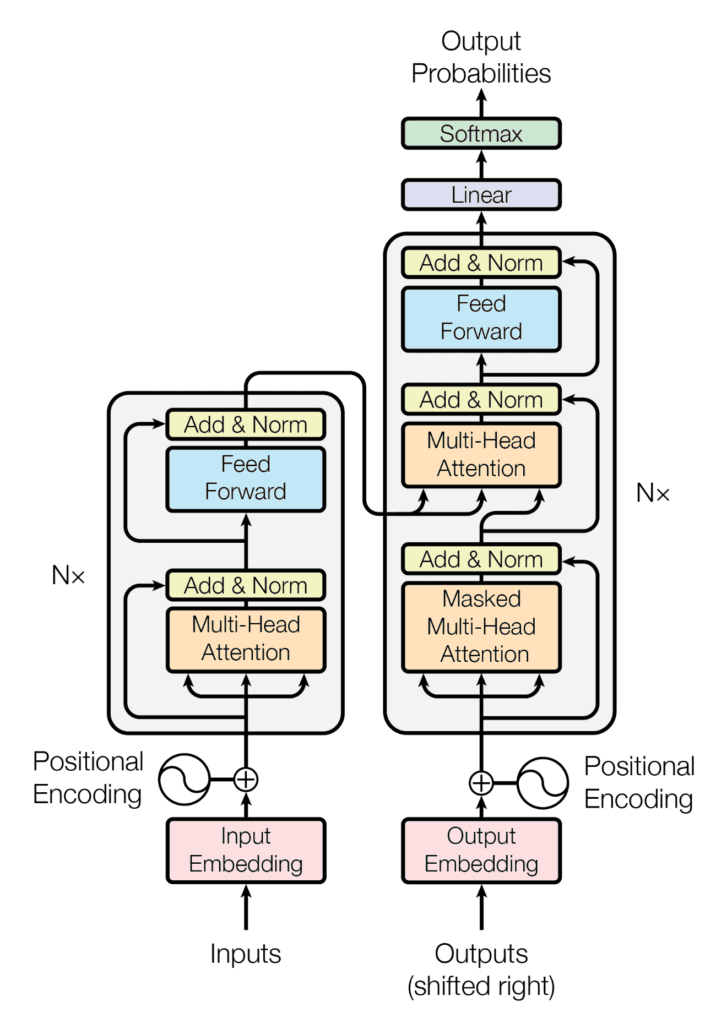
- A transformer consists of multiple encoder - decoder blocks.
- Each individual block is completely separate from each other and they don't share weights.
- Inputs flow in as text
-
Text gets tokenised
-
Tokens get mapped to a
$n_{dim}$ embedding which is unique to each individual token -
Tokens get a positional encoding added to them which the transformer. This can either be a learnt value or one that is fixed at the time of training
- Attention is a position invariant operation - this means that if we were to reorder the tokens, we would still get the same weightage for each token.
- Position is really important when it comes to the sentence meaning therefore we need to account for this using a positional encoding (Eg. I went to the river bank and I bank at HSBC )
-
We first encode the input
- Tokens then pass through an entire transformer block
- First step is self-attention where each token's embedding gets mapped to a low rank embedding dimension that the block has learnt.
- We then calculate a weightage for every token prior to this current token that sums up to 1 before using it to calculate a weighted sum for that specific token
- This then gets used in a feed forward later which adds more semantic meaning to this specific representation
- Note : The initial self-attention results in each token's path through the self-attention block being dependent on each other but the feed forward network is one that can be parallelised easily
- Tokens then pass through an entire transformer block
-
Once we've encoded the input, then we can pass it into our decoder chunks
- Note that in our decoder, we have two forms of attention
- First is Multi Headed Attention where we take the a context vector for that token and apply MHA to it to enrich it with semantic meaning
- Next is [[Cross Attention]] which we utilise to combine the encoder information with our decoder. In this case, our encoder input is fed in to our Query and Value matrices and our decoder output from the previous MHA step is set to the Key matrix.
- K,V comes from the encoder while Q comes from the decoder - this means we're trying to match what we need from the generated sequence with what was encoded using the encoder.
- Note that in our decoder, we have two forms of attention
-
Inside this transformer block, we typically utilise what is known as Multi Headed Attention by splitting up the embedding matrix into smaller chunks before multiplying each chunk by a different query, key and value matrix
- It gives the attention layer multiple “representation subspaces” and expands the model's ability to focus on different positions ( Since each matrix could be focusing on a different portion )
-
[