storageGroup);
+
+// insert record
+TSStatus insertRecord(1:TSInsertRecordReq req);
+
+// insert record in string format
+TSStatus insertStringRecord(1:TSInsertStringRecordReq req);
+
+// insert tablet
+TSStatus insertTablet(1:TSInsertTabletReq req);
+
+// insert tablets in batch
+TSStatus insertTablets(1:TSInsertTabletsReq req);
+
+// insert records in batch
+TSStatus insertRecords(1:TSInsertRecordsReq req);
+
+// insert records of one device
+TSStatus insertRecordsOfOneDevice(1:TSInsertRecordsOfOneDeviceReq req);
+
+// insert records in batch as string format
+TSStatus insertStringRecords(1:TSInsertStringRecordsReq req);
+
+// test the latency of innsert tablet,caution:no data will be inserted, only for test latency
+TSStatus testInsertTablet(1:TSInsertTabletReq req);
+
+// test the latency of innsert tablets,caution:no data will be inserted, only for test latency
+TSStatus testInsertTablets(1:TSInsertTabletsReq req);
+
+// test the latency of innsert record,caution:no data will be inserted, only for test latency
+TSStatus testInsertRecord(1:TSInsertRecordReq req);
+
+// test the latency of innsert record in string format,caution:no data will be inserted, only for test latency
+TSStatus testInsertStringRecord(1:TSInsertStringRecordReq req);
+
+// test the latency of innsert records,caution:no data will be inserted, only for test latency
+TSStatus testInsertRecords(1:TSInsertRecordsReq req);
+
+// test the latency of innsert records of one device,caution:no data will be inserted, only for test latency
+TSStatus testInsertRecordsOfOneDevice(1:TSInsertRecordsOfOneDeviceReq req);
+
+// test the latency of innsert records in string formate,caution:no data will be inserted, only for test latency
+TSStatus testInsertStringRecords(1:TSInsertStringRecordsReq req);
+
+// delete data
+TSStatus deleteData(1:TSDeleteDataReq req);
+
+// execute raw data query
+TSExecuteStatementResp executeRawDataQuery(1:TSRawDataQueryReq req);
+
+// request a statement id from server
+i64 requestStatementId(1:i64 sessionId);
+```
diff --git a/src/UserGuide/V2.0.1/Tree/API/RestServiceV1.md b/src/UserGuide/V2.0.1/Tree/API/RestServiceV1.md
new file mode 100644
index 00000000..738448e8
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/API/RestServiceV1.md
@@ -0,0 +1,930 @@
+
+
+# RESTful API V1(Not Recommend)
+IoTDB's RESTful services can be used for query, write, and management operations, using the OpenAPI standard to define interfaces and generate frameworks.
+
+## Enable RESTful Services
+
+RESTful services are disabled by default.
+
+* Developer
+
+ Find the `IoTDBrestServiceConfig` class under `org.apache.iotdb.db.conf.rest` in the sever module, and modify `enableRestService=true`.
+
+* User
+
+ Find the `conf/conf/iotdb-system.properties` file under the IoTDB installation directory and set `enable_rest_service` to `true` to enable the module.
+
+ ```properties
+ enable_rest_service=true
+ ```
+
+## Authentication
+Except the liveness probe API `/ping`, RESTful services use the basic authentication. Each URL request needs to carry `'Authorization': 'Basic ' + base64.encode(username + ':' + password)`.
+
+The username used in the following examples is: `root`, and password is: `root`.
+
+And the authorization header is
+
+```
+Authorization: Basic cm9vdDpyb290
+```
+
+- If a user authorized with incorrect username or password, the following error is returned:
+
+ HTTP Status Code:`401`
+
+ HTTP response body:
+ ```json
+ {
+ "code": 600,
+ "message": "WRONG_LOGIN_PASSWORD_ERROR"
+ }
+ ```
+
+- If the `Authorization` header is missing,the following error is returned:
+
+ HTTP Status Code:`401`
+
+ HTTP response body:
+ ```json
+ {
+ "code": 603,
+ "message": "UNINITIALIZED_AUTH_ERROR"
+ }
+ ```
+
+## Interface
+
+### ping
+
+The `/ping` API can be used for service liveness probing.
+
+Request method: `GET`
+
+Request path: `http://ip:port/ping`
+
+The user name used in the example is: root, password: root
+
+Example request:
+
+```shell
+$ curl http://127.0.0.1:18080/ping
+```
+
+Response status codes:
+
+- `200`: The service is alive.
+- `503`: The service cannot accept any requests now.
+
+Response parameters:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+|code | integer | status code |
+| message | string | message |
+
+Sample response:
+
+- With HTTP status code `200`:
+
+ ```json
+ {
+ "code": 200,
+ "message": "SUCCESS_STATUS"
+ }
+ ```
+
+- With HTTP status code `503`:
+
+ ```json
+ {
+ "code": 500,
+ "message": "thrift service is unavailable"
+ }
+ ```
+
+> `/ping` can be accessed without authorization.
+
+### query
+
+The query interface can be used to handle data queries and metadata queries.
+
+Request method: `POST`
+
+Request header: `application/json`
+
+Request path: `http://ip:port/rest/v1/query`
+
+Parameter Description:
+
+| parameter name | parameter type | required | parameter description |
+|----------------| -------------- | -------- | ------------------------------------------------------------ |
+| sql | string | yes | |
+| rowLimit | integer | no | The maximum number of rows in the result set that can be returned by a query.
If this parameter is not set, the `rest_query_default_row_size_limit` of the configuration file will be used as the default value.
When the number of rows in the returned result set exceeds the limit, the status code `411` will be returned. |
+
+Response parameters:
+
+| parameter name | parameter type | parameter description |
+|----------------| -------------- | ------------------------------------------------------------ |
+| expressions | array | Array of result set column names for data query, `null` for metadata query |
+| columnNames | array | Array of column names for metadata query result set, `null` for data query |
+| timestamps | array | Timestamp column, `null` for metadata query |
+| values | array | A two-dimensional array, the first dimension has the same length as the result set column name array, and the second dimension array represents a column of the result set |
+
+**Examples:**
+
+Tip: Statements like `select * from root.xx.**` are not recommended because those statements may cause OOM.
+
+**Expression query**
+
+ ```shell
+ curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select s3, s4, s3 + 1 from root.sg27 limit 2"}' http://127.0.0.1:18080/rest/v1/query
+ ````
+Response instance
+ ```json
+ {
+ "expressions": [
+ "root.sg27.s3",
+ "root.sg27.s4",
+ "root.sg27.s3 + 1"
+ ],
+ "columnNames": null,
+ "timestamps": [
+ 1635232143960,
+ 1635232153960
+ ],
+ "values": [
+ [
+ 11,
+ null
+ ],
+ [
+ false,
+ true
+ ],
+ [
+ 12.0,
+ null
+ ]
+ ]
+ }
+ ```
+
+**Show child paths**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show child paths root"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "child paths"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27",
+ "root.sg28"
+ ]
+ ]
+}
+```
+
+**Show child nodes**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show child nodes root"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "child nodes"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "sg27",
+ "sg28"
+ ]
+ ]
+}
+```
+
+**Show all ttl**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show all ttl"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "database",
+ "ttl"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27",
+ "root.sg28"
+ ],
+ [
+ null,
+ null
+ ]
+ ]
+}
+```
+
+**Show ttl**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show ttl on root.sg27"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "database",
+ "ttl"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27"
+ ],
+ [
+ null
+ ]
+ ]
+}
+```
+
+**Show functions**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show functions"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "function name",
+ "function type",
+ "class name (UDF)"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "ABS",
+ "ACOS",
+ "ASIN",
+ ...
+ ],
+ [
+ "built-in UDTF",
+ "built-in UDTF",
+ "built-in UDTF",
+ ...
+ ],
+ [
+ "org.apache.iotdb.db.query.udf.builtin.UDTFAbs",
+ "org.apache.iotdb.db.query.udf.builtin.UDTFAcos",
+ "org.apache.iotdb.db.query.udf.builtin.UDTFAsin",
+ ...
+ ]
+ ]
+}
+```
+
+**Show timeseries**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show timeseries"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "timeseries",
+ "alias",
+ "database",
+ "dataType",
+ "encoding",
+ "compression",
+ "tags",
+ "attributes"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27.s3",
+ "root.sg27.s4",
+ "root.sg28.s3",
+ "root.sg28.s4"
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ],
+ [
+ "root.sg27",
+ "root.sg27",
+ "root.sg28",
+ "root.sg28"
+ ],
+ [
+ "INT32",
+ "BOOLEAN",
+ "INT32",
+ "BOOLEAN"
+ ],
+ [
+ "RLE",
+ "RLE",
+ "RLE",
+ "RLE"
+ ],
+ [
+ "SNAPPY",
+ "SNAPPY",
+ "SNAPPY",
+ "SNAPPY"
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ]
+ ]
+}
+```
+
+**Show latest timeseries**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show latest timeseries"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "timeseries",
+ "alias",
+ "database",
+ "dataType",
+ "encoding",
+ "compression",
+ "tags",
+ "attributes"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg28.s4",
+ "root.sg27.s4",
+ "root.sg28.s3",
+ "root.sg27.s3"
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ],
+ [
+ "root.sg28",
+ "root.sg27",
+ "root.sg28",
+ "root.sg27"
+ ],
+ [
+ "BOOLEAN",
+ "BOOLEAN",
+ "INT32",
+ "INT32"
+ ],
+ [
+ "RLE",
+ "RLE",
+ "RLE",
+ "RLE"
+ ],
+ [
+ "SNAPPY",
+ "SNAPPY",
+ "SNAPPY",
+ "SNAPPY"
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ]
+ ]
+}
+```
+
+**Count timeseries**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"count timeseries root.**"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "count"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ 4
+ ]
+ ]
+}
+```
+
+**Count nodes**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"count nodes root.** level=2"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "count"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ 4
+ ]
+ ]
+}
+```
+
+**Show devices**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show devices"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "devices",
+ "isAligned"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27",
+ "root.sg28"
+ ],
+ [
+ "false",
+ "false"
+ ]
+ ]
+}
+```
+
+**Show devices with database**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show devices with database"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "devices",
+ "database",
+ "isAligned"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27",
+ "root.sg28"
+ ],
+ [
+ "root.sg27",
+ "root.sg28"
+ ],
+ [
+ "false",
+ "false"
+ ]
+ ]
+}
+```
+
+**List user**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"list user"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "user"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root"
+ ]
+ ]
+}
+```
+
+**Aggregation**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select count(*) from root.sg27"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": [
+ "count(root.sg27.s3)",
+ "count(root.sg27.s4)"
+ ],
+ "columnNames": null,
+ "timestamps": [
+ 0
+ ],
+ "values": [
+ [
+ 1
+ ],
+ [
+ 2
+ ]
+ ]
+}
+```
+
+**Group by level**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select count(*) from root.** group by level = 1"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "count(root.sg27.*)",
+ "count(root.sg28.*)"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ 3
+ ],
+ [
+ 3
+ ]
+ ]
+}
+```
+
+**Group by**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select count(*) from root.sg27 group by([1635232143960,1635232153960),1s)"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": [
+ "count(root.sg27.s3)",
+ "count(root.sg27.s4)"
+ ],
+ "columnNames": null,
+ "timestamps": [
+ 1635232143960,
+ 1635232144960,
+ 1635232145960,
+ 1635232146960,
+ 1635232147960,
+ 1635232148960,
+ 1635232149960,
+ 1635232150960,
+ 1635232151960,
+ 1635232152960
+ ],
+ "values": [
+ [
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0
+ ],
+ [
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0
+ ]
+ ]
+}
+```
+
+**Last**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select last s3 from root.sg27"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "expressions": null,
+ "columnNames": [
+ "timeseries",
+ "value",
+ "dataType"
+ ],
+ "timestamps": [
+ 1635232143960
+ ],
+ "values": [
+ [
+ "root.sg27.s3"
+ ],
+ [
+ "11"
+ ],
+ [
+ "INT32"
+ ]
+ ]
+}
+```
+
+**Disable align**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select * from root.sg27 disable align"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "code": 407,
+ "message": "disable align clauses are not supported."
+}
+```
+
+**Align by device**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select count(s3) from root.sg27 align by device"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "code": 407,
+ "message": "align by device clauses are not supported."
+}
+```
+
+**Select into**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select s3, s4 into root.sg29.s1, root.sg29.s2 from root.sg27"}' http://127.0.0.1:18080/rest/v1/query
+```
+
+```json
+{
+ "code": 407,
+ "message": "select into clauses are not supported."
+}
+```
+
+### nonQuery
+
+Request method: `POST`
+
+Request header: `application/json`
+
+Request path: `http://ip:port/rest/v1/nonQuery`
+
+Parameter Description:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+| sql | string | query content |
+
+Example request:
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"CREATE DATABASE root.ln"}' http://127.0.0.1:18080/rest/v1/nonQuery
+```
+
+Response parameters:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+| code | integer | status code |
+| message | string | message |
+
+Sample response:
+```json
+{
+ "code": 200,
+ "message": "SUCCESS_STATUS"
+}
+```
+
+
+
+### insertTablet
+
+Request method: `POST`
+
+Request header: `application/json`
+
+Request path: `http://ip:port/rest/v1/insertTablet`
+
+Parameter Description:
+
+| parameter name |parameter type |is required|parameter describe|
+|:---------------| :--- | :---| :---|
+| timestamps | array | yes | Time column |
+| measurements | array | yes | The name of the measuring point |
+| dataTypes | array | yes | The data type |
+| values | array | yes | Value columns, the values in each column can be `null` |
+| isAligned | boolean | yes | Whether to align the timeseries |
+| deviceId | string | yes | Device name |
+
+Example request:
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"timestamps":[1635232143960,1635232153960],"measurements":["s3","s4"],"dataTypes":["INT32","BOOLEAN"],"values":[[11,null],[false,true]],"isAligned":false,"deviceId":"root.sg27"}' http://127.0.0.1:18080/rest/v1/insertTablet
+```
+
+Sample response:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+| code | integer | status code |
+| message | string | message |
+
+Sample response:
+```json
+{
+ "code": 200,
+ "message": "SUCCESS_STATUS"
+}
+```
+
+## Configuration
+
+The configuration is located in 'iotdb-system.properties'.
+
+* Set 'enable_rest_service' to 'true' to enable the module, and 'false' to disable the module. By default, this value is' false '.
+
+```properties
+enable_rest_service=true
+```
+
+* This parameter is valid only when 'enable_REST_service =true'. Set 'rest_service_port' to a number (1025 to 65535) to customize the REST service socket port. By default, the value is 18080.
+
+```properties
+rest_service_port=18080
+```
+
+* Set 'enable_swagger' to 'true' to display rest service interface information through swagger, and 'false' to do not display the rest service interface information through the swagger. By default, this value is' false '.
+
+```properties
+enable_swagger=false
+```
+
+* The maximum number of rows in the result set that can be returned by a query. When the number of rows in the returned result set exceeds the limit, the status code `411` is returned.
+
+````properties
+rest_query_default_row_size_limit=10000
+````
+
+* Expiration time for caching customer login information (used to speed up user authentication, in seconds, 8 hours by default)
+
+```properties
+cache_expire=28800
+```
+
+
+* Maximum number of users stored in the cache (default: 100)
+
+```properties
+cache_max_num=100
+```
+
+* Initial cache size (default: 10)
+
+```properties
+cache_init_num=10
+```
+
+* REST Service whether to enable SSL configuration, set 'enable_https' to' true 'to enable the module, and set' false 'to disable the module. By default, this value is' false '.
+
+```properties
+enable_https=false
+```
+
+* keyStore location path (optional)
+
+```properties
+key_store_path=
+```
+
+
+* keyStore password (optional)
+
+```properties
+key_store_pwd=
+```
+
+
+* trustStore location path (optional)
+
+```properties
+trust_store_path=
+```
+
+* trustStore password (optional)
+
+```properties
+trust_store_pwd=
+```
+
+
+* SSL timeout period, in seconds
+
+```properties
+idle_timeout=5000
+```
diff --git a/src/UserGuide/V2.0.1/Tree/API/RestServiceV2.md b/src/UserGuide/V2.0.1/Tree/API/RestServiceV2.md
new file mode 100644
index 00000000..b4c733fb
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/API/RestServiceV2.md
@@ -0,0 +1,970 @@
+
+
+# RESTful API V2
+IoTDB's RESTful services can be used for query, write, and management operations, using the OpenAPI standard to define interfaces and generate frameworks.
+
+## Enable RESTful Services
+
+RESTful services are disabled by default.
+
+* Developer
+
+ Find the `IoTDBrestServiceConfig` class under `org.apache.iotdb.db.conf.rest` in the sever module, and modify `enableRestService=true`.
+
+* User
+
+ Find the `conf/iotdb-system.properties` file under the IoTDB installation directory and set `enable_rest_service` to `true` to enable the module.
+
+ ```properties
+ enable_rest_service=true
+ ```
+
+## Authentication
+Except the liveness probe API `/ping`, RESTful services use the basic authentication. Each URL request needs to carry `'Authorization': 'Basic ' + base64.encode(username + ':' + password)`.
+
+The username used in the following examples is: `root`, and password is: `root`.
+
+And the authorization header is
+
+```
+Authorization: Basic cm9vdDpyb290
+```
+
+- If a user authorized with incorrect username or password, the following error is returned:
+
+ HTTP Status Code:`401`
+
+ HTTP response body:
+ ```json
+ {
+ "code": 600,
+ "message": "WRONG_LOGIN_PASSWORD_ERROR"
+ }
+ ```
+
+- If the `Authorization` header is missing,the following error is returned:
+
+ HTTP Status Code:`401`
+
+ HTTP response body:
+ ```json
+ {
+ "code": 603,
+ "message": "UNINITIALIZED_AUTH_ERROR"
+ }
+ ```
+
+## Interface
+
+### ping
+
+The `/ping` API can be used for service liveness probing.
+
+Request method: `GET`
+
+Request path: `http://ip:port/ping`
+
+The user name used in the example is: root, password: root
+
+Example request:
+
+```shell
+$ curl http://127.0.0.1:18080/ping
+```
+
+Response status codes:
+
+- `200`: The service is alive.
+- `503`: The service cannot accept any requests now.
+
+Response parameters:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+|code | integer | status code |
+| message | string | message |
+
+Sample response:
+
+- With HTTP status code `200`:
+
+ ```json
+ {
+ "code": 200,
+ "message": "SUCCESS_STATUS"
+ }
+ ```
+
+- With HTTP status code `503`:
+
+ ```json
+ {
+ "code": 500,
+ "message": "thrift service is unavailable"
+ }
+ ```
+
+> `/ping` can be accessed without authorization.
+
+### query
+
+The query interface can be used to handle data queries and metadata queries.
+
+Request method: `POST`
+
+Request header: `application/json`
+
+Request path: `http://ip:port/rest/v2/query`
+
+Parameter Description:
+
+| parameter name | parameter type | required | parameter description |
+|----------------| -------------- | -------- | ------------------------------------------------------------ |
+| sql | string | yes | |
+| row_limit | integer | no | The maximum number of rows in the result set that can be returned by a query.
If this parameter is not set, the `rest_query_default_row_size_limit` of the configuration file will be used as the default value.
When the number of rows in the returned result set exceeds the limit, the status code `411` will be returned. |
+
+Response parameters:
+
+| parameter name | parameter type | parameter description |
+|----------------| -------------- | ------------------------------------------------------------ |
+| expressions | array | Array of result set column names for data query, `null` for metadata query |
+| column_names | array | Array of column names for metadata query result set, `null` for data query |
+| timestamps | array | Timestamp column, `null` for metadata query |
+| values | array | A two-dimensional array, the first dimension has the same length as the result set column name array, and the second dimension array represents a column of the result set |
+
+**Examples:**
+
+Tip: Statements like `select * from root.xx.**` are not recommended because those statements may cause OOM.
+
+**Expression query**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select s3, s4, s3 + 1 from root.sg27 limit 2"}' http://127.0.0.1:18080/rest/v2/query
+````
+
+```json
+{
+ "expressions": [
+ "root.sg27.s3",
+ "root.sg27.s4",
+ "root.sg27.s3 + 1"
+ ],
+ "column_names": null,
+ "timestamps": [
+ 1635232143960,
+ 1635232153960
+ ],
+ "values": [
+ [
+ 11,
+ null
+ ],
+ [
+ false,
+ true
+ ],
+ [
+ 12.0,
+ null
+ ]
+ ]
+}
+```
+
+**Show child paths**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show child paths root"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "child paths"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27",
+ "root.sg28"
+ ]
+ ]
+}
+```
+
+**Show child nodes**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show child nodes root"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "child nodes"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "sg27",
+ "sg28"
+ ]
+ ]
+}
+```
+
+**Show all ttl**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show all ttl"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "database",
+ "ttl"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27",
+ "root.sg28"
+ ],
+ [
+ null,
+ null
+ ]
+ ]
+}
+```
+
+**Show ttl**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show ttl on root.sg27"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "database",
+ "ttl"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27"
+ ],
+ [
+ null
+ ]
+ ]
+}
+```
+
+**Show functions**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show functions"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "function name",
+ "function type",
+ "class name (UDF)"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "ABS",
+ "ACOS",
+ "ASIN",
+ ...
+ ],
+ [
+ "built-in UDTF",
+ "built-in UDTF",
+ "built-in UDTF",
+ ...
+ ],
+ [
+ "org.apache.iotdb.db.query.udf.builtin.UDTFAbs",
+ "org.apache.iotdb.db.query.udf.builtin.UDTFAcos",
+ "org.apache.iotdb.db.query.udf.builtin.UDTFAsin",
+ ...
+ ]
+ ]
+}
+```
+
+**Show timeseries**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show timeseries"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "timeseries",
+ "alias",
+ "database",
+ "dataType",
+ "encoding",
+ "compression",
+ "tags",
+ "attributes"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27.s3",
+ "root.sg27.s4",
+ "root.sg28.s3",
+ "root.sg28.s4"
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ],
+ [
+ "root.sg27",
+ "root.sg27",
+ "root.sg28",
+ "root.sg28"
+ ],
+ [
+ "INT32",
+ "BOOLEAN",
+ "INT32",
+ "BOOLEAN"
+ ],
+ [
+ "RLE",
+ "RLE",
+ "RLE",
+ "RLE"
+ ],
+ [
+ "SNAPPY",
+ "SNAPPY",
+ "SNAPPY",
+ "SNAPPY"
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ]
+ ]
+}
+```
+
+**Show latest timeseries**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show latest timeseries"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "timeseries",
+ "alias",
+ "database",
+ "dataType",
+ "encoding",
+ "compression",
+ "tags",
+ "attributes"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg28.s4",
+ "root.sg27.s4",
+ "root.sg28.s3",
+ "root.sg27.s3"
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ],
+ [
+ "root.sg28",
+ "root.sg27",
+ "root.sg28",
+ "root.sg27"
+ ],
+ [
+ "BOOLEAN",
+ "BOOLEAN",
+ "INT32",
+ "INT32"
+ ],
+ [
+ "RLE",
+ "RLE",
+ "RLE",
+ "RLE"
+ ],
+ [
+ "SNAPPY",
+ "SNAPPY",
+ "SNAPPY",
+ "SNAPPY"
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ],
+ [
+ null,
+ null,
+ null,
+ null
+ ]
+ ]
+}
+```
+
+**Count timeseries**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"count timeseries root.**"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "count"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ 4
+ ]
+ ]
+}
+```
+
+**Count nodes**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"count nodes root.** level=2"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "count"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ 4
+ ]
+ ]
+}
+```
+
+**Show devices**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show devices"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "devices",
+ "isAligned"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27",
+ "root.sg28"
+ ],
+ [
+ "false",
+ "false"
+ ]
+ ]
+}
+```
+
+**Show devices with database**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"show devices with database"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "devices",
+ "database",
+ "isAligned"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root.sg27",
+ "root.sg28"
+ ],
+ [
+ "root.sg27",
+ "root.sg28"
+ ],
+ [
+ "false",
+ "false"
+ ]
+ ]
+}
+```
+
+**List user**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"list user"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "user"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ "root"
+ ]
+ ]
+}
+```
+
+**Aggregation**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select count(*) from root.sg27"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": [
+ "count(root.sg27.s3)",
+ "count(root.sg27.s4)"
+ ],
+ "column_names": null,
+ "timestamps": [
+ 0
+ ],
+ "values": [
+ [
+ 1
+ ],
+ [
+ 2
+ ]
+ ]
+}
+```
+
+**Group by level**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select count(*) from root.** group by level = 1"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "count(root.sg27.*)",
+ "count(root.sg28.*)"
+ ],
+ "timestamps": null,
+ "values": [
+ [
+ 3
+ ],
+ [
+ 3
+ ]
+ ]
+}
+```
+
+**Group by**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select count(*) from root.sg27 group by([1635232143960,1635232153960),1s)"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": [
+ "count(root.sg27.s3)",
+ "count(root.sg27.s4)"
+ ],
+ "column_names": null,
+ "timestamps": [
+ 1635232143960,
+ 1635232144960,
+ 1635232145960,
+ 1635232146960,
+ 1635232147960,
+ 1635232148960,
+ 1635232149960,
+ 1635232150960,
+ 1635232151960,
+ 1635232152960
+ ],
+ "values": [
+ [
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0
+ ],
+ [
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0
+ ]
+ ]
+}
+```
+
+**Last**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select last s3 from root.sg27"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "expressions": null,
+ "column_names": [
+ "timeseries",
+ "value",
+ "dataType"
+ ],
+ "timestamps": [
+ 1635232143960
+ ],
+ "values": [
+ [
+ "root.sg27.s3"
+ ],
+ [
+ "11"
+ ],
+ [
+ "INT32"
+ ]
+ ]
+}
+```
+
+**Disable align**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select * from root.sg27 disable align"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "code": 407,
+ "message": "disable align clauses are not supported."
+}
+```
+
+**Align by device**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select count(s3) from root.sg27 align by device"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "code": 407,
+ "message": "align by device clauses are not supported."
+}
+```
+
+**Select into**
+
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"select s3, s4 into root.sg29.s1, root.sg29.s2 from root.sg27"}' http://127.0.0.1:18080/rest/v2/query
+```
+
+```json
+{
+ "code": 407,
+ "message": "select into clauses are not supported."
+}
+```
+
+### nonQuery
+
+Request method: `POST`
+
+Request header: `application/json`
+
+Request path: `http://ip:port/rest/v2/nonQuery`
+
+Parameter Description:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+| sql | string | query content |
+
+Example request:
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"sql":"CREATE DATABASE root.ln"}' http://127.0.0.1:18080/rest/v2/nonQuery
+```
+
+Response parameters:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+| code | integer | status code |
+| message | string | message |
+
+Sample response:
+```json
+{
+ "code": 200,
+ "message": "SUCCESS_STATUS"
+}
+```
+
+
+
+### insertTablet
+
+Request method: `POST`
+
+Request header: `application/json`
+
+Request path: `http://ip:port/rest/v2/insertTablet`
+
+Parameter Description:
+
+| parameter name |parameter type |is required|parameter describe|
+|:---------------| :--- | :---| :---|
+| timestamps | array | yes | Time column |
+| measurements | array | yes | The name of the measuring point |
+| data_types | array | yes | The data type |
+| values | array | yes | Value columns, the values in each column can be `null` |
+| is_aligned | boolean | yes | Whether to align the timeseries |
+| device | string | yes | Device name |
+
+Example request:
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"timestamps":[1635232143960,1635232153960],"measurements":["s3","s4"],"data_types":["INT32","BOOLEAN"],"values":[[11,null],[false,true]],"is_aligned":false,"device":"root.sg27"}' http://127.0.0.1:18080/rest/v2/insertTablet
+```
+
+Sample response:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+| code | integer | status code |
+| message | string | message |
+
+Sample response:
+```json
+{
+ "code": 200,
+ "message": "SUCCESS_STATUS"
+}
+```
+
+### insertRecords
+
+Request method: `POST`
+
+Request header: `application/json`
+
+Request path: `http://ip:port/rest/v2/insertRecords`
+
+Parameter Description:
+
+| parameter name |parameter type |is required|parameter describe|
+|:------------------| :--- | :---| :---|
+| timestamps | array | yes | Time column |
+| measurements_list | array | yes | The name of the measuring point |
+| data_types_list | array | yes | The data type |
+| values_list | array | yes | Value columns, the values in each column can be `null` |
+| devices | string | yes | Device name |
+| is_aligned | boolean | yes | Whether to align the timeseries |
+
+Example request:
+```shell
+curl -H "Content-Type:application/json" -H "Authorization:Basic cm9vdDpyb290" -X POST --data '{"timestamps":[1635232113960,1635232151960,1635232143960,1635232143960],"measurements_list":[["s33","s44"],["s55","s66"],["s77","s88"],["s771","s881"]],"data_types_list":[["INT32","INT64"],["FLOAT","DOUBLE"],["FLOAT","DOUBLE"],["BOOLEAN","TEXT"]],"values_list":[[1,11],[2.1,2],[4,6],[false,"cccccc"]],"is_aligned":false,"devices":["root.s1","root.s1","root.s1","root.s3"]}' http://127.0.0.1:18080/rest/v2/insertRecords
+```
+
+Sample response:
+
+|parameter name |parameter type |parameter describe|
+|:--- | :--- | :---|
+| code | integer | status code |
+| message | string | message |
+
+Sample response:
+```json
+{
+ "code": 200,
+ "message": "SUCCESS_STATUS"
+}
+```
+
+
+## Configuration
+
+The configuration is located in 'iotdb-system.properties'.
+
+* Set 'enable_rest_service' to 'true' to enable the module, and 'false' to disable the module. By default, this value is' false '.
+
+```properties
+enable_rest_service=true
+```
+
+* This parameter is valid only when 'enable_REST_service =true'. Set 'rest_service_port' to a number (1025 to 65535) to customize the REST service socket port. By default, the value is 18080.
+
+```properties
+rest_service_port=18080
+```
+
+* Set 'enable_swagger' to 'true' to display rest service interface information through swagger, and 'false' to do not display the rest service interface information through the swagger. By default, this value is' false '.
+
+```properties
+enable_swagger=false
+```
+
+* The maximum number of rows in the result set that can be returned by a query. When the number of rows in the returned result set exceeds the limit, the status code `411` is returned.
+
+````properties
+rest_query_default_row_size_limit=10000
+````
+
+* Expiration time for caching customer login information (used to speed up user authentication, in seconds, 8 hours by default)
+
+```properties
+cache_expire=28800
+```
+
+
+* Maximum number of users stored in the cache (default: 100)
+
+```properties
+cache_max_num=100
+```
+
+* Initial cache size (default: 10)
+
+```properties
+cache_init_num=10
+```
+
+* REST Service whether to enable SSL configuration, set 'enable_https' to' true 'to enable the module, and set' false 'to disable the module. By default, this value is' false '.
+
+```properties
+enable_https=false
+```
+
+* keyStore location path (optional)
+
+```properties
+key_store_path=
+```
+
+
+* keyStore password (optional)
+
+```properties
+key_store_pwd=
+```
+
+
+* trustStore location path (optional)
+
+```properties
+trust_store_path=
+```
+
+* trustStore password (optional)
+
+```properties
+trust_store_pwd=
+```
+
+
+* SSL timeout period, in seconds
+
+```properties
+idle_timeout=5000
+```
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
new file mode 100644
index 00000000..d6f57bf2
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
@@ -0,0 +1,59 @@
+
+
+# Cluster-related Concepts
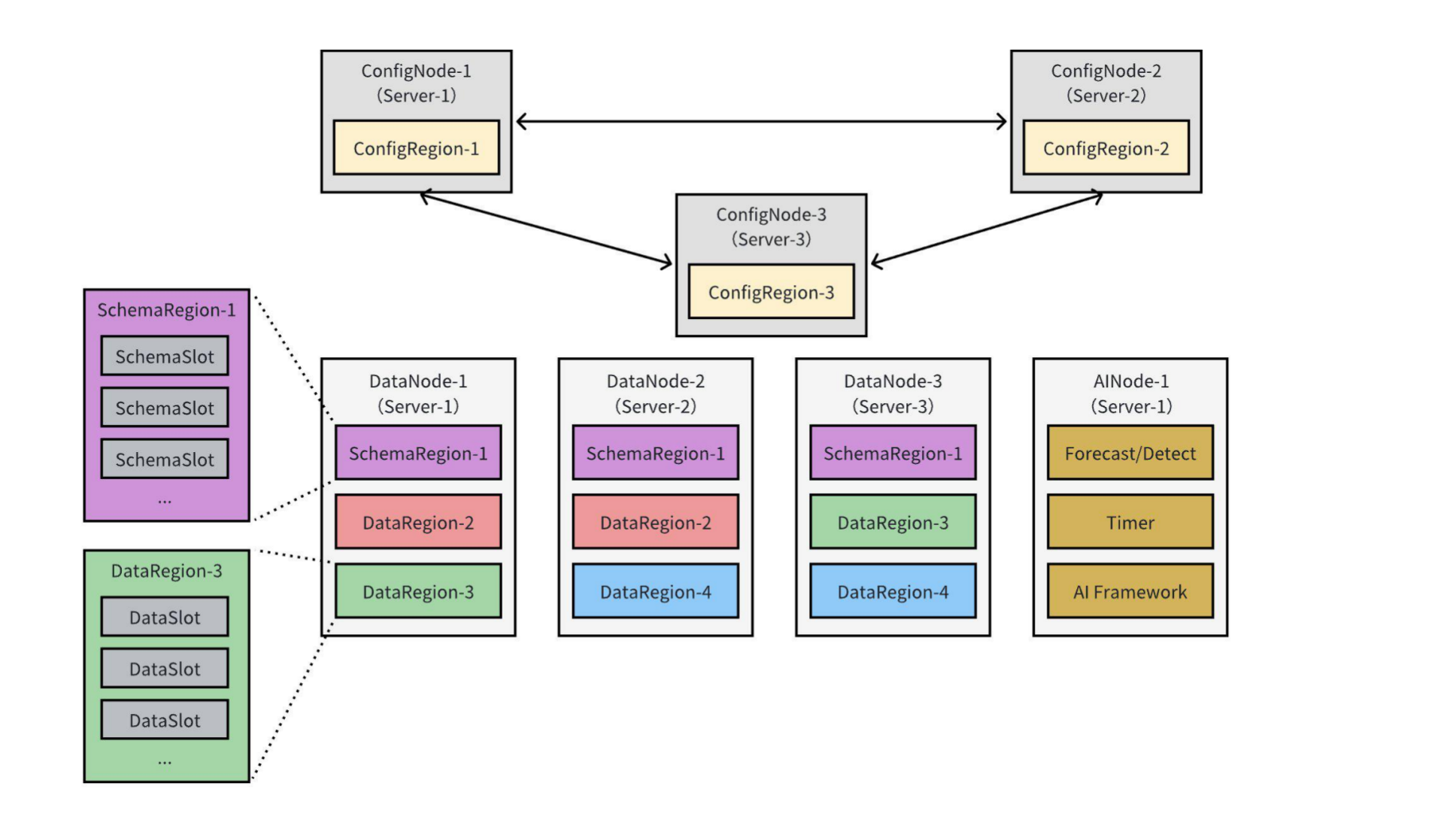
+The figure below illustrates a typical IoTDB 3C3D1A cluster deployment mode, comprising 3 ConfigNodes, 3 DataNodes, and 1 AINode:
+ +
+This deployment involves several key concepts that users commonly encounter when working with IoTDB clusters, including:
+- **Nodes** (ConfigNode, DataNode, AINode);
+- **Slots** (SchemaSlot, DataSlot);
+- **Regions** (SchemaRegion, DataRegion);
+- **Replica Groups**.
+
+The following sections will provide a detailed introduction to these concepts.
+
+## Nodes
+
+An IoTDB cluster consists of three types of nodes (processes): **ConfigNode** (the main node), **DataNode**, and **AINode**, as detailed below:
+- **ConfigNode:** ConfigNodes store cluster configurations, database metadata, the routing information of time series' schema and data. They also monitor cluster nodes and conduct load balancing. All ConfigNodes maintain full mutual backups, as shown in the figure with ConfigNode-1, ConfigNode-2, and ConfigNode-3. ConfigNodes do not directly handle client read or write requests. Instead, they guide the distribution of time series' schema and data within the cluster using a series of [load balancing algorithms](../Technical-Insider/Cluster-data-partitioning.md).
+- **DataNode:** DataNodes are responsible for reading and writing time series' schema and data. Each DataNode can accept client read and write requests and provide corresponding services, as illustrated with DataNode-1, DataNode-2, and DataNode-3 in the above figure. When a DataNode receives client requests, it can process them directly or forward them if it has the relevant routing information cached locally. Otherwise, it queries the ConfigNode for routing details and caches the information to improve the efficiency of subsequent requests.
+- **AINode:** AINodes interact with ConfigNodes and DataNodes to extend IoTDB's capabilities for data intelligence analysis on time series data. They support registering pre-trained machine learning models from external sources and performing time series analysis tasks using simple SQL statements on specified data. This process integrates model creation, management, and inference within the database engine. Currently, the system provides built-in algorithms or self-training models for common time series analysis scenarios, such as forecasting and anomaly detection.
+
+## Slots
+
+IoTDB divides time series' schema and data into smaller, more manageable units called **slots**. Slots are logical entities, and in an IoTDB cluster, the **SchemaSlots** and **DataSlots** are defined as follows:
+- **SchemaSlot:** A SchemaSlot represents a subset of the time series' schema collection. The total number of SchemaSlots is fixed, with a default value of 1000. IoTDB uses a hashing algorithm to evenly distribute all devices across these SchemaSlots.
+- **DataSlot:** A DataSlot represents a subset of the time series' data collection. Based on the SchemaSlots, the data for corresponding devices is further divided into DataSlots by a fixed time interval. The default time interval for a DataSlot is 7 days.
+
+## Region
+
+In IoTDB, time series' schema and data are replicated across DataNodes to ensure high availability in the cluster. However, replicating data at the slot level can increase management complexity and reduce write throughput. To address this, IoTDB introduces the concept of **Region**, which groups SchemaSlots and DataSlots into **SchemaRegions** and **DataRegions** respectively. Replication is then performed at the Region level. The definitions of SchemaRegion and DataRegion are as follows:
+- **SchemaRegion**: A SchemaRegion is the basic unit for storing and replicating time series' schema. All SchemaSlots in a database are evenly distributed across the database's SchemaRegions. SchemaRegions with the same RegionID are replicas of each other. For example, in the figure above, SchemaRegion-1 has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- **DataRegion**: A DataRegion is the basic unit for storing and replicating time series' data. All DataSlots in a database are evenly distributed across the database's DataRegions. DataRegions with the same RegionID are replicas of each other. For instance, in the figure above, DataRegion-2 has two replicas located on DataNode-1 and DataNode-2.
+
+## Replica Groups
+Region replicas are critical for the fault tolerance of the cluster. Each Region's replicas are organized into **replica groups**, where the replicas are assigned roles as either **leader** or **follower**, working together to provide read and write services. Recommended replica group configurations under different architectures are as follows:
+
+| Category | Parameter | Single-node Recommended Configuration | Distributed Recommended Configuration |
+|:------------:|:-----------------------:|:------------------------------------:|:-------------------------------------:|
+| Schema | `schema_replication_factor` | 1 | 3 |
+| Data | `data_replication_factor` | 1 | 2 |
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Data-Type.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Data-Type.md
new file mode 100644
index 00000000..846e8067
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Data-Type.md
@@ -0,0 +1,184 @@
+
+
+# Data Type
+
+## Basic Data Type
+
+IoTDB supports the following data types:
+
+* BOOLEAN (Boolean)
+* INT32 (Integer)
+* INT64 (Long Integer)
+* FLOAT (Single Precision Floating Point)
+* DOUBLE (Double Precision Floating Point)
+* TEXT (Long String)
+* STRING(String)
+* BLOB(Large binary Object)
+* TIMESTAMP(Timestamp)
+* DATE(Date)
+
+The difference between STRING and TEXT types is that STRING type has more statistical information and can be used to optimize value filtering queries, while TEXT type is suitable for storing long strings.
+
+### Float Precision
+
+The time series of **FLOAT** and **DOUBLE** type can specify (MAX\_POINT\_NUMBER, see [this page](../SQL-Manual/SQL-Manual.md) for more information on how to specify), which is the number of digits after the decimal point of the floating point number, if the encoding method is [RLE](Encoding-and-Compression.md) or [TS\_2DIFF](Encoding-and-Compression.md). If MAX\_POINT\_NUMBER is not specified, the system will use [float\_precision](../Reference/DataNode-Config-Manual.md) in the configuration file `iotdb-system.properties`.
+
+```sql
+CREATE TIMESERIES root.vehicle.d0.s0 WITH DATATYPE=FLOAT, ENCODING=RLE, 'MAX_POINT_NUMBER'='2';
+```
+
+* For Float data value, The data range is (-Integer.MAX_VALUE, Integer.MAX_VALUE), rather than Float.MAX_VALUE, and the max_point_number is 19, caused by the limition of function Math.round(float) in Java.
+* For Double data value, The data range is (-Long.MAX_VALUE, Long.MAX_VALUE), rather than Double.MAX_VALUE, and the max_point_number is 19, caused by the limition of function Math.round(double) in Java (Long.MAX_VALUE=9.22E18).
+
+### Data Type Compatibility
+
+When the written data type is inconsistent with the data type of time-series,
+- If the data type of time-series is not compatible with the written data type, the system will give an error message.
+- If the data type of time-series is compatible with the written data type, the system will automatically convert the data type.
+
+The compatibility of each data type is shown in the following table:
+
+| Series Data Type | Supported Written Data Types |
+|------------------|------------------------------|
+| BOOLEAN | BOOLEAN |
+| INT32 | INT32 |
+| INT64 | INT32 INT64 |
+| FLOAT | INT32 FLOAT |
+| DOUBLE | INT32 INT64 FLOAT DOUBLE |
+| TEXT | TEXT |
+
+## Timestamp
+
+The timestamp is the time point at which data is produced. It includes absolute timestamps and relative timestamps
+
+### Absolute timestamp
+
+Absolute timestamps in IoTDB are divided into two types: LONG and DATETIME (including DATETIME-INPUT and DATETIME-DISPLAY). When a user inputs a timestamp, he can use a LONG type timestamp or a DATETIME-INPUT type timestamp, and the supported formats of the DATETIME-INPUT type timestamp are shown in the table below:
+
+
+
+This deployment involves several key concepts that users commonly encounter when working with IoTDB clusters, including:
+- **Nodes** (ConfigNode, DataNode, AINode);
+- **Slots** (SchemaSlot, DataSlot);
+- **Regions** (SchemaRegion, DataRegion);
+- **Replica Groups**.
+
+The following sections will provide a detailed introduction to these concepts.
+
+## Nodes
+
+An IoTDB cluster consists of three types of nodes (processes): **ConfigNode** (the main node), **DataNode**, and **AINode**, as detailed below:
+- **ConfigNode:** ConfigNodes store cluster configurations, database metadata, the routing information of time series' schema and data. They also monitor cluster nodes and conduct load balancing. All ConfigNodes maintain full mutual backups, as shown in the figure with ConfigNode-1, ConfigNode-2, and ConfigNode-3. ConfigNodes do not directly handle client read or write requests. Instead, they guide the distribution of time series' schema and data within the cluster using a series of [load balancing algorithms](../Technical-Insider/Cluster-data-partitioning.md).
+- **DataNode:** DataNodes are responsible for reading and writing time series' schema and data. Each DataNode can accept client read and write requests and provide corresponding services, as illustrated with DataNode-1, DataNode-2, and DataNode-3 in the above figure. When a DataNode receives client requests, it can process them directly or forward them if it has the relevant routing information cached locally. Otherwise, it queries the ConfigNode for routing details and caches the information to improve the efficiency of subsequent requests.
+- **AINode:** AINodes interact with ConfigNodes and DataNodes to extend IoTDB's capabilities for data intelligence analysis on time series data. They support registering pre-trained machine learning models from external sources and performing time series analysis tasks using simple SQL statements on specified data. This process integrates model creation, management, and inference within the database engine. Currently, the system provides built-in algorithms or self-training models for common time series analysis scenarios, such as forecasting and anomaly detection.
+
+## Slots
+
+IoTDB divides time series' schema and data into smaller, more manageable units called **slots**. Slots are logical entities, and in an IoTDB cluster, the **SchemaSlots** and **DataSlots** are defined as follows:
+- **SchemaSlot:** A SchemaSlot represents a subset of the time series' schema collection. The total number of SchemaSlots is fixed, with a default value of 1000. IoTDB uses a hashing algorithm to evenly distribute all devices across these SchemaSlots.
+- **DataSlot:** A DataSlot represents a subset of the time series' data collection. Based on the SchemaSlots, the data for corresponding devices is further divided into DataSlots by a fixed time interval. The default time interval for a DataSlot is 7 days.
+
+## Region
+
+In IoTDB, time series' schema and data are replicated across DataNodes to ensure high availability in the cluster. However, replicating data at the slot level can increase management complexity and reduce write throughput. To address this, IoTDB introduces the concept of **Region**, which groups SchemaSlots and DataSlots into **SchemaRegions** and **DataRegions** respectively. Replication is then performed at the Region level. The definitions of SchemaRegion and DataRegion are as follows:
+- **SchemaRegion**: A SchemaRegion is the basic unit for storing and replicating time series' schema. All SchemaSlots in a database are evenly distributed across the database's SchemaRegions. SchemaRegions with the same RegionID are replicas of each other. For example, in the figure above, SchemaRegion-1 has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- **DataRegion**: A DataRegion is the basic unit for storing and replicating time series' data. All DataSlots in a database are evenly distributed across the database's DataRegions. DataRegions with the same RegionID are replicas of each other. For instance, in the figure above, DataRegion-2 has two replicas located on DataNode-1 and DataNode-2.
+
+## Replica Groups
+Region replicas are critical for the fault tolerance of the cluster. Each Region's replicas are organized into **replica groups**, where the replicas are assigned roles as either **leader** or **follower**, working together to provide read and write services. Recommended replica group configurations under different architectures are as follows:
+
+| Category | Parameter | Single-node Recommended Configuration | Distributed Recommended Configuration |
+|:------------:|:-----------------------:|:------------------------------------:|:-------------------------------------:|
+| Schema | `schema_replication_factor` | 1 | 3 |
+| Data | `data_replication_factor` | 1 | 2 |
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Data-Type.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Data-Type.md
new file mode 100644
index 00000000..846e8067
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Data-Type.md
@@ -0,0 +1,184 @@
+
+
+# Data Type
+
+## Basic Data Type
+
+IoTDB supports the following data types:
+
+* BOOLEAN (Boolean)
+* INT32 (Integer)
+* INT64 (Long Integer)
+* FLOAT (Single Precision Floating Point)
+* DOUBLE (Double Precision Floating Point)
+* TEXT (Long String)
+* STRING(String)
+* BLOB(Large binary Object)
+* TIMESTAMP(Timestamp)
+* DATE(Date)
+
+The difference between STRING and TEXT types is that STRING type has more statistical information and can be used to optimize value filtering queries, while TEXT type is suitable for storing long strings.
+
+### Float Precision
+
+The time series of **FLOAT** and **DOUBLE** type can specify (MAX\_POINT\_NUMBER, see [this page](../SQL-Manual/SQL-Manual.md) for more information on how to specify), which is the number of digits after the decimal point of the floating point number, if the encoding method is [RLE](Encoding-and-Compression.md) or [TS\_2DIFF](Encoding-and-Compression.md). If MAX\_POINT\_NUMBER is not specified, the system will use [float\_precision](../Reference/DataNode-Config-Manual.md) in the configuration file `iotdb-system.properties`.
+
+```sql
+CREATE TIMESERIES root.vehicle.d0.s0 WITH DATATYPE=FLOAT, ENCODING=RLE, 'MAX_POINT_NUMBER'='2';
+```
+
+* For Float data value, The data range is (-Integer.MAX_VALUE, Integer.MAX_VALUE), rather than Float.MAX_VALUE, and the max_point_number is 19, caused by the limition of function Math.round(float) in Java.
+* For Double data value, The data range is (-Long.MAX_VALUE, Long.MAX_VALUE), rather than Double.MAX_VALUE, and the max_point_number is 19, caused by the limition of function Math.round(double) in Java (Long.MAX_VALUE=9.22E18).
+
+### Data Type Compatibility
+
+When the written data type is inconsistent with the data type of time-series,
+- If the data type of time-series is not compatible with the written data type, the system will give an error message.
+- If the data type of time-series is compatible with the written data type, the system will automatically convert the data type.
+
+The compatibility of each data type is shown in the following table:
+
+| Series Data Type | Supported Written Data Types |
+|------------------|------------------------------|
+| BOOLEAN | BOOLEAN |
+| INT32 | INT32 |
+| INT64 | INT32 INT64 |
+| FLOAT | INT32 FLOAT |
+| DOUBLE | INT32 INT64 FLOAT DOUBLE |
+| TEXT | TEXT |
+
+## Timestamp
+
+The timestamp is the time point at which data is produced. It includes absolute timestamps and relative timestamps
+
+### Absolute timestamp
+
+Absolute timestamps in IoTDB are divided into two types: LONG and DATETIME (including DATETIME-INPUT and DATETIME-DISPLAY). When a user inputs a timestamp, he can use a LONG type timestamp or a DATETIME-INPUT type timestamp, and the supported formats of the DATETIME-INPUT type timestamp are shown in the table below:
+
+
+
+**Supported formats of DATETIME-INPUT type timestamp**
+
+
+
+| Format |
+| :--------------------------: |
+| yyyy-MM-dd HH:mm:ss |
+| yyyy/MM/dd HH:mm:ss |
+| yyyy.MM.dd HH:mm:ss |
+| yyyy-MM-dd HH:mm:ssZZ |
+| yyyy/MM/dd HH:mm:ssZZ |
+| yyyy.MM.dd HH:mm:ssZZ |
+| yyyy/MM/dd HH:mm:ss.SSS |
+| yyyy-MM-dd HH:mm:ss.SSS |
+| yyyy.MM.dd HH:mm:ss.SSS |
+| yyyy-MM-dd HH:mm:ss.SSSZZ |
+| yyyy/MM/dd HH:mm:ss.SSSZZ |
+| yyyy.MM.dd HH:mm:ss.SSSZZ |
+| ISO8601 standard time format |
+
+
+
+
+IoTDB can support LONG types and DATETIME-DISPLAY types when displaying timestamps. The DATETIME-DISPLAY type can support user-defined time formats. The syntax of the custom time format is shown in the table below:
+
+
+
+**The syntax of the custom time format**
+
+
+| Symbol | Meaning | Presentation | Examples |
+| :----: | :-------------------------: | :----------: | :--------------------------------: |
+| G | era | era | era |
+| C | century of era (>=0) | number | 20 |
+| Y | year of era (>=0) | year | 1996 |
+| | | | |
+| x | weekyear | year | 1996 |
+| w | week of weekyear | number | 27 |
+| e | day of week | number | 2 |
+| E | day of week | text | Tuesday; Tue |
+| | | | |
+| y | year | year | 1996 |
+| D | day of year | number | 189 |
+| M | month of year | month | July; Jul; 07 |
+| d | day of month | number | 10 |
+| | | | |
+| a | halfday of day | text | PM |
+| K | hour of halfday (0~11) | number | 0 |
+| h | clockhour of halfday (1~12) | number | 12 |
+| | | | |
+| H | hour of day (0~23) | number | 0 |
+| k | clockhour of day (1~24) | number | 24 |
+| m | minute of hour | number | 30 |
+| s | second of minute | number | 55 |
+| S | fraction of second | millis | 978 |
+| | | | |
+| z | time zone | text | Pacific Standard Time; PST |
+| Z | time zone offset/id | zone | -0800; -08:00; America/Los_Angeles |
+| | | | |
+| ' | escape for text | delimiter | |
+| '' | single quote | literal | ' |
+
+
+
+### Relative timestamp
+
+Relative time refers to the time relative to the server time ```now()``` and ```DATETIME``` time.
+
+ Syntax:
+
+ ```
+ Duration = (Digit+ ('Y'|'MO'|'W'|'D'|'H'|'M'|'S'|'MS'|'US'|'NS'))+
+ RelativeTime = (now() | DATETIME) ((+|-) Duration)+
+
+ ```
+
+
+
+**The syntax of the duration unit**
+
+
+| Symbol | Meaning | Presentation | Examples |
+| :----: | :---------: | :----------------------: | :------: |
+| y | year | 1y=365 days | 1y |
+| mo | month | 1mo=30 days | 1mo |
+| w | week | 1w=7 days | 1w |
+| d | day | 1d=1 day | 1d |
+| | | | |
+| h | hour | 1h=3600 seconds | 1h |
+| m | minute | 1m=60 seconds | 1m |
+| s | second | 1s=1 second | 1s |
+| | | | |
+| ms | millisecond | 1ms=1000_000 nanoseconds | 1ms |
+| us | microsecond | 1us=1000 nanoseconds | 1us |
+| ns | nanosecond | 1ns=1 nanosecond | 1ns |
+
+
+
+ eg:
+
+ ```
+ now() - 1d2h //1 day and 2 hours earlier than the current server time
+ now() - 1w //1 week earlier than the current server time
+ ```
+
+ > Note:There must be spaces on the left and right of '+' and '-'.
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Data-Model-and-Terminology.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Data-Model-and-Terminology.md
new file mode 100644
index 00000000..015a4035
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Data-Model-and-Terminology.md
@@ -0,0 +1,150 @@
+
+
+# Data Model
+
+A wind power IoT scenario is taken as an example to illustrate how to create a correct data model in IoTDB.
+
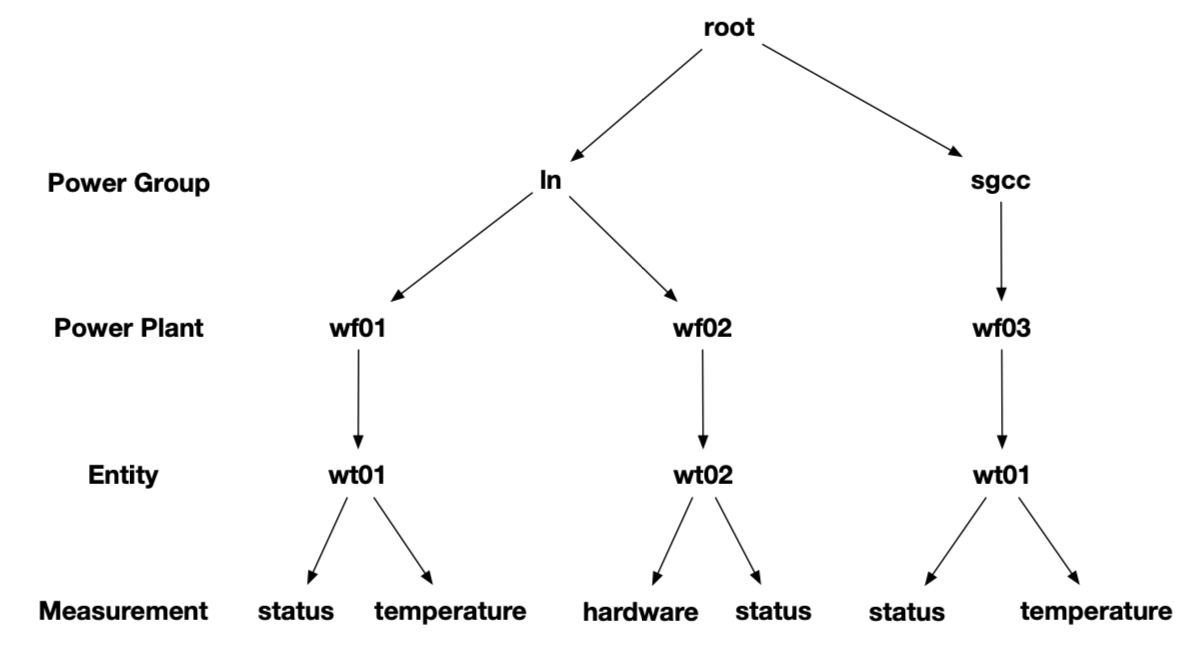
+According to the enterprise organization structure and equipment entity hierarchy, it is expressed as an attribute hierarchy structure, as shown below. The hierarchical from top to bottom is: power group layer - power plant layer - entity layer - measurement layer. ROOT is the root node, and each node of measurement layer is a leaf node. In the process of using IoTDB, the attributes on the path from ROOT node is directly connected to each leaf node with ".", thus forming the name of a timeseries in IoTDB. For example, The left-most path in Figure 2.1 can generate a timeseries named `root.ln.wf01.wt01.status`.
+
+ +
+Here are the basic concepts of the model involved in IoTDB.
+
+## Measurement, Entity, Database, Path
+
+### Measurement (Also called field)
+
+It is information measured by detection equipment in an actual scene and can transform the sensed information into an electrical signal or other desired form of information output and send it to IoTDB. In IoTDB, all data and paths stored are organized in units of measurements.
+
+### Entity (Also called device)
+
+**An entity** is an equipped with measurements in real scenarios. In IoTDB, all measurements should have their corresponding entities. Entities do not need to be created manually, the default is the second last layer.
+
+### Database
+
+**A group of entities.** Users can create any prefix path as a database. Provided that there are four timeseries `root.ln.wf01.wt01.status`, `root.ln.wf01.wt01.temperature`, `root.ln.wf02.wt02.hardware`, `root.ln.wf02.wt02.status`, two devices `wf01`, `wf02` under the path `root.ln` may belong to the same owner or the same manufacturer, so d1 and d2 are closely related. At this point, the prefix path root.vehicle can be designated as a database, which will enable IoTDB to store all devices under it in the same folder. Newly added devices under `root.ln` will also belong to this database.
+
+In general, it is recommended to create 1 database.
+
+> Note1: A full path (`root.ln.wf01.wt01.status` as in the above example) is not allowed to be set as a database.
+>
+> Note2: The prefix of a timeseries must belong to a database. Before creating a timeseries, users must set which database the series belongs to. Only timeseries whose database is set can be persisted to disk.
+>
+> Note3: The number of character in the path as database, including `root.`, shall not exceed 64.
+
+Once a prefix path is set as a database, the database settings cannot be changed.
+
+After a database is set, the ancestral layers, children and descendant layers of the corresponding prefix path are not allowed to be set up again (for example, after `root.ln` is set as the database, the root layer and `root.ln.wf01` are not allowed to be created as database).
+
+The Layer Name of database can only consist of characters, numbers, and underscores, like `root.storagegroup_1`.
+
+### Path
+
+A `path` is an expression that conforms to the following constraints:
+
+```sql
+path
+ : nodeName ('.' nodeName)*
+ ;
+
+nodeName
+ : wildcard? identifier wildcard?
+ | wildcard
+ ;
+
+wildcard
+ : '*'
+ | '**'
+ ;
+```
+
+We call the part of a path divided by `'.'` as a `node` or `nodeName`. For example: `root.a.b.c` is a path with 4 nodes.
+
+The following are the constraints on the `nodeName`:
+
+* `root` is a reserved character, and it is only allowed to appear at the beginning layer of the time series mentioned below. If `root` appears in other layers, it cannot be parsed and an error will be reported.
+* Except for the beginning layer (`root`) of the time series, the characters supported in other layers are as follows:
+
+ * [ 0-9 a-z A-Z _ ] (letters, numbers, underscore)
+ * ['\u2E80'..'\u9FFF'] (Chinese characters)
+* In particular, if the system is deployed on a Windows machine, the database layer name will be case-insensitive. For example, creating both `root.ln` and `root.LN` at the same time is not allowed.
+
+### Special characters (Reverse quotation marks)
+
+If you need to use special characters in the path node name, you can use reverse quotation marks to reference the path node name. For specific usage, please refer to [Reverse Quotation Marks](../Reference/Syntax-Rule.md#reverse-quotation-marks).
+
+### Path Pattern
+
+In order to make it easier and faster to express multiple timeseries paths, IoTDB provides users with the path pattern. Users can construct a path pattern by using wildcard `*` and `**`. Wildcard can appear in any node of the path.
+
+`*` represents one node. For example, `root.vehicle.*.sensor1` represents a 4-node path which is prefixed with `root.vehicle` and suffixed with `sensor1`.
+
+`**` represents (`*`)+, which is one or more nodes of `*`. For example, `root.vehicle.device1.**` represents all paths prefixed by `root.vehicle.device1` with nodes num greater than or equal to 4, like `root.vehicle.device1.*`, `root.vehicle.device1.*.*`, `root.vehicle.device1.*.*.*`, etc; `root.vehicle.**.sensor1` represents a path which is prefixed with `root.vehicle` and suffixed with `sensor1` and has at least 4 nodes.
+
+> Note1: Wildcard `*` and `**` cannot be placed at the beginning of the path.
+
+
+## Timeseries
+
+### Timestamp
+
+The timestamp is the time point at which data is produced. It includes absolute timestamps and relative timestamps. For detailed description, please go to [Data Type doc](./Data-Type.md).
+
+### Data point
+
+**A "time-value" pair**.
+
+### Timeseries
+
+**The record of a measurement of an entity on the time axis.** Timeseries is a series of data points.
+
+A measurement of an entity corresponds to a timeseries.
+
+Also called meter, timeline, and tag, parameter in real time database.
+
+The number of measurements managed by IoTDB can reach more than billions.
+
+For example, if entity wt01 in power plant wf01 of power group ln has a measurement named status, its timeseries can be expressed as: `root.ln.wf01.wt01.status`.
+
+### Aligned timeseries
+
+There is a situation that multiple measurements of an entity are sampled simultaneously in practical applications, forming multiple timeseries with the same time column. Such a group of timeseries can be modeled as aligned timeseries in Apache IoTDB.
+
+The timestamp columns of a group of aligned timeseries need to be stored only once in memory and disk when inserting data, instead of once per timeseries.
+
+It would be best if you created a group of aligned timeseries at the same time.
+
+You cannot create non-aligned timeseries under the entity to which the aligned timeseries belong, nor can you create aligned timeseries under the entity to which the non-aligned timeseries belong.
+
+When querying, you can query each timeseries separately.
+
+When inserting data, it is allowed to insert null value in the aligned timeseries.
+
+
+
+Here are the basic concepts of the model involved in IoTDB.
+
+## Measurement, Entity, Database, Path
+
+### Measurement (Also called field)
+
+It is information measured by detection equipment in an actual scene and can transform the sensed information into an electrical signal or other desired form of information output and send it to IoTDB. In IoTDB, all data and paths stored are organized in units of measurements.
+
+### Entity (Also called device)
+
+**An entity** is an equipped with measurements in real scenarios. In IoTDB, all measurements should have their corresponding entities. Entities do not need to be created manually, the default is the second last layer.
+
+### Database
+
+**A group of entities.** Users can create any prefix path as a database. Provided that there are four timeseries `root.ln.wf01.wt01.status`, `root.ln.wf01.wt01.temperature`, `root.ln.wf02.wt02.hardware`, `root.ln.wf02.wt02.status`, two devices `wf01`, `wf02` under the path `root.ln` may belong to the same owner or the same manufacturer, so d1 and d2 are closely related. At this point, the prefix path root.vehicle can be designated as a database, which will enable IoTDB to store all devices under it in the same folder. Newly added devices under `root.ln` will also belong to this database.
+
+In general, it is recommended to create 1 database.
+
+> Note1: A full path (`root.ln.wf01.wt01.status` as in the above example) is not allowed to be set as a database.
+>
+> Note2: The prefix of a timeseries must belong to a database. Before creating a timeseries, users must set which database the series belongs to. Only timeseries whose database is set can be persisted to disk.
+>
+> Note3: The number of character in the path as database, including `root.`, shall not exceed 64.
+
+Once a prefix path is set as a database, the database settings cannot be changed.
+
+After a database is set, the ancestral layers, children and descendant layers of the corresponding prefix path are not allowed to be set up again (for example, after `root.ln` is set as the database, the root layer and `root.ln.wf01` are not allowed to be created as database).
+
+The Layer Name of database can only consist of characters, numbers, and underscores, like `root.storagegroup_1`.
+
+### Path
+
+A `path` is an expression that conforms to the following constraints:
+
+```sql
+path
+ : nodeName ('.' nodeName)*
+ ;
+
+nodeName
+ : wildcard? identifier wildcard?
+ | wildcard
+ ;
+
+wildcard
+ : '*'
+ | '**'
+ ;
+```
+
+We call the part of a path divided by `'.'` as a `node` or `nodeName`. For example: `root.a.b.c` is a path with 4 nodes.
+
+The following are the constraints on the `nodeName`:
+
+* `root` is a reserved character, and it is only allowed to appear at the beginning layer of the time series mentioned below. If `root` appears in other layers, it cannot be parsed and an error will be reported.
+* Except for the beginning layer (`root`) of the time series, the characters supported in other layers are as follows:
+
+ * [ 0-9 a-z A-Z _ ] (letters, numbers, underscore)
+ * ['\u2E80'..'\u9FFF'] (Chinese characters)
+* In particular, if the system is deployed on a Windows machine, the database layer name will be case-insensitive. For example, creating both `root.ln` and `root.LN` at the same time is not allowed.
+
+### Special characters (Reverse quotation marks)
+
+If you need to use special characters in the path node name, you can use reverse quotation marks to reference the path node name. For specific usage, please refer to [Reverse Quotation Marks](../Reference/Syntax-Rule.md#reverse-quotation-marks).
+
+### Path Pattern
+
+In order to make it easier and faster to express multiple timeseries paths, IoTDB provides users with the path pattern. Users can construct a path pattern by using wildcard `*` and `**`. Wildcard can appear in any node of the path.
+
+`*` represents one node. For example, `root.vehicle.*.sensor1` represents a 4-node path which is prefixed with `root.vehicle` and suffixed with `sensor1`.
+
+`**` represents (`*`)+, which is one or more nodes of `*`. For example, `root.vehicle.device1.**` represents all paths prefixed by `root.vehicle.device1` with nodes num greater than or equal to 4, like `root.vehicle.device1.*`, `root.vehicle.device1.*.*`, `root.vehicle.device1.*.*.*`, etc; `root.vehicle.**.sensor1` represents a path which is prefixed with `root.vehicle` and suffixed with `sensor1` and has at least 4 nodes.
+
+> Note1: Wildcard `*` and `**` cannot be placed at the beginning of the path.
+
+
+## Timeseries
+
+### Timestamp
+
+The timestamp is the time point at which data is produced. It includes absolute timestamps and relative timestamps. For detailed description, please go to [Data Type doc](./Data-Type.md).
+
+### Data point
+
+**A "time-value" pair**.
+
+### Timeseries
+
+**The record of a measurement of an entity on the time axis.** Timeseries is a series of data points.
+
+A measurement of an entity corresponds to a timeseries.
+
+Also called meter, timeline, and tag, parameter in real time database.
+
+The number of measurements managed by IoTDB can reach more than billions.
+
+For example, if entity wt01 in power plant wf01 of power group ln has a measurement named status, its timeseries can be expressed as: `root.ln.wf01.wt01.status`.
+
+### Aligned timeseries
+
+There is a situation that multiple measurements of an entity are sampled simultaneously in practical applications, forming multiple timeseries with the same time column. Such a group of timeseries can be modeled as aligned timeseries in Apache IoTDB.
+
+The timestamp columns of a group of aligned timeseries need to be stored only once in memory and disk when inserting data, instead of once per timeseries.
+
+It would be best if you created a group of aligned timeseries at the same time.
+
+You cannot create non-aligned timeseries under the entity to which the aligned timeseries belong, nor can you create aligned timeseries under the entity to which the non-aligned timeseries belong.
+
+When querying, you can query each timeseries separately.
+
+When inserting data, it is allowed to insert null value in the aligned timeseries.
+
+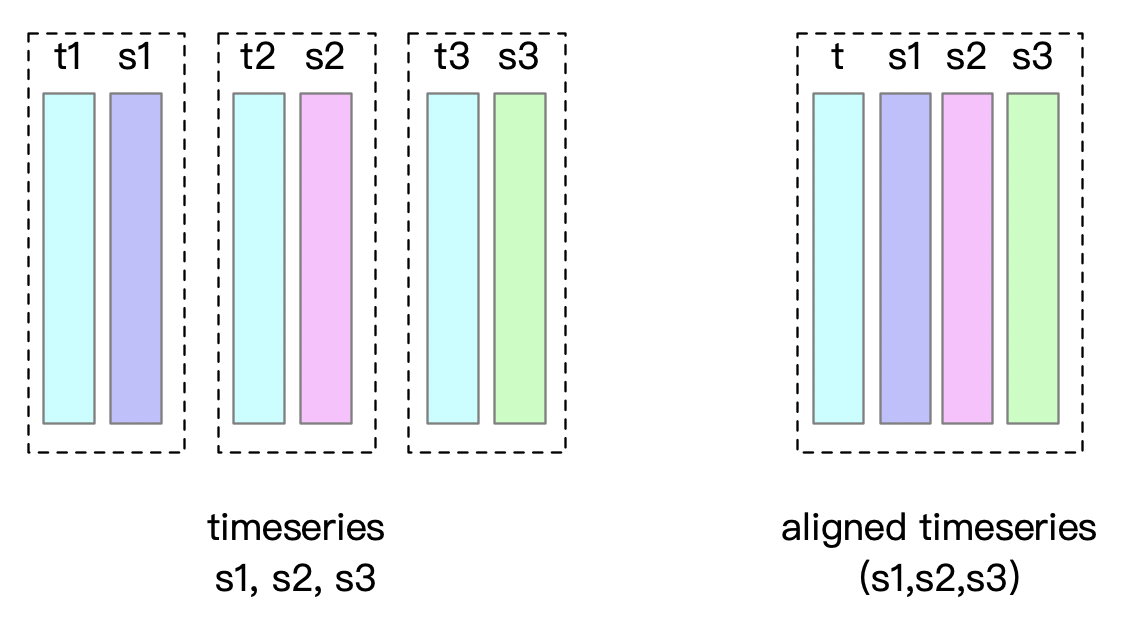 +
+In the following chapters of data definition language, data operation language and Java Native Interface, various operations related to aligned timeseries will be introduced one by one.
+
+## Schema Template
+
+In the actual scenario, many entities collect the same measurements, that is, they have the same measurements name and type. A **schema template** can be declared to define the collectable measurements set. Schema template helps save memory by implementing schema sharing. For detailed description, please refer to [Schema Template doc](../User-Manual/Operate-Metadata_timecho.md#Device-Template).
+
+In the following chapters of, data definition language, data operation language and Java Native Interface, various operations related to schema template will be introduced one by one.
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Navigating_Time_Series_Data.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Navigating_Time_Series_Data.md
new file mode 100644
index 00000000..20aaef32
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Navigating_Time_Series_Data.md
@@ -0,0 +1,64 @@
+
+# Entering Time Series Data
+
+## What Is Time Series Data?
+
+In today's era of the Internet of Things, various scenarios such as the Internet of Things and industrial scenarios are undergoing digital transformation. People collect various states of devices by installing sensors on them. If the motor collects voltage and current, the blade speed, angular velocity, and power generation of the fan; Vehicle collection of latitude and longitude, speed, and fuel consumption; The vibration frequency, deflection, displacement, etc. of the bridge. The data collection of sensors has penetrated into various industries.
+
+
+
+Generally speaking, we refer to each collection point as a measurement point (also known as a physical quantity, time series, timeline, signal quantity, indicator, measurement value, etc.). Each measurement point continuously collects new data information over time, forming a time series. In the form of a table, each time series is a table formed by two columns: time and value; In a graphical way, each time series is a trend chart formed over time, which can also be vividly referred to as the device's electrocardiogram.
+
+
+
+The massive time series data generated by sensors is the foundation of digital transformation in various industries, so our modeling of time series data mainly focuses on equipment and sensors.
+
+## Key Concepts of Time Series Data
+The main concepts involved in time-series data can be divided from bottom to top: data points, measurement points, and equipment.
+
+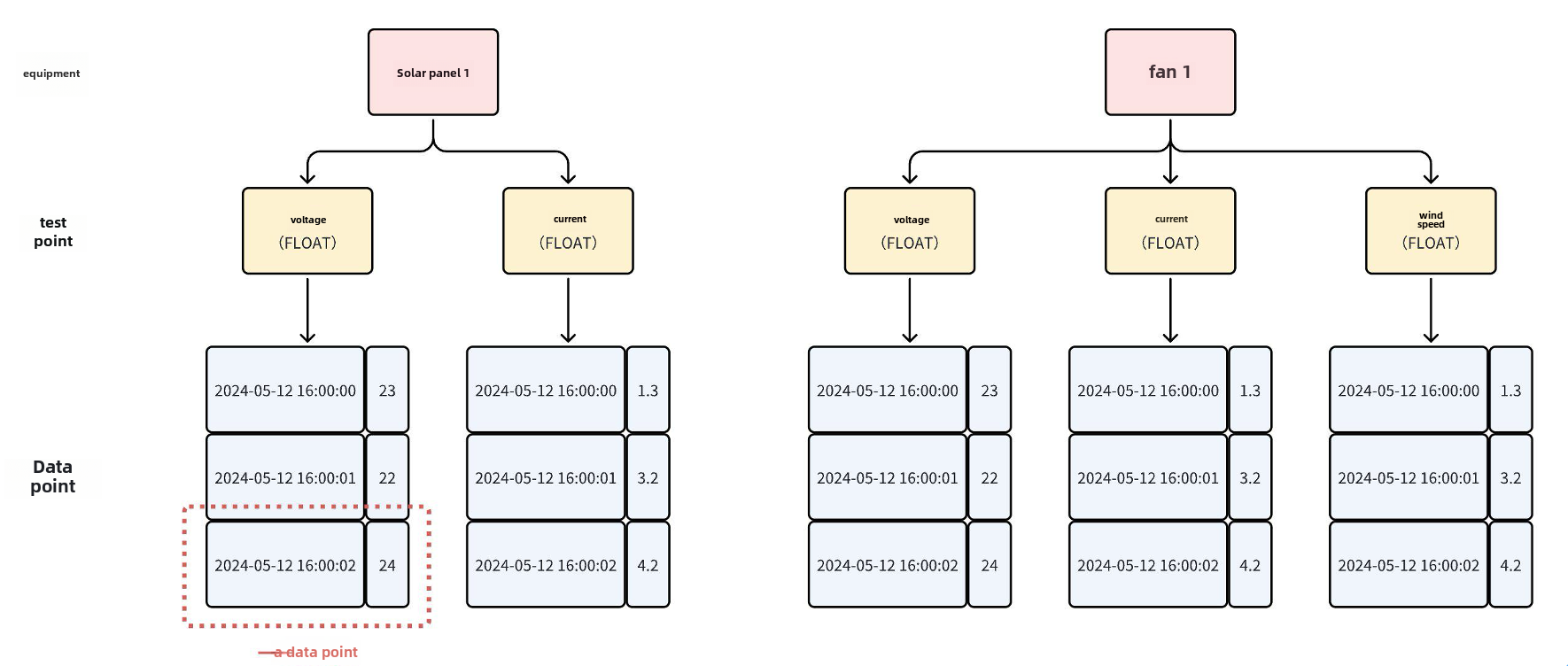
+
+### Data Point
+
+- Definition: Consists of a timestamp and a value, where the timestamp is of type long and the value can be of various types such as BOOLEAN, FLOAT, INT32, etc.
+- Example: A row of a time series in the form of a table in the above figure, or a point of a time series in the form of a graph, is a data point.
+
+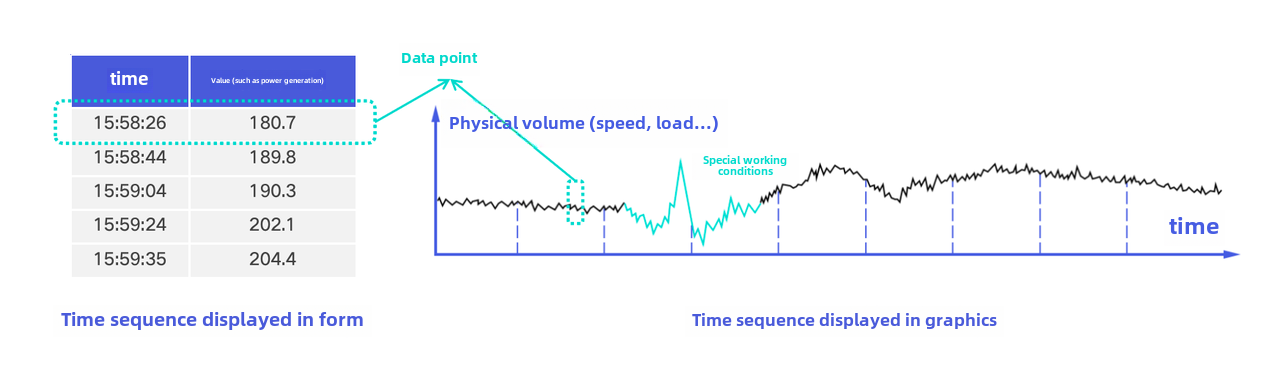
+
+### Measurement Points
+
+- Definition: It is a time series formed by multiple data points arranged in increments according to timestamps. Usually, a measuring point represents a collection point and can regularly collect physical quantities of the environment it is located in.
+- Also known as: physical quantity, time series, timeline, semaphore, indicator, measurement value, etc
+- Example:
+ - Electricity scenario: current, voltage
+ - Energy scenario: wind speed, rotational speed
+ - Vehicle networking scenarios: fuel consumption, vehicle speed, longitude, dimensions
+ - Factory scenario: temperature, humidity
+
+### Device
+
+- Definition: Corresponding to a physical device in an actual scene, usually a collection of measurement points, identified by one to multiple labels
+- Example:
+ - Vehicle networking scenario: Vehicles identified by vehicle identification code (VIN)
+ - Factory scenario: robotic arm, unique ID identification generated by IoT platform
+ - Energy scenario: Wind turbines, identified by region, station, line, model, instance, etc
+ - Monitoring scenario: CPU, identified by machine room, rack, Hostname, device type, etc
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_apache.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_apache.md
new file mode 100644
index 00000000..58c01a88
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_apache.md
@@ -0,0 +1,1253 @@
+
+
+# Timeseries Management
+
+## Database Management
+
+### Create Database
+
+According to the storage model we can set up the corresponding database. Two SQL statements are supported for creating databases, as follows:
+
+```
+IoTDB > create database root.ln
+IoTDB > create database root.sgcc
+```
+
+We can thus create two databases using the above two SQL statements.
+
+It is worth noting that 1 database is recommended.
+
+When the path itself or the parent/child layer of the path is already created as database, the path is then not allowed to be created as database. For example, it is not feasible to create `root.ln.wf01` as database when two databases `root.ln` and `root.sgcc` exist. The system gives the corresponding error prompt as shown below:
+
+```
+IoTDB> CREATE DATABASE root.ln.wf01
+Msg: 300: root.ln has already been created as database.
+IoTDB> create database root.ln.wf01
+Msg: 300: root.ln has already been created as database.
+```
+
+The LayerName of database can only be chinese or english characters, numbers, underscores, dots and backticks. If you want to set it to pure numbers or contain backticks or dots, you need to enclose the database name with backticks (` `` `). In ` `` `,2 backticks represents one, i.e. ` ```` ` represents `` ` ``.
+
+Besides, if deploy on Windows system, the LayerName is case-insensitive, which means it's not allowed to create databases `root.ln` and `root.LN` at the same time.
+
+### Show Databases
+
+After creating the database, we can use the [SHOW DATABASES](../SQL-Manual/SQL-Manual.md) statement and [SHOW DATABASES \](../SQL-Manual/SQL-Manual.md) to view the databases. The SQL statements are as follows:
+
+```
+IoTDB> SHOW DATABASES
+IoTDB> SHOW DATABASES root.**
+```
+
+The result is as follows:
+
+```
++-------------+----+-------------------------+-----------------------+-----------------------+
+|database| ttl|schema_replication_factor|data_replication_factor|time_partition_interval|
++-------------+----+-------------------------+-----------------------+-----------------------+
+| root.sgcc|null| 2| 2| 604800|
+| root.ln|null| 2| 2| 604800|
++-------------+----+-------------------------+-----------------------+-----------------------+
+Total line number = 2
+It costs 0.060s
+```
+
+### Delete Database
+
+User can use the `DELETE DATABASE ` statement to delete all databases matching the pathPattern. Please note the data in the database will also be deleted.
+
+```
+IoTDB > DELETE DATABASE root.ln
+IoTDB > DELETE DATABASE root.sgcc
+// delete all data, all timeseries and all databases
+IoTDB > DELETE DATABASE root.**
+```
+
+### Count Databases
+
+User can use the `COUNT DATABASE ` statement to count the number of databases. It is allowed to specify `PathPattern` to count the number of databases matching the `PathPattern`.
+
+SQL statement is as follows:
+
+```
+IoTDB> count databases
+IoTDB> count databases root.*
+IoTDB> count databases root.sgcc.*
+IoTDB> count databases root.sgcc
+```
+
+The result is as follows:
+
+```
++-------------+
+| database|
++-------------+
+| root.sgcc|
+| root.turbine|
+| root.ln|
++-------------+
+Total line number = 3
+It costs 0.003s
+
++-------------+
+| database|
++-------------+
+| 3|
++-------------+
+Total line number = 1
+It costs 0.003s
+
++-------------+
+| database|
++-------------+
+| 3|
++-------------+
+Total line number = 1
+It costs 0.002s
+
++-------------+
+| database|
++-------------+
+| 0|
++-------------+
+Total line number = 1
+It costs 0.002s
+
++-------------+
+| database|
++-------------+
+| 1|
++-------------+
+Total line number = 1
+It costs 0.002s
+```
+
+### Setting up heterogeneous databases (Advanced operations)
+
+Under the premise of familiar with IoTDB metadata modeling,
+users can set up heterogeneous databases in IoTDB to cope with different production needs.
+
+Currently, the following database heterogeneous parameters are supported:
+
+| Parameter | Type | Description |
+| ------------------------- | ------- | --------------------------------------------- |
+| TTL | Long | TTL of the Database |
+| SCHEMA_REPLICATION_FACTOR | Integer | The schema replication number of the Database |
+| DATA_REPLICATION_FACTOR | Integer | The data replication number of the Database |
+| SCHEMA_REGION_GROUP_NUM | Integer | The SchemaRegionGroup number of the Database |
+| DATA_REGION_GROUP_NUM | Integer | The DataRegionGroup number of the Database |
+
+Note the following when configuring heterogeneous parameters:
+
++ TTL and TIME_PARTITION_INTERVAL must be positive integers.
++ SCHEMA_REPLICATION_FACTOR and DATA_REPLICATION_FACTOR must be smaller than or equal to the number of deployed DataNodes.
++ The function of SCHEMA_REGION_GROUP_NUM and DATA_REGION_GROUP_NUM are related to the parameter `schema_region_group_extension_policy` and `data_region_group_extension_policy` in iotdb-system.properties configuration file. Take DATA_REGION_GROUP_NUM as an example:
+ If `data_region_group_extension_policy=CUSTOM` is set, DATA_REGION_GROUP_NUM serves as the number of DataRegionGroups owned by the Database.
+ If `data_region_group_extension_policy=AUTO`, DATA_REGION_GROUP_NUM is used as the lower bound of the DataRegionGroup quota owned by the Database. That is, when the Database starts writing data, it will have at least this number of DataRegionGroups.
+
+Users can set any heterogeneous parameters when creating a Database, or adjust some heterogeneous parameters during a stand-alone/distributed IoTDB run.
+
+#### Set heterogeneous parameters when creating a Database
+
+The user can set any of the above heterogeneous parameters when creating a Database. The SQL statement is as follows:
+
+```
+CREATE DATABASE prefixPath (WITH databaseAttributeClause (COMMA? databaseAttributeClause)*)?
+```
+
+For example:
+
+```
+CREATE DATABASE root.db WITH SCHEMA_REPLICATION_FACTOR=1, DATA_REPLICATION_FACTOR=3, SCHEMA_REGION_GROUP_NUM=1, DATA_REGION_GROUP_NUM=2;
+```
+
+#### Adjust heterogeneous parameters at run time
+
+Users can adjust some heterogeneous parameters during the IoTDB runtime, as shown in the following SQL statement:
+
+```
+ALTER DATABASE prefixPath WITH databaseAttributeClause (COMMA? databaseAttributeClause)*
+```
+
+For example:
+
+```
+ALTER DATABASE root.db WITH SCHEMA_REGION_GROUP_NUM=1, DATA_REGION_GROUP_NUM=2;
+```
+
+Note that only the following heterogeneous parameters can be adjusted at runtime:
+
++ SCHEMA_REGION_GROUP_NUM
++ DATA_REGION_GROUP_NUM
+
+#### Show heterogeneous databases
+
+The user can query the specific heterogeneous configuration of each Database, and the SQL statement is as follows:
+
+```
+SHOW DATABASES DETAILS prefixPath?
+```
+
+For example:
+
+```
+IoTDB> SHOW DATABASES DETAILS
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+|Database| TTL|SchemaReplicationFactor|DataReplicationFactor|TimePartitionInterval|SchemaRegionGroupNum|MinSchemaRegionGroupNum|MaxSchemaRegionGroupNum|DataRegionGroupNum|MinDataRegionGroupNum|MaxDataRegionGroupNum|
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+|root.db1| null| 1| 3| 604800000| 0| 1| 1| 0| 2| 2|
+|root.db2|86400000| 1| 1| 604800000| 0| 1| 1| 0| 2| 2|
+|root.db3| null| 1| 1| 604800000| 0| 1| 1| 0| 2| 2|
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+Total line number = 3
+It costs 0.058s
+```
+
+The query results in each column are as follows:
+
++ The name of the Database
++ The TTL of the Database
++ The schema replication number of the Database
++ The data replication number of the Database
++ The time partition interval of the Database
++ The current SchemaRegionGroup number of the Database
++ The required minimum SchemaRegionGroup number of the Database
++ The permitted maximum SchemaRegionGroup number of the Database
++ The current DataRegionGroup number of the Database
++ The required minimum DataRegionGroup number of the Database
++ The permitted maximum DataRegionGroup number of the Database
+
+### TTL
+
+IoTDB supports device-level TTL settings, which means it is able to delete old data automatically and periodically. The benefit of using TTL is that hopefully you can control the total disk space usage and prevent the machine from running out of disks. Moreover, the query performance may downgrade as the total number of files goes up and the memory usage also increases as there are more files. Timely removing such files helps to keep at a high query performance level and reduce memory usage.
+
+The default unit of TTL is milliseconds. If the time precision in the configuration file changes to another, the TTL is still set to milliseconds.
+
+When setting TTL, the system will look for all devices included in the set path and set TTL for these devices. The system will delete expired data at the device granularity.
+After the device data expires, it will not be queryable. The data in the disk file cannot be guaranteed to be deleted immediately, but it can be guaranteed to be deleted eventually.
+However, due to operational costs, the expired data will not be physically deleted right after expiring. The physical deletion is delayed until compaction.
+Therefore, before the data is physically deleted, if the TTL is reduced or lifted, it may cause data that was previously invisible due to TTL to reappear.
+The system can only set up to 1000 TTL rules, and when this limit is reached, some TTL rules need to be deleted before new rules can be set.
+
+#### TTL Path Rule
+The path can only be prefix paths (i.e., the path cannot contain \* , except \*\* in the last level).
+This path will match devices and also allows users to specify paths without asterisks as specific databases or devices.
+When the path does not contain asterisks, the system will check if it matches a database; if it matches a database, both the path and path.\*\* will be set at the same time. Note: Device TTL settings do not verify the existence of metadata, i.e., it is allowed to set TTL for a non-existent device.
+```
+qualified paths:
+root.**
+root.db.**
+root.db.group1.**
+root.db
+root.db.group1.d1
+
+unqualified paths:
+root.*.db
+root.**.db.*
+root.db.*
+```
+#### TTL Applicable Rules
+When a device is subject to multiple TTL rules, the more precise and longer rules are prioritized. For example, for the device "root.bj.hd.dist001.turbine001", the rule "root.bj.hd.dist001.turbine001" takes precedence over "root.bj.hd.dist001.\*\*", and the rule "root.bj.hd.dist001.\*\*" takes precedence over "root.bj.hd.**".
+#### Set TTL
+The set ttl operation can be understood as setting a TTL rule, for example, setting ttl to root.sg.group1.** is equivalent to mounting ttl for all devices that can match this path pattern.
+The unset ttl operation indicates unmounting TTL for the corresponding path pattern; if there is no corresponding TTL, nothing will be done.
+If you want to set TTL to be infinitely large, you can use the INF keyword.
+The SQL Statement for setting TTL is as follow:
+```
+set ttl to pathPattern 360000;
+```
+Set the Time to Live (TTL) to a pathPattern of 360,000 milliseconds; the pathPattern should not contain a wildcard (\*) in the middle and must end with a double asterisk (\*\*). The pathPattern is used to match corresponding devices.
+To maintain compatibility with older SQL syntax, if the user-provided pathPattern matches a database (db), the path pattern is automatically expanded to include all sub-paths denoted by path.\*\*.
+For instance, writing "set ttl to root.sg 360000" will automatically be transformed into "set ttl to root.sg.\*\* 360000", which sets the TTL for all devices under root.sg. However, if the specified pathPattern does not match a database, the aforementioned logic will not apply. For example, writing "set ttl to root.sg.group 360000" will not be expanded to "root.sg.group.\*\*" since root.sg.group does not match a database.
+It is also permissible to specify a particular device without a wildcard (*).
+#### Unset TTL
+
+To unset TTL, we can use follwing SQL statement:
+
+```
+IoTDB> unset ttl from root.ln
+```
+
+After unset TTL, all data will be accepted in `root.ln`.
+```
+IoTDB> unset ttl from root.sgcc.**
+```
+
+Unset the TTL in the `root.sgcc` path.
+
+New syntax
+```
+IoTDB> unset ttl from root.**
+```
+
+Old syntax
+```
+IoTDB> unset ttl to root.**
+```
+There is no functional difference between the old and new syntax, and they are compatible with each other.
+The new syntax is just more conventional in terms of wording.
+
+Unset the TTL setting for all path pattern.
+
+#### Show TTL
+
+To Show TTL, we can use following SQL statement:
+
+show all ttl
+
+```
+IoTDB> SHOW ALL TTL
++--------------+--------+
+| path| TTL|
+| root.**|55555555|
+| root.sg2.a.**|44440000|
++--------------+--------+
+```
+
+show ttl on pathPattern
+```
+IoTDB> SHOW TTL ON root.db.**;
++--------------+--------+
+| path| TTL|
+| root.db.**|55555555|
+| root.db.a.**|44440000|
++--------------+--------+
+```
+
+The SHOW ALL TTL example gives the TTL for all path patterns.
+The SHOW TTL ON pathPattern shows the TTL for the path pattern specified.
+
+Display devices' ttl
+```
+IoTDB> show devices
++---------------+---------+---------+
+| Device|IsAligned| TTL|
++---------------+---------+---------+
+|root.sg.device1| false| 36000000|
+|root.sg.device2| true| INF|
++---------------+---------+---------+
+```
+All devices will definitely have a TTL, meaning it cannot be null. INF represents infinity.
+
+## Device Template
+
+IoTDB supports the device template function, enabling different entities of the same type to share metadata, reduce the memory usage of metadata, and simplify the management of numerous entities and measurements.
+
+
+
+
+
+### Create Device Template
+
+The SQL syntax for creating a metadata template is as follows:
+
+```sql
+CREATE DEVICE TEMPLATE ALIGNED? '(' [',' ]+ ')'
+```
+
+**Example 1:** Create a template containing two non-aligned timeseries
+
+```shell
+IoTDB> create device template t1 (temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN compression=SNAPPY)
+```
+
+**Example 2:** Create a template containing a group of aligned timeseries
+
+```shell
+IoTDB> create device template t2 aligned (lat FLOAT encoding=Gorilla, lon FLOAT encoding=Gorilla)
+```
+
+The` lat` and `lon` measurements are aligned.
+
+
+### Set Device Template
+
+After a device template is created, it should be set to specific path before creating related timeseries or insert data.
+
+**It should be ensured that the related database has been set before setting template.**
+
+**It is recommended to set device template to database path. It is not suggested to set device template to some path above database**
+
+**It is forbidden to create timeseries under a path setting s tedeviceplate. Device template shall not be set on a prefix path of an existing timeseries.**
+
+The SQL Statement for setting device template is as follow:
+
+```shell
+IoTDB> set device template t1 to root.sg1.d1
+```
+
+### Activate Device Template
+
+After setting the device template, with the system enabled to auto create schema, you can insert data into the timeseries. For example, suppose there's a database root.sg1 and t1 has been set to root.sg1.d1, then timeseries like root.sg1.d1.temperature and root.sg1.d1.status are available and data points can be inserted.
+
+
+**Attention**: Before inserting data or the system not enabled to auto create schema, timeseries defined by the device template will not be created. You can use the following SQL statement to create the timeseries or activate the templdeviceate, act before inserting data:
+
+```shell
+IoTDB> create timeseries using device template on root.sg1.d1
+```
+
+**Example:** Execute the following statement
+
+```shell
+IoTDB> set device template t1 to root.sg1.d1
+IoTDB> set device template t2 to root.sg1.d2
+IoTDB> create timeseries using device template on root.sg1.d1
+IoTDB> create timeseries using device template on root.sg1.d2
+```
+
+Show the time series:
+
+```sql
+show timeseries root.sg1.**
+````
+
+```shell
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression|tags|attributes|deadband|deadband parameters|
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+|root.sg1.d1.temperature| null| root.sg1| FLOAT| RLE| SNAPPY|null| null| null| null|
+| root.sg1.d1.status| null| root.sg1| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
+| root.sg1.d2.lon| null| root.sg1| FLOAT| GORILLA| SNAPPY|null| null| null| null|
+| root.sg1.d2.lat| null| root.sg1| FLOAT| GORILLA| SNAPPY|null| null| null| null|
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+```
+
+Show the devices:
+
+```sql
+show devices root.sg1.**
+````
+
+```shell
++---------------+---------+
+| devices|isAligned|
++---------------+---------+
+| root.sg1.d1| false|
+| root.sg1.d2| true|
++---------------+---------+
+````
+
+### Show Device Template
+
+- Show all device templates
+
+The SQL statement looks like this:
+
+```shell
+IoTDB> show device templates
+```
+
+The execution result is as follows:
+
+```shell
++-------------+
+|template name|
++-------------+
+| t2|
+| t1|
++-------------+
+```
+
+- Show nodes under in device template
+
+The SQL statement looks like this:
+
+```shell
+IoTDB> show nodes in device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+--------+--------+-----------+
+|child nodes|dataType|encoding|compression|
++-----------+--------+--------+-----------+
+|temperature| FLOAT| RLE| SNAPPY|
+| status| BOOLEAN| PLAIN| SNAPPY|
++-----------+--------+--------+-----------+
+```
+
+- Show the path prefix where a device template is set
+
+```shell
+IoTDB> show paths set device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+
+|child paths|
++-----------+
+|root.sg1.d1|
++-----------+
+```
+
+- Show the path prefix where a device template is used (i.e. the time series has been created)
+
+```shell
+IoTDB> show paths using device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+
+|child paths|
++-----------+
+|root.sg1.d1|
++-----------+
+```
+
+### Deactivate device Template
+
+To delete a group of timeseries represented by device template, namely deactivate the device template, use the following SQL statement:
+
+```shell
+IoTDB> delete timeseries of device template t1 from root.sg1.d1
+```
+
+or
+
+```shell
+IoTDB> deactivate device template t1 from root.sg1.d1
+```
+
+The deactivation supports batch process.
+
+```shell
+IoTDB> delete timeseries of device template t1 from root.sg1.*, root.sg2.*
+```
+
+or
+
+```shell
+IoTDB> deactivate device template t1 from root.sg1.*, root.sg2.*
+```
+
+If the template name is not provided in sql, all template activation on paths matched by given path pattern will be removed.
+
+### Unset Device Template
+
+The SQL Statement for unsetting device template is as follow:
+
+```shell
+IoTDB> unset device template t1 from root.sg1.d1
+```
+
+**Attention**: It should be guaranteed that none of the timeseries represented by the target device template exists, before unset it. It can be achieved by deactivation operation.
+
+### Drop Device Template
+
+The SQL Statement for dropping device template is as follow:
+
+```shell
+IoTDB> drop device template t1
+```
+
+**Attention**: Dropping an already set template is not supported.
+
+### Alter Device Template
+
+In a scenario where measurements need to be added, you can modify the template to add measurements to all devicesdevice using the device template.
+
+The SQL Statement for altering device template is as follow:
+
+```shell
+IoTDB> alter device template t1 add (speed FLOAT encoding=RLE, FLOAT TEXT encoding=PLAIN compression=SNAPPY)
+```
+
+**When executing data insertion to devices with device template set on related prefix path and there are measurements not present in this device template, the measurements will be auto added to this device template.**
+
+## Timeseries Management
+
+### Create Timeseries
+
+According to the storage model selected before, we can create corresponding timeseries in the two databases respectively. The SQL statements for creating timeseries are as follows:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature with datatype=FLOAT,encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware with datatype=TEXT,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature with datatype=FLOAT,encoding=RLE
+```
+
+From v0.13, you can use a simplified version of the SQL statements to create timeseries:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature FLOAT encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware TEXT encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature FLOAT encoding=RLE
+```
+
+Notice that when in the CREATE TIMESERIES statement the encoding method conflicts with the data type, the system gives the corresponding error prompt as shown below:
+
+```
+IoTDB > create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+error: encoding TS_2DIFF does not support BOOLEAN
+```
+
+Please refer to [Encoding](../Basic-Concept/Encoding-and-Compression.md) for correspondence between data type and encoding.
+
+### Create Aligned Timeseries
+
+The SQL statement for creating a group of timeseries are as follows:
+
+```
+IoTDB> CREATE ALIGNED TIMESERIES root.ln.wf01.GPS(latitude FLOAT encoding=PLAIN compressor=SNAPPY, longitude FLOAT encoding=PLAIN compressor=SNAPPY)
+```
+
+You can set different datatype, encoding, and compression for the timeseries in a group of aligned timeseries
+
+It is also supported to set an alias, tag, and attribute for aligned timeseries.
+
+### Delete Timeseries
+
+To delete the timeseries we created before, we are able to use `(DELETE | DROP) TimeSeries ` statement.
+
+The usage are as follows:
+
+```
+IoTDB> delete timeseries root.ln.wf01.wt01.status
+IoTDB> delete timeseries root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware
+IoTDB> delete timeseries root.ln.wf02.*
+IoTDB> drop timeseries root.ln.wf02.*
+```
+
+### Show Timeseries
+
+* SHOW LATEST? TIMESERIES pathPattern? whereClause? limitClause?
+
+ There are four optional clauses added in SHOW TIMESERIES, return information of time series
+
+Timeseries information includes: timeseries path, alias of measurement, database it belongs to, data type, encoding type, compression type, tags and attributes.
+
+Examples:
+
+* SHOW TIMESERIES
+
+ presents all timeseries information in JSON form
+
+* SHOW TIMESERIES <`PathPattern`>
+
+ returns all timeseries information matching the given <`PathPattern`>. SQL statements are as follows:
+
+```
+IoTDB> show timeseries root.**
+IoTDB> show timeseries root.ln.**
+```
+
+The results are shown below respectively:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.sgcc.wf03.wt01.status| null| root.sgcc| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY| null| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 7
+It costs 0.016s
+
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression|tags|attributes|deadband|deadband parameters|
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY|null| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
+|root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY|null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+Total line number = 4
+It costs 0.004s
+```
+
+* SHOW TIMESERIES LIMIT INT OFFSET INT
+
+ returns all the timeseries information start from the offset and limit the number of series returned. For example,
+
+```
+show timeseries root.ln.** limit 10 offset 10
+```
+
+* SHOW TIMESERIES WHERE TIMESERIES contains 'containStr'
+
+ The query result set is filtered by string fuzzy matching based on the names of the timeseries. For example:
+
+```
+show timeseries root.ln.** where timeseries contains 'wf01.wt'
+```
+
+The result is shown below:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 2
+It costs 0.016s
+```
+
+* SHOW TIMESERIES WHERE DataType=type
+
+ The query result set is filtered by data type. For example:
+
+```
+show timeseries root.ln.** where dataType=FLOAT
+```
+
+The result is shown below:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 3
+It costs 0.016s
+
+```
+
+
+* SHOW LATEST TIMESERIES
+
+ all the returned timeseries information should be sorted in descending order of the last timestamp of timeseries
+
+It is worth noting that when the queried path does not exist, the system will return no timeseries.
+
+
+### Count Timeseries
+
+IoTDB is able to use `COUNT TIMESERIES ` to count the number of timeseries matching the path. SQL statements are as follows:
+
+* `WHERE` condition could be used to fuzzy match a time series name with the following syntax: `COUNT TIMESERIES WHERE TIMESERIES contains 'containStr'`.
+* `WHERE` condition could be used to filter result by data type with the syntax: `COUNT TIMESERIES WHERE DataType='`.
+* `WHERE` condition could be used to filter result by tags with the syntax: `COUNT TIMESERIES WHERE TAGS(key)='value'` or `COUNT TIMESERIES WHERE TAGS(key) contains 'value'`.
+* `LEVEL` could be defined to show count the number of timeseries of each node at the given level in current Metadata Tree. This could be used to query the number of sensors under each device. The grammar is: `COUNT TIMESERIES GROUP BY LEVEL=`.
+
+
+```
+IoTDB > COUNT TIMESERIES root.**
+IoTDB > COUNT TIMESERIES root.ln.**
+IoTDB > COUNT TIMESERIES root.ln.*.*.status
+IoTDB > COUNT TIMESERIES root.ln.wf01.wt01.status
+IoTDB > COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc'
+IoTDB > COUNT TIMESERIES root.** WHERE DATATYPE = INT64
+IoTDB > COUNT TIMESERIES root.** WHERE TAGS(unit) contains 'c'
+IoTDB > COUNT TIMESERIES root.** WHERE TAGS(unit) = 'c'
+IoTDB > COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc' group by level = 1
+```
+
+For example, if there are several timeseries (use `show timeseries` to show all timeseries):
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.sgcc.wf03.wt01.status| null| root.sgcc| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY| {"unit":"c"}| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| {"description":"test1"}| null| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 7
+It costs 0.004s
+```
+
+Then the Metadata Tree will be as below:
+
+
+
+In the following chapters of data definition language, data operation language and Java Native Interface, various operations related to aligned timeseries will be introduced one by one.
+
+## Schema Template
+
+In the actual scenario, many entities collect the same measurements, that is, they have the same measurements name and type. A **schema template** can be declared to define the collectable measurements set. Schema template helps save memory by implementing schema sharing. For detailed description, please refer to [Schema Template doc](../User-Manual/Operate-Metadata_timecho.md#Device-Template).
+
+In the following chapters of, data definition language, data operation language and Java Native Interface, various operations related to schema template will be introduced one by one.
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Navigating_Time_Series_Data.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Navigating_Time_Series_Data.md
new file mode 100644
index 00000000..20aaef32
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Navigating_Time_Series_Data.md
@@ -0,0 +1,64 @@
+
+# Entering Time Series Data
+
+## What Is Time Series Data?
+
+In today's era of the Internet of Things, various scenarios such as the Internet of Things and industrial scenarios are undergoing digital transformation. People collect various states of devices by installing sensors on them. If the motor collects voltage and current, the blade speed, angular velocity, and power generation of the fan; Vehicle collection of latitude and longitude, speed, and fuel consumption; The vibration frequency, deflection, displacement, etc. of the bridge. The data collection of sensors has penetrated into various industries.
+
+
+
+Generally speaking, we refer to each collection point as a measurement point (also known as a physical quantity, time series, timeline, signal quantity, indicator, measurement value, etc.). Each measurement point continuously collects new data information over time, forming a time series. In the form of a table, each time series is a table formed by two columns: time and value; In a graphical way, each time series is a trend chart formed over time, which can also be vividly referred to as the device's electrocardiogram.
+
+
+
+The massive time series data generated by sensors is the foundation of digital transformation in various industries, so our modeling of time series data mainly focuses on equipment and sensors.
+
+## Key Concepts of Time Series Data
+The main concepts involved in time-series data can be divided from bottom to top: data points, measurement points, and equipment.
+
+
+
+### Data Point
+
+- Definition: Consists of a timestamp and a value, where the timestamp is of type long and the value can be of various types such as BOOLEAN, FLOAT, INT32, etc.
+- Example: A row of a time series in the form of a table in the above figure, or a point of a time series in the form of a graph, is a data point.
+
+
+
+### Measurement Points
+
+- Definition: It is a time series formed by multiple data points arranged in increments according to timestamps. Usually, a measuring point represents a collection point and can regularly collect physical quantities of the environment it is located in.
+- Also known as: physical quantity, time series, timeline, semaphore, indicator, measurement value, etc
+- Example:
+ - Electricity scenario: current, voltage
+ - Energy scenario: wind speed, rotational speed
+ - Vehicle networking scenarios: fuel consumption, vehicle speed, longitude, dimensions
+ - Factory scenario: temperature, humidity
+
+### Device
+
+- Definition: Corresponding to a physical device in an actual scene, usually a collection of measurement points, identified by one to multiple labels
+- Example:
+ - Vehicle networking scenario: Vehicles identified by vehicle identification code (VIN)
+ - Factory scenario: robotic arm, unique ID identification generated by IoT platform
+ - Energy scenario: Wind turbines, identified by region, station, line, model, instance, etc
+ - Monitoring scenario: CPU, identified by machine room, rack, Hostname, device type, etc
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_apache.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_apache.md
new file mode 100644
index 00000000..58c01a88
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_apache.md
@@ -0,0 +1,1253 @@
+
+
+# Timeseries Management
+
+## Database Management
+
+### Create Database
+
+According to the storage model we can set up the corresponding database. Two SQL statements are supported for creating databases, as follows:
+
+```
+IoTDB > create database root.ln
+IoTDB > create database root.sgcc
+```
+
+We can thus create two databases using the above two SQL statements.
+
+It is worth noting that 1 database is recommended.
+
+When the path itself or the parent/child layer of the path is already created as database, the path is then not allowed to be created as database. For example, it is not feasible to create `root.ln.wf01` as database when two databases `root.ln` and `root.sgcc` exist. The system gives the corresponding error prompt as shown below:
+
+```
+IoTDB> CREATE DATABASE root.ln.wf01
+Msg: 300: root.ln has already been created as database.
+IoTDB> create database root.ln.wf01
+Msg: 300: root.ln has already been created as database.
+```
+
+The LayerName of database can only be chinese or english characters, numbers, underscores, dots and backticks. If you want to set it to pure numbers or contain backticks or dots, you need to enclose the database name with backticks (` `` `). In ` `` `,2 backticks represents one, i.e. ` ```` ` represents `` ` ``.
+
+Besides, if deploy on Windows system, the LayerName is case-insensitive, which means it's not allowed to create databases `root.ln` and `root.LN` at the same time.
+
+### Show Databases
+
+After creating the database, we can use the [SHOW DATABASES](../SQL-Manual/SQL-Manual.md) statement and [SHOW DATABASES \](../SQL-Manual/SQL-Manual.md) to view the databases. The SQL statements are as follows:
+
+```
+IoTDB> SHOW DATABASES
+IoTDB> SHOW DATABASES root.**
+```
+
+The result is as follows:
+
+```
++-------------+----+-------------------------+-----------------------+-----------------------+
+|database| ttl|schema_replication_factor|data_replication_factor|time_partition_interval|
++-------------+----+-------------------------+-----------------------+-----------------------+
+| root.sgcc|null| 2| 2| 604800|
+| root.ln|null| 2| 2| 604800|
++-------------+----+-------------------------+-----------------------+-----------------------+
+Total line number = 2
+It costs 0.060s
+```
+
+### Delete Database
+
+User can use the `DELETE DATABASE ` statement to delete all databases matching the pathPattern. Please note the data in the database will also be deleted.
+
+```
+IoTDB > DELETE DATABASE root.ln
+IoTDB > DELETE DATABASE root.sgcc
+// delete all data, all timeseries and all databases
+IoTDB > DELETE DATABASE root.**
+```
+
+### Count Databases
+
+User can use the `COUNT DATABASE ` statement to count the number of databases. It is allowed to specify `PathPattern` to count the number of databases matching the `PathPattern`.
+
+SQL statement is as follows:
+
+```
+IoTDB> count databases
+IoTDB> count databases root.*
+IoTDB> count databases root.sgcc.*
+IoTDB> count databases root.sgcc
+```
+
+The result is as follows:
+
+```
++-------------+
+| database|
++-------------+
+| root.sgcc|
+| root.turbine|
+| root.ln|
++-------------+
+Total line number = 3
+It costs 0.003s
+
++-------------+
+| database|
++-------------+
+| 3|
++-------------+
+Total line number = 1
+It costs 0.003s
+
++-------------+
+| database|
++-------------+
+| 3|
++-------------+
+Total line number = 1
+It costs 0.002s
+
++-------------+
+| database|
++-------------+
+| 0|
++-------------+
+Total line number = 1
+It costs 0.002s
+
++-------------+
+| database|
++-------------+
+| 1|
++-------------+
+Total line number = 1
+It costs 0.002s
+```
+
+### Setting up heterogeneous databases (Advanced operations)
+
+Under the premise of familiar with IoTDB metadata modeling,
+users can set up heterogeneous databases in IoTDB to cope with different production needs.
+
+Currently, the following database heterogeneous parameters are supported:
+
+| Parameter | Type | Description |
+| ------------------------- | ------- | --------------------------------------------- |
+| TTL | Long | TTL of the Database |
+| SCHEMA_REPLICATION_FACTOR | Integer | The schema replication number of the Database |
+| DATA_REPLICATION_FACTOR | Integer | The data replication number of the Database |
+| SCHEMA_REGION_GROUP_NUM | Integer | The SchemaRegionGroup number of the Database |
+| DATA_REGION_GROUP_NUM | Integer | The DataRegionGroup number of the Database |
+
+Note the following when configuring heterogeneous parameters:
+
++ TTL and TIME_PARTITION_INTERVAL must be positive integers.
++ SCHEMA_REPLICATION_FACTOR and DATA_REPLICATION_FACTOR must be smaller than or equal to the number of deployed DataNodes.
++ The function of SCHEMA_REGION_GROUP_NUM and DATA_REGION_GROUP_NUM are related to the parameter `schema_region_group_extension_policy` and `data_region_group_extension_policy` in iotdb-system.properties configuration file. Take DATA_REGION_GROUP_NUM as an example:
+ If `data_region_group_extension_policy=CUSTOM` is set, DATA_REGION_GROUP_NUM serves as the number of DataRegionGroups owned by the Database.
+ If `data_region_group_extension_policy=AUTO`, DATA_REGION_GROUP_NUM is used as the lower bound of the DataRegionGroup quota owned by the Database. That is, when the Database starts writing data, it will have at least this number of DataRegionGroups.
+
+Users can set any heterogeneous parameters when creating a Database, or adjust some heterogeneous parameters during a stand-alone/distributed IoTDB run.
+
+#### Set heterogeneous parameters when creating a Database
+
+The user can set any of the above heterogeneous parameters when creating a Database. The SQL statement is as follows:
+
+```
+CREATE DATABASE prefixPath (WITH databaseAttributeClause (COMMA? databaseAttributeClause)*)?
+```
+
+For example:
+
+```
+CREATE DATABASE root.db WITH SCHEMA_REPLICATION_FACTOR=1, DATA_REPLICATION_FACTOR=3, SCHEMA_REGION_GROUP_NUM=1, DATA_REGION_GROUP_NUM=2;
+```
+
+#### Adjust heterogeneous parameters at run time
+
+Users can adjust some heterogeneous parameters during the IoTDB runtime, as shown in the following SQL statement:
+
+```
+ALTER DATABASE prefixPath WITH databaseAttributeClause (COMMA? databaseAttributeClause)*
+```
+
+For example:
+
+```
+ALTER DATABASE root.db WITH SCHEMA_REGION_GROUP_NUM=1, DATA_REGION_GROUP_NUM=2;
+```
+
+Note that only the following heterogeneous parameters can be adjusted at runtime:
+
++ SCHEMA_REGION_GROUP_NUM
++ DATA_REGION_GROUP_NUM
+
+#### Show heterogeneous databases
+
+The user can query the specific heterogeneous configuration of each Database, and the SQL statement is as follows:
+
+```
+SHOW DATABASES DETAILS prefixPath?
+```
+
+For example:
+
+```
+IoTDB> SHOW DATABASES DETAILS
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+|Database| TTL|SchemaReplicationFactor|DataReplicationFactor|TimePartitionInterval|SchemaRegionGroupNum|MinSchemaRegionGroupNum|MaxSchemaRegionGroupNum|DataRegionGroupNum|MinDataRegionGroupNum|MaxDataRegionGroupNum|
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+|root.db1| null| 1| 3| 604800000| 0| 1| 1| 0| 2| 2|
+|root.db2|86400000| 1| 1| 604800000| 0| 1| 1| 0| 2| 2|
+|root.db3| null| 1| 1| 604800000| 0| 1| 1| 0| 2| 2|
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+Total line number = 3
+It costs 0.058s
+```
+
+The query results in each column are as follows:
+
++ The name of the Database
++ The TTL of the Database
++ The schema replication number of the Database
++ The data replication number of the Database
++ The time partition interval of the Database
++ The current SchemaRegionGroup number of the Database
++ The required minimum SchemaRegionGroup number of the Database
++ The permitted maximum SchemaRegionGroup number of the Database
++ The current DataRegionGroup number of the Database
++ The required minimum DataRegionGroup number of the Database
++ The permitted maximum DataRegionGroup number of the Database
+
+### TTL
+
+IoTDB supports device-level TTL settings, which means it is able to delete old data automatically and periodically. The benefit of using TTL is that hopefully you can control the total disk space usage and prevent the machine from running out of disks. Moreover, the query performance may downgrade as the total number of files goes up and the memory usage also increases as there are more files. Timely removing such files helps to keep at a high query performance level and reduce memory usage.
+
+The default unit of TTL is milliseconds. If the time precision in the configuration file changes to another, the TTL is still set to milliseconds.
+
+When setting TTL, the system will look for all devices included in the set path and set TTL for these devices. The system will delete expired data at the device granularity.
+After the device data expires, it will not be queryable. The data in the disk file cannot be guaranteed to be deleted immediately, but it can be guaranteed to be deleted eventually.
+However, due to operational costs, the expired data will not be physically deleted right after expiring. The physical deletion is delayed until compaction.
+Therefore, before the data is physically deleted, if the TTL is reduced or lifted, it may cause data that was previously invisible due to TTL to reappear.
+The system can only set up to 1000 TTL rules, and when this limit is reached, some TTL rules need to be deleted before new rules can be set.
+
+#### TTL Path Rule
+The path can only be prefix paths (i.e., the path cannot contain \* , except \*\* in the last level).
+This path will match devices and also allows users to specify paths without asterisks as specific databases or devices.
+When the path does not contain asterisks, the system will check if it matches a database; if it matches a database, both the path and path.\*\* will be set at the same time. Note: Device TTL settings do not verify the existence of metadata, i.e., it is allowed to set TTL for a non-existent device.
+```
+qualified paths:
+root.**
+root.db.**
+root.db.group1.**
+root.db
+root.db.group1.d1
+
+unqualified paths:
+root.*.db
+root.**.db.*
+root.db.*
+```
+#### TTL Applicable Rules
+When a device is subject to multiple TTL rules, the more precise and longer rules are prioritized. For example, for the device "root.bj.hd.dist001.turbine001", the rule "root.bj.hd.dist001.turbine001" takes precedence over "root.bj.hd.dist001.\*\*", and the rule "root.bj.hd.dist001.\*\*" takes precedence over "root.bj.hd.**".
+#### Set TTL
+The set ttl operation can be understood as setting a TTL rule, for example, setting ttl to root.sg.group1.** is equivalent to mounting ttl for all devices that can match this path pattern.
+The unset ttl operation indicates unmounting TTL for the corresponding path pattern; if there is no corresponding TTL, nothing will be done.
+If you want to set TTL to be infinitely large, you can use the INF keyword.
+The SQL Statement for setting TTL is as follow:
+```
+set ttl to pathPattern 360000;
+```
+Set the Time to Live (TTL) to a pathPattern of 360,000 milliseconds; the pathPattern should not contain a wildcard (\*) in the middle and must end with a double asterisk (\*\*). The pathPattern is used to match corresponding devices.
+To maintain compatibility with older SQL syntax, if the user-provided pathPattern matches a database (db), the path pattern is automatically expanded to include all sub-paths denoted by path.\*\*.
+For instance, writing "set ttl to root.sg 360000" will automatically be transformed into "set ttl to root.sg.\*\* 360000", which sets the TTL for all devices under root.sg. However, if the specified pathPattern does not match a database, the aforementioned logic will not apply. For example, writing "set ttl to root.sg.group 360000" will not be expanded to "root.sg.group.\*\*" since root.sg.group does not match a database.
+It is also permissible to specify a particular device without a wildcard (*).
+#### Unset TTL
+
+To unset TTL, we can use follwing SQL statement:
+
+```
+IoTDB> unset ttl from root.ln
+```
+
+After unset TTL, all data will be accepted in `root.ln`.
+```
+IoTDB> unset ttl from root.sgcc.**
+```
+
+Unset the TTL in the `root.sgcc` path.
+
+New syntax
+```
+IoTDB> unset ttl from root.**
+```
+
+Old syntax
+```
+IoTDB> unset ttl to root.**
+```
+There is no functional difference between the old and new syntax, and they are compatible with each other.
+The new syntax is just more conventional in terms of wording.
+
+Unset the TTL setting for all path pattern.
+
+#### Show TTL
+
+To Show TTL, we can use following SQL statement:
+
+show all ttl
+
+```
+IoTDB> SHOW ALL TTL
++--------------+--------+
+| path| TTL|
+| root.**|55555555|
+| root.sg2.a.**|44440000|
++--------------+--------+
+```
+
+show ttl on pathPattern
+```
+IoTDB> SHOW TTL ON root.db.**;
++--------------+--------+
+| path| TTL|
+| root.db.**|55555555|
+| root.db.a.**|44440000|
++--------------+--------+
+```
+
+The SHOW ALL TTL example gives the TTL for all path patterns.
+The SHOW TTL ON pathPattern shows the TTL for the path pattern specified.
+
+Display devices' ttl
+```
+IoTDB> show devices
++---------------+---------+---------+
+| Device|IsAligned| TTL|
++---------------+---------+---------+
+|root.sg.device1| false| 36000000|
+|root.sg.device2| true| INF|
++---------------+---------+---------+
+```
+All devices will definitely have a TTL, meaning it cannot be null. INF represents infinity.
+
+## Device Template
+
+IoTDB supports the device template function, enabling different entities of the same type to share metadata, reduce the memory usage of metadata, and simplify the management of numerous entities and measurements.
+
+
+
+
+
+### Create Device Template
+
+The SQL syntax for creating a metadata template is as follows:
+
+```sql
+CREATE DEVICE TEMPLATE ALIGNED? '(' [',' ]+ ')'
+```
+
+**Example 1:** Create a template containing two non-aligned timeseries
+
+```shell
+IoTDB> create device template t1 (temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN compression=SNAPPY)
+```
+
+**Example 2:** Create a template containing a group of aligned timeseries
+
+```shell
+IoTDB> create device template t2 aligned (lat FLOAT encoding=Gorilla, lon FLOAT encoding=Gorilla)
+```
+
+The` lat` and `lon` measurements are aligned.
+
+
+### Set Device Template
+
+After a device template is created, it should be set to specific path before creating related timeseries or insert data.
+
+**It should be ensured that the related database has been set before setting template.**
+
+**It is recommended to set device template to database path. It is not suggested to set device template to some path above database**
+
+**It is forbidden to create timeseries under a path setting s tedeviceplate. Device template shall not be set on a prefix path of an existing timeseries.**
+
+The SQL Statement for setting device template is as follow:
+
+```shell
+IoTDB> set device template t1 to root.sg1.d1
+```
+
+### Activate Device Template
+
+After setting the device template, with the system enabled to auto create schema, you can insert data into the timeseries. For example, suppose there's a database root.sg1 and t1 has been set to root.sg1.d1, then timeseries like root.sg1.d1.temperature and root.sg1.d1.status are available and data points can be inserted.
+
+
+**Attention**: Before inserting data or the system not enabled to auto create schema, timeseries defined by the device template will not be created. You can use the following SQL statement to create the timeseries or activate the templdeviceate, act before inserting data:
+
+```shell
+IoTDB> create timeseries using device template on root.sg1.d1
+```
+
+**Example:** Execute the following statement
+
+```shell
+IoTDB> set device template t1 to root.sg1.d1
+IoTDB> set device template t2 to root.sg1.d2
+IoTDB> create timeseries using device template on root.sg1.d1
+IoTDB> create timeseries using device template on root.sg1.d2
+```
+
+Show the time series:
+
+```sql
+show timeseries root.sg1.**
+````
+
+```shell
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression|tags|attributes|deadband|deadband parameters|
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+|root.sg1.d1.temperature| null| root.sg1| FLOAT| RLE| SNAPPY|null| null| null| null|
+| root.sg1.d1.status| null| root.sg1| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
+| root.sg1.d2.lon| null| root.sg1| FLOAT| GORILLA| SNAPPY|null| null| null| null|
+| root.sg1.d2.lat| null| root.sg1| FLOAT| GORILLA| SNAPPY|null| null| null| null|
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+```
+
+Show the devices:
+
+```sql
+show devices root.sg1.**
+````
+
+```shell
++---------------+---------+
+| devices|isAligned|
++---------------+---------+
+| root.sg1.d1| false|
+| root.sg1.d2| true|
++---------------+---------+
+````
+
+### Show Device Template
+
+- Show all device templates
+
+The SQL statement looks like this:
+
+```shell
+IoTDB> show device templates
+```
+
+The execution result is as follows:
+
+```shell
++-------------+
+|template name|
++-------------+
+| t2|
+| t1|
++-------------+
+```
+
+- Show nodes under in device template
+
+The SQL statement looks like this:
+
+```shell
+IoTDB> show nodes in device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+--------+--------+-----------+
+|child nodes|dataType|encoding|compression|
++-----------+--------+--------+-----------+
+|temperature| FLOAT| RLE| SNAPPY|
+| status| BOOLEAN| PLAIN| SNAPPY|
++-----------+--------+--------+-----------+
+```
+
+- Show the path prefix where a device template is set
+
+```shell
+IoTDB> show paths set device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+
+|child paths|
++-----------+
+|root.sg1.d1|
++-----------+
+```
+
+- Show the path prefix where a device template is used (i.e. the time series has been created)
+
+```shell
+IoTDB> show paths using device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+
+|child paths|
++-----------+
+|root.sg1.d1|
++-----------+
+```
+
+### Deactivate device Template
+
+To delete a group of timeseries represented by device template, namely deactivate the device template, use the following SQL statement:
+
+```shell
+IoTDB> delete timeseries of device template t1 from root.sg1.d1
+```
+
+or
+
+```shell
+IoTDB> deactivate device template t1 from root.sg1.d1
+```
+
+The deactivation supports batch process.
+
+```shell
+IoTDB> delete timeseries of device template t1 from root.sg1.*, root.sg2.*
+```
+
+or
+
+```shell
+IoTDB> deactivate device template t1 from root.sg1.*, root.sg2.*
+```
+
+If the template name is not provided in sql, all template activation on paths matched by given path pattern will be removed.
+
+### Unset Device Template
+
+The SQL Statement for unsetting device template is as follow:
+
+```shell
+IoTDB> unset device template t1 from root.sg1.d1
+```
+
+**Attention**: It should be guaranteed that none of the timeseries represented by the target device template exists, before unset it. It can be achieved by deactivation operation.
+
+### Drop Device Template
+
+The SQL Statement for dropping device template is as follow:
+
+```shell
+IoTDB> drop device template t1
+```
+
+**Attention**: Dropping an already set template is not supported.
+
+### Alter Device Template
+
+In a scenario where measurements need to be added, you can modify the template to add measurements to all devicesdevice using the device template.
+
+The SQL Statement for altering device template is as follow:
+
+```shell
+IoTDB> alter device template t1 add (speed FLOAT encoding=RLE, FLOAT TEXT encoding=PLAIN compression=SNAPPY)
+```
+
+**When executing data insertion to devices with device template set on related prefix path and there are measurements not present in this device template, the measurements will be auto added to this device template.**
+
+## Timeseries Management
+
+### Create Timeseries
+
+According to the storage model selected before, we can create corresponding timeseries in the two databases respectively. The SQL statements for creating timeseries are as follows:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature with datatype=FLOAT,encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware with datatype=TEXT,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature with datatype=FLOAT,encoding=RLE
+```
+
+From v0.13, you can use a simplified version of the SQL statements to create timeseries:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature FLOAT encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware TEXT encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature FLOAT encoding=RLE
+```
+
+Notice that when in the CREATE TIMESERIES statement the encoding method conflicts with the data type, the system gives the corresponding error prompt as shown below:
+
+```
+IoTDB > create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+error: encoding TS_2DIFF does not support BOOLEAN
+```
+
+Please refer to [Encoding](../Basic-Concept/Encoding-and-Compression.md) for correspondence between data type and encoding.
+
+### Create Aligned Timeseries
+
+The SQL statement for creating a group of timeseries are as follows:
+
+```
+IoTDB> CREATE ALIGNED TIMESERIES root.ln.wf01.GPS(latitude FLOAT encoding=PLAIN compressor=SNAPPY, longitude FLOAT encoding=PLAIN compressor=SNAPPY)
+```
+
+You can set different datatype, encoding, and compression for the timeseries in a group of aligned timeseries
+
+It is also supported to set an alias, tag, and attribute for aligned timeseries.
+
+### Delete Timeseries
+
+To delete the timeseries we created before, we are able to use `(DELETE | DROP) TimeSeries ` statement.
+
+The usage are as follows:
+
+```
+IoTDB> delete timeseries root.ln.wf01.wt01.status
+IoTDB> delete timeseries root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware
+IoTDB> delete timeseries root.ln.wf02.*
+IoTDB> drop timeseries root.ln.wf02.*
+```
+
+### Show Timeseries
+
+* SHOW LATEST? TIMESERIES pathPattern? whereClause? limitClause?
+
+ There are four optional clauses added in SHOW TIMESERIES, return information of time series
+
+Timeseries information includes: timeseries path, alias of measurement, database it belongs to, data type, encoding type, compression type, tags and attributes.
+
+Examples:
+
+* SHOW TIMESERIES
+
+ presents all timeseries information in JSON form
+
+* SHOW TIMESERIES <`PathPattern`>
+
+ returns all timeseries information matching the given <`PathPattern`>. SQL statements are as follows:
+
+```
+IoTDB> show timeseries root.**
+IoTDB> show timeseries root.ln.**
+```
+
+The results are shown below respectively:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.sgcc.wf03.wt01.status| null| root.sgcc| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY| null| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 7
+It costs 0.016s
+
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression|tags|attributes|deadband|deadband parameters|
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY|null| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
+|root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY|null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+Total line number = 4
+It costs 0.004s
+```
+
+* SHOW TIMESERIES LIMIT INT OFFSET INT
+
+ returns all the timeseries information start from the offset and limit the number of series returned. For example,
+
+```
+show timeseries root.ln.** limit 10 offset 10
+```
+
+* SHOW TIMESERIES WHERE TIMESERIES contains 'containStr'
+
+ The query result set is filtered by string fuzzy matching based on the names of the timeseries. For example:
+
+```
+show timeseries root.ln.** where timeseries contains 'wf01.wt'
+```
+
+The result is shown below:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 2
+It costs 0.016s
+```
+
+* SHOW TIMESERIES WHERE DataType=type
+
+ The query result set is filtered by data type. For example:
+
+```
+show timeseries root.ln.** where dataType=FLOAT
+```
+
+The result is shown below:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 3
+It costs 0.016s
+
+```
+
+
+* SHOW LATEST TIMESERIES
+
+ all the returned timeseries information should be sorted in descending order of the last timestamp of timeseries
+
+It is worth noting that when the queried path does not exist, the system will return no timeseries.
+
+
+### Count Timeseries
+
+IoTDB is able to use `COUNT TIMESERIES ` to count the number of timeseries matching the path. SQL statements are as follows:
+
+* `WHERE` condition could be used to fuzzy match a time series name with the following syntax: `COUNT TIMESERIES WHERE TIMESERIES contains 'containStr'`.
+* `WHERE` condition could be used to filter result by data type with the syntax: `COUNT TIMESERIES WHERE DataType='`.
+* `WHERE` condition could be used to filter result by tags with the syntax: `COUNT TIMESERIES WHERE TAGS(key)='value'` or `COUNT TIMESERIES WHERE TAGS(key) contains 'value'`.
+* `LEVEL` could be defined to show count the number of timeseries of each node at the given level in current Metadata Tree. This could be used to query the number of sensors under each device. The grammar is: `COUNT TIMESERIES GROUP BY LEVEL=`.
+
+
+```
+IoTDB > COUNT TIMESERIES root.**
+IoTDB > COUNT TIMESERIES root.ln.**
+IoTDB > COUNT TIMESERIES root.ln.*.*.status
+IoTDB > COUNT TIMESERIES root.ln.wf01.wt01.status
+IoTDB > COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc'
+IoTDB > COUNT TIMESERIES root.** WHERE DATATYPE = INT64
+IoTDB > COUNT TIMESERIES root.** WHERE TAGS(unit) contains 'c'
+IoTDB > COUNT TIMESERIES root.** WHERE TAGS(unit) = 'c'
+IoTDB > COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc' group by level = 1
+```
+
+For example, if there are several timeseries (use `show timeseries` to show all timeseries):
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.sgcc.wf03.wt01.status| null| root.sgcc| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY| {"unit":"c"}| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| {"description":"test1"}| null| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 7
+It costs 0.004s
+```
+
+Then the Metadata Tree will be as below:
+
+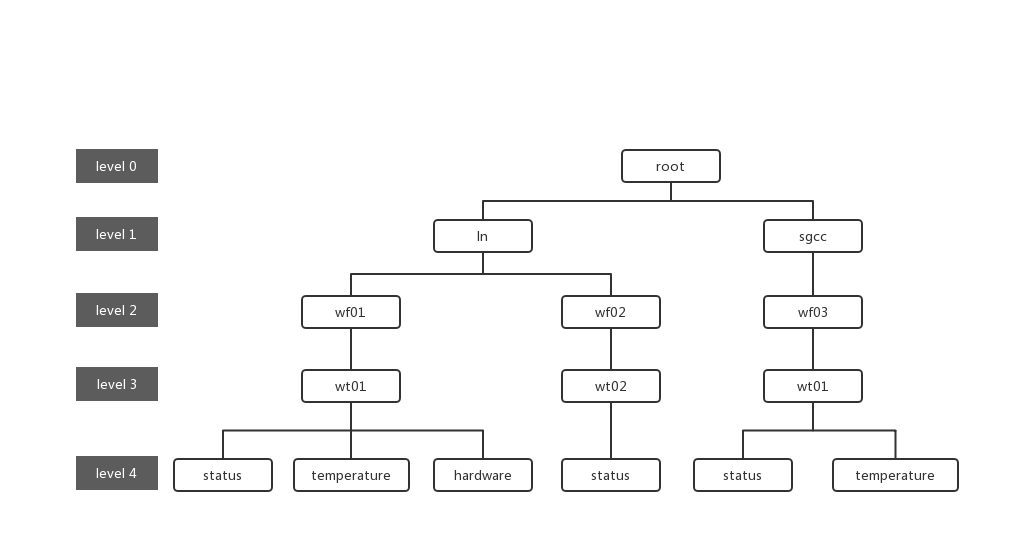 +
+As can be seen, `root` is considered as `LEVEL=0`. So when you enter statements such as:
+
+```
+IoTDB > COUNT TIMESERIES root.** GROUP BY LEVEL=1
+IoTDB > COUNT TIMESERIES root.ln.** GROUP BY LEVEL=2
+IoTDB > COUNT TIMESERIES root.ln.wf01.* GROUP BY LEVEL=2
+```
+
+You will get following results:
+
+```
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+| root.sgcc| 2|
+|root.turbine| 1|
+| root.ln| 4|
++------------+-----------------+
+Total line number = 3
+It costs 0.002s
+
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+|root.ln.wf02| 2|
+|root.ln.wf01| 2|
++------------+-----------------+
+Total line number = 2
+It costs 0.002s
+
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+|root.ln.wf01| 2|
++------------+-----------------+
+Total line number = 1
+It costs 0.002s
+```
+
+> Note: The path of timeseries is just a filter condition, which has no relationship with the definition of level.
+
+### Tag and Attribute Management
+
+We can also add an alias, extra tag and attribute information while creating one timeseries.
+
+The differences between tag and attribute are:
+
+* Tag could be used to query the path of timeseries, we will maintain an inverted index in memory on the tag: Tag -> Timeseries
+* Attribute could only be queried by timeseries path : Timeseries -> Attribute
+
+The SQL statements for creating timeseries with extra tag and attribute information are extended as follows:
+
+```
+create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2)
+```
+
+The `temprature` in the brackets is an alias for the sensor `s1`. So we can use `temprature` to replace `s1` anywhere.
+
+> IoTDB also supports using AS function to set alias. The difference between the two is: the alias set by the AS function is used to replace the whole time series name, temporary and not bound with the time series; while the alias mentioned above is only used as the alias of the sensor, which is bound with it and can be used equivalent to the original sensor name.
+
+> Notice that the size of the extra tag and attribute information shouldn't exceed the `tag_attribute_total_size`.
+
+We can update the tag information after creating it as following:
+
+* Rename the tag/attribute key
+
+```
+ALTER timeseries root.turbine.d1.s1 RENAME tag1 TO newTag1
+```
+
+* Reset the tag/attribute value
+
+```
+ALTER timeseries root.turbine.d1.s1 SET newTag1=newV1, attr1=newV1
+```
+
+* Delete the existing tag/attribute
+
+```
+ALTER timeseries root.turbine.d1.s1 DROP tag1, tag2
+```
+
+* Add new tags
+
+```
+ALTER timeseries root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4
+```
+
+* Add new attributes
+
+```
+ALTER timeseries root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4
+```
+
+* Upsert alias, tags and attributes
+
+> add alias or a new key-value if the alias or key doesn't exist, otherwise, update the old one with new value.
+
+```
+ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(tag3=v3, tag4=v4) ATTRIBUTES(attr3=v3, attr4=v4)
+```
+
+* Show timeseries using tags. Use TAGS(tagKey) to identify the tags used as filter key
+
+```
+SHOW TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
+```
+
+returns all the timeseries information that satisfy the where condition and match the pathPattern. SQL statements are as follows:
+
+```
+ALTER timeseries root.ln.wf02.wt02.hardware ADD TAGS unit=c
+ALTER timeseries root.ln.wf02.wt02.status ADD TAGS description=test1
+show timeseries root.ln.** where TAGS(unit)='c'
+show timeseries root.ln.** where TAGS(description) contains 'test1'
+```
+
+The results are shown below respectly:
+
+```
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags|attributes|deadband|deadband parameters|
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+|root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY|{"unit":"c"}| null| null| null|
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+Total line number = 1
+It costs 0.005s
+
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags|attributes|deadband|deadband parameters|
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+|root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|{"description":"test1"}| null| null| null|
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+Total line number = 1
+It costs 0.004s
+```
+
+- count timeseries using tags
+
+```
+COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
+COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause GROUP BY LEVEL=
+```
+
+returns all the number of timeseries that satisfy the where condition and match the pathPattern. SQL statements are as follows:
+
+```
+count timeseries
+count timeseries root.** where TAGS(unit)='c'
+count timeseries root.** where TAGS(unit)='c' group by level = 2
+```
+
+The results are shown below respectly :
+
+```
+IoTDB> count timeseries
++-----------------+
+|count(timeseries)|
++-----------------+
+| 6|
++-----------------+
+Total line number = 1
+It costs 0.019s
+IoTDB> count timeseries root.** where TAGS(unit)='c'
++-----------------+
+|count(timeseries)|
++-----------------+
+| 2|
++-----------------+
+Total line number = 1
+It costs 0.020s
+IoTDB> count timeseries root.** where TAGS(unit)='c' group by level = 2
++--------------+-----------------+
+| column|count(timeseries)|
++--------------+-----------------+
+| root.ln.wf02| 2|
+| root.ln.wf01| 0|
+|root.sgcc.wf03| 0|
++--------------+-----------------+
+Total line number = 3
+It costs 0.011s
+```
+
+> Notice that, we only support one condition in the where clause. Either it's an equal filter or it is an `contains` filter. In both case, the property in the where condition must be a tag.
+
+create aligned timeseries
+
+```
+create aligned timeseries root.sg1.d1(s1 INT32 tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2), s2 DOUBLE tags(tag3=v3, tag4=v4) attributes(attr3=v3, attr4=v4))
+```
+
+The execution result is as follows:
+
+```
+IoTDB> show timeseries
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+|root.sg1.d1.s1| null| root.sg1| INT32| RLE| SNAPPY|{"tag1":"v1","tag2":"v2"}|{"attr2":"v2","attr1":"v1"}| null| null|
+|root.sg1.d1.s2| null| root.sg1| DOUBLE| GORILLA| SNAPPY|{"tag4":"v4","tag3":"v3"}|{"attr4":"v4","attr3":"v3"}| null| null|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+```
+
+Support query:
+
+```
+IoTDB> show timeseries where TAGS(tag1)='v1'
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+|root.sg1.d1.s1| null| root.sg1| INT32| RLE| SNAPPY|{"tag1":"v1","tag2":"v2"}|{"attr2":"v2","attr1":"v1"}| null| null|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+```
+
+The above operations are supported for timeseries tag, attribute updates, etc.
+
+## Node Management
+
+### Show Child Paths
+
+```
+SHOW CHILD PATHS pathPattern
+```
+
+Return all child paths and their node types of all the paths matching pathPattern.
+
+node types: ROOT -> DB INTERNAL -> DATABASE -> INTERNAL -> DEVICE -> TIMESERIES
+
+
+Example:
+
+* return the child paths of root.ln:show child paths root.ln
+
+```
++------------+----------+
+| child paths|node types|
++------------+----------+
+|root.ln.wf01| INTERNAL|
+|root.ln.wf02| INTERNAL|
++------------+----------+
+Total line number = 2
+It costs 0.002s
+```
+
+> get all paths in form of root.xx.xx.xx:show child paths root.xx.xx
+
+### Show Child Nodes
+
+```
+SHOW CHILD NODES pathPattern
+```
+
+Return all child nodes of the pathPattern.
+
+Example:
+
+* return the child nodes of root:show child nodes root
+
+```
++------------+
+| child nodes|
++------------+
+| ln|
++------------+
+```
+
+* return the child nodes of root.ln:show child nodes root.ln
+
+```
++------------+
+| child nodes|
++------------+
+| wf01|
+| wf02|
++------------+
+```
+
+### Count Nodes
+
+IoTDB is able to use `COUNT NODES LEVEL=` to count the number of nodes at
+ the given level in current Metadata Tree considering a given pattern. IoTDB will find paths that
+ match the pattern and counts distinct nodes at the specified level among the matched paths.
+ This could be used to query the number of devices with specified measurements. The usage are as
+ follows:
+
+```
+IoTDB > COUNT NODES root.** LEVEL=2
+IoTDB > COUNT NODES root.ln.** LEVEL=2
+IoTDB > COUNT NODES root.ln.wf01.** LEVEL=3
+IoTDB > COUNT NODES root.**.temperature LEVEL=3
+```
+
+As for the above mentioned example and Metadata tree, you can get following results:
+
+```
++------------+
+|count(nodes)|
++------------+
+| 4|
++------------+
+Total line number = 1
+It costs 0.003s
+
++------------+
+|count(nodes)|
++------------+
+| 2|
++------------+
+Total line number = 1
+It costs 0.002s
+
++------------+
+|count(nodes)|
++------------+
+| 1|
++------------+
+Total line number = 1
+It costs 0.002s
+
++------------+
+|count(nodes)|
++------------+
+| 2|
++------------+
+Total line number = 1
+It costs 0.002s
+```
+
+> Note: The path of timeseries is just a filter condition, which has no relationship with the definition of level.
+
+### Show Devices
+
+* SHOW DEVICES pathPattern? (WITH DATABASE)? devicesWhereClause? limitClause?
+
+Similar to `Show Timeseries`, IoTDB also supports two ways of viewing devices:
+
+* `SHOW DEVICES` statement presents all devices' information, which is equal to `SHOW DEVICES root.**`.
+* `SHOW DEVICES ` statement specifies the `PathPattern` and returns the devices information matching the pathPattern and under the given level.
+* `WHERE` condition supports `DEVICE contains 'xxx'` to do a fuzzy query based on the device name.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices
+IoTDB> show devices root.ln.**
+IoTDB> show devices root.ln.** where device contains 't'
+```
+
+You can get results below:
+
+```
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+| root.ln.wf01.wt01| false|
+| root.ln.wf02.wt02| false|
+|root.sgcc.wf03.wt01| false|
+| root.turbine.d1| false|
++-------------------+---------+
+Total line number = 4
+It costs 0.002s
+
++-----------------+---------+
+| devices|isAligned|
++-----------------+---------+
+|root.ln.wf01.wt01| false|
+|root.ln.wf02.wt02| false|
++-----------------+---------+
+Total line number = 2
+It costs 0.001s
+```
+
+`isAligned` indicates whether the timeseries under the device are aligned.
+
+To view devices' information with database, we can use `SHOW DEVICES WITH DATABASE` statement.
+
+* `SHOW DEVICES WITH DATABASE` statement presents all devices' information with their database.
+* `SHOW DEVICES WITH DATABASE` statement specifies the `PathPattern` and returns the
+ devices' information under the given level with their database information.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices with database
+IoTDB> show devices root.ln.** with database
+```
+
+You can get results below:
+
+```
++-------------------+-------------+---------+
+| devices| database|isAligned|
++-------------------+-------------+---------+
+| root.ln.wf01.wt01| root.ln| false|
+| root.ln.wf02.wt02| root.ln| false|
+|root.sgcc.wf03.wt01| root.sgcc| false|
+| root.turbine.d1| root.turbine| false|
++-------------------+-------------+---------+
+Total line number = 4
+It costs 0.003s
+
++-----------------+-------------+---------+
+| devices| database|isAligned|
++-----------------+-------------+---------+
+|root.ln.wf01.wt01| root.ln| false|
+|root.ln.wf02.wt02| root.ln| false|
++-----------------+-------------+---------+
+Total line number = 2
+It costs 0.001s
+```
+
+### Count Devices
+
+* COUNT DEVICES /
+
+The above statement is used to count the number of devices. At the same time, it is allowed to specify `PathPattern` to count the number of devices matching the `PathPattern`.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices
+IoTDB> count devices
+IoTDB> count devices root.ln.**
+```
+
+You can get results below:
+
+```
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+|root.sgcc.wf03.wt03| false|
+| root.turbine.d1| false|
+| root.ln.wf02.wt02| false|
+| root.ln.wf01.wt01| false|
++-------------------+---------+
+Total line number = 4
+It costs 0.024s
+
++--------------+
+|count(devices)|
++--------------+
+| 4|
++--------------+
+Total line number = 1
+It costs 0.004s
+
++--------------+
+|count(devices)|
++--------------+
+| 2|
++--------------+
+Total line number = 1
+It costs 0.004s
+```
+
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_timecho.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_timecho.md
new file mode 100644
index 00000000..8d57facb
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_timecho.md
@@ -0,0 +1,1324 @@
+
+
+# Timeseries Management
+
+## Database Management
+
+### Create Database
+
+According to the storage model we can set up the corresponding database. Two SQL statements are supported for creating databases, as follows:
+
+```
+IoTDB > create database root.ln
+IoTDB > create database root.sgcc
+```
+
+We can thus create two databases using the above two SQL statements.
+
+It is worth noting that 1 database is recommended.
+
+When the path itself or the parent/child layer of the path is already created as database, the path is then not allowed to be created as database. For example, it is not feasible to create `root.ln.wf01` as database when two databases `root.ln` and `root.sgcc` exist. The system gives the corresponding error prompt as shown below:
+
+```
+IoTDB> CREATE DATABASE root.ln.wf01
+Msg: 300: root.ln has already been created as database.
+IoTDB> create database root.ln.wf01
+Msg: 300: root.ln has already been created as database.
+```
+
+The LayerName of database can only be chinese or english characters, numbers, underscores, dots and backticks. If you want to set it to pure numbers or contain backticks or dots, you need to enclose the database name with backticks (` `` `). In ` `` `,2 backticks represents one, i.e. ` ```` ` represents `` ` ``.
+
+Besides, if deploy on Windows system, the LayerName is case-insensitive, which means it's not allowed to create databases `root.ln` and `root.LN` at the same time.
+
+### Show Databases
+
+After creating the database, we can use the [SHOW DATABASES](../SQL-Manual/SQL-Manual.md) statement and [SHOW DATABASES \](../SQL-Manual/SQL-Manual.md) to view the databases. The SQL statements are as follows:
+
+```
+IoTDB> SHOW DATABASES
+IoTDB> SHOW DATABASES root.**
+```
+
+The result is as follows:
+
+```
++-------------+----+-------------------------+-----------------------+-----------------------+
+|database| ttl|schema_replication_factor|data_replication_factor|time_partition_interval|
++-------------+----+-------------------------+-----------------------+-----------------------+
+| root.sgcc|null| 2| 2| 604800|
+| root.ln|null| 2| 2| 604800|
++-------------+----+-------------------------+-----------------------+-----------------------+
+Total line number = 2
+It costs 0.060s
+```
+
+### Delete Database
+
+User can use the `DELETE DATABASE ` statement to delete all databases matching the pathPattern. Please note the data in the database will also be deleted.
+
+```
+IoTDB > DELETE DATABASE root.ln
+IoTDB > DELETE DATABASE root.sgcc
+// delete all data, all timeseries and all databases
+IoTDB > DELETE DATABASE root.**
+```
+
+### Count Databases
+
+User can use the `COUNT DATABASE ` statement to count the number of databases. It is allowed to specify `PathPattern` to count the number of databases matching the `PathPattern`.
+
+SQL statement is as follows:
+
+```
+IoTDB> count databases
+IoTDB> count databases root.*
+IoTDB> count databases root.sgcc.*
+IoTDB> count databases root.sgcc
+```
+
+The result is as follows:
+
+```
++-------------+
+| database|
++-------------+
+| root.sgcc|
+| root.turbine|
+| root.ln|
++-------------+
+Total line number = 3
+It costs 0.003s
+
++-------------+
+| database|
++-------------+
+| 3|
++-------------+
+Total line number = 1
+It costs 0.003s
+
++-------------+
+| database|
++-------------+
+| 3|
++-------------+
+Total line number = 1
+It costs 0.002s
+
++-------------+
+| database|
++-------------+
+| 0|
++-------------+
+Total line number = 1
+It costs 0.002s
+
++-------------+
+| database|
++-------------+
+| 1|
++-------------+
+Total line number = 1
+It costs 0.002s
+```
+
+### Setting up heterogeneous databases (Advanced operations)
+
+Under the premise of familiar with IoTDB metadata modeling,
+users can set up heterogeneous databases in IoTDB to cope with different production needs.
+
+Currently, the following database heterogeneous parameters are supported:
+
+| Parameter | Type | Description |
+| ------------------------- | ------- | --------------------------------------------- |
+| TTL | Long | TTL of the Database |
+| SCHEMA_REPLICATION_FACTOR | Integer | The schema replication number of the Database |
+| DATA_REPLICATION_FACTOR | Integer | The data replication number of the Database |
+| SCHEMA_REGION_GROUP_NUM | Integer | The SchemaRegionGroup number of the Database |
+| DATA_REGION_GROUP_NUM | Integer | The DataRegionGroup number of the Database |
+
+Note the following when configuring heterogeneous parameters:
+
++ TTL and TIME_PARTITION_INTERVAL must be positive integers.
++ SCHEMA_REPLICATION_FACTOR and DATA_REPLICATION_FACTOR must be smaller than or equal to the number of deployed DataNodes.
++ The function of SCHEMA_REGION_GROUP_NUM and DATA_REGION_GROUP_NUM are related to the parameter `schema_region_group_extension_policy` and `data_region_group_extension_policy` in iotdb-common.properties configuration file. Take DATA_REGION_GROUP_NUM as an example:
+ If `data_region_group_extension_policy=CUSTOM` is set, DATA_REGION_GROUP_NUM serves as the number of DataRegionGroups owned by the Database.
+ If `data_region_group_extension_policy=AUTO`, DATA_REGION_GROUP_NUM is used as the lower bound of the DataRegionGroup quota owned by the Database. That is, when the Database starts writing data, it will have at least this number of DataRegionGroups.
+
+Users can set any heterogeneous parameters when creating a Database, or adjust some heterogeneous parameters during a stand-alone/distributed IoTDB run.
+
+#### Set heterogeneous parameters when creating a Database
+
+The user can set any of the above heterogeneous parameters when creating a Database. The SQL statement is as follows:
+
+```
+CREATE DATABASE prefixPath (WITH databaseAttributeClause (COMMA? databaseAttributeClause)*)?
+```
+
+For example:
+
+```
+CREATE DATABASE root.db WITH SCHEMA_REPLICATION_FACTOR=1, DATA_REPLICATION_FACTOR=3, SCHEMA_REGION_GROUP_NUM=1, DATA_REGION_GROUP_NUM=2;
+```
+
+#### Adjust heterogeneous parameters at run time
+
+Users can adjust some heterogeneous parameters during the IoTDB runtime, as shown in the following SQL statement:
+
+```
+ALTER DATABASE prefixPath WITH databaseAttributeClause (COMMA? databaseAttributeClause)*
+```
+
+For example:
+
+```
+ALTER DATABASE root.db WITH SCHEMA_REGION_GROUP_NUM=1, DATA_REGION_GROUP_NUM=2;
+```
+
+Note that only the following heterogeneous parameters can be adjusted at runtime:
+
++ SCHEMA_REGION_GROUP_NUM
++ DATA_REGION_GROUP_NUM
+
+#### Show heterogeneous databases
+
+The user can query the specific heterogeneous configuration of each Database, and the SQL statement is as follows:
+
+```
+SHOW DATABASES DETAILS prefixPath?
+```
+
+For example:
+
+```
+IoTDB> SHOW DATABASES DETAILS
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+|Database| TTL|SchemaReplicationFactor|DataReplicationFactor|TimePartitionInterval|SchemaRegionGroupNum|MinSchemaRegionGroupNum|MaxSchemaRegionGroupNum|DataRegionGroupNum|MinDataRegionGroupNum|MaxDataRegionGroupNum|
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+|root.db1| null| 1| 3| 604800000| 0| 1| 1| 0| 2| 2|
+|root.db2|86400000| 1| 1| 604800000| 0| 1| 1| 0| 2| 2|
+|root.db3| null| 1| 1| 604800000| 0| 1| 1| 0| 2| 2|
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+Total line number = 3
+It costs 0.058s
+```
+
+The query results in each column are as follows:
+
++ The name of the Database
++ The TTL of the Database
++ The schema replication number of the Database
++ The data replication number of the Database
++ The time partition interval of the Database
++ The current SchemaRegionGroup number of the Database
++ The required minimum SchemaRegionGroup number of the Database
++ The permitted maximum SchemaRegionGroup number of the Database
++ The current DataRegionGroup number of the Database
++ The required minimum DataRegionGroup number of the Database
++ The permitted maximum DataRegionGroup number of the Database
+
+### TTL
+
+IoTDB supports device-level TTL settings, which means it is able to delete old data automatically and periodically. The benefit of using TTL is that hopefully you can control the total disk space usage and prevent the machine from running out of disks. Moreover, the query performance may downgrade as the total number of files goes up and the memory usage also increases as there are more files. Timely removing such files helps to keep at a high query performance level and reduce memory usage.
+
+The default unit of TTL is milliseconds. If the time precision in the configuration file changes to another, the TTL is still set to milliseconds.
+
+When setting TTL, the system will look for all devices included in the set path and set TTL for these devices. The system will delete expired data at the device granularity.
+After the device data expires, it will not be queryable. The data in the disk file cannot be guaranteed to be deleted immediately, but it can be guaranteed to be deleted eventually.
+However, due to operational costs, the expired data will not be physically deleted right after expiring. The physical deletion is delayed until compaction.
+Therefore, before the data is physically deleted, if the TTL is reduced or lifted, it may cause data that was previously invisible due to TTL to reappear.
+The system can only set up to 1000 TTL rules, and when this limit is reached, some TTL rules need to be deleted before new rules can be set.
+
+#### TTL Path Rule
+The path can only be prefix paths (i.e., the path cannot contain \* , except \*\* in the last level).
+This path will match devices and also allows users to specify paths without asterisks as specific databases or devices.
+When the path does not contain asterisks, the system will check if it matches a database; if it matches a database, both the path and path.\*\* will be set at the same time. Note: Device TTL settings do not verify the existence of metadata, i.e., it is allowed to set TTL for a non-existent device.
+```
+qualified paths:
+root.**
+root.db.**
+root.db.group1.**
+root.db
+root.db.group1.d1
+
+unqualified paths:
+root.*.db
+root.**.db.*
+root.db.*
+```
+#### TTL Applicable Rules
+When a device is subject to multiple TTL rules, the more precise and longer rules are prioritized. For example, for the device "root.bj.hd.dist001.turbine001", the rule "root.bj.hd.dist001.turbine001" takes precedence over "root.bj.hd.dist001.\*\*", and the rule "root.bj.hd.dist001.\*\*" takes precedence over "root.bj.hd.**".
+#### Set TTL
+The set ttl operation can be understood as setting a TTL rule, for example, setting ttl to root.sg.group1.** is equivalent to mounting ttl for all devices that can match this path pattern.
+The unset ttl operation indicates unmounting TTL for the corresponding path pattern; if there is no corresponding TTL, nothing will be done.
+If you want to set TTL to be infinitely large, you can use the INF keyword.
+The SQL Statement for setting TTL is as follow:
+```
+set ttl to pathPattern 360000;
+```
+Set the Time to Live (TTL) to a pathPattern of 360,000 milliseconds; the pathPattern should not contain a wildcard (\*) in the middle and must end with a double asterisk (\*\*). The pathPattern is used to match corresponding devices.
+To maintain compatibility with older SQL syntax, if the user-provided pathPattern matches a database (db), the path pattern is automatically expanded to include all sub-paths denoted by path.\*\*.
+For instance, writing "set ttl to root.sg 360000" will automatically be transformed into "set ttl to root.sg.\*\* 360000", which sets the TTL for all devices under root.sg. However, if the specified pathPattern does not match a database, the aforementioned logic will not apply. For example, writing "set ttl to root.sg.group 360000" will not be expanded to "root.sg.group.\*\*" since root.sg.group does not match a database.
+It is also permissible to specify a particular device without a wildcard (*).
+#### Unset TTL
+
+To unset TTL, we can use follwing SQL statement:
+
+```
+IoTDB> unset ttl from root.ln
+```
+
+After unset TTL, all data will be accepted in `root.ln`.
+```
+IoTDB> unset ttl from root.sgcc.**
+```
+
+Unset the TTL in the `root.sgcc` path.
+
+New syntax
+```
+IoTDB> unset ttl from root.**
+```
+
+Old syntax
+```
+IoTDB> unset ttl to root.**
+```
+There is no functional difference between the old and new syntax, and they are compatible with each other.
+The new syntax is just more conventional in terms of wording.
+
+Unset the TTL setting for all path pattern.
+
+#### Show TTL
+
+To Show TTL, we can use following SQL statement:
+
+show all ttl
+
+```
+IoTDB> SHOW ALL TTL
++--------------+--------+
+| path| TTL|
+| root.**|55555555|
+| root.sg2.a.**|44440000|
++--------------+--------+
+```
+
+show ttl on pathPattern
+```
+IoTDB> SHOW TTL ON root.db.**;
++--------------+--------+
+| path| TTL|
+| root.db.**|55555555|
+| root.db.a.**|44440000|
++--------------+--------+
+```
+
+The SHOW ALL TTL example gives the TTL for all path patterns.
+The SHOW TTL ON pathPattern shows the TTL for the path pattern specified.
+
+Display devices' ttl
+```
+IoTDB> show devices
++---------------+---------+---------+
+| Device|IsAligned| TTL|
++---------------+---------+---------+
+|root.sg.device1| false| 36000000|
+|root.sg.device2| true| INF|
++---------------+---------+---------+
+```
+All devices will definitely have a TTL, meaning it cannot be null. INF represents infinity.
+
+
+## Device Template
+
+IoTDB supports the device template function, enabling different entities of the same type to share metadata, reduce the memory usage of metadata, and simplify the management of numerous entities and measurements.
+
+
+### Create Device Template
+
+The SQL syntax for creating a metadata template is as follows:
+
+```sql
+CREATE DEVICE TEMPLATE ALIGNED? '(' [',' ]+ ')'
+```
+
+**Example 1:** Create a template containing two non-aligned timeseries
+
+```shell
+IoTDB> create device template t1 (temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN compression=SNAPPY)
+```
+
+**Example 2:** Create a template containing a group of aligned timeseries
+
+```shell
+IoTDB> create device template t2 aligned (lat FLOAT encoding=Gorilla, lon FLOAT encoding=Gorilla)
+```
+
+The` lat` and `lon` measurements are aligned.
+
+
+
+
+
+### Set Device Template
+
+After a device template is created, it should be set to specific path before creating related timeseries or insert data.
+
+**It should be ensured that the related database has been set before setting template.**
+
+**It is recommended to set device template to database path. It is not suggested to set device template to some path above database**
+
+**It is forbidden to create timeseries under a path setting s tedeviceplate. Device template shall not be set on a prefix path of an existing timeseries.**
+
+The SQL Statement for setting device template is as follow:
+
+```shell
+IoTDB> set device template t1 to root.sg1.d1
+```
+
+### Activate Device Template
+
+After setting the device template, with the system enabled to auto create schema, you can insert data into the timeseries. For example, suppose there's a database root.sg1 and t1 has been set to root.sg1.d1, then timeseries like root.sg1.d1.temperature and root.sg1.d1.status are available and data points can be inserted.
+
+
+**Attention**: Before inserting data or the system not enabled to auto create schema, timeseries defined by the device template will not be created. You can use the following SQL statement to create the timeseries or activate the templdeviceate, act before inserting data:
+
+```shell
+IoTDB> create timeseries using device template on root.sg1.d1
+```
+
+**Example:** Execute the following statement
+
+```shell
+IoTDB> set device template t1 to root.sg1.d1
+IoTDB> set device template t2 to root.sg1.d2
+IoTDB> create timeseries using device template on root.sg1.d1
+IoTDB> create timeseries using device template on root.sg1.d2
+```
+
+Show the time series:
+
+```sql
+show timeseries root.sg1.**
+````
+
+```shell
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression|tags|attributes|deadband|deadband parameters|
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+|root.sg1.d1.temperature| null| root.sg1| FLOAT| RLE| SNAPPY|null| null| null| null|
+| root.sg1.d1.status| null| root.sg1| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
+| root.sg1.d2.lon| null| root.sg1| FLOAT| GORILLA| SNAPPY|null| null| null| null|
+| root.sg1.d2.lat| null| root.sg1| FLOAT| GORILLA| SNAPPY|null| null| null| null|
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+```
+
+Show the devices:
+
+```sql
+show devices root.sg1.**
+````
+
+```shell
++---------------+---------+
+| devices|isAligned|
++---------------+---------+
+| root.sg1.d1| false|
+| root.sg1.d2| true|
++---------------+---------+
+````
+
+### Show Device Template
+
+- Show all device templates
+
+The SQL statement looks like this:
+
+```shell
+IoTDB> show device templates
+```
+
+The execution result is as follows:
+
+```shell
++-------------+
+|template name|
++-------------+
+| t2|
+| t1|
++-------------+
+```
+
+- Show nodes under in device template
+
+The SQL statement looks like this:
+
+```shell
+IoTDB> show nodes in device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+--------+--------+-----------+
+|child nodes|dataType|encoding|compression|
++-----------+--------+--------+-----------+
+|temperature| FLOAT| RLE| SNAPPY|
+| status| BOOLEAN| PLAIN| SNAPPY|
++-----------+--------+--------+-----------+
+```
+
+- Show the path prefix where a device template is set
+
+```shell
+IoTDB> show paths set device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+
+|child paths|
++-----------+
+|root.sg1.d1|
++-----------+
+```
+
+- Show the path prefix where a device template is used (i.e. the time series has been created)
+
+```shell
+IoTDB> show paths using device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+
+|child paths|
++-----------+
+|root.sg1.d1|
++-----------+
+```
+
+### Deactivate device Template
+
+To delete a group of timeseries represented by device template, namely deactivate the device template, use the following SQL statement:
+
+```shell
+IoTDB> delete timeseries of device template t1 from root.sg1.d1
+```
+
+or
+
+```shell
+IoTDB> deactivate device template t1 from root.sg1.d1
+```
+
+The deactivation supports batch process.
+
+```shell
+IoTDB> delete timeseries of device template t1 from root.sg1.*, root.sg2.*
+```
+
+or
+
+```shell
+IoTDB> deactivate device template t1 from root.sg1.*, root.sg2.*
+```
+
+If the template name is not provided in sql, all template activation on paths matched by given path pattern will be removed.
+
+### Unset Device Template
+
+The SQL Statement for unsetting device template is as follow:
+
+```shell
+IoTDB> unset device template t1 from root.sg1.d1
+```
+
+**Attention**: It should be guaranteed that none of the timeseries represented by the target device template exists, before unset it. It can be achieved by deactivation operation.
+
+### Drop Device Template
+
+The SQL Statement for dropping device template is as follow:
+
+```shell
+IoTDB> drop device template t1
+```
+
+**Attention**: Dropping an already set template is not supported.
+
+### Alter Device Template
+
+In a scenario where measurements need to be added, you can modify the template to add measurements to all devicesdevice using the device template.
+
+The SQL Statement for altering device template is as follow:
+
+```shell
+IoTDB> alter device template t1 add (speed FLOAT encoding=RLE, FLOAT TEXT encoding=PLAIN compression=SNAPPY)
+```
+
+**When executing data insertion to devices with device template set on related prefix path and there are measurements not present in this device template, the measurements will be auto added to this device template.**
+
+## Timeseries Management
+
+### Create Timeseries
+
+According to the storage model selected before, we can create corresponding timeseries in the two databases respectively. The SQL statements for creating timeseries are as follows:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature with datatype=FLOAT,encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware with datatype=TEXT,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature with datatype=FLOAT,encoding=RLE
+```
+
+From v0.13, you can use a simplified version of the SQL statements to create timeseries:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature FLOAT encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware TEXT encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature FLOAT encoding=RLE
+```
+
+Notice that when in the CREATE TIMESERIES statement the encoding method conflicts with the data type, the system gives the corresponding error prompt as shown below:
+
+```
+IoTDB > create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+error: encoding TS_2DIFF does not support BOOLEAN
+```
+
+Please refer to [Encoding](../Basic-Concept/Encoding-and-Compression.md) for correspondence between data type and encoding.
+
+### Create Aligned Timeseries
+
+The SQL statement for creating a group of timeseries are as follows:
+
+```
+IoTDB> CREATE ALIGNED TIMESERIES root.ln.wf01.GPS(latitude FLOAT encoding=PLAIN compressor=SNAPPY, longitude FLOAT encoding=PLAIN compressor=SNAPPY)
+```
+
+You can set different datatype, encoding, and compression for the timeseries in a group of aligned timeseries
+
+It is also supported to set an alias, tag, and attribute for aligned timeseries.
+
+### Delete Timeseries
+
+To delete the timeseries we created before, we are able to use `(DELETE | DROP) TimeSeries ` statement.
+
+The usage are as follows:
+
+```
+IoTDB> delete timeseries root.ln.wf01.wt01.status
+IoTDB> delete timeseries root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware
+IoTDB> delete timeseries root.ln.wf02.*
+IoTDB> drop timeseries root.ln.wf02.*
+```
+
+### Show Timeseries
+
+* SHOW LATEST? TIMESERIES pathPattern? whereClause? limitClause?
+
+ There are four optional clauses added in SHOW TIMESERIES, return information of time series
+
+Timeseries information includes: timeseries path, alias of measurement, database it belongs to, data type, encoding type, compression type, tags and attributes.
+
+Examples:
+
+* SHOW TIMESERIES
+
+ presents all timeseries information in JSON form
+
+* SHOW TIMESERIES <`PathPattern`>
+
+ returns all timeseries information matching the given <`PathPattern`>. SQL statements are as follows:
+
+```
+IoTDB> show timeseries root.**
+IoTDB> show timeseries root.ln.**
+```
+
+The results are shown below respectively:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.sgcc.wf03.wt01.status| null| root.sgcc| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY| null| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 7
+It costs 0.016s
+
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression|tags|attributes|deadband|deadband parameters|
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY|null| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
+|root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY|null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+Total line number = 4
+It costs 0.004s
+```
+
+* SHOW TIMESERIES LIMIT INT OFFSET INT
+
+ returns all the timeseries information start from the offset and limit the number of series returned. For example,
+
+```
+show timeseries root.ln.** limit 10 offset 10
+```
+
+* SHOW TIMESERIES WHERE TIMESERIES contains 'containStr'
+
+ The query result set is filtered by string fuzzy matching based on the names of the timeseries. For example:
+
+```
+show timeseries root.ln.** where timeseries contains 'wf01.wt'
+```
+
+The result is shown below:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 2
+It costs 0.016s
+```
+
+* SHOW TIMESERIES WHERE DataType=type
+
+ The query result set is filtered by data type. For example:
+
+```
+show timeseries root.ln.** where dataType=FLOAT
+```
+
+The result is shown below:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 3
+It costs 0.016s
+
+```
+
+
+* SHOW LATEST TIMESERIES
+
+ all the returned timeseries information should be sorted in descending order of the last timestamp of timeseries
+
+It is worth noting that when the queried path does not exist, the system will return no timeseries.
+
+
+### Count Timeseries
+
+IoTDB is able to use `COUNT TIMESERIES ` to count the number of timeseries matching the path. SQL statements are as follows:
+
+* `WHERE` condition could be used to fuzzy match a time series name with the following syntax: `COUNT TIMESERIES WHERE TIMESERIES contains 'containStr'`.
+* `WHERE` condition could be used to filter result by data type with the syntax: `COUNT TIMESERIES WHERE DataType='`.
+* `WHERE` condition could be used to filter result by tags with the syntax: `COUNT TIMESERIES WHERE TAGS(key)='value'` or `COUNT TIMESERIES WHERE TAGS(key) contains 'value'`.
+* `LEVEL` could be defined to show count the number of timeseries of each node at the given level in current Metadata Tree. This could be used to query the number of sensors under each device. The grammar is: `COUNT TIMESERIES GROUP BY LEVEL=`.
+
+
+```
+IoTDB > COUNT TIMESERIES root.**
+IoTDB > COUNT TIMESERIES root.ln.**
+IoTDB > COUNT TIMESERIES root.ln.*.*.status
+IoTDB > COUNT TIMESERIES root.ln.wf01.wt01.status
+IoTDB > COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc'
+IoTDB > COUNT TIMESERIES root.** WHERE DATATYPE = INT64
+IoTDB > COUNT TIMESERIES root.** WHERE TAGS(unit) contains 'c'
+IoTDB > COUNT TIMESERIES root.** WHERE TAGS(unit) = 'c'
+IoTDB > COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc' group by level = 1
+```
+
+For example, if there are several timeseries (use `show timeseries` to show all timeseries):
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.sgcc.wf03.wt01.status| null| root.sgcc| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY| {"unit":"c"}| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| {"description":"test1"}| null| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 7
+It costs 0.004s
+```
+
+Then the Metadata Tree will be as below:
+
+
+
+As can be seen, `root` is considered as `LEVEL=0`. So when you enter statements such as:
+
+```
+IoTDB > COUNT TIMESERIES root.** GROUP BY LEVEL=1
+IoTDB > COUNT TIMESERIES root.ln.** GROUP BY LEVEL=2
+IoTDB > COUNT TIMESERIES root.ln.wf01.* GROUP BY LEVEL=2
+```
+
+You will get following results:
+
+```
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+| root.sgcc| 2|
+|root.turbine| 1|
+| root.ln| 4|
++------------+-----------------+
+Total line number = 3
+It costs 0.002s
+
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+|root.ln.wf02| 2|
+|root.ln.wf01| 2|
++------------+-----------------+
+Total line number = 2
+It costs 0.002s
+
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+|root.ln.wf01| 2|
++------------+-----------------+
+Total line number = 1
+It costs 0.002s
+```
+
+> Note: The path of timeseries is just a filter condition, which has no relationship with the definition of level.
+
+### Active Timeseries Query
+By adding WHERE time filter conditions to the existing SHOW/COUNT TIMESERIES, we can obtain time series with data within the specified time range.
+
+It is important to note that in metadata queries with time filters, views are not considered; only the time series actually stored in the TsFile are taken into account.
+
+An example usage is as follows:
+```
+IoTDB> insert into root.sg.data(timestamp, s1,s2) values(15000, 1, 2);
+IoTDB> insert into root.sg.data2(timestamp, s1,s2) values(15002, 1, 2);
+IoTDB> insert into root.sg.data3(timestamp, s1,s2) values(16000, 1, 2);
+IoTDB> show timeseries;
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| Timeseries|Alias|Database|DataType|Encoding|Compression|Tags|Attributes|Deadband|DeadbandParameters|ViewType|
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| root.sg.data.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+| root.sg.data.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data3.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data3.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data2.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data2.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+
+IoTDB> show timeseries where time >= 15000 and time < 16000;
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| Timeseries|Alias|Database|DataType|Encoding|Compression|Tags|Attributes|Deadband|DeadbandParameters|ViewType|
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| root.sg.data.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+| root.sg.data.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data2.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data2.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+
+IoTDB> count timeseries where time >= 15000 and time < 16000;
++-----------------+
+|count(timeseries)|
++-----------------+
+| 4|
++-----------------+
+```
+Regarding the definition of active time series, data that can be queried normally is considered active, meaning time series that have been inserted but deleted are not included.
+### Tag and Attribute Management
+
+We can also add an alias, extra tag and attribute information while creating one timeseries.
+
+The differences between tag and attribute are:
+
+* Tag could be used to query the path of timeseries, we will maintain an inverted index in memory on the tag: Tag -> Timeseries
+* Attribute could only be queried by timeseries path : Timeseries -> Attribute
+
+The SQL statements for creating timeseries with extra tag and attribute information are extended as follows:
+
+```
+create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2)
+```
+
+The `temprature` in the brackets is an alias for the sensor `s1`. So we can use `temprature` to replace `s1` anywhere.
+
+> IoTDB also supports using AS function to set alias. The difference between the two is: the alias set by the AS function is used to replace the whole time series name, temporary and not bound with the time series; while the alias mentioned above is only used as the alias of the sensor, which is bound with it and can be used equivalent to the original sensor name.
+
+> Notice that the size of the extra tag and attribute information shouldn't exceed the `tag_attribute_total_size`.
+
+We can update the tag information after creating it as following:
+
+* Rename the tag/attribute key
+
+```
+ALTER timeseries root.turbine.d1.s1 RENAME tag1 TO newTag1
+```
+
+* Reset the tag/attribute value
+
+```
+ALTER timeseries root.turbine.d1.s1 SET newTag1=newV1, attr1=newV1
+```
+
+* Delete the existing tag/attribute
+
+```
+ALTER timeseries root.turbine.d1.s1 DROP tag1, tag2
+```
+
+* Add new tags
+
+```
+ALTER timeseries root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4
+```
+
+* Add new attributes
+
+```
+ALTER timeseries root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4
+```
+
+* Upsert alias, tags and attributes
+
+> add alias or a new key-value if the alias or key doesn't exist, otherwise, update the old one with new value.
+
+```
+ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(tag3=v3, tag4=v4) ATTRIBUTES(attr3=v3, attr4=v4)
+```
+
+* Show timeseries using tags. Use TAGS(tagKey) to identify the tags used as filter key
+
+```
+SHOW TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
+```
+
+returns all the timeseries information that satisfy the where condition and match the pathPattern. SQL statements are as follows:
+
+```
+ALTER timeseries root.ln.wf02.wt02.hardware ADD TAGS unit=c
+ALTER timeseries root.ln.wf02.wt02.status ADD TAGS description=test1
+show timeseries root.ln.** where TAGS(unit)='c'
+show timeseries root.ln.** where TAGS(description) contains 'test1'
+```
+
+The results are shown below respectly:
+
+```
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags|attributes|deadband|deadband parameters|
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+|root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY|{"unit":"c"}| null| null| null|
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+Total line number = 1
+It costs 0.005s
+
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags|attributes|deadband|deadband parameters|
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+|root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|{"description":"test1"}| null| null| null|
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+Total line number = 1
+It costs 0.004s
+```
+
+- count timeseries using tags
+
+```
+COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
+COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause GROUP BY LEVEL=
+```
+
+returns all the number of timeseries that satisfy the where condition and match the pathPattern. SQL statements are as follows:
+
+```
+count timeseries
+count timeseries root.** where TAGS(unit)='c'
+count timeseries root.** where TAGS(unit)='c' group by level = 2
+```
+
+The results are shown below respectly :
+
+```
+IoTDB> count timeseries
++-----------------+
+|count(timeseries)|
++-----------------+
+| 6|
++-----------------+
+Total line number = 1
+It costs 0.019s
+IoTDB> count timeseries root.** where TAGS(unit)='c'
++-----------------+
+|count(timeseries)|
++-----------------+
+| 2|
++-----------------+
+Total line number = 1
+It costs 0.020s
+IoTDB> count timeseries root.** where TAGS(unit)='c' group by level = 2
++--------------+-----------------+
+| column|count(timeseries)|
++--------------+-----------------+
+| root.ln.wf02| 2|
+| root.ln.wf01| 0|
+|root.sgcc.wf03| 0|
++--------------+-----------------+
+Total line number = 3
+It costs 0.011s
+```
+
+> Notice that, we only support one condition in the where clause. Either it's an equal filter or it is an `contains` filter. In both case, the property in the where condition must be a tag.
+
+create aligned timeseries
+
+```
+create aligned timeseries root.sg1.d1(s1 INT32 tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2), s2 DOUBLE tags(tag3=v3, tag4=v4) attributes(attr3=v3, attr4=v4))
+```
+
+The execution result is as follows:
+
+```
+IoTDB> show timeseries
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+|root.sg1.d1.s1| null| root.sg1| INT32| RLE| SNAPPY|{"tag1":"v1","tag2":"v2"}|{"attr2":"v2","attr1":"v1"}| null| null|
+|root.sg1.d1.s2| null| root.sg1| DOUBLE| GORILLA| SNAPPY|{"tag4":"v4","tag3":"v3"}|{"attr4":"v4","attr3":"v3"}| null| null|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+```
+
+Support query:
+
+```
+IoTDB> show timeseries where TAGS(tag1)='v1'
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+|root.sg1.d1.s1| null| root.sg1| INT32| RLE| SNAPPY|{"tag1":"v1","tag2":"v2"}|{"attr2":"v2","attr1":"v1"}| null| null|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+```
+
+The above operations are supported for timeseries tag, attribute updates, etc.
+
+## Node Management
+
+### Show Child Paths
+
+```
+SHOW CHILD PATHS pathPattern
+```
+
+Return all child paths and their node types of all the paths matching pathPattern.
+
+node types: ROOT -> DB INTERNAL -> DATABASE -> INTERNAL -> DEVICE -> TIMESERIES
+
+
+Example:
+
+* return the child paths of root.ln:show child paths root.ln
+
+```
++------------+----------+
+| child paths|node types|
++------------+----------+
+|root.ln.wf01| INTERNAL|
+|root.ln.wf02| INTERNAL|
++------------+----------+
+Total line number = 2
+It costs 0.002s
+```
+
+> get all paths in form of root.xx.xx.xx:show child paths root.xx.xx
+
+### Show Child Nodes
+
+```
+SHOW CHILD NODES pathPattern
+```
+
+Return all child nodes of the pathPattern.
+
+Example:
+
+* return the child nodes of root:show child nodes root
+
+```
++------------+
+| child nodes|
++------------+
+| ln|
++------------+
+```
+
+* return the child nodes of root.ln:show child nodes root.ln
+
+```
++------------+
+| child nodes|
++------------+
+| wf01|
+| wf02|
++------------+
+```
+
+### Count Nodes
+
+IoTDB is able to use `COUNT NODES LEVEL=` to count the number of nodes at
+ the given level in current Metadata Tree considering a given pattern. IoTDB will find paths that
+ match the pattern and counts distinct nodes at the specified level among the matched paths.
+ This could be used to query the number of devices with specified measurements. The usage are as
+ follows:
+
+```
+IoTDB > COUNT NODES root.** LEVEL=2
+IoTDB > COUNT NODES root.ln.** LEVEL=2
+IoTDB > COUNT NODES root.ln.wf01.** LEVEL=3
+IoTDB > COUNT NODES root.**.temperature LEVEL=3
+```
+
+As for the above mentioned example and Metadata tree, you can get following results:
+
+```
++------------+
+|count(nodes)|
++------------+
+| 4|
++------------+
+Total line number = 1
+It costs 0.003s
+
++------------+
+|count(nodes)|
++------------+
+| 2|
++------------+
+Total line number = 1
+It costs 0.002s
+
++------------+
+|count(nodes)|
++------------+
+| 1|
++------------+
+Total line number = 1
+It costs 0.002s
+
++------------+
+|count(nodes)|
++------------+
+| 2|
++------------+
+Total line number = 1
+It costs 0.002s
+```
+
+> Note: The path of timeseries is just a filter condition, which has no relationship with the definition of level.
+
+### Show Devices
+
+* SHOW DEVICES pathPattern? (WITH DATABASE)? devicesWhereClause? limitClause?
+
+Similar to `Show Timeseries`, IoTDB also supports two ways of viewing devices:
+
+* `SHOW DEVICES` statement presents all devices' information, which is equal to `SHOW DEVICES root.**`.
+* `SHOW DEVICES ` statement specifies the `PathPattern` and returns the devices information matching the pathPattern and under the given level.
+* `WHERE` condition supports `DEVICE contains 'xxx'` to do a fuzzy query based on the device name.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices
+IoTDB> show devices root.ln.**
+IoTDB> show devices root.ln.** where device contains 't'
+```
+
+You can get results below:
+
+```
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+| root.ln.wf01.wt01| false|
+| root.ln.wf02.wt02| false|
+|root.sgcc.wf03.wt01| false|
+| root.turbine.d1| false|
++-------------------+---------+
+Total line number = 4
+It costs 0.002s
+
++-----------------+---------+
+| devices|isAligned|
++-----------------+---------+
+|root.ln.wf01.wt01| false|
+|root.ln.wf02.wt02| false|
++-----------------+---------+
+Total line number = 2
+It costs 0.001s
+```
+
+`isAligned` indicates whether the timeseries under the device are aligned.
+
+To view devices' information with database, we can use `SHOW DEVICES WITH DATABASE` statement.
+
+* `SHOW DEVICES WITH DATABASE` statement presents all devices' information with their database.
+* `SHOW DEVICES WITH DATABASE` statement specifies the `PathPattern` and returns the
+ devices' information under the given level with their database information.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices with database
+IoTDB> show devices root.ln.** with database
+```
+
+You can get results below:
+
+```
++-------------------+-------------+---------+
+| devices| database|isAligned|
++-------------------+-------------+---------+
+| root.ln.wf01.wt01| root.ln| false|
+| root.ln.wf02.wt02| root.ln| false|
+|root.sgcc.wf03.wt01| root.sgcc| false|
+| root.turbine.d1| root.turbine| false|
++-------------------+-------------+---------+
+Total line number = 4
+It costs 0.003s
+
++-----------------+-------------+---------+
+| devices| database|isAligned|
++-----------------+-------------+---------+
+|root.ln.wf01.wt01| root.ln| false|
+|root.ln.wf02.wt02| root.ln| false|
++-----------------+-------------+---------+
+Total line number = 2
+It costs 0.001s
+```
+
+### Count Devices
+
+* COUNT DEVICES /
+
+The above statement is used to count the number of devices. At the same time, it is allowed to specify `PathPattern` to count the number of devices matching the `PathPattern`.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices
+IoTDB> count devices
+IoTDB> count devices root.ln.**
+```
+
+You can get results below:
+
+```
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+|root.sgcc.wf03.wt03| false|
+| root.turbine.d1| false|
+| root.ln.wf02.wt02| false|
+| root.ln.wf01.wt01| false|
++-------------------+---------+
+Total line number = 4
+It costs 0.024s
+
++--------------+
+|count(devices)|
++--------------+
+| 4|
++--------------+
+Total line number = 1
+It costs 0.004s
+
++--------------+
+|count(devices)|
++--------------+
+| 2|
++--------------+
+Total line number = 1
+It costs 0.004s
+```
+
+### Active Device Query
+Similar to active timeseries query, we can add time filter conditions to device viewing and statistics to query active devices that have data within a certain time range. The definition of active here is the same as for active time series. An example usage is as follows:
+```
+IoTDB> insert into root.sg.data(timestamp, s1,s2) values(15000, 1, 2);
+IoTDB> insert into root.sg.data2(timestamp, s1,s2) values(15002, 1, 2);
+IoTDB> insert into root.sg.data3(timestamp, s1,s2) values(16000, 1, 2);
+IoTDB> show devices;
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+| root.sg.data| false|
+| root.sg.data2| false|
+| root.sg.data3| false|
++-------------------+---------+
+
+IoTDB> show devices where time >= 15000 and time < 16000;
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+| root.sg.data| false|
+| root.sg.data2| false|
++-------------------+---------+
+
+IoTDB> count devices where time >= 15000 and time < 16000;
++--------------+
+|count(devices)|
++--------------+
+| 2|
++--------------+
+```
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Query-Data.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Query-Data.md
new file mode 100644
index 00000000..62fc3c9f
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Query-Data.md
@@ -0,0 +1,3009 @@
+
+# Query Data
+## OVERVIEW
+
+### Syntax Definition
+
+In IoTDB, `SELECT` statement is used to retrieve data from one or more selected time series. Here is the syntax definition of `SELECT` statement:
+
+```sql
+SELECT [LAST] selectExpr [, selectExpr] ...
+ [INTO intoItem [, intoItem] ...]
+ FROM prefixPath [, prefixPath] ...
+ [WHERE whereCondition]
+ [GROUP BY {
+ ([startTime, endTime), interval [, slidingStep]) |
+ LEVEL = levelNum [, levelNum] ... |
+ TAGS(tagKey [, tagKey] ... ) |
+ VARIATION(expression[,delta][,ignoreNull=true/false]) |
+ CONDITION(expression,[keep>/>=/=/ 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;
+```
+
+which means:
+
+The selected device is ln group wf01 plant wt01 device; the selected timeseries is "status" and "temperature". The SQL statement requires that the status and temperature sensor values between the time point of "2017-11-01T00:05:00.000" and "2017-11-01T00:12:00.000" be selected.
+
+The execution result of this SQL statement is as follows:
+
+```
++-----------------------------+------------------------+-----------------------------+
+| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
++-----------------------------+------------------------+-----------------------------+
+|2017-11-01T00:06:00.000+08:00| false| 20.71|
+|2017-11-01T00:07:00.000+08:00| false| 21.45|
+|2017-11-01T00:08:00.000+08:00| false| 22.58|
+|2017-11-01T00:09:00.000+08:00| false| 20.98|
+|2017-11-01T00:10:00.000+08:00| true| 25.52|
+|2017-11-01T00:11:00.000+08:00| false| 22.91|
++-----------------------------+------------------------+-----------------------------+
+Total line number = 6
+It costs 0.018s
+```
+
+#### Select Multiple Columns of Data for the Same Device According to Multiple Time Intervals
+
+IoTDB supports specifying multiple time interval conditions in a query. Users can combine time interval conditions at will according to their needs. For example, the SQL statement is:
+
+```sql
+select status,temperature from root.ln.wf01.wt01 where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
+```
+
+which means:
+
+The selected device is ln group wf01 plant wt01 device; the selected timeseries is "status" and "temperature"; the statement specifies two different time intervals, namely "2017-11-01T00:05:00.000 to 2017-11-01T00:12:00.000" and "2017-11-01T16:35:00.000 to 2017-11-01T16:37:00.000". The SQL statement requires that the values of selected timeseries satisfying any time interval be selected.
+
+The execution result of this SQL statement is as follows:
+
+```
++-----------------------------+------------------------+-----------------------------+
+| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
++-----------------------------+------------------------+-----------------------------+
+|2017-11-01T00:06:00.000+08:00| false| 20.71|
+|2017-11-01T00:07:00.000+08:00| false| 21.45|
+|2017-11-01T00:08:00.000+08:00| false| 22.58|
+|2017-11-01T00:09:00.000+08:00| false| 20.98|
+|2017-11-01T00:10:00.000+08:00| true| 25.52|
+|2017-11-01T00:11:00.000+08:00| false| 22.91|
+|2017-11-01T16:35:00.000+08:00| true| 23.44|
+|2017-11-01T16:36:00.000+08:00| false| 21.98|
+|2017-11-01T16:37:00.000+08:00| false| 21.93|
++-----------------------------+------------------------+-----------------------------+
+Total line number = 9
+It costs 0.018s
+```
+
+
+#### Choose Multiple Columns of Data for Different Devices According to Multiple Time Intervals
+
+The system supports the selection of data in any column in a query, i.e., the selected columns can come from different devices. For example, the SQL statement is:
+
+```sql
+select wf01.wt01.status,wf02.wt02.hardware from root.ln where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
+```
+
+which means:
+
+The selected timeseries are "the power supply status of ln group wf01 plant wt01 device" and "the hardware version of ln group wf02 plant wt02 device"; the statement specifies two different time intervals, namely "2017-11-01T00:05:00.000 to 2017-11-01T00:12:00.000" and "2017-11-01T16:35:00.000 to 2017-11-01T16:37:00.000". The SQL statement requires that the values of selected timeseries satisfying any time interval be selected.
+
+The execution result of this SQL statement is as follows:
+
+```
++-----------------------------+------------------------+--------------------------+
+| Time|root.ln.wf01.wt01.status|root.ln.wf02.wt02.hardware|
++-----------------------------+------------------------+--------------------------+
+|2017-11-01T00:06:00.000+08:00| false| v1|
+|2017-11-01T00:07:00.000+08:00| false| v1|
+|2017-11-01T00:08:00.000+08:00| false| v1|
+|2017-11-01T00:09:00.000+08:00| false| v1|
+|2017-11-01T00:10:00.000+08:00| true| v2|
+|2017-11-01T00:11:00.000+08:00| false| v1|
+|2017-11-01T16:35:00.000+08:00| true| v2|
+|2017-11-01T16:36:00.000+08:00| false| v1|
+|2017-11-01T16:37:00.000+08:00| false| v1|
++-----------------------------+------------------------+--------------------------+
+Total line number = 9
+It costs 0.014s
+```
+
+#### Order By Time Query
+
+IoTDB supports the 'order by time' statement since 0.11, it's used to display results in descending order by time.
+For example, the SQL statement is:
+
+```sql
+select * from root.ln.** where time > 1 order by time desc limit 10;
+```
+
+The execution result of this SQL statement is as follows:
+
+```
++-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
+| Time|root.ln.wf02.wt02.hardware|root.ln.wf02.wt02.status|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
++-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
+|2017-11-07T23:59:00.000+08:00| v1| false| 21.07| false|
+|2017-11-07T23:58:00.000+08:00| v1| false| 22.93| false|
+|2017-11-07T23:57:00.000+08:00| v2| true| 24.39| true|
+|2017-11-07T23:56:00.000+08:00| v2| true| 24.44| true|
+|2017-11-07T23:55:00.000+08:00| v2| true| 25.9| true|
+|2017-11-07T23:54:00.000+08:00| v1| false| 22.52| false|
+|2017-11-07T23:53:00.000+08:00| v2| true| 24.58| true|
+|2017-11-07T23:52:00.000+08:00| v1| false| 20.18| false|
+|2017-11-07T23:51:00.000+08:00| v1| false| 22.24| false|
+|2017-11-07T23:50:00.000+08:00| v2| true| 23.7| true|
++-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
+Total line number = 10
+It costs 0.016s
+```
+
+### Execution Interface
+
+In IoTDB, there are two ways to execute data query:
+
+- Execute queries using IoTDB-SQL.
+- Efficient execution interfaces for common queries, including time-series raw data query, last query, and aggregation query.
+
+#### Execute queries using IoTDB-SQL
+
+Data query statements can be used in SQL command-line terminals, JDBC, JAVA / C++ / Python / Go and other native APIs, and RESTful APIs.
+
+- Execute the query statement in the SQL command line terminal: start the SQL command line terminal, and directly enter the query statement to execute, see [SQL command line terminal](../Tools-System/CLI.md).
+
+- Execute query statements in JDBC, see [JDBC](../API/Programming-JDBC.md) for details.
+
+- Execute query statements in native APIs such as JAVA / C++ / Python / Go. For details, please refer to the relevant documentation in the Application Programming Interface chapter. The interface prototype is as follows:
+
+ ````java
+ SessionDataSet executeQueryStatement(String sql)
+ ````
+
+- Used in RESTful API, see [HTTP API V1](../API/RestServiceV1.md) or [HTTP API V2](../API/RestServiceV2.md) for details.
+
+#### Efficient execution interfaces
+
+The native APIs provide efficient execution interfaces for commonly used queries, which can save time-consuming operations such as SQL parsing. include:
+
+* Time-series raw data query with time range:
+ - The specified query time range is a left-closed right-open interval, including the start time but excluding the end time.
+
+```java
+SessionDataSet executeRawDataQuery(List paths, long startTime, long endTime);
+```
+
+* Last query:
+ - Query the last data, whose timestamp is greater than or equal LastTime.
+
+```java
+SessionDataSet executeLastDataQuery(List paths, long LastTime);
+```
+
+* Aggregation query:
+ - Support specified query time range: The specified query time range is a left-closed right-open interval, including the start time but not the end time.
+ - Support GROUP BY TIME.
+
+```java
+SessionDataSet executeAggregationQuery(List paths, List aggregations);
+
+SessionDataSet executeAggregationQuery(
+ List paths, List aggregations, long startTime, long endTime);
+
+SessionDataSet executeAggregationQuery(
+ List paths,
+ List aggregations,
+ long startTime,
+ long endTime,
+ long interval);
+
+SessionDataSet executeAggregationQuery(
+ List paths,
+ List aggregations,
+ long startTime,
+ long endTime,
+ long interval,
+ long slidingStep);
+```
+
+## `SELECT` CLAUSE
+The `SELECT` clause specifies the output of the query, consisting of several `selectExpr`. Each `selectExpr` defines one or more columns in the query result. For select expression details, see document [Operator-and-Expression](../SQL-Manual/Operator-and-Expression.md).
+
+- Example 1:
+
+```sql
+select temperature from root.ln.wf01.wt01
+```
+
+- Example 2:
+
+```sql
+select status, temperature from root.ln.wf01.wt01
+```
+
+### Last Query
+
+The last query is a special type of query in Apache IoTDB. It returns the data point with the largest timestamp of the specified time series. In other word, it returns the latest state of a time series. This feature is especially important in IoT data analysis scenarios. To meet the performance requirement of real-time device monitoring systems, Apache IoTDB caches the latest values of all time series to achieve microsecond read latency.
+
+The last query is to return the most recent data point of the given timeseries in a three column format.
+
+The SQL syntax is defined as:
+
+```sql
+select last [COMMA ]* from < PrefixPath > [COMMA < PrefixPath >]*
+
+As can be seen, `root` is considered as `LEVEL=0`. So when you enter statements such as:
+
+```
+IoTDB > COUNT TIMESERIES root.** GROUP BY LEVEL=1
+IoTDB > COUNT TIMESERIES root.ln.** GROUP BY LEVEL=2
+IoTDB > COUNT TIMESERIES root.ln.wf01.* GROUP BY LEVEL=2
+```
+
+You will get following results:
+
+```
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+| root.sgcc| 2|
+|root.turbine| 1|
+| root.ln| 4|
++------------+-----------------+
+Total line number = 3
+It costs 0.002s
+
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+|root.ln.wf02| 2|
+|root.ln.wf01| 2|
++------------+-----------------+
+Total line number = 2
+It costs 0.002s
+
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+|root.ln.wf01| 2|
++------------+-----------------+
+Total line number = 1
+It costs 0.002s
+```
+
+> Note: The path of timeseries is just a filter condition, which has no relationship with the definition of level.
+
+### Tag and Attribute Management
+
+We can also add an alias, extra tag and attribute information while creating one timeseries.
+
+The differences between tag and attribute are:
+
+* Tag could be used to query the path of timeseries, we will maintain an inverted index in memory on the tag: Tag -> Timeseries
+* Attribute could only be queried by timeseries path : Timeseries -> Attribute
+
+The SQL statements for creating timeseries with extra tag and attribute information are extended as follows:
+
+```
+create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2)
+```
+
+The `temprature` in the brackets is an alias for the sensor `s1`. So we can use `temprature` to replace `s1` anywhere.
+
+> IoTDB also supports using AS function to set alias. The difference between the two is: the alias set by the AS function is used to replace the whole time series name, temporary and not bound with the time series; while the alias mentioned above is only used as the alias of the sensor, which is bound with it and can be used equivalent to the original sensor name.
+
+> Notice that the size of the extra tag and attribute information shouldn't exceed the `tag_attribute_total_size`.
+
+We can update the tag information after creating it as following:
+
+* Rename the tag/attribute key
+
+```
+ALTER timeseries root.turbine.d1.s1 RENAME tag1 TO newTag1
+```
+
+* Reset the tag/attribute value
+
+```
+ALTER timeseries root.turbine.d1.s1 SET newTag1=newV1, attr1=newV1
+```
+
+* Delete the existing tag/attribute
+
+```
+ALTER timeseries root.turbine.d1.s1 DROP tag1, tag2
+```
+
+* Add new tags
+
+```
+ALTER timeseries root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4
+```
+
+* Add new attributes
+
+```
+ALTER timeseries root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4
+```
+
+* Upsert alias, tags and attributes
+
+> add alias or a new key-value if the alias or key doesn't exist, otherwise, update the old one with new value.
+
+```
+ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(tag3=v3, tag4=v4) ATTRIBUTES(attr3=v3, attr4=v4)
+```
+
+* Show timeseries using tags. Use TAGS(tagKey) to identify the tags used as filter key
+
+```
+SHOW TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
+```
+
+returns all the timeseries information that satisfy the where condition and match the pathPattern. SQL statements are as follows:
+
+```
+ALTER timeseries root.ln.wf02.wt02.hardware ADD TAGS unit=c
+ALTER timeseries root.ln.wf02.wt02.status ADD TAGS description=test1
+show timeseries root.ln.** where TAGS(unit)='c'
+show timeseries root.ln.** where TAGS(description) contains 'test1'
+```
+
+The results are shown below respectly:
+
+```
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags|attributes|deadband|deadband parameters|
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+|root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY|{"unit":"c"}| null| null| null|
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+Total line number = 1
+It costs 0.005s
+
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags|attributes|deadband|deadband parameters|
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+|root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|{"description":"test1"}| null| null| null|
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+Total line number = 1
+It costs 0.004s
+```
+
+- count timeseries using tags
+
+```
+COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
+COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause GROUP BY LEVEL=
+```
+
+returns all the number of timeseries that satisfy the where condition and match the pathPattern. SQL statements are as follows:
+
+```
+count timeseries
+count timeseries root.** where TAGS(unit)='c'
+count timeseries root.** where TAGS(unit)='c' group by level = 2
+```
+
+The results are shown below respectly :
+
+```
+IoTDB> count timeseries
++-----------------+
+|count(timeseries)|
++-----------------+
+| 6|
++-----------------+
+Total line number = 1
+It costs 0.019s
+IoTDB> count timeseries root.** where TAGS(unit)='c'
++-----------------+
+|count(timeseries)|
++-----------------+
+| 2|
++-----------------+
+Total line number = 1
+It costs 0.020s
+IoTDB> count timeseries root.** where TAGS(unit)='c' group by level = 2
++--------------+-----------------+
+| column|count(timeseries)|
++--------------+-----------------+
+| root.ln.wf02| 2|
+| root.ln.wf01| 0|
+|root.sgcc.wf03| 0|
++--------------+-----------------+
+Total line number = 3
+It costs 0.011s
+```
+
+> Notice that, we only support one condition in the where clause. Either it's an equal filter or it is an `contains` filter. In both case, the property in the where condition must be a tag.
+
+create aligned timeseries
+
+```
+create aligned timeseries root.sg1.d1(s1 INT32 tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2), s2 DOUBLE tags(tag3=v3, tag4=v4) attributes(attr3=v3, attr4=v4))
+```
+
+The execution result is as follows:
+
+```
+IoTDB> show timeseries
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+|root.sg1.d1.s1| null| root.sg1| INT32| RLE| SNAPPY|{"tag1":"v1","tag2":"v2"}|{"attr2":"v2","attr1":"v1"}| null| null|
+|root.sg1.d1.s2| null| root.sg1| DOUBLE| GORILLA| SNAPPY|{"tag4":"v4","tag3":"v3"}|{"attr4":"v4","attr3":"v3"}| null| null|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+```
+
+Support query:
+
+```
+IoTDB> show timeseries where TAGS(tag1)='v1'
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+|root.sg1.d1.s1| null| root.sg1| INT32| RLE| SNAPPY|{"tag1":"v1","tag2":"v2"}|{"attr2":"v2","attr1":"v1"}| null| null|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+```
+
+The above operations are supported for timeseries tag, attribute updates, etc.
+
+## Node Management
+
+### Show Child Paths
+
+```
+SHOW CHILD PATHS pathPattern
+```
+
+Return all child paths and their node types of all the paths matching pathPattern.
+
+node types: ROOT -> DB INTERNAL -> DATABASE -> INTERNAL -> DEVICE -> TIMESERIES
+
+
+Example:
+
+* return the child paths of root.ln:show child paths root.ln
+
+```
++------------+----------+
+| child paths|node types|
++------------+----------+
+|root.ln.wf01| INTERNAL|
+|root.ln.wf02| INTERNAL|
++------------+----------+
+Total line number = 2
+It costs 0.002s
+```
+
+> get all paths in form of root.xx.xx.xx:show child paths root.xx.xx
+
+### Show Child Nodes
+
+```
+SHOW CHILD NODES pathPattern
+```
+
+Return all child nodes of the pathPattern.
+
+Example:
+
+* return the child nodes of root:show child nodes root
+
+```
++------------+
+| child nodes|
++------------+
+| ln|
++------------+
+```
+
+* return the child nodes of root.ln:show child nodes root.ln
+
+```
++------------+
+| child nodes|
++------------+
+| wf01|
+| wf02|
++------------+
+```
+
+### Count Nodes
+
+IoTDB is able to use `COUNT NODES LEVEL=` to count the number of nodes at
+ the given level in current Metadata Tree considering a given pattern. IoTDB will find paths that
+ match the pattern and counts distinct nodes at the specified level among the matched paths.
+ This could be used to query the number of devices with specified measurements. The usage are as
+ follows:
+
+```
+IoTDB > COUNT NODES root.** LEVEL=2
+IoTDB > COUNT NODES root.ln.** LEVEL=2
+IoTDB > COUNT NODES root.ln.wf01.** LEVEL=3
+IoTDB > COUNT NODES root.**.temperature LEVEL=3
+```
+
+As for the above mentioned example and Metadata tree, you can get following results:
+
+```
++------------+
+|count(nodes)|
++------------+
+| 4|
++------------+
+Total line number = 1
+It costs 0.003s
+
++------------+
+|count(nodes)|
++------------+
+| 2|
++------------+
+Total line number = 1
+It costs 0.002s
+
++------------+
+|count(nodes)|
++------------+
+| 1|
++------------+
+Total line number = 1
+It costs 0.002s
+
++------------+
+|count(nodes)|
++------------+
+| 2|
++------------+
+Total line number = 1
+It costs 0.002s
+```
+
+> Note: The path of timeseries is just a filter condition, which has no relationship with the definition of level.
+
+### Show Devices
+
+* SHOW DEVICES pathPattern? (WITH DATABASE)? devicesWhereClause? limitClause?
+
+Similar to `Show Timeseries`, IoTDB also supports two ways of viewing devices:
+
+* `SHOW DEVICES` statement presents all devices' information, which is equal to `SHOW DEVICES root.**`.
+* `SHOW DEVICES ` statement specifies the `PathPattern` and returns the devices information matching the pathPattern and under the given level.
+* `WHERE` condition supports `DEVICE contains 'xxx'` to do a fuzzy query based on the device name.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices
+IoTDB> show devices root.ln.**
+IoTDB> show devices root.ln.** where device contains 't'
+```
+
+You can get results below:
+
+```
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+| root.ln.wf01.wt01| false|
+| root.ln.wf02.wt02| false|
+|root.sgcc.wf03.wt01| false|
+| root.turbine.d1| false|
++-------------------+---------+
+Total line number = 4
+It costs 0.002s
+
++-----------------+---------+
+| devices|isAligned|
++-----------------+---------+
+|root.ln.wf01.wt01| false|
+|root.ln.wf02.wt02| false|
++-----------------+---------+
+Total line number = 2
+It costs 0.001s
+```
+
+`isAligned` indicates whether the timeseries under the device are aligned.
+
+To view devices' information with database, we can use `SHOW DEVICES WITH DATABASE` statement.
+
+* `SHOW DEVICES WITH DATABASE` statement presents all devices' information with their database.
+* `SHOW DEVICES WITH DATABASE` statement specifies the `PathPattern` and returns the
+ devices' information under the given level with their database information.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices with database
+IoTDB> show devices root.ln.** with database
+```
+
+You can get results below:
+
+```
++-------------------+-------------+---------+
+| devices| database|isAligned|
++-------------------+-------------+---------+
+| root.ln.wf01.wt01| root.ln| false|
+| root.ln.wf02.wt02| root.ln| false|
+|root.sgcc.wf03.wt01| root.sgcc| false|
+| root.turbine.d1| root.turbine| false|
++-------------------+-------------+---------+
+Total line number = 4
+It costs 0.003s
+
++-----------------+-------------+---------+
+| devices| database|isAligned|
++-----------------+-------------+---------+
+|root.ln.wf01.wt01| root.ln| false|
+|root.ln.wf02.wt02| root.ln| false|
++-----------------+-------------+---------+
+Total line number = 2
+It costs 0.001s
+```
+
+### Count Devices
+
+* COUNT DEVICES /
+
+The above statement is used to count the number of devices. At the same time, it is allowed to specify `PathPattern` to count the number of devices matching the `PathPattern`.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices
+IoTDB> count devices
+IoTDB> count devices root.ln.**
+```
+
+You can get results below:
+
+```
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+|root.sgcc.wf03.wt03| false|
+| root.turbine.d1| false|
+| root.ln.wf02.wt02| false|
+| root.ln.wf01.wt01| false|
++-------------------+---------+
+Total line number = 4
+It costs 0.024s
+
++--------------+
+|count(devices)|
++--------------+
+| 4|
++--------------+
+Total line number = 1
+It costs 0.004s
+
++--------------+
+|count(devices)|
++--------------+
+| 2|
++--------------+
+Total line number = 1
+It costs 0.004s
+```
+
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_timecho.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_timecho.md
new file mode 100644
index 00000000..8d57facb
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Operate-Metadata_timecho.md
@@ -0,0 +1,1324 @@
+
+
+# Timeseries Management
+
+## Database Management
+
+### Create Database
+
+According to the storage model we can set up the corresponding database. Two SQL statements are supported for creating databases, as follows:
+
+```
+IoTDB > create database root.ln
+IoTDB > create database root.sgcc
+```
+
+We can thus create two databases using the above two SQL statements.
+
+It is worth noting that 1 database is recommended.
+
+When the path itself or the parent/child layer of the path is already created as database, the path is then not allowed to be created as database. For example, it is not feasible to create `root.ln.wf01` as database when two databases `root.ln` and `root.sgcc` exist. The system gives the corresponding error prompt as shown below:
+
+```
+IoTDB> CREATE DATABASE root.ln.wf01
+Msg: 300: root.ln has already been created as database.
+IoTDB> create database root.ln.wf01
+Msg: 300: root.ln has already been created as database.
+```
+
+The LayerName of database can only be chinese or english characters, numbers, underscores, dots and backticks. If you want to set it to pure numbers or contain backticks or dots, you need to enclose the database name with backticks (` `` `). In ` `` `,2 backticks represents one, i.e. ` ```` ` represents `` ` ``.
+
+Besides, if deploy on Windows system, the LayerName is case-insensitive, which means it's not allowed to create databases `root.ln` and `root.LN` at the same time.
+
+### Show Databases
+
+After creating the database, we can use the [SHOW DATABASES](../SQL-Manual/SQL-Manual.md) statement and [SHOW DATABASES \](../SQL-Manual/SQL-Manual.md) to view the databases. The SQL statements are as follows:
+
+```
+IoTDB> SHOW DATABASES
+IoTDB> SHOW DATABASES root.**
+```
+
+The result is as follows:
+
+```
++-------------+----+-------------------------+-----------------------+-----------------------+
+|database| ttl|schema_replication_factor|data_replication_factor|time_partition_interval|
++-------------+----+-------------------------+-----------------------+-----------------------+
+| root.sgcc|null| 2| 2| 604800|
+| root.ln|null| 2| 2| 604800|
++-------------+----+-------------------------+-----------------------+-----------------------+
+Total line number = 2
+It costs 0.060s
+```
+
+### Delete Database
+
+User can use the `DELETE DATABASE ` statement to delete all databases matching the pathPattern. Please note the data in the database will also be deleted.
+
+```
+IoTDB > DELETE DATABASE root.ln
+IoTDB > DELETE DATABASE root.sgcc
+// delete all data, all timeseries and all databases
+IoTDB > DELETE DATABASE root.**
+```
+
+### Count Databases
+
+User can use the `COUNT DATABASE ` statement to count the number of databases. It is allowed to specify `PathPattern` to count the number of databases matching the `PathPattern`.
+
+SQL statement is as follows:
+
+```
+IoTDB> count databases
+IoTDB> count databases root.*
+IoTDB> count databases root.sgcc.*
+IoTDB> count databases root.sgcc
+```
+
+The result is as follows:
+
+```
++-------------+
+| database|
++-------------+
+| root.sgcc|
+| root.turbine|
+| root.ln|
++-------------+
+Total line number = 3
+It costs 0.003s
+
++-------------+
+| database|
++-------------+
+| 3|
++-------------+
+Total line number = 1
+It costs 0.003s
+
++-------------+
+| database|
++-------------+
+| 3|
++-------------+
+Total line number = 1
+It costs 0.002s
+
++-------------+
+| database|
++-------------+
+| 0|
++-------------+
+Total line number = 1
+It costs 0.002s
+
++-------------+
+| database|
++-------------+
+| 1|
++-------------+
+Total line number = 1
+It costs 0.002s
+```
+
+### Setting up heterogeneous databases (Advanced operations)
+
+Under the premise of familiar with IoTDB metadata modeling,
+users can set up heterogeneous databases in IoTDB to cope with different production needs.
+
+Currently, the following database heterogeneous parameters are supported:
+
+| Parameter | Type | Description |
+| ------------------------- | ------- | --------------------------------------------- |
+| TTL | Long | TTL of the Database |
+| SCHEMA_REPLICATION_FACTOR | Integer | The schema replication number of the Database |
+| DATA_REPLICATION_FACTOR | Integer | The data replication number of the Database |
+| SCHEMA_REGION_GROUP_NUM | Integer | The SchemaRegionGroup number of the Database |
+| DATA_REGION_GROUP_NUM | Integer | The DataRegionGroup number of the Database |
+
+Note the following when configuring heterogeneous parameters:
+
++ TTL and TIME_PARTITION_INTERVAL must be positive integers.
++ SCHEMA_REPLICATION_FACTOR and DATA_REPLICATION_FACTOR must be smaller than or equal to the number of deployed DataNodes.
++ The function of SCHEMA_REGION_GROUP_NUM and DATA_REGION_GROUP_NUM are related to the parameter `schema_region_group_extension_policy` and `data_region_group_extension_policy` in iotdb-common.properties configuration file. Take DATA_REGION_GROUP_NUM as an example:
+ If `data_region_group_extension_policy=CUSTOM` is set, DATA_REGION_GROUP_NUM serves as the number of DataRegionGroups owned by the Database.
+ If `data_region_group_extension_policy=AUTO`, DATA_REGION_GROUP_NUM is used as the lower bound of the DataRegionGroup quota owned by the Database. That is, when the Database starts writing data, it will have at least this number of DataRegionGroups.
+
+Users can set any heterogeneous parameters when creating a Database, or adjust some heterogeneous parameters during a stand-alone/distributed IoTDB run.
+
+#### Set heterogeneous parameters when creating a Database
+
+The user can set any of the above heterogeneous parameters when creating a Database. The SQL statement is as follows:
+
+```
+CREATE DATABASE prefixPath (WITH databaseAttributeClause (COMMA? databaseAttributeClause)*)?
+```
+
+For example:
+
+```
+CREATE DATABASE root.db WITH SCHEMA_REPLICATION_FACTOR=1, DATA_REPLICATION_FACTOR=3, SCHEMA_REGION_GROUP_NUM=1, DATA_REGION_GROUP_NUM=2;
+```
+
+#### Adjust heterogeneous parameters at run time
+
+Users can adjust some heterogeneous parameters during the IoTDB runtime, as shown in the following SQL statement:
+
+```
+ALTER DATABASE prefixPath WITH databaseAttributeClause (COMMA? databaseAttributeClause)*
+```
+
+For example:
+
+```
+ALTER DATABASE root.db WITH SCHEMA_REGION_GROUP_NUM=1, DATA_REGION_GROUP_NUM=2;
+```
+
+Note that only the following heterogeneous parameters can be adjusted at runtime:
+
++ SCHEMA_REGION_GROUP_NUM
++ DATA_REGION_GROUP_NUM
+
+#### Show heterogeneous databases
+
+The user can query the specific heterogeneous configuration of each Database, and the SQL statement is as follows:
+
+```
+SHOW DATABASES DETAILS prefixPath?
+```
+
+For example:
+
+```
+IoTDB> SHOW DATABASES DETAILS
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+|Database| TTL|SchemaReplicationFactor|DataReplicationFactor|TimePartitionInterval|SchemaRegionGroupNum|MinSchemaRegionGroupNum|MaxSchemaRegionGroupNum|DataRegionGroupNum|MinDataRegionGroupNum|MaxDataRegionGroupNum|
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+|root.db1| null| 1| 3| 604800000| 0| 1| 1| 0| 2| 2|
+|root.db2|86400000| 1| 1| 604800000| 0| 1| 1| 0| 2| 2|
+|root.db3| null| 1| 1| 604800000| 0| 1| 1| 0| 2| 2|
++--------+--------+-----------------------+---------------------+---------------------+--------------------+-----------------------+-----------------------+------------------+---------------------+---------------------+
+Total line number = 3
+It costs 0.058s
+```
+
+The query results in each column are as follows:
+
++ The name of the Database
++ The TTL of the Database
++ The schema replication number of the Database
++ The data replication number of the Database
++ The time partition interval of the Database
++ The current SchemaRegionGroup number of the Database
++ The required minimum SchemaRegionGroup number of the Database
++ The permitted maximum SchemaRegionGroup number of the Database
++ The current DataRegionGroup number of the Database
++ The required minimum DataRegionGroup number of the Database
++ The permitted maximum DataRegionGroup number of the Database
+
+### TTL
+
+IoTDB supports device-level TTL settings, which means it is able to delete old data automatically and periodically. The benefit of using TTL is that hopefully you can control the total disk space usage and prevent the machine from running out of disks. Moreover, the query performance may downgrade as the total number of files goes up and the memory usage also increases as there are more files. Timely removing such files helps to keep at a high query performance level and reduce memory usage.
+
+The default unit of TTL is milliseconds. If the time precision in the configuration file changes to another, the TTL is still set to milliseconds.
+
+When setting TTL, the system will look for all devices included in the set path and set TTL for these devices. The system will delete expired data at the device granularity.
+After the device data expires, it will not be queryable. The data in the disk file cannot be guaranteed to be deleted immediately, but it can be guaranteed to be deleted eventually.
+However, due to operational costs, the expired data will not be physically deleted right after expiring. The physical deletion is delayed until compaction.
+Therefore, before the data is physically deleted, if the TTL is reduced or lifted, it may cause data that was previously invisible due to TTL to reappear.
+The system can only set up to 1000 TTL rules, and when this limit is reached, some TTL rules need to be deleted before new rules can be set.
+
+#### TTL Path Rule
+The path can only be prefix paths (i.e., the path cannot contain \* , except \*\* in the last level).
+This path will match devices and also allows users to specify paths without asterisks as specific databases or devices.
+When the path does not contain asterisks, the system will check if it matches a database; if it matches a database, both the path and path.\*\* will be set at the same time. Note: Device TTL settings do not verify the existence of metadata, i.e., it is allowed to set TTL for a non-existent device.
+```
+qualified paths:
+root.**
+root.db.**
+root.db.group1.**
+root.db
+root.db.group1.d1
+
+unqualified paths:
+root.*.db
+root.**.db.*
+root.db.*
+```
+#### TTL Applicable Rules
+When a device is subject to multiple TTL rules, the more precise and longer rules are prioritized. For example, for the device "root.bj.hd.dist001.turbine001", the rule "root.bj.hd.dist001.turbine001" takes precedence over "root.bj.hd.dist001.\*\*", and the rule "root.bj.hd.dist001.\*\*" takes precedence over "root.bj.hd.**".
+#### Set TTL
+The set ttl operation can be understood as setting a TTL rule, for example, setting ttl to root.sg.group1.** is equivalent to mounting ttl for all devices that can match this path pattern.
+The unset ttl operation indicates unmounting TTL for the corresponding path pattern; if there is no corresponding TTL, nothing will be done.
+If you want to set TTL to be infinitely large, you can use the INF keyword.
+The SQL Statement for setting TTL is as follow:
+```
+set ttl to pathPattern 360000;
+```
+Set the Time to Live (TTL) to a pathPattern of 360,000 milliseconds; the pathPattern should not contain a wildcard (\*) in the middle and must end with a double asterisk (\*\*). The pathPattern is used to match corresponding devices.
+To maintain compatibility with older SQL syntax, if the user-provided pathPattern matches a database (db), the path pattern is automatically expanded to include all sub-paths denoted by path.\*\*.
+For instance, writing "set ttl to root.sg 360000" will automatically be transformed into "set ttl to root.sg.\*\* 360000", which sets the TTL for all devices under root.sg. However, if the specified pathPattern does not match a database, the aforementioned logic will not apply. For example, writing "set ttl to root.sg.group 360000" will not be expanded to "root.sg.group.\*\*" since root.sg.group does not match a database.
+It is also permissible to specify a particular device without a wildcard (*).
+#### Unset TTL
+
+To unset TTL, we can use follwing SQL statement:
+
+```
+IoTDB> unset ttl from root.ln
+```
+
+After unset TTL, all data will be accepted in `root.ln`.
+```
+IoTDB> unset ttl from root.sgcc.**
+```
+
+Unset the TTL in the `root.sgcc` path.
+
+New syntax
+```
+IoTDB> unset ttl from root.**
+```
+
+Old syntax
+```
+IoTDB> unset ttl to root.**
+```
+There is no functional difference between the old and new syntax, and they are compatible with each other.
+The new syntax is just more conventional in terms of wording.
+
+Unset the TTL setting for all path pattern.
+
+#### Show TTL
+
+To Show TTL, we can use following SQL statement:
+
+show all ttl
+
+```
+IoTDB> SHOW ALL TTL
++--------------+--------+
+| path| TTL|
+| root.**|55555555|
+| root.sg2.a.**|44440000|
++--------------+--------+
+```
+
+show ttl on pathPattern
+```
+IoTDB> SHOW TTL ON root.db.**;
++--------------+--------+
+| path| TTL|
+| root.db.**|55555555|
+| root.db.a.**|44440000|
++--------------+--------+
+```
+
+The SHOW ALL TTL example gives the TTL for all path patterns.
+The SHOW TTL ON pathPattern shows the TTL for the path pattern specified.
+
+Display devices' ttl
+```
+IoTDB> show devices
++---------------+---------+---------+
+| Device|IsAligned| TTL|
++---------------+---------+---------+
+|root.sg.device1| false| 36000000|
+|root.sg.device2| true| INF|
++---------------+---------+---------+
+```
+All devices will definitely have a TTL, meaning it cannot be null. INF represents infinity.
+
+
+## Device Template
+
+IoTDB supports the device template function, enabling different entities of the same type to share metadata, reduce the memory usage of metadata, and simplify the management of numerous entities and measurements.
+
+
+### Create Device Template
+
+The SQL syntax for creating a metadata template is as follows:
+
+```sql
+CREATE DEVICE TEMPLATE ALIGNED? '(' [',' ]+ ')'
+```
+
+**Example 1:** Create a template containing two non-aligned timeseries
+
+```shell
+IoTDB> create device template t1 (temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN compression=SNAPPY)
+```
+
+**Example 2:** Create a template containing a group of aligned timeseries
+
+```shell
+IoTDB> create device template t2 aligned (lat FLOAT encoding=Gorilla, lon FLOAT encoding=Gorilla)
+```
+
+The` lat` and `lon` measurements are aligned.
+
+
+
+
+
+### Set Device Template
+
+After a device template is created, it should be set to specific path before creating related timeseries or insert data.
+
+**It should be ensured that the related database has been set before setting template.**
+
+**It is recommended to set device template to database path. It is not suggested to set device template to some path above database**
+
+**It is forbidden to create timeseries under a path setting s tedeviceplate. Device template shall not be set on a prefix path of an existing timeseries.**
+
+The SQL Statement for setting device template is as follow:
+
+```shell
+IoTDB> set device template t1 to root.sg1.d1
+```
+
+### Activate Device Template
+
+After setting the device template, with the system enabled to auto create schema, you can insert data into the timeseries. For example, suppose there's a database root.sg1 and t1 has been set to root.sg1.d1, then timeseries like root.sg1.d1.temperature and root.sg1.d1.status are available and data points can be inserted.
+
+
+**Attention**: Before inserting data or the system not enabled to auto create schema, timeseries defined by the device template will not be created. You can use the following SQL statement to create the timeseries or activate the templdeviceate, act before inserting data:
+
+```shell
+IoTDB> create timeseries using device template on root.sg1.d1
+```
+
+**Example:** Execute the following statement
+
+```shell
+IoTDB> set device template t1 to root.sg1.d1
+IoTDB> set device template t2 to root.sg1.d2
+IoTDB> create timeseries using device template on root.sg1.d1
+IoTDB> create timeseries using device template on root.sg1.d2
+```
+
+Show the time series:
+
+```sql
+show timeseries root.sg1.**
+````
+
+```shell
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression|tags|attributes|deadband|deadband parameters|
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+|root.sg1.d1.temperature| null| root.sg1| FLOAT| RLE| SNAPPY|null| null| null| null|
+| root.sg1.d1.status| null| root.sg1| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
+| root.sg1.d2.lon| null| root.sg1| FLOAT| GORILLA| SNAPPY|null| null| null| null|
+| root.sg1.d2.lat| null| root.sg1| FLOAT| GORILLA| SNAPPY|null| null| null| null|
++-----------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+```
+
+Show the devices:
+
+```sql
+show devices root.sg1.**
+````
+
+```shell
++---------------+---------+
+| devices|isAligned|
++---------------+---------+
+| root.sg1.d1| false|
+| root.sg1.d2| true|
++---------------+---------+
+````
+
+### Show Device Template
+
+- Show all device templates
+
+The SQL statement looks like this:
+
+```shell
+IoTDB> show device templates
+```
+
+The execution result is as follows:
+
+```shell
++-------------+
+|template name|
++-------------+
+| t2|
+| t1|
++-------------+
+```
+
+- Show nodes under in device template
+
+The SQL statement looks like this:
+
+```shell
+IoTDB> show nodes in device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+--------+--------+-----------+
+|child nodes|dataType|encoding|compression|
++-----------+--------+--------+-----------+
+|temperature| FLOAT| RLE| SNAPPY|
+| status| BOOLEAN| PLAIN| SNAPPY|
++-----------+--------+--------+-----------+
+```
+
+- Show the path prefix where a device template is set
+
+```shell
+IoTDB> show paths set device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+
+|child paths|
++-----------+
+|root.sg1.d1|
++-----------+
+```
+
+- Show the path prefix where a device template is used (i.e. the time series has been created)
+
+```shell
+IoTDB> show paths using device template t1
+```
+
+The execution result is as follows:
+
+```shell
++-----------+
+|child paths|
++-----------+
+|root.sg1.d1|
++-----------+
+```
+
+### Deactivate device Template
+
+To delete a group of timeseries represented by device template, namely deactivate the device template, use the following SQL statement:
+
+```shell
+IoTDB> delete timeseries of device template t1 from root.sg1.d1
+```
+
+or
+
+```shell
+IoTDB> deactivate device template t1 from root.sg1.d1
+```
+
+The deactivation supports batch process.
+
+```shell
+IoTDB> delete timeseries of device template t1 from root.sg1.*, root.sg2.*
+```
+
+or
+
+```shell
+IoTDB> deactivate device template t1 from root.sg1.*, root.sg2.*
+```
+
+If the template name is not provided in sql, all template activation on paths matched by given path pattern will be removed.
+
+### Unset Device Template
+
+The SQL Statement for unsetting device template is as follow:
+
+```shell
+IoTDB> unset device template t1 from root.sg1.d1
+```
+
+**Attention**: It should be guaranteed that none of the timeseries represented by the target device template exists, before unset it. It can be achieved by deactivation operation.
+
+### Drop Device Template
+
+The SQL Statement for dropping device template is as follow:
+
+```shell
+IoTDB> drop device template t1
+```
+
+**Attention**: Dropping an already set template is not supported.
+
+### Alter Device Template
+
+In a scenario where measurements need to be added, you can modify the template to add measurements to all devicesdevice using the device template.
+
+The SQL Statement for altering device template is as follow:
+
+```shell
+IoTDB> alter device template t1 add (speed FLOAT encoding=RLE, FLOAT TEXT encoding=PLAIN compression=SNAPPY)
+```
+
+**When executing data insertion to devices with device template set on related prefix path and there are measurements not present in this device template, the measurements will be auto added to this device template.**
+
+## Timeseries Management
+
+### Create Timeseries
+
+According to the storage model selected before, we can create corresponding timeseries in the two databases respectively. The SQL statements for creating timeseries are as follows:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature with datatype=FLOAT,encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware with datatype=TEXT,encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status with datatype=BOOLEAN,encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature with datatype=FLOAT,encoding=RLE
+```
+
+From v0.13, you can use a simplified version of the SQL statements to create timeseries:
+
+```
+IoTDB > create timeseries root.ln.wf01.wt01.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.ln.wf01.wt01.temperature FLOAT encoding=RLE
+IoTDB > create timeseries root.ln.wf02.wt02.hardware TEXT encoding=PLAIN
+IoTDB > create timeseries root.ln.wf02.wt02.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.status BOOLEAN encoding=PLAIN
+IoTDB > create timeseries root.sgcc.wf03.wt01.temperature FLOAT encoding=RLE
+```
+
+Notice that when in the CREATE TIMESERIES statement the encoding method conflicts with the data type, the system gives the corresponding error prompt as shown below:
+
+```
+IoTDB > create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+error: encoding TS_2DIFF does not support BOOLEAN
+```
+
+Please refer to [Encoding](../Basic-Concept/Encoding-and-Compression.md) for correspondence between data type and encoding.
+
+### Create Aligned Timeseries
+
+The SQL statement for creating a group of timeseries are as follows:
+
+```
+IoTDB> CREATE ALIGNED TIMESERIES root.ln.wf01.GPS(latitude FLOAT encoding=PLAIN compressor=SNAPPY, longitude FLOAT encoding=PLAIN compressor=SNAPPY)
+```
+
+You can set different datatype, encoding, and compression for the timeseries in a group of aligned timeseries
+
+It is also supported to set an alias, tag, and attribute for aligned timeseries.
+
+### Delete Timeseries
+
+To delete the timeseries we created before, we are able to use `(DELETE | DROP) TimeSeries ` statement.
+
+The usage are as follows:
+
+```
+IoTDB> delete timeseries root.ln.wf01.wt01.status
+IoTDB> delete timeseries root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware
+IoTDB> delete timeseries root.ln.wf02.*
+IoTDB> drop timeseries root.ln.wf02.*
+```
+
+### Show Timeseries
+
+* SHOW LATEST? TIMESERIES pathPattern? whereClause? limitClause?
+
+ There are four optional clauses added in SHOW TIMESERIES, return information of time series
+
+Timeseries information includes: timeseries path, alias of measurement, database it belongs to, data type, encoding type, compression type, tags and attributes.
+
+Examples:
+
+* SHOW TIMESERIES
+
+ presents all timeseries information in JSON form
+
+* SHOW TIMESERIES <`PathPattern`>
+
+ returns all timeseries information matching the given <`PathPattern`>. SQL statements are as follows:
+
+```
+IoTDB> show timeseries root.**
+IoTDB> show timeseries root.ln.**
+```
+
+The results are shown below respectively:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.sgcc.wf03.wt01.status| null| root.sgcc| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY| null| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 7
+It costs 0.016s
+
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression|tags|attributes|deadband|deadband parameters|
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY|null| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
+|root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY|null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null| null| null|
++-----------------------------+-----+-------------+--------+--------+-----------+----+----------+--------+-------------------+
+Total line number = 4
+It costs 0.004s
+```
+
+* SHOW TIMESERIES LIMIT INT OFFSET INT
+
+ returns all the timeseries information start from the offset and limit the number of series returned. For example,
+
+```
+show timeseries root.ln.** limit 10 offset 10
+```
+
+* SHOW TIMESERIES WHERE TIMESERIES contains 'containStr'
+
+ The query result set is filtered by string fuzzy matching based on the names of the timeseries. For example:
+
+```
+show timeseries root.ln.** where timeseries contains 'wf01.wt'
+```
+
+The result is shown below:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 2
+It costs 0.016s
+```
+
+* SHOW TIMESERIES WHERE DataType=type
+
+ The query result set is filtered by data type. For example:
+
+```
+show timeseries root.ln.** where dataType=FLOAT
+```
+
+The result is shown below:
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 3
+It costs 0.016s
+
+```
+
+
+* SHOW LATEST TIMESERIES
+
+ all the returned timeseries information should be sorted in descending order of the last timestamp of timeseries
+
+It is worth noting that when the queried path does not exist, the system will return no timeseries.
+
+
+### Count Timeseries
+
+IoTDB is able to use `COUNT TIMESERIES ` to count the number of timeseries matching the path. SQL statements are as follows:
+
+* `WHERE` condition could be used to fuzzy match a time series name with the following syntax: `COUNT TIMESERIES WHERE TIMESERIES contains 'containStr'`.
+* `WHERE` condition could be used to filter result by data type with the syntax: `COUNT TIMESERIES WHERE DataType='`.
+* `WHERE` condition could be used to filter result by tags with the syntax: `COUNT TIMESERIES WHERE TAGS(key)='value'` or `COUNT TIMESERIES WHERE TAGS(key) contains 'value'`.
+* `LEVEL` could be defined to show count the number of timeseries of each node at the given level in current Metadata Tree. This could be used to query the number of sensors under each device. The grammar is: `COUNT TIMESERIES GROUP BY LEVEL=`.
+
+
+```
+IoTDB > COUNT TIMESERIES root.**
+IoTDB > COUNT TIMESERIES root.ln.**
+IoTDB > COUNT TIMESERIES root.ln.*.*.status
+IoTDB > COUNT TIMESERIES root.ln.wf01.wt01.status
+IoTDB > COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc'
+IoTDB > COUNT TIMESERIES root.** WHERE DATATYPE = INT64
+IoTDB > COUNT TIMESERIES root.** WHERE TAGS(unit) contains 'c'
+IoTDB > COUNT TIMESERIES root.** WHERE TAGS(unit) = 'c'
+IoTDB > COUNT TIMESERIES root.** WHERE TIMESERIES contains 'sgcc' group by level = 1
+```
+
+For example, if there are several timeseries (use `show timeseries` to show all timeseries):
+
+```
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+| timeseries| alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+|root.sgcc.wf03.wt01.temperature| null| root.sgcc| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.sgcc.wf03.wt01.status| null| root.sgcc| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
+| root.turbine.d1.s1|newAlias| root.turbine| FLOAT| RLE| SNAPPY|{"newTag1":"newV1","tag4":"v4","tag3":"v3"}|{"attr2":"v2","attr1":"newV1","attr4":"v4","attr3":"v3"}| null| null|
+| root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY| {"unit":"c"}| null| null| null|
+| root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| {"description":"test1"}| null| null| null|
+| root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY| null| null| null| null|
+| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY| null| null| null| null|
++-------------------------------+--------+-------------+--------+--------+-----------+-------------------------------------------+--------------------------------------------------------+--------+-------------------+
+Total line number = 7
+It costs 0.004s
+```
+
+Then the Metadata Tree will be as below:
+
+
+
+As can be seen, `root` is considered as `LEVEL=0`. So when you enter statements such as:
+
+```
+IoTDB > COUNT TIMESERIES root.** GROUP BY LEVEL=1
+IoTDB > COUNT TIMESERIES root.ln.** GROUP BY LEVEL=2
+IoTDB > COUNT TIMESERIES root.ln.wf01.* GROUP BY LEVEL=2
+```
+
+You will get following results:
+
+```
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+| root.sgcc| 2|
+|root.turbine| 1|
+| root.ln| 4|
++------------+-----------------+
+Total line number = 3
+It costs 0.002s
+
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+|root.ln.wf02| 2|
+|root.ln.wf01| 2|
++------------+-----------------+
+Total line number = 2
+It costs 0.002s
+
++------------+-----------------+
+| column|count(timeseries)|
++------------+-----------------+
+|root.ln.wf01| 2|
++------------+-----------------+
+Total line number = 1
+It costs 0.002s
+```
+
+> Note: The path of timeseries is just a filter condition, which has no relationship with the definition of level.
+
+### Active Timeseries Query
+By adding WHERE time filter conditions to the existing SHOW/COUNT TIMESERIES, we can obtain time series with data within the specified time range.
+
+It is important to note that in metadata queries with time filters, views are not considered; only the time series actually stored in the TsFile are taken into account.
+
+An example usage is as follows:
+```
+IoTDB> insert into root.sg.data(timestamp, s1,s2) values(15000, 1, 2);
+IoTDB> insert into root.sg.data2(timestamp, s1,s2) values(15002, 1, 2);
+IoTDB> insert into root.sg.data3(timestamp, s1,s2) values(16000, 1, 2);
+IoTDB> show timeseries;
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| Timeseries|Alias|Database|DataType|Encoding|Compression|Tags|Attributes|Deadband|DeadbandParameters|ViewType|
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| root.sg.data.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+| root.sg.data.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data3.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data3.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data2.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data2.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+
+IoTDB> show timeseries where time >= 15000 and time < 16000;
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| Timeseries|Alias|Database|DataType|Encoding|Compression|Tags|Attributes|Deadband|DeadbandParameters|ViewType|
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+| root.sg.data.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+| root.sg.data.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data2.s1| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
+|root.sg.data2.s2| null| root.sg| FLOAT| GORILLA| LZ4|null| null| null| null| BASE|
++----------------+-----+--------+--------+--------+-----------+----+----------+--------+------------------+--------+
+
+IoTDB> count timeseries where time >= 15000 and time < 16000;
++-----------------+
+|count(timeseries)|
++-----------------+
+| 4|
++-----------------+
+```
+Regarding the definition of active time series, data that can be queried normally is considered active, meaning time series that have been inserted but deleted are not included.
+### Tag and Attribute Management
+
+We can also add an alias, extra tag and attribute information while creating one timeseries.
+
+The differences between tag and attribute are:
+
+* Tag could be used to query the path of timeseries, we will maintain an inverted index in memory on the tag: Tag -> Timeseries
+* Attribute could only be queried by timeseries path : Timeseries -> Attribute
+
+The SQL statements for creating timeseries with extra tag and attribute information are extended as follows:
+
+```
+create timeseries root.turbine.d1.s1(temprature) with datatype=FLOAT, encoding=RLE, compression=SNAPPY tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2)
+```
+
+The `temprature` in the brackets is an alias for the sensor `s1`. So we can use `temprature` to replace `s1` anywhere.
+
+> IoTDB also supports using AS function to set alias. The difference between the two is: the alias set by the AS function is used to replace the whole time series name, temporary and not bound with the time series; while the alias mentioned above is only used as the alias of the sensor, which is bound with it and can be used equivalent to the original sensor name.
+
+> Notice that the size of the extra tag and attribute information shouldn't exceed the `tag_attribute_total_size`.
+
+We can update the tag information after creating it as following:
+
+* Rename the tag/attribute key
+
+```
+ALTER timeseries root.turbine.d1.s1 RENAME tag1 TO newTag1
+```
+
+* Reset the tag/attribute value
+
+```
+ALTER timeseries root.turbine.d1.s1 SET newTag1=newV1, attr1=newV1
+```
+
+* Delete the existing tag/attribute
+
+```
+ALTER timeseries root.turbine.d1.s1 DROP tag1, tag2
+```
+
+* Add new tags
+
+```
+ALTER timeseries root.turbine.d1.s1 ADD TAGS tag3=v3, tag4=v4
+```
+
+* Add new attributes
+
+```
+ALTER timeseries root.turbine.d1.s1 ADD ATTRIBUTES attr3=v3, attr4=v4
+```
+
+* Upsert alias, tags and attributes
+
+> add alias or a new key-value if the alias or key doesn't exist, otherwise, update the old one with new value.
+
+```
+ALTER timeseries root.turbine.d1.s1 UPSERT ALIAS=newAlias TAGS(tag3=v3, tag4=v4) ATTRIBUTES(attr3=v3, attr4=v4)
+```
+
+* Show timeseries using tags. Use TAGS(tagKey) to identify the tags used as filter key
+
+```
+SHOW TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
+```
+
+returns all the timeseries information that satisfy the where condition and match the pathPattern. SQL statements are as follows:
+
+```
+ALTER timeseries root.ln.wf02.wt02.hardware ADD TAGS unit=c
+ALTER timeseries root.ln.wf02.wt02.status ADD TAGS description=test1
+show timeseries root.ln.** where TAGS(unit)='c'
+show timeseries root.ln.** where TAGS(description) contains 'test1'
+```
+
+The results are shown below respectly:
+
+```
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags|attributes|deadband|deadband parameters|
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+|root.ln.wf02.wt02.hardware| null| root.ln| TEXT| PLAIN| SNAPPY|{"unit":"c"}| null| null| null|
++--------------------------+-----+-------------+--------+--------+-----------+------------+----------+--------+-------------------+
+Total line number = 1
+It costs 0.005s
+
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags|attributes|deadband|deadband parameters|
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+|root.ln.wf02.wt02.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|{"description":"test1"}| null| null| null|
++------------------------+-----+-------------+--------+--------+-----------+-----------------------+----------+--------+-------------------+
+Total line number = 1
+It costs 0.004s
+```
+
+- count timeseries using tags
+
+```
+COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause
+COUNT TIMESERIES (<`PathPattern`>)? timeseriesWhereClause GROUP BY LEVEL=
+```
+
+returns all the number of timeseries that satisfy the where condition and match the pathPattern. SQL statements are as follows:
+
+```
+count timeseries
+count timeseries root.** where TAGS(unit)='c'
+count timeseries root.** where TAGS(unit)='c' group by level = 2
+```
+
+The results are shown below respectly :
+
+```
+IoTDB> count timeseries
++-----------------+
+|count(timeseries)|
++-----------------+
+| 6|
++-----------------+
+Total line number = 1
+It costs 0.019s
+IoTDB> count timeseries root.** where TAGS(unit)='c'
++-----------------+
+|count(timeseries)|
++-----------------+
+| 2|
++-----------------+
+Total line number = 1
+It costs 0.020s
+IoTDB> count timeseries root.** where TAGS(unit)='c' group by level = 2
++--------------+-----------------+
+| column|count(timeseries)|
++--------------+-----------------+
+| root.ln.wf02| 2|
+| root.ln.wf01| 0|
+|root.sgcc.wf03| 0|
++--------------+-----------------+
+Total line number = 3
+It costs 0.011s
+```
+
+> Notice that, we only support one condition in the where clause. Either it's an equal filter or it is an `contains` filter. In both case, the property in the where condition must be a tag.
+
+create aligned timeseries
+
+```
+create aligned timeseries root.sg1.d1(s1 INT32 tags(tag1=v1, tag2=v2) attributes(attr1=v1, attr2=v2), s2 DOUBLE tags(tag3=v3, tag4=v4) attributes(attr3=v3, attr4=v4))
+```
+
+The execution result is as follows:
+
+```
+IoTDB> show timeseries
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+|root.sg1.d1.s1| null| root.sg1| INT32| RLE| SNAPPY|{"tag1":"v1","tag2":"v2"}|{"attr2":"v2","attr1":"v1"}| null| null|
+|root.sg1.d1.s2| null| root.sg1| DOUBLE| GORILLA| SNAPPY|{"tag4":"v4","tag3":"v3"}|{"attr4":"v4","attr3":"v3"}| null| null|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+```
+
+Support query:
+
+```
+IoTDB> show timeseries where TAGS(tag1)='v1'
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+| timeseries|alias| database|dataType|encoding|compression| tags| attributes|deadband|deadband parameters|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+|root.sg1.d1.s1| null| root.sg1| INT32| RLE| SNAPPY|{"tag1":"v1","tag2":"v2"}|{"attr2":"v2","attr1":"v1"}| null| null|
++--------------+-----+-------------+--------+--------+-----------+-------------------------+---------------------------+--------+-------------------+
+```
+
+The above operations are supported for timeseries tag, attribute updates, etc.
+
+## Node Management
+
+### Show Child Paths
+
+```
+SHOW CHILD PATHS pathPattern
+```
+
+Return all child paths and their node types of all the paths matching pathPattern.
+
+node types: ROOT -> DB INTERNAL -> DATABASE -> INTERNAL -> DEVICE -> TIMESERIES
+
+
+Example:
+
+* return the child paths of root.ln:show child paths root.ln
+
+```
++------------+----------+
+| child paths|node types|
++------------+----------+
+|root.ln.wf01| INTERNAL|
+|root.ln.wf02| INTERNAL|
++------------+----------+
+Total line number = 2
+It costs 0.002s
+```
+
+> get all paths in form of root.xx.xx.xx:show child paths root.xx.xx
+
+### Show Child Nodes
+
+```
+SHOW CHILD NODES pathPattern
+```
+
+Return all child nodes of the pathPattern.
+
+Example:
+
+* return the child nodes of root:show child nodes root
+
+```
++------------+
+| child nodes|
++------------+
+| ln|
++------------+
+```
+
+* return the child nodes of root.ln:show child nodes root.ln
+
+```
++------------+
+| child nodes|
++------------+
+| wf01|
+| wf02|
++------------+
+```
+
+### Count Nodes
+
+IoTDB is able to use `COUNT NODES LEVEL=` to count the number of nodes at
+ the given level in current Metadata Tree considering a given pattern. IoTDB will find paths that
+ match the pattern and counts distinct nodes at the specified level among the matched paths.
+ This could be used to query the number of devices with specified measurements. The usage are as
+ follows:
+
+```
+IoTDB > COUNT NODES root.** LEVEL=2
+IoTDB > COUNT NODES root.ln.** LEVEL=2
+IoTDB > COUNT NODES root.ln.wf01.** LEVEL=3
+IoTDB > COUNT NODES root.**.temperature LEVEL=3
+```
+
+As for the above mentioned example and Metadata tree, you can get following results:
+
+```
++------------+
+|count(nodes)|
++------------+
+| 4|
++------------+
+Total line number = 1
+It costs 0.003s
+
++------------+
+|count(nodes)|
++------------+
+| 2|
++------------+
+Total line number = 1
+It costs 0.002s
+
++------------+
+|count(nodes)|
++------------+
+| 1|
++------------+
+Total line number = 1
+It costs 0.002s
+
++------------+
+|count(nodes)|
++------------+
+| 2|
++------------+
+Total line number = 1
+It costs 0.002s
+```
+
+> Note: The path of timeseries is just a filter condition, which has no relationship with the definition of level.
+
+### Show Devices
+
+* SHOW DEVICES pathPattern? (WITH DATABASE)? devicesWhereClause? limitClause?
+
+Similar to `Show Timeseries`, IoTDB also supports two ways of viewing devices:
+
+* `SHOW DEVICES` statement presents all devices' information, which is equal to `SHOW DEVICES root.**`.
+* `SHOW DEVICES ` statement specifies the `PathPattern` and returns the devices information matching the pathPattern and under the given level.
+* `WHERE` condition supports `DEVICE contains 'xxx'` to do a fuzzy query based on the device name.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices
+IoTDB> show devices root.ln.**
+IoTDB> show devices root.ln.** where device contains 't'
+```
+
+You can get results below:
+
+```
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+| root.ln.wf01.wt01| false|
+| root.ln.wf02.wt02| false|
+|root.sgcc.wf03.wt01| false|
+| root.turbine.d1| false|
++-------------------+---------+
+Total line number = 4
+It costs 0.002s
+
++-----------------+---------+
+| devices|isAligned|
++-----------------+---------+
+|root.ln.wf01.wt01| false|
+|root.ln.wf02.wt02| false|
++-----------------+---------+
+Total line number = 2
+It costs 0.001s
+```
+
+`isAligned` indicates whether the timeseries under the device are aligned.
+
+To view devices' information with database, we can use `SHOW DEVICES WITH DATABASE` statement.
+
+* `SHOW DEVICES WITH DATABASE` statement presents all devices' information with their database.
+* `SHOW DEVICES WITH DATABASE` statement specifies the `PathPattern` and returns the
+ devices' information under the given level with their database information.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices with database
+IoTDB> show devices root.ln.** with database
+```
+
+You can get results below:
+
+```
++-------------------+-------------+---------+
+| devices| database|isAligned|
++-------------------+-------------+---------+
+| root.ln.wf01.wt01| root.ln| false|
+| root.ln.wf02.wt02| root.ln| false|
+|root.sgcc.wf03.wt01| root.sgcc| false|
+| root.turbine.d1| root.turbine| false|
++-------------------+-------------+---------+
+Total line number = 4
+It costs 0.003s
+
++-----------------+-------------+---------+
+| devices| database|isAligned|
++-----------------+-------------+---------+
+|root.ln.wf01.wt01| root.ln| false|
+|root.ln.wf02.wt02| root.ln| false|
++-----------------+-------------+---------+
+Total line number = 2
+It costs 0.001s
+```
+
+### Count Devices
+
+* COUNT DEVICES /
+
+The above statement is used to count the number of devices. At the same time, it is allowed to specify `PathPattern` to count the number of devices matching the `PathPattern`.
+
+SQL statement is as follows:
+
+```
+IoTDB> show devices
+IoTDB> count devices
+IoTDB> count devices root.ln.**
+```
+
+You can get results below:
+
+```
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+|root.sgcc.wf03.wt03| false|
+| root.turbine.d1| false|
+| root.ln.wf02.wt02| false|
+| root.ln.wf01.wt01| false|
++-------------------+---------+
+Total line number = 4
+It costs 0.024s
+
++--------------+
+|count(devices)|
++--------------+
+| 4|
++--------------+
+Total line number = 1
+It costs 0.004s
+
++--------------+
+|count(devices)|
++--------------+
+| 2|
++--------------+
+Total line number = 1
+It costs 0.004s
+```
+
+### Active Device Query
+Similar to active timeseries query, we can add time filter conditions to device viewing and statistics to query active devices that have data within a certain time range. The definition of active here is the same as for active time series. An example usage is as follows:
+```
+IoTDB> insert into root.sg.data(timestamp, s1,s2) values(15000, 1, 2);
+IoTDB> insert into root.sg.data2(timestamp, s1,s2) values(15002, 1, 2);
+IoTDB> insert into root.sg.data3(timestamp, s1,s2) values(16000, 1, 2);
+IoTDB> show devices;
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+| root.sg.data| false|
+| root.sg.data2| false|
+| root.sg.data3| false|
++-------------------+---------+
+
+IoTDB> show devices where time >= 15000 and time < 16000;
++-------------------+---------+
+| devices|isAligned|
++-------------------+---------+
+| root.sg.data| false|
+| root.sg.data2| false|
++-------------------+---------+
+
+IoTDB> count devices where time >= 15000 and time < 16000;
++--------------+
+|count(devices)|
++--------------+
+| 2|
++--------------+
+```
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Basic-Concept/Query-Data.md b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Query-Data.md
new file mode 100644
index 00000000..62fc3c9f
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Basic-Concept/Query-Data.md
@@ -0,0 +1,3009 @@
+
+# Query Data
+## OVERVIEW
+
+### Syntax Definition
+
+In IoTDB, `SELECT` statement is used to retrieve data from one or more selected time series. Here is the syntax definition of `SELECT` statement:
+
+```sql
+SELECT [LAST] selectExpr [, selectExpr] ...
+ [INTO intoItem [, intoItem] ...]
+ FROM prefixPath [, prefixPath] ...
+ [WHERE whereCondition]
+ [GROUP BY {
+ ([startTime, endTime), interval [, slidingStep]) |
+ LEVEL = levelNum [, levelNum] ... |
+ TAGS(tagKey [, tagKey] ... ) |
+ VARIATION(expression[,delta][,ignoreNull=true/false]) |
+ CONDITION(expression,[keep>/>=/=/ 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;
+```
+
+which means:
+
+The selected device is ln group wf01 plant wt01 device; the selected timeseries is "status" and "temperature". The SQL statement requires that the status and temperature sensor values between the time point of "2017-11-01T00:05:00.000" and "2017-11-01T00:12:00.000" be selected.
+
+The execution result of this SQL statement is as follows:
+
+```
++-----------------------------+------------------------+-----------------------------+
+| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
++-----------------------------+------------------------+-----------------------------+
+|2017-11-01T00:06:00.000+08:00| false| 20.71|
+|2017-11-01T00:07:00.000+08:00| false| 21.45|
+|2017-11-01T00:08:00.000+08:00| false| 22.58|
+|2017-11-01T00:09:00.000+08:00| false| 20.98|
+|2017-11-01T00:10:00.000+08:00| true| 25.52|
+|2017-11-01T00:11:00.000+08:00| false| 22.91|
++-----------------------------+------------------------+-----------------------------+
+Total line number = 6
+It costs 0.018s
+```
+
+#### Select Multiple Columns of Data for the Same Device According to Multiple Time Intervals
+
+IoTDB supports specifying multiple time interval conditions in a query. Users can combine time interval conditions at will according to their needs. For example, the SQL statement is:
+
+```sql
+select status,temperature from root.ln.wf01.wt01 where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
+```
+
+which means:
+
+The selected device is ln group wf01 plant wt01 device; the selected timeseries is "status" and "temperature"; the statement specifies two different time intervals, namely "2017-11-01T00:05:00.000 to 2017-11-01T00:12:00.000" and "2017-11-01T16:35:00.000 to 2017-11-01T16:37:00.000". The SQL statement requires that the values of selected timeseries satisfying any time interval be selected.
+
+The execution result of this SQL statement is as follows:
+
+```
++-----------------------------+------------------------+-----------------------------+
+| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
++-----------------------------+------------------------+-----------------------------+
+|2017-11-01T00:06:00.000+08:00| false| 20.71|
+|2017-11-01T00:07:00.000+08:00| false| 21.45|
+|2017-11-01T00:08:00.000+08:00| false| 22.58|
+|2017-11-01T00:09:00.000+08:00| false| 20.98|
+|2017-11-01T00:10:00.000+08:00| true| 25.52|
+|2017-11-01T00:11:00.000+08:00| false| 22.91|
+|2017-11-01T16:35:00.000+08:00| true| 23.44|
+|2017-11-01T16:36:00.000+08:00| false| 21.98|
+|2017-11-01T16:37:00.000+08:00| false| 21.93|
++-----------------------------+------------------------+-----------------------------+
+Total line number = 9
+It costs 0.018s
+```
+
+
+#### Choose Multiple Columns of Data for Different Devices According to Multiple Time Intervals
+
+The system supports the selection of data in any column in a query, i.e., the selected columns can come from different devices. For example, the SQL statement is:
+
+```sql
+select wf01.wt01.status,wf02.wt02.hardware from root.ln where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);
+```
+
+which means:
+
+The selected timeseries are "the power supply status of ln group wf01 plant wt01 device" and "the hardware version of ln group wf02 plant wt02 device"; the statement specifies two different time intervals, namely "2017-11-01T00:05:00.000 to 2017-11-01T00:12:00.000" and "2017-11-01T16:35:00.000 to 2017-11-01T16:37:00.000". The SQL statement requires that the values of selected timeseries satisfying any time interval be selected.
+
+The execution result of this SQL statement is as follows:
+
+```
++-----------------------------+------------------------+--------------------------+
+| Time|root.ln.wf01.wt01.status|root.ln.wf02.wt02.hardware|
++-----------------------------+------------------------+--------------------------+
+|2017-11-01T00:06:00.000+08:00| false| v1|
+|2017-11-01T00:07:00.000+08:00| false| v1|
+|2017-11-01T00:08:00.000+08:00| false| v1|
+|2017-11-01T00:09:00.000+08:00| false| v1|
+|2017-11-01T00:10:00.000+08:00| true| v2|
+|2017-11-01T00:11:00.000+08:00| false| v1|
+|2017-11-01T16:35:00.000+08:00| true| v2|
+|2017-11-01T16:36:00.000+08:00| false| v1|
+|2017-11-01T16:37:00.000+08:00| false| v1|
++-----------------------------+------------------------+--------------------------+
+Total line number = 9
+It costs 0.014s
+```
+
+#### Order By Time Query
+
+IoTDB supports the 'order by time' statement since 0.11, it's used to display results in descending order by time.
+For example, the SQL statement is:
+
+```sql
+select * from root.ln.** where time > 1 order by time desc limit 10;
+```
+
+The execution result of this SQL statement is as follows:
+
+```
++-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
+| Time|root.ln.wf02.wt02.hardware|root.ln.wf02.wt02.status|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
++-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
+|2017-11-07T23:59:00.000+08:00| v1| false| 21.07| false|
+|2017-11-07T23:58:00.000+08:00| v1| false| 22.93| false|
+|2017-11-07T23:57:00.000+08:00| v2| true| 24.39| true|
+|2017-11-07T23:56:00.000+08:00| v2| true| 24.44| true|
+|2017-11-07T23:55:00.000+08:00| v2| true| 25.9| true|
+|2017-11-07T23:54:00.000+08:00| v1| false| 22.52| false|
+|2017-11-07T23:53:00.000+08:00| v2| true| 24.58| true|
+|2017-11-07T23:52:00.000+08:00| v1| false| 20.18| false|
+|2017-11-07T23:51:00.000+08:00| v1| false| 22.24| false|
+|2017-11-07T23:50:00.000+08:00| v2| true| 23.7| true|
++-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
+Total line number = 10
+It costs 0.016s
+```
+
+### Execution Interface
+
+In IoTDB, there are two ways to execute data query:
+
+- Execute queries using IoTDB-SQL.
+- Efficient execution interfaces for common queries, including time-series raw data query, last query, and aggregation query.
+
+#### Execute queries using IoTDB-SQL
+
+Data query statements can be used in SQL command-line terminals, JDBC, JAVA / C++ / Python / Go and other native APIs, and RESTful APIs.
+
+- Execute the query statement in the SQL command line terminal: start the SQL command line terminal, and directly enter the query statement to execute, see [SQL command line terminal](../Tools-System/CLI.md).
+
+- Execute query statements in JDBC, see [JDBC](../API/Programming-JDBC.md) for details.
+
+- Execute query statements in native APIs such as JAVA / C++ / Python / Go. For details, please refer to the relevant documentation in the Application Programming Interface chapter. The interface prototype is as follows:
+
+ ````java
+ SessionDataSet executeQueryStatement(String sql)
+ ````
+
+- Used in RESTful API, see [HTTP API V1](../API/RestServiceV1.md) or [HTTP API V2](../API/RestServiceV2.md) for details.
+
+#### Efficient execution interfaces
+
+The native APIs provide efficient execution interfaces for commonly used queries, which can save time-consuming operations such as SQL parsing. include:
+
+* Time-series raw data query with time range:
+ - The specified query time range is a left-closed right-open interval, including the start time but excluding the end time.
+
+```java
+SessionDataSet executeRawDataQuery(List paths, long startTime, long endTime);
+```
+
+* Last query:
+ - Query the last data, whose timestamp is greater than or equal LastTime.
+
+```java
+SessionDataSet executeLastDataQuery(List paths, long LastTime);
+```
+
+* Aggregation query:
+ - Support specified query time range: The specified query time range is a left-closed right-open interval, including the start time but not the end time.
+ - Support GROUP BY TIME.
+
+```java
+SessionDataSet executeAggregationQuery(List paths, List aggregations);
+
+SessionDataSet executeAggregationQuery(
+ List paths, List aggregations, long startTime, long endTime);
+
+SessionDataSet executeAggregationQuery(
+ List paths,
+ List aggregations,
+ long startTime,
+ long endTime,
+ long interval);
+
+SessionDataSet executeAggregationQuery(
+ List paths,
+ List aggregations,
+ long startTime,
+ long endTime,
+ long interval,
+ long slidingStep);
+```
+
+## `SELECT` CLAUSE
+The `SELECT` clause specifies the output of the query, consisting of several `selectExpr`. Each `selectExpr` defines one or more columns in the query result. For select expression details, see document [Operator-and-Expression](../SQL-Manual/Operator-and-Expression.md).
+
+- Example 1:
+
+```sql
+select temperature from root.ln.wf01.wt01
+```
+
+- Example 2:
+
+```sql
+select status, temperature from root.ln.wf01.wt01
+```
+
+### Last Query
+
+The last query is a special type of query in Apache IoTDB. It returns the data point with the largest timestamp of the specified time series. In other word, it returns the latest state of a time series. This feature is especially important in IoT data analysis scenarios. To meet the performance requirement of real-time device monitoring systems, Apache IoTDB caches the latest values of all time series to achieve microsecond read latency.
+
+The last query is to return the most recent data point of the given timeseries in a three column format.
+
+The SQL syntax is defined as:
+
+```sql
+select last [COMMA ]* from < PrefixPath > [COMMA < PrefixPath >]*  +
+ +
+  +
+  +
+  +
+  +
+