-
Template class, is a Template for classes. C++ provides us with a way where we can create a class that will serve as a blueprint/template for future classes. A template class will have generic variables and methods of type “T”, which can later be customized to be used with different data types as per the requirement.
这里老师问的应该是 C++模板类的意思是什么
首先需要了解 模板类 是什么,其实有个平级的概念叫做 模板函数 ,他们都是C++模板的基础,注意哦,这个模板在C++里面是核心,但是它理解起来不难,它是落实了面向对象编程的一种设计理念,用来简化代码量的,当然也是很容易学会的
这里有
runoob的一篇文章,做这个题目之前一定要先去仔细读一下这篇文章:https://www.runoob.com/cplusplus/cpp-templates.html读完过后相信你对模板函数和模板类已经有了一定的了解,但是可能对它具体的应用场景还是很模糊,事实上我们写的代码大量使用了模板的概念,
比如我们可能用过
std::list<int>来使用一个链表存储int类型的数据有没有想过这个
std::list<int>中的int为什么要用尖括号包裹起来呢?答案就是因为这里的list就是一个模板类,因为我们这个list类是从C++ STL库中直接调用的,我们如果点进去看它的具体实现的话,会发现这样一段代码template<typename _Tp, typename _Alloc = std::allocator<_Tp> > class list : protected _List_base<_Tp, _Alloc> { //...后面的省略了,因为充斥了大量宏声明,看起来很乱。
可以很明显看见,名称为list的这个类是一个template类,因为它有一个template关键词,然后紧接着有一个尖括号
<typename _Tp, typename _Alloc = std::allocator<_Tp> >,这说明了这个模板类它的创建也需要传入一个尖括号,这个尖括号里接收两个参数,第一个参数就代表我们这个链表里面存放的数据类型,也许是int或者string,当然这由你决定,第二个参数可以缺省,因为她有一个默认值是std::allocator<_Tp>,这个我们就不用管他其实上面的属于拓展了解,但是有个东西我们一定要牢记,就是模板类该怎么去定义,又怎么去根据一个模板类创建对象呢?
template <class type> class class-name { //...这里省略成员函数和成员变量 } //其实我们看很多库里面,它把class这个关键词提行写了,效果和上面其实是一模一样的,一定要辨别出来哦 template <class type> class class-name { //...这里省略成员函数和成员变量 } //还有一种情况就是它是这样声明一个模板类的 template <typename type> class class-name { //...这里省略成员函数和成员变量 } //看出来它和上面的不同了吗,没错就是在尖括号里面class和typename的区别,我们不去深究这两个关键词的意思,因为它们几乎是一模一样的意思 //区别在这里:https://liam.page/2018/03/16/keywords-typename-and-class-in-Cxx/ //不过我们可以初略理解为:class就是typename,无论它代码怎么写他们都是一样的东西!
当我们有了一个模板类的声明过后,我们怎么去根据这个模板类来创建对象呢?来看看下面这段代码
template <typename MI> class Dog{ public: int age; int getMyDogAge(){ return age; } MI keyword; MI getDogKeyword(){ return keyword; } } //我们创建一个Dog类 Dog<string> dog1; //再调用dog1.getDogKeyword()就可以返回string类型的keyword啦,尽管这里还没有赋值( Dog<int> dog2; //再调用dog2.getDogKeyword()就可以返回int类型的keyword啦,尽管这里还没有赋值(
-
template <typename T> class AddNum { public: void setMember(T newValue); protected: T member; };
Improved code reusability
模板类的意义就在于提高了代码的复用性,我们可以看看上面Dog的那个例子,如果不采用模板类,可能我们就需要提前声明两个类了
class Dog_KWD_STR{//关键词是string类型的Dog public: int age; int getMyDogAge(){ return age; } string keyword; string getDogKeyword(){ return keyword; } } class Dog_KWD_INT{//关键词是INT类型的Dog public: int age; int getMyDogAge(){ return age; } string keyword; string getDogKeyword(){ return keyword; } } //我们创建一个Dog_KWD_STR类 Dog_KWD_STR dog1; //再调用dog1.getDogKeyword()就可以返回string类型的keyword啦,尽管这里还没有赋值( Dog_KWD_INT dog2; //再调用dog2.getDogKeyword()就可以返回int类型的keyword啦,尽管这里还没有赋值(
-
注意看第二题的题干,第二题给的题干内容应该是出现在头文件的(.h文件),我们在
.cpp文件写方法的具体代码答案就是下面这个
template <typename T> void AddNum<T>::setMember(T newValue){ this->member = newValue; }
-
这个题是承接第3题的,从左到右依次解释每个名词:
template表明这是模板类 中 的一个函数<typename T>表示这个这个函数的泛型变量取名为Tvoid表示这个函数的返回值是空类型voidsetMember表示这个函数的名称,由题干中的声明中可以得到,这就是我们需要具体完善的函数(T newValue)表示这个函数接收的类型是泛型T的变量,因为它是一个泛型变量,所以它有无限种可能,它在具体应用中可能是一个int,可能是string,可能是char,也有可能是一个vector,等等...this->member = newValue表示把形参newValue的值赋给成员属性member,注意这个member是个泛型为T的成员属性,所以他和newValue都是同一种类型
-
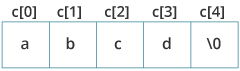
在 C 编程中,字符串是以空字符结尾的字符序列
\0。例如:char c[] = "c string";
当编译器遇到双引号括起来的字符序列时,它
\0默认在末尾附加一个空字符如何声明一个字符串?
以下是声明字符串的方法:
char s[5];
在这里,我们声明了一个 5 个字符的字符串。
如何初始化字符串?
这个应该是回答的重点
char c[] = "abcd"; char c[50] = "abcd"; char c[] = {'a', 'b', 'c', 'd', '\0'}; char c[5] = {'a', 'b', 'c', 'd', '\0'};
-
char* reverseName(char *s) { // 获取字符串长度 int len = 0; char *p = s; while (*p != 0) { len++; p++; } //复制一份输入的字符串,因为题目要求我们不能直接对原字符串进行翻转 char *s_copyed = new char[len]; memcpy(s_copyed,s,len); // 交换 ... int i = 0; char c; while (i <= len / 2 - 1) { c = *(s_copyed + i); *(s_copyed + i) = *(s_copyed + len - 1 - i); *(s_copyed + len - 1 - i) = c; i++; } return s_copyed; }


class Cubeside{
public:
virtual char * getName()=0;
}
Class DialSide: public Cubeside {
public:
char *getName() override;
void setDial(uint16_t value);
protected:
uint16_t dialvalue =0;
static char const * dialName="xxyy";
};-
-
首先讲一下下面这个
uint16_t dialvalue =0;吧,这个非常简单,它就是一个protected访问限制的普通成员属性,这里用了=0只是为了给它初始化赋值为0,这个uint16_t就是typedef起的别名,它的定义在库函数中(typedef unsigned short uint16_t;),我们就无需过多思考啦,但是我们要知道它是一个unsigned short,为两个字节哟!! -
然后就是
virtual char * getName()=0;这个地方用到了"=0",这里的意思是声明了一个纯虚函数!纯虚函数!纯虚函数.....
虚函数是和多态这个概念紧密联系的,在Java里面每个类的成员函数都是虚函数,所以对这个虚函数的理解就比较容易,C++里面的虚函数就需要
virtual这个关键词来声明,具体什么情景下使用需要狠狠阅读菜鸟教程,可能和模板类一样的有一点点抽象,但是一定要耐心阅读,因为它们在面向对象编程里面都是非常非常非常重要的概念。然后就是纯虚函数的概念,一定要去感觉一下
我觉得有几点关于虚函数的一定一定一定要强调一下
虚函数只能借助于指针或者引用来达到多态的效果。而且虚函数的特性想要体现出来,一定会存在类的继承
-
定义一个函数为虚函数,不代表函数为不被实现的函数。
-
定义他为虚函数是为了允许用基类的指针来调用子类的这个函数。
-
定义一个函数为纯虚函数,才代表函数没有被实现。
-
定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序员必须实现这个函数。
-
-
Cubeside *c1 =new Cubeside (); Cubeside *c2 = new DialSide ();
cl->getName(); c2->getName();
这里老师让解释这两行代码的效果,注意看
getName函数,这是一个虚函数,因为这个函数在基类(父类)Cubeside类中被声明为virtual了c1 是基类(父类)/Cubeside类 的指针,当我们通过这个指针去调用getName()方法时,会去虚函数表中寻找getName函数的真实地址,因为这个指针指向的对象是Cubeside类的对象,那么调用的方法也会是 Cubeside类中的getName方法,然后当我们调用的时候会发现报错,为什么呢?因为这是一个纯虚函数,纯虚函数是没有函数内容的,所以这个函数调用会报错!
c2 也是基类Cubeside类的指针,
Cubeside *c2 = new DialSide ();尽管等号右边返回值应该是一个(DialSide对象的指针),这里应该是有一个隐式转换,把(DialSide* 偷偷转换 成了 Cubeside*),那么这样会出现什么效果呢?我们前面说了,虚函数的特性想要展现出来必须通过指针,这里指针类型虽然是Cubeside,但是指向的内存是DialSide类的对象,当我们调用它的getName方法时,会去虚函数表中寻找getName函数的真实地址,由于虚函数的特性是允许用基类的指针来调用子类的这个函数,所以这个时候会调用子类即DialSide类中重写了的getName函数,根据题目已知信息是无法获得结果的(题干中看不到getName函数的具体实现,但是执行c2->getName();调用的一定会是子类(DialSide类)中重写(override)了的getName函数
-
Improve the readability of the function interface, facilitate the expansion of the software, and improve the maintainability
提高了函数接口的可读性,有利于软件的扩展,提高了可维护性
这个可能还很难感觉到它的优势,因为除了C、C++这些语言,都没有把声明(.h)和实现(.cpp)分开写,但是老师这里还让我们解释为什么分开写,其实C++不使用.h(不分开写)一样的能够实现程序功能。只是那样会导致不是很美观,然后链接时会出现一些小问题,反正大家都在分开写我们也分开写吧!考试考到了就写上面的答案
-
这里老师的意思是如何编译创建一个动态库文件,这里又涉及到了一个动态库的概念了,我们以前在Clion中写的程序是通过CMake直接编译成了可执行文件(Windows 下文件后缀名为.exe),但是动态库文件的后缀名是(在Windows下是.dll),怎么办呢?这时候我们需要修改项目中的CMakeLists.txt文件,Clion左边的目录树可以直接看到这个文件
cmake_minimum_required(VERSION 3.21) project(pig) set(CMAKE_CXX_STANDARD 14) # 这行不要=>add_executable(myPigApp main.cpp) #Cmake配置文件里面这样写,注意()内的三个参数 #第一个代表动态库的名称,不用写后缀名(如Windows下的.dll,Linux下的.so) #第二个值是(SHARED,STATIC,MODULE,EXCLUDE_FROM_ALL)里面的一个,题目要求我们是创建共享库,所以我们就填SHARED就行啦 #第三个值是被编译的文件,如果有多个文件则需要用逗号分隔 add_library(myPigShared SHARED main.cpp,main.h)
按照上面的配置,我们再通过Clion->Build->Build Project即可创建(编译)一个名为myPigShared.dll的文件在当前Project的
cmake-build-debug目录下,当然如果我们是Linux的系统编译出来的文件名称可能是myPigShared.so,这个不用考虑太多 -
直接把上面的配置文件稍微一改就可以嘞,注意看它们的区别哟
cmake_minimum_required(VERSION 3.21) project(pig) set(CMAKE_CXX_STANDARD 14) #括号里面的参数是 (可执行文件名称 被编译的文件名称) add_executable(myPigApp main.cpp,main.h) #Cmake配置文件里面这样写,注意()内的三个参数 #第一个代表动态库的名称,不用写后缀名(如Windows下的.dll,Linux下的.so) #第二个值是(SHARED,STATIC,MODULE,EXCLUDE_FROM_ALL)里面的一个,题目要求我们是创建共享库,所以我们就填SHARED就行啦 #第三个值是被编译的文件,如果有多个文件则需要用逗号分隔 #不是这个了=>add_library(myPigShared SHARED main.cpp,main.h)
-
cmake_minimum_required(VERSION 3.21) project(pig) set(CMAKE_CXX_STANDARD 14) #引入头文件环境变量目录,这里一般是导入第三方库的.h头文件,cpp或者h文件中#include会自动去搜索这些头文件 #比如我这里用了Unicorn这个开源库,我们通过这种方式导入头文件,否则我们在#include "unicorn.h"的时候编译器要提示我们找不到这个头文件(这个头文件来自第三方库) include_directories("D:\\unicorn\\include") #引入链接目录 lib 或者 dll so文件的目录,自动去搜索该目录下的lib so dll文件 #比如我这里要用Unicorn库的unicorn.dll文件来作为依赖项编译我们的程序,我们先找到unicorn.dll这个dll的目录,然后把路径填在下面的括号内 #这个目录下有unicorn.dll、unicorn.lib文件 link_directories("D:\\unicorn\\msvc\\Win32\\Debug") #生成可执行文件,还没有链接,等下还需要下一步 add_executable(myPig main.cpp,main.h) #上面link_directories设置了目录后,我们的程序已经编译完成了,现在需要给链接器指明链接的库文件具体名称,注意括号内的第一个参数是 我们的程序的最终名称,第二个参数才是依赖项的名称 target_link_libraries(myPig unicorn.dll,unicorn.lib)
-
我感觉我曲解了老师的意思,上面的答案好像都是用来回复这个问题的
不过上面几个题的答案是没错的,CMake作为跨平台编译工具,它的指令是非常非常精简的,我们编译一个程序肯定是首选CMake
如果上面几个小题我们都使用编译器参数的话会非常复杂,而且编译器的种类太多,每个编译器的参数名称又不一样,所以不说了
举个例子,Clion默认选择的Ninja作为编译工具 ,如果精力比较好可以去看看生成的build.ninja文件,参数非常多,非常不容易读
如果用其他编译器比如gcc,vc,Clang等编译器,参数也不一样,很麻烦很复杂
typedef struct{
char name[10];
char gender[6];
}student;-
讲这个题之前先讲一下这个题干吧
typedef struct{ char name[10]; char gender[6]; }student; //这是一个结构体的声明,typedef这个见过吧? typedef int littleInt; //这个意思就是 给int取了一个别名 叫 littleInt //所以以后我们创建一个int类型的变量可以通过这个方式了 littleInt a; //注意哦,它只是一个别名,所以和以下语法一模一样的效果 int a; //回到这个typedef struct吧 //以前struct是怎么声明的呢?是不是这样 struct student{ char name[10]; char gender[6]; } //所以我们每次创建一个结构体都需要以下的语法 struct student stu_liran; //为了减少代码量,我们使用typedef 简化了 struct student,就如同最上面那种语法,以后创建结构体就只需要以下写法了 student stu_liran; //是不是发现可以少写个struct关键词,就这么简单!
回到这个题,因为被copy的字符串只有5个字节,目标指针是一个长度为10的char数组,所以完全能够存放下这5个字符,不会发生任何问题
student liran; strcpy((char*)stu_liran.name, "liran"); std::cout << stu_liran.name; //当我们打印时,也不会出现任何问题,看后面的意思,老师是想考边界溢出,因为strcpy函数不是一个安全的函数
-
这个地方就有点意思了,老师考的很刁钻啊,10字节的string,当我们调用strcpy函数的时候,因为C语言里面的字符串是以0x00结束的,所以我们strcpy过去的值将不再仅仅是10个字节,将会从name的指针开始copy11个字节过去,这样会导致数据溢出,多出来的那一个字节(字符串结尾的0x00这个字节)将会按照内存中的顺序写入到gender变量的第一个字节
我们来看看下面这个例子吧
student student_liran; student_liran.gender[0] = 'g'; student_liran.gender[1] = 'i'; strcpy((char*)student_liran.name, "aaaabbbbcd"); std::cout << student_liran.name; std::cout << student_liran.gender;
猜猜结果是什么?
name变量是"aaaabbbbcd",但是gender变量变成了[0,'i',0,0,0,0],是不是发现这和我们预期的['g','i',0,0,0,0]不相同了?
对的,这就是strcpy这个危险函数导致的数据溢出
-
和上面相同,这次将会溢出两个字节
student student_liran; student_liran.gender[0] = 'g'; student_liran.gender[1] = 'i'; student_liran.gender[2] = 'r'; strcpy((char*)student_liran.name, "aaaabbbbcde"); std::cout << student_liran.name; std::cout << student_liran.gender;
在这样的前提下,gender将会被赋值为['e',0,'r',0,0,0]
-
这就溢出的更猛了,我们将这个结构体声明在栈内存中,所以当strcpy了20个字符时!
也许栈帧的返回值就被篡改了,说不定还会篡改到其他特殊的变量值,这个和程序上下文有关,不出意外的话程序会Crash掉,这对于一个程序来说是非常非常非常非常危险的
世界顶级软件攻防中,往往就采用这种PWN的常规手段构造代码任意执行,哎不科普了真的太厉害了那些人
-
emmm.终于要写完了!yes!
Your program performs the operation :
int x;
std::ifstream fileStream("test.txt");
fileStream >> x;首先说明一点,如果test.txt里面是这样的内容
#file test.txt
996
那么,这个程序一定一定一定不会按照预期,将996这个数字存到x变量中
为什么呢?因为这个文本里面的可见数字是ASCII编码后的字符
如果我们用二进制文本查看器,看看test.txt的本质是什么,我们会发现它长这个样子
0 1 2 PlainText
0000h: 39 39 36 996
注意这个39是指16进制(Hex) 的0x39 同理 36 是指 16进制(Hex) 0x36
所以这个996其实表示的是3个字符,我们通过查阅ASCII表可以发现它的对应关系:ASCII在线查询
回到这个问题中来,题目问会发生什么事情,当然就是这个int被赋值为[0x39,0x39,0x36,0x00],一共4个字节,在小端序下用int展示就是值为3553593的数字
//测试代码
char* text = "996";
int* i = (int*)text;
std::cout << *i<<std::endl; //结果3553593
std::cout << 0x39393600<<std::endl;//结果960050688
std::cout << 0x00363939; //结果3553593所以如何避免呢?因为这种方法读一个int一定不会是我们的预期值
我们可以采用C++ STL库的stoi函数来对char*变量进行一个格式化处理
char* text = "996";
int* i = (int*)text;
std::cout << *i<<std::endl; //结果3553593
int realInt = std::stoi(text);
std::cout << realInt; //结果996