| 模型名称 | fastspeech2_ljspeech |
|---|---|
| 类别 | 语音-语音合成 |
| 网络 | FastSpeech2 |
| 数据集 | LJSpeech-1.1 |
| 是否支持Fine-tuning | 否 |
| 模型大小 | 425MB |
| 最新更新日期 | 2021-10-20 |
| 数据指标 | - |
FastSpeech2是微软亚洲研究院和微软Azure语音团队联合浙江大学于2020年提出的语音合成(Text to Speech, TTS)模型。FastSpeech2是FastSpeech的改进版,解决了FastSpeech依赖Teacher-Student的知识蒸馏框架,训练流程比较复杂和训练目标相比真实语音存在信息损失的问题。
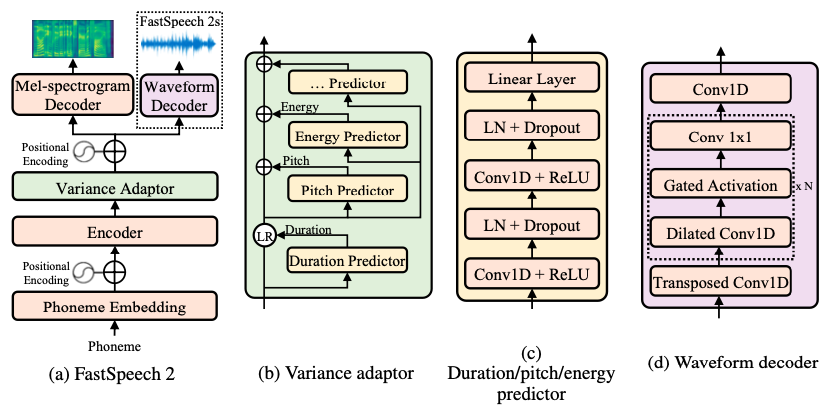
FastSpeech2的模型架构如下图所示,它沿用FastSpeech中提出的Feed-Forward Transformer(FFT)架构,但在音素编码器和梅尔频谱解码器中加入了一个可变信息适配器(Variance Adaptor),从而支持在FastSpeech2中引入更多语音中变化的信息,例如时长、音高、音量(频谱能量)等,来解决语音合成中的一对多映射问题。
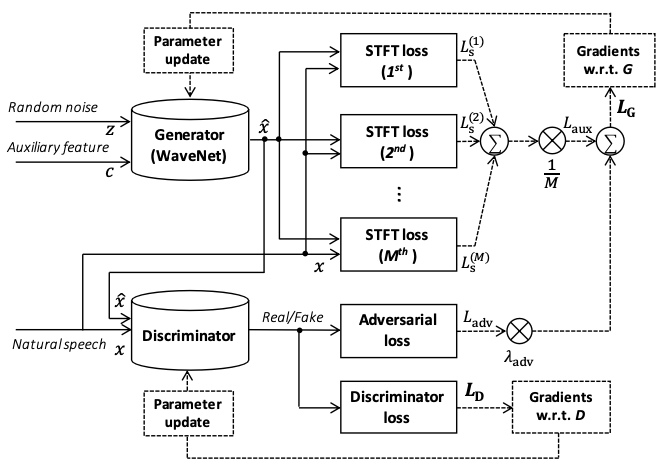
Parallel WaveGAN是一种使用了无蒸馏的对抗生成网络,快速且占用空间小的波形生成方法。该方法通过联合优化多分辨率谱图和对抗损失函数来训练非自回归WaveNet,可以有效捕获真实语音波形的时频分布。Parallel WaveGAN的结构如下图所示:
fastspeech2_ljspeech使用了FastSpeech2作为声学模型,使用Parallel WaveGAN作为声码器,并在The LJ Speech Dataset数据集上进行了预训练,可直接用于预测合成音频。
更多详情请参考:
- FastSpeech 2: Fast and High-Quality End-to-End Text-to-Speech
- FastSpeech语音合成系统技术升级,微软联合浙大提出FastSpeech2
- Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram
-
-
paddlepaddle >= 2.1.0
-
paddlehub >= 2.1.0 | 如何安装PaddleHub
-
-
-
$ hub install fastspeech2_ljspeech
- 如您安装时遇到问题,可参考:零基础windows安装 | 零基础Linux安装 | 零基础MacOS安装
-
-
import paddlehub as hub # 需要合成语音的文本 sentences = ['The quick brown fox jumps over a lazy dog.'] model = hub.Module( name='fastspeech2_ljspeech', version='1.0.0') wav_files = model.generate(sentences) # 打印合成的音频文件的路径 print(wav_files)
详情可参考PaddleHub示例:
-
-
def __init__(output_dir)
-
创建Module对象(动态图组网版本)
-
参数
output_dir: 合成音频文件的输出目录。
-
-
def generate( sentences, device='cpu', )
-
将输入的文本合成为音频文件并保存到输出目录。
-
参数
sentences:合成音频的文本列表,类型为List[str]。device:预测时使用的设备,默认为�cpu,如需使用gpu预测,请设置为gpu。
-
返回
wav_files:List[str]类型,返回合成音频的存放路径。
-
-
-
PaddleHub Serving可以部署一个在线的语音识别服务。
-
-
$ hub serving start -m fastspeech2_ljspeech
-
这样就完成了一个语音识别服务化API的部署,默认端口号为8866。
-
NOTE: 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-
-
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
import requests import json # 需要合成语音的文本 sentences = [ 'The quick brown fox jumps over a lazy dog.', 'Today is a good day!', ] # 以key的方式指定text传入预测方法的时的参数,此例中为"sentences" data = {"sentences": sentences} # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip url = "http://127.0.0.1:8866/predict/fastspeech2_ljspeech" # 指定post请求的headers为application/json方式 headers = {"Content-Type": "application/json"} r = requests.post(url=url, headers=headers, data=json.dumps(data)) print(r.json())
-
-
1.0.0
初始发布
$ hub install fastspeech2_ljspeech