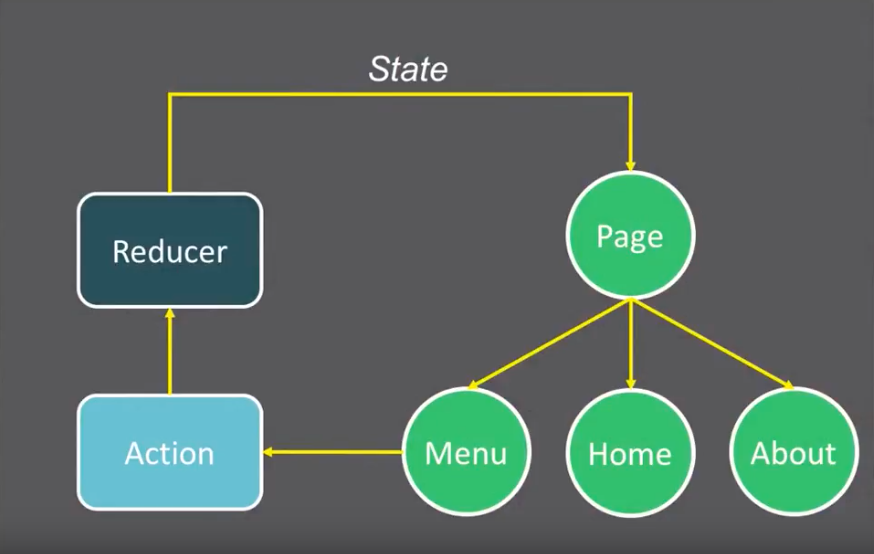
Let's use react-redux to build a system which we can alert users when things trigger. For this we will need to build an action, a reducer and a component to display the alert.
To ensure that these three components are speaking the same language, we need to initialise types which will represent the states being passed around. These variables contain a string. For our alert system we need two variables
We'll start by creating the action which will signify when an alert is triggered. We want all of our alerts to be unique so multiple alerts can handled without a problem which we will use uuid.
-
1
+
1
2
3
4
@@ -212,7 +212,7 @@
Action
The action is declared as a function, which takes in 3 arguments (2 required): msg, alertType and timeout. Which we then use call the dispatch function with an object constructed from the arguments, and then after a specified timeout we dispatch another object to remove the same alert.
Note that we curry the dispatch function in this case, this is only possible from using the middleware redux-thunk, which can also be represented as:
-
1
+
1
2
3
4
@@ -230,7 +230,7 @@
Component
This post won't go into detail around how to build a React component, which you can find over at another post: [INSERT REACT COMPONENT POST]
-
1
+
1
2
3
4
@@ -278,7 +278,7 @@
Component
To break it down, we've created a React component (class) Alert which takes in alerts as an array, verifies it isn't null or empty, and finally iterates over each element in the alerts array to return a div stylized with the appropriate information.
Reducer
Lastly we have the reducer which we want to handle all the states that can be created by the alert action. Luckily we can do this with a switch statement:
First off what's an API and more specifically what's an API route? API stands for Application Programming Interface, meaning it's how to communicate with the system you are creating. A route within an API is a specific path to take to get specific information or data out of. This post will dive into how to set up API routes in Nodejs with express.
We start by 'importing' express into our route and instantiating a router from the express library.
These 4 methods make up the basic CRUD functionality (Create, Read, Update and Delete) of an application.
POST
Let's create a scaffold POST method in node.js.
-
1
+
1
2
3
router.post('/',function(req,res){res.send('POST request to homepage');
@@ -212,7 +212,7 @@
POST
Similarly to do this asynchronously with arrow functions:
-
1
+
1
2
3
router.post('/',async(req,res)=>{res.send('POST request to homepage');
@@ -220,7 +220,7 @@
POST
As we can see above, the first argument to our API route method is the path, and the following is the callback function (what should happen when this path is hit). The callback function can be a function, array of functions, series of functions (separated by commas), or a combination of all of them. This is useful if you are wanting to do validation before the final POST request is made. An example of this is:
-
1
+
1
2
3
router.post('/',[checkInputs()],async(req,res)=>{res.send('POST request to homepage and inputs are valid');
@@ -229,7 +229,7 @@
POST
GET
All the methods within Express.js follow the same principles so to create a scaffold GET request:
-
1
+
1
2
3
router.get('/',async(req,res)=>{res.send('GET request to homepage');
@@ -238,7 +238,7 @@
GET
PUT
Similarly:
-
1
+
1
2
3
router.put('/',async(req,res)=>{res.send('PUT request to homepage');
@@ -247,7 +247,7 @@
PUT
DELETE
Similarly:
-
1
+
1
2
3
router.delete('/',async(req,res)=>{res.send('PUT request to homepage');
@@ -279,7 +279,7 @@
Once you have installed sphinx, inside the project (let's use the directory of this blog post), we can create a docs folder in which all our documentation will live.
-
1
+
1
2
mkdir docs
cd docs
Ensuring to have our virtual environment with sphinx installed active, we run sphinx-quickstart, this tool allows us to populate some information for our documentation in a nice Q&A style.
-
1
+
1
2
3
4
@@ -248,27 +248,27 @@
Automatically Generate
Now let's create an example package that we can write some documentation in.
-
1
+
1
2
mkdir sphinxdemo
cd sphinxdemo
Then we create 3 files inside our example package:
By crashing early, it means the program does a lot less damage than a crippled program. This concept can be implemented by checking for the inverse of the requirement and erroring. By doing this, it means the code is more readable in finding the requirements that it must meet. It captures more potential issues before they cause damage versus checking all the ducks are lined up.
For demonstrating this, we will use the example of a square root function. As we know, square root wants to have a positive number given to it (unless using complex numbers).