| 模型名称 | ernie_skep_sentiment_analysis |
|---|---|
| 类别 | 文本-情感分析 |
| 网络 | SKEP |
| 数据集 | 百度自建数据集 |
| 是否支持Fine-tuning | 否 |
| 模型大小 | 2.4G |
| 最新更新日期 | 2021-02-26 |
| 数据指标 | - |
-
- SKEP(Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis)是百度研究团队在2020年提出的基于情感知识增强的情感预训练算法,此算法采用无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义,在14项中英情感分析典型任务上全面超越SOTA,相关工作已经被ACL 2020录用。SKEP为各类情感分析任务提供统一且强大的情感语义表示。ernie_skep_sentiment_analysis Module可用于句子级情感分析任务预测。其在预训练时使用ERNIE 1.0 large预训练参数作为其网络参数初始化继续预训练。
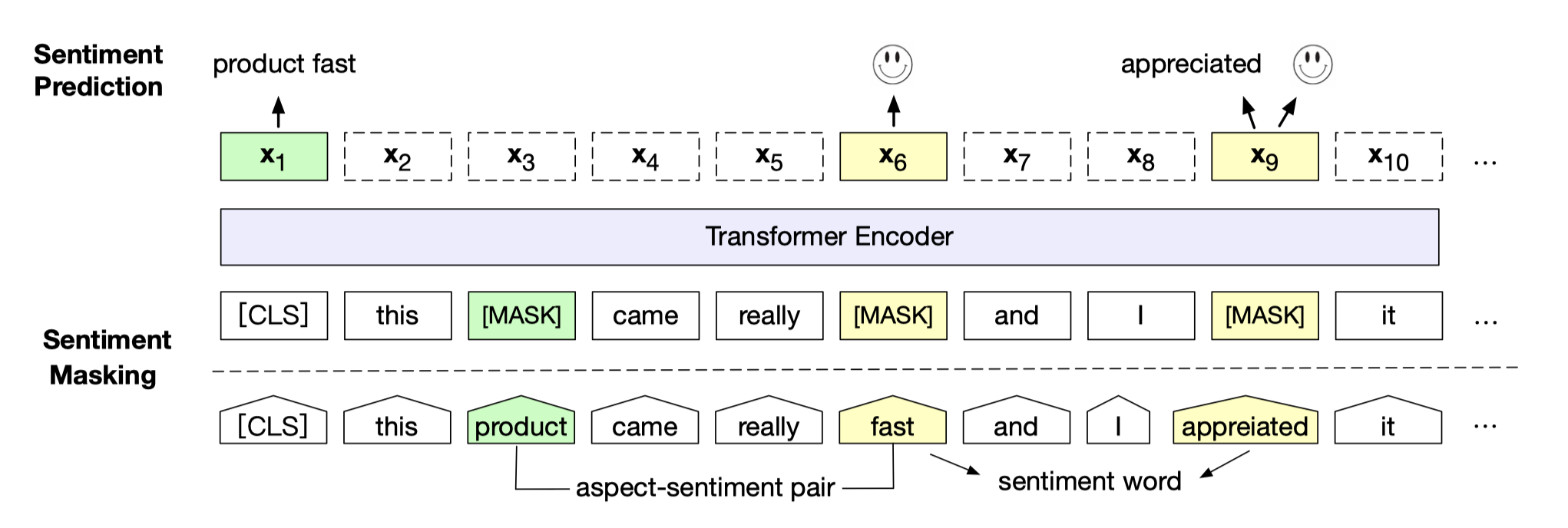
-
-
paddlepaddle >= 1.8.0
-
paddlehub >= 1.7.0 | 如何安装PaddleHub
-
-
-
$ hub install ernie_skep_sentiment_analysis
- 如您安装时遇到问题,可参考:零基础windows安装 | 零基础Linux安装 | 零基础MacOS安装
-
-
-
$ hub run ernie_skep_sentiment_analysis --input_text='虽然小明很努力,但是他还是没有考100分'
-
-
-
import paddlehub as hub # Load ernie_skep_sentiment_analysis module. module = hub.Module(name="ernie_skep_sentiment_analysis") # Predict sentiment label test_texts = ['你不是不聪明,而是不认真', '虽然小明很努力,但是他还是没有考100分'] results = module.predict_sentiment(test_texts, use_gpu=False) for result in results: print(result['text']) print(result['sentiment_label']) print(result['positive_probs']) print(result['negative_probs']) # 你不是不聪明,而是不认真 negative 0.10738129168748856 0.8926186561584473 # 虽然小明很努力,但是他还是没有考100分 negative 0.05391530692577362 0.94608473777771
-
-
-
def predict_sentiment(texts=[], use_gpu=False)
-
预测API,分类输入文本的情感极性。
-
参数
- texts (list[str]): 待预测文本;
- use_gpu (bool): 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量;
-
返回
- res (list[dict]): 情感分类结果的列表,列表中每一个元素为 dict,各字段为:
- text(str): 输入预测文本
- sentiment_label(str): 情感分类结果,或为positive或为negative
- positive_probs: 输入预测文本情感极性属于positive的概率
- negative_probs: 输入预测文本情感极性属于negative的概率
- res (list[dict]): 情感分类结果的列表,列表中每一个元素为 dict,各字段为:
-
-
def get_embedding(texts, use_gpu=False, batch_size=1)
-
用于获取输入文本的句子粒度特征与字粒度特征
-
参数
- texts(list):输入文本列表,格式为[[sample_a_text_a, sample_a_text_b], [sample_b_text_a, sample_b_text_b],…,],其中每个元素都是一个样例,每个样例可以包含text_a与text_b。
- use_gpu(bool):是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量;
-
返回
- results(list): embedding特征,格式为[[sample_a_pooled_feature, sample_a_seq_feature], [sample_b_pooled_feature, sample_b_seq_feature],…,],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled_feature与字粒度特征seq_feature。
-
-
-
PaddleHub Serving 可以部署一个目标检测的在线服务。
-
-
运行启动命令:
$ hub serving start -m ernie_skep_sentiment_analysis
-
这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
-
NOTE: 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-
-
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
import requests import json # 发送HTTP请求 data = {'texts':['你不是不聪明,而是不认真', '虽然小明很努力,但是他还是没有考100分']} headers = {"Content-type": "application/json"} url = "http://127.0.0.1:8866/predict/ernie_skep_sentiment_analysis" r = requests.post(url=url, headers=headers, data=json.dumps(data)) # 打印预测结果 print(r.json()["results"])
-
-
1.0.0
初始发布
-
1.0.1
移除 fluid api
-
$ hub install ernie_skep_sentiment_analysis==1.0.1
-