| marp | theme | paginate | backgroundColor | color | backgroundImage |
|---|---|---|---|---|---|
true |
uncover |
true |
112中電會聯合迎新
| 組別 | 分數 |
|---|---|
| 組別1 | 分數1 |
| 組別2 | 分數2 |
| 組別3 | 分數3 |
| 組別4 | 分數4 |
| 組別5 | 分數5 |

- python 基本語法
- 基本 HTML
- 爬蟲原理
- 實作
- 很多實作
- 做不完的實作

點我加入 Delicious 的 DC
python 是一種直譯式、互動式、 物件導向、腳本語言

Guido van Rossum 可能因為常常找不到鍵盤上的分號 或著是常常忘記宣告變數 於是在1989花三個禮拜做出來這個語言
- 程式邏輯教學
- 影像處理
- 演算法練習
- 軟體開發
- 大數據分析
- 網頁應用
- 圖表繪製
- 後端資料庫
- AI 深度學習
- 作業系統應用
- 遊戲引擎
- 韌體開發
- ......
num1 = 1
num2 = 2
sum = num1 + num2
print("1+2等於", 3)
# 使用 for 迴圈列印數字 1 到 5
for i in range(1, 6):
print(i)下載並安裝
下載完後執行
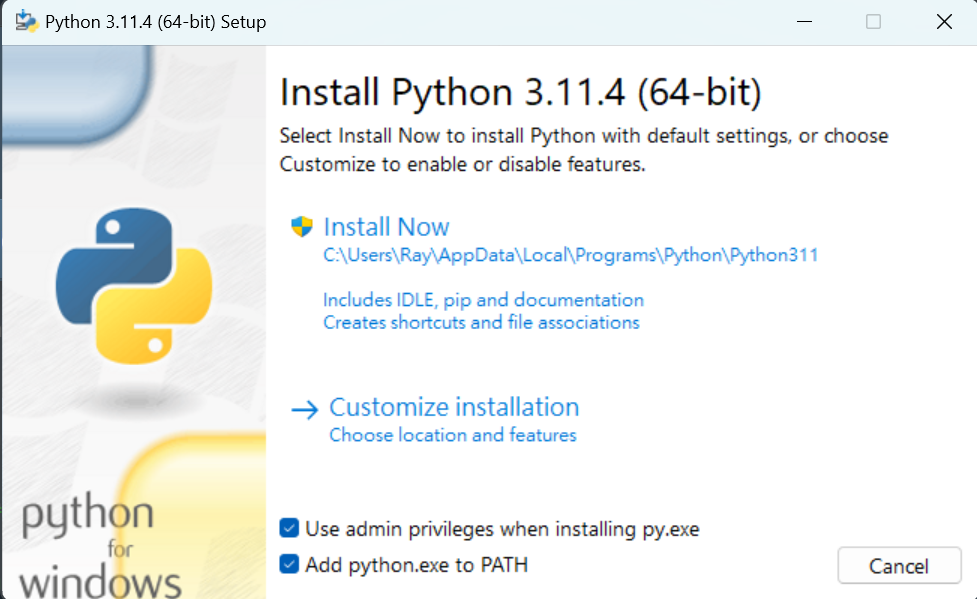
Add python.exe to PATH 記得打勾 忘記就重裝,不然很麻煩
安裝 VSCode 插件
輸出
print("Hello world")輸入
x = input("給IG嗎")- 儲存資料
- 數字不可用於開頭字元。
- 可以使用英文字元、數字或下底線(
_)命名 - 英文大小寫是有差異的
- 名稱不可使用python語言保留字詞。ex : for
- python會自己判斷資料型態
x = "我是變數"給IG嗎? elvisdragonmao
IG是 elvisdragonmao
溫馨提醒: 字串前後要加上
''or""
ig = input("給IG嗎?")
print("我會追蹤")
print(ig)ig = input("給IG嗎? ")
print("我會追蹤", ig)| and | as | assert | break | class | continue |
|---|---|---|---|---|---|
| def | del | elif | else | except | finally |
| for | from | False | global | if | import |
| in | is | lambda | nonlocal | not | None |
| or | pass | raise | return | try | True |
| while | with | yield |
- 數值型態(Numeric type) - int, float, bool
- 字串型態(String type) - str
- 容器型態(Container type) - list, set, dict, tuple
- 用type()查看資料型態
- int - 整數
- float - 浮點數(有小數點)
- bool - true false
- str(string)
- 字串
- 用
''或""包住 - 可用
+連接 len()查看長度
(AKA 清單)
- 放多個資料的地方
- 用中括號
[]包住 - 由中括號組成並以逗號隔開不同資料(型態可不同)
- 索引值從0開始
i_am_list = [] # 宣告一個變數叫i_am_list+加-減*乘/除%取餘數
< 小於
> 大於
<= 小於等於
>= 大於等於
== 相等
!= 不相等
題目: 鉛筆一支5元,一打50元。小明需要幫班上每位同學買一枝鉛筆,請問要多少錢?
由於小明是客家人很注重環保,他絕不會為了省錢而多買任何不需要的東西。也就是說,小明買的鉛筆數量一定等於班上的人數。
測資: 3人15元, 50人210元
a = int(input())
print(a // 12 * 50 + a % 12 * 5)判斷條件
- 對: 執行 if 中的程式
- 錯: 跳出 if 往下執行,如果有 else 執行
- 用於多的條件時
- if 執行時會跳過 elif 和 else
- if 是錯的→判斷 else-if
- 都錯→執行 else

x = True
y = False
if y: # False
print("No way")
elif x and y: # True and False
print("come on!")
elif not x: # not True
print("please")
else # do this
print("嗨壓")重複執行類似的事

可以透過python迴圈來讀取串列中的每一個元素 較適用於「已知迴圈數」的問題
for x in range(1, 10, 2):
# 放要執行的東西range(起始值,結束值,間距值)
較適用於「無法預知迴圈數」的問題
while 條件: # 條件成立
# 放要執行的東西強制跳出整個迴圈
for i in range(1,5):
if(i == 3):
break
print(i) # 會列出1 2強制跳出這過迴圈 範例下載
for i in range(1,5):
if(i == 3):
continue
print(i)1
2
4

超文本標記語言(HyperText Markup Language) 網站的骨架
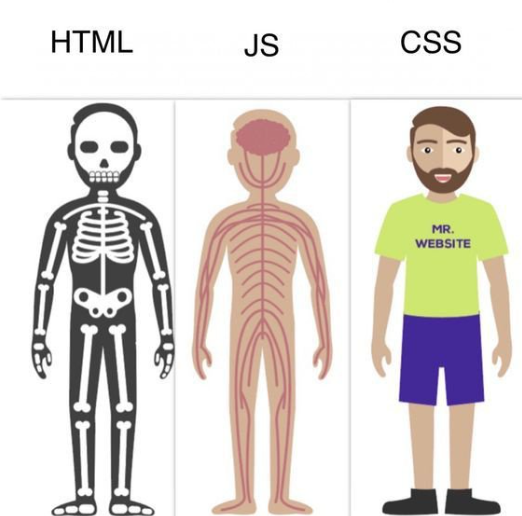
網站所有東西都是由元素組成

<p>段落
<b>粗體</b>
<i>斜體</i>
<s>刪除線</s>
<u>底線</u>
H<sup>+</sup>
CO<sub>2</sub>
</p>粗體
斜體
刪除線
底線
H+ CO2
格式
<img src="來源" alt="文字敘述">範例
<img src="https://www.google.com/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png" alt="Google">
- 從網際網路上擷取資料
- 可以爬偶爾重要的資訊:校網
- 下載網站沒有提供允許下載的內容
- 如: 線上漫畫、曾博恩《破蛋者》
- 可以模擬人類在網頁上的瀏覽行為
- 進入網站、點擊按鈕、輸入文字、下載檔案等

- 不可以壞壞
- 不可以做違法的事
- 認真閱讀網站的使用條款和服務條款
- 不應該對網站造成過大的負擔或破壞
- 告知網路爬蟲哪些網頁可以被訪問或爬取
- 遵守網站的使用規則
- 減少伺服器負載以及保護網站免受不必要的訪問
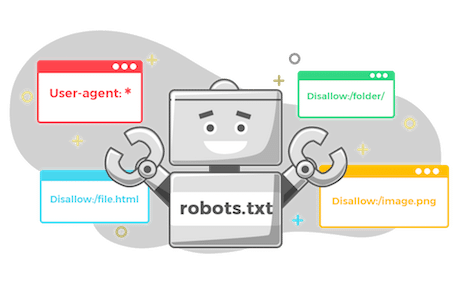
{kind=link}
- 允許所有爬蟲訪問整個網站
User-agent: *
Allow: /
- 禁止所有爬蟲訪問整個網站
User-agent: *
Disallow: /
- 顧名思義就是只能專門爬靜態網站的爬蟲
- 靜態網站:預先產生好 HTML 直接給你爬
- 優點:速度快,好爬
- 缺點:有的網站是載入時才生成內容,爬不到
pip3 install <庫名稱>- 讓你可以用簡單的 python 去對網站做請求
- 請求時可以帶點伴手禮 自訂 Header、帶參數、cookie,、User-Agent...
- 一直請求人家或著是按門鈴又躲起來就叫做 DDOS 攻擊
- 一直煩有可能會被網站 ban 掉
pip3 install requests- aka美麗湯,用來處理HTML中的資料
- 會需要有語法分析器去分析HTML
- 如: lxml, html5lib(這邊使用html5lib)
- 不同語法分析器會有速度、結果的不同,有容錯率之別
pip3 install beautifulsoup4pip3 install requests beautifulsoup4 html5lib
- 引入需要用到的模組
- 進入到學校公告並複製他的網址
- 用名叫url的變數儲存這條網址(字串)
- 以GET方式向網站請求資料,並儲存到變數
from bs4 import BeautifulSoup
import requests
url = "網址"
response = requests.get(url).text
print(response) #看看他的HTMLimport requests
from bs4 import BeautifulSoup
url = 'https://zh.wikipedia.org/zh-tw/臺中高工'
response = requests.get(url).text
print(response)把response丟給美麗湯4解析
soup = BeautifulSoup(response, 'html5lib')我們來抓抓看維基百科條目的第一段介紹8
import requests
from bs4 import BeautifulSoup
url = 'https://zh.m.wikipedia.org/zh-tw/台中高工'
response = requests.get(url).text
soup = BeautifulSoup(response, 'html5lib')
wiki = soup.find_all('p')[0].get_text()
if wiki.replace("\n", "").strip() == '':
wiki = soup.find_all('p')[1].get_text()
print(wiki)臺中市立臺中工業高級中等學校,簡稱臺中高工、中工,是一所位於臺灣臺中市南區的技術型高級中等學校,創立於1938年,最初校名為臺中州立臺中工業學校,首任校長為村田 務;1955年中華民國教育部接受美援購買先進儀器將其模式導入包括該校及全國另外七所高工,為臺灣八大省工之一,現為教育部電機電子群科中心學校。該校對外交通較為便利 ,鄰近的交通設施有高鐵臺中站、大慶車站、捷運大慶站等。
先問使用者要爬哪個維基百科條目 然後把他的第一段介紹爬下來顯示出來
想要查甚麼: 媽媽
母親簡稱母,或稱媽媽、娘,是一種親屬關係的稱謂,
是子女對雙親中的女性的稱呼。母親和子女是重要的直
系親屬關係之一,通常具有親密關係。
import requests
from bs4 import BeautifulSoup
x = input("想要查甚麼: ")
url = 'https://zh.m.wikipedia.org/zh-tw/' + x
response = requests.get(url).text
soup = BeautifulSoup(response, 'html5lib')
wiki = soup.find_all('p')[0].get_text()
if wiki.replace("\n", "").strip() == '':
wiki = soup.find_all('p')[1].get_text()
print(wiki)你可以選擇你自已的學校
這裡以龍津高中為例
因為我喜歡龍
 不難發現,整個我們想要的資料都在這個tbody標籤中
不難發現,整個我們想要的資料都在這個tbody標籤中
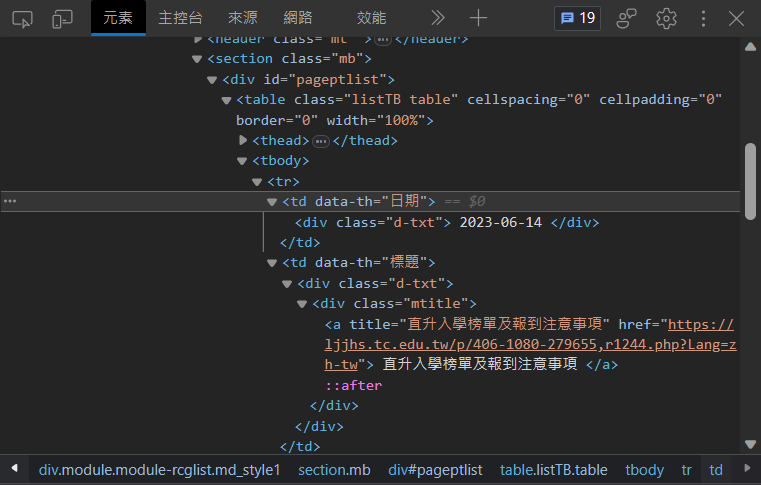
而在tbody中有一個一個td標籤
- 找到tbody(資料的外框)
- 從tbody中找出所有的
<a> - 把它print出來看看
tbody = soup.find('tbody') #6
a_tag_list = tbody.find_all('a') #7
print(a_tag_list) #8
- 可以發現他是個由
<tr>底下的<a>組成的列表 - 再來用for迴圈去跑這些
<a>- 取裡面href跟title屬性的值存到list裡
for a_tag in a_tag_list:
links_list.append(a_tag.get('href'))
titles_list.append(a_tag.get('title')) 除了連結跟標題外我們再蒐集日期。 日期是存在特定td的div裡的,取出後一樣存在list裡
td_tag_list = tbody.find_all('td', attrs={"data-th" : "日期"})
for td_tag in td_tag_list:
div = td_tag.find("div")
dates_list.append(div.text.strip())strip()是用來刪去字串中某些特定字元的 預設是空白
from bs4 import BeautifulSoup
import requests
url = "https://ljjhs.tc.edu.tw/p/403-1080-1244-1.php?Lang=zh-tw"
titles_list = []
links_list = []
dates_list = []
response = requests.get(url).text#得到HTMLsoup = BeautifulSoup(response, 'html5lib')#丟進美麗湯解析
tbody = soup.find('tbody')
a_tag_list = tbody.find_all('a')
for a_tag in a_tag_list:
links_list.append(a_tag.get('href'))
titles_list.append(a_tag.get('title'))
td_tag_list = tbody.find_all('td', attrs={"data-th" : "日期"})
for td_tag in td_tag_list:
div = td_tag.find("div")
dates_list.append(div.text.strip())
for i in range(len(titles_list)):
print(dates_list[i],titles_list[i], links_list[i])- RSS - 一種讓你輕鬆地追蹤網站的更新,類似於一個個性化新聞訂閱服務。(如:部落格文章,Podcast都會提供API讓你不需要使用爬蟲就可以取得資料)
- API - 有些網站會提供一個網址讓你去請求資料,並且會以JSON格式回傳資料。
首先我們要先來看看台中高工網頁是如何讀取公告的。 可以在開發者工具看出他是去找這個網址並提供一些參數(伴手禮)來取得公告。我們只需要把這個網址複製下來,並且帶著伴手禮就可以偷到公告了,不需要去整理 HTML。


import requests
url = "https://w3.tcivs.tc.edu.tw/ischool/widget/site_news/news_query_json.php"
data = {"field": "time", "order": "DESC", "pageNum": "0", "maxRows": "25", "keyword": "",
"uid": "WID_0_2_a18324d5b18f53971c1d32b13dcfe427c6c77ed4", "tf": "1", "auth_type": "user"}
response = requests.post(url, data=data)
if response.status_code == 200:
news_data = response.json()
latest_news = news_data[1:6]
for news in latest_news:
date = news['time']
title = news['title']
news_id = news['newsId']
print(f"日期: {date}\n{title},\nhttps://w3.tcivs.tc.edu.tw/ischool/public/news_view/show.php?nid={news_id}\n\n")
else:
print(f"失敗代碼: {response.status_code}")
- 可以用程式語言(python、C#等等)操作網頁
- 可以模擬使用者操作(點擊、填寫文字、滑動)
在2048網站上右下左一直重複
很爛但很刺激
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.common.by import By
# Open the 2048 game website using Selenium
driver = webdriver.Chrome()
driver.get("https://play2048.co/")
time.sleep(3)
while True:
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.ARROW_UP)
time.sleep(0.1)
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.ARROW_RIGHT)
time.sleep(0.1)
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.ARROW_DOWN)
time.sleep(0.1)
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.ARROW_LEFT)
time.sleep(0.1)from selenium import webdriver
import urllib.request
import time
from selenium.webdriver.common.by import By
import requests
driver = webdriver.Chrome()
driver.get("https://twitter.com/cat_auras")
time.sleep(5)
images = driver.find_elements(By.TAG_NAME, 'img')
for i, image in enumerate(images):
print("正在下載第" + str(i) + "張圖片")
src = image.get_attribute('src')
response = requests.get(src, stream=True)
if response.status_code == 200:
with open(f'image{i}.png', 'wb') as out_file:
out_file.write(response.content)看的不夠
from selenium import webdriver
import urllib.request
import time
from selenium.webdriver.common.by import By
import requests
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://twitter.com/cat_auras")
time.sleep(3)
for i in range(3):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(1)
time.sleep(3)
images = driver.find_elements(By.TAG_NAME, 'img')
for i, image in enumerate(images):
print("正在下載第" + str(i) + "張圖片")
src = image.get_attribute('src')
response = requests.get(src, stream=True)
if response.status_code == 200:
with open(f'image{i}.png', 'wb') as out_file:
out_file.write(response.content)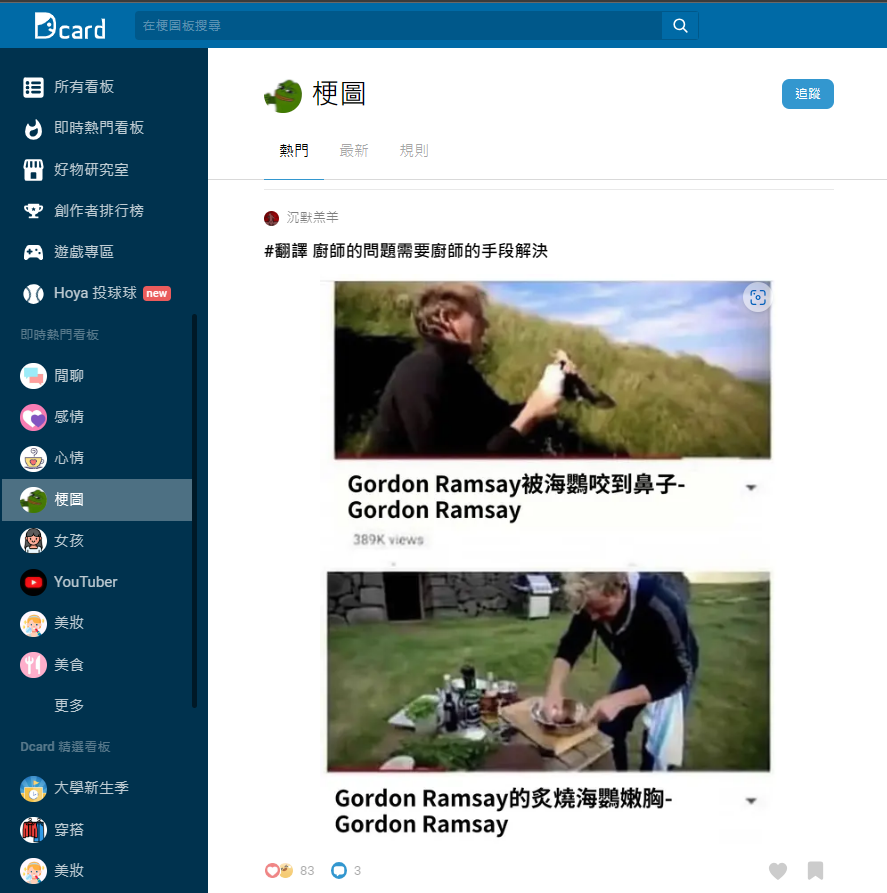
- driver.find_elements (By.id, By.XPATH ......)
- 等等會用XPATH,因為賊好用
- element.get_attribute("attr")
- 取得Tag中特定屬性的值
- string.startswith("123")
- 如果字串的開頭是123的話回傳True,反之為False。
- driver.execute_script('JavaScript')
- 能用Selenium執行JavaScript
- time.sleep(1)
- 直接讓程式睡1秒
- list.append('2')
- 可以直接在list的後面多加入一個東西
- e.g:
number_list = [0, 1] list.append('2') >>> [0, 1, 2]
- 引入需要的模組
- 去複製Dcard梗圖板的網址
- 先開2個list一個存src內的網址
- 一個存請求後的圖片位置(這才是我們要的)
- 用driver請求Dcard
- 在請求後等一下讓他載入
- 用time.sleep(second) #等待second秒
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import requests
url = "https://www.dcard.tw/f/meme"
driver = webdriver.Chrome() #也可以是Edge(), Firefox(), etc.
page_link_list = [] #空list
img_link_list = [] #空list
driver.get(url)
time.sleep(5) #等待網頁載入可以久一點點沒關係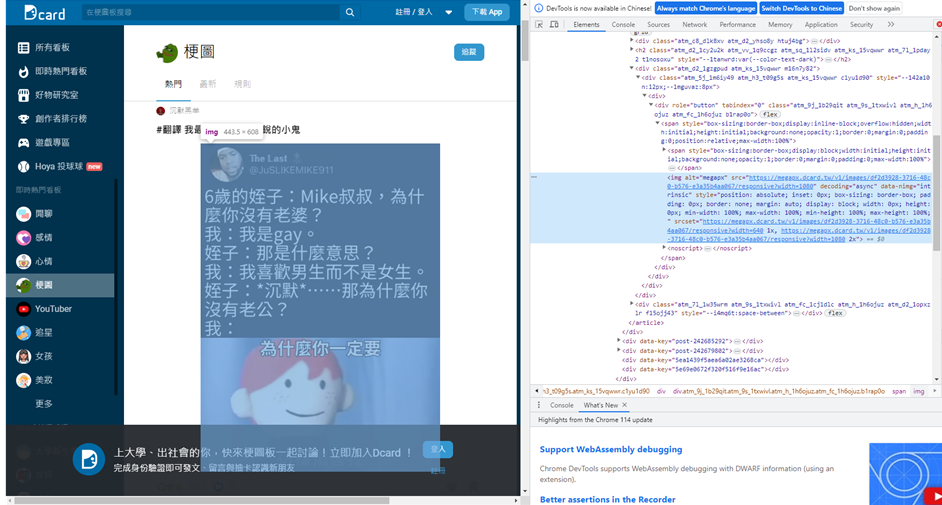
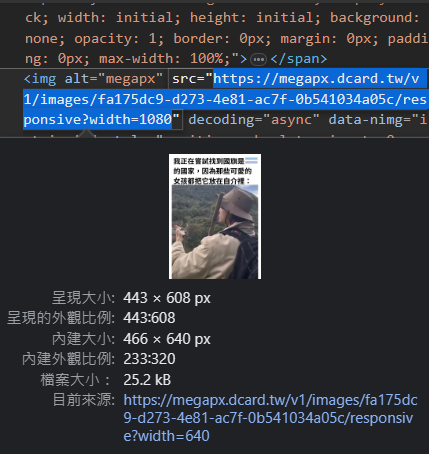
- 可以發現圖片是用
<img>表示- 更方便的是,他的連結就直接在src中, 所以我們要做的就是請求那個連結後下載回傳的結果!
- 因為可以發現,所有圖片有一個alt屬性且名稱都是megapx。
- 我們可以用By.XPATH快樂的找Tag
- 找到了元素後,取他src的值,存進page_elements_list
- 把頁面往下滑
page_elements = driver.find_elements(By.XPATH, "//img[@alt='megapx']")
page_elements_list.append(page_elements.get_attribute("src"))
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")for i in range(0, 5): #可以把後面的值設定大一點,代表一次抓多一點圖片
page_elements = driver.find_elements(By.XPATH, "//img[@alt='megapx']")
for page_element in page_elements:
if page_element.get_attribute("src").startswith("https"): #確保存的是網址
page_link_list.append(page_element.get_attribute("src"))
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(0.5) #每次划完後等待載入因為我們這時候存到的link觀察一下可以發現 它的結尾並不是正常的圖片格式,那我們直接 請求後下載是沒有用的,我們必須請求後找到 圖片真正的位置,請求後下載才會有用。

import requests
url = "圖片的連結" # 替換為要下載的圖片連結
response = requests.get(url)
# 檢查圖片是否下載成功
if response.status_code == 200:
with open("圖片檔名.jpg", "wb") as file:
file.write(response.content)
print("圖片下載成功")
else:
print("無法下載圖片")import requests
from PIL import Image
url = "圖片的連結" #替換為要下載的圖片連結
response = requests.get(url)
if response.status_code == 200: #檢查圖片是否下載成功
with open("圖片檔名.jpg", "wb") as file:
file.write(response.content)
print("圖片下載成功")
img = Image.open("圖片檔名.jpg") #打開圖片
img.show()
else:
print("無法下載圖片")import requests
image_links = [
"https://picsum.photos/200/300","https://picsum.photos/200/300","https://picsum.photos/200/300",
"https://picsum.photos/200/300","https://picsum.photos/200/300",
]
for index, link in enumerate(image_links):
try:
response = requests.get(link)
response.raise_for_status()
with open(f"image_{index+1}.jpg", "wb") as file:
file.write(response.content)
print(f"圖片{index+1}下載成功")
except requests.exceptions.RequestException as e:
print(f"圖片{index+1}下載失敗: {e}")pip3 install pythoninstaller
pythoninstaller -F code.python
pythoninstaller -F code.python -i "a.ico"
-F打包成單一 .exe 檔案-i設定圖示
感謝大家的參與
Credits: 西苑高中資訊志工隊