在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型Recurrent Neural Network (RNN).

近年来随着深度学习的发展,模型参数数量飞速增长,为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集成本过高,非常困难,特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 能够习得通用的语言表示,将预训练模型Fine-tune到下游任务,能够获得出色的表现。另外,预训练模型能够避免从零开始训练模型。
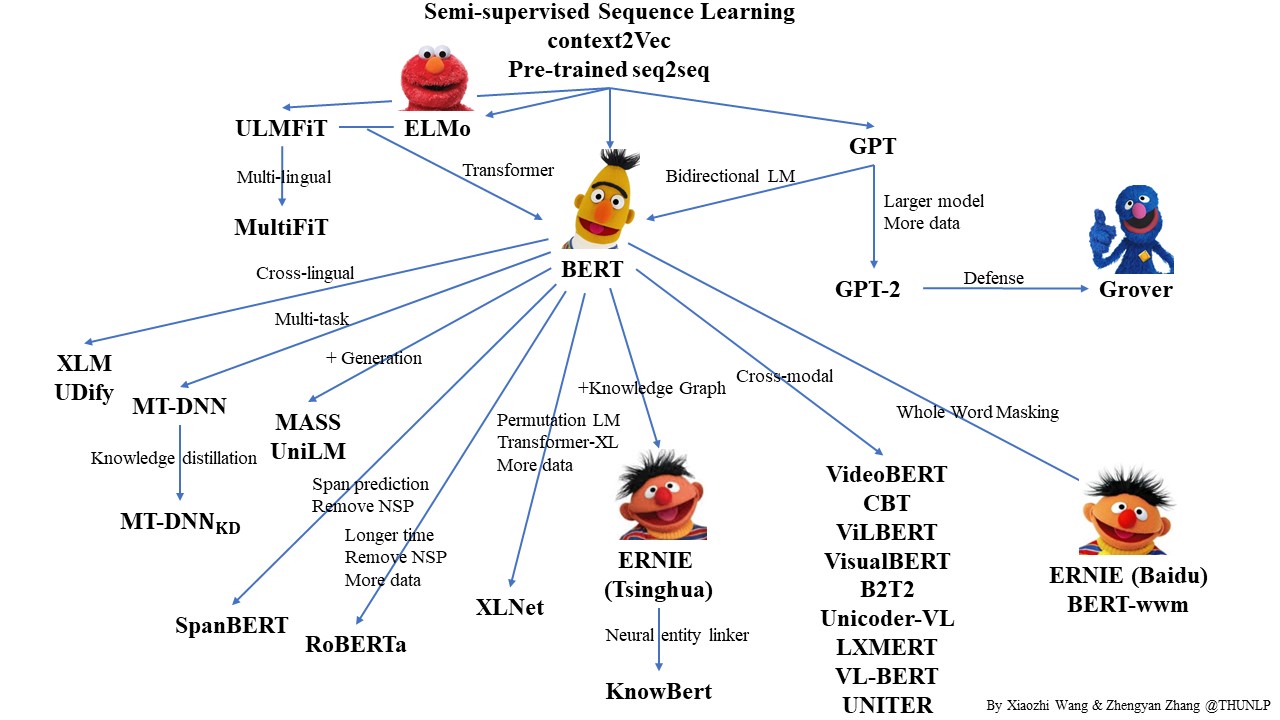
本示例将展示如何使用PaddleHub Transformer模型(如 ERNIE、BERT、RoBERTa等模型)Module 以动态图方式fine-tune并完成预测任务。
我们以微软亚洲研究院发布的中文实体识别数据集MSRA-NER为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证。通过如下命令,即可启动训练。
# 设置使用的GPU卡号
export CUDA_VISIBLE_DEVICES=0
python train.py使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
在命名实体识别的任务中,因不同的数据集标识实体的标签不同,评测的方式也有所差异。因此,在初始化模型的之前,需要先确定实际标签的形式,下方的label_list则是MSRA-NER数据集中使用的标签类别。
如果用户使用的实体识别的数据集的标签方式与MSRA-NER不同,则需要自行根据数据集确定。
label_list = hub.datasets.MSRA_NER.label_list
label_map = {
idx: label for idx, label in enumerate(label_list)
}接下来创建任务所使用的model
import paddlehub as hub
model = hub.Module(name='ernie_tiny', version='2.0.1', task='token-cls', label_map=label_map)其中,参数:
name:模型名称,可以选择ernie,ernie_tiny,bert-base-cased,bert-base-chinese,roberta-wwm-ext,roberta-wwm-ext-large等。version:module版本号task:fine-tune任务。此处为token-cls,表示序列标注任务。label_map:数据集中的标签信息,实体识别任务中需要根据不同标签种类对模型性能进行评价。
PaddleHub还提供BERT等模型可供选择, 当前支持序列标注任务的模型对应的加载示例如下:
| 模型名 | PaddleHub Module |
|---|---|
| ERNIE, Chinese | hub.Module(name='ernie') |
| ERNIE tiny, Chinese | hub.Module(name='ernie_tiny') |
| ERNIE 2.0 Base, English | hub.Module(name='ernie_v2_eng_base') |
| ERNIE 2.0 Large, English | hub.Module(name='ernie_v2_eng_large') |
| BERT-Base, English Cased | hub.Module(name='bert-base-cased') |
| BERT-Base, English Uncased | hub.Module(name='bert-base-uncased') |
| BERT-Large, English Cased | hub.Module(name='bert-large-cased') |
| BERT-Large, English Uncased | hub.Module(name='bert-large-uncased') |
| BERT-Base, Multilingual Cased | hub.Module(nane='bert-base-multilingual-cased') |
| BERT-Base, Multilingual Uncased | hub.Module(nane='bert-base-multilingual-uncased') |
| BERT-Base, Chinese | hub.Module(name='bert-base-chinese') |
| BERT-wwm, Chinese | hub.Module(name='chinese-bert-wwm') |
| BERT-wwm-ext, Chinese | hub.Module(name='chinese-bert-wwm-ext') |
| RoBERTa-wwm-ext, Chinese | hub.Module(name='roberta-wwm-ext') |
| RoBERTa-wwm-ext-large, Chinese | hub.Module(name='roberta-wwm-ext-large') |
| RBT3, Chinese | hub.Module(name='rbt3') |
| RBTL3, Chinese | hub.Module(name='rbtl3') |
| ELECTRA-Small, English | hub.Module(name='electra-small') |
| ELECTRA-Base, English | hub.Module(name='electra-base') |
| ELECTRA-Large, English | hub.Module(name='electra-large') |
| ELECTRA-Base, Chinese | hub.Module(name='chinese-electra-base') |
| ELECTRA-Small, Chinese | hub.Module(name='chinese-electra-small') |
通过以上的一行代码,model初始化为一个适用于序列标注任务的模型,为ERNIE Tiny的预训练模型后拼接上一个输出token共享的全连接网络(Full Connected)。

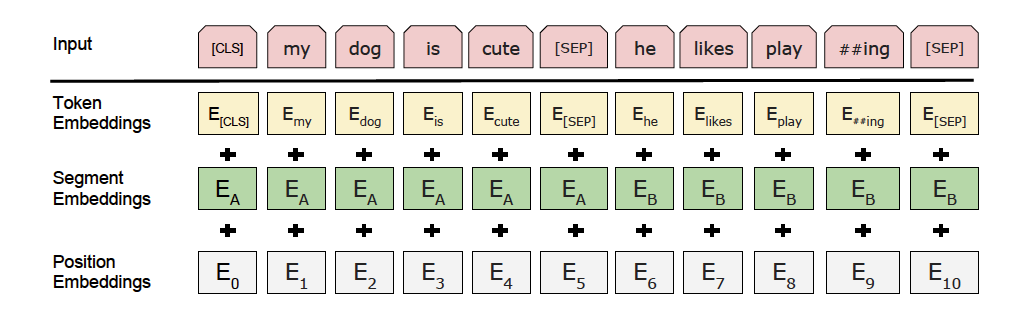
以上图片来自于:https://arxiv.org/pdf/1810.04805.pdf
train_dataset = hub.datasets.MSRA_NER(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')
dev_dataset = hub.datasets.MSRA_NER(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')
test_dataset = hub.datasets.MSRA_NER(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='test')tokenizer:表示该module所需用到的tokenizer,其将对输入文本完成切词,并转化成module运行所需模型输入格式。mode:选择数据模式,可选项有train,test,dev, 默认为train。max_seq_len:ERNIE/BERT模型使用的最大序列长度,若出现显存不足,请适当调低这一参数。
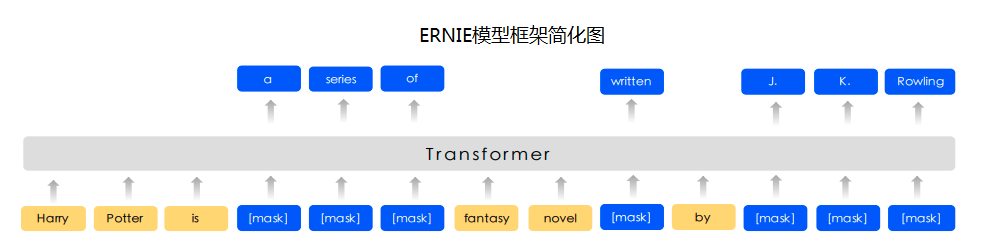
预训练模型ERNIE对中文数据的处理是以字为单位,tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。 PaddleHub 2.0中的各种预训练模型已经内置了相应的tokenizer,可以通过model.get_tokenizer方法获取。
optimizer = paddle.optimizer.AdamW(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='test_ernie_token_cls', use_gpu=True)
trainer.train(train_dataset, epochs=3, batch_size=32, eval_dataset=dev_dataset)
# 在测试集上评估当前训练模型
trainer.evaluate(test_dataset, batch_size=32)Paddle2.0-rc提供了多种优化器选择,如SGD, Adam, Adamax, AdamW等,详细参见策略。
其中AdamW:
learning_rate: 全局学习率。默认为1e-3;parameters: 待优化模型参数。
Trainer 主要控制Fine-tune的训练,包含以下可控制的参数:
model: 被优化模型;optimizer: 优化器选择;use_gpu: 是否使用GPU训练,默认为False;use_vdl: 是否使用vdl可视化训练过程;checkpoint_dir: 保存模型参数的地址;compare_metrics: 保存最优模型的衡量指标;
trainer.train 主要控制具体的训练过程,包含以下可控制的参数:
train_dataset: 训练时所用的数据集;epochs: 训练轮数;batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;num_workers: workers的数量,默认为0;eval_dataset: 验证集;log_interval: 打印日志的间隔, 单位为执行批训练的次数。save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在${CHECKPOINT_DIR}/best_model目录下,其中${CHECKPOINT_DIR}目录为Fine-tune时所选择的保存checkpoint的目录。
我们以以下数据为待预测数据,使用该模型来进行预测
去年十二月二十四日,市委书记张敬涛召集县市主要负责同志研究信访工作时,提出三问:『假如上访群众是我们的父母姐妹,你会用什么样的感情对待他们?
新华社北京5月7日电国务院副总理李岚清今天在中南海会见了美国前商务部长芭芭拉·弗兰克林。
根据测算,海卫1表面温度已经从“旅行者”号探测器1989年造访时的零下236摄氏度上升到零下234摄氏度。
华裔作家韩素音女士曾三次到大足,称“大足石窟是一座未被开发的金矿”。
import paddlehub as hub
split_char = "\002"
label_list = ["B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC", "O"]
text_a = [
'去年十二月二十四日,市委书记张敬涛召集县市主要负责同志研究信访工作时,提出三问:『假如上访群众是我们的父母姐妹,你会用什么样的感情对待他们?',
'新华社北京5月7日电国务院副总理李岚清今天在中南海会见了美国前商务部长芭芭拉·弗兰克林。',
'根据测算,海卫1表面温度已经从“旅行者”号探测器1989年造访时的零下236摄氏度上升到零下234摄氏度。',
'华裔作家韩素音女士曾三次到大足,称“大足石窟是一座未被开发的金矿”。',
]
data = [[split_char.join(text)] for text in text_a]
label_map = {
idx: label for idx, label in enumerate(label_list)
}
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='token-cls',
load_checkpoint='./token_cls_save_dir/best_model/model.pdparams',
label_map=label_map,
)
results = model.predict(data, max_seq_len=128, batch_size=1, use_gpu=True)
for idx, text in enumerate(text_a):
print(f'Data: {text} \t Lable: {", ".join(results[idx][1:len(text)+1])}')参数配置正确后,请执行脚本python predict.py, 加载模型具体可参见加载。
paddlepaddle >= 2.0.0rc
paddlehub >= 2.0.0