Paper submission date: 18 December 2020
Authors: Julien Aimonier-Davat (LS2N), Hala Skaf-Molli (LS2N), and Pascal Molli (LS2N)
Abstract SPARQL property path queries provide a succinct way to write complex navigational queries over RDF knowledge graphs. However, the evaluation of these queries over online knowledge graphs such as DBPedia or Wikidata is often interrupted by quotas, returning no results or partial results. To ensure complete results, property path queries are evaluated client-side. Smart clients decompose property path queries into subqueries for which complete results are ensured. The granularity of the decomposition depend on the expressivity of the server. Whatever the decomposition, it could generate a high number of subqueries, a large data transfer, and finally delivers poor performances. In this paper, we extend a preemptable SPARQL server with a partial transitive closure operator (PTC) based on a depth limited search algorithm. We show that a smart client using the PTC operator is able to process SPARQL property path online and deliver complete results. Experimental results demonstrate that our approach outperforms existing smart client solutions in terms of HTTP calls, data transfer and query execution time.
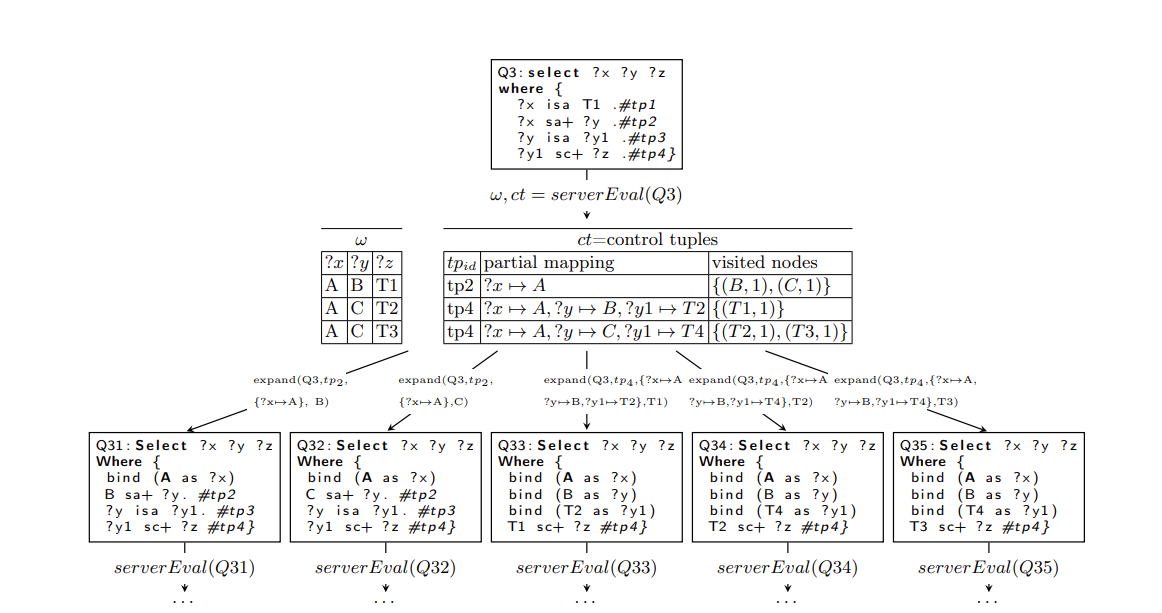
Figure: First iteration of eval(Q3) as defined in Algorithm 3 over the dataset D with MaxDepth = 1
In our experiments, we use the gMark framework, which is a framework designed to generate synthetic graph instances coupled with complex property path query workloads. We generate a graph instance having 7,533,145 edges and 30 queries for the "Shop" gMark scenario. All our queries contain from one to four transitive path expressions.
In our experiments, we compare the following approaches:
- SaGe-PTC is the implementation of the PTC approach defined in our paper. The server-side algorithm
is implemented on the SaGe server. The code is available here. The client-side algorithm
is implemented in javascript. The code is available here. We use the HDT backend of the
SaGe server to store the gMark dataset. The server is configured with a page size limit of 10000 triples
and 10000 control tuples. Concerning the quantum and the MaxDepth parameters, we use different settings
in our experiments:
- SaGe-PTC-2 is configured with a time quantum of 60 seconds and a MaxDepth of 2.
- SaGe-PTC-3 is configured with a time quantum of 60 seconds and a MaxDepth of 3.
- SaGe-PTC-5 is configured with a time quantum of 60 seconds and a MaxDepth of 5.
- SaGe-PTC-10 is configured with a time quantum of 60 seconds and a MaxDepth of 10.
- SaGe-PTC-20 is configured with a time quantum of 60 seconds and a MaxDepth of 20.
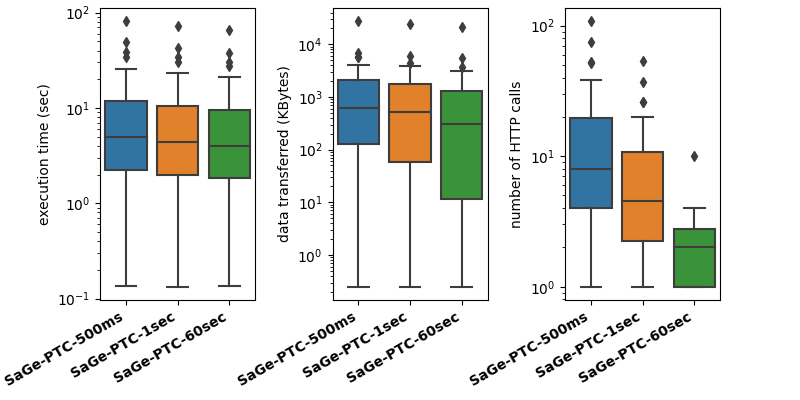
- SaGe-PTC-500ms is configured with a time quantum of 500 ms and a MaxDepth of 20.
- SaGe-PTC-1sec is configured with a time quantum of 1 second and a MaxDepth of 20.
- SaGe-PTC-60sec is configured with a time quantum of 60 seconds and a MaxDepth of 20.
- SaGe-Multi is the implementation of the multi-predicate automaton based approach defined in [1]. SaGe-Multi is a SaGe smart client and interacts with the same server as SaGe-PTC, configured with a time quantum of 60 seconds.
- Virtuoso is the Virtuoso SPARQL endpoint (v7.2.5 as of December 2020). Virtuoso is configured without quotas in order to deliver complete results, and with a single thread per query.
- Jena-Fuseki is the Apache Jena Fuseki endpoint (v3.17.0). The gMark dataset is stored in a TDB database.
- Execution time is the total time between starting the query execution and the production of the final results by the client.
- Data transfer is the total number of bytes transferred from the server to the client during the query execution.
- Number of HTTP calls is the total number of HTTP calls issued by the client during the query execution.
- type:
c2-standard-4 :4 vCPU, 15 Go of memory - processor platform:
Intel Broadwell - OS: ubuntu-1910-eoan-v20191114
- SSD disk of 256GB
Plot 1: Statistics about the evaluation of the 30 gmark queries in terms of execution time, data transfer and number of http calls for different time quantum.
Plot 2: Statistics about the evaluation of the 30 gmark queries in terms of execution time, data transfer and number of http calls for different MaxDepth value.

Plot 3: Execution time, data transfer and number of http calls for the 30 gmark queries

![]()

To run our experiments, the following softwares and packages have to be installed on your system.
- Virtuoso (v7.2.5)
- NodeJS (v14.15.4)
- Python3.7 and Python3-dev
- Virtualenv (v20.4.0)
- Apache-Jena-Fuseki (v3.17.0)
Caution: In the next sections, we assume that Virtuoso is installed at its default location
/usr/local/virtuoso-opensource and Fuseki is installed in the servers/fuseki
directory. If you change the location of Virtuoso or Fuseki, do not forget to propagate this
change in the next instructions and please update the
start_server.sh and
stop_server.sh scripts.
Virtuoso needs to be configured to use a single thread per query and to disable quotas.
- In the [SPARQL] section of the file
/usr/local/virtuoso-opensource/var/lib/virtuoso/db/virtuoso.ini- set ResultSetMaxRows, MaxQueryCostEstimationTime and MaxQueryExecutionTime to 10^9 in order to disable quotas.
- In the [Parameters] section of the file
/usr/local/virtuoso-opensource/var/lib/virtuoso/db/virtuoso.ini- set MaxQueryMem, NumberOfBuffers and MaxDirtyBuffers to an appropriate value based on the amount of RAM available on your machine. In our experiments, we used the settings recommended for a machine with 8Go of RAM.
- set ThreadsPerQuery to 1.
- add your home directory to DirsAllowed.
- At the end of the file
/usr/local/virtuoso-opensource/var/lib/virtuoso/db/virtuoso.iniadd a new section named [Flags]. In this new section, add a new parameter tn_max_memory. The parameter tn_max_memory allow to increase the allocated space used to compute transitive closures. We set this parameter to 2000000000 (bytes) in our experiments. You can adapt this value according to the amount of RAM available on your machine.
Apache Jena Fuseki needs to be configured as Virtuoso.
- open the file
servers/fuseki/fuseki-serverand set the java heap memory to an appropriate value based on the amount of space available on your machine. In our experiments, we set it to 8Go. - copy the file
configs/fuseki/gmark.ttlinto the directoryservers/fuseki/run/configuration. - set the FUSEKI_BASE environement variable to
servers/fuseki/run.
Once all dependencies have been installed, clone this repository and install the project.
git clone https://github.com/JulienDavat/property-paths-experiments.git sage-ppaths-experiments
cd sage-ppaths-experiments
bash install.shThe gMark dataset used in our experiments is available online. Download the .hdt and the .nt into the graphs directory.
wget nas.jadserver.fr/thesis/projects/ppaths/datasets/gmark.hdt
wget nas.jadserver.fr/thesis/projects/ppaths/datasets/gmark.nt# Loads all .nt files in the graphs directory
isql "EXEC=ld_dir('{PROJECT_DIRECTORY}/graphs', '*.nt', 'http://example.org/datasets/default');"
isql "EXEC=rdf_loader_run();"
isql "EXEC=checkpoint;"# Loads the gmark dataset in Apache Jena Fuseki
ruby servers/fuseki/bin/s-put http://localhost:3030/gmark default graphs/gmark.ntAll our experiments can be configured using the file xp.json. Here you have an extract of the configuration file used to run our experiments.
{
"settings": {
"plot1": {
"title": "DepthMax impacts executing the gmark queries",
"settings": {
"depths": ["2", "3", "5", "10"],
"dataset": "gmark",
"queries": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30],
"runs": 3,
"warmup": false
}
},
"plot2" : {
"title": "Time quantum impacts executing the gmark queries",
"settings": {
"quantums": ["500ms", "1sec", "60sec"],
"dataset": "gmark",
"queries": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30],
"runs": 3,
"warmup": false
}
},
"plot3": {
"title": "Performance of the SaGe-PTC approach compared to Virtuoso, Jena and SaGe-Multi over the gmark dataset",
"settings": {
"approaches": ["SaGe-PTC-5", "SaGe-PTC-20", "Jena-Fuseki", "SaGe-Multi"],
"dataset": "gmark",
"queries": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30],
"runs": 3,
"warmup": false
}
}
}
}Configurable fields are detailed below:
- approaches: the approaches to compare.
- accepted values: SaGe-PTC-5, SaGe-PTC-20, SaGe-Multi, Virtuoso and Jena-Fuseki
- dataset: the dataset on which queries will be executed.
- accepted values: gmark
- depths: the differents values of the MaxDepth parameter for which queries will be executed.
- accepted values: 2, 3, 5, 10 and 20
- quantums: the different quantum times for which queries will be executed.
- accepted values: 500ms, 1sec, 60sec
- queries: the queries to execute for each workload.
- accepted values: 1..30 for the gmark dataset
- warmup: true to compute a first run for which no statistics will be recorded, false otherwise
- accepted value: true or false
- runs: the number of run to compute. For each of these run, queries execution statistics will be
recorded and the average will be retained for each metric.
- accepted value: a non-zero positive integer
Our experimental study is powered by Snakemake. To run any part of our experiments, just ask snakemake for the desired output file. For example, the main commands are given below:
# Measures the impact of the quantim time on performance using the gmark queries
snakemake --cores 1 output/figures/quantum-impacts/gmark/figure.png
# Measures the impact of the MaxDepth parameter on performance using the gmark queries
snakemake --cores 1 output/figures/depth-impacts/gmark/figure.png
# Compares the different approaches in terms of execution time, data transfer and number of http calls using the gmark queries
snakemake --cores 1 output/figures/performance/gmark/{nb_calls,data_transfer,execution_time}.pngIt is also possible to run each part of our experiments without Snakemake. For example, some important commands are given below:
# to start the SaGe server
sage $CONFIG_FILE -w $NB_WORKERS -p $PORT
# to start the Virtuoso server on the port 8890
/usr/local/virtuoso-opensource/bin/virtuoso-t -f -c /usr/local/virtuoso-opensource/var/lib/virtuoso/db/virtuoso.ini
# to evaluate a query with the SaGe-PTC approach
node clients/sage-ptc/bin/interface.js $SERVER_URL $GRAPH_IRI --file $QUERY --measure $OUT_STATS --output $OUT_RESULT
# to evaluate a query with the SaGe-Multi approach
node clients/sage-multi/bin/interface.js $SERVER_URL $GRAPH_IRI --file $QUERY --measure $OUT_STATS --output $OUT_RESULT
# to evaluate a query with Virtuoso
python clients/endpoints/interface.py virtuoso $SERVER_URL $GRAPH_IRI --file $QUERY --measure $OUT_STATS --output $OUT_RESULT
# to evaluate a query with Jena-Fuseki
python clients/endpoints/interface.py fuseki $SERVER_URL $GRAPH_IRI --file $QUERY --measure $OUT_STATS --output $OUT_RESULT