In the previous tutorial, we learned how to build the entire pipeline from model training to Snapchat Lens creation with the provided dataset. In this guide, we will see how to capture and process your own object-centric dataset for the rendering pipeline.
For better visualization, we will use the horizontal coordinate system as an example: think of the object you would like to render as the “Observer” and your camera as the “Star”. “Horizon” is the ground.
Follow the step below to collect your own data:
-
Place the object you would like to render in the center of the sphere (Observer in the picture).
-
Place your camera in the position of “Star” where “Altitude” is 0. Then walk round the object and take pictures (the more, the better).
-
Along the “Meridian”, repeat the above process for all “Altitude” until reaching the “Zenith”.

Your data should be saved in MobileR2L/dataset/your-own-dataset/scene-name/*.png(jpeg). For example, the path could look like MobileR2L/dataset/custom_dataset/shoe/*.png(jpeg)
Common Issues of User-collected Data
- Inconsistent Lighting: the NeRF model is sensitive to lighting. Do your best to keep the lighting uniform for all images.
- Non-uniform Radius: the best practice is to make sure your camera always lies on the “Meridian”
- Missing Views: make sure to take overlapping images when walking round the object.
- Blurry images: try to hold your phone steady when taking pictures
Once you have your data collected, several scripts need to run to estimate the pose. Note: you may want to downsize your data proportionally to the height/width at most 1008 pixels. Otherwise, the pose estimation will be very slow. Moreover, try to make the dimensions be divisible by 12. The training code assumes the height/width is divisible by 12.
- Install COLMAP
sudo apt install colmap
If not working, try:
git clone https://github.com/microsoft/vcpkg cd vcpkg ./bootstrap-vcpkg.sh ./vcpkg install colmap[cuda]:x64-linux
- Run COLMAP, replacing $DATASET_PATH with your own data. Note the png images should be palced in
DATASET_PATH/imagesfolder
colmap feature_extractor \ --database_path "$DATASET_PATH"/database.db \ --image_path "$DATASET_PATH"/images \ --ImageReader.single_camera 1 \ --ImageReader.camera_model "SIMPLE_RADIAL" \ # or "OPENCV" --SiftExtraction.use_gpu 1 colmap exhaustive_matcher \ --database_path "$DATASET_PATH"/database.db \ --SiftMatching.use_gpu 1 mkdir -p "$DATASET_PATH"/sparse colmap mapper \ --database_path "$DATASET_PATH"/database.db \ --image_path "$DATASET_PATH"/images \ --output_path "$DATASET_PATH"/sparse \
You should see sparse folder under your dataset folder
3, clone LLFF. Replace $DATASET_PATH with your own dataset folder
git clone https://github.com/Fyusion/LLFF.git cd LLFF python3 img2poses.py $DATASET_PATH
You should see poses_bounds.npy(used in student model).
Note:
- COLMAP has a GUI version. You can visualize the reconstruction by Open File → Import model Find the “sparse” folder in your pose directory and open it
- You could make use of the masks (if available) during the reconstruction. Make sure to rename the masks as xxx.png.png. Otherwise, the COLMAL will ignore it silently.
Visualization of COLMAP pose estimation. Red boxes are cameras.
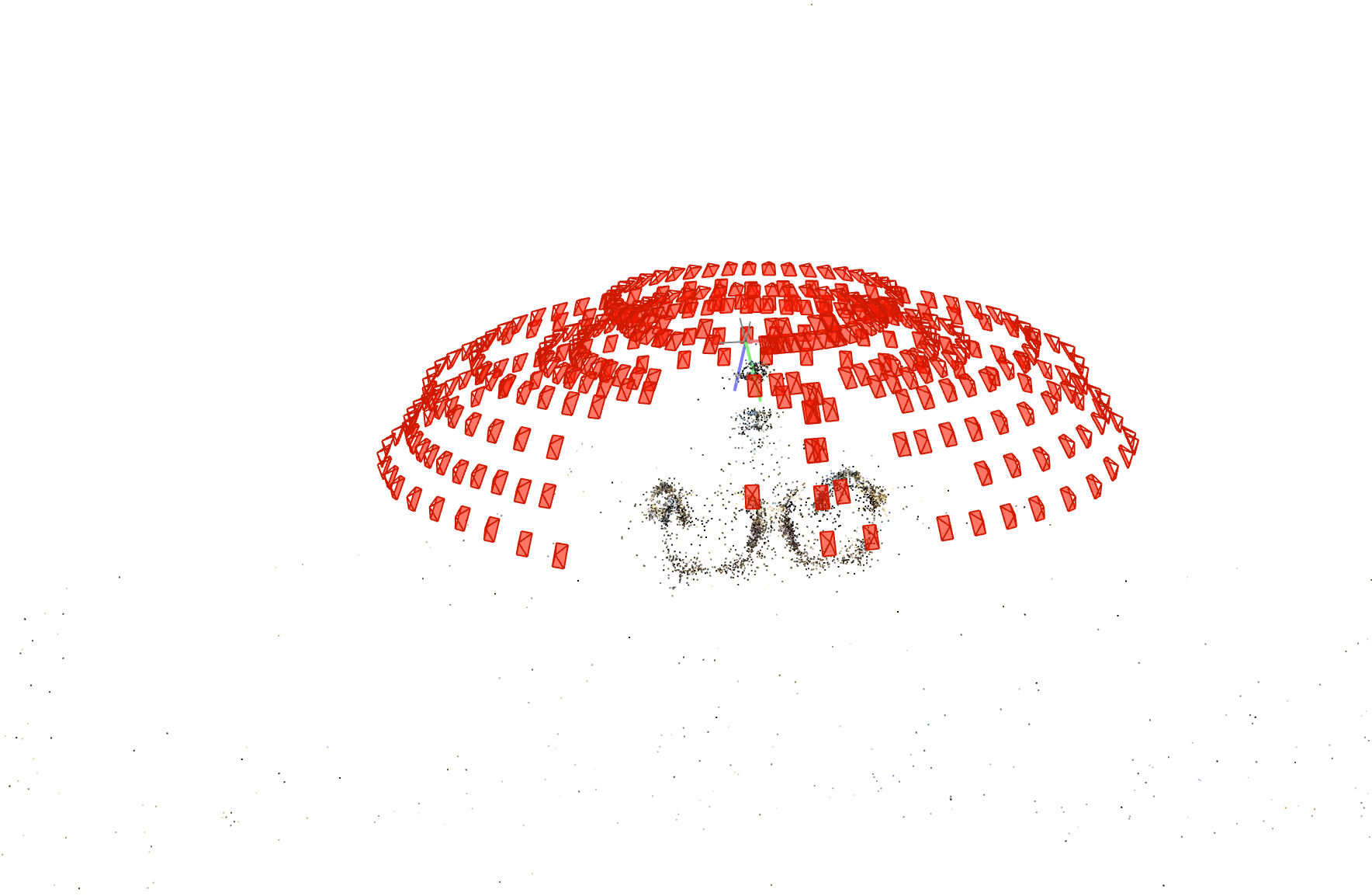

Now, in your dataset folder, you should have
-
imagesfolder -
sparsefolder -
poses_bounds.npy
You are ready to train the teacher and student by following previous tutorial.
export ROOT_DIR=../../../dataset/your-own-data
scene=$1
python3 train.py \
--root_dir $ROOT_DIR/$scene \
--exp_name $scene --dataset_name colmap\
--num_epochs 20 --scale your_scale --downsample 0.25 --lr 2e-2
Note:
- You need to tune the
scaleto make the teacher work well. Try to start with a bigger number, such as 60, then reduce it gradually. downscaleshould be set to 1.0 if the image resolution is already small.ffshould be set to False for object-centric scenes.- When distilling the pseduo-data, you can adujst
sr_downscalebased on your own needs. The default is 12. It would be easier if your dataset resolution is divisible by 12.
export ROOT_DIR=../../../dataset/your-own-data scene=$1 python3 train.py \ --root_dir $ROOT_DIR/$scene \ --exp_name Pseudo_$scene --dataset_name colmap\ --scale your_scale --downsample 1.0 \ --save_pseudo_data \ --n_pseudo_data 8000 --weight_path ckpts/colmap/$scene/epoch=19_slim.ckpt \ --save_pseudo_path Pseudo/$scene --num_gpu 1 --sr_downscale 12
- When training the student, you need to adjust the
input_height,input_width,output_height,output_widthto your own data resolution.output_height/output_widthis the original resolution andinput_height,input_widthare downscaled bysr_downscale:output_heigth/sr_downscaleandoutput_width/sr_downscale
nGPU=$1 scene=$2 python3 -m torch.distributed.launch --nproc_per_node=$nGPU --use_env main.py \ --project_name $scene \ --dataset_type Colmap \ --pseudo_dir model/teacher/ngp_pl/Pseudo/$scene \ --root_dir dataset/your-own-data \ --run_train \ --num_workers 12 \ --batch_size 10 \ --num_iters 600000 \ --input_height your-own-input-height \ --input_width your-own-input-width --output_height your-own-output-height\ --output_width your-own-output-width \ --scene $scene \ --factor 1 \ # use original resolution. The code is looking for folder images_1. Create it and copy your data into it --amp \ --i_testset 10000 \ --lrate 0.0005
Once the model is trained, you should have the ONNX files ready:
- *_SnapGELU.onnx
- Sampler.onnx
- Embedder.onnx
The process of deploying your own NeRF model is very simple: you only need to import the three ONNX files above to the studio. We will show you how to do it step by step.
- Open Lens Studio project here
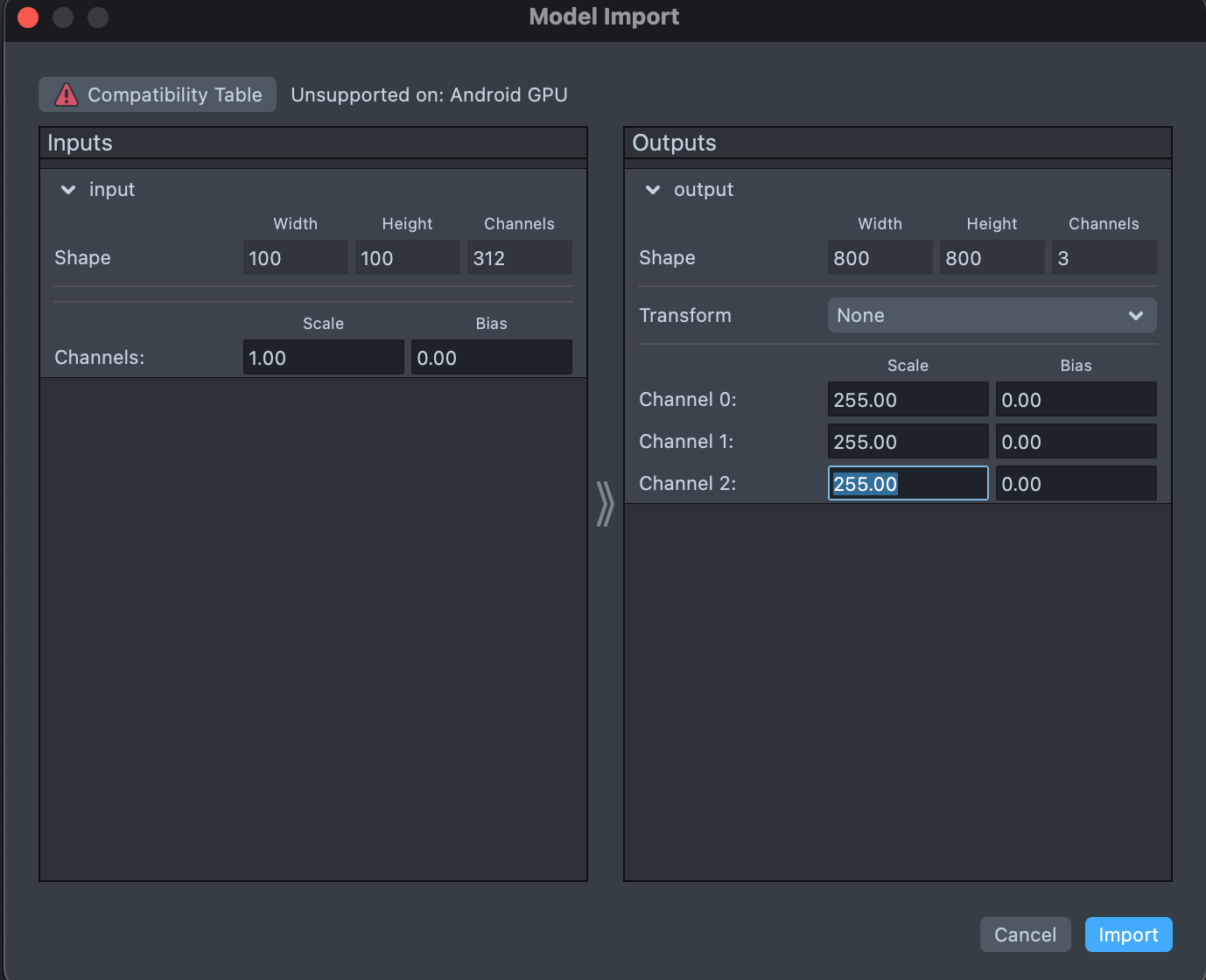
- Import ONNX files to Lens Studio(Drag it into Studio) a. for the *_SnapGELU.onnx, change the Scale of Channel 0 - 3 to 255
Scale the Channel to 255.0

- Swap the ONNX in
ML Conponenta. There are threeML Conponent: 1st is for*_SnapGELU.onnx, 2nd is forEmbedder.onnxand 3rd is forSampler.onnx. b. Drag the ONNX to theModelunder theInspectoron the right pannel of Lens Studio.

- Go to Resources→ Script on the left panel. Modify the model parameters you used in your model. The parameters can be found in your experiment:
logs/Experiments/your-experiments-folder/intrinsics.json
Change
H,W,RADIUS,NEAR,FAR,focalaccordingly.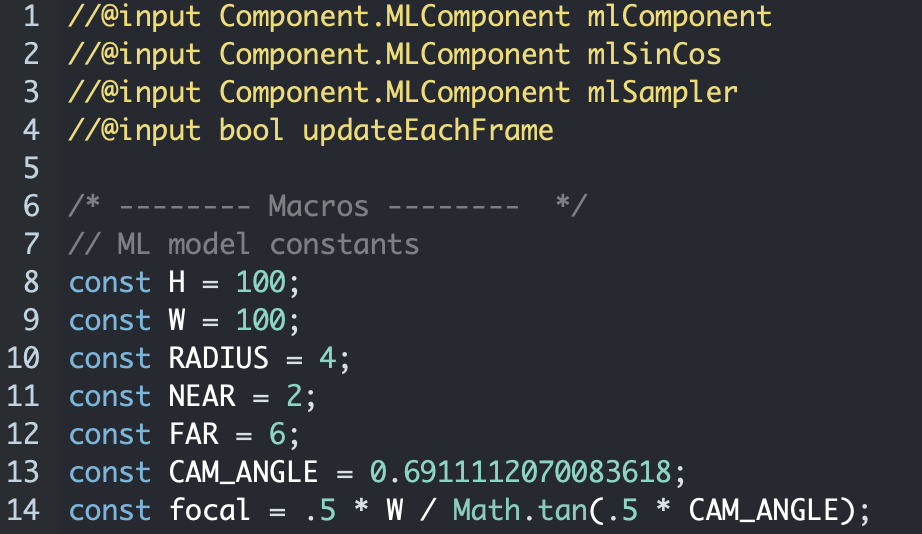

- Save the script. You should see your rendered images in the Preview panel
