Performance optimization skill:Pre Joining
The JOIN performance in SQL is a long-standing problem, especially when there are a lot of tables to be joined, the performance plummets dramatically.
SQL adopts the HASH partition approach to handle JOINs, which first calculates the HASH values of the join keys and then traverses and compares the records with the same HASH values from two tables. The same computation steps are necessary for each JOIN.
If the data volume is small compared to the size of memory, we can load the data into memory in advance and create the association using the in-memory pointer mechanism. Specifically, this approach calculates HASH values and makes comparisons while loading data, and saves the associations with pointers. The subsequent calculations can directly refer to the associated records, which spares the trouble of calculating and comparing HASH values and improves the performance.
The problem is that SQL doesn’t support the pointer type of data to implement this optimization idea. Even if the data can be wholly loaded into the memory, we still can’t take advantage of the pre-association approach, which is also the same drawback of most SQL-based relational databases. On the contrary, SPL can implement the optimization thanks to its support in pointer data type.
In the following part, we’ll test SQL’s performing differences in achieving two-table join and multi-table join and then do the same calculations with SPL using the pre-association technique to make a comparison.
Eight data tables, 50G data in total (to be small enough to fit into the memory), have been generated according to TPCH standards. The structure of TPCH data table is vastly described online, which will not be elaborated here.
The server for testing has two Intel 2670 CPUs, 2.6G frequency, 16 cores in total, 128G memory and an SSD hard disk.
The lineitem table consists of too large data to be loaded in memory, so we create an orderdetail table of the same structure with appropriate data volume that can be loaded in memory. Hereinafter we will use this table for testing.
The following tests are calculated in single-thread without the help of multi-core to make the difference clearer.
The Oracle database is used here as a representative for the SQL test, which queries the orderdetail table to get the total revenue of parts order for every year.
SQL statements:
select
l_year,
sum(volume) as revenue
from
(
select
extract(year from l_shipdate) as l_year,
(l_extendedprice * (1 - l_discount) ) as volume
from
orderdetail,
part
where
p_partkey = l_partkey
and length(p_type)>2
) shipping
group by
l_year
order by
l_year;
SQL statements:
select
l_year,
sum(volume) as revenue
from
(
select
extract(year from l_shipdate) as l_year,
(l_extendedprice * (1 - l_discount) ) as volume
from
supplier,
orderdetail,
orders,
customer,
part,
nation n1,
nation n2
where
s_suppkey = l_suppkey
and p_partkey = l_partkey
and o_orderkey = l_orderkey
and c_custkey = o_custkey
and s_nationkey = n1.n_nationkey
and c_nationkey = n2.n_nationkey
and length(p_type) > 2
and n1.n_name is not null
and n2.n_name is not null
and s_suppkey > 0
) shipping
group by
l_year
order by
l_year;
| Two-table join | Six-table join | |
|---|---|---|
| Query time (s) | 26 | 167 |
Both query statements contain nested queries. The auto-optimized Oracle query performs even better than a query without nested queries (The latter may calculate “group by” and “select” repeatedly).
Both results are the best-performing among multiple executions. We found that the first Oracle query execution is always the slowest, which means that the database will cache all the data into the memory (Oracle has a big cache pool) when the memory is sufficient to hold all the data. We select the fastest execution to get the computing time as pure as possible by getting rid of the external storage retrieval time.
By defining the filtering condition as always true, that is, no record is filtered out, we perform the queries over the whole orderdetail table, thus both tests have equal computing amount.
According to the test results, the six-table join is 167/26=6.4 times slower than the two-table join. Besides the external storage retrieval time, the performance degradation originates from the time-consuming table joins and simple comparisons between join key values.
In conclusion, the JOIN performance in SQL is markedly bad.
SPL script:
| A | |
|---|---|
| 1 | >env(region, file(path+"region.ctx").open().memory().keys@i(R_REGIONKEY)) |
| 2 | >env(nation, file(path+"nation.ctx").open().memory().keys@i(N_NATIONKEY)) |
| 3 | >env(supplier, file(path+"supplier.ctx").open().memory().keys@i(S_SUPPKEY)) |
| 4 | >env(customer, file(path+"customer.ctx").open().memory().keys@i(C_CUSTKEY)) |
| 5 | >env(part, file(path+"part.ctx").open().memory().keys@i(P_PARTKEY)) |
| 6 | >env(orders,file(path+"orders.ctx").open().memory().keys@i(O_ORDERKEY)) |
| 7 | >env(orderdetail,file(path+"orderdetail.ctx").open().memory()) |
| 8 | >nation.switch(N_REGIONKEY,region) |
| 9 | >customer.switch(C_NATIONKEY,nation) |
| 10 | >supplier.switch(S_NATIONKEY,nation) |
| 11 | >orders.switch(O_CUSTKEY,customer) |
| 12 | >orderdetail.switch(L_ORDERKEY,orders;L_PARTKEY,part;L_SUPPKEY,supplier) |
The first 7 lines read in seven composite tables respectively into memory to generate in-memory tables and set them as global variables. The last 5 lines establish association among the seven tables. The pre-association script will be executed at the start of the SPL server to make preparations for subsequent query.
Below is the structure of pre-associated table objects in memory, taking the orderdetail table for example:
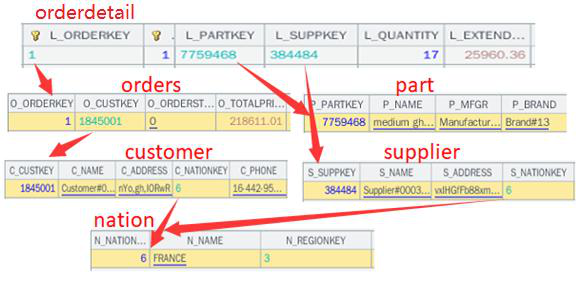
Here only the first pre-associated record of the orderdetail table are shown in the picture, and other records are similar. Limited to the width of the page, only some fields are listed in each table.
SPL script:
| A | |
|---|---|
| 1 | =orderdetail.select(len(L_PARTKEY.P_TYPE)>2) |
| 2 | =A1.groups(year(L_SHIPDATE):l_year; sum(L_EXTENDEDPRICE*(1-L_DISCOUNT)):revenue) |
SPL script:
| A | |
|---|---|
| 1 | =orderdetail.select(len(L_PARTKEY.P_TYPE)>2 && L_ORDERKEY.O_CUSTKEY.C_NATIONKEY.N_NAME!=null && L_SUPPKEY.S_NATIONKEY.N_NAME!=null && L_SUPPKEY.S_SUPPKEY>0 ) |
| 2 | =A1.groups(year(L_SHIPDATE):l_year;sum(L_EXTENDEDPRICE*(1-L_DISCOUNT)):revenue) |
The SPL script is quite simple after the tables are pre-associated. We can directly refer a field of the associated table as the sub-attribute of the referencing attribute, which makes the code easier to understand.
| Two-table join | Six-table join | |
|---|---|---|
| Query time (s) | 28 | 56 |
The six-table join query is only 2 times slower than the two-table join query due to the added computing time (spent in referring the associated field). Yet we don’t spend time on the join thanks to the pre-association.
Test results:
| Query time (s) | Two-table join | Six-table join | Performance decline (times) |
|---|---|---|---|
| SQL | 26 | 167 | 6.4 |
| SPL pre-association | 28 | 56 | 2 |
A six-table SQL join is 6.4 times slower than a two-table SQL join, which means that a SQL join consumes a lot of CPU, resulting in obviously bad performance. With the pre-association method, SPL six-table join is only 2 times slower, and the performance degradation is kept in a very limited range.
On the premise that the memory is sufficient enough to load all the data (the application scenario for in-memory databases), pre-association is an effective technique to improve joins query performance when there are a lot of tables involved. SPL can use the method to make a difference while relational databases, including in-memory databases, cannot adopt the optimization skill.