В этой лекции поговорим о том, как разработка происходит в реальности. Как разработчики взаимодействуют между собой, какие еще роли бывают в команде и зачем они нужны. Как чаще всего используется git. И как при правильном подходе можно автоматизировать все процессы деплоймента.
В достаточно крупных компаниях процессами автоматизации занимаются отдельные специалисты, называются DevOps (Development and Operation) или даже DevSecOps (Development, Security and Operations). Но в небольших компаниях этим занимаются сами разработчики, поэтому я считаю, что нам необходимо понимать как это устроено.
Методология разработки ПО – это процесс описания того, как определенный продукт будет разрабатываться, то есть один из способов организации коллективной разработки. Существует множество разных моделей такого процесса, каждая из которых описывает свой подход. Нельзя сказать, что среди них выделяется одна, которую нужно использовать в каждом проекте, всё сугубо ситуативно.
По сути, это правила и обязанности сотрудников при разработке программного обеспечения, и какие вообще нужны специалисты.
На самом деле, их довольно много, я знаю как минимум 7, но в реальности в современном мире я сталкивался только с 3-я,
и то scrum очень сильно впереди по количеству команд, которые его используют. Давайте разбираться.
Предлагаю рассмотреть подробнее.
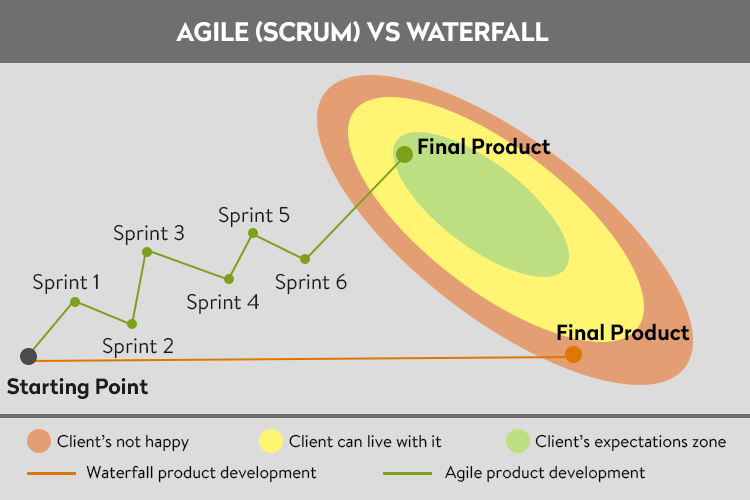
Вотерфол, он же водопад.
Waterfall (каскадная, водопадная) – одна из самых старых методологий и подразумевает строгое последовательное выполнение всех этапов, каждый из которых должен завершиться перед началом следующего. То есть переход на следующий этап означает полное завершение работ на предыдущем. На картинке показано, что сначала мы анализируем задачу (документируем задания, обговариваем сложности), потом происходит дизайн (на этом этапе формируется структура проекта), дальше кодинг и тестирование. Возвраты на следующие этапы не предусмотрены. Использовать такую систему рекомендуется в небольших проектах, где известны заранее требования и мала вероятность, что они будут меняться.

Если мы предположим, что мы разрабатываем автомобиль, чтобы сделать это по вотерфолу, то нужно дать чёткую задачу команде проектирования, когда вся документальная работа будет закончена, нужно прейти к этапу дизайна и проработке автомобиля, потом собрать прототип, после чего провести тестирование.
Преимущества:
- Полная и согласованная документация на каждом этапе;
- Простота использования;
- Стабильные требования.
- Бюджет и дедлайны заранее определены
Недостатки:
- Большое количество документации;
- Не очень гибкая система;
- Нет возможности вернуться на шаг назад.
Канбан – система, построенная на визуализации процесса выполнения задач команды. Основная идея в этой системе уменьшать количество задач, выполняющихся в данный момент (в колонке in progress). В канбане на первом месте задачи. Хорош для проектов, которые в стадии поддержки, где основной функционал уже разработан и остались минимальные доработки и багофиксинг.
В канбане задачи сдаются индивидуально. Задача независимо от других задач проходит по всем этапам на доске, и как только она выполнена, её можно показать заказчику.
Канбан доска состоит из колонок, каждая из которых - это отдельный процесс разработки. На некоторые столбцы (например, in progress) вводят ограничения по количеству тасок, которые там могут находиться. Это помогает легко и быстро находить проблемные места в распределении задач. На картинке пример самой просто такой доски. Количество колонок и названия могут меняться, назову самые распространенные:

На самом деле, колонок может быть какое угодно количество, и они могут быть самыми разнообразными.
Например:
- To do – список задач, которые надо сделать
- In progress – задачи над которыми ведется работа в данный момент
- Code review – задачи, которые сделаны и отправлены на ревью
- In testing – задачи, готовые к тестированию
- Done – сделанные задачи.
Преимущества:
- Простота использования.
- Наглядность (помогает в нахождении узких мест, упрощает понимание)
- Высокая вовлеченность команды в сам процесс.
- Высокая гибкость в разработке.
Недостатки:
- Нестабильный список задач.
- Сложно применять на долгосрочных проектах.
- Отсутствие жестких дедлайнов.
В случае с разработкой автомобиля это бы означало, что мы имели бы кучу разбитых задач, например, спроектировать колесо,
продумать трансмиссию и т. д. И ответственные за это люди. В реальности встречал только на саппорт проектах. Это такие,
где всё давно работает и необходимо только поддерживать или вносить небольшие правки. Но канбан доска очень и очень
часто используется как инструмент внутри процесса scrum, о нём и поговорим.
О нём сильно детальнее.
На самом деле, Scrum - это лишь подвид методологии, которая называется Agile.
Суть Agile заключается в его дословном переводе: Agile - гибкий. Смысл заключается в том, чтобы сконцентрироваться на результате, при этом имея возможность гибкого управления и правок в процессе разработки.
Как его вообще придумали? Вернёмся на сто лет назад и к примеру со сборкой автомобиля. Мы - Генри Форд и хотим первыми собрать массовый, серийный автомобиль. Допустим мы потратили 2 года и 2 миллиона долларов на проектную документацию, потом 3 года и 4 миллиона на чертежи, потом 2 миллиона и 1 год на сборку прототипа и собираемся перейти к тестированию. И на этапе тестирования в первый день мы выясняем, что в документации были допущены ошибки при вычислениях, и наш автомобиль переворачивается на каждом повороте.
Вывод, мы потратили 6 лет и 8 миллионов на работу, которую надо начинать сначала, потому что документацию нужно начинать сначала, и мы понятия не имеем как изменения, связанные с поворотами, повлияют на остальную систему.
Такой подход никого не устраивал, и был придуман Agile. Суть Agile - ввести временные циклы разработки, в конце которых всегда получается како-то результат. Например, мы вводим цикл в 3 месяца, и каждые 3 месяца смотрим на результаты. Например, у нас уже есть мотор, и мы хотим убедиться, что он сможет крутить колёса, и собираем только мотор, колёса и все связующие их детали, если в конце такого цикла всё хорошо, то идём дальше, если нет - ищем ошибку, но мы потеряли всего 3 месяца, а не 6 лет. Если проблема обнаружилась на более поздних этапах, мы всегда можем вернуться к результатам такого цикла и посмотреть лишь то, что было разработано на этом этапе.
Такие циклы разработки называются спринтами.

В итоге мы получаем более долгий процесс, потому что мы в любой момент можем изменить цели или детали текущей работы, но при этом очень сильно уменьшаем бюджет из-за сведения глобальных ошибок к нулю. Практика последних 100 лет показала, что этот подход практически всегда выходит сильно дешевле, если вы создаёте что угодно, сложнее гвоздя.
Из личной практики, клиент почти никогда не знает, что он хочет, есть только примерное понимание того, как всё должно быть в конце.
Если в одно предложение, то суть сводится к фразе, начинали делать автомобиль, в процессе создали вертолёт, а сейчас переделываем его в подводную лодку, но клиент счастлив и платит, потому что именно она ему оказалась и нужна.
В рамках SCRUM существует три основные роли:
- Product Owner (PO) - заказчик, чаще всего это специально назначенный менеджер, который занимается постановкой задач и сбором требований от так называемых stakeholders, в случае больших компаний почти никогда не бывает одного выгодоприобретателя, и важно, чтобы задачи ставил только один человек.
- Developer Team Member - это вы. И не только вы, это любые люди, которые участвуют в процессе разработки, тестировщики, дизайнеры, бизнес аналитики и т. д. Их роль работать работу.
- Scrum Master (SM) - это еще один менеджер. Его задача - это защита команды и отслеживания соблюдения SCRUM процессов, о них дальше. Зачем защищать команду? Потому что Product Owner всегда заинтересован в том, чтобы команда выдавала максимальный результат, несмотря ни на что. В такой ситуации, если бы не было SCRUM мастера, то Product Owner был бы только рад дать задач столько, чтобы они занимали 24/7, одна из основных задач SM - следить, чтобы так не было.
Что нужно сделать, чтобы организовать такой процесс. В первую очередь необходимо определить удобный для вас размер спринта, считается что он должен быть от 1 до 4 недель. Я в реальности за исключением одного проекта работал с двух недельными спринтами, в том исключении было 3 недели. Это размер определяют все вместе (Dev Team + PO + SM)
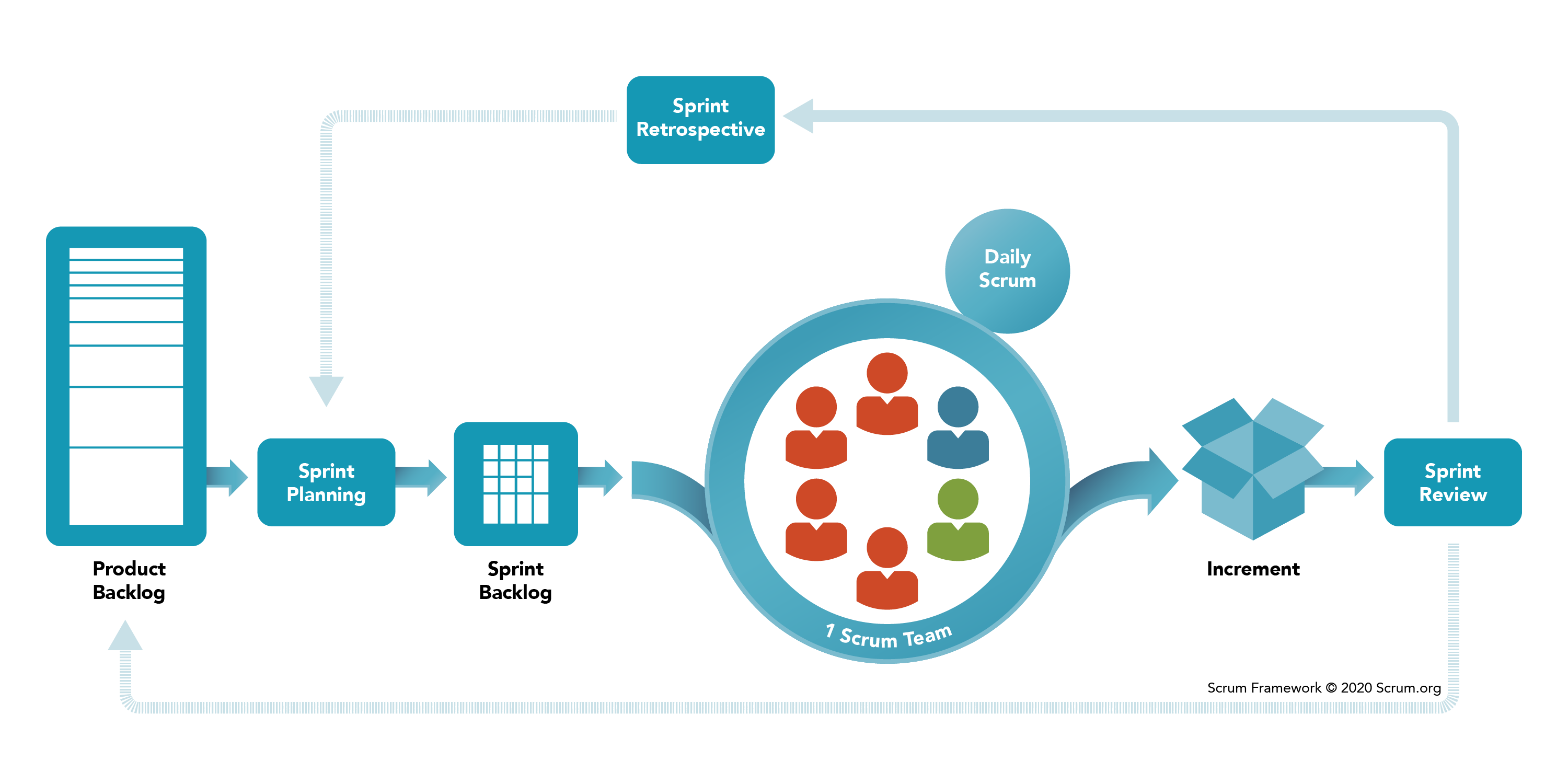
Следующий этап - это заполнение беклога продукта.
Backlog (беклог) - это место, где будут лежать ваши задачи, чаще всего это разные специализированные сервисы, очень часто это Jira или Azure Devops, но на самом деле их существует очень и очень много.
Беклог продукта заполняет Product Owner, чем детальнее описана задача, тем проще потом её выполнять, поэтому следить за детализацией беклога - это задача SCRUM мастера и бизнес аналитиков, если они есть. Бизнес аналитик - это чаще всего переводчик с языка заказчика на технический и наоборот, очень полезные ребята.
В идеальном мире, в беклоге продукта должно быть задач не меньше чем на 2 спринта.
После чего начинается процесс планирования спринта, обычно этим занимается дев команда, как именно это происходит, обсудим дальше, пока общая идея.
Результатом планирования является беклог спринта, то есть список выбранных задач на следующий цикл разработки.
Когда беклог спринта готов, начинается процесс разработки.
Важным элементом разработки является ежедневный митинг всей командой. Такой митинг может называться по-разному: daily,
scrum, stand up и т. д. Могут быть сочетания этих слов.
Зачем он нужен?
На таком митинге каждый участник команды отвечает на 3 самых главных вопроса:
- Что сделал?
- Что собираешься делать?
- Нет ли блокирующих обстоятельств?
Зачем на них отвечать, надеюсь, пояснять не надо.
В конце спринта результатом чаще всего является деплой результата, иногда просто демонстрация результатов Product
Owner. Такой митинг называется review.
После ревью обязательно проходит ретроспектива. Это еще один митинг, который нужен для улучшения SCRUM процессов.

Что это такое? Это митинг, на котором необходимо нарисовать на доске три колонки:
- Плюсы спринта
- Минусы спринта
- Действия
Первые два заполняются участниками команды. Каждый озвучивает плюсы и минусы, которые он увидел.
Если за плюсы обычно просто хвалят, то минусы нужно разбирать.
Например, плюс, что тестировщики очень хорошо сработали и вовремя нашли критичный баг, молодцы.
А минус, что у проекта нет документации, допустим, с логинами и паролями от серверов, а они нужны.
На каждый минус прописывается действие, в моём примере - это будет, создать файл с паролями.
Дальше каждый участник команды имеет какое-то количество голосов, там где я работал, это чаще всего было 2. Голоса можно отдать за те действия, которые для тебя наиболее критичны, несколько самых проголосованных берутся в работу и назначаются ответственные. Следующая ретроспектива начинается с обсуждения прошлых задач и результатов.
Если SCRUM построен нормально, то на первых спринтах действий очень много, но чем дальше заходит процесс, тем их меньше, и тем больше заполняются плюсы и уходят минусы.
Необходимо для того, чтобы помочь самой команде в её процессах.
Итого обязательные митинги:
- Planning
- Daily Meeting
- Review
- Retrospective
После этого начинаем с начала, с планирования спринта. И так до пенсии.

Мем исключительно шутки ради, на самом деле хорошая методология :)
Процесс планирования спринта не так прост, как кажется. Какая возникает проблема? Как понять, какое количество и каких задач команда вообще может сделать?
Чтобы определить это, вводится специальное понятие, story points. Стори поинты - это условная сложность задачи,
которая не зависит ни от ваших навыков, ни от размера команды. Чтобы понять суть, нужно задать себе вопрос, что проще
почистить: банан, папайю или мандарин? Скорее всего, вне зависимости от своих навыков и размера команды вы сможете
сказать, что проще, а что сложнее.
Как эта сложность определяется? Обычно при помощи SCRUM покера.
Если процесс проходит офлайн, то каждому участнику команды выдают карточки с цифрами и символами:
[1, 2, 3, 5, 8, 13, 20, 40, 100, 'Чашка кофе', 'Бесконечность']
Могут быть варианты, но суть всегда одна.
Берём задачу из беклога, обсуждаем и после обсуждения все одновременно переворачивают карту, которую считают правильной.
Если ты не понимаешь сути задачи, например, задача по дизайну, а ты бекэнд разработчик, или наоборот, то выбрасываешь карту с кофе, как символ, что ты не участвуешь в обсуждении этой задачи.
И бесконечность или символ ? в случае если ты считаешь, что эту задачу вообще невозможно сделать или нам не хватает
деталей для её оценки.
Если нет сильно большого разброса, то значение выбирается большинством, например 1 человек кинул 2, 3 человека 3 и еще один 5, то просто возьмут 3.
А если кто-то кидает сильно меньше или сильно больше начинается обсуждение и повторное голосование, возможно, этот кто-то знает простой способ решения или наоборот видит какой-то подводный камень.
Каждой задаче проставляется сложность. Обычно сложность выше чем 20, и даже 13 считается слишком высокой, а значит задачу нужно разбить на более мелкие, которые будут оценены не выше чем в 8. Хотя бывают и исключения.
Когда идёт первый спринт, ни вы, ни Product Owner, ни Scrum Master не знают, сколько задач вы можете выполнить, поэтому берётся то количество задач, которые вы считаете, что вы можете сделать.

Сумма всех стори поинтов, которые вы набрали в спринт называется velocity. И по результатам первого спринта становится
понятно, вы взяли много, мало или как раз, что и можно обсудить на ретроспективе.
Первые несколько спринтов цифра может очень сильно меняться от спринта к спринту, но через 3-4 спринта становится понятно, какая velocity у вашей команды.
И основываясь на этой цифре, Product Owner и Scrum Master могут понимать, какое реальное количество работы, за какое время сможет сделать именно эта команда.
В идеальном мире ваша velocity должна расти, но это очень индивидуально.
Важным элементом является диаграмма сгорания задач в спринте.
Задачи в SCRUM также попадают на доску задач, где у статусов может быть разный вес.
Например:
- Нужно сделать - 0 баллов
- В процессе - 1 балл
- На тестировании - 2 балла
- На проверке у Product Owner - 3 балла
- Готово - 4 балла
И благодаря этим цифрам можно построить график того, как именно меняется процесс выполнения спринта в реальном времени.
Выглядит примерно так:

Естественно, чем вы ближе к идеальной прямой тем лучше. И такая диаграмма может помочь менеджерам следить за процессом выполнения, а вам - понять, есть ли у вас проблемы.
Доступ к такой диаграмме должен быть у всех участников команды.
Такая же диаграмма может быть построена для всего проекта, но на практике почти никогда не делается, потому что никто не знает, сколько раз изменятся или добавятся требования.
- Сложно оценить трудозатраты и стоимость, требуемые на разработку
- Сложно определить самые узкие места до начала разработки.
- Необходимость вовлечения каждого в разработку других членов команды.
Финал проекта может быть очень сильно сдвинут от планов заказчика по всем уже озвученным причинам
В начале проекта очень много случайных факторов. Неправильная оценка сил, неналаженные процессы, нет чёткого понимания, как решать блокеры.
SCRUM подразумевает, что практически каждый может заменить другого в команде, на практике это всегда не так, даже в рамках разработки, джун почти никогда не заменит синьора, что уже говорить о том, чтобы дев выполнял задачи за дизайнера. Так что сложно равномерно распределить задачи, пока процесс не "встанет на рельсы".
Когда дело доходит до работы, возникает очень важный вопрос. Как будем использовать GIT?
На самом деле, это очень сложный вопрос. И на него нет правильного ответа.
Но если мы живём в идеальном мире, где у нас небольшая команда, есть профильные девопсы, мы используем только один репозиторий, и релизы у нас выходят только раз в конце спринта, то в 2010 году за нас придумали правильный ответ.
Ответ называется git flow. И несмотря на все описанные выше "или" и количество статей с матом на этот подход, я еще
никогда не видел структуры, которая работала бы лучше при нормальных условиях.

Что же это такое?
Если одной страшной картинкой, то вот:
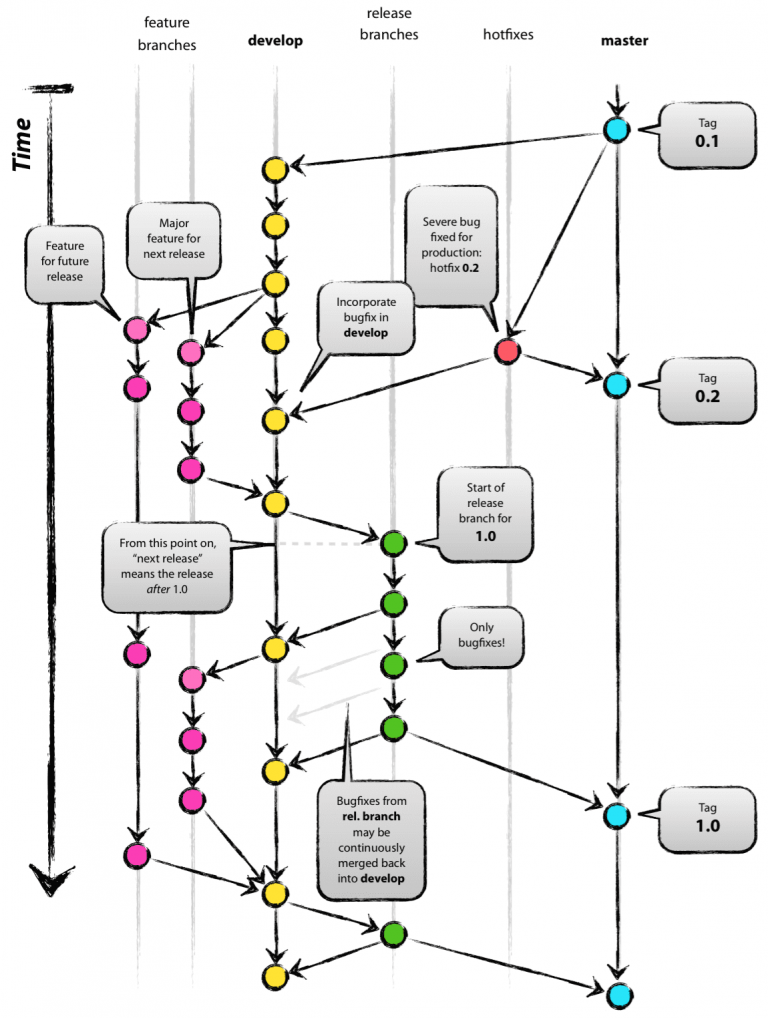
Давайте разбираться.
При таком подходе нам необходимо две long-term ветки. То есть те, которые будут жить долго.
Это будут ветки master и develop.
Если на пальцах, то master - это ветка, в которой всегда хранится последняя версия, которая сейчас находится на
продакшене (боевом сервере, к которому есть доступ у клиентов).
А develop - это то, что сейчас находится в разработке всей командой.
Ветка develop создаётся с мастера сразу на старте проекта, до первого коммита, но может быть создана и позже.
Фича (feature) - это реализация одной задачи из беклога. Например, добавить на сайт логин, логин и будет
фичей.
При таком подходе к гиту для каждой фичи создаётся отдельная ветка, создаётся из ветки develop.
После завершения разработки создаётся pull request в ветку develop, чтобы обновить на ней текущий код.
По сути develop - это местная свалка всего нового кода, который только есть.
Когда команда считает, что пора отдавать фичи на тестирование, из ветки develop создаётся ветка release-x.x,
где x.x - это условный номер релиза.
Из неё происходит деплоймент на тестовый сервер, где тестировщики ищут баги. Если баги незначительные, то прям в релиз ветке фиксятся баги. Если значительные, то возвращаем релиз разработчикам, они всё переделывают и создают новую ветку релиза.
После того как релиз ветка прошла все тесты и готова к тому, чтобы обновлять продакшен, из неё создаются два pull
request'a: на develop и на master.
На develop, чтобы добавить в эту ветку багофиксы, если они были. На master, чтобы выполнить деплоймент на продакшен.
На master после мёрджа обычно создаётся тег, чтобы была возможность откатить до прошлого тега без особой сложности.
Но что делать, если задеплоили продакшен и тут же обнаружили небольшой и легко исправляемый баг? Не проходить же всю процедуру с начала, пока у клиентов явно есть баг?
Для этого придумали хот фикс ветки, их создают прямо из master, и заливают обратно на master и на develop. Итого
на master, чтобы задеплоить исправление бага, а на develop, чтобы этот баг не попадал в новые фичи.
Если для проекта нормально применение такого подхода, то я бы очень рекомендовал его применять. Но в реальности
практически всегда находятся проблемы, которые не совпадают с таким подходом, поэтому очень часто я видел вариации на
тему git flow, чем его сам.
Но идея очень крутая, всё структурировано понятно и возможно найти кто, что и когда.
CI/CD - Continuous Integration / Continuous Deployment
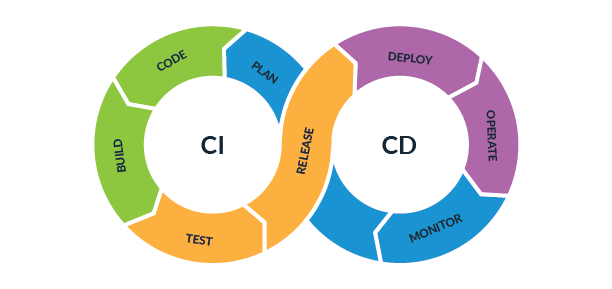
Непрерывная интеграция (Continuous Integration, CI) и непрерывная поставка (Continuous Delivery, CD) представляют собой культуру, набор принципов и практик, которые позволяют разработчикам чаще и надежнее развертывать изменения программного обеспечения.
В реальности, CI/CD - это возможность для разработчика, не задумываться о запуске тестов и процессах деплоймента.
Сделали push и создали pull request, CI за вас запустит тесты и соберёт ваш код в готовый для деплоймента вид.
Смерджили pull request, CD за вас автоматически всё задеплоит и перезапустит.
Это описание только одной из конфигураций, на самом деле их может быть огромное количество в зависимости от нужд проекта.
Непрерывная интеграция — это методология разработки и набор практик, при которых в код вносятся небольшие изменения с
частыми коммитами. И поскольку большинство современных приложений разрабатываются с использованием различных платформ и
инструментов, то появляется необходимость в механизме интеграции и тестировании вносимых изменений.
С технической точки зрения цель CI — это способ обеспечить последовательный и автоматизированный способ сборки,
упаковки и тестирования приложений. При налаженном процессе непрерывной интеграции разработчики с большей вероятностью
будут делать частые коммиты, что в свою очередь будет способствовать улучшению коммуникации и повышению качества
программного обеспечения.

Непрерывная поставка начинается там, где заканчивается непрерывная интеграция. Она автоматизирует развертывание
приложений в различные окружения: большинство разработчиков работают как с продакшн-окружением, так и со средами
разработки и тестирования.
Инструменты CI/CD помогают настраивать специфические параметры окружения, которые конфигурируются при развертывании. А также CI/CD-автоматизация выполняет необходимые запросы к веб-серверам, базам данных и другим сервисам, которые могут нуждаться в перезапуске или выполнении каких-то дополнительных действий при развертывании приложения.
Непрерывная интеграция и непрерывная поставка нуждаются в непрерывном тестировании, поскольку конечная цель — разработка качественных приложений. Непрерывное тестирование часто реализуется в виде набора различных автоматизированных тестов (регрессионных, производительности и других), которые выполняются в CI/CD-конвейере.
Зрелая практика CI/CD позволяет реализовать непрерывное развертывание: при успешном прохождении кода через CI/CD-конвейер, сборки автоматически развертываются в продакшн-окружении. Команды, практикующие непрерывную поставку, могут позволить себе ежедневное или даже ежечасное развертывание. Хотя здесь стоит отметить, что непрерывная поставка подходит не для всех бизнес-приложений.
Существуют десятки, если не сотни, различных утилит и приложений для реализации CI/CD.
Часто вместо термина CI/CD можно увидеть термин pipeline.
У всей "большой тройки" CI/CD процессы называются пайплайнами: AWS pipelines, Azure pipelines и GCP pipelines соответственно.
Также невероятно популярны Jenkins, Circle CI, Travis CI и т. д. Их очень много.
Мы сегодня рассмотрим настройку CI/CD при помощи инструмента вшитого в GitHub, Github Actions.
Plan -> Code -> Build -> Test
-
Plan - продумать, что вы хотите разработать
-
Code - написать код того, что придумали
-
Build - в нашем случае этот степ не нужен, так как Python интерпретируемый язык, а Django не требует каких-либо специальных подготовок. Но в целом этот пункт о том, что преобразовать исходный код в вид, подходящий для деплоймента.
-
Test - запустить тесты
Как выглядит в реальности?
Если мы придерживаемся Scrum и GitFlow, то мы в течение спринта готовим код на ветках feature, сливаем код в
develop, и, когда код готов к релизу, создаём ветку release, и из нее создаём pull request на master. Прямой пуш
в master практически всегда запрещён. И наша система должна автоматически по созданию pull request, запустить тесты,
и не позволить смерджить код, если тесты не были успешными.
В нашем случае мы будем сильно упрощать эту схему и объединим feature, develop и release. То есть у нас будет
всего 2 ветки, ветка с новым кодом и master (То, что вы делали во всех домашках и модуле)
Как такое сделать при помощи GitHub Actions?
Для этого на сайте GitHub переходим в Settings -> Branches и нажимаем Add Rule.
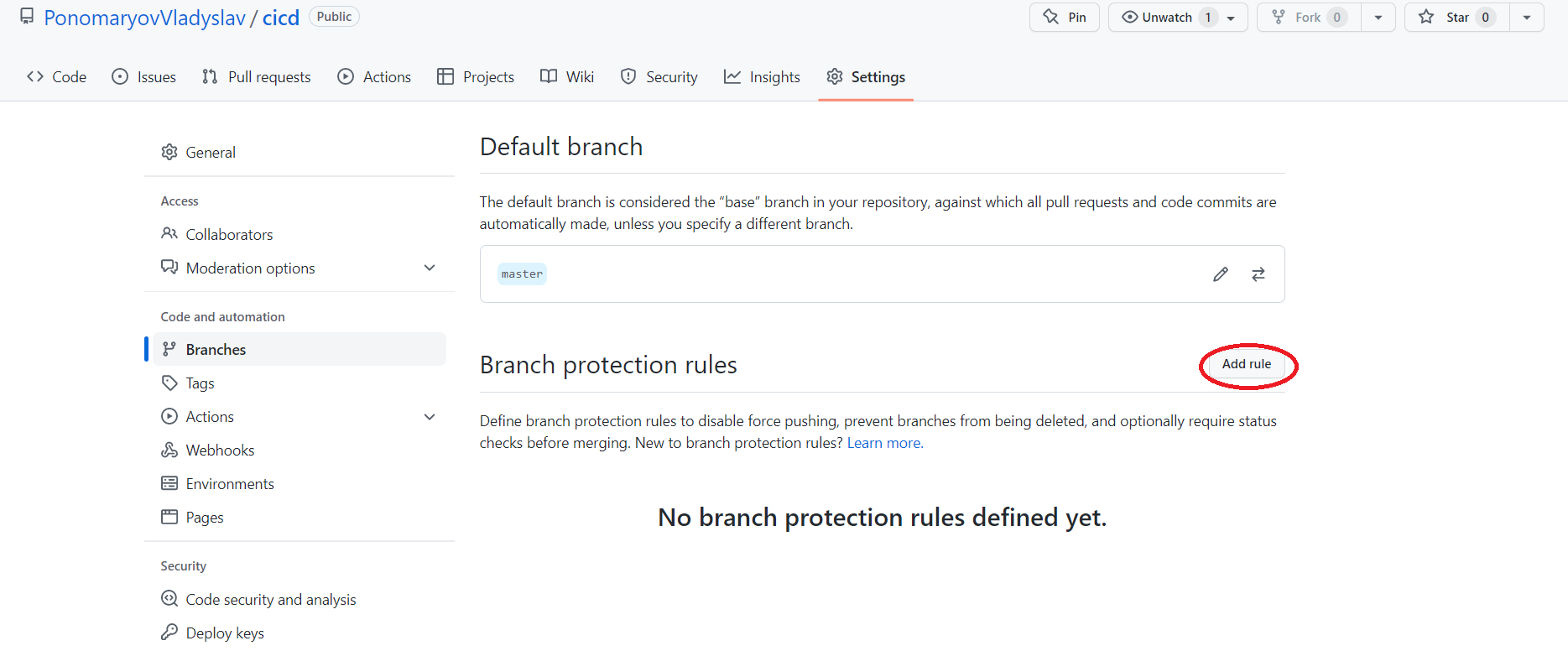
После чего добавляем два правила для нашей основной ветки, в моём случае master.
- Разрешить изменение только через pull request.
- Администраторы включительно, чтобы никто не мог изменить ветку, не через pull request.
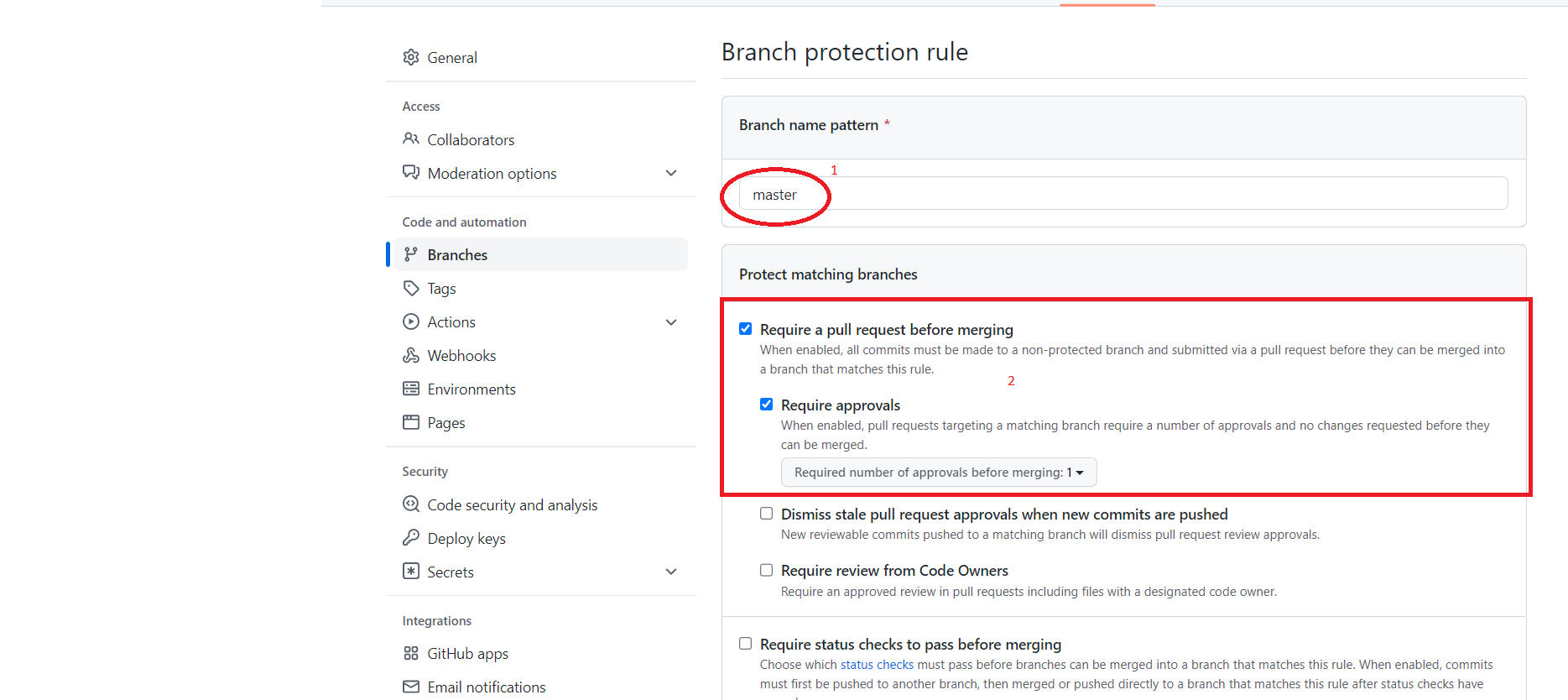

Нажимаем CREATE
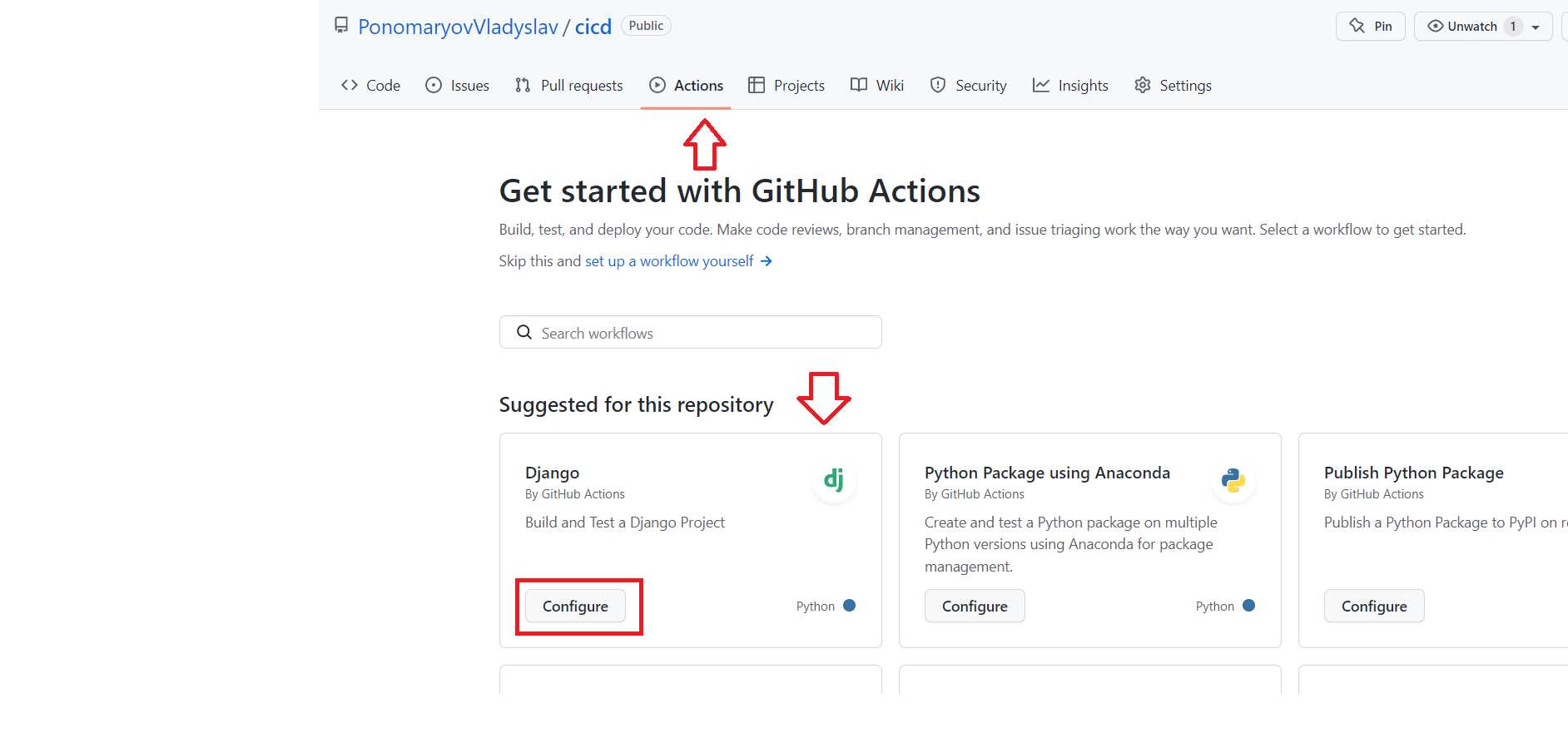
Заходим в раздел Actions, GitHub автоматически предложит нам добавить конфигурацию для Django, если вы залили проект
без ошибок в структуре.
Если автоматически не предложит, то всегда можно найти в поиске.
При нажатии кнопки Configure GitHub предложит нам добавить файл .github/workflows/django.yml, причем название файла
можно поменять, а путь нет, потому что, как мы уже знаем, .github - это скрытая папка с точки зрения линукса, а
workflow - папка, в которой GitHub будет искать файлы конфигурации CI.
Стандартный файл django.yml:
name: Django CI
on:
push:
branches: [ "master" ]
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
max-parallel: 4
matrix:
python-version: [ 3.7, 3.8, 3.9 ]
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Tests
run: |
python manage.py test
Давайте рассмотрим этот файл.
name - название, тут может быть что угодно
on - команда, которая описывает, когда должна выполняться текущая конфигурация, по дефолту - это push в ветку мастер,
или pull request на master, так как мы уже запретили push на master, этот пункт можно удалить
jobs - описание самих выполняемых команд
build - просто название, тут можно было написать что угодно
matrix/python-version - список версий Python, на которых необходимо запускать команды, предлагаю оставить только 3.9
steps - выполняемые шаги и зависимые модули. В нашем примере используется два дополнительных
модуля actions/checkout@v3, actions/setup-python@v3. Первый для взаимодействия с pull request, второй для запуска
Python. И сами команды, обновить pip, запустить установку requirements.txt и запуск команды python manage.py test.
Весь этот процесс запустится на виртуальной машине принадлежащей GitHub, но нам это и не важно, главное, что мы получим результат выполнения тестов, и если тесты не пройдут, то мы не сможем смерджить pull request.
После наших небольших изменений мы получим такой файл:
name: Django CI
on:
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
max-parallel: 4
matrix:
python-version: [ 3.9 ]
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Migrations # run migrations to create table in side car db container
run: python manage.py migrate
- name: Run Tests
run: |
python manage.py test
Сохраняем. Если мы добавили невозможность прямого коммита в master, то GitHub предложит нам создать новую ветку и pull
request, не забудьте его смерджить!!!
По сути в максимально простом виде CI степ уже настроен, и для определённых условий будет даже работать.

Но чего тут не хватает? Настройки базы данных! Ведь для запуска тестов практически всегда необходима база данных!
Давайте добавим её в настройки.
Первым делом нам необходимо добавить базу в описание запуска флоу. И добавить степ с миграцией нашей базы.
name: Django CI
on:
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
services:
postgres: # we need a postgres docker image to be booted a side car service to run the tests that needs a db
image: postgres
env: # the environment variable must match with app/settings.py if block of DATABASES variable otherwise test will fail due to connectivity issue.
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: github-actions
ports:
- 5432:5432 # exposing 5432 port for application to use
# needed because the postgres container does not provide a healthcheck
options: --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5
strategy:
max-parallel: 4
matrix:
python-version: [ 3.9 ]
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v3
with:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Migrate
run: python manage.py migrate
- name: Run Tests
run: |
python manage.py test
В параметре env можно увидеть настроенные юзер, пароль и название базы.
Обратите внимание на параметр options, он нужен, чтобы мы выполняли все команды только после того, как postgres
загрузится.
Также нам необходимо убедиться, что у нас в requirements.txt указан psycopg2.
И внести изменения в settings.py:
if os.getenv('GITHUB_WORKFLOW'):
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'github-actions',
'USER': 'postgres',
'PASSWORD': 'postgres',
'HOST': 'localhost',
'PORT': '5432'
}
}
else:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': os.getenv('DB_NAME'),
'USER': os.getenv('DB_USER'),
'PASSWORD': os.getenv('DB_PASSWORD'),
'HOST': os.getenv('DB_HOST'),
'PORT': os.getenv('DB_PORT')
}
}
Обратите внимание, переменная GITHUB_WORKFLOW будет добавлена автоматически при запуске.
Теперь наш CI полностью готов к работе!
Release -> Deploy -> Operate -> Monitor
-
Release - выпустить продукт. По сути, когда код оказался в ветке
master, продукт релизнут. -
Deploy - загрузка и развёртывание кода на сервере.
-
Operate - провести все необходимые для работы операции, в нашем случае, пересобрать статику и перезапустить NGINX и gunicorn.
-
Monitor - убедиться, что действия успешны. В нашем случае просто обновить сайт и увидеть, что всё хорошо.
На самом деле для того, чтобы собрать CD и у GitHub, и у практически любого другого инструмента существует большое количество разных уже встроенных инструментов, но так как сейчас мы хотим сделать всё наглядно, то и все команды я пропишу вручную.
Нежелательно использовать такой способ на реальных проектах, это только демонстрация логики!!!
Для того, чтобы заставить GitHub выполнять CD, мы создадим еще один воркфлоу, который будет выглядеть примерно так:
name: Django CD
on:
push:
branches: [ "master" ]
jobs:
deploy:
runs-on: ubuntu-latest
strategy:
max-parallel: 4
matrix:
python-version: [ 3.9 ]
steps:
- name: deploy command
uses: JimCronqvist/action-ssh@master
with:
command: |
source venv/bin/activate
cd project_name; git pull
python manage.py collectstatic --no-input
sudo systemctl restart gunicorn; sudo systemctl restart nginx
hosts: ${{ secrets.HOST }}
privateKey: ${{ secrets.PRIVATE_KEY}}
Давайте разбираться, что именно будет делать такой файл.
Срабатывать он будет на push на ветку master. Но мы же запретили push в ветку? Прямой да, но при мёрдже пулл реквеста
выполняется точно такой же пуш. А значит, этот ворк флоу будет срабатывать при мёрже нашего пулл реквеста, что нам и
нужно.
Название новой job - deploy, просто чтобы удобно было читать логи.
Мы будем запускать Python команды, а значит, нам понадобится раздел strategy, точно такой же как для CI.
И добавим один единственный шаг, который выполнит ряд команд сразу на нашем сервере. Вообще это не лучшее решение, но для наглядности, это самый удобный способ продемонстрировать CD.
Мы воспользуемся сторонним модулем JimCronqvist/action-ssh.
В качестве параметров передадим command, hosts, privateKey.
hosts - параметр, в котором мы укажем, куда именно нужно подключаться (в нашем случае url, который выдаёт нам Amazon)
privateKey - закрытый ключ, который выдал нам Amazon при создании сервера.
Обратите внимание, в обоих случаях в качестве значения я указываю ${{ secrets.VAR_NAME }}, что это такое?
Это переменные для Github-actions, мы же не хотим показывать путь к нашему серверу, или тем более ключи от него, конфигурационный файл всё еще лежит в репозитории.
Как их создать?
Settings > Secrets > Action - и там можно создавать переменные.
И давайте разберём, какие команды я указал выполнить.
source venv/bin/activate
cd project_name; git pull
python manage.py collectstatic --no-input
sudo systemctl restart gunicorn; sudo systemctl restart nginx- Активировать виртуальное окружение, так как мы собираемся собирать статику через
manage.py, этот шаг нам необходим - Перейти в папку с проектом и спулить последние изменения
- Собрать статику, параметр
--no-inputпозволит сделать это без дополнительных подтверждений - Перезапустить сервисы Nginx и Gunicorn
Название проекта и путь к виртуальному окружению можно было также скрыть через SECRETS.
Мердж пулл реквеста - это release.
Шаги 1-2 - это deploy.
Шаги 3-4 - это operate.
Остаётся только monitor, в нашем случае мы сделаем это руками.
Создадим любые видимые изменения (например, поменять что-то в html или заменить статический файл), в новой ветке,
допустим cicd_test.
Создадим pull request, посмотрим как GitHub не позволит нам смерджить его, пока не пройдёт шаг с тестами.
Смерджим после успешных тестов.
В разделе actions посмотрим, как выполняется деплой, после чего проверим, что изменения действительно вступили в силу.
Радуемся, что простейший CI/CD работает.

Не забываем, что это только одна из тысяч возможных конфигураций, причём не самая удачная на самом деле еще и упускающая
многие нужные детали и подробности! В крупных компаниях всей этой настройкой занимаются отдельные люди, их
называют DevOps, сокращение от Development and Operation, а еще бывают DevSecOps - Development Secure Operation.
Но в небольших компаниях вся эта настройка тоже на вас :)
Настало время поговорить про архитектуру.

И нет, мы будем говорить не про здания и урбанистику.
Под архитектурой в данном контексте я подразумеваю архитектуру построения технического решения.

Под монолитом обычно подразумевается техническое решение, собранное на одном стеке технологий и разворачиваемое целиком, одним большим пакетом.
Когда вы разрабатывали Django приложение, вы разрабатывали монолит, сами о том не догадываясь.
А как бывает еще?
Как можно догадаться из заголовка еще бывают микросервисы. Что же это такое?
Это когда у нас любые минимальные действия разбиты на маленькие сервисы, и они между собой не зависимы друг от друга.
Возьмем в качестве примера обычный интернет магазин. Предположим, мы уже купили базу данных у Amazon, а Redis сервис у Google.
Как разбить задачу на микросервисы? Например, у нас может быть отдельный сервис (приложение), которое отвечает за логин. Отдельное приложение, которое возвращает список товаров. Отдельное приложение, которое позволяет взаимодействовать с личным кабинетом. Отдельный сервис, отвечающий за рассылку рекламы и новостей, и отдельный сервис, который обрабатывает платежи.
Зачем такое делать и какой в этом смысл? Допустим, вы собрали монолит с таким же функционалом. И вдруг выясняется, что посмотреть на товары заходят сотни тысяч людей, а остальным функционалом почти никто не пользуется. Чтобы выдержать нагрузку, необходимо расширять весь монолит, что может быть очень дорого, и гораздо дешевле для одного отдельного сервиса. Это лишь один из примеров, давайте пройдёмся по всем плюсам и минусам таких архитектур.
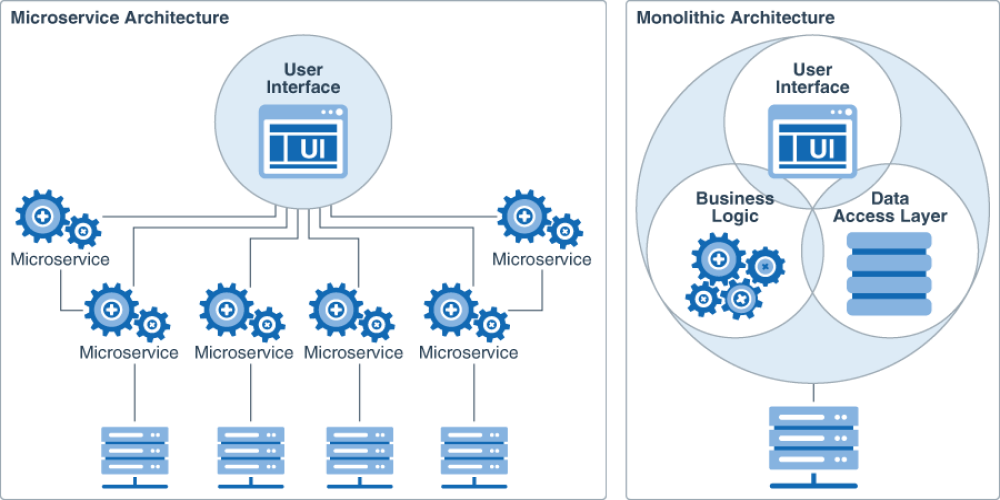
У такой архитектуры достаточно много плюсов
Как я уже описывал в примере раньше, при таком подходе мы легко можем увеличить ресурсы для одного сервиса и убрать для другого, но это еще не всё.
Так как микросервисы могут вообще быть не связаны технологиями, у нас может быть один модуль написан на Python, второй на Go, а третий на Java.
А это значит, что можно распределять разработчиков в зависимости от необходимости конкретного сервиса (нанять два джависта, и уволить питониста)
Каждый микросервис при разработке всегда будет меньше размером чем монолит, а значит, что будет деплоиться быстрее, прогонять тесты быстрее и т. д. Что позволяет значительно ускорить операционные вопросы.
Если у нас есть устаревший монолит, и мы хотим обновить его на новую версию языка или технологию, обычно это невыносимый, мучительный процесс.
В микросервисном подходе в этом нет проблемы, логин может быть написан на устаревшей Java, а платёжная система на самом новом Python, допустим на FastAPI.
Если мы хотим что-то обновить или переписать на другой язык, нам достаточно исправить только один модуль и никак не трогать другие.
Еще одним плюсом является не связанность между собой этих модулей. Не может получиться такой ситуации, когда поправили одну строчку кода, а задели 5 приложений. А значит, не надо писать кучу новых тестов, что экономит время.
Если по какой-то причине у нас отпадёт сервис, который рассылает рекламу, от этого весь проект работать не перестанет, при монолитном подходе это не так.
Гораздо проще разобраться в сервисе, который занимается одним процессом, чем изучать огромное скопление кода, хоть при переходе в другую команду, хоть приходя с улицы.
Да и в целом монолит очень часто со временем перерастает в нечитаемое "месиво".
Минусов тоже хватает :)
Когда нам нужно провести End-2-End тестирование какой-то фичи, это может быть проблемным из-за того, что одна бизнес задача может решаться через большое количество сервисов.
Очень сложно контролировать транзакции, когда процесс проходит сразу во многих микросервисах, особенно когда несколько из них работают над одними и теми же данными.
Если нужно внести какие-то глобальные обновления, очень высок шанс, что необходимо будет координировать несколько команд, а это часто бывает большой проблемой.
Для поддержки таких процессов часто нужен большой штат из девопсов, чтобы они отвечали за отдельные развёртывания отдельных процессов.
Правильного ответа, какую архитектуру использовать, обычно не существует, есть свои плюсы и минусы. В современном мире чаще всё-таки встречаются микросервисы, но это не мешает, например, Instagram работать как монолит. В идеале оставьте вопрос архитектуры для архитекторов, если есть такая возможность.
Кто такой докер?

Docker — один из самых известных инструментов по работе с контейнерами.
Давайте разберёмся, кто такие контейнеры.
Контейнеры — это способ стандартизации развертки приложения и отделения его от общей инфраструктуры. Экземпляр приложения запускается в изолированной среде, не влияющей на основную операционную систему.
Разработчикам не нужно задумываться, в каком окружении будет работать их приложение, будут ли там нужные настройки и зависимости. Они просто создают приложение, упаковывают все зависимости и настройки в некоторый единый образ. Затем этот образ можно запускать на других системах, не беспокоясь, что приложение не запустится.

Docker — это платформа для разработки, доставки и запуска контейнерных приложений. Docker позволяет создавать контейнеры, автоматизировать их запуск и развертывание, управляет жизненным циклом. Он позволяет запускать множество контейнеров на одной хост-машине.
Контейнеры позволяют упаковать в единый образ приложение и все его зависимости: библиотеки, системные утилиты и файлы настройки. Это упрощает перенос приложения на другую инфраструктуру.
Например, разработчики создают приложение в системе разработки — там все настроено, приложение работает. Когда оно готово, его нужно перенести в систему тестирования, а затем в продуктивную среду. Если в одной из них нет нужной зависимости, приложение не будет работать. Программистам придется отвлечься от разработки и совместно с командой поддержки разобраться в ситуации.
В контейнерах такой проблемы нет, так как они содержат в себе все необходимое для запуска приложения. Специалисты занимаются разработкой, а не решением инфраструктурных проблем.
Контейнер — это набор процессов, изолированных от основной операционной системы. Приложения работают только внутри контейнеров и не имеют доступа к основной операционной системе. Это повышает безопасность приложений:они не смогут случайно или умышленно навредить основной системе. Если приложение в контейнере завершится с ошибкой или зависнет, это никак не затронет основную ОС.
Контейнеры упрощают развертывание приложений. В классическом подходе для установки программы нужно совершить несколько действий: выполнить скрипт, изменить файлы настроек и так далее. В этом процессе не исключена вероятность человеческой ошибки: пользователь запустит скрипт два раза, перепутает последовательность или что-то не поймет. Контейнеры позволяют полностью автоматизировать этот процесс, так как включают в себя все нужные зависимости и порядок выполнения действий.
Также контейнеры упрощают развертывание на нескольких серверах. В классическом подходе для того, чтобы развернуть одно и то же приложение на нескольких машинах, нужно будет повторять одни и те же действия. Контейнеры избавляют от этой рутинной работы и позволяют автоматизировать развертывание.

Контейнеры хорошо вписываются в микросервисную архитектуру. Это подход к разработке, при котором приложение разбивается на небольшие компоненты, по возможности независимые. Обычно противопоставляется монолитной архитектуре, где все части системы сильно связаны друг с другом.
Это позволяет разрабатывать новую функциональность быстрее, ведь в случае с монолитной архитектурой изменение какой-то части может затронуть всю остальную систему.
Docker-compose позволяет разворачивать и настраивать несколько контейнеров одновременно. Например, для веб-приложения нужно развернуть стек LAMP: Linux + Apache, MySQL, PHP. Каждое из приложений — это отдельный контейнер для ОС Linux. Но в этой ситуации нам нужны именно все контейнеры вместе, а не отдельно взятое приложение. Docker-compose позволяет развернуть и настроить все приложения одной командой, а без него пришлось бы разворачивать и настраивать каждый контейнер отдельно.
Одна из главных особенностей контейнеров — эфемерность. Это означает, что контейнеры могут быть в любой момент остановлены, перезапущены или уничтожены. При этом все накопленные данные в контейнере будут потеряны. Поэтому приложения нужно разрабатывать так, чтобы они не полагались на хранилище данных в контейнере, это называется принципом Stateless.
Это хорошо подходит для приложений или сервисов, которые не сохраняют результаты своей работы. Например, функции расчета или преобразования данных: им на вход поступил один набор данных, они его преобразовали или рассчитали и вернули результат. Все, ничего никуда сохранять не нужно.

Но далеко не все приложения такие, и есть много данных, которые нужно сохранить. В контейнерах для этого предусмотрены несколько способов.
Поэтому я рекомендую использовать внешние базы данных для реальной разработки, ведь неважно откуда будет запрос, с локали, сервера или докера.
Это некоторый резидентный процесс, который запущен на хост-машине постоянно. Он владеет всей инфраструктурой, а также предоставляет интерфейс взаимодействия с контейнерами, включающего создание и удаление, запуск и остановку.
В ранних версиях платформы Docker можно встретить упоминание о dockerd, но на текущий момент демоны уже успели разбиться на отдельные проекты. Все чаще можно встретить его современника — containerd.
Это интерфейс командной строки для управления Docker daemon. Мы пользуемся этим клиентом, когда создаем и разворачиваем контейнеры, а клиент отправляет эти запросы в Docker daemon.
Это неизменяемый файл (образ), из которого разворачиваются контейнеры. Приложения упаковываются именно в образы, из которых потом уже создаются контейнеры. В технической литературе можно также встретить описание image как шаблона запуска процесса.
Приведем аналогию на примере установки операционной системы. В дистрибутиве (образе) ОС есть все, что необходимо для ее установки. Но этот образ нельзя запустить, для начала его нужно «развернуть» в готовую ОС. Так вот, дистрибутив для установки ОС — это образ, а установленная и работающая ОС — это контейнер. Но контейнеры обычно разворачиваются одной командой — это намного проще и быстрее, чем установка ОС.
Это уже развернутое из образа и работающее приложение.
Это репозиторий с образами. Разработчики создают образы своих программ и выкладывают их в репозиторий, чтобы их можно было скачать и воспользоваться ими. Распространенный публичный репозиторий — Docker Hub. В нем собраны образы множества популярных программ или платформ: базы данных, веб-серверы, компиляторы, операционные системы и так далее. Также можно создать свой приватный репозиторий, например, внутри компании. Разработчики будут размещать там образы, которые будут использоваться всей компанией.
Dockerfile — это инструкция для сборки образа. Это простой текстовый файл, содержащий по одной команде в каждой строке. В нем указываются все программы, зависимости и образы, которые нужны для разворачивания образа.
Пример:
FROM python:3
COPY main.py /
CMD [ "python", "./main.py" ]Первая строчка означает, что за основу мы берем образ с названием Python версии 3 - это называется базовый образ. Docker
найдет его в docker registry, скачает и будет использовать за основу. Вторая строчка означает, что нужно скопировать
файл main.py в корень файловой системы контейнера. Третья строчка означает, что нужно запустить Python и передать ему в
качестве параметра название файла main.py.
-
Команда
docker buildчитает dockerfile и собирает образ. -
Команда
docker pullскачивает образ из docker registry. По умолчанию, docker скачивает образы из публичного репозитория Docker Hub. Но можно создать свой репозиторий и настроить docker, чтобы он работал с ним. -
Команда
docker runберет образ и запускает из него контейнер.
Docker Compose - это возможность запустить несколько контейнеров одновременно и зависимо друг от друга.
Именно таким способом запускается большинство проектов, так как одного образа обычно недостаточно.
Например, нам необходимо сразу запустить, gunicorn, nginx, postgres.
К сожалению, как использовать докер для деплоймента Django приложения, например, на Amazon, настолько огромная тема, что мне не хватило бы и 3 занятия, так что давайте разберём, что успеем по готовым статьям. А изучить это детально, я предлагаю вам самостоятельно:
Статьи: