本文简单记录下如何用 Node.js 开发一个 Alfred workflow 的过程。
之前开发过自己用的小工具,这次打算开发 CDNSearcher,用了半天才回忆起来开发流程,我在想如果之前简单记录了下,或许这次就不用花那么长时间回顾了,遂写此文。
该 workflow 使用方式如下:(使用请点击 这里)

关于 Alfred 以及 Alfred workflow 的使用,这里不赘述,推荐看下这篇 Alfred 神器使用手册,很详细,里面涉及了一些我常用的功能。
个人理解,workflow 是一种简单的 in-out 的形式,简化了中间过程重复的操作,能极大提高效率。许多 chrome 扩展以及命令行工具都可以做成 Alfred workflow 的形式,使之更加通用(很常见的比如 chrome 翻译扩展,图床工具 等等,可以自己脑洞大开)。
接着我们一步步来开发 CDNSearcher 这个 workflow。
首先打开 [Alfred Preferences],在左上角选择 [Workflows] 这个 tab。然后点击左下角的 [+],选择 [Blank Workflow],会出现如下一个弹窗,填写一些关于这个 workflow 的信息。这里注意下 [Bundle Id] 这个 key,这是代表 workflow 的唯一指定 id,需要填写一个唯一的字符串。
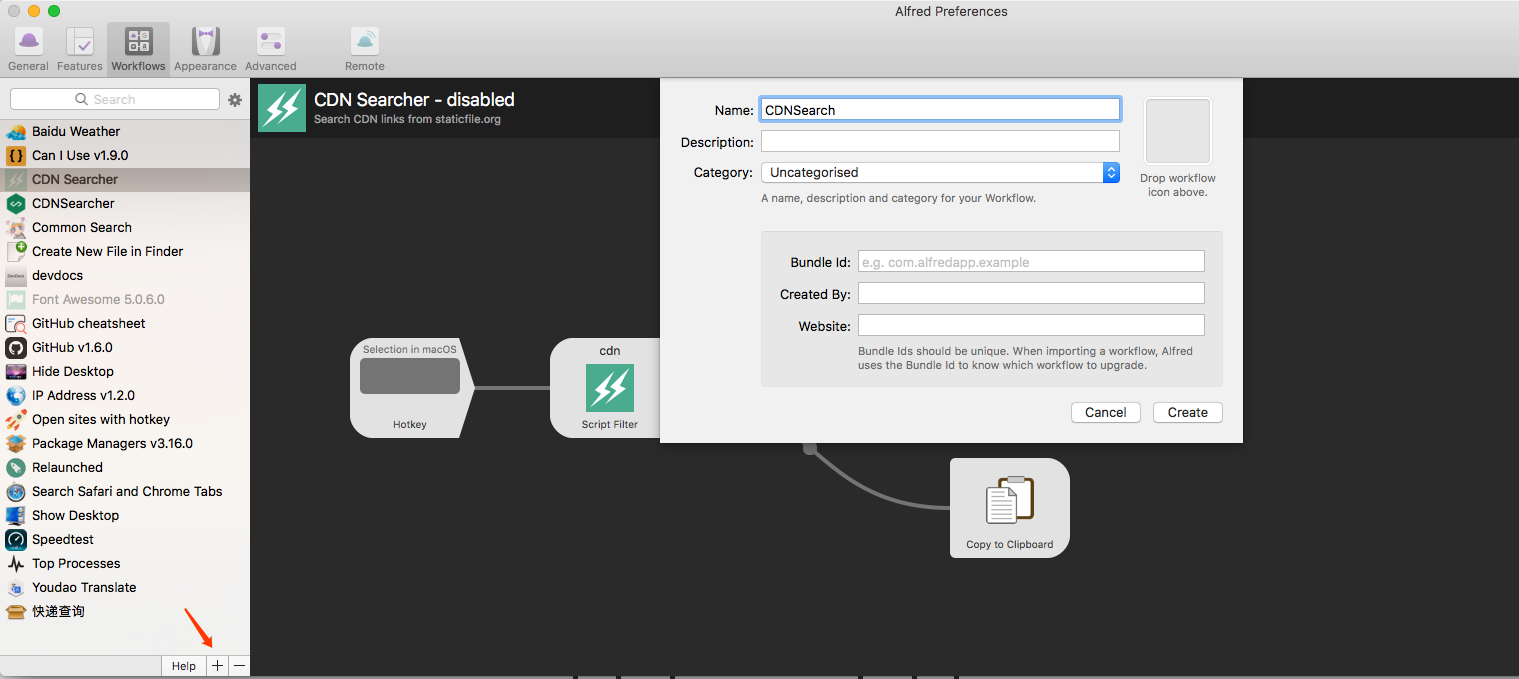
接着左侧的列表便会出现这个新建的 workflow,右键 -> Open In Finder,便可以看到这个 workflow 文件。此时只有一个 info.plist 文件,暂时不用关注它,也无需编辑它,之后在 Alfred 中每一次图形化操作的过程中都会自动更新这个文件。
我们直接看这个编辑好的流程图,操作非常简单,直接右键添加,并且可以自己拖拽,形象地演示了这个 workflow 的步骤:
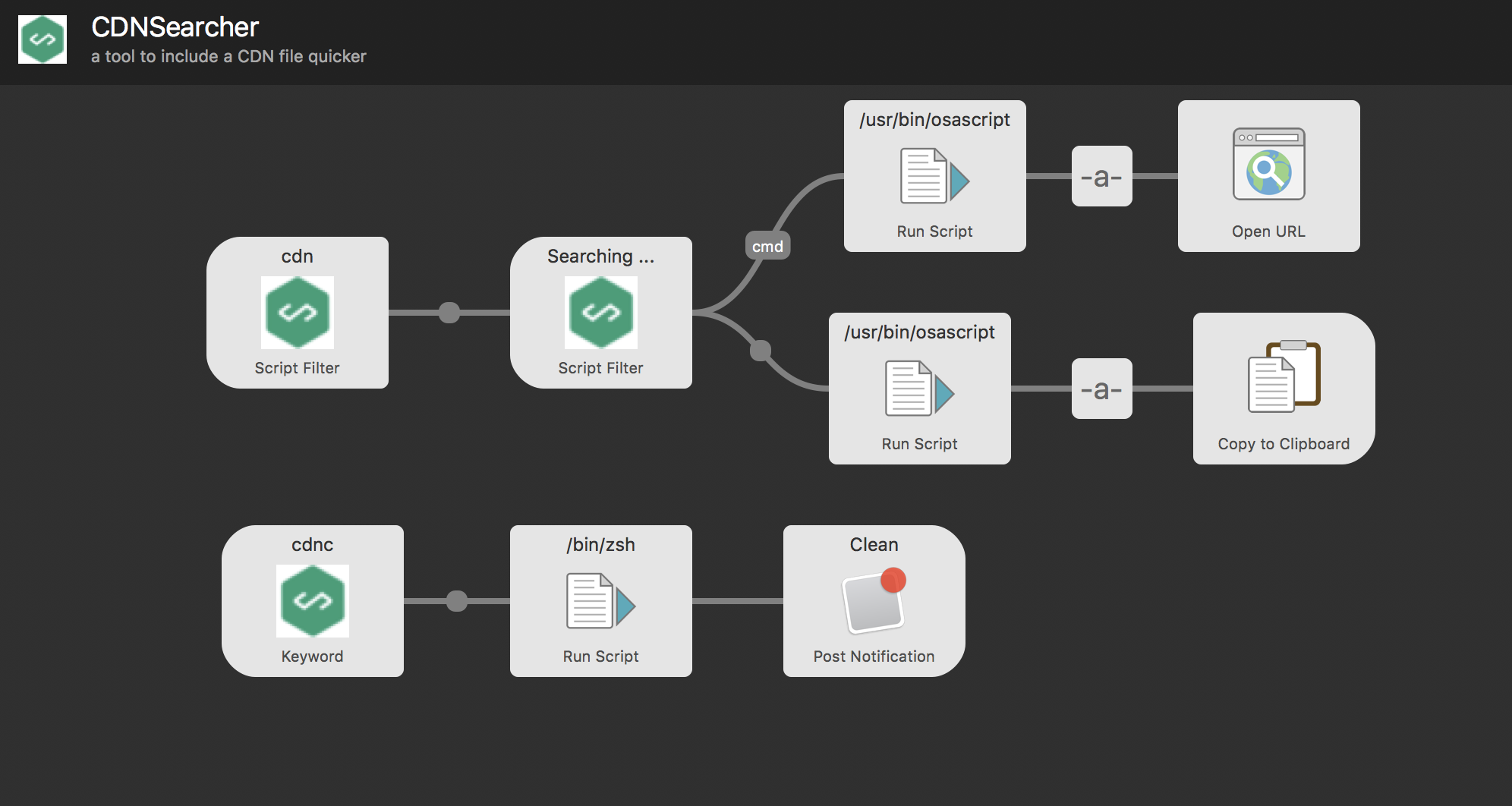
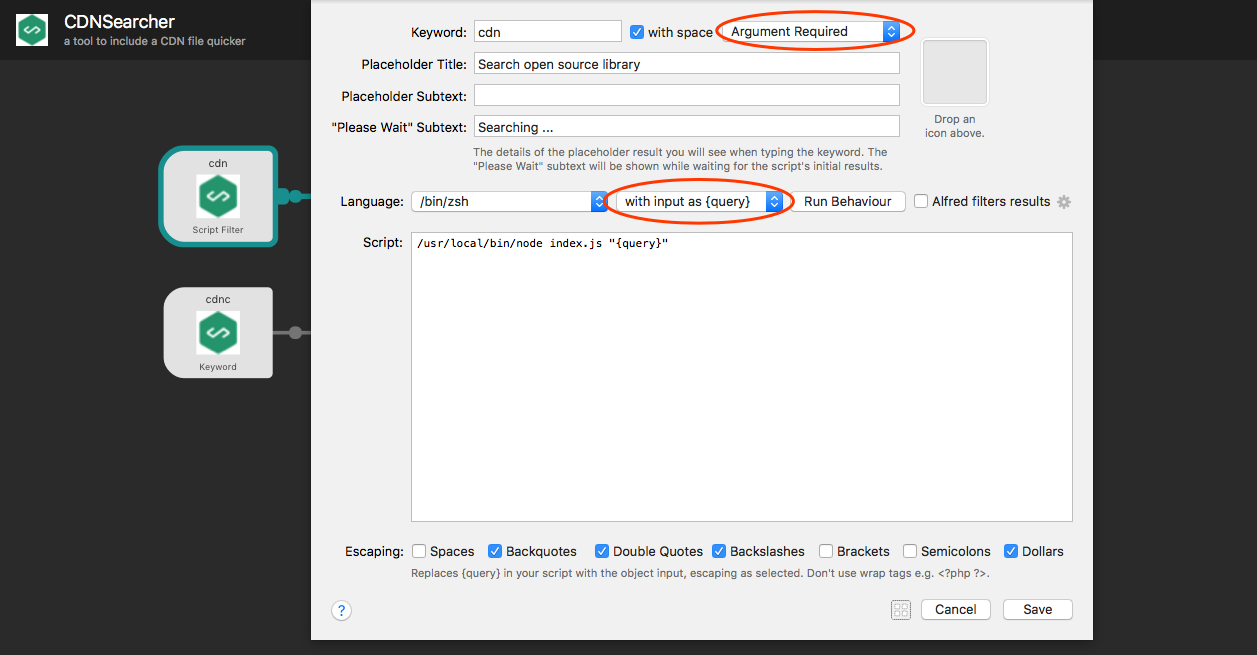
我们看最左上角的这个,这是一个 [Script Filter]。常见的 workflow,需要自己输入关键字,脚本执行后出现列表,基本都是 [Script Filter] 了。双击打开它,如下所示:
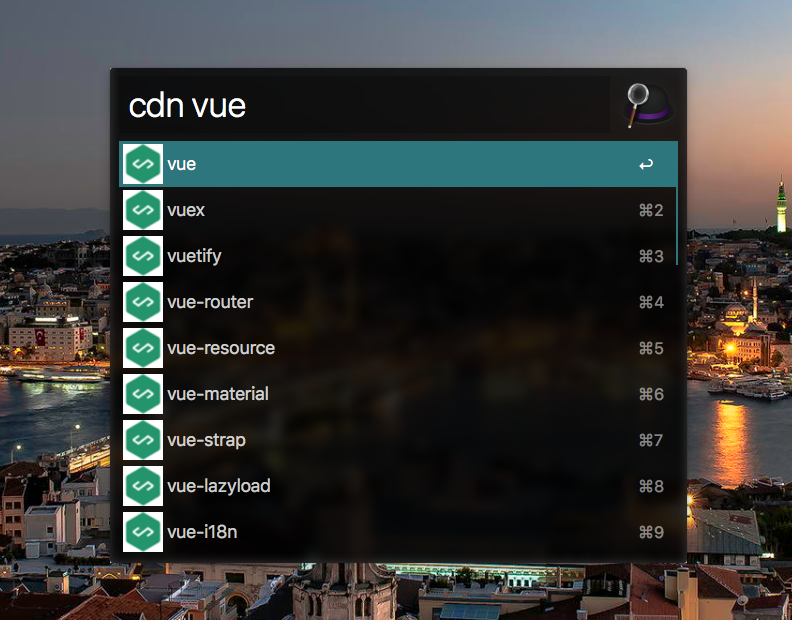
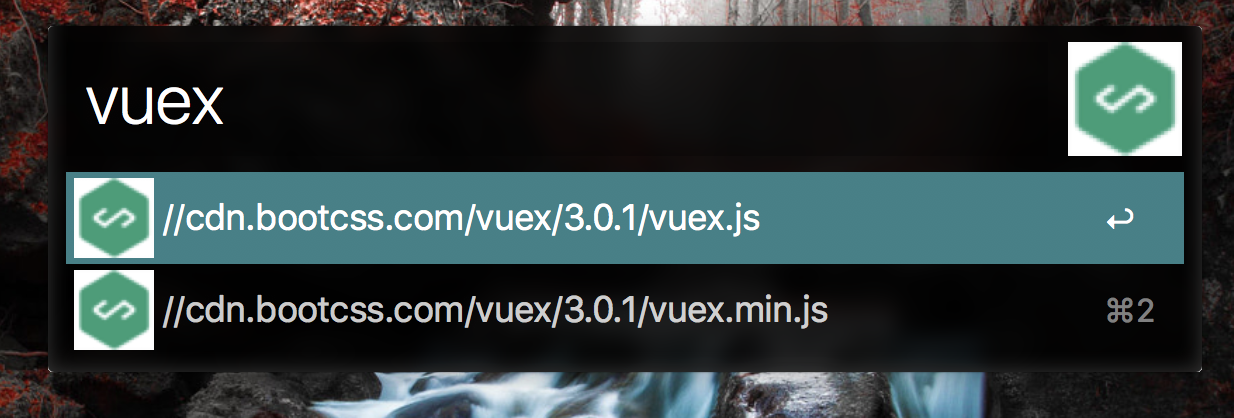
回顾一下使用这个 workflow 的步骤,比如要搜索 vue 相关的 cdn,呼出 Alfred 后键入 cdn vue,然后会出现列表如下:
输入的 vue,其实就是 {query},然后会自动执行这行命令 /usr/local/bin/node index.js "{query}",{query} 会自动被自己输入的字符串代替,这里就很熟悉了吧,执行一个 node 脚本,这个脚本非常简单,无非就是做一个 HTTP 请求,分析并得到一些数据。
如何展示这些数据?如果用的是 js,代码中 console.log() 的数据便会展示在 Alfred 前台。具体看 这个文件(所以用 js 开发的时候,debug 不能用 console.log,可以用 console.warn 等代替)。最终的展示是一个数组,每个元素是一个对象,可以包括如下几个 key:(更多可参考 Script Filter JSON Format)
- title
- subtitle
- icon
- arg
注意一下 arg,按回车后,Alfred 会把这个变量传递给下一个步骤(比如进入粘贴板,或者在浏览器打开,或者继续传入下一个脚本去执行,等等)
我们试了几次,可能会发现 query 的内容还没输入完,就已经显示结果了(即内容还没输入完,脚本就在执行了),我们希望 query 输入完整后再执行脚本,有点类似 js 中的函数节流去抖的意思。单击 [Run Behaviour] 进行调整即可:
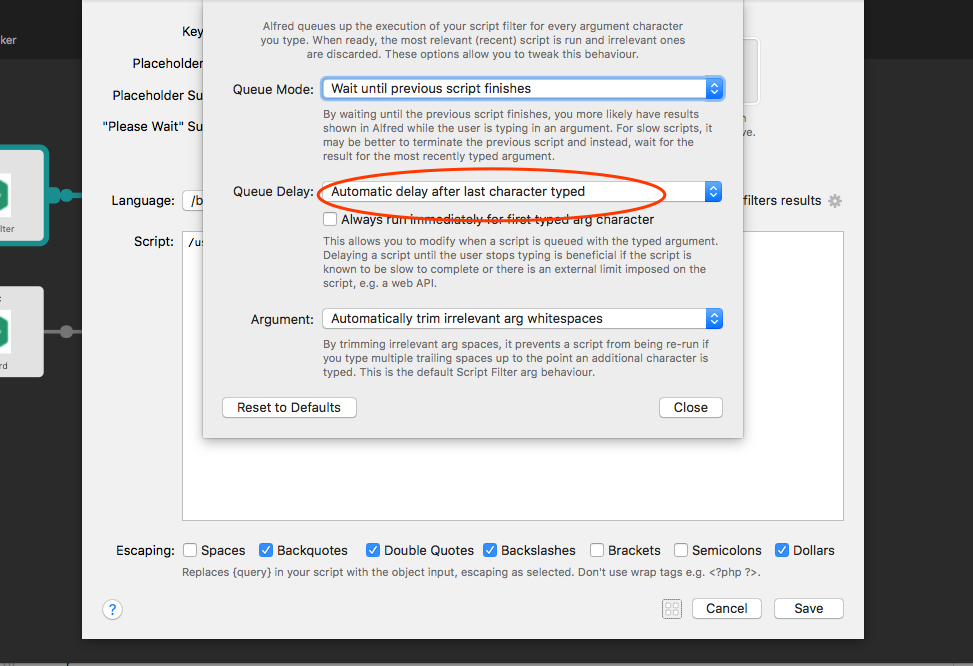
这时我们已经完成了第一步,我们需要完成第二步。还是以上面的 cdn vue 为例,这个列表中,我选择了 vuex,是如何得到以下结果的?
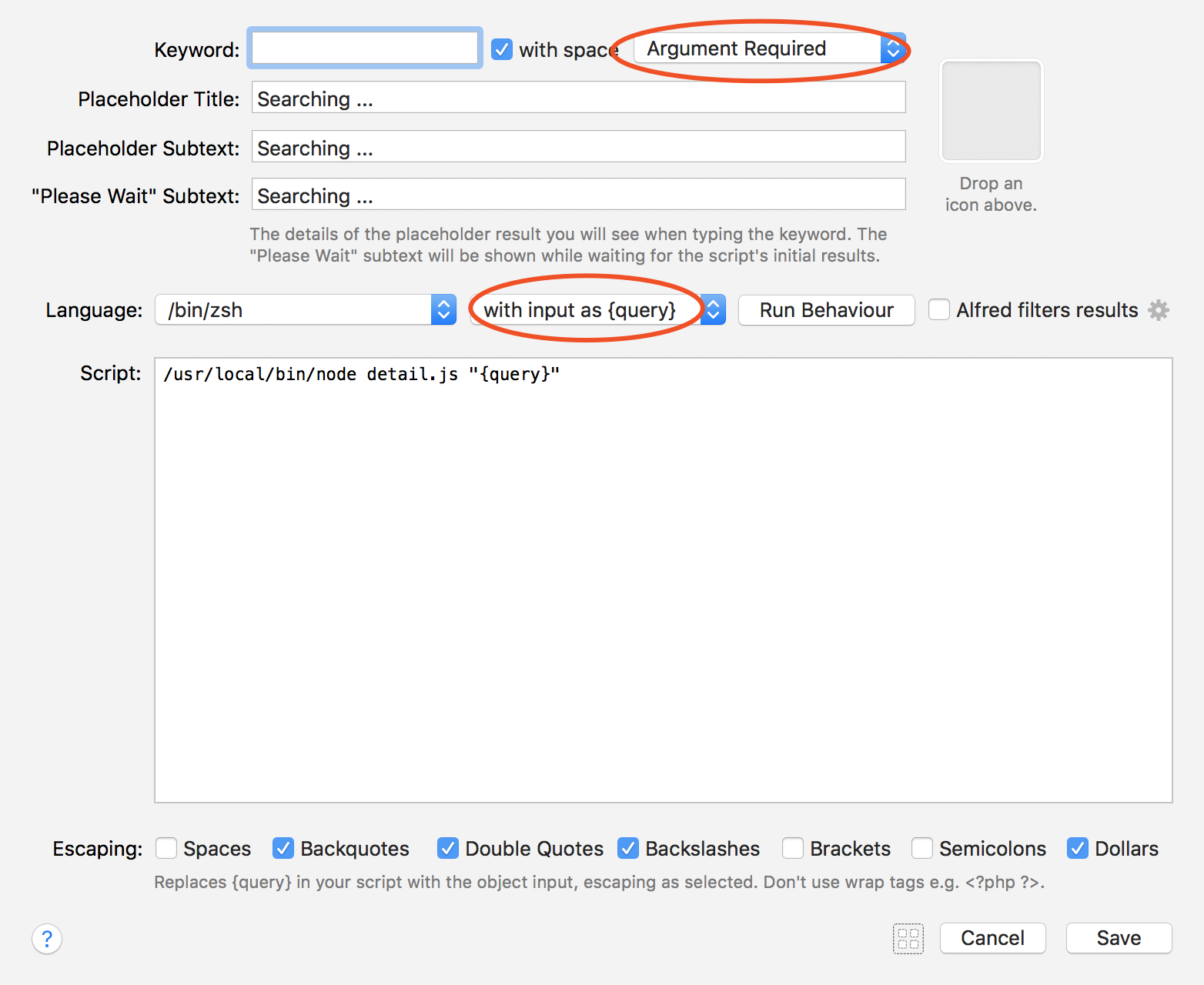
其实这还是一个 [Script Filter],只不过它的 {query} 就是上个步骤的执行结果,而且不需要 [Keyword] 了。
大概长这样:
这部分代码 在这里。最后在流程图上加上 [Copy to Clipboard],enter 后便会复制到粘贴板。
在实际开发的过程中,我希望 enter 后复制 CDN 的链接,cmd+enter 能够在浏览器中打开该 CDN 文件。因为这两步的内容是不一样的,所以需要分两步走。在第二个 [Script Filter] 中,我们可以得到 CDN 的链接,但是如果要引用,我希望能加上 <script> 或者 <style> 标签,这里我又用了一个 [Run Script],继续拼接字符串,因为这个代码比较简单,所以直接用了 Alfred 提供的选项 /usr/bin/osascript(JS):(提醒下,我先用了 ES6 的模版字符串,报错了 ...)
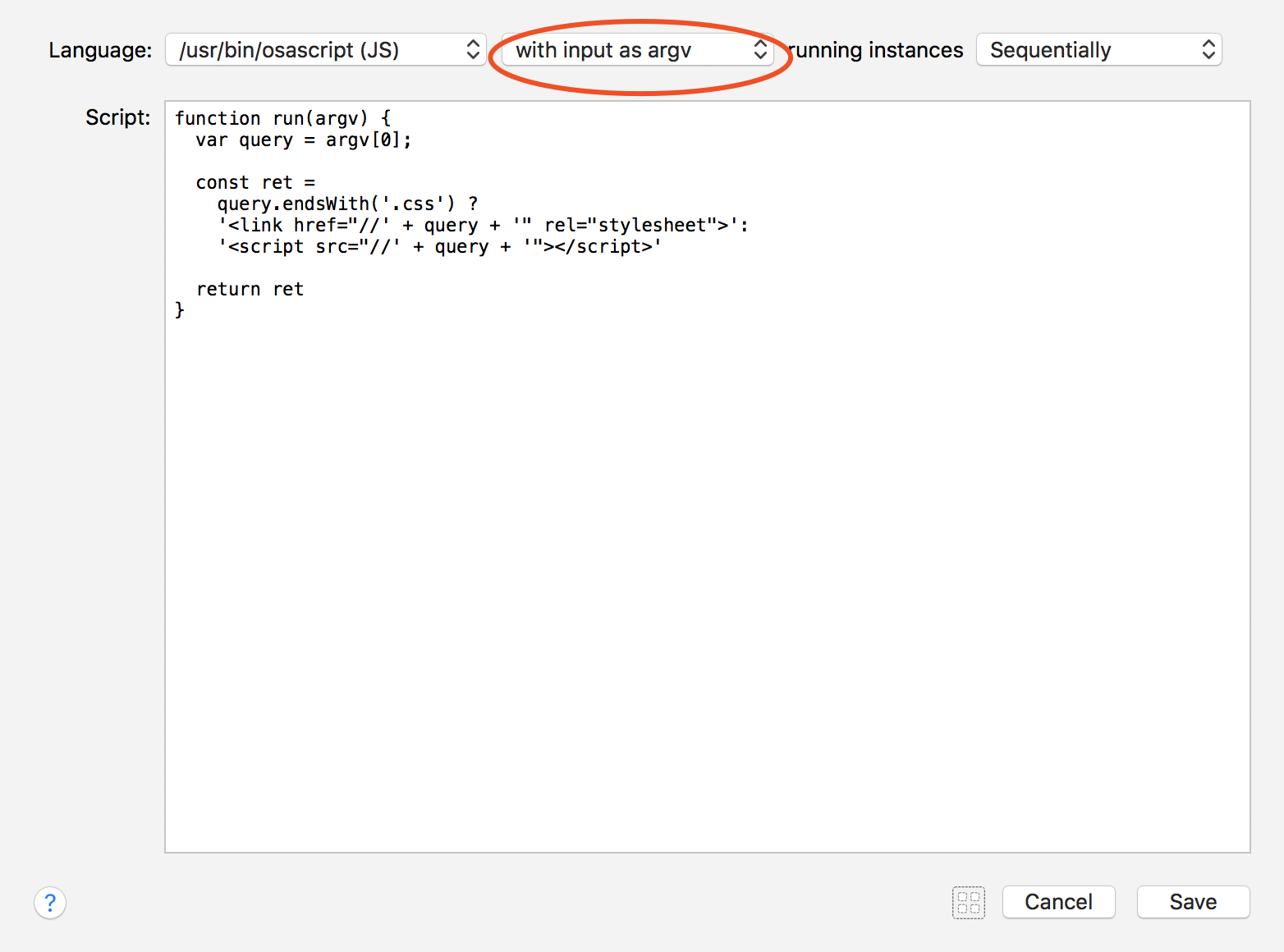
这里又出现了问题,[Run Script] 后返回的字符串,会自动多加一个回车,搜索引擎是个好东西,[Utilities → Transform → Trim Whitespace] 完美解决,详见 这里
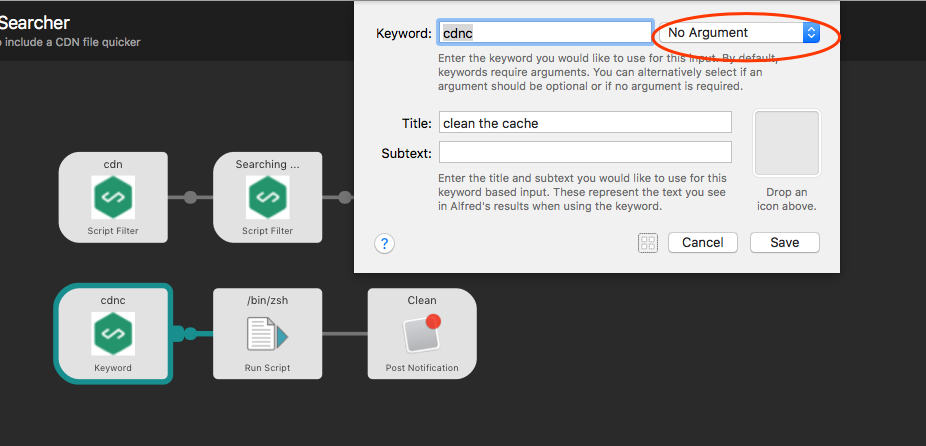
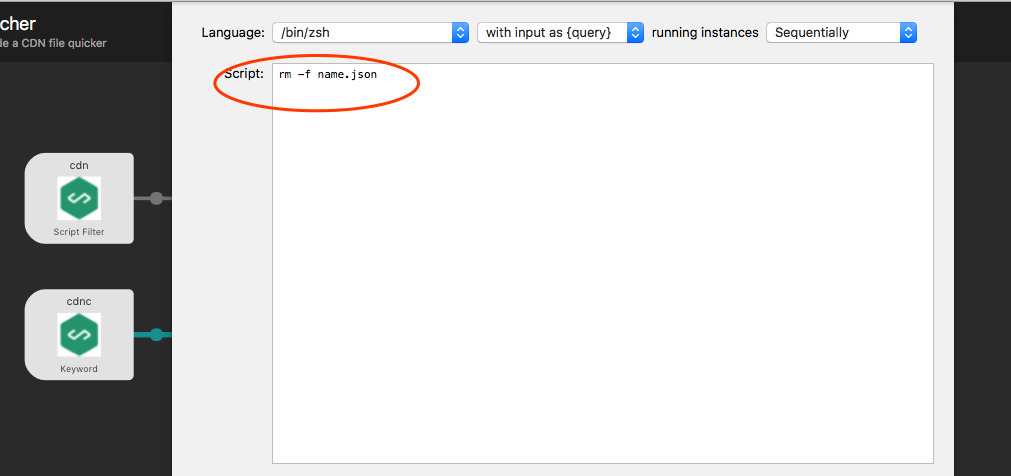
另外一条流程主要是为了删除文件缓存,就不需要 [Script Filter] 了,直接在命令行执行就 ok 了。
至此,这个简单的 workflow 算是完工了。
2023-02-13 Add:
项目中是这样去执行脚本 /usr/local/bin/node index.js "{query}",但是并不是每个用户的电脑中都有 /usr/local/bin/node 这个路径。因为 Alfred 中 zsh 的执行环境和电脑中是隔离的,所以也不能直接用 node xx 去执行
所以需要手动修改下执行路径,可以用 which node 来拿到,然后替换下
也可以用 echo $PATH 获取电脑中所有的执行路径,然后加到 workflow 上:(此时需要确保安装过 Node 并且在命令行里执行 node xx 没问题,这样其实运行 node xx 就会去 PATH 里面找)
PATH=/Users/bytedance/.nvm/versions/node/v16.18.1/bin:/usr/local/bin/:/usr/local/opt/node@14/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/opt/puppetlabs/bin
node index.js "{query}"另一种方式参考 alfred-fkill,用 run-node 去实现,个人认为更通用点,这样用户不需要修改