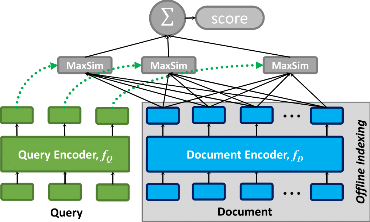
This directory consists of code implementations for retrieving data (from Solr, Watson Discovery and Elasticsearch) and applying the Re-Ranking algorithm to create a more efficient search result. This example demonstrates ColBert based DrDecr reranker model here but you can also replace it with any other re-ranking model such as Perplexity ranking model.
Read our blog for more detailed explanation - https://medium.com/towards-generative-ai/improving-rag-retrieval-augmented-generation-answer-quality-with-re-ranker-55a19931325
- Elastic retriever has various models to improve the relevancy of the returned document.
- es_retriever_reranker.ipynb: This Jupyter notebook explains the process of retrieving data from the ES index and applying the Colbert based DrDecr re-Ranker algorithm using a Deep learning model.
- Solr retrieval works best for very long documents, e.g. books with hundreds of pages.
- solr_retriever_reranker.ipynb: This Jupyter notebook explains the process of retrieving data from the Solr database and applying the Colbert Re-Ranker algorithm using a Deep learning model.
- solr_retriever_reranker.py: This Python script programmatically retrieves data from the Solr database and applies the Colbert Re-Ranker algorithm using a Deep learning model.
- Re-ranker.ipynb: This Jupyter notebook outlines the data retrieval process from Watson Discovery and the subsequent application of the Colbert Re-Ranker algorithm.
- A reusable script to rank and get document that is the closest match to given query.
These scripts and notebooks are helpful guidebooks. They demonstrate how to pull data from different places and make your search results better by using something called the re-ranking algorithm. This algorithm considers how closely a query matches and the data quality, to ensure the best possible results.
- Clone this repository.
- Modify the config.yaml to update the
rerankermodel if required - Run the reranker.py to see the Reranker module in action.