最近想到了可能的创新点,准备开始做实验了。咱想先在 Colab 这种提供免费 GPU 算力的平台上跑一些小实验,后续再转移到实验室机器上。
如果每次都要重复搭建环境多少有些麻烦了。

那咱用容器化技术不就行啦!直接把环境打包成镜像,到时候环境迁移和实验复现都能便捷很多。
比起 Docker,这回咱决定试试更为轻量的 Apptainer(前身为 Singularity):
- Apptainer 默认以普通用户的身份运行容器,没有守护进程,也无需类似于 root 用户的特权,不像 Docker Daemon 那样必须要运行在特权用户下。(因而更安全,也更容易安装部署,不会有什么权限问题)
- ✨ 尽管如此,Apptainer 仍然要求系统支持 User Namespace 等特性,如果平台在各方面限制得比较死的话可以看看第 4 节,有惊喜哦 ( ̄▽ ̄) 。
- Apptainer 针对高性能计算(HPC)这种并行场景进行了优化(虽然我还不太用得上)。
- Apptainer 支持 Docker 镜像,体验上近乎无缝(这个是最爽滴)。
这篇笔记主要记录一下咱在 Google Colab 以及 AutoDL 平台上运行 GPU 容器时的踩坑和爬出坑的过程。
这里不多赘述,图快的话咱主要推荐以下两种安装方式:
注:文档中提到在执行脚本前可能需要安装 curl, cpio, rpm2cpio 等必要的工具:
sudo apt-get update
# rpm2cpio 是 rpm 包的工具
sudo apt-get install -y curl cpio rpmColab 默认是 Ubuntu 系统,copy 官方文档中的命令就能顺利安装了~
Apptainer 可以直接拉取 Docker Hub 上的镜像并构建成 .sif 单文件:
apptainer build hello.sif docker://hello-world
Colab 默认在 root 用户下执行命令,这里建立一个普通用户 somebottle :
adduser --home /home/somebottle --gecos "" --shell /bin/bash --disabled-password somebottle- root 用户当然是可以运行 Apptainer 容器的,但为了安全起见,咱接下来会尝试用普通用户来运行容器。
Colab 对 root 用户的权限有所限制,如果直接尝试启动容器会出现挂载问题:
apptainer run hello.sif
# >> FATAL: container creation failed: mount hook function failure: mount overlay->/var/lib/apptainer/mnt/session/final error: while mounting overlay: can't mount overlay filesystem to /var/lib/apptainer/mnt/session/final: while setting effective capabilities: CAP_DAC_READ_SEARCH is not in the permitted capability set- 相关 issue:apptainer/apptainer#1041
✨ 利用 setcap 进行 capabilities 权限设定还是麻烦了,这里我根据 issue 中的指引,直接在一个新的命名空间下运行了容器:
# 在 root 用户下执行这条命令,容器内用户为 root
unshare -r apptainer run hello.sif
unshare -r建立一个新的用户命名空间,并把当前用户映射为命名空间内的 root 用户,这个命名空间内的进程将会默认拥有完整的 capabilities 权限集。
- 💡 注:如果在 root 用户下执行上面这条命令,其实仍然相当于在特权用户下启动了容器。
✨ 或者以普通用户的身份运行容器:
# 以 somebottle 身份启动容器,容器内用户为 somebottle
sudo -u somebottle apptainer run hello.sifApptainer 借助用户命名空间特性来运行容器,系统应支持以非特权方式建立用户命名空间,经测试 Colab 已经满足了这点。具体要求可查看文档。
✨ 为了能让普通用户在容器内以 root 用户的身份运行,可以加上 --fakeroot 选项:
# 以 somebottle 身份启动容器,容器内用户为 root
sudo -u somebottle apptainer run --fakeroot hello.sif具体行为可见官方文档说明。
这里拉取了 Docker Hub 上 PyTorch 官方的一个 GPU 支持镜像:
# 转换得到 pytorch-gpu.sif 文件
apptainer build pytorch-gpu.sif docker://pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtimeApptainer 默认支持 NVIDIA GPU,前提是宿主机系统中已经安装了 Nvidia 驱动以及 CUDA 相关库。
- 具体要求依旧见官方文档。
在 apptainer 的 run, shell, exec 等命令后加上 --nv 选项即可启用 GPU 支持:
# 以 somebottle 身份启动 GPU 容器,容器内用户为 somebottle
# 启动容器后执行 nvidia-smi 来查看 GPU 状态
sudo -u somebottle apptainer exec --nv pytorch-gpu.sif nvidia-smi
诶?动啊,NVIDIA,为什么不动?

NVIDIA-SMI couldn't find libnvidia-ml.so library in your system. Please make sure that the NVIDIA Display Driver is properly installed and present in your system.
Please also try adding directory that contains libnvidia-ml.so to your system PATH.
定睛一看发现是在容器内找不到动态链接库 libnvidia-ml.so。
提到动态链接库路径,很快能想到一个环境变量 LD_LIBRARY_PATH,动态链接器会在其列出的目录下搜索库。分别在宿主机和容器内输出这个环境变量看看:
# 宿主机上
unshare -r env | grep LD_
# >> LD_LIBRARY_PATH=/usr/lib64-nvidia
# 容器中
unshare -r apptainer exec --nv pytorch-gpu.sif env | grep LD_
# >> LD_LIBRARY_PATH=/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/.singularity.d/libs可见宿主机上 NVIDIA 动态链接库位于 /usr/lib64-nvidia。
容器内列出了三个路径,因为其中前两个路径在容器内是不存在的,所以链接器会去 /.singularity.d/libs 这个路径下找共享库。
# 输出看看目录下有什么
unshare -r apptainer exec --nv pytorch-gpu.sif ls -ahl /.singularity.d/libs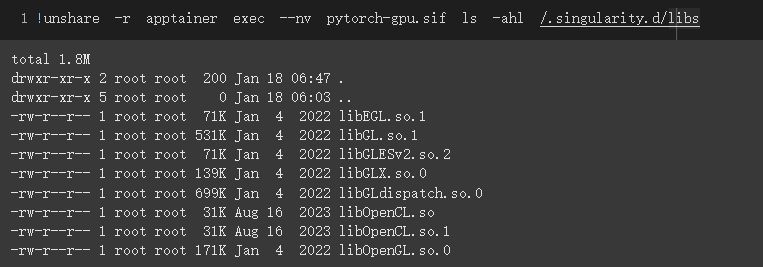
推测在使用 --nv 选项时,Apptainer 会自动将宿主机上的 NVIDIA 动态链接库绑定挂载到容器内的 /.singularity.d/libs 目录下。
从上面两个文档可以得知,为了处理绑定挂载,Apptainer 有一个配置文件 nvliblist.conf,其中指定了 NVIDIA 相关的可执行文件和动态链接库的文件名(没错,仅仅是文件名!)。
- 注: 通过
find / -name "nvliblist.conf"可找到配置文件路径。
在默认的 nvliblist.conf 中可以找到上面 NVIDIA-SMI 运行所缺失的库:
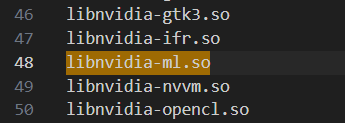
当然也可以找到容器内 /.singularity.d/libs 目录下已有的库。
于是现在问题就转换为了:为什么 /.singularity.d/libs 目录下没有 libnvidia-ml.so 和其他一些必要的库呢?
仍然是看文档, [2] 中提到:
When adding new entries to
nvliblist.confuse the bare filename of executables, and thexxxx.soform of libraries. Libraries are resolved vialdconfig -p, and exectuables are found by searching$PATH.
即共享库(.so)路径是通过 ldconfig -p 来解析的,而可执行文件则是通过 $PATH 来搜索的。很有可能 Apptainer 在挂载时没有找到 NVIDIA 的库路径。
# ldconfig 可以管理动态链接库的缓存
# 查看 ldconfig -p 的输出(输出已缓存的库),筛出有 nvidia 字段的
ldconfig -p | grep nvidia
# 没有输出,说明 nvidia 相关的库没有被缓存哔啵~问题已定位。接下来只需要把宿主机上的 NVIDIA 共享库目录 /usr/lib64-nvidia 加入到缓存中即可。
ldconfig 会从 /etc/ld.so.conf.d 目录中的配置文件读取共享库路径,先看看这个目录下有什么:
ls -hl /etc/ld.so.conf.d
# >> total 36K
# >> -rw-r--r-- 1 root root 41 Sep 9 2023 000_cuda.conf
# >> -rw-r--r-- 1 root root 44 Sep 9 2023 988_cuda-12.conf
# >> -rw-r--r-- 1 root root 15 Jan 17 14:36 colab.conf
# >> -rw-r--r-- 1 root root 38 Mar 5 2022 fakeroot-x86_64-linux-gnu.conf
# >> -rw-r--r-- 1 root root 46 Aug 15 2023 gds-12-2.conf
# >> -rw-r--r-- 1 root root 44 Dec 16 2020 libc.conf
# >> -rw-r--r-- 1 root root 46 Nov 10 2023 nvidia.conf
# >> -rw-r--r-- 1 root root 100 Mar 4 2022 x86_64-linux-gnu.conf
# >> -rw-r--r-- 1 root root 56 May 6 2024 zz_i386-biarch-compat.conf
cat /etc/ld.so.conf.d/nvidia.conf /etc/ld.so.conf.d/*cuda*.conf
# >> /usr/local/nvidia/lib
# >> /usr/local/nvidia/lib64
# >> /usr/local/cuda/targets/x86_64-linux/lib
# >> /usr/local/cuda-12/targets/x86_64-linux/lib
ls /usr/local/nvidia/lib
# >> ls: cannot access '/usr/local/nvidia/lib': No such file or directory看来大概是 Colab 官方的配置有误。
✨ 为了修复这点,咱们直接把库路径 /usr/lib64-nvidia 写入到这里的一个配置文件中:
echo "/usr/lib64-nvidia" >> /etc/ld.so.conf.d/nvidia.conf✨ 然后刷新缓存,让 ldconfig 重新读取配置文件即可:
ldconfig再次查看 ldconfig -p 的输出,就可以看到 libnvidia-ml.so 等共享库已经被缓存了。
再次尝试运行 GPU 容器,nvidia-smi 就能正常打印出 GPU 信息了,冇问题啦!
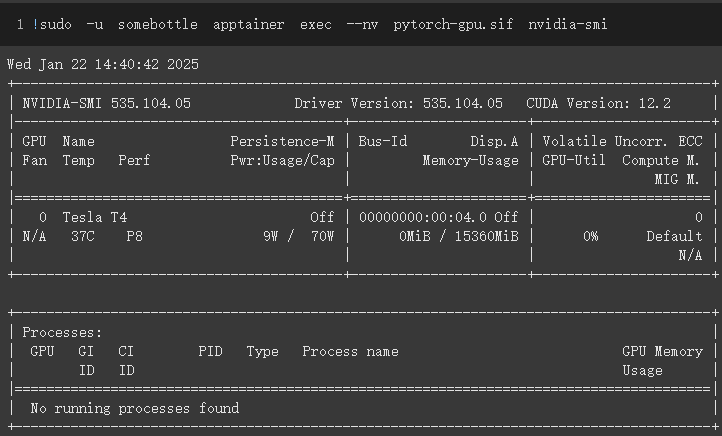
咱先把如下脚本 test.py 放在了 Colab 会话环境的 /content/test 目录下:
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"GPU 可用,设备: {torch.cuda.get_device_name(0)}")
else:
device = torch.device("cpu")
print("GPU 不可用,设备: CPU")
tensor = torch.tensor([1.0, 2.0, 3.0])
tensor = tensor.to(device)
print(f"张量: {tensor}")
print(f"张量所在设备: {tensor.device}")
# compute
result = tensor * 2
print(result)把 Python 脚本挂载到容器内并执行:
sudo -u somebottle apptainer exec --bind /content/test:/mnt/data --nv pytorch-gpu.sif python /mnt/data/test.py
# >> GPU 可用,设备: Tesla T4
# >> 张量: tensor([1., 2., 3.], device='cuda:0')
# >> 张量所在设备: cuda:0
# >> tensor([2., 4., 6.], device='cuda:0')这样一来我应该就能愉快地在 Google Colab 等平台上使用 Apptainer 跑实验啦~
事情并不总是一帆风顺。当我尝试在 AutoDL 平台上复现上面的流程时,发现 AutoDL 禁止了非特权用户创建用户命名空间,且禁用了 unshare,Apptainer 根本就跑不起来:
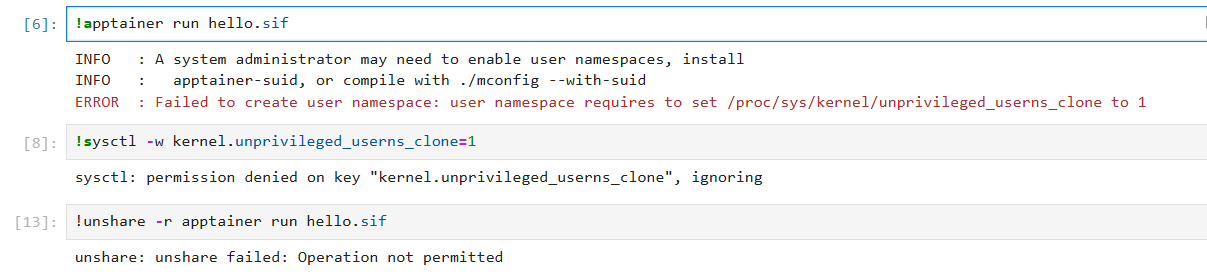
而且 AutoDL 也禁用了
setuid机制。
难道...就要到此为止了吗!

不,还没完!我还能战斗!
其实还有个能完全在用户空间运行的容器工具实现: udocker。
默认情况下 udocker 利用 PRoot 在用户空间拦截并模拟一些系统调用和特权操作,以在非特权用户下运行容器。
-
udocker 的环境隔离性没有 apptainer 和 docker 好。但我本来也就只想要迁移运行时环境,隔离性也无所谓了(详见官方文档 1.3. Security)。
-
udocker 容器中无法执行真正需要特权的操作,比如文件系统挂载、修改受保护的配置等。当然跑个机器学习实验是没啥问题的(详见官方文档 1.2. Limitations)。
-
以下代码暂且以
udocker 1.3.17版本为例。
直接在 root 用户下运行,命令更为简短,注意需要加上 --allow-root 选项:
点击展开示例代码(IPython)
# 下载 udocker 包并解压
!wget https://github.com/indigo-dc/udocker/releases/download/1.3.17/udocker-1.3.17.tar.gz
!tar -xzf udocker-1.3.17.tar.gz
# 把 udocker 添加到环境变量中
# 方便起见,给 udocker --allow-root 起个别名 mydocker
%alias mydocker export PATH=udocker-1.3.17/udocker:$PATH; udocker --allow-root
# 初始化 udocker(即使不初始化,首次执行时也会自动初始化)
mydocker install
# 拉取镜像
# dockerpull.cn 是一个 DockerHub 镜像站
mydocker pull dockerpull.cn/pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
# 创建容器,容器名 gputest
mydocker create --name=gputest dockerpull.cn/pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
# 启动 NVIDIA 支持
mydocker setup --nvidia gputest
# 查看 GPU 信息(如果有问题请见下面的 4.3 节)
mydocker run gputest nvidia-smi
# 挂载测试脚本并运行
mydocker run --volume=/root/test.py:/script/test.py gputest python /script/test.py💡 在 root 用户下执行 run 命令时可能会遇到这样的问题:
Error: invalid host volume path: /tmp/udocker-1623-93007aea-e4b6-38ae-86dc-7695a497b69e-group
究其原因,是因为这一行的 os.getgroups() 返回了空列表,导致没有调用 add_group() 方法,进而相应的临时文件没有被创建。
目前可以加上 --hostauth 选项来暂时解决这个问题,即采用宿主机的用户和用户组信息,而不是临时建立用户:
mydocker run --hostauth gputest nvidia-smi废话不多说,上代码:
点击展开示例代码(IPython)
# 首先还是新建普通用户
!adduser --home /home/somebottle --gecos "" --shell /bin/bash --disabled-password somebottle
# 下载 udocker 包并解压
!wget -P /home/somebottle https://github.com/indigo-dc/udocker/releases/download/1.3.17/udocker-1.3.17.tar.gz
!cd /home/somebottle && tar zxvf udocker-1.3.17.tar.gz && chown somebottle udocker-1.3.17
# 把 udocker 添加到用户的环境变量中
!echo "export PATH=/home/somebottle/udocker-1.3.17/udocker:$PATH" >> /home/somebottle/.profile
# 给以 somebottle 身份运行的命令起个别名 urun
# 加上 -l 选项后才会执行 Shell 配置文件(包括上面的 .profile)
%alias urun su somebottle -l -c
# AutoDL 平台上 python 路径在 /root 目录下,这里为了方便起见直接把目录所有权给 somebottle
# 💡 在 Colab 上可能不需要这一步
!chown -R somebottle /root 2>/dev/null
# 初始化 udocker(即使不初始化,首次执行时也会自动初始化)
urun 'udocker install'
# 接下来就可以拉取镜像试试了
# dockerpull.cn 是一个 DockerHub 镜像站
urun 'udocker pull dockerpull.cn/pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime'
# 创建容器,容器名 gputest
# 从实现上来讲,这一步实际上是把镜像解包到一个用户可访问的目录中,作为 rootfs
urun 'udocker create --name=gputest dockerpull.cn/pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime'
# 启动 NVIDIA 支持
urun 'udocker setup --nvidia gputest'
# 查看 GPU 信息(如果有问题请见下面的 4.3 节)
urun 'udocker run gputest nvidia-smi'
# 挂载测试脚本并运行
urun 'udocker run --volume=/root/test.py:/script/test.py gputest python /script/test.py'udocker 通过将一些 NVIDIA 相关的可执行文件和库文件复制到容器的对应目录中,从而实现了对 GPU 的支持。
但是目前 udocker 复制 NVIDIA 相关文件的逻辑可能有些问题。已知在 Google Colab 平台上可能无法在容器中访问 nvidia-smi 这种可执行文件,但是相关库文件是可以访问的,因此 PyTorch 能正常使用 GPU。
等待修复:
💡 你可以直接用这个 PR 的提交中的 nvidia.py 替换 udocker/engine/nvidia.py 这个文件。
在上面的例子中,我使用了 sudo -u somebottle <command> 来以 somebottle 用户的身份执行命令。
然而 sudo -u 实际上可能会重置环境变量,可以打印出来看看:
echo $PATH
# >> /opt/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/tools/node/bin:/tools/google-cloud-sdk/bin
sudo -u somebottle env | grep PATH
# >> PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin很明显至少环境变量 $PATH 被重置了。
3.4 节中文档 [2] 曾提到:
... , and exectuables are found by searching
$PATH.
即 Apptainer 在挂载时, nvidia-smi 这类可执行文件是依赖于 $PATH 环境变量进行搜索的。
幸运的是,可执行文件 nvidia-smi 在 /usr/bin 目录下有软链,而默认的 $PATH 环境变量中包含有这个目录,因此启动容器时 Apptainer 能成功找到。
whereis nvidia-smi
# >> nvidia-smi: /usr/bin/nvidia-smi /opt/bin/nvidia-smi
ls -hl /usr/bin/nvidia-smi
# >> lrwxrwxrwx 1 root root 27 Jan 22 13:34 /usr/bin/nvidia-smi -> /opt/bin/.nvidia/nvidia-smi假如需要保留 sudo 执行命令时的环境变量,可以使用 sudo -E 选项,但 $PATH 环境变量可能仍然会被重置,因为在配置文件 /etc/sudoers 中可能有 secure_path 配置项进行了限制:
cat /etc/sudoers | grep secure_path
# >> Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin"这种情况下要不直接修改 /etc/sudoers 文件,要不就手动设定 $PATH 环境变量:
# env PATH=$PATH <command>,在指定环境变量后执行命令
sudo -u somebottle env PATH=$PATH printenv PATH
# >> /opt/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/tools/node/bin:/tools/google-cloud-sdk/bin总结一些要点:
-
在 Google Colab 上以
root用户运行 Apptainer 容器时,需要使用unshare -r命令来在新的命名空间下运行容器,以获得完整的 capabilities 权限集。 -
如果容器中部分 NVIDIA 的库
.so文件找不到:- 先在宿主机上查看
$LD_LIBRARY_PATH环境变量找到 NVIDIA 共享库路径。 - 把这个路径写入到
/etc/ld.so.conf.d/目录下的一个配置文件中。 - 利用
ldconfig刷新共享库缓存。
- 先在宿主机上查看
-
如果平台(比如 AutoDL)不支持非特权用户建立命名空间,可以尝试使用 udocker 来运行容器。
希望这篇笔记能多多少少帮助到大家吧,咱也要继续苦逼地做实验去啦!
咱们下次再会~ (∠・ω< )⌒★