TODO ANCHORSZZ
+ + +# Detailed visualizer information and API docs + +## function `pipe.viz_streamlit` + + +Display a highly configurable UI that showcases almost every feature available for Streamlit visualization with model selection dropdowns in your applications. +Ths includes : +- `Similarity Matrix` & `Scalars` & `Embedding Information` for any of the [100+ Word Embedding Models]() +- `NER visualizations` for any of the [200+ Named entity recognizers]() +- `Labled` & `Unlabled Dependency Trees visualizations` with `Part of Speech Tags` for any of the [100+ Part of Speech Models]() +- `Token informations` predicted by any of the [1000+ models]() +- `Classification results` predicted by any of the [100+ models classification models]() +- `Pipeline Configuration` & `Model Information` & `Link to John Snow Labs Modelshub` for all loaded pipelines +- `Auto generate Python code` that can be copy pasted to re-create the individual Streamlit visualization blocks. + NlLU takes the first model specified as `nlu.load()` for the first visualization run. + Once the Streamlit app is running, additional models can easily be added via the UI. + It is recommended to run this first, since you can generate Python code snippets `to recreate individual Streamlit visualization blocks` + +```python +nlu.load('ner').viz_streamlit(['I love NLU and Streamlit!','I hate buggy software']) +``` + + + +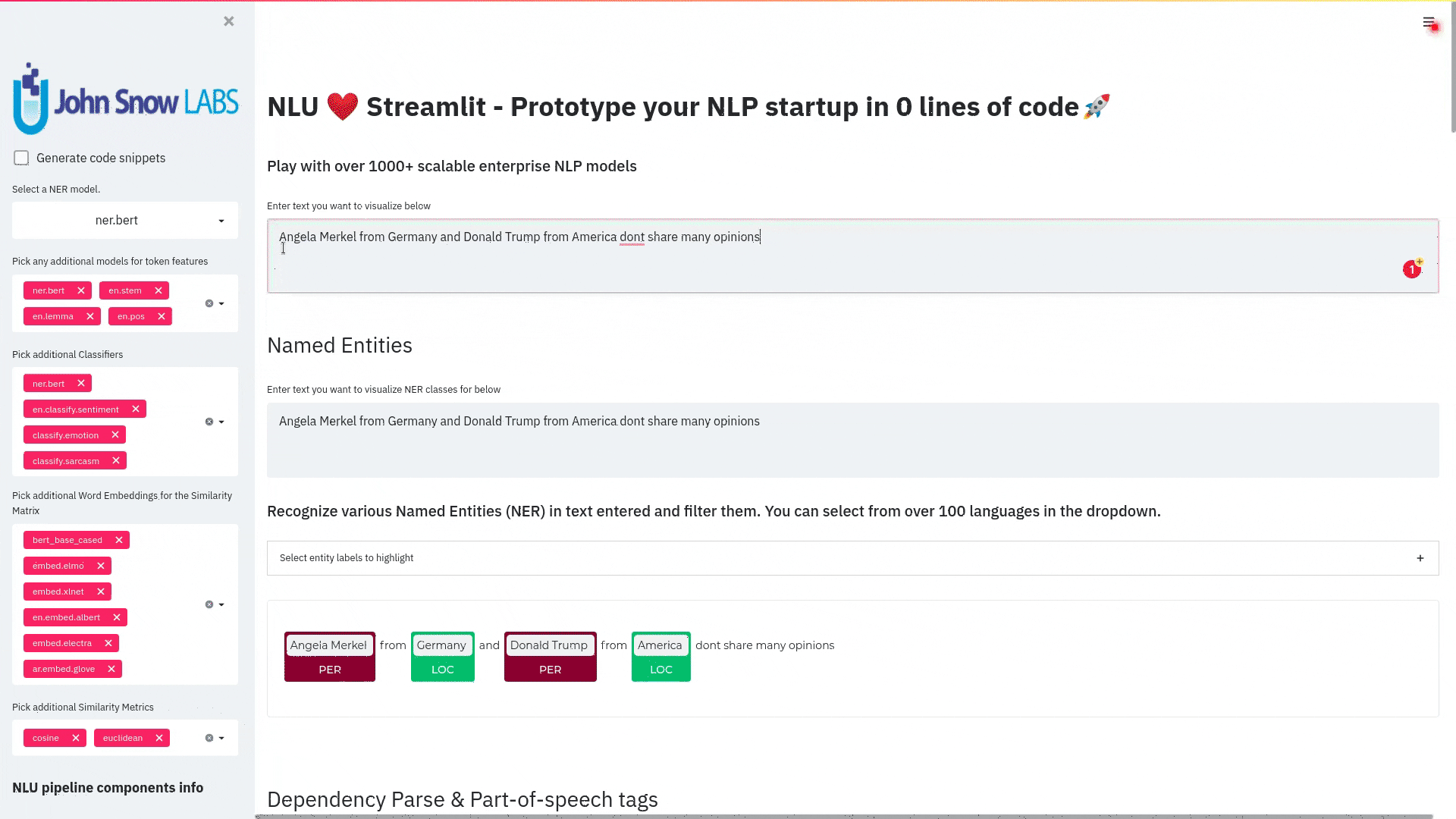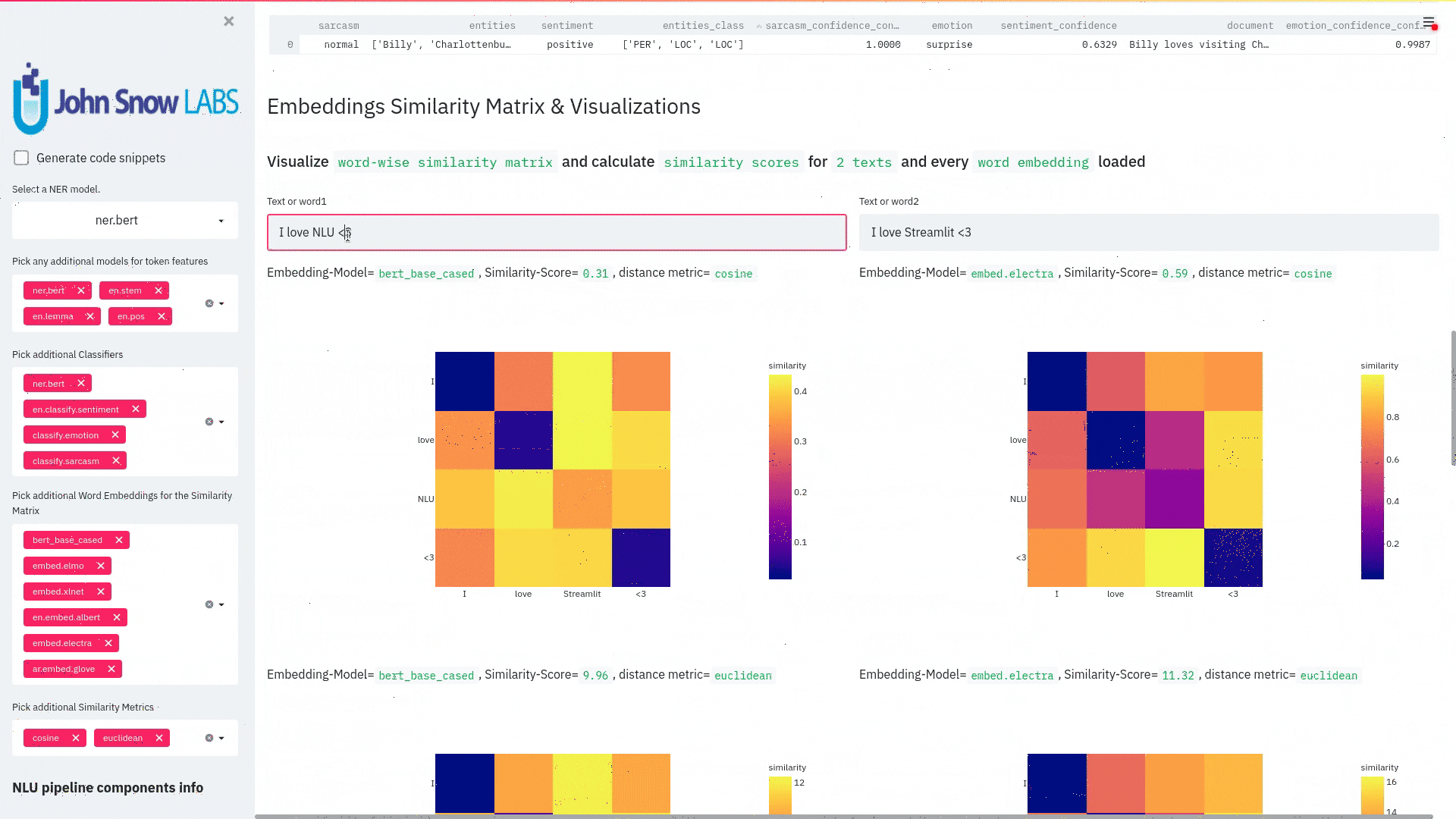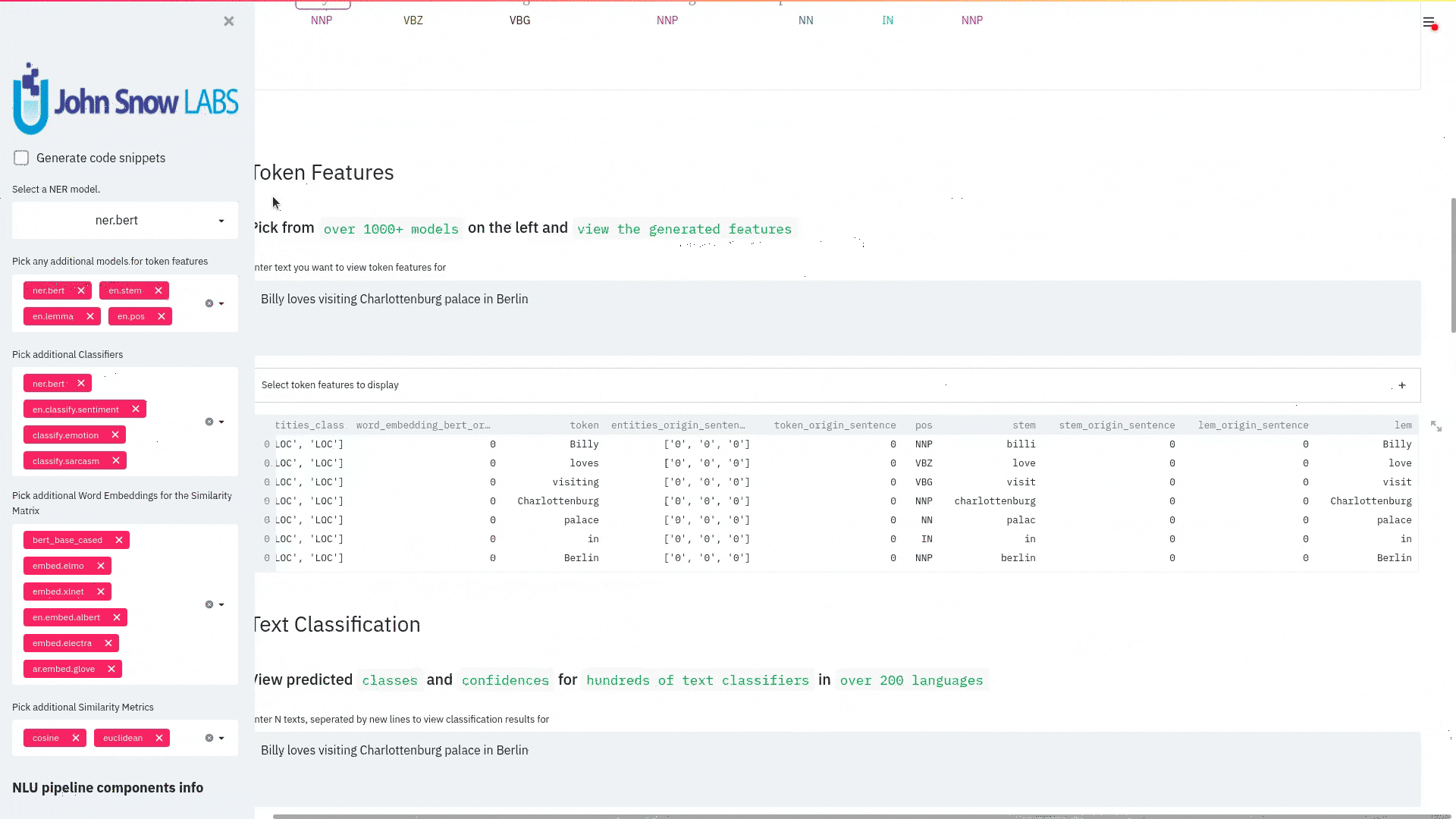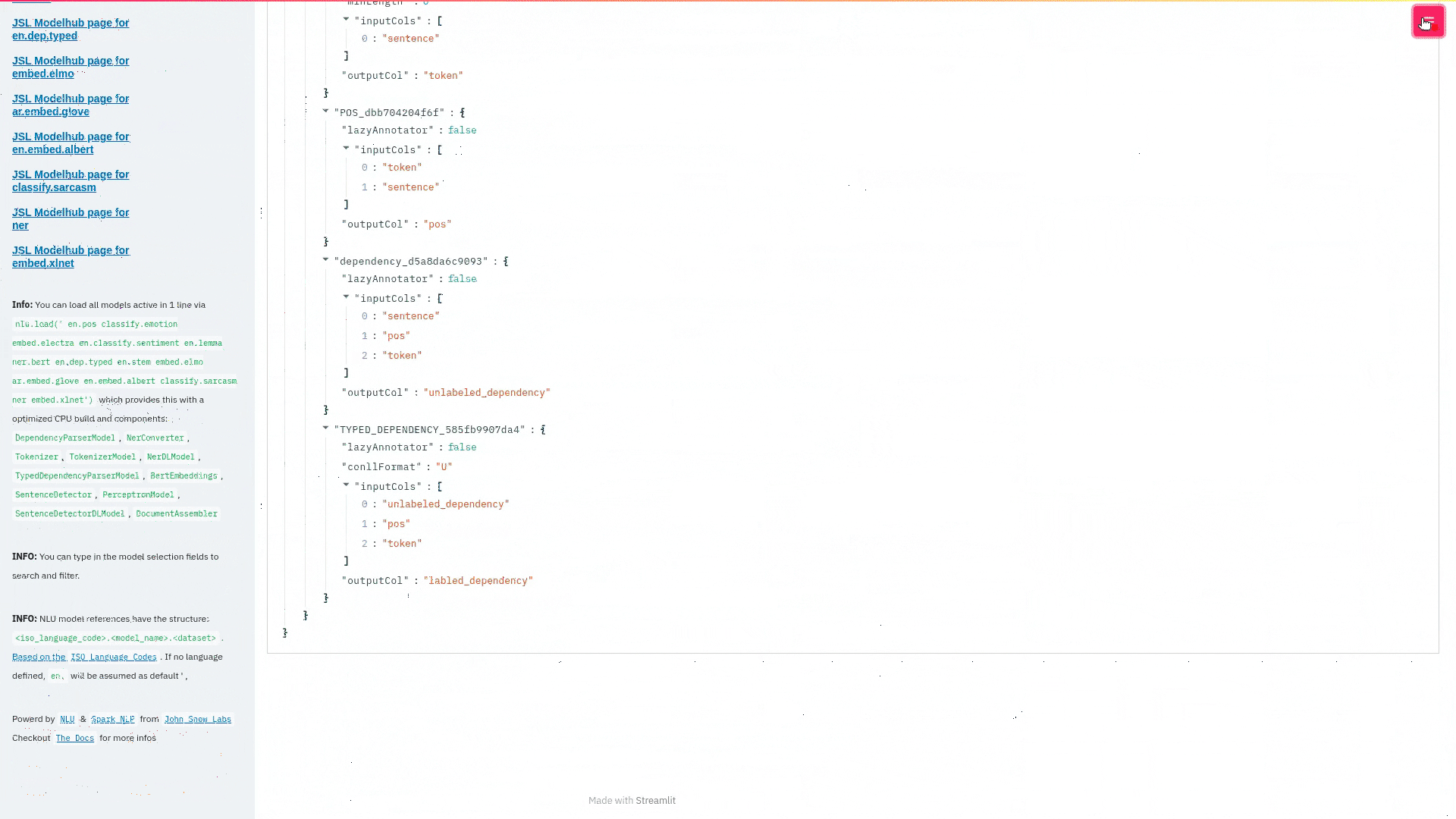 + +### function parameters `pipe.viz_streamlit` + +| Argument | Type | Default |Description | +|-----------------------|--------------------------------------------------|----------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------| +| `text` | `Union [str, List[str], pd.DataFrame, pd.Series]` | `'NLU and Streamlit go together like peanutbutter and jelly'` | Default text for the `Classification`, `Named Entitiy Recognizer`, `Token Information` and `Dependency Tree` visualizations +| `similarity_texts` | `Union[List[str],Tuple[str,str]]` | `('Donald Trump Likes to part', 'Angela Merkel likes to party')` | Default texts for the `Text similarity` visualization. Should contain `exactly 2 strings` which will be compared `token embedding wise`. For each embedding active, a `token wise similarity matrix` and a `similarity scalar` +| `model_selection` | `List[str]` | `[]` | List of nlu references to display in the model selector, see [the NLU Namespace](https://nlu.johnsnowlabs.com/docs/en/namespace) or the [John Snow Labs Modelshub](https://modelshub.johnsnowlabs.com/models) or go [straight to the source](https://github.com/JohnSnowLabs/nlu/blob/master/nlu/namespace.py) for more info +| `title` | `str` | `'NLU ❤️ Streamlit - Prototype your NLP startup in 0 lines of code🚀'` | Title of the Streamlit app +| `sub_title` | `str` | `'Play with over 1000+ scalable enterprise NLP models'` | Sub title of the Streamlit app +| `visualizers` | `List[str]` | `( "dependency_tree", "ner", "similarity", "token_information", 'classification')` | Define which visualizations should be displayed. By default all visualizations are displayed. +| `show_models_info` | `bool` | `True` | Show information for every model loaded in the bottom of the Streamlit app. +| `show_model_select` | `bool` | `True` | Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click +| `show_viz_selection` | `bool` | `False` | Show a selector in the sidebar which lets you configure which visualizations are displayed. +| `show_logo` | `bool` | `True` | Show logo +| `display_infos` | `bool` | `False` | Display additonal information about ISO codes and the NLU namespace structure. +| `set_wide_layout_CSS` | `bool` | `True` | Whether to inject custom CSS or not. +| `key` | `str` | `"NLU_streamlit"` | Key for the Streamlit elements drawn +| `model_select_position` | `str` | `'side'` | [Whether to output the positions of predictions or not, see `pipe.predict(positions=true`) for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-positions-parameter) | +| `show_code_snippets` | `bool` | `False` | Display Python code snippets above visualizations that can be used to re-create the visualization +|`num_similarity_cols` | `int` | `2` | How many columns should for the layout in Streamlit when rendering the similarity matrixes. + + + +## function `pipe.viz_streamlit_classes` + +Visualize the predicted classes and their confidences and additional metadata to streamlit. +Aplicable with [any of the 100+ classifiers](https://nlp.johnsnowlabs.com/models?task=Text+Classification) + +```python +nlu.load('sentiment').viz_streamlit_classes(['I love NLU and Streamlit!','I love buggy software', 'Sign up now get a chance to win 1000$ !', 'I am afraid of Snakes','Unicorns have been sighted on Mars!','Where is the next bus stop?']) +``` +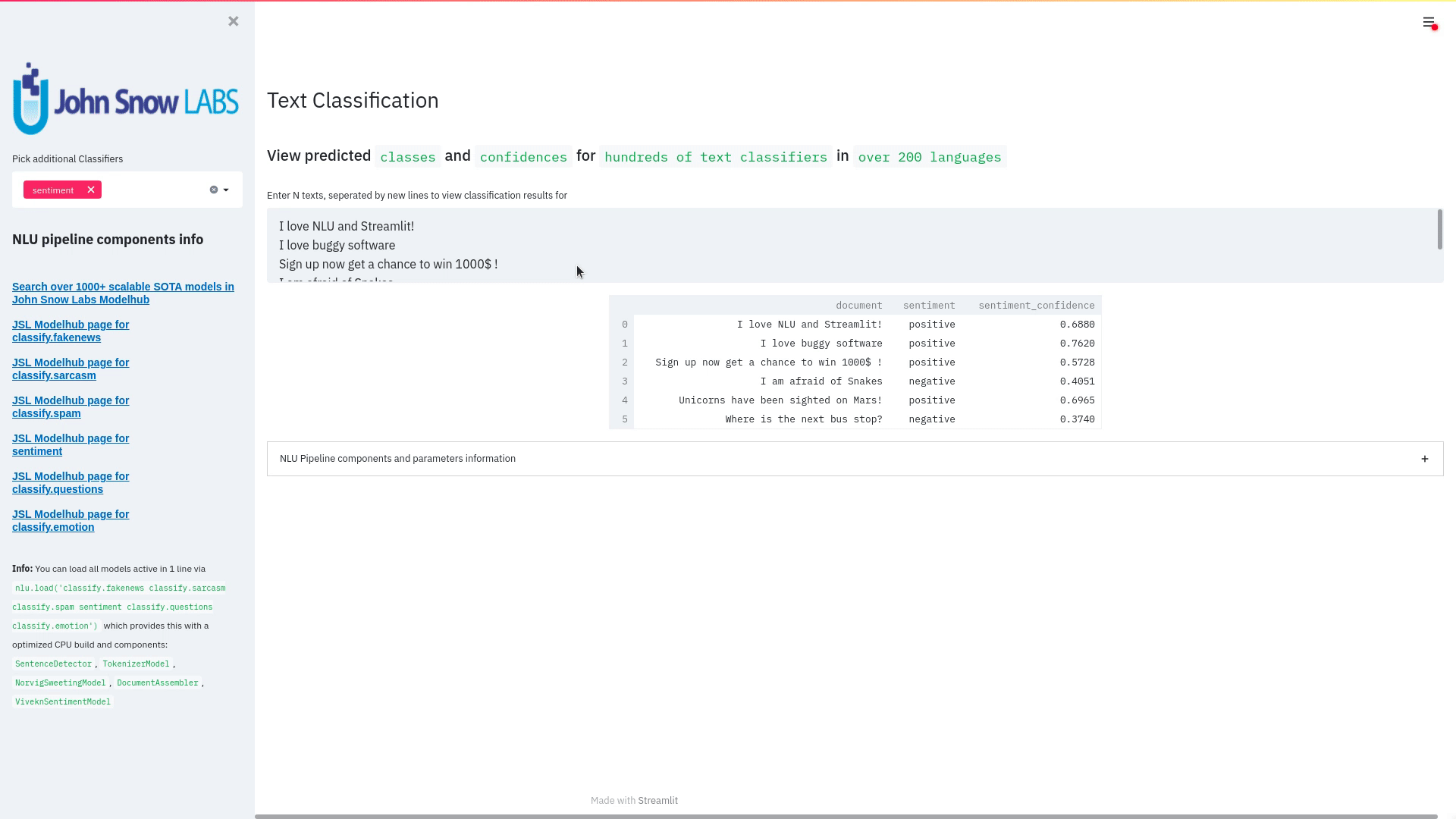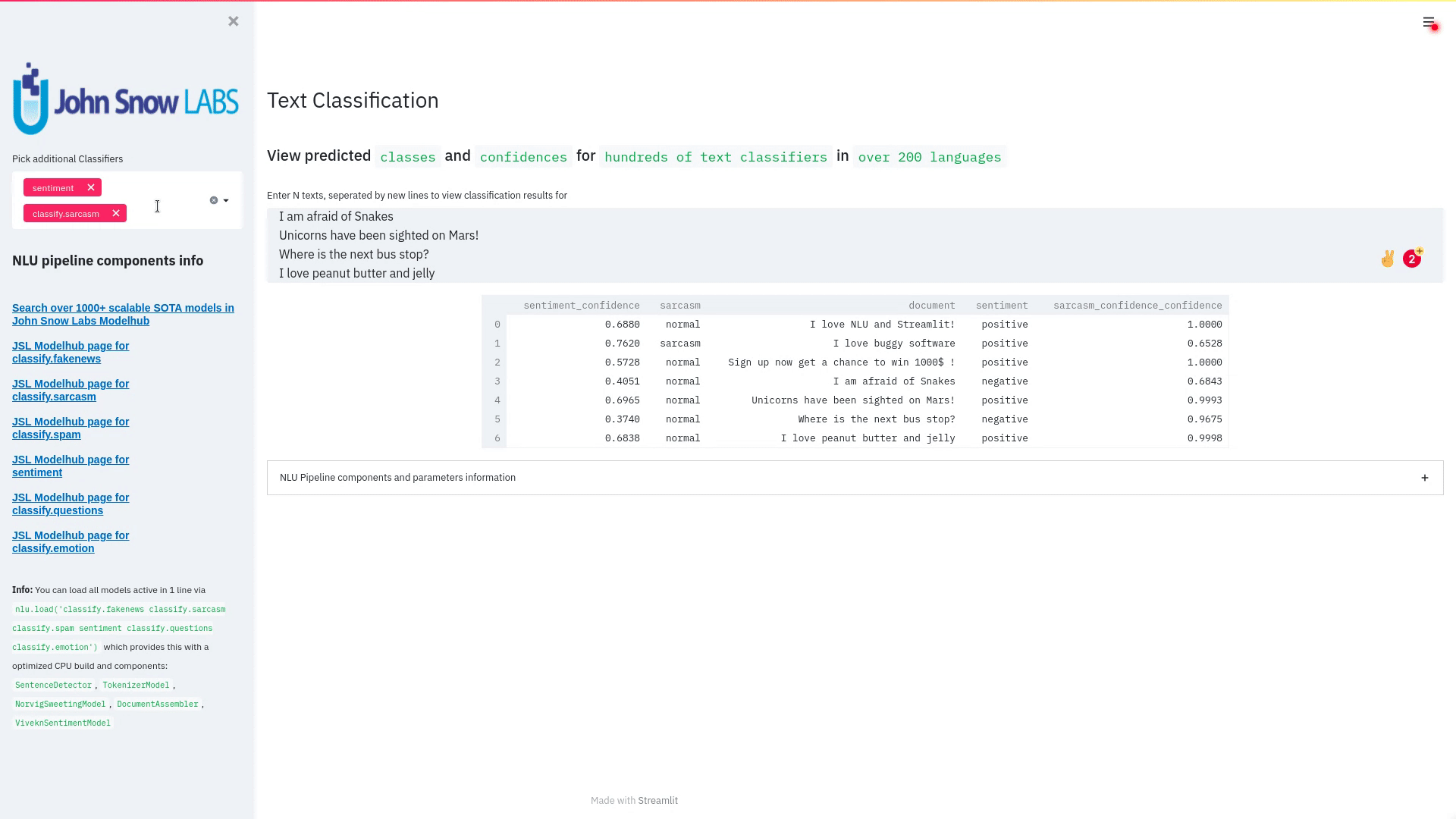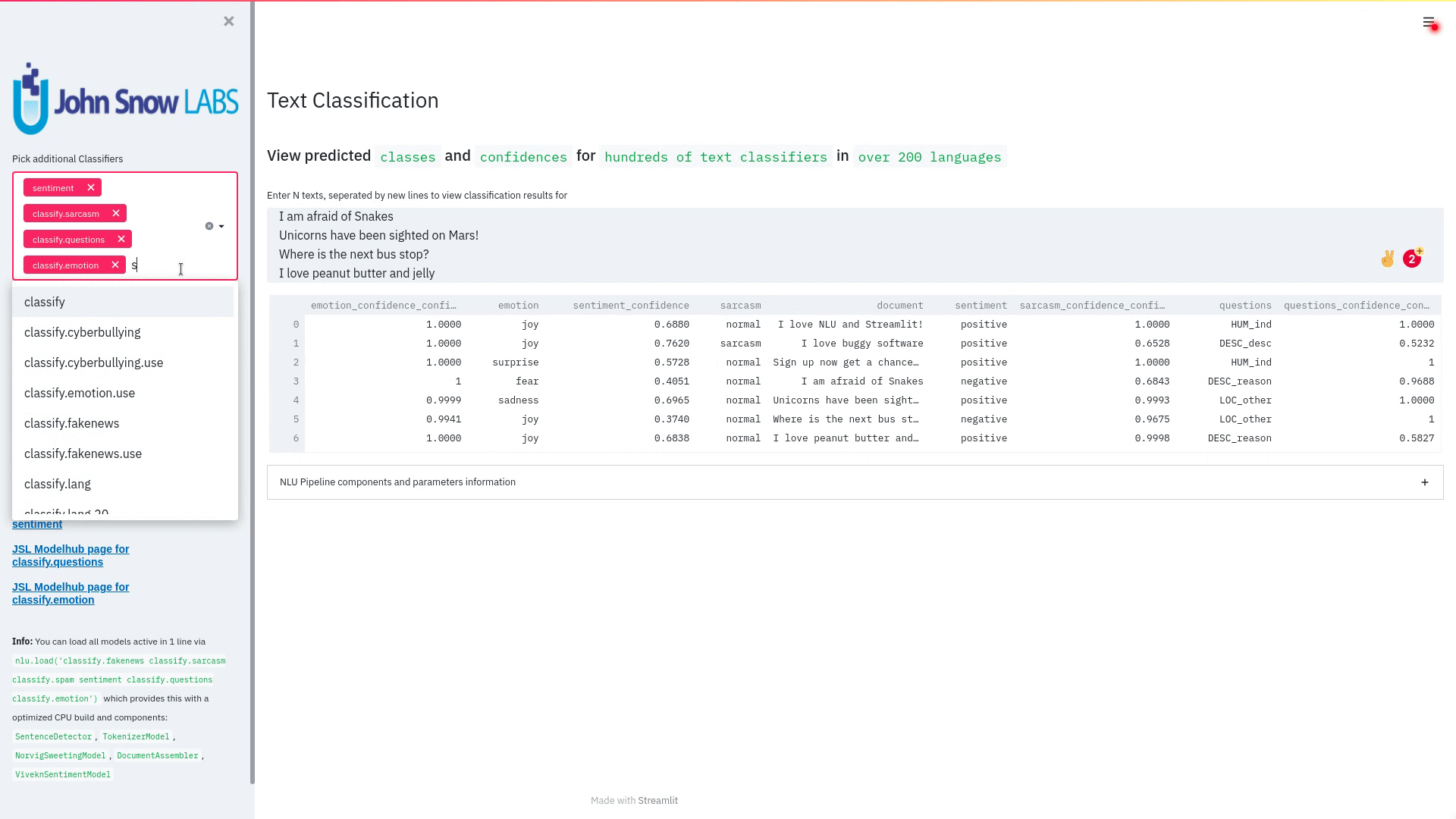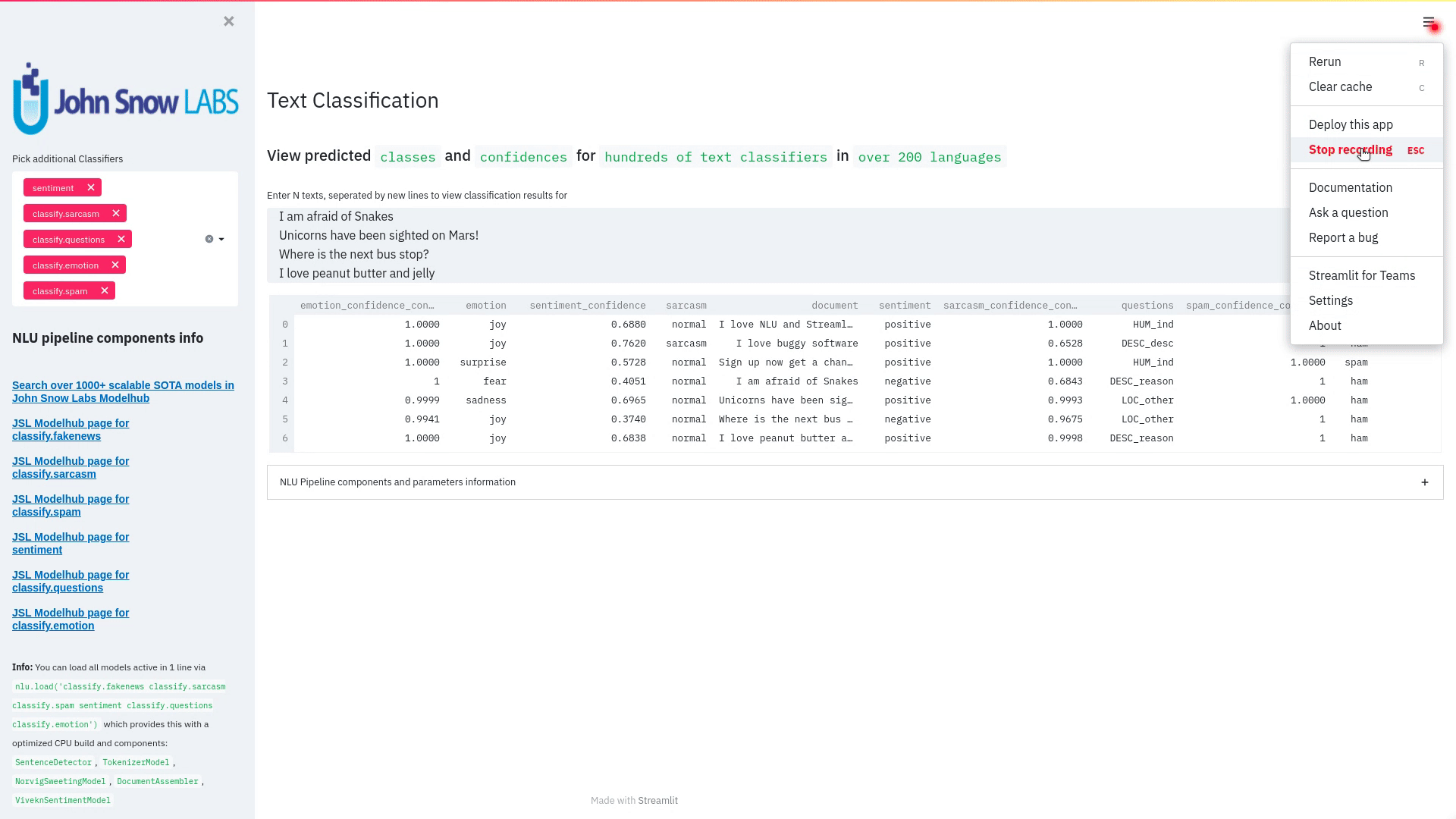 + + +### function parameters `pipe.viz_streamlit_classes` + +| Argument | Type | Default |Description | +|--------------------------- | ---------- |-----------------------------------------------------------| ------------------------------------------------------- | +| `text` | `Union[str,list,pd.DataFrame, pd.Series, pyspark.sql.DataFrame ]` | `'I love NLU and Streamlit and sunny days!'` | Text to predict classes for. Will predict on each input of the iteratable or dataframe if type is not str.| +| `output_level` | `Optional[str]` | `document` | [Outputlevel of NLU pipeline, see `pipe.predict()` docsmore info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-level-parameter)| +| `include_text_col` | `bool` |`True` | Whether to include a e text column in the output table or just the prediction data | +| `title` | `Optional[str]` | `Text Classification` | Title of the Streamlit building block that will be visualized to screen | +| `metadata` | `bool` | `False` | [whether to output addition metadata or not, see `pipe.predict(meta=true)` docs for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-metadata) | +| `positions` | `bool` | `False` | [whether to output the positions of predictions or not, see `pipe.predict(positions=true`) for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-positions-parameter) | +| `set_wide_layout_CSS` | `bool` | `True` | Whether to inject custom CSS or not. +| `key` | `str` | `"NLU_streamlit"` | Key for the Streamlit elements drawn +| `model_select_position` | `str` | `'side'` | [Whether to output the positions of predictions or not, see `pipe.predict(positions=true`) for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-positions-parameter) | +| `generate_code_sample` | `bool` | `False` | Display Python code snippets above visualizations that can be used to re-create the visualization +| `show_model_select` | `bool` | `True` | Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click +| `show_logo` | `bool` | `True` | Show logo +| `display_infos` | `bool` | `False` | Display additonal information about ISO codes and the NLU namespace structure. + + + +## function `pipe.viz_streamlit_ner` +Visualize the predicted classes and their confidences and additional metadata to Streamlit. +Aplicable with [any of the 250+ NER models](https://nlp.johnsnowlabs.com/models?task=Named+Entity+Recognition). +You can filter which NER tags to highlight via the dropdown in the main window. + +Basic usage +```python +nlu.load('ner').viz_streamlit_ner('Donald Trump from America and Angela Merkel from Germany dont share many views') +``` + +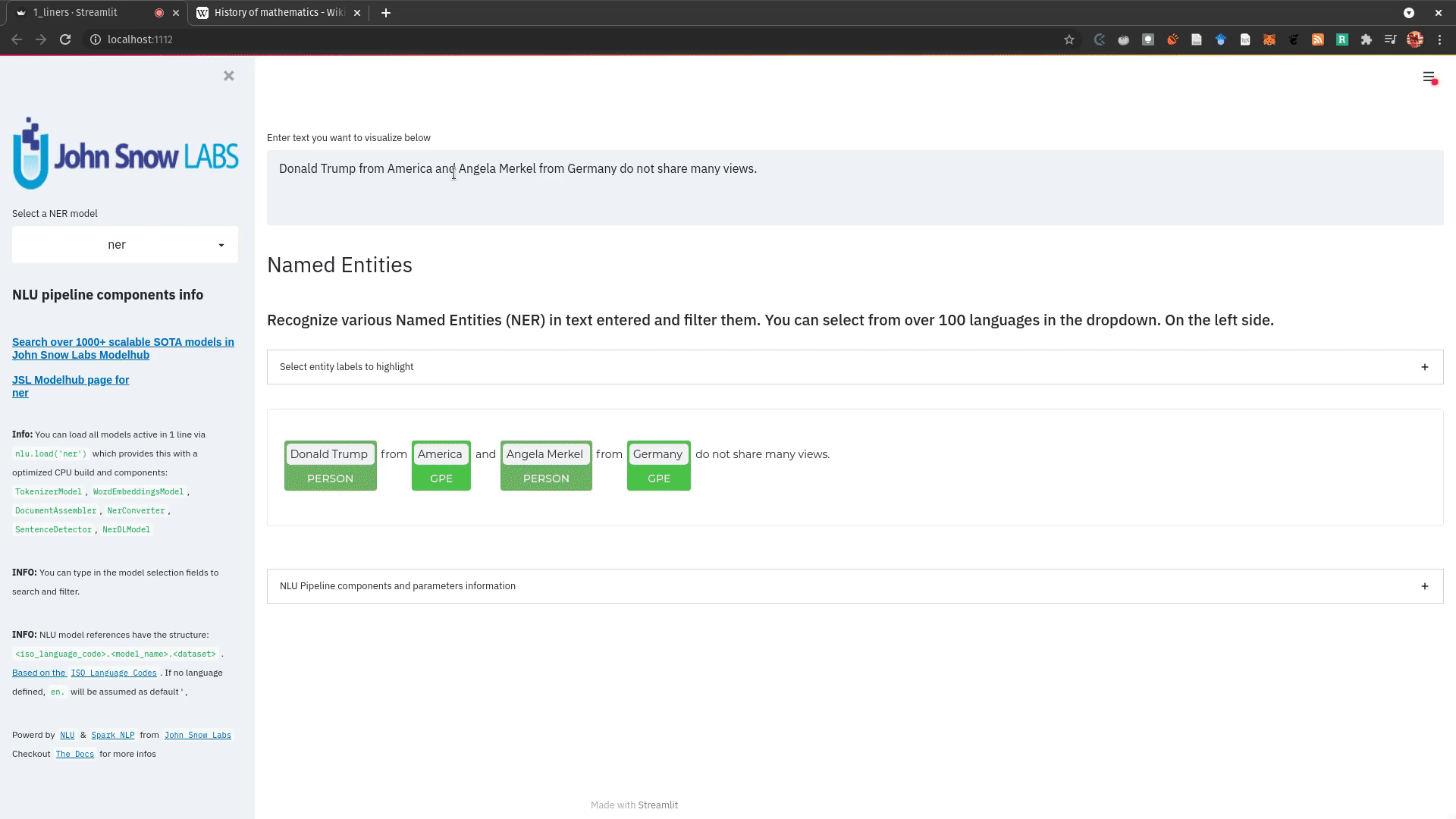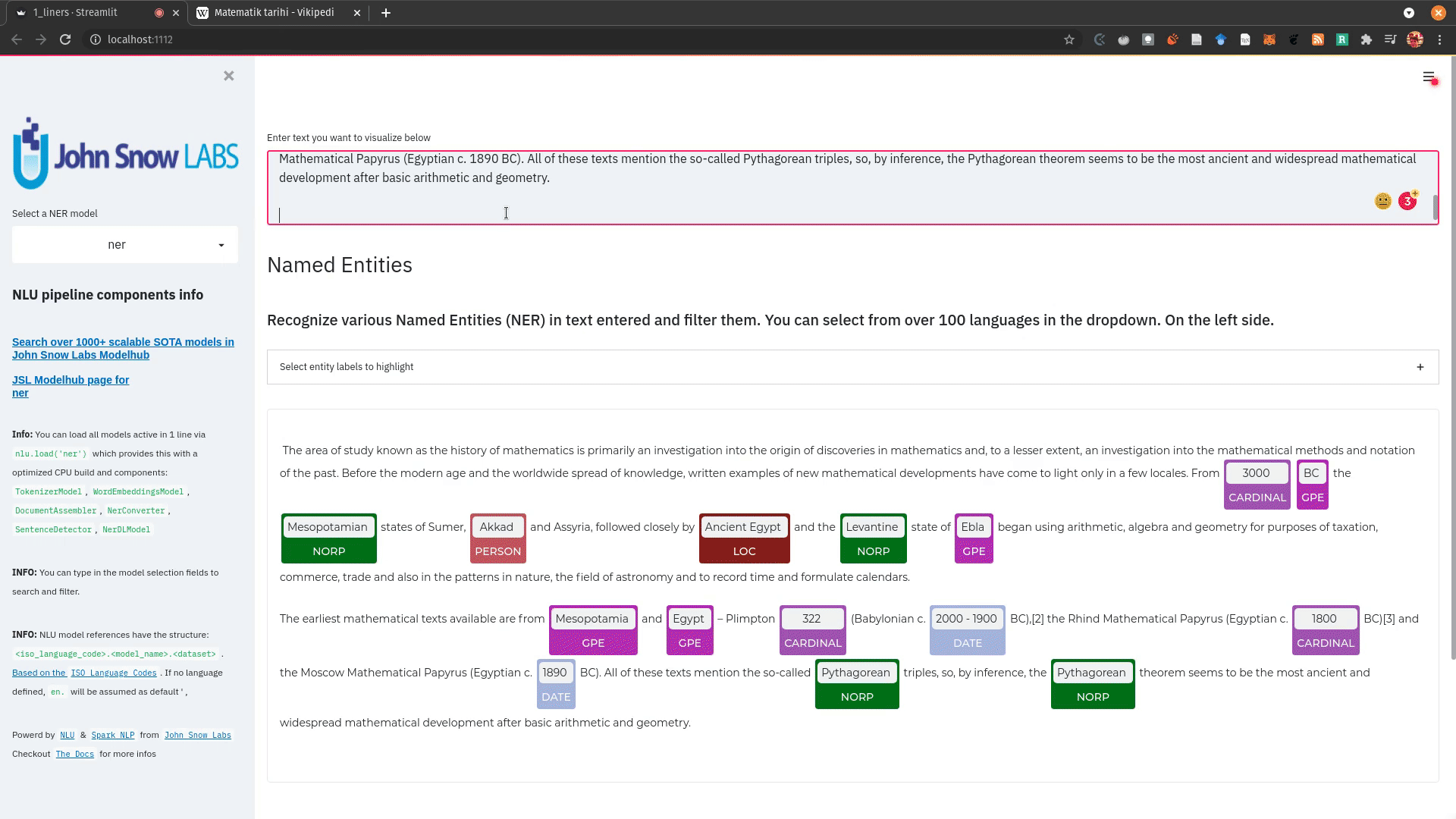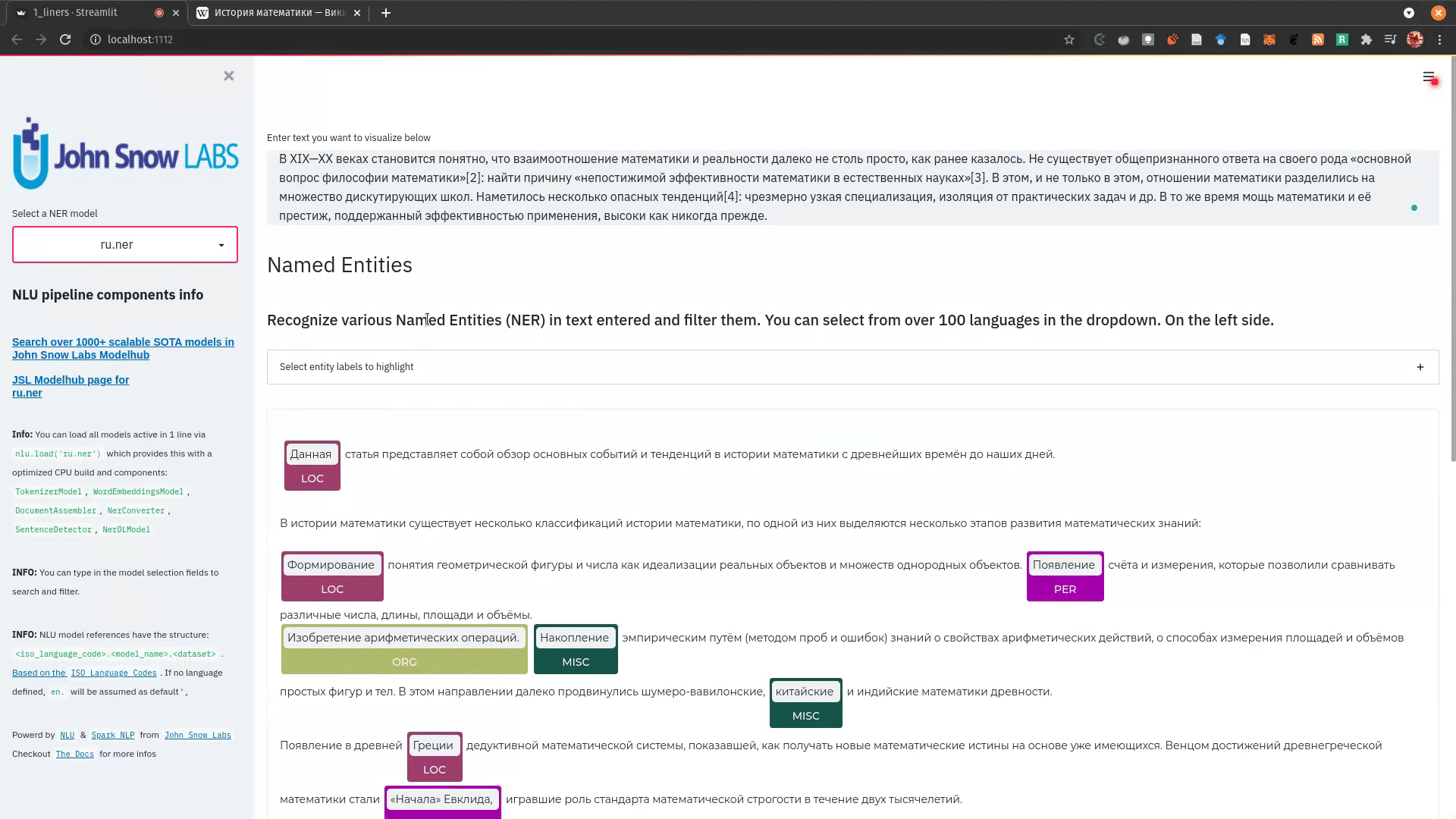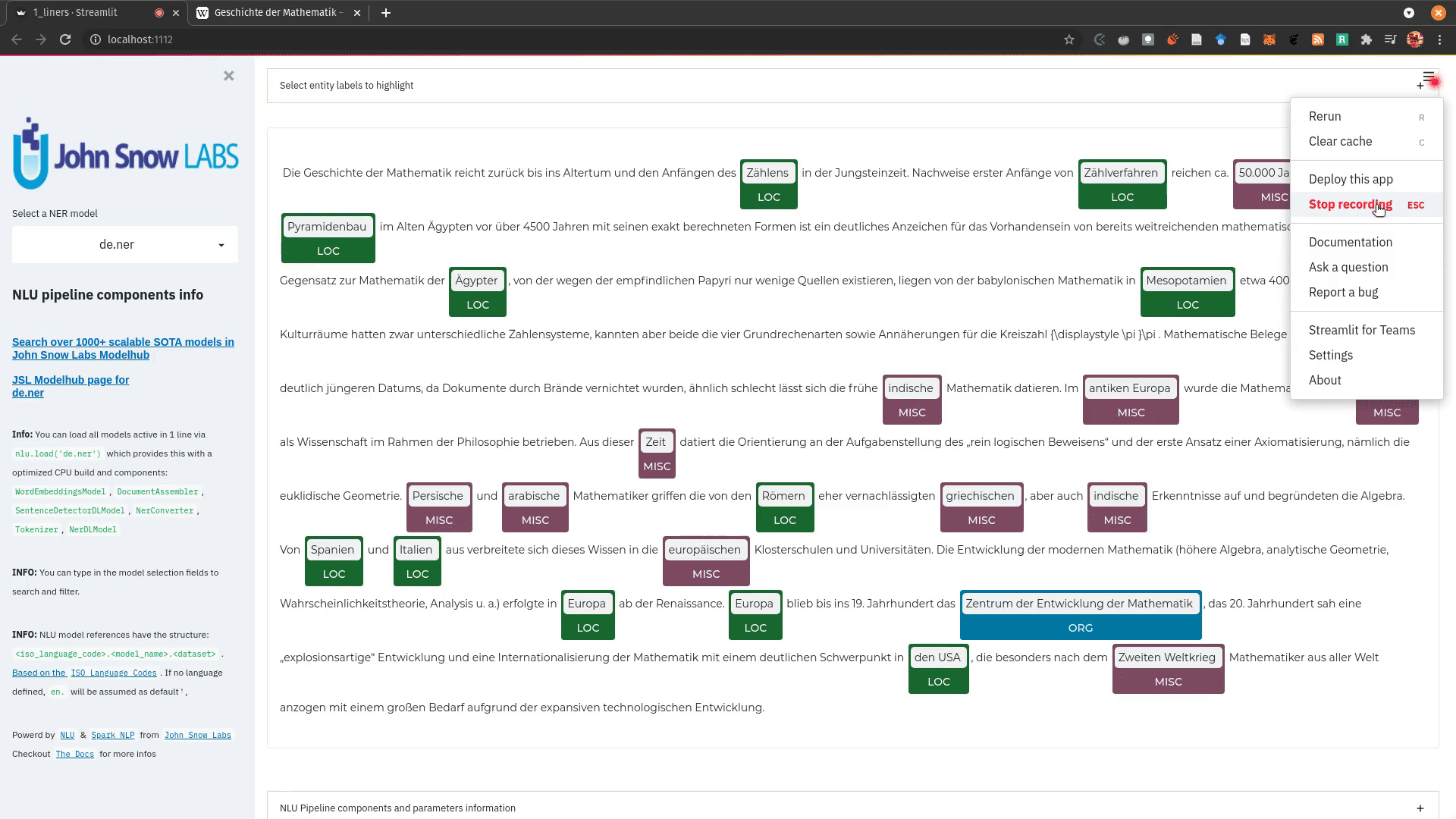 + +Example for coloring +```python +# Color all entities of class GPE black +nlu.load('ner').viz_streamlit_ner('Donald Trump from America and Angela Merkel from Germany dont share many views',colors={'PERSON':'#6e992e', 'GPE':'#000000'}) +``` +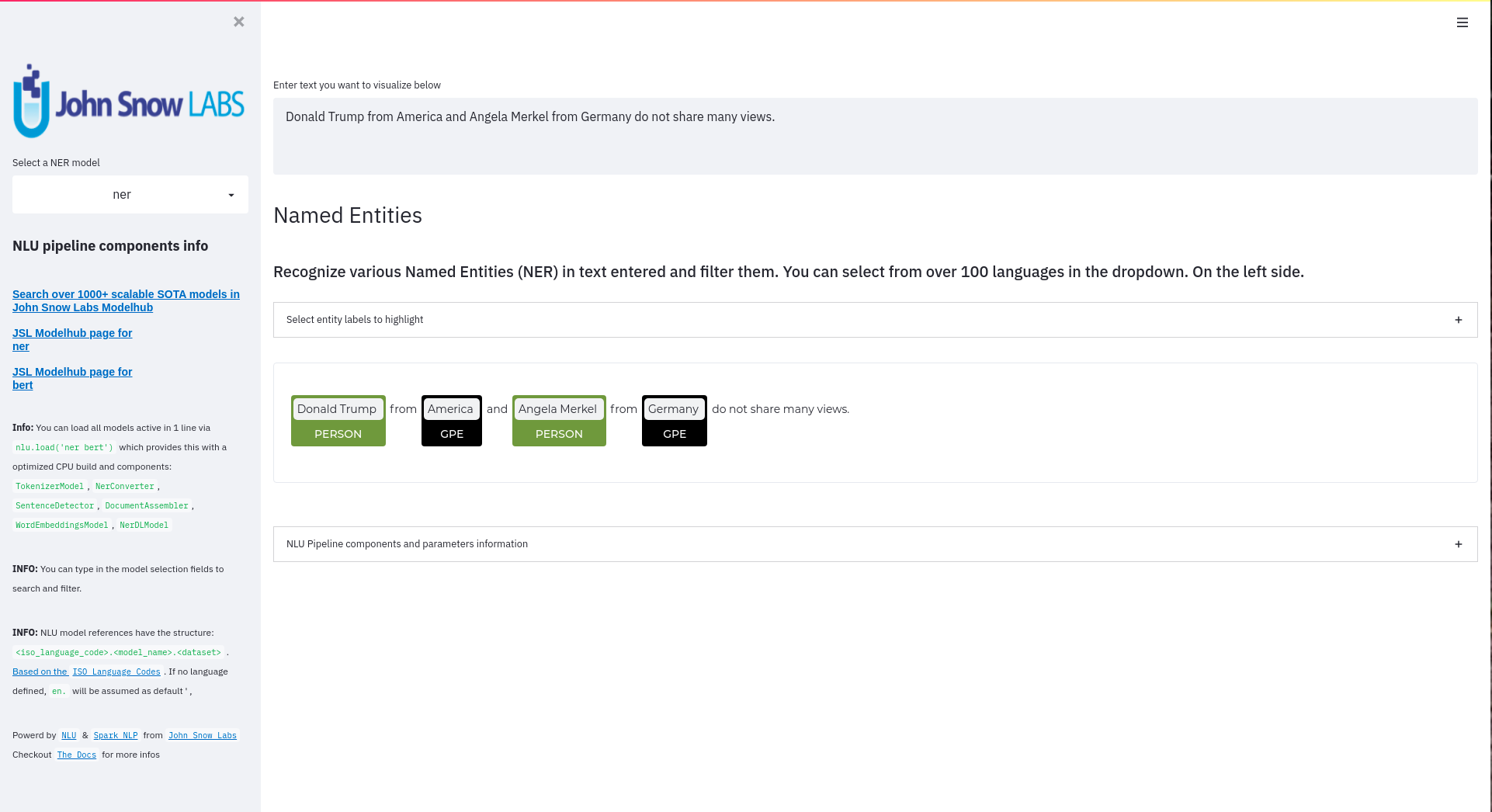 + +### function parameters `pipe.viz_streamlit_ner` + +| Argument | Type | Default |Description | +|--------------------------- | -----------------------|-----------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------ | +| `text` | `str` | `'Donald Trump from America and Anegela Merkel from Germany do not share many views'` | Text to predict classes for.| +| `ner_tags` | `Optional[List[str]]` | `None` |Tags to display. By default all tags will be displayed| +| `show_label_select` | `bool` |`True` | Whether to include the label selector| +| `show_table` | `bool` | `True` | Whether show to predicted pandas table or not| +| `title` | `Optional[str]` | `'Named Entities'` | Title of the Streamlit building block that will be visualized to screen | +| `sub_title` | `Optional[str]` | `'"Recognize various Named Entities (NER) in text entered and filter them. You can select from over 100 languages in the dropdown. On the left side.",'` | Sub-title of the Streamlit building block that will be visualized to screen | +| `colors` | `Dict[str,str]` | `{}` | Dict with `KEY=ENTITY_LABEL` and `VALUE=COLOR_AS_HEX_CODE`,which will change color of highlighted entities.[See custom color labels docs for more info.](https://nlu.johnsnowlabs.com/docs/en/viz_examples#define-custom-colors-for-labels) | +| `set_wide_layout_CSS` | `bool` | `True` | Whether to inject custom CSS or not. +| `key` | `str` | `"NLU_streamlit"` | Key for the Streamlit elements drawn +| `generate_code_sample` | `bool` | `False` | Display Python code snippets above visualizations that can be used to re-create the visualization +| `show_model_select` | `bool` | `True` | Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click +| `model_select_position` | `str` | `'side'` | [Whether to output the positions of predictions or not, see `pipe.predict(positions=true`) for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-positions-parameter) | +| `show_text_input` | `bool` | `True` | Show text input field to input text in +| `show_logo` | `bool` | `True` | Show logo +| `display_infos` | `bool` | `False` | Display additonal information about ISO codes and the NLU namespace structure. + + + + +## function `pipe.viz_streamlit_dep_tree` +Visualize a typed dependency tree, the relations between tokens and part of speech tags predicted. +Aplicable with [any of the 100+ Part of Speech(POS) models and dep tree model](https://nlp.johnsnowlabs.com/models?task=Part+of+Speech+Tagging) + +```python +nlu.load('dep.typed').viz_streamlit_dep_tree('POS tags define a grammatical label for each token and the Dependency Tree classifies Relations between the tokens') +``` +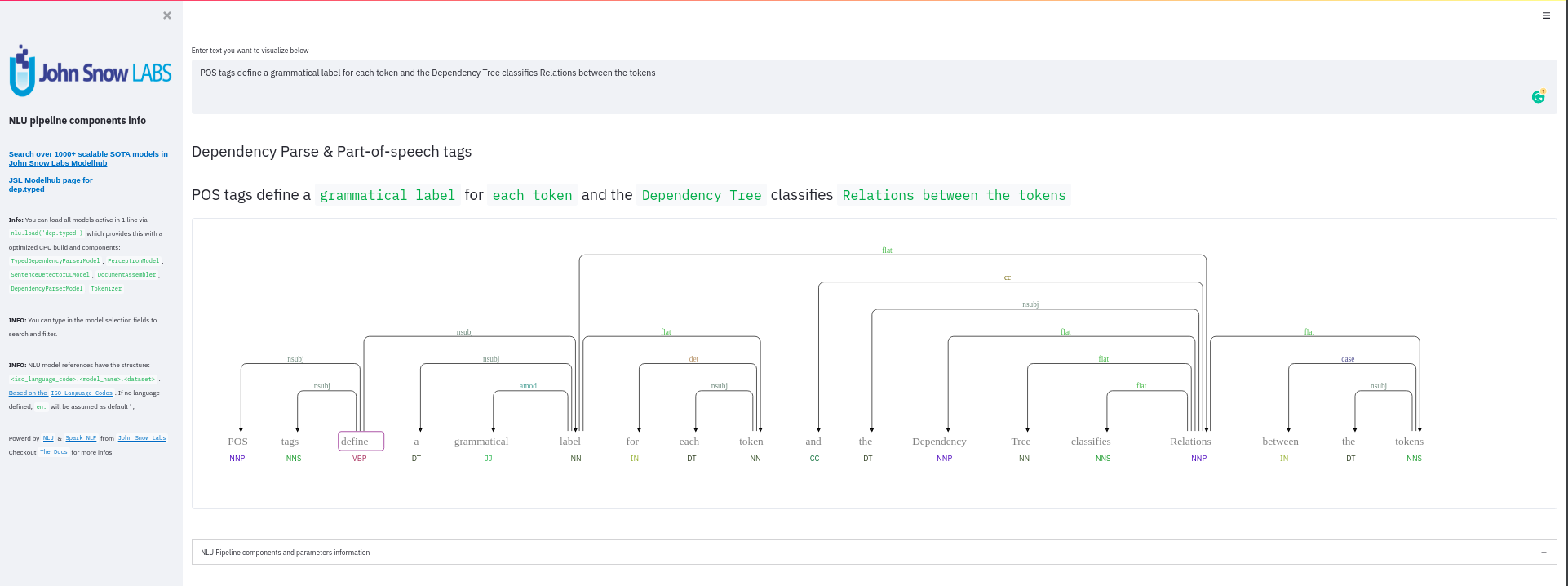 + +### function parameters `pipe.viz_streamlit_dep_tree` + +| Argument | Type | Default |Description | +|--------------------------- | ---------- |-----------------------------------------------------------| ------------------------------------------------------- | +| `text` | `str` | `'Billy likes to swim'` | Text to predict classes for.| +| `title` | `Optional[str]` | `'Dependency Parse Tree & Part-of-speech tags'` | Title of the Streamlit building block that will be visualized to screen | +| `set_wide_layout_CSS` | `bool` | `True` | Whether to inject custom CSS or not. +| `key` | `str` | `"NLU_streamlit"` | Key for the Streamlit elements drawn +| `generate_code_sample` | `bool` | `False` | Display Python code snippets above visualizations that can be used to re-create the visualization +| `set_wide_layout_CSS` | `bool` | `True` | Whether to inject custom CSS or not. +| `key` | `str` | `"NLU_streamlit"` | Key for the Streamlit elements drawn +| `generate_code_sample` | `bool` | `False` | Display Python code snippets above visualizations that can be used to re-create the visualization +| `show_model_select` | `bool` | `True` | Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click +| `model_select_position` | `str` | `'side'` | [Whether to output the positions of predictions or not, see `pipe.predict(positions=true`) for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-positions-parameter) | +| `show_logo` | `bool` | `True` | Show logo +| `display_infos` | `bool` | `False` | Display additonal information about ISO codes and the NLU namespace structure. + + + + + +## function `pipe.viz_streamlit_token` +Visualize predicted token and text features for every model loaded. +You can use this with [any of the 1000+ models](https://nlp.johnsnowlabs.com/models) and select them from the left dropdown. + +```python +nlu.load('stemm pos spell').viz_streamlit_token('I liek pentut buttr and jelly !') +``` +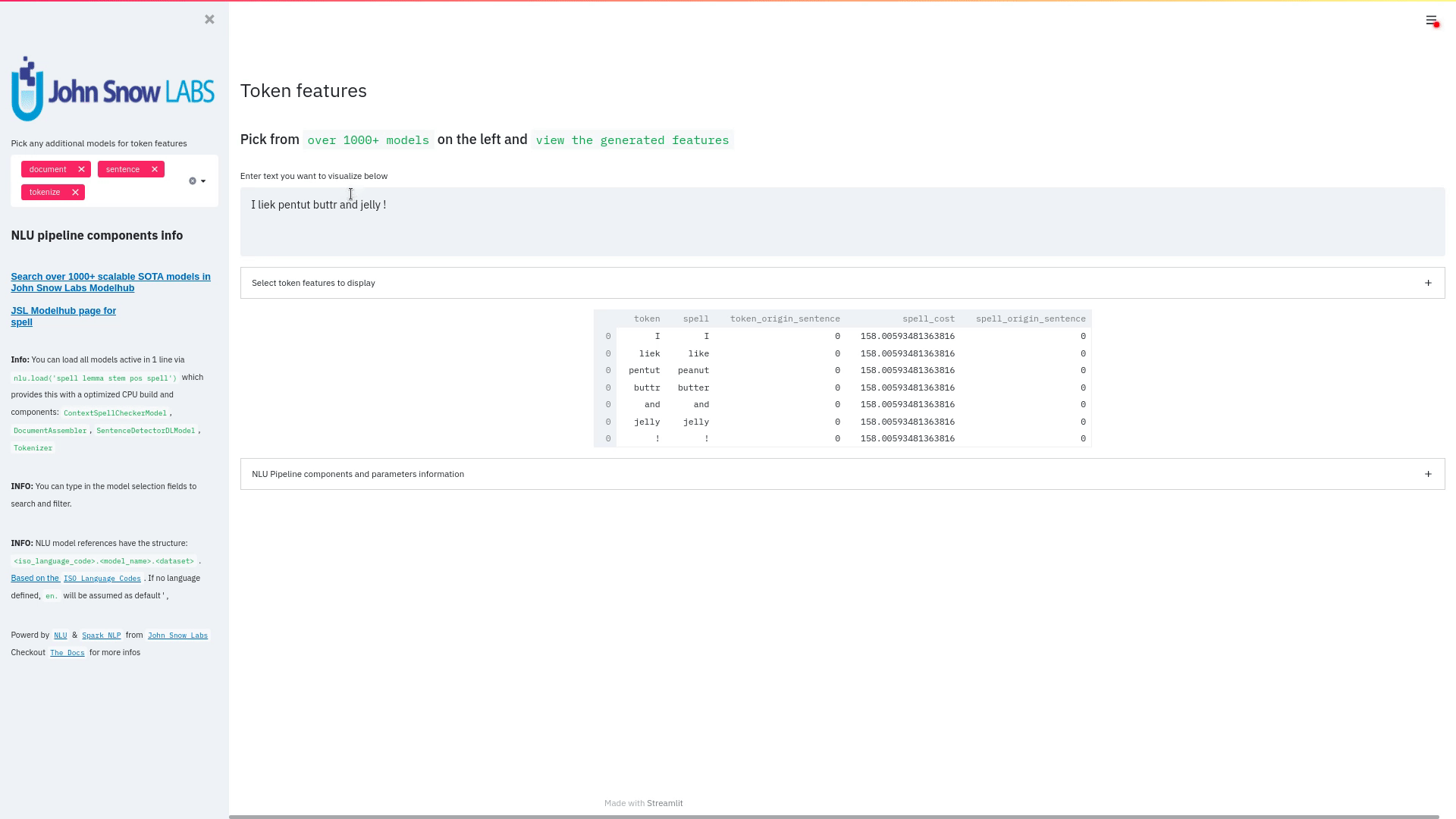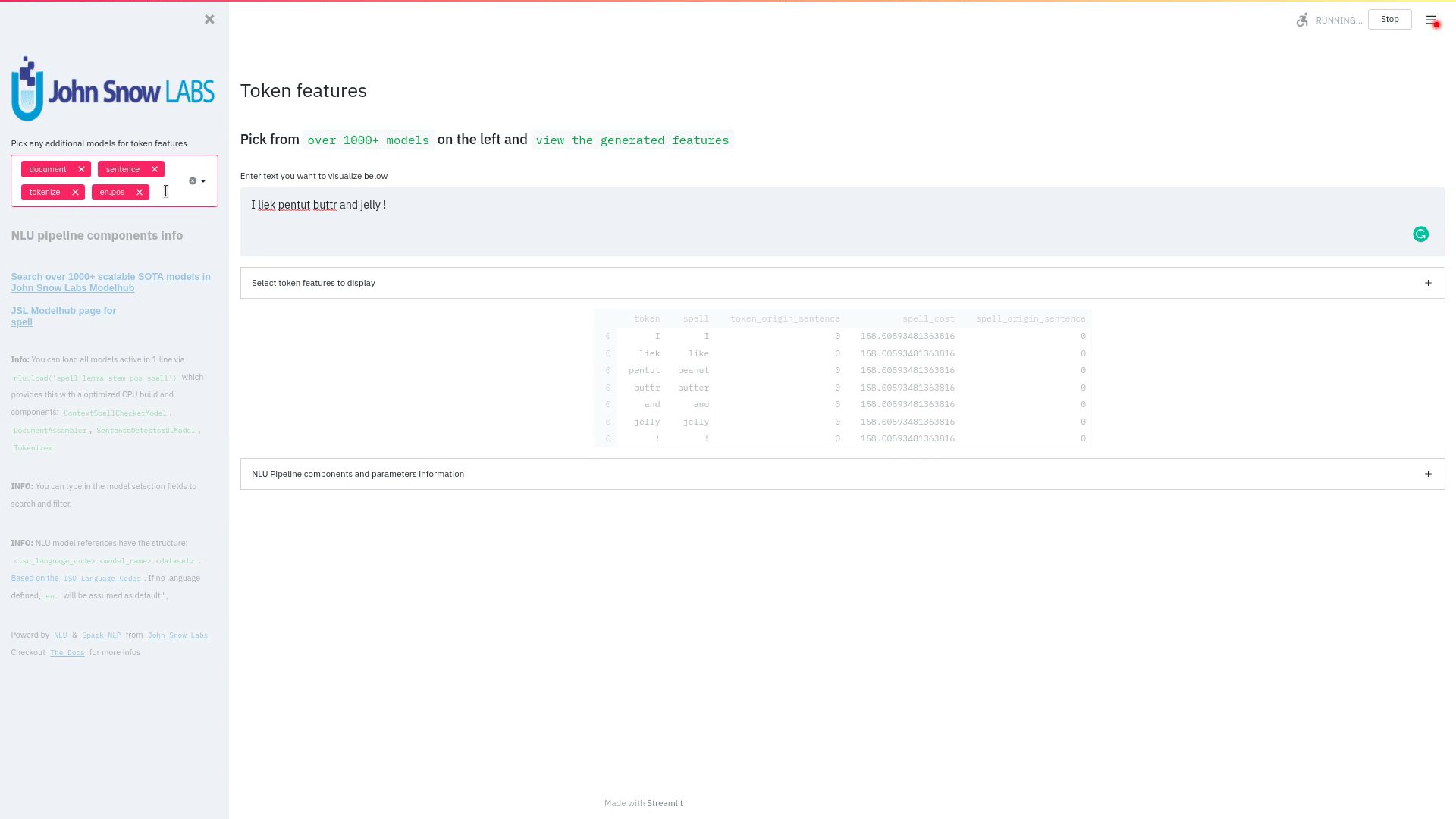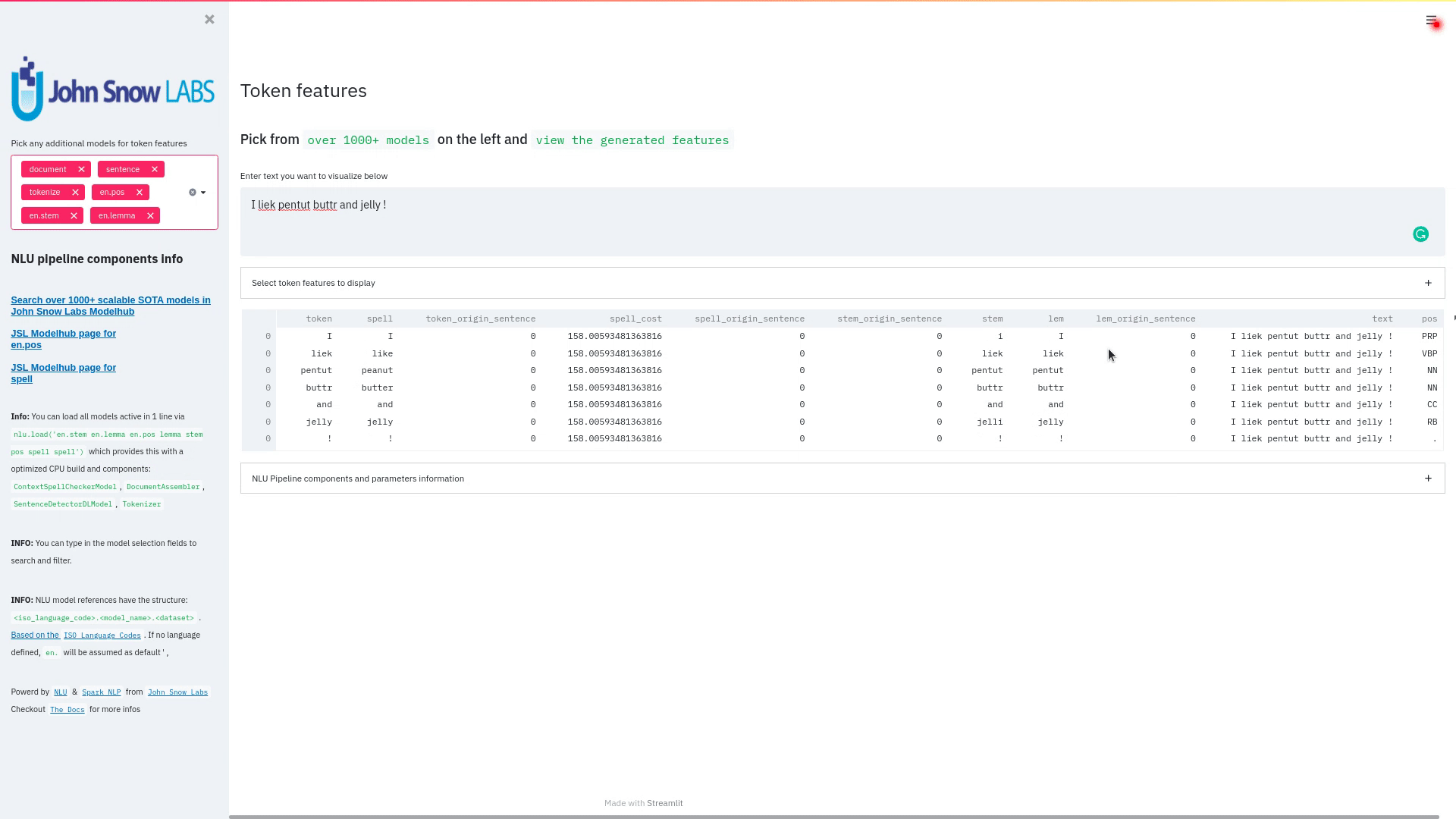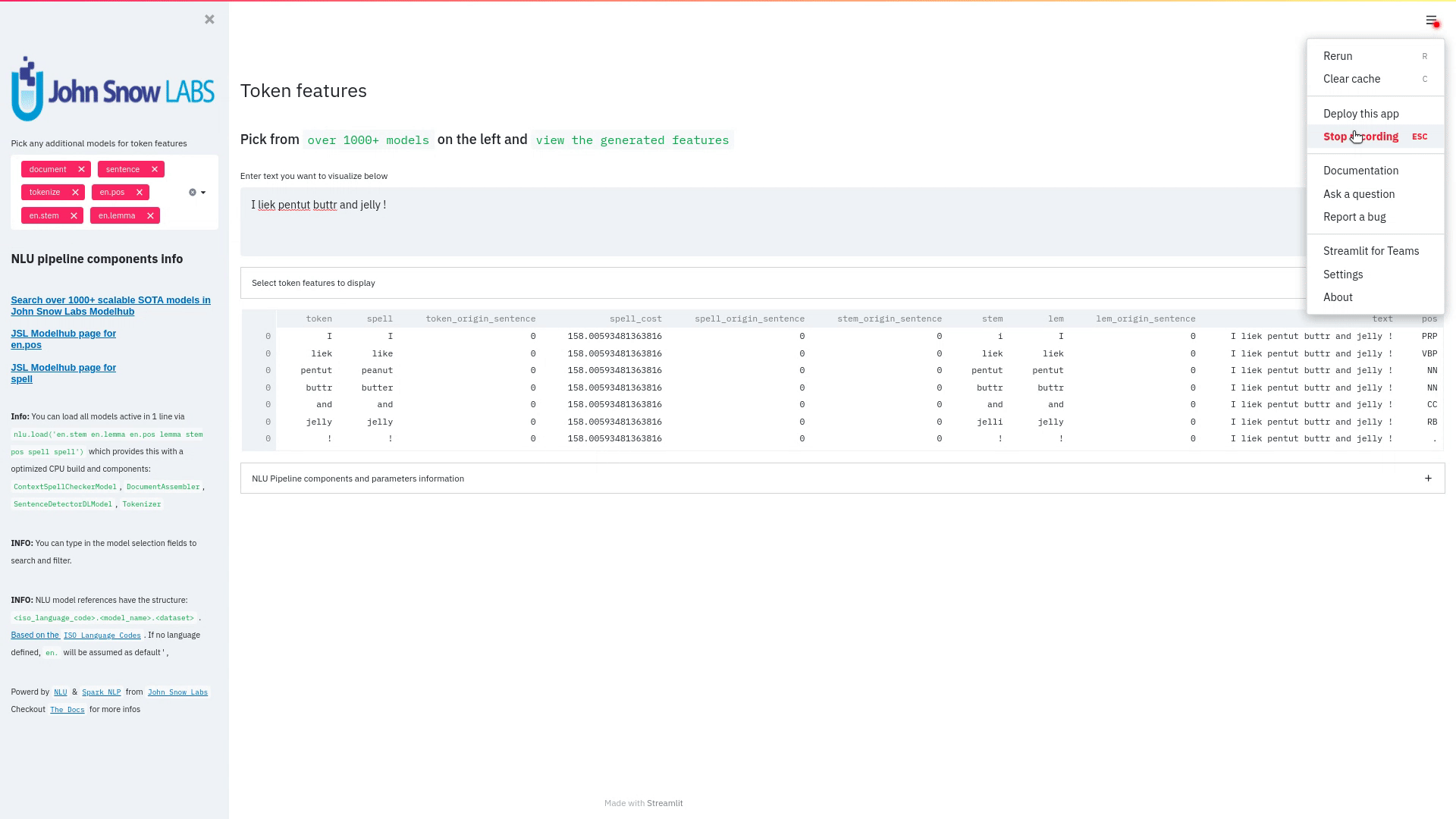 + + +### function parameters `pipe.viz_streamlit_token` + +| Argument | Type | Default |Description | +|--------------------------- | ---------- |-----------------------------------------------------------| ------------------------------------------------------- | +| `text` | `str` | `'NLU and Streamlit are great!'` | Text to predict token information for.| +| `title` | `Optional[str]` | `'Named Entities'` | Title of the Streamlit building block that will be visualized to screen | +| `show_feature_select` | `bool` |`True` | Whether to include the token feature selector| +| `features` | `Optional[List[str]]` | `None` |Features to to display. By default all Features will be displayed| +| `metadata` | `bool` | `False` | [Whether to output addition metadata or not, see `pipe.predict(meta=true)` docs for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-metadata) | +| `output_level` | `Optional[str]` | `'token'` | [Outputlevel of NLU pipeline, see `pipe.predict()` docsmore info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-level-parameter)| +| `positions` | `bool` | `False` | [Whether to output the positions of predictions or not, see `pipe.predict(positions=true`) for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-positions-parameter) | +| `set_wide_layout_CSS` | `bool` | `True` | Whether to inject custom CSS or not. +| `key` | `str` | `"NLU_streamlit"` | Key for the Streamlit elements drawn +| `generate_code_sample` | `bool` | `False` | Display Python code snippets above visualizations that can be used to re-create the visualization +| `show_model_select` | `bool` | `True` | Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click +| `model_select_position` | `str` | `'side'` | [Whether to output the positions of predictions or not, see `pipe.predict(positions=true`) for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-positions-parameter) | +| `show_logo` | `bool` | `True` | Show logo +| `display_infos` | `bool` | `False` | Display additonal information about ISO codes and the NLU namespace structure. + + + + +## function `pipe.viz_streamlit_similarity` + +- Displays a `similarity matrix`, where `x-axis` is every token in the first text and `y-axis` is every token in the second text. +- Index `i,j` in the matrix describes the similarity of `token-i` to `token-j` based on the loaded embeddings and distance metrics, based on [Sklearns Pariwise Metrics.](https://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics.pairwise). [See this article for more elaboration on similarities](https://medium.com/spark-nlp/easy-sentence-similarity-with-bert-sentence-embeddings-using-john-snow-labs-nlu-ea078deb6ebf) +- Displays a dropdown selectors from which various similarity metrics and over 100 embeddings can be selected. + -There will be one similarity matrix per `metric` and `embedding` pair selected. `num_plots = num_metric*num_embeddings` + Also displays embedding vector information. + Applicable with [any of the 100+ Word Embedding models](https://nlp.johnsnowlabs.com/models?task=Embeddings) + + + +```python +nlu.load('bert').viz_streamlit_word_similarity(['I love love loooove NLU! <3','I also love love looove Streamlit! <3']) +``` +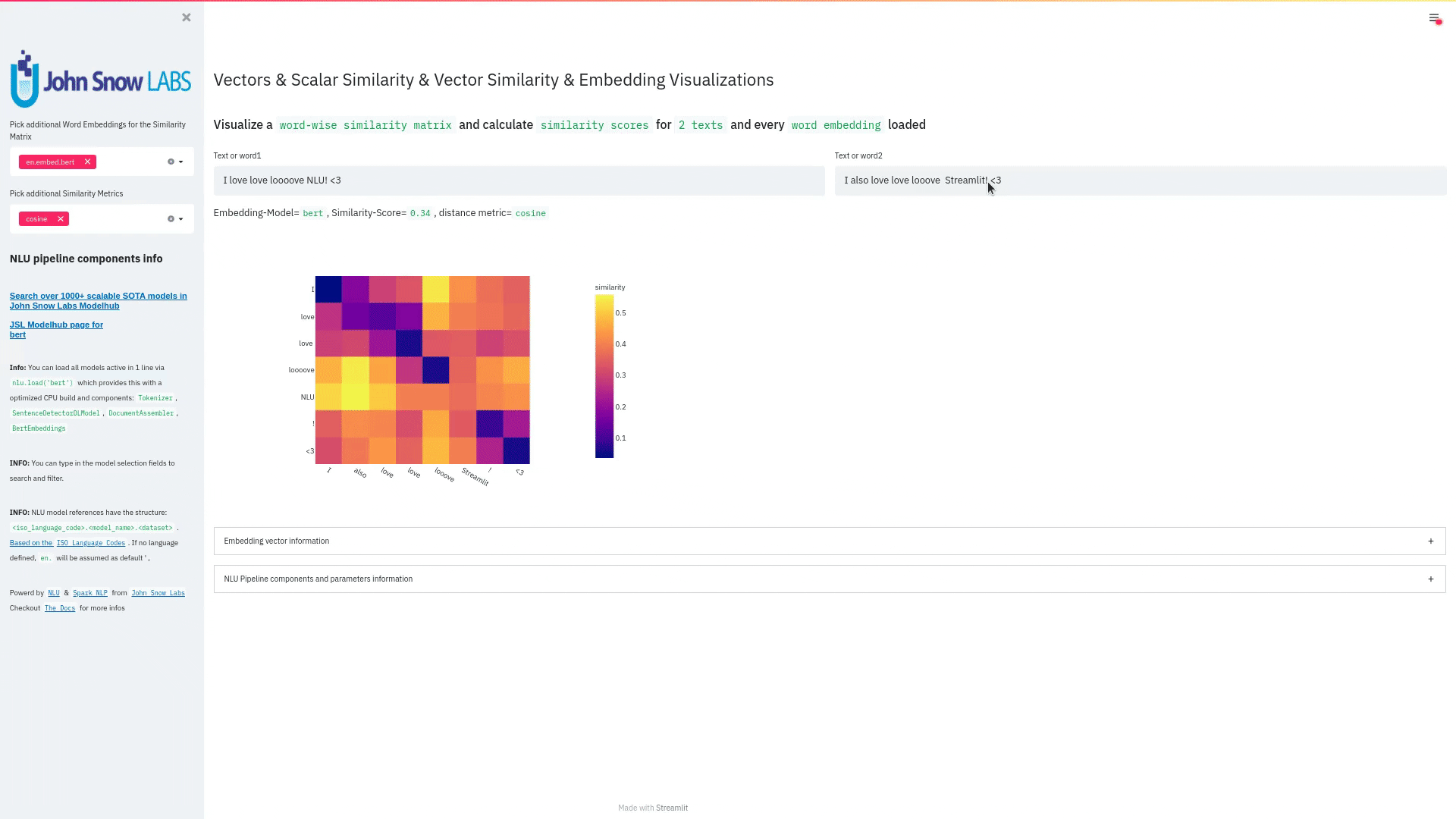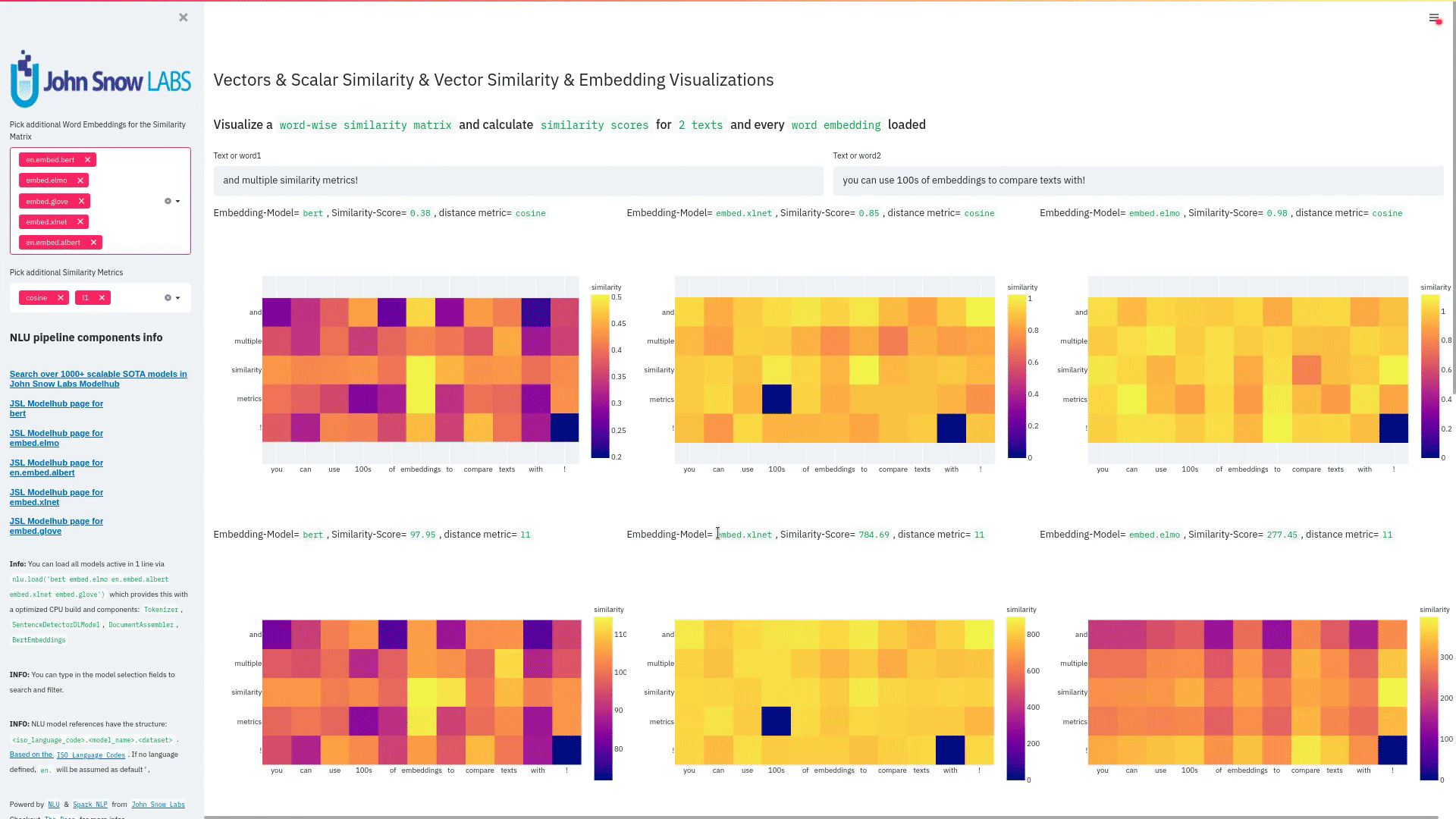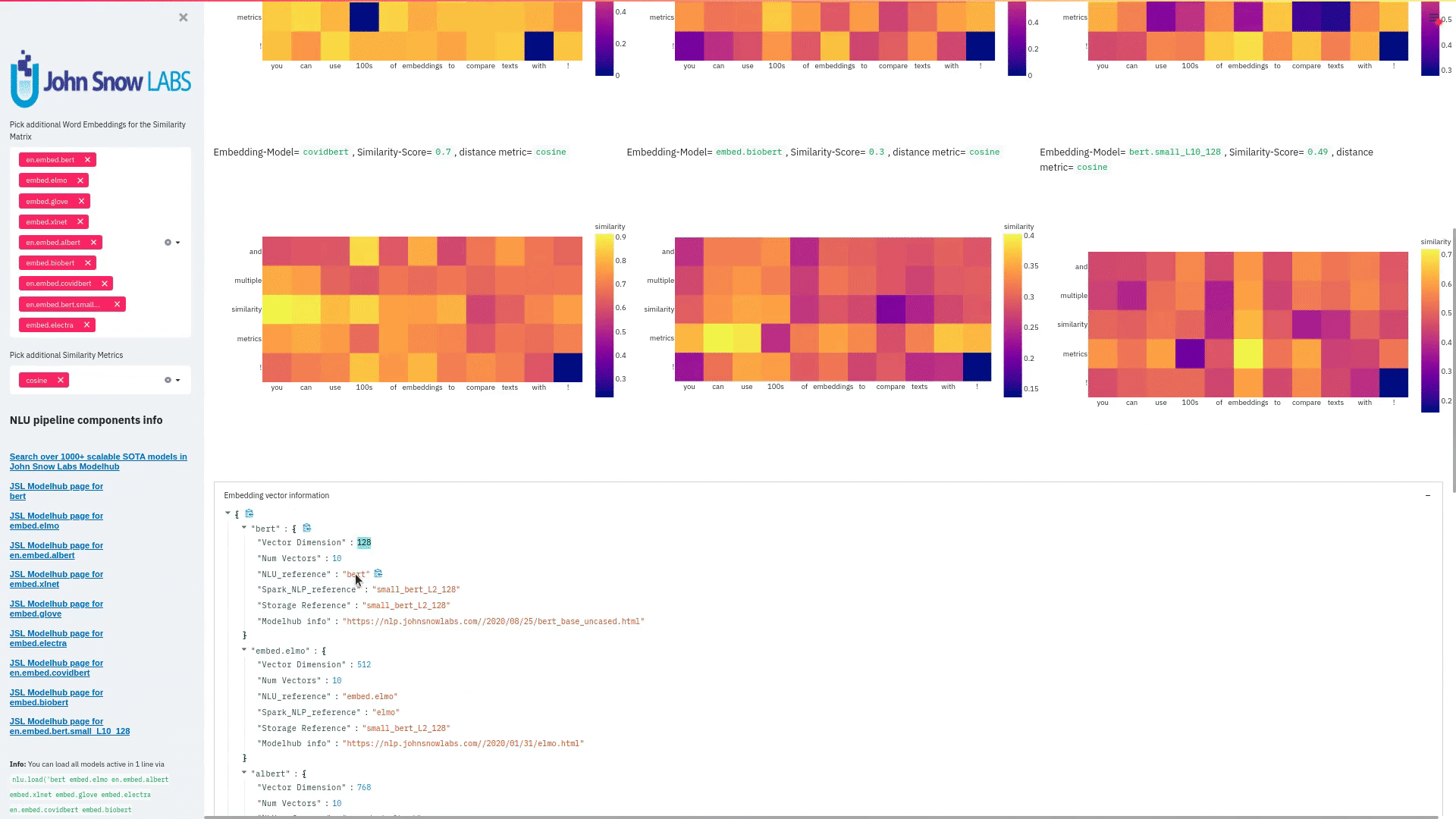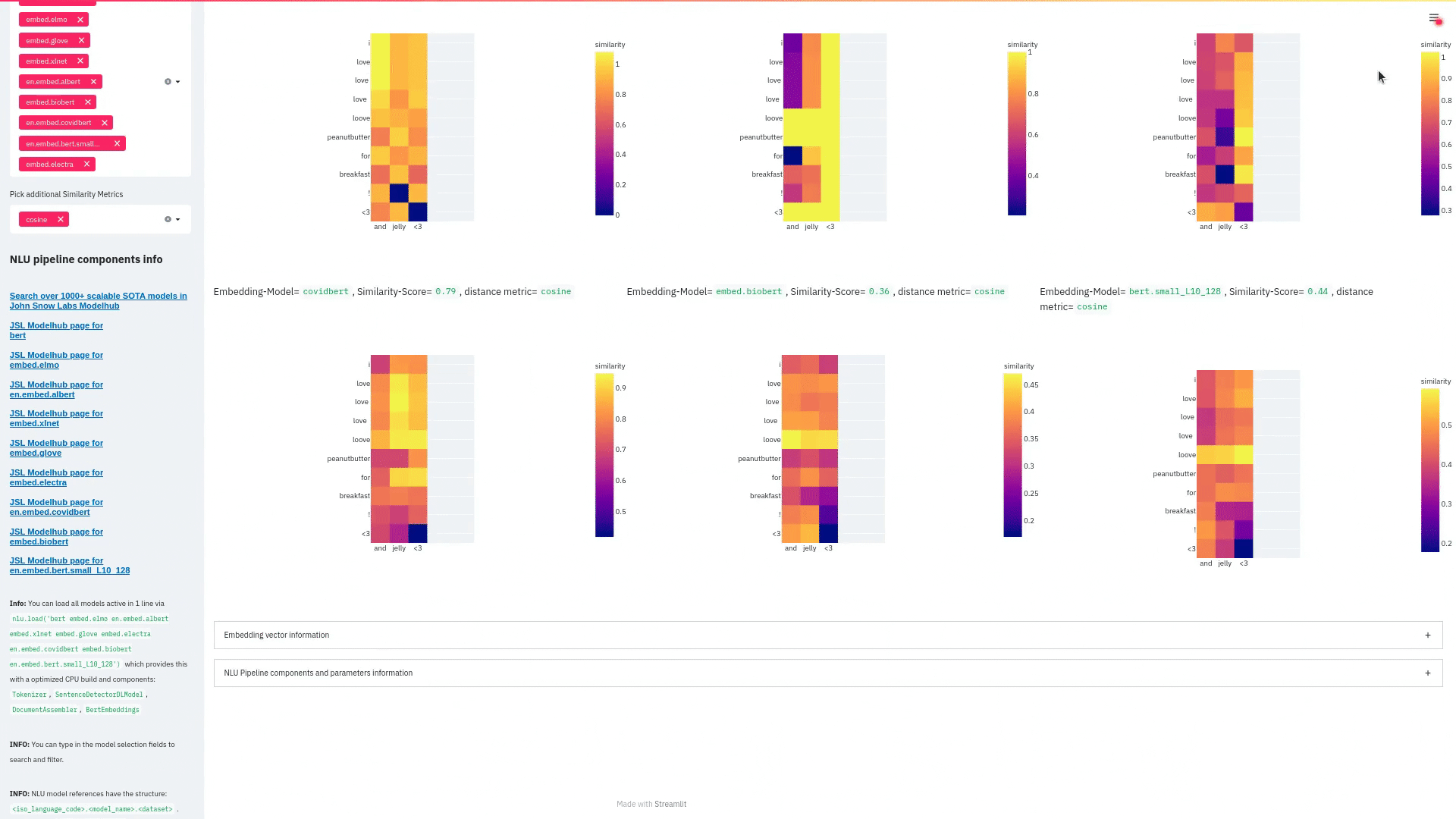 + +### function parameters `pipe.viz_streamlit_similarity` + +| Argument | Type | Default |Description | +|--------------------------- | ---------- |-----------------------------------------------------------| ------------------------------------------------------- | +| `texts` | `str` | `'Donald Trump from America and Anegela Merkel from Germany do not share many views.'` | Text to predict token information for.| +| `title` | `Optional[str]` | `'Named Entities'` | Title of the Streamlit building block that will be visualized to screen | +| `similarity_matrix` | `bool` | `None` |Whether to display similarity matrix or not| +| `show_algo_select` | `bool` |`True` | Whether to show dist algo select or not | +| `show_table` | `bool` | `True` | Whether show to predicted pandas table or not| +| `threshold` | `float` | `0.5` | Threshold for displaying result red on screen | +| `set_wide_layout_CSS` | `bool` | `True` | Whether to inject custom CSS or not. +| `key` | `str` | `"NLU_streamlit"` | Key for the Streamlit elements drawn +| `generate_code_sample` | `bool` | `False` | Display Python code snippets above visualizations that can be used to re-create the visualization +| `show_model_select` | `bool` | `True` | Show a model selection dropdowns that makes any of the 1000+ models avaiable in 1 click +| `model_select_position` | `str` | `'side'` | [Whether to output the positions of predictions or not, see `pipe.predict(positions=true`) for more info](https://nlu.johnsnowlabs.com/docs/en/predict_api#output-positions-parameter) | +|`write_raw_pandas` | `bool` | `False` | Write the raw pandas similarity df to streamlit +|`display_embed_information` | `bool` | `True` | Show additional embedding information like `dimension`, `nlu_reference`, `spark_nlp_reference`, `sotrage_reference`, `modelhub link` and more. +|`dist_metrics` | `List[str]` | `['cosine']` | Which distance metrics to apply. If multiple are selected, there will be multiple plots for each embedding and metric. `num_plots = num_metric*num_embeddings`. Can use multiple at the same time, any of of `cityblock`,`cosine`,`euclidean`,`l2`,`l1`,`manhattan`,`nan_euclidean`. Provided via [Sklearn `metrics.pairwise` package](https://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics.pairwise) +|`num_cols` | `int` | `2` | How many columns should for the layout in streamlit when rendering the similarity matrixes. +|`display_scalar_similarities` | `bool` | `False` | Display scalar simmilarities in an additional field. +|`display_similarity_summary` | `bool` | `False` | Display summary of all similarities for all embeddings and metrics. +| `show_logo` | `bool` | `True` | Show logo +| `display_infos` | `bool` | `False` | Display additonal information about ISO codes and the NLU namespace structure. + + + + + + + +