toTabletInsertionEvents();
+}
+```
+
+### Custom Stream Processing Plugin Programming Interface Definition
+
+Based on the custom stream processing plugin programming interface, users can easily write data extraction plugins, data processing plugins, and data sending plugins, allowing the stream processing functionality to adapt flexibly to various industrial scenarios.
+#### Data Extraction Plugin Interface
+
+Data extraction is the first stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data extraction plugin (PipeExtractor) serves as a bridge between the stream processing engine and the storage engine. It captures various data write events by listening to the behavior of the storage engine.
+```java
+/**
+ * PipeExtractor
+ *
+ * PipeExtractor is responsible for capturing events from sources.
+ *
+ *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
+ *
The lifecycle of a PipeExtractor is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
+ * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeExtractor.
+ *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
+ *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
+ * be called to capture events from sources and then the events will be passed to the
+ * PipeProcessor.
+ *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ * cancelled (the `DROP PIPE` command is executed).
+ *
+ */
+public interface PipeExtractor extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeExtractor. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeExtractor#validate(PipeParameterValidator)} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeExtractor
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * Start the extractor. After this method is called, events should be ready to be supplied by
+ * {@link PipeExtractor#supply()}. This method is called after {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ *
+ * @throws Exception the user can throw errors if necessary
+ */
+ void start() throws Exception;
+
+ /**
+ * Supply single event from the extractor and the caller will send the event to the processor.
+ * This method is called after {@link PipeExtractor#start()} is called.
+ *
+ * @return the event to be supplied. the event may be null if the extractor has no more events at
+ * the moment, but the extractor is still running for more events.
+ * @throws Exception the user can throw errors if necessary
+ */
+ Event supply() throws Exception;
+}
+```
+
+#### Data Processing Plugin Interface
+
+Data processing is the second stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data processing plugin (PipeProcessor) is primarily used for filtering and transforming the various events captured by the data extraction plugin (PipeExtractor).
+
+```java
+/**
+ * PipeProcessor
+ *
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
+ *
The lifecycle of a PipeProcessor is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH PROCESSOR` clause in SQL are
+ * parsed and the validation method {@link PipeProcessor#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeProcessor.
+ *
- While the collaboration task is in progress:
+ *
+ * - PipeExtractor captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ * following 3 methods will be called: {@link
+ * PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
+ * PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
+ * PipeProcessor#process(Event, EventCollector)}.
+ *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
+ * - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
+ * PipeProcessor#close() } method will be called.
+ *
+ */
+public interface PipeProcessor extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeProcessor. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeProcessorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeProcessor#validate(PipeParameterValidator)} is called and before the beginning of the
+ * events processing.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeProcessor
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeProcessorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is called to process the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ void process(TabletInsertionEvent tabletInsertionEvent, EventCollector eventCollector)
+ throws Exception;
+
+ /**
+ * This method is called to process the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void process(TsFileInsertionEvent tsFileInsertionEvent, EventCollector eventCollector)
+ throws Exception {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ process(tabletInsertionEvent, eventCollector);
+ }
+ }
+
+ /**
+ * This method is called to process the Event.
+ *
+ * @param event Event to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ void process(Event event, EventCollector eventCollector) throws Exception;
+}
+```
+
+#### Data Sending Plugin Interface
+
+Data sending is the third stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data sending plugin (PipeConnector) is responsible for sending the various events processed by the data processing plugin (PipeProcessor). It serves as the network implementation layer of the stream processing framework and should support multiple real-time communication protocols and connectors in its interface.
+
+```java
+/**
+ * PipeConnector
+ *
+ *
PipeConnector is responsible for sending events to sinks.
+ *
+ *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
+ *
The lifecycle of a PipeConnector is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
+ * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeConnector and the method {@link
+ * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- While the collaboration task is in progress:
+ *
+ * - PipeExtractor captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeConnector.
+ *
- PipeConnector serializes the events into binaries and send them to sinks. The
+ * following 3 methods will be called: {@link
+ * PipeConnector#transfer(TabletInsertionEvent)}, {@link
+ * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
+ * PipeConnector#transfer(Event)}.
+ *
+ * - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
+ * PipeConnector#close() } method will be called.
+ *
+ *
+ * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
+ * will be called to create a new connection with the sink when the method {@link
+ * PipeConnector#heartbeat()} throws exceptions.
+ */
+public interface PipeConnector extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeConnector. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
+ * PipeConnector#handshake()} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeConnector
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is used to create a connection with sink. This method will be called after the
+ * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
+ * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
+ *
+ * @throws Exception if the connection is failed to be created
+ */
+ void handshake() throws Exception;
+
+ /**
+ * This method will be called periodically to check whether the connection with sink is still
+ * alive.
+ *
+ * @throws Exception if the connection dies
+ */
+ void heartbeat() throws Exception;
+
+ /**
+ * This method is used to transfer the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
+
+ /**
+ * This method is used to transfer the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ }
+
+ /**
+ * This method is used to transfer the Event.
+ *
+ * @param event Event to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(Event event) throws Exception;
+}
+```
+
+## Custom Stream Processing Plugin Management
+
+To ensure the flexibility and usability of user-defined plugins in production environments, the system needs to provide the capability to dynamically manage plugins. This section introduces the management statements for stream processing plugins, which enable the dynamic and unified management of plugins.
+
+### Load Plugin Statement
+
+In IoTDB, to dynamically load a user-defined plugin into the system, you first need to implement a specific plugin class based on PipeExtractor, PipeProcessor, or PipeConnector. Then, you need to compile and package the plugin class into an executable jar file. Finally, you can use the loading plugin management statement to load the plugin into IoTDB.
+
+The syntax of the loading plugin management statement is as follows:
+
+```sql
+CREATE PIPEPLUGIN
+AS
+USING
+```
+
+For example, if a user implements a data processing plugin with the fully qualified class name "edu.tsinghua.iotdb.pipe.ExampleProcessor" and packages it into a jar file, which is stored at "https://example.com:8080/iotdb/pipe-plugin.jar", and the user wants to use this plugin in the stream processing engine, marking the plugin as "example". The creation statement for this data processing plugin is as follows:
+
+```sql
+CREATE PIPEPLUGIN example
+AS 'edu.tsinghua.iotdb.pipe.ExampleProcessor'
+USING URI ''
+```
+
+### Delete Plugin Statement
+
+When user no longer wants to use a plugin and needs to uninstall the plug-in from the system, you can use the Remove plugin statement as shown below.
+```sql
+DROP PIPEPLUGIN
+```
+
+### Show Plugin Statement
+
+User can also view the plugin in the system on need. The statement to view plugin is as follows.
+```sql
+SHOW PIPEPLUGINS
+```
+
+## System Pre-installed Stream Processing Plugin
+
+### Pre-built extractor Plugin
+
+#### iotdb-extractor
+
+Function: Extract historical or realtime data inside IoTDB into pipe.
+
+
+| key | value | value range | required or optional with default |
+| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
+| extractor | iotdb-extractor | String: iotdb-extractor | required |
+| extractor.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
+| extractor.history.enable | whether to sync historical data | Boolean: true, false | optional: true |
+| extractor.history.start-time | start of synchronizing historical data event time,Include start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| extractor.history.end-time | end of synchronizing historical data event time,Include end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| extractor.realtime.enable | Whether to sync realtime data | Boolean: true, false | optional: true |
+
+> 🚫 **extractor.pattern Parameter Description**
+>
+> * Pattern should use backquotes to modify illegal characters or illegal path nodes, for example, if you want to filter root.\`a@b\` or root.\`123\`, you should set the pattern to root.\`a@b\` or root.\`123\`(Refer specifically to [Timing of single and double quotes and backquotes](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
+> * In the underlying implementation, when pattern is detected as root (default value), synchronization efficiency is higher, and any other format will reduce performance.
+> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
+>
+> * root.aligned.1TS
+> * root.aligned.1TS.\`1\`
+> * root.aligned.100TS
+>
+> the data will be synchronized;
+>
+> * root.aligned.\`1\`
+> * root.aligned.\`123\`
+>
+> the data will not be synchronized.
+
+> ❗️**start-time, end-time parameter description of extractor.history**
+>
+> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
+
+> ✅ **a piece of data from production to IoTDB contains two key concepts of time**
+>
+> * **event time:** the time when the data is actually produced (or the generation time assigned to the data by the data production system, which is a time item in the data point), also called the event time.
+> * **arrival time:** the time the data arrived in the IoTDB system.
+>
+> The out-of-order data we often refer to refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
+
+> 💎 **the work of iotdb-extractor can be split into two stages**
+>
+> 1. Historical data extraction: All data with **arrival time** < **current system time** when creating the pipe is called historical data
+> 2. Realtime data extraction: All data with **arrival time** >= **current system time** when the pipe is created is called realtime data
+>
+> The historical data transmission phase and the realtime data transmission phase are executed serially. Only when the historical data transmission phase is completed, the realtime data transmission phase is executed.**
+>
+> Users can specify iotdb-extractor to:
+>
+> * Historical data extraction(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
+> * Realtime data extraction(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
+> * Full data extraction(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
+> * Disable simultaneous sets `extractor.history.enable` and `extractor.realtime.enable` to `false`
+
+### Pre-built Processor Plugin
+
+#### do-nothing-processor
+
+Function: Do not do anything with the events passed in by the extractor.
+
+
+| key | value | value range | required or optional with default |
+| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| processor | do-nothing-processor | String: do-nothing-processor | required |
+### Pre-built Connector Plugin
+
+#### do-nothing-connector
+
+Function: Does not do anything with the events passed in by the processor.
+
+
+| key | value | value range | required or optional with default |
+| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| connector | do-nothing-connector | String: do-nothing-connector | required |
+
+## Stream Processing Task Management
+
+### Create Stream Processing Task
+
+A stream processing task can be created using the `CREATE PIPE` statement, a sample SQL statement is shown below:
+
+```sql
+CREATE PIPE -- PipeId is the name that uniquely identifies the sync task
+WITH EXTRACTOR (
+ -- Default IoTDB Data Extraction Plugin
+ 'extractor' = 'iotdb-extractor',
+ -- Path prefix, only data that can match the path prefix will be extracted for subsequent processing and delivery
+ 'extractor.pattern' = 'root.timecho',
+ -- Whether to extract historical data
+ 'extractor.history.enable' = 'true',
+ -- Describes the time range of the historical data being extracted, indicating the earliest possible time
+ 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ -- Describes the time range of the extracted historical data, indicating the latest time
+ 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
+ -- Whether to extract realtime data
+ 'extractor.realtime.enable' = 'true',
+)
+WITH PROCESSOR (
+ -- Default data processing plugin, means no processing
+ 'processor' = 'do-nothing-processor',
+)
+WITH CONNECTOR (
+ -- IoTDB data sending plugin with target IoTDB
+ 'connector' = 'iotdb-thrift-connector',
+ -- Data service for one of the DataNode nodes on the target IoTDB ip
+ 'connector.ip' = '127.0.0.1',
+ -- Data service port of one of the DataNode nodes of the target IoTDB
+ 'connector.port' = '6667',
+)
+```
+
+**To create a stream processing task it is necessary to configure the PipeId and the parameters of the three plugin sections:**
+
+
+| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
+| --------- | ------------------------------------------------- | --------------------------- | -------------------- | ------------------------------------------------------ | ------------------------- |
+| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
+| extractor | pipe Extractor plug-in, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
+| processor | Pipe Processor plug-in, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
+| connector | Pipe Connector plug-in,for sending data | required | - | - | yes |
+
+In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plug-ins are used to build the data synchronisation task. iotdb has other built-in data synchronisation plug-ins, **see the section "System pre-built data synchronisation plug-ins" **. See the "System Pre-installed Stream Processing Plugin" section**.
+
+**An example of a minimalist CREATE PIPE statement is as follows:**
+
+```sql
+CREATE PIPE -- PipeId is a name that uniquely identifies the task.
+WITH CONNECTOR (
+ -- IoTDB data sending plugin with target IoTDB
+ 'connector' = 'iotdb-thrift-connector',
+ -- Data service for one of the DataNode nodes on the target IoTDB ip
+ 'connector.ip' = '127.0.0.1',
+ -- Data service port of one of the DataNode nodes of the target IoTDB
+ 'connector.port' = '6667',
+)
+```
+
+The expressed semantics are: synchronise the full amount of historical data and subsequent arrivals of realtime data from this database instance to the IoTDB instance with target 127.0.0.1:6667.
+
+**Note:**
+
+- EXTRACTOR and PROCESSOR are optional, if no configuration parameters are filled in, the system will use the corresponding default implementation.
+- The CONNECTOR is a mandatory configuration that needs to be declared in the CREATE PIPE statement for configuring purposes.
+- The CONNECTOR exhibits self-reusability. For different tasks, if their CONNECTOR possesses identical KV properties (where the value corresponds to every key), **the system will ultimately create only one instance of the CONNECTOR** to achieve resource reuse for connections.
+
+ - For example, there are the following pipe1, pipe2 task declarations:
+
+ ```sql
+ CREATE PIPE pipe1
+ WITH CONNECTOR (
+ 'connector' = 'iotdb-thrift-connector',
+ 'connector.thrift.host' = 'localhost',
+ 'connector.thrift.port' = '9999',
+ )
+
+ CREATE PIPE pipe2
+ WITH CONNECTOR (
+ 'connector' = 'iotdb-thrift-connector',
+ 'connector.thrift.port' = '9999',
+ 'connector.thrift.host' = 'localhost',
+ )
+ ```
+
+ - Since they have identical CONNECTOR declarations (**even if the order of some properties is different**), the framework will automatically reuse the CONNECTOR declared by them. Hence, the CONNECTOR instances for pipe1 and pipe2 will be the same.
+- Please note that we should avoid constructing application scenarios that involve data cycle sync (as it can result in an infinite loop):
+
+ - IoTDB A -> IoTDB B -> IoTDB A
+ - IoTDB A -> IoTDB A
+
+### Start Stream Processing Task
+
+After the successful execution of the CREATE PIPE statement, an instance of the stream processing task is created, but the overall task's running status will be set to STOPPED, meaning the task will not immediately process data.
+
+You can use the START PIPE statement to make the stream processing task start processing data:
+```sql
+START PIPE
+```
+
+### Stop Stream Processing Task
+
+Use the STOP PIPE statement to stop the stream processing task from processing data:
+
+```sql
+STOP PIPE
+```
+
+### Delete Stream Processing Task
+
+If a stream processing task is in the RUNNING state, you can use the DROP PIPE statement to stop it and delete the entire task:
+
+```sql
+DROP PIPE
+```
+
+Before deleting a stream processing task, there is no need to execute the STOP operation.
+
+### Show Stream Processing Task
+
+Use the SHOW PIPES statement to view all stream processing tasks:
+```sql
+SHOW PIPES
+```
+
+The query results are as follows:
+
+```sql
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+```
+
+You can use `` to specify the status of a stream processing task you want to see:
+```sql
+SHOW PIPE
+```
+
+Additionally, the WHERE clause can be used to determine if the Pipe Connector used by a specific \ is being reused.
+
+```sql
+SHOW PIPES
+WHERE CONNECTOR USED BY
+```
+
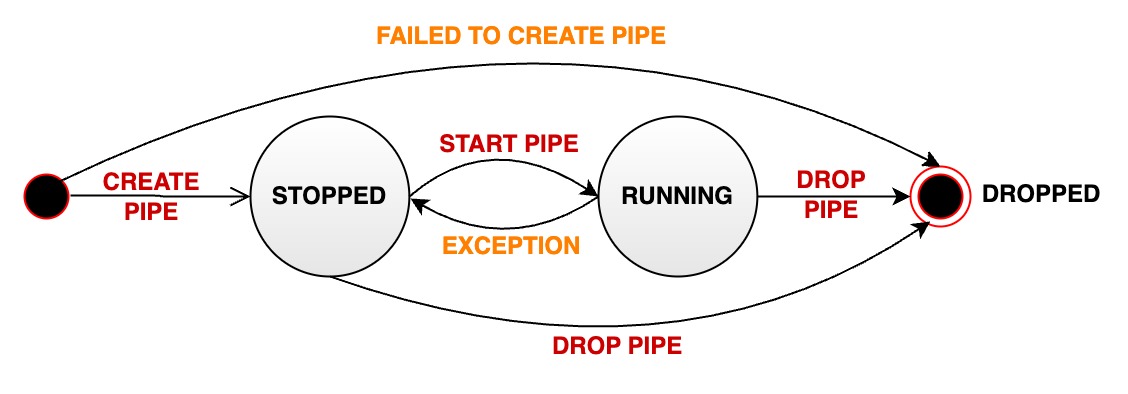
+### Stream Processing Task Running Status Migration
+
+A stream processing task status can transition through several states during the lifecycle of a data synchronization pipe:
+
+- **STOPPED:** The pipe is in a stopped state. It can have the following possibilities:
+ - After the successful creation of a pipe, its initial state is set to stopped
+ - The user manually pauses a pipe that is in normal running state, transitioning its status from RUNNING to STOPPED
+ - If a pipe encounters an unrecoverable error during execution, its status automatically changes from RUNNING to STOPPED.
+- **RUNNING:** The pipe is actively processing data
+- **DROPPED:** The pipe is permanently deleted
+
+The following diagram illustrates the different states and their transitions:
+
+
+
+## Authority Management
+
+### Stream Processing Task
+
+| Authority Name | Description |
+| ----------- | -------------------- |
+| CREATE_PIPE | Register task,path-independent |
+| START_PIPE | Start task,path-independent |
+| STOP_PIPE | Stop task,path-independent |
+| DROP_PIPE | Uninstall task,path-independent |
+| SHOW_PIPES | Query task,path-independent |
+### Stream Processing Task Plugin
+
+
+| Authority Name | Description |
+| ----------------- | ------------------------------ |
+| CREATE_PIPEPLUGIN | Register stream processing task plugin,path-independent |
+| DROP_PIPEPLUGIN | Delete stream processing task plugin,path-independent |
+| SHOW_PIPEPLUGINS | Query stream processing task plugin,path-independent |
+
+## Configure Parameters
+
+In iotdb-common.properties :
+
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_connector_timeout_ms=900000
+```
\ No newline at end of file
diff --git a/src/UserGuide/Master/User-Manual/Streaming_timecho.md b/src/UserGuide/Master/User-Manual/Streaming_timecho.md
index 6005077e..709bfae8 100644
--- a/src/UserGuide/Master/User-Manual/Streaming_timecho.md
+++ b/src/UserGuide/Master/User-Manual/Streaming_timecho.md
@@ -35,7 +35,7 @@ Pipe Extractor is used to extract data, Pipe Processor is used to process data,
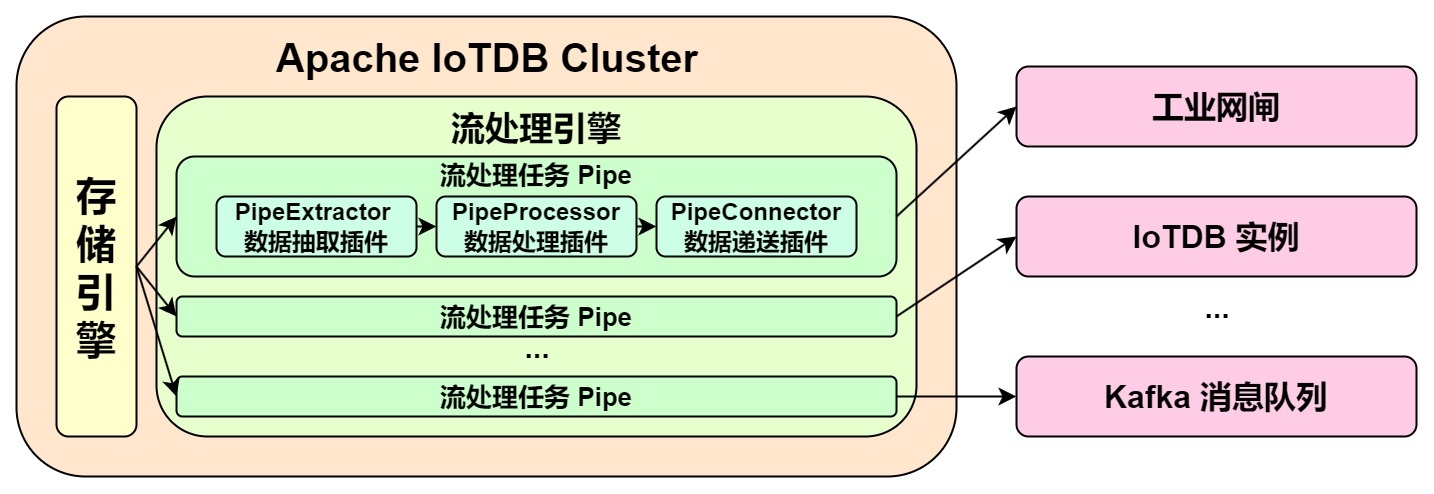
**The model of the Pipe task is as follows:**
-
+
Describing a data flow processing task essentially describes the properties of Pipe Extractor, Pipe Processor and Pipe Connector plugins.
Users can declaratively configure the specific attributes of the three subtasks through SQL statements, and achieve flexible data ETL capabilities by combining different attributes.
@@ -614,14 +614,12 @@ WITH CONNECTOR (
**When creating a stream processing task, you need to configure the PipeId and the parameters of the three plugin parts:**
-
-| Configuration item | Description | Required or not | Default implementation | Default implementation description | Whether custom implementation is allowed |
-| --------- | --------------------------------------------------- | --------------------------- | -------------------- | -------------------------------------------------------- | ------------------------- |
-| PipeId | A globally unique name that identifies a stream processing task | Required | - | - | - |
-| extractor | Pipe Extractor plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-extractor | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
-| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Optional | do-nothing-processor | | processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
- | 是 |
-| connector | Pipe Connector plugin, responsible for sending data | Required | - | - | 是 |
+| Configuration | Description | Required or not | Default implementation | Default implementation description | Default implementation description |
+| ------------- | ------------------------------------------------------------ | ------------------------------- | ---------------------- | ------------------------------------------------------------ | ---------------------------------- |
+| PipeId | A globally unique name that identifies a stream processing | Required | - | - | - |
+| extractor | Pipe Extractor plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-extractor | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
+| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
+| connector | Pipe Connector plugin, responsible for sending data | Required | - | - | Yes |
In the example, the iotdb-extractor, do-nothing-processor and iotdb-thrift-connector plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, **please check the "System Preset Stream Processing plugin" section**.
diff --git a/src/UserGuide/V1.2.x/User-Manual/Data-Sync.md b/src/UserGuide/V1.2.x/User-Manual/Data-Sync.md
index 040b6605..dda912dd 100644
--- a/src/UserGuide/V1.2.x/User-Manual/Data-Sync.md
+++ b/src/UserGuide/V1.2.x/User-Manual/Data-Sync.md
@@ -32,7 +32,7 @@
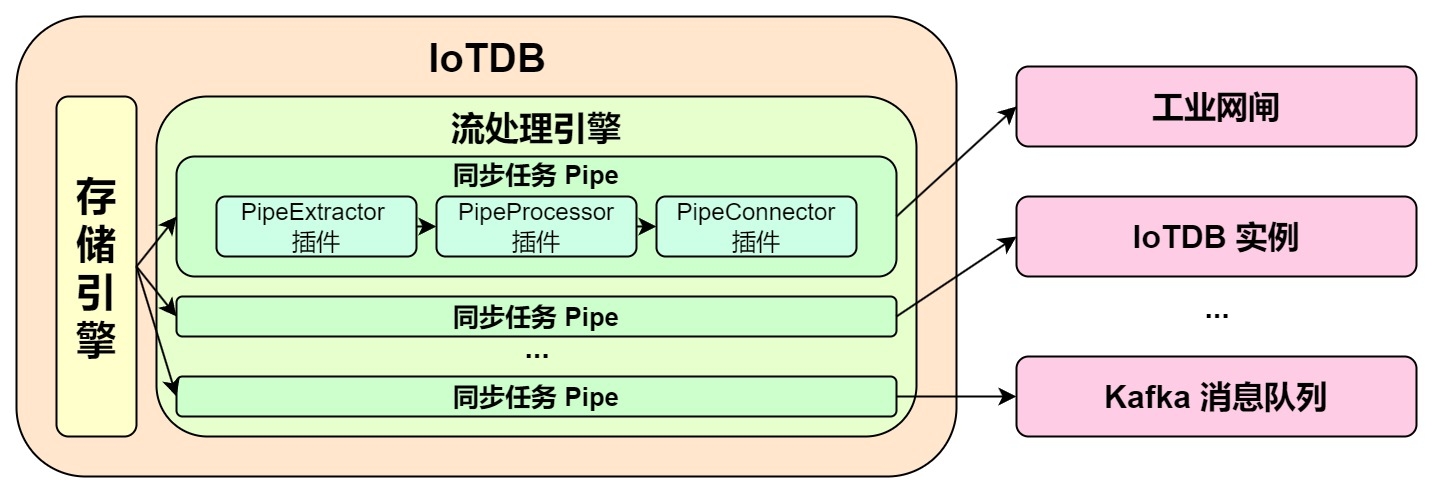
**The model of a Pipe task is as follows:**
-
+
It describes a data sync task, which essentially describes the attributes of the Pipe Extractor, Pipe Processor, and Pipe Connector plugins. Users can declaratively configure the specific attributes of the three subtasks through SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
diff --git a/src/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md b/src/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
index 81bd9f68..933c198f 100644
--- a/src/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
+++ b/src/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
@@ -32,7 +32,7 @@
**The model of a Pipe task is as follows:**
-
+
It describes a data sync task, which essentially describes the attributes of the Pipe Extractor, Pipe Processor, and Pipe Connector plugins. Users can declaratively configure the specific attributes of the three subtasks through SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
diff --git a/src/UserGuide/V1.2.x/User-Manual/Streaming.md b/src/UserGuide/V1.2.x/User-Manual/Streaming.md
index da694d24..553b4702 100644
--- a/src/UserGuide/V1.2.x/User-Manual/Streaming.md
+++ b/src/UserGuide/V1.2.x/User-Manual/Streaming.md
@@ -35,7 +35,7 @@ Pipe Extractor is used to extract data, Pipe Processor is used to process data,
**The model for a Pipe task is as follows:**
-
+
A data stream processing task essentially describes the attributes of the Pipe Extractor, Pipe Processor, and Pipe Connector plugins.
Users can configure the specific attributes of these three subtasks declaratively using SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
diff --git a/src/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md b/src/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
index 61cd393b..06748a40 100644
--- a/src/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
+++ b/src/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
@@ -35,7 +35,8 @@ Pipe Extractor is used to extract data, Pipe Processor is used to process data,
**The model for a Pipe task is as follows:**
-
+
+
A data stream processing task essentially describes the attributes of the Pipe Extractor, Pipe Processor, and Pipe Connector plugins.
Users can configure the specific attributes of these three subtasks declaratively using SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
diff --git a/src/UserGuide/V1.3.x/User-Manual/Data-Sync_timecho.md b/src/UserGuide/V1.3.x/User-Manual/Data-Sync_timecho.md
index c53b3763..52275550 100644
--- a/src/UserGuide/V1.3.x/User-Manual/Data-Sync_timecho.md
+++ b/src/UserGuide/V1.3.x/User-Manual/Data-Sync_timecho.md
@@ -162,7 +162,7 @@ IoTDB> show pipeplugins
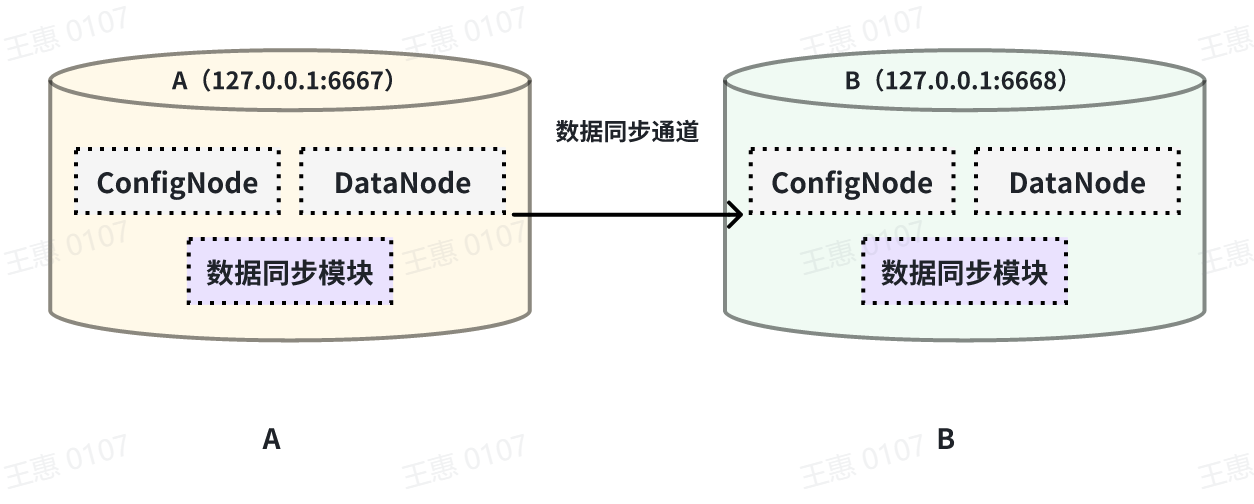
This example is used to demonstrate the synchronisation of all data from one IoTDB to another IoTDB with the data link as shown below:
-
+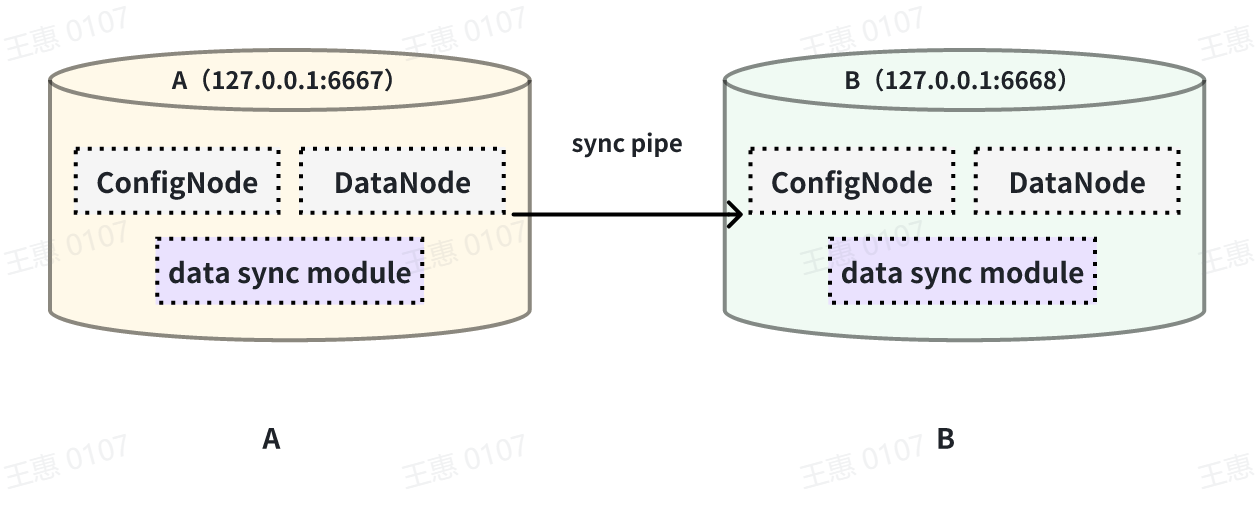
In this example, we can create a synchronisation task named A2B to synchronise the full amount of data from IoTDB A to IoTDB B. Here we need to use the iotdb-thrift-sink plugin (built-in plugin) which uses sink, and we need to specify the address of the receiving end, in this example, we have specified 'sink.ip' and 'sink.port', and we can also specify 'sink.port'. This example specifies 'sink.ip' and 'sink.port', and also 'sink.node-urls', as in the following example statement:
@@ -180,7 +180,7 @@ with sink (
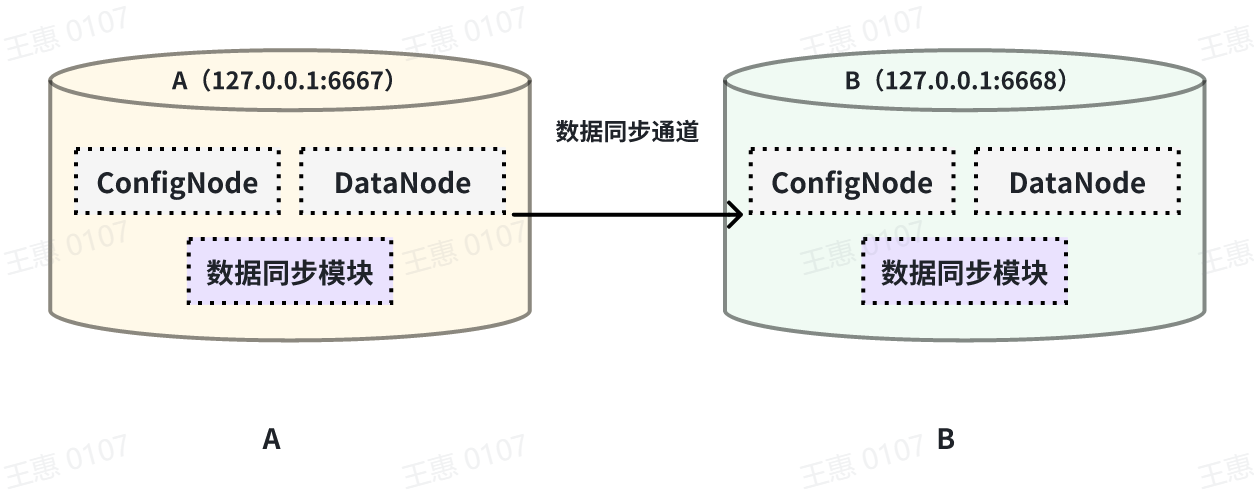
This example is used to demonstrate the synchronisation of data from a certain historical time range (8:00pm 23 August 2023 to 8:00pm 23 October 2023) to another IoTDB, the data link is shown below:
-
+
In this example we can create a synchronisation task called A2B. First of all, we need to define the range of data to be transferred in source, since the data to be transferred is historical data (historical data refers to the data that existed before the creation of the synchronisation task), we need to configure the source.realtime.enable parameter to false; at the same time, we need to configure the start-time and end-time of the data and the mode mode of the transfer. At the same time, you need to configure the start-time and end-time of the data and the mode mode of transmission, and it is recommended that the mode be set to hybrid mode (hybrid mode is a mixed transmission mode, which adopts the real-time transmission mode when there is no backlog of data, and adopts the batch transmission mode when there is a backlog of data, and automatically switches according to the internal situation of the system).
@@ -205,7 +205,7 @@ with SINK (
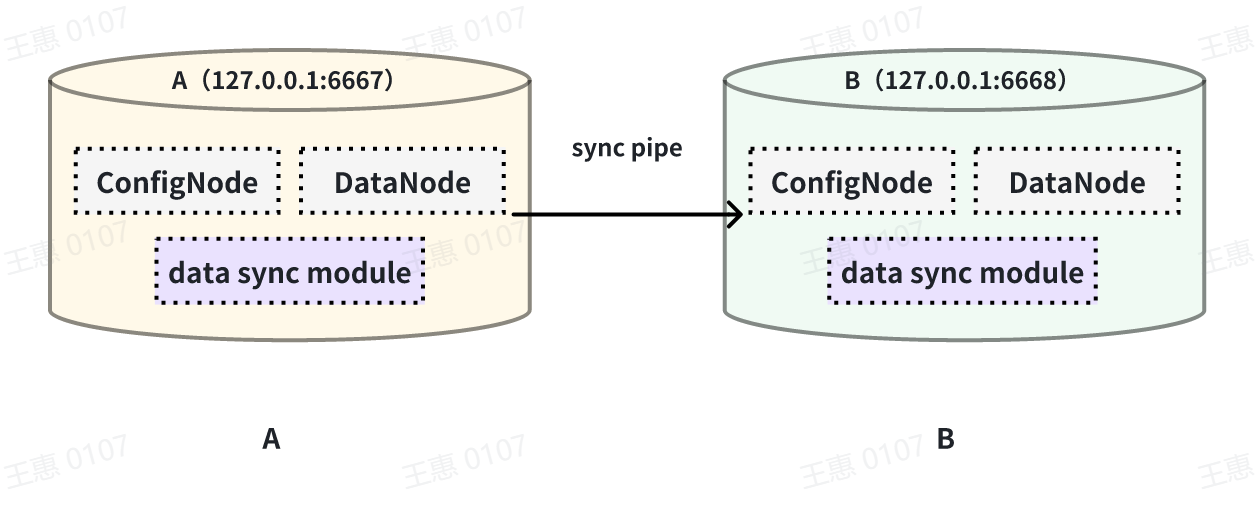
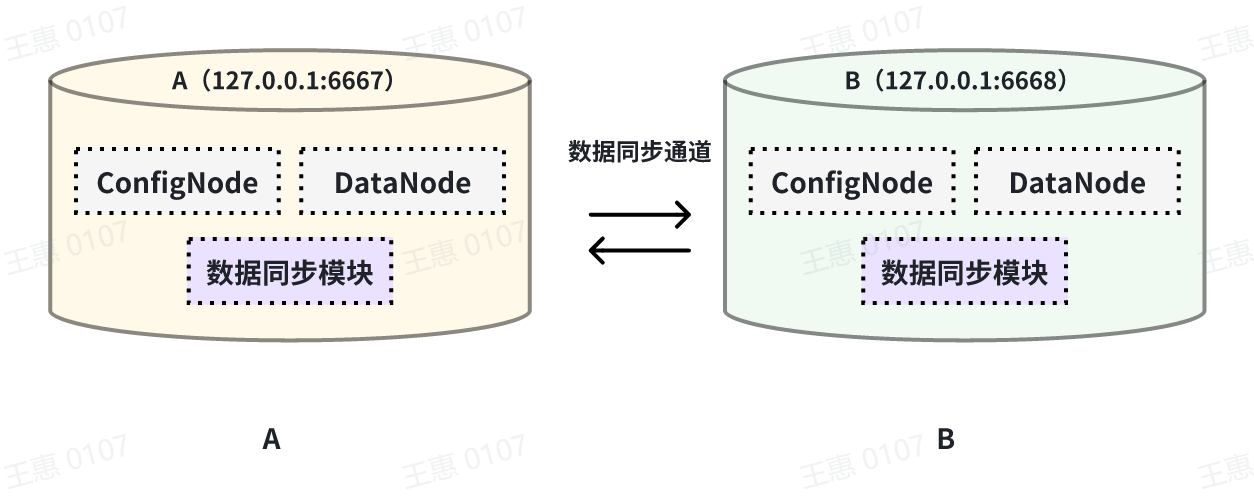
This example is used to demonstrate a scenario where two IoTDBs are dual-active with each other, with the data link shown below:
-
+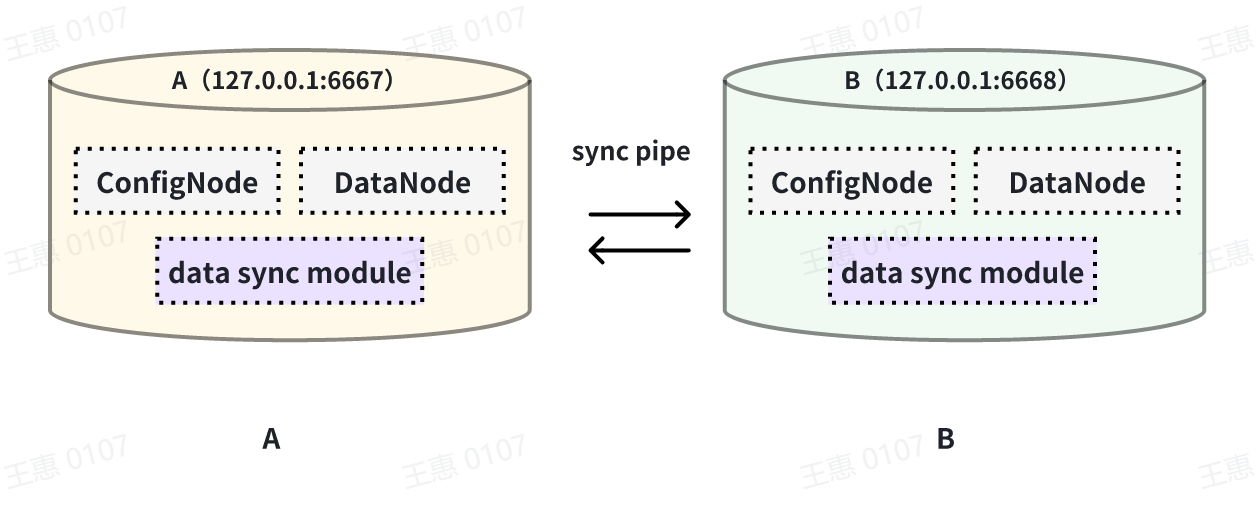
In this example, in order to avoid an infinite loop of data, the parameter `'source.forwarding-pipe-requests` needs to be set to ``false`` on both A and B to indicate that the data transferred from the other pipe will not be forwarded. Also set `'source.history.enable'` to `false` to indicate that historical data is not transferred, i.e., data prior to the creation of the task is not synchronised.
@@ -245,7 +245,7 @@ with sink (
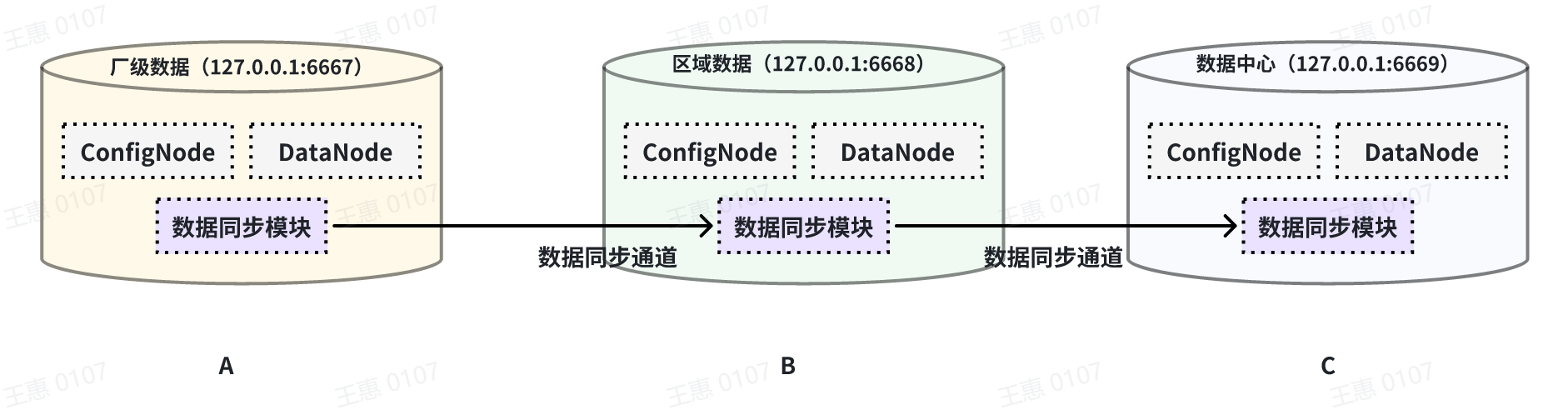
This example is used to demonstrate a cascading data transfer scenario between multiple IoTDBs, where data is synchronised from cluster A to cluster B and then to cluster C. The data link is shown in the figure below:
-
+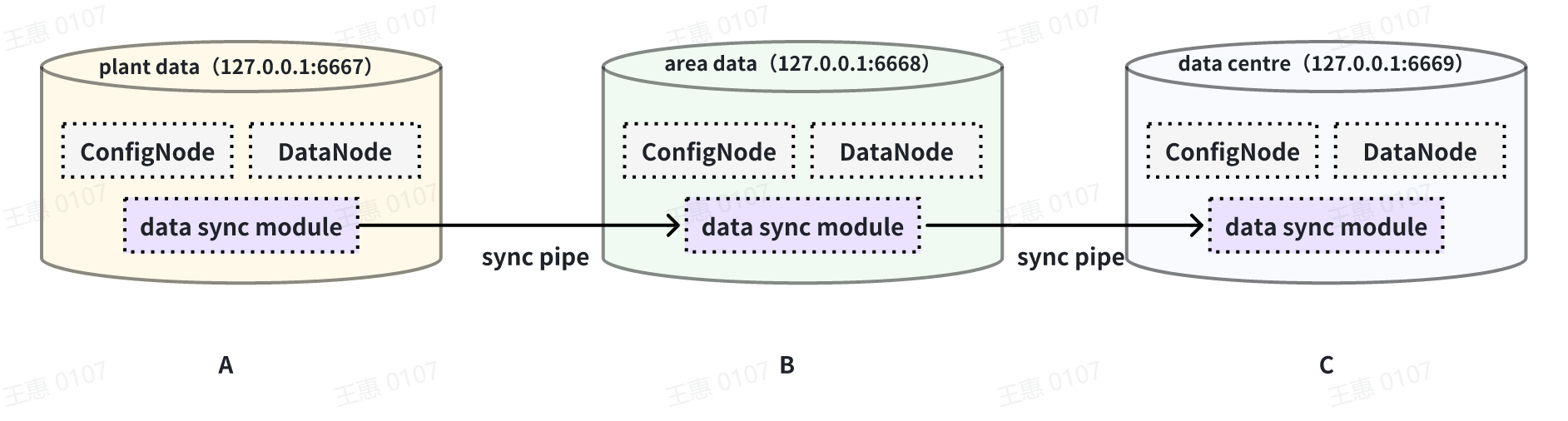
In this example, in order to synchronise the data from cluster A to C, the pipe between BC needs to be configured with `source.forwarding-pipe-requests` to `true`, the detailed statement is as follows:
@@ -277,7 +277,7 @@ with sink (
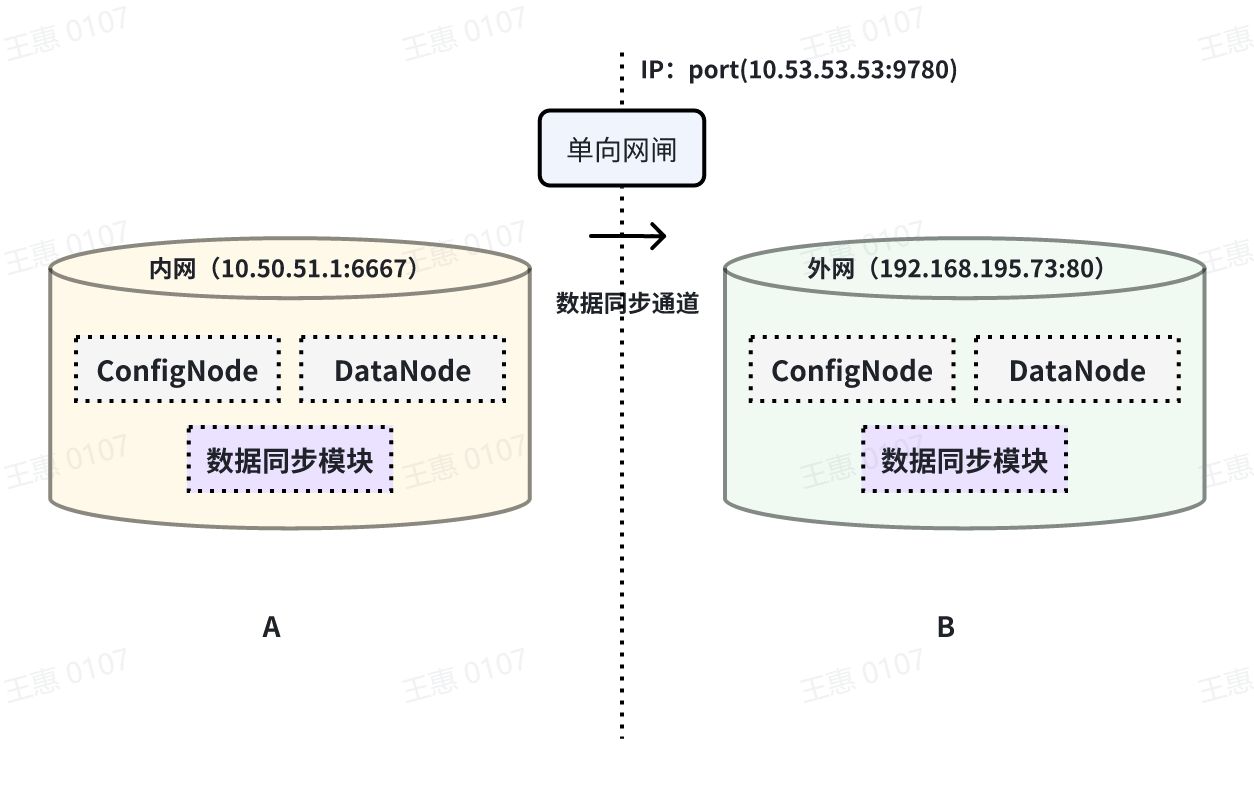
This example is used to demonstrate a scenario where data from one IoTDB is synchronised to another IoTDB via a unidirectional gate, with the data link shown below:
-
+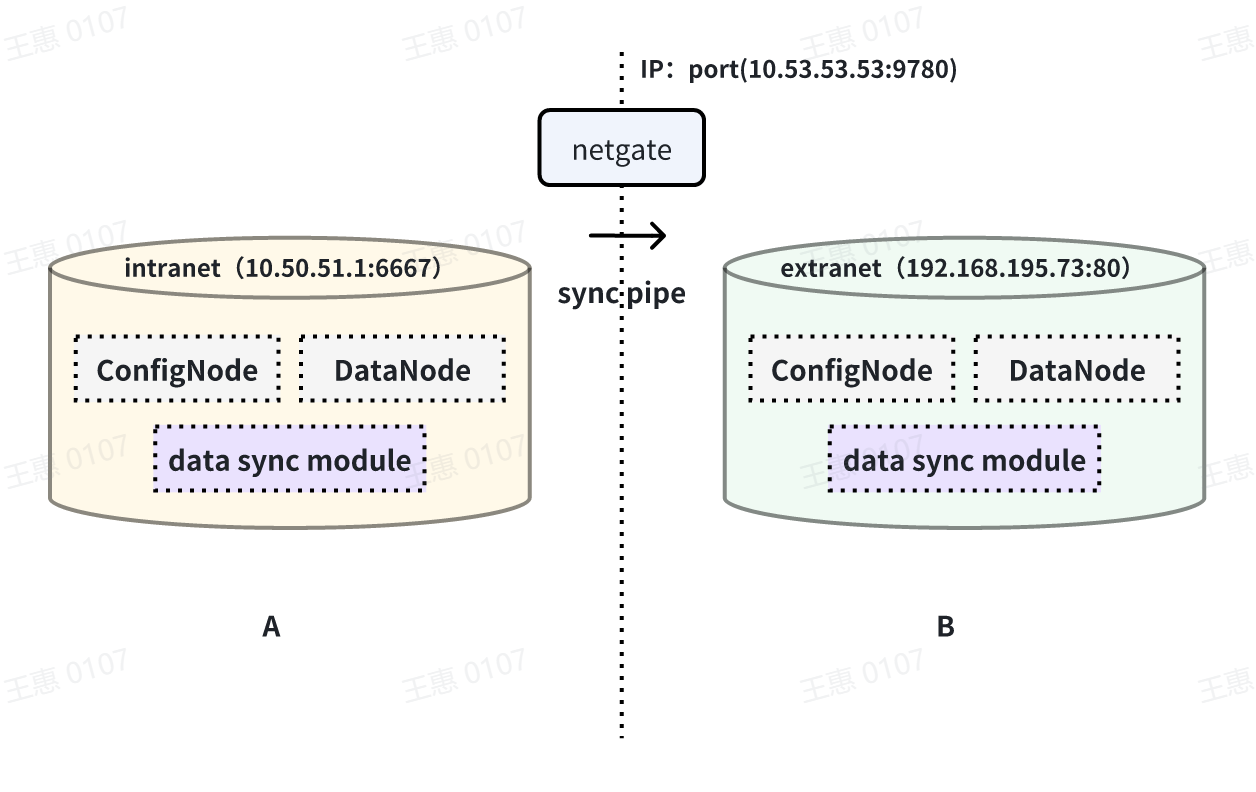
In this example, you need to use the iotdb-air-gap-sink plug-in in the sink task (currently supports some models of network gates, please contact the staff of Tianmou Technology to confirm the specific model), and after configuring the network gate, execute the following statements on IoTDB A, where ip and port fill in the information of the network gate, and the detailed statements are as follows:
diff --git a/src/UserGuide/V1.3.x/User-Manual/Streaming.md b/src/UserGuide/V1.3.x/User-Manual/Streaming.md
index da694d24..553b4702 100644
--- a/src/UserGuide/V1.3.x/User-Manual/Streaming.md
+++ b/src/UserGuide/V1.3.x/User-Manual/Streaming.md
@@ -35,7 +35,7 @@ Pipe Extractor is used to extract data, Pipe Processor is used to process data,
**The model for a Pipe task is as follows:**
-
+
A data stream processing task essentially describes the attributes of the Pipe Extractor, Pipe Processor, and Pipe Connector plugins.
Users can configure the specific attributes of these three subtasks declaratively using SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
diff --git a/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md b/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md
index 6005077e..709bfae8 100644
--- a/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md
+++ b/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md
@@ -35,7 +35,7 @@ Pipe Extractor is used to extract data, Pipe Processor is used to process data,
**The model of the Pipe task is as follows:**
-
+
Describing a data flow processing task essentially describes the properties of Pipe Extractor, Pipe Processor and Pipe Connector plugins.
Users can declaratively configure the specific attributes of the three subtasks through SQL statements, and achieve flexible data ETL capabilities by combining different attributes.
@@ -614,14 +614,12 @@ WITH CONNECTOR (
**When creating a stream processing task, you need to configure the PipeId and the parameters of the three plugin parts:**
-
-| Configuration item | Description | Required or not | Default implementation | Default implementation description | Whether custom implementation is allowed |
-| --------- | --------------------------------------------------- | --------------------------- | -------------------- | -------------------------------------------------------- | ------------------------- |
-| PipeId | A globally unique name that identifies a stream processing task | Required | - | - | - |
-| extractor | Pipe Extractor plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-extractor | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
-| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Optional | do-nothing-processor | | processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
- | 是 |
-| connector | Pipe Connector plugin, responsible for sending data | Required | - | - | 是 |
+| Configuration | Description | Required or not | Default implementation | Default implementation description | Default implementation description |
+| ------------- | ------------------------------------------------------------ | ------------------------------- | ---------------------- | ------------------------------------------------------------ | ---------------------------------- |
+| PipeId | A globally unique name that identifies a stream processing | Required | - | - | - |
+| extractor | Pipe Extractor plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-extractor | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
+| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
+| connector | Pipe Connector plugin, responsible for sending data | Required | - | - | Yes |
In the example, the iotdb-extractor, do-nothing-processor and iotdb-thrift-connector plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, **please check the "System Preset Stream Processing plugin" section**.