You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
save2db(jobList) {
return new Promise((resolve, reject)=>{
Job.create(jobList,function (err,product) {
if (err) {
console.error(err.errmsg)
err.code == 11000 && resolve('丢弃重复数据')
reject(err);
} else {
resolve("save data to database successfully")
}
})
})
},
HTML 数据解析爬取
从上述的json数据其实我们可以看到,JSON返回的信息十分有限,那么我们需要爬取更多的信息,就需要在招聘详情页解析 html 后提取出所需的信息
随便打开一个移动端的招聘详情页https://m.lagou.com/jobs/3638173.html,目测出url结构很简单,就是jobs/{{positionId}}.html
前前言
不想看爬虫过程只想看职位钱途数据分析请看这里:
前端招聘岗位分析
C++招聘岗位分析
JAVA招聘岗位分析
PHP招聘岗位分析
Python招聘岗位分析
想看源码或想自己爬一个请看这里:本文github源码
前言
早在一年前大学校招期间,为了充实下简历,就写了个
node爬虫,可惜当时能力有限,工程存在一定的局限性,不好意思拿出来装逼分享。一年过去了,现在能力依然有限,但是脸皮却练厚了,于是就有了这篇文章。
题纲
关于爬虫,主流技术是用
python,然而随着node的出现,对于对python了解有限的前端同学,用node来实现一个爬虫也不失为一个不错的选择。当然无论是
python爬虫还是node爬虫或者其他品种的爬虫,其实除了语言特性之外,其思路基本大同小异。下面我就为大家详细介绍下node爬虫的具体思路与实现,内容大概如下:JSON数据HTML文档,提取有用信息爬前准备
选择目标
既然要写爬虫,当然要爬一些利益相关的数据比较好玩啦。爬取招聘网站的招聘信息,来看看互联网圈子里各个工种的目前薪酬状况及其发展前景,想来是不错的选择。
经我夜观天下,掐指一算,就选拉勾网吧。
分析可收集数据
一个职位招聘信息,一般来说,我们关注的重点信息会是:
带着想要收集的信息,首先,进入拉勾官网,搜索
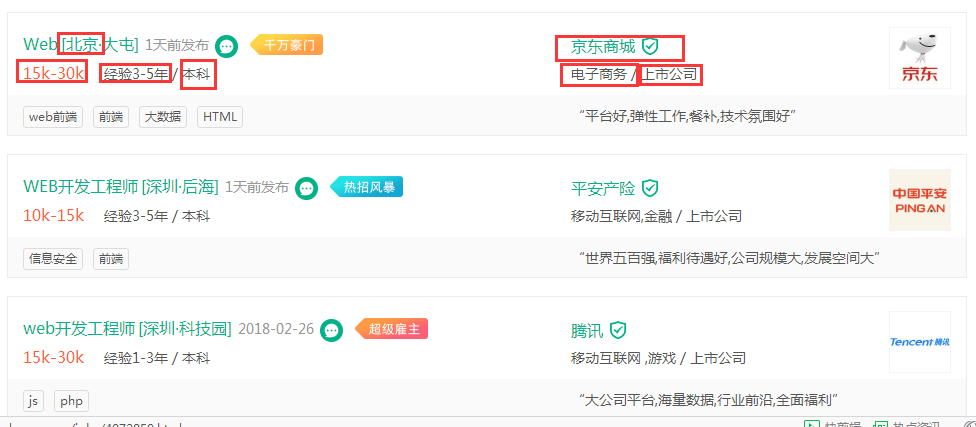
web前端岗位,能看到很好,我们想要的信息基本都有了。
分析目标可爬取入口
PC端入口
F12分析请求资源,可得https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0post 请求体
响应JSON数据
完美!!! 数据格式都已经帮我们整理好了,直接爬就行了。
但,完美的数据总不会这么轻易让你得到,经我用
node和python,还有postman携带浏览器全部header信息一一测试,均发现:好吧,此路不通。(此接口反爬虫机制不明,有研究的大神请留言=_=)
所谓条条大路通罗马,此路不通,咱绕路走。
移动端入口
经过一番探索,发现 拉勾移动端站点 空门大开!
GET请求: https://m.lagou.com/search.json?city=全国&positionName=web前端&pageNo=1&pageSize=15

响应信息:
很好,虽然数据信息有点少,但是总算是一个能爬的接口了。
爬虫
好了,分析也分析完了,现在正式设计爬虫程序。
JSON数据爬取
首先,把请求的路径与参数单独抽离。
发出请求,此处的服务端构造请求使用 superagent,当然,用 request 等类似的包也可以,并无限定。
处理数据
保存数据,此处数据库使用
mongodb,ORM使用moogoose。HTML 数据解析爬取
从上述的
json数据其实我们可以看到,JSON返回的信息十分有限,那么我们需要爬取更多的信息,就需要在招聘详情页解析 html 后提取出所需的信息随便打开一个移动端的招聘详情页https://m.lagou.com/jobs/3638173.html,目测出
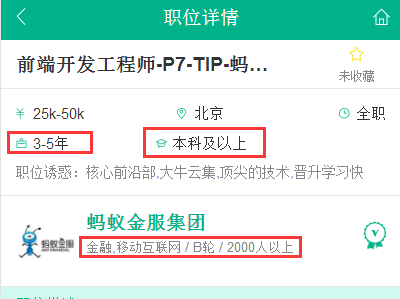
url结构很简单,就是jobs/{{positionId}}.html从详情页中可以找出 JSON 数据中缺少的数据项:工作年限要求,学历要求,雇主公司领域,雇主公司融资情况,雇主公司规模大小。
爬取方法和上述爬取
JSON数据相差无几,主要差别就是数据解析部分,这里需要用到cherrio来解析 爬取到的HTML,从而更简单地提取必要信息。并发控制
做过爬虫的都知道,爬虫的请求并发量是必须要做的,为什么要控制并发?
实现并发控制可以使用
npm包 async.mapLimit,这里为了自由度更大我使用了自己实现的 15 行代码实现并发控制。具体代码如下:
然而,即便严格控制了请求频率,我们还是不可避免地**中招**了。
对于反爬虫措施比较暴躁的网站来说,一个IP爬取太过频繁,被识别成机器爬虫几乎是不可避免的。
一般来讲,我们最简单直接的方法就是:换IP。这个IP访问频率太高了被反爬拦截到,换个IP就行了嘛。
动态IP代理
单个IP爬虫对于反爬较为严厉的网站是走不通的。那么我们需要用到动态IP池,每次爬取时从IP池中拉取一个IP出来爬数据。
道理很简单,
1秒内1个IP访问了100个页面,即便是单身20多年的手速也无法企及。只能是机器爬虫无疑。
但1秒内100个IP访问100个页面,平均每个IP一秒内访问了1个页面,那基本不会被反爬干掉
**怎么搭建动态IP池? **
动态IP池工作流程:

具体实现代码其实和上面的爬虫差不多,无非就是爬岗位变成了爬IP而已,具体实现源码在这,就不在这写了。
数据可视化分析
我们最终折腾爬虫,无非就是想要看爬到的数据到底说明了什么。
成功爬取了拉钩网上多个招聘岗位的具体信息后,数据可视化并得出分析结果如下:
从整体看,北上广深杭这五个城市前端工程师招聘岗位,北京是遥遥领先,是深圳的两倍,是广州的三倍,其次到上海,深圳,杭州,广州居末。
从需求量大概可以看出,整体互联网产业发达程度是 北 > 上 > 深 > 杭 > 广
由平均工资曲线图可以看到,每隔2K算一档的话,北京一档,上海一档,杭州深圳一档,空一档,广州吊车尾,杭州竟然比深圳高了300,这就代表着深圳虽然招聘需求比杭州大,但两者薪酬待遇其实差不多。
从不同薪酬的招聘数量也能看出一些很大的区别,招聘提供薪资水平中,普遍数量最多的是10k-20k这个水平,但,北京牛逼,招聘岗位60%以上都是20K以上的。我们具体来看看,各个城市对高端人才(提供薪酬20k以上)的招聘比例,那就可以看出明显区别了:
基本可以看到一个明显的趋势,公司规模越大,能提供的薪酬越高,不差钱。
另外,从不同规模的公司的前端招聘数量来看,北京又一枝独秀,大公司招聘需求很高。
但从全国来看,不同规模的公司(除了15人以下的)招聘数量基本在同一水平,基本说明:大公司少,但是每个公司招聘的人多;小公司多,但是每个公司招聘的人少。
好像这是句废话。从图上看,工作经历在1-5年的现在需求最旺盛,并且理所当然地,工作资历越高,薪资越高。
其中3-5年的最吃香,广州有点奇怪,1-3年的最吃香?综合上面的多项数据,感觉像是1-3年工资比3-5年低所以广州互联网公司多招1-3年
当然,这里存在这一个幸存者偏差,拉勾上大部分的都是社招性质的招聘,而应届生和1年经验的大部分都跑校招去了吧,所以数量低也不出奇。
移动互联网占据了大半壁江山,剩下之中,金融,电子商务,企业服务,数据服务在同一层次。另外,物联网,智能硬件各有一招聘岗位,薪酬都是5K...嗯虽说node现在也可以做物联网了(还别说,我还真的用node搞过硬件串口通信Orz),但是终究不是主流技术,数据展示表明,前端基本与硬件绝缘。
薪酬待遇倒是都在同一水平上,“大数据”工资倒是一枝独秀,但是数据量太少,参考价值不大。
总结:北京钱多机会多当之无愧第一档;上海稍逊一筹;杭州深圳又低一筹;广州真的是差了两个身位。 而对于前端来说,北京 移动互联网 大公司,钱多!坑多!速来!
The text was updated successfully, but these errors were encountered: