| title | seoTitle | datePublished | cuid | slug | cover | tags |
|---|---|---|---|---|---|---|
Database Designs for Multilingual Apps |
Database Designs for Multilingual Apps |
Fri Mar 31 2023 07:15:06 GMT+0000 (Coordinated Universal Time) |
clfw7miro000109mi9timaxcx |
database-designs-for-multilingual-apps |
postgresql, software-design, sql, database-design, localization |
{kind=link}
This story comes from the necessity of multi-language support across our applications. Dwarves Foundation handles a lot of international clients and there is always some level of concern for supporting multiple languages for certain apps. This is a concern not just from our clients, but also from us, which motivated our research for multilingual support.
In today's globalized world, many applications need to support multiple languages to reach a broader audience. Managing translations in a database is a critical aspect of building a multilingual application. However, designing a multilingual database can be challenging and involves several factors, such as character encoding, language-specific data storage requirements, and translation tables.
In this article, we'll explore three common solutions for designing translation tables:
-
the column-based approach - incorporating languages in a different column as a text field of the same table
-
the column JSON-based approach - similar to the column based support, but using JSON data types as opposed to just a text field.
-
the translation table approach - a separate table to handle multiple languages and translation practices
The column-based approach is the simplest solution for managing translations in a database. For each column in a table, there is a corresponding column for translations in other languages. For example, if a column is in English, there will be another column that stores its translations in different languages such as Spanish, French, and so on.
Here's an example of how a table using this approach might look:

{kind=link}
To query data you would need to use a COALESCE function to retrieve the translation in the desired language, with a fallback to the default column if the translation is not available.
For example, to retrieve the French translation from the above table:
// we wanted to get French translation
SELECT
COALESCE(title_fr, title) AS title,
COALESCE(description_fr, description) AS title
FROM
"example_table"Pros
-
Simple, fast, and easy to implement
-
Requires a small data size
Cons
-
The number of columns grows as the number of supported languages increases, making it difficult to manage and not scalable
-
Adding a new language requires updating the schema
-
Query conditions for selecting a particular language can become complex
The column-based approach may be useful for smaller projects with a limited number of languages to support. Still, it may not be the best approach for larger projects with more languages and complex data.
In the column JSON-based approach, a single column is used to store all translations for the other columns of the table by language. This approach reduces the number of columns needed compared to the column-based approach. The value of the column is a JSON object that contains translation data for each language.
For example, if you have a table with columns for "title" and "description," you can use a single column named translations to store the translations in JSON format. The JSON object will have a key for each language, and each key will contain the translated column values for that language:

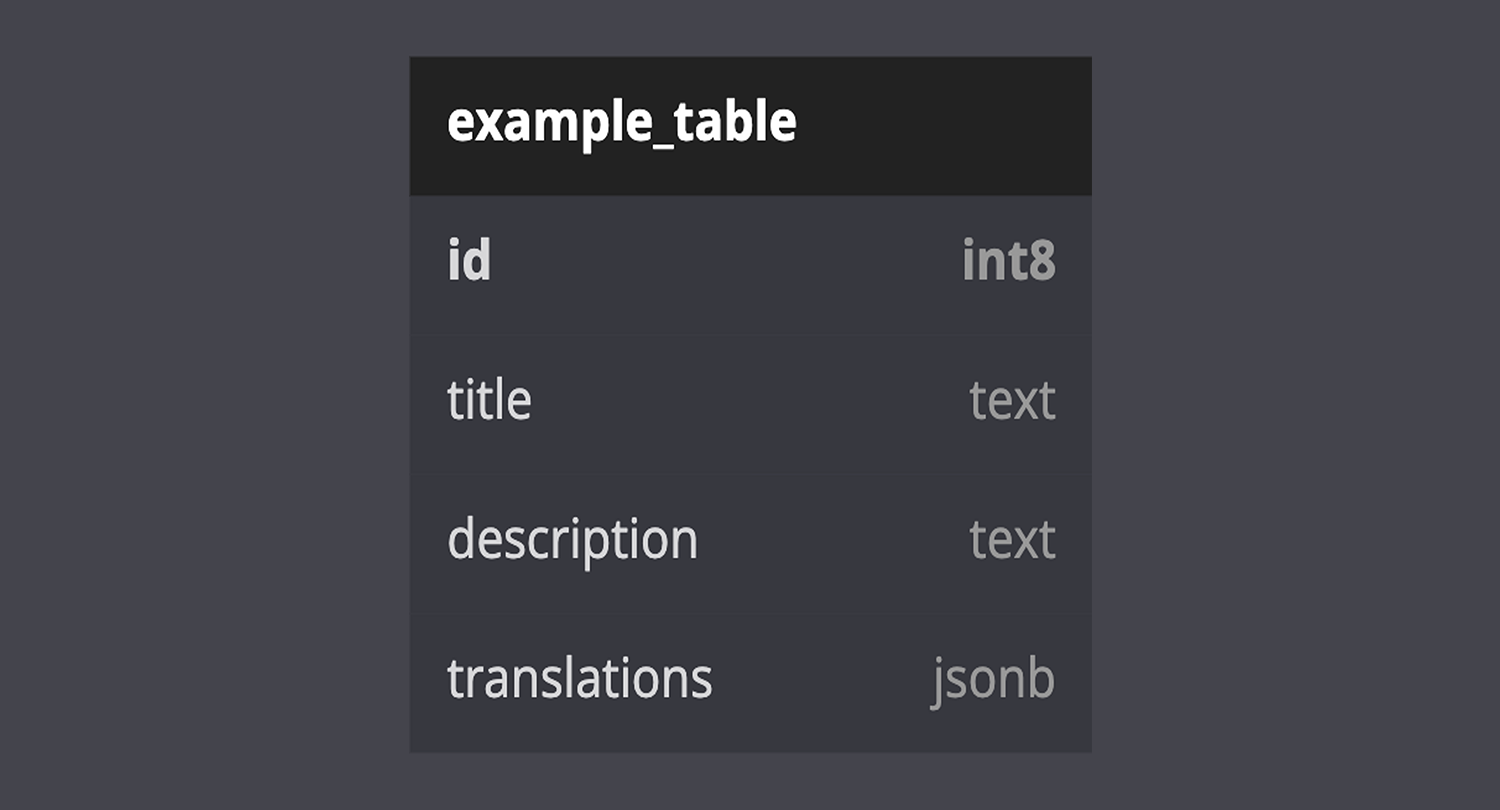{kind=link}
To retrieve data, you need to use specific functions to extract data from the translations column.
// in this example we assume you use Postgres
// mysql, sqlserver might have slighly syntax diffrent
// return translation in translation column
// we wanted to return all translations
SELECT
id,
title,
translations
FROM
"table";
// we only want to return a specific language
SELECT
id,
title,
translations -> "vi" AS translation
FROM
"table";
// omit the translation field
SELECT
id,
translations -> 'vi' -> 'title' AS title,
translations -> 'vi' -> 'description' AS description
FROM
"table";Pros
-
Reduces the number of columns needed in the table, making it more scalable and easier to maintain.
-
Allows for easy addition of new languages without requiring a schema change. This can be a significant advantage when adding support for new languages, as it reduces the amount of work needed to modify the database schema.
-
By storing all the translations in a single JSON object, the amount of data stored can be significantly reduced, which can result in faster query times and reduced storage costs.
Cons
-
The JSON object can become difficult to manage and maintain as the number of languages and translated columns grow. This can lead to errors and inconsistencies in the translations.
-
Queries can become slow and inefficient when retrieving data from the JSON object, especially if there are many translations and a large amount of data to be processed. This can result in increased server load and slower application performance.
-
If multiple users are updating the same JSON object simultaneously, it can result in data inconsistencies and conflicts. This can be mitigated by using locking mechanisms, but it adds an additional layer of complexity to the design.
The column JSON-based approach is particularly useful for applications that are expected to support multiple languages and require flexibility in managing the translations.
The translation table approach involves creating a separate table for storing translations of various text values in different languages. The translations are stored in key-value pairs, with the key representing the original text value, and the value representing the translated text in a specific language.
Here's an example of how a translation table might look:

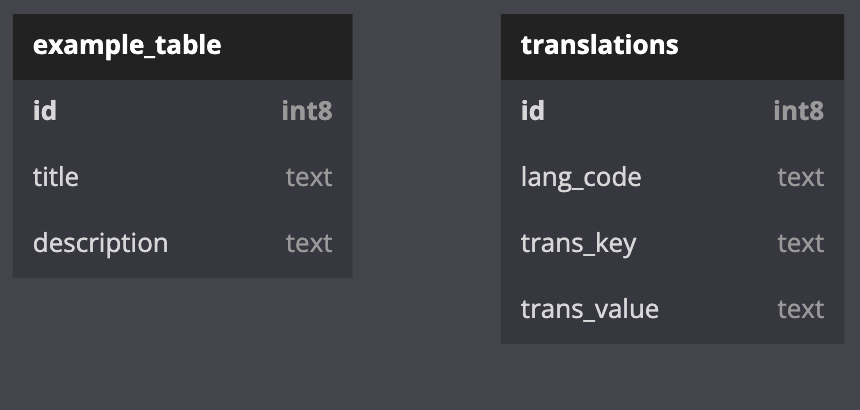{kind=link}

{kind=link}

{kind=link}
To retrieve translations using the translation table approach, you would typically use SQL queries with JOIN statements to combine the relevant data from multiple tables.
SELECT
title_trans.trans_value AS "title",
description_trans.trans_value AS "description",
FROM
"table_a"
LEFT JOIN "translations" AS title_trans ON "table_a"."title" = description_trans.trans_key
AND lang = 'vi'
LEFT JOIN "translations" AS description_trans ON "table_a"."title" = description_trans.trans_key
AND lang = 'vi'Pros
-
Scalable and flexible, allowing for the addition of new languages without requiring a change to the database schema.
-
No duplicate content, as each translation is stored in a separate row in the translation table.
-
Queries can be optimized with indexes to improve performance.
Cons
-
More complex to implement than the column-based or column JSON-based approach.
-
Joins can slow down query performance, especially for larger datasets.
-
Requires additional storage space for the translation table.
The translation table approach is suitable for applications of any size that require support for multiple languages. It is especially useful for large applications where data duplication can become a problem with other approaches. However, it may not be the most efficient approach for small applications as it involves more complex queries and potentially slower performance due to the use of joins.
In conclusion, designing a multilingual database involves several moving parts that need to be taken into account, such as character encoding, language-specific data storage requirements, and translation tables. The selection of an approach depends on the specific requirements of the application and the expected data volume. Small to medium-sized applications may use a column-based or column JSON-based approach, while larger applications may benefit from a translation table-based approach.
In summary, the column-based approach is simple and easy to implement but not scalable, the column JSON-based approach reduces the number of columns needed, but can become difficult to manage, and the translation table approach is scalable and flexible but more complex to implement. By understanding the pros and cons of each approach, developers can make informed decisions about which solution best fits their needs.
At Dwarves, we encourage our people to read, write, share what we learn with others, and contributing to the Brainery is an important part of our learning culture. For visitors, you are welcome to read them, contribute to them, and suggest additions. We maintain a monthly pool of $1500 to reward contributors who support our journey of lifelong growth in knowledge and network.
-
Check out our products
-
Hire us to build your software
-
Join us, we are also hiring
-
Visit our Discord Learning Site
-
Visit our GitHub