
Guid-O-Matic
This example will walk you through converting CSV files from a simple dataset into RDF. The data are from the New York Public Library's Photographers' Identities Catalog (PIC). The complete dataset is available under a Creative Commons CC0 (public domain) license at [https://github.com/NYPL/pic-data]. The full PIC dataset includes information about over 125 000 photographers and firms, but the example dataset makes use of a subset of only 1000.
To complete this example, you need at a minimum:
- a computer with software that can edit CSV files (preferably Open Office or Libre Office, but Excel is OK).
- ability to push to a GitHub repository. This is most easily done if you have the GitHub desktop application installed on your computer. I assume that you know how to use GitHub.
- some way to run the Guid-O-Matic scripts. If your organization has the Guid-O-Matic web server script running on a BaseX server, you don't need to install anything yourself. If not, you will need to install BaseX on your computer and run the scripts directly in BaseX.
Although HTTP identifiers are often referred to as URIs (uniform resource identifiers), there is a broader class of identifiers called IRIs (internationalized resource identifiers) that includes URIs, but also allows a broader set of characters. For this exercise, I will use "URI" and "IRI" interchangeably, recognizing that IRIs are actually a superset of URIs.
The dataset includes CSV tables describing a number of entities, but in this example, we will focus on two.
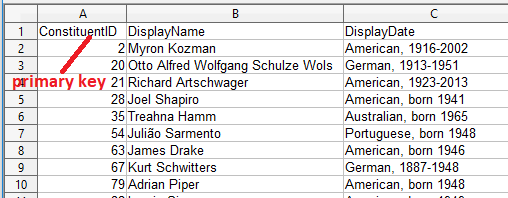
Fig. 1. Table of photographers or studios
The first table, called constituents.csv, contains records about either photographers or studios (Fig. 1). A column in the table (ConstituentID) contains an identifier for the constituent that is unique within the table. If you are familiar with databases, this identifier serves the purpose of a primary key for the consituent record.

Fig. 2. Table of locations
The second table, called address.csv, contains records about locations associated with the constituents (Fig. 2). A column of the table (ConAddressID) contains an identifier for the location that's unique in the table (primary key). Another column (ConstituentID) gives the identifier for the constituent that is associated with the location described by the row. In database terms, this column contains a foreign key relating this table to the constituent table. A single photographer in the constituents table may be associated with birth, activity, and death locations in the address table, so there may be several rows with the same ConstituentID in this table.

Fig. 3. Graph model for some data from the New York Public Library Photographers' Identities Catalog (PIC)
Our goal is to turn the data in these tables into a Linked Data graph, and Fig. 3 shows the simple graph model that can represent the relationships described above.
One best practice of Linked Data is to identify resources using URIs. PIC already assigns URIs to constituents by prepending http://pic.nypl.org/constituents/ to the value in the ConstituentID column. For example, the photographer Richard Long has the ConstituentID 148, and the URI http://pic.nypl.org/constituents/148 will dereference to a web page about him. Using this pattern, we will mint URI identifiers for the locations by prepending http://pic.nypl.org/address/ to the ConAddressID value (e.g. http://pic.nypl.org/address/111242). Nothing happens if you put this URI in a browser, but that's fine - it's not a requirement of Linked Data that a URI "do" anything. At its core, a URI is a unique identifier and this scheme serves that purpose.

Fig. 4. Example graph for the photographer Otto Alfred Wolfgang Schulze Wols
Fig. 4 shows a Linked Data graph about a particular photographer. The photographer and his birth, work, and death locations are identified by particular URIs. The location is linked to the photographer by the predicate ex:hasConstituent (an abbreviation for the made-up linking property http://example.org/hasConstituent). Each of the relationships connecting two bubbles in the diagram can be represented by a single RDF triple. For example the triple:
<http://pic.nypl.org/address/83580> ex:hasConstituent <http://pic.nypl.org/constituents/20>.
relates Berlin, Germany to Otto Wols who was born there.
1. If you want to actually do this exercise, you need to download the blank template files that Guid-O-Matic will use to generate RDF triples. You can do this several ways. One is to clone the Guid-O-Matic GitHub repo. You may find this easy if you are already a GitHub user and if you want to run Guid-O-Matic on your own computer, you'll need the code anyway. Go to https://github.com/baskaufs/guid-o-matic, then click on the Clone or Download button. After you've cloned the repo, you will find the template files in the "blank" directory.
Another alternative is to just download a .zip file that contains the template files. That .zip is at https://github.com/baskaufs/guid-o-matic/blob/master/blank.zip. Unzip the files into an empty directory of your choice.
2. To edit the template files, you will need an application that can edit CSV (comma separated value) files. Microsoft Excel is probably the most well-known application that can handle CSV files, and you can use it if you only intend to edit the configuration files that tell Guid-O-Matic how to do the translation to RDF.
However, if you plan to edit the source data files, Excel is NOT recommended! When opening CSV files, Excel automatically applies conversions to text that it thinks are dates. For example, if you have the code "3-12" in a CSV file, Excel will convert this to "March 12" whether you want it to or not. Excel also does not offer reliable control over character encoding. The source data files are encoded using UTF-8, since they contain special characters like "ã" and "ä". It is better to use Libre Office or Open Office, which allow full control over character encoding and which do not automatically convert strings to dates.
3. These directions will assume that you are starting with the constituents.csv table. (If you are working on the address.csv file, then substitute "address" for "constituents" in the instructions.) In a GitHub repo to which you can push changes, open a new folder called "constituents". From the downloaded templates folder, copy the files constituents.csv, constants.csv, namespace.csv, linked-classes.csv, blank-classes.csv, and blank-column-mappings.csv into your new folder. Change the name of blank-classes.csv to constituents-classes.csv and change the name of blank-column-mappings.csv to constituents-column-mappings.csv .
4. Each of the CSV data tables contains columns that tell you something about the resource described by a row. The column header represents a property whose values are located in that column.
Open the data file (constituents.csv) using your CSV editor. If you are using Excel, that's fine, but don't save this file when you quit.
In the table, notice that there is a column called "DisplayName". That column holds the name of the photographer or studio (a property of the constituent).
5. A Linked Data best practice is to use well-known URI properties to describe resources. In the language of RDF, these properties are called "predicates". Our main task in this exercise is to relate columns in the table to appropriate RDF predicates. Open the file constituents-column-mappings.csv using your editor. The first column will hold the column header and the second column will hold the RDF predicate that corresponds to the property represented by that column. To keep this exercise simple, every row in this table will have "plain" (for plain literal) in the type column, "$root" in the subject_id column, and nothing in the value and attribute columns.
6. You can find a listing of some common properties in this PowerPoint presentation in the "Well-known RDF Vocabularies" section. It contains properties appropriate for describing a number of columns in this exercise.
In the header column of the first row, type (or copy and paste) the column header "DisplayName" from the constituents.csv table. Look through the properties in the PowerPoint until you find one that is appropriate for that column. A good choice is rdfs:label, a generic predicate that can indicate a label for anything. Type (or paste) "rdfs:label" in the second column.
You might have also noticed that "foaf:name" would be a possible property to map to the first column. There is nothing wrong with mapping the same column to two properties, so you could add a second row with "DisplayName" in the first column and "foaf:name" in the second.
7. When a column in the data table is used to make a link to a resource not described in that row of the table (e.g. the arrows shown in Fig. 3), and the linked resource is identified by a URI (as opposed to the column containing a plain literal value object), the "type" column has a value of "iri" rather than "plain". If the value in the data table column contains the unabbreviated URI, nothing else need be done in that row of the mapping table. If the value in the data table column contains a locally unique identifier, rather than a URI, placing a URI or CURIE prefix in the "value" column will prepend that prefix to the locally unique identifier, turning it into a URI.
There are no examples of this in the constituents.csv table, but in the address.csv table, the ConstituentID column contains a foreign key that refers to the constituent that the address is linked to. To generate that link between address and constituent, put "iri" in the type column, and "http://pic.nypl.org/constituents/" in the value column. This will append a foreign key like "20" to the value in the value column to form a URI like "http://pic.nypl.org/constituents/20".
I don't know of any well-known predicate that can be used to make the link, so we will make one up. We can use ex:hasConstituent (see Fig. 4) in the predicate column, where "ex" = "http://example.org/".
(You may wonder why we are making the arrows point from the address to the constituent instead of the other way around. It might make sense to use a property like foaf:based_near to make the link in the direction from the constituent to the address. However, making this happen in Guid-O-Matich is significantly more complicated, so we won't address the issue in this simple example.)
8. Continue adding rows to the mapping table until you have mapped all of the columns that you want or are able to map. You don't have to map all of the columns. The ones you don't map will be ignored. Save the file and close it.
In this simple example, we can consider all of the information in the table to be about a single kind of thing (entities that create photographs). It is a best practice in Linked Data to indicate to potential data consumers the class of which a resource is an instance. The important property rdf:type is used to indicate this.
The value ("object" in RDF terminology) of rdf:type should be the URI of a class. Typically, the local name of a class URI is capitalized. For example, foaf:Image is a class, while foaf:name (a property) has a local name that begins with a lower-case letter. The Dublin Core list of classes (which includes classes in the DCMI Type Vocabulary) is a very well-known source of classes.
9. Open the file constituents-classes.csv (renamed from blank-classes.csv). When you have decided on an appropriate class for the data table, put it in the "class" column of the table in the row that has "$root" in the id column. Save the file and close it.
10. Open the file constants.csv, which contains configuration settings.
11. In the domainRoot column, enter the string that will be prepended to the primary key of the table to form a unique URI identifying the subject of the table row. As we already noted, for the constituents table, the PIC already has chosen "http://pic.nypl.org/constituents/", so replace the default "http://example.org/" value with that.
12. In the coreClassFile column, enter the name of the primary data file ("constituents.csv").
13. The documentClass column is used to indicate the class of the metadata document containing the RDF. foaf:Document is commonly used for this, so you can leave that value unless you have a better idea.
14. The creator column is a literal (string) value giving the name of the person or organization that created the metadata document. You can put your name or the name of your organization there. (Although the New York Public Library created the dataset, they are not creating the RDF document.)
15. The baseIriColumn column is used to indicate the column in the primary data table that contains the locally unique identifier (i.e. the primary key) for the resource in each row. In the constituents table, it's "ConstituentID" (and "ConAddressID" in the address.csv table). Replace the default "primaryKey" value with the column name that's appropriate for your table.
16. Save the file.
17. Open the file namespace.csv .
18. Each row of this file contains an abbreviation that is used for URIs to form "compact URIs" (CURIEs). The default values defined by W3C (rdf:, rdfs:, and xsd:) are already given, as is foaf: (used with the default type for the metadata document in the configuration file). Add additional rows for any namespaces that you used in either the constituents-column-mappings.csv or constituents-classes.csv file.
19. Save the file.
20. The linked-classes.csv file is used when the data file contains information about more than one type of thing. We can consider that to not be true in this example, so you can just leave this file the way it is.
The scripts that Guid-O-Matic use to turn CSV data into RDF can be invoked in several ways and can access the CSV data from local files or from the web. The simplest way is to access the data from GitHub and that's how we'll do it in this example.
21. If you followed the earlier instructions, you should already have been editing the relevant files in a directory called "constituents" located in your local GitHub repo. Use the GitHub desktop application to push the files in the constituents folder to your online GitHub repo. You can go to your GitHub site and check that they are actually there.
22. If your organization has the Guid-O-Matic scripts running on a server, then they also probably are using the rdf-mover.py Python script to load data from GitHub into the BaseX database that the server script operates on. If that is the case and somebody from your organization is helping you with this, they can preform the following step for you. If you want to do the transfer yourself, then you will need to have Python3 installed on your computer and have cloned the Guid-O-Matic repo to your local computer. (If you don't have access to Guid-O-Matic scripts on a remote server, you can set up the scripts on a server operating locally on your computer and accessed through HTTP calls to a localhost: URI. However, explaining how to make this work is beyond the scope of this tutorial.)
23. In a terminal window or command prompt window, navigate to the Guid-O-Matic folder in your local computer's GitHub repo. Invoke the Python script using the command
python rdf-mover.py
If you get an error message, then the Python application may not be in your system's PATH environmental variable (a Windows problem). Get help from somebody who knows about this.

If all goes well, you will see something like in Fig. 5.
24. Edit the Github repo path box appropriately for your GitHub site. If your GitHub username were "baskaufs" and the repo into which you put the directory containing the data were called "test", then you would change the path from "VandyVRC/tcadrt/" to "baskaufs/test/".
25. The database name is the name that you gave to the directory that you created in your repo to hold the files. In this example, it will be "constituents". NOTE: the database name cannot be the same as any existing database on the BaseX server. If it is, it will potentially overwrite the data already in that database.
26. The Github repo subpath will only have a value if you nested the constituents folder at a level below the root folder for the repo. For example, if you placed the constituents directory within the test repo on the path test/exercises/constituents/, then "exercises/" should be put in the Github repo subpath.
27. Edit the BaseX API URI root so that it has the correct domain name for your server installation. Enter the password in the BaseX database pwd box.
28. To know whether your data are being loaded into the BaseX database correctly, you can log into the BaseX database administration GUI and watch what happens. If your server REST API is "http://yourservername.com/gom/rest/", the URL of the GUI would be "http://yourservername.com/gom/dba". Check the list of databases to make sure that there isn't one already that has the name of the database you intend to create.
29. On the rdf-mover GUI, click the Transfer from Github to BaseX button. Watch the Action log to make sure that you get HTTP 201 codes for all of the data transfers. If you encounter error messages (HTTP 4xx codes), you'll have to try to figure out what went wrong.
30. If the transfers were successful, return to the BaseX database admin GUI and refresh the page. You should see the database that you created.
31. The Guid-O-Matic server script has an RDF dump option. To retrieve a dump of triples from an entire database, follow the root server URI with "dump/" followed by the name of the database. In the example above, a dump of the RDF triples generated from the constituents database would be retrieved via HTTP GET from http://yourservername.com/gom/dump/constituents. Dereferencing this URI in a browser produces an RDF/Turtle serialization of the dump.
Other serializations (RDF/XML or JSON-LD) can be retrieved from the server using a client such as PostMan that can specify the appropriate Accept header (application/rdf+xml and application/json respectively).