

A simple, fast, robust job/task queue for Node.js, backed by Redis.
- Simple: ~1000 LOC, and minimal dependencies.
- Fast: maximizes throughput by minimizing Redis and network overhead. Benchmarks well.
- Robust: designed with concurrency, atomicity, and failure in mind; full code coverage.
const Queue = require('bee-queue');
const queue = new Queue('example');
const job = queue.createJob({x: 2, y: 3});
job.save();
job.on('succeeded', (result) => {
console.log(`Received result for job ${job.id}: ${result}`);
});
// Process jobs from as many servers or processes as you like
queue.process(function (job, done) {
console.log(`Processing job ${job.id}`);
return done(null, job.data.x + job.data.y);
});Bee-Queue is meant to power a distributed worker pool and was built with short, real-time jobs in mind. A web server can enqueue a job, wait for a worker process to complete it, and return its results within an HTTP request. Scaling is as simple as running more workers.
Thanks to the folks at Mixmax, Bee-Queue is once again being regularly maintained!
Celery, Resque, Kue, and Bull operate similarly, but are generally designed for longer background jobs, supporting things like job prioritization and repeatable jobs, which Bee-Queue currently does not. Bee-Queue can handle longer background jobs just fine, but they aren't the primary focus.
- Create, save, and process jobs
- Concurrent processing
- Job timeouts, retries, and retry strategies
- Scheduled jobs
- Pass events via Pub/Sub
- Progress reporting
- Send job results back to producers
- Robust design
- Strives for all atomic operations
- Retries stuck jobs for at-least-once delivery
- High code coverage
- Performance-focused
- Minimizes Redis usage
- Uses Lua scripting and pipelining to minimize network overhead
- Benchmarks favorably against similar libraries
- Fully callback- and Promise-compatible API
$ npm install bee-queueYou'll also need Redis 2.8+* running somewhere.
* We've been noticing that some jobs get delayed by virtue of an issue with Redis < 3.2, and therefore recommend the use of Redis 3.2+.
Celery is for Python, and Resque is for Ruby, but Kue and Bull already exist for Node, and they're good at what they do, so why does Bee-Queue also need to exist?
In short: we needed to mix and match things that Kue does well with things that Bull does well, and we needed to squeeze out more performance. There's also a long version with more details.
Bee-Queue starts by combining Bull's simplicity and robustness with Kue's ability to send events back to job creators, then focuses heavily on minimizing overhead, and finishes by being strict about code quality and testing. It compromises on breadth of features, so there are certainly cases where Kue or Bull might be preferable (see Contributing).
Bull and Kue do things really well and deserve a lot of credit. Bee-Queue borrows ideas from both, and Bull was an especially invaluable reference during initial development.
Bee-Queue is like a bee because it:
- is small and simple
- is fast (bees can fly 20mph!)
- carries pollen (messages) between flowers (servers)
- something something "worker bees"
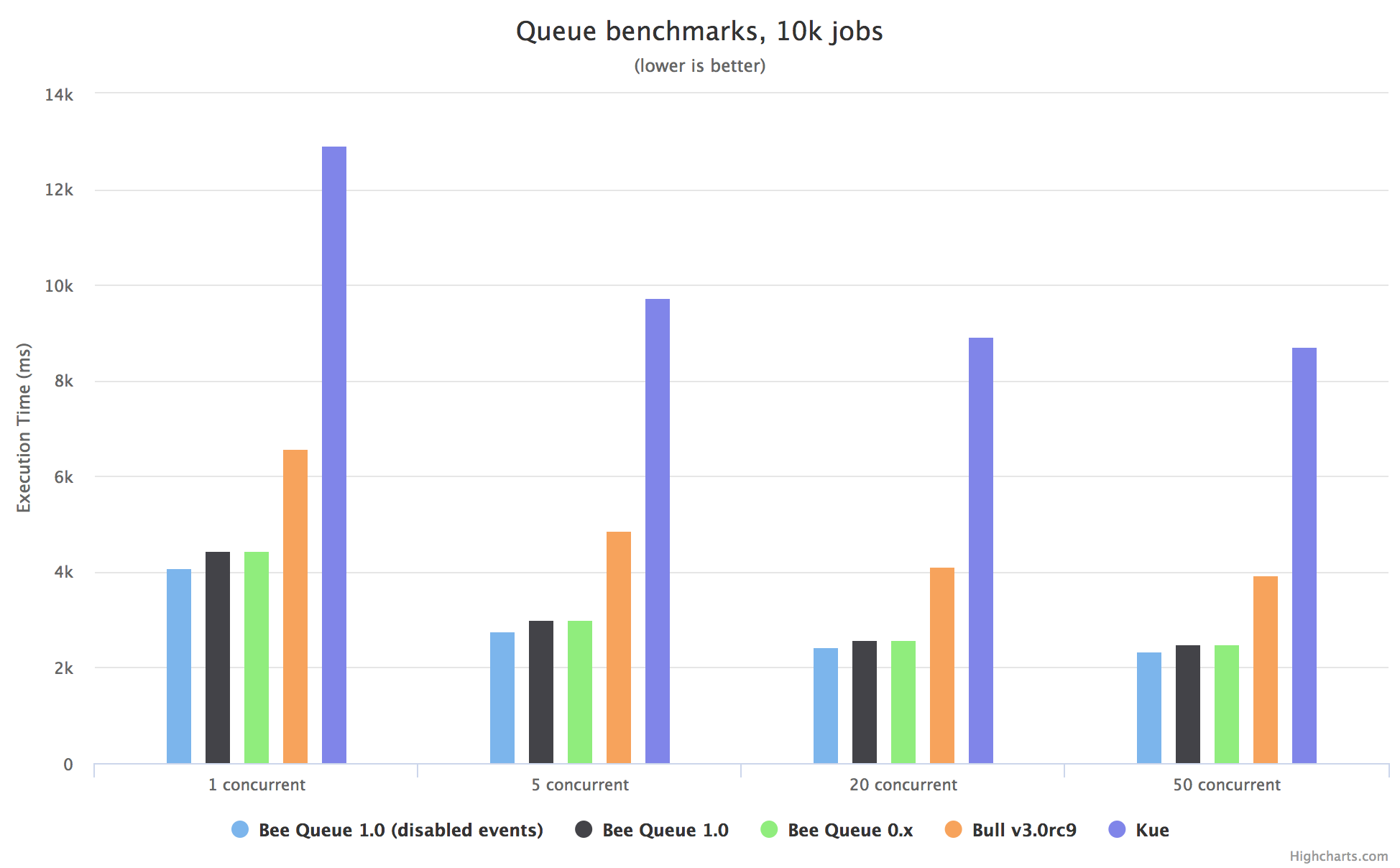
These basic benchmarks ran 10,000 jobs through each library, at varying levels of concurrency, with Node.js (v6.9.1, v6.11.2, v7.6.0, v7.10.1, v8.2.1, v8.3.0) and Redis (v3.2.10, v4.0.1) running directly on an Amazon AWS EC2 m4.large. The numbers shown are averages of 36 runs, 3 for each combination of the aforementioned Redis and Node versions. The raw data collected and code used are available in the benchmark folder.
Check out the Arena web interface to manage jobs and inspect queue health.
Queue objects are the starting point to everything this library does. To make one, we just need to give it a name, typically indicating the sort of job it will process:
const Queue = require('bee-queue');
const addQueue = new Queue('addition');Queues are very lightweight — the only significant overhead is connecting to Redis — so if you need to handle different types of jobs, just instantiate a queue for each:
const subQueue = new Queue('subtraction', {
redis: {
host: 'somewhereElse',
},
isWorker: false,
});Here, we pass a settings object to specify an alternate Redis host and to indicate that this queue will only add jobs (not process them). See Queue Settings for more options.
Jobs are created using Queue.createJob(data), which returns a Job object storing arbitrary data.
Jobs have a chaining API for configuring the Job, and .save([cb]) method to save the job into Redis and enqueue it for processing:
const job = addQueue.createJob({x: 2, y: 3});
job
.timeout(3000)
.retries(2)
.save()
.then((job) => {
// job enqueued, job.id populated
});The Job's save method returns a Promise in addition to calling the optional callback.
Each Job can be configured with the commands .setId(id), .retries(n), .backoff(strategy, delayFactor), .delayUntil(date|timestamp), and .timeout(ms) for setting options.
Jobs can later be retrieved from Redis using Queue#getJob, but most use cases won't need this, and can instead use Job and Queue Events.
Normally, creating and saving jobs blocks the underlying redis client for the full duration of an RTT to the Redis server. This can reduce throughput in cases where many operations should occur without delay - particularly when there are many jobs that need to be created quickly. Use Queue#saveAll to save an iterable (e.g. an Array) containing jobs in a pipelined network request, thus pushing all the work out on the wire before hearing back from the Redis server.
addQueue
.saveAll([addQueue.createJob({x: 3, y: 4}), addQueue.createJob({x: 4, y: 5})])
.then((errors) => {
// The errors value is a Map associating Jobs with Errors. This will often be an empty Map.
});Each job in the array provided to saveAll will be mutated with the ID it gets assigned.
To start processing jobs, call Queue.process and provide a handler function:
addQueue.process(function (job, done) {
console.log(`Processing job ${job.id}`);
return done(null, job.data.x + job.data.y);
});Instead of calling the provided callback, the handler function can return a Promise. This enables the intuitive use of async/await:
addQueue.process(async (job) => {
console.log(`Processing job ${job.id}`);
return job.data.x + job.data.y;
});The handler function is given the job it needs to process, including job.data from when the job was created. It should then pass results either by returning a Promise or by calling the done callback. For more on handlers, see Queue#process.
.process can only be called once per Queue instance, but we can process on as many instances as we like, spanning multiple processes or servers, as long as they all connect to the same Redis instance. From this, we can easily make a worker pool of machines who all run the same code and spend their lives processing our jobs, no matter where those jobs are created.
.process can also take a concurrency parameter. If your jobs spend most of their time just waiting on external resources, you might want each processor instance to handle at most 10 at a time:
const baseUrl = 'http://www.google.com/search?q=';
subQueue.process(10, function (job, done) {
http.get(`${baseUrl}${job.data.x}-${job.data.y}`, function (res) {
// parse the difference out of the response...
return done(null, difference);
});
});Handlers can send progress reports, which will be received as events on the original job instance:
const job = addQueue.createJob({x: 2, y: 3}).save();
job.on('progress', (progress) => {
console.log(
`Job ${job.id} reported progress: page ${progress.page} / ${progress.totalPages}`
);
});
addQueue.process(async (job) => {
// do some work
job.reportProgress({page: 3, totalPages: 11});
// do more work
job.reportProgress({page: 9, totalPages: 11});
// do the rest
});Just like .process, these progress events work across multiple processes or servers; the job instance will receive the progress event no matter where processing happens. The data passed through can be any JSON-serializable value. Note that this mechanism depends on Pub/Sub, and thus will incur additional overhead for each additional worker node.
There are three classes of events emitted by Bee-Queue objects: Queue Local events, Queue PubSub events, and Job events. The linked API Reference sections provide a more complete overview of each.
Progress reporting, demonstrated above, happens via Job events. Jobs also emit succeeded events, which we've seen in the opening example, and failed and retrying events.
Queue PubSub events correspond directly to Job events: job succeeded, job retrying, job failed, and job progress. These events fire from all queue instances and for all jobs on the queue.
Queue local events include ready and error on all queue instances, and succeeded, retrying, and failed on worker queues corresponding to the PubSub events being sent out.
Note that Job events become unreliable across process restarts, since the queue's reference to the associated job object will be lost. Queue-level events are thus potentially more reliable, but Job events are more convenient in places like HTTP requests where a process restart loses state anyway.
Bee-Queue attempts to provide "at least once delivery". Any job enqueued should be processed at least once - and if a worker crashes, gets disconnected, or otherwise fails to confirm completion of the job, the job will be dispatched to another worker for processing.
To make this happen, workers periodically phone home to Redis about each job they're working on, just to say "I'm still working on this and I haven't stalled, so you don't need to retry it." The checkStalledJobs method finds any active jobs whose workers have gone silent (not phoned home for at least stallInterval ms), assumes they have stalled, emits a stalled event with the job id, and re-enqueues them to be picked up by another worker.
By default, every time you create a queue instance with new Queue() a new redis connection will be created. If you have a small number of queues accross a large number of servers this will probably be fine. If you have a large number of queues with a small number of servers, this will probably be fine too. If your deployment gets a bit larger you will likely need to optimize the Redis connections.
Let's say for example you have a web application with 30 producer queues and you run 10 webservers & 10 worker servers, each one with 4 processes/server. With the default settings this is going to add up to a lot of Redis connections. Each Redis connection consumes a fairly large chunk of memory, and it adds up quickly!
The producer queues are the ones that run on the webserver and they push jobs into the queue. These queues do not need to receive events so they can all share one redis connection by passing in an instance of node_redis RedisClient.
Example:
// producer queues running on the web server
const Queue = require('bee-queue');
const redis = require('redis');
const sharedConfig = {
getEvents: false,
isWorker: false,
redis: redis.createClient(process.env.REDIS_URL),
};
const emailQueue = new Queue('EMAIL_DELIVERY', sharedConfig);
const facebookUpdateQueue = new Queue('FACEBOOK_UPDATE', sharedConfig);
emailQueue.createJob({});
facebookUpdateQueue.createJob({});Note that these "producer queues" above are only relevant for the processes that have to put jobs into the queue, not for the workers that need to actually process the jobs.
In your worker process where you define how to process the job with queue.process you will have to run "worker queues" instead of "producer queues". In the example below, even though you are passing in the shared config with the same redis instance, because this is a worker queue Bee-Queue will duplicate() the client because it needs the blocking commands for PubSub subscriptions. This will result in a new connection for each queue.
// worker queues running on the worker server
const Queue = require('bee-queue');
const redis = require('redis');
const sharedConfig = {
redis: redis.createClient(process.env.REDIS_URL),
};
const emailQueue = new Queue('EMAIL_DELIVERY', sharedConfig);
const facebookUpdateQueue = new Queue('FACEBOOK_UPDATE', sharedConfig);
emailQueue.process((job) => {});
facebookUpdateQueue.process((job) => {});For a more detailed example and explanation see #96
The default Queue settings are:
const queue = new Queue('test', {
prefix: 'bq',
stallInterval: 5000,
nearTermWindow: 1200000,
delayedDebounce: 1000,
redis: {
host: '127.0.0.1',
port: 6379,
db: 0,
options: {},
},
isWorker: true,
getEvents: true,
sendEvents: true,
storeJobs: true,
ensureScripts: true,
activateDelayedJobs: false,
removeOnSuccess: false,
removeOnFailure: false,
redisScanCount: 100,
});The settings fields are:
-
prefix: string, defaultbq. Useful if thebq:namespace is, for whatever reason, unavailable or problematic on your redis instance. -
stallInterval: number, ms; the length of the window in which workers must report that they aren't stalling. Higher values will reduce Redis/network overhead, but if a worker stalls, it will take longer before its stalled job(s) will be retried. A higher value will also result in a lower probability of false-positives during stall detection. -
nearTermWindow: number, ms; the window during which delayed jobs will be specifically scheduled usingsetTimeout- if all delayed jobs are further out than this window, the Queue will double-check that it hasn't missed any jobs after the window elapses. -
delayedDebounce: number, ms; to avoid unnecessary churn for several jobs in short succession, the Queue may delay individual jobs by up to this amount. -
redis: object or string, specifies how to connect to Redis. Seeredis.createClient()for the full set of options.host: string, Redis host.port: number, Redis port.socket: string, Redis socket to be used instead of a host and port.
Note that this can also be a node_redis
RedisClientinstance, in which case Bee-Queue will issue normal commands over it. It willduplicate()the client for blocking commands and PubSub subscriptions, if enabled. This is advanced usage, -
isWorker: boolean. Disable if this queue will not process jobs. -
getEvents: boolean. Disable if this queue does not need to receive job events. -
sendEvents: boolean. Disable if this worker does not need to send job events back to other queues. -
storeJobs: boolean. Disable if this worker does not need to associate events with specificJobinstances. This normally improves memory usage, as the storage of jobs is unnecessary for many use-cases. -
ensureScripts: boolean. Ensure that the Lua scripts exist in redis before running any commands against redis. -
activateDelayedJobs: boolean. Activate delayed jobs once they've passed theirdelayUntiltimestamp. Note that this must be enabled on at least oneQueueinstance for the delayed retry strategies (fixedandexponential) - this will reactivate them after their computed delay. -
removeOnSuccess: boolean. Enable to have this worker automatically remove its successfully completed jobs from Redis, so as to keep memory usage down. -
removeOnFailure: boolean. Enable to have this worker automatically remove its failed jobs from Redis, so as to keep memory usage down. This will not remove jobs that are set to retry unless they fail all their retries. -
quitCommandClient: boolean. Whether toQUITthe redis command client (the client it sends normal operations over) whenQueue#closeis called. This defaults totruefor normal usage, andfalseif an existingRedisClientobject was provided to theredisoption. -
redisScanCount: number. For setting the value of theSSCANRedis command used inQueue#getJobsfor succeeded and failed job types. -
clearMissingJobs: boolean. Enable to clear out job references if data is missing.
name: string, the name passed to the constructor.keyPrefix: string, the prefix used for all Redis keys associated with this queue.jobs: aMapassociating the currently tracked jobs (whenstoreJobsandgetEventsare enabled).paused: boolean, whether the queue instance is paused. Only true if the queue is in the process of closing.settings: object, the settings determined between those passed and the defaults
Instead of listening to this event, consider calling Queue#ready([cb]), which returns a Promise that resolves once the Queue is ready. If the Queue is already ready, then the Promise will be already resolved.
queue.on('ready', () => {
console.log('queue now ready to start doing things');
});The queue has connected to Redis and ensured that the Lua scripts are cached. You can often get away without checking for this event, but it's a good idea to wait for it in case the Redis host didn't have the scripts cached beforehand; if you try to enqueue jobs when the scripts are not yet cached, you may run into a Redis error.
queue.on('error', (err) => {
console.log(`A queue error happened: ${err.message}`);
});Any Redis errors are re-emitted from the Queue. Note that this event will not be emitted for failed jobs.
queue.on('succeeded', (job, result) => {
console.log(`Job ${job.id} succeeded with result: ${result}`);
});This queue has successfully processed job. If result is defined, the handler called done(null, result).
queue.on('retrying', (job, err) => {
console.log(
`Job ${job.id} failed with error ${err.message} but is being retried!`
);
});This queue has processed job, but it reported a failure and has been re-enqueued for another attempt. job.options.retries has been decremented, and the stack trace (or error message) has been added to its job.options.stacktraces array.
queue.on('failed', (job, err) => {
console.log(`Job ${job.id} failed with error ${err.message}`);
});This queue has processed job, but its handler reported a failure either by rejecting its returned Promise, or by calling done(err). Note that if you pass an async function to process, you must reject it by returning Promise.reject(...) or throwing an exception (done does not apply).
queue.on('stalled', (jobId) => {
console.log(`Job ${jobId} stalled and will be reprocessed`);
});This queue detected that a job stalled. Note that this might not be the same queue instance that processed the job and ultimately stalled; instead, it's the queue instance that happened to detect the stalled job.
These events are all reported by some worker queue (with sendEvents enabled) and sent as Redis Pub/Sub messages back to any queues listening for them (with getEvents enabled). This means that listening for these events is effectively a monitor for all activity by all workers on the queue.
If the jobId of an event is for a job that was created by that queue instance, a corresponding job event will be emitted from that job object.
Note that Queue PubSub events pass the jobId, but do not have a reference to the job object, since that job might have originally been created by some other queue in some other process. Job events are emitted only in the process that created the job, and are emitted from the job object itself.
queue.on('job succeeded', (jobId, result) => {
console.log(`Job ${jobId} succeeded with result: ${result}`);
});Some worker has successfully processed job jobId. If result is defined, the handler called done(null, result).
queue.on('job retrying', (jobId, err) => {
console.log(
`Job ${jobId} failed with error ${err.message} but is being retried!`
);
});Some worker has processed job jobId, but it reported a failure and has been re-enqueued for another attempt.
queue.on('job failed', (jobId, err) => {
console.log(`Job ${jobId} failed with error ${err.message}`);
});Some worker has processed job, but its handler reported a failure with done(err).
queue.on('job progress', (jobId, progress) => {
console.log(`Job ${jobId} reported progress: ${progress}%`);
});Some worker is processing job jobId, and it sent a progress report of progress percent.
The Queue will activate no delayed jobs unless activateDelayedJobs is set to true.
The promptness of the job activation is controlled with the delayedDebounce setting on the Queue. This setting defines a window across which to group delayed jobs. If three jobs are enqueued for 10s, 10.5s, and 12s in the future, then a delayedDebounce of 1000 will cause the first two jobs to activate when the timestamp of the second job passes.
The nearTermWindow setting on the Queue determines the maximum duration the Queue should wait before attempting to activate any of the elapsed delayed jobs in Redis. This setting is to control for network failures in the delivery of the earlierDelayed event in conjunction with the death of the publishing Queue.
Used to instantiate a new queue; opens connections to Redis.
const job = queue.createJob({...});Returns a new Job object with the associated user data.
queue.getJob(3, function (err, job) {
console.log(`Job 3 has status ${job.status}`);
});
queue.getJob(3).then((job) => console.log(`Job 3 has status ${job.status}`));Looks up a job by its jobId. The returned job will emit events if getEvents and storeJobs is true.
Be careful with this method; most potential uses would be better served by job events on already-existing job instances. Using this method indiscriminately can lead to increasing memory usage when the storeJobs setting is true, as each queue maintains a table of all associated jobs in order to dispatch events.
queue.getJobs('waiting', {start: 0, end: 25}).then((jobs) => {
const jobIds = jobs.map((job) => job.id);
console.log(`Job ids: ${jobIds.join(' ')}`);
});
queue.getJobs('failed', {size: 100}).then((jobs) => {
const jobIds = jobs.map((job) => job.id);
console.log(`Job ids: ${jobIds.join(' ')}`);
});Looks up jobs by their queue type. When looking up jobs of type waiting, active, or delayed, page should be configured with start and end attributes to specify a range of job indices to return. Jobs of type failed and succeeded will return an arbitrary subset of the queue of size page['size']. Note: This is because failed and succeeded job types are represented by a Redis SET, which does not maintain a job ordering.
Note that large values of the attributes of page may cause excess load on the Redis server.
Begins processing jobs with the provided handler function.
The process method should only be called once, and should never be called on a queue where isWorker is false.
The optional concurrency parameter sets the maximum number of simultaneously active jobs for this processor. It defaults to 1.
The handler function should either:
- Return a
Promisethat eventually resolves or rejects, or - Call
doneexactly once- Use
done(err)to indicate job failure - Use
done()ordone(null, result)to indicate job successresultmust be JSON-serializable (forJSON.stringify)
- Use
- Never ever block the event loop (for very long). If you do, the stall detection might think the job stalled, when it was really just blocking the event loop.
N.B. If the handler returns a Promise, calls to the done callback will be ignored.
Checks for jobs that appear to be stalling and thus need to be retried, then re-enqueues them.
queue.checkStalledJobs(5000, (err, numStalled) => {
// prints the number of stalled jobs detected every 5000 ms
console.log('Checked stalled jobs', numStalled);
});What happens after the check is determined by the parameters provided:
cbonly:cbis calledintervalonly: a timeout is set to call the method again inintervalmscbandinterval: a timeout is set, thencbis called
Bee-Queue automatically calls this method once when a worker begins processing, so it will check once if a worker process restarts. You should also make your own call with an interval parameter to make the check happen repeatedly over time; see Under the hood for an explanation why.
The maximum delay from when a job stalls until it will be retried is roughly stallInterval + interval, so to minimize that delay without calling checkStalledJobs unnecessarily often, set interval to be the same or a bit shorter than stallInterval. A good system-wide average frequency for the check is every 0.5-10 seconds, depending on how time-sensitive your jobs are in case of failure. Larger deployments, or deployments where processing has higher CPU variance, may need even higher intervals.
Note that for calls that specify an interval, you must provide a callback if you want results from each subsequent check - the returned Promise can and will only resolve for the first check. If and only if you specify an interval and no cb, then errors encountered after the first check will be emitted as error events.
Check the "health" of the queue. Returns a promise that resolves to the number of jobs in each state (waiting, active, succeeded, failed, delayed), and the newest job ID (if using the default ID behavior) in newestJob. You can periodically query the newestJob ID to estimate the job creation throughput, and can infer the job processing throughput by incorporating the waiting and active counts.
const counts = await queue.checkHealth();
// print all the job counts
console.log('job state counts:', counts);Closes the queue's connections to Redis. Idempotent.
The recommended pattern for gracefully shutting down your worker is:
// Some reasonable period of time for all your concurrent jobs to finish
// processing. If a job does not finish processing in this time, it will stall
// and be retried. As such, do attempt to make your jobs idempotent, as you
// generally should with any queue that provides at-least-once delivery.
const TIMEOUT = 30 * 1000;
process.on('uncaughtException', async () => {
// Queue#close is idempotent - no need to guard against duplicate calls.
try {
await queue.close(TIMEOUT);
} catch (err) {
console.error('bee-queue failed to shut down gracefully', err);
}
process.exit(1);
});Returns true unless the Queue is shutting down due to a call to Queue#close().
Promise resolves to the queue (or callback is called wth null argument) when the queue (and Redis) are ready for jobs. Learn more about 'ready' in Queue Local Events.
const Queue = require('bee-queue');
const queue = new Queue('example');
queue
.ready()
.then(async (queue) => {
console.log('isRunning:', queue.isRunning());
const checkHealth = await queue.checkHealth();
console.log('checkHealth:', checkHealth);
})
.catch((err) => console.log('unreadyable', err));queue.removeJob(3, function (err) {
if (!err) {
console.log('Job 3 was removed');
}
});
queue.removeJob(3).then(() => console.log('Job 3 was removed'));Removes a job by its jobId. Idempotent.
This may have unintended side-effect, e.g. if the job is currently being processed by another worker, so only use this method when you know it's safe.
Returns the Queue instance it was called on.
queue.destroy(function (err) {
if (!err) {
console.log('Queue was destroyed');
}
});
queue.destroy().then(() => console.log('Queue was destroyed'));Removes all Redis keys belonging to this queue (see Under the hood). Idempotent.
It goes without saying that this should be used with great care.
Returns the number of keys removed.
id: string, Job ID unique to each job. Not populated until.savecalls back. Can be overridden withJob#setId.data: object; user data associated with the job. It should:- Be JSON-serializable (for
JSON.stringify) - Never be used to pass large pieces of data (100kB+)
- Ideally be as small as possible (1kB or less)
- Be JSON-serializable (for
options: object used by Bee-Queue to store timeout, retries, stack traces, etc.- Do not modify directly; use job methods instead.
queue: the Queue responsible for this instance of the job. This is either:- the queue that called
createJobto make the job, - the queue that ran
getJobto fetch the job from redis, or - the queue that called
processto process it
- the queue that called
progress: number; progress between 0 and 100, as reported byreportProgress.
These are all Pub/Sub events like Queue PubSub events and are disabled when getEvents is false.
const job = await queue.createJob({...}).save();
job.on('succeeded', (result) => {
console.log(`Job ${job.id} succeeded with result: ${result}`);
});The job has succeeded. If result is defined, the handler called done(null, result).
job.on('retrying', (err) => {
console.log(
`Job ${job.id} failed with error ${err.message} but is being retried!`
);
});The job has failed, but it is being automatically re-enqueued for another attempt. job.options.retries has been decremented accordingly.
job.on('failed', (err) => {
console.log(`Job ${job.id} failed with error ${err.message}`);
});The job has failed, and is not being retried.
job.on('progress', (progress) => {
console.log(`Job ${job.id} reported progress: ${progress}%`);
});The job has sent a progress report of progress percent.
Each Job can be configured with the chainable commands .setId(id), .retries(n), .backoff(strategy, delayFactor), .delayUntil(date|timestamp), and .timeout(ms).
const job = await queue.createJob({...})
.setId('bulk')
.save();Explicitly sets the ID of the job. If a job with the given ID already exists, the Job will not be created, and job.id will be set to null. This method can be used to run a job once for each of an external resource by passing that resource's ID. For instance, you might run the setup job for a user only once by setting the job ID to the ID of the user. Furthermore, when this feature is used with queue settings removeOnSuccess: true and removeOnFailure: true, it will allow that job to be re-run again, effectively ensuring that jobId will have a global concurrency of 1.
Avoid passing a numeric job ID, as it may conflict with an auto-generated ID.
const job = await queue.createJob({...})
.retries(3)
.save();Sets how many times the job should be automatically retried in case of failure.
Stored in job.options.retries and decremented each time the job is retried.
Defaults to 0.
// When the job fails, retry it immediately.
const job = queue.createJob({...})
.backoff('immediate');
// When the job fails, wait the given number of milliseconds before retrying.
job.backoff('fixed', 1000);
// When the job fails, retry using an exponential backoff policy.
// In this example, the first retry will be after one second after completion
// of the first attempt, and the second retry will be two seconds after completion
// of the first retry.
job.backoff('exponential', 1000);Sets the backoff policy when handling retries.
This setting is stored in job.options.backoff as {strategy, delay}.
Defaults to 'immediate'.
const job = await queue.createJob({...})
.delayUntil(Date.parse('2038-01-19T03:14:08.000Z'))
.save();Delay the job until the given Date/timestamp passes. See the Queue settings section for information on controlling the activation of delayed jobs.
Defaults to enqueueing the job for immediate processing.
const job = await queue.createJob({...})
.timeout(10000)
.save();Sets a job runtime timeout in milliseconds; if the job's handler function takes longer than the timeout to call done, the worker assumes the job has failed and reports it as such (causing the job to retry if applicable).
Defaults to no timeout.
const job = queue.createJob({...});
job.save((err, job) => {
console.log(`Saved job ${job.id}`);
});
job.save().then((job) => console.log(`Saved job ${job.id}`));Saves a job, queueing it up for processing. After the callback fires (and associated Promise resolves), job.id will be populated.
queue.process(async (job, done) => {
await doSomethingQuick();
job.reportProgress(10);
await doSomethingBigger();
job.reportProgress(50);
await doFinalizeStep();
});Reports job progress when called within a handler function. Causes a progress event to be emitted. Does not persist the progress to Redis, but will store it on job.progress, and if other Queues have storeJobs and getEvents enabled, then the progress will end up on all corresponding job instances.
const job = queue.createJob({...});
// ...
job.remove(function (err) {
if (!err) {
console.log('Job was removed');
}
});
job.remove()
.then(() => console.log('Job was removed'));Removes a job from the queue. Idempotent.
This may have unintended side-effect, e.g. if the job is currently being processed by another worker, so only use this method when you know it's safe.
Note that this method will call Queue#removeJob with the job id, so if you don't have the job in memory, but knows its id, it's much more efficient to use Queue#removeJob instead of getting the job first.
Returns the Job instance it was called on.
Defaults for Queue settings live in lib/defaults.js. Changing that file will change Bee-Queue's default behavior.
Each Queue uses the following Redis keys:
bq:name:id: Integer, incremented to determine the next Job ID.bq:name:jobs: Hash from Job ID to a JSON string containing its data and options.bq:name:waiting: List of IDs of jobs waiting to be processed.bq:name:active: List of IDs jobs currently being processed.bq:name:succeeded: Set of IDs of jobs which succeeded.bq:name:failed: Set of IDs of jobs which failed.bq:name:delayed: Ordered Set of IDs corresponding to delayed jobs - this set maps delayed timestamp to IDs.bq:name:stalling: Set of IDs of jobs which haven't 'checked in' during this interval.bq:name:stallBlock: Set of IDs of jobs which haven't 'checked in' during this interval.bq:name:events: Pub/Sub channel for workers to send out job results.bq:name:earlierDelayed: When a new delayed job is added prior to all other jobs, the script creating the job will publish the job's timestamp over this Pub/Sub channel.
Bee-Queue is non-polling, so idle workers are listening to receive jobs as soon as they're enqueued to Redis. This is powered by brpoplpush, which is used to move jobs from the waiting list to the active list. Bee-Queue generally follows the "Reliable Queue" pattern described here.
The isWorker setting creates an extra Redis connection dedicated to brpoplpush. If either getEvents or activateDelayedJobs are enabled, another connection is dedicated to receiving Pub/Sub events. As such, these settings should be disabled if you don't need them.
The stalling set is a snapshot of the active list from the beginning of the latest stall interval. During each stalling interval, workers remove their job IDs from the stalling set, so at the end of an interval, any jobs whose IDs are left in the stalling set have missed their window (stalled) and need to be rerun. When checkStalledJobs runs, it re-enqueues any jobs left in the stalling set (to the waiting list), then takes a snapshot of the active list and stores it in the stalling set.
Bee-Queue requires the user to start the repeated checks on their own because if we did it automatically, every queue instance in the system would be doing the check. Checking from all instances is less efficient and provides weaker guarantees than just checking from one or two. For example, a checkStalledJobs interval of 5000ms running on 10 processes would average one check every 500ms, but would only guarantee a check every 5000ms. Two instances checking every 1000ms would also average one check every 500ms, but would be more well-distributed across time and would guarantee a check every 1000ms. Though the check is not expensive, and it doesn't hurt to do it extremely often, avoiding needless inefficiency is a main point of this library, so we leave it to the user to control exactly which processes are doing the check and how often.
Pull requests are welcome; just make sure npm test passes. For significant changes, open an issue for discussion first.
Some significant non-features include:
- Worker tracking: Kue does this.
- All-workers pause-resume: Bull does this.
- Job priority: multiple queues get the job done in simple cases, but Kue has first-class support. Bull provides a wrapper around multiple queues.
Some of these could be worthwhile additions; please comment if you're interested in using or helping implement them!
You'll need a local redis server to run the tests. Note that running the tests may delete some keys in the form of bq:test-*-*:*.