| title | date | order | categories | tags | permalink | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
链路追踪 |
2022-04-20 02:08:29 -0700 |
2 |
|
|
/pages/3da6a371/ |
链路追踪系统广义的概念是:由数据采集、数据处理和数据展示三个相对独立的模块所构成的分布式追踪系统;链路追踪系统狭义的概念是:特指链路追踪的数据采集。譬如 Spring Cloud Sleuth 就属于狭义的链路追踪系统,通常会搭配 Zipkin 作为数据展示,搭配 Elasticsearch 作为数据存储来组合使用;而 Zipkin、Pinpoint、SkyWalking、CAT 都属于广义的链路追踪系统。
个人理解,链路追踪的本质就是,通过全局唯一的 ID,将分布在各个服务节点上的同一次请求产生的数据串联起来,从而梳理出调用关系,进而辅助分析系统问题、分析调用数据并统计各种系统指标。
链路追踪主要有以下作用
- 分析系统瓶颈:通过记录调用经过的每一条链路上的耗时,我们能快速定位整个系统的瓶颈点在哪里。比如你访问微博首页发现很慢,肯定是由于某种原因造成的,有可能是运营商网络延迟,有可能是网关系统异常,有可能是某个服务异常,还有可能是缓存或者数据库异常。通过链路追踪,可以从全局视角上去观察,找出整个系统的瓶颈点所在,然后做出针对性的优化。
- 分析链路调用:通过链路追踪可以分析调用所经过的路径,然后评估是否合理。比如一个服务调用下游依赖了多个服务,通过调用链分析,可以评估是否每个依赖都是必要的,是否可以通过业务优化来减少服务依赖。还有就是,一般业务都会在多个数据中心都部署服务,以实现异地容灾,这个时候经常会出现一种状况就是服务 A 调用了另外一个数据中心的服务 B,而没有调用同处于一个数据中心的服务 B。根据我的经验,跨数据中心的调用视距离远近都会有一定的网络延迟,像北京和广州这种几千公里距离的网络延迟可能达到 30ms 以上,这对于有些业务几乎是不可接受的。通过对调用链路进行分析,可以找出跨数据中心的服务调用,从而进行优化,尽量规避这种情况出现。
- 生成网络拓扑:通过链路追踪中记录的链路信息,可以生成一张系统的网络调用拓扑图,它可以反映系统都依赖了哪些服务,以及服务之间的调用关系是什么样的,可以一目了然。除此之外,在网络拓扑图上还可以把服务调用的详细信息也标出来,也能起到服务监控的作用。
- 透明传输数据:除了链路追踪,业务上经常有一种需求,期望能把一些用户数据,从调用的开始一直往下传递,以便系统中的各个服务都能获取到这个信息。比如业务想做一些 A/B 测试,这时候就想通过链路追踪,把 A/B 测试的开关逻辑一直往下传递,经过的每一层服务都能获取到这个开关值,就能够统一进行 A/B 测试。
Google 发布的一篇的论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure,里面详细讲解了链路追踪的实现原理。Dapper 论文几乎成了现代链路追踪的理论基石,很多主流的链路追踪系统都是基于 Dapper 衍生出来的,比较有名的有 Twitter 的Zipkin、阿里的鹰眼、美团的MTrace等。
Dapper 提出了一些很重要的核心概念:Trace、Span、Annonation 等,这是理解链路追踪原理的前提。
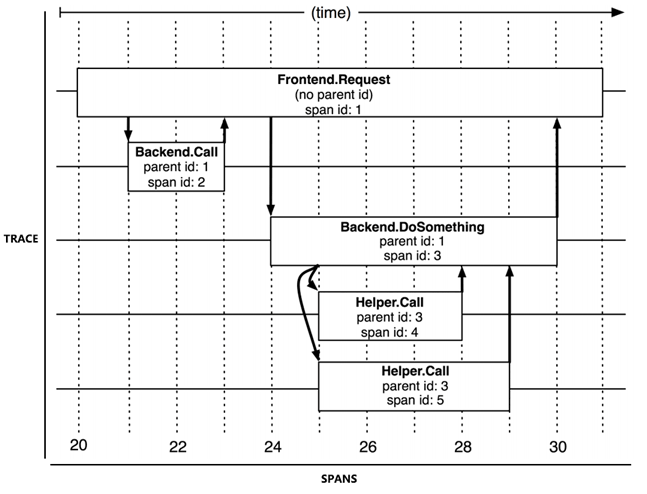
Trace 和 Spans(图片来源于Dapper 论文)
- Trace (追踪) - 代表一次完整的请求。一次完整的请求是指,从客户端发起请求,记录请求流转的每一个服务,直到客户端收到响应为止。整个过程中,当请求分发到第一层级的服务时,就会生成一个全局唯一的 Trace ID,并且会随着请求分发到每一层级。因此,通过 Trace ID 就可以把一次用户请求在系统中调用的链路串联起来。
- Span (跨度) - 代表一次调用,也是链路追踪的基本单元。由于每次 Trace 都可能会调用数量不定、坐标不定的多个服务,为了能够记录具体调用了哪些服务,以及调用的顺序、开始时点、执行时长等信息,每次开始调用服务前都要先埋入一个调用记录,这个记录称为一个 Span。
- Span 的数据结构应该足够简单,以便于能放在日志或者网络协议的报文头里;也应该足够完备,起码应含有时间戳、起止时间、Trace 的 ID、当前 Span 的 ID、父 Span 的 ID 等能够满足追踪需要的信息。
- Trace 实际上都是由若干个有顺序、有层级关系的 Span 所组成一颗 Trace Tree (追踪树)。
- Annotation:用于业务自定义埋点数据,例如:一次请求的用户 ID,某一个支付订单的订单 ID 等。
数据采集的作用就是在系统的各个不同模块中进行埋点,采集数据并上报给数据处理层进行处理。而一次请求可以分为四个阶段:
- CS(Client Send)阶段 - 客户端发起请求时埋点,需要传递一些参数,比如服务的方法名等。
- SR(Server Recieve)阶段 - 服务端接收请求时埋点,需要回填一些参数,比如 traceId,spanId。
- SS(Server Send)阶段 - 服务端返回请求时埋点,这时会将上下文数据传递到异步上传队列中。
- CR(Client Recieve)阶段 - 客户端接收返回结果时埋点,这时会将上下文数据传递到异步上传队列中。
下图显示了 Span 和 Trace 在系统中的样子。
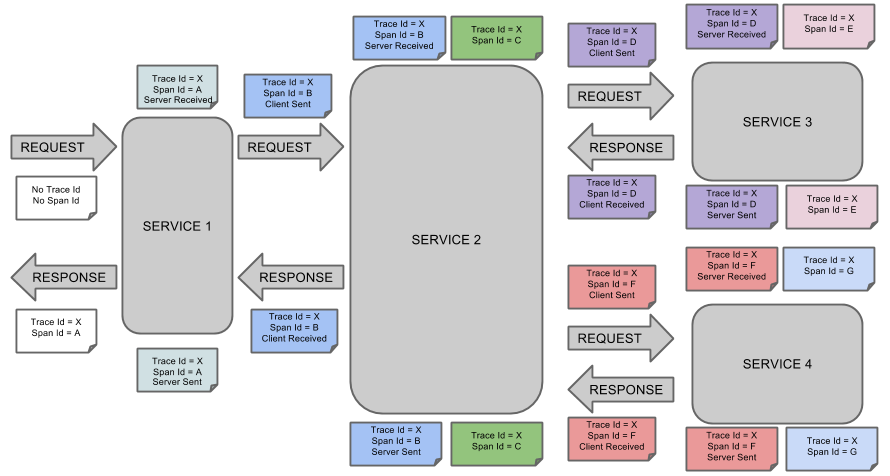
(图片来源于 spring-cloud-sleuth 文档)
图片说明:
每种颜色表示一个跨度(有七个跨度 - 从 A 到 G)。
Trace Id = X Span Id = D Client Sent类似上面的注释,表示当前跨度的跟踪 ID 设置为 X,跨度 ID 设置为 D。此外,从 RPC 的角度来看,发生了客户端发送事件。
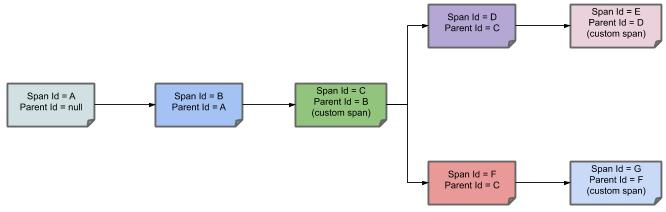
下图显示了 span 的父子关系:
(图片来源于 spring-cloud-sleuth 文档)
一个完整的数据链路系统大致可以分为三个相对独立的模块:
- 数据采集 - 负责数据埋点并上报。
- 数据处理 - 负责数据的存储与计算。
- 数据展示 - 负责数据的可视化展示。
数据采集负责数据埋点并上报。数据采集有三种主流的实现方式,分别是基于日志的追踪(Log-Based Tracing),基于服务的追踪(Service-Based Tracing)和基于边车代理的追踪(Sidecar-Based Tracing)。
基于日志的追踪的思路是:将 Trace、Span 等信息直接输出到应用日志中,然后随着所有节点的日志采集汇聚到一起,再从全局日志信息中反推出完整的调用链拓扑关系。
基于日志的追踪有以下特点:
- 侵入性小、性能影响低 - 对网络消息完全没有侵入性,对应用程序只有很少量的侵入性,对性能影响也非常低。
- 依赖于日志采集过程,导致不够实时、精准 - 直接依赖于日志采集过程,日志本身不追求绝对的连续与一致,这也使得基于日志的追踪往往不如其他两种追踪实现来的精准。另外,业务服务的调用与日志的归集并不是同时完成的,也通常不由同一个进程完成,有可能发生业务调用已经顺利结束了,但由于日志归集不及时或者精度丢失,导致日志出现延迟或缺失记录,进而产生追踪失真。
日志追踪的代表产品是 Spring Cloud Sleuth,下面是一段由 Sleuth 在调用时自动生成的日志记录,可以从中观察到 TraceID、SpanID、父 SpanID 等追踪信息。
# 以下为调用端的日志输出:
Created new Feign span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false]
2019-06-30 09:43:24.022 [http-nio-9010-exec-8] DEBUG o.s.c.s.i.web.client.feign.TraceFeignClient - The modified request equals GET http://localhost:9001/product/findAll HTTP/1.1
X-B3-ParentSpanId: cbe97e67ce162943
X-B3-Sampled: 0
X-B3-TraceId: cbe97e67ce162943
X-Span-Name: http:/product/findAll
X-B3-SpanId: bb1798f7a7c9c142
# 以下为服务端的日志输出:
[findAll] to a span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false]
Adding a class tag with value [ProductController] to a span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false]
基于服务的追踪是目前最为常见的实现方式,被 Zipkin、Pinpoint、SkyWalking 等主流链路追踪系统广泛采用。其实现思路是:通过某些手段给目标应用注入追踪探针(Probe),针对 Java 应用一般就是通过 Java Agent 注入的。探针在结构上可视为一个寄生在目标服务身上的小型微服务系统,它一般会有自己专用的服务注册、心跳检测等功能,有专门的数据收集协议,把从目标系统中监控得到的服务调用信息,通过另一次独立的 HTTP 或者 RPC 请求发送给追踪系统。
基于服务的追踪有以下特点:
- 侵入性强,会有性能损耗
- 追踪更加精准、稳定
因此,基于服务的追踪会比基于日志的追踪消耗更多的资源,也有更强的侵入性,换来的收益是追踪的精确性与稳定性都有所保证,不必再依靠日志归集来传输追踪数据。
基于边车代理的追踪是服务网格的专属方案,也是最理想的分布式追踪模型,它对应用完全透明,无论是日志还是服务本身都不会有任何变化;它与编程语言无关,无论应用采用什么编程语言实现,只要它还是通过网络(HTTP 或者 gRPC)来访问服务就可以被追踪到;它有自己独立的数据通道,追踪数据通过控制平面进行上报,避免了追踪对程序通信或者日志归集的依赖和干扰,保证了最佳的精确性。如果要说这种追踪实现方式还有什么缺点的话,那就是服务网格现在还不够普及,未来随着云原生的发展,相信它会成为追踪系统的主流实现方式之一。还有就是边车代理本身的对应用透明的工作原理决定了它只能实现服务调用层面的追踪,本地方法调用级别的追踪诊断是做不到的。
现在市场占有率最高的代理 Envoy 就提供了相对完善的追踪功能,但没有提供自己的界面端和存储端,所以 Envoy 和 Sleuth 一样都属于狭义的追踪系统,需要配合专门的 UI 与存储来使用,现在 Zipkin、SkyWalking 、Jaeger、LightStep Tracing 等系统都可以接受来自于 Envoy 的追踪数据,充当它的界面端。
数据处理负责数据的存储与计算,就是将数据采集的数据按需计算,然后落地存储供查询使用。
数据处理的需求一般分为两类,一类是实时计算需求,一类是离线计算需求。
实时计算需求对计算效率要求比较高,一般要求对收集的链路数据能够在秒级别完成聚合计算,以供实时查询。而离线计算需求对计算效率要求就没那么高了,一般能在小时级别完成链路数据的聚合计算即可,一般用作数据汇总统计。针对这两类不同的数据处理需求,采用的计算方法和存储也不相同。
- 实时数据处理:针对实时数据处理,一般采用 Flink、Storm、Spark Streaming 来对链路数据进行实时聚合加工,存储一般使用 OLTP 数据仓库,比如 HBase,使用 traceId 作为 RowKey,能天然地把一整条调用链聚合在一起,提高查询效率。
- 离线数据处理:针对离线数据处理,一般通过运行 MapReduce 或者 Spark 批处理程序来对链路数据进行离线计算,存储一般使用 Hive。
数据展示层的作用就是将处理后的链路信息以图形化的方式展示给用户。
实际项目中主要用到两种图形展示,一种是调用链路图,一种是调用拓扑图。
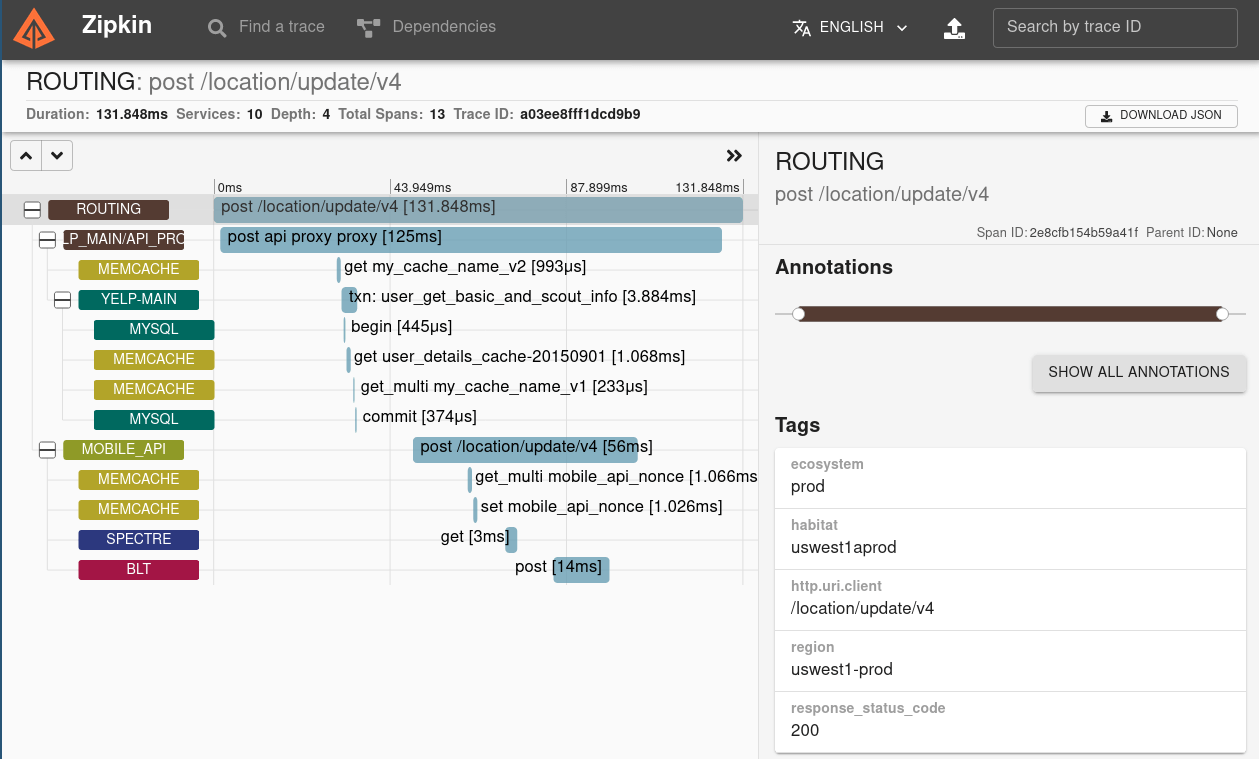
调用链路图一般展示服务总耗时、服务调用的网络深度、每一层经过的系统,以及多少次调用。调用链路图在实际项目中,主要是被用来做故障定位,比如某一次用户调用失败了,可以通过调用链路图查询这次用户调用经过了哪些环节,到底是哪一层的调用失败所导致。
下面是 Zipkin 的调用链路图:
调用拓扑图一般展示系统内都包含哪些应用,它们之间是什么关系,以及依赖调用的 QPS、平均耗时情况。调用拓扑图是一种全局视野图,在实际项目中,主要用作全局监控,用于发现系统中异常的点,从而快速做出决策。比如,某一个服务突然出现异常,那么在调用链路拓扑图中可以看出对这个服务的调用耗时都变高了,可以用红色的图样标出来,用作监控报警。
下面是 Pinpoint 的调用链路图:
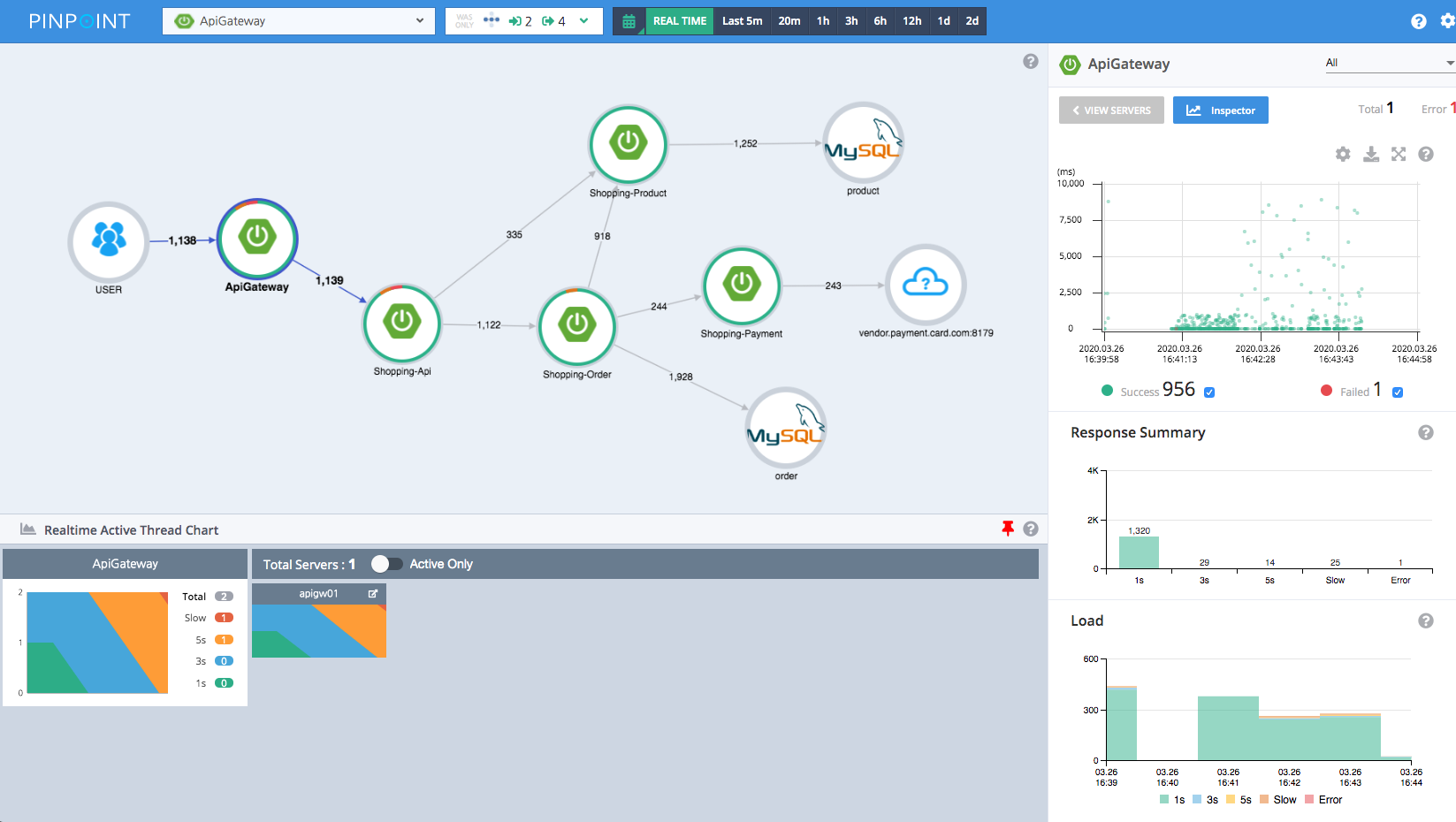
链路追踪的主流开源产品比较丰富,主要有:
- Zipkin - Zipkin 是 Twitter 开源的调用链分析工具,目前基于 spring-cloud-sleuth 得到了广泛的使用,特点是轻量,使用、部署简单。
- Pinpoint - 是韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI 功能强大,接入端无代码侵入。
- SkyWalking - 是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI 功能较强,接入端无代码侵入。目前已加入 Apache 孵化器。
- CAT - CAT 是美团点评开源的基于编码和配置的调用链分析,应用监控分析,日志采集,监控报警等一系列的监控平台工具。
- OpenTelemetry - OpenCensus 和 OpenTracing 两个项目的合并。OpenTelemetry 是工具、API 和 SDK 的集合。用于检测、生成、收集和导出遥测数据(指标、日志和和追踪),以辅助分析软件的性能和行为。
- OpenTracing - 是一套与平台无关、与厂商无关、与语言无关的追踪协议规范。官方提供多种语言的链路追踪库实现。目前官方已经不再维护。
- 标准化
- OpenTelemetry - OpenCensus 和 OpenTracing 两个项目的合并
- OpenTracing - OpenTracing 是一套与平台无关、与厂商无关、与语言无关的追踪协议规范
- 文章
- Dapper 论文 - 即:Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
- Dapper 论文翻译
- 凤凰架构-链路追踪