diff --git a/book/iterate.qmd b/book/iterate.qmd
index c3b4c3b..96e8770 100644
--- a/book/iterate.qmd
+++ b/book/iterate.qmd
@@ -361,7 +361,7 @@ center(x) # вернет ошибку
:::{.callout-warning icon=false}
-Напишите функцию `awesome_plot`, которая будет принимать в качестве аргументов два вектора, трансформировать их в тиббл и строить диаграмму рассеяния при помощи ggplot(). Задайте цвет и прозрачность точек, а в подзаголовке выведите коеффицент корреляции.
+Напишите функцию `awesome_plot`, которая будет принимать в качестве аргументов два вектора, трансформировать их в тиббл и строить диаграмму рассеяния при помощи ggplot(). Задайте цвет и прозрачность точек, а в подзаголовке выведите коэффициент корреляции.
:::
:::{.callout-warning icon=false}
@@ -370,7 +370,7 @@ center(x) # вернет ошибку
(@) Превратите детскую потешку ["Ted in the Bed"](https://supersimple.com/song/ten-in-the-bed/) в функцию. Обобщите до любого числа спящих.
-(@) Преобразуйте песню "99 Bottles of Beer on the Wall". Обобщите до любого числа любых напитков на любой поверхности.
+(@) Запишите в виде функции текст песни ["99 Bottles of Beer on the Wall"](https://www.99-bottles-of-beer.net/lyrics.html). Обобщите до любого числа любых напитков на любой поверхности.
:::
@@ -514,10 +514,9 @@ check_question(options = c("every()", "some()", "none()", "has_element()", "is.f
```
+## Гарри Поттер: цикл vs. `map_()`
-## Дополнительные возможности `purrr`
-
-Вы уже поняли, что благодаря циклам можно прочитать сразу несколько файлов. Та же задача решается и при помощи `map`. Мы потренируемся на датасете, который в 2023 г. был доступен на сайте Британской библиотеки (), но потом оттуда исчез. Однако у нас сохранилась копия.
+Как вы уже поняли, одни и те же задачи можно решать при помощи циклов и при помощи `map_`. Мы потренируемся на датасете, который в 2023 г. был доступен на сайте Британской библиотеки (), но потом оттуда исчез (но у нас сохранилась копия).
Датасет представляет собой набор файлов .csv, содержащих метаданные о ресурсах, связанных с Гарри Поттером, из коллекций Британской библиотеки. Первоначально он был выпущен к 20-летию публикации книги «Гарри Поттер и философский камень» 26 июня 2017 года и с тех пор ежегодно обновлялся. Всего в датасете пять файлов, каждый из которых содержит разное представление данных.
@@ -525,68 +524,94 @@ check_question(options = c("every()", "some()", "none()", "has_element()", "is.f
```{r eval=FALSE}
my_url <- "https://github.com/locusclassicus/text_analysis_2024/raw/main/files/HP.zip"
-download.file(url = my_url, destfile = "HP.zip")
+download.file(url = my_url, destfile = "../files/HP.zip")
```
После этого переходим в директорию с архивом и распаковываем его.
```{r eval=FALSE}
-unzip("HP.zip")
+unzip("../files/HP.zip")
```
-:::{.callout-warning icon=false}
-Практическое задание "Гарри Поттер"
-:::
+Сохраним список всех файлов с расширением .csv, используя подходящую функцию из base R.
-```{r eval=FALSE}
-# сохраните список всех файлов с расширением .csv,
-# используя подходящую функцию из base R
-
-# ваш код здесь
-# my_files <-
-
-# напишите цикл, который:
-# 1) прочитает все файлы из my_files, используя для этого функцию read_csv() из пакета readr
-# (аргумент show_col_types установите на FALSE);
-# 2) для каждого датасета выяснит количество рядов _без_ NA в столбце BNB Number;
-# 3) разделит число таких рядов на общее число рядов;
-# 4) вернет таблицу c четырьми столбцами:
-# - название файла (id),
-# - число рядов (total),
-# - число рядов без NA (complete),
-# - доля полных рядов (ratio)
-
-my_df <- data.frame(id = my_files,
+```{r}
+my_files <- list.files("../files/HP", pattern = ".csv", full.names = TRUE)
+my_files
+```
+### Цикл
+
+Теперь напишем цикл, который
+
+(@) прочитает все файлы из my_files, используя для этого функцию read_csv() из пакета readr;
+(@) для каждого датасета выяснит количество рядов _без_ NA в столбце BNB Number;
+(@) разделит число таких рядов на общее число рядов;
+(@)) вернет таблицу c четырьми столбцами:
+
+ - название файла (id),
+ - число рядов (total),
+ - число рядов без NA (complete),
+ - доля полных рядов (ratio).
+
+Сначала создаем таблицу, в которую будем складывать результат.
+
+```{r}
+my_files_short <- list.files("../files/HP", pattern = ".csv")
+
+my_df <- data.frame(id = my_files_short,
total = rep(0, length(my_files)),
complete = rep(0, length(my_files)),
ratio = rep(0, length(my_files)))
+my_df
+```
+
+Теперь тело цикла:
+
+```{r}
for (i in 1:length(my_files)) {
- # ваш код здесь
+
+ # читаем очередной файл из my_files
+ current_file <- my_files[i]
+ current_df <- readr::read_csv(current_file, show_col_types = FALSE)
+
+ # выявляем общее число рядов и число рядов без NA в BNB number
+ # из-за пробела в названии столбца BNB number нужно использовать
+ # с бэктиками ``, а не с "такими" или 'такими' кавычками
+ current_total <- nrow(current_df)
+ current_complete <- sum(!is.na(current_df$`BNB number`))
+
+
+ # помещаем значения в нужное место в заранее созданном my_df вместо нулей
+ my_df$total[i] <- current_total
+ my_df$complete[i] <- current_complete
+ my_df$ratio[i] <- current_complete / current_total
}
+```
+
+Смотрим на результат.
+```{r}
+my_df
```
+### `map_()`
-Узнаем имена файлов в директории и прочитаем их все одним вызовом функции.
+Теперь исследуем датасет при помощи функционалов. Прочитаем все файлы одним вызовом функции.
```{r}
# чтение файлов
-library(readr)
-
-files <- list.files("../files/HP", pattern = ".csv", full.names = TRUE)
-
-HP <- map(files, read_csv, col_types = cols())
+HP <- map(my_files, read_csv, col_types = cols())
```
-Объект `HP` -- это список. В нем пять элементов, так как на входе у нас было пять файлов. Для удобства назначим имена элементам списка. Пока можно не вникать, что здесь происходит -- регулярные выражения мы рассмотрим в одном из следующих уроков.
+Объект `HP` -- это список. В нем пять элементов, так как на входе у нас было пять файлов. Для удобства назначим имена элементам списка.
```{r}
-library(stringr)
-names(HP) <- str_extract(files, "\\w+(?=.csv)")
-names(HP)
+names(HP) <- my_files_short
```
+
+
Начнем с простого: при помощи `map` можно извлечь столбцы (по имени) или ряды (по условию) из всех пяти таблиц. Прежде чем выполнить код ниже, подумайте, как будет выглядеть результат.
```{r eval=FALSE}
@@ -597,15 +622,12 @@ map(HP, select, `BNB number`)
map(HP, filter, !(is.na(`BNB number`)))
```
-
-
:::{.callout-warning icon=false}
Извлеките все уникальные названия (столбец `Title`) из всех пяти таблиц в `HP`. Используйте функцию `distinct`.
:::
-
-Что, если мы не знаем заранее, какие столбцы есть во всех пяти таблицах, и хотим это выяснить? Для этого подойдет функция `reduce()` из того же `purrr`. Она принимает на входе вектор (или список) и функцию и применяет функцию последовательно к каждой паре значений.
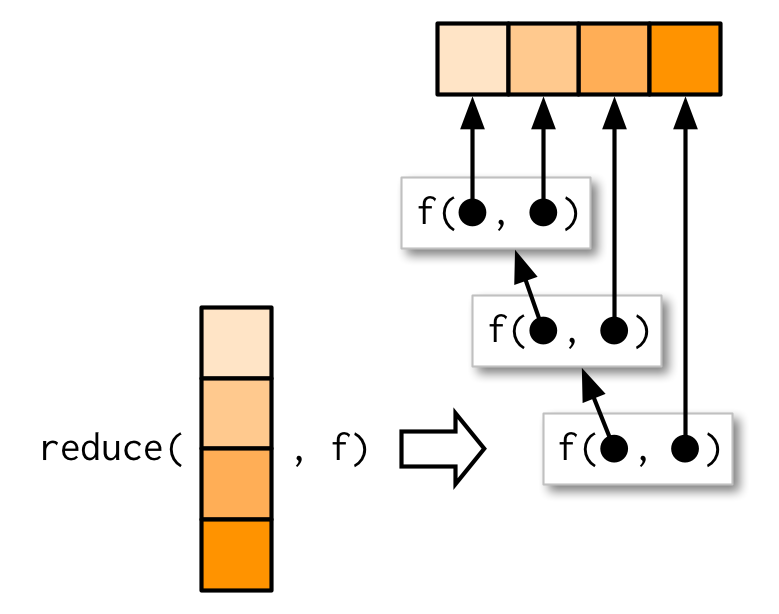
+Что, если мы не знаем заранее, какие столбцы есть _во всех пяти таблицах_, и хотим это выяснить? Для этого подойдет функция `reduce()` из того же `purrr`. Она принимает на входе вектор (или список) и функцию и применяет функцию последовательно к каждой паре значений.
](https://d33wubrfki0l68.cloudfront.net/9c239e1227c69b7a2c9c2df234c21f3e1c74dd57/eec0e/diagrams/functionals/reduce.png){ width="60%" }
@@ -623,13 +645,18 @@ map(HP, colnames) |>
```{r message=FALSE}
HP_joined <- HP |>
reduce(left_join)
+
+HP_joined
```
+### EDA
+
Теперь можно почистить данные и построить несколько разведывательных графиков.
```{r warning=FALSE, message=FALSE}
library(ggplot2)
library(tidyr)
+
data_sum <- HP_joined |>
separate(`Date of publication`, into = c("year", NA)) |>
separate(`Country of publication`, into = c("country", NA), sep = ";") |>
@@ -638,13 +665,18 @@ data_sum <- HP_joined |>
case_when(country == "England" ~ "United Kingdom",
country == "Scotland" ~ "United Kingdom",
TRUE ~ country)) |>
+ filter(!is.na(year)) |>
+ filter(!is.na(country)) |>
group_by(year, country) |>
summarise(n = n()) |>
- filter(!is.na(year)) |>
- filter(!is.na(country))
+ arrange(-n)
-# график
+data_sum
+```
+
+
+```{r}
data_sum |>
ggplot(aes(year, n, fill = country)) +
geom_col() +
@@ -655,7 +687,6 @@ data_sum |>
В качестве небольшого бонуса к этому уроку построим облако слов. Вектор слов возьмем из столбца `Topic`.
```{r warning=FALSE}
-library(tidyr)
data_topics <- HP_joined |>
filter(!is.na(Topics)) |>
separate(Topics, into = c("topic", NA)) |>
@@ -691,23 +722,23 @@ library(wordcloud2)
wordcloud2(data_topics,
- figPath = "./images/hat.png",
+ figPath = "./book/images/Wizard-Hat.png",
size = 1.5,
+ backgroundColor="black",
color="random-light",
fontWeight = "normal",
- backgroundColor="black"
- )
+)
+
```

-
+Теперь попробуйте сами.
:::{.callout-warning icon=false}
Практическое задание "Алиса в стране чудес"
:::
-
```{r eval=FALSE}
# постройте облако слов для "Алисы в стране чудес"
diff --git a/docs/images/HP.png b/docs/images/HP.png
new file mode 100644
index 0000000..1af58db
Binary files /dev/null and b/docs/images/HP.png differ
diff --git a/docs/iterate.html b/docs/iterate.html
index 23c74ef..d91c418 100644
--- a/docs/iterate.html
+++ b/docs/iterate.html
@@ -265,7 +265,12 @@
Но в базовом R для таких случаев существуют функционалы lapply() и sapply(). Они принимают на входе список и функцию и применяют функцию к каждому элементу списка. Получается быстрее:
Может быть, с датафреймами будут полезны циклы? Например, так.
@@ -487,7 +492,7 @@
toc()
-
0.003 sec elapsed
+
0.002 sec elapsed
Но и здесь можно ускориться. Второй аргумент apply означает, что мы работаем со столбцами (1 - строки).
@@ -500,7 +505,7 @@
toc()
-
0.001 sec elapsed
+
0.002 sec elapsed
Есть еще vapply(), tapply() и mapply(), но и про них мы не будем много говорить, потому что все их с успехом заменяет семейство map_() из пакета purrr в tidyverse.
@@ -704,25 +709,25 @@
-
-
@@ -797,7 +802,7 @@
-
Напишите функцию awesome_plot, которая будет принимать в качестве аргументов два вектора, трансформировать их в тиббл и строить диаграмму рассеяния при помощи ggplot(). Задайте цвет и прозрачность точек, а в подзаголовке выведите коеффицент корреляции.
+
Напишите функцию awesome_plot, которая будет принимать в качестве аргументов два вектора, трансформировать их в тиббл и строить диаграмму рассеяния при помощи ggplot(). Задайте цвет и прозрачность точек, а в подзаголовке выведите коэффициент корреляции.
@@ -813,7 +818,7 @@
Напишите код, который распечатает стихи детской песни “Alice the Camel”.
Превратите детскую потешку “Ted in the Bed” в функцию. Обобщите до любого числа спящих.
-
Преобразуйте песню “99 Bottles of Beer on the Wall”. Обобщите до любого числа любых напитков на любой поверхности.
+
Запишите в виде функции текст песни “99 Bottles of Beer on the Wall”. Обобщите до любого числа любых напитков на любой поверхности.
Вы уже поняли, что благодаря циклам можно прочитать сразу несколько файлов. Та же задача решается и при помощи map. Мы потренируемся на датасете, который в 2023 г. был доступен на сайте Британской библиотеки (https://www.bl.uk/), но потом оттуда исчез. Однако у нас сохранилась копия.
+
+
4.5 Гарри Поттер: цикл vs. map_()
+
Как вы уже поняли, одни и те же задачи можно решать при помощи циклов и при помощи map_. Мы потренируемся на датасете, который в 2023 г. был доступен на сайте Британской библиотеки (https://www.bl.uk/), но потом оттуда исчез (но у нас сохранилась копия).
Датасет представляет собой набор файлов .csv, содержащих метаданные о ресурсах, связанных с Гарри Поттером, из коллекций Британской библиотеки. Первоначально он был выпущен к 20-летию публикации книги «Гарри Поттер и философский камень» 26 июня 2017 года и с тех пор ежегодно обновлялся. Всего в датасете пять файлов, каждый из которых содержит разное представление данных.
# сохраните список всех файлов с расширением .csv,
-# используя подходящую функцию из base R
-
-# ваш код здесь
-# my_files <-
-
-# напишите цикл, который:
-# 1) прочитает все файлы из my_files, используя для этого функцию read_csv() из пакета readr
-# (аргумент show_col_types установите на FALSE);
-# 2) для каждого датасета выяснит количество рядов _без_ NA в столбце BNB Number;
-# 3) разделит число таких рядов на общее число рядов;
-# 4) вернет таблицу c четырьми столбцами:
-# - название файла (id),
-# - число рядов (total),
-# - число рядов без NA (complete),
-# - доля полных рядов (ratio)
-
-my_df <-data.frame(id = my_files,
-total =rep(0, length(my_files)),
-complete =rep(0, length(my_files)),
-ratio =rep(0, length(my_files)))
-
-for (i in1:length(my_files)) {
-# ваш код здесь
-}
-
-
Узнаем имена файлов в директории и прочитаем их все одним вызовом функции.
+
for (i in1:length(my_files)) {
+
+# читаем очередной файл из my_files
+ current_file <- my_files[i]
+ current_df <- readr::read_csv(current_file, show_col_types =FALSE)
+
+# выявляем общее число рядов и число рядов без NA в BNB number
+# из-за пробела в названии столбца BNB number нужно использовать
+# с бэктиками ``, а не с "такими" или 'такими' кавычками
+ current_total <-nrow(current_df)
+ current_complete <-sum(!is.na(current_df$`BNB number`))
+
+
+# помещаем значения в нужное место в заранее созданном my_df вместо нулей
+ my_df$total[i] <- current_total
+ my_df$complete[i] <- current_complete
+ my_df$ratio[i] <- current_complete / current_total
+}
Объект HP – это список. В нем пять элементов, так как на входе у нас было пять файлов. Для удобства назначим имена элементам списка. Пока можно не вникать, что здесь происходит – регулярные выражения мы рассмотрим в одном из следующих уроков.
+
my_df
+
+
+
+
+
+
+
+
+
4.5.2map_()
+
Теперь исследуем датасет при помощи функционалов. Прочитаем все файлы одним вызовом функции.
Объект HP – это список. В нем пять элементов, так как на входе у нас было пять файлов. Для удобства назначим имена элементам списка.
+
+
names(HP) <- my_files_short
+
Начнем с простого: при помощи map можно извлечь столбцы (по имени) или ряды (по условию) из всех пяти таблиц. Прежде чем выполнить код ниже, подумайте, как будет выглядеть результат.
# постройте облако слов для "Алисы в стране чудес"
-
-library(languageR)
-library(dplyr)
-library(tidytext)
-
-# вектор с "Алисой"
-alice <-tolower(alice)
-
-# частотности для слов
-freq <-as_tibble(table(alice)) |>
-rename(word = alice)
-
-# удалить стоп-слова
-freq_tidy <- freq |>
-anti_join(stop_words)
-# возможно, вы захотите произвести и другие преобразования
-
-# облако можно строить в любой библиотеке
+
# постройте облако слов для "Алисы в стране чудес"
+
+library(languageR)
+library(dplyr)
+library(tidytext)
+
+# вектор с "Алисой"
+alice <-tolower(alice)
+
+# частотности для слов
+freq <-as_tibble(table(alice)) |>
+rename(word = alice)
+
+# удалить стоп-слова
+freq_tidy <- freq |>
+anti_join(stop_words)
+# возможно, вы захотите произвести и другие преобразования
+
+# облако можно строить в любой библиотеке
@@ -1327,6 +1379,7 @@
diff --git a/docs/iterate_files/figure-html/unnamed-chunk-52-1.png b/docs/iterate_files/figure-html/unnamed-chunk-52-1.png
new file mode 100644
index 0000000..2847026
Binary files /dev/null and b/docs/iterate_files/figure-html/unnamed-chunk-52-1.png differ
diff --git a/docs/iterate_files/figure-html/unnamed-chunk-53-1.png b/docs/iterate_files/figure-html/unnamed-chunk-53-1.png
new file mode 100644
index 0000000..2922b35
Binary files /dev/null and b/docs/iterate_files/figure-html/unnamed-chunk-53-1.png differ
diff --git a/docs/references.html b/docs/references.html
index 3569273..f799d21 100644
--- a/docs/references.html
+++ b/docs/references.html
@@ -1,5 +1,5 @@
-
+
@@ -7,7 +7,7 @@
-Компьютерный анализ текста - References
+Компьютерный анализ текста - Литература