Dissertation Research: Feature Extraction for Narrative Network, Data Mapping, and Community Detection
- Createad a customized image and metadata collector script using the Instaloader package built in Python. Collected 11,000+ images and metadata from Instagram.
- Instagram Affordances and biases for information diffusion analysis
- Ontology Building
- Knowledge base and scene graph building
- Narrative Frame Network Visualization (forthcoming)
- Image feature extraction
- Semantic qualities and distinct features in social media posts
- Data Mapping and Fieldwork (forthcoming)
LLMs for summarization: First project covers using Llama3.2 and Tiny Llama to summarize an academic paper in Natural Language Processing and/or Deep Learning. The Paper summarized is "Multilingual Image Corpus – Towards a Multimodal and Multilingual Dataset" - Svetla Koeva, Ivelina Stoyanova, Jordan Kralev (2022). Paper URL here.
Multimodal & Multilingual LLMs: The next project uses a multimodal & multiingual LLM to practice classifying images, text, and a combination of the two in a non-English language (Italian). The finetuned model used is BLIP-2, which was specifically created to provide an optimal text prompt, in different languages. With respect to this project, it helps identify the different clusters of images and image-caption pairs within a food dataset.
Author Profiling with Naive Bayes and Convolutional Nueral Networks: Based on the Wikipedia page, author profiling has various techniques that can be applied to predict information about the author, which in turn can help with identifying an author from text. Here I used Naive Bayes and Convolutional Neural Networks (CNN) as my main models to provide predictions.
Implemented two video object tracking models: zero-shot transformers - OWL-VIT and LMM gpt-4o on noisy data- dashcam footage of a ride in Afghanistan provided by LAS staff. The goal was to explore improvements for tracking object obfuscation and detecting unknown/unconventional objects in the noisy surveillance video data. We found that pre-trained image models provided the most accurate structured data outputs. Go to Project Repository

NLP researcher comparing chunk-size methods for text summarization. Used extractive summarization occams and abstractive summarization, Retrieval Augmentation Generation (RAG) to test different text segmentation methods. Used and created vector embedding database for evaluation using RAGAs, an LLM RAG evaluator. Used the 2024 TREC Challenge data-MSMarco docs and QA for analysis.

This repository holds data and final analysis for the project, Bibliometric Data: Publishing Behavior of Rochester University Researchers. A project hosted by University of Rochester and backed by the LEADING Fellowship from Drexel University. The research question states where are University of Rochester researchers publishing/depositing data? The goal is to get a better understanding of how and where University of Rochester researchers are saving publishing their data. We attempted to analyze researcher publishing behavior and understand who is depositing data, where are they depositing it, how large are the datasets, and what formats are submitted/supported. The overall objectives were to find out where researchers are making their data publicly available. Identify common topics, relations, and overall trends. Using APIs, refine data collection techniques and conduct analyses on University of Rochester researcher data deposits into disciplinary data repositories.
Go to Project Repository
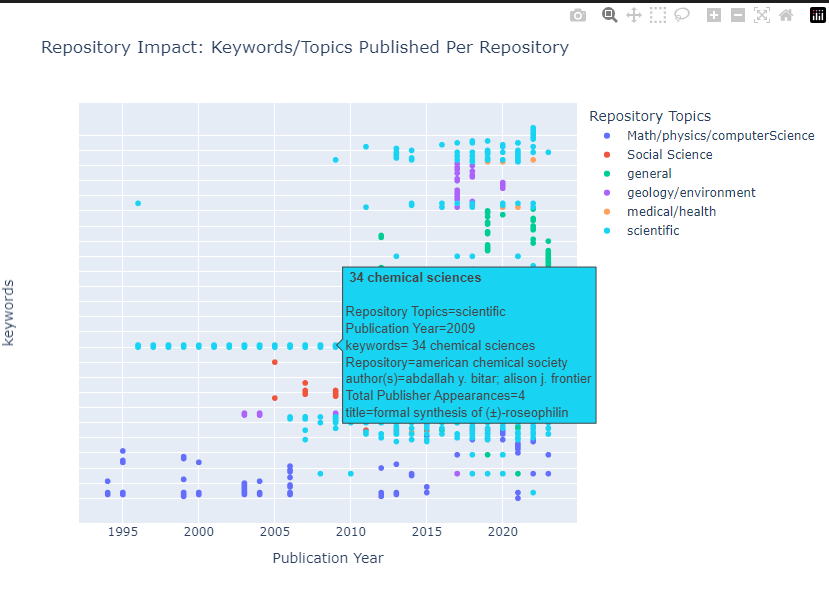 Kewords per Repository Topic Kewords per Repository Topic |
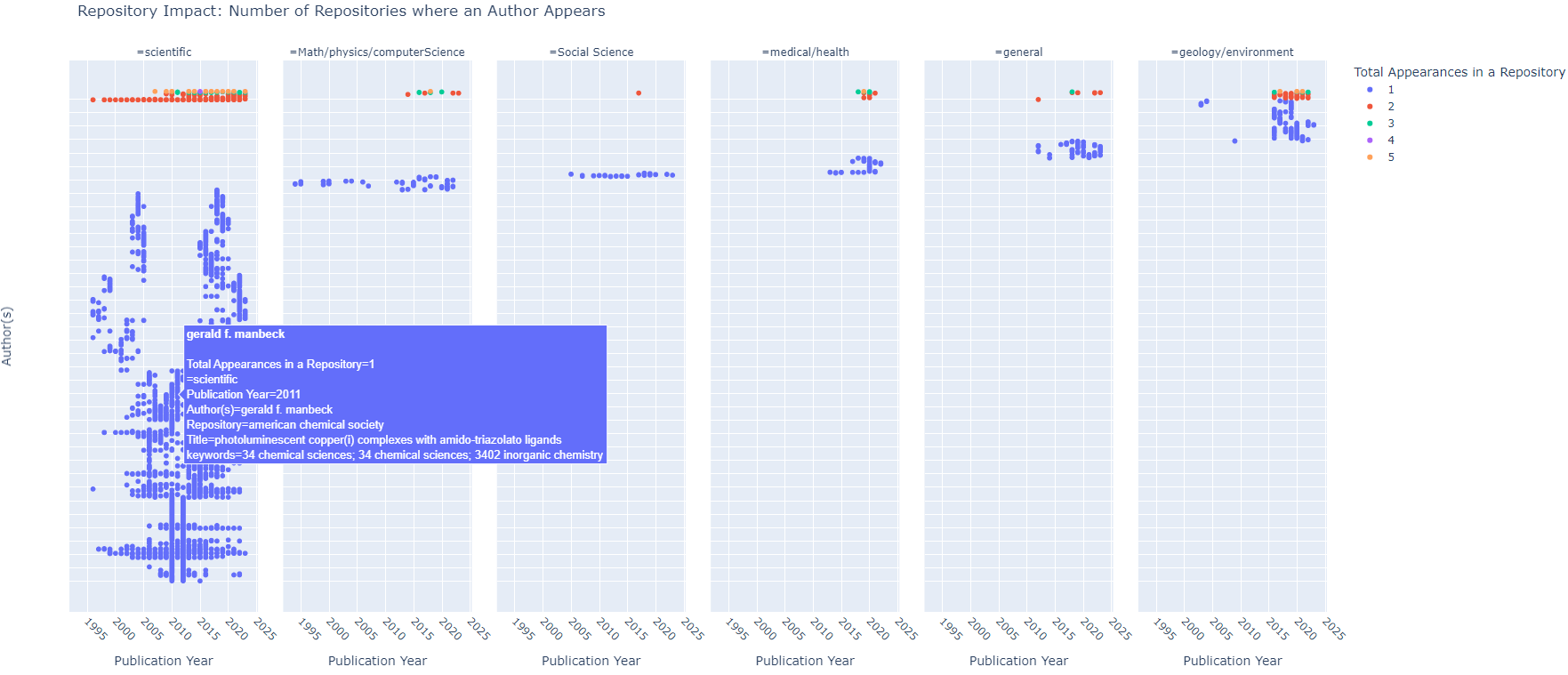 Authors Per Repository Topics Authors Per Repository Topics |
 Keywords Betweeness Centrality Keywords Betweeness Centrality |
In this analysis, Street Art images are considered as a type of visual information that can represent a specific perception of a community as a member of a community space. Dynamic By-partite network analysis was used to understand how different neighborhoods are connected through artist attributes and how they might differ. The results show that specific neighborhood traits, urban, population, culture contribute to stronger ties within the Street Art community network. Street Art as Visual Information: Mixed Methods Approach to Analyzing Community Spaces

Github code: Tucson_Street-Art
This project two natural language processing models on a dataset composed of labeled propaganda data. We reviewed off the shelf BERT and the Hierarchical Attention Network (HAN) models and found they both provide different accuracy levels, with BERT maintaining better results for the binary data classification problem. Identifying Propaganda: Comparing NLP Machine Learning Models on Propagandistic News Articles
 HAN Architecture HAN Architecture |
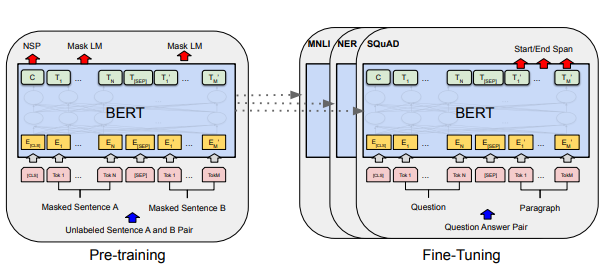 BERT pre-training and fine-tuning procedures BERT pre-training and fine-tuning procedures |
HAN Image taken from Yang et al 2016, BERT Image taken from Delvin et al. 2019
Github code: Identifying Propaganda
This framework combines computational applications with visual methodologies to discover frames of meaning making in a large image collection. Frame analysis and Critical Visual Methodology (Rose, 2016) are reviewed and used in the framework to work in tangent with quantitative research methods. The methods framework is presented in the form of a matrix that enables researchers to identify applications for looking at social movements online through theoretical and computational approaches.
 |
"Mixed Methods Framework for Understanding Visual Frames in Social Movements" - Long Paper Accepted to ASIS&T 2023
Theoretical Matrix Presented at Society for the Social Studies of Science Conference in 2022
Program can be found here
Here I worked with private university data to tackle questions that support internal decision making. I used predictive modeling, statistics, Machine Learning, Data Mining, and other data analysis techniques to collect, explore, and extract insights from structured and unstructured data. Topics include revenue, retention/attrition, and student sentiment and experience.
I analyzed 30K+ student course surveys using sentiment analysis packages in R to identify sentiment for all comments provided in student course surveys across campus. I also used SQL to pull the data from the Oracle database to be used for a personalized instructor dashboard.
I used survival and churn analysis to analyze the expected duration of attrition for female students and The University of Arizona. Here, Kaplan Mier and the supporting cox regression analysis were used to study retention. Churn analysis including methods of logistic regression, decision trees and random forests were used to study attrition. Read the report here
I developed an end-to-end production process of tuition and headcount dashboard visualizations and analysis using R and SQL. This consisted of aggregated data tables from an internal Oracle data warehouse that include descriptive statistics and inflation information of campus-wide Net Tuition Revenue (NTR).
Applied statistical analysis and inference to surveys and collected data to review and test the University of Arizona’s Medical School’s performance for future accreditation. Types of data included survey data, raw archived data, collected government and academic data from large data systems. Used both R and Python to use analysis of variance, chi-square tests, post hoc and assumptions checks, regression analysis, correlation analysis, visualizations.