会有怎样的影响,为什么?
这是一个我在网上看到的前端头条技术终面的一个算法题。我们先不考虑重复元素。
题目要求时间复杂度为 logn,因此基本就是二分法了。 这道题目不是直接的有序数组,不 然就是 easy 了。
首先要知道,我们随便选择一个点,将数组分为前后两部分,其中一部分一定是有序的。
具体步骤:
- 我们可以先找出 mid,然后根据 mid 来判断,mid 是在有序的部分还是无序的部分
假如 mid 小于 start,则 mid 一定在右边有序部分,即 [mid,end] 部分有序。假如 mid 大于 start,则 mid 一定在左边有序部分,即 [start,mid]部分有序。这是这类题目的 突破口。
注意我没有考虑等号,之后我会讲。
- 然后我们继续判断 target 在哪一部分, 就可以舍弃另一部分了。
也就是说只需要比较 target 和有序部分的边界关系就行了。 比如 mid 在右侧有序部 分,即[mid,end] 有序。那么我们只需要判断 target >= mid && target <= end 就能知道 target 在右侧有序部分,我们就可以舍弃左边部分了(通过 start = mid + 1 实现), 反 之亦然。
我们以([6,7,8,1,2,3,4,5], 4)为例讲解一下:
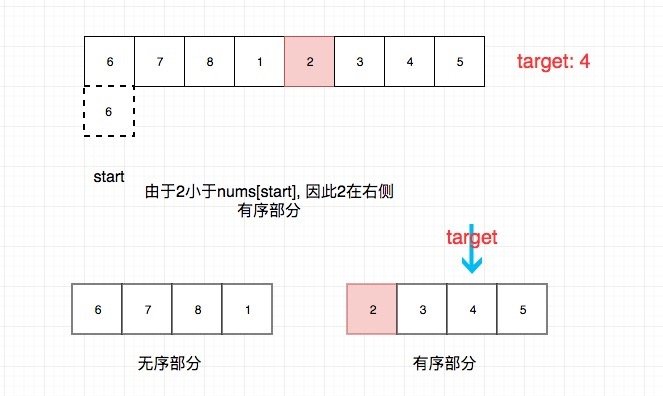

接下来,我们考虑重复元素的问题。如果存在重复数字,就可能会发生 nums[mid] == nums[start] 了,比如 30333 。这个时候可以选择舍弃 start,也就是 start 右移一位。 有的同学会担心”会不会错失目标元素?“。其实这个担心是多余的,前面我们已经介绍了” 搜索区间“。由于搜索区间同时包含 start 和 mid ,因此去除一个 start ,我们还有 mid。假如 3 是我们要找的元素, 这样进行下去绝对不会错过,而是收缩”搜索区间“到一 个元素 3 ,我们就可以心安理得地返回 3 了。
class Solution:
def search(self, nums, target):
l, r = 0, len(nums)-1
while l <= r:
mid = l + (r-l)//2
if nums[mid] == target:
return True
while l < mid and nums[l] == nums[mid]: # tricky part
l += 1
# the first half is ordered
if nums[l] <= nums[mid]:
# target is in the first half
if nums[l] <= target < nums[mid]:
r = mid - 1
else:
l = mid + 1
# the second half is ordered
else:
# target is in the second half
if nums[mid] < target <= nums[r]:
l = mid + 1
else:
r = mid - 1
return False复杂度分析
- 时间复杂度:$O(log N)$
- 空间复杂度:$O(1)$
如果题目不是让你返回 true 和 false,而是返回最左/最右等于 targrt 的索引呢?这不 就又和前面的知识建立联系了么?比如我让你在一个旋转数组中找最左等于 target 的索引 ,其实就是 面试题 10.03. 搜索旋转数组。
思路和前面的最左满足类似,仍然是通过压缩区间,更新备胎,最后返回备胎的方式来实现 。 具体看代码吧。
Python Code:
class Solution:
def search(self, nums: List[int], target: int) -> int:
l, r = 0, len(nums) - 1
while l <= r:
mid = l + (r - l) // 2
# # the first half is ordered
if nums[l] < nums[mid]:
# target is in the first half
if nums[l] <= target <= nums[mid]:
r = mid - 1
else:
l = mid + 1
# # the second half is ordered
elif nums[l] > nums[mid]:
# target is in the second half
if nums[l] <= target or target <= nums[mid]:
r = mid - 1
else:
l = mid + 1
elif nums[l] == nums[mid]:
if nums[l] != target:
l += 1
else:
# l 是一个备胎
r = l - 1
return l if l < len(nums) and nums[l] == target else -1二维数组的二分查找和一维没有本质区别, 我们通过两个题来进行说明。
https://leetcode-cn.com/problems/search-a-2d-matrix/
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
每行中的整数从左到右按升序排列。
每行的第一个整数大于前一行的最后一个整数。
示例 1:
输入:
matrix = [
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
target = 3
输出: true
示例 2:
输入:
matrix = [
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
target = 13
输出: false
简单来说就是将一个一维有序数组切成若干长度相同的段,然后将这些段拼接成一个二维数 组。你的任务就是在这个拼接成的二维数组中找到 target。
需要注意的是,数组是不存在重复元素的。
如果有重复元素,我们该怎么办?
算法:
- 选择矩阵左下角作为起始元素 Q
- 如果 Q > target,右方和下方的元素没有必要看了(相对于一维数组的右边元素)
- 如果 Q < target,左方和上方的元素没有必要看了(相对于一维数组的左边元素)
- 如果 Q == target ,直接 返回 True
- 交回了都找不到,返回 False
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
m = len(matrix)
if m == 0:
return False
n = len(matrix[0])
x = m - 1
y = 0
while x >= 0 and y < n:
if matrix[x][y] > target:
x -= 1
elif matrix[x][y] < target:
y += 1
else:
return True
return False复杂度分析
- 时间复杂度:最坏的情况是只有一行或者只有一列,此时时间复杂度为
$O(M * N)$ 。更 多的情况下时间复杂度为$O(M + N)$ - 空间复杂度:$O(1)$
力扣
240. 搜索二维矩阵 II
发生了一点变化,不再是每行的第一个整数大于前一行的最后一个整数,而是
每列的元素从上到下升序排列。我们仍然可以选择左下进行二分。
上面全部都是找到给定值,这次我们试图寻找最值(最小或者最大)。我们以最小为例,讲 解一下这种题如何切入。
https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array/
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
你可以假设数组中不存在重复元素。
示例 1:
输入: [3,4,5,1,2]
输出: 1
示例 2:
输入: [4,5,6,7,0,1,2]
输出: 0
和查找指定值得思路一样。我们还是:
- 初始化首尾指针 l 和 r
- 如果 nums[mid] 大于 nums[r],说明 mid 在左侧有序部分,由于最小的一定在右侧,因 此可以收缩左区间,即 l = mid + 1
- 否则收缩右侧,即 r = mid(不可以 r = mid - 1)
这里多判断等号没有意义,因为题目没有让我们找指定值
- 当 l >= r 或者 nums[l] < nums[r] 的时候退出循环
nums[l] < nums[r],说明区间 [l, r] 已经是整体有序了,因此 nums[l] 就是我们想要 找的
class Solution:
def findMin(self, nums: List[int]) -> int:
l, r = 0, len(nums) - 1
while l < r:
# important
if nums[l] < nums[r]:
return nums[l]
mid = (l + r) // 2
# left part
if nums[mid] > nums[r]:
l = mid + 1
else:
# right part
r = mid
# l or r is not important
return nums[l]复杂度分析
- 时间复杂度:$O(log N)$
- 空间复杂度:$O(1)$
我们当然也也可以和 nums[l] 比较,而不是上面的 nums[r],我们发现:
-
旋转点左侧元素都大于数组第一个元素
-
旋转点右侧元素都小于数组第一个元素
这样就建立了 nums[mid] 和 nums[0] 的联系。
具体算法:
-
找到数组的中间元素 mid。
-
如果中间元素 > 数组第一个元素,我们需要在 mid 右边搜索。

- 如果中间元素 <= 数组第一个元素,我们需要在 mid 左边搜索。
上面的例子中,中间元素 6 比第一个元素 4 大,因此在中间点右侧继续搜索。
- 当我们找到旋转点时停止搜索,当以下条件满足任意一个即可:
-
nums[mid] > nums[mid + 1],因此 mid+1 是最小值。
-
nums[mid - 1] > nums[mid],因此 mid 是最小值。

class Solution:
def findMin(self, nums):
# If the list has just one element then return that element.
if len(nums) == 1:
return nums[0]
# left pointer
left = 0
# right pointer
right = len(nums) - 1
# if the last element is greater than the first element then there is no rotation.
# e.g. 1 < 2 < 3 < 4 < 5 < 7. Already sorted array.
# Hence the smallest element is first element. A[0]
if nums[right] > nums[0]:
return nums[0]
# Binary search way
while right >= left:
# Find the mid element
mid = left + (right - left) / 2
# if the mid element is greater than its next element then mid+1 element is the smallest
# This point would be the point of change. From higher to lower value.
if nums[mid] > nums[mid + 1]:
return nums[mid + 1]
# if the mid element is lesser than its previous element then mid element is the smallest
if nums[mid - 1] > nums[mid]:
return nums[mid]
# if the mid elements value is greater than the 0th element this means
# the least value is still somewhere to the right as we are still dealing with elements greater than nums[0]
if nums[mid] > nums[0]:
left = mid + 1
# if nums[0] is greater than the mid value then this means the smallest value is somewhere to the left
else:
right = mid - 1复杂度分析
- 时间复杂度:$O(log N)$
- 空间复杂度:$O(1)$
对于一个给定的二叉树,其任意节点最多只有两个子节点。 从这个定义,我们似乎可以嗅 出一点二分法的味道, 但是这并不是二分。但是,二叉树中却和二分有很多联系,我们来 看一下。
最简单的,如果这个二叉树是一个二叉搜索树(BST)。 那么实际上,在一个二叉搜索树种 进行搜索的过程就是二分法。

如上图,我们需要在这样一个二叉搜索树中搜索 7。那么我们的搜索路径则会是 8 -> 3 -> 6 -> 7,这也是一种二分法。只不过相比于普通的有序序列查找给定值二分, 其时间 复杂度的下界更差,原因在于二叉搜索树并不一定是二叉平衡树。
上面讲了二叉搜索树,我们再来看一种同样特殊的树 - 完全二叉树。 如果我们给一颗完全 二叉树的所有节点进行编号(二进制),依次为 01,10,11, ...。
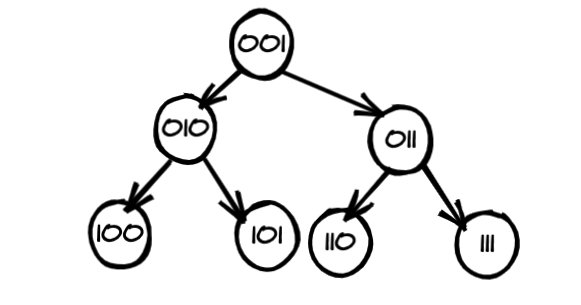
那么实际上,最后一行的编号就是从根节点到该节点的路径。 其中 0 表示向左, 1 表示 向右。(第一位数字不用)。 我们以最后一行的 101 为例,我们需要执行一次左,然后一次 右。

其实原理也不难,如果你用数组表示过完全二叉树,那么就很容易理解。 我们可以发现,左节点的编号都是父节点的二倍,并且右节点都是父节点的二倍 + 1。从二进制的角度来看就是:父节点的编号左移一位就是左节点的编号,左移一位 + 1 就是右节点的编号。 因此反过来, 知道了子节点的最后一位,我们就能知道它是父节点的左节点还是右节点啦。
后面三个题建议一起做
二分查找是一种非常重要且难以掌握的核心算法,大家一定要好好领会。有的题目直接二分 就可以了,有的题目二分只是其中一个环节。不管是哪种,都需要我们对二分的思想和代码 模板非常熟悉才可以。
二分查找的基本题型有:
- 查找满足条件的元素,返回对应索引
- 如果存在多个满足条件的元素,返回最左边满足条件的索引。
- 如果存在多个满足条件的元素,返回最右边满足条件的索引。
- 数组不是整体有序的。 比如先升序再降序,或者先降序再升序。
- 将一维数组变成二维数组。
- 局部有序查找最大(最小)元素
- 。。。
不管是哪一种类型,我们的思维框架都是类似的,都是:
- 先定义搜索区间(非常重要)
- 根据搜索区间定义循环结束条件
- 取中间元素和目标元素做对比(目标元素可能是需要找的元素或者是数组第一个,最后一 个元素等)(非常重要)
- 根据比较的结果收缩区间,舍弃非法解(也就是二分)
如果是整体有序通常只需要 nums[mid] 和 target 比较即可。如果是局部有序,则可能 需要与其周围的特定元素进行比较。
大家可以使用这个思维框架并结合本文介绍的几种题型进行练习,必要的情况可以使用我提 供的解题模板,提供解题速度的同时,有效地降低出错的概率。
特别需要注意的是有无重复元素对二分算法影响很大,我们需要小心对待。