Authors: Julien Aimonier-Davat (LS2N), Hala Skaf-Molli (LS2N), and Pascal Molli (LS2N), Arnaud Grall (GFI Informatique, LS2N), Thomas Minier (LS2N)
Abstract Getting complete results when processing aggregate queries on public SPARQL endpoints is challenging, mainly due to quotas enforcement. Although the Web preemption allows to process aggregation queries online, on preemptable SPARQL servers, data transfer is still very large when processing count-distinct aggregate queries. In this paper, it is shown that countdistinct aggregate queries can be approximated with low data transfer by extending the partial aggregation operator with HyperLogLog sketches. Experimental results demonstrate that the proposed approach outperforms existing approaches by orders of magnitude in terms of the amount of transferred data.
This paper is an extension of the ESWC2020 article: Processing SPARQL Aggregate Queries with Web Preemption. The experimental results of the first paper are available here.
In our experiments, we use two workloads of 18 SPARQL aggregation queries extracted from the SPORTAL queries. The first workload, denoted SP, is composed of 18 SPORTAL queries where CONSTRUCT and FILTER clauses have been removed. The second workload, denoted SP-ND, is defined by removing the DISTINCT modifier from the queries of SP. SP-ND is used to study the impact of the DISTINCT modifier on the query execution performance. We run the SP and SP-ND workloads on synthetic and real-world datasets: the Berlin SPARQL Benchmark (BSBM) with different sizes (5k, 40k, 370k triples for BSBM-10, BSBM-100 and BSBM-1k respectively) and a fragment of DBpedia v3.5.1 (100M triples) respectively.
We compare the following approaches:
-
SaGe is the SaGe query engine as defined in the web preemption model. The SaGe server is implemented in Python and the code is available here. The SaGe smart client is implemented as an extension of Apache Jena. The code is available here. In our experiments, the SaGe server is configured with a maximum page size of results of 10000 mappings. The data are stored in an SQlite database with indexes on SPO, OSP and POS.
-
SaGe-agg is an extension of SaGe with our new partial aggregation operator. The server-side algorithm (Algorithm 1 in the paper) is implemented on the SaGe server. The code is available here. The client-side algorithm (Algorithm 2 in the paper) is implemented in a Python client. The code is available here. For a fair comparison, SaGe-agg runs against the same server as SaGe. Moreover, we add a space limitation to bound the space allocated to the partial aggregation operator. When partial aggregations are used, this space limit replaces the page size limit. We set it to 10MBytes.
-
SaGe-approx is the same extension as SaGe-agg where COUNT DISTINCT queries are evaluated using a probabilistic count algorithm (Hyperloglog). When SaGe-approx is used, the SaGe server is configured to compute COUNT DISTINCT queries with an error rate of 2%.
-
TPF is the TPF query engine as defined in the Triple Pattern Fragments model. We use the Linked Data Fragments Server as the TPF server and Comunica as the TPF smart client. The server is configured without Web cache and with a page size of 10000 triples. The data are stored using the HDT format.
-
Virtuoso is the Virtuoso SPARQL endpoint (v7.2.4). Virtuoso is configured without quotas in order to deliver complete results and optimal data transfer. We also configured Virtuoso with a single thread per query to fairly compare with other engines.
- Execution time is the total time between starting the query execution and the production of the final results by the client.
- Data transfer is the total number of bytes transferred from the server to the client during the query execution.
- type:
n2-highmem-4 :4 vCPU, 32 Go of memory - processor platform:
Intel Broadwell - OS:
ubuntu-1910-eoan-v20191114 - Disk:
Local SSD disk of 375GB
Plot 1: Data Transfer and execution time for BSBM-10, BSBM-100 and BSBM-1k, when running the SP (left) and SP-ND (right) workloads

Plot 2: Impact of the quantum when running SP (left) and SP-ND (right) workloads on BSBM1k

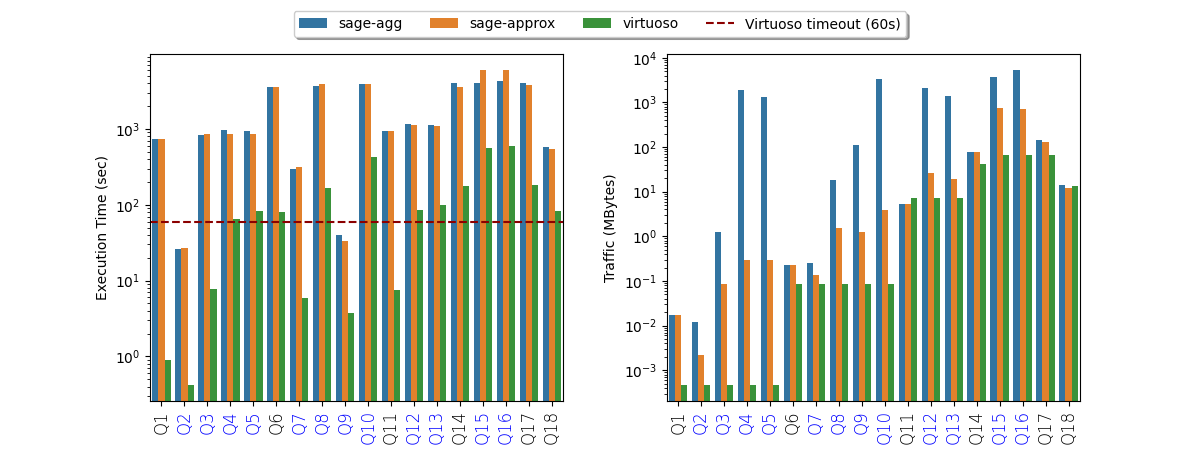
Plot 3: Data transfer and execution time when running the SP workload on DBpedia
Plot 4 Impact of the Hyperloglog precision when running the SP workload on BSBM1k

To run our experiments, the following softwares and packages have to be installed on your system.
Caution: In the next sections, we assume that Virtuoso is installed at its default location
/usr/local/virtuoso-opensource. If you change the location of Virtuoso, do not forget to
propagate this change in the next instructions and please update the
start_server.sh and
stop_server.sh scripts.
Virtuoso needs to be configured to use a single thread per query and to disable quotas.
- In the [SPARQL] section of the file
/usr/local/virtuoso-opensource/var/lib/virtuoso/db/virtuoso.ini- set ResultSetMaxRows, MaxQueryCostEstimationTime and MaxQueryExecutionTime to 10^9 in order to disable quotas.
- In the [Parameters] section of the file
/usr/local/virtuoso-opensource/var/lib/virtuoso/db/virtuoso.ini- set MaxQueryMem, NumberOfBuffers and MaxDirtyBuffers to an appropriate value based on the amount of RAM available on your machine. In our experiments, we used the settings recommended for a machine with 16Go of RAM.
- set ThreadsPerQuery to 1.
- add your home directory to DirsAllowed.
Once all dependencies have been installed, clone this repository and install the project.
git clone https://github.com/JulienDavat/sage-sparql-void.git sage-agg-experiments
cd sage-agg-experiments
bash install.shAll datasets used in our experiments are available online. Download all datasets, both the .hdt and the .nt formats, into the graphs directory.
# Move into the graphs directory
cd graphs
# Downloads the BSBM-10 dataset
wget nas.jadserver.fr/thesis/projects/aggregates/datasets/bsbm10.hdt
wget nas.jadserver.fr/thesis/projects/aggregates/datasets/bsbm10.nt
# Downloads the BSBM-100 dataset
wget nas.jadserver.fr/thesis/projects/aggregates/datasets/bsbm100.hdt
wget nas.jadserver.fr/thesis/projects/aggregates/datasets/bsbm100.nt
# Downloads the BSBM-1K dataset
wget nas.jadserver.fr/thesis/projects/aggregates/datasets/bsbm1k.hdt
wget nas.jadserver.fr/thesis/projects/aggregates/datasets/bsbm1k.nt
# Downloads the DBpedia100M dataset. We do not need the .hdt as TPF is not tested on the DBpedia100M dataset.
wget nas.jadserver.fr/thesis/projects/aggregates/datasets/dbpedia100M.nt- Activate the project environement
source aggregates/bin/activate- Create a table for each dataset
sage-sqlite-init --no-index configs/sage/sage-exact-150ms.yaml bsbm10
sage-sqlite-init --no-index configs/sage/sage-exact-150ms.yaml bsbm100
sage-sqlite-init --no-index configs/sage/sage-exact-150ms.yaml bsbm1k
sage-sqlite-init --no-index configs/sage/sage-exact-150ms.yaml dbpedia100M- Load each dataset into the database
sage-sqlite-put graphs/bsbm10.nt configs/sage/sage-exact-150ms.yaml bsbm10
sage-sqlite-put graphs/bsbm100.nt configs/sage/sage-exact-150ms.yaml bsbm100
sage-sqlite-put graphs/bsbm1k.nt configs/sage/sage-exact-150ms.yaml bsbm1k
sage-sqlite-put graphs/dbpedia100M.nt configs/sage/sage-exact-150ms.yaml dbpedia100M- Create SPO, OSP and POS indexes for each table
sage-sqlite-index configs/sage/sage-exact-150ms.yaml bsbm10
sage-sqlite-index configs/sage/sage-exact-150ms.yaml bsbm100
sage-sqlite-index configs/sage/sage-exact-150ms.yaml bsbm1k
sage-sqlite-index configs/sage/sage-exact-150ms.yaml dbpedia100M# Loads all .nt files stored in the graphs directory
/usr/local/virtuoso-opensource/bin/isql "EXEC=ld_dir('{PROJECT_DIRECTORY}/graphs', '*.nt', 'http://example.org/datasets/default');"
/usr/local/virtuoso-opensource/bin/isql "EXEC=rdf_loader_run();"
/usr/local/virtuoso-opensource/bin/isql "EXEC=checkpoint;"The SaGe server can be configured using a .yaml file. The different configurations used in our experiments are available in the directory configs/sage. An example of a valid configuration file is detailed below.
quota: 150 # the time (in milliseconds) of a quantum.
max_results: 10000 # the maximum number of mappings that can be returned per quantum.
max_group_by_size: 10485760 # the maximum space (in bytes) allocated to the partial aggregation operator. Replaces 'max_results' for aggregation queries.
enable_approximation: false # true to compute COUNT DISTINCT queries with a probabilistic count algorithm, false otherwise.
error_rate: 0.02 # the error rate for the probabilistic count algorithm.
datasets: # the datasets that can be queried.
- name: bsbm10 # the name of the dataset. Used to select the dataset we want to query.
backend: sqlite # the backend used to store the dataset.
database: graphs/sage_sqlite.db # the location of the database file.
- name: bsbm100
backend: sqlite
database: graphs/sage_sqlite.db
- name: bsbm1k
backend: sqlite
database: graphs/sage_sqlite.db
- name: dbpedia100M
backend: sqlite
database: graphs/sage_sqlite.dbThe LDF server can be configured using a .json file. The different configurations used in our experiments are available in the directory configs/ldf. An example of a valid configuration file is detailed below.
{
"pageSize":10000, // the maximum number of mappings that can be returned per triple pattern query.
"datasources": { // the datasets that can be queried.
"bsbm10": { // the name of the dataset. Used to select the dataset we want to query.
"type": "HdtDatasource", // the backend used to store the dataset.
"settings": {
"file": "graphs/bsbm10.hdt" // the location of the HDT file.
}
},
"bsbm100": {
"type": "HdtDatasource",
"settings": { "file": "graphs/bsbm100.hdt" }
},
"bsbm1k": {
"type": "HdtDatasource",
"settings": { "file": "graphs/bsbm1k.hdt" }
}
}
}The configuration of Virtuoso is explained in the Configuration section.
All our experiments can be configured using the file xp.json.
{
"settings": {
"plot1" : {
"title": "Data transfer and execution time for BSBM-10, BSBM-100 and BSBM-1k, when running the SP and SP-ND workload",
"settings": {
"datasets": ["bsbm10", "bsbm100", "bsbm1k"],
"approaches": ["sage", "sage-agg", "sage-approx", "virtuoso", "comunica"],
"workloads": ["SP", "SP-ND"],
"queries": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18],
"warmup": true,
"runs": 3
}
},
"plot2": {
"title": "Time quantum impacts executing SP and SP-ND over BSBM-1k",
"settings": {
"quantums": ["75", "150", "1500", "15000"],
"approaches": ["sage", "sage-agg", "sage-approx", "virtuoso"],
"workloads": ["SP", "SP-ND"],
"queries": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18],
"runs": 3,
"warmup": true
}
},
"plot3": {
"title": "Data transfer and execution time for dbpedia, when running the SP and SP-ND workload",
"settings": {
"datasets": ["dbpedia100M"],
"approaches": ["sage-agg", "sage-approx", "virtuoso"],
"workloads": ["SP", "SP-ND"],
"queries": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18],
"runs": 3,
"warmup": false
}
},
"plot4": {
"title": "Hyperloglog precision impacts executing SP and SP-ND over BSBM-1k",
"settings": {
"precisions": ["98", "95", "90"],
"approaches": ["sage", "sage-agg", "sage-approx", "virtuoso"],
"workloads": ["SP"],
"queries": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18],
"runs": 3,
"warmup": true
}
}
}
}Configurable fields are detailed below:
- datasets: the datasets on which queries will be executed.
- accepted values: bsbm10, bsbm100, bsbm1k and dbpedia100M
- quantums: the different quantum values for which queries will be executed.
- accepted values: 75, 150, 1500 and 15000
- precisions: the different precisions for which queries will be executed.
- accepted values: 90, 95 and 98
- workloads: the workloads to execute.
- accepted values: SP and SP-ND
- queries: the queries to execute for each workload.
- accepted values: 1..18
- warmup: true to compute a first run for which no statistics will be recorded, false otherwise
- accepted value: true or false
- runs: the number of run to compute. For each of these run, queries execution statistics will be recorded and the average will be retained for each metric.
- accepted value: a non-zero positive integer
Our experimental study is powered by Snakemake. To run any part of our experiments, just ask snakemake for the desired output file. For example, the main commands are given below:
# Measures the performance in terms of execution time and data transfer for different graph sizes, for the SP and SP-ND workloads
snakemake --cores 1 output/figures/bsbm_performance.png
# Measures the impact of the quantum in terms of execution time and data transfer, for the SP and SP-ND workloads, on the BSBM-1k dataset
snakemake --cores 1 output/figures/quantum_impacts.png
# Measures the performance in terms of execution time and data transfer, for the SP workload, on the DBpedia100M dataset
snakemake --cores 1 output/figures/dbpedia_performance.png
# Measures the impact of the precision in terms of execution time and data transfer, for the SP workload, on the BSBM-1k dataset
snakemake --cores 1 output/figures/precision_impacts.png
# Runs all experiments
snakemake --cores 1 output/figures/{bsbm_performance,quantum_impacts,dbpedia,precision_impacts}.pngIt is also possible to run each part of our experiments without Snakemake. For example, some important commands are given below:
# to start the SaGe server
sage configs/sage/$CONFIG_FILE -w $NB_WORKERS -p $PORT
# to start the LDF server
node_modules/ldf-server/bin/ldf-server configs/ldf/$CONFIG_FILE $PORT $NB_WORKERS
# to start the Virtuoso server on the port 8890
/usr/local/virtuoso-opensource/bin/virtuoso-t -f -c /usr/local/virtuoso-opensource/var/lib/virtuoso/db/virtuoso.ini
# to evaluate a query with SaGe-agg/approx (depending on the server configuration)
python client/sage-agg/interface.py query http://localhost:$PORT/sparql http://localhost:$PORT/sparql/$DATASET_NAME \
--file $QUERY_FILE \
--measure $OUT_STATS \
--output $OUT_RESULT
# to evaluate a query with SaGe
java -jar client/sage/build/libs/sage-jena-fat-1.0.jar query http://localhost:$PORT/sparql/$DATASET_NAME \
--file $QUERY_FILE \
--measure $OUT_STATS \
--output $OUT_RESULT
# to evaluate a query with Virtuoso
python client/virtuoso/interface.py query http://localhost:8890/sparql http://example.org/datasets/$DATASET_NAME \
--file $QUERY_FILE \
--measure $OUT_STATS \
--output $OUT_RESULT
# to evaluate a query with Comunica
node client/comunica/interface.js http://localhost:$PORT/$DATASET_NAME \
--file $QUERY_FILE \
--measure $OUT_STATS \
--output $OUT_RESULT