toTabletInsertionEvents();
+}
+```
+
+### Custom stream processing plugin programming interface definition
+
+Based on the custom stream processing plugin programming interface, users can easily write data extraction plugins, data processing plugins and data sending plugins, so that the stream processing function can be flexibly adapted to various industrial scenarios.
+
+#### Data extraction plugin interface
+
+Data extraction is the first stage of the three stages of stream processing data from data extraction to data sending. The data extraction plugin (PipeExtractor) is the bridge between the stream processing engine and the storage engine. It monitors the behavior of the storage engine,
+Capture various data write events.
+
+```java
+/**
+ * PipeExtractor
+ *
+ * PipeExtractor is responsible for capturing events from sources.
+ *
+ *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
+ *
The lifecycle of a PipeExtractor is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
+ * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeExtractor.
+ *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
+ *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
+ * be called to capture events from sources and then the events will be passed to the
+ * PipeProcessor.
+ *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ * cancelled (the `DROP PIPE` command is executed).
+ *
+ */
+public interface PipeExtractor extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeExtractor. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeExtractor#validate(PipeParameterValidator)} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeExtractor
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * Start the extractor. After this method is called, events should be ready to be supplied by
+ * {@link PipeExtractor#supply()}. This method is called after {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ *
+ * @throws Exception the user can throw errors if necessary
+ */
+ void start() throws Exception;
+
+ /**
+ * Supply single event from the extractor and the caller will send the event to the processor.
+ * This method is called after {@link PipeExtractor#start()} is called.
+ *
+ * @return the event to be supplied. the event may be null if the extractor has no more events at
+ * the moment, but the extractor is still running for more events.
+ * @throws Exception the user can throw errors if necessary
+ */
+ Event supply() throws Exception;
+}
+```
+
+#### Data processing plugin interface
+
+Data processing is the second stage of the three stages of stream processing data from data extraction to data sending. The data processing plugin (PipeProcessor) is mainly used to filter and transform the data captured by the data extraction plugin (PipeExtractor).
+various events.
+
+```java
+/**
+ * PipeProcessor
+ *
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
+ *
The lifecycle of a PipeProcessor is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH PROCESSOR` clause in SQL are
+ * parsed and the validation method {@link PipeProcessor#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeProcessor.
+ *
- While the collaboration task is in progress:
+ *
+ * - PipeExtractor captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ * following 3 methods will be called: {@link
+ * PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
+ * PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
+ * PipeProcessor#process(Event, EventCollector)}.
+ *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
+ * - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
+ * PipeProcessor#close() } method will be called.
+ *
+ */
+public interface PipeProcessor extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeProcessor. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeProcessorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeProcessor#validate(PipeParameterValidator)} is called and before the beginning of the
+ * events processing.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeProcessor
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeProcessorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is called to process the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ void process(TabletInsertionEvent tabletInsertionEvent, EventCollector eventCollector)
+ throws Exception;
+
+ /**
+ * This method is called to process the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void process(TsFileInsertionEvent tsFileInsertionEvent, EventCollector eventCollector)
+ throws Exception {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ process(tabletInsertionEvent, eventCollector);
+ }
+ }
+
+ /**
+ * This method is called to process the Event.
+ *
+ * @param event Event to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ void process(Event event, EventCollector eventCollector) throws Exception;
+}
+```
+
+#### Data sending plugin interface
+
+Data sending is the third stage of the three stages of stream processing data from data extraction to data sending. The data sending plugin (PipeConnector) is mainly used to send data processed by the data processing plugin (PipeProcessor).
+Various events, it serves as the network implementation layer of the stream processing framework, and the interface should allow access to multiple real-time communication protocols and multiple connectors.
+
+```java
+/**
+ * PipeConnector
+ *
+ *
PipeConnector is responsible for sending events to sinks.
+ *
+ *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
+ *
The lifecycle of a PipeConnector is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
+ * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeConnector and the method {@link
+ * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- While the collaboration task is in progress:
+ *
+ * - PipeExtractor captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeConnector.
+ *
- PipeConnector serializes the events into binaries and send them to sinks. The
+ * following 3 methods will be called: {@link
+ * PipeConnector#transfer(TabletInsertionEvent)}, {@link
+ * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
+ * PipeConnector#transfer(Event)}.
+ *
+ * - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
+ * PipeConnector#close() } method will be called.
+ *
+ *
+ * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
+ * will be called to create a new connection with the sink when the method {@link
+ * PipeConnector#heartbeat()} throws exceptions.
+ */
+public interface PipeConnector extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeConnector. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
+ * PipeConnector#handshake()} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeConnector
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is used to create a connection with sink. This method will be called after the
+ * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
+ * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
+ *
+ * @throws Exception if the connection is failed to be created
+ */
+ void handshake() throws Exception;
+
+ /**
+ * This method will be called periodically to check whether the connection with sink is still
+ * alive.
+ *
+ * @throws Exception if the connection dies
+ */
+ void heartbeat() throws Exception;
+
+ /**
+ * This method is used to transfer the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
+
+ /**
+ * This method is used to transfer the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ }
+
+ /**
+ * This method is used to transfer the Event.
+ *
+ * @param event Event to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(Event event) throws Exception;
+}
+```
+
+## Custom stream processing plugin management
+
+In order to ensure the flexibility and ease of use of user-defined plugins in actual production, the system also needs to provide the ability to dynamically and uniformly manage plugins.
+The stream processing plugin management statements introduced in this chapter provide an entry point for dynamic unified management of plugins.
+
+### Load plugin statement
+
+In IoTDB, if you want to dynamically load a user-defined plugin in the system, you first need to implement a specific plugin class based on PipeExtractor, PipeProcessor or PipeConnector.
+Then the plugin class needs to be compiled and packaged into a jar executable file, and finally the plugin is loaded into IoTDB using the management statement for loading the plugin.
+
+The syntax of the management statement for loading the plugin is shown in the figure.
+
+```sql
+CREATE PIPEPLUGIN
+AS
+USING
+```
+
+For example, the user has implemented a data processing plugin with the full class name edu.tsinghua.iotdb.pipe.ExampleProcessor.
+The packaged jar resource package is stored at https://example.com:8080/iotdb/pipe-plugin.jar. The user wants to use this plugin in the stream processing engine.
+Mark the plugin as example. Then, the creation statement of this data processing plugin is as shown in the figure.
+```sql
+CREATE PIPEPLUGIN example
+AS 'edu.tsinghua.iotdb.pipe.ExampleProcessor'
+USING URI ''
+```
+
+### Delete plugin statement
+
+When the user no longer wants to use a plugin and needs to uninstall the plugin from the system, he can use the delete plugin statement as shown in the figure.
+
+```sql
+DROP PIPEPLUGIN
+```
+
+### View plugin statements
+
+Users can also view plugins in the system on demand. View the statement of the plugin as shown in the figure.
+```sql
+SHOW PIPEPLUGINS
+```
+
+## System preset stream processing plugin
+
+### Preset extractor plugin
+
+####iotdb-extractor
+
+Function: Extract historical or real-time data inside IoTDB into pipe.
+
+
+| key | value | value range | required or not |default value|
+| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | -------- |------|
+| source | iotdb-source | String: iotdb-source | required | - |
+| source.pattern | Path prefix for filtering time series | String: any time series prefix | optional | root |
+| source.history.enable | Whether to synchronise history data | Boolean: true, false | optional | true |
+| source.history.start-time | Synchronise the start event time of historical data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MIN_VALUE |
+| source.history.end-time | end event time for synchronised history data, contains end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MAX_VALUE |
+| source.realtime.enable | Whether to synchronise real-time data | Boolean: true, false | optional | true |
+| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional | hybrid |
+| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional | true |
+
+> 🚫 **extractor.pattern 参数说明**
+>
+>* Pattern needs to use backticks to modify illegal characters or illegal path nodes. For example, if you want to filter root.\`a@b\` or root.\`123\`, you should set pattern to root.\`a@b \` or root.\`123\` (For details, please refer to [When to use single and double quotes and backticks](https://iotdb.apache.org/zh/Download/#_1-0-version incompatible syntax details illustrate))
+> * In the underlying implementation, when pattern is detected as root (default value), the extraction efficiency is higher, and any other format will reduce performance.
+> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
+ >
+ > * root.aligned.1TS
+> * root.aligned.1TS.\`1\`
+> * root.aligned.100T
+ >
+ > The data will be extracted;
+ >
+ > * root.aligned.\`1\`
+> * root.aligned.\`123\`
+ >
+ > The data will not be extracted.
+> * The data of root.\_\_system will not be extracted by pipe. Although users can include any prefix in extractor.pattern, including prefixes with (or overriding) root.\__system, the data under root.__system will always be ignored by pipe
+
+> ❗️**Start-time, end-time parameter description of extractor.history**
+>
+> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
+
+> ✅ **A piece of data from production to IoTDB contains two key concepts of time**
+>
+> * **event time:** The time when the data is actually produced (or the generation time assigned to the data by the data production system, which is the time item in the data point), also called event time.
+> * **arrival time:** The time when data arrives in the IoTDB system.
+>
+> What we often call out-of-order data refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
+
+> 💎 **iotdb-extractor’s work can be split into two stages**
+>
+> 1. Historical data extraction: all data with **arrival time** < **current system time** when creating pipe is called historical data
+> 2. Real-time data extraction: all **arrival time** >= data of **current system time** when creating pipe is called real-time data
+>
+> The historical data transmission phase and the real-time data transmission phase are executed serially. Only when the historical data transmission phase is completed, the real-time data transmission phase is executed. **
+>
+> Users can specify iotdb-extractor to:
+>
+> * Historical data extraction (`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
+> * Real-time data extraction (`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
+> * Full data extraction (`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
+> * Disable setting `extractor.history.enable` and `extractor.realtime.enable` to `false` at the same time
+>
+> 📌 **extractor.realtime.mode: Data extraction mode**
+>
+> * log: In this mode, the task only uses the operation log for data processing and sending
+> * file: In this mode, the task only uses data files for data processing and sending.
+> * hybrid: This mode takes into account the characteristics of low latency but low throughput when sending data one by one in the operation log, and the characteristics of high throughput but high latency when sending in batches of data files. It can automatically operate under different write loads. Switch the appropriate data extraction method. First, adopt the data extraction method based on operation logs to ensure low sending delay. When a data backlog occurs, it will automatically switch to the data extraction method based on data files to ensure high sending throughput. When the backlog is eliminated, it will automatically switch back to the data extraction method based on data files. The data extraction method of the operation log avoids the problem of difficulty in balancing data sending delay or throughput using a single data extraction algorithm.
+
+> 🍕 **extractor.forwarding-pipe-requests: Whether to allow forwarding data transmitted from another pipe**
+>
+> * If you want to use pipe to build data synchronization of A -> B -> C, then the pipe of B -> C needs to set this parameter to true, so that the data written by A to B through the pipe in A -> B can be forwarded correctly. to C
+> * If you want to use pipe to build two-way data synchronization (dual-active) of A \<-> B, then the pipes of A -> B and B -> A need to set this parameter to false, otherwise the data will be endless. inter-cluster round-robin forwarding
+
+### Preset processor plugin
+
+#### do-nothing-processor
+
+Function: No processing is done on the events passed in by the extractor.
+
+
+| key | value | value range | required or optional with default |
+| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| processor | do-nothing-processor | String: do-nothing-processor | required |
+
+### Preset connector plugin
+
+#### do-nothing-connector
+
+Function: No processing is done on the events passed in by the processor.
+
+| key | value | value range | required or optional with default |
+| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| connector | do-nothing-connector | String: do-nothing-connector | required |
+
+## Stream processing task management
+
+### Create a stream processing task
+
+Use the `CREATE PIPE` statement to create a stream processing task. Taking the creation of a data synchronization stream processing task as an example, the sample SQL statement is as follows:
+
+```sql
+CREATE PIPE -- PipeId is a name that uniquely identifies the stream processing task
+WITH EXTRACTOR (
+ --Default IoTDB data extraction plugin
+ 'extractor' = 'iotdb-extractor',
+ --Path prefix, only data that can match the path prefix will be extracted for subsequent processing and sending
+ 'extractor.pattern' = 'root.timecho',
+ -- Whether to extract historical data
+ 'extractor.history.enable' = 'true',
+ -- Describes the time range of the extracted historical data, indicating the earliest time
+ 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ -- Describes the time range of the extracted historical data, indicating the latest time
+ 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
+ -- Whether to extract real-time data
+ 'extractor.realtime.enable' = 'true',
+ --Describe the extraction method of real-time data
+ 'extractor.realtime.mode' = 'hybrid',
+)
+WITH PROCESSOR (
+ --The default data processing plugin, which does not do any processing
+ 'processor' = 'do-nothing-processor',
+)
+WITH CONNECTOR (
+ -- IoTDB data sending plugin, the target is IoTDB
+ 'connector' = 'iotdb-thrift-connector',
+ --The data service IP of one of the DataNode nodes in the target IoTDB
+ 'connector.ip' = '127.0.0.1',
+ -- The data service port of one of the DataNode nodes in the target IoTDB
+ 'connector.port' = '6667',
+)
+```
+
+**When creating a stream processing task, you need to configure the PipeId and the parameters of the three plugin parts:**
+
+
+| Configuration item | Description | Required or not | Default implementation | Default implementation description | Whether custom implementation is allowed |
+| --------- | --------------------------------------------------- | --------------------------- | -------------------- | -------------------------------------------------------- | ------------------------- |
+| PipeId | A globally unique name that identifies a stream processing task | Required | - | - | - |
+| extractor | Pipe Extractor plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-extractor | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
+| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Optional | do-nothing-processor | | processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
+ | 是 |
+| connector | Pipe Connector plugin, responsible for sending data | Required | - | - | 是 |
+
+In the example, the iotdb-extractor, do-nothing-processor and iotdb-thrift-connector plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, **please check the "System Preset Stream Processing plugin" section**.
+
+**A simplest example of the CREATE PIPE statement is as follows:**
+
+```sql
+CREATE PIPE -- PipeId is a name that uniquely identifies the stream processing task
+WITH CONNECTOR (
+ -- IoTDB data sending plugin, the target is IoTDB
+ 'connector' = 'iotdb-thrift-connector',
+ --The data service IP of one of the DataNode nodes in the target IoTDB
+ 'connector.ip' = '127.0.0.1',
+ -- The data service port of one of the DataNode nodes in the target IoTDB
+ 'connector.port' = '6667',
+)
+```
+
+The semantics expressed are: synchronize all historical data in this database instance and subsequent real-time data arriving to the IoTDB instance with the target 127.0.0.1:6667.
+
+**Notice:**
+
+- EXTRACTOR and PROCESSOR are optional configurations. If you do not fill in the configuration parameters, the system will use the corresponding default implementation.
+- CONNECTOR is a required configuration and needs to be configured declaratively in the CREATE PIPE statement
+- CONNECTOR has self-reuse capability. For different stream processing tasks, if their CONNECTORs have the same KV attributes (the keys corresponding to the values of all attributes are the same), then the system will only create one CONNECTOR instance in the end to realize the duplication of connection resources. use.
+
+ - For example, there are the following declarations of two stream processing tasks, pipe1 and pipe2:
+
+ ```sql
+ CREATE PIPE pipe1
+ WITH CONNECTOR (
+ 'connector' = 'iotdb-thrift-connector',
+ 'connector.thrift.host' = 'localhost',
+ 'connector.thrift.port' = '9999',
+ )
+
+ CREATE PIPE pipe2
+ WITH CONNECTOR (
+ 'connector' = 'iotdb-thrift-connector',
+ 'connector.thrift.port' = '9999',
+ 'connector.thrift.host' = 'localhost',
+ )
+ ```
+
+- Because their declarations of CONNECTOR are exactly the same (**even if the order of declaration of some attributes is different**), the framework will automatically reuse the CONNECTORs they declared, and ultimately the CONNECTORs of pipe1 and pipe2 will be the same instance. .
+- When the extractor is the default iotdb-extractor, and extractor.forwarding-pipe-requests is the default value true, please do not build an application scenario that includes data cycle synchronization (it will cause an infinite loop):
+
+ - IoTDB A -> IoTDB B -> IoTDB A
+ - IoTDB A -> IoTDB A
+
+### Start the stream processing task
+
+After the CREATE PIPE statement is successfully executed, the stream processing task-related instance will be created, but the running status of the entire stream processing task will be set to STOPPED, that is, the stream processing task will not process data immediately.
+
+You can use the START PIPE statement to cause a stream processing task to start processing data:
+
+```sql
+START PIPE
+```
+
+### Stop the stream processing task
+
+Use the STOP PIPE statement to stop the stream processing task from processing data:
+
+```sql
+STOP PIPE
+```
+
+### Delete stream processing tasks
+
+Use the DROP PIPE statement to stop the stream processing task from processing data (when the stream processing task status is RUNNING), and then delete the entire stream processing task:
+
+```sql
+DROP PIPE
+```
+
+Users do not need to perform a STOP operation before deleting the stream processing task.
+
+### Display stream processing tasks
+
+Use the SHOW PIPES statement to view all stream processing tasks:
+
+```sql
+SHOW PIPES
+```
+
+The query results are as follows:
+
+```sql
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+```
+
+You can use `` to specify the status of a stream processing task you want to see:
+
+```sql
+SHOW PIPE
+```
+
+You can also use the where clause to determine whether the Pipe Connector used by a certain \ is reused.
+
+```sql
+SHOW PIPES
+WHERE CONNECTOR USED BY
+```
+
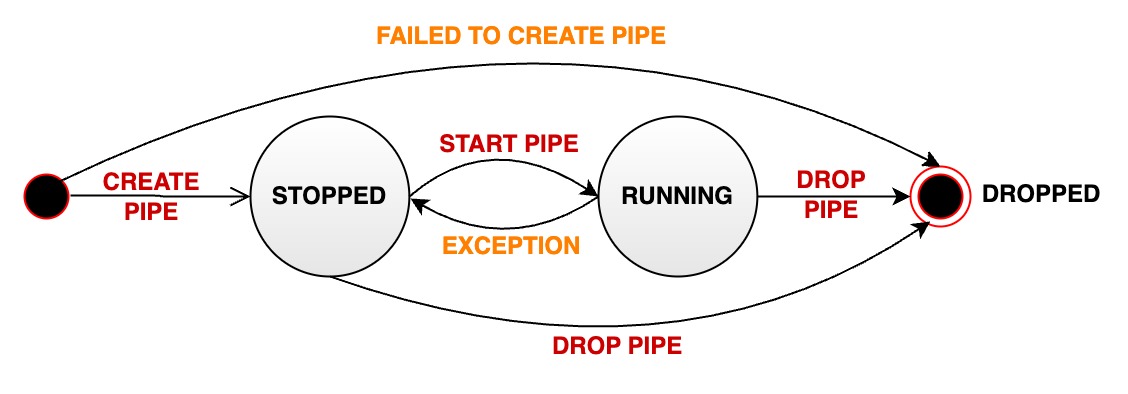
+### Stream processing task running status migration
+
+A stream processing pipe will pass through various states during its managed life cycle:
+
+- **STOPPED:** The pipe is stopped. When the pipeline is in this state, there are several possibilities:
+ - When a pipe is successfully created, its initial state is paused.
+ - The user manually pauses a pipe that is in normal running status, and its status will passively change from RUNNING to STOPPED.
+ - When an unrecoverable error occurs during the running of a pipe, its status will automatically change from RUNNING to STOPPED
+- **RUNNING:** pipe is working properly
+- **DROPPED:** The pipe task was permanently deleted
+
+The following diagram shows all states and state transitions:
+
+
+
+## authority management
+
+### Stream processing tasks
+
+
+| Permission name | Description |
+| ----------- | -------------------------- |
+| CREATE_PIPE | Register a stream processing task. The path is irrelevant. |
+| START_PIPE | Start the stream processing task. The path is irrelevant. |
+| STOP_PIPE | Stop the stream processing task. The path is irrelevant. |
+| DROP_PIPE | Offload stream processing tasks. The path is irrelevant. |
+| SHOW_PIPES | Query stream processing tasks. The path is irrelevant. |
+
+### Stream processing task plugin
+
+
+| Permission name | Description |
+| ------------------ | ---------------------------------- |
+| CREATE_PIPEPLUGIN | Register stream processing task plugin. The path is irrelevant. |
+| DROP_PIPEPLUGIN | Uninstall the stream processing task plugin. The path is irrelevant. |
+| SHOW_PIPEPLUGINS | Query stream processing task plugin. The path is irrelevant. |
+
+## Configuration parameters
+
+In iotdb-common.properties:
+
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_connector_timeout_ms=900000
+```
diff --git a/src/UserGuide/Master/User-Manual/Tiered-Storage_timecho.md b/src/UserGuide/Master/User-Manual/Tiered-Storage_timecho.md
index c5ac54a5..3fe5792f 100644
--- a/src/UserGuide/Master/User-Manual/Tiered-Storage_timecho.md
+++ b/src/UserGuide/Master/User-Manual/Tiered-Storage_timecho.md
@@ -19,6 +19,78 @@
-->
-# Tiered Storage
+# Tiered Storage
+## Overview
-TODO
\ No newline at end of file
+The Tiered storage functionality allows users to define multiple layers of storage, spanning across multiple types of storage media (Memory mapped directory, SSD, rotational hard discs or cloud storage). While memory and cloud storage is usually singular, the local file system storages can consist of multiple directories joined together into one tier. Meanwhile, users can classify data based on its hot or cold nature and store data of different categories in specified "tier". Currently, IoTDB supports the classification of hot and cold data through TTL (Time to live / age) of data. When the data in one tier does not meet the TTL rules defined in the current tier, the data will be automatically migrated to the next tier.
+
+## Parameter Definition
+
+To enable tiered storage in IoTDB, you need to configure the following aspects:
+
+1. configure the data catalogue and divide the data catalogue into different tiers
+2. configure the TTL of the data managed in each tier to distinguish between hot and cold data categories managed in different tiers.
+3. configure the minimum remaining storage space ratio for each tier so that when the storage space of the tier triggers the threshold, the data of the tier will be automatically migrated to the next tier (optional).
+
+The specific parameter definitions and their descriptions are as follows.
+
+| Configuration | Default | Description | Constraint |
+| ---------------------------------------- | ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| dn_data_dirs | None | specify different storage directories and divide the storage directories into tiers | Each level of storage uses a semicolon to separate, and commas to separate within a single level; cloud (OBJECT_STORAGE) configuration can only be used as the last level of storage and the first level can't be used as cloud storage; a cloud object at most; the remote storage directory is denoted by OBJECT_STORAGE |
+| default_ttl_in_ms | None | Define the maximum age of data for which each tier is responsible | Each level of storage is separated by a semicolon; the number of levels should match the number of levels defined by dn_data_dirs |
+| dn_default_space_move_thresholds | 0.15 | Define the minimum remaining space ratio for each tier data catalogue; when the remaining space is less than this ratio, the data will be automatically migrated to the next tier; when the remaining storage space of the last tier falls below this threshold, the system will be set to READ_ONLY | Each level of storage is separated by a semicolon; the number of levels should match the number of levels defined by dn_data_dirs |
+| object_storage_type | AWS_S3 | Cloud Storage Type | IoTDB currently only supports AWS S3 as a remote storage type, and this parameter can't be modified |
+| object_storage_bucket | None | Name of cloud storage bucket | Bucket definition in AWS S3; no need to configure if remote storage is not used |
+| object_storage_endpoiont | | endpoint of cloud storage | endpoint of AWS S3;If remote storage is not used, no configuration required |
+| object_storage_access_key | | Authentication information stored in the cloud: key | AWS S3 credential key;If remote storage is not used, no configuration required |
+| object_storage_access_secret | | Authentication information stored in the cloud: secret | AWS S3 credential secret;If remote storage is not used, no configuration required |
+| remote_tsfile_cache_dirs | data/datanode/data/cache | Cache directory stored locally in the cloud | If remote storage is not used, no configuration required |
+| remote_tsfile_cache_page_size_in_kb | 20480 |Block size of locally cached files stored in the cloud | If remote storage is not used, no configuration required |
+| remote_tsfile_cache_max_disk_usage_in_mb | 51200 | Maximum Disk Occupancy Size for Cloud Storage Local Cache | If remote storage is not used, no configuration required |
+
+## local tiered storag configuration example
+
+The following is an example of a local two-level storage configuration.
+
+```JavaScript
+//Required configuration items
+dn_data_dirs=/data1/data;/data2/data,/data3/data;
+default_ttl_in_ms=86400000;-1
+dn_default_space_move_thresholds=0.2;0.1
+```
+
+In this example, two levels of storage are configured, specifically:
+
+| **tier** | **data path** | **data range** | **threshold for minimum remaining disk space** |
+| -------- | -------------------------------------- | --------------- | ------------------------ |
+| tier 1 | path 1:/data1/data | data for last 1 day | 20% |
+| tier 2 | path 2:/data2/data path 2:/data3/data | data from 1 day ago | 10% |
+
+## remote tiered storag configuration example
+
+The following takes three-level storage as an example:
+
+```JavaScript
+//Required configuration items
+dn_data_dirs=/data1/data;/data2/data,/data3/data;OBJECT_STORAGE
+default_ttl_in_ms=86400000;864000000;-1
+dn_default_space_move_thresholds=0.2;0.15;0.1
+object_storage_name=AWS_S3
+object_storage_bucket=iotdb
+object_storage_endpoiont=
+object_storage_access_key=
+object_storage_access_secret=
+
+// Optional configuration items
+remote_tsfile_cache_dirs=data/datanode/data/cache
+remote_tsfile_cache_page_size_in_kb=20971520
+remote_tsfile_cache_max_disk_usage_in_mb=53687091200
+```
+
+In this example, a total of three levels of storage are configured, specifically:
+
+| **tier** | **data path** | **data range** | **threshold for minimum remaining disk space** |
+| -------- | -------------------------------------- | ---------------------------- | ------------------------ |
+| tier1 | path 1:/data1/data | data for last 1 day | 20% |
+| tier2 | path 1:/data2/data path 2:/data3/data | data from past 1 day to past 10 days | 15% |
+| tier3 | Remote AWS S3 Storage | data from 1 day ago | 10% |
diff --git a/src/UserGuide/V1.2.x/Ecosystem-Integration/Flink-SQL-IoTDB.md b/src/UserGuide/V1.2.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
index 147b119f..6888afa6 100644
--- a/src/UserGuide/V1.2.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
+++ b/src/UserGuide/V1.2.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
@@ -32,6 +32,8 @@ The flink-sql-iotdb-connector seamlessly connects Flink SQL or Flink Table with
We provide two ways to use the flink-sql-iotdb-connector. One is to reference it through Maven during project development, and the other is to use it in Flink's sql-client. We will introduce these two usage methods separately.
+> 📌 Note: flink version requires 1.17.0 and above.
+
### Maven
Simply add the following dependency to your project's pom file:
diff --git a/src/UserGuide/V1.3.x/Ecosystem-Integration/Flink-SQL-IoTDB.md b/src/UserGuide/V1.3.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
new file mode 100644
index 00000000..6888afa6
--- /dev/null
+++ b/src/UserGuide/V1.3.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
@@ -0,0 +1,527 @@
+# flink-sql-iotdb-connector
+
+The flink-sql-iotdb-connector seamlessly connects Flink SQL or Flink Table with IoTDB, enabling real-time read and write operations on IoTDB within Flink tasks. It can be applied to the following scenarios:
+
+1. Real-time data synchronization: Real-time synchronization of data from one database to another.
+2. Real-time data pipeline: Building real-time data processing pipelines to process and analyze data in databases.
+3. Real-time data analysis: Real-time analysis of data in databases, providing real-time business insights.
+4. Real-time applications: Real-time application of database data in real-time applications such as real-time reporting and real-time recommendations.
+5. Real-time monitoring: Real-time monitoring of database data, detecting anomalies and errors.
+
+## Read and Write Modes
+
+| Read Modes (Source) | Write Modes (Sink) |
+| ------------------------- | -------------------------- |
+| Bounded Scan, Lookup, CDC | Streaming Sink, Batch Sink |
+
+### Read Modes (Source)
+
+* **Bounded Scan:** Bounded scan is primarily implemented by specifying the `time series` and optional `upper and lower bounds of the query conditions` to query data, and the query result usually consists of multiple rows of data. This type of query cannot retrieve data that is updated after the query.
+
+* **Lookup:** The lookup query mode differs from the scan query mode. While bounded scan queries data within a time range, the `lookup` query mode only queries data at a precise time point, resulting in a single row of data. Additionally, only the right table of a `lookup join` can use the lookup query mode.
+
+* **CDC:** CDC is mainly used in Flink's ETL tasks. When data in IoTDB changes, Flink can detect it through our provided CDC connector, and we can forward the detected change data to other external data sources to achieve the purpose of ETL.
+
+### Write Modes (Sink)
+
+* **Streaming Sink:** Used in Flink's streaming mode, it synchronizes the insert, update, and delete records of the Dynamic Table in Flink to IoTDB in real-time.
+
+* **Batch Sink:** Used in Flink's batch mode, it writes the batch computation results from Flink to IoTDB in a single operation.
+
+## Usage
+
+We provide two ways to use the flink-sql-iotdb-connector. One is to reference it through Maven during project development, and the other is to use it in Flink's sql-client. We will introduce these two usage methods separately.
+
+> 📌 Note: flink version requires 1.17.0 and above.
+
+### Maven
+
+Simply add the following dependency to your project's pom file:
+
+```xml
+
+ org.apache.iotdb
+ flink-sql-iotdb-connector
+ ${iotdb.version}
+
+```
+
+### sql-client
+
+If you want to use the flink-sql-iotdb-connector in the sql-client, follow these steps to configure the environment:
+
+1. Download the flink-sql-iotdb-connector jar file with dependencies from the [official website](https://iotdb.apache.org/Download/).
+
+2. Copy the jar file to the `$FLINK_HOME/lib` directory.
+
+3. Start the Flink cluster.
+
+4. Start the sql-client.
+
+You can now use the flink-sql-iotdb-connector in the sql-client.
+
+## Table Structure Specification
+
+Regardless of the type of connector used, the following table structure specifications must be met:
+
+- For all tables using the `IoTDB connector`, the first column must be named `Time_` and have a data type of `BIGINT`.
+- All column names, except for the `Time_` column, must start with `root.`. Additionally, any node in the column name cannot be purely numeric. If there are purely numeric or other illegal characters in the column name, they must be enclosed in backticks. For example, the path `root.sg.d0.123` is an illegal path, but `root.sg.d0.`123`` is a valid path.
+- When querying data from IoTDB using either `pattern` or `sql`, the time series names in the query result must include all column names in Flink, except for `Time_`. If there is no corresponding column name in the query result, that column will be filled with null.
+- The supported data types in flink-sql-iotdb-connector are: `INT`, `BIGINT`, `FLOAT`, `DOUBLE`, `BOOLEAN`, `STRING`. The data type of each column in Flink Table must match the corresponding time series type in IoTDB, otherwise an error will occur and the Flink task will exit.
+
+The following examples illustrate the mapping between time series in IoTDB and columns in Flink Table.
+
+## Read Mode (Source)
+
+### Scan Table (Bounded)
+
+#### Parameters
+
+| Parameter | Required | Default | Type | Description |
+| ------------------------- | -------- | --------------- | ------ | ------------------------------------------------------------ |
+| nodeUrls | No | 127.0.0.1:6667 | String | Specifies the datanode addresses of IoTDB. If IoTDB is deployed in cluster mode, multiple addresses can be specified, separated by commas. |
+| user | No | root | String | IoTDB username |
+| password | No | root | String | IoTDB password |
+| scan.bounded.lower-bound | No | -1L | Long | Lower bound (inclusive) of the timestamp for bounded scan queries. Valid when the parameter is greater than `0`. |
+| scan.bounded.upper-bound | No | -1L | Long | Upper bound (inclusive) of the timestamp for bounded scan queries. Valid when the parameter is greater than `0`. |
+| sql | Yes | None | String | Query to be executed in IoTDB. |
+
+#### Example
+
+This example demonstrates how to read data from IoTDB using the `scan table` method in a Flink Table Job:
+
+Assume the data in IoTDB is as follows:
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.028s
+```
+
+```java
+import org.apache.flink.table.api.*;
+
+public class BoundedScanTest {
+ public static void main(String[] args) throws Exception {
+ // setup table environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+ // setup schema
+ Schema iotdbTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ // register table
+ TableDescriptor iotdbDescriptor =
+ TableDescriptor.forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("nodeUrls", "127.0.0.1:6667")
+ .option("sql", "select ** from root")
+ .build();
+ tableEnv.createTemporaryTable("iotdbTable", iotdbDescriptor);
+
+ // output table
+ tableEnv.from("iotdbTable").execute().print();
+ }
+}
+```
+After executing the above job, the output table in the Flink console is as follows:
+```text
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| op | Time_ | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| +I | 1 | 1.0833644 | 2.34874 | 1.2414109 |
+| +I | 2 | 4.929185 | 3.1885583 | 4.6980085 |
+| +I | 3 | 3.5206156 | 3.5600138 | 4.8080945 |
+| +I | 4 | 1.3449302 | 2.8781595 | 3.3195343 |
+| +I | 5 | 3.3079383 | 3.3840187 | 3.7278645 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+```
+
+### Lookup Point
+
+#### Parameters
+
+| Parameter | Required | Default | Type | Description |
+| ------------------------ | -------- | --------------- | ------- | --------------------------------------------------------------------------- |
+| nodeUrls | No | 127.0.0.1:6667 | String | Specifies the addresses of the IoTDB datanode. If IoTDB is deployed in cluster mode, multiple addresses can be specified, separated by commas. |
+| user | No | root | String | IoTDB username |
+| password | No | root | String | IoTDB password |
+| lookup.cache.max-rows | No | -1 | Integer | Maximum number of rows to cache for lookup queries. Effective when the parameter is greater than `0`. |
+| lookup.cache.ttl-sec | No | -1 | Integer | Time-to-live for cached data in lookup queries, in seconds. |
+| sql | Yes | None | String | SQL query to execute in IoTDB. |
+
+#### Example
+
+This example demonstrates how to perform a `lookup` query using the `device` table in IoTDB as a dimension table:
+
+* Use the `datagen connector` to generate two fields as the left table for `Lookup Join`. The first field is an incrementing field representing the timestamp. The second field is a random field representing a measurement time series.
+* Register a table using the `IoTDB connector` as the right table for `Lookup Join`.
+* Join the two tables together.
+
+The current data in IoTDB is as follows:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.028s
+```
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+public class LookupTest {
+ public static void main(String[] args) {
+ // Setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // Register left table
+ Schema dataGenTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("s0", DataTypes.INT())
+ .build();
+
+ TableDescriptor datagenDescriptor =
+ TableDescriptor.forConnector("datagen")
+ .schema(dataGenTableSchema)
+ .option("fields.Time_.kind", "sequence")
+ .option("fields.Time_.start", "1")
+ .option("fields.Time_.end", "5")
+ .option("fields.s0.min", "1")
+ .option("fields.s0.max", "1")
+ .build();
+ tableEnv.createTemporaryTable("leftTable", datagenDescriptor);
+
+ // Register right table
+ Schema iotdbTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+
+ TableDescriptor iotdbDescriptor =
+ TableDescriptor.forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("sql", "select ** from root")
+ .build();
+ tableEnv.createTemporaryTable("rightTable", iotdbDescriptor);
+
+ // Join
+ String sql =
+ "SELECT l.Time_, l.s0, r.`root.sg.d0.s0`, r.`root.sg.d1.s0`, r.`root.sg.d1.s1` "
+ + "FROM (SELECT *, PROCTIME() AS proc_time FROM leftTable) AS l "
+ + "JOIN rightTable FOR SYSTEM_TIME AS OF l.proc_time AS r "
+ + "ON l.Time_ = r.Time_";
+
+ // Output table
+ tableEnv.sqlQuery(sql).execute().print();
+ }
+}
+```
+
+After executing the above task, the output table in Flink's console is as follows:
+```text
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+| op | Time_ | s0 | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+| +I | 5 | 1 | 3.3079383 | 3.3840187 | 3.7278645 |
+| +I | 2 | 1 | 4.929185 | 3.1885583 | 4.6980085 |
+| +I | 1 | 1 | 1.0833644 | 2.34874 | 1.2414109 |
+| +I | 4 | 1 | 1.3449302 | 2.8781595 | 3.3195343 |
+| +I | 3 | 1 | 3.5206156 | 3.5600138 | 4.8080945 |
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+```
+### CDC
+
+#### Parameters
+
+| Parameter | Required | Default | Type | Description |
+| --------------- | -------- | --------------- | ------- | --------------------------------------------------------------------------- |
+| nodeUrls | No | 127.0.0.1:6667 | String | Specifies the datanode address of IoTDB. If IoTDB is deployed in cluster mode, multiple addresses can be specified, separated by commas. |
+| user | No | root | String | IoTDB username |
+| password | No | root | String | IoTDB password |
+| mode | Yes | BOUNDED | ENUM | **This parameter must be set to `CDC` in order to start** |
+| sql | Yes | None | String | SQL query to be executed in IoTDB |
+| cdc.port | No | 8080 | Integer | Port number for the CDC service in IoTDB |
+| cdc.task.name | Yes | None | String | Required when the mode parameter is set to CDC. Used to create a Pipe task in IoTDB. |
+| cdc.pattern | Yes | None | String | Required when the mode parameter is set to CDC. Used as a filtering condition for sending data in IoTDB. |
+
+#### Example
+
+This example demonstrates how to retrieve the changing data from a specific path in IoTDB using the `CDC Connector`:
+
+* Create a `CDC` table using the `CDC Connector`.
+* Print the `CDC` table.
+
+```java
+import org.apache.flink.table.api.*;
+
+public class CDCTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+ // setup schema
+ Schema iotdbTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+
+ // register table
+ TableDescriptor iotdbDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("mode", "CDC")
+ .option("cdc.task.name", "test")
+ .option("cdc.pattern", "root.sg")
+ .build();
+ tableEnv.createTemporaryTable("iotdbTable", iotdbDescriptor);
+
+ // output table
+ tableEnv.from("iotdbTable").execute().print();
+ }
+}
+```
+Run the above Flink CDC task and execute the following SQL in IoTDB-cli:
+```sql
+insert into root.sg.d1(timestamp,s0,s1) values(6,1.0,1.0);
+insert into root.sg.d1(timestamp,s0,s1) values(7,1.0,1.0);
+insert into root.sg.d1(timestamp,s0,s1) values(6,2.0,1.0);
+insert into root.sg.d0(timestamp,s0) values(7,2.0);
+```
+The console of Flink will print the following data:
+```text
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| op | Time_ | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| +I | 7 | | 1.0 | 1.0 |
+| +I | 6 | | 1.0 | 1.0 |
+| +I | 6 | | 2.0 | 1.0 |
+| +I | 7 | 2.0 | | |
+```
+## Write Mode (Sink)
+
+### Streaming Sink
+
+#### Parameters
+
+| Parameter | Required | Default | Type | Description |
+| ----------| -------- | --------------- | ------- | --------------------------------------------------------------------------- |
+| nodeUrls | No | 127.0.0.1:6667 | String | Specifies the datanode address of IoTDB. If IoTDB is deployed in cluster mode, multiple addresses can be specified, separated by commas. |
+| user | No | root | String | IoTDB username |
+| password | No | root | String | IoTDB password |
+| aligned | No | false | Boolean | Whether to call the `aligned` interface when writing data to IoTDB. |
+
+#### Example
+
+This example demonstrates how to write data to IoTDB in a Flink Table Streaming Job:
+
+* Generate a source data table using the `datagen connector`.
+* Register an output table using the `IoTDB connector`.
+* Insert data from the source table into the output table.
+
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+public class StreamingSinkTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // create data source table
+ Schema dataGenTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor descriptor = TableDescriptor
+ .forConnector("datagen")
+ .schema(dataGenTableSchema)
+ .option("rows-per-second", "1")
+ .option("fields.Time_.kind", "sequence")
+ .option("fields.Time_.start", "1")
+ .option("fields.Time_.end", "5")
+ .option("fields.root.sg.d0.s0.min", "1")
+ .option("fields.root.sg.d0.s0.max", "5")
+ .option("fields.root.sg.d1.s0.min", "1")
+ .option("fields.root.sg.d1.s0.max", "5")
+ .option("fields.root.sg.d1.s1.min", "1")
+ .option("fields.root.sg.d1.s1.max", "5")
+ .build();
+ // register source table
+ tableEnv.createTemporaryTable("dataGenTable", descriptor);
+ Table dataGenTable = tableEnv.from("dataGenTable");
+
+ // create iotdb sink table
+ TableDescriptor iotdbDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(dataGenTableSchema)
+ .build();
+ tableEnv.createTemporaryTable("iotdbSinkTable", iotdbDescriptor);
+
+ // insert data
+ dataGenTable.executeInsert("iotdbSinkTable").print();
+ }
+}
+```
+
+After the above job is executed, the query result in the IoTDB CLI is as follows:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.054s
+```
+### Batch Sink
+
+#### Parameters
+
+| Parameter | Required | Default | Type | Description |
+| --------- | -------- | --------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | No | 127.0.0.1:6667 | String | Specifies the addresses of datanodes in IoTDB. If IoTDB is deployed in cluster mode, multiple addresses can be specified, separated by commas. |
+| user | No | root | String | IoTDB username |
+| password | No | root | String | IoTDB password |
+| aligned | No | false | Boolean | Whether to call the `aligned` interface when writing data to IoTDB. |
+
+#### Example
+
+This example demonstrates how to write data to IoTDB in a Batch Job of a Flink Table:
+
+* Generate a source table using the `IoTDB connector`.
+* Register an output table using the `IoTDB connector`.
+* Write the renamed columns from the source table back to IoTDB.
+
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+import static org.apache.flink.table.api.Expressions.$;
+
+public class BatchSinkTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inBatchMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // create source table
+ Schema sourceTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor sourceTableDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(sourceTableSchema)
+ .option("sql", "select ** from root.sg.d0,root.sg.d1")
+ .build();
+
+ tableEnv.createTemporaryTable("sourceTable", sourceTableDescriptor);
+ Table sourceTable = tableEnv.from("sourceTable");
+ // register sink table
+ Schema sinkTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d2.s0", DataTypes.FLOAT())
+ .column("root.sg.d3.s0", DataTypes.FLOAT())
+ .column("root.sg.d3.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor sinkTableDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(sinkTableSchema)
+ .build();
+ tableEnv.createTemporaryTable("sinkTable", sinkTableDescriptor);
+
+ // insert data
+ sourceTable.renameColumns(
+ $("root.sg.d0.s0").as("root.sg.d2.s0"),
+ $("root.sg.d1.s0").as("root.sg.d3.s0"),
+ $("root.sg.d1.s1").as("root.sg.d3.s1")
+ ).insertInto("sinkTable").execute().print();
+ }
+}
+```
+
+After the above task is executed, the query result in the IoTDB cli is as follows:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|root.sg.d2.s0|root.sg.d3.s0|root.sg.d3.s1|
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.015s
+```
diff --git a/src/UserGuide/V1.3.x/User-Manual/Data-Sync_timecho.md b/src/UserGuide/V1.3.x/User-Manual/Data-Sync_timecho.md
new file mode 100644
index 00000000..c53b3763
--- /dev/null
+++ b/src/UserGuide/V1.3.x/User-Manual/Data-Sync_timecho.md
@@ -0,0 +1,387 @@
+
+
+# Data synchronisation
+Data synchronisation is a typical requirement of industrial IoT. Through the data synchronisation mechanism, data sharing between IoTDBs can be achieved, and a complete data link can be built to meet the needs of intranet and extranet data interoperability, end-to-end cloud synchronisation, data migration, data backup, and so on.
+
+## Introduction
+
+### Synchronisation Task Overview
+
+A data synchronisation task consists of 2 phases:
+
+- Source phase: This part is used to extract data from the source IoTDB, which is defined in the source part of the SQL statement.
+- Sink phase: This part is used to send data to the target IoTDB and is defined in the sink part of the SQL statement.
+
+
+
+Flexible data synchronisation capabilities can be achieved by declaratively configuring the specifics of the 2 sections through SQL statements.
+
+### Synchronisation Task - Create
+
+Use the `CREATE PIPE` statement to create a data synchronisation task, the following attributes `PipeId` and `sink` are mandatory, `source` and `processor` are optional, when entering the SQL note that the order of the `SOURCE ` and `SINK` plugins are not interchangeable.
+
+The SQL example is as follows:
+
+```SQL
+CREATE PIPE -- PipeId is the name that uniquely identifies the task.
+-- Data Extraction Plugin, Required Plugin
+WITH SOURCE (
+ [ = ,], [,]
+-- Data connection plugin, required
+WITH SINK (
+ [ = ,], -- data connection plugin, required.
+)
+```
+> 📌 Note: To use the data synchronisation feature, make sure that automatic metadata creation is enabled on the receiving side
+
+
+
+### Synchronisation Tasks - Management
+
+The Data Synchronisation task has three states; RUNNING, STOPPED and DROPPED.The task state transitions are shown below:
+
+
+
+A data synchronisation task passes through multiple states during its lifecycle:
+
+- RUNNING: Running state.
+- STOPPED: Stopped state.
+ - Explanation 1: The initial state of the task is the stopped state, and you need to use SQL statements to start the task.
+ - Description 2: You can also manually stop a running task with a SQL statement, and the state will change from RUNNING to STOPPED.
+ - Description 3: When a task has an unrecoverable error, its status will automatically change from RUNNING to STOPPED.
+- DROPPED: deleted state.
+
+We provide the following SQL statements to manage the status of synchronisation tasks.
+
+#### Starting a Task
+
+After creation, the task will not be processed immediately, you need to start the task. Use the `START PIPE` statement to start the task so that it can begin processing data:
+
+```Go
+START PIPE
+```
+
+#### Stop the task
+
+Stop processing data:
+
+``` Go
+STOP PIPE
+```
+
+#### Delete a task
+
+Deletes the specified task:
+
+``` Go
+DROP PIPE
+```
+Deleting a task does not require you to stop synchronising the task first.
+#### Viewing Tasks
+
+View all tasks:
+
+```Go
+SHOW PIPES
+```
+
+To view a specified task:
+
+```Go
+SHOW PIPE .
+```
+
+### Plugin
+
+In order to make the overall architecture more flexible to match different synchronisation scenarios, IoTDB supports plug-in assembly in the above synchronisation task framework. Some common plug-ins are pre-built for you to use directly, and you can also customise sink plug-ins and load them into the IoTDB system for use.
+
+| Modules | Plug-ins | Pre-configured Plug-ins | Customised Plug-ins |
+| ------- | -------- | ----------------------- | ------------------- |
+| Extract (Source) | Source Plugin | iotdb-source | Not Supported |
+| Send (Sink) | Sink plugin | iotdb-thrift-sink, iotdb-air-gap-sink | Support |
+
+#### Preconfigured Plugins
+
+The preset plug-ins are listed below:
+
+| Plugin Name | Type | Introduction | Available Versions |
+| ---------------------------- | ---- | ------------------------------------------------------------ | --------- |
+| iotdb-source | source plugin | Default source plugin for extracting IoTDB historical or real-time data | 1.2.x | iotdb-thrill | iotdb-thrill | iotdb-thrill | iotdb-thrill
+| | iotdb-thrift-sink | sink plugin | Used for data transfer between IoTDB (v1.2.0 and above) and IoTDB (v1.2.0 and above). Uses the Thrift RPC framework to transfer data, multi-threaded async non-blocking IO model, high transfer performance, especially for scenarios where the target is distributed | 1.2.x | iotdb-air | iotdb-air | iotdb-air | iotdb-air | iotdb-air
+| iotdb-air-gap-sink | sink plug-in | Used for data synchronisation from IoTDB (v1.2.2+) to IoTDB (v1.2.2+) across unidirectional data gates. Supported gate models include Nanrui Syskeeper 2000, etc. | 1.2.1+ |
+
+Detailed parameters for each plug-in can be found in the [Parameter Description](#sink-parameters) section of this document.
+
+#### View Plug-ins
+
+To view the plug-ins in the system (including custom and built-in plug-ins) you can use the following statement:
+
+```Go
+SHOW PIPEPLUGINS
+```
+
+The following results are returned:
+
+```Go
+IoTDB> show pipeplugins
++--------------------+----------+---------------------------------------------------------------------------+---------+
+| PluginName|PluginType| ClassName|PluginJar|
++--------------------+----------+---------------------------------------------------------------------------+---------+
+|DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.DoNothingProcessor| |
+| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.DoNothingSink| |
+| IOTDB-AIR-GAP-SINK| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBAirGapSink| |
+| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.source.IoTDBSOURCE| |
+| IOTDB-THRIFT-SINK| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBThriftSinkr| |
+| OPC-UA-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.OpcUaSink| |
++--------------------+----------+---------------------------------------------------------------------------+---------+
+
+```
+
+## Use examples
+
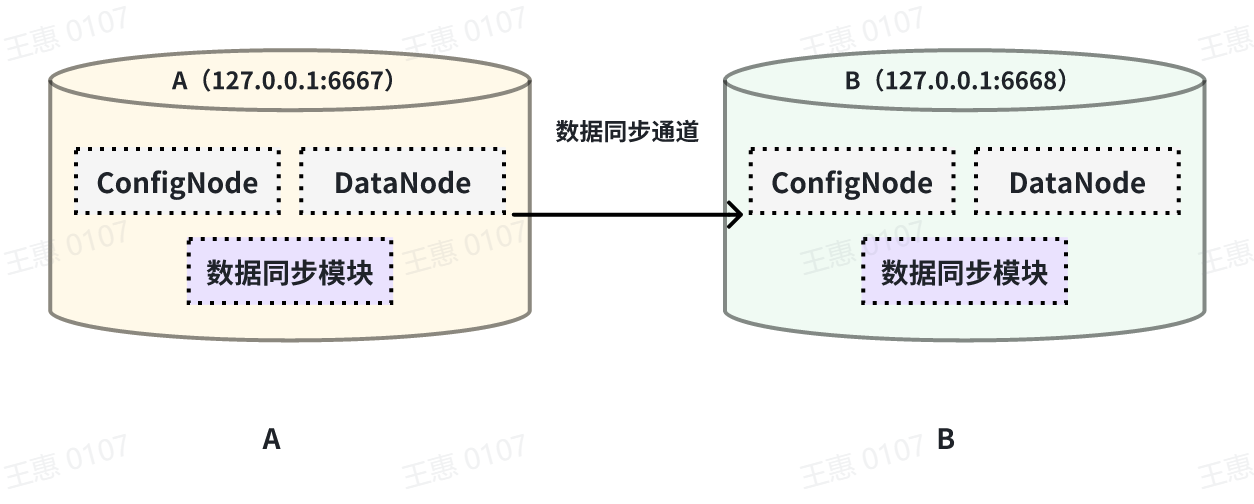
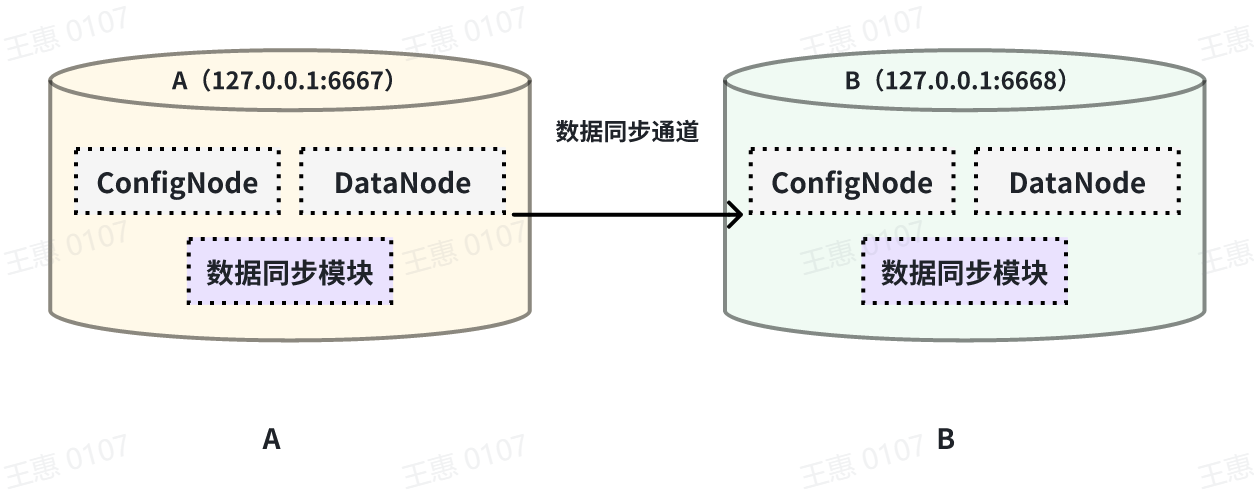
+### Full data synchronisation
+
+This example is used to demonstrate the synchronisation of all data from one IoTDB to another IoTDB with the data link as shown below:
+
+
+
+In this example, we can create a synchronisation task named A2B to synchronise the full amount of data from IoTDB A to IoTDB B. Here we need to use the iotdb-thrift-sink plugin (built-in plugin) which uses sink, and we need to specify the address of the receiving end, in this example, we have specified 'sink.ip' and 'sink.port', and we can also specify 'sink.port'. This example specifies 'sink.ip' and 'sink.port', and also 'sink.node-urls', as in the following example statement:
+
+```Go
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-sink', 'sink.ip'='iotdb-thrift-sink',
+
+ 'sink.port'='6668'
+)
+```
+
+
+### Synchronising historical data
+
+This example is used to demonstrate the synchronisation of data from a certain historical time range (8:00pm 23 August 2023 to 8:00pm 23 October 2023) to another IoTDB, the data link is shown below:
+
+
+
+In this example we can create a synchronisation task called A2B. First of all, we need to define the range of data to be transferred in source, since the data to be transferred is historical data (historical data refers to the data that existed before the creation of the synchronisation task), we need to configure the source.realtime.enable parameter to false; at the same time, we need to configure the start-time and end-time of the data and the mode mode of the transfer. At the same time, you need to configure the start-time and end-time of the data and the mode mode of transmission, and it is recommended that the mode be set to hybrid mode (hybrid mode is a mixed transmission mode, which adopts the real-time transmission mode when there is no backlog of data, and adopts the batch transmission mode when there is a backlog of data, and automatically switches according to the internal situation of the system).
+
+The detailed statements are as follows:
+
+```SQL
+create pipe A2B
+WITH SOURCE (
+'source'= 'iotdb-source',
+'source.realtime.enable' = 'false',
+'source.realtime.mode'='hybrid',
+'source.history.start-time' = '2023.08.23T08:00:00+00:00',
+'source.history.end-time' = '2023.10.23T08:00:00+00:00')
+with SINK (
+'sink'='iotdb-thrift-async-sink',
+'sink.node-urls'='xxxx:6668',
+'sink.batch.enable'='false')
+```
+
+
+### Bidirectional data transfer
+
+This example is used to demonstrate a scenario where two IoTDBs are dual-active with each other, with the data link shown below:
+
+
+
+In this example, in order to avoid an infinite loop of data, the parameter `'source.forwarding-pipe-requests` needs to be set to ``false`` on both A and B to indicate that the data transferred from the other pipe will not be forwarded. Also set `'source.history.enable'` to `false` to indicate that historical data is not transferred, i.e., data prior to the creation of the task is not synchronised.
+
+The detailed statement is as follows:
+
+Execute the following statements on A IoTDB:
+
+```Go
+create pipe AB
+with source (
+ 'source.history.enable' = 'false',
+ 'source.forwarding-pipe-requests' = 'false',
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6668'
+)
+```
+
+Execute the following statements on B IoTDB:
+
+```Go
+create pipe BA
+with source (
+ 'source.history.enable' = 'false',
+ 'source.forwarding-pipe-requests' = 'false',
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6667'
+)
+```
+
+
+### Cascading Data Transfer
+
+
+This example is used to demonstrate a cascading data transfer scenario between multiple IoTDBs, where data is synchronised from cluster A to cluster B and then to cluster C. The data link is shown in the figure below:
+
+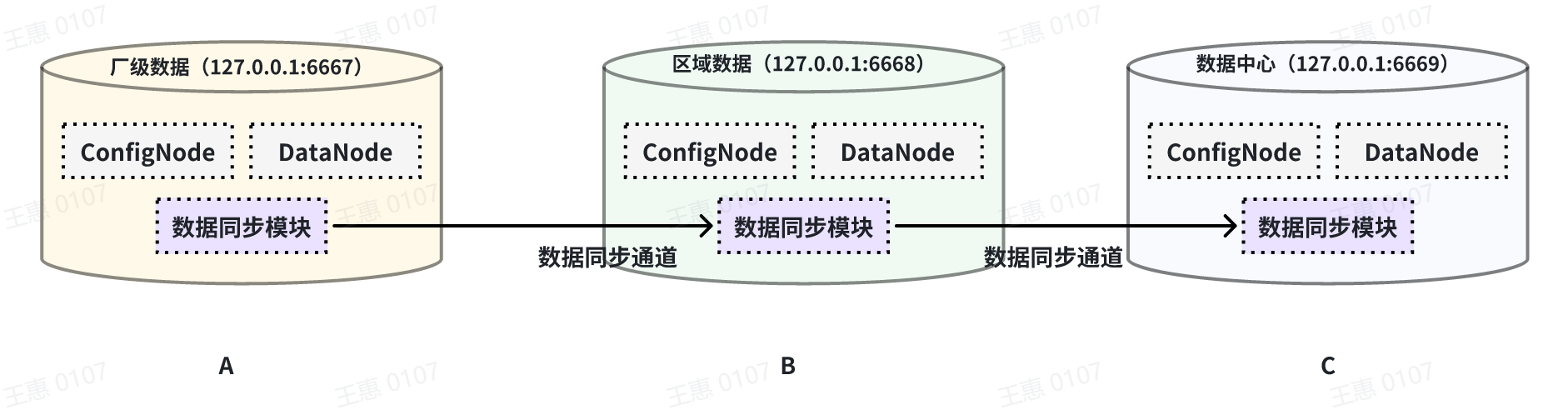
+
+In this example, in order to synchronise the data from cluster A to C, the pipe between BC needs to be configured with `source.forwarding-pipe-requests` to `true`, the detailed statement is as follows:
+
+Execute the following statement on A IoTDB to synchronise data from A to B:
+
+```Go
+create pipe AB
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6668'
+)
+```
+
+Execute the following statement on the B IoTDB to synchronise data in B to C:
+
+```Go
+create pipe BC
+with source (
+ 'source.forwarding-pipe-requests' = 'true',
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6669'
+)
+```
+
+### Transmission of data across a netgate
+
+This example is used to demonstrate a scenario where data from one IoTDB is synchronised to another IoTDB via a unidirectional gate, with the data link shown below:
+
+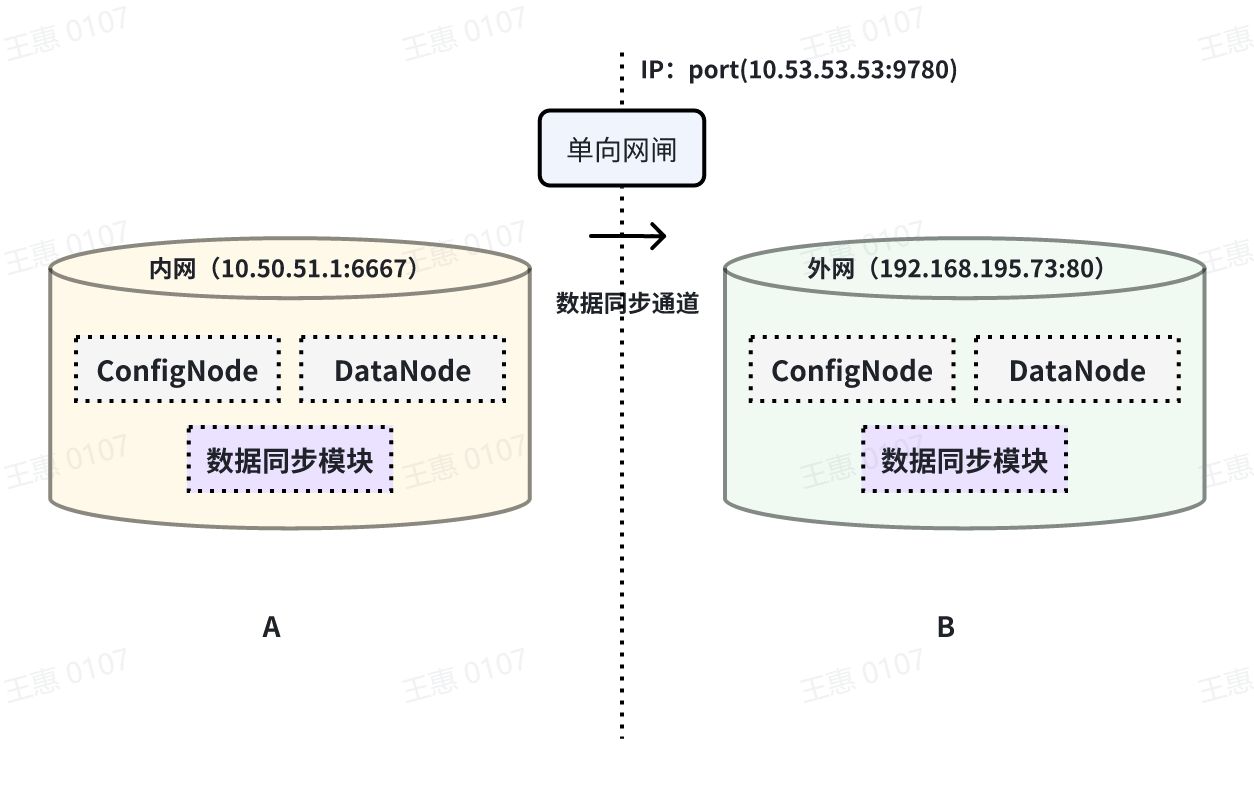
+
+In this example, you need to use the iotdb-air-gap-sink plug-in in the sink task (currently supports some models of network gates, please contact the staff of Tianmou Technology to confirm the specific model), and after configuring the network gate, execute the following statements on IoTDB A, where ip and port fill in the information of the network gate, and the detailed statements are as follows:
+
+```Go
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'sink.ip'='10.53.53.53',
+ 'sink.port'='9780'
+)
+```
+
+## Reference: Notes
+
+The IoTDB configuration file (iotdb-common.properties) can be modified in order to adjust the parameters for data synchronisation, such as the synchronisation data storage directory. The complete configuration is as follows:
+
+```Go
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
+```
+
+## Reference: parameter description
+
+### source parameter
+
+
+| key | value | value range | required or not |default value|
+| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | -------- |------|
+| source | iotdb-source | String: iotdb-source | required | - |
+| source.pattern | Path prefix for filtering time series | String: any time series prefix | optional | root |
+| source.history.enable | Whether to synchronise history data | Boolean: true, false | optional | true |
+| source.history.start-time | Synchronise the start event time of historical data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MIN_VALUE |
+| source.history.end-time | end event time for synchronised history data, contains end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MAX_VALUE |
+| source.realtime.enable | Whether to synchronise real-time data | Boolean: true, false | optional | true |
+| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional | hybrid |
+| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional | true |
+
+> 💎 **Note: Difference between historical and real-time data**
+>
+> * **Historical data**: all data with arrival time < current system time when the pipe was created is called historical data
+> * **Real-time data**: All data with arrival time >= current system time when the pipe was created is called real-time data.
+> * **Full data**: full data = historical data + real time data
+
+
+> 💎 **Explanation: Difference between data extraction modes hybrid, stream and batch**
+>
+> - **hybrid (recommended)**: In this mode, the task will give priority to real-time processing and sending of data, and automatically switch to batch sending mode when data backlog occurs, which is characterised by a balance between timeliness of data synchronisation and throughput
+> - **stream**: In this mode, the task will process and send data in real time, which is characterised by high timeliness and low throughput.
+> - **batch**: In this mode, the task will process and send data in batch (by underlying data file), which is characterised by low latency and high throughput.
+
+### sink parameters
+
+#### iotdb-thrift-sink
+
+| key | value | value range | required or not | default value |
+| --------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------------------------------------- |
+| sink | iotdb-thrift-sink or iotdb-thrift-sync-sink | String: iotdb-thrift-sink or iotdb-thrift-sync-sink | required | |
+| sink.ip | Data service IP of a Datanode node in the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | String | Optional | Fill in either sink.node-urls |
+| sink.port | Data service port of a Datanode node in the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | Integer | Optional | Fill in either sink.node-urls |
+| sink.node-urls | The url of the data service port of any number of DataNode nodes on the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | String. Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
+| sink.batch.enable | Whether to enable the log saving wholesale delivery mode, which is used to improve transmission throughput and reduce IOPS | Boolean: true, false | Optional | true |
+| sink.batch.max-delay-seconds | Effective when the log save and send mode is turned on, indicates the longest time a batch of data waits before being sent (unit: s) | Integer | Optional | 1 |
+| sink.batch.size-bytes | Effective when log saving and delivery mode is enabled, indicates the maximum saving size of a batch of data (unit: byte) | Long | Optional
+
+
+#### iotdb-air-gap-sink
+
+| key | value | value range | required or not | default value |
+| -------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------------------------------------- |
+| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | required | |
+| sink.ip | Data service IP of a Datanode node in the target IoTDB | String | Optional | Fill in either sink.node-urls |
+| sink.port | Data service port of a Datanode node in the target IoTDB | Integer | Optional | Fill in either sink.node-urls |
+| sink.node-urls | URL of the data service port of any multiple DATANODE nodes on the target | String.Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
+| sink.air-gap.handshake-timeout-ms | The timeout length of the handshake request when the sender and the receiver try to establish a connection for the first time, unit: milliseconds | Integer | Optional | 5000 |
\ No newline at end of file
diff --git a/src/UserGuide/V1.3.x/User-Manual/IoTDB-AINode_timecho.md b/src/UserGuide/V1.3.x/User-Manual/IoTDB-AINode_timecho.md
new file mode 100644
index 00000000..dd945269
--- /dev/null
+++ b/src/UserGuide/V1.3.x/User-Manual/IoTDB-AINode_timecho.md
@@ -0,0 +1,648 @@
+
+
+# Endogenous Machine Learning Framework (AINode)
+
+AINode is the third type of endogenous node provided by IoTDB after ConfigNode and DataNode, which extends the capability of machine learning analysis of time series by interacting with DataNode and ConfigNode of IoTDB cluster, supports the introduction of pre-existing machine learning models from the outside to be registered, and uses the registered models in the It supports the process of introducing existing machine learning models from outside for registration, and using the registered models to complete the time series analysis tasks on the specified time series data through simple SQL statements, which integrates the model creation, management and inference in the database engine. At present, we have provided machine learning algorithms or self-developed models for common timing analysis scenarios (e.g. prediction and anomaly detection).
+
+The system architecture is shown below:
+::: center
+ +:::
+The responsibilities of the three nodes are as follows:
+
+- **ConfigNode**: responsible for storing and managing the meta-information of the model; responsible for distributed node management.
+- **DataNode**: responsible for receiving and parsing SQL requests from users; responsible for storing time-series data; responsible for preprocessing computation of data.
+- **AINode**: responsible for model file import creation and model inference.
+
+## 1. Advantageous features
+
+Compared with building a machine learning service alone, it has the following advantages:
+
+- **Simple and easy to use**: no need to use Python or Java programming, the complete process of machine learning model management and inference can be completed using SQL statements. For example, to create a model, you can use the CREATE MODEL statement, and to reason with a model, you can use the CALL INFERENCE(...) statement. statement to create a model and CALL INFERENCE(...) statement to reason with a model, making it easier and more convenient to use.
+
+- **Avoid Data Migration**: With IoTDB native machine learning, data stored in IoTDB can be directly applied to the inference of machine learning models without having to move the data to a separate machine learning service platform, which accelerates data processing, improves security, and reduces costs.
+
+
+
+- **Built-in Advanced Algorithms**: supports industry-leading machine learning analytics algorithms covering typical timing analysis tasks, empowering the timing database with native data analysis capabilities. Such as:
+ - **Time Series Forecasting**: learns patterns of change from past time series; thus outputs the most likely prediction of future series based on observations at a given past time.
+ - **Anomaly Detection for Time Series**: detects and identifies outliers in a given time series data, helping to discover anomalous behaviour in the time series.
+ - **Annotation for Time Series (Time Series Annotation)**: Adds additional information or markers, such as event occurrence, outliers, trend changes, etc., to each data point or specific time period to better understand and analyse the data.
+
+
+
+## 2. Basic Concepts
+
+- **Model**: a machine learning model that takes time-series data as input and outputs the results or decisions of an analysis task. Model is the basic management unit of AINode, which supports adding (registration), deleting, checking, and using (inference) of models.
+- **Create**: Load externally designed or trained model files or algorithms into MLNode for unified management and use by IoTDB.
+- **Inference**: The process of using the created model to complete the timing analysis task applicable to the model on the specified timing data.
+- **Built-in capabilities**: AINode comes with machine learning algorithms or home-grown models for common timing analysis scenarios (e.g., prediction and anomaly detection).
+
+::: center
+
+:::
+The responsibilities of the three nodes are as follows:
+
+- **ConfigNode**: responsible for storing and managing the meta-information of the model; responsible for distributed node management.
+- **DataNode**: responsible for receiving and parsing SQL requests from users; responsible for storing time-series data; responsible for preprocessing computation of data.
+- **AINode**: responsible for model file import creation and model inference.
+
+## 1. Advantageous features
+
+Compared with building a machine learning service alone, it has the following advantages:
+
+- **Simple and easy to use**: no need to use Python or Java programming, the complete process of machine learning model management and inference can be completed using SQL statements. For example, to create a model, you can use the CREATE MODEL statement, and to reason with a model, you can use the CALL INFERENCE(...) statement. statement to create a model and CALL INFERENCE(...) statement to reason with a model, making it easier and more convenient to use.
+
+- **Avoid Data Migration**: With IoTDB native machine learning, data stored in IoTDB can be directly applied to the inference of machine learning models without having to move the data to a separate machine learning service platform, which accelerates data processing, improves security, and reduces costs.
+
+
+
+- **Built-in Advanced Algorithms**: supports industry-leading machine learning analytics algorithms covering typical timing analysis tasks, empowering the timing database with native data analysis capabilities. Such as:
+ - **Time Series Forecasting**: learns patterns of change from past time series; thus outputs the most likely prediction of future series based on observations at a given past time.
+ - **Anomaly Detection for Time Series**: detects and identifies outliers in a given time series data, helping to discover anomalous behaviour in the time series.
+ - **Annotation for Time Series (Time Series Annotation)**: Adds additional information or markers, such as event occurrence, outliers, trend changes, etc., to each data point or specific time period to better understand and analyse the data.
+
+
+
+## 2. Basic Concepts
+
+- **Model**: a machine learning model that takes time-series data as input and outputs the results or decisions of an analysis task. Model is the basic management unit of AINode, which supports adding (registration), deleting, checking, and using (inference) of models.
+- **Create**: Load externally designed or trained model files or algorithms into MLNode for unified management and use by IoTDB.
+- **Inference**: The process of using the created model to complete the timing analysis task applicable to the model on the specified timing data.
+- **Built-in capabilities**: AINode comes with machine learning algorithms or home-grown models for common timing analysis scenarios (e.g., prediction and anomaly detection).
+
+::: center
+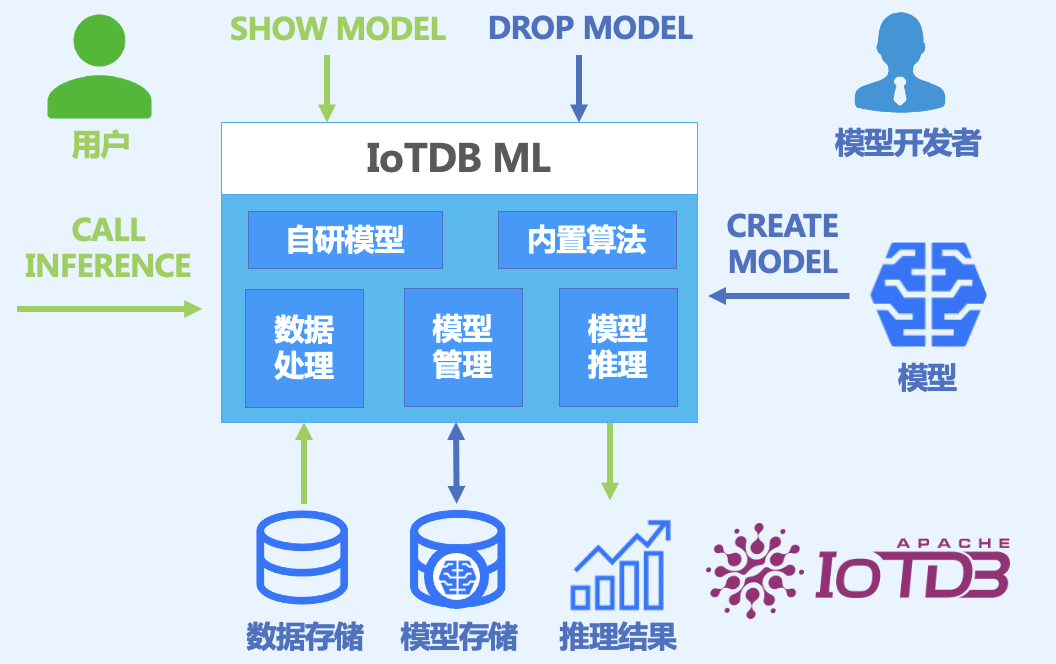 +::::
+
+## 3. Installation and Deployment
+
+The deployment of AINode can be found in the document [Deployment Guidelines](../Deployment-and-Maintenance/Deployment-Guide_timecho.md#AINode-部署) .
+
+
+## 4. Usage Guidelines
+
+AINode provides model creation and deletion process for deep learning models related to timing data. Built-in models do not need to be created and deleted, they can be used directly, and the built-in model instances created after inference is completed will be destroyed automatically.
+
+### 4.1 Registering Models
+
+A trained deep learning model can be registered by specifying the vector dimensions of the model's inputs and outputs, which can be used for model inference. The following is the SQL syntax definition for model registration.
+
+```SQL
+create model using uri
+```
+
+The specific meanings of the parameters in the SQL are as follows:
+
+- model_name: a globally unique identifier for the model, which cannot be repeated. The model name has the following constraints:
+
+ - Identifiers [ 0-9 a-z A-Z _ ] (letters, numbers, underscores) are allowed.
+ - Length is limited to 2-64 characters
+ - Case sensitive
+
+- uri: resource path to the model registration file, which should contain the **model weights model.pt file and the model's metadata description file config.yaml**.
+
+ - Model weight file: the weight file obtained after the training of the deep learning model is completed, currently supporting pytorch training of the .pt file
+
+ - yaml metadata description file: parameters related to the model structure that need to be provided when the model is registered, which must contain the input and output dimensions of the model for model inference:
+
+ - | **Parameter name** | **Parameter description** | **Example** |
+ | ------------ | ---------------------------- | -------- |
+ | input_shape | Rows and columns of model inputs for model inference | [96,2] |
+ | output_shape | rows and columns of model outputs, for model inference | [48,2] |
+
+ - In addition to model inference, the data types of model input and output can be specified:
+
+ - | **Parameter name** | **Parameter description** | **Example** |
+ | ----------- | ------------------ | --------------------- |
+ | input_type | model input data type | ['float32','float32'] |
+ | output_type | data type of the model output | ['float32','float32'] |
+
+ - In addition to this, additional notes can be specified for display during model management
+
+ - | **Parameter name** | **Parameter description** | **Examples** |
+ | ---------- | ---------------------------------------------- | ------------------------------------------- |
+ | attributes | optional, user-defined model notes for model display | 'model_type': 'dlinear','kernel_size': '25' |
+
+
+In addition to registration of local model files, registration can also be done by specifying remote resource paths via URIs, using open source model repositories (e.g. HuggingFace).
+
+#### 4.1.1 Example
+
+In the current example folder, it contains model.pt and config.yaml files, model.pt is the training get, and the content of config.yaml is as follows:
+
+```YAML
+configs.
+ # Required options
+ input_shape: [96, 2] # The model receives data in 96 rows x 2 columns.
+ output_shape: [48, 2] # Indicates that the model outputs 48 rows x 2 columns.
+
+ # Optional Default is all float32 and the number of columns is the number of columns in the shape.
+ input_type: ["int64", "int64"] # Input data type, need to match the number of columns.
+ output_type: ["text", "int64"] #Output data type, need to match the number of columns.
+
+attributes: # Optional user-defined notes for the input.
+ 'model_type': 'dlinear'
+ 'kernel_size': '25'
+```
+
+Specify this folder as the load path to register the model.
+
+```SQL
+IoTDB> create model dlinear_example using uri "file://. /example"
+```
+
+Alternatively, you can download the corresponding model file from huggingFace and register it.
+
+```SQL
+IoTDB> create model dlinear_example using uri "https://huggingface.com/IoTDBML/dlinear/"
+```
+
+After the SQL is executed, the registration process will be carried out asynchronously, and you can view the registration status of the model through the model showcase (see the Model Showcase section), and the time consumed for successful registration is mainly affected by the size of the model file.
+
+Once the model registration is complete, you can call specific functions and perform model inference by using normal queries.
+
+### 4.2 Viewing Models
+
+Successfully registered models can be queried for model-specific information through the show models command. The SQL definition is as follows:
+
+```SQL
+show models
+
+show models
+```
+
+In addition to displaying information about all models directly, you can specify a model id to view information about a specific model. The results of the model show contain the following information:
+
+| **ModelId** | **State** | **Configs** | **Attributes** |
+| ------------ | ------------------------------------- | ---------------------------------------------- | -------------- |
+| Model Unique Identifier | Model Registration Status (LOADING, ACTIVE, DROPPING) | InputShape, outputShapeInputTypes, outputTypes | Model Notes |
+
+State is used to show the current state of model registration, which consists of the following three stages
+
+- **LOADING:** The corresponding model meta information has been added to the configNode, and the model file is being transferred to the AINode node.
+- **ACTIVE:** The model has been set up and the model is in the available state
+- **DROPPING:** Model deletion is in progress, model related information is being deleted from configNode and AINode.
+- **UNAVAILABLE**: Model creation failed, you can delete the failed model_name by drop model.
+
+#### 4.2.1 Example
+
+```SQL
+IoTDB> show models
+
+
++---------------------+--------------------------+-----------+----------------------------+-----------------------+
+| ModelId| ModelType| State| Configs| Notes|
++---------------------+--------------------------+-----------+----------------------------+-----------------------+
+| dlinear_example| USER_DEFINED| ACTIVE| inputShape:[96,2]| |
+| | | | outputShape:[48,2]| |
+| | | | inputDataType:[float,float]| |
+| | | |outputDataType:[float,float]| |
+| _STLForecaster| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
+| _NaiveForecaster| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
+| _ARIMA| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
+|_ExponentialSmoothing| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
+| _GaussianHMM|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
+| _GMMHMM|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
+| _Stray|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
++---------------------+--------------------------+-----------+------------------------------------------------------------+-----------------------+
+```
+
+We have registered the corresponding model earlier, you can view the model status through the corresponding designation, active indicates that the model is successfully registered and can be used for inference.
+
+### 4.3 Delete Model
+
+For a successfully registered model, the user can delete it via SQL. In addition to deleting the meta information on the configNode, this operation also deletes all the related model files under the AINode. The SQL is as follows:
+
+```SQL
+drop model
+```
+
+You need to specify the model model_name that has been successfully registered to delete the corresponding model. Since model deletion involves the deletion of data on multiple nodes, the operation will not be completed immediately, and the state of the model at this time is DROPPING, and the model in this state cannot be used for model inference.
+
+### 4.4 Using Built-in Model Reasoning
+
+The SQL syntax is as follows:
+
+
+```SQL
+call inference(,sql[,=])
+```
+
+Built-in model inference does not require a registration process, the inference function can be used by calling the inference function through the call keyword, and its corresponding parameters are described as follows:
+
+- **built_in_model_name:** built-in model name
+- **parameterName:** parameter name
+- **parameterValue:** parameter value
+
+#### 4.4.1 Built-in Models and Parameter Descriptions
+
+The following machine learning models are currently built-in, please refer to the following links for detailed parameter descriptions.
+
+| Model | built_in_model_name | Task type | Parameter description |
+| -------------------- | --------------------- | -------- | ------------------------------------------------------------ |
+| Arima | _Arima | Forecast | [Arima Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.forecasting.arima.ARIMA.html?highlight=Arima) |
+| STLForecaster | _STLForecaster | Forecast | [STLForecaster Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.forecasting.trend.STLForecaster.html#sktime.forecasting.trend.STLForecaster) |
+| NaiveForecaster | _NaiveForecaster | Forecast | [NaiveForecaster Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.forecasting.naive.NaiveForecaster.html#naiveforecaster) |
+| ExponentialSmoothing | _ExponentialSmoothing | Forecast | [ExponentialSmoothing 参Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.forecasting.exp_smoothing.ExponentialSmoothing.html) |
+| GaussianHMM | _GaussianHMM | Annotation | [GaussianHMMParameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.annotation.hmm_learn.gaussian.GaussianHMM.html) |
+| GMMHMM | _GMMHMM | Annotation | [GMMHMM参数说明](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.annotation.hmm_learn.gmm.GMMHMM.html) |
+| Stray | _Stray | Anomaly detection | [Stray Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.annotation.stray.STRAY.html) |
+
+
+#### 4.4.2 Example
+
+The following is an example of an operation using built-in model inference. The built-in Stray model is used for anomaly detection algorithm. The input is `[144,1]` and the output is `[144,1]`. We use it for reasoning through SQL.
+
+```SQL
+IoTDB> select * from root.eg.airline
++-----------------------------+------------------+
+| Time|root.eg.airline.s0|
++-----------------------------+------------------+
+|1949-01-31T00:00:00.000+08:00| 224.0|
+|1949-02-28T00:00:00.000+08:00| 118.0|
+|1949-03-31T00:00:00.000+08:00| 132.0|
+|1949-04-30T00:00:00.000+08:00| 129.0|
+......
+|1960-09-30T00:00:00.000+08:00| 508.0|
+|1960-10-31T00:00:00.000+08:00| 461.0|
+|1960-11-30T00:00:00.000+08:00| 390.0|
+|1960-12-31T00:00:00.000+08:00| 432.0|
++-----------------------------+------------------+
+Total line number = 144
+
+IoTDB> call inference(_Stray, "select s0 from root.eg.airline", k=2)
++-------+
+|output0|
++-------+
+| 0|
+| 0|
+| 0|
+| 0|
+......
+| 1|
+| 1|
+| 0|
+| 0|
+| 0|
+| 0|
++-------+
+Total line number = 144
+```
+
+### 4.5 Reasoning with Deep Learning Models
+
+The SQL syntax is as follows:
+
+```SQL
+call inference(,sql[,window=])
+
+
+window_function:
+ head(window_size)
+ tail(window_size)
+ count(window_size,sliding_step)
+```
+
+After completing the registration of the model, the inference function can be used by calling the inference function through the call keyword, and its corresponding parameters are described as follows:
+
+- **model_name**: corresponds to a registered model
+- **sql**: sql query statement, the result of the query is used as input to the model for model inference. The dimensions of the rows and columns in the result of the query need to match the size specified in the specific model config. (It is not recommended to use the 'SELECT *' clause for the sql here because in IoTDB, '*' does not sort the columns, so the order of the columns is undefined, you can use 'SELECT s0,s1' to ensure that the columns order matches the expectations of the model input)
+- **window_function**: Window functions that can be used in the inference process, there are currently three types of window functions provided to assist in model inference:
+ - **head(window_size)**: Get the top window_size points in the data for model inference, this window can be used for data cropping.
+ 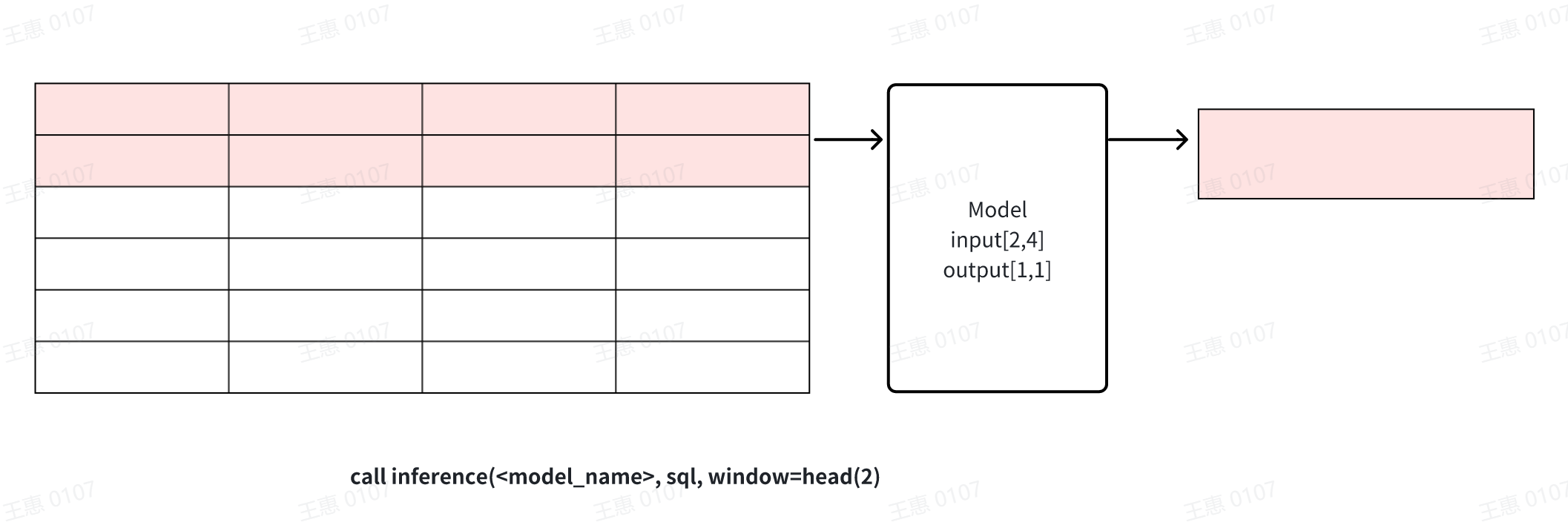
+
+ - **tail(window_size)**: get the last window_size point in the data for model inference, this window can be used for data cropping.
+ 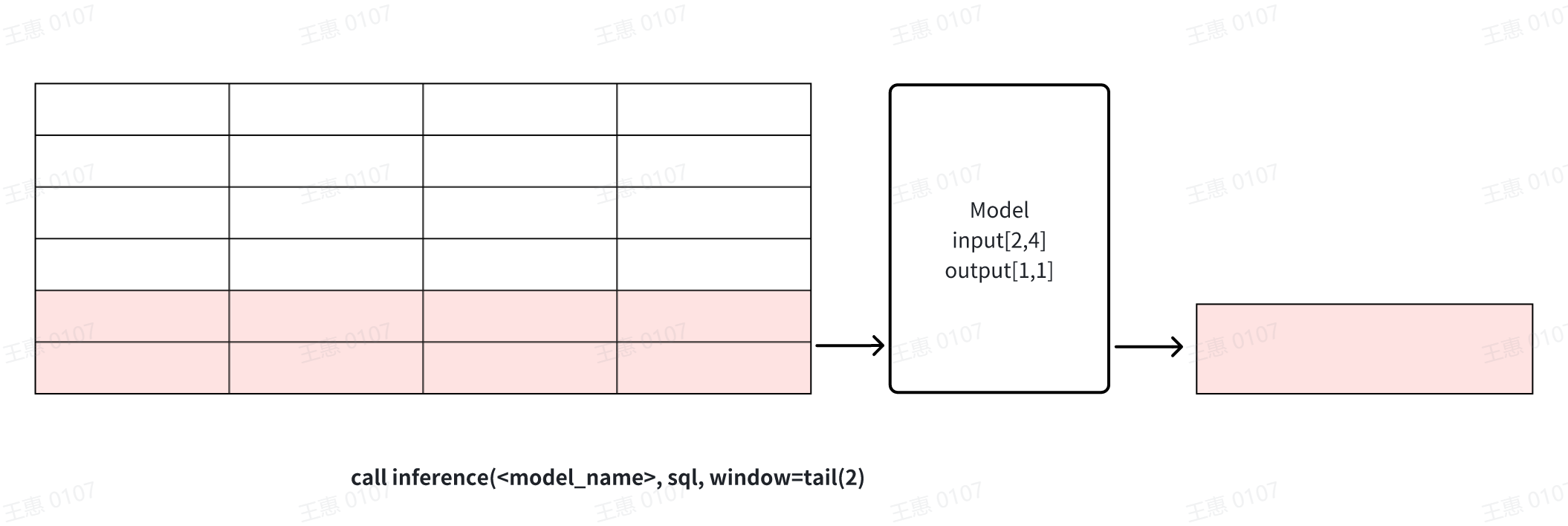
+
+ - **count(window_size, sliding_step):** sliding window based on the number of points, the data in each window will be reasoned through the model respectively, as shown in the example below, window_size for 2 window function will be divided into three windows of the input dataset, and each window will perform reasoning operations to generate results respectively. The window can be used for continuous inference
+ 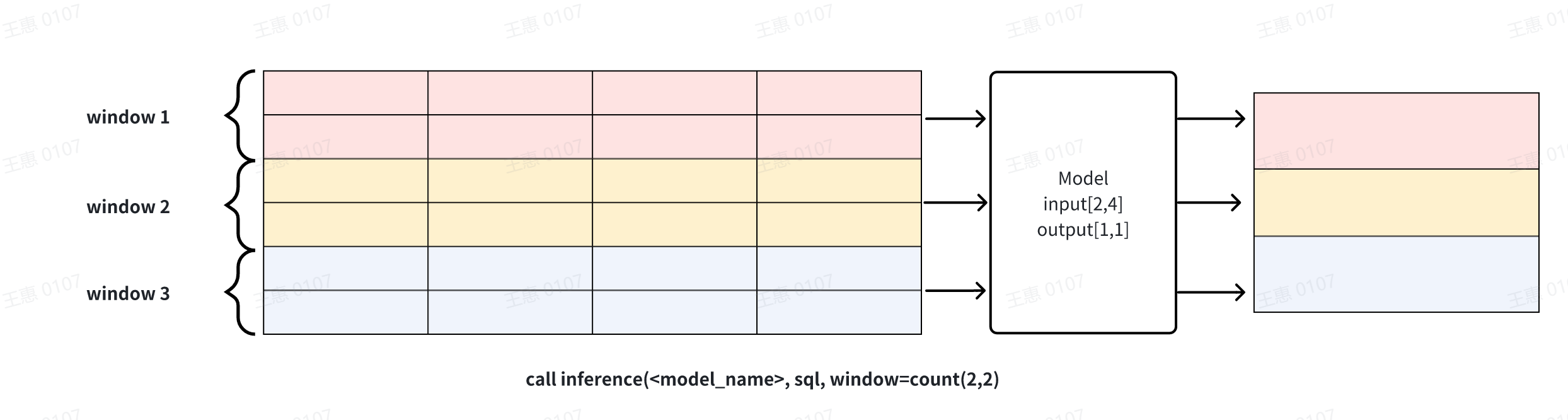
+
+**Explanation 1**: window can be used to solve the problem of cropping rows when the results of the sql query and the input row requirements of the model do not match. Note that when the number of columns does not match or the number of rows is directly less than the model requirement, the inference cannot proceed and an error message will be returned.
+
+**Explanation 2**: In deep learning applications, timestamp-derived features (time columns in the data) are often used as covariates in generative tasks, and are input into the model together to enhance the model, but the time columns are generally not included in the model's output. In order to ensure the generality of the implementation, the model inference results only correspond to the real output of the model, if the model does not output the time column, it will not be included in the results.
+
+
+#### 4.5.1 Example
+
+The following is an example of inference in action using a deep learning model, for the `dlinear` prediction model with input `[96,2]` and output `[48,2]` mentioned above, which we use via SQL.
+
+```Shell
+IoTDB> select s1,s2 from root.**
++-----------------------------+-------------------+-------------------+
+| Time| root.eg.etth.s0| root.eg.etth.s1|
++-----------------------------+-------------------+-------------------+
+|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
+|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
+|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
+|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
+|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
+|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
+|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
+......
+|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
+|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
+|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
+|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
+|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
+|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
+|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
++-----------------------------+-------------------+-------------------+
+Total line number = 96
+
+IoTDB> call inference(dlinear_example,"select s0,s1 from root.**")
++--------------------------------------------+-----------------------------+
+| _result_0| _result_1|
++--------------------------------------------+-----------------------------+
+| 0.726302981376648| 1.6549958229064941|
+| 0.7354921698570251| 1.6482787370681763|
+| 0.7238251566886902| 1.6278168201446533|
+......
+| 0.7692174911499023| 1.654654049873352|
+| 0.7685555815696716| 1.6625318765640259|
+| 0.7856493592262268| 1.6508299350738525|
++--------------------------------------------+-----------------------------+
+Total line number = 48
+```
+
+#### 4.5.2 Example of using the tail/head window function
+
+When the amount of data is variable and you want to take the latest 96 rows of data for inference, you can use the corresponding window function tail. head function is used in a similar way, except that it takes the earliest 96 points.
+
+```Shell
+IoTDB> select s1,s2 from root.**
++-----------------------------+-------------------+-------------------+
+| Time| root.eg.etth.s0| root.eg.etth.s1|
++-----------------------------+-------------------+-------------------+
+|1988-01-01T00:00:00.000+08:00| 0.7355| 1.211|
+......
+|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
+|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
+|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
+|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
+|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
+|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
+|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
+......
+|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
+|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
+|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
+|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
+|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
+|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
+|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
++-----------------------------+-------------------+-------------------+
+Total line number = 996
+
+IoTDB> call inference(dlinear_example,"select s0,s1 from root.**",window=tail(96))
++--------------------------------------------+-----------------------------+
+| _result_0| _result_1|
++--------------------------------------------+-----------------------------+
+| 0.726302981376648| 1.6549958229064941|
+| 0.7354921698570251| 1.6482787370681763|
+| 0.7238251566886902| 1.6278168201446533|
+......
+| 0.7692174911499023| 1.654654049873352|
+| 0.7685555815696716| 1.6625318765640259|
+| 0.7856493592262268| 1.6508299350738525|
++--------------------------------------------+-----------------------------+
+Total line number = 48
+```
+
+#### 4.5.3 Example of using the count window function
+
+This window is mainly used for computational tasks, when the model corresponding to the task can only process a fixed row of data at a time and what is ultimately desired is indeed multiple sets of predictions, using this window function allows for sequential inference using a sliding window of points. Suppose we now have an anomaly detection model anomaly_example(input: [24,2], output[1,1]) that generates a 0/1 label for each row of data, an example of its use is shown below:
+```Shell
+IoTDB> select s1,s2 from root.**
++-----------------------------+-------------------+-------------------+
+| Time| root.eg.etth.s0| root.eg.etth.s1|
++-----------------------------+-------------------+-------------------+
+|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
+|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
+|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
+|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
+|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
+|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
+|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
+......
+|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
+|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
+|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
+|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
+|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
+|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
+|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
++-----------------------------+-------------------+-------------------+
+Total line number = 96
+
+IoTDB> call inference(anomaly_example,"select s0,s1 from root.**",window=count(24,24))
++-------------------------+
+| _result_0|
++-------------------------+
+| 0|
+| 1|
+| 1|
+| 0|
++-------------------------+
+Total line number = 4
+```
+
+where the labels of each row in the result set correspond to the model output corresponding to the 16 rows of input.
+
+## 5. Privilege Management
+
+When using AINode related functions, the authentication of IoTDB itself can be used to do a permission management, users can only use the model management related functions when they have the USE_ML permission. When using the inference function, the user needs to have the permission to access the source sequence corresponding to the SQL of the input model.
+
+| Privilege Name | Privilege Scope | Administrator User (default ROOT) | Normal User | Path Related |
+| --------- | --------------------------------- | ---------------------- | -------- | -------- |
+| USE_MODEL | create modelshow modelsdrop model | √ | √ √ | x |
+| | | call inference | | | | |
+
+## 6. Practical Examples
+
+### 6.1 Power Load Prediction
+
+In some industrial scenarios, there is a need to predict power loads, which can be used to optimise power supply, conserve energy and resources, support planning and expansion, and enhance power system reliability.
+
+The data for the test set of ETTh1 that we use is [ETTh1](https://alioss.timecho.com/docs/img/ETTh1.csv).
+
+
+It contains power data collected at 1h intervals, and each data consists of load and oil temperature as High UseFul Load, High UseLess Load, Middle UseLess Load, Low UseFul Load, Low UseLess Load, Oil Temperature.
+
+On this dataset, the model inference function of IoTDB-ML can predict the oil temperature in the future period of time through the relationship between the past values of high, middle and low use loads and the corresponding time stamp oil temperature, which empowers the automatic regulation and monitoring of grid transformers.
+
+#### Step 1: Data Import
+
+Users can import the ETT dataset into IoTDB using `import-csv.sh` in the tools folder
+
+``Bash
+bash . /import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /ETTh1.csv
+``
+
+#### Step 2: Model Import
+
+We can enter the following SQL in iotdb-cli to pull a trained model from huggingface for registration for subsequent inference.
+
+```SQL
+create model dlinear using uri 'https://huggingface.co/hvlgo/dlinear/resolve/main'
+```
+
+This model is trained on the lighter weight deep model DLinear, which is able to capture as many trends within a sequence and relationships between variables as possible with relatively fast inference, making it more suitable for fast real-time prediction than other deeper models.
+
+#### Step 3: Model inference
+
+```Shell
+IoTDB> select s0,s1,s2,s3,s4,s5,s6 from root.eg.etth LIMIT 96
++-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
+| Time|root.eg.etth.s0|root.eg.etth.s1|root.eg.etth.s2|root.eg.etth.s3|root.eg.etth.s4|root.eg.etth.s5|root.eg.etth.s6|
++-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
+|2017-10-20T00:00:00.000+08:00| 10.449| 3.885| 8.706| 2.025| 2.041| 0.944| 8.864|
+|2017-10-20T01:00:00.000+08:00| 11.119| 3.952| 8.813| 2.31| 2.071| 1.005| 8.442|
+|2017-10-20T02:00:00.000+08:00| 9.511| 2.88| 7.533| 1.564| 1.949| 0.883| 8.16|
+|2017-10-20T03:00:00.000+08:00| 9.645| 2.21| 7.249| 1.066| 1.828| 0.914| 7.949|
+......
+|2017-10-23T20:00:00.000+08:00| 8.105| 0.938| 4.371| -0.569| 3.533| 1.279| 9.708|
+|2017-10-23T21:00:00.000+08:00| 7.167| 1.206| 4.087| -0.462| 3.107| 1.432| 8.723|
+|2017-10-23T22:00:00.000+08:00| 7.1| 1.34| 4.015| -0.32| 2.772| 1.31| 8.864|
+|2017-10-23T23:00:00.000+08:00| 9.176| 2.746| 7.107| 1.635| 2.65| 1.097| 9.004|
++-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
+Total line number = 96
+
+IoTDB> call inference(dlinear_example, "select s0,s1,s2,s3,s4,s5,s6 from root.eg.etth", window=head(96))
++-----------+----------+----------+------------+---------+----------+----------+
+| output0| output1| output2| output3| output4| output5| output6|
++-----------+----------+----------+------------+---------+----------+----------+
+| 10.319546| 3.1450553| 7.877341| 1.5723765|2.7303758| 1.1362307| 8.867775|
+| 10.443649| 3.3286757| 7.8593454| 1.7675098| 2.560634| 1.1177158| 8.920919|
+| 10.883752| 3.2341104| 8.47036| 1.6116762|2.4874182| 1.1760603| 8.798939|
+......
+| 8.0115595| 1.2995274| 6.9900327|-0.098746896| 3.04923| 1.176214| 9.548782|
+| 8.612427| 2.5036244| 5.6790237| 0.66474205|2.8870275| 1.2051733| 9.330128|
+| 10.096699| 3.399722| 6.9909| 1.7478468|2.7642853| 1.1119363| 9.541455|
++-----------+----------+----------+------------+---------+----------+----------+
+Total line number = 48
+```
+
+We compare the results of the prediction of the oil temperature with the real results, and we can get the following image.
+
+The data before 10/24 00:00 in the image is the past data input into the model, the yellow line after 10/24 00:00 is the prediction of oil temperature given by the model, and the blue colour is the actual oil temperature data in the dataset (used for comparison).
+
+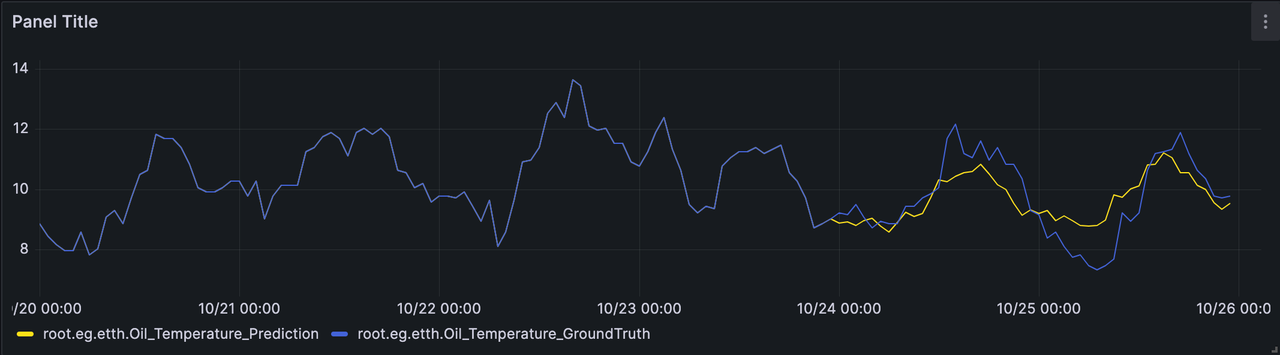
+
+As can be seen, we have used the relationship between the six load information and the corresponding time oil temperatures for the past 96 hours (4 days) to model the possible changes in this data for the oil temperature for the next 48 hours (2 days) based on the inter-relationships between the sequences learned previously, and it can be seen that the predicted curves maintain a high degree of consistency in trend with the actual results after visualisation.
+
+### 6.2 Power Prediction
+
+Power monitoring of current, voltage and power data is required in substations for detecting potential grid problems, identifying faults in the power system, effectively managing grid loads and analysing power system performance and trends.
+
+We have used the current, voltage and power data in a substation to form a dataset in a real scenario. The dataset consists of data such as A-phase voltage, B-phase voltage, and C-phase voltage collected every 5 - 6s for a time span of nearly four months in the substation.
+
+The test set data content is [data](https://alioss.timecho.com/docs/img/data.csv).
+
+On this dataset, the model inference function of IoTDB-ML can predict the C-phase voltage in the future period through the previous values and corresponding timestamps of A-phase voltage, B-phase voltage and C-phase voltage, empowering the monitoring management of the substation.
+
+#### Step 1: Data Import
+
+Users can import the dataset using `import-csv.sh` in the tools folder
+
+```Bash
+bash ./import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /data.csv
+```
+
+#### Step 2: Model Import
+
+We can enter the following SQL in iotdb-cli to pull a trained model from huggingface for registration for subsequent inference.
+
+```SQL
+create model patchtst using uri `https://huggingface.co/hvlgo/patchtst/resolve/main`
+```
+
+We use the deep model PatchTST for prediction, which is a transformer-based temporal prediction model with excellent performance in long time series prediction tasks.
+
+#### Step 3: Model Inference
+
+```Shell
+IoTDB> select * from root.eg.voltage limit 96
++-----------------------------+------------------+------------------+------------------+
+| Time|root.eg.voltage.s0|root.eg.voltage.s1|root.eg.voltage.s2|
++-----------------------------+------------------+------------------+------------------+
+|2023-02-14T20:38:32.000+08:00| 2038.0| 2028.0| 2041.0|
+|2023-02-14T20:38:38.000+08:00| 2014.0| 2005.0| 2018.0|
+|2023-02-14T20:38:44.000+08:00| 2014.0| 2005.0| 2018.0|
+......
+|2023-02-14T20:47:52.000+08:00| 2024.0| 2016.0| 2027.0|
+|2023-02-14T20:47:57.000+08:00| 2024.0| 2016.0| 2027.0|
+|2023-02-14T20:48:03.000+08:00| 2024.0| 2016.0| 2027.0|
++-----------------------------+------------------+------------------+------------------+
+Total line number = 96
+
+IoTDB> call inference(patchtst, "select s0,s1,s2 from root.eg.voltage", window=head(96))
++---------+---------+---------+
+| output0| output1| output2|
++---------+---------+---------+
+|2013.4113|2011.2539|2010.2732|
+|2013.2792| 2007.902|2035.7709|
+|2019.9114|2011.0453|2016.5848|
+......
+|2018.7078|2009.7993|2017.3502|
+|2033.9062|2010.2087|2018.1757|
+|2022.2194| 2011.923|2020.5442|
+|2022.1393|2023.4688|2020.9344|
++---------+---------+---------+
+Total line number = 48
+```
+
+Comparing the predicted results of the C-phase voltage with the real results, we can get the following image.
+
+The data before 01/25 14:33 is the past data input to the model, the yellow line after 01/25 14:33 is the predicted C-phase voltage given by the model, and the blue colour is the actual A-phase voltage data in the dataset (used for comparison).
+
+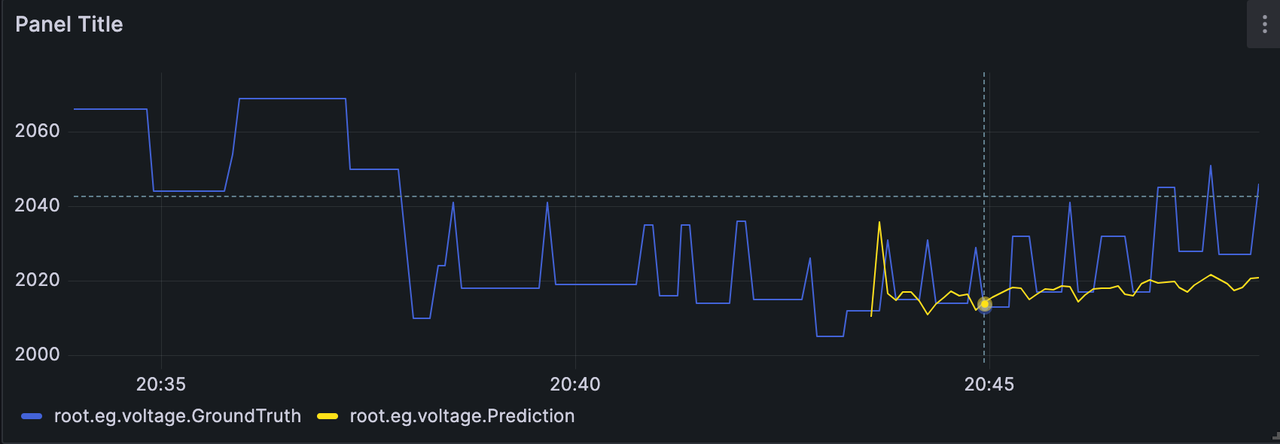
+
+It can be seen that we have used the data of the last 8 minutes of voltage to model the possible changes in the A-phase voltage for the next 4 minutes based on the inter-relationships between the sequences learned earlier, and it can be seen that the predicted curves and the actual results maintain a high degree of synchronicity in terms of trends after visualisation.
+
+### 6.3 Anomaly Detection
+
+In the civil aviation and transport industry, there exists a need for anomaly detection of the number of passengers travelling on an aircraft. The results of anomaly detection can be used to guide the adjustment of flight scheduling to make the organisation more efficient.
+
+Airline Passengers is a time-series dataset that records the number of international air passengers between 1949 and 1960, sampled at one-month intervals. The dataset contains a total of one time series. The dataset is [airline](https://alioss.timecho.com/docs/img/airline.csv).
+On this dataset, the model inference function of IoTDB-ML can empower the transport industry by capturing the changing patterns of the sequence in order to detect anomalies at the sequence time points.
+
+#### Step 1: Data Import
+
+Users can import the dataset using `import-csv.sh` in the tools folder
+
+``Bash
+bash . /import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /data.csv
+``
+
+#### Step 2: Model Inference
+
+IoTDB has some built-in machine learning algorithms that can be used directly, a sample prediction using one of the anomaly detection algorithms is shown below:
+
+```Shell
+IoTDB> select * from root.eg.airline
++-----------------------------+------------------+
+| Time|root.eg.airline.s0|
++-----------------------------+------------------+
+|1949-01-31T00:00:00.000+08:00| 224.0|
+|1949-02-28T00:00:00.000+08:00| 118.0|
+|1949-03-31T00:00:00.000+08:00| 132.0|
+|1949-04-30T00:00:00.000+08:00| 129.0|
+......
+|1960-09-30T00:00:00.000+08:00| 508.0|
+|1960-10-31T00:00:00.000+08:00| 461.0|
+|1960-11-30T00:00:00.000+08:00| 390.0|
+|1960-12-31T00:00:00.000+08:00| 432.0|
++-----------------------------+------------------+
+Total line number = 144
+
+IoTDB> call inference(_Stray, "select s0 from root.eg.airline", k=2)
++-------+
+|output0|
++-------+
+| 0|
+| 0|
+| 0|
+| 0|
+......
+| 1|
+| 1|
+| 0|
+| 0|
+| 0|
+| 0|
++-------+
+Total line number = 144
+```
+
+We plot the results detected as anomalies to get the following image. Where the blue curve is the original time series and the time points specially marked with red dots are the time points that the algorithm detects as anomalies.
+
+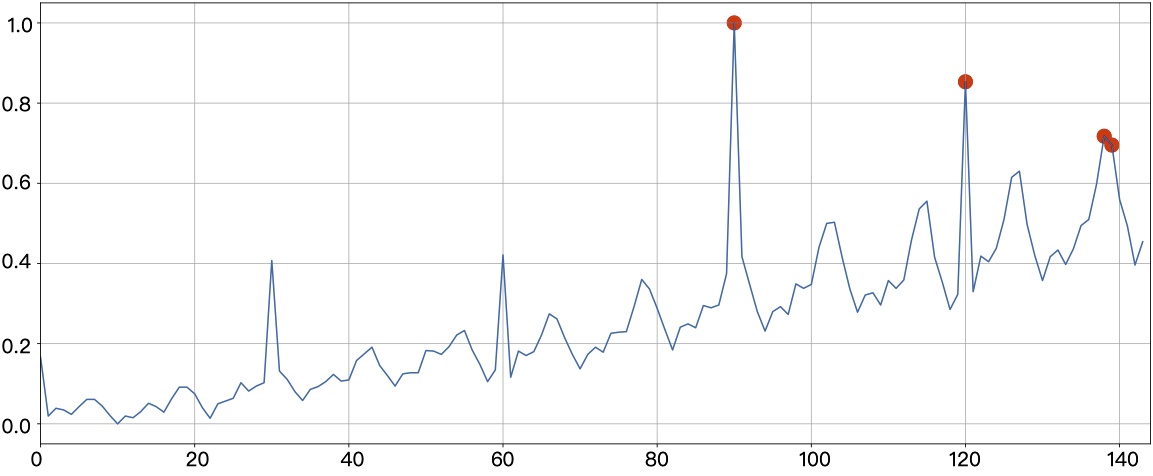
+
+It can be seen that the Stray model has modelled the input sequence changes and successfully detected the time points where anomalies occur.
\ No newline at end of file
diff --git a/src/UserGuide/V1.3.x/User-Manual/IoTDB-View_timecho.md b/src/UserGuide/V1.3.x/User-Manual/IoTDB-View_timecho.md
index a9ea5a7b..6595b591 100644
--- a/src/UserGuide/V1.3.x/User-Manual/IoTDB-View_timecho.md
+++ b/src/UserGuide/V1.3.x/User-Manual/IoTDB-View_timecho.md
@@ -19,6 +19,532 @@
-->
-# IoTDB View
+# View
-TODO
\ No newline at end of file
+## I. Sequence View Application Background
+
+## 1.1 Application Scenario 1 Time Series Renaming (PI Asset Management)
+
+In practice, the equipment collecting data may be named with identification numbers that are difficult to be understood by human beings, which brings difficulties in querying to the business layer.
+
+The Sequence View, on the other hand, is able to re-organise the management of these sequences and access them using a new model structure without changing the original sequence content and without the need to create new or copy sequences.
+
+**For example**: a cloud device uses its own NIC MAC address to form entity numbers and stores data by writing the following time sequence:`root.db.0800200A8C6D.xvjeifg`.
+
+It is difficult for the user to understand. However, at this point, the user is able to rename it using the sequence view feature, map it to a sequence view, and use `root.view.device001.temperature` to access the captured data.
+
+### 1.2 Application Scenario 2 Simplifying business layer query logic
+
+Sometimes users have a large number of devices that manage a large number of time series. When conducting a certain business, the user wants to deal with only some of these sequences. At this time, the focus of attention can be picked out by the sequence view function, which is convenient for repeated querying and writing.
+
+**For example**: Users manage a product assembly line with a large number of time series for each segment of the equipment. The temperature inspector only needs to focus on the temperature of the equipment, so he can extract the temperature-related sequences and compose the sequence view.
+
+### 1.3 Application Scenario 3 Auxiliary Rights Management
+
+In the production process, different operations are generally responsible for different scopes. For security reasons, it is often necessary to restrict the access scope of the operations staff through permission management.
+
+**For example**: The safety management department now only needs to monitor the temperature of each device in a production line, but these data are stored in the same database with other confidential data. At this point, it is possible to create a number of new views that contain only temperature-related time series on the production line, and then to give the security officer access to only these sequence views, thus achieving the purpose of permission restriction.
+
+### 1.4 Motivation for designing sequence view functionality
+
+Combining the above two types of usage scenarios, the motivations for designing sequence view functionality, are:
+
+1. time series renaming.
+2. to simplify the query logic at the business level.
+3. Auxiliary rights management, open data to specific users through the view.
+
+## 2. Sequence View Concepts
+
+### 2.1 Terminology Concepts
+
+Concept: If not specified, the views specified in this document are **Sequence Views**, and new features such as device views may be introduced in the future.
+
+### 2.2 Sequence view
+
+A sequence view is a way of organising the management of time series.
+
+In traditional relational databases, data must all be stored in a table, whereas in time series databases such as IoTDB, it is the sequence that is the storage unit. Therefore, the concept of sequence views in IoTDB is also built on sequences.
+
+A sequence view is a virtual time series, and each virtual time series is like a soft link or shortcut that maps to a sequence or some kind of computational logic external to a certain view. In other words, a virtual sequence either maps to some defined external sequence or is computed from multiple external sequences.
+
+Users can create views using complex SQL queries, where the sequence view acts as a stored query statement, and when data is read from the view, the stored query statement is used as the source of the data in the FROM clause.
+
+### 2.3 Alias Sequences
+
+There is a special class of beings in a sequence view that satisfy all of the following conditions:
+
+1. the data source is a single time series
+2. there is no computational logic
+3. no filtering conditions (e.g., no WHERE clause restrictions).
+
+Such a sequence view is called an **alias sequence**, or alias sequence view. A sequence view that does not fully satisfy all of the above conditions is called a non-alias sequence view. The difference between them is that only aliased sequences support write functionality.
+
+** All sequence views, including aliased sequences, do not currently support Trigger functionality. **
+
+### 2.4 Nested Views
+
+A user may want to select a number of sequences from an existing sequence view to form a new sequence view, called a nested view.
+
+**The current version does not support the nested view feature**.
+
+### 2.5 Some constraints on sequence views in IoTDB
+
+#### Constraint 1 A sequence view must depend on one or several time series
+
+A sequence view has two possible forms of existence:
+
+1. it maps to a time series
+2. it is computed from one or more time series.
+
+The former form of existence has been exemplified in the previous section and is easy to understand; the latter form of existence here is because the sequence view allows for computational logic.
+
+For example, the user has installed two thermometers in the same boiler and now needs to calculate the average of the two temperature values as a measurement. The user has captured the following two sequences: `root.db.d01.temperature01`, `root.db.d01.temperature02`.
+
+At this point, the user can use the average of the two sequences as one sequence in the view: `root.db.d01.avg_temperature`.
+
+This example will 3.1.2 expand in detail.
+
+#### Restriction 2 Non-alias sequence views are read-only
+
+Writing to non-alias sequence views is not allowed.
+
+Only aliased sequence views are supported for writing.
+
+#### Restriction 3 Nested views are not allowed
+
+It is not possible to select certain columns in an existing sequence view to create a sequence view, either directly or indirectly.
+
+An example of this restriction will be given in 3.1.3.
+
+#### Restriction 4 Sequence view and time series cannot be renamed
+
+Both sequence views and time series are located under the same tree, so they cannot be renamed.
+
+The name (path) of any sequence should be uniquely determined.
+
+#### Restriction 5 Sequence views share timing data with time series, metadata such as labels are not shared
+
+Sequence views are mappings pointing to time series, so they fully share timing data, with the time series being responsible for persistent storage.
+
+However, their metadata such as tags and attributes are not shared.
+
+This is because the business query, view-oriented users are concerned about the structure of the current view, and if you use group by tag and other ways to do the query, obviously want to get the view contains the corresponding tag grouping effect, rather than the time series of the tag grouping effect (the user is not even aware of those time series).
+
+## 3. Sequence view functionality
+
+### 3.1 Creating a view
+
+Creating a sequence view is similar to creating a time series, the difference is that you need to specify the data source, i.e., the original sequence, through the AS keyword.
+
+#### 3.1.1. SQL for creating a view
+
+User can select some sequences to create a view:
+
+```SQL
+CREATE VIEW root.view.device.status
+AS
+ SELECT s01
+ FROM root.db.device
+```
+
+It indicates that the user has selected the sequence `s01` from the existing device `root.db.device`, creating the sequence view `root.view.device.status`.
+
+The sequence view can exist under the same entity as the time series, for example:
+
+```SQL
+CREATE VIEW root.db.device.status
+AS
+ SELECT s01
+ FROM root.db.device
+```
+
+Thus, there is a virtual copy of `s01` under `root.db.device`, but with a different name `status`.
+
+It can be noticed that the sequence views in both of the above examples are aliased sequences, and we are giving the user a more convenient way of creating a sequence for that sequence:
+
+```SQL
+CREATE VIEW root.view.device.status
+AS
+ root.db.device.s01
+```
+
+#### 3.1.2 Creating views with computational logic
+
+Following the example in section 2.2 Limitations 1:
+
+> A user has installed two thermometers in the same boiler and now needs to calculate the average of the two temperature values as a measurement. The user has captured the following two sequences: `root.db.d01.temperature01`, `root.db.d01.temperature02`.
+>
+> At this point, the user can use the two sequences averaged as one sequence in the view: `root.view.device01.avg_temperature`.
+
+If the view is not used, the user can query the average of the two temperatures like this:
+
+```SQL
+SELECT (temperature01 + temperature02) / 2
+FROM root.db.d01
+```
+
+And if using a sequence view, the user can create a view this way to simplify future queries:
+
+```SQL
+CREATE VIEW root.db.d01.avg_temperature
+AS
+ SELECT (temperature01 + temperature02) / 2
+ FROM root.db.d01
+```
+
+The user can then query it like this:
+
+```SQL
+SELECT avg_temperature FROM root.db.d01
+```
+
+#### 3.1.3 Nested sequence views not supported
+
+Continuing with the example from 3.1.2, the user now wants to create a new view using the sequence view `root.db.d01.avg_temperature`, which is not allowed. We currently do not support nested views, whether it is an aliased sequence or not.
+
+For example, the following SQL statement will report an error:
+
+```SQL
+CREATE VIEW root.view.device.avg_temp_copy
+AS
+ root.db.d01.avg_temperature -- Not supported. Nested views are not allowed
+```
+
+#### 3.1.4 Creating multiple sequence views at once
+
+If only one sequence view can be specified at a time which is not convenient for the user to use, then multiple sequences can be specified at a time, for example:
+
+```SQL
+CREATE VIEW root.db.device.status, root.db.device.sub.hardware
+AS
+ SELECT s01, s02
+ FROM root.db.device
+```
+
+此外,上述写法可以做简化:
+
+```SQL
+CREATE VIEW root.db.device(status, sub.hardware)
+AS
+ SELECT s01, s02
+ FROM root.db.device
+```
+
+Both statements above are equivalent to the following typing:
+
+```SQL
+CREATE VIEW root.db.device.status
+AS
+ SELECT s01
+ FROM root.db.device;
+
+CREATE VIEW root.db.device.sub.hardware
+AS
+ SELECT s02
+ FROM root.db.device
+```
+
+is also equivalent to the following:
+
+```SQL
+CREATE VIEW root.db.device.status, root.db.device.sub.hardware
+AS
+ root.db.device.s01, root.db.device.s02
+
+-- or
+
+CREATE VIEW root.db.device(status, sub.hardware)
+AS
+ root.db.device(s01, s02)
+```
+
+##### The mapping relationships between all sequences are statically stored
+
+Sometimes, the SELECT clause may contain a number of statements that can only be determined at runtime, such as below:
+
+```SQL
+SELECT s01, s02
+FROM root.db.d01, root.db.d02
+```
+
+The number of sequences that can be matched by the above statement is uncertain and is related to the state of the system. Even so, the user can use it to create views.
+
+However, it is important to note that the mapping relationship between all sequences is stored statically (fixed at creation)! Consider the following example:
+
+The current database contains only three sequences `root.db.d01.s01`, `root.db.d02.s01`, `root.db.d02.s02`, and then the view is created:
+
+```SQL
+CREATE VIEW root.view.d(alpha, beta, gamma)
+AS
+ SELECT s01, s02
+ FROM root.db.d01, root.db.d02
+```
+
+The mapping relationship between time series is as follows:
+
+| sequence number | time series | sequence view |
+| ---- | ----------------- | ----------------- |
+| 1 | `root.db.d01.s01` | root.view.d.alpha |
+| 2 | `root.db.d02.s01` | root.view.d.beta |
+| 3 | `root.db.d02.s02` | root.view.d.gamma |
+
+After that, if the user adds the sequence `root.db.d01.s02`, it does not correspond to any view; then, if the user deletes `root.db.d01.s01`, the query for `root.view.d.alpha` will report an error directly, and it will not correspond to `root.db.d01.s02` either.
+
+Please always note that inter-sequence mapping relationships are stored statically and solidly.
+
+#### 3.1.5 Batch Creation of Sequence Views
+
+There are several existing devices, each with a temperature value, for example:
+
+1. root.db.d1.temperature
+2. root.db.d2.temperature
+3. ...
+
+There may be many other sequences stored under these devices (e.g. `root.db.d1.speed`), but for now it is possible to create a view that contains only the temperature values for these devices, without relation to the other sequences:.
+
+```SQL
+CREATE VIEW root.db.view(${2}_temperature)
+AS
+ SELECT temperature FROM root.db.*
+```
+
+This is modelled on the query writeback (`SELECT INTO`) convention for naming rules, which uses variable placeholders to specify naming rules. See also: [QUERY WRITEBACK (SELECT INTO)](https://iotdb.apache.org/zh/UserGuide/Master/Query-Data/Select-Into.html)
+
+Here `root.db.*.temperature` specifies what time series will be included in the view; and `${2}` specifies from which node in the time series the name is extracted to name the sequence view.
+
+Here, `${2}` refers to level 2 (starting at 0) of `root.db.*.temperature`, which is the result of the `*` match; and `${2}_temperature` is the result of the match and `temperature` spliced together with underscores to make up the node names of the sequences under the view.
+
+The above statement for creating a view is equivalent to the following writeup:
+
+```SQL
+CREATE VIEW root.db.view(${2}_${3})
+AS
+ SELECT temperature from root.db.*
+```
+
+The final view contains these sequences:
+
+1. root.db.view.d1_temperature
+2. root.db.view.d2_temperature
+3. ...
+
+Created using wildcards, only static mapping relationships at the moment of creation will be stored.
+
+#### 3.1.6 SELECT clauses are somewhat limited when creating views
+
+The SELECT clause used when creating a serial view is subject to certain restrictions. The main restrictions are as follows:
+
+1. the `WHERE` clause cannot be used.
+2. `GROUP BY` clause cannot be used. 3.
+3. `MAX_VALUE` and other aggregation functions cannot be used.
+
+Simply put, after `AS` you can only use `SELECT ... FROM ... ` and the results of this query must form a time series.
+
+### 3.2 View Data Queries
+
+For the data query functions that can be supported, the sequence view and time series can be used indiscriminately with identical behaviour when performing time series data queries.
+
+**The types of queries that are not currently supported by the sequence view are as follows:**
+
+1. **align by device query
+2. **group by tags query
+
+Users can also mix time series and sequence view queries in the same SELECT statement, for example:
+
+```SQL
+SELECT temperature01, temperature02, avg_temperature
+FROM root.db.d01
+WHERE temperature01 < temperature02
+```
+
+However, if the user wants to query the metadata of the sequence, such as tag, attributes, etc., the query is the result of the sequence view, not the result of the time series referenced by the sequence view.
+
+In addition, for aliased sequences, if the user wants to get information about the time series such as tags, attributes, etc., the user needs to query the mapping of the view columns to find the corresponding time series, and then query the time series for the tags, attributes, etc. The method of querying the mapping of the view columns will be explained in section 3.5.
+
+### 3.3 Modify Views
+
+Modifying a view, such as changing its name, modifying its calculation logic, deleting it, etc., is similar to creating a new view, in that you need to re-specify all the column descriptions for the entire view.
+
+#### 3.3.1 Modify view data source
+
+```SQL
+ALTER VIEW root.view.device.status
+AS
+ SELECT s01
+ FROM root.ln.wf.d01
+```
+
+#### 3.3.2 Modify the view's calculation logic
+
+```SQL
+ALTER VIEW root.db.d01.avg_temperature
+AS
+ SELECT (temperature01 + temperature02 + temperature03) / 3
+ FROM root.db.d01
+```
+
+#### 3.3.3 Tag point management
+
+- Add a new
+tag
+```SQL
+ALTER view root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4
+```
+
+- Add a new attribute
+
+```SQL
+ALTER view root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4
+```
+
+- rename tag or attribute
+
+```SQL
+ALTER view root.turbine.d1.s1 RENAME tag1 TO newTag1
+```
+
+- Reset the value of a tag or attribute
+
+```SQL
+ALTER view root.turbine.d1.s1 SET newTag1=newV1, attr1=newV1
+```
+
+- Delete an existing tag or attribute
+
+```SQL
+ALTER view root.turbine.d1.s1 DROP tag1, tag2
+```
+
+- Update insert aliases, tags and attributes
+
+> If the alias, tag or attribute did not exist before, insert it, otherwise, update the old value with the new one.
+
+```SQL
+ALTER view root.turbine.d1.s1 UPSERT TAGS(tag2=newV2, tag3=v3) ATTRIBUTES(attr3=v3, attr4=v4)
+```
+
+#### 3.3.4 Deleting Views
+
+Since a view is a sequence, a view can be deleted as if it were a time series.
+
+The original method of deleting a time series is expanded without a new ``DELETE VIEW`` statement.
+
+```SQL
+DELETE VIEW root.view.device.avg_temperatue
+```
+
+### 3.4 View Synchronisation
+
+Sequence view data is always obtained via real-time queries, so data synchronisation is naturally supported.
+
+#### If the dependent original sequence is deleted
+
+When the sequence view is queried (when the sequence is parsed), **the empty result set** is returned if the dependent time series does not exist.
+
+This is similar to the feedback for querying a non-existent sequence, but with a difference: if the dependent time series cannot be parsed, the empty result set is the one that contains the table header as a reminder to the user that the view is problematic.
+
+Additionally, when the dependent time series is deleted, no attempt is made to find out if there is a view that depends on the column, and the user receives no warning.
+
+#### Data Writes to Non-Aliased Sequences Not Supported
+
+Writes to non-alias sequences are not supported.
+
+Please refer to the previous section 2.1.6 Restrictions2 for more details.
+
+#### Metadata for sequences is not shared
+
+Please refer to the previous section 2.1.6 Restriction 5 for details.
+
+### 3.5 View Metadata Queries
+
+View metadata query specifically refers to querying the metadata of the view itself (e.g., how many columns the view has), as well as information about the views in the database (e.g., what views are available).
+
+#### 3.5.1 Viewing Current View Columns
+
+The user has two ways of querying:
+
+1. a query using `SHOW TIMESERIES`, which contains both time series and series views. This query contains both the time series and the sequence view. However, only some of the attributes of the view can be displayed.
+2. a query using `SHOW VIEW`, which contains only the sequence view. It displays the complete properties of the sequence view.
+
+Example:
+
+```Shell
+IoTDB> show timeseries;
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| Timeseries|Alias|Database|DataType|Encoding|Compression|Tags|Attributes|Deadband|DeadbandParameters|ViewType|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.device.s01 | null| root.db| INT32| RLE| SNAPPY|null| null| null| null| BASE|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.view.status | null| root.db| INT32| RLE| SNAPPY|null| null| null| null| VIEW|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.d01.temp01 | null| root.db| FLOAT| RLE| SNAPPY|null| null| null| null| BASE|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.d01.temp02 | null| root.db| FLOAT| RLE| SNAPPY|null| null| null| null| BASE|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.d01.avg_temp| null| root.db| FLOAT| null| null|null| null| null| null| VIEW|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+Total line number = 5
+It costs 0.789s
+IoTDB>
+```
+
+The last column `ViewType` shows the type of the sequence, the time series is BASE and the sequence view is VIEW.
+
+In addition, some of the sequence view properties will be missing, for example `root.db.d01.avg_temp` is calculated from temperature averages, so the `Encoding` and `Compression` properties are null values.
+
+In addition, the query results of the `SHOW TIMESERIES` statement are divided into two main parts.
+
+1. information about the timing data, such as data type, compression, encoding, etc.
+2. other metadata information, such as tag, attribute, database, etc.
+
+For the sequence view, the temporal data information presented is the same as the original sequence or null (e.g., the calculated average temperature has a data type but no compression method); the metadata information presented is the content of the view.
+
+To learn more about the view, use `SHOW ``VIEW`. The `SHOW ``VIEW` shows the source of the view's data, etc.
+
+```Shell
+IoTDB> show VIEW root.**;
++--------------------+--------+--------+----+----------+--------+-----------------------------------------+
+| Timeseries|Database|DataType|Tags|Attributes|ViewType| SOURCE|
++--------------------+--------+--------+----+----------+--------+-----------------------------------------+
+|root.db.view.status | root.db| INT32|null| null| VIEW| root.db.device.s01|
++--------------------+--------+--------+----+----------+--------+-----------------------------------------+
+|root.db.d01.avg_temp| root.db| FLOAT|null| null| VIEW|(root.db.d01.temp01+root.db.d01.temp02)/2|
++--------------------+--------+--------+----+----------+--------+-----------------------------------------+
+Total line number = 2
+It costs 0.789s
+IoTDB>
+```
+
+The last column, `SOURCE`, shows the data source for the sequence view, listing the SQL statement that created the sequence.
+
+##### About Data Types
+
+Both of the above queries involve the data type of the view. The data type of a view is inferred from the original time series type of the query statement or alias sequence that defines the view. This data type is computed in real time based on the current state of the system, so the data type queried at different moments may be changing.
+
+## IV. FAQ
+
+####Q1: I want the view to implement the function of type conversion. For example, a time series of type int32 was originally placed in the same view as other series of type int64. I now want all the data queried through the view to be automatically converted to int64 type.
+
+> Ans: This is not the function of the sequence view. But the conversion can be done using `CAST`, for example:
+
+```SQL
+CREATE VIEW root.db.device.int64_status
+AS
+ SELECT CAST(s1, 'type'='INT64') from root.db.device
+```
+
+> This way, a query for `root.view.status` will yield a result of type int64.
+>
+> Please note in particular that in the above example, the data for the sequence view is obtained by `CAST` conversion, so `root.db.device.int64_status` is not an aliased sequence, and thus **not supported for writing**.
+
+####Q2: Is default naming supported? Select a number of time series and create a view; but I don't specify the name of each series, it is named automatically by the database?
+
+> Ans: Not supported. Users must specify the naming explicitly.
+
+#### Q3: In the original system, create time series `root.db.device.s01`, you can find that database `root.db` is automatically created and device `root.db.device` is automatically created. Next, deleting the time series `root.db.device.s01` reveals that `root.db.device` was automatically deleted, while `root.db` remained. Will this mechanism be followed for creating views? What are the considerations?
+
+> Ans: Keep the original behaviour unchanged, the introduction of view functionality will not change these original logics.
+
+#### Q4: Does it support sequence view renaming?
+
+> A: Renaming is not supported in the current version, you can create your own view with new name to put it into use.
\ No newline at end of file
diff --git a/src/UserGuide/V1.3.x/User-Manual/Security-Management_timecho.md b/src/UserGuide/V1.3.x/User-Manual/Security-Management_timecho.md
new file mode 100644
index 00000000..51070360
--- /dev/null
+++ b/src/UserGuide/V1.3.x/User-Manual/Security-Management_timecho.md
@@ -0,0 +1,144 @@
+
+
+# SecurityManagement
+
+## White List
+
+**function description**
+
+Allow which client addresses can connect to IoTDB
+
+**configuration file**
+
+conf/iotdb-common.properties
+
+conf/white.list
+
+**configuration item**
+
+iotdb-common.properties:
+
+Decide whether to enable white list
+
+```YAML
+
+# Whether to enable white list
+enable_white_list=true
+```
+
+white.list:
+
+Decide which IP addresses can connect to IoTDB
+
+```YAML
+# Support for annotation
+# Supports precise matching, one IP per line
+10.2.3.4
+
+# Support for * wildcards, one ip per line
+10.*.1.3
+10.100.0.*
+```
+
+**note**
+
+1. If the white list itself is cancelled via the session client, the current connection is not immediately disconnected. It is rejected the next time the connection is created.
+2. If white.list is modified directly, it takes effect within one minute. If modified via the session client, it takes effect immediately, updating the values in memory and the white.list disk file.
+3. Enable the whitelist function, there is no white.list file, start the DB service successfully, however, all connections are rejected.
+4. while DB service is running, the white.list file is deleted, and all connections are denied after up to one minute.
+5. whether to enable the configuration of the white list function, can be hot loaded.
+6. Use the Java native interface to modify the whitelist, must be the root user to modify, reject non-root user to modify; modify the content must be legal, otherwise it will throw a StatementExecutionException.
+
+
+
+## Audit log
+
+### Background of the function
+
+Audit log is the record credentials of a database, which can be queried by the audit log function to ensure information security by various operations such as user add, delete, change and check in the database. With the audit log function of IoTDB, the following scenarios can be achieved:
+
+- We can decide whether to record audit logs according to the source of the link ( human operation or not), such as: non-human operation such as hardware collector write data no need to record audit logs, human operation such as ordinary users through cli, workbench and other tools to operate the data need to record audit logs.
+- Filter out system-level write operations, such as those recorded by the IoTDB monitoring system itself.
+
+#### Scene Description
+
+##### Logging all operations (add, delete, change, check) of all users
+
+The audit log function traces all user operations in the database. The information recorded should include data operations (add, delete, query) and metadata operations (add, modify, delete, query), client login information (user name, ip address).
+
+Client Sources:
+- Cli、workbench、Zeppelin、Grafana、通过 Session/JDBC/MQTT 等协议传入的请求
+
+
+
+##### Audit logging can be turned off for some user connections
+
+No audit logs are required for data written by the hardware collector via Session/JDBC/MQTT if it is a non-human action.
+
+### Function Definition
+
+It is available through through configurations:
+
+- Decide whether to enable the audit function or not
+- Decide where to output the audit logs, support output to one or more
+ 1. log file
+ 2. IoTDB storage
+- Decide whether to block the native interface writes to prevent recording too many audit logs to affect performance.
+- Decide the content category of the audit log, supporting recording one or more
+ 1. data addition and deletion operations
+ 2. data and metadata query operations
+ 3. metadata class adding, modifying, and deleting operations.
+
+#### configuration item
+
+In iotdb-engine.properties or iotdb-common.properties, change the following configurations:
+
+```YAML
+####################
+### Audit log Configuration
+####################
+
+# whether to enable the audit log.
+# Datatype: Boolean
+# enable_audit_log=false
+
+# Output location of audit logs
+# Datatype: String
+# IOTDB: the stored time series is: root.__system.audit._{user}
+# LOGGER: log_audit.log in the log directory
+# audit_log_storage=IOTDB,LOGGER
+
+# whether enable audit log for DML operation of data
+# whether enable audit log for DDL operation of schema
+# whether enable audit log for QUERY operation of data and schema
+# Datatype: String
+# audit_log_operation=DML,DDL,QUERY
+
+# whether the local write api records audit logs
+# Datatype: Boolean
+# This contains Session insert api: insertRecord(s), insertTablet(s),insertRecordsOfOneDevice
+# MQTT insert api
+# RestAPI insert api
+# This parameter will cover the DML in audit_log_operation
+# enable_audit_log_for_native_insert_api=true
+```
+
diff --git a/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md b/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md
new file mode 100644
index 00000000..6005077e
--- /dev/null
+++ b/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md
@@ -0,0 +1,796 @@
+
+
+# IoTDB stream processing framework
+
+The IoTDB stream processing framework allows users to implement customized stream processing logic, which can monitor and capture storage engine changes, transform changed data, and push transformed data outward.
+
+We call a data flow processing task a Pipe. A stream processing task (Pipe) contains three subtasks:
+
+- Extract
+- Process
+- Send (Connect)
+
+The stream processing framework allows users to customize the processing logic of three subtasks using Java language and process data in a UDF-like manner.
+In a Pipe, the above three subtasks are executed by three plugins respectively, and the data will be processed by these three plugins in turn:
+Pipe Extractor is used to extract data, Pipe Processor is used to process data, Pipe Connector is used to send data, and the final data will be sent to an external system.
+
+**The model of the Pipe task is as follows:**
+
+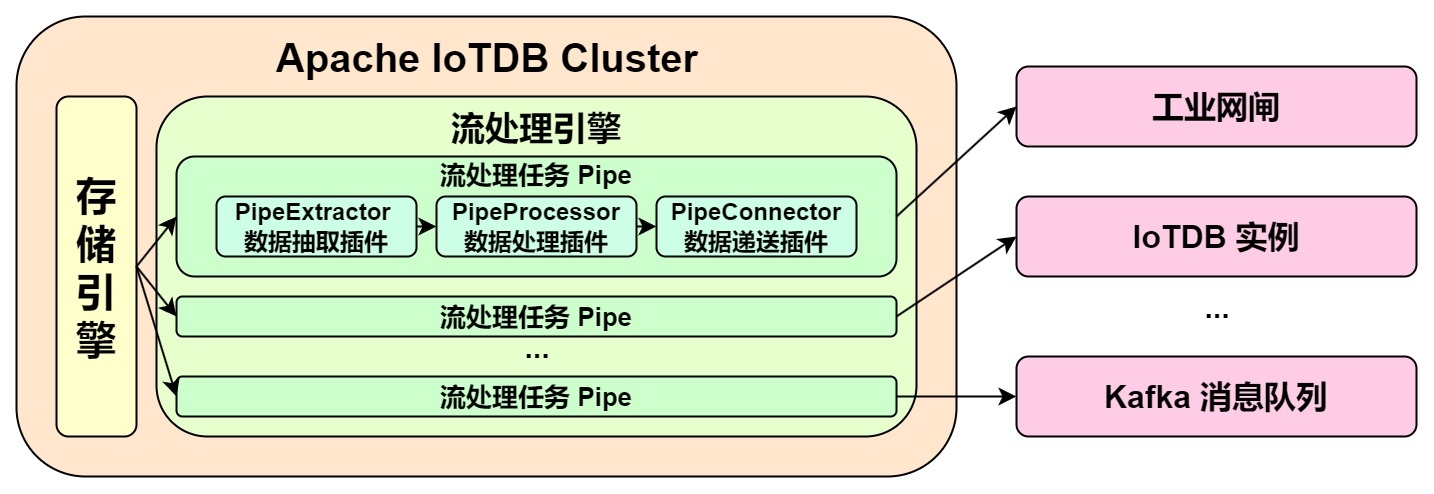
+
+Describing a data flow processing task essentially describes the properties of Pipe Extractor, Pipe Processor and Pipe Connector plugins.
+Users can declaratively configure the specific attributes of the three subtasks through SQL statements, and achieve flexible data ETL capabilities by combining different attributes.
+
+Using the stream processing framework, a complete data link can be built to meet the needs of end-side-cloud synchronization, off-site disaster recovery, and read-write load sub-library*.
+
+## Custom stream processing plugin development
+
+### Programming development dependencies
+
+It is recommended to use maven to build the project and add the following dependencies in `pom.xml`. Please be careful to select the same dependency version as the IoTDB server version.
+
+```xml
+
+ org.apache.iotdb
+ pipe-api
+ 1.2.1
+ provided
+
+```
+
+### Event-driven programming model
+
+The user programming interface design of the stream processing plugin refers to the general design concept of the event-driven programming model. Events are data abstractions in the user programming interface, and the programming interface is decoupled from the specific execution method. It only needs to focus on describing the processing method expected by the system after the event (data) reaches the system.
+
+In the user programming interface of the stream processing plugin, events are an abstraction of database data writing operations. The event is captured by the stand-alone stream processing engine, and is passed to the PipeExtractor plugin, PipeProcessor plugin, and PipeConnector plugin in sequence according to the three-stage stream processing process, and triggers the execution of user logic in the three plugins in turn.
+
+In order to take into account the low latency of stream processing in low load scenarios on the end side and the high throughput of stream processing in high load scenarios on the end side, the stream processing engine will dynamically select processing objects in the operation logs and data files. Therefore, user programming of stream processing The interface requires users to provide processing logic for the following two types of events: operation log writing event TabletInsertionEvent and data file writing event TsFileInsertionEvent.
+
+#### **Operation log writing event (TabletInsertionEvent)**
+
+The operation log write event (TabletInsertionEvent) is a high-level data abstraction for user write requests. It provides users with the ability to manipulate the underlying data of write requests by providing a unified operation interface.
+
+For different database deployment methods, the underlying storage structures corresponding to operation log writing events are different. For stand-alone deployment scenarios, the operation log writing event is an encapsulation of write-ahead log (WAL) entries; for a distributed deployment scenario, the operation log writing event is an encapsulation of a single node consensus protocol operation log entry.
+
+For write operations generated by different write request interfaces in the database, the data structure of the request structure corresponding to the operation log write event is also different. IoTDB provides numerous writing interfaces such as InsertRecord, InsertRecords, InsertTablet, InsertTablets, etc. Each writing request uses a completely different serialization method, and the generated binary entries are also different.
+
+The existence of operation log writing events provides users with a unified view of data operations, which shields the implementation differences of the underlying data structure, greatly reduces the user's programming threshold, and improves the ease of use of the function.
+
+```java
+/** TabletInsertionEvent is used to define the event of data insertion. */
+public interface TabletInsertionEvent extends Event {
+
+ /**
+ * The consumer processes the data row by row and collects the results by RowCollector.
+ *
+ * @return {@code Iterable} a list of new TabletInsertionEvent contains the
+ * results collected by the RowCollector
+ */
+ Iterable processRowByRow(BiConsumer consumer);
+
+ /**
+ * The consumer processes the Tablet directly and collects the results by RowCollector.
+ *
+ * @return {@code Iterable} a list of new TabletInsertionEvent contains the
+ * results collected by the RowCollector
+ */
+ Iterable processTablet(BiConsumer consumer);
+}
+```
+
+#### **Data file writing event (TsFileInsertionEvent)**
+
+The data file writing event (TsFileInsertionEvent) is a high-level abstraction of the database file writing operation. It is a data collection of several operation log writing events (TabletInsertionEvent).
+
+The storage engine of IoTDB is LSM structured. When data is written, the writing operation will first be placed into a log-structured file, and the written data will be stored in the memory at the same time. When the memory reaches the control upper limit, the disk flushing behavior will be triggered, that is, the data in the memory will be converted into a database file, and the previously prewritten operation log will be deleted. When the data in the memory is converted into the data in the database file, it will undergo two compression processes: encoding compression and general compression. Therefore, the data in the database file takes up less space than the original data in the memory.
+
+In extreme network conditions, directly transmitting data files is more economical than transmitting data writing operations. It will occupy lower network bandwidth and achieve faster transmission speeds. Of course, there is no free lunch. Computing and processing data in files requires additional file I/O costs compared to directly computing and processing data in memory. However, it is precisely the existence of two structures, disk data files and memory write operations, with their own advantages and disadvantages, that gives the system the opportunity to make dynamic trade-offs and adjustments. It is based on this observation that data files are introduced into the plugin's event model. Write event.
+
+To sum up, the data file writing event appears in the event stream of the stream processing plugin, and there are two situations:
+
+(1) Historical data extraction: Before a stream processing task starts, all written data that has been placed on the disk will exist in the form of TsFile. After a stream processing task starts, when collecting historical data, the historical data will be abstracted using TsFileInsertionEvent;
+
+(2) Real-time data extraction: When a stream processing task is in progress, when the real-time processing speed of operation log write events in the data stream is slower than the write request speed, after a certain progress, the operation log write events that cannot be processed in the future will be persisted. to disk and exists in the form of TsFile. After this data is extracted by the stream processing engine, TsFileInsertionEvent will be used as an abstraction.
+
+```java
+/**
+ * TsFileInsertionEvent is used to define the event of writing TsFile. Event data stores in disks,
+ * which is compressed and encoded, and requires IO cost for computational processing.
+ */
+public interface TsFileInsertionEvent extends Event {
+
+ /**
+ * The method is used to convert the TsFileInsertionEvent into several TabletInsertionEvents.
+ *
+ * @return {@code Iterable} the list of TabletInsertionEvent
+ */
+ Iterable toTabletInsertionEvents();
+}
+```
+
+### Custom stream processing plugin programming interface definition
+
+Based on the custom stream processing plugin programming interface, users can easily write data extraction plugins, data processing plugins and data sending plugins, so that the stream processing function can be flexibly adapted to various industrial scenarios.
+
+#### Data extraction plugin interface
+
+Data extraction is the first stage of the three stages of stream processing data from data extraction to data sending. The data extraction plugin (PipeExtractor) is the bridge between the stream processing engine and the storage engine. It monitors the behavior of the storage engine,
+Capture various data write events.
+
+```java
+/**
+ * PipeExtractor
+ *
+ *
+::::
+
+## 3. Installation and Deployment
+
+The deployment of AINode can be found in the document [Deployment Guidelines](../Deployment-and-Maintenance/Deployment-Guide_timecho.md#AINode-部署) .
+
+
+## 4. Usage Guidelines
+
+AINode provides model creation and deletion process for deep learning models related to timing data. Built-in models do not need to be created and deleted, they can be used directly, and the built-in model instances created after inference is completed will be destroyed automatically.
+
+### 4.1 Registering Models
+
+A trained deep learning model can be registered by specifying the vector dimensions of the model's inputs and outputs, which can be used for model inference. The following is the SQL syntax definition for model registration.
+
+```SQL
+create model using uri
+```
+
+The specific meanings of the parameters in the SQL are as follows:
+
+- model_name: a globally unique identifier for the model, which cannot be repeated. The model name has the following constraints:
+
+ - Identifiers [ 0-9 a-z A-Z _ ] (letters, numbers, underscores) are allowed.
+ - Length is limited to 2-64 characters
+ - Case sensitive
+
+- uri: resource path to the model registration file, which should contain the **model weights model.pt file and the model's metadata description file config.yaml**.
+
+ - Model weight file: the weight file obtained after the training of the deep learning model is completed, currently supporting pytorch training of the .pt file
+
+ - yaml metadata description file: parameters related to the model structure that need to be provided when the model is registered, which must contain the input and output dimensions of the model for model inference:
+
+ - | **Parameter name** | **Parameter description** | **Example** |
+ | ------------ | ---------------------------- | -------- |
+ | input_shape | Rows and columns of model inputs for model inference | [96,2] |
+ | output_shape | rows and columns of model outputs, for model inference | [48,2] |
+
+ - In addition to model inference, the data types of model input and output can be specified:
+
+ - | **Parameter name** | **Parameter description** | **Example** |
+ | ----------- | ------------------ | --------------------- |
+ | input_type | model input data type | ['float32','float32'] |
+ | output_type | data type of the model output | ['float32','float32'] |
+
+ - In addition to this, additional notes can be specified for display during model management
+
+ - | **Parameter name** | **Parameter description** | **Examples** |
+ | ---------- | ---------------------------------------------- | ------------------------------------------- |
+ | attributes | optional, user-defined model notes for model display | 'model_type': 'dlinear','kernel_size': '25' |
+
+
+In addition to registration of local model files, registration can also be done by specifying remote resource paths via URIs, using open source model repositories (e.g. HuggingFace).
+
+#### 4.1.1 Example
+
+In the current example folder, it contains model.pt and config.yaml files, model.pt is the training get, and the content of config.yaml is as follows:
+
+```YAML
+configs.
+ # Required options
+ input_shape: [96, 2] # The model receives data in 96 rows x 2 columns.
+ output_shape: [48, 2] # Indicates that the model outputs 48 rows x 2 columns.
+
+ # Optional Default is all float32 and the number of columns is the number of columns in the shape.
+ input_type: ["int64", "int64"] # Input data type, need to match the number of columns.
+ output_type: ["text", "int64"] #Output data type, need to match the number of columns.
+
+attributes: # Optional user-defined notes for the input.
+ 'model_type': 'dlinear'
+ 'kernel_size': '25'
+```
+
+Specify this folder as the load path to register the model.
+
+```SQL
+IoTDB> create model dlinear_example using uri "file://. /example"
+```
+
+Alternatively, you can download the corresponding model file from huggingFace and register it.
+
+```SQL
+IoTDB> create model dlinear_example using uri "https://huggingface.com/IoTDBML/dlinear/"
+```
+
+After the SQL is executed, the registration process will be carried out asynchronously, and you can view the registration status of the model through the model showcase (see the Model Showcase section), and the time consumed for successful registration is mainly affected by the size of the model file.
+
+Once the model registration is complete, you can call specific functions and perform model inference by using normal queries.
+
+### 4.2 Viewing Models
+
+Successfully registered models can be queried for model-specific information through the show models command. The SQL definition is as follows:
+
+```SQL
+show models
+
+show models
+```
+
+In addition to displaying information about all models directly, you can specify a model id to view information about a specific model. The results of the model show contain the following information:
+
+| **ModelId** | **State** | **Configs** | **Attributes** |
+| ------------ | ------------------------------------- | ---------------------------------------------- | -------------- |
+| Model Unique Identifier | Model Registration Status (LOADING, ACTIVE, DROPPING) | InputShape, outputShapeInputTypes, outputTypes | Model Notes |
+
+State is used to show the current state of model registration, which consists of the following three stages
+
+- **LOADING:** The corresponding model meta information has been added to the configNode, and the model file is being transferred to the AINode node.
+- **ACTIVE:** The model has been set up and the model is in the available state
+- **DROPPING:** Model deletion is in progress, model related information is being deleted from configNode and AINode.
+- **UNAVAILABLE**: Model creation failed, you can delete the failed model_name by drop model.
+
+#### 4.2.1 Example
+
+```SQL
+IoTDB> show models
+
+
++---------------------+--------------------------+-----------+----------------------------+-----------------------+
+| ModelId| ModelType| State| Configs| Notes|
++---------------------+--------------------------+-----------+----------------------------+-----------------------+
+| dlinear_example| USER_DEFINED| ACTIVE| inputShape:[96,2]| |
+| | | | outputShape:[48,2]| |
+| | | | inputDataType:[float,float]| |
+| | | |outputDataType:[float,float]| |
+| _STLForecaster| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
+| _NaiveForecaster| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
+| _ARIMA| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
+|_ExponentialSmoothing| BUILT_IN_FORECAST| ACTIVE| |Built-in model in IoTDB|
+| _GaussianHMM|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
+| _GMMHMM|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
+| _Stray|BUILT_IN_ANOMALY_DETECTION| ACTIVE| |Built-in model in IoTDB|
++---------------------+--------------------------+-----------+------------------------------------------------------------+-----------------------+
+```
+
+We have registered the corresponding model earlier, you can view the model status through the corresponding designation, active indicates that the model is successfully registered and can be used for inference.
+
+### 4.3 Delete Model
+
+For a successfully registered model, the user can delete it via SQL. In addition to deleting the meta information on the configNode, this operation also deletes all the related model files under the AINode. The SQL is as follows:
+
+```SQL
+drop model
+```
+
+You need to specify the model model_name that has been successfully registered to delete the corresponding model. Since model deletion involves the deletion of data on multiple nodes, the operation will not be completed immediately, and the state of the model at this time is DROPPING, and the model in this state cannot be used for model inference.
+
+### 4.4 Using Built-in Model Reasoning
+
+The SQL syntax is as follows:
+
+
+```SQL
+call inference(,sql[,=])
+```
+
+Built-in model inference does not require a registration process, the inference function can be used by calling the inference function through the call keyword, and its corresponding parameters are described as follows:
+
+- **built_in_model_name:** built-in model name
+- **parameterName:** parameter name
+- **parameterValue:** parameter value
+
+#### 4.4.1 Built-in Models and Parameter Descriptions
+
+The following machine learning models are currently built-in, please refer to the following links for detailed parameter descriptions.
+
+| Model | built_in_model_name | Task type | Parameter description |
+| -------------------- | --------------------- | -------- | ------------------------------------------------------------ |
+| Arima | _Arima | Forecast | [Arima Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.forecasting.arima.ARIMA.html?highlight=Arima) |
+| STLForecaster | _STLForecaster | Forecast | [STLForecaster Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.forecasting.trend.STLForecaster.html#sktime.forecasting.trend.STLForecaster) |
+| NaiveForecaster | _NaiveForecaster | Forecast | [NaiveForecaster Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.forecasting.naive.NaiveForecaster.html#naiveforecaster) |
+| ExponentialSmoothing | _ExponentialSmoothing | Forecast | [ExponentialSmoothing 参Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.forecasting.exp_smoothing.ExponentialSmoothing.html) |
+| GaussianHMM | _GaussianHMM | Annotation | [GaussianHMMParameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.annotation.hmm_learn.gaussian.GaussianHMM.html) |
+| GMMHMM | _GMMHMM | Annotation | [GMMHMM参数说明](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.annotation.hmm_learn.gmm.GMMHMM.html) |
+| Stray | _Stray | Anomaly detection | [Stray Parameter description](https://www.sktime.net/en/latest/api_reference/auto_generated/sktime.annotation.stray.STRAY.html) |
+
+
+#### 4.4.2 Example
+
+The following is an example of an operation using built-in model inference. The built-in Stray model is used for anomaly detection algorithm. The input is `[144,1]` and the output is `[144,1]`. We use it for reasoning through SQL.
+
+```SQL
+IoTDB> select * from root.eg.airline
++-----------------------------+------------------+
+| Time|root.eg.airline.s0|
++-----------------------------+------------------+
+|1949-01-31T00:00:00.000+08:00| 224.0|
+|1949-02-28T00:00:00.000+08:00| 118.0|
+|1949-03-31T00:00:00.000+08:00| 132.0|
+|1949-04-30T00:00:00.000+08:00| 129.0|
+......
+|1960-09-30T00:00:00.000+08:00| 508.0|
+|1960-10-31T00:00:00.000+08:00| 461.0|
+|1960-11-30T00:00:00.000+08:00| 390.0|
+|1960-12-31T00:00:00.000+08:00| 432.0|
++-----------------------------+------------------+
+Total line number = 144
+
+IoTDB> call inference(_Stray, "select s0 from root.eg.airline", k=2)
++-------+
+|output0|
++-------+
+| 0|
+| 0|
+| 0|
+| 0|
+......
+| 1|
+| 1|
+| 0|
+| 0|
+| 0|
+| 0|
++-------+
+Total line number = 144
+```
+
+### 4.5 Reasoning with Deep Learning Models
+
+The SQL syntax is as follows:
+
+```SQL
+call inference(,sql[,window=])
+
+
+window_function:
+ head(window_size)
+ tail(window_size)
+ count(window_size,sliding_step)
+```
+
+After completing the registration of the model, the inference function can be used by calling the inference function through the call keyword, and its corresponding parameters are described as follows:
+
+- **model_name**: corresponds to a registered model
+- **sql**: sql query statement, the result of the query is used as input to the model for model inference. The dimensions of the rows and columns in the result of the query need to match the size specified in the specific model config. (It is not recommended to use the 'SELECT *' clause for the sql here because in IoTDB, '*' does not sort the columns, so the order of the columns is undefined, you can use 'SELECT s0,s1' to ensure that the columns order matches the expectations of the model input)
+- **window_function**: Window functions that can be used in the inference process, there are currently three types of window functions provided to assist in model inference:
+ - **head(window_size)**: Get the top window_size points in the data for model inference, this window can be used for data cropping.
+ 
+
+ - **tail(window_size)**: get the last window_size point in the data for model inference, this window can be used for data cropping.
+ 
+
+ - **count(window_size, sliding_step):** sliding window based on the number of points, the data in each window will be reasoned through the model respectively, as shown in the example below, window_size for 2 window function will be divided into three windows of the input dataset, and each window will perform reasoning operations to generate results respectively. The window can be used for continuous inference
+ 
+
+**Explanation 1**: window can be used to solve the problem of cropping rows when the results of the sql query and the input row requirements of the model do not match. Note that when the number of columns does not match or the number of rows is directly less than the model requirement, the inference cannot proceed and an error message will be returned.
+
+**Explanation 2**: In deep learning applications, timestamp-derived features (time columns in the data) are often used as covariates in generative tasks, and are input into the model together to enhance the model, but the time columns are generally not included in the model's output. In order to ensure the generality of the implementation, the model inference results only correspond to the real output of the model, if the model does not output the time column, it will not be included in the results.
+
+
+#### 4.5.1 Example
+
+The following is an example of inference in action using a deep learning model, for the `dlinear` prediction model with input `[96,2]` and output `[48,2]` mentioned above, which we use via SQL.
+
+```Shell
+IoTDB> select s1,s2 from root.**
++-----------------------------+-------------------+-------------------+
+| Time| root.eg.etth.s0| root.eg.etth.s1|
++-----------------------------+-------------------+-------------------+
+|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
+|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
+|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
+|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
+|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
+|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
+|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
+......
+|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
+|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
+|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
+|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
+|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
+|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
+|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
++-----------------------------+-------------------+-------------------+
+Total line number = 96
+
+IoTDB> call inference(dlinear_example,"select s0,s1 from root.**")
++--------------------------------------------+-----------------------------+
+| _result_0| _result_1|
++--------------------------------------------+-----------------------------+
+| 0.726302981376648| 1.6549958229064941|
+| 0.7354921698570251| 1.6482787370681763|
+| 0.7238251566886902| 1.6278168201446533|
+......
+| 0.7692174911499023| 1.654654049873352|
+| 0.7685555815696716| 1.6625318765640259|
+| 0.7856493592262268| 1.6508299350738525|
++--------------------------------------------+-----------------------------+
+Total line number = 48
+```
+
+#### 4.5.2 Example of using the tail/head window function
+
+When the amount of data is variable and you want to take the latest 96 rows of data for inference, you can use the corresponding window function tail. head function is used in a similar way, except that it takes the earliest 96 points.
+
+```Shell
+IoTDB> select s1,s2 from root.**
++-----------------------------+-------------------+-------------------+
+| Time| root.eg.etth.s0| root.eg.etth.s1|
++-----------------------------+-------------------+-------------------+
+|1988-01-01T00:00:00.000+08:00| 0.7355| 1.211|
+......
+|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
+|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
+|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
+|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
+|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
+|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
+|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
+......
+|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
+|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
+|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
+|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
+|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
+|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
+|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
++-----------------------------+-------------------+-------------------+
+Total line number = 996
+
+IoTDB> call inference(dlinear_example,"select s0,s1 from root.**",window=tail(96))
++--------------------------------------------+-----------------------------+
+| _result_0| _result_1|
++--------------------------------------------+-----------------------------+
+| 0.726302981376648| 1.6549958229064941|
+| 0.7354921698570251| 1.6482787370681763|
+| 0.7238251566886902| 1.6278168201446533|
+......
+| 0.7692174911499023| 1.654654049873352|
+| 0.7685555815696716| 1.6625318765640259|
+| 0.7856493592262268| 1.6508299350738525|
++--------------------------------------------+-----------------------------+
+Total line number = 48
+```
+
+#### 4.5.3 Example of using the count window function
+
+This window is mainly used for computational tasks, when the model corresponding to the task can only process a fixed row of data at a time and what is ultimately desired is indeed multiple sets of predictions, using this window function allows for sequential inference using a sliding window of points. Suppose we now have an anomaly detection model anomaly_example(input: [24,2], output[1,1]) that generates a 0/1 label for each row of data, an example of its use is shown below:
+```Shell
+IoTDB> select s1,s2 from root.**
++-----------------------------+-------------------+-------------------+
+| Time| root.eg.etth.s0| root.eg.etth.s1|
++-----------------------------+-------------------+-------------------+
+|1990-01-01T00:00:00.000+08:00| 0.7855| 1.611|
+|1990-01-02T00:00:00.000+08:00| 0.7818| 1.61|
+|1990-01-03T00:00:00.000+08:00| 0.7867| 1.6293|
+|1990-01-04T00:00:00.000+08:00| 0.786| 1.637|
+|1990-01-05T00:00:00.000+08:00| 0.7849| 1.653|
+|1990-01-06T00:00:00.000+08:00| 0.7866| 1.6537|
+|1990-01-07T00:00:00.000+08:00| 0.7886| 1.662|
+......
+|1990-03-31T00:00:00.000+08:00| 0.7585| 1.678|
+|1990-04-01T00:00:00.000+08:00| 0.7587| 1.6763|
+|1990-04-02T00:00:00.000+08:00| 0.76| 1.6813|
+|1990-04-03T00:00:00.000+08:00| 0.7669| 1.684|
+|1990-04-04T00:00:00.000+08:00| 0.7645| 1.677|
+|1990-04-05T00:00:00.000+08:00| 0.7625| 1.68|
+|1990-04-06T00:00:00.000+08:00| 0.7617| 1.6917|
++-----------------------------+-------------------+-------------------+
+Total line number = 96
+
+IoTDB> call inference(anomaly_example,"select s0,s1 from root.**",window=count(24,24))
++-------------------------+
+| _result_0|
++-------------------------+
+| 0|
+| 1|
+| 1|
+| 0|
++-------------------------+
+Total line number = 4
+```
+
+where the labels of each row in the result set correspond to the model output corresponding to the 16 rows of input.
+
+## 5. Privilege Management
+
+When using AINode related functions, the authentication of IoTDB itself can be used to do a permission management, users can only use the model management related functions when they have the USE_ML permission. When using the inference function, the user needs to have the permission to access the source sequence corresponding to the SQL of the input model.
+
+| Privilege Name | Privilege Scope | Administrator User (default ROOT) | Normal User | Path Related |
+| --------- | --------------------------------- | ---------------------- | -------- | -------- |
+| USE_MODEL | create modelshow modelsdrop model | √ | √ √ | x |
+| | | call inference | | | | |
+
+## 6. Practical Examples
+
+### 6.1 Power Load Prediction
+
+In some industrial scenarios, there is a need to predict power loads, which can be used to optimise power supply, conserve energy and resources, support planning and expansion, and enhance power system reliability.
+
+The data for the test set of ETTh1 that we use is [ETTh1](https://alioss.timecho.com/docs/img/ETTh1.csv).
+
+
+It contains power data collected at 1h intervals, and each data consists of load and oil temperature as High UseFul Load, High UseLess Load, Middle UseLess Load, Low UseFul Load, Low UseLess Load, Oil Temperature.
+
+On this dataset, the model inference function of IoTDB-ML can predict the oil temperature in the future period of time through the relationship between the past values of high, middle and low use loads and the corresponding time stamp oil temperature, which empowers the automatic regulation and monitoring of grid transformers.
+
+#### Step 1: Data Import
+
+Users can import the ETT dataset into IoTDB using `import-csv.sh` in the tools folder
+
+``Bash
+bash . /import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /ETTh1.csv
+``
+
+#### Step 2: Model Import
+
+We can enter the following SQL in iotdb-cli to pull a trained model from huggingface for registration for subsequent inference.
+
+```SQL
+create model dlinear using uri 'https://huggingface.co/hvlgo/dlinear/resolve/main'
+```
+
+This model is trained on the lighter weight deep model DLinear, which is able to capture as many trends within a sequence and relationships between variables as possible with relatively fast inference, making it more suitable for fast real-time prediction than other deeper models.
+
+#### Step 3: Model inference
+
+```Shell
+IoTDB> select s0,s1,s2,s3,s4,s5,s6 from root.eg.etth LIMIT 96
++-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
+| Time|root.eg.etth.s0|root.eg.etth.s1|root.eg.etth.s2|root.eg.etth.s3|root.eg.etth.s4|root.eg.etth.s5|root.eg.etth.s6|
++-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
+|2017-10-20T00:00:00.000+08:00| 10.449| 3.885| 8.706| 2.025| 2.041| 0.944| 8.864|
+|2017-10-20T01:00:00.000+08:00| 11.119| 3.952| 8.813| 2.31| 2.071| 1.005| 8.442|
+|2017-10-20T02:00:00.000+08:00| 9.511| 2.88| 7.533| 1.564| 1.949| 0.883| 8.16|
+|2017-10-20T03:00:00.000+08:00| 9.645| 2.21| 7.249| 1.066| 1.828| 0.914| 7.949|
+......
+|2017-10-23T20:00:00.000+08:00| 8.105| 0.938| 4.371| -0.569| 3.533| 1.279| 9.708|
+|2017-10-23T21:00:00.000+08:00| 7.167| 1.206| 4.087| -0.462| 3.107| 1.432| 8.723|
+|2017-10-23T22:00:00.000+08:00| 7.1| 1.34| 4.015| -0.32| 2.772| 1.31| 8.864|
+|2017-10-23T23:00:00.000+08:00| 9.176| 2.746| 7.107| 1.635| 2.65| 1.097| 9.004|
++-----------------------------+---------------+---------------+---------------+---------------+---------------+---------------+---------------+
+Total line number = 96
+
+IoTDB> call inference(dlinear_example, "select s0,s1,s2,s3,s4,s5,s6 from root.eg.etth", window=head(96))
++-----------+----------+----------+------------+---------+----------+----------+
+| output0| output1| output2| output3| output4| output5| output6|
++-----------+----------+----------+------------+---------+----------+----------+
+| 10.319546| 3.1450553| 7.877341| 1.5723765|2.7303758| 1.1362307| 8.867775|
+| 10.443649| 3.3286757| 7.8593454| 1.7675098| 2.560634| 1.1177158| 8.920919|
+| 10.883752| 3.2341104| 8.47036| 1.6116762|2.4874182| 1.1760603| 8.798939|
+......
+| 8.0115595| 1.2995274| 6.9900327|-0.098746896| 3.04923| 1.176214| 9.548782|
+| 8.612427| 2.5036244| 5.6790237| 0.66474205|2.8870275| 1.2051733| 9.330128|
+| 10.096699| 3.399722| 6.9909| 1.7478468|2.7642853| 1.1119363| 9.541455|
++-----------+----------+----------+------------+---------+----------+----------+
+Total line number = 48
+```
+
+We compare the results of the prediction of the oil temperature with the real results, and we can get the following image.
+
+The data before 10/24 00:00 in the image is the past data input into the model, the yellow line after 10/24 00:00 is the prediction of oil temperature given by the model, and the blue colour is the actual oil temperature data in the dataset (used for comparison).
+
+
+
+As can be seen, we have used the relationship between the six load information and the corresponding time oil temperatures for the past 96 hours (4 days) to model the possible changes in this data for the oil temperature for the next 48 hours (2 days) based on the inter-relationships between the sequences learned previously, and it can be seen that the predicted curves maintain a high degree of consistency in trend with the actual results after visualisation.
+
+### 6.2 Power Prediction
+
+Power monitoring of current, voltage and power data is required in substations for detecting potential grid problems, identifying faults in the power system, effectively managing grid loads and analysing power system performance and trends.
+
+We have used the current, voltage and power data in a substation to form a dataset in a real scenario. The dataset consists of data such as A-phase voltage, B-phase voltage, and C-phase voltage collected every 5 - 6s for a time span of nearly four months in the substation.
+
+The test set data content is [data](https://alioss.timecho.com/docs/img/data.csv).
+
+On this dataset, the model inference function of IoTDB-ML can predict the C-phase voltage in the future period through the previous values and corresponding timestamps of A-phase voltage, B-phase voltage and C-phase voltage, empowering the monitoring management of the substation.
+
+#### Step 1: Data Import
+
+Users can import the dataset using `import-csv.sh` in the tools folder
+
+```Bash
+bash ./import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /data.csv
+```
+
+#### Step 2: Model Import
+
+We can enter the following SQL in iotdb-cli to pull a trained model from huggingface for registration for subsequent inference.
+
+```SQL
+create model patchtst using uri `https://huggingface.co/hvlgo/patchtst/resolve/main`
+```
+
+We use the deep model PatchTST for prediction, which is a transformer-based temporal prediction model with excellent performance in long time series prediction tasks.
+
+#### Step 3: Model Inference
+
+```Shell
+IoTDB> select * from root.eg.voltage limit 96
++-----------------------------+------------------+------------------+------------------+
+| Time|root.eg.voltage.s0|root.eg.voltage.s1|root.eg.voltage.s2|
++-----------------------------+------------------+------------------+------------------+
+|2023-02-14T20:38:32.000+08:00| 2038.0| 2028.0| 2041.0|
+|2023-02-14T20:38:38.000+08:00| 2014.0| 2005.0| 2018.0|
+|2023-02-14T20:38:44.000+08:00| 2014.0| 2005.0| 2018.0|
+......
+|2023-02-14T20:47:52.000+08:00| 2024.0| 2016.0| 2027.0|
+|2023-02-14T20:47:57.000+08:00| 2024.0| 2016.0| 2027.0|
+|2023-02-14T20:48:03.000+08:00| 2024.0| 2016.0| 2027.0|
++-----------------------------+------------------+------------------+------------------+
+Total line number = 96
+
+IoTDB> call inference(patchtst, "select s0,s1,s2 from root.eg.voltage", window=head(96))
++---------+---------+---------+
+| output0| output1| output2|
++---------+---------+---------+
+|2013.4113|2011.2539|2010.2732|
+|2013.2792| 2007.902|2035.7709|
+|2019.9114|2011.0453|2016.5848|
+......
+|2018.7078|2009.7993|2017.3502|
+|2033.9062|2010.2087|2018.1757|
+|2022.2194| 2011.923|2020.5442|
+|2022.1393|2023.4688|2020.9344|
++---------+---------+---------+
+Total line number = 48
+```
+
+Comparing the predicted results of the C-phase voltage with the real results, we can get the following image.
+
+The data before 01/25 14:33 is the past data input to the model, the yellow line after 01/25 14:33 is the predicted C-phase voltage given by the model, and the blue colour is the actual A-phase voltage data in the dataset (used for comparison).
+
+
+
+It can be seen that we have used the data of the last 8 minutes of voltage to model the possible changes in the A-phase voltage for the next 4 minutes based on the inter-relationships between the sequences learned earlier, and it can be seen that the predicted curves and the actual results maintain a high degree of synchronicity in terms of trends after visualisation.
+
+### 6.3 Anomaly Detection
+
+In the civil aviation and transport industry, there exists a need for anomaly detection of the number of passengers travelling on an aircraft. The results of anomaly detection can be used to guide the adjustment of flight scheduling to make the organisation more efficient.
+
+Airline Passengers is a time-series dataset that records the number of international air passengers between 1949 and 1960, sampled at one-month intervals. The dataset contains a total of one time series. The dataset is [airline](https://alioss.timecho.com/docs/img/airline.csv).
+On this dataset, the model inference function of IoTDB-ML can empower the transport industry by capturing the changing patterns of the sequence in order to detect anomalies at the sequence time points.
+
+#### Step 1: Data Import
+
+Users can import the dataset using `import-csv.sh` in the tools folder
+
+``Bash
+bash . /import-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -f ... /... /data.csv
+``
+
+#### Step 2: Model Inference
+
+IoTDB has some built-in machine learning algorithms that can be used directly, a sample prediction using one of the anomaly detection algorithms is shown below:
+
+```Shell
+IoTDB> select * from root.eg.airline
++-----------------------------+------------------+
+| Time|root.eg.airline.s0|
++-----------------------------+------------------+
+|1949-01-31T00:00:00.000+08:00| 224.0|
+|1949-02-28T00:00:00.000+08:00| 118.0|
+|1949-03-31T00:00:00.000+08:00| 132.0|
+|1949-04-30T00:00:00.000+08:00| 129.0|
+......
+|1960-09-30T00:00:00.000+08:00| 508.0|
+|1960-10-31T00:00:00.000+08:00| 461.0|
+|1960-11-30T00:00:00.000+08:00| 390.0|
+|1960-12-31T00:00:00.000+08:00| 432.0|
++-----------------------------+------------------+
+Total line number = 144
+
+IoTDB> call inference(_Stray, "select s0 from root.eg.airline", k=2)
++-------+
+|output0|
++-------+
+| 0|
+| 0|
+| 0|
+| 0|
+......
+| 1|
+| 1|
+| 0|
+| 0|
+| 0|
+| 0|
++-------+
+Total line number = 144
+```
+
+We plot the results detected as anomalies to get the following image. Where the blue curve is the original time series and the time points specially marked with red dots are the time points that the algorithm detects as anomalies.
+
+
+
+It can be seen that the Stray model has modelled the input sequence changes and successfully detected the time points where anomalies occur.
\ No newline at end of file
diff --git a/src/UserGuide/V1.3.x/User-Manual/IoTDB-View_timecho.md b/src/UserGuide/V1.3.x/User-Manual/IoTDB-View_timecho.md
index a9ea5a7b..6595b591 100644
--- a/src/UserGuide/V1.3.x/User-Manual/IoTDB-View_timecho.md
+++ b/src/UserGuide/V1.3.x/User-Manual/IoTDB-View_timecho.md
@@ -19,6 +19,532 @@
-->
-# IoTDB View
+# View
-TODO
\ No newline at end of file
+## I. Sequence View Application Background
+
+## 1.1 Application Scenario 1 Time Series Renaming (PI Asset Management)
+
+In practice, the equipment collecting data may be named with identification numbers that are difficult to be understood by human beings, which brings difficulties in querying to the business layer.
+
+The Sequence View, on the other hand, is able to re-organise the management of these sequences and access them using a new model structure without changing the original sequence content and without the need to create new or copy sequences.
+
+**For example**: a cloud device uses its own NIC MAC address to form entity numbers and stores data by writing the following time sequence:`root.db.0800200A8C6D.xvjeifg`.
+
+It is difficult for the user to understand. However, at this point, the user is able to rename it using the sequence view feature, map it to a sequence view, and use `root.view.device001.temperature` to access the captured data.
+
+### 1.2 Application Scenario 2 Simplifying business layer query logic
+
+Sometimes users have a large number of devices that manage a large number of time series. When conducting a certain business, the user wants to deal with only some of these sequences. At this time, the focus of attention can be picked out by the sequence view function, which is convenient for repeated querying and writing.
+
+**For example**: Users manage a product assembly line with a large number of time series for each segment of the equipment. The temperature inspector only needs to focus on the temperature of the equipment, so he can extract the temperature-related sequences and compose the sequence view.
+
+### 1.3 Application Scenario 3 Auxiliary Rights Management
+
+In the production process, different operations are generally responsible for different scopes. For security reasons, it is often necessary to restrict the access scope of the operations staff through permission management.
+
+**For example**: The safety management department now only needs to monitor the temperature of each device in a production line, but these data are stored in the same database with other confidential data. At this point, it is possible to create a number of new views that contain only temperature-related time series on the production line, and then to give the security officer access to only these sequence views, thus achieving the purpose of permission restriction.
+
+### 1.4 Motivation for designing sequence view functionality
+
+Combining the above two types of usage scenarios, the motivations for designing sequence view functionality, are:
+
+1. time series renaming.
+2. to simplify the query logic at the business level.
+3. Auxiliary rights management, open data to specific users through the view.
+
+## 2. Sequence View Concepts
+
+### 2.1 Terminology Concepts
+
+Concept: If not specified, the views specified in this document are **Sequence Views**, and new features such as device views may be introduced in the future.
+
+### 2.2 Sequence view
+
+A sequence view is a way of organising the management of time series.
+
+In traditional relational databases, data must all be stored in a table, whereas in time series databases such as IoTDB, it is the sequence that is the storage unit. Therefore, the concept of sequence views in IoTDB is also built on sequences.
+
+A sequence view is a virtual time series, and each virtual time series is like a soft link or shortcut that maps to a sequence or some kind of computational logic external to a certain view. In other words, a virtual sequence either maps to some defined external sequence or is computed from multiple external sequences.
+
+Users can create views using complex SQL queries, where the sequence view acts as a stored query statement, and when data is read from the view, the stored query statement is used as the source of the data in the FROM clause.
+
+### 2.3 Alias Sequences
+
+There is a special class of beings in a sequence view that satisfy all of the following conditions:
+
+1. the data source is a single time series
+2. there is no computational logic
+3. no filtering conditions (e.g., no WHERE clause restrictions).
+
+Such a sequence view is called an **alias sequence**, or alias sequence view. A sequence view that does not fully satisfy all of the above conditions is called a non-alias sequence view. The difference between them is that only aliased sequences support write functionality.
+
+** All sequence views, including aliased sequences, do not currently support Trigger functionality. **
+
+### 2.4 Nested Views
+
+A user may want to select a number of sequences from an existing sequence view to form a new sequence view, called a nested view.
+
+**The current version does not support the nested view feature**.
+
+### 2.5 Some constraints on sequence views in IoTDB
+
+#### Constraint 1 A sequence view must depend on one or several time series
+
+A sequence view has two possible forms of existence:
+
+1. it maps to a time series
+2. it is computed from one or more time series.
+
+The former form of existence has been exemplified in the previous section and is easy to understand; the latter form of existence here is because the sequence view allows for computational logic.
+
+For example, the user has installed two thermometers in the same boiler and now needs to calculate the average of the two temperature values as a measurement. The user has captured the following two sequences: `root.db.d01.temperature01`, `root.db.d01.temperature02`.
+
+At this point, the user can use the average of the two sequences as one sequence in the view: `root.db.d01.avg_temperature`.
+
+This example will 3.1.2 expand in detail.
+
+#### Restriction 2 Non-alias sequence views are read-only
+
+Writing to non-alias sequence views is not allowed.
+
+Only aliased sequence views are supported for writing.
+
+#### Restriction 3 Nested views are not allowed
+
+It is not possible to select certain columns in an existing sequence view to create a sequence view, either directly or indirectly.
+
+An example of this restriction will be given in 3.1.3.
+
+#### Restriction 4 Sequence view and time series cannot be renamed
+
+Both sequence views and time series are located under the same tree, so they cannot be renamed.
+
+The name (path) of any sequence should be uniquely determined.
+
+#### Restriction 5 Sequence views share timing data with time series, metadata such as labels are not shared
+
+Sequence views are mappings pointing to time series, so they fully share timing data, with the time series being responsible for persistent storage.
+
+However, their metadata such as tags and attributes are not shared.
+
+This is because the business query, view-oriented users are concerned about the structure of the current view, and if you use group by tag and other ways to do the query, obviously want to get the view contains the corresponding tag grouping effect, rather than the time series of the tag grouping effect (the user is not even aware of those time series).
+
+## 3. Sequence view functionality
+
+### 3.1 Creating a view
+
+Creating a sequence view is similar to creating a time series, the difference is that you need to specify the data source, i.e., the original sequence, through the AS keyword.
+
+#### 3.1.1. SQL for creating a view
+
+User can select some sequences to create a view:
+
+```SQL
+CREATE VIEW root.view.device.status
+AS
+ SELECT s01
+ FROM root.db.device
+```
+
+It indicates that the user has selected the sequence `s01` from the existing device `root.db.device`, creating the sequence view `root.view.device.status`.
+
+The sequence view can exist under the same entity as the time series, for example:
+
+```SQL
+CREATE VIEW root.db.device.status
+AS
+ SELECT s01
+ FROM root.db.device
+```
+
+Thus, there is a virtual copy of `s01` under `root.db.device`, but with a different name `status`.
+
+It can be noticed that the sequence views in both of the above examples are aliased sequences, and we are giving the user a more convenient way of creating a sequence for that sequence:
+
+```SQL
+CREATE VIEW root.view.device.status
+AS
+ root.db.device.s01
+```
+
+#### 3.1.2 Creating views with computational logic
+
+Following the example in section 2.2 Limitations 1:
+
+> A user has installed two thermometers in the same boiler and now needs to calculate the average of the two temperature values as a measurement. The user has captured the following two sequences: `root.db.d01.temperature01`, `root.db.d01.temperature02`.
+>
+> At this point, the user can use the two sequences averaged as one sequence in the view: `root.view.device01.avg_temperature`.
+
+If the view is not used, the user can query the average of the two temperatures like this:
+
+```SQL
+SELECT (temperature01 + temperature02) / 2
+FROM root.db.d01
+```
+
+And if using a sequence view, the user can create a view this way to simplify future queries:
+
+```SQL
+CREATE VIEW root.db.d01.avg_temperature
+AS
+ SELECT (temperature01 + temperature02) / 2
+ FROM root.db.d01
+```
+
+The user can then query it like this:
+
+```SQL
+SELECT avg_temperature FROM root.db.d01
+```
+
+#### 3.1.3 Nested sequence views not supported
+
+Continuing with the example from 3.1.2, the user now wants to create a new view using the sequence view `root.db.d01.avg_temperature`, which is not allowed. We currently do not support nested views, whether it is an aliased sequence or not.
+
+For example, the following SQL statement will report an error:
+
+```SQL
+CREATE VIEW root.view.device.avg_temp_copy
+AS
+ root.db.d01.avg_temperature -- Not supported. Nested views are not allowed
+```
+
+#### 3.1.4 Creating multiple sequence views at once
+
+If only one sequence view can be specified at a time which is not convenient for the user to use, then multiple sequences can be specified at a time, for example:
+
+```SQL
+CREATE VIEW root.db.device.status, root.db.device.sub.hardware
+AS
+ SELECT s01, s02
+ FROM root.db.device
+```
+
+此外,上述写法可以做简化:
+
+```SQL
+CREATE VIEW root.db.device(status, sub.hardware)
+AS
+ SELECT s01, s02
+ FROM root.db.device
+```
+
+Both statements above are equivalent to the following typing:
+
+```SQL
+CREATE VIEW root.db.device.status
+AS
+ SELECT s01
+ FROM root.db.device;
+
+CREATE VIEW root.db.device.sub.hardware
+AS
+ SELECT s02
+ FROM root.db.device
+```
+
+is also equivalent to the following:
+
+```SQL
+CREATE VIEW root.db.device.status, root.db.device.sub.hardware
+AS
+ root.db.device.s01, root.db.device.s02
+
+-- or
+
+CREATE VIEW root.db.device(status, sub.hardware)
+AS
+ root.db.device(s01, s02)
+```
+
+##### The mapping relationships between all sequences are statically stored
+
+Sometimes, the SELECT clause may contain a number of statements that can only be determined at runtime, such as below:
+
+```SQL
+SELECT s01, s02
+FROM root.db.d01, root.db.d02
+```
+
+The number of sequences that can be matched by the above statement is uncertain and is related to the state of the system. Even so, the user can use it to create views.
+
+However, it is important to note that the mapping relationship between all sequences is stored statically (fixed at creation)! Consider the following example:
+
+The current database contains only three sequences `root.db.d01.s01`, `root.db.d02.s01`, `root.db.d02.s02`, and then the view is created:
+
+```SQL
+CREATE VIEW root.view.d(alpha, beta, gamma)
+AS
+ SELECT s01, s02
+ FROM root.db.d01, root.db.d02
+```
+
+The mapping relationship between time series is as follows:
+
+| sequence number | time series | sequence view |
+| ---- | ----------------- | ----------------- |
+| 1 | `root.db.d01.s01` | root.view.d.alpha |
+| 2 | `root.db.d02.s01` | root.view.d.beta |
+| 3 | `root.db.d02.s02` | root.view.d.gamma |
+
+After that, if the user adds the sequence `root.db.d01.s02`, it does not correspond to any view; then, if the user deletes `root.db.d01.s01`, the query for `root.view.d.alpha` will report an error directly, and it will not correspond to `root.db.d01.s02` either.
+
+Please always note that inter-sequence mapping relationships are stored statically and solidly.
+
+#### 3.1.5 Batch Creation of Sequence Views
+
+There are several existing devices, each with a temperature value, for example:
+
+1. root.db.d1.temperature
+2. root.db.d2.temperature
+3. ...
+
+There may be many other sequences stored under these devices (e.g. `root.db.d1.speed`), but for now it is possible to create a view that contains only the temperature values for these devices, without relation to the other sequences:.
+
+```SQL
+CREATE VIEW root.db.view(${2}_temperature)
+AS
+ SELECT temperature FROM root.db.*
+```
+
+This is modelled on the query writeback (`SELECT INTO`) convention for naming rules, which uses variable placeholders to specify naming rules. See also: [QUERY WRITEBACK (SELECT INTO)](https://iotdb.apache.org/zh/UserGuide/Master/Query-Data/Select-Into.html)
+
+Here `root.db.*.temperature` specifies what time series will be included in the view; and `${2}` specifies from which node in the time series the name is extracted to name the sequence view.
+
+Here, `${2}` refers to level 2 (starting at 0) of `root.db.*.temperature`, which is the result of the `*` match; and `${2}_temperature` is the result of the match and `temperature` spliced together with underscores to make up the node names of the sequences under the view.
+
+The above statement for creating a view is equivalent to the following writeup:
+
+```SQL
+CREATE VIEW root.db.view(${2}_${3})
+AS
+ SELECT temperature from root.db.*
+```
+
+The final view contains these sequences:
+
+1. root.db.view.d1_temperature
+2. root.db.view.d2_temperature
+3. ...
+
+Created using wildcards, only static mapping relationships at the moment of creation will be stored.
+
+#### 3.1.6 SELECT clauses are somewhat limited when creating views
+
+The SELECT clause used when creating a serial view is subject to certain restrictions. The main restrictions are as follows:
+
+1. the `WHERE` clause cannot be used.
+2. `GROUP BY` clause cannot be used. 3.
+3. `MAX_VALUE` and other aggregation functions cannot be used.
+
+Simply put, after `AS` you can only use `SELECT ... FROM ... ` and the results of this query must form a time series.
+
+### 3.2 View Data Queries
+
+For the data query functions that can be supported, the sequence view and time series can be used indiscriminately with identical behaviour when performing time series data queries.
+
+**The types of queries that are not currently supported by the sequence view are as follows:**
+
+1. **align by device query
+2. **group by tags query
+
+Users can also mix time series and sequence view queries in the same SELECT statement, for example:
+
+```SQL
+SELECT temperature01, temperature02, avg_temperature
+FROM root.db.d01
+WHERE temperature01 < temperature02
+```
+
+However, if the user wants to query the metadata of the sequence, such as tag, attributes, etc., the query is the result of the sequence view, not the result of the time series referenced by the sequence view.
+
+In addition, for aliased sequences, if the user wants to get information about the time series such as tags, attributes, etc., the user needs to query the mapping of the view columns to find the corresponding time series, and then query the time series for the tags, attributes, etc. The method of querying the mapping of the view columns will be explained in section 3.5.
+
+### 3.3 Modify Views
+
+Modifying a view, such as changing its name, modifying its calculation logic, deleting it, etc., is similar to creating a new view, in that you need to re-specify all the column descriptions for the entire view.
+
+#### 3.3.1 Modify view data source
+
+```SQL
+ALTER VIEW root.view.device.status
+AS
+ SELECT s01
+ FROM root.ln.wf.d01
+```
+
+#### 3.3.2 Modify the view's calculation logic
+
+```SQL
+ALTER VIEW root.db.d01.avg_temperature
+AS
+ SELECT (temperature01 + temperature02 + temperature03) / 3
+ FROM root.db.d01
+```
+
+#### 3.3.3 Tag point management
+
+- Add a new
+tag
+```SQL
+ALTER view root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4
+```
+
+- Add a new attribute
+
+```SQL
+ALTER view root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4
+```
+
+- rename tag or attribute
+
+```SQL
+ALTER view root.turbine.d1.s1 RENAME tag1 TO newTag1
+```
+
+- Reset the value of a tag or attribute
+
+```SQL
+ALTER view root.turbine.d1.s1 SET newTag1=newV1, attr1=newV1
+```
+
+- Delete an existing tag or attribute
+
+```SQL
+ALTER view root.turbine.d1.s1 DROP tag1, tag2
+```
+
+- Update insert aliases, tags and attributes
+
+> If the alias, tag or attribute did not exist before, insert it, otherwise, update the old value with the new one.
+
+```SQL
+ALTER view root.turbine.d1.s1 UPSERT TAGS(tag2=newV2, tag3=v3) ATTRIBUTES(attr3=v3, attr4=v4)
+```
+
+#### 3.3.4 Deleting Views
+
+Since a view is a sequence, a view can be deleted as if it were a time series.
+
+The original method of deleting a time series is expanded without a new ``DELETE VIEW`` statement.
+
+```SQL
+DELETE VIEW root.view.device.avg_temperatue
+```
+
+### 3.4 View Synchronisation
+
+Sequence view data is always obtained via real-time queries, so data synchronisation is naturally supported.
+
+#### If the dependent original sequence is deleted
+
+When the sequence view is queried (when the sequence is parsed), **the empty result set** is returned if the dependent time series does not exist.
+
+This is similar to the feedback for querying a non-existent sequence, but with a difference: if the dependent time series cannot be parsed, the empty result set is the one that contains the table header as a reminder to the user that the view is problematic.
+
+Additionally, when the dependent time series is deleted, no attempt is made to find out if there is a view that depends on the column, and the user receives no warning.
+
+#### Data Writes to Non-Aliased Sequences Not Supported
+
+Writes to non-alias sequences are not supported.
+
+Please refer to the previous section 2.1.6 Restrictions2 for more details.
+
+#### Metadata for sequences is not shared
+
+Please refer to the previous section 2.1.6 Restriction 5 for details.
+
+### 3.5 View Metadata Queries
+
+View metadata query specifically refers to querying the metadata of the view itself (e.g., how many columns the view has), as well as information about the views in the database (e.g., what views are available).
+
+#### 3.5.1 Viewing Current View Columns
+
+The user has two ways of querying:
+
+1. a query using `SHOW TIMESERIES`, which contains both time series and series views. This query contains both the time series and the sequence view. However, only some of the attributes of the view can be displayed.
+2. a query using `SHOW VIEW`, which contains only the sequence view. It displays the complete properties of the sequence view.
+
+Example:
+
+```Shell
+IoTDB> show timeseries;
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| Timeseries|Alias|Database|DataType|Encoding|Compression|Tags|Attributes|Deadband|DeadbandParameters|ViewType|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.device.s01 | null| root.db| INT32| RLE| SNAPPY|null| null| null| null| BASE|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.view.status | null| root.db| INT32| RLE| SNAPPY|null| null| null| null| VIEW|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.d01.temp01 | null| root.db| FLOAT| RLE| SNAPPY|null| null| null| null| BASE|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.d01.temp02 | null| root.db| FLOAT| RLE| SNAPPY|null| null| null| null| BASE|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+|root.db.d01.avg_temp| null| root.db| FLOAT| null| null|null| null| null| null| VIEW|
++--------------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+Total line number = 5
+It costs 0.789s
+IoTDB>
+```
+
+The last column `ViewType` shows the type of the sequence, the time series is BASE and the sequence view is VIEW.
+
+In addition, some of the sequence view properties will be missing, for example `root.db.d01.avg_temp` is calculated from temperature averages, so the `Encoding` and `Compression` properties are null values.
+
+In addition, the query results of the `SHOW TIMESERIES` statement are divided into two main parts.
+
+1. information about the timing data, such as data type, compression, encoding, etc.
+2. other metadata information, such as tag, attribute, database, etc.
+
+For the sequence view, the temporal data information presented is the same as the original sequence or null (e.g., the calculated average temperature has a data type but no compression method); the metadata information presented is the content of the view.
+
+To learn more about the view, use `SHOW ``VIEW`. The `SHOW ``VIEW` shows the source of the view's data, etc.
+
+```Shell
+IoTDB> show VIEW root.**;
++--------------------+--------+--------+----+----------+--------+-----------------------------------------+
+| Timeseries|Database|DataType|Tags|Attributes|ViewType| SOURCE|
++--------------------+--------+--------+----+----------+--------+-----------------------------------------+
+|root.db.view.status | root.db| INT32|null| null| VIEW| root.db.device.s01|
++--------------------+--------+--------+----+----------+--------+-----------------------------------------+
+|root.db.d01.avg_temp| root.db| FLOAT|null| null| VIEW|(root.db.d01.temp01+root.db.d01.temp02)/2|
++--------------------+--------+--------+----+----------+--------+-----------------------------------------+
+Total line number = 2
+It costs 0.789s
+IoTDB>
+```
+
+The last column, `SOURCE`, shows the data source for the sequence view, listing the SQL statement that created the sequence.
+
+##### About Data Types
+
+Both of the above queries involve the data type of the view. The data type of a view is inferred from the original time series type of the query statement or alias sequence that defines the view. This data type is computed in real time based on the current state of the system, so the data type queried at different moments may be changing.
+
+## IV. FAQ
+
+####Q1: I want the view to implement the function of type conversion. For example, a time series of type int32 was originally placed in the same view as other series of type int64. I now want all the data queried through the view to be automatically converted to int64 type.
+
+> Ans: This is not the function of the sequence view. But the conversion can be done using `CAST`, for example:
+
+```SQL
+CREATE VIEW root.db.device.int64_status
+AS
+ SELECT CAST(s1, 'type'='INT64') from root.db.device
+```
+
+> This way, a query for `root.view.status` will yield a result of type int64.
+>
+> Please note in particular that in the above example, the data for the sequence view is obtained by `CAST` conversion, so `root.db.device.int64_status` is not an aliased sequence, and thus **not supported for writing**.
+
+####Q2: Is default naming supported? Select a number of time series and create a view; but I don't specify the name of each series, it is named automatically by the database?
+
+> Ans: Not supported. Users must specify the naming explicitly.
+
+#### Q3: In the original system, create time series `root.db.device.s01`, you can find that database `root.db` is automatically created and device `root.db.device` is automatically created. Next, deleting the time series `root.db.device.s01` reveals that `root.db.device` was automatically deleted, while `root.db` remained. Will this mechanism be followed for creating views? What are the considerations?
+
+> Ans: Keep the original behaviour unchanged, the introduction of view functionality will not change these original logics.
+
+#### Q4: Does it support sequence view renaming?
+
+> A: Renaming is not supported in the current version, you can create your own view with new name to put it into use.
\ No newline at end of file
diff --git a/src/UserGuide/V1.3.x/User-Manual/Security-Management_timecho.md b/src/UserGuide/V1.3.x/User-Manual/Security-Management_timecho.md
new file mode 100644
index 00000000..51070360
--- /dev/null
+++ b/src/UserGuide/V1.3.x/User-Manual/Security-Management_timecho.md
@@ -0,0 +1,144 @@
+
+
+# SecurityManagement
+
+## White List
+
+**function description**
+
+Allow which client addresses can connect to IoTDB
+
+**configuration file**
+
+conf/iotdb-common.properties
+
+conf/white.list
+
+**configuration item**
+
+iotdb-common.properties:
+
+Decide whether to enable white list
+
+```YAML
+
+# Whether to enable white list
+enable_white_list=true
+```
+
+white.list:
+
+Decide which IP addresses can connect to IoTDB
+
+```YAML
+# Support for annotation
+# Supports precise matching, one IP per line
+10.2.3.4
+
+# Support for * wildcards, one ip per line
+10.*.1.3
+10.100.0.*
+```
+
+**note**
+
+1. If the white list itself is cancelled via the session client, the current connection is not immediately disconnected. It is rejected the next time the connection is created.
+2. If white.list is modified directly, it takes effect within one minute. If modified via the session client, it takes effect immediately, updating the values in memory and the white.list disk file.
+3. Enable the whitelist function, there is no white.list file, start the DB service successfully, however, all connections are rejected.
+4. while DB service is running, the white.list file is deleted, and all connections are denied after up to one minute.
+5. whether to enable the configuration of the white list function, can be hot loaded.
+6. Use the Java native interface to modify the whitelist, must be the root user to modify, reject non-root user to modify; modify the content must be legal, otherwise it will throw a StatementExecutionException.
+
+
+
+## Audit log
+
+### Background of the function
+
+Audit log is the record credentials of a database, which can be queried by the audit log function to ensure information security by various operations such as user add, delete, change and check in the database. With the audit log function of IoTDB, the following scenarios can be achieved:
+
+- We can decide whether to record audit logs according to the source of the link ( human operation or not), such as: non-human operation such as hardware collector write data no need to record audit logs, human operation such as ordinary users through cli, workbench and other tools to operate the data need to record audit logs.
+- Filter out system-level write operations, such as those recorded by the IoTDB monitoring system itself.
+
+#### Scene Description
+
+##### Logging all operations (add, delete, change, check) of all users
+
+The audit log function traces all user operations in the database. The information recorded should include data operations (add, delete, query) and metadata operations (add, modify, delete, query), client login information (user name, ip address).
+
+Client Sources:
+- Cli、workbench、Zeppelin、Grafana、通过 Session/JDBC/MQTT 等协议传入的请求
+
+
+
+##### Audit logging can be turned off for some user connections
+
+No audit logs are required for data written by the hardware collector via Session/JDBC/MQTT if it is a non-human action.
+
+### Function Definition
+
+It is available through through configurations:
+
+- Decide whether to enable the audit function or not
+- Decide where to output the audit logs, support output to one or more
+ 1. log file
+ 2. IoTDB storage
+- Decide whether to block the native interface writes to prevent recording too many audit logs to affect performance.
+- Decide the content category of the audit log, supporting recording one or more
+ 1. data addition and deletion operations
+ 2. data and metadata query operations
+ 3. metadata class adding, modifying, and deleting operations.
+
+#### configuration item
+
+In iotdb-engine.properties or iotdb-common.properties, change the following configurations:
+
+```YAML
+####################
+### Audit log Configuration
+####################
+
+# whether to enable the audit log.
+# Datatype: Boolean
+# enable_audit_log=false
+
+# Output location of audit logs
+# Datatype: String
+# IOTDB: the stored time series is: root.__system.audit._{user}
+# LOGGER: log_audit.log in the log directory
+# audit_log_storage=IOTDB,LOGGER
+
+# whether enable audit log for DML operation of data
+# whether enable audit log for DDL operation of schema
+# whether enable audit log for QUERY operation of data and schema
+# Datatype: String
+# audit_log_operation=DML,DDL,QUERY
+
+# whether the local write api records audit logs
+# Datatype: Boolean
+# This contains Session insert api: insertRecord(s), insertTablet(s),insertRecordsOfOneDevice
+# MQTT insert api
+# RestAPI insert api
+# This parameter will cover the DML in audit_log_operation
+# enable_audit_log_for_native_insert_api=true
+```
+
diff --git a/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md b/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md
new file mode 100644
index 00000000..6005077e
--- /dev/null
+++ b/src/UserGuide/V1.3.x/User-Manual/Streaming_timecho.md
@@ -0,0 +1,796 @@
+
+
+# IoTDB stream processing framework
+
+The IoTDB stream processing framework allows users to implement customized stream processing logic, which can monitor and capture storage engine changes, transform changed data, and push transformed data outward.
+
+We call a data flow processing task a Pipe. A stream processing task (Pipe) contains three subtasks:
+
+- Extract
+- Process
+- Send (Connect)
+
+The stream processing framework allows users to customize the processing logic of three subtasks using Java language and process data in a UDF-like manner.
+In a Pipe, the above three subtasks are executed by three plugins respectively, and the data will be processed by these three plugins in turn:
+Pipe Extractor is used to extract data, Pipe Processor is used to process data, Pipe Connector is used to send data, and the final data will be sent to an external system.
+
+**The model of the Pipe task is as follows:**
+
+
+
+Describing a data flow processing task essentially describes the properties of Pipe Extractor, Pipe Processor and Pipe Connector plugins.
+Users can declaratively configure the specific attributes of the three subtasks through SQL statements, and achieve flexible data ETL capabilities by combining different attributes.
+
+Using the stream processing framework, a complete data link can be built to meet the needs of end-side-cloud synchronization, off-site disaster recovery, and read-write load sub-library*.
+
+## Custom stream processing plugin development
+
+### Programming development dependencies
+
+It is recommended to use maven to build the project and add the following dependencies in `pom.xml`. Please be careful to select the same dependency version as the IoTDB server version.
+
+```xml
+
+ org.apache.iotdb
+ pipe-api
+ 1.2.1
+ provided
+
+```
+
+### Event-driven programming model
+
+The user programming interface design of the stream processing plugin refers to the general design concept of the event-driven programming model. Events are data abstractions in the user programming interface, and the programming interface is decoupled from the specific execution method. It only needs to focus on describing the processing method expected by the system after the event (data) reaches the system.
+
+In the user programming interface of the stream processing plugin, events are an abstraction of database data writing operations. The event is captured by the stand-alone stream processing engine, and is passed to the PipeExtractor plugin, PipeProcessor plugin, and PipeConnector plugin in sequence according to the three-stage stream processing process, and triggers the execution of user logic in the three plugins in turn.
+
+In order to take into account the low latency of stream processing in low load scenarios on the end side and the high throughput of stream processing in high load scenarios on the end side, the stream processing engine will dynamically select processing objects in the operation logs and data files. Therefore, user programming of stream processing The interface requires users to provide processing logic for the following two types of events: operation log writing event TabletInsertionEvent and data file writing event TsFileInsertionEvent.
+
+#### **Operation log writing event (TabletInsertionEvent)**
+
+The operation log write event (TabletInsertionEvent) is a high-level data abstraction for user write requests. It provides users with the ability to manipulate the underlying data of write requests by providing a unified operation interface.
+
+For different database deployment methods, the underlying storage structures corresponding to operation log writing events are different. For stand-alone deployment scenarios, the operation log writing event is an encapsulation of write-ahead log (WAL) entries; for a distributed deployment scenario, the operation log writing event is an encapsulation of a single node consensus protocol operation log entry.
+
+For write operations generated by different write request interfaces in the database, the data structure of the request structure corresponding to the operation log write event is also different. IoTDB provides numerous writing interfaces such as InsertRecord, InsertRecords, InsertTablet, InsertTablets, etc. Each writing request uses a completely different serialization method, and the generated binary entries are also different.
+
+The existence of operation log writing events provides users with a unified view of data operations, which shields the implementation differences of the underlying data structure, greatly reduces the user's programming threshold, and improves the ease of use of the function.
+
+```java
+/** TabletInsertionEvent is used to define the event of data insertion. */
+public interface TabletInsertionEvent extends Event {
+
+ /**
+ * The consumer processes the data row by row and collects the results by RowCollector.
+ *
+ * @return {@code Iterable} a list of new TabletInsertionEvent contains the
+ * results collected by the RowCollector
+ */
+ Iterable processRowByRow(BiConsumer consumer);
+
+ /**
+ * The consumer processes the Tablet directly and collects the results by RowCollector.
+ *
+ * @return {@code Iterable} a list of new TabletInsertionEvent contains the
+ * results collected by the RowCollector
+ */
+ Iterable processTablet(BiConsumer consumer);
+}
+```
+
+#### **Data file writing event (TsFileInsertionEvent)**
+
+The data file writing event (TsFileInsertionEvent) is a high-level abstraction of the database file writing operation. It is a data collection of several operation log writing events (TabletInsertionEvent).
+
+The storage engine of IoTDB is LSM structured. When data is written, the writing operation will first be placed into a log-structured file, and the written data will be stored in the memory at the same time. When the memory reaches the control upper limit, the disk flushing behavior will be triggered, that is, the data in the memory will be converted into a database file, and the previously prewritten operation log will be deleted. When the data in the memory is converted into the data in the database file, it will undergo two compression processes: encoding compression and general compression. Therefore, the data in the database file takes up less space than the original data in the memory.
+
+In extreme network conditions, directly transmitting data files is more economical than transmitting data writing operations. It will occupy lower network bandwidth and achieve faster transmission speeds. Of course, there is no free lunch. Computing and processing data in files requires additional file I/O costs compared to directly computing and processing data in memory. However, it is precisely the existence of two structures, disk data files and memory write operations, with their own advantages and disadvantages, that gives the system the opportunity to make dynamic trade-offs and adjustments. It is based on this observation that data files are introduced into the plugin's event model. Write event.
+
+To sum up, the data file writing event appears in the event stream of the stream processing plugin, and there are two situations:
+
+(1) Historical data extraction: Before a stream processing task starts, all written data that has been placed on the disk will exist in the form of TsFile. After a stream processing task starts, when collecting historical data, the historical data will be abstracted using TsFileInsertionEvent;
+
+(2) Real-time data extraction: When a stream processing task is in progress, when the real-time processing speed of operation log write events in the data stream is slower than the write request speed, after a certain progress, the operation log write events that cannot be processed in the future will be persisted. to disk and exists in the form of TsFile. After this data is extracted by the stream processing engine, TsFileInsertionEvent will be used as an abstraction.
+
+```java
+/**
+ * TsFileInsertionEvent is used to define the event of writing TsFile. Event data stores in disks,
+ * which is compressed and encoded, and requires IO cost for computational processing.
+ */
+public interface TsFileInsertionEvent extends Event {
+
+ /**
+ * The method is used to convert the TsFileInsertionEvent into several TabletInsertionEvents.
+ *
+ * @return {@code Iterable} the list of TabletInsertionEvent
+ */
+ Iterable toTabletInsertionEvents();
+}
+```
+
+### Custom stream processing plugin programming interface definition
+
+Based on the custom stream processing plugin programming interface, users can easily write data extraction plugins, data processing plugins and data sending plugins, so that the stream processing function can be flexibly adapted to various industrial scenarios.
+
+#### Data extraction plugin interface
+
+Data extraction is the first stage of the three stages of stream processing data from data extraction to data sending. The data extraction plugin (PipeExtractor) is the bridge between the stream processing engine and the storage engine. It monitors the behavior of the storage engine,
+Capture various data write events.
+
+```java
+/**
+ * PipeExtractor
+ *
+ * PipeExtractor is responsible for capturing events from sources.
+ *
+ *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
+ *
The lifecycle of a PipeExtractor is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
+ * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeExtractor.
+ *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
+ *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
+ * be called to capture events from sources and then the events will be passed to the
+ * PipeProcessor.
+ *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ * cancelled (the `DROP PIPE` command is executed).
+ *
+ */
+public interface PipeExtractor extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeExtractor. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeExtractor#validate(PipeParameterValidator)} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeExtractor
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * Start the extractor. After this method is called, events should be ready to be supplied by
+ * {@link PipeExtractor#supply()}. This method is called after {@link
+ * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ *
+ * @throws Exception the user can throw errors if necessary
+ */
+ void start() throws Exception;
+
+ /**
+ * Supply single event from the extractor and the caller will send the event to the processor.
+ * This method is called after {@link PipeExtractor#start()} is called.
+ *
+ * @return the event to be supplied. the event may be null if the extractor has no more events at
+ * the moment, but the extractor is still running for more events.
+ * @throws Exception the user can throw errors if necessary
+ */
+ Event supply() throws Exception;
+}
+```
+
+#### Data processing plugin interface
+
+Data processing is the second stage of the three stages of stream processing data from data extraction to data sending. The data processing plugin (PipeProcessor) is mainly used to filter and transform the data captured by the data extraction plugin (PipeExtractor).
+various events.
+
+```java
+/**
+ * PipeProcessor
+ *
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
+ *
The lifecycle of a PipeProcessor is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH PROCESSOR` clause in SQL are
+ * parsed and the validation method {@link PipeProcessor#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeProcessor.
+ *
- While the collaboration task is in progress:
+ *
+ * - PipeExtractor captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ * following 3 methods will be called: {@link
+ * PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
+ * PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
+ * PipeProcessor#process(Event, EventCollector)}.
+ *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
+ * - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
+ * PipeProcessor#close() } method will be called.
+ *
+ */
+public interface PipeProcessor extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeProcessor. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeProcessorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeProcessor#validate(PipeParameterValidator)} is called and before the beginning of the
+ * events processing.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeProcessor
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeProcessorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is called to process the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ void process(TabletInsertionEvent tabletInsertionEvent, EventCollector eventCollector)
+ throws Exception;
+
+ /**
+ * This method is called to process the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void process(TsFileInsertionEvent tsFileInsertionEvent, EventCollector eventCollector)
+ throws Exception {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ process(tabletInsertionEvent, eventCollector);
+ }
+ }
+
+ /**
+ * This method is called to process the Event.
+ *
+ * @param event Event to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ void process(Event event, EventCollector eventCollector) throws Exception;
+}
+```
+
+#### Data sending plugin interface
+
+Data sending is the third stage of the three stages of stream processing data from data extraction to data sending. The data sending plugin (PipeConnector) is mainly used to send data processed by the data processing plugin (PipeProcessor).
+Various events, it serves as the network implementation layer of the stream processing framework, and the interface should allow access to multiple real-time communication protocols and multiple connectors.
+
+```java
+/**
+ * PipeConnector
+ *
+ *
PipeConnector is responsible for sending events to sinks.
+ *
+ *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
+ *
The lifecycle of a PipeConnector is as follows:
+ *
+ *
+ * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
+ * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
+ * will be called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link
+ * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
+ * to config the runtime behavior of the PipeConnector and the method {@link
+ * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- While the collaboration task is in progress:
+ *
+ * - PipeExtractor captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeConnector.
+ *
- PipeConnector serializes the events into binaries and send them to sinks. The
+ * following 3 methods will be called: {@link
+ * PipeConnector#transfer(TabletInsertionEvent)}, {@link
+ * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
+ * PipeConnector#transfer(Event)}.
+ *
+ * - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
+ * PipeConnector#close() } method will be called.
+ *
+ *
+ * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
+ * will be called to create a new connection with the sink when the method {@link
+ * PipeConnector#heartbeat()} throws exceptions.
+ */
+public interface PipeConnector extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeConnector. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
+ * PipeConnector#handshake()} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeConnector
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is used to create a connection with sink. This method will be called after the
+ * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
+ * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
+ *
+ * @throws Exception if the connection is failed to be created
+ */
+ void handshake() throws Exception;
+
+ /**
+ * This method will be called periodically to check whether the connection with sink is still
+ * alive.
+ *
+ * @throws Exception if the connection dies
+ */
+ void heartbeat() throws Exception;
+
+ /**
+ * This method is used to transfer the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
+
+ /**
+ * This method is used to transfer the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ }
+
+ /**
+ * This method is used to transfer the Event.
+ *
+ * @param event Event to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(Event event) throws Exception;
+}
+```
+
+## Custom stream processing plugin management
+
+In order to ensure the flexibility and ease of use of user-defined plugins in actual production, the system also needs to provide the ability to dynamically and uniformly manage plugins.
+The stream processing plugin management statements introduced in this chapter provide an entry point for dynamic unified management of plugins.
+
+### Load plugin statement
+
+In IoTDB, if you want to dynamically load a user-defined plugin in the system, you first need to implement a specific plugin class based on PipeExtractor, PipeProcessor or PipeConnector.
+Then the plugin class needs to be compiled and packaged into a jar executable file, and finally the plugin is loaded into IoTDB using the management statement for loading the plugin.
+
+The syntax of the management statement for loading the plugin is shown in the figure.
+
+```sql
+CREATE PIPEPLUGIN
+AS
+USING
+```
+
+For example, the user has implemented a data processing plugin with the full class name edu.tsinghua.iotdb.pipe.ExampleProcessor.
+The packaged jar resource package is stored at https://example.com:8080/iotdb/pipe-plugin.jar. The user wants to use this plugin in the stream processing engine.
+Mark the plugin as example. Then, the creation statement of this data processing plugin is as shown in the figure.
+```sql
+CREATE PIPEPLUGIN example
+AS 'edu.tsinghua.iotdb.pipe.ExampleProcessor'
+USING URI ''
+```
+
+### Delete plugin statement
+
+When the user no longer wants to use a plugin and needs to uninstall the plugin from the system, he can use the delete plugin statement as shown in the figure.
+
+```sql
+DROP PIPEPLUGIN
+```
+
+### View plugin statements
+
+Users can also view plugins in the system on demand. View the statement of the plugin as shown in the figure.
+```sql
+SHOW PIPEPLUGINS
+```
+
+## System preset stream processing plugin
+
+### Preset extractor plugin
+
+####iotdb-extractor
+
+Function: Extract historical or real-time data inside IoTDB into pipe.
+
+
+| key | value | value range | required or not |default value|
+| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | -------- |------|
+| source | iotdb-source | String: iotdb-source | required | - |
+| source.pattern | Path prefix for filtering time series | String: any time series prefix | optional | root |
+| source.history.enable | Whether to synchronise history data | Boolean: true, false | optional | true |
+| source.history.start-time | Synchronise the start event time of historical data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MIN_VALUE |
+| source.history.end-time | end event time for synchronised history data, contains end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MAX_VALUE |
+| source.realtime.enable | Whether to synchronise real-time data | Boolean: true, false | optional | true |
+| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional | hybrid |
+| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional | true |
+
+> 🚫 **extractor.pattern 参数说明**
+>
+>* Pattern needs to use backticks to modify illegal characters or illegal path nodes. For example, if you want to filter root.\`a@b\` or root.\`123\`, you should set pattern to root.\`a@b \` or root.\`123\` (For details, please refer to [When to use single and double quotes and backticks](https://iotdb.apache.org/zh/Download/#_1-0-version incompatible syntax details illustrate))
+> * In the underlying implementation, when pattern is detected as root (default value), the extraction efficiency is higher, and any other format will reduce performance.
+> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
+ >
+ > * root.aligned.1TS
+> * root.aligned.1TS.\`1\`
+> * root.aligned.100T
+ >
+ > The data will be extracted;
+ >
+ > * root.aligned.\`1\`
+> * root.aligned.\`123\`
+ >
+ > The data will not be extracted.
+> * The data of root.\_\_system will not be extracted by pipe. Although users can include any prefix in extractor.pattern, including prefixes with (or overriding) root.\__system, the data under root.__system will always be ignored by pipe
+
+> ❗️**Start-time, end-time parameter description of extractor.history**
+>
+> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
+
+> ✅ **A piece of data from production to IoTDB contains two key concepts of time**
+>
+> * **event time:** The time when the data is actually produced (or the generation time assigned to the data by the data production system, which is the time item in the data point), also called event time.
+> * **arrival time:** The time when data arrives in the IoTDB system.
+>
+> What we often call out-of-order data refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
+
+> 💎 **iotdb-extractor’s work can be split into two stages**
+>
+> 1. Historical data extraction: all data with **arrival time** < **current system time** when creating pipe is called historical data
+> 2. Real-time data extraction: all **arrival time** >= data of **current system time** when creating pipe is called real-time data
+>
+> The historical data transmission phase and the real-time data transmission phase are executed serially. Only when the historical data transmission phase is completed, the real-time data transmission phase is executed. **
+>
+> Users can specify iotdb-extractor to:
+>
+> * Historical data extraction (`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
+> * Real-time data extraction (`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
+> * Full data extraction (`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
+> * Disable setting `extractor.history.enable` and `extractor.realtime.enable` to `false` at the same time
+>
+> 📌 **extractor.realtime.mode: Data extraction mode**
+>
+> * log: In this mode, the task only uses the operation log for data processing and sending
+> * file: In this mode, the task only uses data files for data processing and sending.
+> * hybrid: This mode takes into account the characteristics of low latency but low throughput when sending data one by one in the operation log, and the characteristics of high throughput but high latency when sending in batches of data files. It can automatically operate under different write loads. Switch the appropriate data extraction method. First, adopt the data extraction method based on operation logs to ensure low sending delay. When a data backlog occurs, it will automatically switch to the data extraction method based on data files to ensure high sending throughput. When the backlog is eliminated, it will automatically switch back to the data extraction method based on data files. The data extraction method of the operation log avoids the problem of difficulty in balancing data sending delay or throughput using a single data extraction algorithm.
+
+> 🍕 **extractor.forwarding-pipe-requests: Whether to allow forwarding data transmitted from another pipe**
+>
+> * If you want to use pipe to build data synchronization of A -> B -> C, then the pipe of B -> C needs to set this parameter to true, so that the data written by A to B through the pipe in A -> B can be forwarded correctly. to C
+> * If you want to use pipe to build two-way data synchronization (dual-active) of A \<-> B, then the pipes of A -> B and B -> A need to set this parameter to false, otherwise the data will be endless. inter-cluster round-robin forwarding
+
+### Preset processor plugin
+
+#### do-nothing-processor
+
+Function: No processing is done on the events passed in by the extractor.
+
+
+| key | value | value range | required or optional with default |
+| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| processor | do-nothing-processor | String: do-nothing-processor | required |
+
+### Preset connector plugin
+
+#### do-nothing-connector
+
+Function: No processing is done on the events passed in by the processor.
+
+| key | value | value range | required or optional with default |
+| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| connector | do-nothing-connector | String: do-nothing-connector | required |
+
+## Stream processing task management
+
+### Create a stream processing task
+
+Use the `CREATE PIPE` statement to create a stream processing task. Taking the creation of a data synchronization stream processing task as an example, the sample SQL statement is as follows:
+
+```sql
+CREATE PIPE -- PipeId is a name that uniquely identifies the stream processing task
+WITH EXTRACTOR (
+ --Default IoTDB data extraction plugin
+ 'extractor' = 'iotdb-extractor',
+ --Path prefix, only data that can match the path prefix will be extracted for subsequent processing and sending
+ 'extractor.pattern' = 'root.timecho',
+ -- Whether to extract historical data
+ 'extractor.history.enable' = 'true',
+ -- Describes the time range of the extracted historical data, indicating the earliest time
+ 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ -- Describes the time range of the extracted historical data, indicating the latest time
+ 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
+ -- Whether to extract real-time data
+ 'extractor.realtime.enable' = 'true',
+ --Describe the extraction method of real-time data
+ 'extractor.realtime.mode' = 'hybrid',
+)
+WITH PROCESSOR (
+ --The default data processing plugin, which does not do any processing
+ 'processor' = 'do-nothing-processor',
+)
+WITH CONNECTOR (
+ -- IoTDB data sending plugin, the target is IoTDB
+ 'connector' = 'iotdb-thrift-connector',
+ --The data service IP of one of the DataNode nodes in the target IoTDB
+ 'connector.ip' = '127.0.0.1',
+ -- The data service port of one of the DataNode nodes in the target IoTDB
+ 'connector.port' = '6667',
+)
+```
+
+**When creating a stream processing task, you need to configure the PipeId and the parameters of the three plugin parts:**
+
+
+| Configuration item | Description | Required or not | Default implementation | Default implementation description | Whether custom implementation is allowed |
+| --------- | --------------------------------------------------- | --------------------------- | -------------------- | -------------------------------------------------------- | ------------------------- |
+| PipeId | A globally unique name that identifies a stream processing task | Required | - | - | - |
+| extractor | Pipe Extractor plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-extractor | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
+| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Optional | do-nothing-processor | | processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
+ | 是 |
+| connector | Pipe Connector plugin, responsible for sending data | Required | - | - | 是 |
+
+In the example, the iotdb-extractor, do-nothing-processor and iotdb-thrift-connector plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, **please check the "System Preset Stream Processing plugin" section**.
+
+**A simplest example of the CREATE PIPE statement is as follows:**
+
+```sql
+CREATE PIPE -- PipeId is a name that uniquely identifies the stream processing task
+WITH CONNECTOR (
+ -- IoTDB data sending plugin, the target is IoTDB
+ 'connector' = 'iotdb-thrift-connector',
+ --The data service IP of one of the DataNode nodes in the target IoTDB
+ 'connector.ip' = '127.0.0.1',
+ -- The data service port of one of the DataNode nodes in the target IoTDB
+ 'connector.port' = '6667',
+)
+```
+
+The semantics expressed are: synchronize all historical data in this database instance and subsequent real-time data arriving to the IoTDB instance with the target 127.0.0.1:6667.
+
+**Notice:**
+
+- EXTRACTOR and PROCESSOR are optional configurations. If you do not fill in the configuration parameters, the system will use the corresponding default implementation.
+- CONNECTOR is a required configuration and needs to be configured declaratively in the CREATE PIPE statement
+- CONNECTOR has self-reuse capability. For different stream processing tasks, if their CONNECTORs have the same KV attributes (the keys corresponding to the values of all attributes are the same), then the system will only create one CONNECTOR instance in the end to realize the duplication of connection resources. use.
+
+ - For example, there are the following declarations of two stream processing tasks, pipe1 and pipe2:
+
+ ```sql
+ CREATE PIPE pipe1
+ WITH CONNECTOR (
+ 'connector' = 'iotdb-thrift-connector',
+ 'connector.thrift.host' = 'localhost',
+ 'connector.thrift.port' = '9999',
+ )
+
+ CREATE PIPE pipe2
+ WITH CONNECTOR (
+ 'connector' = 'iotdb-thrift-connector',
+ 'connector.thrift.port' = '9999',
+ 'connector.thrift.host' = 'localhost',
+ )
+ ```
+
+- Because their declarations of CONNECTOR are exactly the same (**even if the order of declaration of some attributes is different**), the framework will automatically reuse the CONNECTORs they declared, and ultimately the CONNECTORs of pipe1 and pipe2 will be the same instance. .
+- When the extractor is the default iotdb-extractor, and extractor.forwarding-pipe-requests is the default value true, please do not build an application scenario that includes data cycle synchronization (it will cause an infinite loop):
+
+ - IoTDB A -> IoTDB B -> IoTDB A
+ - IoTDB A -> IoTDB A
+
+### Start the stream processing task
+
+After the CREATE PIPE statement is successfully executed, the stream processing task-related instance will be created, but the running status of the entire stream processing task will be set to STOPPED, that is, the stream processing task will not process data immediately.
+
+You can use the START PIPE statement to cause a stream processing task to start processing data:
+
+```sql
+START PIPE
+```
+
+### Stop the stream processing task
+
+Use the STOP PIPE statement to stop the stream processing task from processing data:
+
+```sql
+STOP PIPE
+```
+
+### Delete stream processing tasks
+
+Use the DROP PIPE statement to stop the stream processing task from processing data (when the stream processing task status is RUNNING), and then delete the entire stream processing task:
+
+```sql
+DROP PIPE
+```
+
+Users do not need to perform a STOP operation before deleting the stream processing task.
+
+### Display stream processing tasks
+
+Use the SHOW PIPES statement to view all stream processing tasks:
+
+```sql
+SHOW PIPES
+```
+
+The query results are as follows:
+
+```sql
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
+```
+
+You can use `` to specify the status of a stream processing task you want to see:
+
+```sql
+SHOW PIPE
+```
+
+You can also use the where clause to determine whether the Pipe Connector used by a certain \ is reused.
+
+```sql
+SHOW PIPES
+WHERE CONNECTOR USED BY
+```
+
+### Stream processing task running status migration
+
+A stream processing pipe will pass through various states during its managed life cycle:
+
+- **STOPPED:** The pipe is stopped. When the pipeline is in this state, there are several possibilities:
+ - When a pipe is successfully created, its initial state is paused.
+ - The user manually pauses a pipe that is in normal running status, and its status will passively change from RUNNING to STOPPED.
+ - When an unrecoverable error occurs during the running of a pipe, its status will automatically change from RUNNING to STOPPED
+- **RUNNING:** pipe is working properly
+- **DROPPED:** The pipe task was permanently deleted
+
+The following diagram shows all states and state transitions:
+
+
+
+## authority management
+
+### Stream processing tasks
+
+
+| Permission name | Description |
+| ----------- | -------------------------- |
+| CREATE_PIPE | Register a stream processing task. The path is irrelevant. |
+| START_PIPE | Start the stream processing task. The path is irrelevant. |
+| STOP_PIPE | Stop the stream processing task. The path is irrelevant. |
+| DROP_PIPE | Offload stream processing tasks. The path is irrelevant. |
+| SHOW_PIPES | Query stream processing tasks. The path is irrelevant. |
+
+### Stream processing task plugin
+
+
+| Permission name | Description |
+| ------------------ | ---------------------------------- |
+| CREATE_PIPEPLUGIN | Register stream processing task plugin. The path is irrelevant. |
+| DROP_PIPEPLUGIN | Uninstall the stream processing task plugin. The path is irrelevant. |
+| SHOW_PIPEPLUGINS | Query stream processing task plugin. The path is irrelevant. |
+
+## Configuration parameters
+
+In iotdb-common.properties:
+
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_connector_timeout_ms=900000
+```
diff --git a/src/UserGuide/V1.3.x/User-Manual/Tiered-Storage_timecho.md b/src/UserGuide/V1.3.x/User-Manual/Tiered-Storage_timecho.md
index c5ac54a5..3fe5792f 100644
--- a/src/UserGuide/V1.3.x/User-Manual/Tiered-Storage_timecho.md
+++ b/src/UserGuide/V1.3.x/User-Manual/Tiered-Storage_timecho.md
@@ -19,6 +19,78 @@
-->
-# Tiered Storage
+# Tiered Storage
+## Overview
-TODO
\ No newline at end of file
+The Tiered storage functionality allows users to define multiple layers of storage, spanning across multiple types of storage media (Memory mapped directory, SSD, rotational hard discs or cloud storage). While memory and cloud storage is usually singular, the local file system storages can consist of multiple directories joined together into one tier. Meanwhile, users can classify data based on its hot or cold nature and store data of different categories in specified "tier". Currently, IoTDB supports the classification of hot and cold data through TTL (Time to live / age) of data. When the data in one tier does not meet the TTL rules defined in the current tier, the data will be automatically migrated to the next tier.
+
+## Parameter Definition
+
+To enable tiered storage in IoTDB, you need to configure the following aspects:
+
+1. configure the data catalogue and divide the data catalogue into different tiers
+2. configure the TTL of the data managed in each tier to distinguish between hot and cold data categories managed in different tiers.
+3. configure the minimum remaining storage space ratio for each tier so that when the storage space of the tier triggers the threshold, the data of the tier will be automatically migrated to the next tier (optional).
+
+The specific parameter definitions and their descriptions are as follows.
+
+| Configuration | Default | Description | Constraint |
+| ---------------------------------------- | ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| dn_data_dirs | None | specify different storage directories and divide the storage directories into tiers | Each level of storage uses a semicolon to separate, and commas to separate within a single level; cloud (OBJECT_STORAGE) configuration can only be used as the last level of storage and the first level can't be used as cloud storage; a cloud object at most; the remote storage directory is denoted by OBJECT_STORAGE |
+| default_ttl_in_ms | None | Define the maximum age of data for which each tier is responsible | Each level of storage is separated by a semicolon; the number of levels should match the number of levels defined by dn_data_dirs |
+| dn_default_space_move_thresholds | 0.15 | Define the minimum remaining space ratio for each tier data catalogue; when the remaining space is less than this ratio, the data will be automatically migrated to the next tier; when the remaining storage space of the last tier falls below this threshold, the system will be set to READ_ONLY | Each level of storage is separated by a semicolon; the number of levels should match the number of levels defined by dn_data_dirs |
+| object_storage_type | AWS_S3 | Cloud Storage Type | IoTDB currently only supports AWS S3 as a remote storage type, and this parameter can't be modified |
+| object_storage_bucket | None | Name of cloud storage bucket | Bucket definition in AWS S3; no need to configure if remote storage is not used |
+| object_storage_endpoiont | | endpoint of cloud storage | endpoint of AWS S3;If remote storage is not used, no configuration required |
+| object_storage_access_key | | Authentication information stored in the cloud: key | AWS S3 credential key;If remote storage is not used, no configuration required |
+| object_storage_access_secret | | Authentication information stored in the cloud: secret | AWS S3 credential secret;If remote storage is not used, no configuration required |
+| remote_tsfile_cache_dirs | data/datanode/data/cache | Cache directory stored locally in the cloud | If remote storage is not used, no configuration required |
+| remote_tsfile_cache_page_size_in_kb | 20480 |Block size of locally cached files stored in the cloud | If remote storage is not used, no configuration required |
+| remote_tsfile_cache_max_disk_usage_in_mb | 51200 | Maximum Disk Occupancy Size for Cloud Storage Local Cache | If remote storage is not used, no configuration required |
+
+## local tiered storag configuration example
+
+The following is an example of a local two-level storage configuration.
+
+```JavaScript
+//Required configuration items
+dn_data_dirs=/data1/data;/data2/data,/data3/data;
+default_ttl_in_ms=86400000;-1
+dn_default_space_move_thresholds=0.2;0.1
+```
+
+In this example, two levels of storage are configured, specifically:
+
+| **tier** | **data path** | **data range** | **threshold for minimum remaining disk space** |
+| -------- | -------------------------------------- | --------------- | ------------------------ |
+| tier 1 | path 1:/data1/data | data for last 1 day | 20% |
+| tier 2 | path 2:/data2/data path 2:/data3/data | data from 1 day ago | 10% |
+
+## remote tiered storag configuration example
+
+The following takes three-level storage as an example:
+
+```JavaScript
+//Required configuration items
+dn_data_dirs=/data1/data;/data2/data,/data3/data;OBJECT_STORAGE
+default_ttl_in_ms=86400000;864000000;-1
+dn_default_space_move_thresholds=0.2;0.15;0.1
+object_storage_name=AWS_S3
+object_storage_bucket=iotdb
+object_storage_endpoiont=
+object_storage_access_key=
+object_storage_access_secret=
+
+// Optional configuration items
+remote_tsfile_cache_dirs=data/datanode/data/cache
+remote_tsfile_cache_page_size_in_kb=20971520
+remote_tsfile_cache_max_disk_usage_in_mb=53687091200
+```
+
+In this example, a total of three levels of storage are configured, specifically:
+
+| **tier** | **data path** | **data range** | **threshold for minimum remaining disk space** |
+| -------- | -------------------------------------- | ---------------------------- | ------------------------ |
+| tier1 | path 1:/data1/data | data for last 1 day | 20% |
+| tier2 | path 1:/data2/data path 2:/data3/data | data from past 1 day to past 10 days | 15% |
+| tier3 | Remote AWS S3 Storage | data from 1 day ago | 10% |
diff --git a/src/zh/UserGuide/Master/API/Programming-Kafka.md b/src/zh/UserGuide/Master/API/Programming-Kafka.md
index a03f3183..61bfaab0 100644
--- a/src/zh/UserGuide/Master/API/Programming-Kafka.md
+++ b/src/zh/UserGuide/Master/API/Programming-Kafka.md
@@ -21,11 +21,11 @@
# Kafka
-[Apache Kafka](https://kafka.apache.org/) is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
+[Apache Kafka](https://kafka.apache.org/) 是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
-## Coding Example
+## 示例代码
-### kafka Producer Producing Data Java Code Example
+### kafka 生产者生产数据 Java 代码示例
```java
Properties props = new Properties();
@@ -39,7 +39,7 @@
producer.close();
```
-### kafka Consumer Receiving Data Java Code Example
+### kafka 消费者接收数据 Java 代码示例
```java
Properties props = new Properties();
@@ -53,7 +53,7 @@
ConsumerRecords records = kafkaConsumer.poll(Duration.ofSeconds(1));
```
-### Example of Java Code Stored in IoTDB Server
+### 存入 IoTDB 服务器的 Java 代码示例
```java
SessionPool pool =
@@ -67,7 +67,7 @@
List datas = new ArrayList<>(records.count());
for (ConsumerRecord record : records) {
datas.add(record.value());
- }
+ }
int size = datas.size();
List deviceIds = new ArrayList<>(size);
List times = new ArrayList<>(size);
diff --git a/src/zh/UserGuide/Master/Ecosystem-Integration/Flink-SQL-IoTDB.md b/src/zh/UserGuide/Master/Ecosystem-Integration/Flink-SQL-IoTDB.md
new file mode 100644
index 00000000..0296b079
--- /dev/null
+++ b/src/zh/UserGuide/Master/Ecosystem-Integration/Flink-SQL-IoTDB.md
@@ -0,0 +1,529 @@
+# flink-sql-iotdb-connector
+
+flink-sql-iotdb-connector 将 Flink SQL 或者 Flink Table 与 IoTDB 无缝衔接了起来,使得在 Flink 的任务中可以对 IoTDB 进行实时读写,具体可以应用到如下场景中:
+
+1. 实时数据同步:将数据从一个数据库实时同步到另一个数据库。
+2. 实时数据管道:构建实时数据处理管道,处理和分析数据库中的数据。
+3. 实时数据分析:实时分析数据库中的数据,提供实时的业务洞察。
+4. 实时应用:将数据库中的数据实时应用于实时应用程序,如实时报表、实时推荐等。
+5. 实时监控:实时监控数据库中的数据,检测异常和错误。
+
+## 读写模式
+
+| 读模式(Source) | 写模式(Sink) |
+| ------------------------- | -------------------------- |
+| Bounded Scan, Lookup, CDC | Streaming Sink, Batch Sink |
+
+### 读模式(Source)
+
+* **Bounded Scan:** bounded scan 的主要实现方式是通过指定 `时间序列` 以及 `查询条件的上下界(可选)`来进行查询,并且查询结果通常为多行数据。这种查询无法获取到查询之后更新的数据。
+
+* **Lookup:** lookup 查询模式与 scan 查询模式不同,bounded scan 是对一个时间范围内的数据进行查询,而 `lookup` 查询只会对一个精确的时间点进行查询,所以查询结果只有一行数据。另外只有 `lookup join` 的右表才能使用 lookup 查询模式。
+
+* **CDC:** 主要用于 Flink 的 `ETL` 任务当中。当 IoTDB 中的数据发生变化时,flink 会通过我们提供的 `CDC connector` 感知到,我们可以将感知到的变化数据转发给其他的外部数据源,以此达到 ETL 的目的。
+
+### 写模式(Sink)
+
+* **Streaming sink:** 用于 Flink 的 streaming mode 中,会将 Flink 中 Dynamic Table 的增删改记录实时的同步到 IoTDB 中。
+
+* **Batch sink:** 用于 Flink 的 batch mode 中,用于将 Flink 的批量计算结果一次性写入 IoTDB 中。
+
+## 使用方式
+
+我们提供的 flink-sql-iotdb-connector 总共提供两种使用方式,一种是在项目开发过程中通过 Maven 的方式引用,另外一种是在 Flink 的 sql-client 中使用。我们将分别介绍这两种使用方式。
+
+> 📌注:flink 版本要求 1.17.0 及以上
+### Maven
+
+我们只需要在项目的 pom 文件中添加以下依赖即可:
+
+```xml
+
+ org.apache.iotdb
+ flink-sql-iotdb-connector
+ ${iotdb.version}
+
+```
+
+### sql-client
+
+如果需要在 sql-client 中使用 flink-sql-iotdb-connector,先通过以下步骤来配置环境:
+
+1. 在 [官网](https://iotdb.apache.org/Download/) 下载带依赖的 flink-sql-iotdb-connector 的 jar 包。
+
+2. 将 jar 包拷贝到 `$FLINK_HOME/lib` 目录下。
+
+3. 启动 Flink 集群。
+
+4. 启动 sql-client。
+
+此时就可以在 sql-client 中使用 flink-sql-iotdb-connector 了。
+
+## 表结构规范
+
+无论使用哪种类型的连接器,都需要满足以下的表结构规范:
+
+- 所有使用 `IoTDB connector` 的表,第一列的列名必须是 `Time_`,而且数据类型必须是 `BIGINT` 类型。
+- 除了 `Time_` 列以外的列名必须以 `root.` 开头。另外列名中的任意节点不能是纯数字,如果有纯数字,或者其他非法字符,必须使用反引号扩起来。比如:路径 root.sg.d0.123 是一个非法路径,但是 root.sg.d0.\`123\` 就是一个合法路径。
+- 无论使用 `pattern` 或者 `sql` 从 IoTDB 中查询数据,查询结果的时间序列名需要包含 Flink 中除了 `Time_` 以外的所有列名。如果没有查询结果中没有相应的列名,则该列将用 null 去填充。
+- flink-sql-iotdb-connector 中支持的数据类型有:`INT`, `BIGINT`, `FLOAT`, `DOUBLE`, `BOOLEAN`, `STRING`。Flink Table 中每一列的数据类型与其 IoTDB 中对应的时间序列类型都要匹配上,否则将会报错,并退出 Flink 任务。
+
+以下用几个例子来说明 IoTDB 中的时间序列与 Flink Table 中列的对应关系。
+
+## 读模式(Source)
+
+### Scan Table (Bounded)
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| ------------------------ | ---- | -------------- | ------ | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| scan.bounded.lower-bound | 否 | -1L | Long | bounded 的 scan 查询时的时间戳下界(包括),参数大于`0`时有效。 |
+| scan.bounded.upper-bound | 否 | -1L | Long | bounded 的 scan 查询时的时间戳下界(包括),参数大于`0`时有效。 |
+| sql | 是 | 无 | String | 用于在 IoTDB 端做查询。 |
+
+#### 示例
+
+该示例演示了如何在一个 Flink Table Job 中从 IoTDB 中通过`scan table`的方式读取数据:
+当前 IoTDB 中的数据如下:
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.028s
+```
+
+```java
+import org.apache.flink.table.api.*;
+
+public class BoundedScanTest {
+ public static void main(String[] args) throws Exception {
+ // setup table environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+ // setup schema
+ Schema iotdbTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ // register table
+ TableDescriptor iotdbDescriptor =
+ TableDescriptor.forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("nodeUrls", "127.0.0.1:6667")
+ .option("sql", "select ** from root")
+ .build();
+ tableEnv.createTemporaryTable("iotdbTable", iotdbDescriptor);
+
+ // output table
+ tableEnv.from("iotdbTable").execute().print();
+ }
+}
+```
+执行完以上任务后,Flink 的控制台中输出的表如下:
+```text
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| op | Time_ | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| +I | 1 | 1.0833644 | 2.34874 | 1.2414109 |
+| +I | 2 | 4.929185 | 3.1885583 | 4.6980085 |
+| +I | 3 | 3.5206156 | 3.5600138 | 4.8080945 |
+| +I | 4 | 1.3449302 | 2.8781595 | 3.3195343 |
+| +I | 5 | 3.3079383 | 3.3840187 | 3.7278645 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+```
+
+### Lookup Point
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| --------------------- | ---- | -------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| lookup.cache.max-rows | 否 | -1 | Integer | lookup 查询时,缓存表的最大行数,参数大于`0`时生效。 |
+| lookup.cache.ttl-sec | 否 | -1 | Integer | lookup 查询时,单点数据的丢弃时间,单位为`秒`。 |
+| sql | 是 | 无 | String | 用于在 IoTDB 端做查询。 |
+
+#### 示例
+
+该示例演示了如何将 IoTDB 中的`device`作为维度表进行`lookup`查询:
+
+* 使用 `datagen connector` 生成两个字段作为 `Lookup Join` 的左表。第一个字段为自增字段,用来表示时间戳。第二个字段为随机字段,用来表示一个
+ measurement 产生的时间序列。
+* 通过 `IoTDB connector` 注册一个表作为 `Lookup Join` 的右表。
+* 将两个表 join 起来。
+
+当前 IoTDB 中的数据如下:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.028s
+```
+
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+public class LookupTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // register left table
+ Schema dataGenTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("s0", DataTypes.INT())
+ .build();
+
+ TableDescriptor datagenDescriptor =
+ TableDescriptor.forConnector("datagen")
+ .schema(dataGenTableSchema)
+ .option("fields.Time_.kind", "sequence")
+ .option("fields.Time_.start", "1")
+ .option("fields.Time_.end", "5")
+ .option("fields.s0.min", "1")
+ .option("fields.s0.max", "1")
+ .build();
+ tableEnv.createTemporaryTable("leftTable", datagenDescriptor);
+
+ // register right table
+ Schema iotdbTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+
+ TableDescriptor iotdbDescriptor =
+ TableDescriptor.forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("sql", "select ** from root")
+ .build();
+ tableEnv.createTemporaryTable("rightTable", iotdbDescriptor);
+
+ // join
+ String sql =
+ "SELECT l.Time_, l.s0,r.`root.sg.d0.s0`, r.`root.sg.d1.s0`, r.`root.sg.d1.s1`"
+ + "FROM (select *,PROCTIME() as proc_time from leftTable) AS l "
+ + "JOIN rightTable FOR SYSTEM_TIME AS OF l.proc_time AS r "
+ + "ON l.Time_ = r.Time_";
+
+ // output table
+ tableEnv.sqlQuery(sql).execute().print();
+ }
+}
+```
+执行完以上任务后,Flink 的控制台中输出的表如下:
+```text
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+| op | Time_ | s0 | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+| +I | 5 | 1 | 3.3079383 | 3.3840187 | 3.7278645 |
+| +I | 2 | 1 | 4.929185 | 3.1885583 | 4.6980085 |
+| +I | 1 | 1 | 1.0833644 | 2.34874 | 1.2414109 |
+| +I | 4 | 1 | 1.3449302 | 2.8781595 | 3.3195343 |
+| +I | 3 | 1 | 3.5206156 | 3.5600138 | 4.8080945 |
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+```
+
+### CDC
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| ------------- | ---- | -------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| mode | 是 | BOUNDED | ENUM | **必须将此参数设置为 `CDC` 才能启动** |
+| sql | 是 | 无 | String | 用于在 IoTDB 端做查询。 |
+| cdc.port | 否 | 8080 | Integer | 在 IoTDB 端提供 CDC 服务的端口号。 |
+| cdc.task.name | 是 | 无 | String | 当 mode 参数设置为 CDC 时是必填项。用于在 IoTDB 端创建 Pipe 任务。 |
+| cdc.pattern | 是 | 无 | String | 当 mode 参数设置为 CDC 时是必填项。用于在 IoTDB 端作为发送数据的过滤条件。 |
+
+#### 示例
+
+该示例演示了如何通过 `CDC Connector` 去获取 IoTDB 中指定路径下的变化数据:
+
+* 通过 `CDC Connector` 创建一张 `CDC` 表。
+* 将 `CDC` 表打印出来。
+
+```java
+import org.apache.flink.table.api.*;
+
+public class CDCTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+ // setup schema
+ Schema iotdbTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+
+ // register table
+ TableDescriptor iotdbDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("mode", "CDC")
+ .option("cdc.task.name", "test")
+ .option("cdc.pattern", "root.sg")
+ .build();
+ tableEnv.createTemporaryTable("iotdbTable", iotdbDescriptor);
+
+ // output table
+ tableEnv.from("iotdbTable").execute().print();
+ }
+}
+```
+运行以上的 Flink CDC 任务,然后在 IoTDB-cli 中执行以下 SQL:
+```sql
+insert into root.sg.d1(timestamp,s0,s1) values(6,1.0,1.0);
+insert into root.sg.d1(timestamp,s0,s1) values(7,1.0,1.0);
+insert into root.sg.d1(timestamp,s0,s1) values(6,2.0,1.0);
+insert into root.sg.d0(timestamp,s0) values(7,2.0);
+```
+然后,Flink 的控制台中将打印该条数据:
+```text
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| op | Time_ | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| +I | 7 | | 1.0 | 1.0 |
+| +I | 6 | | 1.0 | 1.0 |
+| +I | 6 | | 2.0 | 1.0 |
+| +I | 7 | 2.0 | | |
+```
+
+## 写模式(Sink)
+
+### Streaming Sink
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| -------- | ---- | -------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| aligned | 否 | false | Boolean | 向 IoTDB 写入数据时是否调用`aligned`接口。 |
+
+#### 示例
+
+该示例演示了如何在一个 Flink Table 的 Streaming Job 中如何将数据写入到 IoTDB 中:
+
+* 通过 `datagen connector` 生成一张源数据表。
+* 通过 `IoTDB connector` 注册一个输出表。
+* 将数据源表的数据插入到输出表中。
+
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+public class StreamingSinkTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // create data source table
+ Schema dataGenTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor descriptor = TableDescriptor
+ .forConnector("datagen")
+ .schema(dataGenTableSchema)
+ .option("rows-per-second", "1")
+ .option("fields.Time_.kind", "sequence")
+ .option("fields.Time_.start", "1")
+ .option("fields.Time_.end", "5")
+ .option("fields.root.sg.d0.s0.min", "1")
+ .option("fields.root.sg.d0.s0.max", "5")
+ .option("fields.root.sg.d1.s0.min", "1")
+ .option("fields.root.sg.d1.s0.max", "5")
+ .option("fields.root.sg.d1.s1.min", "1")
+ .option("fields.root.sg.d1.s1.max", "5")
+ .build();
+ // register source table
+ tableEnv.createTemporaryTable("dataGenTable", descriptor);
+ Table dataGenTable = tableEnv.from("dataGenTable");
+
+ // create iotdb sink table
+ TableDescriptor iotdbDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(dataGenTableSchema)
+ .build();
+ tableEnv.createTemporaryTable("iotdbSinkTable", iotdbDescriptor);
+
+ // insert data
+ dataGenTable.executeInsert("iotdbSinkTable").print();
+ }
+}
+```
+
+上述任务执行完成后,在 IoTDB 的 cli 中查询结果如下:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.054s
+```
+
+### Batch Sink
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| -------- | ---- | -------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| aligned | 否 | false | Boolean | 向 IoTDB 写入数据时是否调用`aligned`接口。 |
+
+#### 示例
+
+该示例演示了如何在一个 Flink Table 的 Batch Job 中如何将数据写入到 IoTDB 中:
+
+* 通过 `IoTDB connector` 生成一张源数据表。
+* 通过 `IoTDB connector` 注册一个输出表。
+* 将原数据表中的列重命名后写入写回 IoTDB。
+
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+import static org.apache.flink.table.api.Expressions.$;
+
+public class BatchSinkTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inBatchMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // create source table
+ Schema sourceTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor sourceTableDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(sourceTableSchema)
+ .option("sql", "select ** from root.sg.d0,root.sg.d1")
+ .build();
+
+ tableEnv.createTemporaryTable("sourceTable", sourceTableDescriptor);
+ Table sourceTable = tableEnv.from("sourceTable");
+ // register sink table
+ Schema sinkTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d2.s0", DataTypes.FLOAT())
+ .column("root.sg.d3.s0", DataTypes.FLOAT())
+ .column("root.sg.d3.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor sinkTableDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(sinkTableSchema)
+ .build();
+ tableEnv.createTemporaryTable("sinkTable", sinkTableDescriptor);
+
+ // insert data
+ sourceTable.renameColumns(
+ $("root.sg.d0.s0").as("root.sg.d2.s0"),
+ $("root.sg.d1.s0").as("root.sg.d3.s0"),
+ $("root.sg.d1.s1").as("root.sg.d3.s1")
+ ).insertInto("sinkTable").execute().print();
+ }
+}
+```
+
+上述任务执行完成后,在 IoTDB 的 cli 中查询结果如下:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|root.sg.d2.s0|root.sg.d3.s0|root.sg.d3.s1|
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.015s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/SQL-Manual/SQL-Manual.md b/src/zh/UserGuide/Master/SQL-Manual/SQL-Manual.md
index ed42eec3..8531b723 100644
--- a/src/zh/UserGuide/Master/SQL-Manual/SQL-Manual.md
+++ b/src/zh/UserGuide/Master/SQL-Manual/SQL-Manual.md
@@ -304,8 +304,6 @@ IoTDB> show paths set schema template t1
IoTDB> show paths using schema template t1
-IoTDB> show devices using schema template t1
-
#### 解除元数据模板
IoTDB> delete timeseries of schema template t1 from root.sg1.d1
diff --git a/src/zh/UserGuide/Master/User-Manual/IoTDB-AINode_timecho.md b/src/zh/UserGuide/Master/User-Manual/IoTDB-AINode_timecho.md
index ff1a02e8..f8212429 100644
--- a/src/zh/UserGuide/Master/User-Manual/IoTDB-AINode_timecho.md
+++ b/src/zh/UserGuide/Master/User-Manual/IoTDB-AINode_timecho.md
@@ -24,9 +24,9 @@
AINode 是 IoTDB 在ConfigNode、DataNode后提供的第三种内生节点,该节点通过与 IoTDB 集群的 DataNode、ConfigNode 的交互,扩展了对时间序列进行机器学习分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
系统架构如下图所示:
-
+::: center
-
+:::
三种节点的职责如下:
- **ConfigNode**:负责保存和管理模型的元信息;负责分布式节点管理。
diff --git a/src/zh/UserGuide/Master/User-Manual/Write-Delete-Data.md b/src/zh/UserGuide/Master/User-Manual/Write-Delete-Data.md
index 5a2cafab..d3b7ada8 100644
--- a/src/zh/UserGuide/Master/User-Manual/Write-Delete-Data.md
+++ b/src/zh/UserGuide/Master/User-Manual/Write-Delete-Data.md
@@ -23,9 +23,9 @@
# 写入和删除数据
## CLI写入数据
-IoTDB 为用户提供多种插入实时数据的方式,例如在 [Cli/Shell 工具](../QuickStart/Command-Line-Interface.md) 中直接输入插入数据的 INSERT 语句,或使用 Java API(标准 [Java JDBC](../API/Programming-JDBC.md) 接口)单条或批量执行插入数据的 INSERT 语句。
+IoTDB 为用户提供多种插入实时数据的方式,例如在 [Cli/Shell 工具](../Tools-System/CLI.md) 中直接输入插入数据的 INSERT 语句,或使用 Java API(标准 [Java JDBC](../API/Programming-JDBC.md) 接口)单条或批量执行插入数据的 INSERT 语句。
-本节主要为您介绍实时数据接入的 INSERT 语句在场景中的实际使用示例,有关 INSERT SQL 语句的详细语法请参见本文 [INSERT 语句](../Reference/SQL-Reference.md) 节。
+本节主要为您介绍实时数据接入的 INSERT 语句在场景中的实际使用示例,有关 INSERT SQL 语句的详细语法请参见本文 [INSERT 语句](../SQL-Manual/SQL-Manual.md#写入数据) 节。
注:写入重复时间戳的数据则原时间戳数据被覆盖,可视为更新数据。
@@ -184,7 +184,7 @@ CSV 是以纯文本形式存储表格数据,您可以在CSV文件中写入多
## 删除数据
-用户使用 [DELETE 语句](../Reference/SQL-Reference.md) 可以删除指定的时间序列中符合时间删除条件的数据。在删除数据时,用户可以选择需要删除的一个或多个时间序列、时间序列的前缀、时间序列带、*路径对某一个时间区间内的数据进行删除。
+用户使用 [DELETE 语句](../SQL-Manual/SQL-Manual.md#删除数据) 可以删除指定的时间序列中符合时间删除条件的数据。在删除数据时,用户可以选择需要删除的一个或多个时间序列、时间序列的前缀、时间序列带、*路径对某一个时间区间内的数据进行删除。
在 JAVA 编程环境中,您可以使用 JDBC API 单条或批量执行 DELETE 语句。
diff --git a/src/zh/UserGuide/V1.2.x/Ecosystem-Integration/Flink-SQL-IoTDB.md b/src/zh/UserGuide/V1.2.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
index 1648a3be..0296b079 100644
--- a/src/zh/UserGuide/V1.2.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
+++ b/src/zh/UserGuide/V1.2.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
@@ -32,6 +32,7 @@ flink-sql-iotdb-connector 将 Flink SQL 或者 Flink Table 与 IoTDB 无缝衔
我们提供的 flink-sql-iotdb-connector 总共提供两种使用方式,一种是在项目开发过程中通过 Maven 的方式引用,另外一种是在 Flink 的 sql-client 中使用。我们将分别介绍这两种使用方式。
+> 📌注:flink 版本要求 1.17.0 及以上
### Maven
我们只需要在项目的 pom 文件中添加以下依赖即可:
diff --git a/src/zh/UserGuide/V1.3.x/API/Programming-Kafka.md b/src/zh/UserGuide/V1.3.x/API/Programming-Kafka.md
index a03f3183..61bfaab0 100644
--- a/src/zh/UserGuide/V1.3.x/API/Programming-Kafka.md
+++ b/src/zh/UserGuide/V1.3.x/API/Programming-Kafka.md
@@ -21,11 +21,11 @@
# Kafka
-[Apache Kafka](https://kafka.apache.org/) is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
+[Apache Kafka](https://kafka.apache.org/) 是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
-## Coding Example
+## 示例代码
-### kafka Producer Producing Data Java Code Example
+### kafka 生产者生产数据 Java 代码示例
```java
Properties props = new Properties();
@@ -39,7 +39,7 @@
producer.close();
```
-### kafka Consumer Receiving Data Java Code Example
+### kafka 消费者接收数据 Java 代码示例
```java
Properties props = new Properties();
@@ -53,7 +53,7 @@
ConsumerRecords records = kafkaConsumer.poll(Duration.ofSeconds(1));
```
-### Example of Java Code Stored in IoTDB Server
+### 存入 IoTDB 服务器的 Java 代码示例
```java
SessionPool pool =
@@ -67,7 +67,7 @@
List datas = new ArrayList<>(records.count());
for (ConsumerRecord record : records) {
datas.add(record.value());
- }
+ }
int size = datas.size();
List deviceIds = new ArrayList<>(size);
List times = new ArrayList<>(size);
diff --git a/src/zh/UserGuide/V1.3.x/Ecosystem-Integration/Flink-SQL-IoTDB.md b/src/zh/UserGuide/V1.3.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
new file mode 100644
index 00000000..0296b079
--- /dev/null
+++ b/src/zh/UserGuide/V1.3.x/Ecosystem-Integration/Flink-SQL-IoTDB.md
@@ -0,0 +1,529 @@
+# flink-sql-iotdb-connector
+
+flink-sql-iotdb-connector 将 Flink SQL 或者 Flink Table 与 IoTDB 无缝衔接了起来,使得在 Flink 的任务中可以对 IoTDB 进行实时读写,具体可以应用到如下场景中:
+
+1. 实时数据同步:将数据从一个数据库实时同步到另一个数据库。
+2. 实时数据管道:构建实时数据处理管道,处理和分析数据库中的数据。
+3. 实时数据分析:实时分析数据库中的数据,提供实时的业务洞察。
+4. 实时应用:将数据库中的数据实时应用于实时应用程序,如实时报表、实时推荐等。
+5. 实时监控:实时监控数据库中的数据,检测异常和错误。
+
+## 读写模式
+
+| 读模式(Source) | 写模式(Sink) |
+| ------------------------- | -------------------------- |
+| Bounded Scan, Lookup, CDC | Streaming Sink, Batch Sink |
+
+### 读模式(Source)
+
+* **Bounded Scan:** bounded scan 的主要实现方式是通过指定 `时间序列` 以及 `查询条件的上下界(可选)`来进行查询,并且查询结果通常为多行数据。这种查询无法获取到查询之后更新的数据。
+
+* **Lookup:** lookup 查询模式与 scan 查询模式不同,bounded scan 是对一个时间范围内的数据进行查询,而 `lookup` 查询只会对一个精确的时间点进行查询,所以查询结果只有一行数据。另外只有 `lookup join` 的右表才能使用 lookup 查询模式。
+
+* **CDC:** 主要用于 Flink 的 `ETL` 任务当中。当 IoTDB 中的数据发生变化时,flink 会通过我们提供的 `CDC connector` 感知到,我们可以将感知到的变化数据转发给其他的外部数据源,以此达到 ETL 的目的。
+
+### 写模式(Sink)
+
+* **Streaming sink:** 用于 Flink 的 streaming mode 中,会将 Flink 中 Dynamic Table 的增删改记录实时的同步到 IoTDB 中。
+
+* **Batch sink:** 用于 Flink 的 batch mode 中,用于将 Flink 的批量计算结果一次性写入 IoTDB 中。
+
+## 使用方式
+
+我们提供的 flink-sql-iotdb-connector 总共提供两种使用方式,一种是在项目开发过程中通过 Maven 的方式引用,另外一种是在 Flink 的 sql-client 中使用。我们将分别介绍这两种使用方式。
+
+> 📌注:flink 版本要求 1.17.0 及以上
+### Maven
+
+我们只需要在项目的 pom 文件中添加以下依赖即可:
+
+```xml
+
+ org.apache.iotdb
+ flink-sql-iotdb-connector
+ ${iotdb.version}
+
+```
+
+### sql-client
+
+如果需要在 sql-client 中使用 flink-sql-iotdb-connector,先通过以下步骤来配置环境:
+
+1. 在 [官网](https://iotdb.apache.org/Download/) 下载带依赖的 flink-sql-iotdb-connector 的 jar 包。
+
+2. 将 jar 包拷贝到 `$FLINK_HOME/lib` 目录下。
+
+3. 启动 Flink 集群。
+
+4. 启动 sql-client。
+
+此时就可以在 sql-client 中使用 flink-sql-iotdb-connector 了。
+
+## 表结构规范
+
+无论使用哪种类型的连接器,都需要满足以下的表结构规范:
+
+- 所有使用 `IoTDB connector` 的表,第一列的列名必须是 `Time_`,而且数据类型必须是 `BIGINT` 类型。
+- 除了 `Time_` 列以外的列名必须以 `root.` 开头。另外列名中的任意节点不能是纯数字,如果有纯数字,或者其他非法字符,必须使用反引号扩起来。比如:路径 root.sg.d0.123 是一个非法路径,但是 root.sg.d0.\`123\` 就是一个合法路径。
+- 无论使用 `pattern` 或者 `sql` 从 IoTDB 中查询数据,查询结果的时间序列名需要包含 Flink 中除了 `Time_` 以外的所有列名。如果没有查询结果中没有相应的列名,则该列将用 null 去填充。
+- flink-sql-iotdb-connector 中支持的数据类型有:`INT`, `BIGINT`, `FLOAT`, `DOUBLE`, `BOOLEAN`, `STRING`。Flink Table 中每一列的数据类型与其 IoTDB 中对应的时间序列类型都要匹配上,否则将会报错,并退出 Flink 任务。
+
+以下用几个例子来说明 IoTDB 中的时间序列与 Flink Table 中列的对应关系。
+
+## 读模式(Source)
+
+### Scan Table (Bounded)
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| ------------------------ | ---- | -------------- | ------ | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| scan.bounded.lower-bound | 否 | -1L | Long | bounded 的 scan 查询时的时间戳下界(包括),参数大于`0`时有效。 |
+| scan.bounded.upper-bound | 否 | -1L | Long | bounded 的 scan 查询时的时间戳下界(包括),参数大于`0`时有效。 |
+| sql | 是 | 无 | String | 用于在 IoTDB 端做查询。 |
+
+#### 示例
+
+该示例演示了如何在一个 Flink Table Job 中从 IoTDB 中通过`scan table`的方式读取数据:
+当前 IoTDB 中的数据如下:
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.028s
+```
+
+```java
+import org.apache.flink.table.api.*;
+
+public class BoundedScanTest {
+ public static void main(String[] args) throws Exception {
+ // setup table environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+ // setup schema
+ Schema iotdbTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ // register table
+ TableDescriptor iotdbDescriptor =
+ TableDescriptor.forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("nodeUrls", "127.0.0.1:6667")
+ .option("sql", "select ** from root")
+ .build();
+ tableEnv.createTemporaryTable("iotdbTable", iotdbDescriptor);
+
+ // output table
+ tableEnv.from("iotdbTable").execute().print();
+ }
+}
+```
+执行完以上任务后,Flink 的控制台中输出的表如下:
+```text
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| op | Time_ | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| +I | 1 | 1.0833644 | 2.34874 | 1.2414109 |
+| +I | 2 | 4.929185 | 3.1885583 | 4.6980085 |
+| +I | 3 | 3.5206156 | 3.5600138 | 4.8080945 |
+| +I | 4 | 1.3449302 | 2.8781595 | 3.3195343 |
+| +I | 5 | 3.3079383 | 3.3840187 | 3.7278645 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+```
+
+### Lookup Point
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| --------------------- | ---- | -------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| lookup.cache.max-rows | 否 | -1 | Integer | lookup 查询时,缓存表的最大行数,参数大于`0`时生效。 |
+| lookup.cache.ttl-sec | 否 | -1 | Integer | lookup 查询时,单点数据的丢弃时间,单位为`秒`。 |
+| sql | 是 | 无 | String | 用于在 IoTDB 端做查询。 |
+
+#### 示例
+
+该示例演示了如何将 IoTDB 中的`device`作为维度表进行`lookup`查询:
+
+* 使用 `datagen connector` 生成两个字段作为 `Lookup Join` 的左表。第一个字段为自增字段,用来表示时间戳。第二个字段为随机字段,用来表示一个
+ measurement 产生的时间序列。
+* 通过 `IoTDB connector` 注册一个表作为 `Lookup Join` 的右表。
+* 将两个表 join 起来。
+
+当前 IoTDB 中的数据如下:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.028s
+```
+
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+public class LookupTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // register left table
+ Schema dataGenTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("s0", DataTypes.INT())
+ .build();
+
+ TableDescriptor datagenDescriptor =
+ TableDescriptor.forConnector("datagen")
+ .schema(dataGenTableSchema)
+ .option("fields.Time_.kind", "sequence")
+ .option("fields.Time_.start", "1")
+ .option("fields.Time_.end", "5")
+ .option("fields.s0.min", "1")
+ .option("fields.s0.max", "1")
+ .build();
+ tableEnv.createTemporaryTable("leftTable", datagenDescriptor);
+
+ // register right table
+ Schema iotdbTableSchema =
+ Schema.newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+
+ TableDescriptor iotdbDescriptor =
+ TableDescriptor.forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("sql", "select ** from root")
+ .build();
+ tableEnv.createTemporaryTable("rightTable", iotdbDescriptor);
+
+ // join
+ String sql =
+ "SELECT l.Time_, l.s0,r.`root.sg.d0.s0`, r.`root.sg.d1.s0`, r.`root.sg.d1.s1`"
+ + "FROM (select *,PROCTIME() as proc_time from leftTable) AS l "
+ + "JOIN rightTable FOR SYSTEM_TIME AS OF l.proc_time AS r "
+ + "ON l.Time_ = r.Time_";
+
+ // output table
+ tableEnv.sqlQuery(sql).execute().print();
+ }
+}
+```
+执行完以上任务后,Flink 的控制台中输出的表如下:
+```text
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+| op | Time_ | s0 | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+| +I | 5 | 1 | 3.3079383 | 3.3840187 | 3.7278645 |
+| +I | 2 | 1 | 4.929185 | 3.1885583 | 4.6980085 |
+| +I | 1 | 1 | 1.0833644 | 2.34874 | 1.2414109 |
+| +I | 4 | 1 | 1.3449302 | 2.8781595 | 3.3195343 |
+| +I | 3 | 1 | 3.5206156 | 3.5600138 | 4.8080945 |
++----+----------------------+-------------+---------------+----------------------+--------------------------------+
+```
+
+### CDC
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| ------------- | ---- | -------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| mode | 是 | BOUNDED | ENUM | **必须将此参数设置为 `CDC` 才能启动** |
+| sql | 是 | 无 | String | 用于在 IoTDB 端做查询。 |
+| cdc.port | 否 | 8080 | Integer | 在 IoTDB 端提供 CDC 服务的端口号。 |
+| cdc.task.name | 是 | 无 | String | 当 mode 参数设置为 CDC 时是必填项。用于在 IoTDB 端创建 Pipe 任务。 |
+| cdc.pattern | 是 | 无 | String | 当 mode 参数设置为 CDC 时是必填项。用于在 IoTDB 端作为发送数据的过滤条件。 |
+
+#### 示例
+
+该示例演示了如何通过 `CDC Connector` 去获取 IoTDB 中指定路径下的变化数据:
+
+* 通过 `CDC Connector` 创建一张 `CDC` 表。
+* 将 `CDC` 表打印出来。
+
+```java
+import org.apache.flink.table.api.*;
+
+public class CDCTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+ // setup schema
+ Schema iotdbTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+
+ // register table
+ TableDescriptor iotdbDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(iotdbTableSchema)
+ .option("mode", "CDC")
+ .option("cdc.task.name", "test")
+ .option("cdc.pattern", "root.sg")
+ .build();
+ tableEnv.createTemporaryTable("iotdbTable", iotdbDescriptor);
+
+ // output table
+ tableEnv.from("iotdbTable").execute().print();
+ }
+}
+```
+运行以上的 Flink CDC 任务,然后在 IoTDB-cli 中执行以下 SQL:
+```sql
+insert into root.sg.d1(timestamp,s0,s1) values(6,1.0,1.0);
+insert into root.sg.d1(timestamp,s0,s1) values(7,1.0,1.0);
+insert into root.sg.d1(timestamp,s0,s1) values(6,2.0,1.0);
+insert into root.sg.d0(timestamp,s0) values(7,2.0);
+```
+然后,Flink 的控制台中将打印该条数据:
+```text
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| op | Time_ | root.sg.d0.s0 | root.sg.d1.s0 | root.sg.d1.s1 |
++----+----------------------+--------------------------------+--------------------------------+--------------------------------+
+| +I | 7 | | 1.0 | 1.0 |
+| +I | 6 | | 1.0 | 1.0 |
+| +I | 6 | | 2.0 | 1.0 |
+| +I | 7 | 2.0 | | |
+```
+
+## 写模式(Sink)
+
+### Streaming Sink
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| -------- | ---- | -------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| aligned | 否 | false | Boolean | 向 IoTDB 写入数据时是否调用`aligned`接口。 |
+
+#### 示例
+
+该示例演示了如何在一个 Flink Table 的 Streaming Job 中如何将数据写入到 IoTDB 中:
+
+* 通过 `datagen connector` 生成一张源数据表。
+* 通过 `IoTDB connector` 注册一个输出表。
+* 将数据源表的数据插入到输出表中。
+
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+public class StreamingSinkTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inStreamingMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // create data source table
+ Schema dataGenTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor descriptor = TableDescriptor
+ .forConnector("datagen")
+ .schema(dataGenTableSchema)
+ .option("rows-per-second", "1")
+ .option("fields.Time_.kind", "sequence")
+ .option("fields.Time_.start", "1")
+ .option("fields.Time_.end", "5")
+ .option("fields.root.sg.d0.s0.min", "1")
+ .option("fields.root.sg.d0.s0.max", "5")
+ .option("fields.root.sg.d1.s0.min", "1")
+ .option("fields.root.sg.d1.s0.max", "5")
+ .option("fields.root.sg.d1.s1.min", "1")
+ .option("fields.root.sg.d1.s1.max", "5")
+ .build();
+ // register source table
+ tableEnv.createTemporaryTable("dataGenTable", descriptor);
+ Table dataGenTable = tableEnv.from("dataGenTable");
+
+ // create iotdb sink table
+ TableDescriptor iotdbDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(dataGenTableSchema)
+ .build();
+ tableEnv.createTemporaryTable("iotdbSinkTable", iotdbDescriptor);
+
+ // insert data
+ dataGenTable.executeInsert("iotdbSinkTable").print();
+ }
+}
+```
+
+上述任务执行完成后,在 IoTDB 的 cli 中查询结果如下:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|
++-----------------------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.054s
+```
+
+### Batch Sink
+
+#### 参数
+
+| 参数 | 必填 | 默认 | 类型 | 描述 |
+| -------- | ---- | -------------- | ------- | ------------------------------------------------------------ |
+| nodeUrls | 否 | 127.0.0.1:6667 | String | 用来指定 IoTDB 的 datanode 地址,如果 IoTDB 是用集群模式搭建的话,可以指定多个地址,每个节点用逗号隔开。 |
+| user | 否 | root | String | IoTDB 用户名 |
+| password | 否 | root | String | IoTDB 密码 |
+| aligned | 否 | false | Boolean | 向 IoTDB 写入数据时是否调用`aligned`接口。 |
+
+#### 示例
+
+该示例演示了如何在一个 Flink Table 的 Batch Job 中如何将数据写入到 IoTDB 中:
+
+* 通过 `IoTDB connector` 生成一张源数据表。
+* 通过 `IoTDB connector` 注册一个输出表。
+* 将原数据表中的列重命名后写入写回 IoTDB。
+
+```java
+import org.apache.flink.table.api.DataTypes;
+import org.apache.flink.table.api.EnvironmentSettings;
+import org.apache.flink.table.api.Schema;
+import org.apache.flink.table.api.Table;
+import org.apache.flink.table.api.TableDescriptor;
+import org.apache.flink.table.api.TableEnvironment;
+
+import static org.apache.flink.table.api.Expressions.$;
+
+public class BatchSinkTest {
+ public static void main(String[] args) {
+ // setup environment
+ EnvironmentSettings settings = EnvironmentSettings
+ .newInstance()
+ .inBatchMode()
+ .build();
+ TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+ // create source table
+ Schema sourceTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d0.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s0", DataTypes.FLOAT())
+ .column("root.sg.d1.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor sourceTableDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(sourceTableSchema)
+ .option("sql", "select ** from root.sg.d0,root.sg.d1")
+ .build();
+
+ tableEnv.createTemporaryTable("sourceTable", sourceTableDescriptor);
+ Table sourceTable = tableEnv.from("sourceTable");
+ // register sink table
+ Schema sinkTableSchema = Schema
+ .newBuilder()
+ .column("Time_", DataTypes.BIGINT())
+ .column("root.sg.d2.s0", DataTypes.FLOAT())
+ .column("root.sg.d3.s0", DataTypes.FLOAT())
+ .column("root.sg.d3.s1", DataTypes.FLOAT())
+ .build();
+ TableDescriptor sinkTableDescriptor = TableDescriptor
+ .forConnector("IoTDB")
+ .schema(sinkTableSchema)
+ .build();
+ tableEnv.createTemporaryTable("sinkTable", sinkTableDescriptor);
+
+ // insert data
+ sourceTable.renameColumns(
+ $("root.sg.d0.s0").as("root.sg.d2.s0"),
+ $("root.sg.d1.s0").as("root.sg.d3.s0"),
+ $("root.sg.d1.s1").as("root.sg.d3.s1")
+ ).insertInto("sinkTable").execute().print();
+ }
+}
+```
+
+上述任务执行完成后,在 IoTDB 的 cli 中查询结果如下:
+
+```text
+IoTDB> select ** from root;
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+| Time|root.sg.d0.s0|root.sg.d1.s0|root.sg.d1.s1|root.sg.d2.s0|root.sg.d3.s0|root.sg.d3.s1|
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+|1970-01-01T08:00:00.001+08:00| 1.0833644| 2.34874| 1.2414109| 1.0833644| 2.34874| 1.2414109|
+|1970-01-01T08:00:00.002+08:00| 4.929185| 3.1885583| 4.6980085| 4.929185| 3.1885583| 4.6980085|
+|1970-01-01T08:00:00.003+08:00| 3.5206156| 3.5600138| 4.8080945| 3.5206156| 3.5600138| 4.8080945|
+|1970-01-01T08:00:00.004+08:00| 1.3449302| 2.8781595| 3.3195343| 1.3449302| 2.8781595| 3.3195343|
+|1970-01-01T08:00:00.005+08:00| 3.3079383| 3.3840187| 3.7278645| 3.3079383| 3.3840187| 3.7278645|
++-----------------------------+-------------+-------------+-------------+-------------+-------------+-------------+
+Total line number = 5
+It costs 0.015s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V1.3.x/SQL-Manual/SQL-Manual.md b/src/zh/UserGuide/V1.3.x/SQL-Manual/SQL-Manual.md
index ed42eec3..8531b723 100644
--- a/src/zh/UserGuide/V1.3.x/SQL-Manual/SQL-Manual.md
+++ b/src/zh/UserGuide/V1.3.x/SQL-Manual/SQL-Manual.md
@@ -304,8 +304,6 @@ IoTDB> show paths set schema template t1
IoTDB> show paths using schema template t1
-IoTDB> show devices using schema template t1
-
#### 解除元数据模板
IoTDB> delete timeseries of schema template t1 from root.sg1.d1
diff --git a/src/zh/UserGuide/V1.3.x/User-Manual/IoTDB-AINode_timecho.md b/src/zh/UserGuide/V1.3.x/User-Manual/IoTDB-AINode_timecho.md
index ff1a02e8..f8212429 100644
--- a/src/zh/UserGuide/V1.3.x/User-Manual/IoTDB-AINode_timecho.md
+++ b/src/zh/UserGuide/V1.3.x/User-Manual/IoTDB-AINode_timecho.md
@@ -24,9 +24,9 @@
AINode 是 IoTDB 在ConfigNode、DataNode后提供的第三种内生节点,该节点通过与 IoTDB 集群的 DataNode、ConfigNode 的交互,扩展了对时间序列进行机器学习分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
系统架构如下图所示:
-
+::: center
-
+:::
三种节点的职责如下:
- **ConfigNode**:负责保存和管理模型的元信息;负责分布式节点管理。
diff --git a/src/zh/UserGuide/V1.3.x/User-Manual/Query-Data.md b/src/zh/UserGuide/V1.3.x/User-Manual/Query-Data.md
index c84491eb..a0ecc32c 100644
--- a/src/zh/UserGuide/V1.3.x/User-Manual/Query-Data.md
+++ b/src/zh/UserGuide/V1.3.x/User-Manual/Query-Data.md
@@ -277,10 +277,10 @@ It costs 0.016s
数据查询语句支持在 SQL 命令行终端、JDBC、JAVA / C++ / Python / Go 等编程语言 API、RESTful API 中使用。
-- 在 SQL 命令行终端中执行查询语句:启动 SQL 命令行终端,直接输入查询语句执行即可,详见 [SQL 命令行终端](../QuickStart/Command-Line-Interface.md)。
+- 在 SQL 命令行终端中执行查询语句:启动 SQL 命令行终端,直接输入查询语句执行即可,详见 [SQL 命令行终端](../Tools-System/CLI.md)。
- 在 JDBC 中执行查询语句,详见 [JDBC](../API/Programming-JDBC.md) 。
-
+-
- 在 JAVA / C++ / Python / Go 等编程语言 API 中执行查询语句,详见应用编程接口一章相应文档。接口原型如下:
```java
@@ -368,7 +368,7 @@ select s1 as temperature, s2 as speed from root.ln.wf01.wt01;
### 运算符
-IoTDB 中支持的运算符列表见文档 [运算符和函数](../Operators-Functions/Overview.md)。
+IoTDB 中支持的运算符列表见文档 [运算符和函数](../User-Manual/Operator-and-Expression.md)。
### 函数
@@ -386,7 +386,7 @@ select sin(s1), count(s1) from root.sg.d1;
select s1, count(s1) from root.sg.d1 group by ([10,100),10ms);
```
-IoTDB 支持的聚合函数见文档 [聚合函数](../Operators-Functions/Aggregation.md)。
+IoTDB 支持的聚合函数见文档 [聚合函数](../User-Manual/Operator-and-Expression.md#内置函数)。
#### 时间序列生成函数
@@ -396,11 +396,11 @@ IoTDB 支持的聚合函数见文档 [聚合函数](../Operators-Functions/Aggre
##### 内置时间序列生成函数
-IoTDB 中支持的内置函数列表见文档 [运算符和函数](../Operators-Functions/Overview.md)。
+IoTDB 中支持的内置函数列表见文档 [运算符和函数](../User-Manual/Operator-and-Expression.md)。
##### 自定义时间序列生成函数
-IoTDB 支持通过用户自定义函数(点击查看: [用户自定义函数](../Operators-Functions/User-Defined-Function.md) )能力进行函数功能扩展。
+IoTDB 支持通过用户自定义函数(点击查看: [用户自定义函数](../User-Manual/Database-Programming.md#用户自定义函数) )能力进行函数功能扩展。
### 嵌套表达式举例
diff --git a/src/zh/UserGuide/V1.3.x/User-Manual/Write-Delete-Data.md b/src/zh/UserGuide/V1.3.x/User-Manual/Write-Delete-Data.md
index 5a2cafab..d3b7ada8 100644
--- a/src/zh/UserGuide/V1.3.x/User-Manual/Write-Delete-Data.md
+++ b/src/zh/UserGuide/V1.3.x/User-Manual/Write-Delete-Data.md
@@ -23,9 +23,9 @@
# 写入和删除数据
## CLI写入数据
-IoTDB 为用户提供多种插入实时数据的方式,例如在 [Cli/Shell 工具](../QuickStart/Command-Line-Interface.md) 中直接输入插入数据的 INSERT 语句,或使用 Java API(标准 [Java JDBC](../API/Programming-JDBC.md) 接口)单条或批量执行插入数据的 INSERT 语句。
+IoTDB 为用户提供多种插入实时数据的方式,例如在 [Cli/Shell 工具](../Tools-System/CLI.md) 中直接输入插入数据的 INSERT 语句,或使用 Java API(标准 [Java JDBC](../API/Programming-JDBC.md) 接口)单条或批量执行插入数据的 INSERT 语句。
-本节主要为您介绍实时数据接入的 INSERT 语句在场景中的实际使用示例,有关 INSERT SQL 语句的详细语法请参见本文 [INSERT 语句](../Reference/SQL-Reference.md) 节。
+本节主要为您介绍实时数据接入的 INSERT 语句在场景中的实际使用示例,有关 INSERT SQL 语句的详细语法请参见本文 [INSERT 语句](../SQL-Manual/SQL-Manual.md#写入数据) 节。
注:写入重复时间戳的数据则原时间戳数据被覆盖,可视为更新数据。
@@ -184,7 +184,7 @@ CSV 是以纯文本形式存储表格数据,您可以在CSV文件中写入多
## 删除数据
-用户使用 [DELETE 语句](../Reference/SQL-Reference.md) 可以删除指定的时间序列中符合时间删除条件的数据。在删除数据时,用户可以选择需要删除的一个或多个时间序列、时间序列的前缀、时间序列带、*路径对某一个时间区间内的数据进行删除。
+用户使用 [DELETE 语句](../SQL-Manual/SQL-Manual.md#删除数据) 可以删除指定的时间序列中符合时间删除条件的数据。在删除数据时,用户可以选择需要删除的一个或多个时间序列、时间序列的前缀、时间序列带、*路径对某一个时间区间内的数据进行删除。
在 JAVA 编程环境中,您可以使用 JDBC API 单条或批量执行 DELETE 语句。