Bring AI inside your database system and build AI-powered apps
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
![]() +
+
+
+
Follow EvaDB
+ + - EvaDB is a database system for building simpler and faster AI-powered applications.
Share EvaDB
-EvaDB is a database system for developing AI apps. We aim to simplify the development and deployment of AI apps that operate on unstructured data (text documents, videos, PDFs, podcasts, etc.) and structured data (tables, vector index). +
-The high-level Python and SQL APIs allow beginners to use EvaDB in a few lines of code. Advanced users can define custom user-defined functions that wrap around any AI model or Python library. EvaDB is fully implemented in Python and licensed under an Apache license.
+
+



 |
| |
+* Run ChatGPT on the `text` column in a table.
-### 🔮 [PDF Question Answering](https://evadb.readthedocs.io/en/stable/source/tutorials/12-query-pdf.html) (Question Answering Model)
+```sql
+SELECT ChatGPT('Is this video summary related to Ukraine russia war', text)
+ FROM text_summary;
+```
-| App |
-|-----|
-|
|
+* Run ChatGPT on the `text` column in a table.
-### 🔮 [PDF Question Answering](https://evadb.readthedocs.io/en/stable/source/tutorials/12-query-pdf.html) (Question Answering Model)
+```sql
+SELECT ChatGPT('Is this video summary related to Ukraine russia war', text)
+ FROM text_summary;
+```
-| App |
-|-----|
-| |
+* Train an ML model using the Ludwig AI engine to predict a column in a table.
-### 🔮 [MNIST Digit Recognition](https://evadb.readthedocs.io/en/stable/source/tutorials/01-mnist.html) (Image Classification Model)
-| Source Video | Query Result |
-|---------------|--------------|
-|
|
+* Train an ML model using the Ludwig AI engine to predict a column in a table.
-### 🔮 [MNIST Digit Recognition](https://evadb.readthedocs.io/en/stable/source/tutorials/01-mnist.html) (Image Classification Model)
-| Source Video | Query Result |
-|---------------|--------------|
-| |
| |
+```sql
+CREATE FUNCTION IF NOT EXISTS PredictHouseRent FROM
+( SELECT * FROM HomeRentals )
+TYPE Ludwig
+PREDICT 'rental_price'
+TIME_LIMIT 120;
+```
-### 🔮 [Movie Emotion Analysis](https://evadb.readthedocs.io/en/stable/source/tutorials/03-emotion-analysis.html) (Face Detection + Emotion Classification Models)
+
|
+```sql
+CREATE FUNCTION IF NOT EXISTS PredictHouseRent FROM
+( SELECT * FROM HomeRentals )
+TYPE Ludwig
+PREDICT 'rental_price'
+TIME_LIMIT 120;
+```
-### 🔮 [Movie Emotion Analysis](https://evadb.readthedocs.io/en/stable/source/tutorials/03-emotion-analysis.html) (Face Detection + Emotion Classification Models)
+ |
| |
+## Architecture of EvaDB
-### 🔮 [License Plate Recognition](https://github.com/georgia-tech-db/evadb-application-template) (Plate Detection + OCR Extraction Models)
+
|
+## Architecture of EvaDB
-### 🔮 [License Plate Recognition](https://github.com/georgia-tech-db/evadb-application-template) (Plate Detection + OCR Extraction Models)
+ |
+
|
+
+ 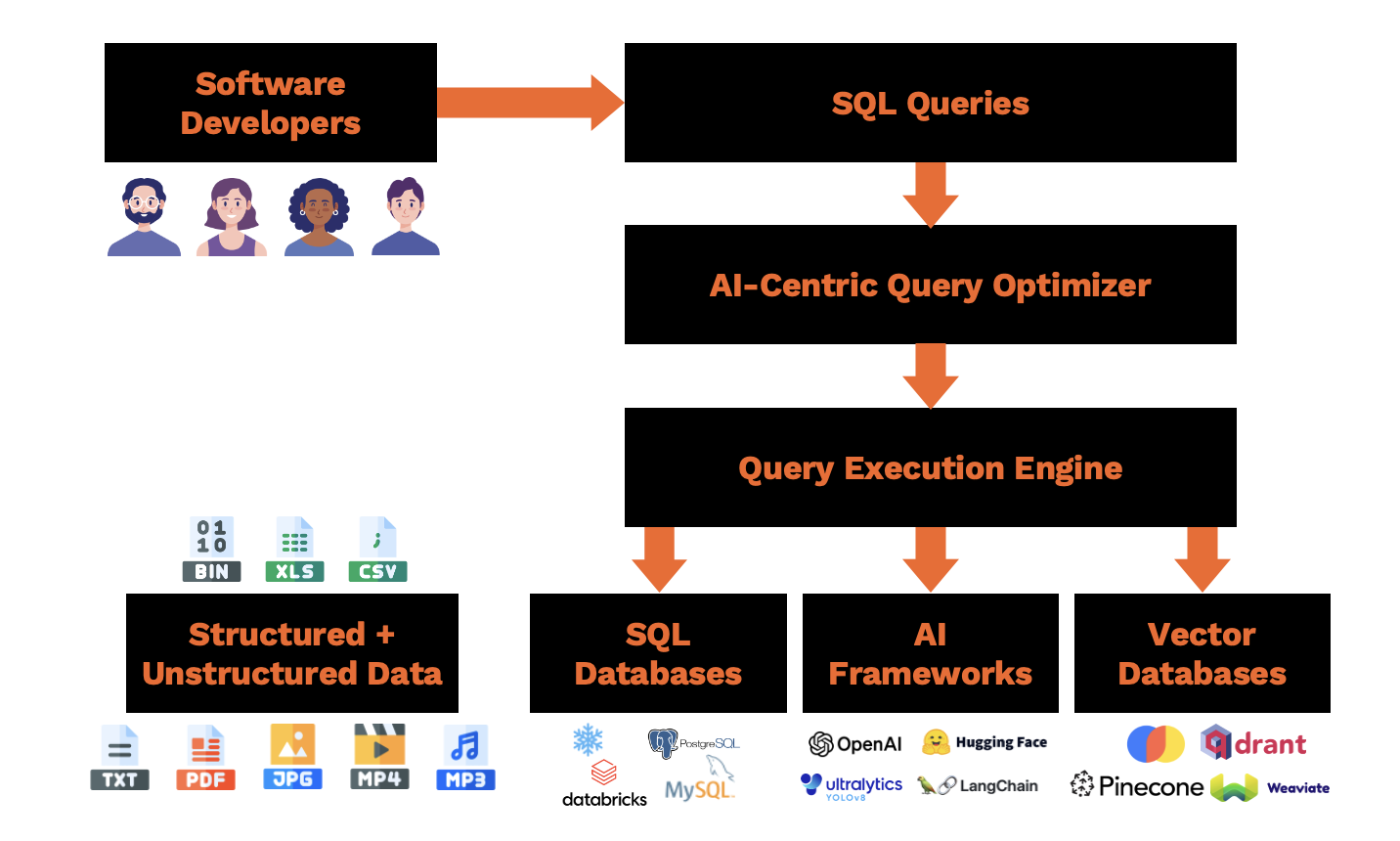 +
+
 -
+
-If you run into any problems or issues, please create a Github issue.
+If you run into any bugs or have any comments, you can reach us on our Slack Community 📟 or create a [Github Issue :bug:](https://github.com/georgia-tech-db/evadb/issues).
-Don't see a feature in the list? Search our issue tracker if someone has already requested it and add a comment to it explaining your use-case, or open a new issue if not. We prioritize our [roadmap](https://github.com/orgs/georgia-tech-db/projects/3) based on user feedback, so we'd love to hear from you.
+Here is EvaDB's public [roadmap 🛤️](https://github.com/orgs/georgia-tech-db/projects/3). We prioritize features based on user feedback, so we'd love to hear from you!
## Contributing
-[](https://pypi.org/project/evadb)
-[](https://circleci.com/gh/georgia-tech-db/evadb)
-[](https://evadb.readthedocs.io/en/latest/index.html)
+We are a lean team on a mission to bring AI inside database systems! All kinds of contributions to EvaDB are appreciated 🙌 If you'd like to get involved, here's information on where we could use your help: [contribution guide](https://evadb.readthedocs.io/en/latest/source/dev-guide/contribute.html) 🤗
-EvaDB is the beneficiary of many [contributors](https://github.com/georgia-tech-db/evadb/graphs/contributors). All kinds of contributions to EvaDB are appreciated. To file a bug or to request a feature, please use GitHub issues. Pull requests are welcome.
+
-
+
-If you run into any problems or issues, please create a Github issue.
+If you run into any bugs or have any comments, you can reach us on our Slack Community 📟 or create a [Github Issue :bug:](https://github.com/georgia-tech-db/evadb/issues).
-Don't see a feature in the list? Search our issue tracker if someone has already requested it and add a comment to it explaining your use-case, or open a new issue if not. We prioritize our [roadmap](https://github.com/orgs/georgia-tech-db/projects/3) based on user feedback, so we'd love to hear from you.
+Here is EvaDB's public [roadmap 🛤️](https://github.com/orgs/georgia-tech-db/projects/3). We prioritize features based on user feedback, so we'd love to hear from you!
## Contributing
-[](https://pypi.org/project/evadb)
-[](https://circleci.com/gh/georgia-tech-db/evadb)
-[](https://evadb.readthedocs.io/en/latest/index.html)
+We are a lean team on a mission to bring AI inside database systems! All kinds of contributions to EvaDB are appreciated 🙌 If you'd like to get involved, here's information on where we could use your help: [contribution guide](https://evadb.readthedocs.io/en/latest/source/dev-guide/contribute.html) 🤗
-EvaDB is the beneficiary of many [contributors](https://github.com/georgia-tech-db/evadb/graphs/contributors). All kinds of contributions to EvaDB are appreciated. To file a bug or to request a feature, please use GitHub issues. Pull requests are welcome.
+
+
+
+
+
+
+
+
+
Understand how to use EvaDB to build AI apps.
Understand how to use EvaDB to build AI apps.
@@ -58,14 +52,16 @@ Getting StartedLearn about the EvaDB features.
-Learn about the EvaDB features.
+Learn the + high-level concepts related to EvaDB.
++ Learn the high-level concepts related to EvaDB.
Learn more >
Support >
| \n",
+ " | \n",
+ " \n",
+ "  View source on GitHub\n",
+ " View source on GitHub\n",
+ " | \n",
+ " \n",
+ " | \n",
+ "
| \n", + " | 0 | \n", + "
|---|---|
| 0 | \n", + "The database postgres_data has been successful... | \n", + "
| \n", + " | status | \n", + "
|---|---|
| 0 | \n", + "success | \n", + "
| \n", + " | status | \n", + "
|---|---|
| 0 | \n", + "success | \n", + "
| \n", + " | status | \n", + "
|---|---|
| 0 | \n", + "success | \n", + "
| \n", + " | status | \n", + "
|---|---|
| 0 | \n", + "success | \n", + "
| \n", + " | status | \n", + "
|---|---|
| 0 | \n", + "success | \n", + "
| \n", + " | review_table.name | \n", + "review_table.review | \n", + "
|---|---|---|
| 0 | \n", + "Customer 1 | \n", + "ordered fried rice but it is too salty. | \n", + "
| 1 | \n", + "Customer 2 | \n", + "I ordered burger. It tastes very good and the ... | \n", + "
| 2 | \n", + "Customer 3 | \n", + "I ordered a takeout order, but the chicken san... | \n", + "
| \n", + " | chatgpt.response | \n", + "
|---|---|
| 0 | \n", + "negative | \n", + "
| 1 | \n", + "positive | \n", + "
| 2 | \n", + "negative | \n", + "
| \n", + " | chatgpt.response | \n", + "
|---|---|
| 0 | \n", + "Dear valued customer, Thank you for bringing this matter to our attention. We apologize for the inconvenience caused by the excessive saltiness of your fried rice. We understand how important it is to have a satisfying dining experience, and we would like to make it right for you. To address your concern, we have taken the following steps: 1. Recipe adjustment: We have reviewed our fried rice recipe and made necessary adjustments to ensure that the saltiness is balanced and meets our customers' expectations. 2. Staff training: We have conducted additional training sessions with our kitchen staff to emphasize the importance of proper seasoning and taste testing before serving any dish. 3. Quality control: Our management team will be implementing stricter quality control measures to ensure that every dish leaving our kitchen meets our high standards. We would like to invite you to give us another chance to serve you. Please reach out to our customer service team, and we will be more than happy to offer you a replacement dish or a refund for your order. We value your feedback and want to ensure that you have a positive experience with us. Once again, we apologize for any inconvenience caused, and we appreciate your understanding. We look forward to the opportunity to make it right for you. Best regards, [Your Name] [Restaurant Name] | \n",
+ "
| 1 | \n", + "Dear [Customer's Name], Thank you for bringing this issue to our attention. We apologize for the inconvenience caused by the missing chicken sandwich in your takeout order. We understand how frustrating it can be when an item is missing from your meal. To address this concern, we would like to offer you two possible solutions: 1. Replacement: We can arrange for a new chicken sandwich to be prepared and delivered to your location as soon as possible. Please let us know your preferred time for the replacement. 2. Refund: If you prefer not to receive a replacement, we can issue a refund for the missing chicken sandwich. The refund will be processed through the same payment method used for the original order. Please let us know which option you would prefer, and we will take immediate action to resolve this issue for you. We value your satisfaction and want to ensure that you have a positive experience with our service. Once again, we apologize for any inconvenience caused, and we appreciate your understanding. If you have any further questions or concerns, please don't hesitate to reach out to us. Best regards, [Your Name] [Restaurant Name] | \n",
+ "
 -
-  +
+ +
+