- 文本清洗、去除停用词
- 文本标准化
- tokenize
-
数据清洗,洗去噪声
-
数据增强
-
早停法
-
dropout
-
正则化
-
集成
-
使用简单模型
-
继续预训练
- 分层学习率(克服灾难遗忘)
-
在相关领域的数据集上微调
-
取[CLS]向量、多层隐藏层加权平均
-
warm up
-
文本截断:head-only、tail-only、head-tail
-
学习率设置为:2e-5、3e-5、5e-5
-
Multi Sample Dropout
- 创建多个dropout样本,平均所有dropout的损失,从而得到最终损失
- 相当于对这份样本训练了多次,相对于给样本训练多次来说,省略了每次都经过前面的全连接层,加快了计算的速度
- 还能增加模型的泛化能力
-
AdamW
-
BCE
-
CrossEntropy
- Stratified K Fold
- Group K Fold
- batch_size:16, 32
- lr:2e-5、3e-5、5e-5
- warm_up ratio:0.1
- IM聊天的随意性和碎片化,各个地方的语言习惯不同。
- 要求模型的泛化性好。在测试集上模型的度量指标。
- 要求模型的复杂度小。最终提交模型需要符合生产环境使用要求。
- 数据领域性强,有较多难样本。
- 只尝试了QA-pair的形式,没有尝试QA-point或者QA-list
- 继续预训练Bert
- 改进mask方式,从数据中抽取领域相关的新词,然后对新词的实体做mask
- 改进nsp(句子的连续性预测)任务,采用sop/aop(句子的顺序预测)的方式
- 邱锡鹏:How to Fine-Tune BERT for Text Classification?提到:更新10k steps模型效果在下游任务中效果最好
- PET(基于模式的训练)
- reinit
- f1 search
- softlabel
- 伪标签
- 融入手工特征
-
线性回归
-
逻辑回归
-
逻辑回归原理?
- 逻辑回归的任务目的是对数据进行二分类划分,他假设数据服从伯努利分布,然后通过极大似然估计来求解参数
-
逻辑回归目的?
- 数据二分类
-
逻辑回归如何做分类的?
- 主要是先求出结果,结果是连续值,经过sigmoid函数映射成概率的值,然后设定一个阈值,大于阈值的就为正类,小于阈值的就是负类
-
逻辑回归的假设条件?
- 假设数据服从伯努利分布
- 假设样本的正类的概率是:$p=\frac{1}{1+e^{-\theta^T x}}$
-
逻辑回归的损失函数?
- 极大似然函数,网上有的写log loss,有的写logistical loss
$$ L=\sum_{i=1}^n(p(Y=1|x_i))^{y_i}(1-p(Y=1|x_i))^{1-y_i} $$
-
参数求解的方法?
- GD:梯度下降法得到的是全局最优解,但是每次更新参数需要计算所有的数据,计算量很大,还有很多冗余的计算,导致参数更新很慢
- SGD:随机梯度下降优点是会更新到潜在更好的局部最优解,缺点是收敛过程更复杂
- Mini-Batch SGD:结合上面两种方法的优点,每次对一小批数据进行计算更新参数,减少了参数更新的次数,也可以更加稳定收敛的结果
-
为什么用对数损失不用平方损失?
- 因为在逻辑回归里面用平方损失,函数会变成非凸的,而我们用的是梯度下降法求解参数,所以用平方损失很容易陷入局部最优值;而用对数似然函数作为损失得到的是一个可导的凸函数,能够计算出最优解
-
逻辑回归的优缺点?
- 优点:形式比较简单,可解释性比较强,可以作为baseline;训练的速度也非常快
- 缺点:准确率不太高,主要是由于形式简单,很难拟合数据的真实分布;处理不平衡的数据比较困难
-
与线性回归的区别?
-
逻辑回归中如果有很多的特征高度相关或者说有一个特征重复了很多遍,会造成怎样的影响?
- 影响不会很大,如果不考虑采样的话,特征重复多次,相当于它的权重也会随之按比例跟着下调;
-
为什么在训练过程中要将高度相关的特征去掉?
- 去掉高度相关的特征会让模型可解释性更好
- 加快训练速度
-
为什么使用sigmoid?
- 0-1损失函数不可导,sigmoid是连续可导,且是凸函数,易于优化
- sigmoid保证结果在0-1之间,可以理解为概率
-
逻辑回归是线性模型吗?
- 是的,因为逻辑回归的决策边界是线性的
$$ p(Y=1|x)=\frac{1}{1+e^{-\theta^Tx}}\ p(Y=0|x)=\frac{e^{-\theta ^Tx}}{1+e^{-\theta^Tx}}\ 令p(Y=1|x)=p(Y=0|x)求决策边界\ \frac{1}{1+e^{-\theta^Tx}}=\frac{e^{-\theta ^Tx}}{1+e^{-\theta^Tx}}\ \theta^Tx=0 $$
-
-
Softmax回归
-
支持向量机
- SVM介绍?
- SVM是一种二分类模型,它的基本思想是在特征空间中寻找间隔最大的超平面的二分类模型,主要有三种方式
- 硬间隔:如果数据线性可分,通过硬间隔最大化,学习到的是线性可分支持向量机
- 软间隔:如果数据近似线性可分,通过引入松弛变量,使得软间隔最大化,学习到的是线性支持向量机
- 核函数:如果数据线性不可分,通过引入核函数和软间隔最大化,学习非线性支持向量机
- SVM为什么采用间隔最大化?
- 数据线性可分的时候,有无穷多个超平面可以将数据二分,如果像感知机那样求出来的超平面对边界上的点泛化性不够好,SVM的目的是在这无穷多个超平面中找出泛化性最好的超平面,这样求出的解是唯一的
- SVM原理?
- SVM的目标是:在空间中找到一个超平面将数据二分类,并且这个超平面的间隔必须是最大的
- SVM定义的间隔就是所有点到分离超平面的距离最近的距离,然后最原始的优化目标就是:最大化几何间隔,并且使得每个点都满足到超平面几何间隔大于等于这个间隔
- SVM又定义了函数间隔,也就是几何间隔除以||w||,并且超平面的参数在成比例发生改变时平面并不会改变,几何间隔也不会发生改变,但是函数间隔会发生改变;根据这个性质上面的优化目标可以变成:最大化1/2||w||^2,使得所有点被正确分类,这是一个带约束条件的凸二次规划问题
- 直接根据拉格朗日乘子法求解这个问题比较复杂,所以引入了拉格朗日对偶性;由于原优化目标函数是凸函数,并且约束条件都是严格取小于或者等于号的,满足slater条件,原问题和其对偶问题的最优解等价,原问题是极大极小问题变成了极小极大问题,然后直接求解对偶问题
- 当数据集近似线性可分的时候,又引入了软间隔,也就是允许一部分点不满足线性可分,但是去掉这些点之后大部分点还是满足线性可分的条件的,所以在优化目标函数上加了一个松弛变量,也就等价于使用了合页损失函数作为作为优化目标
- 在满足Slater条件的情况下,可以使用KKT条件求解原问题与对偶问题的最优解,KKT条件分别是:稳定性条件(拉格朗日函数对各参数的偏导为0)、互补松弛条件(不等式约束和拉格朗日乘数的积为0)、原问题的可行性(原问题约束条件需得到满足)、对偶问题的可行性(不等式约束的拉格朗日乘数需要大于0)
- 对于线性不可分的数据集,引入核函数之后,可以将原数据集从低维空间映射到高维空间,从而使得数据线性可分
- 为什么引入对偶?
- 降低计算复杂度,便于核函数的引进
- 参数有哪些?
- 正则化项C
- 核函数的参数,如:高斯核参数gamma
- SVM核函数?
- 常见核函数:线性核函数、多项式核函数、高斯核函数
- 为什么要引入核函数?
- 当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。而引入这样的映射后,所要求解的对偶问题的求解中,无需求解真正的映射函数,而只需要知道其核函数。核函数的定义:K(x,y)=<ϕ(x),ϕ(y)>,即在特征空间的内积等于它们在原始样本空间中通过核函数 K 计算的结果。一方面数据变成了高维空间中线性可分的数据,另一方面不需要求解具体的映射函数,只需要给定具体的核函数即可,这样使得求解的难度大大降低。
- 为什么SVM对缺失数据敏感?
- SVM 没有处理缺失值的策略。而 SVM 希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
- SVM的支持向量?
- 线性可分支持向量机:支持向量是距离分离超平面的最近的点,落在最大间隔边界上,支持向量机的参数w和b仅由支持向量决定,与其他样本无关
- 线性支持向量机:支持向量在最大间隔边界、间隔边界与分离超平面之间或者分布超平面误分类的那一侧
- SVM的优缺点?
- 优点:
- SVM是凸二次规划问题,求得的解一定是全局最优解
- 适用于线性可分和线性不可分的数据
- 高维度的数据也可以使用,因为模型的参数依赖于支持向量而不是数据集的维度
- 理论完善,有良好的可解释性
- 缺点:
- 只适用于二分类
- 不适用于大量的数据
- 优点:
- SVM的训练方法?
- SMO:类似于坐标上升算法,每次选取一对参数进行优化直到求出所有参数的最优解
- SVM介绍?
- HMM
- 简单介绍HMM原理? +
- 维特比算法?
- CRF
- HMM和CRF的区别?
- CRF的原理?
- ID3
- C4.5
- CART
- Adaboost
- GDBT
XGBoostLightGBM
-
kmeans
-
kmeans与knn的区别?
- knn是分类算法,kmeans是聚类算法
- knn是有监督学习,kmeans是无监督学习
- knn无明显学习过程,kmeans有学习过程
两者相似之处:都通过距离度量判断两个样本相似性
-
原理?
- 输入:数据集合、中心点个数
- 从数据中随机选取k个点作为质心
- 遍历数据,计算点到各个质心的距离,将数据点标记为离得最近的质心的类别
- 重新计算质心:新的质心等于所有相同类别的点的均值
- 如果k个质心都没发生变化,则跳出循环;否则继续标记数据的类别,计算新的质心
- 输出所有样本的类别划分
-
-
DBSCAN
-
Mean Shift
-
LSA、pLSA、LDA
期望错误 = 偏差 + 方差 + 损失
偏差:当前模型与最优模型的差异,用于衡量模型的拟合能力
方差:一个模型在不同训练集上的差异,用于衡量模型是否容易过拟合
方差一般会随着训练样本的增加而减少。当样本比较多时,方差比较少,这时可以选择能力强的模型来减少偏差。然而在很多机器学习任务上,训练集往往都比较有限,最优的偏差和最优的方差就无法兼顾。**随着模型复杂度的增加,模型的拟合能力变强,偏差减少而方差增大,从而导致过拟合。**以结构风险最小化为例,我们可以调整正则化系数 𝜆 来控制模型的复杂度。当 𝜆 变大时,模型复杂度会降低,可以有效地减少方差,避免过拟合,但偏差会上升。当 𝜆 过大时,总的期望错误反而会上升。因此,一个好的正则化系数 𝜆 需要在偏差和方差之间取得比较好的平衡。下图给出了机器学习模型的期望错误、偏差和方差随复杂度的变化情况,其中红色虚线表示最优模型。最优模型并不一定是偏差曲线和方差曲线的交点。
梯度下降法、拟牛顿法
- 经验风险最小化
- 结构风险最小化
- 极大似然估计
- 最大后验估计
- 留出法
- 每次随机划分样本为互斥的两部分,采用分层抽样,多次划分取平均值
- 交叉验证法
- 从数据中分层采样得到K份数据分布大致相同的数据,然后每次以k-1份作为训练集,剩下的一份作为验证集
- 自助法
- 有放回抽样
- 数据集较小、难以有效划分时使用
sklearn中的划分:
- KFold
- Stratified KFold:分层抽样,保持数据分布相同
- Group KFold:分组KFold,保证同一个group的数据不会同时出现在训练集和测试集上。因为如果训练集中包含了每个group的几个样例,可能训练得到的模型能够足够灵活地从这些样例中学习到特征,在测试集上也会表现很好。但一旦遇到一个新的group它就会表现很差。
-
MSE $$ L=\sum_{i=1}^N(y_i-\hat{y}_i)^2 $$
-
BCE/CE
- 交叉熵的推导?
- 交叉熵由KL散度推导而来,KL散度是度量两个概率分布的差异的函数,即交叉熵是度量真实分布与预测分布差异的损失函数
- 为什么分类用交叉熵而不用平方损失?
- 当激活函数是sigmoid函数时,使用平方损失函数得到的优化目标函数是非凸的函数,很容易陷入局部最小值
- 从概率的角度来看,分类问题的样本服从多项式分布,经过推导其负对数似然函数是交叉熵;回归问题的样本服从高斯分布,经过推导其负对数似然函数是平方损失
$$ L = -y^Tlog(\hat{y}) $$
- 交叉熵的推导?
-
Hinge
健壮性高,对异常点、噪声不敏感 $$ L=max(0, 1-y\hat{y}) $$
-
Focal Loss
- 主要思想:降低高置信度样本(易分样本)的损失函数,让模型更加关注难分样本
$$ FL=\left{ \begin{aligned} -\alpha(1-p)^\gamma log(p), y=1\ -(1-\alpha)p^\gamma log(1-p),y=0 \end{aligned} \right. $$
gamma和alpha都是超参数,一般取2和0.25
-
GHM Loss
- 主要思想:在Focal Loss的基础上关注一定范围的难样本,因为有的样本可能是离群点,不用过多关注
-
Dice Loss
- 重采样
- 上采样、下采样
- SMOTE
- 重加权
- 统计样本分布,给不同类别计算其权值,主要关注样本数量不平衡
- Focal Loss:样本难易不平衡
- GHM Loss
- Dice Loss
-
数据清洗,洗去噪声
-
数据增强
-
随机删除、随机替换、随机插入、随机交换
-
打乱句子顺序
-
回译
-
Bert MLM替换
-
-
早停法
-
dropout
-
正则化
-
集成
-
使用简单模型
-
batch normalization
二分类
-
正确率 $$ acc = \frac{1}{n}\sum_{i=1}^msign(\hat{y}_i, y_i) $$
-
错误率 $$ error = 1-acc $$
-
TP、FP、TN、FN前面的都表示预测的正确性,后面的表示预测的结果,实际的结果就是两者的运算结果
-
真正例:TP,预测正确的正例,实际为正例
-
假正例:FP,预测错误的正例,实际为负例
-
真负例:TN,预测正确的负例,实际为负例
-
假负例:FN,预测错误的负例,实际为正例
-
精准率:所有预测为正例的样本中,实际为正例的样本比例 $$ Precision=\frac{TP}{TP+FP} $$
-
召回率:所有实际为正例的样本中,被预测为正样本的比例 $$ Recall=\frac{TP}{TP+FN} $$
-
f1 $$ f1=\frac{2\times Precision}{Precision+Recall} $$
-
$f_{\beta}$ $$ f_{\beta}=\frac{(\alpha^2+1)PR}{\alpha^2(P+R)} $$ -
auc
- FPR:真正例率=$\frac{预测正确的正例}{实际全部的正例}=\frac{TP}{TP+FN}$=召回率
- TPR:假正例率=$\frac{预测错误的正例}{实际全部的负例}=\frac{FP}{TN+FP}$
- ROC:不同分类阈值下,TPR和FPR构成的曲线
- AUC:ROC曲线下的面积
- 定义:随机抽取一对样本(一正一负),用分类器预测结果,AUC就是:正样本的概率大于负样本的概率的概率
多分类:
- TP、FP、TN、FN分别表示不同类别的指标,计算时和二分类一样,只不过,二分类只有两类,而这里是多分类,因此有多个TP、FP、TN、FN,计算时将计算的那一类记做正类,其余的类别都是负类,一般使用混淆矩阵计算
- 混淆矩阵:对角线上表示预测结果和真实结果一致的
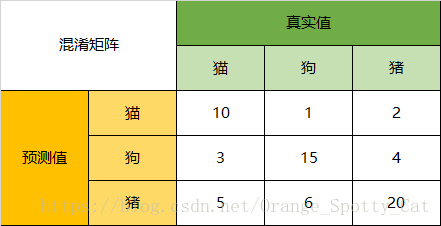
如上图,猫的$TP=10(真实值是猫,预测是也是猫),TN=15+20=35(真实值不是猫,预测也不是猫)$$FP=1+2=3(真实标签不是猫,但是预测成猫),FN=3+5=8(真实值是猫,但是预测值不是猫)$,图中猫的精准率为:$precision=\frac{10}{10+1+2}=\frac{10}{13}$,查全率为:$recall=\frac{10}{10+3+5}=\frac{10}{18}$
这样就可以计算出各个类别的召回率和精准率
-
macro-f1: $$ macro-P=\frac{1}{n}\sum_{i=1}^nP_i\ macro-R=\frac{1}{n}\sum_{i=1}^nR_i\ macro-F1=\frac{2\times macro-P\times macroR}{macro-P+macro-R} $$
-
micro-f1: $$ 先计算各个类别的TP、FP、FN、TN,然后计算平均\overline{TP},\overline{FP},\overline{FN},\overline{TN}\ micro-P=\frac{\overline{TP}}{\overline{TP}+\overline{FP}}\ micro-R=\frac{\overline{TP}}{\overline{TP}+\overline{FN}}\ micro-F1=\frac{2\times micro-P\times microR}{micro-P+micro-R} $$
-
macro-f1与micro-f1各自有什么特点,适用于什么场景?:
- macro-f1:计算过程中没有考虑各个类别的数量,每个类别平等地看待
- micro-f1:计算过程中考虑到了不同类别的数量,对其求了平均,适用于数据不平衡下的场景
-
l1, l2
- 为什么正则化能解决过拟合?
- 通过加入正则化项,抑制参数增大
- 为什么正则化能解决过拟合?
-
权重衰减
- 权重衰减和L2正则化的区别?
-
早停法
-
dropout
-
dropout的原理?
通过随机将部分神经元输出失活,减少
-
dropout的作用?
-
-
数据增强
-
标签平滑
-
为什么要引入标签平滑?
神经网络会促使自身往正确标签和错误标签差值最大的方向学习,在训练数据较少,不足以表征所有的样本特征的情况下,会导致网络过拟合。
-
标签平滑如何减少网络过拟合?
主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。
-
- bagging
- boosting
- stacking
- 判别模型的任务是对条件概率$p(y|x)$建模,目标是学习到决策边界,主要关心结果,通过学习到的决策边界直接判断输入数据的类别
- 生成模型的任务是对联合概率$p(x, y)$建模,目标是对数据分布建模,主要关心结果是如何产生的,然后通过学习到的分布然后计算出数据的类别
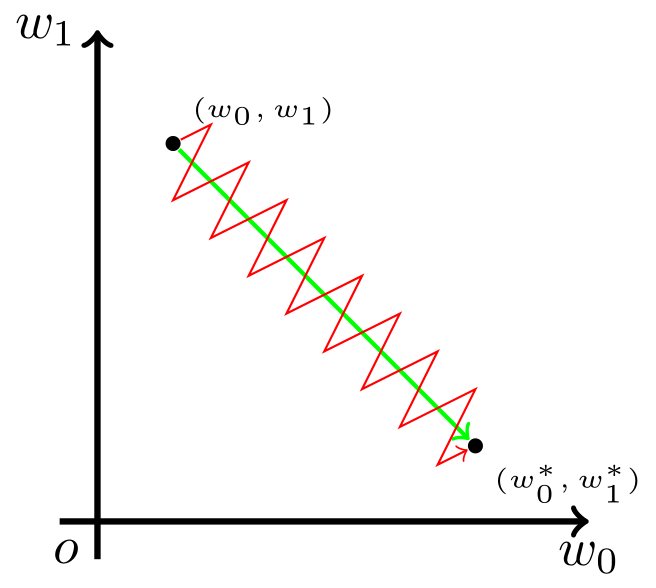
零中心化问题:如果使用sigmoid函数作为上一级的激活函数,其函数输出值恒为正,这一级的参数中某两个参数$w_0$和$w_1$的更新梯度的方向不一致时,影响梯度更新的方向只能是上一级sigmoid的输出值,而它的输出值全为正,会发生震荡,无法高效地更新梯度。
零中心化、两端饱和、偏置偏移
- sigmoid
- 优点:梯度平滑,函数可微,预测明确,很接近0或1
- 缺点:导数值小于1,容易发生梯度消失;非0中心,降低梯度更新效率;指数运算计算成本高
- 适用场景:需要归一化成概率时
- tanh
- 优点:相比于sigmoid,零中心化,梯度下降效率高
- 缺点:两端饱和,容易发生梯度消失;指数运算计算成本高
- 适用场景:一般做隐藏层的激活函数
- ReLU
- 优点:梯度不饱和、收敛速度快;相比于sigmoid和tanh,极大程度改善梯度消失的问题,运算速度快,复杂度低;造成网络的稀疏性,减少了参数依赖,缓解了过拟合的发生
- 缺点:对参数初始化和学习率较敏感;第一个隐藏层梯度为0以后,后面的训练都不能被激活(死亡ReLU问题);偏移问题和死亡神经元会影响网络的收敛;不能解决梯度爆炸的问题
- GELU
- 优点:能避免梯度消失问题;更适合transformer
- 缺点:计算量大
数值微分、符号微分、自动微分
静态图和动态图:静态图编译时构建,构建好后不能改变;动态图运行时构建
- 初始化不当或者选用激活函数不当
- 网络太深
- CNN中卷积操作和卷积核作用
- maxpooling作用
- 卷积层与全连接层的联系
- 池化层loss是如何反向传播的?
- 残差网络的由来,为什么要用残差网络/残差网络解决了什么问题?
- 残差网络为什么有效?
-
LSTM/GRU门控机制的作用?
-
LSTM主要解决了RNN的什么问题?为什么能解决?
-
LSTM能否解决梯度消失问题?梯度爆炸呢?如何解决的?
- RNN梯度消失的原因?
- 如何解决RNN梯度消失?
-
梯度下降和随机梯度下降的区别?
-
随机梯度的平均是总体梯度的无偏估计,GD更新一次参数的时间复杂度是O(n),SGD和Mini Batch SGD是O(1),Mini Batch SGD结合两种方法的优点:收敛快、参数更新时间复杂度低
- 随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的样本的数据,而是仅仅选取一个样本来求梯度。随机梯度下降法,和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
-
牛顿法?
-
方程求根:对f(x)在$x=x_0$处展开,$f(x)=f(x_0)+f'(x_0)(x-x_0)$忽略高阶无穷小,令f(x)=0得:$x=x_0-\frac{f(x_0)}{f'(x_0)}$,这样可以得到一个对f(x)求解的近似解,然后得到的x又可以参与下一次迭代,即:$x_{n+1}=x_n-\frac{f(x_n)}{f'(x_n)}$
-
对$\Delta f(x)$在$x_k$处展开: $$ \Delta f(x)=g_k+H_k(x-x^{(k)}) $$ 当f(x)的一阶导为0,且海森矩阵正定时,f(x)取得最小值,令$\Delta f(x)=0$: $$ x=x^{(k)}-H_k^{-1}g_k $$ 那就就可以按照迭代的方式更新参数
-
-
拟牛顿法
-
拟牛顿条件 $$ \Delta f(x)=g_k+H_k(x-x^{(k)})\ g_{k-1}-g_k=H_k^{-1}(x_{k-1}-x_k)\ 记y_k=g_k-g_{k-1},\delta_k=x^{(k)}-x^{(k-1)}\ \delta_k=H_k^{-1}y_{k-1}(拟牛顿条件) $$
-
拟牛顿法的思想:通过寻找满足拟牛顿条件的矩阵代替计算海森矩阵的逆达到牛顿法的效果
-
-
Momentum
- 算法思想:参数更新时在一定程度上保留之前更新的方向,同时又利用当前梯度微调最终方向
- 优点:加快网络收敛,减少震荡;能逃脱鞍点
自适应学习率
- AdaGrad
- 算法思想:给不同维度的参数以不同的学习率
- 用一个状态$S_t$记录之前的梯度平方和,也即二阶动量,以及当前的二阶动量,每次更新参数时,不同维度除以$\sqrt{S_t+\epsilon}$
- RMSProp
- 算法思想:在历史二阶动量和当前的二阶动量前增加了超参数
- 解决了学习率不断减小,后期学习缓慢的问题
- Adam
- 算法思想:结合了RMSProp和Monmentum
- AdamW
- 算法思想:Adam后面加上weight decay
- Adam优化器用L2正则化与用Weight Decay不等价,实验证明Weight Decay效果比L2正则更好
- fasttext
- textcnn
- 输入:[batch_size, seq_len, emb_dim],输出通道为num_filters,卷积核的尺寸为filter_sizes
- 将数据的第二个维度扩充作为通道,通过尝试不同的卷积核大小得到len(filter_sizes)个conv2d得到[batch_sizes, num_filters, output_size],接着对最后一个维度最大池化,然后将它们拼接起来,成为[batch_size, num_filters*len(filter_sizes)]
- 最后经过映射层映射到n_classes的维度
- textrnn +
- textrnn + attention
- textrcnn
- dpcnn
- transformer
- bert+后接结构
- 清洗较强无意义的pattern、特殊字符、emoji、颜文字
- 特征工程
- 统计特征:词频、文本长度等
- NLP特征:词性等
- 其他特征:共享词
- 业务特征:如以“xxx宝”为结尾的词
- 图特征:以共现矩阵构造图,计算其连通分量等特征
介绍:动态规划主要解决的问题是原问题可以拆分成多个子问题,原问题的解与最优子问题的解有关,通过子问题的迭代来求解原问题的解