CogVideoX/CogVideoX1.5 是有文本/图像生成视频的模型。xDiT 目前整合了 USP 技术(包括 Ulysses 注意力和 Ring 注意力)和 CFG 并行来提高推理速度,同时 PipeFusion 的工作正在进行中。我们对基于 diffusers 库的单 GPU CogVideoX 推理与我们提出的并行化版本在生成 49帧(6秒)720x480 分辨率视频时的性能差异进行了深入分析。由于我们可以任意组合不同的并行方式以获得不同的性能。在本文中,我们对xDiT在1-12张L40(PCIe)GPU上的加速性能进行了系统测试。
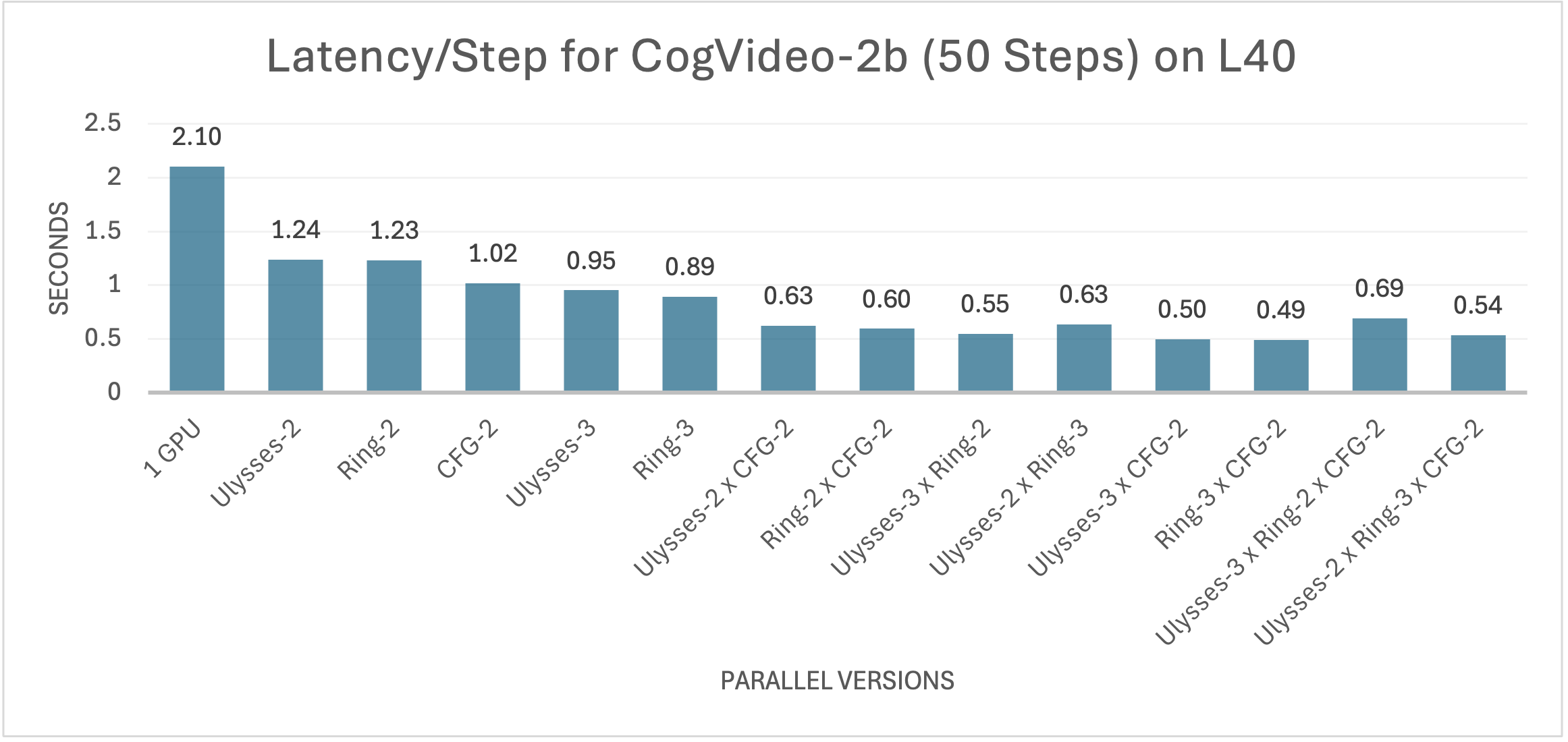
如图所示,对于基础模型 CogVideoX-2b,无论是采用 Ulysses Attention、Ring Attention 还是 Classifier-Free Guidance(CFG)并行,均观察到推理延迟的显著降低。值得注意的是,由于其较低的通信开销,CFG 并行方法在性能上优于其他两种技术。通过结合序列并行和 CFG 并行,我们成功提升了推理效率。随着并行度的增加,推理延迟持续下降。在最优配置下,xDiT 相对于单GPU推理实现了 4.29 倍的加速,使得每次迭代仅需 0.49 秒。鉴于 CogVideoX 默认的 50 次迭代,总计 30 秒即可完成 24.5 秒视频的端到端生成。
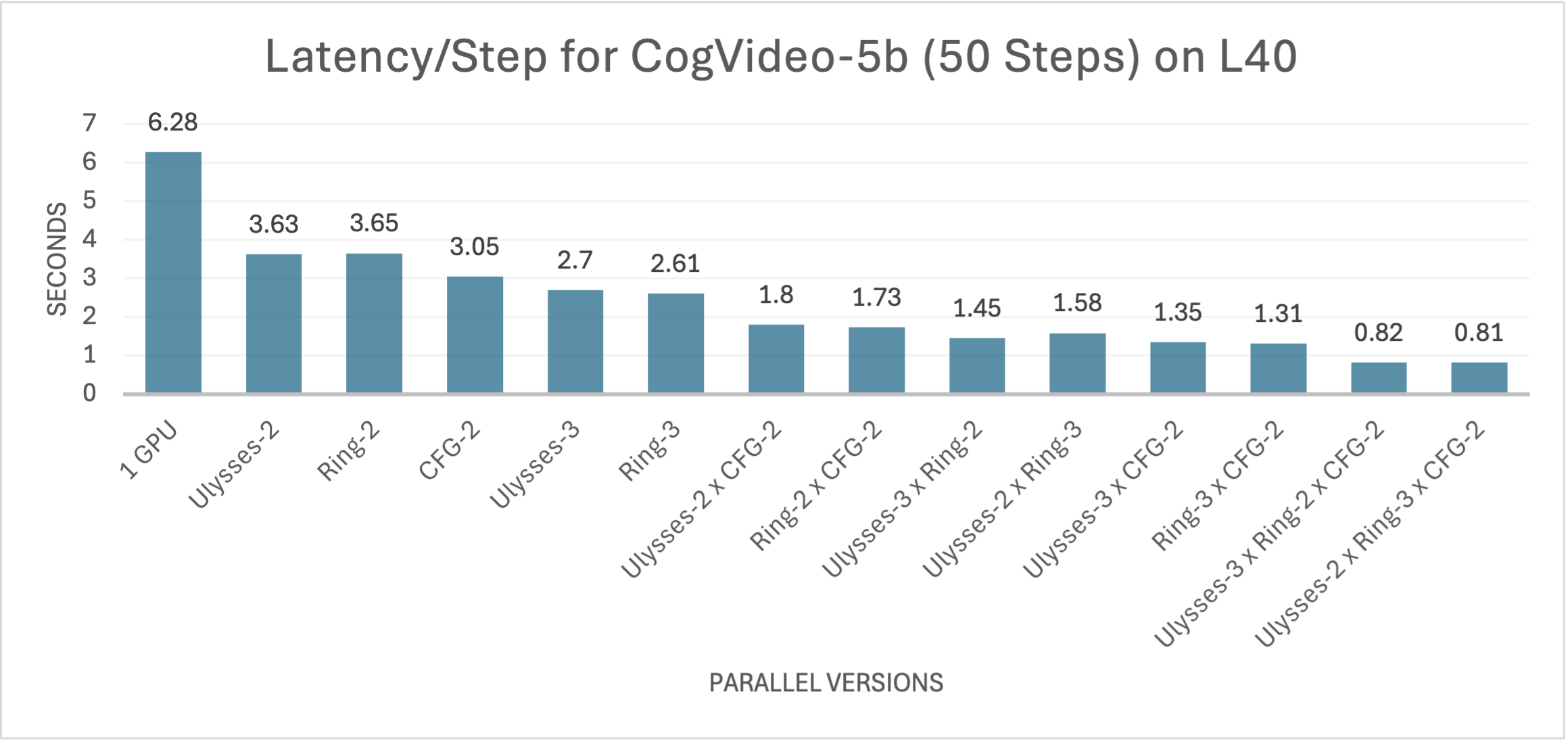
针对更复杂的CogVideoX-5b模型,虽然参数增加以提升视频质量和视觉效果,导致计算成本显著上升,但在该模型上,所有方法仍然保持与CogVideoX-2b相似的性能趋势,且并行版本的加速效果进一步提升。相较于单GPU版本,xDiT实现了高达7.75倍的推理速度提升,将端到端视频生成时间缩短至约40秒。
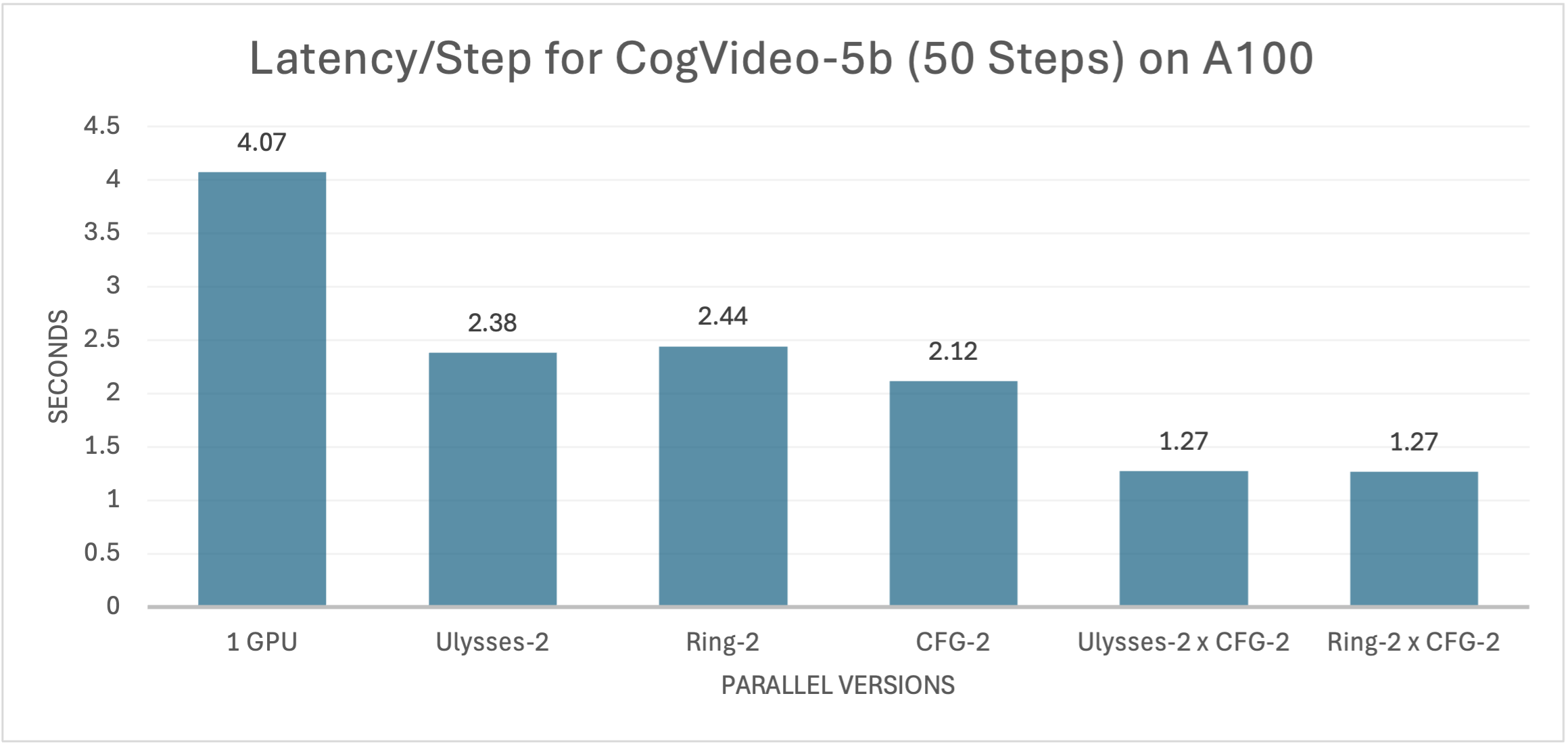
在搭载A100 GPU的系统中,xDiT 在 CogVideoX-2b 和 CogVideoX-5b 上展现出类似的加速效果,具体表现可见下方两图。
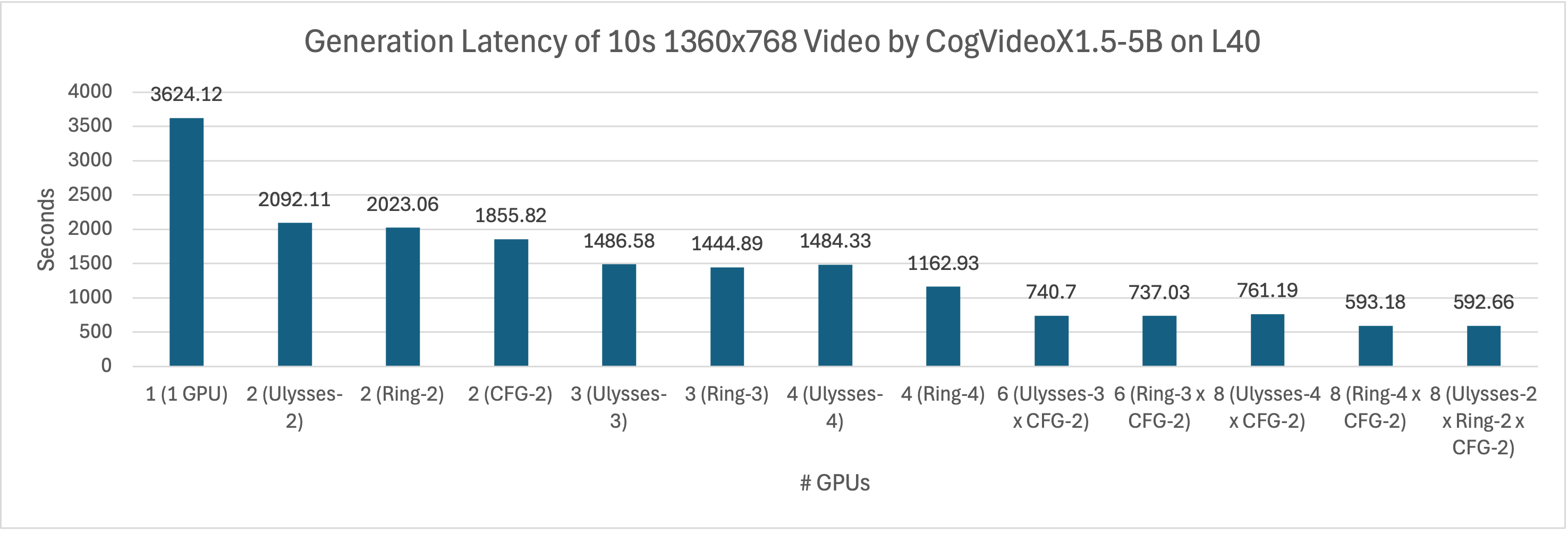
同样,我们在配备了L40(PCIe)GPU的系统上用CogVideoX1.5-5B生成161帧1360x768分辨率的视频,我们对比了diffusers库中单卡的推理实现与xDiT的并行版本在推理延迟上的差异。 如图所示,无论Ulysses Attention、Ring Attention还是CFG并行,均可以降低xDiT的推理延迟。其中,给定2张GPU卡时,CFG并行由于通信量较小,表现出比Ulysses Attention、Ring Attention更高的性能。通过结合序列并行和CFG并行,我们进一步提高了推理效率。随着并行度的增加,推理延迟持续降低。在8卡环境下,混合Ulysses-2,Ring-2,CFG-2时xDiT可以获得最佳性能,相比于单卡推理方法可以实现6.12倍的加速,生成一个视频只需不到10分钟。
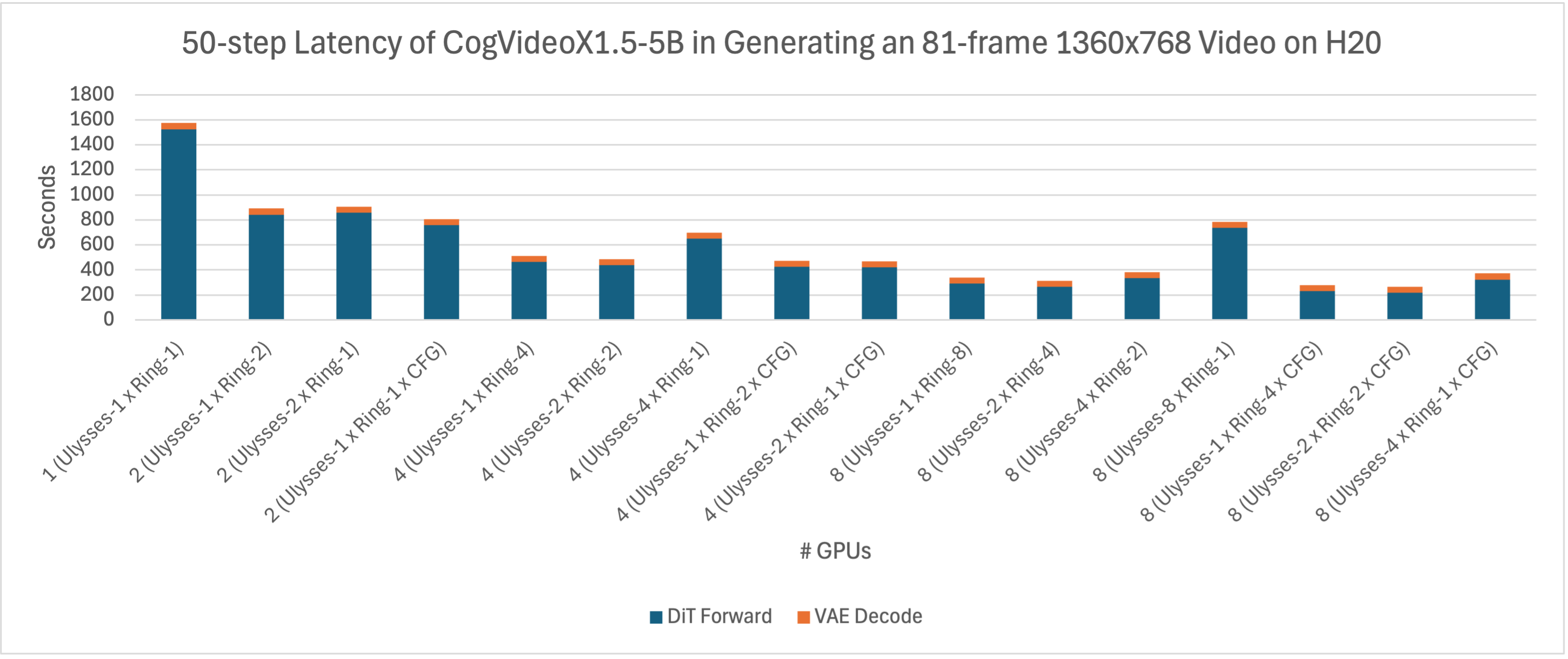
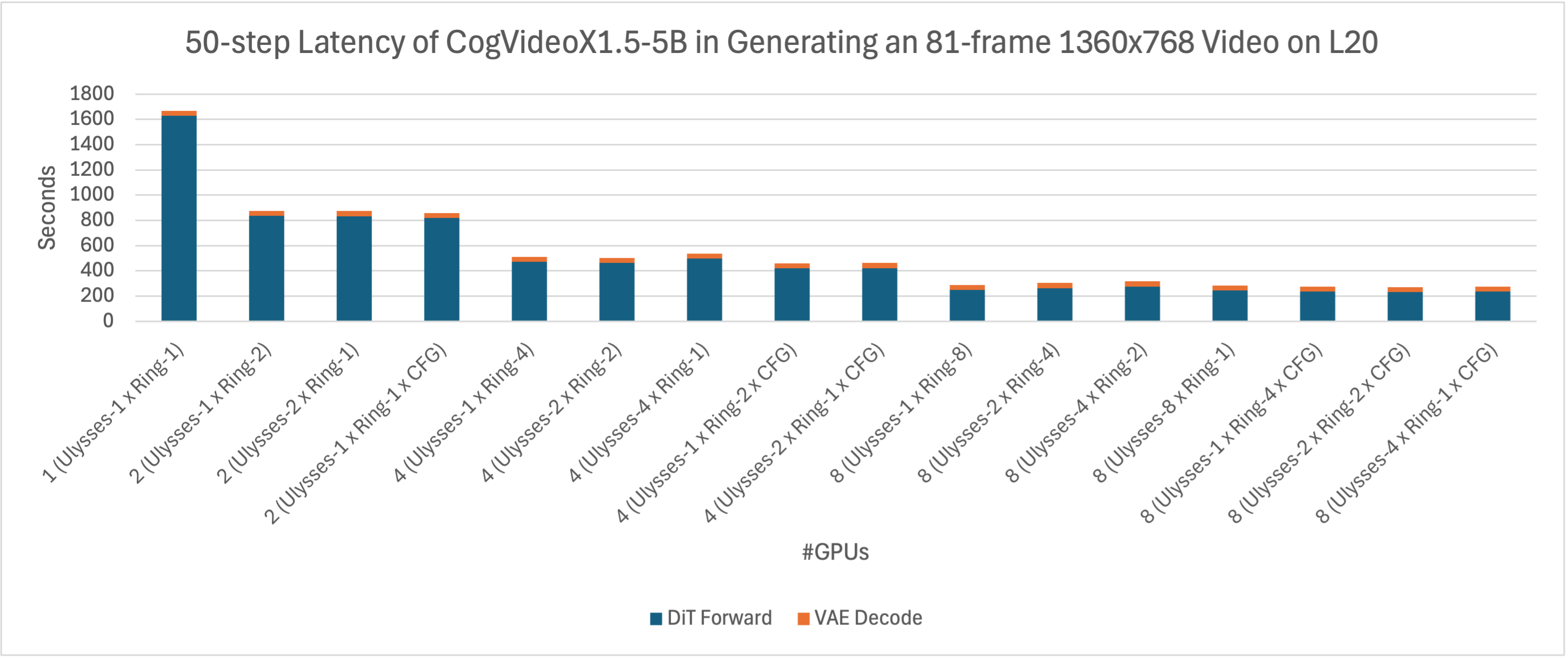
我们对xDiT在H20和L20上生成81帧1360x768分辨率视频的加速效果进行了进一步比较。从下图可以观察到,在这两台设备上,CogVideoX1.5-5B的推理延迟非常相似,然而考虑到H20的价格高于L20,L20展现出了更高的性价比。