diff --git a/README.md b/README.md
index 300f4271b..2e698b5aa 100644
--- a/README.md
+++ b/README.md
@@ -39,11 +39,19 @@ Defines a standard format for storing and sharing business logic. A clear set of
> _Morphir’s automated processing helps disseminate information which otherwise may not be understood or shared at all, a useful tool when brining elements of business logic to conversation outside of its immediate audience (i.e developers)._
----
+## FINOS Morphir Resources
[Morphir Resource Centre](https://resources.finos.org/morphir/)
----
+| Episode | Description |
+| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------ |
+|  | Introduction to the Morphir Showcase |
+|
| Introduction to the Morphir Showcase |
+|  | What Morphir is with Stephen Goldbaum |
+|
| What Morphir is with Stephen Goldbaum |
+|  | How Morphir works with Attila Mihaly |
+|
| How Morphir works with Attila Mihaly |
+| 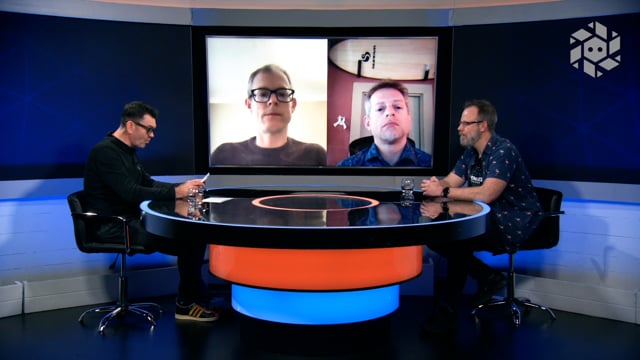 | Why Morphir is Important – with Colin, James & Stephen |
+|
| Why Morphir is Important – with Colin, James & Stephen |
+| 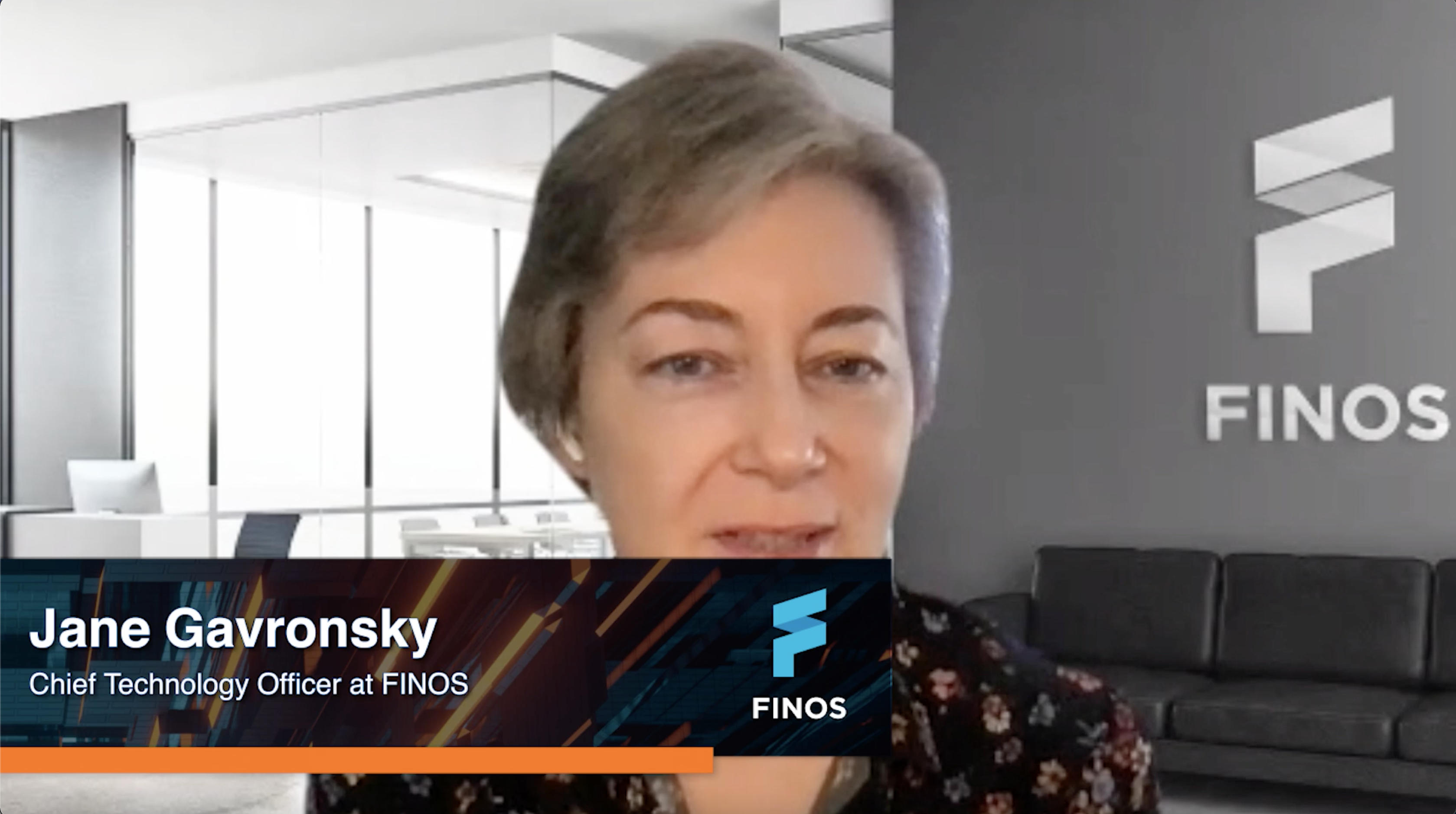 | The Benefits & Use Case of Morphir with Jane, Chris & Stephen |
+|
| The Benefits & Use Case of Morphir with Jane, Chris & Stephen |
+|  | How to get involved – Closing Panel Q&A |
+|
| How to get involved – Closing Panel Q&A |
+|  | Morphir Showcase – Full Show |
# An ecosystem of innovative features
diff --git a/docs/application_modeling.md b/docs/application_modeling.md
index 8aae84e5e..907406af4 100644
--- a/docs/application_modeling.md
+++ b/docs/application_modeling.md
@@ -1,52 +1,62 @@
+---
+sidebar_position: 4
+id: modeling-applications
+title: Modeling Entire Applications
+---
+
# Modeling Entire Applications
Morphir Application Modeling imagines an evolution of programming as:
-* You code, just pure business logic.
-* That code is guaranteed to be free of exceptions.
-* Merging your code triggers full SDLC automation through to deployment.
-* Your application automatically conforms to your firm's standards now and in the future.
-* Your users have transparency into how your application behaves and why.
-* You retain full control to modify any of the above.
+
+- You code, just pure business logic.
+- That code is guaranteed to be free of exceptions.
+- Merging your code triggers full SDLC automation through to deployment.
+- Your application automatically conforms to your firm's standards now and in the future.
+- Your users have transparency into how your application behaves and why.
+- You retain full control to modify any of the above.
Most applications generally follow a small set of well known patterns based on how the application will run
-(as opposed to its business purpose). These patterns are what many application frameworks are built around. As a
-result, much of the development process is simply following recipes to build code to these patterns.
+(as opposed to its business purpose). These patterns are what many application frameworks are built around. As a
+result, much of the development process is simply following recipes to build code to these patterns.
-There is another set of patterns that sits in the fuzzy area where the business patterns meet the technical ones. These
-patterns are not entirely business and are consistent across applications regardless of how they will end up being
-executed. It's likely that these patterns will remain unchanged even as technology evolves. If we can capture these
-patterns in our models, it would allow us to move execution across different technologies without changing our models
-at all. This is important because an individual application usually exists within a larger ecosystem. Constantly
-keeping large numbers of existing applications up-to-date with the latest ecosystem changes, commonly referred to as
-*hygiene*, takes a lot of development effort that subtracts from a team's ability to provide business value.
+There is another set of patterns that sits in the fuzzy area where the business patterns meet the technical ones. These
+patterns are not entirely business and are consistent across applications regardless of how they will end up being
+executed. It's likely that these patterns will remain unchanged even as technology evolves. If we can capture these
+patterns in our models, it would allow us to move execution across different technologies without changing our models
+at all. This is important because an individual application usually exists within a larger ecosystem. Constantly
+keeping large numbers of existing applications up-to-date with the latest ecosystem changes, commonly referred to as
+_hygiene_, takes a lot of development effort that subtracts from a team's ability to provide business value.
-So what are these patterns? Here are some core patterns that drive a vast subset of applications:
+So what are these patterns? Here are some core patterns that drive a vast subset of applications:
-* **API** - The combination of inputs and outputs that external applications use to interact with the application.
-* **Local State** - The information owned and managed by the application.
-* **Remote State** - Any information that is required by this application but not managed by it.
+- **API** - The combination of inputs and outputs that external applications use to interact with the application.
+- **Local State** - The information owned and managed by the application.
+- **Remote State** - Any information that is required by this application but not managed by it.
These are the core building blocks of many applications and can be implemented in a variety of technologies.
-Let's look at an example. We'll use Morphir's Elm modeling support, so
+Let's look at an example. We'll use Morphir's Elm modeling support, so
[follow the installation instructions](https://github.com/Morgan-Stanley/morphir-elm#installation-1) to get started.
## Application Overview
-For this example, we'll look at a set of interacting applications that form a complete order processing system. They include:
-* [Books and Records](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/BooksAndRecords) - Keeps
+For this example, we'll look at a set of interacting applications that form a complete order processing system. They include:
+
+- [Books and Records](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/BooksAndRecords) - Keeps
the books on what orders have been executed.
-* [Order](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/Order) - Processes
+- [Order](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/Order) - Processes
order requests and records any confirmations to Books and Records.
-* [Trader](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/Trader) - An automated
- trading algorithm that makes decisions based on the market and the state of the current book of deals. It
+- [Trader](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/Trader) - An automated
+ trading algorithm that makes decisions based on the market and the state of the current book of deals. It
relies on Books, Records, and Order.
## Modeling the Persistent App specification
-All three of these are instances of applications that manage:
+
+All three of these are instances of applications that manage:
## Modeling the API
-Books and Records is used by Order to book executions, so it needs a way to accept orders. We model this in Morphir
+
+Books and Records is used by Order to book executions, so it needs a way to accept orders. We model this in Morphir
using the API type as such:
```elm
@@ -55,14 +65,15 @@ type alias API =
, closeDeal : ID -> Result CloseRequestFault Event
}
```
-This states that Books and Records exposes an endpoint to open a deal and another to close an existing deal. In each
-case, the outcome of the request is communicated by an event that either confirms or gives a message about why the
-request was rejected. Note that it doesn't state whether these calls are synchronous or asynchronous. That's because
-that decision is an infrastructure ecosystem concern, not a business concern. That means we should save the decision to
-a later stage when we decide how the application fits into the ecosystem. If we decide now, we're locking ourselves to
+
+This states that Books and Records exposes an endpoint to open a deal and another to close an existing deal. In each
+case, the outcome of the request is communicated by an event that either confirms or gives a message about why the
+request was rejected. Note that it doesn't state whether these calls are synchronous or asynchronous. That's because
+that decision is an infrastructure ecosystem concern, not a business concern. That means we should save the decision to
+a later stage when we decide how the application fits into the ecosystem. If we decide now, we're locking ourselves to
one execution paradigm before we have enough information.
-We know that other applications will be interested in knowing what's happening in Books and Records even if they're not
+We know that other applications will be interested in knowing what's happening in Books and Records even if they're not
making requests. So we declare that Books and Records publishes events about what's going on:
```elm
@@ -72,15 +83,17 @@ type Event
```
## Modeling the Local State
-Books and Records by definition owns the state required for book management. We want to declare what state is owned so
-that we can plug it into our persistence ecosystem eventually. We do this with:
+
+Books and Records by definition owns the state required for book management. We want to declare what state is owned so
+that we can plug it into our persistence ecosystem eventually. We do this with:
```elm
-type alias LocalState =
+type alias LocalState =
Dict ID Deal
```
## Modeling Remote State Dependencies
+
Some applications need information managed outside their domain. The Order application demonstrates this. It declares
these external dependencies using the RemoteState type:
@@ -94,45 +107,49 @@ type alias RemoteState =
}
```
-Here we state that Order depends on the ability to book order executions, to look up the current state of a deal,
-to get the current market price for a product, and to get the product's inventory. It needs all of this information to
-make decisions. Notice that it doesn't specify what's going to satisfy these dependencies. That's an infrastructure
+Here we state that Order depends on the ability to book order executions, to look up the current state of a deal,
+to get the current market price for a product, and to get the product's inventory. It needs all of this information to
+make decisions. Notice that it doesn't specify what's going to satisfy these dependencies. That's an infrastructure
ecosystem decision based on knowledge that we don't have as modellers.
## The Full Models
-These three patterns cover most applications. For the full example models take a look at
+
+These three patterns cover most applications. For the full example models take a look at
[the Morphir examples project](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps).
# Execution
-There are many ways that we can run these applications. The advantage of modeling them is that we can choose and
-customize as needed without rewriting any of our core business concepts. For this example, we will take advantage of
-the fact that Microsoft has recognized this very set of patterns in its cloud-ready [Dapr Platform](http://dapr.io). Each
+
+There are many ways that we can run these applications. The advantage of modeling them is that we can choose and
+customize as needed without rewriting any of our core business concepts. For this example, we will take advantage of
+the fact that Microsoft has recognized this very set of patterns in its cloud-ready [Dapr Platform](http://dapr.io). Each
of our modeled patterns has a corresponding Dapr feature that we can take advantage of.
Our model patterns map to Dapr in the following ways:
-* **API Requests** - Our API requests turn into REST services defined by generating OpenAPI specifications. Alternatively,
+- **API Requests** - Our API requests turn into REST services defined by generating OpenAPI specifications. Alternatively,
we could choose to use a message queue or Kafka for asynchronous requests.
-* **API Events** - Events are published to Kafka as event logs.
-* **Local State** - Dapr supports Redis natively, so we'll use that for persistence.
-* **Remote State** - Given that we've made the REST decision, all the external applications will also be exposed that
+- **API Events** - Events are published to Kafka as event logs.
+- **Local State** - Dapr supports Redis natively, so we'll use that for persistence.
+- **Remote State** - Given that we've made the REST decision, all the external applications will also be exposed that
way. These will turn into REST calls and get bound to the owning applications during the SDLC pipeline.
For more information on Morphir's Dapr support, take a look at the [morphir-dapr](https://github.com/Morgan-Stanley/morphir-dapr) project.
# SDLC Pipeline
-We can utilize various SDLC technologies to create straight-through deployment. In this example, we'll utilize GitHub's
-pipeline technology to trigger a full deployment lifecycle every time we make a change to the model.
+
+We can utilize various SDLC technologies to create straight-through deployment. In this example, we'll utilize GitHub's
+pipeline technology to trigger a full deployment lifecycle every time we make a change to the model.
# Summing Up
-In this example we've created a full set of distributed applications using Morphir, and we've managed to do so without
-writing a single bit of non-business code. The cool part is that it doesn't mean that we're locked into a particular
-platform or vendor. We can always change the execution target by using another Morphir backend or writing our own.
-We've also demonstrated a true front-to-back SDLC pipeline that automates full deployment from the moment you check in your model.
+In this example we've created a full set of distributed applications using Morphir, and we've managed to do so without
+writing a single bit of non-business code. The cool part is that it doesn't mean that we're locked into a particular
+platform or vendor. We can always change the execution target by using another Morphir backend or writing our own.
+
+We've also demonstrated a true front-to-back SDLC pipeline that automates full deployment from the moment you check in your model.
-The end result is an application development that finally **lets developers focus solely on providing business value
-without sacrificing technical flexibility**. That should be pretty compelling to anyone who's struggled to balance
+The end result is an application development that finally **lets developers focus solely on providing business value
+without sacrificing technical flexibility**. That should be pretty compelling to anyone who's struggled to balance
providing business value against all the cursory development tasks.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/background.md b/docs/background.md
index 70e079d8d..8ef1c577c 100644
--- a/docs/background.md
+++ b/docs/background.md
@@ -1,67 +1,79 @@
+---
+sidebar_position: 2
+id: background-story
+title: The Morphir Background Story
+---
+
# The Morphir Background Story
-Morphir evolved from years of frustration trying to work around technical limitations to adequately model business concepts. Then after so much effort and pain, we inevitably have to start over to adapt to some new technology. This came to a head when one of our businesses suddenly faced a convergence of major new business requirements and technical upgrades that required yet another major rewrite. There was so much work to be done and so much frustration from our business clients that they issued the challenge below...
+
+Morphir evolved from years of frustration trying to work around technical limitations to adequately model business concepts. Then after so much effort and pain, we inevitably have to start over to adapt to some new technology. This came to a head when one of our businesses suddenly faced a convergence of major new business requirements and technical upgrades that required yet another major rewrite. There was so much work to be done and so much frustration from our business clients that they issued the challenge below...
## The Challenge
-> **Stop the cycle of rewrites** - Our users recognized that we were in a constant cycle of upgrading technology. Each pass in the cycle required significant effort and posed the risk of implementing core business logic incorrectly.
+> **Stop the cycle of rewrites** - Our users recognized that we were in a constant cycle of upgrading technology. Each pass in the cycle required significant effort and posed the risk of implementing core business logic incorrectly.
-> **Stop making us use multiple applications with inconsistent values** - Our users noticed that different systems came to different results for what should have theoretically been the same calculations. As a result, they had to navigate across applications to get the information they needed.
+> **Stop making us use multiple applications with inconsistent values** - Our users noticed that different systems came to different results for what should have theoretically been the same calculations. As a result, they had to navigate across applications to get the information they needed.
> **Show us that the system is behaving correctly** - Our users demanded that if we were going to rewrite core business logic again, we needed to provide transparency so that they could understand exactly how the system was behaving with respect to the business.
> **Deliver faster** - A never ending, desired request.
## Common Cause
-This challenge made us re-examine our whole development process. It soon became clear that there was a theme across them: **the fundamental issue was the fact that the business knowledge was tightly wrapped into the technologies of the moment**. It stood to reason that freeing the business knowledge from the technology would address these challenges. That's the approach we took and that is what eventually evolved into Morphir.
+
+This challenge made us re-examine our whole development process. It soon became clear that there was a theme across them: **the fundamental issue was the fact that the business knowledge was tightly wrapped into the technologies of the moment**. It stood to reason that freeing the business knowledge from the technology would address these challenges. That's the approach we took and that is what eventually evolved into Morphir.
## Morphir In Action
-Let's take a look at what that all means and how Morphir works to address these challenges. Let's consider a component of an online store application. The purpose of this application is to decide on:
+Let's take a look at what that all means and how Morphir works to address these challenges. Let's consider a component of an online store application. The purpose of this application is to decide on:
### Promoting Business Knowledge
-The business concepts underlying your application are its most valuable asset. It's often difficult to discern
-business concepts when they're embedded within platform and execution code. On top of that, many programming languages
+
+The business concepts underlying your application are its most valuable asset. It's often difficult to discern
+business concepts when they're embedded within platform and execution code. On top of that, many programming languages
are so full of abstractions that it can become difficult to understand the business meaning at all.
Morphir tackles this challenge in a few ways. First, it provides a common structure to save business concepts, including
-both data and logic. This is the Morphir IR. The key to this structure is that it focuses solely on business logic and
+both data and logic. This is the Morphir IR. The key to this structure is that it focuses solely on business logic and
data. No side effects (like saving to a database or reading from a file) are allowed. The IR is the core to Morphir and
allows it to work across languages and platforms.
-Having an application's business knowledge in a common data structure allows teams to build useful tools that promote
-knowledge dissemination. Some useful examples include interactive visualizations that allow users to understand the
-application's logic, interactive audit tools to replay calculations interactively, automatic data dictionary and data
-lineage registration, and more.
+Having an application's business knowledge in a common data structure allows teams to build useful tools that promote
+knowledge dissemination. Some useful examples include interactive visualizations that allow users to understand the
+application's logic, interactive audit tools to replay calculations interactively, automatic data dictionary and data
+lineage registration, and more.
-The combination of these creates an ecosystem where users, new developers, and support personnel can gain insight into
+The combination of these creates an ecosystem where users, new developers, and support personnel can gain insight into
an application interactively without requiring developers to go back and study stale documentation and arcane code.
### Showing Correctness
+
If you're going to treat business knowledge as a valuable asset, you want to make sure that it's correct. Morphir's use
of functional programming structures that are tuned towards codifying business concepts eliminates many of the bugs that
-are common in less concise tools. This is really just the beginning of the story. What's even more powerful is the fact
-that Morphir is compatible with a variety of source languages, so it can take advantage of the powerful tools that they
+are common in less concise tools. This is really just the beginning of the story. What's even more powerful is the fact
+that Morphir is compatible with a variety of source languages, so it can take advantage of the powerful tools that they
offer. We currently support the [Elm programming language](http://elm-lang.org) due to its simplicity and power. The Elm
compiler is supercharged to catch huge classes of bugs. The common saying is that if it compiles, it's guaranteed not to
-have runtime errors (excluding limitations of the physical environment, of course). Another particularly exciting
-language is Microsoft's [Bosque programming language](https://github.com/microsoft/BosqueLanguage), which takes the
+have runtime errors (excluding limitations of the physical environment, of course). Another particularly exciting
+language is Microsoft's [Bosque programming language](https://github.com/microsoft/BosqueLanguage), which takes the
ability to verify program correctness up whole other level. Keep an eye out for further progress in this space.
-Finally, the aforementioned business knowledge tools are a big help in establishing correctness. When users have the
-ability to fully understand the system with helpful tools in real-time, it makes the user/developer feedback cycle very
+Finally, the aforementioned business knowledge tools are a big help in establishing correctness. When users have the
+ability to fully understand the system with helpful tools in real-time, it makes the user/developer feedback cycle very
efficient.
### Delivering Faster
-An important role of developers is to decide how the business concepts fit into an executable computer system. Once
-that shape is decided, a great deal of the actual coding is very repetative and templated. Add to this the various best
-practices and team standards and you get a lot of boilerplate code that can be automated for faster production with
-fewer errors. Morphir relies heavily on such automation, which we call Dev Bots. As with any automation, smart use can
-lead to drastic efficiency improvements, like taking seconds to generate what a developer would take days to
+
+An important role of developers is to decide how the business concepts fit into an executable computer system. Once
+that shape is decided, a great deal of the actual coding is very repetative and templated. Add to this the various best
+practices and team standards and you get a lot of boilerplate code that can be automated for faster production with
+fewer errors. Morphir relies heavily on such automation, which we call Dev Bots. As with any automation, smart use can
+lead to drastic efficiency improvements, like taking seconds to generate what a developer would take days to
produce. Check out the [Dev Bot post](dev_bots) for more information on this topic.
### Eliminating Rewrites
+
Technology is evolving ever more quickly. It is no longer feasible to stay competitive if you need to completely rewrite
-you application every time you want to upgrade to newer technologies. That's especially true if there is a risk of
+you application every time you want to upgrade to newer technologies. That's especially true if there is a risk of
getting your core business logic wrong in a rewrite. In addition to automating boilerplate code, Morphir Dev Bots convert
Morphir IR into system code. This means the same Morphir model can run in different technologies. And with the business
concepts protected in the Morphir model, there's no risk to losing it with the next big technology. Keep an eye out for
@@ -69,8 +81,8 @@ the evolving list of target environments available in the Morphir ecosystem. Or,
Morphir provides the tools to do it yourself.
# Summing Up
-Hopefully this gives a good background into what Morphir does and why. If you have any questions or comments, feel free
-to drop us a note through the [Morphir project](https://github.com/finos/morphir).
+Hopefully this gives a good background into what Morphir does and why. If you have any questions or comments, feel free
+to drop us a note through the [Morphir project](https://github.com/finos/morphir).
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/dev_bots.md b/docs/dev_bots.md
index 353fed8f8..9b14ada4c 100644
--- a/docs/dev_bots.md
+++ b/docs/dev_bots.md
@@ -1,21 +1,28 @@
-# Dev Bots
-The premise of Dev Bots is that we can and should automate a significant portion of the code that we currently write by hand.
+---
+sidebar_position: 5
+id: dev-bots
+title: Explaining Dev Bots
+---
-Consider the portion of an application's code that is of no direct business value, includeing things like
-persistence and ORM, interprocess communication, platform-specific code, object wiring, and more. We need this code
-to make our applications run, but it is of no direct business value. A large portion of this non-business code comes
-in the form of recipes to follow or "best practices" templates. The fact that it takes up the majority of our
-applications often reduces us to human code robots. We often refer to this code as boilerplate, and it is
+# Explaining Dev Bots
+
+The premise of Dev Bots is that we can and should automate a significant portion of the code that we currently write by hand.
+
+Consider the portion of an application's code that is of no direct business value, includeing things like
+persistence and ORM, interprocess communication, platform-specific code, object wiring, and more. We need this code
+to make our applications run, but it is of no direct business value. A large portion of this non-business code comes
+in the form of recipes to follow or "best practices" templates. The fact that it takes up the majority of our
+applications often reduces us to human code robots. We often refer to this code as boilerplate, and it is
highly amenable to automation.
-We can also look into automating certain aspects of business code. Much of that code also follows templates and best
-practices, and as a result, there is an abundance of tools that process code for quality and conformance
-to rules. These tools ensure that the code that developers write fits into a small window of variability. Again,
-developers are reduced to human code robots. You have to wonder: *If we have such sophisticated tools that automatically
-ensure that all of our code conforms to a limited set of templates after the code is written, why don't we have tools
-that automatically write the code to those specifications in the first place?* The answer is that we can.
+We can also look into automating certain aspects of business code. Much of that code also follows templates and best
+practices, and as a result, there is an abundance of tools that process code for quality and conformance
+to rules. These tools ensure that the code that developers write fits into a small window of variability. Again,
+developers are reduced to human code robots. You have to wonder: _If we have such sophisticated tools that automatically
+ensure that all of our code conforms to a limited set of templates after the code is written, why don't we have tools
+that automatically write the code to those specifications in the first place?_ The answer is that we can.
-This is what Morphir Dev Bots do. They automate the production of all the boilerplate and templated code and
+This is what Morphir Dev Bots do. They automate the production of all the boilerplate and templated code and
let developers focus on what they do best: provide the bridge between the business and computer world.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/index.md b/docs/index.md
deleted file mode 100644
index 121c0ea95..000000000
--- a/docs/index.md
+++ /dev/null
@@ -1,83 +0,0 @@
-# Morphir
-
-Morphir is a multi-language system built on a data format that captures an application's domain model and business logic
-in a technology agnostic manner. Having all the business knowledge available as data allows you to process it
-programmatically in various ways:
-
-- **Translate it** to move between languages and platforms effortlessly as technology evolves
-- **Visualize it** to turn black-box logic into insightful explanations for your business users
-- **Share it** across different departments or organizations for consistent interpretation
-- **Store it** to retrieve and explain earlier versions of the logic in seconds
-- and much more ...
-
-While the core idea behind Morphir is very simple it's still challenging to describe it because it doesn't fit into
-any well-known categories. To help you understand what it is and how you can use it to solve real-world problems we
-put together a tutorial and list of questions and short answers:
-
-- [Tutorial](https://github.com/stephengoldbaum/morphir-examples/tree/master/tutorial)
-- [How do I define my domain model and business logic?](#how-do-I-define-my-domain-model-and-business-logic)
-- [How does Morphir turn logic into data?](#how-does-morphir-turn-logic-into-data)
-- [What does the data format look like?](#what-does-the-data-format-look-like)
-
-
-## How do I define my domain model and business logic?
-
-Morphir is a multi-language system, so it gives you flexibility in what language or tool you use to define your
-domain model and business logic (we refer to them as frontends). As a community we are continuously building new
-language frontends and if the one you are looking for is not available we provide tools for you to build it yourself.
-
-Our main frontend is currently the [Elm](https://elm-lang.org/) programming language. We support the whole language
-(except for some very platform specific features like ports) so defining your domain model and business logic boils down
-to writing Elm code. To learn more about the frontend see [morphir-elm](https://github.com/Morgan-Stanley/morphir-elm).
-
-Other frontends:
-
-- [Bosque Programming Language](https://github.com/Morgan-Stanley/morphir-bosque)
-
-## How does Morphir turn logic into data?
-
-The process of turning logic into data is well known because every programming language compiler and interpreter does
-it. They parse the source code to generate an [abstract syntax tree](https://en.wikipedia.org/wiki/Abstract_syntax_tree)
-which is then transformed into an [intermediate representation](https://en.wikipedia.org/wiki/Intermediate_representation) of some sort.
-
-Morphir simply turns that intermediate representation into a developer-friendly data format that makes it easy to build
-automation on top of it.
-
-## What does the data format look like?
-
-It's easiest to start with an example. Say you have some simple business logic like this:
-
-```javascript
-quantity * unitPrice
-```
-
-In Morphir's data format this would translate into something like this:
-
-```javascript
-["Apply"
-, ["Apply"
- , ["Reference", [["Morphir", "SDK"], ["Number"], "multiply"]]
- , ["Variable", ["quantity"]]]
-, ["Variable", ["unit", "price"]]
-]
-```
-
-# Further reading
-
-## Introduction and Background
-* [Background](background)
-* [Community](morphir_community)
-* [What's it all about?](whats_it_about)
-* [Working Across Technologies](work_across_languages_and_platforms)
-* [Why we use Functional Programming?](why_functional_programming)
-
-## Using Morphir
-* [What Makes a Good Model](what-makes-a-good-domain-model)
-* [Development Automation (Dev Bots)](dev_bots)
-* [Modeling an Application](application_modeling)
-* [Modeling Decision Tables](https://github.com/finos/morphir-examples/tree/master/src/Morphir/Sample/Rules)
-* [Modeling for database developers](modeling/modeling-for-database-developers.md)
-
-## Applicability
-* [Sharing Business Logic Across Application Boundaries](shared_logic_modeling)
-* [Regulatory Technology](regtech_modeling)
diff --git a/docs/index2.md b/docs/index2.md
deleted file mode 100644
index 065272543..000000000
--- a/docs/index2.md
+++ /dev/null
@@ -1,11 +0,0 @@
-## Where business meets technology
-
-Morphir turns a programming language inside out to provide ...
-
-> **Transparency** - Turn business rules into insightful data visualizations
-
-> **Agility** - Move between languages and platforms effortlessly
-
-> **Reliability** - No runtime exceptions, integrated testing and quality checks
-
-> **Transformation** - Renovate your applications in-place with no migration period
diff --git a/docs/index3.md b/docs/index3.md
index 00c5acccc..7f751fc0b 100644
--- a/docs/index3.md
+++ b/docs/index3.md
@@ -1,6 +1,12 @@
-# Maximize the soul of your application
+---
+sidebar_position: 3
+id: soul-application
+title: Soul of your Application
+---
-Morphir approaches application development from the perspective that the application's business knowledge should be enshrined. Adopting this knowledge-first has brought us great benefits, including:
+# Maximize the Soul of your Application
+
+Morphir approaches application development from the perspective that the application's business knowledge should be enshrined. Adopting this knowledge-first has brought us great benefits, including:
> **Transparency** - Turn business rules into insightful data visualizations
@@ -13,14 +19,13 @@ Morphir approaches application development from the perspective that the applica
This has been impactful enough that we want to bring it to the open-source community. Morphir is all about potential. We have benefited and will contribute these. The true potential is in what the community can bring to the Morphir ecosystem.
## Why use Morphir?
-Your application has a soul - it's reason for existing. It might be embodied in calculations, business rules, and other logic. Collectively these are your application's most important assets. You need to protect these assets. You also want to do useful things with it.
-
-For starters, you definately want it to **[function correctly](why_functional_programming)**. Ideally, it could do that **[across different technologies and platforms](work_across_languages_and_platforms)**. In addition, you also want to **[share the knowledge](shared_logic_modeling)** to your application's stakeholders. This provides transparency and gives them **[confidence](build_confidence)** in what you're delivering. It also makes supporting and learning about your application easier. The world is changing fast, so you want all of these characteristics while **[delivering quickly and efficiently](dev_bots)**.
-This is where Morphir comes in. **Morphir treats logic like data**. This simple concept makes it possible to do all of these things and more. Morphir makes development better. To learn more ...
+Your application has a soul - it's reason for existing. It might be embodied in calculations, business rules, and other logic. Collectively these are your application's most important assets. You need to protect these assets. You also want to do useful things with it.
+For starters, you definately want it to **[function correctly](why_functional_programming)**. Ideally, it could do that **[across different technologies and platforms](work_across_languages_and_platforms)**. In addition, you also want to **[share the knowledge](shared_logic_modeling)** to your application's stakeholders. This provides transparency and gives them **[confidence](build_confidence)** in what you're delivering. It also makes supporting and learning about your application easier. The world is changing fast, so you want all of these characteristics while **[delivering quickly and efficiently](dev_bots)**.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
------|------|------
- | |
+This is where Morphir comes in. **Morphir treats logic like data**. This simple concept makes it possible to do all of these things and more. Morphir makes development better. To learn more ...
+| [Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/) |
+| -------------- | -------------- | ------------------------------------------------------ |
+| |
diff --git a/docs/intro.md b/docs/intro.md
index 5a8f422b4..668b20c27 100644
--- a/docs/intro.md
+++ b/docs/intro.md
@@ -10,20 +10,34 @@ Morphir is a multi-language system built on a data format that captures an appli
in a technology agnostic manner. Having all the business knowledge available as data allows you to process it
programmatically in various ways:
-- **Translate it** to move between languages and platforms effortlessly as technology evolves
-- **Visualize it** to turn black-box logic into insightful explanations for your business users
-- **Share it** across different departments or organizations for consistent interpretation
-- **Store it** to retrieve and explain earlier versions of the logic in seconds
-- and much more ...
+- **Translate it** to move between languages and platforms effortlessly as technology evolves
+- **Visualize it** to turn black-box logic into insightful explanations for your business users
+- **Share it** across different departments or organizations for consistent interpretation
+- **Store it** to retrieve and explain earlier versions of the logic in seconds
+- and much more ...
While the core idea behind Morphir is very simple it's still challenging to describe it because it doesn't fit into
any well-known categories. To help you understand what it is and how you can use it to solve real-world problems we
put together a tutorial and list of questions and short answers:
-- [Tutorial](https://github.com/stephengoldbaum/morphir-examples/tree/master/tutorial)
-- [How do I define my domain model and business logic?](#how-do-I-define-my-domain-model-and-business-logic)
-- [How does Morphir turn logic into data?](#how-does-morphir-turn-logic-into-data)
-- [What does the data format look like?](#what-does-the-data-format-look-like)
+- [Tutorial](https://github.com/stephengoldbaum/morphir-examples/tree/master/tutorial)
+- [How do I define my domain model and business logic?](#how-do-I-define-my-domain-model-and-business-logic)
+- [How does Morphir turn logic into data?](#how-does-morphir-turn-logic-into-data)
+- [What does the data format look like?](#what-does-the-data-format-look-like)
+
+## FINOS Morphir Resources
+
+- [Morphir Resource Centre](https://resources.finos.org/morphir/)
+
+| Episode | Description |
+| --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------ |
+| | Introduction to the Morphir Showcase |
+| | What Morphir is with Stephen Goldbaum |
+| | How Morphir works with Attila Mihaly |
+| | Why Morphir is Important – with Colin, James & Stephen |
+| | The Benefits & Use Case of Morphir with Jane, Chris & Stephen |
+| | How to get involved – Closing Panel Q&A |
+| | Morphir Showcase – Full Show |
## How do I define my domain model and business logic?
@@ -37,7 +51,7 @@ to writing Elm code. To learn more about the frontend see [morphir-elm](https://
Other frontends:
-- [Bosque Programming Language](https://github.com/Morgan-Stanley/morphir-bosque)
+- [Bosque Programming Language](https://github.com/Morgan-Stanley/morphir-bosque)
## How does Morphir turn logic into data?
@@ -60,9 +74,13 @@ In Morphir's data format this would translate into something like this:
```javascript
[
- 'Apply',
- ['Apply', ['Reference', [['Morphir', 'SDK'], ['Number'], 'multiply']], ['Variable', ['quantity']]],
- ['Variable', ['unit', 'price']],
+ "Apply",
+ [
+ "Apply",
+ ["Reference", [["Morphir", "SDK"], ["Number"], "multiply"]],
+ ["Variable", ["quantity"]],
+ ],
+ ["Variable", ["unit", "price"]],
];
```
diff --git a/docs/modeling/modeling-finance.md b/docs/modeling/modeling-finance.md
index 92a156982..8c916b53b 100644
--- a/docs/modeling/modeling-finance.md
+++ b/docs/modeling/modeling-finance.md
@@ -1,11 +1,17 @@
+---
+id: modeling-financial-concepts
+title: Modeling Financial Concepts
+---
+
# Modeling Financial Concepts
-Functional Domain Modeling (FDM) is all about capturing business concepts in a precise, unambiguous, and processable manner. Those coming from a coding background will be comfortable with its use of first class programming language. There will be some differences from general purpose languages, and especially object-oriented languages, that are more focused on execution than capturing business concepts. This tuturial reviews how we can capture common business concepts concisely and expressively with Morphir. Morphir uses Elm as its main FDM language of choice, so we'll demonstrate the concepts with Elm examples.
+Functional Domain Modeling (FDM) is all about capturing business concepts in a precise, unambiguous, and processable manner. Those coming from a coding background will be comfortable with its use of first class programming language. There will be some differences from general purpose languages, and especially object-oriented languages, that are more focused on execution than capturing business concepts. This tuturial reviews how we can capture common business concepts concisely and expressively with Morphir. Morphir uses Elm as its main FDM language of choice, so we'll demonstrate the concepts with Elm examples.
## Using The Language Of The Business
-FDM relies heavily on Domain Driven Design, which has the concept of the *ubiquitous language*: making sure that the business and technology stakeholders establish a consistent language to describe the business. The best way to do this is to ensure that the code uses that language directly with no translation. Morphir makes this easy by being very friendly for labeling data in the form of types.
-We can use a standard trade as an example. When the business talks about trading, they probably refer to the trade's quantity, price, and value as ```Trade Quantity``` and ```Trade Price```, and ```Trade Value```. So we want to capture those concepts in our code. As technologists, we know that these fields instances of integers and decimals. While we might be tempted to declare them as such, it would be better if we could use the business language. And this is how we want to approach modeling these concepts in Morphir. Elm has the concept of type aliases, so we'll take advantage of that.
+FDM relies heavily on Domain Driven Design, which has the concept of the _ubiquitous language_: making sure that the business and technology stakeholders establish a consistent language to describe the business. The best way to do this is to ensure that the code uses that language directly with no translation. Morphir makes this easy by being very friendly for labeling data in the form of types.
+
+We can use a standard trade as an example. When the business talks about trading, they probably refer to the trade's quantity, price, and value as `Trade Quantity` and `Trade Price`, and `Trade Value`. So we want to capture those concepts in our code. As technologists, we know that these fields instances of integers and decimals. While we might be tempted to declare them as such, it would be better if we could use the business language. And this is how we want to approach modeling these concepts in Morphir. Elm has the concept of type aliases, so we'll take advantage of that.
```elm
type alias TradeQuantity = Int
@@ -15,7 +21,7 @@ type alias TradePrice = Decimal
type alias TradeValue = Decimal
```
-Now when we see these values in our code, we know they map directly to the business concepts that the users know them as. For example:
+Now when we see these values in our code, we know they map directly to the business concepts that the users know them as. For example:
```elm
value : TradeQuantity -> TradePrice -> TradeValue
@@ -23,10 +29,11 @@ value quantity price =
(ToDecimal quantity) * price
```
-This bit of Elm defines a function that takes a ```TradeQuantity``` and ```TradePrice``` and calculates the ```TradeValue```. This simple act is incredibly effective in avoiding misunderstandings and mistakes.
+This bit of Elm defines a function that takes a `TradeQuantity` and `TradePrice` and calculates the `TradeValue`. This simple act is incredibly effective in avoiding misunderstandings and mistakes.
## Keeping Incompatible Concepts Separate
-In our trade example, we aliased ```TradePrice``` and ```TradeValue``` as aliases of Decimal. That means that the compile considers them to be of the same Decimal type, so anything you can do with Decimals can be done with these two types. That's useful in some ways, like applying functions like absolute value. In other ways, we don't want to mix the two. For example, what does it mean to do ```TradePrice + TradeValue```? From a business perspective, this makes no sense, so we shouldn't be able to do it in code. Morphir has the concept of *Units of Measure*, which you might have seen as a first class concept in F#. In Elm it's implemented via a mechanism called *Phantom Types*. So we probably want to implement some core types of ```Value``` and ```Price```.
+
+In our trade example, we aliased `TradePrice` and `TradeValue` as aliases of Decimal. That means that the compile considers them to be of the same Decimal type, so anything you can do with Decimals can be done with these two types. That's useful in some ways, like applying functions like absolute value. In other ways, we don't want to mix the two. For example, what does it mean to do `TradePrice + TradeValue`? From a business perspective, this makes no sense, so we shouldn't be able to do it in code. Morphir has the concept of _Units of Measure_, which you might have seen as a first class concept in F#. In Elm it's implemented via a mechanism called _Phantom Types_. So we probably want to implement some core types of `Value` and `Price`.
```elm
type Price a = Price Decimal
@@ -36,14 +43,15 @@ type Quantity a = Quantity Int
type Value a = Value Decimal
```
-This will ensure that we don't mix ```Price```, ```Quantity```, and ```Value``` in invalid ways. There are a lot of concepts in finance that we might want to approach this way. For example, we'd never want to accidentally use prices in different currencies without normalizing them. The same goes for things like fixed rate versus variable rate loans.
+This will ensure that we don't mix `Price`, `Quantity`, and `Value` in invalid ways. There are a lot of concepts in finance that we might want to approach this way. For example, we'd never want to accidentally use prices in different currencies without normalizing them. The same goes for things like fixed rate versus variable rate loans.
## Categorizing Things
-Categorizing stuff is one of the most common actions in enterprise development. Finance is full of categorizing, like categorizing trades, accounts, and products into different sets. This often gets very complex and categorization is usually highly contextual, meaning the same things might get categorized differently across different parts of the business. This has historically been a major source of complexity in finance. One of the main causes is the fact that categorization is usually approached up front, meaning the categories are decided first and then the things are created directly into those categories. This limits later flexibility for different contexts and often creates incredibly complex graphs of categories. In practice, we usually see this with object-oriented systems where the base classes or traits are decided first and then the specific things are specified with classes that extend them.
-Functional Domain Modeling takes a different approach to these challenges. In FDM, the structure of things are defined first and only put into categories in contexts as needed. This simplifies the modelers' jobs by alleviating the need to account for all possible use cases up front. The tradeoff is that it requires mapping into categories later.
+Categorizing stuff is one of the most common actions in enterprise development. Finance is full of categorizing, like categorizing trades, accounts, and products into different sets. This often gets very complex and categorization is usually highly contextual, meaning the same things might get categorized differently across different parts of the business. This has historically been a major source of complexity in finance. One of the main causes is the fact that categorization is usually approached up front, meaning the categories are decided first and then the things are created directly into those categories. This limits later flexibility for different contexts and often creates incredibly complex graphs of categories. In practice, we usually see this with object-oriented systems where the base classes or traits are decided first and then the specific things are specified with classes that extend them.
+
+Functional Domain Modeling takes a different approach to these challenges. In FDM, the structure of things are defined first and only put into categories in contexts as needed. This simplifies the modelers' jobs by alleviating the need to account for all possible use cases up front. The tradeoff is that it requires mapping into categories later.
-Let's look at an example. A classic financial modeling exercise is to model various financial products. For this example, let's take a subset of a Treasury function since Treasury needs to work across asset classes. The standard object-orient approach is to start with something like this:
+Let's look at an example. A classic financial modeling exercise is to model various financial products. For this example, let's take a subset of a Treasury function since Treasury needs to work across asset classes. The standard object-orient approach is to start with something like this:
```java
public interface Product {
@@ -77,10 +85,12 @@ public class Stock {
TODO...
## Data sets
-As we model data we come across a few established patterns, which we'll discuss below. These are general guideliness that should be balanced with the context of the project.
+
+As we model data we come across a few established patterns, which we'll discuss below. These are general guideliness that should be balanced with the context of the project.
## Infrequently changing limited values
-This category describes a finite set of infrequently changing data. Some good examples of this type are days of the week, months of the year, ISO country codes, and currency codes. Often, programmers will want to refer to these directly without the possibility of mistakes. The standard approach to specifying these values is to use an enum. The functional way tends to focus on discriminated union types. In Elm, this looks like:
+
+This category describes a finite set of infrequently changing data. Some good examples of this type are days of the week, months of the year, ISO country codes, and currency codes. Often, programmers will want to refer to these directly without the possibility of mistakes. The standard approach to specifying these values is to use an enum. The functional way tends to focus on discriminated union types. In Elm, this looks like:
```elm
type DayOfWeek = Sunday | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday
@@ -91,14 +101,15 @@ isWeekend day =
```
## Frequently changing limited values
-This category describes a finite set of frequently changing data. A good example of this might something like pizza toppings, where there's a core set of common toppings and frequent changes based on market conditions. In theory, the frequency of change shouldn't affect how we model. It would be great to model these as enums as well and rely on continuous delivery to get that into production. In practice, many environments are not agile enough so rely on the database. So the common approach is to define these as such:
+
+This category describes a finite set of frequently changing data. A good example of this might something like pizza toppings, where there's a core set of common toppings and frequent changes based on market conditions. In theory, the frequency of change shouldn't affect how we model. It would be great to model these as enums as well and rely on continuous delivery to get that into production. In practice, many environments are not agile enough so rely on the database. So the common approach is to define these as such:
```elm
type alias PizzaTopping = String
```
```elm
-type Topping
+type Topping
= Cheese
| Pepperoni
| Mushrooms
@@ -123,7 +134,8 @@ toppingToString topping =
```
## Unlimited values
-This category describes a set of data that is unbounded for all practical purposes. The most common approach to these is simply to define a type alias:
+
+This category describes a set of data that is unbounded for all practical purposes. The most common approach to these is simply to define a type alias:
```elm
type alias Name = String
@@ -142,7 +154,7 @@ hi (Name name) =
# Custom Types
-When you have something in your domain that you can describe as a list of alternatives (X can either be A or B or C or ...)
+When you have something in your domain that you can describe as a list of alternatives (X can either be A or B or C or ...)
you probably want to model it as a [custom type](https://guide.elm-lang.org/types/custom_types.html). A simple special case
of this is enumerations. For example a Trade's Status can either be Open or Closed:
@@ -162,8 +174,8 @@ type OrderPrice
```
Notice that a market price doesn't have a specific value associated with it since it moves with the market but a limit price
-would have a specific price limit. In order to take full advantage of this flexibility you should use a pattern match to
-branch out on the various cases.
+would have a specific price limit. In order to take full advantage of this flexibility you should use a pattern match to
+branch out on the various cases.
## Special case: enumerations
@@ -186,13 +198,13 @@ Here's how you would do that for the `RAG` type above:
toCode : RAG -> String
toCode rag =
case rag of
- Red ->
+ Red ->
"R"
- Amber ->
+ Amber ->
"A"
- Green ->
+ Green ->
"G"
@@ -209,7 +221,7 @@ fromCode string =
Ok Green
other ->
- Err other
+ Err other
```
Notice that `fromCode` returns a `Result`. This is a way to explicitly say that the operation may fail. Since you can pass in
diff --git a/docs/modeling/modeling-for-database-developers.md b/docs/modeling/modeling-for-database-developers.md
index de70bfbfd..603fd2765 100644
--- a/docs/modeling/modeling-for-database-developers.md
+++ b/docs/modeling/modeling-for-database-developers.md
@@ -1,14 +1,19 @@
+---
+id: modeling-database-developers
+title: Modeling for database developers
+---
+
# Modeling for database developers
## Introduction
As a database developer you will find it very easy and enjoyable to learn Elm
because it's basically an extended version of SQL. Being a functional programming
-language, Elm is based on the same strong, mathematical foundations as relational
+language, Elm is based on the same strong, mathematical foundations as relational
algebra, and you get very similar declarative building blocks.
The syntax is different from SQL, but Elm is very lightweight and easy to pick up.
-Probably the best way to start learning is to see a few examples. Let's start
+Probably the best way to start learning is to see a few examples. Let's start
with a simple SQL query:
```sql
@@ -33,18 +38,18 @@ query1 =
There are a few things here that will look unfamiliar so let me explain:
-* `trades` is the source collection, similar to a table in SQL.
-* `|>` is the pipe operator. It's a way to chain transformations (operators in relational algebra).
-* `filter` is selection. It corresponds to the `WHERE` clause in SQL.
-* The `(\t -> ...)` syntax is a lambda. It's a way define a function inline. Some details about the syntax:
- * A lambda always starts with `\` which is followed by a list of argument names separated by spaces. This one has a single variable `t`.
- * After the argument names, there is an `->` to show that you are mapping the arguments to some other value.
- * You can specify any expressions after the arrow, and you can use the arguments as variables.
- * `t.buySell == "S"` this is very similar to how you would write this expression in SQL.
- * The only difference is that we use double-equals for comparison because single-equals is used for assignment.
-* `map` is projection. It corresponds to the `SELECT` clause in SQL.
- * `{ field1 = value1, field2 = value2 }` is the syntax to create a record.
- * This is slightly more involved than the SQL version, but it's also much more powerful. As you'll see later, Elm is
+- `trades` is the source collection, similar to a table in SQL.
+- `|>` is the pipe operator. It's a way to chain transformations (operators in relational algebra).
+- `filter` is selection. It corresponds to the `WHERE` clause in SQL.
+- The `(\t -> ...)` syntax is a lambda. It's a way define a function inline. Some details about the syntax:
+ - A lambda always starts with `\` which is followed by a list of argument names separated by spaces. This one has a single variable `t`.
+ - After the argument names, there is an `->` to show that you are mapping the arguments to some other value.
+ - You can specify any expressions after the arrow, and you can use the arguments as variables.
+ - `t.buySell == "S"` this is very similar to how you would write this expression in SQL.
+ - The only difference is that we use double-equals for comparison because single-equals is used for assignment.
+- `map` is projection. It corresponds to the `SELECT` clause in SQL.
+ - `{ field1 = value1, field2 = value2 }` is the syntax to create a record.
+ - This is slightly more involved than the SQL version, but it's also much more powerful. As you'll see later, Elm is
not limited to flat record structures.
**Note**: At this point you might be thinking: hold on, this is actually doing the whole operation in-memory, that's completely different.
@@ -104,13 +109,13 @@ type alias Trade =
Let's go through the type definition to understand what it means:
-* The overall structure is very similar to the DDL:
- * Just like a table, a type has a name and a structure.
- * The structure is a list of field names and types.
-* There are some differences too:
- * The field types are less granular than the DDL. This is just to avoid getting too deep too soon. We will
- make these very granular later on.
- * Nullability is expressed through the types: we simply prefix the type of nullable fields with `Maybe`.
+- The overall structure is very similar to the DDL:
+ - Just like a table, a type has a name and a structure.
+ - The structure is a list of field names and types.
+- There are some differences too:
+ - The field types are less granular than the DDL. This is just to avoid getting too deep too soon. We will
+ make these very granular later on.
+ - Nullability is expressed through the types: we simply prefix the type of nullable fields with `Maybe`.
As mentioned, we did lose some granularity in this definition. One of the main goals of modeling is to very accurately model
your domain, so we need to address this. Fortunately Elm makes this easy. As a first step let's define `buySell` as an enumeration.
@@ -124,21 +129,21 @@ type alias Trade =
}
-- this type captures the fact that there are only 2 valid values here
-type BuySell
- = Buy
+type BuySell
+ = Buy
| Sell
```
Elm allows you to define types as a choice between different values. The simplest way to use these is to
define enums. The definition above is pretty self-explanatory: the type `BuySell` can either be a `Buy` or a `Sell`.
-The type in the DDL is less accurate because it allows any single character strings as values. This makes
-it easy to overload the field, which tends to happen in systems a lot. This definition makes it impossible
+The type in the DDL is less accurate because it allows any single character strings as values. This makes
+it easy to overload the field, which tends to happen in systems a lot. This definition makes it impossible
to overload the value while also makes it easy to add new values if needed. The big difference is that you
are forced to at least document the valid values.
An enum like this can be mapped to the DDL in many ways depending on the database product or team best-practices.
-The bottom line is that when you are modeling your data, you don't need to deal with that. You can leave that to
+The bottom line is that when you are modeling your data, you don't need to deal with that. You can leave that to
the physical mapping layer.
The other thing we lost here is the lengths of some of the remaining columns. We can easily address that too:
@@ -152,19 +157,19 @@ type alias Trade =
}
-type BuySell
- = Buy
+type BuySell
+ = Buy
| Sell
-type Cusip =
+type Cusip =
Cusip String
cusip =
String.ofLength 9 Cusip
-type Comment =
+type Comment =
Comment String
comment =
@@ -175,9 +180,8 @@ comment =
_Coming soon_
-
## More relational operators
_Coming soon_
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/modeling/modeling-overview.md b/docs/modeling/modeling-overview.md
index b6405c1bf..ff1594bf5 100644
--- a/docs/modeling/modeling-overview.md
+++ b/docs/modeling/modeling-overview.md
@@ -1,33 +1,38 @@
+---
+id: morphir-entail
+title: What Does Using Morphir Entail?
+---
+
# What Does Using Morphir Entail?
So, you're thinking about using Morphir for your project. What does that mean exactly and what are you in for if you do?
## How using Morphir is different?
-Morphir embraces the Functional Domain Modeling (FDM) approach to development. FDM's emphasis is on capturing the business concepts and then projecting them into various runtime contexts. In practice, this means that we approach development in a different way than is often done. It's more of a formalized Hexogonal Architecture approach.
+Morphir embraces the Functional Domain Modeling (FDM) approach to development. FDM's emphasis is on capturing the business concepts and then projecting them into various runtime contexts. In practice, this means that we approach development in a different way than is often done. It's more of a formalized Hexogonal Architecture approach.
-## Modeling
+## Modeling
-One of the main pillars of FDM is that modeling the business is a unique discipline that must be approached independent from the technology. What this means in Morphir is that you'll start with the models and work them out before ever getting into the technology needed to execute them. We currently do this modeling in the Elm programming langauge. As a general rule, we start with the business logic and model the data to provide just enough to supply that logic. See [Modeling business concepts](modeling-finance.md) for a more detailed review on modeling strategies in Elm.
+One of the main pillars of FDM is that modeling the business is a unique discipline that must be approached independent from the technology. What this means in Morphir is that you'll start with the models and work them out before ever getting into the technology needed to execute them. We currently do this modeling in the Elm programming langauge. As a general rule, we start with the business logic and model the data to provide just enough to supply that logic. See [Modeling business concepts](modeling-finance.md) for a more detailed review on modeling strategies in Elm.
## Testing the models
-We can test the validity of our models directly in Elm using Elm's built in testing tools. Elm tests tend to be thinner than those of procedural and object-oriented languages since the Elm compiler eliminates the are large portion of the errors that occur in those languages. If it compiles it will run without error, which means you're really just testing the validity of your logic.
+We can test the validity of our models directly in Elm using Elm's built in testing tools. Elm tests tend to be thinner than those of procedural and object-oriented languages since the Elm compiler eliminates the are large portion of the errors that occur in those languages. If it compiles it will run without error, which means you're really just testing the validity of your logic.
The Morphir roadmap contains a significant amount of tools to give users confidence, including visualization, audit, and instant testing tools.
## Processing the models
-Once the models are ready, the next step is to convert them whatever form they'll be executed in. This is aspect of FDM utilizes techniques from Model-Driven Development in the form of code generation. This is similar to the codegen phase of many projects when dealing with things like XSD, IDL, or OpenAPI processing. We refer to these as Dev Bots, since they are automating away many of the mundane and error prone aspects of development for which humans provide no value.
+Once the models are ready, the next step is to convert them whatever form they'll be executed in. This is aspect of FDM utilizes techniques from Model-Driven Development in the form of code generation. This is similar to the codegen phase of many projects when dealing with things like XSD, IDL, or OpenAPI processing. We refer to these as Dev Bots, since they are automating away many of the mundane and error prone aspects of development for which humans provide no value.
## Incorporating into your code
-One of the advantages of Morphir is that it is completely open, so teams can customize their own Dev Bots as needed for their projects. Morphir has support for common Dev Bots to fit different paradigms of development.
+One of the advantages of Morphir is that it is completely open, so teams can customize their own Dev Bots as needed for their projects. Morphir has support for common Dev Bots to fit different paradigms of development.
### Micro integration: Libraries
-The most basic approach to using Morphir is to have it generate from models into your project's language of choice. This is analogous to writing your business logic as a set of libraries and using them from your handwritten code. Morphir models can be generated into various target languages, which allows execution in different contexts with guaranteed consistency.
+The most basic approach to using Morphir is to have it generate from models into your project's language of choice. This is analogous to writing your business logic as a set of libraries and using them from your handwritten code. Morphir models can be generated into various target languages, which allows execution in different contexts with guaranteed consistency.
### Macro integration: Platforms
-A more advanced use of Morphir is to use Dev Bots to target execution within an entire platform. Platform-level targets is a great way to ensure consistency and efficiency across the entire plant. Of course, this requires that Dev Bots exist for the target platforms.
\ No newline at end of file
+A more advanced use of Morphir is to use Dev Bots to target execution within an entire platform. Platform-level targets is a great way to ensure consistency and efficiency across the entire plant. Of course, this requires that Dev Bots exist for the target platforms.
diff --git a/docs/modeling/testing.md b/docs/modeling/testing.md
index 4d72d89e0..79c6ebba7 100644
--- a/docs/modeling/testing.md
+++ b/docs/modeling/testing.md
@@ -1,3 +1,8 @@
+---
+id: morphir-setup
+title: Setup
+---
+
# Setup
Elm's standard testing library is elm-test. You can install it by running the following command \
@@ -7,14 +12,14 @@ in your project. It will ask questions, just say yes to everything:
elm install elm-explorations/test
```
-The next thing you need to do is set up a test framework. We have [Lobo](https://github.com/benansell/lobo)
+The next thing you need to do is set up a test framework. We have [Lobo](https://github.com/benansell/lobo)
available internally. This is how you install it for your project:
```
npm install lobo --save
```
-Now make sure you have a `tests` directory in the root of the project and that in your `elm.json`
+Now make sure you have a `tests` directory in the root of the project and that in your `elm.json`
it is listed in `source-directories`.
Now you are ready to run the tests:
@@ -23,7 +28,7 @@ Now you are ready to run the tests:
npx lobo --framework=elm-test
```
-This will also ask a lot of questions, just say yes to everything (you only need to do this once). In the end
+This will also ask a lot of questions, just say yes to everything (you only need to do this once). In the end
it will show something like this:
```
@@ -68,4 +73,4 @@ npx lobo --framework=elm-test
```
This should report 2 passing tests. Now you are ready to add real tests. For that follow the inestructions here:
-[elm-explorations/test](https://package.elm-lang.org/packages/elm-explorations/test/latest/)
\ No newline at end of file
+[elm-explorations/test](https://package.elm-lang.org/packages/elm-explorations/test/latest/)
diff --git a/docs/morphir_community.md b/docs/morphir_community.md
index e4c98180c..b224a0229 100644
--- a/docs/morphir_community.md
+++ b/docs/morphir_community.md
@@ -1,12 +1,23 @@
+---
+sidebar_position: 6
+id: morphir-community
+title: Morphir Community
+---
+
# Morphir Community
-Morphir's success will depend on its community. While this might be obvious, we want to state that up front. The
-open-sourcing of Morphir was based on the successes that we had with it in Morgan Stanley. Those successes demonstrate
-the potential that Morphir has. We are contributing, and will continue to contribute, useful tools to the Morphir
-ecosystem. We recognize that there is a vast difference between building tools for a company's controlled
-infrastructure and making them robust for the general open-source community. Filling that gap and moving beyond our
-own vision will require a broad Morphir community. So as you browse the Morphir project and read about possible uses,
-view these more of indications of potential instead of polished products. It's all about the Morphir community. If you
-see the same potential that we have, we hope you join us.
+**Morphir's success will depend on its community.**
+
+While this might be obvious, we want to state that up front. The open-sourcing of Morphir was based on the successes that we had with it in Morgan Stanley.
+
+Those successes demonstrate the potential that Morphir has. We are contributing, and will continue to contribute, useful tools to the Morphir ecosystem.
+
+We recognize that there is a vast difference between building tools for a company's controlled infrastructure and making them robust for the general open-source community.
+
+Filling that gap and moving beyond our own vision will require a broad Morphir community.
+
+So as you browse the Morphir project and read about possible uses, view these more of indications of potential instead of polished products. It's all about the Morphir community.
+
+If you see the same potential that we have, we hope you join us.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/posts.md b/docs/posts.md
deleted file mode 100644
index 994a53acb..000000000
--- a/docs/posts.md
+++ /dev/null
@@ -1,24 +0,0 @@
-# Morphir Documents
-
-## Introduction and Background
-* [Background](background)
-* [Community](morphir_community)
-* [What's it all about?](whats_it_about)
-* [Working Across Technologies](work_across_languages_and_platforms)
-* [Why we use Functional Programming?](why_functional_programming)
-
-## Using Morphir
-* [What Makes a Good Model](what-makes-a-good-domain-model)
-* [Development Automation (Dev Bots)](dev_bots)
-* [Modeling An Application](application_modeling)
-
-## Applicability
-* [Sharing Business Logic Across Application Boundaries](shared_logic_modeling)
-* [Regulatory Technology](regtech_modeling)
-
-
-
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
------|------|------
- | |
-
diff --git a/docs/regtech_modeling.md b/docs/regtech_modeling.md
index e07dbffa8..7fb5eb6a3 100644
--- a/docs/regtech_modeling.md
+++ b/docs/regtech_modeling.md
@@ -1,53 +1,64 @@
+---
+sidebar_position: 7
+id: automating-regtech
+title: Automating RegTech
+---
+
# Automating RegTech
-There are a number of highly regulated industries that must adhere to complex regulations from various regulatory
-bodies. These often come in the form of lengthy documents that can be arcane, ambiguous, and expensive to interpret
-into computer code. It's even more expensive to adapt these regulations to a firm's internal systems. There is no
+There are a number of highly regulated industries that must adhere to complex regulations from various regulatory
+bodies. These often come in the form of lengthy documents that can be arcane, ambiguous, and expensive to interpret
+into computer code. It's even more expensive to adapt these regulations to a firm's internal systems. There is no
competitive advantage for firms in processing these regulations separately, so it would be mutually beneficial to codify
and test the rules once across all firms.
-There have been attempts to do so using shared libraries. The challenge with this approach is that these libraries don't
-work natively across the complexities of each firm's existing systems. In order to use them, they would need to invest
-significantly to build new systems that use the shared libraries. Another issue is that technology advances quickly, and
+There have been attempts to do so using shared libraries. The challenge with this approach is that these libraries don't
+work natively across the complexities of each firm's existing systems. In order to use them, they would need to invest
+significantly to build new systems that use the shared libraries. Another issue is that technology advances quickly, and
an optimal solution at any point in time is not likely to be the best solution in a short time.
-There is an alternative. If regulations were codified in a declarative model that could be cross-compiled to run in
+There is an alternative. If regulations were codified in a declarative model that could be cross-compiled to run in
different execution contexts, then that would enable firms to create their own processors to translate the model to work
-in their systems. In that way they get the advantage of a codified, unambiguous, and verifiable model while still
-retaining their existing systems. Morphir provides exactly this capability by providing tools to project a unified model
+in their systems. In that way they get the advantage of a codified, unambiguous, and verifiable model while still
+retaining their existing systems. Morphir provides exactly this capability by providing tools to project a unified model
into various execution contexts.
# Use case: US LCR
+
The [US Liquidity Coverage Ratio](https://en.wikipedia.org/wiki/Basel_III#US_version_of_the_Basel_Liquidity_Coverage_Ratio_requirements)
-is a required report for certain banks and systemically important financial institutions. Its definition can be found at
-[https://www.govinfo.gov/content/pkg/FR-2014-10-10/pdf/2014-22520.pdf](https://www.govinfo.gov/content/pkg/FR-2014-10-10/pdf/2014-22520.pdf). It's
-complex enough that there are accompanying documents and samples that attempt to clarify it. Ultimately it's a set of
+is a required report for certain banks and systemically important financial institutions. Its definition can be found at
+[https://www.govinfo.gov/content/pkg/FR-2014-10-10/pdf/2014-22520.pdf](https://www.govinfo.gov/content/pkg/FR-2014-10-10/pdf/2014-22520.pdf). It's
+complex enough that there are accompanying documents and samples that attempt to clarify it. Ultimately it's a set of
calculations that can be defined concisely and unambiguously in a concise and unambiguous programming language.
We'll step through how we can define such a regulation using Morphir with the LCR as an example.
# Getting started
-If you've not already done so, install Morphir as per the [getting started](./getting_started) instructions. Create a project called "lcr":
+
+If you've not already done so, install Morphir as per the [getting started](./getting_started) instructions. Create a project called "lcr":
```bash
morphir init lcr
cd lcr
```
-In this example, we'll use Elm as the Morphir modeling language. If you've not done so, [install elm](https://guide.elm-lang.org/install/elm.html).
+
+In this example, we'll use Elm as the Morphir modeling language. If you've not done so, [install elm](https://guide.elm-lang.org/install/elm.html).
# Modeling the LCR
-Let's define the core of the calculation for Morphir. The full LCR is quite extensive, so we'll focus on a few examples
-that highlight different aspects of modeling.
+
+Let's define the core of the calculation for Morphir. The full LCR is quite extensive, so we'll focus on a few examples
+that highlight different aspects of modeling.
## Modeling calculations
-At a high level, the LCR is a calculation. In fact if you look it up, the first thing you'll run into is probably this calculation:
-``` LCR = High quality liquid asset amount (HQLA) / Total net cash flow amount```
+
+At a high level, the LCR is a calculation. In fact if you look it up, the first thing you'll run into is probably this calculation:
+` LCR = High quality liquid asset amount (HQLA) / Total net cash flow amount`
.
-In modeling terms, it's not actually that simple since the LCR is calculated using a window from a given date. It also
-needs to run on a set of data. So in our model, we'll define it as a function:
+In modeling terms, it's not actually that simple since the LCR is calculated using a window from a given date. It also
+needs to run on a set of data. So in our model, we'll define it as a function:
```elm
-lcr toCounterparty product t flowsForDate reserveBalanceRequirement =
+lcr toCounterparty product t flowsForDate reserveBalanceRequirement =
let
hqla = hqlaAmount product (flowsForDate t) reserveBalanceRequirement
totalNetCashOutflow = totalNetCashOutflowAmount toCounterparty t flowsForDate
@@ -55,18 +66,18 @@ lcr toCounterparty product t flowsForDate reserveBalanceRequirement =
hqla / totalNetCashOutflow
```
-As you can see, that's pretty expressive, and the last line matches the calculation. For anyone new to Elm, the first
-line declares the function. Elm uses spaces rather than (,) to itemize parameters. You might be wondering what some of
-these extra parameters are all about. These are the points where the logical model meets the physical context that it
-will be run in. They are parameters at the top level so that individual firms can specify them as needed. The parameter
-named ```product``` is a good example. It's a function that takes a product key and returns the product structure. It's
+As you can see, that's pretty expressive, and the last line matches the calculation. For anyone new to Elm, the first
+line declares the function. Elm uses spaces rather than (,) to itemize parameters. You might be wondering what some of
+these extra parameters are all about. These are the points where the logical model meets the physical context that it
+will be run in. They are parameters at the top level so that individual firms can specify them as needed. The parameter
+named `product` is a good example. It's a function that takes a product key and returns the product structure. It's
up to the model user to determine how product identification and lookup will be supplied by their system.
-If you read the specification, you'll see a fair amount of space used to describe something called the adjusted excess
-HQLA amount. This happens to be a nice calculation to demonstrate mathematical modeling:
+If you read the specification, you'll see a fair amount of space used to describe something called the adjusted excess
+HQLA amount. This happens to be a nice calculation to demonstrate mathematical modeling:
```elm
-adjustedExcessHQLAAmount =
+adjustedExcessHQLAAmount =
let
adjustedLevel1LiquidAssetAmount = level1LiquidAssetAmount
@@ -74,7 +85,7 @@ adjustedExcessHQLAAmount =
adjustedlevel2bLiquidAssetAmount = level2bLiquidAssetAmount * 0.50
- adjustedLevel2CapExcessAmount =
+ adjustedLevel2CapExcessAmount =
max (adjustedlevel2aLiquidAssetAmount + adjustedlevel2bLiquidAssetAmount - 0.6667 * adjustedLevel1LiquidAssetAmount) 0.0
adjustedlevel2bCapExcessAmount =
@@ -83,15 +94,17 @@ adjustedExcessHQLAAmount =
adjustedLevel2CapExcessAmount + adjustedlevel2bCapExcessAmount
```
-It's included here just to show how much easier it is to understand a model than the written description:
+It's included here just to show how much easier it is to understand a model than the written description:
+
```
-There are two categories of assets that can be included in the stock. Assets to be included in each category are those
-that the bank is holding on the first day of the stress period, irrespective of their residual maturity. “Level 1”
+There are two categories of assets that can be included in the stock. Assets to be included in each category are those
+that the bank is holding on the first day of the stress period, irrespective of their residual maturity. “Level 1”
assets can be included without limit, while “Level 2” assets can only comprise up to 40% of the stock.
```
## Modeling collection operations
-The LCR spec is peppered with operations of collections of data. For example:
+
+The LCR spec is peppered with operations of collections of data. For example:
```elm
level2aLiquidAssetsThatAreEligibleHQLA =
@@ -101,17 +114,18 @@ level2aLiquidAssetsThatAreEligibleHQLA =
|> List.sum
```
-It's pretty easy to see that this takes a collection, filters it, then sums the "amount" of the remaining. The important
-point to note here is that we're letting the model know of a collection while also leaving the implementation entirely
-undefined. This allows us to process this model into a variety of execution contexts.
+It's pretty easy to see that this takes a collection, filters it, then sums the "amount" of the remaining. The important
+point to note here is that we're letting the model know of a collection while also leaving the implementation entirely
+undefined. This allows us to process this model into a variety of execution contexts.
## Modeling structures
-The previous example contained a collection name t0Flows. We can see from the example that it has `assetType` and `amount`
-fields. In fact, this is defined in the spec as a cash flow, which contains a few other fields. At this point in our
-modeling, we have a couple of options. We can either use a single common structure throughout the model, even when
+
+The previous example contained a collection name t0Flows. We can see from the example that it has `assetType` and `amount`
+fields. In fact, this is defined in the spec as a cash flow, which contains a few other fields. At this point in our
+modeling, we have a couple of options. We can either use a single common structure throughout the model, even when
large portions of the app don't require all of those fields, or we can create multiple structures that are more aligned
-with the usage. Since the LCR actually defines a cash flow, we'll go with the first option since it matches the language
-of the business. The cash flow is defined as:
+with the usage. Since the LCR actually defines a cash flow, we'll go with the first option since it matches the language
+of the business. The cash flow is defined as:
```elm
type alias BusinessDate = Date
@@ -137,48 +151,52 @@ type alias Flow =
}
```
-Notice that most of the types are named using the language of the business. This is an aspect of domain modeling, the
+Notice that most of the types are named using the language of the business. This is an aspect of domain modeling, the
ubiquitous language, that helps all the stakeholders to reduce misunderstandings.
# Verifying the model
+
This is just a small sampling of what's required to turn a full specification into functioning code. It's enough to see
-that it's not a trivial task, and there's a significant advantage if someone else could do it for you *and* prove
-that it's correct. This is where the use of a pure functional programming language for business modeling really
-shines. The common statement that *"if it compiles, it's guaranteed to run without errors"* really applies well to
-RegTech. The Elm compiler catches a huge number of potential errors that would otherwise be impossible in non-FP languages.
+that it's not a trivial task, and there's a significant advantage if someone else could do it for you _and_ prove
+that it's correct. This is where the use of a pure functional programming language for business modeling really
+shines. The common statement that _"if it compiles, it's guaranteed to run without errors"_ really applies well to
+RegTech. The Elm compiler catches a huge number of potential errors that would otherwise be impossible in non-FP languages.
-It's worth noting that there are languages that provide even more guarantees, like Coq and Microsoft's Bosque. In
-creating Morphir, we were careful not to write our own or locking on a particular language. This leaves the option of using
+It's worth noting that there are languages that provide even more guarantees, like Coq and Microsoft's Bosque. In
+creating Morphir, we were careful not to write our own or locking on a particular language. This leaves the option of using
the best language for the job, as long as that language can be co-compiled into the Morphir IR.
[TODO] show examples of catching errors
-The OCC helpfully provided some test examples that we can also use to verify our models. We've done so in the form of
-unit tests on our Elm code. [These tests](https://github.com/finos/morphir-examples/tree/master/tests/Morphir/Sample/LCR/)
+The OCC helpfully provided some test examples that we can also use to verify our models. We've done so in the form of
+unit tests on our Elm code. [These tests](https://github.com/finos/morphir-examples/tree/master/tests/Morphir/Sample/LCR/)
demonstrate how the OCC's tests, which were provided in a document, could actually be codified into the modeled rules.
# Using automation to adapt the model to your systems
-Now that we've ensured that our model of the LCR is correct, we want to turn it into code that can execute in our
-systems. For this purpose, we'll assume that the regulatory reporting data is currently housed in a SQL data
-warehouse. Let's take a look at how the sample above translates to SQL:
+
+Now that we've ensured that our model of the LCR is correct, we want to turn it into code that can execute in our
+systems. For this purpose, we'll assume that the regulatory reporting data is currently housed in a SQL data
+warehouse. Let's take a look at how the sample above translates to SQL:
```sql
select sum amount
from t0_flows tf
where tf.assetType = 'Level 2a Assets' and tf.isHQLA = 'T'
```
-You can see in the example that the generated code makes some assumptions about the physical environment. These are the
-things that are likely to be very different across firms. The value of modeling is that each firm can customize the
+
+You can see in the example that the generated code makes some assumptions about the physical environment. These are the
+things that are likely to be very different across firms. The value of modeling is that each firm can customize the
code generation to match their own environments.
-Of course, it's naive to think that the full LCR calculation would be able to execute entirely in a data warehouse. In
+Of course, it's naive to think that the full LCR calculation would be able to execute entirely in a data warehouse. In
fact, many firms are migrating these calculations to new technologies like Spark. Doing a large scale migration of a
report like the LCR to a new technology is usually a significant and risky effort. On the other hand, if you're running
from a model, it's just a matter of switching to a new backend generator. While that's not trivial, it sure is a good
-deal easier, cheaper, and less risky that rewriting the entire calculation from scratch. Let's take a look at the Spark
+deal easier, cheaper, and less risky that rewriting the entire calculation from scratch. Let's take a look at the Spark
version of our sample:
**Spark Scala**
+
```scala
t0Flows
.filter {flow => flow.assetType == Level2aAssets && isHQLA(product, flow)}
@@ -187,11 +205,12 @@ t0Flows
```
## Summing up
-We've seen how using an industry standard RegTech can save an industry valuable time, effort, and risk. We've also seen
-that doing so with a shared model allows firms to adopt RegTech without the costly exercise of rewriting their
-systems. Finally, we've seen how capturing regulations in a technology-agnostic model can ease migration to new technologies.
-To view the entire LCR example, take a look at [the Morphir Examples project](/morphir-examples/src/Morphir/Sample/Reg/LCR). For
+We've seen how using an industry standard RegTech can save an industry valuable time, effort, and risk. We've also seen
+that doing so with a shared model allows firms to adopt RegTech without the costly exercise of rewriting their
+systems. Finally, we've seen how capturing regulations in a technology-agnostic model can ease migration to new technologies.
+
+To view the entire LCR example, take a look at [the Morphir Examples project](/morphir-examples/src/Morphir/Sample/Reg/LCR). For
generating SQL and Spark from Morphir models, be sure to keep an eye out for the upcoming **morphir-sql** and **morphir-spark** projects.
[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/shared_logic_modeling.md b/docs/shared_logic_modeling.md
deleted file mode 100644
index 6858b29b8..000000000
--- a/docs/shared_logic_modeling.md
+++ /dev/null
@@ -1,4 +0,0 @@
-#Sharing Business Logic Across Application Boundaries
-Coming soon
-
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
diff --git a/docs/spark-backend/design.md b/docs/spark-backend/design.md
index 6783ec9c8..d79f2b3fe 100644
--- a/docs/spark-backend/design.md
+++ b/docs/spark-backend/design.md
@@ -1,3 +1,8 @@
+---
+id: morphir-spark
+title: Morphir to Spark mapping
+---
+
# Morphir to Spark mapping
To understand how the Morphir to Apache Spark mapping works let's begin with an example Morphir domain model and business logic that we might want to transpile to Spark. We present the Morphir logic using Elm syntax to make it easy to read:
@@ -19,7 +24,7 @@ job : List RecordA -> List RecordB
job input =
input
|> List.filter (\a -> a.field2 < 100)
- |> List.map
+ |> List.map
(\a ->
{ sum = a.number1 + a.number2
, product = a.number1 * a.number2
@@ -34,8 +39,8 @@ The above is a representative example of the base functionality. There are a few
- The record types in the input and output need to be completely flat and use only built-in SDK types or be enumerations (custom types with only no-argument constructors)
- The input value in the function can only be passed through the following collection operations:
- [List.filter](https://package.elm-lang.org/packages/elm/core/latest/List#filter) to filter the data set (corresponds to a WHERE clause in SQL)
- - [List.map](https://package.elm-lang.org/packages/elm/core/latest/List#map) to trasform each input row to an output row (corresponds to the SELECT clause in SQL)
-- Field expressions can:
+ - [List.map](https://package.elm-lang.org/packages/elm/core/latest/List#map) to trasform each input row to an output row (corresponds to the SELECT clause in SQL)
+- Field expressions can:
- use any combination of operations from the [Morphir SDK](https://package.elm-lang.org/packages/elm/core/latest/) as long as every intermediary result within the expression is a simple type
- include `if-then-else` expressions
@@ -47,18 +52,16 @@ The above is a representative example of the base functionality. There are a few
- [String](https://package.elm-lang.org/packages/elm/core/latest/String#String)
- [Maybe](https://package.elm-lang.org/packages/elm/core/latest/Maybe#Maybe)
-
## Supported Field Operations
-- [Basics](https://package.elm-lang.org/packages/elm/core/latest/Basics):
+- [Basics](https://package.elm-lang.org/packages/elm/core/latest/Basics):
- All number operations
- All comparison operations
- All boolean operations
- [String](https://package.elm-lang.org/packages/elm/core/latest/String)
- - All operations
+ - All operations
## Supported DataSet Operations
- [List.filter](https://package.elm-lang.org/packages/elm/core/latest/List#filter)
- [List.map](https://package.elm-lang.org/packages/elm/core/latest/List#map)
-
diff --git a/docs/tutorials/quick_start.md b/docs/tutorials/quick_start.md
index f1f0219f2..105193805 100644
--- a/docs/tutorials/quick_start.md
+++ b/docs/tutorials/quick_start.md
@@ -1,12 +1,19 @@
+---
+id: morphir-quick-start
+title: Morphir Quick Start
+---
+
# Morphir Quick Start
+
## Install
-The first step to using Morphir is installing. For this example we'll use the Elm front end for our modeling and generator into the JSON representation of the Morphir IR. So the first step is to install the Morphir Elm tooling. Take a look at the [Installation Instructions](https://github.com/Morgan-Stanley/morphir-elm) for getting setup.
+
+The first step to using Morphir is installing. For this example we'll use the Elm front end for our modeling and generator into the JSON representation of the Morphir IR. So the first step is to install the Morphir Elm tooling. Take a look at the [Installation Instructions](https://github.com/Morgan-Stanley/morphir-elm) for getting setup.
## Create a project
+
Let's create a new project.
```
mkdir scratch
cd scratch
```
-
diff --git a/docs/versioning/versioning.md b/docs/versioning.md
similarity index 68%
rename from docs/versioning/versioning.md
rename to docs/versioning.md
index ff0ba8681..66544554d 100644
--- a/docs/versioning/versioning.md
+++ b/docs/versioning.md
@@ -1,34 +1,40 @@
+---
+sidebar_position: 11
+id: model-versioning
+title: Model Versioning
+---
+
# Model Versioning
## Properties
-Model versioning in Morphir is very similar to library versioning in any
-other programming language but thanks to the declarative nature of the
-language it is much more automated and convenient for the modeler. It
-was largely inspired by Elm that has enforced semantic versioning but
-has been adapted and extended to fit our requirements better. Below is
-a high-level overview of the important properties that should give you
+Model versioning in Morphir is very similar to library versioning in any
+other programming language but thanks to the declarative nature of the
+language it is much more automated and convenient for the modeler. It
+was largely inspired by Elm that has enforced semantic versioning but
+has been adapted and extended to fit our requirements better. Below is
+a high-level overview of the important properties that should give you
a general idea on what you can expect.
### Automatic
Morphir comes with automatic enforced versioning out-of-the-box. Users of
-Morphir never have to (and are not allowed to) specify model versions
+Morphir never have to (and are not allowed to) specify model versions
manually. Instead the Morphir tooling will compare the current version of
-the model to the latest previously released version and increase the
+the model to the latest previously released version and increase the
version number if needed.
### Granular
-Versioning is applied at a much more granular level compared to
+Versioning is applied at a much more granular level compared to
traditional package management systems. The lowest level of granularity
-is a named function (or value) or type within a module. This allows
+is a named function (or value) or type within a module. This allows
users to track changes in the logic very accurately.
### Hierarchical
Versioning is also applied on higher levels of the package hierarchy.
-This allows users to pick the right level of granularity for their
+This allows users to pick the right level of granularity for their
use-case and even flip between different levels as needed.
Here are the different granularity levels where versioning is available:
@@ -40,67 +46,65 @@ Here are the different granularity levels where versioning is available:
### Sequential and Semantic
-Morphir generates semantic (major.minor.path) versions on a package level
-to make it more informative to users but on lower levels of the
-hierarchy it uses simple sequential version numbers.
+Morphir generates semantic (major.minor.path) versions on a package level
+to make it more informative to users but on lower levels of the
+hierarchy it uses simple sequential version numbers.
## Implementation
### Overview
-Versioning is implemented as a self-contained add-on working separately
-from all other Morphir tooling. This means that you can run a command to
-calculate versions at any point in time. Versioning takes source model,
-target model and source versions as inputs and returns target versions
+Versioning is implemented as a self-contained add-on working separately
+from all other Morphir tooling. This means that you can run a command to
+calculate versions at any point in time. Versioning takes source model,
+target model and source versions as inputs and returns target versions
as the output. This can be formalized as:
```
Model -> Model -> Versions -> Versions
-```
+```
-This can be further broken down into two functions: first we calculate
-the diff between two models, then we use the diff to calculate new
+This can be further broken down into two functions: first we calculate
+the diff between two models, then we use the diff to calculate new
version numbers using the last released versions.
### Diffing
Since the model is represented as an AST we can do simple tree diffing.
The resulting diff is a set of insert, update and delete operations on
-each leaf node (types and functions within a module). Versions on higher
+each leaf node (types and functions within a module). Versions on higher
levels of the hierarchy are then derived from lower levels increasing
-the version number if there were any changes below the node.
+the version number if there were any changes below the node.
-Finally, on the package level we calculate the semantic version using
+Finally, on the package level we calculate the semantic version using
the following rules:
-* **Patch**: If there are no changes above level 1. In other words if
-only the implementation changed without any API changes.
-* **Minor**: If there are new functions/types added but none of the
-existing
-APIs changed or got removed.
-* **Major**: If any existing APIs changed.
-
+- **Patch**: If there are no changes above level 1. In other words if
+ only the implementation changed without any API changes.
+- **Minor**: If there are new functions/types added but none of the
+ existing
+ APIs changed or got removed.
+- **Major**: If any existing APIs changed.
### Versions File
-Versions are stored in a JSON file for convenient access from any
-technology. By default version files are stored on AFS under the
-```etc/morphir``` directory in ```versions.json``` file.
+Versions are stored in a JSON file for convenient access from any
+technology. By default version files are stored on AFS under the
+`etc/morphir` directory in `versions.json` file.
-The format is easy to follow based on the properties described above.
+The format is easy to follow based on the properties described above.
Here is the general layout:
-* ```package```: This is the name of the package.
-* ```semantic```: This is the semantic version number for the package.
-* ```sequence```: This is the sequential version number for the package.
-* ```modules```: This is a JSON object where each field corresponds to a
-module. Fully-qualified names are used to identify the module and the
-structure is flattened out. Each module has the following fields:
- * ```sequence```: This is the sequential version number for the module.
- * ```type_aliases```: Sequential version number for each type alias.
- * ```union_types```: Sequential version number for each union type.
- * ```value_types```: Sequential version number for each value (function) type.
- * ```values```: Sequential version number for each value (function).
+- `package`: This is the name of the package.
+- `semantic`: This is the semantic version number for the package.
+- `sequence`: This is the sequential version number for the package.
+- `modules`: This is a JSON object where each field corresponds to a
+ module. Fully-qualified names are used to identify the module and the
+ structure is flattened out. Each module has the following fields:
+ _ `sequence`: This is the sequential version number for the module.
+ _ `type_aliases`: Sequential version number for each type alias.
+ _ `union_types`: Sequential version number for each union type.
+ _ `value_types`: Sequential version number for each value (function) type. \* `values`: Sequential version number for each value (function).
Here's an example:
diff --git a/docs/visualizing/index.md b/docs/visualizing/index.md
deleted file mode 100644
index d3ed404e9..000000000
--- a/docs/visualizing/index.md
+++ /dev/null
@@ -1 +0,0 @@
-[Visualization examples](index.html)
diff --git a/docs/what-makes-a-good-domain-model.md b/docs/what-makes-a-good-domain-model.md
index a2f32416e..254bdae6d 100644
--- a/docs/what-makes-a-good-domain-model.md
+++ b/docs/what-makes-a-good-domain-model.md
@@ -1,36 +1,42 @@
-# What makes a good domain model?
+---
+sidebar_position: 9
+id: domain-model
+title: What Makes a Good Domain Model?
+---
-We all strive to build high-quality software and that begins with a clean and well-defined
+# What Makes a Good Domain Model?
+
+We all strive to build high-quality software and that begins with a clean and well-defined
domain model. But what do we mean when we say "clean" or "well-defined"?
It is difficult to decide whether a change in the domain model is an improvement without specific measures.
In this post, we'll dive into how we can measure and improve the quality of our domain models.
-[Making illegal state unrepresentable](https://fsharpforfunandprofit.com/posts/designing-with-types-making-illegal-states-unrepresentable/)
-is a well-known principle in the functional-programming community which refers to avoiding
+[Making illegal state unrepresentable](https://fsharpforfunandprofit.com/posts/designing-with-types-making-illegal-states-unrepresentable/)
+is a well-known principle in the functional-programming community which refers to avoiding
ambiguity that leaves the model open to more than one interpretation. A simple example is
-when a model uses strings instead of enums. Strings are ambiguous because they leave the
+when a model uses strings instead of enums. Strings are ambiguous because they leave the
interpretation completely to the consumer while enums limit the possible values significantly.
Is there a way to measure the ambiguity? One approximation we can use is the cardinality of types.
-Taking the above example a String has an infinite cardinality while an enum is always finite,
+Taking the above example a String has an infinite cardinality while an enum is always finite,
usually less than 100 values. So a String is infinitely more ambiguous than an enum.
-Stepping up a level, we can derive a few more useful metrics by looking at type cardinalities
+Stepping up a level, we can derive a few more useful metrics by looking at type cardinalities
in the context of functions:
## Domain-to-Range Cardinality Ratio
Take a simple example of a `String -> Enum` function. This takes an ambiguous value and turns it
-into a less ambiguous one which is great since it decreases ambiguity. Taking the opposite
+into a less ambiguous one which is great since it decreases ambiguity. Taking the opposite
`Enum -> String` though turns a relatively unambiguous value to a completely ambiguous one, which
decreases the quality of the output model. So clearly, you want to avoid the latter.
## Domain Test Coverage
-Adding test cases to the picture, you can measure what percentage of possible inputs are covered
-by test cases. When the cardinality of the input type is finite, it is possible to achieve full
+Adding test cases to the picture, you can measure what percentage of possible inputs are covered
+by test cases. When the cardinality of the input type is finite, it is possible to achieve full
coverage which means you can be confident that the function works as expected.
More to come ...
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/whats_it_about.md b/docs/whats_it_about.md
index 8986a6005..40f183523 100644
--- a/docs/whats_it_about.md
+++ b/docs/whats_it_about.md
@@ -1,35 +1,44 @@
-# An application
-I have an application.
-* It tracks product inventories and decides how much to grant an order request based on the product's availability.
-* It is deployed as a set of microservices.
- * We're thinking about moving the microservices to serverless.
-* Orders are made via REST.
- * The REST is exposed via OpenAPI.
-* Inventory levels are tracked in real-time with stream processing and come from a variety of sources.
- * We currently use Kafka for streaming.
- * Some sources contain nuances about how to interpret their contents into trustworthy inventory numbers.
- * There are also rules for how to distribute inventory across requests to try to get a good balance of happy customers.
-* We use a standard SQL database for transaction processing.
+---
+sidebar_position: 10
+id: application-article
+title: I Have an Application
+---
+
+# I Have an Application
+
+- It tracks product inventories and decides how much to grant an order request based on the product's availability.
+- It is deployed as a set of microservices.
+ - We're thinking about moving the microservices to serverless.
+- Orders are made via REST.
+ - The REST is exposed via OpenAPI.
+- Inventory levels are tracked in real-time with stream processing and come from a variety of sources.
+ - We currently use Kafka for streaming.
+ - Some sources contain nuances about how to interpret their contents into trustworthy inventory numbers.
+ - There are also rules for how to distribute inventory across requests to try to get a good balance of happy customers.
+- We use a standard SQL database for transaction processing.
# What's important?
-As you're reading this, what do you consider to be the most important information in my description? Is it the Kafka
-stream processing? The standard microservices architecture? Or the fact that we're thinking of moving to serverless?
+
+As you're reading this, what do you consider to be the most important information in my description? Is it the Kafka
+stream processing? The standard microservices architecture? Or the fact that we're thinking of moving to serverless?
While the answer might be subjective, I can tell you that, for the users of this application, the most important parts are:
+
1. The application processes orders for products.
1. It allocates to those orders based on availability and distribution rules.
1. It aggregates inventory from multiple suppliers.
# Morphir
-You probably know these as the application's business logic, and it's easy to see why users think this is most
-important: it is the whole reason the application exists at all. Everything else is temporary details about how it's implemented. Chances are that these details will change a few times over the application's lifetime. It would be a shame to risk breaking the most important parts of the application just because we want to change from microservices to serverless, yet that's exactly what happens with a huge portion of applications. We want something that allows the business and technology to evolve independently. This is what Morphir does; it's all about the business concepts.
+
+You probably know these as the application's business logic, and it's easy to see why users think this is most
+important: it is the whole reason the application exists at all. Everything else is temporary details about how it's implemented. Chances are that these details will change a few times over the application's lifetime. It would be a shame to risk breaking the most important parts of the application just because we want to change from microservices to serverless, yet that's exactly what happens with a huge portion of applications. We want something that allows the business and technology to evolve independently. This is what Morphir does; it's all about the business concepts.
# Working Across Technologies
+
Most applications mix the business concepts with the technology choices of the moment. Given the importance of the
-business concepts, it makes sense to protect them from transient technical decisions as much as possible.
+business concepts, it makes sense to protect them from transient technical decisions as much as possible.
-For starters, you definitely want it to perform correctly, ideally across different technologies and
-platforms. Finding yourself constantly rewriting your API? Technology is advancing quickly; you certainly don't want
+For starters, you definitely want it to perform correctly, ideally across different technologies and
+platforms. Finding yourself constantly rewriting your API? Technology is advancing quickly; you certainly don't want
your API locked in legacy technology.
-
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/why_functional_programming.md b/docs/why_functional_programming.md
index 0852f87d0..6b7ca4021 100644
--- a/docs/why_functional_programming.md
+++ b/docs/why_functional_programming.md
@@ -1,17 +1,23 @@
+---
+sidebar_position: 8
+id: functional-programming
+title: Why Functional Programming?
+---
+
# Why Functional Programming?
-The core of Morphir is the idea your business concepts (data and logic) are valuable assets that deserve to be
-stored independently. Morphir needs to understand the intent of your application, which is not easy to do when the
-business code is intertwined with the execution code. To make this easier, Morphir prefers using a concise and
-unambiguous way to specify business concepts. In particular, Morphir wants to know *what* the application should do
-and *why* without any indication of *how*. If you know *what* and *why*, it's easier to adjust *how* to different
-execution contexts. The flip side of this is that once code starts to specify how it should work, it becomes much more
-difficult to figure out what the real intent is.
+The core of Morphir is the idea your business concepts (data and logic) are valuable assets that deserve to be
+stored independently. Morphir needs to understand the intent of your application, which is not easy to do when the
+business code is intertwined with the execution code. To make this easier, Morphir prefers using a concise and
+unambiguous way to specify business concepts. In particular, Morphir wants to know _what_ the application should do
+and _why_ without any indication of _how_. If you know _what_ and _why_, it's easier to adjust _how_ to different
+execution contexts. The flip side of this is that once code starts to specify how it should work, it becomes much more
+difficult to figure out what the real intent is.
-If you've looked at the topic of programming languages, you'll recognize all of this as part of the comparison between
-various programming styles: functional and imperative languages in particular. To our great advantage, functional
-programming has evolved around specifying intent without implementation. Even better, it's been honing this for decades,
-so it's actually *really* great for modeling business concepts.
+If you've looked at the topic of programming languages, you'll recognize all of this as part of the comparison between
+various programming styles: functional and imperative languages in particular. To our great advantage, functional
+programming has evolved around specifying intent without implementation. Even better, it's been honing this for decades,
+so it's actually _really_ great for modeling business concepts.
Just to give an example, it's difficult to write a program that figures out the intent of this code:
@@ -30,24 +36,24 @@ public Map processSupplies(Supplier[] suppliers) {
maxSupplier = supplier.supplierId;
}
}
-
+
Map result = new HashMap();
result.put("total", total);
-
+
if(max > -1) {
result.put("maxSupplier", maxSupplier);
}
-
+
return result;
}
```
-It's even harder to project that intent into a variety of execution contexts. On the other hand, this code is easy to interpret:
+It's even harder to project that intent into a variety of execution contexts. On the other hand, this code is easy to interpret:
```elm
processSupplies suppliers =
let
- total =
+ total =
suppliers
|> List.map .quantity
|> List.sum
@@ -61,8 +67,8 @@ processSupplies suppliers =
(total, max)
```
-That's much easier to process and much easier to translate into different contexts. We can turn this into efficient Java code and efficient SQL. You might say it's inefficient because it's traversing the list twice, once for total and again for max. The cool thing is that we can recognize this pretty easily and have our code generators optimize the execution to take this into account.
+That's much easier to process and much easier to translate into different contexts. We can turn this into efficient Java code and efficient SQL. You might say it's inefficient because it's traversing the list twice, once for total and again for max. The cool thing is that we can recognize this pretty easily and have our code generators optimize the execution to take this into account.
-With all of that said, it's certainly possible to derive intent from other types of languages. In fact, we've found much success in giving a lifeline to the plethora of bespoke expression languages and domain-specific languages (DSLs) that pepper most enterprises. Parsing these languages into Morphir offers a way to transpile them into other languages and to take advantage of the other tools Morphir offers. This has been an effective way to upgrade application technologies without risking their important behaviors.
+With all of that said, it's certainly possible to derive intent from other types of languages. In fact, we've found much success in giving a lifeline to the plethora of bespoke expression languages and domain-specific languages (DSLs) that pepper most enterprises. Parsing these languages into Morphir offers a way to transpile them into other languages and to take advantage of the other tools Morphir offers. This has been an effective way to upgrade application technologies without risking their important behaviors.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/website/sidebars.js b/website/sidebars.js
index 54ba60940..edafd149f 100644
--- a/website/sidebars.js
+++ b/website/sidebars.js
@@ -22,7 +22,7 @@ const sidebars = {
{
type: 'category',
label: 'Tutorial',
- items: ['hello'],
+ items: ['hello world'],
},
],
*/
| Morphir Showcase – Full Show |
# An ecosystem of innovative features
diff --git a/docs/application_modeling.md b/docs/application_modeling.md
index 8aae84e5e..907406af4 100644
--- a/docs/application_modeling.md
+++ b/docs/application_modeling.md
@@ -1,52 +1,62 @@
+---
+sidebar_position: 4
+id: modeling-applications
+title: Modeling Entire Applications
+---
+
# Modeling Entire Applications
Morphir Application Modeling imagines an evolution of programming as:
-* You code, just pure business logic.
-* That code is guaranteed to be free of exceptions.
-* Merging your code triggers full SDLC automation through to deployment.
-* Your application automatically conforms to your firm's standards now and in the future.
-* Your users have transparency into how your application behaves and why.
-* You retain full control to modify any of the above.
+
+- You code, just pure business logic.
+- That code is guaranteed to be free of exceptions.
+- Merging your code triggers full SDLC automation through to deployment.
+- Your application automatically conforms to your firm's standards now and in the future.
+- Your users have transparency into how your application behaves and why.
+- You retain full control to modify any of the above.
Most applications generally follow a small set of well known patterns based on how the application will run
-(as opposed to its business purpose). These patterns are what many application frameworks are built around. As a
-result, much of the development process is simply following recipes to build code to these patterns.
+(as opposed to its business purpose). These patterns are what many application frameworks are built around. As a
+result, much of the development process is simply following recipes to build code to these patterns.
-There is another set of patterns that sits in the fuzzy area where the business patterns meet the technical ones. These
-patterns are not entirely business and are consistent across applications regardless of how they will end up being
-executed. It's likely that these patterns will remain unchanged even as technology evolves. If we can capture these
-patterns in our models, it would allow us to move execution across different technologies without changing our models
-at all. This is important because an individual application usually exists within a larger ecosystem. Constantly
-keeping large numbers of existing applications up-to-date with the latest ecosystem changes, commonly referred to as
-*hygiene*, takes a lot of development effort that subtracts from a team's ability to provide business value.
+There is another set of patterns that sits in the fuzzy area where the business patterns meet the technical ones. These
+patterns are not entirely business and are consistent across applications regardless of how they will end up being
+executed. It's likely that these patterns will remain unchanged even as technology evolves. If we can capture these
+patterns in our models, it would allow us to move execution across different technologies without changing our models
+at all. This is important because an individual application usually exists within a larger ecosystem. Constantly
+keeping large numbers of existing applications up-to-date with the latest ecosystem changes, commonly referred to as
+_hygiene_, takes a lot of development effort that subtracts from a team's ability to provide business value.
-So what are these patterns? Here are some core patterns that drive a vast subset of applications:
+So what are these patterns? Here are some core patterns that drive a vast subset of applications:
-* **API** - The combination of inputs and outputs that external applications use to interact with the application.
-* **Local State** - The information owned and managed by the application.
-* **Remote State** - Any information that is required by this application but not managed by it.
+- **API** - The combination of inputs and outputs that external applications use to interact with the application.
+- **Local State** - The information owned and managed by the application.
+- **Remote State** - Any information that is required by this application but not managed by it.
These are the core building blocks of many applications and can be implemented in a variety of technologies.
-Let's look at an example. We'll use Morphir's Elm modeling support, so
+Let's look at an example. We'll use Morphir's Elm modeling support, so
[follow the installation instructions](https://github.com/Morgan-Stanley/morphir-elm#installation-1) to get started.
## Application Overview
-For this example, we'll look at a set of interacting applications that form a complete order processing system. They include:
-* [Books and Records](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/BooksAndRecords) - Keeps
+For this example, we'll look at a set of interacting applications that form a complete order processing system. They include:
+
+- [Books and Records](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/BooksAndRecords) - Keeps
the books on what orders have been executed.
-* [Order](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/Order) - Processes
+- [Order](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/Order) - Processes
order requests and records any confirmations to Books and Records.
-* [Trader](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/Trader) - An automated
- trading algorithm that makes decisions based on the market and the state of the current book of deals. It
+- [Trader](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps/Trader) - An automated
+ trading algorithm that makes decisions based on the market and the state of the current book of deals. It
relies on Books, Records, and Order.
## Modeling the Persistent App specification
-All three of these are instances of applications that manage:
+
+All three of these are instances of applications that manage:
## Modeling the API
-Books and Records is used by Order to book executions, so it needs a way to accept orders. We model this in Morphir
+
+Books and Records is used by Order to book executions, so it needs a way to accept orders. We model this in Morphir
using the API type as such:
```elm
@@ -55,14 +65,15 @@ type alias API =
, closeDeal : ID -> Result CloseRequestFault Event
}
```
-This states that Books and Records exposes an endpoint to open a deal and another to close an existing deal. In each
-case, the outcome of the request is communicated by an event that either confirms or gives a message about why the
-request was rejected. Note that it doesn't state whether these calls are synchronous or asynchronous. That's because
-that decision is an infrastructure ecosystem concern, not a business concern. That means we should save the decision to
-a later stage when we decide how the application fits into the ecosystem. If we decide now, we're locking ourselves to
+
+This states that Books and Records exposes an endpoint to open a deal and another to close an existing deal. In each
+case, the outcome of the request is communicated by an event that either confirms or gives a message about why the
+request was rejected. Note that it doesn't state whether these calls are synchronous or asynchronous. That's because
+that decision is an infrastructure ecosystem concern, not a business concern. That means we should save the decision to
+a later stage when we decide how the application fits into the ecosystem. If we decide now, we're locking ourselves to
one execution paradigm before we have enough information.
-We know that other applications will be interested in knowing what's happening in Books and Records even if they're not
+We know that other applications will be interested in knowing what's happening in Books and Records even if they're not
making requests. So we declare that Books and Records publishes events about what's going on:
```elm
@@ -72,15 +83,17 @@ type Event
```
## Modeling the Local State
-Books and Records by definition owns the state required for book management. We want to declare what state is owned so
-that we can plug it into our persistence ecosystem eventually. We do this with:
+
+Books and Records by definition owns the state required for book management. We want to declare what state is owned so
+that we can plug it into our persistence ecosystem eventually. We do this with:
```elm
-type alias LocalState =
+type alias LocalState =
Dict ID Deal
```
## Modeling Remote State Dependencies
+
Some applications need information managed outside their domain. The Order application demonstrates this. It declares
these external dependencies using the RemoteState type:
@@ -94,45 +107,49 @@ type alias RemoteState =
}
```
-Here we state that Order depends on the ability to book order executions, to look up the current state of a deal,
-to get the current market price for a product, and to get the product's inventory. It needs all of this information to
-make decisions. Notice that it doesn't specify what's going to satisfy these dependencies. That's an infrastructure
+Here we state that Order depends on the ability to book order executions, to look up the current state of a deal,
+to get the current market price for a product, and to get the product's inventory. It needs all of this information to
+make decisions. Notice that it doesn't specify what's going to satisfy these dependencies. That's an infrastructure
ecosystem decision based on knowledge that we don't have as modellers.
## The Full Models
-These three patterns cover most applications. For the full example models take a look at
+
+These three patterns cover most applications. For the full example models take a look at
[the Morphir examples project](https://github.com/Morgan-Stanley/morphir-examples/tree/master/src/Morphir/Sample/Apps).
# Execution
-There are many ways that we can run these applications. The advantage of modeling them is that we can choose and
-customize as needed without rewriting any of our core business concepts. For this example, we will take advantage of
-the fact that Microsoft has recognized this very set of patterns in its cloud-ready [Dapr Platform](http://dapr.io). Each
+
+There are many ways that we can run these applications. The advantage of modeling them is that we can choose and
+customize as needed without rewriting any of our core business concepts. For this example, we will take advantage of
+the fact that Microsoft has recognized this very set of patterns in its cloud-ready [Dapr Platform](http://dapr.io). Each
of our modeled patterns has a corresponding Dapr feature that we can take advantage of.
Our model patterns map to Dapr in the following ways:
-* **API Requests** - Our API requests turn into REST services defined by generating OpenAPI specifications. Alternatively,
+- **API Requests** - Our API requests turn into REST services defined by generating OpenAPI specifications. Alternatively,
we could choose to use a message queue or Kafka for asynchronous requests.
-* **API Events** - Events are published to Kafka as event logs.
-* **Local State** - Dapr supports Redis natively, so we'll use that for persistence.
-* **Remote State** - Given that we've made the REST decision, all the external applications will also be exposed that
+- **API Events** - Events are published to Kafka as event logs.
+- **Local State** - Dapr supports Redis natively, so we'll use that for persistence.
+- **Remote State** - Given that we've made the REST decision, all the external applications will also be exposed that
way. These will turn into REST calls and get bound to the owning applications during the SDLC pipeline.
For more information on Morphir's Dapr support, take a look at the [morphir-dapr](https://github.com/Morgan-Stanley/morphir-dapr) project.
# SDLC Pipeline
-We can utilize various SDLC technologies to create straight-through deployment. In this example, we'll utilize GitHub's
-pipeline technology to trigger a full deployment lifecycle every time we make a change to the model.
+
+We can utilize various SDLC technologies to create straight-through deployment. In this example, we'll utilize GitHub's
+pipeline technology to trigger a full deployment lifecycle every time we make a change to the model.
# Summing Up
-In this example we've created a full set of distributed applications using Morphir, and we've managed to do so without
-writing a single bit of non-business code. The cool part is that it doesn't mean that we're locked into a particular
-platform or vendor. We can always change the execution target by using another Morphir backend or writing our own.
-We've also demonstrated a true front-to-back SDLC pipeline that automates full deployment from the moment you check in your model.
+In this example we've created a full set of distributed applications using Morphir, and we've managed to do so without
+writing a single bit of non-business code. The cool part is that it doesn't mean that we're locked into a particular
+platform or vendor. We can always change the execution target by using another Morphir backend or writing our own.
+
+We've also demonstrated a true front-to-back SDLC pipeline that automates full deployment from the moment you check in your model.
-The end result is an application development that finally **lets developers focus solely on providing business value
-without sacrificing technical flexibility**. That should be pretty compelling to anyone who's struggled to balance
+The end result is an application development that finally **lets developers focus solely on providing business value
+without sacrificing technical flexibility**. That should be pretty compelling to anyone who's struggled to balance
providing business value against all the cursory development tasks.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/background.md b/docs/background.md
index 70e079d8d..8ef1c577c 100644
--- a/docs/background.md
+++ b/docs/background.md
@@ -1,67 +1,79 @@
+---
+sidebar_position: 2
+id: background-story
+title: The Morphir Background Story
+---
+
# The Morphir Background Story
-Morphir evolved from years of frustration trying to work around technical limitations to adequately model business concepts. Then after so much effort and pain, we inevitably have to start over to adapt to some new technology. This came to a head when one of our businesses suddenly faced a convergence of major new business requirements and technical upgrades that required yet another major rewrite. There was so much work to be done and so much frustration from our business clients that they issued the challenge below...
+
+Morphir evolved from years of frustration trying to work around technical limitations to adequately model business concepts. Then after so much effort and pain, we inevitably have to start over to adapt to some new technology. This came to a head when one of our businesses suddenly faced a convergence of major new business requirements and technical upgrades that required yet another major rewrite. There was so much work to be done and so much frustration from our business clients that they issued the challenge below...
## The Challenge
-> **Stop the cycle of rewrites** - Our users recognized that we were in a constant cycle of upgrading technology. Each pass in the cycle required significant effort and posed the risk of implementing core business logic incorrectly.
+> **Stop the cycle of rewrites** - Our users recognized that we were in a constant cycle of upgrading technology. Each pass in the cycle required significant effort and posed the risk of implementing core business logic incorrectly.
-> **Stop making us use multiple applications with inconsistent values** - Our users noticed that different systems came to different results for what should have theoretically been the same calculations. As a result, they had to navigate across applications to get the information they needed.
+> **Stop making us use multiple applications with inconsistent values** - Our users noticed that different systems came to different results for what should have theoretically been the same calculations. As a result, they had to navigate across applications to get the information they needed.
> **Show us that the system is behaving correctly** - Our users demanded that if we were going to rewrite core business logic again, we needed to provide transparency so that they could understand exactly how the system was behaving with respect to the business.
> **Deliver faster** - A never ending, desired request.
## Common Cause
-This challenge made us re-examine our whole development process. It soon became clear that there was a theme across them: **the fundamental issue was the fact that the business knowledge was tightly wrapped into the technologies of the moment**. It stood to reason that freeing the business knowledge from the technology would address these challenges. That's the approach we took and that is what eventually evolved into Morphir.
+
+This challenge made us re-examine our whole development process. It soon became clear that there was a theme across them: **the fundamental issue was the fact that the business knowledge was tightly wrapped into the technologies of the moment**. It stood to reason that freeing the business knowledge from the technology would address these challenges. That's the approach we took and that is what eventually evolved into Morphir.
## Morphir In Action
-Let's take a look at what that all means and how Morphir works to address these challenges. Let's consider a component of an online store application. The purpose of this application is to decide on:
+Let's take a look at what that all means and how Morphir works to address these challenges. Let's consider a component of an online store application. The purpose of this application is to decide on:
### Promoting Business Knowledge
-The business concepts underlying your application are its most valuable asset. It's often difficult to discern
-business concepts when they're embedded within platform and execution code. On top of that, many programming languages
+
+The business concepts underlying your application are its most valuable asset. It's often difficult to discern
+business concepts when they're embedded within platform and execution code. On top of that, many programming languages
are so full of abstractions that it can become difficult to understand the business meaning at all.
Morphir tackles this challenge in a few ways. First, it provides a common structure to save business concepts, including
-both data and logic. This is the Morphir IR. The key to this structure is that it focuses solely on business logic and
+both data and logic. This is the Morphir IR. The key to this structure is that it focuses solely on business logic and
data. No side effects (like saving to a database or reading from a file) are allowed. The IR is the core to Morphir and
allows it to work across languages and platforms.
-Having an application's business knowledge in a common data structure allows teams to build useful tools that promote
-knowledge dissemination. Some useful examples include interactive visualizations that allow users to understand the
-application's logic, interactive audit tools to replay calculations interactively, automatic data dictionary and data
-lineage registration, and more.
+Having an application's business knowledge in a common data structure allows teams to build useful tools that promote
+knowledge dissemination. Some useful examples include interactive visualizations that allow users to understand the
+application's logic, interactive audit tools to replay calculations interactively, automatic data dictionary and data
+lineage registration, and more.
-The combination of these creates an ecosystem where users, new developers, and support personnel can gain insight into
+The combination of these creates an ecosystem where users, new developers, and support personnel can gain insight into
an application interactively without requiring developers to go back and study stale documentation and arcane code.
### Showing Correctness
+
If you're going to treat business knowledge as a valuable asset, you want to make sure that it's correct. Morphir's use
of functional programming structures that are tuned towards codifying business concepts eliminates many of the bugs that
-are common in less concise tools. This is really just the beginning of the story. What's even more powerful is the fact
-that Morphir is compatible with a variety of source languages, so it can take advantage of the powerful tools that they
+are common in less concise tools. This is really just the beginning of the story. What's even more powerful is the fact
+that Morphir is compatible with a variety of source languages, so it can take advantage of the powerful tools that they
offer. We currently support the [Elm programming language](http://elm-lang.org) due to its simplicity and power. The Elm
compiler is supercharged to catch huge classes of bugs. The common saying is that if it compiles, it's guaranteed not to
-have runtime errors (excluding limitations of the physical environment, of course). Another particularly exciting
-language is Microsoft's [Bosque programming language](https://github.com/microsoft/BosqueLanguage), which takes the
+have runtime errors (excluding limitations of the physical environment, of course). Another particularly exciting
+language is Microsoft's [Bosque programming language](https://github.com/microsoft/BosqueLanguage), which takes the
ability to verify program correctness up whole other level. Keep an eye out for further progress in this space.
-Finally, the aforementioned business knowledge tools are a big help in establishing correctness. When users have the
-ability to fully understand the system with helpful tools in real-time, it makes the user/developer feedback cycle very
+Finally, the aforementioned business knowledge tools are a big help in establishing correctness. When users have the
+ability to fully understand the system with helpful tools in real-time, it makes the user/developer feedback cycle very
efficient.
### Delivering Faster
-An important role of developers is to decide how the business concepts fit into an executable computer system. Once
-that shape is decided, a great deal of the actual coding is very repetative and templated. Add to this the various best
-practices and team standards and you get a lot of boilerplate code that can be automated for faster production with
-fewer errors. Morphir relies heavily on such automation, which we call Dev Bots. As with any automation, smart use can
-lead to drastic efficiency improvements, like taking seconds to generate what a developer would take days to
+
+An important role of developers is to decide how the business concepts fit into an executable computer system. Once
+that shape is decided, a great deal of the actual coding is very repetative and templated. Add to this the various best
+practices and team standards and you get a lot of boilerplate code that can be automated for faster production with
+fewer errors. Morphir relies heavily on such automation, which we call Dev Bots. As with any automation, smart use can
+lead to drastic efficiency improvements, like taking seconds to generate what a developer would take days to
produce. Check out the [Dev Bot post](dev_bots) for more information on this topic.
### Eliminating Rewrites
+
Technology is evolving ever more quickly. It is no longer feasible to stay competitive if you need to completely rewrite
-you application every time you want to upgrade to newer technologies. That's especially true if there is a risk of
+you application every time you want to upgrade to newer technologies. That's especially true if there is a risk of
getting your core business logic wrong in a rewrite. In addition to automating boilerplate code, Morphir Dev Bots convert
Morphir IR into system code. This means the same Morphir model can run in different technologies. And with the business
concepts protected in the Morphir model, there's no risk to losing it with the next big technology. Keep an eye out for
@@ -69,8 +81,8 @@ the evolving list of target environments available in the Morphir ecosystem. Or,
Morphir provides the tools to do it yourself.
# Summing Up
-Hopefully this gives a good background into what Morphir does and why. If you have any questions or comments, feel free
-to drop us a note through the [Morphir project](https://github.com/finos/morphir).
+Hopefully this gives a good background into what Morphir does and why. If you have any questions or comments, feel free
+to drop us a note through the [Morphir project](https://github.com/finos/morphir).
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/dev_bots.md b/docs/dev_bots.md
index 353fed8f8..9b14ada4c 100644
--- a/docs/dev_bots.md
+++ b/docs/dev_bots.md
@@ -1,21 +1,28 @@
-# Dev Bots
-The premise of Dev Bots is that we can and should automate a significant portion of the code that we currently write by hand.
+---
+sidebar_position: 5
+id: dev-bots
+title: Explaining Dev Bots
+---
-Consider the portion of an application's code that is of no direct business value, includeing things like
-persistence and ORM, interprocess communication, platform-specific code, object wiring, and more. We need this code
-to make our applications run, but it is of no direct business value. A large portion of this non-business code comes
-in the form of recipes to follow or "best practices" templates. The fact that it takes up the majority of our
-applications often reduces us to human code robots. We often refer to this code as boilerplate, and it is
+# Explaining Dev Bots
+
+The premise of Dev Bots is that we can and should automate a significant portion of the code that we currently write by hand.
+
+Consider the portion of an application's code that is of no direct business value, includeing things like
+persistence and ORM, interprocess communication, platform-specific code, object wiring, and more. We need this code
+to make our applications run, but it is of no direct business value. A large portion of this non-business code comes
+in the form of recipes to follow or "best practices" templates. The fact that it takes up the majority of our
+applications often reduces us to human code robots. We often refer to this code as boilerplate, and it is
highly amenable to automation.
-We can also look into automating certain aspects of business code. Much of that code also follows templates and best
-practices, and as a result, there is an abundance of tools that process code for quality and conformance
-to rules. These tools ensure that the code that developers write fits into a small window of variability. Again,
-developers are reduced to human code robots. You have to wonder: *If we have such sophisticated tools that automatically
-ensure that all of our code conforms to a limited set of templates after the code is written, why don't we have tools
-that automatically write the code to those specifications in the first place?* The answer is that we can.
+We can also look into automating certain aspects of business code. Much of that code also follows templates and best
+practices, and as a result, there is an abundance of tools that process code for quality and conformance
+to rules. These tools ensure that the code that developers write fits into a small window of variability. Again,
+developers are reduced to human code robots. You have to wonder: _If we have such sophisticated tools that automatically
+ensure that all of our code conforms to a limited set of templates after the code is written, why don't we have tools
+that automatically write the code to those specifications in the first place?_ The answer is that we can.
-This is what Morphir Dev Bots do. They automate the production of all the boilerplate and templated code and
+This is what Morphir Dev Bots do. They automate the production of all the boilerplate and templated code and
let developers focus on what they do best: provide the bridge between the business and computer world.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/index.md b/docs/index.md
deleted file mode 100644
index 121c0ea95..000000000
--- a/docs/index.md
+++ /dev/null
@@ -1,83 +0,0 @@
-# Morphir
-
-Morphir is a multi-language system built on a data format that captures an application's domain model and business logic
-in a technology agnostic manner. Having all the business knowledge available as data allows you to process it
-programmatically in various ways:
-
-- **Translate it** to move between languages and platforms effortlessly as technology evolves
-- **Visualize it** to turn black-box logic into insightful explanations for your business users
-- **Share it** across different departments or organizations for consistent interpretation
-- **Store it** to retrieve and explain earlier versions of the logic in seconds
-- and much more ...
-
-While the core idea behind Morphir is very simple it's still challenging to describe it because it doesn't fit into
-any well-known categories. To help you understand what it is and how you can use it to solve real-world problems we
-put together a tutorial and list of questions and short answers:
-
-- [Tutorial](https://github.com/stephengoldbaum/morphir-examples/tree/master/tutorial)
-- [How do I define my domain model and business logic?](#how-do-I-define-my-domain-model-and-business-logic)
-- [How does Morphir turn logic into data?](#how-does-morphir-turn-logic-into-data)
-- [What does the data format look like?](#what-does-the-data-format-look-like)
-
-
-## How do I define my domain model and business logic?
-
-Morphir is a multi-language system, so it gives you flexibility in what language or tool you use to define your
-domain model and business logic (we refer to them as frontends). As a community we are continuously building new
-language frontends and if the one you are looking for is not available we provide tools for you to build it yourself.
-
-Our main frontend is currently the [Elm](https://elm-lang.org/) programming language. We support the whole language
-(except for some very platform specific features like ports) so defining your domain model and business logic boils down
-to writing Elm code. To learn more about the frontend see [morphir-elm](https://github.com/Morgan-Stanley/morphir-elm).
-
-Other frontends:
-
-- [Bosque Programming Language](https://github.com/Morgan-Stanley/morphir-bosque)
-
-## How does Morphir turn logic into data?
-
-The process of turning logic into data is well known because every programming language compiler and interpreter does
-it. They parse the source code to generate an [abstract syntax tree](https://en.wikipedia.org/wiki/Abstract_syntax_tree)
-which is then transformed into an [intermediate representation](https://en.wikipedia.org/wiki/Intermediate_representation) of some sort.
-
-Morphir simply turns that intermediate representation into a developer-friendly data format that makes it easy to build
-automation on top of it.
-
-## What does the data format look like?
-
-It's easiest to start with an example. Say you have some simple business logic like this:
-
-```javascript
-quantity * unitPrice
-```
-
-In Morphir's data format this would translate into something like this:
-
-```javascript
-["Apply"
-, ["Apply"
- , ["Reference", [["Morphir", "SDK"], ["Number"], "multiply"]]
- , ["Variable", ["quantity"]]]
-, ["Variable", ["unit", "price"]]
-]
-```
-
-# Further reading
-
-## Introduction and Background
-* [Background](background)
-* [Community](morphir_community)
-* [What's it all about?](whats_it_about)
-* [Working Across Technologies](work_across_languages_and_platforms)
-* [Why we use Functional Programming?](why_functional_programming)
-
-## Using Morphir
-* [What Makes a Good Model](what-makes-a-good-domain-model)
-* [Development Automation (Dev Bots)](dev_bots)
-* [Modeling an Application](application_modeling)
-* [Modeling Decision Tables](https://github.com/finos/morphir-examples/tree/master/src/Morphir/Sample/Rules)
-* [Modeling for database developers](modeling/modeling-for-database-developers.md)
-
-## Applicability
-* [Sharing Business Logic Across Application Boundaries](shared_logic_modeling)
-* [Regulatory Technology](regtech_modeling)
diff --git a/docs/index2.md b/docs/index2.md
deleted file mode 100644
index 065272543..000000000
--- a/docs/index2.md
+++ /dev/null
@@ -1,11 +0,0 @@
-## Where business meets technology
-
-Morphir turns a programming language inside out to provide ...
-
-> **Transparency** - Turn business rules into insightful data visualizations
-
-> **Agility** - Move between languages and platforms effortlessly
-
-> **Reliability** - No runtime exceptions, integrated testing and quality checks
-
-> **Transformation** - Renovate your applications in-place with no migration period
diff --git a/docs/index3.md b/docs/index3.md
index 00c5acccc..7f751fc0b 100644
--- a/docs/index3.md
+++ b/docs/index3.md
@@ -1,6 +1,12 @@
-# Maximize the soul of your application
+---
+sidebar_position: 3
+id: soul-application
+title: Soul of your Application
+---
-Morphir approaches application development from the perspective that the application's business knowledge should be enshrined. Adopting this knowledge-first has brought us great benefits, including:
+# Maximize the Soul of your Application
+
+Morphir approaches application development from the perspective that the application's business knowledge should be enshrined. Adopting this knowledge-first has brought us great benefits, including:
> **Transparency** - Turn business rules into insightful data visualizations
@@ -13,14 +19,13 @@ Morphir approaches application development from the perspective that the applica
This has been impactful enough that we want to bring it to the open-source community. Morphir is all about potential. We have benefited and will contribute these. The true potential is in what the community can bring to the Morphir ecosystem.
## Why use Morphir?
-Your application has a soul - it's reason for existing. It might be embodied in calculations, business rules, and other logic. Collectively these are your application's most important assets. You need to protect these assets. You also want to do useful things with it.
-
-For starters, you definately want it to **[function correctly](why_functional_programming)**. Ideally, it could do that **[across different technologies and platforms](work_across_languages_and_platforms)**. In addition, you also want to **[share the knowledge](shared_logic_modeling)** to your application's stakeholders. This provides transparency and gives them **[confidence](build_confidence)** in what you're delivering. It also makes supporting and learning about your application easier. The world is changing fast, so you want all of these characteristics while **[delivering quickly and efficiently](dev_bots)**.
-This is where Morphir comes in. **Morphir treats logic like data**. This simple concept makes it possible to do all of these things and more. Morphir makes development better. To learn more ...
+Your application has a soul - it's reason for existing. It might be embodied in calculations, business rules, and other logic. Collectively these are your application's most important assets. You need to protect these assets. You also want to do useful things with it.
+For starters, you definately want it to **[function correctly](why_functional_programming)**. Ideally, it could do that **[across different technologies and platforms](work_across_languages_and_platforms)**. In addition, you also want to **[share the knowledge](shared_logic_modeling)** to your application's stakeholders. This provides transparency and gives them **[confidence](build_confidence)** in what you're delivering. It also makes supporting and learning about your application easier. The world is changing fast, so you want all of these characteristics while **[delivering quickly and efficiently](dev_bots)**.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
------|------|------
- | |
+This is where Morphir comes in. **Morphir treats logic like data**. This simple concept makes it possible to do all of these things and more. Morphir makes development better. To learn more ...
+| [Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/) |
+| -------------- | -------------- | ------------------------------------------------------ |
+| |
diff --git a/docs/intro.md b/docs/intro.md
index 5a8f422b4..668b20c27 100644
--- a/docs/intro.md
+++ b/docs/intro.md
@@ -10,20 +10,34 @@ Morphir is a multi-language system built on a data format that captures an appli
in a technology agnostic manner. Having all the business knowledge available as data allows you to process it
programmatically in various ways:
-- **Translate it** to move between languages and platforms effortlessly as technology evolves
-- **Visualize it** to turn black-box logic into insightful explanations for your business users
-- **Share it** across different departments or organizations for consistent interpretation
-- **Store it** to retrieve and explain earlier versions of the logic in seconds
-- and much more ...
+- **Translate it** to move between languages and platforms effortlessly as technology evolves
+- **Visualize it** to turn black-box logic into insightful explanations for your business users
+- **Share it** across different departments or organizations for consistent interpretation
+- **Store it** to retrieve and explain earlier versions of the logic in seconds
+- and much more ...
While the core idea behind Morphir is very simple it's still challenging to describe it because it doesn't fit into
any well-known categories. To help you understand what it is and how you can use it to solve real-world problems we
put together a tutorial and list of questions and short answers:
-- [Tutorial](https://github.com/stephengoldbaum/morphir-examples/tree/master/tutorial)
-- [How do I define my domain model and business logic?](#how-do-I-define-my-domain-model-and-business-logic)
-- [How does Morphir turn logic into data?](#how-does-morphir-turn-logic-into-data)
-- [What does the data format look like?](#what-does-the-data-format-look-like)
+- [Tutorial](https://github.com/stephengoldbaum/morphir-examples/tree/master/tutorial)
+- [How do I define my domain model and business logic?](#how-do-I-define-my-domain-model-and-business-logic)
+- [How does Morphir turn logic into data?](#how-does-morphir-turn-logic-into-data)
+- [What does the data format look like?](#what-does-the-data-format-look-like)
+
+## FINOS Morphir Resources
+
+- [Morphir Resource Centre](https://resources.finos.org/morphir/)
+
+| Episode | Description |
+| --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------ |
+| | Introduction to the Morphir Showcase |
+| | What Morphir is with Stephen Goldbaum |
+| | How Morphir works with Attila Mihaly |
+| | Why Morphir is Important – with Colin, James & Stephen |
+| | The Benefits & Use Case of Morphir with Jane, Chris & Stephen |
+| | How to get involved – Closing Panel Q&A |
+| | Morphir Showcase – Full Show |
## How do I define my domain model and business logic?
@@ -37,7 +51,7 @@ to writing Elm code. To learn more about the frontend see [morphir-elm](https://
Other frontends:
-- [Bosque Programming Language](https://github.com/Morgan-Stanley/morphir-bosque)
+- [Bosque Programming Language](https://github.com/Morgan-Stanley/morphir-bosque)
## How does Morphir turn logic into data?
@@ -60,9 +74,13 @@ In Morphir's data format this would translate into something like this:
```javascript
[
- 'Apply',
- ['Apply', ['Reference', [['Morphir', 'SDK'], ['Number'], 'multiply']], ['Variable', ['quantity']]],
- ['Variable', ['unit', 'price']],
+ "Apply",
+ [
+ "Apply",
+ ["Reference", [["Morphir", "SDK"], ["Number"], "multiply"]],
+ ["Variable", ["quantity"]],
+ ],
+ ["Variable", ["unit", "price"]],
];
```
diff --git a/docs/modeling/modeling-finance.md b/docs/modeling/modeling-finance.md
index 92a156982..8c916b53b 100644
--- a/docs/modeling/modeling-finance.md
+++ b/docs/modeling/modeling-finance.md
@@ -1,11 +1,17 @@
+---
+id: modeling-financial-concepts
+title: Modeling Financial Concepts
+---
+
# Modeling Financial Concepts
-Functional Domain Modeling (FDM) is all about capturing business concepts in a precise, unambiguous, and processable manner. Those coming from a coding background will be comfortable with its use of first class programming language. There will be some differences from general purpose languages, and especially object-oriented languages, that are more focused on execution than capturing business concepts. This tuturial reviews how we can capture common business concepts concisely and expressively with Morphir. Morphir uses Elm as its main FDM language of choice, so we'll demonstrate the concepts with Elm examples.
+Functional Domain Modeling (FDM) is all about capturing business concepts in a precise, unambiguous, and processable manner. Those coming from a coding background will be comfortable with its use of first class programming language. There will be some differences from general purpose languages, and especially object-oriented languages, that are more focused on execution than capturing business concepts. This tuturial reviews how we can capture common business concepts concisely and expressively with Morphir. Morphir uses Elm as its main FDM language of choice, so we'll demonstrate the concepts with Elm examples.
## Using The Language Of The Business
-FDM relies heavily on Domain Driven Design, which has the concept of the *ubiquitous language*: making sure that the business and technology stakeholders establish a consistent language to describe the business. The best way to do this is to ensure that the code uses that language directly with no translation. Morphir makes this easy by being very friendly for labeling data in the form of types.
-We can use a standard trade as an example. When the business talks about trading, they probably refer to the trade's quantity, price, and value as ```Trade Quantity``` and ```Trade Price```, and ```Trade Value```. So we want to capture those concepts in our code. As technologists, we know that these fields instances of integers and decimals. While we might be tempted to declare them as such, it would be better if we could use the business language. And this is how we want to approach modeling these concepts in Morphir. Elm has the concept of type aliases, so we'll take advantage of that.
+FDM relies heavily on Domain Driven Design, which has the concept of the _ubiquitous language_: making sure that the business and technology stakeholders establish a consistent language to describe the business. The best way to do this is to ensure that the code uses that language directly with no translation. Morphir makes this easy by being very friendly for labeling data in the form of types.
+
+We can use a standard trade as an example. When the business talks about trading, they probably refer to the trade's quantity, price, and value as `Trade Quantity` and `Trade Price`, and `Trade Value`. So we want to capture those concepts in our code. As technologists, we know that these fields instances of integers and decimals. While we might be tempted to declare them as such, it would be better if we could use the business language. And this is how we want to approach modeling these concepts in Morphir. Elm has the concept of type aliases, so we'll take advantage of that.
```elm
type alias TradeQuantity = Int
@@ -15,7 +21,7 @@ type alias TradePrice = Decimal
type alias TradeValue = Decimal
```
-Now when we see these values in our code, we know they map directly to the business concepts that the users know them as. For example:
+Now when we see these values in our code, we know they map directly to the business concepts that the users know them as. For example:
```elm
value : TradeQuantity -> TradePrice -> TradeValue
@@ -23,10 +29,11 @@ value quantity price =
(ToDecimal quantity) * price
```
-This bit of Elm defines a function that takes a ```TradeQuantity``` and ```TradePrice``` and calculates the ```TradeValue```. This simple act is incredibly effective in avoiding misunderstandings and mistakes.
+This bit of Elm defines a function that takes a `TradeQuantity` and `TradePrice` and calculates the `TradeValue`. This simple act is incredibly effective in avoiding misunderstandings and mistakes.
## Keeping Incompatible Concepts Separate
-In our trade example, we aliased ```TradePrice``` and ```TradeValue``` as aliases of Decimal. That means that the compile considers them to be of the same Decimal type, so anything you can do with Decimals can be done with these two types. That's useful in some ways, like applying functions like absolute value. In other ways, we don't want to mix the two. For example, what does it mean to do ```TradePrice + TradeValue```? From a business perspective, this makes no sense, so we shouldn't be able to do it in code. Morphir has the concept of *Units of Measure*, which you might have seen as a first class concept in F#. In Elm it's implemented via a mechanism called *Phantom Types*. So we probably want to implement some core types of ```Value``` and ```Price```.
+
+In our trade example, we aliased `TradePrice` and `TradeValue` as aliases of Decimal. That means that the compile considers them to be of the same Decimal type, so anything you can do with Decimals can be done with these two types. That's useful in some ways, like applying functions like absolute value. In other ways, we don't want to mix the two. For example, what does it mean to do `TradePrice + TradeValue`? From a business perspective, this makes no sense, so we shouldn't be able to do it in code. Morphir has the concept of _Units of Measure_, which you might have seen as a first class concept in F#. In Elm it's implemented via a mechanism called _Phantom Types_. So we probably want to implement some core types of `Value` and `Price`.
```elm
type Price a = Price Decimal
@@ -36,14 +43,15 @@ type Quantity a = Quantity Int
type Value a = Value Decimal
```
-This will ensure that we don't mix ```Price```, ```Quantity```, and ```Value``` in invalid ways. There are a lot of concepts in finance that we might want to approach this way. For example, we'd never want to accidentally use prices in different currencies without normalizing them. The same goes for things like fixed rate versus variable rate loans.
+This will ensure that we don't mix `Price`, `Quantity`, and `Value` in invalid ways. There are a lot of concepts in finance that we might want to approach this way. For example, we'd never want to accidentally use prices in different currencies without normalizing them. The same goes for things like fixed rate versus variable rate loans.
## Categorizing Things
-Categorizing stuff is one of the most common actions in enterprise development. Finance is full of categorizing, like categorizing trades, accounts, and products into different sets. This often gets very complex and categorization is usually highly contextual, meaning the same things might get categorized differently across different parts of the business. This has historically been a major source of complexity in finance. One of the main causes is the fact that categorization is usually approached up front, meaning the categories are decided first and then the things are created directly into those categories. This limits later flexibility for different contexts and often creates incredibly complex graphs of categories. In practice, we usually see this with object-oriented systems where the base classes or traits are decided first and then the specific things are specified with classes that extend them.
-Functional Domain Modeling takes a different approach to these challenges. In FDM, the structure of things are defined first and only put into categories in contexts as needed. This simplifies the modelers' jobs by alleviating the need to account for all possible use cases up front. The tradeoff is that it requires mapping into categories later.
+Categorizing stuff is one of the most common actions in enterprise development. Finance is full of categorizing, like categorizing trades, accounts, and products into different sets. This often gets very complex and categorization is usually highly contextual, meaning the same things might get categorized differently across different parts of the business. This has historically been a major source of complexity in finance. One of the main causes is the fact that categorization is usually approached up front, meaning the categories are decided first and then the things are created directly into those categories. This limits later flexibility for different contexts and often creates incredibly complex graphs of categories. In practice, we usually see this with object-oriented systems where the base classes or traits are decided first and then the specific things are specified with classes that extend them.
+
+Functional Domain Modeling takes a different approach to these challenges. In FDM, the structure of things are defined first and only put into categories in contexts as needed. This simplifies the modelers' jobs by alleviating the need to account for all possible use cases up front. The tradeoff is that it requires mapping into categories later.
-Let's look at an example. A classic financial modeling exercise is to model various financial products. For this example, let's take a subset of a Treasury function since Treasury needs to work across asset classes. The standard object-orient approach is to start with something like this:
+Let's look at an example. A classic financial modeling exercise is to model various financial products. For this example, let's take a subset of a Treasury function since Treasury needs to work across asset classes. The standard object-orient approach is to start with something like this:
```java
public interface Product {
@@ -77,10 +85,12 @@ public class Stock {
TODO...
## Data sets
-As we model data we come across a few established patterns, which we'll discuss below. These are general guideliness that should be balanced with the context of the project.
+
+As we model data we come across a few established patterns, which we'll discuss below. These are general guideliness that should be balanced with the context of the project.
## Infrequently changing limited values
-This category describes a finite set of infrequently changing data. Some good examples of this type are days of the week, months of the year, ISO country codes, and currency codes. Often, programmers will want to refer to these directly without the possibility of mistakes. The standard approach to specifying these values is to use an enum. The functional way tends to focus on discriminated union types. In Elm, this looks like:
+
+This category describes a finite set of infrequently changing data. Some good examples of this type are days of the week, months of the year, ISO country codes, and currency codes. Often, programmers will want to refer to these directly without the possibility of mistakes. The standard approach to specifying these values is to use an enum. The functional way tends to focus on discriminated union types. In Elm, this looks like:
```elm
type DayOfWeek = Sunday | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday
@@ -91,14 +101,15 @@ isWeekend day =
```
## Frequently changing limited values
-This category describes a finite set of frequently changing data. A good example of this might something like pizza toppings, where there's a core set of common toppings and frequent changes based on market conditions. In theory, the frequency of change shouldn't affect how we model. It would be great to model these as enums as well and rely on continuous delivery to get that into production. In practice, many environments are not agile enough so rely on the database. So the common approach is to define these as such:
+
+This category describes a finite set of frequently changing data. A good example of this might something like pizza toppings, where there's a core set of common toppings and frequent changes based on market conditions. In theory, the frequency of change shouldn't affect how we model. It would be great to model these as enums as well and rely on continuous delivery to get that into production. In practice, many environments are not agile enough so rely on the database. So the common approach is to define these as such:
```elm
type alias PizzaTopping = String
```
```elm
-type Topping
+type Topping
= Cheese
| Pepperoni
| Mushrooms
@@ -123,7 +134,8 @@ toppingToString topping =
```
## Unlimited values
-This category describes a set of data that is unbounded for all practical purposes. The most common approach to these is simply to define a type alias:
+
+This category describes a set of data that is unbounded for all practical purposes. The most common approach to these is simply to define a type alias:
```elm
type alias Name = String
@@ -142,7 +154,7 @@ hi (Name name) =
# Custom Types
-When you have something in your domain that you can describe as a list of alternatives (X can either be A or B or C or ...)
+When you have something in your domain that you can describe as a list of alternatives (X can either be A or B or C or ...)
you probably want to model it as a [custom type](https://guide.elm-lang.org/types/custom_types.html). A simple special case
of this is enumerations. For example a Trade's Status can either be Open or Closed:
@@ -162,8 +174,8 @@ type OrderPrice
```
Notice that a market price doesn't have a specific value associated with it since it moves with the market but a limit price
-would have a specific price limit. In order to take full advantage of this flexibility you should use a pattern match to
-branch out on the various cases.
+would have a specific price limit. In order to take full advantage of this flexibility you should use a pattern match to
+branch out on the various cases.
## Special case: enumerations
@@ -186,13 +198,13 @@ Here's how you would do that for the `RAG` type above:
toCode : RAG -> String
toCode rag =
case rag of
- Red ->
+ Red ->
"R"
- Amber ->
+ Amber ->
"A"
- Green ->
+ Green ->
"G"
@@ -209,7 +221,7 @@ fromCode string =
Ok Green
other ->
- Err other
+ Err other
```
Notice that `fromCode` returns a `Result`. This is a way to explicitly say that the operation may fail. Since you can pass in
diff --git a/docs/modeling/modeling-for-database-developers.md b/docs/modeling/modeling-for-database-developers.md
index de70bfbfd..603fd2765 100644
--- a/docs/modeling/modeling-for-database-developers.md
+++ b/docs/modeling/modeling-for-database-developers.md
@@ -1,14 +1,19 @@
+---
+id: modeling-database-developers
+title: Modeling for database developers
+---
+
# Modeling for database developers
## Introduction
As a database developer you will find it very easy and enjoyable to learn Elm
because it's basically an extended version of SQL. Being a functional programming
-language, Elm is based on the same strong, mathematical foundations as relational
+language, Elm is based on the same strong, mathematical foundations as relational
algebra, and you get very similar declarative building blocks.
The syntax is different from SQL, but Elm is very lightweight and easy to pick up.
-Probably the best way to start learning is to see a few examples. Let's start
+Probably the best way to start learning is to see a few examples. Let's start
with a simple SQL query:
```sql
@@ -33,18 +38,18 @@ query1 =
There are a few things here that will look unfamiliar so let me explain:
-* `trades` is the source collection, similar to a table in SQL.
-* `|>` is the pipe operator. It's a way to chain transformations (operators in relational algebra).
-* `filter` is selection. It corresponds to the `WHERE` clause in SQL.
-* The `(\t -> ...)` syntax is a lambda. It's a way define a function inline. Some details about the syntax:
- * A lambda always starts with `\` which is followed by a list of argument names separated by spaces. This one has a single variable `t`.
- * After the argument names, there is an `->` to show that you are mapping the arguments to some other value.
- * You can specify any expressions after the arrow, and you can use the arguments as variables.
- * `t.buySell == "S"` this is very similar to how you would write this expression in SQL.
- * The only difference is that we use double-equals for comparison because single-equals is used for assignment.
-* `map` is projection. It corresponds to the `SELECT` clause in SQL.
- * `{ field1 = value1, field2 = value2 }` is the syntax to create a record.
- * This is slightly more involved than the SQL version, but it's also much more powerful. As you'll see later, Elm is
+- `trades` is the source collection, similar to a table in SQL.
+- `|>` is the pipe operator. It's a way to chain transformations (operators in relational algebra).
+- `filter` is selection. It corresponds to the `WHERE` clause in SQL.
+- The `(\t -> ...)` syntax is a lambda. It's a way define a function inline. Some details about the syntax:
+ - A lambda always starts with `\` which is followed by a list of argument names separated by spaces. This one has a single variable `t`.
+ - After the argument names, there is an `->` to show that you are mapping the arguments to some other value.
+ - You can specify any expressions after the arrow, and you can use the arguments as variables.
+ - `t.buySell == "S"` this is very similar to how you would write this expression in SQL.
+ - The only difference is that we use double-equals for comparison because single-equals is used for assignment.
+- `map` is projection. It corresponds to the `SELECT` clause in SQL.
+ - `{ field1 = value1, field2 = value2 }` is the syntax to create a record.
+ - This is slightly more involved than the SQL version, but it's also much more powerful. As you'll see later, Elm is
not limited to flat record structures.
**Note**: At this point you might be thinking: hold on, this is actually doing the whole operation in-memory, that's completely different.
@@ -104,13 +109,13 @@ type alias Trade =
Let's go through the type definition to understand what it means:
-* The overall structure is very similar to the DDL:
- * Just like a table, a type has a name and a structure.
- * The structure is a list of field names and types.
-* There are some differences too:
- * The field types are less granular than the DDL. This is just to avoid getting too deep too soon. We will
- make these very granular later on.
- * Nullability is expressed through the types: we simply prefix the type of nullable fields with `Maybe`.
+- The overall structure is very similar to the DDL:
+ - Just like a table, a type has a name and a structure.
+ - The structure is a list of field names and types.
+- There are some differences too:
+ - The field types are less granular than the DDL. This is just to avoid getting too deep too soon. We will
+ make these very granular later on.
+ - Nullability is expressed through the types: we simply prefix the type of nullable fields with `Maybe`.
As mentioned, we did lose some granularity in this definition. One of the main goals of modeling is to very accurately model
your domain, so we need to address this. Fortunately Elm makes this easy. As a first step let's define `buySell` as an enumeration.
@@ -124,21 +129,21 @@ type alias Trade =
}
-- this type captures the fact that there are only 2 valid values here
-type BuySell
- = Buy
+type BuySell
+ = Buy
| Sell
```
Elm allows you to define types as a choice between different values. The simplest way to use these is to
define enums. The definition above is pretty self-explanatory: the type `BuySell` can either be a `Buy` or a `Sell`.
-The type in the DDL is less accurate because it allows any single character strings as values. This makes
-it easy to overload the field, which tends to happen in systems a lot. This definition makes it impossible
+The type in the DDL is less accurate because it allows any single character strings as values. This makes
+it easy to overload the field, which tends to happen in systems a lot. This definition makes it impossible
to overload the value while also makes it easy to add new values if needed. The big difference is that you
are forced to at least document the valid values.
An enum like this can be mapped to the DDL in many ways depending on the database product or team best-practices.
-The bottom line is that when you are modeling your data, you don't need to deal with that. You can leave that to
+The bottom line is that when you are modeling your data, you don't need to deal with that. You can leave that to
the physical mapping layer.
The other thing we lost here is the lengths of some of the remaining columns. We can easily address that too:
@@ -152,19 +157,19 @@ type alias Trade =
}
-type BuySell
- = Buy
+type BuySell
+ = Buy
| Sell
-type Cusip =
+type Cusip =
Cusip String
cusip =
String.ofLength 9 Cusip
-type Comment =
+type Comment =
Comment String
comment =
@@ -175,9 +180,8 @@ comment =
_Coming soon_
-
## More relational operators
_Coming soon_
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/modeling/modeling-overview.md b/docs/modeling/modeling-overview.md
index b6405c1bf..ff1594bf5 100644
--- a/docs/modeling/modeling-overview.md
+++ b/docs/modeling/modeling-overview.md
@@ -1,33 +1,38 @@
+---
+id: morphir-entail
+title: What Does Using Morphir Entail?
+---
+
# What Does Using Morphir Entail?
So, you're thinking about using Morphir for your project. What does that mean exactly and what are you in for if you do?
## How using Morphir is different?
-Morphir embraces the Functional Domain Modeling (FDM) approach to development. FDM's emphasis is on capturing the business concepts and then projecting them into various runtime contexts. In practice, this means that we approach development in a different way than is often done. It's more of a formalized Hexogonal Architecture approach.
+Morphir embraces the Functional Domain Modeling (FDM) approach to development. FDM's emphasis is on capturing the business concepts and then projecting them into various runtime contexts. In practice, this means that we approach development in a different way than is often done. It's more of a formalized Hexogonal Architecture approach.
-## Modeling
+## Modeling
-One of the main pillars of FDM is that modeling the business is a unique discipline that must be approached independent from the technology. What this means in Morphir is that you'll start with the models and work them out before ever getting into the technology needed to execute them. We currently do this modeling in the Elm programming langauge. As a general rule, we start with the business logic and model the data to provide just enough to supply that logic. See [Modeling business concepts](modeling-finance.md) for a more detailed review on modeling strategies in Elm.
+One of the main pillars of FDM is that modeling the business is a unique discipline that must be approached independent from the technology. What this means in Morphir is that you'll start with the models and work them out before ever getting into the technology needed to execute them. We currently do this modeling in the Elm programming langauge. As a general rule, we start with the business logic and model the data to provide just enough to supply that logic. See [Modeling business concepts](modeling-finance.md) for a more detailed review on modeling strategies in Elm.
## Testing the models
-We can test the validity of our models directly in Elm using Elm's built in testing tools. Elm tests tend to be thinner than those of procedural and object-oriented languages since the Elm compiler eliminates the are large portion of the errors that occur in those languages. If it compiles it will run without error, which means you're really just testing the validity of your logic.
+We can test the validity of our models directly in Elm using Elm's built in testing tools. Elm tests tend to be thinner than those of procedural and object-oriented languages since the Elm compiler eliminates the are large portion of the errors that occur in those languages. If it compiles it will run without error, which means you're really just testing the validity of your logic.
The Morphir roadmap contains a significant amount of tools to give users confidence, including visualization, audit, and instant testing tools.
## Processing the models
-Once the models are ready, the next step is to convert them whatever form they'll be executed in. This is aspect of FDM utilizes techniques from Model-Driven Development in the form of code generation. This is similar to the codegen phase of many projects when dealing with things like XSD, IDL, or OpenAPI processing. We refer to these as Dev Bots, since they are automating away many of the mundane and error prone aspects of development for which humans provide no value.
+Once the models are ready, the next step is to convert them whatever form they'll be executed in. This is aspect of FDM utilizes techniques from Model-Driven Development in the form of code generation. This is similar to the codegen phase of many projects when dealing with things like XSD, IDL, or OpenAPI processing. We refer to these as Dev Bots, since they are automating away many of the mundane and error prone aspects of development for which humans provide no value.
## Incorporating into your code
-One of the advantages of Morphir is that it is completely open, so teams can customize their own Dev Bots as needed for their projects. Morphir has support for common Dev Bots to fit different paradigms of development.
+One of the advantages of Morphir is that it is completely open, so teams can customize their own Dev Bots as needed for their projects. Morphir has support for common Dev Bots to fit different paradigms of development.
### Micro integration: Libraries
-The most basic approach to using Morphir is to have it generate from models into your project's language of choice. This is analogous to writing your business logic as a set of libraries and using them from your handwritten code. Morphir models can be generated into various target languages, which allows execution in different contexts with guaranteed consistency.
+The most basic approach to using Morphir is to have it generate from models into your project's language of choice. This is analogous to writing your business logic as a set of libraries and using them from your handwritten code. Morphir models can be generated into various target languages, which allows execution in different contexts with guaranteed consistency.
### Macro integration: Platforms
-A more advanced use of Morphir is to use Dev Bots to target execution within an entire platform. Platform-level targets is a great way to ensure consistency and efficiency across the entire plant. Of course, this requires that Dev Bots exist for the target platforms.
\ No newline at end of file
+A more advanced use of Morphir is to use Dev Bots to target execution within an entire platform. Platform-level targets is a great way to ensure consistency and efficiency across the entire plant. Of course, this requires that Dev Bots exist for the target platforms.
diff --git a/docs/modeling/testing.md b/docs/modeling/testing.md
index 4d72d89e0..79c6ebba7 100644
--- a/docs/modeling/testing.md
+++ b/docs/modeling/testing.md
@@ -1,3 +1,8 @@
+---
+id: morphir-setup
+title: Setup
+---
+
# Setup
Elm's standard testing library is elm-test. You can install it by running the following command \
@@ -7,14 +12,14 @@ in your project. It will ask questions, just say yes to everything:
elm install elm-explorations/test
```
-The next thing you need to do is set up a test framework. We have [Lobo](https://github.com/benansell/lobo)
+The next thing you need to do is set up a test framework. We have [Lobo](https://github.com/benansell/lobo)
available internally. This is how you install it for your project:
```
npm install lobo --save
```
-Now make sure you have a `tests` directory in the root of the project and that in your `elm.json`
+Now make sure you have a `tests` directory in the root of the project and that in your `elm.json`
it is listed in `source-directories`.
Now you are ready to run the tests:
@@ -23,7 +28,7 @@ Now you are ready to run the tests:
npx lobo --framework=elm-test
```
-This will also ask a lot of questions, just say yes to everything (you only need to do this once). In the end
+This will also ask a lot of questions, just say yes to everything (you only need to do this once). In the end
it will show something like this:
```
@@ -68,4 +73,4 @@ npx lobo --framework=elm-test
```
This should report 2 passing tests. Now you are ready to add real tests. For that follow the inestructions here:
-[elm-explorations/test](https://package.elm-lang.org/packages/elm-explorations/test/latest/)
\ No newline at end of file
+[elm-explorations/test](https://package.elm-lang.org/packages/elm-explorations/test/latest/)
diff --git a/docs/morphir_community.md b/docs/morphir_community.md
index e4c98180c..b224a0229 100644
--- a/docs/morphir_community.md
+++ b/docs/morphir_community.md
@@ -1,12 +1,23 @@
+---
+sidebar_position: 6
+id: morphir-community
+title: Morphir Community
+---
+
# Morphir Community
-Morphir's success will depend on its community. While this might be obvious, we want to state that up front. The
-open-sourcing of Morphir was based on the successes that we had with it in Morgan Stanley. Those successes demonstrate
-the potential that Morphir has. We are contributing, and will continue to contribute, useful tools to the Morphir
-ecosystem. We recognize that there is a vast difference between building tools for a company's controlled
-infrastructure and making them robust for the general open-source community. Filling that gap and moving beyond our
-own vision will require a broad Morphir community. So as you browse the Morphir project and read about possible uses,
-view these more of indications of potential instead of polished products. It's all about the Morphir community. If you
-see the same potential that we have, we hope you join us.
+**Morphir's success will depend on its community.**
+
+While this might be obvious, we want to state that up front. The open-sourcing of Morphir was based on the successes that we had with it in Morgan Stanley.
+
+Those successes demonstrate the potential that Morphir has. We are contributing, and will continue to contribute, useful tools to the Morphir ecosystem.
+
+We recognize that there is a vast difference between building tools for a company's controlled infrastructure and making them robust for the general open-source community.
+
+Filling that gap and moving beyond our own vision will require a broad Morphir community.
+
+So as you browse the Morphir project and read about possible uses, view these more of indications of potential instead of polished products. It's all about the Morphir community.
+
+If you see the same potential that we have, we hope you join us.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/posts.md b/docs/posts.md
deleted file mode 100644
index 994a53acb..000000000
--- a/docs/posts.md
+++ /dev/null
@@ -1,24 +0,0 @@
-# Morphir Documents
-
-## Introduction and Background
-* [Background](background)
-* [Community](morphir_community)
-* [What's it all about?](whats_it_about)
-* [Working Across Technologies](work_across_languages_and_platforms)
-* [Why we use Functional Programming?](why_functional_programming)
-
-## Using Morphir
-* [What Makes a Good Model](what-makes-a-good-domain-model)
-* [Development Automation (Dev Bots)](dev_bots)
-* [Modeling An Application](application_modeling)
-
-## Applicability
-* [Sharing Business Logic Across Application Boundaries](shared_logic_modeling)
-* [Regulatory Technology](regtech_modeling)
-
-
-
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
------|------|------
- | |
-
diff --git a/docs/regtech_modeling.md b/docs/regtech_modeling.md
index e07dbffa8..7fb5eb6a3 100644
--- a/docs/regtech_modeling.md
+++ b/docs/regtech_modeling.md
@@ -1,53 +1,64 @@
+---
+sidebar_position: 7
+id: automating-regtech
+title: Automating RegTech
+---
+
# Automating RegTech
-There are a number of highly regulated industries that must adhere to complex regulations from various regulatory
-bodies. These often come in the form of lengthy documents that can be arcane, ambiguous, and expensive to interpret
-into computer code. It's even more expensive to adapt these regulations to a firm's internal systems. There is no
+There are a number of highly regulated industries that must adhere to complex regulations from various regulatory
+bodies. These often come in the form of lengthy documents that can be arcane, ambiguous, and expensive to interpret
+into computer code. It's even more expensive to adapt these regulations to a firm's internal systems. There is no
competitive advantage for firms in processing these regulations separately, so it would be mutually beneficial to codify
and test the rules once across all firms.
-There have been attempts to do so using shared libraries. The challenge with this approach is that these libraries don't
-work natively across the complexities of each firm's existing systems. In order to use them, they would need to invest
-significantly to build new systems that use the shared libraries. Another issue is that technology advances quickly, and
+There have been attempts to do so using shared libraries. The challenge with this approach is that these libraries don't
+work natively across the complexities of each firm's existing systems. In order to use them, they would need to invest
+significantly to build new systems that use the shared libraries. Another issue is that technology advances quickly, and
an optimal solution at any point in time is not likely to be the best solution in a short time.
-There is an alternative. If regulations were codified in a declarative model that could be cross-compiled to run in
+There is an alternative. If regulations were codified in a declarative model that could be cross-compiled to run in
different execution contexts, then that would enable firms to create their own processors to translate the model to work
-in their systems. In that way they get the advantage of a codified, unambiguous, and verifiable model while still
-retaining their existing systems. Morphir provides exactly this capability by providing tools to project a unified model
+in their systems. In that way they get the advantage of a codified, unambiguous, and verifiable model while still
+retaining their existing systems. Morphir provides exactly this capability by providing tools to project a unified model
into various execution contexts.
# Use case: US LCR
+
The [US Liquidity Coverage Ratio](https://en.wikipedia.org/wiki/Basel_III#US_version_of_the_Basel_Liquidity_Coverage_Ratio_requirements)
-is a required report for certain banks and systemically important financial institutions. Its definition can be found at
-[https://www.govinfo.gov/content/pkg/FR-2014-10-10/pdf/2014-22520.pdf](https://www.govinfo.gov/content/pkg/FR-2014-10-10/pdf/2014-22520.pdf). It's
-complex enough that there are accompanying documents and samples that attempt to clarify it. Ultimately it's a set of
+is a required report for certain banks and systemically important financial institutions. Its definition can be found at
+[https://www.govinfo.gov/content/pkg/FR-2014-10-10/pdf/2014-22520.pdf](https://www.govinfo.gov/content/pkg/FR-2014-10-10/pdf/2014-22520.pdf). It's
+complex enough that there are accompanying documents and samples that attempt to clarify it. Ultimately it's a set of
calculations that can be defined concisely and unambiguously in a concise and unambiguous programming language.
We'll step through how we can define such a regulation using Morphir with the LCR as an example.
# Getting started
-If you've not already done so, install Morphir as per the [getting started](./getting_started) instructions. Create a project called "lcr":
+
+If you've not already done so, install Morphir as per the [getting started](./getting_started) instructions. Create a project called "lcr":
```bash
morphir init lcr
cd lcr
```
-In this example, we'll use Elm as the Morphir modeling language. If you've not done so, [install elm](https://guide.elm-lang.org/install/elm.html).
+
+In this example, we'll use Elm as the Morphir modeling language. If you've not done so, [install elm](https://guide.elm-lang.org/install/elm.html).
# Modeling the LCR
-Let's define the core of the calculation for Morphir. The full LCR is quite extensive, so we'll focus on a few examples
-that highlight different aspects of modeling.
+
+Let's define the core of the calculation for Morphir. The full LCR is quite extensive, so we'll focus on a few examples
+that highlight different aspects of modeling.
## Modeling calculations
-At a high level, the LCR is a calculation. In fact if you look it up, the first thing you'll run into is probably this calculation:
-``` LCR = High quality liquid asset amount (HQLA) / Total net cash flow amount```
+
+At a high level, the LCR is a calculation. In fact if you look it up, the first thing you'll run into is probably this calculation:
+` LCR = High quality liquid asset amount (HQLA) / Total net cash flow amount`
.
-In modeling terms, it's not actually that simple since the LCR is calculated using a window from a given date. It also
-needs to run on a set of data. So in our model, we'll define it as a function:
+In modeling terms, it's not actually that simple since the LCR is calculated using a window from a given date. It also
+needs to run on a set of data. So in our model, we'll define it as a function:
```elm
-lcr toCounterparty product t flowsForDate reserveBalanceRequirement =
+lcr toCounterparty product t flowsForDate reserveBalanceRequirement =
let
hqla = hqlaAmount product (flowsForDate t) reserveBalanceRequirement
totalNetCashOutflow = totalNetCashOutflowAmount toCounterparty t flowsForDate
@@ -55,18 +66,18 @@ lcr toCounterparty product t flowsForDate reserveBalanceRequirement =
hqla / totalNetCashOutflow
```
-As you can see, that's pretty expressive, and the last line matches the calculation. For anyone new to Elm, the first
-line declares the function. Elm uses spaces rather than (,) to itemize parameters. You might be wondering what some of
-these extra parameters are all about. These are the points where the logical model meets the physical context that it
-will be run in. They are parameters at the top level so that individual firms can specify them as needed. The parameter
-named ```product``` is a good example. It's a function that takes a product key and returns the product structure. It's
+As you can see, that's pretty expressive, and the last line matches the calculation. For anyone new to Elm, the first
+line declares the function. Elm uses spaces rather than (,) to itemize parameters. You might be wondering what some of
+these extra parameters are all about. These are the points where the logical model meets the physical context that it
+will be run in. They are parameters at the top level so that individual firms can specify them as needed. The parameter
+named `product` is a good example. It's a function that takes a product key and returns the product structure. It's
up to the model user to determine how product identification and lookup will be supplied by their system.
-If you read the specification, you'll see a fair amount of space used to describe something called the adjusted excess
-HQLA amount. This happens to be a nice calculation to demonstrate mathematical modeling:
+If you read the specification, you'll see a fair amount of space used to describe something called the adjusted excess
+HQLA amount. This happens to be a nice calculation to demonstrate mathematical modeling:
```elm
-adjustedExcessHQLAAmount =
+adjustedExcessHQLAAmount =
let
adjustedLevel1LiquidAssetAmount = level1LiquidAssetAmount
@@ -74,7 +85,7 @@ adjustedExcessHQLAAmount =
adjustedlevel2bLiquidAssetAmount = level2bLiquidAssetAmount * 0.50
- adjustedLevel2CapExcessAmount =
+ adjustedLevel2CapExcessAmount =
max (adjustedlevel2aLiquidAssetAmount + adjustedlevel2bLiquidAssetAmount - 0.6667 * adjustedLevel1LiquidAssetAmount) 0.0
adjustedlevel2bCapExcessAmount =
@@ -83,15 +94,17 @@ adjustedExcessHQLAAmount =
adjustedLevel2CapExcessAmount + adjustedlevel2bCapExcessAmount
```
-It's included here just to show how much easier it is to understand a model than the written description:
+It's included here just to show how much easier it is to understand a model than the written description:
+
```
-There are two categories of assets that can be included in the stock. Assets to be included in each category are those
-that the bank is holding on the first day of the stress period, irrespective of their residual maturity. “Level 1”
+There are two categories of assets that can be included in the stock. Assets to be included in each category are those
+that the bank is holding on the first day of the stress period, irrespective of their residual maturity. “Level 1”
assets can be included without limit, while “Level 2” assets can only comprise up to 40% of the stock.
```
## Modeling collection operations
-The LCR spec is peppered with operations of collections of data. For example:
+
+The LCR spec is peppered with operations of collections of data. For example:
```elm
level2aLiquidAssetsThatAreEligibleHQLA =
@@ -101,17 +114,18 @@ level2aLiquidAssetsThatAreEligibleHQLA =
|> List.sum
```
-It's pretty easy to see that this takes a collection, filters it, then sums the "amount" of the remaining. The important
-point to note here is that we're letting the model know of a collection while also leaving the implementation entirely
-undefined. This allows us to process this model into a variety of execution contexts.
+It's pretty easy to see that this takes a collection, filters it, then sums the "amount" of the remaining. The important
+point to note here is that we're letting the model know of a collection while also leaving the implementation entirely
+undefined. This allows us to process this model into a variety of execution contexts.
## Modeling structures
-The previous example contained a collection name t0Flows. We can see from the example that it has `assetType` and `amount`
-fields. In fact, this is defined in the spec as a cash flow, which contains a few other fields. At this point in our
-modeling, we have a couple of options. We can either use a single common structure throughout the model, even when
+
+The previous example contained a collection name t0Flows. We can see from the example that it has `assetType` and `amount`
+fields. In fact, this is defined in the spec as a cash flow, which contains a few other fields. At this point in our
+modeling, we have a couple of options. We can either use a single common structure throughout the model, even when
large portions of the app don't require all of those fields, or we can create multiple structures that are more aligned
-with the usage. Since the LCR actually defines a cash flow, we'll go with the first option since it matches the language
-of the business. The cash flow is defined as:
+with the usage. Since the LCR actually defines a cash flow, we'll go with the first option since it matches the language
+of the business. The cash flow is defined as:
```elm
type alias BusinessDate = Date
@@ -137,48 +151,52 @@ type alias Flow =
}
```
-Notice that most of the types are named using the language of the business. This is an aspect of domain modeling, the
+Notice that most of the types are named using the language of the business. This is an aspect of domain modeling, the
ubiquitous language, that helps all the stakeholders to reduce misunderstandings.
# Verifying the model
+
This is just a small sampling of what's required to turn a full specification into functioning code. It's enough to see
-that it's not a trivial task, and there's a significant advantage if someone else could do it for you *and* prove
-that it's correct. This is where the use of a pure functional programming language for business modeling really
-shines. The common statement that *"if it compiles, it's guaranteed to run without errors"* really applies well to
-RegTech. The Elm compiler catches a huge number of potential errors that would otherwise be impossible in non-FP languages.
+that it's not a trivial task, and there's a significant advantage if someone else could do it for you _and_ prove
+that it's correct. This is where the use of a pure functional programming language for business modeling really
+shines. The common statement that _"if it compiles, it's guaranteed to run without errors"_ really applies well to
+RegTech. The Elm compiler catches a huge number of potential errors that would otherwise be impossible in non-FP languages.
-It's worth noting that there are languages that provide even more guarantees, like Coq and Microsoft's Bosque. In
-creating Morphir, we were careful not to write our own or locking on a particular language. This leaves the option of using
+It's worth noting that there are languages that provide even more guarantees, like Coq and Microsoft's Bosque. In
+creating Morphir, we were careful not to write our own or locking on a particular language. This leaves the option of using
the best language for the job, as long as that language can be co-compiled into the Morphir IR.
[TODO] show examples of catching errors
-The OCC helpfully provided some test examples that we can also use to verify our models. We've done so in the form of
-unit tests on our Elm code. [These tests](https://github.com/finos/morphir-examples/tree/master/tests/Morphir/Sample/LCR/)
+The OCC helpfully provided some test examples that we can also use to verify our models. We've done so in the form of
+unit tests on our Elm code. [These tests](https://github.com/finos/morphir-examples/tree/master/tests/Morphir/Sample/LCR/)
demonstrate how the OCC's tests, which were provided in a document, could actually be codified into the modeled rules.
# Using automation to adapt the model to your systems
-Now that we've ensured that our model of the LCR is correct, we want to turn it into code that can execute in our
-systems. For this purpose, we'll assume that the regulatory reporting data is currently housed in a SQL data
-warehouse. Let's take a look at how the sample above translates to SQL:
+
+Now that we've ensured that our model of the LCR is correct, we want to turn it into code that can execute in our
+systems. For this purpose, we'll assume that the regulatory reporting data is currently housed in a SQL data
+warehouse. Let's take a look at how the sample above translates to SQL:
```sql
select sum amount
from t0_flows tf
where tf.assetType = 'Level 2a Assets' and tf.isHQLA = 'T'
```
-You can see in the example that the generated code makes some assumptions about the physical environment. These are the
-things that are likely to be very different across firms. The value of modeling is that each firm can customize the
+
+You can see in the example that the generated code makes some assumptions about the physical environment. These are the
+things that are likely to be very different across firms. The value of modeling is that each firm can customize the
code generation to match their own environments.
-Of course, it's naive to think that the full LCR calculation would be able to execute entirely in a data warehouse. In
+Of course, it's naive to think that the full LCR calculation would be able to execute entirely in a data warehouse. In
fact, many firms are migrating these calculations to new technologies like Spark. Doing a large scale migration of a
report like the LCR to a new technology is usually a significant and risky effort. On the other hand, if you're running
from a model, it's just a matter of switching to a new backend generator. While that's not trivial, it sure is a good
-deal easier, cheaper, and less risky that rewriting the entire calculation from scratch. Let's take a look at the Spark
+deal easier, cheaper, and less risky that rewriting the entire calculation from scratch. Let's take a look at the Spark
version of our sample:
**Spark Scala**
+
```scala
t0Flows
.filter {flow => flow.assetType == Level2aAssets && isHQLA(product, flow)}
@@ -187,11 +205,12 @@ t0Flows
```
## Summing up
-We've seen how using an industry standard RegTech can save an industry valuable time, effort, and risk. We've also seen
-that doing so with a shared model allows firms to adopt RegTech without the costly exercise of rewriting their
-systems. Finally, we've seen how capturing regulations in a technology-agnostic model can ease migration to new technologies.
-To view the entire LCR example, take a look at [the Morphir Examples project](/morphir-examples/src/Morphir/Sample/Reg/LCR). For
+We've seen how using an industry standard RegTech can save an industry valuable time, effort, and risk. We've also seen
+that doing so with a shared model allows firms to adopt RegTech without the costly exercise of rewriting their
+systems. Finally, we've seen how capturing regulations in a technology-agnostic model can ease migration to new technologies.
+
+To view the entire LCR example, take a look at [the Morphir Examples project](/morphir-examples/src/Morphir/Sample/Reg/LCR). For
generating SQL and Spark from Morphir models, be sure to keep an eye out for the upcoming **morphir-sql** and **morphir-spark** projects.
[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/shared_logic_modeling.md b/docs/shared_logic_modeling.md
deleted file mode 100644
index 6858b29b8..000000000
--- a/docs/shared_logic_modeling.md
+++ /dev/null
@@ -1,4 +0,0 @@
-#Sharing Business Logic Across Application Boundaries
-Coming soon
-
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
diff --git a/docs/spark-backend/design.md b/docs/spark-backend/design.md
index 6783ec9c8..d79f2b3fe 100644
--- a/docs/spark-backend/design.md
+++ b/docs/spark-backend/design.md
@@ -1,3 +1,8 @@
+---
+id: morphir-spark
+title: Morphir to Spark mapping
+---
+
# Morphir to Spark mapping
To understand how the Morphir to Apache Spark mapping works let's begin with an example Morphir domain model and business logic that we might want to transpile to Spark. We present the Morphir logic using Elm syntax to make it easy to read:
@@ -19,7 +24,7 @@ job : List RecordA -> List RecordB
job input =
input
|> List.filter (\a -> a.field2 < 100)
- |> List.map
+ |> List.map
(\a ->
{ sum = a.number1 + a.number2
, product = a.number1 * a.number2
@@ -34,8 +39,8 @@ The above is a representative example of the base functionality. There are a few
- The record types in the input and output need to be completely flat and use only built-in SDK types or be enumerations (custom types with only no-argument constructors)
- The input value in the function can only be passed through the following collection operations:
- [List.filter](https://package.elm-lang.org/packages/elm/core/latest/List#filter) to filter the data set (corresponds to a WHERE clause in SQL)
- - [List.map](https://package.elm-lang.org/packages/elm/core/latest/List#map) to trasform each input row to an output row (corresponds to the SELECT clause in SQL)
-- Field expressions can:
+ - [List.map](https://package.elm-lang.org/packages/elm/core/latest/List#map) to trasform each input row to an output row (corresponds to the SELECT clause in SQL)
+- Field expressions can:
- use any combination of operations from the [Morphir SDK](https://package.elm-lang.org/packages/elm/core/latest/) as long as every intermediary result within the expression is a simple type
- include `if-then-else` expressions
@@ -47,18 +52,16 @@ The above is a representative example of the base functionality. There are a few
- [String](https://package.elm-lang.org/packages/elm/core/latest/String#String)
- [Maybe](https://package.elm-lang.org/packages/elm/core/latest/Maybe#Maybe)
-
## Supported Field Operations
-- [Basics](https://package.elm-lang.org/packages/elm/core/latest/Basics):
+- [Basics](https://package.elm-lang.org/packages/elm/core/latest/Basics):
- All number operations
- All comparison operations
- All boolean operations
- [String](https://package.elm-lang.org/packages/elm/core/latest/String)
- - All operations
+ - All operations
## Supported DataSet Operations
- [List.filter](https://package.elm-lang.org/packages/elm/core/latest/List#filter)
- [List.map](https://package.elm-lang.org/packages/elm/core/latest/List#map)
-
diff --git a/docs/tutorials/quick_start.md b/docs/tutorials/quick_start.md
index f1f0219f2..105193805 100644
--- a/docs/tutorials/quick_start.md
+++ b/docs/tutorials/quick_start.md
@@ -1,12 +1,19 @@
+---
+id: morphir-quick-start
+title: Morphir Quick Start
+---
+
# Morphir Quick Start
+
## Install
-The first step to using Morphir is installing. For this example we'll use the Elm front end for our modeling and generator into the JSON representation of the Morphir IR. So the first step is to install the Morphir Elm tooling. Take a look at the [Installation Instructions](https://github.com/Morgan-Stanley/morphir-elm) for getting setup.
+
+The first step to using Morphir is installing. For this example we'll use the Elm front end for our modeling and generator into the JSON representation of the Morphir IR. So the first step is to install the Morphir Elm tooling. Take a look at the [Installation Instructions](https://github.com/Morgan-Stanley/morphir-elm) for getting setup.
## Create a project
+
Let's create a new project.
```
mkdir scratch
cd scratch
```
-
diff --git a/docs/versioning/versioning.md b/docs/versioning.md
similarity index 68%
rename from docs/versioning/versioning.md
rename to docs/versioning.md
index ff0ba8681..66544554d 100644
--- a/docs/versioning/versioning.md
+++ b/docs/versioning.md
@@ -1,34 +1,40 @@
+---
+sidebar_position: 11
+id: model-versioning
+title: Model Versioning
+---
+
# Model Versioning
## Properties
-Model versioning in Morphir is very similar to library versioning in any
-other programming language but thanks to the declarative nature of the
-language it is much more automated and convenient for the modeler. It
-was largely inspired by Elm that has enforced semantic versioning but
-has been adapted and extended to fit our requirements better. Below is
-a high-level overview of the important properties that should give you
+Model versioning in Morphir is very similar to library versioning in any
+other programming language but thanks to the declarative nature of the
+language it is much more automated and convenient for the modeler. It
+was largely inspired by Elm that has enforced semantic versioning but
+has been adapted and extended to fit our requirements better. Below is
+a high-level overview of the important properties that should give you
a general idea on what you can expect.
### Automatic
Morphir comes with automatic enforced versioning out-of-the-box. Users of
-Morphir never have to (and are not allowed to) specify model versions
+Morphir never have to (and are not allowed to) specify model versions
manually. Instead the Morphir tooling will compare the current version of
-the model to the latest previously released version and increase the
+the model to the latest previously released version and increase the
version number if needed.
### Granular
-Versioning is applied at a much more granular level compared to
+Versioning is applied at a much more granular level compared to
traditional package management systems. The lowest level of granularity
-is a named function (or value) or type within a module. This allows
+is a named function (or value) or type within a module. This allows
users to track changes in the logic very accurately.
### Hierarchical
Versioning is also applied on higher levels of the package hierarchy.
-This allows users to pick the right level of granularity for their
+This allows users to pick the right level of granularity for their
use-case and even flip between different levels as needed.
Here are the different granularity levels where versioning is available:
@@ -40,67 +46,65 @@ Here are the different granularity levels where versioning is available:
### Sequential and Semantic
-Morphir generates semantic (major.minor.path) versions on a package level
-to make it more informative to users but on lower levels of the
-hierarchy it uses simple sequential version numbers.
+Morphir generates semantic (major.minor.path) versions on a package level
+to make it more informative to users but on lower levels of the
+hierarchy it uses simple sequential version numbers.
## Implementation
### Overview
-Versioning is implemented as a self-contained add-on working separately
-from all other Morphir tooling. This means that you can run a command to
-calculate versions at any point in time. Versioning takes source model,
-target model and source versions as inputs and returns target versions
+Versioning is implemented as a self-contained add-on working separately
+from all other Morphir tooling. This means that you can run a command to
+calculate versions at any point in time. Versioning takes source model,
+target model and source versions as inputs and returns target versions
as the output. This can be formalized as:
```
Model -> Model -> Versions -> Versions
-```
+```
-This can be further broken down into two functions: first we calculate
-the diff between two models, then we use the diff to calculate new
+This can be further broken down into two functions: first we calculate
+the diff between two models, then we use the diff to calculate new
version numbers using the last released versions.
### Diffing
Since the model is represented as an AST we can do simple tree diffing.
The resulting diff is a set of insert, update and delete operations on
-each leaf node (types and functions within a module). Versions on higher
+each leaf node (types and functions within a module). Versions on higher
levels of the hierarchy are then derived from lower levels increasing
-the version number if there were any changes below the node.
+the version number if there were any changes below the node.
-Finally, on the package level we calculate the semantic version using
+Finally, on the package level we calculate the semantic version using
the following rules:
-* **Patch**: If there are no changes above level 1. In other words if
-only the implementation changed without any API changes.
-* **Minor**: If there are new functions/types added but none of the
-existing
-APIs changed or got removed.
-* **Major**: If any existing APIs changed.
-
+- **Patch**: If there are no changes above level 1. In other words if
+ only the implementation changed without any API changes.
+- **Minor**: If there are new functions/types added but none of the
+ existing
+ APIs changed or got removed.
+- **Major**: If any existing APIs changed.
### Versions File
-Versions are stored in a JSON file for convenient access from any
-technology. By default version files are stored on AFS under the
-```etc/morphir``` directory in ```versions.json``` file.
+Versions are stored in a JSON file for convenient access from any
+technology. By default version files are stored on AFS under the
+`etc/morphir` directory in `versions.json` file.
-The format is easy to follow based on the properties described above.
+The format is easy to follow based on the properties described above.
Here is the general layout:
-* ```package```: This is the name of the package.
-* ```semantic```: This is the semantic version number for the package.
-* ```sequence```: This is the sequential version number for the package.
-* ```modules```: This is a JSON object where each field corresponds to a
-module. Fully-qualified names are used to identify the module and the
-structure is flattened out. Each module has the following fields:
- * ```sequence```: This is the sequential version number for the module.
- * ```type_aliases```: Sequential version number for each type alias.
- * ```union_types```: Sequential version number for each union type.
- * ```value_types```: Sequential version number for each value (function) type.
- * ```values```: Sequential version number for each value (function).
+- `package`: This is the name of the package.
+- `semantic`: This is the semantic version number for the package.
+- `sequence`: This is the sequential version number for the package.
+- `modules`: This is a JSON object where each field corresponds to a
+ module. Fully-qualified names are used to identify the module and the
+ structure is flattened out. Each module has the following fields:
+ _ `sequence`: This is the sequential version number for the module.
+ _ `type_aliases`: Sequential version number for each type alias.
+ _ `union_types`: Sequential version number for each union type.
+ _ `value_types`: Sequential version number for each value (function) type. \* `values`: Sequential version number for each value (function).
Here's an example:
diff --git a/docs/visualizing/index.md b/docs/visualizing/index.md
deleted file mode 100644
index d3ed404e9..000000000
--- a/docs/visualizing/index.md
+++ /dev/null
@@ -1 +0,0 @@
-[Visualization examples](index.html)
diff --git a/docs/what-makes-a-good-domain-model.md b/docs/what-makes-a-good-domain-model.md
index a2f32416e..254bdae6d 100644
--- a/docs/what-makes-a-good-domain-model.md
+++ b/docs/what-makes-a-good-domain-model.md
@@ -1,36 +1,42 @@
-# What makes a good domain model?
+---
+sidebar_position: 9
+id: domain-model
+title: What Makes a Good Domain Model?
+---
-We all strive to build high-quality software and that begins with a clean and well-defined
+# What Makes a Good Domain Model?
+
+We all strive to build high-quality software and that begins with a clean and well-defined
domain model. But what do we mean when we say "clean" or "well-defined"?
It is difficult to decide whether a change in the domain model is an improvement without specific measures.
In this post, we'll dive into how we can measure and improve the quality of our domain models.
-[Making illegal state unrepresentable](https://fsharpforfunandprofit.com/posts/designing-with-types-making-illegal-states-unrepresentable/)
-is a well-known principle in the functional-programming community which refers to avoiding
+[Making illegal state unrepresentable](https://fsharpforfunandprofit.com/posts/designing-with-types-making-illegal-states-unrepresentable/)
+is a well-known principle in the functional-programming community which refers to avoiding
ambiguity that leaves the model open to more than one interpretation. A simple example is
-when a model uses strings instead of enums. Strings are ambiguous because they leave the
+when a model uses strings instead of enums. Strings are ambiguous because they leave the
interpretation completely to the consumer while enums limit the possible values significantly.
Is there a way to measure the ambiguity? One approximation we can use is the cardinality of types.
-Taking the above example a String has an infinite cardinality while an enum is always finite,
+Taking the above example a String has an infinite cardinality while an enum is always finite,
usually less than 100 values. So a String is infinitely more ambiguous than an enum.
-Stepping up a level, we can derive a few more useful metrics by looking at type cardinalities
+Stepping up a level, we can derive a few more useful metrics by looking at type cardinalities
in the context of functions:
## Domain-to-Range Cardinality Ratio
Take a simple example of a `String -> Enum` function. This takes an ambiguous value and turns it
-into a less ambiguous one which is great since it decreases ambiguity. Taking the opposite
+into a less ambiguous one which is great since it decreases ambiguity. Taking the opposite
`Enum -> String` though turns a relatively unambiguous value to a completely ambiguous one, which
decreases the quality of the output model. So clearly, you want to avoid the latter.
## Domain Test Coverage
-Adding test cases to the picture, you can measure what percentage of possible inputs are covered
-by test cases. When the cardinality of the input type is finite, it is possible to achieve full
+Adding test cases to the picture, you can measure what percentage of possible inputs are covered
+by test cases. When the cardinality of the input type is finite, it is possible to achieve full
coverage which means you can be confident that the function works as expected.
More to come ...
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/whats_it_about.md b/docs/whats_it_about.md
index 8986a6005..40f183523 100644
--- a/docs/whats_it_about.md
+++ b/docs/whats_it_about.md
@@ -1,35 +1,44 @@
-# An application
-I have an application.
-* It tracks product inventories and decides how much to grant an order request based on the product's availability.
-* It is deployed as a set of microservices.
- * We're thinking about moving the microservices to serverless.
-* Orders are made via REST.
- * The REST is exposed via OpenAPI.
-* Inventory levels are tracked in real-time with stream processing and come from a variety of sources.
- * We currently use Kafka for streaming.
- * Some sources contain nuances about how to interpret their contents into trustworthy inventory numbers.
- * There are also rules for how to distribute inventory across requests to try to get a good balance of happy customers.
-* We use a standard SQL database for transaction processing.
+---
+sidebar_position: 10
+id: application-article
+title: I Have an Application
+---
+
+# I Have an Application
+
+- It tracks product inventories and decides how much to grant an order request based on the product's availability.
+- It is deployed as a set of microservices.
+ - We're thinking about moving the microservices to serverless.
+- Orders are made via REST.
+ - The REST is exposed via OpenAPI.
+- Inventory levels are tracked in real-time with stream processing and come from a variety of sources.
+ - We currently use Kafka for streaming.
+ - Some sources contain nuances about how to interpret their contents into trustworthy inventory numbers.
+ - There are also rules for how to distribute inventory across requests to try to get a good balance of happy customers.
+- We use a standard SQL database for transaction processing.
# What's important?
-As you're reading this, what do you consider to be the most important information in my description? Is it the Kafka
-stream processing? The standard microservices architecture? Or the fact that we're thinking of moving to serverless?
+
+As you're reading this, what do you consider to be the most important information in my description? Is it the Kafka
+stream processing? The standard microservices architecture? Or the fact that we're thinking of moving to serverless?
While the answer might be subjective, I can tell you that, for the users of this application, the most important parts are:
+
1. The application processes orders for products.
1. It allocates to those orders based on availability and distribution rules.
1. It aggregates inventory from multiple suppliers.
# Morphir
-You probably know these as the application's business logic, and it's easy to see why users think this is most
-important: it is the whole reason the application exists at all. Everything else is temporary details about how it's implemented. Chances are that these details will change a few times over the application's lifetime. It would be a shame to risk breaking the most important parts of the application just because we want to change from microservices to serverless, yet that's exactly what happens with a huge portion of applications. We want something that allows the business and technology to evolve independently. This is what Morphir does; it's all about the business concepts.
+
+You probably know these as the application's business logic, and it's easy to see why users think this is most
+important: it is the whole reason the application exists at all. Everything else is temporary details about how it's implemented. Chances are that these details will change a few times over the application's lifetime. It would be a shame to risk breaking the most important parts of the application just because we want to change from microservices to serverless, yet that's exactly what happens with a huge portion of applications. We want something that allows the business and technology to evolve independently. This is what Morphir does; it's all about the business concepts.
# Working Across Technologies
+
Most applications mix the business concepts with the technology choices of the moment. Given the importance of the
-business concepts, it makes sense to protect them from transient technical decisions as much as possible.
+business concepts, it makes sense to protect them from transient technical decisions as much as possible.
-For starters, you definitely want it to perform correctly, ideally across different technologies and
-platforms. Finding yourself constantly rewriting your API? Technology is advancing quickly; you certainly don't want
+For starters, you definitely want it to perform correctly, ideally across different technologies and
+platforms. Finding yourself constantly rewriting your API? Technology is advancing quickly; you certainly don't want
your API locked in legacy technology.
-
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/docs/why_functional_programming.md b/docs/why_functional_programming.md
index 0852f87d0..6b7ca4021 100644
--- a/docs/why_functional_programming.md
+++ b/docs/why_functional_programming.md
@@ -1,17 +1,23 @@
+---
+sidebar_position: 8
+id: functional-programming
+title: Why Functional Programming?
+---
+
# Why Functional Programming?
-The core of Morphir is the idea your business concepts (data and logic) are valuable assets that deserve to be
-stored independently. Morphir needs to understand the intent of your application, which is not easy to do when the
-business code is intertwined with the execution code. To make this easier, Morphir prefers using a concise and
-unambiguous way to specify business concepts. In particular, Morphir wants to know *what* the application should do
-and *why* without any indication of *how*. If you know *what* and *why*, it's easier to adjust *how* to different
-execution contexts. The flip side of this is that once code starts to specify how it should work, it becomes much more
-difficult to figure out what the real intent is.
+The core of Morphir is the idea your business concepts (data and logic) are valuable assets that deserve to be
+stored independently. Morphir needs to understand the intent of your application, which is not easy to do when the
+business code is intertwined with the execution code. To make this easier, Morphir prefers using a concise and
+unambiguous way to specify business concepts. In particular, Morphir wants to know _what_ the application should do
+and _why_ without any indication of _how_. If you know _what_ and _why_, it's easier to adjust _how_ to different
+execution contexts. The flip side of this is that once code starts to specify how it should work, it becomes much more
+difficult to figure out what the real intent is.
-If you've looked at the topic of programming languages, you'll recognize all of this as part of the comparison between
-various programming styles: functional and imperative languages in particular. To our great advantage, functional
-programming has evolved around specifying intent without implementation. Even better, it's been honing this for decades,
-so it's actually *really* great for modeling business concepts.
+If you've looked at the topic of programming languages, you'll recognize all of this as part of the comparison between
+various programming styles: functional and imperative languages in particular. To our great advantage, functional
+programming has evolved around specifying intent without implementation. Even better, it's been honing this for decades,
+so it's actually _really_ great for modeling business concepts.
Just to give an example, it's difficult to write a program that figures out the intent of this code:
@@ -30,24 +36,24 @@ public Map processSupplies(Supplier[] suppliers) {
maxSupplier = supplier.supplierId;
}
}
-
+
Map result = new HashMap();
result.put("total", total);
-
+
if(max > -1) {
result.put("maxSupplier", maxSupplier);
}
-
+
return result;
}
```
-It's even harder to project that intent into a variety of execution contexts. On the other hand, this code is easy to interpret:
+It's even harder to project that intent into a variety of execution contexts. On the other hand, this code is easy to interpret:
```elm
processSupplies suppliers =
let
- total =
+ total =
suppliers
|> List.map .quantity
|> List.sum
@@ -61,8 +67,8 @@ processSupplies suppliers =
(total, max)
```
-That's much easier to process and much easier to translate into different contexts. We can turn this into efficient Java code and efficient SQL. You might say it's inefficient because it's traversing the list twice, once for total and again for max. The cool thing is that we can recognize this pretty easily and have our code generators optimize the execution to take this into account.
+That's much easier to process and much easier to translate into different contexts. We can turn this into efficient Java code and efficient SQL. You might say it's inefficient because it's traversing the list twice, once for total and again for max. The cool thing is that we can recognize this pretty easily and have our code generators optimize the execution to take this into account.
-With all of that said, it's certainly possible to derive intent from other types of languages. In fact, we've found much success in giving a lifeline to the plethora of bespoke expression languages and domain-specific languages (DSLs) that pepper most enterprises. Parsing these languages into Morphir offers a way to transpile them into other languages and to take advantage of the other tools Morphir offers. This has been an effective way to upgrade application technologies without risking their important behaviors.
+With all of that said, it's certainly possible to derive intent from other types of languages. In fact, we've found much success in giving a lifeline to the plethora of bespoke expression languages and domain-specific languages (DSLs) that pepper most enterprises. Parsing these languages into Morphir offers a way to transpile them into other languages and to take advantage of the other tools Morphir offers. This has been an effective way to upgrade application technologies without risking their important behaviors.
-[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
\ No newline at end of file
+[Home](/index) | [Posts](posts) | [Examples](https://github.com/finos/morphir-examples/)
diff --git a/website/sidebars.js b/website/sidebars.js
index 54ba60940..edafd149f 100644
--- a/website/sidebars.js
+++ b/website/sidebars.js
@@ -22,7 +22,7 @@ const sidebars = {
{
type: 'category',
label: 'Tutorial',
- items: ['hello'],
+ items: ['hello world'],
},
],
*/