+
+ | Disk classification |
+ Disk set |
+ Drive |
+ Capacity |
+ File system type |
+
+
+ | System disk |
+ Disk group0 |
+ /boot |
+ 1GB |
+ Acquiesce |
+
+
+ | / |
+ Remaining space of the disk group |
+ Acquiesce |
+
+
+ | Data disk |
+ Disk set1 |
+ /data1 |
+ Full space of disk group1 |
+ Acquiesce |
+
+
+ | Disk set2 |
+ /data2 |
+ Full space of disk group2 |
+ Acquiesce |
+
+
+ | ...... |
+
+
+### Network Configuration
+
+1. Disable the firewall
+
+```Bash
+# View firewall
+systemctl status firewalld
+# Disable firewall
+systemctl stop firewalld
+# Disable firewall permanently
+systemctl disable firewalld
+```
+2. Ensure that the required port is not occupied
+
+(1) Check the ports occupied by the cluster: In the default cluster configuration, ConfigNode occupies ports 10710 and 10720, and DataNode occupies ports 6667, 10730, 10740, 10750, 10760, 9090, 9190, and 3000. Ensure that these ports are not occupied. Check methods are as follows:
+
+```Bash
+lsof -i:6667 or netstat -tunp | grep 6667
+lsof -i:10710 or netstat -tunp | grep 10710
+lsof -i:10720 or netstat -tunp | grep 10720
+# If the command outputs, the port is occupied.
+```
+
+(2) Checking the port occupied by the cluster deployment tool: When using the cluster management tool opskit to install and deploy the cluster, enable the SSH remote connection service configuration and open port 22.
+
+```Bash
+yum install openssh-server # Install the ssh service
+systemctl start sshd # Enable port 22
+```
+
+3. Ensure that servers are connected to each other
+
+### Other Configuration
+
+1. Disable the system swap memory
+
+```Bash
+echo "vm.swappiness = 0">> /etc/sysctl.conf
+# The swapoff -a and swapon -a commands are executed together to dump the data in swap back to memory and to empty the data in swap.
+# Do not omit the swappiness setting and just execute swapoff -a; Otherwise, swap automatically opens again after the restart, making the operation invalid.
+swapoff -a && swapon -a
+# Make the configuration take effect without restarting.
+sysctl -p
+# Check memory allocation, expecting swap to be 0
+free -m
+```
+2. Set the maximum number of open files to 65535 to avoid the error of "too many open files".
+
+```Bash
+# View current restrictions
+ulimit -n
+# Temporary changes
+ulimit -n 65535
+# Permanent modification
+echo "* soft nofile 65535" >> /etc/security/limits.conf
+echo "* hard nofile 65535" >> /etc/security/limits.conf
+# View after exiting the current terminal session, expect to display 65535
+ulimit -n
+```
+## Software Dependence
+
+Install the Java runtime environment (Java version >= 1.8). Ensure that jdk environment variables are set. (It is recommended to deploy JDK17 for V1.3.2.2 or later. In some scenarios, the performance of JDK of earlier versions is compromised, and Datanodes cannot be stopped.)
+
+```Bash
+# The following is an example of installing in centos7 using JDK-17:
+tar -zxvf JDk-17_linux-x64_bin.tar # Decompress the JDK file
+Vim ~/.bashrc # Configure the JDK environment
+{ export JAVA_HOME=/usr/lib/jvm/jdk-17.0.9
+ export PATH=$JAVA_HOME/bin:$PATH
+} # Add JDK environment variables
+source ~/.bashrc # The configuration takes effect
+java -version # Check the JDK environment
+```
\ No newline at end of file
diff --git a/src/UserGuide/Master/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md b/src/UserGuide/Master/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md
new file mode 100644
index 000000000..57cad838b
--- /dev/null
+++ b/src/UserGuide/Master/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md
@@ -0,0 +1,42 @@
+
+# Obtain TimechoDB
+## How to obtain TimechoDB
+The enterprise version installation package can be obtained through product trial application or by directly contacting the business personnel who are in contact with you.
+
+## Installation Package Structure
+The directory structure after unpacking the installation package is as follows:
+| **catalogue** | **Type** | **Explanation** |
+| :--------------: | -------- | ------------------------------------------------------------ |
+| activation | folder | The directory where the activation file is located, including the generated machine code and the enterprise version activation code obtained from the business side (this directory will only be generated after starting ConfigNode to obtain the activation code) |
+| conf | folder | Configuration file directory, including configuration files such as ConfigNode, DataNode, JMX, and logback |
+| data | folder | The default data file directory contains data files for ConfigNode and DataNode. (The directory will only be generated after starting the program) |
+| lib | folder | IoTDB executable library file directory |
+| licenses | folder | Open source community certificate file directory |
+| logs | folder | The default log file directory, which includes log files for ConfigNode and DataNode (this directory will only be generated after starting the program) |
+| sbin | folder | Main script directory, including start, stop, and other scripts |
+| tools | folder | Directory of System Peripheral Tools |
+| ext | folder | Related files for pipe, trigger, and UDF plugins (created by the user when needed) |
+| LICENSE | file | certificate |
+| NOTICE | file | Tip |
+| README_ZH\.md | file | Explanation of the Chinese version in Markdown format |
+| README\.md | file | Instructions for use |
+| RELEASE_NOTES\.md | file | Version Description |
diff --git a/src/UserGuide/Master/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md b/src/UserGuide/Master/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md
new file mode 100644
index 000000000..4e9a50a1a
--- /dev/null
+++ b/src/UserGuide/Master/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md
@@ -0,0 +1,680 @@
+
+# Monitoring Panel Deployment
+
+The IoTDB monitoring panel is one of the supporting tools for the IoTDB Enterprise Edition. It aims to solve the monitoring problems of IoTDB and its operating system, mainly including operating system resource monitoring, IoTDB performance monitoring, and hundreds of kernel monitoring indicators, in order to help users monitor the health status of the cluster, and perform cluster optimization and operation. This article will take common 3C3D clusters (3 Confignodes and 3 Datanodes) as examples to introduce how to enable the system monitoring module in an IoTDB instance and use Prometheus+Grafana to visualize the system monitoring indicators.
+
+## Installation Preparation
+
+1. Installing IoTDB: You need to first install IoTDB V1.0 or above Enterprise Edition. You can contact business or technical support to obtain
+2. Obtain the IoTDB monitoring panel installation package: Based on the enterprise version of IoTDB database monitoring panel, you can contact business or technical support to obtain
+
+## Installation Steps
+
+### Step 1: IoTDB enables monitoring indicator collection
+
+1. Open the monitoring configuration item. The configuration items related to monitoring in IoTDB are disabled by default. Before deploying the monitoring panel, you need to open the relevant configuration items (note that the service needs to be restarted after enabling monitoring configuration).
+
+| **Configuration** | Located in the configuration file | **Description** |
+| :--------------------------------- | :-------------------------------- | :----------------------------------------------------------- |
+| cn_metric_reporter_list | conf/iotdb-system.properties | Uncomment the configuration item and set the value to PROMETHEUS |
+| cn_metric_level | conf/iotdb-system.properties | Uncomment the configuration item and set the value to IMPORTANT |
+| cn_metric_prometheus_reporter_port | conf/iotdb-system.properties | Uncomment the configuration item to maintain the default setting of 9091. If other ports are set, they will not conflict with each other |
+| dn_metric_reporter_list | conf/iotdb-system.properties | Uncomment the configuration item and set the value to PROMETHEUS |
+| dn_metric_level | conf/iotdb-system.properties | Uncomment the configuration item and set the value to IMPORTANT |
+| dn_metric_prometheus_reporter_port | conf/iotdb-system.properties | Uncomment the configuration item and set it to 9092 by default. If other ports are set, they will not conflict with each other |
+
+Taking the 3C3D cluster as an example, the monitoring configuration that needs to be modified is as follows:
+
+| Node IP | Host Name | Cluster Role | Configuration File Path | Configuration |
+| ----------- | --------- | ------------ | -------------------------------- | ------------------------------------------------------------ |
+| 192.168.1.3 | iotdb-1 | confignode | conf/iotdb-system.properties | cn_metric_reporter_list=PROMETHEUS cn_metric_level=IMPORTANT cn_metric_prometheus_reporter_port=9091 |
+| 192.168.1.4 | iotdb-2 | confignode | conf/iotdb-system.properties | cn_metric_reporter_list=PROMETHEUS cn_metric_level=IMPORTANT cn_metric_prometheus_reporter_port=9091 |
+| 192.168.1.5 | iotdb-3 | confignode | conf/iotdb-system.properties | cn_metric_reporter_list=PROMETHEUS cn_metric_level=IMPORTANT cn_metric_prometheus_reporter_port=9091 |
+| 192.168.1.3 | iotdb-1 | datanode | conf/iotdb-system.properties | dn_metric_reporter_list=PROMETHEUS dn_metric_level=IMPORTANT dn_metric_prometheus_reporter_port=9092 |
+| 192.168.1.4 | iotdb-2 | datanode | conf/iotdb-system.properties | dn_metric_reporter_list=PROMETHEUS dn_metric_level=IMPORTANT dn_metric_prometheus_reporter_port=9092 |
+| 192.168.1.5 | iotdb-3 | datanode | conf/iotdb-system.properties | dn_metric_reporter_list=PROMETHEUS dn_metric_level=IMPORTANT dn_metric_prometheus_reporter_port=9092 |
+
+2. Restart all nodes. After modifying the monitoring indicator configuration of three nodes, the confignode and datanode services of all nodes can be restarted:
+
+```Bash
+./sbin/stop-standalone.sh #Stop confignode and datanode first
+./sbin/start-confignode.sh -d #Start confignode
+./sbin/start-datanode.sh -d #Start datanode
+```
+
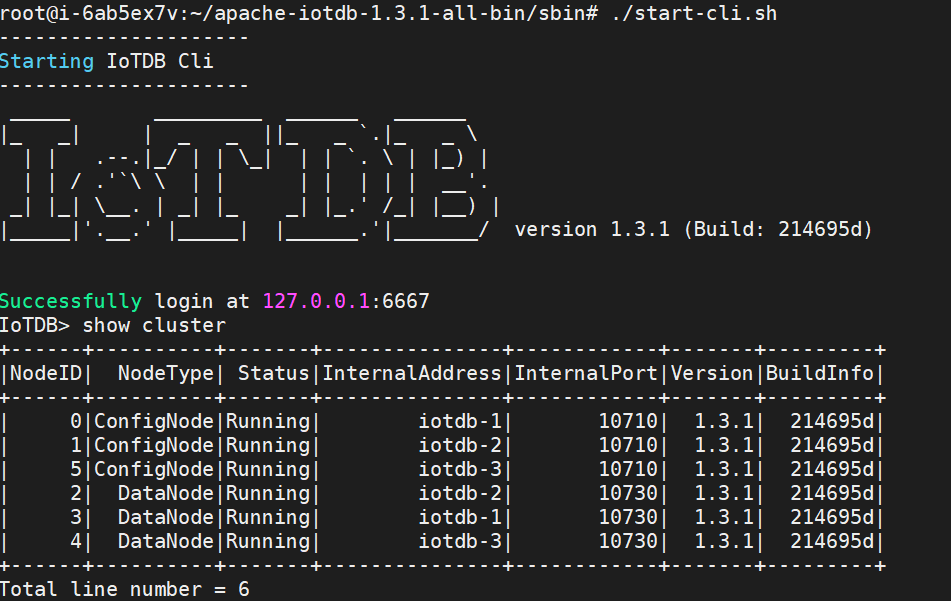
+3. After restarting, confirm the running status of each node through the client. If the status is Running, it indicates successful configuration:
+
+
+
+### Step 2: Install and configure Prometheus
+
+> Taking Prometheus installed on server 192.168.1.3 as an example.
+
+1. Download the Prometheus installation package, which requires installation of V2.30.3 and above. You can go to the Prometheus official website to download it(https://prometheus.io/docs/introduction/first_steps/)
+2. Unzip the installation package and enter the unzipped folder:
+
+```Shell
+tar xvfz prometheus-*.tar.gz
+cd prometheus-*
+```
+
+3. Modify the configuration. Modify the configuration file prometheus.yml as follows
+ 1. Add configNode task to collect monitoring data for ConfigNode
+ 2. Add a datanode task to collect monitoring data for DataNodes
+
+```YAML
+global:
+ scrape_interval: 15s
+ evaluation_interval: 15s
+scrape_configs:
+ - job_name: "prometheus"
+ static_configs:
+ - targets: ["localhost:9090"]
+ - job_name: "confignode"
+ static_configs:
+ - targets: ["iotdb-1:9091","iotdb-2:9091","iotdb-3:9091"]
+ honor_labels: true
+ - job_name: "datanode"
+ static_configs:
+ - targets: ["iotdb-1:9092","iotdb-2:9092","iotdb-3:9092"]
+ honor_labels: true
+```
+
+4. Start Prometheus. The default expiration time for Prometheus monitoring data is 15 days. In production environments, it is recommended to adjust it to 180 days or more to track historical monitoring data for a longer period of time. The startup command is as follows:
+
+```Shell
+./prometheus --config.file=prometheus.yml --storage.tsdb.retention.time=180d
+```
+
+5. Confirm successful startup. Enter in browser http://192.168.1.3:9090 Go to Prometheus and click on the Target interface under Status. When you see that all States are Up, it indicates successful configuration and connectivity.
+
+  +
+ +
+  +
+  +
+  +
+  +
+  +
+