diff --git a/README.md b/README.md
index 89ed3a153d..2bb693eee0 100644
--- a/README.md
+++ b/README.md
@@ -1,5 +1,5 @@
[](https://github.com/estuary/flow/actions)
-[](https://join.slack.com/t/gazette-dev/shared_invite/enQtNjQxMzgyNTEzNzk1LTU0ZjZlZmY5ODdkOTEzZDQzZWU5OTk3ZTgyNjY1ZDE1M2U1ZTViMWQxMThiMjU1N2MwOTlhMmVjYjEzMjEwMGQ) | **[Docs home](https://docs.estuary.dev/)** | **[Free account](https://go.estuary.dev/sign-up)** | **[Data platform comparison reference](https://docs.estuary.dev/overview/comparisons)** | **[Email list](https://www.estuary.dev/newsletter-signup/)**
+[](https://join.slack.com/t/gazette-dev/shared_invite/enQtNjQxMzgyNTEzNzk1LTU0ZjZlZmY5ODdkOTEzZDQzZWU5OTk3ZTgyNjY1ZDE1M2U1ZTViMWQxMThiMjU1N2MwOTlhMmVjYjEzMjEwMGQ) | **[Docs home](https://docs.estuary.dev/)** | **[Free account](https://go.estuary.dev/sign-up)** | **[Data platform comparison reference](https://docs.estuary.dev/getting-started/comparisons)** | **[Email list](https://www.estuary.dev/newsletter-signup/)**
 {() => }
-
-4. Grant the application access to your storage account via the
-[`Storage Blob Data Owner`](https://learn.microsoft.com/en-us/azure/role-based-access-control/built-in-roles#storage-blob-data-owner) IAM role.
-
- - Inside your storage account's **Access Control (IAM)** tab, click **Add Role Assignment**.
-
- - Search for `Storage Blob Data Owner` and select it.
-
- - On the next page, make sure `User, group, or service principal` is selected, then click **+ Select Members**.
-
- - You must search for the exact name of the application, otherwise it won't show up: `Estuary Storage Mappings Prod`
-
- - Once you've selected the application, finish granting the role.
-
- For more help, see the [Azure docs](https://learn.microsoft.com/en-us/azure/role-based-access-control/role-assignments-portal).
-
-### Add the Bucket
-
-If your bucket is for Google Cloud Storage or AWS S3, you can add it yourself. Once you've finished the above steps, head to "Admin", "Settings" then "Configure Cloud Storage"
-and enter the relevant information there and we'll start to use your bucket for all data going forward.
-
-If your bucket is for Azure, send support@estuary.dev an email with the name of the storage bucket and any other information you gathered per the steps above.
-Let us know whether you want to use this storage bucket to for your whole Flow account, or just a specific [prefix](../concepts/catalogs.md#namespace).
-We'll be in touch when it's done!
-
-
-## What's next?
-
-Start using Flow with these recommended resources.
-
-- **[Create your first data flow](../guides/create-dataflow.md)**:
- Follow this guide to create your first data flow in the Flow web app, while learning essential flow concepts.
-
-- **[High level concepts](../concepts/README.md)**: Start here to learn more about important Flow terms.
diff --git a/site/docs/getting-started/quickstart/_category_.json b/site/docs/getting-started/quickstart/_category_.json
new file mode 100644
index 0000000000..34e1a5b4b7
--- /dev/null
+++ b/site/docs/getting-started/quickstart/_category_.json
@@ -0,0 +1,4 @@
+{
+ "label": "Quickstart for Flow",
+ "position": 1
+}
\ No newline at end of file
diff --git a/site/docs/getting-started/quickstart/quickstart.md b/site/docs/getting-started/quickstart/quickstart.md
new file mode 100644
index 0000000000..092af43b35
--- /dev/null
+++ b/site/docs/getting-started/quickstart/quickstart.md
@@ -0,0 +1,118 @@
+# Quickstart for Flow
+
+
{() => }
-
-4. Grant the application access to your storage account via the
-[`Storage Blob Data Owner`](https://learn.microsoft.com/en-us/azure/role-based-access-control/built-in-roles#storage-blob-data-owner) IAM role.
-
- - Inside your storage account's **Access Control (IAM)** tab, click **Add Role Assignment**.
-
- - Search for `Storage Blob Data Owner` and select it.
-
- - On the next page, make sure `User, group, or service principal` is selected, then click **+ Select Members**.
-
- - You must search for the exact name of the application, otherwise it won't show up: `Estuary Storage Mappings Prod`
-
- - Once you've selected the application, finish granting the role.
-
- For more help, see the [Azure docs](https://learn.microsoft.com/en-us/azure/role-based-access-control/role-assignments-portal).
-
-### Add the Bucket
-
-If your bucket is for Google Cloud Storage or AWS S3, you can add it yourself. Once you've finished the above steps, head to "Admin", "Settings" then "Configure Cloud Storage"
-and enter the relevant information there and we'll start to use your bucket for all data going forward.
-
-If your bucket is for Azure, send support@estuary.dev an email with the name of the storage bucket and any other information you gathered per the steps above.
-Let us know whether you want to use this storage bucket to for your whole Flow account, or just a specific [prefix](../concepts/catalogs.md#namespace).
-We'll be in touch when it's done!
-
-
-## What's next?
-
-Start using Flow with these recommended resources.
-
-- **[Create your first data flow](../guides/create-dataflow.md)**:
- Follow this guide to create your first data flow in the Flow web app, while learning essential flow concepts.
-
-- **[High level concepts](../concepts/README.md)**: Start here to learn more about important Flow terms.
diff --git a/site/docs/getting-started/quickstart/_category_.json b/site/docs/getting-started/quickstart/_category_.json
new file mode 100644
index 0000000000..34e1a5b4b7
--- /dev/null
+++ b/site/docs/getting-started/quickstart/_category_.json
@@ -0,0 +1,4 @@
+{
+ "label": "Quickstart for Flow",
+ "position": 1
+}
\ No newline at end of file
diff --git a/site/docs/getting-started/quickstart/quickstart.md b/site/docs/getting-started/quickstart/quickstart.md
new file mode 100644
index 0000000000..092af43b35
--- /dev/null
+++ b/site/docs/getting-started/quickstart/quickstart.md
@@ -0,0 +1,118 @@
+# Quickstart for Flow
+
+
+
+
+
+In this tutorial, you will learn how to set up a streaming Change Data Capture (CDC) pipeline from PostgreSQL to
+Snowflake using Estuary Flow.
+
+Before you get started, make sure you do two things.
+
+1. Sign up for Estuary Flow [here](https://dashboard.estuary.dev/register). It’s simple, fast and free.
+
+2. Make sure you also join
+ the [Estuary Slack Community](https://estuary-dev.slack.com/ssb/redirect#/shared-invite/email). Don’t struggle. Just
+ ask a question.
+
+When you register for Flow, your account will use Flow's secure cloud storage bucket to store your data.
+Data in Flow's cloud storage bucket is deleted 20 days after collection.
+
+For production use cases, you
+should [configure your own cloud storage bucket to use with Flow](#configuring-your-cloud-storage-bucket-for-use-with-flow).
+
+## Step 1. Set up a Capture
+
+Head over to your Flow dashboard (if you haven’t registered yet, you can do
+so [here](https://dashboard.estuary.dev/register).) and create a new **Capture.** A capture is how Flow ingests data
+from an external source.
+
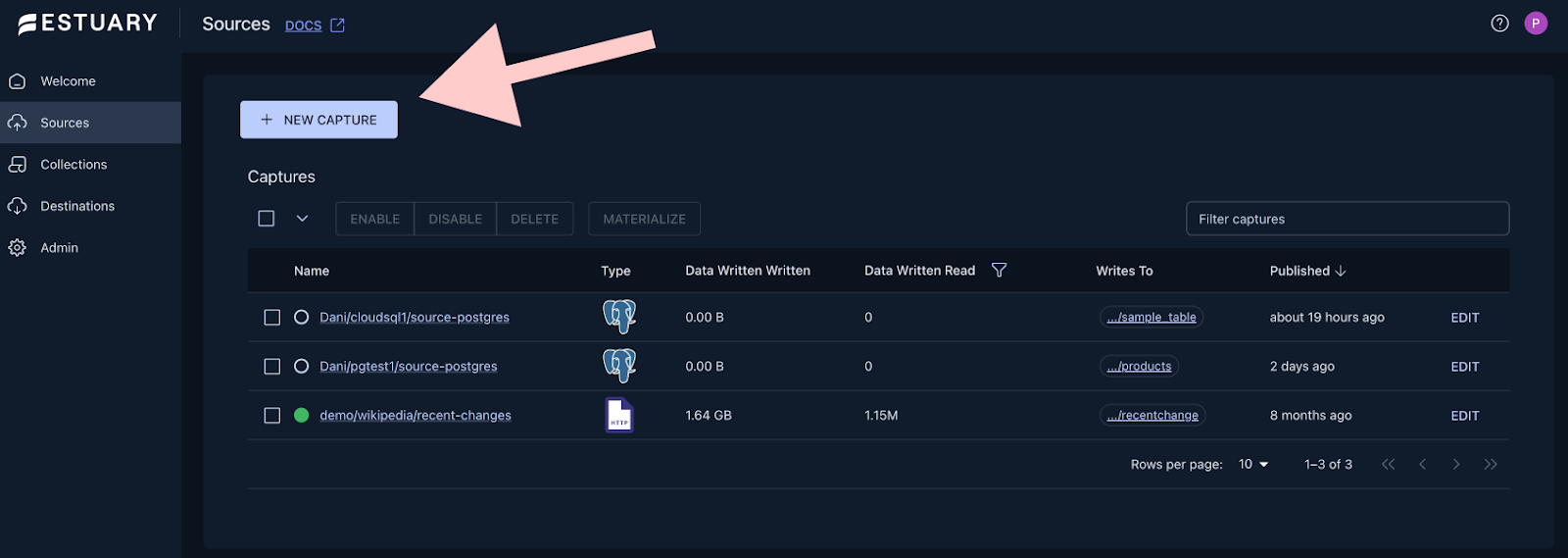
+Go to the sources page by clicking on the **Sources** on the left hand side of your screen, then click on **+ New
+Capture**
+
+
+
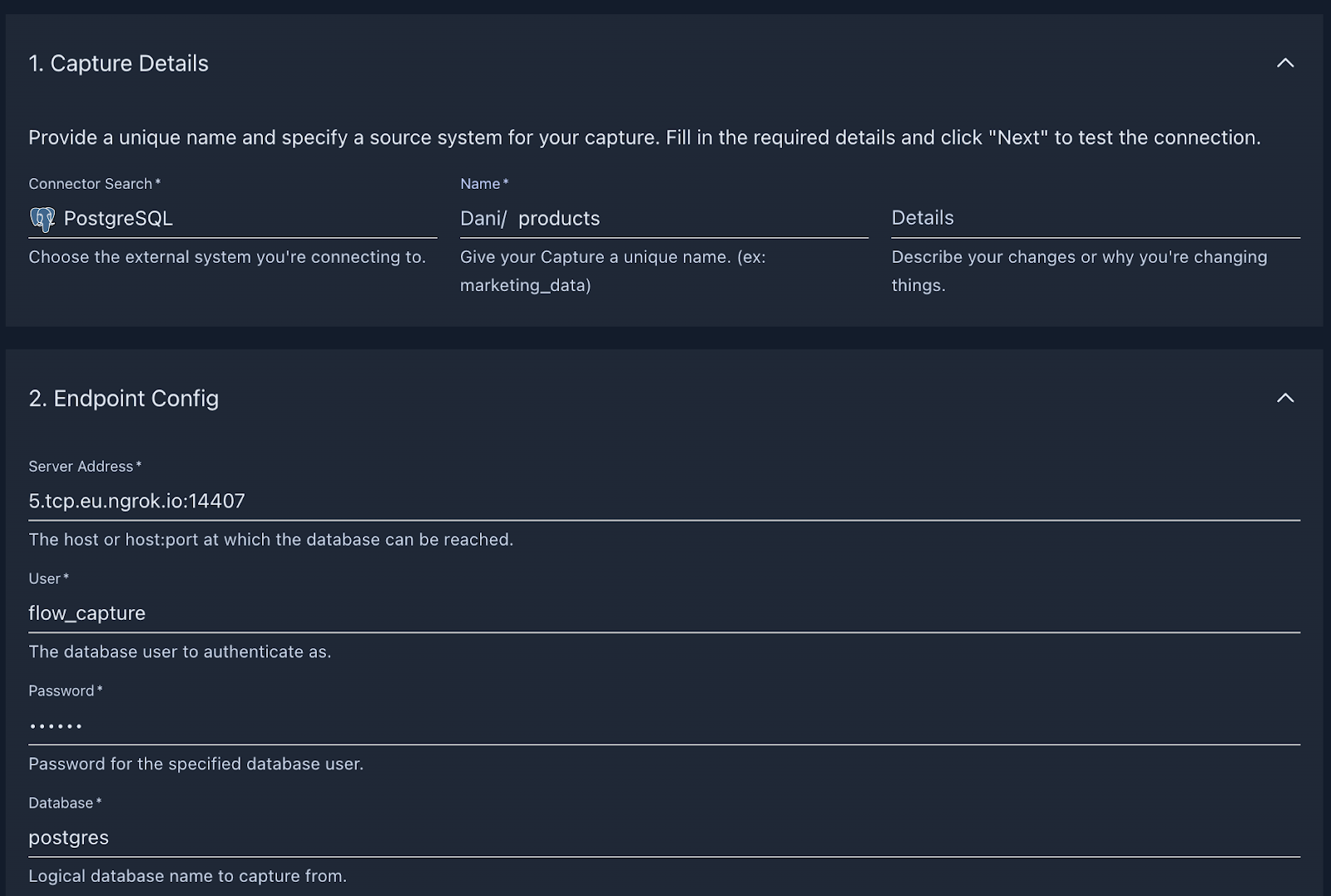
+Configure the connection to the database and press **Next.**
+
+
+
+On the following page, we can configure how our incoming data should be represented in Flow as collections. As a quick
+refresher, let’s recap how Flow represents data on a high level.
+
+**Documents**
+
+The documents of your flows are stored in collections: real-time data lakes of JSON documents in cloud storage.
+Documents being backed by an object storage mean that once you start capturing data, you won’t have to worry about it
+not being available to replay – object stores such as S3 can be configured to cheaply store data forever.
+See [docs page](https://docs.estuary.dev/concepts/collections/#documents) for more information.
+
+**Schemas**
+
+Flow documents and collections always have an associated schema that defines the structure, representation, and
+constraints of your documents. In most cases, Flow generates a functioning schema on your behalf during the discovery
+phase of capture, which has already automatically happened - that’s why you’re able to take a peek into the structure of
+the incoming data!
+
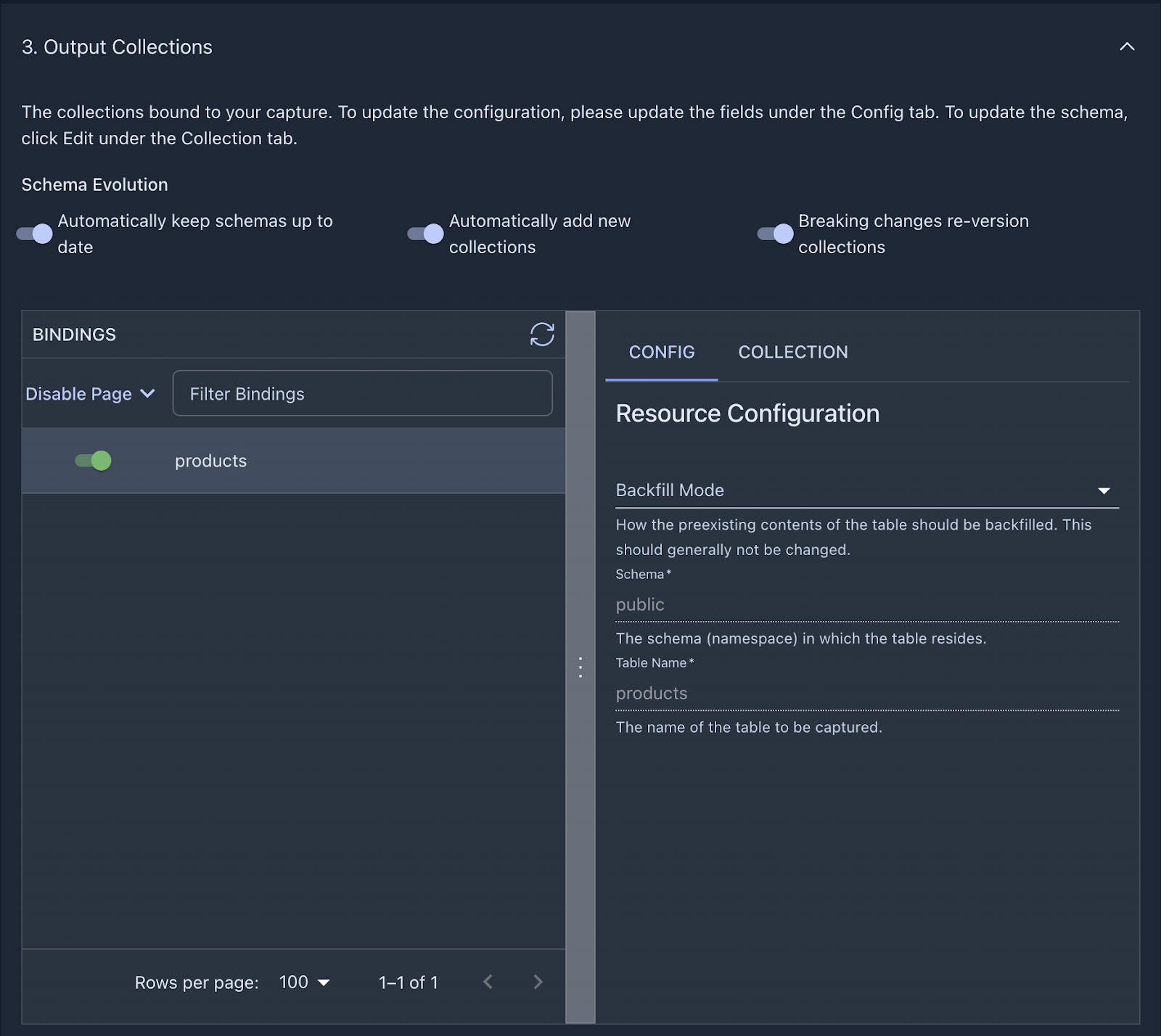
+To see how Flow parsed the incoming records, click on the Collection tab and verify the inferred schema looks correct.
+
+
+
+## Step 2. Set up a Materialization
+
+Similarly to the source side, we’ll need to set up some initial configuration in Snowflake to allow Flow to materialize
+collections into a table.
+
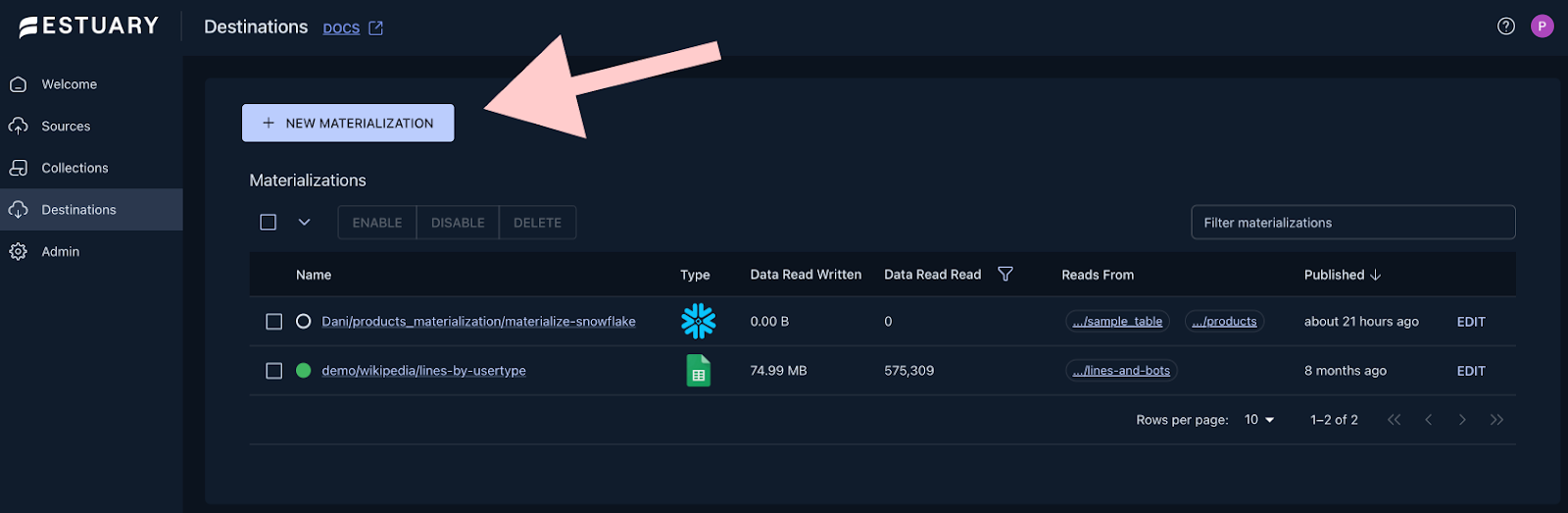
+Head over to the **Destinations** page, where you
+can [create a new Materialization](https://dashboard.estuary.dev/materializations/create).
+
+
+
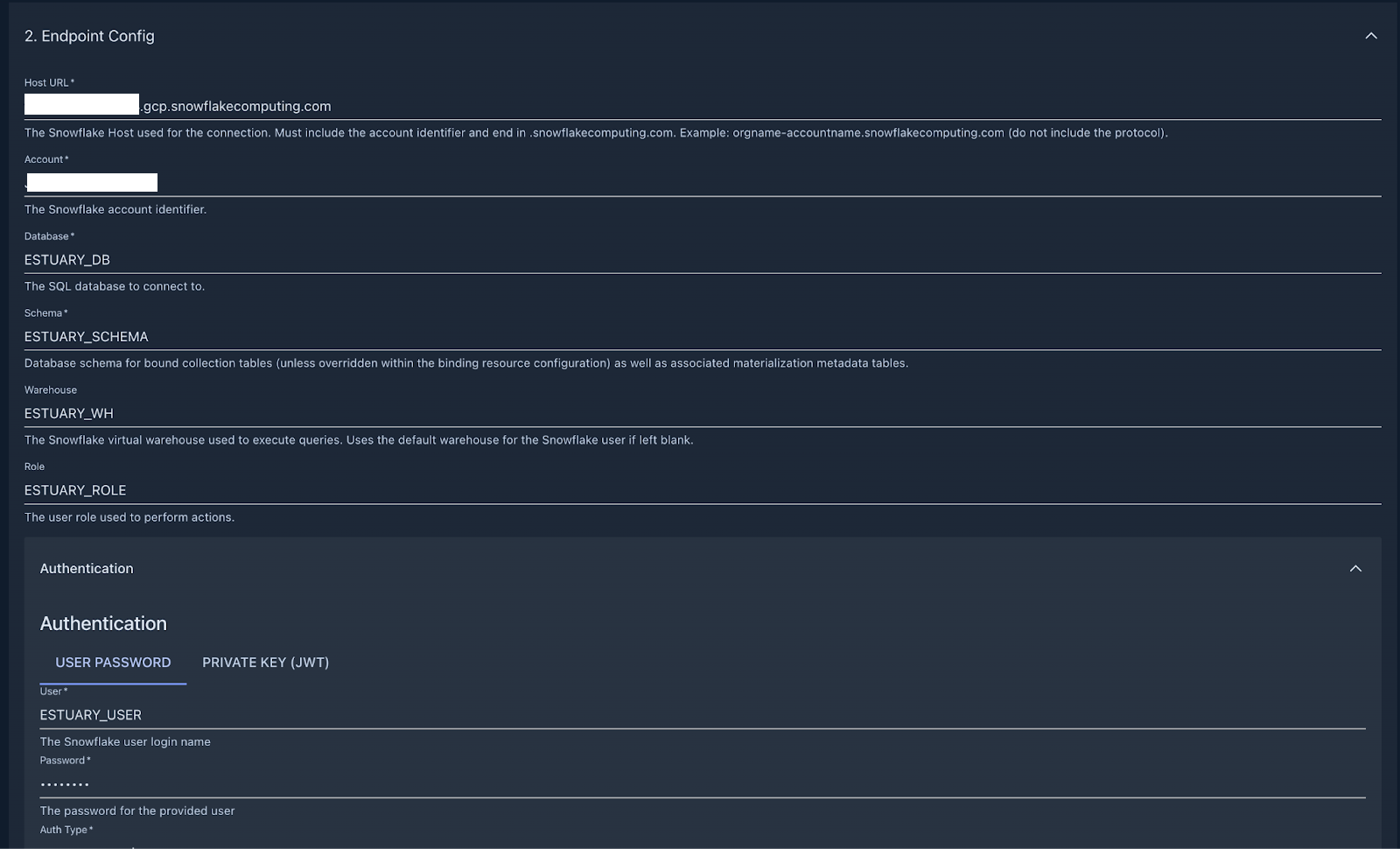
+Choose Snowflake and start filling out the connection details based on the values inside the script you executed in the
+previous step. If you haven’t changed anything, this is how the connector configuration should look like:
+
+
+
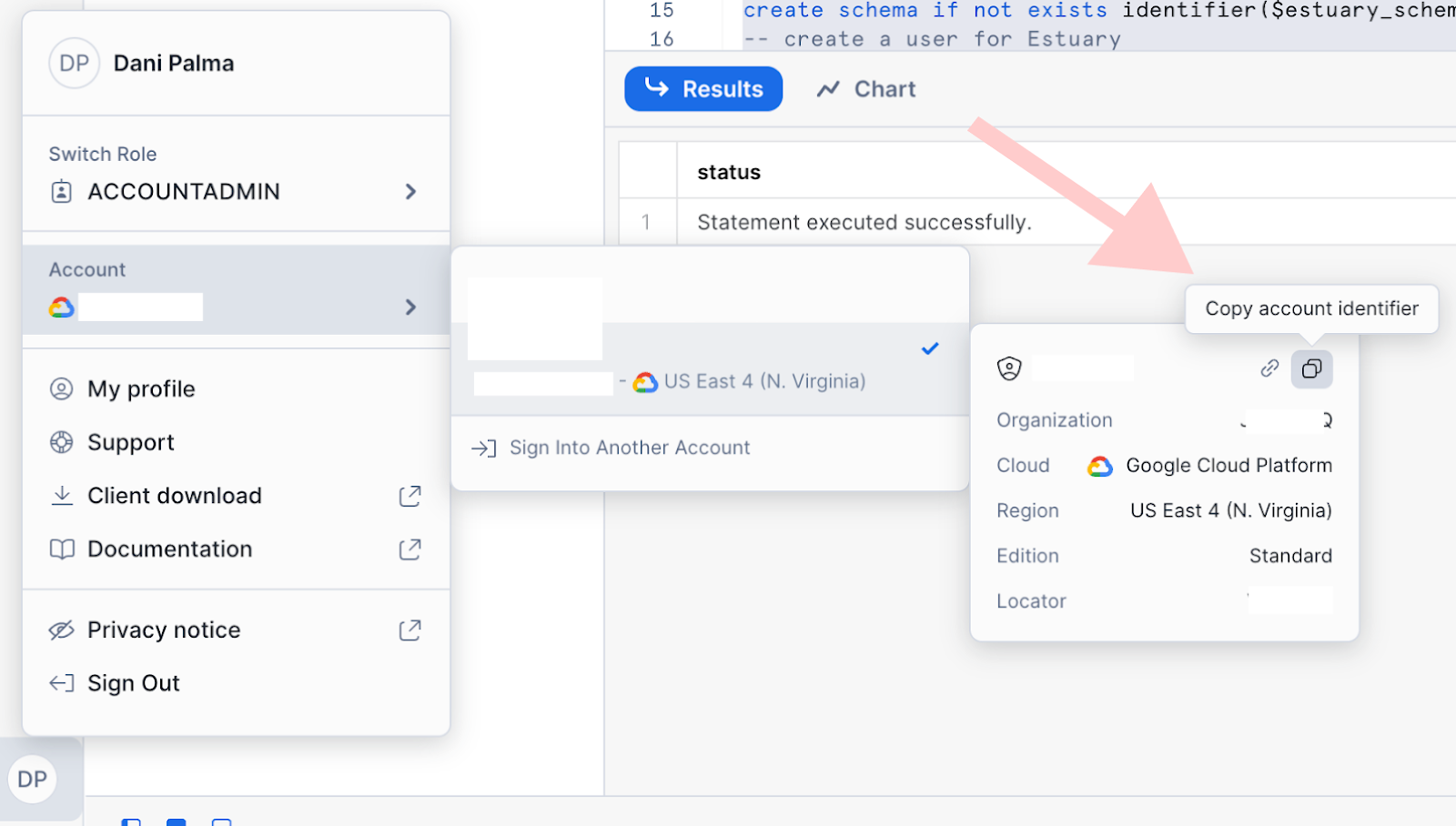
+You can grab your Snowflake host URL and account identifier by navigating to these two little buttons on the Snowflake
+UI.
+
+
+
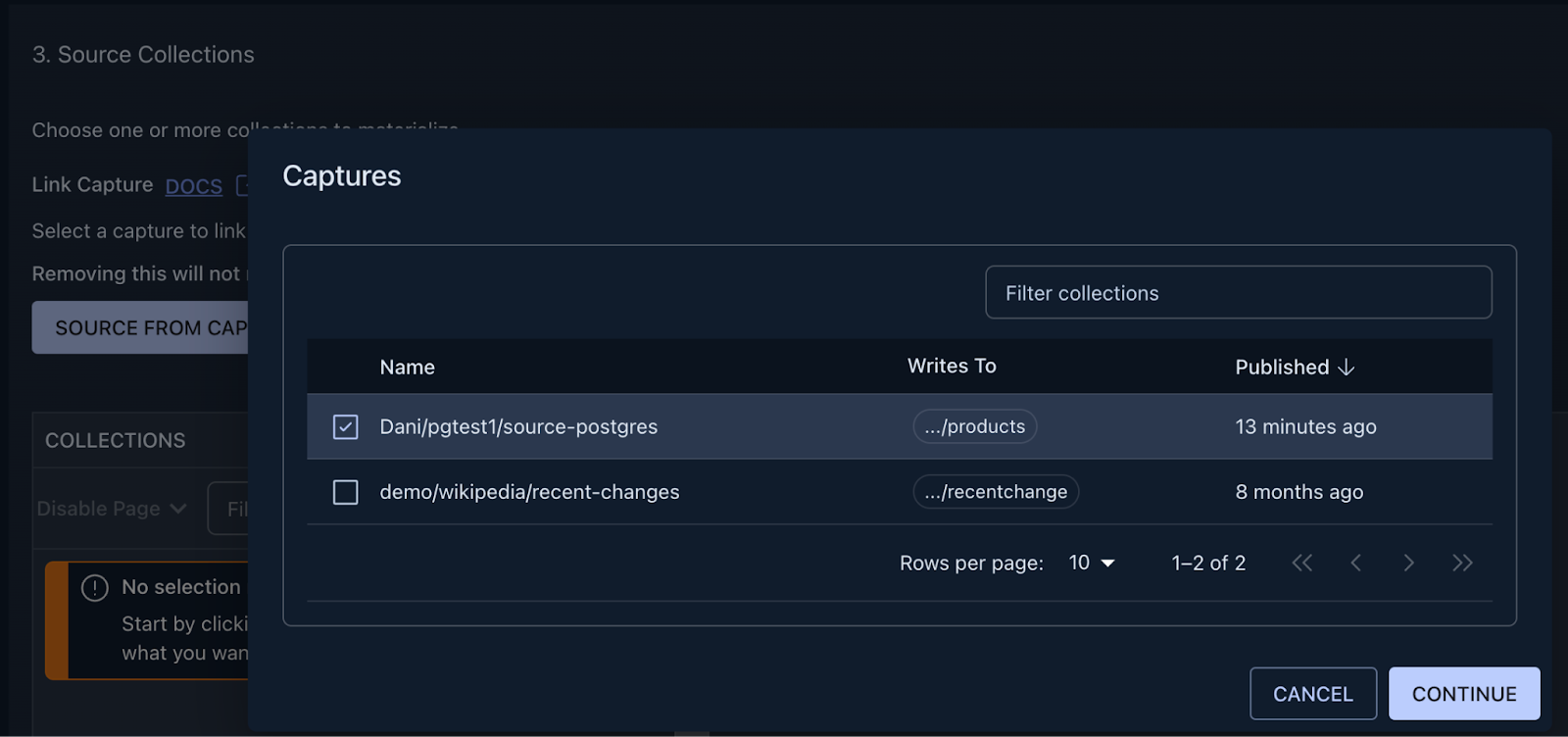
+After the connection details are in place, the next step is to link the capture we just created to Flow is able to see
+collections we are loading data into from Postgres.
+
+You can achieve this by clicking on the “Source from Capture” button, and selecting the name of the capture from the
+table.
+
+
+
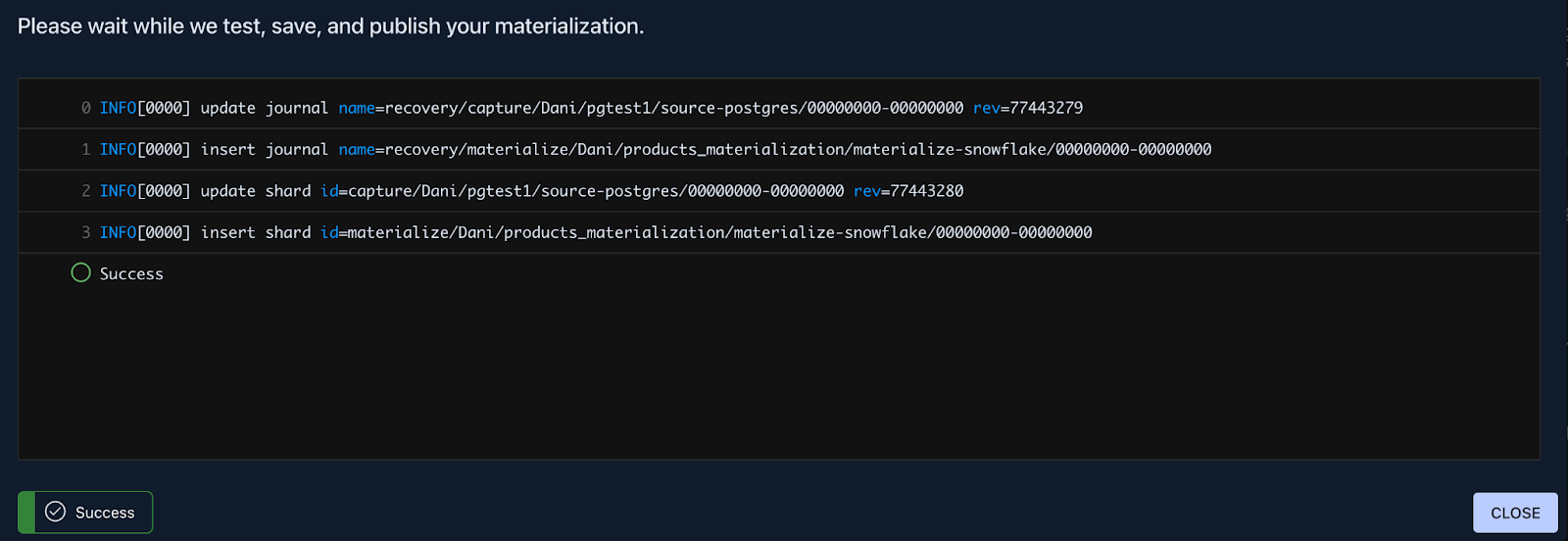
+After pressing continue, you are met with a few configuration options, but for now, feel free to press **Next,** then *
+*Save and Publish** in the top right corner, the defaults will work perfectly fine for this tutorial.
+
+A successful deployment will look something like this:
+
+
+
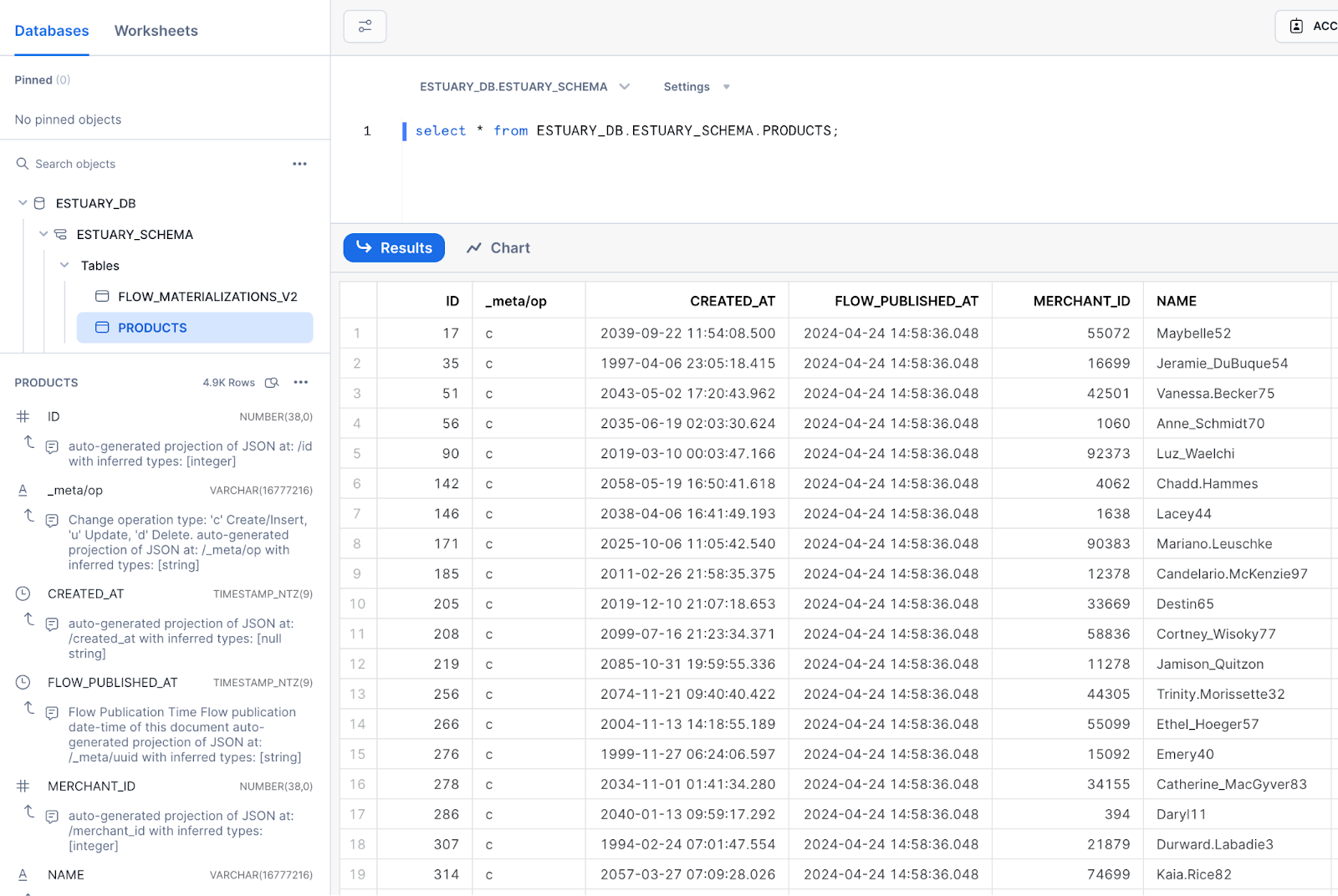
+And that’s it, you’ve successfully published a real-time CDC pipeline. Let’s check out Snowflake to see how
+the data looks.
+
+
+
+Looks like the data is arriving as expected, and the schema of the table is properly configured by the connector based
+on the types of the original table in Postgres.
+
+To get a feel for how the data flow works; head over to the collection details page on the Flow web UI to see your
+changes immediately. On the Snowflake end, they will be materialized after the next update.
+
+## Next Steps
+
+That’s it! You should have everything you need to know to create your own data pipeline for loading data into Snowflake!
+
+Now try it out on your own PostgreSQL database or other sources.
+
+If you want to learn more, make sure you read through the [Estuary documentation](https://docs.estuary.dev/).
+
+You’ll find instructions on how to use other connectors [here](https://docs.estuary.dev/). There are more
+tutorials [here](https://docs.estuary.dev/guides/).
+
+Also, don’t forget to join
+the [Estuary Slack Community](https://estuary-dev.slack.com/ssb/redirect#/shared-invite/email)!
diff --git a/site/docs/getting-started/tutorials/_category_.json b/site/docs/getting-started/tutorials/_category_.json
index 37e404e4f8..07b81ad886 100644
--- a/site/docs/getting-started/tutorials/_category_.json
+++ b/site/docs/getting-started/tutorials/_category_.json
@@ -1,4 +1,4 @@
{
"label": "Tutorials",
- "position": 2
+ "position": 4
}
\ No newline at end of file
diff --git a/site/docs/getting-started/tutorials/continuous-materialized-view.md b/site/docs/getting-started/tutorials/continuous-materialized-view.md
index d8b47a64f0..9f4a575099 100644
--- a/site/docs/getting-started/tutorials/continuous-materialized-view.md
+++ b/site/docs/getting-started/tutorials/continuous-materialized-view.md
@@ -19,7 +19,7 @@ a materialized view that updates continuously based on a real-time data feed.
* A GitLab, GitHub, or BitBucket account. You'll use this to log into [GitPod](https://www.gitpod.io/), the cloud development environment integrated with Flow.
* Alternatively, you can complete this tutorial using a local development environment.
- In that case, you'll need to [install flowctl locally](../../getting-started/installation.mdx#get-started-with-the-flow-cli).
+ In that case, you'll need to [install flowctl locally](../../guides/get-started-with-flowctl.md).
Note that the steps you'll need to take will be different. Refer to this [guide](../../guides/flowctl/create-derivation.md#create-a-derivation-locally) for help.
* A Postgres database set up to [allow connections from Flow](/reference/Connectors/materialization-connectors/PostgreSQL/#setup).
diff --git a/site/docs/overview/who-should-use-flow.md b/site/docs/getting-started/who-should-use-flow.md
similarity index 100%
rename from site/docs/overview/who-should-use-flow.md
rename to site/docs/getting-started/who-should-use-flow.md
diff --git a/site/docs/getting-started/azureAuthorize.jsx b/site/docs/guides/azureAuthorize.jsx
similarity index 100%
rename from site/docs/getting-started/azureAuthorize.jsx
rename to site/docs/guides/azureAuthorize.jsx
diff --git a/site/docs/guides/configure-cloud-storage.md b/site/docs/guides/configure-cloud-storage.md
new file mode 100644
index 0000000000..25e609d826
--- /dev/null
+++ b/site/docs/guides/configure-cloud-storage.md
@@ -0,0 +1,134 @@
+# Configuring your cloud storage bucket for use with Flow
+
+New Flow accounts are connected to Flow's secure cloud storage bucket to store collection data.
+To switch to your own bucket, choose a cloud provider and complete the setup steps:
+
+* [Google Cloud Storage](#google-cloud-storage-buckets)
+
+* [Amazon S3](#amazon-s3-buckets)
+
+* [Azure Blob Storage](#azure-blob-storage)
+
+Once you're done, [get in touch](#give-us-a-ring).
+
+## Google Cloud Storage buckets
+
+You'll need to grant Estuary Flow access to your GCS bucket.
+
+1. [Create a bucket to use with Flow](https://cloud.google.com/storage/docs/creating-buckets), if you haven't already.
+
+2. Follow the steps
+ to [add a principal to a bucket level policy](https://cloud.google.com/storage/docs/access-control/using-iam-permissions#bucket-add).
+ As you do so:
+
+ - For the principal, enter `flow-258@helpful-kingdom-273219.iam.gserviceaccount.com`
+
+ - Select the [`roles/storage.admin`](https://cloud.google.com/storage/docs/access-control/iam-roles) role.
+
+## Amazon S3 buckets
+
+You'll need to grant Estuary Flow access to your S3 bucket.
+
+1. [Create a bucket to use with Flow](https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html),
+ if you haven't already.
+
+2. Follow the steps
+ to [add a bucket policy](https://docs.aws.amazon.com/AmazonS3/latest/userguide/add-bucket-policy.html), pasting the
+ policy below.
+ Be sure to replace `YOUR-S3-BUCKET` with the actual name of your bucket.
+
+```json
+{
+ "Version": "2012-10-17",
+ "Statement": [
+ {
+ "Sid": "AllowUsersToAccessObjectsUnderPrefix",
+ "Effect": "Allow",
+ "Principal": {
+ "AWS": "arn:aws:iam::789740162118:user/flow-aws"
+ },
+ "Action": [
+ "s3:GetObject",
+ "s3:PutObject",
+ "s3:DeleteObject"
+ ],
+ "Resource": "arn:aws:s3:::YOUR-S3-BUCKET/*"
+ },
+ {
+ "Effect": "Allow",
+ "Principal": {
+ "AWS": "arn:aws:iam::789740162118:user/flow-aws"
+ },
+ "Action": "s3:ListBucket",
+ "Resource": "arn:aws:s3:::YOUR-S3-BUCKET"
+ },
+ {
+ "Effect": "Allow",
+ "Principal": {
+ "AWS": "arn:aws:iam::789740162118:user/flow-aws"
+ },
+ "Action": "s3:GetBucketPolicy",
+ "Resource": "arn:aws:s3:::YOUR-S3-BUCKET"
+ }
+ ]
+}
+```
+
+## Azure Blob Storage
+
+You'll need to grant Estuary Flow access to your storage account and container.
+You'll also need to provide some identifying information.
+
+1. [Create an Azure Blob Storage container](https://learn.microsoft.com/en-us/azure/storage/blobs/storage-quickstart-blobs-portal#create-a-container)
+ to use with Flow, if you haven't already.
+
+2. Gather the following information. You'll need this when you contact us to complete setup.
+
+ - Your **Azure AD tenant ID**. You can find this in the **Azure Active Directory** page.
+ 
+
+ - Your **Azure Blob Storage account ID**. You can find this in the **Storage Accounts** page.
+ 
+
+ - Your **Azure Blob Storage container ID**. You can find this inside your storage account.
+ 
+
+ You'll grant Flow access to your storage resources by connecting to Estuary's
+ [Azure application](https://learn.microsoft.com/en-us/azure/active-directory/manage-apps/what-is-application-management).
+
+3. Add Estuary's Azure application to your tenant.
+
+import { AzureAuthorizeComponent } from "./azureAuthorize";
+import BrowserOnly from "@docusaurus/BrowserOnly";
+
+{() => }
+
+4. Grant the application access to your storage account via the
+ [
+ `Storage Blob Data Owner`](https://learn.microsoft.com/en-us/azure/role-based-access-control/built-in-roles#storage-blob-data-owner)
+ IAM role.
+
+ - Inside your storage account's **Access Control (IAM)** tab, click **Add Role Assignment**.
+
+ - Search for `Storage Blob Data Owner` and select it.
+
+ - On the next page, make sure `User, group, or service principal` is selected, then click **+ Select Members**.
+
+ - You must search for the exact name of the application, otherwise it won't show up: `Estuary Storage Mappings Prod`
+
+ - Once you've selected the application, finish granting the role.
+
+ For more help, see
+ the [Azure docs](https://learn.microsoft.com/en-us/azure/role-based-access-control/role-assignments-portal).
+
+## Add the Bucket
+
+If your bucket is for Google Cloud Storage or AWS S3, you can add it yourself. Once you've finished the above steps,
+head to "Admin", "Settings" then "Configure Cloud Storage"
+and enter the relevant information there and we'll start to use your bucket for all data going forward.
+
+If your bucket is for Azure, send support@estuary.dev an email with the name of the storage bucket and any other
+information you gathered per the steps above.
+Let us know whether you want to use this storage bucket to for your whole Flow account, or just a
+specific [prefix](../concepts/catalogs.md#namespace).
+We'll be in touch when it's done!
\ No newline at end of file
diff --git a/site/docs/guides/flowctl/create-derivation.md b/site/docs/guides/flowctl/create-derivation.md
index 2a261b90ae..e477620c2f 100644
--- a/site/docs/guides/flowctl/create-derivation.md
+++ b/site/docs/guides/flowctl/create-derivation.md
@@ -24,7 +24,7 @@ If you need help, see the [guide to create a Data Flow](../create-dataflow.md).
* [GitPod](https://www.gitpod.io/), the cloud development environment integrated with Flow.
GitPod comes ready for derivation writing, with stubbed out files and flowctl installed. You'll need a GitLab, GitHub, or BitBucket account to log in.
- * Your local development environment. [Install flowctl locally](../../getting-started/installation.mdx#get-started-with-the-flow-cli)
+ * Your local development environment. * [Install flowctl locally](../get-started-with-flowctl.md)
## Get started with GitPod
diff --git a/site/docs/guides/flowctl/edit-draft-from-webapp.md b/site/docs/guides/flowctl/edit-draft-from-webapp.md
index 61f3fe60ef..a1d08ffa32 100644
--- a/site/docs/guides/flowctl/edit-draft-from-webapp.md
+++ b/site/docs/guides/flowctl/edit-draft-from-webapp.md
@@ -25,9 +25,9 @@ you can pull the draft into a local environment, finish making changes, and publ
To complete this workflow, you need:
-* An [Estuary account](../../getting-started/installation.mdx)
+* An [Estuary account](../../getting-started/getting-started.md)
-* [flowctl installed locally](../../getting-started/installation.mdx#get-started-with-the-flow-cli)
+* [flowctl installed locally](../get-started-with-flowctl.md)
## Identify the draft and pull it locally
diff --git a/site/docs/guides/flowctl/edit-specification-locally.md b/site/docs/guides/flowctl/edit-specification-locally.md
index 2bc7ee8c25..8c95b612d8 100644
--- a/site/docs/guides/flowctl/edit-specification-locally.md
+++ b/site/docs/guides/flowctl/edit-specification-locally.md
@@ -37,9 +37,9 @@ editing their specifications, and re-publishing them.
To complete this workflow, you need:
-* An [Estuary account](../../getting-started/installation.mdx#registration-and-setup)
+* An [Estuary account](../../getting-started/getting-started.md)
-* [flowctl installed locally](../../getting-started/installation.mdx#get-started-with-the-flow-cli)
+* [flowctl installed locally](../get-started-with-flowctl.md)
* One or more published Flow entities. (To edit unpublished drafts, [use this guide](./edit-draft-from-webapp.md).)
diff --git a/site/docs/guides/flowctl/troubleshoot-task.md b/site/docs/guides/flowctl/troubleshoot-task.md
index e0b6a2113a..c70af5b538 100644
--- a/site/docs/guides/flowctl/troubleshoot-task.md
+++ b/site/docs/guides/flowctl/troubleshoot-task.md
@@ -14,9 +14,9 @@ If a task has errors or is failing in the web app, you'll be able to troubleshoo
To complete this workflow, you need:
-* An [Estuary account](../../getting-started/installation.mdx)
+* An [Estuary account](../../getting-started/getting-started.md)
-* [flowctl installed locally](../../getting-started/installation.mdx#get-started-with-the-flow-cli)
+* [flowctl installed locally](../get-started-with-flowctl.md)
## Print task logs
diff --git a/site/docs/guides/get-started-with-flowctl.md b/site/docs/guides/get-started-with-flowctl.md
new file mode 100644
index 0000000000..e46c899905
--- /dev/null
+++ b/site/docs/guides/get-started-with-flowctl.md
@@ -0,0 +1,61 @@
+# Getting Started With flowctl
+
+After your account has been activated through the [web app](#get-started-with-the-flow-web-application), you can begin to work with your data flows from the command line.
+This is not required, but it enables more advanced workflows or might simply be your preference.
+
+Flow has a single binary, **flowctl**.
+
+flowctl is available for:
+
+- **Linux** x86-64. All distributions are supported.
+- **MacOS** 11 (Big Sur) or later. Both Intel and M1 chips are supported.
+
+To install, copy and paste the appropriate script below into your terminal. This will download flowctl, make it executable, and add it to your `PATH`.
+
+- For Linux:
+
+```console
+sudo curl -o /usr/local/bin/flowctl -L 'https://github.com/estuary/flow/releases/latest/download/flowctl-x86_64-linux' && sudo chmod +x /usr/local/bin/flowctl
+```
+
+- For Mac:
+
+```console
+sudo curl -o /usr/local/bin/flowctl -L 'https://github.com/estuary/flow/releases/latest/download/flowctl-multiarch-macos' && sudo chmod +x /usr/local/bin/flowctl
+```
+
+Alternatively, Mac users can install with Homebrew:
+
+```console
+brew tap estuary/flowctl
+brew install flowctl
+```
+
+flowctl isn't currently available for Windows.
+For Windows users, we recommend running the Linux version inside [WSL](https://learn.microsoft.com/en-us/windows/wsl/),
+or using a remote development environment.
+
+The flowctl source files are also on GitHub [here](https://go.estuary.dev/flowctl).
+
+Once you've installed flowctl and are ready to begin working, authenticate your session using an access token.
+
+1. Ensure that you have an Estuary account and have signed into the Flow web app before.
+
+2. In the terminal of your local development environment, run:
+
+ ```console
+ flowctl auth login
+ ```
+
+ In a browser window, the web app opens to the CLI-API tab.
+
+3. Copy the access token.
+
+4. Return to the terminal, paste the access token, and press Enter.
+
+The token will expire after a predetermined duration. Repeat this process to re-authenticate.
+
+# Next steps
+
+1. [flowctl concepts](../concepts/flowctl.md): Learn more about using flowctl.
+2. [User guides](../guides/flowctl/README.md): Check out some of the detailed user guides to see flowctl in action.
diff --git a/site/docs/overview/README.md b/site/docs/overview/README.md
deleted file mode 100644
index d912c516a4..0000000000
--- a/site/docs/overview/README.md
+++ /dev/null
@@ -1,58 +0,0 @@
----
-sidebar_position: 1
-description: Get to know Estuary Flow and learn how to get started.
-slug: /
----
-
-# Flow documentation
-
-Estuary Flow is a data movement and transformation platform for the whole data team.
-
-With Flow, you build, test, and evolve streaming pipelines (called **data flows** in the Flow ecosystem) that continuously move data across all of your systems with optional in-flight transformations.
-
-You work with Flow through its intuitive web application or using the command line interface.
-Business users and analysts can configure data flows to connect disparate systems in minutes,
-and engineers can then refine those data flows, troubleshoot, and configure complex transformations in their preferred environment.
-
-### Quick start
-
-**Want to get up and running ASAP?**
-
-[Use the web app to sign up.](https://dashboard.estuary.dev) (You start for [free](https://estuary.dev/pricing).)
-
-See the [get started documentation](../getting-started/installation.mdx).
-
-**Wondering if Flow is right for you?**
-
-If you're unsure if Flow is the right solution for your data integration needs, you can read about the technical benefits and clear comparisons with similar systems that may be familiar to you.
-
-* **[Who should use Flow?](overview/who-should-use-flow.md)**
-* **[Comparisons with other systems](overview/comparisons.md)**
-
-**Looking to understand the concepts behind Flow at a deeper level?**
-
-We recommend starting with a tutorial or [guide](../guides/create-dataflow.md) to get acquainted with basic Flow concepts in action.
-After that, read the **[Concepts](concepts/README.md)** to go deeper.
-
-## Real-time data and Flow
-
-Flow synchronizes your systems – SaaS, databases, streaming, and more – around the same datasets, which it stores in the cloud and updates in milliseconds. It combines the easy cross-system integration of an ELT tool and a flexible streaming backbone,
-all while remaining aware of your data's complete history.
-
-A few examples of what you can do with Flow:
-
- * Perform *change data capture* from MySQL tables into PostgreSQL or a cloud analytics warehouse
- * Fetch, transform, and load logs from cloud delivery networks (CDNs) into Elasticsearch or BigQuery
- * Instrument real-time analytics over your business events, accessible from current tools like PostgreSQL or even Google Sheets
- * Capture and organize your data from your SaaS vendors (like Hubspot or Facebook), into a Parquet data lake
-
-Under the hood, Flow comprises cloud-native streaming infrastructure, a powerful runtime for data processing,
-and an open-source ecosystem of pluggable connectors for integrating your existing data systems.
-
-****
-
-### **Other resources**
-
-* Our [website](https://www.estuary.dev) offers general information about Flow, Estuary, and how we fit into the data infrastructure landscape.
-* Our source code lives on [GitHub](https://github.com/estuary).
-
diff --git a/site/docs/overview/_category_.json b/site/docs/overview/_category_.json
deleted file mode 100644
index 4471655de5..0000000000
--- a/site/docs/overview/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "Overview",
- "position": 1
-}
\ No newline at end of file
diff --git a/site/docs/reference/Connectors/capture-connectors/MariaDB/MariaDB.md b/site/docs/reference/Connectors/capture-connectors/MariaDB/MariaDB.md
index 0211eea86c..08b3764f02 100644
--- a/site/docs/reference/Connectors/capture-connectors/MariaDB/MariaDB.md
+++ b/site/docs/reference/Connectors/capture-connectors/MariaDB/MariaDB.md
@@ -195,7 +195,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## Troubleshooting Capture Errors
diff --git a/site/docs/reference/Connectors/capture-connectors/MariaDB/amazon-rds-mariadb.md b/site/docs/reference/Connectors/capture-connectors/MariaDB/amazon-rds-mariadb.md
index 438eafbfd2..44bbd78ec3 100644
--- a/site/docs/reference/Connectors/capture-connectors/MariaDB/amazon-rds-mariadb.md
+++ b/site/docs/reference/Connectors/capture-connectors/MariaDB/amazon-rds-mariadb.md
@@ -163,7 +163,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## Troubleshooting Capture Errors
diff --git a/site/docs/reference/Connectors/capture-connectors/MySQL/MySQL.md b/site/docs/reference/Connectors/capture-connectors/MySQL/MySQL.md
index 1170b77cf4..5c8b48cc60 100644
--- a/site/docs/reference/Connectors/capture-connectors/MySQL/MySQL.md
+++ b/site/docs/reference/Connectors/capture-connectors/MySQL/MySQL.md
@@ -271,7 +271,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## Troubleshooting Capture Errors
diff --git a/site/docs/reference/Connectors/capture-connectors/MySQL/amazon-rds-mysql.md b/site/docs/reference/Connectors/capture-connectors/MySQL/amazon-rds-mysql.md
index 6af8c7e1df..eff6d08e53 100644
--- a/site/docs/reference/Connectors/capture-connectors/MySQL/amazon-rds-mysql.md
+++ b/site/docs/reference/Connectors/capture-connectors/MySQL/amazon-rds-mysql.md
@@ -184,7 +184,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## Troubleshooting Capture Errors
diff --git a/site/docs/reference/Connectors/capture-connectors/MySQL/google-cloud-sql-mysql.md b/site/docs/reference/Connectors/capture-connectors/MySQL/google-cloud-sql-mysql.md
index ae7b5f318b..d865c7003c 100644
--- a/site/docs/reference/Connectors/capture-connectors/MySQL/google-cloud-sql-mysql.md
+++ b/site/docs/reference/Connectors/capture-connectors/MySQL/google-cloud-sql-mysql.md
@@ -159,7 +159,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## Troubleshooting Capture Errors
diff --git a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
index 760c9c6e2b..9b67b6a7d0 100644
--- a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
+++ b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/PostgreSQL.md
@@ -344,7 +344,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## TOASTed values
diff --git a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/Supabase.md b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/Supabase.md
index 9ec6dff460..87181c8372 100644
--- a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/Supabase.md
+++ b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/Supabase.md
@@ -171,7 +171,7 @@ captures:
```
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## TOASTed values
diff --git a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/amazon-rds-postgres.md b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/amazon-rds-postgres.md
index ccf0b048d7..78eb1b2644 100644
--- a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/amazon-rds-postgres.md
+++ b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/amazon-rds-postgres.md
@@ -144,7 +144,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## TOASTed values
diff --git a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/google-cloud-sql-postgres.md b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/google-cloud-sql-postgres.md
index 71a96c3573..819ccc4bcc 100644
--- a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/google-cloud-sql-postgres.md
+++ b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/google-cloud-sql-postgres.md
@@ -128,7 +128,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](../../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## TOASTed values
diff --git a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/neon-postgres.md b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/neon-postgres.md
index 9abc6619c1..1bd3e46777 100644
--- a/site/docs/reference/Connectors/capture-connectors/PostgreSQL/neon-postgres.md
+++ b/site/docs/reference/Connectors/capture-connectors/PostgreSQL/neon-postgres.md
@@ -184,7 +184,7 @@ captures:
```
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](../../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## TOASTed values
diff --git a/site/docs/reference/Connectors/capture-connectors/SQLServer/amazon-rds-sqlserver.md b/site/docs/reference/Connectors/capture-connectors/SQLServer/amazon-rds-sqlserver.md
index 4035ab7ae1..9da364bb04 100644
--- a/site/docs/reference/Connectors/capture-connectors/SQLServer/amazon-rds-sqlserver.md
+++ b/site/docs/reference/Connectors/capture-connectors/SQLServer/amazon-rds-sqlserver.md
@@ -126,7 +126,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## Specifying Flow collection keys
diff --git a/site/docs/reference/Connectors/capture-connectors/SQLServer/google-cloud-sql-sqlserver.md b/site/docs/reference/Connectors/capture-connectors/SQLServer/google-cloud-sql-sqlserver.md
index 90ba6049dd..4852f0edd8 100644
--- a/site/docs/reference/Connectors/capture-connectors/SQLServer/google-cloud-sql-sqlserver.md
+++ b/site/docs/reference/Connectors/capture-connectors/SQLServer/google-cloud-sql-sqlserver.md
@@ -119,7 +119,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## Specifying Flow collection keys
diff --git a/site/docs/reference/Connectors/capture-connectors/SQLServer/sqlserver.md b/site/docs/reference/Connectors/capture-connectors/SQLServer/sqlserver.md
index bd72dcd0c4..83a1b56d6a 100644
--- a/site/docs/reference/Connectors/capture-connectors/SQLServer/sqlserver.md
+++ b/site/docs/reference/Connectors/capture-connectors/SQLServer/sqlserver.md
@@ -171,7 +171,7 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](/concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](/concepts/captures.md)
## Specifying Flow collection keys
diff --git a/site/docs/reference/Connectors/capture-connectors/alloydb.md b/site/docs/reference/Connectors/capture-connectors/alloydb.md
index 5d1258dc7b..0b6049f597 100644
--- a/site/docs/reference/Connectors/capture-connectors/alloydb.md
+++ b/site/docs/reference/Connectors/capture-connectors/alloydb.md
@@ -139,4 +139,4 @@ captures:
```
Your capture definition will likely be more complex, with additional bindings for each table in the source database.
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
diff --git a/site/docs/reference/Connectors/capture-connectors/amazon-kinesis.md b/site/docs/reference/Connectors/capture-connectors/amazon-kinesis.md
index 762f9f8ddc..e687ac7817 100644
--- a/site/docs/reference/Connectors/capture-connectors/amazon-kinesis.md
+++ b/site/docs/reference/Connectors/capture-connectors/amazon-kinesis.md
@@ -72,4 +72,4 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each Kinesis stream.
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures).
+[Learn more about capture definitions.](../../../concepts/captures.md).
diff --git a/site/docs/reference/Connectors/capture-connectors/amazon-s3.md b/site/docs/reference/Connectors/capture-connectors/amazon-s3.md
index 4c780fa795..a96c7981cb 100644
--- a/site/docs/reference/Connectors/capture-connectors/amazon-s3.md
+++ b/site/docs/reference/Connectors/capture-connectors/amazon-s3.md
@@ -141,7 +141,7 @@ captures:
Your capture definition may be more complex, with additional bindings for different S3 prefixes within the same bucket.
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
### Advanced: Parsing cloud storage data
diff --git a/site/docs/reference/Connectors/capture-connectors/apache-kafka.md b/site/docs/reference/Connectors/capture-connectors/apache-kafka.md
index 069d198fb9..18a7aa529f 100644
--- a/site/docs/reference/Connectors/capture-connectors/apache-kafka.md
+++ b/site/docs/reference/Connectors/capture-connectors/apache-kafka.md
@@ -133,4 +133,4 @@ captures:
Your capture definition will likely be more complex, with additional bindings for each Kafka topic.
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures).
+[Learn more about capture definitions.](../../../concepts/captures.md).
diff --git a/site/docs/reference/Connectors/capture-connectors/exchange-rates.md b/site/docs/reference/Connectors/capture-connectors/exchange-rates.md
index ddac77e1a3..bb0eeac66c 100644
--- a/site/docs/reference/Connectors/capture-connectors/exchange-rates.md
+++ b/site/docs/reference/Connectors/capture-connectors/exchange-rates.md
@@ -62,4 +62,4 @@ captures:
This capture definition should only have one binding, as `exchange_rates` is the only available data stream.
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
diff --git a/site/docs/reference/Connectors/capture-connectors/facebook-marketing.md b/site/docs/reference/Connectors/capture-connectors/facebook-marketing.md
index 11c0cd0db3..2e5ba73c08 100644
--- a/site/docs/reference/Connectors/capture-connectors/facebook-marketing.md
+++ b/site/docs/reference/Connectors/capture-connectors/facebook-marketing.md
@@ -191,4 +191,4 @@ captures:
target: ${PREFIX}/ad_creatives
```
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
diff --git a/site/docs/reference/Connectors/capture-connectors/gcs.md b/site/docs/reference/Connectors/capture-connectors/gcs.md
index 2d16c79ffe..23085fbcf4 100644
--- a/site/docs/reference/Connectors/capture-connectors/gcs.md
+++ b/site/docs/reference/Connectors/capture-connectors/gcs.md
@@ -83,7 +83,7 @@ captures:
Your capture definition may be more complex, with additional bindings for different GCS prefixes within the same bucket.
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
### Advanced: Parsing cloud storage data
diff --git a/site/docs/reference/Connectors/capture-connectors/google-analytics.md b/site/docs/reference/Connectors/capture-connectors/google-analytics.md
index 0e58855b21..cbe9fa0f48 100644
--- a/site/docs/reference/Connectors/capture-connectors/google-analytics.md
+++ b/site/docs/reference/Connectors/capture-connectors/google-analytics.md
@@ -209,7 +209,7 @@ captures:
target: ${PREFIX}/${COLLECTION_NAME}
```
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
## Performance considerations
diff --git a/site/docs/reference/Connectors/capture-connectors/google-sheets.md b/site/docs/reference/Connectors/capture-connectors/google-sheets.md
index 50960edfa6..d2adc193af 100644
--- a/site/docs/reference/Connectors/capture-connectors/google-sheets.md
+++ b/site/docs/reference/Connectors/capture-connectors/google-sheets.md
@@ -107,4 +107,4 @@ captures:
target: ${PREFIX}/${COLLECTION_NAME}
```
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
diff --git a/site/docs/reference/Connectors/capture-connectors/hubspot.md b/site/docs/reference/Connectors/capture-connectors/hubspot.md
index 3b9eec16f4..351b82729e 100644
--- a/site/docs/reference/Connectors/capture-connectors/hubspot.md
+++ b/site/docs/reference/Connectors/capture-connectors/hubspot.md
@@ -127,4 +127,4 @@ captures:
Your configuration will have many more bindings representing all supported [resources](#supported-data-resources)
in your Hubspot account.
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
diff --git a/site/docs/reference/Connectors/capture-connectors/mailchimp.md b/site/docs/reference/Connectors/capture-connectors/mailchimp.md
index ddf74e4a58..e2033716eb 100644
--- a/site/docs/reference/Connectors/capture-connectors/mailchimp.md
+++ b/site/docs/reference/Connectors/capture-connectors/mailchimp.md
@@ -82,4 +82,4 @@ captures:
target: ${PREFIX}/${COLLECTION_NAME}
```
-[Learn more about capture definitions.](../../../concepts/captures.md#pull-captures)
+[Learn more about capture definitions.](../../../concepts/captures.md)
diff --git a/site/docusaurus.config.js b/site/docusaurus.config.js
index bfeaea06b4..824ee7e7ce 100644
--- a/site/docusaurus.config.js
+++ b/site/docusaurus.config.js
@@ -123,7 +123,7 @@ const config = {
items: [
{
type: 'doc',
- docId: 'overview/README',
+ docId: 'getting-started/getting-started',
position: 'left',
label: 'Documentation',
},