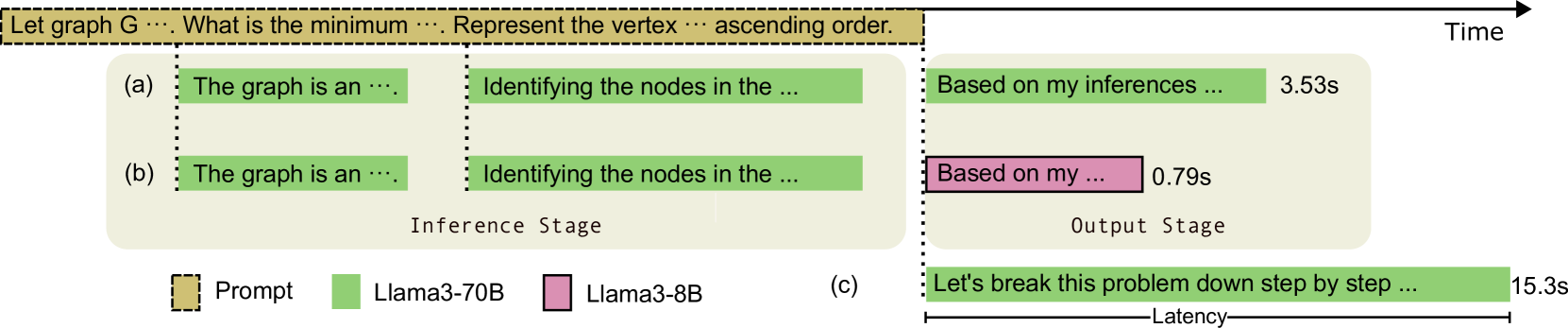
Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
Zichang Liu, Jue WANG, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, Beidi Chen |
 |
Github
Paper |

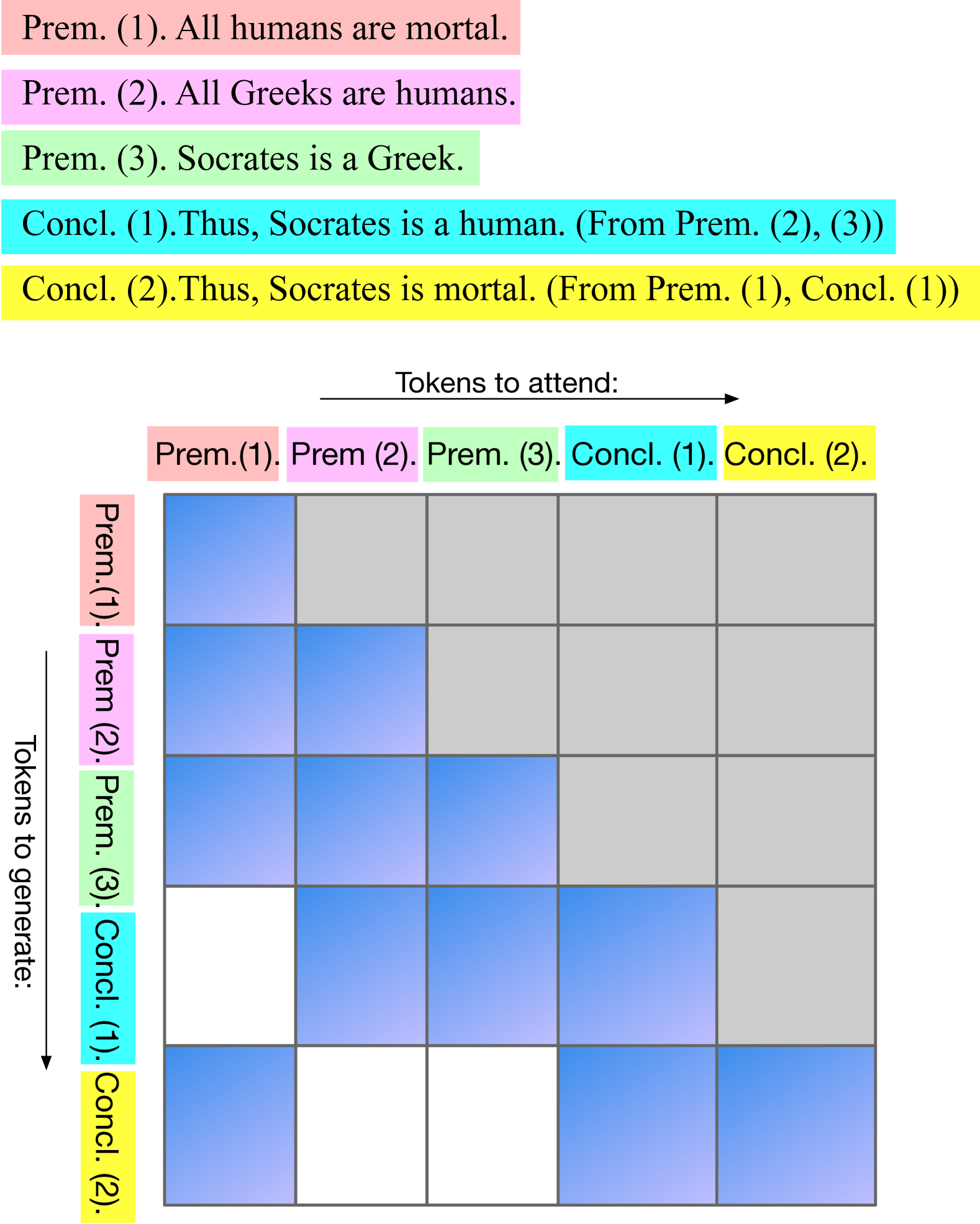
Dynamic Context Pruning for Efficient and Interpretable Autoregressive Transformers
Sotiris Anagnostidis, Dario Pavllo, Luca Biggio, Lorenzo Noci, Aurelien Lucchi, Thomas Hofmann |
 |
Paper |

H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, Beidi Chen |
 |
Github
Paper |
 
Fast and Robust Early-Exiting Framework for Autoregressive Language Models with Synchronized Parallel Decoding
Sangmin Bae, Jongwoo Ko, Hwanjun Song, Se-Young Yun |
 |
Github
Paper |

Compressing Context to Enhance Inference Efficiency of Large Language Models
Yucheng Li, Bo Dong, Chenghua Lin, Frank Guerin |
 |
Github
Paper |

ConsistentEE: A Consistent and Hardness-Guided Early Exiting Method for Accelerating Language Models Inference
Ziqian Zeng, Yihuai Hong, Hongliang Dai, Huiping Zhuang, Cen Chen |
 |
Paper |

Accelerating LLM Inference with Staged Speculative Decoding
Benjamin Spector, Chris Re |
 |
Paper |

TCRA-LLM: Token Compression Retrieval Augmented Large Language Model for Inference Cost Reduction
Junyi Liu, Liangzhi Li, Tong Xiang, Bowen Wang, Yiming Qian |
 |
Paper |
Inference with Reference: Lossless Acceleration of Large Language Models
Nan Yang, Tao Ge, Liang Wang, Binxing Jiao, Daxin Jiang, Linjun Yang, Rangan Majumder, Furu Wei |
 |
Github
paper |

SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, Zhihao Jia |
 |
Github
paper |
SkipDecode: Autoregressive Skip Decoding with Batching and Caching for Efficient LLM Inference
Luciano Del Corro, Allie Del Giorno, Sahaj Agarwal, Bin Yu, Ahmed Awadallah, Subhabrata Mukherjee |
 |
Paper |
Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
Xuefei Ning, Zinan Lin, Zixuan Zhou, Huazhong Yang, Yu Wang |
 |
Paper |

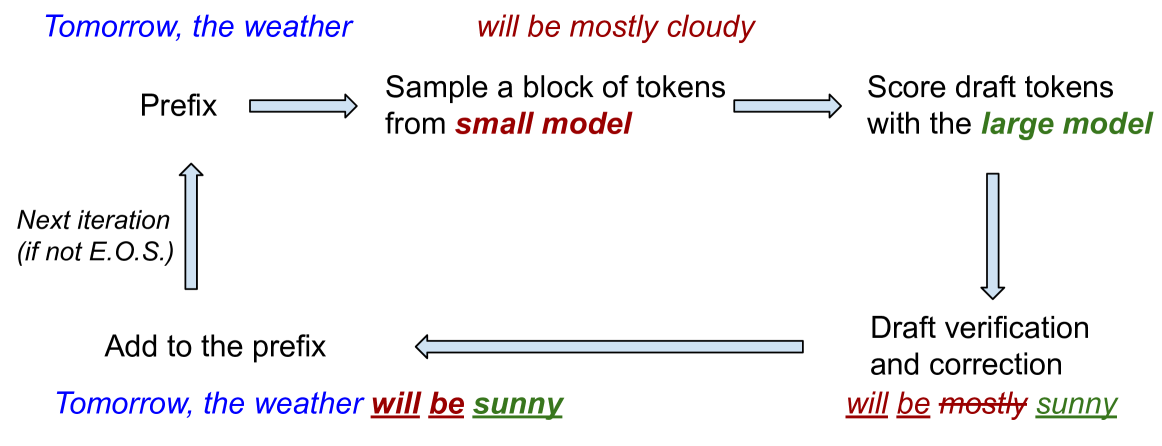
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, Sharad Mehrotra |
 |
Github
Paper |

Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis |
 |
Github
Paper |
(Dynamic) Prompting might be all you need to repair Compressed LLMs
Duc N.M Hoang, Minsik Cho, Thomas Merth, Mohammad Rastegari, Zhangyang Wang |
 |
Paper |

Large Language Model Cascades with Mixture of Thoughts Representations for Cost-efficient Reasoning
Murong Yue, Jie Zhao, Min Zhang, Liang Du, Ziyu Yao |
 |
Github
Paper |
CacheGen: Fast Context Loading for Language Model Applications
Yuhan Liu, Hanchen Li, Kuntai Du, Jiayi Yao, Yihua Cheng, Yuyang Huang, Shan Lu, Michael Maire, Henry Hoffmann, Ari Holtzman, Ganesh Ananthanarayanan, Junchen Jiang |
 |
Paper |

Context Compression for Auto-regressive Transformers with Sentinel Tokens
Siyu Ren, Qi Jia, Kenny Q. Zhu |
 |
Github
Paper |

A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, Guido Zuccon |
 |
Github
Paper |
SPEED: Speculative Pipelined Execution for Efficient Decoding
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Hasan Genc, Kurt Keutzer, Amir Gholami, Sophia Shao |
 |
Paper |
Accelerating LLM Inference by Enabling Intermediate Layer Decoding
Neeraj Varshney, Agneet Chatterjee, Mihir Parmar, Chitta Baral |
 |
Paper |
Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster
Hongxuan Zhang, Zhining Liu, Jiaqi Zheng, Chenyi Zhuang, Jinjie Gu, Guihai Chen |
 |
Paper |

Compressed Context Memory For Online Language Model Interaction
Jang-Hyun Kim, Junyoung Yeom, Sangdoo Yun, Hyun Oh Song |
 |
Github
Paper |
SparQ Attention: Bandwidth-Efficient LLM Inference
Luka Ribar, Ivan Chelombiev, Luke Hudlass-Galley, Charlie Blake, Carlo Luschi, Douglas Orr |
 |
Paper |
Lookahead: An Inference Acceleration Framework for Large Language Model with Lossless Generation Accuracy
Yao Zhao, Zhitian Xie, Chenyi Zhuang, Jinjie Gu |
 |
Paper |
Cascade Speculative Drafting for Even Faster LLM Inference
Ziyi Chen, Xiaocong Yang, Jiacheng Lin, Chenkai Sun, Jie Huang, Kevin Chen-Chuan Chang |
 |
Paper |

EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation
Yuhui Li, Chao Zhang, and Hongyang Zhang |
 |
Github
Blog |
LoMA: Lossless Compressed Memory Attention
Yumeng Wang, Zhenyang Xiao |
 |
Paper |

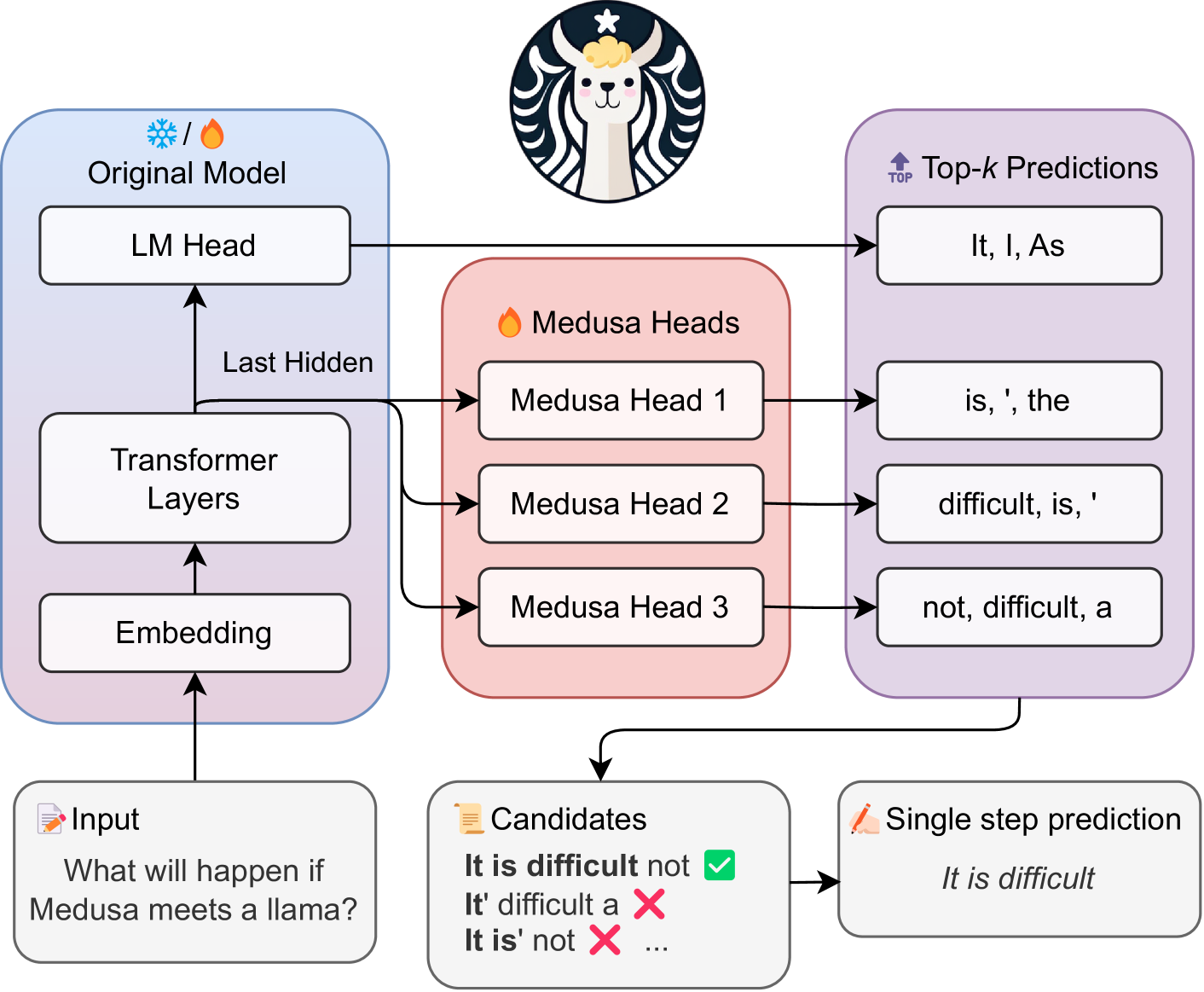
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, Tri Dao |
 |
Github
Paper |
APAR: LLMs Can Do Auto-Parallel Auto-Regressive Decoding
Mingdao Liu, Aohan Zeng, Bowen Wang, Peng Zhang, Jie Tang, Yuxiao Dong |
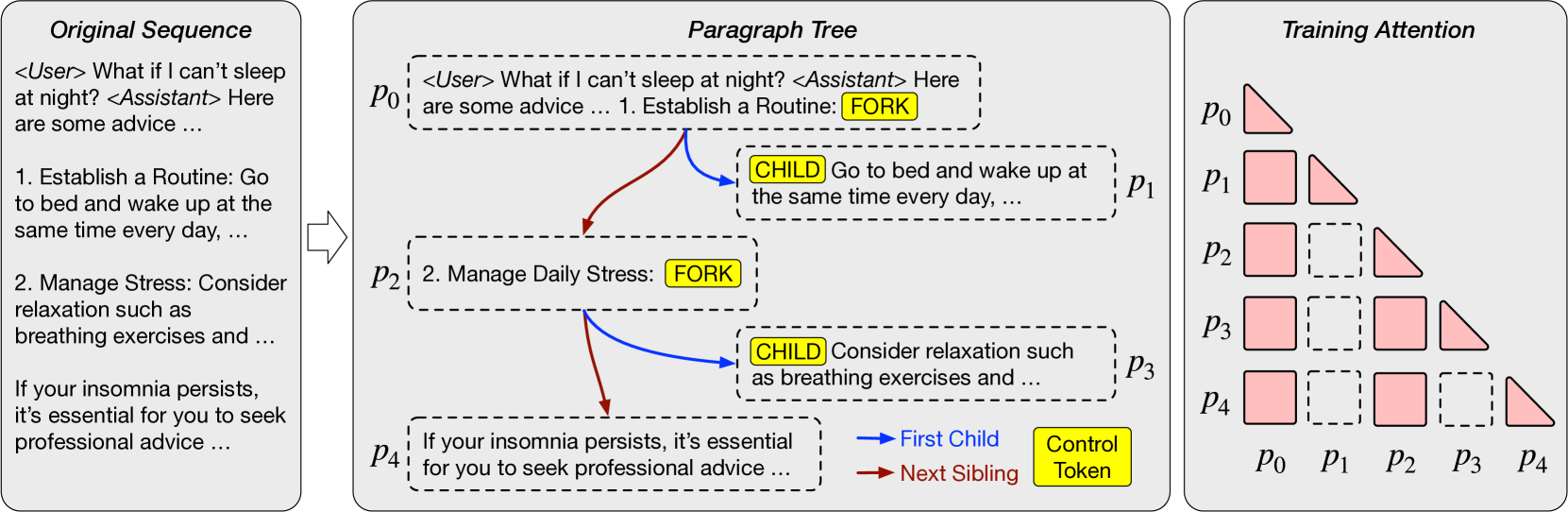 |
Paper |

BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
Feng Lin, Hanling Yi, Hongbin Li, Yifan Yang, Xiaotian Yu, Guangming Lu, Rong Xiao |
 |
Github
Paper |
Speculative Streaming: Fast LLM Inference without Auxiliary Models
Nikhil Bhendawade, Irina Belousova, Qichen Fu, Henry Mason, Mohammad Rastegari, Mahyar Najibi |
 |
Paper |
RelayAttention for Efficient Large Language Model Serving with Long System Prompts
Lei Zhu, Xinjiang Wang, Wayne Zhang, Rynson W.H. Lau |
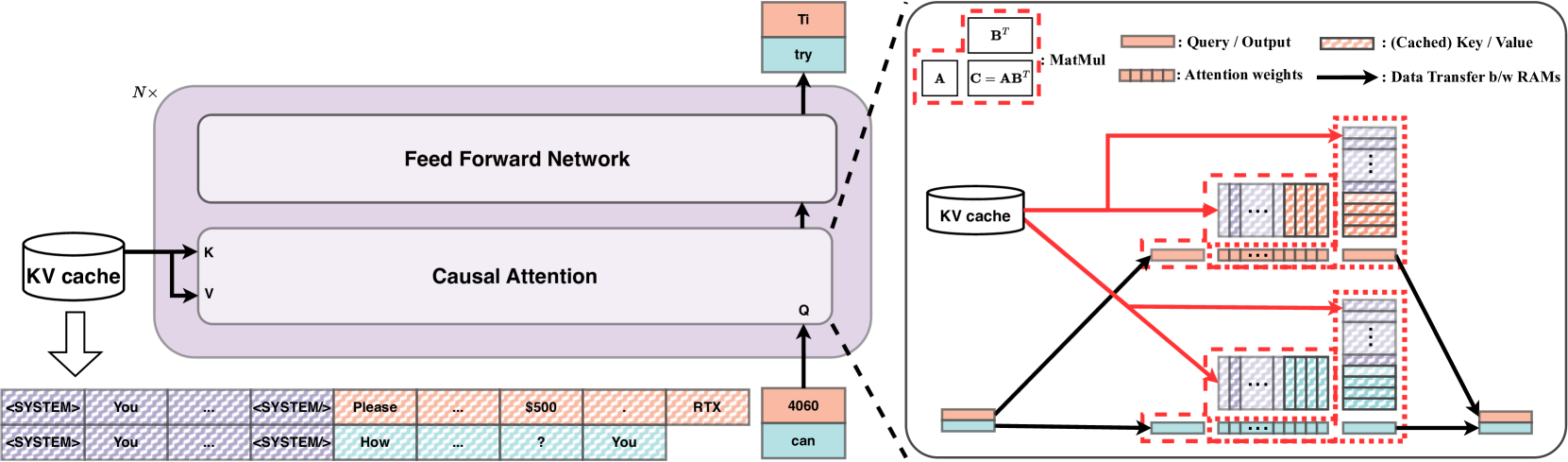 |
Paper |
Recursive Speculative Decoding: Accelerating LLM Inference via Sampling Without Replacement
Wonseok Jeon, Mukul Gagrani, Raghavv Goel, Junyoung Park, Mingu Lee, Christopher Lott |
 |
Paper |

Chimera: A Lossless Decoding Method for Accelerating Large Language Models Inference by Fusing all Tokens
Ziqian Zeng, Jiahong Yu, Qianshi Pang, Zihao Wang, Huiping Zhuang, Cen Chen |
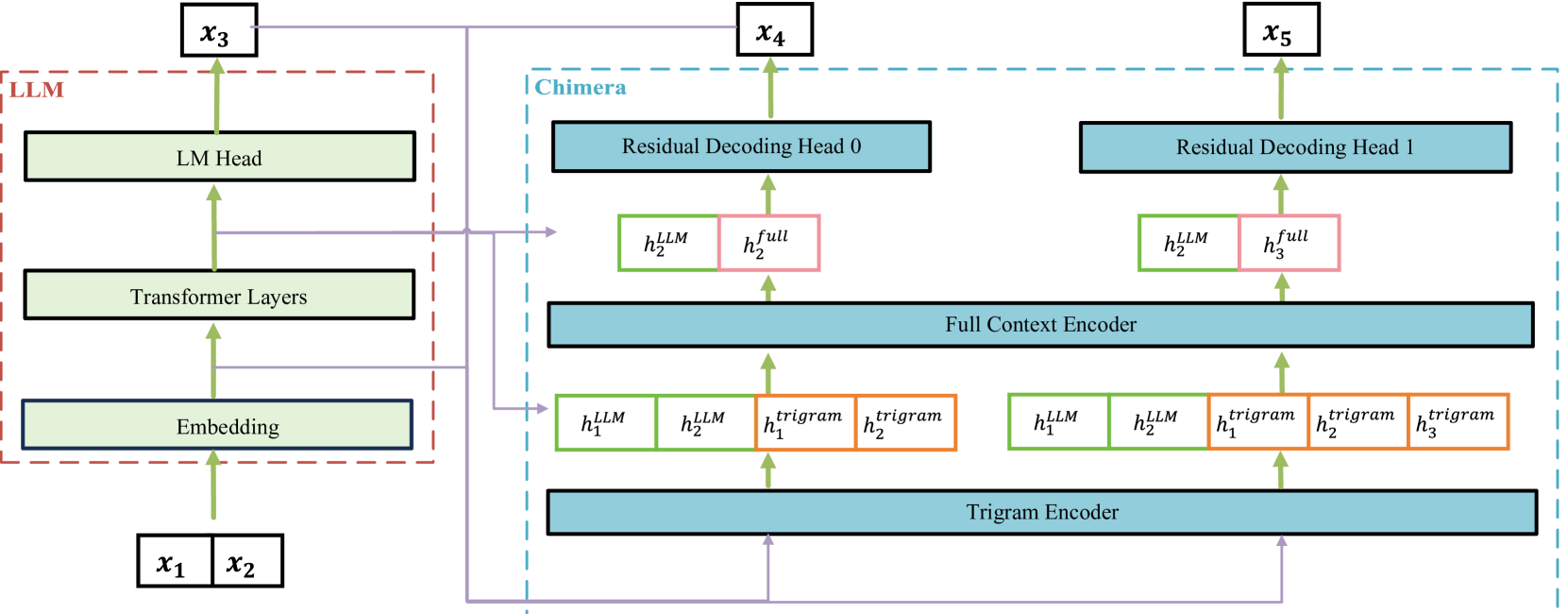 |
Github
Paper |
CHAI: Clustered Head Attention for Efficient LLM Inference
Saurabh Agarwal, Bilge Acun, Basil Homer, Mostafa Elhoushi, Yejin Lee, Shivaram Venkataraman, Dimitris Papailiopoulos, Carole-Jean Wu |
 |
Paper |
Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference
Piotr Nawrot, Adrian Łańcucki, Marcin Chochowski, David Tarjan, Edoardo M. Ponti |
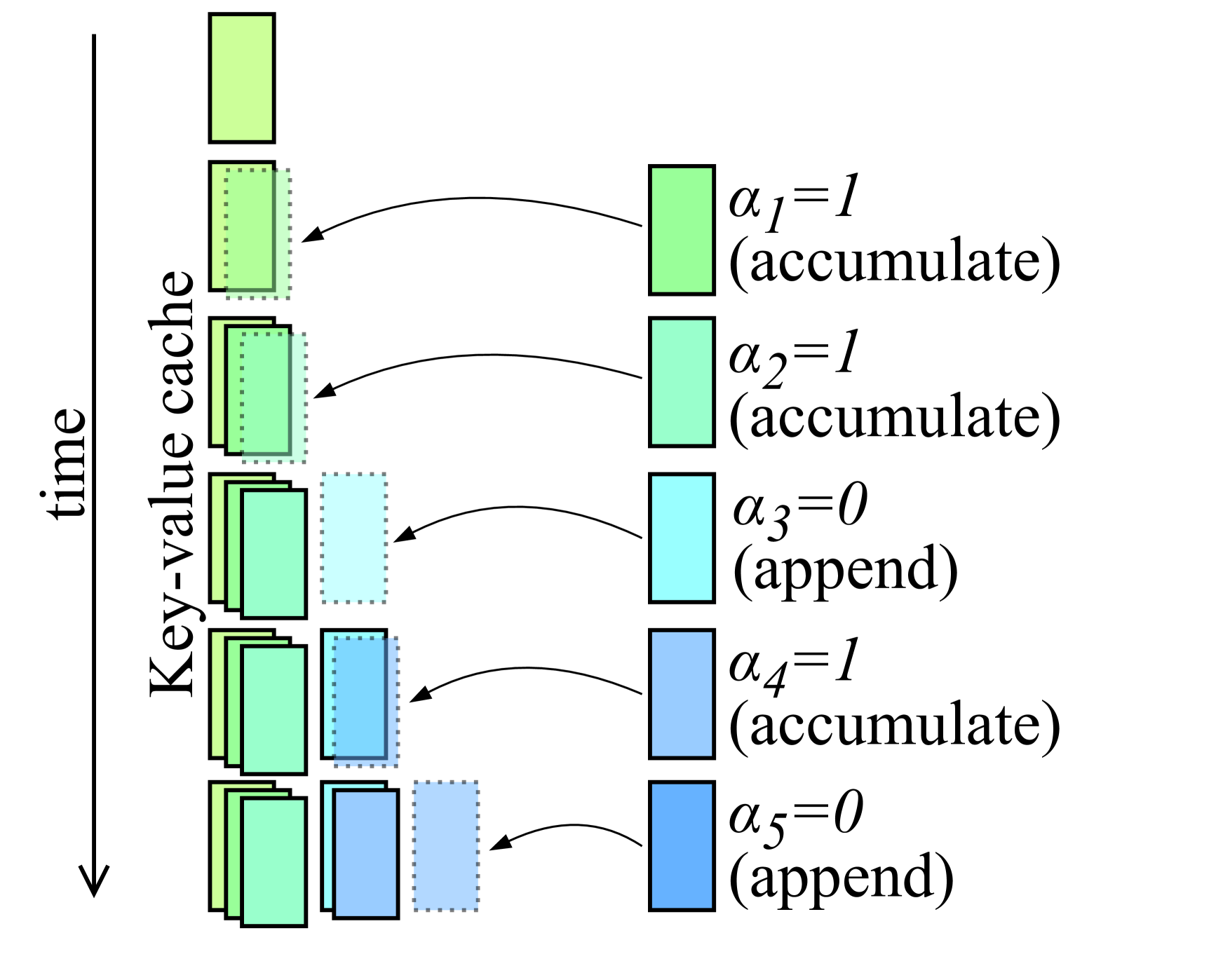 |
Paper |
Recurrent Drafter for Fast Speculative Decoding in Large Language Models
Aonan Zhang, Chong Wang, Yi Wang, Xuanyu Zhang, Yunfei Cheng |
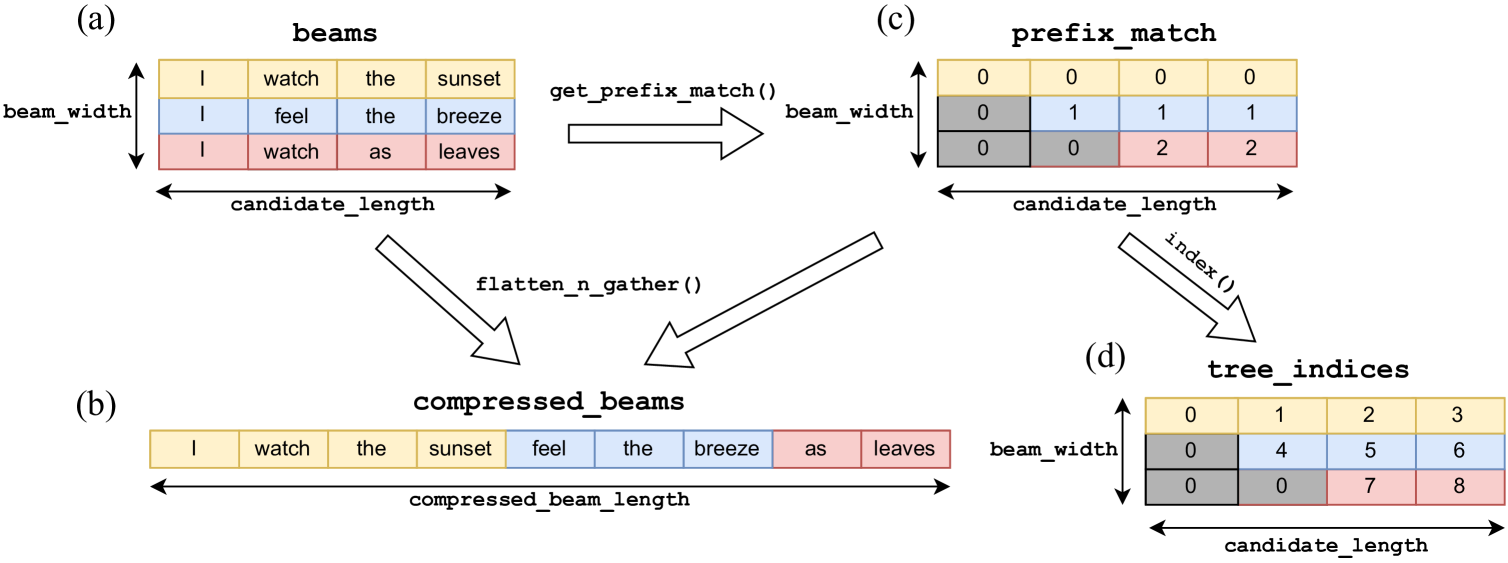 |
Paper |
Optimal Block-Level Draft Verification for Accelerating Speculative Decoding
Ziteng Sun, Jae Hun Ro, Ahmad Beirami, Ananda Theertha Suresh |
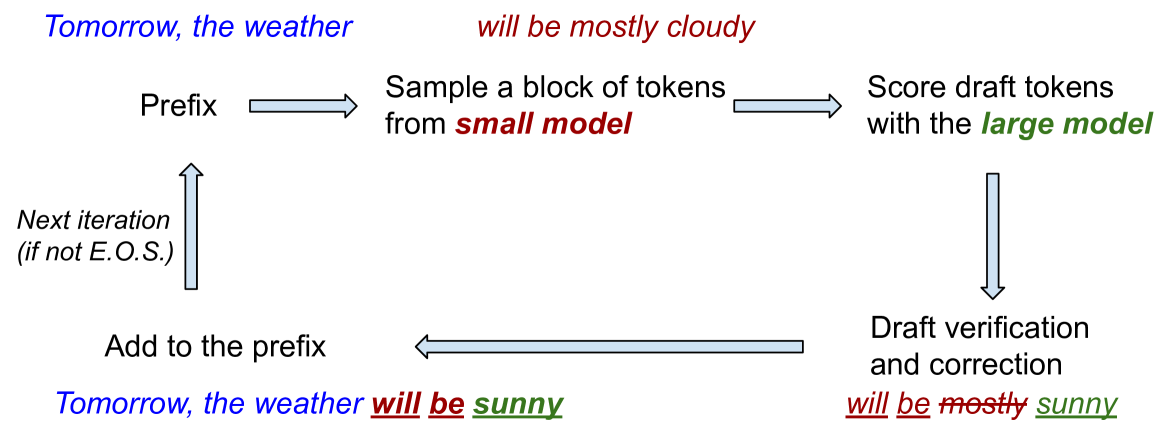 |
Paper |
Hierarchical Skip Decoding for Efficient Autoregressive Text Generation
Yunqi Zhu, Xuebing Yang, Yuanyuan Wu, Wensheng Zhang |
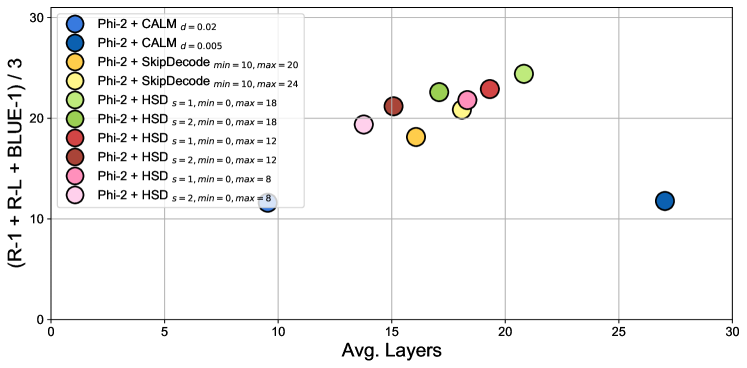 |
Paper |

SDSAT: Accelerating LLM Inference through Speculative Decoding with Semantic Adaptive Tokens
Chengbo Liu, Yong Zhu |
 |
Github
Paper |

Prepacking: A Simple Method for Fast Prefilling and Increased Throughput in Large Language Models
Siyan Zhao, Daniel Israel, Guy Van den Broeck, Aditya Grover |
 |
Github
Paper |
Exploring and Improving Drafts in Blockwise Parallel Decoding
Taehyeon Kim, Ananda Theertha Suresh, Kishore Papineni, Michael Riley, Sanjiv Kumar, Adrian Benton |
 |
Paper |

Lossless Acceleration of Large Language Model via Adaptive N-gram Parallel Decoding
Jie Ou, Yueming Chen, Wenhong Tian |
 |
Github
Paper |
Self-Selected Attention Span for Accelerating Large Language Model Inference
Tian Jin, Wanzin Yazar, Zifei Xu, Sayeh Sharify, Xin Wang |
 |
Paper |
Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
Pengfei Wu, Jiahao Liu, Zhuocheng Gong, Qifan Wang, Jinpeng Li, Jingang Wang, Xunliang Cai, Dongyan Zhao |
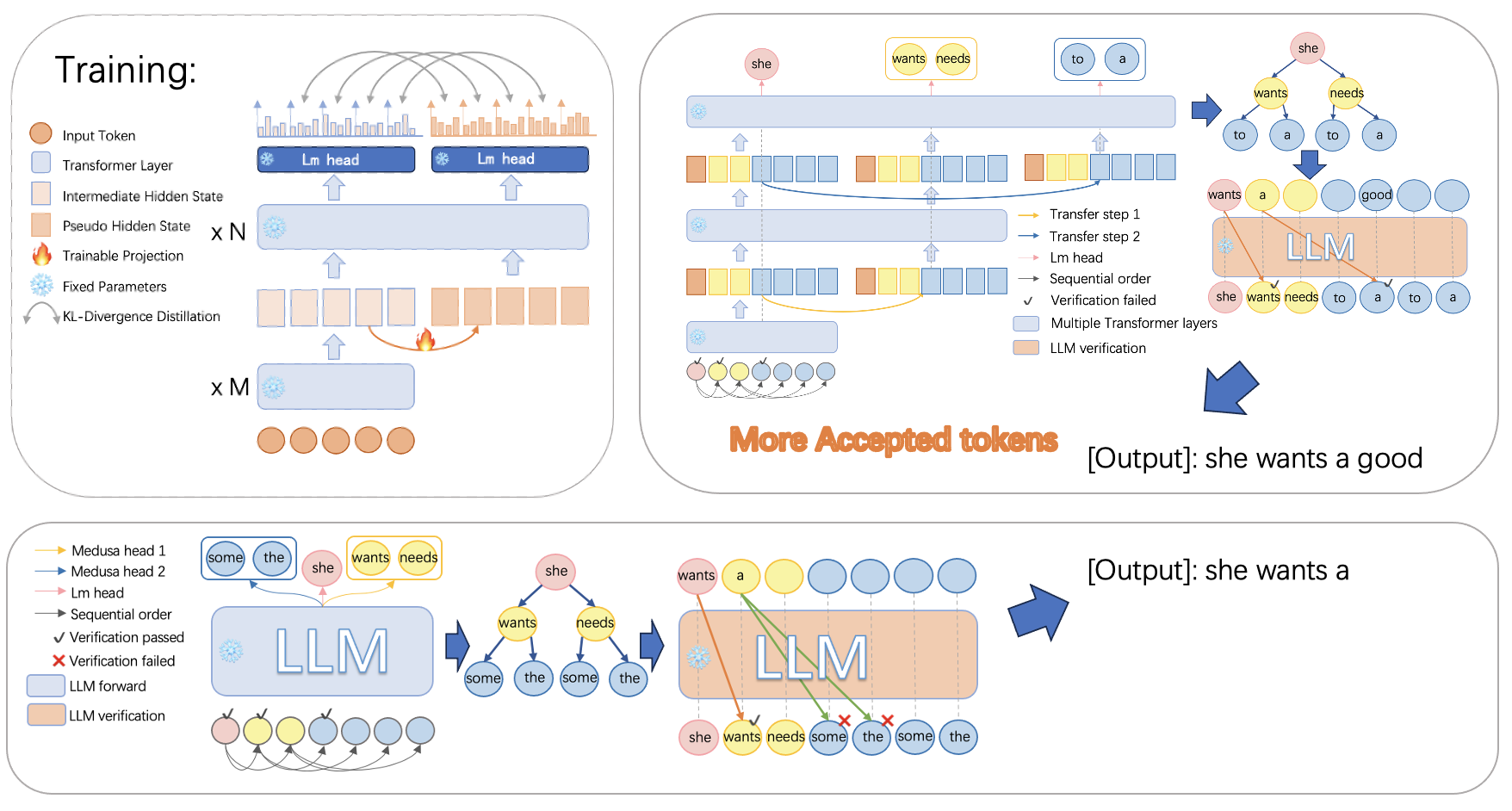 |
Paper |
XC-Cache: Cross-Attending to Cached Context for Efficient LLM Inference
João Monteiro, Étienne Marcotte, Pierre-André Noël, Valentina Zantedeschi, David Vázquez, Nicolas Chapados, Christopher Pal, Perouz Taslakian |
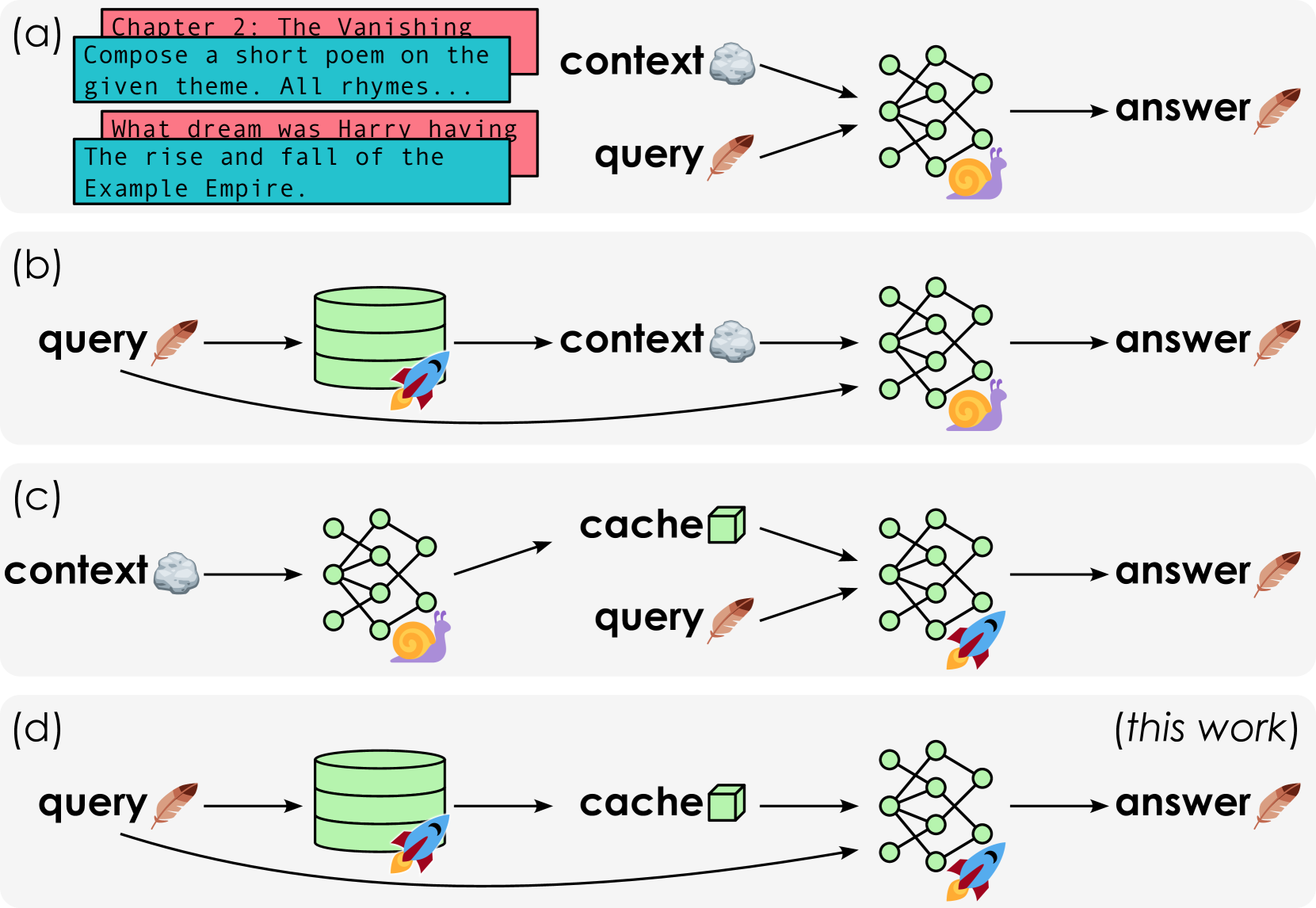 |
Paper |
 
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V.S. Lakshmanan, Ahmed Hassan Awadallah |
 |
Github
Paper |
Efficient LLM Inference with Kcache
Qiaozhi He, Zhihua Wu |
 |
Paper |
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, Gabriel Synnaeve |
 |
Paper |

KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation
Minsik Cho, Mohammad Rastegari, Devang Naik |
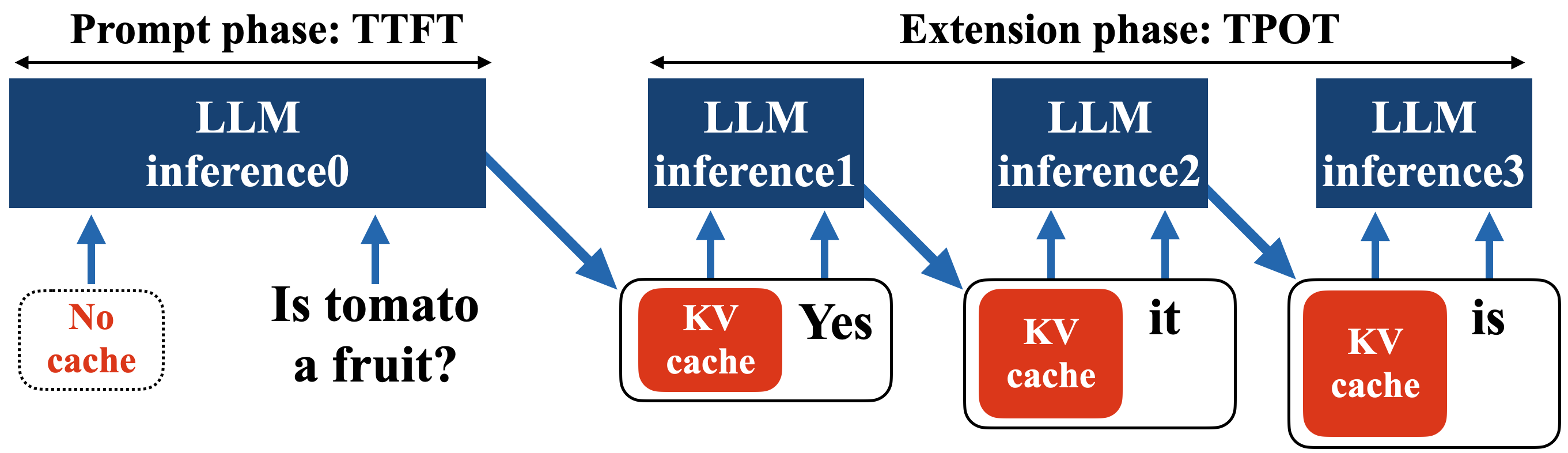 |
Paper |
You Only Cache Once: Decoder-Decoder Architectures for Language Models
Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, Furu Wei |
 |
Github
Paper |

Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting
Fangcheng Liu, Yehui Tang, Zhenhua Liu, Yunsheng Ni, Kai Han, Yunhe Wang |
 |
Github
Paper |
Accelerating Speculative Decoding using Dynamic Speculation Length
Jonathan Mamou, Oren Pereg, Daniel Korat, Moshe Berchansky, Nadav Timor, Moshe Wasserblat, Roy Schwartz |
 |
Paper |
Clover: Regressive Lightweight Speculative Decoding with Sequential Knowledge
Bin Xiao, Chunan Shi, Xiaonan Nie, Fan Yang, Xiangwei Deng, Lei Su, Weipeng Chen, Bin Cui |
 |
Paper |

EMS-SD: Efficient Multi-sample Speculative Decoding for Accelerating Large Language Models
Yunsheng Ni, Chuanjian Liu, Yehui Tang, Kai Han, Yunhe Wang |
 |
Github
Paper |
Distributed Speculative Inference of Large Language Models
Nadav Timor, Jonathan Mamou, Daniel Korat, Moshe Berchansky, Oren Pereg, Moshe Wasserblat, Tomer Galanti, Michal Gordon, David Harel |
 |
Paper |

SirLLM: Streaming Infinite Retentive LLM
Yao Yao, Zuchao Li, Hai Zhao |
 |
Github
Paper |

Hardware-Aware Parallel Prompt Decoding for Memory-Efficient Acceleration of LLM Inference
Hao (Mark)Chen, Wayne Luk, Ka Fai Cedric Yiu, Rui Li, Konstantin Mishchenko, Stylianos I. Venieris, Hongxiang Fan |
 |
Github
Paper |
Faster Cascades via Speculative Decoding
Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Seungyeon Kim, Neha Gupta, Aditya Krishna Menon, Sanjiv Kumar |
 |
Paper |

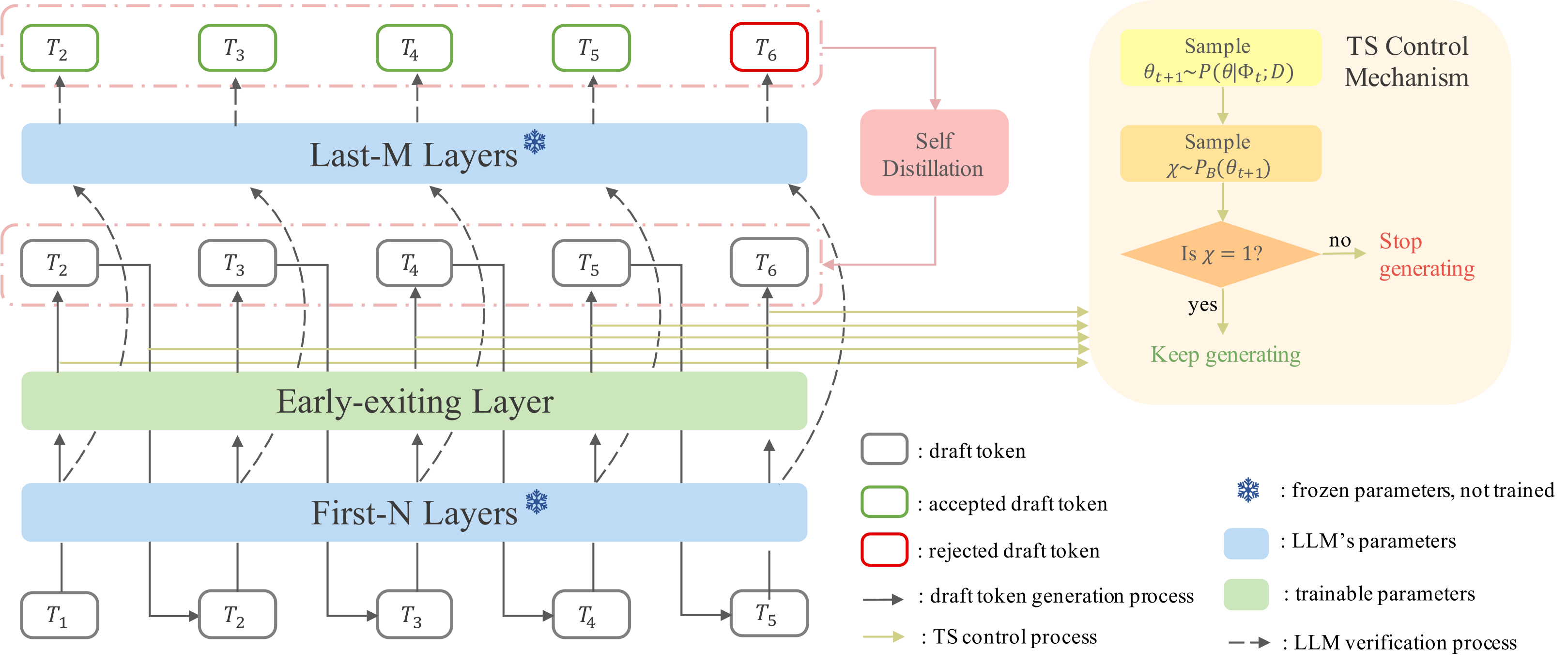
Speculative Decoding via Early-exiting for Faster LLM Inference with Thompson Sampling Control Mechanism
Jiahao Liu, Qifan Wang, Jingang Wang, Xunliang Cai |
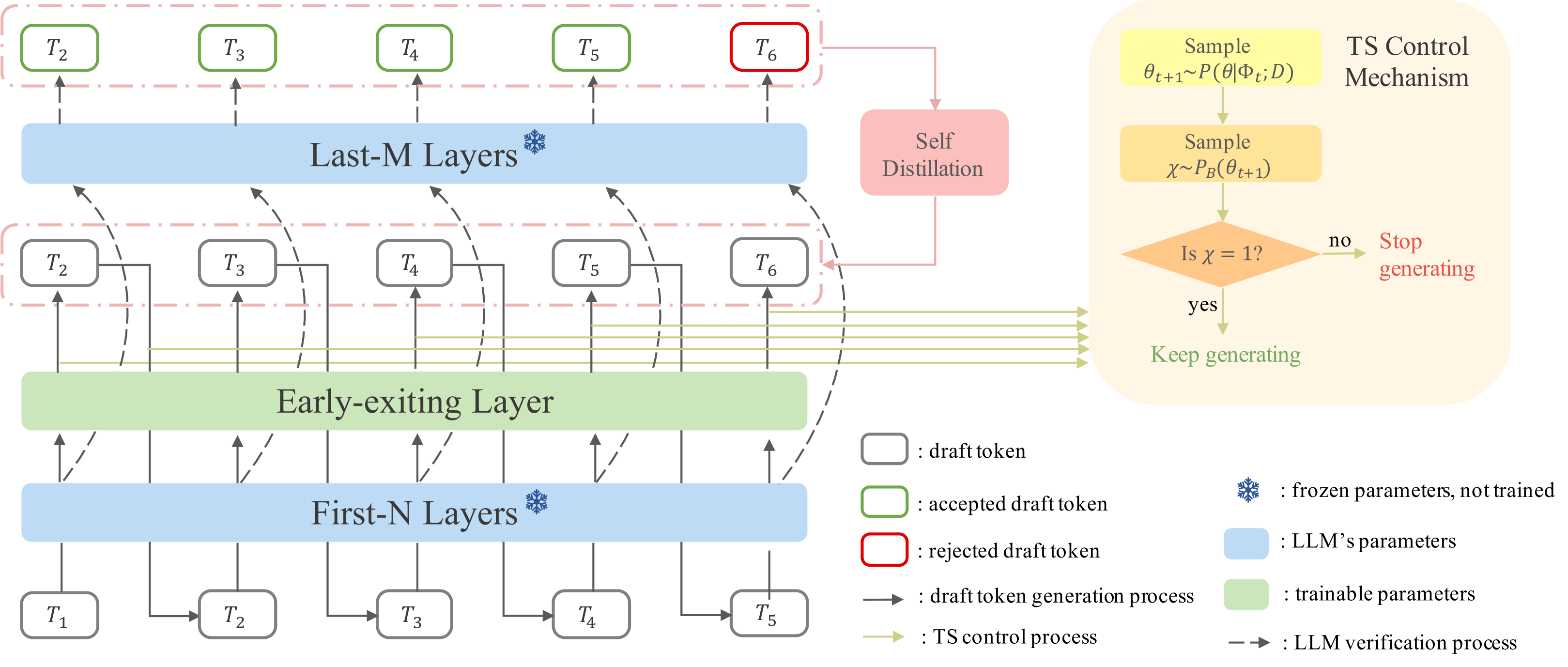 |
Paper |

QuickLLaMA: Query-aware Inference Acceleration for Large Language Models
Jingyao Li, Han Shi, Xin Jiang, Zhenguo Li, Hong Xu, Jiaya Jia |
 |
Github
Paper |

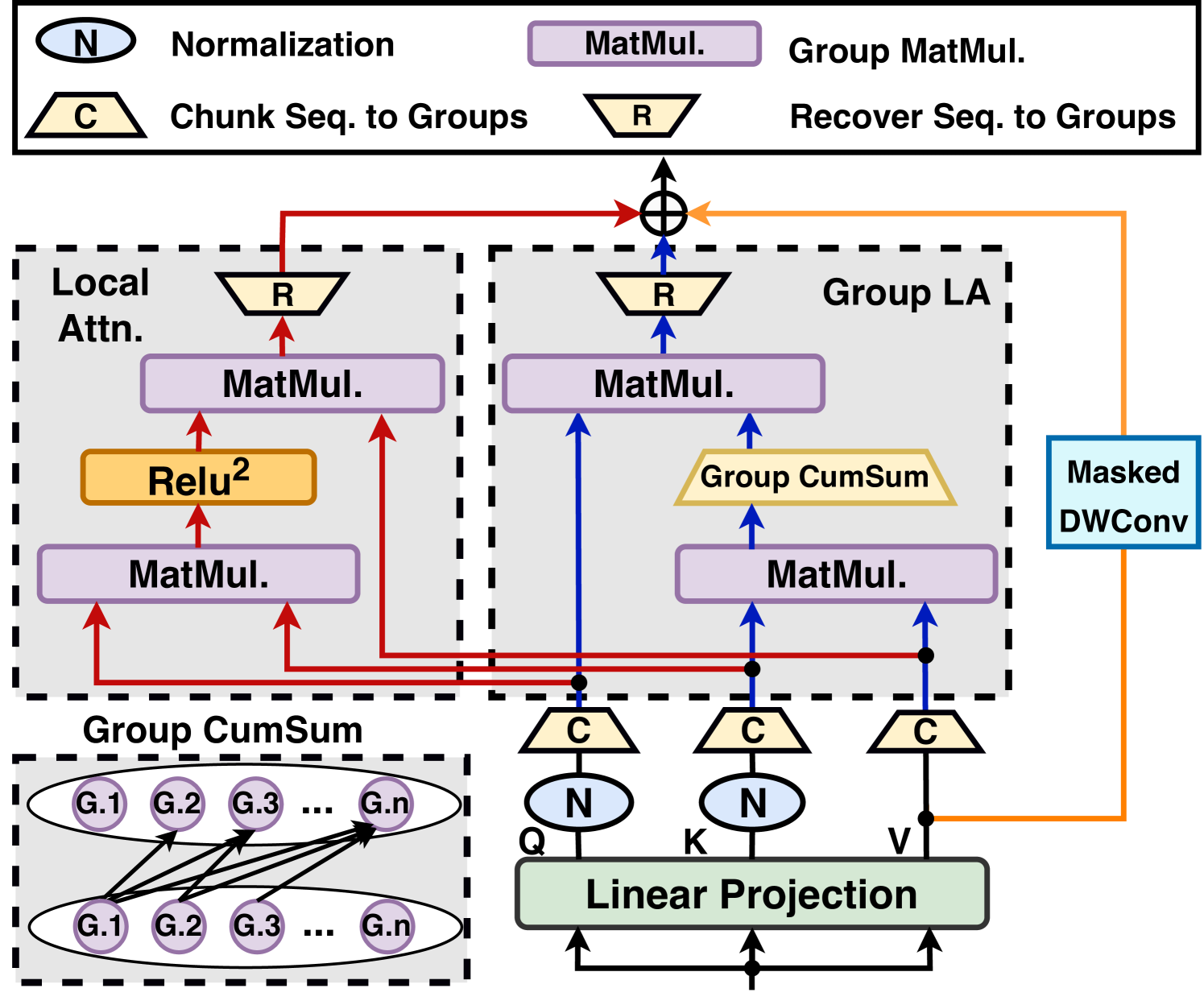
When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
Haoran You, Yichao Fu, Zheng Wang, Amir Yazdanbakhsh, Yingyan (Celine)Lin |
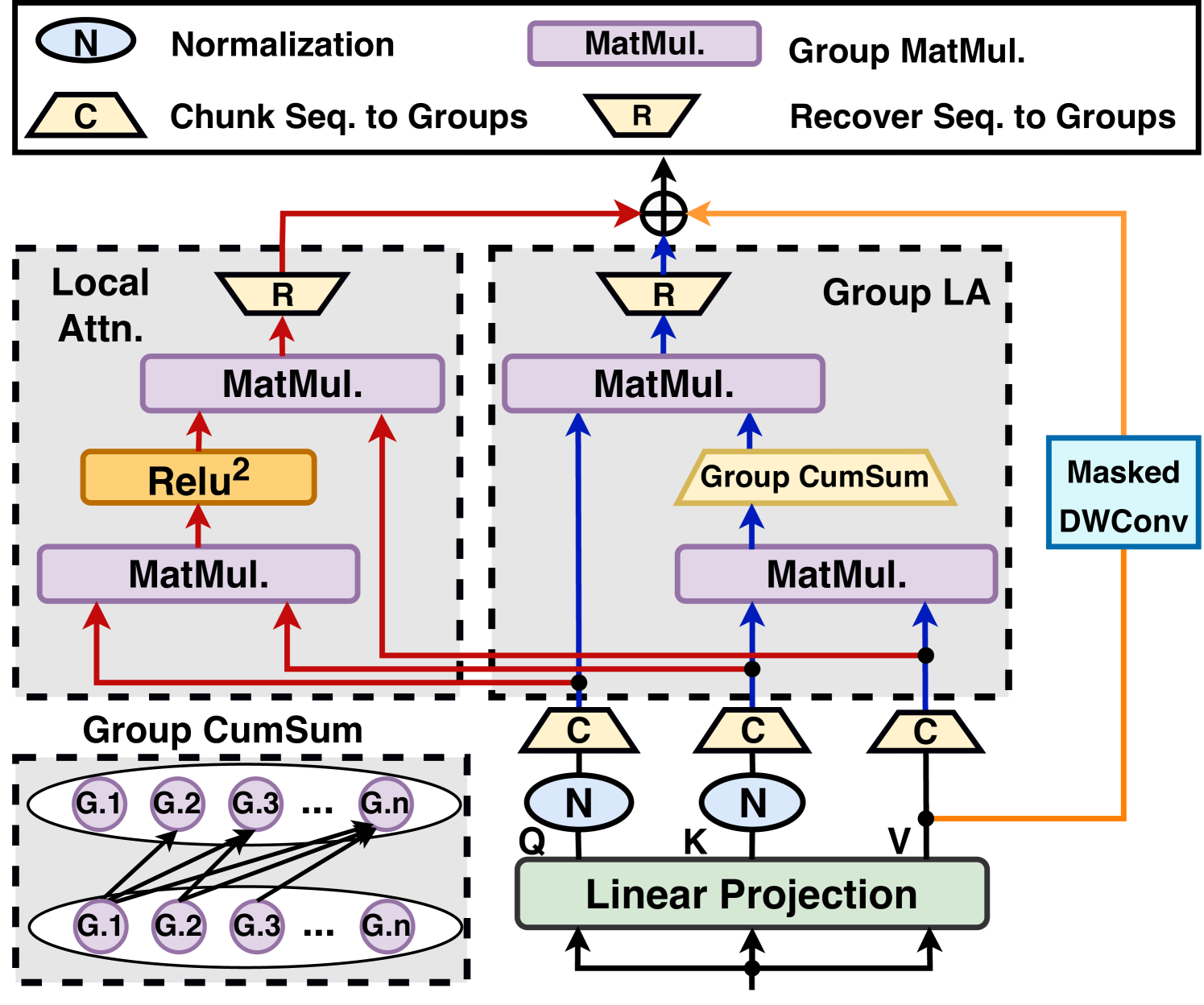 |
Github
Paper |
HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning
Heejun Lee, Geon Park, Youngwan Lee, Jina Kim, Wonyoung Jeong, Myeongjae Jeon, Sung Ju Hwang |
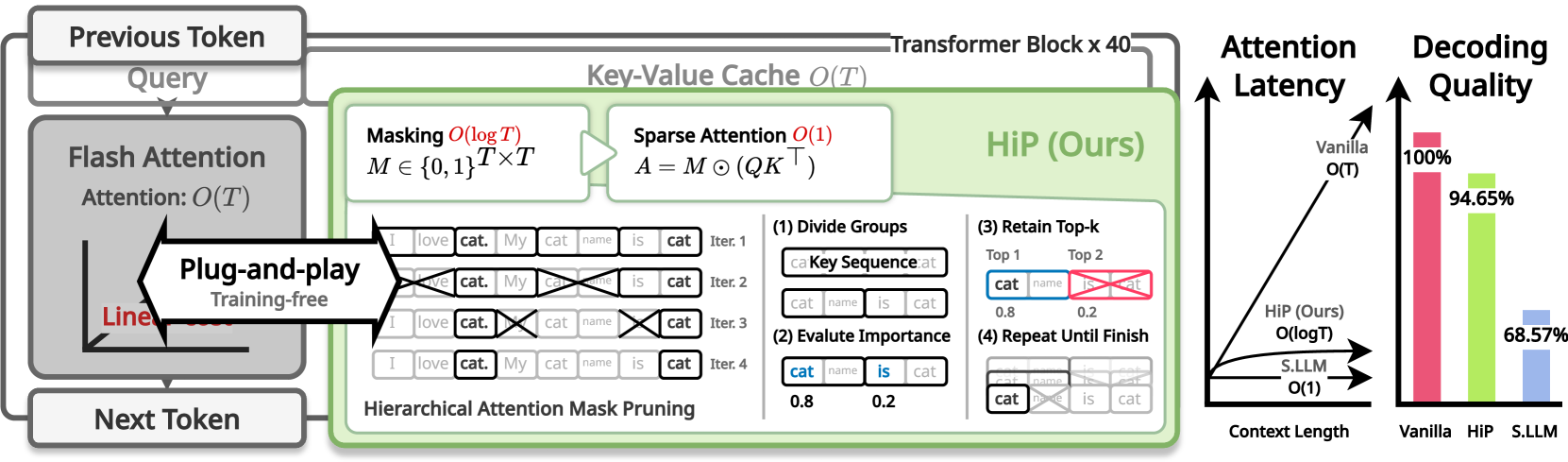 |
Paper |
Optimized Speculative Sampling for GPU Hardware Accelerators
Dominik Wagner, Seanie Lee, Ilja Baumann, Philipp Seeberger, Korbinian Riedhammer, Tobias Bocklet |
 |
Paper |

MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression
Tianyu Fu, Haofeng Huang, Xuefei Ning, Genghan Zhang, Boju Chen, Tianqi Wu, Hongyi Wang, Zixiao Huang, Shiyao Li, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang |
 |
Github
Paper |
Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Huanqi Cao, Xiao Chuanfu, Xingcheng Zhang, Dahua Lin, Chao Yang |
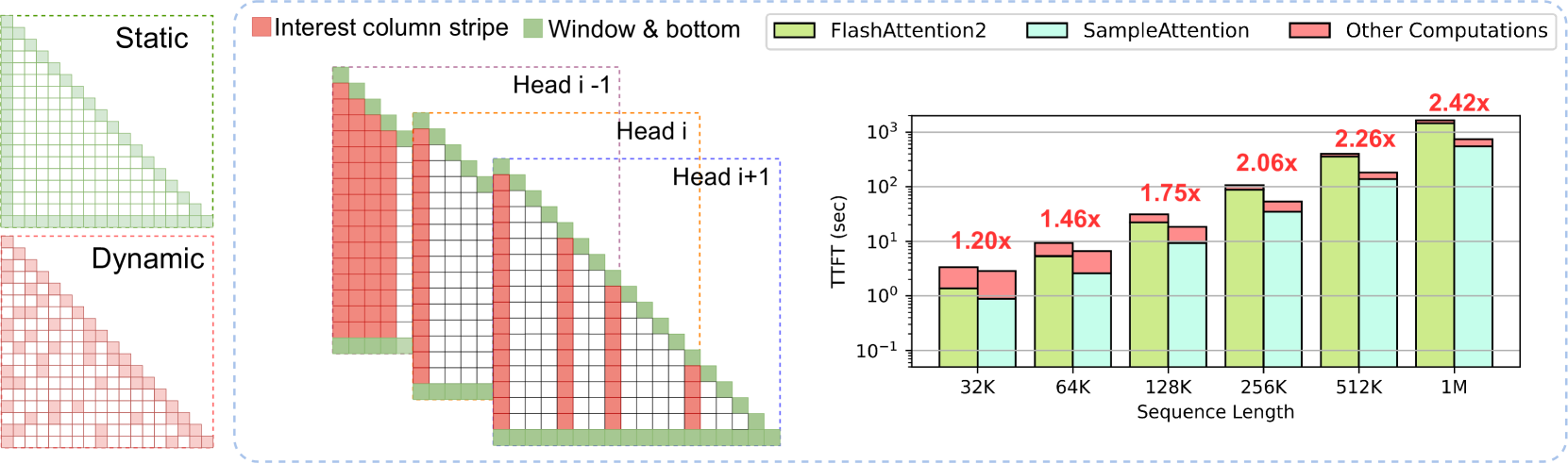 |
Paper |
Interpreting Attention Layer Outputs with Sparse Autoencoders
Connor Kissane, Robert Krzyzanowski, Joseph Isaac Bloom, Arthur Conmy, Neel Nanda |
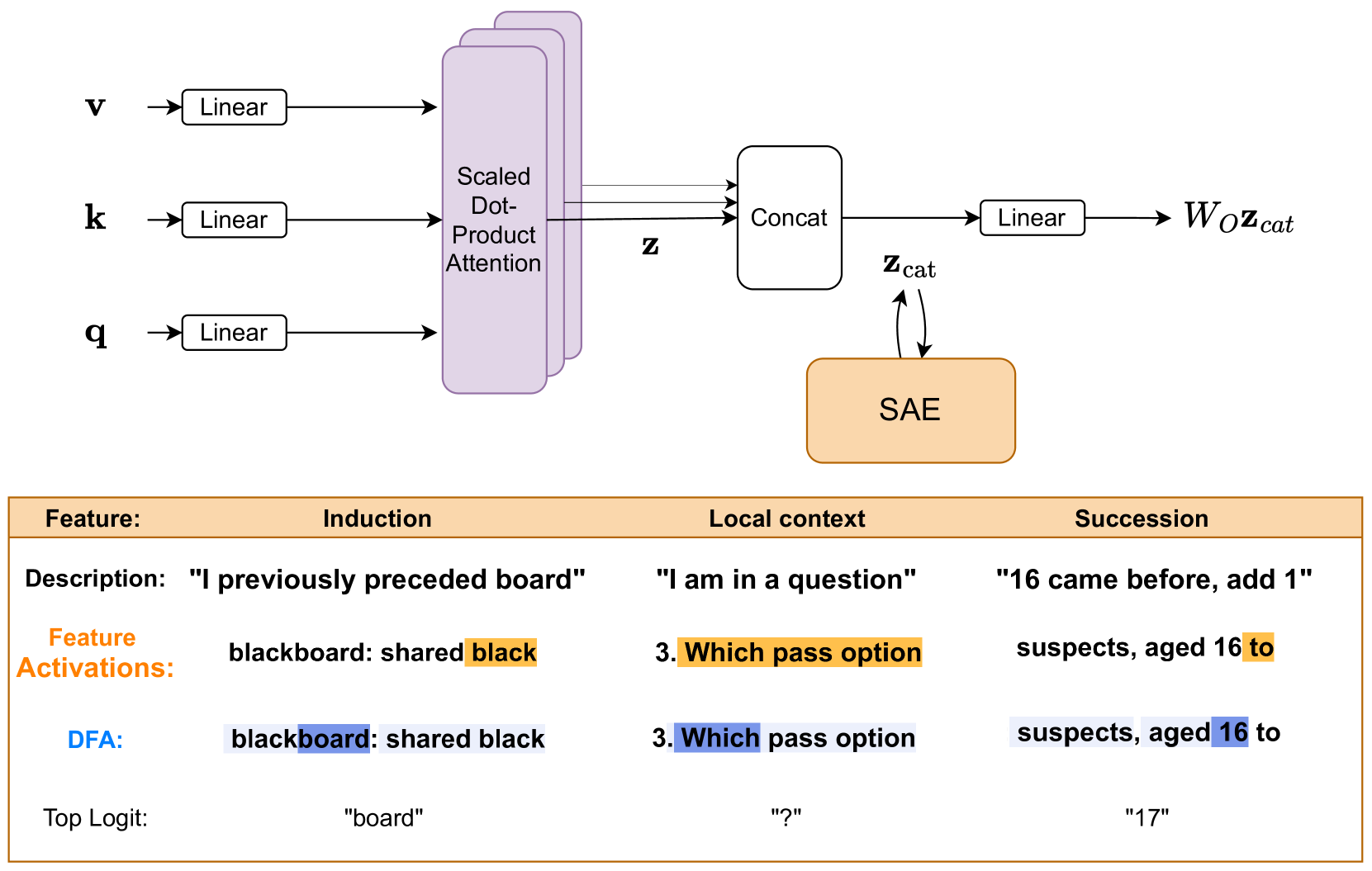 |
Paper |
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
Yuhui Li, Fangyun Wei, Chao Zhang, Hongyang Zhang |
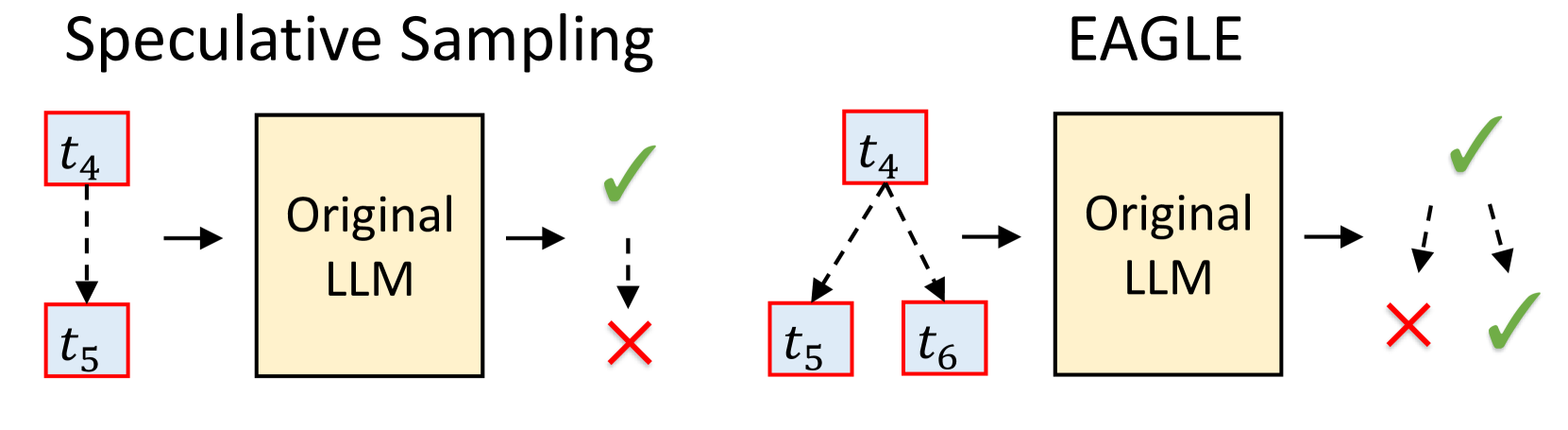 |
Github
Paper |
Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers
Chao Lou, Zixia Jia, Zilong Zheng, Kewei Tu |
 |
Paper |
S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language Models
Parsa Kavehzadeh, Mohammadreza Pourreza, Mojtaba Valipour, Tinashu Zhu, Haoli Bai, Ali Ghodsi, Boxing Chen, Mehdi Rezagholizadeh |
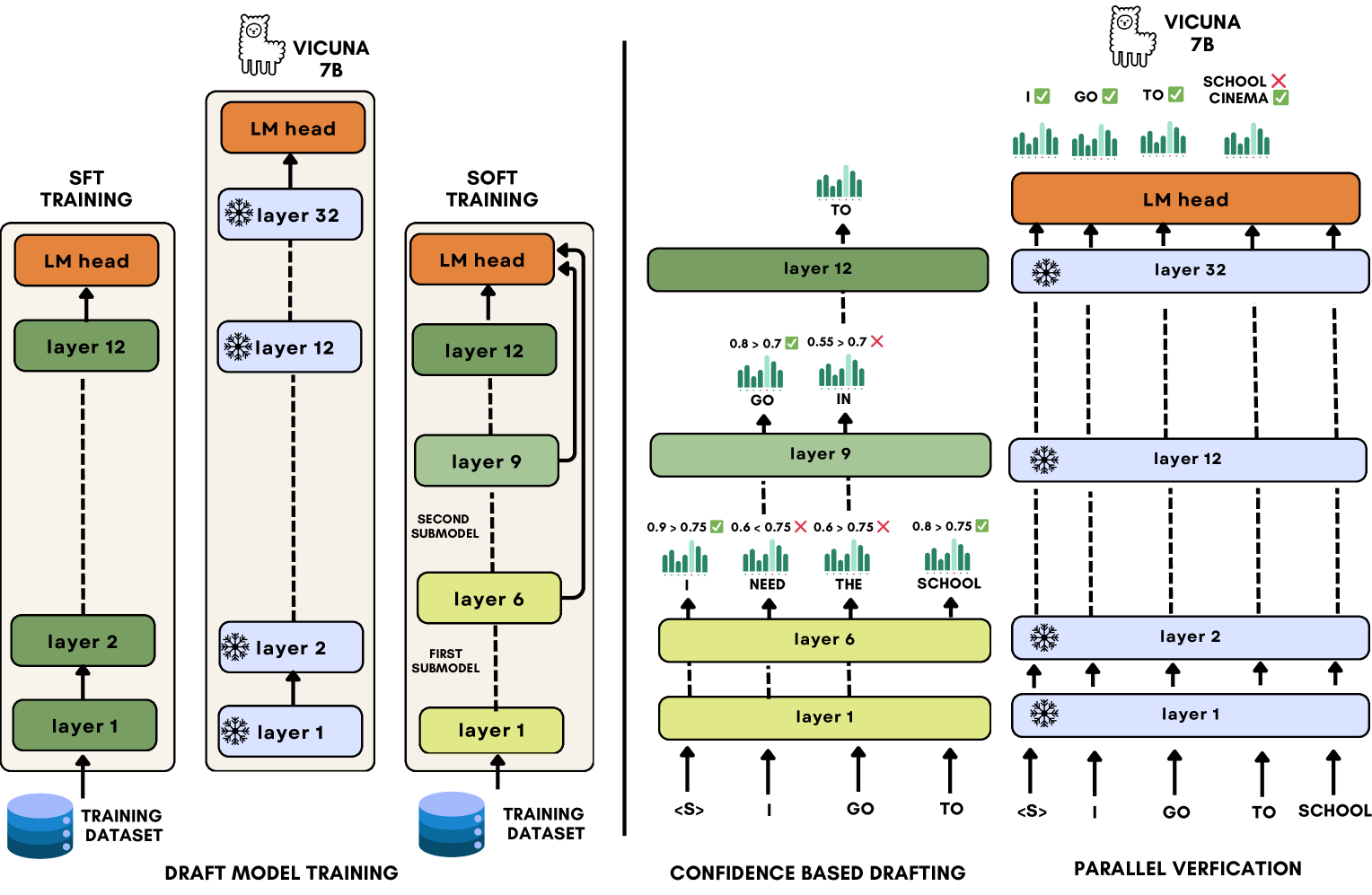 |
Paper |

LiveMind: Low-latency Large Language Models with Simultaneous Inference
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li |
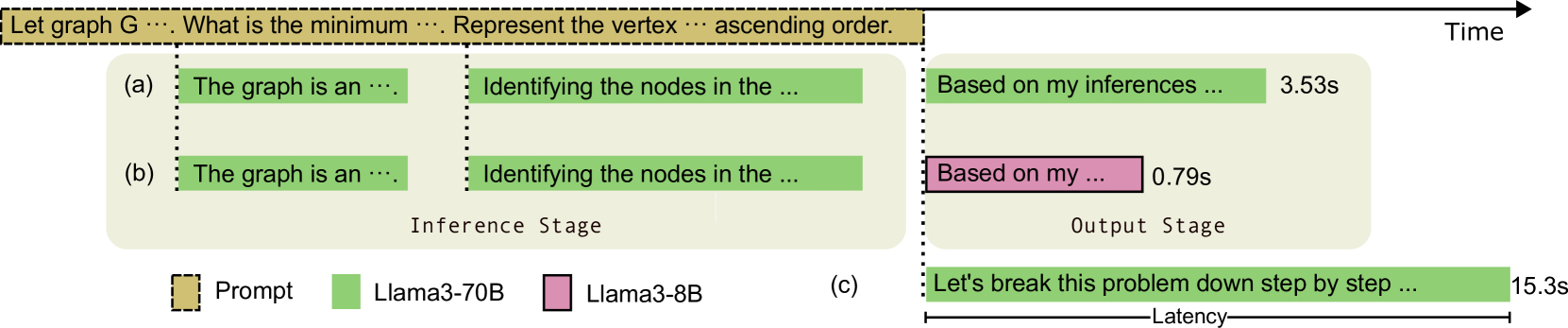 |
Github
Paper |
Multi-Token Joint Speculative Decoding for Accelerating Large Language Model Inference
Zongyue Qin, Ziniu Hu, Zifan He, Neha Prakriya, Jason Cong, Yizhou Sun |
 |
Paper |
Adaptive Draft-Verification for Efficient Large Language Model Decoding
Xukun Liu, Bowen Lei, Ruqi Zhang, Dongkuan Xu |
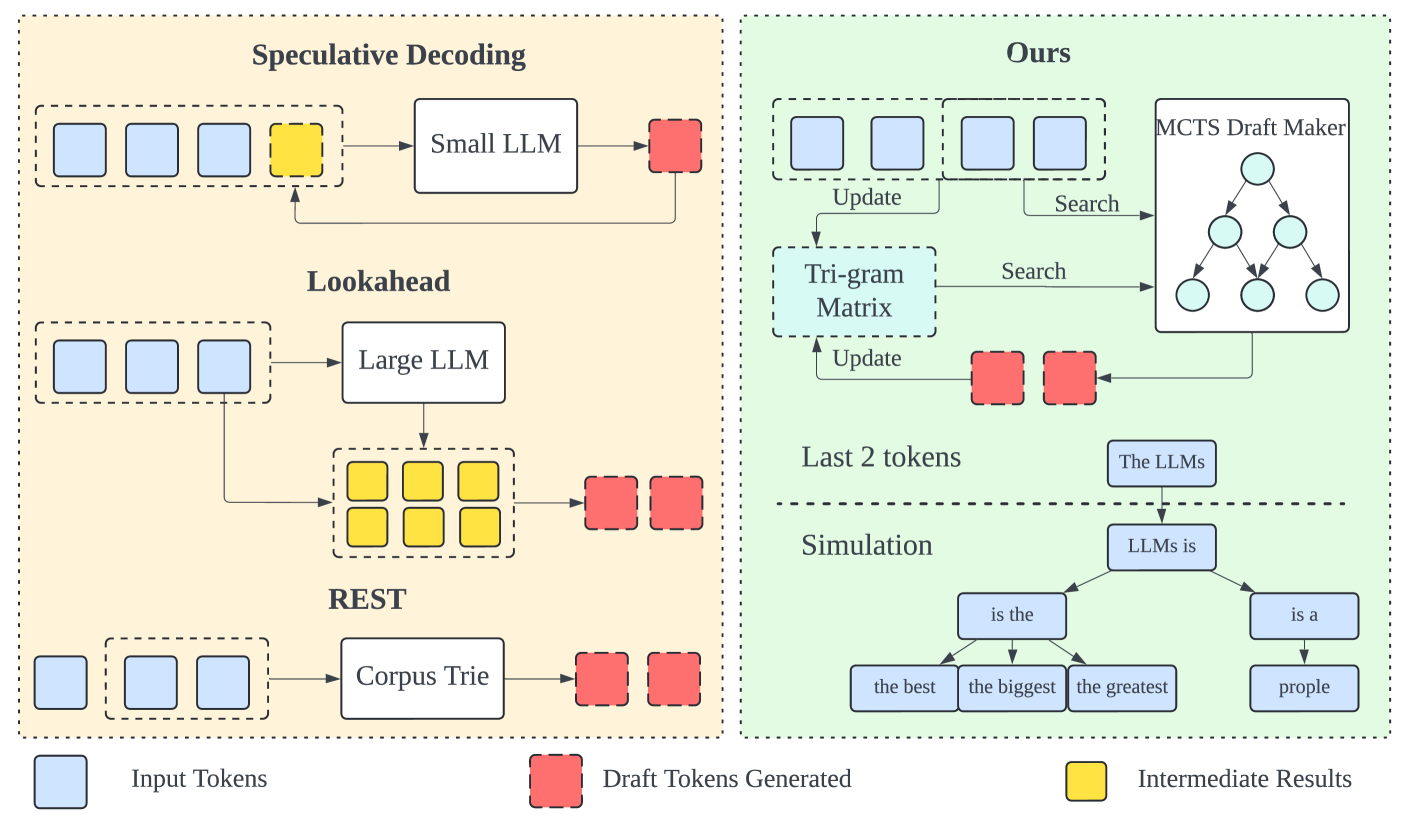 |
Paper |
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
Qichen Fu, Minsik Cho, Thomas Merth, Sachin Mehta, Mohammad Rastegari, Mahyar Najibi |
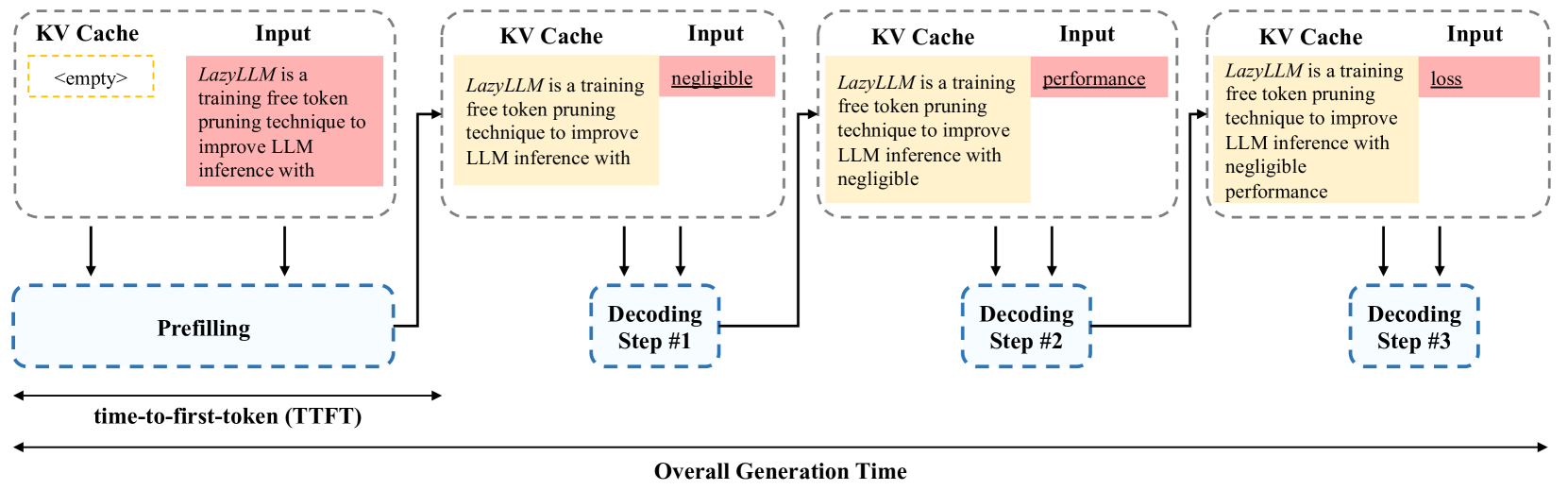 |
Paper |

Inference acceleration for large language models using "stairs" assisted greedy generation
Domas Grigaliūnas, Mantas Lukoševičius |
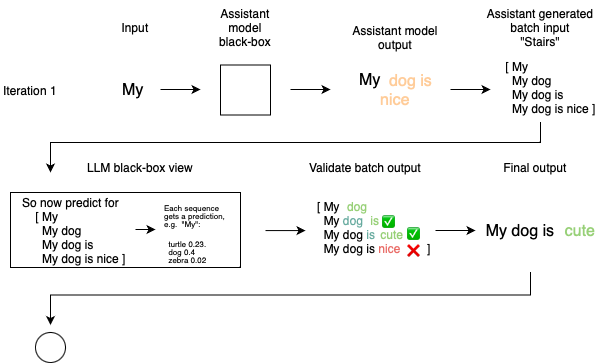 |
Paper |
An Efficient Inference Framework for Early-exit Large Language Models
Ruijie Miao, Yihan Yan, Xinshuo Yao, Tong Yang |
|
Paper |
Accelerating Large Language Model Inference with Self-Supervised Early Exits
Florian Valade |
|
Paper |

Clover-2: Accurate Inference for Regressive Lightweight Speculative Decoding
Bin Xiao, Lujun Gui, Lei Su, Weipeng Chen |
 |
Github
Paper |
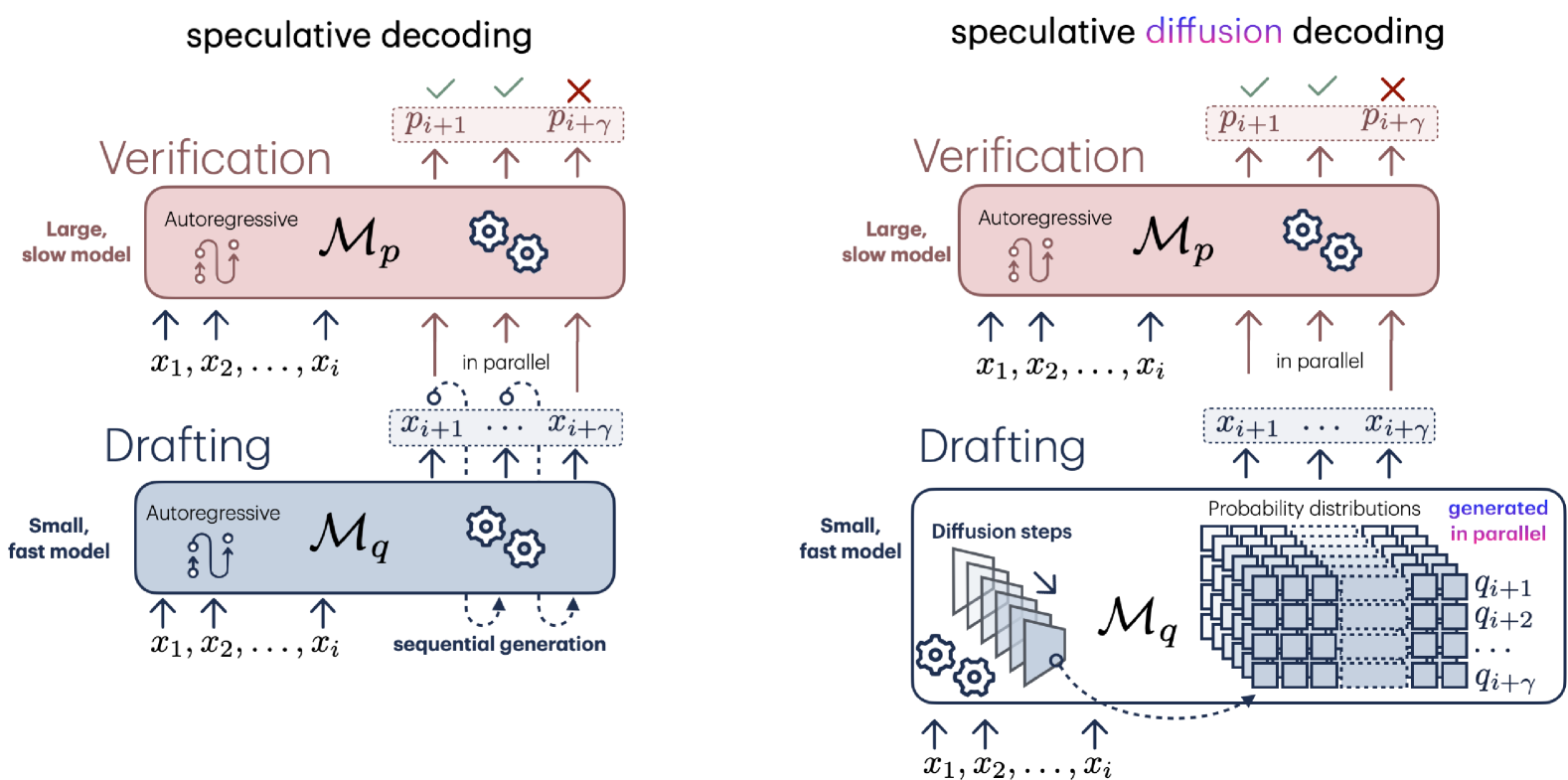
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
Jacob K Christopher, Brian R Bartoldson, Bhavya Kailkhura, Ferdinando Fioretto |
 |
Paper |
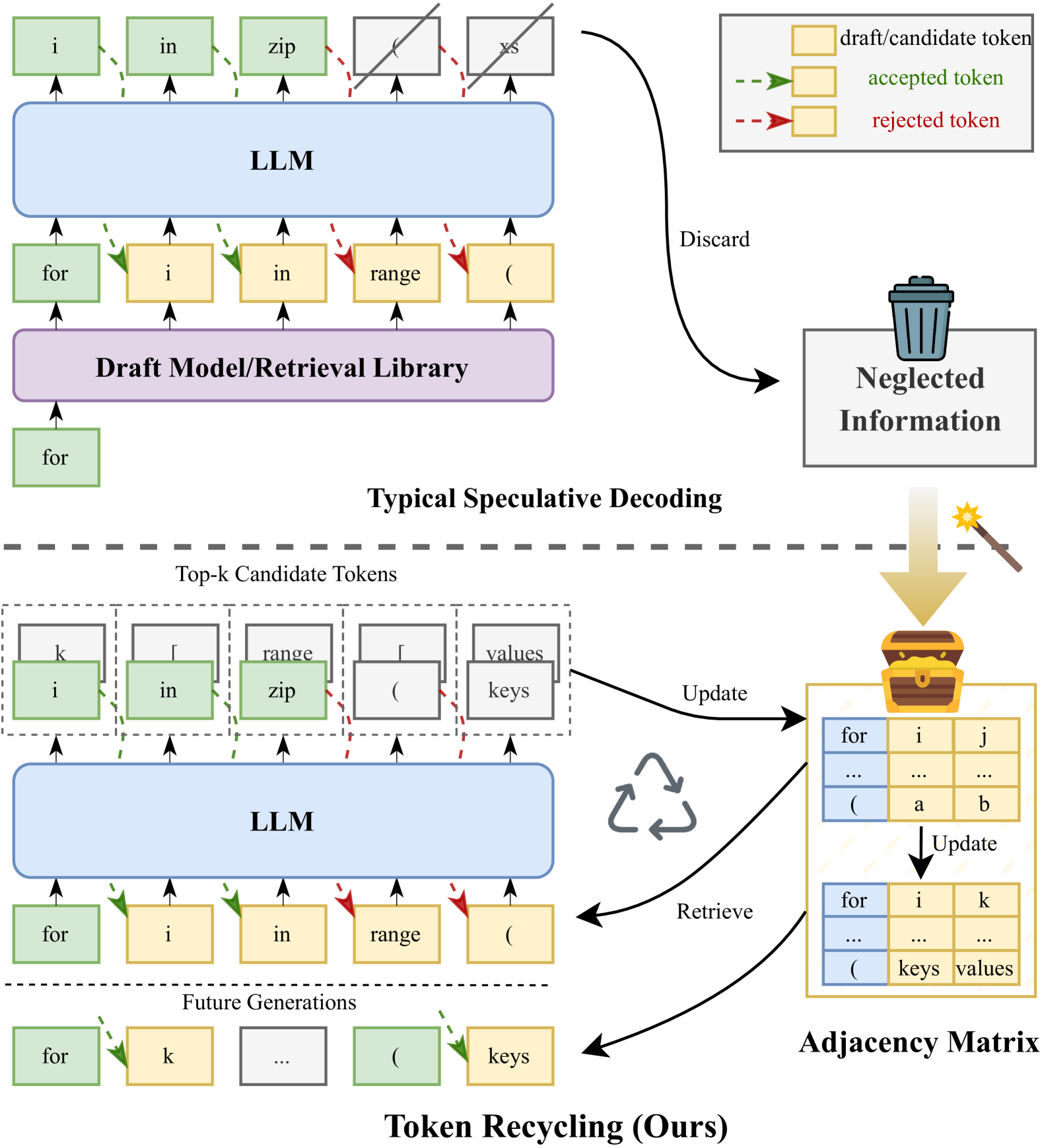
Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling
Xianzhen Luo, Yixuan Wang, Qingfu Zhu, Zhiming Zhang, Xuanyu Zhang, Qing Yang, Dongliang Xu, Wanxiang Che |
 |
Paper |
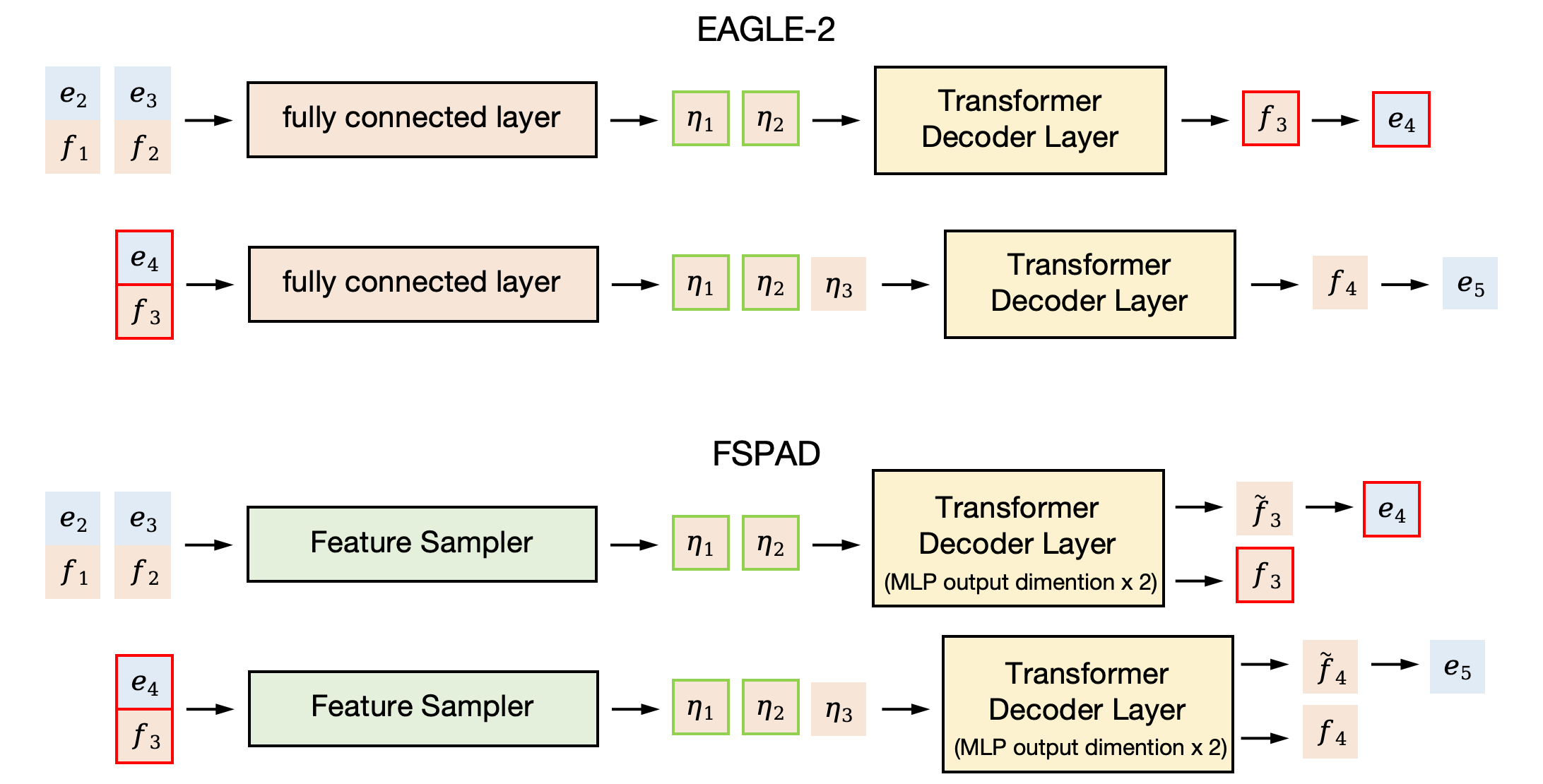
Boosting Lossless Speculative Decoding via Feature Sampling and Partial Alignment Distillation
Lujun Gui, Bin Xiao, Lei Su, Weipeng Chen |
 |
Paper |
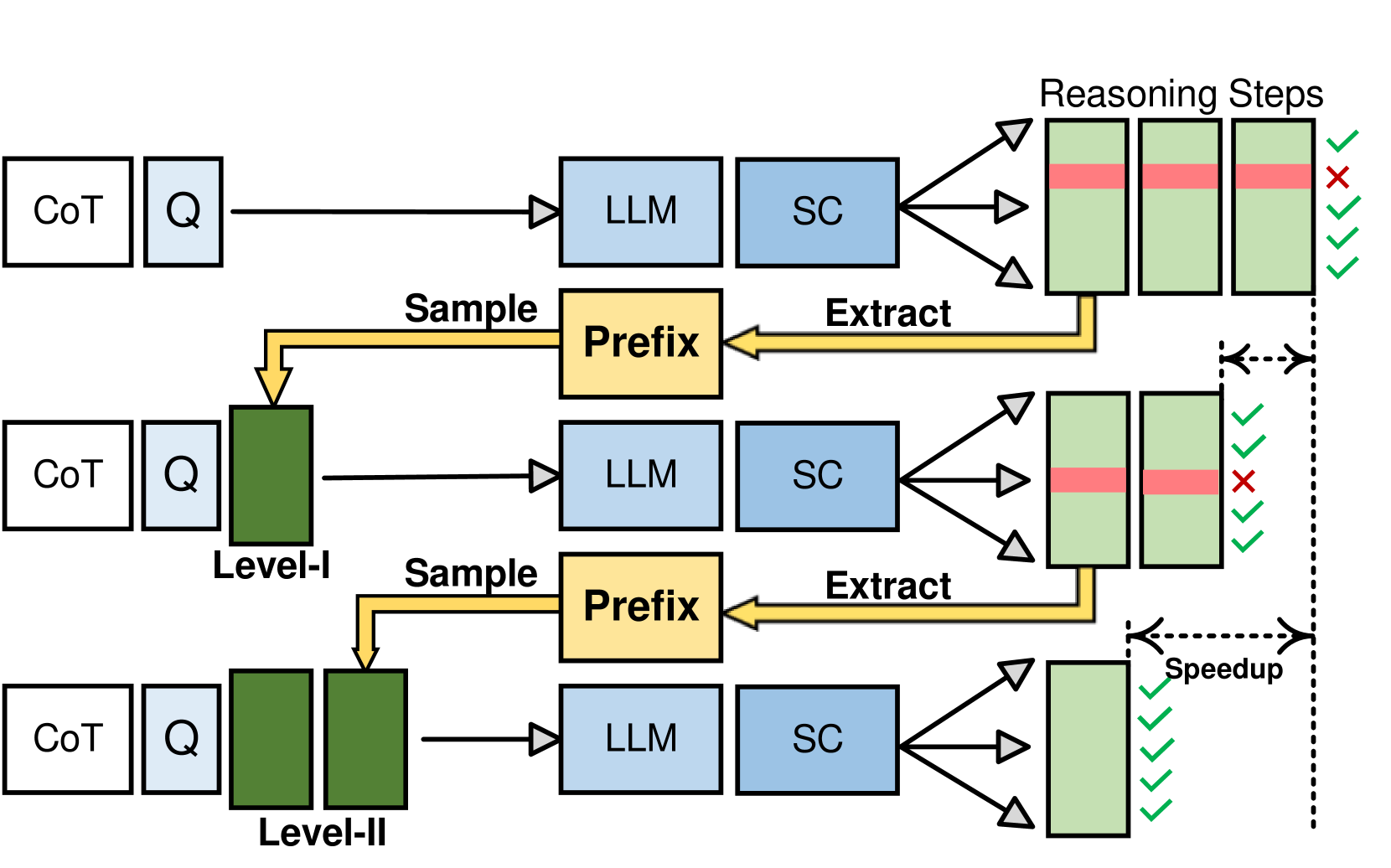
Path-Consistency: Prefix Enhancement for Efficient Inference in LLM
Jiace Zhu, Yingtao Shen, Jie Zhao, An Zou |
 |
Paper |

OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs
Jintian Zhang, Cheng Peng, Mengshu Sun, Xiang Chen, Lei Liang, Zhiqiang Zhang, Jun Zhou, Huajun Chen, Ningyu Zhang |
 |
Github
Paper |

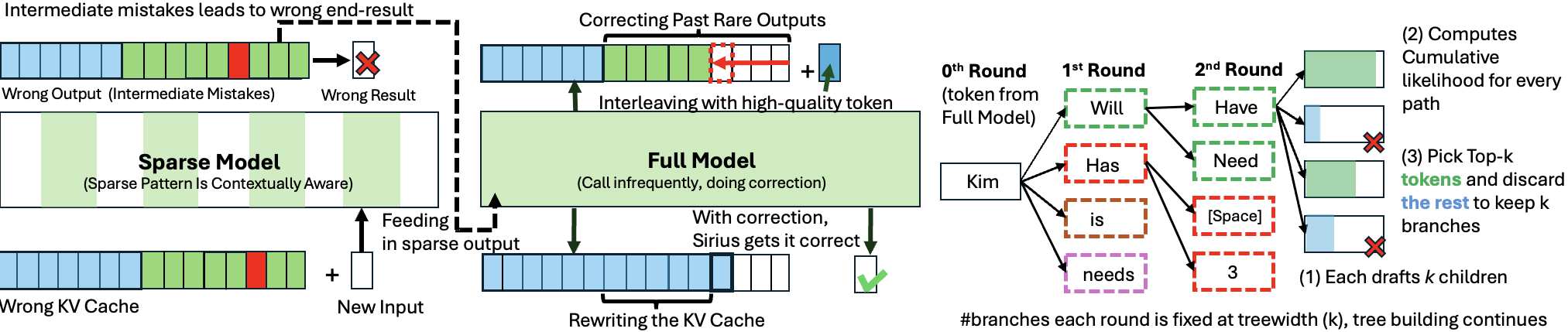
Sirius: Contextual Sparsity with Correction for Efficient LLMs
Yang Zhou, Zhuoming Chen, Zhaozhuo Xu, Victoria Lin, Beidi Chen |
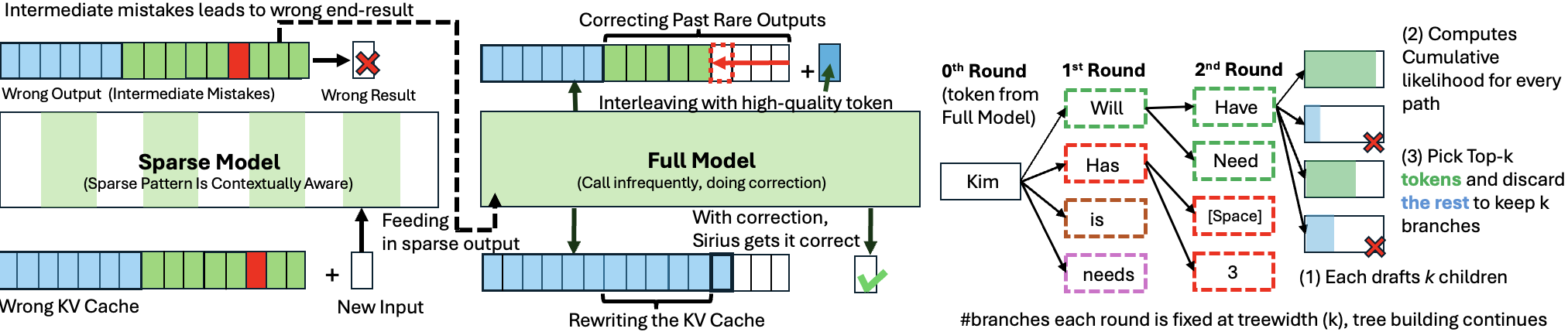 |
Github
Paper |
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, Lili Qiu |
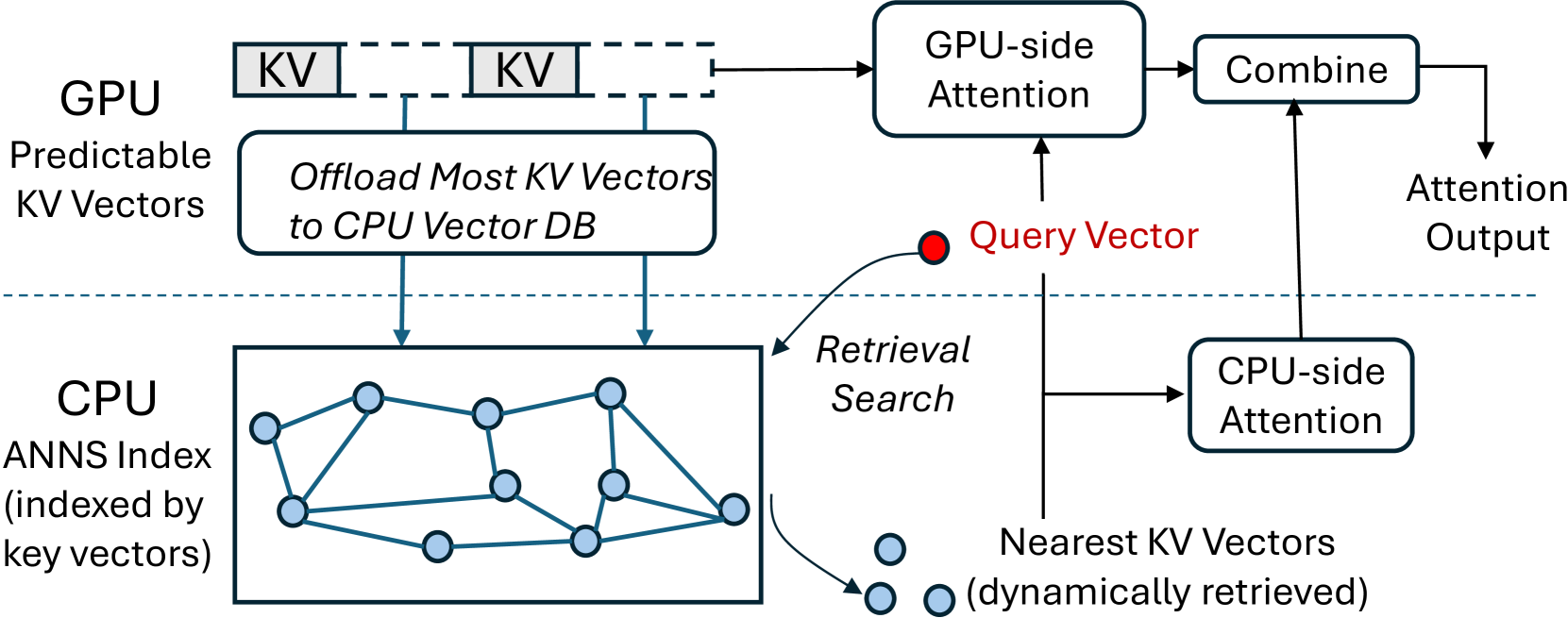 |
Paper |

CritiPrefill: A Segment-wise Criticality-based Approach for Prefilling Acceleration in LLMs
Junlin Lv, Yuan Feng, Xike Xie, Xin Jia, Qirong Peng, Guiming Xie |
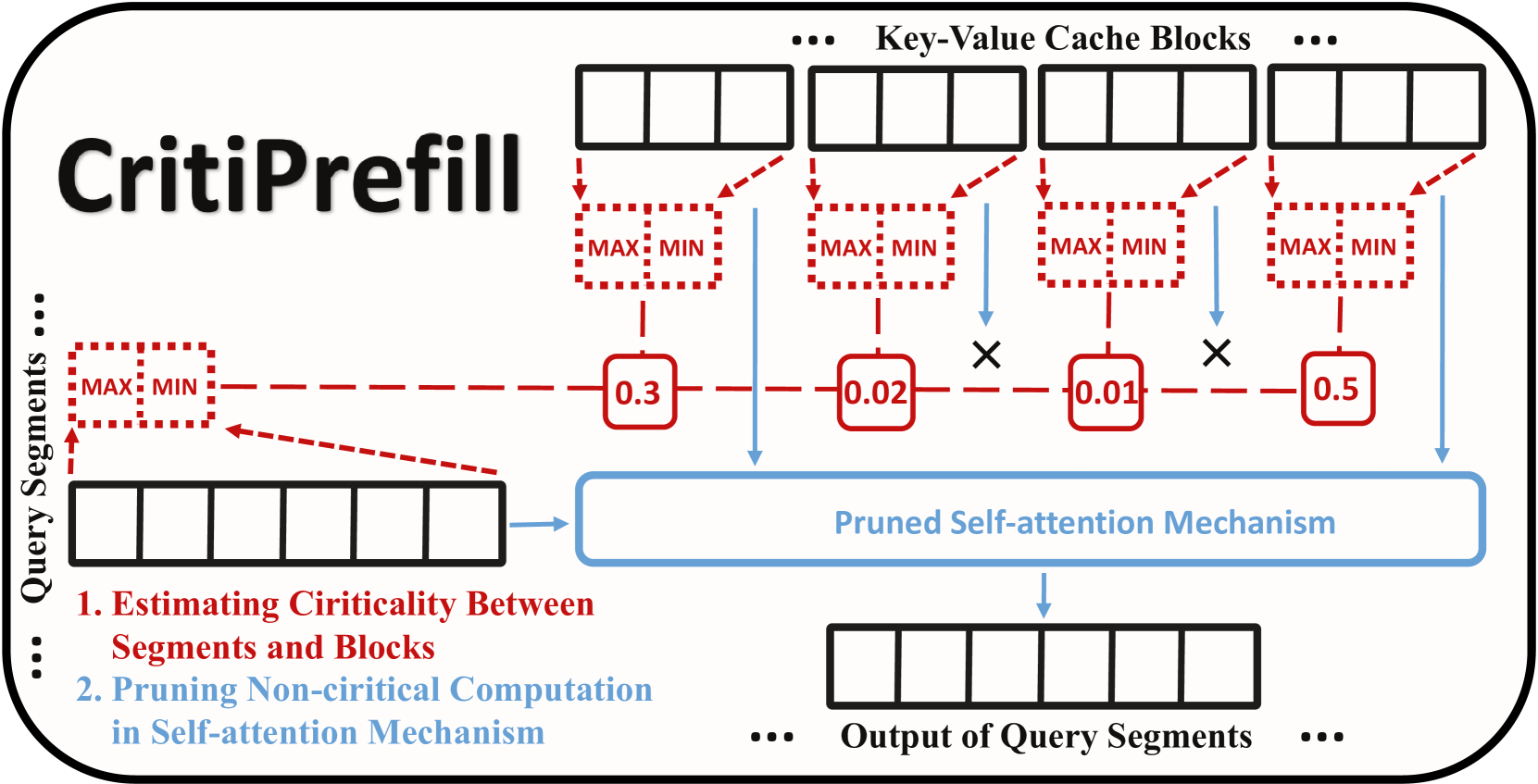 |
Github
Paper |
Dynamic-Width Speculative Beam Decoding for Efficient LLM Inference
Zongyue Qin, Zifan He, Neha Prakriya, Jason Cong, Yizhou Sun |
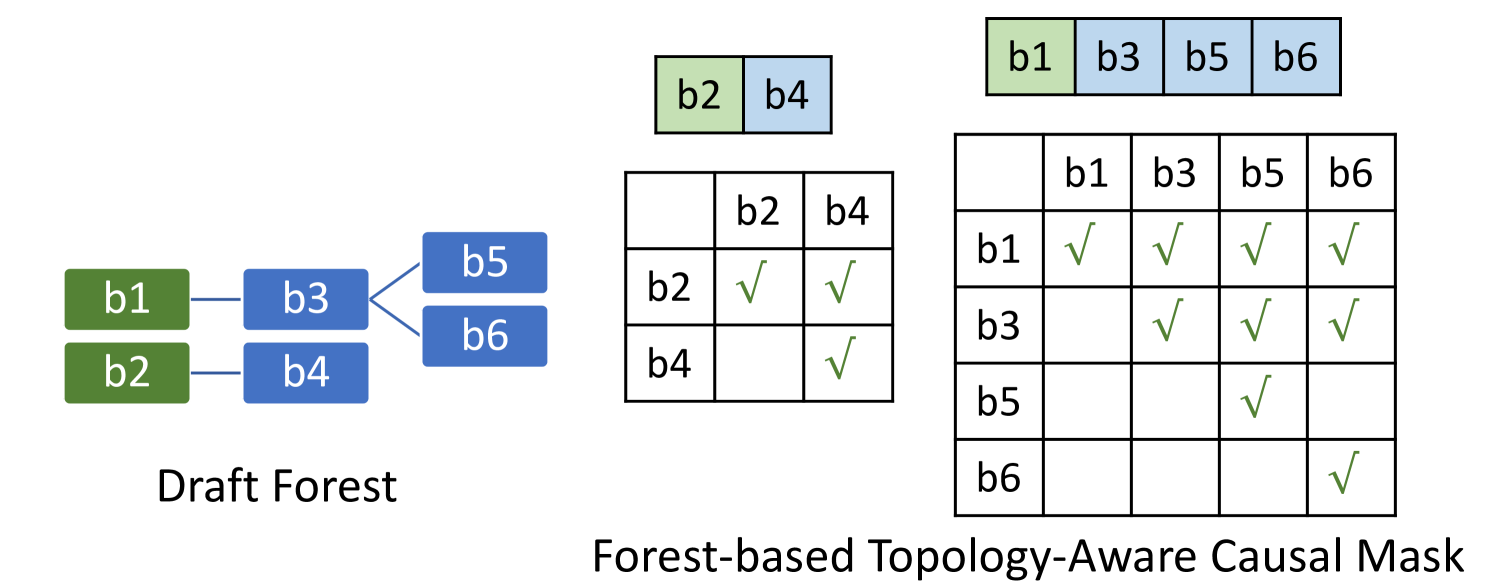 |
Paper |

Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction
Zhenmei Shi, Yifei Ming, Xuan-Phi Nguyen, Yingyu Liang, Shafiq Joty |
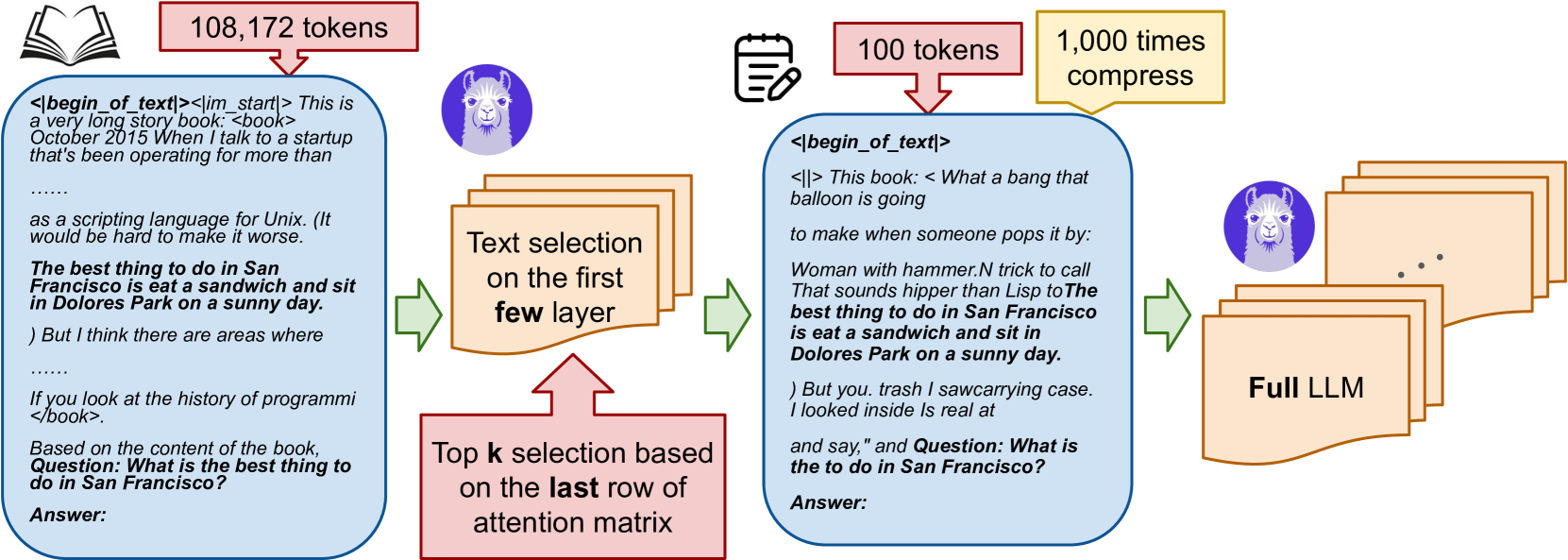 |
Github
Paper |
Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length LLM Inference Requests Without Approximations
Amey Agrawal, Junda Chen, Íñigo Goiri, Ramachandran Ramjee, Chaojie Zhang, Alexey Tumanov, Esha Choukse |
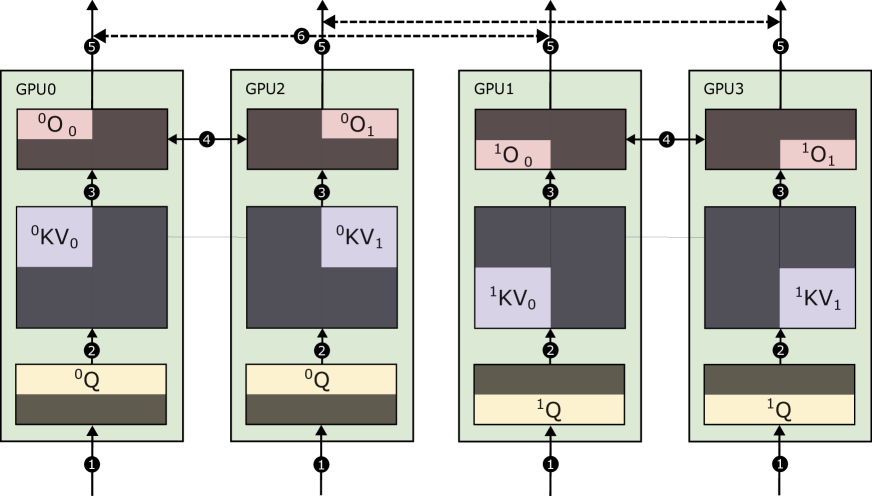 |
Paper |
A Little Goes a Long Way: Efficient Long Context Training and Inference with Partial Contexts
Suyu Ge, Xihui Lin, Yunan Zhang, Jiawei Han, Hao Peng |
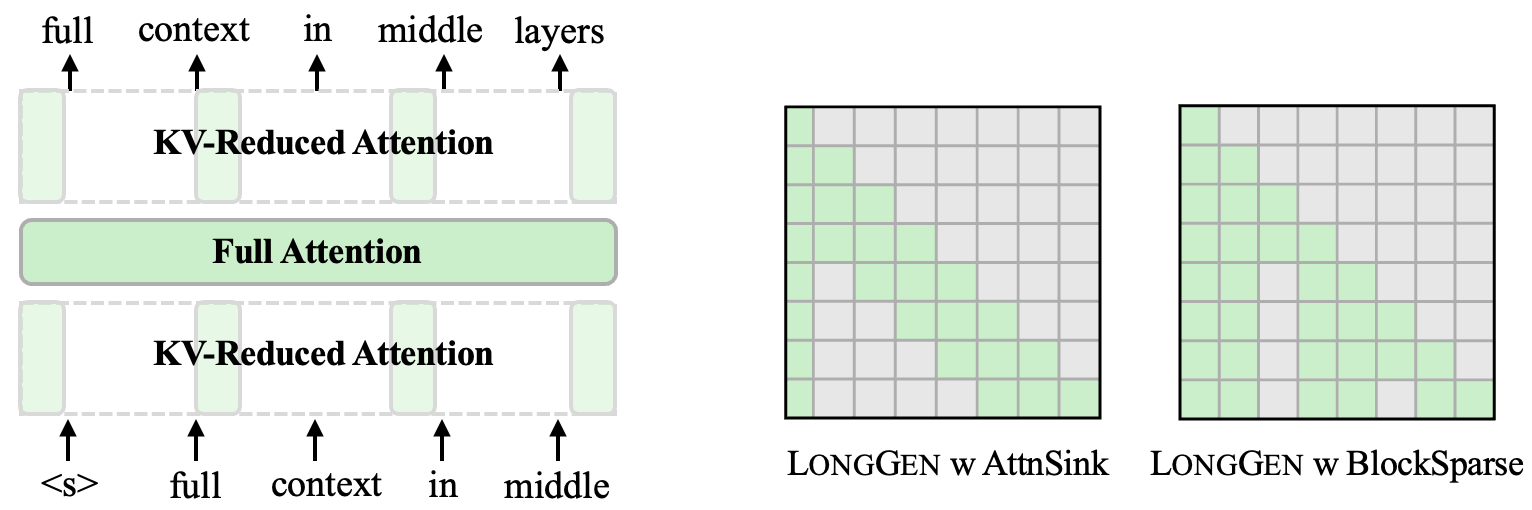 |
Paper |

TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
Songshuo Lu, Hua Wang, Yutian Rong, Zhi Chen, Yaohua Tang |
 |
Github
Paper |

SWIFT: On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration
Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, Wenjie Li |
 |
Github
Paper |
ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Zilin Xiao, Hongming Zhang, Tao Ge, Siru Ouyang, Vicente Ordonez, Dong Yu |
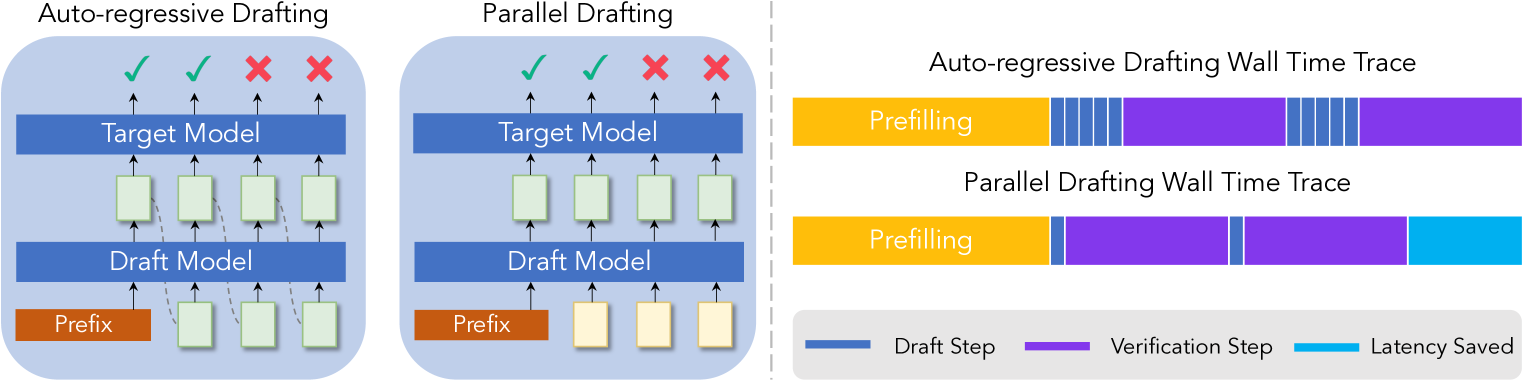 |
Paper |
TidalDecode: Fast and Accurate LLM Decoding with Position Persistent Sparse Attention
Lijie Yang, Zhihao Zhang, Zhuofu Chen, Zikun Li, Zhihao Jia |
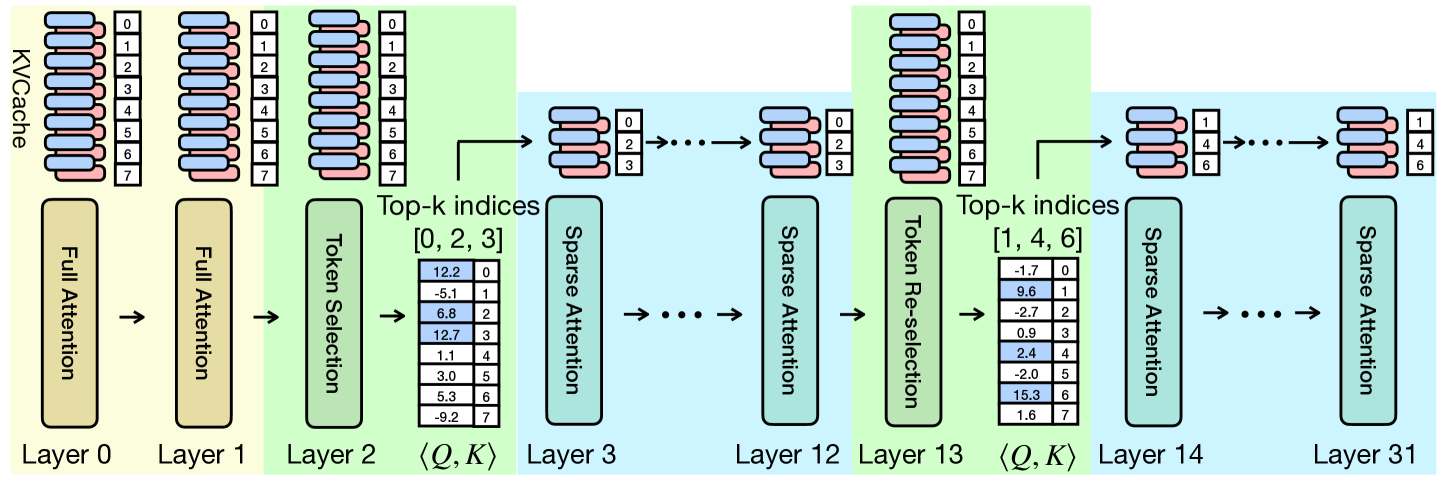 |
Paper |
DySpec: Faster Speculative Decoding with Dynamic Token Tree Structure
Yunfan Xiong, Ruoyu Zhang, Yanzeng Li, Tianhao Wu, Lei Zou |
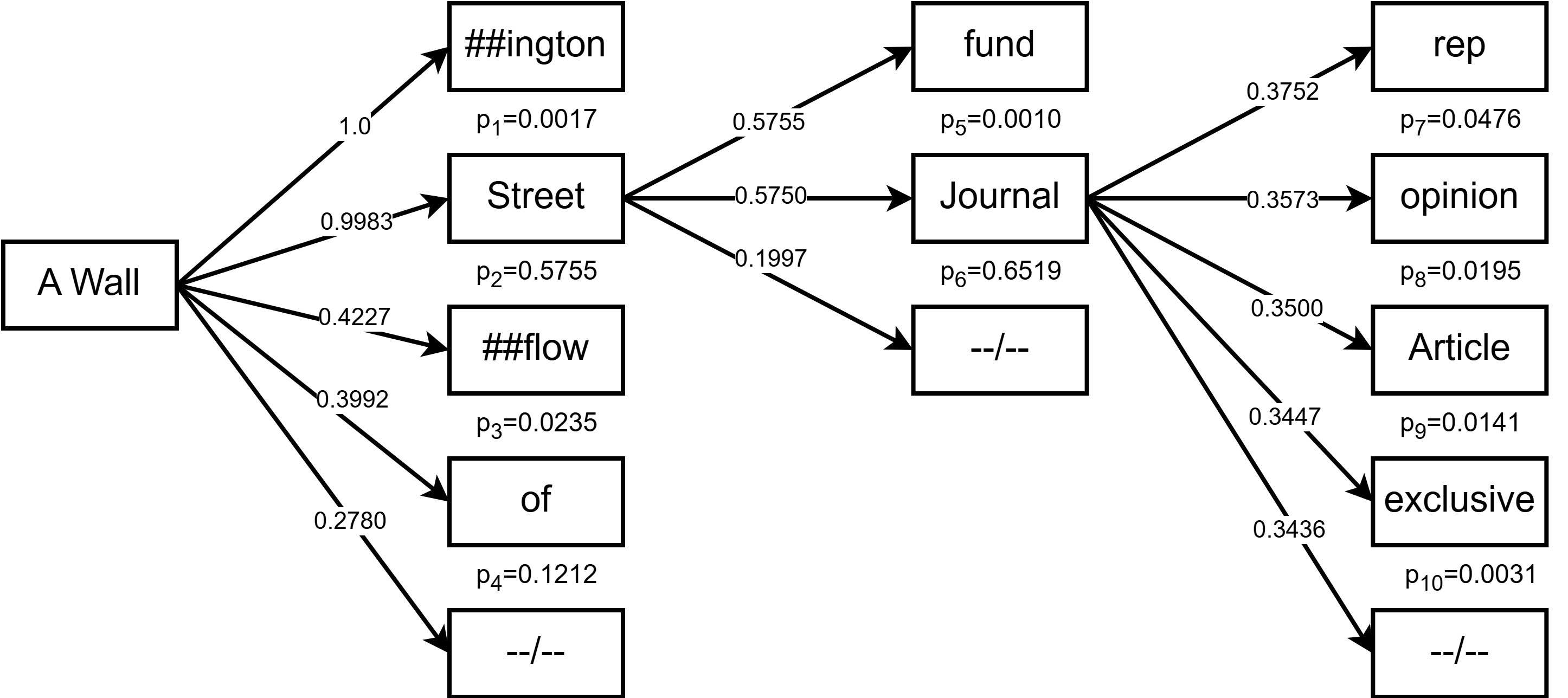 |
Paper |
QSpec: Speculative Decoding with Complementary Quantization Schemes
Juntao Zhao, Wenhao Lu, Sheng Wang, Lingpeng Kong, Chuan Wu |
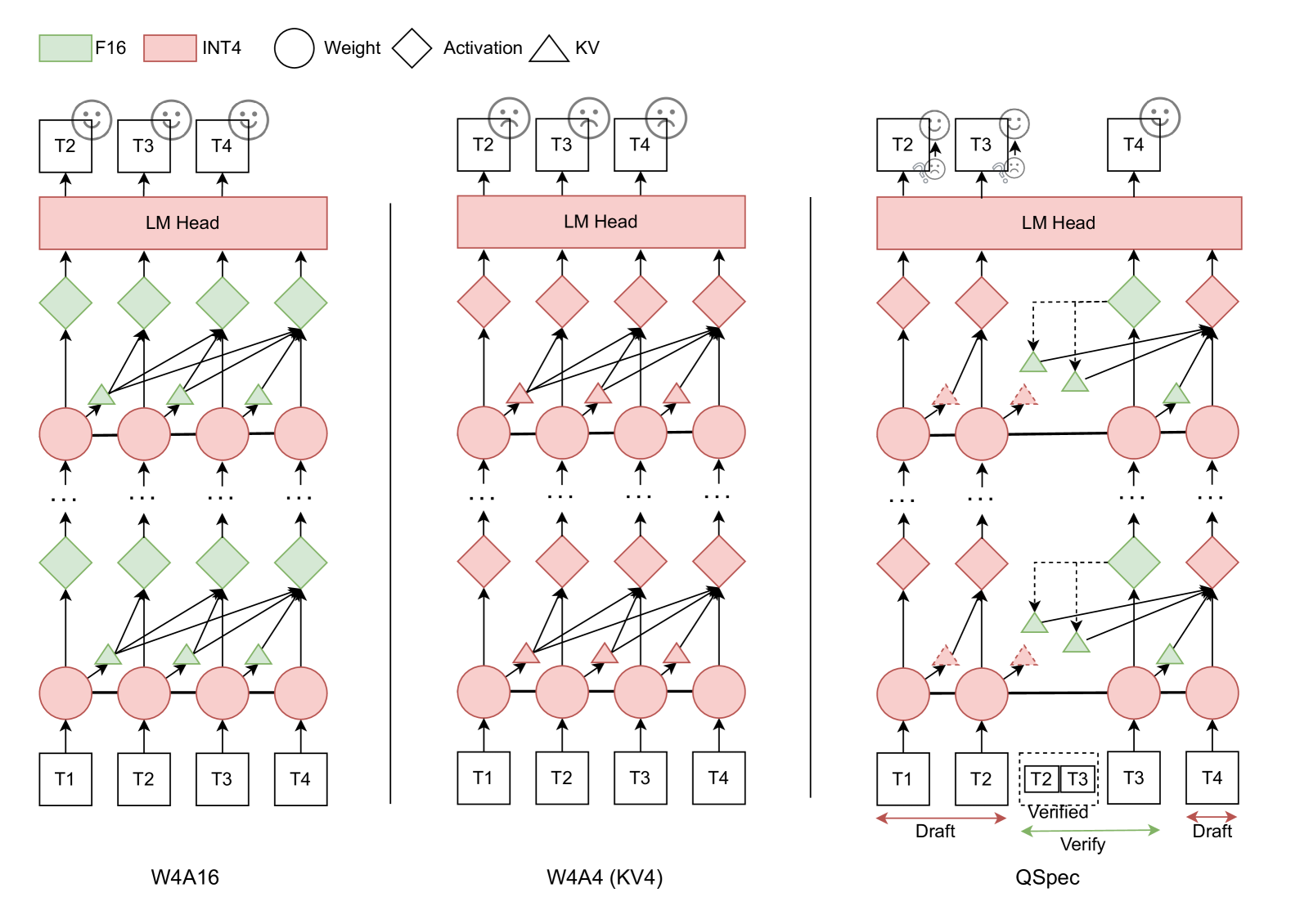 |
Paper |

DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, Song Han |
 |
Github
Paper |
 
CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, Junchen Jiang |
 |
Github
Paper |

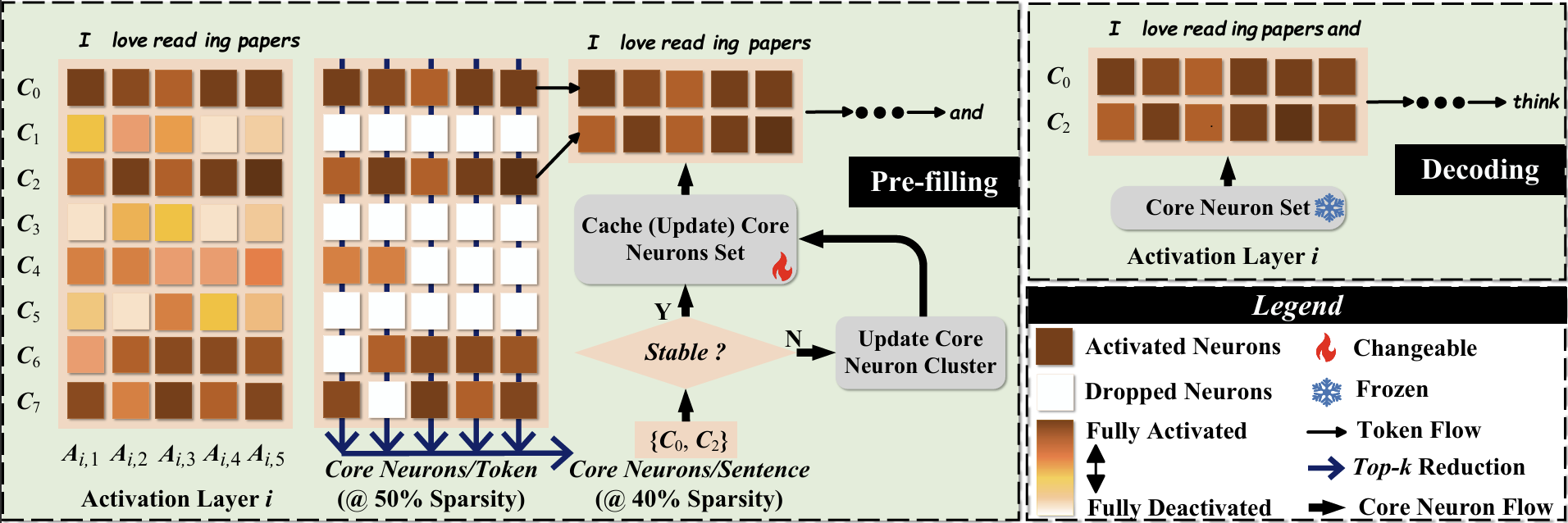
CoreInfer: Accelerating Large Language Model Inference with Semantics-Inspired Adaptive Sparse Activation
Qinsi Wang, Saeed Vahidian, Hancheng Ye, Jianyang Gu, Jianyi Zhang, Yiran Chen |
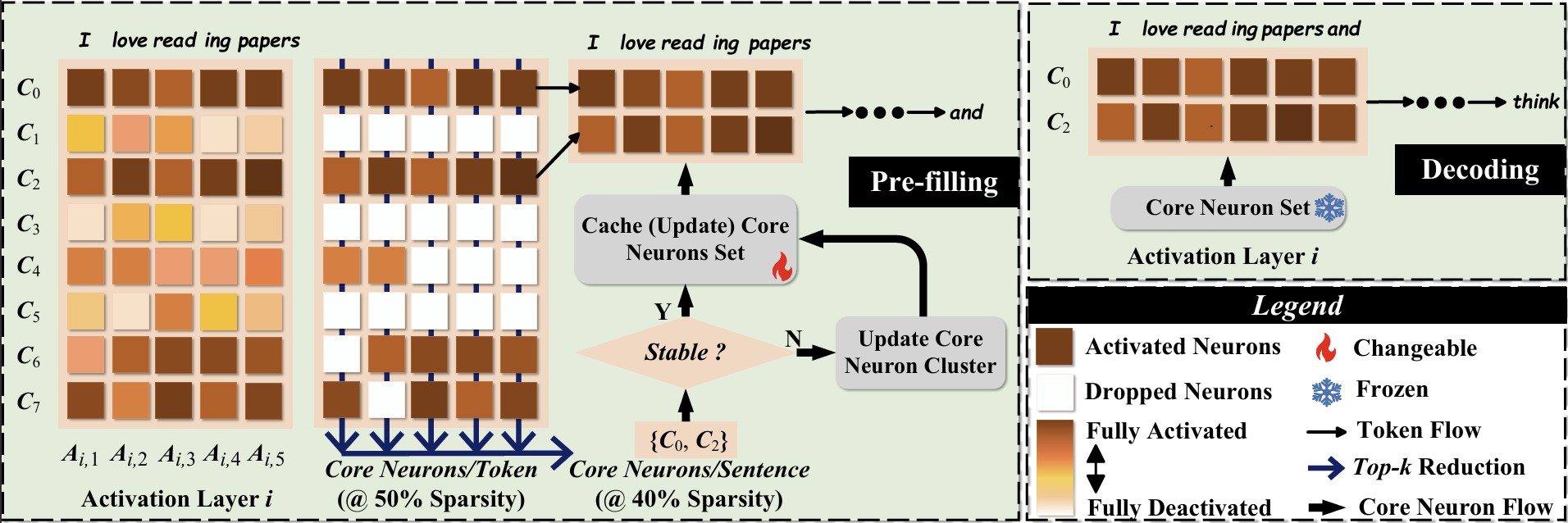 |
Github
Paper |

Dynamic Vocabulary Pruning in Early-Exit LLMs
Jort Vincenti, Karim Abdel Sadek, Joan Velja, Matteo Nulli, Metod Jazbec |
 |
Github
Paper |
Efficient Inference for Augmented Large Language Models
Rana Shahout, Cong Liang, Shiji Xin, Qianru Lao, Yong Cui, Minlan Yu, Michael Mitzenmacher |
 |
Paper |
Faster Language Models with Better Multi-Token Prediction Using Tensor Decomposition
Artem Basharin, Andrei Chertkov, Ivan Oseledets |
 |
Paper |

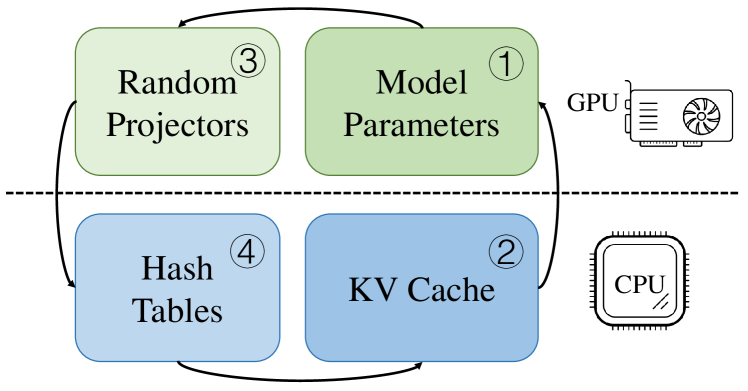
MagicPIG: LSH Sampling for Efficient LLM Generation
Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, Beidi Chen |
 |
Github
Paper |
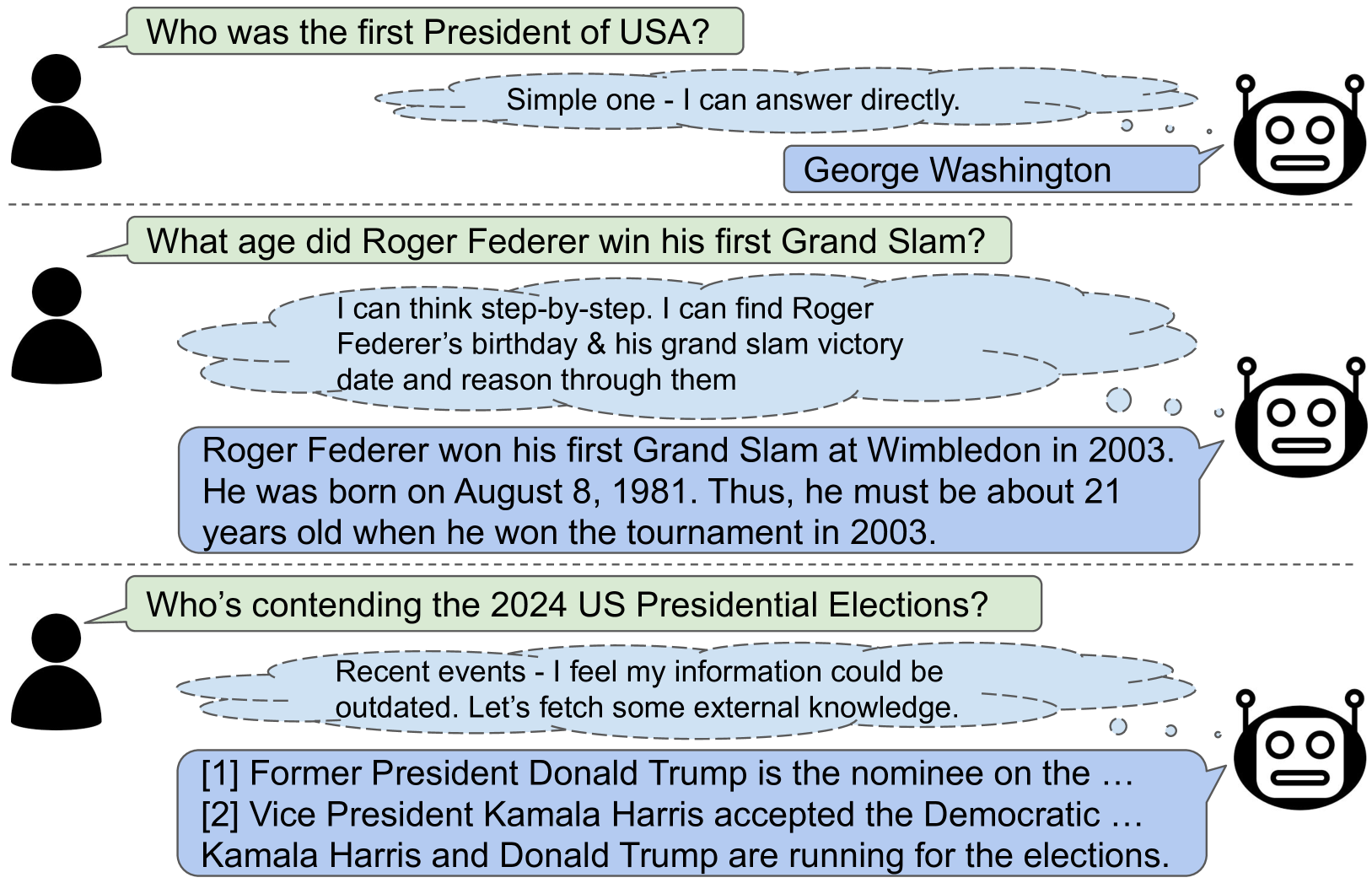
Dynamic Strategy Planning for Efficient Question Answering with Large Language Models
Tanmay Parekh, Pradyot Prakash, Alexander Radovic, Akshay Shekher, Denis Savenkov |
 |
Paper |
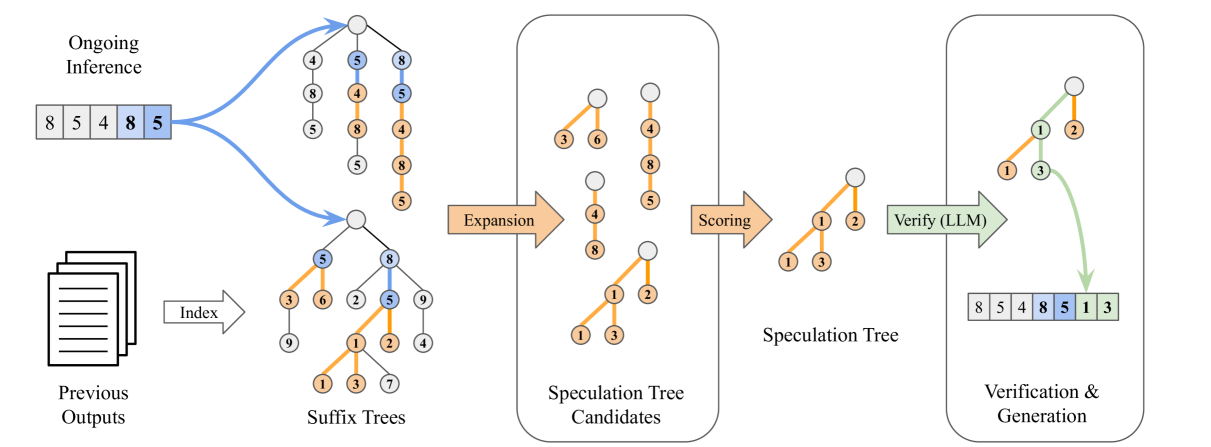
SuffixDecoding: A Model-Free Approach to Speeding Up Large Language Model Inference
Gabriele Oliaro, Zhihao Jia, Daniel Campos, Aurick Qiao |
 |
Paper |
The N-Grammys: Accelerating Autoregressive Inference with Learning-Free Batched Speculation
Lawrence Stewart, Matthew Trager, Sujan Kumar Gonugondla, Stefano Soatto |
|
Paper |
Accelerated AI Inference via Dynamic Execution Methods
Haim Barad, Jascha Achterberg, Tien Pei Chou, Jean Yu |
|
Paper |

SMoA: Improving Multi-agent Large Language Models with Sparse Mixture-of-Agents
Dawei Li, Zhen Tan, Peijia Qian, Yifan Li, Kumar Satvik Chaudhary, Lijie Hu, Jiayi Shen |
 |
Github
Paper |

FastDraft: How to Train Your Draft
Ofir Zafrir, Igor Margulis, Dorin Shteyman, Guy Boudoukh |
|
Paper |