本人简介: 曼彻斯特大学研究生,目前就职于北京某车企,专注于AI包括不限于NLP & CV技术,助力工业落地项目, 有合作或者比赛联系可以联系[email protected]
本人C站主页 : 曼城周杰伦-CSDN博客
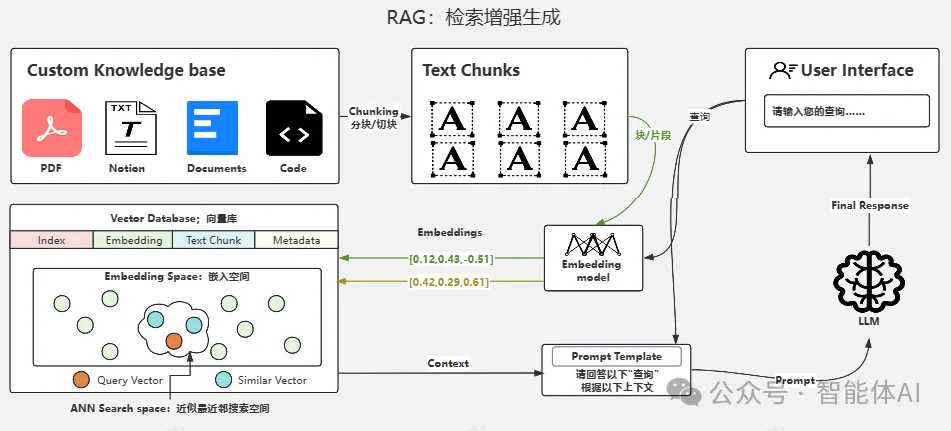
本项目主要是日常的有关于NLP基础的介绍 & 原理 & 面经 & 经验 & 框架 & 应用 , 欢迎补充。
| 序号 |
类别 |
项目名称 |
简介 |
地址 |
| 1 |
原理 |
N-gram |
每个词出现的概率只取决于前面n - 1个单词的 |
|
| 2 |
原理 |
word2vec |
词向量 |
jmlr.csail.mit.edu/papers/volume3/bengio03a/bengio03a.pdf |
| 3 |
原理 |
NPLM |
神经概率语言模型 |
bengio03a.dvi (mit.edu) |
| 4 |
原理 |
seq2seq |
端到端的神经网络 |
Sequence to Sequence Learning with Neural Networks (arxiv.org) |
| 5 |
原理 |
attention |
注意力机制 |
Attention Is All You Need (arxiv.org) |
| 6 |
模型架构 |
Transformer |
变形金刚,大模型基础结构 |
Attention Is All You Need (arxiv.org) |
| 7 |
模型架构 |
GPT |
GPT-3 |
GPT-3: Its Nature, Scope, Limits, and Consequences |
| 8 |
模型架构 |
chatGPT |
如何让GPT - 》 chatGPT |
Training language models to follow instructions with human feedback (arxiv.org) |
| 9 |
训练框架 |
DeepSpeed |
微软推出的提供了一站式的快速以及大规模的训练及推理框架,目前使用最广泛的训练框架 |
microsoft/DeepSpeed: DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective. (github.com) |
| 10 |
应用 |
Openai |
openai接口 |
ChatGPT |
| 11 |
模型架构 |
BERT |
自编码器-唯一的架构,初期使用最广泛的语言模型 |
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org) |
| 12 |
微调 |
Lora |
目前广泛使用的微调技术,通过冻结模型而训练增加adapter,从而达到微调适配下游任务的目的 |
LoRA: Low-Rank Adaptation of Large Language Models (arxiv.org) |
| 13 |
微调 |
Ptuning_V1 |
利用在下游任务中前置添加若干个可更新参数的虚拟[tokens] 所构成的模板prompt 再输入到文本中 |
GPT Understands, Too (arxiv.org) |
| 13 |
微调 |
Ptuning_V2 |
在V1的基础上,通过构造训练一个少量参数的prompt-encoder(lstm+mlp) 构建无真实语义信息的 virtual token |
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks (arxiv.org) |
| 14 |
推理框架 |
Xinference |
性能强大且功能全面的分布式推理框架 |
xorbitsai/inference: Replace OpenAI GPT with another LLM in your app by changing a single line of code. Xinference gives you the freedom to use any LLM you need. With Xinference, you're empowered to run inference with any open-source language models, speech recognition models, and multimodal models, whether in the cloud, on-premises, or even on your laptop. (github.com) |
| 15 |
RAG |
naive-RAG |
检索召回技术, 目前最主流减少大模型幻觉的落地技术 |
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (arxiv.org) |
| 16 |
RAG |
advanced-RAG |
增强的检索召回技术思路 |
|
| 17 |
RAG |
RAGAS |
RAG性能评估框架 |
explodinggradients/ragas: Supercharge Your LLM Application Evaluations 🚀 (github.com) |
| 1w |
微调 |
QLora |
量化版的Lora微调技术 |
artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs (github.com) |
| 19 |
微调 |
Lora & QLora |
lora & QLora 微调技巧 |
lightning.ai/pages/community/tutorial/lora-llm/ |
| 20 |
RAG框架 |
Dify |
工业主流RAG & agent 框架部署指南 |
langgenius/dify: Dify is an open-source LLM app development platform. Dify's intuitive interface combines AI workflow, RAG pipeline, agent capabilities, model management, observability features and more, letting you quickly go from prototype to production. (github.com) |
| 21 |
模型架构 |
LLama1 |
META公司推出的SOTA 开源大模型 |
https://arxiv.org/pdf/2302.13971.pdf |
| 22 |
模型架构 |
LLama2 |
META公司推出的SOTA 开源大模型 |
2302.13971 (arxiv.org) |
| 23 |
模型架构 |
Mistral 7B |
Mistral AI公司推出的第一个基座大模型 |
2401.04088 (arxiv.org) |
| 24 |
原理 |
layerNorm |
为什么在NLP领域中普遍用LayerNorm 而不是BatchNorm |
|
| 25 |
微调 |
SFT-trick |
微调技术的一些小技巧 |
|
| 26 |
模型架构 |
Mistral 8x7B |
第一个知名的MOE架构的大模型 |
2401.04088 (arxiv.org) |
| 27 |
微调 |
Parameter |
TrainingArguments参数设置 |
|
| 28 |
模型架构 |
LLama3 |
META公司推出的SOTA 开源大模型 |
meta-llama/llama3: The official Meta Llama 3 GitHub site |
| 29 |
应用 |
gpt |
一些好用的gpt套壳网站 |
|
| 30 |
微调 |
trainer |
transformer.Trainer参数设置 |
|
| 31 |
RAG |
advanced-RAG |
优化的检索召回技术思路 |
|
| 32 |
RAG |
HippoRAG |
HippoRAG结合了大型语言模型(LLMs)、知识图谱和个性化PageRank算法 |
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models |
| 33 |
RAG |
FILCORAG |
过滤内容增强的RAG技术 |
Learning to Filter Context for Retrieval-Augmented Generation (arxiv.org) |
| 34 |
微调 |
lora VS finetuning |
到底是应该选择Lora还是选择全量微调? |
LoRA Learns Less and Forgets Less |
| 35 |
评测 |
MTEB |
embedding模型性能评测榜单 |
MTEB: Massive Text Embedding Benchmark (arxiv.org)](https://arxiv.org/abs/2210.07316) |
| 36 |
RAG |
HyKGERAG |
北大结合知识图谱的意料RAG |
HyKGE: A Hypothesis Knowledge Graph Enhanced Framework for Accurate and Reliable Medical LLMs Responses |
| 37 |
RAG |
RAFT |
该技术通过结合相关文档的检索和模型的微调,从而提升模型在特定领域内的推理能力 |
RAFT: Adapting Language Model to Domain Specific RAG (arxiv.org) |
| 38 |
模型架构 |
Timsfm |
专为时间序列预测设计的解码器通用大基础模型 |
A decoder-only foundation model for time-series forecasting (arxiv.org) |
| 39 |
评测 |
CEval |
全面评估中文环境下基础模型能力的解决方案 |
2305.08322 |
| 40 |
prompt工程 |
prompt |
如何与大模型交流--prompt工程 |
Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4 |
| 41 |
原理 |
parameter |
解读大模型的参数 |
|
| 42 |
RAG |
ClashEval |
但当检索到的内容存在错误或有害信息时,模型会优先同意召回的信息而不是大模型本身信息 |
ClashEval: Quantifying the tug-of-war between an LLM's internal prior and external evidence |
| 43 |
RAG |
VisualRAG |
视觉+RAGpipeline |
|
| 45 |
RAG |
GraphRAG |
微软开源的知识图谱+ RAG |
microsoft/graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system |
| 46 |
RAG |
GraphRAG |
GraphRAG快速入门 |
microsoft/graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system |
| 47 |
微调 |
prompt-tuning |
prompt tuing & instruction tuning & chain-of-though三者区别 |
|
| 48 |
微调 |
DDP |
分布式训练 |
|
| 49 |
面经 |
Lora面经 |
Lora面经 |
|
| 50 |
模型架构 |
OLMoE |
第一个开源MOE大模型 |
2409.02060 |
| 51 |
面经 |
langchain面经 |
langchain面经 |
|
| 52 |
RAG |
longCite |
助力大模型找到长文本引用 |
THUDM/LongCite: LongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA |
| 53 |
推理框架 |
Ollama |
大模型部署框架 |
ollama/ollama: Get up and running with Llama 3.2, Mistral, Gemma 2, and other large language models. |
| 54 |
训练框架 |
Llama-factory |
一站式中文训练模型框架 |
hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs (ACL 2024) |
| 55 |
RAG框架 |
FastGPT |
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力 |
labring/FastGPT: FastGPT is a knowledge-based platform built on the LLMs, offers a comprehensive suite of out-of-the-box capabilities such as data processing, RAG retrieval, and visual AI workflow orchestration, letting you easily develop and deploy complex question-answering systems without the need for extensive setup or configuration. |
| 56 |
面经 |
RAG |
RAG面经 |
|
| 57 |
原理 |
RoPE |
旋转位置编码原理详解 |
|
| 58 |
原理 |
LLM |
从0->1构建自己的大模型 |
如何从头训练大语言模型: A simple technical report - 知乎 |
| 59 |
评测 |
evaluate |
LLM评估指南如何从头训练大语言模型: A simple technical report - 知乎 |
|
| 60 |
RAG |
text2vec |
如何选择chunksize 和splitter |
HuixiangDou/README_zh.md at main · InternLM/HuixiangDou |
| 61 |
RAG |
embedding |
微调embedding |
|
| 62 |
RAG |
KAG |
KAG 旨在充分利用知识图谱和向量检索的优势,并通过四个方面双向增强大型语言模型和知识图谱,以解决 RAG 挑战 |
OpenSPG/KAG: KAG is a knowledge-enhanced generation framework based on OpenSPG engine, which is used to build knowledge-enhanced rigorous decision-making and information retrieval knowledge services |
| 63 |
模型架构 |
Qwen2 |
阿里千问Qwen2系列 |
QwenLM/Qwen2.5: Qwen2.5 is the large language model series developed by Qwen team, Alibaba Cloud. |
| 64 |
模型架构 |
Qwen2代码 |
Qwen2代码解析 |
|
| 65 |
文档解析 |
MinerU |
免费精准解析PDF文档的开源解决方案 |
|
| 66 |
prompt工程 |
prompt |
prompt 工程合辑 |
|
| 67 |
prompt工程 |
Promptim |
LangChain推出自动化提示优化工具Promptim:一键优化,效率倍增LangChain推出自动化提示优化工具Promptim:一键优化,效率倍增 |
hinthornw/promptimizer: Prompt optimization scratch |
| 68 |
prompt工程 |
De_Ai |
一键去除Ai味 |
|
| 69 |
推理框架 |
vllm |
大模型集群分部署部署框架 |
|
| 70 |
Langchain |
Langchain_Summary |
Langchain的长文本总结处理方式 |
vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs |
| 71 |
RAG |
Table_RAG |
表格RAG的处理方式command 'office.markdown.switch' not found |
|
| 72 |
RAG |
LazyGraphRAG |
微软重磅推出高性价比下一代GraphRAG |
|
| 73 |
RAG |
Advanced_RAG |
十种提升RAG效果的方法 |
|
| 74 |
RAG |
Graph_RAG |
深度解读GraphRAG(转载) |
|
| 75 |
RAG |
PDF |
利用LLM从非结构化PDF中提取结构化知识 |
|
| 76 |
面经 |
RoPE |
手写一下正弦编码和旋转位置编码的代码 |
|
| 77 |
面经 |
ScallingLaw |
scalling law = 幂律? |
|
| 78 |
RAG |
RAG |
GraphRAG、Naive RAG框架总结主流框架推荐(共23个):LightRAG、nano-GraphRAG、Dify等GraphRAG、Naive RAG框架总结主流框架推荐(共23个):LightRAG、nano-GraphRAG、Dify等 |
|
| 79 |
RAG |
AdvancedRAG |
RAG落地解决方案 |
|
| 80 |
RAG |
RAG_Chunk |
RAG分块策略 |
|
| 81 |
RAG |
GraphRAG_Milvus |
利用Milvus向量数据库,实现GraphRAG:主流方法(递归、jina-seg)+前沿推荐(Meta-chunking、Late chunking、SLM-SFT) |
|
| 82 |
面经 |
GPU |
如何估算大模型显存 |
|
| 83 |
prompt工程 |
Prompt_template |
Prompt格式的重要性 |
|
| 84 |
RAG |
Markdown |
Markdown文档如何切分 |
|
| 85 |
MultiModal |
Qwen2VL |
Qwen2VL 多模态模型实践 |
|
| 86 |
面经 |
Deepspeed_ZeRO |
Deepspeed_ZeRO各阶段配置 |
|
| 87 |
RAG |
MarkitDown |
微软开源MarkitDown,RAG文档解析就这么解决了~ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Todo |
RAG |
Open Parse |
提取PDF文档文字、表格混排自动识别 |
Filimoa/open-parse: Improved file parsing for LLM’s (github.com) |
|
|
|
|
|
随着自然语言处理技术的快速发展,RAG(Retrieval-Augmented Generation)作为一种结合了检索和生成的方法,逐渐成为构建高效问答系统的重要工具。然而,在实际应用中,RAG系统仍然面临许多挑战。本文将详细介绍RAG过程中常见的问题及其解决方案,并结合应用场景进行优化,帮助开发者和研究人员更好地应对这些挑战,后续的文章中将详细讲解每一个问题的解决思路及代码实现。
描述: 用户的查询可能无法准确地表达其需求,特别是在电商或特定领域的搜索中,用户的查询可能包含多个条件,这些条件难以通过简单的embedding来表达。
解决方案:
- 多条件处理:将用户的查询拆分成多个子查询,分别处理后再合并结果。例如,用户查询“我想要一条黑色皮质迷你裙,价格低于20美元”,可以将其拆分为“黑色”、“皮质”、“迷你裙”、“价格低于20美元”等多个条件,分别进行检索,最后合并结果。
- 属性提取:从用户的查询中提取关键属性(如价格、颜色等),并通过这些属性进行精确过滤。例如,使用大模型对用户的查询进行解析,提取出“黑色”、“皮质”、“迷你裙”、“价格 < 20美元”等属性,然后通过这些属性在数据库中进行精确检索。
应用场景: 在电商平台中,用户查询“我想要一条黑色皮质迷你裙,价格低于20美元”。系统首先使用大模型解析出关键属性“黑色”、“皮质”、“迷你裙”和“价格 < 20美元”,然后通过这些属性在数据库中进行精确检索,确保返回的商品列表符合用户的查询条件。
描述: 将用户的自然语言查询转换为系统能够理解的形式时,可能存在转换不准确的问题,导致检索结果与用户需求不符。
解决方案:
- 大模型辅助:使用大模型对用户的自然语言查询进行理解和转换,生成更精确的检索条件。例如,使用BERT或其他预训练模型对用户的查询进行嵌入,然后通过这些嵌入向量在向量数据库中进行搜索。
- 多角度生成:生成多个不同角度的查询,以覆盖更多的可能性。例如,用户查询“我想要一条黑色皮质迷你裙”,可以生成多个查询变体,如“我想要一条黑色迷你裙,材质是皮质”、“我想要一条皮质迷你裙,颜色是黑色”等,然后对这些变体进行检索,合并结果。
应用场景: 在旅游搜索引擎中,用户查询“我想找一个有免费Wi-Fi的海滩附近的酒店”。系统使用大模型生成多个查询变体,如“我想找一个有免费Wi-Fi的海滩附近的酒店”、“我想找一个海滩附近有免费Wi-Fi的酒店”等,然后对这些变体进行检索,确保返回的酒店列表符合用户的查询条件。
描述: 从向量数据库中检索出的文档可能与用户的查询不相关,无法提供有效的上下文信息。
解决方案:
- 属性过滤:在检索过程中,先通过属性过滤减少无关文档的数量,再进行向量搜索。例如,用户查询“我想要一条黑色皮质迷你裙”,可以先通过属性过滤筛选出所有“黑色”和“皮质”的商品,然后再进行向量搜索。
- 多轮检索:进行多轮检索,逐步细化检索条件,提高结果的相关性。例如,第一轮检索可以使用较宽泛的条件,如“迷你裙”,第二轮检索可以使用更具体的条件,如“黑色皮质迷你裙”。
应用场景: 在医疗问答系统中,用户查询“如何治疗普通感冒”。系统首先使用宽泛的条件“普通感冒”进行检索,然后根据用户的进一步提问(如“普通感冒的症状”)进行更具体的检索,确保返回的信息与用户的查询高度相关。
描述: 即使检索结果包含相关信息,也可能缺乏完整性,无法全面回答用户的问题。
解决方案:
- Sentence Window Retrieval:通过窗口机制,提取与检索结果相邻的上下文信息,确保信息的完整性。例如,如果检索结果是一个句子,可以提取该句子前后几个句子的信息,形成一个更大的上下文。
- Parent-Child Trans Retrieval:将文档划分为父级和子级片段,先检索父级片段,再根据父级片段的结果检索子级片段,确保信息的精确性和完整性。例如,将一个文档划分为多个父级片段,每个父级片段再划分为多个子级片段,先检索父级片段,再根据父级片段的结果检索子级片段。
应用场景: 在法律咨询系统中,用户查询“创办企业的法律要求有哪些?”系统使用Sentence Window Retrieval方法,提取与检索结果相邻的上下文信息,确保返回的法律条款和要求信息完整且准确。
描述: 检索出的文档可能包含大量无关信息,导致上下文过于冗长,影响系统性能和用户体验。
解决方案:
- 信息过滤:对检索结果进行过滤,去除冗余信息,只保留关键内容。例如,使用TF-IDF或其他文本分析方法,筛选出最相关的句子或段落。
- 动态窗口大小:根据查询的复杂度动态调整窗口大小,避免不必要的信息。例如,对于复杂的查询,可以扩大窗口大小,对于简单的查询,可以缩小窗口大小。
应用场景: 在新闻推荐系统中,用户查询“最新气候变化新闻”。系统使用TF-IDF方法对检索结果进行过滤,去除冗余信息,确保返回的新闻文章简洁且相关。
描述: 检索出的文档未经过有效排序,可能导致重要的信息未能优先呈现。
解决方案:
- 传统排序算法:借鉴搜索引擎和推荐系统的排序算法,如TF-IDF、BM25等。这些算法可以根据关键词频率、文档长度等因素对检索结果进行排序。
- 自定义排序:根据具体应用场景,设计自定义的排序算法,确保重要信息优先呈现。例如,可以结合用户的搜索历史、点击率等因素进行排序。
应用场景: 在学术论文检索系统中,用户查询“近期机器学习的研究进展”。系统使用BM25算法对检索结果进行排序,确保最新的研究成果优先呈现。
描述: 检索出的上下文信息可能不足以回答用户的问题,导致生成的回答不准确或不完整。
解决方案:
- 多源检索:从多个数据源检索上下文信息,确保信息的全面性。例如,可以从多个数据库、知识图谱、网页等来源检索相关信息。
- 知识图谱融合:将知识图谱中的事实信息融入上下文中,提高信息的准确性。例如,用户查询“什么是人工智能”,可以从知识图谱中提取“人工智能”的定义、发展历程等相关信息。
应用场景: 在教育辅导系统中,用户查询“量子力学的关键概念有哪些?”系统从多个数据源(如教科书、学术论文、在线课程)检索相关信息,并将知识图谱中的关键概念融入上下文中,确保生成的回答全面且准确。
描述: 过多的上下文信息不仅增加了系统的负担,还可能导致生成的回答中包含不必要的信息。
解决方案:
- 信息去重:对检索结果进行去重处理,避免重复信息。例如,使用哈希函数或相似度计算方法,去除重复的句子或段落。
- 摘要生成:使用大模型生成摘要,提取关键信息,减少冗余。例如,使用T5或BART等模型生成摘要,提取出最相关的句子或段落。
应用场景: 在金融资讯系统中,用户查询“最近亚洲的经济趋势”。系统对检索结果进行去重处理,并使用T5模型生成摘要,确保返回的经济趋势信息简洁且相关。
描述: 检索出的上下文信息可能与用户的问题不相关,影响回答的质量。
解决方案:
- 相关性评分:对检索结果进行相关性评分,只保留高相关性的上下文信息。例如,使用余弦相似度或Jaccard相似度等方法,计算检索结果与用户查询的相关性。
- 用户反馈:根据用户的反馈,不断优化上下文的选择和生成。例如,用户可以对生成的回答进行评分,系统根据评分调整上下文的选择策略。
应用场景: 在健康咨询系统中,用户查询“疫情期间如何改善心理健康”。系统对检索结果进行相关性评分,确保返回的心理健康建议与用户的查询高度相关。
描述: 选择合适的排序算法以确保检索结果的有效性和相关性是一个挑战。
解决方案:
- 实验对比:通过实验对比不同排序算法的效果,选择最适合的算法。例如,可以使用A/B测试方法,对比不同排序算法在用户满意度、点击率等方面的性能。
- 组合排序:结合多种排序算法,取长补短,提高排序效果。例如,可以结合TF-IDF、BM25和深度学习模型等多种算法,综合考虑关键词频率、文档长度和语义相似度等因素。
应用场景: 在音乐推荐系统中,用户查询“2000年代的热门歌曲”。系统使用A/B测试方法,对比不同排序算法的效果,最终选择综合性能最优的排序算法。
描述:异常值的存在可能严重影响排序结果,导致重要的信息被忽略。
解决方案:
- 异常检测:使用统计方法或机器学习模型检测和处理异常值。例如,可以使用Z-score或箱线图等方法,识别和剔除异常值。
- 鲁棒性优化:优化排序算法的鲁棒性,减少异常值的影响。例如,可以使用鲁棒性更强的损失函数,如Huber损失,替代传统的均方误差损失。
应用场景: 在新闻推荐系统中,用户查询“最新新闻”。系统使用Z-score方法检测和处理异常值,确保返回的新闻文章真实可靠。
描述: 生成的回答可能偏离用户的实际需求,或者包含错误的信息。
解决方案:
- 多模型融合:结合多个大模型的输出,提高回答的准确性。例如,可以使用集成学习方法,结合BERT、RoBERTa和T5等多个模型的输出,生成最终的回答。
- 后处理:对生成的回答进行后处理,修正错误和不一致的地方。例如,可以使用规则匹配或语法检查等方法,修正生成的回答中的错误。
应用场景: 在法律咨询系统中,用户查询“如何申请专利”。系统结合多个大模型的输出,生成详细的专利申请指南,并使用语法检查方法修正生成的回答中的错误。
描述: 生成的回答可能与用户的问题不相关,无法提供有效的帮助。
解决方案:
- 上下文验证:验证生成的回答是否与上下文信息一致,确保相关性。例如,可以使用相似度计算方法,验证生成的回答与检索出的上下文信息的相似度。
- 用户反馈:根据用户的反馈,不断优化生成的回答。例如,用户可以对生成的回答进行评分,系统根据评分调整生成策略。
应用场景: 在旅游搜索引擎中,用户查询“巴黎最好的旅游景点”。系统验证生成的回答与检索出的巴黎景点信息的相似度,确保返回的旅游建议与用户的查询高度相关。
描述: 生成的回答可能包含大量无关信息,影响用户体验。
解决方案:
- 信息精简:对生成的回答进行精简,去除不必要的信息。例如,可以使用文本摘要方法,提取出最相关的句子或段落。
- 摘要生成:生成回答的摘要,突出关键信息。例如,可以使用T5或BART等模型生成摘要,提取出最相关的句子或段落。
应用场景: 在新闻推荐系统中,用户查询“最新气候变化新闻”。系统使用T5模型生成回答的摘要,确保返回的新闻文章简洁且相关。
描述: 不同格式的文档(如PDF、HTML、PPT等)解析难度大,可能影响数据的质量和系统的性能。
解决方案:
- 使用成熟工具:使用成熟的文档解析工具,如PDFMiner、BeautifulSoup等,提高解析质量。这些工具提供了丰富的功能,可以处理多种格式的文档。
- 自定义解析:根据文档的具体格式,编写自定义解析脚本,确保解析的准确性和效率。
应用场景: 在科研文献管理系统中,用户上传了多篇不同格式的论文。系统使用PDFMiner和BeautifulSoup等工具对这些文档进行解析,提取出标题、作者、摘要等关键信息,确保数据的准确性和完整性。
描述: 在多轮对话中,用户的Query可能不完整,因为用户可能依赖于之前的对话内容,导致当前的Query信息不足。
解决方案:
- 历史上下文融合:将用户的对话历史与当前Query结合起来,生成一个更完整的Query。例如,使用大模型将用户的对话历史和当前Query进行融合,生成一个新的Query。
- 多轮对话管理:设计多轮对话管理系统,确保每一轮对话都能获取到足够的上下文信息。例如,系统可以在每一轮对话中提示用户提供更多信息,以确保Query的完整性。
应用场景: 在一个客服聊天机器人中,用户在多轮对话中询问关于某个产品的详细信息。系统将用户的对话历史与当前Query结合起来,生成一个新的Query:“我想了解这款产品的详细规格和价格”,确保生成的回答包含所有相关信息。
描述: 生成的Query扩展可能不准确,导致检索结果与用户需求不符。
解决方案:
- 多角度生成:生成多个不同角度的Query扩展,以覆盖更多的可能性。例如,用户查询“我想要一条黑色皮质迷你裙”,可以生成多个Query扩展,如“我想要一条黑色迷你裙,材质是皮质”、“我想要一条皮质迷你裙,颜色是黑色”等。
- 用户反馈:根据用户的反馈,不断优化Query扩展生成策略。例如,用户可以对生成的Query扩展进行评分,系统根据评分调整生成策略。
应用场景: 在电商平台中,用户查询“我想要一条黑色皮质迷你裙”。系统生成多个Query扩展,并根据用户的反馈选择最合适的Query扩展,确保返回的商品列表符合用户的查询条件。
描述: 从多个数据源检索出的结果可能需要进一步融合,以提供更全面的信息。
解决方案:
- 多源融合:将从多个数据源检索出的结果进行融合,生成一个更全面的上下文。例如,可以使用TF-IDF或其他文本分析方法,对多个数据源的结果进行融合。
- 知识图谱融合:将知识图谱中的信息融入检索结果中,提高信息的准确性和全面性。例如,用户查询“什么是人工智能”,可以从知识图谱中提取“人工智能”的定义、发展历程等相关信息。
应用场景: 在教育辅导系统中,用户查询“量子力学的关键概念有哪些?”系统从多个数据源(如教科书、学术论文、在线课程)检索相关信息,并将知识图谱中的关键概念融入上下文中,确保生成的回答全面且准确。
描述: 排序结果可能受噪声影响,导致不稳定的排序结果。
解决方案:
- 鲁棒性优化:优化排序算法的鲁棒性,减少噪声的影响。例如,可以使用鲁棒性更强的损失函数,如Huber损失,替代传统的均方误差损失。
- 动态调整:根据用户的反馈和使用情况,动态调整排序策略。例如,系统可以根据用户的点击率和满意度,动态调整排序权重。
应用场景: 在新闻推荐系统中,用户查询“最新气候变化新闻”。系统使用鲁棒性更强的排序算法,减少噪声的影响,并根据用户的点击率和满意度动态调整排序权重,确保返回的新闻文章真实可靠。
描述: 生成的回答可能缺乏连贯性,影响用户的阅读体验。
解决方案:
- 连贯性优化:优化生成的回答,确保其连贯性和逻辑性。例如,可以使用大模型生成回答时,加入连贯性约束,确保生成的回答逻辑清晰、连贯。
- 多段落生成:生成多个段落,每个段落专注于一个主题,确保回答的整体连贯性。例如,用户查询“全球变暖的原因和影响”,系统可以生成多个段落,分别回答“全球变暖的原因”和“全球变暖的影响”。
应用场景: 在环保咨询系统中,用户查询“全球变暖的原因和影响”。系统生成多个段落,分别回答“全球变暖的原因”和“全球变暖的影响”,确保回答的整体连贯性和逻辑性。
通过对RAG过程中常见问题的深入分析和解决方案的提出,我们可以显著提升系统的性能和用户体验。具体来说,通过优化Query处理、检索、上下文生成、排序和生成回答等各个环节,可以有效解决RAG系统在实际应用中面临的问题。希望这些优化方案能够为开发者和研究人员提供有益的参考,帮助他们在构建高效问答系统时取得更好的成果,后续的文章中将详细讲解每一个问题的解决思路及代码实现,敬请期待。