| 模型名称 | ge2e_fastspeech2_pwgan |
|---|---|
| 类别 | 语音-声音克隆 |
| 网络 | FastSpeech2 |
| 数据集 | AISHELL-3 |
| 是否支持Fine-tuning | 否 |
| 模型大小 | 462MB |
| 最新更新日期 | 2021-12-17 |
| 数据指标 | - |
声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。
在训练语音克隆模型时,目标音色作为Speaker Encoder的输入,模型会提取这段语音的说话人特征(音色)作为Speaker Embedding。接着,在训练模型重新合成此类音色的语音时,除了输入的目标文本外,说话人的特征也将成为额外条件加入模型的训练。
在预测时,选取一段新的目标音色作为Speaker Encoder的输入,并提取其说话人特征,最终实现输入为一段文本和一段目标音色,模型生成目标音色说出此段文本的语音片段。
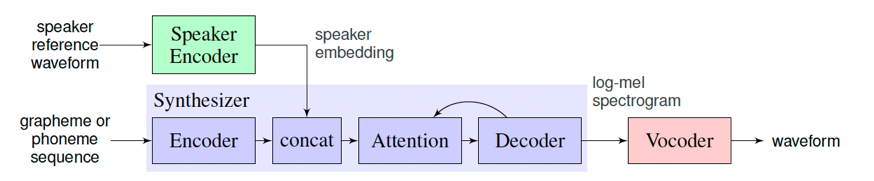
ge2e_fastspeech2_pwgan是一个支持中文的语音克隆模型,分别使用了LSTMSpeakerEncoder、FastSpeech2和PWGan模型分别用于语音特征提取、目标音频特征合成和语音波形转换。
关于模型的详请可参考PaddleSpeech。
-
-
paddlepaddle >= 2.2.0
-
paddlehub >= 2.1.0 | 如何安装PaddleHub
-
-
-
$ hub install ge2e_fastspeech2_pwgan
- 如您安装时遇到问题,可参考:零基础windows安装 | 零基础Linux安装 | 零基础MacOS安装
-
-
-
import paddlehub as hub model = hub.Module(name='ge2e_fastspeech2_pwgan', output_dir='./', speaker_audio='/data/man.wav') # 指定目标音色音频文件 texts = [ '语音的表现形式在未来将变得越来越重要$', '今天的天气怎么样$', ] wavs = model.generate(texts, use_gpu=True) for text, wav in zip(texts, wavs): print('='*30) print(f'Text: {text}') print(f'Wav: {wav}')
-
-
-
def __init__(speaker_audio: str = None, output_dir: str = './')
-
初始化module,可配置模型的目标音色的音频文件和输出的路径。
-
参数
speaker_audio(str): 目标说话人语音音频文件(*.wav)的路径,默认为None(使用默认的女声作为目标音色)。output_dir(str): 合成音频的输出文件,默认为当前目录。
-
-
def get_speaker_embedding()
-
获取模型的目标说话人特征。
-
返回
results(numpy.ndarray): 长度为256的numpy数组,代表目标说话人的特征。
-
-
def set_speaker_embedding(speaker_audio: str)
-
设置模型的目标说话人特征。
-
参数
speaker_audio(str): 必填,目标说话人语音音频文件(*.wav)的路径。
-
-
def generate(data: Union[str, List[str]], use_gpu: bool = False):
-
根据输入文字,合成目标说话人的语音音频文件。
-
参数
data(Union[str, List[str]]): 必填,目标音频的内容文本列表,目前只支持中文,不支持添加标点符号。use_gpu(bool): 是否使用gpu执行计算,默认为False。
-
-
-
1.0.0
初始发布。
$ hub install ge2e_fastspeech2_pwgan