Allow specifying adapter_id on chat/completions requests
#2939
Comments
|
Hi here @tsvisab thanks for the question, indeed that's supported via the curl http://localhost:8080/v1/chat/completions \
-X POST \
-d '{"messages":[{"role":"user","content":"What is Deep Learning?"}],"temperature":0.7,"top_p":0.95,"max_tokens":256,"model":"your-username/your-lora-adapter"}}' \
-H 'Content-Type: application/json'And to send requests to the base model instead just remove the curl http://localhost:8080/v1/chat/completions \
-X POST \
-d '{"messages":[{"role":"user","content":"What is Deep Learning?"}],"temperature":0.7,"top_p":0.95,"max_tokens":256,"model":"meta-llama/Llama-3.1-8B-Instruct"}}' \
-H 'Content-Type: application/json' |
|
Thanks! this definitely does something, when i use "model" : "something that does not exists" it acts as the base model but when i use the adapter key (i.e: |
|
So on start up you should be seeing something like the following:
Retrieved from https://huggingface.co/docs/google-cloud/examples/gke-tgi-multi-lora-deployment in case that tutorial is useful to you too! |
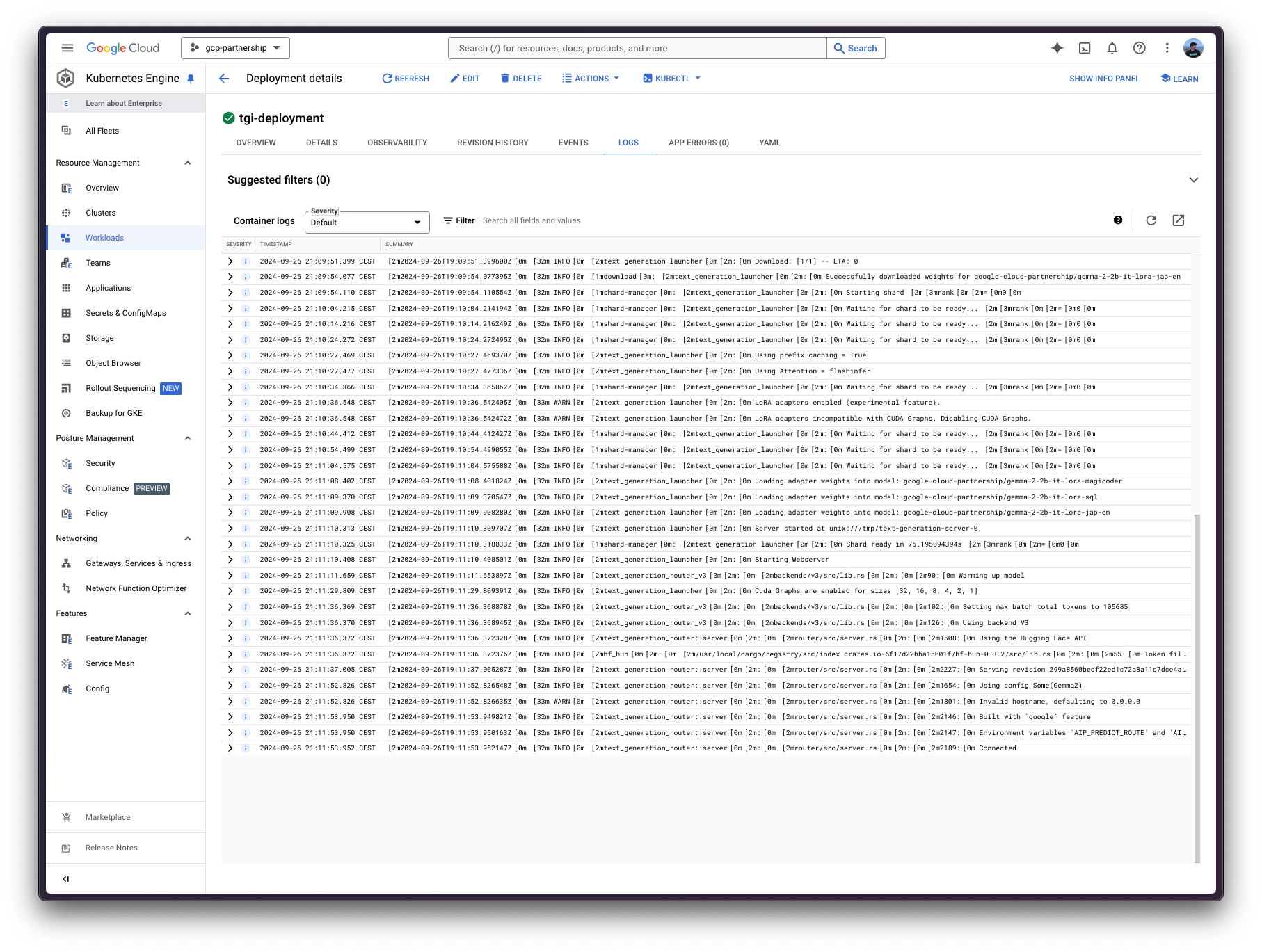
|
P.S. If the adapters are public on the Hub, I'll be happy to reproduce and let you know! |
Feature request
It seems that if i want to load a base model with an adapter and consume it, i'll have to use the
generateroute only which allows specifyingadapter_id`curl 127.0.0.1:3000/generate
-X POST
-H 'Content-Type: application/json'
-d '{
"inputs": "Was "The office" the funniest tv series ever?",
"parameters": {
"max_new_tokens": 200,
"adapter_id": "tv_knowledge_id"
}
}'
but can't use
v1/chat/completionsare you planing to support this?
Motivation
Many use
v1/chat/completionsand train lora adapters for itYour contribution
Maybe, if you're over your capacity
The text was updated successfully, but these errors were encountered: