Hi there!👋
I’m KurisaW,or you can call me yifang.
| |
Contact me:
- Github Address :https://github.com/kurisaW
- Email :yifang.wangyq@foxmail.com
- My Website :https://kurisaw.github.io/
You can also choose to get in touch with me by adding wechat!

I’m KurisaW,or you can call me yifang.
| |
Contact me:
You can also choose to get in touch with me by adding wechat!





















































































这里我存放了一些个人搜集的文档资源,支持PDF在线查看,同时也欢迎各位在评论区留下相关资源链接!
由于构建方式使用的是PDF.js插件,是为html5实现的在线预览pdf框架,所以使用的前提是浏览器要支持html5。该插件不需要任何本地支持,对浏览器的兼容性也比较好(低版本的IE浏览器不支持)。
配置仓库入口:https://github.com/kurisaW/Npdf
注:目前本博客的pdf资源已部分上传至infinityfree服务器,较之pdf.js有更快响应速度,后续考虑国内CDN加速,当然想要学习和了解pdf.js的构建方式也可参考此仓库Npdf;由于部分pdf文件较大,反应速度慢属于正常现象。
如果你有相关资源想要集合到一个网站以便随时访问而又拘于时间问题没法搭建网站的话,可以与我取得联系,我将帮助你整理好资源,以此为你提供更加便利的阅读!
欢迎你的来访,期待与你有更好的合作!
If you have resources or tools that you recommend, you can contribute in the format below
This page’s frontmatter:
| |
image field accepts both local and external images.





To use this feature, add links section to frontmatter.
This page’s frontmatter:
| |
image field accepts both local and external images.

| |
#include <iostream>(输入输出流)using namespace std;cin >> :用于输入;cout << :用于输出; endl:用于换行主要分为三类:基本数据类型、构造数据类型、类
简单来说,函数重载就是让功能相似的函数使用同一函数名,以增加程序的可读性。
如:
| |
类由说明部分和实现部分组成,其说明部分的形式如下:
| |
实现部分的形式如下:
| |
注意:在类内不能对数据成员进行初始化,同时,private\protect\public三个关键字对数据成员有不同的访问控制
类的成员函数的定义一般在类外完成(也可以在类内完成),其形式如下:
| |
其中::被称为作用域运算符,能指出函数成员是属于哪个类的
如果把类看作是数据类型,则该数据类型定义的变量就是对象。
在定义类之后,就可以定义对象了,一般格式为:
| |
也可以定义一个指向对象的指针,如Clock *p;则指针p指向Clock类的一个对象
对于一般对象(非对象指针),访问其成员的方式为:
| |
对于指向对象的指针,访问其成员的方式为:
| |
注意:其中.为点运算符;->为箭头运算符(类似结构体)
在主函数中调用Clock类中的show()函数,可写成如下形式:
| |
| 继承方式 | 基类的public成员 | 基类的protected成员 | 基类的private成员 | 继承引起的访问控制关系变化概括 |
|---|---|---|---|---|
| public继承 | 仍为public成员 | 仍为protected成员 | 不可见 | 基类的非私有成员在子类的访问属性不变 |
| protected继承 | 变为protected成员 | 变为protected成员 | 不可见 | 基类的非私有成员都为子类的保护成员 |
| private继承 | 变为private成员 | 变为private成员 | 不可见 | 基类中的非私有成员都称为子类的私有成员 |
构造函数的功能是将对象初始化,其特点是与类同名,且无返回类型
| |
类的析构函数是类的一种特殊的成员函数,它会在每次删除所创建的对象时执行。
析构函数的名称与类的名称时完全相同的,只是在前面加了一个波浪号(~)作为前缀,它不会返回任何值,也不能带有任何参数。
只要类的对象被销毁,就会调用该类的析构函数。
析构函数有利于在跳出程序(比如关闭文件、释放内存等)之前释放资源。
| |
拷贝构造函数时一种特殊的构造函数,其功能是用一个已知的对象去创建另一个同类对象。
拷贝构造函数常用于:
如果在类中没有定义拷贝构造函数,编译器会自行定义一个。如果类带有指针变量,并由动态内存分配,则它必须有一个拷贝构造函数。
拷贝构造函数的常见形式如下:
| |
在C++中,主要有以下几种情况会调用拷贝构造函数:
| |
| |
| |
| |
| |
以上主要情况会触发调用拷贝构造函数。熟悉这些情况,可以帮助诊断代码中拷贝构造的调用情况。
| |
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。
虽然友元函数的原型有在类的定义中出现过,但友元函数并不是成员函数。
友元可以是一个函数,该函数称为友元函数;友元也可以是一个类,该类称为友元类,在这种情况下,整个类机器所有成员都是友元。
声明函数为一个类的友元,需要在类定义中该函数原型前使用关键字friend
| |
声明类ClassTwo的所有成员函数作为类ClassOne的友元,需要在类ClassOne的定义中进行声明,声明格式如下:
| |
C++友元函数的主要使用场景包括:
如果类A需要访问类B的私有成员,可以将A声明为B的友元类,这样A就可以直接访问B的私有成员。
重载像+、-等运算符时,需要访问类的私有成员,这时可以将运算符函数定义为类的友元。
当类模板需要访问一个类的私有成员时,可以将这个类模板定义为该类的友元。
在类的实现和测试阶段,可以使用友元函数方便地访问类的私有成员,以方便调试和测试。
友元函数可以直接访问私有数据,避免定义许多getter和setter方法。
友元函数可以方便地访问对象的状态,用于调试等目的。
需要注意的是,友元关系不可传递,过度使用友元会影响类的封装性。所以在保证必要的功能性的情况下,要优先使用公有接口,而非友元函数。
| |
C++的内联函数通常是与类一起使用,如果一个函数是内联函数,那么在编译时,编译器会把该函数的代码副本放置在每个调用该函数的地方。
对内联函数进行任何修改,都需要重新编译函数的所有客户端,因为编译器需要重新更换一次所有的代码,否则会继续使用旧的函数。
如果想把一个函数定义为内联函数,则需要在函数名前放置inline关键字,在调用函数之前需要对函数进行定义。如果已定义的函数多于一行,编译器会忽略inline限定符。
在类定义中定义的函数都是内联函数,即使没有使用inline关键字,也就是隐式内联。
优点: 当函数体比较小的时候, 内联该函数可以令目标代码更加高效. 对于存取函数以及其它函数体比较短, 性能关键的函数, 鼓励使用内联.
缺点: 滥用内联将导致程序变慢. 内联可能使目标代码量或增或减, 这取决于内联函数的大小. 内联非常短小的存取函数通常会减少代码大小, 但内联一个相当大的函数将戏剧性的增加代码大小. 现代处理器由于更好的利用了指令缓存, 小巧的代码往往执行更快。
结论:一个较为合理的经验准则是, 不要内联超过 10 行的函数. 谨慎对待析构函数, 析构函数往往比其表面看起来要更长, 因为有隐含的成员和基类析构函数被调用!
另一个实用的经验准则: 内联那些包含循环或 switch 语句的函数常常是得不偿失 (除非在大多数情况下, 这些循环或 switch 语句从不被执行)。
有些函数即使声明为内联的也不一定会被编译器内联, 这点很重要;比如虚函数和递归函数就不会被正常内联。
通常,递归函数不应该声明成内联函数。(递归调用堆栈的展开并不像循环那么简单, 比如递归层数在编译时可能是未知的, 大多数编译器都不支持内联递归函数)。
虚函数内联的主要原因则是想把它的函数体放在类定义内, 为了图个方便, 抑或是当作文档描述其行为, 比如精短的存取函数.
| |
在C++中,this指针是一个特殊指针,它指向当前对象的实例。
在C++中,每个对象都 能通过 this 指针来访问自己的地址。
this 是一个隐藏的指针,可以在类的成员函数中使用,它可以用来指向调用对象。
当一个对象的成员函数被调用时,编译器会隐式地传递该对象的地址作为 this 指针。
友元函数没有 this 指针,因为友元不是类的成员,只有成员函数才有 this 指针。
| |

函数是一个完成特定功能的代码模块,其程序代码独立,通常要求有返回值,也可以是空值。
一般形式如下:
<数据类型> <函数名称>(<形式参数说明>)
函数之间的参数传递方式:
全局变量就是在函数体外说明的变量,它们在程序中的每个函数里都是可见的。
全局变量一经定义就会在程序的任何地方可见。函数调用的位置不同,程序的执行结果可能会收到影响。不建议使用
调用函数将实参传递给被调函数,被调用函数将创建同类型的形参并用实参初始化。
形参是新开辟的存储空间,因此,在函数中改变形参的值,不会影响到实参。
按地址传递,实参为变量的地址,而形参为同类型的指针。
被调用函数中对形参的操作,将直接改变实参的值(被调用函数对指针的目标操作,相当于对实参本身的操作)。
| |

全局数组传递方式
复制传递方式:实参为数组的指针,形参为数组名(本质是一个指针变量)
地址传递方式:实参为数组的指针,形参为同类型的指针变量
| |

上述程序需要我们对数组的元素个数进行计算,如果函数单纯传入一个数组,并且在程序代码段中再进行数组长度的计算,由于我们传入的是int data[],此时的int data[]实际就是int *data,使用sizeof()函数则会得到一个指针的字节长度,而并非我们想要的数组长度。
| |
此处是删除一段字符串中的空格字符,在void del_space()函数中,我们采取的是指针地址传递的形式,由于我们需要实现的功能是删除字符串中多余的空格,所以当字符指针为空格时,指针向后移动一位,当遇到字符时,将指针字符2复制给指针字符1,同时两者地址同时后移一位,这里需要注意的是,当字符指针便利到最后一位\0时,代表字符串的末尾,因此我们也需要为赋值*p = '\0';代表末位。
指针函数是指一个函数的返回值为地址量的函数。
函数指针的定义的一般形式如下:
| |
| |

| |

| |

递归函数是指一个函数的函数体中直接或间接调用了该函数自身
递归函数调用的执行过程分为两个阶段:
| |

| |

函数指针用来存放函数的地址,这个地址是一个函数的入口地址
函数指针变量说明的一般形式如下:
| |
定义:函数指针数组是一个保存若干个函数名的数组。
一般形式如下:
| |
| |


在c语言中,内存单元的地址成为指针,专门用来存放地址的变量,称为指针变量。
在不影响理解的情况中,有时对地址、指针和指针变量不区分,统称为指针。
在计算机内存中,每一个字节单元(Byte),都有一个编号,称为地址。
编译或函数调用时为其分配内存单元。
变量是对程序中数据存储空间的抽象。
一般形式如下:
| |
指针的存储类型是指针变量本身的存储类型。
指针说明时指定的数据类型不是指针变量本身的数据类型,而是指针目标的数据类型。简称为指针的数据类型。
指针在说明的同时,也可以被赋值初值,成为指针的初始化
一般形式如下:
| |
在上面的语句中,把变量a的地址作为初值赋了刚说明的int型指针pa。
| |
下面是一个程序示例:
| |
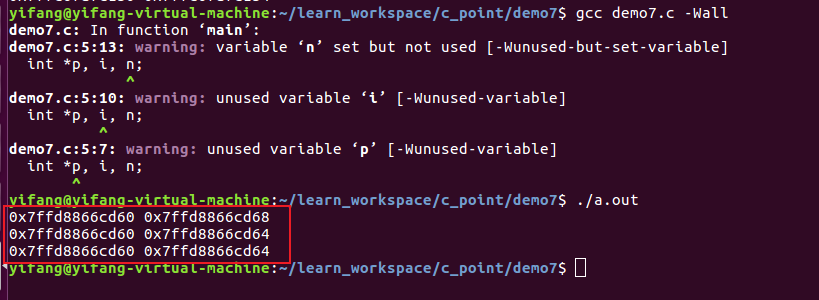
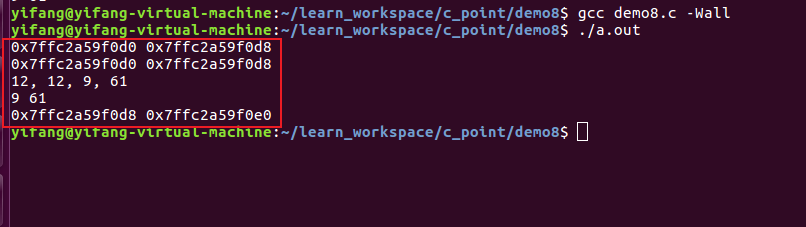
可以看到由于整型变量a取地址给指针变量p,最后打印可以发现这两个变量分配的地址都是0x7fff64003e1c

下面为了更清楚指针变量赋值与指针变量的地址,我们修改代码:
| |
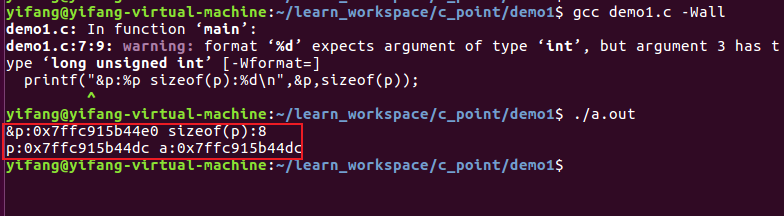
编译查看结果,可以发现上述的p = &a是作为一个赋值操作,将a的地址赋值给了指针变量p,而指针变量本身还会分配一个地址单元,也就是上面显示的0x7ffc915b44e0
一般我们清楚,在指针中*p是作为取值,而&p则是取地址,我们再次对程序作出修改:
| |
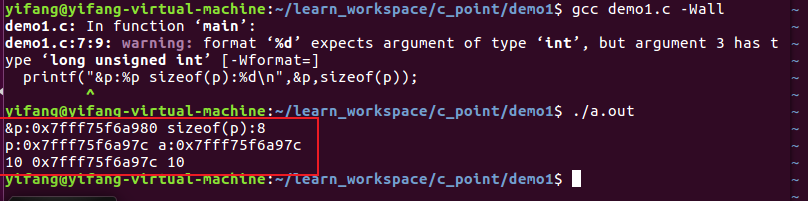
那么我们可以看到a = *p = *(*(&p)) = 10,仔细理解*(*(&p)),也就是对p这个指针变量取地址之后再取值,此时所表示的意思其实一个地址量,也就是p = *(&p),此时对其取地址,可以发现和p所对应的地址相同,此时再对*(*(&p))取值,那么也就是对应的一个数据,同理,&p = &(*(&p))也就是指针变量p所占用存储区域的地址,作为一个系统随机默认分配的常量,这也是成立的。
指针指向的内存区域中的数据成为指针的目标。
如果它指向的区域是程序中的一个变量的内存空间,则这个变量成为指针的目标变量。简称指针的目标。
在上述程序中,整型指针变量p所指向的就是整型变量a的内存空间,那么也可以称变量a是指针p的目标变量。
引入指针要注意程序中的px, *px和&px三种表示方法的不同意义。设px为一个指针,则:
px — 指针变量,它的内容是地址量
*px — 指针所指向的对象,它的内容是数据
&px — 指针变量所占用的存储区域的地址,是个常量
指针的赋值运算指的是通过赋值运算符指向指针变量送一个地址值。
向一个指针变量赋值时,送的值必须时地址常量或指针变量,不能时普通的整数(除了赋零)
指针赋值运算常见的有以下几种形式:
| |
下面是一个程序案例:
| |
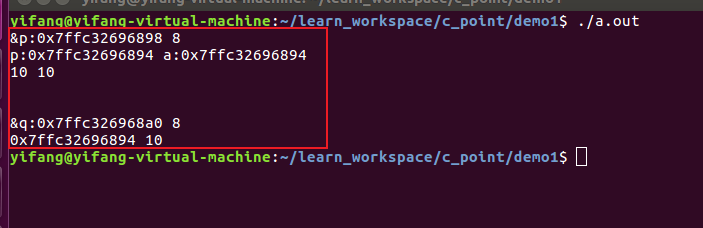
在上述程序中,我们将a的地址量分别传给指针p和指针q,然后打印这两个指针对应的地址,可以发现两者间相差8位(一个指针在32位的计算机上,占4个字节;一个指针在64位的计算机上,占8个字节。此处由于我是64位系统,所以一个指针对应的就是8位,),也就是说指针p和指针q都是指向目标变量a。
指针运算是以指针变量所存放的地址量作为运算量而进行的运算。
指针运算的实质就是地址的计算。
指针运算的种类是有限的,它只能进行赋值运算、算术运算和关系运算。
| 运算符 | 计算形式 | 意 义 |
|---|---|---|
| + | px+n | 指针向地址大的方向移动n个数据 |
| - | px-n | 指针向地址小的方向移动n个数据 |
| ++ | px++ | 指针向地址小的方向移动1个数据 |
| – | px– | 指针向地址小的方向移动1个数据 |
| - | px-py | 两个指针之间相隔数据元素的个数 |
不同数据类型的两个指针实行加减整数运算是无意义的。
px+n表示的实际位置的地址量是:(px) + sizeof(px的类型)*n
px-n表示的实际位置的地址量是:(px) - sizeof(px的类型)*n
px-py运算的结果是两指针指向的地址位置之间相隔数据的个数,因此两指针相减不是两指针持有的地址量相减的结果,而是一个整数值,表示两指针之间相隔数据的个数。
两指针之间的关系运算表示它们指向的地址位置之间的关系。指向地址大的指针大于指向地址小的指针。
指针与一般整型变量之间的关系运算没有意义。但可以和零进行等于或不等于的关系运算,判断指针是否为空。
注意:
两个指针之间的运算需要有连续的内存地址,否则会发生预想不到的错误,示例如下:
正确的运行示例:
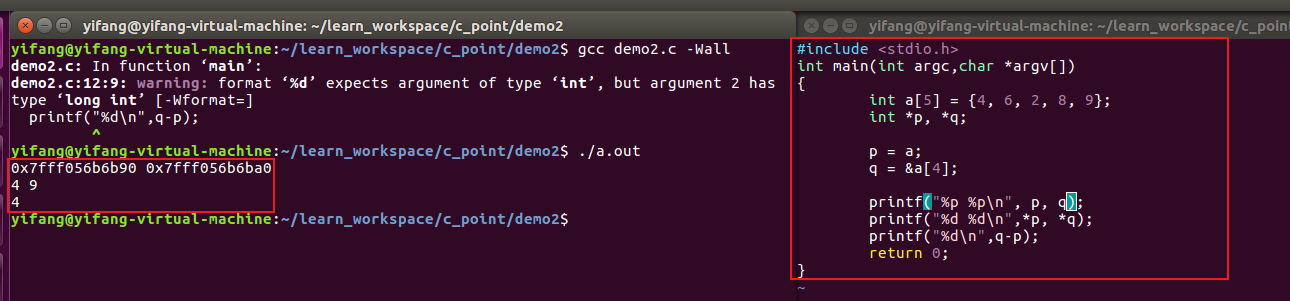
这里也可以与上面的知识点相对应:px-py运算的结果是两指针指向的地址位置之间相隔数据的个数
下面是一些指针运算的示例:
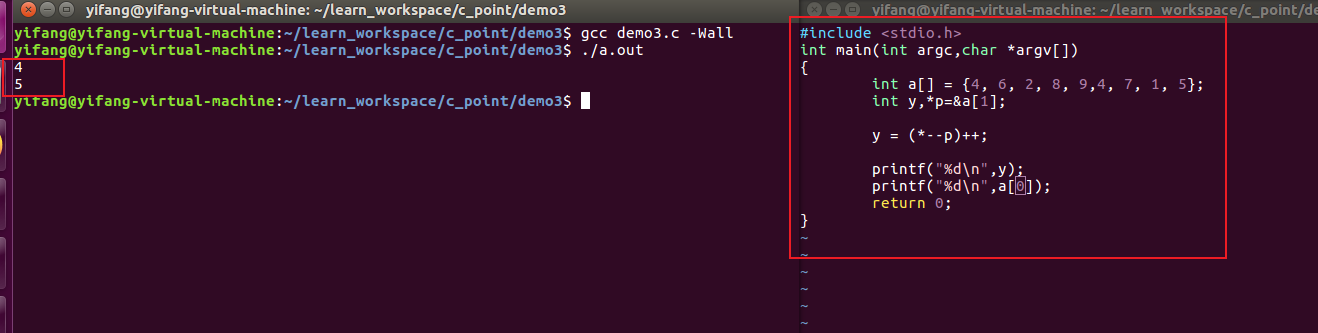
上述程序重要的就是理顺指针的关系以及运算符优先级问题。
知识扩展:
在32位系统与64位系统下,不同数据类型所对应的字节数—>
| 数据类型 | 32位 | 64位 | 备注 |
|---|---|---|---|
| char | 1 | 1 | |
| short | 2 | 2 | |
| int | 4 | 4 | |
| long | 4 | 8 | 32位与64位不同 |
| float | 4 | 4 | |
| char * | 4 | 8 | 其他指针类型如long *,int *也是如此 |
| long long | 8 | 8 | |
| double | 8 | 8 | |
| long double | 10/12 | 10/16 | 有效位10字节。32位为了对其实际分配12字节;64位分配16字节 |
在c语言中,数组的指针是指数据在内存中的起始地址,数组元素的地址是指数组元素在内存中的起始地址。
一维数组的数组名为以为数组的指针(起始地址)。
例如:
| |
因此,x为x数组的起始地址。
设指针变量px的地址值等于数组指针x(即指针变量px指向数组的首元素),则:
x[i]、*(px+i)、 *(x+i)和px[i]具有完全相同的功能,也就是说,x[i] = *(px+i) = *(x+i) = px[i]:访问数组第i+1个数组元素,下面参照示例:
| |
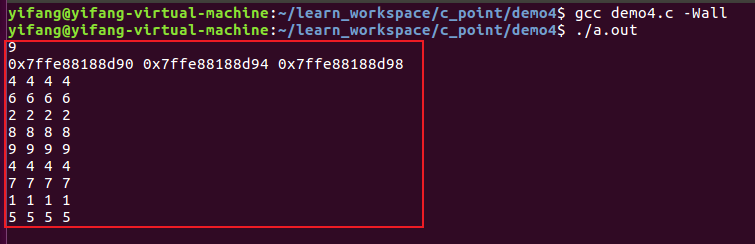
那么参照上述程序,在某种程度上p和a是否是等效的呢?其实这还是有区别的,数组a作为一个整型数组常量,而整型指针p则是一个变量,只能说在他们有相似的使用方法,这种情况还是需要区分的。
注意:
指针变量和数组在访问数组中元素时,一定条件下其使用方法具有相同形式,因为指针变量和数组名都是地址量
但是指针变量和数组的指针(或叫数组名)在本质上不同,指针变量时地址变量,而数组的指针是地址常量
程序1:下面编写一个程序,使用指针将整型数组中n个数按反序存放:
| |

程序2
| |
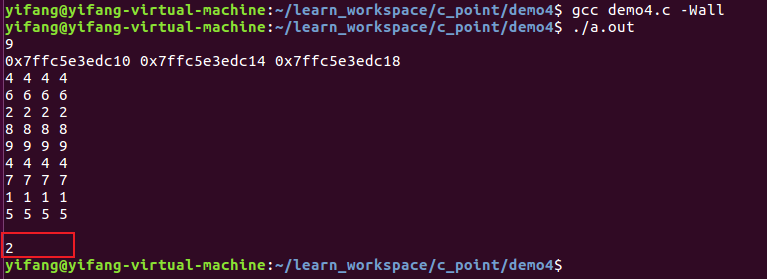
这里我们发现,数组下标p[1]的本质,其实就是*(p+1),前面已经p++了,此时的p[1]其实就相当于 *(p+1+1),也就是 *p[2] = 2
知识点:
数组p[i],其实就相当于*(p+i),也就是:p[i] = *(p+i)
多维数组就是具有两个或两个以上下标的数组。
在c语言中,二维数组的元素连续存储,按行优先存取。
下面看程序案例:
案例一:
| |
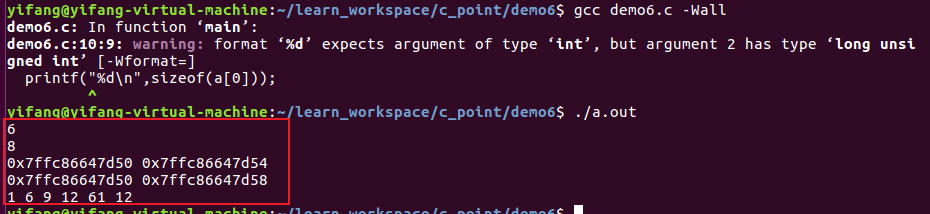
上述程序中可以看出:a[0]为8个字节大小,所以可以看出数组名加1,移动的是一行元素。
案例二:
| |
从上述程序中可以看出,a与a+1之间是相隔8个字节,而a[0]与a[0]+1则相隔4个字节,我们发现地址的移动步长发生变化了,原本是按行地址索引,加入指针即*a+1后,则变成了按列索引,更准确的说是原本的一行元素的索引变成了单个元素的索引。
二维数组名代表数组的起始地址,数组名加1,是移动一行元素。因此,二维数组名常被称为行地址
**存储行地址的指针变量,叫做行指针变量。**形式如下:
<存储类型> <数据类型> (*<指针变量名>)[表达式];例如:int a[2] [3]; int (*p)[3]
注意:!!方括号中的常量表达式表示指针加1,移动几个数据。当用行指针操作二维数组时,表达式一般写成1行的元素个数,即列数。
我们用一个程序案例来解释:
| |
根据上述程序,其实就很好理解二维数组与数组指针的关系了,在二维数组中,对于指针的使用,一个取值符号*代表的其实就是行指针的地址量,而两个取值符号**代表的就是对行指针的第一个元素进行取值操作;同理,对一个地址量【 *(a+1)】进行取地址操作&,代表的就是取地址【&( *(a+1))】。
C语言通过使用字符数组来处理字符串。通常,我们把char数据类型的指针变量称为字符指针变量。字符指针变量与字符数组有着密切关系,它也被用来处理字符串。
**初始化字符指针是把内存中字符串的首地址赋予指针,**并不是把该字符串复制到指针中。
| |
在C编程中,当一个 字符指针指向一个字符串常量时,不能修改指针指向的对象的值。
| |
| |
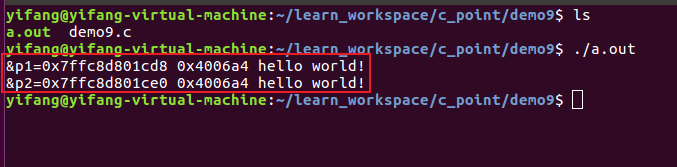
此处我们可以看到,由于字符指针的内容都是hello world!,也就是申请了一段字符串空间存取的内容为hello world!,当我们打印字符指针p1和p2指向的地址时可以发现都指向了0x4006a4,接着我们打印指针存放的地址,可以发现&p1=0x7ffc8d801cd8、&p2=0x7ffc8d801ce0,也就是说指针申请的空间都在栈中,而字符串常量空间的申请则是放在静态区**(放在静态区的有三种情况:全局变量、static修饰的局部变量、常量)**
所谓指针数组是指若干个具有相同存储类型和数据类型的指针变量构成的集合。
指针数组的一般说明形式:
<存储类型> <数据类型> *<指针数组名>[<大小>];
指针数组名表示该指针数组的起始地址
声明一个指针数组:
| |
把一维数组a[0]和a[1]的首地址分别赋予指针数组的数据元素pa[0]和pa[1]:
| |
| |
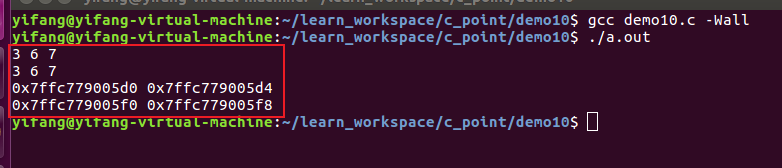
问:指针数组名相当于什么样的指针? 答:二级指针。
把一个指向指针变量的指针变量,称为多级指针。
对于指向处理数据的指针变量称为一级指针变量,简称一级指针变量,简称一级指针。
对于指向一级指针的指针变量称为二级指针变量,简称一级指针变量,简称二级指针。
二级指针变量的说明形式如下:
<存储类型> <数据类型> **<指针名>;
**指针变量加1,是向地址大的方向移动一个目标数据。**类似的道理,多级指针运算也是以其目标变量为单位进行偏移。
比如:int **p; p+1移动一个int *变量所占的内存空间。
| |

| |
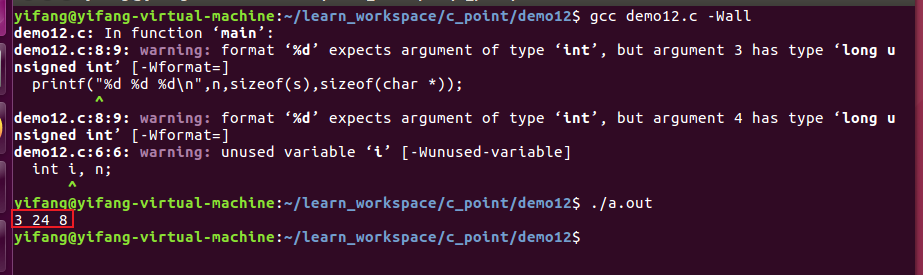
void指针是一种不能确定数据类型的指针变量,它可以通过强制类型转换让该变量指向任何数据类型的变量。
一般形式为:
void * <指针变量名>
对于void指针,在没有强制类型转换前,不能做任何指针的算数运算。
| |

| |

此处需要注意:对于void指针,在没有强制类型转换前,不能做任何指针的算数运算。所以在上述程序中对void指针的使用首先需要(int *)p进行强转,之后对于用户的算数运算就没什么问题了。
一般说明形式如下:
const <数据类型> * <指针变量名>[= <指针运算表达式>]
常量化指针目标是限制通过指针改变其目标的数值,但<指针变量> --->存储的地址值可以修改。
一般说明形式如下:
<数据类型> * const <指针变量名>[= <指针运算表达式>]
使得<指针变量>存储的地址值不能修改。但可以通过* <指针变量名>可以修改指针所指向变量的数值。
一般说明形式如下:
const <数据类型> * const <指针变量名>[= <指针运算表达式>]
常量化指针变量及目标表达式,使得既不可以修改<指针变量名>的地址,也不可以通过* <指针变量名>修改指针所指向变量的值。

在软件开发中,使用Git作为代码管理工具是非常普遍的。而GitHub和Gitee则是我们熟知的两个在线Git代码托管平台。如果我们在这两个平台上都有代码仓库,并且希望实现自动同步,应该怎么做呢?这就需要使用GitHub Action中的Hub Mirror Action了。
Hub Mirror Action是GitHub Action中的一个组件,可以将GitHub仓库内容自动同步到Gitee上,也可以实现从Gitee到GitHub的自动同步。Hub Mirror Action提供了多种同步方式,支持单向同步和双向同步,可以在配置文件中进行灵活设置。
| |
附:详细使用案例请查看官方仓库 https://github.com/Yikun/hub-mirror-action
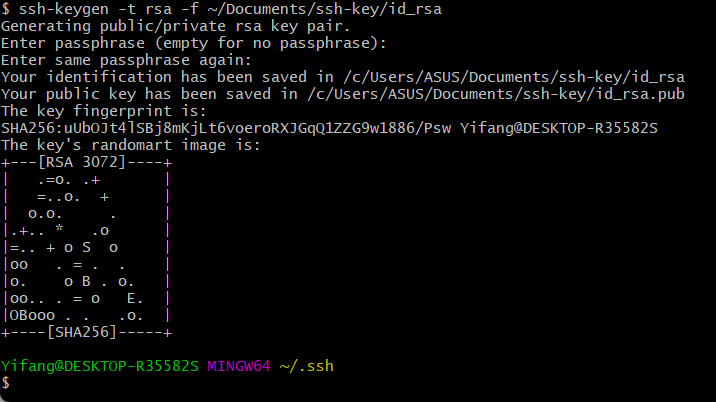
我们先在本地使用git命令行打开终端,输入如下命令:
| |
注:请确保文件夹~/Documents/ssh-key/存在,当然你也可以选择放置在其他地方
过程中一路回车即可,注意不要设置密码。
首先为了存放自动化脚本,我们需要创建一个新的GitHub仓库,并为其配置相关环境。
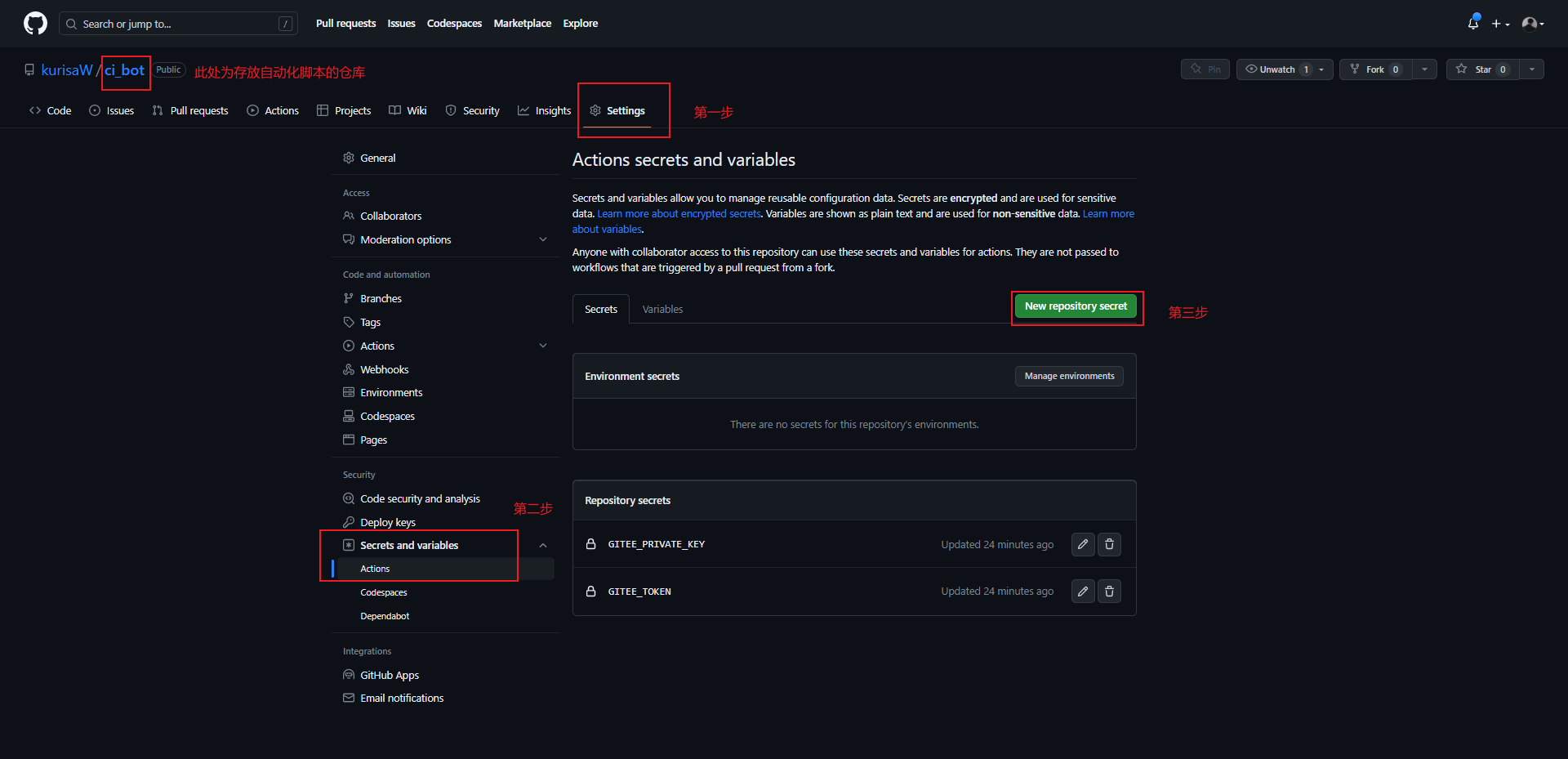
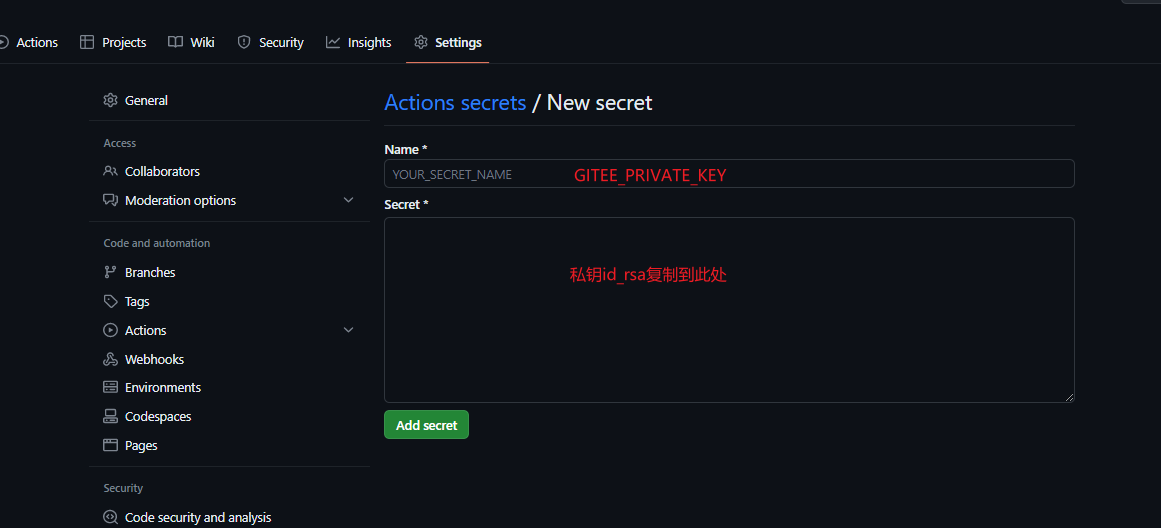
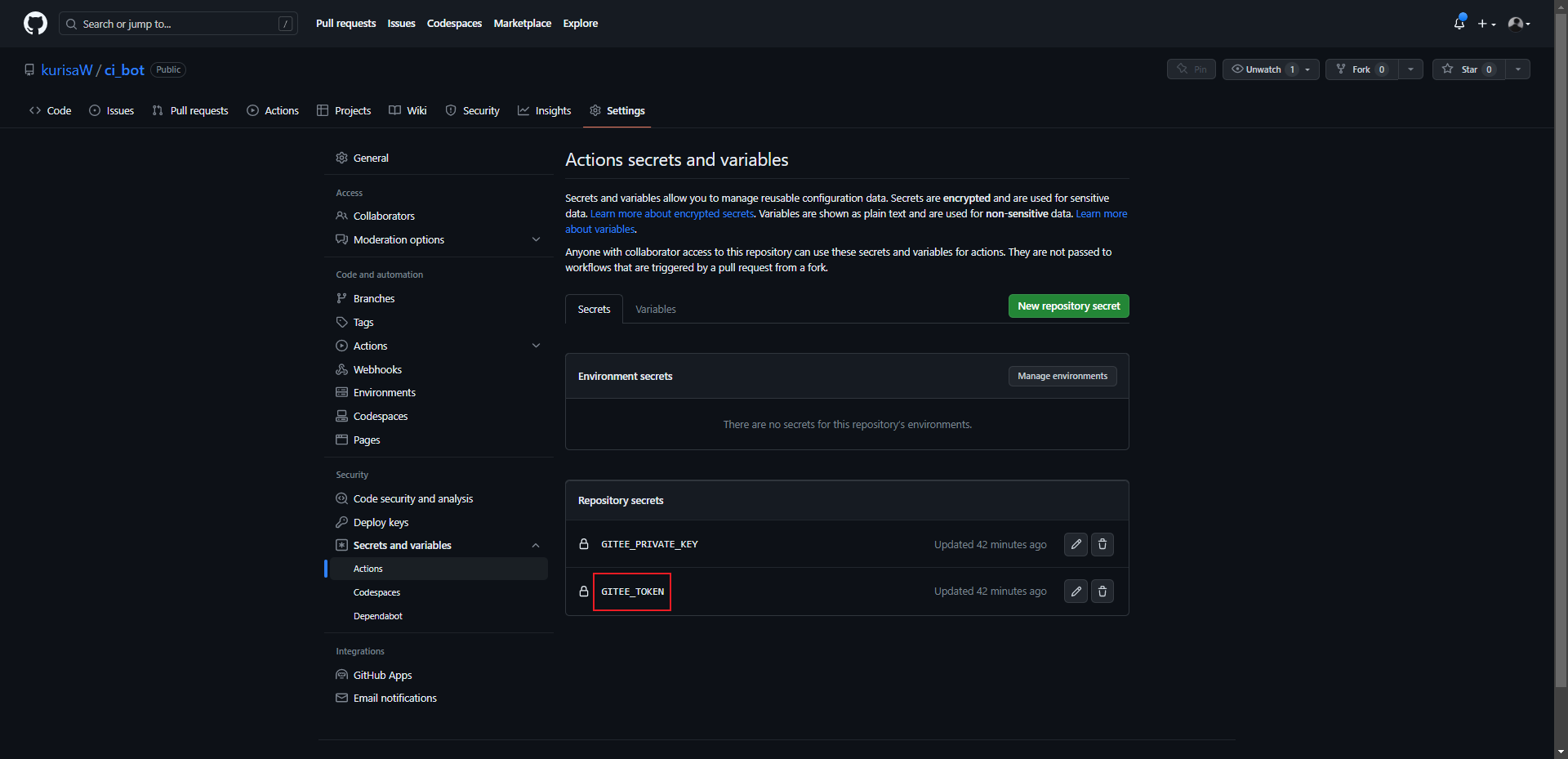
依次点击Settings->Secrets and variables->Actions
点击New respository secret,创建一个名为GITEE_PRIVATE_KEY的secret,值为我们之前生成的密钥对中的私钥(id_rsa)
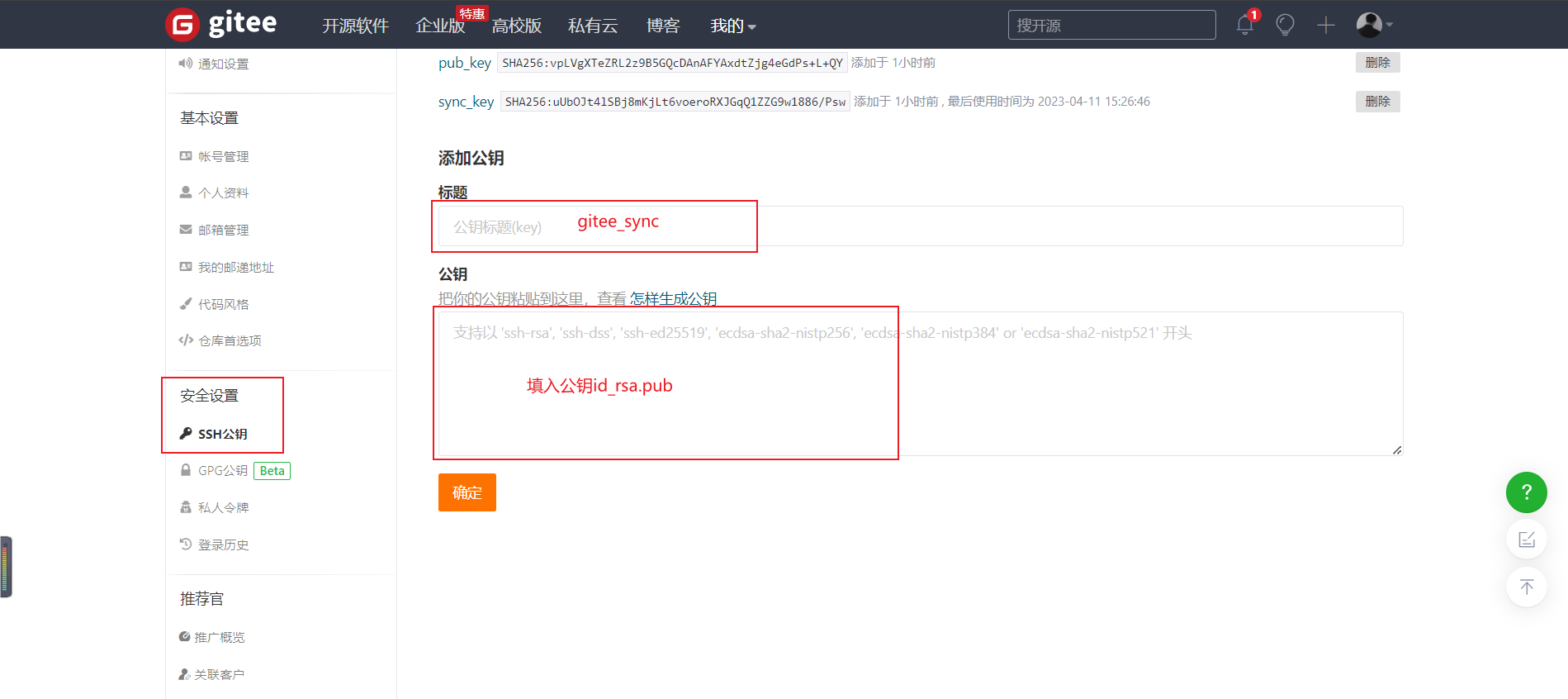
我们打开Gitee账号,进入Settings->安全设置->SSH公钥
添加一个名为gitee_sync的公钥,值也就是我们前面生成的公钥(id_rsa.pub)
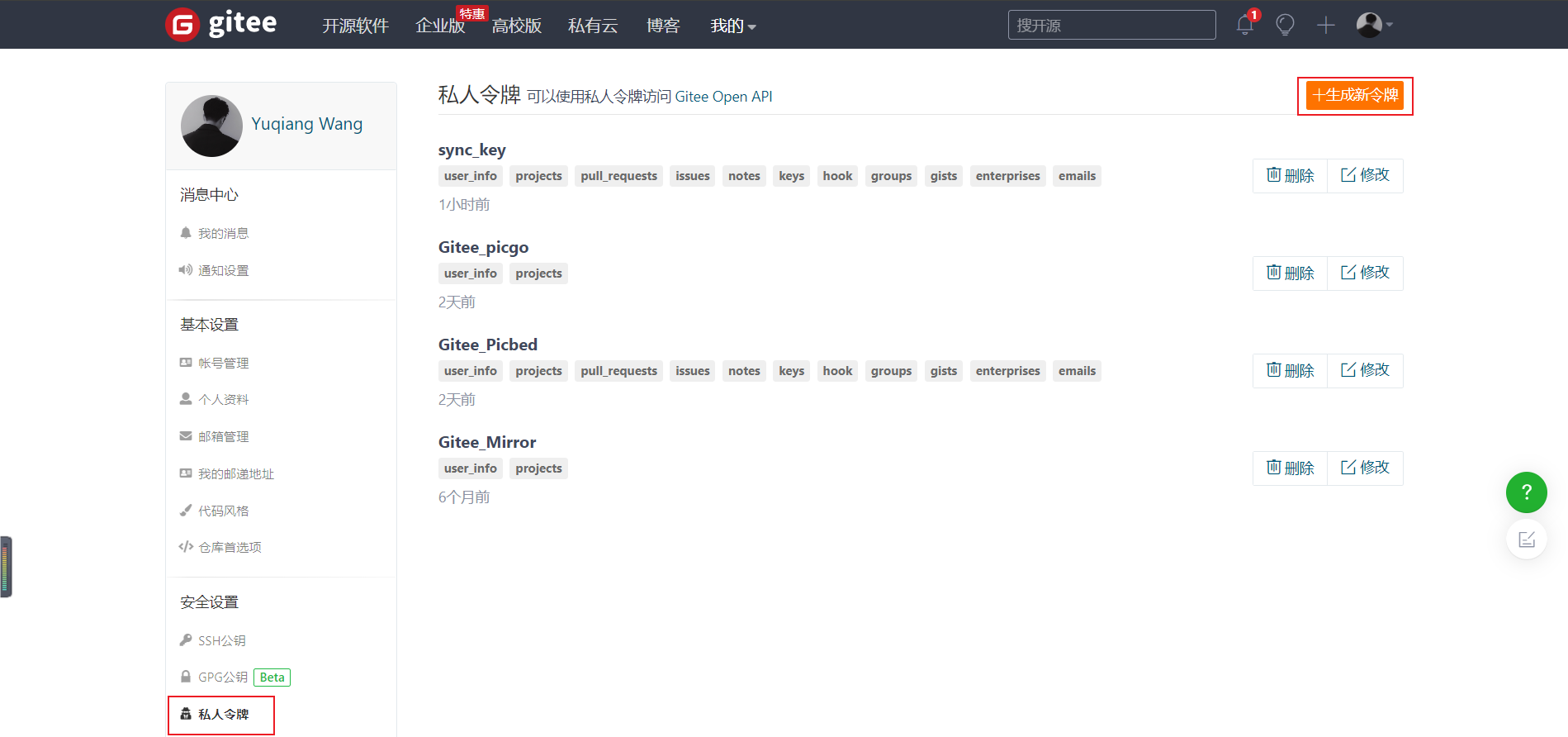
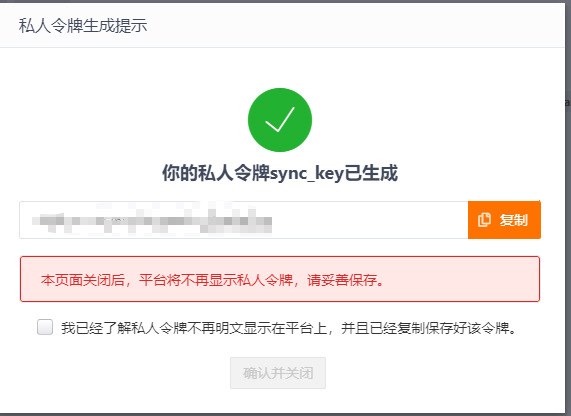
令牌名称随意,同时复制生成的令牌值。
依次点击Settings->Secrets and variables->Actions
点击New respository secret,创建一个名为GITEE_TOKEN的secret,值为Gitee生成的令牌值
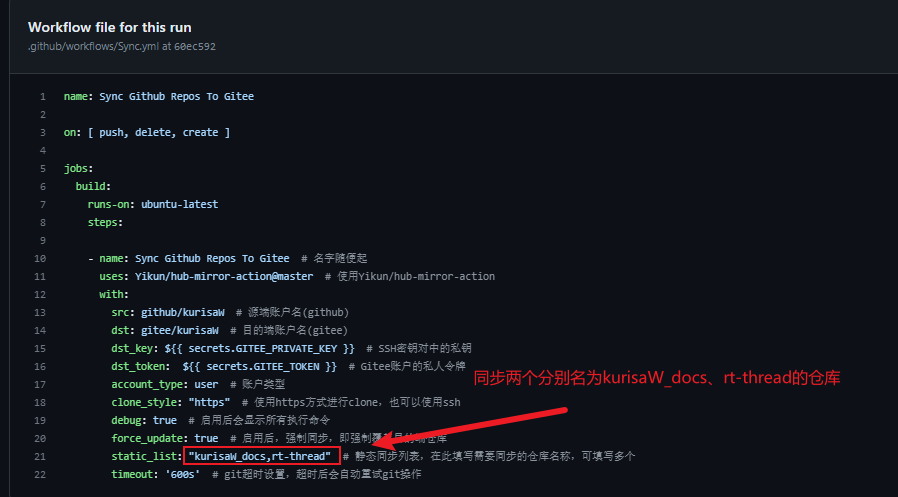
将ci_bot仓库(放置及部署自动化脚本的仓库)下载到本地,同时创建这样的文件层次目录:
| |
在Sync.yml文件中,添加以下代码:
| |
保存退出后,将本次修改push到远端仓库。
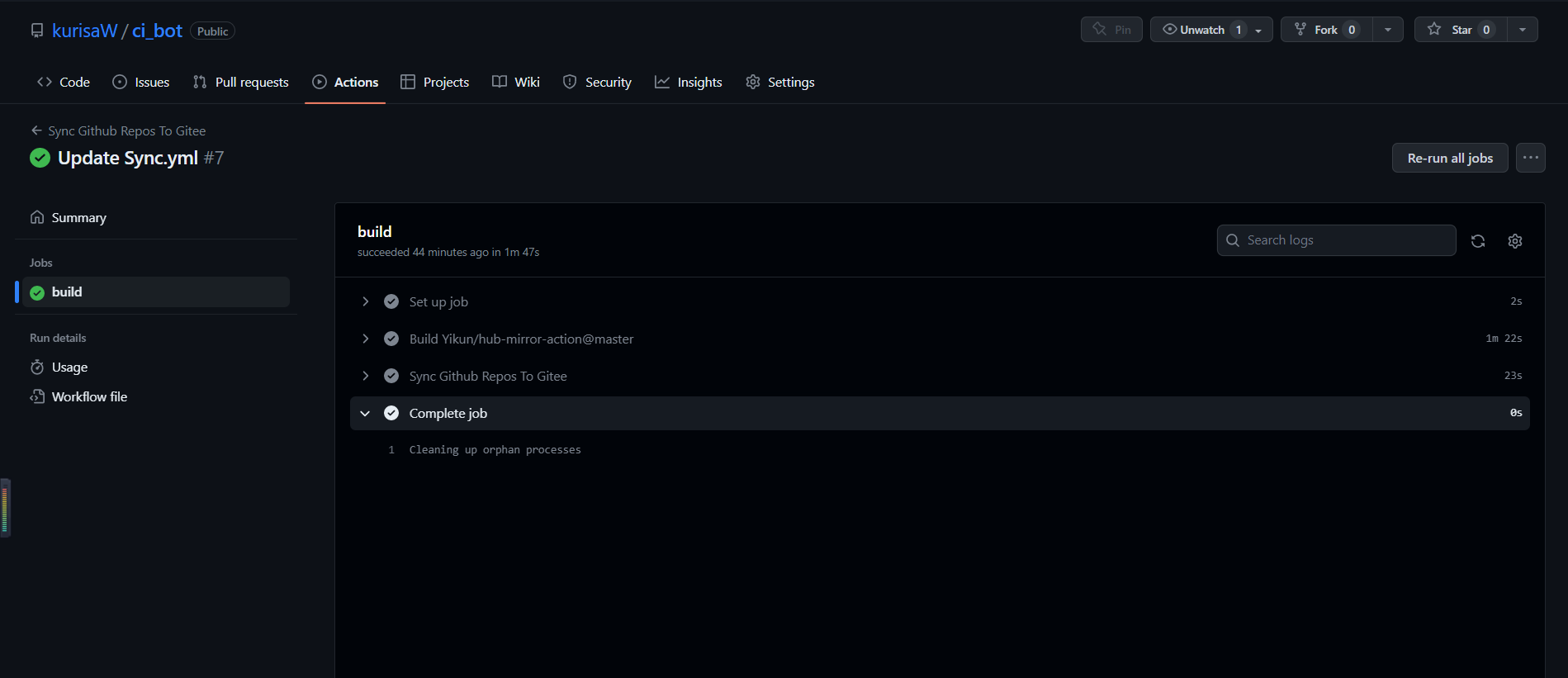
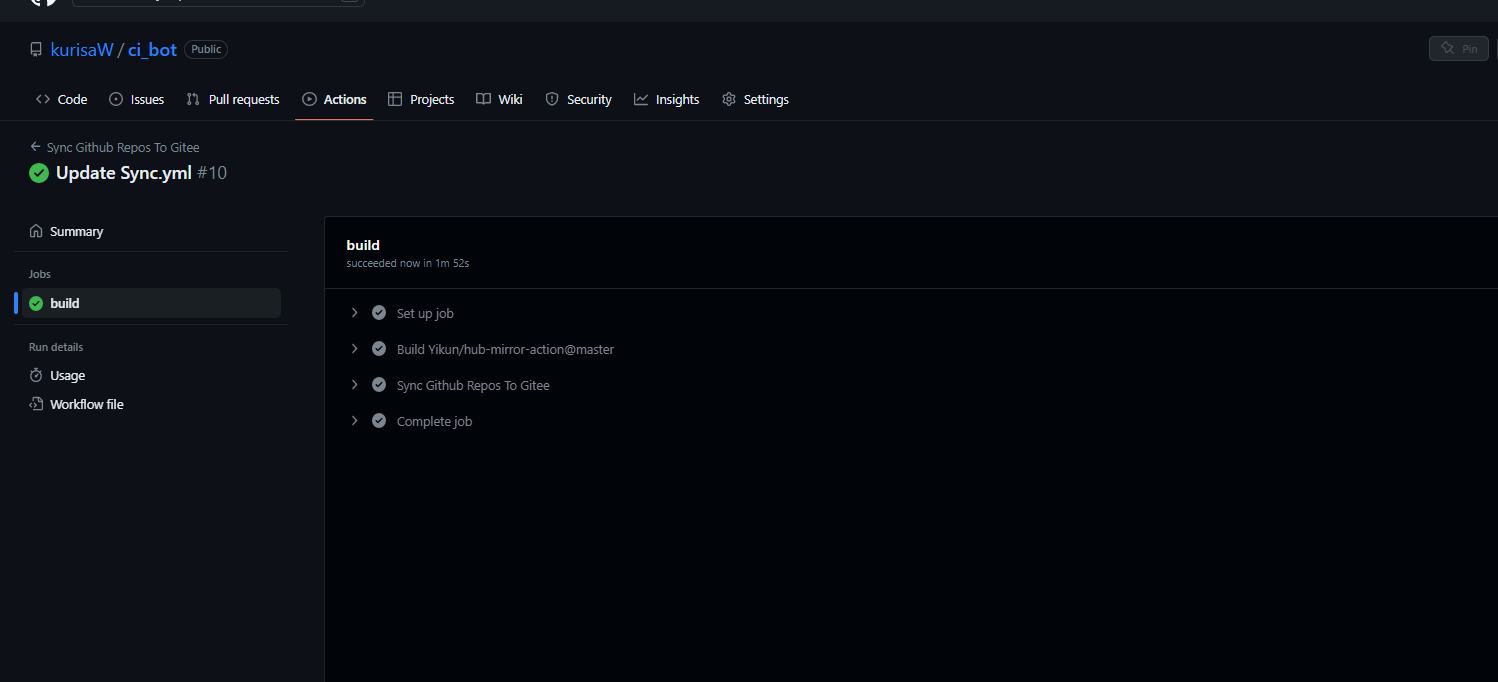
查看Action运行情况:
如果你想同时同步多个仓库,只需要完成如下修改
| |
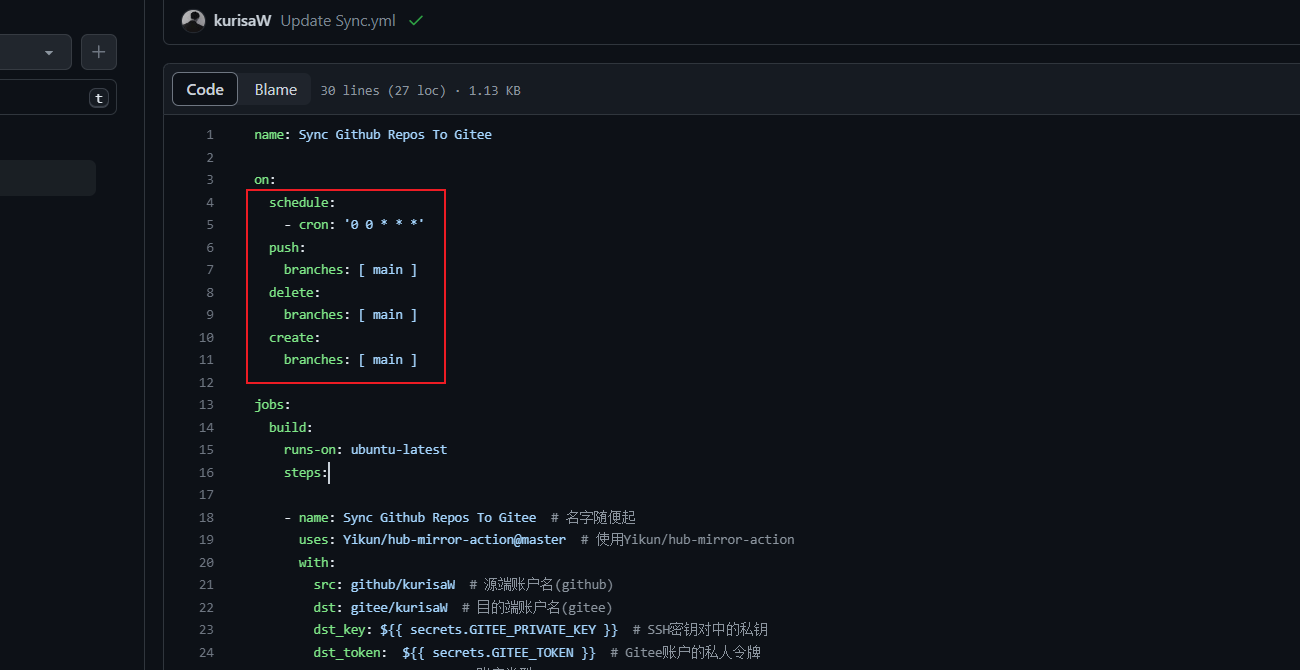
为了方便该脚本每天定时完成自动同步任务,我们可以使用GitHub提供的schedule事件完成:
修改Sync.yml文件:
| |
也就是说该自动化脚本会每天零时进行自动化脚本的运行,自动更新镜像仓库,同时如果该配置文件发生推送、删除和创建文件操作时也会触发Action行为。
通过以上步骤,我们已经完成了GitHub同步Gitee镜像仓库自动化脚本配置的操作。Hub Mirror Action作为GitHub Action中的一个组件,可以帮助我们在两个平台之间实现代码自动同步,极大地减轻了我们手动同步代码的工作量。当然如果你有任何问题欢迎留言区提出,我将竭力为你解答。

最近在使用 WSL 时会同时用到 GitHub和 Gitlab ,因此与传统配置 ssh 方式有些不一样的地方,这里特别记录一下
首先确保把之前的 ssh 信息清除,也可以将整个 ~/.ssh 目录删除
| |
我们分别生成 Github 和 Gitlab账号的 SSH 密钥
| |
| |
注意不要选择其他操作,一路回车即可
此时打开 ~/.ssh/ 目录可以看到生成了四个文件:github_id-rsa github_id-rsa.pub gitlab_id-rsa gitlab_id-rsa.pub
其中 .pub 后缀的文件为公钥,需要上传到远程仓库SSH;没有后缀的则是私钥,本地留存
我们先打开 Github 的 Settings选项,然后选择 SSH and GPG keys->New SSH key ,Title可以随意拟定,Key需要查看刚刚的 github_id-rsa.pub 文件,并且复制到 Gitlab 的key一栏中;
Gitlab 的操作方式与 Github 类似,具体步骤:
打开 Gitlab -> 用户设置 -> SSH密钥 ,在密钥一栏填入 gitlab_id-rsa.pub文件中的具体值,标题自拟即可。
回到 ~/.ssh/ 目录下,并且创建一个名为 config 的文件,在该文件中填写以下具体代码,其中部分参数依照自己的信息填写:
| |

使用下面的命令分别验证 Github 和 Gitlab的 SSH 配置
| |
| |
如果出现如下提示即表示远程仓库 SSH 公钥和本地 SSH 密钥配对成功


最近突然想起年前图床仓库发生的一个遗留问题:由于我的网络图床服务是Github + Typora的形式,本地的图片会自动转义成网络图片并存储在图床仓库下,一般我们会指定一个目录进行图片存储,但是由于GitHub设定的单个目录最大存储文件数不能超过1000.
所以在注意到这件事的情况下GitHub的图床仓库就发生了问题:新加入的图片文件由于没有文件位,会自动代替旧的图片文件,这就导致了部分文件的丢失,所以这里想写一个GitHub仓库的自动化Action,每天检测仓库下每个目录下的文件个数,超过999个文件自动给GitHub默认绑定的邮箱发送信息提醒。
当每天自动检测仓库中每个目录中的文件数量,并且如果超过999个文件时,自动向与GitHub账户关联的默认邮箱发送消息。
在GitHub仓库中,转到.github/workflows目录并创建一个新文件,比如file_count.yml。该文件将定义运行自动化操作的工作流。
在file_count.yml文件中,添加以下代码:
| |
requirements.txt文件在GitHub仓库中创建一个名为requirements.txt的文件,并将以下内容添加到文件中:
| |
send_email.py文件在GitHub仓库中创建一个名为send_email.py的文件,并将以下代码添加到文件中:
| |
使用这些步骤,工作流将每天UTC时间午夜运行,计算仓库中的文件数量,如果文件数量超过999,则会向与GitHub账户关联的默认邮箱发送邮件提醒。

Git 是一个分布式版本管理工具,版本管理工具就是大家在写东西的时候都用过 回撤这个功能,但是回撤只能回撤几步,假如想要找回我三天之前的修改,光用回撤是找不回来的。而版本管理工具能记录每次的修改,只要提交到版本仓库,就可以找到之前任何时刻的状态(文本状态)。
下面的内容就是列举了常用的 Git 命令和一些小技巧,可以通过页面内查找的方式 Ctrl/Command+f 进行快速查找。
| |
The command output as below:
| |
抛弃本地所有的修改,回到远程仓库的状态。
| |
也就是把所有的改动都重新放回工作区,并清空所有的 commit,这样就可以重新提交第一个 commit 了
| |
展示工作区的冲突文件列表
| |
输出工作区和暂存区的 different (不同)。
| |
还可以展示本地仓库中任意两个 commit 之间的文件变动:
| |
输出暂存区和本地最近的版本 (commit) 的 different (不同)。
| |
输出工作区、暂存区 和本地最近的版本 (commit) 的 different (不同)。
| |
| |
| |
| |
关联之后,git branch -vv 就可以展示关联的远程分支名了,同时推送到远程仓库直接:git push,不需要指定远程仓库了。
| |
或者在 push 时加上 -u 参数
| |
-r 参数相当于:remote
| |
-a 参数相当于:all
| |
| |
| |
| |
| |
| |
| |
或者
| |
| |
| |
展示当前分支的最近的 tag
| |
| |
| |
默认 tag 是打在最近的一次 commit 上,如果需要指定 commit 打 tag:
| |
首先要保证本地创建好了标签才可以推送标签到远程仓库:
| |
一次性推送所有标签,同步到远程仓库:
| |
| |
| |
一般上线之前都会打 tag,就是为了防止上线后出现问题,方便快速回退到上一版本。下面的命令是回到某一标签下的状态:
| |
| |
放弃所有修改:
| |
| |
| |
和 revert 的区别:reset 命令会抹去某个 commit id 之后的所有 commit
| |
如果暂存区有改动,同时也会将暂存区的改动提交到上一个 commit
| |
| |
blame 的意思为‘责怪’,你懂的。
| |
每次更新了 HEAD 的 git 命令比如 commit、amend、cherry-pick、reset、revert 等都会被记录下来(不限分支),就像 shell 的 history 一样。 这样你可以 reset 到任何一次更新了 HEAD 的操作之后,而不仅仅是回到当前分支下的某个 commit 之后的状态。
| |
| |
| |
| |
| |
| |
这个过程需要 cherry-pick 命令,参考
| |
简化命令
| |
详解可以参考廖雪峰老师的 git 教程
| |
untracked 文件:新建的文件
| |
| |
| |
| |
| |
| |
| |
| |
| |
可以用来删除新建的文件。如果不指定文件文件名,则清空所有工作的 untracked 文件。clean 命令,注意两点:
| |
可以用来删除新建的目录,注意:这个命令也可以用来删除 untracked 的文件。详情见上一条
| |
| |
| |
新建一个分支,分支内容就是上面 git bundle create 命令导出的内容
| |
| |
| |
| |
| |
注意: config 分为:当前目录(local)和全局(golbal)的 config,默认为当前目录的 config
| |
| |
| |
| |
| |
相当于保存修改,但是重写 commit 历史
| |
| |
| |
只会 clone 最近一次提交,将减少 clone 时间
| |
关闭 track 指定文件的改动,也就是 Git 将不会在记录这个文件的改动
| |
恢复 track 指定文件的改动
| |
不再将文件的权限变化视作改动
| |
最新的放在最上面
| |
通过 grep 查找,given-text:所需要查找的字段
| |
不添加参数,默认是 -mixed
| |
| |

TortoiseGit 是 Git 的 Windows Shell 接口,基于 TortoiseSVN。它是开源的,可以完全使用免费提供的软件构建。
由于它不是针对特定 IDE(如 Visual Studio、Eclipse 或其他)的集成,因此您可以将它与您喜欢的任何开发工具以及任何类型的文件一起使用。与 TortoiseGit 的主要交互将使用 Windows 资源管理器的上下文菜单。
TortoiseGit 通过常规任务为您提供支持,例如提交、显示日志、区分两个版本、创建分支和标签、创建补丁等等。
它是在GPL下开发的。这意味着任何人都可以完全免费使用,包括在商业环境中,没有任何限制。源代码也是免费提供的,因此您甚至可以根据需要开发自己的版本。


当然这里也有百度网盘链接,也可点击下方链接进行下载
链接:https://pan.baidu.com/s/1eSmu-opC0nzMsL-5GrUHQg?pwd=dzbs +提取码:dzbs
完成上述安装后,单击鼠标右键可发现Git及TortoiseGit相关选项
这里选择TortoiseGit-Setting(上图已经完成汉化),选择语言修改为简体中文
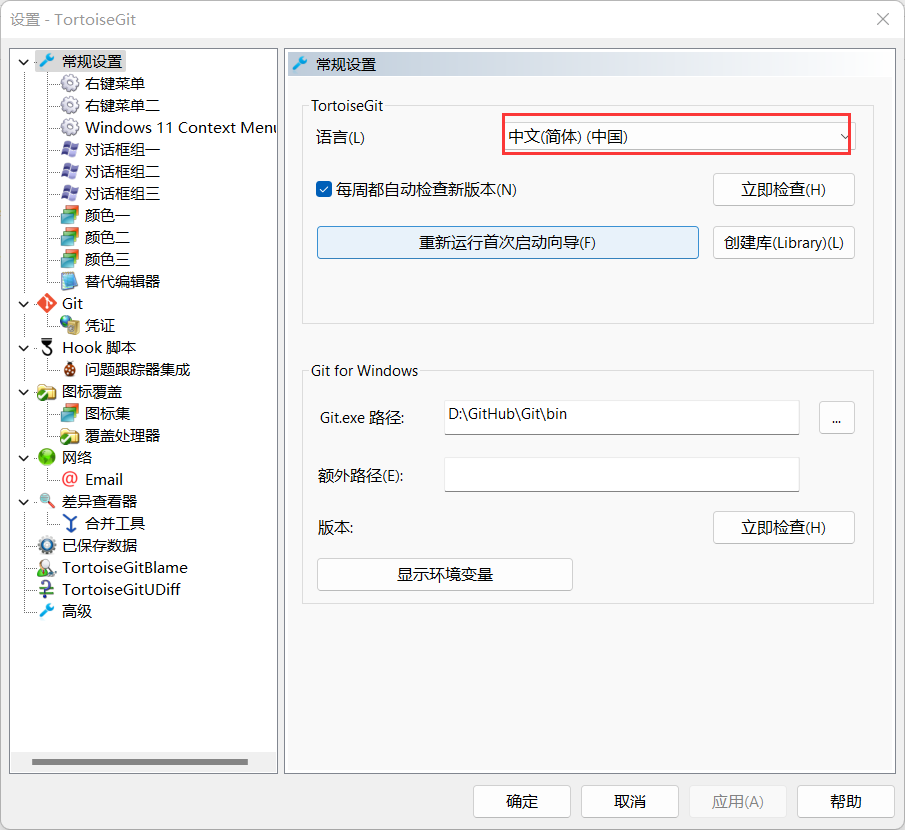
配置用户,用户作为你操作git的个人标识,进入设置,点选左边的Git标签,可以发现,右边可以配置用户的名字与Email信息. 如下图所示:
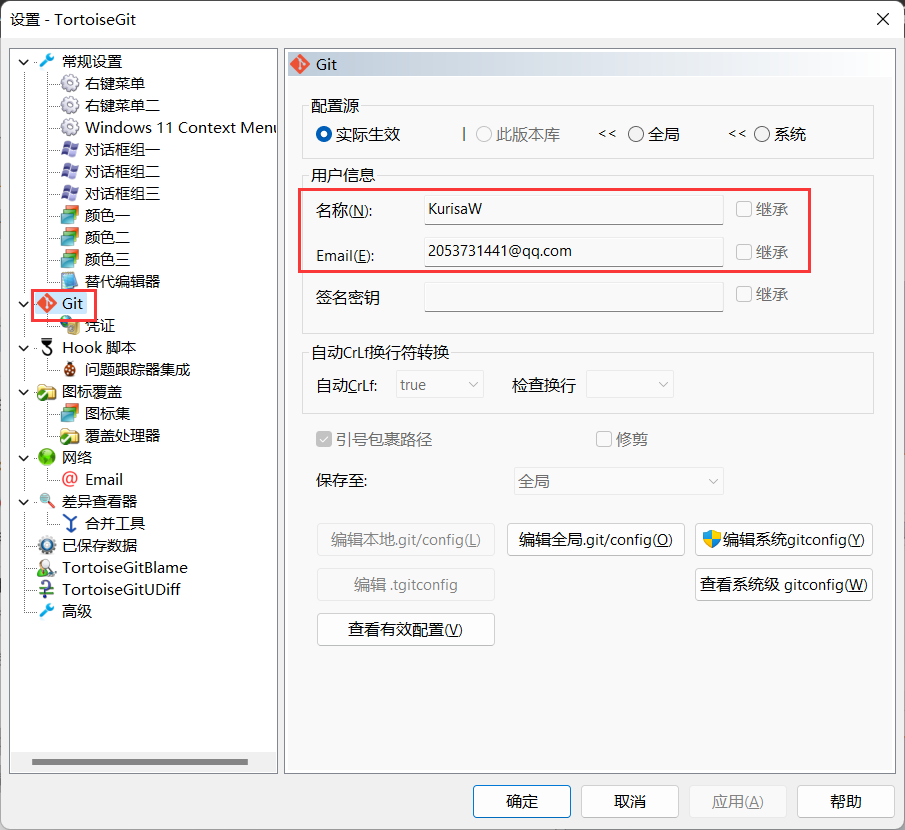
点击 “编辑全局 .git/config(O)”按钮,会使用记事本打开全局配置文件,在全局配置文件中,在后面加上下面的内容(记住密码):
| |
完成后保存,关闭记事本,确定即可。
则当你使用 HTTPS URL 方式推送项目到GitHub等在线仓库时,海龟git会记住你输入的用户名和密码(这里不是用户的姓名和Email),可以避免每次提交都要输入用户名和密码。
如果你编辑的是 本地 .git/config(L),其实这个翻译为本地有点问题,应该叫局部,也就是在某个项目下面设置,只对此项目有效,配置是一样的。
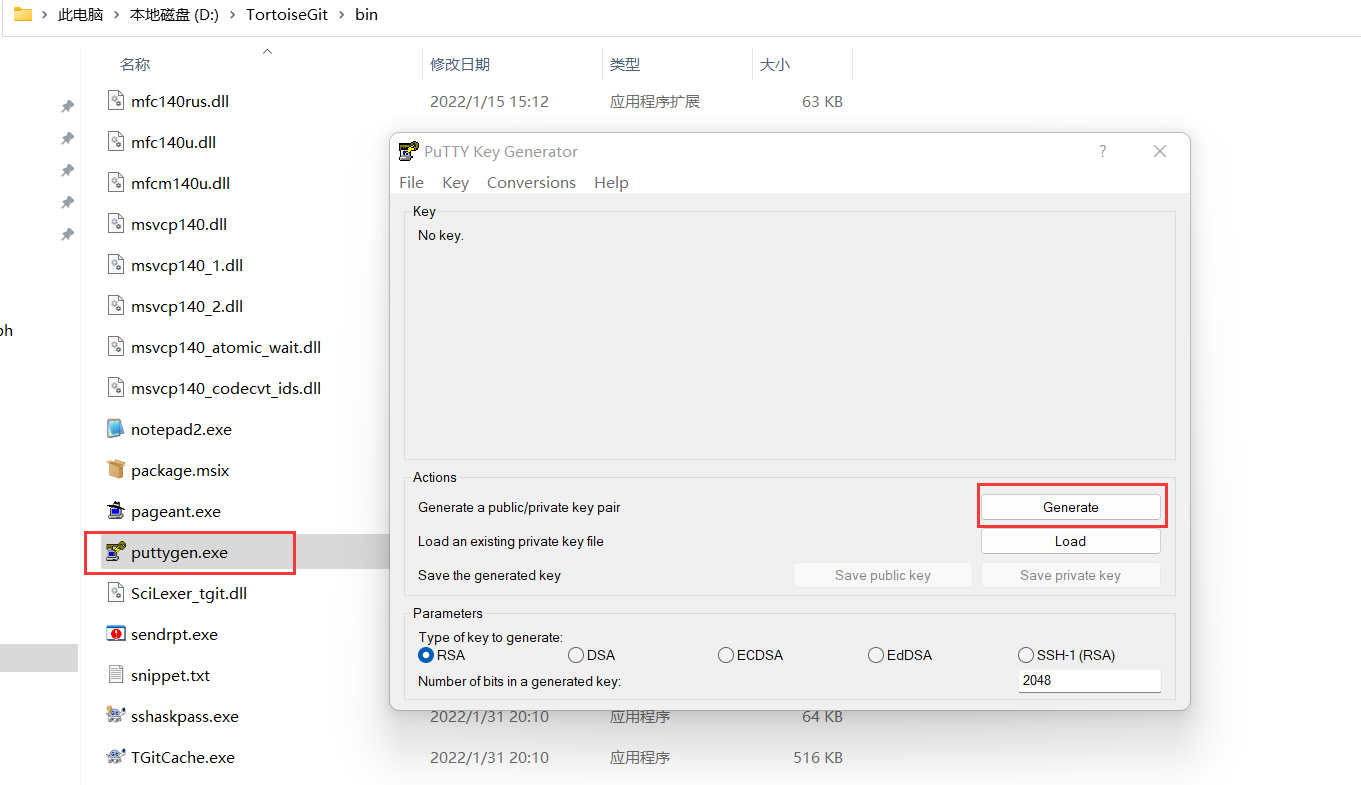
首先找到想要选择的仓库克隆到本地的一个文件夹,然后找到你们安装TortoiseGit的位置(\TortoiseGit\bin\puttygen.exe),点击Generate生成钥匙,等待进度条结束后,保存公钥和私钥位置(记住位置)
 +
+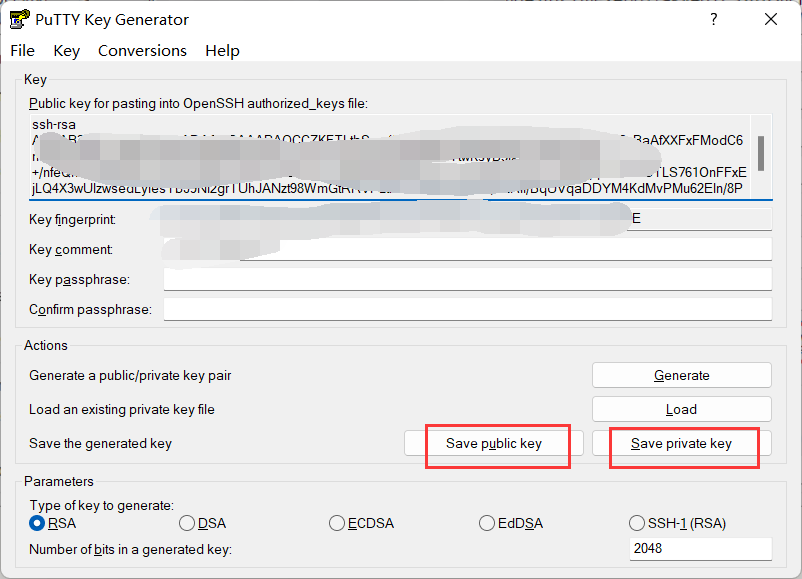
然后复制下方公钥,
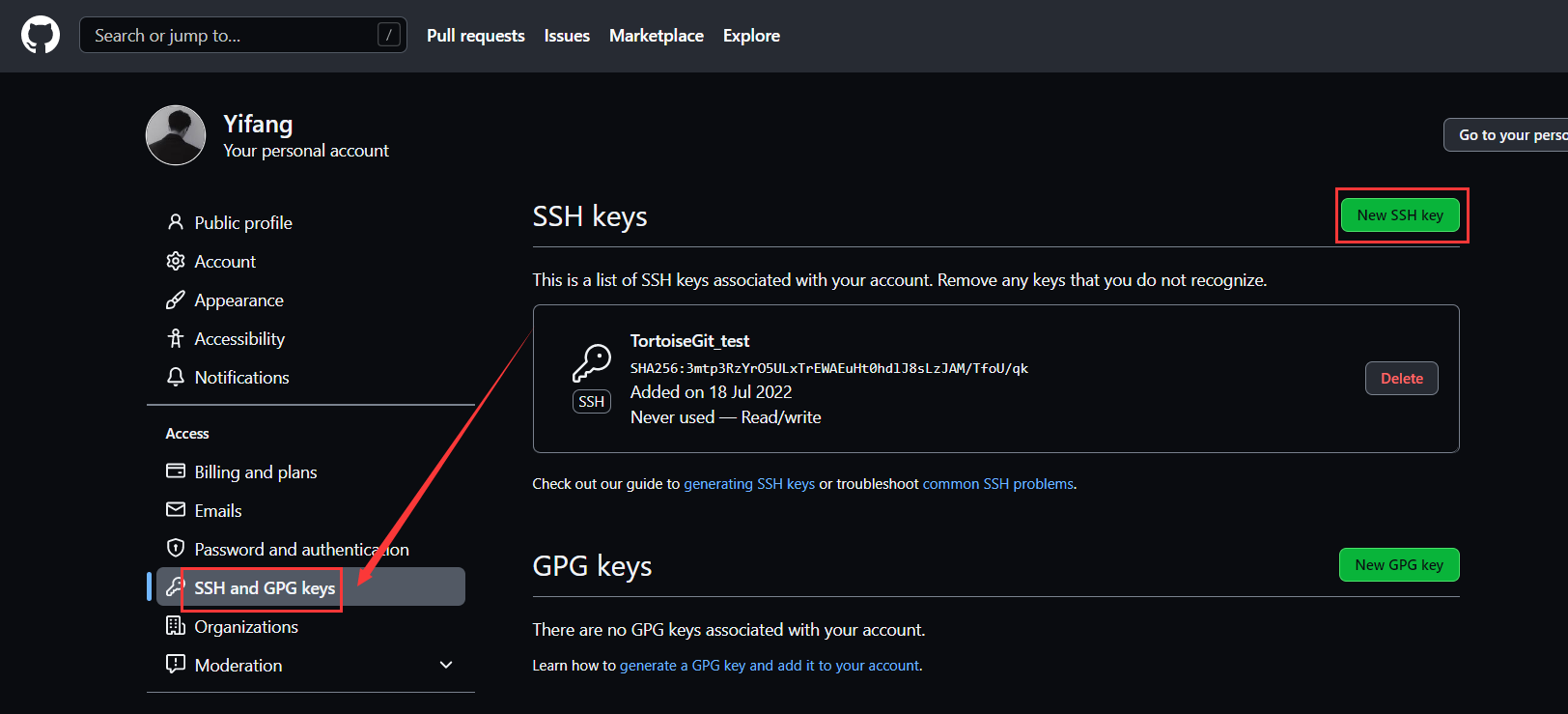
打开github,完成下图操作:
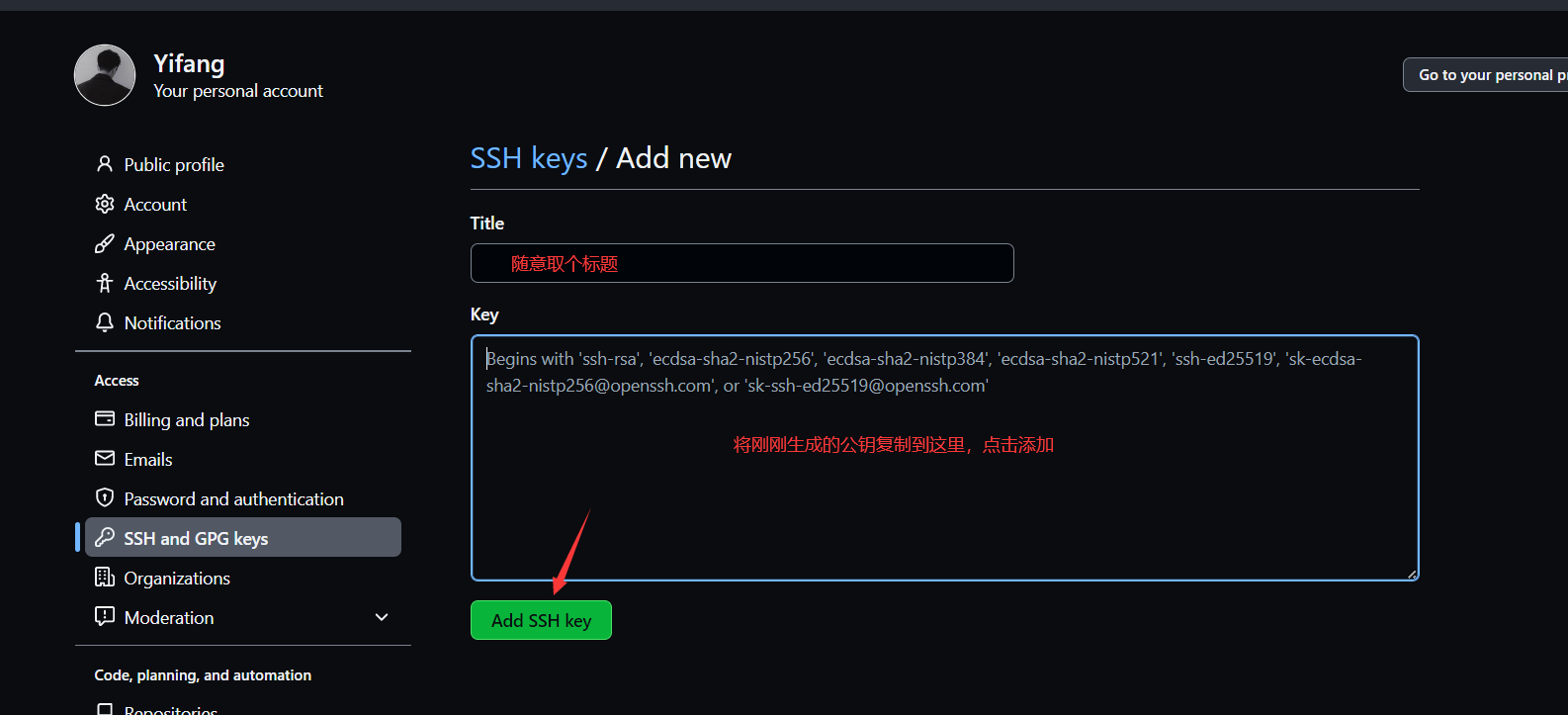
在Github自建一个仓库(自行选择即可,用于代码托管和版本控制),使用Git clone命令复制到本地文件夹
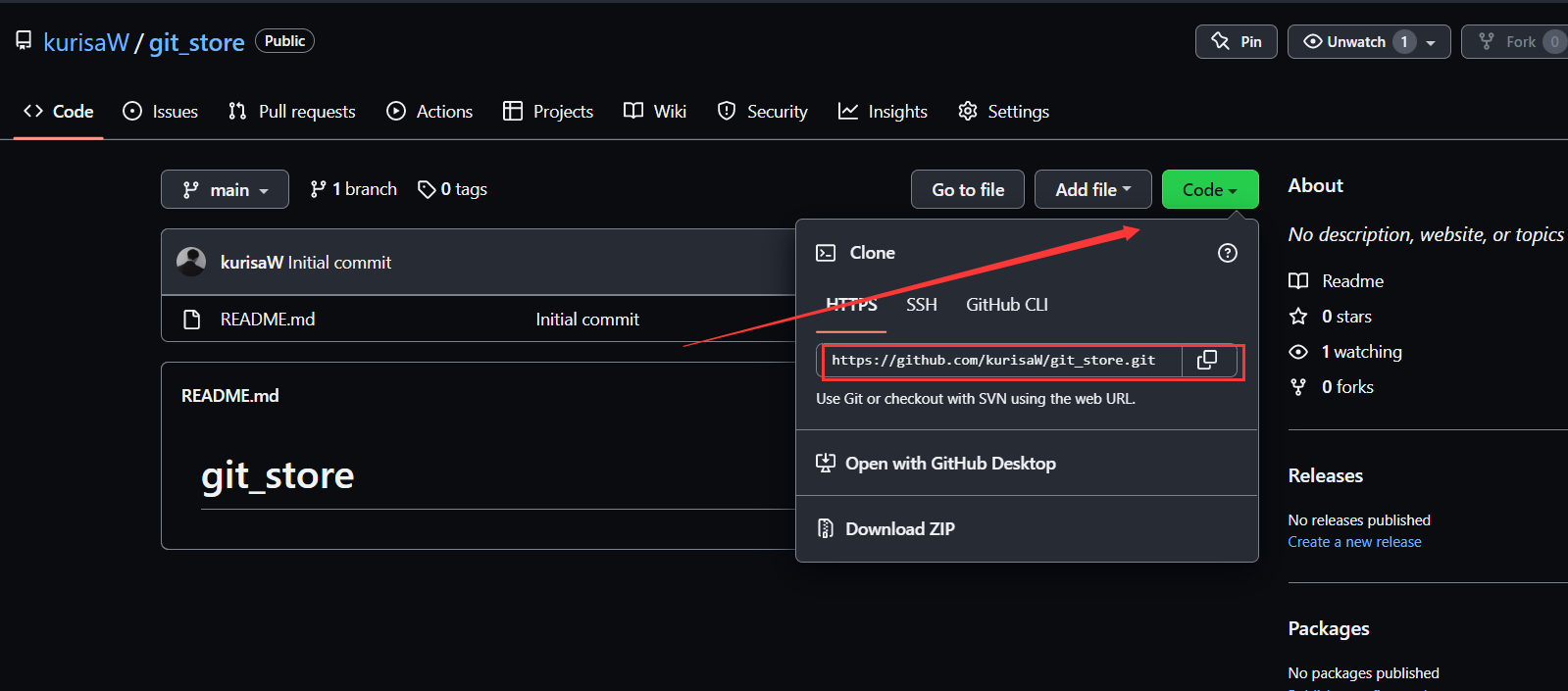
鼠标右键可以看到选项Git在这里创建版本库,点击创建版本库
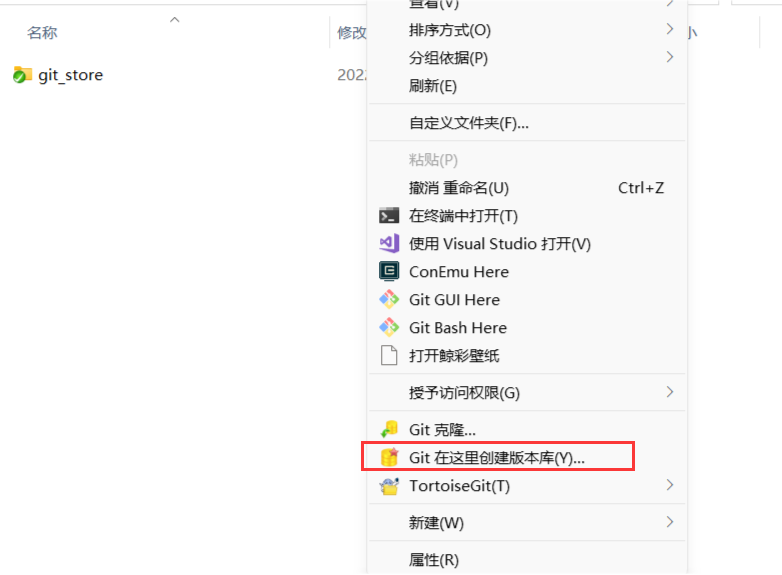
鼠标右键打开TortoiseGit->设置(Settings)->Git->远端(Remote),进行如下配置
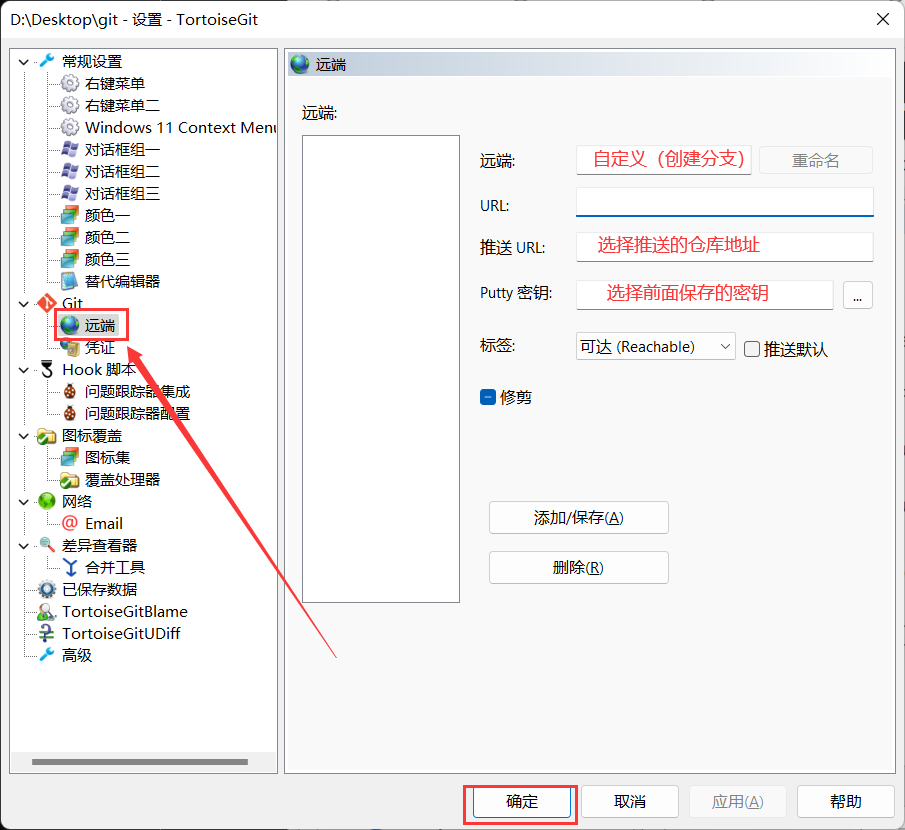
此时就可以将需要托管的代码放到这个文件夹内,然后进行代码的托管和版本控制了,下面简单做个示范:
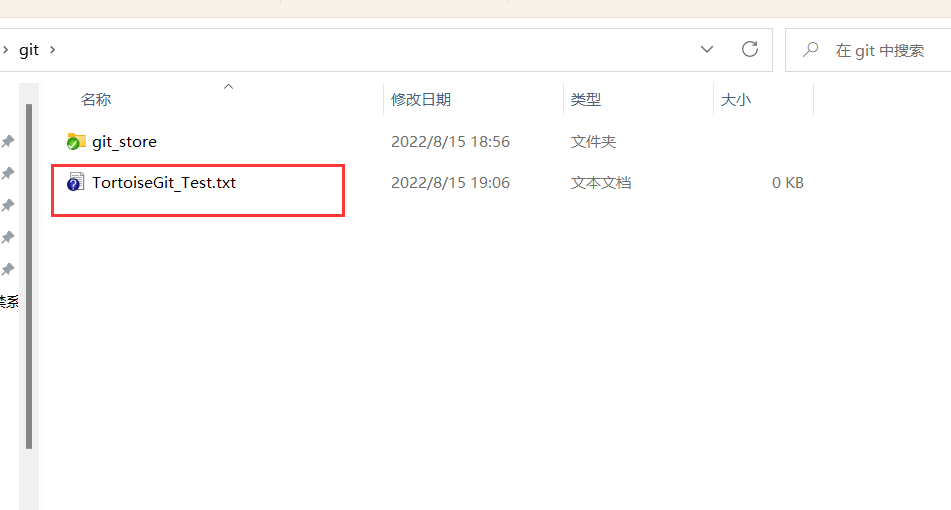
我们创建一个文本文件,可以发现在文件上还有一个附带的图标显示,这分别代表不同的文件状态:
| |
鼠标右键添加文件
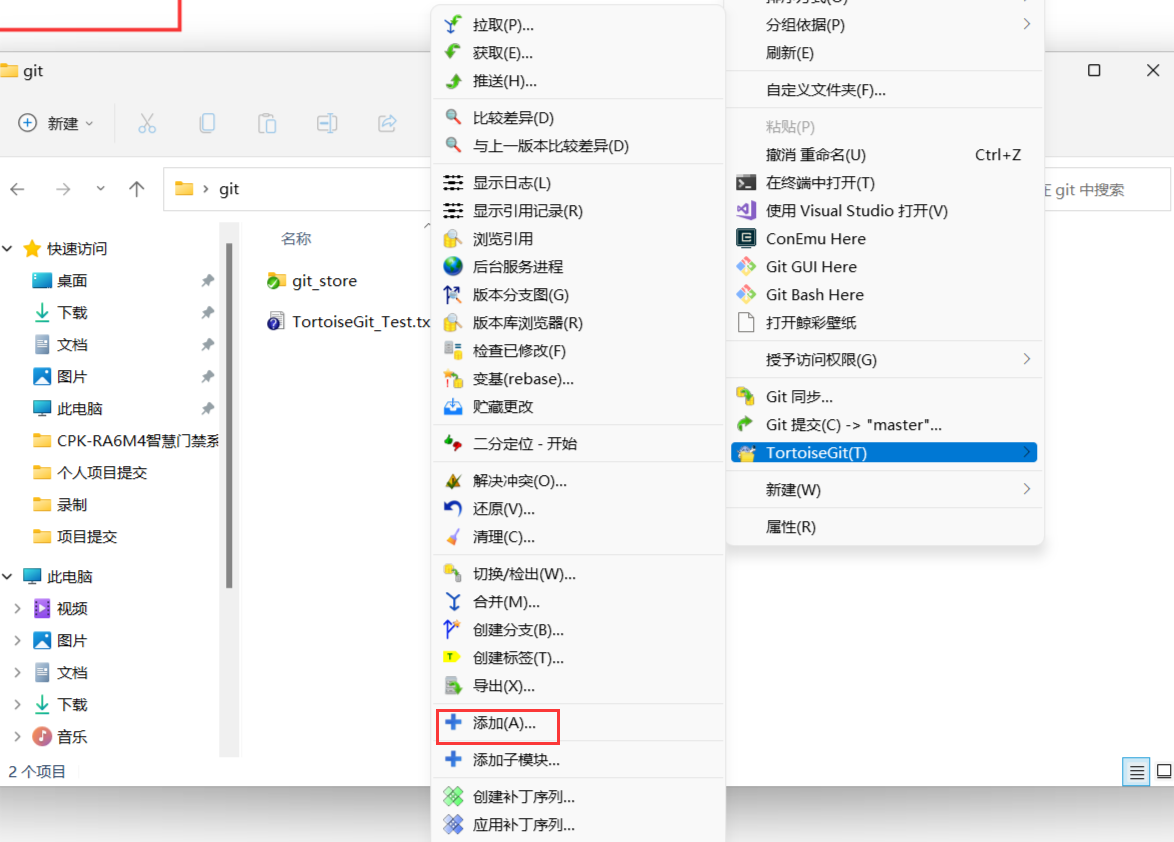
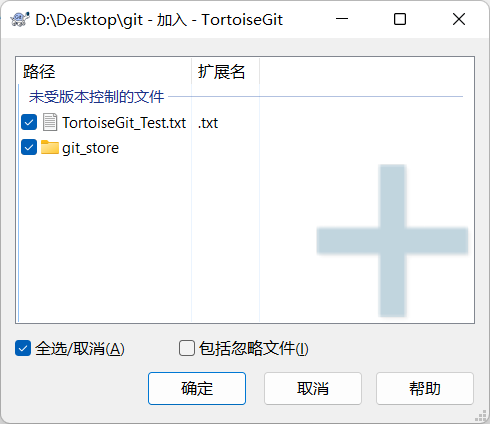


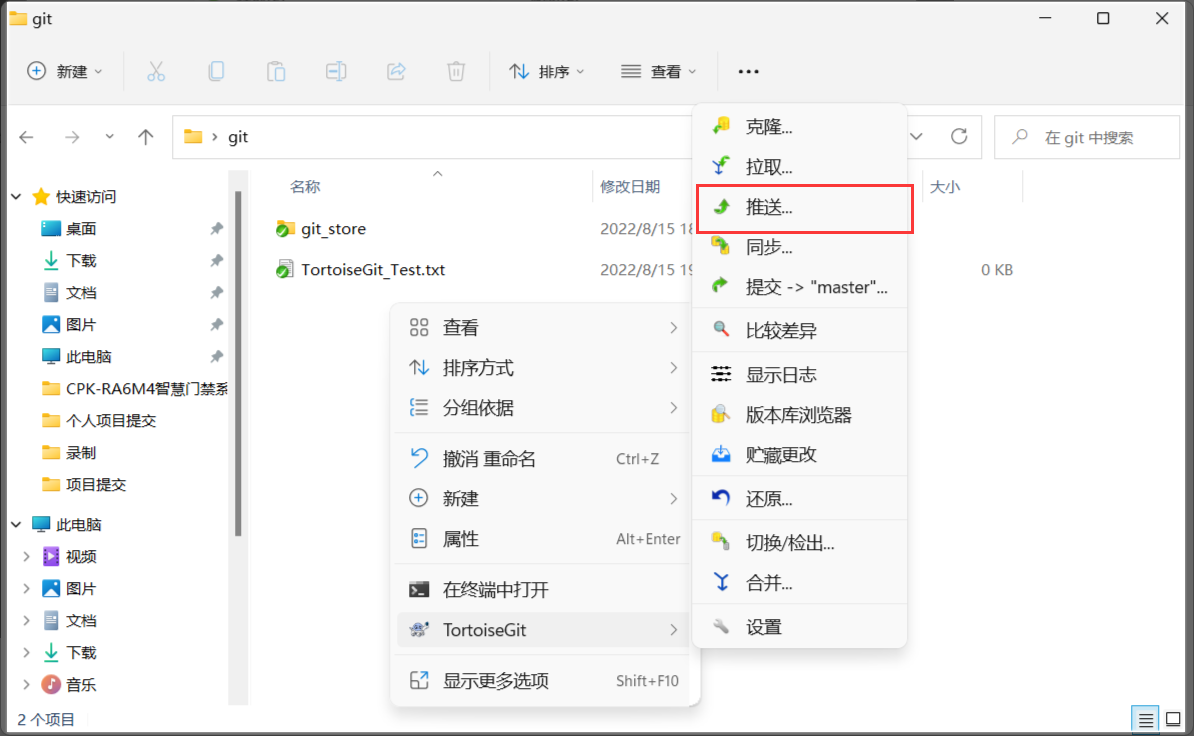
注意:由于代理问题,需要开加速器,然后会出现拉取或提交失败,这都是正常现象,多试几次
总结:使用TortoiseGit提交代码到远端仓库的步骤(配置完成后)
添加->提交->拉取->推送
那么以上就是TortoiseGit配置及代码托管的所有教学了,有问题欢迎在评论区或私信提问!

在使用Git管理项目时,经常需要知道当前所在的分支是哪一个。这个信息对于协作和版本控制非常重要。然而,Git默认情况下并不会在命令行中显示当前分支名称,这可能会导致一些混淆和不便。在本篇博文中,我们将介绍如何通过编辑.bashrc文件,使Git在命令行中显示当前分支的名称,让你的Git工作更加顺畅和高效。
首先,打开你的终端,并进入home目录。你可以使用以下命令来完成这一步:
| |
接下来,我们需要编辑.bashrc文件,这是Linux和macOS系统中存储Shell配置的文件。你可以使用vi编辑器或其他文本编辑器来打开它,这里我们以vi为例:
| |
在打开的.bashrc文件中,将以下代码添加到文件的末尾:
| |
这段代码定义了一个名为git_branch的函数,用于获取并显示当前Git分支的名称。然后,通过export命令将这个信息添加到Shell的提示符中,以便在命令行中实时显示当前分支名称。
完成以上代码的添加后,按下Esc键退出编辑模式,然后输入以下命令保存并退出vi编辑器:
| |
最后,执行以下命令来使新的配置生效:
| |
现在,当你进入一个包含Git仓库的目录时,命令行提示符将会显示当前分支的名称,让你随时了解项目的状态。
通过这个简单的配置,你可以提高Git工作的效率,更轻松地进行版本控制和协作。希望这个小技巧对你的开发工作有所帮助!

BearPi-HM Micro开发板是一块高度集成并可运行Openharmony系统的开发板,板载高性能的工业级处理器STM32MP157芯片,搭配4.3寸LCD电容式触摸屏,并板载wifi电路及标准的E53接口,标准的E53接口可扩展智能加湿器、智能台灯、智能安防、智能烟感等案例。可折叠式屏幕设计大大提高用户开发体验,便于携带和存放,更好地满足不同用户的需求,拓展无限可能。
下载官方提供镜像(任选一种方式下载)
在完成上面的镜像下载后,我们需要对BearPi-HM Micro环境进行编译环境的配置
| |
| |
| |
| |
| |
| |
| |
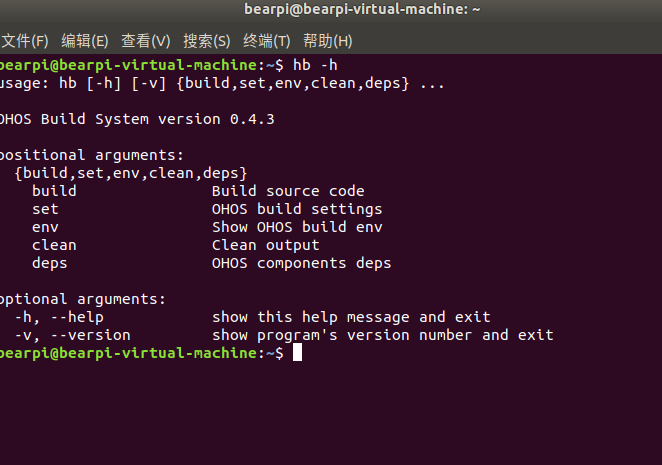
首先解释这个工具的用途:用来制作不压缩或者压缩的多种可启动映象文件。
| |
~/tools目录,并复制到/home/bearpi/tools/目录下 | |
| |
准备好前面的Linux镜像,并解压该文件,打开VMware station,选择上方导航栏:文件->打开(O),选择我们Linux镜像中的BearPi-HM_Micro_Ubuntu.ovf文件,等待镜像文件的导入,开始登录
| |
首先将网络连接模式更改为NAT模式,选择上方导航栏:虚拟机(M)->设置->网络适配器->NAT模式
此时打开一个终端,输入ifconfig查看ip
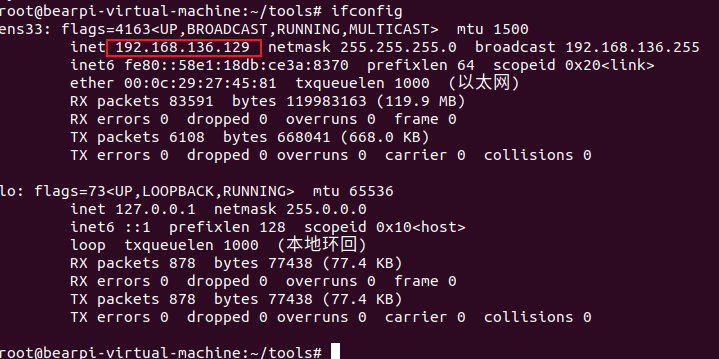
| |
首先进入到项目文件夹中
| |
执行如下命令(普通用户模式终端下):
| |
出现[OHOS INFO] Input code path: 提示信息后再输入.

我们选择bearpi-hm_micro后回车

输入下面的命令,等待下载程序完成
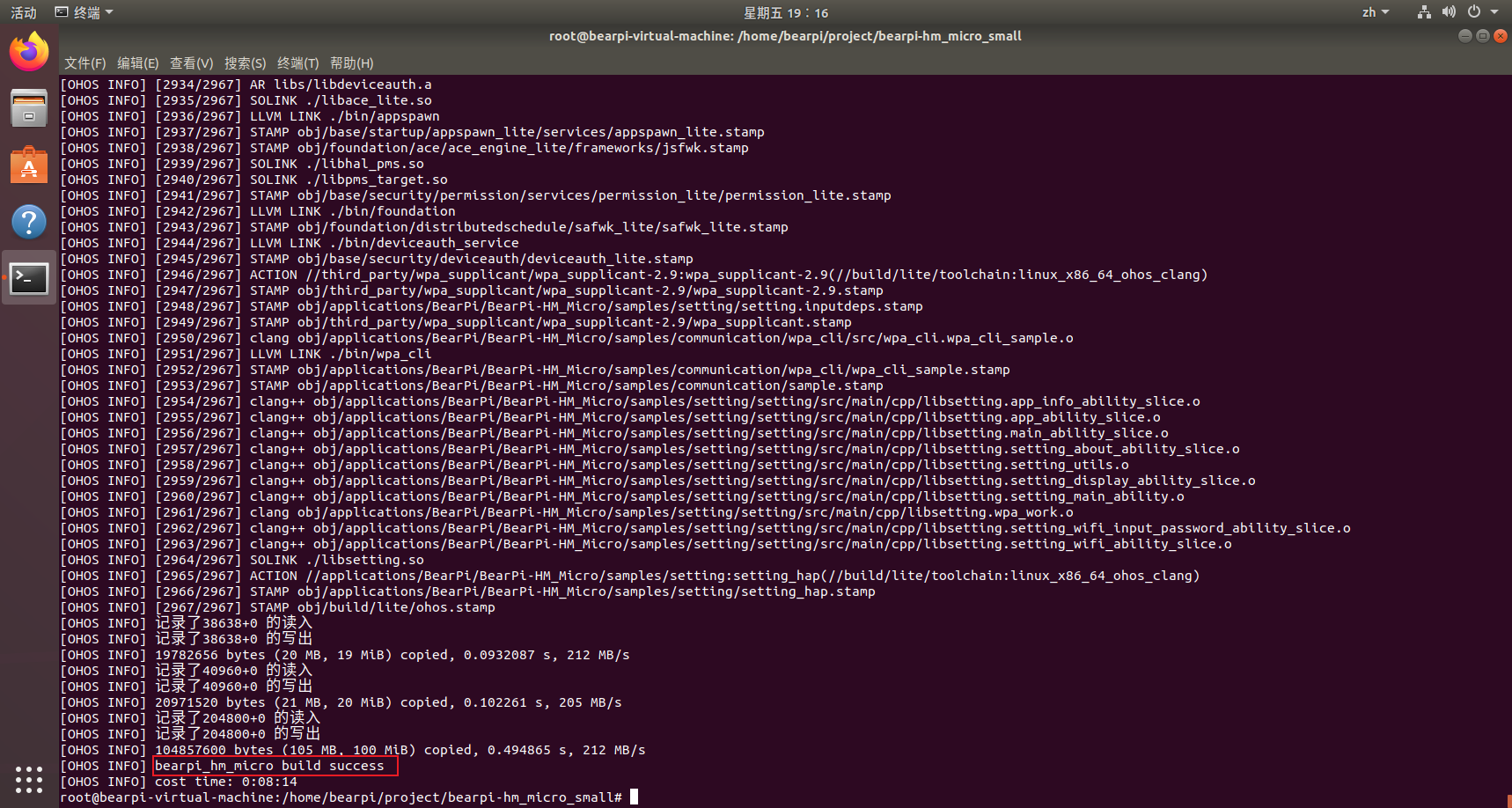
| |
当出现build success时,即代表编译成功
当编译完后,在Windows中可以直接查看到最终编译的固件,具体路径在: /home/bearpi/project/bearpi-hm_micro_small/out/bearpi_hm_micro/bearpi_hm_micro 其中有以下文件是后面烧录系统需要使用的。
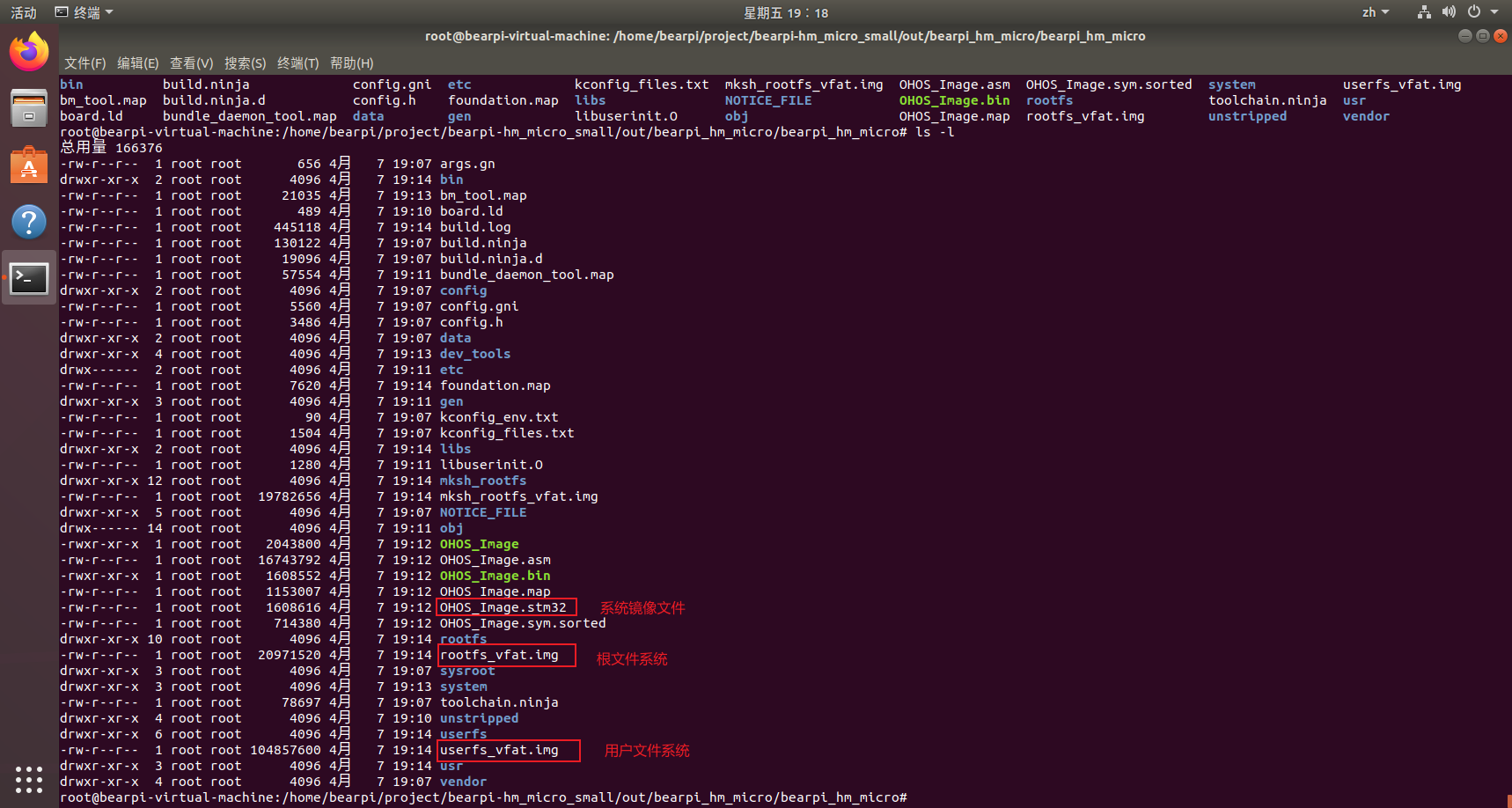
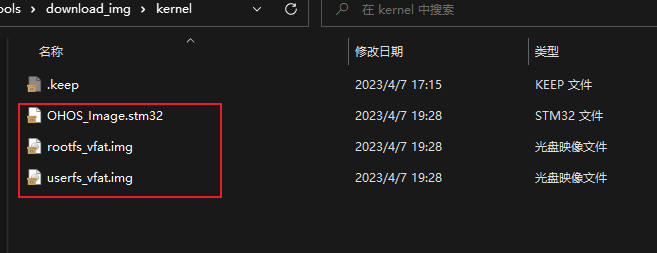
我们将这三个文件复制到该目录下:/home/bearpi/project/bearpi-hm_micro_small/applications/BearPi/BearPi-HM_Micro/tools/download_img/kernel/,方便后续烧录系统使用
| |
首先将电脑的虚拟机和RailDriver打开,确保SFTP服务能够正常使用。(关于RailDriver配置可以查看这篇文章:【Linux系统开发】Ubuntu配置SFTP服务)
当计算机本地磁盘出现一个SFTP(Y:)的网络盘符出现即代表服务能正常使用。
我们将开发板的usb接口连接到电脑,此时由于虚拟机会识别到设备,我们选择连接到本机
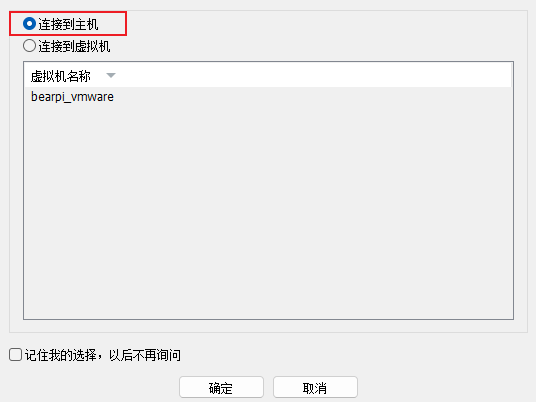
首先将开发板的拨码开关拨至“000”模式,然后再按下Reset键。
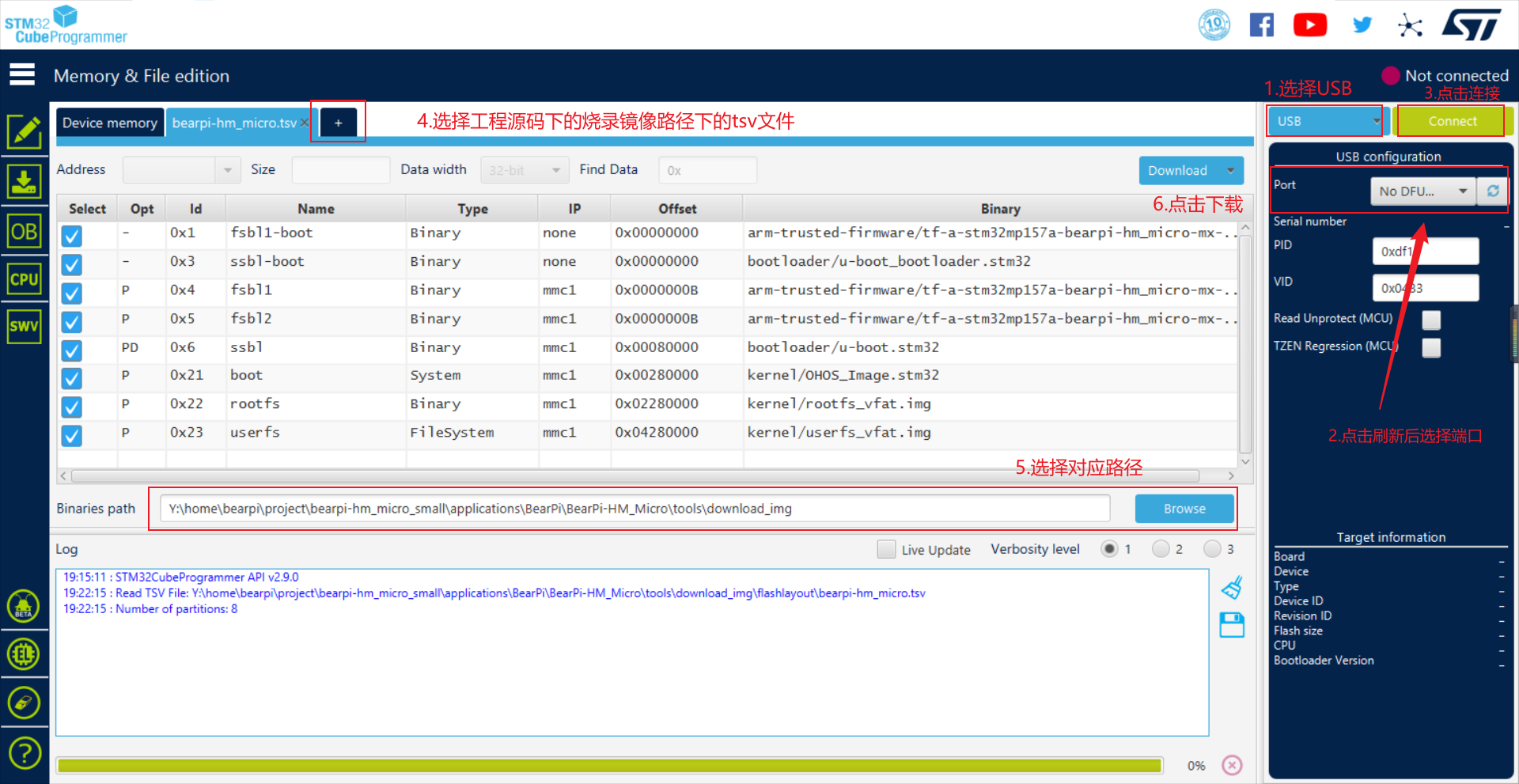
打开STM32CubeProgramme,选择USB设备和正确的端口后,点击Connect连接小熊派。
点击STM32CubeProgrammer工具的“+”按钮,然后选择烧录配置的tvs文件(路径:Y:\home\bearpi\project\bearpi-hm_micro_small\applications\BearPi\BearPi-HM_Micro\tools\download_img\flashlayout\bearpi-hm_micro.tsv)。
点击Browse按钮,然后选择工程源码下的烧录镜像路径
点击下载,等待烧录成功,中间会有一次断开连接,需要再虚拟机界面再次选择将USB设备连接到主机
将开发板背面的拨码开关切换至“010”启动模式,并按一下RESET重启开发板,之后等待几秒中会看到屏幕中出现桌面及预装软件,之后就可以结合SSH进行远程终端开发了。


安装模块
+lsmod module_test.ko
+创建设备文件
+mknod /dev/test c 250 0
+查看设备状态
+lsmod module_test.ko
+查看设备注册信息(分为字符设备和块设备)
+cat /proc/devices
| |
首先进入x210_bsp/kernel
make menuconfig
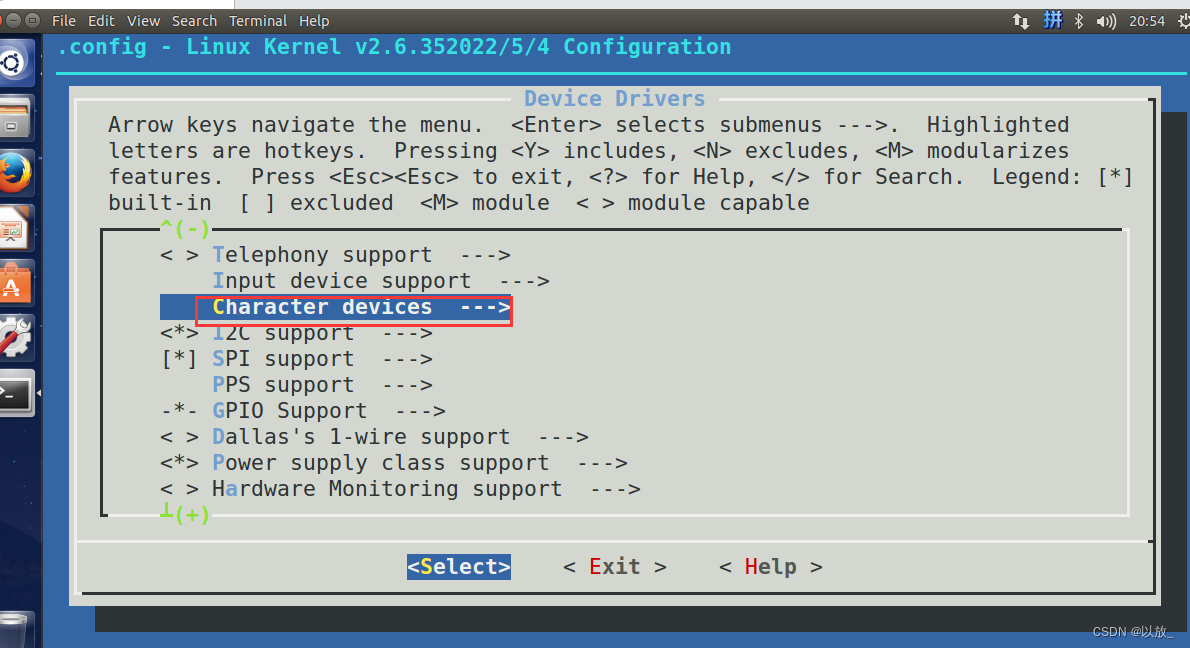

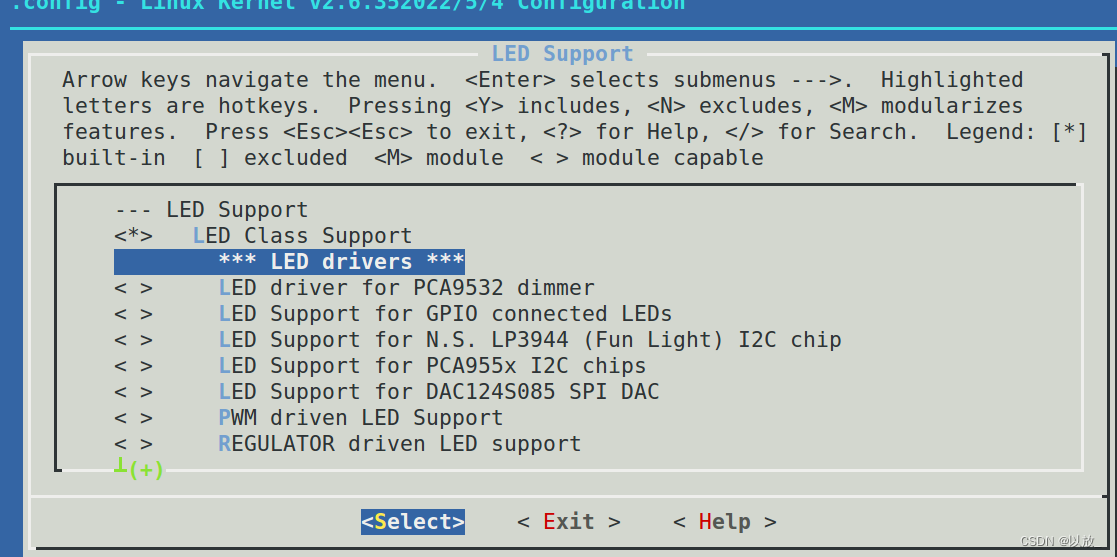
make -j4
cp arch/arm/boot/zImage /tftpboot/ -f
重启开发板查看开发板设备
ls /sys/devices/platform/


cd sys/class/leds
led_test_4编写完成后
编译不报错即可
cd /root/x210_bsp/kernel/drivers/leds/
cp /mnt/hgfs/Myshare/driver/led_test_4/leds-s5pv210.c ./
vi Makefile->
obj-$(CONFIG_LEDS_S5PV210) += leds-s5pv210.o
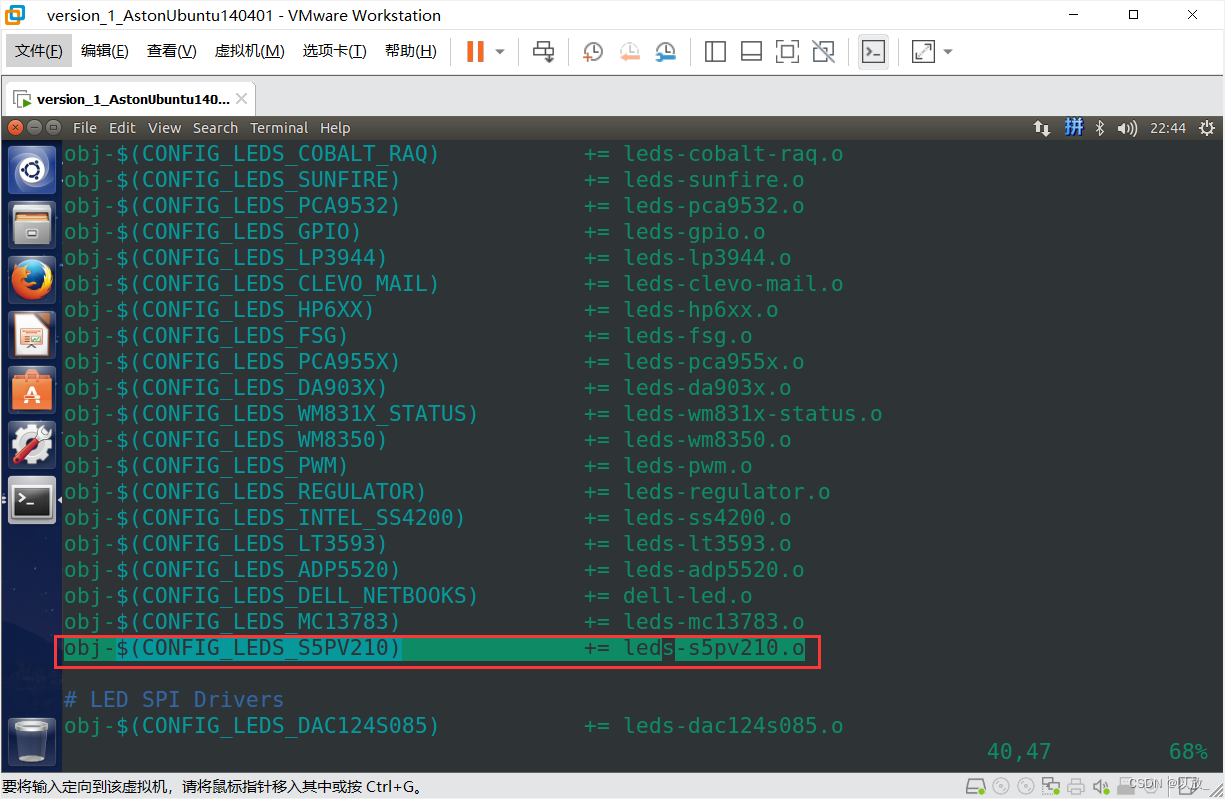
vi Kconfig更改依赖(添加以下文件)
config LEDS_S5PV210 tristate "LED Support for S5PV210" help This option enables support for on-chip LED drivers found on Marvell Semiconductor 88PM8606 PMIC.
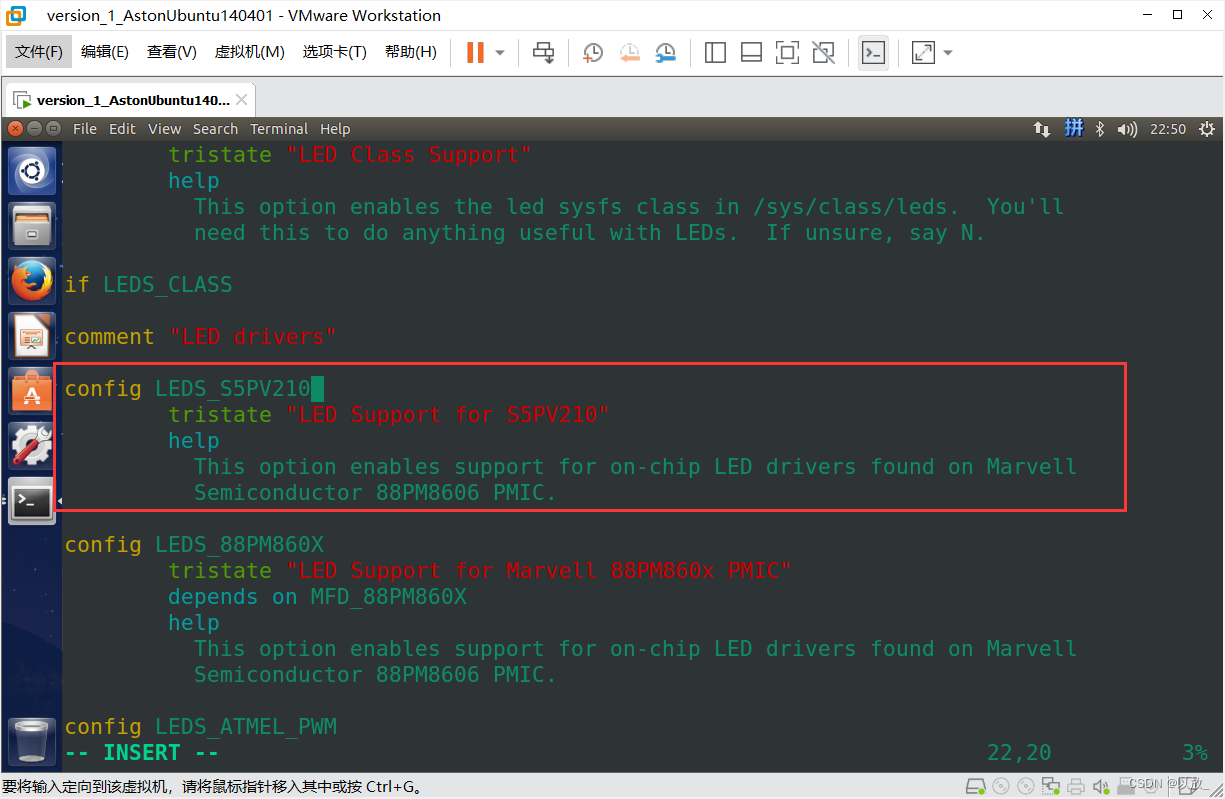
进入到x210_bsp/kernel
执行make menuconfig
可以发现生成了新的配置(Device Drivers-> LED_Support),使能这个
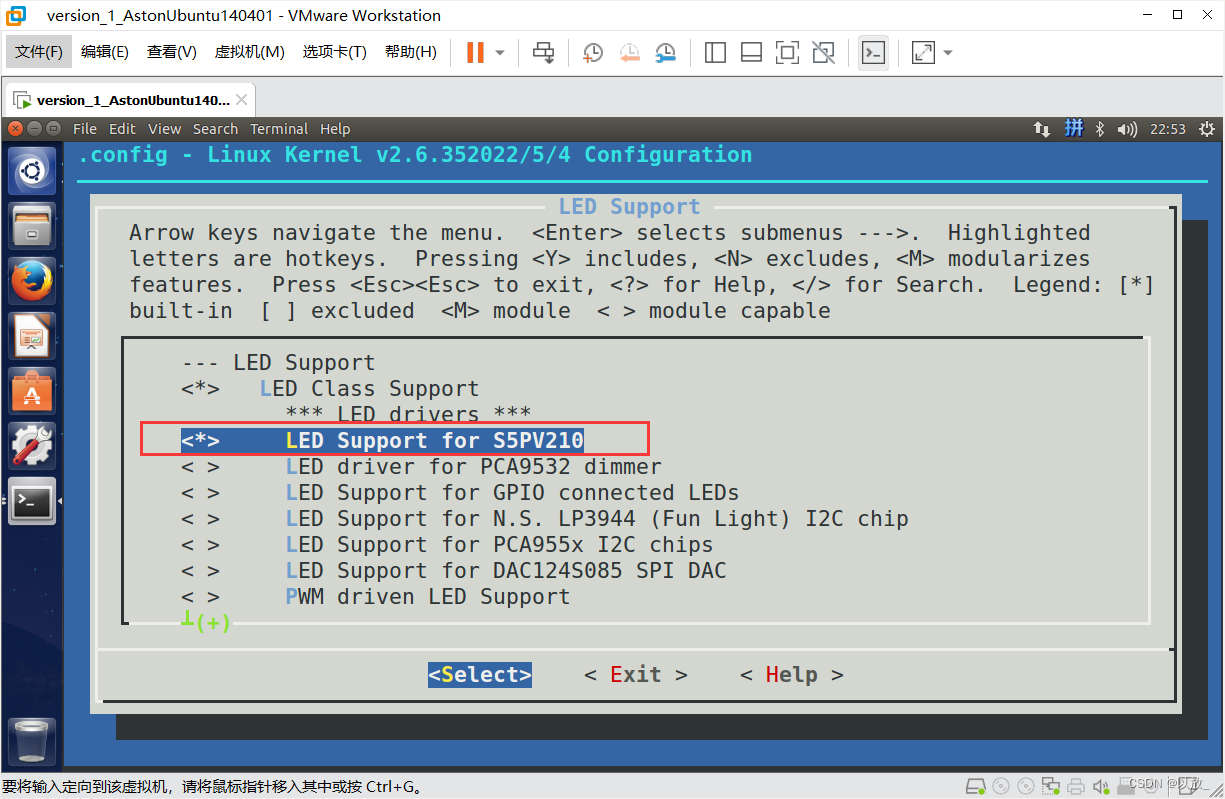
执行make编译
cp arch/arm/boot/zImage /tftpboot/ -f
secureCRT:
cd sys/class/leds
进入LED1,执行
echo 1 > brightness // 灯亮
echo 0 > brightness //灯灭
最后附上源代码:
leds-s5pv210.c
| |
Makefile
| |

问题一. ifconfig之后只显示lo,没有看到eth0 +问题二. ifconfig之后显示eth0,但是没有显示静态IP地址,即无inet、地址、广播、掩码。 +问题三. ping命令不能使用,因为dns还没设置,编辑/etc/resolv.conf,加上dns服务器地址。
1.eth0设置不正确,导致无法正常启动,修改eth0配置文件就好 +ubuntu 12.04的网络设置文件是/etc/network/interfaces,打开文件,会看到auto lo iface lo inet loopback +这边的设置是本地回路。在后面加上
| |
其中eth0就是电脑的网卡,如果电脑有多块网卡,比如还会有eth1,都可以在这里进行设置。iface eth0 inet 设置为dhcp是动态获取IP,设置为static则用自定义的IP。这边要自定义IP地址,所以选择static选项。
2.eth0被关了 +输入命令行:ifconfig eth0 up #开启eth0
1.先用sudo dhclient eth0更新IP地址 +2.然后运行sudo ifconfig eth0 +3.reboot
设置好后,如果直接ping www.baidu.com会发现ping不通,因为dns还没设置,编辑/etc/resolv.conf,加上dns服务器地址。
nameserver 8.8.8.8
+nameserver 8.8.4.4
+这两个是Google提供的免费DNS服务器的IP地址

执行如下步骤:
| |
终端安装 fcitx
| |
到搜狗官方下载 deb 包:
使用linux自带的安装程序安装输入法后,安装如下输入法依赖:
| |
重启即可
首先去官网下载所需版本的压缩包:
执行解压命令
| |
安装相关依赖:
| |
进入解压后的cmake文件,执行:
| |
编译构建:
| |
安装:
| |
安装依赖项:
| |
依次执行如下步骤:
| |
尝试烧录代码
| |
具体的GDB调试可以参考这篇文章:

| |
选择自己需求对应的安装包下载解压即可(此处可点击下载)
首先在Project Explorer的空白栏右键单击->New->C Project
+ +项目名称填写LED_test
+
+项目名称填写LED_test
+ +点击next,finish
+点击next,finish
找到我们的项目工程示例,将全部文件复制到剪贴板
+ +工程右键选择paste,选择粘贴全部
+
+工程右键选择paste,选择粘贴全部
+ +这是粘贴好的文件项目
+
+这是粘贴好的文件项目
+ +工程右键Build Project或直接CTRL+B编译
+
+工程右键Build Project或直接CTRL+B编译
+ +此时回到我们存放工程的workplace文件目录下,可以发现生成了output文件目录
+
+此时回到我们存放工程的workplace文件目录下,可以发现生成了output文件目录
+ +进入该目录下,可以发现生成了led.bin映像文件
+
+进入该目录下,可以发现生成了led.bin映像文件
+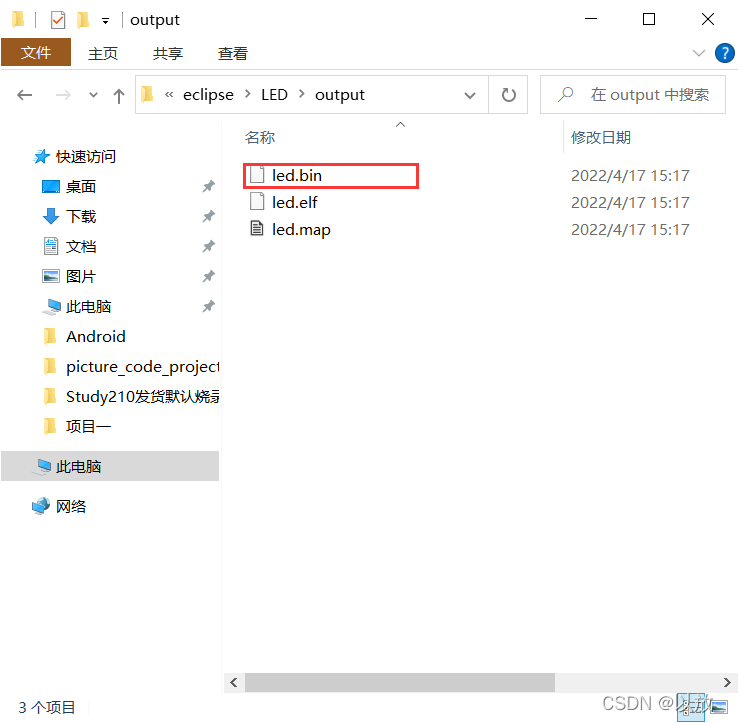
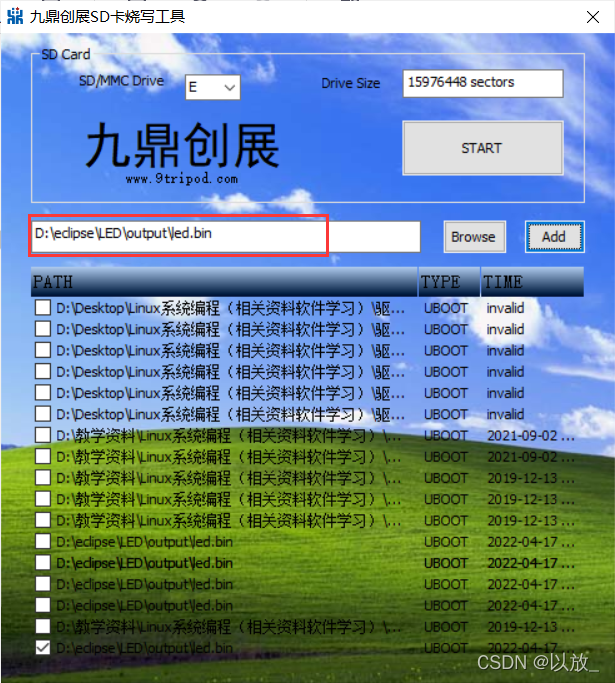
打开SD卡烧写工具,将上面生成的映像文件下载到SD卡
+
由于S5PV210芯片无法直接从SD2通道启动,首先会从SD0通道启动,而SD0通道接了emmc芯片,因此我们务必将emmc中已存在的bootloader破坏掉!(关于Windows下破坏板载BootLoader方法可借鉴【Linux系统开发】Study210开发板刷安卓系统)
将烧有裸机程序的SD卡插到Study210开发板上,长按POWER键,约3秒后即可松手,这时可以发现,四盏LED灯已经在来回闪烁了。
+

1.用USB转串口线连接电脑与开发板,打开SecureCRT串口监视软件(此步骤注意:开发板上使用UART2)

2.长按开发板POWER按键开机,进入控制台。(让secureCRT读完全部信息)
3.输入root(password:123456)
4.然后输入
busybox dd if=/dev/zero of=/dev/mmcblk0 bs=512 seek=1 count=1 conv=sync
5.回车后显示
| |
6.然后再输入 sync 命令 ,此时第1扇区已经破坏。 +此时重新启动开发板就无法启动了
1.将SD卡插入到电脑的SD卡槽,使用SD卡烧录工具x210_Fusing_Tool 进行烧录。

此处如果SD烧写不成功,可尝试用管理员身份运行。
+插卡后,此软件会自动识别,然后在自己的电脑里选择一个uboot.bin文件。然后点击START.
2.完成后将SD卡插入开发板的SD卡槽。然后开机就可以进入uboot界面了。在uboot开机自动启动倒数3秒之内迅速按下电脑回车键,打断自动启动。(否则会自动启动iNand中的android)
1.用USB线的USB口 连接电脑,另一端连接开发板的OTG口,然后在SecureCRT 的uboot控制台输入fastboot命令,这时电脑会识别USB硬件,然后需要安装驱动。
2.然后将电脑内的fastboot压缩包解压到一个容易找到的文件目录下,如 D盘。打开windows控制台进入到相应目录下。
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wex7LBk8-1650028395333)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20220415202849623.png)\]](https://img-blog.csdnimg.cn/bc1cb6ad4904482baaad59e05da074bc.png)
3.下一步 在fastboot文件夹下,新建一个文件夹存放要烧录的文件,如Android
fastboot目录下应该包含的文件

Android中应该包含的文件(由于这里我烧写的是安卓系统)
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G3DezB8H-1650028395333)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20220415203108592.png)\]](https://img-blog.csdnimg.cn/d97c6282c3ba46aba3a44b34a72e99a4.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5Lul5pS-Xw==,size_20,color_FFFFFF,t_70,g_se,x_16)
4.进行内核和系统的烧写 ,具体代码如下:
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Dhso3IG-1650028395334)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20220415203639928.png)\]](https://img-blog.csdnimg.cn/eb401fcf50ec4f228025341cfcb28fca.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5Lul5pS-Xw==,size_20,color_FFFFFF,t_70,g_se,x_16)
同时在SecureCRT下可以看到下载结果
5.最后在windows控制台下输入
fastboot reboot命令重启系统即可。
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jaxHZTvW-1650028395335)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20220415204109660.png)\]](https://img-blog.csdnimg.cn/763acfc49ae34659b891a95ccd3de444.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5Lul5pS-Xw==,size_20,color_FFFFFF,t_70,g_se,x_16)
注意:
(1)安装SecBulk.sys Njsmodi 2416 dnw drive的驱动程序在\X210V3S_A\tools\USB驱动\dnw_driver下,安装驱动需要禁用数字签名(可参考win10如何永久关闭数字签名)
(2)在使用dnw过程中需要长按电源键,否则会断开连接。
刷机步骤:
1.将拨码开关拨到USB启动位置。
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rua1zZN3-1650028395335)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20220415205448252.png)\]](https://img-blog.csdnimg.cn/51ddaa8b66494111899de8774b695007.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5Lul5pS-Xw==,size_20,color_FFFFFF,t_70,g_se,x_16)
2.按住开机键(长按不放),DNW 配置下载地址为0xd0020010 ,然后transmit x210_usb.bin



3.(
同上操作)DNW 修改下载地址为 0x23e00000 ,下载uboot.bin
注意!!!:下载的同时要看SecureCRT界面,串口终端有信息打印出来,在3s倒计时内按下回车键,进入shell界面。
4.回到secureCRT
| |
5.cmd打开系统终端,切换到fastboot目录分别执行下列红框的命令:
 +
+最后再输入
| |
全部执行完成后,将拨码开关切换回原来的状态,重新启动,此次刷机完成。

此文章参考于S5PV210 Study210开发板刷系统

1.top命令
- top命令是一个常用的查看系统资源使用情况和查看占用系统资源最多的进程的命令。
- top以列形式显示所有的进程,占最多CPU资源的进程会显示在最上面。
2.htop命令
- htop命令是top的改进版。
- 默认情况下,大多数Linux发行版本都没有安装htop。
- htop命令显示的信息与top相同,但它的界面更人性化。
3.pstree
- pstree命令也可以显示进程信息。
- 它以树的形式显示进程。
4.kill
- kill命令可以根据进程ID来杀死进程。
- 你可以使用ps -A,top,或者grep命令获取到进程ID。
从技术层面来讲,kill命令可以发送任何信号给一个进程。
+你可以使用 kill -KILL [id] 或者 kill -9 [id] 来杀死顽固的进程。
+新建文件:touch
详细文档通过 man [command] 查看
管理文件
压缩tzip文件
解压zip文件
查找含
spark的目录、文件
更改密码
更改文件名或移动文件位置
删除文件
首先需要输入安装命令:
+apt install ufw
查看防火墙当前状态 +
sudo ufw status
开启防火墙 +
sudo ufw enable
关闭防火墙 +
sudo ufw disable
查看防火墙版本 +
sudo ufw version
默认允许外部访问本机 +
sudo ufw default allow
默认拒绝外部访问主机 +
sudo ufw default deny
允许外部访问443端口 +
sudo ufw allow 443
拒绝外部访问443端口 +
sudo ufw deny 443
允许某个IP地址访问本机所有端口 +
sudo ufw allow from 192.168.0.1
重置网卡 +sudo /etc/init.d/networking restart

1.打开Ubuntu,在终端进入/usr/local/目录下
cd /usr/local/
+2.在local/目录下创建一个名为arm的文件夹
mkdir arm
+3.在自己的共享文件夹下找到arm-2009q3.tar.bz2,并复制到之前创建的arm目录下
cp /mnt/hgfs/Myshare/arm-2009q3.tar.bz2 /usr/local/arm/
+4.进入到arm目录下,解压该其中文件
cd /usr/local/arm
+tar -jxvf arm-2009q3.tar.bz2
+5.然后执行:
cd arm-2009q3/bin
+./arm-none-linux-gnueabi-gcc -v
+注意:这里如果输入./arm-none-linux-gnueabi-gcc -v终端显示 ‘没有这样的文件存在’ ,这是因为在64位的系统下安装32位交叉编译工具链,会无法使用,所以我们需要安装32位库的支持
sudo apt-get install libc6:i386
+安装好了之后重新输入./arm-none-linux-gnueabi-gcc -v
+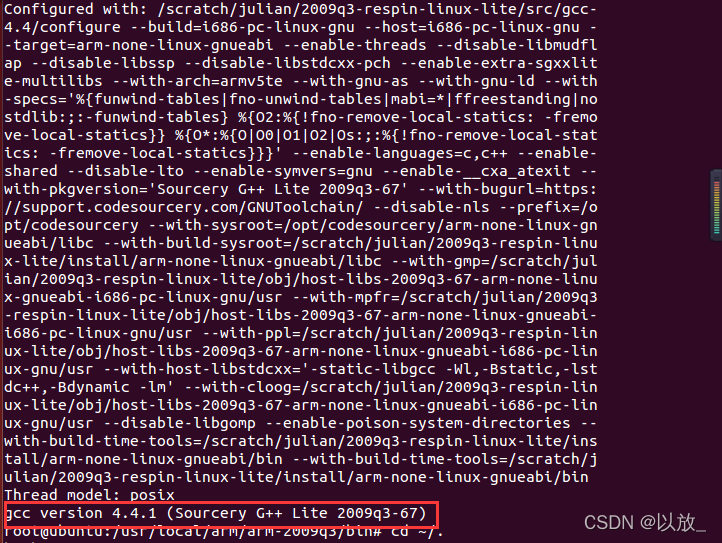 +操作成功!
+操作成功!
6.为了能让它其他目录中也可以这么操作,我们把它导出到环境变量中 +打开配置文件
sudo vim /etc/profile
+7.在vi界面末尾处加入
export PATH=$PATH:/usr/local/arm/arm-2009q3/bin
+8.回到主目录,查看交叉编译工具是否可用
cd ~
+source /etc/profile
+注 这里如果没有出现相关信息,切换root用户再次输入命令
使用 echo $PATH查看交叉编译链的安装路径是否加入了环境变量。
+使用arm-linux-gnueabihf-gcc -v测试交叉编译链是否好使
9.建立一个符号链接,进入到/usr/local/arm/arm-2009q3/bin#目录下,vi新建一个[mk-arm-linux-.sh]脚本(文章最后可复制粘贴该脚本),然后输入命令:
chmod 777 mk-arm-linux-.sh
+./mk-arm-linux-.sh
+这里由于运行时报错,原因详见解决linux的-bash: ./xx.sh: Permission denied
ls查看,可以发现符号链接出现,到此,交叉编译链配置成功!
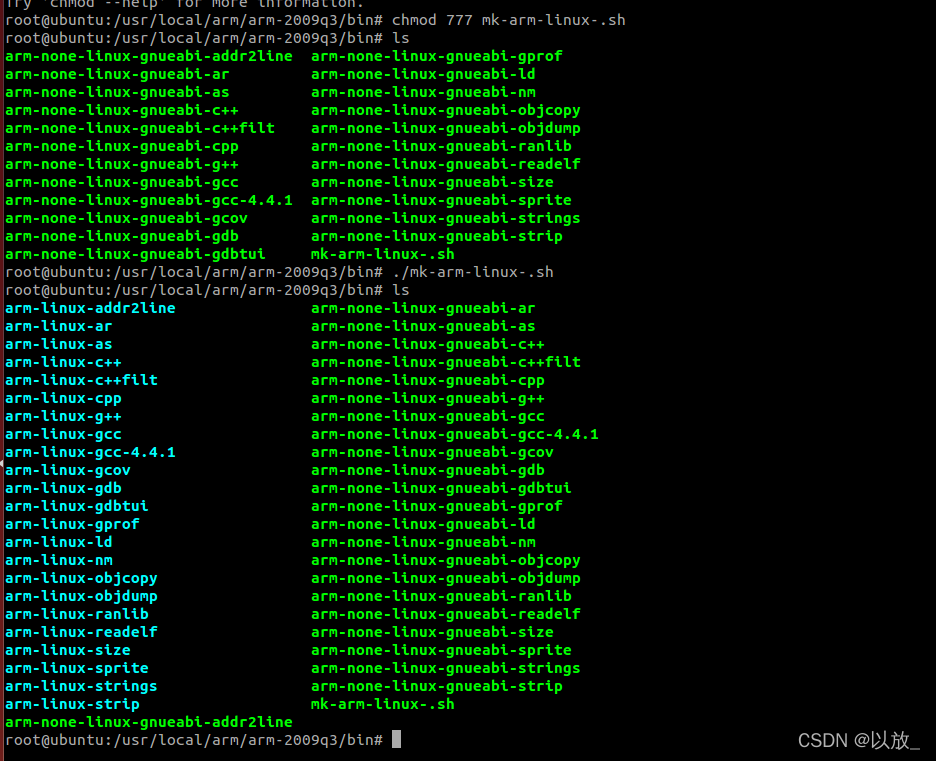
附件:
mk-arm-linux-.sh脚本文件
| |
有问题欢迎评论留言致信:blogs

SFTP是指Secure File Transfer Protocol,即安全文件传输协议。它提供了一种安全的网络加密方法来传输文件。SFTP与FTP具有几乎相同的语法和功能,是SSH的其中一部分,可安全地将文件传输到服务器。在SSH软件包中,已经包含了一个名为SFTP(Secure File Transfer Protocol)的安全文件信息传输子系统。SFTP本身没有单独的守护进程,必须使用sshd守护进程(默认端口号为22)来完成相应的连接和答复操作。因此,从某种意义上说,SFTP并不像服务器程序,而更像客户端程序。由于SFTP也使用加密传输认证信息和数据,因此使用SFTP非常安全。但是,由于这种传输方式使用了加密/解密技术,因此传输效率比普通的FTP要低得多。如果您对网络安全性要求更高,可以使用SFTP代替FTP。(参考资料:百度百科)
在Ubuntu系统上开通SFTP文件服务,允许某些用户上传及下载文件。这些用户只能使用SFTP传输文件,不能使用SSH终端访问服务器,并且SFTP不能访问系统文件。系统管理员则既能使用SFTP传输文件,也能使用SSH远程管理服务器。 +以下是将允许SFTP-users用户组内的用户使用SFTP,但不允许使用SSH Shell,且该组用户不能访问系统文件。在SFTP-users组内创建一个名为“SFTP”的用户。允许SSH-users用户组内的用户使用SFTP以及SSH。系统管理员的账户名为yifang。
在Linux系统中,一般RedHat系统默认已经安装了openssh-client和openssh-server,即默认已经集成了SFTP服务,不需要重新安装;而Ubuntu系统默认只安装了openssh-client,要用SFTP的话还需要安装openssh-server。如果系统已安装有openssh-client,则为了防止安装openssh-server时两者版本不兼容,可以先将openssh-client卸载后再安装。如下所示,如果Ubuntu没有安装SFTP,则会显示没有安装:
| |
这里由于我已经完成安装了,此处就不做安装演示,具体下载命令如上所示。
为了方便管理权限,创建用户组可以用于SFTP访问。然后创建sftp用户:
| |
将SFTP从其他所有用户组中移除并加入SFTP-users组,然后关闭其Shell访问:
| |
创建SSH用户组,并将管理员添加到该组(请注意usermod命令中的-a参数意味着不从其他用户组中移除)。
| |
为“监狱”根目录和共享目录做准备,“监狱”根目录必须满足以下要求: +所有者为root,其他任何用户都不能拥有写入权限。因此,为了让SFTP用户能够上传文件,还必须在“监狱”根目录下创建一个普通用户能够写入的共享文件目录。为了方便管理员通过SFTP管理上传的文件,把这个共享文件目录配置为由yifang所有,允许SFTP-users读写,这样,管理员和SFTP用户组成员都能读写这个目录。
| |
在sshd_config文件的最后添加以下内容:
| |
| |
这些内容的意思是:
首先将虚拟机重启:
| |
在本地Windows系统中,可以通过SFTP客户端来连接Ubuntu系统的SFTP服务,例如使用RaiDrive。
查看ubuntu网络ip地址
| |
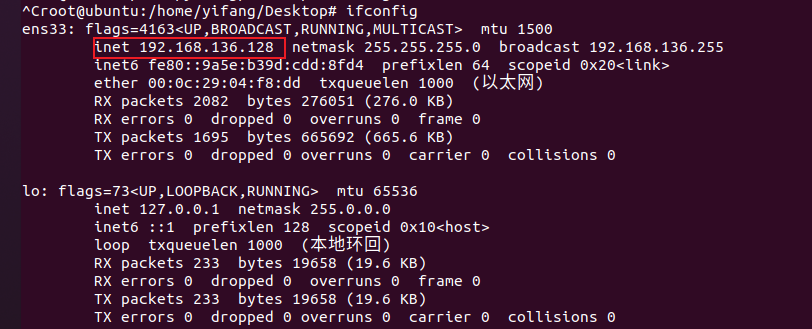 zhe
zhe
这里我的IP地址为192.168.136.128。我们接着打开RaiDrive(安装配置可参考RaiDrive—将网盘映射为磁盘)
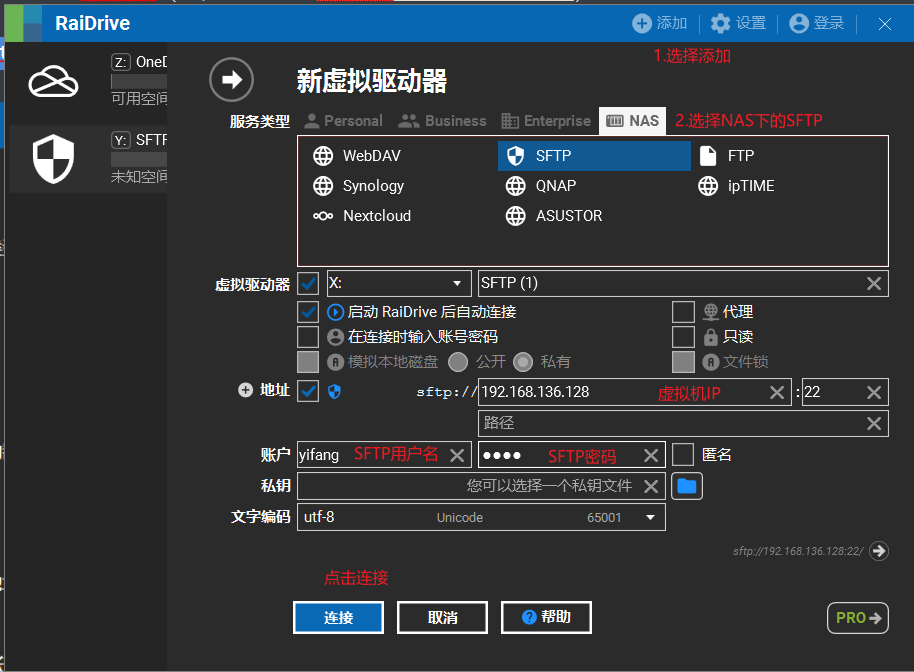
此时我们点击连接并连接成功后会自动在我们windows下自动生成一个名为SFTP的网络磁盘,这时候我们就可以在windows下对虚拟机进行文件操作了。
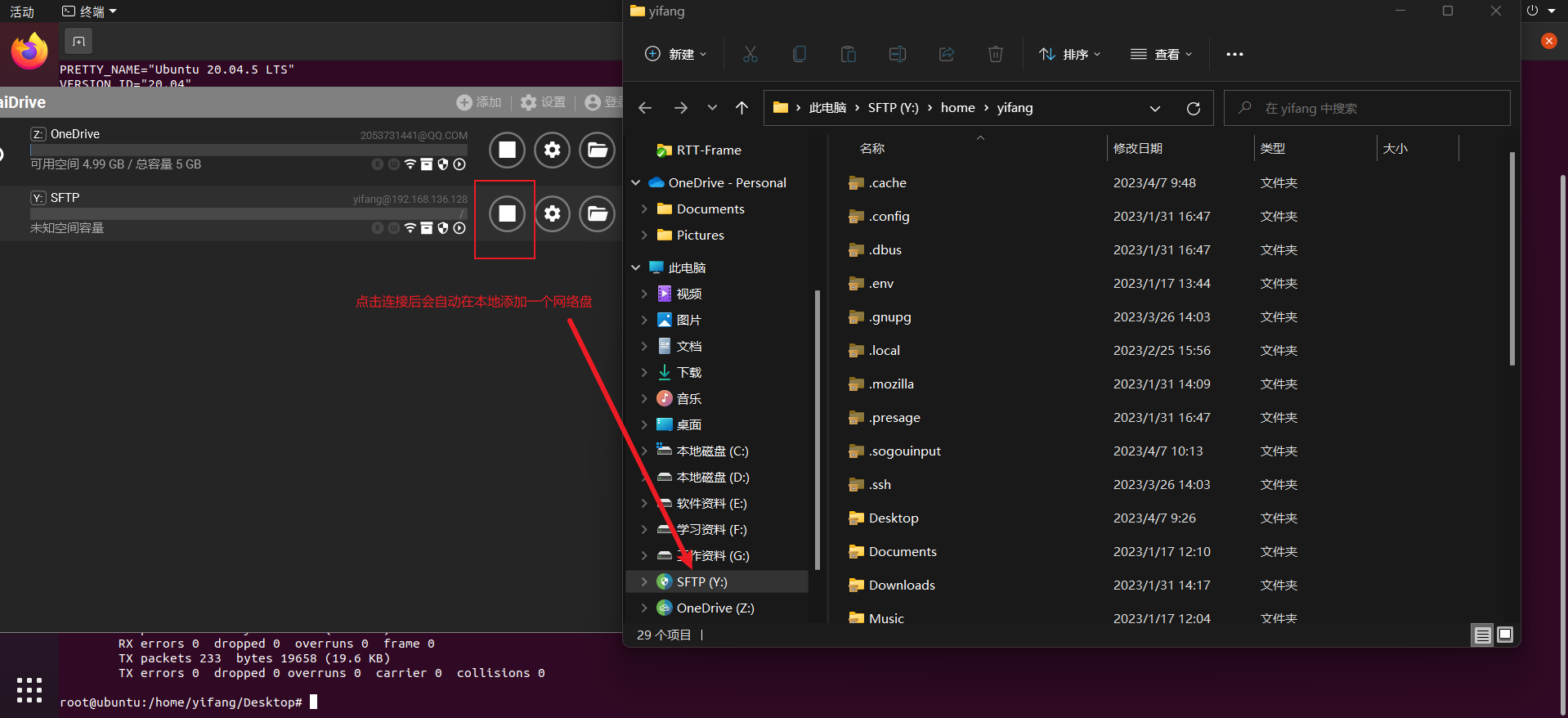

(使用secureCRT) +首先确保开发板完成以下配置:
主机IP:
+set ipaddr192.168.1.10
+服务器IP:
+set serverip 192.168.1.141
+网关:
+set gatewayip 192.168.1.1
+子网掩码:
+set netmask 255.255.255.0
+内核驱动设置:
+set bootcmd 'tftp 30008000 zImage; bootm 30008000'
+bootargs配置:
+set bootargs root=/dev/nfs nfsroot=192.168.1.141:/root/rootfs/x210_bsp ip=192.168.1.10:192.168.1.141:192.168.1.1:255.255.255.0::eth0:off init=/linuxrc console=ttySAC2,115200
最后输入save保存一下,这样开发板的网络和内核配置就设置好了
rootfs的两种表现形式: +1、nfs方式启动的文件夹形式的rootfs(主机)
2、用来烧录的镜像形式rootfs(开发板)
首先我们需要root进入超级用户模式,在虚拟机的root目录下再次创建以下两个目录:
+rootfs x210_bsp
这时候我们需要知道这两个文件夹下有什么:
- x210_bsp:用于uboot烧录和配置
- rootfs:用于挂载开发板根文件系统
首先进入到该目录下,并将文件qt_x210v3s_160307.tar.bz2复制到该目录下解压

以上是解压qt_x210v3s_160307.tar.bz2内的文件内容,后面会说到这个目录如何使用
首先我们需要在该目录下继续创建一个名为x210_rootfs的文件夹,并且进入到该文件夹下,将我们上面提到的busybox文件复制到此目录下并解压

以上是解压busybox-1.24.1(这是我选择的busybox版本)的全部文件
进入x210_bsp/kernel 目录下,输入命令:make menuconfig进入图形化菜单
这里我们按下面操作完成网络配置
| |
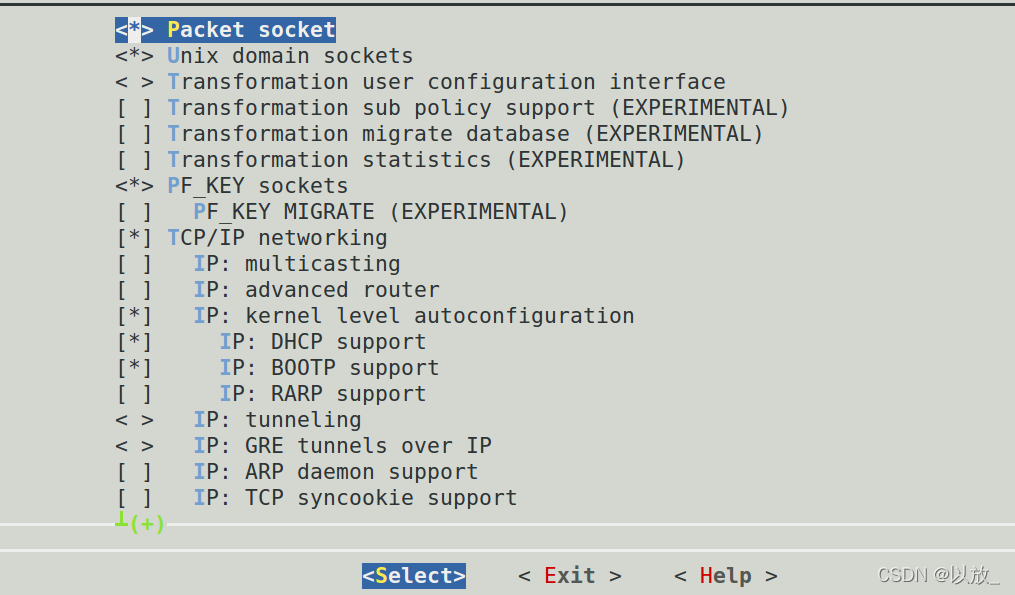
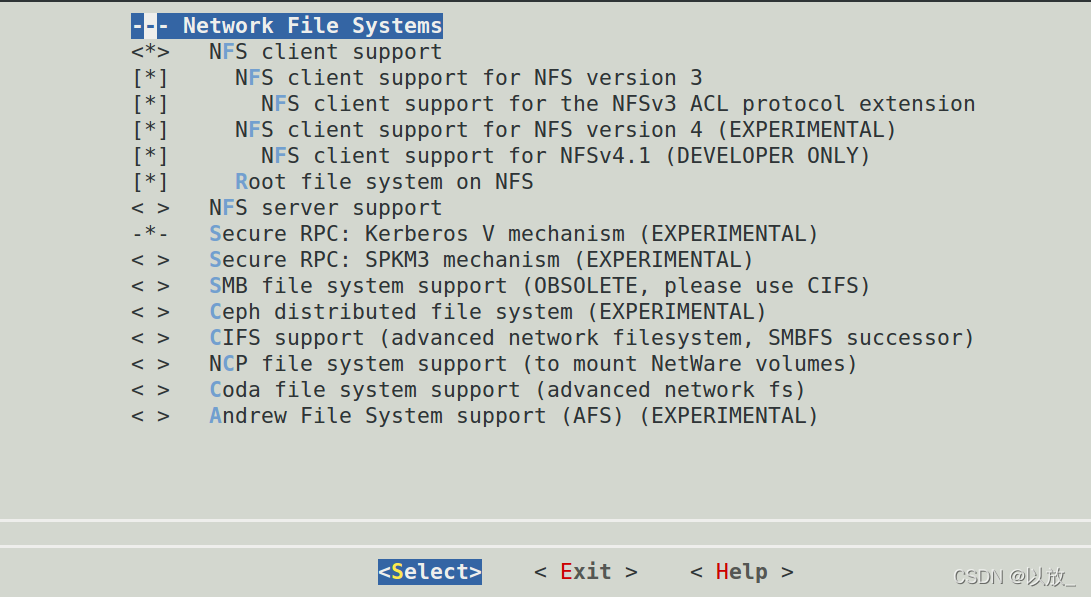
网络文件系统设置
| |
有需要把开发板作为服务器端的也可以选择把NFS server support设置打开,这里我们仅实验客户端
以上配置结束后输入命令make编译,至此开发板uboot的网络和文件系统部分配置结束。
busybox是一个集成了一百多个最常用linux命令和工具的软件,他甚至还集成了一个http服务器和一个telnet服务器,而所有这一切功能却只有区区1M左右的大小.我们平时用的那些linux命令就好比是分立式的电子元件,而busybox就好比是一个集成电路,把常用的工具和命令集成压缩在一个可执行文件里,功能基本不变,而大小却小很多倍。
注意:我们在文件系统构建中,内核编译和文件系统的程序编译都必须是使用的统一交叉编译器。(选择将虚拟机中的交叉编译文件复制一份到开发板构建的文件系统下)
(1)修改Makefile
首先进入~/rootfs/x210_rootfs/busybox-1.24.1目录下
输入命令vi Makefile进入脚本进行以下修改
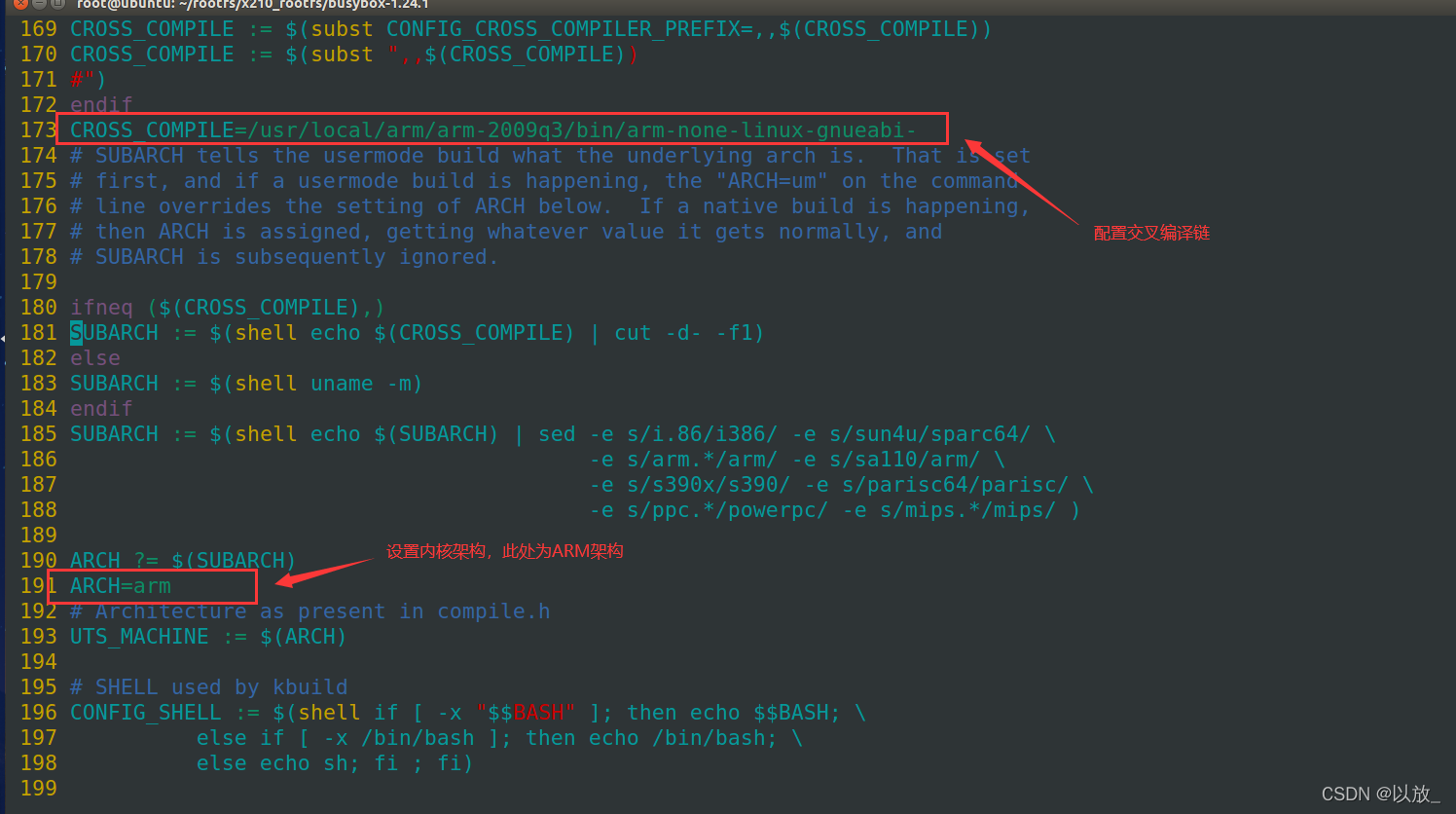
173行:CROSS_COMPILE=/usr/local/arm/arm-2009q3/bin/arm-none-linux-gnueabi-
+注意:此处的交叉编译链需要对照自己电脑的交叉编译链
+191行:ARCH=arm
(2)make menuconfig配置
Tip:此处的图形化菜单需要ncurses库(联网下载),由于之前博主自己在这里没有很深的基础知识,走了很多弯路。 +因为后面的文件系统的挂载需要虚拟机切换网络状态为桥接模式,但是我的虚拟机桥接网络总是会反复重连,所以建议先将该库下载好,方便后续使用。
make menuconfig
| |
大家学习使用的时候跟着上面的进行配置即可
+配置完成后,输入以下命令:
+make -j4 (4代表我主机的内核数)
+无报错继续下一步:
+make install
解释:在Linux系统中安装软件的一般步骤:下载-配置-编译-安装,所以上面的make -j4就代表编译,make install代表安装
(3)设置busybox安装路径
make menuconfig | |

(4)解决方案 +在虚拟机的配置中,由于代码的复杂性时常让我们不能很全面清晰的看到自己所做的改变,有时候就会出现各种各样的状况。
make -j4编译可能遇到的问题:
sync.c(text.sync_main+0x78):undefined reference to 'syncfs'分析:可能是gcc和当前busybox版本不兼容造成的,我们只需要将其禁用即可。
解决方法:
make menuconfig
+点击/进入搜索,输入SYNC,根据提示禁用SYNC
+最后再make -j4编译一下即可
 +
+
其实还可以选择在源代码中解决这个问题,过程有些繁琐就不赘述,动手能力强的可以一试。
(5)make install简述
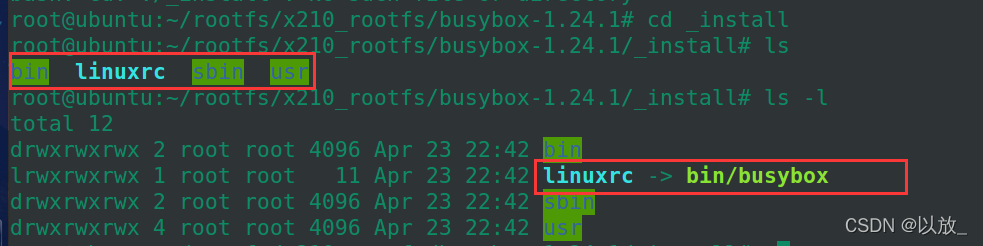
ls -l可以看到: linuxrc -> bin/busybox //这个linuxrc其实就是个符号链接
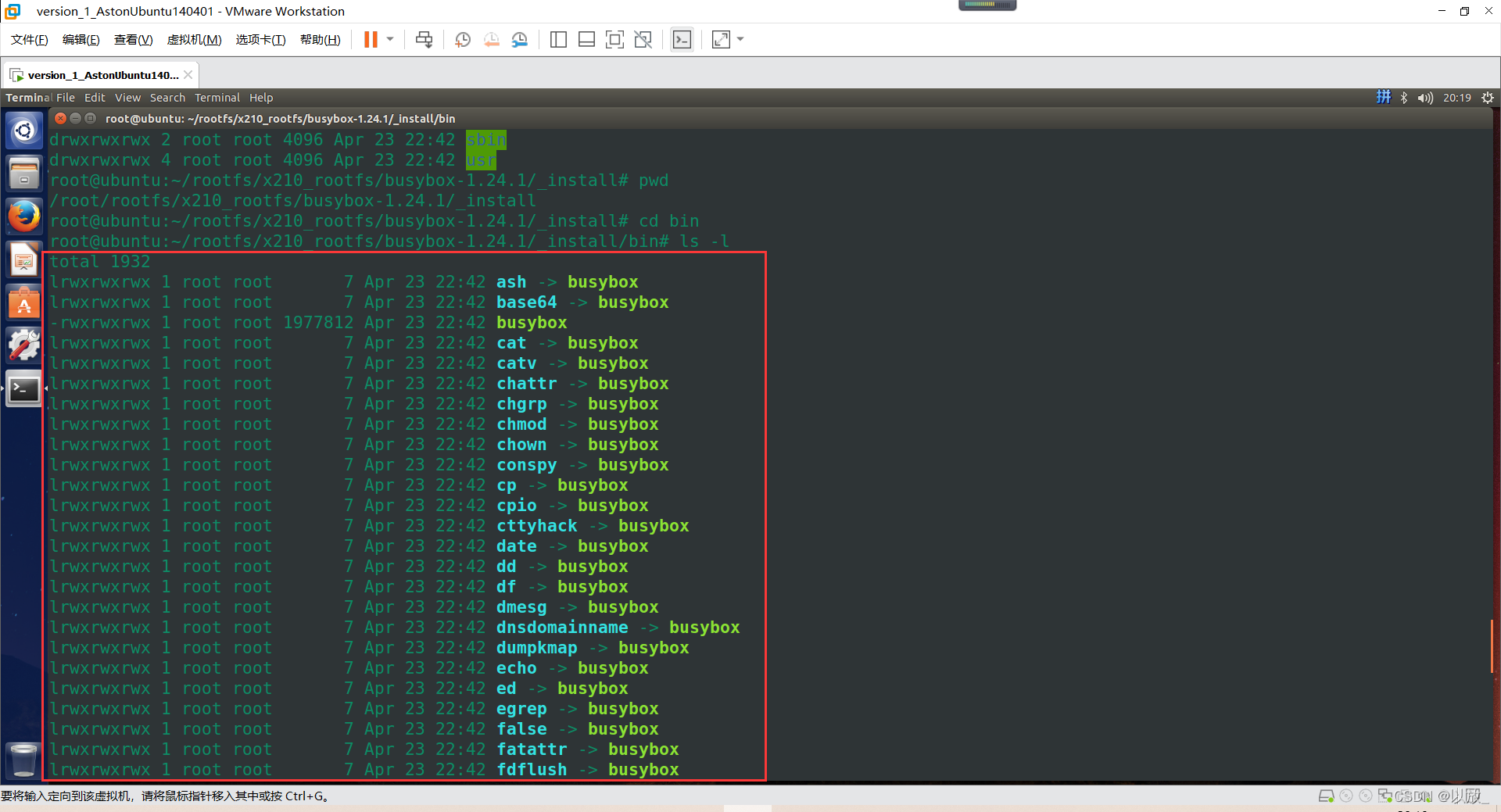
这里也不难发现,bin下的所有的符号链接都指向了busybox
(6)make menuconfig更改NFS挂载目录到/root/rootfs/x210_rootfs下
| |
执行make install后,回到被挂载的目录下,可以发现这四个文件已经生成。
sudo apt-get install nfs-kernel-server
启动NFS服务器->启动NFS客户端->挂载NFS目录
vim /etc/exports在最后一行修改
"文件挂载目录" *(rw,sync,no_root_squash,no_subtree_check)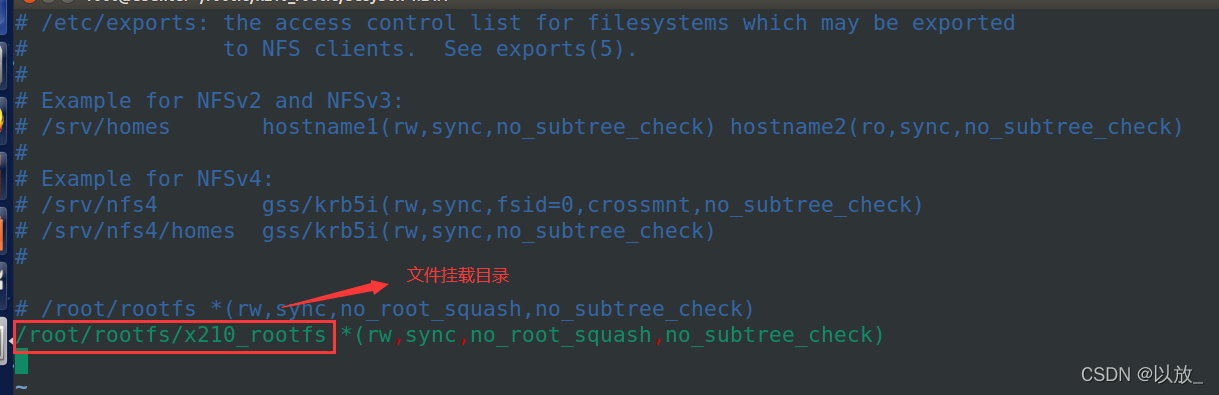
mount -t nfs -o nolock 192.168.240.33:/root/rootfs/x210_rootfs(根据实际情况修改)
/etc/init.d/nfs-kernel-server restart重启NFS服务首先将etc目录放置到挂载根目录下
etc目录下载:
<1>添加一个典型的inittab文件到etc目录下
<2>inittab格式解析
id:runlevels:action:process
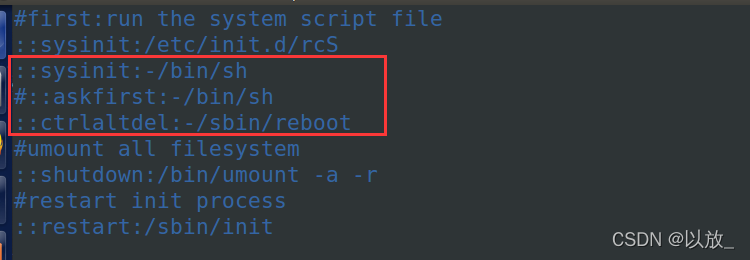
解释:


<3>了解busybox init与inittab之间的关系
busybox init进程的工作流程:
为init设置信号处理过程->初始化控制台->剖析/etc/inittab文件->执行系统初始化命令行,缺省(默认)情况下会使用/etc/init.d/rcS->执行所有导致 init 暂停的 inittab 命令(动作类型: wait)->执行所有仅执行一次的 inittab(动作类型: once)
循环执行以下进程:<1>执行所有终止时必须重新启动的 inittab 命令(动作类型: respawn) +<2>执行所有终止时必须重新启动但启动前必须询问用户的 inittab 命令(动作类型: askfirst)
注意:理解inittab的关键就是明白“当满足action的条件时就会执行process这个程序。” 去分析busybox的源代码就会发现,busybox最终会进入一个死循环,在这个死循环中去反复检查是否满足各个action的条件,如果某个action的条件满足就会去执行对应的process。
<4>配置 +vi命令打开inittab模板文件
| |
修改脚本:
+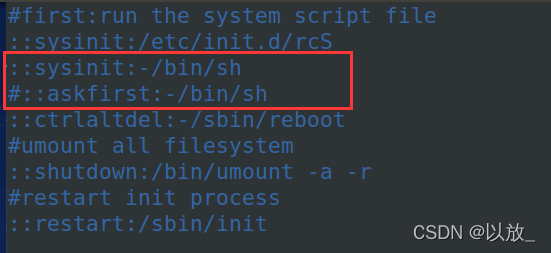
<1>添加一个典型的rcS文件到etc目录下
<2>rcS文件解析
| |
PATH这个环境变量是linux系统内部定义的一个环境变量,含义是操作系统去执行程序时会默认到PATH指定的各个目录下去寻找。如果找不到就认定这个程序不存在,如果找到了就去执行它。将一个可执行程序的目录导出到PATH,可以让我们不带路径来执行这个程序。
linux操作系统自从开始启动至启动完毕需要经历几个不同的阶段,这几个阶段就叫做runlevel。例如init 0就是关机,init 6 就是重启

umask是linux的一个命令,作用是设置linux系统的umask值,而umask值决定当前用户在创建文件时的默认权限。
mount -a是挂载所有的应该被挂载的文件系统,在busybox中mount -a时busybox会去查找一个文件/etc/fstab文件,这个文件按照一定的格式列出来所有应该被挂载的文件系统(包括了虚拟文件系统)
首先将前面提供的etc压缩包模板下载至共享文件夹
<1>输入命令打开rcS脚本:vi etc/init.d/rcS。我们可以发现在每一行代码的后面都有一个^m,将其删除,这样开发板启动的时候就不会报错了
<2>mdev
udev/mdev的工作就是配合linux驱动生成相应的/dev目录下的设备文件。
rcS文件中没有启动mdev的时候,ls查看/dev目录下启动后是空的;在rcS文件中添加以下与mdev有关的2行配置项后:
| |
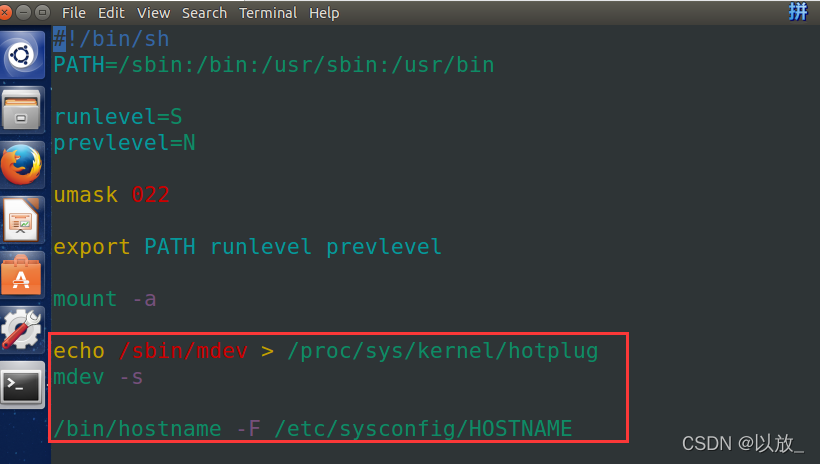
再次启动系统后发现/dev目录下生成了很多的设备驱动文件
<3>hostname
我们进入etc目录下创建一个名为sysconfig的文件夹,并在该目录下再次touch创建一个名为HOSTNAME的文件,vi命令进入可修改当前系统主机名
hostname是linux中的一个shell命令。hostname xxx执行后可以设置当前主机名为xxx ,直接hostname不加参数可以显示当前系统的主机名。
<4>ifconfig
(1)有时候我们希望开机后进入命令行时ip地址就是一个指定的ip地址(譬如192.168.240.40),这时候就可以在rcS文件中ifconfig eth0 192.168.240.40
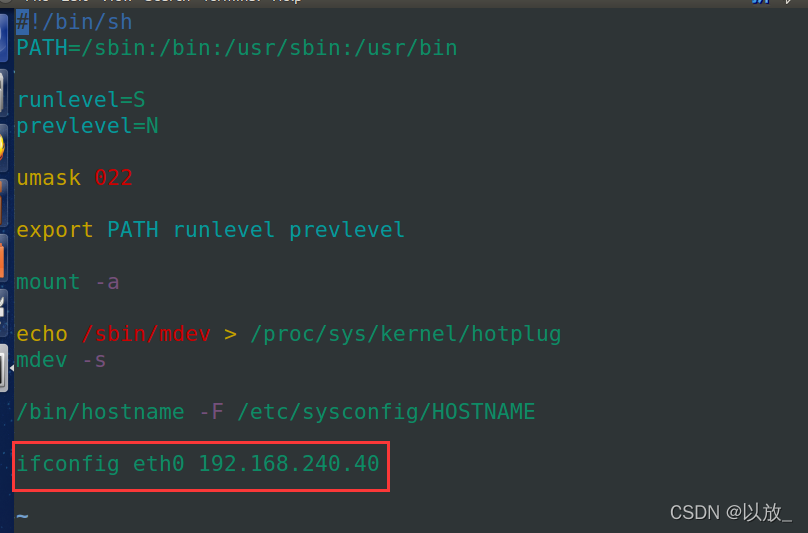
<5>mount挂载测试
这时候我们在secureCRT中启动开发板,可以发现还是存在一些报错,例如
| |
这是由于我们的之前创建的根目录挂载文件中没有创建这些文件,输入mkdir命令在根目录依次创建即可。
首先我们在开发板根目录下touch a.c文件,然后gcc编译一下它,可以发现在虚拟机中可以成功打印,但是在开发板端执行编译命令却并没有成功,这是因为在开发板中并没有交叉编译的相关文件
| |
拷贝一份动态链接库文件到开发板根目录下
| |

这时候执行命令./a.out发现可以正常打印
动态链接库so文件中包含了调试符号信息,这些符号信息在运行时是没用的(调试时用的),这些符号会占用一定空间。在传统的嵌入式系统中flash空间是有限的,为了节省空间常常把这些符号信息去掉。这样节省空间并且不影响运行。
去掉符号信息的命令:
arm-linux-strip *so*
前面我们已经提前配置好,此处不再赘述

首先我们在~/rootfs目录下mkdir ext2_rootfs创建用于我们的挂载目录。
然后输入以下命令:
| |
| |
| |
至此开发板根目录构建完成,其中也是遇到很多问题,也因此给自己挖了很多坑,然后又给自己填坑,虽然过程不尽人意,但是最后获得的都是自己的,大家在尝试这个实验的时候欢迎博客私信交流!
参考资料:

(1)线程:指运行中的程序的调度单位。
(2)多线程的优点:
(3)线程的生命周期
就绪->运行->阻塞->终止
(1)线程创建
头文件包含 +#include <pthread.h>
定义函数:
int pthread_create(pthread_t *restrict tidp,const pthread_attr_t *restrict attr, void *(*start_rtn)(void),void *restrict arg)
+函数说明:
+tidp:线程id
+attr:线程属性(通常为空)
+start_rtn:线程要执行的函数
arg: start_rtn的参数
(2)线程退出
(3)线程等待
头文件包含: +#include <pthread.h>
定义函数:
int pthread_join(pthread_t tid,void **rval_ptr)
+功能:阻塞调用线程,直到指定的线程终止。
函数说明: +Tid :等待退出的线程id +Rval_ptr:线程退出的返回值的指针
(4)线程标识获取
(5)线程清除
头文件包含: +#include <pthread.h>
定义函数:
void pthread_cleanup_push(void (*rtn)(void *),void *arg)
+功能:将清除函数压入清除栈
函数说明: +Rtn:清除函数 +Arg:清除函数的参数
进行多线程编程,因为无法知道哪个线程会在哪个时候对共享资源进行操作,因此让如何保护共享资源变得复杂,通过下面这些技术的使用,可以解决线程之间对资源的竞争:
互斥量(互斥锁)Mutex +信号灯(信号量)Semaphore +条件变量Conditions
线程在取出头节点前必须要等待互斥量,如果此时有其他线程已经获得该互斥量,那么该线程将会阻塞在这里。只有等到其他线程释放掉该互斥量后,该线程才有可能得到该互斥量。互斥量从本质上说就是一把锁, 提供对共享资源的保护访问。
(1)创建
在Linux中, 互斥量使用类型pthread_mutex_t表示。在使用前, 要对它进行初始化:
函数使用: +头文件: +#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restric attr)
+int pthread_mutex_destroy(pthread_mutex_t *mutex)
+(2)加锁
对共享资源的访问, 要使用互斥量进行加锁, 如果互斥量已经上了锁, 调用线程会阻塞, 直到互斥量被解锁。
函数使用:
int pthread_mutex_lock(pthread_mutex_t *mutex)
+int pthread_mutex_trylock(pthread_mutex_t *mutex)
+返回值: 成功则返回0, 出错则返回错误编号. +注意:trylock是非阻塞调用模式, 如果互斥量没被锁住, trylock函数将对互斥量加锁, 并获得对共享资源的访问权限; 如果互斥量被锁住了, trylock函数将不会阻塞等待而直接返回EBUSY, 表示共享资源处于忙状态。
(3)解锁
在操作完成后,必须给互斥量解锁,也就是前面所说的释放。这样其他等待该锁的线程才有机会获得该锁,否则其他线程将会永远阻塞。
int pthread_mutex_unlock(pthread_mutex_t *mutex)
+Mutex是一把钥匙,一个人拿了就可进入一个房间,出来的时候把钥匙交给队列的第一个。 +Semaphore是一件可以容纳N人的房间,如果人不满就可以进去,如果人满了,就要等待有人出来。对于N=1的情况,称为binary semaphore。 +Binary semaphore与Mutex的差异:
- mutex要由获得锁的线程来释放(谁获得,谁释放)。而semaphore可以由其它线程释放
- 初始状态可能不一样:mutex的初始值是1 ,而semaphore的初始值可能是0(或者为1)。
| |
| |
| |

本文档包含与 CHIP 设备层 ( src/platform) 内部设计相关的概述、注释和其他信息材料。它旨在作为对实现者有价值的主题的托管文档的地方,但由于大小或范围的原因,它自然不适合代码中的注释。
这是一个动态文档,具有非正式的结构,随代码一起发展。我们鼓励开发人员添加他们认为对其他工程师有用的东西。
本文档包含以下部分:
设备层使用各种设计模式,使代码更容易适应不同的平台和操作环境。
CHIP 设备层旨在跨各种平台和操作环境工作。这些环境可能因系统类型、操作系统、网络堆栈和/或线程模型而异。设备层的目标之一是使 CHIP 应用程序堆栈能够轻松适应新环境。在新平台与现有改编基本相似的情况下,这是特别理想的。
作为其设计的一部分,CHIP 设备层支持代码重用模式,努力减少对预处理器条件(例如#ifdef)的需求。虽然没有完全消除#ifdef,但该设计允许将行为中的主要差异表示为不同的代码库(通常是单独的 C++ 类),然后通过组合将它们组合在一起以实现特定的适应。
为了提高应用程序的可移植性,CHIP 设备层采用静态多态性模式将其应用程序可见的 API 与底层特定于平台的实现隔离开来。设备层本身使用类似的接口模式来提供组件之间的划分。
尽可能通过使用零成本抽象模式(代码大小和执行开销方面的零成本)来实现上述目标。我们努力使模式易于使用,没有太多的概念负担或繁琐的语法。
以下各节描述了用于实现这些目标的一些模式。
CHIP设备层使用双类模式将组件对象的抽象特征(通常是其外部可见的方法)与特定平台上这些特征的具体实现分开。遵循这种模式,设备层中的每个主要组件都体现在(至少)两个 C++ 类中:一个抽象接口类和一个实现类。
外部可见的抽象接口类定义了一组通用方法(以及可能的其他成员),这些方法对组件用户普遍可用,但独立于底层实现。接口类本身不包含任何功能,而是使用零成本抽象技术将所有方法调用转发到关联的实现类。接口类用于形式化组件的功能接口,并提供托管与实现无关的 API 文档的位置。
实现类提供了接口类公开的逻辑功能的具体的、特定于平台的实现。这一功能可以由类本身直接提供(即在其方法内),或者通过委托给一个或多个辅助类来提供。
设备层的每个主要应用程序可见组件都存在成对的抽象接口类和实现类。此外,在设备层中定义了类似的类对,以帮助组件之间的隔离。
抽象接口类根据它们提供的功能来命名,例如ConfigurationManager、ConnectivityManager 等。实现类采用其接口类的名称并附加后缀Impl。在所有情况下,实现类都需要从其接口类公开继承。
| |
接口类通过称为转发方法的短内联函数将***方法调用转发***到其实现类。this这些方法通过向下转换对象的指针并调用实现类上类似命名的方法来转发来自应用程序的调用。此模式类似于 C++ 奇怪的重复模板模式 ,不同之处在于基类和子类之间的关系是固定的,而不是表示为模板参数。接口内使用了类型别名named,ImplClass使转发方法定义更加简洁。
| |
该模式的一个便利功能是它允许转发静态方法以及实例方法。例如:
| |
作为转发方法目标的实现类上的方法称为*实现方法*。每一种转发方法都必须有相应的实现方法。
前导下划线(_)用于区分实现方法与其转发方法。这种安排有助于强调两者之间的区别,并确保在实现者忽略提供实现方法时生成编译错误。
实现方法并不意味着直接调用。为了阻止这种类型的使用,实现类将其实现方法声明为私有,然后使用友元声明为接口类提供(唯一)调用这些方法作为转发的一部分的权利。
| |
实现类提供了在特定平台上使用的设备层组件的具体实现。同一组件的设备层源代码树中可能存在多个实现类。每个类都具有相同的名称,但它们的代码对于相关平台来说是唯一的。在编译时选择包含哪个实现类是通过计算的 #include 指令完成的,其形式如下:
| |
该指令出现在定义组件接口类的头文件中。C++ 预处理器自动扩展 #include 行以根据所选平台选择适当的实现标头。这样,包含组件接口头文件的源文件自然也可以获得正确的实现头文件。
每个受支持平台的实现头文件都排列在以其目标平台命名的子目录中(例如ESP32)。所有此类文件都具有相同的文件名(例如ConfigurationManagerImpl.h),并且每个文件都包含类似名称的类的定义(ConfigurationManagerImpl)。
特定于平台的源文件放置在紧邻设备层根源目录下面的子目录中(例如 src/adaptations/device-layer/ESP32)。与特定于平台的头目录一样,这些子目录以目标平台命名。
设备层目标平台的选择是在项目配置时使用配置脚本选项指定的 --device-layer=<target-platform>。传递 –device-layer 选项会导致一对预处理器符号的定义,其中目标平台的名称已合并到定义中。例如:
| |
–device-layer 配置选项还选择要包含在生成的库文件中的适当的特定于平台的源文件集。这是通过设备层 Makefile.am 中的逻辑完成的。
通常可以在一系列平台上共享实现代码。在某些情况下,所有目标的相关代码基本上都是相同的,每种情况下只需要进行少量的定制。在其他情况下,实现的通用性扩展到共享特定架构功能的平台子集,例如通用操作系统(Linux、FreeRTOS)或网络堆栈(套接字、LwIP)。
为了适应这一点,CHIP 设备层鼓励采用一种将通用功能分解为***通用实现基类的***模式。然后,这些基类用于组成(通过继承)构成组件基础的具体实现类。
通用实现基类被实现为遵循 C++ 奇怪重复模板模式的C++ 类模板。希望合并常见行为的实现类从模板的实例继承,将实现类本身作为模板的参数传递。
| |
在许多情况下,通用实现基类本身将直接提供满足组件接口所需的部分或全部实现方法。C++ 方法解析的规则是对接口类上的转发方法的调用直接映射到基类方法。在这种情况下,派生实现类根本不需要声明目标方法的版本,并且方法调用在编译时静态转发,没有任何开销。
| |
如果需要,具体实现类可以自由地覆盖通用基类提供的实现方法。这是通过在实现类上定义该方法的特定于平台的版本来完成的。C++ 的规则导致优先于泛型方法调用实现类上的方法。
新方法可以完全取代通用方法的行为,或者可以通过在其自己的实现过程中调用通用方法来增强其行为。
| |
具体实现类可以自由地从多个通用基类继承。当组件的整体功能可以自然地分割成独立的片(例如支持 WiFi 的方法和支持 Thread 的方法)时,此模式特别有用。然后,每个这样的切片都可以通过一个不同的基类来实现,该基类最终在最终实现中与其他基类组合在一起。
| |
通用实现基类还可以从其他通用基类继承。这对于“专门化”特定用例子范围(例如,特定操作系统类型)的通用实现非常有用。
| |
在创建通用实现基类时,如果操作可能或必须以特定于平台的方式实现,则鼓励开发人员使用静态虚拟化模式将操作委托给具体实现类。
例如,考虑 ConfigurationManager 组件的通用实现,其中值访问器方法通过GetDeviceId()从底层键值存储中检索值来进行操作。键值存储的实现方式的细节可能会因平台而异。为了实现这一点,通用实现类被构造为将检索键值的操作委托给具体实现类上的方法。
this遵循奇怪的重复模板模式,通过将指针强制转换为实现类并调用具有适当签名的方法来完成委托。名为 的内联辅助函数Impl()有助于使代码简洁。
| |
在上面的示例中,委托方法在概念上是“纯虚拟”的,因为具体实现类必须提供该方法的版本,否则编译将失败。在其他情况下,可以使用类似的模式来允许实现根据需要覆盖基类提供的默认行为。
同样,委托是通过转换this指针并调用适当的方法来发生的。然而,在这种情况下,通用基类提供了目标方法的默认实现,除非子类重写它,否则将使用该目标方法。
| |
C++ 模板的规则要求编译器在实例化时“查看”类模板的完整定义。(在此上下文中的实例化意味着编译器被迫根据模板提供的配方生成实际的类)。通常,这需要将类模板的整个定义(包括其所有方法)放入头文件中,然后必须在实例化之前将其包含在内。
为了将类模板的定义与其成员的定义分开,CHIP 设备层将所有非内联模板成员定义放入单独的文件中。该文件与模板头文件具有相同的基本名称,但带有后缀.cpp。这种模式减少了头文件中的混乱,并且可以仅在需要时才包含非内联成员定义(更多内容见下文)。
| |
| |
通常情况下,C++ 编译器被迫多次实例化类模板,为其编译的每个 .cpp 文件实例化一次。这会显着增加编译过程的开销。为了避免这种情况,设备层使用显式模板实例化的 C++11 技术 来指示编译器仅实例化模板一次。这是通过两个步骤完成的:首先,所有使用类模板的头文件extern template class在使用模板类之前都包含一个声明。这告诉编译器不要在该上下文中实例化模板。
| |
然后,在相应的 .cpp 文件中,包含模板的 .cpp 文件,并template class使用定义来强制显式实例化模板。
| |
结果是,在编译引用的 .cpp 文件期间,模板的非内联成员仅被解析和实例化一次,从而避免了其他上下文中的冗余处理。

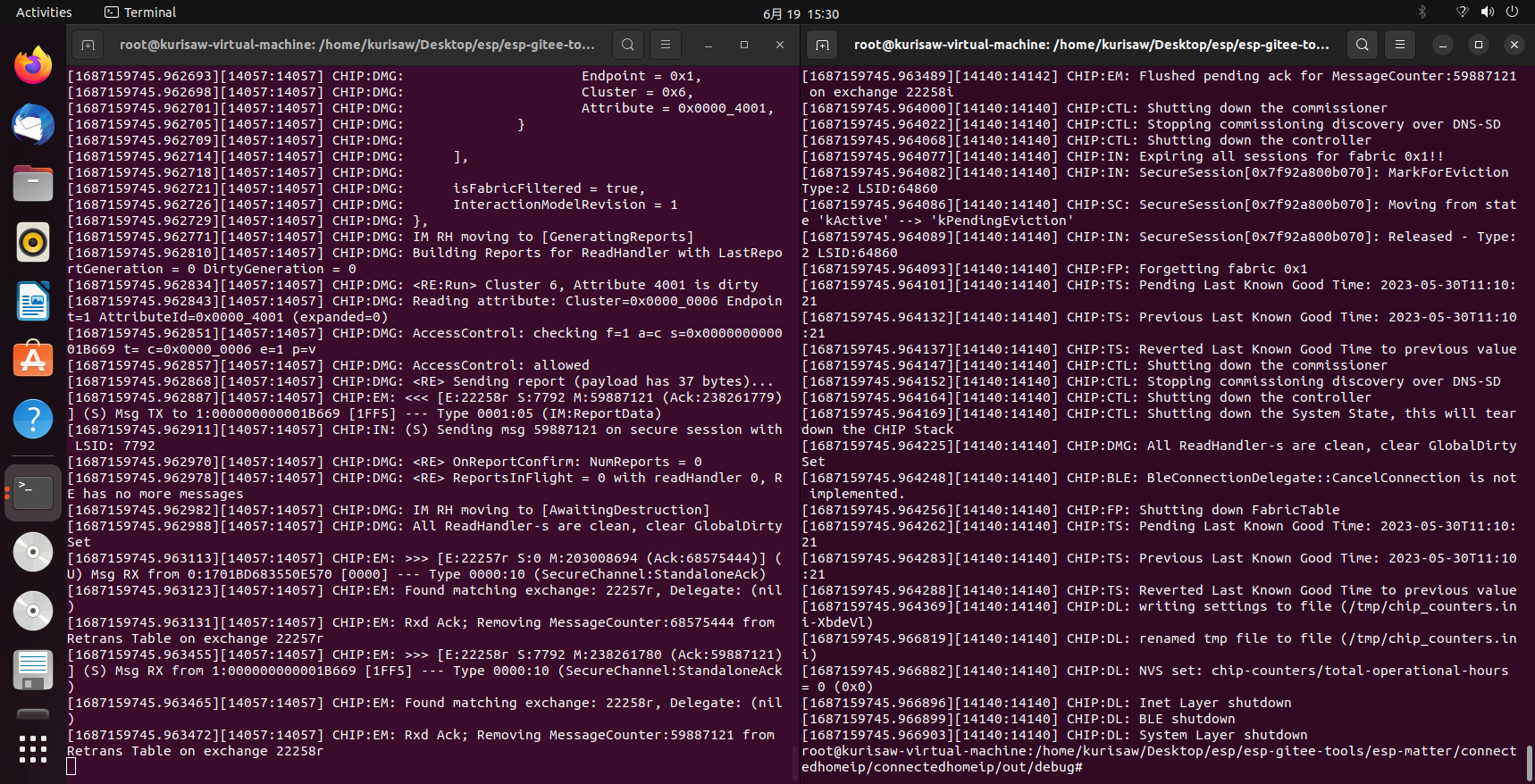
由于后面的 esp-matter 测试的时候需要使用到科学上网环境,所以我们需要提前确保 linux 环境能够使用科学上网。
参考https://docs.espressif.com/projects/esp-idf/en/v4.4.3/esp32/get-started/linux-setup.html
| |
由于在克隆官方esp-idf仓库的时候一般会发生如下两个错误:
所以我们这里特别着重讲解,注意,这里解决问题的顺序与esp-idf环境搭建是一起进行的,读者可以顺着流程走。
首先使用递归克隆命令克隆整个仓库到文件夹下
| |
由于 esp-idf 仓库下有很多递归的下游仓库,一般使用 GitHub 下载的话也会导致递归下载失败,所以乐鑫官方提供了两种解决方案,包括镜像仓库使用、submodule 更新、开发工具安装等,可加速环境的搭建。解决方案如下:
| |
| |
当我们使用命令 git clone https://github.com/espressif/esp-idf 时,默认的 URL https://github.com/espressif/esp-idf 将被自动替换成 https://jihulab.com/esp-mirror/espressif/esp-idf。
| |
使用命令 ./jihu-mirror.sh unset 恢复,不使用镜像的 URL。
| |
当然如果不想使用镜像的URL可以使用如下命令进行恢复:
| |
Step 1:
| |
Step 2:
| |
可以有两种方式来更新 submodules。
方式一
进入 esp-gitee-tools 目录,export submodule-update.sh 所在路径,方便后期使用,如:
| |
进入 esp-idf 目录执行 submodule-update.sh 脚本:
| |
方式二
submodule-update.sh 脚本支持将待更新 submodules 的工程路径作为参数传入,例如:submodule-update.sh PATH_OF_PROJ。
假如 Step 2 中 clone 的 esp-idf 位于 ~/git/esp32-sdk/esp-idf 目录,可使用以下方式来更新:
| |
如果要更新其他工程,可以同样方式。
值得吐槽的是, submodule-update 这种方法还需要保持上游代码分支的提交历史一致,如果官方未及时更新则会导致该脚本暂时失效,不推荐使用,避坑!!
下面说第二个问题:执行./install.sh速度慢的问题
在 Espressif Systems 的 esp-idf 开发框架中,某些组件的构建过程需要从 GitHub 的 release 页面下载预编译的二进制文件。然而,在中国大陆访问 GitHub 的速度往往较慢并且不稳定,为了改善这个问题,Espressif Systems 将这些预编译的二进制文件托管在国内的服务器上,并提供了一个名为 IDF_GITHUB_ASSETS 的环境变量来指定这个地址。在设置了 IDF_GITHUB_ASSETS 变量之后,构建过程将会从这个指定的地址下载预编译的二进制文件
| |
然后再执行安装命令
| |
在这还报了一个错误
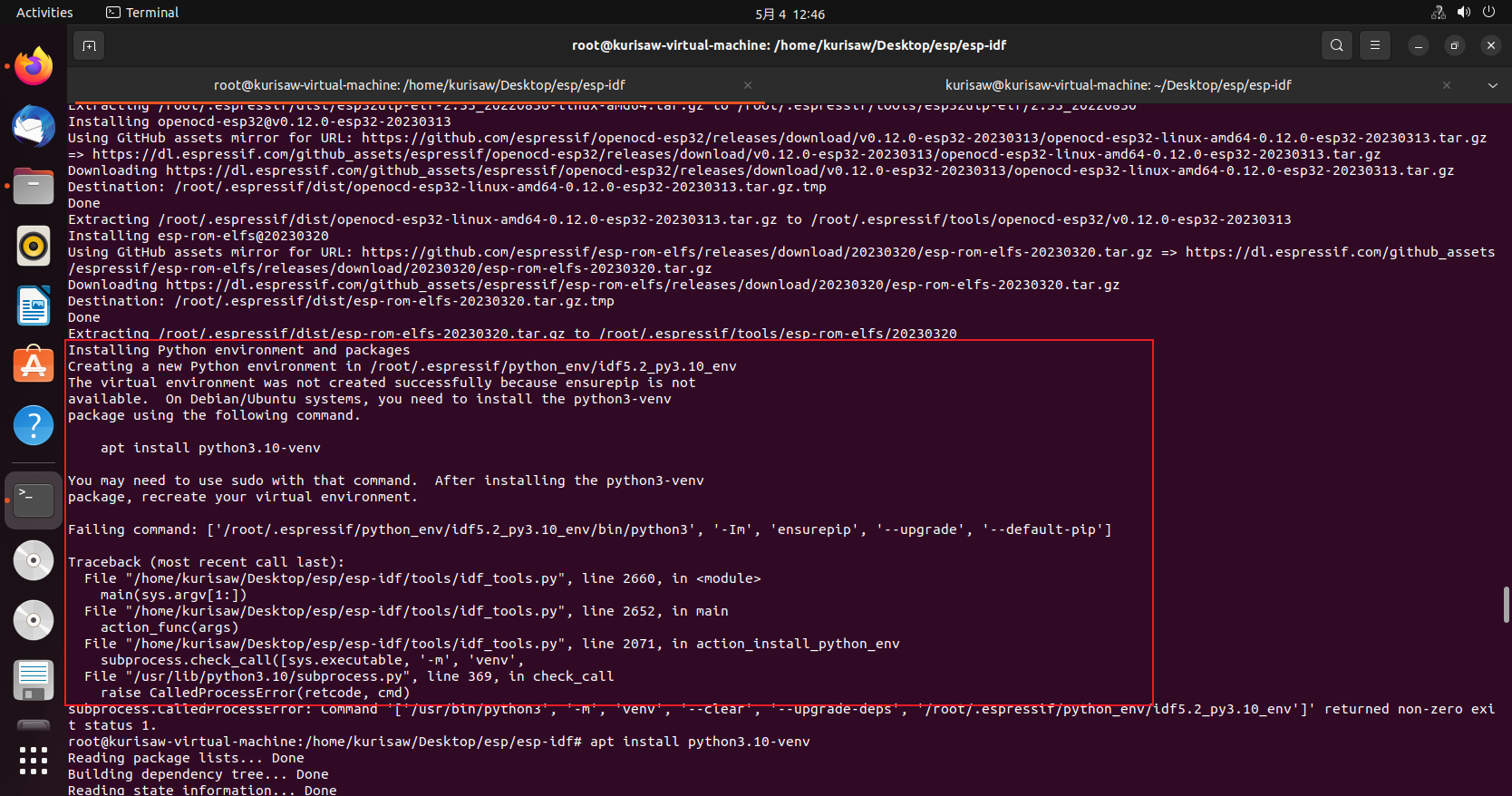
我们根据提示安装python3.10-venv,并再次执行安装命令:
| |
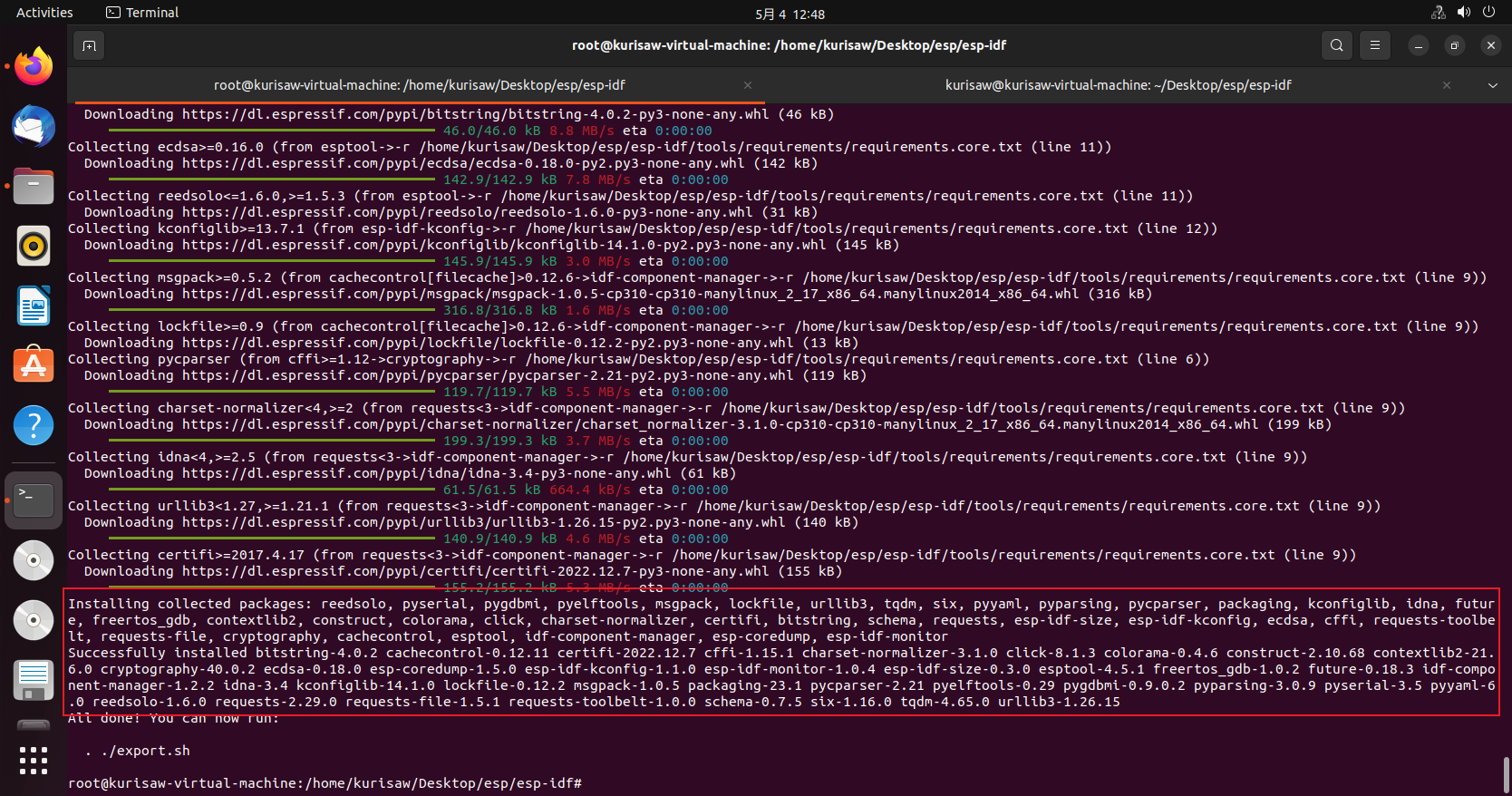
至此,esp-idf 的安装工具就告一段落了。
**注意:如果上面的 esp-idf 开发环境的搭建使用的是 jihu-mirror 方式,那么你需要取消esp镜像,按理说这部分错误不应该发生,但实际上确实存在这部分问题,请执行命令:./jihu-mirror.sh unset取消esp镜像!! **
| |
若过程有报错,请执行下面命令在Git 仓库中获取到所有子模块,并将所有子模块及其下层子模块更新至最新版本。
| |
执行安装命令:
| |
本以为到这就结束了,但不出意外的话意外发生了,在安装过程中发生了报错…
| |
我们查看install.sh文件
| |
发现问题出在第10到13行,我尝试安装系统必要的依赖项来解决这个问题,成功解决!命令如下:
| |
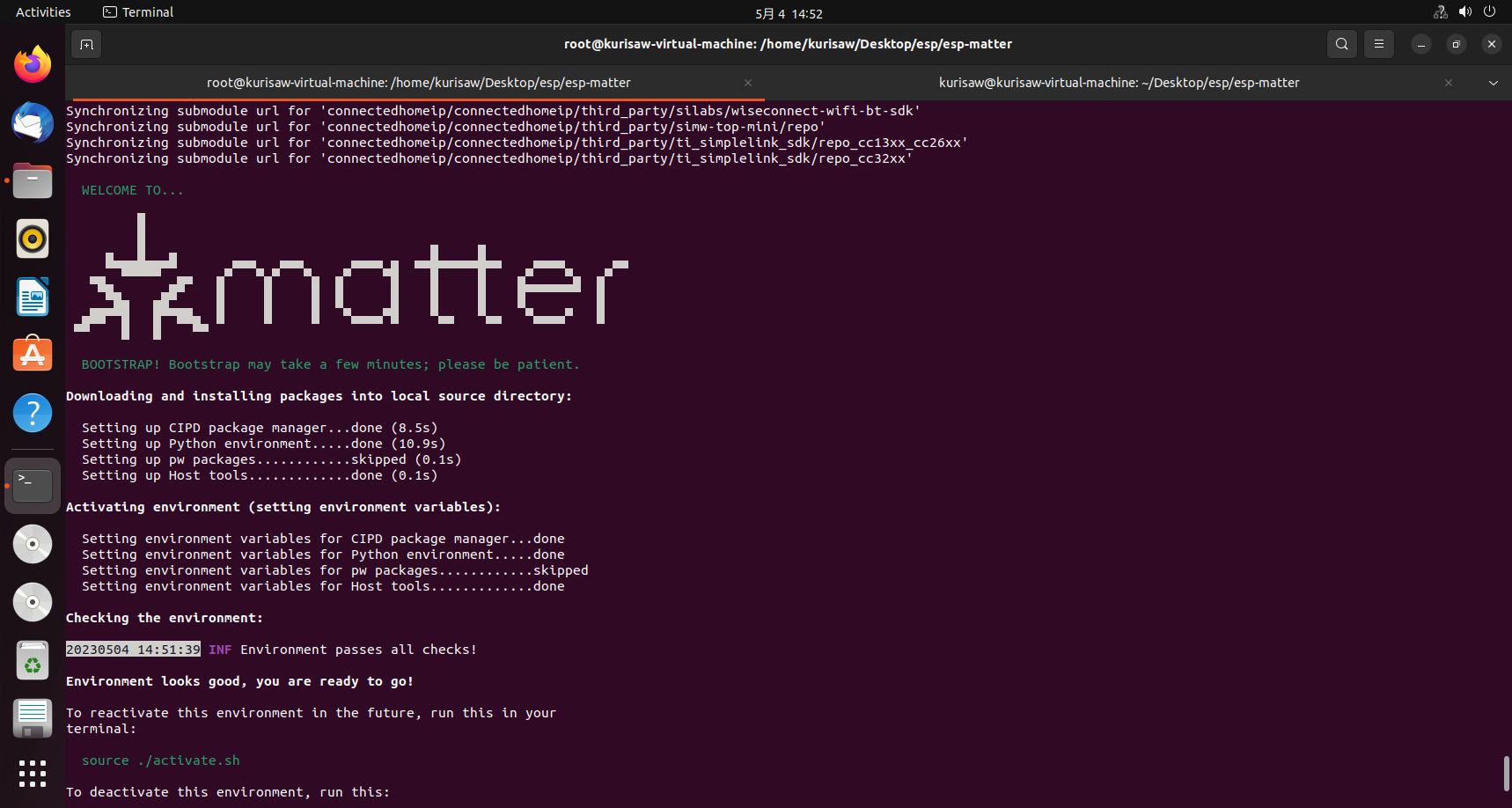
接着在安装zap-cli的时候再次发生报错,需要安装以下依赖库,并再次运行安装脚本命令,等待编译
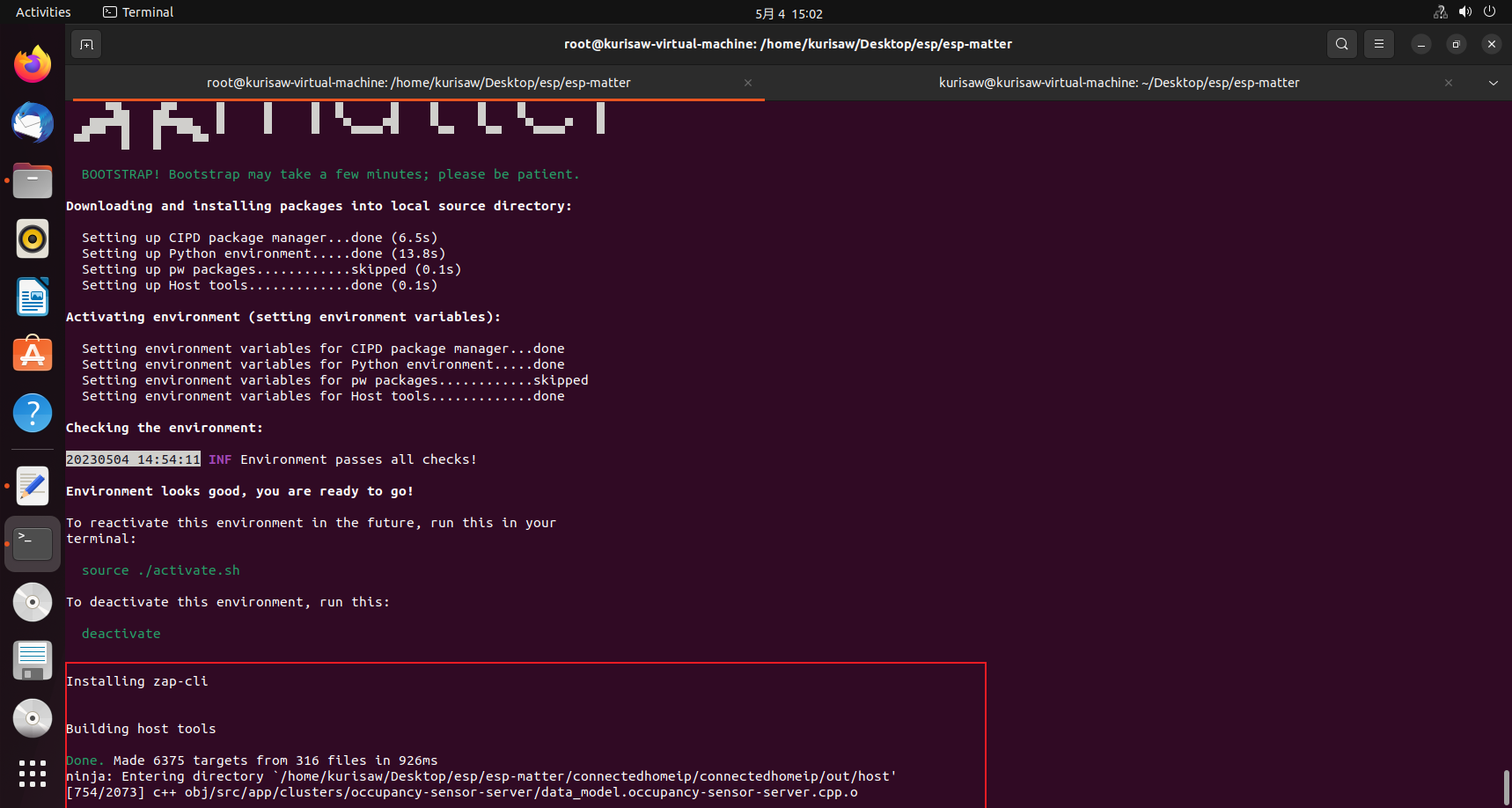
| |
最后看到All done!即代表环境安装成功!
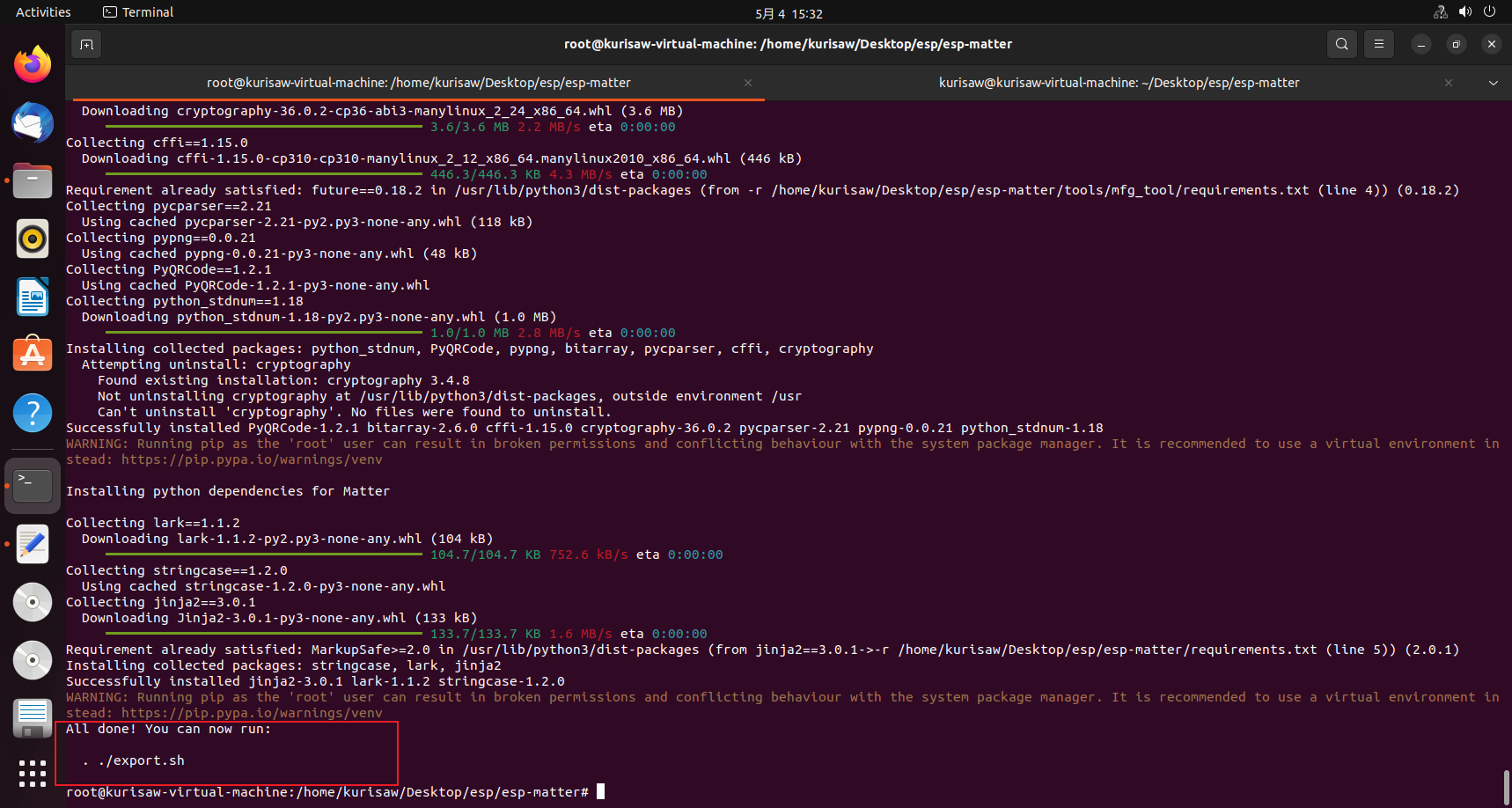
至此,esp-matter开发环境搭建成功!

请确保你本地已经配置好 esp-idf 及esp-matter环境,可参考此博客【Matter】esp-matter开发环境搭建
根据官网提示,我们需要设置linux平台下的标准工具链,安装以下软件包:
| |
使用 ESP-IDF 需要 CMake 3.5 或以上版本。较早的 Linux 发行版可能需要升级自身的软件源仓库,或开启 backports 套件库,或安装 “cmake3” 软件包(不是安装 “cmake”)。
| |
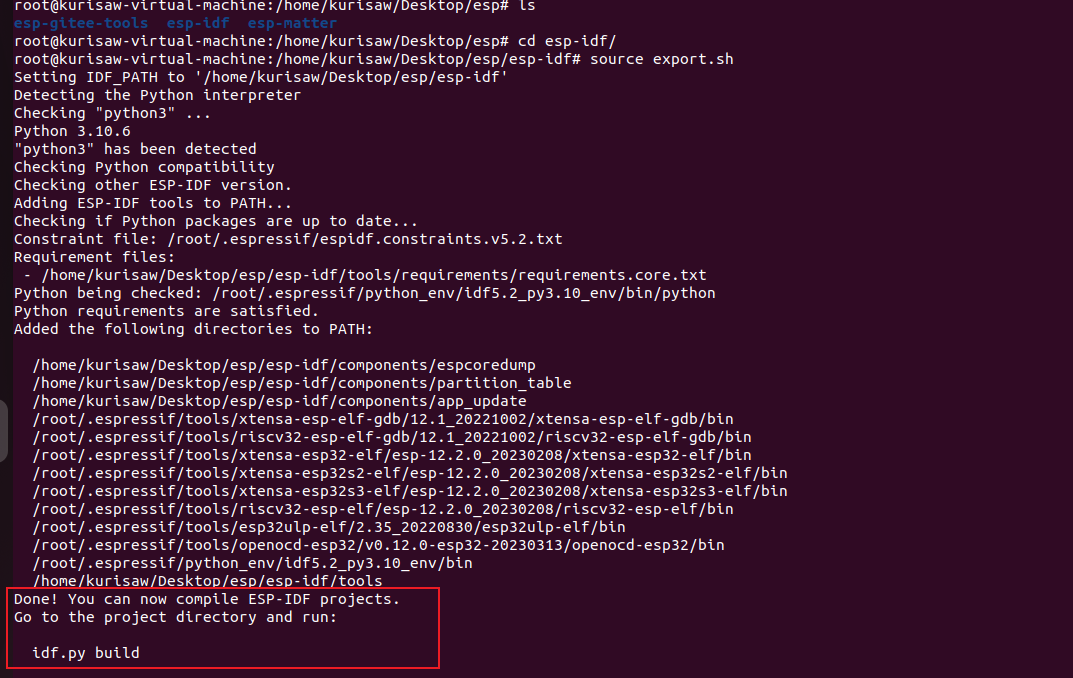
由于我们使用的是Linux环境,所以此处仅作Linux下的说明,macOS可详见此处
在基于 Debian 的 Linux 发行版(例如 Ubuntu)上,可以使用以下命令满足这些依赖项:
| |
准备编译matter所需环境。注:如切换了其他分支需要重新运行
| |
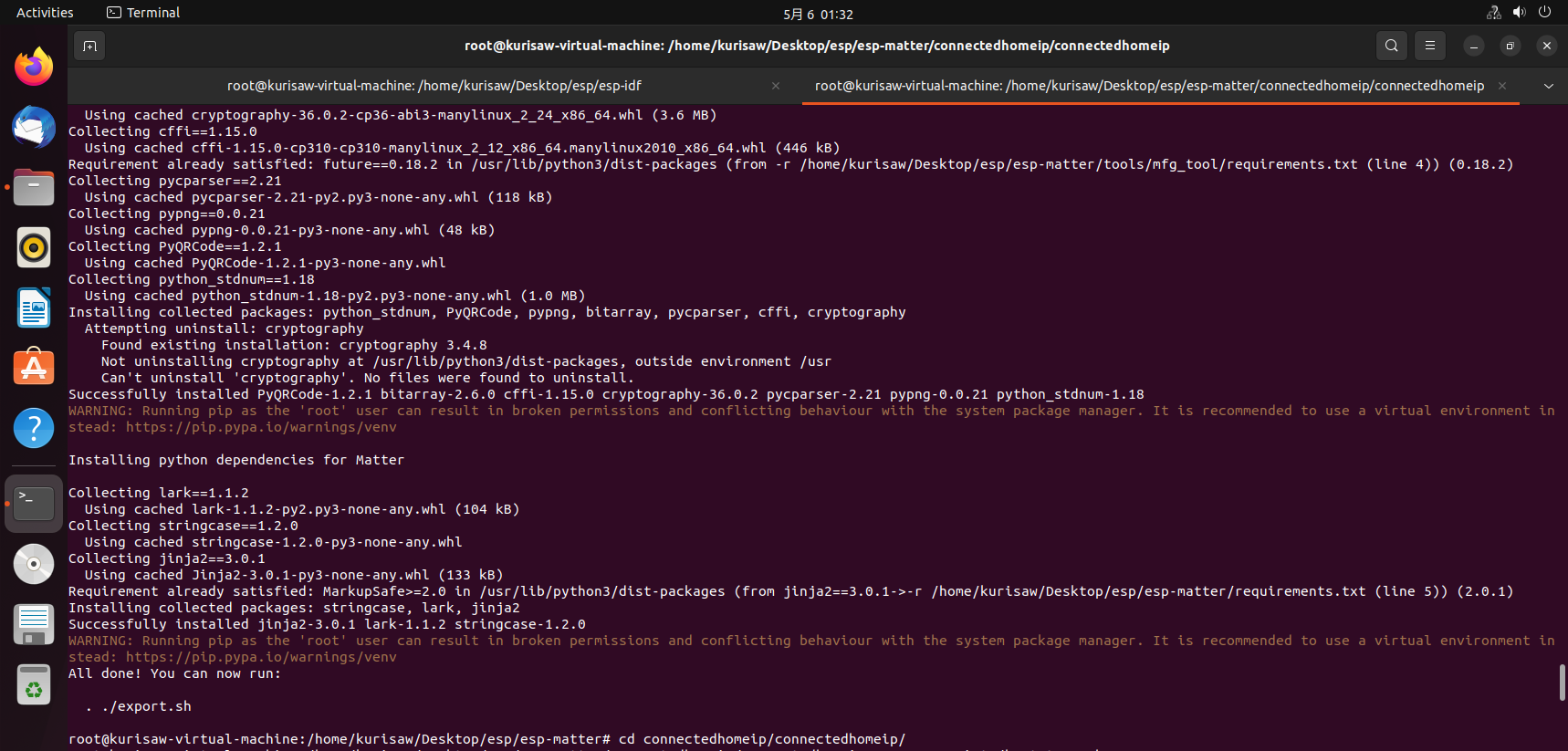
激活编译matter环境
| |
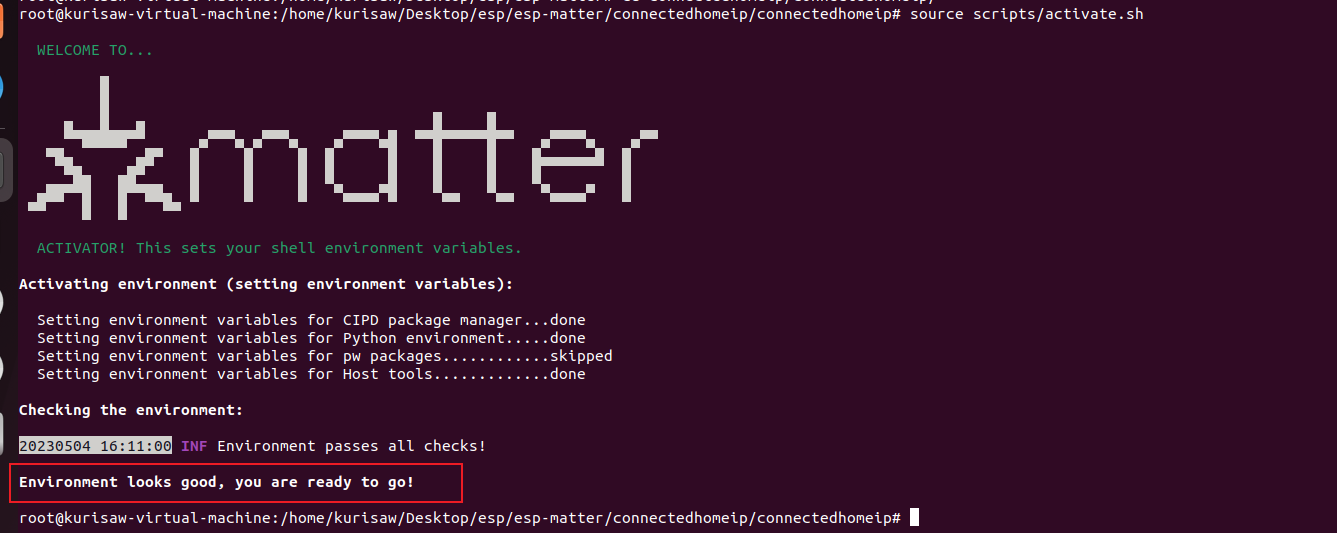
| |
| |
| |
初次执行这个命令发生了如下报错:
| |
在GitHub上参考此issue,并执行以下命令:
| |
同时重新执行esp-matter安装脚本:
由于需要重新运行安装脚本命令,此处直接执行的话会报错,参考此issue
| |
| |
然后回到示例工程下继续执行esp设备选择
| |
此时发生了新的错误:

由于示例工程下的build以前遗留的构建文件,而系统在执行程序时并不会覆盖或主动删除旧的构建文件,因此需要用户手动删除,因此正确的操作就是:
| |
最后成功解决问题:

| |
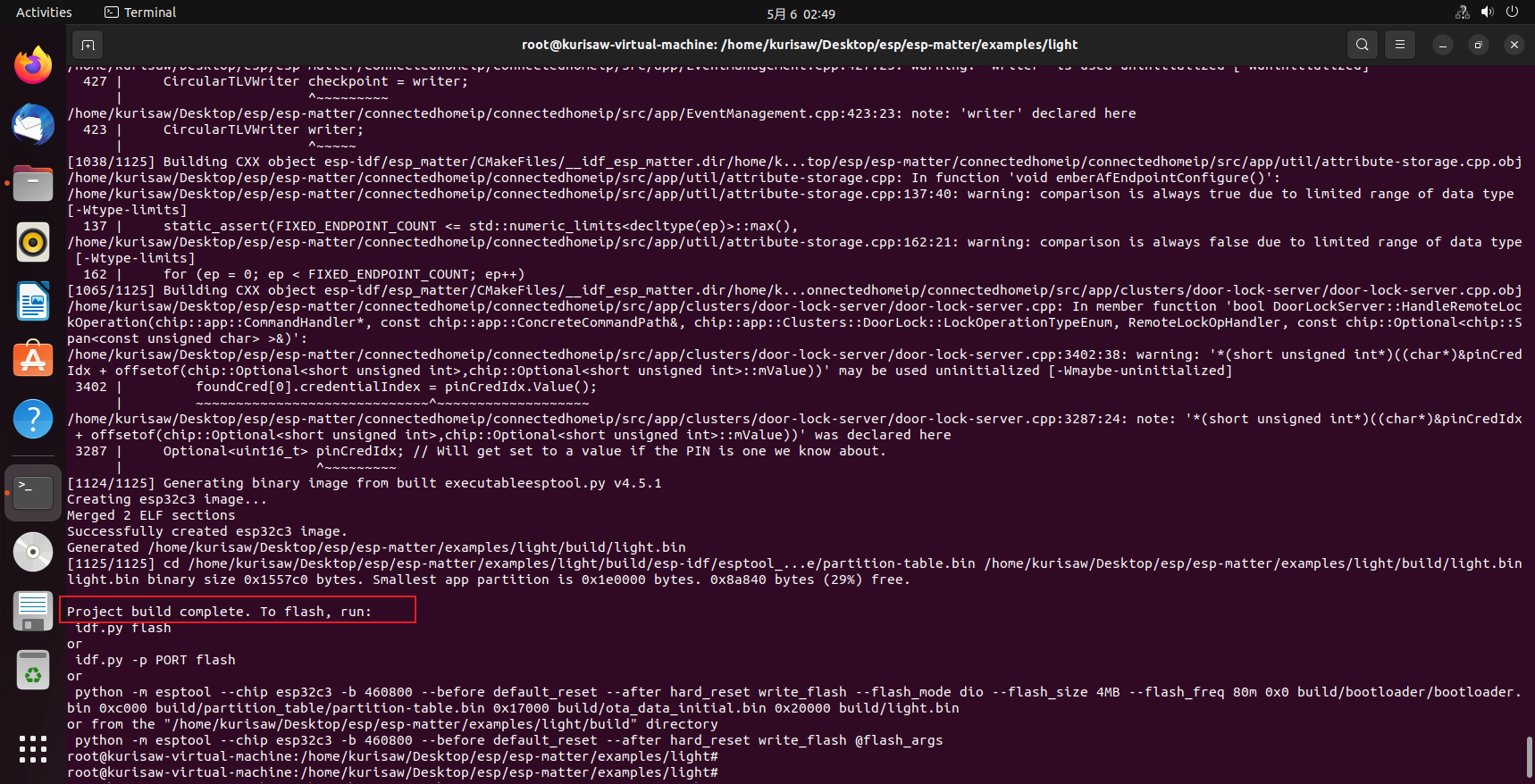
第一次烧写 SDK 时,需要擦除整个 flash 再执行烧录命令
| |
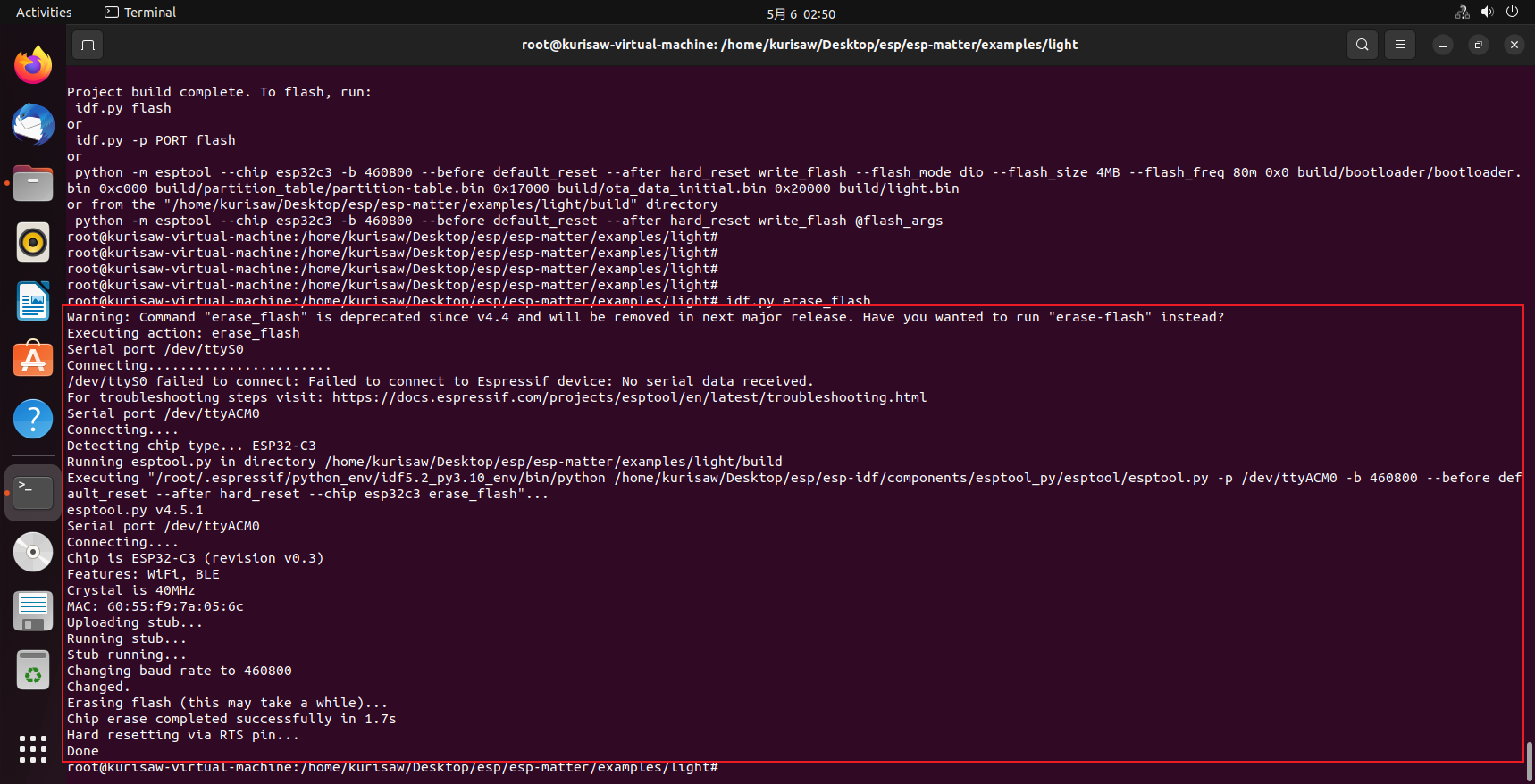
烧录程序并打开串口监视
| |
可以看到烧录进度:
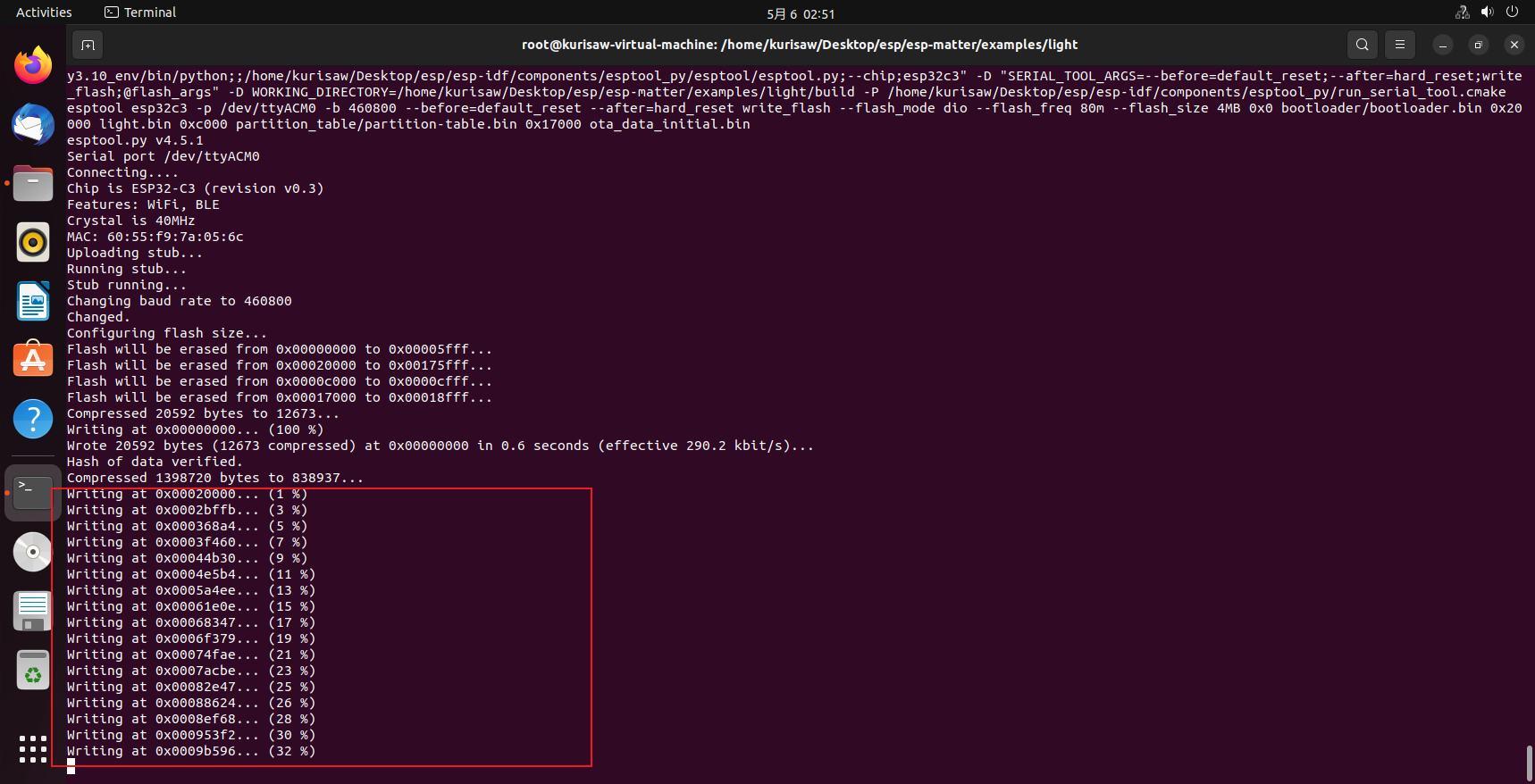
包括串口监视器的提示信息,同时执行以下命令可退出串口监视:
| |
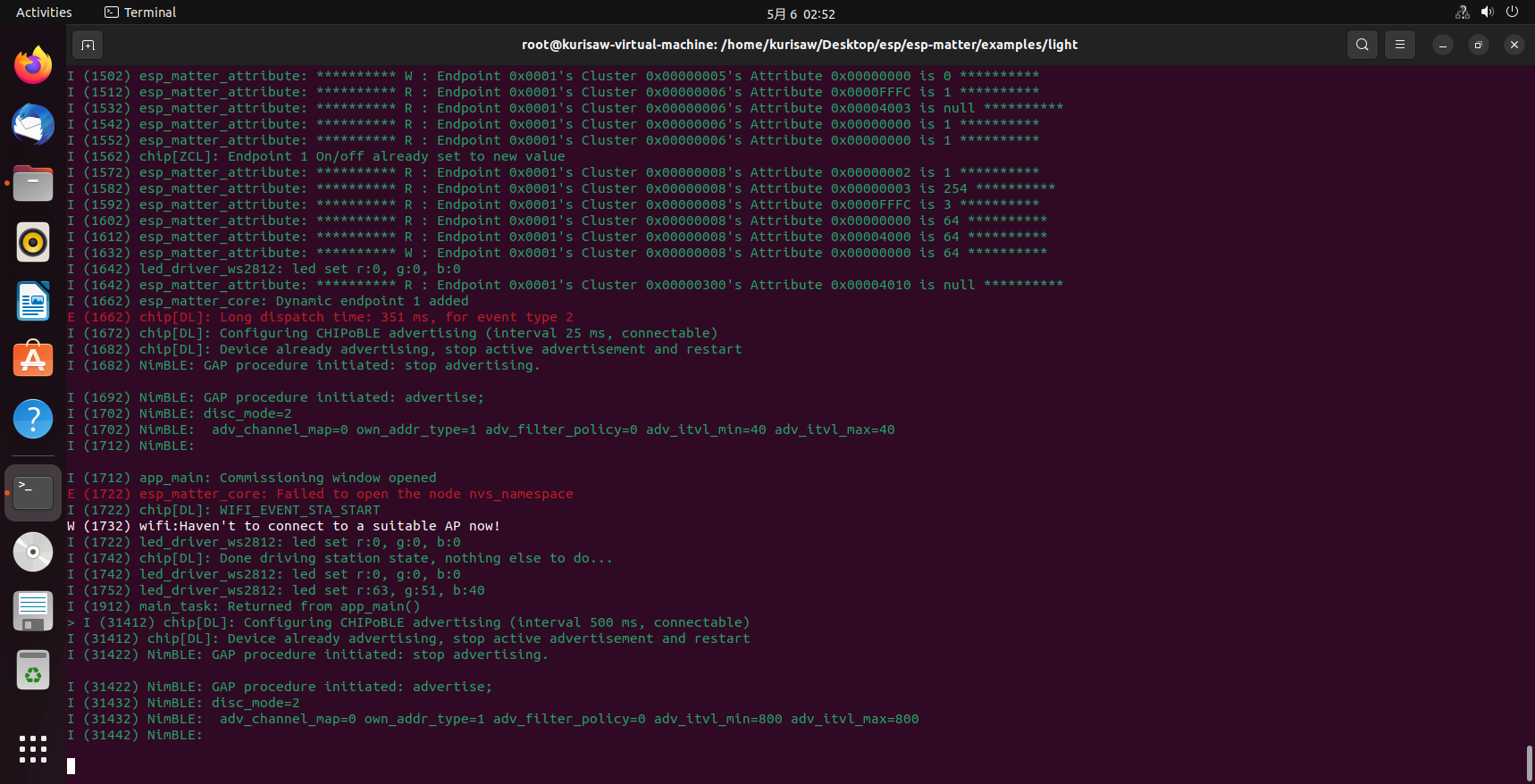
那么esp-matter项目环境的编译下载就先讲到这里,后面再进行详细的使用教程的讲解。
参考链接:
Matter Over Wifi 例程体验(CHIP Over Wifi)
https://docs.espressif.com/projects/esp-matter/en/main/esp32/developing.html

在了解Matter之前,可以选择先了解以下前提知识:
以上资料来自CSDN博主:Eagle115
近日,CSA联盟(Connectivity Standards Alliance)正式对外发布了Matter 1.0 标准,并宣布认证计划现已开放。这意味着智能家居品牌可以对其产品进行相关测试和认证,一旦获得认证,公司就可以开始销售带有Matter 标志的设备。
Matter 最初的项目名称是Project Chip(CHIP),目前由 CSA联盟维护。它是一个统一标准的物联网通信协议,旨在将繁杂的智能家居设备收归到统一的通信标准。
Matter 作为一个应用级的协议,向下屏蔽了设备制造商的生态和系统,让各种智能家居设备之间能相互通信。例如,一个 Matter 认证的智能灯泡可以由另一个厂家生产的同样经过认证的设备来控制。Matter 是基于ip的协议,支持wifi、 Thread、 Internet三种不同的底层协议栈。
Matter 采用不同的通讯协议和技术为未来智能家居行业提供了不同场景下的解决方案:
该标准建立在一个共同的信念之上,即智能家居设备应该安全、可靠且无缝使用。通过建立在互联网协议 (IP) 之上,Matter 支持智能家居设备、移动应用程序和云服务之间的通信,并为设备认证定义了一组特定的基于 IP 的网络技术。
IPv6(Internet Protocol version 6)是互联网协议的一种,它是 IPv4 协议的后继者,当然并不是说这是一种全新的技术,更多的可以看作是IPV4 协议的扩展。IPv6 提供了更大的地址空间(128位)、更好的安全性(引入IPsec协议作为默认选项)、更高的性能和更多的扩展性,是未来互联网发展的重要基础。
下面是IPV4 和 IPV6 的一些区别:
| 区别 | IPV4 | IPV6 |
|---|---|---|
| 地址长度 | 32 bits | 128 bits |
| 地址数量 | 约4x10^9 | 约3.4×10^38 |
| 地址类型 | 公网地址和私有地址 | 全局地址和本地地址 |
| 地址分配方式 | 静态地址和动态地址 | 通过 DHCPv6 动态分配 |
| 安全性 | IPsec(Internet协议安全标准) 为可选项 | IPsec 为默认选项 |
| — | — | — |
Matter 旨在为智能家居设备构建一个通用的基于 IPv6 的通信协议。该协议定义了将部署在设备上的应用层和不同的链路层,以帮助维护互操作性。
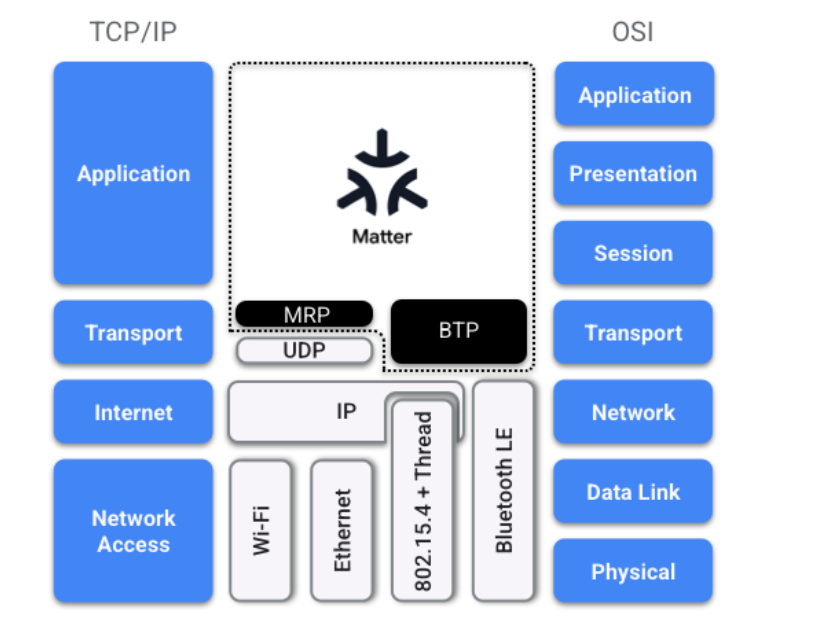
为了解决网络通信壁垒,Matter网络层本身基于 IPV6,因此天生具备IP连接能力,可以与WIFI、Thread、以太网等通讯协议配合使用,而蓝牙则仅在配网过程使用;
Matter 还支持桥接等其他智能家居技术(例如 Zigbee、Bluetooth Mesh 和 Z-Wave)。这也就意味着,基于这些协议的设备可以像使用 Matter 设备一样运行Bridge;
由于Matter是基于应用层的协议,也就是说在未来即便有新的网络层协议的出现,Matter也可以很方便的兼容和支持到新协议,从长远发展来看具有很好的前瞻性!
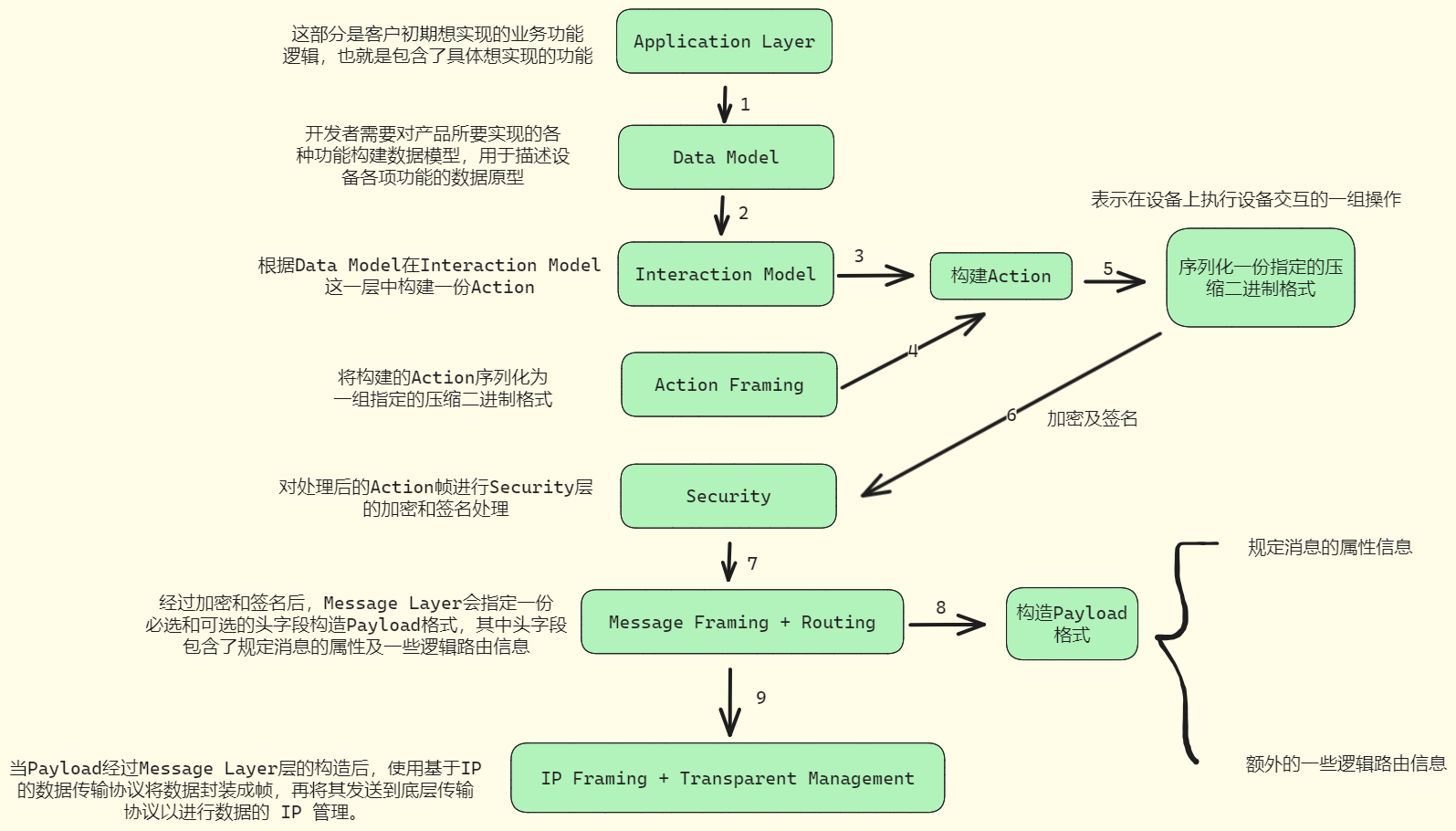
Matter标准协议架构总体流程分析:
首先使用Interaction Model构建一个Action;在Action Framing这一层中,该Action会被序列化为一份指定的压缩二进制格式,表示可以在设备上执行设备交互的一组操作;处理后的Action帧通过Security层进行加密和签名处理,确保通信双方信息传输的机密性和可靠性;当Action经过序列化、加密和签名后,Message Layer会指定一份必选及可选的头字段构造Payload格式,其中头字段中包含了规定消息的属性及一些逻辑路由信息;当payload被 Message Layer 层构造后, 会使用基于IP的数据传输协议 (TCP协议或Matter的消息可靠协议Message Reliability Protocol);一旦对方设备收到数据后,数据流则沿着协议栈向上移动,即各个层反转发送方对数据执行的操作,最终将消息传递给应用程序。
后面我们会重点讲解设备数据模型(Data Model)和互动模型(Interaction Model),这两部分是Matter互联互通的前提!
原理上,任何支持IPV6协议的网络都可以部署Matter,我们重点关注三种链路层技术:以太网(Ethernet)、WIFI和 Thread。
在 Matter 协议中,Matter将网络视为共享资源,它不规定独占网络的所有权或访问权。因此我们可以在同一组成IP的网络下覆盖多个Matter网络。
Matter协议还可以在没有公网IPv6基础设施的情况下运行,经资料查询得知,主要是因为Matter协议也支持Thread网络协议,其底层是基于IEEE 802.15.4的,并使用了6LoWPAN作为IPv6的适配层。而 6LoWPAN协议 提供了一种在低功耗无线传感器网络中使用IPv6的方法,它可以将IPv6数据包压缩到非常小的尺寸,从而使得这些数据包可以在不需要较大的IP地址空间的情况下传输。这使得Matter设备可以使用私有IPv6地址而不需要公共IPv6地址,因此不需要依赖公网IPv6基础设施。
因此,Matter协议不需要依赖公网IPv6基础设施,也不需要依赖互联网服务提供商的支持,可以在与公网断开连接或有防火墙的网络中操作,这使得它可以在更广泛的场景下进行部署和使用。
在了解Matter网络拓扑结构之前,我们可以先来了解下 Mesh 组网。
目前最流行的全屋WiFi方案主要有两种:Mesh路由器组网和AC+AP两种方案。而Mesh路由器组网由于其实惠的价格和较为稳定的链路连接性能以及安装的简便性,目前在全屋智能网络的选择还是比较热门的。
无线Mesh网络是一种新无线局域网类型,与传统WLAN不同的是,无线Mesh网络中的AP可以采用无线连接的方式进行互连,并且AP间可以建立多跳的无线链路。简单来说,就是当WIFI覆盖不了的时候,在有WIFI信号的时候放置一个路由器,可以作为Mesh路由的中继节点,透过这个节点,将WIFI信号覆盖到所有需要覆盖的地方;是一个动态的可以不断扩展的网络架构,任意的WIFI节点设备均可以保持无线互联。
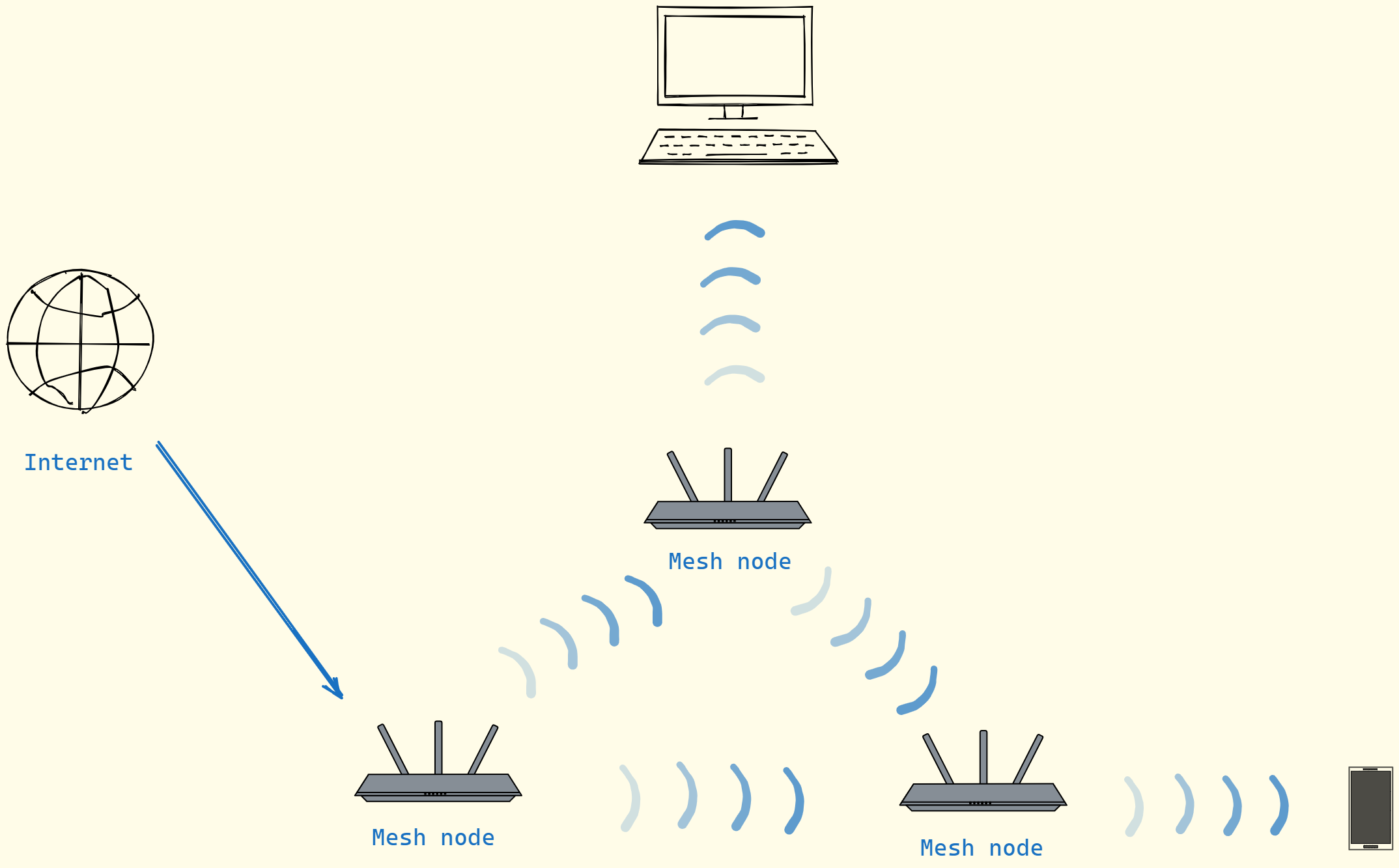
这个很直观的体现就是大学里每层走廊中间都会架设一台路由,而你每移动一个楼层,你手机的校园网都会重新连接,也就是手机信号会快速自动重连距离你最近的一台路由,这就构成了一个庞大的无线链路网络。下面我们再来了解下Matter 的网络拓扑结构主要分为单一网络拓扑和星形网络拓扑:
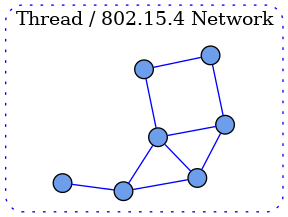
在单一网络拓扑中,所有的 Matter 设备都连接到一个单一的逻辑网络。 它可以是Thread/802.15.4网络、Wi-Fi网络或以太网网络。在 Wi-Fi/以太网的情况下,网络实际上可以跨越多个Wi-Fi和/或以太网段,前提是所有段都在链路层桥接。 节点(Node)是Fabric中的 Matter设备的单个实例,可在IP网络上运行。
在单一网络拓扑中的每个节点都通过单个网络接口与Fabric中的每个其他节点进行通信。
在Matter 中,分属不同网络的设备可以进行同端通信,这也就意味着一个WIFI设备可以和一个Thread进行相互的信息转发,而Matter则扮演了一个虚拟网络的身份,并称其为Fabric。
注:Fabric是共享同一个Trusted Root的Matter设备的集合。Matter中Trusted Root作为根CA,颁发NOC证书,识别节点身份。在一个Fabric内,每个节点都有一个唯一标识Node ID。Fabric作为一个命名空间来管理所有权,在Fabric范围内使用标识符确保资源的分配和选择的唯一性。
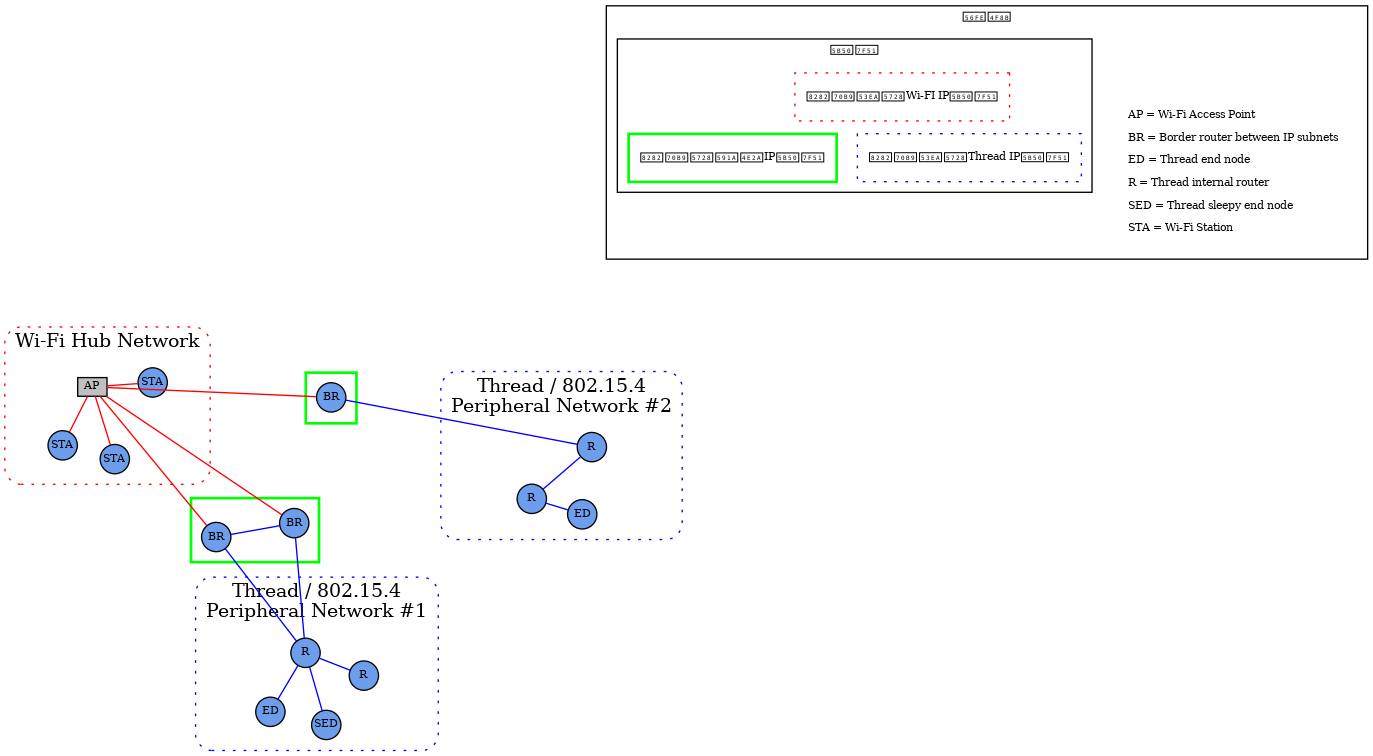
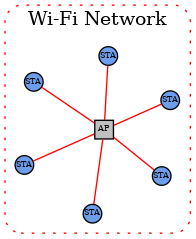
星形网络拓扑由多个外围网络组成,这些网络通过Hub连接在一起。Hub通常是客户家庭网络(Wi-Fi/以太网)中的设备,而外围网络可以是任何支持的网络类型。外围网络必须始终通过一个或多个边界路由器(Border Router)直接连接到Hub。
在架构上,任何数量的外围网络可以存在于单个Fabric中,包括相同类型的多个网络。节点可以具有到任何网络(Hub或外围设备)的接口,并且可以直接与同一网络上的其他节点通信。然而,任何必须跨越网络边界才能到达目的地的通信必须通过边界路由器(Border Router)。
该协议对边界路由器提出了一系列要求。这些要求涉及地址分配、路由分配和广播、多播支持和代理发现。
注:在现Matter1.0版本规范中,Thread是主要支持的LLN(Low-Power and Lossy Network)。在许多情况下,客户安装将尝试维护一简单的网络拓扑,包括一个Wi-Fi/以太网子网和一个单Thread网络。但是,可以支持多个Thread网络。
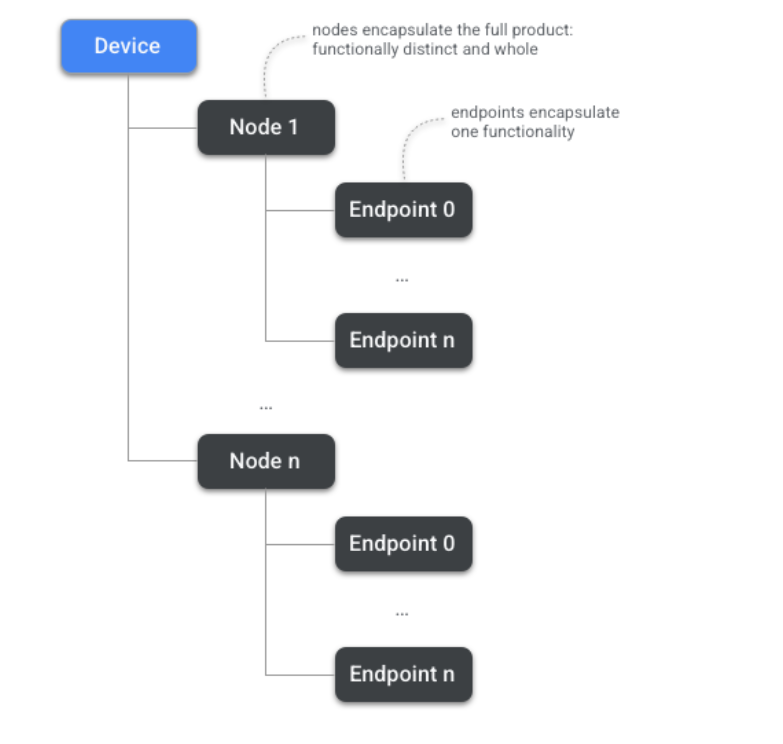
在 Matter 中的设备具有明确定义的数据模型 (DM),这是对设备功能的分层建模。在此层次结构的顶层,有一个Device。
所有设备(包括智能手机和家居助理)均由**Node(节点)**组成。“节点”是网络中可以标识为唯一且可寻址的资源,用户可以感知到整个功能。Matter 中的网络通信始于和终止节点。
一组节点包含了多组Endpoint(端点)。而每个端点都封装了一个功能集。例如,端点1可能涉及照明功能,而端点2可能涉及移动侦测,以及其他与实用程序(例如设备 OTA)的处理方式。
在Matter 中,每一个物理设备都被称之为Node,Node 使用**Node ID(64bit)**来进行表示,在Fabric范围内是唯一的!
Node roles是一组相关的行为。每个节点可能有一个或多个role。Node roles 包括:
在一个Endpoint中,一个 Node 有一个或多个Clusters。这些是设备层次结构中的另一个步骤,因为它们将特定功能分组,例如 智能插头上的开/关集群,或可调光端点上的电平控制集群。
一个节点也可能有多个端点,每个端点都创建一个具有相同功能的实例。例如,灯具可能会暴露对单个灯的独立控制,或者电源板可能会暴露对单个插座的控制。
在最后一层,我们会找到Attributes,这是节点持有的状态,表示可以读取或写入的内容,支持多种数据格式,实际中代表了智能设备的相关属性(如门的开关、室内温度等)。
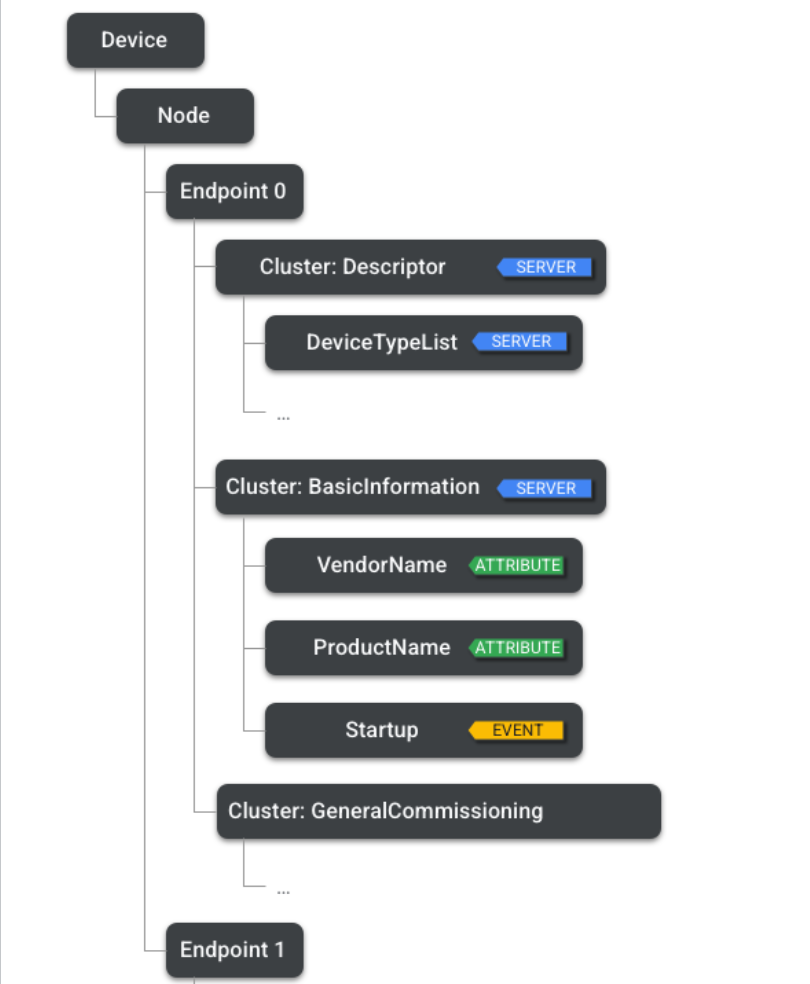
除了 Attributes 之外,Clusters 还有Commands,也就是触发 Cluster 进行某种行为的指令。它们等同于Matter远程过程调用的 DM。命令类似于动词,例如Door Lock集群上的 lock door。命令可能会产生响应和结果;在 Matter,这样的响应也被定义为命令,以相反的方向进行。
最后,Clusters 也可能有Events,它可以被认为是过去状态转换的记录。虽然属性代表当前状态,但事件是过去的日志,包括单调递增的计数器、时间戳和优先级。它们能够捕获状态转换,以及使用属性不容易实现的数据建模。
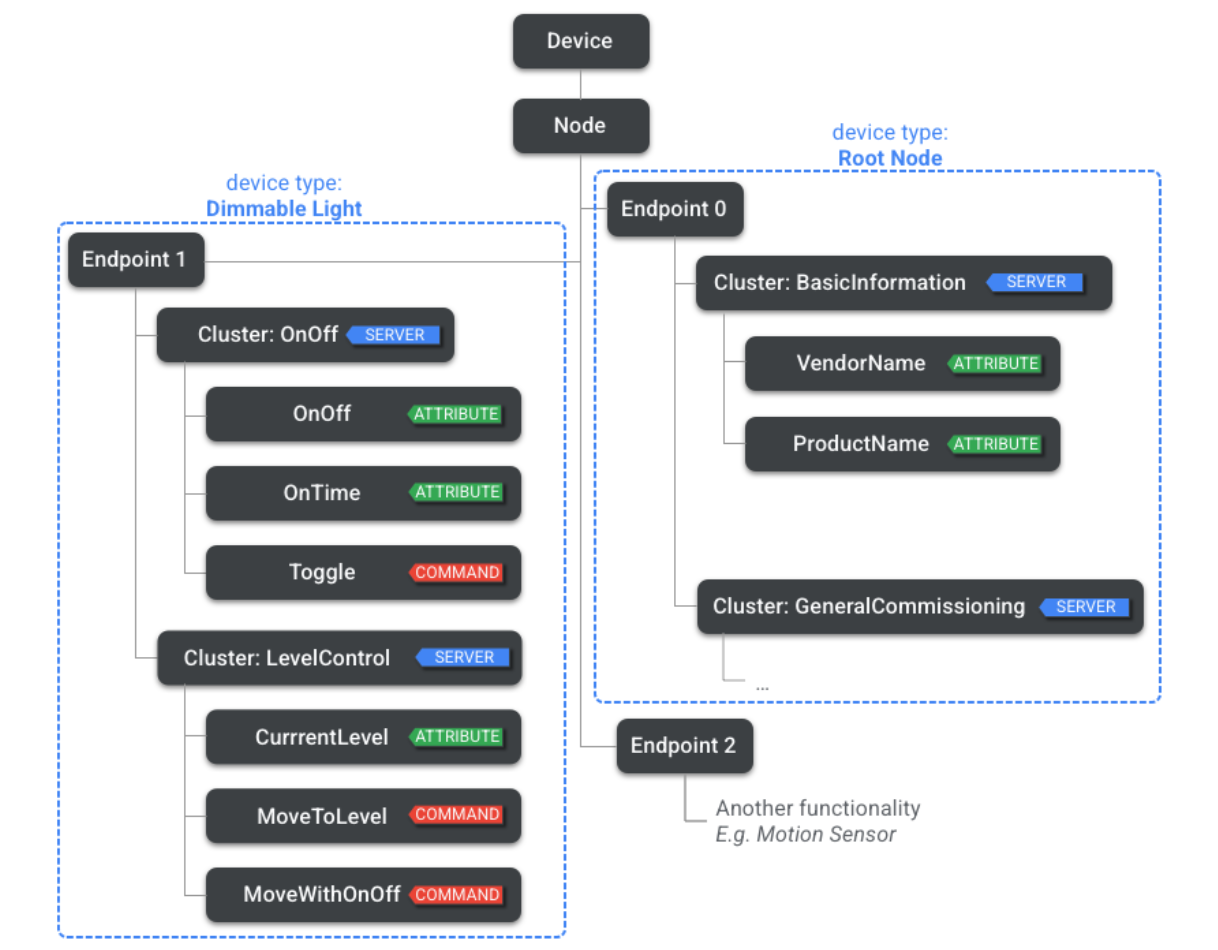
Endpoint 0作为Utility Clusters保留。Utility Clusters 是特定的集群,它包含端点上的服务功能,例如发现、寻址、诊断和软件更新。另一方面,**Application(应用集群)**支持主要操作,例如开/关或温度测量。
cluster可以定义为工具(Utility) Cluster或应用(Application) Cluster。
工具cluster不是端点的主要应用程序操作的一部分。它可以用于配置、发现、寻址、诊断、监控设备运行状况、软件更新等。它可能与对应的cluster存在临时关系。
作用域为端点的工具cluster示例:标识符、描述符、绑定、组等。 适用于该节点的工具cluster +示例:基本信息、诊断等。
应用cluster支持端点的主要操作。应用cluster可以支持和一个或多个应用程序交互,既包括client也包括server。
应用cluster示例:
- On/Off cluster —— client向server发送命令
- Temperature Measurement cluster —— server向client报告数据
应用程序cluster不是工具cluster,即使它本身可能支持实用的工具功能,如校准、操作模式等。但应用程序cluster规范不应该涉及其应用领域之外的层级和过程。
示例:一个特定的温度测量cluster可能存在于不同的设备上,或在不同的网络中,每个设备具有不同的安全与配网机制和/或策略。 +示例:commissioning cluster的范围是配网,而不是测温。
Clusters 可能是Client Cluster或Server Cluster。服务器是有状态的,保存属性、事件和命令;而客户端是 无状态的,其职责是启动与远程服务器集群的交互,从而执行:
虽然 DM 在节点内是分层的,但节点之间的关系不是。Matter中的节点没有controller/peripheral 或 leader/follower关系。相反,关系是水平的:任何 Cluster 都可以是Server或Client。因此,对于不同的集群和功能,节点可能既是服务器又是客户端。
例如,我们可能有两个台灯:节点 A和节点 B。两个节点都实现了一个开/关灯设备类型。此设备类型包括控制其各自物理光输出的开/关服务器集群。
但是,就像典型的台灯一样,我们的物理设备还将包括一个开/关灯 开关设备类型,用于其本地开/关。此设备类型必须实现开/关客户端集群,以便它可以控制服务器集群。
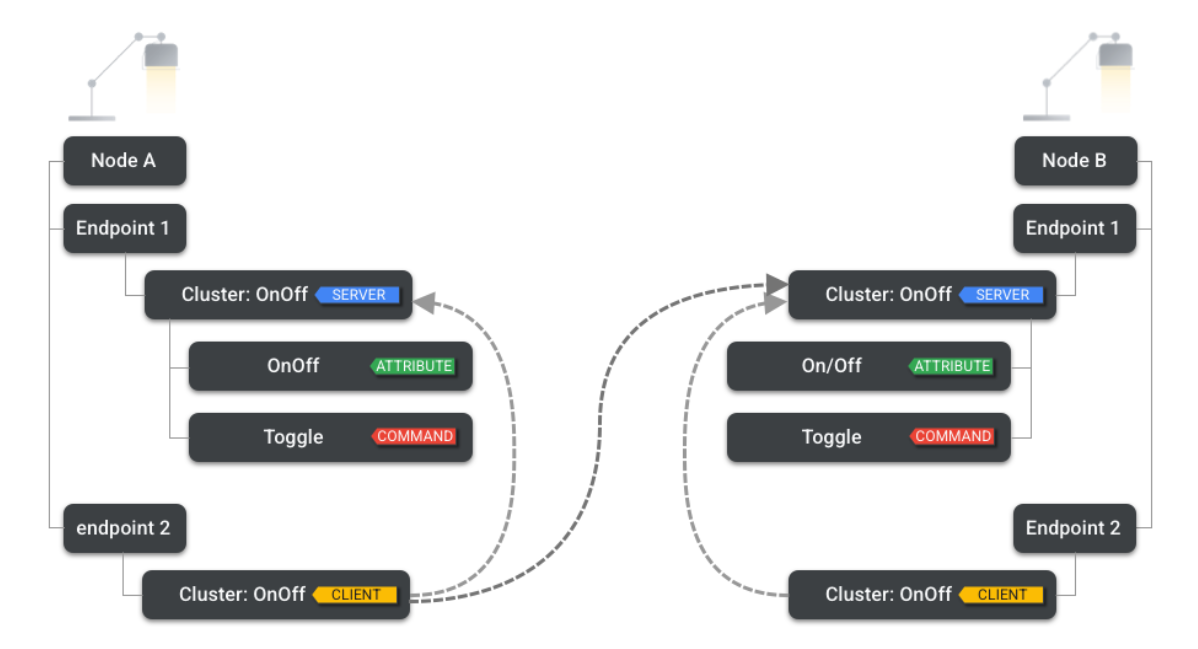
在此示例中,节点 A 上的开/关客户端集群正在更改节点 A 和节点 B 上的开/关服务器集群的属性,而节点 B 的客户端集群仅更改节点 B 本身上的服务器集群。
在下一节中,我们将详细介绍客户端和服务器集群如何交互: Interaction Model(交互模型)。
如果我们不能对节点执行操作,那么节点的数据模型 (DM) 就不相关了。交互模型(IM),定义了一个节点的 DM 与其他节点的 DM 的关系:即 IM 作为 DM 之间通信的通用语言。
节点通过以下方式相互交互:
每当一个节点与另一个节点建立加密通信序列时,它们就构成了交互关系。Interactions 可能由一个或多个Transactions组成,而 Transactions 由一个或多个Action组成,可以理解为 Node 之间的 IM 级消息。
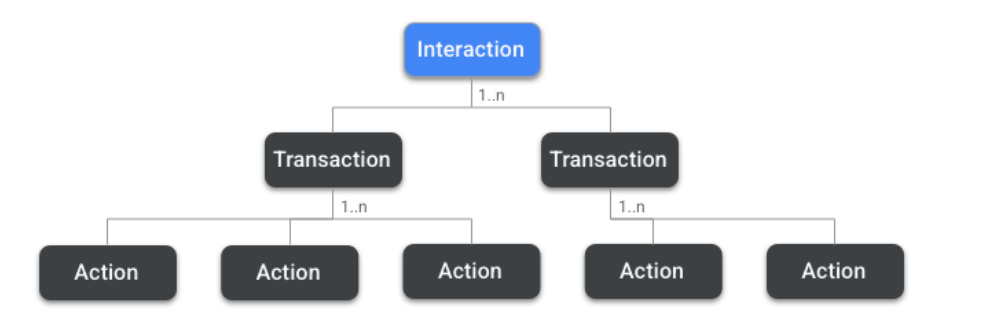
Matter 支持多个操作,例如从另一个节点请求属性或事件的读取请求操作,或其响应,报告数据操作,它将信息从服务器返回到客户端。
在Matter中,节点的发起目标被称为发起者(Initiators ),而响应的节点则作为目标(Target)。一般来说,发起者是客户端集群,而目标是客户端集群。
在Matter中节点可能隶属于某个组。设备组作为一种机制,主要用于在统一操作中同时寻址并向多个设备发送消息。在一个 Group 中,所有的节点共享同一个 Group ID(16位整型)。
为了完成组级通信(群播),Matter 利用IPV6 多播消息,并且让所有的组成员都具有相同的多播地址。
当我们想要与属性、事件或命令进行交互时,我们需要为这种交互指定 Path ,也就是属性、事件和命令在节点的数据模型层次结构中的位置。
注:Path 也可以使用Groups或者**统配交互符(Wildcard Operators)**同时处理多个节点或集群,从而减少操作的数量。
Path这种机制对提高通信的响应能力起到很重要的作用。例如:当用户想要关闭所有灯光,语音助手可以与组内多个灯建立单个的交互,而不是传统的一系列单独的交互。
Matter Path 使用规范:
| |
在这些路径构建块中,端点和集群还可能包括用于选择多个节点实例的通配符运算符。
有两种执行写入或调用 Matter 的方式:定时的和非定时的。定时交易为写入/调用动作的发送建立了一个最大的超时。这个超时的目的是为了防止对交易的拦截攻击。它特别适用于对资产进行门禁的设备,如车库开门器和锁。
与 Nodes 交互时的第一个用例 Matter是从另一个节点读取的属性,例如来自传感器的温度值。在此类交互中,必须执行的第一个操作是读取请求操作。
发起者 -> 目标
在此 Action 中,Initiator 会查询 Target 提供的以下请求:
目标接收到读取请求操作后,它将使用请求的信息组装一个报告数据操作;当目标接收到读取请求操作后,它将使用请求的信息组装一个报告数据操作。详见下图:
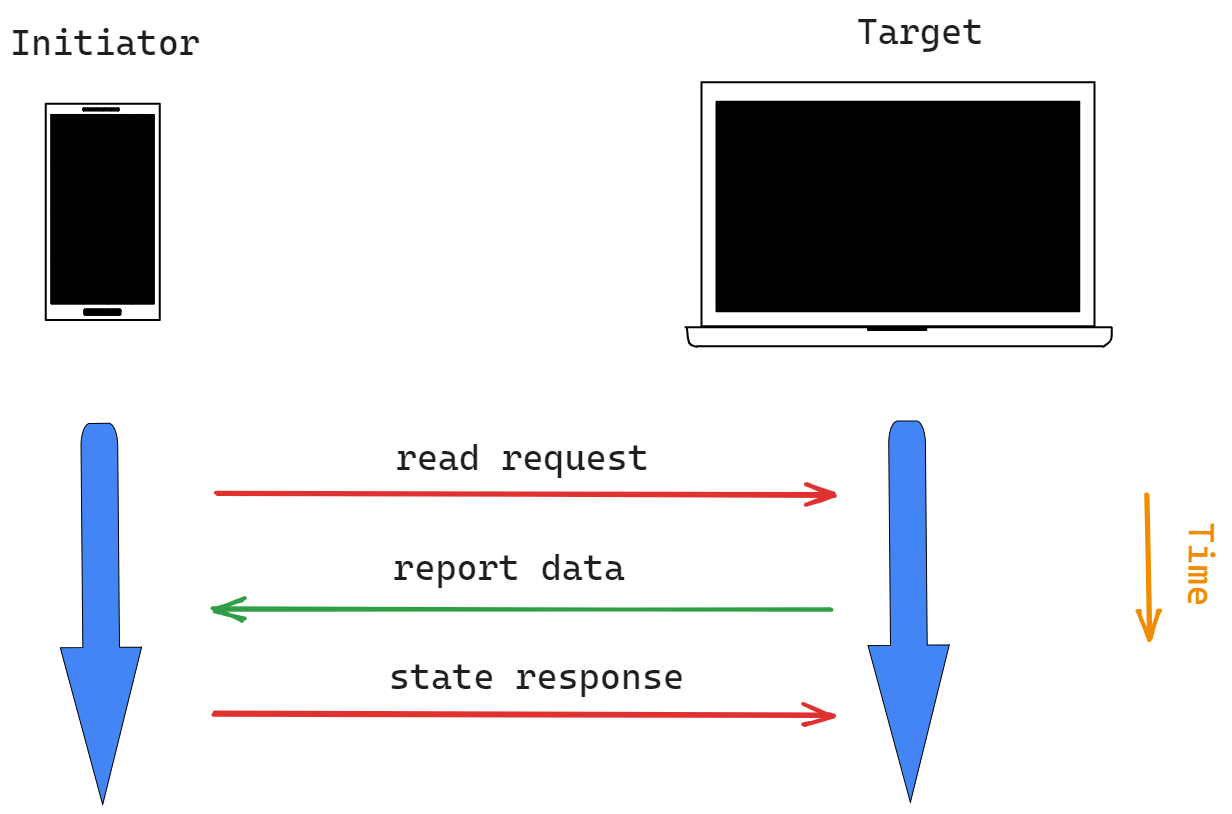
目标 -> 发起者
在此 Action 中,Target 响应:
目标 -> 发起者 -> 目标
一旦 Initiator 接收到请求的数据,默认情况下它必须生成一个 Status Response Action。此操作由启动器发送,确认已收到报告的数据。如果设置了 Suppress Status Response 标志,则 Initiator 不得发送 Status Response Action。
一旦启动器发送了状态响应操作,或者启动器接收到启用了抑制响应标志的报告数据操作,读取/报告查询就完成了。
状态响应操作仅包含一个状态字段,该字段将确认操作成功或显示失败代码。
发起者 -> 目标
除了单一的读请求动作外,发起者还可以订阅属性或事件的定期更新。因此,同样的报告数据 Action 可以作为订阅交易后的定期数据更新的结果而产生。
订阅交互创建两个节点之间的关系,其中目标定期向发起者生成报告数据操作。 Initiator 是 Subscriber,Target 是 Publisher。
订阅请求操作包含:
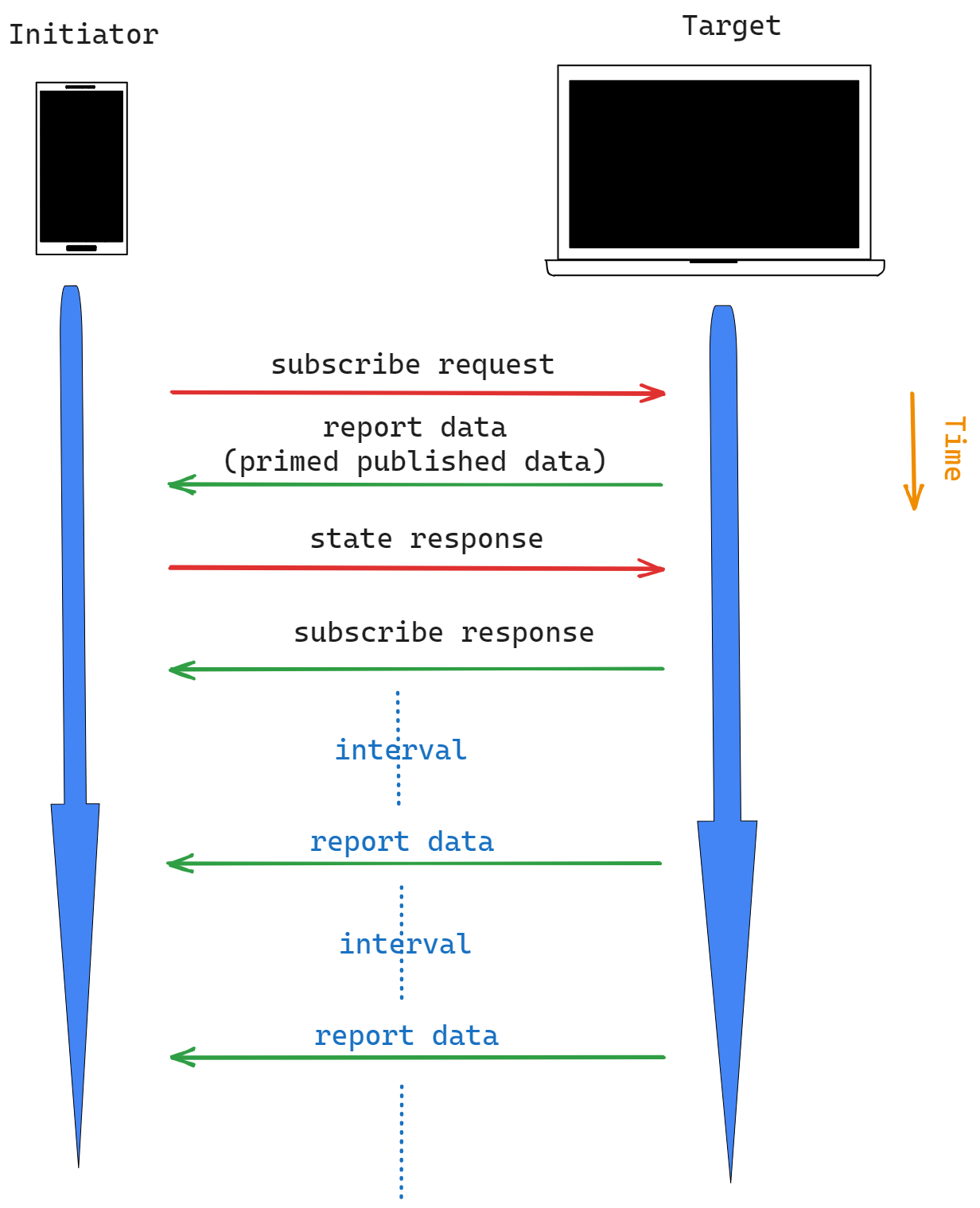
在订阅请求之后,目标用包含第一批报告数据的报告数据操作响应发起者:Primed Published Data。
然后,发起者通过发送到目标的状态响应操作来确认报告数据操作。一旦目标接收到一个状态响应动作报告没有错误,它发送一个订阅响应动作。
目标随后将以协商的间隔定期发送报告数据操作,发起者将响应这些操作,直到订阅丢失或取消。
目标 -> 发起者
这是订阅交易的最后一个操作,并结束了该过程。这包括:
发起者 -> 目标
与读取请求操作类似,在此操作中,发起者为目标提供:
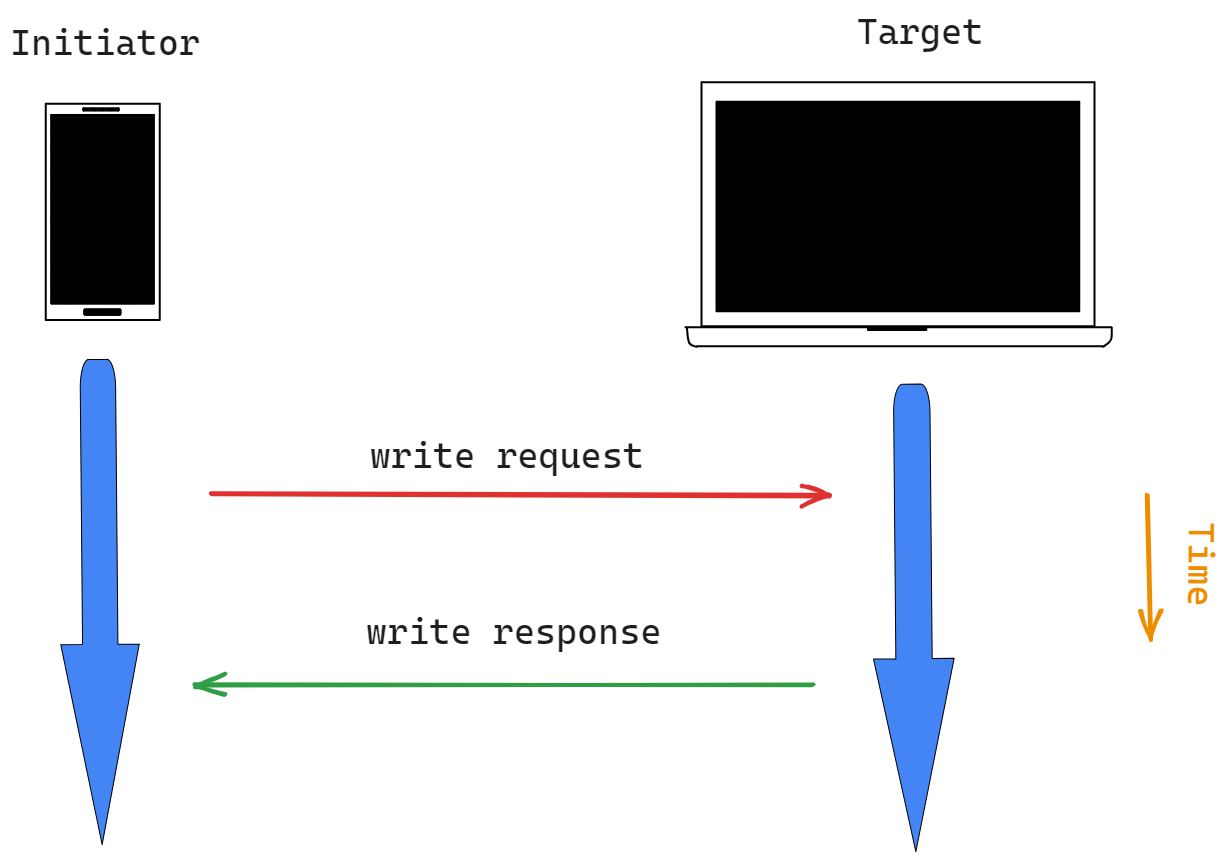
目标 -> 发起者
写入请求动作可以是一个组播,但在这种情况下,必须设置抑制响应标志。其理由是,否则网络可能会被来自一个组的每个成员的同时响应所淹没。
为了启用这种行为,在写请求列表中使用的路径可以包含组,或者它们可以包含通配符,但只在端点字段上。
在定时写入事务中比非定时写入事务多了几个步骤。
发起者 -> 目标
Initiator 启动事务发送此操作,其中包含:
一旦接收到定时请求操作,目标必须使用状态响应操作确认定时请求操作。一旦 Initiator 收到报告没有错误的 Status Response Action,它将发送 Write Request Action。
与前面描述的 4.1.1 写请求操作 相同。
与前面描述的 4.1.2 写响应操作 相同。
定时请求动作、写请求动作和写响应动作是单播的。
调用事务用于在目标节点上调用一个或多个集群命令。它类似于对集群中定义的命令进行的远程过程调用。
与写入事务类似,调用事务支持定时和不定时事务。 有关定时事务的更多信息,请参阅 交互模型:1.4.定时和非定时
发起者 -> 目标
类似于读请求动作和写请求动作,在这个动作中,发起者为目标提供:
目标 -> 发起者
目标收到调用请求操作后,它将使用包含以下内容的调用响应操作来完成事务:
Invoke Request Action可以是一个组播,但在这种情况下,必须设置抑制响应标志。其理由是,否则网络可能会被来自一个组的每个成员的同时响应所淹没。
为了启用这种行为,在调用请求列表中使用的路径可以包含组,或者它们可以包含通配符,但仅在端点字段上。此外,如果行动是组播,这个事务就会在没有响应的情况下终止。
与定时写入事务类似,定时调用事务也从定时请求操作开始。
发起者 -> 目标
Initiator 启动事务发送此操作,其中包含:
一旦接收到定时请求操作,目标必须使用状态响应操作确认定时请求操作。一旦 Initiator 收到状态响应操作报告没有错误,它将发送调用请求操作。
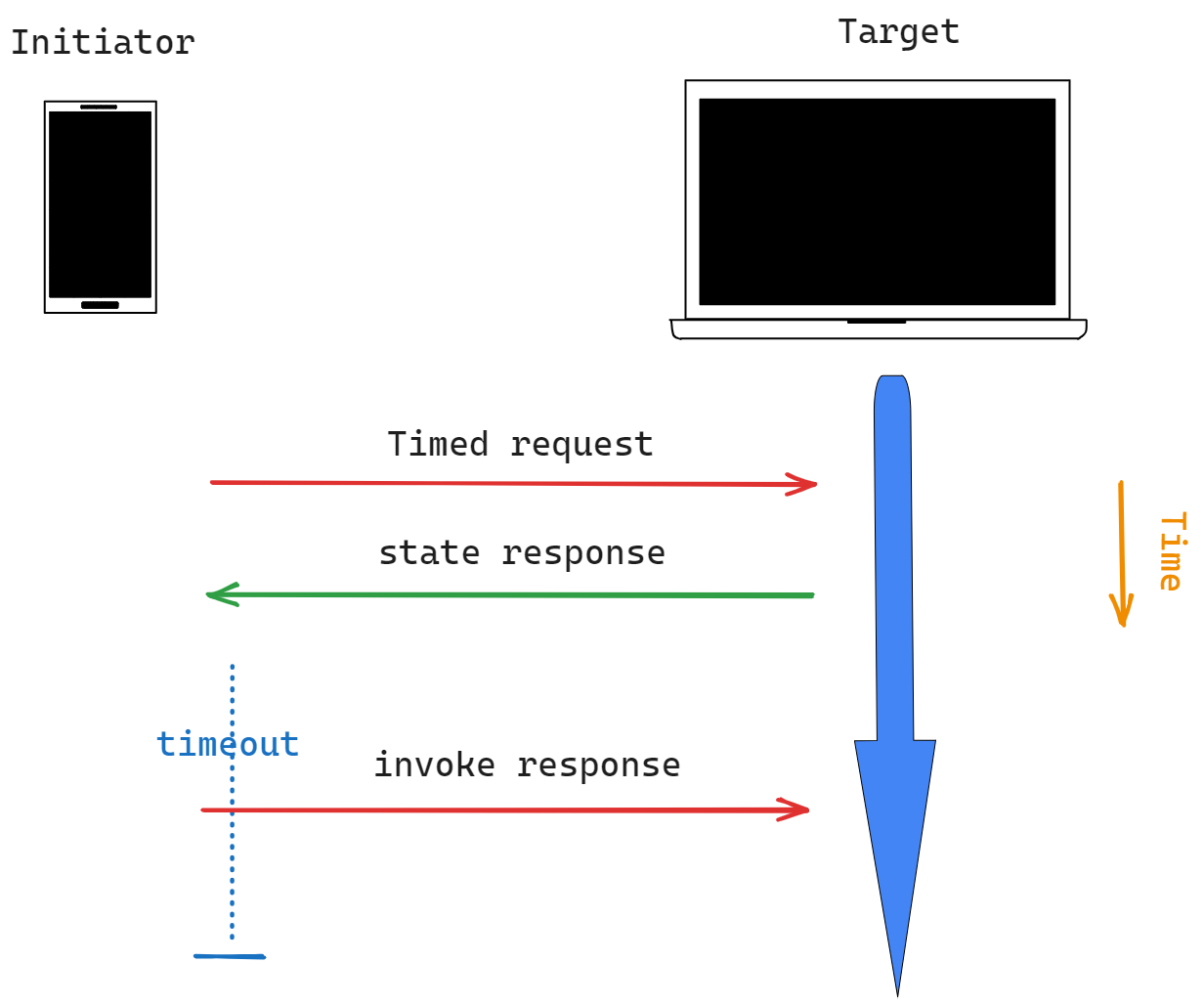
与前面描述的 5.1.1 调用请求操作 相同。
与前面描述的 5.1.2 调用响应操作 相同。
所有的调用命令都可以在定时交互中调用。定时请求动作、调用请求动作和调用响应动作都是单播的,因此不能在定时调用事务上作为群播使用。
Invoke Request Action支持使用带组的路径,以及通配符,但Invoke Response Action不支持通配符的使用。

Matter支持用GN配置构建,一个快速且可扩展的元构建系统,生成输入到ninja。
该构建系统已经在以下操作系统上进行了测试:
Matter构建系统有以下特点:
gn格式。要检查Matter资源库,请运行以下命令:
| |
如果你已经签出了Matter的代码,运行下面的命令来同步子模块:
| |
在构建之前,你必须安装一些操作系统的特定依赖。
在基于Debian的Linux发行版上,如Ubuntu,这些依赖项可以通过以下命令来满足:
| |
如果通过build_examples.py和with-ui变体构建,也要安装SDL2:
| |
在macOS上,从 Mac App Store上安装 Xcode 。
如果构建-with-ui变体,也要安装 SDL2 :
| |
完成以下步骤:
rpi-imager安装适用于 arm64 架构的 Ubuntu 22.04 64 位服务器操作系统。 | |
默认情况下,wpa_supplicant是不允许更新(覆盖)配置的。如果你想让Matter应用程序能够存储配置的变化,您需要进行以下更改:
dbus-fi.w1.wpa_supplicant1.service 文件以使用配置文件来代替,运行以下命令: | |
| |
wpa-supplicant配置文件: | |
wpa-supplicant文件中添加以下内容: | |
bootstrap.sh将下载一个兼容的ZAP工具版本并将其设置在$PATH。如果你想安装或使用一个不同版本的工具,你可以从ZAP项目的Release 页面下载。
Zap不提供ARM的二进制版本。Rosetta为Darwin解决了这个问题、然而,对于linux arm,你必须使用本地的ZAP,一般通过设置$ZAP_DEVELOPMENT_PATH(见下面 使用哪种ZAP一节)。
文件scripts/setup/zap.json包含CIPD会下载的版本、所以你可以从zap项目中下载一个兼容的版本Release。要作为源代码签出代码,相应的标签应该存在于zap中repository tags 列表中。
命令示例:
| |
ZAP工具脚本使用以下检测,按重要性排序:
$ZAP_DEVELOPMENT_PATH指向一个ZAP检出。
如果你在本地开发ZAP,并希望用你的改动来运行ZAP和你的改动。
$ZAP_INSTALL_PATH指向zap-linux.zip或`zap-m
在运行任何其他构建命令之前,scripts/activate.sh的环境设置脚本应该在最高层。这个脚本负责下载GN、ninja,并在Python环境中设置用于构建和测试的库来构建和测试。
运行以下命令:
| |
如果脚本说环境已经过期,你可以通过运行下面的命令来更新它:
| |
脚本 scripts/bootstrap.sh从头开始重新创建环境,这是很昂贵的,所以避免运行它,除非环境已经过期。
运行以下命令,为主机平台构建所有的源代码、库和测试:
| |
这些命令生成了一个适合调试的配置。要配置一个构建,请指定is_debug=false:
| |
**注意:**目录名称 “out/host “可以是任何目录,通常是在
out目录下构建。这个例子使用host来强调为主机系统构建。不同的构建目录可以用于不同的配置,或者使用一个目录,并在必要时可以根据需要通过gn args重新配置。
要运行所有测试,请运行以下命令:
| |
要想只运行src/inet/tests中的测试,可以运行以下命令:
| |
**注意:**构建系统会缓存通过的测试,所以你可能会看到以下消息:
1 +ninja: no work to do +这意味着测试在之前的构建中通过了。
build_examples.py该脚本./scripts/build/build_examples.py提供了一个统一的编译构建接口,可以使用gn、cmake、ninja和其他必要的工具来编译各种平台。
使用 ./scripts/build/build_examples.py targets 来查看支持的目标。
构建命令的例子:
| |
libfuzzer单元测试libfuzzer单元测试测试只被编译而不被执行(你必须手动执行它们)。为了获得最佳的错误检测,应该使用某种形式的净化器,如asan应该被使用。
可执行以下命令:
| |
之后,测试应该被定位在out/linux-x64-tests-lang-asan-libfuzzer/tests/。
ossfuzz的配置ossfuzz配置不是独立的模糊测试,而是作为一个与外部模糊测试自动构建的集成点。它们会获取环境变量,如$CFLAGS、$CXXFLAGS和$lib_fuzzing_engine。
你可能需要libfuzzer+asan的构建来代替本地测试。
构建是通过设置构建参数来配置的。你可以通过以下方式设置这些参数:
--args选项传递给gn gen。gn args。args.gn。要配置一个新的构建或编辑现有构建的参数,请运行以下命令:
| |
两个关键的内置构建参数是 target_os 和 target_cpu,它们分别控制构建的操作系统和CPU。
要查看所有可用的构建参数的帮助,请运行以下命令:
| |
你可以通过两种方式构建例子。
要把例子作为单独的项目来构建,在Matter的third_party directory,运行下面的命令,输入正确的路径到例子的正确路径(这里是 “chip-shell”):
| |
你可以在Matter项目的顶层构建例子。请看下面的统一构建一节了解详情。
要构建一个近似于连续构建集的统一配置,请运行以下命令:
| |
你可以在改变提交配置之前使用这组命令构建,并测试GCC、Clang、MbedTLS和例子的配置。在一个并行的构建中。每个配置都有一个单独的子目录在输出目录中。
这种统一的构建可以用于日常的开发,尽管为每一次编辑而构建所有的东西会更昂贵。构建每一个编辑项目的成本。为了节省时间,你可以将配置来构建:
| |
用配置的名称替换host_gcc,它可以在根目录下的 “BUILD.gn “中找到。
你也可以用参数对生成的配置进行微调。比如说
| |
完整的列表请参见根目录BUILD.gn。
在统一的构建中,目标有多个实例,需要通过添加通过添加(toolchain)后缀来区分。使用gn ls out/debug来列出所有的目标实例。例如:
| |
**注意:**有些平台可以作为统一构建的一部分来构建需要下载额外的工具。要将这些工具添加到构建中,必须将其位置 +必须作为构建参数提供。例如,要添加
Simplelink cc13x2_26x2例子到统一构建中,安装SysConfig 并添加以下构建:
1 +gn gen out/unified --args="target_os=\"all\" enable_ti_simplelink_builds=true > ti_sysconfig_root=\"/path/to/sysconfig\"" +
GN集成了帮助,你可以通过gn help命令访问。
请确保查看以下推荐的主题:
| |
也可参见 快速入门指南。
GN有各种自省工具来帮助你检查构建配置。下面的例子以out/host输出目录为例:
显示一个输出目录中的所有目标:
| |
显示所有将被构建的文件:
| |
显示配置的目标的GN表示:
| |
将整个构建的GN表示转为JSON格式:
| |
显示依赖关系树:
| |
查找依赖性路径:
| |
列出与`libCHIP’连接的有用信息:
| |
代码覆盖率脚本会生成一份报告,其中详细说明了 Matter SDK 源代码的执行量。它还提供了有关 Matter SDK 执行代码段的频率并生成源文件副本的信息,并用执行频率进行了注释。
运行以下命令来启动该脚本:
| |
默认情况下,代码覆盖脚本在单元测试级别执行。单元测试由开发人员创建,因此可以让他们最好地了解单元测试中要包含哪些测试。您可以使用以下参数按范围和执行方式扩展覆盖率测试:
| |
此外,请参阅 Matter SDK 的最新单元测试覆盖率报告(每天收集): matter coverage。
如果你对GN构建系统做了任何改变,下一次构建会自动重新生成ninja文件。不需要做任何事情。

子页面:
Thread:Thread是一种开放的低功耗无线通信协议,旨在为物联网设备提供安全、稳定、高效的IPv6连接。它基于IEEE 802.15.4标准,支持多种应用场景,如智能家居、建筑自动化、工业自动化等。Thread协议的特点是易于扩展、安全性高、可靠性好、覆盖范围广、低功耗等。WI-FI:Wi-Fi是一种无线局域网技术,采用IEEE 802.11标准,可以实现高速的无线数据传输。它广泛应用于智能手机、平板电脑、笔记本电脑、智能家居、智能电视等设备中,可以通过无线方式连接互联网和其他设备。Wi-Fi的主要特点是速度快、覆盖范围广、使用方便等。Ethernet(以太网):Ethernet(以太网)是一种有线局域网技术,采用IEEE 802.3标准,可以通过网线连接设备和网络。它是一种广泛应用于计算机网络中的技术,可以实现高速的数据传输和可靠的网络连接。Ethernet的主要特点是速度快、可靠性高、稳定性好等。Matter binding(Matter协议):Matter是一个由智能家居设备制造商、芯片厂商和互联网巨头等多个公司发起的开放性联盟,旨在促进智能家居设备之间的互操作性和互连性。Matter协议是该联盟发布的一种通信协议,可以让智能家居设备之间相互通信和交互。Matter协议的特点是开放性强、互操作性好、安全性高、可扩展性强等。Matter binding是指将Matter协议与其他通信协议(如蓝牙、Wi-Fi等)进行绑定,实现智能家居设备之间的互连和互操作。运行 Matter 协议应用程序的硬件必须满足规范要求,包括提供适量的闪存以及能够同时运行蓝牙 LE 和 Thread 或 Wi-Fi。
Linux PC withsoftware installed:
对于matter设备在不同协议下的配置和使用,官方提供以下几种方式:
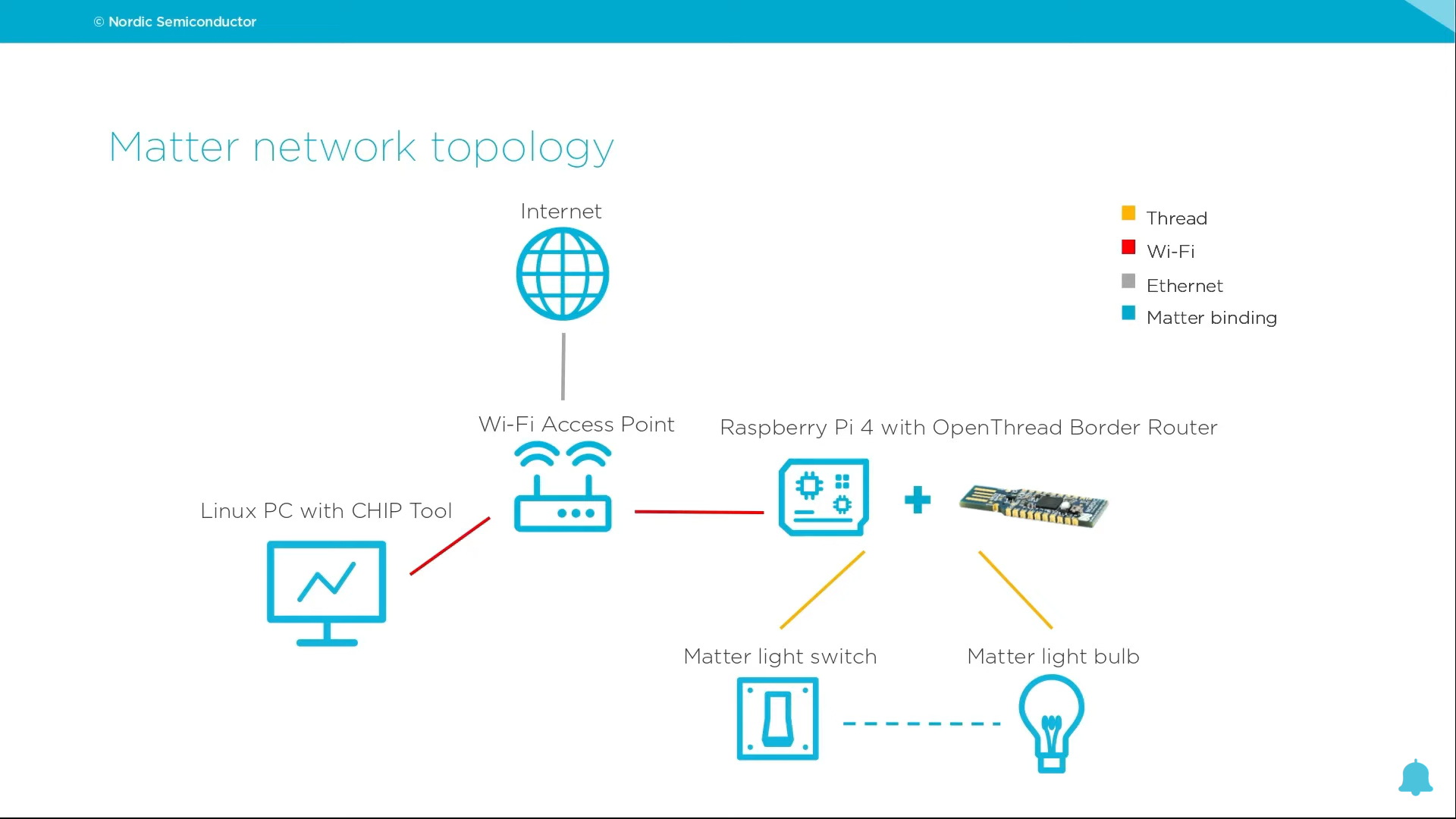
注意:这里我们基于Matter over Thread:在一台设备上配置边界路由器和控制器进行过程演示。
如果你只有一台设备,无论是装有 Linux 的 PC 还是 Raspberry Pi,你都可以设置和测试 Matter over Thread 开发环境,同时在这台设备上运行 Thread Border Router 和 Matter 控制器。
在此设置中,PC 或 Raspberry Pi 同时运行 Thread Border Router 和适用于 Linux 或 macOS 的 CHIP 工具。为了简化 Thread 与 Matter 附件设备的通信,使用带有 OpenThread Border Router 图像的 Docker 容器,而不是本地安装 OpenThread Border Router。
下面是在同一台设备上设置 OpenThread Board Router 和 Matter 控制器的拓扑结构图,我们结合 CHIP TOOL 进行开发
若要使用此设置,需要以下硬件:
要在同一设备上配置和使用线程边界路由器和 Matter 控制器,请完成以下步骤。
使用可用的 Matter 样本之一对 Matter 附件设备的开发套件进行编程。 我们建议使用Matter light bulb。
在 PC 或树莓派上配置线程边界路由器,具体取决于您使用的硬件。 有关详细步骤,请参阅 nRF Connect SDK 文档中 Thread Border Router页面上的使用 Docker 运行 OTBR 部分。
适用于 Linux 或 macOS 的 CHIP Tool 是 Matter controller 角色的默认实现,建议用于 nRF Connect 平台。 对于此线程问题,您将在与线程边界路由器相同的设备上配置控制器。
完成以下步骤:
a. 选择以下选项之一:
modules/lib/matter/examples/chip-toolb. 配置芯片工具控制器。 按照 Matter 文档中的使用 CHIP TOOL用户指南中的步骤完成以下操作:
根据您在开发工具包上编程的 Matter 示例,转到对应示例的文档页面并完成“测试”部分中的步骤。
这部分仅作为开发大纲,后面会出一系列系统教程,以Matter over Thread::在一台设备上配置边界路由器和控制器为例。

请确保你已经能够完成在esp-matter下的应用程序的烧录及串口监视,可参考此博客【Matter】esp-matter环境下的应用实践(程序烧录及串口监视)
ubuntu最好使用20以上的版本,因为matter最低需要python3.8的环境
PC机需要支持蓝牙4.0及以上版本,如果没有的话需要购买一个USB蓝牙适配器,而且需要支持Linux,可以参考购买这款蓝牙适配器
| |
| |
| |
| |
对于 MacOS,
gdbguipython 包不会使用bootstrap.sh脚本安装,因为它仅限于 x64 Linux 平台。它受到限制,因为在 MacOS 上为gevent(依赖于gdbgui)构建轮子失败。对于ARM-based Mac,如果Python3版本大于或等于3.11,则不需要进一步的安装步骤。
如果 Python3 版本低于 3.11 或者您使用的是 x86(基于英特尔)Mac,那么请在每次引导后运行以下命令以将 gdbgui wheels 安装为二进制文件
1 +2 +python3 -m pip install -c scripts/setup/constraints.txt --no-cache --prefer-binary gdbgui==0.13.2.0 +deactivate +
| |
| |
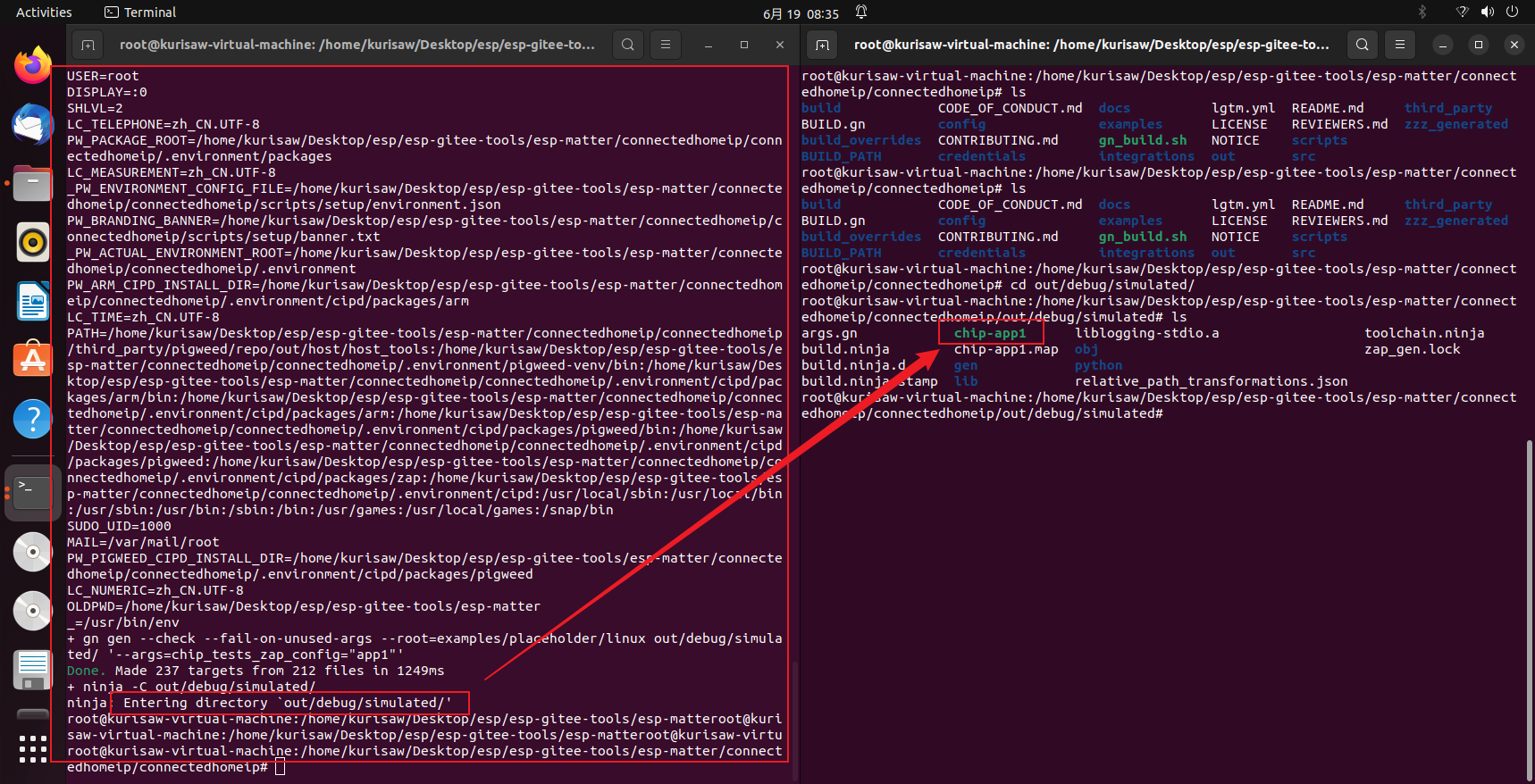
在 ~/esp/esp-matter/connectedhomeip/connectedhomeip目录下,执行命令
| |
执行完之后,会在根目录下生成 out/debug/standalone/chip-tool一个二进制文件。

如果上述命令:./gn_build.sh执行失败,也可以执行如下命令:
| |
执行完毕后,在以下路径 connetedhomeip/connectedhomeip/SOME-PATH也可以发现生成了 chip-tool 工具

为了向设备发送命令,必须使用客户端对其进行调试。芯片工具目前一次只支持调试和记忆一个设备。配置状态存储在/tmp/chip_tool_config.ini中;
另外删除/tmp中的此文件和其他.ini文件有时可以解决由于过时配置导致的问题。
| |
要向设备发起客户端调试请求,需要运行构建的可执行文件并选择配对模式,具体操作如下:
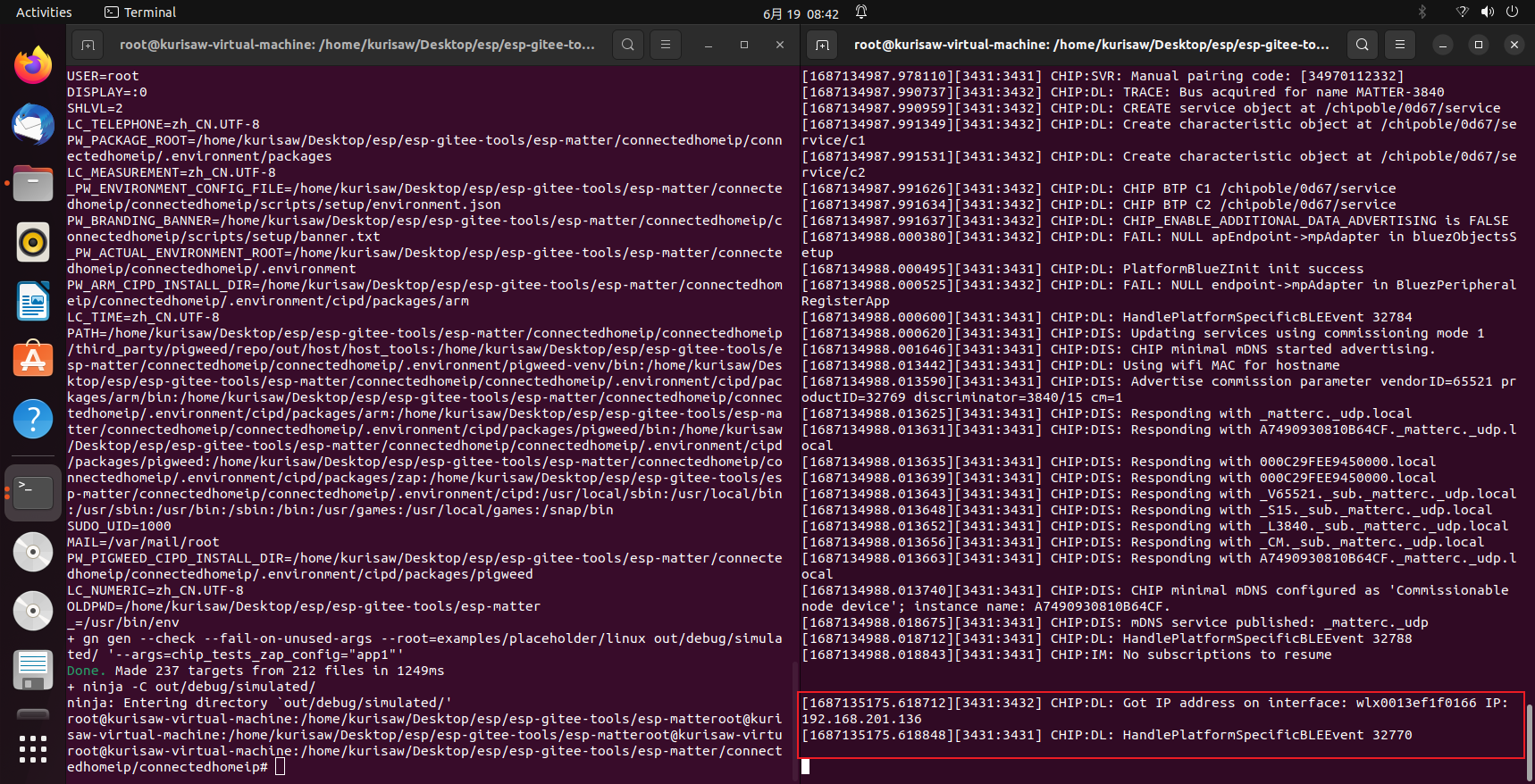
运行构建的可执行文件并将远程设备的鉴别器和配对代码以及要使用的网络凭据传递给它。下面的命令使用硬编码到 ESP32 all-clusters-app 调试版本中的默认值来将其调试到 Wi-Fi 网络:
| |
${NODE_ID_TO_ASSIGN}(必须是十进制数或0x- 前缀的十六进制数)是要分配给正在调试的节点的节点 ID。${SSID} 是 Wi-Fi SSID 可以是字符串,也可以是hex:XXXXXXXX SSID 的字节被编码为两位十六进制数字的形式。${PASSWORD} 是 Wi-Fi 密码,同样是字符串或十六进制数据 | |
下面的命令将发现设备并尝试使用提供的设置代码与它发现的第一个设备配对。
| |
下面的命令将发现具有长鉴别器 3840 的设备,并尝试使用提供的设置代码与它发现的第一个设备配对。
| |
下面的命令将根据给定的二维码(哪些设备在启动时记录)发现设备,并尝试与它发现的第一个配对。
| |
在所有这些情况下,将为设备分配节点 ID ${NODE_ID_TO_ASSIGN} (必须是十进制数或以 0x 为前缀的十六进制数)。
Trust store 将使用默认的 Test Attestation PAA 自动创建。要使用不同的 PAA 集,请在运行构建的可执行文件时使用可选参数 –paa-trust-store-path 传递路径。受信任的 PAA 位于 credentials/development/paa-root-certs/。
下面的命令将选择一组受信任的 PAA,以在证明验证期间使用。它还会发现具有长鉴别器 3840 的设备,并尝试使用提供的设置代码与它发现的第一个设备配对。
| |
| |
由于每次配置的 esp-idf 和 esp-matter 环境激活仅在当前终端有效,这里我们编写一个脚本文件,每次打开一个终端执行此脚本即可完成matter环境的激活:
| |
| |
| |
| |
| |
这里我使用的是 ESP32C3,所以执行以下命令即可
| |
要构建特定配置(示例m5stack):
| |
注意:如果使用特定的设备配置,强烈建议从默认设置之一开始并在此基础上进行自定义。某些配置具有在设备特定配置中自定义的不同约束(例如:主应用程序堆栈大小)。
要自定义配置,请运行 menuconfig,在菜单中可完成自定义配置:
| |
| |
构建应用程序后,要通过 USB 连接您的设备来闪擦除它。然后运行以下命令擦除整个闪存,将演示应用程序闪存到设备上,然后监控其输出。
请注意,有时您可能必须在设备尝试连接时按住设备上的启动按钮,然后才能刷机。对于 ESP32-DevKitC 设备,这在functional description diagram中有所提及。
| |
请替换(PORT)为您系统的正确 USB 设备名称(如/dev/ttyUSB0在 Linux 或/dev/tty.usbserial-101Mac 上)。
查看USB设备,esp32c3设备名为 ttyUSB0,因此执行以下命令 :
| |
CTRL+]关闭设备串口调试
注意:某些用户可能必须在设备出现在 /dev/tty 之前安装VCP 驱动程序。
提示:在监视器运行时,您可以通过按 Ctrl+t Ctrl+h 来查看各种监视器命令的菜单。
以下四种方式可以用于调试在ESP32上运行应用程序:
注:这里使用 Standalone chip-tool进行项目调试
打开一个新的终端2,我们需要运行构建的可执行文件并将远程设备的鉴别器和配对代码以及要使用的网络凭据传递给它,执行命令:
| |
如果你使用的是Thread设备(ESPH2)或以太网设备(ESP32-Ethernet-Kit),设备调试具体可以查看此链接
执行下面命令将 matter 设备接入现有现有IP网络,这里我们基于BLE调试
需要注意的是,你需要确保你的 Linux 蓝牙可用,如果是使用虚拟机的话需要考虑购买一个蓝牙适配器,可参考这个购买链接
接下来请按照我的步骤一步步执行:
| |
| |

如果未运行,请执行:
| |
| |

根据提示信息我们可以得知我的蓝牙适配器名为"hci0",并且状态为 “DOWN”,因此我们需要启用该蓝牙适配器。
| |
Adapters...--->Visibility Setting--->Always visible,这一步很关键,每次基于 BLE 调试都需要检查这一步!!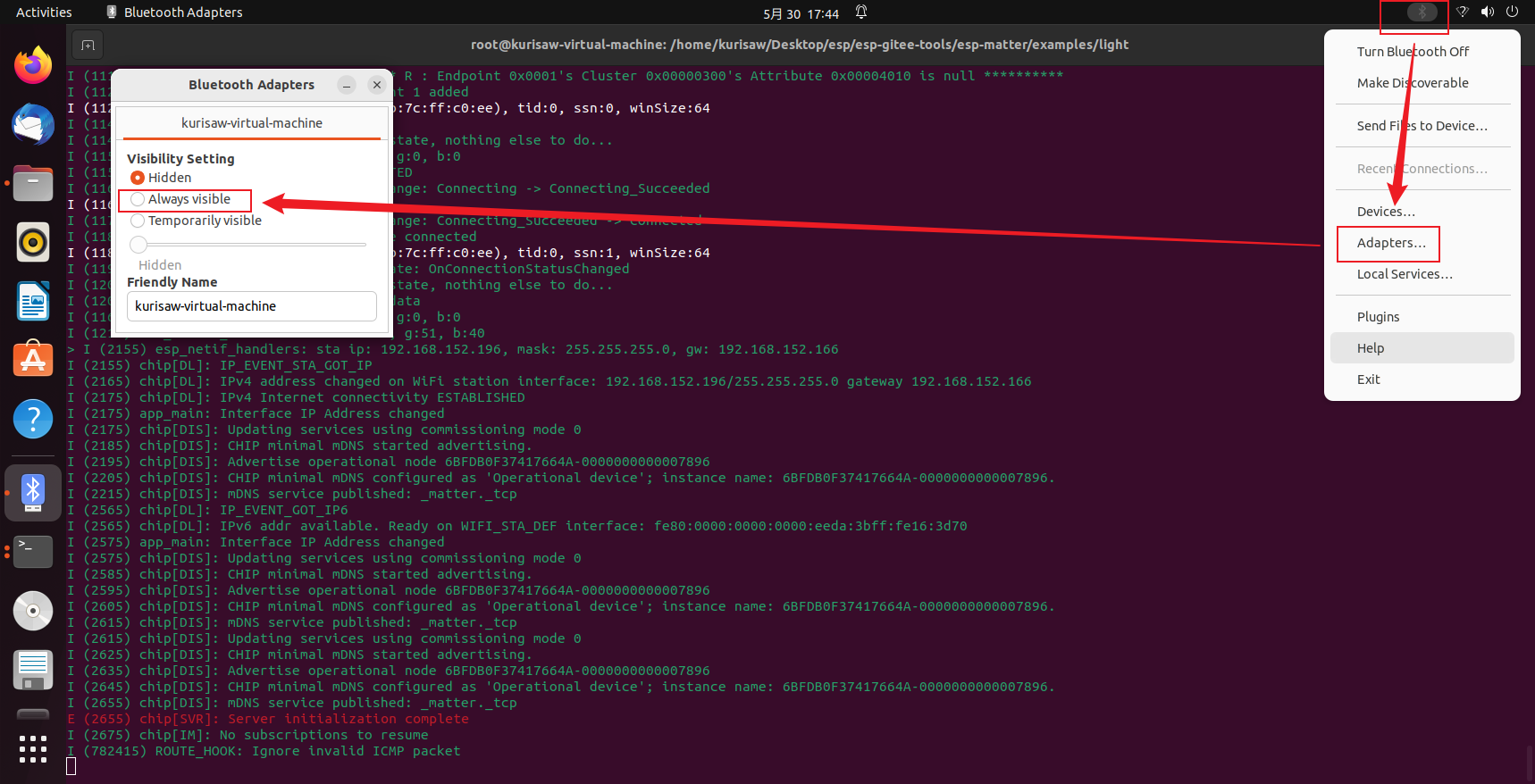
| |
注意:本机ip和matter设备ip必须在同一局域网下
0x7283(必须是十进制数或0x- 前缀的十六进制数)是要分配给正在调试的节点的节点 ID,随意填写即可。jetbot 是 Wi-Fi SSID可以是字符串,也可以是hex:XXXXXXXXSSID 的字节被编码为两位十六进制数字的形式。jetbotwyq是 Wi-Fi 密码,同样是字符串或十六进制数据
在终端1我们可以看到相关的ip信息:
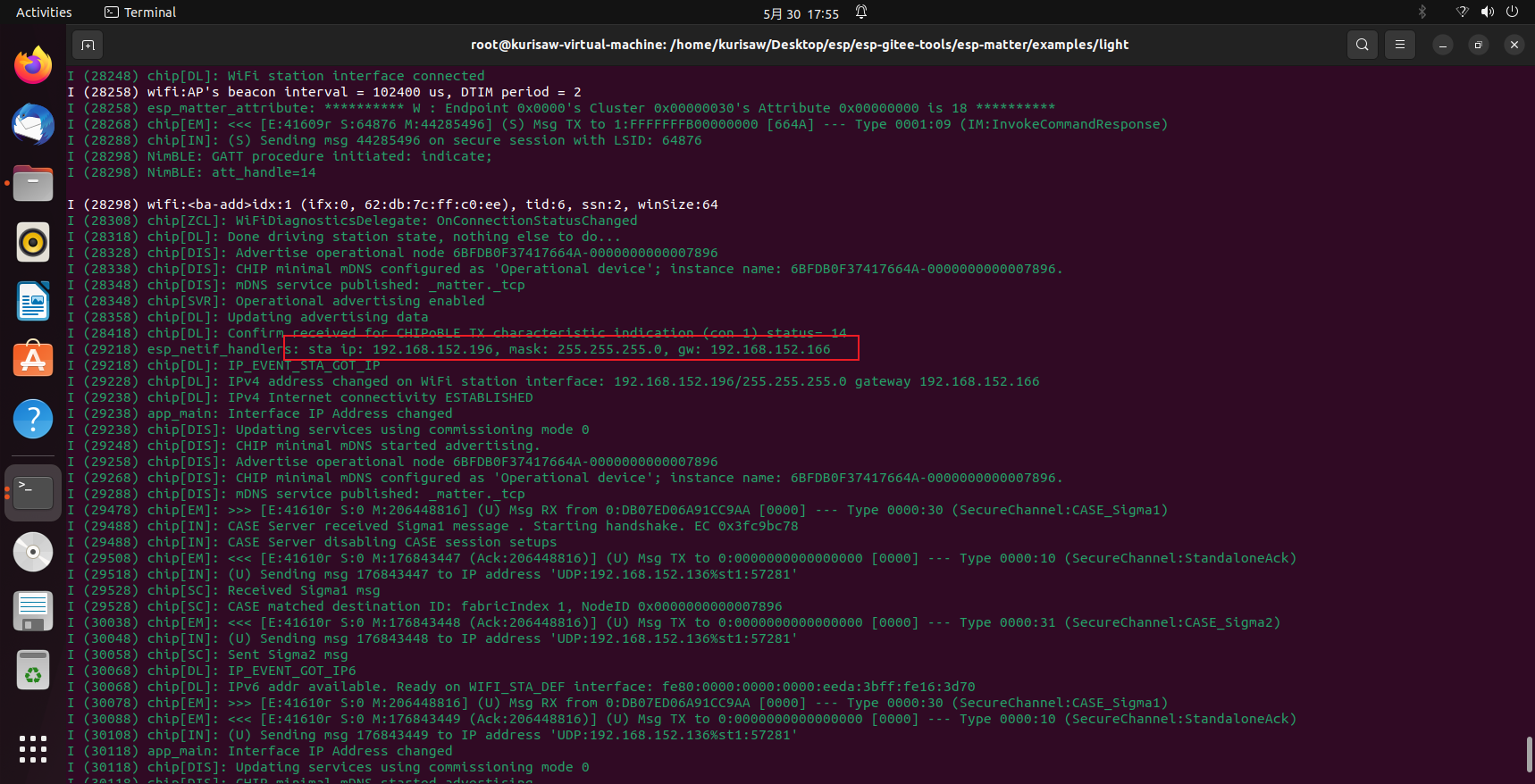
| |
这里的节点ID:0x7896需要和前面保持一致
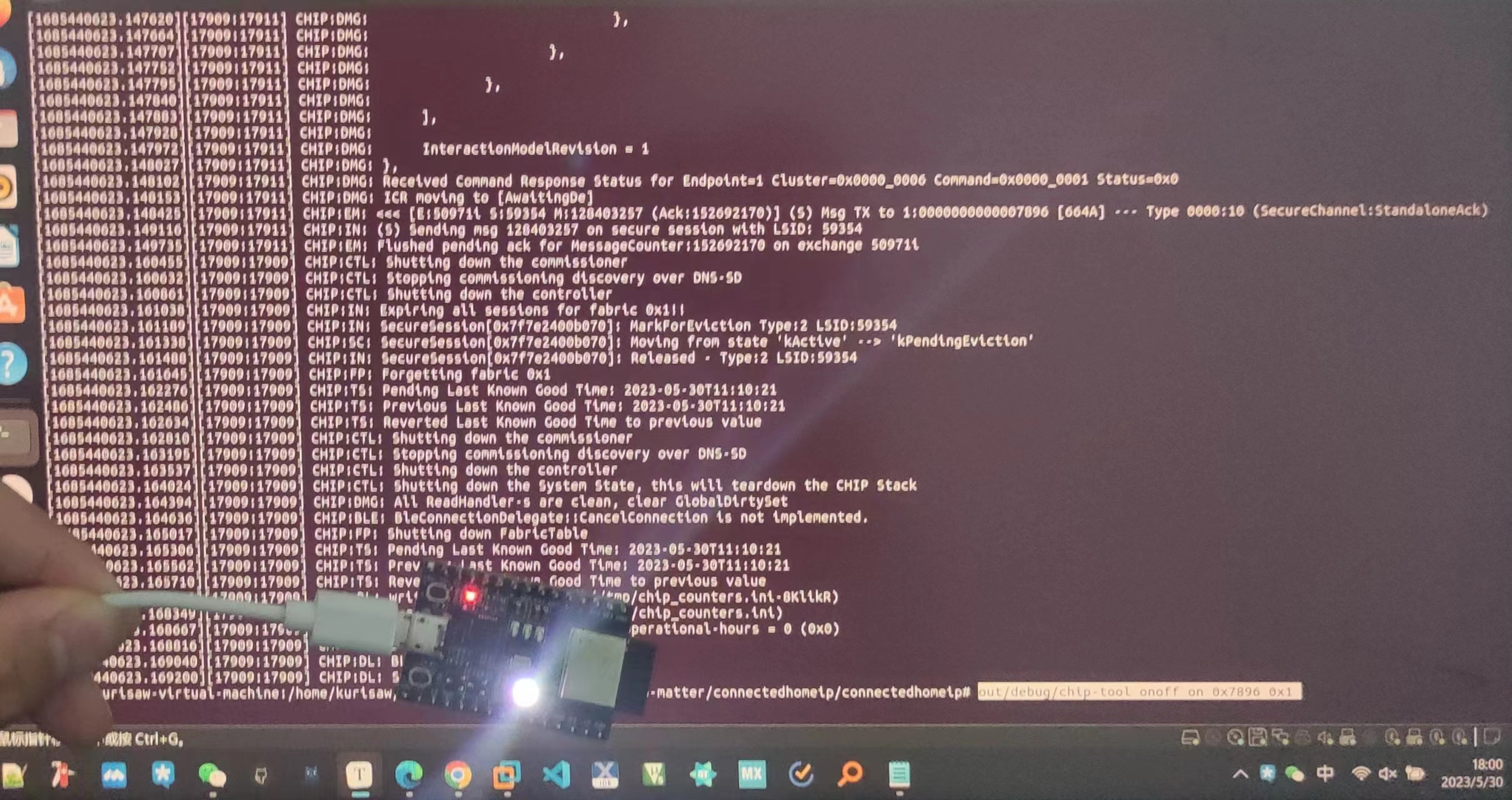

执行如下命令:
| |
如果克隆过程中发生报错,请执行如下命令来同步子模块:
| |
由于我们的环境构建配置均是基于Matter1.0,所以我们需要切换到v1.0分支下
| |
Matter 构建依赖于以下软件包及环境库:
| |
如果通过 build_examples.py 和 -with-ui 变体进行构建,也要安装 SDL2:
| |
执行scripts/activate.sh脚本。该脚本负责下载 GN、ninja,并使用用于构建和测试的库设置 Python 环境。
| |
如果显示环境已过期可执行如下命令进行更新(一般如果没提示环境已过期的提示不建议执行这一步,编译会花一段时间):
| |
注意:zap 包目前不可用
arm64(比如在 Raspberry PI 上编译时)。
| |
如果安装的话不出意外会出现版本号。
| |
下面是安装日志:
| |
我们看上面 zap 安装日志,其中最后导出了zap 的安装路径为/home/kurisaw/Desktop/esp/esp-gitee-tools/esp-matter/connectedhomeip/connectedhomeip/.zap/zap-v2023.04.27-nightly,在此目录下有个 zap 脚本,我们这个位置一定要记住!!
设置ZAP_DEVELOPMENT_PATH环境变量(这里的路径需要根据上面安装zap后提示的路径进行设置,不能一昧照抄)
| |
执行如下代码:
| |
效果如下:
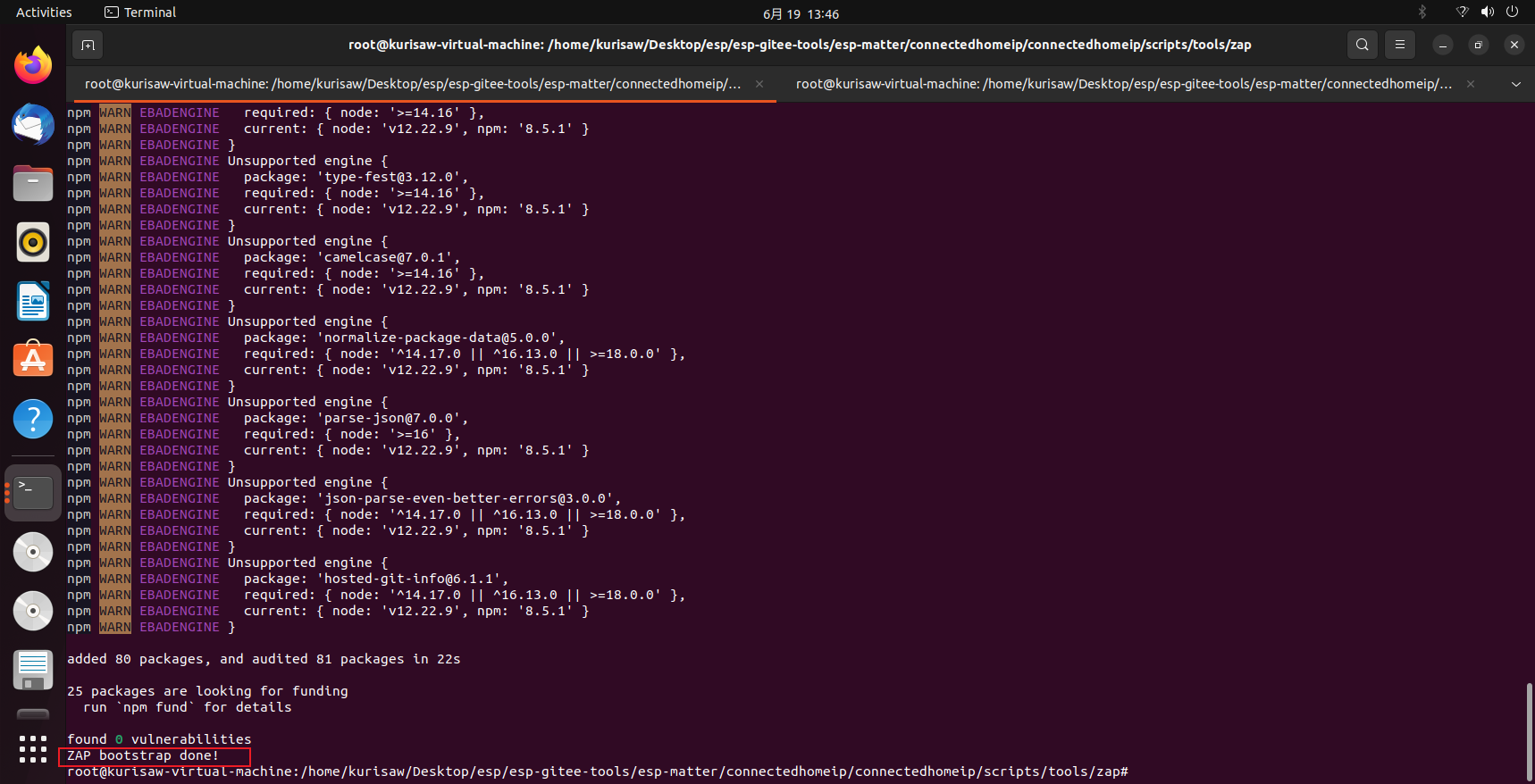
| |
在.bashrc文件最末添加如下代码,也就是配置zap环境变量
| |
保存退出!
在官方文档中提供有两种构建方式:
| |
build_script.sh 是脚本的文件名;EXAMPLE_DIR 是示例项目的目录路径;OUTPUT_DIR 是构建输出的目录路径;[ARGUMENTS] 是可选的其他参数,用于设置gn和ninja命令的选项。 | |
| |
| |
| |
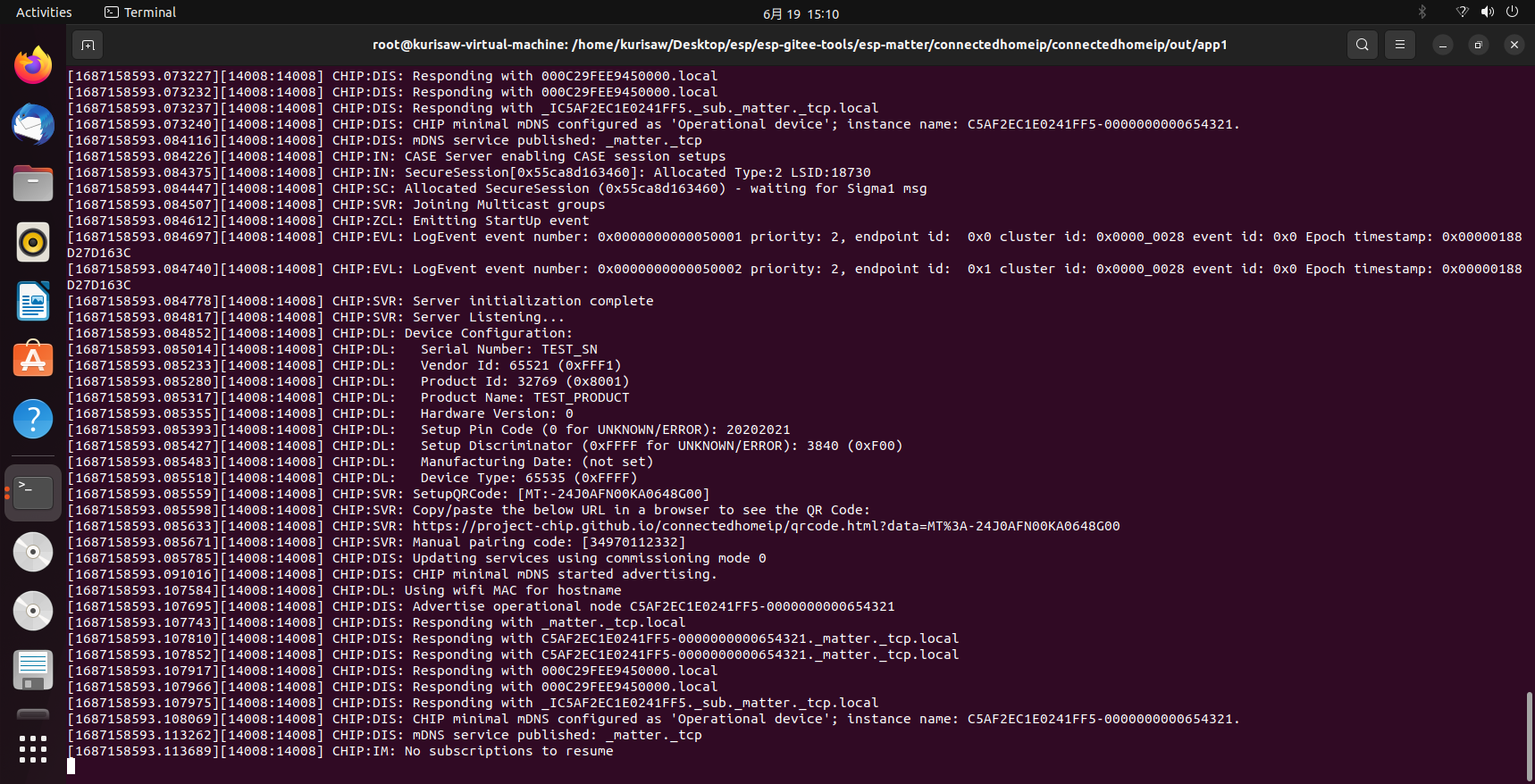
在前面的应用程序构建那一节中我们已经完成了应用程序的构建并且成功运行了构建,同时我们在日志中也可以看到生成了QR码的链接,我们将其复制到浏览器打开即可得到二维码
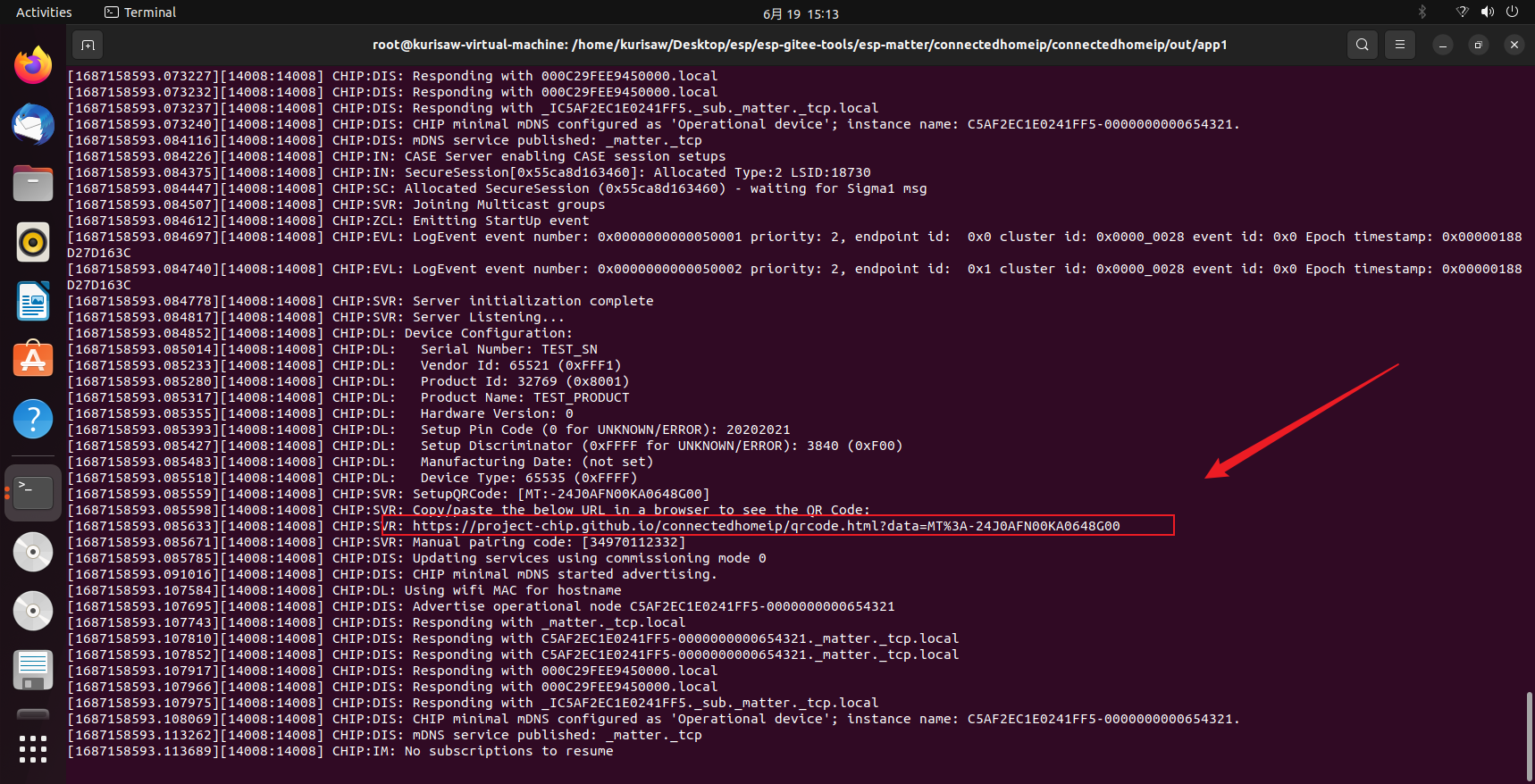
我们使用chip tool结合生成的QR码进行调试,重新打开一个终端,使用默认的chip tool工具(记住不是之前构建应用程序生成的chip tool),通过QR码可以快捷迅速地将虚拟设备添加到网络中,我们使用chip tool对设备进行调试:
| |
具体更多的使用命令可参考:Chip tool
Micro-ROS(Micro Robot Operating System)是ROS 2(Robot Operating System 2)的嵌入式版本,专门设计用于在嵌入式系统中运行,以支持机器人和嵌入式设备的实时控制和通信。Micro-ROS的目标是将ROS 2的强大功能扩展到资源受限的嵌入式平台,例如微控制器和嵌入式系统。
Micro-ROS的出现使得嵌入式系统和机器人应用能够更紧密地与ROS 2生态系统集成,从而实现更高级别的机器人自动化和控制。它为开发人员提供了一种在嵌入式环境中构建复杂机器人系统的方法,无论是在无人机、自动导航车辆还是其他嵌入式控制应用方面。

以下是Micro-ROS的一些关键特点和概念:
嵌入式系统支持: Micro-ROS旨在在嵌入式系统上运行,包括微控制器和其他资源受限的硬件。它提供了一个轻量级的ROS 2堆栈,以便将ROS 2功能集成到这些系统中。
实时性和硬件抽象: Micro-ROS支持实时性需求,使其适用于对实时性要求较高的应用程序。此外,它提供了硬件抽象层(HAL),允许在不同嵌入式平台上使用相同的ROS 2代码。
通信和中间件: Micro-ROS使用ROS 2通信机制,因此可以无缝地与其他ROS 2系统通信。它支持多种通信方式,包括串口、UDP、以太网等。
适用于机器人和自动化: Micro-ROS的主要应用领域包括机器人和自动化系统。通过将ROS 2的能力引入嵌入式系统,开发人员可以更轻松地构建具有传感器、执行器和通信需求的机器人应用。
可扩展性: Micro-ROS可以根据应用程序的需求进行扩展和定制。开发人员可以选择要包括的ROS 2功能和模块,以适应其特定应用场景。
开源: Micro-ROS是开源项目,遵循ROS 2的开源精神。这意味着开发人员可以自由地访问、使用和贡献到该项目。
本文将教你如何快速上手使用如何在 RT-Thread上运行 micro-ros,使用包括串口(serial)和UDP两种通信方式与主机 ROS 通信。
| |
| |
克隆下来的 env-windows 可以放在D盘,同时双击打开 env.exe,待启动ConEmu终端后将其注册到鼠标右键快捷方式

首先去官网安装如下工具:
打开 windows powershell ,使用 python 安装 scons
| |
GNU make 的安装可以参考该 issue 的三种方式
这里我选择的是使用choco安装make,打开windows powershell(管理员):
| |
为了防止在后续下载 micro ros 过程中 GitHub 仓库拉取失败,可以下一个 Fastgithub 来加速 GitHub
选择一份 bsp 进行 micro_ros 的开发,这里我使用的是 RTT 最近出的星火Spark
| |
去官网下载 gcc-arm-none-eabi-10-2020-q4-major-win32工具链,注意不用配置到环境变量中,以免发生冲突
修改 bsp 工程下的 rtconfig.py 文件,指定 gcc 工具链

回到.\rt-thread\bsp\stm32\stm32f407-rt-spark目录下,打开 ConEmu 执行如下命令生成 packages 目录
| |
克隆 micro_ros 配置仓库
| |
我们来看下目录层次:
| |
这里我们需要将micro_ros_rtthread_package目录复制一份到..\env-windows\packages目录下,同时修改..\env-windows\packages\Kconfig内容如下:
| |
想要在 RT-Thread 中使用 micro_ros ,需要先通过 Cmake 编译得到一份 libmicroros.a静态链接库文件,下面是 micro_ros Cmake 的相关配置:
回到目录:..\rt-thread\bsp\stm32\stm32f407-rt-spark
使用 ENV 生成 CMakeLists.txt 文件,里面包含了工程的配置编译选项:
| |
此时我们在当前目录下就可以看见一个 CMakeLists.txt文件了,同时我们进入目录.\rt-thread\bsp\stm32\stm32f407-rt-spark\packages\micro_ros_rtthread_component\builder,找到toolchain.cmake文件,参考前面生成的CMakeLists.txt文件修改toolchain.cmake

再次回到..\rt-thread\bsp\stm32\stm32f407-rt-spark目录下,打开 ENV 勾选配置:
| |
其中在Memory configuration中的Publishers和Subscribers这两个参数值要求大于2,因为在 micro_ros 的示例工程:micro_ros_ping_pong要求至少两个发布者和两个订阅者,同时我们选择通信模式为 serial
此外,我们需要一个串口进行通信,根据板载情况勾选一个串口设备,并确保该串口成功创建!!
同时我们使用 vscode 打开文件packages\micro_ros_rtthread_component\src\rtt_serial_transport.c,搜索宏MICRO_ROS_SERIAL_NAME并修改为你新创建的串口设备名。
回到.\rt-thread\bsp\stm32\stm32f407-rt-spark目录下,鼠标右键打开 windows powershell ,输入如下命令:
| |
此时我们就可以看到 python 会自动安装依赖包并且开始下载 microros所需的依赖库,并且该依赖库的安装位置位于 C:\Users\$user\AppData\Local\Temp\micro下
这里的配置项主要位于packages\micro_ros_rtthread_component\builder\SConscript文件中,由于不同的工具链和平台所使用的一些标准C库函数有些不同差异,所以目前是基于 cortex-M4 适配了 micro_ros 库,在packages\micro_ros_rtthread_component\builder\microros_utils\repositories.py文件中更改了一些仓库分支为我修改的仓库分支,后续会以补丁文件的形式发布

编译完成后会使用 ar 将所有依赖的 micro_ros 库文件静态链接成 packages\micro_ros_rtthread_component\builder\libmicroros\libmicroros.a文件,同时将C:\Users\20537\AppData\Local\Temp\micro\mcu\install\include目录复制到packages\micro_ros_rtthread_component\builder\libmicroros\include目录下
编译完成后我们就得到了 rt-thread.elf 文件,可以使用 STM32CubeProgrammer 工具进行烧录到星火Spark上
附:这里说下 GCC-AR 是什么:GCC-AR 是 gcc配套的库管理工具,它可以创建,修改和提取静态库(.a文件)。 通过使用 GCC-AR,可以将多个相关的对象文件(.o文件)打包成一个静态库,以方便在后续的编译过程中重复使用这些对象文件。

WSL安装:WSL的安装具体可以看网上怎么操作的,此处不再赘述
Docker安装:打开 wsl 终端,使用官网脚本一键安装即可
| |
请参考这篇文章完成 usbipd 的支持:https://club.rt-thread.org/ask/article/8671e03210f950a7.html
此处仅给出相关命令,具体流程请参考演示视频:
| |
演示视频:[点击此处精准空降: microros_rtt_serial]
首先需要在linux本地 搭建好 ROS 环境,micro-ros环境的安装参考**鱼香大佬的网站**
注意:我们安装的ros版本为 ros:foxy
继续搭建 micro-ros 构建环境,打开linux终端,按照如下步骤一步步走:
| |
完成上述工作后我们micro ros的代理环境就准备就绪了
| |
这里就不讲详细的配置了,具体过程请看下方链接:
演示视频:[点击此处精准空降: microros_rtt_serial]
为什么编译不使用 ConEmu :因为 ConEmu 内部集成的是 python27 ,而 micro_ros 编译所需的 python 版本最低为 python36,建议使用 python38 及以上版本
如果是使用的串口方式通信,不推荐在虚拟机上运行docker microros 代理,虚拟机似乎会造成消息的多次转发,导致无法正常接收到数据,建议使用 windows wsl服务
如果是使用UDP通信的话,并且在wsl中运行 agent ,需要允许 WLS 的出入站规则,可以打开windows powershell ,并输入如下代码:
| |
如果使用udp通信不建议使用docker运行agent,docker不能直接外部访问IP,建议还是在linux本地搭建好 micro-ros代理环境
具体的实现细节在此处没有具体说明,如果是基于其他平台移植,并且想要一起学习的可以艾特我一起讨论,后面会考虑对多个架构进行支持适配

MicroPython 是 Python 3 编程语言的一种精简而高效的实现,它包含 Python 标准库的一个子集,并被优化为在微控制器和受限环境中运行。
RT-Thread MicroPython 可以运行在任何搭载了 RT-Thread 操作系统并且有一定资源的嵌入式平台上。
MicroPython 可以运行在有一定资源的开发板上,给你一个低层次的 Python 操作系统,可以用来控制各种电子系统。
MicroPython 富有各种高级特性,比如交互式提示、任意精度整数、闭包函数、列表解析、生成器、异常处理等等。
MicroPython 的目标是尽可能与普通 Python 兼容,使开发者能够轻松地将代码从桌面端转移到微控制器或嵌入式系统。程序可移植性很强,因为不需要考虑底层驱动,所以程序移植变得轻松和容易。
首先从RT-Thread官方仓库克隆master分支的仓库到本地
来到该目录:.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk,鼠标右键打开ENV工具,首先打开命令行菜单
| |
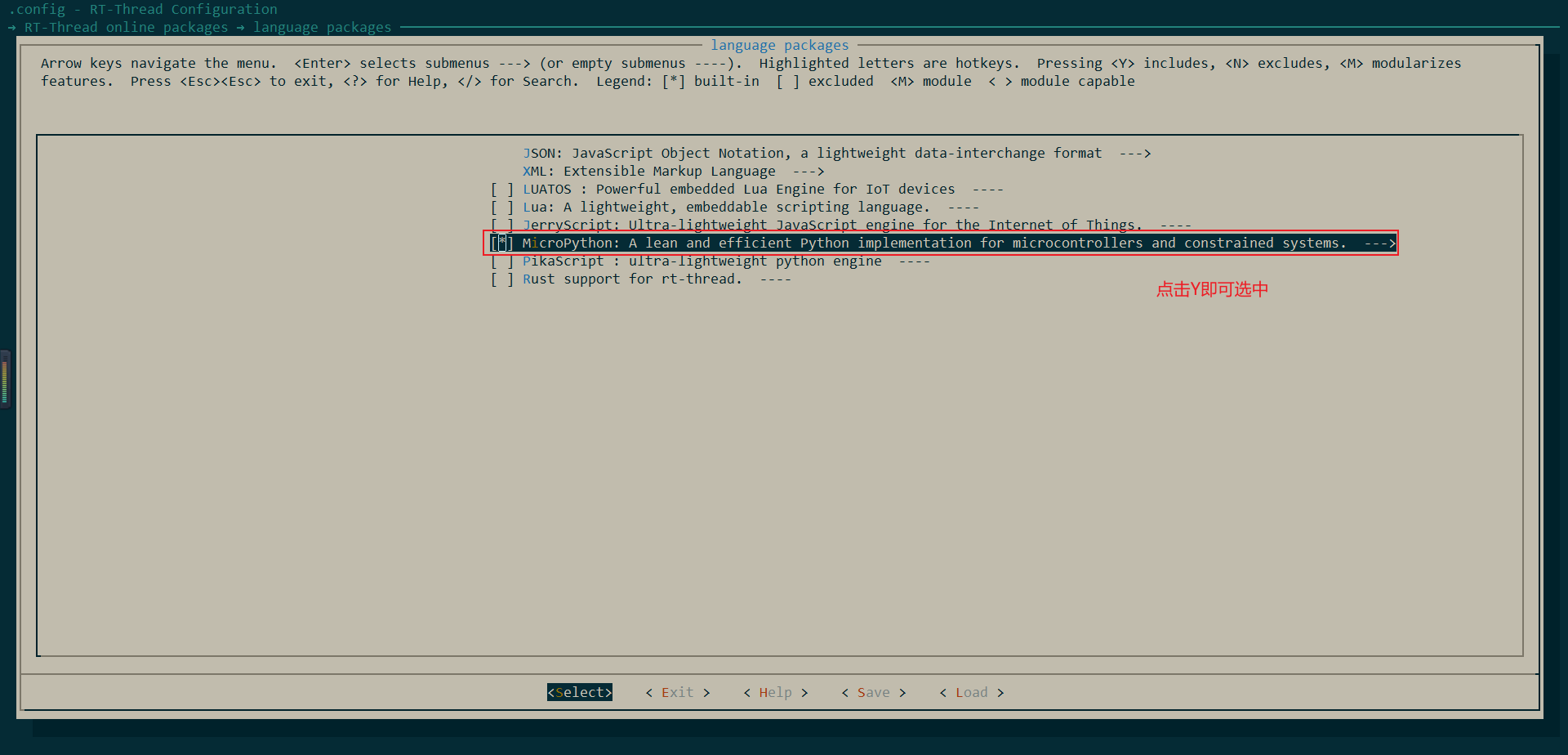
使能添加Micropython软件包:RT-Thread Online Packages--->launage packages--->Micropython
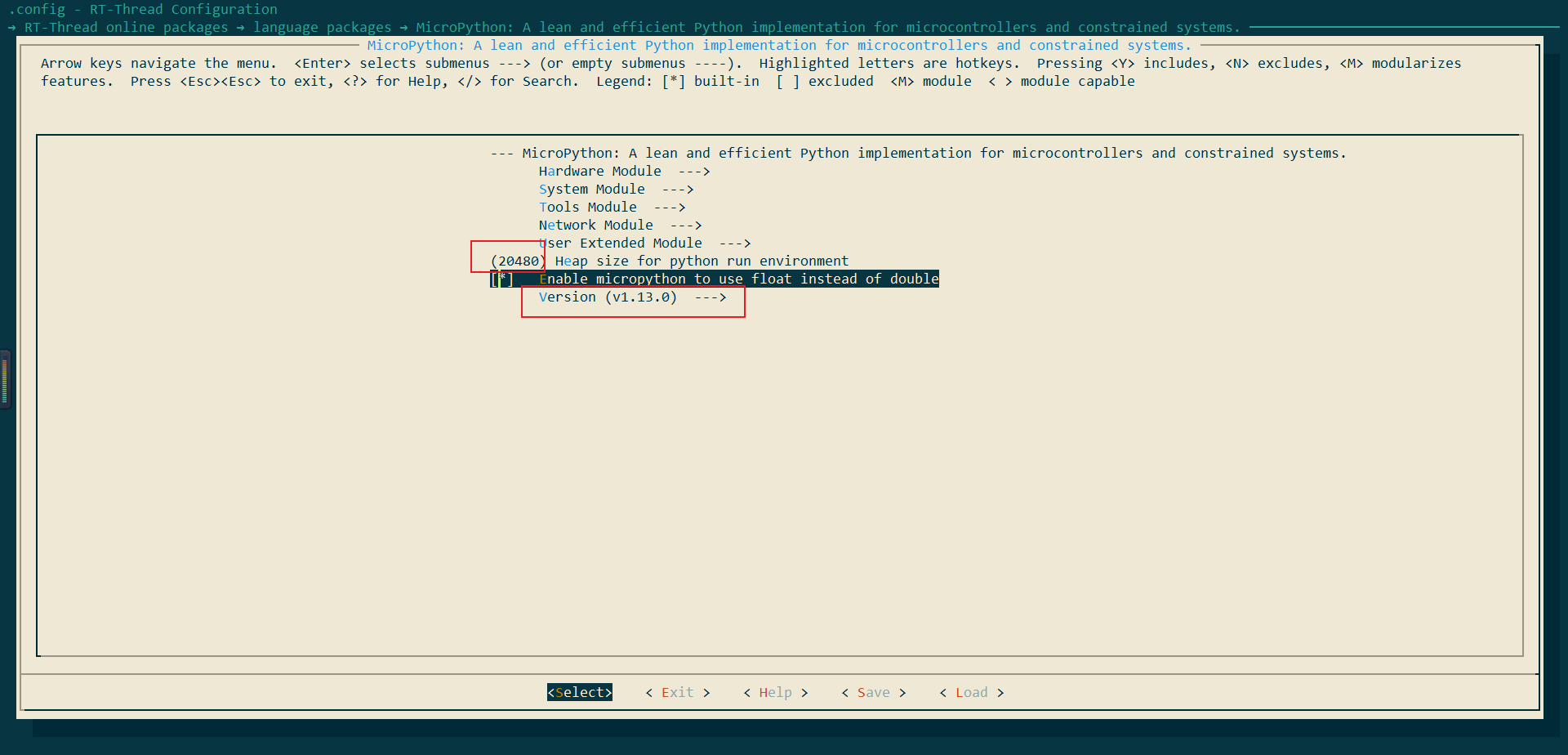
Heap size修改为20480(初次分配20K,后续用户可根据需求修改),同时版本选择最新版(这里由于我选择版本时没有注意到最下方的latest版本,但是经测试并于多出的报错问题,相关的报错也可参考该文章)
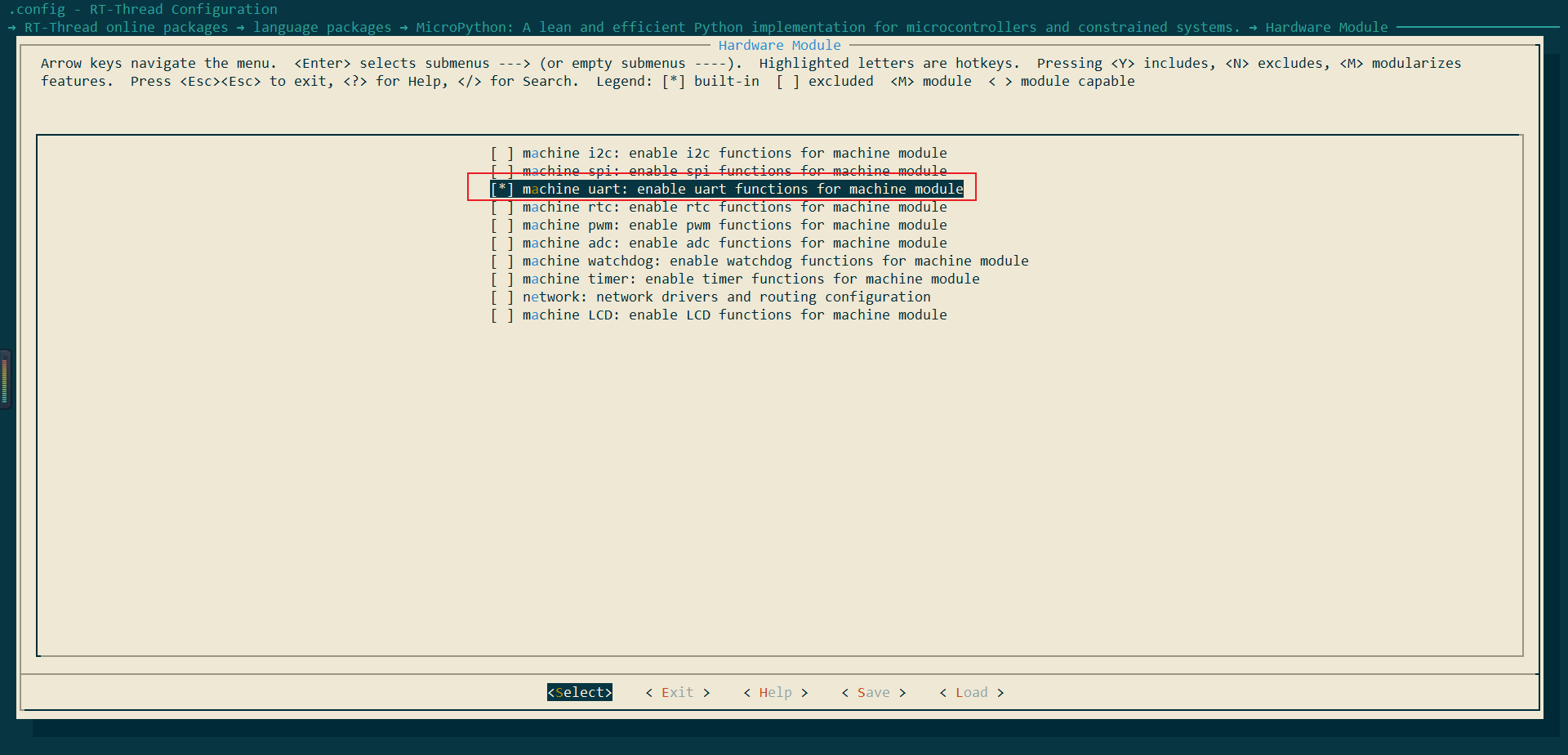
进入Hardware Module,使能machine uart
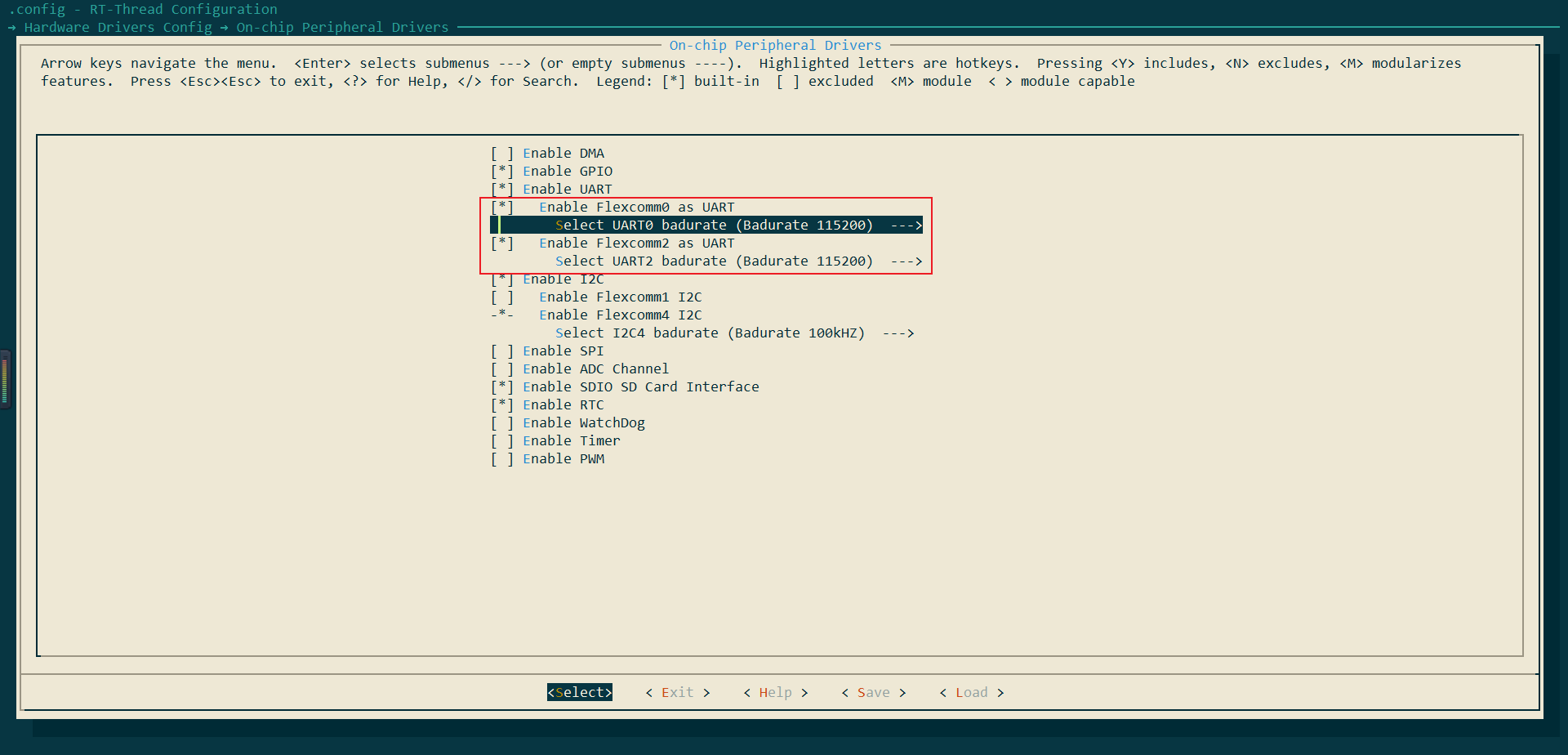
同时我们回到主菜单界面,进入Hardware Drives config--->on-chip Peripheral Drivers,使能UART0和UART2
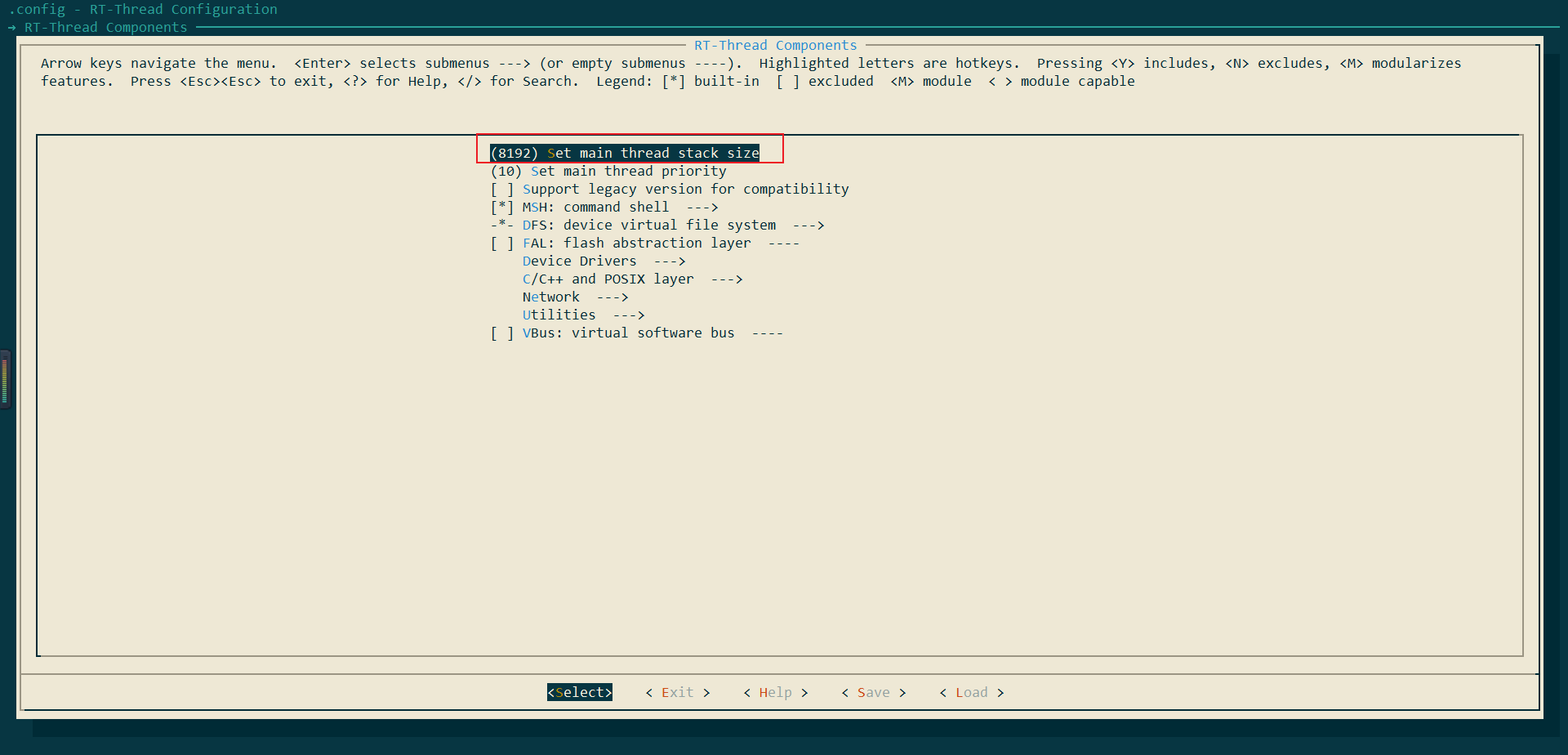
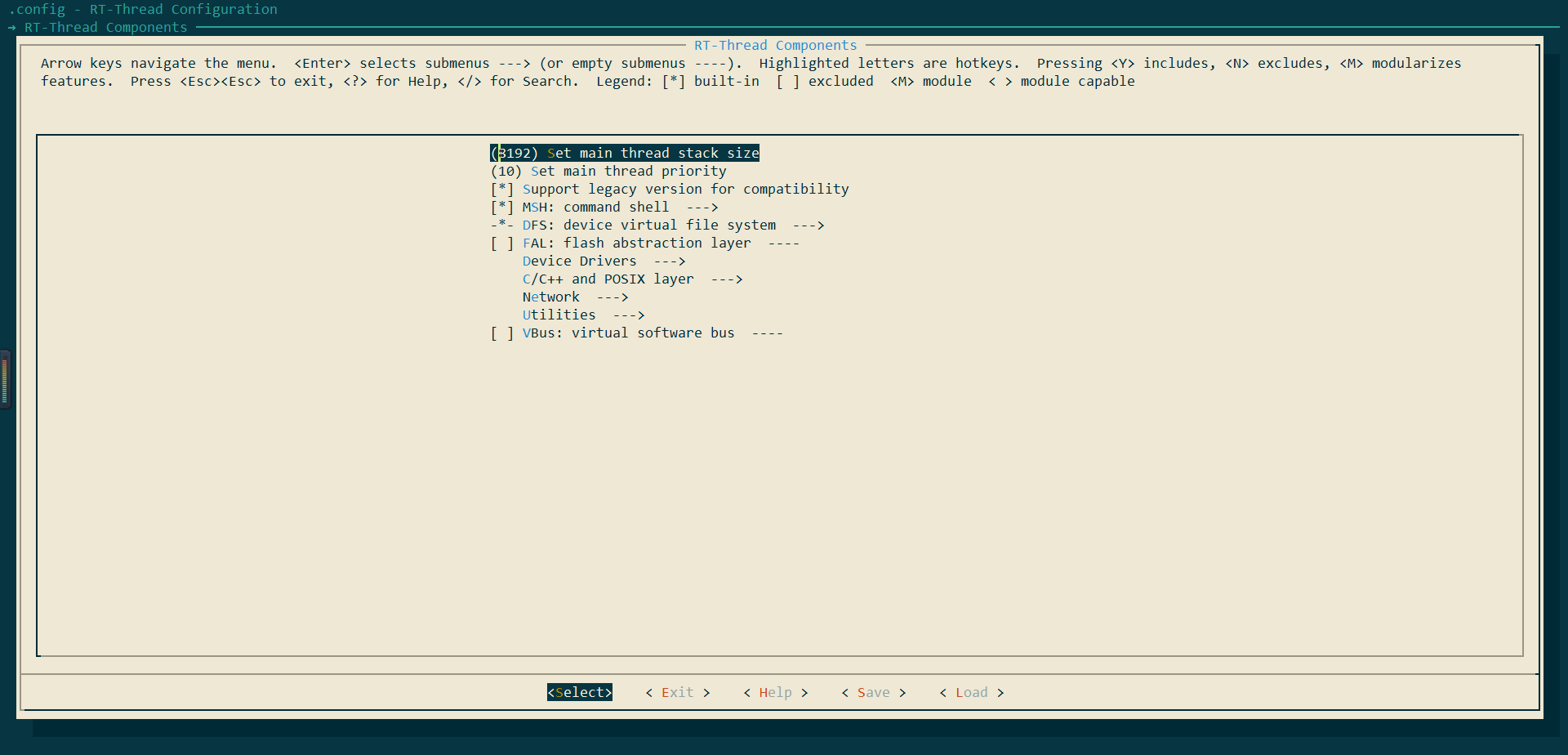
由于后续需要在main线程中启动Micropython运行时环境,需要增大main线程的栈大小,这里我们选择栈大小修改为8k:回到主界面RT-Thread Components--->set main thread stack size修改为8192
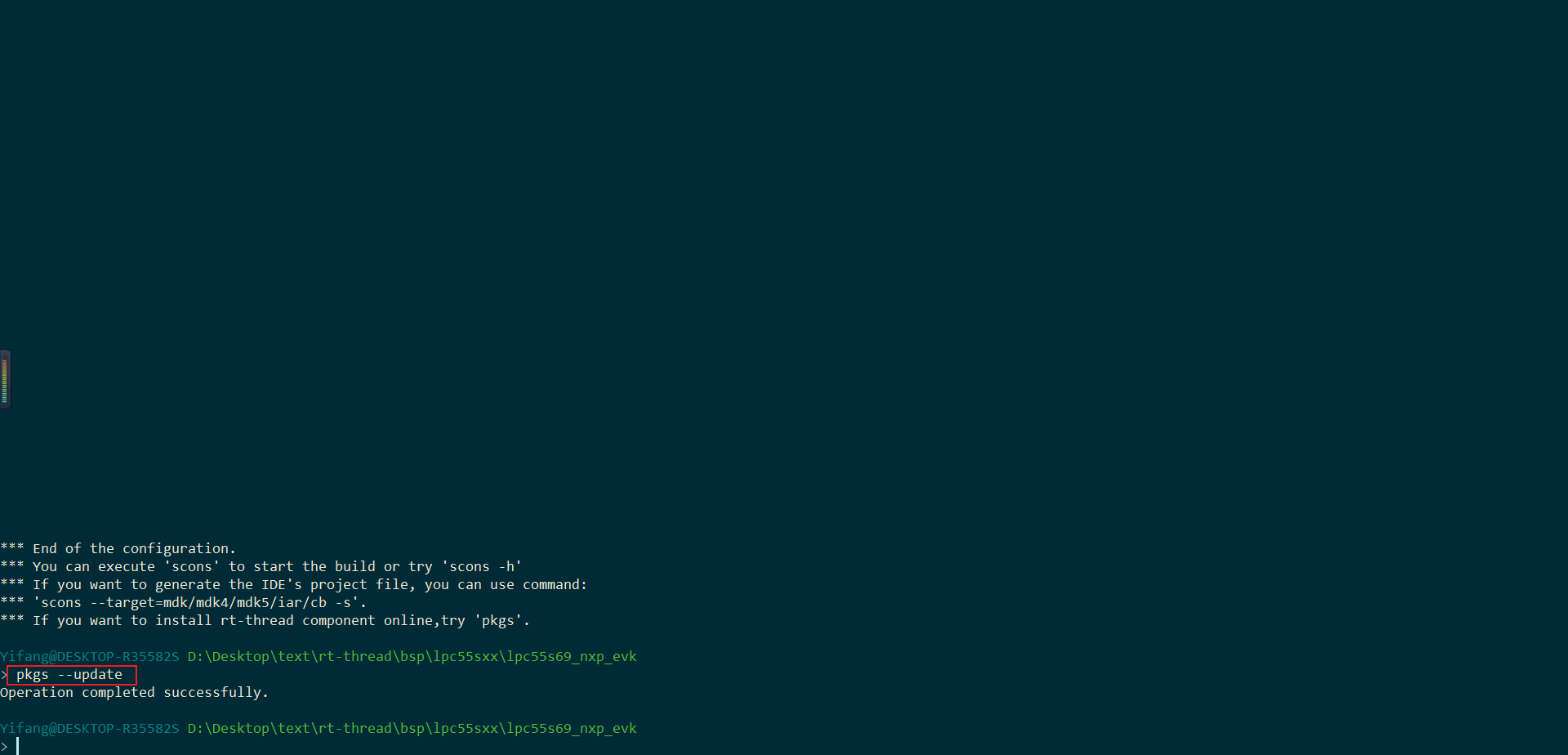
保存退出,并使用命令下载软件包:
| |
使用ENV生成MDK工程:
| |
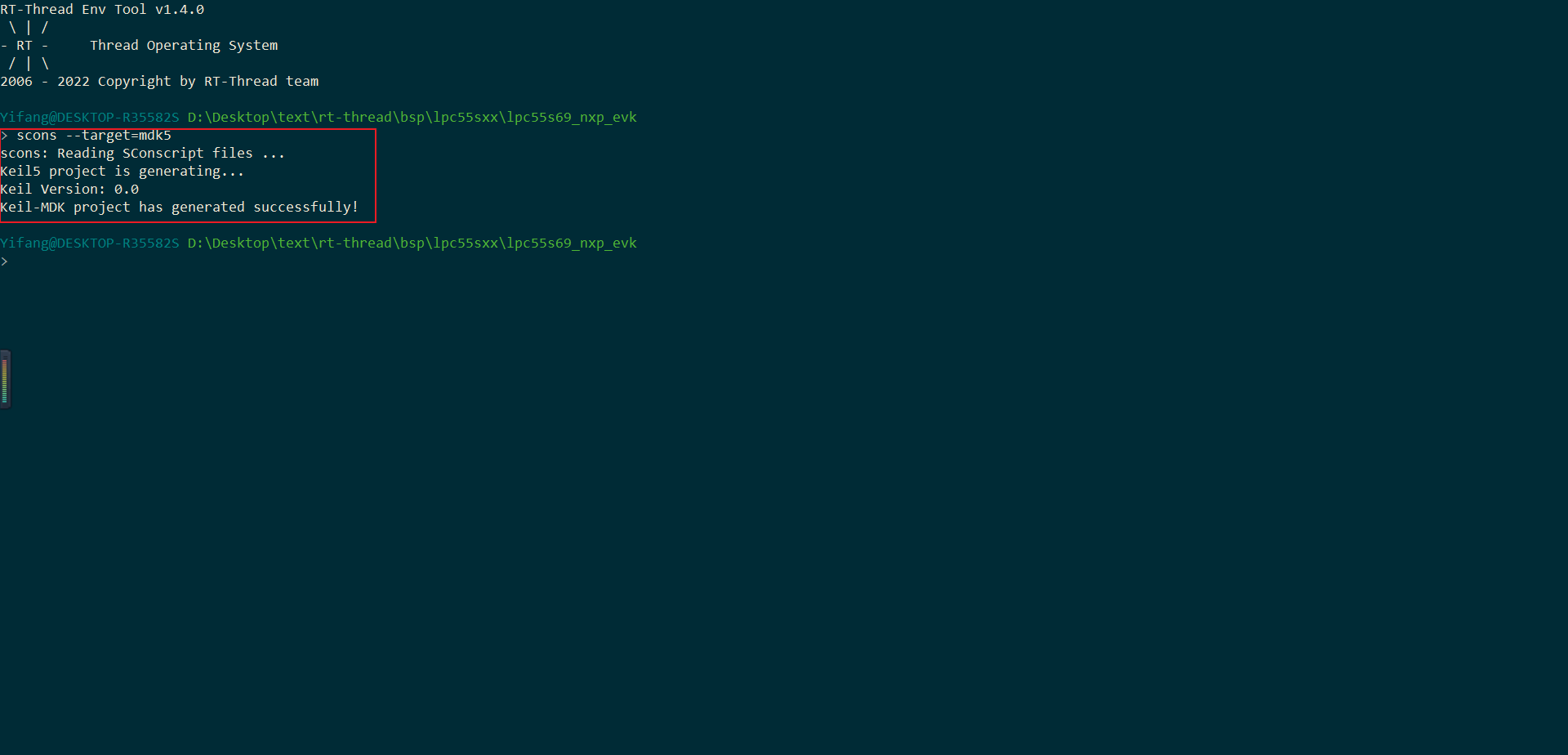
双击打开project.uvprojx,进行编译
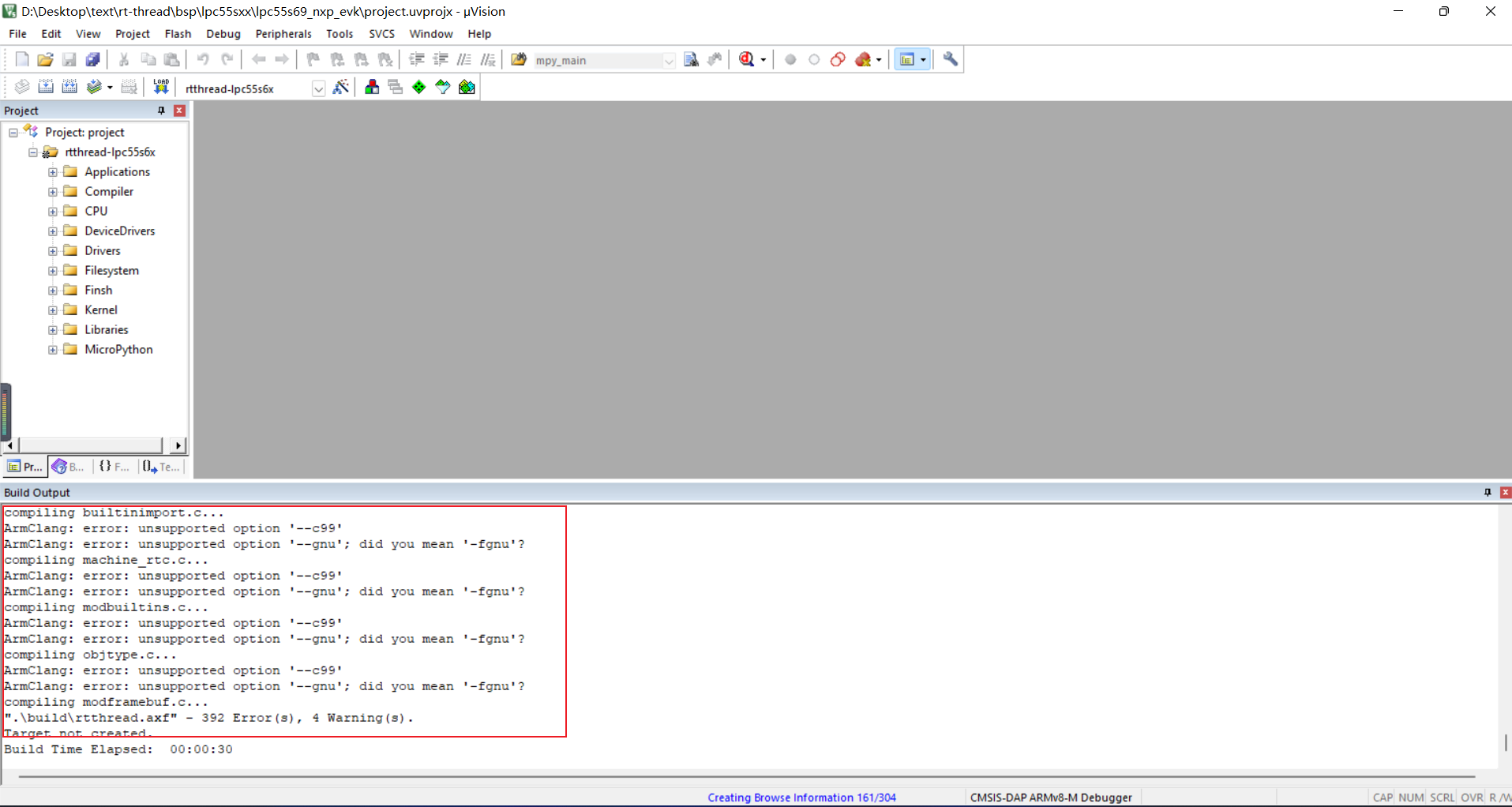
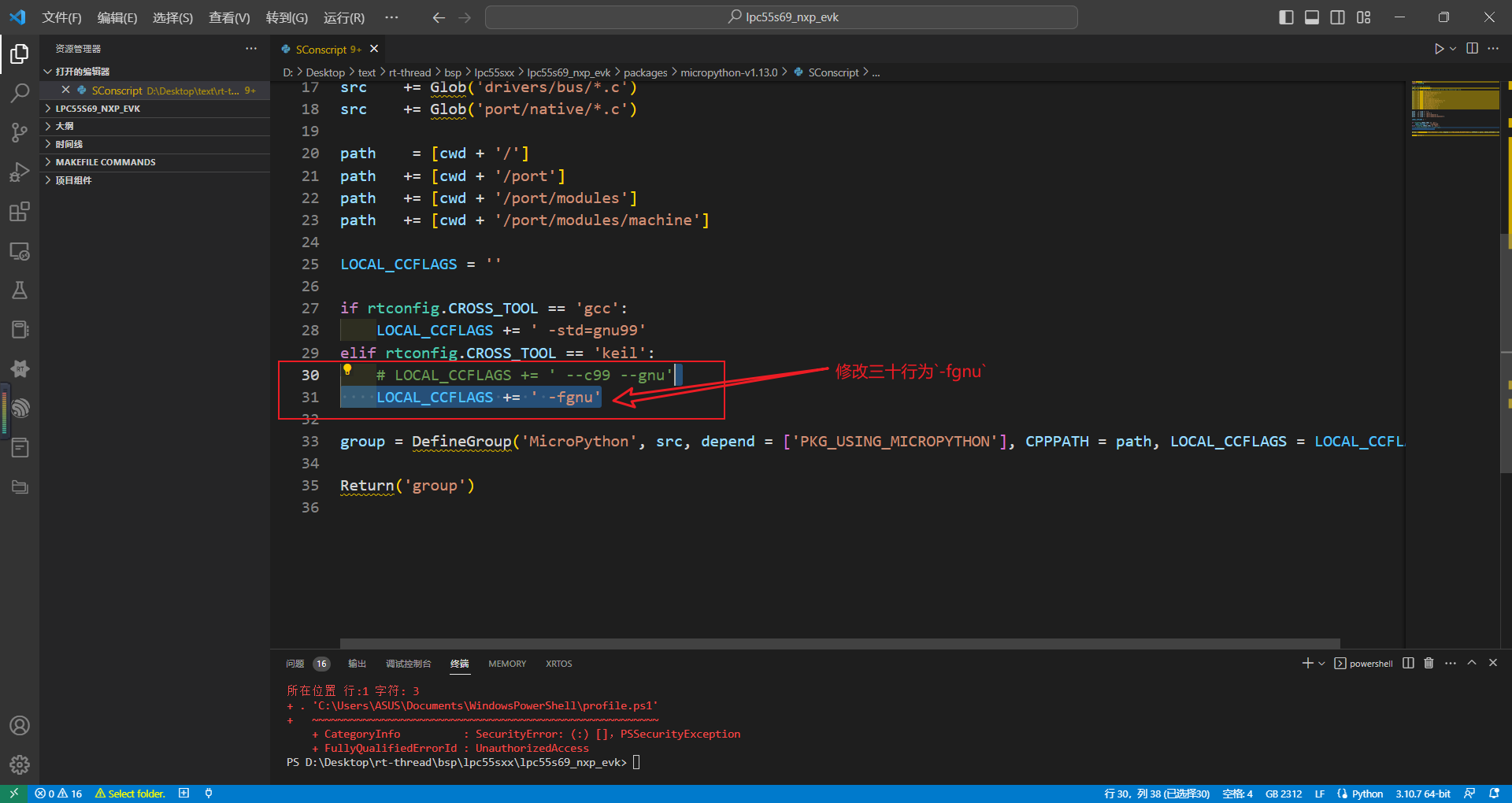
这里由于我们的keil工程为AC6版本(如果您的编译器版本为AC5,应该不需要修改,仅猜测),需要将软件包进行修改:.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk\packages\micropython-v1.13.0\SConscript
切记此时需要回到bsp目录下,重新使用ENV工具生成MDK文件,然后再回到keil重新编译工程:
| |
此时编译错误大大减少,只剩下三个错误:

第一个错误需要在菜单中使能Support legacy version for compatibility(目前该问题以推送至官方仓库,已被修复此问题),并重新使用ENV生成MDK工程文件
重新编译继续有报错,这里我们找不到该函数的定义,先在头文件中进行外部声明

找到头文件所在位置:.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk\packages\micropython-v1.13.0\port\mpgetcharport.h
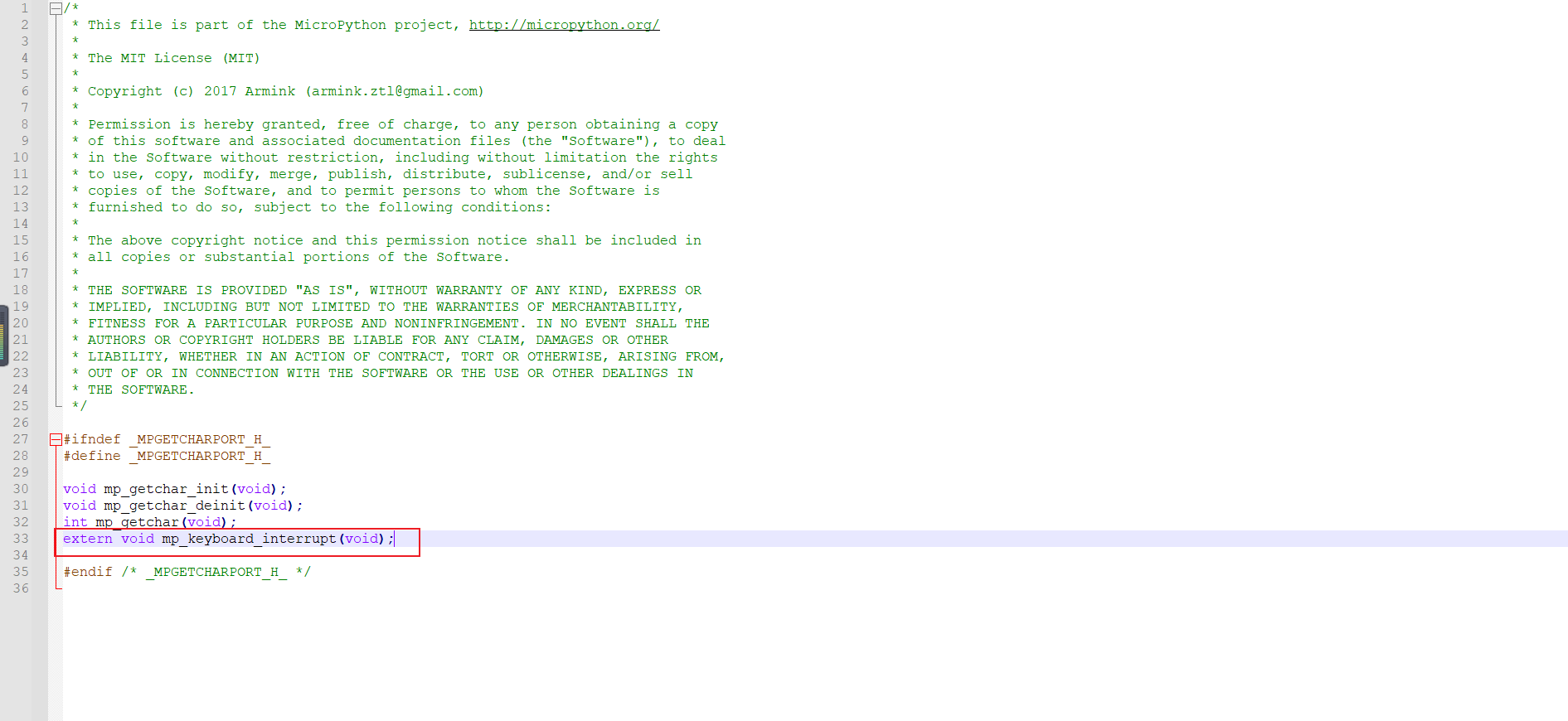
此时就剩下最后一个错误啦,这里报错是说这个宏没有定义,通过翻阅RT-Thread库函数,确定该宏是文件系统的一个宏,且定义为整型3,具体作用可查看此PR,所以解决该问题就是重新定义一下DFS_FD_OFFSET

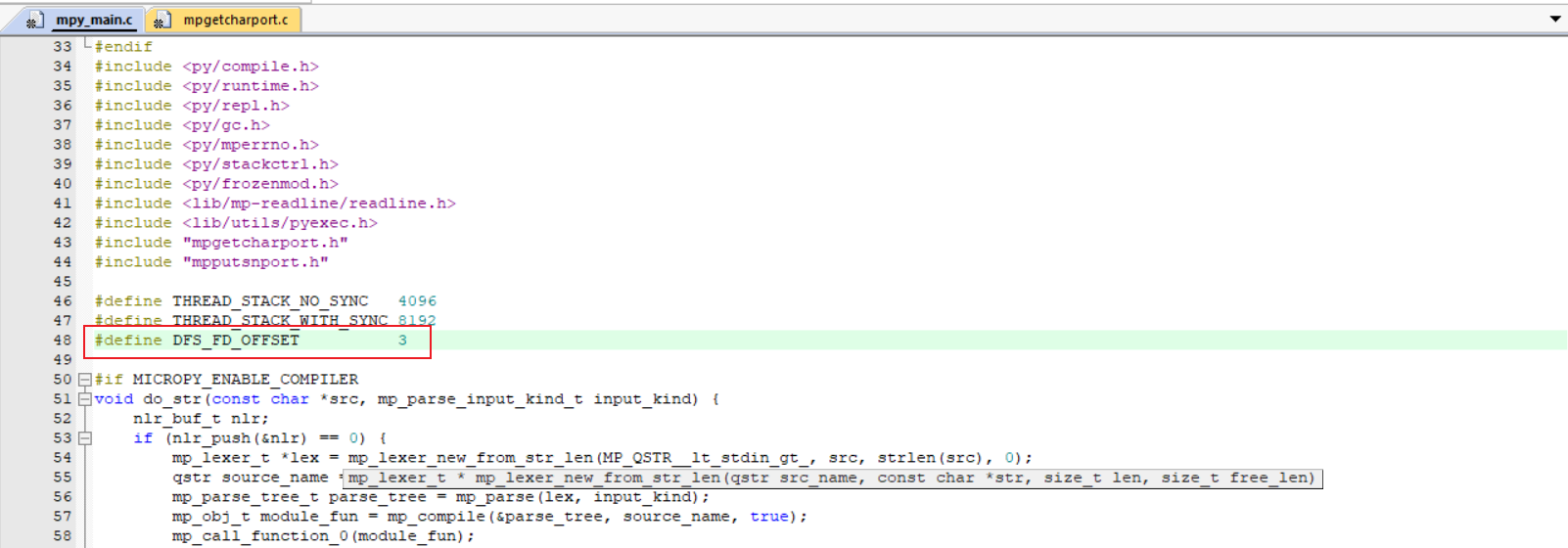
想不到编译之后居然还有一个错误,这里参考这位开发者的issue,将list_mem();注释(此处可能是个官方BUG,后续尝试修复)

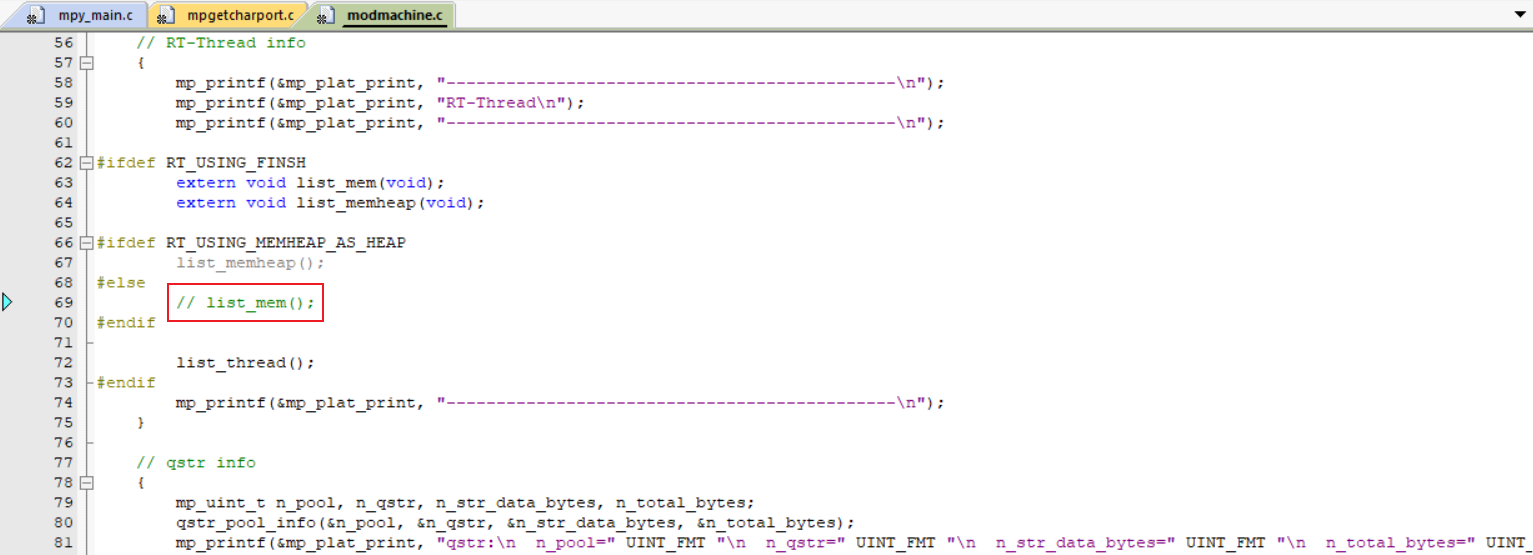
最后发现,终于没有错误啦!!!

VScode扩展搜索下载RT-Thread Micropython
vscode下方导航栏点击创建Micropython工程,创建一个新的MicroPython工程,并选择工程存放路径
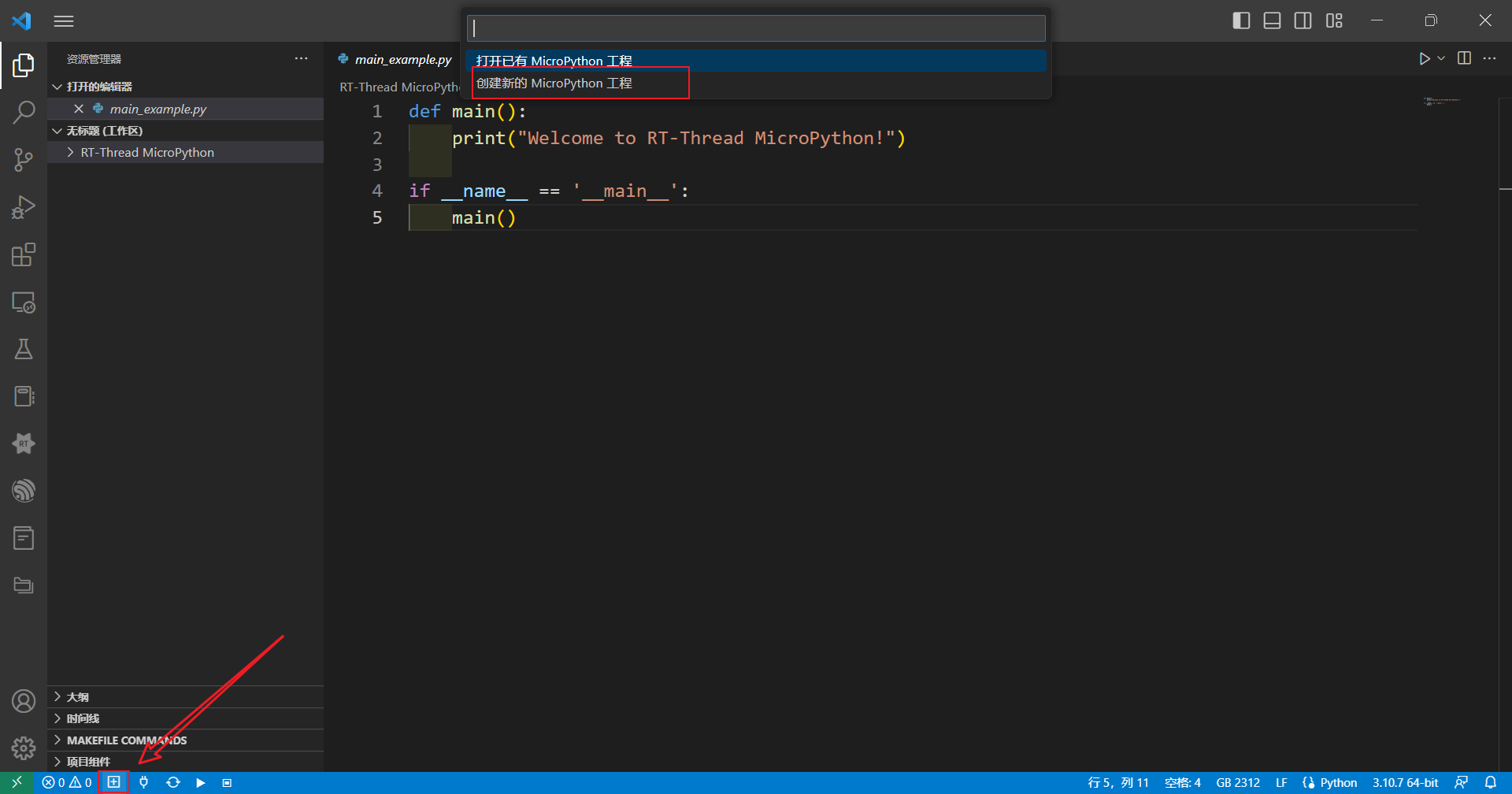
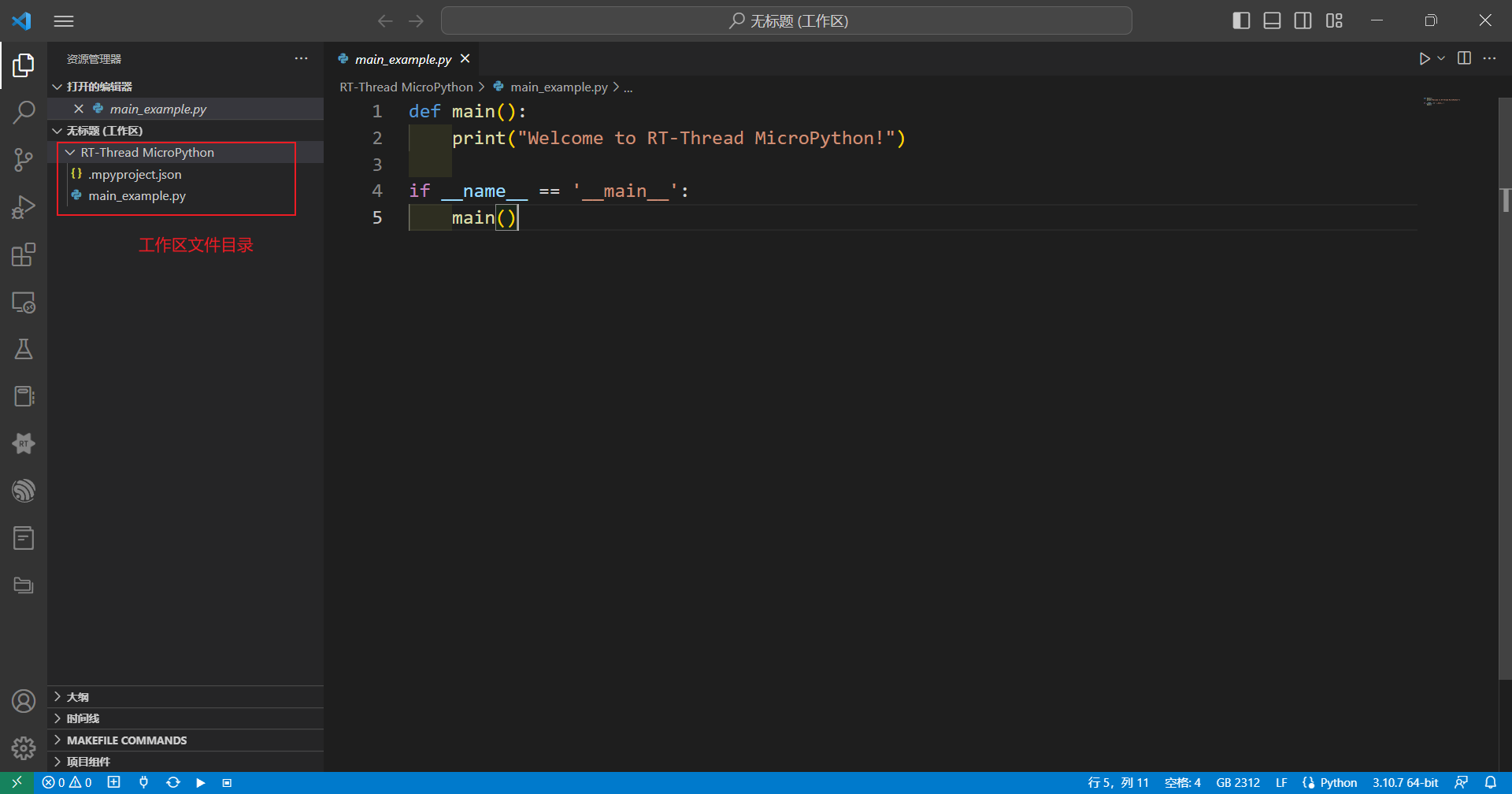
点击下方工具栏连接开发板,打开串口设备后点击复位,此时出现RT-Thread官方LOGO
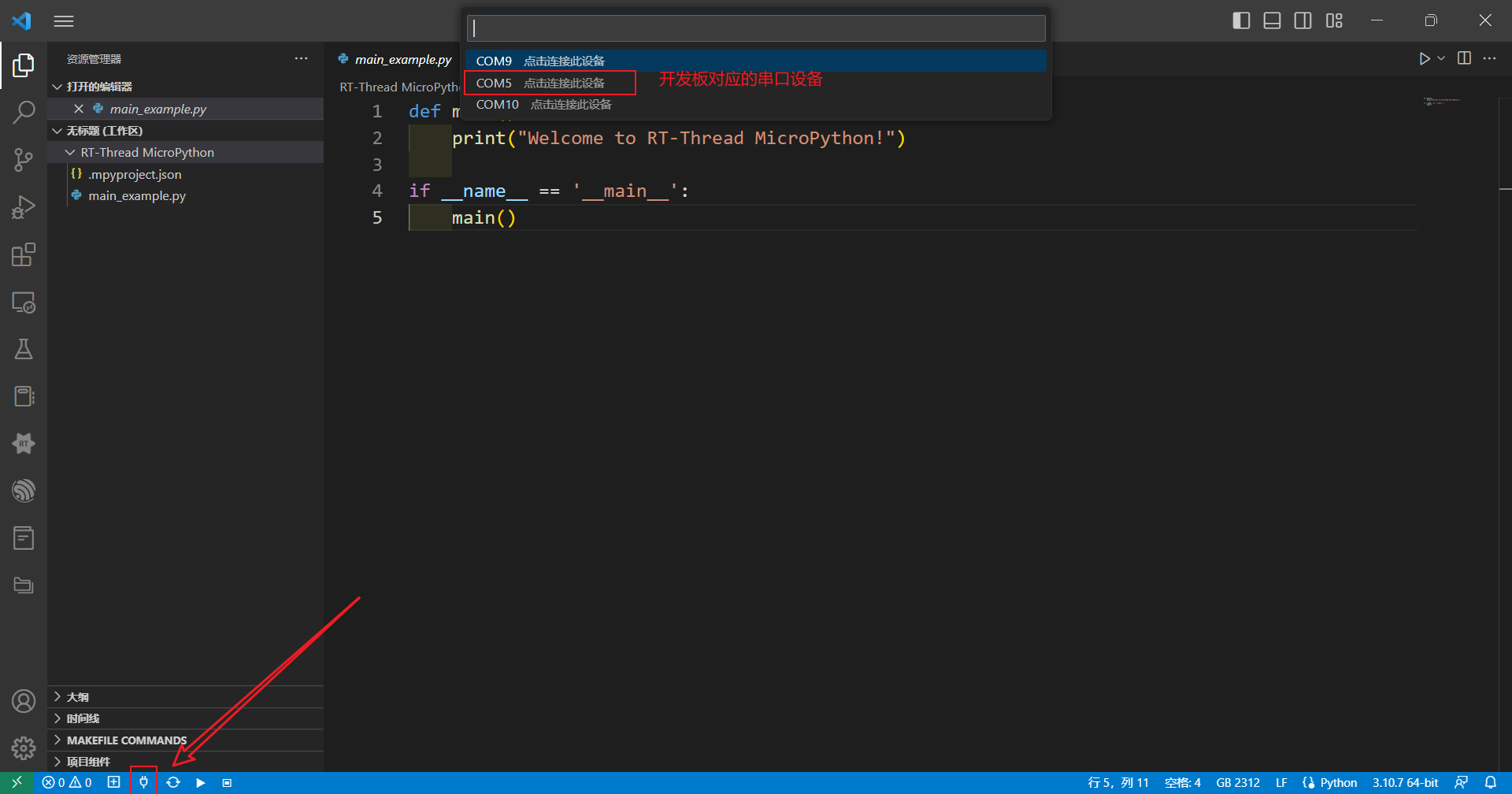
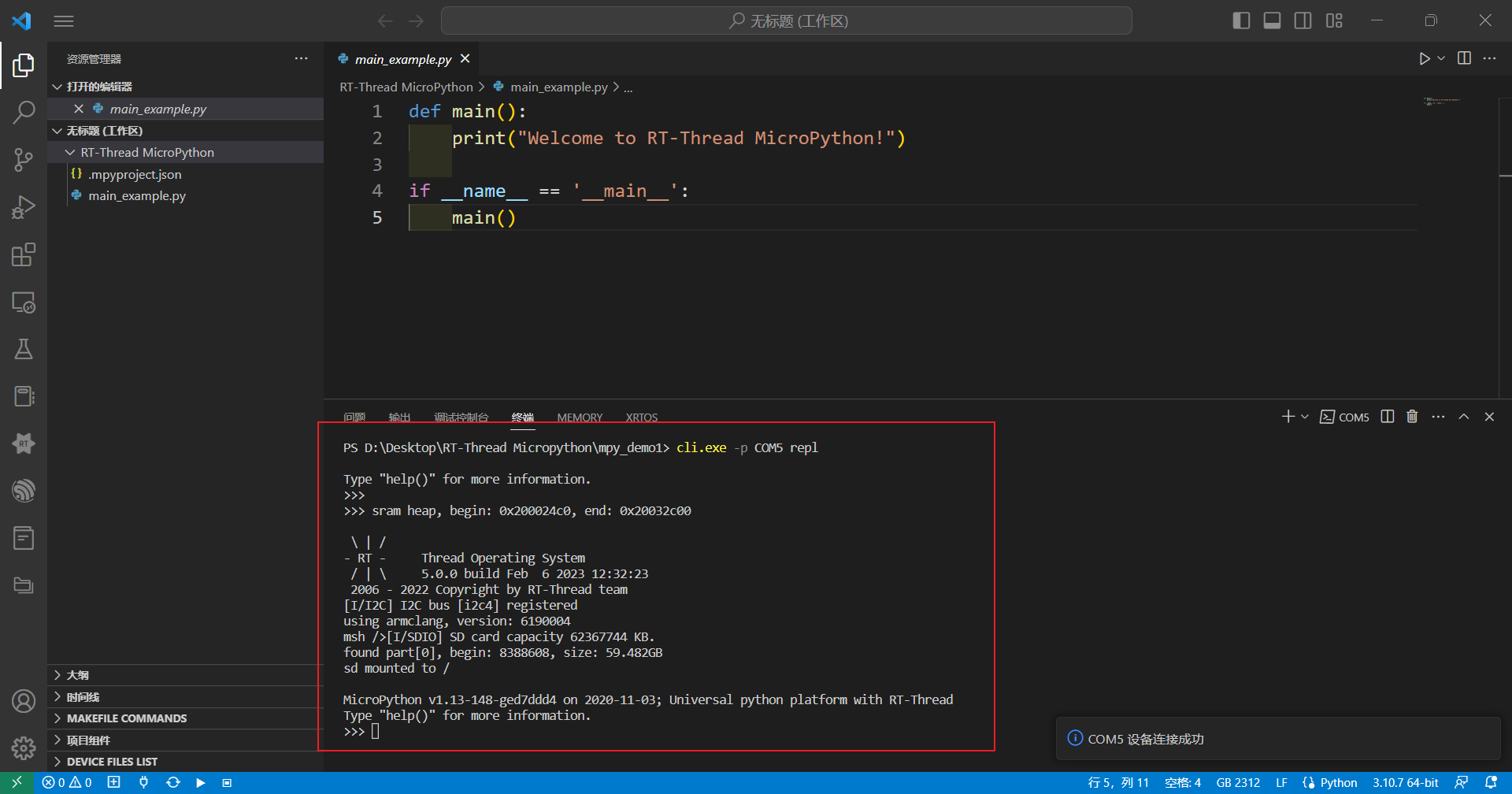
LPC55S69也成功移植了RT-Thread的FINSH组件,点击TAB键可查看Finsh控制台命令,我们可以看到有一个python命令行
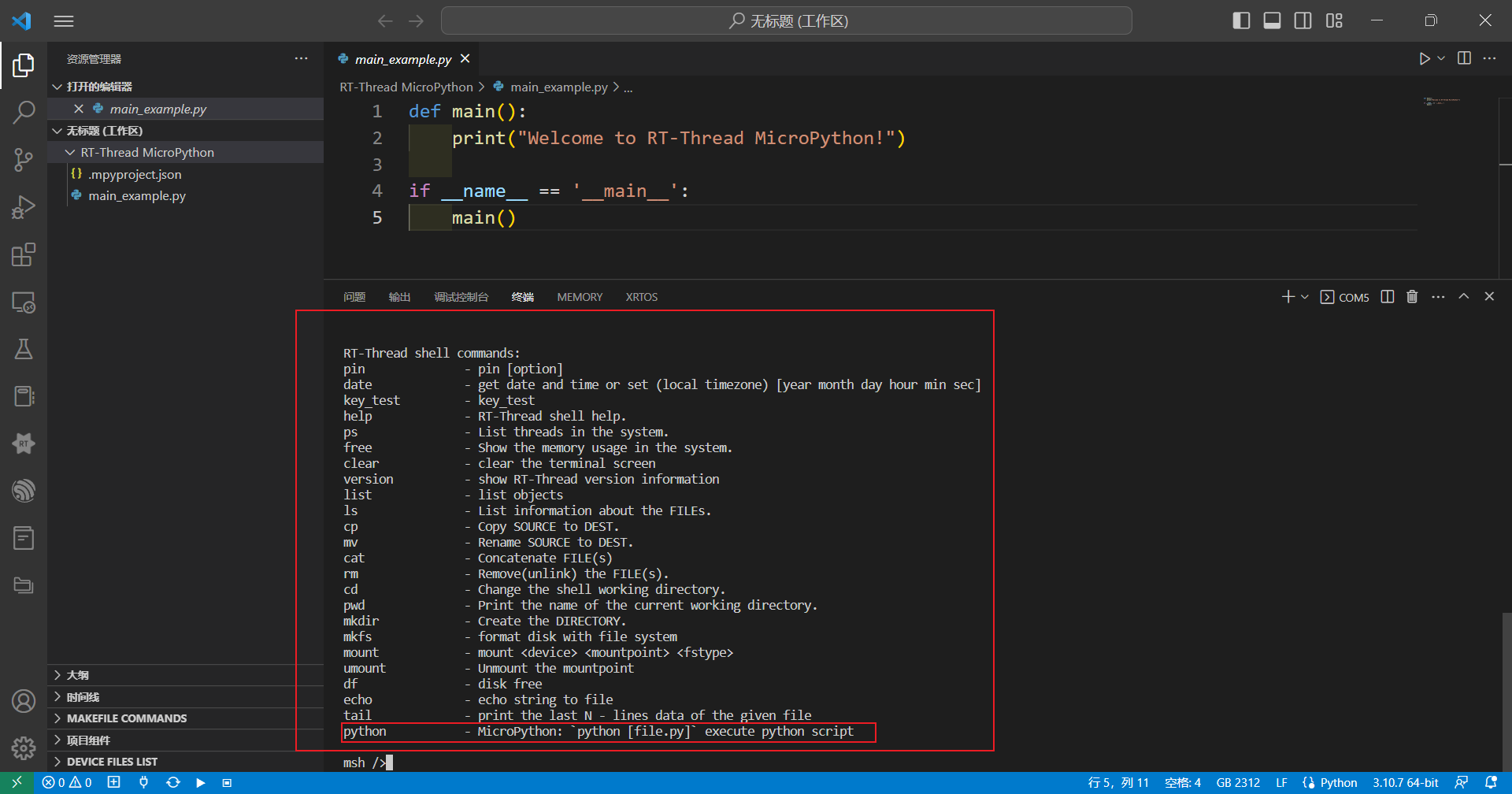
Finsh控制台输入python,转到python控制台,同时还支持quit()、exit()命令退回Finsh控制台
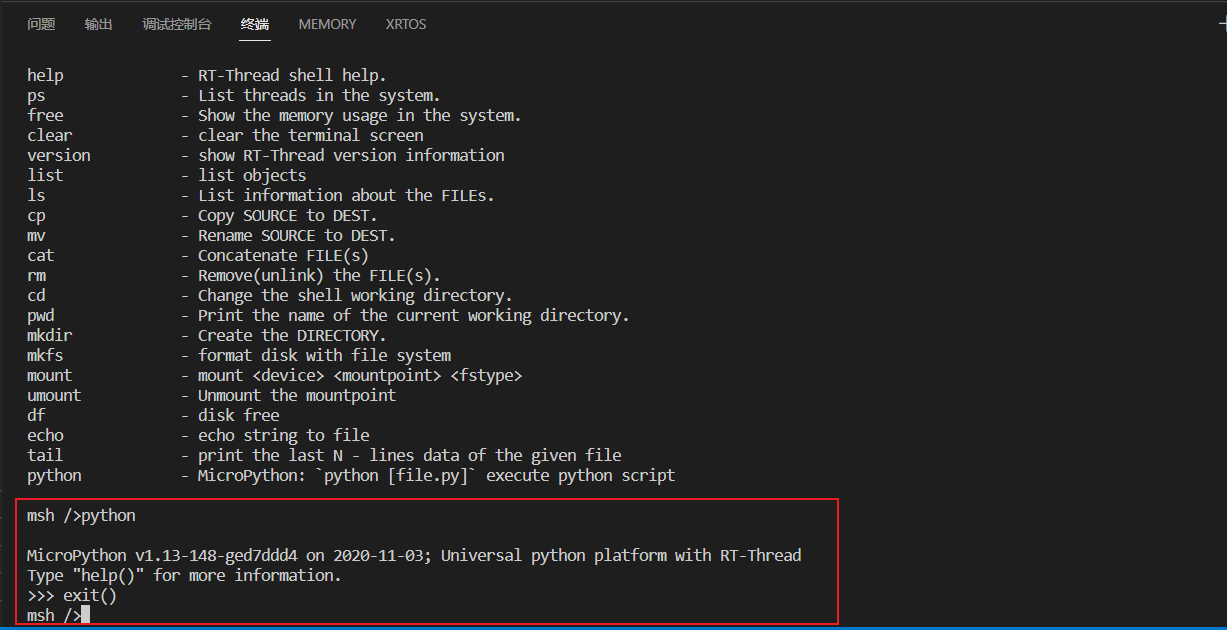
简单测试下micropython,下面使用python命令运行脚本时给了一个提示说未使能uos module
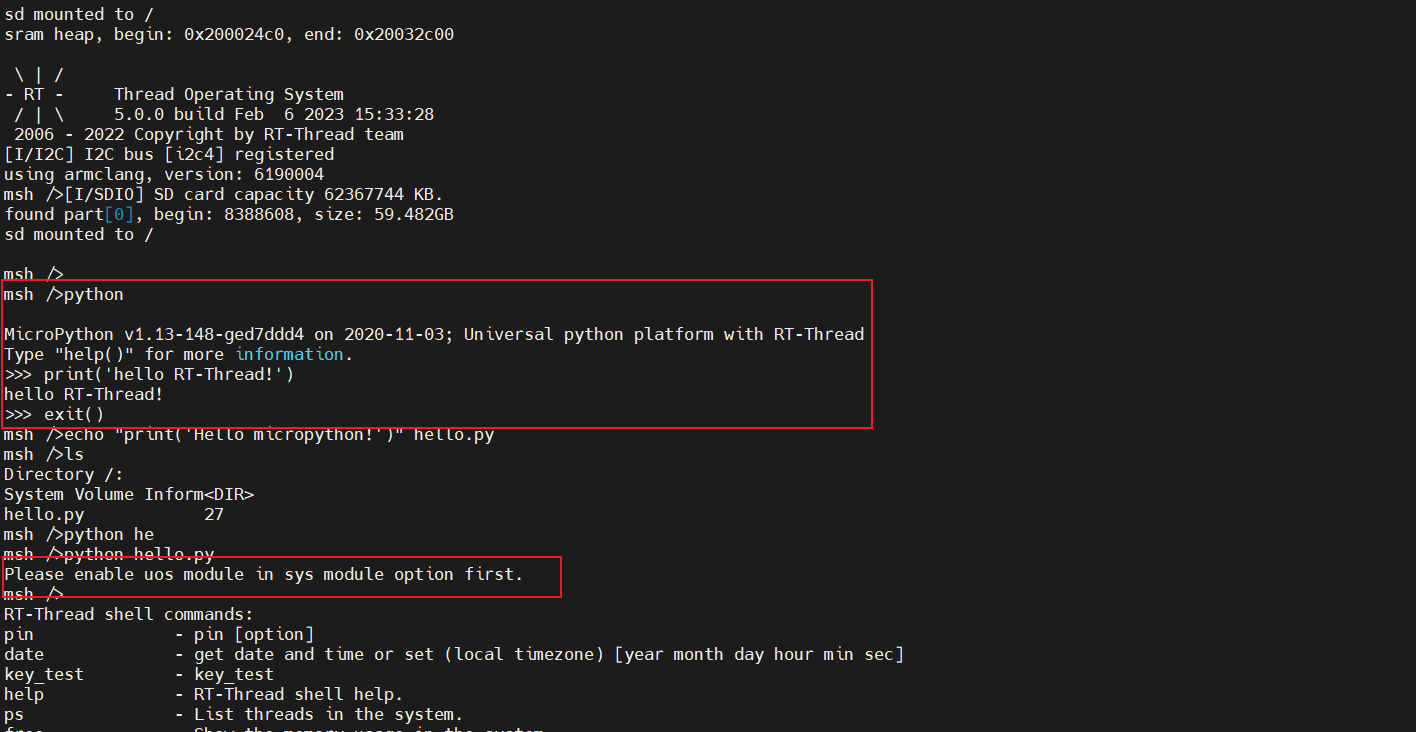
打开图形化菜单进入该路径下:RT-Thread online packages-->launage packages--->system module,使能uos:basic 'operating system' services
同时更新软件包,并使用env工具重新生成MDK,再进行编译下载,成功解决问题!
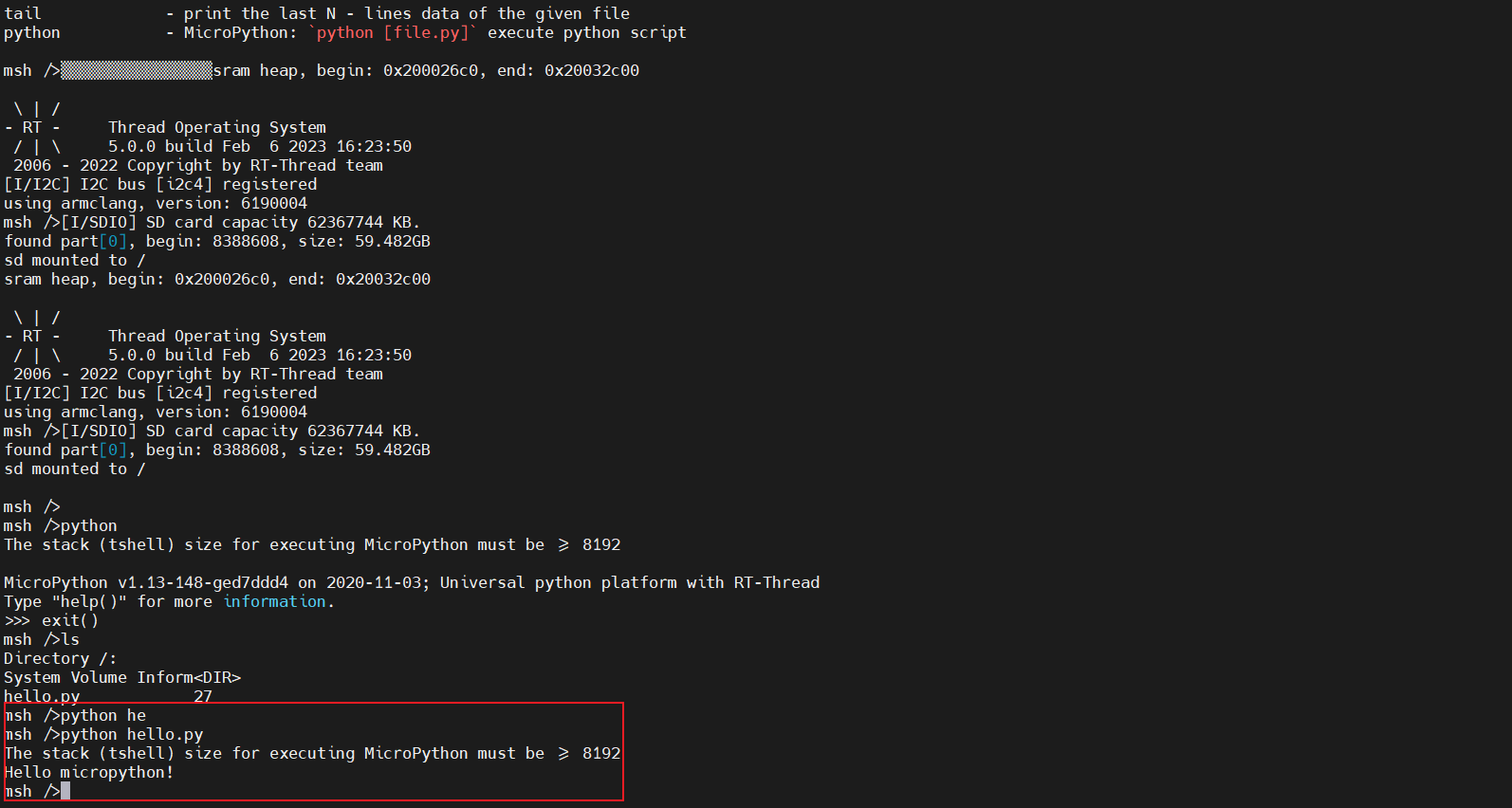
搭建好Micropython后,那么就可以自由发挥才能去创作自己的作品啦!

FAL (Flash Abstraction Layer) Flash 抽象层,是对 Flash 及基于 Flash 的分区进行管理、操作的抽象层,对上层统一了 Flash 及 分区操作的 API (框架图如下所示),并具有以下特性:
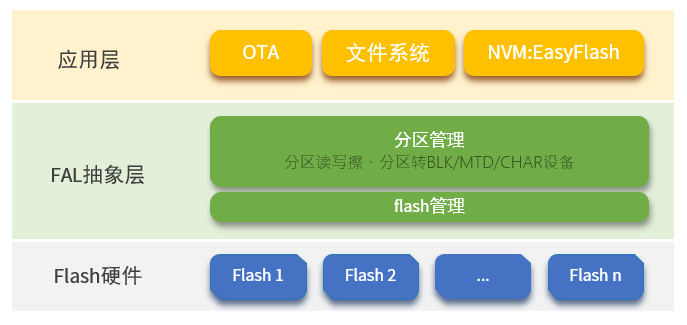
通过上图我们也可以清晰明了看到,FAL抽象层向下可以通过Flash硬件进行统一管理,当然也可以使用SFUD框架(串行Flash通用驱动库,这部分RT-Thread官方已完成框架的移植同时提供多个应用历程),而对上也可以使用如DFS、NVM提供的Flash硬件统一访问接口,方便用户更加直接方便对底层flash硬件的访问操作。
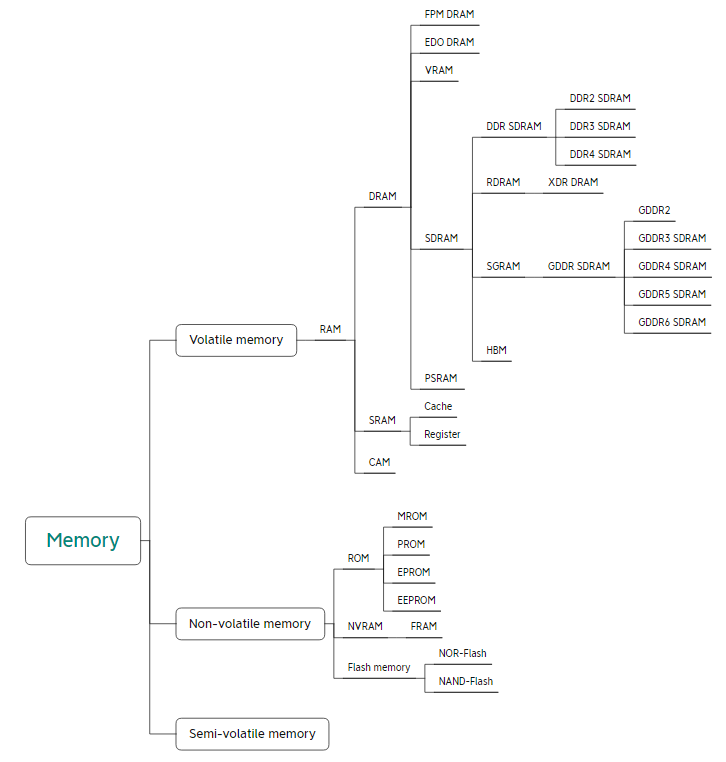
注:非易失性存储器 (NVM):在芯片电源关闭期间保存存储在其中的数据。 因此,它被用于没有磁盘的便携式设备中的内存,以及用于可移动存储卡等用途。 主要类型有:非易失性半导体存储器 (Non-volatile semiconductor memory, NVSM) 将数据存储在浮栅存储单元中,每个单元都由一个浮栅(floating-gate) MOSFET 组成。
关于存储,可以用一张图来解释:
在RT-Thread v4.1.0之前,FAL是作为软件包形式对用户开放使用的,而v4.1.0之后,FAL被RT-Thread官方重新定义为RTT组件的一部分,这样也能更加方便用户的开发。
我们下面正式讲解FAL组件的使用:
首先打开ENV工具,根据以下路径打开FAL使能RT-Thread Components->[*]FAL: flash abstraction layer,由于我们后面会用到SFUD,所以这里把FAL uses SFUD drivers一并使能,并修改FAL设备名称为W25Q128.
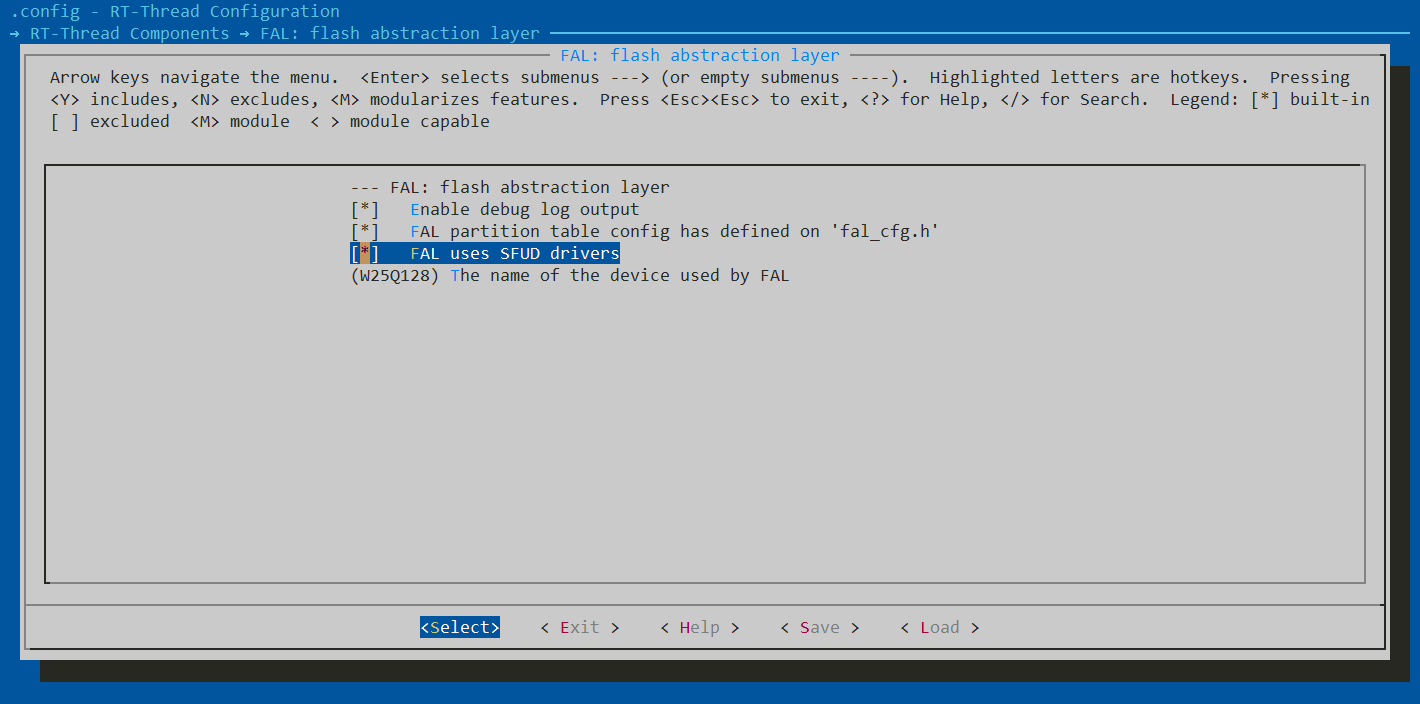
完成上述操作后保存退出,并使用scons --target=mdk5重新生成MDK5文件并打开
为了提供示例,我们选用W25Q128 spi flash作为测试模块,并且使用SFUD框架对spi flash设备进行管理和驱动。
由于目前RT-Thread的SFUD已经对W25Q128 完成支持,根据官方的使用手册,我们仅需编写fal_cfg.h文件完成对FAL_FLASH_DEV_TABLE及FAL_PART_TABLE的定义即可。文件存放路径:.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk\board\ports\fal_cfg.h
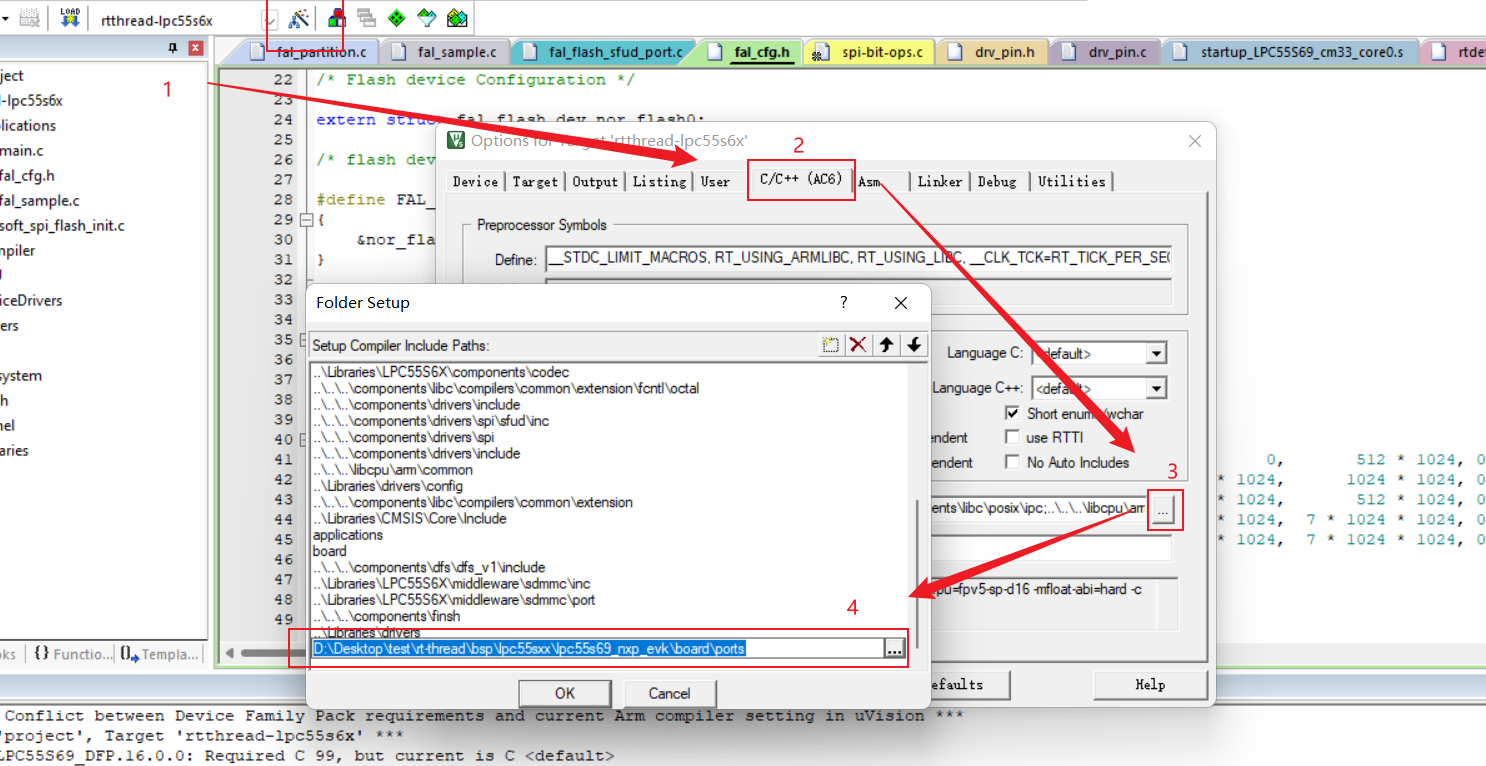
| |
此时编译的话是找不到该头文件的,需要我们在Keil中设置:
在RTT FAL组件中的SFUD提供的fal_flash_dev对象默认的nor_flash0参数中,flash大小默认为8M,而W25Q128最大最16M,我们可以选择在.\rt-thread\components\fal\samples\porting\fal_flash_sfud_port.c文件中对struct fal_flash_dev nor_flash0进行修改:
| |
当然也可以选择不进行修改,根据大佬的原话就是因为在调用初始化接口函数init后,会从flash设备读取正确的参数更新到nor_flash0表项中,我们在使用FAL组件前都需要调用FAL初始化函数fal_init,其内调用flash设备初始化函数fal_flash_init,最后会调用注册到fal_flash_dev设备表项中的初始化函数device_table[i]->ops.init,所以nor_flash0表项参数会在FAL初始化时被更新。
同时我们需要开启SFUD框架支持,打开ENV工具,由于SFUD的使用需要指定一个spi设备,这里我选择使用最近移植好的软件spi,路径Hardware Drivers Config->On-chip Peripheral Drivers->[*] Enable soft SPI BUS-> [*] Enable soft SPI1 BUS (software simulation),这里我的测试开发板是恩智浦的LPC55S69-EVK,并且这款bsp的软件模拟spi由我本人对接,关于这部分的软件spi引脚定义可以选用默认即可,当然也可以使用自定义引脚,记住不要与其他引脚产生冲突。
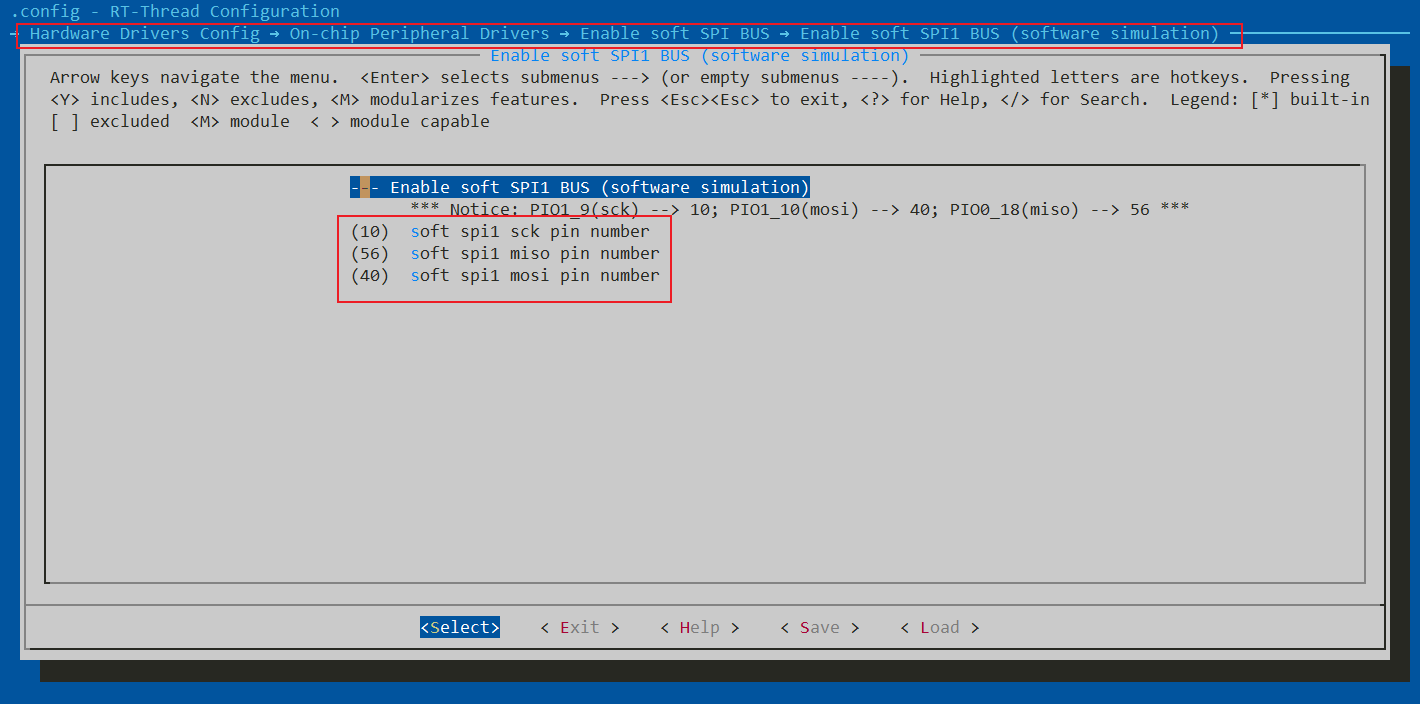
此时我们回到ENV主界面,进入RT-Thread Components->Device Drivers->Using Serial Flash Universal Driver,此时我们才可以看到SFUD选项出现(如果没有使能spi是没法看到的),使能后保持默认即可
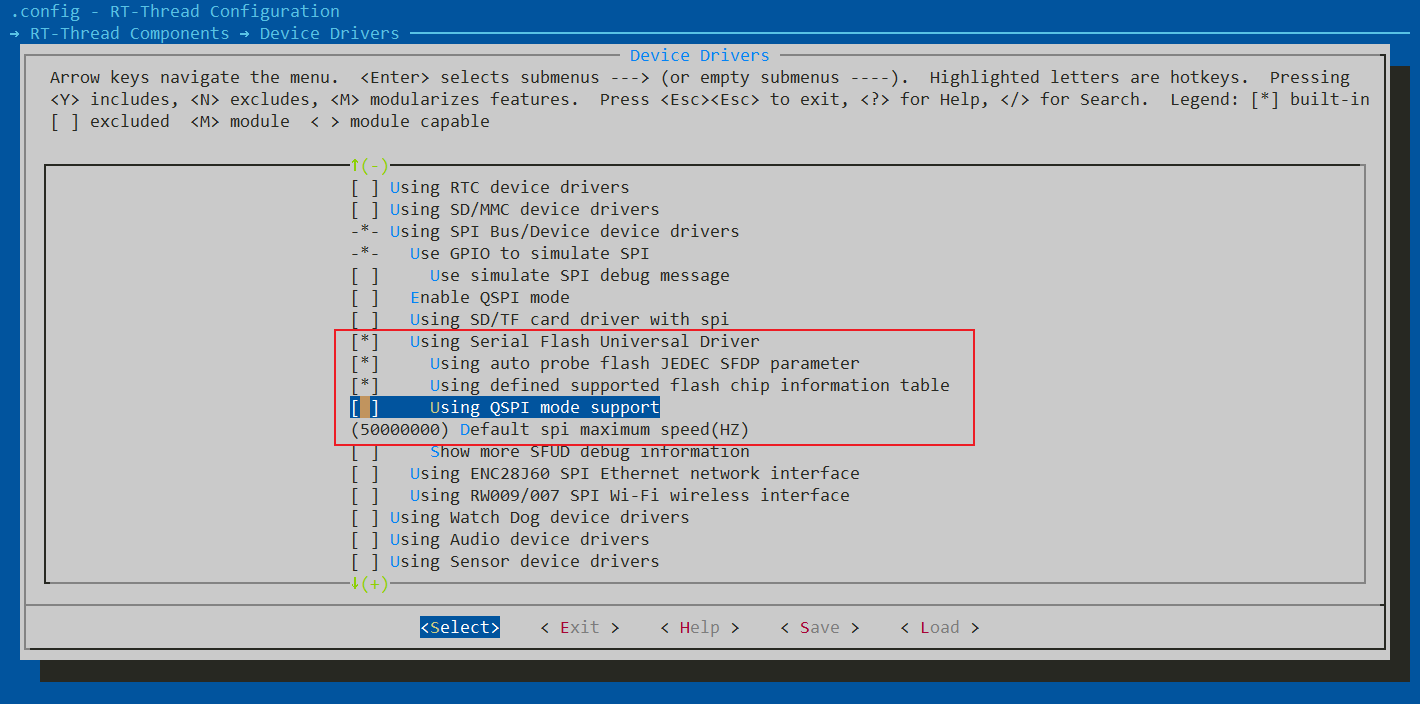
到这里,ENV的配置暂时告一段落!
为了验证W25Q128及软件模拟spi在SFUD框架上是否能够成功运行,我们在.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk\board\ports\下新建一个soft_spi_flash_init.c文件,代码如下
| |
这里我们需要指定一个片选引脚,我暂时使用了sspi2的SCK引脚作为片选,这里注意不要同时打开sspi1和sspi2,后续我会专门上传一个通用GPIO作为片选引脚,到时候就不会产生问题了。然后软件spi设备的挂载使用的是sspi1 bus及sspi10 device,并且挂载flash设备到sspi10。
另外我们在.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk\board\ports\下新建fal_sample.c文件,并编写测试代码:
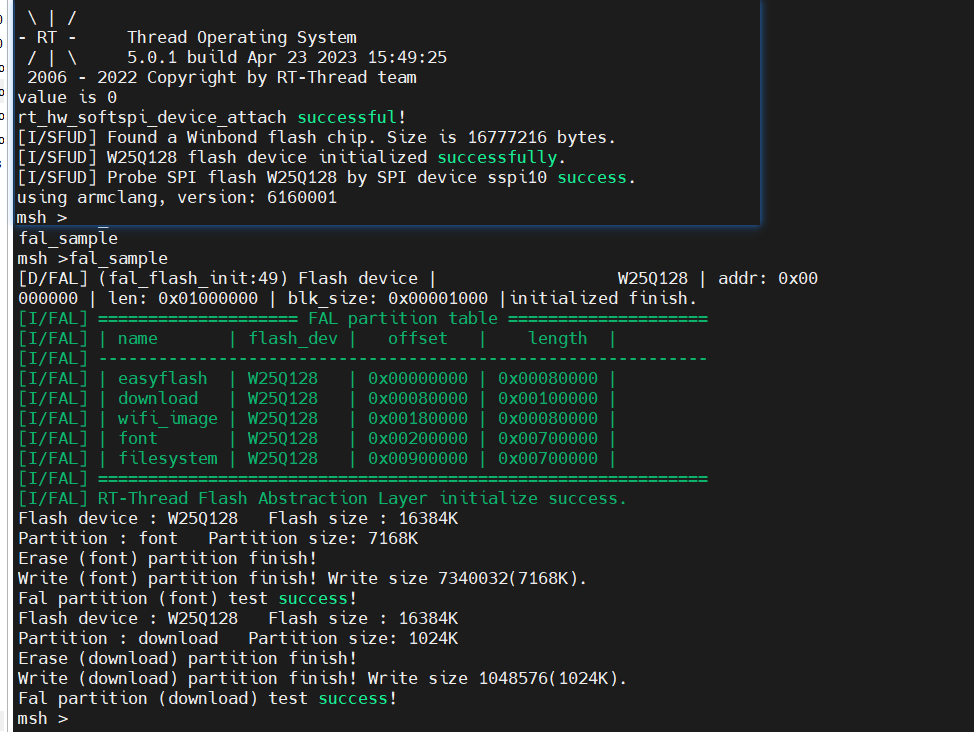
| |
到这里就可以进行编译下载了,成功后的截图如下:
DFS 是 RT-Thread 提供的虚拟文件系统组件,全称为 Device File System,即设备虚拟文件系统,文件系统的名称使用类似 UNIX 文件、文件夹的风格,目录结构如下图所示:
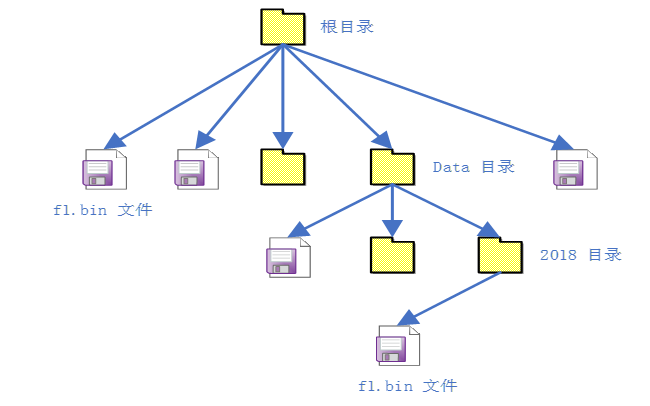
在 RT-Thread DFS 中,文件系统有统一的根目录,使用 / 来表示。而在根目录下的 f1.bin 文件则使用 /f1.bin 来表示,2018 目录下的 f1.bin 目录则使用 /data/2018/f1.bin 来表示。即目录的分割符号是 /,这与 UNIX/Linux 完全相同,与 Windows 则不相同(Windows 操作系统上使用 \ 来作为目录的分割符)。
RT-Thread DFS 组件的主要功能特点有:
DFS 的层次架构如下图所示,主要分为 POSIX 接口层、虚拟文件系统层和设备抽象层。
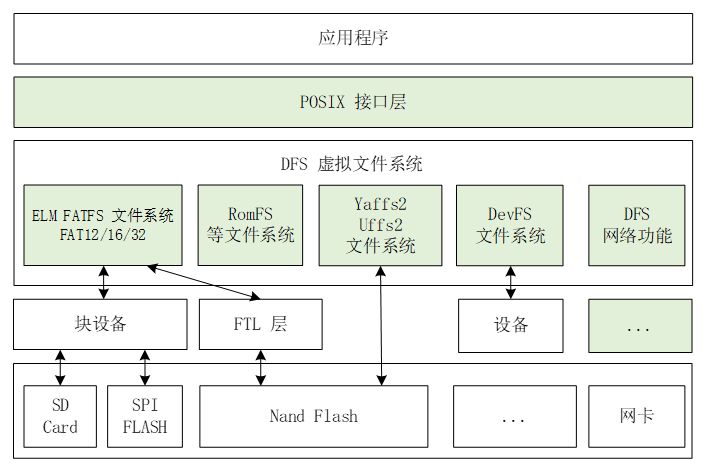
打开ENV,进入路径RT-Thread Components → DFS: device virtual file system,使能[*] DFS: device virtual file system
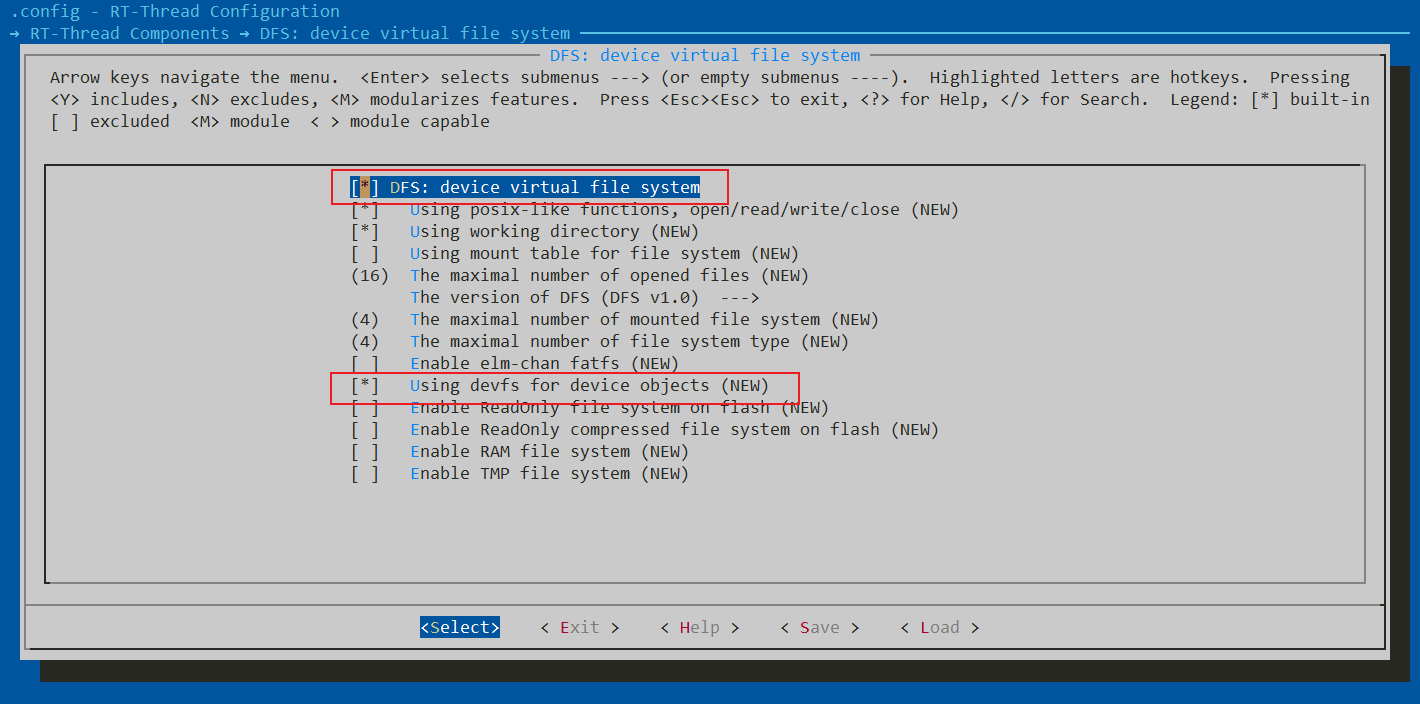
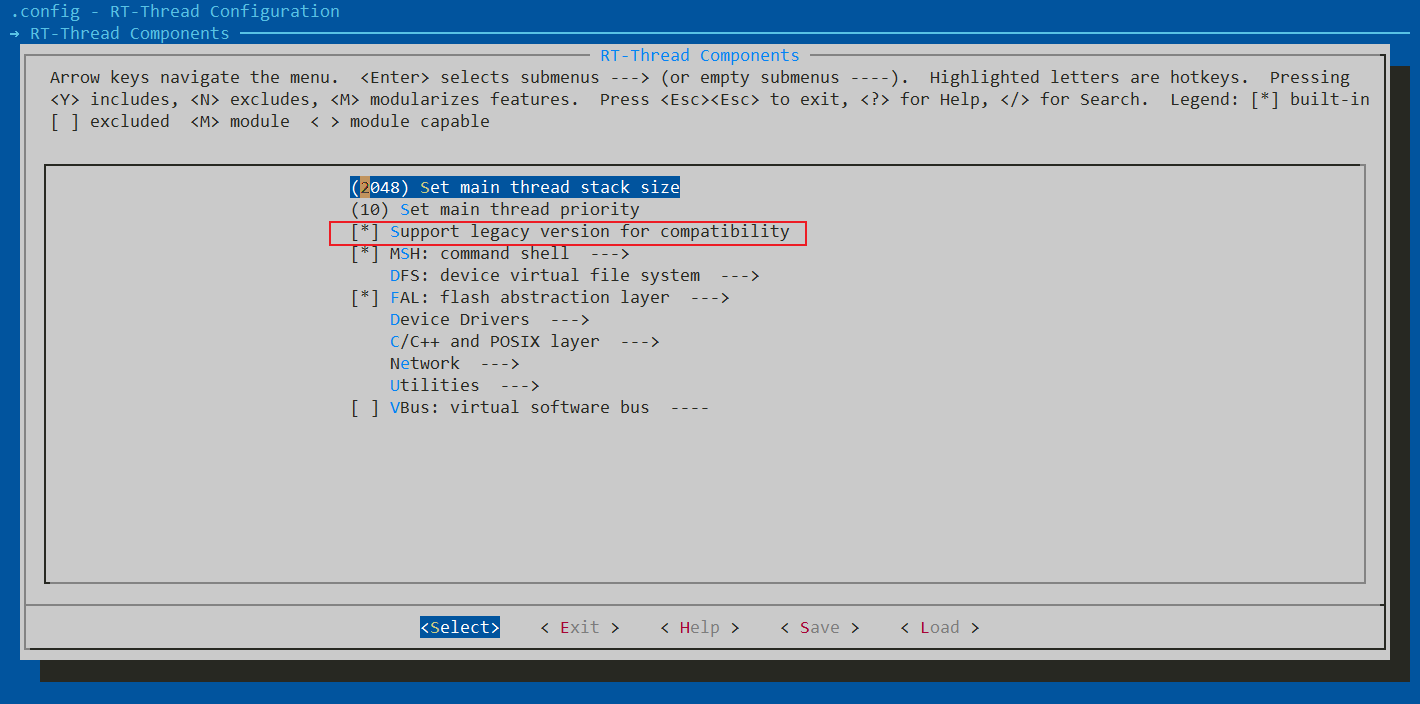
由于DFS使用的是POSIX接口,而dfs_posix.h已经在新版本中被移除了,如果想要兼容老版本,可以在menuconfig中使能RT-Thread Components->[*] Support legacy version for compatibility
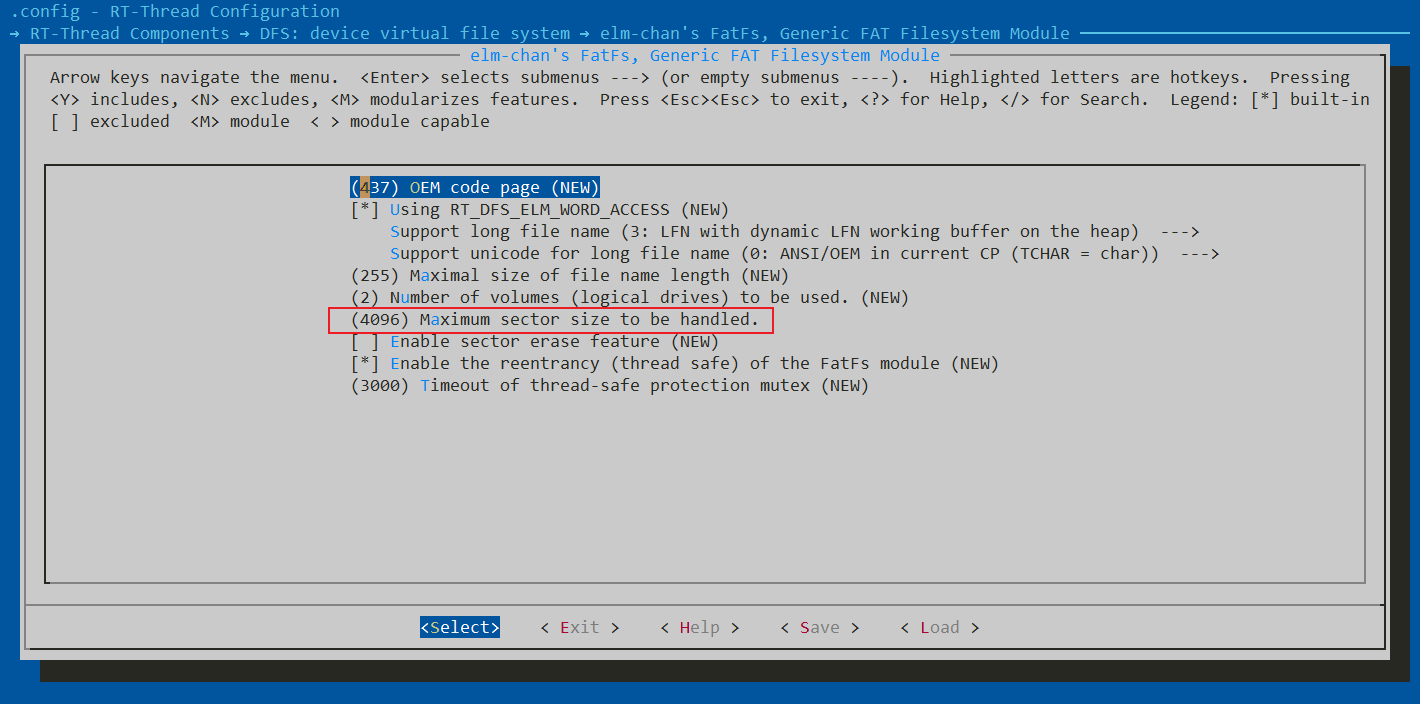
由于elmfat文件系统默认最大扇区大小为512,但我们使用的flash模块W25Q128的Flash扇区大小为4096,为了将elmfat文件系统挂载到W25Q128上,这里的Maximum sector size需要和W25Q128扇区大小保持一致,修改为4096,路径:RT-Thread Components → DFS: device virtual file system → [*] Enable elm-chan fatfs / elm-chan's FatFs, Generic FAT Filesystem Module
保存退出后使用scons --target=mdk5生成MDK5工程。
这里增加FAL flash抽象层,我们将elmfat文件系统挂载到W25Q128 flash设备的filesystem分区上,由于FAL管理的filesystem分区不是块设备,需要先使用FAL分区转BLK设备接口函数将filesystem分区转换为块设备,然后再将DFS elmfat文件系统挂载到filesystem块设备上。
我们接着修改fal_sample.c文件,修改后代码:
| |
测试结果如下:
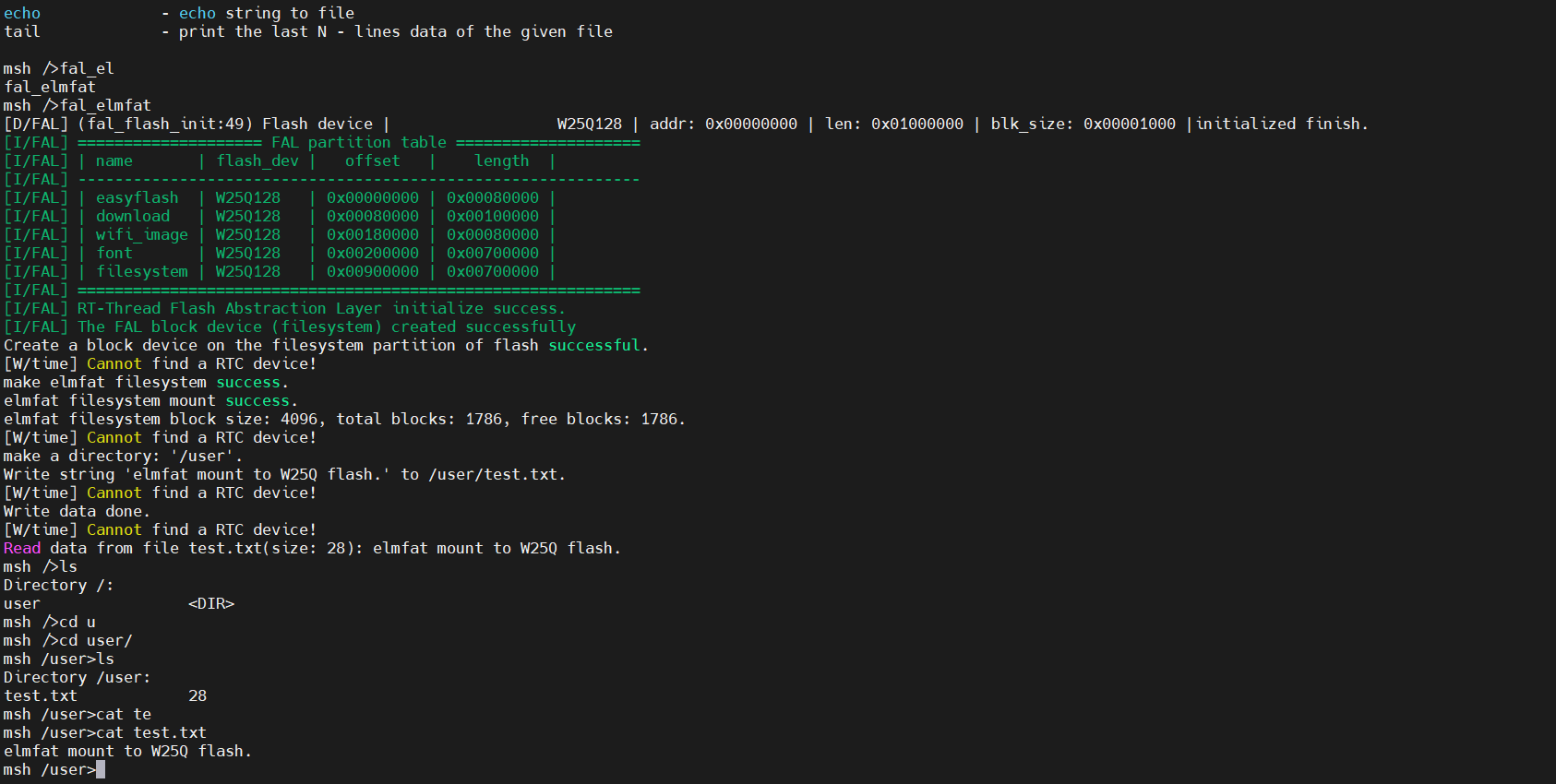
关于EasyFlash的来源我们已经讲过了,此处不再赘述。EasyFlash是一款开源的轻量级嵌入式Flash存储器库,方便开发者更加轻松的实现基于Flash存储器的常见应用开发。非常适合智能家居、可穿戴、工控、医疗、物联网等需要断电存储功能的产品,资源占用极低,支持各种 MCU 片上存储器。
EasyFlash不仅能够实现对产品的 设定参数 或 运行日志 等信息的掉电保存功能,还封装了简洁的 增加、删除、修改及查询 方法, 降低了开发者对产品参数的处理难度,也保证了产品在后期升级时拥有更好的扩展性。让Flash变为NoSQL(非关系型数据库)模型的小型键值(Key-Value)存储数据库。
打开ENV进入路径:RT-Thread online packages → tools packages → EasyFlash: Lightweight embedded flash memory library.,选择软件包版本为最新版。
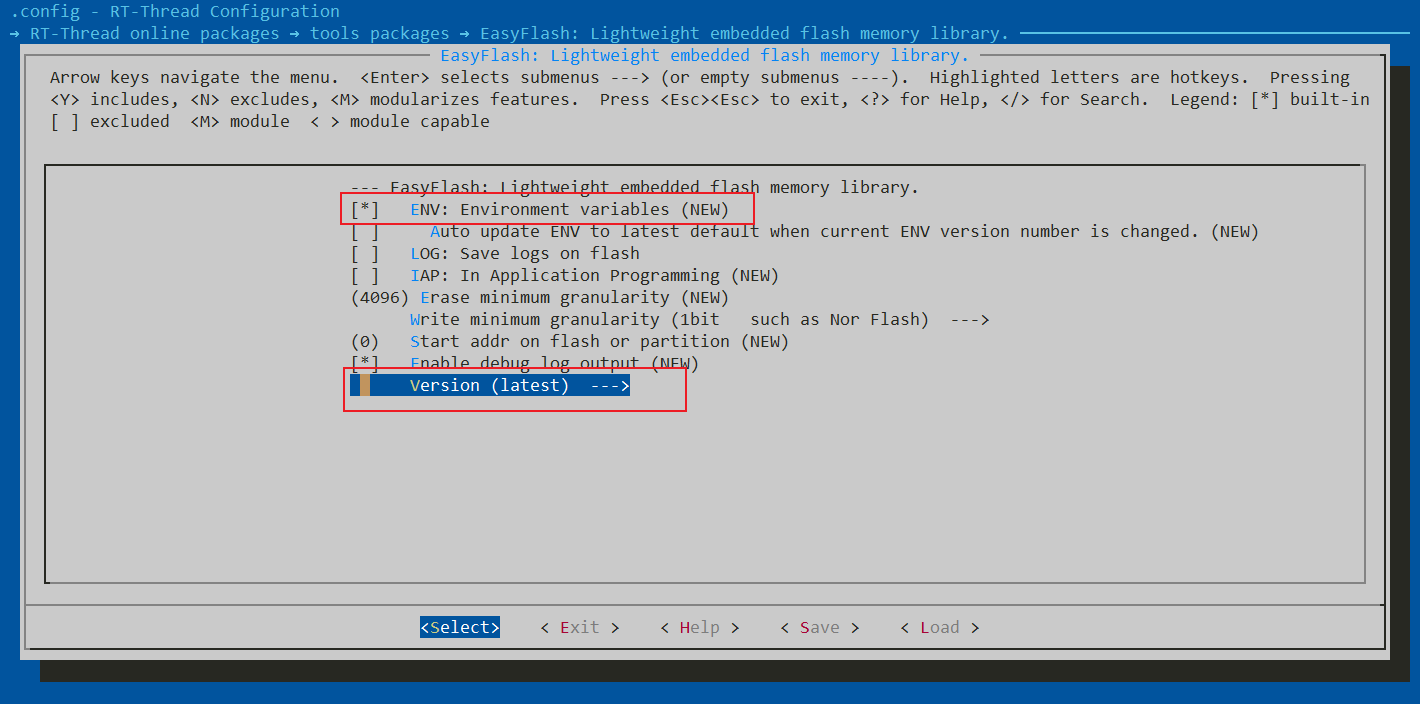
配置后退出ENV,同时使用pkgs --update下载软件包,然后再使用scons --target=mdk5重新生成MDK5文件
下载完easyflash软件包后,我们复制.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk\packages\EasyFlash-latest\ports\ef_fal_port.c到目录.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk\board\ports\easyflash\ef_fal_port.c,双击打开该文件,完成以下修改:
| |
| |
| |
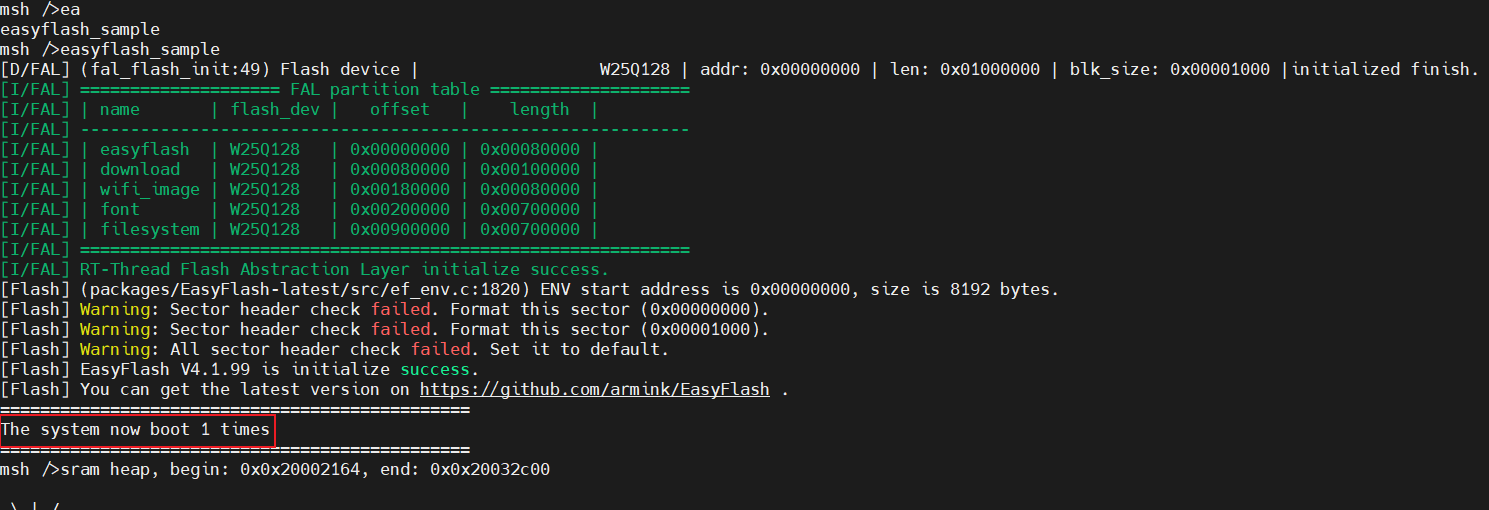
打开串口助手,输入命令:
| |
第一次命令调用:
第二次RESET开发板后调用:
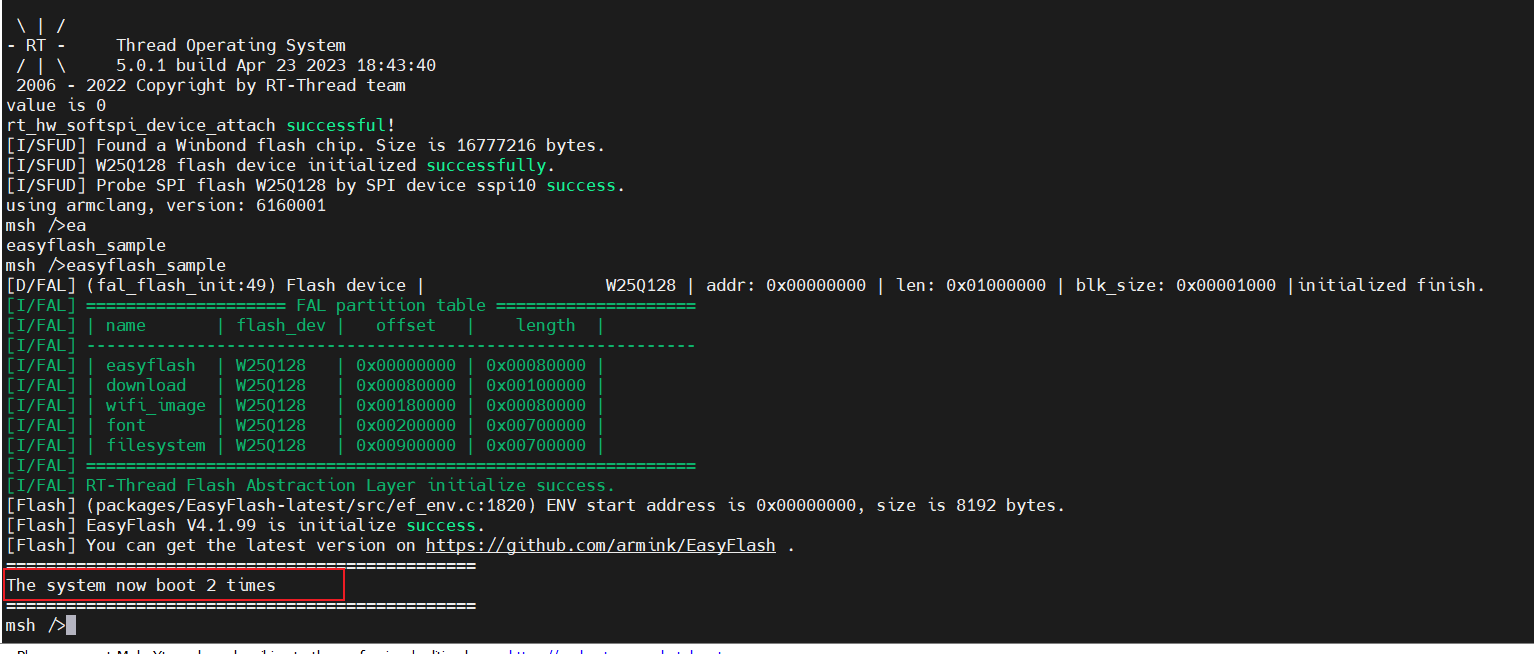
至此本博客就到此结束,经历从移植软件模拟spi框架到LPC55S69,到移植过程中遇到不断的问题,到最后解决所有问题并提供应用示例,完成开发日记、开发笔记及应用教学,这个过程确实使我受益良多,其中感受最深的就是当然也更加感谢的是一些前辈们的指点迷津和博文记录,就目前国内嵌入式这个领域,相关开发经验相比较其他计算机行业确实有些不够包容和开放,也希望未来的朋友们能够怀揣着一颗求知及授学之心,共同建设好这个领域!

前段时间看到恩智浦社区有一个LPC55S69的开发板测评活动,很荣幸能通过报名,第二天也是成功的收到的板子,本次作为开箱测评。
首先从RT-Thread仓库的master分支克隆整个仓库,进入目录:.\rt-thread\bsp\lpc55sxx\lpc55s69_nxp_evk,首先使用RT-Thread的ENV工具生成MDK工程:
| |
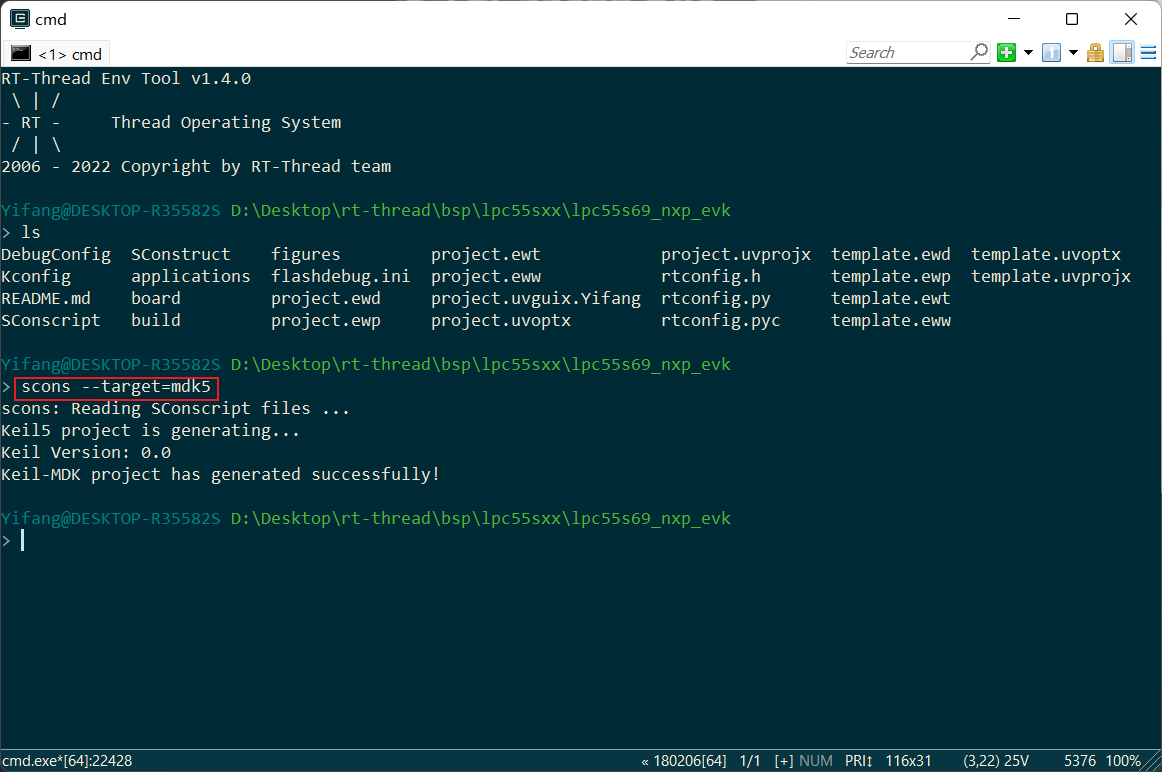
这里建议大家使用最新版ENV工具。然后双击打开project.uvprojx工程,点击重新编译。
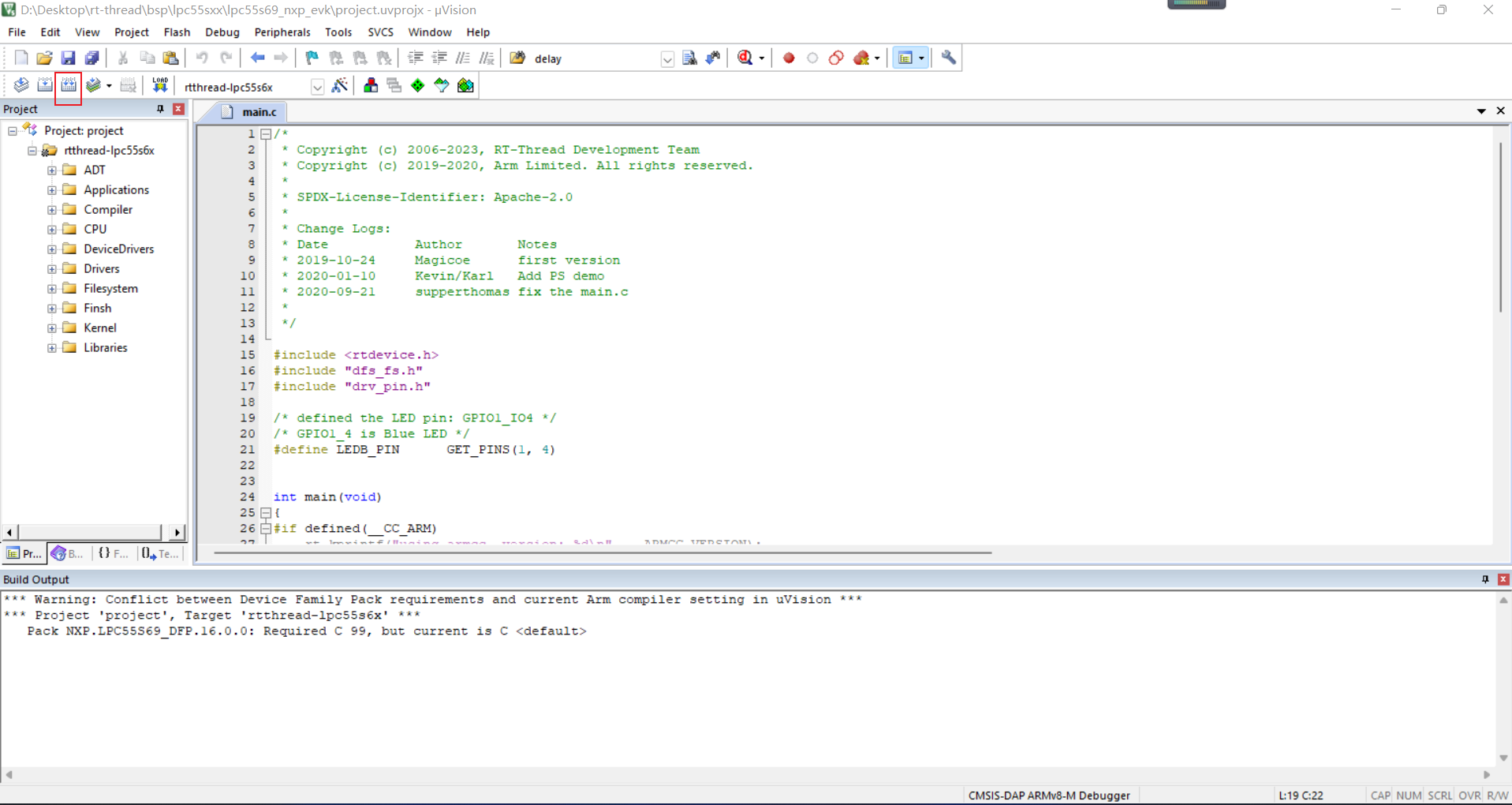
但是编译之后发现会有报错,找了很久都没解决,后来经过RTT社区的满老师提示成功解决BUG,下面是解决过程与分析。


首先先看一下我的keil版本为V5.25:
听满老师讲LPC55S69的工程可能是使用的AC6编译器,但是Keil的V5.25的AC6可能存在问题,所以解决办法就是更新下Keil的版本(建议最新版)
此处附上Keil最新版下载官网
下载好最新版本后,前面的步骤重复,然后重新编译下载即可。
下面是RT-Thread成功在LPC55S69的示例,可以看到LED灯以500ms进行闪烁:

本博客仅作为开箱测试,后续会继续上传相关测试用例,欢迎讨论交流。

资料:
开发环境(官方直链)
MCUXpresso Config Tools和MCUXpresso IDE的安装不再赘述,下面是SDK代码包的安装教学
1.选择开发板–>
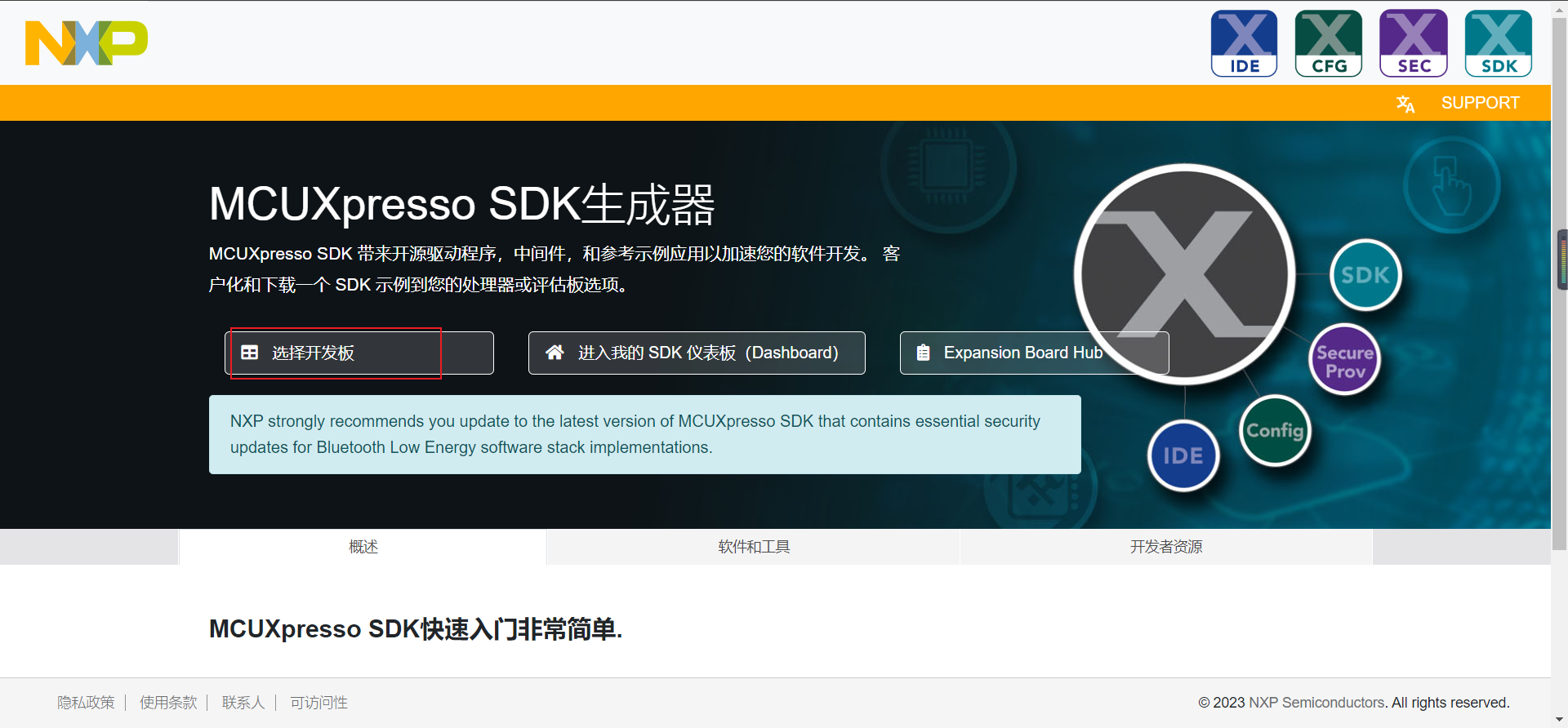
2.这里我们选择处理器为LPC55S69(选择自己所需的处理器型号),点击构建MCUXpresso SDK v2.13.0(默认最新即可)
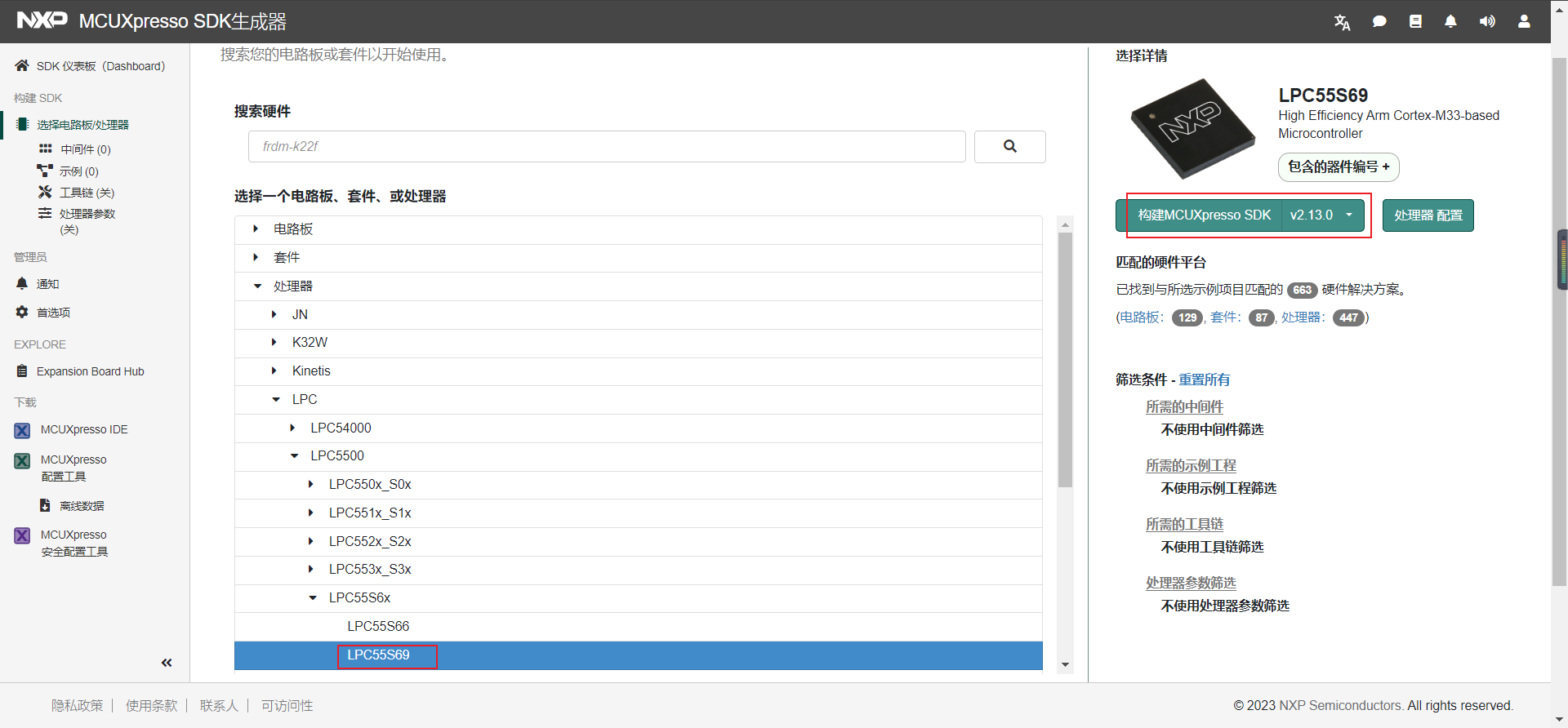
3.根据自己的开发需求进行组件及中间件等,同时选择需要的工具链,这里我们全选,包括工具链和IDE,并点击下载SDK
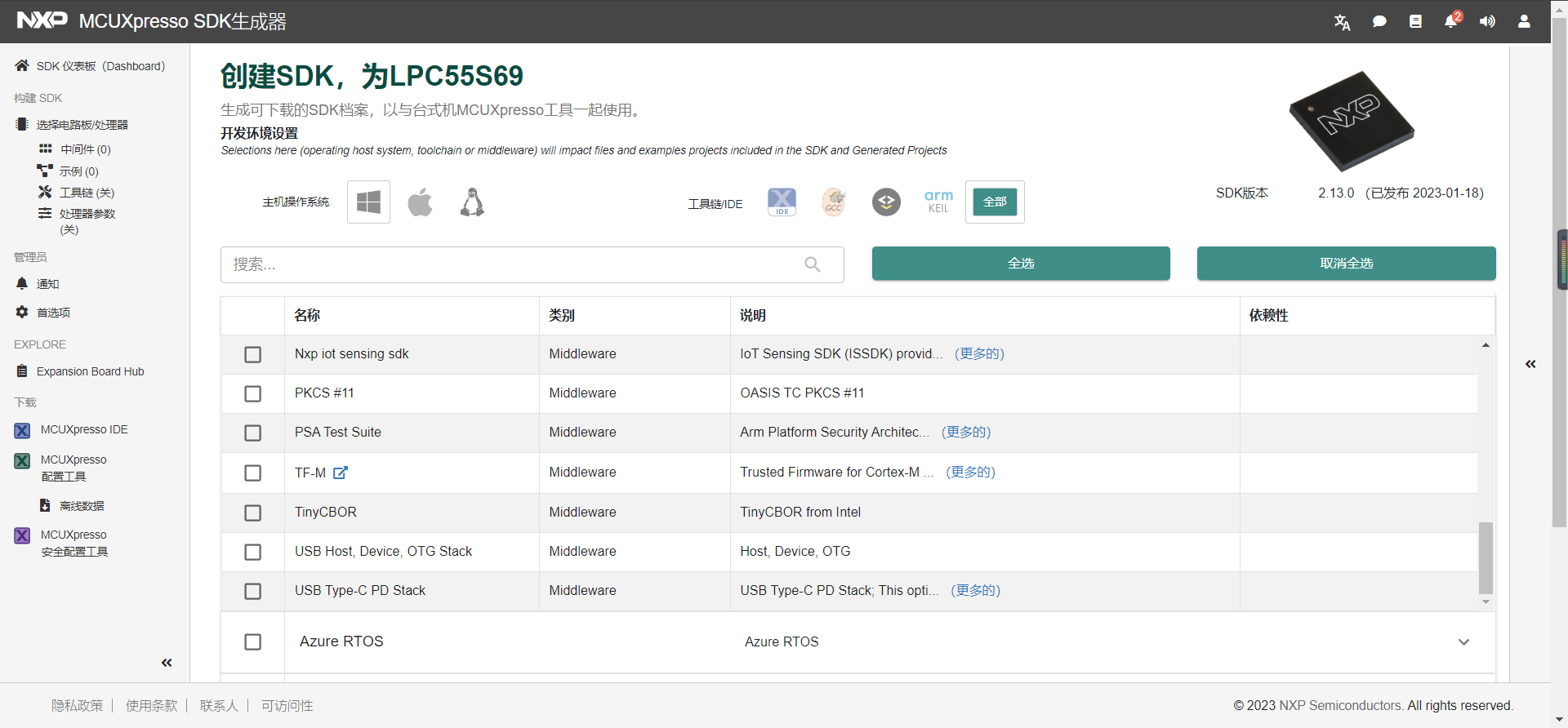
4.等待构建完成,这里我们选择我们刚刚生成的档案,点击下载软件包
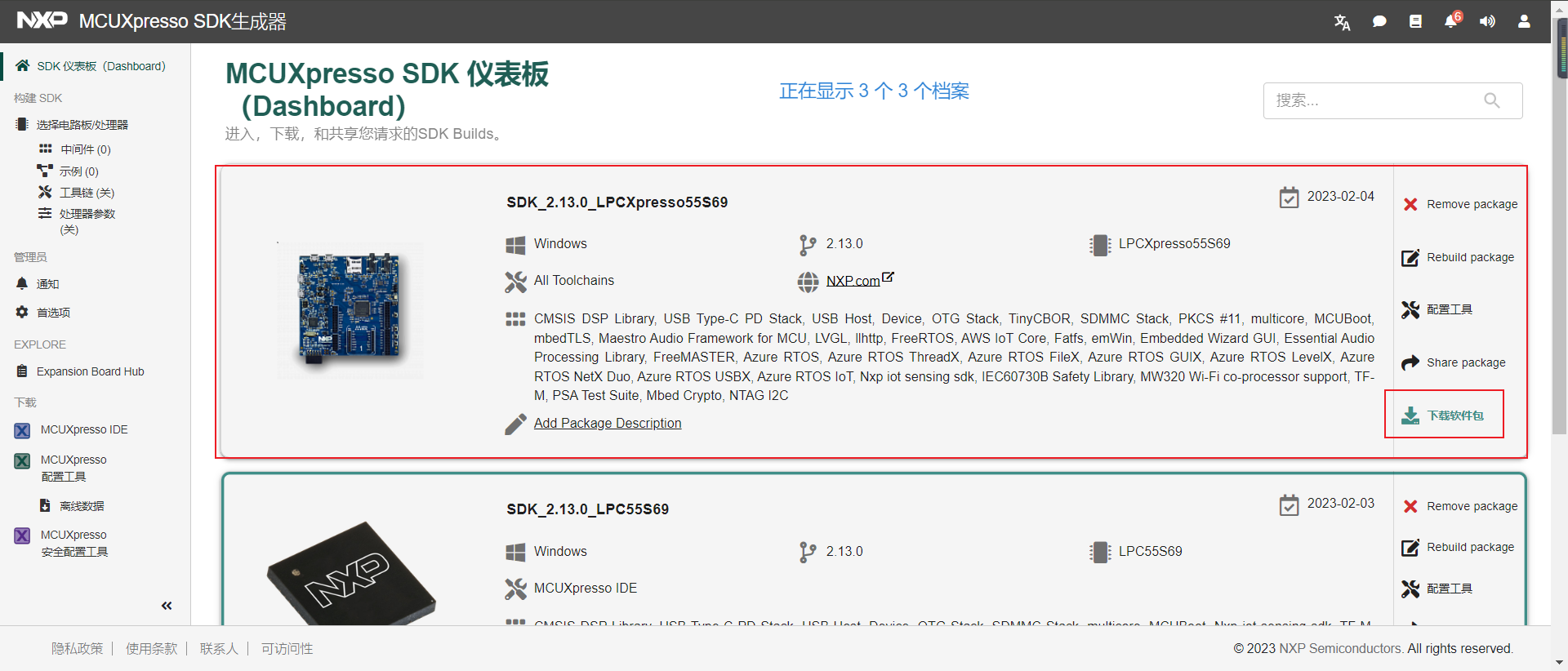
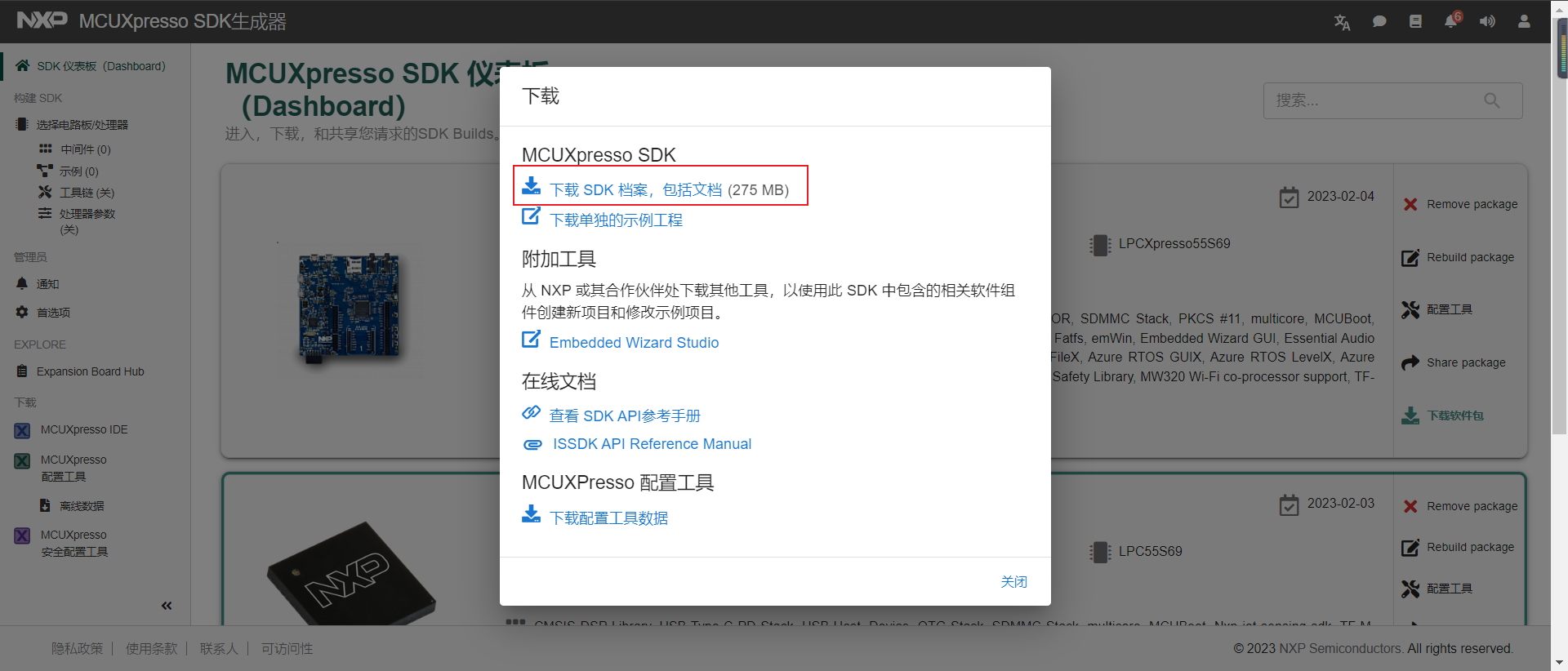
5.直接选择点击下载SDK档案,包括文档。当然这里也提供了单独的示例工程和API参考手册,需要的朋友也可根据需求下载
完成IDE软件、配置工具的安装还有SDK代码包的下载后,我们打开MCUXpresso IDE,在主界面的下方栏可以看到有一个Installed SDKs,准备好刚刚下载的SDK代码包,导入其中
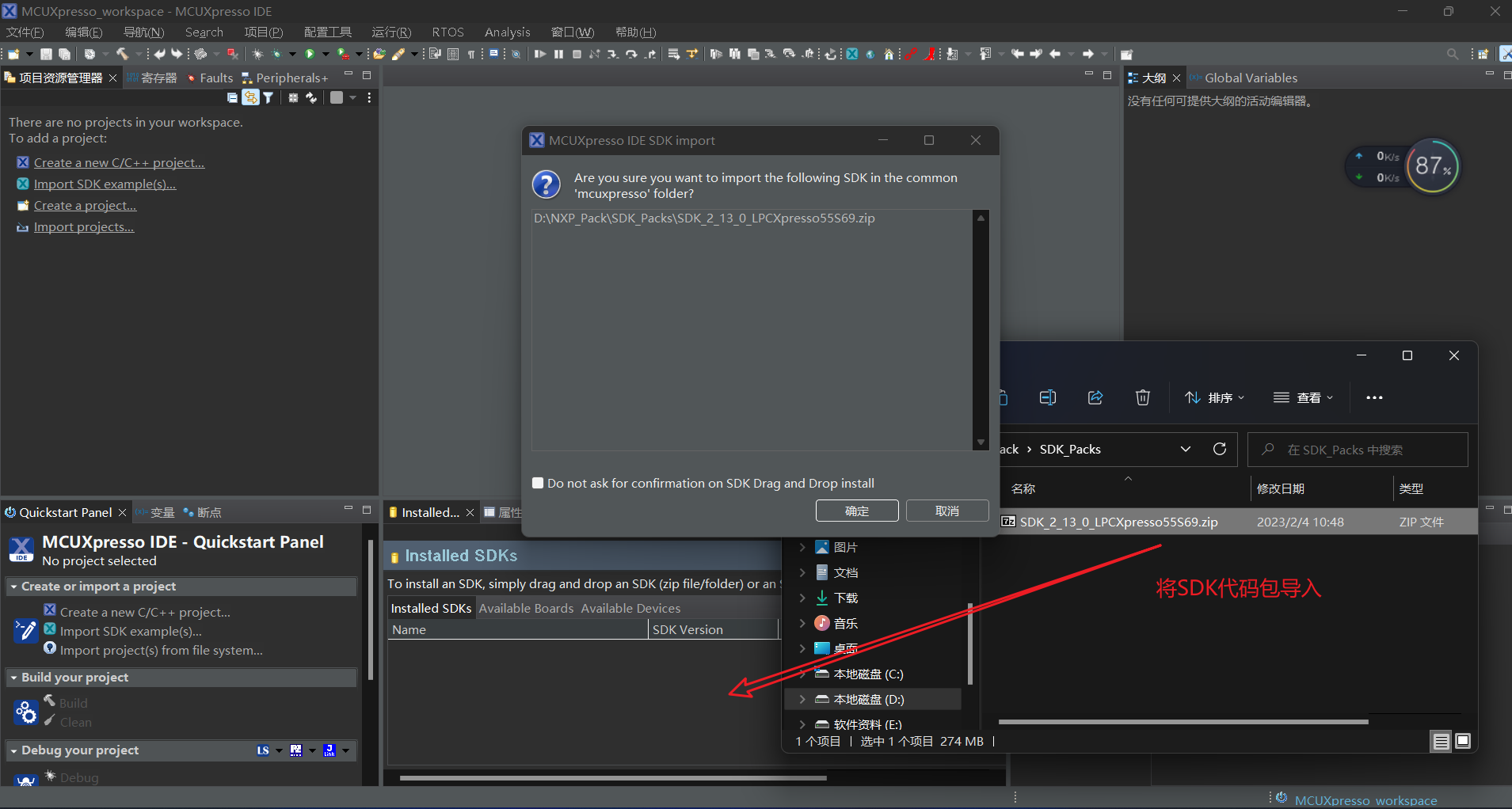
之后我们就可以使用这个SDK代码包去创建一个新的工程了。
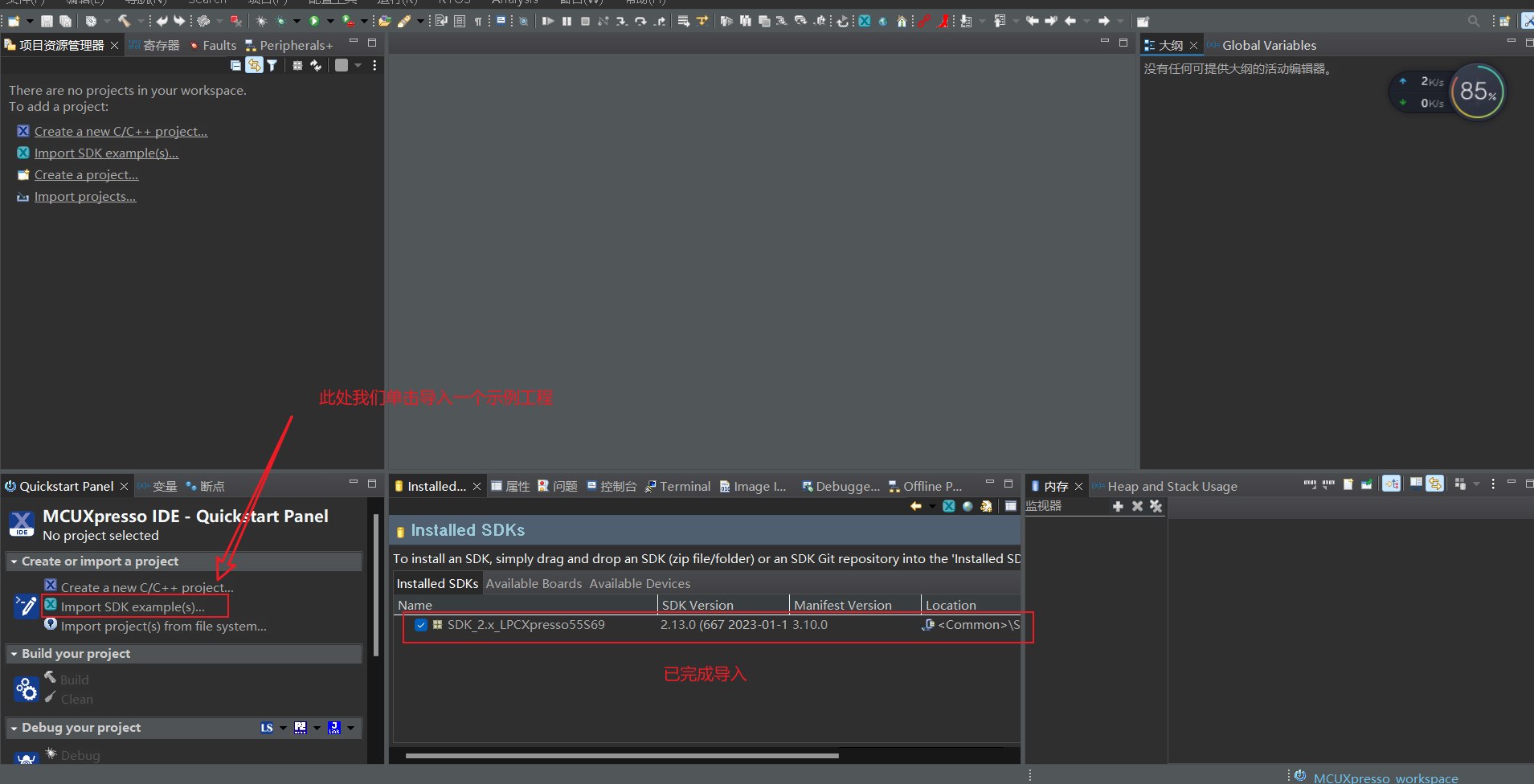
这里我们简单做个示范,选择导入示例工程
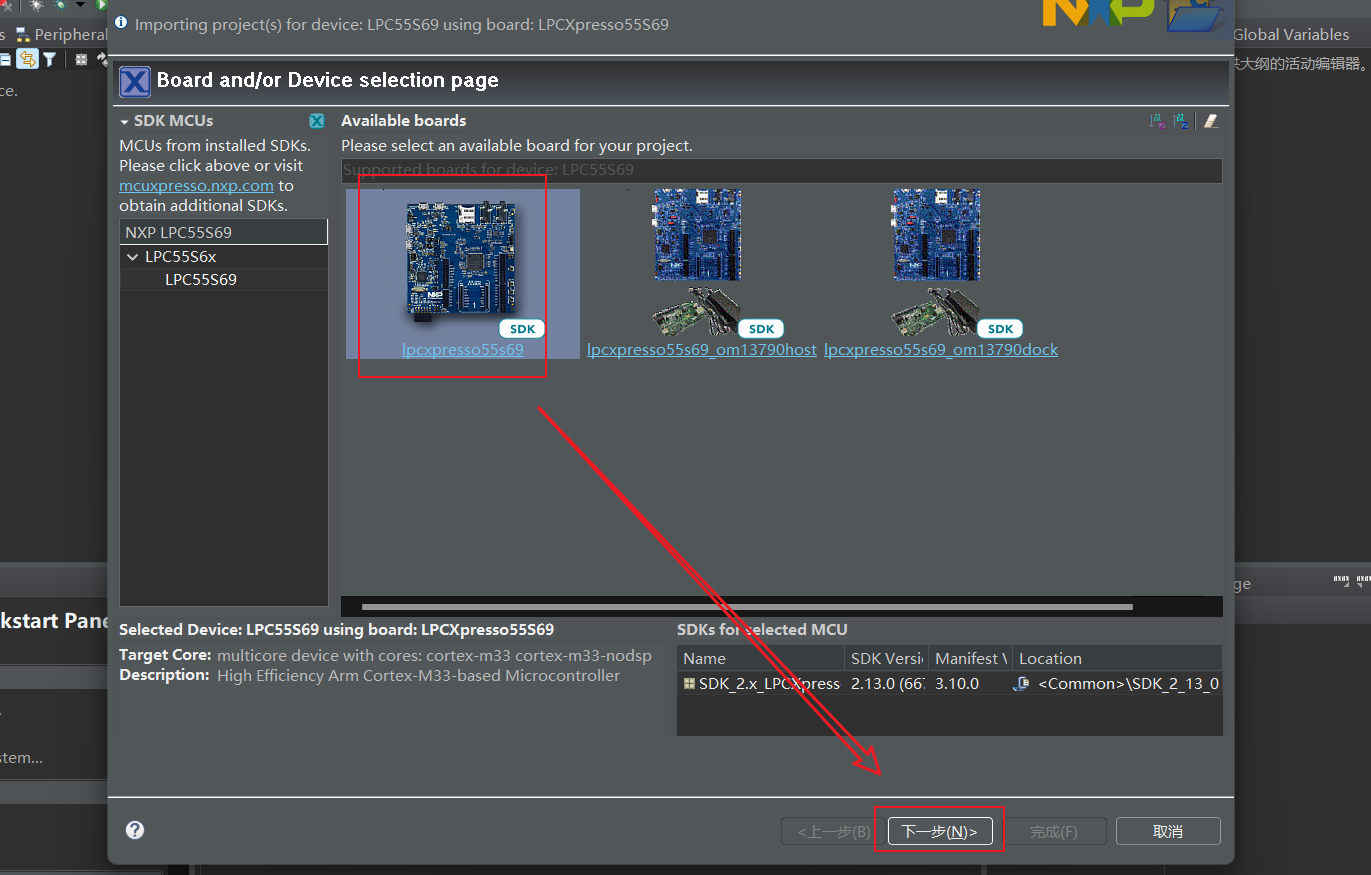
选择指定的开发板后点击下一步
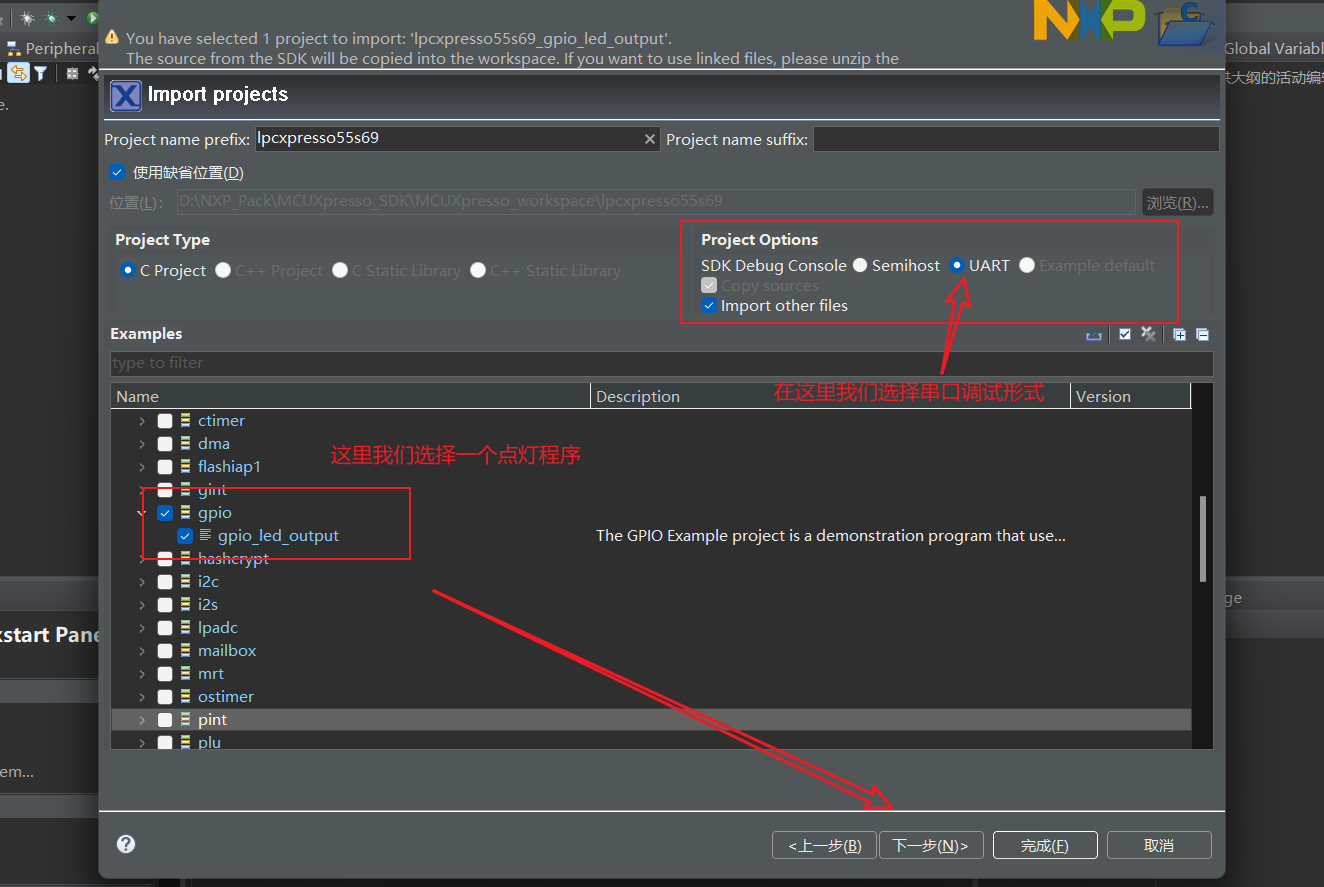
在下一步这里,就主要是一些Memory的分散加载问题,还有就是编译器语言的标准问题,一般来讲我们默认不做更改,点击完成即可
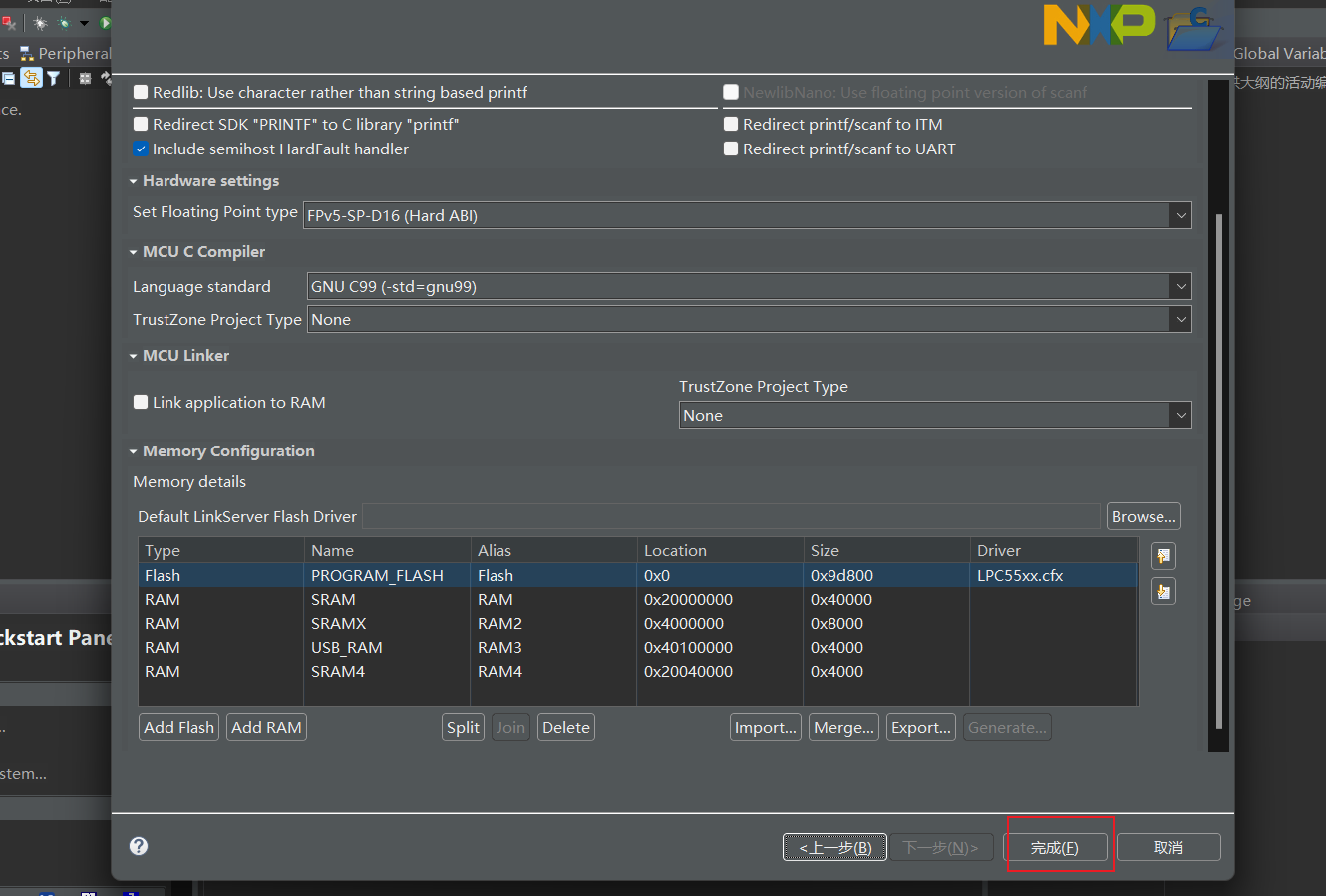
工程的用户代码是存放在source目录下的,我们这时候就可以给开发板上电,然后点击编译
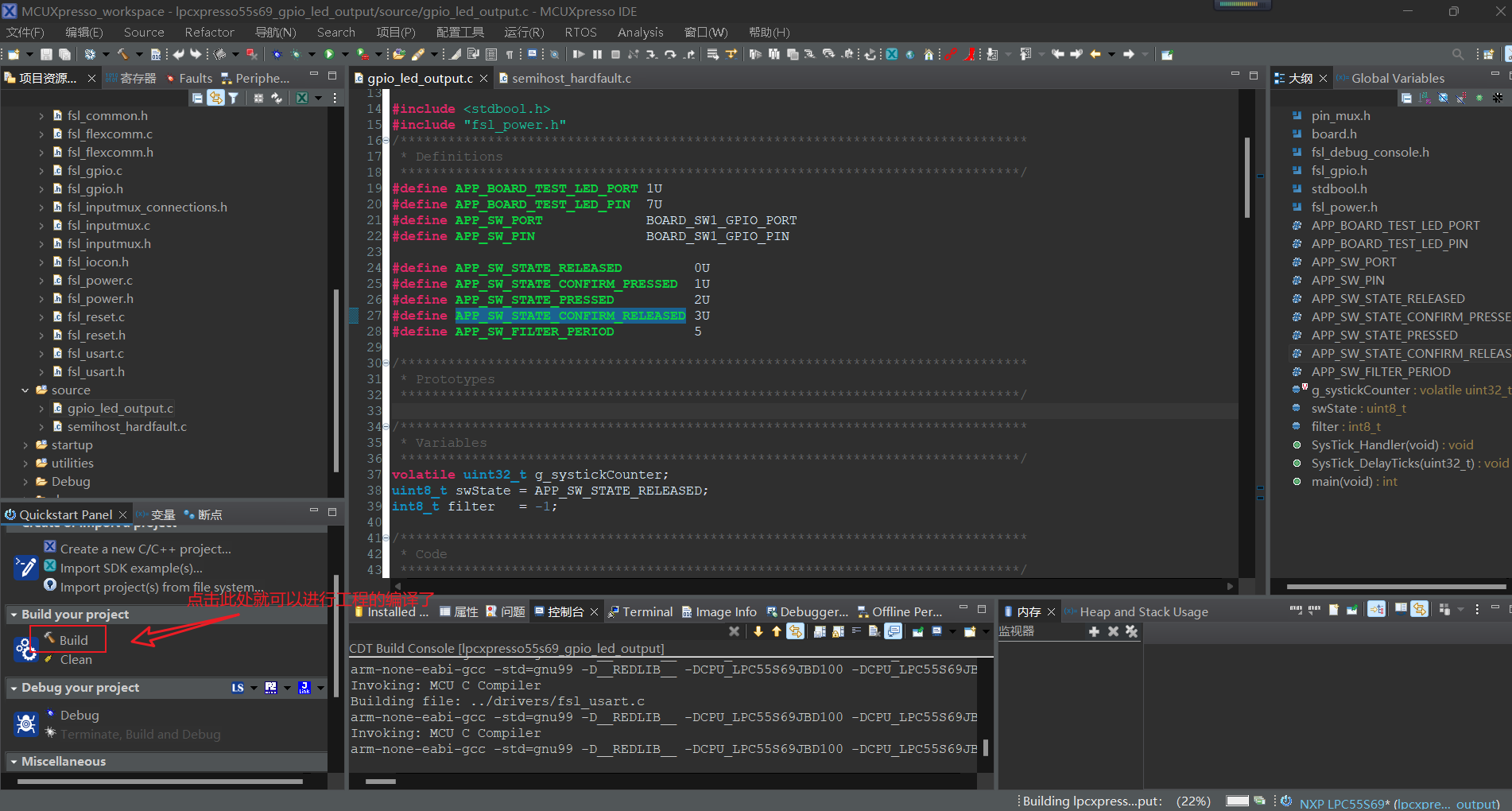
MCUXpresso IDE有两个地方都可以启动调试,选择一个习惯的即可
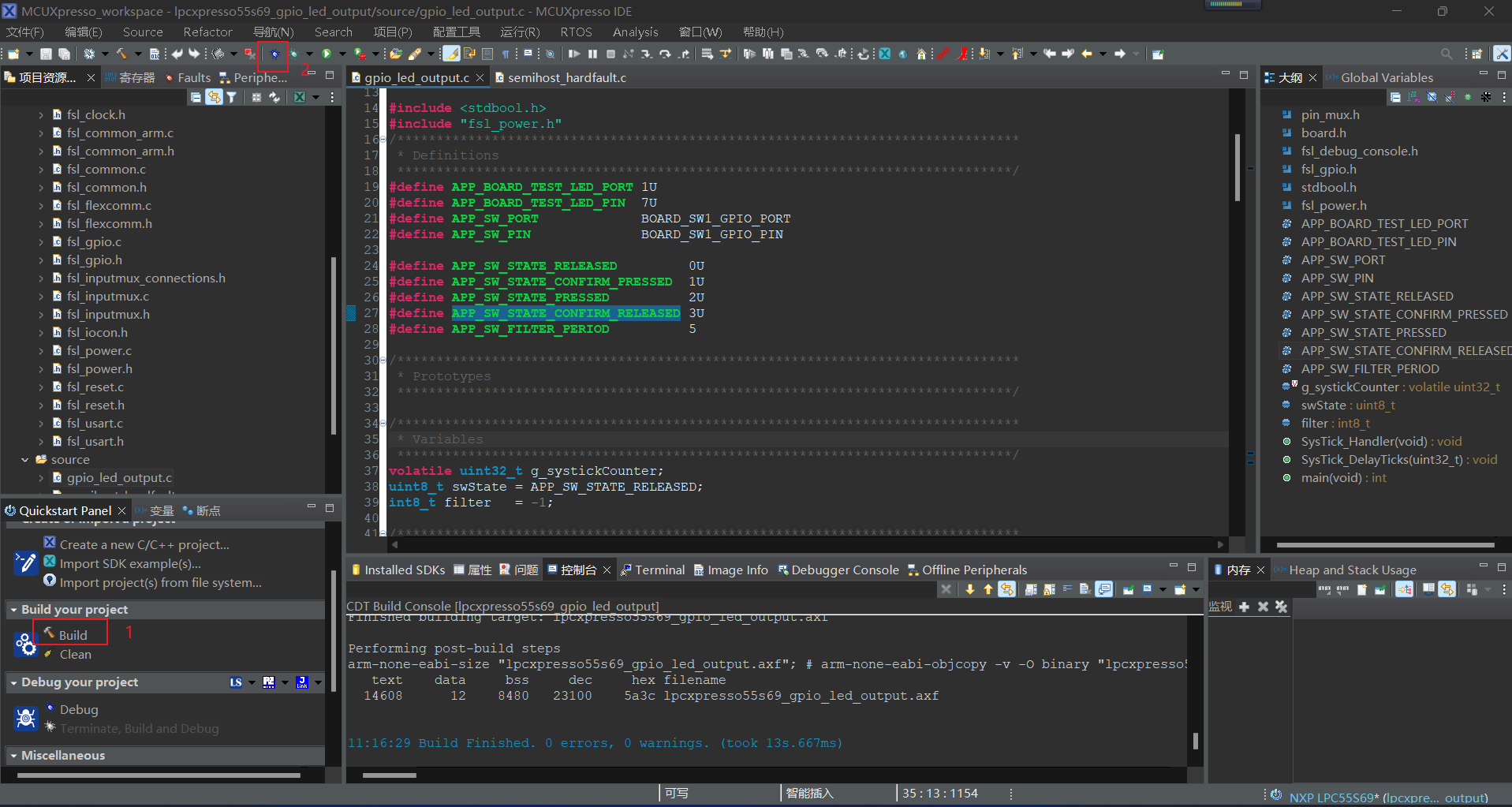
和MCUXpresso IDE配套的还有MCUXpresso Config Tools,打开MCUXpresso IDE,找到配置工具按钮打开
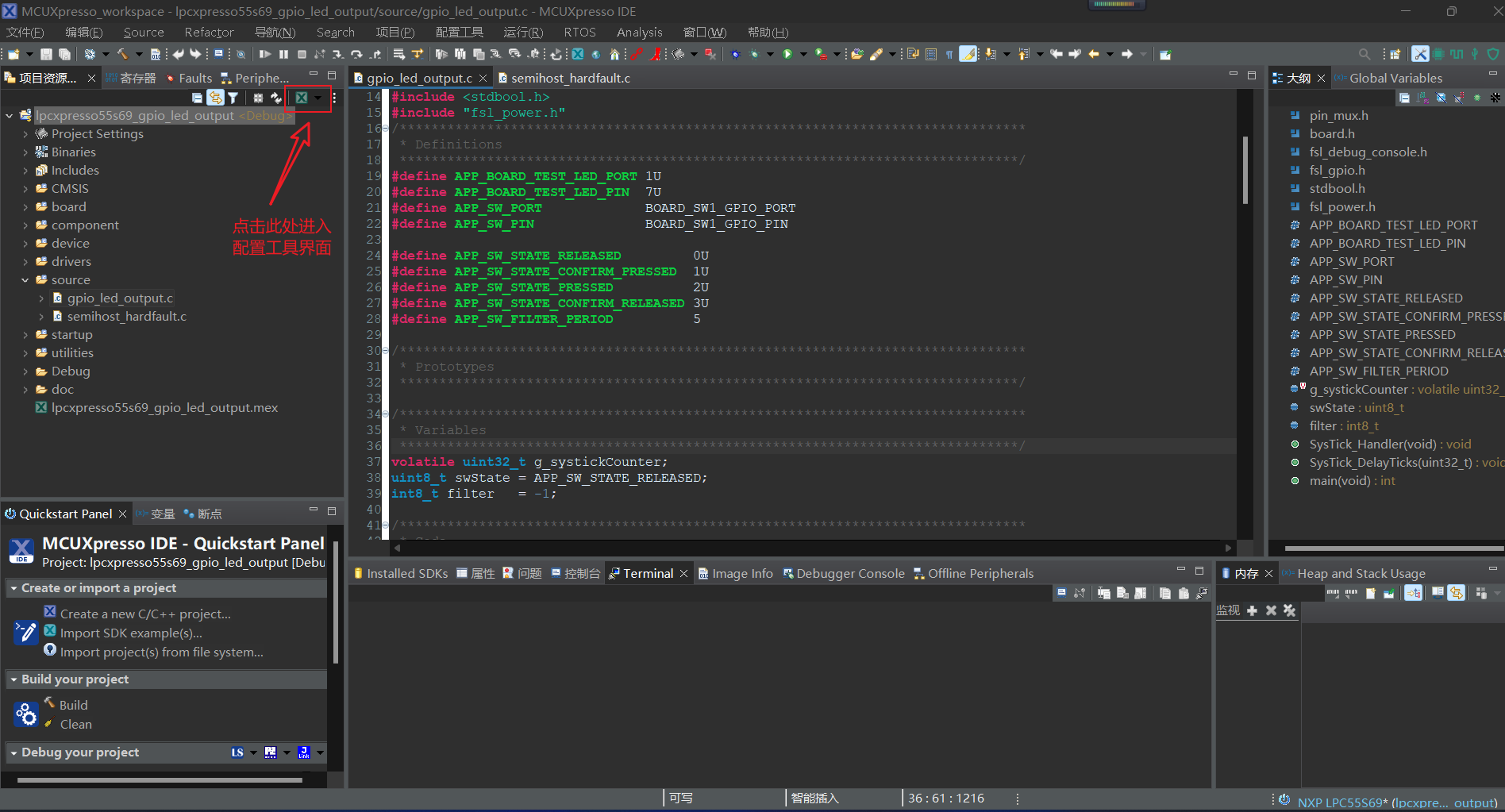
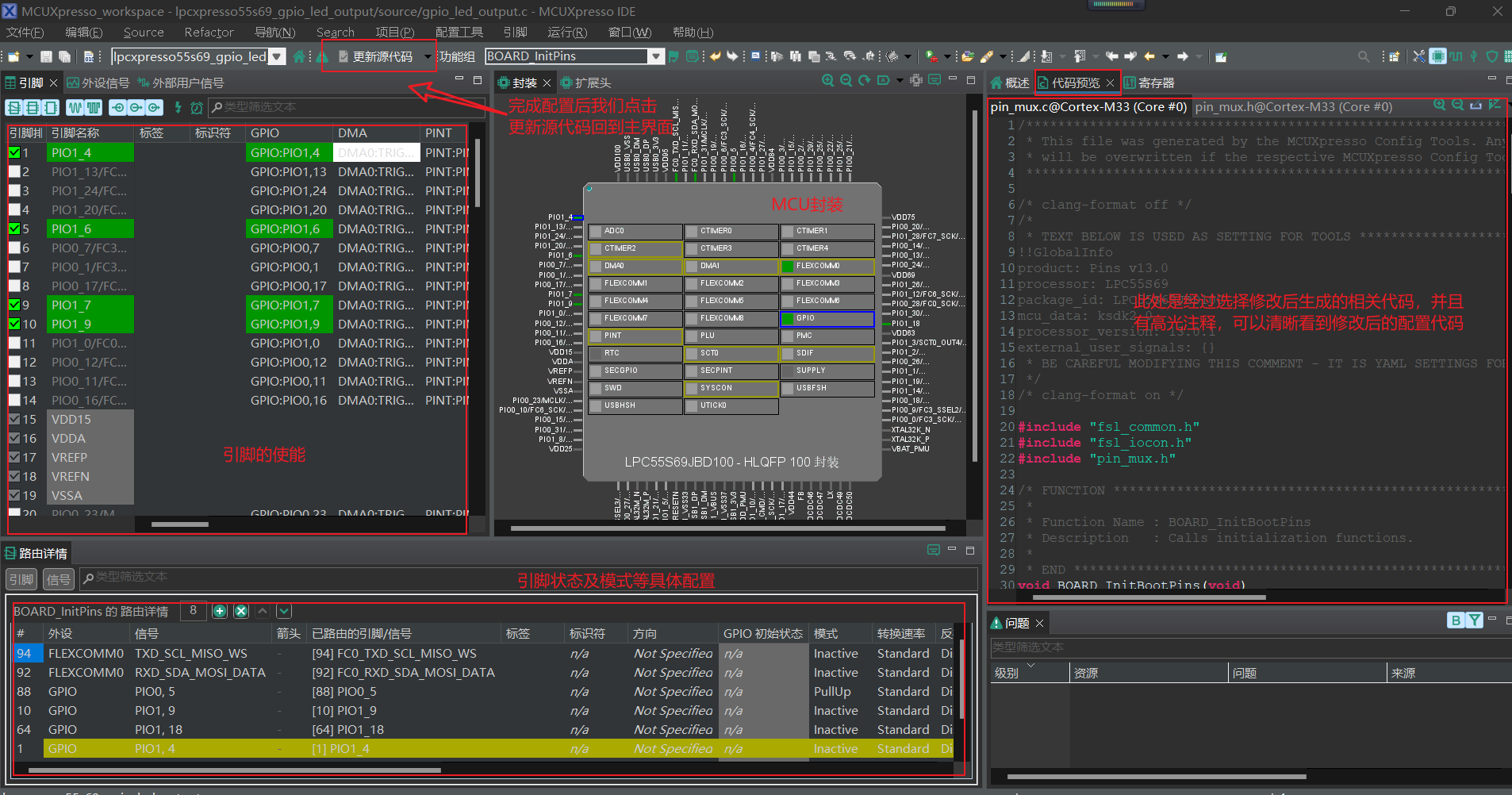
到这里就是LPC55S69基本的开发环境的配置及测试了,欢迎大家合作交流!

软件
硬件
首先打开虚拟机,创建一个目录存放本次测试的代码,然后克隆RT-Smart用户态代码。
| |

在userapps目录下克隆RT-Thread仓库代码
| |

进入userapps/tools,运行 get_toolchain.py 的脚本,会下载对应的工具链并展开到 userapps\tools\gun_gcc 目录。
| |
返回上一级,刷新工具链环境,同时记住这里的EXEC_PATH工具链路径,后面需要修改为此路径
| |

环境编译会用到scons,所以我们先下载scons
| |
查看scons版本信息可判断是否安装成功

依次执行以下程序:
| |
使用 scons 命令进行编译,编译成功后会在 userapps/rt-thread/bsp/allwinner/d1s 目录下生成 sd.bin,这个文件就是我们需要烧录到开发板中的文件,它包括了 uboot.dtb,opensbi,rtthread.bin。
| |
此时直接编译会报错,因为工具链路径还没有修改

我们复制上面的工具链路径,vi命令修改rtconfig.py,这里的路径依据你自己的工具链路径
再次执行scons命令编译
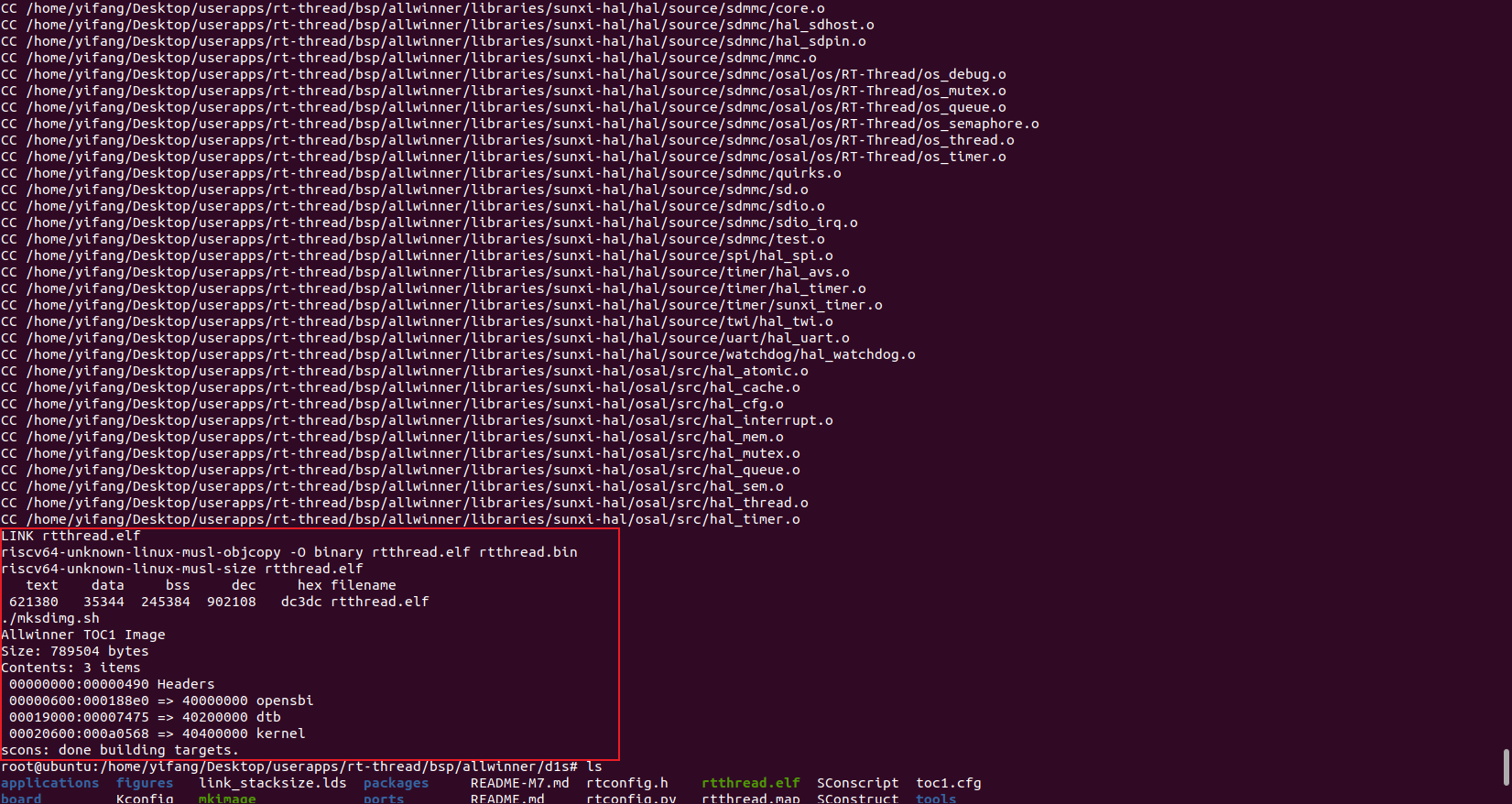
我这里采用的是从TF卡作为启动方式。
1、首先准备一张容量在128G的空白TF卡
2、格式化TF卡,并使用ubuntu的gparted工具重新分区
如果没有下载该工具可使用下面的命令进行下载:
| |
启动该工具
| |
这里我使用的是一张64G的TF卡,扇区大小为512字节,同时我们需要预留8M的前空间,并且分区的文件系统格式为fat32
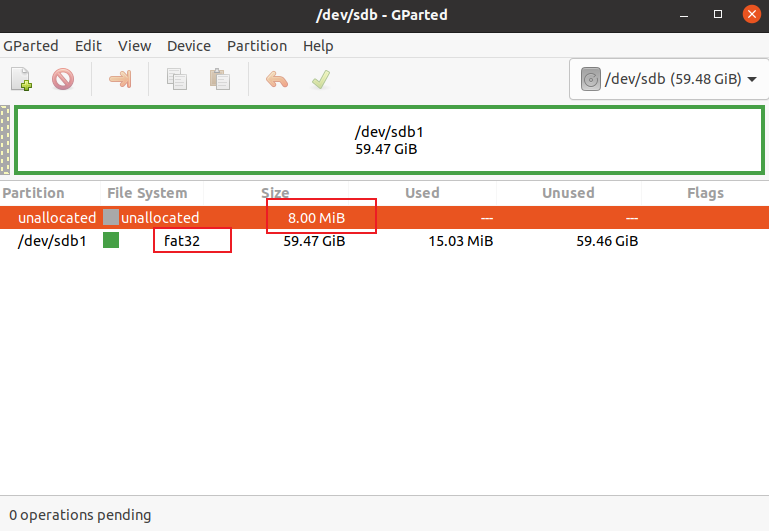
3、接下来进行程序的烧录
首先进入userapps/rt-thread/bsp/allwinner/d1s/tools,执行命令:
| |

返回上一级,再次执行命令:
| |

到此烧录工作已完成。
我们将刚刚烧录好程序的TF卡直接插入到开发板卡槽,并连接开发板UART端口进行串口查看验证。
此处注意串口波特率为500000

简单测试下MSH命令:
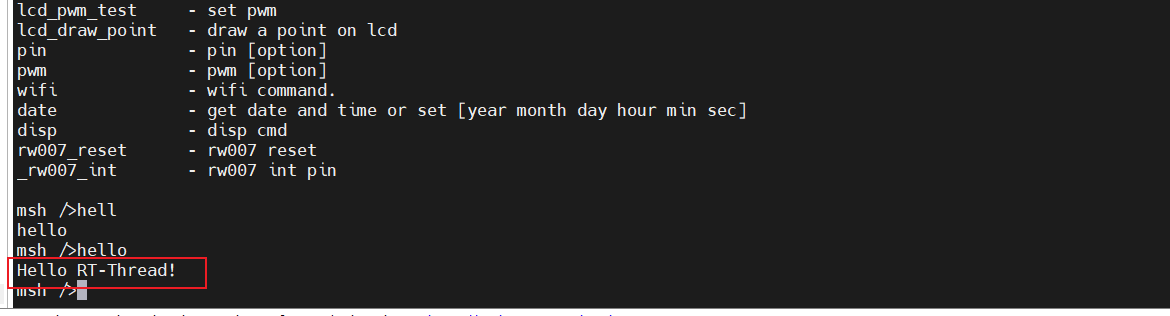
到此就测试结束啦,欢迎大家讨论交流。

以删除apache2为例,其它程序也都是这么删…
1.先通过apt删除程序和相关配置文件
| |
2.自动删除不使用的软件包
| |
3.找出与apache2相关的程序
| |
没有就不显示,如果有就删除这些相关的程序
| |
4.查看apache2是否还有进程存在
| |
如果有就杀掉
| |
5.全局查找和apache2相关的文件,需要一定时间,稍等
| |
将找到的文件逐个删掉
| |
这样就彻底删除掉apache2了

起因:我是一个windows重度用户,实验室配置了Ubuntu服务器,我试图用远程桌面控制控制服务器的桌面。由于对Linux一窍不通,一顿乱改。结果虽然能远程控制桌面了,可是原有的显示管理器被我更改了。原先跑的好好的深度学习代码也不能跑了,原先的桌面风格(gnome图形管理器)也变成了我不喜欢的风格(轻量级的LightDM)了,大家以后要慎重。
注意:我是个半吊子,仅供参考。
GDM, KDM, LightDM, SDDM的区别和安装配置
gdm3,kdm 和 lightdm 都是显示管理器。 它们提供图形化登录并处理用户身份验证。
| |
| |
kdm 是kde管理器的显示。 但在KDE5中,它被否决为 SDDM,它更适合作为显示管理器,因此在默认情况下,它是在屏幕。
| |
| |
LightDM用于显示管理器的规范解决方案。 它应该是轻量级的,默认情况下是 Ubuntu。Xubuntu和 Lubuntu。 它是可以配置的,有多种欢迎主题可用。
| |
| |
| |
你可以在上述命令中使用管理器的名字代替 gdm3,可在它们之间进行选择。 必须重新启动才生效。
要检查当前正在使用的显示管理器,请运行以下命令:
| |
Lightdm,gdm3和KDM都是针对linux的图形化登录。 Lightdm是Ubuntu的默认版本。 要在显示管理器之间进行 switch,请使用以下命令:
| |
Lightdm,gdm3和KDM都是针对linux的图形化登录。 Lightdm是Ubuntu的默认版本。 要在显示管理器之间进行 switch,请使用以下命令:
| |
GDM(GNOME Display Manager),LightDM(Light Display Manager) 和 KDM(KDE Display Manager) 是为不同版本的Ubuntu配置的管理器。 他们帮助启动X 服务器。用户会话和欢迎( 登录屏幕)。 你可以运行 sudo dpkg-reconfigure gdm 以在 lightdm。gdm和KDM之间进行更改。 安装它们就像 sudo apt-get install ( 显示manger将被 kdm,gdm 和 lightdm 替换。
恢复ubuntu20.04默认桌面管理器
目前Ubuntu的主流桌面GNOME, Ubntu的内置桌面是Untiy
| |
打开终端,用管理员口令下载相关资源
| |
提示:
管理员权限需要输入密码,但是系统不会显示你输入的密码
输入完成后,直接回车即可
| |
| |
| |
然后一切恢复如初,仿佛没发生过。

| |
直接安装成功。
密码存储在/etc/目录里面
| |
放在这个位置,需要设置文件读取权限
否则会提示密码校验失败
| |
在/etc/init 下创建一个x11vnc.conf的文件
| |
文件内容如下:
| |
我的密码创建在/etc目录下,可以直接复制这段,不需要按照别人博客的修改成自己的,这里用的5900端口,也可以自己换成其他的。
| |
启动了VNC和X11服务,端口号为5902,我这里用的5902,5900和5901被我分给其他的了
我直接添加开机启动项没有成功,又写了一个脚本,将脚本添加到开机启动项才成功了。
| |
添加以下内容
第一行是要添加的解释器,后面是要执行的指令内容
| |
防止误删,从home移动到/etc/init.d/文件夹中
并添加权限
| |
点开ubuntu的显示所有应用程序,左下角9个点,找到启动应用程序打开,图中第二行第5个。
点击右侧添加,添加自动启动项。
添加内容如下;重要的是第二行,
| |
用bash启动才能成功,保存之后重启,确实可以开机自启了。
如果你没有实时使用显示器而又想通过vnc远程查看桌面的话,可以考虑安装虚拟显卡驱动,唯一的缺点就是配置好后显示器那边可能无法正常显示
| |
/etc/X11/xorg.conf | |
| |
| |
如果想要恢复显示器的连接,可以先使用ssh访问终端并将/etc/X11/xorg.conf这个文件删除,再次重启即可
MPU全名称为 Micro processor Unit,MCU全称为Micro Controller Uint,首先这两个词都带有一个Micro开头,这就表明了这是计算、控制单元小型化后出现的技术,由于集成电路进步带来的计算机系统集成程度提高的结果,是的原来有多片分化的组成的计算机系统向高度集成化发展,多个芯片或元件的功能在向一颗芯片集中,这也是一个大的技术演进的背景。
但是在这种技术的演进过程中,出现了两种不同的需求:“以软制硬”和“以硬助软”。所谓以软制硬,就是通过一段软件程序来控制硬件,也就是所谓的“程控”,在这种使用模式下,计算机系统不承担主要的工作负载,而主要起辅助、协调、控制作用。
在这种情况下集成化的计算机系统就不需要太强大的计算、处理能力,所以对应的形态应该是运行频率低、运算能力一般,但是需要集成化的程度高(使用方便)、价格低廉(辅助系统不应该增加太多成本)等因素。
由于主要完成“控制”相关的任务,所以称为 Controller。也就是根据外界信号(刺激),产生一些响应,做点简单的人机界面。对于这种需求,通常不需要芯片主频太高。在早期的8051系列主频不过是10几MHZ,还是12个周期执行一条指令。而经过多年的“魔改”,最终也达到了100MHZ。其次就是处理能力不强,8位的MCU长期是微控制器的主流,而后来16位的MCU逐步开始占领市场,随着ARM的32位MCU的出现,采用ARM的M系列MCU也开始逐步扩大市场,并以ST、NXP公司的产品为主要代表。但是这些ARM的M系列MCU的主频一般也是在几十MHZ和100多MHZ的量级。再然后由于执行的“控制相关”的任务,通常不需要支持负载的图形界面和处理能力。在MCU上完成的任务大多数情况下是一些简单的刺激-响应式的任务,而且任务类型单一,任务执行过程简单。在这种情况下一般不需要MCU去执行功能复杂、运算量大的程序,因此通过也不需要运行大型操作系统来支持复杂的多任务管理,这就造成了MCU一般对于存储器的容量要求比较低。
而Processor,顾名思义就是处理器。处理器就是能够执行“处理”功能的器件,其实具备Processor 这个单词的器件不少,比如CPU就成为“中央处理器”,那既然有“中央”就应该有“外围”。GPU在经典的桌面计算机中就是一个典型的“外围”设备,主要负责图形图像处理。
以上对处理器说了这么多,核心意思就是一个,处理器一定要处理/运算能力强,能够执行比较复杂的任务;而微处理器,其实就是微型化/集成化了的处理器,标准来说是微型化/集成化的“中央处理器”,这就是把传统的CPU之外继承了原属于“芯片组”的各类接口和部分“外设”而形成的。MPU从一开始就定位了具备相当的处理和运算能力,一般需要运行较大的操作系统来实现复杂的任务处理。因此这就决定了MPU应该具备比较高的主频和较为强大的运算能力。
为了支撑MPU强大的算力,是的“物尽其用”,必然要求在MPU上运行比较复杂的、运算量大的程序和任务,通常需要有大容量的存储器来配合支撑。而大容量的存储器难以被集成到以逻辑功能为主的MPU内部,因此通常需要“外挂”大容量的存储器,主要是大容量的DDR存储器和FLASH,在手机领域,前者被称为“运存”,而后者被称之为“内存”,为了支撑运行复杂操作系统和大型程序,往往还需要MPU中集成高性能的存储控制器、存储管理单元(MMU)等一套复杂的存储机制和硬件。
从形态上看,MPU由于需要运行对处理能力要求复杂的大程序,一般都需要外挂存储器才能运行起来。而MCU往往只是执行刺激-响应式的过程控制和辅助,功能比较单一,仅仅需要使用偏上集成的小存储器即可。这是区分MPU和MCU的重要表象,但不是核心原因。
总结一下,MPU和MCU的区别本质上是因为应用定位的不同,为了满足不同的应用场景而按不同方式优化出来的两类器件。MPU注重通过较为强大的运算/处理能力,执行复杂多样的大型程序,通常需要外挂大容量的存储器。而MCU通常运行比较单一的任务,执行对于硬件设备的管理/控制功能,通常不需要很强的运算/处理能力,因此也不需要有大容量的存储器来支撑运行大程序,通常以单片机集成的方式在单个芯片内部集成小容量的存储器实现系统的“单片化”。

- 一个特殊变量
- 用于进程间传递信息的一个整数值
定义如下:
| |
- 信号量说明:semaphore s;
- 对信号量可以实施的操作:初始化、P和V(P、V分别是荷兰语的test(proberen)和increment(verhogen))
P(s)
| |
down,semwait:也代表P操作
V(s)
| |
up,semsignal:也代表V操作
相关说明
- P,V操作为原语操作
- 在信号量上定义了三个操作 +初始化(非负数)、P操作、V操作
- 最初提出的是二元信号量(解决互斥) +之后,推广到一般信号量(多值)或技术信号量(解决同步)
- 分析并发进程的关键活动,划定临界区
- 设置信号量mutux,初值为1
- 在临界区前实施P(mutux)
- 在临界区之后实施V(mutux)
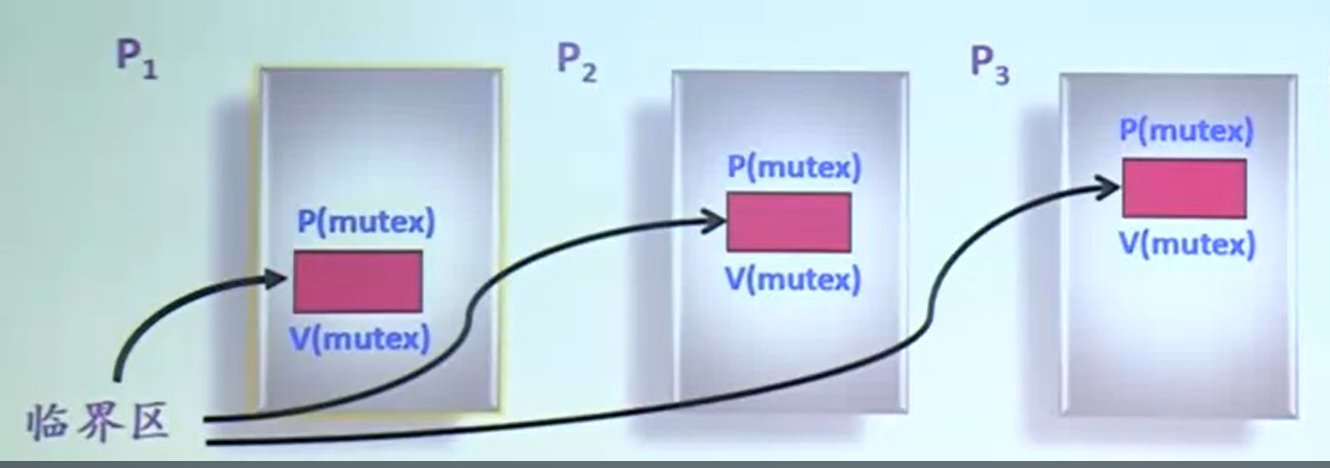
相关解释:
临界区 : 我们把并发进程中与共享变量有关的程序段称为临界区。
信号量 : 信号量的值与相应资源的使用情况有关。当它的值大于0时,表示当前可用资源的数量;当它的值小于0时,其绝对值表示等待使用该资源的进程个数。
进程的互斥:是指当有若干个进程都要使用某一共享资源时,任何时刻最多只允许一个进程去使用该资源,其他要使用它的进程必须等待,直到该资源的占用着释放了该资源。
进程的同步:是指在并发进程之间存在这一种制约关系,一个进程依赖另一个进程的消息,当一个进程没有得到另一个进程的消息时应等待,直到消息到达才被唤醒。
pv操作又称wait,signal原语。
+主要是操作进程中对进程控制的信息量的加减控制。
注意:在霍尔管程中,wait操作和signal操作用于被设计为两个可以中断的过程,而非原语。+在管程中,引入一种数据结构—条件变量(仅在管程中可以被访问)。 +条件变量的两种操作:
- wait()操作[阻塞调用进程]
- signal()操作[释放/唤醒在条件变量上阻塞的进程]
本文资源来自Operating Systems +参考:操作系统P,V(wait,signal原语)操作讲解

操作系统资源分配的基本单位,也就是指计算机中已执行的程序。
进程是程序的基本执行实体;线程的容器。进程才是程序(那些指令和数据)的真正执行实例.进程上下文就是表示进程信息的一系列东西,包括各种变量、寄存器以及进程的运行的环境。这样,当进程被切换后,下次再切换回来继续执行,能够知道原来的状态。
拿Linux进程举例:
+—-进程的运行环境主要包括:
1.进程空间中的代码和数据、各种数据结构、进程堆栈和共享内存区等。 +2.环境变量:提供进程运行所需的环境信息。 +3.系统数据:进程空间中的对进程进行管理和控制所需的信息,包括进程任务结构体以及内核堆栈等。 +4.进程访问设备或者文件时的权限。 +5.各种硬件寄存器。 +6.地址转换信息。
由上可知,进程的运行环境是动态变化的,尤其是硬件寄存器的值以及进程控制信息是随着进程的运行而不断变化的。在Linux中把系统提供给进程的的处于动态变化的运行环境总和称为进程上下文。
操作系统能够进行运算调度的最小单位。
进程的上下文的多数信息都与地址空间的描述有关。进程的上下文使用很多系统资源,而且会花费一些时间来从一个进程的上下文切换到另一个进程的上下文。同样的,线程也有上下文。
当线程被抢占时,就会发生线程之间的上下文切换。 +如果线程属于相同的进程,它们共享相同的地址空间,因为线程包含在它们所属于的进程的地址空间内。这样,进程需要恢复的多数信息对于线程而言是不需要的。尽管进程和它的线程共享了很多内容,但最为重要的是其地址空间和资源,有些信息对于线程而言是本地且唯一的,而线程的其他方面包含在进程的各个段的内部。
线程上下文与进程上下文对比
| 上下文内容 | 进程 | 线程 |
|---|---|---|
| 指向可执行文件的指针 | × | |
| 栈 | × | × |
| 内存(数据段和堆) | × | |
| 状态 | × | × |
| 优先级 | × | × |
| 程序IO的状态 | × | |
| 授予权限 | × | |
| 调度信息 | × | |
| 审计信息 | × | |
| 文件描述符 | × | |
| 文件读/写指针 | × | |
| 寄存器组 | × | × |

哈希表理论基础
242.有效的字母异位词
349.两个数组的交集
202.快乐数
1.两数之和
哈希表(Hash table,国内也有一些书籍翻译为散列表):是根据关键码的值而直接访问的数据结构。
最常见的哈希表例子就是数组。
哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素,如下图所示:
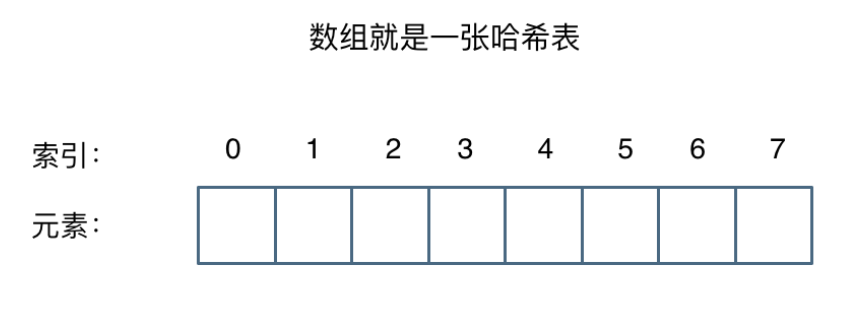
那么哈希表一般适用于哪些场景呢?一般哈希表都是用来快速判断一个元素是否出现在集合里。
例如我们需要对指定商品信息进行查询,如果使用枚举的话,时间复杂度为O(n),但是如果我们选择使用哈希表,只需要O(1)就可以做到。
我们只需要初始化时将所有的商品名称存入哈希表,在查询的时候直接通过索引就可以知道该商品是否存在了。
这里将商品列表映射到哈希表上就涉及到哈希函数(Hash function)。
哈希函数,直接将商品的名称映射为哈希表上的索引,通过索引下标查询就可以知道该商品是否在售了。
哈希函数如下图所示,通过HashCode将名字转化为数值,一般HashCode是通过特定编码方式,可以将其他数据格式转化成不同的数值,这样就可以将商品名称映射到哈希表上的索引数字了。
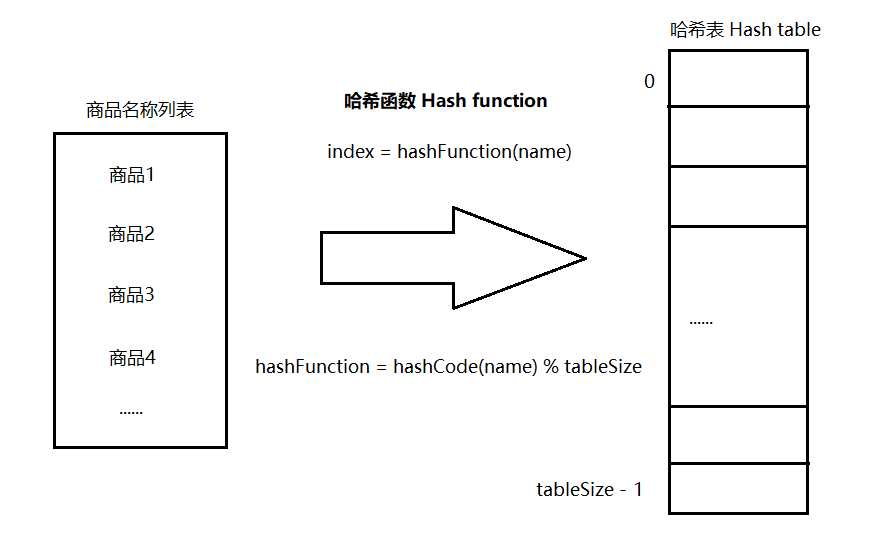
此时我们需要额外考虑一件事,如果通过hashCode得到的数值大于哈希表的大小,该怎么办?
为了保证映射出来的索引数值都落在哈希表上,我们会再一次对数值进行一个取模操作,这样我们就保证了商品名称就一定可以映射到哈希表上了。
此时由于哈希表本质上就是一个数组,如果商品的数量大于哈希表的大小该怎么办?哈希函数就算分的再均匀,也避免不了有几个商品名称同时映射到哈希表同一索引下标的位置。
这时候就需要引入哈希碰撞了。
如下图所示,商品1和商品3都映射到索引1的位置上,这个现象称之为哈希碰撞。
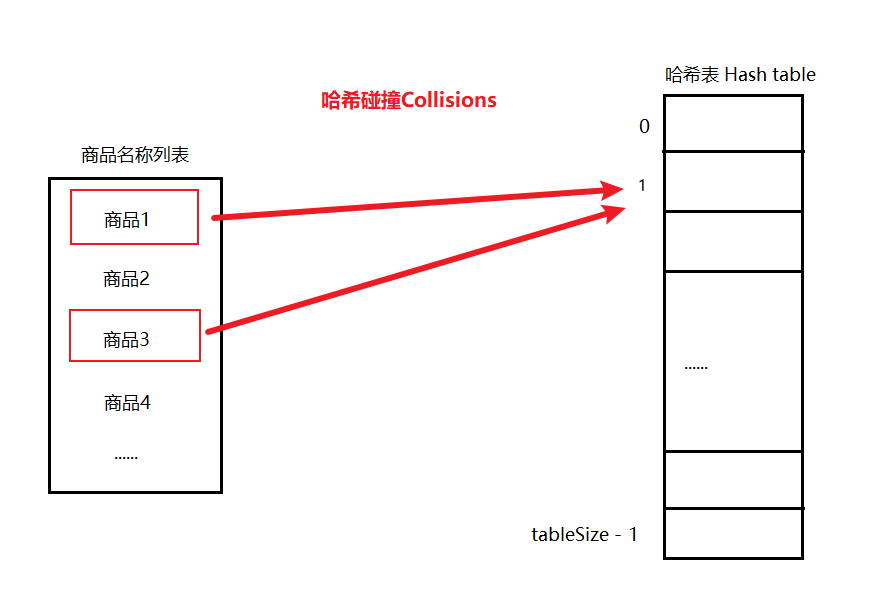
对于哈希碰撞一般有两种解决方法:链地址法(拉链法)和线性探测法
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
由于商品1和商品3再索引2的位置发生了冲突,并且发生冲突的元素都被存储在链表中,这样我们就可以通过索引找到商品1和商品3了
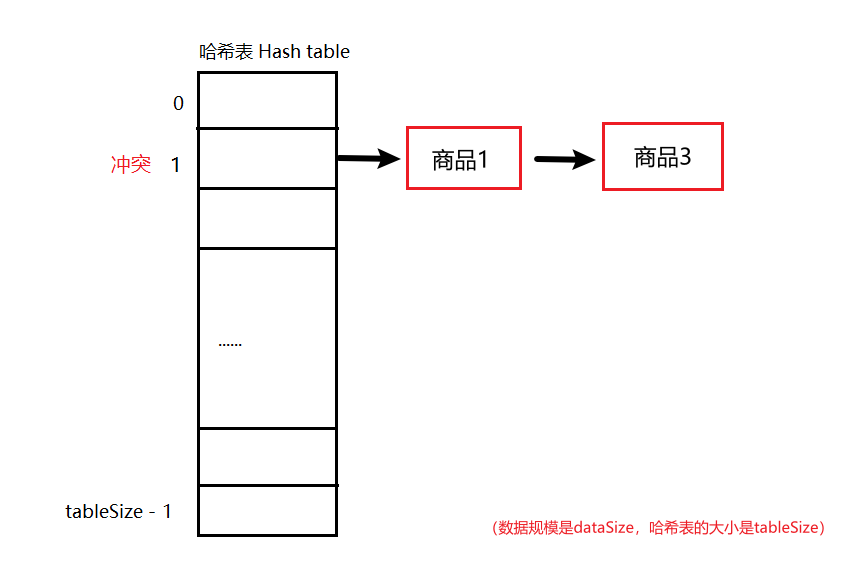
使用线性探测法,一定要保证tableSize大于dataSize。我们需要依靠哈希表中的空位来解决碰撞问题。
例如索引1的位置已经存放了商品1的名称,那么当商品3再次进入索引1的位置就发生了冲突,当冲突发生后,就顺序查看表中的下一单元,直到找到一个空单元去存放商品3的名称。
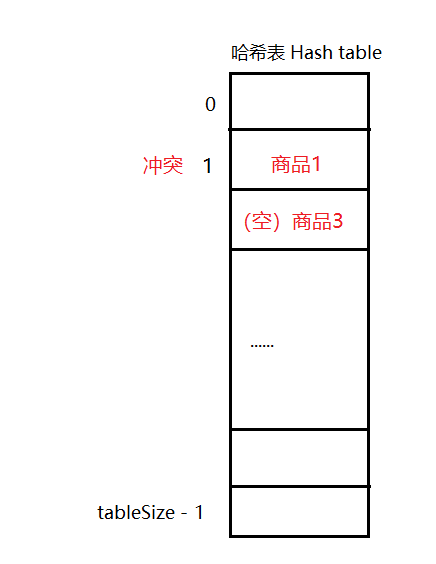
此外对于哈希碰撞的常用解决方法还有开放定址法、再哈希法、建立公共溢出区等等…
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构:
数组在前面已经简单介绍了,此处不再赘述,我们看下set(集合):
set(集合)
在C++中,set和map分别提供以下三种数据结构,其底层优化以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
map(映射)
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
当我们遇到这样一个场景:快速判断一个元素是否出现在集合里,就需要考虑哈希法。
但是哈希法的缺点也显而易见的:牺牲空间去换取时间。
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/valid-anagram
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
示例 1:
| |
示例 2:
| |
提示:
进阶: 如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
前面我们讲了数组其实就是一个简单的哈希表,在本题中,我们可以定义一个数组,来记录字符串s中出现的字符次数。
由于都是字母,对应的也就是26个字符,所以这里我们设置的数组长度为26即可,并且初始化为0.
例如,我们对字符串s = “aee”, t = ‘“eae”,我们观察动画:

我们定义一个record的数组来记录字符串s里所有字符出现的次数。
需要将字符映射到数组也就是哈希表的下标上,字符a映射为下标0,字符z映射为下标25。
在遍历字符串s的时候,只需要将s[i] = ‘a’所在的元素作+1操作即可;同时在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再作-1操作;最后再检查一下,record数组如果有的元素不为0,那么就说明字符t和字符s一定不互为字母异位词,return false.
最后如果record数组所有元素都为0,则说明字符s和字符t是字母异位词,return true。
时间复杂度为O(n),空间上因为定义的是一个常量大小的辅助数组,所以空间复杂度为O(1)
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/intersection-of-two-arrays
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
| |
示例 2:
| |
提示:
在这道题目中,需要我们掌握哈希数据结构:unordered_set,如下图所示:
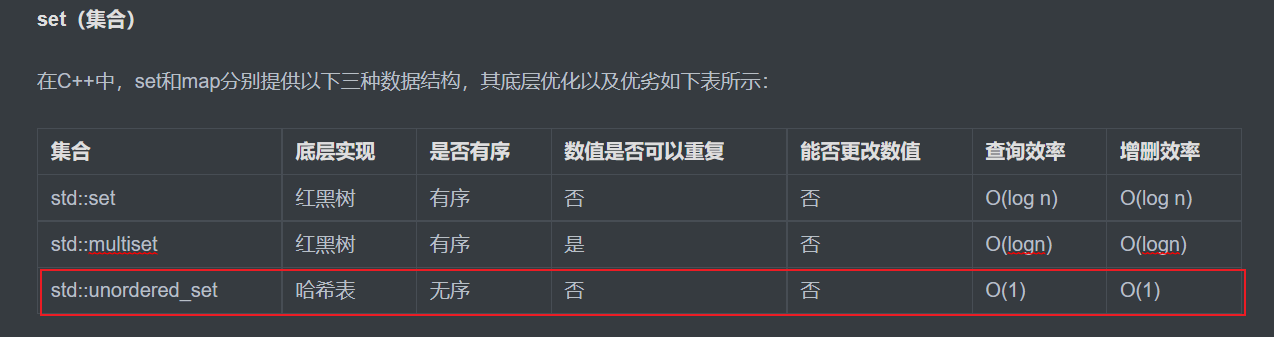
题目中特别声明:输出结果的每个元素一定是唯一的,也就是说输出的结果不用对重复出现的元素输出,同时可以不考虑输出结果的顺序。
之所以这里不使用数组,是因为题目限制了数组的大小,并且如果哈希值比较少、特别分散、跨度大,使用数组就会造成空间的极大浪费。
所以结合std::unordered_set的无序性,查询效率和增删效率都是O(1)的情况下,果断使用unordered_set
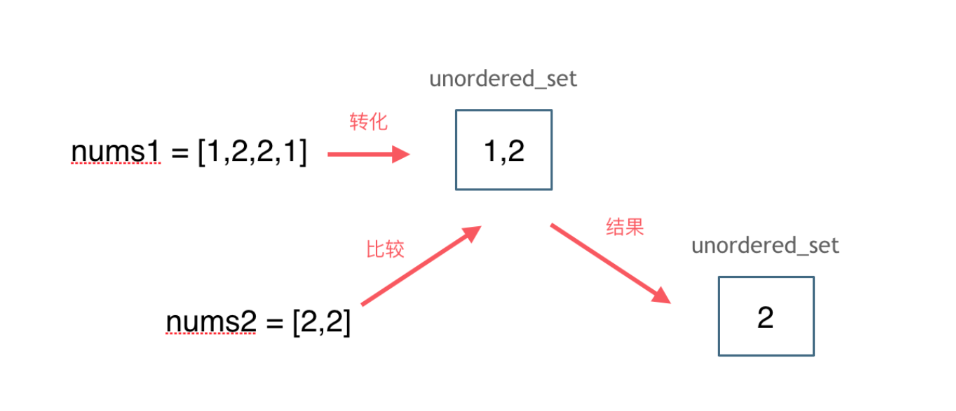
| |
当然这道题也可以使用数组的方式进行求解:
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/happy-number
编写一个算法来判断一个数 n 是不是快乐数。
**「快乐数」 **定义为:
对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
如果这个过程 结果为 1,那么这个数就是快乐数。
如果 n 是 快乐数 就返回 true ;不是,则返回 false 。
示例 1:
| |
示例 2:
| |
提示:
根据题目所给出的提示:重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
简单解释下这句话,那么我们是不是可以理解为如果存在循环的数的话,那么这是不是就说明这个数不是开心数?
那么对于判断是否存在重复出现的数,我们选择使用哈希法,如果重复了的话就返回false,否则一直找到sum = 1为止。
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/two-sum
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
| |
示例 2:
| |
示例 3:
| |
提示:
进阶:你可以想出一个时间复杂度小于 O(n2) 的算法吗?
根据提示:只存在一个有效答案。所以我们这里可以选择unordered_map
接下来我们明确两点:
拿target = 9举例子:map的目的是用来存取我们访问过的元素,当我们遍历数组的时候,需要我们记录之前遍历过哪些元素和对应的下标,首先先选定一个值(比如2),通过map查询是否存在与之满足条件的符合 因子(只能是7),此时如果在map中索引到该值,那么就得出我们想要的结果了;如果没有则继续选定下一个值,再去寻找与之相对应的符合因子。
所以在map中的存储结构为:{key:数据元素, value:数组元素对应的下标}
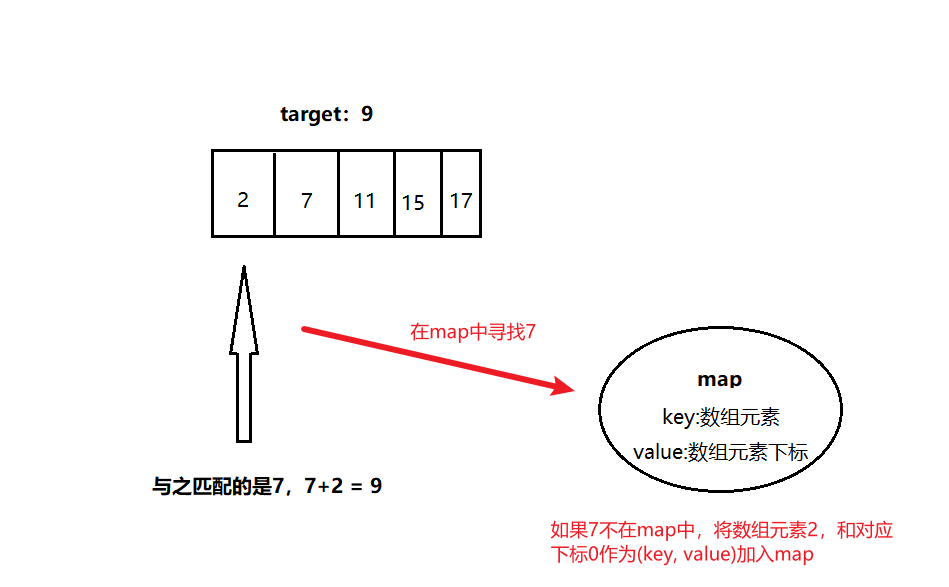
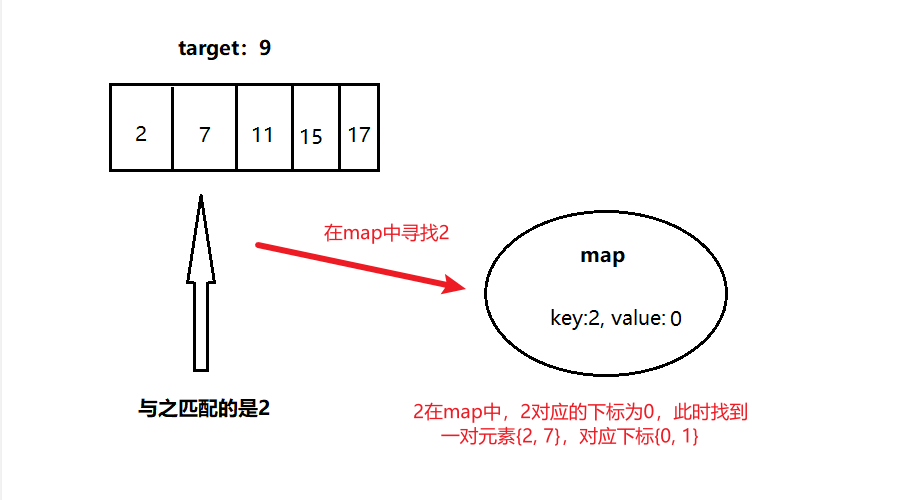
| |

来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/4sum-ii
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
示例 1:
| |
示例 2:
| |
提示:
分析题意,题目中是四个独立数组,要求我们只要找到nums1[i] + nums2[j] + nums3[k] + nums4[l] = 0,同时这四个数组长度相同,并且在本题目中并没有限制数组元素出现的次数,也就是说只要满足四数组元素相加为0都可以作为一组解。
解题步骤:
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/ransom-note
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
示例 1:
| |
示例 2:
| |
示例 3:
| |
提示:
首先锁定提示:两个字符串均由小写英文字母组成,并且magazine 中的每个字符只能在 ransomNote 中使用一次,这就跟战争时期的加密信件差不多一个意思,密信的内容在杂志中都可以找到。
对于这道题的解法,使用暴力解法,数组、map都可以实现,我们这里主要讲解暴力解法和数组,至于为什么不使用map,根据carl大神的说法就是这道题中使用map,空间消耗要比数组大一些,因为map需要维护红黑树或哈希表,并且还要做哈希函数,是很费时的,所以数组和map果断选择map。
暴力解法就是简单两层for循环,只要找到两个字符串中存在相同的字符就将ransomNote中对应的字符删去,直至最后ransomNote中无元素为止。
使用哈希解法的话,前面的学习我们也已经知道,数组也是一种简单的哈希表,通过定义一个record[26]的数组(因为条件说明仅为小写字母),首先遍历所有magazine中的元素对应record数组中的索引,出现相同的key值就将该value加一
| |
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/3sum
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例 1:
| |
示例 2:
| |
示例 3:
| |
提示:
这道题和Leetcode454.四数相加II有点相似,不过在本题目中,特别限制了答案中不可包含重复的三元组。所以解题思路不能一概而论,同样可以使用哈希解法,但是现在目前最大的问题就是对三元组的去重工作,哈希解法的细节需要考虑的太多了,这里还是不建议使用,博主已经是晕了,当然大佬们可以尝试着理清关系。
那么另外一种解题思路就是使用双指针法。拿数组nums举例,首先将数组排序,元素i从下标0开始,同时设下一个下标 left 在 i + 1 的位置上,下标right在数组末尾,如下图所示:
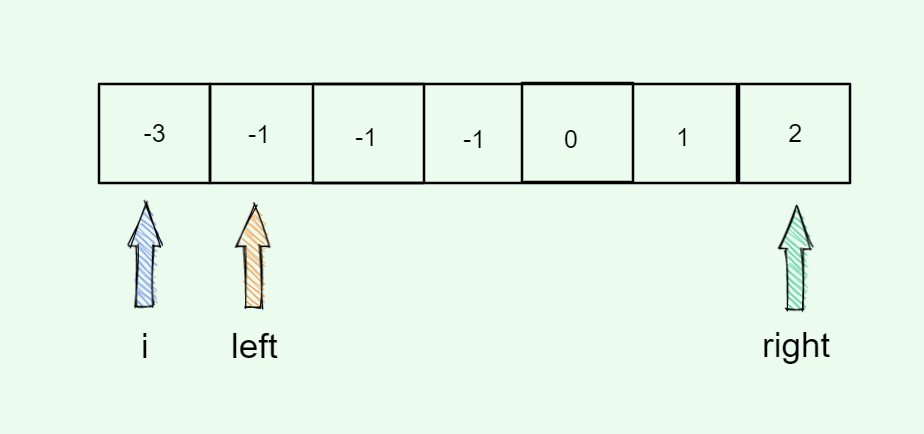
我们的目的是在数组nums中找到a、b、c,那么对于上图也就是a = nums[i], b = nums[left], c = nums[right]。由于我们提前排好序,所以此时abc相加会出现三种结果:
此外,我们还需要解决去重的问题:
<1>对a去重:
按照一贯的理解我们可能是下面这种做法:
| |
但是我们看这种情况:如果我们这里选择上面的去重做法,当遍历第一个-1的时候,此时nums[i + 1]也就是-1,那么这组数据直接就被pass了,根据题意:返回不能有重复的三元组,但是三元组内的元素是可以重复的,如果按照上面的写法,那么我们很可能漏掉一组解。
所以应该是下面这段代码这样:
| |
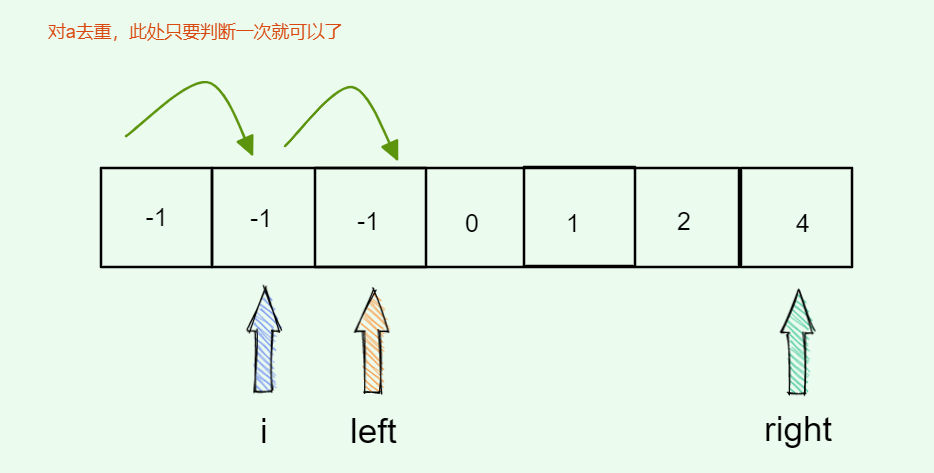
<2>b与c的去重:
当我们收割到符合条件的结果的时候,如果不进行去重,可能会出现多个相同的结果,所以我们left和right会造成的相同结果进行去重,去重之后将两个指针再移动到一位进行比较。
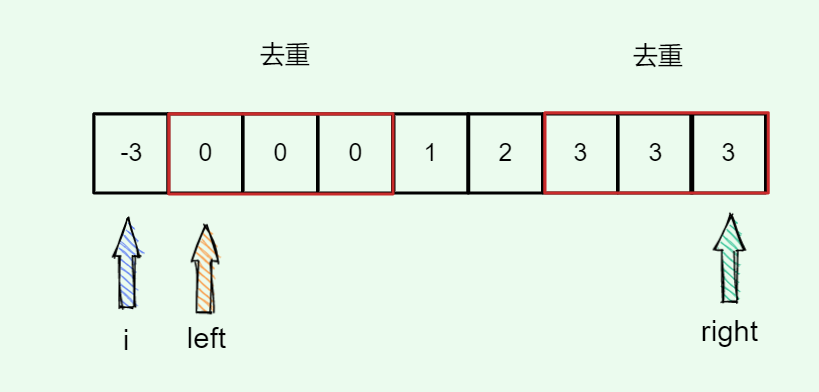
| |
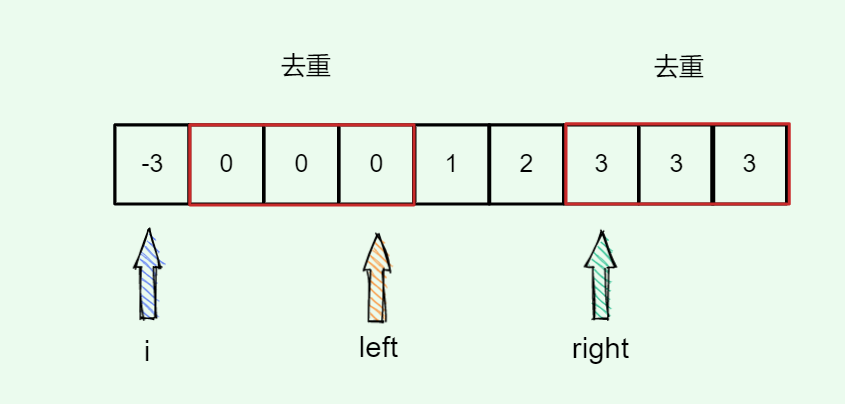
| |
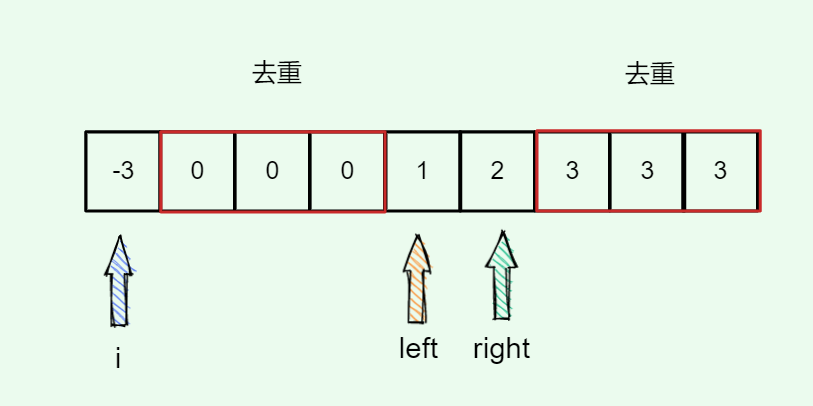
| |
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/4sum
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < n
a、b、c 和 d 互不相同
nums[a] + nums[b] + nums[c] + nums[d] == target
你可以按 任意顺序 返回答案 。
示例 1:
| |
示例 2:
| |
提示:
这道题算的上是Leetcode15.三数之和的一个延伸,四数之和其实是在三数之和的基础上再外层再套了一层循环。
但是有些许细节需要我们认真对待:
nums[k] + nums[i] + nums[left] + nums[right] == target的所有可解集合,所以我们的解决方法是两层for循环nums[k] + nums[i]为确定值,双指针法依然是left和right作为下标。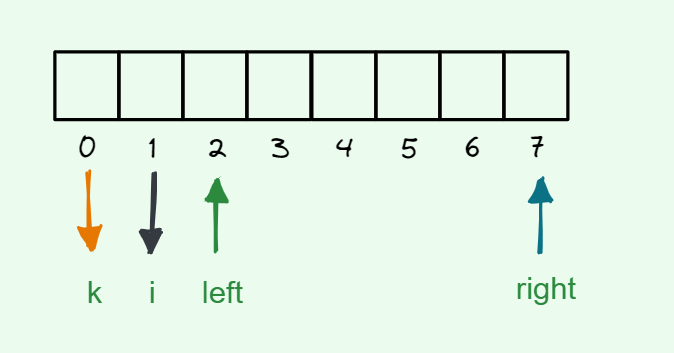
| |

来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/reverse-string
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
示例 1:
| |
示例 2:
| |
提示:
看到这道题的第一反应就是双指针法,不得不说,双指针法对这种排序问题真的YYDS,相比于我们前面在学习链表的时候所使用到的双指针法,字符串的反转其实比起链表还要简单一些。在内存中链表可以是无序的,但是字符串本质上也可以说的上是一种数组,所以元素在内存中是连续分布的。
那么对于这道题我们选择使用双指针法:分别定义指针i位于字符串下标0的位置和指针j位于字符串末尾的位置,通过互换元素的方式来完成字符串的反转。
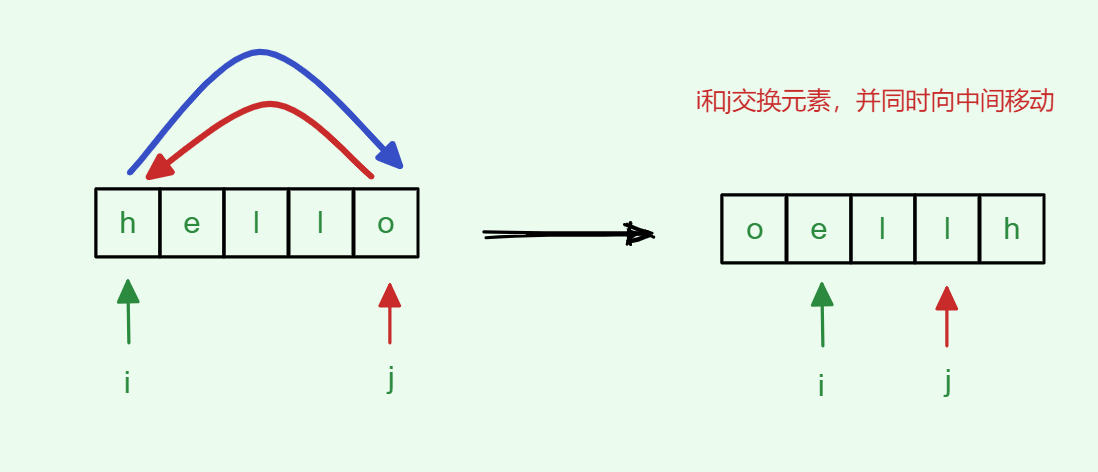
对应的部分C++代码:
| |
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/reverse-string-ii
给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符。
示例 1:
| |
示例 2:
| |
提示:
我们在遍历字符串的过程中,只要让 i += (2 * k),i 每次移动 2 * k 就可以了,然后判断是否需要有反转的区间。
该题主要需要解决两个问题:
具体详细的解题步骤请看下图及代码:
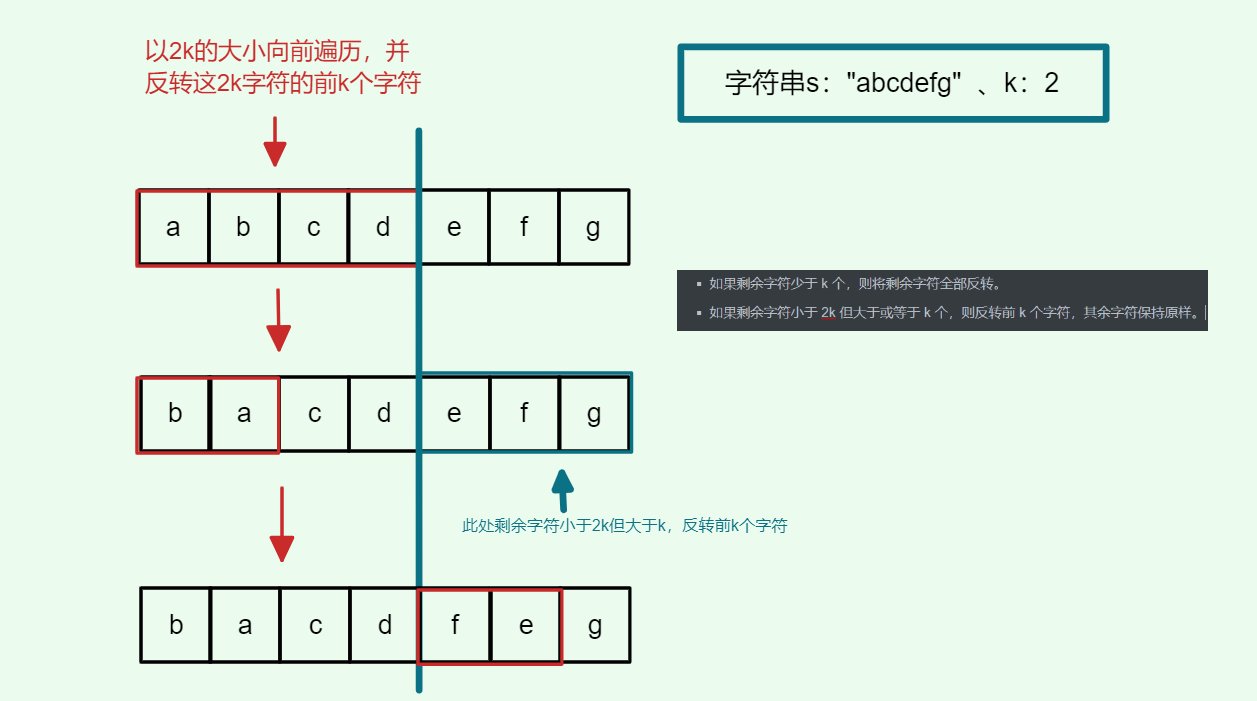
| |
reverse()
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/ti-huan-kong-ge-lcof
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
| |
限制:
对这道题的求解,主要分三个步骤:
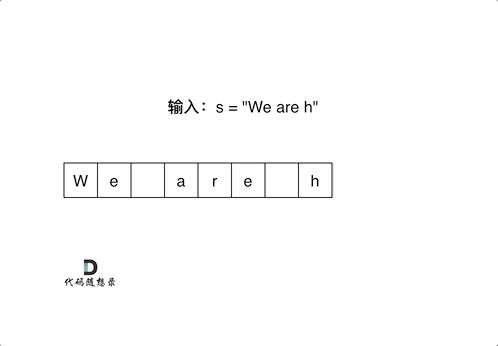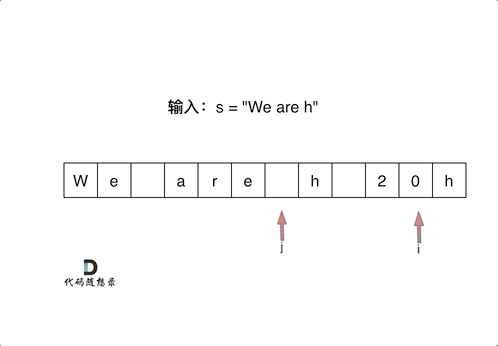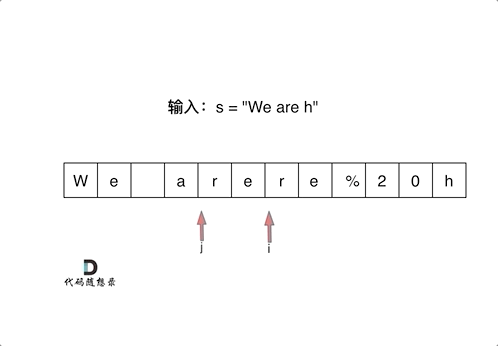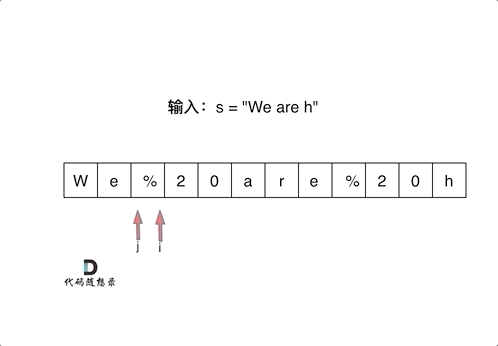
而这里也有一个小技巧:遇到很多数组填充类的问题,都可以先预留给数组扩容带填充后的大小,然后再从后往前操作。
这样做的好处:
| |
resize()
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/reverse-words-in-a-string
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
| |
示例 2:
| |
示例 3:
| |
提示:
进阶:如果字符串在你使用的编程语言中是一种可变数据类型,请尝试使用 O(1) 额外空间复杂度的 原地 解法。
对于这样一道题,我们不使用辅助空间,空间复杂度要求为O(1)
所以对此我们有这样一种解法:使用整体反转加局部反转的方式解决
演示如下:
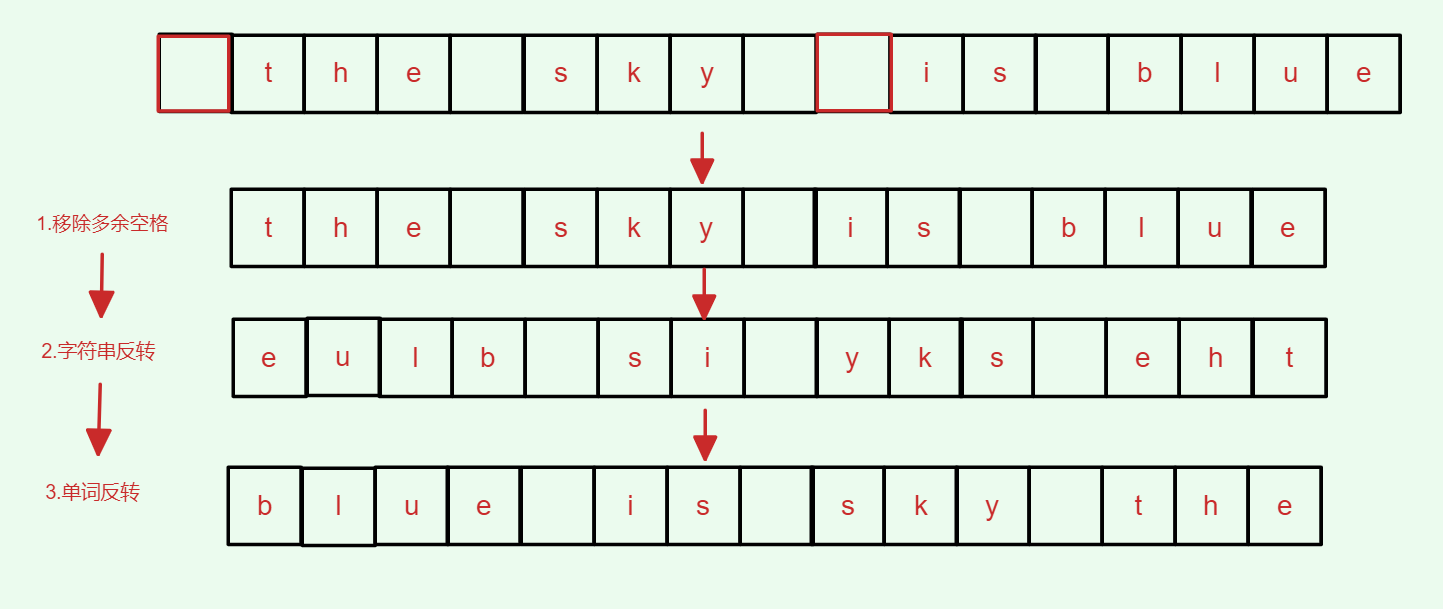
前面讲了整体的一个逻辑思维方式,那么代码怎么实现呢,首先我们看移除多余空格:我们的做法是通过快慢指针的方式来去除所有空格并且在相邻单词之间添加空格。
| |
此外就是字符串反转的问题,其代码实现逻辑如下:
| |
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
示例 1:
| |
示例 2:
| |
限制:
在本题目中,carl老师继续升级难度:要求不能申请额外空间,只能在本串上操作
但是对于上面Leetcode151题,我们依旧可以有借鉴之法,具体步骤如下:
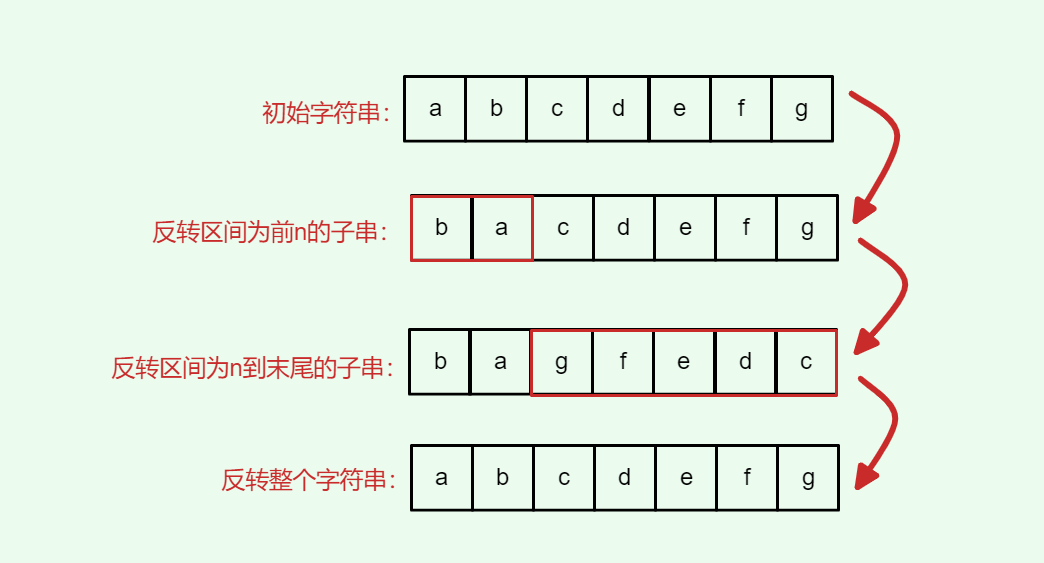
这样一来,整体的代码逻辑就特别简单啦!
| |
没想到最后一个代码的实现这么简单哈哈哈,在经历Leetcode151.反转字符串里的单词这道题的洗礼后是不是有种小巫见大巫的想法。

由于今天的算法题涉及到KMP算法,所以这里我们提前学习一下。
说到KMP,先说一下KMP这个名字是怎么来的,为什么叫做KMP呢。
因为是由这三位学者发明的:Knuth,Morris和Pratt,所以取了三位学者名字的首字母。所以叫做KMP。
KMP主要体现在字符串匹配上。
KMP算法的主要思想是当出现字符串不相匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头到尾再去匹配。
因此如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任。
前缀表有什么作用呢?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配时,模式串应该从哪里开始重新匹配。
其中我们会了解到next数组,next数组其实就是一个前缀表(prefix table)。
为了更加清楚地了解前缀表的来历,我们来举一个例子:
在文本串:aabaabaafa中查找是否出现过一个模式串:aabaaf。
如下面动画所示(来源:代码随想录):
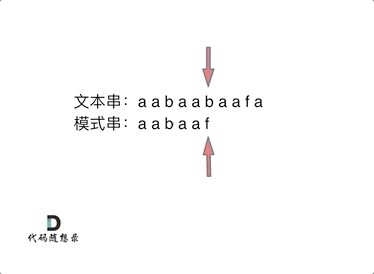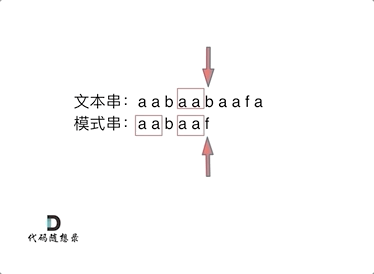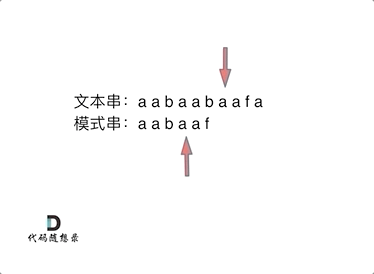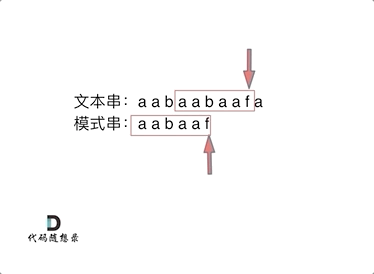
我们从上面的动画可以看出,文本串中第六个字符b和模式串的第六个个字符f已经不匹配了。如果暴力匹配的话,需要从头开始匹配;但是如果我们使用前缀表的话,就不会从头匹配,而是从上次已经匹配的内容开始匹配,也就是模式串中第三个字符b继续开始匹配。
那么前缀表时如何记录的呢?
首先要知道前缀表的任务是当前任务匹配失败,找到之前已经匹配上的位置,再重新匹配,这也意味着再某个字符失配时,前缀表会告诉你,下一步匹配中,模式串应该跳到哪个位置。
所以前缀表的定义是:记录下标i之前(包含i)的字符串中,有多大长度的相同前缀后缀。
前文中字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
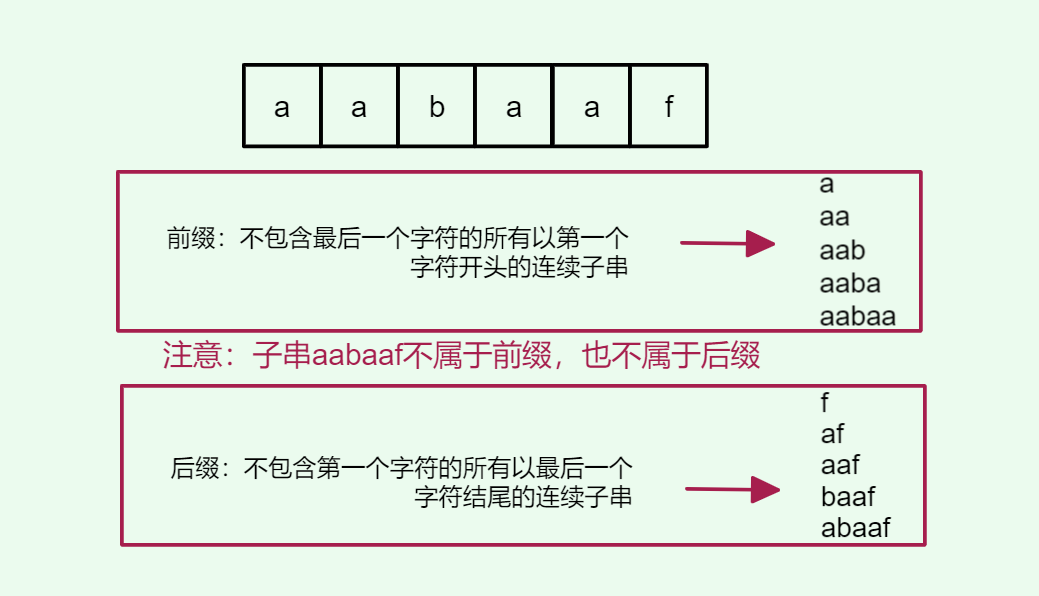
那么我们回到最长公共前后缀,更加准确的理解应该是“最长相等前后缀”,因为前缀表的要求就是相同前后缀。
而最长公共前后缀里面的“公共”,更像是在说前缀和后缀公共的长度。这其实并不是前缀表所需要的。
所以字符串a的最长相等前后缀为0;字符串aa的最长相等前后缀为1,字符串aaa的最长相等前后缀为2。
我们先来看几个例子:
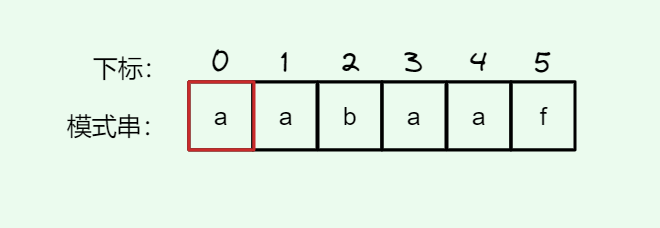
解说:长度为前1个字符的子串a,最长相同前后缀的长度为0.
注意:字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
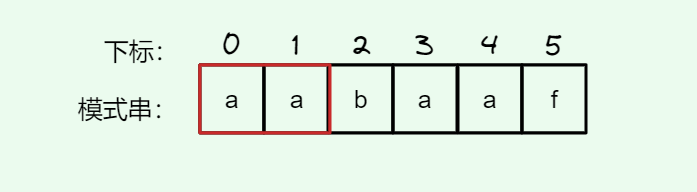
解说:长度为前2个字符的子串aa,最长相同前后缀的长度为1.
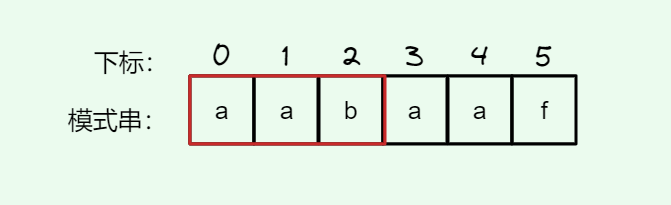
解说:长度为前3个字符的子串aab,最长相同前后缀的长度为0.
…
以此类推:长度为前4个字符的子串aaba,最长相同前后缀的长度为1;长度为前5个字符的子串aabaa,最长相同前后缀的长度为2;长度为前6个字符的子串aabaaf,相同前后缀的长度为0.
最后把求得的最长相同前后缀的长度就是对应前后缀表的元素,如下图:
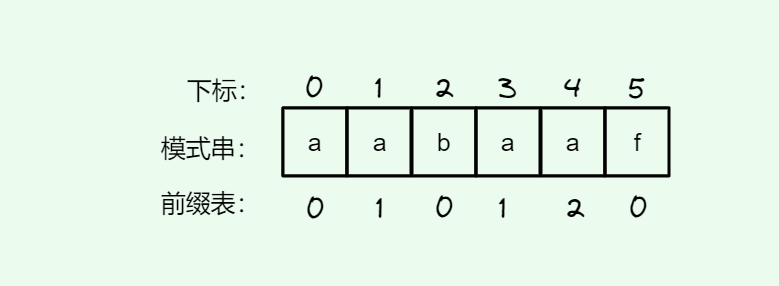
可以看出模式串与前缀表对应位置的数字表示的就是:下标i之前(包括i)的字符串中,有多大长度的相同前后缀.
我们再来看下如何利用前缀表找到:当字符不匹配的时候指针应该移动的位置。如下动画所示:
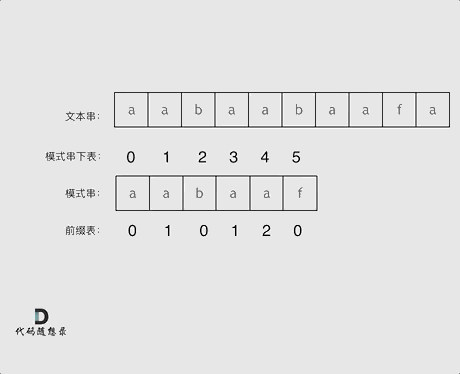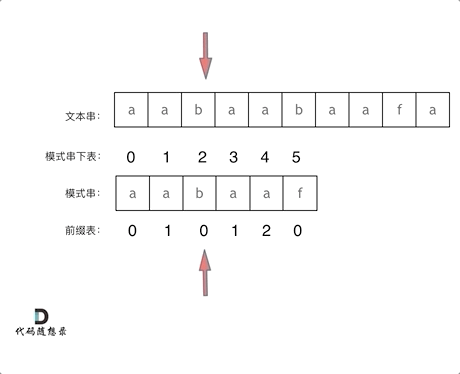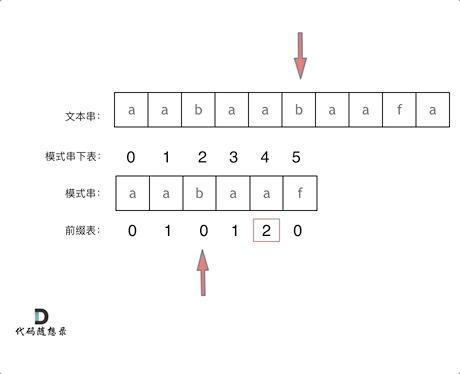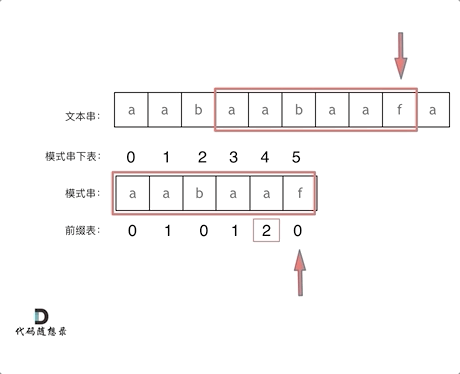
当找到不匹配的位置,此时我们需要看它的前一个字符的前缀表的数值是多少。
之所以要前一个字符的前缀表的数值,是因为要找到前面字符串的最长相同的前后缀。
所以我们要看前一位的前缀表数值,动画中显示为2,所以将下标移动到下标2的位置继续匹配。直到在文本串中找到和模式串匹配的子串。
很多KMP算法的时间都是使用next数组做回退操作,那么next数组与前缀表有什么关系?
前面我们讲了,next数组其实就可以被认为是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)。
以下我们以前缀表统一减一之后的next数组来做演示。
注意此时的前缀表已经实现同一减一了,匹配动画如下:
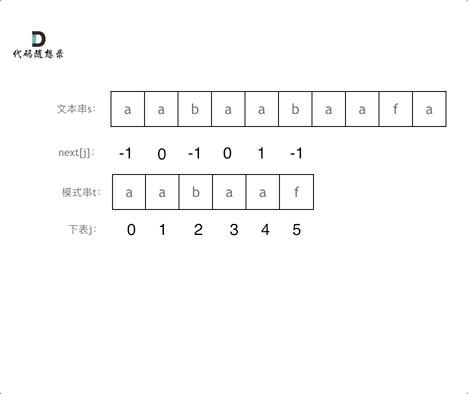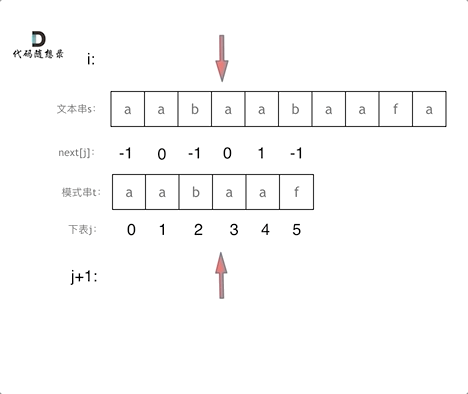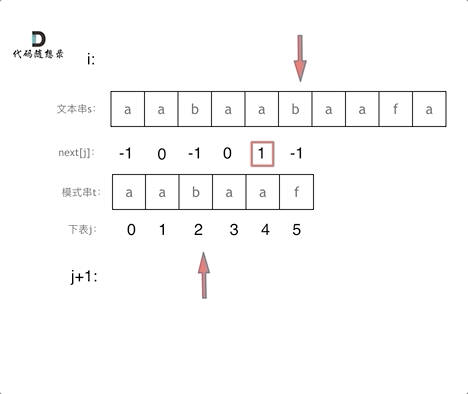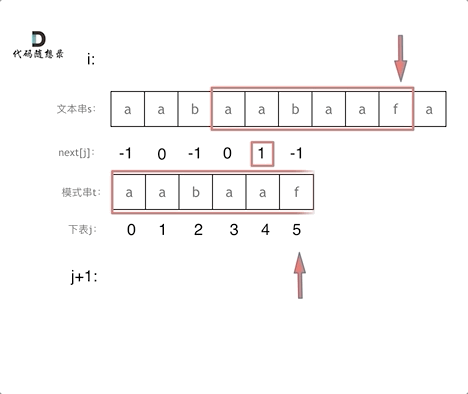
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)
而暴力解法的时间复杂度明显是O(n * m),所以可知KMP在字符串匹配中极大地提高了搜索的效率。
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
| |
示例 2:
| |
提示:
前提说明:学习该小结需要提前对KMP算法有一定的了解,请详细阅读第一小节。
在本题目中,haystack(文本串),needle(模式串)。
解答此题目我们需要使用到KMP算法,那么使用KMP算法,需要我们构造next数组。
我们定义一个函数getNext来构建next数组,函数参数为指向next数组的指针,和一个字符串。代码如下:
| |
**构造next数组其实就是计算模式串s、前缀表的过程。**主要有三步:
下面我们来详细讲解:
1.初始化
定义了两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置。
然后对next数组进行初始化赋值:
| |
这里之所以将j初始化为-1,是因为前面我们讲过前缀表要统一减一(当然也可以选择j不初始化为-1)
next[i]表示i(包括i)之前最长相等的前后缀长度(其实就是j)
所以初始化为next[0] = j;
2.处理前后缀不相同的情况
因为j初始化为-1,那么i就从1开始,并将s[i]与s[j + 1]进行比较。
所以遍历模式串s的循环下标i要从1开始,代码如下:
| |
如果s[i]与s[j + 1]不相同,也就是遇到前后缀末尾不相同的情况,就要向前回退。
这里我们再次明确一点:next[j]记录着j(包括j)之前的子串的相同前后缀的长度。
s[i]与s[j + 1]不相同,那么我们就要找一个j + 1前一个元素在next数组里的值(就是next[j])。
所以,处理前后缀不相同的情况的代码如下所示:
| |
注意:此处之所以写成while而不是if,是因为字符串回退并不是一步就可以的,而是一个连续回退的过程。
3.处理前后缀相同的情况
如果s[i]与s[j + 1]相同,那么就同时向后移动i和j说明找到了相同的前后缀,同时还要将j(前缀的长度)赋值给next[i],因为next[i]要记录相同前后缀的长度。如下所示:
| |
最后整体构建next数组的函数代码如下所示:
| |
代码构造next数组的逻辑流程动画如下(来源:代码随想录):
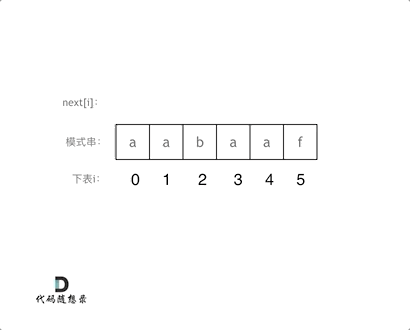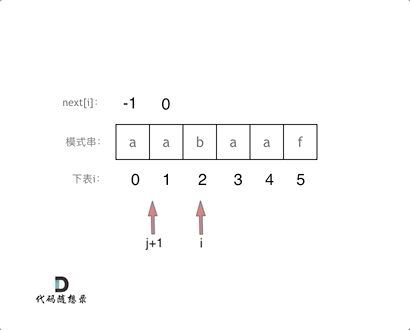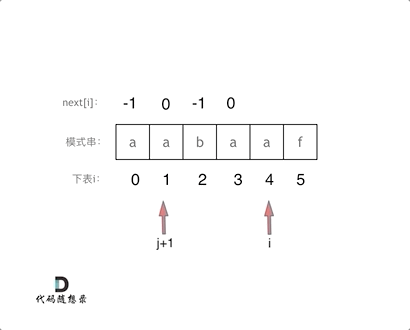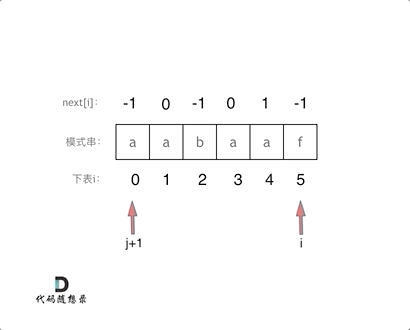
目标:在文本串中找是否出现过模式串t。
首先定义两个下标j指向模式串起始位置,i指向文本串起始位置。
此时j初始值依然为-1,因为next数组中记录的起始位置为-1.
i从0开始,遍历文本串,代码如下:
| |
接下来就是s[i]与t[j + 1](因为从-1开始)进行比较。
如果s[i]与t[j + 1]不相同,就要从next数组中需按照下一个匹配的位置,代码如下:
| |
如果s[i]与t[j + 1]相同,那么i和j同时向后移动,代码如下:
| |
那么如何判断在文本串中出现了模式串t?如果j指向了模式串t的末尾,那么就说明模式串t完全匹配文本串s里的某个子串了。
模式串出现的位置:当前在文本串匹配模式串的位置i减去模式串的长度。代码如下:
| |
因此使用next数组,用模式串匹配文本串的整体代码如下:
| |
| |
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/repeated-substring-pattern
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
| |
示例 2:
| |
示例 3:
| |
提示:
对这道题我们有三种解决方法:暴力解法、移动匹配和KMP。
首先来看暴力解法,也就是一个for循环去获取子串的终止位置,再嵌套一个for循环判断子串是否能够重复构成字符串,所以时间复杂度为O(n^2)。
这里我们主要对移动匹配和KMP两种方法进行讲解。
首先我们来看题目,假设字符串s为:abcabc,内部由重复子串组成,那么该字符串的结构如下图所示:
那么既然前面有相同的子串,后面也有相同的子串,我们换个思路,是不是将后面的子串作为前串,前面的子串作为后串,这样一来是不是也能构成一个字符串s呢。
所以我们的思路就是:将两个s拼接起来,如果还能出现额外的一个s,那就说明该串是由重复子串构成。
这里为了避免在s+s搜索的时候搜索出原来的字符串s,这里我们需要进行掐头去尾(刨除s+s的首字符和尾字符),代码如下:
| |
虽然这个解法可行,但是后面我们还需要对字符串(s+s)是否出现过s做一个判断,在这个过程是增加了时间复杂度的算法成本的,例如使用库函数find、contains,一般的库函数的实现的时间复杂度为O(m + n)。
想到KMP,就想到了KMP算法的字符串匹配,我们要在一个串中查找是否出现另外一个串,这才是KMP算法的专长所在.
代码如下:
| |
对于本章节,涉及到很多经典的算法,最常见的就是双指针法,以及我们头疼的KMP算法(这部分其实我本人也没有很理解,需要反复理解)。

数组理论基础
704.二分查找
27.移除元素
(1)数组是存放在连续内存空间上的相同类型数据的集合。
注意:
(2)正因为数组在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
例如删除下标为3的元素,我们需要堆下标为3的元素后面的所有元素都要做移动操作,如图所示:
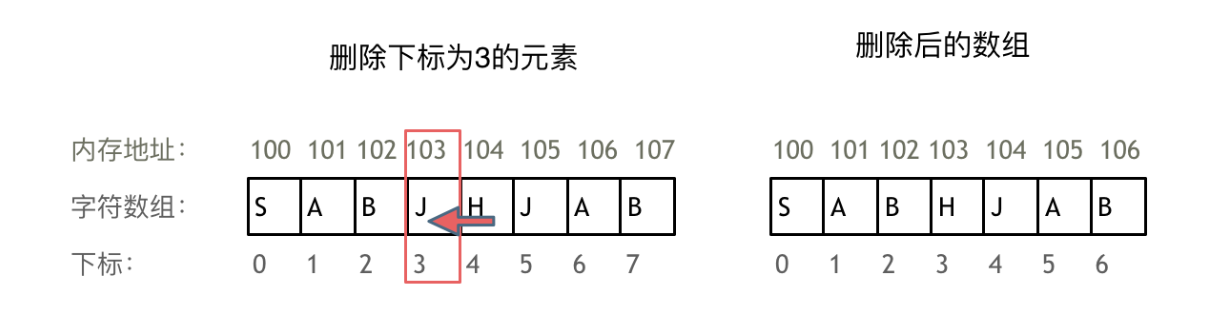
(3)数组的元素是不能删除的,只能使用覆盖的方式。
(4)C++中二维数组在地址空间上是连续的。
通过编写一个程序来验证:
| |

在C++中,一个int(整型)变量占据4个字节,所以相邻两个数组元素的地址差4个字节
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/binary-search
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
| |
示例 2:
| |
提示:
首先确定关键词:
根据题目和提示,我们联想到二分法。
简单说下二分法,就是查找出特定元素(target)的位置,如果找到的话返回该元素的下标,如果没找到的话就返回-1。
关于二分法的写法,区间的定义一般分为两种:
根据二分法的两种写法,我们分别求解:
<1>第一种写法,我们定义target是在一个左闭右闭,也就是[left, right]
区间的定义这就决定了二分法的代码如何编写,因为定义target在[left, right]区间,所以有如下两点:
| |
| |
<2>第二种写法,我们定义target是在一个左闭右开,也就是[left, right)
根据左闭右开的方式,那么处理方式有如下两点:
| |
| |
上面对二分法的两种方式都已经做出解释,分别提供了伪代码和程序代码,其中有些知识点在下方做出解释:
解析一:int middle = left + ((right - left) / 2);// 防止溢出 等同于(left + right)/2
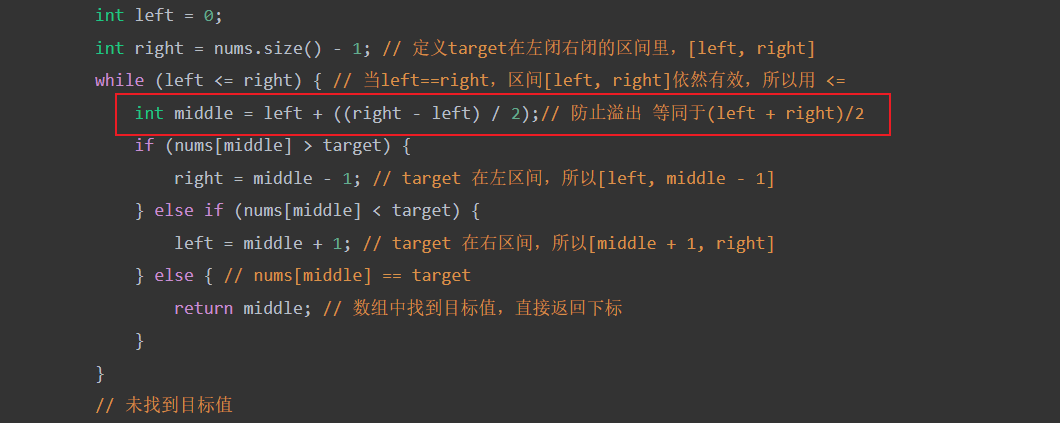
解答:对于上面这段代码做出这样修改的原因,主要就是为了防止溢出,如果在进行特别大的数值运算的时候,先进行加除操作很容易导致加法溢出最大限制,而首先进行减除操作则会大大降低风险。
解析二:int middle = left + ((right - left) >> 1);
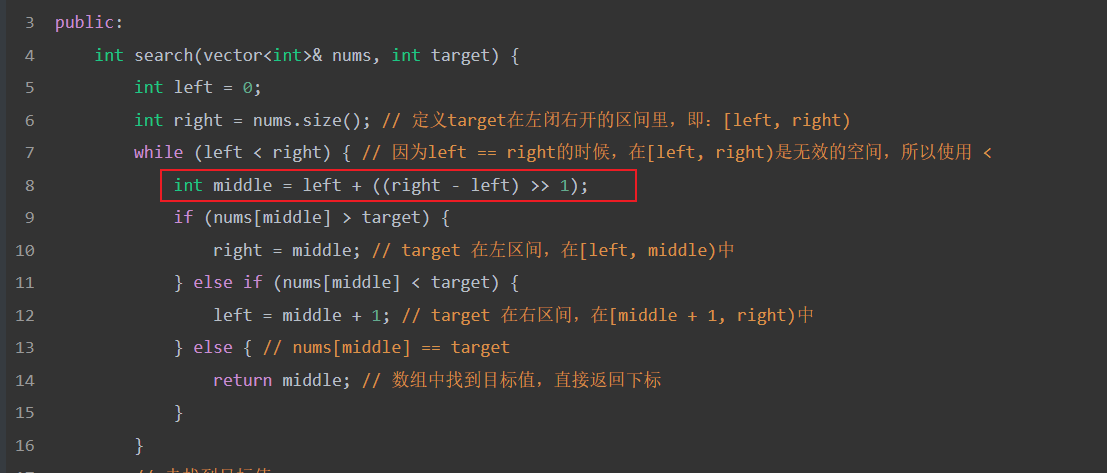
解答:>>是位运算的符号,>>1代表右移一位,这里我们记住尖号对准的方向就是位移方向。而对一个数右移一位,也就是代表除2操作。例如:11»1,将11转成二进制为1011,而对二进制数向右移动1位则变成了0101,也就是代表5,其实也就代表除2操作。
此外还要补充一下,从效率上看,使用移位指令有更高的效率,因为移位指令占2个机器周期,而乘除法指令占4个机器周期。从硬件上看,移位对硬件更容易实现,所以会用移位,移一位就乘2,这种乘法当然考虑移位了。
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/remove-element
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
| |
示例 1:
| |
示例 2:
| |
提示:
首先我们应该知道,在数组中,数组的元素在内存地址中是连续的,不能单独删除数组中的某个元素,只能覆盖。
对此我们使用暴力解法
解法:通过使用两层for循环,一层for循环遍历数组元素,一层for循环更新数组。
| |
说明:通过上面的程序可以看出暴力破解使用了两层for循环,也导致它的时间复杂度为O(n^2),通过遍历的形式找出目标值,并将目标值后一位前移覆盖掉目标值的形式,从而达到移除数组元素的目的。
除了暴力解法,双指针法也同样适用于此场景。
通过定义两个指针,一个slow指针和一个fast指针, 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
| |

977.有序数列的平方
209.长度最小的子数组
59.螺旋矩阵II
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/squares-of-a-sorted-array
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
| |
示例 2:
| |
提示:
进阶:
请你设计时间复杂度为 O(n) 的算法解决本问题
最开始的一个想法,就是首先对每个数进行平方,然后再对新数组进行排序。
有了昨天的经验,我们可以直接使用暴力排序的方式进行编程:
| |
说明:
解答:上面的求平方数我用了两种方式求解,但是很明显可以看出注释的那一段代码明显执行的时间复杂度更高,也就是O(nlogn+1+nlog2n),而另外的一种方式的时间复杂度则是O(n+nlogn)
**在这里也有大佬提出:二分法的log2就直接logn就可以,平衡二叉树 排序都直接nlogn就行 **
根据数组最大值通过平方之后,不是最大值就是最小值,我们可以考虑使用双指针法,i指向起始位置,j指向终止位置。
K指向result数组终止位置 | |
通过双指针法求解有序数列的平方,此时的时间复杂度为O(n),相比较暴力排序这个还是更加推荐!
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/minimum-size-subarray-sum
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, …, numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
| |
示例 2:
| |
示例 3:
| |
提示:
进阶:
如果你已经实现 O(n) 时间复杂度的解法, 请尝试设计一个 O(n log(n)) 时间复杂度的解法。
首先分析题意,最明显的就是要求是连续子数组,然后就是要求这个子数组长度最小,遇到这个问题,我们想到的就是首先分出若干个有效子数组(要求是连续的),然后对这些子数组的长度进行筛选,留下长度最小的返回该数组长度。
对这道题暴力排序的解法是通过使用两个for循环,然后不断寻找符合条件的子序列,具体判断时间复杂度是O(n^2)。
| |
对于这部分的暴力排序其实有些还没看懂,先在这插个眼,并且根据力扣的测试,该方法已经超时,应该是不建议使用。
所谓滑动窗口,就是不断的调节子序列的起始位置和终止位置,从而得出我们想要的结果。
那怎么理解滑动窗口呢,其实滑动窗口的做法也可以作为双指针法的一种,通过动态变换滑动窗口的起始和终止位置构成的滑动区域,依次遍历可能出现的子数组。
这里放上Carl大神的一张图,方便大家理解:
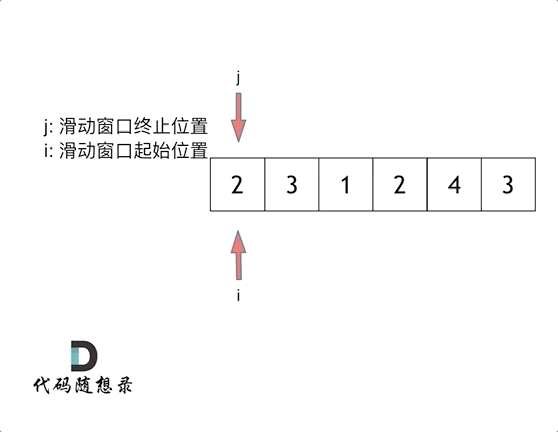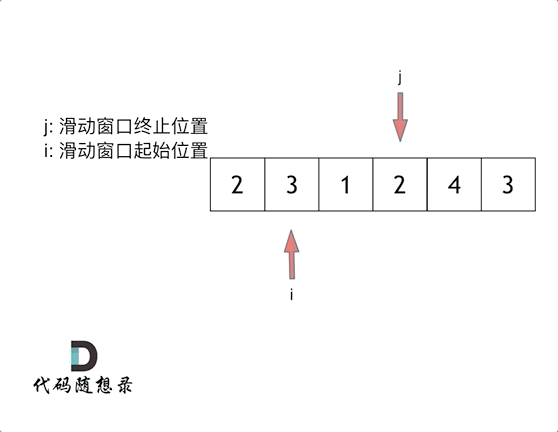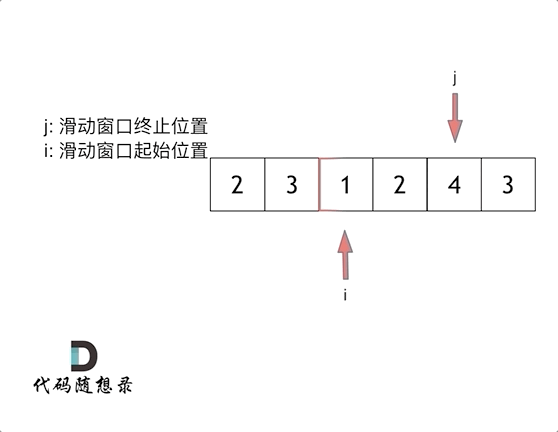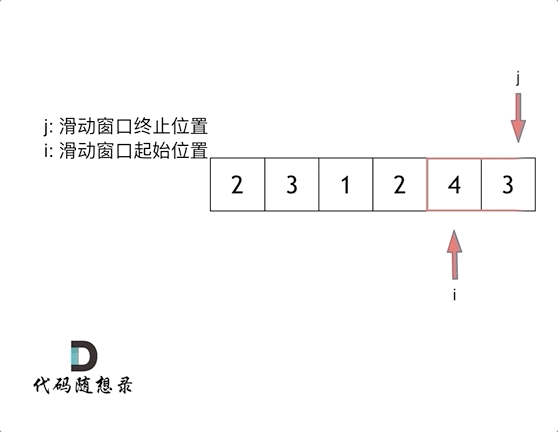
那么最重要的两点来了:
解答如下:
| |
在这里的话也才发现滑动窗口这个算法精妙所在,通过不断变更一个窗口的位置,将算法的复杂度明显优化,而且相比较暴力排序,滑动窗口也只用了一个for循环和一个while循环,从而将算法复杂度降为O(n)
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/spiral-matrix-ii
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
| |
示例 2:
| |
提示:
在这里悉心听取Carl大神的教诲,每次遇到二分法一定要坚持循环不变量原则。
那么我们在模拟顺时针画矩阵时,遵循以下规则:
也就是如下图所示,好好理解一下!
回到题目,对于这种螺旋矩阵,我们首先要明确的坚持循环不变量原则,要么选择左闭右闭,要么选择左闭右开,选择好一种处理方式就贯彻到底,不要再做改变了。
这里我们选择左闭右开,首先还是看到上面的螺旋矩阵图,我们分别将3X3矩阵内的所有元素切割为9个部分,解决螺旋矩阵问题,最重要就是确定外围的四个点,即图中的1、3、5、7,前面我们说我们遵循左闭右开规则,其实意思就是对左节点进行处理,而右节点暂不处理,而等待下一次处理时将第一次的右节点作为第二次的左节点,这样就是我们所说的左闭右开原则。
直接看代码部分:
| |
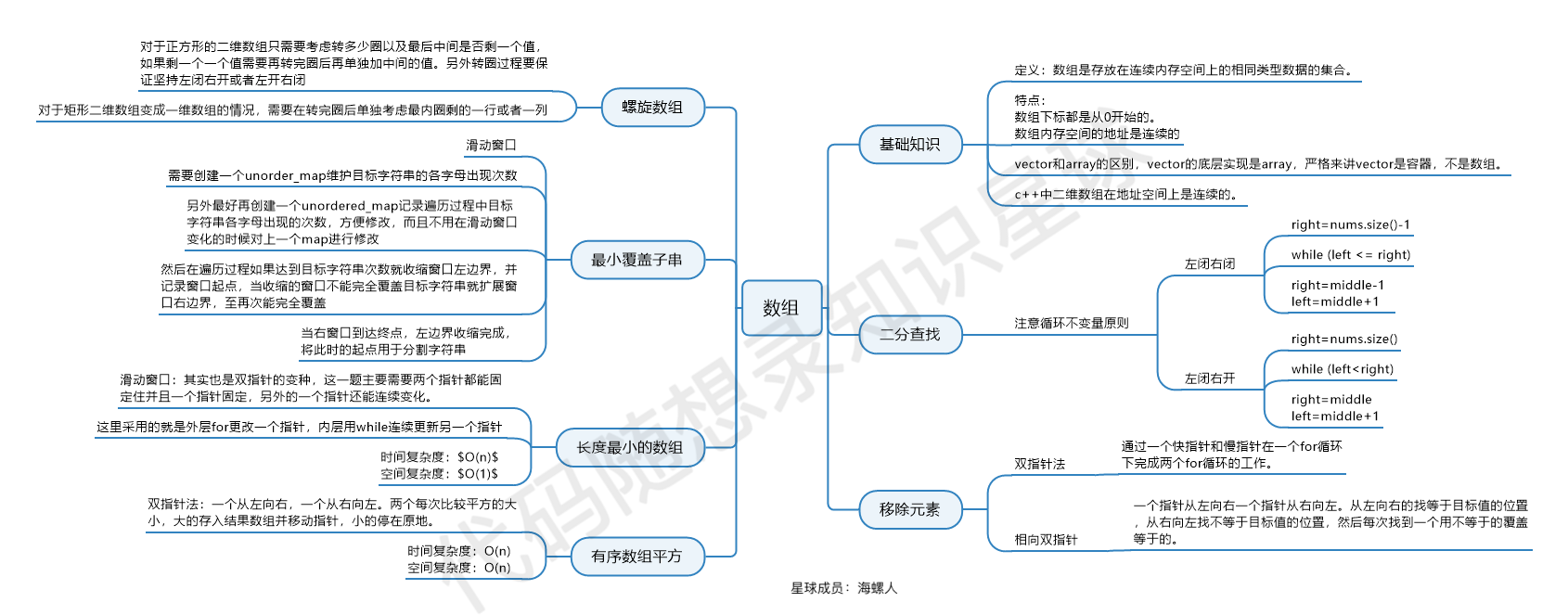

链表理论基础
203.移除链表元素
707.设计链表
206.反转链表
链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链表的入口节点称为链表的头节点也就是head。
常见的链表类型有以下几种:
<1>单链表
单向链表是一种包含两部分的数据结构,即一个是数据部分(数据域),另一个是地址部分(指针域),其中包含下一个或后继节点的地址。节点中的地址部分也称为指针。
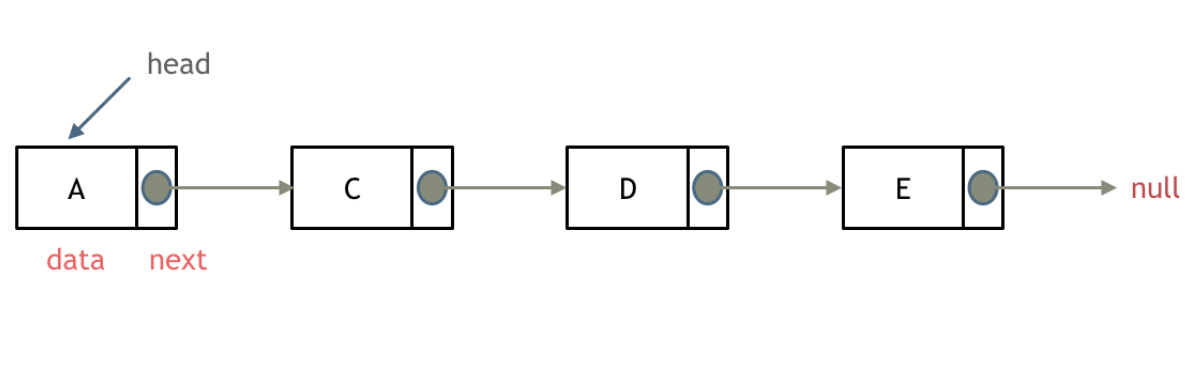
在单链表中,每一个节点除了包括自身的数值外,还包含了下一个节点的地址,在第三个节点它的地址部分包含的是NULL值,因为它不指向任何节点。此外,保存初始节点地址的指针称为头指针。
由于单链表的指针域只保存了下一个节点的地址,因此在单链表中,只能向前遍历,而不能反向遍历。
| |
<2>双链表
前面说了单链表中的指针域只能指向节点的下一个节点。而在双链表中,每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
这就意味着,双向链表不仅支持向前查询,还可以向后查询。
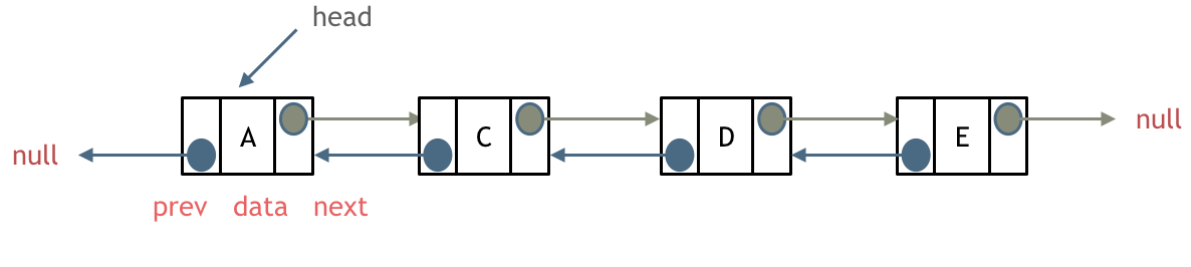
| |
<3>循环链表
循环链表,是指头节点和尾节点首位相连,以此形成一个循环结构。也可以这么认为,循环链表是单链表的变体。也就是说,循环链表没有起始节点和结束节点,我们可以朝任意方向进行遍历(向前或者向后)。
| |
乍一看,循环链表和单链表节点的表示一样,其实他们之间唯一最本质的区别就是最后一个节点不指向单链表中的任何节点,因此单链表的链接部分包含一个NULL值;相反,循环链表的最后一个节点的链接部分保存着第一个节点的地址。
前面在学习数组的时候我们知道,数组在内存中是连续分布的,但是链表则是通过指针域的指针 链接在内存中的各个节点上,也就是说链表中的节点在内存中不是连续分布的,而是零散分布在内存中的某个地址上,分配机制取决于操作系统的内存管理。
在上图中我们可以看出,该链表的起始节点为2,终止节点为7,各个节点分布在内存中的不同地址空间上,通过指针串联在一起。
给出链表节点的定义:
| |
下面给出使用自己定义构造函数和使用默认构造函数的区别(推荐自定义构造函数):
1、通过自己定义构造函数初始化节点:
| |
2、使用默认构造函数初始化节点:
| |
从上面不难看出,如果使用默认构造函数的话,在初始化时是不可以直接给变量赋值的。
<1>删除节点
我们以下图为例,目的时删除D节点:
具体操作:
C节点的next指针指向的是D节点,而我们的需求是删除D节点,那么只需要将C节点的next指针指向E节点就可以了。
此时的D节点从链表中删除,但是它依然存放在内存中,需要我们手动释放这段内存。
<2>添加节点
在下图中,我们需要在C节点和D节点中添加一个F节点:
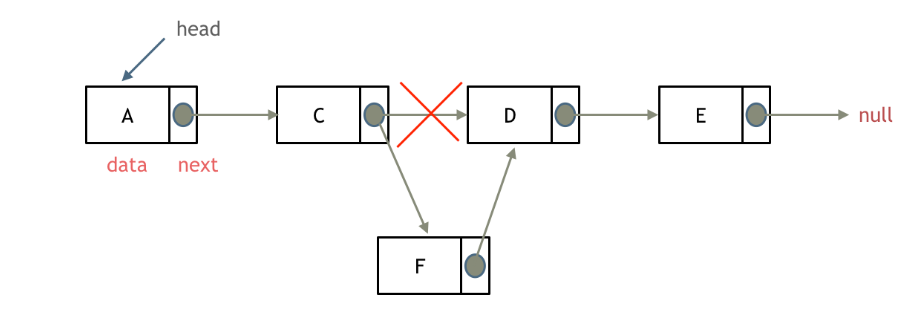
添加F节点,只需要将C节点的next指针指向F节点,同时F节点的next指针指向D节点,这样就完成了节点的添加。
这里我们将链表和数组做一个对比,详见下图:
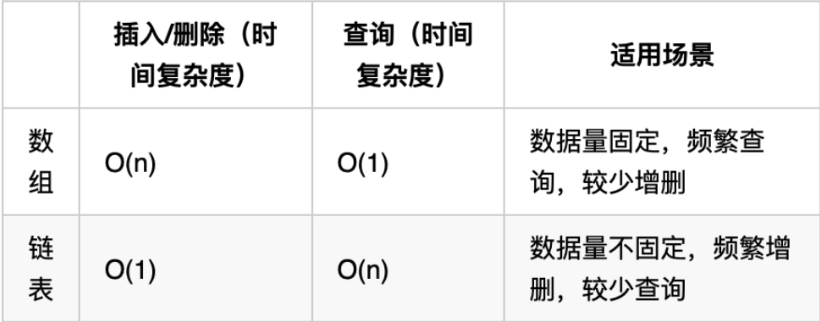
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/remove-linked-list-elements
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
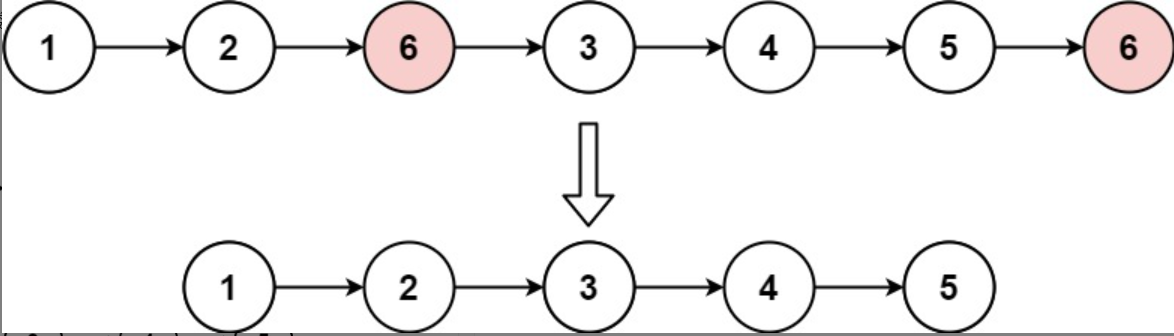
| |
示例 2:
| |
示例 3:
| |
提示:
案例1:
链表:1->4->2->4 目的:移除元素4
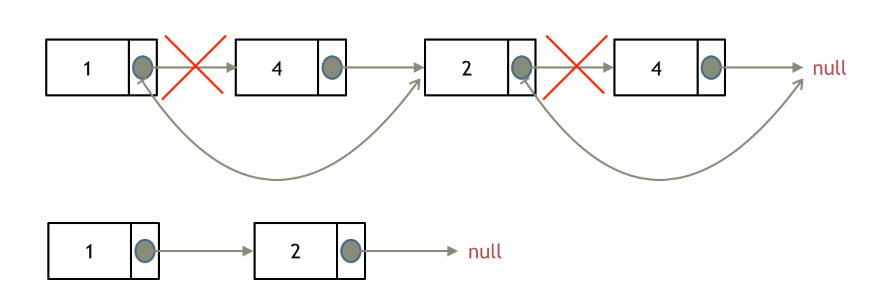
其实这道题还是比较简单的,首先可以看出它是一个单链表,那么我们定义好节点的数据域和地址域,让节点1的next指针指向节点2,并且让节点2的next指针指向NULL,那么这道题就算完成了,最后的结果也就是下面这张图。
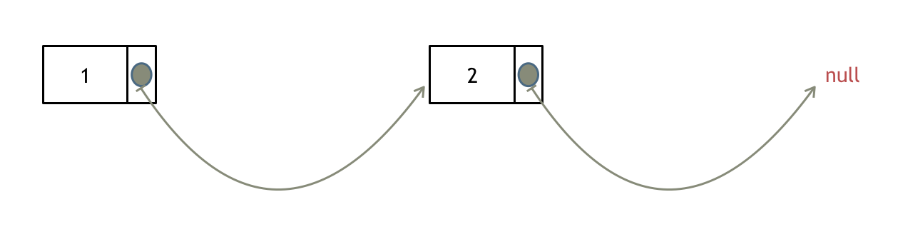
那么此外我们还需要完成节点4的内存回收工作!
案例二:
由于考虑到在实际应用中可能存在对头节点的删除需求,所以我们这里也额外做个分析。
对于链表的操作有两种形式:
<操作1>:直接使用原来的链表进行移除
移除头节点和移除其他节点的擦欧总是不一样的,因为链表的其他节点都是通过前面一个节点来移除房前节点,而头节点没有前节点。
那么对于头节点的移除,需要将头节点向后移动一位就可以了,同时记得将原头节点从内存中释放。
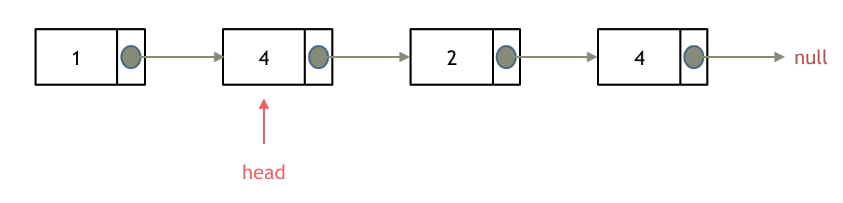
对于操作一这种方法虽然可以实现,但是无疑是增加了代码的逻辑性,需要我们单独写一段逻辑处理头节点。那么这样的话不妨我们试试操作2的方法。
<操作2>:设置一个虚拟头节点再进行删除操作
如何设置虚拟头节点,首先我们需要给链表添加一个虚拟头节点作为新的头节点,同时我们移除旧的头节点,也就是下图中的元素1,并且将新的头节点的next指针指向第二个节点4。

具体实现我们详见代码。
| |
这里需要注意几点:
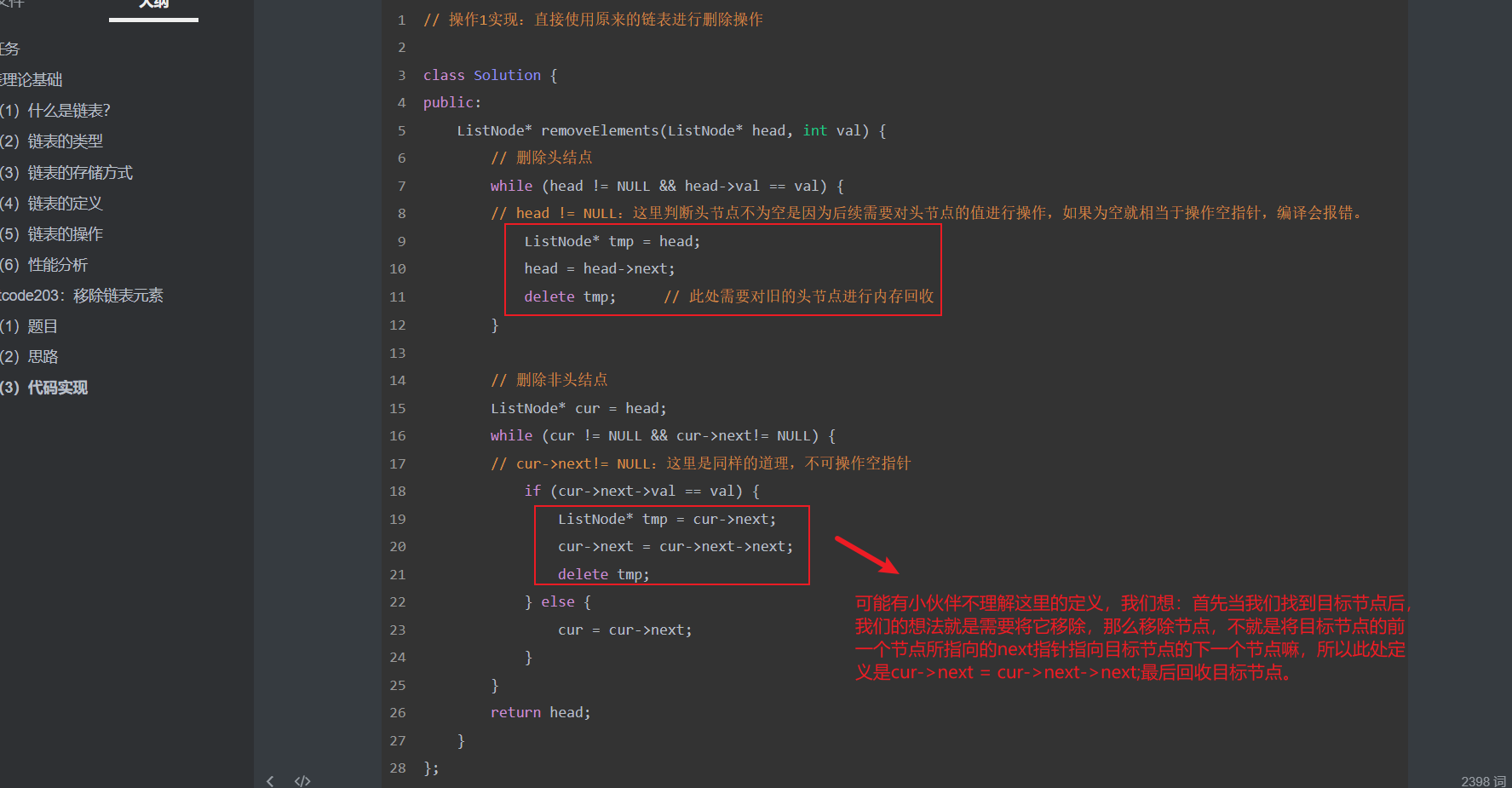
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/design-linked-list
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
示例:
| |
提示:
分析题目给出的要求,主要是需要完成以下功能:
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/reverse-linked-list
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
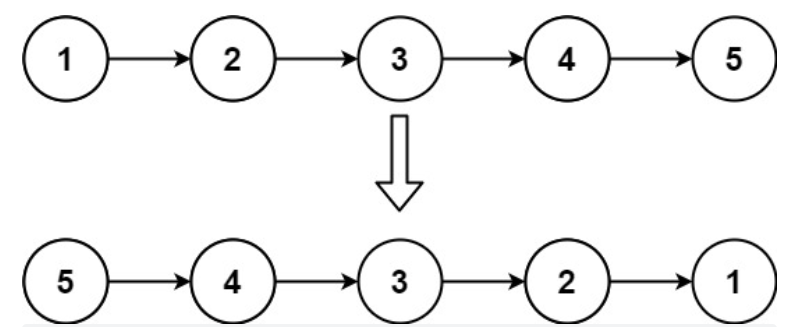
| |
示例 2:
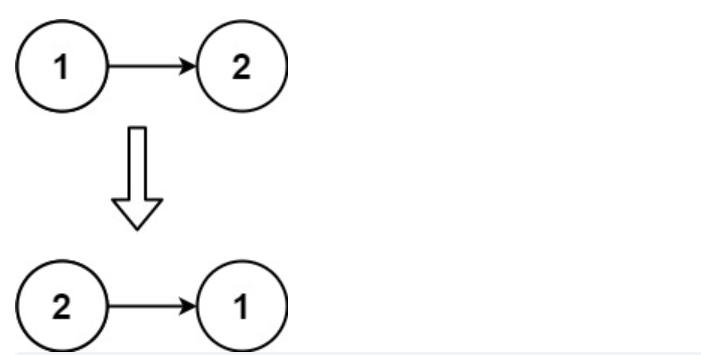
| |
示例 3:
| |
提示:
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
链表的反转,只需要改变next指针的指向即可。

对于链表的反转问题,我们可以通过使用双指针的方式来解决这个问题。
| |
前面讲了双指针法,其实递归法与之逻辑都是大体一样的,不过对于递归,我们有自前向后递归、以及自后向前递归两种方法。
| |
| |

24.两两交换链表中的节点
19.删除链表的倒数第N个节点
面试题02.07.链表相交
142.环形链表II
总结
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/swap-nodes-in-pairs
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
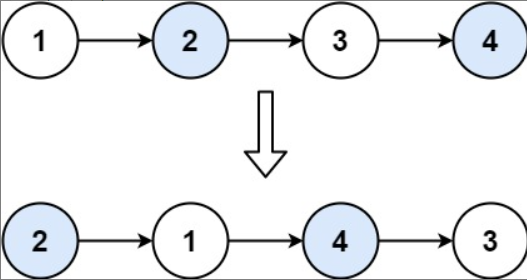
| |
示例 2:
| |
示例 3:
| |
提示:
前面我们有了链表的相关基础知识,知道了对于链表节点的操作有两种形式:
相比较第一种,第二种虚拟头节点的形式更加方便。
初始时,cur指向虚拟头节点,然后依次进行三步:
步骤1:将原链表的头节点变成节点2步骤2:将原链表的节点2变成一个临时节点tmp(tmp:指向原链表的头节点)步骤3:将原链表的节点3变成一个临时节点tmp2(tmp2:指向原链表的节点3)(ps:此处这样重复定义是为了后续循环条件的退出)ps:原链表:未加入虚拟头节点的链表,也就是初始化时的链表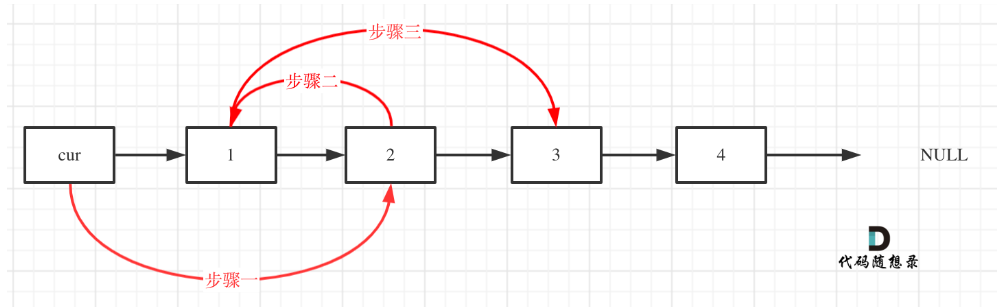
操作后的链表:
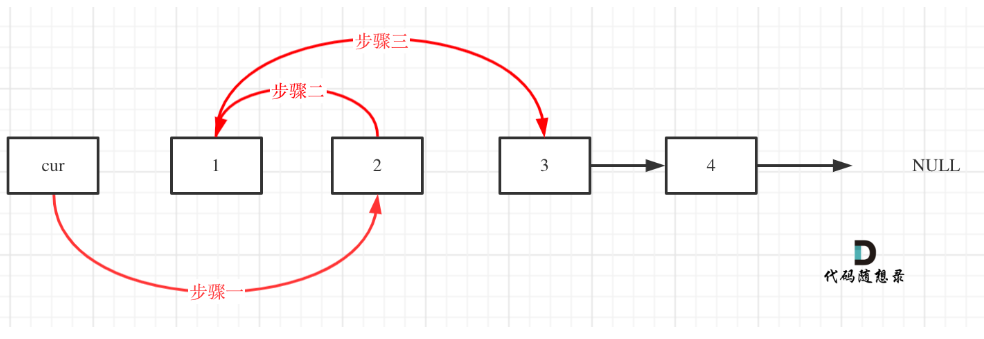
终止条件:
当cur节点经过第一轮循环时,说明这个链表至少有2个节点,此时cur已经成了原链表的节点2,再进行下一次循环时,如果还有新的节点,只要满足cur节点之后还存在1个或2个节点,循环继续,否则结束循环,并返回原链表的头节点
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/remove-nth-node-from-end-of-list
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
| |
示例 2:
| |
示例 3:
| |
提示:
进阶:你能尝试使用一趟扫描实现吗?
先抓题意,删除倒数第n个节点,我们很自然的就想到快慢指针法,通过设置一个fast指针和一个slow指针,首先让fast指针移动n步,到达目的节点后,fast指针和slow指针再同时移动,直到fast指针移至尾节点,此时slow指针也刚好指向目标节点,那么这里我们只需要让slow->next = slow->next->next即可完成对目标节点的删除。
同样的对于链表的操作,我们还是采取虚拟头节点的方式进行设计。
<1>首先定义fast指针和slow指针,初始值为虚拟头节点:
<2>fast走n+1步(因为加入了虚拟头节点)
<3>fast和slow同时移动,直到fast指向链表末
<4>删除slow指向的下一个节点
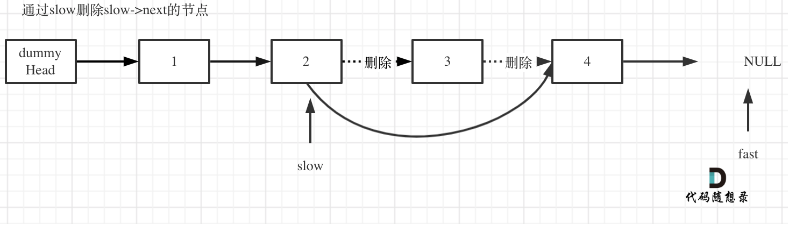
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/intersection-of-two-linked-lists-lcci
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交:
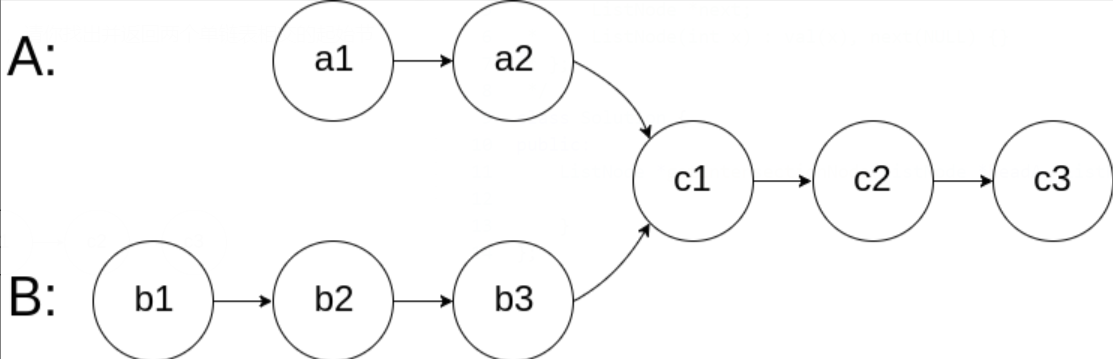
题目数据保证整个链式结构中不存在环。
注意,函数返回结果后,链表必须保持其原始结构 。
示例 1:
| |
示例 2:
| |
示例 3:
| |
提示:
进阶:你能否设计一个时间复杂度 O(n) 、仅用 O(1) 内存的解决方案?
根据题意,我们可以有这样一种思路,首先想要找到相交节点,但是可能两个链表的长度不一样,怎么对其是需要考虑的,通过上面的几个示例我们也可以看出,只要让链表1和链表二右对齐即可。
那么在算法中如何实现呢,那么只需要先分别求出两个链表的长度,然后我们就可以得出两个链表长度的差值n,这个差值就是我们对其的关键所在啦。
先让长链表移动n步,然后两个链表同时向后移动,并对节点的数值进行判断是否一致,相同的话就是我们所要求解的相交节点了。
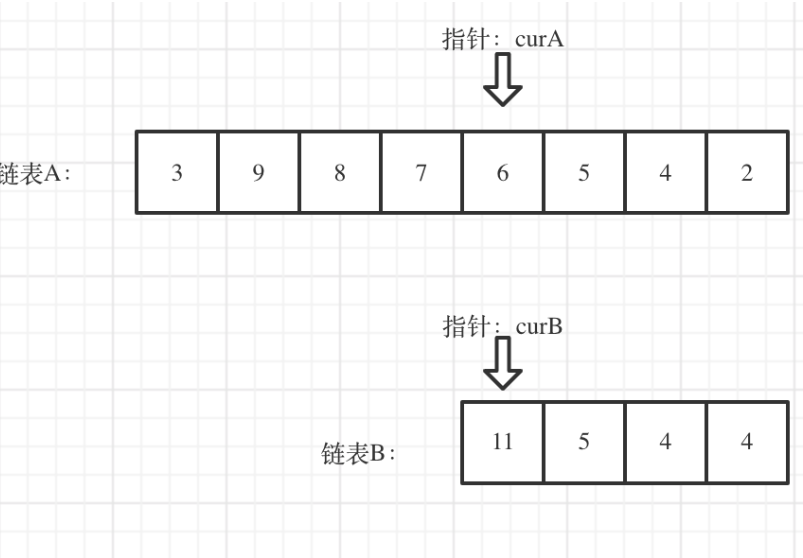
| |
来源:力扣(LeetCode) +链接:https://leetcode.cn/problems/linked-list-cycle-ii
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改链表。
示例 1:
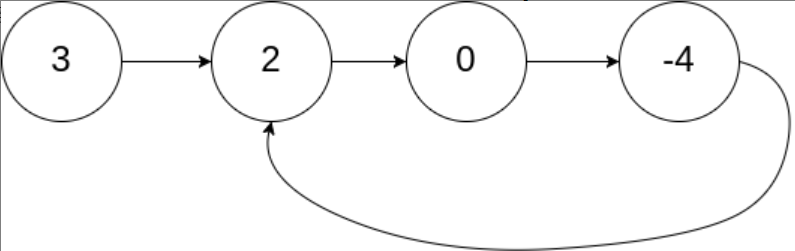
| |
示例 2:
| |
示例 3:

| |
提示:
进阶:你是否可以使用 O(1) 空间解决此题?
对于这道题的分析,就是为了让我们求解一个链表中是否存在环形链表,如果存在则返回该环形链表的头节点,无环则返回NULL。
对于这道题我们需要解决以下两点:
<1>如何判断链表有环
对于环形链表的判断,我们采取快慢指针法,分别定义fast指针和slow指针,从头节点出发,fast指针每次移动2个节点,slow指针移动1个节点,如果fast指针和slow指针在中途相遇,则说明存在环形链表。
由于fast指针走两步,slow指针走一步,那么理论上讲,如果存在环形链表的话是一定存在相遇机会的,动画如下,选自carl大神制作:
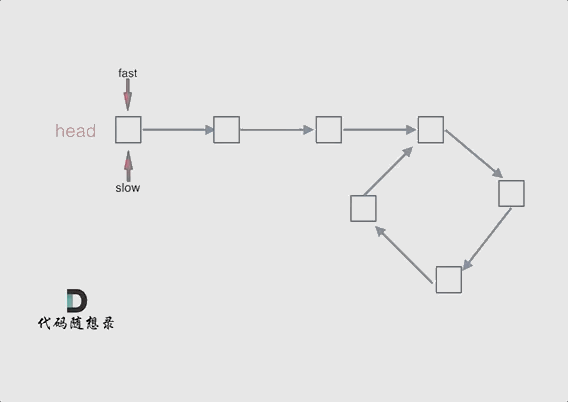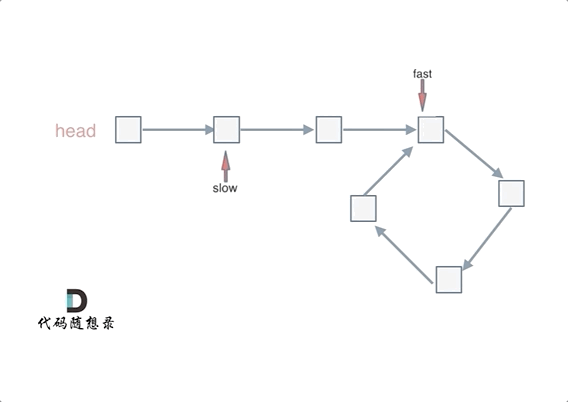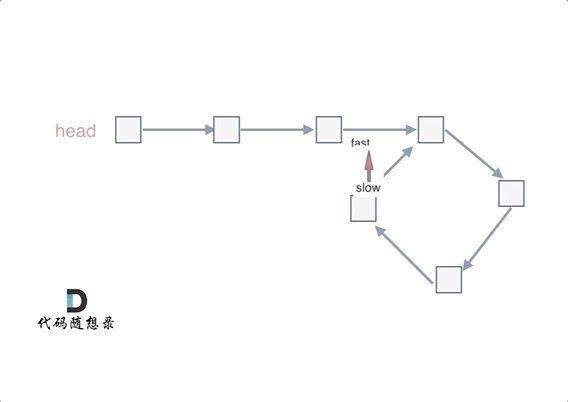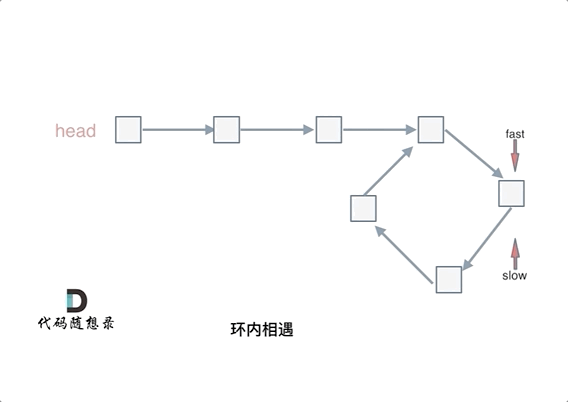
<2>如果有环,怎么找到这个环的入口
既然我们已经有了判断唤醒链表的方式,那么接下来就需要找到环形链表的入口了。
假设从头节点到环形入口的节点数为x,环形入口节点到fast指针与slow指针的相遇节点的节点数为y。
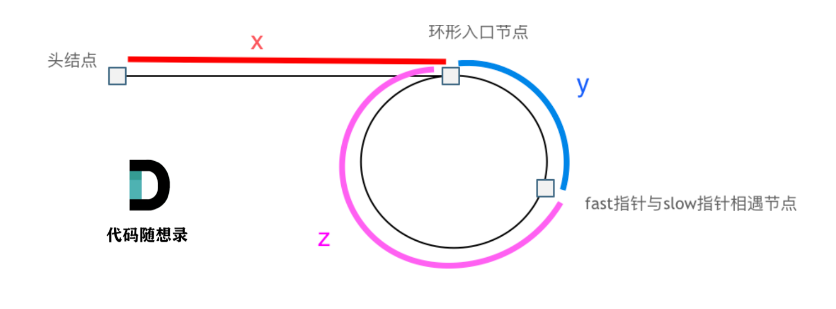
当快指针和慢指针相遇时,快指针的走过的节点数不就等于慢指针走过节点数的两倍嘛,只要我们求出快慢指针走过的节点数,就可以联立成一个等式,并且等式中的x值就是我们要求的结果,那么据此我们可以得出以下结论:
1.
slow指针走过的节点数 = x + y
2.
fast指针走过的节点数 = x + y + n*(y+z)n:代表slow指针进入环形链表后,此时fast指针在环中的循环次数
3.得到等式:
x + y = x + y + n*(y+z)此处需要注意:n >= 1,因为在环中fast指针必然是会经历一次循环才有可能被slow指针追上,朋友们可以自己推算一遍
4.我们的目标为x,因此化简上式:
x = n (y + z) - y
5.当n等于1时,我们可以得知上式结果为:
x = z,这就意味着此时从相遇节点到环形链表的入口节点正好等于从头节点到入口节点的长度。
6.根据结论5的分析,我们只需要在fast指针和slow指针相遇时定义一个index指针,同时从头节点也定义一个index2指针,两个指针同时出发,当这两个指针相遇的时候正好就是环形入口的节点
动画如下:
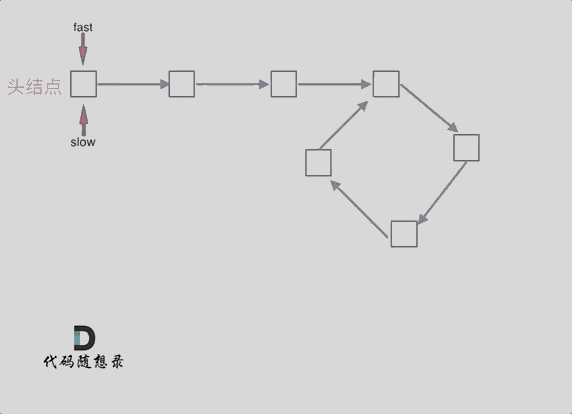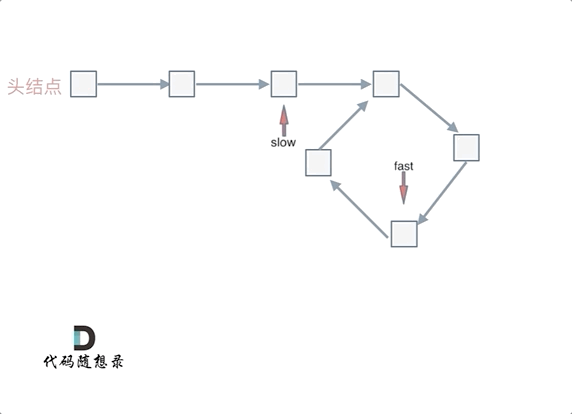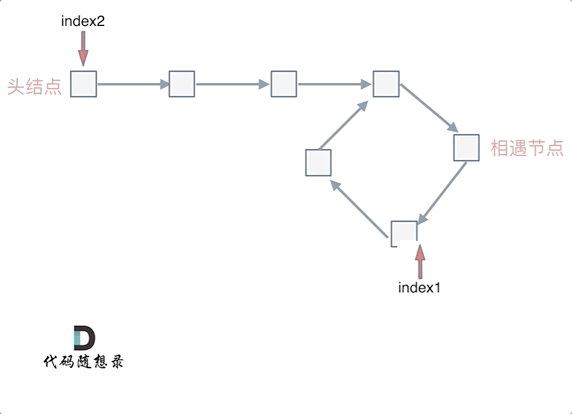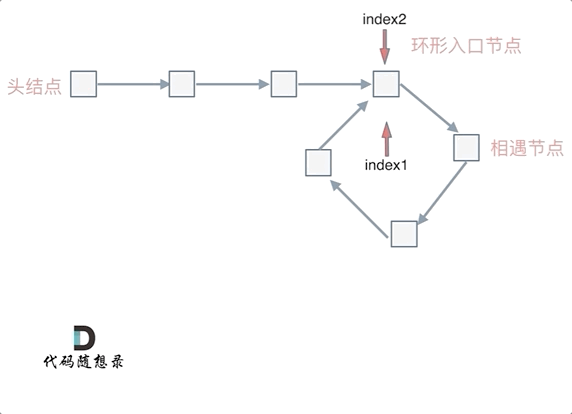
上面分析的结论是基于n等于1的,那么当循环此处大于1该如何分析呢?
其实即便n大于1,结果也是一样的,不同的是index1指针会在环中多转(n - 1)圈,然后再遇到index2,建议可以做个示例自己试试。
| |
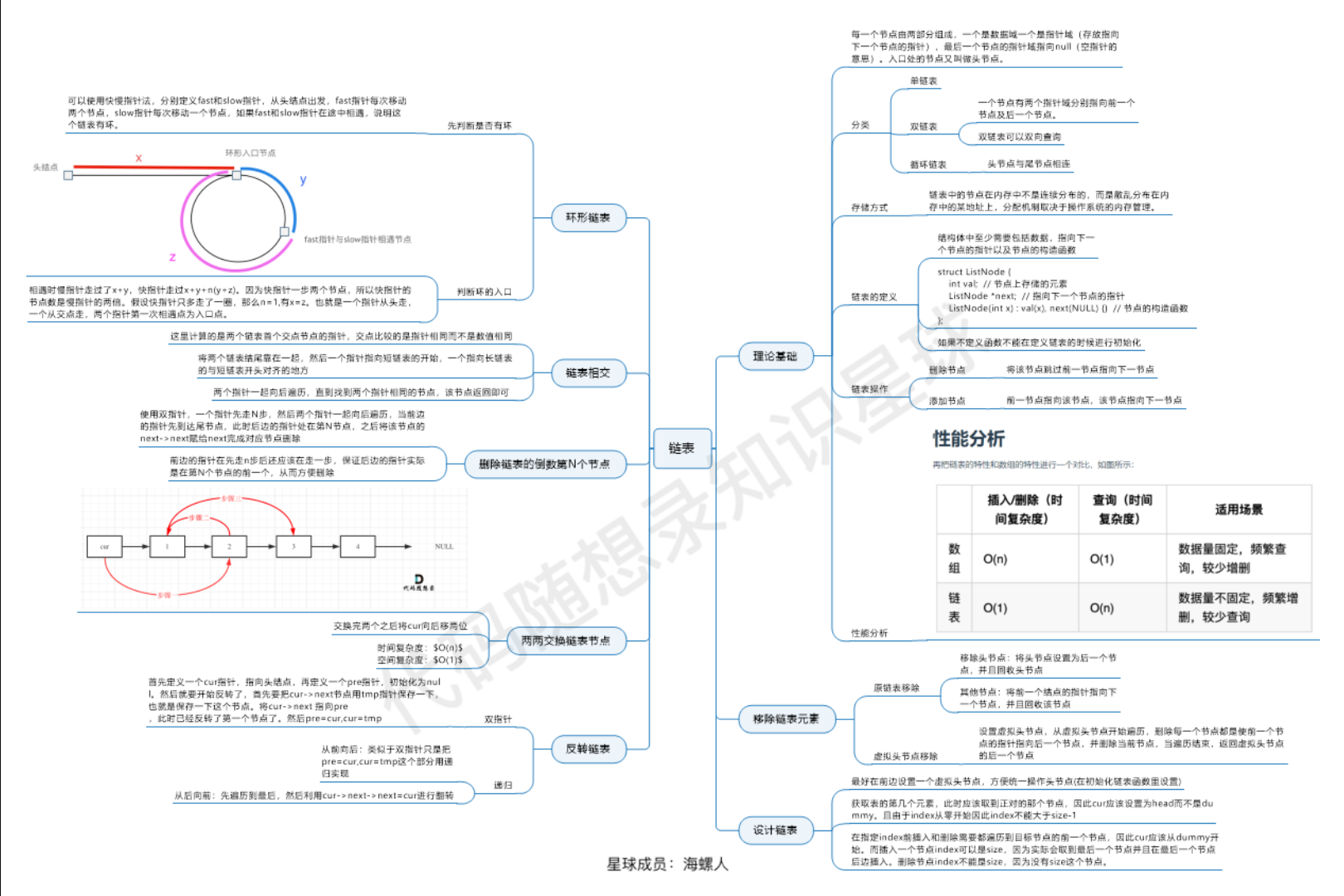

@[toc]
开发平台:RT-Thread Studio
开发板:ART-PI
主控芯片:STM32H750
温湿度传感器:SHT30
显示模组:0.96’OLED(SSD1306)
串口调试助手:SecureCRT
注意:这里由于ART-PI开发板自带WiFi模组,可直接使能。如果使用其他开发板,可考虑使用ESP8266通信模块。


这里的i2c引脚配置依自己开发板而定,配置完成后CTRL+S保存配置


CTRL+S保存配置,点击编译并下载
具体RT-Thread Studio的一般使用可参照【玩转RT-Thread】 RT-Thread Studio使用(1)(按键控制电机正反转、蜂鸣器)
此时打开串口工具,可以看到前面配置的i2c1和i2c3已经注册成功

此时在串口输入help,可以看出有一个sht3x配置

| |


鼠标右键netutils打开配置项
使能NTP (网络时间协议)客户端

使能软件模拟RTC

CTRL+S保存配置
修改配置
| |
此时再编译并下载到开发板中
| |
(1)在board/port 目录下创建wifi_config.c文件来实现wifi上电自动连接 代码如下:
| |
(2)在main.c中添加自动连接函数
| |
编译并下载,此时开发板就能够从flash中自动读取上次连接数据并自动连接WiFi了。

(1)在application分组下创建一个用户文件oled_display.cpp文件,存放本项目中的OLED显示代码。
代码如下:
| |
(2)在 applications 文件夹下创建oled_display.h
| |
(3)最终的主函数
| |
(4)参考board.h关于i2c的引脚配置,同款开发板的作者可参照,当然此处的i2c1也可以直接在oled_display.cpp中直接定义,因为前面在RT-Thread Setting中就已经配置好了,可以直接定义,此处只作为一个重定义。
| |



注意:由于我们是在C主程序下调用c++代码,但是RT-Thread对于C++不太友好,需要我们将CPP程序封装成C。同样的在cpp程序中调用C也需要封装
| |
在使用开发板的过程中,一定需要频繁的去翻阅数据手册和引脚图,有时候开发工具也会莫名的出故障,一般可以尝试下重新构建思路和原理,重启以及寻求大佬帮助。
这次的分享就到这里,有相关问题的欢迎留言私信!

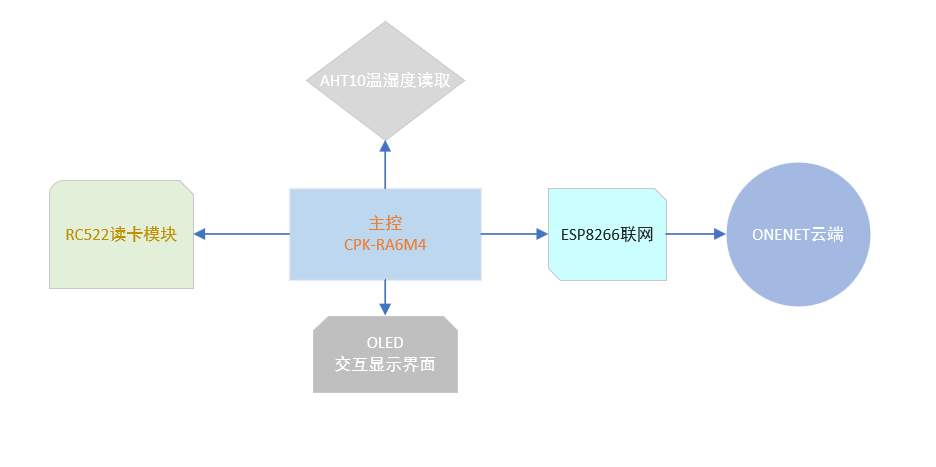
本次项目主控为CPK-RA6M4开发板,是瑞萨RA6高性能系列的一款基于Arm架构的开发板,而RA产品家族也是提供了一套成熟的工具生态链来帮助开发者更好的进行产品的研发。本次我们使用瑞萨FSP(灵活配置软件包)结合RT-Thread Studio工具进行项目的研发。
下面来说说本次项目的功能:主要就是通过四大模块结合RT-Thread内核机制,开发出一款具有人员签到打卡、温湿度读取,OLED显示以及云端数据上报这四大功能。
开发工具:
RT-Thread Studio是一套一站式的 RT-Thread 开发工具,通过简单易用的图形化配置系统以及丰富的软件包和组件资源,让物联网开发变得简单和高效。
RT-Thread Studio 主要包括工程创建和管理,代码编辑,SDK管理,RT-Thread配置,构建配置,调试配置,程序下载和调试等功能,结合图形化配置系统以及软件包和组件资源,减少重复工作,提高开发效率。
下载链接:RT-Thread Studio 下载

瑞萨电子灵活配置软件包 (FSP) 是一款增强型软件包,旨在为使用瑞萨电子 RA 系列 ARM 微控制器的嵌入式系统设计提供简单易用且可扩展的高质量软件。
下载链接:瑞萨FSP v3.5.0
模块:
I2C(Inter Integrated Circuit)总线是 PHILIPS 公司开发的一种半双工、双向二线制同步串行总线。I2C 总线传输数据时只需两根信号线,一根是双向数据线 SDA(serial data),另一根是双向时钟线 SCL(serial clock)。SPI 总线有两根线分别用于主从设备之间接收数据和发送数据,而 I2C 总线只使用一根线进行数据收发。
而I2C通信的读写数据是通过等待从机的应答信号(ACK)。
也就是说,当配置方向为“写数据”时,主机每发送完一个字节数据,都要等待从机的应答信号,而当数据传输结束时,主机向从机发送一个停止传输信号,表示不再传输数据;当配置方向为“读数据”时,从机每发送完一个数据,都需要等待主机的应答信号,当主机希望停止接收数据时,会向从机发送一个非应答信号(NACK),从机就不再向主机继续发送数据。
这里需要注意的是,I2C通讯常用的是复合格式,该传输过程中有两次起始信号。在第一次传输中,主机通过slave_address找到从设备后会发送一段数据(通常表示从设备内部的寄存器或存储器系统);而在第二次的传输中,对该地址的内容进行读写,也就是说,第一次通讯时告诉从机读写地址,第二次通讯才是读写的实际内容。
当 SCL 线是高电平时, SDA 线从高电平向低电平切换,这时候代表通讯的起始;当SCL 是高电平时, SDA线由低电平向高电平切换,这代表通讯的结束。
简单来说,就是I2C 使用 SDA 信号线来传输数据,使用 SCL 信号线进行数据同步。
在RT-Thread中,我们需要了解sensor设备的作用,是为上层提供统一的操作接口,提高上层代码的可重用性。
掌握sensor框架的使用,需要了解一下API的调用:
| 函数 | 描述 |
|---|---|
| rt_device_find() | 根据传感器设备设备名称查找设备获取设备句柄 |
| rt_device_open() | 打开传感器设备 |
| rt_device_read() | 读取数据 |
| rt_device_control() | 控制传感器设备 |
| rt_device_set_rx_indicate() | 设置接收回调函数 |
| rt_device_close() | 关闭传感器设备 |
首先先来介绍下接线:
| 引脚功能 | 引脚接线 |
|---|---|
| SCL | P512 |
| SDA | P511 |
| VCC | 3.3V |
| GND | GND |
然后我们打开settings,在硬件部分使能I2C1(芯片设备驱动->Enable I2C BUS->使能I2C1),同时可以检查下组件部分I2C设备驱动程序是否使能

然后使用下面的程序完成模块初始化工作
| |
AHT10温湿度数据读取
| |
UART(Universal Asynchronous Receiver/Transmitter)通用异步收发传输器,UART 作为异步串口通信协议的一种,工作原理是将传输数据的每个字符一位接一位地传输。是在应用程序开发过程中使用频率最高的数据总线。
UART作为异步串行通信协议的一种,工作原理是将传输数据的每个二进制位一位接一位地传输。在UART通信协议中信号线上的状态为高电平时代表‘1’,信号线上的状态为低电平时代表‘0’。比如使用UART通信协议进行一个字节数据的传输时就是在信号线上产生八个高低电平的组合。
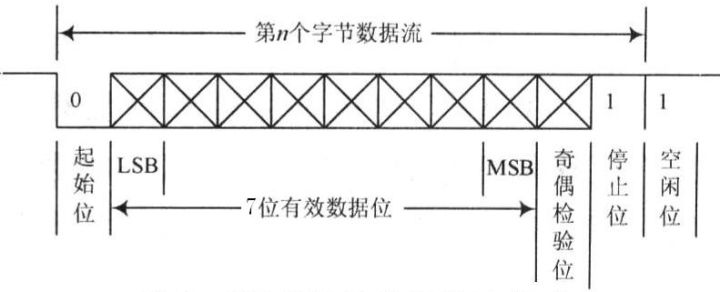
空闲位:UART协议规定,当总线处于空闲状态时信号线的状态为‘1’即高电平,表示当前线路上没有数据传输。
起始位:每开始一次通信时发送方先发出一个逻辑”0”的信号(低电平),表示传输字符的开始。因为总线空闲时为高电平所以开始一次通信时先发送一个明显区别于空闲状态的信号即低电平。
数据位:起始位之后就是我们所要传输的数据,数据位可以是5、6、7、8,9位等,构成一个字符(一般都是8位)。如ASCII码(7位,剩下的1位二进制为0),扩展BCD码(8位)。先发送最低位,最后发送最高位,使用低电平表示‘0’高电平表示‘1’完成数据位的传输。
MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议),是一种基于发布/订阅(publish/subscribe)模式的"轻量级"通讯协议,该协议构建于TCP/IP协议上,由IBM在1999年发布。
其优点就是利用极少的代码和有限的带框,为物联网设备远程通讯提供消息传输服务, 相比于HTTP协议在互联网上的客户端请求,服务端应答模式,MQTT的发布订阅模式在物联网设备上更适用。
实现MQTT协议需要客户端和服务器端通讯完成,在通讯过程中,MQTT协议中有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。
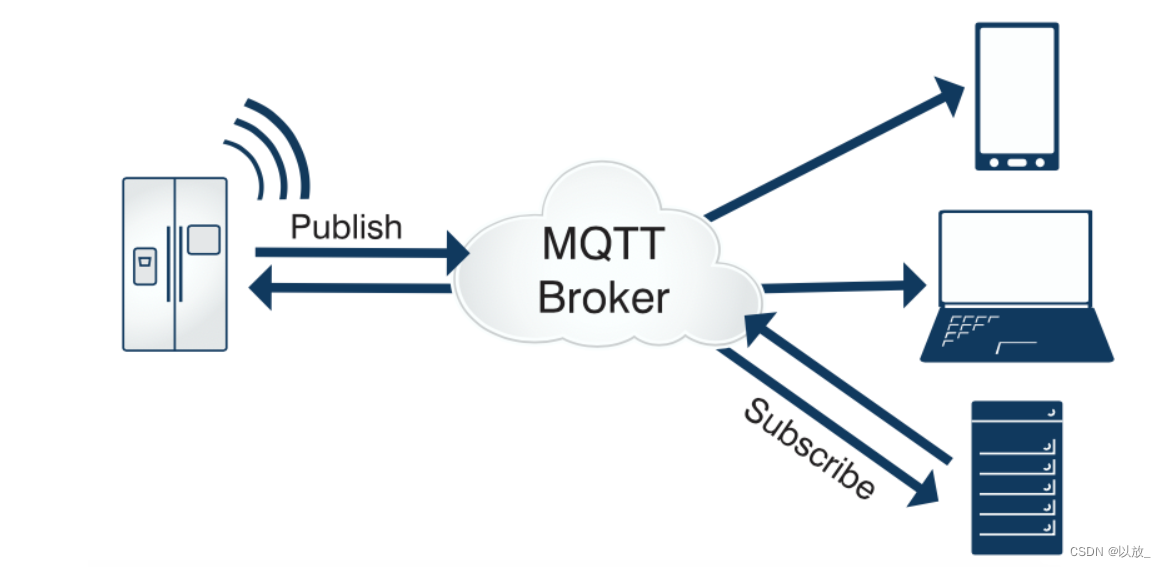
AT 命令集是一种应用于 AT 服务器(AT Server)与 AT 客户端(AT Client)间的设备连接与数据通信的方式。 其基本结构如下图所示:
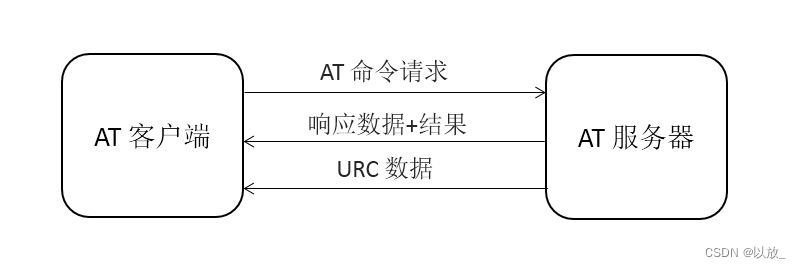
由上图可知,AT的使用需要AT Client和AT Server这两部分共同完成,AT Client通过AT命令向Server发送请求,等待Server的响应,并对响应的数据或主动发送给Client的数据(URC数据)进行解析处理,并获取相关信息。
RT-Thread Settings设置
添加AT Device及OneNET软件包
AT Device配置:
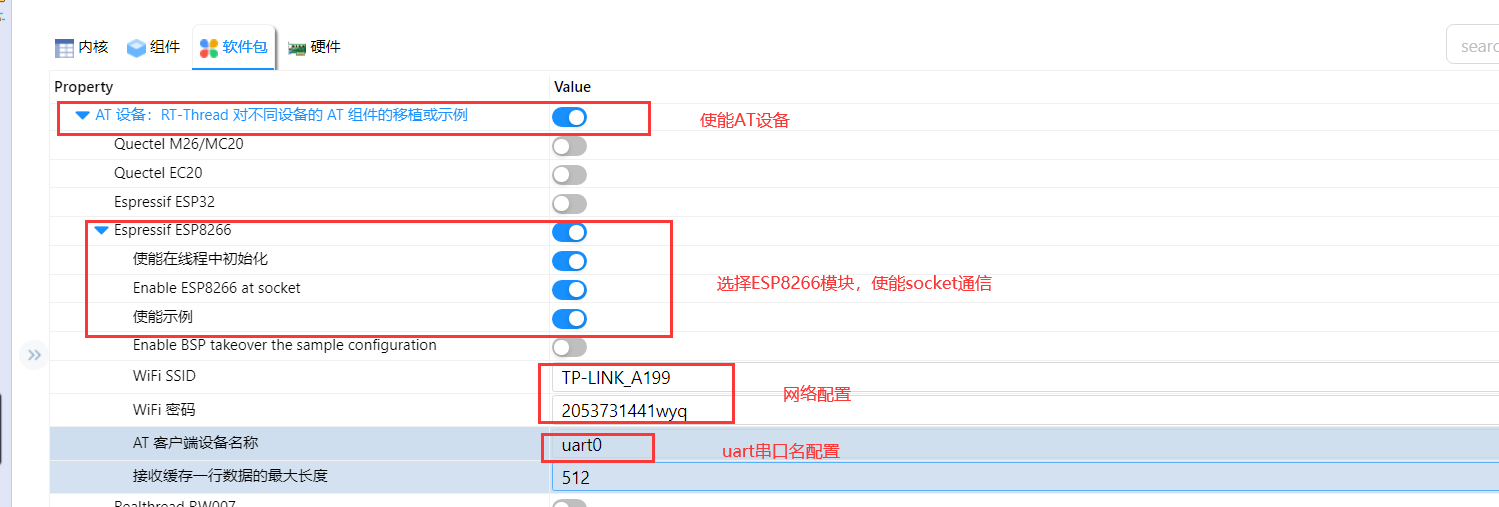
OneNET配置:
首先我们需要前往ONENET官网进行产品创建及设备绑定,没有onenet账号的可以去注册一个。
 +
+
然后将创建的信息填写到settings中
在组件中使能AT命令
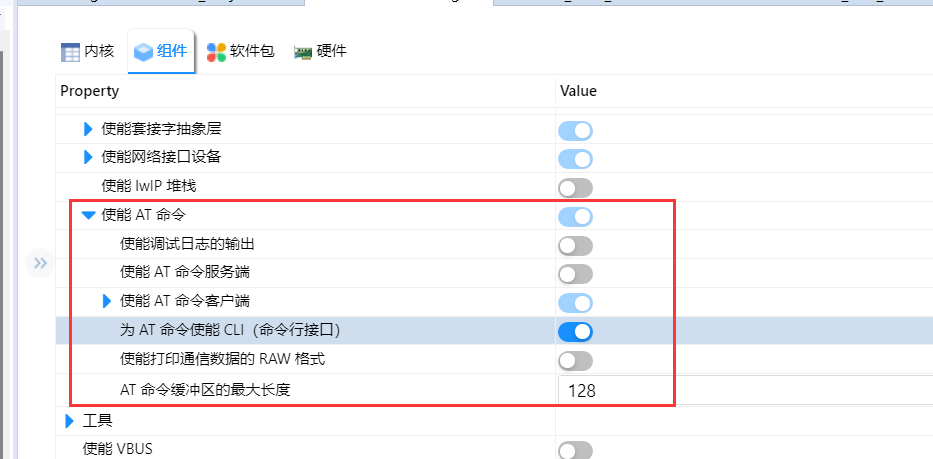
接线示意:
| 引脚功能 | 引脚接线 |
|---|---|
| TX | P100 |
| RX | P101 |
| VCC | 5V |
| GND | GND |
FSP配置
由于RT-Thread提供了有限的驱动配置,所以需要我们使用瑞萨FSP进行相关的配置
首先点击RA Smart Configurator,记住这里使用的FSP版本为v3.5.0
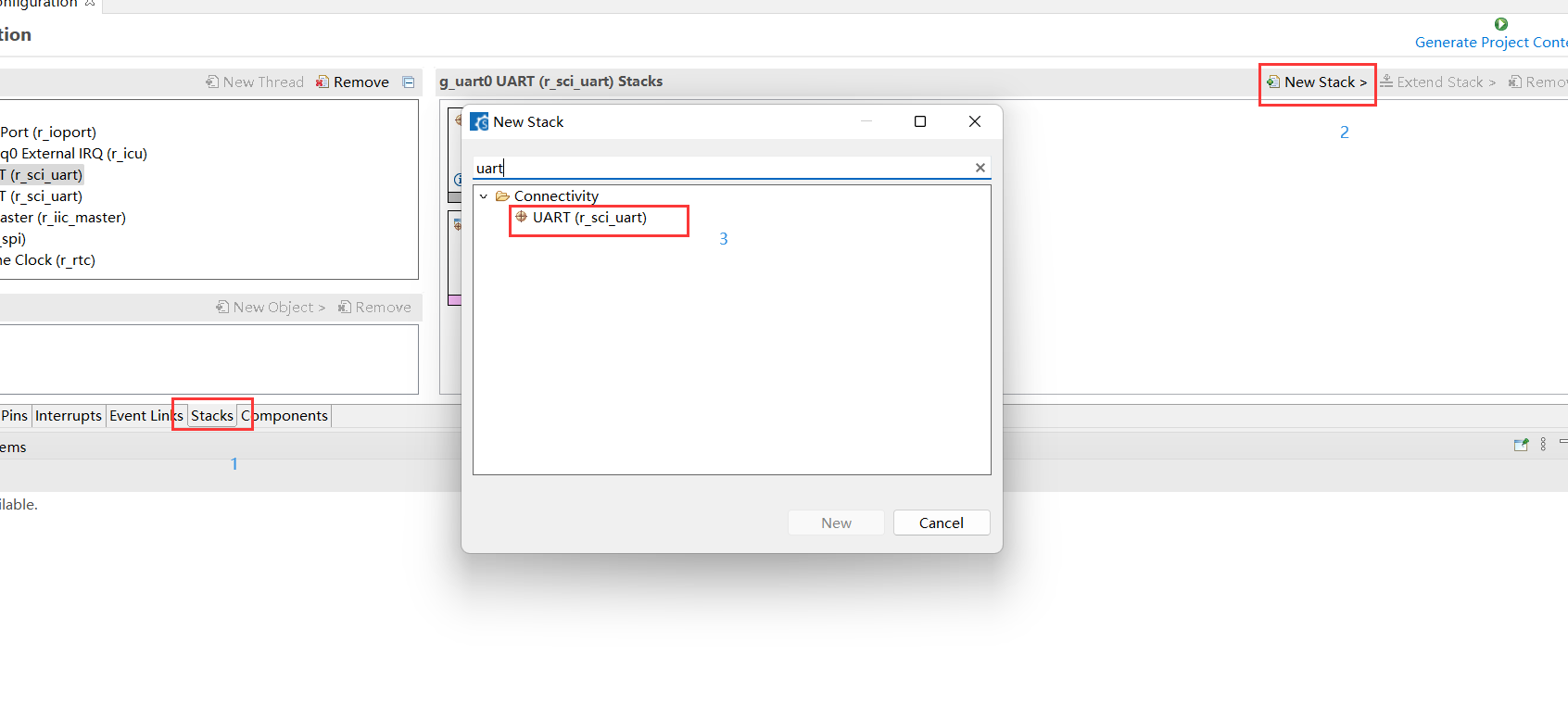

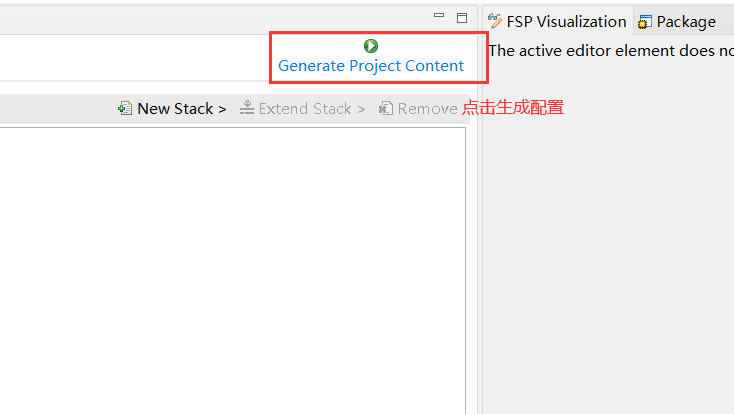
完成上述操作后保存并编译,注意这里由于RT-Thread版本问题,可能出现#include <dfs_posix.h>未参与编译以及还有其他一些问题,可以参考这一issue[CPK-RA6M4] onenet上云报错<RT-Thread 的版本为 4.1.0 及以上>
现在可以下载到开发板了,由于我们使用的AT例程中是默认初始化运行,所以在上电后就会自动连接WIFI了。
然后就是数据上云,代码如下:
| |
这里我们创建了两个数据流,分别是温度以及湿度。在AHT10读取温湿度之后,就可以进行数据的上报了,然后可以在onenet官网不断看到数据的上报了。
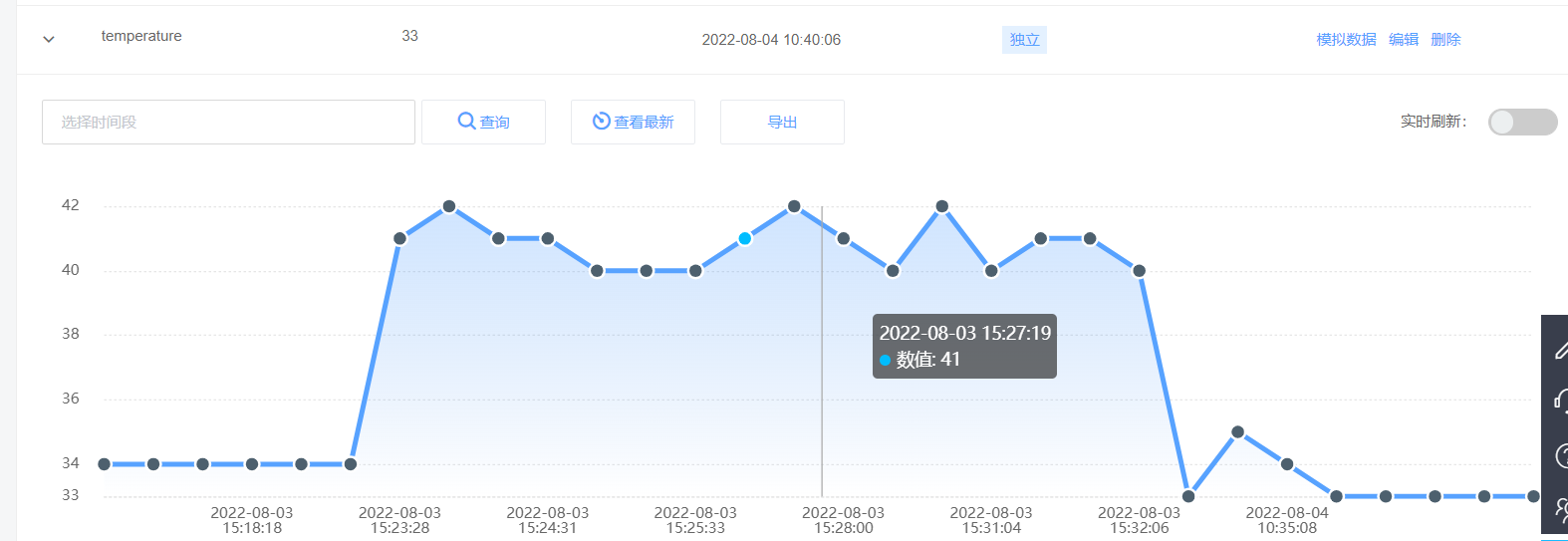

SPI(Serial Peripheral Interface,串行外设接口)是一种高速、全双工、同步通信总线,常用于短距离通讯,主要应用于 EEPROM、FLASH、实时时钟、AD 转换器、还有数字信号处理器和数字信号解码器之间。SPI 一般使用 4 根线通信,如下图所示:
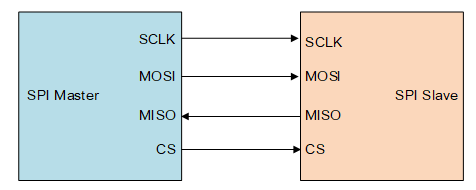
整体的传输大概可以分为以下几个过程:
(1)主机先将NSS信号拉低,这样保证开始接收数据;
(2)当接收端检测到时钟的边沿信号时,它将立即读取数据线上的信号,这样就得到了一位数据(1bit;由于时钟是随数据一起发送的,因此指定数据的传输速度并不重要,尽管设备将具有可以运行的最高速度。
(3)主机发送到从机时:主机产生相应的时钟信号,然后数据一位一位地将从MOSI信号线上进行发送到从机;
(4)主机接收从机数据:如果从机需要将数据发送回主机,则主机将继续生成预定数量的时钟信号,并且从机会将数据通过MISO信号线发送;

首先来看下RC522与M1卡的通讯流程:
寻卡->防止卡片冲撞->选卡->休眠->发送0x40(7bit)->发送0x43->发送0xa0等4字节->发送0x00等18字节
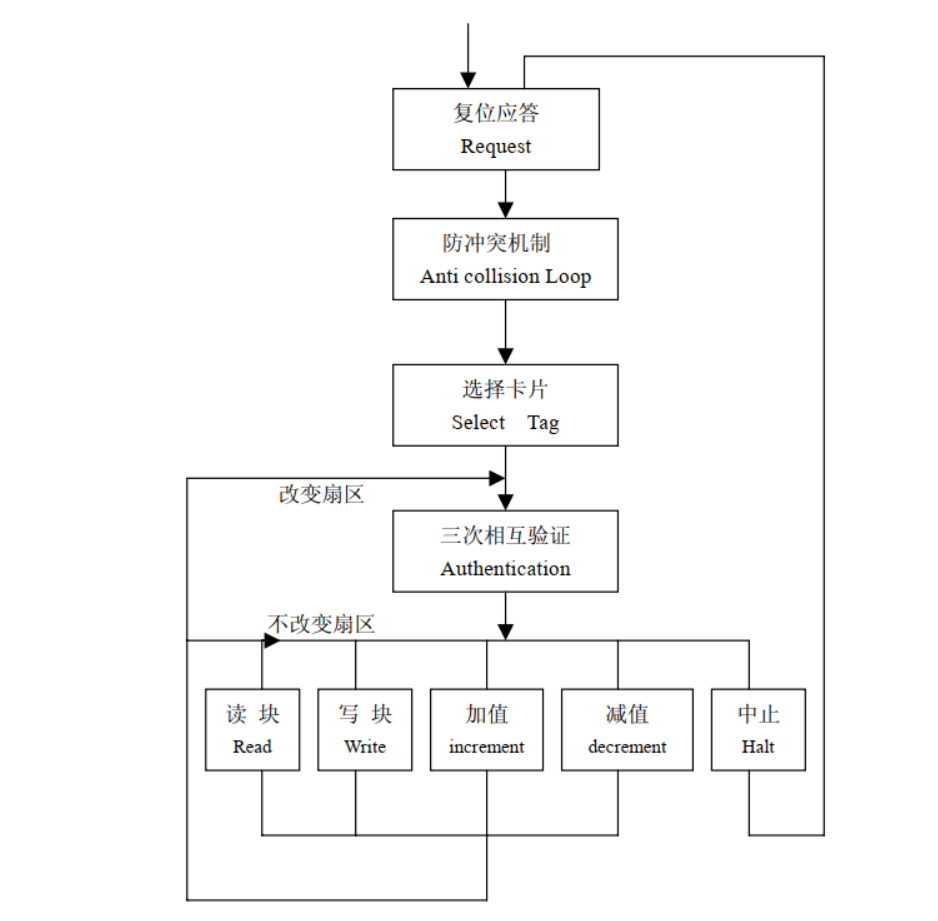
复位应答(Request):M1卡的通信协议和通信波特率是定义好的,当有卡片进入读卡器的工作范围时,读卡器要以特定的协议与卡片通信,从而确定卡片的卡型。
防冲突机制(Anticollision Loop):当有多张卡片进入读写器操作范围时,会从中选择一张卡片进行操作,并返回选中卡片的序列号。
选择卡片(Select Tag):选择被选中的卡的序列号,并同时返回卡的容量代码。
三次相互确认(3 Pass Authentication):选定要处理的卡片后,读写器就要确定访问的扇区号,并且对扇区密码进行密码校验。在三次互相认证后就可以通过加密流进行通信。每次在选择扇区的时候都要进行扇区的密码校验。
对数据块的操作: +读(Read):读一个块的数据; +写(Write):在一个块中写数据; +加(Increment):对数据块中的数值进行加值; +减(Decrement):对数据块中的数值进行减值; +传输(Transfer):将数据寄存器中的内容写入数据块中; +中止(Halt):暂停卡片的工作;
首先打开settings,添加RC522软件包,并在硬件部分使能SPI1
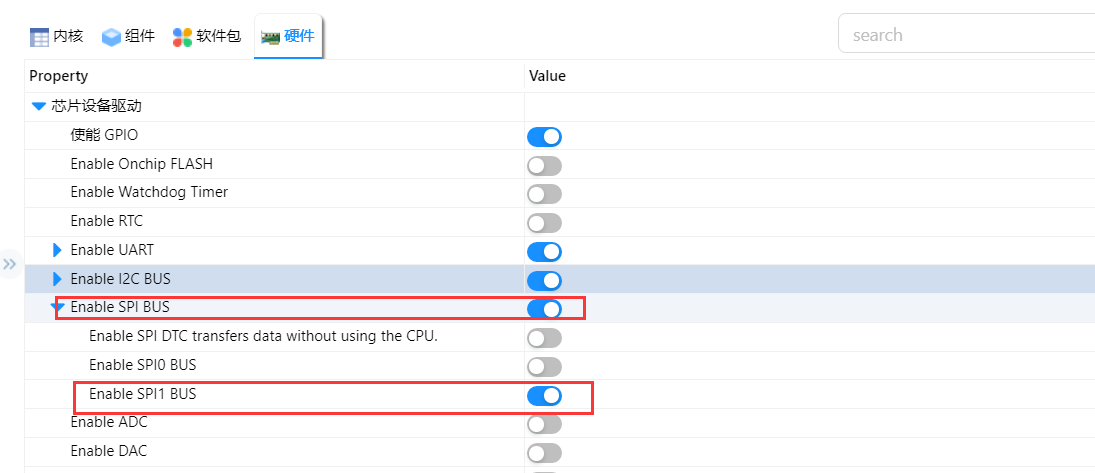
打开瑞萨FSP,添加一个名为r_spi的新stack,并进行如下配置:
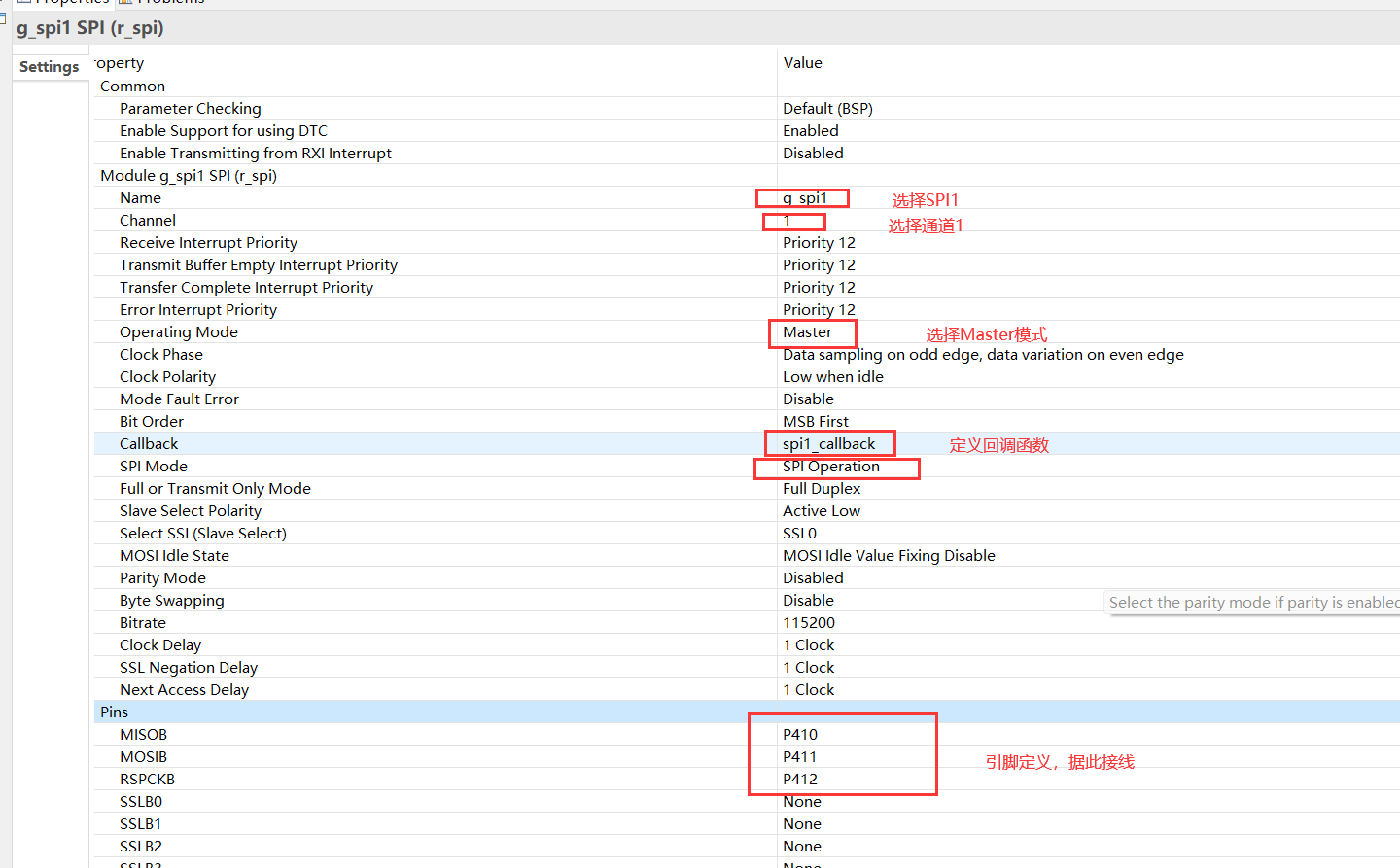
引脚接线:
| 引脚功能 | 引脚接线 |
|---|---|
| MOSI | P411 |
| MISO | P410 |
| SCL | P412 |
| SDA | P311 |
| RST | P312 |
| VCC | 3.3V |
| GND | GND |
| IRQ | 悬空 |
代码部分参考RC522sample
SPI初始化配置:
| |
另外需要在完成一下配置,双击打开mfrc522.h,修改MFRC522_SS_PIN为0x3b,MFRC522_RST_PIN为0x3c,分别对应SDA和RST引脚
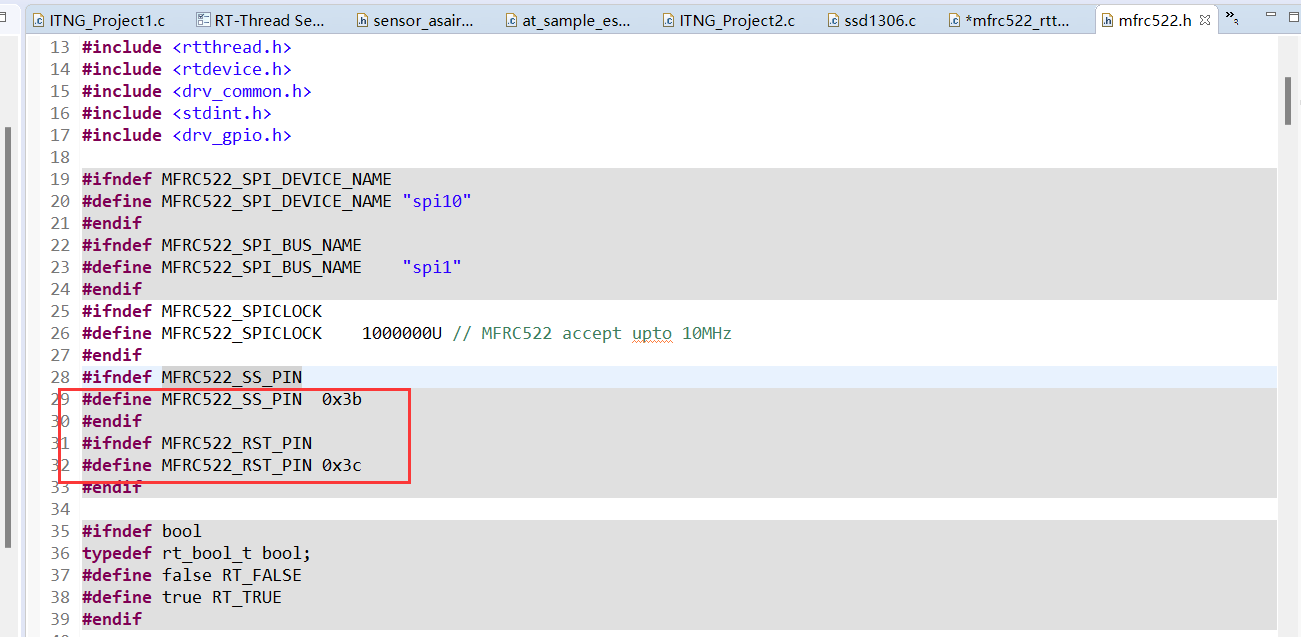
打开mfrc522.c,修改配置MFRC522_SS_PIN及MFRC522_RST_PIN
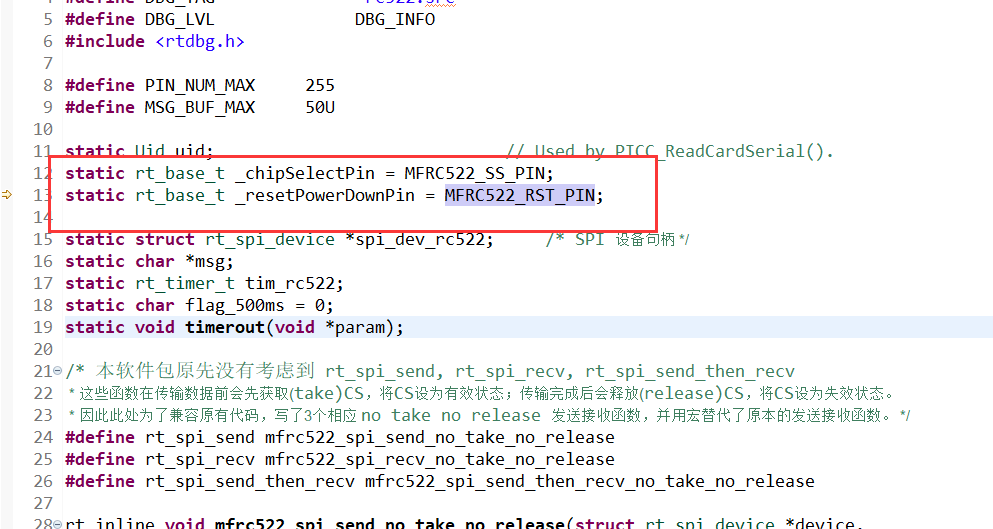
打开rtconfig.h,找到以下两个引脚的定义,修改成如下:
注意:一旦在RT-Thread settings中做了相关操作并保存设置后,在rtconfig.h中的配置都会以settings中的配置为准而被全部刷新,所以需要保留一个备份,下次保存设置的时候记得重新修改配置
| |
至此,RC522的相关配置结束
(这里参考AHT10关于I2C通信协议的介绍,此处不再赘述)
接线示意:
| 引脚功能 | 引脚接线 |
|---|---|
| SCL | P400 |
| SDA | P401 |
| VCC | 3.3V |
| GND | GND |
RT-Thread Settings配置:
添加ssd1306软件包,然后跳转到配置界面修改i2c address为0x3c,bus name为i2c0
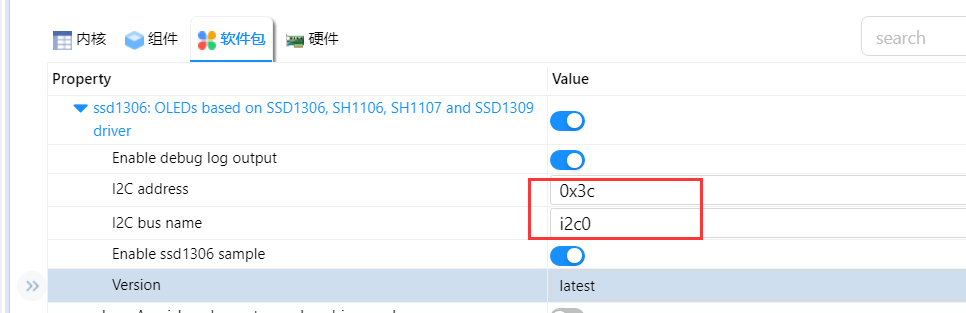
打开rtconfig.h,添加i2c代码,注意之前在rtconfig.h中进行的配置已经被刷新,需要重新添加配置代码:
| |
打开drv_soft_i2c.c文件,添加代码:
| |
打开瑞萨FSP,新建一个r_iic_master的new stack,完成以下配置:
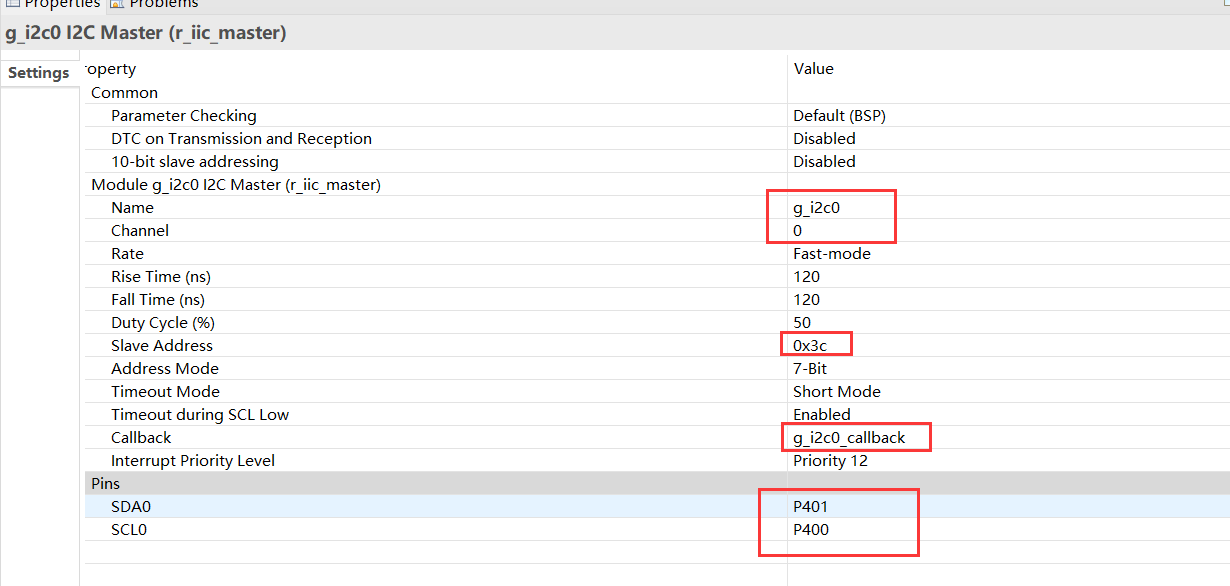
生成配置之后添加用户代码:
| |
实时时钟显示代码:
| |
温湿度数据显示代码:
| |
本次细分作品功能,共分为四大模块:分别是AHT10温湿度读取、onenet上云、oled显示、rc522读卡。
所以共创建四个线程:
(1)RC522_thread:用于RC522读卡
(2)aht10_read_thread:用于aht10读取温湿度数值
(3)onenet_aht10_thread:云端数据上报
(4)oled_thread:OLED显示
本次在IPC方面的使用很不成熟,只是在每个线程的入口函数中进行互斥量的保护,并没有将RT-Thread内核机制灵活运用到代码中,是我此次学习的最大不足,其实也做过一些例如邮箱机制的使用,但是由于数据显示异常而没有进行下去,在工程源码的ITNG_Project2中包含了这种机制的使用,也就是说提供了两套方案,但是确实个人效率太低,第二种方案被搁置。
在本次的程序设计中,我使用了一个while循环结合switch选择语句来保证整体代码的运行,在线程的入口程序使用互斥量来完成资源的保护,但是RT-Thread多线程机制的使用也是仍显不足。
都说程序设计也是艺术设计,要学会使用代码抽象人类社会的运行机制,程序设计方面,我设计的不合理,导致整个项目如同流水线般运行,亮点不大,值得反思。

其实大部分踩坑说明在上面的教学指南中一般都有说明,这里简单说些:
(1)注意瑞萨FSP目前在RT-Thread中的支持包版本为v3.5.0
(2)由于瑞萨有自己完整的生态开发工具,所以RT-Thread与瑞萨合作时对于底层驱动的定义只有部分,还有一些需要在FSP中进行配置并生成配置。同时在HAL库中也需要添加相应的驱动代码,同时记得需要在settings中将相应的外设支持打开。
(3)对于每次的settings设置,其实都会生成相关的宏和定义在rtconfig.h文件中,所以每次更行settings时都会将用户在rtconfig.h中添加的代码删除,这时候需要重新添加,否则会生成一些宏未定义的错误。

1.首先需要下载git并配置好相应的环境变量
2.双击env,在setting中设置
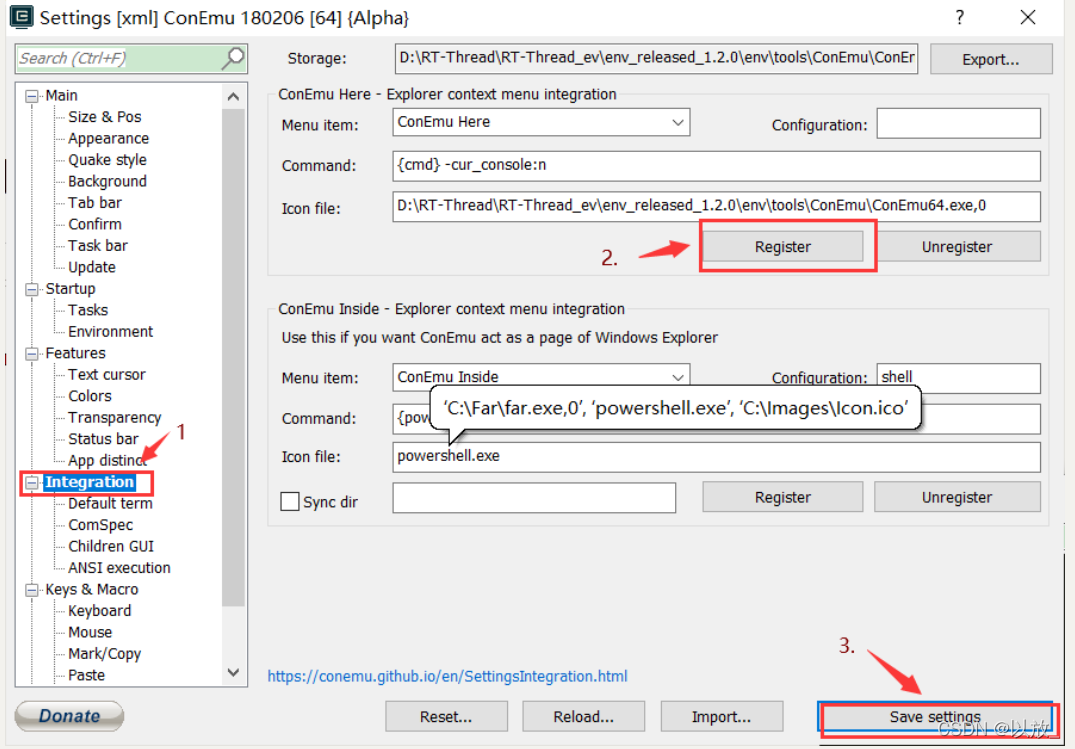
这样就可以指定文件夹打开env工具了
1.scons:编译
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fPYlwcMS-1649693722218)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20220411234217601.png)\]](https://img-blog.csdnimg.cn/976aba29a258481d9128f4b984f78139.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5Lul5pS-Xw==,size_20,color_FFFFFF,t_70,g_se,x_16)
(1)scons:编译并打印相关内部信息
+(2)scons -c:清除编译目标。这个命令会清除执行 scons 时生成的临时文件和目标文件。
+(3)scons -s:编译而不打印具体的内部命令
+(4)scons --target=XXX:使用以下命令中的其中一种重新生成对应的定制化的工程,然后在 mdk/iar 进行编译下载
| |
(5)scons -jN:多线程编译目标,在多核计算机上可以使用此命令加快编译速度
| |
注意:一般不建议使用,容易将编译信息和错误混杂
+(6)scons --dist:搭建项目框架,使用此命令会在 BSP 目录下生成 dist 目录
+2.指定编译器安装路径
| |
3.menuconfig +打开菜单配置界面,可用户自定义模块
4.scons进阶学习 +scons内置函数
GetCurrentDir(): +获取当前路径。
Glob(’*.c’): +获取当前目录下的所有 C 文件。修改参数的值为其他后缀就可以匹配当前目录下的所有某类型的文件。
GetDepend(macro): +该函数定义在 tools 目录下的脚本文件中,它会从 rtconfig.h 文件读取配置信息,其参数为 rtconfig.h 中的宏名。如果 rtconfig.h 打开了某个宏,则这个方法(函数)返回真,否则返回假。
Split(str): +将字符串 str 分割成一个列表 list。
DefineGroup(name, src, depend,**parameters):
+这是 RT-Thread 基于 SCons 扩展的一个方法(函数)。DefineGroup 用于定义一个组件。组件可以是一个目录(下的文件或子目录),也是后续一些 IDE 工程文件中的一个 Group 或文件夹。
+DefineGroup() 函数的参数描述:
| 参数 | 描述 |
|---|---|
| name | Group 的名字 |
| src | Group 中包含的文件,一般指的是 C/C++ 源文件。方便起见,也能够通过 Glob 函数采用通配符的方式列出 SConscript 文件所在目录中匹配的文件 |
| depend | Group 编译时所依赖的选项(例如 FinSH 组件依赖于 RT_USING_FINSH 宏定义)。编译选项一般指 rtconfig.h 中定义的 RT_USING_xxx 宏。当在 rtconfig.h 配置文件中定义了相应宏时,那么这个 Group 才会被加入到编译环境中进行编译。如果依赖的宏并没在 rtconfig.h 中被定义,那么这个 Group 将不会被加入编译。相类似的,在使用 scons 生成为 IDE 工程文件时,如果依赖的宏未被定义,相应的 Group 也不会在工程文件中出现 |
| parameters | 配置其他参数,可取值见下表,实际使用时不需要配置所有参数 |
parameters可加入的参数:
| 参数 | 描述 |
|---|---|
| dirs | SConscript 文件路径 |
| variant_dir | 指定生成的目标文件的存放路径 |
| duiplicate | 设定是否拷贝或链接源文件到 variant_dir |

由飞利浦公司开发,支持设备间的短距离通信。i2c通信需要的引脚少,硬件实现简单、可扩展性强,被广泛应用在系统内多个集成电路(IC)间的通信。
i2c通信总线可连接多个i2c通信设备,支持多个通信主机和多个通信从机。i2c通信只需要两条双向总线——SDA(串行数据线)和SCL(串行时钟线)。
+SDA:用于传输数据
+SCL:用于同步数据收发
每个连接到总线的设备都有一个独立地址,共7bit,主机正是利用该地址对设备进行访问
i2c支持多主控,任何时间点都只能有一个主控。
+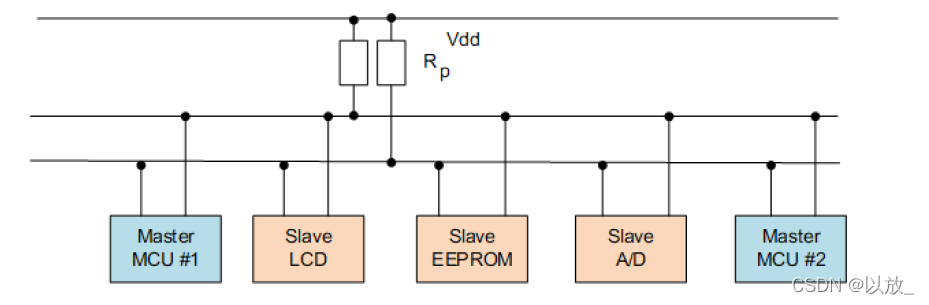
i2c器件的SDA引脚和SCL引脚是开漏电路(参照资料)形式,因此,SDA和SCL总线都需要连接上拉电阻(参照资料),当总线空闲时,两条总线均为高电平。
各器件的SDA和SCL信号线在总线上都是线与关系。(即连接到总线上的任意器件输出低电平都会将总线信号拉低)
协议层定义了i2c的通信协议。一个完整的i2c数据传输包含开始信号,器件地址,读写控制,器件内访问地址,有效数据,应答信号和结束信号。
数据传输:当SCL位高电平时,SDA必须保持稳定,SDA上传1位数据。
+数据改变:当SCL为低电平时,SDA才可以改变电平
+i2c位传输时序图
+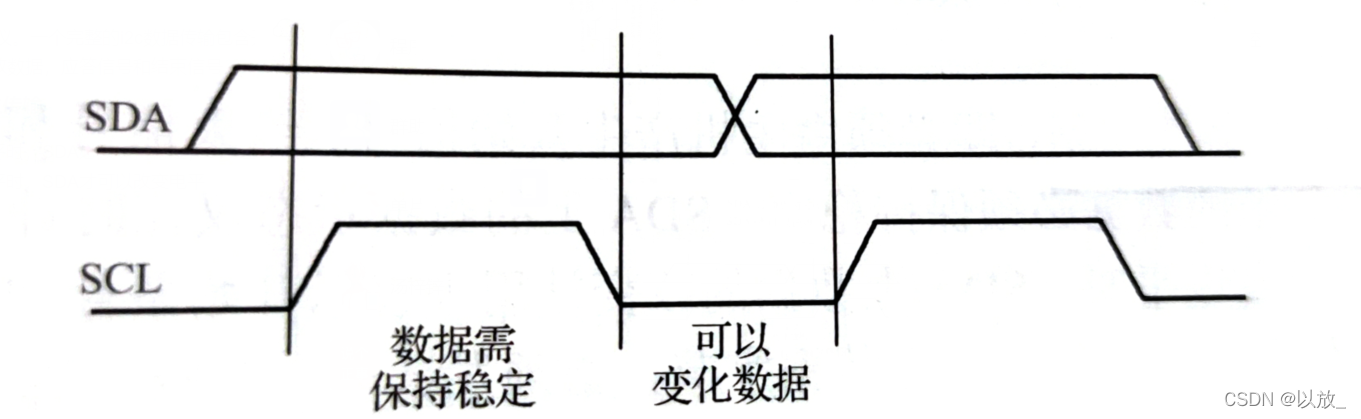
开始信号:SCL 为高电平时,主机将SDA 拉低,表示数据传输即将开始。
+结束信号:在SDA 为低电平时,主机将SCL 拉高并保持高电平,然后在将SDA 拉高,表示传输结束。
主机发送完每一个字节数据后,释放SDA(保持高电平),被寻址的接收器在成功接收到每一个字节后,必须产生一个应答ACK(从机将SDA拉低,使它在这个时钟脉冲的高电平期间保持稳定的低电平)从机接收不到数据或通信故障时,从机必须使SDA保持高电平,主机产生一个结束信号终止传输或者产生新的传输。线与逻辑功能的原理上的。线与连接。一般情况下MCU 的I2C 器件都是作为主机和从机通讯,在RT-Thread 中将I2C 主机虚拟为I2C 总线设备,I2C 从机通过I2C 设备接口和I2C 总线通讯,相关接口如下所示:
| 函数 | 描述 |
|---|---|
| rt_device_find() | 根据I2C 总线设备名称查找设备获取设备句柄 |
| rt_i2c_transfer() | 传输数据 |
在使用I2C 总线设备前需要根据I2C 总线设备名称获取设备句柄,进而才可以操作I2C 总线设备,查找设备函数如下所示,
rt_device_t rt_device_find(const char* name);
+| 参数 | 描述 |
|---|---|
| name | i2c总线设备名称 |
| 返回 | – |
| 设备句柄 | 查找到对应设备将返回相应的设备句柄 |
| RT-NULL | 没有找到相应的设备对象 |
一般情况下,注册到系统的I2C 设备名称为i2c0 ,i2c1 等,使用示例如下所示:
| |
获取到I2C 总线设备句柄就可以使用rt_i2c_transfer() 进行数据传输。函数原型如下所示:
| |
| 参数 | 描述 |
|---|---|
| bus | i2c总线设备句柄 |
| msgs[] | 待传输的消息数组指针 |
| num | 消息数组的元素个数 |
| 返回 | - |
| - | - |
| 消息数组的元素个数 | 成功 |
| 错误码 | 失败 |
!!! note “注意事项” 此函数会调用rt_mutex_take(), 不能在中断服务程序里面调用,会导致assertion报错。I2C 消息数据结构原型如下:
| |
!!! note “注意事项” RT-Thread I2C 设备接口使用的从机地址均不包含读写位,读写位控制需修改标志flags。 | |
使用示例如下所示:
| |
I2C 设备的具体使用方式可以参考如下示例代码,示例代码的主要步骤如下:
| |

详细原理参考:【玩转RT-Thread】线程管理(详细原理)
| |
首先我们来看看线程创建函数返回值类型:

可以看到线程创建函数的返回值类型为:
rt_thread_t,找到定义处(如下图),可以看到它的返回值类型是一个结构体指针变量。

那么我们先定义一个结构体指针的线程th1_ptr,这样通过rt_thread_create函数创建的进程控制块的地址就能直接赋值给th1_ptr变量:
| |
接下来就是我们给进程控制块传参了


由于线程创建有返回值,所以我们此处再加入一个判断函数去判断线程是否创建成功
我们先来看下线程返回值(如下图)
如果
成功创建的话,返回值是会返回我们所创建的线程对象的
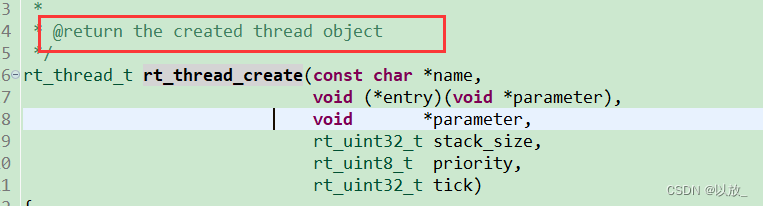
如果创建失败的话,可以看到是会返回一个RT_NULL,也就是0

| |
我们在线程的入口处理函数写一个循环函数:
| |
注意:我们在使用线程的处理函数的循环函数的时候,一定要记得及时释放资源,也就是出让CPU资源,不然这个线程会一直执行并占用系统资源

由于RTT studio有内置的串口终端,我们直接打开

终端输入list_thread可以查看所有的线程

这里也许就有疑问了,为什么线程入口函数的打印命令没有被执行?
其实我们再看th_demo线程的状态可以看到是init,参考【玩转RT-Thread】线程管理(详细原理)
当线程刚开始创建还没开始运行时就处于初始状态;在初始状态下,线程不参与调度。此状态在RT-Thread 中的宏定义为RT_THREAD_INIT
其实这句话就表明当线程处于初始化状态下是不参与系统调度的!
线程错误码:

函数原型
在主函数中加入命令,使线程进入就绪态:
| |
但是我们此时打开终端可以发现:线程入口函数虽然被执行,但线程状态为挂起态

解释:虽然我们调用rt_thread_startup函数使线程进入就绪态,但是回到入口函数我们可以看到,我们调用了rt_thread_mdelay函数使其有一定时间的休眠,从而进入了挂起态`
rt_thread_init
| |
| |
此处我们需要定义一个ret整型变量用于
rt_thread_init的返回值传参,然后定义一个线程结构体,用于静态线程传参。同时需要为线程栈分配内存,所以我们创建一个栈数组,注意这里的线程栈大小我们设定512,而线程的优先级设为19,比线程th1_demo要高一个优先级,后续观察现象。


代码如下:
| |
静态线程创建成功的话会返回0,失败的话会返回一个负值,若成功创建线程,我们调用rt_thread_startup函数使线程2进入就绪态,并执行线程处理函数。
| |
这里注意:由于我们线程2定义是一个数组,所以需要取地址进行线程开启
分析:首先我们把线程1和线程2的启动函数都开启,可以看到线程1和线程2都处于挂起态,线程2的命令先于线程1执行,这是由于前面我们设定优先级给线程2(优先级19)比线程1(优先级20)高,所以在命令执行是先线程2,再线程1。
线程2在执行完10次循环后就结束进程了,此时在终端再次输入list_thread可以发现线程2已经退出,只剩下线程1还在循环执行


做世界级的 OS,让万物互联,信息畅通无阻。
+成为未来 AIoT 领域最为主流的操作系统平台。
RT-Thread 是一个集
实时操作系统(RTOS)内核、中间件组件和开发者社区于一体的技术平台,由熊谱翔先生带领并集合开源社区力量开发而成,RT-Thread 也是一个组件完整丰富、高度可伸缩、简易开发、超低功耗、高安全性的物联网操作系统。
RT-Thread 具备一个 IoT OS 平台所需的所有关键组件,例如GUI、网络协议栈、安全传输、低功耗组件等等。经过11年的累积发展,RT-Thread 已经拥有一个
国内最大的嵌入式开源社区,同时被广泛应用于能源、车载、医疗、消费电子等多个行业,累积装机量超过 14亿 台,成为国人自主开发、国内最成熟稳定和装机量最大的开源 RTOS。
RT-Thread 拥有
良好的软件生态,支持市面上所有主流的编译工具如 GCC、Keil、IAR 等,工具链完善、友好,支持各类标准接口,如 POSIX、CMSIS、C++应用环境、Javascript 执行环境等,方便开发者移植各类应用程序。商用支持所有主流MCU架构,如 ARM Cortex-M/R/A, MIPS, X86, Xtensa, C-Sky, RISC-V,几乎支持市场上所有主流的 MCU 和 Wi-Fi 芯片。
RT-Thread studio潘多拉STM32L475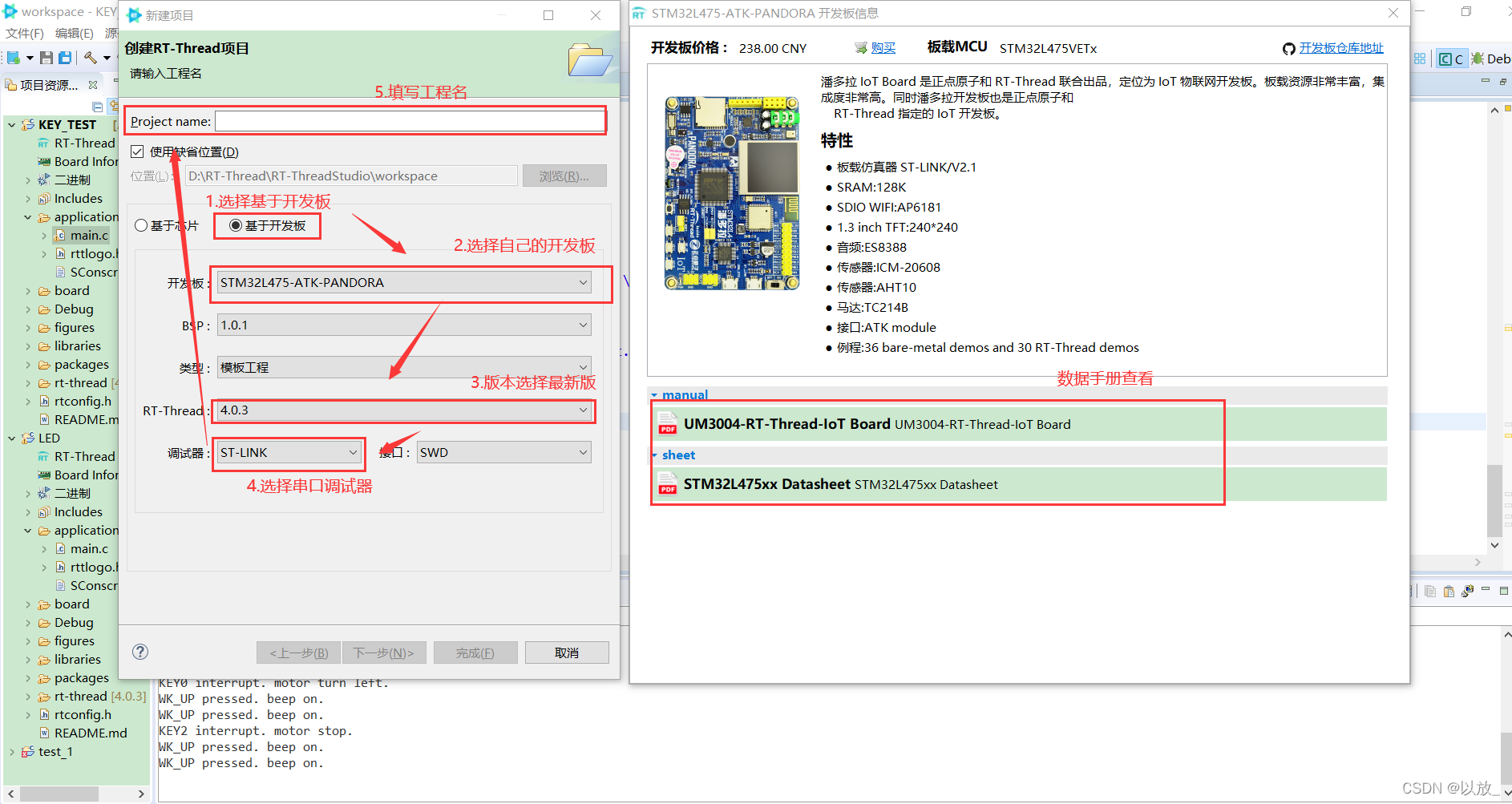
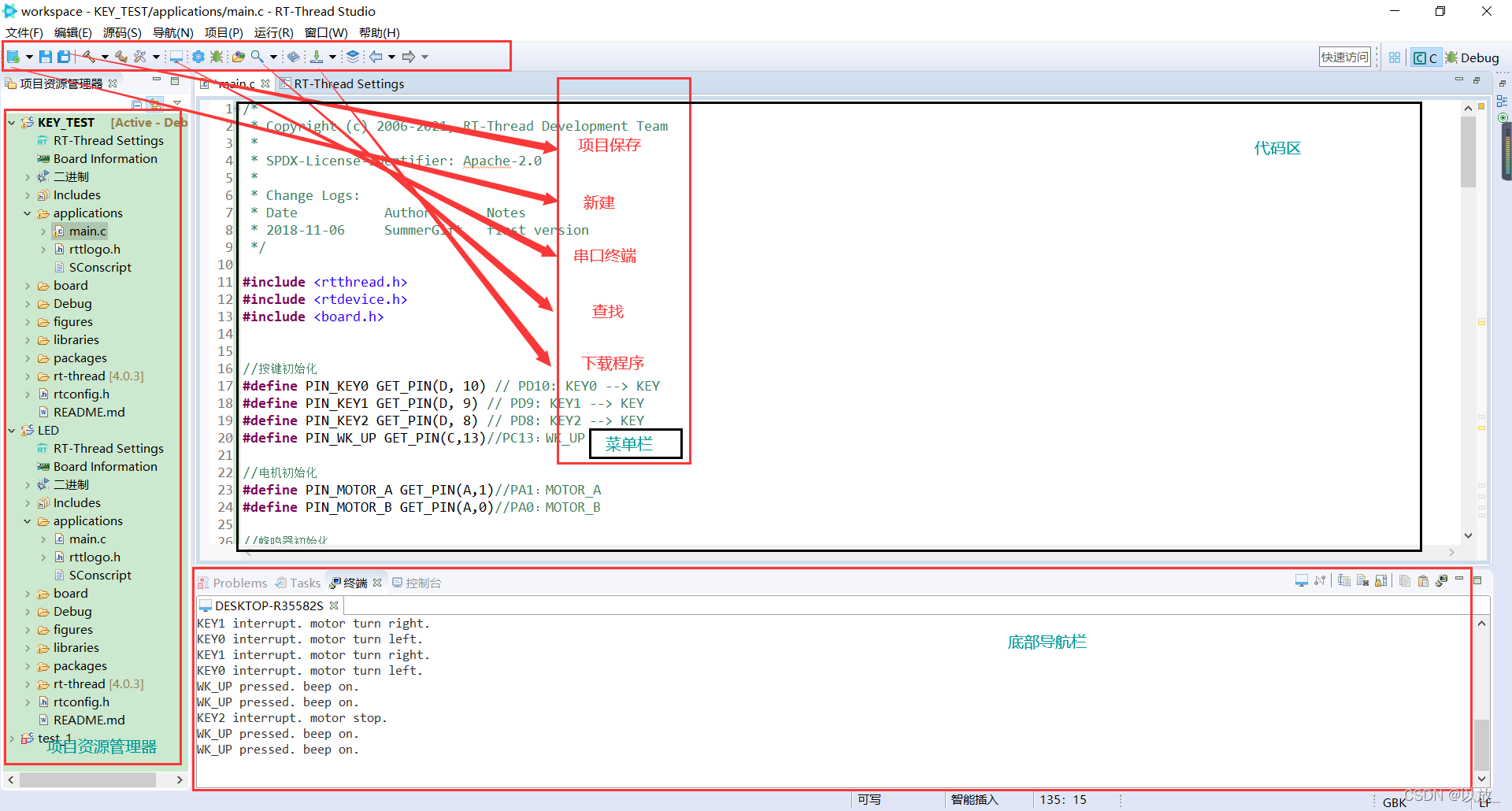
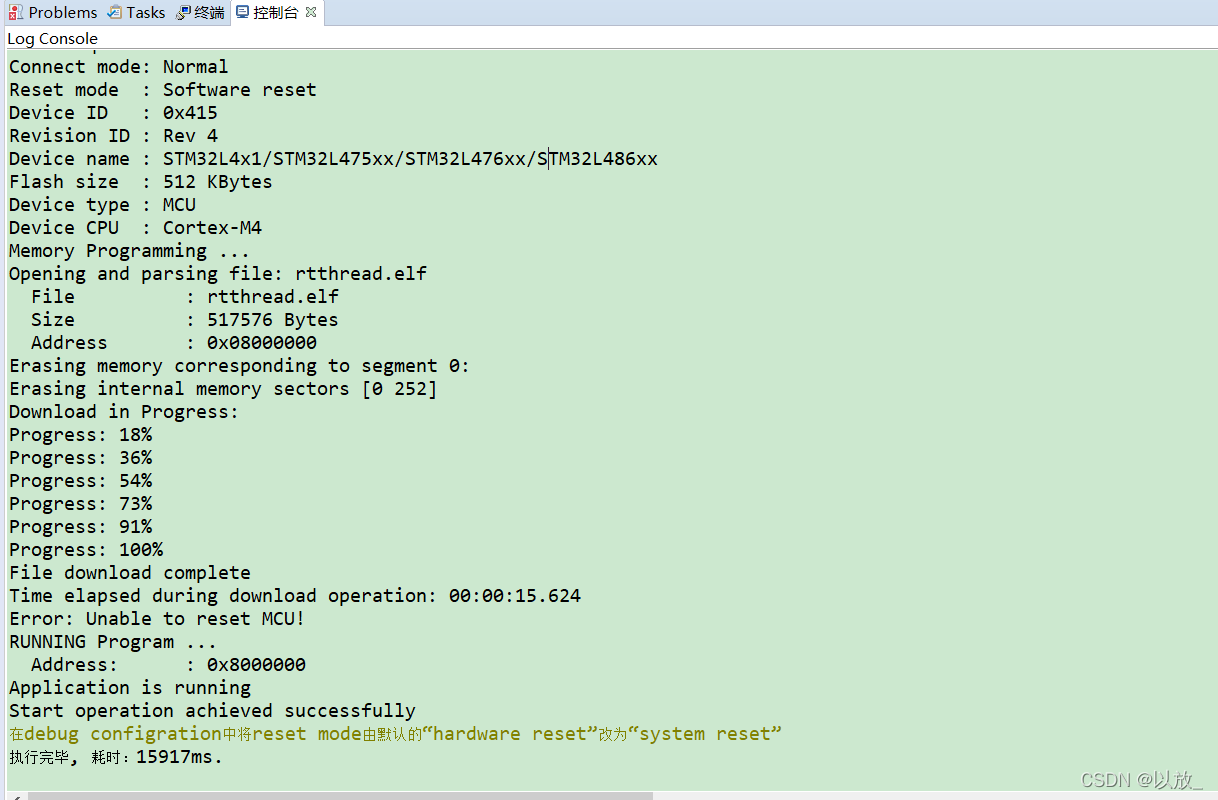
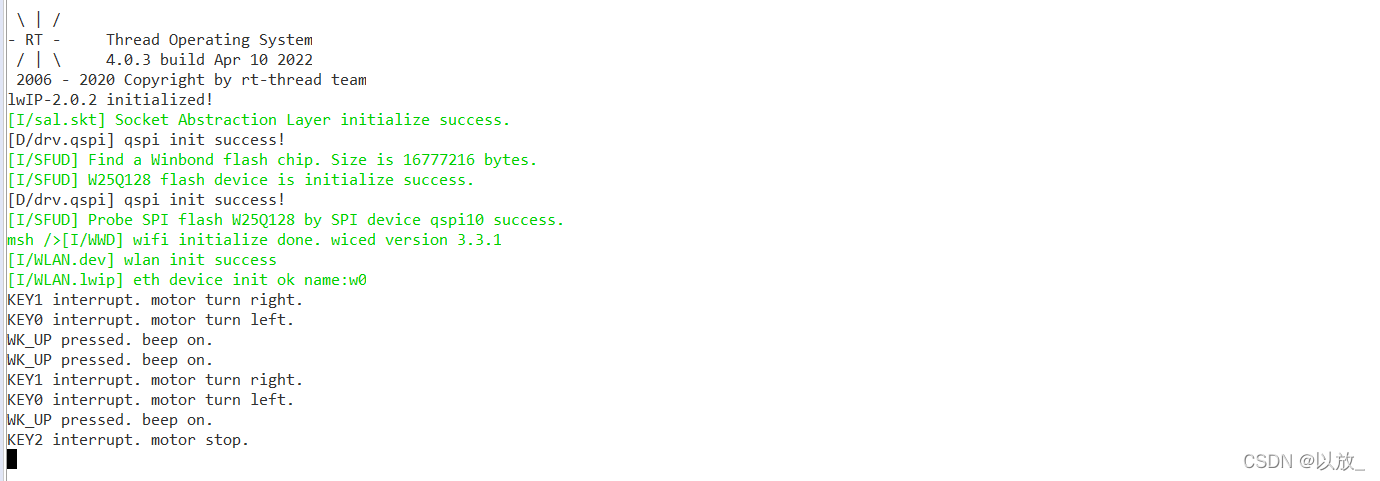
1.头文件
#include <rtthread.h>
+#include <rtdevice.h>
+#include <board.h>
+2.宏定义
| |
3.void motor_ctrl(rt_uint8_t turn) //电机控制函数
| |
4.void beep_ctrl(rt_uint8_t on) //蜂鸣器控制函数
| |
5.void irq_callback(void *args) // 中断回调函数
| |
5.主函数
| |
通过按键引脚、电机以及蜂鸣器的输入输出模式,并对按键设置中断编写中断回调函数,在使能中断后。 +1.电机控制:当有外部事件触发引脚状态(按下按键)时,中断回调函数对特定的触发引脚进行判断,并执行相应的操作 +2.蜂鸣器控制:在主函数中循环执行判断是否WK_UP按键是否按下,按下触发蜂鸣器响,松开停止发声。
| 按键 | 功能 |
|---|---|
| KEY0 | 电机左转 |
| KEY1 | 电机右转 |
| KEY2 | 电机停止 |
| WK_UP | 蜂鸣器响 |

| |
使用方法:可用于bsp指定RT-Thread版本
例如:
| |
| |
rt_base_t:为了使代码可以在不同的CPU上移植并保持向后兼容性。long类型的位数(bit数)可能因不同的CPU体系结构而有所不同,但是使用rt_base_t代替long可以隐藏这种差异,以实现代码的可移植性。(rt_ubase_t原理相同)
rt_err_t:代表错误码的数据类型,这里使用了之前定义的rt_base_t作为它的别名。
rt_time_t:代表时间戳的数据类型,这里使用了rt_uint32_t作为它的别名。rt_uint32_t是一个32位无符号整数类型,可以用来表示1970年1月1日以来的秒数。
rt_tick_t:代表系统时钟节拍计数的数据类型,这里也使用了rt_uint32_t作为它的别名。在嵌入式系统中,通常会使用硬件定时器来产生一个固定频率的中断信号,并且在每次中断时对rt_tick_t进行递增操作,从而实现对时间的计数。
rt_flag_t:代表标志位的数据类型,这里使用了之前定义的rt_base_t作为它的别名。
rt_dev_t:代表设备号的数据类型,这里使用了rt_ubase_t作为它的别名。在嵌入式系统中,通常会有多个外设需要使用不同的设备号进行标识,因此需要定义一个数据类型来保存设备号。
rt_off_t:代表偏移量的数据类型,这里也使用了之前定义的rt_base_t作为它的别名。在文件系统中,通常需要记录某个文件中的偏移量(即当前读写位置),因此需要定义一个数据类型来保存偏移量。
| |
附:此处的UINT8_MAX、UINT16_MAX、UINT32_MAX为编译器预定的宏定义
| |
| |
| |
**该宏定义表示将变量x强制转换为void类型,从而告诉编译器该变量未被使用,从而避免编译器发出“未使用变量”的警告。这种空操作常常用于函数参数或者结构体成员的声明中,因为有时候我们为了某些原因不得不声明一个变量,但在实际使用中却无需使用它,这时候就可以使用这个宏来标记变量未被使用。 **
下面是一个例子:假设在编写一个C语言程序时,需要使用qsort()函数进行数组排序。
该函数的第一个参数是一个void类型的指针,用于表示要排序的数组。
在实际使用中,我们可能并不需要使用这个参数。但是,由于该函数的参数列表中必须要有第一个参数,而且其类型为void*,因此我们不得不将一个无用的参数传递给函数,否则就会编译错误。
这时候,就可以使用RT_UNUSED宏来标记这个参数未被使用,代码如下:
| |
这样就可以避免编译器报“未使用变量a/b”的警告了。
| |
RT_SECTION(x):表示将所修饰的数据/函数放置在指定的section中,x为section名字,通常是一个字符串。这个宏可以用于在程序中指定某些数据/函数位于特定的内存区域,比如放在Flash中或者RAM中,以满足不同的需求。该宏使用了GCC的语法扩展。RT_USED:表示告诉编译器保留所修饰的数据/函数,即使它没有被直接引用或调用。该宏通常用于防止删除不需要的代码和变量,以及确保所需的函数和变量在链接时能够正确地生成和调用。该宏使用了GCC的语法扩展。ALIGN(n):表示将所修饰的数据/函数按照n字节对齐,即从地址0开始,每隔n个字节就对齐一次。该宏通常用于解决访问未对齐的数据导致的性能问题,以及操作系统中数据结构对齐的需求。该宏同样使用了GCC的语法扩展。RT_WEAK:表示将所修饰的数据/函数标记为弱引用,即该数据/函数可以被重定义。当出现多个同名的弱引用时,链接器会选择其中优先级最高的一个。该宏通常用于提供一些默认实现,但允许用户在需要时重写它们。该宏同样使用了GCC的语法扩展。rt_inline:表示将所修饰的函数定义为静态内联函数,即在编译时将函数的代码直接嵌入到调用处,以避免隐式调用带来的额外开销。该宏同样使用了GCC的语法扩展。 | |
typedef __builtin_va_list __gnuc_va_list: 定义了一个新类型__gnuc_va_list,并使用 __builtin_va_list 进行初始化。__builtin_va_list 是GCC内建的类型,用于表示可变参数列表中的参数,并在实现中进行处理。由于可变参数的实现和操作系统和编译器等因素相关,因此需要使用 __builtin_va_list 类型来实现可变参数列表。typedef __gnuc_va_list va_list: 定义了一个名为va_list的新类型,并将其重命名为__gnuc_va_list。#define va_start(v,l) __builtin_va_start(v,l): 将 va_start() 重命名为 __builtin_va_start(),从而能够使用 GCC 内建的函数 __builtin_va_start() 实现可变参数的功能。该宏的作用是对变参列表进行初始化,获取第一个参数的地址和类型,并返回可变参数队列中下一个参数的地址。#define va_end(v) __builtin_va_end(v): 将 va_end() 重命名为 __builtin_va_end(),从而能够使用 GCC 内建的函数 __builtin_va_end() 实现可变参数的功能。该宏的作用是清除可变参数列表,并将其指针置为 NULL。#define va_arg(v,l) __builtin_va_arg(v,l): 将 va_arg() 重命名为 __builtin_va_arg(),并使用 GCC 内建的函数 __builtin_va_arg() 实现可变参数的功能。该宏的作用是获取可变参数队列中的下一个参数,并将指针指向该参数的位置。#define PRAGMA(x) _Pragma(#x):将参数x转化为字符串并使用_Pragma()将其作为编译指令执行。_Pragma是C99标准引入的一个新特性,它允许程序员在说明文件中进行诸如#pragma等命令式编译指令的嵌入式编程。而#pragma则是一种编译指令,用于控制编译器的一些行为,比如告诉编译器去链接某个库、指定编译器选项等。 | |
RT_EOK:表示没有错误。RT_ERROR:表示发生了一般性的错误。RT_ETIMEOUT:表示超时错误。RT_EFULL:表示资源已满。RT_EEMPTY:表示资源为空。RT_ENOMEM:表示内存不足。RT_ENOSYS:表示没有该系统。RT_EBUSY:表示忙碌。RT_EIO:表示输入/输出错误。RT_EINTR:表示中断的系统调用。RT_EINVAL:表示无效的参数。
TCP(Transmission Control Protocol 传输控制协议):是一种面向连接、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
UDP(User Datagram Protocol 用户数据报协议):是OSI(Open System Interconnection 开放式系统互联):参考模型中的一种无连接的传输层协议,提供面向事务的简单不可靠传送服务。
OSI七层模型和TCP/IP四层模型详解请看此处
区别:
socket():创建一个socketsetsockopt():设置socket属性bind():绑定IP地址、端口等信息到socket类上listen():开启监听accept():接收来自客户端的连接send()、recv()、read()、write()socket():创建一个socketsetsockopt():设置socket属性,可选bind():绑定IP地址、端口等信息到socket上recvfrom():循环接收数据socket():创建一个socketsetsockopt():设置socket属性,可选bind():绑定IP地址、端口等信息到socket上sendto():发送数据SAL(套接字抽象层)是RT-Thread官方为避免系统对单一网络协议栈的依赖,同时也为适配更多网络协议栈类型而提供的一套网络组件,该组件主要完成对不同网络协议栈或网络实现接口的抽象并对上层一共一组标准BSD Socket API,这样开发者只需关心和使用网络应用层提供的网络接口,而无需关心底层具体网络协议栈类型和实现,极大提高了系统的兼容性。
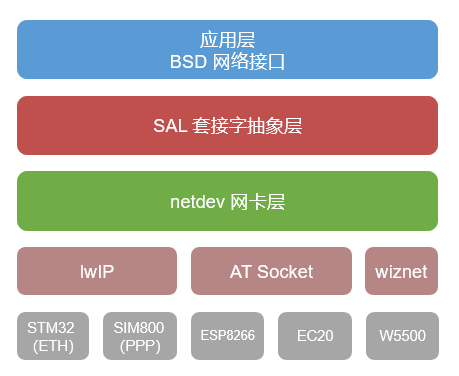
SAL组件工作原理的介绍主要分为如下两部分:
由于不同协议栈或网络功能的实现,其网络接口的名称各有不同,已连接函数为例,lwip协议栈中接口名称为lwip_connect,而AT Socket网络实现接口为at_connect。通过SAL组件可以完成对不同协议栈或网络实现接口的抽象和统一,组件再socket创建时通过判断传入的协议簇(domain)类型来判断使用的协议栈或网络功能。
目前RT-Thread SAL组件支持的协议栈或网络实现类型有:LWIP协议栈(AT_INET)、AT Socket协议栈(AF_AT)、WIZnet硬件 TCP/IP协议栈(AT_WIZ)2。
| |
为了动态适配不同协议栈或网络实现的接入,SAL组件中对于每个协议栈或者网络实现提供两种协议类型匹配方式:主协议簇类型和次协议簇类型,在socket创建之初收i西安判断传入协议簇类型是否存在已经支持的主协议类型,如果是则使用对应协议栈或网络实现,如果不是则判断次协议簇类型是否支持。
具体而言,主协议簇类型是指一个协议簇的最基本类型,例如 IPv4 或 IPv6。次协议簇类型则是在主协议簇类型的基础上进行扩展或增强,例如 TCP 或 UDP 协议。主协议簇类型可以被多个次协议簇类型所支持,但一个次协议簇类型只能属于一个主协议簇类型。
目前系统支持协议簇类型如下:
| |
SAL组件的主要作用是统一BSD Socket API接口,我们以官方示例对SAL组件函数进行调用方式的实现:
| |
在TCP、UDP等协议数据传输时,由于数据包是明文的,所以很可能被拦截,甚至被解析出数据,为了保证网络传输的安全性,需要用户在应用层和传输层之间添加SSL/TLS协议。
TLS(Transport Layer Security,传输层安全协议)是建立在传输层TCP协议之上的协议,其前身是SSL(Secure Socket Layer,安全套接字层),主要作用是将应用层的报文进行非对称加密后再由TCP协议进行传输,实现了数据的加密安全交互。3
对于通过的加密方式,需要使用其指定的加密接口和流程进行加密,而SAL TLS功能的主要作用是提供Socket层面的TLS加密传输特性,抽象多种TLS处理方式,提供统一的接口用于完成TLS数据交互。
使用流程:
配置完成后,需要在socket创建时传入的potocol类型是使用PROTOCOL_TLS或者PROTOCOL_DTLS,即可使用标准BSD Socket API接口,完成TLS连接的建立和数据的收发。
示例如下,参考RT-Threda文档中心:
| |
为通信创建一个端点并返回一个文件描述符
| |
| |
| |
当使用socket()创造一个套接字时,只是给定了协议簇,并没有分配地址。在套接字能够接收来自其他主机的连接时,必须bind()给它绑定一个地址。
| |
附:SAL组件依赖netdev组件,当使用bind()函数时,可通过netdev网卡名称获取网卡对象中IP地址信息,用于将创建的Socket套接字绑定到指定的网卡对象。
来自RT-Thread文档中心,完成通过传入的网卡名称绑定该网卡IP地址并和服务器进行连接的过程:
| |
当有一个套接字和一个地址联系之后,listen()监听到来的连接。只适用于面向连接的模式。
| |
当应用程序监听来自其他他主机的面向数据流的连接时,通过事件通知它,必须用accept()函数初始化连接。该函数为每个连接创建新的套接字并从监听队列中移除这个连接。
| |
该函数用于建立与指定 socket 的连接。
| |
该函数常用于 TCP 连接发送数据。
| |
该函数用于TCP连接接收数据。
| |
该函数用于UDP连接发送数据。
| |
该函数用于UDP连接发送数据。
| |
网络协议栈或网络功能实现的接入,主要是对协议簇结构体的初始化和注册处理,并且添加到SAL组件中协议簇列表中,协议簇结构体定义如下:
| |
伯克利套接字(Berkeley sockets),也称BSD Socket,伯克利套接字的应用编程接口(API)是采用C语言的进程间通信的库,经常用在计算机网络间的通信。 BSD Socket的应用编程接口已经是网络套接字的抽象标准。大多数其他程序语言使用一种相似的编程接口。最初是由加州伯克利大学为Unix系统开发出来。 ↩︎
WIZnet的硬件TCP/IP协议栈采用了TOE(TCP/IP Core Offload Engine)技术,将TCP/IP协议栈等网络处理功能转移到专用硬件中,从而减少了CPU的负担,提高了整个系统的性能和稳定性。同时,WIZnet的硬件TCP/IP协议栈还支持多种网络协议,并提供了Socket API封装等高层次接口,方便用户进行开发和集成。 ↩︎
在 TLS 协议中,使用了非对称加密和对称加密两种加密方式。其中,非对称加密主要用于密钥协商和身份认证,而对称加密则用于数据传输的加密和解密。在TLS握手过程中,客户端和服务器会相互发送自己的公钥,并通过对方的公钥加密生成一个随机数的方式协商出用来进行对称加密的对称密钥。这个对称密钥就是用非对称加密算法加密后的数据包。接收方拿到这个数据包后,使用自己的私钥进行解密,获取生成的对称密钥。然后,双方就开始使用协商好的对称密钥进行数据传输。接收方会利用对称密钥对收到的数据进行解密,得到明文数据。这样,在整个数据传输过程中,只有公钥被公开,密钥等关键信息都是使用非对称加密算法进行加密传输的,保证了安全性。总之,在 TLS 协议中,接收方通过使用自己的私钥解密协商出的对称密钥,从而完成对加密数据的解析。这个过程是整个 TLS 协议中非常重要的一个环节,确保了加密数据在传输过程中的安全性和可靠性。 ↩︎

任何操作系统都需要提供一个时钟节拍, 以供系统处理所有和时间有关的事件,如线程的延时、线程的时间片轮转调度以及定时器超时等。
RT-Thread 中,时钟节拍的长度可以根据 RT_TICK_PER_SECOND 的定义来调整,等于 1/RT_TICK_PER_SECOND 秒。也就是说,在RT-Thread中,系统的时钟节拍频率是由RT_TICK_PER_SECOND决定的!
rtconfig.h配置文件中定义:
频率是1000HZ周期是1/1000 s
所以节拍是1ms
#define RT_ TiCK PER_ SECOND 1000

在RT-Thread中,当系统滴答定时器时间到了的时候,就会执行void SysTick_Handler(系统滴答定时器中断处理函数)这个回调函数(中断处理函数)

可以发现在
void SysTick_Handler()这个函数中,首先会执行中断入口函数,然后void rt_tick_increase对rt_tick(系统滴答时钟,初值为0,静态全局变量)进行自加操作,会记录从启动到现在的时钟节拍数

也就是说,系统滴答定时器中断处理函数会每1ms触发一次systick定时器中断
名称:获取系统统计函数
功能:返回当前操作系统的时钟数
返回值:返回当前时钟数

定时器,是指从指定的时刻开始,经过一定的指定时间后触发一个事件,例如定个时间提醒第二天能够按时起床。定时器有硬件定时器和软件定时器之分:
1)硬件定时器是芯片本身提供的定时功能。一般是由外部晶振(HSE)提供给芯片输入时钟,芯片向软件模块提供一组配置寄存器,接受控制输入,到达设定时间值后芯片中断控制器产生时钟中断。硬件定时器的精度一般很高,可以达到纳秒级别,并且是中断触发方式。
2)软件定时器是由操作系统提供的一类系统接口,它构建在硬件定时器基础之上,使系统能够提供不受数目限制的定时器服务。
RT-Thread 操作系统提供软件实现的定时器,以时钟节拍(OS Tick)的时间长度为单位,即定时数值必须是 OS Tick 的整数倍,例如一个 OS Tick 是 10ms,那么上层软件定时器只能是 10ms,20ms,100ms 等,而不能定时为 15ms。RT-Thread 的定时器也基于系统的节拍,提供了基于节拍整数倍的定时能力。
RT-Thread 的定时器提供两类定时器机制:
第一类是单次触发定时器,这类定时器在启动后只会触发一次定时器事件,然后定时器自动停止。
+第二类是周期触发定时器,这类定时器会周期性的触发定时器事件,直到用户手动的停止,否则将永远持续执行下去。
另外,根据超时函数执行时所处的上下文环境,RT-Thread 的定时器可以分为 HARD_TIMER 模式(硬件定时器模式)与 SOFT_TIMER 模式(软件定时器模式),如下图。
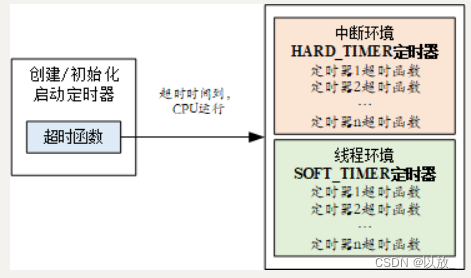
1)HARD_TIMER 模式:中断上下文
HARD_TIMER 模式的定时器超时函数在中断上下文环境中执行,可以在初始化 / 创建定时器时使用参数RT_TIMER_FLAG_HARD_TIMER来指定。
在中断上下文环境中执行时,对于超时函数的要求与中断服务例程的要求相同:执行时间应该尽量短,执行时不应导致当前上下文挂起、等待。例如在中断上下文中执行的超时函数它不应该试图去申请动态内存、释放动态内存等。
2)SOFT_TIMER 模式:线程上下文
SOFT_TIMER 模式可配置,通过宏定义 RT_USING_TIMER_SOFT 来决定是否启用该模式。
该模式被启用后,系统会在初始化时创建一个 timer 线程,然后 SOFT_TIMER 模式的定时器超时函数在都会在 timer 线程的上下文环境中执行。可以在初始化 / 创建定时器时使用参数 RT_TIMER_FLAG_SOFT_TIMER 来指定设置 SOFT_TIMER 模式。
1)RT-Thread OS 启动阶段,执行rtthread_startup函数,在该函数中调用了定时器初始化函数

2)rt_system_timer_init(硬件定时器初始化)
| |
3)rt_system_timer_thread_init(软件定时器初始化)

下面以一个例子来说明 RT-Thread 定时器的工作机制。在 RT-Thread 定时器模块中维护着两个重要的全局变量:
(1)当前系统经过的 tick 时间 rt_tick(当硬件定时器中断来临时,它将加 1);
(2)定时器链表 rt_timer_list。系统新创建并激活的定时器都会按照以超时时间排序的方式插入到 rt_timer_list 链表中。
如下图所示,系统当前 tick 值为 20,在当前系统中已经创建并启动了三个定时器,分别是定时时间为 50 个 tick 的 Timer1、100 个 tick 的 Timer2 和 500 个 tick 的 Timer3,这三个定时器分别加上系统当前时间 rt_tick=20,从小到大排序链接在 rt_timer_list 链表中,形成如图所示的定时器链表结构。

而 rt_tick 随着硬件定时器的触发一直在增长(每一次硬件定时器中断来临,rt_tick 变量会加 1),50 个 tick 以后,rt_tick 从 20 增长到 70,与 Timer1 的 timeout 值相等,这时会触发与 Timer1 定时器相关联的超时函数,同时将 Timer1 从 rt_timer_list 链表上删除。
同理,100 个 tick 和 500 个 tick 过去后,与 Timer2 和 Timer3 定时器相关联的超时函数会被触发,接着将 Timer2 和 Timer3 定时器从 rt_timer_list 链表中删除。
如果系统当前定时器状态在 10 个 tick 以后(rt_tick=30)有一个任务新创建了一个 tick 值为 300 的 Timer4 定时器,由于 Timer4 定时器的 timeout=rt_tick+300=330, 因此它将被插入到 Timer2 和 Timer3 定时器中间,形成如下图所示链表结构:

1)动态创建定时器
动态创建声明:
| |
详细函数定义:

查看flag定义:
| |
同时这里我们注意到
rt_timer_create这个函数的返回值是rt_timer_t,通过查找定义可以发现该类型是通过typedef重命名的也就是说
struct rt_timer<=>*rt_timer_t
| |
下面我们也可以详细看到rt_time这个结构体对定时器的一个详细描述
| |
2)删除定时器
函数声明:
| |
函数返回值:返回操作系统的状态,成功返回0,失败返回1

3)动态创建定时器演示
| |
在这里也可以看到,我们设置了一个名为tm_demo的定时器,设置超时时间为3s,同时flag我们是设置为周期定时和软件定时(flag设置详见上文flag定义 )。
| |
| |
4)开启定时器
函数声明:
| |
函数返回值:成功返回0,失败返回1

5)实例:
| |
此时我们在超时函数中编写代码:
| |
此时回到串口查看,就可以发现tm_demo这个定时器已经被激活了,并且定时器的周期和超时时间也都发生改变,由于我们在上面设置的超时时间为3S,所以在串口显示会三秒打印一次信息
6)静态创建定时器
函数定义:
| |
这里我们看下rt_timer_init这个函数的返回值和参数
返回值:void
参数:
| 参数 | 描述 |
|---|---|
| timer | 结构体指针类型 |
| name | 名字 |
| timeout | 超时回调函数指针 |
| parameter | 传递给超时回调函数的参数 |
| time | 定时器时间 |
| flag | 定时器标志 |
7)脱离函数(静态创建时使用)
描述:当静态创建的定时器不需要在使用时,我们调用下面这个函数接口
函数声明:
| |
返回值:成功返回0,失败返回1
8)定时器控制
函数声明:
| |
cmd命令定义查看
| |
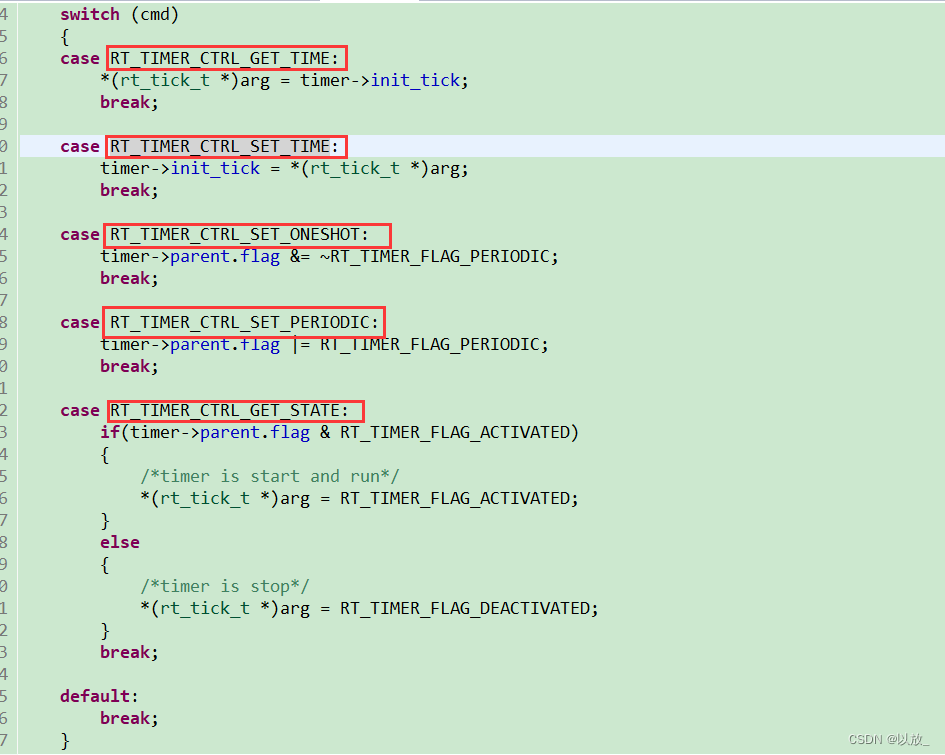
实例:
查看终端数据,可以发现终端执行顺序为:打印一次tm的中断回调函数信息,然后打印三次tm2的信息。
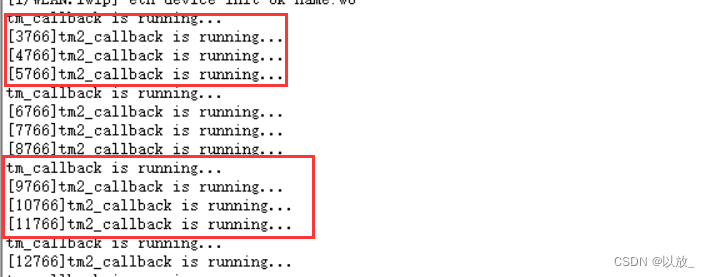
| |
注意:这个函数只支持低于1个OS Tick的延时,否则 SysTick会出现溢出而不能够获 得指定的延时时间
void rt_hw_us_delay(rt_uint32_t us);
软件环境:
硬件环境:
首先我们需要准备好上述所需内容,在将 RT-Thread 源码拉取到本地后,进入如下目录:
| |
这里需要我们提前安装好 ENV 环境,具体细节请参考 Env编译环境搭建 。
鼠标右键打开 ENV 工具后,使用 menuconfig 命令打开可视化菜单,勾选上 RTduino 的使能项,保存并退出

| |

此时我们可以注意到在使能该项后,系统会自动勾选上RTduino所需的软件包库及一些系统控制宏,同时我们还需要更新软件包进行下载(注意国内用户需要关闭代理后调用该命令):
| |
我们可以注意到在 bsp 根目录下生成了一个 packages 目录,并下载了我们所需的 RTduino 依赖库:

打开 ENV ,同时执行如下命令:
| |

在工程编译完成后会生成一个 .elf后缀的可执行文件,到这里工程的编译就顺利结束了。
首先我们需要在 vscode 中安装 Cortex-Debug 插件,打开 vscode 扩展,搜索 Cortex-Debug并安装扩展:

接下来就是安装 pyocd 到本机了,当然也可以使用 python 进行安装,不过我们推荐使用 RT-Thread 官方提供的 pyocd,打开如下链接并下载到本地,这里下载最新版本即可:
| |
接下来就是创建一份 debug 配置文件了,找到 vscode 左侧菜单栏的调试图标,点击 create a launch.json file:

之后 vscode 会创建一份 launch.json 文件,我们需要替换文件内容为:
| |
注意:launch.json文件中的部分参数需要根据具体位置配置
serverpath:这部分路径在前面所安装的 sdk-debugger-pyocd位置armToolchainPath:gcc 工具链,找不到位置的可以点击此处下载gdbPath在完成上述配置后就可以点击 F5 进行调试了,可能下载速度会比较慢,需要等待一会,调试成功效果如下:

我们点击全速运行,并打开串口终端,可以看到系统启动后会自动打印 RTduino 线程信息:

到这里 RTduino 就已经成功运行在 RT-Thread 啦!
在上面的环节中我们已经成功运行 RTduino 了,接下来我们将通过RTduino,并在RT-Thread中使用 Arduino 源码驱动一个 oled 屏幕。
我们接着回到 ENV 中,使用 menuconfig命令打开菜单,同时使用 shift + /打开搜索界面,并且输入:ssd1306关键字后回车搜索,在出现的页面我们使用键盘的方向键向下翻找,找到 Adafruit SSD1306对应的 2选项,进入点击 y 使能:


这样我们就成功把 Adafruit SSD1306 示例库下载到本地了,同时还有一下依赖库:

我们找到路径:rt-thread\bsp\renesas\ra6m3-hmi-board\packages\Adafruit-SSD1306-latest\examples\ssd1306_128x64_i2c,可以看到该文件夹下有一个ssd1306_128x64_i2c.ino文件,这就是 Arduino 的工程文件,我们复制该文件内容到如下路径下的arduino_main.cpp文件中:
| |
| |
在此示例中有几点注意事项:
#include <Arduino.h>0x3c,所以对应示例工程中的 SCREEN_ADDRESS需要修改为 0X3C

接着我们继续编译工程源码,同时准备接线,由于在这份示例工程中默认使用的是 RTduino 默认的 i2c 设备(具体可查看文件:pins_arduino.h),而这份 bsp 对接 RTduino 默认为 RT-Thread 的软件模拟 i2c0,其对应引脚为:
| pin | func |
|---|---|
| P203 | i2c0-sda |
| P202 | i2c0-scl |
| VCC | vcc |
| GND | gnd |
接着我们启动调试,在等待下载后可以看到系统初始化会同时启动 RT-Thread main线程和 RTduino线程

查看demo:


原理实战请查看【玩转RT-Thread】 RT-Thread Studio使用(2) 内核实战篇(线程)
在日常生活中,我们通常会将一个大的问题拆分细化,拆开成若干个小问题,通过逐个解决小问题,大问题也就解决了。 +同样的在RT-Thread多线程操作系统中,开发人员基于这种分而治之的思想,将一个复杂的应用问题抽象成若干个小的、可调度的、可序列化的程序单元。当合理地划分任务并正确地执行时,这种设计能够让系统满足实时系统的性能及时间的要求。
下面看一个例子:我们的任务是读取传感器上的数据,并将相关数据显示出来。通过拆分结构,我们可以发现主要有两个任务:
1.读取数据 +2.显示数据
简单来说,就是一个子任务不间断地读取传感器数据,并将数据写到共享内存中,另外一个子任务周期性的从共享内存中读取数据,并将传感器数据输出到显示屏上。
+ +在RT-Thread 中,与上述子任务对应的程序实体就是线程,
+在RT-Thread 中,与上述子任务对应的程序实体就是线程,线程是实现任务的载体。
+它是RT-Thread中最基本的调度单位,它描述了一个任务执行的运行环境,也描述了这个任务所处的优先等级,重要的任务可设置相对较高的优先级,非重要的任务可以设置较低的优先级,不同的任务还可以设置相同的优先级,轮流运行。
+上下文:当线程运行时,它会认为自己是以独占CPU 的方式在运行,线程执行时的运行环境称为上下文,具体来说就是各个变量和数据,包括所有的寄存器变量、堆栈、内存信息等。
RT-Thread 线程管理的主要功能是对线程进行管理和调度,系统中总共存在两类线程,分别是系统线程和用户线程。系统线程是由RT-Thread 内核创建的线程,用户线程是由应用程序创建的线程,这两类线程都会从内核对象容器中分配线程对象,当线程被删除时,也会被从对象容器中删除。
如图所示,每个线程都有重要的属性,如线程控制块、线程栈、入口函数等。
+
抢占式的,主要的工作就是从就绪线程列表中查找最高优先级线程,保证最高优先级的线程能够被运行,最高优先级的任务一旦就绪,总能得到CPU 的使用权。详细内容可参考【操作系统】进程上下文和线程上下文)信息恢复。在RT-Thread 中,线程控制块由结构体struct rt_thread 表示,线程控制块是操作系统用于管理线程的一个数据结构,它会存放线程的一些信息,例如优先级、线程名称、线程状态等,也包含线程与线程之间连接用的链表结构,线程等待事件集合等,详细定义如下:
| |
其中init_priority 是线程创建时指定的线程优先级,在线程运行过程当中是不会被改变的(除非用户 执行线程控制函数进行手动调整线程优先级)。cleanup 会在线程退出时,被空闲线程回调一次以执行用户设置的清理现场等工作。最后的一个成员user_data 可由用户挂接一些数据信息到线程控制块中,以提供类似线程私有数据的实现。
线程运行的过程中,同一时间内只允许一个线程在处理器中运行,从运行的过程上划分,线程有多种不同的运行状态,如初始状态、挂起状态、就绪状态等。 +在RT-Thread 中,线程包含五种状态,操作系统会自动根据它运行的情况来动态调整它的状态。如下表所示:
| 状态 | 描述 |
|---|---|
| 初始态 | 当线程刚开始创建还没开始运行时就处于初始状态;在初始状态下,线程不参与调度。此状态在RT-Thread 中的宏定义为RT_THREAD_INIT |
| 就绪态 | 在就绪状态下,线程按照优先级排队,等待被执行;一旦当前线程运行完毕让出处理器,操作系统会马上寻找最高优先级的就绪态线程运行。此状态在RT-Thread 中的宏定义为RT_THREAD_READY |
| 运行态 | 线程当前正在运行。在单核系统中,只有rt_thread_self() 函数返回的线程处于运行状态;在多核系统中,可能就不止这一个线程处于运行状态。此状态在RT-Thread 中的宏定义为RT_THREAD_RUNNING |
| 挂起态 | 也称阻塞态。它可能因为资源不可用而挂起等待,或线程主动延时一段时间而挂起。在挂起状态下,线程不参与调度。此状态在RT-Thread 中的宏定义为RT_THREAD_SUSPEND |
| 关闭态 | 当线程运行结束时将处于关闭状态。关闭状态的线程不参与线程的调度。此状态在RT-Thread 中的宏定义为RT_THREAD_CLOSE |
RT-Thread 线程的优先级是表示线程被调度的优先程度。每个线程都具有优先级,线程越重要,赋予的优先级就应越高,线程被调度的可能才会越大。
RT-Thread 最大支持256 个线程优先级(0~255),数值越小的优先级越高,0 为最高优先级。在一些资源比较紧张的系统中,可以根据实际情况选择只支持8 个或32 个优先级的系统配置;对于ARM Cortex-M系列,普遍采用32 个优先级。最低优先级默认分配给空闲线程使用,用户一般不使用。在系统中,当有比当前线程优先级更高的线程就绪时,当前线程将立刻被换出,高优先级线程抢占处理器运行。
每个线程都有时间片这个参数,但时间片仅对优先级相同的就绪态线程有效。系统对优先级相同的就绪态线程采用时间片轮转的调度方式进行调度时,时间片起到约束线程单次运行时长的作用,其单位是一个系统节拍(OS Tick)。
假设有2 个优先级相同的就绪态线程A 与B,A 线程的时间片设置为10,B 线程的时间片设置为5,那么当系统中不存在比A 优先级高的就绪态线程时,系统会在A、B 线程间来回切换执行,并且每次对A 线程执行10 个节拍的时长,对B 线程执行5 个节拍的时长,如下图。
+
线程控制块中的entry是线程的入口函数,它是线程实现预期功能的函数。
线程的入口函数由用户设计实现,一般有以下两种代码形式:
+1.无限循环模式
在实时系统中,线程通常是被动式的:这个是由实时系统的特性所决定的,实时系统通常总是等待外 +界事件的发生,而后进行相应的服务:
| |
作为一个实时系统,一个优先级明确的实时系统,如果一个线程中的程序陷入了死循环操作,那么比它优先级低的线程都将不能够得到执行。 +所以在实时操作系统中必须注意的一点就是:线程中不能陷入死循环操作,必须要有让出CPU使用权的动作,如循环中调用延时函数或者主动挂起。用户设计这种无线循环的线程的目的,就是为了让这个线程一直被系统循环调度运行,永不删除。
2.顺序执行或有限次循环模式
如简单的顺序语句、do whlie() 或for() 循环等,此类线程不会循环或不会永久循环,可谓是“一次性”线程,一定会被执行完毕。在执行完毕后,线程将被系统自动删除。
| |
| |
RT-Thread 提供一系列的操作系统调用接口,使得线程的状态在这五个状态之间来回切换。几种状态间的转换关系如下图所示:
+
- 线程通过调用函数
rt_thread_create/init()进入到初始状态(RT_THREAD_INIT);- 初始状态的线程通过调用函数
rt_thread_startup()进入到就绪状态(RT_THREAD_READY);- 就绪状态的线程被调度器调度后进入运行状态
(RT_THREAD_RUNNING);- 当处于运行状态的线程调用rt_thread_delay(),rt_sem_take(),rt_mutex_take(),rt_mb_recv() 等函数或者获取不到资源时, 将进入到挂起状态
(RT_THREAD_SUSPEND);
- 处于挂起状态的线程,如果等待超时依然未能获得资源或由于其他线程释放了资源,那么它将返回到就绪状态。
- 挂起状态的线程,如果调用
rt_thread_delete/detach()函数,将更改为关闭状态(RT_THREAD_CLOSE);- 而运行状态的线程,如果运行结束,就会在线程的最后部分执行
rt_thread_exit()函数,将状态更改为关闭状态。
!!! note “注意事项” RT-Thread 中,实际上线程并不存在运行状态,就绪状态和运行状态是等同的。
系统线程是指由系统创建的线程,用户线程是由用户程序调用线程管理接口创建的线程,在RT-Thread 内核中的系统线程有空闲线程和主线程。
空闲线程是系统创建的最低优先级的线程,线程状态永远为就绪态。当系统中无其他就绪线程存在时,调度器将调度到空闲线程,它通常是一个死循环,且永远不能被挂起。
另外,空闲线程在RT-Thread 也有着它的特殊用途:
在系统启动时,系统会创建main 线程,它的入口函数为main_thread_entry(),用户的应用入口函数main() 就是从这里真正开始的,系统调度器启动后,main 线程就开始运行。
过程如下图,用户可以在main() 函数里添加自己的应用程序初始化代码。
+
可以使用rt_thread_create() 创建一个动态线程,使用rt_thread_init() 初始化一个静态线程。
动态线程与静态线程的区别是:动态线程是系统自动从动态内存堆上分配栈空间与线程句柄(初始化heap 之后才能使用create 创建动态线程),静态线程是由用户分配栈空间与线程句柄。
下图描述了线程的相关操作,包含:创建/ 初始化线程、启动线程、运行线程、删除/ 脱离线程。
+
一个线程要成为可执行的对象,就必须由操作系统的内核来为它创建一个线程。可以通过如下的接口创建一个动态线程:
| |
调用这个函数时,系统会从动态堆内存中分配一个线程句柄以及按照参数中指定的栈大小从动态堆内存中分配相应的空间。分配出来的栈空间是按照rtconfig.h 中配置的RT_ALIGN_SIZE 方式对齐。
线程创建rt_thread_create() 的参数和返回值见下图:
+
对于一些使用rt_thread_create() 创建出来的线程,当不需要使用,或者运行出错时,我们可以使用下面的函数接口来从系统中把线程完全删除掉:
rt_err_t rt_thread_delete(rt_thread_t thread);
+调用该函数后,线程对象将会被移出线程队列并且从内核对象管理器中删除,线程占用的堆栈空间也会被释放,收回的空间将重新用于其他的内存分配。实际上,用rt_thread_delete() 函数删除线程接口,仅仅是把相应的线程状态更改为RT_THREAD_CLOSE 状态,然后放入到rt_thread_defunct 队列中;而真正的删除动作(释放线程控制块和释放线程栈)需要到下一次执行空闲线程时,由空闲线程完成最后的线程删除动作。
线程删除rt_thread_delete() 接口的参数和返回值见下图:
+ +
+这个函数仅在使能了系统动态堆时才有效(即RT_USING_HEAP 宏定义已经定义了)。
线程的初始化可以使用下面的函数接口完成,来初始化静态线程对象:
| |

对于用rt_thread_init() 初始化的线程,使用rt_thread_detach() 将使线程对象在线程队列和内核对象管理器中被脱离。线程脱离函数如下:
rt_err_t rt_thread_detach (rt_thread_t thread);
+| 参数 | 描述 |
|---|---|
| thread | 线程句柄,它应该是由rt_thread_init 进行初始化的线程句柄。 |
| 返回 | — |
| RT_EOK | 线程脱离成功 |
| -RT_ERROR | 线程脱离失败 |
创建(初始化)的线程状态处于初始状态,并未进入就绪线程的调度队列,我们可以在线程初始化/创建成功后调用下面的函数接口让该线程进入就绪态:
rt_err_t rt_thread_startup(rt_thread_t thread);
+
当调用这个函数时,将把线程的状态更改为就绪状态,并放到相应优先级队列中等待调度。如果新启 +动的线程优先级比当前线程优先级高,将立刻切换到这个线程。
在程序的运行过程中,相同的一段代码可能会被多个线程执行,在执行的时候可以通过下面的函数接口获得当前执行的线程句柄:
rt_thread_t rt_thread_self(void);
+
当前线程的时间片用完或者该线程主动要求让出处理器资源时,它将不再占有处理器,调度器会选择相同优先级的下一个线程执行。线程调用这个接口后,这个线程仍然在就绪队列中。
线程让出处理器使用下面的函数接口:
rt_err_t rt_thread_yield(void);
+调用该函数后,当前线程首先把自己从它所在的就绪优先级线程队列中删除,然后把自己挂到这个优先级队列链表的尾部,然后激活调度器进行线程上下文切换(如果当前优先级只有这一个线程,则这个线程继续执行,不进行上下文切换动作)。
在实际应用中,我们有时需要让运行的当前线程延迟一段时间,在指定的时间到达后重新运行,这就叫做“线程睡眠”。
线程睡眠可使用以下三个函数接口:
| |
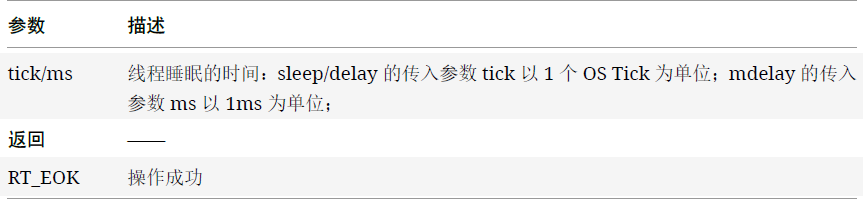
- 当线程调用rt_thread_delay() 时,线程将主动挂起;当调用rt_sem_take(),rt_mb_recv() 等函数时,资源不可使用也将导致线程挂起。
- 处于挂起状态的线程,如果其等待的资源超时(超过其设定的等待时间),那么该线程将不再等待这些资源,并返回到就绪状态;或者,当其他线程释放掉该线程所等待的资源时,该线程也会返回到就绪状态。
线程挂起使用下面的函数接口:
rt_err_t rt_thread_suspend (rt_thread_t thread);
+ +
+!!! note “注意事项” 通常不应该使用这个函数来挂起线程本身, 如果确实需要采用rt_thread_suspend() 函数挂起当前任务, 需要在调用rt_thread_suspend() 函数后立刻调用rt_schedule() 函数进行手动的线程上下文切换。
恢复线程就是让挂起的线程重新进入就绪状态,并将线程放入系统的就绪队列中;如果被恢复线程在 +所有就绪态线程中,位于最高优先级链表的第一位,那么系统将进行线程上下文的切换。
线程恢复使用下面的函数接口:
rt_err_t rt_thread_resume (rt_thread_t thread);
+
当需要对线程进行一些其他控制时,例如动态更改线程的优先级,可以调用如下函数接口:
rt_err_t rt_thread_control(rt_thread_t thread, rt_uint8_t cmd, void* arg);
+
指示控制命令cmd 当前支持的命令包括:
+•RT_THREAD_CTRL_CHANGE_PRIORITY:动态更改线程的优先级;
+•RT_THREAD_CTRL_STARTUP:开始运行一个线程,等同于rt_thread_startup() 函数调用;
+•RT_THREAD_CTRL_CLOSE:关闭一个线程,等同于rt_thread_delete() 函数调用。
+空闲钩子函数是空闲线程的钩子函数,如果设置了空闲钩子函数,就可以在系统执行空闲线程时,自动执行空闲钩子函数来做一些其他事情,比如系统指示灯。
设置/ 删除空闲钩子的接口如下:
rt_err_t rt_thread_idle_sethook(void (*hook)(void));
+rt_err_t rt_thread_idle_delhook(void (*hook)(void));
+| 参数 | 描述 |
|---|---|
| hook | 设置/删除的钩子函数 |
| 返回 | — |
| RT-EOK | 设置/删除成功 |
| -RT_EFULL | 设置失败 |
| -RT_ENOSYS | 删除失败 |
!!! note “注意事项” 空闲线程是一个线程状态永远为就绪态的线程,因此设置的钩子函数必须保证空闲线程在任何时刻都不会处于挂起状态,例如rt_thread_delay(),rt_sem_take() 等可能会导致线程挂起的函数都不能使用。
在整个系统的运行时,系统都处于线程运行、中断触发- 响应中断、切换到其他线程,甚至是线程间的切换过程中,或者说系统的上下文切换是系统中最普遍的事件。有时用户可能会想知道在一个时刻发生了什么样的线程切换,可以通过调用下面的函数接口设置一个相应的钩子函数。
在系统线程切换时,这个钩子函数将被调用:
void rt_scheduler_sethook(void (*hook)(struct rt_thread* from, struct rt_thread* to));
+设置调度器钩子函数的输入参数如下表所示:
| 参数 | 描述 |
|---|---|
| hook | 表示用户定义的钩子函数指针 |
钩子函数hook() 的声明如下:
void hook(struct rt_thread* from, struct rt_thread* to);
+| 参数 | 描述 |
|---|---|
| from | 表示系统所要切换出的线程控制块指针 |
| to | 表示系统所要切换到的线程控制块指针 |
!!! note “注意事项” 请仔细编写你的钩子函数,稍有不慎将很可能导致整个系统运行不正常(在这个 钩子函数中,基本上不允许调用系统API,更不应该导致当前运行的上下文挂起)。
资料参考: +(1)【STM32】HAL库 STM32CubeMX教程五—-看门狗(独立看门狗,窗口看门狗) +(2)什么是钩子函数 +(3)RT-Thread文档中心

多个执行单元(线程、中断)同时执行临界区,操作临界资源,会导致竟态产生,为了解决这种竟态问题,RT-Thread OS提供了如下几种同步互斥机制:
信号量(semaphore)、互斥量(mutex)、和事件集(event)
信号量是一种轻型的用于解决线程间同步问题的内核对象,线程可以获取或释放它,从而达到同步或互斥的目的。
信号量工作示意图如下图所示,每个信号量对象都有一个信号量值和一个线程等待队列,信号量的值对应了信号量对象的实例数目、资源数目,假如信号量值为 5,则表示共有 5 个信号量实例(资源)可以被使用,当信号量实例数目为零时,再申请该信号量的线程就会被挂起在该信号量的等待队列上,等待可用的信号量实例(资源)。
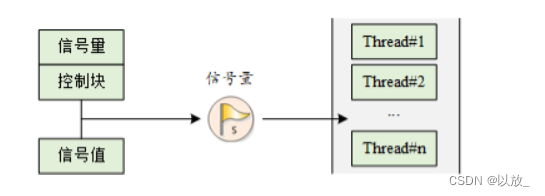
| |
当线程对资源进行获取时,value值进行减一操作;直到该信号量被释放,value进行加一操作。
对一个信号量的操作包含:
创建/初始化信号量、获取信号量、释放信号量、删除/脱离信号量。
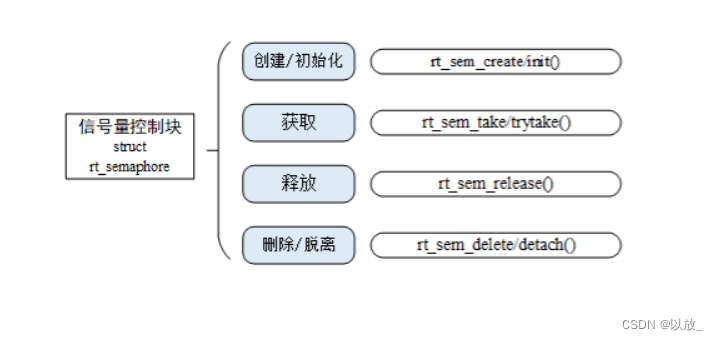
1)动态创建信号量
当调用这个函数时,系统将先从对象管理器中分配一个 semaphore 对象,并初始化这个对象,然后初始化父类 IPC 对象以及与 semaphore 相关的部分。在创建信号量指定的参数中,信号量标志参数决定了当信号量不可用时,多个线程等待的排队方式。
当选择
RT_IPC_FLAG_FIFO(先进先出)方式时,那么等待线程队列将按照先进先出的方式排队,先进入的线程将先获得等待的信号量; +当选择RT_IPC_FLAG_PRIO(优先级等待)方式时,等待线程队列将按照优先级进行排队,优先级高的等待线程将先获得等待的信号量。
函数声明:
rt_sem_t rt_sem_create(const char *name, rt_uint32_t value, rt_uint8_t flag);
参数介绍:

注意:
(1)此处的*name定义最多只能显示八个字符
(2)查看rt_sem_create()函数返回值是-->typedef struct rt_semaphore *rt_sem_t;,也就是一个重命名的结构体rt_semaphore
| |
2)动态创建的信号量删除
系统不再使用信号量时,可通过删除信号量以释放系统资源,适用于动态创建的信号量。
调用这个函数时,系统将删除这个信号量。
如果删除该信号量时,有线程正在等待该信号量,那么删除操作会先唤醒等待在该信号量上的线程(等待线程的返回值是 - RT_ERROR),然后再释放信号量的内存资源。
函数声明
+rt_err_t rt_sem_delete(rt_sem_t sem);
实例
| |
3)静态创建信号量
描述
对于静态信号量对象,它的内存空间在编译时期就被编译器分配出来,放在读写数据段或未初始化数据段上,此时使用信号量就不再需要使用 rt_sem_create 接口来创建它,而只需在使用前对它进行初始化即可。
函数声明
| |
参数描述

4)脱离信号量
描述
脱离信号量就是让信号量对象从内核对象管理器中脱离,适用于
静态初始化的信号量。
函数声明
| |
5)获取信号量
描述
线程通过获取信号量来获得信号量资源实例,当信号量值大于零时,线程将获得信号量,并且相应的信号量值会减 1。
如果信号量的值等于零,那么说明当前信号量资源实例不可用,申请该信号量的线程将根据 time 参数的情况选择
直接返回、或挂起等待一段时间、或永久等待,直到其他线程或中断释放该信号量。如果在参数 time 指定的时间内依然得不到信号量,线程将
超时返回,返回值是- RT_ETIMEOUT。
函数声明
| |
参数描述
| |
| |
6)信号量释放
函数声明
| |
描述
例如当信号量的值等于零时,并且有线程等待这个信号量时,释放信号量将唤醒等待在该信号量线程队列中的第一个线程,由它获取信号量;否则将把信号量的值加 1。
这里可以看到创建了两个线程,而且线程的优先级都是符合我们定义的20,但是查看线程状态可以发现,线程1和线程2都是阻塞态。这是因为我们在线程的入口函数中使用了mdelay延时函数,执行这个函数,线程会短暂地进入阻塞态
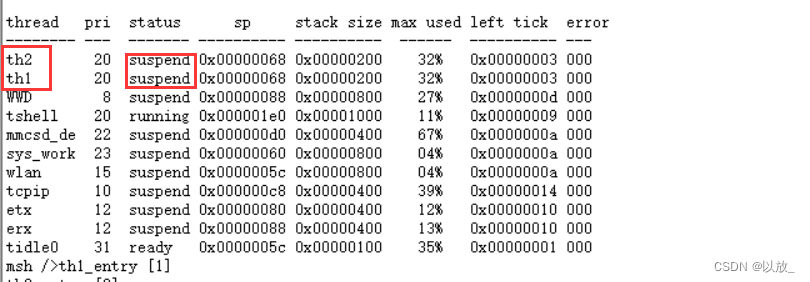
由于我们在线程2的入口函数中执行了信号量获取函数,但是我们在初始化信号量2的时候设定的初值是0,所以此时线程2由于未获取到信号量而陷入阻塞态
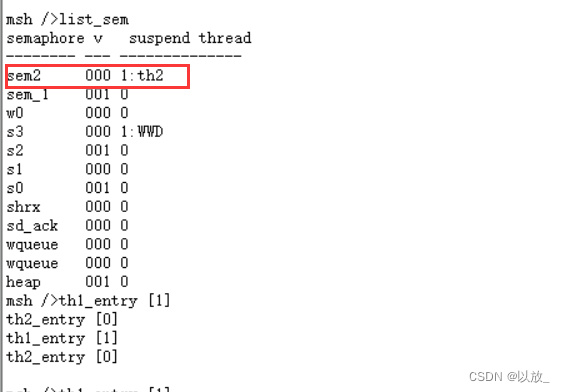
查看信号量设定的标志位是
RT_IPC_FLAG_FIFO,是按照先进先出的方式进行信号量的获取的,所以在函数的执行顺序中可以发现都是按照线程1->线程2->线程1->线程2…的顺序执行的,这样就实现了线程的并发互斥运行。
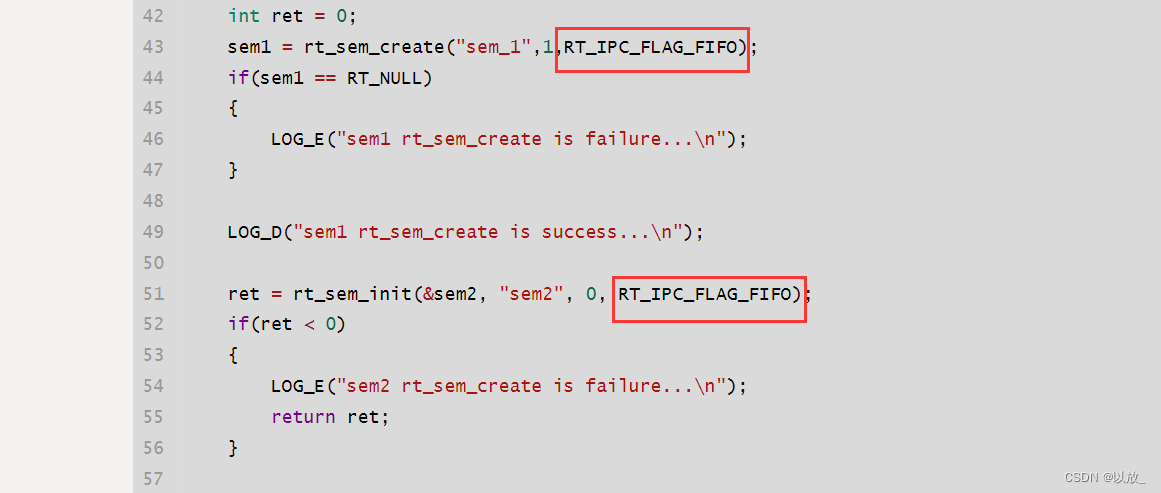

最后附上测试源代码
| |

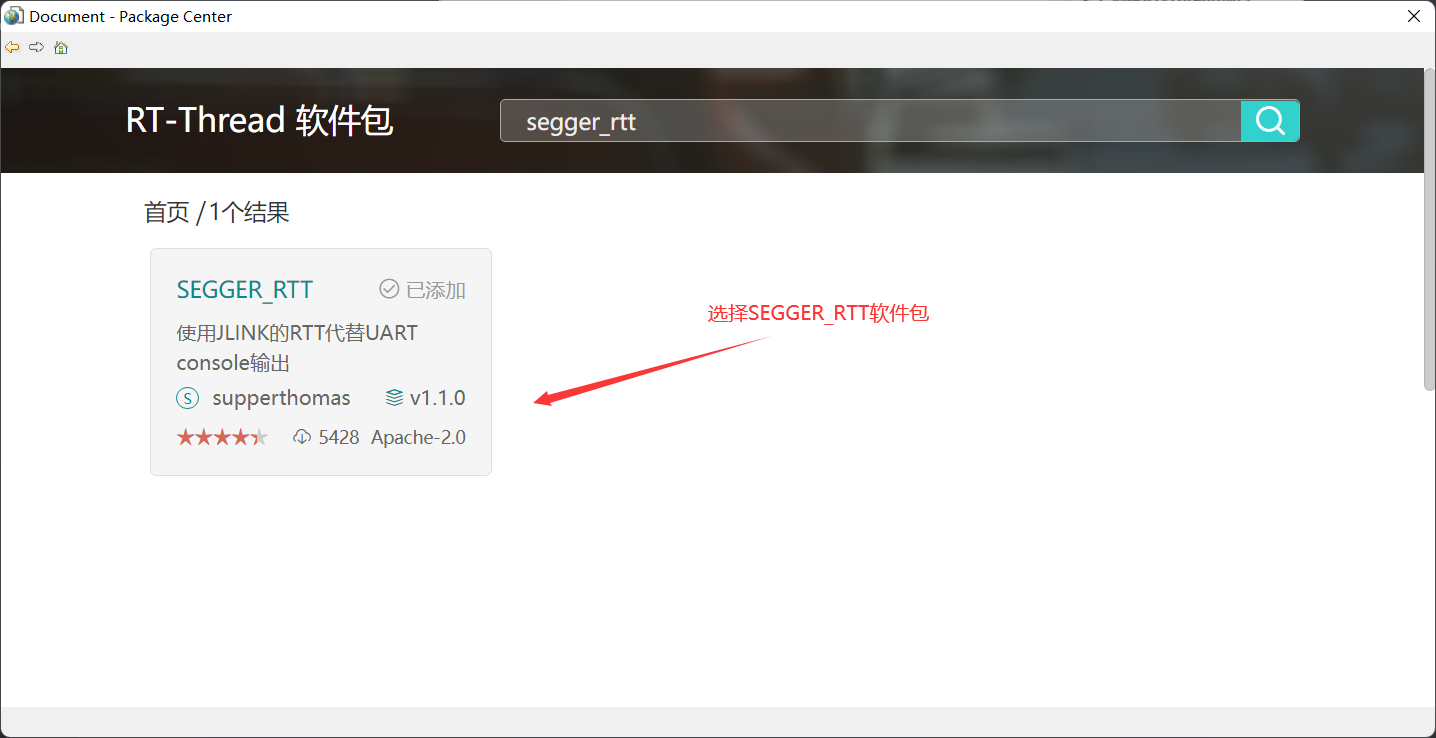
在rt_console_set_device前调用rt_hw_jlink_rtt_init初始化函数
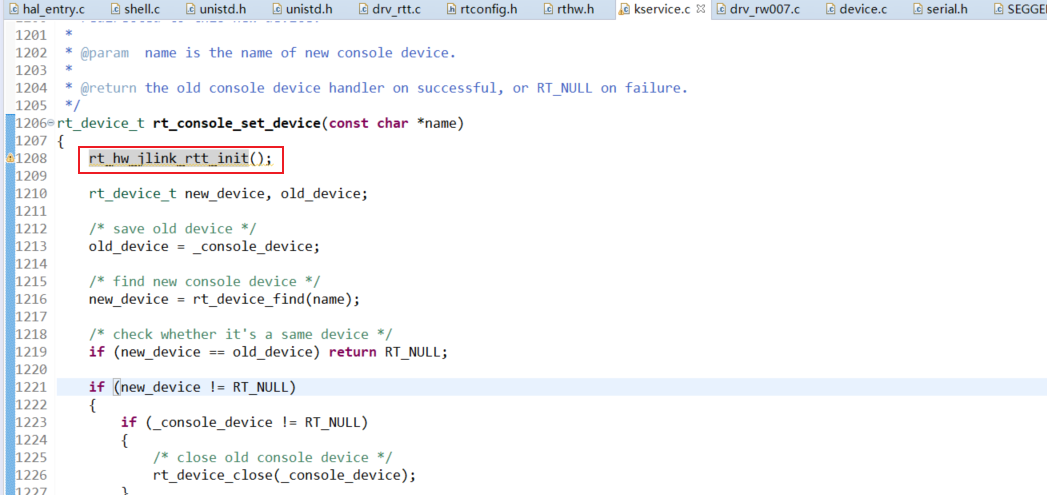
| |
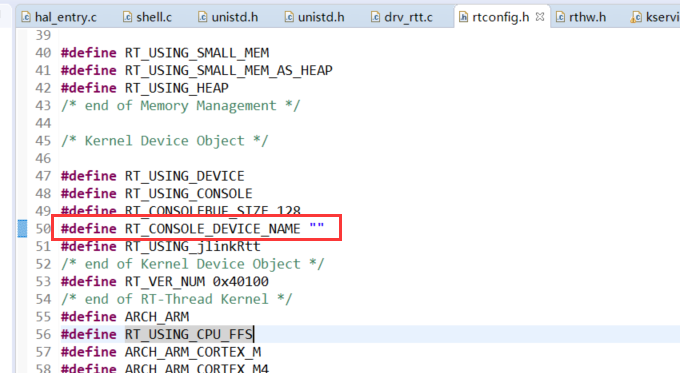
| |
| |
首先确保已经下载好J-Link RTT Viewer,直接去官网下载最新版本即可
然后编译和下载工程,注意下载方式为J-Link
双击打开rtthread.map[ 路径: /Debug/rtthread.map ]文件,查看_SEGGER_RTT变量地址(全局搜索即可,找到.bss._SEGGER_RTT)
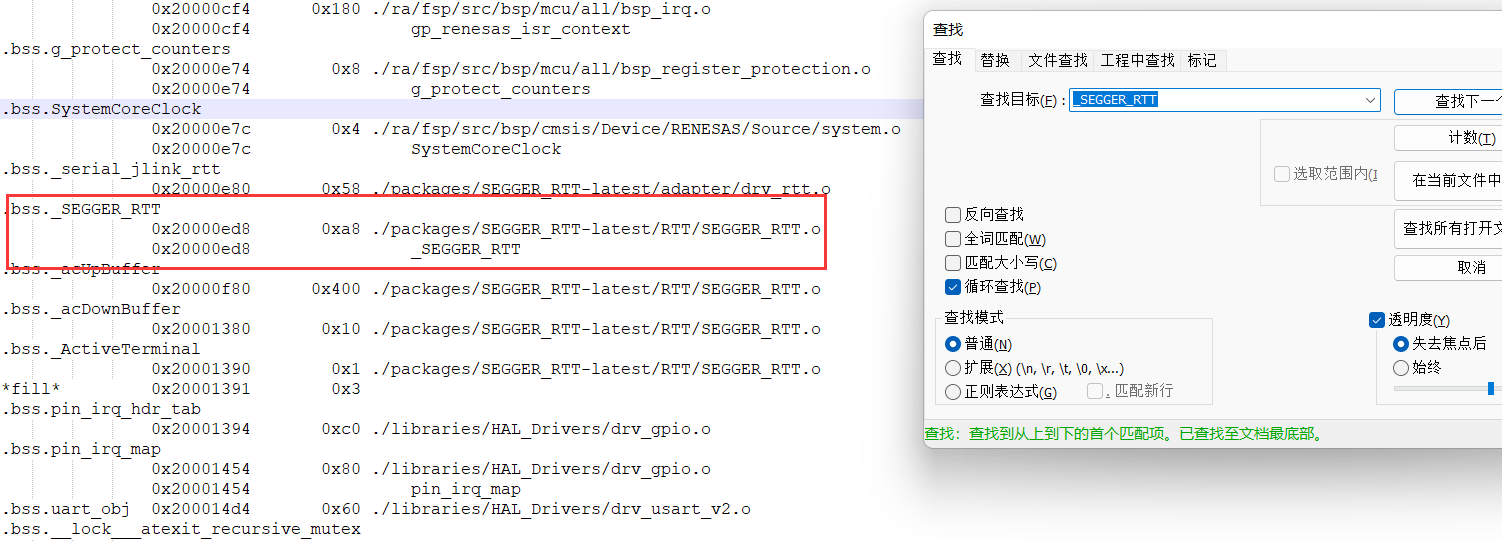
打开J-Link RTT Viewer
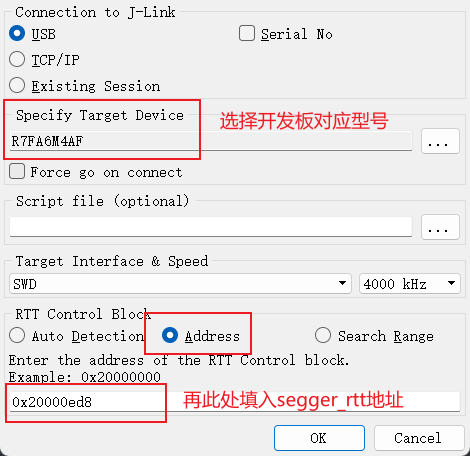
此时就可以正常使用segger_rtt了!
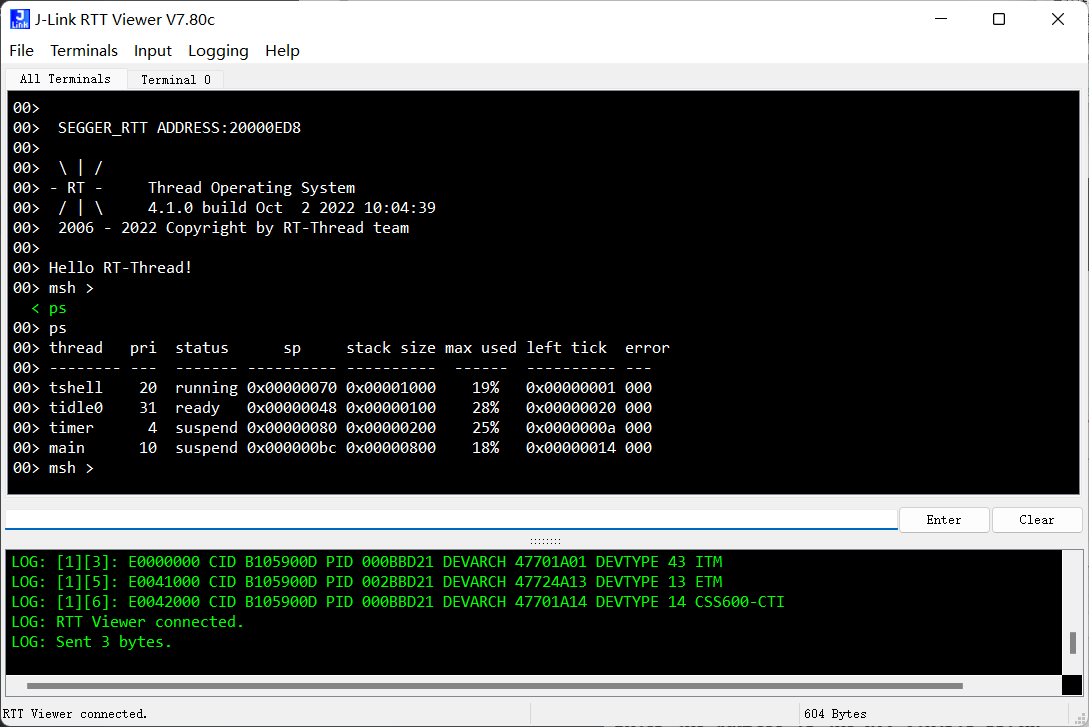

| 指令名称 | 作用 |
|---|---|
| EQU | 给数字常量设置一个符号名,相当于C语言中的define |
| AREA | 汇编一个新的代码段或者数据段 |
| SPACE | 分配内存空间 |
| PRESERVE8 | 当前文件栈需要按照8字节对齐 |
| EXPORT | 声明一个符号具有全局属性,可被外部文件使用 |
| DCD | 以字为单位分配内存,要求4字节对齐,并要求初始化这些内存 |
| PROC | 定义子程序,与ENDP成对使用,表示子程序结束 |
| WEAK | 弱定义,如果外部文件声明了一个标号,则优先使用外部文件定义的标号,即使外部文件没有定义也不出错。要注意的是,这不是ARM的指令,而是编译器的,这里要放一起只是为了方便 |
| IMPORT | 声明标号来自外部文件,与C语言的EXETERN关键字类似 |
| B | 跳转到一个标号 |
| ALIGN | 编译器对指令或者数据的存放地址进行对齐,一般需要跟一个立即数,默认为4字节对齐。要注意的是,这不是ARM的指令,而是编译器的,这里要放一起只是为了方便 |
| END | 到达文件的末尾,文件结束 |
| IF,ELSE,ENDIF | 汇编条件分支语句,与C语言的if else类似 |
| MRS | 加载特殊功能寄存器的值到特殊功能寄存器 |
| CBZ | 比较,如果结果为0则转移 |
| CBNZ | 比较,如果结果非0则转移 |
| LDR | 从存储器中加载字到一个寄存器中 |
| LDR[伪指令] | 加载一个立即数或者一个地址到一个寄存器中。 |
| LDRH | 从存储器中加载半字到一个寄存器中 |
| LDRB | 从存储器中加载字节到一个寄存器中 |
| STR | 把一个寄存器按字节存储到存储器中 |
| STRH | 把一个寄存器的低半字存储到存储器中 |
| STRB | 把一个寄存器的低字节存储到存储器中 |
| LDMIA | 加载多个字,并且在加载后自增基址寄存器 |
| STMIA | 存储多个字,并且在存储后自增基址寄存器 |
| ORR | 按位或 |
| BX | 直接跳转到由寄存器给定的地址 |
| BL | 跳转到标号对应的地址,并且把跳转前的下一条指令地址保存到LR |
| BLX | 跳转到由寄存器REG给出的地址,并且根据REG的LSB切换处理器模式,还要把转移前的下一条指令地址保存到LR中。ARM(LSB=0),Thumb(LSB=1)。cortex-M3只在Thumb中运行,那就必须保证reg的LSB=1,否则会报错 |

v2ray官方文档:https://v2raya.org/
| |
| |
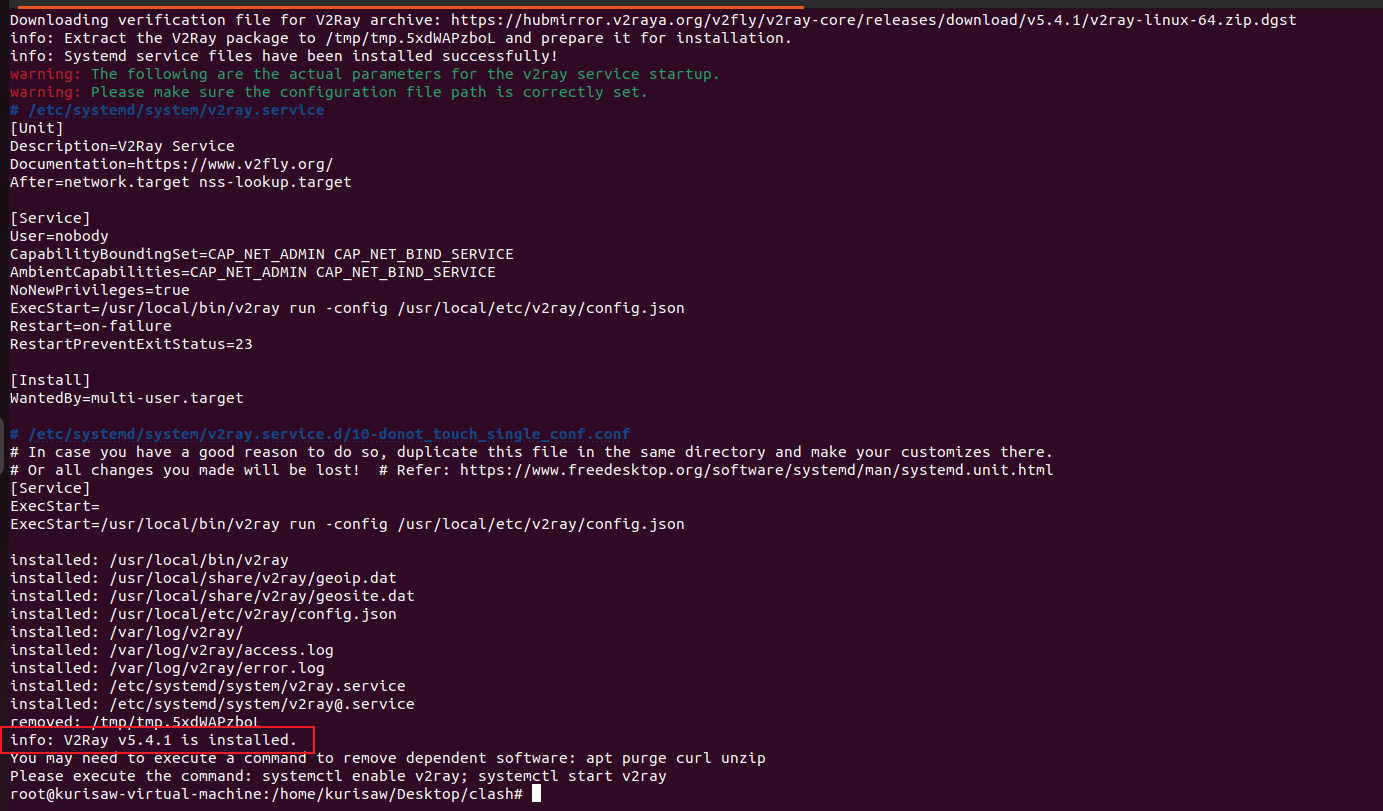
出现该提示信息则表示安装成功:info: V2Ray v5.4.1 is installed.
接着关掉服务,因为 v2rayA 不依赖于该 systemd 服务,如果是 Xray内核,则需要把后面的v2ray替换xray
| |
仓库release地址:https://github.com/v2rayA/v2rayA/releases
选择合适自己 Linux 内核架构,可以使用dpkg --print-architecture查看

这里我选择``下载到 Linux 共享文件夹
将共享文件夹下的installer_debian_amd64_2.0.5.deb文件保存到一个文件夹下,在任务管理器中选择使用软件安装打开并进行安装
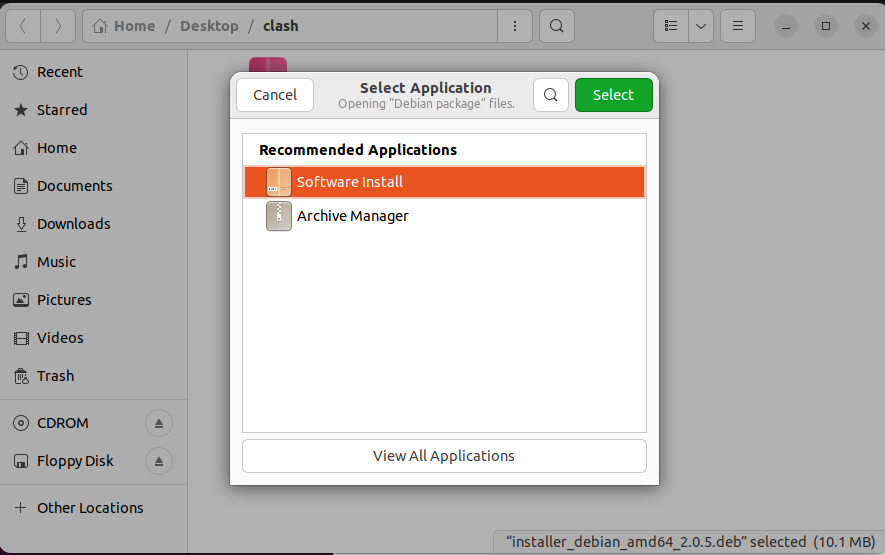
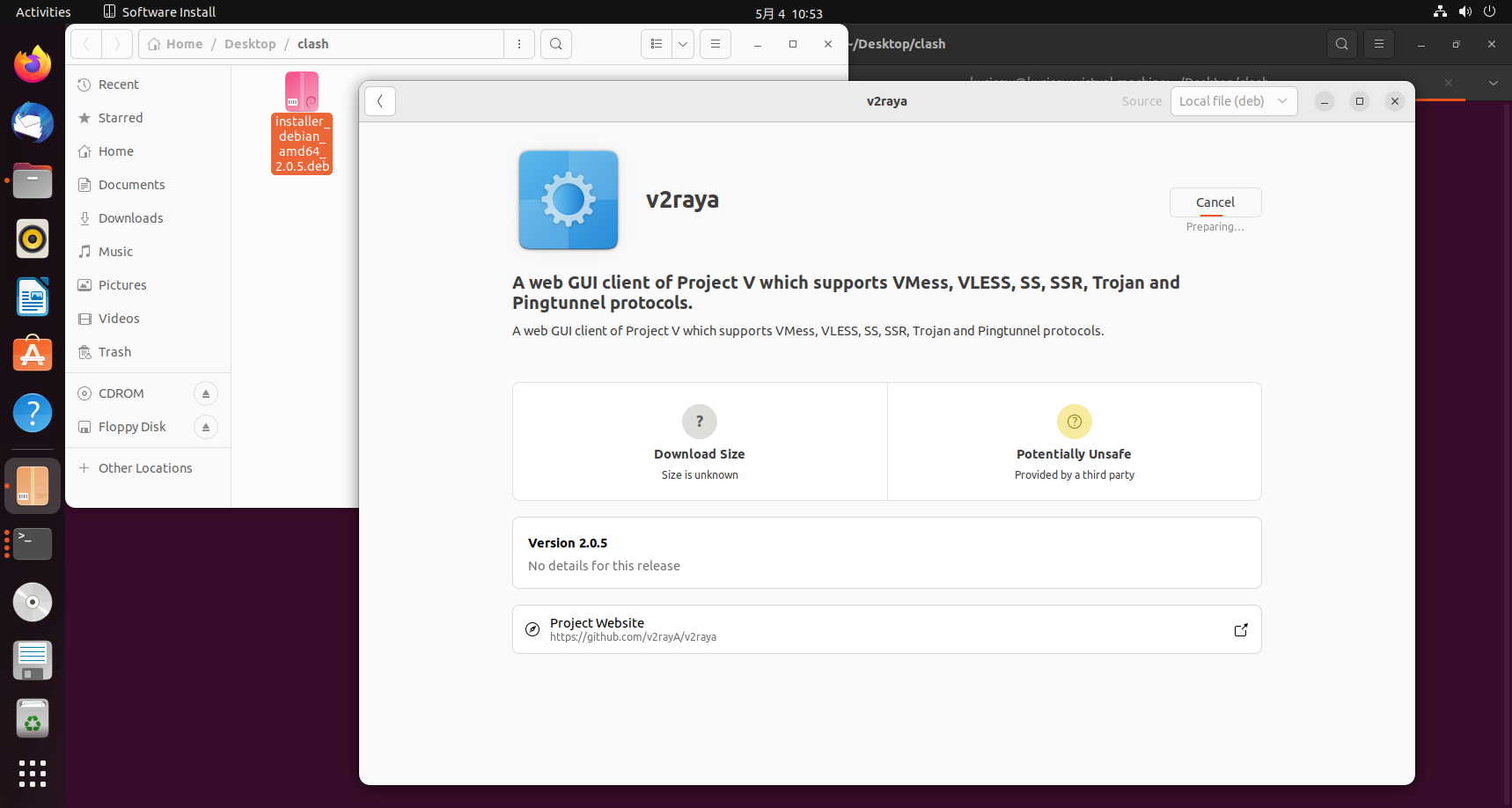
| |
| |
打开火狐浏览器,输入 http://localhost:2017/
输入你要设置的用户名和密码,任意填写自己记着就好,最后点击创建
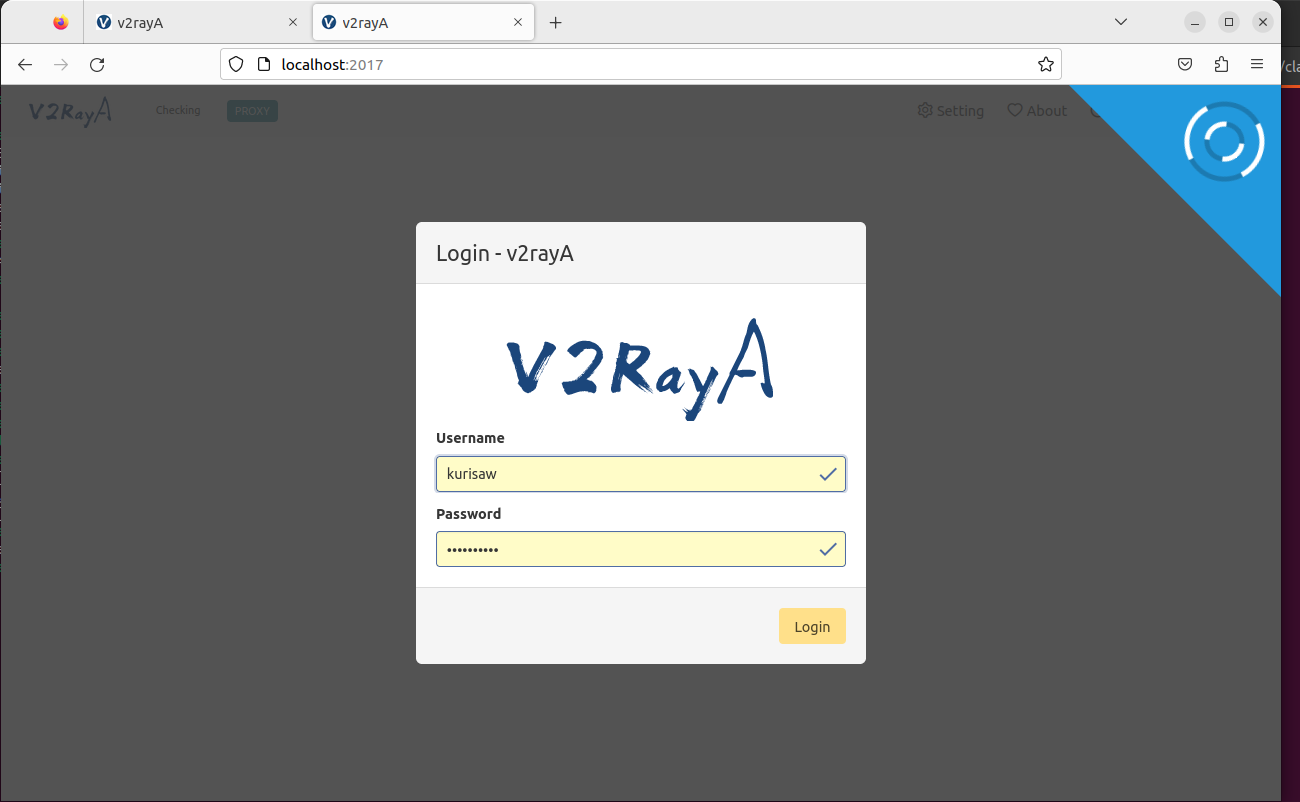
导入我们的机场订阅地址
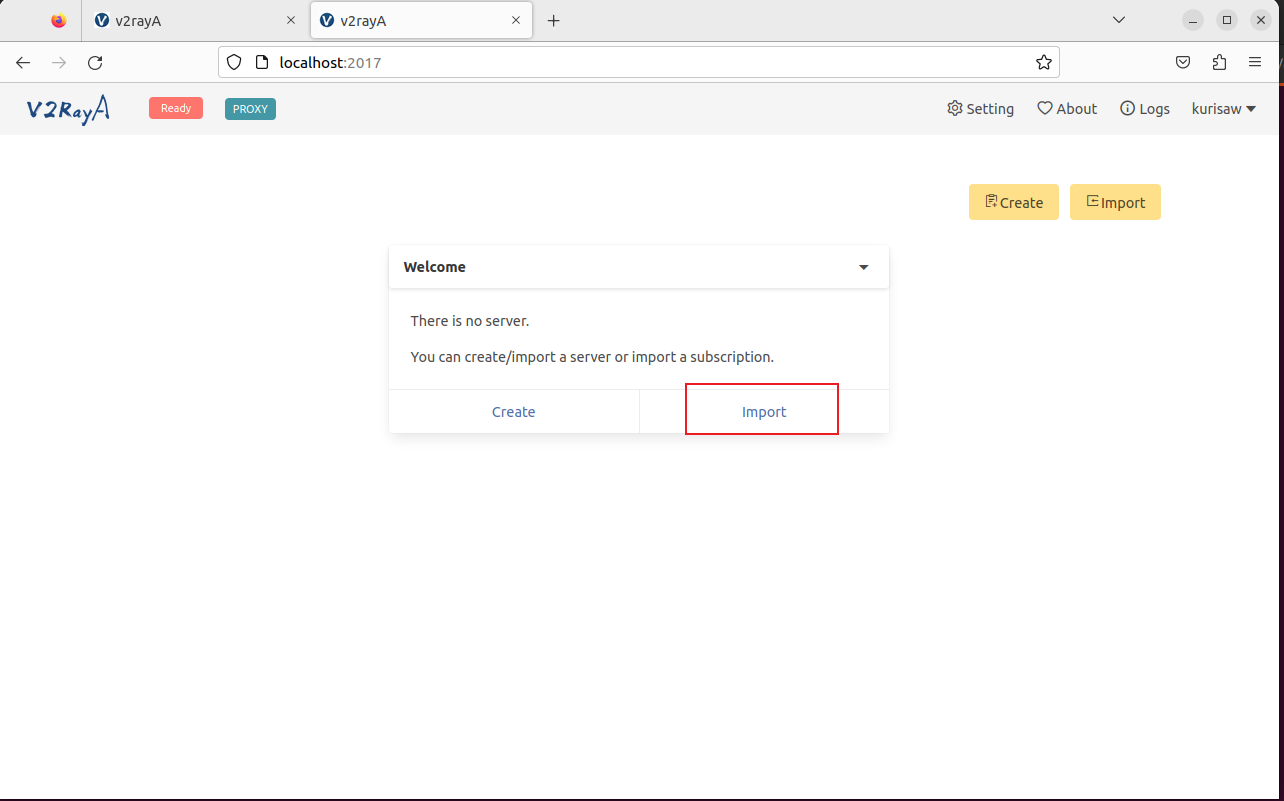
选择想要使用的节点后,点击 Ready
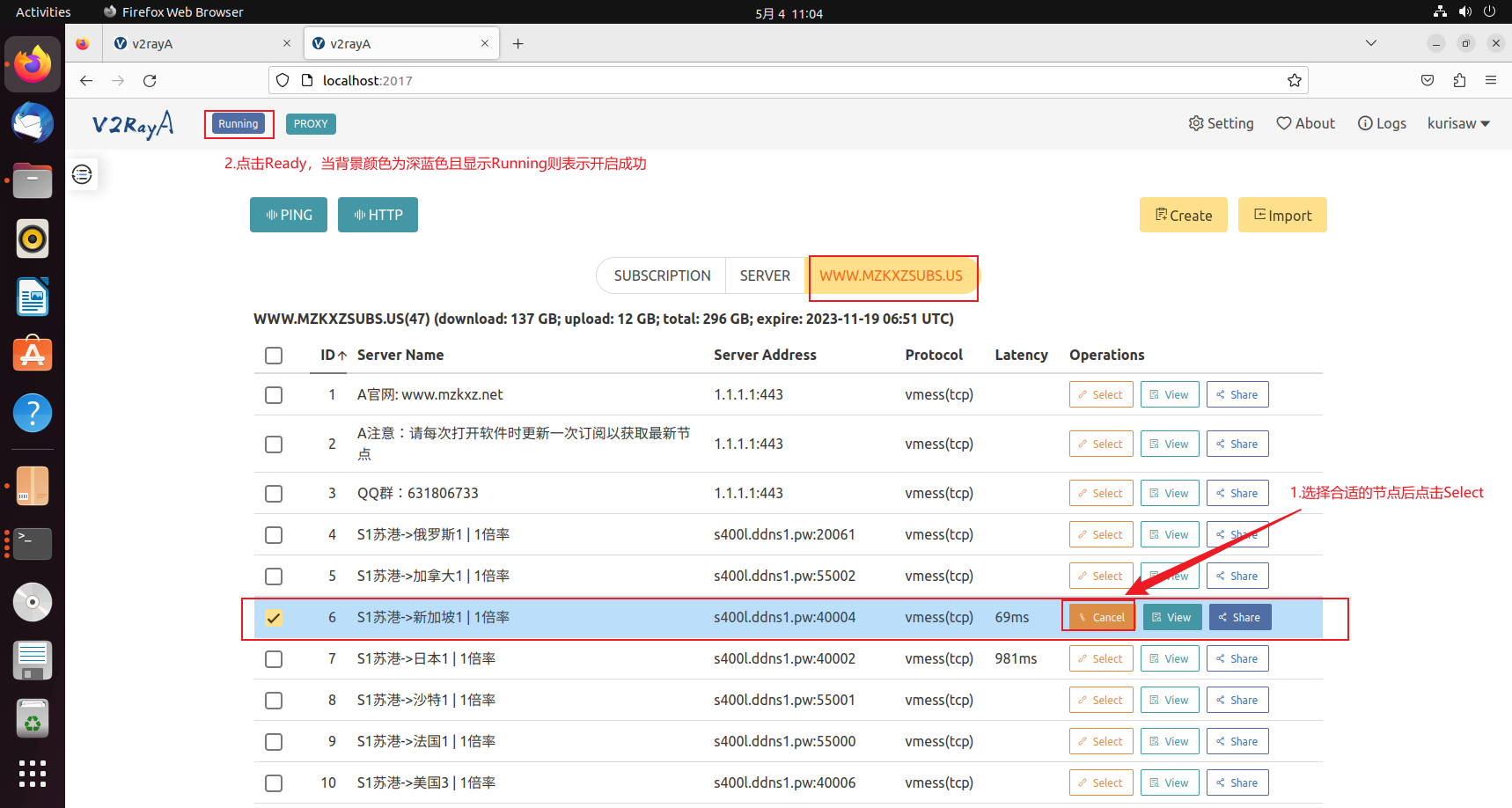
我们点击网页上右上角的Setting,进行如下修改
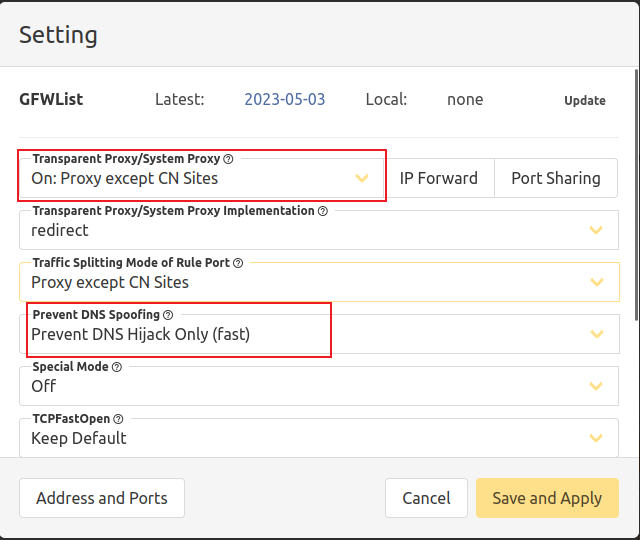
至此所有的配置就完成了,我们打开 youtube 测试一下,没有问题,可以进行开发了

这里附上百度网盘下载链接: +链接: https://pan.baidu.com/s/1t5GWGymN6mFHDNlgrmD0yw?pwd=ec88 提取码: ec88
下载完成后双击打开
+
默认下载方式即可
打开下载好的pycocotools,双击打开setup.py(文件路径:\cocoapi\PythonAPI\setup.py)
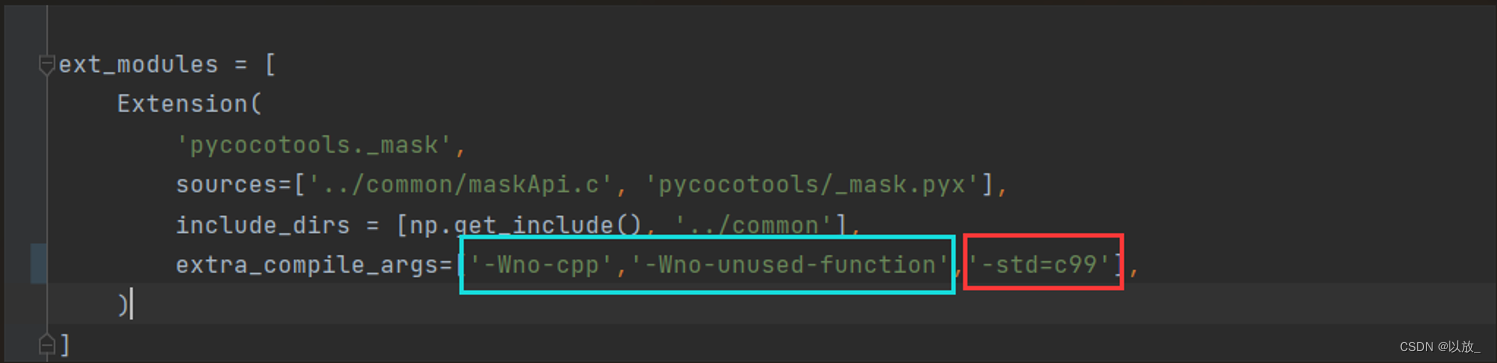
这里将蓝色部分删除,只保留红色部分(切记需要执行这一步!!!)
开始界面找到所有应用并打开Anaconda Powershell Prompt

先打开自己创建的虚拟环境,这里我的虚拟环境为python_env,可供参考。
如上图所示进入到\cocoapi\PythonAPI该目录下
分别执行以下两个命令:
| |
执行pip list查看
 +此时回到
+此时回到\cocoapi\PythonAPI目录下,可以看到生成了相关文件
+ +将
+将pycocotools和pycocotools.egg-info文件夹复制到你所创建的虚拟环境中(位置:Anaconda3->envs->python_env->Lib->site-packages)
+
至此所有问题解决!

Wireshark是非常流行的网络封包分析软件,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程各种问题定位。本文主要内容包括:
1、Wireshark软件下载和安装以及Wireshark主界面介绍。
2、WireShark简单抓包示例。通过该例子学会怎么抓包以及如何简单查看分析数据包内容。
3、Wireshark过滤器使用。通过过滤器可以筛选出想要分析的内容。包括按照协议过滤、端口和主机名过滤、数据包内容过滤。
软件下载路径:wireshark官网。按照系统版本选择下载,下载完成后,按照软件提示一路Next安装。
如果你是Win10系统,安装完成后,选择抓包但是不显示网卡,下载win10pcap兼容性安装包。下载路径:win10pcap兼容性安装包
先介绍一个使用wireshark工具抓取ping命令操作的示例,让读者可以先上手操作感受一下抓包的具体过程。
1、打开wireshark 2.6.5,主界面如下:

2、选择菜单栏上Capture -> Option,勾选WLAN网卡(这里需要根据各自电脑网卡使用情况选择,简单的办法可以看使用的IP对应的网卡)。点击Start。启动抓包。
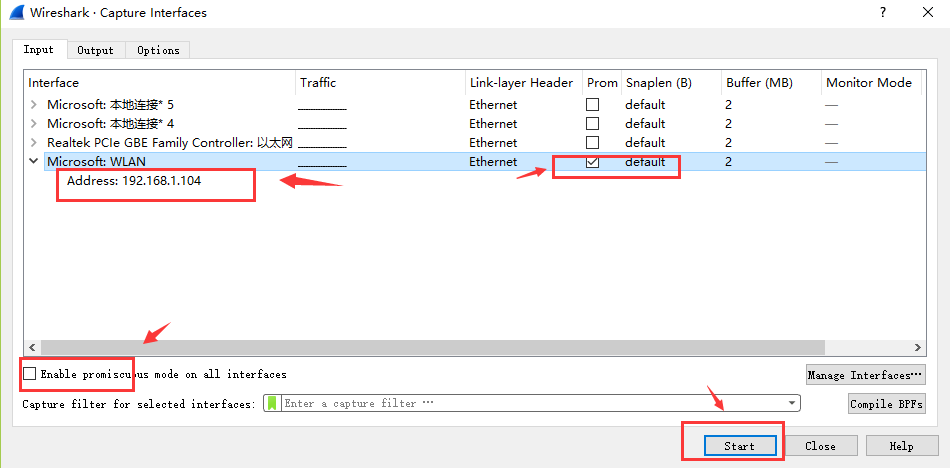
3、wireshark启动后,wireshark处于抓包状态中。

4、执行需要抓包的操作,如ping www.baidu.com。
5、操作完成后相关数据包就抓取到了。为避免其他无用的数据包影响分析,可以通过在过滤栏设置过滤条件进行数据包列表过滤,获取结果如下。说明:ip.addr == 119.75.217.26 and icmp 表示只显示ICPM协议且源主机IP或者目的主机IP为119.75.217.26的数据包。
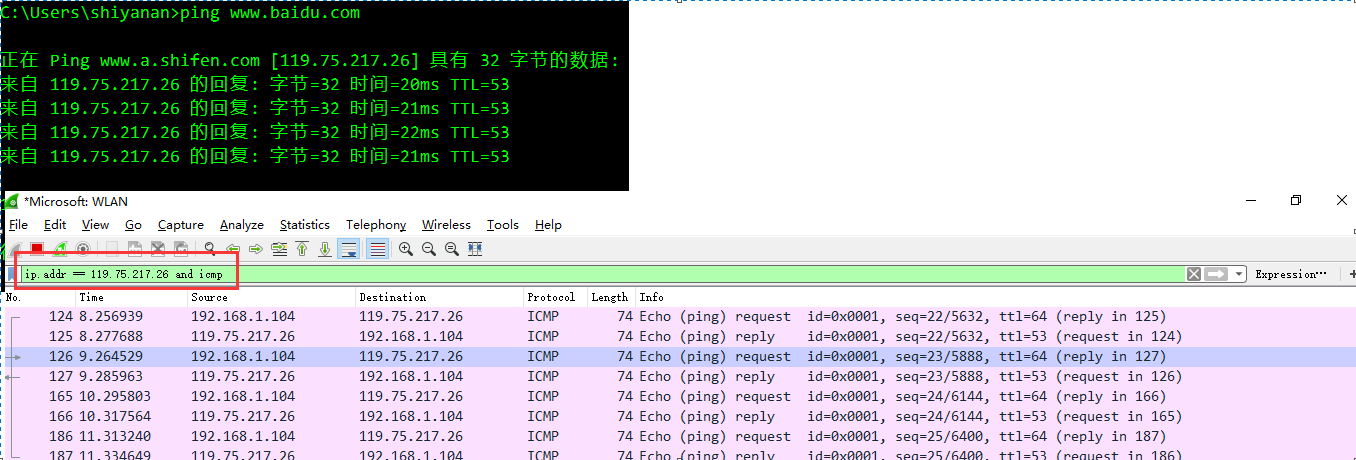
5、wireshark抓包完成,就这么简单。关于wireshark过滤条件和如何查看数据包中的详细内容在后面介绍。
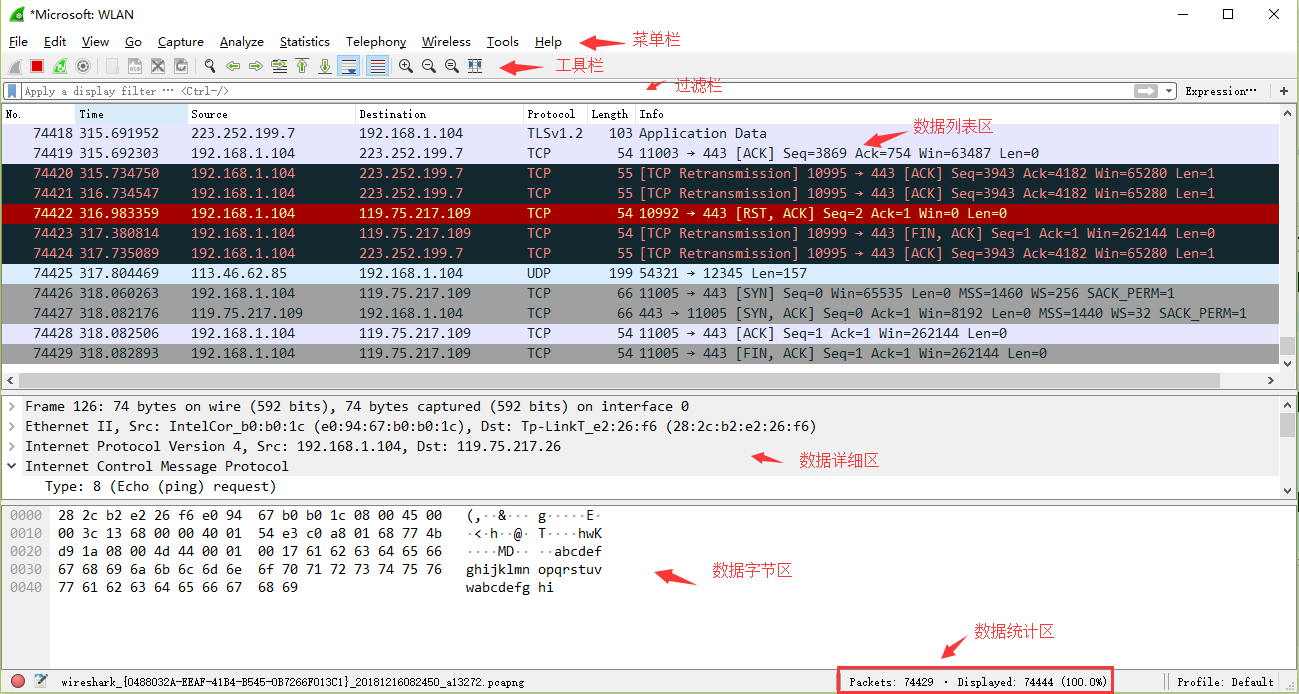
说明:数据包列表区中不同的协议使用了不同的颜色区分。协议颜色标识定位在菜单栏View --> Coloring Rules。如下所示
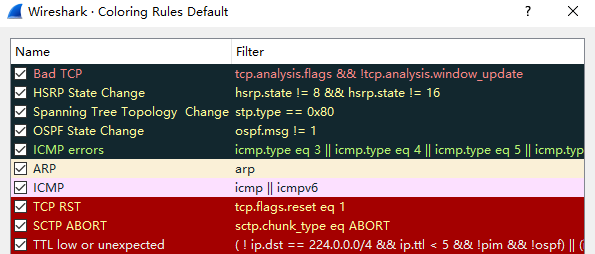
WireShark 主要分为这几个界面
1. Display Filter(显示过滤器), 用于设置过滤条件进行数据包列表过滤。菜单路径:Analyze --> Display Filters。

2. Packet List Pane(数据包列表), 显示捕获到的数据包,每个数据包包含编号,时间戳,源地址,目标地址,协议,长度,以及数据包信息。 不同协议的数据包使用了不同的颜色区分显示。

3. Packet Details Pane(数据包详细信息), 在数据包列表中选择指定数据包,在数据包详细信息中会显示数据包的所有详细信息内容。数据包详细信息面板是最重要的,用来查看协议中的每一个字段。各行信息分别为
(1)Frame: 物理层的数据帧概况
(2)Ethernet II: 数据链路层以太网帧头部信息
(3)Internet Protocol Version 4: 互联网层IP包头部信息
(4)Transmission Control Protocol: 传输层T的数据段头部信息,此处是TCP
(5)Hypertext Transfer Protocol: 应用层的信息,此处是HTTP协议
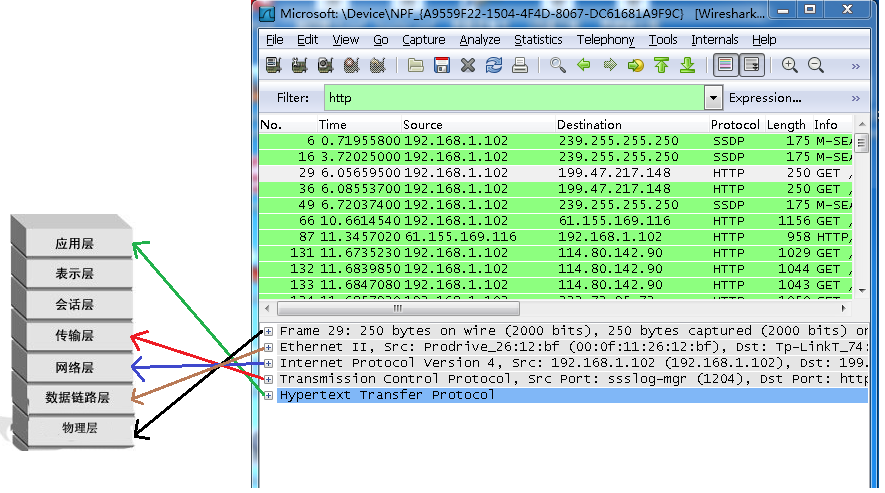
TCP包的具体内容
从下图可以看到wireshark捕获到的TCP包中的每个字段。
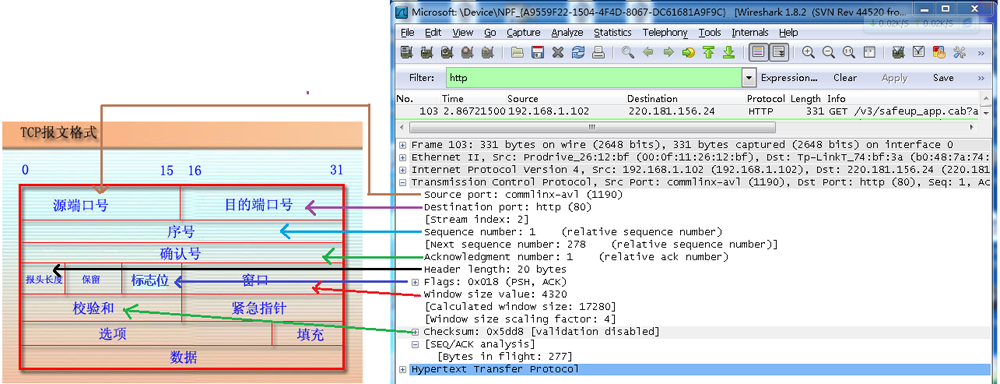
4. Dissector Pane(数据包字节区)。
初学者使用wireshark时,将会得到大量的冗余数据包列表,以至于很难找到自己自己抓取的数据包部分。wireshar工具中自带了两种类型的过滤器,学会使用这两种过滤器会帮助我们在大量的数据中迅速找到我们需要的信息。
(1)抓包过滤器
捕获过滤器的菜单栏路径为Capture --> Capture Filters。用于在抓取数据包前设置。
如何使用?可以在抓取数据包前设置如下。
ip host 60.207.246.216 and icmp表示只捕获主机IP为60.207.246.216的ICMP数据包。获取结果如下:
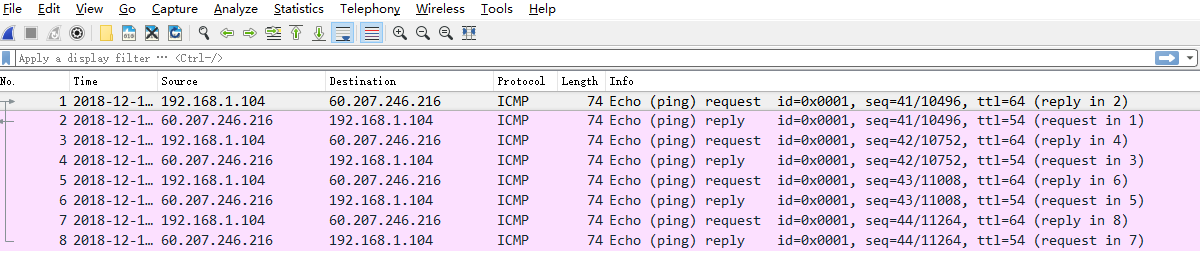
(2)显示过滤器
显示过滤器是用于在抓取数据包后设置过滤条件进行过滤数据包。通常是在抓取数据包时设置条件相对宽泛,抓取的数据包内容较多时使用显示过滤器设置条件顾虑以方便分析。同样上述场景,在捕获时未设置捕获规则直接通过网卡进行抓取所有数据包,如下
执行ping www.huawei.com获取的数据包列表如下
观察上述获取的数据包列表,含有大量的无效数据。这时可以通过设置显示器过滤条件进行提取分析信息。ip.addr == 211.162.2.183 and icmp。并进行过滤。
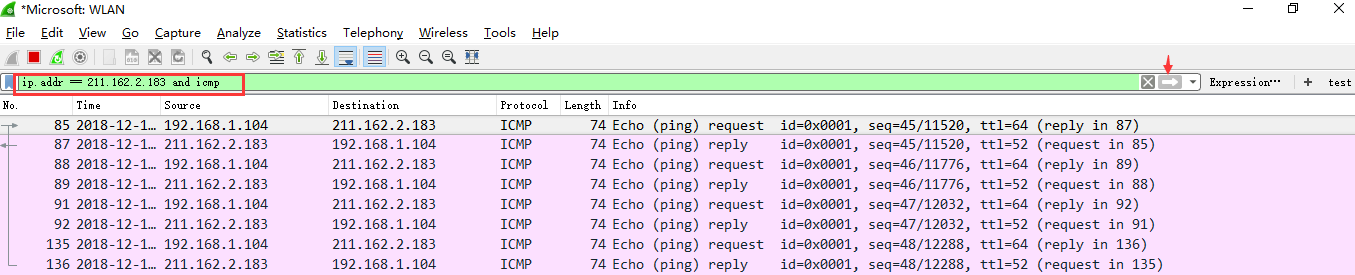
上述介绍了抓包过滤器和显示过滤器的基本使用方法。**在组网不复杂或者流量不大情况下,使用显示器过滤器进行抓包后处理就可以满足我们使用。**下面介绍一下两者间的语法以及它们的区别。
wireshark过滤器表达式的规则
1、抓包过滤器语法和实例
抓包过滤器类型Type(host、net、port)、方向Dir(src、dst)、协议Proto(ether、ip、tcp、udp、http、icmp、ftp等)、逻辑运算符(&& 与、|| 或、!非)
(1)协议过滤
比较简单,直接在抓包过滤框中直接输入协议名即可。
TCP,只显示TCP协议的数据包列表
HTTP,只查看HTTP协议的数据包列表
ICMP,只显示ICMP协议的数据包列表
(2)IP过滤
host 192.168.1.104
src host 192.168.1.104
dst host 192.168.1.104
(3)端口过滤
port 80
src port 80
dst port 80
(4)逻辑运算符&& 与、|| 或、!非
src host 192.168.1.104 && dst port 80 抓取主机地址为192.168.1.80、目的端口为80的数据包
host 192.168.1.104 || host 192.168.1.102 抓取主机为192.168.1.104或者192.168.1.102的数据包
!broadcast 不抓取广播数据包
2、显示过滤器语法和实例
(1)比较操作符
比较操作符有== 等于、!= 不等于、> 大于、< 小于、>= 大于等于、<=小于等于。
(2)协议过滤
比较简单,直接在Filter框中直接输入协议名即可。注意:协议名称需要输入小写。
tcp,只显示TCP协议的数据包列表
http,只查看HTTP协议的数据包列表
icmp,只显示ICMP协议的数据包列表

(3) ip过滤
ip.src ==192.168.1.104 显示源地址为192.168.1.104的数据包列表
ip.dst==192.168.1.104, 显示目标地址为192.168.1.104的数据包列表
ip.addr == 192.168.1.104 显示源IP地址或目标IP地址为192.168.1.104的数据包列表
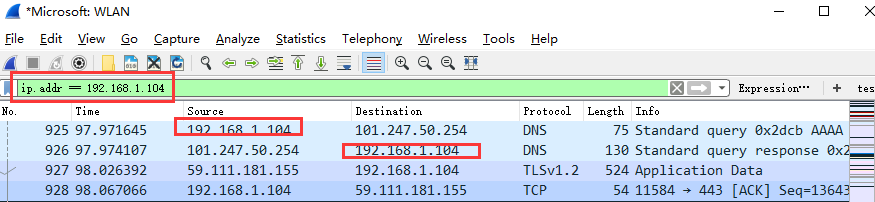
(4)端口过滤
tcp.port ==80, 显示源主机或者目的主机端口为80的数据包列表。
tcp.srcport == 80, 只显示TCP协议的源主机端口为80的数据包列表。
tcp.dstport == 80,只显示TCP协议的目的主机端口为80的数据包列表。
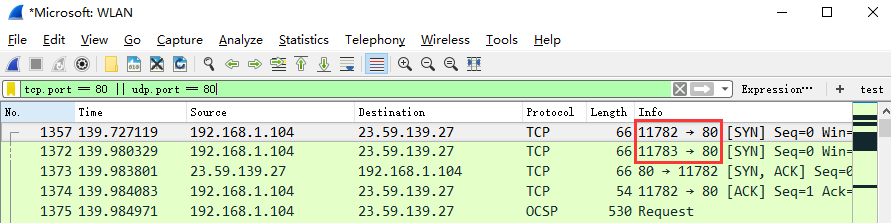
(5) Http模式过滤
http.request.method==“GET”, 只显示HTTP GET方法的。
(6)逻辑运算符为 and/or/not
过滤多个条件组合时,使用and/or。比如获取IP地址为192.168.1.104的ICMP数据包表达式为ip.addr == 192.168.1.104 and icmp
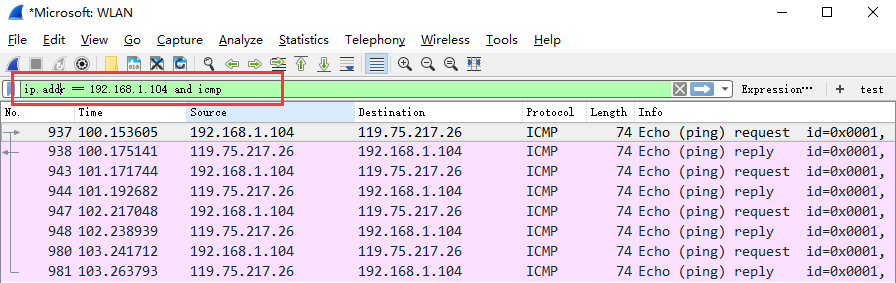
(7)按照数据包内容过滤。假设我要以IMCP层中的内容进行过滤,可以单击选中界面中的码流,在下方进行选中数据。如下
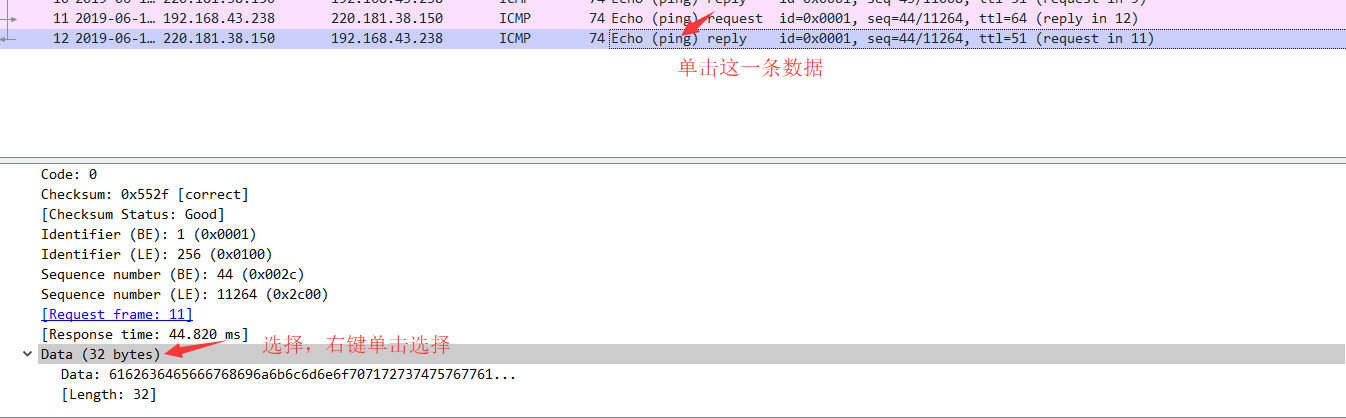
右键单击选中后出现如下界面
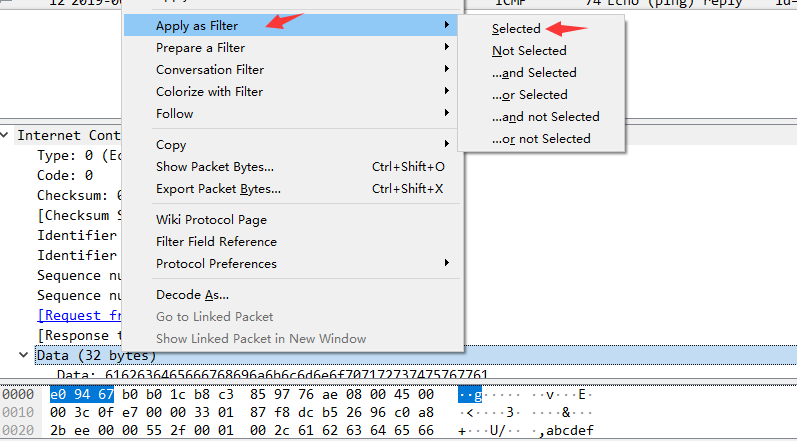
选中Select后在过滤器中显示如下

后面条件表达式就需要自己填写。如下我想过滤出data数据包中包含"abcd"内容的数据流。包含的关键词是contains 后面跟上内容。
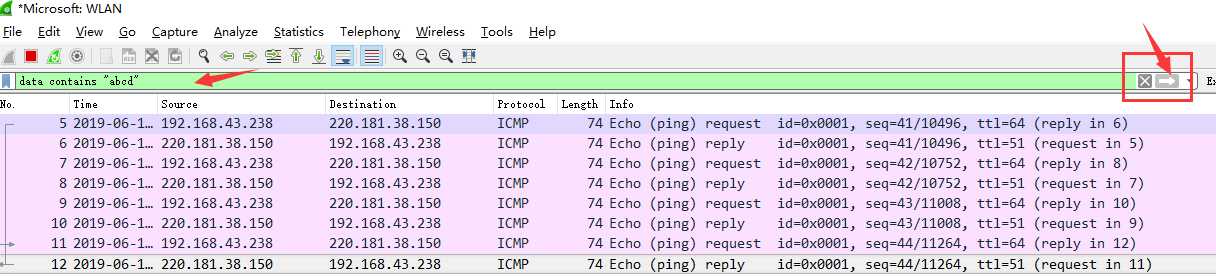
看到这, 基本上对wireshak有了初步了解。
(1)TCP三次握手连接建立过程
Step1:客户端发送一个SYN=1,ACK=0标志的数据包给服务端,请求进行连接,这是第一次握手;
Step2:服务端收到请求并且允许连接的话,就会发送一个SYN=1,ACK=1标志的数据包给发送端,告诉它,可以通讯了,并且让客户端发送一个确认数据包,这是第二次握手;
Step3:服务端发送一个SYN=0,ACK=1的数据包给客户端端,告诉它连接已被确认,这就是第三次握手。TCP连接建立,开始通讯。
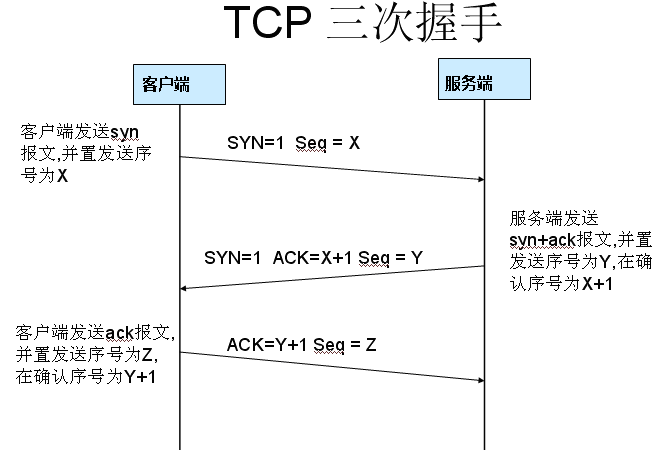
(2)wireshark抓包获取访问指定服务端数据包
Step1:启动wireshark抓包,打开浏览器输入www.huawei.com。
Step2:使用ping www.huawei.com获取IP。

Step3:输入过滤条件获取待分析数据包列表 ip.addr == 211.162.2.183
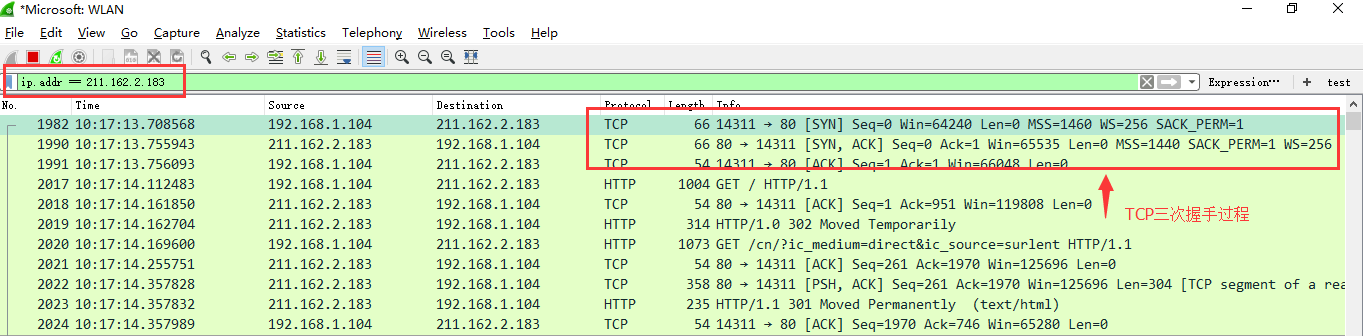
图中可以看到wireshark截获到了三次握手的三个数据包。第四个包才是HTTP的, 这说明HTTP的确是使用TCP建立连接的。
第一次握手数据包
客户端发送一个TCP,标志位为SYN,序列号为0, 代表客户端请求建立连接。 如下图。
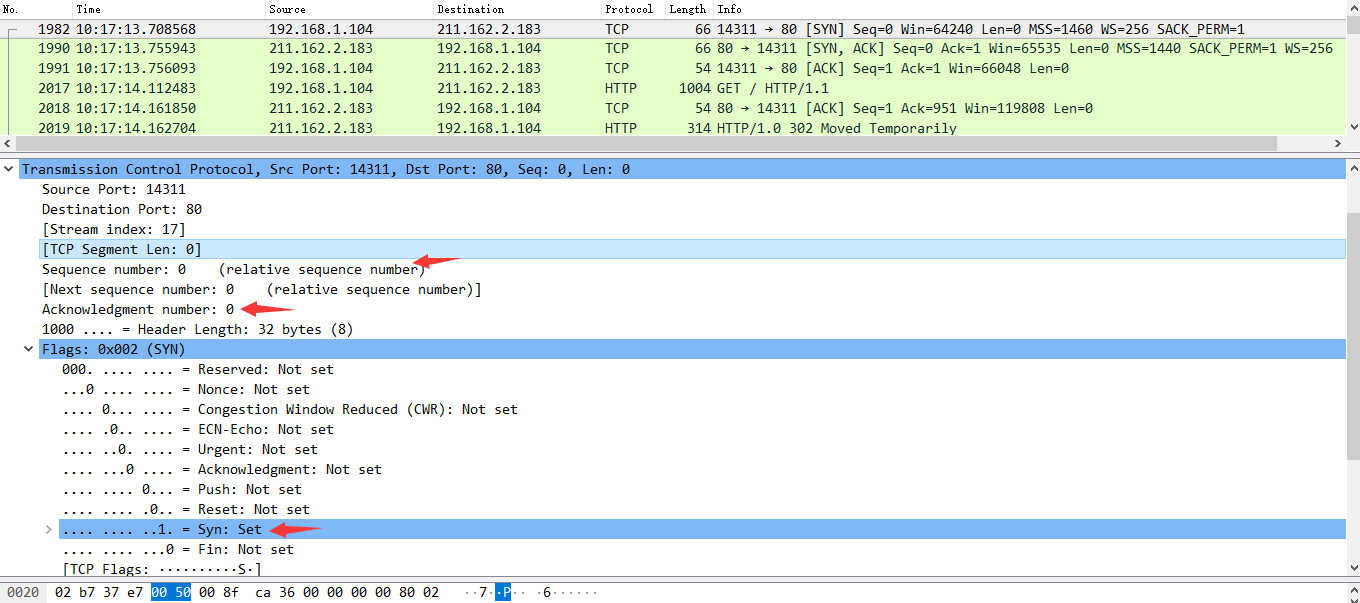
数据包的关键属性如下:
SYN :标志位,表示请求建立连接
Seq = 0 :初始建立连接值为0,数据包的相对序列号从0开始,表示当前还没有发送数据
Ack =0:初始建立连接值为0,已经收到包的数量,表示当前没有接收到数据
第二次握手的数据包
服务器发回确认包, 标志位为 SYN,ACK. 将确认序号(Acknowledgement Number)设置为客户的I S N加1以.即0+1=1, 如下图
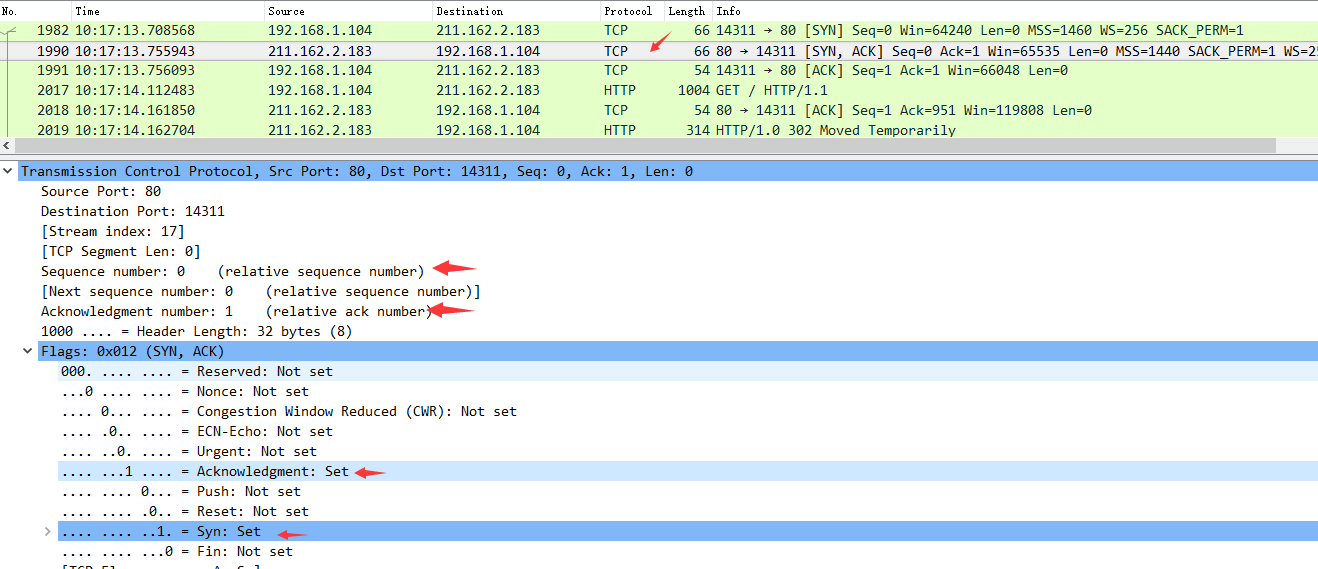
数据包的关键属性如下:
[SYN + ACK]: 标志位,同意建立连接,并回送SYN+ACK
Seq = 0 :初始建立值为0,表示当前还没有发送数据
Ack = 1:表示当前端成功接收的数据位数,虽然客户端没有发送任何有效数据,确认号还是被加1,因为包含SYN或FIN标志位。(并不会对有效数据的计数产生影响,因为含有SYN或FIN标志位的包并不携带有效数据)
第三次握手的数据包
客户端再次发送确认包(ACK) SYN标志位为0,ACK标志位为1.并且把服务器发来ACK的序号字段+1,放在确定字段中发送给对方.并且在数据段放写ISN的+1, 如下图:
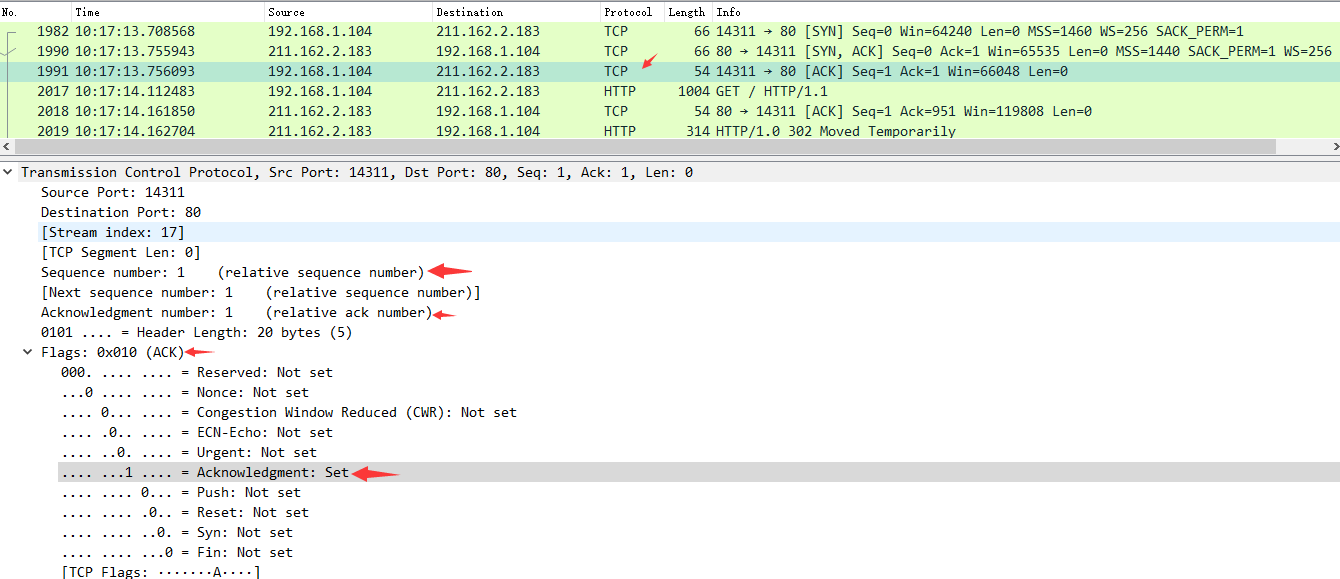
数据包的关键属性如下:
ACK :标志位,表示已经收到记录
Seq = 1 :表示当前已经发送1个数据
Ack = 1 : 表示当前端成功接收的数据位数,虽然服务端没有发送任何有效数据,确认号还是被加1,因为包含SYN或FIN标志位(并不会对有效数据的计数产生影响,因为含有SYN或FIN标志位的包并不携带有效数据)。
就这样通过了TCP三次握手,建立了连接。开始进行数据交互
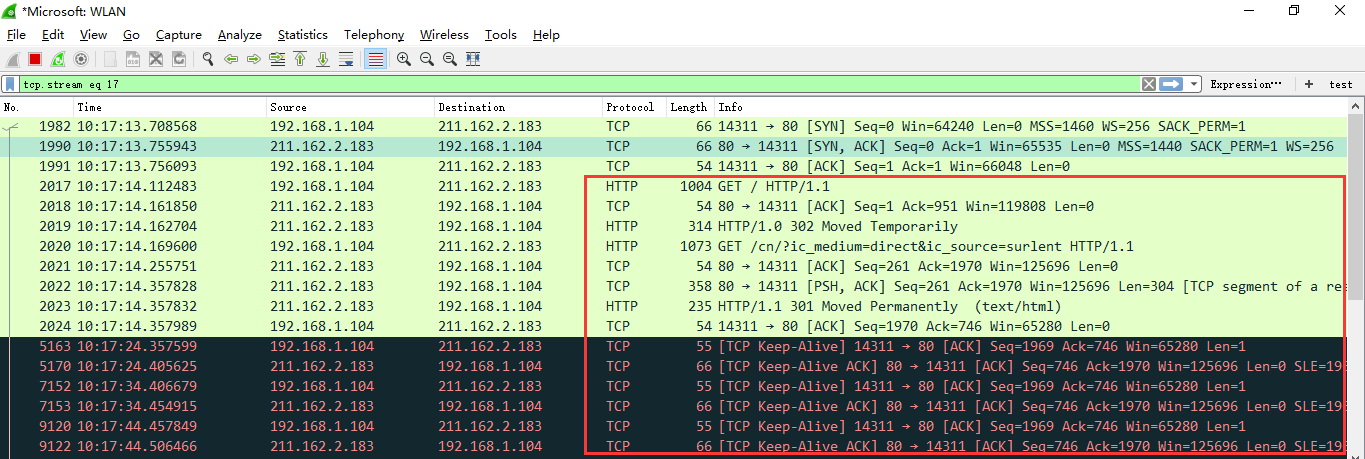
下面针对数据交互过程的数据包进行一些说明:
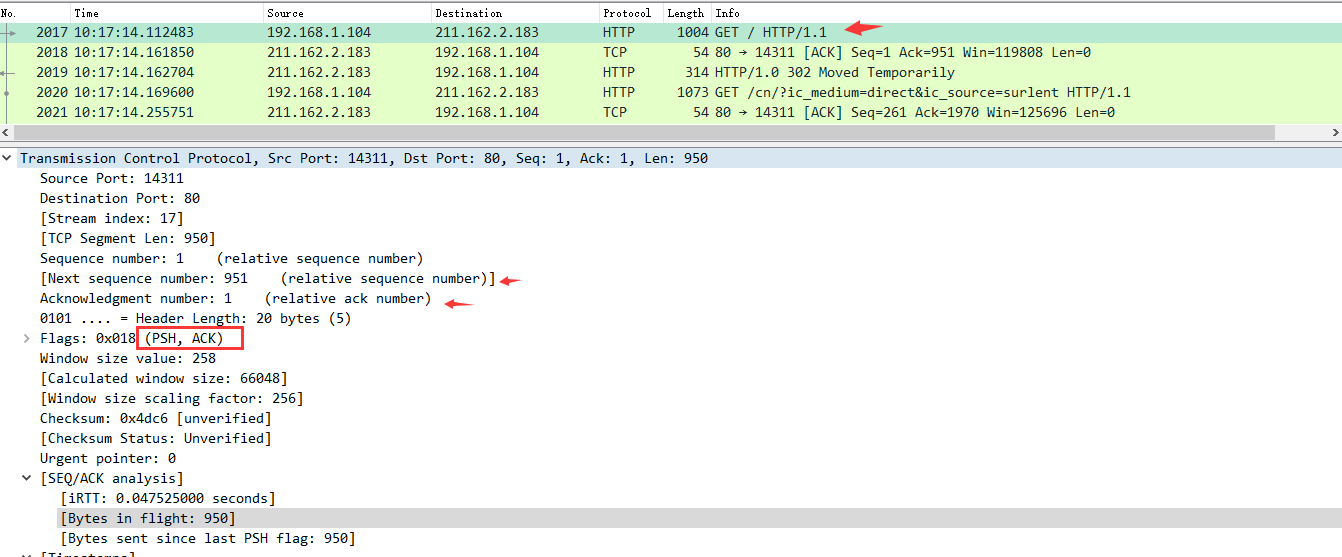
数据包的关键属性说明
Seq: 1
Ack: 1: 说明现在共收到1字节数据
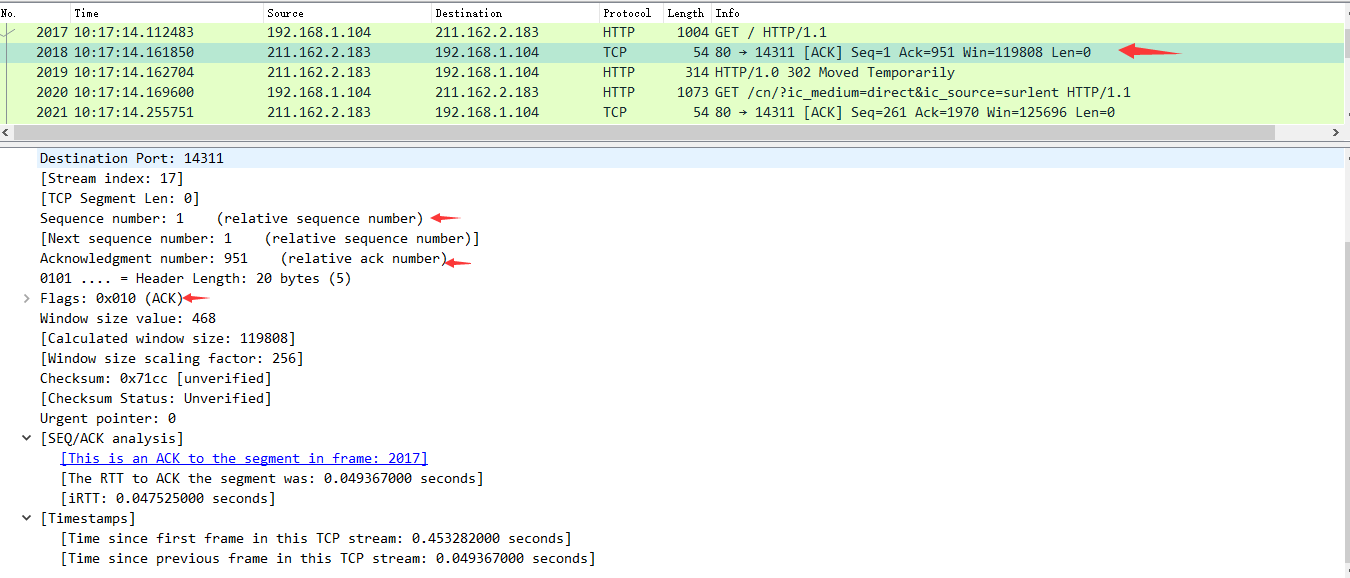
Seq: 1
Ack: 951: 说明现在服务端共收到951字节数据
在TCP层,有个FLAGS字段,这个字段有以下几个标识:SYN, FIN, ACK, PSH, RST, URG。如下
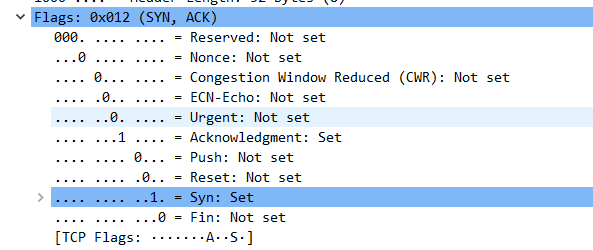
其中,对于我们日常的分析有用的就是前面的五个字段。它们的含义是:SYN表示建立连接,FIN表示关闭连接,ACK表示响应,PSH表示有DATA数据传输,RST表示连接重置。
调整数据包列表中时间戳显示格式。调整方法为View -->Time Display Format --> Date and Time of Day。调整后格式如下:

首先在windows中安装 USBIP 工具,在GitHub上下载安装包并根据README文档的说明进行操作:
下载链接:https://github.com/dorssel/usbipd-win/releases
同时在 WSL Linux 端也需要安装编译内核所需的库和工具,为后续做准备:
| |
打开wsl ubuntu终端使用命令:uname -r得到版本号,同时根据版本号使用管理员模式新建目录

| |
同时我们去GitHub下载一份wsl内核源码:https://github.com/microsoft/WSL2-Linux-Kernel/releases
这里的版本就是你使用命令 uname -r 得到的版本号,建议可以先手动安装压缩包,然后使用vscode连接wsl,把文件拖拽到wsl下
然后解压到指定路径下(这部分注意区分版本号,不要一昧照搬命令):
| |
然后将内核的一些配置信息复制到当前文件夹下:
| |
接着我们执行menuconfig命令打开图形化菜单
| |
进入如下路径:> Device Drivers > USB support
下面是一些必须的添加项,一般默认都是选中的,不过最好还是检查下:
| |
同时记得关闭 Device Drivers -> USB Support -> USB/IP -> Debug messages for USB/IP这一选项,否则调试信息会非常影响你的使用体验
另外也可以添加你具体所需的USB模块勾选上,保存退出后执行内核编译
| |
内核编译期间发生报错:

这主要是由于系统缺少dwarves软件包导致的,我们使用apt命令安装并继续执行编译:
| |
发现又产生了报错:

查找资料似乎说明的是这仅仅是个警告,我通过禁用BTF的调试信息解决了这个问题
| |
安装内核时发生报错:

解决方式有两种:
.config中禁用宏CONFIG_X86_X32我选择的是第一种,根据我在网上找到的说法是:
| |
所以我选择禁用宏CONFIG_X86_X32,之后继续执行命令:
| |

之后就可以选择编译 USBIP 工具了:
| |
复制工具库位置,以便 usbip 工具可以获取到:
| |
安装 usb.ids 以便显示 USB 设备的名称:
| |
重启WSL:
| |
下面进行测试是否成功: +打开powershell:
| |
假设我们需要在wsl使用的 usb 设备为 ST-Link Debug, USB 大容量存储设备, USB 串行设备 (COM3),设备id为 0483:374b
我们使用命令附加设备到 wsl2 中
| |

此时我们打开一个 wsl 终端,使用命令 lsusb 即可看到附加到 wsl 的设备

然后我们再次回到 powershell ,执行 usbipd wsl list命令,可以看到此时的 usb 设备已经成功添加到 wsl 了

在 Linux 系统上配置 oh-my-zsh 并更改主题以及启用历史回溯非常简单。下面是详细步骤:
确保你的系统上已经安装了 zsh。你可以使用系统的包管理器进行安装。例如,在基于 Debian/Ubuntu 的系统上,你可以运行:
| |
在终端中运行以下命令来安装 oh-my-zsh:
| |
或者,如果你没有安装 curl,可以使用 wget:
| |
打开 ~/.zshrc 文件以编辑它:
| |
找到 ZSH_THEME 行并更改主题。你可以在 oh-my-zsh 主题库中选择一个主题,例如:
| |
保存并关闭文件。
oh-my-zsh 默认启用历史回溯。确保 ~/.zshrc 中没有明确禁用该功能的设置。检查是否存在以下行:
| |
这将显示历史命令的时间戳。如果你想要简单地显示命令历史而不包含时间戳,可以将其设置为:
| |
在更改 ~/.zshrc 文件后,你需要重新启动 zsh 或者打开一个新的终端窗口以应用更改。
| |
现在,你的 oh-my-zsh 应该已经配置好,并且你可以享受新的主题和命令历史回溯功能。如果你在终端中输入 zsh 并按 Enter,也可以切换到 zsh 提示符,体验更改后的主题和配置。
在 Windows 下,你可以使用一些工具来实现类似 oh-my-zsh 的命令历史显示和补全功能。其中之一是使用 PowerShell,并安装 PSReadLine 模块,它提供了丰富的命令行编辑和历史记录功能。
以下是在 PowerShell 中配置类似 oh-my-zsh 的历史记录显示的步骤:
安装 PSReadLine 模块:
+打开 PowerShell 终端,并执行以下命令来安装 PSReadLine 模块:
| |
配置 PowerShell 用户配置文件: +执行以下命令打开 PowerShell 配置文件(如果不存在,会创建一个新文件):
| |
在配置文件中添加以下行: +在打开的配置文件中,添加以下内容:
| |
保存并关闭文件。
重新启动 PowerShell: +关闭当前的 PowerShell 终端,并重新打开一个新的终端。
使用历史记录搜索:
+可以在 PowerShell 终端中使用 Ctrl + r 来搜索并显示命令历史记录。输入字符,它会匹配历史记录中的命令。

是指需手动配置虚拟机的IP地址(IP地址可自定义,但要和主机在同一个网段下)子网掩码,网关,此时虚拟机相当于局域网的另一台电脑,占用一个IP地址
如果你的虚拟机选择了桥接模式,那么建议最好是不要使用校园网,因为一般校园网会需要验证登录,但是在虚拟机中好像并不会弹出登录界面(个人理解),因此你的网络在虚拟机中是无法运行的。
<1>选择直接使用网线连接到电脑,然后在虚拟机中桥接选择自己对应的网卡即可,博主自己是没有连接网线的,所以我自己是没有采取这个办法的。
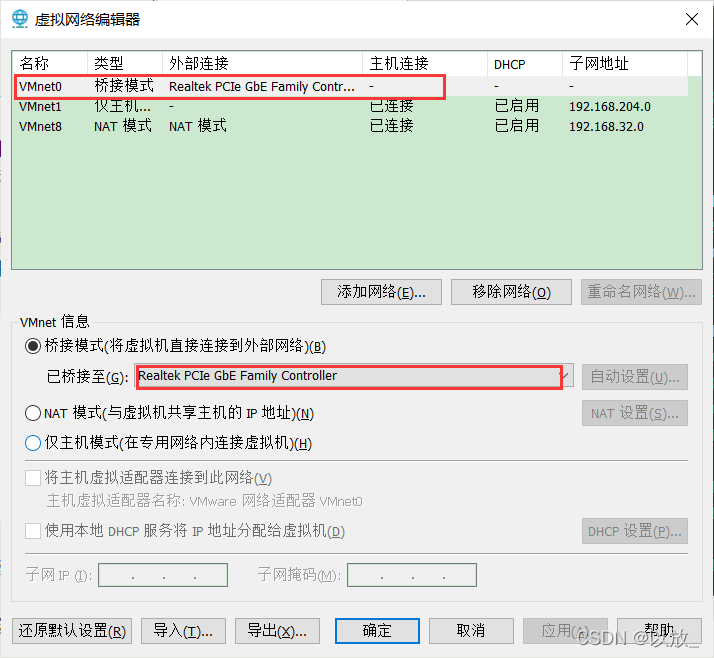
<2>无线网卡连接
考虑到生活的便捷性,大多数人一般都是使用的无线网卡上网,所以这里我们采用连接自己的个人热点进行网络桥接(当然也可以选择WiFi热点,此处为个人热点指南,WiFi连接可同样参考)
如下配置:
首先电脑win+R,输入cmd进入终端,然后输入命令:ipconfig,找到自己的热点网络信息
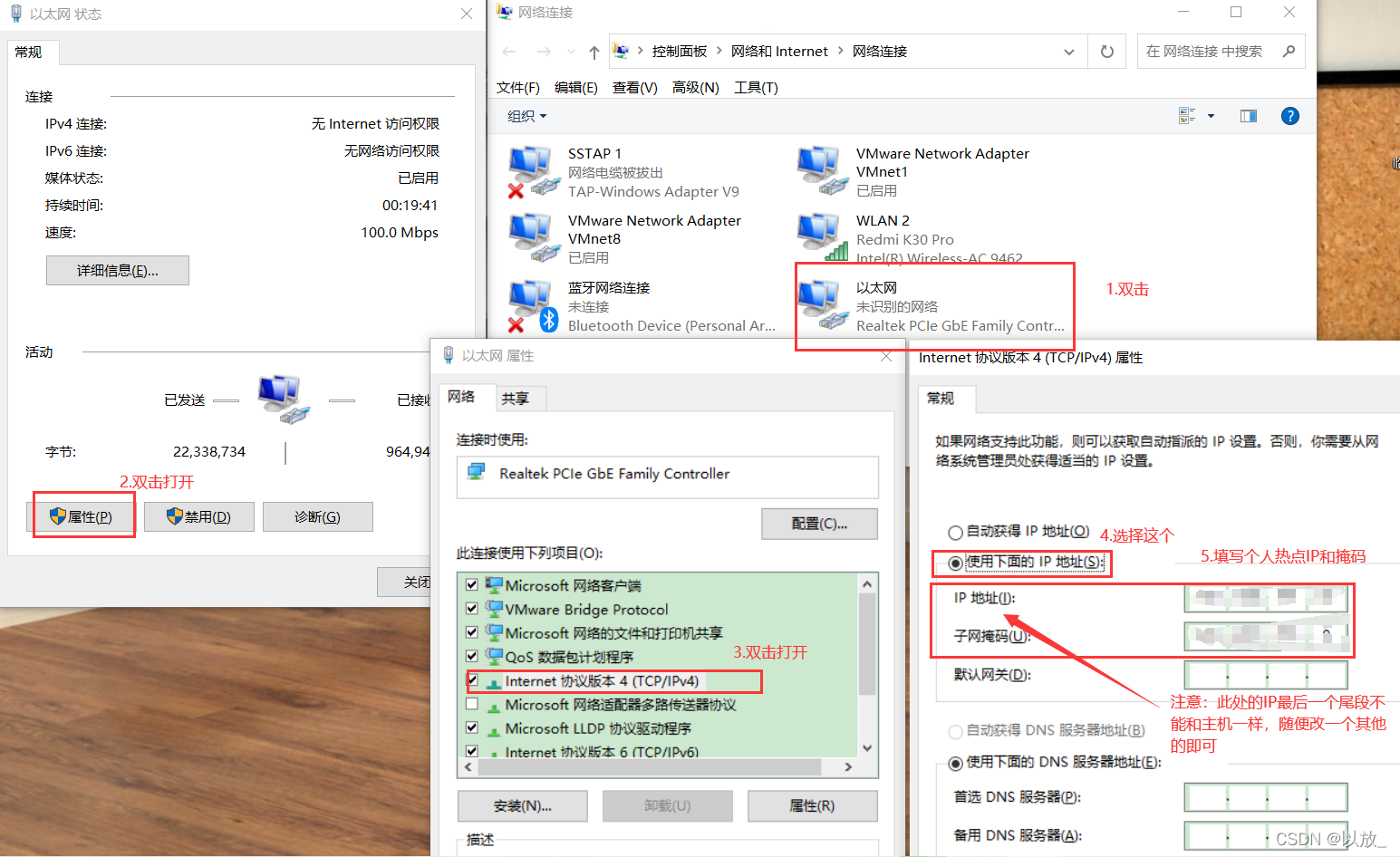
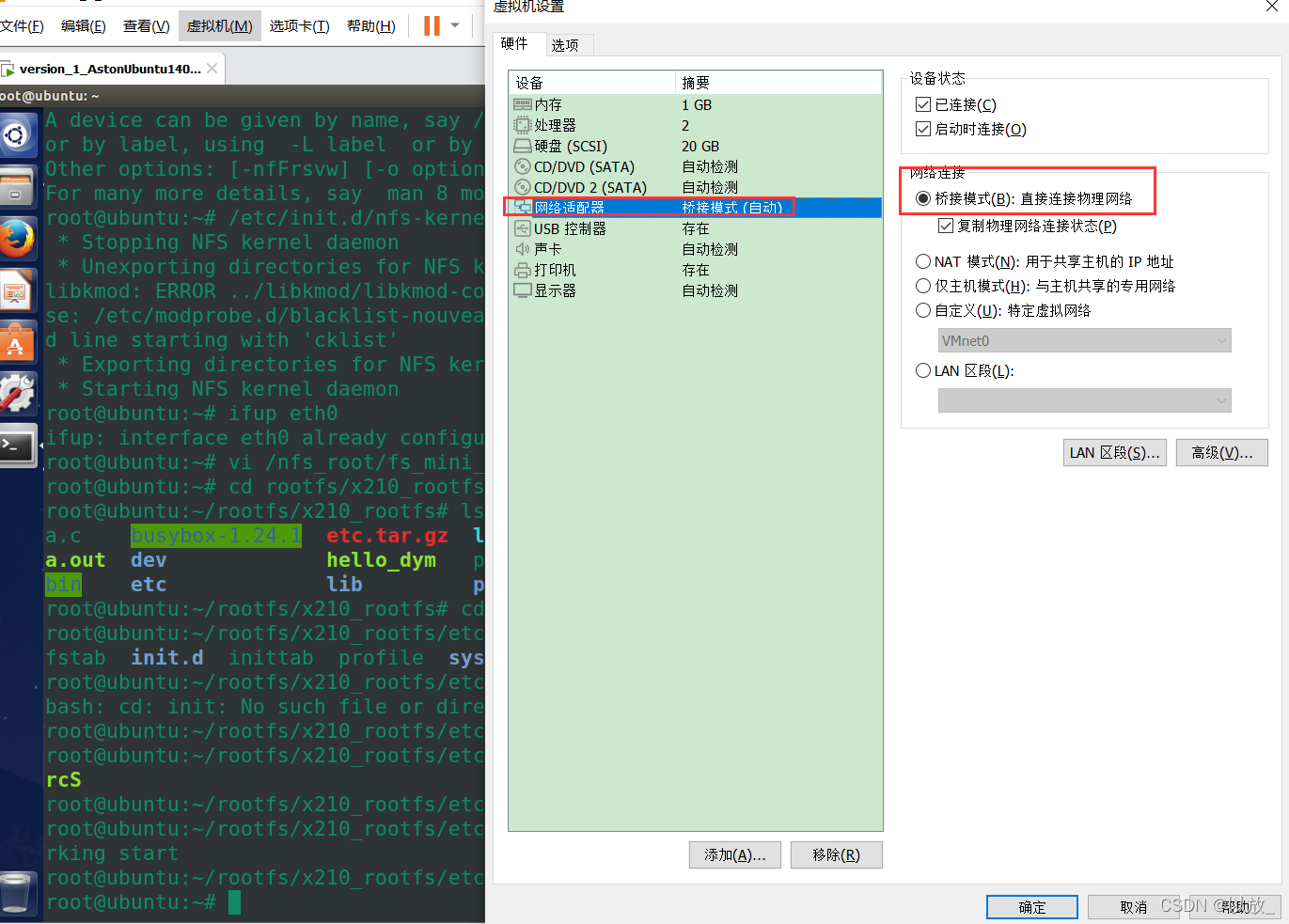
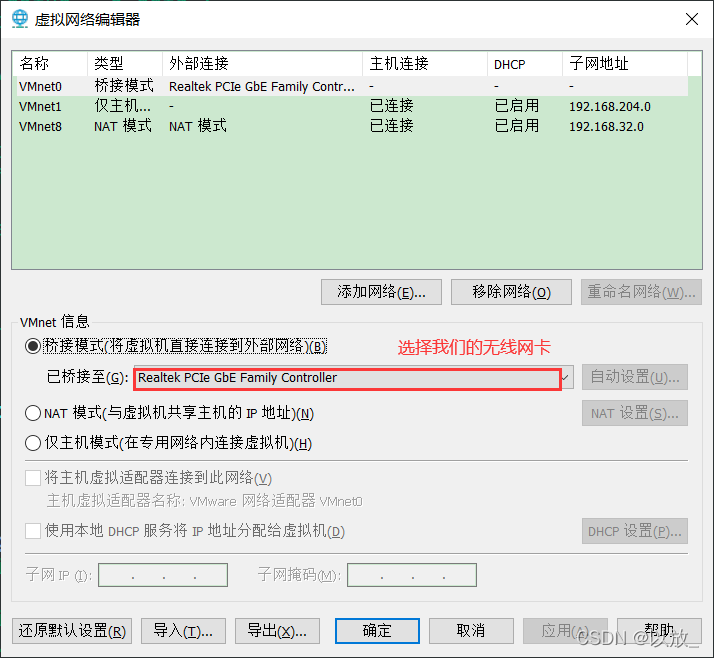
| |

| |
以下内容为开发板挂载根文件系统,感兴趣的可以动手实践一下借鉴下面这篇博客
我们打开secureCRT:
开机先ping下虚拟机网络:ping '虚拟机IP'
注意:此处如果无法ping通虚拟机,一般是自己的虚拟机网络有问题,可以尝试输入以下命令解决
| |
| |
当开发板ping通虚拟机后,我们在secureCRT控制台输入reset命令重启开发板
这里的内核加载过程中再次出现了问题,显示我nfs服务端无回应
解决:
| |
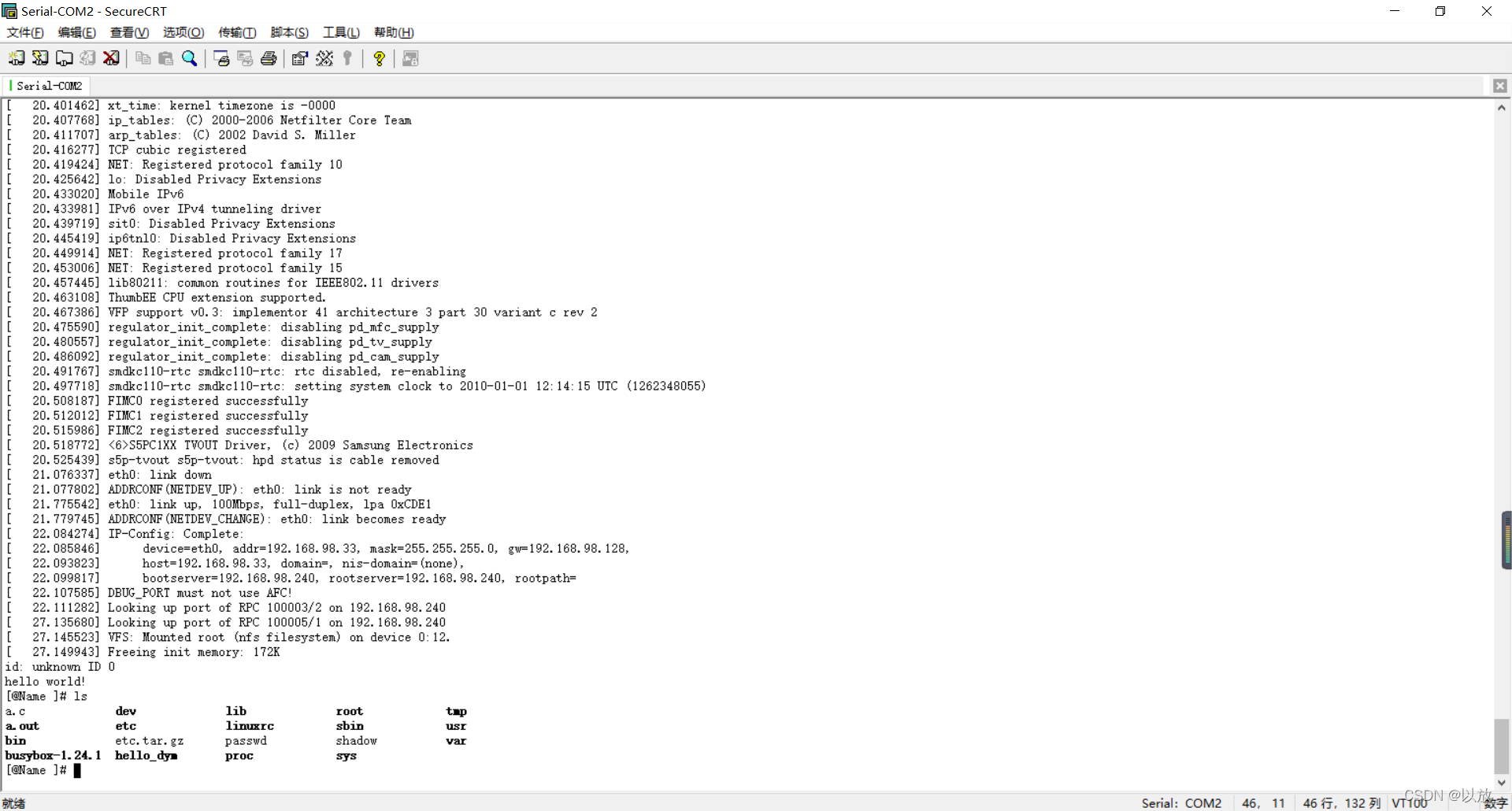
问题解决!

七层模型,亦称OSI(Open System Interconnection)。参考模型是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,一般称为OSI参考模型或七层模型。它是一个七层的、抽象的模型体,不仅包括一系列抽象的术语或概念,也包括具体的协议。
建立、维护、断开物理连接。(由底层网络定义协议)
机械、电子、定时接口通信信道上的原始比特流传输TCP/IP 层级模型结构,应用层之间的协议通过逐级调用传输层(Transport layer)、网络层(Network Layer)和物理数据链路层(Physical Data Link)而可以实现应用层的应用程序通信互联。
应用层需要关心应用程序的逻辑细节,而不是数据在网络中的传输活动。应用层其下三层则处理真正的通信细节。在 Internet 整个发展过程中的所有思想和着重点都以一种称为 RFC(Request For Comments)的文档格式存在。针对每一种特定的 TCP/IP 应用,有相应的 RFC一些典型的 TCP/IP 应用有 FTP、Telnet、SMTP、SNTP、REXEC、TFTP、LPD、SNMP、NFS、INETD 等。RFC 使一些基本相同的 TCP/IP 应用程序实现了标准化,从而使得不同厂家开发的应用程序可以互相通信。
建立逻辑连接、进行硬件地址寻址、差错校验等功能。(由底层网络定义协议)
将比特组合成字节进而组合成帧,用MAC地址访问介质,错误发现但不能纠正。 +物理寻址、同时将原始比特流转变为逻辑传输线路 +地址解析协议:ARP、PARP(反向地址转换协议)
进行逻辑地址寻址,实现不同网络之间的路径选择。
控制子网的运行,如逻辑编址、分组传输、路由选择 +协议有:ICMP(互联网控制信息协议) IGMP(组管理协议) IP(IPV4 IPV6)(互联网协议) +安全协议、路由协议(vrrp虚拟路由冗余)
定义传输数据的协议端口号,以及流控和差错校验。
+接受上一层数据,在必要的时候把数据进行切割,并将这些数据交给网络层,并保证这些数据段有效到达对端
+协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层
建立、管理、终止会话。(在五层模型里面已经合并到了应用层)
不同机器上的用户之间建立及管理会话 +对应主机进程,指本地主机与远程主机正在进行的会话 +安全协议:SSL(安全套接字层协议)、TLS(安全传输层协议)
数据的表示、安全、压缩。(在五层模型里面已经合并到了应用层)
信息的语法语义以及他们的关联,如加密解密、转换翻译、压缩解压 +格式有,JPEG、ASCll、EBCDIC、加密格式等 [2] +如LPP(轻量级表示协议)
网络服务与最终用户的一个接口
各种应用程序协议: +HTTP(超文本传输协议)、FTP(文本传输协议)、TFTP(简单文件传输协议)、SMTP(简单邮件传输协议)、SNMP(简单网络管理协议)、DNS(域名系统)、TELNET(远程终端协议)、HTTPS(超文本传输安全协议)、POP3(邮局协议版本3 )、DHCP(动态主机配置协议)
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇。TCP/IP协议不仅仅指的是TCP 和IP两个协议,而是指一个由FTP、SMTP、TCP、UDP、IP等协议构成的协议簇, 只是因为在TCP/IP协议中TCP协议和IP协议最具代表性,所以被称为TCP/IP协议。
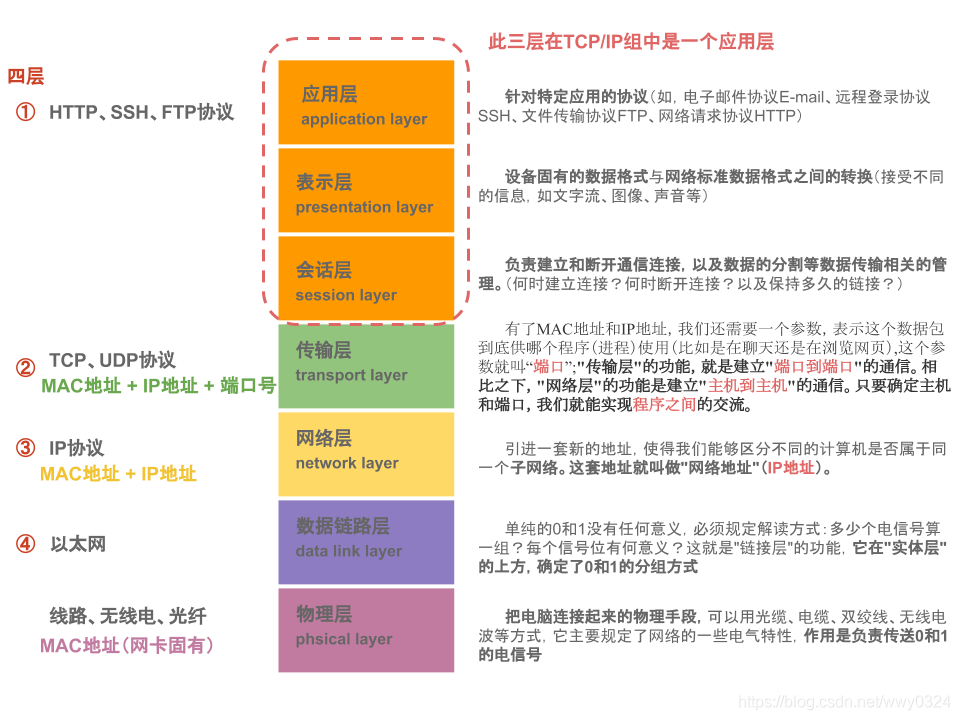
TCP/IP协议在一定程度上参考了OSI的体系结构,在TCP/IP中,OSI的七层模型被简化了四个层面。如下图所示
应用层是TCP/IP协议的第一层,是直接为应用进程提供服务的。
作为TCP/IP协议的第二层,运输层在整个TCP/IP协议中起到了中流砥柱的作用。且在运输层中,TCP和UDP也同样起到了中流砥柱的作用
网络层在TCP/IP协议中的位于第三层。在TCP/IP协议中网络层可以进行网络连接的建立和终止以及IP地址的寻找等功能
在TCP/IP协议中,网络接口层位于第四层。由于网络接口层兼并了物理层和数据链路层所以,网络接口层既是传输数据的物理媒介,也可以为网络层提供一条准确无误的线路

来源:https://zhuanlan.zhihu.com/p/585079427
目前嵌入式薪资上涨的原因,我觉得很大一部分是芯片公司带起来的。特别是一些初创的GPU、AI、自动驾驶芯片公司,给得都比较高,当然老牌的一线大厂薪资也很可观。芯片行业是招嵌入式的大户,因为芯片从生产出来,需要写配套的固件、驱动等程序,这样才能形成软硬件生态,下游厂商才能够拿去就能够用或者进行二次开发。芯片行业薪资水平整体比较高,并且玩家多,跳槽也方便。
代表性公司:
(1)中国企业:海思、中兴微电子、联发科、紫光系列、兆易创新、长江存储、芯原微电子、哲库、平头哥、汇顶、地平线机器人、黑芝麻智能,寒武纪、摩尔线程、海光、兆芯、龙芯中科、安路、比特大陆等
(2)外企:AMD、英伟达、ARM、NXP、MPS、Intel等
(1)自动驾驶方向也算是目前嵌入式软件薪资给得比较高的行业之一,因为这个行业在国内发展时间不久,非常需要人才,需要高薪去吸引人才进入这个行业,并且自动驾驶企业融资一般也比较多,给得起钱。自动驾驶公司招嵌入式软件主要集中在中间件、操作系统开发和优化、车辆底层控制等方面。自动驾驶车辆本质上来说就是一个跑着各种算法的机械电子系统,所以它肯定需要嵌入式工程师。代表性的企业:小马智行、魔门塔、元戎启行、图森未来、文远知行等自动驾驶公司,百度,美团,京东等互联网公司,蔚来,理想,小鹏等新能源车企,比亚迪,吉利、长安等智能化比较好的传统车企,还有的话就是像华为、大疆这些公司也是在搞无人驾驶。
(2)机器人方向机器人这个其实和自动驾驶也是有重叠的,比如自动驾驶车本身就是一个移动机器人,像视觉、雷达、控制、地图等自动驾驶和很多机器人方向都要招。机器人国内主要就是扫地机器人、搬运机器人、物流机器人、工业制造机器人、飞行机器人等,机器人行业嵌入式软件需求也比较多,比如Linux、ROS、RTOS、驱动开发等需求量都是挺大的。代表企业:大疆、高仙、科沃斯、普渡、星猿哲、美的、汇川、石头科技、海康机器人等
消费电子比如手机,机顶盒,路由器,无人机、运动相机、安防设备等都是。这个行业必然是嵌入式招聘的大户,因为这些产品本质上就是个嵌入式系统,比如手机,跑的是系统是安卓,各种外设都需要写驱动,还要写相关应用程序。一般来说,这些企业招嵌入式软件基本是搞linux,rtos,裸机开发,各种协议开发这些方向。薪资主要看企业规模和产品的利润率,一般大公司,像华为、oppo、vivo、大疆等这些老牌一线厂商工资都还是比较可观的,其他的一些呢比上不足比下有余。代表性企业:华为,oppo,小米,vivo,荣耀等手机厂,大疆、影石、海康威视、大华、海信、TCL、联想等
传统汽车行业不像新能源汽车行业那么注重智能化,很多时候智能化靠其他厂商提供,并不自研,大多也是智能座舱和车机系统这种开发。当然嵌入式软件工程师还是要招的,比如车辆的整个电控系统、汽车电子、车机系统开发、智能座舱这些都是需要嵌入式的。传统车企一般来说给钱比较少一点,不如现在的蔚小理给钱多。(哔哔一句,我觉得汽车最重要的还是机械素质,智能化只能是锦上添花的东西)。代表性企业:吉利、长城、长安、奇瑞、广汽、东风、一汽等
国企军工呢主要就是一些研究所,比如像研究军用通信、雷达、飞机、兵器等,做这些东西必然是需要嵌入式开发的,不管是裸机开发还是操作系统需求量都比较大。薪资呢不算多,但优点是稳定,基本不会有啥裁员的情况。代表性企业:中国电子科技集团系列、航天科工系列、航天工业系列、中国兵器系列等,还有其他各种研究院、研究所都是这一类,还有像中兴、京东方、大唐、烽火等也都是国有企业。
这一类主要是家电、各种小电器、电子产品等。比如电视、冰箱、空调、洗衣机都是这一类产品。这些产品虽然可以用纯电路加机械就能实现,但是在现在智能化浪潮下,空调、冰箱这种越来越智能,所以对嵌入式软件工程师的需求也很大,而且现在的智能家具在蓬勃发展,相关的人才需求也越来越大。传统的这种电子电器行业薪资一般不高,但是需求量大。代表企业:美的、海尔、格力、TCL、海信等
主要是做网络以及通信设备,比如企业级的交换机、路由器、网络管理中心、小基站设备等等。这些产品很明显的也是一个嵌入式设备,比如一个路由器或者基站里面都会跑相关算法和控制程序等。代表企业:华为、新华三、锐捷、TP-link、腾达、迈普、思科、海格、爱瑞无线等
每个人手上都拿着一张随时可能会输的牌,在人生中寻找补救的方法。
― 星野道夫, 《在漫长的旅途中》
人只有在举棋不定,无从把握的时候才感到疲惫。只有去行动就能获得解放,哪怕做的不好也比无所作为强。
― 斯蒂夫·茨威格, 《创世纪》
虚心佐我闪光 谦卑助我制胜 德行辅我压迫
― 阿尔贝·加缪, 《堕落》