Example
#Examples of Queries
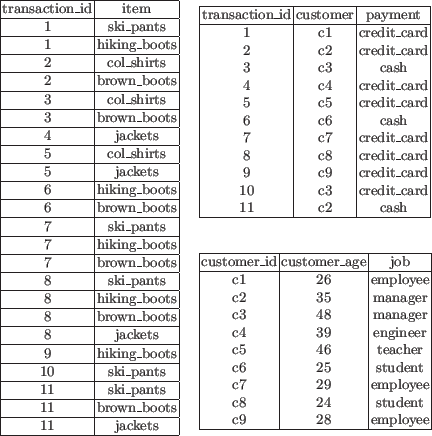
We describe here a complete KDD process centered around the
classical basket analysis problem that will
serve as a running example throughout.
We are considering information of relations Sales, Transactions and
Customers shown in Figure 1.
In relation Sales we have stored
information on sold items in the purchase transactions; in relation
Transactions we identify the customers that have purchased in the
transactions and record the method of payment;
in relation Customers we collect information on the customers.
From the information of these tables we want to look for association rules between bought items and customer's age for payments with credit cards. The discovered association rules are meant to predict the age of customers according to their purchase habits. This data mining step requires at first some manipulations as a preprocessing step (selection of the items bought by credit card and encoding of the age attribute) in order to prepare data for the successive pattern extraction; then the actual pattern extraction step may take place.
Suppose that by inspecting the result of a previous data mining extraction step, we are now interested in investigating the purchases that violate certain extracted patterns. In particular, we are interested in obtaining association rules between sets of bought items in the purchase transactions that violate the rules with 'ski_pants' in their antecedent. To this aim, we can cross-over between extracted rules and original data, selecting tuples of the source table that violate the interesting rules, and perform a second mining step, based on the results of the previous mining step: from the selected set of tuples, we extract the association rules between two sets of items with a high confidence threshold. Finally, we allow two post-processing operations over the extracted association rules: selection of rules with 2 items in the body and selection of rules with a maximal body among the rules with the same consequent.
MINE RULE does not require a specific format for the input table. Therefore we can suppose to receive data either in the set of normalized relations Sales, Transactions and Customers of Figure 1 or in a view obtained joining them. This view is named SalesView and is shown in Table 1 and we assume it is the input of the mining task. Using a view is not necessary but it allows to make SQL querying easier by gathering all the necessary information in one table even though all these data are initially scattered in different tables. Thus, the user can focus the query writing on the constraints useful for its mining task.
|
Pre-processing Step 1: selection of the subset of data to be mined. In contrast to MSQL, MINE RULE does not require to apply some pre-defined view on the original data. As it is designed as an extension to SQL, it perfectly nests SQL, and thus, it is possible to select the relevant subset of data to be mined by specifying it in the FROM.. WHERE.. clauses of the query.
Pre-processing Step 2: encoding age. Since MINE RULE does not have an encoding operator for performing pre-processing tasks, we must discretize the interval values.
Rules extraction over a set of items and customers' age. In MINE RULE, we specify that we are looking for rules associating one or more items (rule's body) and customer's age (rule's head):
MINE RULE SalesRB AS |
|
SELECT DISTINCT 1..n item AS BODY, 1..1 customer_age AS HEAD, |
|
SUPPORT, CONFIDENCE |
|
FROM SalesView WHERE payment='credit_card' (7) |
|
GROUP BY t_id |
|
EXTRACTING RULES WITH SUPPORT: 0.25, CONFIDENCE: 0.5 |
If we want to store results in a database supporting the relational model, extracted rules are stored into the table SalesRB(rid, bid, hid, sup, conf) where rid, bid, hid are respectively the identifiers assigned to rules, body itemsets and head itemsets. The body and head itemsets are stored respectively in tables SalesRBB(bid,item) and SalesRBH(hid,customerage). Tables SalesRB, SalesRBB and SalesRBH are shown in Figure 2.
|  |
Crossing-over: looking for exceptions in the original data. We want to find transactions of the original relation whose tuples violate all rules with ski_pants in the body. As rule components (bodies and heads) are stored in relational tables, we use an SQL query to manipulate itemsets. The corresponding query is the following:
SELECT * FROM SalesView AS S1 WHERE NOT EXISTS |
|
(SELECT * FROM SalesRB AS R1, |
|
SalesRB_B AS R1_B, SalesRB_H AS R1_H |
|
WHERE R1.b_id=R1_B.b_id AND R1.h_id=R1_H.h_id AND |
|
S1.customer_age=R1_H.customer_age AND S1.item=R1_B.item (8) |
|
AND EXISTS(SELECT * FROM SalesRB_B AS R2_B |
|
WHERE R2_B.b_id=R1_B.b_id AND R2_B.item='ski_pants') |
|
AND NOT EXISTS |
|
(SELECT * FROM SalesRB_B AS R3_B |
|
WHERE R1_B.b_id=R3_B.b_id AND NOT EXISTS |
|
(SELECT * FROM SalesView AS S2 |
|
WHERE S2.t_id=S1.t_id AND S2.item=R3_B.item))) |
This query is hard to write and to understand. It aims at selecting
tuples of the original SalesView relation, renamed S1, such that
there are no rules with ski_pants in the antecedent, that hold on
them. These properties are verified by the first two nested SELECT clauses. Furthermore, we want to be sure that the above rules
are satisfied by tuples belonging to the same transaction of the
original tuple in S1. In other words, that there are no elements
of the body of the rule that are not satisfied by tuples of the same
original transaction. Therefore, we verify that each body element in
the rule is satisfied by a tuple of the ![]() relation (renamed
S2) in the same transaction of the tuple in S1 we are
considering for the output.
relation (renamed
S2) in the same transaction of the tuple in S1 we are
considering for the output.
Rules extraction over two sets of items. This is the classical example of extraction of association rules, formed by two sets of items. Using MINE RULE it is specified as follows:
MINE RULE SalesRB2 AS |
|
SELECT DISTINCT 1..n item AS BODY, 1..n item AS HEAD, |
|
SUPPORT, CONFIDENCE (9) |
|
FROM Sales2 |
|
GROUP BY t_id |
|
EXTRACTING RULES WITH SUPPORT: 0.0, CONFIDENCE: 0.9 |
Post-processing Step 1: manipulation of rules.
Once again, as itemsets corresponding to rule's components are
stored in tables (![]() ,
, ![]() ),
we can select rules having two items in the body
with a simple SQL query.
),
we can select rules having two items in the body
with a simple SQL query.
SELECT * FROM SalesRB AS R1 WHERE 2= (10) |
|
(SELECT COUNT(*) FROM SalesRB_B R2 WHERE R1.b_id=R2.b_id) |
Post-processing Step 2: selection of rules with a maximal body. We select rules with a maximal body for a given consequent. As rules' components are stored in relational tables, we use again a SQL query to perform such a task.
SELECT * FROM SalesRB AS R1 # We select the rules in R1 |
|
WHERE NOT EXISTS # such that there are no |
|
(SELECT * FROM SalesRB AS R2 # other rules (in R2) with |
|
WHERE R2.h_id=R1.h_id # the same head, a different |
|
AND NOT R2.b_id=R1.b_id # body such that it has no |
|
AND NOT EXISTS (SELECT * # items that do not occur in |
|
FROM SalesRB_B AS B1 # the body of the R1 rule |
|
WHERE R1.b_id=B1.b_id AND NOT EXISTS (SELECT * |
|
FROM SalesRB_B AS B2 (11) |
|
WHERE B2.b_id=R2.b_id AND B2.item=B1.item))) |
This rather complex query aims at selecting rules such that there are no rules with the same consequent and a body that strictly includes the body of the former rule. The two inner sub-queries are used to check that rule body in R1 is a superset of the rule body in R2. These post-processing queries probably could be simpler if SQL-3 standard for the ouput of the rules were adopted.