Various data sources can be supported by implementing different PipeExtractor classes.
+ *
Various data sources can be supported by implementing different PipeSource classes.
*
- *
This method is called after the method {@link
- * PipeExtractor#validate(PipeParameterValidator)} is called.
+ *
This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
+ * is called.
*
* @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeExtractor
+ * @param configuration used to set the required properties of the running PipeSource
* @throws Exception the user can throw errors if necessary
*/
- void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
+ void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
throws Exception;
/**
- * Start the extractor. After this method is called, events should be ready to be supplied by
- * {@link PipeExtractor#supply()}. This method is called after {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ * Start the source. After this method is called, events should be ready to be supplied by
+ * {@link PipeSource#supply()}. This method is called after {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @throws Exception the user can throw errors if necessary
*/
void start() throws Exception;
/**
- * Supply single event from the extractor and the caller will send the event to the processor.
- * This method is called after {@link PipeExtractor#start()} is called.
+ * Supply single event from the source and the caller will send the event to the processor.
+ * This method is called after {@link PipeSource#start()} is called.
*
- * @return the event to be supplied. the event may be null if the extractor has no more events at
- * the moment, but the extractor is still running for more events.
+ * @return the event to be supplied. the event may be null if the source has no more events at
+ * the moment, but the source is still running for more events.
* @throws Exception the user can throw errors if necessary
*/
Event supply() throws Exception;
@@ -212,13 +212,13 @@ public interface PipeExtractor extends PipePlugin {
#### Data Processing Plugin Interface
-Data processing is the second stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data processing plugin (PipeProcessor) is primarily used for filtering and transforming the various events captured by the data extraction plugin (PipeExtractor).
+Data processing is the second stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data processing plugin (PipeProcessor) is primarily used for filtering and transforming the various events captured by the data extraction plugin (PipeSource).
```java
/**
* PipeProcessor
*
- *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
*
The lifecycle of a PipeProcessor is as follows:
*
@@ -231,13 +231,13 @@ Data processing is the second stage of the three-stage process of stream process
* to config the runtime behavior of the PipeProcessor.
*
When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
@@ -312,50 +312,48 @@ public interface PipeProcessor extends PipePlugin {
#### Data Sending Plugin Interface
-Data sending is the third stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data sending plugin (PipeConnector) is responsible for sending the various events processed by the data processing plugin (PipeProcessor). It serves as the network implementation layer of the stream processing framework and should support multiple real-time communication protocols and connectors in its interface.
+Data sending is the third stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data sending plugin (PipeSink) is responsible for sending the various events processed by the data processing plugin (PipeProcessor). It serves as the network implementation layer of the stream processing framework and should support multiple real-time communication protocols and connectors in its interface.
```java
/**
- * PipeConnector
+ * PipeSink
*
- * PipeConnector is responsible for sending events to sinks.
+ *
PipeSink is responsible for sending events to sinks.
*
- *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
Various network protocols can be supported by implementing different PipeSink classes.
*
- *
The lifecycle of a PipeConnector is as follows:
+ *
The lifecycle of a PipeSink is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
- * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
- *
- Before the collaboration task starts, the method {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeConnector and the method {@link
- * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
+ * parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
+ * called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
+ * PipeSinkRuntimeConfiguration)} will be called to configure the runtime behavior of the
+ * PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
+ * with sink.
*
- While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector.
- *
- PipeConnector serializes the events into binaries and send them to sinks. The
- * following 3 methods will be called: {@link
- * PipeConnector#transfer(TabletInsertionEvent)}, {@link
- * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
- * PipeConnector#transfer(Event)}.
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink.
+ *
- PipeSink serializes the events into binaries and send them to sinks. The following 3
+ * methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
+ * PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
*
* - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
- * PipeConnector#close() } method will be called.
+ * PipeSink#close() } method will be called.
*
*
- * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
- * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
- * will be called to create a new connection with the sink when the method {@link
- * PipeConnector#heartbeat()} throws exceptions.
+ *
In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
+ * called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
+ * throws exceptions.
*/
-public interface PipeConnector extends PipePlugin {
+public interface PipeSink extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
+ * PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
@@ -363,29 +361,28 @@ public interface PipeConnector extends PipePlugin {
void validate(PipeParameterValidator validator) throws Exception;
/**
- * This method is mainly used to customize PipeConnector. In this method, the user can do the
- * following things:
+ * This method is mainly used to customize PipeSink. In this method, the user can do the following
+ * things:
*
*
* - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
+ *
- Set the running configurations in PipeSinkRuntimeConfiguration.
*
*
- * This method is called after the method {@link
- * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
- * PipeConnector#handshake()} is called.
+ *
This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
+ * called and before the method {@link PipeSink#handshake()} is called.
*
* @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeConnector
+ * @param configuration used to set the required properties of the running PipeSink
* @throws Exception the user can throw errors if necessary
*/
- void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
+ void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
throws Exception;
/**
* This method is used to create a connection with sink. This method will be called after the
- * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
- * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
+ * method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
+ * will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
*
* @throws Exception if the connection is failed to be created
*/
@@ -416,14 +413,18 @@ public interface PipeConnector extends PipePlugin {
* @throws Exception the user can throw errors if necessary
*/
default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- transfer(tabletInsertionEvent);
+ try {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ } finally {
+ tsFileInsertionEvent.close();
}
}
/**
- * This method is used to transfer the Event.
+ * This method is used to transfer the generic events, including HeartbeatEvent.
*
* @param event Event to be transferred
* @throws PipeConnectionException if the connection is broken
@@ -439,7 +440,7 @@ To ensure the flexibility and usability of user-defined plugins in production en
### Load Plugin Statement
-In IoTDB, to dynamically load a user-defined plugin into the system, you first need to implement a specific plugin class based on PipeExtractor, PipeProcessor, or PipeConnector. Then, you need to compile and package the plugin class into an executable jar file. Finally, you can use the loading plugin management statement to load the plugin into IoTDB.
+In IoTDB, to dynamically load a user-defined plugin into the system, you first need to implement a specific plugin class based on PipeSource, PipeProcessor, or PipeSink. Then, you need to compile and package the plugin class into an executable jar file. Finally, you can use the loading plugin management statement to load the plugin into IoTDB.
The syntax of the loading plugin management statement is as follows:
@@ -459,7 +460,7 @@ USING URI ''
### Delete Plugin Statement
-When user no longer wants to use a plugin and needs to uninstall the plug-in from the system, you can use the Remove plugin statement as shown below.
+When user no longer wants to use a plugin and needs to uninstall the plugin from the system, you can use the Remove plugin statement as shown below.
```sql
DROP PIPEPLUGIN
```
@@ -473,84 +474,76 @@ SHOW PIPEPLUGINS
## System Pre-installed Stream Processing Plugin
-### Pre-built extractor Plugin
+### Pre-built Source Plugin
-#### iotdb-extractor
+#### iotdb-source
Function: Extract historical or realtime data inside IoTDB into pipe.
-| key | value | value range | required or optional with default |
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor | String: iotdb-extractor | required |
-| extractor.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
-| extractor.history.enable | whether to sync historical data | Boolean: true, false | optional: true |
-| extractor.history.start-time | start of synchronizing historical data event time,Include start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | end of synchronizing historical data event time,Include end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | Whether to sync realtime data | Boolean: true, false | optional: true |
+| key | value | value range | required or optional with default |
+|---------------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
+| source.history.start-time | start of synchronizing historical data event time,including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | end of synchronizing historical data event time,including end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-> 🚫 **extractor.pattern Parameter Description**
+> 🚫 **source.pattern Parameter Description**
>
> * Pattern should use backquotes to modify illegal characters or illegal path nodes, for example, if you want to filter root.\`a@b\` or root.\`123\`, you should set the pattern to root.\`a@b\` or root.\`123\`(Refer specifically to [Timing of single and double quotes and backquotes](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
-> * In the underlying implementation, when pattern is detected as root (default value), synchronization efficiency is higher, and any other format will reduce performance.
-> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
->
-> * root.aligned.1TS
+> * In the underlying implementation, when pattern is detected as root (default value) or a database name, synchronization efficiency is higher, and any other format will reduce performance.
+> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'source.pattern'='root.aligned.1':
+ >
+ > * root.aligned.1TS
> * root.aligned.1TS.\`1\`
> * root.aligned.100TS
+ >
+ > the data will be synchronized;
+ >
+ > * root.aligned.\`123\`
+ >
+ > the data will not be synchronized.
+
+> ❗️**start-time, end-time parameter description of source**
>
-> the data will be synchronized;
->
-> * root.aligned.\`1\`
-> * root.aligned.\`123\`
->
-> the data will not be synchronized.
-
-> ❗️**start-time, end-time parameter description of extractor.history**
->
-> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
+> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00. However, version 1.3.1+ supports timeStamp format like 1706704494000.
-> ✅ **a piece of data from production to IoTDB contains two key concepts of time**
+> ✅ **A piece of data from production to IoTDB contains two key concepts of time**
>
> * **event time:** the time when the data is actually produced (or the generation time assigned to the data by the data production system, which is a time item in the data point), also called the event time.
> * **arrival time:** the time the data arrived in the IoTDB system.
>
> The out-of-order data we often refer to refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
-> 💎 **the work of iotdb-extractor can be split into two stages**
+> 💎 **the work of iotdb-source can be split into two stages**
>
> 1. Historical data extraction: All data with **arrival time** < **current system time** when creating the pipe is called historical data
> 2. Realtime data extraction: All data with **arrival time** >= **current system time** when the pipe is created is called realtime data
>
> The historical data transmission phase and the realtime data transmission phase are executed serially. Only when the historical data transmission phase is completed, the realtime data transmission phase is executed.**
->
-> Users can specify iotdb-extractor to:
->
-> * Historical data extraction(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * Realtime data extraction(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * Full data extraction(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * Disable simultaneous sets `extractor.history.enable` and `extractor.realtime.enable` to `false`
### Pre-built Processor Plugin
#### do-nothing-processor
-Function: Do not do anything with the events passed in by the extractor.
+Function: Do not do anything with the events passed in by the source.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value range | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### Pre-built Connector Plugin
+### Pre-built Sink Plugin
-#### do-nothing-connector
+#### do-nothing-sink
Function: Does not do anything with the events passed in by the processor.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value range | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## Stream Processing Task Management
@@ -560,57 +553,57 @@ A stream processing task can be created using the `CREATE PIPE` statement, a sam
```sql
CREATE PIPE -- PipeId is the name that uniquely identifies the sync task
-WITH EXTRACTOR (
+WITH SOURCE (
-- Default IoTDB Data Extraction Plugin
- 'extractor' = 'iotdb-extractor',
+ 'source' = 'iotdb-source',
-- Path prefix, only data that can match the path prefix will be extracted for subsequent processing and delivery
- 'extractor.pattern' = 'root.timecho',
+ 'source.pattern' = 'root.timecho',
-- Whether to extract historical data
- 'extractor.history.enable' = 'true',
+ 'source.history.enable' = 'true',
-- Describes the time range of the historical data being extracted, indicating the earliest possible time
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- Describes the time range of the extracted historical data, indicating the latest time
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
-- Whether to extract realtime data
- 'extractor.realtime.enable' = 'true',
+ 'source.realtime.enable' = 'true',
)
WITH PROCESSOR (
-- Default data processing plugin, means no processing
'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB data sending plugin with target IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- Data service for one of the DataNode nodes on the target IoTDB ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
**To create a stream processing task it is necessary to configure the PipeId and the parameters of the three plugin sections:**
-| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
-| --------- | ------------------------------------------------- | --------------------------- | -------------------- | ------------------------------------------------------ | ------------------------- |
-| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
-| extractor | pipe Extractor plug-in, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
-| processor | Pipe Processor plug-in, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
-| connector | Pipe Connector plug-in,for sending data | required | - | - | yes |
+| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
+|--------------------|-------------------------------------------------------------------------------------|---------------------------------|------------------------|-----------------------------------------------------------------------------------------------|-----------------------------------------|
+| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
+| source | pipe Source plugin, for extracting synchronized data at the bottom of the database | Optional | iotdb-source | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
+| processor | Pipe Processor plugin, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
+| sink | Pipe Sink plugin,for sending data | required | - | - | yes |
-In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plug-ins are used to build the data synchronisation task. iotdb has other built-in data synchronisation plug-ins, **see the section "System pre-built data synchronisation plug-ins" **. See the "System Pre-installed Stream Processing Plugin" section**.
+In the example, the iotdb-source, do-nothing-processor, and iotdb-thrift-sink plugins are used to build the data synchronisation task. iotdb has other built-in data synchronisation plugins, **see the section "System pre-built data synchronisation plugins" **. See the "System Pre-installed Stream Processing Plugin" section**.
**An example of a minimalist CREATE PIPE statement is as follows:**
```sql
CREATE PIPE -- PipeId is a name that uniquely identifies the task.
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB data sending plugin with target IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- Data service for one of the DataNode nodes on the target IoTDB ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -618,37 +611,37 @@ The expressed semantics are: synchronise the full amount of historical data and
**Note:**
-- EXTRACTOR and PROCESSOR are optional, if no configuration parameters are filled in, the system will use the corresponding default implementation.
-- The CONNECTOR is a mandatory configuration that needs to be declared in the CREATE PIPE statement for configuring purposes.
-- The CONNECTOR exhibits self-reusability. For different tasks, if their CONNECTOR possesses identical KV properties (where the value corresponds to every key), **the system will ultimately create only one instance of the CONNECTOR** to achieve resource reuse for connections.
+- SOURCE and PROCESSOR are optional, if no configuration parameters are filled in, the system will use the corresponding default implementation.
+- The SINK is a mandatory configuration that needs to be declared in the CREATE PIPE statement for configuring purposes.
+- The SINK exhibits self-reusability. For different tasks, if their SINK possesses identical KV properties (where the value corresponds to every key), **the system will ultimately create only one instance of the SINK** to achieve resource reuse for connections.
- - For example, there are the following pipe1, pipe2 task declarations:
+ - For example, there are the following pipe1, pipe2 task declarations:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.thrift.host' = 'localhost',
+ 'sink.thrift.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.thrift.port' = '9999',
+ 'sink.thrift.host' = 'localhost',
)
```
- - Since they have identical CONNECTOR declarations (**even if the order of some properties is different**), the framework will automatically reuse the CONNECTOR declared by them. Hence, the CONNECTOR instances for pipe1 and pipe2 will be the same.
+- Since they have identical SINK declarations (**even if the order of some properties is different**), the framework will automatically reuse the SINK declared by them. Hence, the SINK instances for pipe1 and pipe2 will be the same.
- Please note that we should avoid constructing application scenarios that involve data cycle sync (as it can result in an infinite loop):
- - IoTDB A -> IoTDB B -> IoTDB A
- - IoTDB A -> IoTDB A
+- IoTDB A -> IoTDB B -> IoTDB A
+- IoTDB A -> IoTDB A
### Start Stream Processing Task
-After the successful execution of the CREATE PIPE statement, an instance of the stream processing task is created, but the overall task's running status will be set to STOPPED, meaning the task will not immediately process data.
+After the successful execution of the CREATE PIPE statement, task-related instances will be created. However, the overall task's running status will be set to STOPPED(V1.3.0), meaning the task will not immediately process data. In version 1.3.1 and later, the status of the task will be set to RUNNING after CREATE.
You can use the START PIPE statement to make the stream processing task start processing data:
```sql
@@ -683,13 +676,13 @@ SHOW PIPES
The query results are as follows:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime | State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
You can use `` to specify the status of a stream processing task you want to see:
@@ -697,22 +690,23 @@ You can use `` to specify the status of a stream processing task you wan
SHOW PIPE
```
-Additionally, the WHERE clause can be used to determine if the Pipe Connector used by a specific \ is being reused.
+Additionally, the WHERE clause can be used to determine if the Pipe Sink used by a specific \ is being reused.
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### Stream Processing Task Running Status Migration
A stream processing task status can transition through several states during the lifecycle of a data synchronization pipe:
+- **RUNNING:** The pipe is actively processing data
+ - After the successful creation of a pipe, its initial state is set to RUNNING (V1.3.1+)
- **STOPPED:** The pipe is in a stopped state. It can have the following possibilities:
- - After the successful creation of a pipe, its initial state is set to stopped
+ - After the successful creation of a pipe, its initial state is set to STOPPED (V1.3.0)
- The user manually pauses a pipe that is in normal running state, transitioning its status from RUNNING to STOPPED
- If a pipe encounters an unrecoverable error during execution, its status automatically changes from RUNNING to STOPPED.
-- **RUNNING:** The pipe is actively processing data
- **DROPPED:** The pipe is permanently deleted
The following diagram illustrates the different states and their transitions:
@@ -723,26 +717,27 @@ The following diagram illustrates the different states and their transitions:
### Stream Processing Task
-| Authority Name | Description |
-| ----------- | -------------------- |
-| USE_PIPE | Register task,path-independent |
-| USE_PIPE | Start task,path-independent |
-| USE_PIPE | Stop task,path-independent |
-| USE_PIPE | Uninstall task,path-independent |
-| USE_PIPE | Query task,path-independent |
+| Authority Name | Description |
+|----------------|---------------------------------|
+| USE_PIPE | Register task,path-independent |
+| USE_PIPE | Start task,path-independent |
+| USE_PIPE | Stop task,path-independent |
+| USE_PIPE | Uninstall task,path-independent |
+| USE_PIPE | Query task,path-independent |
### Stream Processing Task Plugin
-| Authority Name | Description |
-| ----------------- | ------------------------------ |
-| USE_PIPE | Register stream processing task plugin,path-independent |
-| USE_PIPE | Delete stream processing task plugin,path-independent |
-| USE_PIPE | Query stream processing task plugin,path-independent |
+| Authority Name | Description |
+|----------------|---------------------------------------------------------|
+| USE_PIPE | Register stream processing task plugin,path-independent |
+| USE_PIPE | Delete stream processing task plugin,path-independent |
+| USE_PIPE | Query stream processing task plugin,path-independent |
## Configure Parameters
In iotdb-common.properties :
+V1.3.0:
```Properties
####################
### Pipe Configuration
@@ -763,4 +758,43 @@ In iotdb-common.properties :
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+```
+
+V1.3.1+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
```
\ No newline at end of file
diff --git a/src/UserGuide/Master/User-Manual/Streaming_timecho.md b/src/UserGuide/Master/User-Manual/Streaming_timecho.md
index 8d121314..95505658 100644
--- a/src/UserGuide/Master/User-Manual/Streaming_timecho.md
+++ b/src/UserGuide/Master/User-Manual/Streaming_timecho.md
@@ -25,19 +25,19 @@ The IoTDB stream processing framework allows users to implement customized strea
We call a data flow processing task a Pipe. A stream processing task (Pipe) contains three subtasks:
-- Extract
-- Process
-- Send (Connect)
+- Source task
+- Processor task
+- Sink task
The stream processing framework allows users to customize the processing logic of three subtasks using Java language and process data in a UDF-like manner.
In a Pipe, the above three subtasks are executed by three plugins respectively, and the data will be processed by these three plugins in turn:
-Pipe Extractor is used to extract data, Pipe Processor is used to process data, Pipe Connector is used to send data, and the final data will be sent to an external system.
+Pipe Source is used to extract data, Pipe Processor is used to process data, Pipe Sink is used to send data, and the final data will be sent to an external system.
**The model of the Pipe task is as follows:**
-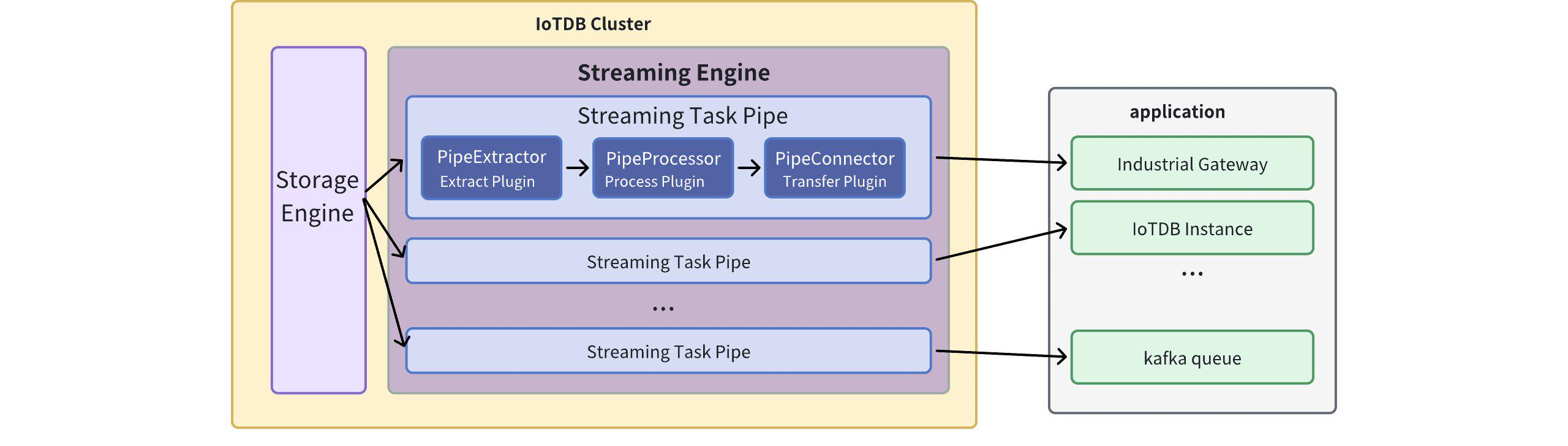
+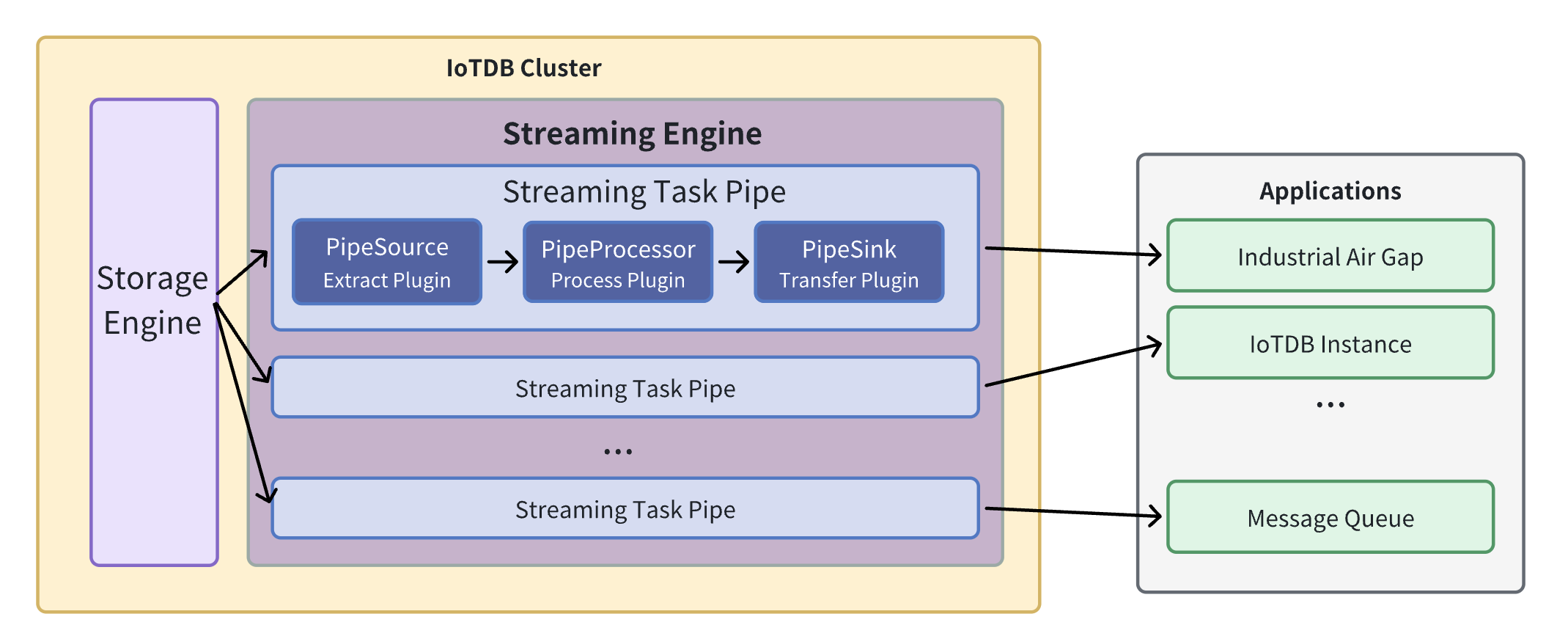
-Describing a data flow processing task essentially describes the properties of Pipe Extractor, Pipe Processor and Pipe Connector plugins.
+Describing a data flow processing task essentially describes the properties of Pipe Source, Pipe Processor and Pipe Sink plugins.
Users can declaratively configure the specific attributes of the three subtasks through SQL statements, and achieve flexible data ETL capabilities by combining different attributes.
Using the stream processing framework, a complete data link can be built to meet the needs of end-side-cloud synchronization, off-site disaster recovery, and read-write load sub-library*.
@@ -52,7 +52,7 @@ It is recommended to use maven to build the project and add the following depend
org.apache.iotdb
pipe-api
- 1.2.1
+ 1.3.1
provided
```
@@ -61,7 +61,7 @@ It is recommended to use maven to build the project and add the following depend
The user programming interface design of the stream processing plugin refers to the general design concept of the event-driven programming model. Events are data abstractions in the user programming interface, and the programming interface is decoupled from the specific execution method. It only needs to focus on describing the processing method expected by the system after the event (data) reaches the system.
-In the user programming interface of the stream processing plugin, events are an abstraction of database data writing operations. The event is captured by the stand-alone stream processing engine, and is passed to the PipeExtractor plugin, PipeProcessor plugin, and PipeConnector plugin in sequence according to the three-stage stream processing process, and triggers the execution of user logic in the three plugins in turn.
+In the user programming interface of the stream processing plugin, events are an abstraction of database data writing operations. The event is captured by the stand-alone stream processing engine, and is passed to the PipeSource plugin, PipeProcessor plugin, and PipeSink plugin in sequence according to the three-stage stream processing process, and triggers the execution of user logic in the three plugins in turn.
In order to take into account the low latency of stream processing in low load scenarios on the end side and the high throughput of stream processing in high load scenarios on the end side, the stream processing engine will dynamically select processing objects in the operation logs and data files. Therefore, user programming of stream processing The interface requires users to provide processing logic for the following two types of events: operation log writing event TabletInsertionEvent and data file writing event TsFileInsertionEvent.
@@ -79,21 +79,21 @@ The existence of operation log writing events provides users with a unified view
/** TabletInsertionEvent is used to define the event of data insertion. */
public interface TabletInsertionEvent extends Event {
- /**
- * The consumer processes the data row by row and collects the results by RowCollector.
- *
- * @return {@code Iterable} a list of new TabletInsertionEvent contains the
- * results collected by the RowCollector
- */
- Iterable processRowByRow(BiConsumer consumer);
-
- /**
- * The consumer processes the Tablet directly and collects the results by RowCollector.
- *
- * @return {@code Iterable} a list of new TabletInsertionEvent contains the
- * results collected by the RowCollector
- */
- Iterable processTablet(BiConsumer consumer);
+ /**
+ * The consumer processes the data row by row and collects the results by RowCollector.
+ *
+ * @return {@code Iterable} a list of new TabletInsertionEvent contains the
+ * results collected by the RowCollector
+ */
+ Iterable processRowByRow(BiConsumer consumer);
+
+ /**
+ * The consumer processes the Tablet directly and collects the results by RowCollector.
+ *
+ * @return {@code Iterable} a list of new TabletInsertionEvent contains the
+ * results collected by the RowCollector
+ */
+ Iterable processTablet(BiConsumer consumer);
}
```
@@ -118,12 +118,12 @@ To sum up, the data file writing event appears in the event stream of the stream
*/
public interface TsFileInsertionEvent extends Event {
- /**
- * The method is used to convert the TsFileInsertionEvent into several TabletInsertionEvents.
- *
- * @return {@code Iterable} the list of TabletInsertionEvent
- */
- Iterable toTabletInsertionEvents();
+ /**
+ * The method is used to convert the TsFileInsertionEvent into several TabletInsertionEvents.
+ *
+ * @return {@code Iterable} the list of TabletInsertionEvent
+ */
+ Iterable toTabletInsertionEvents();
}
```
@@ -133,95 +133,95 @@ Based on the custom stream processing plugin programming interface, users can ea
#### Data extraction plugin interface
-Data extraction is the first stage of the three stages of stream processing data from data extraction to data sending. The data extraction plugin (PipeExtractor) is the bridge between the stream processing engine and the storage engine. It monitors the behavior of the storage engine,
+Data extraction is the first stage of the three stages of stream processing data from data extraction to data sending. The data extraction plugin (PipeSource) is the bridge between the stream processing engine and the storage engine. It monitors the behavior of the storage engine,
Capture various data write events.
```java
/**
- * PipeExtractor
+ * PipeSource
*
- * PipeExtractor is responsible for capturing events from sources.
+ *
PipeSource is responsible for capturing events from sources.
*
- *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
Various data sources can be supported by implementing different PipeSource classes.
*
- *
The lifecycle of a PipeExtractor is as follows:
+ *
The lifecycle of a PipeSource is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
- * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
+ *
- When a collaboration task is created, the KV pairs of `WITH Source` clause in SQL are
+ * parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
+ * be called to validate the parameters.
*
- Before the collaboration task starts, the method {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeExtractor.
- *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
- *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
- * be called to capture events from sources and then the events will be passed to the
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
+ * configure the runtime behavior of the PipeSource.
+ *
- Then the method {@link PipeSource#start()} will be called to start the PipeSource.
+ *
- While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
+ * called to capture events from sources and then the events will be passed to the
* PipeProcessor.
- *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ *
- The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
*
*/
-public interface PipeExtractor extends PipePlugin {
-
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeExtractor. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeExtractor#validate(PipeParameterValidator)} is called.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeExtractor
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * Start the extractor. After this method is called, events should be ready to be supplied by
- * {@link PipeExtractor#supply()}. This method is called after {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
- *
- * @throws Exception the user can throw errors if necessary
- */
- void start() throws Exception;
-
- /**
- * Supply single event from the extractor and the caller will send the event to the processor.
- * This method is called after {@link PipeExtractor#start()} is called.
- *
- * @return the event to be supplied. the event may be null if the extractor has no more events at
- * the moment, but the extractor is still running for more events.
- * @throws Exception the user can throw errors if necessary
- */
- Event supply() throws Exception;
+public interface PipeSource extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeSource. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeSourceRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
+ * is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeSource
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * Start the Source. After this method is called, events should be ready to be supplied by
+ * {@link PipeSource#supply()}. This method is called after {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
+ *
+ * @throws Exception the user can throw errors if necessary
+ */
+ void start() throws Exception;
+
+ /**
+ * Supply single event from the Source and the caller will send the event to the processor.
+ * This method is called after {@link PipeSource#start()} is called.
+ *
+ * @return the event to be supplied. the event may be null if the Source has no more events at
+ * the moment, but the Source is still running for more events.
+ * @throws Exception the user can throw errors if necessary
+ */
+ Event supply() throws Exception;
}
```
#### Data processing plugin interface
-Data processing is the second stage of the three stages of stream processing data from data extraction to data sending. The data processing plugin (PipeProcessor) is mainly used to filter and transform the data captured by the data extraction plugin (PipeExtractor).
+Data processing is the second stage of the three stages of stream processing data from data extraction to data sending. The data processing plugin (PipeProcessor) is mainly used to filter and transform the data captured by the data extraction plugin (PipeSource).
various events.
```java
/**
* PipeProcessor
*
- *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
*
The lifecycle of a PipeProcessor is as follows:
*
@@ -231,16 +231,16 @@ various events.
* will be called to validate the parameters.
*
Before the collaboration task starts, the method {@link
* PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeProcessor.
+ * to configure the runtime behavior of the PipeProcessor.
* While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSource. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
- *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
- PipeSink serializes the events into binaries and send them to sinks.
*
* When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
@@ -248,192 +248,193 @@ various events.
*/
public interface PipeProcessor extends PipePlugin {
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeProcessor. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeProcessorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeProcessor#validate(PipeParameterValidator)} is called and before the beginning of the
- * events processing.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeProcessor
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeProcessorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * This method is called to process the TabletInsertionEvent.
- *
- * @param tabletInsertionEvent TabletInsertionEvent to be processed
- * @param eventCollector used to collect result events after processing
- * @throws Exception the user can throw errors if necessary
- */
- void process(TabletInsertionEvent tabletInsertionEvent, EventCollector eventCollector)
- throws Exception;
-
- /**
- * This method is called to process the TsFileInsertionEvent.
- *
- * @param tsFileInsertionEvent TsFileInsertionEvent to be processed
- * @param eventCollector used to collect result events after processing
- * @throws Exception the user can throw errors if necessary
- */
- default void process(TsFileInsertionEvent tsFileInsertionEvent, EventCollector eventCollector)
- throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- process(tabletInsertionEvent, eventCollector);
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeProcessor. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeProcessorRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link
+ * PipeProcessor#validate(PipeParameterValidator)} is called and before the beginning of the
+ * events processing.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeProcessor
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeProcessorRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is called to process the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ void process(TabletInsertionEvent tabletInsertionEvent, EventCollector eventCollector)
+ throws Exception;
+
+ /**
+ * This method is called to process the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void process(TsFileInsertionEvent tsFileInsertionEvent, EventCollector eventCollector)
+ throws Exception {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ process(tabletInsertionEvent, eventCollector);
+ }
}
- }
-
- /**
- * This method is called to process the Event.
- *
- * @param event Event to be processed
- * @param eventCollector used to collect result events after processing
- * @throws Exception the user can throw errors if necessary
- */
- void process(Event event, EventCollector eventCollector) throws Exception;
+
+ /**
+ * This method is called to process the Event.
+ *
+ * @param event Event to be processed
+ * @param eventCollector used to collect result events after processing
+ * @throws Exception the user can throw errors if necessary
+ */
+ void process(Event event, EventCollector eventCollector) throws Exception;
}
```
#### Data sending plugin interface
-Data sending is the third stage of the three stages of stream processing data from data extraction to data sending. The data sending plugin (PipeConnector) is mainly used to send data processed by the data processing plugin (PipeProcessor).
-Various events, it serves as the network implementation layer of the stream processing framework, and the interface should allow access to multiple real-time communication protocols and multiple connectors.
+Data sending is the third stage of the three stages of stream processing data from data extraction to data sending. The data sending plugin (PipeSink) is mainly used to send data processed by the data processing plugin (PipeProcessor).
+Various events, it serves as the network implementation layer of the stream processing framework, and the interface should allow access to multiple real-time communication protocols and multiple sinks.
```java
/**
- * PipeConnector
+ * PipeSink
*
- *
PipeConnector is responsible for sending events to sinks.
+ *
PipeSink is responsible for sending events to sinks.
*
- *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
Various network protocols can be supported by implementing different PipeSink classes.
*
- *
The lifecycle of a PipeConnector is as follows:
+ *
The lifecycle of a PipeSink is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
- * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
- *
- Before the collaboration task starts, the method {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeConnector and the method {@link
- * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
+ * parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
+ * called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
+ * PipeSinkRuntimeConfiguration)} will be called to configure the runtime behavior of the
+ * PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
+ * with sink.
*
- While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector.
- *
- PipeConnector serializes the events into binaries and send them to sinks. The
- * following 3 methods will be called: {@link
- * PipeConnector#transfer(TabletInsertionEvent)}, {@link
- * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
- * PipeConnector#transfer(Event)}.
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink.
+ *
- PipeSink serializes the events into binaries and send them to sinks. The following 3
+ * methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
+ * PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
*
* - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
- * PipeConnector#close() } method will be called.
+ * PipeSink#close() } method will be called.
*
*
- * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
- * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
- * will be called to create a new connection with the sink when the method {@link
- * PipeConnector#heartbeat()} throws exceptions.
+ *
In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
+ * called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
+ * throws exceptions.
*/
-public interface PipeConnector extends PipePlugin {
-
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeConnector. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
- * PipeConnector#handshake()} is called.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeConnector
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * This method is used to create a connection with sink. This method will be called after the
- * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
- * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
- *
- * @throws Exception if the connection is failed to be created
- */
- void handshake() throws Exception;
-
- /**
- * This method will be called periodically to check whether the connection with sink is still
- * alive.
- *
- * @throws Exception if the connection dies
- */
- void heartbeat() throws Exception;
-
- /**
- * This method is used to transfer the TabletInsertionEvent.
- *
- * @param tabletInsertionEvent TabletInsertionEvent to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
-
- /**
- * This method is used to transfer the TsFileInsertionEvent.
- *
- * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- transfer(tabletInsertionEvent);
+public interface PipeSink extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeSink. In this method, the user can do the following
+ * things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeSinkRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
+ * called and before the method {@link PipeSink#handshake()} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeSink
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is used to create a connection with sink. This method will be called after the
+ * method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
+ * will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
+ *
+ * @throws Exception if the connection is failed to be created
+ */
+ void handshake() throws Exception;
+
+ /**
+ * This method will be called periodically to check whether the connection with sink is still
+ * alive.
+ *
+ * @throws Exception if the connection dies
+ */
+ void heartbeat() throws Exception;
+
+ /**
+ * This method is used to transfer the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
+
+ /**
+ * This method is used to transfer the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
+ try {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ } finally {
+ tsFileInsertionEvent.close();
+ }
}
- }
-
- /**
- * This method is used to transfer the Event.
- *
- * @param event Event to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- void transfer(Event event) throws Exception;
+
+ /**
+ * This method is used to transfer the generic events, including HeartbeatEvent.
+ *
+ * @param event Event to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(Event event) throws Exception;
}
```
@@ -444,7 +445,7 @@ The stream processing plugin management statements introduced in this chapter pr
### Load plugin statement
-In IoTDB, if you want to dynamically load a user-defined plugin in the system, you first need to implement a specific plugin class based on PipeExtractor, PipeProcessor or PipeConnector.
+In IoTDB, if you want to dynamically load a user-defined plugin in the system, you first need to implement a specific plugin class based on PipeSource, PipeProcessor or PipeSink.
Then the plugin class needs to be compiled and packaged into a jar executable file, and finally the plugin is loaded into IoTDB using the management statement for loading the plugin.
The syntax of the management statement for loading the plugin is shown in the figure.
@@ -455,7 +456,7 @@ AS
USING
```
-Example: If you implement a data processing plugin named edu.tsinghua.iotdb.pipe.ExampleProcessor, and the packaged jar package is pipe-plugin.jar, you want to use this plugin in the stream processing engine, and mark the plugin as example. There are two ways to use the plug-in package, one is to upload to the URI server, and the other is to upload to the local directory of the cluster.
+Example: If you implement a data processing plugin named edu.tsinghua.iotdb.pipe.ExampleProcessor, and the packaged jar package is pipe-plugin.jar, you want to use this plugin in the stream processing engine, and mark the plugin as example. There are two ways to use the plugin package, one is to upload to the URI server, and the other is to upload to the local directory of the cluster.
Method 1: Upload to the URI server
@@ -498,74 +499,67 @@ SHOW PIPEPLUGINS
## System preset stream processing plugin
-### Preset extractor plugin
+### Pre-built Source Plugin
-####iotdb-extractor
+#### iotdb-source
-Function: Extract historical or real-time data inside IoTDB into pipe.
+Function: Extract historical or realtime data inside IoTDB into pipe.
-| key | value | value range | required or not |default value|
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | -------- |------|
-| source | iotdb-source | String: iotdb-source | required | - |
-| source.pattern | Path prefix for filtering time series | String: any time series prefix | optional | root |
-| source.history.enable | Whether to synchronise history data | Boolean: true, false | optional | true |
-| source.history.start-time | Synchronise the start event time of historical data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MIN_VALUE |
-| source.history.end-time | end event time for synchronised history data, contains end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MAX_VALUE |
-| source.realtime.enable | Whether to synchronise real-time data | Boolean: true, false | optional | true |
-| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional | hybrid |
-| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional | true |
+| key | value | value range | required or optional with default |
+|---------------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
+| source.history.start-time | start of synchronizing historical data event time,including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | end of synchronizing historical data event time,including end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional:true |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional:hybrid |
+| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional:true |
-> 🚫 **extractor.pattern 参数说明**
+> 🚫 **source.pattern Parameter Description**
>
->* Pattern needs to use backticks to modify illegal characters or illegal path nodes. For example, if you want to filter root.\`a@b\` or root.\`123\`, you should set pattern to root.\`a@b \` or root.\`123\` (For details, please refer to [When to use single and double quotes and backticks](https://iotdb.apache.org/zh/Download/#_1-0-version incompatible syntax details illustrate))
-> * In the underlying implementation, when pattern is detected as root (default value), the extraction efficiency is higher, and any other format will reduce performance.
-> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
- >
- > * root.aligned.1TS
-> * root.aligned.1TS.\`1\`
-> * root.aligned.100T
- >
- > The data will be extracted;
- >
- > * root.aligned.\`1\`
-> * root.aligned.\`123\`
- >
- > The data will not be extracted.
-> * The data of root.\_\_system will not be extracted by pipe. Although users can include any prefix in extractor.pattern, including prefixes with (or overriding) root.\__system, the data under root.__system will always be ignored by pipe
-
-> ❗️**Start-time, end-time parameter description of extractor.history**
+> * Pattern should use backquotes to modify illegal characters or illegal path nodes, for example, if you want to filter root.\`a@b\` or root.\`123\`, you should set the pattern to root.\`a@b\` or root.\`123\`(Refer specifically to [Timing of single and double quotes and backquotes](https://iotdb.apache.org/Download/))
+> * In the underlying implementation, when pattern is detected as root (default value) or a database name, synchronization efficiency is higher, and any other format will reduce performance.
+> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'source.pattern'='root.aligned.1':
+ >
+ > * root.aligned.1TS
+ > * root.aligned.1TS.\`1\`
+ > * root.aligned.100TS
+ >
+ > the data will be synchronized;
+ >
+ > * root.aligned.\`1\`
+> * root.aligned.\`123\`
+ >
+ > the data will not be synchronized.
+
+> ❗️**start-time, end-time parameter description of source**
>
-> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
+> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00. However, version 1.3.1+ supports timeStamp format like 1706704494000.
> ✅ **A piece of data from production to IoTDB contains two key concepts of time**
>
> * **event time:** The time when the data is actually produced (or the generation time assigned to the data by the data production system, which is the time item in the data point), also called event time.
> * **arrival time:** The time when data arrives in the IoTDB system.
>
-> What we often call out-of-order data refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
+> The out-of-order data we often refer to refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
-> 💎 **iotdb-extractor’s work can be split into two stages**
+> 💎 **The work of iotdb-source can be split into two stages**
>
-> 1. Historical data extraction: all data with **arrival time** < **current system time** when creating pipe is called historical data
-> 2. Real-time data extraction: all **arrival time** >= data of **current system time** when creating pipe is called real-time data
+> 1. Historical data extraction: All data with **arrival time** < **current system time** when creating the pipe is called historical data
+> 2. Realtime data extraction: All data with **arrival time** >= **current system time** when the pipe is created is called realtime data
>
-> The historical data transmission phase and the real-time data transmission phase are executed serially. Only when the historical data transmission phase is completed, the real-time data transmission phase is executed. **
->
-> Users can specify iotdb-extractor to:
->
-> * Historical data extraction (`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * Real-time data extraction (`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * Full data extraction (`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * Disable setting `extractor.history.enable` and `extractor.realtime.enable` to `false` at the same time
->
-> 📌 **extractor.realtime.mode: Data extraction mode**
+> The historical data transmission phase and the realtime data transmission phase are executed serially. Only when the historical data transmission phase is completed, the realtime data transmission phase is executed.**
+
+> 📌 **source.realtime.mode: Data extraction mode**
>
> * log: In this mode, the task only uses the operation log for data processing and sending
> * file: In this mode, the task only uses data files for data processing and sending.
> * hybrid: This mode takes into account the characteristics of low latency but low throughput when sending data one by one in the operation log, and the characteristics of high throughput but high latency when sending in batches of data files. It can automatically operate under different write loads. Switch the appropriate data extraction method. First, adopt the data extraction method based on operation logs to ensure low sending delay. When a data backlog occurs, it will automatically switch to the data extraction method based on data files to ensure high sending throughput. When the backlog is eliminated, it will automatically switch back to the data extraction method based on data files. The data extraction method of the operation log avoids the problem of difficulty in balancing data sending delay or throughput using a single data extraction algorithm.
-> 🍕 **extractor.forwarding-pipe-requests: Whether to allow forwarding data transmitted from another pipe**
+> 🍕 **source.forwarding-pipe-requests: Whether to allow forwarding data transmitted from another pipe**
>
> * If you want to use pipe to build data synchronization of A -> B -> C, then the pipe of B -> C needs to set this parameter to true, so that the data written by A to B through the pipe in A -> B can be forwarded correctly. to C
> * If you want to use pipe to build two-way data synchronization (dual-active) of A \<-> B, then the pipes of A -> B and B -> A need to set this parameter to false, otherwise the data will be endless. inter-cluster round-robin forwarding
@@ -574,22 +568,22 @@ Function: Extract historical or real-time data inside IoTDB into pipe.
#### do-nothing-processor
-Function: No processing is done on the events passed in by the extractor.
+Function: No processing is done on the events passed in by the source.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value range | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### Preset connector plugin
+### Preset sink plugin
-#### do-nothing-connector
+#### do-nothing-sink
Function: No processing is done on the events passed in by the processor.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value range | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## Stream processing task management
@@ -598,59 +592,57 @@ Function: No processing is done on the events passed in by the processor.
Use the `CREATE PIPE` statement to create a stream processing task. Taking the creation of a data synchronization stream processing task as an example, the sample SQL statement is as follows:
```sql
-CREATE PIPE -- PipeId is a name that uniquely identifies the stream processing task
-WITH EXTRACTOR (
- --Default IoTDB data extraction plugin
- 'extractor' = 'iotdb-extractor',
- --Path prefix, only data that can match the path prefix will be extracted for subsequent processing and sending
- 'extractor.pattern' = 'root.timecho',
- -- Whether to extract historical data
- 'extractor.history.enable' = 'true',
- -- Describes the time range of the extracted historical data, indicating the earliest time
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
- -- Describes the time range of the extracted historical data, indicating the latest time
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
- -- Whether to extract real-time data
- 'extractor.realtime.enable' = 'true',
- --Describe the extraction method of real-time data
- 'extractor.realtime.mode' = 'hybrid',
+CREATE PIPE -- PipeId is the name that uniquely identifies the sync task
+WITH SOURCE (
+ -- Default IoTDB Data Extraction Plugin
+ 'source' = 'iotdb-source',
+ -- Path prefix, only data that can match the path prefix will be extracted for subsequent processing and delivery
+ 'source.pattern' = 'root.timecho',
+ -- Whether to extract historical data
+ 'source.history.enable' = 'true',
+ -- Describes the time range of the historical data being extracted, indicating the earliest possible time
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
+ -- Describes the time range of the extracted historical data, indicating the latest time
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
+ -- Whether to extract realtime data
+ 'source.realtime.enable' = 'true',
)
WITH PROCESSOR (
- --The default data processing plugin, which does not do any processing
- 'processor' = 'do-nothing-processor',
+ -- Default data processing plugin, means no processing
+ 'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
- -- IoTDB data sending plugin, the target is IoTDB
- 'connector' = 'iotdb-thrift-connector',
- --The data service IP of one of the DataNode nodes in the target IoTDB
- 'connector.ip' = '127.0.0.1',
- -- The data service port of one of the DataNode nodes in the target IoTDB
- 'connector.port' = '6667',
+WITH SINK (
+ -- IoTDB data sending plugin with target IoTDB
+ 'sink' = 'iotdb-thrift-sink',
+ -- Data service for one of the DataNode nodes on the target IoTDB ip
+ 'sink.ip' = '127.0.0.1',
+ -- Data service port of one of the DataNode nodes of the target IoTDB
+ 'sink.port' = '6667',
)
```
**When creating a stream processing task, you need to configure the PipeId and the parameters of the three plugin parts:**
-| Configuration | Description | Required or not | Default implementation | Default implementation description | Default implementation description |
-| ------------- | ------------------------------------------------------------ | ------------------------------- | ---------------------- | ------------------------------------------------------------ | ---------------------------------- |
-| PipeId | A globally unique name that identifies a stream processing | Required | - | - | - |
-| extractor | Pipe Extractor plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-extractor | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
-| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
-| connector | Pipe Connector plugin, responsible for sending data | Required | - | - | Yes |
+| Configuration | Description | Required or not | Default implementation | Default implementation description | Default implementation description |
+|---------------|-----------------------------------------------------------------------------------------------------|---------------------------------|------------------------|---------------------------------------------------------------------------------------------------------------------------|------------------------------------|
+| PipeId | A globally unique name that identifies a stream processing | Required | - | - | - |
+| source | Pipe Source plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-source | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
+| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
+| sink | Pipe Sink plugin, responsible for sending data | Required | - | - | Yes |
-In the example, the iotdb-extractor, do-nothing-processor and iotdb-thrift-connector plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, **please check the "System Preset Stream Processing plugin" section**.
+In the example, the iotdb-source, do-nothing-processor and iotdb-thrift-sink plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, **please check the "System Preset Stream Processing plugin" section**.
**A simplest example of the CREATE PIPE statement is as follows:**
```sql
CREATE PIPE -- PipeId is a name that uniquely identifies the stream processing task
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB data sending plugin, the target is IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
--The data service IP of one of the DataNode nodes in the target IoTDB
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- The data service port of one of the DataNode nodes in the target IoTDB
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -658,37 +650,37 @@ The semantics expressed are: synchronize all historical data in this database in
**Notice:**
-- EXTRACTOR and PROCESSOR are optional configurations. If you do not fill in the configuration parameters, the system will use the corresponding default implementation.
-- CONNECTOR is a required configuration and needs to be configured declaratively in the CREATE PIPE statement
-- CONNECTOR has self-reuse capability. For different stream processing tasks, if their CONNECTORs have the same KV attributes (the keys corresponding to the values of all attributes are the same), then the system will only create one CONNECTOR instance in the end to realize the duplication of connection resources. use.
+- SOURCE and PROCESSOR are optional configurations. If you do not fill in the configuration parameters, the system will use the corresponding default implementation.
+- SINK is a required configuration and needs to be configured declaratively in the CREATE PIPE statement
+- SINK has self-reuse capability. For different stream processing tasks, if their SINKs have the same KV attributes (the keys corresponding to the values of all attributes are the same), then the system will only create one SINK instance in the end to realize the duplication of connection resources.
- - For example, there are the following declarations of two stream processing tasks, pipe1 and pipe2:
+ - For example, there are the following declarations of two stream processing tasks, pipe1 and pipe2:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
)
```
-- Because their declarations of CONNECTOR are exactly the same (**even if the order of declaration of some attributes is different**), the framework will automatically reuse the CONNECTORs they declared, and ultimately the CONNECTORs of pipe1 and pipe2 will be the same instance. .
-- When the extractor is the default iotdb-extractor, and extractor.forwarding-pipe-requests is the default value true, please do not build an application scenario that includes data cycle synchronization (it will cause an infinite loop):
+- Because their declarations of SINK are exactly the same (**even if the order of declaration of some attributes is different**), the framework will automatically reuse the SINKs they declared, and ultimately the SINKs of pipe1 and pipe2 will be the same instance. .
+- When the source is the default iotdb-source, and source.forwarding-pipe-requests is the default value true, please do not build an application scenario that includes data cycle synchronization (it will cause an infinite loop):
- - IoTDB A -> IoTDB B -> IoTDB A
- - IoTDB A -> IoTDB A
+ - IoTDB A -> IoTDB B -> IoTDB A
+ - IoTDB A -> IoTDB A
### Start the stream processing task
-After the CREATE PIPE statement is successfully executed, the stream processing task-related instance will be created, but the running status of the entire stream processing task will be set to STOPPED, that is, the stream processing task will not process data immediately.
+After the CREATE PIPE statement is successfully executed, the stream processing task-related instance will be created, but the running status of the entire stream processing task will be set to STOPPED(V1.3.0), that is, the stream processing task will not process data immediately. In version 1.3.1 and later, the status of the task will be set to RUNNING after CREATE.
You can use the START PIPE statement to cause a stream processing task to start processing data:
@@ -725,13 +717,13 @@ SHOW PIPES
The query results are as follows:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime| State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
You can use `` to specify the status of a stream processing task you want to see:
@@ -740,22 +732,23 @@ You can use `` to specify the status of a stream processing task you wan
SHOW PIPE
```
-You can also use the where clause to determine whether the Pipe Connector used by a certain \ is reused.
+You can also use the where clause to determine whether the Pipe Sink used by a certain \ is reused.
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### Stream processing task running status migration
A stream processing pipe will pass through various states during its managed life cycle:
-- **STOPPED:** The pipe is stopped. When the pipeline is in this state, there are several possibilities:
- - When a pipe is successfully created, its initial state is paused.
- - The user manually pauses a pipe that is in normal running status, and its status will passively change from RUNNING to STOPPED.
- - When an unrecoverable error occurs during the running of a pipe, its status will automatically change from RUNNING to STOPPED
- **RUNNING:** pipe is working properly
+ - When a pipe is successfully created, its initial state is RUNNING.(V1.3.1+)
+- **STOPPED:** The pipe is stopped. When the pipeline is in this state, there are several possibilities:
+ - When a pipe is successfully created, its initial state is STOPPED.(V1.3.0)
+ - The user manually pauses a pipe that is in normal running status, and its status will passively change from RUNNING to STOPPED.
+ - When an unrecoverable error occurs during the running of a pipe, its status will automatically change from RUNNING to STOPPED
- **DROPPED:** The pipe task was permanently deleted
The following diagram shows all states and state transitions:
@@ -767,27 +760,28 @@ The following diagram shows all states and state transitions:
### Stream processing tasks
-| Permission name | Description |
-| ----------- | -------------------------- |
-| USE_PIPE | Register a stream processing task. The path is irrelevant. |
-| USE_PIPE | Start the stream processing task. The path is irrelevant. |
-| USE_PIPE | Stop the stream processing task. The path is irrelevant. |
-| USE_PIPE | Offload stream processing tasks. The path is irrelevant. |
-| USE_PIPE | Query stream processing tasks. The path is irrelevant. |
+| Permission name | Description |
+|-----------------|------------------------------------------------------------|
+| USE_PIPE | Register a stream processing task. The path is irrelevant. |
+| USE_PIPE | Start the stream processing task. The path is irrelevant. |
+| USE_PIPE | Stop the stream processing task. The path is irrelevant. |
+| USE_PIPE | Offload stream processing tasks. The path is irrelevant. |
+| USE_PIPE | Query stream processing tasks. The path is irrelevant. |
### Stream processing task plugin
-| Permission name | Description |
-| ------------------ | ---------------------------------- |
-| USE_PIPE | Register stream processing task plugin. The path is irrelevant. |
-| USE_PIPE | Uninstall the stream processing task plugin. The path is irrelevant. |
-| USE_PIPE | Query stream processing task plugin. The path is irrelevant. |
+| Permission name | Description |
+|-----------------|----------------------------------------------------------------------|
+| USE_PIPE | Register stream processing task plugin. The path is irrelevant. |
+| USE_PIPE | Uninstall the stream processing task plugin. The path is irrelevant. |
+| USE_PIPE | Query stream processing task plugin. The path is irrelevant. |
## Configuration parameters
In iotdb-common.properties:
+V1.3.0+:
```Properties
####################
### Pipe Configuration
@@ -808,4 +802,53 @@ In iotdb-common.properties:
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
+```
+
+V1.3.1+:
+```Properties
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
```
diff --git a/src/UserGuide/V1.1.x/Ecosystem-Integration/Grafana-Plugin.md b/src/UserGuide/V1.1.x/Ecosystem-Integration/Grafana-Plugin.md
index 6b5ec570..3588e5cc 100644
--- a/src/UserGuide/V1.1.x/Ecosystem-Integration/Grafana-Plugin.md
+++ b/src/UserGuide/V1.1.x/Ecosystem-Integration/Grafana-Plugin.md
@@ -55,7 +55,7 @@ grafana-cli plugins install apache-iotdb-datasource
* Click on Configuration ->Plugins ->Search IoTDB from local Grafana to install the plugin
-### Method 3: Manually install the grafana-plugin plug-in (not recommended)
+### Method 3: Manually install the grafana-plugin plugin (not recommended)
* Copy the front-end project target folder generated above to Grafana's plugin directory `${Grafana directory}\data\plugins\`。If there is no such directory, you can manually create it or start grafana and it will be created automatically. Of course, you can also modify the location of plugins. For details, please refer to the following instructions for modifying the location of Grafana's plugin directory.
diff --git a/src/UserGuide/V1.2.x/Ecosystem-Integration/Grafana-Plugin.md b/src/UserGuide/V1.2.x/Ecosystem-Integration/Grafana-Plugin.md
index 5ad37a13..992ca684 100644
--- a/src/UserGuide/V1.2.x/Ecosystem-Integration/Grafana-Plugin.md
+++ b/src/UserGuide/V1.2.x/Ecosystem-Integration/Grafana-Plugin.md
@@ -55,7 +55,7 @@ grafana-cli plugins install apache-iotdb-datasource
* Click on Configuration ->Plugins ->Search IoTDB from local Grafana to install the plugin
-### Method 3: Manually install the grafana-plugin plug-in (not recommended)
+### Method 3: Manually install the grafana-plugin plugin (not recommended)
* Copy the front-end project target folder generated above to Grafana's plugin directory `${Grafana directory}\data\plugins\`。If there is no such directory, you can manually create it or start grafana and it will be created automatically. Of course, you can also modify the location of plugins. For details, please refer to the following instructions for modifying the location of Grafana's plugin directory.
diff --git a/src/UserGuide/V1.2.x/User-Manual/Data-Sync.md b/src/UserGuide/V1.2.x/User-Manual/Data-Sync.md
index 32c62e52..d2882051 100644
--- a/src/UserGuide/V1.2.x/User-Manual/Data-Sync.md
+++ b/src/UserGuide/V1.2.x/User-Manual/Data-Sync.md
@@ -70,7 +70,7 @@ By utilizing the data sync functionality, a complete data pipeline can be built
> ❗️**Note: The current IoTDB -> IoTDB implementation of data sync does not support DDL sync**
>
-> That is: ttl, trigger, alias, template, view, create/delete sequence, create/delete storage group, etc. are not supported.
+> That is: ttl, trigger, alias, template, view, create/delete sequence, create/delete database, etc. are not supported.
>
> **IoTDB -> IoTDB data sync requires the target IoTDB:**
>
@@ -119,11 +119,11 @@ WITH CONNECTOR (
| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
| --------- | ------------------------------------------------- | --------------------------- | -------------------- | ------------------------------------------------------ | ------------------------- |
| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
-| extractor | pipe Extractor plug-in, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
-| processor | Pipe Processor plug-in, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
-| connector | Pipe Connector plug-in,for sending data | required | - | - | yes |
+| extractor | pipe Extractor plugin, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
+| processor | Pipe Processor plugin, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
+| connector | Pipe Connector plugin,for sending data | required | - | - | yes |
-In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plug-ins are used to build the data sync task. iotdb has other built-in data sync plug-ins, **see the section "System Pre-built Data Sync Plugin"**.
+In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plugins are used to build the data sync task. iotdb has other built-in data sync plugins, **see the section "System Pre-built Data Sync Plugin"**.
**An example of a minimalist CREATE PIPE statement is as follows:**
```sql
@@ -250,7 +250,7 @@ The following diagram illustrates the different states and their transitions:
### View pre-built plugin
-User can view the plug-ins in the system on demand. The statement for viewing plug-ins is shown below.
+User can view the plugins in the system on demand. The statement for viewing plugins is shown below.
```sql
SHOW PIPEPLUGINS
```
@@ -386,19 +386,19 @@ Note: In theory, any version prior to v1.2.0 of IoTDB can serve as the data sync
Function: Does not do anything with the events passed in by the processor.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value range | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| connector | do-nothing-connector | String: do-nothing-connector | required |
## Authority Management
-| Authority Name | Description |
-| ----------- | -------------------- |
-| CREATE_PIPE | Register task,path-independent |
-| START_PIPE | Start task,path-independent |
-| STOP_PIPE | Stop task,path-independent |
-| DROP_PIPE | Uninstall task,path-independent |
-| SHOW_PIPES | Query task,path-independent |
+| Authority Name | Description |
+|----------------|---------------------------------|
+| CREATE_PIPE | Register task,path-independent |
+| START_PIPE | Start task,path-independent |
+| STOP_PIPE | Stop task,path-independent |
+| DROP_PIPE | Uninstall task,path-independent |
+| SHOW_PIPES | Query task,path-independent |
## Configure Parameters
diff --git a/src/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md b/src/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
index d8cdf631..31b2ed0c 100644
--- a/src/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
+++ b/src/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
@@ -70,7 +70,7 @@ By utilizing the data sync functionality, a complete data pipeline can be built
> ❗️**Note: The current IoTDB -> IoTDB implementation of data sync does not support DDL sync**
>
-> That is: ttl, trigger, alias, template, view, create/delete sequence, create/delete storage group, etc. are not supported.
+> That is: ttl, trigger, alias, template, view, create/delete sequence, create/delete database, etc. are not supported.
>
> **IoTDB -> IoTDB data sync requires the target IoTDB:**
>
@@ -119,11 +119,11 @@ WITH CONNECTOR (
| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
| --------- | ------------------------------------------------- | --------------------------- | -------------------- | ------------------------------------------------------ | ------------------------- |
| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
-| extractor | pipe Extractor plug-in, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
-| processor | Pipe Processor plug-in, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
-| connector | Pipe Connector plug-in,for sending data | required | - | - | yes |
+| extractor | pipe Extractor plugin, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
+| processor | Pipe Processor plugin, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
+| connector | Pipe Connector plugin,for sending data | required | - | - | yes |
-In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plug-ins are used to build the data sync task. iotdb has other built-in data sync plug-ins, **see the section "System Pre-built Data Sync Plugin"**.
+In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plugins are used to build the data sync task. iotdb has other built-in data sync plugins, **see the section "System Pre-built Data Sync Plugin"**.
**An example of a minimalist CREATE PIPE statement is as follows:**
```sql
@@ -250,7 +250,7 @@ The following diagram illustrates the different states and their transitions:
### View pre-built plugin
-User can view the plug-ins in the system on demand. The statement for viewing plug-ins is shown below.
+User can view the plugins in the system on demand. The statement for viewing plugins is shown below.
```sql
SHOW PIPEPLUGINS
```
diff --git a/src/UserGuide/V1.2.x/User-Manual/Streaming.md b/src/UserGuide/V1.2.x/User-Manual/Streaming.md
index 553b4702..44c185e9 100644
--- a/src/UserGuide/V1.2.x/User-Manual/Streaming.md
+++ b/src/UserGuide/V1.2.x/User-Manual/Streaming.md
@@ -458,7 +458,7 @@ USING URI ''
### Delete Plugin Statement
-When user no longer wants to use a plugin and needs to uninstall the plug-in from the system, you can use the Remove plugin statement as shown below.
+When user no longer wants to use a plugin and needs to uninstall the plugin from the system, you can use the Remove plugin statement as shown below.
```sql
DROP PIPEPLUGIN
```
@@ -593,11 +593,11 @@ WITH CONNECTOR (
| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
| --------- | ------------------------------------------------- | --------------------------- | -------------------- | ------------------------------------------------------ | ------------------------- |
| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
-| extractor | pipe Extractor plug-in, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
-| processor | Pipe Processor plug-in, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
-| connector | Pipe Connector plug-in,for sending data | required | - | - | yes |
+| extractor | pipe Extractor plugin, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
+| processor | Pipe Processor plugin, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
+| connector | Pipe Connector plugin,for sending data | required | - | - | yes |
-In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plug-ins are used to build the data synchronisation task. iotdb has other built-in data synchronisation plug-ins, **see the section "System pre-built data synchronisation plug-ins" **. See the "System Pre-installed Stream Processing Plugin" section**.
+In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plugins are used to build the data synchronisation task. iotdb has other built-in data synchronisation plugins, **see the section "System pre-built data synchronisation plugins" **. See the "System Pre-installed Stream Processing Plugin" section**.
**An example of a minimalist CREATE PIPE statement is as follows:**
@@ -722,21 +722,21 @@ The following diagram illustrates the different states and their transitions:
### Stream Processing Task
-| Authority Name | Description |
-| ----------- | -------------------- |
-| CREATE_PIPE | Register task,path-independent |
-| START_PIPE | Start task,path-independent |
-| STOP_PIPE | Stop task,path-independent |
-| DROP_PIPE | Uninstall task,path-independent |
-| SHOW_PIPES | Query task,path-independent |
+| Authority Name | Description |
+|----------------|---------------------------------|
+| CREATE_PIPE | Register task,path-independent |
+| START_PIPE | Start task,path-independent |
+| STOP_PIPE | Stop task,path-independent |
+| DROP_PIPE | Uninstall task,path-independent |
+| SHOW_PIPES | Query task,path-independent |
### Stream Processing Task Plugin
-| Authority Name | Description |
-| ----------------- | ------------------------------ |
+| Authority Name | Description |
+|-------------------|---------------------------------------------------------|
| CREATE_PIPEPLUGIN | Register stream processing task plugin,path-independent |
-| DROP_PIPEPLUGIN | Delete stream processing task plugin,path-independent |
-| SHOW_PIPEPLUGINS | Query stream processing task plugin,path-independent |
+| DROP_PIPEPLUGIN | Delete stream processing task plugin,path-independent |
+| SHOW_PIPEPLUGINS | Query stream processing task plugin,path-independent |
## Configure Parameters
diff --git a/src/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md b/src/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
index 6c4a6334..5b2940a2 100644
--- a/src/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
+++ b/src/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
@@ -455,7 +455,7 @@ AS
USING
```
-Example: If you implement a data processing plugin named edu.tsinghua.iotdb.pipe.ExampleProcessor, and the packaged jar package is pipe-plugin.jar, you want to use this plugin in the stream processing engine, and mark the plugin as example. There are two ways to use the plug-in package, one is to upload to the URI server, and the other is to upload to the local directory of the cluster.
+Example: If you implement a data processing plugin named edu.tsinghua.iotdb.pipe.ExampleProcessor, and the packaged jar package is pipe-plugin.jar, you want to use this plugin in the stream processing engine, and mark the plugin as example. There are two ways to use the plugin package, one is to upload to the URI server, and the other is to upload to the local directory of the cluster.
Method 1: Upload to the URI server
diff --git a/src/UserGuide/latest/Ecosystem-Integration/Grafana-Plugin.md b/src/UserGuide/latest/Ecosystem-Integration/Grafana-Plugin.md
index ca9aec49..9eb2a667 100644
--- a/src/UserGuide/latest/Ecosystem-Integration/Grafana-Plugin.md
+++ b/src/UserGuide/latest/Ecosystem-Integration/Grafana-Plugin.md
@@ -55,7 +55,7 @@ grafana-cli plugins install apache-iotdb-datasource
* Click on Configuration ->Plugins ->Search IoTDB from local Grafana to install the plugin
-### Method 3: Manually install the grafana-plugin plug-in (not recommended)
+### Method 3: Manually install the grafana-plugin plugin (not recommended)
* Copy the front-end project target folder generated above to Grafana's plugin directory `${Grafana directory}\data\plugins\`。If there is no such directory, you can manually create it or start grafana and it will be created automatically. Of course, you can also modify the location of plugins. For details, please refer to the following instructions for modifying the location of Grafana's plugin directory.
diff --git a/src/UserGuide/latest/User-Manual/Data-Sync.md b/src/UserGuide/latest/User-Manual/Data-Sync.md
index 040b6605..9c022dfc 100644
--- a/src/UserGuide/latest/User-Manual/Data-Sync.md
+++ b/src/UserGuide/latest/User-Manual/Data-Sync.md
@@ -24,17 +24,17 @@
**A Pipe consists of three subtasks (plugins):**
-- Extract
+- Source
- Process
-- Connect
+- Sink
-**Pipe allows users to customize the processing logic of these three subtasks, just like handling data using UDF (User-Defined Functions)**. Within a Pipe, the aforementioned subtasks are executed and implemented by three types of plugins. Data flows through these three plugins sequentially: Pipe Extractor is used to extract data, Pipe Processor is used to process data, and Pipe Connector is used to send data to an external system.
+**Pipe allows users to customize the processing logic of these three subtasks, just like handling data using UDF (User-Defined Functions)**. Within a Pipe, the aforementioned subtasks are executed and implemented by three types of plugins. Data flows through these three plugins sequentially: Pipe Source is used to extract data, Pipe Processor is used to process data, and Pipe Sink is used to send data to an external system.
**The model of a Pipe task is as follows:**
-
+
-It describes a data sync task, which essentially describes the attributes of the Pipe Extractor, Pipe Processor, and Pipe Connector plugins. Users can declaratively configure the specific attributes of the three subtasks through SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
+It describes a data sync task, which essentially describes the attributes of the Pipe Source, Pipe Processor, and Pipe Sink plugins. Users can declaratively configure the specific attributes of the three subtasks through SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
By utilizing the data sync functionality, a complete data pipeline can be built to fulfill various requirements such as edge-to-cloud sync, remote disaster recovery, and read-write workload distribution across multiple databases.
@@ -47,10 +47,10 @@ By utilizing the data sync functionality, a complete data pipeline can be built
```sql
create pipe a2b
- with connector (
- 'connector'='iotdb-thrift-connector',
- 'connector.ip'='127.0.0.1',
- 'connector.port'='6668'
+ with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6668'
)
```
- start a Pipe from A -> B, and execute on A
@@ -70,7 +70,7 @@ By utilizing the data sync functionality, a complete data pipeline can be built
> ❗️**Note: The current IoTDB -> IoTDB implementation of data sync does not support DDL sync**
>
-> That is: ttl, trigger, alias, template, view, create/delete sequence, create/delete storage group, etc. are not supported.
+> That is: ttl, trigger, alias, template, view, create/delete sequence, create/delete database, etc. are not supported.
>
> **IoTDB -> IoTDB data sync requires the target IoTDB:**
>
@@ -85,86 +85,82 @@ A data sync task can be created using the `CREATE PIPE` statement, a sample SQL
```sql
CREATE PIPE -- PipeId is the name that uniquely identifies the sync task
-WITH EXTRACTOR (
+WITH SOURCE (
-- Default IoTDB Data Extraction Plugin
- 'extractor' = 'iotdb-extractor',
+ 'source' = 'iotdb-source',
-- Path prefix, only data that can match the path prefix will be extracted for subsequent processing and delivery
- 'extractor.pattern' = 'root.timecho',
- -- Whether to extract historical data
- 'extractor.history.enable' = 'true',
- -- Describes the time range of the historical data being extracted, indicating the earliest possible time
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
- -- Describes the time range of the extracted historical data, indicating the latest time
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
- -- Whether to extract realtime data
- 'extractor.realtime.enable' = 'true',
+ 'source.pattern' = 'root.timecho',
+ -- Describes the time range of the data being extracted, indicating the earliest possible time
+ 'source.historical.start-time' = '2011.12.03T10:15:30+01:00',
+ -- Describes the time range of the extracted data, indicating the latest time
+ 'source.historical.end-time' = '2022.12.03T10:15:30+01:00',
)
WITH PROCESSOR (
-- Default data processing plugin, means no processing
'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB data sending plugin with target IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- Data service for one of the DataNode nodes on the target IoTDB ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
**To create a sync task it is necessary to configure the PipeId and the parameters of the three plugin sections:**
-| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
-| --------- | ------------------------------------------------- | --------------------------- | -------------------- | ------------------------------------------------------ | ------------------------- |
-| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
-| extractor | pipe Extractor plug-in, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
-| processor | Pipe Processor plug-in, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
-| connector | Pipe Connector plug-in,for sending data | required | - | - | yes |
+| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
+|--------------------|-------------------------------------------------------------------------------------|---------------------------------|------------------------|-----------------------------------------------------------------------------------------------|-----------------------------------------|
+| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
+| source | pipe Source plugin, for extracting synchronized data at the bottom of the database | Optional | iotdb-source | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
+| processor | Pipe Processor plugin, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
+| sink | Pipe Sink plugin,for sending data | required | - | - | yes |
-In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plug-ins are used to build the data sync task. iotdb has other built-in data sync plug-ins, **see the section "System Pre-built Data Sync Plugin"**.
+In the example, the iotdb-source, do-nothing-processor, and iotdb-thrift-sink plugins are used to build the data sync task. IoTDB has other built-in data sync plugins, **see the section "System Pre-built Data Sync Plugin"**.
**An example of a minimalist CREATE PIPE statement is as follows:**
```sql
CREATE PIPE -- PipeId is a name that uniquely identifies the task.
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB data sending plugin with target IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- Data service for one of the DataNode nodes on the target IoTDB ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
-The expressed semantics are: synchronise the full amount of historical data and subsequent arrivals of realtime data from this database instance to the IoTDB instance with target 127.0.0.1:6667.
+The expressed semantics are: synchronize the full amount of historical data and subsequent arrivals of realtime data from this database instance to the IoTDB instance with target 127.0.0.1:6667.
**Note:**
-- EXTRACTOR and PROCESSOR are optional, if no configuration parameters are filled in, the system will use the corresponding default implementation.
-- The CONNECTOR is a mandatory configuration that needs to be declared in the CREATE PIPE statement for configuring purposes.
-- The CONNECTOR exhibits self-reusability. For different tasks, if their CONNECTOR possesses identical KV properties (where the value corresponds to every key), **the system will ultimately create only one instance of the CONNECTOR** to achieve resource reuse for connections.
+- SOURCE and PROCESSOR are optional, if no configuration parameters are filled in, the system will use the corresponding default implementation.
+- The SINK is a mandatory configuration that needs to be declared in the CREATE PIPE statement for configuring purposes.
+- The SINK exhibits self-reusability. For different tasks, if their SINK possesses identical KV properties (where the value corresponds to every key), **the system will ultimately create only one instance of the SINK** to achieve resource reuse for connections.
- For example, there are the following pipe1, pipe2 task declarations:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
)
```
- - Since they have identical CONNECTOR declarations (**even if the order of some properties is different**), the framework will automatically reuse the CONNECTOR declared by them. Hence, the CONNECTOR instances for pipe1 and pipe2 will be the same.
+ - Since they have identical SINK declarations (**even if the order of some properties is different**), the framework will automatically reuse the SINK declared by them. Hence, the SINK instances for pipe1 and pipe2 will be the same.
- Please note that we should avoid constructing application scenarios that involve data cycle sync (as it can result in an infinite loop):
- IoTDB A -> IoTDB B -> IoTDB A
@@ -172,7 +168,7 @@ The expressed semantics are: synchronise the full amount of historical data and
### START TASK
-After the successful execution of the CREATE PIPE statement, task-related instances will be created. However, the overall task's running status will be set to STOPPED, meaning the task will not immediately process data.
+After the successful execution of the CREATE PIPE statement, task-related instances will be created. However, the overall task's running status will be set to STOPPED(V1.3.0), meaning the task will not immediately process data. In version 1.3.1 and later, the status of the task will be set to RUNNING after CREATE.
You can use the START PIPE statement to begin processing data for a task:
@@ -209,13 +205,13 @@ SHOW PIPES
The query results are as follows:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime | State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
You can use \ to specify the status of a particular synchronization task:
@@ -224,22 +220,23 @@ You can use \ to specify the status of a particular synchronization tas
SHOW PIPE
```
-Additionally, the WHERE clause can be used to determine if the Pipe Connector used by a specific \ is being reused.
+Additionally, the WHERE clause can be used to determine if the Pipe Sink used by a specific \ is being reused.
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### Task Running Status Migration
The task running status can transition through several states during the lifecycle of a data synchronization pipe:
-- **STOPPED:** The pipe is in a stopped state. It can have the following possibilities:
- - After the successful creation of a pipe, its initial state is set to stopped
+- **STOPPED:** The pipe is in a stopped state. It has the following causes:
+ - After the successful creation of a pipe, its initial state is set to STOPPED (V1.3.0)
- The user manually pauses a pipe that is in normal running state, transitioning its status from RUNNING to STOPPED
- If a pipe encounters an unrecoverable error during execution, its status automatically changes from RUNNING to STOPPED.
-- **RUNNING:** The pipe is actively processing data
+- **RUNNING:** The pipe is actively processing data. It has the following cause:
+ - After the successful creation of a pipe, its initial state is set to RUNNING (V1.3.1+)
- **DROPPED:** The pipe is permanently deleted
The following diagram illustrates the different states and their transitions:
@@ -247,35 +244,52 @@ The following diagram illustrates the different states and their transitions:
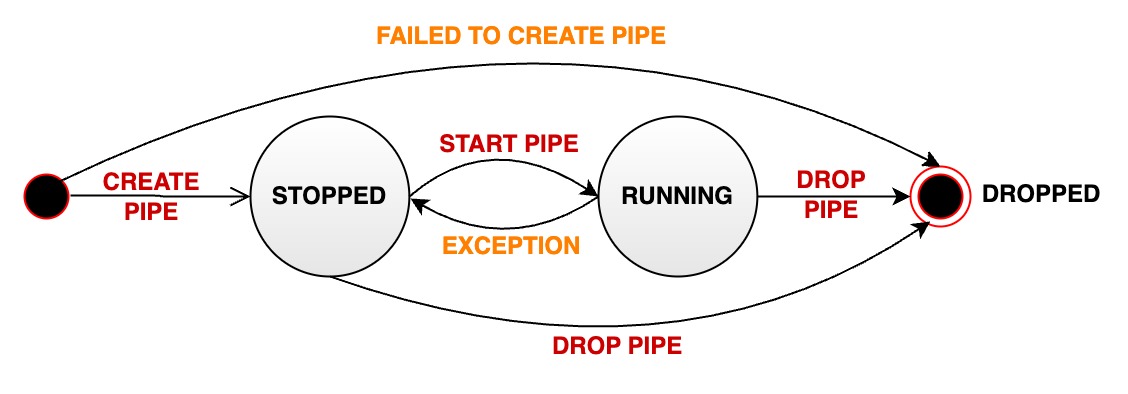
## System Pre-built Data Sync Plugin
-
+📌 Notes: for version 1.3.1 or later, any parameters other than "source", "processor", "sink" themselves need not be with the prefixes. For instance:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6668'
+)
+```
+can be written as
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'ip'='127.0.0.1',
+ 'port'='6668'
+)
+```
### View pre-built plugin
-User can view the plug-ins in the system on demand. The statement for viewing plug-ins is shown below.
+User can view the plugins in the system on demand. The statement for viewing plugins is shown below.
```sql
SHOW PIPEPLUGINS
```
-### Pre-built Extractor Plugin
+### Pre-built Source Plugin
-#### iotdb-extractor
+#### iotdb-source
Function: Extract historical or realtime data inside IoTDB into pipe.
-| key | value | value range | required or optional with default |
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor | String: iotdb-extractor | required |
-| extractor.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
-| extractor.history.enable | whether to synchronize historical data | Boolean: true, false | optional: true |
-| extractor.history.start-time | start of synchronizing historical data event time,Include start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | end of synchronizing historical data event time,Include end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | Whether to synchronize realtime data | Boolean: true, false | optional: true |
+| key | value | value range | required or optional with default |
+|---------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
+| source.history.start-time | start of synchronizing historical data event time,including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | end of synchronizing historical data event time,including end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-> 🚫 **extractor.pattern Parameter Description**
+> 🚫 **source.pattern Parameter Description**
>
> * Pattern should use backquotes to modify illegal characters or illegal path nodes, for example, if you want to filter root.\`a@b\` or root.\`123\`, you should set the pattern to root.\`a@b\` or root.\`123\`(Refer specifically to [Timing of single and double quotes and backquotes](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
-> * In the underlying implementation, when pattern is detected as root (default value), synchronization efficiency is higher, and any other format will reduce performance.
-> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
+> * In the underlying implementation, when pattern is detected as root (default value) or a database name, synchronization efficiency is higher, and any other format will reduce performance.
+> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'source.pattern'='root.aligned.1':
>
> * root.aligned.1TS
> * root.aligned.1TS.\`1\`
@@ -288,9 +302,9 @@ Function: Extract historical or realtime data inside IoTDB into pipe.
>
> the data will not be synchronized.
-> ❗️**start-time, end-time parameter description of extractor.history**
+> ❗️**start-time, end-time parameter description of source**
>
-> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
+> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00. Version 1.3.1+ supports timeStamp format like 1706704494000.
> ✅ **a piece of data from production to IoTDB contains two key concepts of time**
>
@@ -299,50 +313,43 @@ Function: Extract historical or realtime data inside IoTDB into pipe.
>
> The out-of-order data we often refer to refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
-> 💎 **the work of iotdb-extractor can be split into two stages**
+> 💎 **the work of iotdb-source can be split into two stages**
>
> 1. Historical data extraction: All data with **arrival time** < **current system time** when creating the pipe is called historical data
> 2. Realtime data extraction: All data with **arrival time** >= **current system time** when the pipe is created is called realtime data
>
> The historical data transmission phase and the realtime data transmission phase are executed serially. Only when the historical data transmission phase is completed, the realtime data transmission phase is executed.**
->
-> Users can specify iotdb-extractor to:
->
-> * Historical data extraction(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * Realtime data extraction(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * Full data extraction(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * Disable simultaneous sets `extractor.history.enable` and `extractor.realtime.enable` to `false`
### Pre-built Processor Plugin
#### do-nothing-processor
-Function: Do not do anything with the events passed in by the extractor.
+Function: Do nothing with the events passed in by the source.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value range | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### pre-connector plugin
+### Pre-built Sink plugin
-#### iotdb-thrift-sync-connector(alias:iotdb-thrift-connector)
+#### iotdb-thrift-sync-sink
Function: Primarily used for data transfer between IoTDB instances (v1.2.0+). Data is transmitted using the Thrift RPC framework and a single-threaded blocking IO model. It guarantees that the receiving end applies the data in the same order as the sending end receives the write requests.
Limitation: Both the source and target IoTDB versions need to be v1.2.0+.
-| key | value | value range | required or optional with default |
-| --------------------------------- | --------------------------------------------------------------------------- | ---------------------------------------------------------------------------- | ----------------------------------------------------- |
-| connector | iotdb-thrift-connector or iotdb-thrift-sync-connector | String: iotdb-thrift-connector or iotdb-thrift-sync-connector | required |
-| connector.ip | the data service IP of one of the DataNode nodes in the target IoTDB | String | optional: and connector.node-urls fill in either one |
-| connector.port | the data service port of one of the DataNode nodes in the target IoTDB | Integer | optional: and connector.node-urls fill in either one |
-| connector.node-urls | the URL of the data service port of any multiple DataNode nodes in the target IoTDB | String。eg:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: and connector.ip:connector.port fill in either one |
+| key | value | value range | required or optional with default |
+|----------------|-------------------------------------------------------------------------------------|----------------------------------------------------------------------------|----------------------------------------------------|
+| sink | iotdb-thrift-sync-sink | String: iotdb-thrift-sync-sink | required |
+| sink.ip | the data service IP of one of the DataNode nodes in the target IoTDB | String | optional: and sink.node-urls fill in either one |
+| sink.port | the data service port of one of the DataNode nodes in the target IoTDB | Integer | optional: and sink.node-urls fill in either one |
+| sink.node-urls | the URL of the data service port of any multiple DataNode nodes in the target IoTDB | String。eg:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: and sink.ip:sink.port fill in either one |
> 📌 Please ensure that the receiving end has already created all the time series present in the sending end or has enabled automatic metadata creation. Otherwise, it may result in the failure of the pipe operation.
-#### iotdb-thrift-async-connector
+#### iotdb-thrift-async-sink(alias:iotdb-thrift-sink)
Function: Primarily used for data transfer between IoTDB instances (v1.2.0+).
Data is transmitted using the Thrift RPC framework, employing a multi-threaded async non-blocking IO model, resulting in high transfer performance. It is particularly suitable for distributed scenarios on the target end.
@@ -351,18 +358,18 @@ It does not guarantee that the receiving end applies the data in the same order
Limitation: Both the source and target IoTDB versions need to be v1.2.0+.
-| key | value | value range | required or optional with default |
-| --------------------------------- | --------------------------------------------------------------------------- | ---------------------------------------------------------------------------- | ----------------------------------------------------- |
-| connector | iotdb-thrift-async-connector | String: iotdb-thrift-async-connector | required |
-| connector.ip | the data service IP of one of the DataNode nodes in the target IoTDB | String | optional: and connector.node-urls fill in either one |
-| connector.port | the data service port of one of the DataNode nodes in the target IoTDB | Integer | optional: and connector.node-urls fill in either one |
-| connector.node-urls | the URL of the data service port of any multiple DataNode nodes in the target IoTDB | String。eg:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: and connector.ip:connector.port fill in either one |
+| key | value | value range | required or optional with default |
+|----------------|-------------------------------------------------------------------------------------|-----------------------------------------------------------------------------|----------------------------------------------------|
+| sink | iotdb-thrift-sink or iotdb-thrift-async-sink | String: iotdb-thrift-sink or iotdb-thrift-async-sink | required |
+| sink.ip | the data service IP of one of the DataNode nodes in the target IoTDB | String | optional: and sink.node-urls fill in either one |
+| sink.port | the data service port of one of the DataNode nodes in the target IoTDB | Integer | optional: and sink.node-urls fill in either one |
+| sink.node-urls | the URL of the data service port of any multiple DataNode nodes in the target IoTDB | String. eg:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: and sink.ip:sink.port fill in either one |
> 📌 Please ensure that the receiving end has already created all the time series present in the sending end or has enabled automatic metadata creation. Otherwise, it may result in the failure of the pipe operation.
-#### iotdb-legacy-pipe-connector
+#### iotdb-legacy-pipe-sink
-Function: Mainly used to transfer data from IoTDB (v1.2.0+) to lower versions of IoTDB, using the data synchronization (Sync) protocol before version v1.2.0.
+Function: Mainly used to transfer data from IoTDB (v1.2.0+) to versions lower than v1.2.0 of IoTDB, using the data synchronization (Sync) protocol before version v1.2.0.
Data is transmitted using the Thrift RPC framework. It employs a single-threaded sync blocking IO model, resulting in weak transfer performance.
Limitation: The source IoTDB version needs to be v1.2.0+. The target IoTDB version can be either v1.2.0+, v1.1.x (lower versions of IoTDB are theoretically supported but untested).
@@ -370,40 +377,40 @@ Limitation: The source IoTDB version needs to be v1.2.0+. The target IoTDB versi
Note: In theory, any version prior to v1.2.0 of IoTDB can serve as the data synchronization (Sync) receiver for v1.2.0+.
-| key | value | value range | required or optional with default |
-| ------------------ | --------------------------------------------------------------------- | ----------------------------------- | --------------------------------- |
-| connector | iotdb-legacy-pipe-connector | string: iotdb-legacy-pipe-connector | required |
-| connector.ip | data service of one DataNode node of the target IoTDB ip | string | required |
-| connector.port | the data service port of one of the DataNode nodes in the target IoTDB | integer | required |
-| connector.user | the user name of the target IoTDB. Note that the user needs to support data writing and TsFile Load permissions. | string | optional: root |
-| connector.password | the password of the target IoTDB. Note that the user needs to support data writing and TsFile Load permissions. | string | optional: root |
-| connector.version | the version of the target IoTDB, used to disguise its actual version and bypass the version consistency check of the target. | string | optional: 1.1 |
+| key | value | value range | required or optional with default |
+|---------------|------------------------------------------------------------------------------------------------------------------------------|--------------------------------|-----------------------------------|
+| sink | iotdb-legacy-pipe-sink | string: iotdb-legacy-pipe-sink | required |
+| sink.ip | data service of one DataNode node of the target IoTDB ip | string | required |
+| sink.port | the data service port of one of the DataNode nodes in the target IoTDB | integer | required |
+| sink.user | the user name of the target IoTDB. Note that the user needs to support data writing and TsFile Load permissions. | string | optional: root |
+| sink.password | the password of the target IoTDB. Note that the user needs to support data writing and TsFile Load permissions. | string | optional: root |
+| sink.version | the version of the target IoTDB, used to disguise its actual version and bypass the version consistency check of the target. | string | optional: 1.1 |
> 📌 Make sure that the receiver has created all the time series on the sender side, or that automatic metadata creation is turned on, otherwise the pipe run will fail.
-#### do-nothing-connector
-
-Function: Does not do anything with the events passed in by the processor.
+#### do-nothing-sink
+Function: Does nothing with the events passed in by the processor.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value 取值范围 | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## Authority Management
-| Authority Name | Description |
-| ----------- | -------------------- |
-| CREATE_PIPE | Register task,path-independent |
-| START_PIPE | Start task,path-independent |
-| STOP_PIPE | Stop task,path-independent |
-| DROP_PIPE | Uninstall task,path-independent |
-| SHOW_PIPES | Query task,path-independent |
+| Authority Name | Description |
+|----------------|---------------------------------|
+| USE_PIPE | Register task,path-independent |
+| USE_PIPE | Start task,path-independent |
+| USE_PIPE | Stop task,path-independent |
+| USE_PIPE | Uninstall task,path-independent |
+| USE_PIPE | Query task,path-independent |
## Configure Parameters
In iotdb-common.properties :
+V1.3.0:
```Properties
####################
### Pipe Configuration
@@ -435,6 +442,36 @@ In iotdb-common.properties :
# pipe_async_connector_max_client_number=16
```
+V1.3.1+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+```
+
## Functionality Features
### At least one semantic guarantee **at-least-once**
diff --git a/src/UserGuide/latest/User-Manual/Data-Sync_timecho.md b/src/UserGuide/latest/User-Manual/Data-Sync_timecho.md
index 1efe0e6e..811d05d9 100644
--- a/src/UserGuide/latest/User-Manual/Data-Sync_timecho.md
+++ b/src/UserGuide/latest/User-Manual/Data-Sync_timecho.md
@@ -64,9 +64,10 @@ The Data Synchronisation task has three states; RUNNING, STOPPED and DROPPED.The
A data synchronisation task passes through multiple states during its lifecycle:
- RUNNING: Running state.
+ - Explanation 1: The initial state of the task is the running state(V1.3.1+).
- STOPPED: Stopped state.
- - Explanation 1: The initial state of the task is the stopped state, and you need to use SQL statements to start the task.
- - Description 2: You can also manually stop a running task with a SQL statement, and the state will change from RUNNING to STOPPED.
+ - Description 1: The initial state of the task is the stopped state(V1.3.0). A SQL statement is required to start the task.
+ - Description 2: You can manually stop a running task with a SQL statement, and the state will change from RUNNING to STOPPED.
- Description 3: When a task has an unrecoverable error, its status will automatically change from RUNNING to STOPPED.
- DROPPED: deleted state.
@@ -112,28 +113,29 @@ SHOW PIPE .
### Plugin
-In order to make the overall architecture more flexible to match different synchronisation scenarios, IoTDB supports plug-in assembly in the above synchronisation task framework. Some common plug-ins are pre-built for you to use directly, and you can also customise sink plug-ins and load them into the IoTDB system for use.
+In order to make the overall architecture more flexible to match different synchronisation scenarios, IoTDB supports plugin assembly in the above synchronisation task framework. Some common plugins are pre-built for you to use directly, and you can also customise sink plugins and load them into the IoTDB system for use.
-| Modules | Plug-ins | Pre-configured Plug-ins | Customised Plug-ins |
-| ------- | -------- | ----------------------- | ------------------- |
-| Extract (Source) | Source Plugin | iotdb-source | Not Supported |
-| Send (Sink) | Sink plugin | iotdb-thrift-sink, iotdb-air-gap-sink | Support |
+| Modules | Plugins | Pre-configured Plugins | Customised Plugins |
+|------------------|---------------|---------------------------------------|--------------------|
+| Extract (Source) | Source Plugin | iotdb-source | Not Supported |
+| Send (Sink) | Sink plugin | iotdb-thrift-sink, iotdb-air-gap-sink | Support |
#### Preconfigured Plugins
-The preset plug-ins are listed below:
+The preset plugins are listed below:
-| Plugin Name | Type | Introduction | Available Versions |
-| ---------------------------- | ---- | ------------------------------------------------------------ | --------- |
-| iotdb-source | source plugin | Default source plugin for extracting IoTDB historical or real-time data | 1.2.x | iotdb-thrill | iotdb-thrill | iotdb-thrill | iotdb-thrill
-| | iotdb-thrift-sink | sink plugin | Used for data transfer between IoTDB (v1.2.0 and above) and IoTDB (v1.2.0 and above). Uses the Thrift RPC framework to transfer data, multi-threaded async non-blocking IO model, high transfer performance, especially for scenarios where the target is distributed | 1.2.x | iotdb-air | iotdb-air | iotdb-air | iotdb-air | iotdb-air
-| iotdb-air-gap-sink | sink plug-in | Used for data synchronisation from IoTDB (v1.2.2+) to IoTDB (v1.2.2+) across unidirectional data gates. Supported gate models include Nanrui Syskeeper 2000, etc. | 1.2.1+ |
+| Plugin Name | Type | Introduction | Available Versions |
+|-----------------------|---------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------|
+| iotdb-source | source plugin | Default source plugin for extracting IoTDB historical or real-time data | 1.2.x |
+| iotdb-thrift-sink | sink plugin | Used for data transfer between IoTDB (v1.2.0 and above) and IoTDB (v1.2.0 and above). Uses the Thrift RPC framework to transfer data, multi-threaded async non-blocking IO model, high transfer performance, especially for scenarios where the target is distributed | 1.2.x |
+| iotdb-air-gap-sink | sink plugin | Used for data synchronization from IoTDB (v1.2.2+) to IoTDB (v1.2.2+) across unidirectional data gates. Supported gate models include Nanrui Syskeeper 2000, etc. | 1.2.2+ |
+| iotdb-thrift-ssl-sink | sink plugin | Used for data synchronization from IoTDB (v1.3.1+) to IoTDB (v1.2.0+). Uses the Thrift RPC framework to transfer data, single-thread blocking IO model. | 1.3.1+ |
-Detailed parameters for each plug-in can be found in the [Parameter Description](#sink-parameters) section of this document.
+Detailed parameters for each plugin can be found in the [Parameter Description](#sink-parameters) section of this document.
-#### View Plug-ins
+#### View Plugins
-To view the plug-ins in the system (including custom and built-in plug-ins) you can use the following statement:
+To view the plugins in the system (including custom and built-in plugins) you can use the following statement:
```Go
SHOW PIPEPLUGINS
@@ -143,16 +145,16 @@ The following results are returned:
```Go
IoTDB> show pipeplugins
-+--------------------+----------+---------------------------------------------------------------------------+---------+
-| PluginName|PluginType| ClassName|PluginJar|
-+--------------------+----------+---------------------------------------------------------------------------+---------+
-|DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.DoNothingProcessor| |
-| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.DoNothingSink| |
-| IOTDB-AIR-GAP-SINK| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBAirGapSink| |
-| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.source.IoTDBSOURCE| |
-| IOTDB-THRIFT-SINK| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBThriftSinkr| |
-| OPC-UA-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.OpcUaSink| |
-+--------------------+----------+---------------------------------------------------------------------------+---------+
++------------------------------+----------+---------------------------------------------------------------------------------+---------+
+| PluginName|PluginType| ClassName|PluginJar|
++------------------------------+--------------------------------------------------------------------------------------------+---------+
+| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.DoNothingProcessor| |
+| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.DoNothingSink| |
+| IOTDB-AIR-GAP-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBAirGapSink| |
+| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.source.IoTDBSOURCE| |
+| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBThriftSink| |
+|IOTDB-THRIFT-SSL-SINK(V1.3.1+)| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.iotdb.thrift.IoTDBThriftSslSink| |
++------------------------------+----------+---------------------------------------------------------------------------------+---------+
```
@@ -169,8 +171,8 @@ In this example, we can create a synchronisation task named A2B to synchronise t
```Go
create pipe A2B
with sink (
- 'sink'='iotdb-thrift-sink', 'sink.ip'='iotdb-thrift-sink',
-
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
'sink.port'='6668'
)
```
@@ -182,7 +184,7 @@ This example is used to demonstrate the synchronisation of data from a certain h

-In this example we can create a synchronisation task called A2B. First of all, we need to define the range of data to be transferred in source, since the data to be transferred is historical data (historical data refers to the data that existed before the creation of the synchronisation task), we need to configure the source.realtime.enable parameter to false; at the same time, we need to configure the start-time and end-time of the data and the mode mode of the transfer. At the same time, you need to configure the start-time and end-time of the data and the mode mode of transmission, and it is recommended that the mode be set to hybrid mode (hybrid mode is a mixed transmission mode, which adopts the real-time transmission mode when there is no backlog of data, and adopts the batch transmission mode when there is a backlog of data, and automatically switches according to the internal situation of the system).
+In this example we can create a synchronisation task called A2B. First of all, we need to define the range of data to be transferred in source, since the data to be transferred is historical data (historical data refers to the data that existed before the creation of the synchronisation task), we need to configure the source.realtime.enable parameter to false; at the same time, we need to configure the start-time and end-time of the data and the mode of the transfer. At the same time, you need to configure the start-time and end-time of the data and the mode of transmission, and it is recommended that the mode be set to hybrid mode (hybrid mode is a mixed transmission mode, which adopts the real-time transmission mode when there is no backlog of data, and adopts the batch transmission mode when there is a backlog of data, and automatically switches according to the internal situation of the system).
The detailed statements are as follows:
@@ -190,7 +192,6 @@ The detailed statements are as follows:
create pipe A2B
WITH SOURCE (
'source'= 'iotdb-source',
-'source.realtime.enable' = 'false',
'source.realtime.mode'='hybrid',
'source.history.start-time' = '2023.08.23T08:00:00+00:00',
'source.history.end-time' = '2023.10.23T08:00:00+00:00')
@@ -208,7 +209,7 @@ This example is used to demonstrate a scenario where two IoTDBs are dual-active

In this example, in order to avoid an infinite loop of data, the parameter `'source.forwarding-pipe-requests` needs to be set to ``false`` on both A and B to indicate that the data transferred from the other pipe will not be forwarded. Also set `'source.history.enable'` to `false` to indicate that historical data is not transferred, i.e., data prior to the creation of the task is not synchronised.
-
+
The detailed statement is as follows:
Execute the following statements on A IoTDB:
@@ -216,7 +217,6 @@ Execute the following statements on A IoTDB:
```Go
create pipe AB
with source (
- 'source.history.enable' = 'false',
'source.forwarding-pipe-requests' = 'false',
with sink (
'sink'='iotdb-thrift-sink',
@@ -230,7 +230,6 @@ Execute the following statements on B IoTDB:
```Go
create pipe BA
with source (
- 'source.history.enable' = 'false',
'source.forwarding-pipe-requests' = 'false',
with sink (
'sink'='iotdb-thrift-sink',
@@ -260,7 +259,7 @@ with sink (
)
```
-Execute the following statement on the B IoTDB to synchronise data in B to C:
+Execute the following statement on B IoTDB to synchronise data in B to C:
```Go
create pipe BC
@@ -273,13 +272,13 @@ with sink (
)
```
-### Transmission of data across a netgate
+### Transmission of data through an air gap
This example is used to demonstrate a scenario where data from one IoTDB is synchronised to another IoTDB via a unidirectional gate, with the data link shown below:
-
+
-In this example, you need to use the iotdb-air-gap-sink plug-in in the sink task (currently supports some models of network gates, please contact the staff of Tianmou Technology to confirm the specific model), and after configuring the network gate, execute the following statements on IoTDB A, where ip and port fill in the information of the network gate, and the detailed statements are as follows:
+In this example, you need to use the iotdb-air-gap-sink plugin in the sink task (currently supports some models of network gates, please contact the staff of Timecho Technology to confirm the specific model), and after configuring the network gate, execute the following statements on IoTDB A, where ip and port fill in the information of the network gate, and the detailed statements are as follows:
```Go
create pipe A2B
@@ -290,11 +289,30 @@ with sink (
)
```
+### Transfer data using SSL protocol
+
+This example demonstrates the scenario of configuring IoTDB one-way data synchronization using the SSL protocol, with the data link shown in the following figure:
+
+
+
+In this scenario, it is necessary to use IoTDB's iotdb-thrift-ssl-sink plugin. We can create a synchronization task called A2B and configure the password and address of our own certificate. The detailed statement is as follows:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-ssl-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6669',
+ 'ssl.trust-store-path'='pki/trusted'
+ 'ssl.trust-store-pwd'='root'
+)
+```
+
## Reference: Notes
The IoTDB configuration file (iotdb-common.properties) can be modified in order to adjust the parameters for data synchronisation, such as the synchronisation data storage directory. The complete configuration is as follows:
-```Go
+V1.3.0+:
+```Properties
####################
### Pipe Configuration
####################
@@ -332,31 +350,79 @@ The IoTDB configuration file (iotdb-common.properties) can be modified in order
# pipe_air_gap_receiver_port=9780
```
+V1.3.1+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
+```
+
## Reference: parameter description
+📌 Notes: for version 1.3.1 or later, any parameters other than "source", "processor", "sink" themselves need not be with the prefixes. For instance:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'sink.ip'='10.53.53.53',
+ 'sink.port'='9780'
+)
+```
+can be written as
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'ip'='10.53.53.53',
+ 'port'='9780'
+)
+```
### source parameter
-| key | value | value range | required or not |default value|
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | -------- |------|
-| source | iotdb-source | String: iotdb-source | required | - |
-| source.pattern | Path prefix for filtering time series | String: any time series prefix | optional | root |
-| source.history.enable | Whether to synchronise history data | Boolean: true, false | optional | true |
-| source.history.start-time | Synchronise the start event time of historical data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MIN_VALUE |
-| source.history.end-time | end event time for synchronised history data, contains end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MAX_VALUE |
-| source.realtime.enable | Whether to synchronise real-time data | Boolean: true, false | optional | true |
-| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional | hybrid |
-| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional | true |
+| key | value | value range | required or not | default value |
+|---------------------------------|---------------------------------------------------------------------------|----------------------------------------|-----------------|----------------|
+| source | iotdb-source | String: iotdb-source | required | - |
+| source.pattern | Path prefix for filtering time series | String: any time series prefix | optional | root |
+| source.history.start-time | Synchronise the start event time of historical data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MIN_VALUE |
+| source.history.end-time | end event time for synchronised history data, contains end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MAX_VALUE |
+| start-time(V1.3.1+) | Synchronise the start event time of all data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MIN_VALUE |
+| end-time(V1.3.1+) | end event time for synchronised all data, contains end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MAX_VALUE |
+| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional | hybrid |
+| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional | true |
> 💎 **Note: Difference between historical and real-time data**
->
+>
> * **Historical data**: all data with arrival time < current system time when the pipe was created is called historical data
> * **Real-time data**: All data with arrival time >= current system time when the pipe was created is called real-time data.
> * **Full data**: full data = historical data + real time data
> 💎 **Explanation: Difference between data extraction modes hybrid, stream and batch**
->
+>
> - **hybrid (recommended)**: In this mode, the task will give priority to real-time processing and sending of data, and automatically switch to batch sending mode when data backlog occurs, which is characterised by a balance between timeliness of data synchronisation and throughput
> - **stream**: In this mode, the task will process and send data in real time, which is characterised by high timeliness and low throughput.
> - **batch**: In this mode, the task will process and send data in batch (by underlying data file), which is characterised by low latency and high throughput.
@@ -365,23 +431,36 @@ The IoTDB configuration file (iotdb-common.properties) can be modified in order
#### iotdb-thrift-sink
-| key | value | value range | required or not | default value |
-| --------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------------------------------------- |
-| sink | iotdb-thrift-sink or iotdb-thrift-sync-sink | String: iotdb-thrift-sink or iotdb-thrift-sync-sink | required | |
-| sink.ip | Data service IP of a Datanode node in the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | String | Optional | Fill in either sink.node-urls |
-| sink.port | Data service port of a Datanode node in the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | Integer | Optional | Fill in either sink.node-urls |
-| sink.node-urls | The url of the data service port of any number of DataNode nodes on the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | String. Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
-| sink.batch.enable | Whether to enable the log saving wholesale delivery mode, which is used to improve transmission throughput and reduce IOPS | Boolean: true, false | Optional | true |
-| sink.batch.max-delay-seconds | Effective when the log save and send mode is turned on, indicates the longest time a batch of data waits before being sent (unit: s) | Integer | Optional | 1 |
-| sink.batch.size-bytes | Effective when log saving and delivery mode is enabled, indicates the maximum saving size of a batch of data (unit: byte) | Long | Optional
-
+| key | value | value range | required or not | default value |
+|------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|-----------------|----------------------------------|
+| sink | iotdb-thrift-sink or iotdb-thrift-async-sink | String: iotdb-thrift-sink or iotdb-thrift-async-sink | required | |
+| sink.ip | Data service IP of a DataNode in the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | String | Optional | Fill in either sink.node-urls |
+| sink.port | Data service port of a DataNode in the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | Integer | Optional | Fill in either sink.node-urls |
+| sink.node-urls | The url of the data service port of any number of DataNodes on the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | String. Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
+| sink.batch.enable | Whether to enable the log saving wholesale delivery mode, which is used to improve transmission throughput and reduce IOPS | Boolean: true, false | Optional | true |
+| sink.batch.max-delay-seconds | Effective when the log save and send mode is turned on, indicates the longest time a batch of data waits before being sent (unit: s) | Integer | Optional | 1 |
+| sink.batch.size-bytes | Effective when log saving and delivery mode is enabled, indicates the maximum saving size of a batch of data (unit: byte) | Long | Optional | |
#### iotdb-air-gap-sink
-| key | value | value range | required or not | default value |
-| -------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------------------------------------- |
-| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | required | |
-| sink.ip | Data service IP of a Datanode node in the target IoTDB | String | Optional | Fill in either sink.node-urls |
-| sink.port | Data service port of a Datanode node in the target IoTDB | Integer | Optional | Fill in either sink.node-urls |
-| sink.node-urls | URL of the data service port of any multiple DATANODE nodes on the target | String.Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
-| sink.air-gap.handshake-timeout-ms | The timeout length of the handshake request when the sender and the receiver try to establish a connection for the first time, unit: milliseconds | Integer | Optional | 5000 |
\ No newline at end of file
+| key | value | value range | required or not | default value |
+|-----------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------|-----------------|----------------------------------|
+| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | required | |
+| sink.ip | Data service IP of a DataNode in the target IoTDB | String | Optional | Fill in either sink.node-urls |
+| sink.port | Data service port of a DataNode in the target IoTDB | Integer | Optional | Fill in either sink.node-urls |
+| sink.node-urls | URL of the data service port of any multiple DataNodes on the target | String.Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
+| sink.air-gap.handshake-timeout-ms | The timeout length of the handshake request when the sender and the receiver try to establish a connection for the first time, unit: milliseconds | Integer | Optional | 5000 |
+
+#### iotdb-thrift-ssl-sink(V1.3.1+)
+
+| key | value | value range | required or not | default value |
+|------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|-----------------|----------------------------------|
+| sink | iotdb-thrift-sink or iotdb-thrift-async-sink | String: iotdb-thrift-sink or iotdb-thrift-sync-sink | required | |
+| sink.ip | Data service IP of a DataNode in the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | String | Optional | Fill in either sink.node-urls |
+| sink.port | Data service port of a DataNode in the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | Integer | Optional | Fill in either sink.node-urls |
+| sink.node-urls | The url of the data service port of any number of DataNodes on the target IoTDB (note that the synchronisation task does not support forwarding to its own service) | String. Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
+| sink.batch.enable | Whether to enable the log saving wholesale delivery mode, which is used to improve transmission throughput and reduce IOPS | Boolean: true, false | Optional | true |
+| sink.batch.max-delay-seconds | Effective when the log save and send mode is turned on, indicates the longest time a batch of data waits before being sent (unit: s) | Integer | Optional | 1 |
+| sink.batch.size-bytes | Effective when log saving and delivery mode is enabled, indicates the maximum saving size of a batch of data (unit: byte) | Long | Optional | |
+| ssl.trust-store-path | The certificate trust store path to connect to the target DataNodes | String.Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
+| ssl.trust-store-pwd | The certificate trust store password to connect to the target DataNodes | Integer | Optional | 5000 |
\ No newline at end of file
diff --git a/src/UserGuide/latest/User-Manual/Streaming.md b/src/UserGuide/latest/User-Manual/Streaming.md
index d911ee83..349c430b 100644
--- a/src/UserGuide/latest/User-Manual/Streaming.md
+++ b/src/UserGuide/latest/User-Manual/Streaming.md
@@ -25,19 +25,19 @@ The IoTDB stream processing framework allows users to implement customized strea
We call a data flow processing task a Pipe. A stream processing task (Pipe) contains three subtasks:
-- Extract
-- Process
-- Send (Connect)
+- Source task
+- Processor task
+- Sink task
The stream processing framework allows users to customize the processing logic of three subtasks using Java language and process data in a UDF-like manner.
In a Pipe, the three subtasks mentioned above are executed and implemented by three types of plugins. Data flows through these three plugins sequentially for processing:
-Pipe Extractor is used to extract data, Pipe Processor is used to process data, Pipe Connector is used to send data, and the final data will be sent to an external system.
+Pipe Source is used to extract data, Pipe Processor is used to process data, Pipe Sink is used to send data, and the final data will be sent to an external system.
**The model for a Pipe task is as follows:**
-
+
-A data stream processing task essentially describes the attributes of the Pipe Extractor, Pipe Processor, and Pipe Connector plugins.
+A data stream processing task essentially describes the attributes of the Pipe Source, Pipe Processor, and Pipe Sink plugins.
Users can configure the specific attributes of these three subtasks declaratively using SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
@@ -53,7 +53,7 @@ It is recommended to use Maven to build the project. Add the following dependenc
org.apache.iotdb
pipe-api
- 1.2.1
+ 1.3.1
provided
```
@@ -62,7 +62,7 @@ It is recommended to use Maven to build the project. Add the following dependenc
The design of user programming interfaces for stream processing plugins follows the principles of the event-driven programming model. In this model, events serve as the abstraction of data in the user programming interface. The programming interface is decoupled from the specific execution method, allowing the focus to be on describing how the system expects events (data) to be processed upon arrival.
-In the user programming interface of stream processing plugins, events abstract the write operations of database data. Events are captured by the local stream processing engine and passed sequentially through the three stages of stream processing, namely Pipe Extractor, Pipe Processor, and Pipe Connector plugins. User logic is triggered and executed within these three plugins.
+In the user programming interface of stream processing plugins, events abstract the write operations of database data. Events are captured by the local stream processing engine and passed sequentially through the three stages of stream processing, namely Pipe Source, Pipe Processor, and Pipe Sink plugins. User logic is triggered and executed within these three plugins.
To accommodate both low-latency stream processing in low-load scenarios and high-throughput stream processing in high-load scenarios at the edge, the stream processing engine dynamically chooses the processing objects from operation logs and data files. Therefore, the user programming interface for stream processing requires the user to provide the handling logic for two types of events: TabletInsertionEvent for operation log write events and TsFileInsertionEvent for data file write events.
@@ -133,37 +133,37 @@ public interface TsFileInsertionEvent extends Event {
Based on the custom stream processing plugin programming interface, users can easily write data extraction plugins, data processing plugins, and data sending plugins, allowing the stream processing functionality to adapt flexibly to various industrial scenarios.
#### Data Extraction Plugin Interface
-Data extraction is the first stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data extraction plugin (PipeExtractor) serves as a bridge between the stream processing engine and the storage engine. It captures various data write events by listening to the behavior of the storage engine.
+Data extraction is the first stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data extraction plugin (PipeSource) serves as a bridge between the stream processing engine and the storage engine. It captures various data write events by listening to the behavior of the storage engine.
```java
/**
- * PipeExtractor
+ * PipeSource
*
- * PipeExtractor is responsible for capturing events from sources.
+ *
PipeSource is responsible for capturing events from sources.
*
- *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
Various data sources can be supported by implementing different PipeSource classes.
*
- *
The lifecycle of a PipeExtractor is as follows:
+ *
The lifecycle of a PipeSource is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
- * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
+ *
- When a collaboration task is created, the KV pairs of `WITH SOURCE` clause in SQL are
+ * parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
+ * be called to validate the parameters.
*
- Before the collaboration task starts, the method {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeExtractor.
- *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
- *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
- * be called to capture events from sources and then the events will be passed to the
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
+ * config the runtime behavior of the PipeSource.
+ *
- Then the method {@link PipeSource#start()} will be called to start the PipeSource.
+ *
- While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
+ * called to capture events from sources and then the events will be passed to the
* PipeProcessor.
- *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ *
- The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
*
*/
-public interface PipeExtractor extends PipePlugin {
+public interface PipeSource extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
@@ -171,39 +171,39 @@ public interface PipeExtractor extends PipePlugin {
void validate(PipeParameterValidator validator) throws Exception;
/**
- * This method is mainly used to customize PipeExtractor. In this method, the user can do the
+ * This method is mainly used to customize PipeSource. In this method, the user can do the
* following things:
*
*
* - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
+ *
- Set the running configurations in PipeSourceRuntimeConfiguration.
*
*
- * This method is called after the method {@link
- * PipeExtractor#validate(PipeParameterValidator)} is called.
+ *
This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
+ * is called.
*
* @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeExtractor
+ * @param configuration used to set the required properties of the running PipeSource
* @throws Exception the user can throw errors if necessary
*/
- void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
+ void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
throws Exception;
/**
- * Start the extractor. After this method is called, events should be ready to be supplied by
- * {@link PipeExtractor#supply()}. This method is called after {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ * Start the source. After this method is called, events should be ready to be supplied by
+ * {@link PipeSource#supply()}. This method is called after {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @throws Exception the user can throw errors if necessary
*/
void start() throws Exception;
/**
- * Supply single event from the extractor and the caller will send the event to the processor.
- * This method is called after {@link PipeExtractor#start()} is called.
+ * Supply single event from the source and the caller will send the event to the processor.
+ * This method is called after {@link PipeSource#start()} is called.
*
- * @return the event to be supplied. the event may be null if the extractor has no more events at
- * the moment, but the extractor is still running for more events.
+ * @return the event to be supplied. the event may be null if the source has no more events at
+ * the moment, but the source is still running for more events.
* @throws Exception the user can throw errors if necessary
*/
Event supply() throws Exception;
@@ -212,13 +212,13 @@ public interface PipeExtractor extends PipePlugin {
#### Data Processing Plugin Interface
-Data processing is the second stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data processing plugin (PipeProcessor) is primarily used for filtering and transforming the various events captured by the data extraction plugin (PipeExtractor).
+Data processing is the second stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data processing plugin (PipeProcessor) is primarily used for filtering and transforming the various events captured by the data extraction plugin (PipeSource).
```java
/**
* PipeProcessor
*
- *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
*
The lifecycle of a PipeProcessor is as follows:
*
@@ -231,13 +231,13 @@ Data processing is the second stage of the three-stage process of stream process
* to config the runtime behavior of the PipeProcessor.
*
While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
- *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
- PipeSink serializes the events into binaries and send them to sinks.
*
* When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
@@ -312,50 +312,48 @@ public interface PipeProcessor extends PipePlugin {
#### Data Sending Plugin Interface
-Data sending is the third stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data sending plugin (PipeConnector) is responsible for sending the various events processed by the data processing plugin (PipeProcessor). It serves as the network implementation layer of the stream processing framework and should support multiple real-time communication protocols and connectors in its interface.
+Data sending is the third stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data sending plugin (PipeSink) is responsible for sending the various events processed by the data processing plugin (PipeProcessor). It serves as the network implementation layer of the stream processing framework and should support multiple real-time communication protocols and connectors in its interface.
```java
/**
- * PipeConnector
+ * PipeSink
*
- * PipeConnector is responsible for sending events to sinks.
+ *
PipeSink is responsible for sending events to sinks.
*
- *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
Various network protocols can be supported by implementing different PipeSink classes.
*
- *
The lifecycle of a PipeConnector is as follows:
+ *
The lifecycle of a PipeSink is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
- * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
- *
- Before the collaboration task starts, the method {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeConnector and the method {@link
- * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
+ * parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
+ * called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
+ * PipeSinkRuntimeConfiguration)} will be called to configure the runtime behavior of the
+ * PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
+ * with sink.
*
- While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector.
- *
- PipeConnector serializes the events into binaries and send them to sinks. The
- * following 3 methods will be called: {@link
- * PipeConnector#transfer(TabletInsertionEvent)}, {@link
- * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
- * PipeConnector#transfer(Event)}.
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink.
+ *
- PipeSink serializes the events into binaries and send them to sinks. The following 3
+ * methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
+ * PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
*
* - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
- * PipeConnector#close() } method will be called.
+ * PipeSink#close() } method will be called.
*
*
- * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
- * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
- * will be called to create a new connection with the sink when the method {@link
- * PipeConnector#heartbeat()} throws exceptions.
+ *
In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
+ * called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
+ * throws exceptions.
*/
-public interface PipeConnector extends PipePlugin {
+public interface PipeSink extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
+ * PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
@@ -363,29 +361,28 @@ public interface PipeConnector extends PipePlugin {
void validate(PipeParameterValidator validator) throws Exception;
/**
- * This method is mainly used to customize PipeConnector. In this method, the user can do the
- * following things:
+ * This method is mainly used to customize PipeSink. In this method, the user can do the following
+ * things:
*
*
* - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
+ *
- Set the running configurations in PipeSinkRuntimeConfiguration.
*
*
- * This method is called after the method {@link
- * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
- * PipeConnector#handshake()} is called.
+ *
This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
+ * called and before the method {@link PipeSink#handshake()} is called.
*
* @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeConnector
+ * @param configuration used to set the required properties of the running PipeSink
* @throws Exception the user can throw errors if necessary
*/
- void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
+ void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
throws Exception;
/**
* This method is used to create a connection with sink. This method will be called after the
- * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
- * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
+ * method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
+ * will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
*
* @throws Exception if the connection is failed to be created
*/
@@ -416,14 +413,18 @@ public interface PipeConnector extends PipePlugin {
* @throws Exception the user can throw errors if necessary
*/
default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- transfer(tabletInsertionEvent);
+ try {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ } finally {
+ tsFileInsertionEvent.close();
}
}
/**
- * This method is used to transfer the Event.
+ * This method is used to transfer the generic events, including HeartbeatEvent.
*
* @param event Event to be transferred
* @throws PipeConnectionException if the connection is broken
@@ -439,7 +440,7 @@ To ensure the flexibility and usability of user-defined plugins in production en
### Load Plugin Statement
-In IoTDB, to dynamically load a user-defined plugin into the system, you first need to implement a specific plugin class based on PipeExtractor, PipeProcessor, or PipeConnector. Then, you need to compile and package the plugin class into an executable jar file. Finally, you can use the loading plugin management statement to load the plugin into IoTDB.
+In IoTDB, to dynamically load a user-defined plugin into the system, you first need to implement a specific plugin class based on PipeSource, PipeProcessor, or PipeSink. Then, you need to compile and package the plugin class into an executable jar file. Finally, you can use the loading plugin management statement to load the plugin into IoTDB.
The syntax of the loading plugin management statement is as follows:
@@ -459,7 +460,7 @@ USING URI ''
### Delete Plugin Statement
-When user no longer wants to use a plugin and needs to uninstall the plug-in from the system, you can use the Remove plugin statement as shown below.
+When user no longer wants to use a plugin and needs to uninstall the plugin from the system, you can use the Remove plugin statement as shown below.
```sql
DROP PIPEPLUGIN
```
@@ -473,27 +474,27 @@ SHOW PIPEPLUGINS
## System Pre-installed Stream Processing Plugin
-### Pre-built extractor Plugin
+### Pre-built Source Plugin
-#### iotdb-extractor
+#### iotdb-source
Function: Extract historical or realtime data inside IoTDB into pipe.
-| key | value | value range | required or optional with default |
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor | String: iotdb-extractor | required |
-| extractor.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
-| extractor.history.enable | whether to sync historical data | Boolean: true, false | optional: true |
-| extractor.history.start-time | start of synchronizing historical data event time,Include start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | end of synchronizing historical data event time,Include end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | Whether to sync realtime data | Boolean: true, false | optional: true |
+| key | value | value range | required or optional with default |
+|---------------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
+| source.history.start-time | start of synchronizing historical data event time,including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | end of synchronizing historical data event time,including end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-> 🚫 **extractor.pattern Parameter Description**
+> 🚫 **source.pattern Parameter Description**
>
> * Pattern should use backquotes to modify illegal characters or illegal path nodes, for example, if you want to filter root.\`a@b\` or root.\`123\`, you should set the pattern to root.\`a@b\` or root.\`123\`(Refer specifically to [Timing of single and double quotes and backquotes](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
-> * In the underlying implementation, when pattern is detected as root (default value), synchronization efficiency is higher, and any other format will reduce performance.
-> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
+> * In the underlying implementation, when pattern is detected as root (default value) or a database name, synchronization efficiency is higher, and any other format will reduce performance.
+> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'source.pattern'='root.aligned.1':
>
> * root.aligned.1TS
> * root.aligned.1TS.\`1\`
@@ -501,56 +502,48 @@ Function: Extract historical or realtime data inside IoTDB into pipe.
>
> the data will be synchronized;
>
-> * root.aligned.\`1\`
> * root.aligned.\`123\`
>
> the data will not be synchronized.
-> ❗️**start-time, end-time parameter description of extractor.history**
+> ❗️**start-time, end-time parameter description of source**
>
-> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
+> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00. However, version 1.3.1+ supports timeStamp format like 1706704494000.
-> ✅ **a piece of data from production to IoTDB contains two key concepts of time**
+> ✅ **A piece of data from production to IoTDB contains two key concepts of time**
>
> * **event time:** the time when the data is actually produced (or the generation time assigned to the data by the data production system, which is a time item in the data point), also called the event time.
> * **arrival time:** the time the data arrived in the IoTDB system.
>
> The out-of-order data we often refer to refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
-> 💎 **the work of iotdb-extractor can be split into two stages**
+> 💎 **the work of iotdb-source can be split into two stages**
>
> 1. Historical data extraction: All data with **arrival time** < **current system time** when creating the pipe is called historical data
> 2. Realtime data extraction: All data with **arrival time** >= **current system time** when the pipe is created is called realtime data
>
> The historical data transmission phase and the realtime data transmission phase are executed serially. Only when the historical data transmission phase is completed, the realtime data transmission phase is executed.**
->
-> Users can specify iotdb-extractor to:
->
-> * Historical data extraction(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * Realtime data extraction(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * Full data extraction(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * Disable simultaneous sets `extractor.history.enable` and `extractor.realtime.enable` to `false`
### Pre-built Processor Plugin
#### do-nothing-processor
-Function: Do not do anything with the events passed in by the extractor.
+Function: Do not do anything with the events passed in by the source.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value range | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### Pre-built Connector Plugin
+### Pre-built Sink Plugin
-#### do-nothing-connector
+#### do-nothing-sink
Function: Does not do anything with the events passed in by the processor.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value range | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## Stream Processing Task Management
@@ -560,57 +553,57 @@ A stream processing task can be created using the `CREATE PIPE` statement, a sam
```sql
CREATE PIPE -- PipeId is the name that uniquely identifies the sync task
-WITH EXTRACTOR (
+WITH SOURCE (
-- Default IoTDB Data Extraction Plugin
- 'extractor' = 'iotdb-extractor',
+ 'source' = 'iotdb-source',
-- Path prefix, only data that can match the path prefix will be extracted for subsequent processing and delivery
- 'extractor.pattern' = 'root.timecho',
+ 'source.pattern' = 'root.timecho',
-- Whether to extract historical data
- 'extractor.history.enable' = 'true',
+ 'source.history.enable' = 'true',
-- Describes the time range of the historical data being extracted, indicating the earliest possible time
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- Describes the time range of the extracted historical data, indicating the latest time
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
-- Whether to extract realtime data
- 'extractor.realtime.enable' = 'true',
+ 'source.realtime.enable' = 'true',
)
WITH PROCESSOR (
-- Default data processing plugin, means no processing
'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB data sending plugin with target IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- Data service for one of the DataNode nodes on the target IoTDB ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
**To create a stream processing task it is necessary to configure the PipeId and the parameters of the three plugin sections:**
-| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
-| --------- | ------------------------------------------------- | --------------------------- | -------------------- | ------------------------------------------------------ | ------------------------- |
-| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
-| extractor | pipe Extractor plug-in, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
-| processor | Pipe Processor plug-in, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
-| connector | Pipe Connector plug-in,for sending data | required | - | - | yes |
+| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
+|--------------------|-------------------------------------------------------------------------------------|---------------------------------|------------------------|-----------------------------------------------------------------------------------------------|-----------------------------------------|
+| pipeId | Globally uniquely identifies the name of a sync task | required | - | - | - |
+| source | pipe Source plugin, for extracting synchronized data at the bottom of the database | Optional | iotdb-source | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
+| processor | Pipe Processor plugin, for processing data | Optional | do-nothing-processor | no processing of incoming data | yes |
+| sink | Pipe Sink plugin,for sending data | required | - | - | yes |
-In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plug-ins are used to build the data synchronisation task. iotdb has other built-in data synchronisation plug-ins, **see the section "System pre-built data synchronisation plug-ins" **. See the "System Pre-installed Stream Processing Plugin" section**.
+In the example, the iotdb-source, do-nothing-processor, and iotdb-thrift-sink plugins are used to build the data synchronisation task. iotdb has other built-in data synchronisation plugins, **see the section "System pre-built data synchronisation plugins" **. See the "System Pre-installed Stream Processing Plugin" section**.
**An example of a minimalist CREATE PIPE statement is as follows:**
```sql
CREATE PIPE -- PipeId is a name that uniquely identifies the task.
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB data sending plugin with target IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- Data service for one of the DataNode nodes on the target IoTDB ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -618,37 +611,37 @@ The expressed semantics are: synchronise the full amount of historical data and
**Note:**
-- EXTRACTOR and PROCESSOR are optional, if no configuration parameters are filled in, the system will use the corresponding default implementation.
-- The CONNECTOR is a mandatory configuration that needs to be declared in the CREATE PIPE statement for configuring purposes.
-- The CONNECTOR exhibits self-reusability. For different tasks, if their CONNECTOR possesses identical KV properties (where the value corresponds to every key), **the system will ultimately create only one instance of the CONNECTOR** to achieve resource reuse for connections.
+- SOURCE and PROCESSOR are optional, if no configuration parameters are filled in, the system will use the corresponding default implementation.
+- The SINK is a mandatory configuration that needs to be declared in the CREATE PIPE statement for configuring purposes.
+- The SINK exhibits self-reusability. For different tasks, if their SINK possesses identical KV properties (where the value corresponds to every key), **the system will ultimately create only one instance of the SINK** to achieve resource reuse for connections.
- For example, there are the following pipe1, pipe2 task declarations:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.thrift.host' = 'localhost',
+ 'sink.thrift.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.thrift.port' = '9999',
+ 'sink.thrift.host' = 'localhost',
)
```
- - Since they have identical CONNECTOR declarations (**even if the order of some properties is different**), the framework will automatically reuse the CONNECTOR declared by them. Hence, the CONNECTOR instances for pipe1 and pipe2 will be the same.
+- Since they have identical SINK declarations (**even if the order of some properties is different**), the framework will automatically reuse the SINK declared by them. Hence, the SINK instances for pipe1 and pipe2 will be the same.
- Please note that we should avoid constructing application scenarios that involve data cycle sync (as it can result in an infinite loop):
- - IoTDB A -> IoTDB B -> IoTDB A
- - IoTDB A -> IoTDB A
+- IoTDB A -> IoTDB B -> IoTDB A
+- IoTDB A -> IoTDB A
### Start Stream Processing Task
-After the successful execution of the CREATE PIPE statement, an instance of the stream processing task is created, but the overall task's running status will be set to STOPPED, meaning the task will not immediately process data.
+After the successful execution of the CREATE PIPE statement, task-related instances will be created. However, the overall task's running status will be set to STOPPED(V1.3.0), meaning the task will not immediately process data. In version 1.3.1 and later, the status of the task will be set to RUNNING after CREATE.
You can use the START PIPE statement to make the stream processing task start processing data:
```sql
@@ -683,13 +676,13 @@ SHOW PIPES
The query results are as follows:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime | State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
You can use `` to specify the status of a stream processing task you want to see:
@@ -697,22 +690,23 @@ You can use `` to specify the status of a stream processing task you wan
SHOW PIPE
```
-Additionally, the WHERE clause can be used to determine if the Pipe Connector used by a specific \ is being reused.
+Additionally, the WHERE clause can be used to determine if the Pipe Sink used by a specific \ is being reused.
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### Stream Processing Task Running Status Migration
A stream processing task status can transition through several states during the lifecycle of a data synchronization pipe:
+- **RUNNING:** The pipe is actively processing data
+ - After the successful creation of a pipe, its initial state is set to RUNNING (V1.3.1+)
- **STOPPED:** The pipe is in a stopped state. It can have the following possibilities:
- - After the successful creation of a pipe, its initial state is set to stopped
+ - After the successful creation of a pipe, its initial state is set to RUNNING (V1.3.0)
- The user manually pauses a pipe that is in normal running state, transitioning its status from RUNNING to STOPPED
- If a pipe encounters an unrecoverable error during execution, its status automatically changes from RUNNING to STOPPED.
-- **RUNNING:** The pipe is actively processing data
- **DROPPED:** The pipe is permanently deleted
The following diagram illustrates the different states and their transitions:
@@ -723,26 +717,27 @@ The following diagram illustrates the different states and their transitions:
### Stream Processing Task
-| Authority Name | Description |
-| ----------- | -------------------- |
-| USE_PIPE | Register task,path-independent |
-| USE_PIPE | Start task,path-independent |
-| USE_PIPE | Stop task,path-independent |
-| USE_PIPE | Uninstall task,path-independent |
-| USE_PIPE | Query task,path-independent |
+| Authority Name | Description |
+|----------------|---------------------------------|
+| USE_PIPE | Register task,path-independent |
+| USE_PIPE | Start task,path-independent |
+| USE_PIPE | Stop task,path-independent |
+| USE_PIPE | Uninstall task,path-independent |
+| USE_PIPE | Query task,path-independent |
### Stream Processing Task Plugin
-| Authority Name | Description |
-| ----------------- | ------------------------------ |
-| USE_PIPE | Register stream processing task plugin,path-independent |
-| USE_PIPE | Delete stream processing task plugin,path-independent |
-| USE_PIPE | Query stream processing task plugin,path-independent |
+| Authority Name | Description |
+|----------------|---------------------------------------------------------|
+| USE_PIPE | Register stream processing task plugin,path-independent |
+| USE_PIPE | Delete stream processing task plugin,path-independent |
+| USE_PIPE | Query stream processing task plugin,path-independent |
## Configure Parameters
In iotdb-common.properties :
+V1.3.0:
```Properties
####################
### Pipe Configuration
@@ -763,4 +758,43 @@ In iotdb-common.properties :
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+```
+
+V1.3.1+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
```
\ No newline at end of file
diff --git a/src/UserGuide/latest/User-Manual/Streaming_timecho.md b/src/UserGuide/latest/User-Manual/Streaming_timecho.md
index 8d121314..357df1d6 100644
--- a/src/UserGuide/latest/User-Manual/Streaming_timecho.md
+++ b/src/UserGuide/latest/User-Manual/Streaming_timecho.md
@@ -25,19 +25,19 @@ The IoTDB stream processing framework allows users to implement customized strea
We call a data flow processing task a Pipe. A stream processing task (Pipe) contains three subtasks:
-- Extract
-- Process
-- Send (Connect)
+- Source task
+- Processor task
+- Sink task
The stream processing framework allows users to customize the processing logic of three subtasks using Java language and process data in a UDF-like manner.
In a Pipe, the above three subtasks are executed by three plugins respectively, and the data will be processed by these three plugins in turn:
-Pipe Extractor is used to extract data, Pipe Processor is used to process data, Pipe Connector is used to send data, and the final data will be sent to an external system.
+Pipe Source is used to extract data, Pipe Processor is used to process data, Pipe Sink is used to send data, and the final data will be sent to an external system.
**The model of the Pipe task is as follows:**
-
+
-Describing a data flow processing task essentially describes the properties of Pipe Extractor, Pipe Processor and Pipe Connector plugins.
+Describing a data flow processing task essentially describes the properties of Pipe Source, Pipe Processor and Pipe Sink plugins.
Users can declaratively configure the specific attributes of the three subtasks through SQL statements, and achieve flexible data ETL capabilities by combining different attributes.
Using the stream processing framework, a complete data link can be built to meet the needs of end-side-cloud synchronization, off-site disaster recovery, and read-write load sub-library*.
@@ -52,7 +52,7 @@ It is recommended to use maven to build the project and add the following depend
org.apache.iotdb
pipe-api
- 1.2.1
+ 1.3.1
provided
```
@@ -61,7 +61,7 @@ It is recommended to use maven to build the project and add the following depend
The user programming interface design of the stream processing plugin refers to the general design concept of the event-driven programming model. Events are data abstractions in the user programming interface, and the programming interface is decoupled from the specific execution method. It only needs to focus on describing the processing method expected by the system after the event (data) reaches the system.
-In the user programming interface of the stream processing plugin, events are an abstraction of database data writing operations. The event is captured by the stand-alone stream processing engine, and is passed to the PipeExtractor plugin, PipeProcessor plugin, and PipeConnector plugin in sequence according to the three-stage stream processing process, and triggers the execution of user logic in the three plugins in turn.
+In the user programming interface of the stream processing plugin, events are an abstraction of database data writing operations. The event is captured by the stand-alone stream processing engine, and is passed to the PipeSource plugin, PipeProcessor plugin, and PipeSink plugin in sequence according to the three-stage stream processing process, and triggers the execution of user logic in the three plugins in turn.
In order to take into account the low latency of stream processing in low load scenarios on the end side and the high throughput of stream processing in high load scenarios on the end side, the stream processing engine will dynamically select processing objects in the operation logs and data files. Therefore, user programming of stream processing The interface requires users to provide processing logic for the following two types of events: operation log writing event TabletInsertionEvent and data file writing event TsFileInsertionEvent.
@@ -133,95 +133,95 @@ Based on the custom stream processing plugin programming interface, users can ea
#### Data extraction plugin interface
-Data extraction is the first stage of the three stages of stream processing data from data extraction to data sending. The data extraction plugin (PipeExtractor) is the bridge between the stream processing engine and the storage engine. It monitors the behavior of the storage engine,
+Data extraction is the first stage of the three stages of stream processing data from data extraction to data sending. The data extraction plugin (PipeSource) is the bridge between the stream processing engine and the storage engine. It monitors the behavior of the storage engine,
Capture various data write events.
```java
/**
- * PipeExtractor
+ * PipeSource
*
- * PipeExtractor is responsible for capturing events from sources.
+ *
PipeSource is responsible for capturing events from sources.
*
- *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
Various data sources can be supported by implementing different PipeSource classes.
*
- *
The lifecycle of a PipeExtractor is as follows:
+ *
The lifecycle of a PipeSource is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
- * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
+ *
- When a collaboration task is created, the KV pairs of `WITH Source` clause in SQL are
+ * parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
+ * be called to validate the parameters.
*
- Before the collaboration task starts, the method {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeExtractor.
- *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
- *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
- * be called to capture events from sources and then the events will be passed to the
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
+ * configure the runtime behavior of the PipeSource.
+ *
- Then the method {@link PipeSource#start()} will be called to start the PipeSource.
+ *
- While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
+ * called to capture events from sources and then the events will be passed to the
* PipeProcessor.
- *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ *
- The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
*
*/
-public interface PipeExtractor extends PipePlugin {
-
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeExtractor. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeExtractor#validate(PipeParameterValidator)} is called.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeExtractor
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * Start the extractor. After this method is called, events should be ready to be supplied by
- * {@link PipeExtractor#supply()}. This method is called after {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
- *
- * @throws Exception the user can throw errors if necessary
- */
- void start() throws Exception;
-
- /**
- * Supply single event from the extractor and the caller will send the event to the processor.
- * This method is called after {@link PipeExtractor#start()} is called.
- *
- * @return the event to be supplied. the event may be null if the extractor has no more events at
- * the moment, but the extractor is still running for more events.
- * @throws Exception the user can throw errors if necessary
- */
- Event supply() throws Exception;
+public interface PipeSource extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeSource. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeSourceRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
+ * is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeSource
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * Start the Source. After this method is called, events should be ready to be supplied by
+ * {@link PipeSource#supply()}. This method is called after {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
+ *
+ * @throws Exception the user can throw errors if necessary
+ */
+ void start() throws Exception;
+
+ /**
+ * Supply single event from the Source and the caller will send the event to the processor.
+ * This method is called after {@link PipeSource#start()} is called.
+ *
+ * @return the event to be supplied. the event may be null if the Source has no more events at
+ * the moment, but the Source is still running for more events.
+ * @throws Exception the user can throw errors if necessary
+ */
+ Event supply() throws Exception;
}
```
#### Data processing plugin interface
-Data processing is the second stage of the three stages of stream processing data from data extraction to data sending. The data processing plugin (PipeProcessor) is mainly used to filter and transform the data captured by the data extraction plugin (PipeExtractor).
+Data processing is the second stage of the three stages of stream processing data from data extraction to data sending. The data processing plugin (PipeProcessor) is mainly used to filter and transform the data captured by the data extraction plugin (PipeSource).
various events.
```java
/**
* PipeProcessor
*
- *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
*
The lifecycle of a PipeProcessor is as follows:
*
@@ -231,16 +231,16 @@ various events.
* will be called to validate the parameters.
*
Before the collaboration task starts, the method {@link
* PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeProcessor.
+ * to configure the runtime behavior of the PipeProcessor.
* While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSource. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
- *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
- PipeSink serializes the events into binaries and send them to sinks.
*
* When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
@@ -315,125 +315,126 @@ public interface PipeProcessor extends PipePlugin {
#### Data sending plugin interface
-Data sending is the third stage of the three stages of stream processing data from data extraction to data sending. The data sending plugin (PipeConnector) is mainly used to send data processed by the data processing plugin (PipeProcessor).
-Various events, it serves as the network implementation layer of the stream processing framework, and the interface should allow access to multiple real-time communication protocols and multiple connectors.
+Data sending is the third stage of the three stages of stream processing data from data extraction to data sending. The data sending plugin (PipeSink) is mainly used to send data processed by the data processing plugin (PipeProcessor).
+Various events, it serves as the network implementation layer of the stream processing framework, and the interface should allow access to multiple real-time communication protocols and multiple sinks.
```java
/**
- * PipeConnector
+ * PipeSink
*
- * PipeConnector is responsible for sending events to sinks.
+ *
PipeSink is responsible for sending events to sinks.
*
- *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
Various network protocols can be supported by implementing different PipeSink classes.
*
- *
The lifecycle of a PipeConnector is as follows:
+ *
The lifecycle of a PipeSink is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
- * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
- *
- Before the collaboration task starts, the method {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeConnector and the method {@link
- * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
+ * parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
+ * called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
+ * PipeSinkRuntimeConfiguration)} will be called to configure the runtime behavior of the
+ * PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
+ * with sink.
*
- While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector.
- *
- PipeConnector serializes the events into binaries and send them to sinks. The
- * following 3 methods will be called: {@link
- * PipeConnector#transfer(TabletInsertionEvent)}, {@link
- * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
- * PipeConnector#transfer(Event)}.
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink.
+ *
- PipeSink serializes the events into binaries and send them to sinks. The following 3
+ * methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
+ * PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
*
* - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
- * PipeConnector#close() } method will be called.
+ * PipeSink#close() } method will be called.
*
*
- * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
- * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
- * will be called to create a new connection with the sink when the method {@link
- * PipeConnector#heartbeat()} throws exceptions.
+ *
In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
+ * called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
+ * throws exceptions.
*/
-public interface PipeConnector extends PipePlugin {
-
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeConnector. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
- * PipeConnector#handshake()} is called.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeConnector
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * This method is used to create a connection with sink. This method will be called after the
- * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
- * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
- *
- * @throws Exception if the connection is failed to be created
- */
- void handshake() throws Exception;
-
- /**
- * This method will be called periodically to check whether the connection with sink is still
- * alive.
- *
- * @throws Exception if the connection dies
- */
- void heartbeat() throws Exception;
-
- /**
- * This method is used to transfer the TabletInsertionEvent.
- *
- * @param tabletInsertionEvent TabletInsertionEvent to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
-
- /**
- * This method is used to transfer the TsFileInsertionEvent.
- *
- * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- transfer(tabletInsertionEvent);
+public interface PipeSink extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeSink. In this method, the user can do the following
+ * things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeSinkRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
+ * called and before the method {@link PipeSink#handshake()} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeSink
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is used to create a connection with sink. This method will be called after the
+ * method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
+ * will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
+ *
+ * @throws Exception if the connection is failed to be created
+ */
+ void handshake() throws Exception;
+
+ /**
+ * This method will be called periodically to check whether the connection with sink is still
+ * alive.
+ *
+ * @throws Exception if the connection dies
+ */
+ void heartbeat() throws Exception;
+
+ /**
+ * This method is used to transfer the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
+
+ /**
+ * This method is used to transfer the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
+ try {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ } finally {
+ tsFileInsertionEvent.close();
+ }
}
- }
- /**
- * This method is used to transfer the Event.
- *
- * @param event Event to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- void transfer(Event event) throws Exception;
+ /**
+ * This method is used to transfer the generic events, including HeartbeatEvent.
+ *
+ * @param event Event to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(Event event) throws Exception;
}
```
@@ -444,7 +445,7 @@ The stream processing plugin management statements introduced in this chapter pr
### Load plugin statement
-In IoTDB, if you want to dynamically load a user-defined plugin in the system, you first need to implement a specific plugin class based on PipeExtractor, PipeProcessor or PipeConnector.
+In IoTDB, if you want to dynamically load a user-defined plugin in the system, you first need to implement a specific plugin class based on PipeSource, PipeProcessor or PipeSink.
Then the plugin class needs to be compiled and packaged into a jar executable file, and finally the plugin is loaded into IoTDB using the management statement for loading the plugin.
The syntax of the management statement for loading the plugin is shown in the figure.
@@ -455,7 +456,7 @@ AS
USING
```
-Example: If you implement a data processing plugin named edu.tsinghua.iotdb.pipe.ExampleProcessor, and the packaged jar package is pipe-plugin.jar, you want to use this plugin in the stream processing engine, and mark the plugin as example. There are two ways to use the plug-in package, one is to upload to the URI server, and the other is to upload to the local directory of the cluster.
+Example: If you implement a data processing plugin named edu.tsinghua.iotdb.pipe.ExampleProcessor, and the packaged jar package is pipe-plugin.jar, you want to use this plugin in the stream processing engine, and mark the plugin as example. There are two ways to use the plugin package, one is to upload to the URI server, and the other is to upload to the local directory of the cluster.
Method 1: Upload to the URI server
@@ -498,74 +499,67 @@ SHOW PIPEPLUGINS
## System preset stream processing plugin
-### Preset extractor plugin
+### Pre-built Source Plugin
-####iotdb-extractor
+#### iotdb-source
-Function: Extract historical or real-time data inside IoTDB into pipe.
+Function: Extract historical or realtime data inside IoTDB into pipe.
-| key | value | value range | required or not |default value|
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | -------- |------|
-| source | iotdb-source | String: iotdb-source | required | - |
-| source.pattern | Path prefix for filtering time series | String: any time series prefix | optional | root |
-| source.history.enable | Whether to synchronise history data | Boolean: true, false | optional | true |
-| source.history.start-time | Synchronise the start event time of historical data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MIN_VALUE |
-| source.history.end-time | end event time for synchronised history data, contains end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional | Long.MAX_VALUE |
-| source.realtime.enable | Whether to synchronise real-time data | Boolean: true, false | optional | true |
-| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional | hybrid |
-| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional | true |
+| key | value | value range | required or optional with default |
+|---------------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
+| source.history.start-time | start of synchronizing historical data event time,including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | end of synchronizing historical data event time,including end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional:true |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional:hybrid |
+| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional:true |
-> 🚫 **extractor.pattern 参数说明**
+> 🚫 **source.pattern Parameter Description**
>
->* Pattern needs to use backticks to modify illegal characters or illegal path nodes. For example, if you want to filter root.\`a@b\` or root.\`123\`, you should set pattern to root.\`a@b \` or root.\`123\` (For details, please refer to [When to use single and double quotes and backticks](https://iotdb.apache.org/zh/Download/#_1-0-version incompatible syntax details illustrate))
-> * In the underlying implementation, when pattern is detected as root (default value), the extraction efficiency is higher, and any other format will reduce performance.
-> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
- >
- > * root.aligned.1TS
-> * root.aligned.1TS.\`1\`
-> * root.aligned.100T
- >
- > The data will be extracted;
- >
- > * root.aligned.\`1\`
-> * root.aligned.\`123\`
- >
- > The data will not be extracted.
-> * The data of root.\_\_system will not be extracted by pipe. Although users can include any prefix in extractor.pattern, including prefixes with (or overriding) root.\__system, the data under root.__system will always be ignored by pipe
-
-> ❗️**Start-time, end-time parameter description of extractor.history**
+> * Pattern should use backquotes to modify illegal characters or illegal path nodes, for example, if you want to filter root.\`a@b\` or root.\`123\`, you should set the pattern to root.\`a@b\` or root.\`123\`(Refer specifically to [Timing of single and double quotes and backquotes](https://iotdb.apache.org/Download/))
+> * In the underlying implementation, when pattern is detected as root (default value) or a database name, synchronization efficiency is higher, and any other format will reduce performance.
+> * The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'source.pattern'='root.aligned.1':
+ >
+ > * root.aligned.1TS
+ > * root.aligned.1TS.\`1\`
+> * root.aligned.100TS
+ >
+ > the data will be synchronized;
+ >
+ > * root.aligned.\`1\`
+> * root.aligned.\`123\`
+ >
+ > the data will not be synchronized.
+
+> ❗️**start-time, end-time parameter description of source**
>
-> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
+> * start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00. However, version 1.3.1+ supports timeStamp format like 1706704494000.
> ✅ **A piece of data from production to IoTDB contains two key concepts of time**
>
> * **event time:** The time when the data is actually produced (or the generation time assigned to the data by the data production system, which is the time item in the data point), also called event time.
> * **arrival time:** The time when data arrives in the IoTDB system.
>
-> What we often call out-of-order data refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
+> The out-of-order data we often refer to refers to data whose **event time** is far behind the current system time (or the maximum **event time** that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their **arrival time** will increase with the order in which the data arrives at IoTDB.
-> 💎 **iotdb-extractor’s work can be split into two stages**
->
-> 1. Historical data extraction: all data with **arrival time** < **current system time** when creating pipe is called historical data
-> 2. Real-time data extraction: all **arrival time** >= data of **current system time** when creating pipe is called real-time data
+> 💎 **The work of iotdb-source can be split into two stages**
>
-> The historical data transmission phase and the real-time data transmission phase are executed serially. Only when the historical data transmission phase is completed, the real-time data transmission phase is executed. **
+> 1. Historical data extraction: All data with **arrival time** < **current system time** when creating the pipe is called historical data
+> 2. Realtime data extraction: All data with **arrival time** >= **current system time** when the pipe is created is called realtime data
>
-> Users can specify iotdb-extractor to:
->
-> * Historical data extraction (`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * Real-time data extraction (`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * Full data extraction (`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * Disable setting `extractor.history.enable` and `extractor.realtime.enable` to `false` at the same time
->
-> 📌 **extractor.realtime.mode: Data extraction mode**
+> The historical data transmission phase and the realtime data transmission phase are executed serially. Only when the historical data transmission phase is completed, the realtime data transmission phase is executed.**
+
+> 📌 **source.realtime.mode: Data extraction mode**
>
> * log: In this mode, the task only uses the operation log for data processing and sending
> * file: In this mode, the task only uses data files for data processing and sending.
> * hybrid: This mode takes into account the characteristics of low latency but low throughput when sending data one by one in the operation log, and the characteristics of high throughput but high latency when sending in batches of data files. It can automatically operate under different write loads. Switch the appropriate data extraction method. First, adopt the data extraction method based on operation logs to ensure low sending delay. When a data backlog occurs, it will automatically switch to the data extraction method based on data files to ensure high sending throughput. When the backlog is eliminated, it will automatically switch back to the data extraction method based on data files. The data extraction method of the operation log avoids the problem of difficulty in balancing data sending delay or throughput using a single data extraction algorithm.
-> 🍕 **extractor.forwarding-pipe-requests: Whether to allow forwarding data transmitted from another pipe**
+> 🍕 **source.forwarding-pipe-requests: Whether to allow forwarding data transmitted from another pipe**
>
> * If you want to use pipe to build data synchronization of A -> B -> C, then the pipe of B -> C needs to set this parameter to true, so that the data written by A to B through the pipe in A -> B can be forwarded correctly. to C
> * If you want to use pipe to build two-way data synchronization (dual-active) of A \<-> B, then the pipes of A -> B and B -> A need to set this parameter to false, otherwise the data will be endless. inter-cluster round-robin forwarding
@@ -574,22 +568,22 @@ Function: Extract historical or real-time data inside IoTDB into pipe.
#### do-nothing-processor
-Function: No processing is done on the events passed in by the extractor.
+Function: No processing is done on the events passed in by the source.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value range | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### Preset connector plugin
+### Preset sink plugin
-#### do-nothing-connector
+#### do-nothing-sink
Function: No processing is done on the events passed in by the processor.
-| key | value | value range | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value range | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## Stream processing task management
@@ -598,59 +592,57 @@ Function: No processing is done on the events passed in by the processor.
Use the `CREATE PIPE` statement to create a stream processing task. Taking the creation of a data synchronization stream processing task as an example, the sample SQL statement is as follows:
```sql
-CREATE PIPE -- PipeId is a name that uniquely identifies the stream processing task
-WITH EXTRACTOR (
- --Default IoTDB data extraction plugin
- 'extractor' = 'iotdb-extractor',
- --Path prefix, only data that can match the path prefix will be extracted for subsequent processing and sending
- 'extractor.pattern' = 'root.timecho',
- -- Whether to extract historical data
- 'extractor.history.enable' = 'true',
- -- Describes the time range of the extracted historical data, indicating the earliest time
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
- -- Describes the time range of the extracted historical data, indicating the latest time
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
- -- Whether to extract real-time data
- 'extractor.realtime.enable' = 'true',
- --Describe the extraction method of real-time data
- 'extractor.realtime.mode' = 'hybrid',
+CREATE PIPE -- PipeId is the name that uniquely identifies the sync task
+WITH SOURCE (
+ -- Default IoTDB Data Extraction Plugin
+ 'source' = 'iotdb-source',
+ -- Path prefix, only data that can match the path prefix will be extracted for subsequent processing and delivery
+ 'source.pattern' = 'root.timecho',
+ -- Whether to extract historical data
+ 'source.history.enable' = 'true',
+ -- Describes the time range of the historical data being extracted, indicating the earliest possible time
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
+ -- Describes the time range of the extracted historical data, indicating the latest time
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
+ -- Whether to extract realtime data
+ 'source.realtime.enable' = 'true',
)
WITH PROCESSOR (
- --The default data processing plugin, which does not do any processing
- 'processor' = 'do-nothing-processor',
+ -- Default data processing plugin, means no processing
+ 'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
- -- IoTDB data sending plugin, the target is IoTDB
- 'connector' = 'iotdb-thrift-connector',
- --The data service IP of one of the DataNode nodes in the target IoTDB
- 'connector.ip' = '127.0.0.1',
- -- The data service port of one of the DataNode nodes in the target IoTDB
- 'connector.port' = '6667',
+WITH SINK (
+ -- IoTDB data sending plugin with target IoTDB
+ 'sink' = 'iotdb-thrift-sink',
+ -- Data service for one of the DataNode nodes on the target IoTDB ip
+ 'sink.ip' = '127.0.0.1',
+ -- Data service port of one of the DataNode nodes of the target IoTDB
+ 'sink.port' = '6667',
)
```
**When creating a stream processing task, you need to configure the PipeId and the parameters of the three plugin parts:**
-| Configuration | Description | Required or not | Default implementation | Default implementation description | Default implementation description |
-| ------------- | ------------------------------------------------------------ | ------------------------------- | ---------------------- | ------------------------------------------------------------ | ---------------------------------- |
-| PipeId | A globally unique name that identifies a stream processing | Required | - | - | - |
-| extractor | Pipe Extractor plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-extractor | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
-| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
-| connector | Pipe Connector plugin, responsible for sending data | Required | - | - | Yes |
+| Configuration | Description | Required or not | Default implementation | Default implementation description | Default implementation description |
+|---------------|-----------------------------------------------------------------------------------------------------|---------------------------------|------------------------|---------------------------------------------------------------------------------------------------------------------------|------------------------------------|
+| PipeId | A globally unique name that identifies a stream processing | Required | - | - | - |
+| source | Pipe Source plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-source | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
+| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | Yes |
+| sink | Pipe Sink plugin, responsible for sending data | Required | - | - | Yes |
-In the example, the iotdb-extractor, do-nothing-processor and iotdb-thrift-connector plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, **please check the "System Preset Stream Processing plugin" section**.
+In the example, the iotdb-source, do-nothing-processor and iotdb-thrift-sink plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, **please check the "System Preset Stream Processing plugin" section**.
**A simplest example of the CREATE PIPE statement is as follows:**
```sql
CREATE PIPE -- PipeId is a name that uniquely identifies the stream processing task
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB data sending plugin, the target is IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
--The data service IP of one of the DataNode nodes in the target IoTDB
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- The data service port of one of the DataNode nodes in the target IoTDB
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -658,37 +650,37 @@ The semantics expressed are: synchronize all historical data in this database in
**Notice:**
-- EXTRACTOR and PROCESSOR are optional configurations. If you do not fill in the configuration parameters, the system will use the corresponding default implementation.
-- CONNECTOR is a required configuration and needs to be configured declaratively in the CREATE PIPE statement
-- CONNECTOR has self-reuse capability. For different stream processing tasks, if their CONNECTORs have the same KV attributes (the keys corresponding to the values of all attributes are the same), then the system will only create one CONNECTOR instance in the end to realize the duplication of connection resources. use.
+- SOURCE and PROCESSOR are optional configurations. If you do not fill in the configuration parameters, the system will use the corresponding default implementation.
+- SINK is a required configuration and needs to be configured declaratively in the CREATE PIPE statement
+- SINK has self-reuse capability. For different stream processing tasks, if their SINKs have the same KV attributes (the keys corresponding to the values of all attributes are the same), then the system will only create one SINK instance in the end to realize the duplication of connection resources.
- For example, there are the following declarations of two stream processing tasks, pipe1 and pipe2:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
)
```
-- Because their declarations of CONNECTOR are exactly the same (**even if the order of declaration of some attributes is different**), the framework will automatically reuse the CONNECTORs they declared, and ultimately the CONNECTORs of pipe1 and pipe2 will be the same instance. .
-- When the extractor is the default iotdb-extractor, and extractor.forwarding-pipe-requests is the default value true, please do not build an application scenario that includes data cycle synchronization (it will cause an infinite loop):
+- Because their declarations of SINK are exactly the same (**even if the order of declaration of some attributes is different**), the framework will automatically reuse the SINKs they declared, and ultimately the SINKs of pipe1 and pipe2 will be the same instance. .
+- When the source is the default iotdb-source, and source.forwarding-pipe-requests is the default value true, please do not build an application scenario that includes data cycle synchronization (it will cause an infinite loop):
- IoTDB A -> IoTDB B -> IoTDB A
- IoTDB A -> IoTDB A
### Start the stream processing task
-After the CREATE PIPE statement is successfully executed, the stream processing task-related instance will be created, but the running status of the entire stream processing task will be set to STOPPED, that is, the stream processing task will not process data immediately.
+After the CREATE PIPE statement is successfully executed, the stream processing task-related instance will be created, but the running status of the entire stream processing task will be set to STOPPED(V1.3.0), that is, the stream processing task will not process data immediately. In version 1.3.1 and later, the status of the task will be set to RUNNING after CREATE.
You can use the START PIPE statement to cause a stream processing task to start processing data:
@@ -725,13 +717,13 @@ SHOW PIPES
The query results are as follows:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime| State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
You can use `` to specify the status of a stream processing task you want to see:
@@ -740,22 +732,23 @@ You can use `` to specify the status of a stream processing task you wan
SHOW PIPE
```
-You can also use the where clause to determine whether the Pipe Connector used by a certain \ is reused.
+You can also use the where clause to determine whether the Pipe Sink used by a certain \ is reused.
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### Stream processing task running status migration
A stream processing pipe will pass through various states during its managed life cycle:
+- **RUNNING:** pipe is working properly
+ - When a pipe is successfully created, its initial state is RUNNING.(V1.3.1+)
- **STOPPED:** The pipe is stopped. When the pipeline is in this state, there are several possibilities:
- - When a pipe is successfully created, its initial state is paused.
+ - When a pipe is successfully created, its initial state is STOPPED.(V1.3.0)
- The user manually pauses a pipe that is in normal running status, and its status will passively change from RUNNING to STOPPED.
- When an unrecoverable error occurs during the running of a pipe, its status will automatically change from RUNNING to STOPPED
-- **RUNNING:** pipe is working properly
- **DROPPED:** The pipe task was permanently deleted
The following diagram shows all states and state transitions:
@@ -767,27 +760,28 @@ The following diagram shows all states and state transitions:
### Stream processing tasks
-| Permission name | Description |
-| ----------- | -------------------------- |
-| USE_PIPE | Register a stream processing task. The path is irrelevant. |
-| USE_PIPE | Start the stream processing task. The path is irrelevant. |
-| USE_PIPE | Stop the stream processing task. The path is irrelevant. |
-| USE_PIPE | Offload stream processing tasks. The path is irrelevant. |
-| USE_PIPE | Query stream processing tasks. The path is irrelevant. |
+| Permission name | Description |
+|-----------------|------------------------------------------------------------|
+| USE_PIPE | Register a stream processing task. The path is irrelevant. |
+| USE_PIPE | Start the stream processing task. The path is irrelevant. |
+| USE_PIPE | Stop the stream processing task. The path is irrelevant. |
+| USE_PIPE | Offload stream processing tasks. The path is irrelevant. |
+| USE_PIPE | Query stream processing tasks. The path is irrelevant. |
### Stream processing task plugin
-| Permission name | Description |
-| ------------------ | ---------------------------------- |
-| USE_PIPE | Register stream processing task plugin. The path is irrelevant. |
-| USE_PIPE | Uninstall the stream processing task plugin. The path is irrelevant. |
-| USE_PIPE | Query stream processing task plugin. The path is irrelevant. |
+| Permission name | Description |
+|-----------------|----------------------------------------------------------------------|
+| USE_PIPE | Register stream processing task plugin. The path is irrelevant. |
+| USE_PIPE | Uninstall the stream processing task plugin. The path is irrelevant. |
+| USE_PIPE | Query stream processing task plugin. The path is irrelevant. |
## Configuration parameters
In iotdb-common.properties:
+V1.3.0+:
```Properties
####################
### Pipe Configuration
@@ -808,4 +802,53 @@ In iotdb-common.properties:
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
+```
+
+V1.3.1+:
+```Properties
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
```
diff --git a/src/zh/UserGuide/Master/User-Manual/Data-Sync.md b/src/zh/UserGuide/Master/User-Manual/Data-Sync.md
new file mode 100644
index 00000000..b33a46ba
--- /dev/null
+++ b/src/zh/UserGuide/Master/User-Manual/Data-Sync.md
@@ -0,0 +1,506 @@
+
+
+# IoTDB 数据同步
+
+**IoTDB 数据同步功能可以将 IoTDB 的数据传输到另一个数据平台,我们将一个数据同步任务称为 Pipe。**
+
+**一个 Pipe 包含三个子任务(插件):**
+
+- 抽取(Source)
+- 处理(Process)
+- 发送(Sink)
+
+**Pipe 允许用户自定义三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。** 在一个 Pipe 中,上述的子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:Pipe Source 用于抽取数据,Pipe Processor 用于处理数据,Pipe Sink 用于发送数据,最终数据将被发至外部系统。
+
+**Pipe 任务的模型如下:**
+
+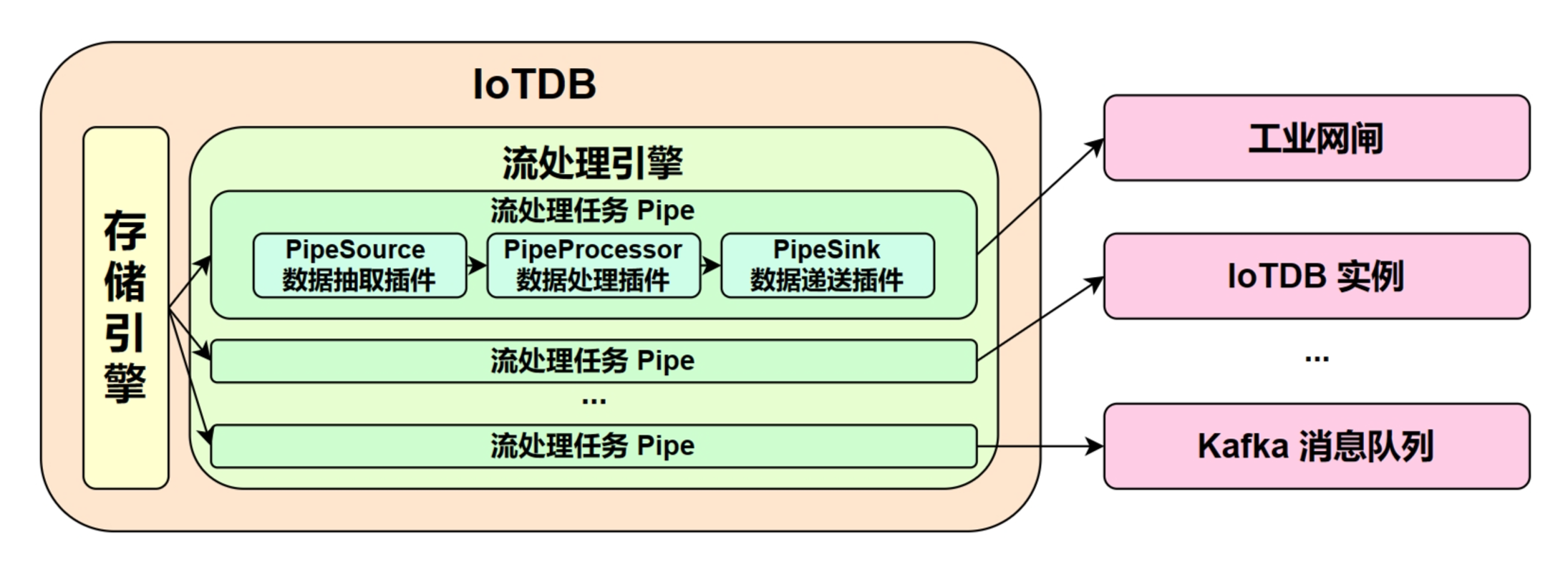
+
+描述一个数据同步任务,本质就是描述 Pipe Source、Pipe Processor 和 Pipe Sink 插件的属性。用户可以通过 SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
+
+利用数据同步功能,可以搭建完整的数据链路来满足端*边云同步、异地灾备、读写负载分库*等需求。
+
+## 快速开始
+
+**🎯 目标:实现 IoTDB A -> IoTDB B 的全量数据同步**
+
+- 启动两个 IoTDB,A(datanode -> 127.0.0.1:6667) B(datanode -> 127.0.0.1:6668)
+- 创建 A -> B 的 Pipe,在 A 上执行
+
+ ```sql
+ create pipe a2b
+ with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6668'
+ )
+ ```
+- 启动 A -> B 的 Pipe,在 A 上执行
+
+ ```sql
+ start pipe a2b
+ ```
+- 向 A 写入数据
+
+ ```sql
+ INSERT INTO root.db.d(time, m) values (1, 1)
+ ```
+- 在 B 检查由 A 同步过来的数据
+
+ ```sql
+ SELECT ** FROM root
+ ```
+
+> ❗️**注:目前的 IoTDB -> IoTDB 的数据同步实现并不支持 DDL 同步**
+>
+> 即:不支持 ttl,trigger,别名,模板,视图,创建/删除序列,创建/删除数据库等操作
+>
+> **IoTDB -> IoTDB 的数据同步要求目标端 IoTDB:**
+>
+> * 开启自动创建元数据:需要人工配置数据类型的编码和压缩与发送端保持一致
+> * 不开启自动创建元数据:手工创建与源端一致的元数据
+
+## 同步任务管理
+
+### 创建同步任务
+
+可以使用 `CREATE PIPE` 语句来创建一条数据同步任务,示例 SQL 语句如下所示:
+
+```sql
+CREATE PIPE -- PipeId 是能够唯一标定同步任务任务的名字
+WITH SOURCE (
+ -- 默认的 IoTDB 数据抽取插件
+ 'source' = 'iotdb-source',
+ -- 路径前缀,只有能够匹配该路径前缀的数据才会被抽取,用作后续的处理和发送
+ 'source.pattern' = 'root.timecho',
+ -- 描述被抽取的历史数据的时间范围,表示最早时间
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
+ -- 描述被抽取的历史数据的时间范围,表示最晚时间
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
+)
+WITH PROCESSOR (
+ -- 默认的数据处理插件,即不做任何处理
+ 'processor' = 'do-nothing-processor',
+)
+WITH SINK (
+ -- IoTDB 数据发送插件,目标端为 IoTDB
+ 'sink' = 'iotdb-thrift-sink',
+ -- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
+ 'sink.ip' = '127.0.0.1',
+ -- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
+ 'sink.port' = '6667',
+)
+```
+
+**创建同步任务时需要配置 PipeId 以及三个插件部分的参数:**
+
+
+| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
+|-----------|-------------------------------|---------------------------|----------------------|-----------------------------|--------------------------|
+| PipeId | 全局唯一标定一个同步任务的名称 | 必填 | - | - | - |
+| source | Pipe Source 插件,负责在数据库底层抽取同步数据 | 选填 | iotdb-source | 将数据库的全量历史数据和后续到达的实时数据接入同步任务 | 否 |
+| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
+| sink | Pipe Sink 插件,负责发送数据 | 必填 | - | - | 是 |
+
+示例中,使用了 iotdb-source、do-nothing-processor 和 iotdb-thrift-sink 插件构建数据同步任务。IoTDB 还内置了其他的数据同步插件,**请查看“系统预置数据同步插件”一节**。
+
+**一个最简的 CREATE PIPE 语句示例如下:**
+
+```sql
+CREATE PIPE -- PipeId 是能够唯一标定任务任务的名字
+WITH SINK (
+ -- IoTDB 数据发送插件,目标端为 IoTDB
+ 'sink' = 'iotdb-thrift-sink',
+ -- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
+ 'sink.ip' = '127.0.0.1',
+ -- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
+ 'sink.port' = '6667',
+)
+```
+
+其表达的语义是:将本数据库实例中的全量历史数据和后续到达的实时数据,同步到目标为 127.0.0.1:6667 的 IoTDB 实例上。
+
+**注意:**
+
+- SOURCE 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
+- SINK 为必填配置,需要在 CREATE PIPE 语句中声明式配置
+- SINK 具备自复用能力。对于不同的任务,如果他们的 SINK 具备完全相同的 KV 属性(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 SINK 实例**,以实现对连接资源的复用。
+
+ - 例如,有下面 pipe1, pipe2 两个任务的声明:
+
+ ```sql
+ CREATE PIPE pipe1
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
+ )
+
+ CREATE PIPE pipe2
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
+ )
+ ```
+
+ - 因为它们对 SINK 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 SINK 进行复用,最终 pipe1, pipe2 的 SINK 将会是同一个实例。
+- 请不要构建出包含数据循环同步的应用场景(会导致无限循环):
+
+ - IoTDB A -> IoTDB B -> IoTDB A
+ - IoTDB A -> IoTDB A
+
+### 启动任务
+
+CREATE PIPE 语句成功执行后,任务相关实例会被创建,但整个任务的运行状态会被置为 STOPPED(V1.3.0),即任务不会立刻处理数据。在 V1.3.1 及以后的版本,任务的状态在 CREATE 后将会被置为 RUNNING。
+
+当任务状态为 STOPPED 时,可以使用 START PIPE 语句使任务开始处理数据:
+
+```sql
+START PIPE
+```
+
+### 停止任务
+
+使用 STOP PIPE 语句使任务停止处理数据:
+
+```sql
+STOP PIPE
+```
+
+### 删除任务
+
+使用 DROP PIPE 语句使任务停止处理数据(当任务状态为 RUNNING 时),然后删除整个任务同步任务:
+
+```sql
+DROP PIPE
+```
+
+用户在删除任务前,不需要执行 STOP 操作。
+
+### 展示任务
+
+使用 SHOW PIPES 语句查看所有任务:
+
+```sql
+SHOW PIPES
+```
+
+查询结果如下:
+
+```sql
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime | State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+```
+
+可以使用 `` 指定想看的某个同步任务状态:
+
+```sql
+SHOW PIPE
+```
+
+您也可以通过 where 子句,判断某个 \ 使用的 Pipe Sink 被复用的情况。
+
+```sql
+SHOW PIPES
+WHERE SINK USED BY
+```
+
+### 任务运行状态迁移
+
+一个数据同步 pipe 在其生命周期中会经过多种状态:
+
+- **STOPPED:** pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
+ - 当一个 pipe 被成功创建之后,其初始状态为暂停状态(V1.3.0)
+ - 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
+ - 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
+- **RUNNING:** pipe 正在正常工作
+ - 当一个 pipe 被成功创建之后,其初始状态为工作状态(V1.3.1)
+- **DROPPED:** pipe 任务被永久删除
+
+下图表明了所有状态以及状态的迁移:
+
+
+
+## 系统预置数据同步插件
+📌 说明:在 1.3.1 及以上的版本中,除 source、processor、sink 本身外,各项参数不再需要额外增加 source、processor、sink 前缀。例如:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6668'
+)
+```
+可以写作
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'ip'='127.0.0.1',
+ 'port'='6668'
+)
+```
+### 查看预置插件
+
+用户可以按需查看系统中的插件。查看插件的语句如图所示。
+
+```sql
+SHOW PIPEPLUGINS
+```
+
+### 预置 Source 插件
+
+#### iotdb-source
+
+作用:抽取 IoTDB 内部的历史或实时数据进入 pipe。
+
+
+| key | value | value 取值范围 | required or optional with default |
+|---------------------------|--------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
+| source.history.start-time | 同步历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | 同步历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | 同步所有数据的开始 event time,包含 start-time, 配置时 source.historical.start-time 及 source.historical.end-time 将被忽略 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | 同步所有数据的结束 event time,包含 end-time, 配置时 source.historical.start-time 及 source.historical.end-time 将被忽略 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+
+> 🚫 **source.pattern 参数说明**
+>
+> * Pattern 需用反引号修饰不合法字符或者是不合法路径节点,例如如果希望筛选 root.\`a@b\` 或者 root.\`123\`,应设置 pattern 为 root.\`a@b\` 或者 root.\`123\`(具体参考 [单双引号和反引号的使用时机](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
+> * 在底层实现中,当检测到 pattern 为 root(默认值)或某个 Database 时,同步效率较高,其他任意格式都将降低性能
+> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'source.pattern'='root.aligned.1' 的 pipe 时:
+ >
+ > * root.aligned.1TS
+> * root.aligned.1TS.\`1\`
+> * root.aligned.100TS
+ >
+ > 的数据会被同步;
+ >
+ > * root.aligned.\`1\`
+> * root.aligned.\`123\`
+ >
+ > 的数据不会被同步。
+
+> ❗️** start-time,end-time 参数说明**
+>
+> * start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或 2011-12-03T10:15:30+01:00。V1.3.1 及以后的版本能够支持纯时间戳格式,如 1706704494000。
+
+> ✅ **一条数据从生产到落库 IoTDB,包含两个关键的时间概念**
+>
+> * **event time:** 数据实际生产时的时间(或者数据生产系统给数据赋予的生成时间,是数据点中的时间项),也称为事件时间。
+> * **arrival time:** 数据到达 IoTDB 系统内的时间。
+>
+> 我们常说的乱序数据,指的是数据到达时,其 **event time** 远落后于当前系统时间(或者已经落库的最大 **event time**)的数据。另一方面,不论是乱序数据还是顺序数据,只要它们是新到达系统的,那它们的 **arrival time** 都是会随着数据到达 IoTDB 的顺序递增的。
+
+> 💎 **iotdb-source 的工作可以拆分成两个阶段**
+>
+> 1. 历史数据抽取:所有 **arrival time** < 创建 pipe 时**当前系统时间**的数据称为历史数据
+> 2. 实时数据抽取:所有 **arrival time** >= 创建 pipe 时**当前系统时间**的数据称为实时数据
+>
+> 历史数据传输阶段和实时数据传输阶段,**两阶段串行执行,只有当历史数据传输阶段完成后,才执行实时数据传输阶段。**
+
+### 预置 processor 插件
+
+#### do-nothing-processor
+
+作用:不对 source 传入的事件做任何的处理。
+
+
+| key | value | value 取值范围 | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
+| processor | do-nothing-processor | String: do-nothing-processor | required |
+
+### 预置 sink 插件
+
+#### iotdb-thrift-sync-sink
+
+作用:主要用于 IoTDB(v1.2.0+)与 IoTDB(v1.2.0+)之间的数据传输。
+使用 Thrift RPC 框架传输数据,单线程 blocking IO 模型。
+保证接收端 apply 数据的顺序与发送端接受写入请求的顺序一致。
+
+限制:源端 IoTDB 与 目标端 IoTDB 版本都需要在 v1.2.0+。
+
+
+| key | value | value 取值范围 | required or optional with default |
+|----------------|----------------------------------------|---------------------------------------------------------------------------|--------------------------------------|
+| sink | iotdb-thrift-sync-sink | String: iotdb-thrift-sync-sink | required |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | optional: 与 sink.node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | optional: 与 sink.node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: 与 sink.ip:sink.port 任选其一填写 |
+
+> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
+
+#### iotdb-thrift-async-sink(别名:iotdb-thrift-sink)
+
+作用:主要用于 IoTDB(v1.2.0+)与 IoTDB(v1.2.0+)之间的数据传输。
+使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景。
+不保证接收端 apply 数据的顺序与发送端接受写入请求的顺序一致,但是保证数据发送的完整性(at-least-once)。
+
+限制:源端 IoTDB 与 目标端 IoTDB 版本都需要在 v1.2.0+。
+
+
+| key | value | value 取值范围 | required or optional with default |
+|----------------|---------------------------------------------|---------------------------------------------------------------------------|-----------------------------------|
+| sink | iotdb-thrift-async-sink 或 iotdb-thrift-sink | String: iotdb-thrift-async-sink 或 iotdb-thrift-sink | required |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | optional: 与 node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | optional: 与 node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: 与 ip:port 任选其一填写 |
+
+> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
+
+#### iotdb-legacy-pipe-sink
+
+作用:主要用于 IoTDB(v1.2.0+)向 v1.2.0 前的 IoTDB 传输数据,使用 v1.2.0 版本前的数据同步(Sync)协议。
+使用 Thrift RPC 框架传输数据。单线程 sync blocking IO 模型,传输性能较弱。
+
+限制:源端 IoTDB 版本需要在 v1.2.0+,目标端 IoTDB 版本可以是 v1.2.0+、v1.1.x(更低版本的 IoTDB 理论上也支持,但是未经测试)。
+
+注意:理论上 v1.2.0+ IoTDB 可作为 v1.2.0 版本前的任意版本的数据同步(Sync)接收端。
+
+
+| key | value | value 取值范围 | required or optional with default |
+|---------------|----------------------------------------------|--------------------------------|-----------------------------------|
+| sink | iotdb-legacy-pipe-sink | String: iotdb-legacy-pipe-sink | required |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | required |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | required |
+| sink.user | 目标端 IoTDB 的用户名,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
+| sink.password | 目标端 IoTDB 的密码,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
+| sink.version | 目标端 IoTDB 的版本,用于伪装自身实际版本,绕过目标端的版本一致性检查 | String | optional: 1.1 |
+
+> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
+
+#### do-nothing-sink
+
+作用:不对 processor 传入的事件做任何的处理。
+
+
+| key | value | value 取值范围 | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
+
+## 权限管理
+
+| 权限名称 | 描述 |
+|----------|------------|
+| USE_PIPE | 注册任务。路径无关。 |
+| USE_PIPE | 开启任务。路径无关。 |
+| USE_PIPE | 停止任务。路径无关。 |
+| USE_PIPE | 卸载任务。路径无关。 |
+| USE_PIPE | 查询任务。路径无关。 |
+
+## 配置参数
+
+在 iotdb-common.properties 中:
+
+V1.3.0+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+```
+
+V1.3.1+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+```
+
+## 功能特性
+
+### 最少一次语义保证 **at-least-once**
+
+数据同步功能向外部系统传输数据时,提供 at-least-once 的传输语义。在大部分场景下,同步功能可提供 exactly-once 保证,即所有数据被恰好同步一次。
+
+但是在以下场景中,可能存在部分数据被同步多次 **(断点续传)** 的情况:
+
+- 临时的网络故障:某次数据传输请求失败后,系统会进行重试发送,直至到达最大尝试次数
+- Pipe 插件逻辑实现异常:插件运行中抛出错误,系统会进行重试发送,直至到达最大尝试次数
+- 数据节点宕机、重启等导致的数据分区切主:分区变更完成后,受影响的数据会被重新传输
+- 集群不可用:集群可用后,受影响的数据会重新传输
+
+### 源端:数据写入与 Pipe 处理、发送数据异步解耦
+
+数据同步功能中,数据传输采用的是异步复制模式。
+
+数据同步与写入操作完全脱钩,不存在对写入关键路径的影响。该机制允许框架在保证持续数据同步的前提下,保持时序数据库的写入速度。
+
+### 源端:高可用集群部署时,Pipe 服务高可用
+
+当发送端 IoTDB 为高可用集群部署模式时,数据同步服务也将是高可用的。 数据同步框架将监控每个数据节点的数据同步进度,并定期做轻量级的分布式一致性快照以保存同步状态。
+
+- 当发送端集群某数据节点宕机时,数据同步框架可以利用一致性快照以及保存在副本上的数据快速恢复同步,以此实现数据同步服务的高可用。
+- 当发送端集群整体宕机并重启时,数据同步框架也能使用快照恢复同步服务。
diff --git a/src/zh/UserGuide/Master/User-Manual/Data-Sync_timecho.md b/src/zh/UserGuide/Master/User-Manual/Data-Sync_timecho.md
index b1344cab..81a62fbd 100644
--- a/src/zh/UserGuide/Master/User-Manual/Data-Sync_timecho.md
+++ b/src/zh/UserGuide/Master/User-Manual/Data-Sync_timecho.md
@@ -20,7 +20,7 @@
-->
# 数据同步
-数据同步是工业物联网的典型需求,通过数据同步机制,可实现IoTDB之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
+数据同步是工业物联网的典型需求,通过数据同步机制,可实现 IoTDB 之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
## 功能介绍
@@ -28,8 +28,8 @@
一个数据同步任务包含2个阶段:
-- 抽取(Source)阶段:该部分用于从源 IoTDB 抽取数据,在SQL语句中的 source 部分定义
-- 发送(Sink)阶段:该部分用于向目标 IoTDB 发送数据,在SQL语句中的 sink 部分定义
+- 抽取(Source)阶段:该部分用于从源 IoTDB 抽取数据,在 SQL 语句中的 source 部分定义
+- 发送(Sink)阶段:该部分用于向目标 IoTDB 发送数据,在 SQL 语句中的 sink 部分定义
@@ -64,8 +64,9 @@ WITH SINK (
一个数据同步任务在生命周期中会经过多种状态:
- RUNNING: 运行状态。
+ - 说明1:任务的初始状态为运行状态(V1.3.1 及以上)
- STOPPED: 停止状态。
- - 说明1:任务的初始状态为停止状态,需要使用SQL语句启动任务
+ - 说明1:任务的初始状态为停止状态(V1.3.0),需要使用SQL语句启动任务
- 说明2:用户也可以使用SQL语句手动将一个处于运行状态的任务停止,此时状态会从 RUNNING 变为 STOPPED
- 说明3:当一个任务出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
- DROPPED:删除状态。
@@ -112,22 +113,23 @@ SHOW PIPE
### 插件
-为了使得整体架构更加灵活以匹配不同的同步场景需求,在上述同步任务框架中IoTDB支持进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义 sink 插件,并加载至IoTDB系统进行使用。
+为了使得整体架构更加灵活以匹配不同的同步场景需求,在上述同步任务框架中 IoTDB 支持进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义 Sink 插件,并加载至 IoTDB 系统进行使用。
-| 模块 | 插件 | 预置插件 | 自定义插件 |
-| --- | --- | --- | --- |
-| 抽取(Source) | Source 插件 | iotdb-source | 不支持 |
-| 发送(Sink) | Sink 插件 | iotdb-thrift-sink、iotdb-air-gap-sink| 支持 |
+| 模块 | 插件 | 预置插件 | 自定义插件 |
+|----------------|--------------|--------------------------------------|-------|
+| 抽取(Source) | Source 插件 | iotdb-source | 不支持 |
+| 发送(Sink) | Sink 插件 | iotdb-thrift-sink、iotdb-air-gap-sink | 支持 |
#### 预置插件
预置插件如下:
-| 插件名称 | 类型 | 介绍 | 适用版本 |
-| ---------------------------- | ---- | ------------------------------------------------------------ | --------- |
-| iotdb-source | source 插件 | 默认的 source 插件,用于抽取 IoTDB 历史或实时数据 | 1.2.x |
-| iotdb-thrift-sink | sink 插件 | 用于 IoTDB(v1.2.0及以上)与 IoTDB(v1.2.0及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景 | 1.2.x |
-| iotdb-air-gap-sink | sink 插件 | 用于 IoTDB(v1.2.2+)向 IoTDB(v1.2.2+)跨单向数据网闸的数据同步。支持的网闸型号包括南瑞 Syskeeper 2000 等 | 1.2.1以上 |
+| 插件名称 | 类型 | 介绍 | 适用版本 |
+|-----------------------|--------------|-----------------------------------------------------------------------------------------------------------------------|-----------|
+| iotdb-source | source 插件 | 默认的 source 插件,用于抽取 IoTDB 历史或实时数据 | 1.2.x |
+| iotdb-thrift-sink | sink 插件 | 用于 IoTDB(v1.2.0及以上)与 IoTDB(v1.2.0及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景 | 1.2.x |
+| iotdb-air-gap-sink | sink 插件 | 用于 IoTDB(v1.2.2+)向 IoTDB(v1.2.2+)跨单向数据网闸的数据同步。支持的网闸型号包括南瑞 Syskeeper 2000 等 | 1.2.2 及以上 |
+| iotdb-thrift-ssl-sink | sink plugin | 用于 IoTDB(v1.3.1及以上)与 IoTDB(v1.2.0及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,单线程 sync blocking IO 模型,适用于安全需求较高的场景 | 1.3.1 及以上 |
每个插件的详细参数可参考本文[参数说明](#sink-参数)章节。
@@ -143,16 +145,16 @@ SHOW PIPEPLUGINS
```Go
IoTDB> show pipeplugins
-+--------------------+----------+---------------------------------------------------------------------------+---------+
-| PluginName|PluginType| ClassName|PluginJar|
-+--------------------+----------+---------------------------------------------------------------------------+---------+
-|DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.DoNothingProcessor| |
-| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.DoNothingSink| |
-| IOTDB-AIR-GAP-SINK| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBAirGapSink| |
-| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.source.IoTDBSOURCE| |
-| IOTDB-THRIFT-SINK| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBThriftSinkr| |
-| OPC-UA-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.OpcUaSink| |
-+--------------------+----------+---------------------------------------------------------------------------+---------+
++------------------------------+----------+---------------------------------------------------------------------------------+---------+
+| PluginName|PluginType| ClassName|PluginJar|
++------------------------------+--------------------------------------------------------------------------------------------+---------+
+| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.DoNothingProcessor| |
+| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.DoNothingSink| |
+| IOTDB-AIR-GAP-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBAirGapSink| |
+| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.source.IoTDBSOURCE| |
+| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBThriftSink| |
+|IOTDB-THRIFT-SSL-SINK(V1.3.1+)| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.iotdb.thrift.IoTDBThriftSslSink| |
++------------------------------+----------+---------------------------------------------------------------------------------+---------+
```
@@ -160,7 +162,7 @@ IoTDB> show pipeplugins
### 全量数据同步
-本例子用来演示将一个 IoTDB 的所有数据同步至另一个IoTDB,数据链路如下图所示:
+本例子用来演示将一个 IoTDB 的所有数据同步至另一个 IoTDB,数据链路如下图所示:
@@ -178,26 +180,26 @@ with sink (
### 历史数据同步
-本例子用来演示同步某个历史时间范围(2023年8月23日8点到2023年10月23日8点)的数据至另一个IoTDB,数据链路如下图所示:
+本例子用来演示同步某个历史时间范围( 2023 年 8 月 23 日 8 点到 2023 年 10 月 23 日 8 点)的数据至另一个 IoTDB,数据链路如下图所示:
-在这个例子中,我们可以创建一个名为 A2B 的同步任务。首先我们需要在 source 中定义传输数据的范围,由于传输的是历史数据(历史数据是指同步任务创建之前存在的数据),所以需要将source.realtime.enable参数配置为false;同时需要配置数据的起止时间start-time和end-time以及传输的模式mode,此处推荐mode设置为 hybrid 模式(hybrid模式为混合传输,在无数据积压时采用实时传输方式,有数据积压时采用批量传输方式,并根据系统内部情况自动切换)。
+在这个例子中,我们可以创建一个名为 A2B 的同步任务。首先我们需要在 source 中定义传输数据的范围,由于传输的是历史数据(历史数据是指同步任务创建之前存在的数据),所以需要将 source.realtime.enable 参数配置为 false;同时需要配置数据的起止时间 start-time 和 end-time 以及传输的模式 mode,此处推荐 mode 设置为 hybrid 模式(hybrid 模式为混合传输,在无数据积压时采用实时传输方式,有数据积压时采用批量传输方式,并根据系统内部情况自动切换)。
详细语句如下:
```SQL
create pipe A2B
WITH SOURCE (
-'source'= 'iotdb-source',
-'source.realtime.enable' = 'false',
-'source.realtime.mode'='hybrid',
-'source.history.start-time' = '2023.08.23T08:00:00+00:00',
-'source.history.end-time' = '2023.10.23T08:00:00+00:00')
+ 'source'= 'iotdb-source',
+ 'source.start-time' = '2023.08.23T08:00:00+00:00',
+ 'source.end-time' = '2023.10.23T08:00:00+00:00'
+)
with SINK (
-'sink'='iotdb-thrift-async-sink',
-'sink.node-urls'='xxxx:6668',
-'sink.batch.enable'='false')
+ 'sink'='iotdb-thrift-async-sink',
+ 'sink.node-urls'='xxxx:6668',
+ 'sink.batch.enable'='false'
+)
```
@@ -205,19 +207,19 @@ with SINK (
本例子用来演示两个 IoTDB 之间互为双活的场景,数据链路如下图所示:
-
+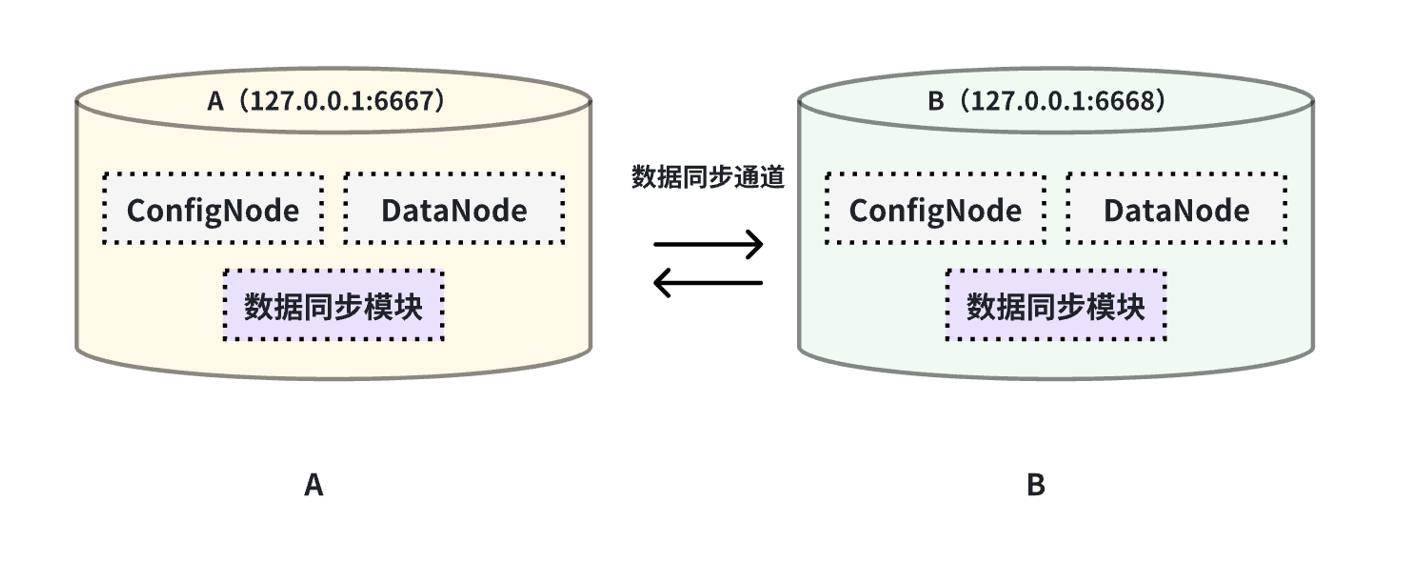
+
+在这个例子中,为了避免数据无限循环,需要将 A 和 B 上的参数`source.forwarding-pipe-requests` 均设置为 `false`,表示不转发从另一pipe传输而来的数据。
-在这个例子中,为了避免数据无限循环,需要将A和B上的参数`source.forwarding-pipe-requests` 均设置为 `false`,表示不转发从另一pipe传输而来的数据。同时将`'source.history.enable'` 设置为 `false`,表示不传输历史数据,即不同步创建该任务前的数据。
-
详细语句如下:
-在 A IoTDB 上执行下列语句:
+在 A IoTDB 上执行下列语句:
```Go
create pipe AB
with source (
- 'source.history.enable' = 'false',
- 'source.forwarding-pipe-requests' = 'false',
+ 'source.forwarding-pipe-requests' = 'false'
+)
with sink (
'sink'='iotdb-thrift-sink',
'sink.ip'='127.0.0.1',
@@ -230,8 +232,8 @@ with sink (
```Go
create pipe BA
with source (
- 'source.history.enable' = 'false',
- 'source.forwarding-pipe-requests' = 'false',
+ 'source.forwarding-pipe-requests' = 'false'
+)
with sink (
'sink'='iotdb-thrift-sink',
'sink.ip'='127.0.0.1',
@@ -243,13 +245,13 @@ with sink (
### 级联数据传输
-本例子用来演示多个 IoTDB 之间级联传输数据的场景,数据由A集群同步至B集群,再同步至C集群,数据链路如下图所示:
+本例子用来演示多个 IoTDB 之间级联传输数据的场景,数据由 A 集群同步至 B 集群,再同步至 C 集群,数据链路如下图所示:
-
+
-在这个例子中,为了将A集群的数据同步至C,在BC之间的pipe需要将 `source.forwarding-pipe-requests` 配置为`true`,详细语句如下:
+在这个例子中,为了将 A 集群的数据同步至 C,在 BC 之间的 pipe 需要将 `source.forwarding-pipe-requests` 配置为`true`,详细语句如下:
-在A IoTDB上执行下列语句,将A中数据同步至B:
+在 A IoTDB 上执行下列语句,将 A 中数据同步至 B:
```Go
create pipe AB
@@ -260,12 +262,13 @@ with sink (
)
```
-在B IoTDB上执行下列语句,将B中数据同步至C:
+在 B IoTDB 上执行下列语句,将 B 中数据同步至 C:
```Go
create pipe BC
with source (
- 'source.forwarding-pipe-requests' = 'true',
+ 'source.forwarding-pipe-requests' = 'true'
+)
with sink (
'sink'='iotdb-thrift-sink',
'sink.ip'='127.0.0.1',
@@ -275,13 +278,13 @@ with sink (
### 跨网闸数据传输
-本例子用来演示将一个 IoTDB 的数据,经过单向网闸,同步至另一个IoTDB的场景,数据链路如下图所示:
+本例子用来演示将一个 IoTDB 的数据,经过单向网闸,同步至另一个 IoTDB 的场景,数据链路如下图所示:
-在这个例子中,需要使用 sink 任务中的iotdb-air-gap-sink 插件(目前支持部分型号网闸,具体型号请联系天谋科技工作人员确认),配置网闸后,在 A IoTDB 上执行下列语句,其中ip和port填写网闸信息,详细语句如下:
+在这个例子中,需要使用 sink 任务中的 iotdb-air-gap-sink 插件(目前支持部分型号网闸,具体型号请联系天谋科技工作人员确认),配置网闸后,在 A IoTDB 上执行下列语句,其中 ip 和 port 填写网闸配置的虚拟 ip 和相关 port,详细语句如下:
-```Go
+```Sql
create pipe A2B
with sink (
'sink'='iotdb-air-gap-sink',
@@ -290,11 +293,30 @@ with sink (
)
```
+### SSL协议数据传输
+
+本例子演示了使用 SSL 协议配置 IoTDB 单向数据同步的场景,数据链路如下图所示:
+
+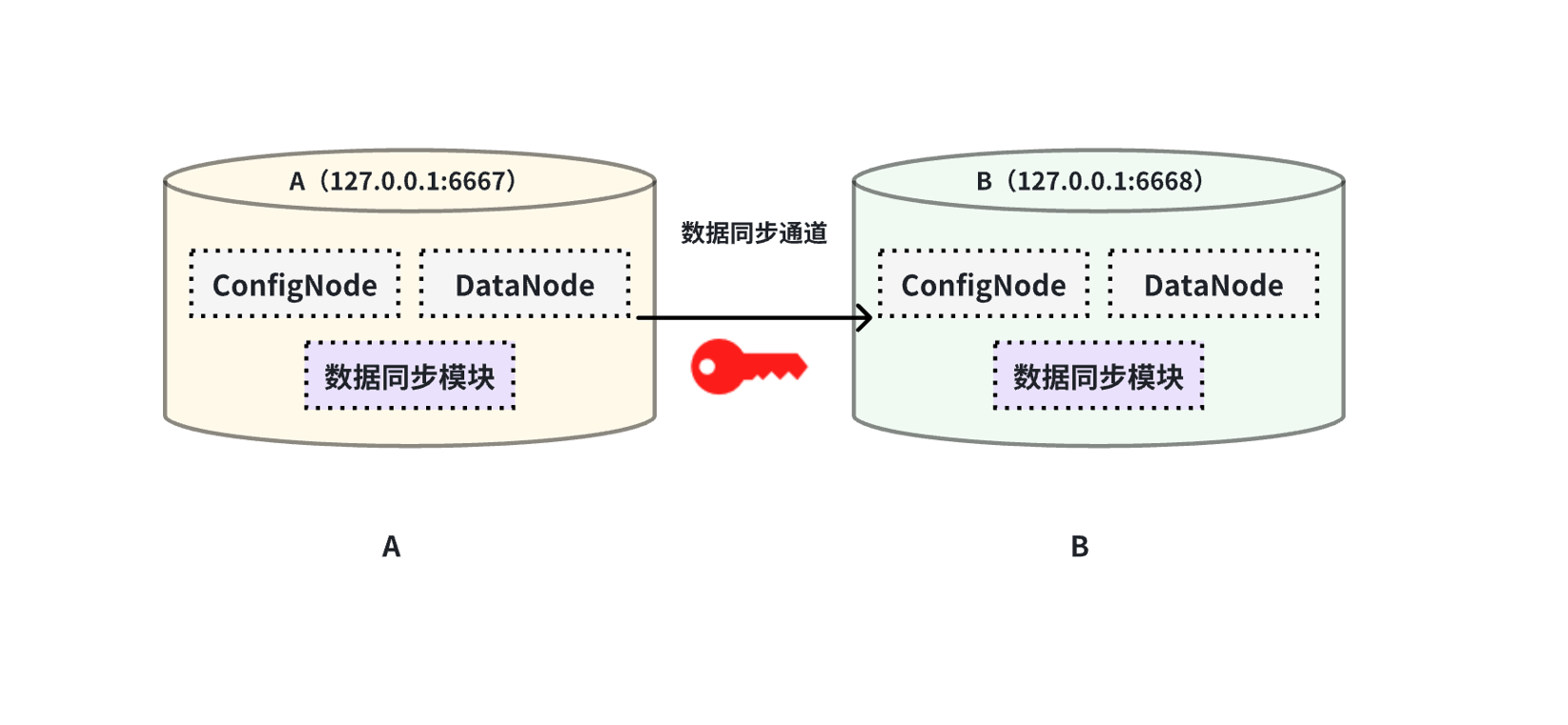
+
+在该场景下,需要使用 IoTDB 的 iotdb-thrift-ssl-sink 插件。我们可以创建一个名为 A2B 的同步任务,并配置自身证书的密码和地址,详细语句如下:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-ssl-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6669',
+ 'ssl.trust-store-path'='pki/trusted'
+ 'ssl.trust-store-pwd'='root'
+)
+```
+
## 参考:注意事项
可通过修改 IoTDB 配置文件(iotdb-common.properties)以调整数据同步的参数,如同步数据存储目录等。完整配置如下:
-```Go
+V1.3.0+:
+```Properties
####################
### Pipe Configuration
####################
@@ -332,30 +354,81 @@ with sink (
# pipe_air_gap_receiver_port=9780
```
+V1.3.1+:
+```Properties
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
+```
+
## 参考:参数说明
+📌 说明:在 1.3.1 及以上的版本中,除 source、processor、sink 本身外,各项参数不再需要额外增加 source、processor、sink 前缀。例如:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'sink.ip'='10.53.53.53',
+ 'sink.port'='9780'
+)
+```
+可以写作
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'ip'='10.53.53.53',
+ 'port'='9780'
+)
+```
### source 参数
-| key | value | value 取值范围 | 是否必填 |默认取值|
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | -------- |------|
-| source | iotdb-source | String: iotdb-source | 必填 | - |
-| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | 选填 | root |
-| source.history.enable | 是否同步历史数据 | Boolean: true, false | 选填 | true |
-| source.history.start-time | 同步历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MIN_VALUE |
-| source.history.end-time | 同步历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MAX_VALUE |
-| source.realtime.enable | 是否同步实时数据 | Boolean: true, false | 选填 | true |
-| source.realtime.mode | 实时数据的抽取模式 | String: hybrid, stream, batch | 选填 | hybrid |
-| source.forwarding-pipe-requests | 是否转发由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | 选填 | true |
+| key | value | value 取值范围 | 是否必填 | 默认取值 |
+|---------------------------------|------------------------------------|----------------------------------------|------|----------------|
+| source | iotdb-source | String: iotdb-source | 必填 | - |
+| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | 选填 | root |
+| source.history.start-time | 同步历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MIN_VALUE |
+| source.history.end-time | 同步历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MAX_VALUE |
+| start-time(V1.3.1+) | 同步所有数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MIN_VALUE |
+| end-time(V1.3.1+) | 同步所有数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MAX_VALUE |
+| source.realtime.mode | 实时数据的抽取模式 | String: hybrid, stream, batch | 选填 | hybrid |
+| source.forwarding-pipe-requests | 是否转发由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | 选填 | true |
> 💎 **说明:历史数据与实时数据的差异**
->
+>
> * **历史数据**:所有 arrival time < 创建 pipe 时当前系统时间的数据称为历史数据
> * **实时数据**:所有 arrival time >= 创建 pipe 时当前系统时间的数据称为实时数据
> * **全量数据**: 全量数据 = 历史数据 + 实时数据
> 💎 **说明:数据抽取模式hybrid, stream和batch的差异**
->
+>
> - **hybrid(推荐)**:该模式下,任务将优先对数据进行实时处理、发送,当数据产生积压时自动切换至批量发送模式,其特点是平衡了数据同步的时效性和吞吐量
> - **stream**:该模式下,任务将对数据进行实时处理、发送,其特点是高时效、低吞吐
> - **batch**:该模式下,任务将对数据进行批量(按底层数据文件)处理、发送,其特点是低时效、高吞吐
@@ -365,24 +438,36 @@ with sink (
#### iotdb-thrift-sink
-| key | value | value 取值范围 | 是否必填 | 默认取值 |
-| --------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------------------------------------- |
-| sink | iotdb-thrift-sink 或 iotdb-thrift-sync-sink | String: iotdb-thrift-sink 或 iotdb-thrift-sync-sink | 必填 | |
-| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip(请注意同步任务不支持向自身服务进行转发) | String | 选填 | 与 sink.node-urls 任选其一填写 |
-| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port(请注意同步任务不支持向自身服务进行转发) | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
-| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
-| sink.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
-| sink.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
-| sink.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填
-
-
+| key | value | value 取值范围 | 是否必填 | 默认取值 |
+|------------------------------|-------------------------------------------------------------|---------------------------------------------------------------------------|------|----------------------------|
+| sink | iotdb-thrift-sink 或 iotdb-thrift-async-sink | String: iotdb-thrift-sink 或 iotdb-thrift-async-sink | 必填 | |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip(请注意同步任务不支持向自身服务进行转发) | String | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port(请注意同步任务不支持向自身服务进行转发) | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
+| sink.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
+| sink.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
+| sink.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | |
#### iotdb-air-gap-sink
-| key | value | value 取值范围 | 是否必填 | 默认取值 |
-| -------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------------------------------------- |
-| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | 必填 | |
-| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | 选填 | 与 sink.node-urls 任选其一填写 |
-| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
-| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
-| sink.air-gap.handshake-timeout-ms | 发送端与接收端在首次尝试建立连接时握手请求的超时时长,单位:毫秒 | Integer | 选填 | 5000 |
\ No newline at end of file
+| key | value | value 取值范围 | 是否必填 | 默认取值 |
+|-----------------------------------|----------------------------------------|---------------------------------------------------------------------------|------|----------------------------|
+| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | 必填 | |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
+| sink.air-gap.handshake-timeout-ms | 发送端与接收端在首次尝试建立连接时握手请求的超时时长,单位:毫秒 | Integer | 选填 | 5000 |
+
+#### iotdb-thrift-ssl-sink(V1.3.1+)
+
+| key | value | value range | required or not | default value |
+|------------------------------|-------------------------------------------------------------|----------------------------------------------------------------------------------|-----------------|----------------------------------|
+| sink | iotdb-thrift-ssl-sink | String: iotdb-thrift-ssl-sink | 必填 | |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip(请注意同步任务不支持向自身服务进行转发) | String | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port(请注意同步任务不支持向自身服务进行转发) | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
+| sink.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
+| sink.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
+| sink.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | |
+| ssl.trust-store-path | 连接目标端 DataNode 所需的 trust store 证书路径 | String.Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
+| ssl.trust-store-pwd | 连接目标端 DataNode 所需的 trust store 证书密码 | Integer | Optional | 5000 |
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/User-Manual/IoTDB-Data-Pipe_timecho.md b/src/zh/UserGuide/Master/User-Manual/IoTDB-Data-Pipe_timecho.md
index 8aa2568d..157f91fd 100644
--- a/src/zh/UserGuide/Master/User-Manual/IoTDB-Data-Pipe_timecho.md
+++ b/src/zh/UserGuide/Master/User-Manual/IoTDB-Data-Pipe_timecho.md
@@ -828,21 +828,21 @@ SHOW PIPEPLUGINS
## Pipe 任务
-| 权限名称 | 描述 |
-| ----------- | ---------------------- |
-| CREATE_PIPE | 注册流水线。路径无关。 |
-| START_PIPE | 开启流水线。路径无关。 |
-| STOP_PIPE | 停止流水线。路径无关。 |
-| DROP_PIPE | 卸载流水线。路径无关。 |
-| SHOW_PIPES | 查询流水线。路径无关。 |
+| 权限名称 | 描述 |
+|----------|-------------|
+| USE_PIPE | 注册流水线。路径无关。 |
+| USE_PIPE | 开启流水线。路径无关。 |
+| USE_PIPE | 停止流水线。路径无关。 |
+| USE_PIPE | 卸载流水线。路径无关。 |
+| USE_PIPE | 查询流水线。路径无关。 |
## Pipe 插件
-| 权限名称 | 描述 |
-| ----------------- | -------------------------- |
-| CREATE_PIPEPLUGIN | 注册流水线插件。路径无关。 |
-| DROP_PIPEPLUGIN | 开启流水线插件。路径无关。 |
-| SHOW_PIPEPLUGINS | 查询流水线插件。路径无关。 |
+| 权限名称 | 描述 |
+|----------|---------------|
+| USE_PIPE | 注册流水线插件。路径无关。 |
+| USE_PIPE | 开启流水线插件。路径无关。 |
+| USE_PIPE | 查询流水线插件。路径无关。 |
# 功能特性
diff --git a/src/zh/UserGuide/Master/User-Manual/Streaming.md b/src/zh/UserGuide/Master/User-Manual/Streaming.md
index bd23ab71..a6bc959a 100644
--- a/src/zh/UserGuide/Master/User-Manual/Streaming.md
+++ b/src/zh/UserGuide/Master/User-Manual/Streaming.md
@@ -25,19 +25,19 @@ IoTDB 流处理框架允许用户实现自定义的流处理逻辑,可以实
我们将一个数据流处理任务称为 Pipe。一个流处理任务(Pipe)包含三个子任务:
-- 抽取(Extract)
+- 抽取(Source)
- 处理(Process)
-- 发送(Connect)
+- 发送(Sink)
流处理框架允许用户使用 Java 语言自定义编写三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。
在一个 Pipe 中,上述的三个子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:
-Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Connector 用于发送数据,最终数据将被发至外部系统。
+Pipe Source 用于抽取数据,Pipe Processor 用于处理数据,Pipe Sink 用于发送数据,最终数据将被发至外部系统。
**Pipe 任务的模型如下:**
-
+
-描述一个数据流处理任务,本质就是描述 Pipe Extractor、Pipe Processor 和 Pipe Connector 插件的属性。
+描述一个数据流处理任务,本质就是描述 Pipe Source、Pipe Processor 和 Pipe Sink 插件的属性。
用户可以通过 SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
利用流处理框架,可以搭建完整的数据链路来满足端*边云同步、异地灾备、读写负载分库*等需求。
@@ -50,10 +50,10 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
```xml
- org.apache.iotdb
- pipe-api
- 1.2.1
- provided
+ org.apache.iotdb
+ pipe-api
+ 1.3.1
+ provided
```
@@ -61,7 +61,7 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
流处理插件的用户编程接口设计,参考了事件驱动编程模型的通用设计理念。事件(Event)是用户编程接口中的数据抽象,而编程接口与具体的执行方式解耦,只需要专注于描述事件(数据)到达系统后,系统期望的处理方式即可。
-在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeExtractor 插件,PipeProcessor 插件和 PipeConnector 插件,并依次在三个插件中触发用户逻辑的执行。
+在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeSource 插件,PipeProcessor 插件和 PipeSink 插件,并依次在三个插件中触发用户逻辑的执行。
为了兼顾端侧低负载场景下的流处理低延迟和端侧高负载场景下的流处理高吞吐,流处理引擎会动态地在操作日志和数据文件中选择处理对象,因此,流处理的用户编程接口要求用户提供下列两类事件的处理逻辑:操作日志写入事件 TabletInsertionEvent 和数据文件写入事件 TsFileInsertionEvent。
@@ -133,39 +133,39 @@ public interface TsFileInsertionEvent extends Event {
#### 数据抽取插件接口
-数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeExtractor)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,
+数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeSource)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,
捕获各种数据写入事件。
```java
/**
- * PipeExtractor
+ * PipeSource
*
- * PipeExtractor is responsible for capturing events from sources.
+ *
PipeSource is responsible for capturing events from sources.
*
- *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
Various data sources can be supported by implementing different PipeSource classes.
*
- *
The lifecycle of a PipeExtractor is as follows:
+ *
The lifecycle of a PipeSource is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
- * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
+ *
- When a collaboration task is created, the KV pairs of `WITH SOURCE` clause in SQL are
+ * parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
+ * be called to validate the parameters.
*
- Before the collaboration task starts, the method {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeExtractor.
- *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
- *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
- * be called to capture events from sources and then the events will be passed to the
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
+ * config the runtime behavior of the PipeSource.
+ *
- Then the method {@link PipeSource#start()} will be called to start the PipeSource.
+ *
- While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
+ * called to capture events from sources and then the events will be passed to the
* PipeProcessor.
- *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ *
- The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
*
*/
-public interface PipeExtractor extends PipePlugin {
+public interface PipeSource extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
@@ -173,39 +173,39 @@ public interface PipeExtractor extends PipePlugin {
void validate(PipeParameterValidator validator) throws Exception;
/**
- * This method is mainly used to customize PipeExtractor. In this method, the user can do the
+ * This method is mainly used to customize PipeSource. In this method, the user can do the
* following things:
*
*
* - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
+ *
- Set the running configurations in PipeSourceRuntimeConfiguration.
*
*
- * This method is called after the method {@link
- * PipeExtractor#validate(PipeParameterValidator)} is called.
+ *
This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
+ * is called.
*
* @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeExtractor
+ * @param configuration used to set the required properties of the running PipeSource
* @throws Exception the user can throw errors if necessary
*/
- void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
+ void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
throws Exception;
/**
- * Start the extractor. After this method is called, events should be ready to be supplied by
- * {@link PipeExtractor#supply()}. This method is called after {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ * Start the Source. After this method is called, events should be ready to be supplied by
+ * {@link PipeSource#supply()}. This method is called after {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @throws Exception the user can throw errors if necessary
*/
void start() throws Exception;
/**
- * Supply single event from the extractor and the caller will send the event to the processor.
- * This method is called after {@link PipeExtractor#start()} is called.
+ * Supply single event from the Source and the caller will send the event to the processor.
+ * This method is called after {@link PipeSource#start()} is called.
*
- * @return the event to be supplied. the event may be null if the extractor has no more events at
- * the moment, but the extractor is still running for more events.
+ * @return the event to be supplied. the event may be null if the Source has no more events at
+ * the moment, but the Source is still running for more events.
* @throws Exception the user can throw errors if necessary
*/
Event supply() throws Exception;
@@ -214,14 +214,14 @@ public interface PipeExtractor extends PipePlugin {
#### 数据处理插件接口
-数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeExtractor)捕获的
+数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeSource)捕获的
各种事件。
```java
/**
* PipeProcessor
*
- *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
*
The lifecycle of a PipeProcessor is as follows:
*
@@ -234,13 +234,13 @@ public interface PipeExtractor extends PipePlugin {
* to config the runtime behavior of the PipeProcessor.
*
While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
- *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
- PipeSink serializes the events into binaries and send them to sinks.
*
* When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
@@ -315,51 +315,49 @@ public interface PipeProcessor extends PipePlugin {
#### 数据发送插件接口
-数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeConnector)主要用于发送经由数据处理插件(PipeProcessor)处理过后的
+数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeSink)主要用于发送经由数据处理插件(PipeProcessor)处理过后的
各种事件,它作为流处理框架的网络实现层,接口上应允许接入多种实时通信协议和多种连接器。
```java
/**
- * PipeConnector
+ * PipeSink
*
- * PipeConnector is responsible for sending events to sinks.
+ *
PipeSink is responsible for sending events to sinks.
*
- *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
Various network protocols can be supported by implementing different PipeSink classes.
*
- *
The lifecycle of a PipeConnector is as follows:
+ *
The lifecycle of a PipeSink is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
- * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
- *
- Before the collaboration task starts, the method {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeConnector and the method {@link
- * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
+ * parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
+ * called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
+ * PipeSinkRuntimeConfiguration)} will be called to config the runtime behavior of the
+ * PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
+ * with sink.
*
- While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector.
- *
- PipeConnector serializes the events into binaries and send them to sinks. The
- * following 3 methods will be called: {@link
- * PipeConnector#transfer(TabletInsertionEvent)}, {@link
- * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
- * PipeConnector#transfer(Event)}.
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink.
+ *
- PipeSink serializes the events into binaries and send them to sinks. The following 3
+ * methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
+ * PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
*
* - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
- * PipeConnector#close() } method will be called.
+ * PipeSink#close() } method will be called.
*
*
- * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
- * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
- * will be called to create a new connection with the sink when the method {@link
- * PipeConnector#heartbeat()} throws exceptions.
+ *
In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
+ * called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
+ * throws exceptions.
*/
-public interface PipeConnector extends PipePlugin {
+public interface PipeSink extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
+ * PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
@@ -367,29 +365,28 @@ public interface PipeConnector extends PipePlugin {
void validate(PipeParameterValidator validator) throws Exception;
/**
- * This method is mainly used to customize PipeConnector. In this method, the user can do the
- * following things:
+ * This method is mainly used to customize PipeSink. In this method, the user can do the following
+ * things:
*
*
* - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
+ *
- Set the running configurations in PipeSinkRuntimeConfiguration.
*
*
- * This method is called after the method {@link
- * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
- * PipeConnector#handshake()} is called.
+ *
This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
+ * called and before the method {@link PipeSink#handshake()} is called.
*
* @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeConnector
+ * @param configuration used to set the required properties of the running PipeSink
* @throws Exception the user can throw errors if necessary
*/
- void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
+ void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
throws Exception;
/**
* This method is used to create a connection with sink. This method will be called after the
- * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
- * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
+ * method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
+ * will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
*
* @throws Exception if the connection is failed to be created
*/
@@ -420,14 +417,18 @@ public interface PipeConnector extends PipePlugin {
* @throws Exception the user can throw errors if necessary
*/
default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- transfer(tabletInsertionEvent);
+ try {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ } finally {
+ tsFileInsertionEvent.close();
}
}
/**
- * This method is used to transfer the Event.
+ * This method is used to transfer the generic events, including HeartbeatEvent.
*
* @param event Event to be transferred
* @throws PipeConnectionException if the connection is broken
@@ -444,7 +445,7 @@ public interface PipeConnector extends PipePlugin {
### 加载插件语句
-在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeExtractor、 PipeProcessor 或者 PipeConnector 实现一个具体的插件类,
+在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeSource、 PipeProcessor 或者 PipeSink 实现一个具体的插件类,
然后需要将插件类编译打包成 jar 可执行文件,最后使用加载插件的管理语句将插件载入 IoTDB。
加载插件的管理语句的语法如图所示。
@@ -483,40 +484,40 @@ SHOW PIPEPLUGINS
## 系统预置的流处理插件
-### 预置 extractor 插件
+### 预置 source 插件
-#### iotdb-extractor
+#### iotdb-source
作用:抽取 IoTDB 内部的历史或实时数据进入 pipe。
-| key | value | value 取值范围 | required or optional with default |
-| ---------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor | String: iotdb-extractor | required |
-| extractor.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
-| extractor.history.enable | 是否抽取历史数据 | Boolean: true, false | optional: true |
-| extractor.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | 是否抽取实时数据 | Boolean: true, false | optional: true |
+| key | value | value 取值范围 | required or optional with default |
+|---------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
+| source.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-> 🚫 **extractor.pattern 参数说明**
+> 🚫 **source.pattern 参数说明**
>
> * Pattern 需用反引号修饰不合法字符或者是不合法路径节点,例如如果希望筛选 root.\`a@b\` 或者 root.\`123\`,应设置 pattern 为 root.\`a@b\` 或者 root.\`123\`(具体参考 [单双引号和反引号的使用时机](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
> * 在底层实现中,当检测到 pattern 为 root(默认值)时,抽取效率较高,其他任意格式都将降低性能
-> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'extractor.pattern'='root.aligned.1' 的 pipe 时:
->
-> * root.aligned.1TS
+> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'source.pattern'='root.aligned.1' 的 pipe 时:
+ >
+ > * root.aligned.1TS
> * root.aligned.1TS.\`1\`
> * root.aligned.100T
->
-> 的数据会被抽取;
->
-> * root.aligned.\`1\`
+ >
+ > 的数据会被抽取;
+ >
+ > * root.aligned.\`1\`
> * root.aligned.\`123\`
->
-> 的数据不会被抽取。
+ >
+ > 的数据不会被抽取。
-> ❗️**extractor.history 的 start-time,end-time 参数说明**
+> ❗️**source.history 的 start-time,end-time 参数说明**
>
> * start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或 2011-12-03T10:15:30+01:00
@@ -527,41 +528,34 @@ SHOW PIPEPLUGINS
>
> 我们常说的乱序数据,指的是数据到达时,其 **event time** 远落后于当前系统时间(或者已经落库的最大 **event time**)的数据。另一方面,不论是乱序数据还是顺序数据,只要它们是新到达系统的,那它们的 **arrival time** 都是会随着数据到达 IoTDB 的顺序递增的。
-> 💎 **iotdb-extractor 的工作可以拆分成两个阶段**
+> 💎 **iotdb-source 的工作可以拆分成两个阶段**
>
> 1. 历史数据抽取:所有 **arrival time** < 创建 pipe 时**当前系统时间**的数据称为历史数据
> 2. 实时数据抽取:所有 **arrival time** >= 创建 pipe 时**当前系统时间**的数据称为实时数据
>
> 历史数据传输阶段和实时数据传输阶段,**两阶段串行执行,只有当历史数据传输阶段完成后,才执行实时数据传输阶段。**
->
-> 用户可以指定 iotdb-extractor 进行:
->
-> * 历史数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * 实时数据抽取(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * 全量数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * 禁止同时设置 `extractor.history.enable` 和 `extractor.realtime.enable` 为 `false`
### 预置 processor 插件
#### do-nothing-processor
-作用:不对 extractor 传入的事件做任何的处理。
+作用:不对 source 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value 取值范围 | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### 预置 connector 插件
+### 预置 sink 插件
-#### do-nothing-connector
+#### do-nothing-sink
作用:不对 processor 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value 取值范围 | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## 流处理任务管理
@@ -571,57 +565,53 @@ SHOW PIPEPLUGINS
```sql
CREATE PIPE -- PipeId 是能够唯一标定流处理任务的名字
-WITH EXTRACTOR (
+WITH SOURCE (
-- 默认的 IoTDB 数据抽取插件
- 'extractor' = 'iotdb-extractor',
+ 'source' = 'iotdb-source',
-- 路径前缀,只有能够匹配该路径前缀的数据才会被抽取,用作后续的处理和发送
- 'extractor.pattern' = 'root.timecho',
- -- 是否抽取历史数据
- 'extractor.history.enable' = 'true',
+ 'source.pattern' = 'root.timecho',
-- 描述被抽取的历史数据的时间范围,表示最早时间
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- 描述被抽取的历史数据的时间范围,表示最晚时间
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
- -- 是否抽取实时数据
- 'extractor.realtime.enable' = 'true',
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
)
WITH PROCESSOR (
-- 默认的数据处理插件,即不做任何处理
'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
**创建流处理任务时需要配置 PipeId 以及三个插件部分的参数:**
-| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
-| --------- | --------------------------------------------------- | --------------------------- | -------------------- | -------------------------------------------------------- | ------------------------- |
-| PipeId | 全局唯一标定一个流处理任务的名称 | 必填 | - | - | - |
-| extractor | Pipe Extractor 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-extractor | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
-| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
-| connector | Pipe Connector 插件,负责发送数据 | 必填 | - | - | 是 |
+| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
+|-----------|--------------------------------|---------------------------|----------------------|------------------------------|--------------------------|
+| PipeId | 全局唯一标定一个流处理任务的名称 | 必填 | - | - | - |
+| source | Pipe Source 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-source | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
+| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
+| sink | Pipe Sink 插件,负责发送数据 | 必填 | - | - | 是 |
-示例中,使用了 iotdb-extractor、do-nothing-processor 和 iotdb-thrift-connector 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,**请查看“系统预置流处理插件”一节**。
+示例中,使用了 iotdb-source、do-nothing-processor 和 iotdb-thrift-sink 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,**请查看“系统预置流处理插件”一节**。
**一个最简的 CREATE PIPE 语句示例如下:**
```sql
CREATE PIPE -- PipeId 是能够唯一标定流处理任务的名字
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -629,29 +619,29 @@ WITH CONNECTOR (
**注意:**
-- EXTRACTOR 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
-- CONNECTOR 为必填配置,需要在 CREATE PIPE 语句中声明式配置
-- CONNECTOR 具备自复用能力。对于不同的流处理任务,如果他们的 CONNECTOR 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 CONNECTOR 实例**,以实现对连接资源的复用。
+- SOURCE 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
+- SINK 为必填配置,需要在 CREATE PIPE 语句中声明式配置
+- SINK 具备自复用能力。对于不同的流处理任务,如果他们的 SINK 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 SINK 实例**,以实现对连接资源的复用。
- 例如,有下面 pipe1, pipe2 两个流处理任务的声明:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
)
```
- - 因为它们对 CONNECTOR 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 CONNECTOR 进行复用,最终 pipe1, pipe2 的CONNECTOR 将会是同一个实例。
+ - 因为它们对 SINK 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 SINK 进行复用,最终 pipe1, pipe2 的 SINK 将会是同一个实例。
- 请不要构建出包含数据循环同步的应用场景(会导致无限循环):
- IoTDB A -> IoTDB B -> IoTDB A
@@ -659,7 +649,7 @@ WITH CONNECTOR (
### 启动流处理任务
-CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED,即流处理任务不会立刻处理数据。
+CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED(V1.3.0),即流处理任务不会立刻处理数据。在 1.3.1 及以上的版本,流处理任务的运行状态在创建后将被立即置为 RUNNING。
可以使用 START PIPE 语句使流处理任务开始处理数据:
@@ -696,13 +686,13 @@ SHOW PIPES
查询结果如下:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime| State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
可以使用 `` 指定想看的某个流处理任务状态:
@@ -711,22 +701,23 @@ SHOW PIPES
SHOW PIPE
```
-您也可以通过 where 子句,判断某个 \ 使用的 Pipe Connector 被复用的情况。
+您也可以通过 where 子句,判断某个 \ 使用的 Pipe Sink 被复用的情况。
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### 流处理任务运行状态迁移
-一个流处理 pipe 在其被管理的生命周期中会经过多种状态:
+一个流处理 pipe 在其生命周期中会经过多种状态:
+- **RUNNING:** pipe 正在正常工作
+ - 当一个 pipe 被成功创建之后,其初始状态为工作状态(V1.3.1+)
- **STOPPED:** pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
- - 当一个 pipe 被成功创建之后,其初始状态为暂停状态
+ - 当一个 pipe 被成功创建之后,其初始状态为暂停状态(V1.3.0)
- 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
- 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
-- **RUNNING:** pipe 正在正常工作
- **DROPPED:** pipe 任务被永久删除
下图表明了所有状态以及状态的迁移:
@@ -738,8 +729,8 @@ WHERE CONNECTOR USED BY
### 流处理任务
-| 权限名称 | 描述 |
-| -------- | -------------------------- |
+| 权限名称 | 描述 |
+|----------|---------------|
| USE_PIPE | 注册流处理任务。路径无关。 |
| USE_PIPE | 开启流处理任务。路径无关。 |
| USE_PIPE | 停止流处理任务。路径无关。 |
@@ -749,8 +740,8 @@ WHERE CONNECTOR USED BY
### 流处理任务插件
-| 权限名称 | 描述 |
-| :------- | ------------------------------ |
+| 权限名称 | 描述 |
+|:---------|-----------------|
| USE_PIPE | 注册流处理任务插件。路径无关。 |
| USE_PIPE | 卸载流处理任务插件。路径无关。 |
| USE_PIPE | 查询流处理任务插件。路径无关。 |
@@ -759,6 +750,7 @@ WHERE CONNECTOR USED BY
在 iotdb-common.properties 中:
+V1.3.0:
```Properties
####################
### Pipe Configuration
@@ -779,4 +771,43 @@ WHERE CONNECTOR USED BY
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+```
+
+V1.3.1+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
```
diff --git a/src/zh/UserGuide/Master/User-Manual/Streaming_timecho.md b/src/zh/UserGuide/Master/User-Manual/Streaming_timecho.md
index dd13b2b4..7b410bfa 100644
--- a/src/zh/UserGuide/Master/User-Manual/Streaming_timecho.md
+++ b/src/zh/UserGuide/Master/User-Manual/Streaming_timecho.md
@@ -25,19 +25,19 @@ IoTDB 流处理框架允许用户实现自定义的流处理逻辑,可以实
我们将一个数据流处理任务称为 Pipe。一个流处理任务(Pipe)包含三个子任务:
-- 抽取(Extract)
+- 抽取(Source)
- 处理(Process)
-- 发送(Connect)
+- 发送(Sink)
流处理框架允许用户使用 Java 语言自定义编写三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。
在一个 Pipe 中,上述的三个子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:
-Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Connector 用于发送数据,最终数据将被发至外部系统。
+Pipe Source 用于抽取数据,Pipe Processor 用于处理数据,Pipe Sink 用于发送数据,最终数据将被发至外部系统。
**Pipe 任务的模型如下:**
-
+
-描述一个数据流处理任务,本质就是描述 Pipe Extractor、Pipe Processor 和 Pipe Connector 插件的属性。
+描述一个数据流处理任务,本质就是描述 Pipe Source、Pipe Processor 和 Pipe Sink 插件的属性。
用户可以通过 SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
利用流处理框架,可以搭建完整的数据链路来满足端*边云同步、异地灾备、读写负载分库*等需求。
@@ -52,7 +52,7 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
org.apache.iotdb
pipe-api
- 1.2.1
+ 1.3.1
provided
```
@@ -61,7 +61,7 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
流处理插件的用户编程接口设计,参考了事件驱动编程模型的通用设计理念。事件(Event)是用户编程接口中的数据抽象,而编程接口与具体的执行方式解耦,只需要专注于描述事件(数据)到达系统后,系统期望的处理方式即可。
-在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeExtractor 插件,PipeProcessor 插件和 PipeConnector 插件,并依次在三个插件中触发用户逻辑的执行。
+在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeSource 插件,PipeProcessor 插件和 PipeSink 插件,并依次在三个插件中触发用户逻辑的执行。
为了兼顾端侧低负载场景下的流处理低延迟和端侧高负载场景下的流处理高吞吐,流处理引擎会动态地在操作日志和数据文件中选择处理对象,因此,流处理的用户编程接口要求用户提供下列两类事件的处理逻辑:操作日志写入事件 TabletInsertionEvent 和数据文件写入事件 TsFileInsertionEvent。
@@ -79,21 +79,21 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
/** TabletInsertionEvent is used to define the event of data insertion. */
public interface TabletInsertionEvent extends Event {
- /**
- * The consumer processes the data row by row and collects the results by RowCollector.
- *
- * @return {@code Iterable} a list of new TabletInsertionEvent contains the
- * results collected by the RowCollector
- */
- Iterable processRowByRow(BiConsumer consumer);
-
- /**
- * The consumer processes the Tablet directly and collects the results by RowCollector.
- *
- * @return {@code Iterable} a list of new TabletInsertionEvent contains the
- * results collected by the RowCollector
- */
- Iterable processTablet(BiConsumer consumer);
+ /**
+ * The consumer processes the data row by row and collects the results by RowCollector.
+ *
+ * @return {@code Iterable} a list of new TabletInsertionEvent contains the
+ * results collected by the RowCollector
+ */
+ Iterable processRowByRow(BiConsumer consumer);
+
+ /**
+ * The consumer processes the Tablet directly and collects the results by RowCollector.
+ *
+ * @return {@code Iterable} a list of new TabletInsertionEvent contains the
+ * results collected by the RowCollector
+ */
+ Iterable processTablet(BiConsumer consumer);
}
```
@@ -118,12 +118,12 @@ IoTDB 的存储引擎是 LSM 结构的。数据写入时会先将写入操作落
*/
public interface TsFileInsertionEvent extends Event {
- /**
- * The method is used to convert the TsFileInsertionEvent into several TabletInsertionEvents.
- *
- * @return {@code Iterable} the list of TabletInsertionEvent
- */
- Iterable toTabletInsertionEvents();
+ /**
+ * The method is used to convert the TsFileInsertionEvent into several TabletInsertionEvents.
+ *
+ * @return {@code Iterable} the list of TabletInsertionEvent
+ */
+ Iterable toTabletInsertionEvents();
}
```
@@ -133,95 +133,95 @@ public interface TsFileInsertionEvent extends Event {
#### 数据抽取插件接口
-数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeExtractor)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,
+数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeSource)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,
捕获各种数据写入事件。
```java
/**
- * PipeExtractor
+ * PipeSource
*
- * PipeExtractor is responsible for capturing events from sources.
+ *
PipeSource is responsible for capturing events from sources.
*
- *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
Various data sources can be supported by implementing different PipeSource classes.
*
- *
The lifecycle of a PipeExtractor is as follows:
+ *
The lifecycle of a PipeSource is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
- * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
+ *
- When a collaboration task is created, the KV pairs of `WITH SOURCE` clause in SQL are
+ * parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
+ * be called to validate the parameters.
*
- Before the collaboration task starts, the method {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeExtractor.
- *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
- *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
- * be called to capture events from sources and then the events will be passed to the
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
+ * config the runtime behavior of the PipeSource.
+ *
- Then the method {@link PipeSource#start()} will be called to start the PipeSource.
+ *
- While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
+ * called to capture events from sources and then the events will be passed to the
* PipeProcessor.
- *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ *
- The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
*
*/
-public interface PipeExtractor extends PipePlugin {
-
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeExtractor. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeExtractor#validate(PipeParameterValidator)} is called.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeExtractor
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * Start the extractor. After this method is called, events should be ready to be supplied by
- * {@link PipeExtractor#supply()}. This method is called after {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
- *
- * @throws Exception the user can throw errors if necessary
- */
- void start() throws Exception;
-
- /**
- * Supply single event from the extractor and the caller will send the event to the processor.
- * This method is called after {@link PipeExtractor#start()} is called.
- *
- * @return the event to be supplied. the event may be null if the extractor has no more events at
- * the moment, but the extractor is still running for more events.
- * @throws Exception the user can throw errors if necessary
- */
- Event supply() throws Exception;
+public interface PipeSource extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeSource. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeSourceRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
+ * is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeSource
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * Start the Source. After this method is called, events should be ready to be supplied by
+ * {@link PipeSource#supply()}. This method is called after {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
+ *
+ * @throws Exception the user can throw errors if necessary
+ */
+ void start() throws Exception;
+
+ /**
+ * Supply single event from the Source and the caller will send the event to the processor.
+ * This method is called after {@link PipeSource#start()} is called.
+ *
+ * @return the event to be supplied. the event may be null if the Source has no more events at
+ * the moment, but the Source is still running for more events.
+ * @throws Exception the user can throw errors if necessary
+ */
+ Event supply() throws Exception;
}
```
#### 数据处理插件接口
-数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeExtractor)捕获的
+数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeSource)捕获的
各种事件。
```java
/**
* PipeProcessor
*
- *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
*
The lifecycle of a PipeProcessor is as follows:
*
@@ -234,13 +234,13 @@ public interface PipeExtractor extends PipePlugin {
* to config the runtime behavior of the PipeProcessor.
*
While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
- *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
- PipeSink serializes the events into binaries and send them to sinks.
*
* When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
@@ -315,125 +315,126 @@ public interface PipeProcessor extends PipePlugin {
#### 数据发送插件接口
-数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeConnector)主要用于发送经由数据处理插件(PipeProcessor)处理过后的
+数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeSink)主要用于发送经由数据处理插件(PipeProcessor)处理过后的
各种事件,它作为流处理框架的网络实现层,接口上应允许接入多种实时通信协议和多种连接器。
```java
/**
- * PipeConnector
+ * PipeSink
*
- * PipeConnector is responsible for sending events to sinks.
+ *
PipeSink is responsible for sending events to sinks.
*
- *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
Various network protocols can be supported by implementing different PipeSink classes.
*
- *
The lifecycle of a PipeConnector is as follows:
+ *
The lifecycle of a PipeSink is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
- * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
- *
- Before the collaboration task starts, the method {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeConnector and the method {@link
- * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
+ * parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
+ * called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
+ * PipeSinkRuntimeConfiguration)} will be called to config the runtime behavior of the
+ * PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
+ * with sink.
*
- While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector.
- *
- PipeConnector serializes the events into binaries and send them to sinks. The
- * following 3 methods will be called: {@link
- * PipeConnector#transfer(TabletInsertionEvent)}, {@link
- * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
- * PipeConnector#transfer(Event)}.
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink.
+ *
- PipeSink serializes the events into binaries and send them to sinks. The following 3
+ * methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
+ * PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
*
* - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
- * PipeConnector#close() } method will be called.
+ * PipeSink#close() } method will be called.
*
*
- * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
- * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
- * will be called to create a new connection with the sink when the method {@link
- * PipeConnector#heartbeat()} throws exceptions.
+ *
In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
+ * called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
+ * throws exceptions.
*/
-public interface PipeConnector extends PipePlugin {
-
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeConnector. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
- * PipeConnector#handshake()} is called.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeConnector
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * This method is used to create a connection with sink. This method will be called after the
- * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
- * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
- *
- * @throws Exception if the connection is failed to be created
- */
- void handshake() throws Exception;
-
- /**
- * This method will be called periodically to check whether the connection with sink is still
- * alive.
- *
- * @throws Exception if the connection dies
- */
- void heartbeat() throws Exception;
-
- /**
- * This method is used to transfer the TabletInsertionEvent.
- *
- * @param tabletInsertionEvent TabletInsertionEvent to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
-
- /**
- * This method is used to transfer the TsFileInsertionEvent.
- *
- * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- transfer(tabletInsertionEvent);
+public interface PipeSink extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeSink. In this method, the user can do the following
+ * things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeSinkRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
+ * called and before the method {@link PipeSink#handshake()} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeSink
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is used to create a connection with sink. This method will be called after the
+ * method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
+ * will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
+ *
+ * @throws Exception if the connection is failed to be created
+ */
+ void handshake() throws Exception;
+
+ /**
+ * This method will be called periodically to check whether the connection with sink is still
+ * alive.
+ *
+ * @throws Exception if the connection dies
+ */
+ void heartbeat() throws Exception;
+
+ /**
+ * This method is used to transfer the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
+
+ /**
+ * This method is used to transfer the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
+ try {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ } finally {
+ tsFileInsertionEvent.close();
+ }
}
- }
- /**
- * This method is used to transfer the Event.
- *
- * @param event Event to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- void transfer(Event event) throws Exception;
+ /**
+ * This method is used to transfer the generic events, including HeartbeatEvent.
+ *
+ * @param event Event to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(Event event) throws Exception;
}
```
@@ -444,7 +445,7 @@ public interface PipeConnector extends PipePlugin {
### 加载插件语句
-在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeExtractor、 PipeProcessor 或者 PipeConnector 实现一个具体的插件类,
+在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeSource、 PipeProcessor 或者 PipeSink 实现一个具体的插件类,
然后需要将插件类编译打包成 jar 可执行文件,最后使用加载插件的管理语句将插件载入 IoTDB。
加载插件的管理语句的语法如图所示。
@@ -499,43 +500,42 @@ SHOW PIPEPLUGINS
## 系统预置的流处理插件
-### 预置 extractor 插件
+### 预置 source 插件
-#### iotdb-extractor
+#### iotdb-source
作用:抽取 IoTDB 内部的历史或实时数据进入 pipe。
-| key | value | value 取值范围 | required or optional with default |
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor | String: iotdb-extractor | required |
-| extractor.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
-| extractor.history.enable | 是否抽取历史数据 | Boolean: true, false | optional: true |
-| extractor.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | 是否抽取实时数据 | Boolean: true, false | optional: true |
-| extractor.realtime.mode | 实时数据的抽取模式 | String: hybrid, log, file | optional: hybrid |
-| extractor.forwarding-pipe-requests | 是否抽取由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | optional: true |
+| key | value | value 取值范围 | required or optional with default |
+|---------------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
+| source.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| source.realtime.mode | 实时数据的抽取模式 | String: hybrid, log, file | optional: hybrid |
+| source.forwarding-pipe-requests | 是否抽取由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | optional: true |
-> 🚫 **extractor.pattern 参数说明**
+> 🚫 **source.pattern 参数说明**
>
> * Pattern 需用反引号修饰不合法字符或者是不合法路径节点,例如如果希望筛选 root.\`a@b\` 或者 root.\`123\`,应设置 pattern 为 root.\`a@b\` 或者 root.\`123\`(具体参考 [单双引号和反引号的使用时机](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
> * 在底层实现中,当检测到 pattern 为 root(默认值)时,抽取效率较高,其他任意格式都将降低性能
-> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'extractor.pattern'='root.aligned.1' 的 pipe 时:
+> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'source.pattern'='root.aligned.1' 的 pipe 时:
>
> * root.aligned.1TS
-> * root.aligned.1TS.\`1\`
+ > * root.aligned.1TS.\`1\`
> * root.aligned.100T
- >
- > 的数据会被抽取;
- >
- > * root.aligned.\`1\`
+ >
+ > 的数据会被抽取;
+ >
+ > * root.aligned.\`1\`
> * root.aligned.\`123\`
- >
- > 的数据不会被抽取。
-> * root.\_\_system 的数据不会被 pipe 抽取。用户虽然可以在 extractor.pattern 中包含任意前缀,包括带有(或覆盖) root.\__system 的前缀,但是 root.__system 下的数据总是会被 pipe 忽略的
+ >
+ > 的数据不会被抽取。
-> ❗️**extractor.history 的 start-time,end-time 参数说明**
+> ❗️**source.history 的 start-time,end-time 参数说明**
>
> * start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或 2011-12-03T10:15:30+01:00
@@ -546,27 +546,20 @@ SHOW PIPEPLUGINS
>
> 我们常说的乱序数据,指的是数据到达时,其 **event time** 远落后于当前系统时间(或者已经落库的最大 **event time**)的数据。另一方面,不论是乱序数据还是顺序数据,只要它们是新到达系统的,那它们的 **arrival time** 都是会随着数据到达 IoTDB 的顺序递增的。
-> 💎 **iotdb-extractor 的工作可以拆分成两个阶段**
+> 💎 **iotdb-source 的工作可以拆分成两个阶段**
>
> 1. 历史数据抽取:所有 **arrival time** < 创建 pipe 时**当前系统时间**的数据称为历史数据
> 2. 实时数据抽取:所有 **arrival time** >= 创建 pipe 时**当前系统时间**的数据称为实时数据
>
> 历史数据传输阶段和实时数据传输阶段,**两阶段串行执行,只有当历史数据传输阶段完成后,才执行实时数据传输阶段。**
->
-> 用户可以指定 iotdb-extractor 进行:
->
-> * 历史数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * 实时数据抽取(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * 全量数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * 禁止同时设置 `extractor.history.enable` 和 `extractor.realtime.enable` 为 `false`
-> 📌 **extractor.realtime.mode:数据抽取的模式**
+> 📌 **source.realtime.mode:数据抽取的模式**
>
> * log:该模式下,任务仅使用操作日志进行数据处理、发送
> * file:该模式下,任务仅使用数据文件进行数据处理、发送
> * hybrid:该模式,考虑了按操作日志逐条目发送数据时延迟低但吞吐低的特点,以及按数据文件批量发送时发送吞吐高但延迟高的特点,能够在不同的写入负载下自动切换适合的数据抽取方式,首先采取基于操作日志的数据抽取方式以保证低发送延迟,当产生数据积压时自动切换成基于数据文件的数据抽取方式以保证高发送吞吐,积压消除时自动切换回基于操作日志的数据抽取方式,避免了采用单一数据抽取算法难以平衡数据发送延迟或吞吐的问题。
-> 🍕 **extractor.forwarding-pipe-requests:是否允许转发从另一 pipe 传输而来的数据**
+> 🍕 **source.forwarding-pipe-requests:是否允许转发从另一 pipe 传输而来的数据**
>
> * 如果要使用 pipe 构建 A -> B -> C 的数据同步,那么 B -> C 的 pipe 需要将该参数为 true 后,A -> B 中 A 通过 pipe 写入 B 的数据才能被正确转发到 C
> * 如果要使用 pipe 构建 A \<-> B 的双向数据同步(双活),那么 A -> B 和 B -> A 的 pipe 都需要将该参数设置为 false,否则将会造成数据无休止的集群间循环转发
@@ -575,23 +568,23 @@ SHOW PIPEPLUGINS
#### do-nothing-processor
-作用:不对 extractor 传入的事件做任何的处理。
+作用:不对 source 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value 取值范围 | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### 预置 connector 插件
+### 预置 sink 插件
-#### do-nothing-connector
+#### do-nothing-sink
作用:不对 processor 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value 取值范围 | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## 流处理任务管理
@@ -601,59 +594,59 @@ SHOW PIPEPLUGINS
```sql
CREATE PIPE -- PipeId 是能够唯一标定流处理任务的名字
-WITH EXTRACTOR (
+WITH SOURCE (
-- 默认的 IoTDB 数据抽取插件
- 'extractor' = 'iotdb-extractor',
+ 'source' = 'iotdb-source',
-- 路径前缀,只有能够匹配该路径前缀的数据才会被抽取,用作后续的处理和发送
- 'extractor.pattern' = 'root.timecho',
+ 'source.pattern' = 'root.timecho',
-- 是否抽取历史数据
- 'extractor.history.enable' = 'true',
+ 'source.history.enable' = 'true',
-- 描述被抽取的历史数据的时间范围,表示最早时间
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- 描述被抽取的历史数据的时间范围,表示最晚时间
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
-- 是否抽取实时数据
- 'extractor.realtime.enable' = 'true',
+ 'source.realtime.enable' = 'true',
-- 描述实时数据的抽取方式
- 'extractor.realtime.mode' = 'hybrid',
+ 'source.realtime.mode' = 'hybrid',
)
WITH PROCESSOR (
-- 默认的数据处理插件,即不做任何处理
'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
**创建流处理任务时需要配置 PipeId 以及三个插件部分的参数:**
-| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
-| --------- | --------------------------------------------------- | --------------------------- | -------------------- | -------------------------------------------------------- | ------------------------- |
-| PipeId | 全局唯一标定一个流处理任务的名称 | 必填 | - | - | - |
-| extractor | Pipe Extractor 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-extractor | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
-| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
-| connector | Pipe Connector 插件,负责发送数据 | 必填 | - | - | 是 |
+| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
+|-----------|--------------------------------|---------------------------|----------------------|------------------------------|--------------------------|
+| PipeId | 全局唯一标定一个流处理任务的名称 | 必填 | - | - | - |
+| source | Pipe Source 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-source | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
+| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
+| sink | Pipe Sink 插件,负责发送数据 | 必填 | - | - | 是 |
-示例中,使用了 iotdb-extractor、do-nothing-processor 和 iotdb-thrift-connector 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,**请查看“系统预置流处理插件”一节**。
+示例中,使用了 iotdb-source、do-nothing-processor 和 iotdb-thrift-sink 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,**请查看“系统预置流处理插件”一节**。
**一个最简的 CREATE PIPE 语句示例如下:**
```sql
CREATE PIPE -- PipeId 是能够唯一标定流处理任务的名字
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -661,37 +654,37 @@ WITH CONNECTOR (
**注意:**
-- EXTRACTOR 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
-- CONNECTOR 为必填配置,需要在 CREATE PIPE 语句中声明式配置
-- CONNECTOR 具备自复用能力。对于不同的流处理任务,如果他们的 CONNECTOR 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 CONNECTOR 实例**,以实现对连接资源的复用。
+- SOURCE 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
+- SINK 为必填配置,需要在 CREATE PIPE 语句中声明式配置
+- SINK 具备自复用能力。对于不同的流处理任务,如果他们的 SINK 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 SINK 实例**,以实现对连接资源的复用。
- - 例如,有下面 pipe1, pipe2 两个流处理任务的声明:
+ - 例如,有下面 pipe1, pipe2 两个流处理任务的声明:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
)
```
- - 因为它们对 CONNECTOR 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 CONNECTOR 进行复用,最终 pipe1, pipe2 的CONNECTOR 将会是同一个实例。
-- 在 extractor 为默认的 iotdb-extractor,且 extractor.forwarding-pipe-requests 为默认值 true 时,请不要构建出包含数据循环同步的应用场景(会导致无限循环):
+ - 因为它们对 SINK 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 SINK 进行复用,最终 pipe1, pipe2 的 SINK 将会是同一个实例。
+- 在 source 为默认的 iotdb-source,且 source.forwarding-pipe-requests 为默认值 true 时,请不要构建出包含数据循环同步的应用场景(会导致无限循环):
- - IoTDB A -> IoTDB B -> IoTDB A
- - IoTDB A -> IoTDB A
+ - IoTDB A -> IoTDB B -> IoTDB A
+ - IoTDB A -> IoTDB A
### 启动流处理任务
-CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED,即流处理任务不会立刻处理数据。
+CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED,即流处理任务不会立刻处理数据(V1.3.0)。在 1.3.1 及以上的版本,流处理任务的运行状态在创建后将被立即置为 RUNNING。
可以使用 START PIPE 语句使流处理任务开始处理数据:
@@ -728,13 +721,13 @@ SHOW PIPES
查询结果如下:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime | State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
可以使用 `` 指定想看的某个流处理任务状态:
@@ -743,22 +736,23 @@ SHOW PIPES
SHOW PIPE
```
-您也可以通过 where 子句,判断某个 \ 使用的 Pipe Connector 被复用的情况。
+您也可以通过 where 子句,判断某个 \ 使用的 Pipe Sink 被复用的情况。
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### 流处理任务运行状态迁移
-一个流处理 pipe 在其被管理的生命周期中会经过多种状态:
+一个流处理 pipe 在其的生命周期中会经过多种状态:
-- **STOPPED:** pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
- - 当一个 pipe 被成功创建之后,其初始状态为暂停状态
- - 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
- - 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
- **RUNNING:** pipe 正在正常工作
+ - 当一个 pipe 被成功创建之后,其初始状态为工作状态(V1.3.1+)
+- **STOPPED:** pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
+ - 当一个 pipe 被成功创建之后,其初始状态为暂停状态(V1.3.0)
+ - 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
+ - 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
- **DROPPED:** pipe 任务被永久删除
下图表明了所有状态以及状态的迁移:
@@ -770,8 +764,8 @@ WHERE CONNECTOR USED BY
### 流处理任务
-| 权限名称 | 描述 |
-| -------- | -------------------------- |
+| 权限名称 | 描述 |
+|----------|---------------|
| USE_PIPE | 注册流处理任务。路径无关。 |
| USE_PIPE | 开启流处理任务。路径无关。 |
| USE_PIPE | 停止流处理任务。路径无关。 |
@@ -781,8 +775,8 @@ WHERE CONNECTOR USED BY
### 流处理任务插件
-| 权限名称 | 描述 |
-| -------- | ------------------------------ |
+| 权限名称 | 描述 |
+|----------|-----------------|
| USE_PIPE | 注册流处理任务插件。路径无关。 |
| USE_PIPE | 卸载流处理任务插件。路径无关。 |
| USE_PIPE | 查询流处理任务插件。路径无关。 |
@@ -791,6 +785,7 @@ WHERE CONNECTOR USED BY
在 iotdb-common.properties 中:
+V1.3.0+:
```Properties
####################
### Pipe Configuration
@@ -811,4 +806,53 @@ WHERE CONNECTOR USED BY
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
+```
+
+V1.3.1+:
+```Properties
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
```
diff --git a/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync.md b/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync.md
index 77ffd3f7..7f3dbbd3 100644
--- a/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync.md
+++ b/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync.md
@@ -72,7 +72,7 @@
> ❗️**注:目前的 IoTDB -> IoTDB 的数据同步实现并不支持 DDL 同步**
>
-> 即:不支持 ttl,trigger,别名,模板,视图,创建/删除序列,创建/删除存储组等操作
+> 即:不支持 ttl,trigger,别名,模板,视图,创建/删除序列,创建/删除数据库等操作
>
> **IoTDB -> IoTDB 的数据同步要求目标端 IoTDB:**
>
@@ -376,14 +376,14 @@ SHOW PIPEPLUGINS
注意:理论上 v1.2.0+ IoTDB 可作为 v1.2.0 版本前的任意版本的数据同步(Sync)接收端。
-| key | value | value 取值范围 | required or optional with default |
-| ------------------ | --------------------------------------------------------------------- | ----------------------------------- | --------------------------------- |
-| connector | iotdb-legacy-pipe-connector | String: iotdb-legacy-pipe-connector | required |
-| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | required |
-| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | required |
+| key | value | value 取值范围 | required or optional with default |
+|--------------------|----------------------------------------------|-------------------------------------|-----------------------------------|
+| connector | iotdb-legacy-pipe-connector | String: iotdb-legacy-pipe-connector | required |
+| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | required |
+| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | required |
| connector.user | 目标端 IoTDB 的用户名,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
-| connector.password | 目标端 IoTDB 的密码,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
-| connector.version | 目标端 IoTDB 的版本,用于伪装自身实际版本,绕过目标端的版本一致性检查 | String | optional: 1.1 |
+| connector.password | 目标端 IoTDB 的密码,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
+| connector.version | 目标端 IoTDB 的版本,用于伪装自身实际版本,绕过目标端的版本一致性检查 | String | optional: 1.1 |
> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
@@ -392,14 +392,14 @@ SHOW PIPEPLUGINS
作用:不对 processor 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value 取值范围 | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| connector | do-nothing-connector | String: do-nothing-connector | required |
## 权限管理
-| 权限名称 | 描述 |
-| ----------- | -------------------- |
+| 权限名称 | 描述 |
+|-------------|------------|
| CREATE_PIPE | 注册任务。路径无关。 |
| START_PIPE | 开启任务。路径无关。 |
| STOP_PIPE | 停止任务。路径无关。 |
diff --git a/src/zh/UserGuide/V1.2.x/User-Manual/Streaming.md b/src/zh/UserGuide/V1.2.x/User-Manual/Streaming.md
index 0f25baca..691a1325 100644
--- a/src/zh/UserGuide/V1.2.x/User-Manual/Streaming.md
+++ b/src/zh/UserGuide/V1.2.x/User-Manual/Streaming.md
@@ -738,8 +738,8 @@ WHERE CONNECTOR USED BY
### 流处理任务
-| 权限名称 | 描述 |
-| ----------- | -------------------------- |
+| 权限名称 | 描述 |
+|-------------|---------------|
| CREATE_PIPE | 注册流处理任务。路径无关。 |
| START_PIPE | 开启流处理任务。路径无关。 |
| STOP_PIPE | 停止流处理任务。路径无关。 |
@@ -749,8 +749,8 @@ WHERE CONNECTOR USED BY
### 流处理任务插件
-| 权限名称 | 描述 |
-| ----------------- | ------------------------------ |
+| 权限名称 | 描述 |
+|-------------------|-----------------|
| CREATE_PIPEPLUGIN | 注册流处理任务插件。路径无关。 |
| DROP_PIPEPLUGIN | 卸载流处理任务插件。路径无关。 |
| SHOW_PIPEPLUGINS | 查询流处理任务插件。路径无关。 |
diff --git a/src/zh/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md b/src/zh/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
index c319f18f..af2e2841 100644
--- a/src/zh/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
+++ b/src/zh/UserGuide/V1.2.x/User-Manual/Streaming_timecho.md
@@ -770,8 +770,8 @@ WHERE CONNECTOR USED BY
### 流处理任务
-| 权限名称 | 描述 |
-| ----------- | -------------------------- |
+| 权限名称 | 描述 |
+|-------------|---------------|
| CREATE_PIPE | 注册流处理任务。路径无关。 |
| START_PIPE | 开启流处理任务。路径无关。 |
| STOP_PIPE | 停止流处理任务。路径无关。 |
@@ -781,8 +781,8 @@ WHERE CONNECTOR USED BY
### 流处理任务插件
-| 权限名称 | 描述 |
-| ----------------- | ------------------------------ |
+| 权限名称 | 描述 |
+|-------------------|-----------------|
| CREATE_PIPEPLUGIN | 注册流处理任务插件。路径无关。 |
| DROP_PIPEPLUGIN | 卸载流处理任务插件。路径无关。 |
| SHOW_PIPEPLUGINS | 查询流处理任务插件。路径无关。 |
diff --git a/src/zh/UserGuide/latest/User-Manual/Data-Sync.md b/src/zh/UserGuide/latest/User-Manual/Data-Sync.md
index c829de21..2c2e9ee0 100644
--- a/src/zh/UserGuide/latest/User-Manual/Data-Sync.md
+++ b/src/zh/UserGuide/latest/User-Manual/Data-Sync.md
@@ -25,17 +25,17 @@
**一个 Pipe 包含三个子任务(插件):**
-- 抽取(Extract)
+- 抽取(Source)
- 处理(Process)
-- 发送(Connect)
+- 发送(Sink)
-**Pipe 允许用户自定义三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。** 在一个 Pipe 中,上述的子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Connector 用于发送数据,最终数据将被发至外部系统。
+**Pipe 允许用户自定义三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。** 在一个 Pipe 中,上述的子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:Pipe Source 用于抽取数据,Pipe Processor 用于处理数据,Pipe Sink 用于发送数据,最终数据将被发至外部系统。
**Pipe 任务的模型如下:**
-
+
-描述一个数据同步任务,本质就是描述 Pipe Extractor、Pipe Processor 和 Pipe Connector 插件的属性。用户可以通过 SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
+描述一个数据同步任务,本质就是描述 Pipe Source、Pipe Processor 和 Pipe Sink 插件的属性。用户可以通过 SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
利用数据同步功能,可以搭建完整的数据链路来满足端*边云同步、异地灾备、读写负载分库*等需求。
@@ -48,10 +48,10 @@
```sql
create pipe a2b
- with connector (
- 'connector'='iotdb-thrift-connector',
- 'connector.ip'='127.0.0.1',
- 'connector.port'='6668'
+ with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6668'
)
```
- 启动 A -> B 的 Pipe,在 A 上执行
@@ -87,57 +87,53 @@
```sql
CREATE PIPE -- PipeId 是能够唯一标定同步任务任务的名字
-WITH EXTRACTOR (
+WITH SOURCE (
-- 默认的 IoTDB 数据抽取插件
- 'extractor' = 'iotdb-extractor',
+ 'source' = 'iotdb-source',
-- 路径前缀,只有能够匹配该路径前缀的数据才会被抽取,用作后续的处理和发送
- 'extractor.pattern' = 'root.timecho',
- -- 是否抽取历史数据
- 'extractor.history.enable' = 'true',
+ 'source.pattern' = 'root.timecho',
-- 描述被抽取的历史数据的时间范围,表示最早时间
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- 描述被抽取的历史数据的时间范围,表示最晚时间
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
- -- 是否抽取实时数据
- 'extractor.realtime.enable' = 'true',
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
)
WITH PROCESSOR (
-- 默认的数据处理插件,即不做任何处理
'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
**创建同步任务时需要配置 PipeId 以及三个插件部分的参数:**
-| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
-| --------- | ------------------------------------------------- | --------------------------- | -------------------- | ------------------------------------------------------ | ------------------------- |
-| PipeId | 全局唯一标定一个同步任务的名称 | 必填 | - | - | - |
-| extractor | Pipe Extractor 插件,负责在数据库底层抽取同步数据 | 选填 | iotdb-extractor | 将数据库的全量历史数据和后续到达的实时数据接入同步任务 | 否 |
-| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
-| connector | Pipe Connector 插件,负责发送数据 | 必填 | - | - | 是 |
+| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
+|-----------|-------------------------------|---------------------------|----------------------|-----------------------------|--------------------------|
+| PipeId | 全局唯一标定一个同步任务的名称 | 必填 | - | - | - |
+| source | Pipe Source 插件,负责在数据库底层抽取同步数据 | 选填 | iotdb-source | 将数据库的全量历史数据和后续到达的实时数据接入同步任务 | 否 |
+| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
+| sink | Pipe Sink 插件,负责发送数据 | 必填 | - | - | 是 |
-示例中,使用了 iotdb-extractor、do-nothing-processor 和 iotdb-thrift-connector 插件构建数据同步任务。IoTDB 还内置了其他的数据同步插件,**请查看“系统预置数据同步插件”一节**。
+示例中,使用了 iotdb-source、do-nothing-processor 和 iotdb-thrift-sink 插件构建数据同步任务。IoTDB 还内置了其他的数据同步插件,**请查看“系统预置数据同步插件”一节**。
**一个最简的 CREATE PIPE 语句示例如下:**
```sql
CREATE PIPE -- PipeId 是能够唯一标定任务任务的名字
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -145,29 +141,29 @@ WITH CONNECTOR (
**注意:**
-- EXTRACTOR 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
-- CONNECTOR 为必填配置,需要在 CREATE PIPE 语句中声明式配置
-- CONNECTOR 具备自复用能力。对于不同的任务,如果他们的 CONNECTOR 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 CONNECTOR 实例**,以实现对连接资源的复用。
+- SOURCE 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
+- SINK 为必填配置,需要在 CREATE PIPE 语句中声明式配置
+- SINK 具备自复用能力。对于不同的任务,如果他们的 SINK 具备完全相同的 KV 属性(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 SINK 实例**,以实现对连接资源的复用。
- 例如,有下面 pipe1, pipe2 两个任务的声明:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
)
```
- - 因为它们对 CONNECTOR 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 CONNECTOR 进行复用,最终 pipe1, pipe2 的CONNECTOR 将会是同一个实例。
+ - 因为它们对 SINK 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 SINK 进行复用,最终 pipe1, pipe2 的 SINK 将会是同一个实例。
- 请不要构建出包含数据循环同步的应用场景(会导致无限循环):
- IoTDB A -> IoTDB B -> IoTDB A
@@ -175,9 +171,9 @@ WITH CONNECTOR (
### 启动任务
-CREATE PIPE 语句成功执行后,任务相关实例会被创建,但整个任务的运行状态会被置为 STOPPED,即任务不会立刻处理数据。
+CREATE PIPE 语句成功执行后,任务相关实例会被创建,但整个任务的运行状态会被置为 STOPPED(V1.3.0),即任务不会立刻处理数据。在 V1.3.1 及以后的版本,任务的状态在 CREATE 后将会被置为 RUNNING。
-可以使用 START PIPE 语句使任务开始处理数据:
+当任务状态为 STOPPED 时,可以使用 START PIPE 语句使任务开始处理数据:
```sql
START PIPE
@@ -212,13 +208,13 @@ SHOW PIPES
查询结果如下:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime | State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
可以使用 `` 指定想看的某个同步任务状态:
@@ -227,22 +223,23 @@ SHOW PIPES
SHOW PIPE
```
-您也可以通过 where 子句,判断某个 \ 使用的 Pipe Connector 被复用的情况。
+您也可以通过 where 子句,判断某个 \ 使用的 Pipe Sink 被复用的情况。
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### 任务运行状态迁移
-一个数据同步 pipe 在其被管理的生命周期中会经过多种状态:
+一个数据同步 pipe 在其生命周期中会经过多种状态:
- **STOPPED:** pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
- - 当一个 pipe 被成功创建之后,其初始状态为暂停状态
+ - 当一个 pipe 被成功创建之后,其初始状态为暂停状态(V1.3.0)
- 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
- 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
- **RUNNING:** pipe 正在正常工作
+ - 当一个 pipe 被成功创建之后,其初始状态为工作状态(V1.3.1)
- **DROPPED:** pipe 任务被永久删除
下图表明了所有状态以及状态的迁移:
@@ -250,7 +247,24 @@ WHERE CONNECTOR USED BY

## 系统预置数据同步插件
-
+📌 说明:在 1.3.1 及以上的版本中,除 source、processor、sink 本身外,各项参数不再需要额外增加 source、processor、sink 前缀。例如:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6668'
+)
+```
+可以写作
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'ip'='127.0.0.1',
+ 'port'='6668'
+)
+```
### 查看预置插件
用户可以按需查看系统中的插件。查看插件的语句如图所示。
@@ -259,27 +273,27 @@ WHERE CONNECTOR USED BY
SHOW PIPEPLUGINS
```
-### 预置 extractor 插件
+### 预置 Source 插件
-#### iotdb-extractor
+#### iotdb-source
作用:抽取 IoTDB 内部的历史或实时数据进入 pipe。
-| key | value | value 取值范围 | required or optional with default |
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor | String: iotdb-extractor | required |
-| extractor.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
-| extractor.history.enable | 是否同步历史数据 | Boolean: true, false | optional: true |
-| extractor.history.start-time | 同步历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | 同步历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | 是否同步实时数据 | Boolean: true, false | optional: true |
+| key | value | value 取值范围 | required or optional with default |
+|---------------------------|--------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
+| source.history.start-time | 同步历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | 同步历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | 同步所有数据的开始 event time,包含 start-time, 配置时 source.historical.start-time 及 source.historical.end-time 将被忽略 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | 同步所有数据的结束 event time,包含 end-time, 配置时 source.historical.start-time 及 source.historical.end-time 将被忽略 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-> 🚫 **extractor.pattern 参数说明**
+> 🚫 **source.pattern 参数说明**
>
> * Pattern 需用反引号修饰不合法字符或者是不合法路径节点,例如如果希望筛选 root.\`a@b\` 或者 root.\`123\`,应设置 pattern 为 root.\`a@b\` 或者 root.\`123\`(具体参考 [单双引号和反引号的使用时机](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
-> * 在底层实现中,当检测到 pattern 为 root(默认值)时,同步效率较高,其他任意格式都将降低性能
-> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'extractor.pattern'='root.aligned.1' 的 pipe 时:
+> * 在底层实现中,当检测到 pattern 为 root(默认值)或某个 Database 时,同步效率较高,其他任意格式都将降低性能
+> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'source.pattern'='root.aligned.1' 的 pipe 时:
>
> * root.aligned.1TS
> * root.aligned.1TS.\`1\`
@@ -292,9 +306,9 @@ SHOW PIPEPLUGINS
>
> 的数据不会被同步。
-> ❗️**extractor.history 的 start-time,end-time 参数说明**
+> ❗️** start-time,end-time 参数说明**
>
-> * start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或 2011-12-03T10:15:30+01:00
+> * start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或 2011-12-03T10:15:30+01:00。V1.3.1 及以后的版本能够支持纯时间戳格式,如 1706704494000。
> ✅ **一条数据从生产到落库 IoTDB,包含两个关键的时间概念**
>
@@ -303,34 +317,27 @@ SHOW PIPEPLUGINS
>
> 我们常说的乱序数据,指的是数据到达时,其 **event time** 远落后于当前系统时间(或者已经落库的最大 **event time**)的数据。另一方面,不论是乱序数据还是顺序数据,只要它们是新到达系统的,那它们的 **arrival time** 都是会随着数据到达 IoTDB 的顺序递增的。
-> 💎 **iotdb-extractor 的工作可以拆分成两个阶段**
+> 💎 **iotdb-source 的工作可以拆分成两个阶段**
>
> 1. 历史数据抽取:所有 **arrival time** < 创建 pipe 时**当前系统时间**的数据称为历史数据
> 2. 实时数据抽取:所有 **arrival time** >= 创建 pipe 时**当前系统时间**的数据称为实时数据
>
> 历史数据传输阶段和实时数据传输阶段,**两阶段串行执行,只有当历史数据传输阶段完成后,才执行实时数据传输阶段。**
->
-> 用户可以指定 iotdb-extractor 进行:
->
-> * 历史数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * 实时数据抽取(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * 全量数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * 禁止同时设置 `extractor.history.enable` 和 `extractor.realtime.enable` 为 `false`
### 预置 processor 插件
#### do-nothing-processor
-作用:不对 extractor 传入的事件做任何的处理。
+作用:不对 source 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value 取值范围 | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### 预置 connector 插件
+### 预置 sink 插件
-#### iotdb-thrift-sync-connector(别名:iotdb-thrift-connector)
+#### iotdb-thrift-sync-sink
作用:主要用于 IoTDB(v1.2.0+)与 IoTDB(v1.2.0+)之间的数据传输。
使用 Thrift RPC 框架传输数据,单线程 blocking IO 模型。
@@ -339,16 +346,16 @@ SHOW PIPEPLUGINS
限制:源端 IoTDB 与 目标端 IoTDB 版本都需要在 v1.2.0+。
-| key | value | value 取值范围 | required or optional with default |
-| --------------------------------- | --------------------------------------------------------------------------- | ---------------------------------------------------------------------------- | ----------------------------------------------------- |
-| connector | iotdb-thrift-connector 或 iotdb-thrift-sync-connector | String: iotdb-thrift-connector 或 iotdb-thrift-sync-connector | required |
-| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | optional: 与 connector.node-urls 任选其一填写 |
-| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | optional: 与 connector.node-urls 任选其一填写 |
-| connector.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: 与 connector.ip:connector.port 任选其一填写 |
+| key | value | value 取值范围 | required or optional with default |
+|----------------|----------------------------------------|---------------------------------------------------------------------------|--------------------------------------|
+| sink | iotdb-thrift-sync-sink | String: iotdb-thrift-sync-sink | required |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | optional: 与 sink.node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | optional: 与 sink.node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: 与 sink.ip:sink.port 任选其一填写 |
> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
-#### iotdb-thrift-async-connector
+#### iotdb-thrift-async-sink(别名:iotdb-thrift-sink)
作用:主要用于 IoTDB(v1.2.0+)与 IoTDB(v1.2.0+)之间的数据传输。
使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景。
@@ -357,18 +364,18 @@ SHOW PIPEPLUGINS
限制:源端 IoTDB 与 目标端 IoTDB 版本都需要在 v1.2.0+。
-| key | value | value 取值范围 | required or optional with default |
-| --------------------------------- | --------------------------------------------------------------------------- | ---------------------------------------------------------------------------- | ----------------------------------------------------- |
-| connector | iotdb-thrift-async-connector | String: iotdb-thrift-async-connector | required |
-| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | optional: 与 connector.node-urls 任选其一填写 |
-| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | optional: 与 connector.node-urls 任选其一填写 |
-| connector.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: 与 connector.ip:connector.port 任选其一填写 |
+| key | value | value 取值范围 | required or optional with default |
+|----------------|---------------------------------------------|---------------------------------------------------------------------------|-----------------------------------|
+| sink | iotdb-thrift-async-sink 或 iotdb-thrift-sink | String: iotdb-thrift-async-sink 或 iotdb-thrift-sink | required |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | optional: 与 node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | optional: 与 node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: 与 ip:port 任选其一填写 |
> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
-#### iotdb-legacy-pipe-connector
+#### iotdb-legacy-pipe-sink
-作用:主要用于 IoTDB(v1.2.0+)向更低版本的 IoTDB 传输数据,使用 v1.2.0 版本前的数据同步(Sync)协议。
+作用:主要用于 IoTDB(v1.2.0+)向 v1.2.0 前的 IoTDB 传输数据,使用 v1.2.0 版本前的数据同步(Sync)协议。
使用 Thrift RPC 框架传输数据。单线程 sync blocking IO 模型,传输性能较弱。
限制:源端 IoTDB 版本需要在 v1.2.0+,目标端 IoTDB 版本可以是 v1.2.0+、v1.1.x(更低版本的 IoTDB 理论上也支持,但是未经测试)。
@@ -376,40 +383,41 @@ SHOW PIPEPLUGINS
注意:理论上 v1.2.0+ IoTDB 可作为 v1.2.0 版本前的任意版本的数据同步(Sync)接收端。
-| key | value | value 取值范围 | required or optional with default |
-| ------------------ | --------------------------------------------------------------------- | ----------------------------------- | --------------------------------- |
-| connector | iotdb-legacy-pipe-connector | String: iotdb-legacy-pipe-connector | required |
-| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | required |
-| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | required |
-| connector.user | 目标端 IoTDB 的用户名,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
-| connector.password | 目标端 IoTDB 的密码,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
-| connector.version | 目标端 IoTDB 的版本,用于伪装自身实际版本,绕过目标端的版本一致性检查 | String | optional: 1.1 |
+| key | value | value 取值范围 | required or optional with default |
+|---------------|----------------------------------------------|--------------------------------|-----------------------------------|
+| sink | iotdb-legacy-pipe-sink | String: iotdb-legacy-pipe-sink | required |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | required |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | required |
+| sink.user | 目标端 IoTDB 的用户名,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
+| sink.password | 目标端 IoTDB 的密码,注意该用户需要支持数据写入、TsFile Load 的权限 | String | optional: root |
+| sink.version | 目标端 IoTDB 的版本,用于伪装自身实际版本,绕过目标端的版本一致性检查 | String | optional: 1.1 |
> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
-#### do-nothing-connector
+#### do-nothing-sink
作用:不对 processor 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value 取值范围 | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## 权限管理
-| 权限名称 | 描述 |
-| ----------- | -------------------- |
-| CREATE_PIPE | 注册任务。路径无关。 |
-| START_PIPE | 开启任务。路径无关。 |
-| STOP_PIPE | 停止任务。路径无关。 |
-| DROP_PIPE | 卸载任务。路径无关。 |
-| SHOW_PIPES | 查询任务。路径无关。 |
+| 权限名称 | 描述 |
+|----------|------------|
+| USE_PIPE | 注册任务。路径无关。 |
+| USE_PIPE | 开启任务。路径无关。 |
+| USE_PIPE | 停止任务。路径无关。 |
+| USE_PIPE | 卸载任务。路径无关。 |
+| USE_PIPE | 查询任务。路径无关。 |
## 配置参数
在 iotdb-common.properties 中:
+V1.3.0+:
```Properties
####################
### Pipe Configuration
@@ -441,6 +449,36 @@ SHOW PIPEPLUGINS
# pipe_async_connector_max_client_number=16
```
+V1.3.1+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+```
+
## 功能特性
### 最少一次语义保证 **at-least-once**
diff --git a/src/zh/UserGuide/latest/User-Manual/Data-Sync_timecho.md b/src/zh/UserGuide/latest/User-Manual/Data-Sync_timecho.md
index b1344cab..809b35d5 100644
--- a/src/zh/UserGuide/latest/User-Manual/Data-Sync_timecho.md
+++ b/src/zh/UserGuide/latest/User-Manual/Data-Sync_timecho.md
@@ -20,7 +20,7 @@
-->
# 数据同步
-数据同步是工业物联网的典型需求,通过数据同步机制,可实现IoTDB之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
+数据同步是工业物联网的典型需求,通过数据同步机制,可实现 IoTDB 之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
## 功能介绍
@@ -28,8 +28,8 @@
一个数据同步任务包含2个阶段:
-- 抽取(Source)阶段:该部分用于从源 IoTDB 抽取数据,在SQL语句中的 source 部分定义
-- 发送(Sink)阶段:该部分用于向目标 IoTDB 发送数据,在SQL语句中的 sink 部分定义
+- 抽取(Source)阶段:该部分用于从源 IoTDB 抽取数据,在 SQL 语句中的 source 部分定义
+- 发送(Sink)阶段:该部分用于向目标 IoTDB 发送数据,在 SQL 语句中的 sink 部分定义
@@ -64,8 +64,9 @@ WITH SINK (
一个数据同步任务在生命周期中会经过多种状态:
- RUNNING: 运行状态。
+ - 说明1:任务的初始状态为运行状态(V1.3.1 及以上)
- STOPPED: 停止状态。
- - 说明1:任务的初始状态为停止状态,需要使用SQL语句启动任务
+ - 说明1:任务的初始状态为停止状态(V1.3.0),需要使用SQL语句启动任务
- 说明2:用户也可以使用SQL语句手动将一个处于运行状态的任务停止,此时状态会从 RUNNING 变为 STOPPED
- 说明3:当一个任务出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
- DROPPED:删除状态。
@@ -112,22 +113,23 @@ SHOW PIPE
### 插件
-为了使得整体架构更加灵活以匹配不同的同步场景需求,在上述同步任务框架中IoTDB支持进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义 sink 插件,并加载至IoTDB系统进行使用。
+为了使得整体架构更加灵活以匹配不同的同步场景需求,在上述同步任务框架中 IoTDB 支持进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义 Sink 插件,并加载至 IoTDB 系统进行使用。
-| 模块 | 插件 | 预置插件 | 自定义插件 |
-| --- | --- | --- | --- |
-| 抽取(Source) | Source 插件 | iotdb-source | 不支持 |
-| 发送(Sink) | Sink 插件 | iotdb-thrift-sink、iotdb-air-gap-sink| 支持 |
+| 模块 | 插件 | 预置插件 | 自定义插件 |
+|----------------|--------------|--------------------------------------|-------|
+| 抽取(Source) | Source 插件 | iotdb-source | 不支持 |
+| 发送(Sink) | Sink 插件 | iotdb-thrift-sink、iotdb-air-gap-sink | 支持 |
#### 预置插件
预置插件如下:
-| 插件名称 | 类型 | 介绍 | 适用版本 |
-| ---------------------------- | ---- | ------------------------------------------------------------ | --------- |
-| iotdb-source | source 插件 | 默认的 source 插件,用于抽取 IoTDB 历史或实时数据 | 1.2.x |
-| iotdb-thrift-sink | sink 插件 | 用于 IoTDB(v1.2.0及以上)与 IoTDB(v1.2.0及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景 | 1.2.x |
-| iotdb-air-gap-sink | sink 插件 | 用于 IoTDB(v1.2.2+)向 IoTDB(v1.2.2+)跨单向数据网闸的数据同步。支持的网闸型号包括南瑞 Syskeeper 2000 等 | 1.2.1以上 |
+| 插件名称 | 类型 | 介绍 | 适用版本 |
+|-----------------------|--------------|-----------------------------------------------------------------------------------------------------------------------|-----------|
+| iotdb-source | source 插件 | 默认的 source 插件,用于抽取 IoTDB 历史或实时数据 | 1.2.x |
+| iotdb-thrift-sink | sink 插件 | 用于 IoTDB(v1.2.0及以上)与 IoTDB(v1.2.0及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景 | 1.2.x |
+| iotdb-air-gap-sink | sink 插件 | 用于 IoTDB(v1.2.2+)向 IoTDB(v1.2.2+)跨单向数据网闸的数据同步。支持的网闸型号包括南瑞 Syskeeper 2000 等 | 1.2.2 及以上 |
+| iotdb-thrift-ssl-sink | sink plugin | 用于 IoTDB(v1.3.1及以上)与 IoTDB(v1.2.0及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,单线程 sync blocking IO 模型,适用于安全需求较高的场景 | 1.3.1 及以上 |
每个插件的详细参数可参考本文[参数说明](#sink-参数)章节。
@@ -143,16 +145,16 @@ SHOW PIPEPLUGINS
```Go
IoTDB> show pipeplugins
-+--------------------+----------+---------------------------------------------------------------------------+---------+
-| PluginName|PluginType| ClassName|PluginJar|
-+--------------------+----------+---------------------------------------------------------------------------+---------+
-|DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.DoNothingProcessor| |
-| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.DoNothingSink| |
-| IOTDB-AIR-GAP-SINK| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBAirGapSink| |
-| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.source.IoTDBSOURCE| |
-| IOTDB-THRIFT-SINK| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBThriftSinkr| |
-| OPC-UA-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.OpcUaSink| |
-+--------------------+----------+---------------------------------------------------------------------------+---------+
++------------------------------+----------+---------------------------------------------------------------------------------+---------+
+| PluginName|PluginType| ClassName|PluginJar|
++------------------------------+--------------------------------------------------------------------------------------------+---------+
+| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.DoNothingProcessor| |
+| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.DoNothingSink| |
+| IOTDB-AIR-GAP-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBAirGapSink| |
+| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.source.IoTDBSOURCE| |
+| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.sink.IoTDBThriftSink| |
+|IOTDB-THRIFT-SSL-SINK(V1.3.1+)| Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.sink.iotdb.thrift.IoTDBThriftSslSink| |
++------------------------------+----------+---------------------------------------------------------------------------------+---------+
```
@@ -160,7 +162,7 @@ IoTDB> show pipeplugins
### 全量数据同步
-本例子用来演示将一个 IoTDB 的所有数据同步至另一个IoTDB,数据链路如下图所示:
+本例子用来演示将一个 IoTDB 的所有数据同步至另一个 IoTDB,数据链路如下图所示:

@@ -178,26 +180,26 @@ with sink (
### 历史数据同步
-本例子用来演示同步某个历史时间范围(2023年8月23日8点到2023年10月23日8点)的数据至另一个IoTDB,数据链路如下图所示:
+本例子用来演示同步某个历史时间范围( 2023 年 8 月 23 日 8 点到 2023 年 10 月 23 日 8 点)的数据至另一个 IoTDB,数据链路如下图所示:

-在这个例子中,我们可以创建一个名为 A2B 的同步任务。首先我们需要在 source 中定义传输数据的范围,由于传输的是历史数据(历史数据是指同步任务创建之前存在的数据),所以需要将source.realtime.enable参数配置为false;同时需要配置数据的起止时间start-time和end-time以及传输的模式mode,此处推荐mode设置为 hybrid 模式(hybrid模式为混合传输,在无数据积压时采用实时传输方式,有数据积压时采用批量传输方式,并根据系统内部情况自动切换)。
+在这个例子中,我们可以创建一个名为 A2B 的同步任务。首先我们需要在 source 中定义传输数据的范围,由于传输的是历史数据(历史数据是指同步任务创建之前存在的数据),所以需要将 source.realtime.enable 参数配置为 false;同时需要配置数据的起止时间 start-time 和 end-time 以及传输的模式 mode,此处推荐 mode 设置为 hybrid 模式(hybrid 模式为混合传输,在无数据积压时采用实时传输方式,有数据积压时采用批量传输方式,并根据系统内部情况自动切换)。
详细语句如下:
```SQL
create pipe A2B
WITH SOURCE (
-'source'= 'iotdb-source',
-'source.realtime.enable' = 'false',
-'source.realtime.mode'='hybrid',
-'source.history.start-time' = '2023.08.23T08:00:00+00:00',
-'source.history.end-time' = '2023.10.23T08:00:00+00:00')
+ 'source'= 'iotdb-source',
+ 'source.start-time' = '2023.08.23T08:00:00+00:00',
+ 'source.end-time' = '2023.10.23T08:00:00+00:00'
+)
with SINK (
-'sink'='iotdb-thrift-async-sink',
-'sink.node-urls'='xxxx:6668',
-'sink.batch.enable'='false')
+ 'sink'='iotdb-thrift-async-sink',
+ 'sink.node-urls'='xxxx:6668',
+ 'sink.batch.enable'='false'
+)
```
@@ -205,19 +207,19 @@ with SINK (
本例子用来演示两个 IoTDB 之间互为双活的场景,数据链路如下图所示:
-
+
-在这个例子中,为了避免数据无限循环,需要将A和B上的参数`source.forwarding-pipe-requests` 均设置为 `false`,表示不转发从另一pipe传输而来的数据。同时将`'source.history.enable'` 设置为 `false`,表示不传输历史数据,即不同步创建该任务前的数据。
+在这个例子中,为了避免数据无限循环,需要将 A 和 B 上的参数`source.forwarding-pipe-requests` 均设置为 `false`,表示不转发从另一pipe传输而来的数据。
详细语句如下:
-在 A IoTDB 上执行下列语句:
+在 A IoTDB 上执行下列语句:
```Go
create pipe AB
with source (
- 'source.history.enable' = 'false',
- 'source.forwarding-pipe-requests' = 'false',
+ 'source.forwarding-pipe-requests' = 'false'
+)
with sink (
'sink'='iotdb-thrift-sink',
'sink.ip'='127.0.0.1',
@@ -230,8 +232,8 @@ with sink (
```Go
create pipe BA
with source (
- 'source.history.enable' = 'false',
- 'source.forwarding-pipe-requests' = 'false',
+ 'source.forwarding-pipe-requests' = 'false'
+)
with sink (
'sink'='iotdb-thrift-sink',
'sink.ip'='127.0.0.1',
@@ -243,13 +245,13 @@ with sink (
### 级联数据传输
-本例子用来演示多个 IoTDB 之间级联传输数据的场景,数据由A集群同步至B集群,再同步至C集群,数据链路如下图所示:
+本例子用来演示多个 IoTDB 之间级联传输数据的场景,数据由 A 集群同步至 B 集群,再同步至 C 集群,数据链路如下图所示:
-
+
-在这个例子中,为了将A集群的数据同步至C,在BC之间的pipe需要将 `source.forwarding-pipe-requests` 配置为`true`,详细语句如下:
+在这个例子中,为了将 A 集群的数据同步至 C,在 BC 之间的 pipe 需要将 `source.forwarding-pipe-requests` 配置为`true`,详细语句如下:
-在A IoTDB上执行下列语句,将A中数据同步至B:
+在 A IoTDB 上执行下列语句,将 A 中数据同步至 B:
```Go
create pipe AB
@@ -260,12 +262,13 @@ with sink (
)
```
-在B IoTDB上执行下列语句,将B中数据同步至C:
+在 B IoTDB 上执行下列语句,将 B 中数据同步至 C:
```Go
create pipe BC
with source (
- 'source.forwarding-pipe-requests' = 'true',
+ 'source.forwarding-pipe-requests' = 'true'
+)
with sink (
'sink'='iotdb-thrift-sink',
'sink.ip'='127.0.0.1',
@@ -275,13 +278,13 @@ with sink (
### 跨网闸数据传输
-本例子用来演示将一个 IoTDB 的数据,经过单向网闸,同步至另一个IoTDB的场景,数据链路如下图所示:
+本例子用来演示将一个 IoTDB 的数据,经过单向网闸,同步至另一个 IoTDB 的场景,数据链路如下图所示:

-在这个例子中,需要使用 sink 任务中的iotdb-air-gap-sink 插件(目前支持部分型号网闸,具体型号请联系天谋科技工作人员确认),配置网闸后,在 A IoTDB 上执行下列语句,其中ip和port填写网闸信息,详细语句如下:
+在这个例子中,需要使用 sink 任务中的 iotdb-air-gap-sink 插件(目前支持部分型号网闸,具体型号请联系天谋科技工作人员确认),配置网闸后,在 A IoTDB 上执行下列语句,其中 ip 和 port 填写网闸配置的虚拟 ip 和相关 port,详细语句如下:
-```Go
+```Sql
create pipe A2B
with sink (
'sink'='iotdb-air-gap-sink',
@@ -290,11 +293,30 @@ with sink (
)
```
+### SSL协议数据传输
+
+本例子演示了使用 SSL 协议配置 IoTDB 单向数据同步的场景,数据链路如下图所示:
+
+
+
+在该场景下,需要使用 IoTDB 的 iotdb-thrift-ssl-sink 插件。我们可以创建一个名为 A2B 的同步任务,并配置自身证书的密码和地址,详细语句如下:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-ssl-sink',
+ 'sink.ip'='127.0.0.1',
+ 'sink.port'='6669',
+ 'ssl.trust-store-path'='pki/trusted'
+ 'ssl.trust-store-pwd'='root'
+)
+```
+
## 参考:注意事项
可通过修改 IoTDB 配置文件(iotdb-common.properties)以调整数据同步的参数,如同步数据存储目录等。完整配置如下:
-```Go
+V1.3.0+:
+```Properties
####################
### Pipe Configuration
####################
@@ -332,20 +354,71 @@ with sink (
# pipe_air_gap_receiver_port=9780
```
+V1.3.1+:
+```Properties
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
+```
+
## 参考:参数说明
+📌 说明:在 1.3.1 及以上的版本中,除 source、processor、sink 本身外,各项参数不再需要额外增加 source、processor、sink 前缀。例如:
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'sink.ip'='10.53.53.53',
+ 'sink.port'='9780'
+)
+```
+可以写作
+```Sql
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'ip'='10.53.53.53',
+ 'port'='9780'
+)
+```
### source 参数
-| key | value | value 取值范围 | 是否必填 |默认取值|
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | -------- |------|
-| source | iotdb-source | String: iotdb-source | 必填 | - |
-| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | 选填 | root |
-| source.history.enable | 是否同步历史数据 | Boolean: true, false | 选填 | true |
-| source.history.start-time | 同步历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MIN_VALUE |
-| source.history.end-time | 同步历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MAX_VALUE |
-| source.realtime.enable | 是否同步实时数据 | Boolean: true, false | 选填 | true |
-| source.realtime.mode | 实时数据的抽取模式 | String: hybrid, stream, batch | 选填 | hybrid |
-| source.forwarding-pipe-requests | 是否转发由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | 选填 | true |
+| key | value | value 取值范围 | 是否必填 | 默认取值 |
+|---------------------------------|------------------------------------|----------------------------------------|------|----------------|
+| source | iotdb-source | String: iotdb-source | 必填 | - |
+| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | 选填 | root |
+| source.history.start-time | 同步历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MIN_VALUE |
+| source.history.end-time | 同步历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MAX_VALUE |
+| start-time(V1.3.1+) | 同步所有数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MIN_VALUE |
+| end-time(V1.3.1+) | 同步所有数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MAX_VALUE |
+| source.realtime.mode | 实时数据的抽取模式 | String: hybrid, stream, batch | 选填 | hybrid |
+| source.forwarding-pipe-requests | 是否转发由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | 选填 | true |
> 💎 **说明:历史数据与实时数据的差异**
>
@@ -365,24 +438,36 @@ with sink (
#### iotdb-thrift-sink
-| key | value | value 取值范围 | 是否必填 | 默认取值 |
-| --------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------------------------------------- |
-| sink | iotdb-thrift-sink 或 iotdb-thrift-sync-sink | String: iotdb-thrift-sink 或 iotdb-thrift-sync-sink | 必填 | |
-| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip(请注意同步任务不支持向自身服务进行转发) | String | 选填 | 与 sink.node-urls 任选其一填写 |
-| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port(请注意同步任务不支持向自身服务进行转发) | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
-| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
-| sink.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
-| sink.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
-| sink.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填
-
-
+| key | value | value 取值范围 | 是否必填 | 默认取值 |
+|------------------------------|-------------------------------------------------------------|---------------------------------------------------------------------------|------|----------------------------|
+| sink | iotdb-thrift-sink 或 iotdb-thrift-async-sink | String: iotdb-thrift-sink 或 iotdb-thrift-async-sink | 必填 | |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip(请注意同步任务不支持向自身服务进行转发) | String | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port(请注意同步任务不支持向自身服务进行转发) | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
+| sink.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
+| sink.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
+| sink.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | |
#### iotdb-air-gap-sink
-| key | value | value 取值范围 | 是否必填 | 默认取值 |
-| -------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------------------------------------- |
-| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | 必填 | |
-| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | 选填 | 与 sink.node-urls 任选其一填写 |
-| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
-| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
-| sink.air-gap.handshake-timeout-ms | 发送端与接收端在首次尝试建立连接时握手请求的超时时长,单位:毫秒 | Integer | 选填 | 5000 |
\ No newline at end of file
+| key | value | value 取值范围 | 是否必填 | 默认取值 |
+|-----------------------------------|----------------------------------------|---------------------------------------------------------------------------|------|----------------------------|
+| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | 必填 | |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip | String | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
+| sink.air-gap.handshake-timeout-ms | 发送端与接收端在首次尝试建立连接时握手请求的超时时长,单位:毫秒 | Integer | 选填 | 5000 |
+
+#### iotdb-thrift-ssl-sink(V1.3.1+)
+
+| key | value | value range | required or not | default value |
+|------------------------------|-------------------------------------------------------------|----------------------------------------------------------------------------------|-----------------|----------------------------------|
+| sink | iotdb-thrift-ssl-sink | String: iotdb-thrift-ssl-sink | 必填 | |
+| sink.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip(请注意同步任务不支持向自身服务进行转发) | String | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port(请注意同步任务不支持向自身服务进行转发) | Integer | 选填 | 与 sink.node-urls 任选其一填写 |
+| sink.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填 | 与 sink.ip:sink.port 任选其一填写 |
+| sink.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
+| sink.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
+| sink.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | |
+| ssl.trust-store-path | 连接目标端 DataNode 所需的 trust store 证书路径 | String.Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Optional | Fill in either sink.ip:sink.port |
+| ssl.trust-store-pwd | 连接目标端 DataNode 所需的 trust store 证书密码 | Integer | Optional | 5000 |
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/User-Manual/IoTDB-Data-Pipe_timecho.md b/src/zh/UserGuide/latest/User-Manual/IoTDB-Data-Pipe_timecho.md
index 8aa2568d..157f91fd 100644
--- a/src/zh/UserGuide/latest/User-Manual/IoTDB-Data-Pipe_timecho.md
+++ b/src/zh/UserGuide/latest/User-Manual/IoTDB-Data-Pipe_timecho.md
@@ -828,21 +828,21 @@ SHOW PIPEPLUGINS
## Pipe 任务
-| 权限名称 | 描述 |
-| ----------- | ---------------------- |
-| CREATE_PIPE | 注册流水线。路径无关。 |
-| START_PIPE | 开启流水线。路径无关。 |
-| STOP_PIPE | 停止流水线。路径无关。 |
-| DROP_PIPE | 卸载流水线。路径无关。 |
-| SHOW_PIPES | 查询流水线。路径无关。 |
+| 权限名称 | 描述 |
+|----------|-------------|
+| USE_PIPE | 注册流水线。路径无关。 |
+| USE_PIPE | 开启流水线。路径无关。 |
+| USE_PIPE | 停止流水线。路径无关。 |
+| USE_PIPE | 卸载流水线。路径无关。 |
+| USE_PIPE | 查询流水线。路径无关。 |
## Pipe 插件
-| 权限名称 | 描述 |
-| ----------------- | -------------------------- |
-| CREATE_PIPEPLUGIN | 注册流水线插件。路径无关。 |
-| DROP_PIPEPLUGIN | 开启流水线插件。路径无关。 |
-| SHOW_PIPEPLUGINS | 查询流水线插件。路径无关。 |
+| 权限名称 | 描述 |
+|----------|---------------|
+| USE_PIPE | 注册流水线插件。路径无关。 |
+| USE_PIPE | 开启流水线插件。路径无关。 |
+| USE_PIPE | 查询流水线插件。路径无关。 |
# 功能特性
diff --git a/src/zh/UserGuide/latest/User-Manual/Streaming.md b/src/zh/UserGuide/latest/User-Manual/Streaming.md
index bd23ab71..4339dd0d 100644
--- a/src/zh/UserGuide/latest/User-Manual/Streaming.md
+++ b/src/zh/UserGuide/latest/User-Manual/Streaming.md
@@ -25,19 +25,19 @@ IoTDB 流处理框架允许用户实现自定义的流处理逻辑,可以实
我们将一个数据流处理任务称为 Pipe。一个流处理任务(Pipe)包含三个子任务:
-- 抽取(Extract)
+- 抽取(Source)
- 处理(Process)
-- 发送(Connect)
+- 发送(Sink)
流处理框架允许用户使用 Java 语言自定义编写三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。
在一个 Pipe 中,上述的三个子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:
-Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Connector 用于发送数据,最终数据将被发至外部系统。
+Pipe Source 用于抽取数据,Pipe Processor 用于处理数据,Pipe Sink 用于发送数据,最终数据将被发至外部系统。
**Pipe 任务的模型如下:**
-
+
-描述一个数据流处理任务,本质就是描述 Pipe Extractor、Pipe Processor 和 Pipe Connector 插件的属性。
+描述一个数据流处理任务,本质就是描述 Pipe Source、Pipe Processor 和 Pipe Sink 插件的属性。
用户可以通过 SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
利用流处理框架,可以搭建完整的数据链路来满足端*边云同步、异地灾备、读写负载分库*等需求。
@@ -52,7 +52,7 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
org.apache.iotdb
pipe-api
- 1.2.1
+ 1.3.1
provided
```
@@ -61,7 +61,7 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
流处理插件的用户编程接口设计,参考了事件驱动编程模型的通用设计理念。事件(Event)是用户编程接口中的数据抽象,而编程接口与具体的执行方式解耦,只需要专注于描述事件(数据)到达系统后,系统期望的处理方式即可。
-在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeExtractor 插件,PipeProcessor 插件和 PipeConnector 插件,并依次在三个插件中触发用户逻辑的执行。
+在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeSource 插件,PipeProcessor 插件和 PipeSink 插件,并依次在三个插件中触发用户逻辑的执行。
为了兼顾端侧低负载场景下的流处理低延迟和端侧高负载场景下的流处理高吞吐,流处理引擎会动态地在操作日志和数据文件中选择处理对象,因此,流处理的用户编程接口要求用户提供下列两类事件的处理逻辑:操作日志写入事件 TabletInsertionEvent 和数据文件写入事件 TsFileInsertionEvent。
@@ -133,39 +133,39 @@ public interface TsFileInsertionEvent extends Event {
#### 数据抽取插件接口
-数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeExtractor)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,
+数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeSource)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,
捕获各种数据写入事件。
```java
/**
- * PipeExtractor
+ * PipeSource
*
- * PipeExtractor is responsible for capturing events from sources.
+ *
PipeSource is responsible for capturing events from sources.
*
- *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
Various data sources can be supported by implementing different PipeSource classes.
*
- *
The lifecycle of a PipeExtractor is as follows:
+ *
The lifecycle of a PipeSource is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
- * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
+ *
- When a collaboration task is created, the KV pairs of `WITH SOURCE` clause in SQL are
+ * parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
+ * be called to validate the parameters.
*
- Before the collaboration task starts, the method {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeExtractor.
- *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
- *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
- * be called to capture events from sources and then the events will be passed to the
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
+ * config the runtime behavior of the PipeSource.
+ *
- Then the method {@link PipeSource#start()} will be called to start the PipeSource.
+ *
- While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
+ * called to capture events from sources and then the events will be passed to the
* PipeProcessor.
- *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ *
- The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
*
*/
-public interface PipeExtractor extends PipePlugin {
+public interface PipeSource extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
@@ -173,39 +173,39 @@ public interface PipeExtractor extends PipePlugin {
void validate(PipeParameterValidator validator) throws Exception;
/**
- * This method is mainly used to customize PipeExtractor. In this method, the user can do the
+ * This method is mainly used to customize PipeSource. In this method, the user can do the
* following things:
*
*
* - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
+ *
- Set the running configurations in PipeSourceRuntimeConfiguration.
*
*
- * This method is called after the method {@link
- * PipeExtractor#validate(PipeParameterValidator)} is called.
+ *
This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
+ * is called.
*
* @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeExtractor
+ * @param configuration used to set the required properties of the running PipeSource
* @throws Exception the user can throw errors if necessary
*/
- void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
+ void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
throws Exception;
/**
- * Start the extractor. After this method is called, events should be ready to be supplied by
- * {@link PipeExtractor#supply()}. This method is called after {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
+ * Start the Source. After this method is called, events should be ready to be supplied by
+ * {@link PipeSource#supply()}. This method is called after {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @throws Exception the user can throw errors if necessary
*/
void start() throws Exception;
/**
- * Supply single event from the extractor and the caller will send the event to the processor.
- * This method is called after {@link PipeExtractor#start()} is called.
+ * Supply single event from the Source and the caller will send the event to the processor.
+ * This method is called after {@link PipeSource#start()} is called.
*
- * @return the event to be supplied. the event may be null if the extractor has no more events at
- * the moment, but the extractor is still running for more events.
+ * @return the event to be supplied. the event may be null if the Source has no more events at
+ * the moment, but the Source is still running for more events.
* @throws Exception the user can throw errors if necessary
*/
Event supply() throws Exception;
@@ -214,14 +214,14 @@ public interface PipeExtractor extends PipePlugin {
#### 数据处理插件接口
-数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeExtractor)捕获的
+数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeSource)捕获的
各种事件。
```java
/**
* PipeProcessor
*
- *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
*
The lifecycle of a PipeProcessor is as follows:
*
@@ -234,13 +234,13 @@ public interface PipeExtractor extends PipePlugin {
* to config the runtime behavior of the PipeProcessor.
*
While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
- *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
- PipeSink serializes the events into binaries and send them to sinks.
*
* When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
@@ -315,51 +315,49 @@ public interface PipeProcessor extends PipePlugin {
#### 数据发送插件接口
-数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeConnector)主要用于发送经由数据处理插件(PipeProcessor)处理过后的
+数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeSink)主要用于发送经由数据处理插件(PipeProcessor)处理过后的
各种事件,它作为流处理框架的网络实现层,接口上应允许接入多种实时通信协议和多种连接器。
```java
/**
- * PipeConnector
+ * PipeSink
*
- * PipeConnector is responsible for sending events to sinks.
+ *
PipeSink is responsible for sending events to sinks.
*
- *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
Various network protocols can be supported by implementing different PipeSink classes.
*
- *
The lifecycle of a PipeConnector is as follows:
+ *
The lifecycle of a PipeSink is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
- * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
- *
- Before the collaboration task starts, the method {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeConnector and the method {@link
- * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
+ * parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
+ * called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
+ * PipeSinkRuntimeConfiguration)} will be called to config the runtime behavior of the
+ * PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
+ * with sink.
*
- While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector.
- *
- PipeConnector serializes the events into binaries and send them to sinks. The
- * following 3 methods will be called: {@link
- * PipeConnector#transfer(TabletInsertionEvent)}, {@link
- * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
- * PipeConnector#transfer(Event)}.
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink.
+ *
- PipeSink serializes the events into binaries and send them to sinks. The following 3
+ * methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
+ * PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
*
* - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
- * PipeConnector#close() } method will be called.
+ * PipeSink#close() } method will be called.
*
*
- * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
- * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
- * will be called to create a new connection with the sink when the method {@link
- * PipeConnector#heartbeat()} throws exceptions.
+ *
In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
+ * called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
+ * throws exceptions.
*/
-public interface PipeConnector extends PipePlugin {
+public interface PipeSink extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
+ * PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
@@ -367,29 +365,28 @@ public interface PipeConnector extends PipePlugin {
void validate(PipeParameterValidator validator) throws Exception;
/**
- * This method is mainly used to customize PipeConnector. In this method, the user can do the
- * following things:
+ * This method is mainly used to customize PipeSink. In this method, the user can do the following
+ * things:
*
*
* - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
+ *
- Set the running configurations in PipeSinkRuntimeConfiguration.
*
*
- * This method is called after the method {@link
- * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
- * PipeConnector#handshake()} is called.
+ *
This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
+ * called and before the method {@link PipeSink#handshake()} is called.
*
* @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeConnector
+ * @param configuration used to set the required properties of the running PipeSink
* @throws Exception the user can throw errors if necessary
*/
- void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
+ void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
throws Exception;
/**
* This method is used to create a connection with sink. This method will be called after the
- * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
- * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
+ * method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
+ * will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
*
* @throws Exception if the connection is failed to be created
*/
@@ -420,14 +417,18 @@ public interface PipeConnector extends PipePlugin {
* @throws Exception the user can throw errors if necessary
*/
default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- transfer(tabletInsertionEvent);
+ try {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ } finally {
+ tsFileInsertionEvent.close();
}
}
/**
- * This method is used to transfer the Event.
+ * This method is used to transfer the generic events, including HeartbeatEvent.
*
* @param event Event to be transferred
* @throws PipeConnectionException if the connection is broken
@@ -444,7 +445,7 @@ public interface PipeConnector extends PipePlugin {
### 加载插件语句
-在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeExtractor、 PipeProcessor 或者 PipeConnector 实现一个具体的插件类,
+在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeSource、 PipeProcessor 或者 PipeSink 实现一个具体的插件类,
然后需要将插件类编译打包成 jar 可执行文件,最后使用加载插件的管理语句将插件载入 IoTDB。
加载插件的管理语句的语法如图所示。
@@ -483,27 +484,27 @@ SHOW PIPEPLUGINS
## 系统预置的流处理插件
-### 预置 extractor 插件
+### 预置 source 插件
-#### iotdb-extractor
+#### iotdb-source
作用:抽取 IoTDB 内部的历史或实时数据进入 pipe。
-| key | value | value 取值范围 | required or optional with default |
-| ---------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor | String: iotdb-extractor | required |
-| extractor.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
-| extractor.history.enable | 是否抽取历史数据 | Boolean: true, false | optional: true |
-| extractor.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | 是否抽取实时数据 | Boolean: true, false | optional: true |
+| key | value | value 取值范围 | required or optional with default |
+|---------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
+| source.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-> 🚫 **extractor.pattern 参数说明**
+> 🚫 **source.pattern 参数说明**
>
> * Pattern 需用反引号修饰不合法字符或者是不合法路径节点,例如如果希望筛选 root.\`a@b\` 或者 root.\`123\`,应设置 pattern 为 root.\`a@b\` 或者 root.\`123\`(具体参考 [单双引号和反引号的使用时机](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
> * 在底层实现中,当检测到 pattern 为 root(默认值)时,抽取效率较高,其他任意格式都将降低性能
-> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'extractor.pattern'='root.aligned.1' 的 pipe 时:
+> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'source.pattern'='root.aligned.1' 的 pipe 时:
>
> * root.aligned.1TS
> * root.aligned.1TS.\`1\`
@@ -516,7 +517,7 @@ SHOW PIPEPLUGINS
>
> 的数据不会被抽取。
-> ❗️**extractor.history 的 start-time,end-time 参数说明**
+> ❗️**source.history 的 start-time,end-time 参数说明**
>
> * start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或 2011-12-03T10:15:30+01:00
@@ -527,41 +528,34 @@ SHOW PIPEPLUGINS
>
> 我们常说的乱序数据,指的是数据到达时,其 **event time** 远落后于当前系统时间(或者已经落库的最大 **event time**)的数据。另一方面,不论是乱序数据还是顺序数据,只要它们是新到达系统的,那它们的 **arrival time** 都是会随着数据到达 IoTDB 的顺序递增的。
-> 💎 **iotdb-extractor 的工作可以拆分成两个阶段**
+> 💎 **iotdb-source 的工作可以拆分成两个阶段**
>
> 1. 历史数据抽取:所有 **arrival time** < 创建 pipe 时**当前系统时间**的数据称为历史数据
> 2. 实时数据抽取:所有 **arrival time** >= 创建 pipe 时**当前系统时间**的数据称为实时数据
>
> 历史数据传输阶段和实时数据传输阶段,**两阶段串行执行,只有当历史数据传输阶段完成后,才执行实时数据传输阶段。**
->
-> 用户可以指定 iotdb-extractor 进行:
->
-> * 历史数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * 实时数据抽取(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * 全量数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * 禁止同时设置 `extractor.history.enable` 和 `extractor.realtime.enable` 为 `false`
### 预置 processor 插件
#### do-nothing-processor
-作用:不对 extractor 传入的事件做任何的处理。
+作用:不对 source 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value 取值范围 | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### 预置 connector 插件
+### 预置 sink 插件
-#### do-nothing-connector
+#### do-nothing-sink
作用:不对 processor 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value 取值范围 | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## 流处理任务管理
@@ -571,57 +565,53 @@ SHOW PIPEPLUGINS
```sql
CREATE PIPE -- PipeId 是能够唯一标定流处理任务的名字
-WITH EXTRACTOR (
+WITH SOURCE (
-- 默认的 IoTDB 数据抽取插件
- 'extractor' = 'iotdb-extractor',
+ 'source' = 'iotdb-source',
-- 路径前缀,只有能够匹配该路径前缀的数据才会被抽取,用作后续的处理和发送
- 'extractor.pattern' = 'root.timecho',
- -- 是否抽取历史数据
- 'extractor.history.enable' = 'true',
+ 'source.pattern' = 'root.timecho',
-- 描述被抽取的历史数据的时间范围,表示最早时间
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- 描述被抽取的历史数据的时间范围,表示最晚时间
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
- -- 是否抽取实时数据
- 'extractor.realtime.enable' = 'true',
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
)
WITH PROCESSOR (
-- 默认的数据处理插件,即不做任何处理
'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
**创建流处理任务时需要配置 PipeId 以及三个插件部分的参数:**
-| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
-| --------- | --------------------------------------------------- | --------------------------- | -------------------- | -------------------------------------------------------- | ------------------------- |
-| PipeId | 全局唯一标定一个流处理任务的名称 | 必填 | - | - | - |
-| extractor | Pipe Extractor 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-extractor | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
-| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
-| connector | Pipe Connector 插件,负责发送数据 | 必填 | - | - | 是 |
+| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
+|-----------|--------------------------------|---------------------------|----------------------|------------------------------|--------------------------|
+| PipeId | 全局唯一标定一个流处理任务的名称 | 必填 | - | - | - |
+| source | Pipe Source 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-source | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
+| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
+| sink | Pipe Sink 插件,负责发送数据 | 必填 | - | - | 是 |
-示例中,使用了 iotdb-extractor、do-nothing-processor 和 iotdb-thrift-connector 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,**请查看“系统预置流处理插件”一节**。
+示例中,使用了 iotdb-source、do-nothing-processor 和 iotdb-thrift-sink 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,**请查看“系统预置流处理插件”一节**。
**一个最简的 CREATE PIPE 语句示例如下:**
```sql
CREATE PIPE -- PipeId 是能够唯一标定流处理任务的名字
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -629,29 +619,29 @@ WITH CONNECTOR (
**注意:**
-- EXTRACTOR 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
-- CONNECTOR 为必填配置,需要在 CREATE PIPE 语句中声明式配置
-- CONNECTOR 具备自复用能力。对于不同的流处理任务,如果他们的 CONNECTOR 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 CONNECTOR 实例**,以实现对连接资源的复用。
+- SOURCE 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
+- SINK 为必填配置,需要在 CREATE PIPE 语句中声明式配置
+- SINK 具备自复用能力。对于不同的流处理任务,如果他们的 SINK 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 SINK 实例**,以实现对连接资源的复用。
- 例如,有下面 pipe1, pipe2 两个流处理任务的声明:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
)
```
- - 因为它们对 CONNECTOR 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 CONNECTOR 进行复用,最终 pipe1, pipe2 的CONNECTOR 将会是同一个实例。
+ - 因为它们对 SINK 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 SINK 进行复用,最终 pipe1, pipe2 的 SINK 将会是同一个实例。
- 请不要构建出包含数据循环同步的应用场景(会导致无限循环):
- IoTDB A -> IoTDB B -> IoTDB A
@@ -659,7 +649,7 @@ WITH CONNECTOR (
### 启动流处理任务
-CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED,即流处理任务不会立刻处理数据。
+CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED(V1.3.0),即流处理任务不会立刻处理数据。在 1.3.1 及以上的版本,流处理任务的运行状态在创建后将被立即置为 RUNNING。
可以使用 START PIPE 语句使流处理任务开始处理数据:
@@ -696,13 +686,13 @@ SHOW PIPES
查询结果如下:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime| State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
可以使用 `` 指定想看的某个流处理任务状态:
@@ -711,22 +701,23 @@ SHOW PIPES
SHOW PIPE
```
-您也可以通过 where 子句,判断某个 \ 使用的 Pipe Connector 被复用的情况。
+您也可以通过 where 子句,判断某个 \ 使用的 Pipe Sink 被复用的情况。
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### 流处理任务运行状态迁移
-一个流处理 pipe 在其被管理的生命周期中会经过多种状态:
+一个流处理 pipe 在其生命周期中会经过多种状态:
+- **RUNNING:** pipe 正在正常工作
+ - 当一个 pipe 被成功创建之后,其初始状态为工作状态(V1.3.1+)
- **STOPPED:** pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
- - 当一个 pipe 被成功创建之后,其初始状态为暂停状态
+ - 当一个 pipe 被成功创建之后,其初始状态为暂停状态(V1.3.0)
- 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
- 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
-- **RUNNING:** pipe 正在正常工作
- **DROPPED:** pipe 任务被永久删除
下图表明了所有状态以及状态的迁移:
@@ -738,8 +729,8 @@ WHERE CONNECTOR USED BY
### 流处理任务
-| 权限名称 | 描述 |
-| -------- | -------------------------- |
+| 权限名称 | 描述 |
+|----------|---------------|
| USE_PIPE | 注册流处理任务。路径无关。 |
| USE_PIPE | 开启流处理任务。路径无关。 |
| USE_PIPE | 停止流处理任务。路径无关。 |
@@ -749,8 +740,8 @@ WHERE CONNECTOR USED BY
### 流处理任务插件
-| 权限名称 | 描述 |
-| :------- | ------------------------------ |
+| 权限名称 | 描述 |
+|:---------|-----------------|
| USE_PIPE | 注册流处理任务插件。路径无关。 |
| USE_PIPE | 卸载流处理任务插件。路径无关。 |
| USE_PIPE | 查询流处理任务插件。路径无关。 |
@@ -759,6 +750,7 @@ WHERE CONNECTOR USED BY
在 iotdb-common.properties 中:
+V1.3.0:
```Properties
####################
### Pipe Configuration
@@ -779,4 +771,43 @@ WHERE CONNECTOR USED BY
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+```
+
+V1.3.1+:
+```Properties
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
```
diff --git a/src/zh/UserGuide/latest/User-Manual/Streaming_timecho.md b/src/zh/UserGuide/latest/User-Manual/Streaming_timecho.md
index dd13b2b4..f032ca62 100644
--- a/src/zh/UserGuide/latest/User-Manual/Streaming_timecho.md
+++ b/src/zh/UserGuide/latest/User-Manual/Streaming_timecho.md
@@ -25,19 +25,19 @@ IoTDB 流处理框架允许用户实现自定义的流处理逻辑,可以实
我们将一个数据流处理任务称为 Pipe。一个流处理任务(Pipe)包含三个子任务:
-- 抽取(Extract)
+- 抽取(Source)
- 处理(Process)
-- 发送(Connect)
+- 发送(Sink)
流处理框架允许用户使用 Java 语言自定义编写三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。
在一个 Pipe 中,上述的三个子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:
-Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Connector 用于发送数据,最终数据将被发至外部系统。
+Pipe Source 用于抽取数据,Pipe Processor 用于处理数据,Pipe Sink 用于发送数据,最终数据将被发至外部系统。
**Pipe 任务的模型如下:**
-
+
-描述一个数据流处理任务,本质就是描述 Pipe Extractor、Pipe Processor 和 Pipe Connector 插件的属性。
+描述一个数据流处理任务,本质就是描述 Pipe Source、Pipe Processor 和 Pipe Sink 插件的属性。
用户可以通过 SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
利用流处理框架,可以搭建完整的数据链路来满足端*边云同步、异地灾备、读写负载分库*等需求。
@@ -52,7 +52,7 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
org.apache.iotdb
pipe-api
- 1.2.1
+ 1.3.1
provided
```
@@ -61,7 +61,7 @@ Pipe Extractor 用于抽取数据,Pipe Processor 用于处理数据,Pipe Con
流处理插件的用户编程接口设计,参考了事件驱动编程模型的通用设计理念。事件(Event)是用户编程接口中的数据抽象,而编程接口与具体的执行方式解耦,只需要专注于描述事件(数据)到达系统后,系统期望的处理方式即可。
-在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeExtractor 插件,PipeProcessor 插件和 PipeConnector 插件,并依次在三个插件中触发用户逻辑的执行。
+在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeSource 插件,PipeProcessor 插件和 PipeSink 插件,并依次在三个插件中触发用户逻辑的执行。
为了兼顾端侧低负载场景下的流处理低延迟和端侧高负载场景下的流处理高吞吐,流处理引擎会动态地在操作日志和数据文件中选择处理对象,因此,流处理的用户编程接口要求用户提供下列两类事件的处理逻辑:操作日志写入事件 TabletInsertionEvent 和数据文件写入事件 TsFileInsertionEvent。
@@ -133,95 +133,95 @@ public interface TsFileInsertionEvent extends Event {
#### 数据抽取插件接口
-数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeExtractor)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,
+数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeSource)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,
捕获各种数据写入事件。
```java
/**
- * PipeExtractor
+ * PipeSource
*
- * PipeExtractor is responsible for capturing events from sources.
+ *
PipeSource is responsible for capturing events from sources.
*
- *
Various data sources can be supported by implementing different PipeExtractor classes.
+ *
Various data sources can be supported by implementing different PipeSource classes.
*
- *
The lifecycle of a PipeExtractor is as follows:
+ *
The lifecycle of a PipeSource is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH EXTRACTOR` clause in SQL are
- * parsed and the validation method {@link PipeExtractor#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
+ *
- When a collaboration task is created, the KV pairs of `WITH SOURCE` clause in SQL are
+ * parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
+ * be called to validate the parameters.
*
- Before the collaboration task starts, the method {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeExtractor.
- *
- Then the method {@link PipeExtractor#start()} will be called to start the PipeExtractor.
- *
- While the collaboration task is in progress, the method {@link PipeExtractor#supply()} will
- * be called to capture events from sources and then the events will be passed to the
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
+ * config the runtime behavior of the PipeSource.
+ *
- Then the method {@link PipeSource#start()} will be called to start the PipeSource.
+ *
- While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
+ * called to capture events from sources and then the events will be passed to the
* PipeProcessor.
- *
- The method {@link PipeExtractor#close()} will be called when the collaboration task is
+ *
- The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
*
*/
-public interface PipeExtractor extends PipePlugin {
-
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeExtractor. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeExtractorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeExtractor#validate(PipeParameterValidator)} is called.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeExtractor
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeExtractorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * Start the extractor. After this method is called, events should be ready to be supplied by
- * {@link PipeExtractor#supply()}. This method is called after {@link
- * PipeExtractor#customize(PipeParameters, PipeExtractorRuntimeConfiguration)} is called.
- *
- * @throws Exception the user can throw errors if necessary
- */
- void start() throws Exception;
-
- /**
- * Supply single event from the extractor and the caller will send the event to the processor.
- * This method is called after {@link PipeExtractor#start()} is called.
- *
- * @return the event to be supplied. the event may be null if the extractor has no more events at
- * the moment, but the extractor is still running for more events.
- * @throws Exception the user can throw errors if necessary
- */
- Event supply() throws Exception;
+public interface PipeSource extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeSource. In this method, the user can do the
+ * following things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeSourceRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
+ * is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeSource
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * Start the Source. After this method is called, events should be ready to be supplied by
+ * {@link PipeSource#supply()}. This method is called after {@link
+ * PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
+ *
+ * @throws Exception the user can throw errors if necessary
+ */
+ void start() throws Exception;
+
+ /**
+ * Supply single event from the Source and the caller will send the event to the processor.
+ * This method is called after {@link PipeSource#start()} is called.
+ *
+ * @return the event to be supplied. the event may be null if the Source has no more events at
+ * the moment, but the Source is still running for more events.
+ * @throws Exception the user can throw errors if necessary
+ */
+ Event supply() throws Exception;
}
```
#### 数据处理插件接口
-数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeExtractor)捕获的
+数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeSource)捕获的
各种事件。
```java
/**
* PipeProcessor
*
- *
PipeProcessor is used to filter and transform the Event formed by the PipeExtractor.
+ *
PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
*
The lifecycle of a PipeProcessor is as follows:
*
@@ -234,13 +234,13 @@ public interface PipeExtractor extends PipePlugin {
* to config the runtime behavior of the PipeProcessor.
*
While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector. The
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
- *
- PipeConnector serializes the events into binaries and send them to sinks.
+ *
- PipeSink serializes the events into binaries and send them to sinks.
*
* When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
@@ -315,125 +315,126 @@ public interface PipeProcessor extends PipePlugin {
#### 数据发送插件接口
-数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeConnector)主要用于发送经由数据处理插件(PipeProcessor)处理过后的
+数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeSink)主要用于发送经由数据处理插件(PipeProcessor)处理过后的
各种事件,它作为流处理框架的网络实现层,接口上应允许接入多种实时通信协议和多种连接器。
```java
/**
- * PipeConnector
+ * PipeSink
*
- * PipeConnector is responsible for sending events to sinks.
+ *
PipeSink is responsible for sending events to sinks.
*
- *
Various network protocols can be supported by implementing different PipeConnector classes.
+ *
Various network protocols can be supported by implementing different PipeSink classes.
*
- *
The lifecycle of a PipeConnector is as follows:
+ *
The lifecycle of a PipeSink is as follows:
*
*
- * - When a collaboration task is created, the KV pairs of `WITH CONNECTOR` clause in SQL are
- * parsed and the validation method {@link PipeConnector#validate(PipeParameterValidator)}
- * will be called to validate the parameters.
- *
- Before the collaboration task starts, the method {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} will be called
- * to config the runtime behavior of the PipeConnector and the method {@link
- * PipeConnector#handshake()} will be called to create a connection with sink.
+ *
- When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
+ * parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
+ * called to validate the parameters.
+ *
- Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
+ * PipeSinkRuntimeConfiguration)} will be called to config the runtime behavior of the
+ * PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
+ * with sink.
*
- While the collaboration task is in progress:
*
- * - PipeExtractor captures the events and wraps them into three types of Event instances.
- *
- PipeProcessor processes the event and then passes them to the PipeConnector.
- *
- PipeConnector serializes the events into binaries and send them to sinks. The
- * following 3 methods will be called: {@link
- * PipeConnector#transfer(TabletInsertionEvent)}, {@link
- * PipeConnector#transfer(TsFileInsertionEvent)} and {@link
- * PipeConnector#transfer(Event)}.
+ *
- PipeSource captures the events and wraps them into three types of Event instances.
+ *
- PipeProcessor processes the event and then passes them to the PipeSink.
+ *
- PipeSink serializes the events into binaries and send them to sinks. The following 3
+ * methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
+ * PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
*
* - When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
- * PipeConnector#close() } method will be called.
+ * PipeSink#close() } method will be called.
*
*
- * In addition, the method {@link PipeConnector#heartbeat()} will be called periodically to check
- * whether the connection with sink is still alive. The method {@link PipeConnector#handshake()}
- * will be called to create a new connection with the sink when the method {@link
- * PipeConnector#heartbeat()} throws exceptions.
+ *
In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
+ * whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
+ * called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
+ * throws exceptions.
*/
-public interface PipeConnector extends PipePlugin {
-
- /**
- * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
- * PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is called.
- *
- * @param validator the validator used to validate {@link PipeParameters}
- * @throws Exception if any parameter is not valid
- */
- void validate(PipeParameterValidator validator) throws Exception;
-
- /**
- * This method is mainly used to customize PipeConnector. In this method, the user can do the
- * following things:
- *
- *
- * - Use PipeParameters to parse key-value pair attributes entered by the user.
- *
- Set the running configurations in PipeConnectorRuntimeConfiguration.
- *
- *
- * This method is called after the method {@link
- * PipeConnector#validate(PipeParameterValidator)} is called and before the method {@link
- * PipeConnector#handshake()} is called.
- *
- * @param parameters used to parse the input parameters entered by the user
- * @param configuration used to set the required properties of the running PipeConnector
- * @throws Exception the user can throw errors if necessary
- */
- void customize(PipeParameters parameters, PipeConnectorRuntimeConfiguration configuration)
- throws Exception;
-
- /**
- * This method is used to create a connection with sink. This method will be called after the
- * method {@link PipeConnector#customize(PipeParameters, PipeConnectorRuntimeConfiguration)} is
- * called or will be called when the method {@link PipeConnector#heartbeat()} throws exceptions.
- *
- * @throws Exception if the connection is failed to be created
- */
- void handshake() throws Exception;
-
- /**
- * This method will be called periodically to check whether the connection with sink is still
- * alive.
- *
- * @throws Exception if the connection dies
- */
- void heartbeat() throws Exception;
-
- /**
- * This method is used to transfer the TabletInsertionEvent.
- *
- * @param tabletInsertionEvent TabletInsertionEvent to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
-
- /**
- * This method is used to transfer the TsFileInsertionEvent.
- *
- * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
- for (final TabletInsertionEvent tabletInsertionEvent :
- tsFileInsertionEvent.toTabletInsertionEvents()) {
- transfer(tabletInsertionEvent);
+public interface PipeSink extends PipePlugin {
+
+ /**
+ * This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
+ * PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
+ *
+ * @param validator the validator used to validate {@link PipeParameters}
+ * @throws Exception if any parameter is not valid
+ */
+ void validate(PipeParameterValidator validator) throws Exception;
+
+ /**
+ * This method is mainly used to customize PipeSink. In this method, the user can do the following
+ * things:
+ *
+ *
+ * - Use PipeParameters to parse key-value pair attributes entered by the user.
+ *
- Set the running configurations in PipeSinkRuntimeConfiguration.
+ *
+ *
+ * This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
+ * called and before the method {@link PipeSink#handshake()} is called.
+ *
+ * @param parameters used to parse the input parameters entered by the user
+ * @param configuration used to set the required properties of the running PipeSink
+ * @throws Exception the user can throw errors if necessary
+ */
+ void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
+ throws Exception;
+
+ /**
+ * This method is used to create a connection with sink. This method will be called after the
+ * method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
+ * will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
+ *
+ * @throws Exception if the connection is failed to be created
+ */
+ void handshake() throws Exception;
+
+ /**
+ * This method will be called periodically to check whether the connection with sink is still
+ * alive.
+ *
+ * @throws Exception if the connection dies
+ */
+ void heartbeat() throws Exception;
+
+ /**
+ * This method is used to transfer the TabletInsertionEvent.
+ *
+ * @param tabletInsertionEvent TabletInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
+
+ /**
+ * This method is used to transfer the TsFileInsertionEvent.
+ *
+ * @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
+ try {
+ for (final TabletInsertionEvent tabletInsertionEvent :
+ tsFileInsertionEvent.toTabletInsertionEvents()) {
+ transfer(tabletInsertionEvent);
+ }
+ } finally {
+ tsFileInsertionEvent.close();
+ }
}
- }
- /**
- * This method is used to transfer the Event.
- *
- * @param event Event to be transferred
- * @throws PipeConnectionException if the connection is broken
- * @throws Exception the user can throw errors if necessary
- */
- void transfer(Event event) throws Exception;
+ /**
+ * This method is used to transfer the generic events, including HeartbeatEvent.
+ *
+ * @param event Event to be transferred
+ * @throws PipeConnectionException if the connection is broken
+ * @throws Exception the user can throw errors if necessary
+ */
+ void transfer(Event event) throws Exception;
}
```
@@ -444,7 +445,7 @@ public interface PipeConnector extends PipePlugin {
### 加载插件语句
-在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeExtractor、 PipeProcessor 或者 PipeConnector 实现一个具体的插件类,
+在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeSource、 PipeProcessor 或者 PipeSink 实现一个具体的插件类,
然后需要将插件类编译打包成 jar 可执行文件,最后使用加载插件的管理语句将插件载入 IoTDB。
加载插件的管理语句的语法如图所示。
@@ -499,29 +500,29 @@ SHOW PIPEPLUGINS
## 系统预置的流处理插件
-### 预置 extractor 插件
+### 预置 source 插件
-#### iotdb-extractor
+#### iotdb-source
作用:抽取 IoTDB 内部的历史或实时数据进入 pipe。
-| key | value | value 取值范围 | required or optional with default |
-| ---------------------------------- | ------------------------------------------------ | -------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor | String: iotdb-extractor | required |
-| extractor.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
-| extractor.history.enable | 是否抽取历史数据 | Boolean: true, false | optional: true |
-| extractor.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | 是否抽取实时数据 | Boolean: true, false | optional: true |
-| extractor.realtime.mode | 实时数据的抽取模式 | String: hybrid, log, file | optional: hybrid |
-| extractor.forwarding-pipe-requests | 是否抽取由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | optional: true |
+| key | value | value 取值范围 | required or optional with default |
+|---------------------------------|-------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------|-----------------------------------|
+| source | iotdb-source | String: iotdb-source | required |
+| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
+| source.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| source.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
+| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
+| source.realtime.mode | 实时数据的抽取模式 | String: hybrid, log, file | optional: hybrid |
+| source.forwarding-pipe-requests | 是否抽取由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | optional: true |
-> 🚫 **extractor.pattern 参数说明**
+> 🚫 **source.pattern 参数说明**
>
> * Pattern 需用反引号修饰不合法字符或者是不合法路径节点,例如如果希望筛选 root.\`a@b\` 或者 root.\`123\`,应设置 pattern 为 root.\`a@b\` 或者 root.\`123\`(具体参考 [单双引号和反引号的使用时机](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
> * 在底层实现中,当检测到 pattern 为 root(默认值)时,抽取效率较高,其他任意格式都将降低性能
-> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'extractor.pattern'='root.aligned.1' 的 pipe 时:
+> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'source.pattern'='root.aligned.1' 的 pipe 时:
>
> * root.aligned.1TS
> * root.aligned.1TS.\`1\`
@@ -533,9 +534,8 @@ SHOW PIPEPLUGINS
> * root.aligned.\`123\`
>
> 的数据不会被抽取。
-> * root.\_\_system 的数据不会被 pipe 抽取。用户虽然可以在 extractor.pattern 中包含任意前缀,包括带有(或覆盖) root.\__system 的前缀,但是 root.__system 下的数据总是会被 pipe 忽略的
-> ❗️**extractor.history 的 start-time,end-time 参数说明**
+> ❗️**source.history 的 start-time,end-time 参数说明**
>
> * start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或 2011-12-03T10:15:30+01:00
@@ -546,27 +546,20 @@ SHOW PIPEPLUGINS
>
> 我们常说的乱序数据,指的是数据到达时,其 **event time** 远落后于当前系统时间(或者已经落库的最大 **event time**)的数据。另一方面,不论是乱序数据还是顺序数据,只要它们是新到达系统的,那它们的 **arrival time** 都是会随着数据到达 IoTDB 的顺序递增的。
-> 💎 **iotdb-extractor 的工作可以拆分成两个阶段**
+> 💎 **iotdb-source 的工作可以拆分成两个阶段**
>
> 1. 历史数据抽取:所有 **arrival time** < 创建 pipe 时**当前系统时间**的数据称为历史数据
> 2. 实时数据抽取:所有 **arrival time** >= 创建 pipe 时**当前系统时间**的数据称为实时数据
>
> 历史数据传输阶段和实时数据传输阶段,**两阶段串行执行,只有当历史数据传输阶段完成后,才执行实时数据传输阶段。**
->
-> 用户可以指定 iotdb-extractor 进行:
->
-> * 历史数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'false'` )
-> * 实时数据抽取(`'extractor.history.enable' = 'false'`, `'extractor.realtime.enable' = 'true'` )
-> * 全量数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable' = 'true'` )
-> * 禁止同时设置 `extractor.history.enable` 和 `extractor.realtime.enable` 为 `false`
-> 📌 **extractor.realtime.mode:数据抽取的模式**
+> 📌 **source.realtime.mode:数据抽取的模式**
>
> * log:该模式下,任务仅使用操作日志进行数据处理、发送
> * file:该模式下,任务仅使用数据文件进行数据处理、发送
> * hybrid:该模式,考虑了按操作日志逐条目发送数据时延迟低但吞吐低的特点,以及按数据文件批量发送时发送吞吐高但延迟高的特点,能够在不同的写入负载下自动切换适合的数据抽取方式,首先采取基于操作日志的数据抽取方式以保证低发送延迟,当产生数据积压时自动切换成基于数据文件的数据抽取方式以保证高发送吞吐,积压消除时自动切换回基于操作日志的数据抽取方式,避免了采用单一数据抽取算法难以平衡数据发送延迟或吞吐的问题。
-> 🍕 **extractor.forwarding-pipe-requests:是否允许转发从另一 pipe 传输而来的数据**
+> 🍕 **source.forwarding-pipe-requests:是否允许转发从另一 pipe 传输而来的数据**
>
> * 如果要使用 pipe 构建 A -> B -> C 的数据同步,那么 B -> C 的 pipe 需要将该参数为 true 后,A -> B 中 A 通过 pipe 写入 B 的数据才能被正确转发到 C
> * 如果要使用 pipe 构建 A \<-> B 的双向数据同步(双活),那么 A -> B 和 B -> A 的 pipe 都需要将该参数设置为 false,否则将会造成数据无休止的集群间循环转发
@@ -575,23 +568,23 @@ SHOW PIPEPLUGINS
#### do-nothing-processor
-作用:不对 extractor 传入的事件做任何的处理。
+作用:不对 source 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
+| key | value | value 取值范围 | required or optional with default |
+|-----------|----------------------|------------------------------|-----------------------------------|
| processor | do-nothing-processor | String: do-nothing-processor | required |
-### 预置 connector 插件
+### 预置 sink 插件
-#### do-nothing-connector
+#### do-nothing-sink
作用:不对 processor 传入的事件做任何的处理。
-| key | value | value 取值范围 | required or optional with default |
-| --------- | -------------------- | ---------------------------- | --------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required |
+| key | value | value 取值范围 | required or optional with default |
+|------|-----------------|-------------------------|-----------------------------------|
+| sink | do-nothing-sink | String: do-nothing-sink | required |
## 流处理任务管理
@@ -601,59 +594,59 @@ SHOW PIPEPLUGINS
```sql
CREATE PIPE -- PipeId 是能够唯一标定流处理任务的名字
-WITH EXTRACTOR (
+WITH SOURCE (
-- 默认的 IoTDB 数据抽取插件
- 'extractor' = 'iotdb-extractor',
+ 'source' = 'iotdb-source',
-- 路径前缀,只有能够匹配该路径前缀的数据才会被抽取,用作后续的处理和发送
- 'extractor.pattern' = 'root.timecho',
+ 'source.pattern' = 'root.timecho',
-- 是否抽取历史数据
- 'extractor.history.enable' = 'true',
+ 'source.history.enable' = 'true',
-- 描述被抽取的历史数据的时间范围,表示最早时间
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
+ 'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- 描述被抽取的历史数据的时间范围,表示最晚时间
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
+ 'source.history.end-time' = '2022.12.03T10:15:30+01:00',
-- 是否抽取实时数据
- 'extractor.realtime.enable' = 'true',
+ 'source.realtime.enable' = 'true',
-- 描述实时数据的抽取方式
- 'extractor.realtime.mode' = 'hybrid',
+ 'source.realtime.mode' = 'hybrid',
)
WITH PROCESSOR (
-- 默认的数据处理插件,即不做任何处理
'processor' = 'do-nothing-processor',
)
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
**创建流处理任务时需要配置 PipeId 以及三个插件部分的参数:**
-| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
-| --------- | --------------------------------------------------- | --------------------------- | -------------------- | -------------------------------------------------------- | ------------------------- |
-| PipeId | 全局唯一标定一个流处理任务的名称 | 必填 | - | - | - |
-| extractor | Pipe Extractor 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-extractor | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
-| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
-| connector | Pipe Connector 插件,负责发送数据 | 必填 | - | - | 是 |
+| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
+|-----------|--------------------------------|---------------------------|----------------------|------------------------------|--------------------------|
+| PipeId | 全局唯一标定一个流处理任务的名称 | 必填 | - | - | - |
+| source | Pipe Source 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-source | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
+| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | 是 |
+| sink | Pipe Sink 插件,负责发送数据 | 必填 | - | - | 是 |
-示例中,使用了 iotdb-extractor、do-nothing-processor 和 iotdb-thrift-connector 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,**请查看“系统预置流处理插件”一节**。
+示例中,使用了 iotdb-source、do-nothing-processor 和 iotdb-thrift-sink 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,**请查看“系统预置流处理插件”一节**。
**一个最简的 CREATE PIPE 语句示例如下:**
```sql
CREATE PIPE -- PipeId 是能够唯一标定流处理任务的名字
-WITH CONNECTOR (
+WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
+ 'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
+ 'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ 'sink.port' = '6667',
)
```
@@ -661,37 +654,37 @@ WITH CONNECTOR (
**注意:**
-- EXTRACTOR 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
-- CONNECTOR 为必填配置,需要在 CREATE PIPE 语句中声明式配置
-- CONNECTOR 具备自复用能力。对于不同的流处理任务,如果他们的 CONNECTOR 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 CONNECTOR 实例**,以实现对连接资源的复用。
+- SOURCE 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
+- SINK 为必填配置,需要在 CREATE PIPE 语句中声明式配置
+- SINK 具备自复用能力。对于不同的流处理任务,如果他们的 SINK 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),**那么系统最终只会创建一个 SINK 实例**,以实现对连接资源的复用。
- 例如,有下面 pipe1, pipe2 两个流处理任务的声明:
```sql
CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.ip' = 'localhost',
+ 'sink.port' = '9999',
)
CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
+ WITH SINK (
+ 'sink' = 'iotdb-thrift-sink',
+ 'sink.port' = '9999',
+ 'sink.ip' = 'localhost',
)
```
- - 因为它们对 CONNECTOR 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 CONNECTOR 进行复用,最终 pipe1, pipe2 的CONNECTOR 将会是同一个实例。
-- 在 extractor 为默认的 iotdb-extractor,且 extractor.forwarding-pipe-requests 为默认值 true 时,请不要构建出包含数据循环同步的应用场景(会导致无限循环):
+ - 因为它们对 SINK 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 SINK 进行复用,最终 pipe1, pipe2 的 SINK 将会是同一个实例。
+- 在 source 为默认的 iotdb-source,且 source.forwarding-pipe-requests 为默认值 true 时,请不要构建出包含数据循环同步的应用场景(会导致无限循环):
- IoTDB A -> IoTDB B -> IoTDB A
- IoTDB A -> IoTDB A
### 启动流处理任务
-CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED,即流处理任务不会立刻处理数据。
+CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED,即流处理任务不会立刻处理数据(V1.3.0)。在 1.3.1 及以上的版本,流处理任务的运行状态在创建后将被立即置为 RUNNING。
可以使用 START PIPE 语句使流处理任务开始处理数据:
@@ -728,13 +721,13 @@ SHOW PIPES
查询结果如下:
```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+| ID| CreationTime | State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
+|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
++-----------+-----------------------+-------+----------+-------------+--------+----------------+
```
可以使用 `` 指定想看的某个流处理任务状态:
@@ -743,22 +736,23 @@ SHOW PIPES
SHOW PIPE
```
-您也可以通过 where 子句,判断某个 \ 使用的 Pipe Connector 被复用的情况。
+您也可以通过 where 子句,判断某个 \ 使用的 Pipe Sink 被复用的情况。
```sql
SHOW PIPES
-WHERE CONNECTOR USED BY
+WHERE SINK USED BY
```
### 流处理任务运行状态迁移
-一个流处理 pipe 在其被管理的生命周期中会经过多种状态:
+一个流处理 pipe 在其的生命周期中会经过多种状态:
+- **RUNNING:** pipe 正在正常工作
+ - 当一个 pipe 被成功创建之后,其初始状态为工作状态(V1.3.1+)
- **STOPPED:** pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
- - 当一个 pipe 被成功创建之后,其初始状态为暂停状态
+ - 当一个 pipe 被成功创建之后,其初始状态为暂停状态(V1.3.0)
- 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
- 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
-- **RUNNING:** pipe 正在正常工作
- **DROPPED:** pipe 任务被永久删除
下图表明了所有状态以及状态的迁移:
@@ -770,8 +764,8 @@ WHERE CONNECTOR USED BY
### 流处理任务
-| 权限名称 | 描述 |
-| -------- | -------------------------- |
+| 权限名称 | 描述 |
+|----------|---------------|
| USE_PIPE | 注册流处理任务。路径无关。 |
| USE_PIPE | 开启流处理任务。路径无关。 |
| USE_PIPE | 停止流处理任务。路径无关。 |
@@ -781,8 +775,8 @@ WHERE CONNECTOR USED BY
### 流处理任务插件
-| 权限名称 | 描述 |
-| -------- | ------------------------------ |
+| 权限名称 | 描述 |
+|----------|-----------------|
| USE_PIPE | 注册流处理任务插件。路径无关。 |
| USE_PIPE | 卸载流处理任务插件。路径无关。 |
| USE_PIPE | 查询流处理任务插件。路径无关。 |
@@ -791,6 +785,7 @@ WHERE CONNECTOR USED BY
在 iotdb-common.properties 中:
+V1.3.0+:
```Properties
####################
### Pipe Configuration
@@ -811,4 +806,53 @@ WHERE CONNECTOR USED BY
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the async connector.
+# pipe_async_connector_selector_number=1
+
+# The core number of clients that can be used in the async connector.
+# pipe_async_connector_core_client_number=8
+
+# The maximum number of clients that can be used in the async connector.
+# pipe_async_connector_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
+```
+
+V1.3.1+:
+```Properties
+# Uncomment the following field to configure the pipe lib directory.
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# pipe_sink_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# pipe_air_gap_receiver_port=9780
```