Spark big data
Apache Spark™ is a fast and general engine for large-scale data processing.
Apache Spark是用于大数据处理的集群计算框架。与Hadoop的大数据处理框架不同,Spark并没有使用MapReduce作为执行引擎,而是使用了它自己的分布式运行环境在集群上执行工作。Spark与Hadoop紧密集成,它可以运行在YARN上,并支持HDFS。
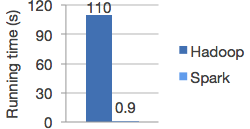
Spark最突出的表示在于他能将作业与作业之间产生的大规模的工作数据集存储在内存中。这种能力使Spark在性能上超过了等效的MapReduce工作流,而MapReduce始终需要在磁盘中加载数据。
Spark还是用于构建分析工具的出色平台,为此Spark项目还包含:
- 机器学习(MLib)
- 图算法 (GraphX)
- 流式计算(Spark Streaming)
- SQL查询(Spark SQL)