-
Download the Plugin
-
Choose Your Preferred Service:
a) OpenAI - Requires authentication via OpenAI API key.
b) Azure - Requires authentication via Active Directory or API key.
c) Custom OpenAI-compatible service - Choose between multiple different providers, such as Together, Anyscale, Groq, Ollama and many more.
d) Anthropic - Requires authentication via API key.
e) You.com - A free, web-connected service with an optional upgrade to You⚡Pro for enhanced features.
f) LLaMA C/C++ Port - Recommended to have a decent computer to handle the computational requirements of running inference.
Note: Currently supported only on Linux and MacOS.
-
Start Using the Features
The plugin is available from JetBrains Marketplace.
You can install it directly from your IDE via the File | Settings/Preferences | Plugins screen.
On the Marketplace tab simply search for codegpt and select the CodeGPT suggestion:

After successful installation, configure your API key. Navigate to the plugin's settings via File |
Settings/Preferences | Tools | CodeGPT. Paste your OpenAI API key into the field and click Apply/OK.
For Azure OpenAI services, you'll need to input three additional fields:
- Resource name: The name of your Azure OpenAI Cognitive Services. It's the first part of the url you're provided to
use the service: "https://my-resource-name.openai.azure.com/". You can find it in your Azure Cognitive Services
page, under
Resource Management→Resource Management→Keys and Endpoints. - Deployment ID: The name of your Deployment. You can find it in the Azure AI Studio,
under
Management→Deployment→Deployment Namecolumn in the table. - API version: The most recent non-preview version.
In addition to these, you need to input one of the two API Keys provided, found along with the Resource Name.
You.com is a search engine that summarizes the best parts of the internet for you, with private ads and with privacy options.
You⚡Pro
Use the CodeGPT coupon for a free month of unlimited GPT-4 usage.
Check out the full feature list for more details.
Note: Currently supported only on Linux and MacOS.
The main goal of llama.cpp is to run the LLaMA model using 4-bit integer quantization on a MacBook.
-
Select the Model: Depending on your hardware capabilities, choose the appropriate model from the provided list. Once selected, click on the
Download Modellink. A progress bar will appear, indicating the download process. -
Start the Server: After successfully downloading the model, initiate the server by clicking on the
Start Serverbutton. A status message will be displayed, indicating that the server is starting up. -
Apply Settings: With the server running, you can now apply the settings to start using the features. Click on the
Apply/OKbutton to save your settings and start using the application.
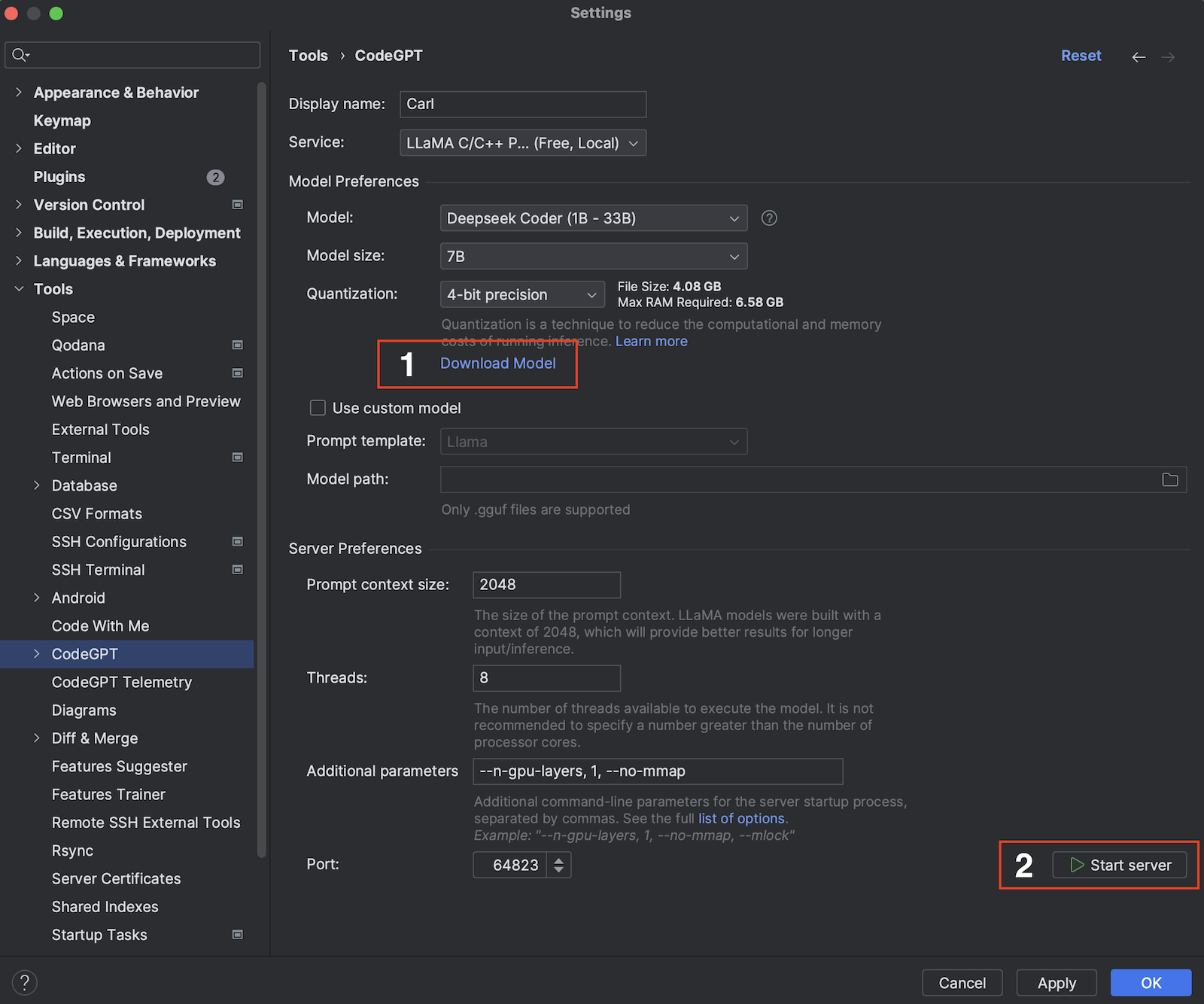
Note: If you're already running a server and wish to configure the plugin against that, then simply select the port and click
Apply/OK.