These are some of the main principles underlying the course structure.
The software product you build is a side effect only. You are the product of this course. This means,
- We may not take the most efficient route to building the software product. We take the route that allows you to learn the most.
- Building a software product that is unique, creative, and shiny is not our priority (although we try to do a bit of that too). Learning to take pride in, and discovering the joy of, high quality software engineering work is our priority.
Following from that, we evaluate you on not just how much you've done, but also, how well you've done those things. Here are some of the aspects in which we focus on:
We appreciate ... | But we value more ... |
Ability to deal with low-level details | Ability to abstract over details, generalize, see the big picture |
A drive to learn latest and greatest technologies | Ability to make the best of given tools |
Ability to find problems that interest you and solve them | Ability to solve the given problem to the best of your ability |
Ability to burn the midnight oil to meet a deadline | Ability to schedule work so that the need for 'last minute heroics' is minimal |
Preference to do things you like or things you are good at | Ability to buckle down and deliver on important things that you don't necessarily like or are good at |
Ability to deliver desired end results | Ability to deliver in a way that shows how well you delivered (i.e. visibility of your work) |
We learn together, NOT compete against each other.
You are not in a competition. Our grading is not forced on a bell curve.
Learn from each other. That is why we open-source your submissions.
Teach each other, even those in other teams. Those who do it well can become tutors next time.
Continuously engage, NOT last minute heroics.
We want to train you to do software engineering in a steady and repeatable manner that does not require 'last minute heroics'.
In this course, last minute heroics will not earn you a good project grade, and last minute mugging will not earn you a good exam grade.
Where you reach at the end matters, NOT what you knew at the beginning.
When you start the course, some others in the class may appear to know a lot more than you. Don't let that worry you. The final grade depends on what you know at the end, not what you knew to begin with. All marks allocated to intermediate deliverables are within the reach of everyone in the class irrespective of their prior knowledge.













































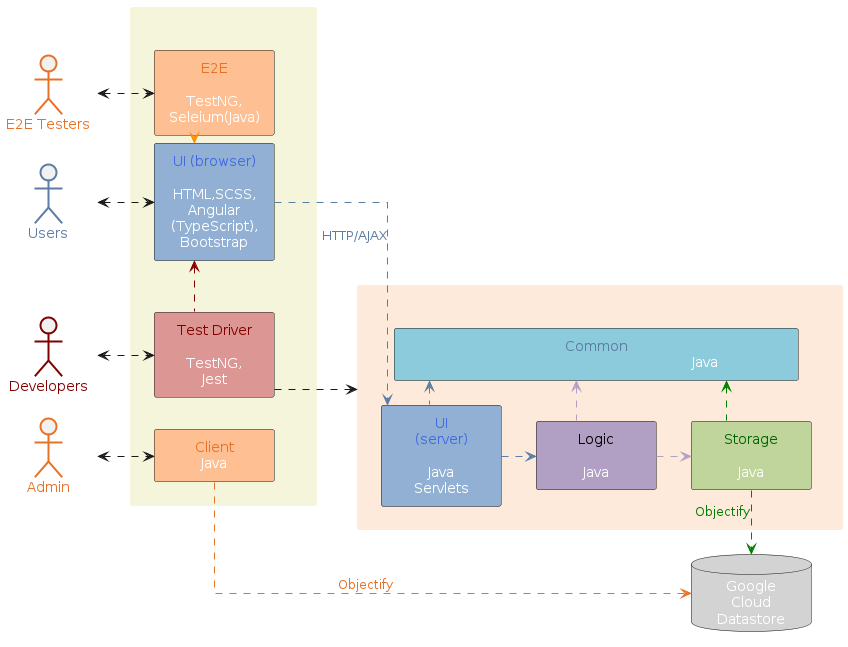
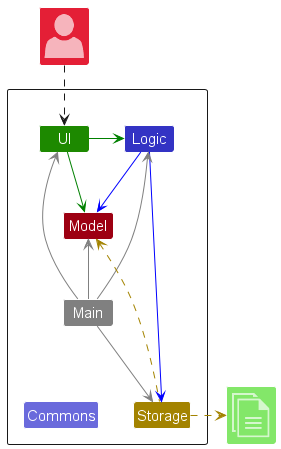

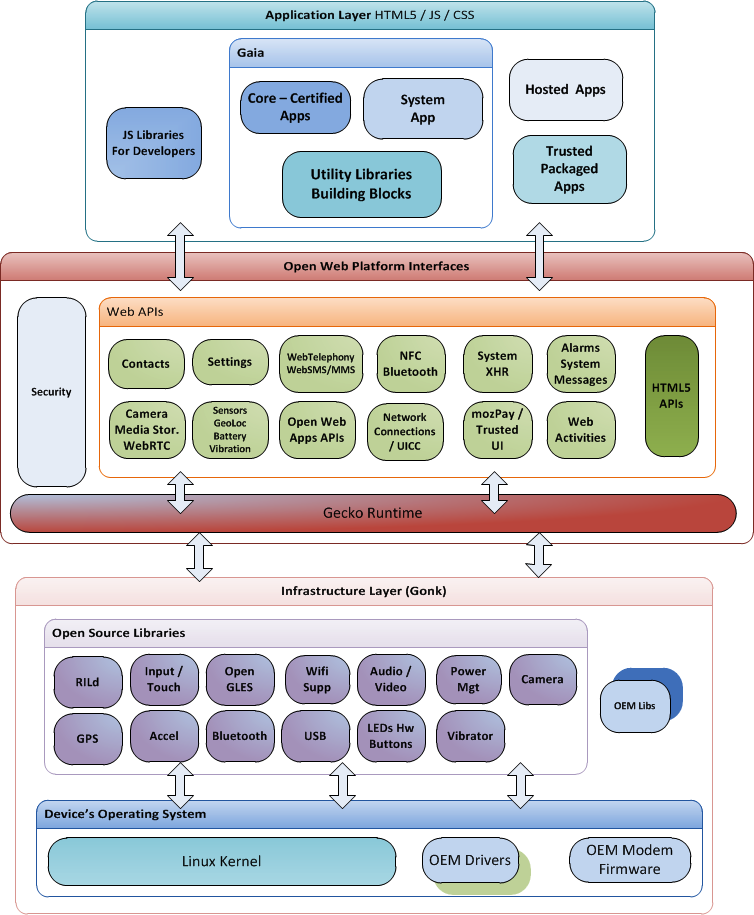





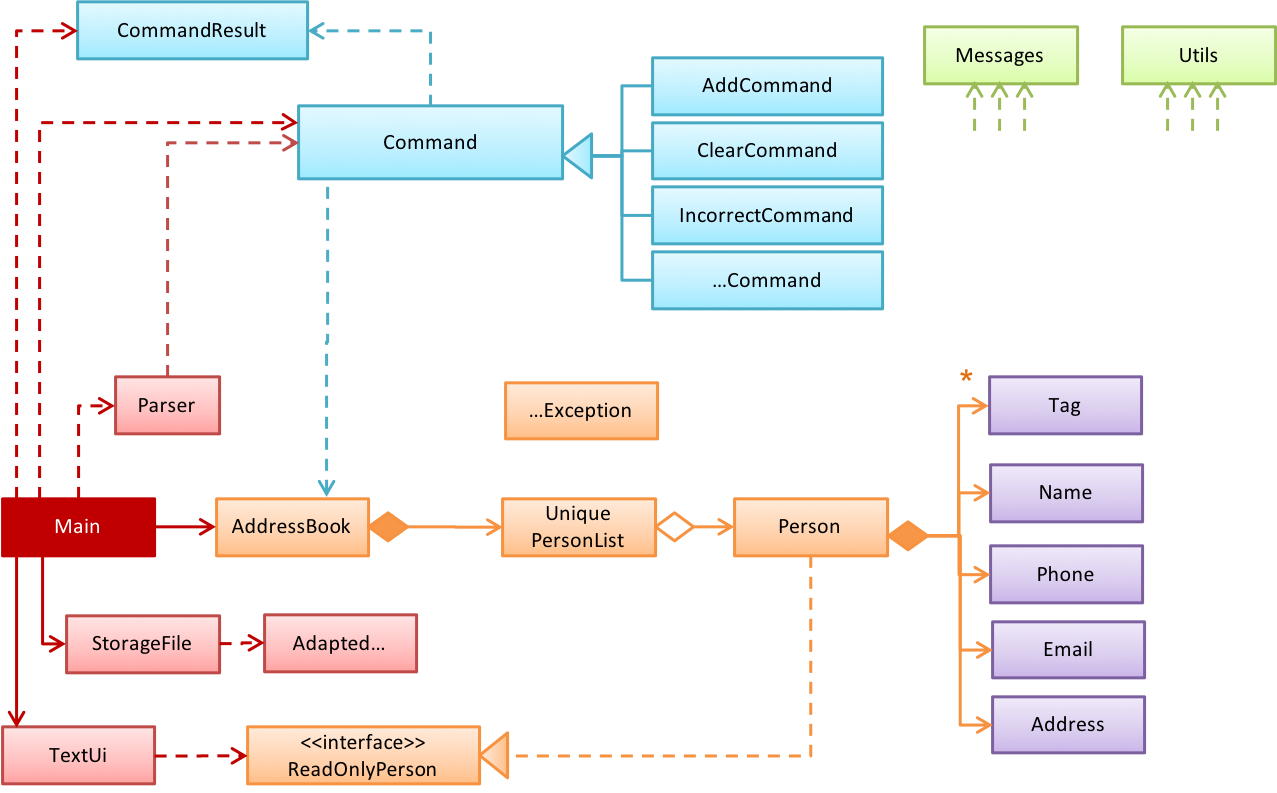































































































































































{kind=link}
{kind=link}