

⌨️ Coding
编程让我解构世界。
404
But if you don't change your direction, and if you keep looking, you may end up where you are heading.
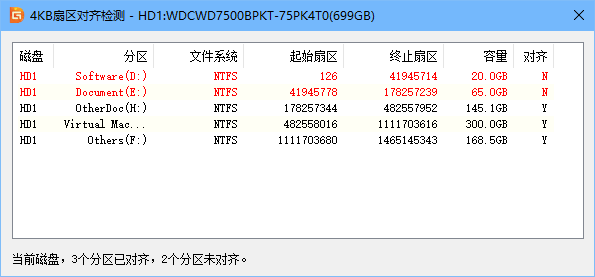
开发中经常有这样一种场景,一个接口需要处理的请求中的内容包含多种不同的类型。比如支付系统,订单支付的时候可能是支付宝支付,微信支付或者银联支付等。又或者是订单系统,订单可能是普通订单,可能是团购订单,也可能是秒杀订单。前阵子做的一个预览Office文件的功能也与之类似,文件的类型不同,也需要采取不同的处理方案。这时候最简单的做法就是在controller中写n多个if else:
if ( "excel".equals(file.getType)) {
+ //***
+} else if("word".equals(file.getType()){
+ //***
+} ……如果后面再加其他的类型,那就继续加if else语句,这样代码就会变的很丑陋,而且每次都需要对controller代码进行修改,后续的扩展很麻烦。所以这种情况通常会采用策略模式来进行处理,这样我们的代码会变得更加优雅,方便后续的维护。
策略模式是一种行为模式,主要作用是在程序运行时动态切换一个类的行为或者算法。我们需要做的就是创建一个定义行为的Strategy接口以及它的具体策略实现类,以及一个策略的上下文来动态切换策略。 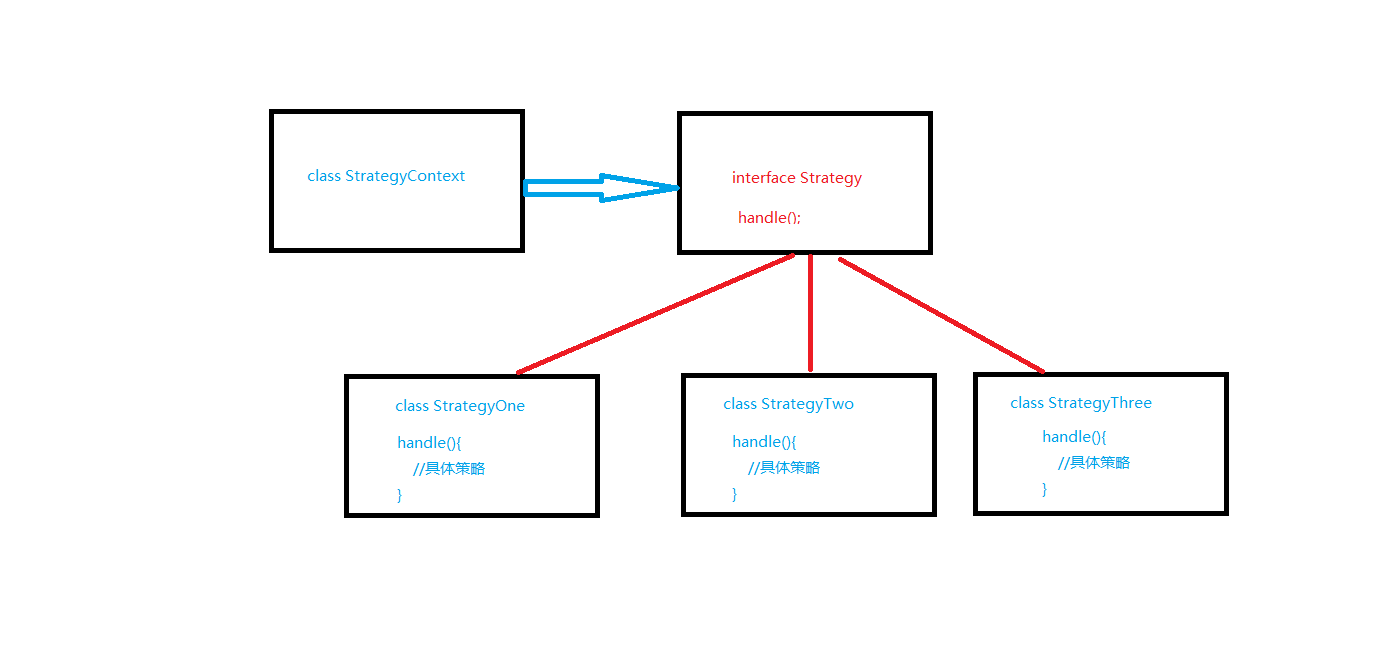
下面将介绍具体的实现方案,以订单系统为例
环境搭建
<parent>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter-parent</artifactId>
+ <version>2.1.4.RELEASE</version>
+</parent>
+<dependencies>
+ <dependency>
+ <groupId>org.projectlombok</groupId>
+ <artifactId>lombok</artifactId>
+ <version>1.18.6</version>
+ </dependency>
+ <dependency>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter-web</artifactId>
+ <version>2.1.4.RELEASE</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.commons</groupId>
+ <artifactId>commons-lang3</artifactId>
+ <version>3.8.1</version>
+ </dependency>
+</dependencies>订单实体类
@Data
+public class Order {
+ private String code;
+ private BigDecimal price;
+ /**
+ * 1: 普通订单
+ * 2: 秒杀订单
+ * 3: 团购订单
+ */
+ private String type;
+}抽象策略接口
public interface OrderStrategy {
+ String handleOrder(Order order);
+}策略具体实现
@Component
+public class NormalHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(Order order) {
+ return "普通订单处理完毕";
+ }
+}
+
+@Component
+public class GroupHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(Order order) {
+ return "团购订单处理完毕";
+ }
+}
+
+@Component
+public class SecKillHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(Order order) {
+ return "秒杀订单处理完毕";
+ }
+}SpringUtils
@Component
+public class SpringUtils implements ApplicationContextAware {
+
+ private static ApplicationContext applicationContext;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ SpringUtils.applicationContext = applicationContext;
+ }
+
+ //获取applicationContext
+ private static ApplicationContext getApplicationContext() {
+ return applicationContext;
+ }
+
+ //通过name获取 Bean.
+ public static Object getBean(String name){
+ return getApplicationContext().getBean(name);
+ }
+
+ //通过class获取Bean.
+ public static <T> T getBean(Class<T> clazz){
+ return getApplicationContext().getBean(clazz);
+ }
+
+ //通过name,以及Clazz返回指定的Bean
+ public static <T> T getBean(String name,Class<T> clazz){
+ return getApplicationContext().getBean(name, clazz);
+ }
+
+}可以采取配置的方式,将不同类型和对应的handler的bean name配置在配置文件或者是数据库中,这样我们在context中可以直接获取配置文件中的bean name或者去数据库中查询,然后从spring容器中获取对应的bean并调用处理方法即可。
以将映射关系持久化到数据库为例,我们需要建一张表来维护类型和具体处理器之间的关系 字段为type和对应处理器的bean名称
controller
@RestController
+@RequestMapping("/api/order")
+public class OrderController {
+
+ @Autowired
+ private IOrderService orderService;
+
+
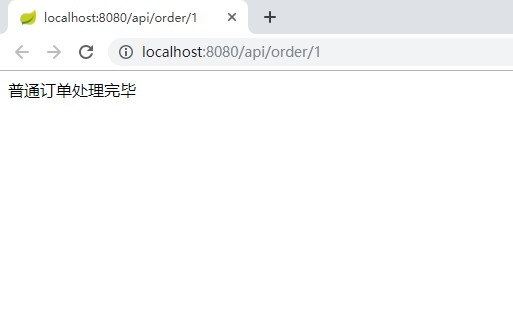
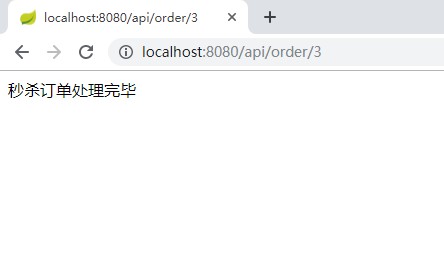
+ @GetMapping("/{type}")
+ public String handleOrder(@PathVariable String type){
+ return orderService.handleOrder(type);
+ }
+}service
@Service
+public class OrderServiceImpl implements IOrderService {
+
+ @Autowired
+ private OrderStrategyContext context;
+
+ @Override
+ public String handleOrder(String type) {
+ return context.getBean(type).handleOrder(type);
+ }
+}context
@Component
+public class OrderStrategyContext {
+ @Autowired
+ private StrategyMapper mapper;
+
+ public OrderStrategy getBean(String type){
+ String beanName = mapper.getBeanName(type);
+ return SpringUtils.getBean(beanName);
+ }
+
+}第一种方案相较于无尽的if else已经好很多了,但是还是需要增加配置文件或者数据库中新建表来维护类型和对应处理器的映射关系。还可以直接自定义注解来实现这个关系的对应。
自定义注解HandlerType
@Target({ElementType.TYPE})
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Inherited
+public @interface HandlerType {
+ String value();
+}然后在每个具体策略类上加上注解
@Component
+@HandlerType("1")
+public class NormalHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(String type) {
+ return "普通订单处理完毕";
+ }
+}@Component
+@HandlerType("2")
+public class GroupHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(String type) {
+ return "团购订单处理完毕";
+ }
+}@Component
+@HandlerType("3")
+public class SecKillHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(String type) {
+ return "秒杀订单处理完毕";
+ }
+}策略上下文context修改为
public class OrderStrategyContext {
+
+ private Map<String,Class> handlerMap;
+
+ public OrderStrategyContext(Map<String,Class> handlerMap){
+ this.handlerMap = handlerMap;
+ }
+
+ public OrderStrategy getBean(String type){
+ Class clazz = handlerMap.get(type);
+ if (clazz == null) {
+ throw new IllegalArgumentException("not found handler for type :" + type);
+ }
+ return (OrderStrategy) SpringUtils.getBean(clazz);
+ }
+}自定义注解后,我们需要将注解的value和对应策略类的bean_name放到上下文的handlerMap中,并将策略上下文对象注册到spring容器里,需要一个处理类HandlerProcessor
@Component
+public class HandlerProcessor implements BeanFactoryPostProcessor {
+
+ private static final String HANDLE_PACKAGE = "com.test.handler";
+
+ @Override
+ public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
+ Map<String,Class> map = new HashMap<>();
+ ClassScaner.scan(HANDLE_PACKAGE, HandlerType.class).forEach(clazz -> {
+ //获取注解中对应的类型
+ String type = clazz.getAnnotation(HandlerType.class).value();
+ //注解的类型值作为key,对应的类作为value,存储在map中
+ map.put(type,clazz);
+ });
+ //初始化HandlerContext,注册到Spring容器中
+ OrderStrategyContext context = new OrderStrategyContext(map);
+ beanFactory.registerSingleton(OrderStrategyContext.class.getName(),context);
+ }
+}ClassScaner
public class ClassScaner implements ResourceLoaderAware {
+
+ private final List<TypeFilter> includeFilters = new LinkedList<TypeFilter>();
+ private final List<TypeFilter> excludeFilters = new LinkedList<TypeFilter>();
+
+ private ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
+ private MetadataReaderFactory metadataReaderFactory = new CachingMetadataReaderFactory(this.resourcePatternResolver);
+
+ @SafeVarargs
+ public static Set<Class<?>> scan(String[] basePackages, Class<? extends Annotation>... annotations) {
+ ClassScaner cs = new ClassScaner();
+
+ if (ArrayUtils.isNotEmpty(annotations)) {
+ for (Class anno : annotations) {
+ cs.addIncludeFilter(new AnnotationTypeFilter(anno));
+ }
+ }
+
+ Set<Class<?>> classes = new HashSet<>();
+ for (String s : basePackages) {
+ classes.addAll(cs.doScan(s));
+ }
+
+ return classes;
+ }
+
+ @SafeVarargs
+ public static Set<Class<?>> scan(String basePackages, Class<? extends Annotation>... annotations) {
+ return ClassScaner.scan(StringUtils.tokenizeToStringArray(basePackages, ",; \t\n"), annotations);
+ }
+
+ public final ResourceLoader getResourceLoader() {
+ return this.resourcePatternResolver;
+ }
+
+ @Override
+ public void setResourceLoader(ResourceLoader resourceLoader) {
+ this.resourcePatternResolver = ResourcePatternUtils
+ .getResourcePatternResolver(resourceLoader);
+ this.metadataReaderFactory = new CachingMetadataReaderFactory(
+ resourceLoader);
+ }
+
+ public void addIncludeFilter(TypeFilter includeFilter) {
+ this.includeFilters.add(includeFilter);
+ }
+
+ public void addExcludeFilter(TypeFilter excludeFilter) {
+ this.excludeFilters.add(0, excludeFilter);
+ }
+
+ public void resetFilters(boolean useDefaultFilters) {
+ this.includeFilters.clear();
+ this.excludeFilters.clear();
+ }
+
+ public Set<Class<?>> doScan(String basePackage) {
+ Set<Class<?>> classes = new HashSet<>();
+ try {
+ String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX
+ + org.springframework.util.ClassUtils
+ .convertClassNameToResourcePath(SystemPropertyUtils
+ .resolvePlaceholders(basePackage))
+ + "/**/*.class";
+ Resource[] resources = this.resourcePatternResolver
+ .getResources(packageSearchPath);
+
+ for (int i = 0; i < resources.length; i++) {
+ Resource resource = resources[i];
+ if (resource.isReadable()) {
+ MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
+ if ((includeFilters.size() == 0 && excludeFilters.size() == 0) || matches(metadataReader)) {
+ try {
+ classes.add(Class.forName(metadataReader
+ .getClassMetadata().getClassName()));
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+ } catch (IOException ex) {
+ throw new BeanDefinitionStoreException(
+ "I/O failure during classpath scanning", ex);
+ }
+ return classes;
+ }
+
+ protected boolean matches(MetadataReader metadataReader) throws IOException {
+ for (TypeFilter tf : this.excludeFilters) {
+ if (tf.match(metadataReader, this.metadataReaderFactory)) {
+ return false;
+ }
+ }
+ for (TypeFilter tf : this.includeFilters) {
+ if (tf.match(metadataReader, this.metadataReaderFactory)) {
+ return true;
+ }
+ }
+ return false;
+ }
+}扫描指定的包还是很麻烦,还可以直接使用ioc容器来直接进行操作 将OrderStrategyContext进行修改,不再需要processor类
@Component
+public class OrderStrategyContext implements ApplicationContextAware, CommandLineRunner {
+
+ private Map<String,Object> handlerMap = new HashMap<>();
+
+ public OrderStrategy getInstance(String type) {
+ Object obj = handlerMap.get(type);
+ if (obj == null) {
+ throw new IllegalArgumentException("handler not found for type : " + type);
+ }
+ if (obj instanceof OrderStrategy) {
+ return (OrderStrategy) obj;
+ } else {
+ throw new IllegalArgumentException("handler not found for type : " + type);
+ }
+ }
+
+ private ApplicationContext context;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ this.context = applicationContext;
+ }
+
+
+ @Override
+ public void run(String... args) throws Exception {
+ this.loadBean();
+ }
+
+ public void loadBean() {
+ Map<String, Object> beansWithAnnotation = context.getBeansWithAnnotation(HandlerType.class);
+ beansWithAnnotation.forEach((handlerBeanName,handlerBean)->{
+ Class<?> clazz = handlerBean.getClass();
+ HandlerType annotation = clazz.getAnnotation(HandlerType.class);
+ String annotationValue = annotation.value();
+ handlerMap.put(annotationValue,handlerBean);
+ });
+ }
+}
之前个人博客一直用的travisCI部署在github page上,但是偶尔会抽风无法访问。之前一直偷懒没部署jenkins,手动部署到云服务器又比较麻烦,打包上传很浪费时间,这次就直接动手一步到位,在自己服务器上部署下jekins。
最开始用的jenkins中文社区的镜像发现有个很恶心的问题,jenkins版本比较低而且安装了NodeJS插件后在全局工具配置中配置NodeJS安装环境时无法选择版本,所以还是官方镜像比较靠谱。
# 拉取官方镜像
+docker pull jenkins/jenkins:lts
+lts: Pulling from jenkins/jenkins
+4c25b3090c26: Pull complete
+750d566fdd60: Pull complete
+2718cc36ca02: Pull complete
+5678b027ee14: Pull complete
+c839cd2df78d: Pull complete
+50861a5addda: Pull complete
+ff2b028e5cf5: Pull complete
+ee710b58f452: Pull complete
+2625c929bb0e: Pull complete
+6a6bf9181c04: Pull complete
+bee5e6792ac4: Pull complete
+6cc5edd2133e: Pull complete
+c07b16426ded: Pull complete
+e9ac42647ae3: Pull complete
+fa925738a490: Pull complete
+4a08c3886279: Pull complete
+2d43fec22b7e: Pull complete
+Digest: sha256:a942c30fc3bcf269a1c32ba27eb4a470148eff9aba086911320031a3c3943e6c
+Status: Downloaded newer image for jenkins/jenkins:lts
+docker.io/jenkins/jenkins:lts
+# 启动jenkins
+docker run --name jenkins -dp 8099:8080 -v /story/dist:/story/dist -v ~/jenkins_data:/var/jenkins_home -u root -e TZ="Asia/Shanghai" -v /etc/localtime:/etc/localtime:ro jenkins/jenkins:lts
+# 参数说明 --name 指定容器名为jenkins -d 后台启动 -p 将容器的8080端口映射到宿主机的8099端口
+# -v 挂载宿主机目录 宿主机和容器的目录会同步 -u 指定用户为root 这里是必须的 不然后续操作文件系统会报无权限
+# 挂载时区的目录是因为镜像中的linux系统默认时区非北京时间,会导致时间显示不正确http://localhost:8099/(我这里是本地测试,实际请替换成自己的服务器地址)curl -fsSL https://pkg.jenkins.io/debian-stable/jenkins.io-2023.key | sudo tee \
+ /usr/share/keyrings/jenkins-keyring.asc > /dev/null
+
+sudo sh -c 'echo "deb [signed-by=/usr/share/keyrings/jenkins-keyring.asc] https://pkg.jenkins.io/debian-stable binary/" > /etc/apt/sources.list.d/jenkins.list'
+
+sudo apt update
+
+# Jenkins requires Java 11 or 17 since Jenkins 2.357 and LTS 2.361.1.
+apt install openjdk-17-jdk
+
+sudo apt install jenkins
docker exec -it jenkins /bin/bash
+cat /var/jenkins_home/secrets/initialAdminPassword或者直接在上面挂载的目录查询但要改一下路径
cat ~/jenkins_data/secrets/initialAdminPassword
实例配置
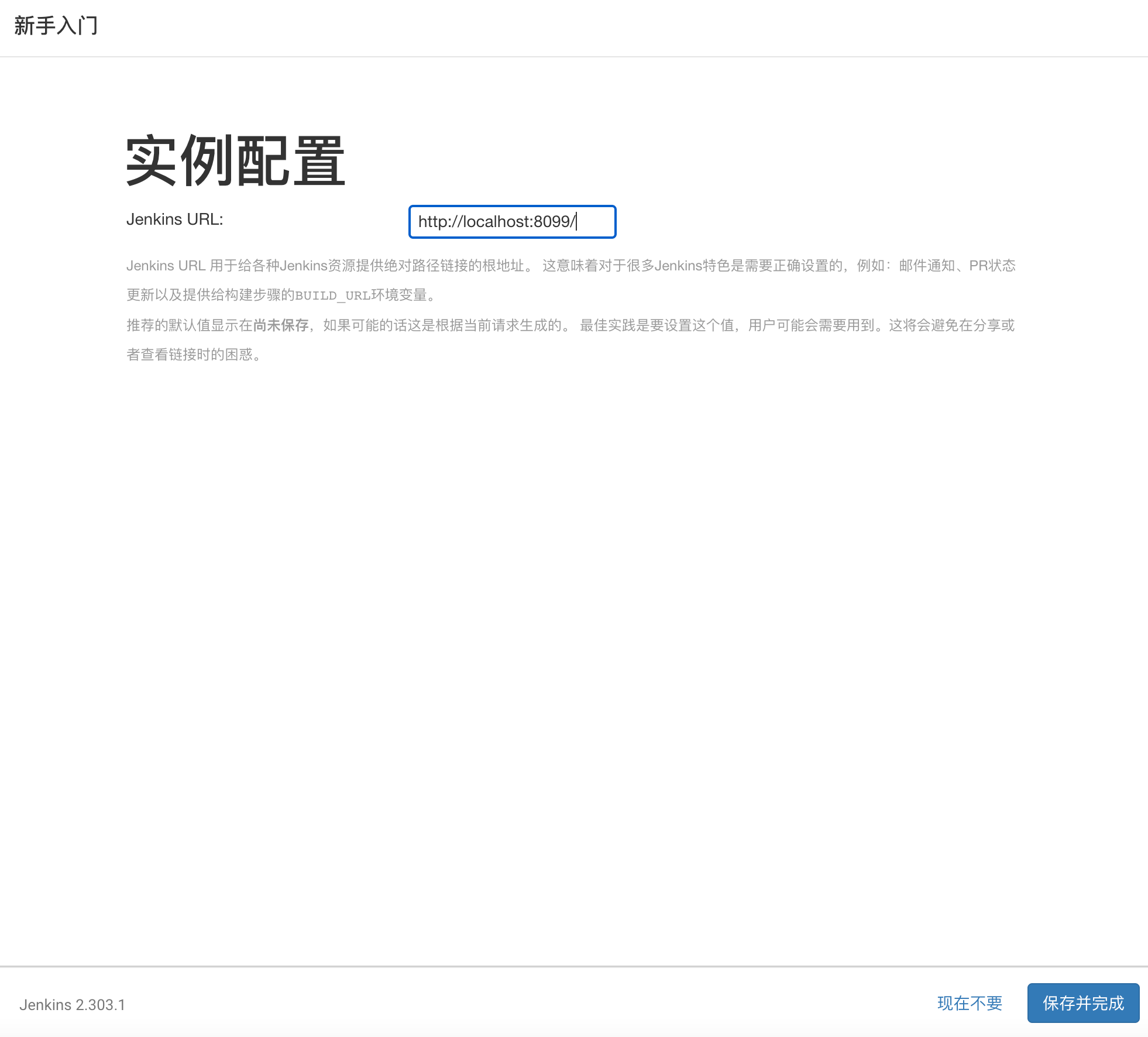
完成
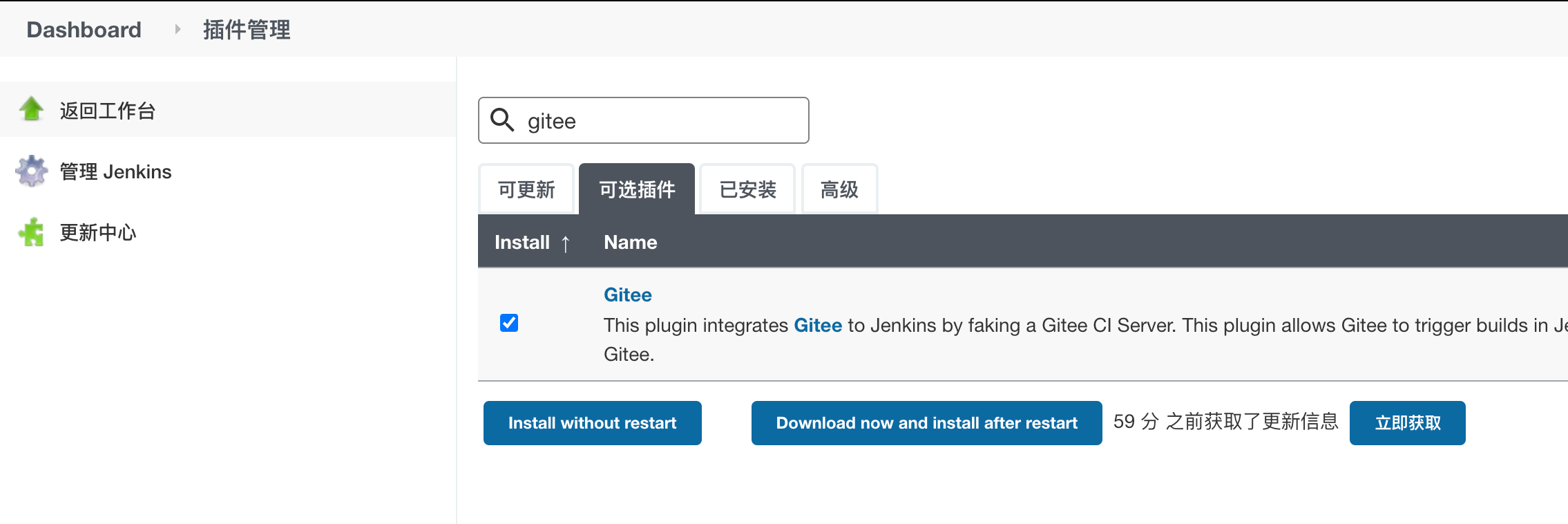
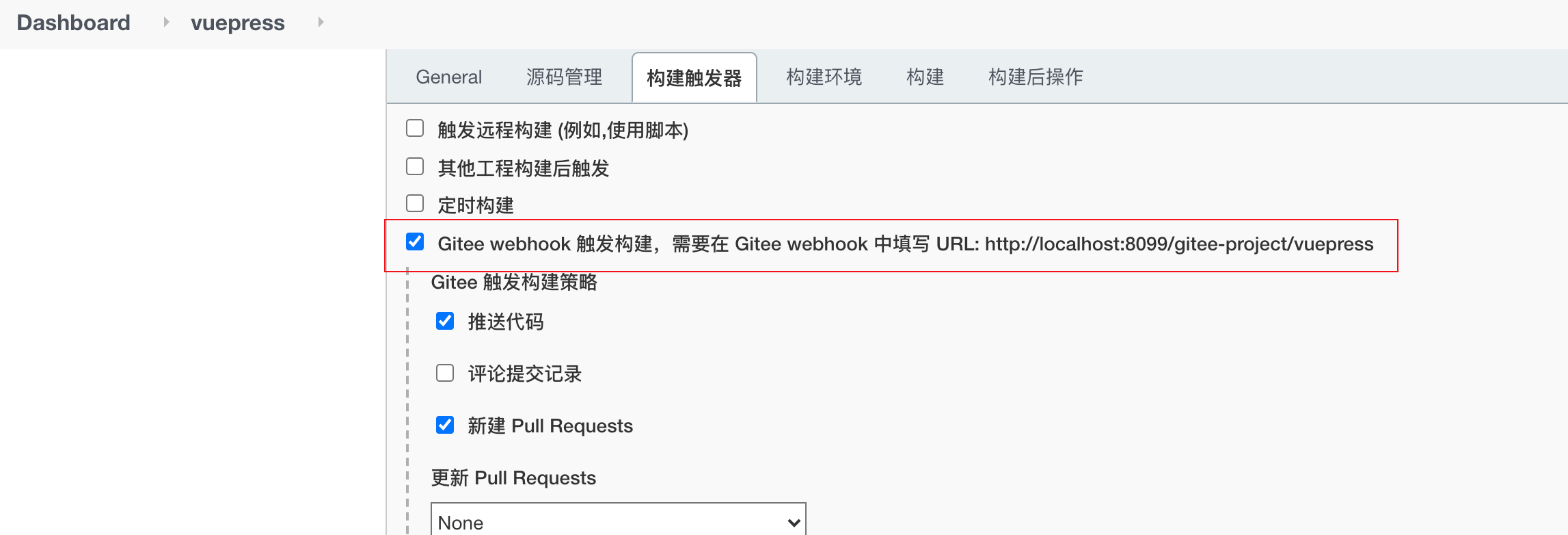
Manage Jenkins ---> Manage Plugins ---> 可选插件分别搜索gitee和nodejs 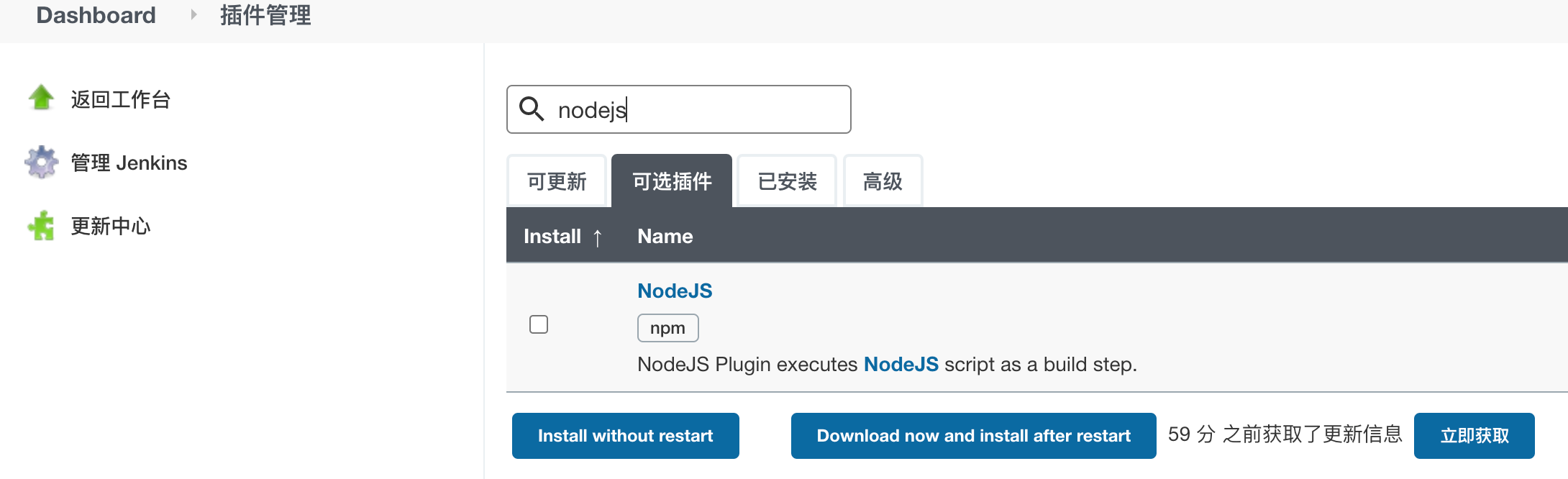
选择install without restart
安装完毕后返回工作台
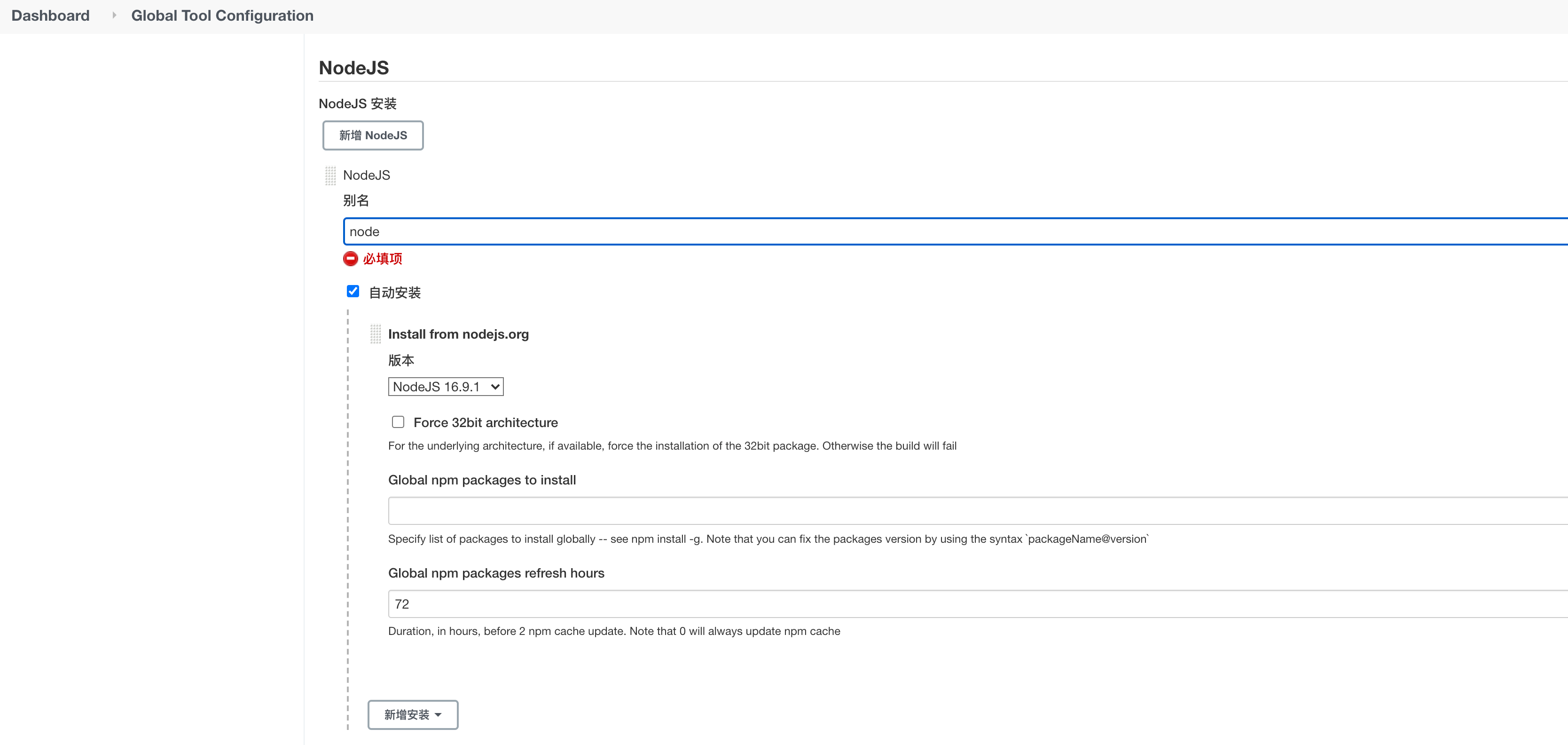
Manage Jenkins ---> Global Tool Configuration ---> NodeJS
新增NodeJS取别名后保存即可
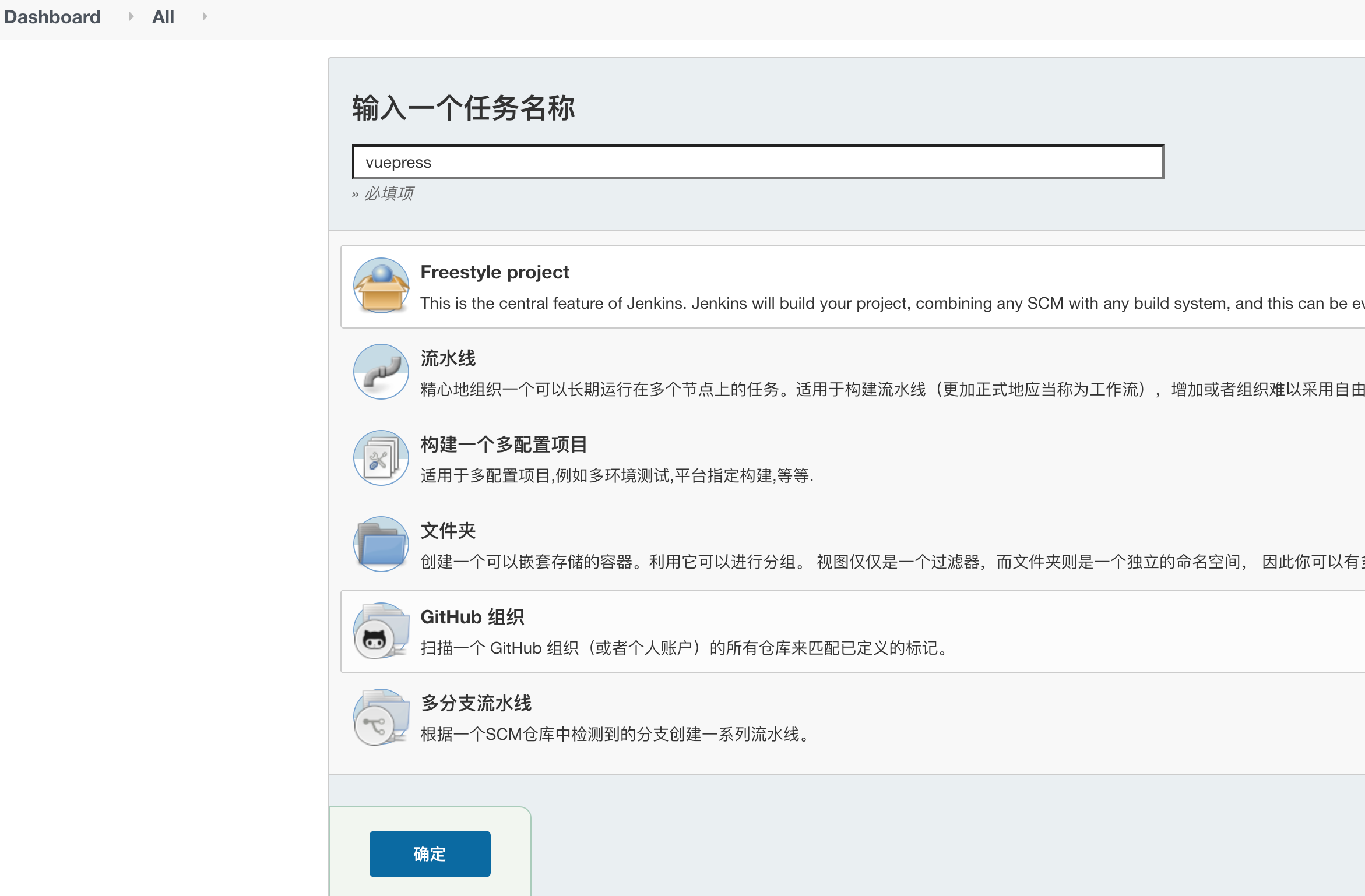
工作台点击新建Item,输入任务名称后选择freestyle project确定
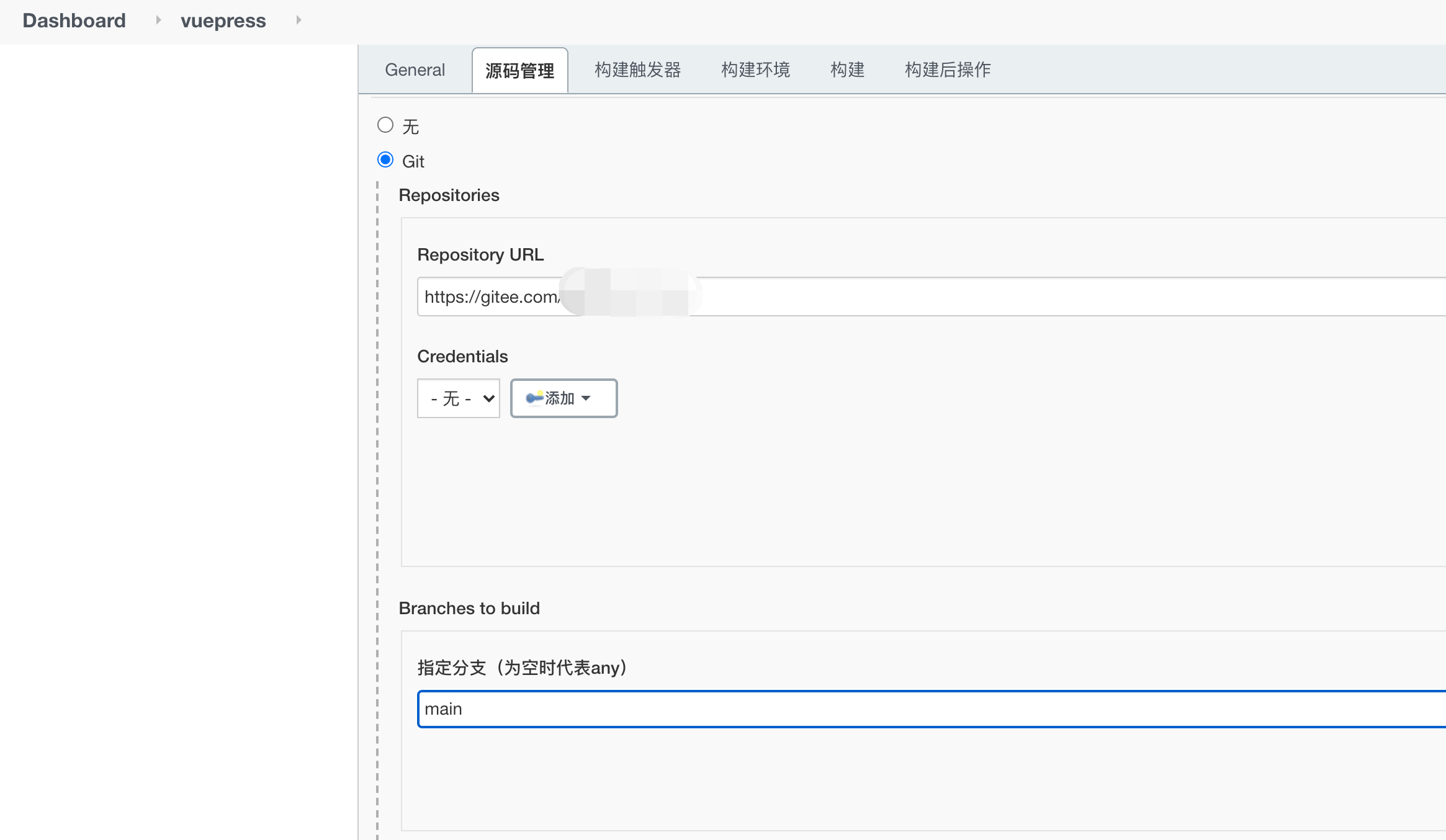
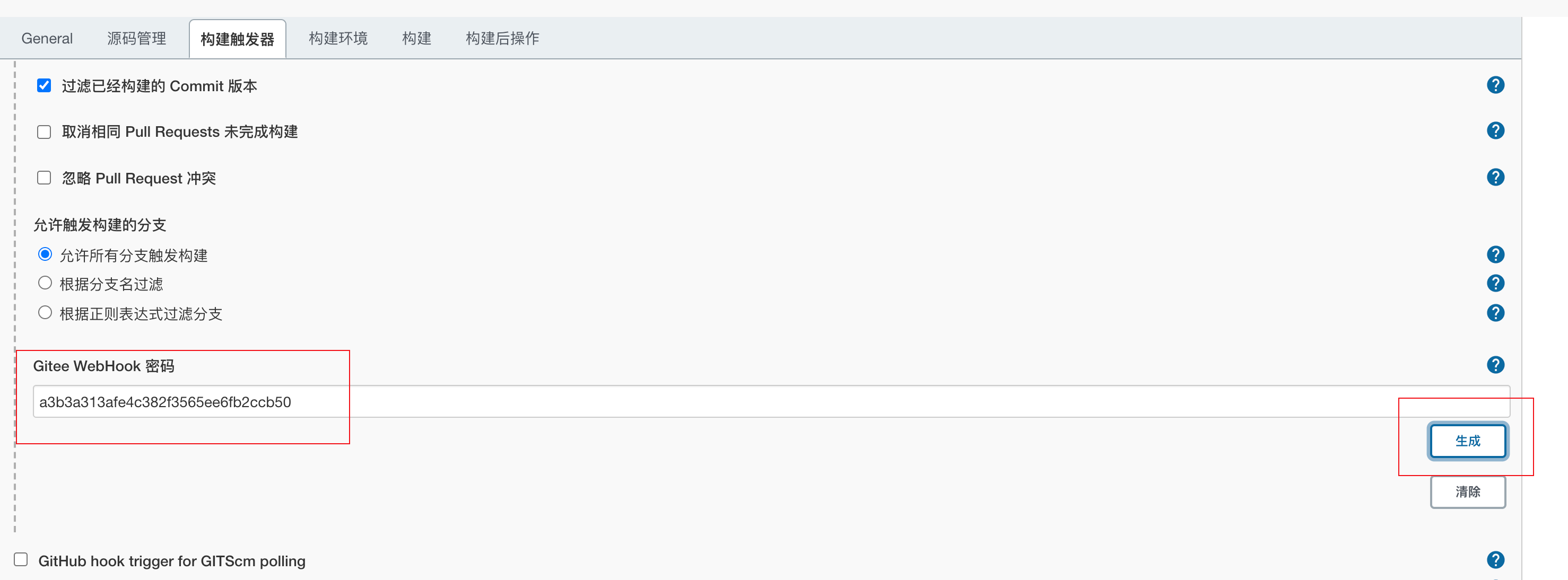
去gitee仓库中配置webhook内容
仓库的管理tab页添加webhook
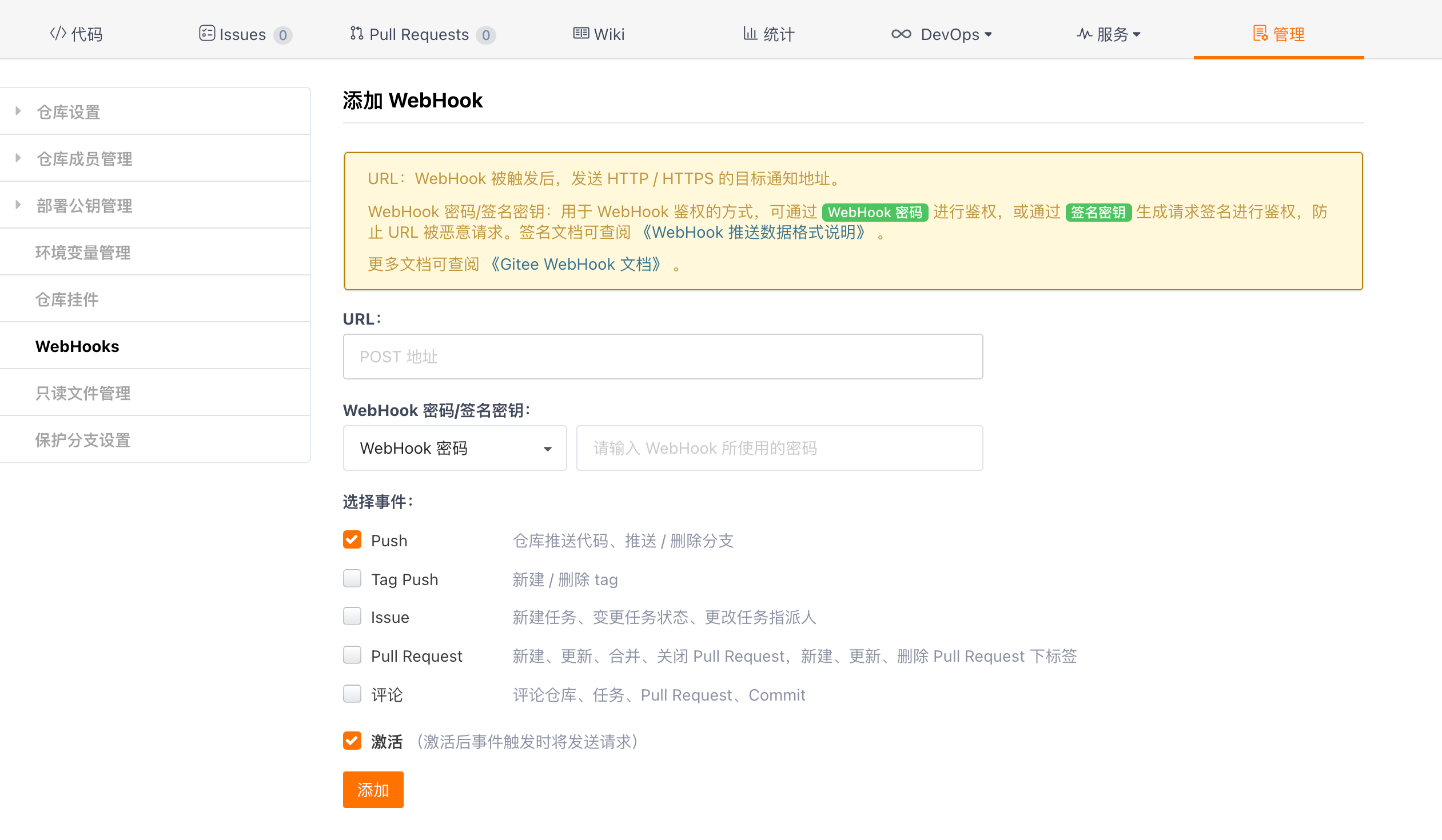
url和webhook密码分别填写后保存
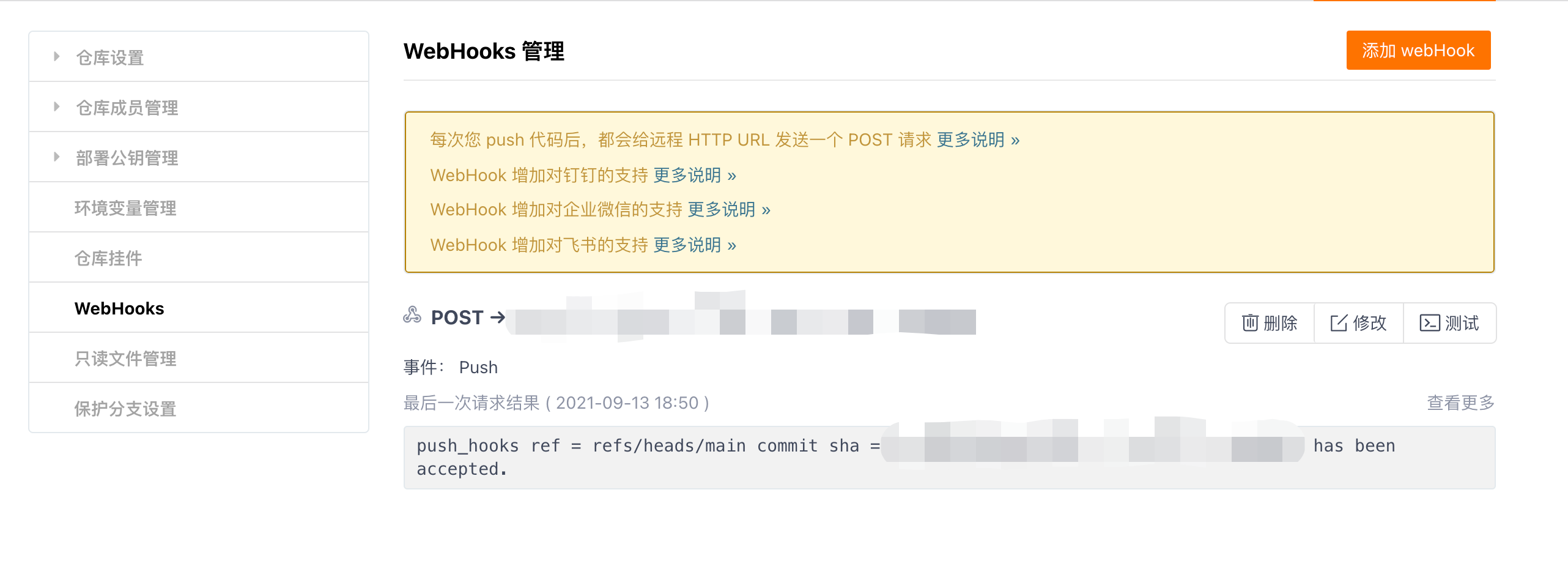
在这个页面点击测试,如果看到xxx has been accepted即为成功。
选择前面已经配置好的node环境即可
首先在任务面板中点击立即构建,这样才会生成工作空间
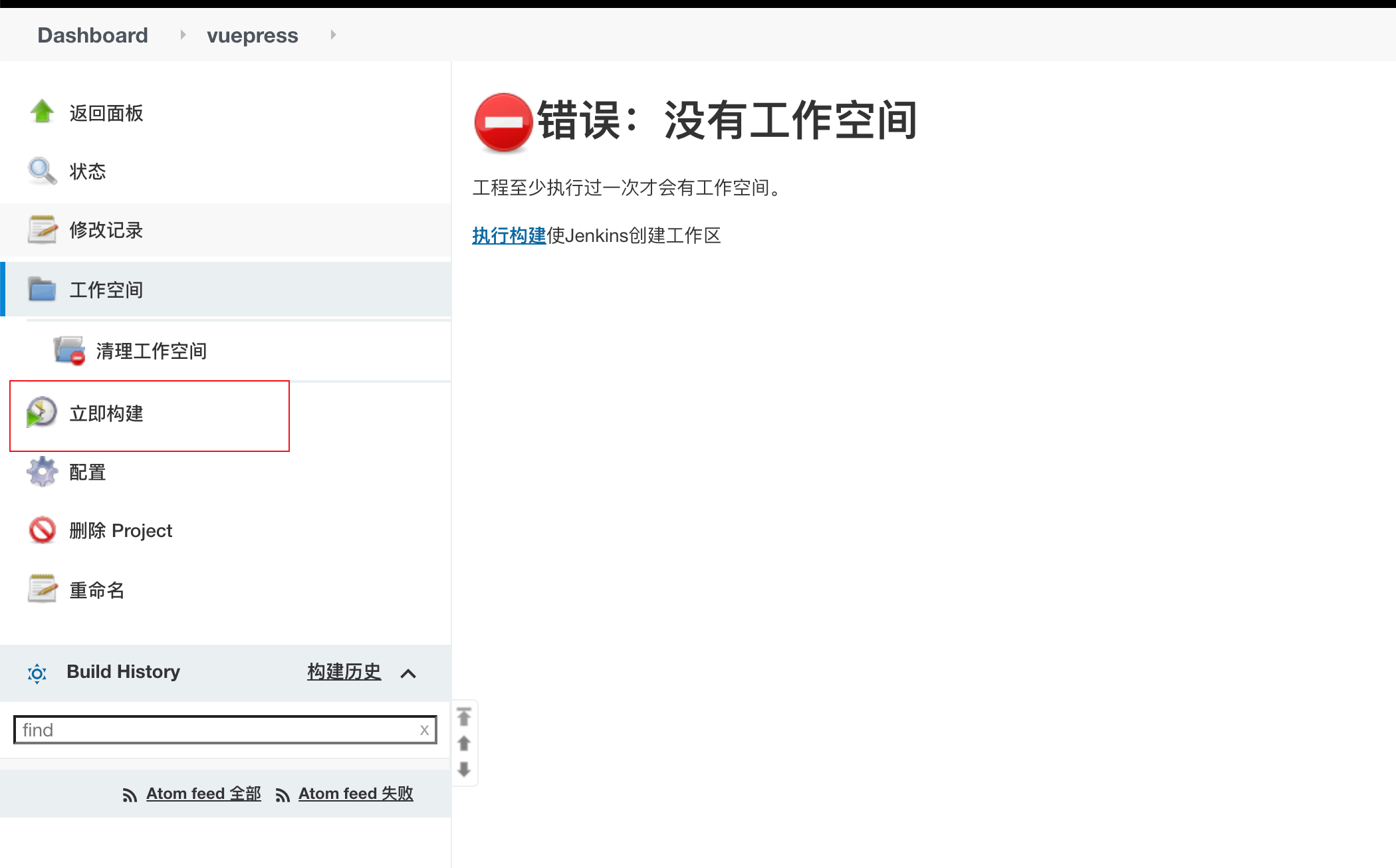
我这里选择执行shell
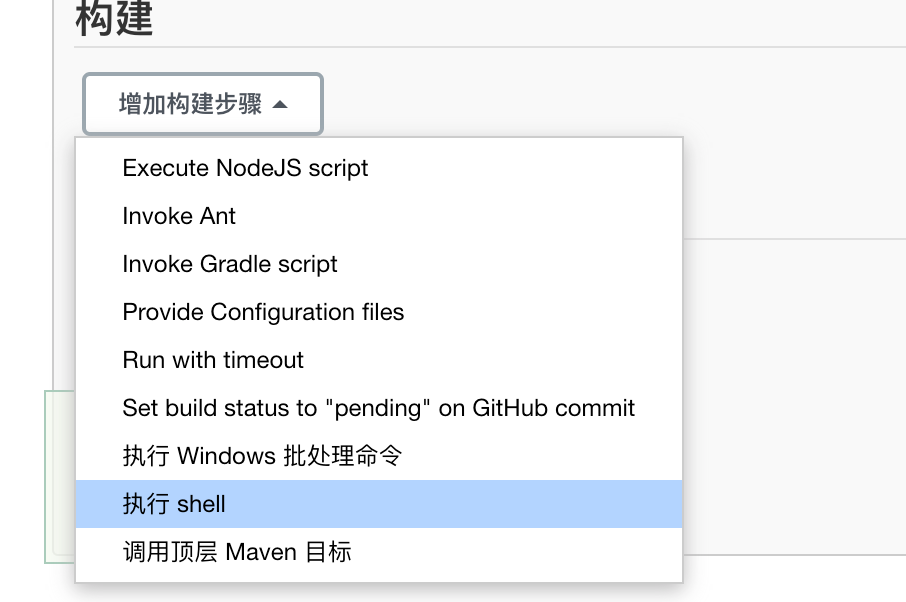
然后就是写个简单的脚本执行打包,替换的工作
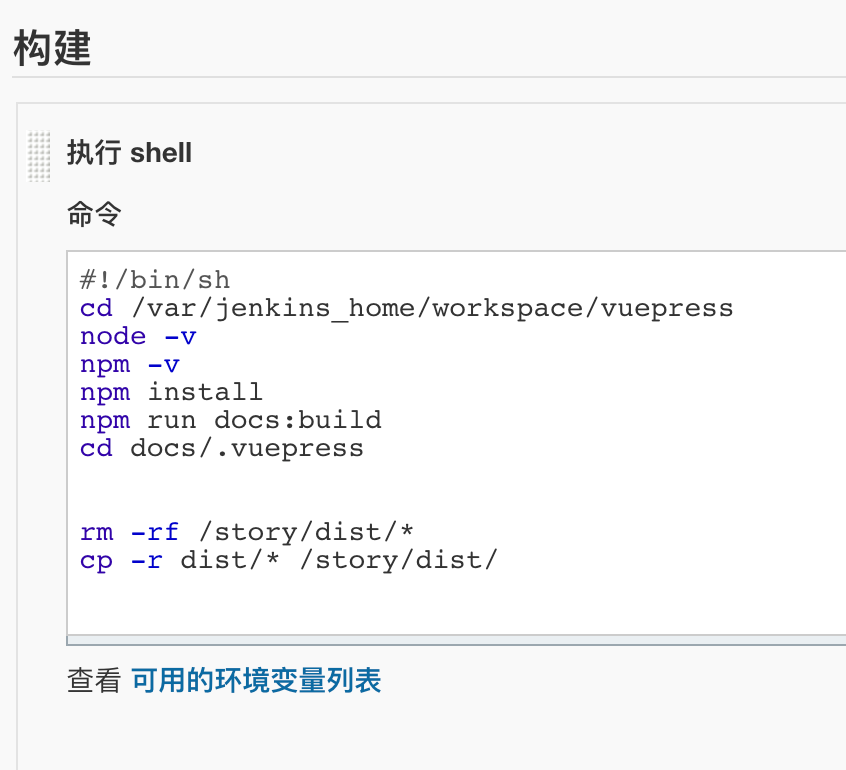
第一步cd进入的目录是当前任务的工作空间,这里要把vuepress替换成自己的任务名称即可
TIP
这里涉及到文件系统操作的内容rm cp等命令需要root用户才能执行,所以在启动docker容器的时候必须使用-u root参数指定root用户,否则打包会失败,操作文件时会提示无权限
配置完毕保存即可
点击立即构建或者往gitee仓库推送一次更新即可触发构建任务,然后等待构建完成即可。
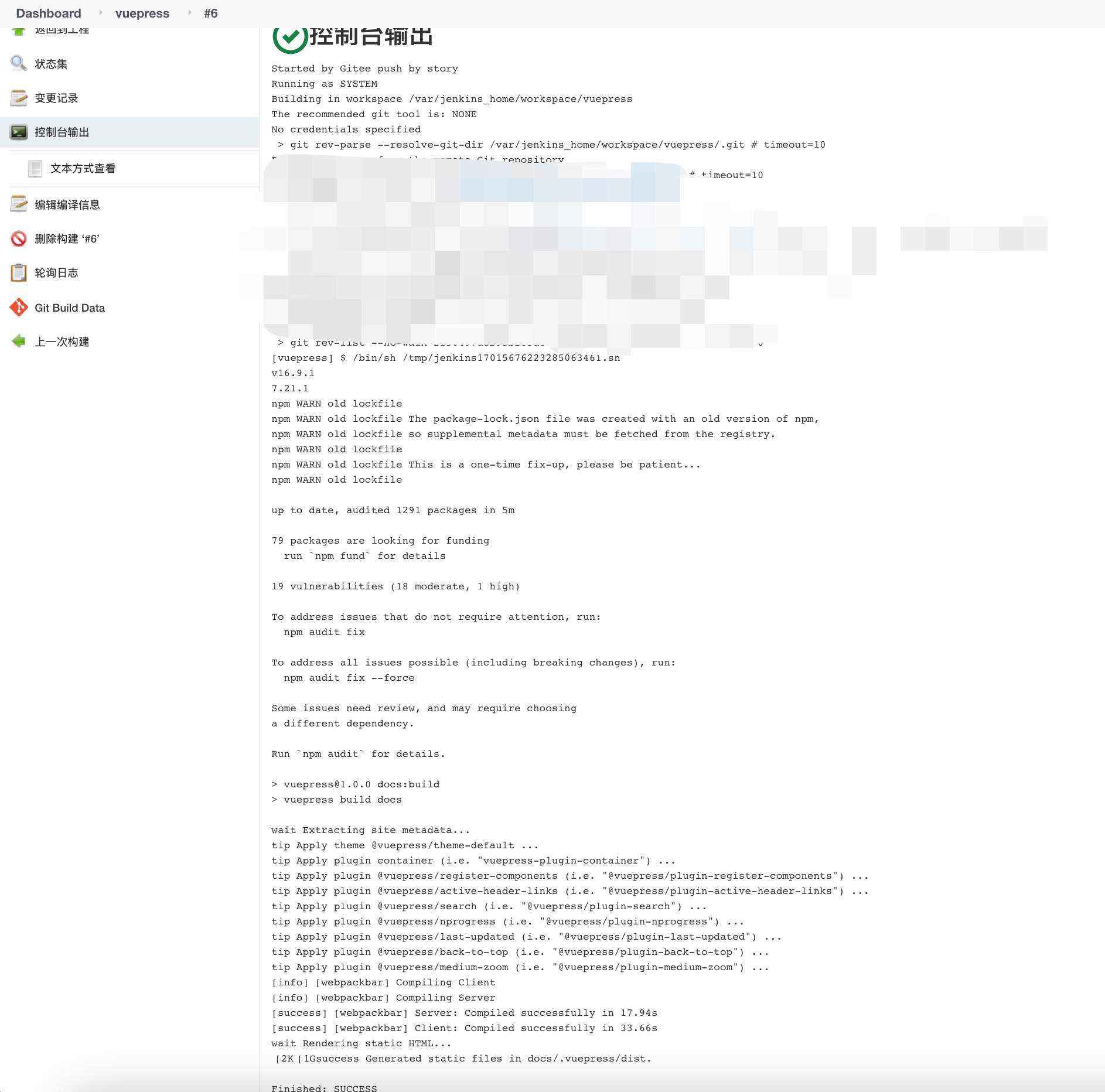
如果是第一次执行构建,jenkins还会自动安装解压nodejs。
通过脚本替换完打包好的dist后,通过nginx配置部署静态项目即可。
这里是用宿主机直接安装的jenkins
把jenkins用户添加到docker组中然后重启jenkins:sudo usermod -aG docker jenkins
getent group groupname 查看组中有哪些用户
shell
#!/bin/sh
+cd /var/lib/jenkins/workspace/xxx
+node -v
+npm -v
+docker -v
+
+npm install
+npm run build
+docker buildx ls
+docker buildx create --use --name jenkinsbuilder
+docker buildx ls
+
+# Dockerfile
+cat > Dockerfile <<EOF
+// doSomething
+EOF
+
+docker login xxx.com --username='xxx' --password=='xxx'
+docker buildx build --platform linux/amd64,linux/arm64 -t xxx/xxx . --push在Execute shell中添加如下变量
BUILD_ID=DONTKILLMEgitee或者gitlab账号和个人git账号同时在一台机器上使用时,可以为不同git服务器设置不同的ssh-key
生成一个个人github的ssh-key
ssh-keygen -t rsa -C 'xxxxx@163.com' -f ~/.ssh/github_id_rsa
生成一个gitee的ssh-key
ssh-keygen -t rsa -C 'xxxxx@company.cn' -f ~/.ssh/gitee_id_rsa
在~/.ssh下新建config文件vim ~/.ssh/config,添加以下内容
# gitee
+Host gitee.com
+HostName gitee.com
+PreferredAuthentications publickey
+IdentityFile ~/.ssh/gitee_id_rsa
+# github
+Host github.com
+HostName github.com
+PreferredAuthentications publickey
+IdentityFile ~/.ssh/github_id_rsa分别在gitee和github中添加前两步生成的对应地址的公钥
ssh命令测试
ssh -T git@gitee.com
+ssh -T git@github.com如果看到 hi xxx!。。。内容则证明配置成功
假设我们有一个项目同时在github和gitee上都有仓库,当直接使用git clone命令拉取的代码默认remote为origin,如果要分别更新,我们要分别在两个本地仓库中push。这时我们可以给本地仓库添加多个origin,然后更新的时候分别推送即可实现一个本地仓库分别推送两个不同的远程仓库。
删除原有的remote地址
git remote remove origin
添加新的远程仓库地址(gitee)
git remote add 远程仓库名 远程仓库地址
+eg: git remote add gitee git@gitee.com:xxx/xxx.git添加新的远程仓库地址(github)
git remote add 远程仓库名 远程仓库地址
+eg: git remote add github git@github.com:xxx/xxx.git再次查看git remote:

推送的时候git push 远程仓库名即可
修改仓库下.git/config文件,新增内容
[remote "all"]
+ url = repo1.git
+ url = repo2.git
+ url = repo3.git直接git push all
Github Actions官方文档https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#name
Github推出的持续集成工具
Github Actions的配置文件叫做workflow文件,需要存放在repo根路径下的./github/workflows目录中。workflow文件使用yaml格式编写,文件名可以自定义,后缀统一为yml,一个repo中可以有多个workflow,Github只要发现./github/workflows目录中有.yml文件就会自动运行。
本博客的workflow文件:
# 自定义当前执行文件的名称
+name: vuepress
+# 整个流程在main分支发生push事件时触发
+on:
+ push:
+ branches:
+ - main
+jobs:
+ build-and-deploy:
+ runs-on: ubuntu-latest # 运行在ubuntu-latest环境的虚拟机中
+ strategy:
+ matrix: # 矩阵
+ node-version: [10.x]
+ steps: # 每个 job 由多个 step 构成,它会从上至下依次执行。
+ # 获取仓库源码
+ - name: Checkout
+ uses: actions/checkout@v2 # github actions提供了一些官方的action,例如checkout @v2是action的版本
+ # 安装node
+ - name: Use Node.js ${{ matrix.node-version }} # 定义好的node版本
+ uses: actions/setup-node@v1 # 作用:安装nodejs
+ with:
+ node-version: ${{ matrix.node-version }} # 定义好的node版本
+ # 构建和部署
+ - name: Deploy
+ env: # 环境变量
+ GITHUB_TOKEN: ${{ secrets.vuepress_actions_access_token }}
+ run: npm install && npm run deploy # npm run deploy需要在package.json中定义"deploy: bash deploy.sh"steps:

#!/usr/bin/env sh
+
+# 确保脚本抛出遇到的错误
+set -e
+
+# 生成静态文件
+npm run build
+
+# 进入生成的文件夹
+cd docs/.vuepress/dist
+
+# 如果是发布到自定义域名
+echo 'blog.storyxc.com' > CNAME
+
+if [ -z "${GITHUB_TOKEN}" ]; then
+ echo "GITHUB_TOKEN is not set"
+ exit 1
+else
+ msg='github actions自动部署'
+ githubUrl=https://storyxc:${GITHUB_TOKEN}@github.com/storyxc/vuepress.git
+ git config --global user.name "storyxc"
+ git config --global user.email "storyxc@163.com"
+fi
+
+git init
+git add -A
+git commit -m "${msg}"
+
+git push -f $githubUrl master:gh-pages
+
+cd -这里我是用了github pages发布,然后配置了自定义域名,这个域名要在服务商域名解析配置CNAME,然后在仓库的page页面添加自定义域名即可
Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档。
Markdown 语言在 2004 由约翰·格鲁伯(英语:John Gruber)创建。
Markdown 编写的文档可以导出 HTML 、Word、图像、PDF、Epub 等多种格式的文档。
Markdown 编写的文档后缀为 .md, .markdown。
示例:
# 一级标题
+## 二级标题
+### 三级标题
+#### 四级标题
+##### 五级标题
+###### 六级标题加粗 要加粗的文字左右分别用两个*号包起来
斜体 要倾斜的文字左右分别用一个*号包起来
斜体加粗 要倾斜和加粗的文字左右分别用三个*号包起来
删除线 要加删除线的文字左右分别用两个~~号包起来
示例:
**这是加粗的文字**
+*这是倾斜的文字*`
+***这是斜体加粗的文字***
+~~这是加删除线的文字~~效果: 这是加粗的文字这是倾斜的文字` 这是斜体加粗的文字这是加删除线的文字
只需要在你希望引用的文字前面加上 > 就好,例如:
> 这是一条引用效果如下:
这是一条引用
引用还可以进行多级嵌套
> 这是一条引用
+>> 这是一条引用
+>>> 这是一条引用效果:
这是一条引用
这是一条引用
这是一条引用
三个或者三个以上的 - 或者 * 都可以。
---
+----
+***
+*****语法:

+
+图片alt就是显示在图片下面的文字,相当于对图片内容的解释。
+图片title是图片的标题,当鼠标移到图片上时显示的内容。title可加可不加示例:
效果: 
语法:
[超链接名](超链接地址 "超链接title")
+title可加可不加示例:
[故事的博客](https://www.storyxc.com "故事的博客")效果 故事的博客
无序列表 语法: 无序列表用 - + * 任何一种都可以 示例:
- 列表1
++ 列表2
+* 列表3效果
有序列表 语法: 数字加点 示例:
1. 111
+2. 222
+3. 333效果:
列表嵌套
上一级和下一级之间tab即可
语法:
表头|表头|表头
+---|:--:|---:
+内容|内容|内容
+内容|内容|内容
+
+第二行分割表头和内容。
+- 有一个就行,为了对齐,多加了几个
+文字默认居左
+-两边加:表示文字居中
+-右边加:表示文字居右
+注:原生的语法两边都要用 | 包起来。此处省略
+
+姓名|技能|排行
+--|:--:|--:
+刘备|哭|大哥
+关羽|打|二哥
+张飞|骂|三弟效果:
| 姓名 | 技能 | 排行 |
|---|---|---|
| 刘备 | 哭 | 大哥 |
| 关羽 | 打 | 二哥 |
| 张飞 | 骂 | 三弟 |
示例:
`这是一行代码`效果: 这是一行代码
(```)语言名
+ 代码
+(```)示例:以java为例
(```)java
+ public class HelloWorld{
+ public static void main(Stringargs[]){
+ System.out.println("Hello World!");
+ }
+ }
+(```)效果
public class HelloWorld{
+ public static void main(String args[]){
+ System.out.println("Hello World!");
+ }
+}由于最近刚把博客迁到VuePress上来,写博客从原来自己博客项目自定义的web端Markdown编辑器换回了原来的Typora,这个文本编辑工具虽然很好用,但是在markdown中插入图片的时候就会碰到比较烦的问题,可能随便截了个图放在桌面了,在markdown中引入的话还要先把图片放到vuepress项目的静态资源文件夹里面。原来我自己开发的博客编辑器是通过axios调用后台接口把图片传到七牛云图床上去,现在换了博客框架原来的方案不好使了。之前typora也没有这方面的支持。不过我发现typora更新之后也支持了添加图片后的事件触发。
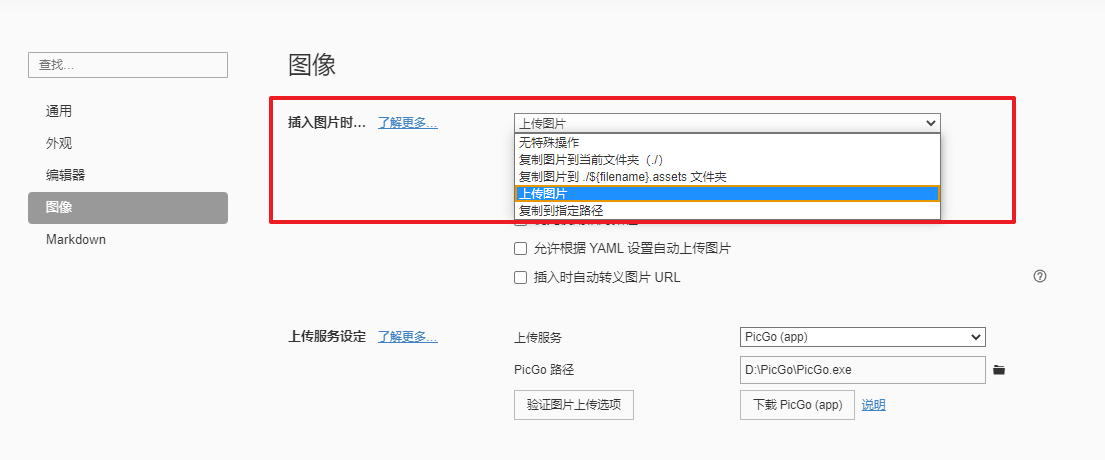
选项还是很多样的,为typora点赞。
这里我还是选择了上传到图床,上传支持PicGo和自定义脚本,本来打算写个python脚本的,后来发现picgo这个应用也很好用,那就直接拿过来用吧。
点击PicGo 进入仓库下载,这里选择windows版的执行程序,下载之后打开
没有图床的可以搜一下相关教程,这里不再赘述
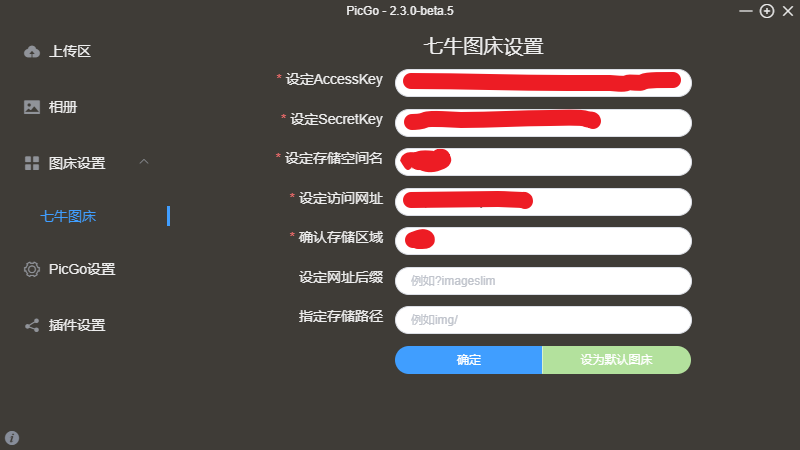

选择七牛云图床、或者自己选择其他图床也许,按照自己情况来。
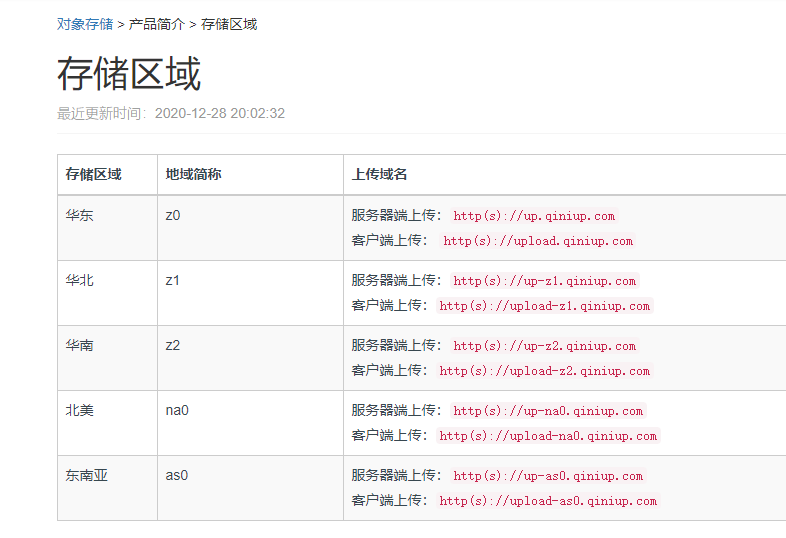

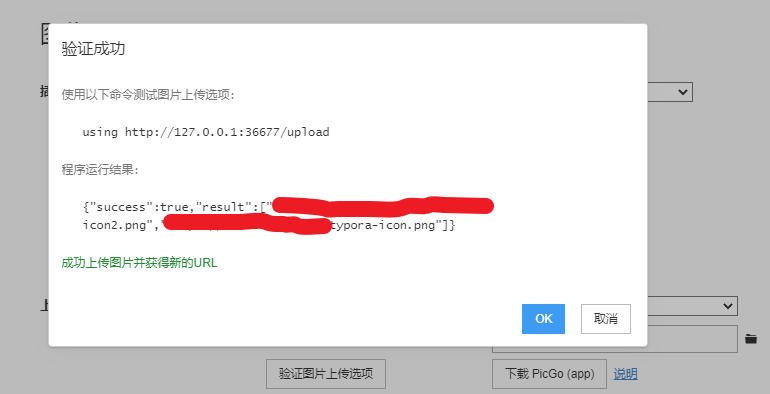
先验证一下,可以看到成功了。这样再在typora中添加图片就可以看到图片会自动上传到你的图床并修改markdown中的地址了。
npm安装picgo-core:npm install -g picgo
配置uploader:picgo set uploader
使用uploader:picgo use uploader
配置文件地址为~/.picgo/config.json,可以手动修改
配置完成后在typora中配置自定义命令上传,命令格式 node_path picgo_path upload例如我的是/opt/homebrew/bin/node /opt/homebrew/bin/picgo upload
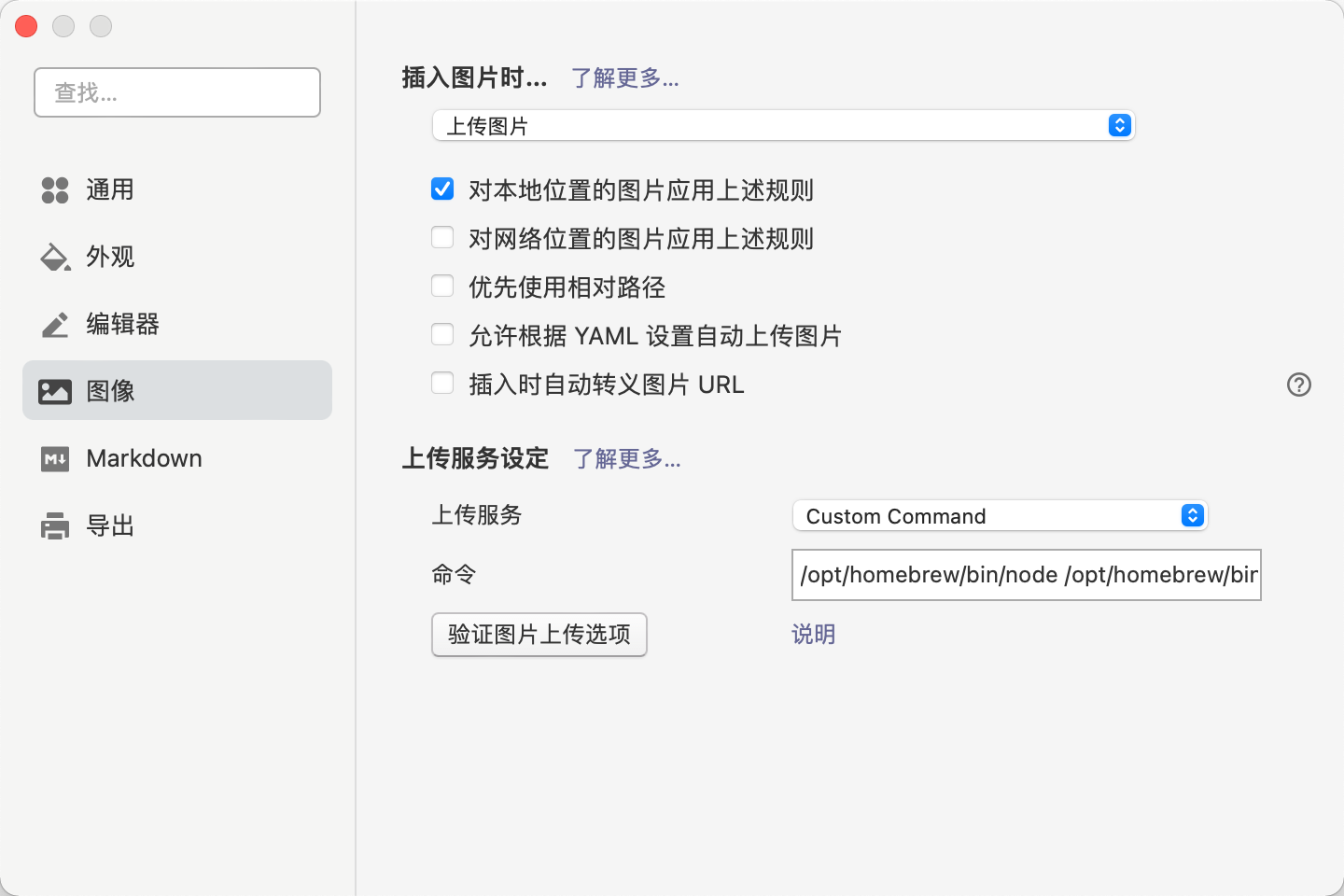
验证上传选项,看到返回图片地址即可
版本控制工具一直用的GIT,之前提交代码都是用IDEA集成的GIT可视化工具,命令行几乎不怎么用,由于接下来项目要整合到微服务平台中,项目代码管理也要迁到Gerrit,idea的集成支持不太好,所以整理下GIT的命令,方便后面使用命令行提交代码。 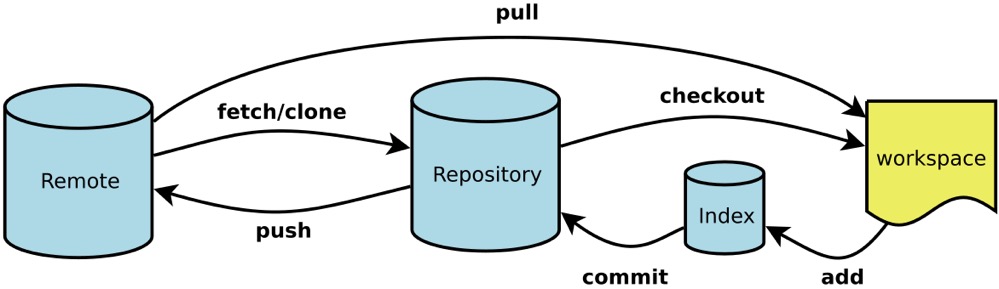
Remote:远程仓库
+Reporsitory:本地仓库
+WorkSpace:工作区
+Index:暂存区git commit --amend :提交完发现漏掉了几个文件没有添加,或者提交信息写错了,此时,可以运行带有 --amend 选项的提交命令来重新提交
git checkout -- <file> 把readme.txt文件在工作区的修改全部撤销,这里有两种情况:
一种是readme.txt自修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态;
一种是readme.txt已经添加到暂存区后,又作了修改,现在,撤销修改就回到添加到暂存区后的状态。
git reset [--soft | --mixed | --hard] [HEAD]
关于git checkout和git reset建议看下这篇文章,git重置
git checkout branch_name
切换分之前要注意本地分支是否有未commit的文件,如果有可以撤销改动,或者commit,再或者使用git stash将当前分支的改动临时保存起来,使当前分支的工作空间和暂存区变干净。然后再进行切换分支;切换回之前的分支,需要恢复被临时保存的改动
git stash -u
恢复本地修改:
1.先查看有多少个临时保存的改动
git stash list
2.再用git stash apply --index stash@{n},n为使用git stash list查看到的某个改动的数字
3.再用git stash drop stash@{n}删除临时保存的改动
如果只有一个临时的stash,那么可以直接git stash apply即可恢复上次的临时保存记录
基于本地master分支创建test分支为例:
先切换到master分支:git checkout master
建分支: git branch test
切分支:git checkout test
或者
建分支后切到该分支:git checkout -b test master
以基于某次commit id创建test分支为例:
git checkout -b test 0faceff
其中的0faceff为commit id的前7位
以基于某个tag创建test分支为例
git checkout -b test v0.1.0
v0.1.0为tag的名称
git branch: 只显示本地分支名,当前分支名前有星号
git branch -v:显示本地分支名,当前分支前有星号,显示commit id
git branch -vv:显示本地分支名,当前分支名前有星号,显示commit id,显示追踪的远程分支名
git branch -a:显示所有分支名(包括远程分支)
git branch -r:查看远程分支名
普通删除:git branch -d branch_name
强制删除(分支上有修改未合并到其他分支):git branch -D branch_name
git pull或者git fetch
git pull -v --progress "origin"命令可以显示更详细的信息,git pull命令会fetch所有的远程分支的信息到本地,同时当前本地分支会被合并。
如果本地有修改文件,而且远程仓库也修改了该文件,pull会失败,提示本地的修改会被合并覆盖,此时可以commit本地的修改或者stash本地的修改,再pull。
首先使用git checkout branch_name切换到正确分支,pull,新建或修改代码,再使用git add 文件名把修改或新增的文件添加到暂存区,再执行commit命令提交到本地仓库。
其中:
git add 某个文件
git add 多个文件(文件名用空格隔开)
git add -u 添加所有修改的文件到暂存区
git add .添加所有修改和新增的文件到暂存区
git add -A:添加所有修改,新增和删除的文件到暂存区
git commit 文件名 -m "注释":commit某个文件
git commit 文件1 文件2 -m "注释" commit多个文件,用空格隔开
git commit -m "注释"commit所有文件
如果是删除文件,可以使用
rm 文件
git add 文件
git commit 文件 -m "注释"
如果是重命名文件或者移动文件,可以使用
git mv 源文件路径 目标文件路径
git commit 文件 -m "注释"
本地代码从本地branch_name分支推到远端branch_name分支:
git checkout branch_name
git pull
git push origin HEAD:refs/for/branch_name
或者
git checkout branch_name
git pull
git push origin branch_name:refs/for/branch_name
git status 显示有变更的文件
git log 显示当前分支的版本历史
git log --stat 显示commit历史,以及每次commit发生变更的文件
git log -S [keyword] 搜索提交历史,根据关键词
git log [tag] HEAD --pretty=format:%s 显示某个commit之后的所有变动,每个commit占据一行
git log [tag] HEAD --grep feature 显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件
git log -p [file] 显示指定文件相关的每一次diff
git log -5 --pretty --oneline 显示过去5次提交
git shortlog -sn 显示所有提交过的用户,按提交次数排序
git blame [file] 显示指定文件是什么人在什么时间修改过
git diff 显示暂存区和工作区的代码差异
git diff --cached [file] 显示暂存区和上一个commit的差异
git diff HEAD 显示工作区与当前分支最新commit之间的差异
git diff [first-branch]...[second-branch] 显示两次提交之间的差异
git diff --shortstat "@{0 day ago}" 显示今天你写了多少行代码
git show [commit] 显示某次提交的元数据和内容变化
git show --name-only [commit] 显示某次提交发生变化的文件
git show [commit]:[filename] 显示某次提交时,某个文件的内容
git rebase [branch] 从本地master拉取代码更新当前分支:branch 一般为master
git fetch是将远程的最新内容拉到本地,用户在检查了以后决定是否合并到本地分支中。 而git pull 则是将远程的最新内容拉下来后直接合并,即:git pull = git fetch + git merge,这样可能会产生冲突,需要手动解决。
官网下载:https://iterm2.com/
安装脚本:sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
因为网络原因无法执行这个脚本的可以找gitee上的国内源
仓库地址: https://github.com/dracula/iterm.git
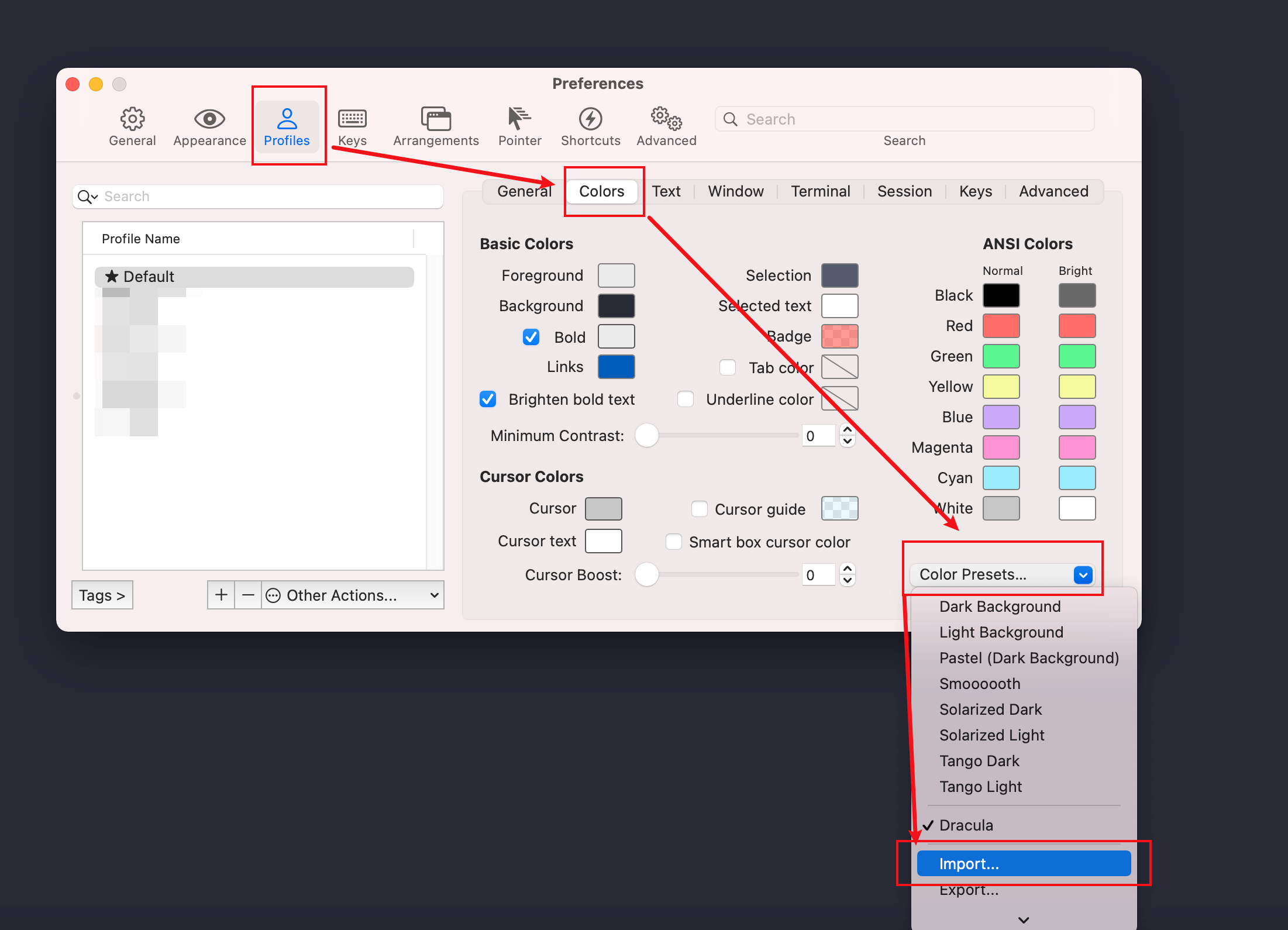
如图,导入完之后就可以选择导入的dracula主题颜色
git clone https://github.com/zsh-users/zsh-syntax-highlighting $ZSH_CUSTOM/plugins/zsh-syntax-highlighting
git clone https://github.com/zsh-users/zsh-autosuggestions $ZSH_CUSTOM/plugins/zsh-autosuggestions
source ~/.zsh/zsh-autosuggestions/zsh-autosuggestions.zshsource ~/.zsh/zsh-syntax-highlighting/zsh-syntax-highlighting.zsh# ~/.zshrc
+plugins=(
+ git
+ zsh-autosuggestions
+ zsh-syntax-highlighting
+)
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ~/powerlevel10k
+echo 'source ~/powerlevel10k/powerlevel10k.zsh-theme' >>~/.zshrc
+
+p10k configuremacos生态的ssh工具有很多,但是试了很多还是感觉很差劲,不如windows生态的mobaxterm和xshell,可惜这两个软件没有mac的版本。不过iterm2作为mac生态下的终端工具代表倒是很简洁方便,但是没有专门的ssh工具那种简易的远程连接配置,需要自己动手折腾一下才可以。
官网下载,不赘述。
command+,打开偏好设置,选择profiles
新建一个profile设置,将command设置从login shell改为command,并输入需要执行的ssh指令
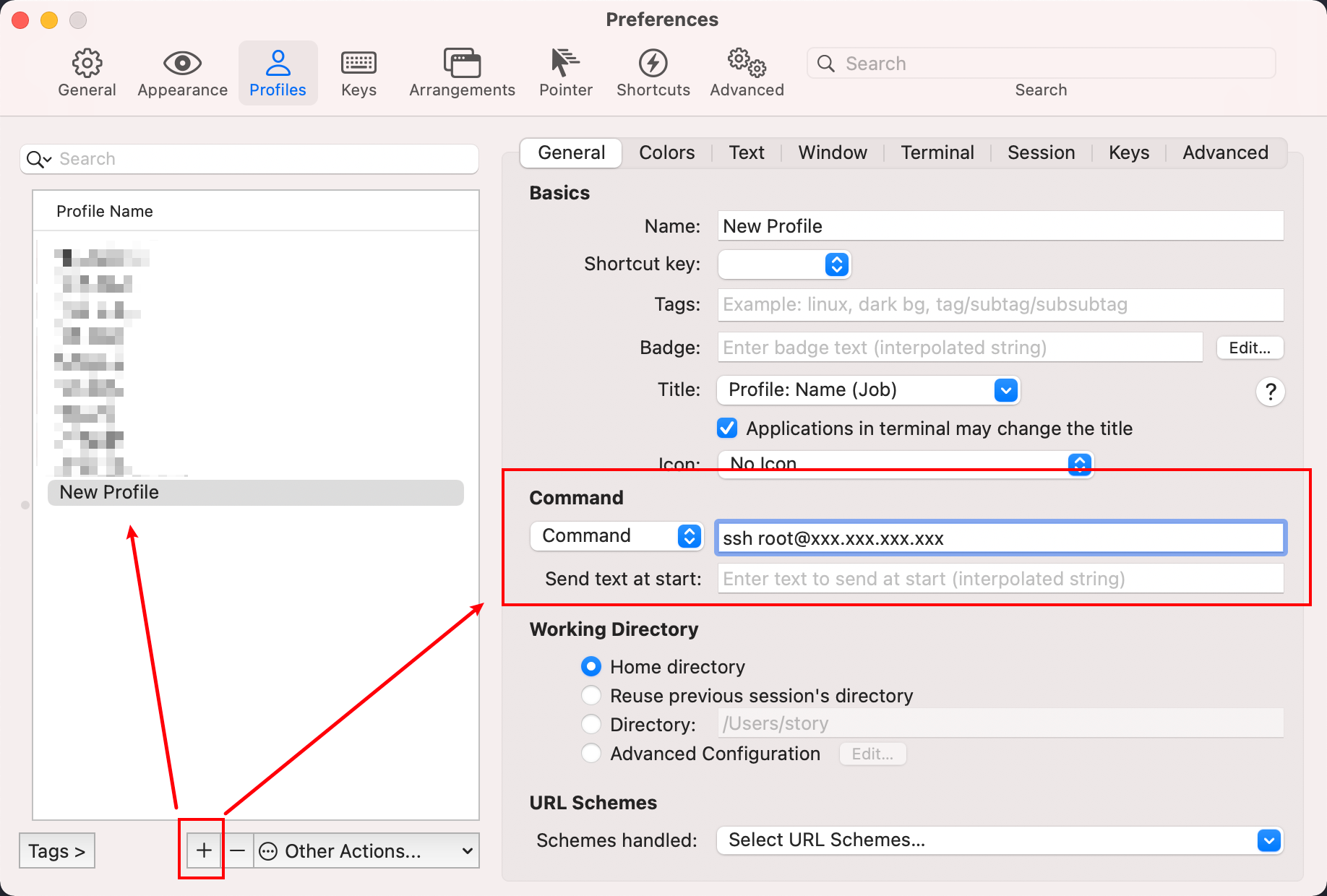
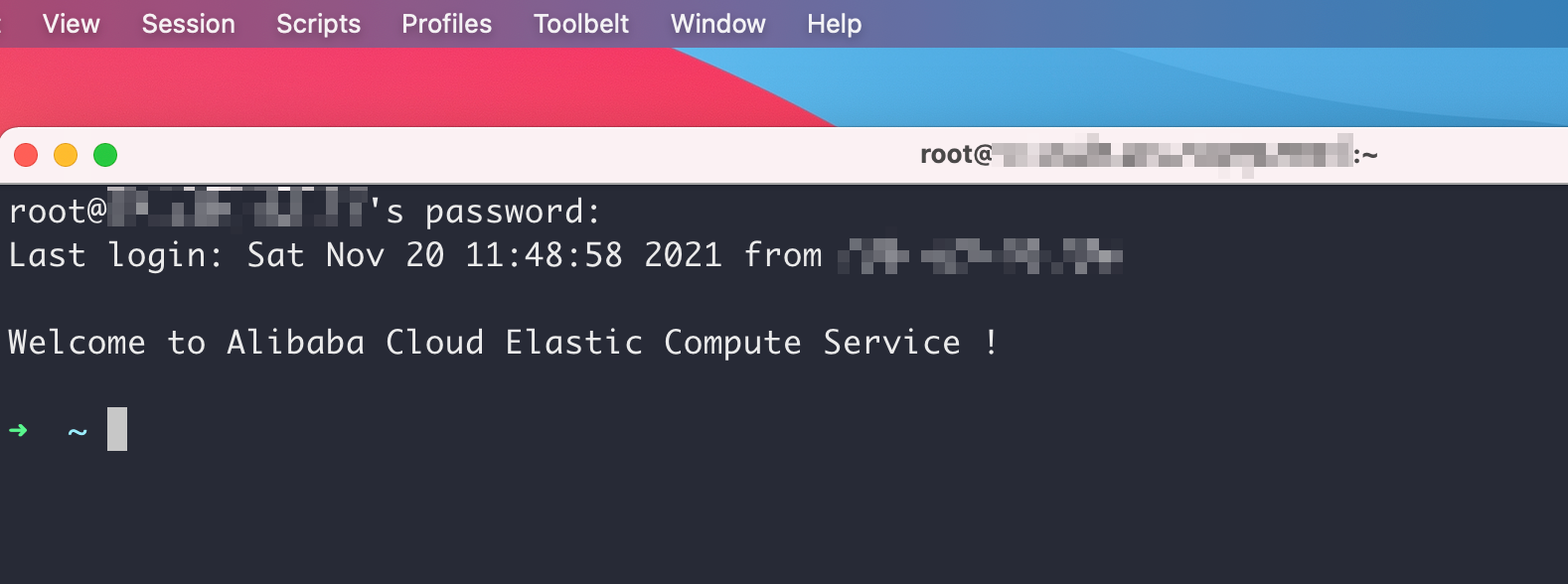
切换到advanced选项卡,选择编辑triggers触发器。新增一个触发器,action选择send text,触发的表达式改为root@xxx.xxx.xxx.xxx's password,参数改为登陆账户的密码+\n,这里注意一定要加\n代表输入回车,不然就会卡在输入密码那里需要手动回车才能登陆,然后勾选上instant立即触发。
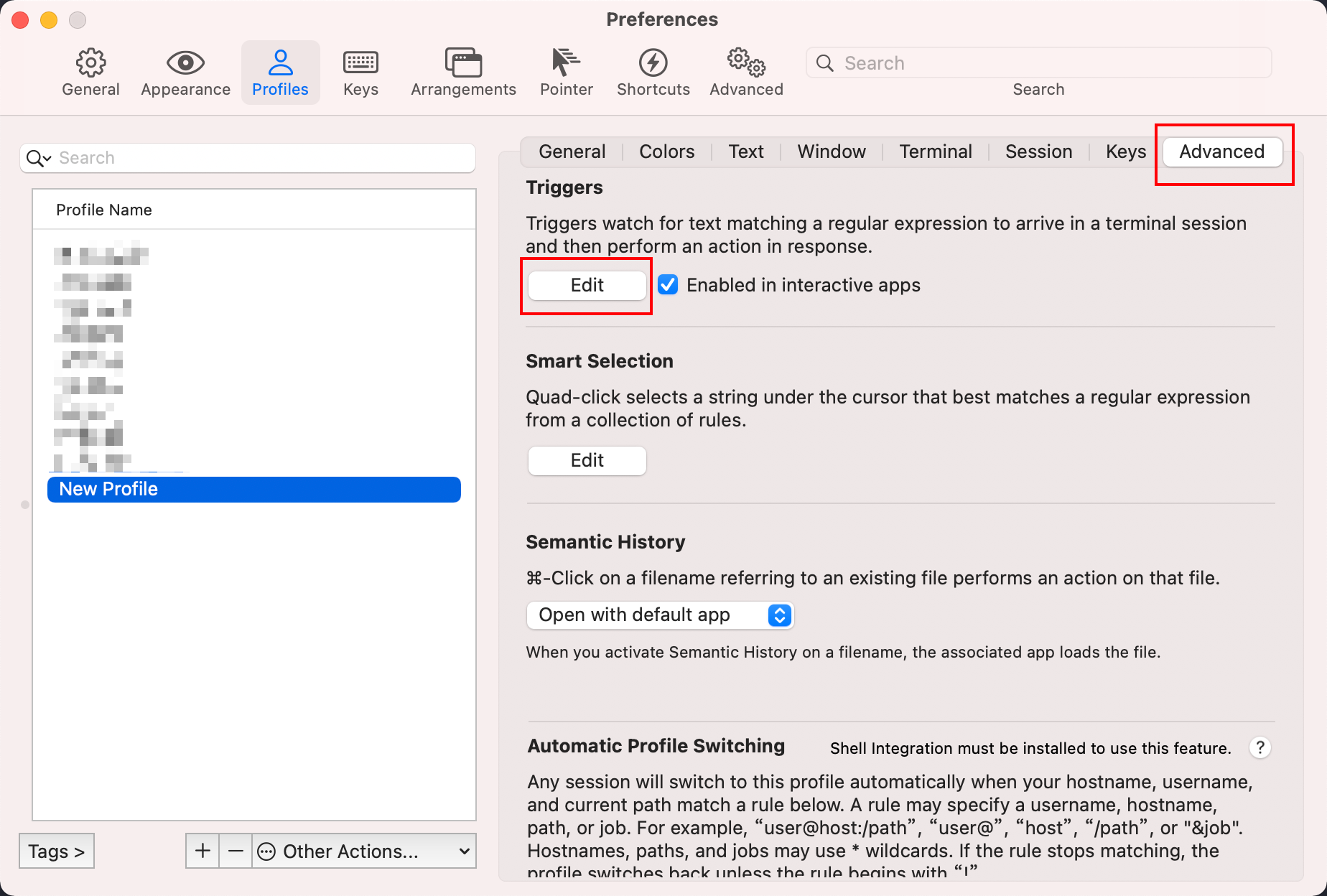
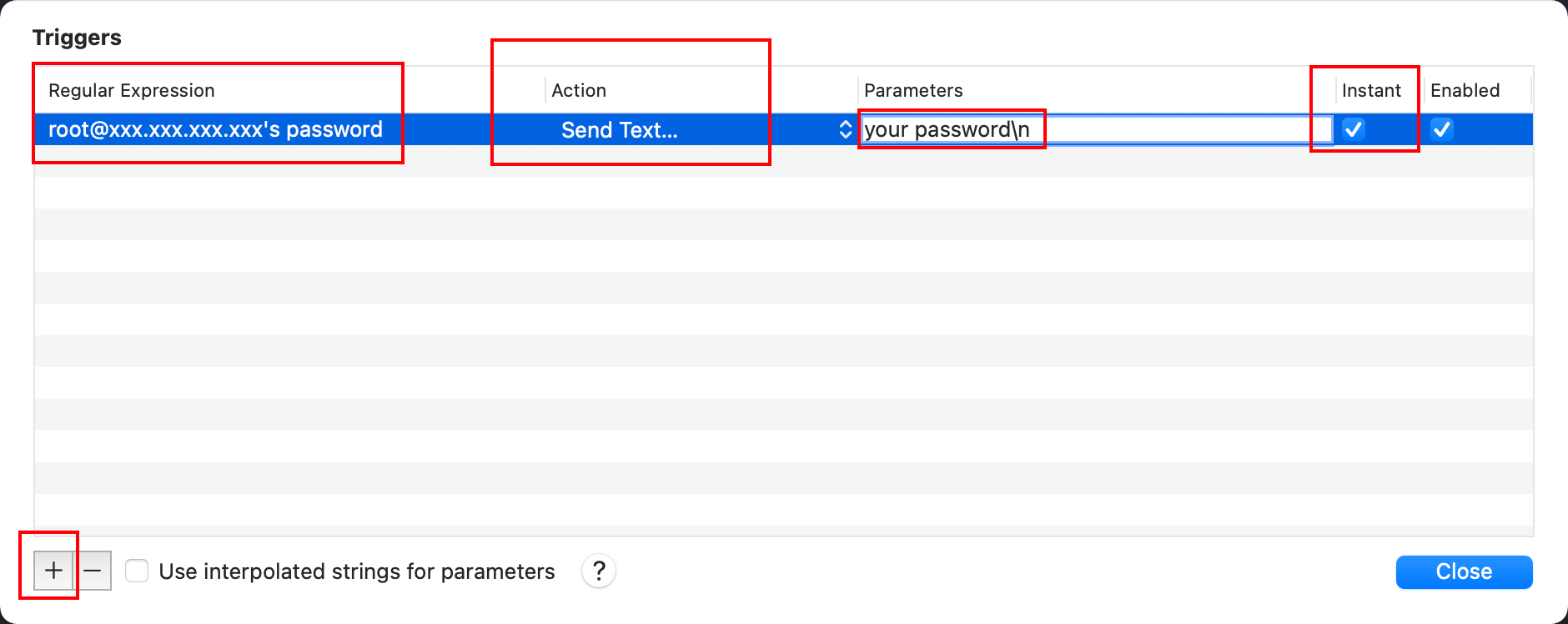
这里触发器的表达式即是输入ssh命令时,服务器给出的需要输入密码的提示文字,所以想配置什么服务器的触发器直接改个登陆名和服务器地址就可以
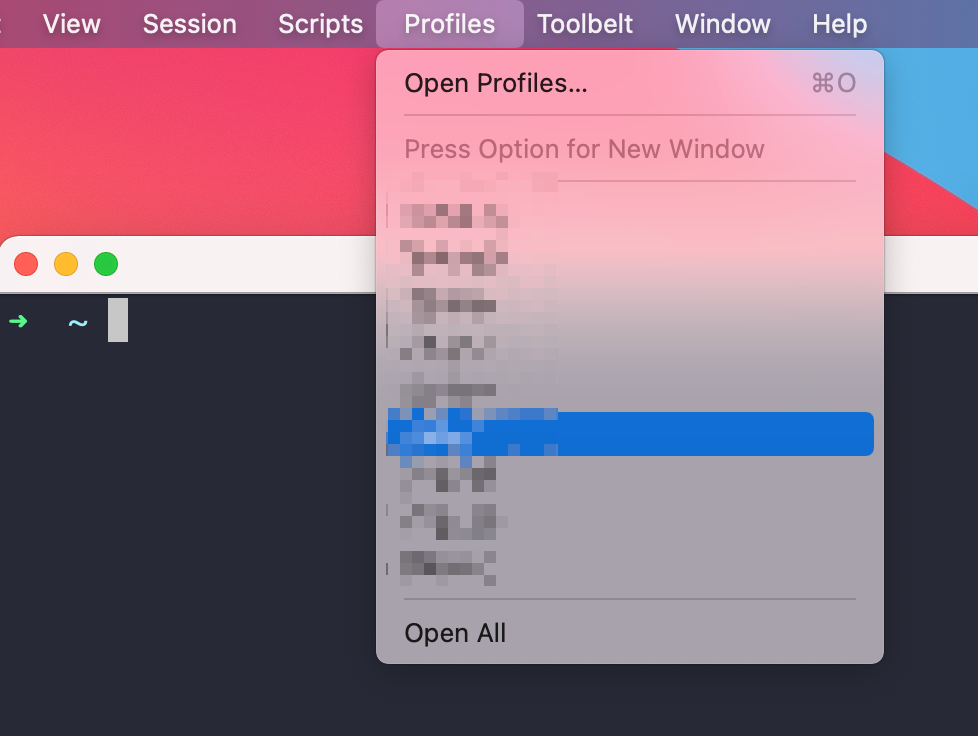
配置完毕后,可以根据菜单栏的profiles选项卡,选择需要连接的服务器即可
Set-ExecutionPolicy Bypass -Scope Process -Force; Invoke-Expression ((New-Object System.Net.WebClient).DownloadString('https://ohmyposh.dev/install.ps1'))如果不安装Nerd Fonts会有乱码情况,oh-my-posh推荐安装Meslo LGM NF字体,也可以从https://www.nerdfonts.com/font-downloads自行选择下载。下载后解压放到C:\windows\Fonts文件夹中。编辑Windows Terminal默认设置将默认字体改为喜欢的Nerd Fonts。
code $PROFILE或notepad $PROFILE
oh-my-posh init pwsh | Invoke-Expression # 默认主题
+
+oh-my-posh init pwsh --config C:\Users\story\AppData\Local\Programs\oh-my-posh\themes\robbyrussel.omp.json | Invoke-Expression # --config可以配置喜欢的主题
+
+--config 'https://raw.githubusercontent.com/JanDeDobbeleer/oh-my-posh/main/themes/jandedobbeleer.omp.json' # 也可以配置远程主题# 设置预测文本来源为历史记录
+Set-PSReadLineOption -PredictionSource History
+# 设置向上键为后向搜索历史记录
+Set-PSReadLineKeyHandler -Key UpArrow -Function HistorySearchBackward
+# 设置向下键为前向搜索历史纪录
+Set-PSReadLineKeyHandler -Key DownArrow -Function HistorySearchForwardwindows安装后默认的主题文件夹为:C:\Users\[your username]\AppData\Local\Programs\oh-my-posh\themes,也可以通过echo $env:POSH_THEMES_PATH命令查看主题的路径
配置立即生效:
. $PROFILE效果图:
默认:
jandedobbeleer:
开发中经常有这样一种场景,一个接口需要处理的请求中的内容包含多种不同的类型。比如支付系统,订单支付的时候可能是支付宝支付,微信支付或者银联支付等。又或者是订单系统,订单可能是普通订单,可能是团购订单,也可能是秒杀订单。前阵子做的一个预览Office文件的功能也与之类似,文件的类型不同,也需要采取不同的处理方案。这时候最简单的做法就是在controller中写n多个if else:
if ( "excel".equals(file.getType)) {
+ //***
+} else if("word".equals(file.getType()){
+ //***
+} ……如果后面再加其他的类型,那就继续加if else语句,这样代码就会变的很丑陋,而且每次都需要对controller代码进行修改,后续的扩展很麻烦。所以这种情况通常会采用策略模式来进行处理,这样我们的代码会变得更加优雅,方便后续的维护。
策略模式是一种行为模式,主要作用是在程序运行时动态切换一个类的行为或者算法。我们需要做的就是创建一个定义行为的Strategy接口以及它的具体策略实现类,以及一个策略的上下文来动态切换策略。
下面将介绍具体的实现方案,以订单系统为例
环境搭建
<parent>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter-parent</artifactId>
+ <version>2.1.4.RELEASE</version>
+</parent>
+<dependencies>
+ <dependency>
+ <groupId>org.projectlombok</groupId>
+ <artifactId>lombok</artifactId>
+ <version>1.18.6</version>
+ </dependency>
+ <dependency>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter-web</artifactId>
+ <version>2.1.4.RELEASE</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.commons</groupId>
+ <artifactId>commons-lang3</artifactId>
+ <version>3.8.1</version>
+ </dependency>
+</dependencies>订单实体类
@Data
+public class Order {
+ private String code;
+ private BigDecimal price;
+ /**
+ * 1: 普通订单
+ * 2: 秒杀订单
+ * 3: 团购订单
+ */
+ private String type;
+}抽象策略接口
public interface OrderStrategy {
+ String handleOrder(Order order);
+}策略具体实现
@Component
+public class NormalHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(Order order) {
+ return "普通订单处理完毕";
+ }
+}
+
+@Component
+public class GroupHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(Order order) {
+ return "团购订单处理完毕";
+ }
+}
+
+@Component
+public class SecKillHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(Order order) {
+ return "秒杀订单处理完毕";
+ }
+}SpringUtils
@Component
+public class SpringUtils implements ApplicationContextAware {
+
+ private static ApplicationContext applicationContext;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ SpringUtils.applicationContext = applicationContext;
+ }
+
+ //获取applicationContext
+ private static ApplicationContext getApplicationContext() {
+ return applicationContext;
+ }
+
+ //通过name获取 Bean.
+ public static Object getBean(String name){
+ return getApplicationContext().getBean(name);
+ }
+
+ //通过class获取Bean.
+ public static <T> T getBean(Class<T> clazz){
+ return getApplicationContext().getBean(clazz);
+ }
+
+ //通过name,以及Clazz返回指定的Bean
+ public static <T> T getBean(String name,Class<T> clazz){
+ return getApplicationContext().getBean(name, clazz);
+ }
+
+}可以采取配置的方式,将不同类型和对应的handler的bean name配置在配置文件或者是数据库中,这样我们在context中可以直接获取配置文件中的bean name或者去数据库中查询,然后从spring容器中获取对应的bean并调用处理方法即可。
以将映射关系持久化到数据库为例,我们需要建一张表来维护类型和具体处理器之间的关系 字段为type和对应处理器的bean名称
controller
@RestController
+@RequestMapping("/api/order")
+public class OrderController {
+
+ @Autowired
+ private IOrderService orderService;
+
+
+ @GetMapping("/{type}")
+ public String handleOrder(@PathVariable String type){
+ return orderService.handleOrder(type);
+ }
+}service
@Service
+public class OrderServiceImpl implements IOrderService {
+
+ @Autowired
+ private OrderStrategyContext context;
+
+ @Override
+ public String handleOrder(String type) {
+ return context.getBean(type).handleOrder(type);
+ }
+}context
@Component
+public class OrderStrategyContext {
+ @Autowired
+ private StrategyMapper mapper;
+
+ public OrderStrategy getBean(String type){
+ String beanName = mapper.getBeanName(type);
+ return SpringUtils.getBean(beanName);
+ }
+
+}第一种方案相较于无尽的if else已经好很多了,但是还是需要增加配置文件或者数据库中新建表来维护类型和对应处理器的映射关系。还可以直接自定义注解来实现这个关系的对应。
自定义注解HandlerType
@Target({ElementType.TYPE})
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Inherited
+public @interface HandlerType {
+ String value();
+}然后在每个具体策略类上加上注解
@Component
+@HandlerType("1")
+public class NormalHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(String type) {
+ return "普通订单处理完毕";
+ }
+}@Component
+@HandlerType("2")
+public class GroupHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(String type) {
+ return "团购订单处理完毕";
+ }
+}@Component
+@HandlerType("3")
+public class SecKillHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(String type) {
+ return "秒杀订单处理完毕";
+ }
+}策略上下文context修改为
public class OrderStrategyContext {
+
+ private Map<String,Class> handlerMap;
+
+ public OrderStrategyContext(Map<String,Class> handlerMap){
+ this.handlerMap = handlerMap;
+ }
+
+ public OrderStrategy getBean(String type){
+ Class clazz = handlerMap.get(type);
+ if (clazz == null) {
+ throw new IllegalArgumentException("not found handler for type :" + type);
+ }
+ return (OrderStrategy) SpringUtils.getBean(clazz);
+ }
+}自定义注解后,我们需要将注解的value和对应策略类的bean_name放到上下文的handlerMap中,并将策略上下文对象注册到spring容器里,需要一个处理类HandlerProcessor
@Component
+public class HandlerProcessor implements BeanFactoryPostProcessor {
+
+ private static final String HANDLE_PACKAGE = "com.test.handler";
+
+ @Override
+ public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
+ Map<String,Class> map = new HashMap<>();
+ ClassScaner.scan(HANDLE_PACKAGE, HandlerType.class).forEach(clazz -> {
+ //获取注解中对应的类型
+ String type = clazz.getAnnotation(HandlerType.class).value();
+ //注解的类型值作为key,对应的类作为value,存储在map中
+ map.put(type,clazz);
+ });
+ //初始化HandlerContext,注册到Spring容器中
+ OrderStrategyContext context = new OrderStrategyContext(map);
+ beanFactory.registerSingleton(OrderStrategyContext.class.getName(),context);
+ }
+}ClassScaner
public class ClassScaner implements ResourceLoaderAware {
+
+ private final List<TypeFilter> includeFilters = new LinkedList<TypeFilter>();
+ private final List<TypeFilter> excludeFilters = new LinkedList<TypeFilter>();
+
+ private ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
+ private MetadataReaderFactory metadataReaderFactory = new CachingMetadataReaderFactory(this.resourcePatternResolver);
+
+ @SafeVarargs
+ public static Set<Class<?>> scan(String[] basePackages, Class<? extends Annotation>... annotations) {
+ ClassScaner cs = new ClassScaner();
+
+ if (ArrayUtils.isNotEmpty(annotations)) {
+ for (Class anno : annotations) {
+ cs.addIncludeFilter(new AnnotationTypeFilter(anno));
+ }
+ }
+
+ Set<Class<?>> classes = new HashSet<>();
+ for (String s : basePackages) {
+ classes.addAll(cs.doScan(s));
+ }
+
+ return classes;
+ }
+
+ @SafeVarargs
+ public static Set<Class<?>> scan(String basePackages, Class<? extends Annotation>... annotations) {
+ return ClassScaner.scan(StringUtils.tokenizeToStringArray(basePackages, ",; \\t\\n"), annotations);
+ }
+
+ public final ResourceLoader getResourceLoader() {
+ return this.resourcePatternResolver;
+ }
+
+ @Override
+ public void setResourceLoader(ResourceLoader resourceLoader) {
+ this.resourcePatternResolver = ResourcePatternUtils
+ .getResourcePatternResolver(resourceLoader);
+ this.metadataReaderFactory = new CachingMetadataReaderFactory(
+ resourceLoader);
+ }
+
+ public void addIncludeFilter(TypeFilter includeFilter) {
+ this.includeFilters.add(includeFilter);
+ }
+
+ public void addExcludeFilter(TypeFilter excludeFilter) {
+ this.excludeFilters.add(0, excludeFilter);
+ }
+
+ public void resetFilters(boolean useDefaultFilters) {
+ this.includeFilters.clear();
+ this.excludeFilters.clear();
+ }
+
+ public Set<Class<?>> doScan(String basePackage) {
+ Set<Class<?>> classes = new HashSet<>();
+ try {
+ String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX
+ + org.springframework.util.ClassUtils
+ .convertClassNameToResourcePath(SystemPropertyUtils
+ .resolvePlaceholders(basePackage))
+ + "/**/*.class";
+ Resource[] resources = this.resourcePatternResolver
+ .getResources(packageSearchPath);
+
+ for (int i = 0; i < resources.length; i++) {
+ Resource resource = resources[i];
+ if (resource.isReadable()) {
+ MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
+ if ((includeFilters.size() == 0 && excludeFilters.size() == 0) || matches(metadataReader)) {
+ try {
+ classes.add(Class.forName(metadataReader
+ .getClassMetadata().getClassName()));
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+ } catch (IOException ex) {
+ throw new BeanDefinitionStoreException(
+ "I/O failure during classpath scanning", ex);
+ }
+ return classes;
+ }
+
+ protected boolean matches(MetadataReader metadataReader) throws IOException {
+ for (TypeFilter tf : this.excludeFilters) {
+ if (tf.match(metadataReader, this.metadataReaderFactory)) {
+ return false;
+ }
+ }
+ for (TypeFilter tf : this.includeFilters) {
+ if (tf.match(metadataReader, this.metadataReaderFactory)) {
+ return true;
+ }
+ }
+ return false;
+ }
+}扫描指定的包还是很麻烦,还可以直接使用ioc容器来直接进行操作 将OrderStrategyContext进行修改,不再需要processor类
@Component
+public class OrderStrategyContext implements ApplicationContextAware, CommandLineRunner {
+
+ private Map<String,Object> handlerMap = new HashMap<>();
+
+ public OrderStrategy getInstance(String type) {
+ Object obj = handlerMap.get(type);
+ if (obj == null) {
+ throw new IllegalArgumentException("handler not found for type : " + type);
+ }
+ if (obj instanceof OrderStrategy) {
+ return (OrderStrategy) obj;
+ } else {
+ throw new IllegalArgumentException("handler not found for type : " + type);
+ }
+ }
+
+ private ApplicationContext context;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ this.context = applicationContext;
+ }
+
+
+ @Override
+ public void run(String... args) throws Exception {
+ this.loadBean();
+ }
+
+ public void loadBean() {
+ Map<String, Object> beansWithAnnotation = context.getBeansWithAnnotation(HandlerType.class);
+ beansWithAnnotation.forEach((handlerBeanName,handlerBean)->{
+ Class<?> clazz = handlerBean.getClass();
+ HandlerType annotation = clazz.getAnnotation(HandlerType.class);
+ String annotationValue = annotation.value();
+ handlerMap.put(annotationValue,handlerBean);
+ });
+ }
+}
开发中经常有这样一种场景,一个接口需要处理的请求中的内容包含多种不同的类型。比如支付系统,订单支付的时候可能是支付宝支付,微信支付或者银联支付等。又或者是订单系统,订单可能是普通订单,可能是团购订单,也可能是秒杀订单。前阵子做的一个预览Office文件的功能也与之类似,文件的类型不同,也需要采取不同的处理方案。这时候最简单的做法就是在controller中写n多个if else:
if ( "excel".equals(file.getType)) {
+ //***
+} else if("word".equals(file.getType()){
+ //***
+} ……如果后面再加其他的类型,那就继续加if else语句,这样代码就会变的很丑陋,而且每次都需要对controller代码进行修改,后续的扩展很麻烦。所以这种情况通常会采用策略模式来进行处理,这样我们的代码会变得更加优雅,方便后续的维护。
策略模式是一种行为模式,主要作用是在程序运行时动态切换一个类的行为或者算法。我们需要做的就是创建一个定义行为的Strategy接口以及它的具体策略实现类,以及一个策略的上下文来动态切换策略。
下面将介绍具体的实现方案,以订单系统为例
环境搭建
<parent>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter-parent</artifactId>
+ <version>2.1.4.RELEASE</version>
+</parent>
+<dependencies>
+ <dependency>
+ <groupId>org.projectlombok</groupId>
+ <artifactId>lombok</artifactId>
+ <version>1.18.6</version>
+ </dependency>
+ <dependency>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter-web</artifactId>
+ <version>2.1.4.RELEASE</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.commons</groupId>
+ <artifactId>commons-lang3</artifactId>
+ <version>3.8.1</version>
+ </dependency>
+</dependencies>订单实体类
@Data
+public class Order {
+ private String code;
+ private BigDecimal price;
+ /**
+ * 1: 普通订单
+ * 2: 秒杀订单
+ * 3: 团购订单
+ */
+ private String type;
+}抽象策略接口
public interface OrderStrategy {
+ String handleOrder(Order order);
+}策略具体实现
@Component
+public class NormalHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(Order order) {
+ return "普通订单处理完毕";
+ }
+}
+
+@Component
+public class GroupHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(Order order) {
+ return "团购订单处理完毕";
+ }
+}
+
+@Component
+public class SecKillHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(Order order) {
+ return "秒杀订单处理完毕";
+ }
+}SpringUtils
@Component
+public class SpringUtils implements ApplicationContextAware {
+
+ private static ApplicationContext applicationContext;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ SpringUtils.applicationContext = applicationContext;
+ }
+
+ //获取applicationContext
+ private static ApplicationContext getApplicationContext() {
+ return applicationContext;
+ }
+
+ //通过name获取 Bean.
+ public static Object getBean(String name){
+ return getApplicationContext().getBean(name);
+ }
+
+ //通过class获取Bean.
+ public static <T> T getBean(Class<T> clazz){
+ return getApplicationContext().getBean(clazz);
+ }
+
+ //通过name,以及Clazz返回指定的Bean
+ public static <T> T getBean(String name,Class<T> clazz){
+ return getApplicationContext().getBean(name, clazz);
+ }
+
+}可以采取配置的方式,将不同类型和对应的handler的bean name配置在配置文件或者是数据库中,这样我们在context中可以直接获取配置文件中的bean name或者去数据库中查询,然后从spring容器中获取对应的bean并调用处理方法即可。
以将映射关系持久化到数据库为例,我们需要建一张表来维护类型和具体处理器之间的关系 字段为type和对应处理器的bean名称
controller
@RestController
+@RequestMapping("/api/order")
+public class OrderController {
+
+ @Autowired
+ private IOrderService orderService;
+
+
+ @GetMapping("/{type}")
+ public String handleOrder(@PathVariable String type){
+ return orderService.handleOrder(type);
+ }
+}service
@Service
+public class OrderServiceImpl implements IOrderService {
+
+ @Autowired
+ private OrderStrategyContext context;
+
+ @Override
+ public String handleOrder(String type) {
+ return context.getBean(type).handleOrder(type);
+ }
+}context
@Component
+public class OrderStrategyContext {
+ @Autowired
+ private StrategyMapper mapper;
+
+ public OrderStrategy getBean(String type){
+ String beanName = mapper.getBeanName(type);
+ return SpringUtils.getBean(beanName);
+ }
+
+}第一种方案相较于无尽的if else已经好很多了,但是还是需要增加配置文件或者数据库中新建表来维护类型和对应处理器的映射关系。还可以直接自定义注解来实现这个关系的对应。
自定义注解HandlerType
@Target({ElementType.TYPE})
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Inherited
+public @interface HandlerType {
+ String value();
+}然后在每个具体策略类上加上注解
@Component
+@HandlerType("1")
+public class NormalHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(String type) {
+ return "普通订单处理完毕";
+ }
+}@Component
+@HandlerType("2")
+public class GroupHandler implements OrderStrategy {
+ @Override
+ public String handleOrder(String type) {
+ return "团购订单处理完毕";
+ }
+}@Component
+@HandlerType("3")
+public class SecKillHandler implements OrderStrategy {
+
+ @Override
+ public String handleOrder(String type) {
+ return "秒杀订单处理完毕";
+ }
+}策略上下文context修改为
public class OrderStrategyContext {
+
+ private Map<String,Class> handlerMap;
+
+ public OrderStrategyContext(Map<String,Class> handlerMap){
+ this.handlerMap = handlerMap;
+ }
+
+ public OrderStrategy getBean(String type){
+ Class clazz = handlerMap.get(type);
+ if (clazz == null) {
+ throw new IllegalArgumentException("not found handler for type :" + type);
+ }
+ return (OrderStrategy) SpringUtils.getBean(clazz);
+ }
+}自定义注解后,我们需要将注解的value和对应策略类的bean_name放到上下文的handlerMap中,并将策略上下文对象注册到spring容器里,需要一个处理类HandlerProcessor
@Component
+public class HandlerProcessor implements BeanFactoryPostProcessor {
+
+ private static final String HANDLE_PACKAGE = "com.test.handler";
+
+ @Override
+ public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
+ Map<String,Class> map = new HashMap<>();
+ ClassScaner.scan(HANDLE_PACKAGE, HandlerType.class).forEach(clazz -> {
+ //获取注解中对应的类型
+ String type = clazz.getAnnotation(HandlerType.class).value();
+ //注解的类型值作为key,对应的类作为value,存储在map中
+ map.put(type,clazz);
+ });
+ //初始化HandlerContext,注册到Spring容器中
+ OrderStrategyContext context = new OrderStrategyContext(map);
+ beanFactory.registerSingleton(OrderStrategyContext.class.getName(),context);
+ }
+}ClassScaner
public class ClassScaner implements ResourceLoaderAware {
+
+ private final List<TypeFilter> includeFilters = new LinkedList<TypeFilter>();
+ private final List<TypeFilter> excludeFilters = new LinkedList<TypeFilter>();
+
+ private ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
+ private MetadataReaderFactory metadataReaderFactory = new CachingMetadataReaderFactory(this.resourcePatternResolver);
+
+ @SafeVarargs
+ public static Set<Class<?>> scan(String[] basePackages, Class<? extends Annotation>... annotations) {
+ ClassScaner cs = new ClassScaner();
+
+ if (ArrayUtils.isNotEmpty(annotations)) {
+ for (Class anno : annotations) {
+ cs.addIncludeFilter(new AnnotationTypeFilter(anno));
+ }
+ }
+
+ Set<Class<?>> classes = new HashSet<>();
+ for (String s : basePackages) {
+ classes.addAll(cs.doScan(s));
+ }
+
+ return classes;
+ }
+
+ @SafeVarargs
+ public static Set<Class<?>> scan(String basePackages, Class<? extends Annotation>... annotations) {
+ return ClassScaner.scan(StringUtils.tokenizeToStringArray(basePackages, ",; \\t\\n"), annotations);
+ }
+
+ public final ResourceLoader getResourceLoader() {
+ return this.resourcePatternResolver;
+ }
+
+ @Override
+ public void setResourceLoader(ResourceLoader resourceLoader) {
+ this.resourcePatternResolver = ResourcePatternUtils
+ .getResourcePatternResolver(resourceLoader);
+ this.metadataReaderFactory = new CachingMetadataReaderFactory(
+ resourceLoader);
+ }
+
+ public void addIncludeFilter(TypeFilter includeFilter) {
+ this.includeFilters.add(includeFilter);
+ }
+
+ public void addExcludeFilter(TypeFilter excludeFilter) {
+ this.excludeFilters.add(0, excludeFilter);
+ }
+
+ public void resetFilters(boolean useDefaultFilters) {
+ this.includeFilters.clear();
+ this.excludeFilters.clear();
+ }
+
+ public Set<Class<?>> doScan(String basePackage) {
+ Set<Class<?>> classes = new HashSet<>();
+ try {
+ String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX
+ + org.springframework.util.ClassUtils
+ .convertClassNameToResourcePath(SystemPropertyUtils
+ .resolvePlaceholders(basePackage))
+ + "/**/*.class";
+ Resource[] resources = this.resourcePatternResolver
+ .getResources(packageSearchPath);
+
+ for (int i = 0; i < resources.length; i++) {
+ Resource resource = resources[i];
+ if (resource.isReadable()) {
+ MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
+ if ((includeFilters.size() == 0 && excludeFilters.size() == 0) || matches(metadataReader)) {
+ try {
+ classes.add(Class.forName(metadataReader
+ .getClassMetadata().getClassName()));
+ } catch (ClassNotFoundException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+ } catch (IOException ex) {
+ throw new BeanDefinitionStoreException(
+ "I/O failure during classpath scanning", ex);
+ }
+ return classes;
+ }
+
+ protected boolean matches(MetadataReader metadataReader) throws IOException {
+ for (TypeFilter tf : this.excludeFilters) {
+ if (tf.match(metadataReader, this.metadataReaderFactory)) {
+ return false;
+ }
+ }
+ for (TypeFilter tf : this.includeFilters) {
+ if (tf.match(metadataReader, this.metadataReaderFactory)) {
+ return true;
+ }
+ }
+ return false;
+ }
+}扫描指定的包还是很麻烦,还可以直接使用ioc容器来直接进行操作 将OrderStrategyContext进行修改,不再需要processor类
@Component
+public class OrderStrategyContext implements ApplicationContextAware, CommandLineRunner {
+
+ private Map<String,Object> handlerMap = new HashMap<>();
+
+ public OrderStrategy getInstance(String type) {
+ Object obj = handlerMap.get(type);
+ if (obj == null) {
+ throw new IllegalArgumentException("handler not found for type : " + type);
+ }
+ if (obj instanceof OrderStrategy) {
+ return (OrderStrategy) obj;
+ } else {
+ throw new IllegalArgumentException("handler not found for type : " + type);
+ }
+ }
+
+ private ApplicationContext context;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ this.context = applicationContext;
+ }
+
+
+ @Override
+ public void run(String... args) throws Exception {
+ this.loadBean();
+ }
+
+ public void loadBean() {
+ Map<String, Object> beansWithAnnotation = context.getBeansWithAnnotation(HandlerType.class);
+ beansWithAnnotation.forEach((handlerBeanName,handlerBean)->{
+ Class<?> clazz = handlerBean.getClass();
+ HandlerType annotation = clazz.getAnnotation(HandlerType.class);
+ String annotationValue = annotation.value();
+ handlerMap.put(annotationValue,handlerBean);
+ });
+ }
+}
根据不同的订单结算金额规则配置,来计算出每一条订单商品的结算金额,每条规则都有自己的匹配条件,匹配上的则应用该条规则所配置的结算金额计算公式。客户可以配置多条不同的规则,组成一条规则链。每条订单商品记录按规则的顺序依次进行条件匹配,如果匹配上则停止,匹配不上继续,直至规则链结束,没有匹配则使用默认规则进行兜底。
责任链模式(Chain of Responsibility Pattern)是一种软件设计模式,它可以让多个对象都有机会处理请求,从而避免了请求的发送者和接收者之间的耦合关系。在责任链模式中,每个对象都有其对应的处理请求的方法,如果一个对象不能够处理该请求,那么它会将这个请求传递给下一个对象来处理,直到找到能够处理该请求的对象为止。
责任链模式通常由以下几个角色组成:
责任链模式的优点在于它能够降低系统的耦合度,增强系统的可扩展性和灵活性。同时,由于责任链模式中的处理者之间是松散耦合的,因此可以方便地增加或删除处理者,而不会影响到其他部分的功能。
上述需求,其实就是典型的责任链模式的应用场景。而责任链模式一般有两种实现:指针和集合的方式。
指针模式是最常见的责任链模式实现方式之一。在这种模式下,每个处理对象都持有一个指向下一个处理对象的引用,形成一个链表。当请求到达一个处理对象时,如果该对象无法处理该请求,则将请求传递给链表中的下一个对象,直到找到能够处理该请求的对象为止。
集合模式是另一种责任链模式实现方式。与指针模式不同的是,集合模式下,所有的处理对象被封装在一个集合中,每个对象都具有相同的处理机会。当请求到达集合时,集合中的每个对象都有机会去处理请求,直到有一个对象成功地处理了请求或者所有对象都无法处理该请求为止。
public abstract class HandlerChain<T, R extends Rule> {
+
+ protected List<Handler<T, R>> handlers;
+
+ public void setHandlers(List<Handler<T, R>> handlers) {
+ this.handlers = handlers;
+ }
+
+ public List<Handler<T, R>> getHandlers() {
+ return handlers;
+ }
+
+ public void handle(T t) {
+ if (CollUtil.isNotEmpty(handlers)) {
+ for (Handler<T, R> handler : handlers) {
+ if (!handler.handle(t)) {
+ break;
+ }
+ }
+ }
+ }
+
+ public void clear() {
+ if (CollUtil.isNotEmpty(handlers)) {
+ handlers.clear();
+ }
+ }
+}public abstract class Handler<T, R extends Rule> {
+
+ protected CommonDynamicParam param;
+ protected R rule;
+
+ public abstract boolean handle(T t);
+
+ public CommonDynamicParam getParam() {
+ return param;
+ }
+
+ public void setParam(CommonDynamicParam param) {
+ this.param = param;
+ }
+
+ public R getRule() {
+ return rule;
+ }
+
+ public void setRule(R rule) {
+ this.rule = rule;
+ this.param = JSON.parseObject(rule.getSettlementCondition(), CommonDynamicParam.class);
+ }
+}实现具体的Handler处理器逻辑(handle)
初始化处理器集合List<Handler>,并交给责任链对象HandlerChain管理
调用责任链的handle方法处理对象
根据不同的订单结算金额规则配置,来计算出每一条订单商品的结算金额,每条规则都有自己的匹配条件,匹配上的则应用该条规则所配置的结算金额计算公式。客户可以配置多条不同的规则,组成一条规则链。每条订单商品记录按规则的顺序依次进行条件匹配,如果匹配上则停止,匹配不上继续,直至规则链结束,没有匹配则使用默认规则进行兜底。
责任链模式(Chain of Responsibility Pattern)是一种软件设计模式,它可以让多个对象都有机会处理请求,从而避免了请求的发送者和接收者之间的耦合关系。在责任链模式中,每个对象都有其对应的处理请求的方法,如果一个对象不能够处理该请求,那么它会将这个请求传递给下一个对象来处理,直到找到能够处理该请求的对象为止。
责任链模式通常由以下几个角色组成:
责任链模式的优点在于它能够降低系统的耦合度,增强系统的可扩展性和灵活性。同时,由于责任链模式中的处理者之间是松散耦合的,因此可以方便地增加或删除处理者,而不会影响到其他部分的功能。
上述需求,其实就是典型的责任链模式的应用场景。而责任链模式一般有两种实现:指针和集合的方式。
指针模式是最常见的责任链模式实现方式之一。在这种模式下,每个处理对象都持有一个指向下一个处理对象的引用,形成一个链表。当请求到达一个处理对象时,如果该对象无法处理该请求,则将请求传递给链表中的下一个对象,直到找到能够处理该请求的对象为止。
集合模式是另一种责任链模式实现方式。与指针模式不同的是,集合模式下,所有的处理对象被封装在一个集合中,每个对象都具有相同的处理机会。当请求到达集合时,集合中的每个对象都有机会去处理请求,直到有一个对象成功地处理了请求或者所有对象都无法处理该请求为止。
public abstract class HandlerChain<T, R extends Rule> {
+
+ protected List<Handler<T, R>> handlers;
+
+ public void setHandlers(List<Handler<T, R>> handlers) {
+ this.handlers = handlers;
+ }
+
+ public List<Handler<T, R>> getHandlers() {
+ return handlers;
+ }
+
+ public void handle(T t) {
+ if (CollUtil.isNotEmpty(handlers)) {
+ for (Handler<T, R> handler : handlers) {
+ if (!handler.handle(t)) {
+ break;
+ }
+ }
+ }
+ }
+
+ public void clear() {
+ if (CollUtil.isNotEmpty(handlers)) {
+ handlers.clear();
+ }
+ }
+}public abstract class Handler<T, R extends Rule> {
+
+ protected CommonDynamicParam param;
+ protected R rule;
+
+ public abstract boolean handle(T t);
+
+ public CommonDynamicParam getParam() {
+ return param;
+ }
+
+ public void setParam(CommonDynamicParam param) {
+ this.param = param;
+ }
+
+ public R getRule() {
+ return rule;
+ }
+
+ public void setRule(R rule) {
+ this.rule = rule;
+ this.param = JSON.parseObject(rule.getSettlementCondition(), CommonDynamicParam.class);
+ }
+}实现具体的Handler处理器逻辑(handle)
初始化处理器集合List<Handler>,并交给责任链对象HandlerChain管理
调用责任链的handle方法处理对象
# server.properties
+listeners=PLAINTEXT://:9092
+advertised.listeners=PLAINTEXT://host.docker.internal:9092127.0.0.1 host.docker.internal# List brokers and topics in cluster
+$ docker run -it --rm --network=host --platform=linux/amd64 edenhill/kcat:1.7.1 -b host.docker.internal -Lbootstrap.servers配置的地址去连接kafka的brokeradvertised.listeners配置的地址给kafka客户端advertised.listeners配置的地址去连接kafka的broker如果kafka只配置listeners=PLAINTEXT://:9092而不配置advertised.listeners=PLAINTEXT://host.docker.internal:9092,那么kafka容器内部的客户端是无法访问到kafka的,因为kafka容器内部的客户端会通过advertised.listeners配置的地址去访问kafka,而默认的advertised.listeners配置和listeners一致,也是PLAINTEXT://:9092,对于容器内的客户端来说这个地址是容器内部的地址,所以容器内部的客户端无法访问到宿主机kafka。因此要加上advertised.listeners=PLAINTEXT://host.docker.internal:9092。
因为配置了advertised.listeners=PLAINTEXT://host.docker.internal:9092,所以宿主机上的客户端也会通过host.docker.internal:9092访问kafka的broker,所以要在/etc/hosts中增加解析host.docker.internal到本地回环地址的配置。
# server.properties
+listeners=PLAINTEXT://:9092
+advertised.listeners=PLAINTEXT://host.docker.internal:9092127.0.0.1 host.docker.internal# List brokers and topics in cluster
+$ docker run -it --rm --network=host --platform=linux/amd64 edenhill/kcat:1.7.1 -b host.docker.internal -Lbootstrap.servers配置的地址去连接kafka的brokeradvertised.listeners配置的地址给kafka客户端advertised.listeners配置的地址去连接kafka的broker如果kafka只配置listeners=PLAINTEXT://:9092而不配置advertised.listeners=PLAINTEXT://host.docker.internal:9092,那么kafka容器内部的客户端是无法访问到kafka的,因为kafka容器内部的客户端会通过advertised.listeners配置的地址去访问kafka,而默认的advertised.listeners配置和listeners一致,也是PLAINTEXT://:9092,对于容器内的客户端来说这个地址是容器内部的地址,所以容器内部的客户端无法访问到宿主机kafka。因此要加上advertised.listeners=PLAINTEXT://host.docker.internal:9092。
因为配置了advertised.listeners=PLAINTEXT://host.docker.internal:9092,所以宿主机上的客户端也会通过host.docker.internal:9092访问kafka的broker,所以要在/etc/hosts中增加解析host.docker.internal到本地回环地址的配置。
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestartdism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestartwsl --set-default-version 2https://docs.microsoft.com/zh-cn/windows/wsl/install-manual,下载完成后cd到下载的目录,执行Add-AppxPackage .\\filename即可wsl --list --allwsl --unregister <DistributionName>win+R运行shell:startup打开开机启动程序文件夹,创建vbs脚本wsl.vbs
Set objShell = CreateObject("WScript.Shell")
+objShell.Run "cmd /c wsl -d Debian", 0
+Set objShell = Nothinghttps://devblogs.microsoft.com/commandline/systemd-support-is-now-available-in-wsl/
//wsl.conf
+[boot]
+systemd=truesystemctl list-unit-files --type=service检查systemd运行状态
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestartdism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestartwsl --set-default-version 2https://docs.microsoft.com/zh-cn/windows/wsl/install-manual,下载完成后cd到下载的目录,执行Add-AppxPackage .\\filename即可wsl --list --allwsl --unregister <DistributionName>win+R运行shell:startup打开开机启动程序文件夹,创建vbs脚本wsl.vbs
Set objShell = CreateObject("WScript.Shell")
+objShell.Run "cmd /c wsl -d Debian", 0
+Set objShell = Nothinghttps://devblogs.microsoft.com/commandline/systemd-support-is-now-available-in-wsl/
//wsl.conf
+[boot]
+systemd=truesystemctl list-unit-files --type=service检查systemd运行状态
之前个人博客一直用的travisCI部署在github page上,但是偶尔会抽风无法访问。之前一直偷懒没部署jenkins,手动部署到云服务器又比较麻烦,打包上传很浪费时间,这次就直接动手一步到位,在自己服务器上部署下jekins。
最开始用的jenkins中文社区的镜像发现有个很恶心的问题,jenkins版本比较低而且安装了NodeJS插件后在全局工具配置中配置NodeJS安装环境时无法选择版本,所以还是官方镜像比较靠谱。
# 拉取官方镜像
+docker pull jenkins/jenkins:lts
+lts: Pulling from jenkins/jenkins
+4c25b3090c26: Pull complete
+750d566fdd60: Pull complete
+2718cc36ca02: Pull complete
+5678b027ee14: Pull complete
+c839cd2df78d: Pull complete
+50861a5addda: Pull complete
+ff2b028e5cf5: Pull complete
+ee710b58f452: Pull complete
+2625c929bb0e: Pull complete
+6a6bf9181c04: Pull complete
+bee5e6792ac4: Pull complete
+6cc5edd2133e: Pull complete
+c07b16426ded: Pull complete
+e9ac42647ae3: Pull complete
+fa925738a490: Pull complete
+4a08c3886279: Pull complete
+2d43fec22b7e: Pull complete
+Digest: sha256:a942c30fc3bcf269a1c32ba27eb4a470148eff9aba086911320031a3c3943e6c
+Status: Downloaded newer image for jenkins/jenkins:lts
+docker.io/jenkins/jenkins:lts
+# 启动jenkins
+docker run --name jenkins -dp 8099:8080 -v /story/dist:/story/dist -v ~/jenkins_data:/var/jenkins_home -u root -e TZ="Asia/Shanghai" -v /etc/localtime:/etc/localtime:ro jenkins/jenkins:lts
+# 参数说明 --name 指定容器名为jenkins -d 后台启动 -p 将容器的8080端口映射到宿主机的8099端口
+# -v 挂载宿主机目录 宿主机和容器的目录会同步 -u 指定用户为root 这里是必须的 不然后续操作文件系统会报无权限
+# 挂载时区的目录是因为镜像中的linux系统默认时区非北京时间,会导致时间显示不正确http://localhost:8099/(我这里是本地测试,实际请替换成自己的服务器地址)curl -fsSL https://pkg.jenkins.io/debian-stable/jenkins.io-2023.key | sudo tee \\
+ /usr/share/keyrings/jenkins-keyring.asc > /dev/null
+
+sudo sh -c 'echo "deb [signed-by=/usr/share/keyrings/jenkins-keyring.asc] https://pkg.jenkins.io/debian-stable binary/" > /etc/apt/sources.list.d/jenkins.list'
+
+sudo apt update
+
+# Jenkins requires Java 11 or 17 since Jenkins 2.357 and LTS 2.361.1.
+apt install openjdk-17-jdk
+
+sudo apt install jenkins
docker exec -it jenkins /bin/bash
+cat /var/jenkins_home/secrets/initialAdminPassword或者直接在上面挂载的目录查询但要改一下路径
cat ~/jenkins_data/secrets/initialAdminPassword
实例配置
完成
Manage Jenkins ---> Manage Plugins ---> 可选插件分别搜索gitee和nodejs
选择install without restart
安装完毕后返回工作台
Manage Jenkins ---> Global Tool Configuration ---> NodeJS
新增NodeJS取别名后保存即可
工作台点击新建Item,输入任务名称后选择freestyle project确定
去gitee仓库中配置webhook内容
仓库的管理tab页添加webhook
url和webhook密码分别填写后保存
在这个页面点击测试,如果看到xxx has been accepted即为成功。
选择前面已经配置好的node环境即可
首先在任务面板中点击立即构建,这样才会生成工作空间
我这里选择执行shell
然后就是写个简单的脚本执行打包,替换的工作
第一步cd进入的目录是当前任务的工作空间,这里要把vuepress替换成自己的任务名称即可
TIP
这里涉及到文件系统操作的内容rm cp等命令需要root用户才能执行,所以在启动docker容器的时候必须使用-u root参数指定root用户,否则打包会失败,操作文件时会提示无权限
配置完毕保存即可
点击立即构建或者往gitee仓库推送一次更新即可触发构建任务,然后等待构建完成即可。
如果是第一次执行构建,jenkins还会自动安装解压nodejs。
通过脚本替换完打包好的dist后,通过nginx配置部署静态项目即可。
这里是用宿主机直接安装的jenkins
把jenkins用户添加到docker组中然后重启jenkins:sudo usermod -aG docker jenkins
getent group groupname 查看组中有哪些用户
shell
#!/bin/sh
+cd /var/lib/jenkins/workspace/xxx
+node -v
+npm -v
+docker -v
+
+npm install
+npm run build
+docker buildx ls
+docker buildx create --use --name jenkinsbuilder
+docker buildx ls
+
+# Dockerfile
+cat > Dockerfile <<EOF
+// doSomething
+EOF
+
+docker login xxx.com --username='xxx' --password=='xxx'
+docker buildx build --platform linux/amd64,linux/arm64 -t xxx/xxx . --push在Execute shell中添加如下变量
BUILD_ID=DONTKILLME之前个人博客一直用的travisCI部署在github page上,但是偶尔会抽风无法访问。之前一直偷懒没部署jenkins,手动部署到云服务器又比较麻烦,打包上传很浪费时间,这次就直接动手一步到位,在自己服务器上部署下jekins。
最开始用的jenkins中文社区的镜像发现有个很恶心的问题,jenkins版本比较低而且安装了NodeJS插件后在全局工具配置中配置NodeJS安装环境时无法选择版本,所以还是官方镜像比较靠谱。
# 拉取官方镜像
+docker pull jenkins/jenkins:lts
+lts: Pulling from jenkins/jenkins
+4c25b3090c26: Pull complete
+750d566fdd60: Pull complete
+2718cc36ca02: Pull complete
+5678b027ee14: Pull complete
+c839cd2df78d: Pull complete
+50861a5addda: Pull complete
+ff2b028e5cf5: Pull complete
+ee710b58f452: Pull complete
+2625c929bb0e: Pull complete
+6a6bf9181c04: Pull complete
+bee5e6792ac4: Pull complete
+6cc5edd2133e: Pull complete
+c07b16426ded: Pull complete
+e9ac42647ae3: Pull complete
+fa925738a490: Pull complete
+4a08c3886279: Pull complete
+2d43fec22b7e: Pull complete
+Digest: sha256:a942c30fc3bcf269a1c32ba27eb4a470148eff9aba086911320031a3c3943e6c
+Status: Downloaded newer image for jenkins/jenkins:lts
+docker.io/jenkins/jenkins:lts
+# 启动jenkins
+docker run --name jenkins -dp 8099:8080 -v /story/dist:/story/dist -v ~/jenkins_data:/var/jenkins_home -u root -e TZ="Asia/Shanghai" -v /etc/localtime:/etc/localtime:ro jenkins/jenkins:lts
+# 参数说明 --name 指定容器名为jenkins -d 后台启动 -p 将容器的8080端口映射到宿主机的8099端口
+# -v 挂载宿主机目录 宿主机和容器的目录会同步 -u 指定用户为root 这里是必须的 不然后续操作文件系统会报无权限
+# 挂载时区的目录是因为镜像中的linux系统默认时区非北京时间,会导致时间显示不正确http://localhost:8099/(我这里是本地测试,实际请替换成自己的服务器地址)curl -fsSL https://pkg.jenkins.io/debian-stable/jenkins.io-2023.key | sudo tee \\
+ /usr/share/keyrings/jenkins-keyring.asc > /dev/null
+
+sudo sh -c 'echo "deb [signed-by=/usr/share/keyrings/jenkins-keyring.asc] https://pkg.jenkins.io/debian-stable binary/" > /etc/apt/sources.list.d/jenkins.list'
+
+sudo apt update
+
+# Jenkins requires Java 11 or 17 since Jenkins 2.357 and LTS 2.361.1.
+apt install openjdk-17-jdk
+
+sudo apt install jenkins
docker exec -it jenkins /bin/bash
+cat /var/jenkins_home/secrets/initialAdminPassword或者直接在上面挂载的目录查询但要改一下路径
cat ~/jenkins_data/secrets/initialAdminPassword
实例配置
完成
Manage Jenkins ---> Manage Plugins ---> 可选插件分别搜索gitee和nodejs
选择install without restart
安装完毕后返回工作台
Manage Jenkins ---> Global Tool Configuration ---> NodeJS
新增NodeJS取别名后保存即可
工作台点击新建Item,输入任务名称后选择freestyle project确定
去gitee仓库中配置webhook内容
仓库的管理tab页添加webhook
url和webhook密码分别填写后保存
在这个页面点击测试,如果看到xxx has been accepted即为成功。
选择前面已经配置好的node环境即可
首先在任务面板中点击立即构建,这样才会生成工作空间
我这里选择执行shell
然后就是写个简单的脚本执行打包,替换的工作
第一步cd进入的目录是当前任务的工作空间,这里要把vuepress替换成自己的任务名称即可
TIP
这里涉及到文件系统操作的内容rm cp等命令需要root用户才能执行,所以在启动docker容器的时候必须使用-u root参数指定root用户,否则打包会失败,操作文件时会提示无权限
配置完毕保存即可
点击立即构建或者往gitee仓库推送一次更新即可触发构建任务,然后等待构建完成即可。
如果是第一次执行构建,jenkins还会自动安装解压nodejs。
通过脚本替换完打包好的dist后,通过nginx配置部署静态项目即可。
这里是用宿主机直接安装的jenkins
把jenkins用户添加到docker组中然后重启jenkins:sudo usermod -aG docker jenkins
getent group groupname 查看组中有哪些用户
shell
#!/bin/sh
+cd /var/lib/jenkins/workspace/xxx
+node -v
+npm -v
+docker -v
+
+npm install
+npm run build
+docker buildx ls
+docker buildx create --use --name jenkinsbuilder
+docker buildx ls
+
+# Dockerfile
+cat > Dockerfile <<EOF
+// doSomething
+EOF
+
+docker login xxx.com --username='xxx' --password=='xxx'
+docker buildx build --platform linux/amd64,linux/arm64 -t xxx/xxx . --push在Execute shell中添加如下变量
BUILD_ID=DONTKILLME# 设置代理
+git config --global http.proxy 'socks5://127.0.0.1:10880'
+
+git config --global https.proxy 'socks5://127.0.0.1:10880'
+
+# 取消代理
+git config --global --unset http.proxy
+
+git config --global --unset https.proxy端口号根据自己本地的代理端口填写
`,3)]))}const c=i(h,[["render",p]]);export{r as __pageData,c as default}; diff --git "a/assets/actions_env_git\351\205\215\347\275\256socks5\344\273\243\347\220\206\350\247\243\345\206\263github\344\270\212down\344\273\243\347\240\201\346\205\242\347\232\204\351\227\256\351\242\230.md.DD0Yfery.lean.js" "b/assets/actions_env_git\351\205\215\347\275\256socks5\344\273\243\347\220\206\350\247\243\345\206\263github\344\270\212down\344\273\243\347\240\201\346\205\242\347\232\204\351\227\256\351\242\230.md.DD0Yfery.lean.js" new file mode 100644 index 00000000..1369b328 --- /dev/null +++ "b/assets/actions_env_git\351\205\215\347\275\256socks5\344\273\243\347\220\206\350\247\243\345\206\263github\344\270\212down\344\273\243\347\240\201\346\205\242\347\232\204\351\227\256\351\242\230.md.DD0Yfery.lean.js" @@ -0,0 +1,9 @@ +import{_ as i,c as a,a2 as n,o as t}from"./chunks/framework.BjcrtTwI.js";const r=JSON.parse('{"title":"git配置socks5代理解决github上down代码慢的问题","description":"","frontmatter":{},"headers":[],"relativePath":"actions/env/git配置socks5代理解决github上down代码慢的问题.md","filePath":"actions/env/git配置socks5代理解决github上down代码慢的问题.md","lastUpdated":1729217313000}'),h={name:"actions/env/git配置socks5代理解决github上down代码慢的问题.md"};function p(l,s,e,k,o,g){return t(),a("div",null,s[0]||(s[0]=[n(`# 设置代理
+git config --global http.proxy 'socks5://127.0.0.1:10880'
+
+git config --global https.proxy 'socks5://127.0.0.1:10880'
+
+# 取消代理
+git config --global --unset http.proxy
+
+git config --global --unset https.proxy端口号根据自己本地的代理端口填写
`,3)]))}const c=i(h,[["render",p]]);export{r as __pageData,c as default}; diff --git "a/assets/actions_env_git\351\205\215\347\275\256\345\244\232ssh-key __ Gitee \345\222\214 Github \345\220\214\346\255\245\346\233\264\346\226\260.md.BXEkznmY.js" "b/assets/actions_env_git\351\205\215\347\275\256\345\244\232ssh-key __ Gitee \345\222\214 Github \345\220\214\346\255\245\346\233\264\346\226\260.md.BXEkznmY.js" new file mode 100644 index 00000000..0549c191 --- /dev/null +++ "b/assets/actions_env_git\351\205\215\347\275\256\345\244\232ssh-key __ Gitee \345\222\214 Github \345\220\214\346\255\245\346\233\264\346\226\260.md.BXEkznmY.js" @@ -0,0 +1,16 @@ +import{_ as i,c as a,a2 as e,o as t}from"./chunks/framework.BjcrtTwI.js";const r=JSON.parse('{"title":"git配置多ssh-key && Gitee 和 Github 同步更新","description":"","frontmatter":{},"headers":[],"relativePath":"actions/env/git配置多ssh-key && Gitee 和 Github 同步更新.md","filePath":"actions/env/git配置多ssh-key && Gitee 和 Github 同步更新.md","lastUpdated":1729217313000}'),n={name:"actions/env/git配置多ssh-key && Gitee 和 Github 同步更新.md"};function p(h,s,l,k,g,o){return t(),a("div",null,s[0]||(s[0]=[e(`gitee或者gitlab账号和个人git账号同时在一台机器上使用时,可以为不同git服务器设置不同的ssh-key
生成一个个人github的ssh-key
ssh-keygen -t rsa -C 'xxxxx@163.com' -f ~/.ssh/github_id_rsa
生成一个gitee的ssh-key
ssh-keygen -t rsa -C 'xxxxx@company.cn' -f ~/.ssh/gitee_id_rsa
在~/.ssh下新建config文件vim ~/.ssh/config,添加以下内容
# gitee
+Host gitee.com
+HostName gitee.com
+PreferredAuthentications publickey
+IdentityFile ~/.ssh/gitee_id_rsa
+# github
+Host github.com
+HostName github.com
+PreferredAuthentications publickey
+IdentityFile ~/.ssh/github_id_rsa分别在gitee和github中添加前两步生成的对应地址的公钥
ssh命令测试
ssh -T git@gitee.com
+ssh -T git@github.com如果看到 hi xxx!。。。内容则证明配置成功
假设我们有一个项目同时在github和gitee上都有仓库,当直接使用git clone命令拉取的代码默认remote为origin,如果要分别更新,我们要分别在两个本地仓库中push。这时我们可以给本地仓库添加多个origin,然后更新的时候分别推送即可实现一个本地仓库分别推送两个不同的远程仓库。
删除原有的remote地址
git remote remove origin
添加新的远程仓库地址(gitee)
git remote add 远程仓库名 远程仓库地址
+eg: git remote add gitee git@gitee.com:xxx/xxx.git添加新的远程仓库地址(github)
git remote add 远程仓库名 远程仓库地址
+eg: git remote add github git@github.com:xxx/xxx.git再次查看git remote:
推送的时候git push 远程仓库名即可
修改仓库下.git/config文件,新增内容
[remote "all"]
+ url = repo1.git
+ url = repo2.git
+ url = repo3.git直接git push all
gitee或者gitlab账号和个人git账号同时在一台机器上使用时,可以为不同git服务器设置不同的ssh-key
生成一个个人github的ssh-key
ssh-keygen -t rsa -C 'xxxxx@163.com' -f ~/.ssh/github_id_rsa
生成一个gitee的ssh-key
ssh-keygen -t rsa -C 'xxxxx@company.cn' -f ~/.ssh/gitee_id_rsa
在~/.ssh下新建config文件vim ~/.ssh/config,添加以下内容
# gitee
+Host gitee.com
+HostName gitee.com
+PreferredAuthentications publickey
+IdentityFile ~/.ssh/gitee_id_rsa
+# github
+Host github.com
+HostName github.com
+PreferredAuthentications publickey
+IdentityFile ~/.ssh/github_id_rsa分别在gitee和github中添加前两步生成的对应地址的公钥
ssh命令测试
ssh -T git@gitee.com
+ssh -T git@github.com如果看到 hi xxx!。。。内容则证明配置成功
假设我们有一个项目同时在github和gitee上都有仓库,当直接使用git clone命令拉取的代码默认remote为origin,如果要分别更新,我们要分别在两个本地仓库中push。这时我们可以给本地仓库添加多个origin,然后更新的时候分别推送即可实现一个本地仓库分别推送两个不同的远程仓库。
删除原有的remote地址
git remote remove origin
添加新的远程仓库地址(gitee)
git remote add 远程仓库名 远程仓库地址
+eg: git remote add gitee git@gitee.com:xxx/xxx.git添加新的远程仓库地址(github)
git remote add 远程仓库名 远程仓库地址
+eg: git remote add github git@github.com:xxx/xxx.git再次查看git remote:
推送的时候git push 远程仓库名即可
修改仓库下.git/config文件,新增内容
[remote "all"]
+ url = repo1.git
+ url = repo2.git
+ url = repo3.git直接git push all
例如要走socks5的代理
export https_proxy=socks5://127.0.0.1:10880这样配置只对当前终端有效,不会影响其他
export http_proxy=socks5://127.0.0.1:10880
+export https_proxy=socks5://127.0.0.1:10880修改后保存,然后source ~/.zshrc立即成效。重启终端后即可全局代理。
也可以通过alias建立个别名,这样可以快速开启代理,编辑.zshrc 添加
alias proxy_on='export https_proxy=socks5://127.0.0.1:10880'
例如要走socks5的代理
export https_proxy=socks5://127.0.0.1:10880这样配置只对当前终端有效,不会影响其他
export http_proxy=socks5://127.0.0.1:10880
+export https_proxy=socks5://127.0.0.1:10880修改后保存,然后source ~/.zshrc立即成效。重启终端后即可全局代理。
也可以通过alias建立个别名,这样可以快速开启代理,编辑.zshrc 添加
alias proxy_on='export https_proxy=socks5://127.0.0.1:10880'
linux开机启动可以用systemd很方便的实现,mac上稍微复杂一些,需要自己写个.plist文件
launchd 是 Mac OS 下用于初始化系统环境的关键进程,它是内核装载成功之后在 OS 环境下启动的第一个进程,可以用来控制服务的自动启动或者关闭。
它的作用就是我们平时说的守护进程,简单来说,用户守护进程是作为系统的一部分运行在后台的非图形化程序。
采用这种方式来配置自启动项很简单,只需要一个 plist 文件,该文件存在的目录有:
用户登陆前 LaunchDaemons:
~/Library/LaunchDaemons
用户登录后 LaunchAgents:
~/Library/LaunchAgents
<?xml version="1.0" encoding="UTF-8"?>
+<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN""http://www.apple.com/DTDs/PropertyList-1.0.dtd">
+<plist version="1.0">
+ <dict>
+ <key>KeepAlive</key>
+ <dict>
+ <key>SuccessfulExit</key>
+ <false/>
+ </dict>
+ <key>Label</key>
+ <string>com.storyxc.frpc</string>
+ <key>ProgramArguments</key>
+ <array>
+ <string>/Users/story/project/widget/frp/frpc</string>
+ <string>-c</string>
+ <string>/Users/story/project/widget/frp/frpc.ini</string>
+ </array>
+ <key>RunAtLoad</key>
+ <true/>
+ </dict>
+</plist>将脚本命名为frpc.plist,然后移动到~/Library/LaunchAgents/下
启动服务:
launchctl [load|enable|bootstrap] -w plist_path
卸载服务:
launchctl [unload|disable|bootout] -w plist_path
# frpc启动、停止
+alias frpc.start='launchctl load -w ~/Library/LaunchAgents/frpc.plist'
+alias frpc.stop='launchctl unload -w ~/Library/LaunchAgents/frpc.plist'linux开机启动可以用systemd很方便的实现,mac上稍微复杂一些,需要自己写个.plist文件
launchd 是 Mac OS 下用于初始化系统环境的关键进程,它是内核装载成功之后在 OS 环境下启动的第一个进程,可以用来控制服务的自动启动或者关闭。
它的作用就是我们平时说的守护进程,简单来说,用户守护进程是作为系统的一部分运行在后台的非图形化程序。
采用这种方式来配置自启动项很简单,只需要一个 plist 文件,该文件存在的目录有:
用户登陆前 LaunchDaemons:
~/Library/LaunchDaemons
用户登录后 LaunchAgents:
~/Library/LaunchAgents
<?xml version="1.0" encoding="UTF-8"?>
+<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN""http://www.apple.com/DTDs/PropertyList-1.0.dtd">
+<plist version="1.0">
+ <dict>
+ <key>KeepAlive</key>
+ <dict>
+ <key>SuccessfulExit</key>
+ <false/>
+ </dict>
+ <key>Label</key>
+ <string>com.storyxc.frpc</string>
+ <key>ProgramArguments</key>
+ <array>
+ <string>/Users/story/project/widget/frp/frpc</string>
+ <string>-c</string>
+ <string>/Users/story/project/widget/frp/frpc.ini</string>
+ </array>
+ <key>RunAtLoad</key>
+ <true/>
+ </dict>
+</plist>将脚本命名为frpc.plist,然后移动到~/Library/LaunchAgents/下
启动服务:
launchctl [load|enable|bootstrap] -w plist_path
卸载服务:
launchctl [unload|disable|bootout] -w plist_path
# frpc启动、停止
+alias frpc.start='launchctl load -w ~/Library/LaunchAgents/frpc.plist'
+alias frpc.stop='launchctl unload -w ~/Library/LaunchAgents/frpc.plist'今天访问我自己的老博客(www.storyxc.com )发现网站挂掉了,ssh上去看了一下nginx和我自己的java后台博客服务都挂掉了,可能是阿里云抽风服务器重启了。然后重启了nignx和服务访问了一下,查询一直在pending,再去看后台日志,发现获取不到连接,估计是mysql也挂了。
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
+### Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.mysql.cj.jdbc.exceptions.Communi
+cationsException: Communications link failure
+
+The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
+### The error may exist in class path resource [mapper/ArticleDao.xml]
+### The error may involve com.storyxc.mapper.ArticleDao.queryHotArticle
+### The error occurred while executing a query
+### Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.mysql.cj.jdbc.exceptions.CommunicationsException: Communic
+ations link failure
+
+The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
+ at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:77) ~[mybatis-spring-1.3.1.jar!/:1.3.1]
+ at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:446) ~[mybatis-spring-1.3.1.jar!/:1.3.1]
+ at com.sun.proxy.$Proxy61.selectList(Unknown Source) ~[na:na]
+ at org.mybatis.spring.SqlSessionTemplate.selectList(SqlSessionTemplate.java:230) ~[mybatis-spring-1.3.1.jar!/:1.3.1]
+ at org.apache.ibatis.binding.MapperMethod.executeForMany(MapperMethod.java:137) ~[mybatis-3.4.5.jar!/:3.4.5]
+ at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:75) ~[mybatis-3.4.5.jar!/:3.4.5]
+ at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:59) ~[mybatis-3.4.5.jar!/:3.4.5]
+ at com.sun.proxy.$Proxy82.queryHotArticle(Unknown Source) ~[na:na]
+ at com.storyxc.service.impl.ArticleServiceImpl.queryHotArticle(ArticleServiceImpl.java:113) ~[classes!/:1.0-SNAPSHOT]
+ at com.storyxc.service.impl.ArticleServiceImpl$$FastClassBySpringCGLIB$$edb0e759.invoke(<generated>) ~[classes!/:1.0-SNAPSHOT]
+ at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218) ~[spring-core-5.1.6.RELEASE.jar!/:5.1.6.RELEASE]
+ at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:684) ~[spring-aop-5.1.6.RELEASE.jar!/:5.1.6.RELEASE]
+ at com.storyxc.service.impl.ArticleServiceImpl$$EnhancerBySpringCGLIB$$5695fd69.queryHotArticle(<generated>) ~[classes!/:1.0-SNAPSHOT]
+ at com.storyxc.controller.ArticleController.queryHotArticle(ArticleController.java:73) ~[classes!/:1.0-SNAPSHOT]
+ at com.storyxc.controller.ArticleController$$FastClassBySpringCGLIB$$954e681b.invoke(<generated>) ~[classes!/:1.0-SNAPSHOT]
+ at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218) ~[spring-core-5.1.6.RELEASE.jar!/:5.1.6.RELEASE]
+ at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:684) ~[spring-aop-5.1.6.RELEASE.jar!/:5.1.6.RELEASE]
+ at com.storyxc.controller.ArticleController$$EnhancerBySpringCGLIB$$7f3f634c.queryHotArticle(<generated>) ~[classes!/:1.0-SNAPSHOT]
+ at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_282]
+ at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_282]
+ at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_282]
+ at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_282]然后尝试重启mysql:service mysql start
直接报错:Starting MySQL...The server quit without updating PID file [FAILED]b/mysql/iz2ze09hymnzdn4lgmltlmz.pid).
但就这样的报错没法排查,试图看下mysql的错误日志:less /var/log/mysql/error.log结果没有,
这才想起来当时没给mysql配置错误日志路径。
给mysql配置错误文件的路径:vim /etc/my.cnf
在[mysqld]下面加一行:log_error=/var/log/mysql/error.log ,然后创建/var/log/mysql这个目录
再次启动,依旧报错,但这次我们可以去看错误日志了。继续 less /var/log/mysql/error.log
210627 00:34:02 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
+2021-06-27 00:34:03 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
+2021-06-27 00:34:03 3127 [Note] Plugin 'FEDERATED' is disabled.
+2021-06-27 00:34:03 3127 [Note] InnoDB: Using atomics to ref count buffer pool pages
+2021-06-27 00:34:03 3127 [Note] InnoDB: The InnoDB memory heap is disabled
+2021-06-27 00:34:03 3127 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
+2021-06-27 00:34:03 3127 [Note] InnoDB: Memory barrier is not used
+2021-06-27 00:34:03 3127 [Note] InnoDB: Compressed tables use zlib 1.2.3
+2021-06-27 00:34:03 3127 [Note] InnoDB: Using Linux native AIO
+2021-06-27 00:34:03 3127 [Note] InnoDB: Not using CPU crc32 instructions
+2021-06-27 00:34:03 3127 [Note] InnoDB: Initializing buffer pool, size = 128.0M
+InnoDB: mmap(136019968 bytes) failed; errno 12
+2021-06-27 00:34:03 3127 [ERROR] InnoDB: Cannot allocate memory for the buffer pool
+2021-06-27 00:34:03 3127 [ERROR] Plugin 'InnoDB' init function returned error.
+2021-06-27 00:34:03 3127 [ERROR] Plugin 'InnoDB' registration as a STORAGE ENGINE failed.
+2021-06-27 00:34:03 3127 [ERROR] Unknown/unsupported storage engine: InnoDB
+2021-06-27 00:34:03 3127 [ERROR] Aborting
+
+2021-06-27 00:34:03 3127 [Note] Binlog end查看内存情况:free -h,由于我买的是阿里云的轻量级应用服务器-穷逼版,只有2G内存
total used free shared buff/cache available
+ Mem: 1.8G 1.2G 245M 88M 323M 268M
+ Swap: 0B 0B 0Bswap为0,执行命令建立临时分区
dd if=/dev/zero of=/swap bs=1M count=128 //创建一个swap文件,大小为128M
+mkswap /swap //将swap文件变为swap分区文件
+swapon /swap //将其映射为swap分区再次查看内存:
total used free shared buff/cache available
+Mem: 1.8G 1.3G 82M 88M 463M 236M
+Swap: 127M 0B 127Mswap分区已存在,执行命令使系统重启swap分区自动加载:vim /etc/fstab
/swap swap swap defaults 0 0再次启动 还是他喵不行,执行命令查看下当前内存占用大户。
ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%mem | head
PID PPID %MEM %CPU CMD
+19872 1 14.0 45.7 ./phpupdate
+20228 1 14.0 45.7 /etc/phpupdate
+ 9372 1 8.0 1.3 java -jar storyxc.jar
+27880 1 3.1 0.0 /opt/openoffice4/program/soffice.bin -headless -accept=socket,host=127.0.0.1,port=8100;urp; -nofirststartwizard
+13389 1 2.6 0.0 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
+23244 21287 2.3 4.7 ./networkmanager 15
+13322 1 1.3 0.0 /usr/bin/containerd
+ 489 455 1.0 0.1 CmsGoAgent-Worker start
+19905 1 0.6 0.0 ./phpguard好家伙,从哪冒出来的phpupdate 直接全杀掉,世界瞬间清净了,腾出来600M的内存,
再次启动mysql,成功,问题解决。
`,24)]))}const F=a(e,[["render",t]]);export{d as __pageData,F as default}; diff --git "a/assets/actions_env_mysql\345\220\257\345\212\250\346\212\245\351\224\231\346\216\222\346\237\245\345\217\212\345\244\204\347\220\206.md.DlY6zJyH.lean.js" "b/assets/actions_env_mysql\345\220\257\345\212\250\346\212\245\351\224\231\346\216\222\346\237\245\345\217\212\345\244\204\347\220\206.md.DlY6zJyH.lean.js" new file mode 100644 index 00000000..48a4af3a --- /dev/null +++ "b/assets/actions_env_mysql\345\220\257\345\212\250\346\212\245\351\224\231\346\216\222\346\237\245\345\217\212\345\244\204\347\220\206.md.DlY6zJyH.lean.js" @@ -0,0 +1,67 @@ +import{_ as a,c as i,a2 as n,o as p}from"./chunks/framework.BjcrtTwI.js";const d=JSON.parse('{"title":"mysql启动报错排查及处理","description":"","frontmatter":{},"headers":[],"relativePath":"actions/env/mysql启动报错排查及处理.md","filePath":"actions/env/mysql启动报错排查及处理.md","lastUpdated":1729217313000}'),e={name:"actions/env/mysql启动报错排查及处理.md"};function t(l,s,h,r,k,o){return p(),i("div",null,s[0]||(s[0]=[n(`今天访问我自己的老博客(www.storyxc.com )发现网站挂掉了,ssh上去看了一下nginx和我自己的java后台博客服务都挂掉了,可能是阿里云抽风服务器重启了。然后重启了nignx和服务访问了一下,查询一直在pending,再去看后台日志,发现获取不到连接,估计是mysql也挂了。
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
+### Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.mysql.cj.jdbc.exceptions.Communi
+cationsException: Communications link failure
+
+The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
+### The error may exist in class path resource [mapper/ArticleDao.xml]
+### The error may involve com.storyxc.mapper.ArticleDao.queryHotArticle
+### The error occurred while executing a query
+### Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.mysql.cj.jdbc.exceptions.CommunicationsException: Communic
+ations link failure
+
+The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
+ at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:77) ~[mybatis-spring-1.3.1.jar!/:1.3.1]
+ at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:446) ~[mybatis-spring-1.3.1.jar!/:1.3.1]
+ at com.sun.proxy.$Proxy61.selectList(Unknown Source) ~[na:na]
+ at org.mybatis.spring.SqlSessionTemplate.selectList(SqlSessionTemplate.java:230) ~[mybatis-spring-1.3.1.jar!/:1.3.1]
+ at org.apache.ibatis.binding.MapperMethod.executeForMany(MapperMethod.java:137) ~[mybatis-3.4.5.jar!/:3.4.5]
+ at org.apache.ibatis.binding.MapperMethod.execute(MapperMethod.java:75) ~[mybatis-3.4.5.jar!/:3.4.5]
+ at org.apache.ibatis.binding.MapperProxy.invoke(MapperProxy.java:59) ~[mybatis-3.4.5.jar!/:3.4.5]
+ at com.sun.proxy.$Proxy82.queryHotArticle(Unknown Source) ~[na:na]
+ at com.storyxc.service.impl.ArticleServiceImpl.queryHotArticle(ArticleServiceImpl.java:113) ~[classes!/:1.0-SNAPSHOT]
+ at com.storyxc.service.impl.ArticleServiceImpl$$FastClassBySpringCGLIB$$edb0e759.invoke(<generated>) ~[classes!/:1.0-SNAPSHOT]
+ at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218) ~[spring-core-5.1.6.RELEASE.jar!/:5.1.6.RELEASE]
+ at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:684) ~[spring-aop-5.1.6.RELEASE.jar!/:5.1.6.RELEASE]
+ at com.storyxc.service.impl.ArticleServiceImpl$$EnhancerBySpringCGLIB$$5695fd69.queryHotArticle(<generated>) ~[classes!/:1.0-SNAPSHOT]
+ at com.storyxc.controller.ArticleController.queryHotArticle(ArticleController.java:73) ~[classes!/:1.0-SNAPSHOT]
+ at com.storyxc.controller.ArticleController$$FastClassBySpringCGLIB$$954e681b.invoke(<generated>) ~[classes!/:1.0-SNAPSHOT]
+ at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218) ~[spring-core-5.1.6.RELEASE.jar!/:5.1.6.RELEASE]
+ at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:684) ~[spring-aop-5.1.6.RELEASE.jar!/:5.1.6.RELEASE]
+ at com.storyxc.controller.ArticleController$$EnhancerBySpringCGLIB$$7f3f634c.queryHotArticle(<generated>) ~[classes!/:1.0-SNAPSHOT]
+ at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_282]
+ at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_282]
+ at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_282]
+ at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_282]然后尝试重启mysql:service mysql start
直接报错:Starting MySQL...The server quit without updating PID file [FAILED]b/mysql/iz2ze09hymnzdn4lgmltlmz.pid).
但就这样的报错没法排查,试图看下mysql的错误日志:less /var/log/mysql/error.log结果没有,
这才想起来当时没给mysql配置错误日志路径。
给mysql配置错误文件的路径:vim /etc/my.cnf
在[mysqld]下面加一行:log_error=/var/log/mysql/error.log ,然后创建/var/log/mysql这个目录
再次启动,依旧报错,但这次我们可以去看错误日志了。继续 less /var/log/mysql/error.log
210627 00:34:02 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
+2021-06-27 00:34:03 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
+2021-06-27 00:34:03 3127 [Note] Plugin 'FEDERATED' is disabled.
+2021-06-27 00:34:03 3127 [Note] InnoDB: Using atomics to ref count buffer pool pages
+2021-06-27 00:34:03 3127 [Note] InnoDB: The InnoDB memory heap is disabled
+2021-06-27 00:34:03 3127 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
+2021-06-27 00:34:03 3127 [Note] InnoDB: Memory barrier is not used
+2021-06-27 00:34:03 3127 [Note] InnoDB: Compressed tables use zlib 1.2.3
+2021-06-27 00:34:03 3127 [Note] InnoDB: Using Linux native AIO
+2021-06-27 00:34:03 3127 [Note] InnoDB: Not using CPU crc32 instructions
+2021-06-27 00:34:03 3127 [Note] InnoDB: Initializing buffer pool, size = 128.0M
+InnoDB: mmap(136019968 bytes) failed; errno 12
+2021-06-27 00:34:03 3127 [ERROR] InnoDB: Cannot allocate memory for the buffer pool
+2021-06-27 00:34:03 3127 [ERROR] Plugin 'InnoDB' init function returned error.
+2021-06-27 00:34:03 3127 [ERROR] Plugin 'InnoDB' registration as a STORAGE ENGINE failed.
+2021-06-27 00:34:03 3127 [ERROR] Unknown/unsupported storage engine: InnoDB
+2021-06-27 00:34:03 3127 [ERROR] Aborting
+
+2021-06-27 00:34:03 3127 [Note] Binlog end查看内存情况:free -h,由于我买的是阿里云的轻量级应用服务器-穷逼版,只有2G内存
total used free shared buff/cache available
+ Mem: 1.8G 1.2G 245M 88M 323M 268M
+ Swap: 0B 0B 0Bswap为0,执行命令建立临时分区
dd if=/dev/zero of=/swap bs=1M count=128 //创建一个swap文件,大小为128M
+mkswap /swap //将swap文件变为swap分区文件
+swapon /swap //将其映射为swap分区再次查看内存:
total used free shared buff/cache available
+Mem: 1.8G 1.3G 82M 88M 463M 236M
+Swap: 127M 0B 127Mswap分区已存在,执行命令使系统重启swap分区自动加载:vim /etc/fstab
/swap swap swap defaults 0 0再次启动 还是他喵不行,执行命令查看下当前内存占用大户。
ps -eo pid,ppid,%mem,%cpu,cmd --sort=-%mem | head
PID PPID %MEM %CPU CMD
+19872 1 14.0 45.7 ./phpupdate
+20228 1 14.0 45.7 /etc/phpupdate
+ 9372 1 8.0 1.3 java -jar storyxc.jar
+27880 1 3.1 0.0 /opt/openoffice4/program/soffice.bin -headless -accept=socket,host=127.0.0.1,port=8100;urp; -nofirststartwizard
+13389 1 2.6 0.0 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
+23244 21287 2.3 4.7 ./networkmanager 15
+13322 1 1.3 0.0 /usr/bin/containerd
+ 489 455 1.0 0.1 CmsGoAgent-Worker start
+19905 1 0.6 0.0 ./phpguard好家伙,从哪冒出来的phpupdate 直接全杀掉,世界瞬间清净了,腾出来600M的内存,
再次启动mysql,成功,问题解决。
`,24)]))}const F=a(e,[["render",t]]);export{d as __pageData,F as default}; diff --git "a/assets/actions_env_typecho\351\203\250\347\275\262.md.DQrSApbn.js" "b/assets/actions_env_typecho\351\203\250\347\275\262.md.DQrSApbn.js" new file mode 100644 index 00000000..29c19205 --- /dev/null +++ "b/assets/actions_env_typecho\351\203\250\347\275\262.md.DQrSApbn.js" @@ -0,0 +1,14 @@ +import{_ as i,c as a,a2 as h,o as p}from"./chunks/framework.BjcrtTwI.js";const c=JSON.parse('{"title":"typecho部署","description":"","frontmatter":{},"headers":[],"relativePath":"actions/env/typecho部署.md","filePath":"actions/env/typecho部署.md","lastUpdated":1729217313000}'),n={name:"actions/env/typecho部署.md"};function t(l,s,e,k,r,d){return p(),a("div",null,s[0]||(s[0]=[h(`apt install php7.4 php7.4-fpm php7.4-mysql php7.4-curl php7.4-gd php7.4-mbstring php7.4-xml php7.4-xmlrpc php7.4-zipadd-apt-repository ppa:ondrej/php
+apt update
+apt install php7.4 php7.4-mysql php7.4-curl php7.4-json php7.4-cgi php7.4-gd php7.4-cli php7.4-fpm php7.4-mbstring php7.4-xmlvim /etc/php/7.4/fpm/pool.d/www.conf
; listen = /run/php/php7.4-fpm.sock
+listen = 127.0.0.1:9000;systemctl restart php7.4-fpm
root /var/www/typecho
+location ~ .*\\.php(\\/.*)*$ {
+ fastcgi_pass 127.0.0.1:9000;
+ fastcgi_split_path_info ^(.+?.php)(/.*)$;
+ fastcgi_index index.php;
+ fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
+ include fastcgi_params;
+}create database typecho;
+CREATE USER 'typecho_user'@'localhost' IDENTIFIED BY 'your_password';
+GRANT ALL PRIVILEGES ON typecho.* TO 'typecho_user'@'localhost';
+FLUSH PRIVILEGES;chmod -R 755 /var/www/typecho
apt install php7.4 php7.4-fpm php7.4-mysql php7.4-curl php7.4-gd php7.4-mbstring php7.4-xml php7.4-xmlrpc php7.4-zipadd-apt-repository ppa:ondrej/php
+apt update
+apt install php7.4 php7.4-mysql php7.4-curl php7.4-json php7.4-cgi php7.4-gd php7.4-cli php7.4-fpm php7.4-mbstring php7.4-xmlvim /etc/php/7.4/fpm/pool.d/www.conf
; listen = /run/php/php7.4-fpm.sock
+listen = 127.0.0.1:9000;systemctl restart php7.4-fpm
root /var/www/typecho
+location ~ .*\\.php(\\/.*)*$ {
+ fastcgi_pass 127.0.0.1:9000;
+ fastcgi_split_path_info ^(.+?.php)(/.*)$;
+ fastcgi_index index.php;
+ fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
+ include fastcgi_params;
+}create database typecho;
+CREATE USER 'typecho_user'@'localhost' IDENTIFIED BY 'your_password';
+GRANT ALL PRIVILEGES ON typecho.* TO 'typecho_user'@'localhost';
+FLUSH PRIVILEGES;chmod -R 755 /var/www/typecho
Github Actions官方文档https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#name
Github推出的持续集成工具
Github Actions的配置文件叫做workflow文件,需要存放在repo根路径下的./github/workflows目录中。workflow文件使用yaml格式编写,文件名可以自定义,后缀统一为yml,一个repo中可以有多个workflow,Github只要发现./github/workflows目录中有.yml文件就会自动运行。
本博客的workflow文件:
# 自定义当前执行文件的名称
+name: vuepress
+# 整个流程在main分支发生push事件时触发
+on:
+ push:
+ branches:
+ - main
+jobs:
+ build-and-deploy:
+ runs-on: ubuntu-latest # 运行在ubuntu-latest环境的虚拟机中
+ strategy:
+ matrix: # 矩阵
+ node-version: [10.x]
+ steps: # 每个 job 由多个 step 构成,它会从上至下依次执行。
+ # 获取仓库源码
+ - name: Checkout
+ uses: actions/checkout@v2 # github actions提供了一些官方的action,例如checkout @v2是action的版本
+ # 安装node
+ - name: Use Node.js \${{ matrix.node-version }} # 定义好的node版本
+ uses: actions/setup-node@v1 # 作用:安装nodejs
+ with:
+ node-version: \${{ matrix.node-version }} # 定义好的node版本
+ # 构建和部署
+ - name: Deploy
+ env: # 环境变量
+ GITHUB_TOKEN: \${{ secrets.vuepress_actions_access_token }}
+ run: npm install && npm run deploy # npm run deploy需要在package.json中定义"deploy: bash deploy.sh"steps:
#!/usr/bin/env sh
+
+# 确保脚本抛出遇到的错误
+set -e
+
+# 生成静态文件
+npm run build
+
+# 进入生成的文件夹
+cd docs/.vuepress/dist
+
+# 如果是发布到自定义域名
+echo 'blog.storyxc.com' > CNAME
+
+if [ -z "\${GITHUB_TOKEN}" ]; then
+ echo "GITHUB_TOKEN is not set"
+ exit 1
+else
+ msg='github actions自动部署'
+ githubUrl=https://storyxc:\${GITHUB_TOKEN}@github.com/storyxc/vuepress.git
+ git config --global user.name "storyxc"
+ git config --global user.email "storyxc@163.com"
+fi
+
+git init
+git add -A
+git commit -m "\${msg}"
+
+git push -f $githubUrl master:gh-pages
+
+cd -这里我是用了github pages发布,然后配置了自定义域名,这个域名要在服务商域名解析配置CNAME,然后在仓库的page页面添加自定义域名即可
Github Actions官方文档https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#name
Github推出的持续集成工具
Github Actions的配置文件叫做workflow文件,需要存放在repo根路径下的./github/workflows目录中。workflow文件使用yaml格式编写,文件名可以自定义,后缀统一为yml,一个repo中可以有多个workflow,Github只要发现./github/workflows目录中有.yml文件就会自动运行。
本博客的workflow文件:
# 自定义当前执行文件的名称
+name: vuepress
+# 整个流程在main分支发生push事件时触发
+on:
+ push:
+ branches:
+ - main
+jobs:
+ build-and-deploy:
+ runs-on: ubuntu-latest # 运行在ubuntu-latest环境的虚拟机中
+ strategy:
+ matrix: # 矩阵
+ node-version: [10.x]
+ steps: # 每个 job 由多个 step 构成,它会从上至下依次执行。
+ # 获取仓库源码
+ - name: Checkout
+ uses: actions/checkout@v2 # github actions提供了一些官方的action,例如checkout @v2是action的版本
+ # 安装node
+ - name: Use Node.js \${{ matrix.node-version }} # 定义好的node版本
+ uses: actions/setup-node@v1 # 作用:安装nodejs
+ with:
+ node-version: \${{ matrix.node-version }} # 定义好的node版本
+ # 构建和部署
+ - name: Deploy
+ env: # 环境变量
+ GITHUB_TOKEN: \${{ secrets.vuepress_actions_access_token }}
+ run: npm install && npm run deploy # npm run deploy需要在package.json中定义"deploy: bash deploy.sh"steps:
#!/usr/bin/env sh
+
+# 确保脚本抛出遇到的错误
+set -e
+
+# 生成静态文件
+npm run build
+
+# 进入生成的文件夹
+cd docs/.vuepress/dist
+
+# 如果是发布到自定义域名
+echo 'blog.storyxc.com' > CNAME
+
+if [ -z "\${GITHUB_TOKEN}" ]; then
+ echo "GITHUB_TOKEN is not set"
+ exit 1
+else
+ msg='github actions自动部署'
+ githubUrl=https://storyxc:\${GITHUB_TOKEN}@github.com/storyxc/vuepress.git
+ git config --global user.name "storyxc"
+ git config --global user.email "storyxc@163.com"
+fi
+
+git init
+git add -A
+git commit -m "\${msg}"
+
+git push -f $githubUrl master:gh-pages
+
+cd -这里我是用了github pages发布,然后配置了自定义域名,这个域名要在服务商域名解析配置CNAME,然后在仓库的page页面添加自定义域名即可
Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档。
Markdown 语言在 2004 由约翰·格鲁伯(英语:John Gruber)创建。
Markdown 编写的文档可以导出 HTML 、Word、图像、PDF、Epub 等多种格式的文档。
Markdown 编写的文档后缀为 .md, .markdown。
示例:
# 一级标题
+## 二级标题
+### 三级标题
+#### 四级标题
+##### 五级标题
+###### 六级标题加粗 要加粗的文字左右分别用两个*号包起来
斜体 要倾斜的文字左右分别用一个*号包起来
斜体加粗 要倾斜和加粗的文字左右分别用三个*号包起来
删除线 要加删除线的文字左右分别用两个~~号包起来
示例:
**这是加粗的文字**
+*这是倾斜的文字*\`
+***这是斜体加粗的文字***
+~~这是加删除线的文字~~效果: 这是加粗的文字这是倾斜的文字\` 这是斜体加粗的文字这是加删除线的文字
只需要在你希望引用的文字前面加上 > 就好,例如:
> 这是一条引用效果如下:
这是一条引用
引用还可以进行多级嵌套
> 这是一条引用
+>> 这是一条引用
+>>> 这是一条引用效果:
这是一条引用
这是一条引用
这是一条引用
三个或者三个以上的 - 或者 * 都可以。
---
+----
+***
+*****语法:

+
+图片alt就是显示在图片下面的文字,相当于对图片内容的解释。
+图片title是图片的标题,当鼠标移到图片上时显示的内容。title可加可不加示例:
效果:
语法:
[超链接名](超链接地址 "超链接title")
+title可加可不加示例:
[故事的博客](https://www.storyxc.com "故事的博客")效果 故事的博客
无序列表 语法: 无序列表用 - + * 任何一种都可以 示例:
- 列表1
++ 列表2
+* 列表3效果
有序列表 语法: 数字加点 示例:
1. 111
+2. 222
+3. 333效果:
列表嵌套
上一级和下一级之间tab即可
语法:
表头|表头|表头
+---|:--:|---:
+内容|内容|内容
+内容|内容|内容
+
+第二行分割表头和内容。
+- 有一个就行,为了对齐,多加了几个
+文字默认居左
+-两边加:表示文字居中
+-右边加:表示文字居右
+注:原生的语法两边都要用 | 包起来。此处省略
+
+姓名|技能|排行
+--|:--:|--:
+刘备|哭|大哥
+关羽|打|二哥
+张飞|骂|三弟效果:
| 姓名 | 技能 | 排行 |
|---|---|---|
| 刘备 | 哭 | 大哥 |
| 关羽 | 打 | 二哥 |
| 张飞 | 骂 | 三弟 |
示例:
\`这是一行代码\`效果: 这是一行代码
(\`\`\`)语言名
+ 代码
+(\`\`\`)示例:以java为例
(\`\`\`)java
+ public class HelloWorld{
+ public static void main(Stringargs[]){
+ System.out.println("Hello World!");
+ }
+ }
+(\`\`\`)效果
public class HelloWorld{
+ public static void main(String args[]){
+ System.out.println("Hello World!");
+ }
+}Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档。
Markdown 语言在 2004 由约翰·格鲁伯(英语:John Gruber)创建。
Markdown 编写的文档可以导出 HTML 、Word、图像、PDF、Epub 等多种格式的文档。
Markdown 编写的文档后缀为 .md, .markdown。
示例:
# 一级标题
+## 二级标题
+### 三级标题
+#### 四级标题
+##### 五级标题
+###### 六级标题加粗 要加粗的文字左右分别用两个*号包起来
斜体 要倾斜的文字左右分别用一个*号包起来
斜体加粗 要倾斜和加粗的文字左右分别用三个*号包起来
删除线 要加删除线的文字左右分别用两个~~号包起来
示例:
**这是加粗的文字**
+*这是倾斜的文字*\`
+***这是斜体加粗的文字***
+~~这是加删除线的文字~~效果: 这是加粗的文字这是倾斜的文字\` 这是斜体加粗的文字这是加删除线的文字
只需要在你希望引用的文字前面加上 > 就好,例如:
> 这是一条引用效果如下:
这是一条引用
引用还可以进行多级嵌套
> 这是一条引用
+>> 这是一条引用
+>>> 这是一条引用效果:
这是一条引用
这是一条引用
这是一条引用
三个或者三个以上的 - 或者 * 都可以。
---
+----
+***
+*****语法:

+
+图片alt就是显示在图片下面的文字,相当于对图片内容的解释。
+图片title是图片的标题,当鼠标移到图片上时显示的内容。title可加可不加示例:
效果:
语法:
[超链接名](超链接地址 "超链接title")
+title可加可不加示例:
[故事的博客](https://www.storyxc.com "故事的博客")效果 故事的博客
无序列表 语法: 无序列表用 - + * 任何一种都可以 示例:
- 列表1
++ 列表2
+* 列表3效果
有序列表 语法: 数字加点 示例:
1. 111
+2. 222
+3. 333效果:
列表嵌套
上一级和下一级之间tab即可
语法:
表头|表头|表头
+---|:--:|---:
+内容|内容|内容
+内容|内容|内容
+
+第二行分割表头和内容。
+- 有一个就行,为了对齐,多加了几个
+文字默认居左
+-两边加:表示文字居中
+-右边加:表示文字居右
+注:原生的语法两边都要用 | 包起来。此处省略
+
+姓名|技能|排行
+--|:--:|--:
+刘备|哭|大哥
+关羽|打|二哥
+张飞|骂|三弟效果:
| 姓名 | 技能 | 排行 |
|---|---|---|
| 刘备 | 哭 | 大哥 |
| 关羽 | 打 | 二哥 |
| 张飞 | 骂 | 三弟 |
示例:
\`这是一行代码\`效果: 这是一行代码
(\`\`\`)语言名
+ 代码
+(\`\`\`)示例:以java为例
(\`\`\`)java
+ public class HelloWorld{
+ public static void main(Stringargs[]){
+ System.out.println("Hello World!");
+ }
+ }
+(\`\`\`)效果
public class HelloWorld{
+ public static void main(String args[]){
+ System.out.println("Hello World!");
+ }
+}ctrl+Rz/option+zspacecmd+shift+l选择拖动+option矩形R
椭圆O
圆角矩形U:也可以使用矩形,然后拖动四角的点实现
直线L
形状选中后在边角点位处按住cmd可以旋转
双击形状进入编辑模式,可以编辑形状,鼠标点击边框线可增加锚点进行调整
选中按住option拖动可以直接复制、cmd+d可以重复复制动作进行等距复制
以上工具可以按住
option使用扩散的绘制效果
f切换填充b切换边框ctrl+c吸色工具v钢笔p铅笔t+点文本t+框选段落文本a创建画板s切片ctrl+cmd+m蒙版工具
cmd+k缩放工具
cmd+option+o轮廓
ctrl+Rz/option+zspacecmd+shift+l选择拖动+option矩形R
椭圆O
圆角矩形U:也可以使用矩形,然后拖动四角的点实现
直线L
形状选中后在边角点位处按住cmd可以旋转
双击形状进入编辑模式,可以编辑形状,鼠标点击边框线可增加锚点进行调整
选中按住option拖动可以直接复制、cmd+d可以重复复制动作进行等距复制
以上工具可以按住
option使用扩散的绘制效果
f切换填充b切换边框ctrl+c吸色工具v钢笔p铅笔t+点文本t+框选段落文本a创建画板s切片ctrl+cmd+m蒙版工具
cmd+k缩放工具
cmd+option+o轮廓
由于最近刚把博客迁到VuePress上来,写博客从原来自己博客项目自定义的web端Markdown编辑器换回了原来的Typora,这个文本编辑工具虽然很好用,但是在markdown中插入图片的时候就会碰到比较烦的问题,可能随便截了个图放在桌面了,在markdown中引入的话还要先把图片放到vuepress项目的静态资源文件夹里面。原来我自己开发的博客编辑器是通过axios调用后台接口把图片传到七牛云图床上去,现在换了博客框架原来的方案不好使了。之前typora也没有这方面的支持。不过我发现typora更新之后也支持了添加图片后的事件触发。
选项还是很多样的,为typora点赞。
这里我还是选择了上传到图床,上传支持PicGo和自定义脚本,本来打算写个python脚本的,后来发现picgo这个应用也很好用,那就直接拿过来用吧。
点击PicGo 进入仓库下载,这里选择windows版的执行程序,下载之后打开
没有图床的可以搜一下相关教程,这里不再赘述
选择七牛云图床、或者自己选择其他图床也许,按照自己情况来。
先验证一下,可以看到成功了。这样再在typora中添加图片就可以看到图片会自动上传到你的图床并修改markdown中的地址了。
npm安装picgo-core:npm install -g picgo
配置uploader:picgo set uploader
使用uploader:picgo use uploader
配置文件地址为~/.picgo/config.json,可以手动修改
配置完成后在typora中配置自定义命令上传,命令格式 node_path picgo_path upload例如我的是/opt/homebrew/bin/node /opt/homebrew/bin/picgo upload
验证上传选项,看到返回图片地址即可
',30)]))}const h=o(i,[["render",p]]);export{m as __pageData,h as default}; diff --git "a/assets/actions_tools_Typora\343\200\201PicGo\343\200\201\344\270\203\347\211\233\344\272\221\345\256\236\347\216\260markdown\345\233\276\347\211\207\350\207\252\345\212\250\344\270\212\344\274\240\345\233\276\345\272\212.md.BCuXrc42.lean.js" "b/assets/actions_tools_Typora\343\200\201PicGo\343\200\201\344\270\203\347\211\233\344\272\221\345\256\236\347\216\260markdown\345\233\276\347\211\207\350\207\252\345\212\250\344\270\212\344\274\240\345\233\276\345\272\212.md.BCuXrc42.lean.js" new file mode 100644 index 00000000..52578126 --- /dev/null +++ "b/assets/actions_tools_Typora\343\200\201PicGo\343\200\201\344\270\203\347\211\233\344\272\221\345\256\236\347\216\260markdown\345\233\276\347\211\207\350\207\252\345\212\250\344\270\212\344\274\240\345\233\276\345\272\212.md.BCuXrc42.lean.js" @@ -0,0 +1 @@ +import{_ as o,c as e,a2 as r,o as t}from"./chunks/framework.BjcrtTwI.js";const m=JSON.parse('{"title":"Typora、PicGo、七牛云实现markdown图片自动上传图床","description":"","frontmatter":{},"headers":[],"relativePath":"actions/tools/Typora、PicGo、七牛云实现markdown图片自动上传图床.md","filePath":"actions/tools/Typora、PicGo、七牛云实现markdown图片自动上传图床.md","lastUpdated":1729217313000}'),i={name:"actions/tools/Typora、PicGo、七牛云实现markdown图片自动上传图床.md"};function p(c,a,l,n,s,g){return t(),e("div",null,a[0]||(a[0]=[r('由于最近刚把博客迁到VuePress上来,写博客从原来自己博客项目自定义的web端Markdown编辑器换回了原来的Typora,这个文本编辑工具虽然很好用,但是在markdown中插入图片的时候就会碰到比较烦的问题,可能随便截了个图放在桌面了,在markdown中引入的话还要先把图片放到vuepress项目的静态资源文件夹里面。原来我自己开发的博客编辑器是通过axios调用后台接口把图片传到七牛云图床上去,现在换了博客框架原来的方案不好使了。之前typora也没有这方面的支持。不过我发现typora更新之后也支持了添加图片后的事件触发。
选项还是很多样的,为typora点赞。
这里我还是选择了上传到图床,上传支持PicGo和自定义脚本,本来打算写个python脚本的,后来发现picgo这个应用也很好用,那就直接拿过来用吧。
点击PicGo 进入仓库下载,这里选择windows版的执行程序,下载之后打开
没有图床的可以搜一下相关教程,这里不再赘述
选择七牛云图床、或者自己选择其他图床也许,按照自己情况来。
先验证一下,可以看到成功了。这样再在typora中添加图片就可以看到图片会自动上传到你的图床并修改markdown中的地址了。
npm安装picgo-core:npm install -g picgo
配置uploader:picgo set uploader
使用uploader:picgo use uploader
配置文件地址为~/.picgo/config.json,可以手动修改
配置完成后在typora中配置自定义命令上传,命令格式 node_path picgo_path upload例如我的是/opt/homebrew/bin/node /opt/homebrew/bin/picgo upload
验证上传选项,看到返回图片地址即可
',30)]))}const h=o(i,[["render",p]]);export{m as __pageData,h as default}; diff --git "a/assets/actions_tools_book-searcher\347\224\265\345\255\220\344\271\246\351\225\234\345\203\217.md.C57EBPA-.js" "b/assets/actions_tools_book-searcher\347\224\265\345\255\220\344\271\246\351\225\234\345\203\217.md.C57EBPA-.js" new file mode 100644 index 00000000..ff5c716d --- /dev/null +++ "b/assets/actions_tools_book-searcher\347\224\265\345\255\220\344\271\246\351\225\234\345\203\217.md.C57EBPA-.js" @@ -0,0 +1,14 @@ +import{_ as a,c as i,a2 as e,o as n}from"./chunks/framework.BjcrtTwI.js";const d=JSON.parse('{"title":"book-searcher电子书镜像站点","description":"","frontmatter":{},"headers":[],"relativePath":"actions/tools/book-searcher电子书镜像.md","filePath":"actions/tools/book-searcher电子书镜像.md","lastUpdated":1729217313000}'),t={name:"actions/tools/book-searcher电子书镜像.md"};function h(r,s,l,o,p,k){return n(),i("div",null,s[0]||(s[0]=[e(`version: '3'
+
+services:
+ book-searcher:
+ image: ghcr.io/book-searcher-org/book-searcher:latest
+ container_name: book-searcher
+ restart: always
+ ports:
+ - "7070:7070"
+ volumes:
+ - ./index:/indexhttps://cloudflare-ipfs.com
+https://dweb.link
+https://ipfs.io
+https://dw.oho.imversion: '3'
+
+services:
+ book-searcher:
+ image: ghcr.io/book-searcher-org/book-searcher:latest
+ container_name: book-searcher
+ restart: always
+ ports:
+ - "7070:7070"
+ volumes:
+ - ./index:/indexhttps://cloudflare-ipfs.com
+https://dweb.link
+https://ipfs.io
+https://dw.oho.im版本控制工具一直用的GIT,之前提交代码都是用IDEA集成的GIT可视化工具,命令行几乎不怎么用,由于接下来项目要整合到微服务平台中,项目代码管理也要迁到Gerrit,idea的集成支持不太好,所以整理下GIT的命令,方便后面使用命令行提交代码。
Remote:远程仓库
+Reporsitory:本地仓库
+WorkSpace:工作区
+Index:暂存区git commit --amend :提交完发现漏掉了几个文件没有添加,或者提交信息写错了,此时,可以运行带有 --amend 选项的提交命令来重新提交
git checkout -- <file> 把readme.txt文件在工作区的修改全部撤销,这里有两种情况:
一种是readme.txt自修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态;
一种是readme.txt已经添加到暂存区后,又作了修改,现在,撤销修改就回到添加到暂存区后的状态。
git reset [--soft | --mixed | --hard] [HEAD]
关于git checkout和git reset建议看下这篇文章,git重置
git checkout branch_name
切换分之前要注意本地分支是否有未commit的文件,如果有可以撤销改动,或者commit,再或者使用git stash将当前分支的改动临时保存起来,使当前分支的工作空间和暂存区变干净。然后再进行切换分支;切换回之前的分支,需要恢复被临时保存的改动
git stash -u
恢复本地修改:
1.先查看有多少个临时保存的改动
git stash list
2.再用git stash apply --index stash@{n},n为使用git stash list查看到的某个改动的数字
3.再用git stash drop stash@{n}删除临时保存的改动
如果只有一个临时的stash,那么可以直接git stash apply即可恢复上次的临时保存记录
基于本地master分支创建test分支为例:
先切换到master分支:git checkout master
建分支: git branch test
切分支:git checkout test
或者
建分支后切到该分支:git checkout -b test master
以基于某次commit id创建test分支为例:
git checkout -b test 0faceff
其中的0faceff为commit id的前7位
以基于某个tag创建test分支为例
git checkout -b test v0.1.0
v0.1.0为tag的名称
git branch: 只显示本地分支名,当前分支名前有星号
git branch -v:显示本地分支名,当前分支前有星号,显示commit id
git branch -vv:显示本地分支名,当前分支名前有星号,显示commit id,显示追踪的远程分支名
git branch -a:显示所有分支名(包括远程分支)
git branch -r:查看远程分支名
普通删除:git branch -d branch_name
强制删除(分支上有修改未合并到其他分支):git branch -D branch_name
git pull或者git fetch
git pull -v --progress "origin"命令可以显示更详细的信息,git pull命令会fetch所有的远程分支的信息到本地,同时当前本地分支会被合并。
如果本地有修改文件,而且远程仓库也修改了该文件,pull会失败,提示本地的修改会被合并覆盖,此时可以commit本地的修改或者stash本地的修改,再pull。
首先使用git checkout branch_name切换到正确分支,pull,新建或修改代码,再使用git add 文件名把修改或新增的文件添加到暂存区,再执行commit命令提交到本地仓库。
其中:
git add 某个文件
git add 多个文件(文件名用空格隔开)
git add -u 添加所有修改的文件到暂存区
git add .添加所有修改和新增的文件到暂存区
git add -A:添加所有修改,新增和删除的文件到暂存区
git commit 文件名 -m "注释":commit某个文件
git commit 文件1 文件2 -m "注释" commit多个文件,用空格隔开
git commit -m "注释"commit所有文件
如果是删除文件,可以使用
rm 文件
git add 文件
git commit 文件 -m "注释"
如果是重命名文件或者移动文件,可以使用
git mv 源文件路径 目标文件路径
git commit 文件 -m "注释"
本地代码从本地branch_name分支推到远端branch_name分支:
git checkout branch_name
git pull
git push origin HEAD:refs/for/branch_name
或者
git checkout branch_name
git pull
git push origin branch_name:refs/for/branch_name
git status 显示有变更的文件
git log 显示当前分支的版本历史
git log --stat 显示commit历史,以及每次commit发生变更的文件
git log -S [keyword] 搜索提交历史,根据关键词
git log [tag] HEAD --pretty=format:%s 显示某个commit之后的所有变动,每个commit占据一行
git log [tag] HEAD --grep feature 显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件
git log -p [file] 显示指定文件相关的每一次diff
git log -5 --pretty --oneline 显示过去5次提交
git shortlog -sn 显示所有提交过的用户,按提交次数排序
git blame [file] 显示指定文件是什么人在什么时间修改过
git diff 显示暂存区和工作区的代码差异
git diff --cached [file] 显示暂存区和上一个commit的差异
git diff HEAD 显示工作区与当前分支最新commit之间的差异
git diff [first-branch]...[second-branch] 显示两次提交之间的差异
git diff --shortstat "@{0 day ago}" 显示今天你写了多少行代码
git show [commit] 显示某次提交的元数据和内容变化
git show --name-only [commit] 显示某次提交发生变化的文件
git show [commit]:[filename] 显示某次提交时,某个文件的内容
git rebase [branch] 从本地master拉取代码更新当前分支:branch 一般为master
git fetch是将远程的最新内容拉到本地,用户在检查了以后决定是否合并到本地分支中。 而git pull 则是将远程的最新内容拉下来后直接合并,即:git pull = git fetch + git merge,这样可能会产生冲突,需要手动解决。
`,92)]))}const m=t(i,[["render",p]]);export{g as __pageData,m as default}; diff --git "a/assets/actions_tools_git\345\221\275\344\273\244\346\225\264\347\220\206.md.BB4ue52M.lean.js" "b/assets/actions_tools_git\345\221\275\344\273\244\346\225\264\347\220\206.md.BB4ue52M.lean.js" new file mode 100644 index 00000000..3fa4da8c --- /dev/null +++ "b/assets/actions_tools_git\345\221\275\344\273\244\346\225\264\347\220\206.md.BB4ue52M.lean.js" @@ -0,0 +1,4 @@ +import{_ as t,c as o,a2 as c,o as a}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"git命令整理","description":"","frontmatter":{},"headers":[],"relativePath":"actions/tools/git命令整理.md","filePath":"actions/tools/git命令整理.md","lastUpdated":1729217313000}'),i={name:"actions/tools/git命令整理.md"};function p(d,e,s,r,l,n){return a(),o("div",null,e[0]||(e[0]=[c(`版本控制工具一直用的GIT,之前提交代码都是用IDEA集成的GIT可视化工具,命令行几乎不怎么用,由于接下来项目要整合到微服务平台中,项目代码管理也要迁到Gerrit,idea的集成支持不太好,所以整理下GIT的命令,方便后面使用命令行提交代码。
Remote:远程仓库
+Reporsitory:本地仓库
+WorkSpace:工作区
+Index:暂存区git commit --amend :提交完发现漏掉了几个文件没有添加,或者提交信息写错了,此时,可以运行带有 --amend 选项的提交命令来重新提交
git checkout -- <file> 把readme.txt文件在工作区的修改全部撤销,这里有两种情况:
一种是readme.txt自修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态;
一种是readme.txt已经添加到暂存区后,又作了修改,现在,撤销修改就回到添加到暂存区后的状态。
git reset [--soft | --mixed | --hard] [HEAD]
关于git checkout和git reset建议看下这篇文章,git重置
git checkout branch_name
切换分之前要注意本地分支是否有未commit的文件,如果有可以撤销改动,或者commit,再或者使用git stash将当前分支的改动临时保存起来,使当前分支的工作空间和暂存区变干净。然后再进行切换分支;切换回之前的分支,需要恢复被临时保存的改动
git stash -u
恢复本地修改:
1.先查看有多少个临时保存的改动
git stash list
2.再用git stash apply --index stash@{n},n为使用git stash list查看到的某个改动的数字
3.再用git stash drop stash@{n}删除临时保存的改动
如果只有一个临时的stash,那么可以直接git stash apply即可恢复上次的临时保存记录
基于本地master分支创建test分支为例:
先切换到master分支:git checkout master
建分支: git branch test
切分支:git checkout test
或者
建分支后切到该分支:git checkout -b test master
以基于某次commit id创建test分支为例:
git checkout -b test 0faceff
其中的0faceff为commit id的前7位
以基于某个tag创建test分支为例
git checkout -b test v0.1.0
v0.1.0为tag的名称
git branch: 只显示本地分支名,当前分支名前有星号
git branch -v:显示本地分支名,当前分支前有星号,显示commit id
git branch -vv:显示本地分支名,当前分支名前有星号,显示commit id,显示追踪的远程分支名
git branch -a:显示所有分支名(包括远程分支)
git branch -r:查看远程分支名
普通删除:git branch -d branch_name
强制删除(分支上有修改未合并到其他分支):git branch -D branch_name
git pull或者git fetch
git pull -v --progress "origin"命令可以显示更详细的信息,git pull命令会fetch所有的远程分支的信息到本地,同时当前本地分支会被合并。
如果本地有修改文件,而且远程仓库也修改了该文件,pull会失败,提示本地的修改会被合并覆盖,此时可以commit本地的修改或者stash本地的修改,再pull。
首先使用git checkout branch_name切换到正确分支,pull,新建或修改代码,再使用git add 文件名把修改或新增的文件添加到暂存区,再执行commit命令提交到本地仓库。
其中:
git add 某个文件
git add 多个文件(文件名用空格隔开)
git add -u 添加所有修改的文件到暂存区
git add .添加所有修改和新增的文件到暂存区
git add -A:添加所有修改,新增和删除的文件到暂存区
git commit 文件名 -m "注释":commit某个文件
git commit 文件1 文件2 -m "注释" commit多个文件,用空格隔开
git commit -m "注释"commit所有文件
如果是删除文件,可以使用
rm 文件
git add 文件
git commit 文件 -m "注释"
如果是重命名文件或者移动文件,可以使用
git mv 源文件路径 目标文件路径
git commit 文件 -m "注释"
本地代码从本地branch_name分支推到远端branch_name分支:
git checkout branch_name
git pull
git push origin HEAD:refs/for/branch_name
或者
git checkout branch_name
git pull
git push origin branch_name:refs/for/branch_name
git status 显示有变更的文件
git log 显示当前分支的版本历史
git log --stat 显示commit历史,以及每次commit发生变更的文件
git log -S [keyword] 搜索提交历史,根据关键词
git log [tag] HEAD --pretty=format:%s 显示某个commit之后的所有变动,每个commit占据一行
git log [tag] HEAD --grep feature 显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件
git log -p [file] 显示指定文件相关的每一次diff
git log -5 --pretty --oneline 显示过去5次提交
git shortlog -sn 显示所有提交过的用户,按提交次数排序
git blame [file] 显示指定文件是什么人在什么时间修改过
git diff 显示暂存区和工作区的代码差异
git diff --cached [file] 显示暂存区和上一个commit的差异
git diff HEAD 显示工作区与当前分支最新commit之间的差异
git diff [first-branch]...[second-branch] 显示两次提交之间的差异
git diff --shortstat "@{0 day ago}" 显示今天你写了多少行代码
git show [commit] 显示某次提交的元数据和内容变化
git show --name-only [commit] 显示某次提交发生变化的文件
git show [commit]:[filename] 显示某次提交时,某个文件的内容
git rebase [branch] 从本地master拉取代码更新当前分支:branch 一般为master
git fetch是将远程的最新内容拉到本地,用户在检查了以后决定是否合并到本地分支中。 而git pull 则是将远程的最新内容拉下来后直接合并,即:git pull = git fetch + git merge,这样可能会产生冲突,需要手动解决。
`,92)]))}const m=t(i,[["render",p]]);export{g as __pageData,m as default}; diff --git "a/assets/actions_tools_iterm2\351\205\215\345\220\210oh-my-zsh\351\205\215\347\275\256\344\270\252\346\200\247\344\270\273\351\242\230\347\273\210\347\253\257.md.B4zFeTdZ.js" "b/assets/actions_tools_iterm2\351\205\215\345\220\210oh-my-zsh\351\205\215\347\275\256\344\270\252\346\200\247\344\270\273\351\242\230\347\273\210\347\253\257.md.B4zFeTdZ.js" new file mode 100644 index 00000000..a8131a9c --- /dev/null +++ "b/assets/actions_tools_iterm2\351\205\215\345\220\210oh-my-zsh\351\205\215\347\275\256\344\270\252\346\200\247\344\270\273\351\242\230\347\273\210\347\253\257.md.B4zFeTdZ.js" @@ -0,0 +1,9 @@ +import{_ as s,c as e,a2 as i,o as t}from"./chunks/framework.BjcrtTwI.js";const m=JSON.parse('{"title":"iterm2配合oh-my-zsh配置个性主题终端","description":"","frontmatter":{},"headers":[],"relativePath":"actions/tools/iterm2配合oh-my-zsh配置个性主题终端.md","filePath":"actions/tools/iterm2配合oh-my-zsh配置个性主题终端.md","lastUpdated":1729217313000}'),h={name:"actions/tools/iterm2配合oh-my-zsh配置个性主题终端.md"};function l(r,a,o,n,p,c){return t(),e("div",null,a[0]||(a[0]=[i(`官网下载:https://iterm2.com/
安装脚本:sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
因为网络原因无法执行这个脚本的可以找gitee上的国内源
仓库地址: https://github.com/dracula/iterm.git
如图,导入完之后就可以选择导入的dracula主题颜色
git clone https://github.com/zsh-users/zsh-syntax-highlighting $ZSH_CUSTOM/plugins/zsh-syntax-highlighting
git clone https://github.com/zsh-users/zsh-autosuggestions $ZSH_CUSTOM/plugins/zsh-autosuggestions
source ~/.zsh/zsh-autosuggestions/zsh-autosuggestions.zshsource ~/.zsh/zsh-syntax-highlighting/zsh-syntax-highlighting.zsh# ~/.zshrc
+plugins=(
+ git
+ zsh-autosuggestions
+ zsh-syntax-highlighting
+)
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ~/powerlevel10k
+echo 'source ~/powerlevel10k/powerlevel10k.zsh-theme' >>~/.zshrc
+
+p10k configure官网下载:https://iterm2.com/
安装脚本:sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
因为网络原因无法执行这个脚本的可以找gitee上的国内源
仓库地址: https://github.com/dracula/iterm.git
如图,导入完之后就可以选择导入的dracula主题颜色
git clone https://github.com/zsh-users/zsh-syntax-highlighting $ZSH_CUSTOM/plugins/zsh-syntax-highlighting
git clone https://github.com/zsh-users/zsh-autosuggestions $ZSH_CUSTOM/plugins/zsh-autosuggestions
source ~/.zsh/zsh-autosuggestions/zsh-autosuggestions.zshsource ~/.zsh/zsh-syntax-highlighting/zsh-syntax-highlighting.zsh# ~/.zshrc
+plugins=(
+ git
+ zsh-autosuggestions
+ zsh-syntax-highlighting
+)
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ~/powerlevel10k
+echo 'source ~/powerlevel10k/powerlevel10k.zsh-theme' >>~/.zshrc
+
+p10k configuremacos生态的ssh工具有很多,但是试了很多还是感觉很差劲,不如windows生态的mobaxterm和xshell,可惜这两个软件没有mac的版本。不过iterm2作为mac生态下的终端工具代表倒是很简洁方便,但是没有专门的ssh工具那种简易的远程连接配置,需要自己动手折腾一下才可以。
官网下载,不赘述。
command+,打开偏好设置,选择profiles
新建一个profile设置,将command设置从login shell改为command,并输入需要执行的ssh指令
切换到advanced选项卡,选择编辑triggers触发器。新增一个触发器,action选择send text,触发的表达式改为root@xxx.xxx.xxx.xxx's password,参数改为登陆账户的密码+\\n,这里注意一定要加\\n代表输入回车,不然就会卡在输入密码那里需要手动回车才能登陆,然后勾选上instant立即触发。
这里触发器的表达式即是输入ssh命令时,服务器给出的需要输入密码的提示文字,所以想配置什么服务器的触发器直接改个登陆名和服务器地址就可以
配置完毕后,可以根据菜单栏的profiles选项卡,选择需要连接的服务器即可
macos生态的ssh工具有很多,但是试了很多还是感觉很差劲,不如windows生态的mobaxterm和xshell,可惜这两个软件没有mac的版本。不过iterm2作为mac生态下的终端工具代表倒是很简洁方便,但是没有专门的ssh工具那种简易的远程连接配置,需要自己动手折腾一下才可以。
官网下载,不赘述。
command+,打开偏好设置,选择profiles
新建一个profile设置,将command设置从login shell改为command,并输入需要执行的ssh指令
切换到advanced选项卡,选择编辑triggers触发器。新增一个触发器,action选择send text,触发的表达式改为root@xxx.xxx.xxx.xxx's password,参数改为登陆账户的密码+\\n,这里注意一定要加\\n代表输入回车,不然就会卡在输入密码那里需要手动回车才能登陆,然后勾选上instant立即触发。
这里触发器的表达式即是输入ssh命令时,服务器给出的需要输入密码的提示文字,所以想配置什么服务器的触发器直接改个登陆名和服务器地址就可以
配置完毕后,可以根据菜单栏的profiles选项卡,选择需要连接的服务器即可
sudo apt install netatalk avahi-daemon
sudo vim /etc/netatalk/afp.conf
[Time Machine]
+path = /mnt/data/backup/time_machine
+time machine = yessudo mkdir -p /mnt/data/backup/time_machine
sudo chown nobody:nogroup /mnt/data/backup/time_machine
sudo chmod 777 /mnt/data/backup/time_machine
sudo systemctl restart netatalk
时间机器中选择磁盘,连接linux server即可。
`,15)]))}const u=e(o,[["render",i]]);export{p as __pageData,u as default}; diff --git "a/assets/actions_tools_linux\350\256\276\347\275\256macOS\346\227\266\351\227\264\346\234\272\345\231\250server.md.Bb2792Qq.lean.js" "b/assets/actions_tools_linux\350\256\276\347\275\256macOS\346\227\266\351\227\264\346\234\272\345\231\250server.md.Bb2792Qq.lean.js" new file mode 100644 index 00000000..a2acec15 --- /dev/null +++ "b/assets/actions_tools_linux\350\256\276\347\275\256macOS\346\227\266\351\227\264\346\234\272\345\231\250server.md.Bb2792Qq.lean.js" @@ -0,0 +1,3 @@ +import{_ as e,c as t,a2 as n,o as s}from"./chunks/framework.BjcrtTwI.js";const p=JSON.parse('{"title":"linux设置macOS时间机器server","description":"","frontmatter":{},"headers":[],"relativePath":"actions/tools/linux设置macOS时间机器server.md","filePath":"actions/tools/linux设置macOS时间机器server.md","lastUpdated":1729217313000}'),o={name:"actions/tools/linux设置macOS时间机器server.md"};function i(c,a,r,l,d,h){return s(),t("div",null,a[0]||(a[0]=[n(`sudo apt install netatalk avahi-daemon
sudo vim /etc/netatalk/afp.conf
[Time Machine]
+path = /mnt/data/backup/time_machine
+time machine = yessudo mkdir -p /mnt/data/backup/time_machine
sudo chown nobody:nogroup /mnt/data/backup/time_machine
sudo chmod 777 /mnt/data/backup/time_machine
sudo systemctl restart netatalk
时间机器中选择磁盘,连接linux server即可。
`,15)]))}const u=e(o,[["render",i]]);export{p as __pageData,u as default}; diff --git "a/assets/actions_tools_powershell\347\276\216\345\214\226.md.HmPrbNtA.js" "b/assets/actions_tools_powershell\347\276\216\345\214\226.md.HmPrbNtA.js" new file mode 100644 index 00000000..6bcc67b0 --- /dev/null +++ "b/assets/actions_tools_powershell\347\276\216\345\214\226.md.HmPrbNtA.js" @@ -0,0 +1,10 @@ +import{_ as i,c as a,a2 as e,o as t}from"./chunks/framework.BjcrtTwI.js";const F=JSON.parse('{"title":"powershell美化","description":"","frontmatter":{},"headers":[],"relativePath":"actions/tools/powershell美化.md","filePath":"actions/tools/powershell美化.md","lastUpdated":1729217313000}'),n={name:"actions/tools/powershell美化.md"};function l(h,s,p,o,r,k){return t(),a("div",null,s[0]||(s[0]=[e(`Set-ExecutionPolicy Bypass -Scope Process -Force; Invoke-Expression ((New-Object System.Net.WebClient).DownloadString('https://ohmyposh.dev/install.ps1'))如果不安装Nerd Fonts会有乱码情况,oh-my-posh推荐安装Meslo LGM NF字体,也可以从https://www.nerdfonts.com/font-downloads自行选择下载。下载后解压放到C:\\windows\\Fonts文件夹中。编辑Windows Terminal默认设置将默认字体改为喜欢的Nerd Fonts。
code $PROFILE或notepad $PROFILE
oh-my-posh init pwsh | Invoke-Expression # 默认主题
+
+oh-my-posh init pwsh --config C:\\Users\\story\\AppData\\Local\\Programs\\oh-my-posh\\themes\\robbyrussel.omp.json | Invoke-Expression # --config可以配置喜欢的主题
+
+--config 'https://raw.githubusercontent.com/JanDeDobbeleer/oh-my-posh/main/themes/jandedobbeleer.omp.json' # 也可以配置远程主题# 设置预测文本来源为历史记录
+Set-PSReadLineOption -PredictionSource History
+# 设置向上键为后向搜索历史记录
+Set-PSReadLineKeyHandler -Key UpArrow -Function HistorySearchBackward
+# 设置向下键为前向搜索历史纪录
+Set-PSReadLineKeyHandler -Key DownArrow -Function HistorySearchForwardwindows安装后默认的主题文件夹为:C:\\Users\\[your username]\\AppData\\Local\\Programs\\oh-my-posh\\themes,也可以通过echo $env:POSH_THEMES_PATH命令查看主题的路径
配置立即生效:
. $PROFILE效果图:
默认:
jandedobbeleer:
Set-ExecutionPolicy Bypass -Scope Process -Force; Invoke-Expression ((New-Object System.Net.WebClient).DownloadString('https://ohmyposh.dev/install.ps1'))如果不安装Nerd Fonts会有乱码情况,oh-my-posh推荐安装Meslo LGM NF字体,也可以从https://www.nerdfonts.com/font-downloads自行选择下载。下载后解压放到C:\\windows\\Fonts文件夹中。编辑Windows Terminal默认设置将默认字体改为喜欢的Nerd Fonts。
code $PROFILE或notepad $PROFILE
oh-my-posh init pwsh | Invoke-Expression # 默认主题
+
+oh-my-posh init pwsh --config C:\\Users\\story\\AppData\\Local\\Programs\\oh-my-posh\\themes\\robbyrussel.omp.json | Invoke-Expression # --config可以配置喜欢的主题
+
+--config 'https://raw.githubusercontent.com/JanDeDobbeleer/oh-my-posh/main/themes/jandedobbeleer.omp.json' # 也可以配置远程主题# 设置预测文本来源为历史记录
+Set-PSReadLineOption -PredictionSource History
+# 设置向上键为后向搜索历史记录
+Set-PSReadLineKeyHandler -Key UpArrow -Function HistorySearchBackward
+# 设置向下键为前向搜索历史纪录
+Set-PSReadLineKeyHandler -Key DownArrow -Function HistorySearchForwardwindows安装后默认的主题文件夹为:C:\\Users\\[your username]\\AppData\\Local\\Programs\\oh-my-posh\\themes,也可以通过echo $env:POSH_THEMES_PATH命令查看主题的路径
配置立即生效:
. $PROFILE效果图:
默认:
jandedobbeleer:
之前从网上下软件一直没有校验的习惯,直到从某知名mac破解网站上下了个被人恶意投毒的navicat,本文记录下各系统下校验的操作。内容引用自Apache Kafka官方文档。
| Windows | Linux | Mac | |
|---|---|---|---|
| SHA-1 (deprecated) | certUtil -hashfile file SHA1 | sha1sum file | shasum -a 1 file |
| SHA-256 | certUtil -hashfile file SHA256 | sha256sum file | shasum -a 256 file |
| SHA-512 | certUtil -hashfile file SHA512 | sha512sum file | shasum -a 512 file |
| MD5 (deprecated) | certUtil -hashfile file MD5 | md5sum file | md5 file |
之前从网上下软件一直没有校验的习惯,直到从某知名mac破解网站上下了个被人恶意投毒的navicat,本文记录下各系统下校验的操作。内容引用自Apache Kafka官方文档。
| Windows | Linux | Mac | |
|---|---|---|---|
| SHA-1 (deprecated) | certUtil -hashfile file SHA1 | sha1sum file | shasum -a 1 file |
| SHA-256 | certUtil -hashfile file SHA256 | sha256sum file | shasum -a 256 file |
| SHA-512 | certUtil -hashfile file SHA512 | sha512sum file | shasum -a 512 file |
| MD5 (deprecated) | certUtil -hashfile file MD5 | md5sum file | md5 file |
docker inspect dashboard-dashboard-1 --format='{{.GraphDriver.Data.MergedDir}}'路径:/var/lib/docker/overlay2/xxxx/merged/dashboard/resource/template
替换文件common/header.html
{{define "common/header"}}
+<!DOCTYPE html>
+<html lang="{{.Conf.Language}}">
+
+<head>
+ <meta charset="UTF-8">
+ <meta name="viewport" content="width=device-width, initial-scale=1.0">
+ <meta http-equiv="X-UA-Compatible" content="ie=edge">
+ <meta content="telephone=no" name="format-detection">
+ <title>{{.Title}}</title>
+ <link rel="stylesheet" type="text/css"
+ href="https://cdn.staticfile.org/semantic-ui/2.4.1/semantic.min.css">
+ <link href="https://cdn.staticfile.org/font-logos/0.17/font-logos.min.css" type="text/css"
+ rel="stylesheet" />
+ <link href="https://cdn.staticfile.org/bootstrap-icons/1.10.3/font/bootstrap-icons.css" type="text/css"
+ rel="stylesheet" />
+ <link rel="stylesheet" type="text/css" href="/static/semantic-ui-alerts.min.css">
+ <link rel="stylesheet" type="text/css" href="/static/main.css?v2022042314">
+ <link rel="shortcut icon" type="image/png" href="/static/logo.svg?v20210804" />
+</head>
+
+<body>
+ {{end}}替换文件theme-default/home.html
{{define "theme-default/home"}}
+{{template "common/header" .}}
+{{if ts .CustomCode}} {{.CustomCode|safe}} {{end}}
+{{template "common/menu" .}}
+<div class="nb-container">
+ <div class="ui container">
+ <div id="app">
+ <div class="ui styled fluid accordion" v-for="group in groups">
+ <div class="active title">
+ <i class="dropdown icon"></i>
+ @#(group.Tag!==''?group.Tag:'{{tr "Default"}}')#@
+ </div>
+ <div class="active content">
+ <div class="ui four stackable status cards">
+ <div v-for="server in group.data" :id="server.ID" class="ui card">
+ <div class="content" v-if="server.Host" style="margin-top: 10px; padding-bottom: 5px">
+ <div class="header">
+ <i :class="server.Host.CountryCode + ' flag'"></i> <i v-if='server.Host.Platform == "darwin"'
+ class="apple icon"></i><i v-else-if='isWindowsPlatform(server.Host.Platform)'
+ class="windows icon"></i><i v-else :class="'fl-' + getFontLogoClass(server.Host.Platform)"></i>
+ @#server.Name + (server.live?'':'[{{tr "Offline"}}]')#@
+ <i class="nezha-secondary-font info circle icon" style="height: 28px"></i>
+ <div class="ui content popup" style="margin-bottom: 0">
+ {{tr "Platform"}}: @#server.Host.Platform#@-@#server.Host.PlatformVersion#@
+ [<span
+ v-if="server.Host.Virtualization">@#server.Host.Virtualization#@:</span>@#server.Host.Arch#@]<br />
+ CPU: @#server.Host.CPU#@<br />
+ {{tr "DiskUsed"}}:
+ @#formatByteSize(server.State.DiskUsed)#@/@#formatByteSize(server.Host.DiskTotal)#@<br />
+ {{tr "MemUsed"}}:
+ @#formatByteSize(server.State.MemUsed)#@/@#formatByteSize(server.Host.MemTotal)#@<br />
+ {{tr "SwapUsed"}}:
+ @#formatByteSize(server.State.SwapUsed)#@/@#formatByteSize(server.Host.SwapTotal)#@<br />
+ {{tr "NetTransfer"}}: <i
+ class="arrow alternate circle down outline icon"></i>@#formatByteSize(server.State.NetInTransfer)#@<i
+ class="arrow alternate circle up outline icon"></i>@#formatByteSize(server.State.NetOutTransfer)#@<br />
+ {{tr "Load"}}: @# toFixed2(server.State.Load1) #@/@# toFixed2(server.State.Load5) #@/@#
+ toFixed2(server.State.Load15) #@<br />
+ {{tr "ProcessCount"}}: @# server.State.ProcessCount #@<br />
+ {{tr "ConnCount"}}: TCP @# server.State.TcpConnCount #@ / UDP @# server.State.UdpConnCount #@<br />
+ {{tr "BootTime"}}: @# formatTimestamp(server.Host.BootTime) #@<br />
+ {{tr "LastActive"}}: @# new Date(server.LastActive).toLocaleString() #@<br />
+ {{tr "Version"}}: @#server.Host.Version#@<br />
+ </div>
+ <div class="ui divider" style="margin-bottom: 5px"></div>
+ </div>
+ <div class="description">
+ <div class="ui grid">
+ <div class="three wide column">CPU</div>
+ <div class="thirteen wide column">
+ <div :class="formatPercent(server.live,server.State.CPU, 100).class">
+ <div class="bar" :style="formatPercent(server.live,server.State.CPU, 100).style">
+ <small>@#formatPercent(server.live,server.State.CPU,100).percent#@%</small>
+ </div>
+ </div>
+ </div>
+ <div class="three wide column">{{tr "MemUsed"}}</div>
+ <div class="thirteen wide column">
+ <div :class="formatPercent(server.live,server.State.MemUsed, server.Host.MemTotal).class">
+ <div class="bar"
+ :style="formatPercent(server.live,server.State.MemUsed, server.Host.MemTotal).style">
+ <small>@#parseInt(server.State?server.State.MemUsed/server.Host.MemTotal*100:0)#@%</small>
+ </div>
+ </div>
+ </div>
+ <div class="three wide column">{{tr "SwapUsed"}}</div>
+ <div class="thirteen wide column">
+ <div :class="formatPercent(server.live,server.State.SwapUsed, server.Host.SwapTotal).class">
+ <div class="bar"
+ :style="formatPercent(server.live,server.State.SwapUsed, server.Host.SwapTotal).style">
+ <small>@#parseInt(server.State?server.State.SwapUsed/server.Host.SwapTotal*100:0)#@%</small>
+ </div>
+ </div>
+ </div>
+ <div class="three wide column">{{tr "DiskUsed"}}</div>
+ <div class="thirteen wide column">
+ <div :class="formatPercent(server.live,server.State.DiskUsed, server.Host.DiskTotal).class">
+ <div class="bar"
+ :style="formatPercent(server.live,server.State.DiskUsed, server.Host.DiskTotal).style">
+ <small>@#parseInt(server.State?server.State.DiskUsed/server.Host.DiskTotal*100:0)#@%</small>
+ </div>
+ </div>
+ </div>
+ <div class="three wide column">{{tr "NetSpeed"}}</div>
+ <div class="thirteen wide column">
+ <i class="arrow alternate circle down outline icon"></i>
+ @#formatByteSize(server.State.NetInSpeed)#@/s
+ <i class="arrow alternate circle up outline icon"></i>
+ @#formatByteSize(server.State.NetOutSpeed)#@/s
+ </div>
+ <div class="three wide column">流量</div>
+ <div class="thirteen wide column">
+ <i class="arrow circle down icon"></i>
+ @#formatByteSize(server.State.NetInTransfer)#@
+
+ <i class="arrow circle up icon"></i>
+ @#formatByteSize(server.State.NetOutTransfer)#@
+ </div>
+ <div class="three wide column">信息</div>
+ <div class="thirteen wide column">
+ <i class="bi bi-cpu-fill" style="font-size: 1.1rem; color: #4a86e8;"></i> @#getCoreAndGHz(server.Host.CPU)#@
+
+ <i class="bi bi-memory" style="font-size: 1.1rem; color: #00ac0d;"></i> @#getK2Gb(server.Host.MemTotal)#@
+
+ <i class="bi bi-hdd-rack-fill" style="font-size: 1.1rem; color: #980000"></i> @#getK2Gb(server.Host.DiskTotal)#@
+ </div>
+ <div class="three wide column">{{tr "Uptime"}}</div>
+ <div class="thirteen wide column">
+ <i class="clock icon"></i>@#secondToDate(server.State.Uptime)#@
+ </div>
+ </div>
+ </div>
+ </div>
+ <div class="content" v-else>
+ <p>@#server.Name#@</p>
+ <p>{{tr "ServerIsOffline"}}</p>
+ </div>
+ </div>
+ </div>
+ </div>
+ </div>
+ </div>
+ </div>
+</div>
+{{template "common/footer" .}}
+<script>
+ const initData = JSON.parse('{{.Servers}}').servers;
+ var statusCards = new Vue({
+ el: '#app',
+ delimiters: ['@#', '#@'],
+ data: {
+ data: initData,
+ groups: [],
+ cache: [],
+ },
+ created() {
+ this.group()
+ },
+ mounted() {
+ $('.nezha-secondary-font.info.icon').popup({
+ popup: '.ui.content.popup',
+ exclusive: true,
+ });
+ },
+ methods: {
+ toFixed2(f) {
+ return f.toFixed(2)
+ },
+ isWindowsPlatform(str) {
+ return str.includes('Windows')
+ },
+ getFontLogoClass(str) {
+ if (["almalinux",
+ "alpine",
+ "aosc",
+ "apple",
+ "archlinux",
+ "archlabs",
+ "artix",
+ "budgie",
+ "centos",
+ "coreos",
+ "debian",
+ "deepin",
+ "devuan",
+ "docker",
+ "elementary",
+ "fedora",
+ "ferris",
+ "flathub",
+ "freebsd",
+ "gentoo",
+ "gnu-guix",
+ "illumos",
+ "kali-linux",
+ "linuxmint",
+ "mageia",
+ "mandriva",
+ "manjaro",
+ "nixos",
+ "openbsd",
+ "opensuse",
+ "pop-os",
+ "raspberry-pi",
+ "redhat",
+ "rocky-linux",
+ "sabayon",
+ "slackware",
+ "snappy",
+ "solus",
+ "tux",
+ "ubuntu",
+ "void",
+ "zorin"].indexOf(str)
+ > -1) {
+ return str;
+ }
+ if (['openwrt','linux'].indexOf(str) > -1) {
+ return 'tux';
+ }
+ if (str == 'amazon') {
+ return 'redhat';
+ }
+ if (str == 'arch') {
+ return 'archlinux';
+ }
+ return '';
+ },
+ group() {
+ this.groups = groupingData(this.data, "Tag")
+ },
+ formatPercent(live, used, total) {
+ const percent = live ? (parseInt(used / total * 100) || 0) : -1
+ if (!this.cache[percent]) {
+ this.cache[percent] = {
+ class: {
+ ui: true,
+ progress: true,
+ },
+ style: {
+ 'transition-duration': '300ms',
+ 'min-width': 'unset',
+ width: percent + '% !important',
+ },
+ percent,
+ }
+ if (percent < 0) {
+ this.cache[percent].style['background-color'] = 'slategray'
+ this.cache[percent].class.offline = true
+ } else if (percent < 51) {
+ this.cache[percent].style['background-color'] = '#0a94f2'
+ this.cache[percent].class.fine = true
+ } else if (percent < 81) {
+ this.cache[percent].style['background-color'] = 'orange'
+ this.cache[percent].class.warning = true
+ } else {
+ this.cache[percent].style['background-color'] = 'crimson'
+ this.cache[percent].class.error = true
+ }
+ }
+ return this.cache[percent]
+ },
+ secondToDate(s) {
+ var d = Math.floor(s / 3600 / 24);
+ if (d > 0) {
+ return d + " {{tr "Day"}}"
+ }
+ var h = Math.floor(s / 3600 % 24);
+ var m = Math.floor(s / 60 % 60);
+ var s = Math.floor(s % 60);
+ return h + ":" + ("0" + m).slice(-2) + ":" + ("0" + s).slice(-2);
+ },
+ formatTimestamp(t) {
+ return new Date(t * 1000).toLocaleString()
+ },
+ formatByteSize(bs) {
+ const x = readableBytes(bs)
+ return x != "NaN undefined" ? x : '0B'
+ },
+ getCoreAndGHz(str){
+ if((str || []).hasOwnProperty(0) === false){
+ return '';
+ }
+ str = str[0];
+ let GHz = str.match(/(\\d|\\.)+GHz/g);
+ let Core = str.match(/(\\d|\\.)+ Physical/g);
+ GHz = GHz!==null?GHz.hasOwnProperty(0)===false?'':GHz[0]:''
+ Core = Core!==null?Core.hasOwnProperty(0)===false?'?':Core[0]:'?'
+ if(Core === '?'){
+ let Core = str.match(/(\\d|\\.)+ Virtual/g);
+ Core = Core!==null?Core.hasOwnProperty(0)===false?'?':Core[0]:'?'
+ return Core.replace('Virtual','Core')
+ }
+ return Core.replace('Physical','Core');
+
+ },
+ getK2Gb(bs){
+ bs = bs / 1024 /1024 /1024;
+ return Math.ceil(bs.toFixed(2)) + 'GB';
+ },
+ listTipsMouseenter(obj,strs,tipsNum=1){
+ this.layerIndex = layer.tips(strs, '#'+obj,{tips: [tipsNum, 'rgb(0 0 0 / 85%)'],time:0});
+ $('#'+obj).attr('layerIndex',this.layerIndex)
+ },
+ listTipsMouseleave(obj){
+ layer.close(this.layerIndex)
+ }
+ }
+ })
+
+ function groupingData(data, field) {
+ let map = {};
+ let dest = [];
+ data.forEach(item => {
+ if (!map[item[field]]) {
+ dest.push({
+ [field]: item[field],
+ data: [item]
+ });
+ map[item[field]] = item;
+ } else {
+ dest.forEach(dItem => {
+ if (dItem[field] == item[field]) {
+ dItem.data.push(item);
+ }
+ });
+ }
+ })
+ return dest;
+ }
+
+ let canShowError = true;
+ function connect() {
+ const wsProtocol = window.location.protocol == "https:" ? "wss" : "ws"
+ const ws = new WebSocket(wsProtocol + '://' + window.location.host + '/ws');
+ ws.onopen = function (evt) {
+ canShowError = true;
+ $.suiAlert({
+ title: '{{tr "RealtimeChannelEstablished"}}',
+ description: '{{tr "GetTheLatestMonitoringDataInRealTime"}}',
+ type: 'success',
+ time: '2',
+ position: 'top-center',
+ });
+ }
+ ws.onmessage = function (evt) {
+ const oldServers = statusCards.servers
+ const data = JSON.parse(evt.data)
+ statusCards.servers = data.servers
+ for (let i = 0; i < statusCards.servers.length; i++) {
+ const ns = statusCards.servers[i];
+ if (!ns.Host) ns.live = false
+ else {
+ const lastActive = new Date(ns.LastActive).getTime()
+ if (data.now - lastActive > 10 * 1000) {
+ ns.live = false
+ } else {
+ ns.live = true
+ }
+ }
+ }
+ statusCards.groups = groupingData(statusCards.servers, "Tag")
+ }
+ ws.onclose = function () {
+ if (canShowError) {
+ canShowError = false;
+ $.suiAlert({
+ title: '{{tr "RealtimeChannelDisconnect"}}',
+ description: '{{tr "CanNotGetTheLatestMonitoringDataInRealTime"}}',
+ type: 'warning',
+ time: '2',
+ position: 'top-center',
+ });
+ }
+ setTimeout(function () {
+ connect()
+ }, 3000);
+ }
+ ws.onerror = function () {
+ ws.close()
+ }
+ }
+
+ connect();
+
+ $('.ui.accordion').accordion({ "exclusive": false });
+</script>
+{{end}}docker restart dashboard-dashboard-1
<style>
+/* 屏幕适配 */
+@media only screen and (min-width: 1200px) {
+.ui.container {
+width: 80% !important;
+}
+}
+
+@media only screen and (max-width: 767px) {
+.ui.card>.content>.header:not(.ui), .ui.cards>.card>.content>.header:not(.ui) {
+ margin-top: 0.4em !important;
+}
+}
+
+/* 整体图标 */
+i.icon {
+color: #000;
+width: 1.2em !important;
+}
+
+/* 背景图片 */
+body {
+content: " " !important;
+background: fixed !important;
+z-index: -1 !important;
+top: 0 !important;
+right: 0 !important;
+bottom: 0 !important;
+left: 0 !important;
+background-position: top !important;
+background-repeat: no-repeat !important;
+background-size: cover !important;
+//background-image: url(https://api.kdcc.cn/img/) !important;
+font-family: Arial,Helvetica,sans-serif !important;
+}
+
+/* 导航栏 */
+.ui.large.menu {
+border: 0 !important;
+border-radius: 0px !important;
+background-color: rgba(255, 255, 255, 55%) !important;
+}
+
+/* 首页按钮 */
+.ui.menu .active.item {
+background-color: transparent !important;
+}
+
+/* 导航栏下拉框 */
+.ui.dropdown .menu {
+border: 0 !important;
+border-radius: 0 !important;
+background-color: rgba(255, 255, 255, 80%) !important;
+}
+
+/* 登陆按钮 */
+.nezha-primary-btn {
+background-color: transparent !important;
+color: #000 !important;
+}
+
+/* 大卡片 */
+#app .ui.fluid.accordion {
+background-color: #fbfbfb26 !important;
+border-radius: 0.4rem !important;
+}
+
+/* 小卡片 */
+.ui.four.cards>.card {
+border-radius: 0.6rem !important;
+background-color: #fafafaa3 !important;
+}
+
+.status.cards .wide.column {
+padding-top: 0 !important;
+padding-bottom: 0 !important;
+height: 3.3rem !important;
+}
+
+.status.cards .three.wide.column {
+padding-right: 0rem !important;
+}
+
+.status.cards .wide.column:nth-child(1) {
+margin-top: 2rem !important;
+}
+
+.status.cards .wide.column:nth-child(2) {
+margin-top: 2rem !important;
+}
+
+.status.cards .description {
+padding-bottom: 0 !important;
+}
+
+/* 小鸡名 */
+.status.cards .flag {
+margin-right: 0.5rem !important;
+}
+
+/* 弹出卡片图标 */
+.status.cards .header > .info.icon {
+margin-right: 0 !important;
+}
+
+.nezha-secondary-font {
+color: #21ba45 !important;
+}
+
+/* 进度条 */
+.ui.progress {
+border-radius: 50rem !important;
+}
+
+.ui.progress .bar {
+min-width: 1.8em !important;
+border-radius: 15px !important;
+line-height: 1.65em !important;
+}
+
+.ui.fine.progress> .bar {
+background-color: #21ba45 !important;
+}
+
+.ui.progress> .bar {
+background-color: #000 !important;
+}
+
+.ui.progress.fine .bar {
+background-color: #21ba45 !important;
+}
+
+.ui.progress.warning .bar {
+background-color: #ff9800 !important;
+}
+
+.ui.progress.error .bar {
+background-color: #e41e10 !important;
+}
+
+.ui.progress.offline .bar {
+background-color: #000 !important;
+}
+
+/* 上传下载 */
+.status.cards .outline.icon {
+margin-right: 1px !important;
+}
+
+
+i.arrow.alternate.circle.down.outline.icon
+{
+color: #21ba45 !important;
+}
+i.arrow.alternate.circle.up.outline.icon
+
+
+{
+color: red !important;
+}
+
+/* 弹出卡片小箭头 */
+.ui.right.center.popup {
+margin: -3px 0 0 0.914286em !important;
+-webkit-transform-origin: left 50% !important;
+transform-origin: left 50% !important;
+}
+
+.ui.bottom.left.popup {
+margin-left: 1px !important;
+margin-top: 3px !important;
+}
+
+.ui.top.left.popup {
+margin-left: 0 !important;
+margin-bottom: 10px !important;
+}
+
+.ui.top.right.popup {
+margin-right: 0 !important;
+margin-bottom: 8px !important;
+}
+
+.ui.left.center.popup {
+margin: -3px .91428571em 0 0 !important;
+-webkit-transform-origin: right 50% !important;
+transform-origin: right 50% !important;
+}
+
+.ui.right.center.popup:before,
+.ui.left.center.popup:before {
+border: 0px solid #fafafaeb !important;
+background: #fafafaeb !important;
+}
+
+.ui.top.popup:before {
+border-color: #fafafaeb transparent transparent !important;
+}
+
+.ui.popup:before {
+border-color: #fafafaeb transparent transparent !important;
+}
+
+.ui.bottom.left.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important;
+-webkit-box-shadow: 0px 0px 0 0
+#fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+.ui.bottom.right.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important
+-webkit-box-shadow: 0px 0px 0 0 #fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+.ui.top.left.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important;
+-webkit-box-shadow: 0px 0px 0 0 #fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+.ui.top.right.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important;
+-webkit-box-shadow: 0px 0px 0 0 #fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+.ui.left.center.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important;
+-webkit-box-shadow: 0px 0px 0 0 #fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+/* 弹出卡片 */
+.status.cards .ui.content.popup {
+min-width: 20rem !important;
+line-height: 2rem !important;
+border-radius: 5px !important;
+border: 1px solid transparent !important;
+background-color: #fafafaeb !important;
+font-family: Arial,Helvetica,sans-serif !important;
+}
+
+.ui.content {
+margin: 0 !important;
+padding: 1em !important;
+}
+
+/* 服务页 */
+.ui.table {
+background: RGB(225,225,225,0.6) !important;
+}
+
+.ui.table thead th {
+background: transparent !important;
+}
+
+/* 服务页进度条 */
+.service-status .good {
+background-color: #21ba45 !important;
+}
+
+.service-status .danger {
+background-color: red !important;
+}
+
+.service-status .warning {
+background-color: orange !important;
+}
+
+/* 版权 */
+.ui.inverted.segment,
+.ui.primary.inverted.segment {
+color: #000 !important;
+font-weight: bold !important;
+background-color: #fafafaa3 !important;
+}
+</style>
+
+<script>
+window.onload = function(){
+var avatar=document.querySelector(".item img")
+var footer=document.querySelector("div.is-size-7")
+footer.innerHTML="Copyright © 2023 All Rights Reserved."
+footer.style.visibility="visible"
+avatar.src="/static/logo.svg"
+avatar.style.visibility="visible"
+}
+</script>docker inspect dashboard-dashboard-1 --format='{{.GraphDriver.Data.MergedDir}}'路径:/var/lib/docker/overlay2/xxxx/merged/dashboard/resource/template
替换文件common/header.html
{{define "common/header"}}
+<!DOCTYPE html>
+<html lang="{{.Conf.Language}}">
+
+<head>
+ <meta charset="UTF-8">
+ <meta name="viewport" content="width=device-width, initial-scale=1.0">
+ <meta http-equiv="X-UA-Compatible" content="ie=edge">
+ <meta content="telephone=no" name="format-detection">
+ <title>{{.Title}}</title>
+ <link rel="stylesheet" type="text/css"
+ href="https://cdn.staticfile.org/semantic-ui/2.4.1/semantic.min.css">
+ <link href="https://cdn.staticfile.org/font-logos/0.17/font-logos.min.css" type="text/css"
+ rel="stylesheet" />
+ <link href="https://cdn.staticfile.org/bootstrap-icons/1.10.3/font/bootstrap-icons.css" type="text/css"
+ rel="stylesheet" />
+ <link rel="stylesheet" type="text/css" href="/static/semantic-ui-alerts.min.css">
+ <link rel="stylesheet" type="text/css" href="/static/main.css?v2022042314">
+ <link rel="shortcut icon" type="image/png" href="/static/logo.svg?v20210804" />
+</head>
+
+<body>
+ {{end}}替换文件theme-default/home.html
{{define "theme-default/home"}}
+{{template "common/header" .}}
+{{if ts .CustomCode}} {{.CustomCode|safe}} {{end}}
+{{template "common/menu" .}}
+<div class="nb-container">
+ <div class="ui container">
+ <div id="app">
+ <div class="ui styled fluid accordion" v-for="group in groups">
+ <div class="active title">
+ <i class="dropdown icon"></i>
+ @#(group.Tag!==''?group.Tag:'{{tr "Default"}}')#@
+ </div>
+ <div class="active content">
+ <div class="ui four stackable status cards">
+ <div v-for="server in group.data" :id="server.ID" class="ui card">
+ <div class="content" v-if="server.Host" style="margin-top: 10px; padding-bottom: 5px">
+ <div class="header">
+ <i :class="server.Host.CountryCode + ' flag'"></i> <i v-if='server.Host.Platform == "darwin"'
+ class="apple icon"></i><i v-else-if='isWindowsPlatform(server.Host.Platform)'
+ class="windows icon"></i><i v-else :class="'fl-' + getFontLogoClass(server.Host.Platform)"></i>
+ @#server.Name + (server.live?'':'[{{tr "Offline"}}]')#@
+ <i class="nezha-secondary-font info circle icon" style="height: 28px"></i>
+ <div class="ui content popup" style="margin-bottom: 0">
+ {{tr "Platform"}}: @#server.Host.Platform#@-@#server.Host.PlatformVersion#@
+ [<span
+ v-if="server.Host.Virtualization">@#server.Host.Virtualization#@:</span>@#server.Host.Arch#@]<br />
+ CPU: @#server.Host.CPU#@<br />
+ {{tr "DiskUsed"}}:
+ @#formatByteSize(server.State.DiskUsed)#@/@#formatByteSize(server.Host.DiskTotal)#@<br />
+ {{tr "MemUsed"}}:
+ @#formatByteSize(server.State.MemUsed)#@/@#formatByteSize(server.Host.MemTotal)#@<br />
+ {{tr "SwapUsed"}}:
+ @#formatByteSize(server.State.SwapUsed)#@/@#formatByteSize(server.Host.SwapTotal)#@<br />
+ {{tr "NetTransfer"}}: <i
+ class="arrow alternate circle down outline icon"></i>@#formatByteSize(server.State.NetInTransfer)#@<i
+ class="arrow alternate circle up outline icon"></i>@#formatByteSize(server.State.NetOutTransfer)#@<br />
+ {{tr "Load"}}: @# toFixed2(server.State.Load1) #@/@# toFixed2(server.State.Load5) #@/@#
+ toFixed2(server.State.Load15) #@<br />
+ {{tr "ProcessCount"}}: @# server.State.ProcessCount #@<br />
+ {{tr "ConnCount"}}: TCP @# server.State.TcpConnCount #@ / UDP @# server.State.UdpConnCount #@<br />
+ {{tr "BootTime"}}: @# formatTimestamp(server.Host.BootTime) #@<br />
+ {{tr "LastActive"}}: @# new Date(server.LastActive).toLocaleString() #@<br />
+ {{tr "Version"}}: @#server.Host.Version#@<br />
+ </div>
+ <div class="ui divider" style="margin-bottom: 5px"></div>
+ </div>
+ <div class="description">
+ <div class="ui grid">
+ <div class="three wide column">CPU</div>
+ <div class="thirteen wide column">
+ <div :class="formatPercent(server.live,server.State.CPU, 100).class">
+ <div class="bar" :style="formatPercent(server.live,server.State.CPU, 100).style">
+ <small>@#formatPercent(server.live,server.State.CPU,100).percent#@%</small>
+ </div>
+ </div>
+ </div>
+ <div class="three wide column">{{tr "MemUsed"}}</div>
+ <div class="thirteen wide column">
+ <div :class="formatPercent(server.live,server.State.MemUsed, server.Host.MemTotal).class">
+ <div class="bar"
+ :style="formatPercent(server.live,server.State.MemUsed, server.Host.MemTotal).style">
+ <small>@#parseInt(server.State?server.State.MemUsed/server.Host.MemTotal*100:0)#@%</small>
+ </div>
+ </div>
+ </div>
+ <div class="three wide column">{{tr "SwapUsed"}}</div>
+ <div class="thirteen wide column">
+ <div :class="formatPercent(server.live,server.State.SwapUsed, server.Host.SwapTotal).class">
+ <div class="bar"
+ :style="formatPercent(server.live,server.State.SwapUsed, server.Host.SwapTotal).style">
+ <small>@#parseInt(server.State?server.State.SwapUsed/server.Host.SwapTotal*100:0)#@%</small>
+ </div>
+ </div>
+ </div>
+ <div class="three wide column">{{tr "DiskUsed"}}</div>
+ <div class="thirteen wide column">
+ <div :class="formatPercent(server.live,server.State.DiskUsed, server.Host.DiskTotal).class">
+ <div class="bar"
+ :style="formatPercent(server.live,server.State.DiskUsed, server.Host.DiskTotal).style">
+ <small>@#parseInt(server.State?server.State.DiskUsed/server.Host.DiskTotal*100:0)#@%</small>
+ </div>
+ </div>
+ </div>
+ <div class="three wide column">{{tr "NetSpeed"}}</div>
+ <div class="thirteen wide column">
+ <i class="arrow alternate circle down outline icon"></i>
+ @#formatByteSize(server.State.NetInSpeed)#@/s
+ <i class="arrow alternate circle up outline icon"></i>
+ @#formatByteSize(server.State.NetOutSpeed)#@/s
+ </div>
+ <div class="three wide column">流量</div>
+ <div class="thirteen wide column">
+ <i class="arrow circle down icon"></i>
+ @#formatByteSize(server.State.NetInTransfer)#@
+
+ <i class="arrow circle up icon"></i>
+ @#formatByteSize(server.State.NetOutTransfer)#@
+ </div>
+ <div class="three wide column">信息</div>
+ <div class="thirteen wide column">
+ <i class="bi bi-cpu-fill" style="font-size: 1.1rem; color: #4a86e8;"></i> @#getCoreAndGHz(server.Host.CPU)#@
+
+ <i class="bi bi-memory" style="font-size: 1.1rem; color: #00ac0d;"></i> @#getK2Gb(server.Host.MemTotal)#@
+
+ <i class="bi bi-hdd-rack-fill" style="font-size: 1.1rem; color: #980000"></i> @#getK2Gb(server.Host.DiskTotal)#@
+ </div>
+ <div class="three wide column">{{tr "Uptime"}}</div>
+ <div class="thirteen wide column">
+ <i class="clock icon"></i>@#secondToDate(server.State.Uptime)#@
+ </div>
+ </div>
+ </div>
+ </div>
+ <div class="content" v-else>
+ <p>@#server.Name#@</p>
+ <p>{{tr "ServerIsOffline"}}</p>
+ </div>
+ </div>
+ </div>
+ </div>
+ </div>
+ </div>
+ </div>
+</div>
+{{template "common/footer" .}}
+<script>
+ const initData = JSON.parse('{{.Servers}}').servers;
+ var statusCards = new Vue({
+ el: '#app',
+ delimiters: ['@#', '#@'],
+ data: {
+ data: initData,
+ groups: [],
+ cache: [],
+ },
+ created() {
+ this.group()
+ },
+ mounted() {
+ $('.nezha-secondary-font.info.icon').popup({
+ popup: '.ui.content.popup',
+ exclusive: true,
+ });
+ },
+ methods: {
+ toFixed2(f) {
+ return f.toFixed(2)
+ },
+ isWindowsPlatform(str) {
+ return str.includes('Windows')
+ },
+ getFontLogoClass(str) {
+ if (["almalinux",
+ "alpine",
+ "aosc",
+ "apple",
+ "archlinux",
+ "archlabs",
+ "artix",
+ "budgie",
+ "centos",
+ "coreos",
+ "debian",
+ "deepin",
+ "devuan",
+ "docker",
+ "elementary",
+ "fedora",
+ "ferris",
+ "flathub",
+ "freebsd",
+ "gentoo",
+ "gnu-guix",
+ "illumos",
+ "kali-linux",
+ "linuxmint",
+ "mageia",
+ "mandriva",
+ "manjaro",
+ "nixos",
+ "openbsd",
+ "opensuse",
+ "pop-os",
+ "raspberry-pi",
+ "redhat",
+ "rocky-linux",
+ "sabayon",
+ "slackware",
+ "snappy",
+ "solus",
+ "tux",
+ "ubuntu",
+ "void",
+ "zorin"].indexOf(str)
+ > -1) {
+ return str;
+ }
+ if (['openwrt','linux'].indexOf(str) > -1) {
+ return 'tux';
+ }
+ if (str == 'amazon') {
+ return 'redhat';
+ }
+ if (str == 'arch') {
+ return 'archlinux';
+ }
+ return '';
+ },
+ group() {
+ this.groups = groupingData(this.data, "Tag")
+ },
+ formatPercent(live, used, total) {
+ const percent = live ? (parseInt(used / total * 100) || 0) : -1
+ if (!this.cache[percent]) {
+ this.cache[percent] = {
+ class: {
+ ui: true,
+ progress: true,
+ },
+ style: {
+ 'transition-duration': '300ms',
+ 'min-width': 'unset',
+ width: percent + '% !important',
+ },
+ percent,
+ }
+ if (percent < 0) {
+ this.cache[percent].style['background-color'] = 'slategray'
+ this.cache[percent].class.offline = true
+ } else if (percent < 51) {
+ this.cache[percent].style['background-color'] = '#0a94f2'
+ this.cache[percent].class.fine = true
+ } else if (percent < 81) {
+ this.cache[percent].style['background-color'] = 'orange'
+ this.cache[percent].class.warning = true
+ } else {
+ this.cache[percent].style['background-color'] = 'crimson'
+ this.cache[percent].class.error = true
+ }
+ }
+ return this.cache[percent]
+ },
+ secondToDate(s) {
+ var d = Math.floor(s / 3600 / 24);
+ if (d > 0) {
+ return d + " {{tr "Day"}}"
+ }
+ var h = Math.floor(s / 3600 % 24);
+ var m = Math.floor(s / 60 % 60);
+ var s = Math.floor(s % 60);
+ return h + ":" + ("0" + m).slice(-2) + ":" + ("0" + s).slice(-2);
+ },
+ formatTimestamp(t) {
+ return new Date(t * 1000).toLocaleString()
+ },
+ formatByteSize(bs) {
+ const x = readableBytes(bs)
+ return x != "NaN undefined" ? x : '0B'
+ },
+ getCoreAndGHz(str){
+ if((str || []).hasOwnProperty(0) === false){
+ return '';
+ }
+ str = str[0];
+ let GHz = str.match(/(\\d|\\.)+GHz/g);
+ let Core = str.match(/(\\d|\\.)+ Physical/g);
+ GHz = GHz!==null?GHz.hasOwnProperty(0)===false?'':GHz[0]:''
+ Core = Core!==null?Core.hasOwnProperty(0)===false?'?':Core[0]:'?'
+ if(Core === '?'){
+ let Core = str.match(/(\\d|\\.)+ Virtual/g);
+ Core = Core!==null?Core.hasOwnProperty(0)===false?'?':Core[0]:'?'
+ return Core.replace('Virtual','Core')
+ }
+ return Core.replace('Physical','Core');
+
+ },
+ getK2Gb(bs){
+ bs = bs / 1024 /1024 /1024;
+ return Math.ceil(bs.toFixed(2)) + 'GB';
+ },
+ listTipsMouseenter(obj,strs,tipsNum=1){
+ this.layerIndex = layer.tips(strs, '#'+obj,{tips: [tipsNum, 'rgb(0 0 0 / 85%)'],time:0});
+ $('#'+obj).attr('layerIndex',this.layerIndex)
+ },
+ listTipsMouseleave(obj){
+ layer.close(this.layerIndex)
+ }
+ }
+ })
+
+ function groupingData(data, field) {
+ let map = {};
+ let dest = [];
+ data.forEach(item => {
+ if (!map[item[field]]) {
+ dest.push({
+ [field]: item[field],
+ data: [item]
+ });
+ map[item[field]] = item;
+ } else {
+ dest.forEach(dItem => {
+ if (dItem[field] == item[field]) {
+ dItem.data.push(item);
+ }
+ });
+ }
+ })
+ return dest;
+ }
+
+ let canShowError = true;
+ function connect() {
+ const wsProtocol = window.location.protocol == "https:" ? "wss" : "ws"
+ const ws = new WebSocket(wsProtocol + '://' + window.location.host + '/ws');
+ ws.onopen = function (evt) {
+ canShowError = true;
+ $.suiAlert({
+ title: '{{tr "RealtimeChannelEstablished"}}',
+ description: '{{tr "GetTheLatestMonitoringDataInRealTime"}}',
+ type: 'success',
+ time: '2',
+ position: 'top-center',
+ });
+ }
+ ws.onmessage = function (evt) {
+ const oldServers = statusCards.servers
+ const data = JSON.parse(evt.data)
+ statusCards.servers = data.servers
+ for (let i = 0; i < statusCards.servers.length; i++) {
+ const ns = statusCards.servers[i];
+ if (!ns.Host) ns.live = false
+ else {
+ const lastActive = new Date(ns.LastActive).getTime()
+ if (data.now - lastActive > 10 * 1000) {
+ ns.live = false
+ } else {
+ ns.live = true
+ }
+ }
+ }
+ statusCards.groups = groupingData(statusCards.servers, "Tag")
+ }
+ ws.onclose = function () {
+ if (canShowError) {
+ canShowError = false;
+ $.suiAlert({
+ title: '{{tr "RealtimeChannelDisconnect"}}',
+ description: '{{tr "CanNotGetTheLatestMonitoringDataInRealTime"}}',
+ type: 'warning',
+ time: '2',
+ position: 'top-center',
+ });
+ }
+ setTimeout(function () {
+ connect()
+ }, 3000);
+ }
+ ws.onerror = function () {
+ ws.close()
+ }
+ }
+
+ connect();
+
+ $('.ui.accordion').accordion({ "exclusive": false });
+</script>
+{{end}}docker restart dashboard-dashboard-1
<style>
+/* 屏幕适配 */
+@media only screen and (min-width: 1200px) {
+.ui.container {
+width: 80% !important;
+}
+}
+
+@media only screen and (max-width: 767px) {
+.ui.card>.content>.header:not(.ui), .ui.cards>.card>.content>.header:not(.ui) {
+ margin-top: 0.4em !important;
+}
+}
+
+/* 整体图标 */
+i.icon {
+color: #000;
+width: 1.2em !important;
+}
+
+/* 背景图片 */
+body {
+content: " " !important;
+background: fixed !important;
+z-index: -1 !important;
+top: 0 !important;
+right: 0 !important;
+bottom: 0 !important;
+left: 0 !important;
+background-position: top !important;
+background-repeat: no-repeat !important;
+background-size: cover !important;
+//background-image: url(https://api.kdcc.cn/img/) !important;
+font-family: Arial,Helvetica,sans-serif !important;
+}
+
+/* 导航栏 */
+.ui.large.menu {
+border: 0 !important;
+border-radius: 0px !important;
+background-color: rgba(255, 255, 255, 55%) !important;
+}
+
+/* 首页按钮 */
+.ui.menu .active.item {
+background-color: transparent !important;
+}
+
+/* 导航栏下拉框 */
+.ui.dropdown .menu {
+border: 0 !important;
+border-radius: 0 !important;
+background-color: rgba(255, 255, 255, 80%) !important;
+}
+
+/* 登陆按钮 */
+.nezha-primary-btn {
+background-color: transparent !important;
+color: #000 !important;
+}
+
+/* 大卡片 */
+#app .ui.fluid.accordion {
+background-color: #fbfbfb26 !important;
+border-radius: 0.4rem !important;
+}
+
+/* 小卡片 */
+.ui.four.cards>.card {
+border-radius: 0.6rem !important;
+background-color: #fafafaa3 !important;
+}
+
+.status.cards .wide.column {
+padding-top: 0 !important;
+padding-bottom: 0 !important;
+height: 3.3rem !important;
+}
+
+.status.cards .three.wide.column {
+padding-right: 0rem !important;
+}
+
+.status.cards .wide.column:nth-child(1) {
+margin-top: 2rem !important;
+}
+
+.status.cards .wide.column:nth-child(2) {
+margin-top: 2rem !important;
+}
+
+.status.cards .description {
+padding-bottom: 0 !important;
+}
+
+/* 小鸡名 */
+.status.cards .flag {
+margin-right: 0.5rem !important;
+}
+
+/* 弹出卡片图标 */
+.status.cards .header > .info.icon {
+margin-right: 0 !important;
+}
+
+.nezha-secondary-font {
+color: #21ba45 !important;
+}
+
+/* 进度条 */
+.ui.progress {
+border-radius: 50rem !important;
+}
+
+.ui.progress .bar {
+min-width: 1.8em !important;
+border-radius: 15px !important;
+line-height: 1.65em !important;
+}
+
+.ui.fine.progress> .bar {
+background-color: #21ba45 !important;
+}
+
+.ui.progress> .bar {
+background-color: #000 !important;
+}
+
+.ui.progress.fine .bar {
+background-color: #21ba45 !important;
+}
+
+.ui.progress.warning .bar {
+background-color: #ff9800 !important;
+}
+
+.ui.progress.error .bar {
+background-color: #e41e10 !important;
+}
+
+.ui.progress.offline .bar {
+background-color: #000 !important;
+}
+
+/* 上传下载 */
+.status.cards .outline.icon {
+margin-right: 1px !important;
+}
+
+
+i.arrow.alternate.circle.down.outline.icon
+{
+color: #21ba45 !important;
+}
+i.arrow.alternate.circle.up.outline.icon
+
+
+{
+color: red !important;
+}
+
+/* 弹出卡片小箭头 */
+.ui.right.center.popup {
+margin: -3px 0 0 0.914286em !important;
+-webkit-transform-origin: left 50% !important;
+transform-origin: left 50% !important;
+}
+
+.ui.bottom.left.popup {
+margin-left: 1px !important;
+margin-top: 3px !important;
+}
+
+.ui.top.left.popup {
+margin-left: 0 !important;
+margin-bottom: 10px !important;
+}
+
+.ui.top.right.popup {
+margin-right: 0 !important;
+margin-bottom: 8px !important;
+}
+
+.ui.left.center.popup {
+margin: -3px .91428571em 0 0 !important;
+-webkit-transform-origin: right 50% !important;
+transform-origin: right 50% !important;
+}
+
+.ui.right.center.popup:before,
+.ui.left.center.popup:before {
+border: 0px solid #fafafaeb !important;
+background: #fafafaeb !important;
+}
+
+.ui.top.popup:before {
+border-color: #fafafaeb transparent transparent !important;
+}
+
+.ui.popup:before {
+border-color: #fafafaeb transparent transparent !important;
+}
+
+.ui.bottom.left.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important;
+-webkit-box-shadow: 0px 0px 0 0
+#fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+.ui.bottom.right.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important
+-webkit-box-shadow: 0px 0px 0 0 #fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+.ui.top.left.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important;
+-webkit-box-shadow: 0px 0px 0 0 #fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+.ui.top.right.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important;
+-webkit-box-shadow: 0px 0px 0 0 #fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+.ui.left.center.popup:before {
+border-radius: 0 !important;
+border: 1px solid transparent !important;
+border-color: #fafafaeb transparent transparent !important;
+background: #fafafaeb !important;
+-webkit-box-shadow: 0px 0px 0 0 #fafafaeb !important;
+box-shadow: 0px 0px 0 0 #fafafaeb !important;
+-webkit-tap-highlight-color: rgba(0,0,0,0) !important;
+}
+
+/* 弹出卡片 */
+.status.cards .ui.content.popup {
+min-width: 20rem !important;
+line-height: 2rem !important;
+border-radius: 5px !important;
+border: 1px solid transparent !important;
+background-color: #fafafaeb !important;
+font-family: Arial,Helvetica,sans-serif !important;
+}
+
+.ui.content {
+margin: 0 !important;
+padding: 1em !important;
+}
+
+/* 服务页 */
+.ui.table {
+background: RGB(225,225,225,0.6) !important;
+}
+
+.ui.table thead th {
+background: transparent !important;
+}
+
+/* 服务页进度条 */
+.service-status .good {
+background-color: #21ba45 !important;
+}
+
+.service-status .danger {
+background-color: red !important;
+}
+
+.service-status .warning {
+background-color: orange !important;
+}
+
+/* 版权 */
+.ui.inverted.segment,
+.ui.primary.inverted.segment {
+color: #000 !important;
+font-weight: bold !important;
+background-color: #fafafaa3 !important;
+}
+</style>
+
+<script>
+window.onload = function(){
+var avatar=document.querySelector(".item img")
+var footer=document.querySelector("div.is-size-7")
+footer.innerHTML="Copyright © 2023 All Rights Reserved."
+footer.style.visibility="visible"
+avatar.src="/static/logo.svg"
+avatar.style.visibility="visible"
+}
+</script>Docker可以通过读取Dockerfile中的指令自动构建映像。Dockerfile是一个文本文档,其中包含用户在命令行上调用来组装镜像的所有命令。
# 注释
+INSTRUCTION arguments指令大小写不敏感,所以使用小写也不影响构建,但习惯上都将指令大写用于区分指令和参数。
Dockerfile必须以FROM指令开始(特殊情况:ARG指令)。
dockerfileARG CODE_VERSION=latest +FROM base:\${CODE_VERSION} +CMD /code/run-app
ADDCOPYENVEXPOSEFROMLABELSTOPSIGNALUSERVOLUMEWORKDIRONBUILDdockerfileFROM busybox +ENV FOO=/bar +WORKDIR \${FOO} # WORKDIR /bar +ADD . $FOO # ADD . /bar +COPY \\$FOO /quux # COPY $FOO /quux
FROM image_name:version as alias1
+# FROM [--platform=<platform>] <image>[:<tag>] [AS <name>] 一个Dockerfile中FROM可以多次出现 用于构建多个镜像或者将一个构建阶段用作另一个构建阶段的依赖项
+MAINTAINER storyxc #维护文档的人,现在用LABEL xxx=xxx代替了
+
+RUN xxx
+# RUN <command> shell格式,默认在linux上使用/bin/sh -c执行,windows上 cmd /S /C执行
+# RUN ['executable', 'param1', 'param2'] exec格式
+
+# Deploy Biliup
+FROM python:3.9 as alias2
+
+ENV TZ=Asia/Shanghai
+# ENV指定环境变量
+
+EXPOSE 19159/tcp
+EXPOSE 19149/udp
+# 注明暴露的端口,只是声明作用,实际没有功能
+
+ADD hom* /mydir/
+# ADD指令用于向镜像内拷贝文件 目录 不仅能复制本机的文件,也能将远程URL的资源复制到镜像中
+# ADD [--chown=<user>:<group>] [--chmod=<perms>] [--checksum=<checksum>] <src>... <dest>
+# ADD [--chown=<user>:<group>] [--chmod=<perms>] ["<src>",... "<dest>"]
+# ADD可以识别压缩格式,把可解压的文件解压为目录,远程URL资源不会被解压
+
+VOLUME /opt
+# 指定创建一个具有指定名称的挂载点 可以使用JSON数组格式 或多个参数纯字符串
+
+COPY --from=alias1 /dir1 /dir2
+# COPY [--chown=<user>:<group>] [--chmod=<perms>] <src>... <dest>
+# COPY [--chown=<user>:<group>] [--chmod=<perms>] ["<src>",... "<dest>"]
+
+WORKDIR /opt
+# WORKDIR指定工作目录,如果没有则会被创建,如果WORKDIR后出现了相对路径,都是相对WORKDIR的
+
+CMD ["param1", "param2"]
+# CMD指令有三种格式
+# CMD ["executable","param1","param2"] exec格式 最常用,不会有变量替换,需要变量替换需要使用shell格式或类似["shell", "-c", "e cho $HOME"]
+# CMD ["param1","param2"] 作为ENTRYPOINT的默认参数,如果是这个用法 那么ENTRYPOINT指令也要用JSON数组的格式书写
+# CMD command param1 param2 shell格式
+# 一个Dockerfile中只能有一个CMD指令,如果写了多个那么只有最后一个生效
+
+ENTRYPOINT ["biliup"]
+# ENTRYPOINT ["executable", "param1", "param2"]
+# ENTRYPOINT command param1 param2
Docker可以通过读取Dockerfile中的指令自动构建映像。Dockerfile是一个文本文档,其中包含用户在命令行上调用来组装镜像的所有命令。
# 注释
+INSTRUCTION arguments指令大小写不敏感,所以使用小写也不影响构建,但习惯上都将指令大写用于区分指令和参数。
Dockerfile必须以FROM指令开始(特殊情况:ARG指令)。
dockerfileARG CODE_VERSION=latest +FROM base:\${CODE_VERSION} +CMD /code/run-app
ADDCOPYENVEXPOSEFROMLABELSTOPSIGNALUSERVOLUMEWORKDIRONBUILDdockerfileFROM busybox +ENV FOO=/bar +WORKDIR \${FOO} # WORKDIR /bar +ADD . $FOO # ADD . /bar +COPY \\$FOO /quux # COPY $FOO /quux
FROM image_name:version as alias1
+# FROM [--platform=<platform>] <image>[:<tag>] [AS <name>] 一个Dockerfile中FROM可以多次出现 用于构建多个镜像或者将一个构建阶段用作另一个构建阶段的依赖项
+MAINTAINER storyxc #维护文档的人,现在用LABEL xxx=xxx代替了
+
+RUN xxx
+# RUN <command> shell格式,默认在linux上使用/bin/sh -c执行,windows上 cmd /S /C执行
+# RUN ['executable', 'param1', 'param2'] exec格式
+
+# Deploy Biliup
+FROM python:3.9 as alias2
+
+ENV TZ=Asia/Shanghai
+# ENV指定环境变量
+
+EXPOSE 19159/tcp
+EXPOSE 19149/udp
+# 注明暴露的端口,只是声明作用,实际没有功能
+
+ADD hom* /mydir/
+# ADD指令用于向镜像内拷贝文件 目录 不仅能复制本机的文件,也能将远程URL的资源复制到镜像中
+# ADD [--chown=<user>:<group>] [--chmod=<perms>] [--checksum=<checksum>] <src>... <dest>
+# ADD [--chown=<user>:<group>] [--chmod=<perms>] ["<src>",... "<dest>"]
+# ADD可以识别压缩格式,把可解压的文件解压为目录,远程URL资源不会被解压
+
+VOLUME /opt
+# 指定创建一个具有指定名称的挂载点 可以使用JSON数组格式 或多个参数纯字符串
+
+COPY --from=alias1 /dir1 /dir2
+# COPY [--chown=<user>:<group>] [--chmod=<perms>] <src>... <dest>
+# COPY [--chown=<user>:<group>] [--chmod=<perms>] ["<src>",... "<dest>"]
+
+WORKDIR /opt
+# WORKDIR指定工作目录,如果没有则会被创建,如果WORKDIR后出现了相对路径,都是相对WORKDIR的
+
+CMD ["param1", "param2"]
+# CMD指令有三种格式
+# CMD ["executable","param1","param2"] exec格式 最常用,不会有变量替换,需要变量替换需要使用shell格式或类似["shell", "-c", "e cho $HOME"]
+# CMD ["param1","param2"] 作为ENTRYPOINT的默认参数,如果是这个用法 那么ENTRYPOINT指令也要用JSON数组的格式书写
+# CMD command param1 param2 shell格式
+# 一个Dockerfile中只能有一个CMD指令,如果写了多个那么只有最后一个生效
+
+ENTRYPOINT ["biliup"]
+# ENTRYPOINT ["executable", "param1", "param2"]
+# ENTRYPOINT command param1 param2
https://docs.docker.com/compose/compose-file/03-compose-file/
version: "3.8" # version是compose文件格式版本号 需要和Docker Engine对应 https://docs.docker.com/compose/compose-file/compose-file-v3/
+
+services:
+ service1:
+ image: image_name:version #指定镜像
+ container_name: service1 #容器名
+ environment: #指定环境变量
+ - A=1
+ - B=2
+ restart: always #重启策略
+ volumes: #数据卷挂载
+ - /etc/localtime:/etc/localtime:ro # 挂载宿主机文件
+ - data:/opt/data # 具名卷挂载
+ ports: #端口映射配置
+ - "6610:6610"
+ - "6611:6611"
+ privileged: true # 将服务容器配置为以提升的权限运行
+ links: #定义到另一个服务中的容器的网络链接,可以在此容器直接用服务名访问另一个容器,links也有服务之间的隐式依赖关系,因此也决定了服务启动的顺序。
+ - service2
+ env_file:
+ - ./a.env
+ - ./b.env
+ devices:
+ - "/dev/ttyUSB0:/dev/ttyUSB0"
+ - "/dev/sda:/dev/xvda:rwm"
+ dns:
+ - 8.8.8.8
+ service2:
+ build: #构建配置
+ context: . #指定包含Dockerfile的目录或一个git仓库的url
+ dockerfile: webapp.Dockerfile #指定要使用的Dockerfile名称,默认找Dockerfile,和dockerfile_inline参数不能同时使用
+ dockerfile_inline: #直接在compose文件里写Dockerfile指令 和dockerfile参数不能同时使用
+ FROM xxx
+ RUN some command
+ container_name: service2
+ network_mode: "host" #配置网络模式,none(禁用所有容器网络)/host(使用宿主接口)/service:{name}(只能访问指定服务)
+ networks: #指定容器连接的docker网络
+ - netA
+ - netB
+ depends_on: #依赖某个服务,决定了服务的启动和关闭顺序
+ - service3
+
+volumes:
+ data:
+
+networks:
+ netA:
+ netB:https://docs.docker.com/compose/compose-file/03-compose-file/
version: "3.8" # version是compose文件格式版本号 需要和Docker Engine对应 https://docs.docker.com/compose/compose-file/compose-file-v3/
+
+services:
+ service1:
+ image: image_name:version #指定镜像
+ container_name: service1 #容器名
+ environment: #指定环境变量
+ - A=1
+ - B=2
+ restart: always #重启策略
+ volumes: #数据卷挂载
+ - /etc/localtime:/etc/localtime:ro # 挂载宿主机文件
+ - data:/opt/data # 具名卷挂载
+ ports: #端口映射配置
+ - "6610:6610"
+ - "6611:6611"
+ privileged: true # 将服务容器配置为以提升的权限运行
+ links: #定义到另一个服务中的容器的网络链接,可以在此容器直接用服务名访问另一个容器,links也有服务之间的隐式依赖关系,因此也决定了服务启动的顺序。
+ - service2
+ env_file:
+ - ./a.env
+ - ./b.env
+ devices:
+ - "/dev/ttyUSB0:/dev/ttyUSB0"
+ - "/dev/sda:/dev/xvda:rwm"
+ dns:
+ - 8.8.8.8
+ service2:
+ build: #构建配置
+ context: . #指定包含Dockerfile的目录或一个git仓库的url
+ dockerfile: webapp.Dockerfile #指定要使用的Dockerfile名称,默认找Dockerfile,和dockerfile_inline参数不能同时使用
+ dockerfile_inline: #直接在compose文件里写Dockerfile指令 和dockerfile参数不能同时使用
+ FROM xxx
+ RUN some command
+ container_name: service2
+ network_mode: "host" #配置网络模式,none(禁用所有容器网络)/host(使用宿主接口)/service:{name}(只能访问指定服务)
+ networks: #指定容器连接的docker网络
+ - netA
+ - netB
+ depends_on: #依赖某个服务,决定了服务的启动和关闭顺序
+ - service3
+
+volumes:
+ data:
+
+networks:
+ netA:
+ netB:在日常使用docker的时候,可以通过设置端口映射的方式,实现通过宿主机ip访问docker容器的目的。当然,也有办法可以实现给docker镜像设置单独的IP。这里就要用到macvlan技术。
macvlan 是 Linux kernel 支持的新特性,macvlan能将一块物理网卡虚拟成多块虚拟网卡,docker这种容器就可以通过虚拟网卡获取IP,利用IP进行独立上网,真正做到跟物理机完全一样的体验。
docker中的macvlan 是 Docker中的一种网络驱动,它允许容器直接使用物理网络接口的 MAC 地址。这使得容器可以像物理设备一样存在于网络中,而不需要进行端口映射或NAT。
// 加载 macvlan 模块
+modprobe macvlan
+// 查看是否已加载
+lsmod | grep macvlan
+// 如果有有输出证明已经加载macvlan模块,否则说明不支持
+// macvlan 24576 0docker network create -d macvlan \\
+ --subnet=192.168.2.0/24 \\
+ --gateway=192.168.2.1 \\
+ -o parent=enp3s0 \\
+ vlansubnet:与物理网络相同的子网。gateway:与物理网络相同的网关。-o parent:宿主机上的物理网络接口,如 eth0。docker run -d --name 容器名 --net vlan --ip=指定的IP地址 镜像名例如
docker run -it --name busybox --net vlan --ip=192.168.2.166 busybox /bin/shversion: "3"
+
+services:
+ busybox:
+ ...
+ networks:
+ vlan:
+ ipv4_address: 192.168.2.166
+
+
+networks:
+ vlan:
+ external: true容器启动后就可以通过指定的固定ip来访问docker容器中的服务了
`,17)]))}const F=a(e,[["render",h]]);export{o as __pageData,F as default}; diff --git "a/assets/docker_docker\347\275\221\347\273\234\344\271\213macvlan.md.Dg_KfifW.lean.js" "b/assets/docker_docker\347\275\221\347\273\234\344\271\213macvlan.md.Dg_KfifW.lean.js" new file mode 100644 index 00000000..8004ed55 --- /dev/null +++ "b/assets/docker_docker\347\275\221\347\273\234\344\271\213macvlan.md.Dg_KfifW.lean.js" @@ -0,0 +1,22 @@ +import{_ as a,c as i,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const o=JSON.parse('{"title":"macvlan","description":"","frontmatter":{},"headers":[],"relativePath":"docker/docker网络之macvlan.md","filePath":"docker/docker网络之macvlan.md","lastUpdated":1729217313000}'),e={name:"docker/docker网络之macvlan.md"};function h(p,s,t,k,d,r){return l(),i("div",null,s[0]||(s[0]=[n(`在日常使用docker的时候,可以通过设置端口映射的方式,实现通过宿主机ip访问docker容器的目的。当然,也有办法可以实现给docker镜像设置单独的IP。这里就要用到macvlan技术。
macvlan 是 Linux kernel 支持的新特性,macvlan能将一块物理网卡虚拟成多块虚拟网卡,docker这种容器就可以通过虚拟网卡获取IP,利用IP进行独立上网,真正做到跟物理机完全一样的体验。
docker中的macvlan 是 Docker中的一种网络驱动,它允许容器直接使用物理网络接口的 MAC 地址。这使得容器可以像物理设备一样存在于网络中,而不需要进行端口映射或NAT。
// 加载 macvlan 模块
+modprobe macvlan
+// 查看是否已加载
+lsmod | grep macvlan
+// 如果有有输出证明已经加载macvlan模块,否则说明不支持
+// macvlan 24576 0docker network create -d macvlan \\
+ --subnet=192.168.2.0/24 \\
+ --gateway=192.168.2.1 \\
+ -o parent=enp3s0 \\
+ vlansubnet:与物理网络相同的子网。gateway:与物理网络相同的网关。-o parent:宿主机上的物理网络接口,如 eth0。docker run -d --name 容器名 --net vlan --ip=指定的IP地址 镜像名例如
docker run -it --name busybox --net vlan --ip=192.168.2.166 busybox /bin/shversion: "3"
+
+services:
+ busybox:
+ ...
+ networks:
+ vlan:
+ ipv4_address: 192.168.2.166
+
+
+networks:
+ vlan:
+ external: true容器启动后就可以通过指定的固定ip来访问docker容器中的服务了
`,17)]))}const F=a(e,[["render",h]]);export{o as __pageData,F as default}; diff --git a/assets/docker_index.md.9lhqb5Yh.js b/assets/docker_index.md.9lhqb5Yh.js new file mode 100644 index 00000000..c3f8923f --- /dev/null +++ b/assets/docker_index.md.9lhqb5Yh.js @@ -0,0 +1 @@ +import{_ as o,c as n,m as e,a as r,o as t}from"./chunks/framework.BjcrtTwI.js";const f=JSON.parse('{"title":"Docker","description":"","frontmatter":{},"headers":[],"relativePath":"docker/index.md","filePath":"docker/index.md","lastUpdated":1729217313000}'),i={name:"docker/index.md"};function c(s,a,d,l,p,u){return t(),n("div",null,a[0]||(a[0]=[e("h1",{id:"docker",tabindex:"-1"},[r("Docker "),e("a",{class:"header-anchor",href:"#docker","aria-label":'Permalink to "Docker"'},"")],-1),e("blockquote",null,[e("p",null,"Docker is an open platform for developing, shipping, and running applications. Docker enables you to separate your applications from your infrastructure so you can deliver software quickly. With Docker, you can manage your infrastructure in the same ways you manage your applications. By taking advantage of Docker’s methodologies for shipping, testing, and deploying code quickly, you can significantly reduce the delay between writing code and running it in production.")],-1)]))}const m=o(i,[["render",c]]);export{f as __pageData,m as default}; diff --git a/assets/docker_index.md.9lhqb5Yh.lean.js b/assets/docker_index.md.9lhqb5Yh.lean.js new file mode 100644 index 00000000..c3f8923f --- /dev/null +++ b/assets/docker_index.md.9lhqb5Yh.lean.js @@ -0,0 +1 @@ +import{_ as o,c as n,m as e,a as r,o as t}from"./chunks/framework.BjcrtTwI.js";const f=JSON.parse('{"title":"Docker","description":"","frontmatter":{},"headers":[],"relativePath":"docker/index.md","filePath":"docker/index.md","lastUpdated":1729217313000}'),i={name:"docker/index.md"};function c(s,a,d,l,p,u){return t(),n("div",null,a[0]||(a[0]=[e("h1",{id:"docker",tabindex:"-1"},[r("Docker "),e("a",{class:"header-anchor",href:"#docker","aria-label":'Permalink to "Docker"'},"")],-1),e("blockquote",null,[e("p",null,"Docker is an open platform for developing, shipping, and running applications. Docker enables you to separate your applications from your infrastructure so you can deliver software quickly. With Docker, you can manage your infrastructure in the same ways you manage your applications. By taking advantage of Docker’s methodologies for shipping, testing, and deploying code quickly, you can significantly reduce the delay between writing code and running it in production.")],-1)]))}const m=o(i,[["render",c]]);export{f as __pageData,m as default}; diff --git "a/assets/docker_\345\270\270\347\224\250\346\214\207\344\273\244.md.BdKk0Dar.js" "b/assets/docker_\345\270\270\347\224\250\346\214\207\344\273\244.md.BdKk0Dar.js" new file mode 100644 index 00000000..a27e450b --- /dev/null +++ "b/assets/docker_\345\270\270\347\224\250\346\214\207\344\273\244.md.BdKk0Dar.js" @@ -0,0 +1,17 @@ +import{_ as i,c as a,a2 as e,o as t}from"./chunks/framework.BjcrtTwI.js";const c=JSON.parse('{"title":"常用指令","description":"","frontmatter":{},"headers":[],"relativePath":"docker/常用指令.md","filePath":"docker/常用指令.md","lastUpdated":1729217313000}'),l={name:"docker/常用指令.md"};function n(h,s,p,k,d,r){return t(),a("div",null,s[0]||(s[0]=[e(`curl -fsSL https://get.docker.com | shRUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list-e TZ=\`ls -la /etc/localtime | cut -d/ -f8-9\`可以用host.docker.internal来访问宿主机
https://docs.docker.com/desktop/networking/#use-cases-and-workarounds
# 创建builder
+docker buildx create --name cross-platform-builder --driver docker-container --use
+# 执行构建
+docker buildx build --platform linux/amd64,linux/arm64 -t 镜像名:tag [-o type=registry | --push] .
+# 查看推送到远程的镜像信息
+docker buildx imagetools inspect 镜像名:tagbuildx 实例通过两种方式来执行构建任务,两种执行方式被称为使用不同的「驱动」:
docker 驱动:使用 Docker 服务程序中集成的 BuildKit 库执行构建。docker-container 驱动:启动一个包含 BuildKit 的容器并在容器中执行构建。docker 驱动无法使用一小部分 buildx 的特性(如在一次运行中同时构建多个平台镜像),此外在镜像的默认输出格式上也有所区别:docker 驱动默认将构建结果以 Docker 镜像格式直接输出到 docker 的镜像目录(通常是 /var/lib/overlay2),之后执行 docker images 命令可以列出所输出的镜像;而 docker container 则需要通过 --output 选项指定输出格式为镜像或其他格式。
docker buildx build 支持丰富的输出行为,通过--output=[PATH,-,type=TYPE[,KEY=VALUE] 选项可以指定构建结果的输出类型和路径等,常用的输出类型有以下几种:
dest 指定的本地路径, 如 --output type=local,dest=./output。dest 指定的本地路径。dest 指定的本地路径。dest 指定的本地路径或加载到 docker 的镜像库中。同时指定多个目标平台时无法使用该选项。push=true 选项直接推送到远程仓库,同时指定多个目标平台时可使用该选项。type=image,push=true 的精简表示。https://waynerv.com/posts/building-multi-architecture-images-with-docker-buildx/
vim /etc/systemd/system/docker.service.d/http-proxy.conf
+
+# [Service]
+# Environment="HTTP_PROXY=http://ip:port"
+# Environment="HTTPS_PROXY=http://ip:port"
+
+systemctl daemon-reload
+systemctl restart docker
+# 可以通过下面命令检查是否生效
+systemctl show --property=Environment docker
+# 或
+docker infocurl -fsSL https://get.docker.com | shRUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list-e TZ=\`ls -la /etc/localtime | cut -d/ -f8-9\`可以用host.docker.internal来访问宿主机
https://docs.docker.com/desktop/networking/#use-cases-and-workarounds
# 创建builder
+docker buildx create --name cross-platform-builder --driver docker-container --use
+# 执行构建
+docker buildx build --platform linux/amd64,linux/arm64 -t 镜像名:tag [-o type=registry | --push] .
+# 查看推送到远程的镜像信息
+docker buildx imagetools inspect 镜像名:tagbuildx 实例通过两种方式来执行构建任务,两种执行方式被称为使用不同的「驱动」:
docker 驱动:使用 Docker 服务程序中集成的 BuildKit 库执行构建。docker-container 驱动:启动一个包含 BuildKit 的容器并在容器中执行构建。docker 驱动无法使用一小部分 buildx 的特性(如在一次运行中同时构建多个平台镜像),此外在镜像的默认输出格式上也有所区别:docker 驱动默认将构建结果以 Docker 镜像格式直接输出到 docker 的镜像目录(通常是 /var/lib/overlay2),之后执行 docker images 命令可以列出所输出的镜像;而 docker container 则需要通过 --output 选项指定输出格式为镜像或其他格式。
docker buildx build 支持丰富的输出行为,通过--output=[PATH,-,type=TYPE[,KEY=VALUE] 选项可以指定构建结果的输出类型和路径等,常用的输出类型有以下几种:
dest 指定的本地路径, 如 --output type=local,dest=./output。dest 指定的本地路径。dest 指定的本地路径。dest 指定的本地路径或加载到 docker 的镜像库中。同时指定多个目标平台时无法使用该选项。push=true 选项直接推送到远程仓库,同时指定多个目标平台时可使用该选项。type=image,push=true 的精简表示。https://waynerv.com/posts/building-multi-architecture-images-with-docker-buildx/
vim /etc/systemd/system/docker.service.d/http-proxy.conf
+
+# [Service]
+# Environment="HTTP_PROXY=http://ip:port"
+# Environment="HTTPS_PROXY=http://ip:port"
+
+systemctl daemon-reload
+systemctl restart docker
+# 可以通过下面命令检查是否生效
+systemctl show --property=Environment docker
+# 或
+docker info继承 < 通配符选择器 < 标签选择器 < 类选择器 < id选择器 < 行内样式 < !important!important写在属性值后面,分号前面!important不能提升继承的优先级,只要是继承优先级最低书写顺序:浏览器执行效率更高
- 浮动 / display
- 盒子模型 margin border padding 宽高背景色
- 文字样式
标签选择器 tagName { css }
类选择器: .class { css }
id选择器: #id { css }
通配符选择器: * { css }
复合选择器
选择器1 选择器2 { css }选择器1 > 选择器2 { css }属性选择器: 选择器[attribute=xxx]
并集选择器: 选择器1,选择器2 { css }
交集选择器: 选择器1选择器2 { css }
伪类选择器: 标签:伪类选择器 { css }
伪类
伪对象
页面中非主体内容可以使用伪对象,由css模拟出标签效果
::before、::after
.content::before {
+ content: 'test1';
+}
+
+.content::after {
+ content: 'test2';
+}默认是行内元素,content必须添加 否则伪对象不生效
字体大小:font-size
字体粗细:font-weight
字体样式:font-style
字体类型:font-family
字体类型:属性连写
文本缩进:text-indent
文本水平对齐方式(内容对齐方式):text-align
文本修饰:text-decoration
行高:line-heigh
line-height:1;可以取消上下间距font: style weight size/line-height family;属性:backgroud-color
取值:
默认是透明:rgba(0,0,0,0)、transparent
span {
+ display: inline-block;
+}
+
+div {
+ display: inline;
+}
+
+button {
+ display: block;
+}页面中的每一个标签都可以看作一个“盒子”,通过盒子的视角更方便的进行布局。
每个盒子分别由:内容区域(content)、内边距区域(padding)、边框区域(border)、外边距区域(margin)构成。
border和padding会撑大盒子,css属性box-sizing: border-box; 可以设置内减模式
外边距:margin
顺序和padding一样
清除默认的内外边距
* {
+ margin: 0;
+ padding: 0;
+}版心居中
#main {
+ margin: 0 auto;
+}顺序: 宽高背景色-> 放内容 -> 调整位置 -> 调整文字细节
外边距问题
折叠现象:垂直布局的块级元素,上下的margin会被合并,取两者的最大值
塌陷现象:互相嵌套的块级元素,子元素的margin-top会作用在父元素上
overflow: hidden;3.转换为行内块元素4.设置浮动行内元素的内外边距问题:如果想通过margin/padding改变行内元素的垂直(top/bottom)位置,无法生效
块级元素转行内块时 换行会产生空格
向左浮动或者向右浮动直到自己的边界紧贴着包含块(一般是父元素)或者其他浮动元素的边界为止
不能超出包含块,如果元素是向左(右)浮动,浮动元素的左(右)边界不能超出包含块的左(右)边界
浮动元素不能层叠
浮动元素会将行内级元素内容推出
浮动元素不能与行内级内容层叠,行内级内容将会被浮动元素推出
比如行内级元素、inline-block元素、块级元素的文字内容
图文环绕效果
浮动只能左右浮动, 不能超出本行的高度
浮动的元素不能通过text-align: center 或者margin: 0 auto居中
含义:清除浮动带来的影响。如果子元素浮动,此时子元素不能撑开标准流的块级父元素
原因:子元素浮动后脱离标准流 -> 不占位置
目的:需要父元素有高度,不影响其他元素的布局
方法:
给父元素加高度
额外标签:给父元素内容的最后加一个块级元素,给添加的块级元素设置clear: both;
单伪元素:用伪元素代替额外标签
.clearfix::after {
+ content: '';
+ display: block;
+ clear: both;
+}
+---
+.clearfix::after {
+ content: '';
+ displat: block;
+ clear: both;
+ height: 0;
+ visibility: hidden;
+}双伪元素:
.clearfix::before, /* 解决外边距塌陷问题 */
+.clearfix::after {
+ content: '';
+ display: table;
+}
+.clearfix::after {
+ clear: both;
+}父元素设置overflow: hidden
BFC(Block Formatting Context)全称是块级格式化上下文,用于对块级元素排版,默认情况下只有根元素(body)一个块级上下文,但是如果一个块级元素设置了float:left,overflow:hidden或position:absolute样式,就会为这个块级元素生产一个独立的块级上下文,使这个块级元素内部的排版完全独立。
作用:独立的块级上下文可以包裹浮动流,全部浮动子元素也不会引起容器高度塌陷,就是说包含块会把浮动元素的高度也计算在内,所以就不用清除浮动来撑起包含块的高度。
那什么时候会触发 BFC 呢?常见的情况如下:
• 根元素;
• float的值不为none;
• overflow的值为auto、scroll或hidden;
• display的值为table-cell、table-caption和inline-block中的任何一个;
• position的值不为relative和static。
设置定位方式
属性名:position
常见属性:
静态定位:static
相对定位:relative,相对自己之前的位置进行移动
绝对定位:absolute,先找已经定位的父级(逐级查找),如果有这样的父级就以这个父级为参照定位,有父级但父级没有定位则以浏览器为参照定位
页面中不占位置(脱标)
改变标签的显示模式特点,具备行内块特点
绝对定位的元素不能使用margin: 0 auto居中
position: absolute;
+left: 50%;
+top: 50%;
+transform: translate(-50%, -50%);固定定位:fixed,相对于浏览器进行定位移动
设置偏移值
浏览器遇到行内和行内块标签当作文字处理,默认文字按照基线对齐
属性:border-radius
常见取值:数字+px、百分比
赋值:从左上角开始,顺时针赋值,没有赋值的看对角
正圆:正方形盒子,border-radius: 50%
胶囊按钮:长方形盒子,border-radius: 高度的一半
百分比表示的是圆角半径的大小为盒子较小边长的一半,例如盒子宽200px,高100px,border-radius: 50% 50%; 则这两个50%都是相对于100px的。
CSS精灵图是一种将多个小的背景图片合并到一张大图中的技术,通过CSS的background-position属性控制显示不同的小图片,达到减少HTTP请求、减小页面大小、提高加载速度的效果。
CSS精灵图可以将多个小背景图像合并为一张大图,这样在页面上加载一次大图后,就可以通过background-position属性来控制显示不同的小图像,实现了将多个HTTP请求转化为一次请求,减小了网络延迟和服务器压力。同时,由于减少了HTTP请求和加载的内容大小,减小了页面的带宽消耗,加快了网页的加载速度,提高了用户的体验感受。
在web前端开发中,经常使用CSS精灵图技术,特别是在一些需要大量小icon的场合,如网站菜单栏、按钮、分页等等。
设置背景图片的大小:background-size: 宽 高
取值
backgound:color image repeat position/size
box-shadowtransition.box {
width: 200px;
height: 200px;
background-color: pink;
/transition: all 1s/
transition: width 1s, background-color 2s;
}
.box hover {
width: 600px;
background-color: red;
}
展示的是图标,实质是文字,用作处理简单的、颜色单一的图片
iconfont
<link rel="stylesheet" href="./iconfont.css"
<span class="iconfont icon-kuaijiezhifu"></span>
平面转换(2D转换):改变盒子在平面内的形态,可以使用transform属性实现元素的位移、旋转、缩放等效果
transform: translate(水平移动距离, 垂直移动距离)transform: rotate(度数 + deg); 正数:顺时针;负数:逆时针transform-origin: 原点水平位置 原点垂直位置transform: translate() rotate()
rotate会改变坐标轴向,位移方向会受影响
多重转换如果涉及旋转,旋转往最后写
transform: scale(x轴缩放倍数, y轴缩放倍数) linear-gradient
在空间内位移、旋转、缩放等效果
transform: tranlate3d(x,y,z)
单个坐标轴
transform: translat[X|Y|Z]
使用perspective(视距)属性实现透视效果,添加给父级元素,取值一般800-1200
transform: rotateX()
transform: rotateY()
transform: rotateZ()
transform: rotate3d(x,y,z,角度度数):用来设置自定义旋转轴的位置及旋转角度,xyz取值为0-1之间的数字
使用transform-style: perserve-3d呈现立体图形
父元素添加transform-style: perserve-3d使子集元素处于3d空间
默认值flat,表示子元素处于2D平面
transform: scaleX()
transform: scaleY()
transform: scaleY()
transform: scale3d(x,y,z)
使用animation实现多个状态间的变化过程,动画过程可控(重复播放、最终画面、是否暂停)
定义动画
@keyframes 动画名称 {
+ from {}
+ to {}
+}
+
+@keyframes 动画名称 {
+ /* 百分比指的是动画总时长的占比 */
+ 0% {}
+ 10% {}
+ 15% {}
+ 100% {}
+}使用动画: animation: 动画名称 动画花费时长
animation: 动画名称 动画时长 速度曲线 延迟时间 重复次数 动画方向 执行完毕时状态 播放状态
- animation-name:
- animation-duration
- animation-timing-function:ease;ease-in;ease-out;ease-in-out;linear;step;
- animation-delay
- animation-iteration-count: 1,2,..infinite;
- animation-direction: normal;reverse;alternate;alternate-reverse;
- animation-fill-mode: forward;backward;both;
- animation-play-state: pause;running;
- animation-
animation: 动画1,动画2...,动画n;
浮动脱标的问题display: flex;justify-content
取值:
flex flex-grow(增长系数)、flex-shrink(收缩系数)和flex-basis(初始尺寸)三个属性的简写,第一个无单位数代表flex-grow、第二无单位数代表flex-shrink,带像素单位的是flex-basis的值@media 逻辑操作符 媒体类型 and (媒体特性) {
+ 选择器 {
+ CSS属性
+ }
+}
+
+@media (媒体特性) {
+ 选择器 {
+ CSS属性
+ }
+}
+
+@media (min-width:320px) {
+ html {
+ font-size: 32px;
+ }
+}Less(Leaner Style Sheets)是一门向后兼容的CSS 扩展语言,是一个CSS预处理器,扩充了CSS,使CSS具备一定的逻辑性、计算能力。
@width: 10px;
+@height: @width + 10px;
+
+#header {
+ width: @width;
+ height: @height;
+}编译为
#header {
+ width: 10px;
+ height: 20px;
+}.bordered {
+ border-top: dotted 1px black;
+ border-bottom: solid 2px black;
+}
+
+#menu a {
+ color: #111;
+ .bordered();
+}
+
+.post a {
+ color: red;
+ .bordered();
+}.bordered 类所包含的属性就将同时出现在 #menu a 和 .post a 中了。
#header {
+ color: black;
+ .navigation {
+ font-size: 12px;
+ }
+ .logo {
+ width: 300px;
+ }
+}#header {
+ color: black;
+}
+#header .navigation {
+ font-size: 12px;
+}
+#header .logo {
+ width: 300px;
+}.component {
+ width: 300px;
+ @media (min-width: 768px) {
+ width: 600px;
+ @media (min-resolution: 192dpi) {
+ background-image: url(/img/retina2x.png);
+ }
+ }
+ @media (min-width: 1280px) {
+ width: 800px;
+ }
+}编译为
.component {
+ width: 300px;
+}
+@media (min-width: 768px) {
+ .component {
+ width: 600px;
+ }
+}
+@media (min-width: 768px) and (min-resolution: 192dpi) {
+ .component {
+ background-image: url(/img/retina2x.png);
+ }
+}
+@media (min-width: 1280px) {
+ .component {
+ width: 800px;
+ }
+}算术运算符 +、-、*、/ 可以对任何数字、颜色或变量进行运算。如果可能的话,算术运算符在加、减或比较之前会进行单位换算。计算的结果以最左侧操作数的单位类型为准。如果单位换算无效或失去意义,则忽略单位。无效的单位换算例如:px 到 cm 或 rad 到 % 的转换。
// 所有操作数被转换成相同的单位
+@conversion-1: 5cm + 10mm; // 结果是 6cm
+@conversion-2: 2 - 3cm - 5mm; // 结果是 -1.5cm
+
+// conversion is impossible
+@incompatible-units: 2 + 5px - 3cm; // 结果是 4px
+
+// example with variables
+@base: 5%;
+@filler: @base * 2; // 结果是 10%
+@other: @base + @filler; // 结果是 15%乘法和除法不作转换。因为这两种运算在大多数情况下都没有意义,一个长度乘以一个长度就得到一个区域,而 CSS 是不支持指定区域的。Less 将按数字的原样进行操作,并将为计算结果指定明确的单位类型。
@base: 2cm * 3mm; // 结果是 6cm转义(Escaping)允许你使用任意字符串作为属性或变量值。任何 ~"anything" 或 ~'anything' 形式的内容都将按原样输出,除非 interpolation。
@min768: ~"(min-width: 768px)";
+.element {
+ @media @min768 {
+ font-size: 1.2rem;
+ }
+}编译为:
@media (min-width: 768px) {
+ .element {
+ font-size: 1.2rem;
+ }
+}注意,从 Less 3.5 开始,可以简写为:
@min768: (min-width: 768px);
+.element {
+ @media @min768 {
+ font-size: 1.2rem;
+ }
+}Less 内置了多种函数用于转换颜色、处理字符串、算术运算等。这些函数在Less 函数手册中有详细介绍。
函数的用法非常简单。下面这个例子利用 percentage 函数将 0.5 转换为 50%,将颜色饱和度增加 5%,以及颜色亮度降低 25% 并且色相值增加 8 等用法:
@base: #f04615;
+@width: 0.5;
+
+.class {
+ width: percentage(@width); // returns \`50%\`
+ color: saturate(@base, 5%);
+ background-color: spin(lighten(@base, 25%), 8);
+}从 Less 3.5 版本开始,你还可以将混合(mixins)和规则集(rulesets)作为一组值的映射(map)使用。
#colors() {
+ primary: blue;
+ secondary: green;
+}
+
+.button {
+ color: #colors[primary];
+ border: 1px solid #colors[secondary];
+}输出符合预期:
.button {
+ color: blue;
+ border: 1px solid green;
+}Less 中的作用域与 CSS 中的作用域非常类似。首先在本地查找变量和混合(mixins),如果找不到,则从“父”级作用域继承。
@var: red;
+
+#page {
+ @var: white;
+ #header {
+ color: @var; // white
+ }
+}与 CSS 自定义属性一样,混合(mixin)和变量的定义不必在引用之前事先定义。因此,下面的 Less 代码示例和上面的代码示例是相同的:
@var: red;
+
+#page {
+ #header {
+ color: @var; // white
+ }
+ @var: white;
+}@import "library"; // library.less
+@import "typo.css";被引入的less文件不会生成单独的css文件
webstorm FileWatcher配置:
- npm install -g less
- aruments:
--no-color $FileName$ ../css/$FileNameWithoutExtension$.css- output paths to refresh :
../css/$FileNameWithoutExtension$.cssVS Code EasyLess配置:
- out: "../css/"
- 首行添加注释控制编译的输出情况
- // out: ./dir/
- // out: ./dir/xxx.css
- // out: false
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/css/bootstrap.min.css">
<script src="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/js/bootstrap.min.js"></script>
| 超小屏幕 | 小屏幕 | 中等屏幕 | 大屏幕 | |
|---|---|---|---|---|
| 响应断点 | <768px | >=768px | >=992px | >=1200px |
| 别名 | xs | sm | md | lg |
| 容器宽度 | 100% | 750px | 970px | 1170px |
| 类前缀 | col-xs-* | col-sm-* | col-md-* | col-lg-* |
| 列数 | 12 | 12 | 12 | 12 |
| 列间隙 | 30px | 30px | 30px | 30px |
.container是BootStrap中提供的类名,应用该类名的盒子,默认被指定宽度且居中.container-fluid是BootStrap中提供的类名,所有应用的盒子,宽度为100%.row类名和.col类名定义栅格布局的行和列TIP
https://v3.bootcss.com/components/
html {
+ scroll-behavior: smooth;
+}继承 < 通配符选择器 < 标签选择器 < 类选择器 < id选择器 < 行内样式 < !important!important写在属性值后面,分号前面!important不能提升继承的优先级,只要是继承优先级最低书写顺序:浏览器执行效率更高
- 浮动 / display
- 盒子模型 margin border padding 宽高背景色
- 文字样式
标签选择器 tagName { css }
类选择器: .class { css }
id选择器: #id { css }
通配符选择器: * { css }
复合选择器
选择器1 选择器2 { css }选择器1 > 选择器2 { css }属性选择器: 选择器[attribute=xxx]
并集选择器: 选择器1,选择器2 { css }
交集选择器: 选择器1选择器2 { css }
伪类选择器: 标签:伪类选择器 { css }
伪类
伪对象
页面中非主体内容可以使用伪对象,由css模拟出标签效果
::before、::after
.content::before {
+ content: 'test1';
+}
+
+.content::after {
+ content: 'test2';
+}默认是行内元素,content必须添加 否则伪对象不生效
字体大小:font-size
字体粗细:font-weight
字体样式:font-style
字体类型:font-family
字体类型:属性连写
文本缩进:text-indent
文本水平对齐方式(内容对齐方式):text-align
文本修饰:text-decoration
行高:line-heigh
line-height:1;可以取消上下间距font: style weight size/line-height family;属性:backgroud-color
取值:
默认是透明:rgba(0,0,0,0)、transparent
span {
+ display: inline-block;
+}
+
+div {
+ display: inline;
+}
+
+button {
+ display: block;
+}页面中的每一个标签都可以看作一个“盒子”,通过盒子的视角更方便的进行布局。
每个盒子分别由:内容区域(content)、内边距区域(padding)、边框区域(border)、外边距区域(margin)构成。
border和padding会撑大盒子,css属性box-sizing: border-box; 可以设置内减模式
外边距:margin
顺序和padding一样
清除默认的内外边距
* {
+ margin: 0;
+ padding: 0;
+}版心居中
#main {
+ margin: 0 auto;
+}顺序: 宽高背景色-> 放内容 -> 调整位置 -> 调整文字细节
外边距问题
折叠现象:垂直布局的块级元素,上下的margin会被合并,取两者的最大值
塌陷现象:互相嵌套的块级元素,子元素的margin-top会作用在父元素上
overflow: hidden;3.转换为行内块元素4.设置浮动行内元素的内外边距问题:如果想通过margin/padding改变行内元素的垂直(top/bottom)位置,无法生效
块级元素转行内块时 换行会产生空格
向左浮动或者向右浮动直到自己的边界紧贴着包含块(一般是父元素)或者其他浮动元素的边界为止
不能超出包含块,如果元素是向左(右)浮动,浮动元素的左(右)边界不能超出包含块的左(右)边界
浮动元素不能层叠
浮动元素会将行内级元素内容推出
浮动元素不能与行内级内容层叠,行内级内容将会被浮动元素推出
比如行内级元素、inline-block元素、块级元素的文字内容
图文环绕效果
浮动只能左右浮动, 不能超出本行的高度
浮动的元素不能通过text-align: center 或者margin: 0 auto居中
含义:清除浮动带来的影响。如果子元素浮动,此时子元素不能撑开标准流的块级父元素
原因:子元素浮动后脱离标准流 -> 不占位置
目的:需要父元素有高度,不影响其他元素的布局
方法:
给父元素加高度
额外标签:给父元素内容的最后加一个块级元素,给添加的块级元素设置clear: both;
单伪元素:用伪元素代替额外标签
.clearfix::after {
+ content: '';
+ display: block;
+ clear: both;
+}
+---
+.clearfix::after {
+ content: '';
+ displat: block;
+ clear: both;
+ height: 0;
+ visibility: hidden;
+}双伪元素:
.clearfix::before, /* 解决外边距塌陷问题 */
+.clearfix::after {
+ content: '';
+ display: table;
+}
+.clearfix::after {
+ clear: both;
+}父元素设置overflow: hidden
BFC(Block Formatting Context)全称是块级格式化上下文,用于对块级元素排版,默认情况下只有根元素(body)一个块级上下文,但是如果一个块级元素设置了float:left,overflow:hidden或position:absolute样式,就会为这个块级元素生产一个独立的块级上下文,使这个块级元素内部的排版完全独立。
作用:独立的块级上下文可以包裹浮动流,全部浮动子元素也不会引起容器高度塌陷,就是说包含块会把浮动元素的高度也计算在内,所以就不用清除浮动来撑起包含块的高度。
那什么时候会触发 BFC 呢?常见的情况如下:
• 根元素;
• float的值不为none;
• overflow的值为auto、scroll或hidden;
• display的值为table-cell、table-caption和inline-block中的任何一个;
• position的值不为relative和static。
设置定位方式
属性名:position
常见属性:
静态定位:static
相对定位:relative,相对自己之前的位置进行移动
绝对定位:absolute,先找已经定位的父级(逐级查找),如果有这样的父级就以这个父级为参照定位,有父级但父级没有定位则以浏览器为参照定位
页面中不占位置(脱标)
改变标签的显示模式特点,具备行内块特点
绝对定位的元素不能使用margin: 0 auto居中
position: absolute;
+left: 50%;
+top: 50%;
+transform: translate(-50%, -50%);固定定位:fixed,相对于浏览器进行定位移动
设置偏移值
浏览器遇到行内和行内块标签当作文字处理,默认文字按照基线对齐
属性:border-radius
常见取值:数字+px、百分比
赋值:从左上角开始,顺时针赋值,没有赋值的看对角
正圆:正方形盒子,border-radius: 50%
胶囊按钮:长方形盒子,border-radius: 高度的一半
百分比表示的是圆角半径的大小为盒子较小边长的一半,例如盒子宽200px,高100px,border-radius: 50% 50%; 则这两个50%都是相对于100px的。
CSS精灵图是一种将多个小的背景图片合并到一张大图中的技术,通过CSS的background-position属性控制显示不同的小图片,达到减少HTTP请求、减小页面大小、提高加载速度的效果。
CSS精灵图可以将多个小背景图像合并为一张大图,这样在页面上加载一次大图后,就可以通过background-position属性来控制显示不同的小图像,实现了将多个HTTP请求转化为一次请求,减小了网络延迟和服务器压力。同时,由于减少了HTTP请求和加载的内容大小,减小了页面的带宽消耗,加快了网页的加载速度,提高了用户的体验感受。
在web前端开发中,经常使用CSS精灵图技术,特别是在一些需要大量小icon的场合,如网站菜单栏、按钮、分页等等。
设置背景图片的大小:background-size: 宽 高
取值
backgound:color image repeat position/size
box-shadowtransition.box {
width: 200px;
height: 200px;
background-color: pink;
/transition: all 1s/
transition: width 1s, background-color 2s;
}
.box hover {
width: 600px;
background-color: red;
}
展示的是图标,实质是文字,用作处理简单的、颜色单一的图片
iconfont
<link rel="stylesheet" href="./iconfont.css"
<span class="iconfont icon-kuaijiezhifu"></span>
平面转换(2D转换):改变盒子在平面内的形态,可以使用transform属性实现元素的位移、旋转、缩放等效果
transform: translate(水平移动距离, 垂直移动距离)transform: rotate(度数 + deg); 正数:顺时针;负数:逆时针transform-origin: 原点水平位置 原点垂直位置transform: translate() rotate()
rotate会改变坐标轴向,位移方向会受影响
多重转换如果涉及旋转,旋转往最后写
transform: scale(x轴缩放倍数, y轴缩放倍数) linear-gradient
在空间内位移、旋转、缩放等效果
transform: tranlate3d(x,y,z)
单个坐标轴
transform: translat[X|Y|Z]
使用perspective(视距)属性实现透视效果,添加给父级元素,取值一般800-1200
transform: rotateX()
transform: rotateY()
transform: rotateZ()
transform: rotate3d(x,y,z,角度度数):用来设置自定义旋转轴的位置及旋转角度,xyz取值为0-1之间的数字
使用transform-style: perserve-3d呈现立体图形
父元素添加transform-style: perserve-3d使子集元素处于3d空间
默认值flat,表示子元素处于2D平面
transform: scaleX()
transform: scaleY()
transform: scaleY()
transform: scale3d(x,y,z)
使用animation实现多个状态间的变化过程,动画过程可控(重复播放、最终画面、是否暂停)
定义动画
@keyframes 动画名称 {
+ from {}
+ to {}
+}
+
+@keyframes 动画名称 {
+ /* 百分比指的是动画总时长的占比 */
+ 0% {}
+ 10% {}
+ 15% {}
+ 100% {}
+}使用动画: animation: 动画名称 动画花费时长
animation: 动画名称 动画时长 速度曲线 延迟时间 重复次数 动画方向 执行完毕时状态 播放状态
- animation-name:
- animation-duration
- animation-timing-function:ease;ease-in;ease-out;ease-in-out;linear;step;
- animation-delay
- animation-iteration-count: 1,2,..infinite;
- animation-direction: normal;reverse;alternate;alternate-reverse;
- animation-fill-mode: forward;backward;both;
- animation-play-state: pause;running;
- animation-
animation: 动画1,动画2...,动画n;
浮动脱标的问题display: flex;justify-content
取值:
flex flex-grow(增长系数)、flex-shrink(收缩系数)和flex-basis(初始尺寸)三个属性的简写,第一个无单位数代表flex-grow、第二无单位数代表flex-shrink,带像素单位的是flex-basis的值@media 逻辑操作符 媒体类型 and (媒体特性) {
+ 选择器 {
+ CSS属性
+ }
+}
+
+@media (媒体特性) {
+ 选择器 {
+ CSS属性
+ }
+}
+
+@media (min-width:320px) {
+ html {
+ font-size: 32px;
+ }
+}Less(Leaner Style Sheets)是一门向后兼容的CSS 扩展语言,是一个CSS预处理器,扩充了CSS,使CSS具备一定的逻辑性、计算能力。
@width: 10px;
+@height: @width + 10px;
+
+#header {
+ width: @width;
+ height: @height;
+}编译为
#header {
+ width: 10px;
+ height: 20px;
+}.bordered {
+ border-top: dotted 1px black;
+ border-bottom: solid 2px black;
+}
+
+#menu a {
+ color: #111;
+ .bordered();
+}
+
+.post a {
+ color: red;
+ .bordered();
+}.bordered 类所包含的属性就将同时出现在 #menu a 和 .post a 中了。
#header {
+ color: black;
+ .navigation {
+ font-size: 12px;
+ }
+ .logo {
+ width: 300px;
+ }
+}#header {
+ color: black;
+}
+#header .navigation {
+ font-size: 12px;
+}
+#header .logo {
+ width: 300px;
+}.component {
+ width: 300px;
+ @media (min-width: 768px) {
+ width: 600px;
+ @media (min-resolution: 192dpi) {
+ background-image: url(/img/retina2x.png);
+ }
+ }
+ @media (min-width: 1280px) {
+ width: 800px;
+ }
+}编译为
.component {
+ width: 300px;
+}
+@media (min-width: 768px) {
+ .component {
+ width: 600px;
+ }
+}
+@media (min-width: 768px) and (min-resolution: 192dpi) {
+ .component {
+ background-image: url(/img/retina2x.png);
+ }
+}
+@media (min-width: 1280px) {
+ .component {
+ width: 800px;
+ }
+}算术运算符 +、-、*、/ 可以对任何数字、颜色或变量进行运算。如果可能的话,算术运算符在加、减或比较之前会进行单位换算。计算的结果以最左侧操作数的单位类型为准。如果单位换算无效或失去意义,则忽略单位。无效的单位换算例如:px 到 cm 或 rad 到 % 的转换。
// 所有操作数被转换成相同的单位
+@conversion-1: 5cm + 10mm; // 结果是 6cm
+@conversion-2: 2 - 3cm - 5mm; // 结果是 -1.5cm
+
+// conversion is impossible
+@incompatible-units: 2 + 5px - 3cm; // 结果是 4px
+
+// example with variables
+@base: 5%;
+@filler: @base * 2; // 结果是 10%
+@other: @base + @filler; // 结果是 15%乘法和除法不作转换。因为这两种运算在大多数情况下都没有意义,一个长度乘以一个长度就得到一个区域,而 CSS 是不支持指定区域的。Less 将按数字的原样进行操作,并将为计算结果指定明确的单位类型。
@base: 2cm * 3mm; // 结果是 6cm转义(Escaping)允许你使用任意字符串作为属性或变量值。任何 ~"anything" 或 ~'anything' 形式的内容都将按原样输出,除非 interpolation。
@min768: ~"(min-width: 768px)";
+.element {
+ @media @min768 {
+ font-size: 1.2rem;
+ }
+}编译为:
@media (min-width: 768px) {
+ .element {
+ font-size: 1.2rem;
+ }
+}注意,从 Less 3.5 开始,可以简写为:
@min768: (min-width: 768px);
+.element {
+ @media @min768 {
+ font-size: 1.2rem;
+ }
+}Less 内置了多种函数用于转换颜色、处理字符串、算术运算等。这些函数在Less 函数手册中有详细介绍。
函数的用法非常简单。下面这个例子利用 percentage 函数将 0.5 转换为 50%,将颜色饱和度增加 5%,以及颜色亮度降低 25% 并且色相值增加 8 等用法:
@base: #f04615;
+@width: 0.5;
+
+.class {
+ width: percentage(@width); // returns \`50%\`
+ color: saturate(@base, 5%);
+ background-color: spin(lighten(@base, 25%), 8);
+}从 Less 3.5 版本开始,你还可以将混合(mixins)和规则集(rulesets)作为一组值的映射(map)使用。
#colors() {
+ primary: blue;
+ secondary: green;
+}
+
+.button {
+ color: #colors[primary];
+ border: 1px solid #colors[secondary];
+}输出符合预期:
.button {
+ color: blue;
+ border: 1px solid green;
+}Less 中的作用域与 CSS 中的作用域非常类似。首先在本地查找变量和混合(mixins),如果找不到,则从“父”级作用域继承。
@var: red;
+
+#page {
+ @var: white;
+ #header {
+ color: @var; // white
+ }
+}与 CSS 自定义属性一样,混合(mixin)和变量的定义不必在引用之前事先定义。因此,下面的 Less 代码示例和上面的代码示例是相同的:
@var: red;
+
+#page {
+ #header {
+ color: @var; // white
+ }
+ @var: white;
+}@import "library"; // library.less
+@import "typo.css";被引入的less文件不会生成单独的css文件
webstorm FileWatcher配置:
- npm install -g less
- aruments:
--no-color $FileName$ ../css/$FileNameWithoutExtension$.css- output paths to refresh :
../css/$FileNameWithoutExtension$.cssVS Code EasyLess配置:
- out: "../css/"
- 首行添加注释控制编译的输出情况
- // out: ./dir/
- // out: ./dir/xxx.css
- // out: false
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/css/bootstrap.min.css">
<script src="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/js/bootstrap.min.js"></script>
| 超小屏幕 | 小屏幕 | 中等屏幕 | 大屏幕 | |
|---|---|---|---|---|
| 响应断点 | <768px | >=768px | >=992px | >=1200px |
| 别名 | xs | sm | md | lg |
| 容器宽度 | 100% | 750px | 970px | 1170px |
| 类前缀 | col-xs-* | col-sm-* | col-md-* | col-lg-* |
| 列数 | 12 | 12 | 12 | 12 |
| 列间隙 | 30px | 30px | 30px | 30px |
.container是BootStrap中提供的类名,应用该类名的盒子,默认被指定宽度且居中.container-fluid是BootStrap中提供的类名,所有应用的盒子,宽度为100%.row类名和.col类名定义栅格布局的行和列TIP
https://v3.bootcss.com/components/
html {
+ scroll-behavior: smooth;
+}标题:h1-h6
段落:p
换行:br
水平分割线:hr
加粗:strong/b
下划线:ins/u
倾斜:em/i
删除线:del/s
图片:img
音频:audio [src|controls|autoplay|loop]
视频:video [src|controls|autoplay|loop]
超链接:a
有序列表:ol > li
无序列表:ul > li
自定义列表:dl > dt > dd
table > tr > td
th:表头
caption:标题
结构标签:thead/tbody/tfoot
合并单元格:rowspan-跨行合并 colspan-跨列合并(不能跨结构标签合并)
input系列:text/password/radio/checkbox/file/submit/reset/button
button
select
textarea
label
没有语义的布局标签:div/span
语义化标签:header/nav/footer/aside/section/article(显示特点和div一致,多了语义)
空格: 
<!DOCTYPE html>:声明网页HTML版本<html lang="en":标识网页使用的语言,作用:搜索引擎归类+浏览器翻译, zh-CN/en<meta>:元数据标签,元数据是关于文档的数据,例如文档的作者、字符集、关键字和描述等信息,这些信息对于搜索引擎的抓取和用户的浏览很有帮助。 <title>:网页标题<meta name="description">:网页描述标签<meta name="keywords":网页关键词<link rel="icon" href="favicon.ico">
标题:h1-h6
段落:p
换行:br
水平分割线:hr
加粗:strong/b
下划线:ins/u
倾斜:em/i
删除线:del/s
图片:img
音频:audio [src|controls|autoplay|loop]
视频:video [src|controls|autoplay|loop]
超链接:a
有序列表:ol > li
无序列表:ul > li
自定义列表:dl > dt > dd
table > tr > td
th:表头
caption:标题
结构标签:thead/tbody/tfoot
合并单元格:rowspan-跨行合并 colspan-跨列合并(不能跨结构标签合并)
input系列:text/password/radio/checkbox/file/submit/reset/button
button
select
textarea
label
没有语义的布局标签:div/span
语义化标签:header/nav/footer/aside/section/article(显示特点和div一致,多了语义)
空格: 
<!DOCTYPE html>:声明网页HTML版本<html lang="en":标识网页使用的语言,作用:搜索引擎归类+浏览器翻译, zh-CN/en<meta>:元数据标签,元数据是关于文档的数据,例如文档的作者、字符集、关键字和描述等信息,这些信息对于搜索引擎的抓取和用户的浏览很有帮助。 <title>:网页标题<meta name="description">:网页描述标签<meta name="keywords":网页关键词<link rel="icon" href="favicon.ico">
prompt()
console.log()
document.write()
alert()
alert和prompt会跳过页面渲染先被执行
let比较旧的JavaScript中使用var声明变量
var的一些问题:
- 可以先使用,再声明
- var声明过的变量可以重复声明
- 变量提升、全局变量、没有块级作用域
let arr = [1, 2, 3] / let arr = new Array(1, 2, 3)
数组有序
取值:数组[下标]
长度:数组.length
修改:arr[下标] = 新值
增加
删除
constnumber
string
模板字符串: 使用反引号包裹数据,使用\${}替换数据
let age = 20
+console.log(\`我今年\${age}岁\`)boolean
undefined
null
NaN代表一个计算错误,是一个不正确或未定义的数学操作得到的结果,任何对NaN的操作都会返回NaN
+号两边只要有字符串,都会转字符串+,其他算数运算符会把数据转换为数字类型+作为正号可以转换数字object
let obj = {
+ uname: 'abc',
+ age: 18,
+ gender: '女',
+ speak: function(x) {
+ console.log('hello' + x)
+ }
+}查看:
修改: 对象.属性 = 新值
新增: 对象.新属性 = 值
删除: delete 对象.属性
对象方法: 对象.方法名()
遍历对象
for (let k in obj) {
+ console.log(obj[k]) //k带引号
+}for in遍历数组 是数组下标,但是是字符串
++--<>>=<===: 值是否相等===:类型和值是否都相等!==:是否不全等&&||!if
switch case
数据和值必须满足全等===
switch (数据) {
+ case 值1:
+ 代码1
+ break
+ case 值2:
+ 代码2
+ break
+ default:
+ 代码n
+}三元运算符
function 函数名(参数列表) {
+ 函数体
+}命名 小驼峰
return
函数表达式:把匿名函数赋值给一个变量,通过变量名调用
let fn = function () {}立即执行函数
(function() {...})();
+(function() {...})();
+---
+(function(x, y) {
+ console.log(x + y)
+})(1, 3)前一个括号声明,后一个括号调用
分号
&&和||中,当满足一定条件会让右边代码不执行 &&:左边为false就短路||:左边为true就短路"": false
0: false
undefined: false
null: false
NaN: false
"" + 1 = 1
null经过数字转换会变0
undefined经过数字转换会变NaN
对象.innerText
对象.innerHTML
对象.属性=值
const image = document.querySelector('img')
+image.src = 'xxx.jpg'
+image.title = '123'对象.style.样式属性=值
box.style.width = '300px'
+box.backgroundColor = 'pink' //小驼峰通过类名修改属性,会覆盖
//定义好类对应的属性,给对象添加类名
+对象.className = 类名通过classList操作类控制CSS,用于追加和删除
元素.classList.add(类名)//追加
+元素.classList.remove(类名)//删除
+元素.classList.toggle(类名)//切换自定义属性
H5中推出的data-自定义属性
在标签上一律以data-开头
DOM对象上一律以dataset对象方式获取
<body>
+ <div class="box" data-id="10">盒子</div>
+ <script>
+ const box = document.querySelector('.box')
+ console.log(box.dataset.id)
+ </script>
+</body>元素.on事件:也可以添加事件监听,但会被覆盖,且只能冒泡 不能捕获,addEventListener不会被覆盖,能冒泡 也能捕获。
事件对象中有事件触发时的相关信息,例如鼠标点击时的位置,键盘按下时的键位
btn.addEventListener('click', function(e){
+ console.log(e)
+})指的是函数内部特殊的变量this,它代表着当前函数运行时所处的环境
this的指代对象也不通this指向的粗略规则是谁调用指向谁(addEventListener指向绑定的元素,普通函数指向window)函数A作为参数传递给函数B,A就被称为回调函数
事件流指的是事件完整执行过程中的流动路径
DOM的根元素开始去执行对应的事件(从父元素到子元素)
DOM.addEventListener(事件类型, 函数, 是否使用捕获机制)L0事件只有冒泡,没有捕获
当一个元素的事件被触发时,同样的事件会在该元素的所有祖先元素中依次被触发。这一过程被称为事件冒泡(从子元素到父元素)
简单理解:当一个元素触发事件后,会依次向上调用所有父级元素的同名事件
事件冒泡是默认存在的
btn.addEventListener('click', function(e){
+ e.stopPropagation()
+})on事件方式
// 绑定事件
+btn.onClick = function(e){
+ console.log(e)
+}
+// 解绑事件
+btn.onClick = nulladdEventListener方式
function fn(e){
+ console.log(e)
+}
+//绑定事件
+btn.addEventListener('click', fn)
+//解绑事件
+btn.removeEventListener('click', fn)匿名函数无法解绑
事件委托是利用事件流特征解决开发问题的技巧,可以减少事件注册次数,提高程序性能,原理是利用事件冒泡特点,给父元素注册事件,当触发子元素的时候,会冒泡到父元素身上,从而触发父元素的事件
e.preventDefault()
页面加载事件
外部资源加载完毕时触发的事件
等待页面所有资源加载完毕,执行回调函数:window.addEventListener('load', function() {})
也可以针对某个资源绑定事件:img.addEventListener('load', function() {})
初始HTML文档被完全加载和解析完成后,DOMContentLoaded事件被触发,无需等待样式表、图像等完全加载
document.addEventListener('DOMContentLoaded', function() {})页面滚动事件
滚动条在滚动的时候持续触发的事件
window.addEventListener('scroll', function() {})获取滚动位置
scrollLeft**(可读写)**
scrollTop**(可读写)**
window.addEventListener('scroll', function() {
+ const n = document.documentElement.scrollTop
+ console.log(n)
+})document.documentElement返回对象为HTML元素
......
滚动到指定坐标
页面尺寸事件
resizewindow.addEventListener('resize', function() {})clientWidth、clientHeightelement.getBoundingClientRect()实例化
const date = new Date()const date = new Date('2023-4-8 08:00:00')常用方法
时间戳
date.getTime()+new Date()Date.now()const div = document.createElement('div')父元素.appendChild(div)
父元素.insertBefore(要插入的元素, 在哪个元素前面):插入某个元素之前
ul.insertBefore(li, ul.children[0])父元素.removeChild(子元素)BOM(Browser Object Model)是浏览器对象模型,包含:navigator、location、document、history、screen
window是一个全局对象,document、alert()、console.log()都是window的属性
var定义在全局作用域中的变量、函数都会变成window对象的属性和方法let timer = setTimeout(回调函数, 等待时间ms),返回id,setTimeout只执行一次clearTimeout(timer)let interval = setInterval(函数, 间隔时间ms),返回的是的是一个id数字,不断执行clearInterval(interval)js是单线程,所有任务需要排队。HTML5提出了Web Worker标准,允许JavaScript脚本创建多个线程。于是JS出现了同步和异步。
localtion的数据类型是对象,它拆分保存了URL地址的各个组成部分
location.href:常用于页面跳转
location.search:获取地址中携带的参数,符号?后面的部分
location.hash:获取地址中的hash值,符号#后面的部分
location.reload():用来刷新当前页面,传入参数true时强制刷新
navigator的数据类型是对象,该对象下记录了浏览器自身的相关信息
history数据类型是对象,主要管理历史记录,该对象与浏览器地址栏的操作相对应,如前进、后退、历史记录等
数据存储在用户浏览器中,设置、读取方便,刷新页面不会丢失数据,sessionStorage和localStorage约5M
localStorage.setItem(key, value)localStorage.getItem(key)localStorage.removeItem(key)localStorage一致把复杂数据类型转成字符串形式存储
JSON.stringifyJSON.parse遍历数组处理数据,返回新的数组
const arr = ['red', 'blue']
+const newArr = arr.map(function(ele, index) {
+ return ele + '颜色'
+})
+console.log(newArr) // ['red颜色', 'blue颜色']const newStr = join(字符串):元素用指定字符串相连const reg = /表达式/reg.test(被检测字符串),匹配返回true,否则falsereg.exec(被检测字符串),找到返回数组,否则为null边界符
^:开始$:结束量词
*:0或多次+:1或多次?:0或1次{n}:重复n次{n,}:重复n次或更多{n,m}:重复n次到m次字符类
[]:匹配字符集合,匹配任一个都是true[a-zA-Z]:字母[^a-z]:[]中的^表示取反.:除换行之外的任何单个字符\\d:数字\\D:所有0-9以外字符,等于[^0-9]\\w:任一字母、数字、下划线,相当于[a-zA-Z0-9_]\\W:匹配除字母、数字、下划线之外的字符,相当于[^a-zA-Z0-9_]\\s:匹配空格(包括制表符、换行符、空格符等),相当于[\\t\\r\\n\\v\\f]\\S:匹配非空格,相当于[^\\t\\r\\n\\v\\f]语法:/表达式/修饰符
修饰符:
字符串.replace(/正则表达式/, 替换的文本),返回替换后的字符串局部作用域
全局作用域
作用域链
JS垃圾回收机制
引用计数法(有循环引用问题)
- 定义“内存不再使用”,看一个对象是否有指向它的引用,没有引用就回收对象
- 根据记录被引用的次数
- 被引用一次,就+1,多次引用会累加
- 如果减少一个引用就-1
- 如果引用次数是0,则释放内存
标记清除法
- 将不再使用的对象定义为无法达到的对象
- 从根部(JS中就是全局对象)出发定时扫描内存中的对象,凡是能从根部到达的对象,都是还需要使用的
- 无法由根部出发触及的对象标记为不再使用,稍后进行回收
闭包
如果在一个外部函数中定义一个内部函数,内部函数对外部作用域的变量进行引用,外部函数的返回值是内部函数,这样的函数就被认为是闭包(closure)。变量提升
函数提升
函数表达式特殊,必须先声明赋值后调用
动态参数:arguments,只存在于函数里,伪数组
剩余参数:function getSum(paramA, paramB, ...arr),arr是个真数组
展开运算符:...能将一个数组进行展开
const arr = [1,5,3]
+console.log(...arr)// 1 5 3用于求数组最大/小值Math.max(...arr)
用于合并数组:const arr = [...arr1, ...arr2]
引入箭头函数是为了更简洁的写法,适用于需要匿名函数的地方
const fn = () => {}
+const fn = x => { console.log(x) }
+const fn = x => console.log(x)
+const fn = x => x * 2
+const fn = (uname) => ({ uname: uname }) //返回一个对象箭头函数不会创建自己的this对象,它只会从自己的作用域链的上一层
数组结构是将数组的单元值快速批量赋值给一系列变量的简洁语法
const [max, min, avg] = [100, 60, 80]const [a, ,c, d] = [1, 2, 3, 4]js必须加分号场景:
- 两个连续的立即执行函数
- 使用数组
对象解构是将对象的属性和方法快速批量赋值给一系列变量的简介语法
const user = {
+ name: '小明',
+ age: 18
+}
+const {name, age} = user对象的属性值将会被赋值给与属性名相同的变量
对象中找不到与变量名一致的属性时变量值为undefined
数组对象解构
const pig = [
+ {
+ name: '佩奇',
+ age: 6
+ }
+]
+
+const [{ name, age }] = pig
+console.log(name,age)多级对象解构
const pig = {
+ name: '佩奇',
+ age: 6,
+ family: {
+ mother: 'mon',
+ father: 'dad'
+ }
+}
+
+const { name, family: { mother, father }} = pig字面量创建
构造函数
new操作符来执行Date.now()、Math.PI、Math.random()Object
Array
实例方法:forEach、filter、map、reduce、join、find、every、some、concat、splice、reverse、findIndex...
伪数组转换为真数组:Array.from()
arr.some((item, index)=> {
+ //some code, some循环可以终止
+ return true
+})
+
+//every 判断数组每一项是否都满足条件
+let res = arr.every(item => item.state)
+
+//reduce
+arr.reduce((累加的结果, 当前循环项) => {}, 初始值)
+arr.reduce((amt, item) => amt += item.price, 0)String
Number
prototype属性,指向另一个对象,所以也称为原型对象每个原型对象里都有个constructor属性,该属性指向该原型对象的构造函数
每个对象都有一个属性__proto__,指向构造函数的prototype对象
__proto__是JS非标准属性__proto__意义相同__proto__对象原型里也有一个constructor属性,指向创建该实例对象的构造函数通过原型可以继承公共属性
const Person = {
+ eyes: 2,
+ nose: 1
+}
+
+function Man() {
+
+}
+Man.prototype = Person
+Man.prototype.constructor = Man
+
+---
+
+const Person = {
+ this.eyes: 2,
+ this.nose: 1
+}
+
+function Man() {
+
+}
+Man.prototype = new Person()基于原型对象的继承使得不同构造函数的原型对象关联在一起,并且这种关联关系是一种链状的解构,称为原型链
__proto__指向的prototype对象)__proto__对象原型的意义就在于为对象成员查找机制提供方向instanceof运算符检测构造函数的prototype属性是否出现在某个实例对象的原型链上深浅拷贝只针对引用数据类型
_.cloneDeep()try {
+
+} catch (err) {
+
+} finally {
+
+}debugger
普通函数的调用方式决定了this的值,即谁调用 this的值指向谁
普通函数没有明确调用者时this的值为window,严格模式下没有调用者时this的值为undefined
单位时间内,频繁触发事件,只执行最后一次
lodash库的_.debounce(fun, 时间)
const box = document.querySelector('.box')
+let i = 1
+function mouseMove() {
+ box.innerHTML = i++
+}
+
+function debounce(fn, t) {
+ let timer
+ return function() {
+ if (timer) clearTimeout(timer)
+ timer = setTimeout(function() {
+ fn()
+ }, t)
+ }
+}
+
+box.addEventListener('mousemove', debounce(mouseMove, 500))_.throttle(fun, 时间)function throttle(fn, t) {
+ let timer = null
+ return function() {
+ if(!timer) {
+ timer = setTimeout(function(){
+ fn()
+ // setTimeout中无法删除定时器,因为定时器还在运作,所以不能用clearTimeout
+ timer = null
+ }, t)
+ }
+ }
+}
+
+box.addEventListener('mousemove', throttle(mouseMove, 500))video.ontimeupdadte = _.throttle(() => {
+ localStorage.setItem('currentTime', video.currentTime)
+}, 1000)
+
+video.onloadeddata = () => {
+ video.currentTime = localStorage.getItem('currentTime') || 0
+}所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。从语法上说,Promise 是一个对象,从它可以获取异步操作的消息。Promise 提供统一的 API,各种异步操作都可以用同样的方法进行处理。
Promise对象有以下两个特点。
(1)对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是Promise这个名字的由来,它的英语意思就是“承诺”,表示其他手段无法改变。
(2)一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从pending变为fulfilled和从pending变为rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果,这时就称为 resolved(已定型)。如果改变已经发生了,你再对Promise对象添加回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。
ES6 规定,Promise对象是一个构造函数,用来生成Promise实例。
下面代码创造了一个Promise实例。
const promise = new Promise(function(resolve, reject) {
+ // ... some code
+
+ if (/* 异步操作成功 */){
+ resolve(value);
+ } else {
+ reject(error);
+ }
+});Promise构造函数接受一个函数作为参数,该函数的两个参数分别是resolve和reject。它们是两个函数,由 JavaScript 引擎提供。
resolve函数的作用是,将Promise对象的状态从“未完成”变为“成功”(即从 pending 变为 resolved),在异步操作成功时调用,并将异步操作的结果,作为参数传递出去;reject函数的作用是,将Promise对象的状态从“未完成”变为“失败”(即从 pending 变为 rejected),在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去。
Promise实例生成以后,可以用then方法分别指定resolved状态和rejected状态的回调函数。
promise.then(function(value) {
+ // success
+}, function(error) {
+ // failure
+});then方法可以接受两个回调函数作为参数。第一个回调函数是Promise对象的状态变为resolved时调用,第二个回调函数是Promise对象的状态变为rejected时调用。这两个函数都是可选的,不一定要提供。它们都接受Promise对象传出的值作为参数。
下面是一个Promise对象的简单例子。
function timeout(ms) {
+ return new Promise((resolve, reject) => {
+ setTimeout(resolve, ms, 'done');//setTimeout的第三个参数是给第一个函数参数传递的参数,即done会传递给resolve函数作为参数
+ });
+}
+
+timeout(100).then((value) => {
+ console.log(value);
+});上面代码中,timeout方法返回一个Promise实例,表示一段时间以后才会发生的结果。过了指定的时间(ms参数)以后,Promise实例的状态变为resolved,就会触发then方法绑定的回调函数。
Promise 新建后就会立即执行。
let promise = new Promise(function(resolve, reject) {
+ console.log('Promise');
+ resolve();
+});
+
+promise.then(function() {
+ console.log('resolved.');
+});
+
+console.log('Hi!');
+
+// Promise
+// Hi!
+// resolved上面代码中,Promise 新建后立即执行,所以首先输出的是Promise。然后,then方法指定的回调函数,将在当前脚本所有同步任务执行完才会执行,所以resolved最后输出。
下面是异步加载图片的例子。
function loadImageAsync(url) {
+ return new Promise(function(resolve, reject) {
+ const image = new Image();
+
+ image.onload = function() {
+ resolve(image);
+ };
+
+ image.onerror = function() {
+ reject(new Error('Could not load image at ' + url));
+ };
+
+ image.src = url;
+ });
+}上面代码中,使用Promise包装了一个图片加载的异步操作。如果加载成功,就调用resolve方法,否则就调用reject方法。
Generator 函数是 ES6 提供的一种异步编程解决方案,语法行为与传统函数完全不同。本章详细介绍 Generator 函数的语法和 API,它的异步编程应用请看《Generator 函数的异步应用》一章。
Generator 函数有多种理解角度。语法上,首先可以把它理解成,Generator 函数是一个状态机,封装了多个内部状态。
执行 Generator 函数会返回一个遍历器对象,也就是说,Generator 函数除了状态机,还是一个遍历器对象生成函数。返回的遍历器对象,可以依次遍历 Generator 函数内部的每一个状态。
形式上,Generator 函数是一个普通函数,但是有两个特征。一是,function关键字与函数名之间有一个星号;二是,函数体内部使用yield表达式,定义不同的内部状态(yield在英语里的意思就是“产出”)。
function* helloWorldGenerator() {
+ yield 'hello';
+ yield 'world';
+ return 'ending';
+}
+
+var hw = helloWorldGenerator();上面代码定义了一个 Generator 函数helloWorldGenerator,它内部有两个yield表达式(hello和world),即该函数有三个状态:hello,world 和 return 语句(结束执行)。
然后,Generator 函数的调用方法与普通函数一样,也是在函数名后面加上一对圆括号。不同的是,调用 Generator 函数后,该函数并不执行,返回的也不是函数运行结果,而是一个指向内部状态的指针对象,也就是上一章介绍的遍历器对象(Iterator Object)。
下一步,必须调用遍历器对象的next方法,使得指针移向下一个状态。也就是说,每次调用next方法,内部指针就从函数头部或上一次停下来的地方开始执行,直到遇到下一个yield表达式(或return语句)为止。换言之,Generator 函数是分段执行的,yield表达式是暂停执行的标记,而next方法可以恢复执行。
hw.next()
+// { value: 'hello', done: false }
+
+hw.next()
+// { value: 'world', done: false }
+
+hw.next()
+// { value: 'ending', done: true }
+
+hw.next()
+// { value: undefined, done: true }由于 Generator 函数返回的遍历器对象,只有调用next方法才会遍历下一个内部状态,所以其实提供了一种可以暂停执行的函数。yield表达式就是暂停标志。
遍历器对象的next方法的运行逻辑如下。
(1)遇到yield表达式,就暂停执行后面的操作,并将紧跟在yield后面的那个表达式的值,作为返回的对象的value属性值。
(2)下一次调用next方法时,再继续往下执行,直到遇到下一个yield表达式。
(3)如果没有再遇到新的yield表达式,就一直运行到函数结束,直到return语句为止,并将return语句后面的表达式的值,作为返回的对象的value属性值。
(4)如果该函数没有return语句,则返回的对象的value属性值为undefined。
需要注意的是,yield表达式后面的表达式,只有当调用next方法、内部指针指向该语句时才会执行,因此等于为 JavaScript 提供了手动的“惰性求值”(Lazy Evaluation)的语法功能。
function* gen() {
+ yield 123 + 456;
+}上面代码中,yield后面的表达式123 + 456,不会立即求值,只会在next方法将指针移到这一句时,才会求值。
yield表达式与return语句既有相似之处,也有区别。相似之处在于,都能返回紧跟在语句后面的那个表达式的值。区别在于每次遇到yield,函数暂停执行,下一次再从该位置继续向后执行,而return语句不具备位置记忆的功能。一个函数里面,只能执行一次(或者说一个)return语句,但是可以执行多次(或者说多个)yield表达式。正常函数只能返回一个值,因为只能执行一次return;Generator 函数可以返回一系列的值,因为可以有任意多个yield。从另一个角度看,也可以说 Generator 生成了一系列的值,这也就是它的名称的来历(英语中,generator 这个词是“生成器”的意思)。
正常情况下,await命令后面是一个 Promise 对象,返回该对象的结果。如果不是 Promise 对象,就直接返回对应的值。
async function f() {
+ // 等同于
+ // return 123;
+ return await 123;
+}
+
+f().then(v => console.log(v))
+// 123上面代码中,await命令的参数是数值123,这时等同于return 123。
另一种情况是,await命令后面是一个thenable对象(即定义了then方法的对象),那么await会将其等同于 Promise 对象。
class Sleep {
+ constructor(timeout) {
+ this.timeout = timeout;
+ }
+ then(resolve, reject) {
+ const startTime = Date.now();
+ setTimeout(
+ () => resolve(Date.now() - startTime),
+ this.timeout
+ );
+ }
+}
+
+(async () => {
+ const sleepTime = await new Sleep(1000);
+ console.log(sleepTime);
+})();
+// 1000上面代码中,await命令后面是一个Sleep对象的实例。这个实例不是 Promise 对象,但是因为定义了then方法,await会将其视为Promise处理。
这个例子还演示了如何实现休眠效果。JavaScript 一直没有休眠的语法,但是借助await命令就可以让程序停顿指定的时间。下面给出了一个简化的sleep实现。
function sleep(interval) {
+ return new Promise(resolve => {
+ setTimeout(resolve, interval);
+ })
+}
+
+// 用法
+async function one2FiveInAsync() {
+ for(let i = 1; i <= 5; i++) {
+ console.log(i);
+ await sleep(1000);
+ }
+}
+
+one2FiveInAsync();await命令后面的 Promise 对象如果变为reject状态,则reject的参数会被catch方法的回调函数接收到。
async function f() {
+ await Promise.reject('出错了');
+}
+
+f()
+.then(v => console.log(v))
+.catch(e => console.log(e))
+// 出错了注意,上面代码中,await语句前面没有return,但是reject方法的参数依然传入了catch方法的回调函数。这里如果在await前面加上return,效果是一样的。
任何一个await语句后面的 Promise 对象变为reject状态,那么整个async函数都会中断执行。
async function f() {
+ await Promise.reject('出错了');
+ await Promise.resolve('hello world'); // 不会执行
+}上面代码中,第二个await语句是不会执行的,因为第一个await语句状态变成了reject。
有时,我们希望即使前一个异步操作失败,也不要中断后面的异步操作。这时可以将第一个await放在try...catch结构里面,这样不管这个异步操作是否成功,第二个await都会执行。
async function f() {
+ try {
+ await Promise.reject('出错了');
+ } catch(e) {
+ }
+ return await Promise.resolve('hello world');
+}
+
+f()
+.then(v => console.log(v))
+// hello world另一种方法是await后面的 Promise 对象再跟一个catch方法,处理前面可能出现的错误。
async function f() {
+ await Promise.reject('出错了')
+ .catch(e => console.log(e));
+ return await Promise.resolve('hello world');
+}
+
+f()
+.then(v => console.log(v))
+// 出错了
+// hello worldasync 函数是什么?一句话,它就是 Generator 函数的语法糖。返回值是 Promise 对象。
Generator 函数,依次读取两个文件。
const fs = require('fs');
+
+const readFile = function (fileName) {
+ return new Promise(function (resolve, reject) {
+ fs.readFile(fileName, function(error, data) {
+ if (error) return reject(error);
+ resolve(data);
+ });
+ });
+};
+
+const gen = function* () {
+ const f1 = yield readFile('/etc/fstab');
+ const f2 = yield readFile('/etc/shells');
+ console.log(f1.toString());
+ console.log(f2.toString());
+};
+
+const g = gen();
+g.next().value.then(function (data) {
+ g.next(data).value.then(function (data) {
+ g.next(data);
+ });
+});上面代码的函数gen可以写成async函数,就是下面这样。
const asyncReadFile = async function () {
+ const f1 = await readFile('/etc/fstab');
+ const f2 = await readFile('/etc/shells');
+ console.log(f1.toString());
+ console.log(f2.toString());
+};一比较就会发现,async函数就是将 Generator 函数的星号(*)替换成async,将yield替换成await,仅此而已。
async函数对 Generator 函数的改进,体现在以下四点。
(1)内置执行器。
Generator 函数的执行必须靠执行器,所以才有了co模块,而async函数自带执行器。也就是说,async函数的执行,与普通函数一模一样,只要一行。
asyncReadFile();上面的代码调用了asyncReadFile函数,然后它就会自动执行,输出最后结果。这完全不像 Generator 函数,需要调用next方法,或者用co模块,才能真正执行,得到最后结果。
(2)更好的语义。
async和await,比起星号和yield,语义更清楚了。async表示函数里有异步操作,await表示紧跟在后面的表达式需要等待结果。
(3)更广的适用性。
co模块约定,yield命令后面只能是 Thunk 函数或 Promise 对象,而async函数的await命令后面,可以是 Promise 对象和原始类型的值(数值、字符串和布尔值,但这时会自动转成立即 resolved 的 Promise 对象)。
(4)返回值是 Promise。
async函数的返回值是 Promise 对象,这比 Generator 函数的返回值是 Iterator 对象方便多了。你可以用then方法指定下一步的操作。
进一步说,async函数完全可以看作多个异步操作,包装成的一个 Promise 对象,而await命令就是内部then命令的语法糖。
async函数返回一个 Promise 对象,可以使用then方法添加回调函数。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
下面是一个例子。
async function getStockPriceByName(name) {
+ const symbol = await getStockSymbol(name);
+ const stockPrice = await getStockPrice(symbol);
+ return stockPrice;
+}
+
+getStockPriceByName('goog').then(function (result) {
+ console.log(result);
+});上面代码是一个获取股票报价的函数,函数前面的async关键字,表明该函数内部有异步操作。调用该函数时,会立即返回一个Promise对象。
下面是另一个例子,指定多少毫秒后输出一个值。
function timeout(ms) {
+ return new Promise((resolve) => {
+ setTimeout(resolve, ms);
+ });
+}
+
+async function asyncPrint(value, ms) {
+ await timeout(ms);
+ console.log(value);
+}
+
+asyncPrint('hello world', 50);上面代码指定 50 毫秒以后,输出hello world。
由于async函数返回的是 Promise 对象,可以作为await命令的参数。所以,上面的例子也可以写成下面的形式。
async function timeout(ms) {
+ await new Promise((resolve) => {
+ setTimeout(resolve, ms);
+ });
+}
+
+async function asyncPrint(value, ms) {
+ await timeout(ms);
+ console.log(value);
+}
+
+asyncPrint('hello world', 50);async 函数有多种使用形式。
// 函数声明
+async function foo() {}
+
+// 函数表达式
+const foo = async function () {};
+
+// 对象的方法
+let obj = { async foo() {} };
+obj.foo().then(...)
+
+// Class 的方法
+class Storage {
+ constructor() {
+ this.cachePromise = caches.open('avatars');
+ }
+
+ async getAvatar(name) {
+ const cache = await this.cachePromise;
+ return cache.match(\`/avatars/\${name}.jpg\`);
+ }
+}
+
+const storage = new Storage();
+storage.getAvatar('jake').then(…);
+
+// 箭头函数
+const foo = async () => {};async函数返回一个 Promise 对象。
async函数内部return语句返回的值,会成为then方法回调函数的参数。
async function f() {
+ return 'hello world';
+}
+
+f().then(v => console.log(v))
+// "hello world"上面代码中,函数f内部return命令返回的值,会被then方法回调函数接收到。
async函数内部抛出错误,会导致返回的 Promise 对象变为reject状态。抛出的错误对象会被catch方法回调函数接收到。
async function f() {
+ throw new Error('出错了');
+}
+
+f().then(
+ v => console.log('resolve', v),
+ e => console.log('reject', e)
+)
+//reject Error: 出错了async函数返回的 Promise 对象,必须等到内部所有await命令后面的 Promise 对象执行完,才会发生状态改变,除非遇到return语句或者抛出错误。也就是说,只有async函数内部的异步操作执行完,才会执行then方法指定的回调函数。
下面是一个例子。
async function getTitle(url) {
+ let response = await fetch(url);
+ let html = await response.text();
+ return html.match(/<title>([\\s\\S]+)<\\/title>/i)[1];
+}
+getTitle('https://tc39.github.io/ecma262/').then(console.log)
+// "ECMAScript 2017 Language Specification"上面代码中,函数getTitle内部有三个操作:抓取网页、取出文本、匹配页面标题。只有这三个操作全部完成,才会执行then方法里面的console.log。
如果await后面的异步操作出错,那么等同于async函数返回的 Promise 对象被reject。
async function f() {
+ await new Promise(function (resolve, reject) {
+ throw new Error('出错了');
+ });
+}
+
+f()
+.then(v => console.log(v))
+.catch(e => console.log(e))
+// Error:出错了上面代码中,async函数f执行后,await后面的 Promise 对象会抛出一个错误对象,导致catch方法的回调函数被调用,它的参数就是抛出的错误对象。
防止出错的方法,也是将其放在try...catch代码块之中。
async function f() {
+ try {
+ await new Promise(function (resolve, reject) {
+ throw new Error('出错了');
+ });
+ } catch(e) {
+ }
+ return await('hello world');
+}如果有多个await命令,可以统一放在try...catch结构中。
async function main() {
+ try {
+ const val1 = await firstStep();
+ const val2 = await secondStep(val1);
+ const val3 = await thirdStep(val1, val2);
+
+ console.log('Final: ', val3);
+ }
+ catch (err) {
+ console.error(err);
+ }
+}下面的例子使用try...catch结构,实现多次重复尝试。
const superagent = require('superagent');
+const NUM_RETRIES = 3;
+
+async function test() {
+ let i;
+ for (i = 0; i < NUM_RETRIES; ++i) {
+ try {
+ await superagent.get('http://google.com/this-throws-an-error');
+ break;
+ } catch(err) {}
+ }
+ console.log(i); // 3
+}
+
+test();上面代码中,如果await操作成功,就会使用break语句退出循环;如果失败,会被catch语句捕捉,然后进入下一轮循环。
async 函数的实现原理,就是将 Generator 函数和自动执行器,包装在一个函数里。
async function fn(args) {
+ // ...
+}
+
+// 等同于
+
+function fn(args) {
+ return spawn(function* () {
+ // ...
+ });
+}所有的async函数都可以写成上面的第二种形式,其中的spawn函数就是自动执行器。
spawn函数的实现
function spawn(genF) {
+ return new Promise(function(resolve, reject) {
+ const gen = genF();
+ function step(nextF) {
+ let next;
+ try {
+ next = nextF();
+ } catch(e) {
+ return reject(e);
+ }
+ if(next.done) {
+ return resolve(next.value);
+ }
+ Promise.resolve(next.value).then(function(v) {
+ step(function() { return gen.next(v); });
+ }, function(e) {
+ step(function() { return gen.throw(e); });
+ });
+ }
+ step(function() { return gen.next(undefined); });
+ });
+}实际开发中,经常遇到一组异步操作,需要按照顺序完成。比如,依次远程读取一组 URL,然后按照读取的顺序输出结果。
Promise 的写法如下。
function logInOrder(urls) {
+ // 远程读取所有URL
+ const textPromises = urls.map(url => {
+ return fetch(url).then(response => response.text());
+ });
+
+ // 按次序输出
+ textPromises.reduce((chain, textPromise) => {
+ return chain.then(() => textPromise)
+ .then(text => console.log(text));
+ }, Promise.resolve());
+}上面代码使用fetch方法,同时远程读取一组 URL。每个fetch操作都返回一个 Promise 对象,放入textPromises数组。然后,reduce方法依次处理每个 Promise 对象,然后使用then,将所有 Promise 对象连起来,因此就可以依次输出结果。
这种写法不太直观,可读性比较差。下面是 async 函数实现。
async function logInOrder(urls) {
+ for (const url of urls) {
+ const response = await fetch(url);
+ console.log(await response.text());
+ }
+}上面代码确实大大简化,问题是所有远程操作都是继发。只有前一个 URL 返回结果,才会去读取下一个 URL,这样做效率很差,非常浪费时间。我们需要的是并发发出远程请求。
async function logInOrder(urls) {
+ // 并发读取远程URL
+ const textPromises = urls.map(async url => {
+ const response = await fetch(url);
+ return response.text();
+ });
+
+ // 按次序输出
+ for (const textPromise of textPromises) {
+ console.log(await textPromise);
+ }
+}上面代码中,虽然map方法的参数是async函数,但它是并发执行的,因为只有async函数内部是继发执行,外部不受影响。后面的for..of循环内部使用了await,因此实现了按顺序输出。
JavaScript 语言中,生成实例对象的传统方法是通过构造函数。下面是一个例子。
function Point(x, y) {
+ this.x = x;
+ this.y = y;
+}
+
+Point.prototype.toString = function () {
+ return '(' + this.x + ', ' + this.y + ')';
+};
+
+var p = new Point(1, 2);ES6 提供了更接近传统语言的写法,引入了 Class(类)这个概念,作为对象的模板。通过class关键字,可以定义类。
基本上,ES6 的class可以看作只是一个语法糖,它的绝大部分功能,ES5 都可以做到,新的class写法只是让对象原型的写法更加清晰、更像面向对象编程的语法而已。上面的代码用 ES6 的class改写,就是下面这样。
class Point {
+ constructor(x, y) {
+ this.x = x;
+ this.y = y;
+ }
+
+ toString() {
+ return '(' + this.x + ', ' + this.y + ')';
+ }
+}上面代码定义了一个“类”,可以看到里面有一个constructor()方法,这就是构造方法,而this关键字则代表实例对象。这种新的 Class 写法,本质上与本章开头的 ES5 的构造函数Point是一致的。
Point类除了构造方法,还定义了一个toString()方法。注意,定义toString()方法的时候,前面不需要加上function这个关键字,直接把函数定义放进去了就可以了。另外,方法与方法之间不需要逗号分隔,加了会报错。
ES6 的类,完全可以看作构造函数的另一种写法。
class Point {
+ // ...
+}
+
+typeof Point // "function"
+Point === Point.prototype.constructor // true上面代码表明,类的数据类型就是函数,类本身就指向构造函数。
使用的时候,也是直接对类使用new命令,跟构造函数的用法完全一致。
class Bar {
+ doStuff() {
+ console.log('stuff');
+ }
+}
+
+const b = new Bar();
+b.doStuff() // "stuff"构造函数的prototype属性,在 ES6 的“类”上面继续存在。事实上,类的所有方法都定义在类的prototype属性上面。
class Point {
+ constructor() {
+ // ...
+ }
+
+ toString() {
+ // ...
+ }
+
+ toValue() {
+ // ...
+ }
+}
+
+// 等同于
+
+Point.prototype = {
+ constructor() {},
+ toString() {},
+ toValue() {},
+};上面代码中,constructor()、toString()、toValue()这三个方法,其实都是定义在Point.prototype上面。
ES2022 为类的实例属性,又规定了一种新写法。实例属性现在除了可以定义在constructor()方法里面的this上面,也可以定义在类内部的最顶层。
// 原来的写法
+class IncreasingCounter {
+ constructor() {
+ this._count = 0;
+ }
+ get value() {
+ console.log('Getting the current value!');
+ return this._count;
+ }
+ increment() {
+ this._count++;
+ }
+}上面示例中,实例属性_count定义在constructor()方法里面的this上面。
现在的新写法是,这个属性也可以定义在类的最顶层,其他都不变。
class IncreasingCounter {
+ _count = 0;
+ get value() {
+ console.log('Getting the current value!');
+ return this._count;
+ }
+ increment() {
+ this._count++;
+ }
+}上面代码中,实例属性_count与取值函数value()和increment()方法,处于同一个层级。这时,不需要在实例属性前面加上this。
注意,新写法定义的属性是实例对象自身的属性,而不是定义在实例对象的原型上面。
这种新写法的好处是,所有实例对象自身的属性都定义在类的头部,看上去比较整齐,一眼就能看出这个类有哪些实例属性。
class foo {
+ bar = 'hello';
+ baz = 'world';
+
+ constructor() {
+ // ...
+ }
+}上面的代码,一眼就能看出,foo类有两个实例属性,一目了然。另外,写起来也比较简洁。
与 ES5 一样,在“类”的内部可以使用get和set关键字,对某个属性设置存值函数和取值函数,拦截该属性的存取行为。
class MyClass {
+ constructor() {
+ // ...
+ }
+ get prop() {
+ return 'getter';
+ }
+ set prop(value) {
+ console.log('setter: '+value);
+ }
+}
+
+let inst = new MyClass();
+
+inst.prop = 123;
+// setter: 123
+
+inst.prop
+// 'getter'上面代码中,prop属性有对应的存值函数和取值函数,因此赋值和读取行为都被自定义了。
存值函数和取值函数是设置在属性的 Descriptor 对象上的。
class CustomHTMLElement {
+ constructor(element) {
+ this.element = element;
+ }
+
+ get html() {
+ return this.element.innerHTML;
+ }
+
+ set html(value) {
+ this.element.innerHTML = value;
+ }
+}
+
+var descriptor = Object.getOwnPropertyDescriptor(
+ CustomHTMLElement.prototype, "html"
+);
+
+"get" in descriptor // true
+"set" in descriptor // true上面代码中,存值函数和取值函数是定义在html属性的描述对象上面,这与 ES5 完全一致。
类的属性名,可以采用表达式。
let methodName = 'getArea';
+
+class Square {
+ constructor(length) {
+ // ...
+ }
+
+ [methodName]() {
+ // ...
+ }
+}上面代码中,Square类的方法名getArea,是从表达式得到的。
与函数一样,类也可以使用表达式的形式定义。
const MyClass = class Me {
+ getClassName() {
+ return Me.name;
+ }
+};上面代码使用表达式定义了一个类。需要注意的是,这个类的名字是Me,但是Me只在 Class 的内部可用,指代当前类。在 Class 外部,这个类只能用MyClass引用。
类相当于实例的原型,所有在类中定义的方法,都会被实例继承。如果在一个方法前,加上static关键字,就表示该方法不会被实例继承,而是直接通过类来调用,这就称为“静态方法”。
class Foo {
+ static classMethod() {
+ return 'hello';
+ }
+}
+
+Foo.classMethod() // 'hello'
+
+var foo = new Foo();
+foo.classMethod()
+// TypeError: foo.classMethod is not a function上面代码中,Foo类的classMethod方法前有static关键字,表明该方法是一个静态方法,可以直接在Foo类上调用(Foo.classMethod()),而不是在Foo类的实例上调用。如果在实例上调用静态方法,会抛出一个错误,表示不存在该方法。
注意,如果静态方法包含this关键字,这个this指的是类,而不是实例。
静态方法可以与非静态方法重名。
父类的静态方法,可以被子类继承。
静态属性指的是 Class 本身的属性,即Class.propName,而不是定义在实例对象(this)上的属性。
class Foo {
+}
+
+Foo.prop = 1;
+Foo.prop // 1上面的写法为Foo类定义了一个静态属性prop。
在属性名之前使用#表示。
Class 可以通过extends关键字实现继承,让子类继承父类的属性和方法。extends 的写法比 ES5 的原型链继承,要清晰和方便很多。
class Point {
+}
+
+class ColorPoint extends Point {
+}在子类的构造函数中,只有调用super()之后,才可以使用this关键字,否则会报错。这是因为子类实例的构建,必须先完成父类的继承,只有super()方法才能让子类实例继承父类。
父类所有的属性和方法,都会被子类继承,除了私有的属性和方法。
父类的静态属性和静态方法,也会被子类继承。
super关键字,既可以当作函数使用,也可以当作对象使用。
大多数浏览器的 ES5 实现之中,每一个对象都有__proto__属性,指向对应的构造函数的prototype属性。Class 作为构造函数的语法糖,同时有prototype属性和__proto__属性,因此同时存在两条继承链。
(1)子类的__proto__属性,表示构造函数的继承,总是指向父类。
(2)子类prototype属性的__proto__属性,表示方法的继承,总是指向父类的prototype属性。
__proto__属性的__proto__属性,指向父类实例的__proto__属性。也就是说,子类的原型的原型,是父类的原型。CommonJS 模块就是对象,输入时必须查找对象属性。
// CommonJS模块
+let { stat, exists, readfile } = require('fs');
+
+// 等同于
+let _fs = require('fs');
+let stat = _fs.stat;
+let exists = _fs.exists;
+let readfile = _fs.readfile;上面代码的实质是整体加载fs模块(即加载fs的所有方法),生成一个对象(_fs),然后再从这个对象上面读取 3 个方法。这种加载称为“运行时加载”,因为只有运行时才能得到这个对象,导致完全没办法在编译时做“静态优化”。
ES6 模块不是对象,而是通过export命令显式指定输出的代码,再通过import命令输入。
// ES6模块
+import { stat, exists, readFile } from 'fs';上面代码的实质是从fs模块加载 3 个方法,其他方法不加载。这种加载称为“编译时加载”或者静态加载,即 ES6 可以在编译时就完成模块加载,效率要比 CommonJS 模块的加载方式高。当然,这也导致了没法引用 ES6 模块本身,因为它不是对象。
由于 ES6 模块是编译时加载,使得静态分析成为可能。有了它,就能进一步拓宽 JavaScript 的语法,比如引入宏(macro)和类型检验(type system)这些只能靠静态分析实现的功能。
ES6 的模块自动采用严格模式,不管你有没有在模块头部加上"use strict";。
模块功能主要由两个命令构成:export和import。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。
一个模块就是一个独立的文件。该文件内部的所有变量,外部无法获取。如果你希望外部能够读取模块内部的某个变量,就必须使用export关键字输出该变量。下面是一个 JS 文件,里面使用export命令输出变量。
// profile.js
+export var firstName = 'Michael';
+export var lastName = 'Jackson';
+export var year = 1958;上面代码是profile.js文件,保存了用户信息。ES6 将其视为一个模块,里面用export命令对外部输出了三个变量。
export的写法,除了像上面这样,还有另外一种。
// profile.js
+var firstName = 'Michael';
+var lastName = 'Jackson';
+var year = 1958;
+
+export { firstName, lastName, year };上面代码在export命令后面,使用大括号指定所要输出的一组变量。它与前一种写法(直接放置在var语句前)是等价的,但是应该优先考虑使用这种写法。因为这样就可以在脚本尾部,一眼看清楚输出了哪些变量。
export命令除了输出变量,还可以输出函数或类(class)。
export function multiply(x, y) {
+ return x * y;
+};上面代码对外输出一个函数multiply。
通常情况下,export输出的变量就是本来的名字,但是可以使用as关键字重命名。
function v1() { ... }
+function v2() { ... }
+
+export {
+ v1 as streamV1,
+ v2 as streamV2,
+ v2 as streamLatestVersion
+};上面代码使用as关键字,重命名了函数v1和v2的对外接口。重命名后,v2可以用不同的名字输出两次。
需要特别注意的是,export命令规定的是对外的接口,必须与模块内部的变量建立一一对应关系。
使用export命令定义了模块的对外接口以后,其他 JS 文件就可以通过import命令加载这个模块。
// main.js
+import { firstName, lastName, year } from './profile.js';
+
+function setName(element) {
+ element.textContent = firstName + ' ' + lastName;
+}面代码的import命令,用于加载profile.js文件,并从中输入变量。import命令接受一对大括号,里面指定要从其他模块导入的变量名。大括号里面的变量名,必须与被导入模块(profile.js)对外接口的名称相同。
如果想为输入的变量重新取一个名字,import命令要使用as关键字,将输入的变量重命名。
import { lastName as surname } from './profile.js';import命令输入的变量都是只读的,因为它的本质是输入接口。也就是说,不允许在加载模块的脚本里面,改写接口。
import {a} from './xxx.js'
+
+a = {}; // Syntax Error : 'a' is read-only;上面代码中,脚本加载了变量a,对其重新赋值就会报错,因为a是一个只读的接口。但是,如果a是一个对象,改写a的属性是允许的。
import {a} from './xxx.js'
+
+a.foo = 'hello'; // 合法操作上面代码中,a的属性可以成功改写,并且其他模块也可以读到改写后的值。不过,这种写法很难查错,建议凡是输入的变量,都当作完全只读,不要轻易改变它的属性。
import后面的from指定模块文件的位置,可以是相对路径,也可以是绝对路径。如果不带有路径,只是一个模块名,那么必须有配置文件,告诉 JavaScript 引擎该模块的位置。
import { myMethod } from 'util';上面代码中,util是模块文件名,由于不带有路径,必须通过配置,告诉引擎怎么取到这个模块。
除了指定加载某个输出值,还可以使用整体加载,即用星号(*)指定一个对象,所有输出值都加载在这个对象上面。
import * as circle from './circle';
+
+console.log('圆面积:' + circle.area(4));
+console.log('圆周长:' + circle.circumference(14));使用import命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。
为了给用户提供方便,让他们不用阅读文档就能加载模块,就要用到export default命令,为模块指定默认输出。
// export-default.js
+export default function () {
+ console.log('foo');
+}上面代码是一个模块文件export-default.js,它的默认输出是一个函数。
其他模块加载该模块时,import命令可以为该匿名函数指定任意名字。
// import-default.js
+import customName from './export-default';
+customName(); // 'foo'上面代码的import命令,可以用任意名称指向export-default.js输出的方法,这时就不需要知道原模块输出的函数名。需要注意的是,这时import命令后面,不使用大括号。
export default命令用在非匿名函数前,也是可以的。
// export-default.js
+export default function foo() {
+ console.log('foo');
+}
+
+// 或者写成
+
+function foo() {
+ console.log('foo');
+}
+
+export default foo;上面代码中,foo函数的函数名foo,在模块外部是无效的。加载的时候,视同匿名函数加载。
export { foo, bar } from 'my_module';
+
+// 可以简单理解为
+import { foo, bar } from 'my_module';
+export { foo, bar };上面代码中,export和import语句可以结合在一起,写成一行。但需要注意的是,写成一行以后,foo和bar实际上并没有被导入当前模块,只是相当于对外转发了这两个接口,导致当前模块不能直接使用foo和bar。
模块的接口改名和整体输出,也可以采用这种写法。
// 接口改名
+export { foo as myFoo } from 'my_module';
+
+// 整体输出
+export * from 'my_module';默认接口的写法如下。
export { default } from 'foo';具名接口改为默认接口的写法如下。
export { es6 as default } from './someModule';
+
+// 等同于
+import { es6 } from './someModule';
+export default es6;同样地,默认接口也可以改名为具名接口。
export { default as es6 } from './someModule';// constants.js 模块
+export const A = 1;
+export const B = 3;
+export const C = 4;
+
+// test1.js 模块
+import * as constants from './constants';
+console.log(constants.A); // 1
+console.log(constants.B); // 3
+
+// test2.js 模块
+import {A, B} from './constants';
+console.log(A); // 1
+console.log(B); // 3circleplus模块,继承了circle模块。
// circleplus.js
+
+export * from 'circle';
+export var e = 2.71828182846;
+export default function(x) {
+ return Math.exp(x);
+}这时,也可以将circle的属性或方法,改名后再输出。
// circleplus.js
+
+export { area as circleArea } from 'circle';上面代码表示,只输出circle模块的area方法,且将其改名为circleArea。
加载上面模块的写法如下。
// main.js
+
+import * as math from 'circleplus';
+import exp from 'circleplus';
+console.log(exp(math.e));上面代码中的import exp表示,将circleplus模块的默认方法加载为exp方法。
prompt()
console.log()
document.write()
alert()
alert和prompt会跳过页面渲染先被执行
let比较旧的JavaScript中使用var声明变量
var的一些问题:
- 可以先使用,再声明
- var声明过的变量可以重复声明
- 变量提升、全局变量、没有块级作用域
let arr = [1, 2, 3] / let arr = new Array(1, 2, 3)
数组有序
取值:数组[下标]
长度:数组.length
修改:arr[下标] = 新值
增加
删除
constnumber
string
模板字符串: 使用反引号包裹数据,使用\${}替换数据
let age = 20
+console.log(\`我今年\${age}岁\`)boolean
undefined
null
NaN代表一个计算错误,是一个不正确或未定义的数学操作得到的结果,任何对NaN的操作都会返回NaN
+号两边只要有字符串,都会转字符串+,其他算数运算符会把数据转换为数字类型+作为正号可以转换数字object
let obj = {
+ uname: 'abc',
+ age: 18,
+ gender: '女',
+ speak: function(x) {
+ console.log('hello' + x)
+ }
+}查看:
修改: 对象.属性 = 新值
新增: 对象.新属性 = 值
删除: delete 对象.属性
对象方法: 对象.方法名()
遍历对象
for (let k in obj) {
+ console.log(obj[k]) //k带引号
+}for in遍历数组 是数组下标,但是是字符串
++--<>>=<===: 值是否相等===:类型和值是否都相等!==:是否不全等&&||!if
switch case
数据和值必须满足全等===
switch (数据) {
+ case 值1:
+ 代码1
+ break
+ case 值2:
+ 代码2
+ break
+ default:
+ 代码n
+}三元运算符
function 函数名(参数列表) {
+ 函数体
+}命名 小驼峰
return
函数表达式:把匿名函数赋值给一个变量,通过变量名调用
let fn = function () {}立即执行函数
(function() {...})();
+(function() {...})();
+---
+(function(x, y) {
+ console.log(x + y)
+})(1, 3)前一个括号声明,后一个括号调用
分号
&&和||中,当满足一定条件会让右边代码不执行 &&:左边为false就短路||:左边为true就短路"": false
0: false
undefined: false
null: false
NaN: false
"" + 1 = 1
null经过数字转换会变0
undefined经过数字转换会变NaN
对象.innerText
对象.innerHTML
对象.属性=值
const image = document.querySelector('img')
+image.src = 'xxx.jpg'
+image.title = '123'对象.style.样式属性=值
box.style.width = '300px'
+box.backgroundColor = 'pink' //小驼峰通过类名修改属性,会覆盖
//定义好类对应的属性,给对象添加类名
+对象.className = 类名通过classList操作类控制CSS,用于追加和删除
元素.classList.add(类名)//追加
+元素.classList.remove(类名)//删除
+元素.classList.toggle(类名)//切换自定义属性
H5中推出的data-自定义属性
在标签上一律以data-开头
DOM对象上一律以dataset对象方式获取
<body>
+ <div class="box" data-id="10">盒子</div>
+ <script>
+ const box = document.querySelector('.box')
+ console.log(box.dataset.id)
+ </script>
+</body>元素.on事件:也可以添加事件监听,但会被覆盖,且只能冒泡 不能捕获,addEventListener不会被覆盖,能冒泡 也能捕获。
事件对象中有事件触发时的相关信息,例如鼠标点击时的位置,键盘按下时的键位
btn.addEventListener('click', function(e){
+ console.log(e)
+})指的是函数内部特殊的变量this,它代表着当前函数运行时所处的环境
this的指代对象也不通this指向的粗略规则是谁调用指向谁(addEventListener指向绑定的元素,普通函数指向window)函数A作为参数传递给函数B,A就被称为回调函数
事件流指的是事件完整执行过程中的流动路径
DOM的根元素开始去执行对应的事件(从父元素到子元素)
DOM.addEventListener(事件类型, 函数, 是否使用捕获机制)L0事件只有冒泡,没有捕获
当一个元素的事件被触发时,同样的事件会在该元素的所有祖先元素中依次被触发。这一过程被称为事件冒泡(从子元素到父元素)
简单理解:当一个元素触发事件后,会依次向上调用所有父级元素的同名事件
事件冒泡是默认存在的
btn.addEventListener('click', function(e){
+ e.stopPropagation()
+})on事件方式
// 绑定事件
+btn.onClick = function(e){
+ console.log(e)
+}
+// 解绑事件
+btn.onClick = nulladdEventListener方式
function fn(e){
+ console.log(e)
+}
+//绑定事件
+btn.addEventListener('click', fn)
+//解绑事件
+btn.removeEventListener('click', fn)匿名函数无法解绑
事件委托是利用事件流特征解决开发问题的技巧,可以减少事件注册次数,提高程序性能,原理是利用事件冒泡特点,给父元素注册事件,当触发子元素的时候,会冒泡到父元素身上,从而触发父元素的事件
e.preventDefault()
页面加载事件
外部资源加载完毕时触发的事件
等待页面所有资源加载完毕,执行回调函数:window.addEventListener('load', function() {})
也可以针对某个资源绑定事件:img.addEventListener('load', function() {})
初始HTML文档被完全加载和解析完成后,DOMContentLoaded事件被触发,无需等待样式表、图像等完全加载
document.addEventListener('DOMContentLoaded', function() {})页面滚动事件
滚动条在滚动的时候持续触发的事件
window.addEventListener('scroll', function() {})获取滚动位置
scrollLeft**(可读写)**
scrollTop**(可读写)**
window.addEventListener('scroll', function() {
+ const n = document.documentElement.scrollTop
+ console.log(n)
+})document.documentElement返回对象为HTML元素
......
滚动到指定坐标
页面尺寸事件
resizewindow.addEventListener('resize', function() {})clientWidth、clientHeightelement.getBoundingClientRect()实例化
const date = new Date()const date = new Date('2023-4-8 08:00:00')常用方法
时间戳
date.getTime()+new Date()Date.now()const div = document.createElement('div')父元素.appendChild(div)
父元素.insertBefore(要插入的元素, 在哪个元素前面):插入某个元素之前
ul.insertBefore(li, ul.children[0])父元素.removeChild(子元素)BOM(Browser Object Model)是浏览器对象模型,包含:navigator、location、document、history、screen
window是一个全局对象,document、alert()、console.log()都是window的属性
var定义在全局作用域中的变量、函数都会变成window对象的属性和方法let timer = setTimeout(回调函数, 等待时间ms),返回id,setTimeout只执行一次clearTimeout(timer)let interval = setInterval(函数, 间隔时间ms),返回的是的是一个id数字,不断执行clearInterval(interval)js是单线程,所有任务需要排队。HTML5提出了Web Worker标准,允许JavaScript脚本创建多个线程。于是JS出现了同步和异步。
localtion的数据类型是对象,它拆分保存了URL地址的各个组成部分
location.href:常用于页面跳转
location.search:获取地址中携带的参数,符号?后面的部分
location.hash:获取地址中的hash值,符号#后面的部分
location.reload():用来刷新当前页面,传入参数true时强制刷新
navigator的数据类型是对象,该对象下记录了浏览器自身的相关信息
history数据类型是对象,主要管理历史记录,该对象与浏览器地址栏的操作相对应,如前进、后退、历史记录等
数据存储在用户浏览器中,设置、读取方便,刷新页面不会丢失数据,sessionStorage和localStorage约5M
localStorage.setItem(key, value)localStorage.getItem(key)localStorage.removeItem(key)localStorage一致把复杂数据类型转成字符串形式存储
JSON.stringifyJSON.parse遍历数组处理数据,返回新的数组
const arr = ['red', 'blue']
+const newArr = arr.map(function(ele, index) {
+ return ele + '颜色'
+})
+console.log(newArr) // ['red颜色', 'blue颜色']const newStr = join(字符串):元素用指定字符串相连const reg = /表达式/reg.test(被检测字符串),匹配返回true,否则falsereg.exec(被检测字符串),找到返回数组,否则为null边界符
^:开始$:结束量词
*:0或多次+:1或多次?:0或1次{n}:重复n次{n,}:重复n次或更多{n,m}:重复n次到m次字符类
[]:匹配字符集合,匹配任一个都是true[a-zA-Z]:字母[^a-z]:[]中的^表示取反.:除换行之外的任何单个字符\\d:数字\\D:所有0-9以外字符,等于[^0-9]\\w:任一字母、数字、下划线,相当于[a-zA-Z0-9_]\\W:匹配除字母、数字、下划线之外的字符,相当于[^a-zA-Z0-9_]\\s:匹配空格(包括制表符、换行符、空格符等),相当于[\\t\\r\\n\\v\\f]\\S:匹配非空格,相当于[^\\t\\r\\n\\v\\f]语法:/表达式/修饰符
修饰符:
字符串.replace(/正则表达式/, 替换的文本),返回替换后的字符串局部作用域
全局作用域
作用域链
JS垃圾回收机制
引用计数法(有循环引用问题)
- 定义“内存不再使用”,看一个对象是否有指向它的引用,没有引用就回收对象
- 根据记录被引用的次数
- 被引用一次,就+1,多次引用会累加
- 如果减少一个引用就-1
- 如果引用次数是0,则释放内存
标记清除法
- 将不再使用的对象定义为无法达到的对象
- 从根部(JS中就是全局对象)出发定时扫描内存中的对象,凡是能从根部到达的对象,都是还需要使用的
- 无法由根部出发触及的对象标记为不再使用,稍后进行回收
闭包
如果在一个外部函数中定义一个内部函数,内部函数对外部作用域的变量进行引用,外部函数的返回值是内部函数,这样的函数就被认为是闭包(closure)。变量提升
函数提升
函数表达式特殊,必须先声明赋值后调用
动态参数:arguments,只存在于函数里,伪数组
剩余参数:function getSum(paramA, paramB, ...arr),arr是个真数组
展开运算符:...能将一个数组进行展开
const arr = [1,5,3]
+console.log(...arr)// 1 5 3用于求数组最大/小值Math.max(...arr)
用于合并数组:const arr = [...arr1, ...arr2]
引入箭头函数是为了更简洁的写法,适用于需要匿名函数的地方
const fn = () => {}
+const fn = x => { console.log(x) }
+const fn = x => console.log(x)
+const fn = x => x * 2
+const fn = (uname) => ({ uname: uname }) //返回一个对象箭头函数不会创建自己的this对象,它只会从自己的作用域链的上一层
数组结构是将数组的单元值快速批量赋值给一系列变量的简洁语法
const [max, min, avg] = [100, 60, 80]const [a, ,c, d] = [1, 2, 3, 4]js必须加分号场景:
- 两个连续的立即执行函数
- 使用数组
对象解构是将对象的属性和方法快速批量赋值给一系列变量的简介语法
const user = {
+ name: '小明',
+ age: 18
+}
+const {name, age} = user对象的属性值将会被赋值给与属性名相同的变量
对象中找不到与变量名一致的属性时变量值为undefined
数组对象解构
const pig = [
+ {
+ name: '佩奇',
+ age: 6
+ }
+]
+
+const [{ name, age }] = pig
+console.log(name,age)多级对象解构
const pig = {
+ name: '佩奇',
+ age: 6,
+ family: {
+ mother: 'mon',
+ father: 'dad'
+ }
+}
+
+const { name, family: { mother, father }} = pig字面量创建
构造函数
new操作符来执行Date.now()、Math.PI、Math.random()Object
Array
实例方法:forEach、filter、map、reduce、join、find、every、some、concat、splice、reverse、findIndex...
伪数组转换为真数组:Array.from()
arr.some((item, index)=> {
+ //some code, some循环可以终止
+ return true
+})
+
+//every 判断数组每一项是否都满足条件
+let res = arr.every(item => item.state)
+
+//reduce
+arr.reduce((累加的结果, 当前循环项) => {}, 初始值)
+arr.reduce((amt, item) => amt += item.price, 0)String
Number
prototype属性,指向另一个对象,所以也称为原型对象每个原型对象里都有个constructor属性,该属性指向该原型对象的构造函数
每个对象都有一个属性__proto__,指向构造函数的prototype对象
__proto__是JS非标准属性__proto__意义相同__proto__对象原型里也有一个constructor属性,指向创建该实例对象的构造函数通过原型可以继承公共属性
const Person = {
+ eyes: 2,
+ nose: 1
+}
+
+function Man() {
+
+}
+Man.prototype = Person
+Man.prototype.constructor = Man
+
+---
+
+const Person = {
+ this.eyes: 2,
+ this.nose: 1
+}
+
+function Man() {
+
+}
+Man.prototype = new Person()基于原型对象的继承使得不同构造函数的原型对象关联在一起,并且这种关联关系是一种链状的解构,称为原型链
__proto__指向的prototype对象)__proto__对象原型的意义就在于为对象成员查找机制提供方向instanceof运算符检测构造函数的prototype属性是否出现在某个实例对象的原型链上深浅拷贝只针对引用数据类型
_.cloneDeep()try {
+
+} catch (err) {
+
+} finally {
+
+}debugger
普通函数的调用方式决定了this的值,即谁调用 this的值指向谁
普通函数没有明确调用者时this的值为window,严格模式下没有调用者时this的值为undefined
单位时间内,频繁触发事件,只执行最后一次
lodash库的_.debounce(fun, 时间)
const box = document.querySelector('.box')
+let i = 1
+function mouseMove() {
+ box.innerHTML = i++
+}
+
+function debounce(fn, t) {
+ let timer
+ return function() {
+ if (timer) clearTimeout(timer)
+ timer = setTimeout(function() {
+ fn()
+ }, t)
+ }
+}
+
+box.addEventListener('mousemove', debounce(mouseMove, 500))_.throttle(fun, 时间)function throttle(fn, t) {
+ let timer = null
+ return function() {
+ if(!timer) {
+ timer = setTimeout(function(){
+ fn()
+ // setTimeout中无法删除定时器,因为定时器还在运作,所以不能用clearTimeout
+ timer = null
+ }, t)
+ }
+ }
+}
+
+box.addEventListener('mousemove', throttle(mouseMove, 500))video.ontimeupdadte = _.throttle(() => {
+ localStorage.setItem('currentTime', video.currentTime)
+}, 1000)
+
+video.onloadeddata = () => {
+ video.currentTime = localStorage.getItem('currentTime') || 0
+}所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。从语法上说,Promise 是一个对象,从它可以获取异步操作的消息。Promise 提供统一的 API,各种异步操作都可以用同样的方法进行处理。
Promise对象有以下两个特点。
(1)对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是Promise这个名字的由来,它的英语意思就是“承诺”,表示其他手段无法改变。
(2)一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种可能:从pending变为fulfilled和从pending变为rejected。只要这两种情况发生,状态就凝固了,不会再变了,会一直保持这个结果,这时就称为 resolved(已定型)。如果改变已经发生了,你再对Promise对象添加回调函数,也会立即得到这个结果。这与事件(Event)完全不同,事件的特点是,如果你错过了它,再去监听,是得不到结果的。
ES6 规定,Promise对象是一个构造函数,用来生成Promise实例。
下面代码创造了一个Promise实例。
const promise = new Promise(function(resolve, reject) {
+ // ... some code
+
+ if (/* 异步操作成功 */){
+ resolve(value);
+ } else {
+ reject(error);
+ }
+});Promise构造函数接受一个函数作为参数,该函数的两个参数分别是resolve和reject。它们是两个函数,由 JavaScript 引擎提供。
resolve函数的作用是,将Promise对象的状态从“未完成”变为“成功”(即从 pending 变为 resolved),在异步操作成功时调用,并将异步操作的结果,作为参数传递出去;reject函数的作用是,将Promise对象的状态从“未完成”变为“失败”(即从 pending 变为 rejected),在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去。
Promise实例生成以后,可以用then方法分别指定resolved状态和rejected状态的回调函数。
promise.then(function(value) {
+ // success
+}, function(error) {
+ // failure
+});then方法可以接受两个回调函数作为参数。第一个回调函数是Promise对象的状态变为resolved时调用,第二个回调函数是Promise对象的状态变为rejected时调用。这两个函数都是可选的,不一定要提供。它们都接受Promise对象传出的值作为参数。
下面是一个Promise对象的简单例子。
function timeout(ms) {
+ return new Promise((resolve, reject) => {
+ setTimeout(resolve, ms, 'done');//setTimeout的第三个参数是给第一个函数参数传递的参数,即done会传递给resolve函数作为参数
+ });
+}
+
+timeout(100).then((value) => {
+ console.log(value);
+});上面代码中,timeout方法返回一个Promise实例,表示一段时间以后才会发生的结果。过了指定的时间(ms参数)以后,Promise实例的状态变为resolved,就会触发then方法绑定的回调函数。
Promise 新建后就会立即执行。
let promise = new Promise(function(resolve, reject) {
+ console.log('Promise');
+ resolve();
+});
+
+promise.then(function() {
+ console.log('resolved.');
+});
+
+console.log('Hi!');
+
+// Promise
+// Hi!
+// resolved上面代码中,Promise 新建后立即执行,所以首先输出的是Promise。然后,then方法指定的回调函数,将在当前脚本所有同步任务执行完才会执行,所以resolved最后输出。
下面是异步加载图片的例子。
function loadImageAsync(url) {
+ return new Promise(function(resolve, reject) {
+ const image = new Image();
+
+ image.onload = function() {
+ resolve(image);
+ };
+
+ image.onerror = function() {
+ reject(new Error('Could not load image at ' + url));
+ };
+
+ image.src = url;
+ });
+}上面代码中,使用Promise包装了一个图片加载的异步操作。如果加载成功,就调用resolve方法,否则就调用reject方法。
Generator 函数是 ES6 提供的一种异步编程解决方案,语法行为与传统函数完全不同。本章详细介绍 Generator 函数的语法和 API,它的异步编程应用请看《Generator 函数的异步应用》一章。
Generator 函数有多种理解角度。语法上,首先可以把它理解成,Generator 函数是一个状态机,封装了多个内部状态。
执行 Generator 函数会返回一个遍历器对象,也就是说,Generator 函数除了状态机,还是一个遍历器对象生成函数。返回的遍历器对象,可以依次遍历 Generator 函数内部的每一个状态。
形式上,Generator 函数是一个普通函数,但是有两个特征。一是,function关键字与函数名之间有一个星号;二是,函数体内部使用yield表达式,定义不同的内部状态(yield在英语里的意思就是“产出”)。
function* helloWorldGenerator() {
+ yield 'hello';
+ yield 'world';
+ return 'ending';
+}
+
+var hw = helloWorldGenerator();上面代码定义了一个 Generator 函数helloWorldGenerator,它内部有两个yield表达式(hello和world),即该函数有三个状态:hello,world 和 return 语句(结束执行)。
然后,Generator 函数的调用方法与普通函数一样,也是在函数名后面加上一对圆括号。不同的是,调用 Generator 函数后,该函数并不执行,返回的也不是函数运行结果,而是一个指向内部状态的指针对象,也就是上一章介绍的遍历器对象(Iterator Object)。
下一步,必须调用遍历器对象的next方法,使得指针移向下一个状态。也就是说,每次调用next方法,内部指针就从函数头部或上一次停下来的地方开始执行,直到遇到下一个yield表达式(或return语句)为止。换言之,Generator 函数是分段执行的,yield表达式是暂停执行的标记,而next方法可以恢复执行。
hw.next()
+// { value: 'hello', done: false }
+
+hw.next()
+// { value: 'world', done: false }
+
+hw.next()
+// { value: 'ending', done: true }
+
+hw.next()
+// { value: undefined, done: true }由于 Generator 函数返回的遍历器对象,只有调用next方法才会遍历下一个内部状态,所以其实提供了一种可以暂停执行的函数。yield表达式就是暂停标志。
遍历器对象的next方法的运行逻辑如下。
(1)遇到yield表达式,就暂停执行后面的操作,并将紧跟在yield后面的那个表达式的值,作为返回的对象的value属性值。
(2)下一次调用next方法时,再继续往下执行,直到遇到下一个yield表达式。
(3)如果没有再遇到新的yield表达式,就一直运行到函数结束,直到return语句为止,并将return语句后面的表达式的值,作为返回的对象的value属性值。
(4)如果该函数没有return语句,则返回的对象的value属性值为undefined。
需要注意的是,yield表达式后面的表达式,只有当调用next方法、内部指针指向该语句时才会执行,因此等于为 JavaScript 提供了手动的“惰性求值”(Lazy Evaluation)的语法功能。
function* gen() {
+ yield 123 + 456;
+}上面代码中,yield后面的表达式123 + 456,不会立即求值,只会在next方法将指针移到这一句时,才会求值。
yield表达式与return语句既有相似之处,也有区别。相似之处在于,都能返回紧跟在语句后面的那个表达式的值。区别在于每次遇到yield,函数暂停执行,下一次再从该位置继续向后执行,而return语句不具备位置记忆的功能。一个函数里面,只能执行一次(或者说一个)return语句,但是可以执行多次(或者说多个)yield表达式。正常函数只能返回一个值,因为只能执行一次return;Generator 函数可以返回一系列的值,因为可以有任意多个yield。从另一个角度看,也可以说 Generator 生成了一系列的值,这也就是它的名称的来历(英语中,generator 这个词是“生成器”的意思)。
正常情况下,await命令后面是一个 Promise 对象,返回该对象的结果。如果不是 Promise 对象,就直接返回对应的值。
async function f() {
+ // 等同于
+ // return 123;
+ return await 123;
+}
+
+f().then(v => console.log(v))
+// 123上面代码中,await命令的参数是数值123,这时等同于return 123。
另一种情况是,await命令后面是一个thenable对象(即定义了then方法的对象),那么await会将其等同于 Promise 对象。
class Sleep {
+ constructor(timeout) {
+ this.timeout = timeout;
+ }
+ then(resolve, reject) {
+ const startTime = Date.now();
+ setTimeout(
+ () => resolve(Date.now() - startTime),
+ this.timeout
+ );
+ }
+}
+
+(async () => {
+ const sleepTime = await new Sleep(1000);
+ console.log(sleepTime);
+})();
+// 1000上面代码中,await命令后面是一个Sleep对象的实例。这个实例不是 Promise 对象,但是因为定义了then方法,await会将其视为Promise处理。
这个例子还演示了如何实现休眠效果。JavaScript 一直没有休眠的语法,但是借助await命令就可以让程序停顿指定的时间。下面给出了一个简化的sleep实现。
function sleep(interval) {
+ return new Promise(resolve => {
+ setTimeout(resolve, interval);
+ })
+}
+
+// 用法
+async function one2FiveInAsync() {
+ for(let i = 1; i <= 5; i++) {
+ console.log(i);
+ await sleep(1000);
+ }
+}
+
+one2FiveInAsync();await命令后面的 Promise 对象如果变为reject状态,则reject的参数会被catch方法的回调函数接收到。
async function f() {
+ await Promise.reject('出错了');
+}
+
+f()
+.then(v => console.log(v))
+.catch(e => console.log(e))
+// 出错了注意,上面代码中,await语句前面没有return,但是reject方法的参数依然传入了catch方法的回调函数。这里如果在await前面加上return,效果是一样的。
任何一个await语句后面的 Promise 对象变为reject状态,那么整个async函数都会中断执行。
async function f() {
+ await Promise.reject('出错了');
+ await Promise.resolve('hello world'); // 不会执行
+}上面代码中,第二个await语句是不会执行的,因为第一个await语句状态变成了reject。
有时,我们希望即使前一个异步操作失败,也不要中断后面的异步操作。这时可以将第一个await放在try...catch结构里面,这样不管这个异步操作是否成功,第二个await都会执行。
async function f() {
+ try {
+ await Promise.reject('出错了');
+ } catch(e) {
+ }
+ return await Promise.resolve('hello world');
+}
+
+f()
+.then(v => console.log(v))
+// hello world另一种方法是await后面的 Promise 对象再跟一个catch方法,处理前面可能出现的错误。
async function f() {
+ await Promise.reject('出错了')
+ .catch(e => console.log(e));
+ return await Promise.resolve('hello world');
+}
+
+f()
+.then(v => console.log(v))
+// 出错了
+// hello worldasync 函数是什么?一句话,它就是 Generator 函数的语法糖。返回值是 Promise 对象。
Generator 函数,依次读取两个文件。
const fs = require('fs');
+
+const readFile = function (fileName) {
+ return new Promise(function (resolve, reject) {
+ fs.readFile(fileName, function(error, data) {
+ if (error) return reject(error);
+ resolve(data);
+ });
+ });
+};
+
+const gen = function* () {
+ const f1 = yield readFile('/etc/fstab');
+ const f2 = yield readFile('/etc/shells');
+ console.log(f1.toString());
+ console.log(f2.toString());
+};
+
+const g = gen();
+g.next().value.then(function (data) {
+ g.next(data).value.then(function (data) {
+ g.next(data);
+ });
+});上面代码的函数gen可以写成async函数,就是下面这样。
const asyncReadFile = async function () {
+ const f1 = await readFile('/etc/fstab');
+ const f2 = await readFile('/etc/shells');
+ console.log(f1.toString());
+ console.log(f2.toString());
+};一比较就会发现,async函数就是将 Generator 函数的星号(*)替换成async,将yield替换成await,仅此而已。
async函数对 Generator 函数的改进,体现在以下四点。
(1)内置执行器。
Generator 函数的执行必须靠执行器,所以才有了co模块,而async函数自带执行器。也就是说,async函数的执行,与普通函数一模一样,只要一行。
asyncReadFile();上面的代码调用了asyncReadFile函数,然后它就会自动执行,输出最后结果。这完全不像 Generator 函数,需要调用next方法,或者用co模块,才能真正执行,得到最后结果。
(2)更好的语义。
async和await,比起星号和yield,语义更清楚了。async表示函数里有异步操作,await表示紧跟在后面的表达式需要等待结果。
(3)更广的适用性。
co模块约定,yield命令后面只能是 Thunk 函数或 Promise 对象,而async函数的await命令后面,可以是 Promise 对象和原始类型的值(数值、字符串和布尔值,但这时会自动转成立即 resolved 的 Promise 对象)。
(4)返回值是 Promise。
async函数的返回值是 Promise 对象,这比 Generator 函数的返回值是 Iterator 对象方便多了。你可以用then方法指定下一步的操作。
进一步说,async函数完全可以看作多个异步操作,包装成的一个 Promise 对象,而await命令就是内部then命令的语法糖。
async函数返回一个 Promise 对象,可以使用then方法添加回调函数。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
下面是一个例子。
async function getStockPriceByName(name) {
+ const symbol = await getStockSymbol(name);
+ const stockPrice = await getStockPrice(symbol);
+ return stockPrice;
+}
+
+getStockPriceByName('goog').then(function (result) {
+ console.log(result);
+});上面代码是一个获取股票报价的函数,函数前面的async关键字,表明该函数内部有异步操作。调用该函数时,会立即返回一个Promise对象。
下面是另一个例子,指定多少毫秒后输出一个值。
function timeout(ms) {
+ return new Promise((resolve) => {
+ setTimeout(resolve, ms);
+ });
+}
+
+async function asyncPrint(value, ms) {
+ await timeout(ms);
+ console.log(value);
+}
+
+asyncPrint('hello world', 50);上面代码指定 50 毫秒以后,输出hello world。
由于async函数返回的是 Promise 对象,可以作为await命令的参数。所以,上面的例子也可以写成下面的形式。
async function timeout(ms) {
+ await new Promise((resolve) => {
+ setTimeout(resolve, ms);
+ });
+}
+
+async function asyncPrint(value, ms) {
+ await timeout(ms);
+ console.log(value);
+}
+
+asyncPrint('hello world', 50);async 函数有多种使用形式。
// 函数声明
+async function foo() {}
+
+// 函数表达式
+const foo = async function () {};
+
+// 对象的方法
+let obj = { async foo() {} };
+obj.foo().then(...)
+
+// Class 的方法
+class Storage {
+ constructor() {
+ this.cachePromise = caches.open('avatars');
+ }
+
+ async getAvatar(name) {
+ const cache = await this.cachePromise;
+ return cache.match(\`/avatars/\${name}.jpg\`);
+ }
+}
+
+const storage = new Storage();
+storage.getAvatar('jake').then(…);
+
+// 箭头函数
+const foo = async () => {};async函数返回一个 Promise 对象。
async函数内部return语句返回的值,会成为then方法回调函数的参数。
async function f() {
+ return 'hello world';
+}
+
+f().then(v => console.log(v))
+// "hello world"上面代码中,函数f内部return命令返回的值,会被then方法回调函数接收到。
async函数内部抛出错误,会导致返回的 Promise 对象变为reject状态。抛出的错误对象会被catch方法回调函数接收到。
async function f() {
+ throw new Error('出错了');
+}
+
+f().then(
+ v => console.log('resolve', v),
+ e => console.log('reject', e)
+)
+//reject Error: 出错了async函数返回的 Promise 对象,必须等到内部所有await命令后面的 Promise 对象执行完,才会发生状态改变,除非遇到return语句或者抛出错误。也就是说,只有async函数内部的异步操作执行完,才会执行then方法指定的回调函数。
下面是一个例子。
async function getTitle(url) {
+ let response = await fetch(url);
+ let html = await response.text();
+ return html.match(/<title>([\\s\\S]+)<\\/title>/i)[1];
+}
+getTitle('https://tc39.github.io/ecma262/').then(console.log)
+// "ECMAScript 2017 Language Specification"上面代码中,函数getTitle内部有三个操作:抓取网页、取出文本、匹配页面标题。只有这三个操作全部完成,才会执行then方法里面的console.log。
如果await后面的异步操作出错,那么等同于async函数返回的 Promise 对象被reject。
async function f() {
+ await new Promise(function (resolve, reject) {
+ throw new Error('出错了');
+ });
+}
+
+f()
+.then(v => console.log(v))
+.catch(e => console.log(e))
+// Error:出错了上面代码中,async函数f执行后,await后面的 Promise 对象会抛出一个错误对象,导致catch方法的回调函数被调用,它的参数就是抛出的错误对象。
防止出错的方法,也是将其放在try...catch代码块之中。
async function f() {
+ try {
+ await new Promise(function (resolve, reject) {
+ throw new Error('出错了');
+ });
+ } catch(e) {
+ }
+ return await('hello world');
+}如果有多个await命令,可以统一放在try...catch结构中。
async function main() {
+ try {
+ const val1 = await firstStep();
+ const val2 = await secondStep(val1);
+ const val3 = await thirdStep(val1, val2);
+
+ console.log('Final: ', val3);
+ }
+ catch (err) {
+ console.error(err);
+ }
+}下面的例子使用try...catch结构,实现多次重复尝试。
const superagent = require('superagent');
+const NUM_RETRIES = 3;
+
+async function test() {
+ let i;
+ for (i = 0; i < NUM_RETRIES; ++i) {
+ try {
+ await superagent.get('http://google.com/this-throws-an-error');
+ break;
+ } catch(err) {}
+ }
+ console.log(i); // 3
+}
+
+test();上面代码中,如果await操作成功,就会使用break语句退出循环;如果失败,会被catch语句捕捉,然后进入下一轮循环。
async 函数的实现原理,就是将 Generator 函数和自动执行器,包装在一个函数里。
async function fn(args) {
+ // ...
+}
+
+// 等同于
+
+function fn(args) {
+ return spawn(function* () {
+ // ...
+ });
+}所有的async函数都可以写成上面的第二种形式,其中的spawn函数就是自动执行器。
spawn函数的实现
function spawn(genF) {
+ return new Promise(function(resolve, reject) {
+ const gen = genF();
+ function step(nextF) {
+ let next;
+ try {
+ next = nextF();
+ } catch(e) {
+ return reject(e);
+ }
+ if(next.done) {
+ return resolve(next.value);
+ }
+ Promise.resolve(next.value).then(function(v) {
+ step(function() { return gen.next(v); });
+ }, function(e) {
+ step(function() { return gen.throw(e); });
+ });
+ }
+ step(function() { return gen.next(undefined); });
+ });
+}实际开发中,经常遇到一组异步操作,需要按照顺序完成。比如,依次远程读取一组 URL,然后按照读取的顺序输出结果。
Promise 的写法如下。
function logInOrder(urls) {
+ // 远程读取所有URL
+ const textPromises = urls.map(url => {
+ return fetch(url).then(response => response.text());
+ });
+
+ // 按次序输出
+ textPromises.reduce((chain, textPromise) => {
+ return chain.then(() => textPromise)
+ .then(text => console.log(text));
+ }, Promise.resolve());
+}上面代码使用fetch方法,同时远程读取一组 URL。每个fetch操作都返回一个 Promise 对象,放入textPromises数组。然后,reduce方法依次处理每个 Promise 对象,然后使用then,将所有 Promise 对象连起来,因此就可以依次输出结果。
这种写法不太直观,可读性比较差。下面是 async 函数实现。
async function logInOrder(urls) {
+ for (const url of urls) {
+ const response = await fetch(url);
+ console.log(await response.text());
+ }
+}上面代码确实大大简化,问题是所有远程操作都是继发。只有前一个 URL 返回结果,才会去读取下一个 URL,这样做效率很差,非常浪费时间。我们需要的是并发发出远程请求。
async function logInOrder(urls) {
+ // 并发读取远程URL
+ const textPromises = urls.map(async url => {
+ const response = await fetch(url);
+ return response.text();
+ });
+
+ // 按次序输出
+ for (const textPromise of textPromises) {
+ console.log(await textPromise);
+ }
+}上面代码中,虽然map方法的参数是async函数,但它是并发执行的,因为只有async函数内部是继发执行,外部不受影响。后面的for..of循环内部使用了await,因此实现了按顺序输出。
JavaScript 语言中,生成实例对象的传统方法是通过构造函数。下面是一个例子。
function Point(x, y) {
+ this.x = x;
+ this.y = y;
+}
+
+Point.prototype.toString = function () {
+ return '(' + this.x + ', ' + this.y + ')';
+};
+
+var p = new Point(1, 2);ES6 提供了更接近传统语言的写法,引入了 Class(类)这个概念,作为对象的模板。通过class关键字,可以定义类。
基本上,ES6 的class可以看作只是一个语法糖,它的绝大部分功能,ES5 都可以做到,新的class写法只是让对象原型的写法更加清晰、更像面向对象编程的语法而已。上面的代码用 ES6 的class改写,就是下面这样。
class Point {
+ constructor(x, y) {
+ this.x = x;
+ this.y = y;
+ }
+
+ toString() {
+ return '(' + this.x + ', ' + this.y + ')';
+ }
+}上面代码定义了一个“类”,可以看到里面有一个constructor()方法,这就是构造方法,而this关键字则代表实例对象。这种新的 Class 写法,本质上与本章开头的 ES5 的构造函数Point是一致的。
Point类除了构造方法,还定义了一个toString()方法。注意,定义toString()方法的时候,前面不需要加上function这个关键字,直接把函数定义放进去了就可以了。另外,方法与方法之间不需要逗号分隔,加了会报错。
ES6 的类,完全可以看作构造函数的另一种写法。
class Point {
+ // ...
+}
+
+typeof Point // "function"
+Point === Point.prototype.constructor // true上面代码表明,类的数据类型就是函数,类本身就指向构造函数。
使用的时候,也是直接对类使用new命令,跟构造函数的用法完全一致。
class Bar {
+ doStuff() {
+ console.log('stuff');
+ }
+}
+
+const b = new Bar();
+b.doStuff() // "stuff"构造函数的prototype属性,在 ES6 的“类”上面继续存在。事实上,类的所有方法都定义在类的prototype属性上面。
class Point {
+ constructor() {
+ // ...
+ }
+
+ toString() {
+ // ...
+ }
+
+ toValue() {
+ // ...
+ }
+}
+
+// 等同于
+
+Point.prototype = {
+ constructor() {},
+ toString() {},
+ toValue() {},
+};上面代码中,constructor()、toString()、toValue()这三个方法,其实都是定义在Point.prototype上面。
ES2022 为类的实例属性,又规定了一种新写法。实例属性现在除了可以定义在constructor()方法里面的this上面,也可以定义在类内部的最顶层。
// 原来的写法
+class IncreasingCounter {
+ constructor() {
+ this._count = 0;
+ }
+ get value() {
+ console.log('Getting the current value!');
+ return this._count;
+ }
+ increment() {
+ this._count++;
+ }
+}上面示例中,实例属性_count定义在constructor()方法里面的this上面。
现在的新写法是,这个属性也可以定义在类的最顶层,其他都不变。
class IncreasingCounter {
+ _count = 0;
+ get value() {
+ console.log('Getting the current value!');
+ return this._count;
+ }
+ increment() {
+ this._count++;
+ }
+}上面代码中,实例属性_count与取值函数value()和increment()方法,处于同一个层级。这时,不需要在实例属性前面加上this。
注意,新写法定义的属性是实例对象自身的属性,而不是定义在实例对象的原型上面。
这种新写法的好处是,所有实例对象自身的属性都定义在类的头部,看上去比较整齐,一眼就能看出这个类有哪些实例属性。
class foo {
+ bar = 'hello';
+ baz = 'world';
+
+ constructor() {
+ // ...
+ }
+}上面的代码,一眼就能看出,foo类有两个实例属性,一目了然。另外,写起来也比较简洁。
与 ES5 一样,在“类”的内部可以使用get和set关键字,对某个属性设置存值函数和取值函数,拦截该属性的存取行为。
class MyClass {
+ constructor() {
+ // ...
+ }
+ get prop() {
+ return 'getter';
+ }
+ set prop(value) {
+ console.log('setter: '+value);
+ }
+}
+
+let inst = new MyClass();
+
+inst.prop = 123;
+// setter: 123
+
+inst.prop
+// 'getter'上面代码中,prop属性有对应的存值函数和取值函数,因此赋值和读取行为都被自定义了。
存值函数和取值函数是设置在属性的 Descriptor 对象上的。
class CustomHTMLElement {
+ constructor(element) {
+ this.element = element;
+ }
+
+ get html() {
+ return this.element.innerHTML;
+ }
+
+ set html(value) {
+ this.element.innerHTML = value;
+ }
+}
+
+var descriptor = Object.getOwnPropertyDescriptor(
+ CustomHTMLElement.prototype, "html"
+);
+
+"get" in descriptor // true
+"set" in descriptor // true上面代码中,存值函数和取值函数是定义在html属性的描述对象上面,这与 ES5 完全一致。
类的属性名,可以采用表达式。
let methodName = 'getArea';
+
+class Square {
+ constructor(length) {
+ // ...
+ }
+
+ [methodName]() {
+ // ...
+ }
+}上面代码中,Square类的方法名getArea,是从表达式得到的。
与函数一样,类也可以使用表达式的形式定义。
const MyClass = class Me {
+ getClassName() {
+ return Me.name;
+ }
+};上面代码使用表达式定义了一个类。需要注意的是,这个类的名字是Me,但是Me只在 Class 的内部可用,指代当前类。在 Class 外部,这个类只能用MyClass引用。
类相当于实例的原型,所有在类中定义的方法,都会被实例继承。如果在一个方法前,加上static关键字,就表示该方法不会被实例继承,而是直接通过类来调用,这就称为“静态方法”。
class Foo {
+ static classMethod() {
+ return 'hello';
+ }
+}
+
+Foo.classMethod() // 'hello'
+
+var foo = new Foo();
+foo.classMethod()
+// TypeError: foo.classMethod is not a function上面代码中,Foo类的classMethod方法前有static关键字,表明该方法是一个静态方法,可以直接在Foo类上调用(Foo.classMethod()),而不是在Foo类的实例上调用。如果在实例上调用静态方法,会抛出一个错误,表示不存在该方法。
注意,如果静态方法包含this关键字,这个this指的是类,而不是实例。
静态方法可以与非静态方法重名。
父类的静态方法,可以被子类继承。
静态属性指的是 Class 本身的属性,即Class.propName,而不是定义在实例对象(this)上的属性。
class Foo {
+}
+
+Foo.prop = 1;
+Foo.prop // 1上面的写法为Foo类定义了一个静态属性prop。
在属性名之前使用#表示。
Class 可以通过extends关键字实现继承,让子类继承父类的属性和方法。extends 的写法比 ES5 的原型链继承,要清晰和方便很多。
class Point {
+}
+
+class ColorPoint extends Point {
+}在子类的构造函数中,只有调用super()之后,才可以使用this关键字,否则会报错。这是因为子类实例的构建,必须先完成父类的继承,只有super()方法才能让子类实例继承父类。
父类所有的属性和方法,都会被子类继承,除了私有的属性和方法。
父类的静态属性和静态方法,也会被子类继承。
super关键字,既可以当作函数使用,也可以当作对象使用。
大多数浏览器的 ES5 实现之中,每一个对象都有__proto__属性,指向对应的构造函数的prototype属性。Class 作为构造函数的语法糖,同时有prototype属性和__proto__属性,因此同时存在两条继承链。
(1)子类的__proto__属性,表示构造函数的继承,总是指向父类。
(2)子类prototype属性的__proto__属性,表示方法的继承,总是指向父类的prototype属性。
__proto__属性的__proto__属性,指向父类实例的__proto__属性。也就是说,子类的原型的原型,是父类的原型。CommonJS 模块就是对象,输入时必须查找对象属性。
// CommonJS模块
+let { stat, exists, readfile } = require('fs');
+
+// 等同于
+let _fs = require('fs');
+let stat = _fs.stat;
+let exists = _fs.exists;
+let readfile = _fs.readfile;上面代码的实质是整体加载fs模块(即加载fs的所有方法),生成一个对象(_fs),然后再从这个对象上面读取 3 个方法。这种加载称为“运行时加载”,因为只有运行时才能得到这个对象,导致完全没办法在编译时做“静态优化”。
ES6 模块不是对象,而是通过export命令显式指定输出的代码,再通过import命令输入。
// ES6模块
+import { stat, exists, readFile } from 'fs';上面代码的实质是从fs模块加载 3 个方法,其他方法不加载。这种加载称为“编译时加载”或者静态加载,即 ES6 可以在编译时就完成模块加载,效率要比 CommonJS 模块的加载方式高。当然,这也导致了没法引用 ES6 模块本身,因为它不是对象。
由于 ES6 模块是编译时加载,使得静态分析成为可能。有了它,就能进一步拓宽 JavaScript 的语法,比如引入宏(macro)和类型检验(type system)这些只能靠静态分析实现的功能。
ES6 的模块自动采用严格模式,不管你有没有在模块头部加上"use strict";。
模块功能主要由两个命令构成:export和import。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。
一个模块就是一个独立的文件。该文件内部的所有变量,外部无法获取。如果你希望外部能够读取模块内部的某个变量,就必须使用export关键字输出该变量。下面是一个 JS 文件,里面使用export命令输出变量。
// profile.js
+export var firstName = 'Michael';
+export var lastName = 'Jackson';
+export var year = 1958;上面代码是profile.js文件,保存了用户信息。ES6 将其视为一个模块,里面用export命令对外部输出了三个变量。
export的写法,除了像上面这样,还有另外一种。
// profile.js
+var firstName = 'Michael';
+var lastName = 'Jackson';
+var year = 1958;
+
+export { firstName, lastName, year };上面代码在export命令后面,使用大括号指定所要输出的一组变量。它与前一种写法(直接放置在var语句前)是等价的,但是应该优先考虑使用这种写法。因为这样就可以在脚本尾部,一眼看清楚输出了哪些变量。
export命令除了输出变量,还可以输出函数或类(class)。
export function multiply(x, y) {
+ return x * y;
+};上面代码对外输出一个函数multiply。
通常情况下,export输出的变量就是本来的名字,但是可以使用as关键字重命名。
function v1() { ... }
+function v2() { ... }
+
+export {
+ v1 as streamV1,
+ v2 as streamV2,
+ v2 as streamLatestVersion
+};上面代码使用as关键字,重命名了函数v1和v2的对外接口。重命名后,v2可以用不同的名字输出两次。
需要特别注意的是,export命令规定的是对外的接口,必须与模块内部的变量建立一一对应关系。
使用export命令定义了模块的对外接口以后,其他 JS 文件就可以通过import命令加载这个模块。
// main.js
+import { firstName, lastName, year } from './profile.js';
+
+function setName(element) {
+ element.textContent = firstName + ' ' + lastName;
+}面代码的import命令,用于加载profile.js文件,并从中输入变量。import命令接受一对大括号,里面指定要从其他模块导入的变量名。大括号里面的变量名,必须与被导入模块(profile.js)对外接口的名称相同。
如果想为输入的变量重新取一个名字,import命令要使用as关键字,将输入的变量重命名。
import { lastName as surname } from './profile.js';import命令输入的变量都是只读的,因为它的本质是输入接口。也就是说,不允许在加载模块的脚本里面,改写接口。
import {a} from './xxx.js'
+
+a = {}; // Syntax Error : 'a' is read-only;上面代码中,脚本加载了变量a,对其重新赋值就会报错,因为a是一个只读的接口。但是,如果a是一个对象,改写a的属性是允许的。
import {a} from './xxx.js'
+
+a.foo = 'hello'; // 合法操作上面代码中,a的属性可以成功改写,并且其他模块也可以读到改写后的值。不过,这种写法很难查错,建议凡是输入的变量,都当作完全只读,不要轻易改变它的属性。
import后面的from指定模块文件的位置,可以是相对路径,也可以是绝对路径。如果不带有路径,只是一个模块名,那么必须有配置文件,告诉 JavaScript 引擎该模块的位置。
import { myMethod } from 'util';上面代码中,util是模块文件名,由于不带有路径,必须通过配置,告诉引擎怎么取到这个模块。
除了指定加载某个输出值,还可以使用整体加载,即用星号(*)指定一个对象,所有输出值都加载在这个对象上面。
import * as circle from './circle';
+
+console.log('圆面积:' + circle.area(4));
+console.log('圆周长:' + circle.circumference(14));使用import命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。
为了给用户提供方便,让他们不用阅读文档就能加载模块,就要用到export default命令,为模块指定默认输出。
// export-default.js
+export default function () {
+ console.log('foo');
+}上面代码是一个模块文件export-default.js,它的默认输出是一个函数。
其他模块加载该模块时,import命令可以为该匿名函数指定任意名字。
// import-default.js
+import customName from './export-default';
+customName(); // 'foo'上面代码的import命令,可以用任意名称指向export-default.js输出的方法,这时就不需要知道原模块输出的函数名。需要注意的是,这时import命令后面,不使用大括号。
export default命令用在非匿名函数前,也是可以的。
// export-default.js
+export default function foo() {
+ console.log('foo');
+}
+
+// 或者写成
+
+function foo() {
+ console.log('foo');
+}
+
+export default foo;上面代码中,foo函数的函数名foo,在模块外部是无效的。加载的时候,视同匿名函数加载。
export { foo, bar } from 'my_module';
+
+// 可以简单理解为
+import { foo, bar } from 'my_module';
+export { foo, bar };上面代码中,export和import语句可以结合在一起,写成一行。但需要注意的是,写成一行以后,foo和bar实际上并没有被导入当前模块,只是相当于对外转发了这两个接口,导致当前模块不能直接使用foo和bar。
模块的接口改名和整体输出,也可以采用这种写法。
// 接口改名
+export { foo as myFoo } from 'my_module';
+
+// 整体输出
+export * from 'my_module';默认接口的写法如下。
export { default } from 'foo';具名接口改为默认接口的写法如下。
export { es6 as default } from './someModule';
+
+// 等同于
+import { es6 } from './someModule';
+export default es6;同样地,默认接口也可以改名为具名接口。
export { default as es6 } from './someModule';// constants.js 模块
+export const A = 1;
+export const B = 3;
+export const C = 4;
+
+// test1.js 模块
+import * as constants from './constants';
+console.log(constants.A); // 1
+console.log(constants.B); // 3
+
+// test2.js 模块
+import {A, B} from './constants';
+console.log(A); // 1
+console.log(B); // 3circleplus模块,继承了circle模块。
// circleplus.js
+
+export * from 'circle';
+export var e = 2.71828182846;
+export default function(x) {
+ return Math.exp(x);
+}这时,也可以将circle的属性或方法,改名后再输出。
// circleplus.js
+
+export { area as circleArea } from 'circle';上面代码表示,只输出circle模块的area方法,且将其改名为circleArea。
加载上面模块的写法如下。
// main.js
+
+import * as math from 'circleplus';
+import exp from 'circleplus';
+console.log(exp(math.e));上面代码中的import exp表示,将circleplus模块的默认方法加载为exp方法。
Node.js是一个基于Chrome V8引擎的JavaScript运行环境。
浏览器是js的前端运行环境
Node.js是js的后端运行环境
__dirname替代当前文件所处目录 __dirname + '/file/1.txt'const http = require('http')
+
+const server = http.createServer()
+server.on('request', (req, res) => {
+ console.log('visit')
+ res.setHeader('Content-Type', 'text/html; charset=utf-8')
+ res.end('111')
+})
+
+server.listen(80, () => {
+ console.log("http server running at http://127.0.0.1")
+})模块化是指解决一个复杂问题时,自顶向下逐层把系统划分为若干模块的过程,对于整个系统来说,模块是可组合、分解和更换的单元。
模块化优势:
const moduleName = require('moduleName')使用require加载模块时会执行被加载模块的代码
使用自定义模块可以省略
.js
在自定义模块中定义的变量、方法等成员只能在当前模块内被访问,这种模块级别的访问限制,叫做模块作用域。
好处:防止全局变量污染
module对象:在每个.js自定义模块中都有一个module对象,里面存储了和当前模块有关的信息
console.log(module)module.exports:可以使用此对象将模块内的成员共享出去供外部使用,外界使用require()导入自定义模块时,得到的就是module.exports所指向的对象
module.exports.username = 'test'
+module.exports.sayHello = function() {
+ console.log('hello')
+}exports对象是module.exports的简化写法,两者指向同一个对象
Node.js遵循Common.js的模块化规范
CommonJS规定
npm是Node.js的包管理工具
npm install
npm uninstall
npm install package
npm i package
npm i package@version
包版本的语义化规范
点分十进制,总共三位数字,例如2.14.0
第一位数:大版本
第二位数:功能版本
第三位数:bug修复版本
版本号提升规则:前面版本增长,后面版本号归零
npm规定,项目根目录必须提供package.json的包管理配置文件。用来记录与项目有关的配置信息,例如:
npm创建package.json命令:npm init -y
运行npm install时,npm会自动把包名、版本记录到package.json中
package.json中有一个dependencies节点专门记录npm install安装了哪些包
记录只在开发阶段使用、上线不会用到的包
npm i packageName -D / npm install packageName --save-devnpm config get registry
npm config set registry=https://registry.npm.taobao.org/
nrm工具切换镜像源
npm i nrm -gnrm lsnrm use taobaoi5ting_toc: md转换为html工具
i5ting_toc -f md -o
规范的包结构必须符合:
./或../开头的路径标识符,否则会被当作内置模块或第三方模块,同时如果导入时省略了扩展名,Node.js会按顺序尝试加载以下文件: ./开头的路径标识符会被当作第三方模块,会从/node_modules中加载第三方模块 Node.js是一个基于Chrome V8引擎的JavaScript运行环境。
浏览器是js的前端运行环境
Node.js是js的后端运行环境
__dirname替代当前文件所处目录 __dirname + '/file/1.txt'const http = require('http')
+
+const server = http.createServer()
+server.on('request', (req, res) => {
+ console.log('visit')
+ res.setHeader('Content-Type', 'text/html; charset=utf-8')
+ res.end('111')
+})
+
+server.listen(80, () => {
+ console.log("http server running at http://127.0.0.1")
+})模块化是指解决一个复杂问题时,自顶向下逐层把系统划分为若干模块的过程,对于整个系统来说,模块是可组合、分解和更换的单元。
模块化优势:
const moduleName = require('moduleName')使用require加载模块时会执行被加载模块的代码
使用自定义模块可以省略
.js
在自定义模块中定义的变量、方法等成员只能在当前模块内被访问,这种模块级别的访问限制,叫做模块作用域。
好处:防止全局变量污染
module对象:在每个.js自定义模块中都有一个module对象,里面存储了和当前模块有关的信息
console.log(module)module.exports:可以使用此对象将模块内的成员共享出去供外部使用,外界使用require()导入自定义模块时,得到的就是module.exports所指向的对象
module.exports.username = 'test'
+module.exports.sayHello = function() {
+ console.log('hello')
+}exports对象是module.exports的简化写法,两者指向同一个对象
Node.js遵循Common.js的模块化规范
CommonJS规定
npm是Node.js的包管理工具
npm install
npm uninstall
npm install package
npm i package
npm i package@version
包版本的语义化规范
点分十进制,总共三位数字,例如2.14.0
第一位数:大版本
第二位数:功能版本
第三位数:bug修复版本
版本号提升规则:前面版本增长,后面版本号归零
npm规定,项目根目录必须提供package.json的包管理配置文件。用来记录与项目有关的配置信息,例如:
npm创建package.json命令:npm init -y
运行npm install时,npm会自动把包名、版本记录到package.json中
package.json中有一个dependencies节点专门记录npm install安装了哪些包
记录只在开发阶段使用、上线不会用到的包
npm i packageName -D / npm install packageName --save-devnpm config get registry
npm config set registry=https://registry.npm.taobao.org/
nrm工具切换镜像源
npm i nrm -gnrm lsnrm use taobaoi5ting_toc: md转换为html工具
i5ting_toc -f md -o
规范的包结构必须符合:
./或../开头的路径标识符,否则会被当作内置模块或第三方模块,同时如果导入时省略了扩展名,Node.js会按顺序尝试加载以下文件: ./开头的路径标识符会被当作第三方模块,会从/node_modules中加载第三方模块 在编程阶段还不清楚类型的变量指定的一个类型
某种程度上来说,void类型像是与any类型相反,它表示没有任何类型。
TypeScript里,undefined和null两者各自有自己的类型分别叫做undefined和null。 和 void相似,它们的本身的类型用处不是很大。
默认情况下null和undefined是所有类型的子类型。 就是说你可以把 null和undefined赋值给number类型的变量。
然而,当指定了--strictNullChecks标记,null和undefined只能赋值给void和它们各自。 这能避免 很多常见的问题。
Object:包含所有类型object:表示非原始类型也就是除number,string,boolean,symbol,null或undefined之外的类型。{}:同new Object(),包含所有类型,但无法修改属性、赋值等typescript中定义对象的方式是用interface,定义一种约束,让数据结构满足约束格式
interface Man extends Person{
+ age?:number
+ [propName:string]:any
+ readonly id:number
+}
+
+interface Person {
+ name:string
+}
+
+let p:Man = {
+ name: 'zs',
+ id: 1,
+ age: 18,
+ a:1,
+ b:2
+}
+
+
+interface Fn {
+ (name:string):number[]
+}
+
+const fn:Fn = function(name:string) {
+ return [1]
+}interface完全一致interface会被合并?readonly[],例如:number[]、string[]Array<number>interfacelet arr:number[][] = [[1], [2]]any[]//返回值
+function add(a:number, b:number): number {
+ return a+b
+}
+//箭头函数和定义返回值
+const add = (a:number,b:number):number => a+b
+
+//默认参数
+function add(a:number = 10, b:number = 20) {
+ return a+b
+}
+//可选参数
+function add(a:number = 10, b?:number): number{
+ return a+b
+}
+//传对象
+interface User {
+ name:string
+ age:nubmer
+}
+
+function add(user: User): User{
+ return user
+}
+console.log(add({ name: "111", age: 18}))
+
+//ts可以定义this的类型,在js中无法使用,必须是第一个参数定义this的类型(有点类似python里面的self?)
+interface Obj {
+ user:number[]
+ add:(this:Obj,num:number)=>void
+}
+
+let obj:Obj = {
+ user:[1,2,3],
+ add(this:Obj,num:number) {
+ this.user.push(num)
+ }
+}
+obj.add(4)
+console.log(obj)
+
+//函数重载
+let user:number[] = [1,2,3]
+
+
+function findNum():number[]
+function findNum(id:number):number[]
+function findNum(add:number[]):number[]
+
+//跟据入参走不同逻辑
+function findNum(ids?:number | number[]):number[] {
+ if(typeof ids == 'number') {
+ return user.filter(v=> v == ids)
+ }else if (Array.isArray(ids)) {
+ user.push(...ids)
+ return user
+ }else {
+ return user
+ }
+}
+console.log(findNum())let phone:number | string = '123456'
+
+//函数使用联合类型
+let fn = function(type:number | boolean):boolean {
+ return !!type
+}TypeScript中的 !!是一个逻辑非(not)操作符的双重否定形式,它可以用于将一个值转换成对应的布尔值。基本上,!!可以将任何值强制转换为对应的布尔值类型。
例如,使用!!可以将下列值转换为布尔类型的值:
!!true // true
!!1 // true
!!"hello" // true
!!undefined // false
!!null // false
!!0 // false
!!"" // false
interface People {
+ name:string,
+ age:string
+}
+
+interface Man {
+ sex:number
+}
+
+const p = (param:People & Man):void => {
+ console.log(man)
+}
+
+p({
+ name:"ikun",
+ age:"两年半",
+ sex:1
+})尖括号写法
let someValue: any = "this is a string";
+
+let strLength: number = (<string>someValue).length;as写法
let someValue: any = "this is a string";
+
+let strLength: number = (someValue as string).length;使用JSX时只允许as写法
Number(1)Date()RegExp(/\\w/)Error('wrong')XMLHttpRequestHTML(元素名称)Element / HTMLElement / ElementNodeList / NodeListOf<HTMLDivElement | HTMLElement>StorageLocationPromise//class的基本用法 继承 和类型约束 implements
+interface Options {
+ el: string | HTMLElement;
+}
+interface VueClass {
+ options: Options;
+ init(): void;
+}
+interface Vnode {
+ tag: string;
+ text: string;
+ children?: Vnode[];
+}
+//虚拟dom
+class Dom {
+ //创建dom节点
+ createElement(el: string) {
+ return document.createElement(el);
+ }
+ //填充文本
+ setText(el: HTMLElement, text: string | null) {
+ el.textContent = text;
+ }
+ //渲染函数
+ render(data: Vnode) {
+ let root = this.createElement(data.tag);
+ if (data.children && Array.isArray(data.children)) {
+ data.children.forEach((item) => {
+ let child = this.render(item);
+ root.appendChild(child);
+ });
+ } else {
+ this.setText(root, data.text === undefined ? "" : data.text);
+ }
+ return root;
+ }
+}
+
+class Vue extends Dom implements VueClass {
+ options: Options;
+ constructor(options: Options) {
+ super();
+ this.options = options;
+ this.init();
+ }
+ init(): void {
+ let data: Vnode = {
+ tag: "div",
+ text: '111',
+ children: [
+ {
+ tag: "section",
+ text: "子节点1",
+ },
+ {
+ tag: "section",
+ text: "子节点2",
+ },
+ {
+ tag: "section",
+ text: "子节点3",
+ }
+ ],
+ };
+ let app =
+ typeof this.options.el == "string"
+ ? document.querySelector(this.options.el)
+ : this.options.el;
+ app?.appendChild(this.render(data));
+ }
+}
+
+new Vue({
+ el: "#app"
+});元组类型允许表示一个已知元素数量和类型的数组,各元素的类型不必相同。
// Declare a tuple type
+let x: [string, number];
+// Initialize it
+x = ['hello', 10]; // OK
+// Initialize it incorrectly
+x = [10, 'hello']; // Error当访问一个已知索引的元素,会得到正确的类型:
console.log(x[0].substr(1)); // OK
+console.log(x[1].substr(1)); // Error, 'number' does not have 'substr'当访问一个越界的元素,会使用联合类型替代:
x[3] = 'world'; // OK, 字符串可以赋值给(string | number)类型
+
+console.log(x[5].toString()); // OK, 'string' 和 'number' 都有 toString
+
+x[6] = true; // Error, 布尔不是(string | number)类型enum类型是对JavaScript标准数据类型的一个补充。
enum Color {Red, Green, Blue}
+let c: Color = Color.Green;默认情况下,从0开始为元素编号。 你也可以手动的指定成员的数值。 例如,我们将上面的例子改成从 1开始编号:
enum Color {Red = 1, Green, Blue}
+let c: Color = Color.Green;或者,全部都采用手动赋值:
enum Color {Red = 1, Green = 2, Blue = 4}
+let c: Color = Color.Green;枚举类型提供的一个便利是你可以由枚举的值得到它的名字。 例如,我们知道数值为2,但是不确定它映射到Color里的哪个名字,我们可以查找相应的名字:
enum Color {Red = 1, Green, Blue}
+let colorName: string = Color[2];
+
+console.log(colorName); // 显示'Green'因为上面代码里它的值是2TypeScript里,在有些没有明确指出类型的地方,类型推论会帮助提供类型。
如果没有指出类型 & 没赋值 会被推断成any类型。
type s = string | null
+
+let str:s = 'test'
+
+let str1 = '123'
+type s1 = typeof str1
+
+
+type num = 1 extends number ? 1 : 0
never类型表示的是那些永不存在的值的类型。 例如, never类型是那些总是会抛出异常或根本就不会有返回值的函数表达式或箭头函数表达式的返回值类型; 变量也可能是 never类型,当它们被永不为真的类型保护所约束时。
never类型是任何类型的子类型,也可以赋值给任何类型;然而,没有类型是never的子类型或可以赋值给never类型(除了never本身之外)。 即使 any也不可以赋值给never。
type A = string & number //never
+type A = void | number | never //never会被忽略掉
+
+
+type A = '唱' | '跳' | 'rap'
+
+function kun(value: A) {
+ switch (value) {
+ case '唱':
+ break;
+ case '跳':
+ break;
+ case 'rap':
+ break;
+ default:
+ const check: never = value;
+ break;
+ }
+}let a1:symbol = Symbol(1)
+let a2:symbol = Symbol(2)
+console.log(a1 === a2) // false
+
+//for Symbol 有没有注册过这个key 如果有直接用 没有就创建
+console.log(Symbol.for('1') === Symbol.for('1')) // truefunction* gen() {
+ yield Promise.resovle('111')
+ yield '1'
+ yield '2'
+}
+const g = gen()
+console.log(g.next())
+console.log(g.next())
+console.log(g.next())
+console.log(g.next())
+/*
+{ value: Promise { '111' }, done: false }
+{ value: '1', done: false }
+{ value: '2', done: false }
+{ value: undefined, done: true }
+*/let Set:Set<number> = new Set([1,1,2,3,3,3]) // 1 2 3
+
+let map:Map<any, any> = new Map()
+let arr = [1,2,3]
+map.set(arr, '123')
+
+function args(){
+ console.log(arguments) //伪数组 IArguments
+}
+
+const each = (value:any) => {
+ let It: any = value[Symbol.iterator]()
+ let next: any = { done: false }
+ while (!next.done) {
+ next = It.next()
+ if (!next.done) {
+ console.log(next.value)
+ }
+ }
+}
+each([1,2,3])
+/*
+1
+2
+3
+*/
+
+
+//迭代器语法糖 for of
+//对象不能用 for of语法
+for (let value of map) {
+ console.log(value)
+}
+
+//数组解构 底层原理也是调用iterator
+let a = [4,5,6]
+let copy = [...a]
+console.log(a)
+
+let obj = {
+ max:5,
+ current:0,
+ [Symbol.iterator]() {
+ return {
+ max: this.max,
+ current: this.current,
+ next() {
+ if (this.current == this.max) {
+ return {
+ value: undefined,
+ done:true
+ }
+ }else {
+ return {
+ value: this.current++,
+ done:false
+ }
+ }
+ }
+ }
+ }
+}
+
+for (let value of obj) {
+ console.log(value)
+}
+/*
+0
+1
+2
+3
+4
+*/function fun<T>(a:T, b:T):Array<T> {
+ return [a,b]
+}
+
+type A<T> = string | number | T
+let a:A<boolean> = true
+
+interface Date<T> {
+ msg:T
+}
+let data:Date<number> = {
+ msg:1
+}
+
+function add<T = number,K = number>(a:T,b:K):Array<T | K> {
+ return [a,b]
+}
+add(false, '1')
+
+const axios = {
+ get<T>(url:string) {
+ return new Promise<T>((resolve,reject)=>{
+ let xhr:XMLHttpRequest = new XMLHttpRequest()
+ xhr.open('GET',url)
+ xhr.onreadystatechange = () => {
+ if(xhr.readyState ==4 && xhr.status == 200) {
+ resolve(JSON.parse(xhr.responseText))
+ }
+ }
+ xhr.send(null)
+ })
+ }
+}// extends
+interface Len {
+ length:number
+}
+
+function func<T extends Len)(a:T) {
+ console.log(a.length)
+}
+
+let obj = {
+ name: 'test',
+ sex: 1
+}
+
+// 约束对象的key
+type key = keyof typeof obj // "name" | "sex"
+
+function ob<T extends object, K extends keyof T>(obj:T, key:K) {
+
+}
+
+
+interface Data {
+ name:string
+ age:number
+ sex:string
+}
+
+type Options<T extends object> = {
+ //readonly [Key in keyof T]?:T[Key]
+ [Key in keyof T]?:T[Key]
+}
+
+type B = Options<Data>
+/*
+type B = {
+ name?: string | undefined;
+ age?: number | undefined;
+ sex?: string | undefined;
+}
+type B = {
+ name?: string | undefined;
+ age?: number | undefined;
+ sex?: string | undefined;
+}
+*/通过tsc --init生成
"compilerOptions": {
+ "incremental": true, // TS编译器在第一次编译之后会生成一个存储编译信息的文件,第二次编译会在第一次的基础上进行增量编译,可以提高编译的速度
+ "tsBuildInfoFile": "./buildFile", // 增量编译文件的存储位置
+ "diagnostics": true, // 打印诊断信息
+ "target": "ES5", // 目标语言的版本
+ "module": "CommonJS", // 生成代码的模板标准
+ "outFile": "./app.js", // 将多个相互依赖的文件生成一个文件,可以用在AMD模块中,即开启时应设置"module": "AMD",
+ "lib": ["DOM", "ES2015", "ScriptHost", "ES2019.Array"], // TS需要引用的库,即声明文件,es5 默认引用dom、es5、scripthost,如需要使用es的高级版本特性,通常都需要配置,如es8的数组新特性需要引入"ES2019.Array",
+ "allowJS": true, // 允许编译器编译JS,JSX文件
+ "checkJs": true, // 允许在JS文件中报错,通常与allowJS一起使用
+ "outDir": "./dist", // 指定输出目录
+ "rootDir": "./", // 指定输出文件目录(用于输出),用于控制输出目录结构
+ "declaration": true, // 生成声明文件,开启后会自动生成声明文件
+ "declarationDir": "./file", // 指定生成声明文件存放目录
+ "emitDeclarationOnly": true, // 只生成声明文件,而不会生成js文件
+ "sourceMap": true, // 生成目标文件的sourceMap文件
+ "inlineSourceMap": true, // 生成目标文件的inline SourceMap,inline SourceMap会包含在生成的js文件中
+ "declarationMap": true, // 为声明文件生成sourceMap
+ "typeRoots": [], // 声明文件目录,默认时node_modules/@types
+ "types": [], // 加载的声明文件包
+ "removeComments":true, // 删除注释
+ "noEmit": true, // 不输出文件,即编译后不会生成任何js文件
+ "noEmitOnError": true, // 发送错误时不输出任何文件
+ "noEmitHelpers": true, // 不生成helper函数,减小体积,需要额外安装,常配合importHelpers一起使用
+ "importHelpers": true, // 通过tslib引入helper函数,文件必须是模块
+ "downlevelIteration": true, // 降级遍历器实现,如果目标源是es3/5,那么遍历器会有降级的实现
+ "strict": true, // 开启所有严格的类型检查
+ "alwaysStrict": true, // 在代码中注入'use strict'
+ "noImplicitAny": true, // 不允许隐式的any类型
+ "strictNullChecks": true, // 不允许把null、undefined赋值给其他类型的变量
+ "strictFunctionTypes": true, // 不允许函数参数双向协变
+ "strictPropertyInitialization": true, // 类的实例属性必须初始化
+ "strictBindCallApply": true, // 严格的bind/call/apply检查
+ "noImplicitThis": true, // 不允许this有隐式的any类型
+ "noUnusedLocals": true, // 检查只声明、未使用的局部变量(只提示不报错)
+ "noUnusedParameters": true, // 检查未使用的函数参数(只提示不报错)
+ "noFallthroughCasesInSwitch": true, // 防止switch语句贯穿(即如果没有break语句后面不会执行)
+ "noImplicitReturns": true, //每个分支都会有返回值
+ "esModuleInterop": true, // 允许export=导出,由import from 导入
+ "allowUmdGlobalAccess": true, // 允许在模块中全局变量的方式访问umd模块
+ "moduleResolution": "node", // 模块解析策略,ts默认用node的解析策略,即相对的方式导入
+ "baseUrl": "./", // 解析非相对模块的基地址,默认是当前目录
+ "paths": { // 路径映射,相对于baseUrl
+ // 如使用jq时不想使用默认版本,而需要手动指定版本,可进行如下配置
+ "jquery": ["node_modules/jquery/dist/jquery.min.js"]
+ },
+ "rootDirs": ["src","out"], // 将多个目录放在一个虚拟目录下,用于运行时,即编译后引入文件的位置可能发生变化,这也设置可以虚拟src和out在同一个目录下,不用再去改变路径也不会报错
+ "listEmittedFiles": true, // 打印输出文件
+ "listFiles": true// 打印编译的文件(包括引用的声明文件)
+}
+
+// 指定一个匹配列表(属于自动指定该路径下的所有ts相关文件)
+"include": [
+ "src/**/*"
+],
+// 指定一个排除列表(include的反向操作)
+ "exclude": [
+ "demo.ts"
+],
+// 指定哪些文件使用该配置(属于手动一个个指定文件)
+ "files": [
+ "demo.ts"
+]typescript提供了namespace避免全局变量污染的问题。
任何包含顶级import或export的文件都被当作一个模块。相反的,如果不带,那么它的内容被视为全局可见的。
内部模块,外部模块现在简称为模块。namespace A {
+ export const a = 1
+}
+// 实现:
+"use strict"
+var A;
+(function (A) {
+ A.a = 1;
+})(A || A = {});
+
+// 嵌套命名空间
+namespace A {
+ export namespace C {
+ export const D = 5;
+ }
+}
+
+console.log(A.C.D)
+
+//抽离命名空间
+export namespace V {
+ export const a = 1
+}
+
+import {V} from '../index'
+console.log(V)// {a:1}
+
+
+//简化命名空间
+namespace A {
+ export namespace C {
+ export const D = 5;
+ }
+}
+
+import a = A.C
+console.log(a.D)
+
+//命名空间合并
+namespace A {
+ export const b = 2
+}
+namespace A {
+ export const a = 1
+}
+//等价于
+namespace A {
+ export const b = 2
+ export const a = 1
+}三斜线指令是包含单个XML标签的单行注释。 注释的内容会做为编译器指令使用。
/// <reference path="..." />
+/// <reference path="..." />指令是三斜线指令中最常见的一种。 它用于声明文件间的 依赖。三斜线引用告诉编译器在编译过程中要引入的额外的文件。
/// <reference types="..." />
+与 /// <reference path="..." />指令相似,这个指令是用来声明 依赖的; 一个 /// <reference types="..." />指令则声明了对某个包的依赖。
+
+对这些包的名字的解析与在 import语句里对模块名的解析类似。 可以简单地把三斜线类型引用指令当做 import声明的包。
+
+例如,把 /// <reference types="node" />引入到声明文件,表明这个文件使用了 @types/node/index.d.ts里面声明的名字; 并且,这个包需要在编译阶段与声明文件一起被包含进来。
+
+仅当在你需要写一个d.ts文件时才使用这个指令。
+
+对于那些在编译阶段生成的声明文件,编译器会自动地添加/// <reference types="..." />; 当且仅当结果文件中使用了引用的包里的声明时才会在生成的声明文件里添加/// <reference types="..." />语句。
+
+若要在.ts文件里声明一个对@types包的依赖,使用--types命令行选项或在tsconfig.json里指定。使用第三方库时需要引用它的声明文件d.ts才能获得对应的代码补全、接口提示等功能
npm i @types/xxx除了传统的面向对象继承方式,还流行一种通过可重用组件创建类的方式,就是联合另一个简单类的代码。
// Disposable Mixin
+class Disposable {
+ isDisposed: boolean;
+ dispose() {
+ this.isDisposed = true;
+ }
+
+}
+
+// Activatable Mixin
+class Activatable {
+ isActive: boolean;
+ activate() {
+ this.isActive = true;
+ }
+ deactivate() {
+ this.isActive = false;
+ }
+}
+
+class SmartObject implements Disposable, Activatable {
+ constructor() {
+ setInterval(() => console.log(this.isActive + " : " + this.isDisposed), 500);
+ }
+
+ interact() {
+ this.activate();
+ }
+
+ // Disposable
+ isDisposed: boolean = false;
+ dispose: () => void;
+ // Activatable
+ isActive: boolean = false;
+ activate: () => void;
+ deactivate: () => void;
+}
+applyMixins(SmartObject, [Disposable, Activatable]);
+
+let smartObj = new SmartObject();
+setTimeout(() => smartObj.interact(), 1000);
+
+////////////////////////////////////////
+// In your runtime library somewhere
+////////////////////////////////////////
+
+function applyMixins(derivedCtor: any, baseCtors: any[]) {
+ baseCtors.forEach(baseCtor => {
+ Object.getOwnPropertyNames(baseCtor.prototype).forEach(name => {
+ derivedCtor.prototype[name] = baseCtor.prototype[name];
+ });
+ });
+}随着TypeScript和ES6里引入了类,在一些场景下我们需要额外的特性来支持标注或修改类及其成员。 装饰器(Decorators)为我们在类的声明及成员上通过元编程语法添加标注提供了一种方式。
若要启用实验性的装饰器特性,你必须在命令行或tsconfig.json里启用experimentalDecorators编译器选项:
命令行:
tsc --target ES5 --experimentalDecoratorstsconfig.json:
{
+ "compilerOptions": {
+ "target": "ES5",
+ "experimentalDecorators": true
+ }
+}装饰器是一种特殊类型的声明,它能够被附加到类声明,方法, 访问符,属性或参数上。 装饰器使用 @expression这种形式,expression求值后必须为一个函数,它会在运行时被调用,被装饰的声明信息做为参数传入。
const IKun: ClassDecorator = (target) => {
+ console.log(target);
+ target.prototype.name = 'ikun';
+ target.prototype.slogan = () => {
+ console.log('鸡你太美');
+ }
+}
+
+@IKun
+class Person {
+
+}
+
+const person = new Person() as any;
+person.slogan(); // 鸡你太美const IKun = (name: string) => {
+ const decorator: ClassDecorator = (target) => {
+ target.prototype.name = name;
+ target.prototype.slogan = () => {
+ console.log('鸡你太美');
+ }
+ }
+ return decorator
+
+}
+
+@IKun('小黑子')
+class Person {
+
+}
+
+const person = new Person() as any;
+console.log(person.name); // 小黑子
+person.slogan(); // 鸡你太美方法装饰器声明在一个方法的声明之前(紧靠着方法声明)。 它会被应用到方法的 属性描述符上,可以用来监视,修改或者替换方法定义。 方法装饰器不能用在声明文件( .d.ts),重载或者任何外部上下文(比如declare的类)中。
方法装饰器表达式会在运行时当作函数被调用,传入下列3个参数:
如果方法装饰器返回一个值,它会被用作方法的属性描述符。
const logResult = (target: any, propertyKey: string, descriptor: PropertyDescriptor) => {
+ const fn = descriptor.value
+ descriptor.value = function(...rest) {
+ // 使用新的方法来替换原有方法,输出 方法名称 + 输入的参数 实现日志的增强功能
+ const result = fn.apply(this, rest)
+ console.log(propertyKey + ':' + result)
+ return result
+ }
+}
+
+class Person {
+ name: string = ''
+ age: number = 0
+
+ constructor(name: string, age: number) {
+ this.name = name
+ this.age = age
+ }
+
+ @logResult
+ getName() {
+ return this.name
+ }
+
+ @logResult
+ getAge() {
+ return this.age
+ }
+}
+
+const p = new Person('张三', 18)
+p.getName() // getName:张三
+p.getAge() // getAge:18import "reflect-metadata";
+
+const formatMetadataKey = Symbol("format");
+
+function format(formatString: string) {
+ return Reflect.metadata(formatMetadataKey, formatString);
+}
+
+function getFormat(target: any, propertyKey: string) {
+ return Reflect.getMetadata(formatMetadataKey, target, propertyKey);
+}
+
+class Greeter {
+ @format("Hello, %s")
+ greeting: string;
+
+ constructor(message: string) {
+ this.greeting = message;
+ }
+
+ greet() {
+ let formatString = getFormat(this, "greeting");
+ return formatString.replace("%s", this.greeting);
+ }
+}
+
+console.log(new Greeter("world").greet()); // "Hello, world"参数装饰器用于装饰函数参数,参数装饰器接收3个参数:
target: 对于静态成员来说是类的构造函数,对于实例成员是类的原型对象propertyKey: 方法名。paramIndex: 参数所在位置的索引。const paramDecorator = (target: any, propertyKey: string, paramIndex: number) => {
+ console.log(target, propertyKey, paramIndex)
+}
+
+class Person {
+ name: string = ''
+ age: number = 0
+
+ constructor(name: string, age: number) {
+ this.name = name
+ this.age = age
+ }
+
+ setName(@paramDecorator name: string) {
+ this.name = name
+ }
+}
+
+const p = new Person('张三', 18) // Person、setName、0
+p.setName('李四')在编程阶段还不清楚类型的变量指定的一个类型
某种程度上来说,void类型像是与any类型相反,它表示没有任何类型。
TypeScript里,undefined和null两者各自有自己的类型分别叫做undefined和null。 和 void相似,它们的本身的类型用处不是很大。
默认情况下null和undefined是所有类型的子类型。 就是说你可以把 null和undefined赋值给number类型的变量。
然而,当指定了--strictNullChecks标记,null和undefined只能赋值给void和它们各自。 这能避免 很多常见的问题。
Object:包含所有类型object:表示非原始类型也就是除number,string,boolean,symbol,null或undefined之外的类型。{}:同new Object(),包含所有类型,但无法修改属性、赋值等typescript中定义对象的方式是用interface,定义一种约束,让数据结构满足约束格式
interface Man extends Person{
+ age?:number
+ [propName:string]:any
+ readonly id:number
+}
+
+interface Person {
+ name:string
+}
+
+let p:Man = {
+ name: 'zs',
+ id: 1,
+ age: 18,
+ a:1,
+ b:2
+}
+
+
+interface Fn {
+ (name:string):number[]
+}
+
+const fn:Fn = function(name:string) {
+ return [1]
+}interface完全一致interface会被合并?readonly[],例如:number[]、string[]Array<number>interfacelet arr:number[][] = [[1], [2]]any[]//返回值
+function add(a:number, b:number): number {
+ return a+b
+}
+//箭头函数和定义返回值
+const add = (a:number,b:number):number => a+b
+
+//默认参数
+function add(a:number = 10, b:number = 20) {
+ return a+b
+}
+//可选参数
+function add(a:number = 10, b?:number): number{
+ return a+b
+}
+//传对象
+interface User {
+ name:string
+ age:nubmer
+}
+
+function add(user: User): User{
+ return user
+}
+console.log(add({ name: "111", age: 18}))
+
+//ts可以定义this的类型,在js中无法使用,必须是第一个参数定义this的类型(有点类似python里面的self?)
+interface Obj {
+ user:number[]
+ add:(this:Obj,num:number)=>void
+}
+
+let obj:Obj = {
+ user:[1,2,3],
+ add(this:Obj,num:number) {
+ this.user.push(num)
+ }
+}
+obj.add(4)
+console.log(obj)
+
+//函数重载
+let user:number[] = [1,2,3]
+
+
+function findNum():number[]
+function findNum(id:number):number[]
+function findNum(add:number[]):number[]
+
+//跟据入参走不同逻辑
+function findNum(ids?:number | number[]):number[] {
+ if(typeof ids == 'number') {
+ return user.filter(v=> v == ids)
+ }else if (Array.isArray(ids)) {
+ user.push(...ids)
+ return user
+ }else {
+ return user
+ }
+}
+console.log(findNum())let phone:number | string = '123456'
+
+//函数使用联合类型
+let fn = function(type:number | boolean):boolean {
+ return !!type
+}TypeScript中的 !!是一个逻辑非(not)操作符的双重否定形式,它可以用于将一个值转换成对应的布尔值。基本上,!!可以将任何值强制转换为对应的布尔值类型。
例如,使用!!可以将下列值转换为布尔类型的值:
!!true // true
!!1 // true
!!"hello" // true
!!undefined // false
!!null // false
!!0 // false
!!"" // false
interface People {
+ name:string,
+ age:string
+}
+
+interface Man {
+ sex:number
+}
+
+const p = (param:People & Man):void => {
+ console.log(man)
+}
+
+p({
+ name:"ikun",
+ age:"两年半",
+ sex:1
+})尖括号写法
let someValue: any = "this is a string";
+
+let strLength: number = (<string>someValue).length;as写法
let someValue: any = "this is a string";
+
+let strLength: number = (someValue as string).length;使用JSX时只允许as写法
Number(1)Date()RegExp(/\\w/)Error('wrong')XMLHttpRequestHTML(元素名称)Element / HTMLElement / ElementNodeList / NodeListOf<HTMLDivElement | HTMLElement>StorageLocationPromise//class的基本用法 继承 和类型约束 implements
+interface Options {
+ el: string | HTMLElement;
+}
+interface VueClass {
+ options: Options;
+ init(): void;
+}
+interface Vnode {
+ tag: string;
+ text: string;
+ children?: Vnode[];
+}
+//虚拟dom
+class Dom {
+ //创建dom节点
+ createElement(el: string) {
+ return document.createElement(el);
+ }
+ //填充文本
+ setText(el: HTMLElement, text: string | null) {
+ el.textContent = text;
+ }
+ //渲染函数
+ render(data: Vnode) {
+ let root = this.createElement(data.tag);
+ if (data.children && Array.isArray(data.children)) {
+ data.children.forEach((item) => {
+ let child = this.render(item);
+ root.appendChild(child);
+ });
+ } else {
+ this.setText(root, data.text === undefined ? "" : data.text);
+ }
+ return root;
+ }
+}
+
+class Vue extends Dom implements VueClass {
+ options: Options;
+ constructor(options: Options) {
+ super();
+ this.options = options;
+ this.init();
+ }
+ init(): void {
+ let data: Vnode = {
+ tag: "div",
+ text: '111',
+ children: [
+ {
+ tag: "section",
+ text: "子节点1",
+ },
+ {
+ tag: "section",
+ text: "子节点2",
+ },
+ {
+ tag: "section",
+ text: "子节点3",
+ }
+ ],
+ };
+ let app =
+ typeof this.options.el == "string"
+ ? document.querySelector(this.options.el)
+ : this.options.el;
+ app?.appendChild(this.render(data));
+ }
+}
+
+new Vue({
+ el: "#app"
+});元组类型允许表示一个已知元素数量和类型的数组,各元素的类型不必相同。
// Declare a tuple type
+let x: [string, number];
+// Initialize it
+x = ['hello', 10]; // OK
+// Initialize it incorrectly
+x = [10, 'hello']; // Error当访问一个已知索引的元素,会得到正确的类型:
console.log(x[0].substr(1)); // OK
+console.log(x[1].substr(1)); // Error, 'number' does not have 'substr'当访问一个越界的元素,会使用联合类型替代:
x[3] = 'world'; // OK, 字符串可以赋值给(string | number)类型
+
+console.log(x[5].toString()); // OK, 'string' 和 'number' 都有 toString
+
+x[6] = true; // Error, 布尔不是(string | number)类型enum类型是对JavaScript标准数据类型的一个补充。
enum Color {Red, Green, Blue}
+let c: Color = Color.Green;默认情况下,从0开始为元素编号。 你也可以手动的指定成员的数值。 例如,我们将上面的例子改成从 1开始编号:
enum Color {Red = 1, Green, Blue}
+let c: Color = Color.Green;或者,全部都采用手动赋值:
enum Color {Red = 1, Green = 2, Blue = 4}
+let c: Color = Color.Green;枚举类型提供的一个便利是你可以由枚举的值得到它的名字。 例如,我们知道数值为2,但是不确定它映射到Color里的哪个名字,我们可以查找相应的名字:
enum Color {Red = 1, Green, Blue}
+let colorName: string = Color[2];
+
+console.log(colorName); // 显示'Green'因为上面代码里它的值是2TypeScript里,在有些没有明确指出类型的地方,类型推论会帮助提供类型。
如果没有指出类型 & 没赋值 会被推断成any类型。
type s = string | null
+
+let str:s = 'test'
+
+let str1 = '123'
+type s1 = typeof str1
+
+
+type num = 1 extends number ? 1 : 0
never类型表示的是那些永不存在的值的类型。 例如, never类型是那些总是会抛出异常或根本就不会有返回值的函数表达式或箭头函数表达式的返回值类型; 变量也可能是 never类型,当它们被永不为真的类型保护所约束时。
never类型是任何类型的子类型,也可以赋值给任何类型;然而,没有类型是never的子类型或可以赋值给never类型(除了never本身之外)。 即使 any也不可以赋值给never。
type A = string & number //never
+type A = void | number | never //never会被忽略掉
+
+
+type A = '唱' | '跳' | 'rap'
+
+function kun(value: A) {
+ switch (value) {
+ case '唱':
+ break;
+ case '跳':
+ break;
+ case 'rap':
+ break;
+ default:
+ const check: never = value;
+ break;
+ }
+}let a1:symbol = Symbol(1)
+let a2:symbol = Symbol(2)
+console.log(a1 === a2) // false
+
+//for Symbol 有没有注册过这个key 如果有直接用 没有就创建
+console.log(Symbol.for('1') === Symbol.for('1')) // truefunction* gen() {
+ yield Promise.resovle('111')
+ yield '1'
+ yield '2'
+}
+const g = gen()
+console.log(g.next())
+console.log(g.next())
+console.log(g.next())
+console.log(g.next())
+/*
+{ value: Promise { '111' }, done: false }
+{ value: '1', done: false }
+{ value: '2', done: false }
+{ value: undefined, done: true }
+*/let Set:Set<number> = new Set([1,1,2,3,3,3]) // 1 2 3
+
+let map:Map<any, any> = new Map()
+let arr = [1,2,3]
+map.set(arr, '123')
+
+function args(){
+ console.log(arguments) //伪数组 IArguments
+}
+
+const each = (value:any) => {
+ let It: any = value[Symbol.iterator]()
+ let next: any = { done: false }
+ while (!next.done) {
+ next = It.next()
+ if (!next.done) {
+ console.log(next.value)
+ }
+ }
+}
+each([1,2,3])
+/*
+1
+2
+3
+*/
+
+
+//迭代器语法糖 for of
+//对象不能用 for of语法
+for (let value of map) {
+ console.log(value)
+}
+
+//数组解构 底层原理也是调用iterator
+let a = [4,5,6]
+let copy = [...a]
+console.log(a)
+
+let obj = {
+ max:5,
+ current:0,
+ [Symbol.iterator]() {
+ return {
+ max: this.max,
+ current: this.current,
+ next() {
+ if (this.current == this.max) {
+ return {
+ value: undefined,
+ done:true
+ }
+ }else {
+ return {
+ value: this.current++,
+ done:false
+ }
+ }
+ }
+ }
+ }
+}
+
+for (let value of obj) {
+ console.log(value)
+}
+/*
+0
+1
+2
+3
+4
+*/function fun<T>(a:T, b:T):Array<T> {
+ return [a,b]
+}
+
+type A<T> = string | number | T
+let a:A<boolean> = true
+
+interface Date<T> {
+ msg:T
+}
+let data:Date<number> = {
+ msg:1
+}
+
+function add<T = number,K = number>(a:T,b:K):Array<T | K> {
+ return [a,b]
+}
+add(false, '1')
+
+const axios = {
+ get<T>(url:string) {
+ return new Promise<T>((resolve,reject)=>{
+ let xhr:XMLHttpRequest = new XMLHttpRequest()
+ xhr.open('GET',url)
+ xhr.onreadystatechange = () => {
+ if(xhr.readyState ==4 && xhr.status == 200) {
+ resolve(JSON.parse(xhr.responseText))
+ }
+ }
+ xhr.send(null)
+ })
+ }
+}// extends
+interface Len {
+ length:number
+}
+
+function func<T extends Len)(a:T) {
+ console.log(a.length)
+}
+
+let obj = {
+ name: 'test',
+ sex: 1
+}
+
+// 约束对象的key
+type key = keyof typeof obj // "name" | "sex"
+
+function ob<T extends object, K extends keyof T>(obj:T, key:K) {
+
+}
+
+
+interface Data {
+ name:string
+ age:number
+ sex:string
+}
+
+type Options<T extends object> = {
+ //readonly [Key in keyof T]?:T[Key]
+ [Key in keyof T]?:T[Key]
+}
+
+type B = Options<Data>
+/*
+type B = {
+ name?: string | undefined;
+ age?: number | undefined;
+ sex?: string | undefined;
+}
+type B = {
+ name?: string | undefined;
+ age?: number | undefined;
+ sex?: string | undefined;
+}
+*/通过tsc --init生成
"compilerOptions": {
+ "incremental": true, // TS编译器在第一次编译之后会生成一个存储编译信息的文件,第二次编译会在第一次的基础上进行增量编译,可以提高编译的速度
+ "tsBuildInfoFile": "./buildFile", // 增量编译文件的存储位置
+ "diagnostics": true, // 打印诊断信息
+ "target": "ES5", // 目标语言的版本
+ "module": "CommonJS", // 生成代码的模板标准
+ "outFile": "./app.js", // 将多个相互依赖的文件生成一个文件,可以用在AMD模块中,即开启时应设置"module": "AMD",
+ "lib": ["DOM", "ES2015", "ScriptHost", "ES2019.Array"], // TS需要引用的库,即声明文件,es5 默认引用dom、es5、scripthost,如需要使用es的高级版本特性,通常都需要配置,如es8的数组新特性需要引入"ES2019.Array",
+ "allowJS": true, // 允许编译器编译JS,JSX文件
+ "checkJs": true, // 允许在JS文件中报错,通常与allowJS一起使用
+ "outDir": "./dist", // 指定输出目录
+ "rootDir": "./", // 指定输出文件目录(用于输出),用于控制输出目录结构
+ "declaration": true, // 生成声明文件,开启后会自动生成声明文件
+ "declarationDir": "./file", // 指定生成声明文件存放目录
+ "emitDeclarationOnly": true, // 只生成声明文件,而不会生成js文件
+ "sourceMap": true, // 生成目标文件的sourceMap文件
+ "inlineSourceMap": true, // 生成目标文件的inline SourceMap,inline SourceMap会包含在生成的js文件中
+ "declarationMap": true, // 为声明文件生成sourceMap
+ "typeRoots": [], // 声明文件目录,默认时node_modules/@types
+ "types": [], // 加载的声明文件包
+ "removeComments":true, // 删除注释
+ "noEmit": true, // 不输出文件,即编译后不会生成任何js文件
+ "noEmitOnError": true, // 发送错误时不输出任何文件
+ "noEmitHelpers": true, // 不生成helper函数,减小体积,需要额外安装,常配合importHelpers一起使用
+ "importHelpers": true, // 通过tslib引入helper函数,文件必须是模块
+ "downlevelIteration": true, // 降级遍历器实现,如果目标源是es3/5,那么遍历器会有降级的实现
+ "strict": true, // 开启所有严格的类型检查
+ "alwaysStrict": true, // 在代码中注入'use strict'
+ "noImplicitAny": true, // 不允许隐式的any类型
+ "strictNullChecks": true, // 不允许把null、undefined赋值给其他类型的变量
+ "strictFunctionTypes": true, // 不允许函数参数双向协变
+ "strictPropertyInitialization": true, // 类的实例属性必须初始化
+ "strictBindCallApply": true, // 严格的bind/call/apply检查
+ "noImplicitThis": true, // 不允许this有隐式的any类型
+ "noUnusedLocals": true, // 检查只声明、未使用的局部变量(只提示不报错)
+ "noUnusedParameters": true, // 检查未使用的函数参数(只提示不报错)
+ "noFallthroughCasesInSwitch": true, // 防止switch语句贯穿(即如果没有break语句后面不会执行)
+ "noImplicitReturns": true, //每个分支都会有返回值
+ "esModuleInterop": true, // 允许export=导出,由import from 导入
+ "allowUmdGlobalAccess": true, // 允许在模块中全局变量的方式访问umd模块
+ "moduleResolution": "node", // 模块解析策略,ts默认用node的解析策略,即相对的方式导入
+ "baseUrl": "./", // 解析非相对模块的基地址,默认是当前目录
+ "paths": { // 路径映射,相对于baseUrl
+ // 如使用jq时不想使用默认版本,而需要手动指定版本,可进行如下配置
+ "jquery": ["node_modules/jquery/dist/jquery.min.js"]
+ },
+ "rootDirs": ["src","out"], // 将多个目录放在一个虚拟目录下,用于运行时,即编译后引入文件的位置可能发生变化,这也设置可以虚拟src和out在同一个目录下,不用再去改变路径也不会报错
+ "listEmittedFiles": true, // 打印输出文件
+ "listFiles": true// 打印编译的文件(包括引用的声明文件)
+}
+
+// 指定一个匹配列表(属于自动指定该路径下的所有ts相关文件)
+"include": [
+ "src/**/*"
+],
+// 指定一个排除列表(include的反向操作)
+ "exclude": [
+ "demo.ts"
+],
+// 指定哪些文件使用该配置(属于手动一个个指定文件)
+ "files": [
+ "demo.ts"
+]typescript提供了namespace避免全局变量污染的问题。
任何包含顶级import或export的文件都被当作一个模块。相反的,如果不带,那么它的内容被视为全局可见的。
内部模块,外部模块现在简称为模块。namespace A {
+ export const a = 1
+}
+// 实现:
+"use strict"
+var A;
+(function (A) {
+ A.a = 1;
+})(A || A = {});
+
+// 嵌套命名空间
+namespace A {
+ export namespace C {
+ export const D = 5;
+ }
+}
+
+console.log(A.C.D)
+
+//抽离命名空间
+export namespace V {
+ export const a = 1
+}
+
+import {V} from '../index'
+console.log(V)// {a:1}
+
+
+//简化命名空间
+namespace A {
+ export namespace C {
+ export const D = 5;
+ }
+}
+
+import a = A.C
+console.log(a.D)
+
+//命名空间合并
+namespace A {
+ export const b = 2
+}
+namespace A {
+ export const a = 1
+}
+//等价于
+namespace A {
+ export const b = 2
+ export const a = 1
+}三斜线指令是包含单个XML标签的单行注释。 注释的内容会做为编译器指令使用。
/// <reference path="..." />
+/// <reference path="..." />指令是三斜线指令中最常见的一种。 它用于声明文件间的 依赖。三斜线引用告诉编译器在编译过程中要引入的额外的文件。
/// <reference types="..." />
+与 /// <reference path="..." />指令相似,这个指令是用来声明 依赖的; 一个 /// <reference types="..." />指令则声明了对某个包的依赖。
+
+对这些包的名字的解析与在 import语句里对模块名的解析类似。 可以简单地把三斜线类型引用指令当做 import声明的包。
+
+例如,把 /// <reference types="node" />引入到声明文件,表明这个文件使用了 @types/node/index.d.ts里面声明的名字; 并且,这个包需要在编译阶段与声明文件一起被包含进来。
+
+仅当在你需要写一个d.ts文件时才使用这个指令。
+
+对于那些在编译阶段生成的声明文件,编译器会自动地添加/// <reference types="..." />; 当且仅当结果文件中使用了引用的包里的声明时才会在生成的声明文件里添加/// <reference types="..." />语句。
+
+若要在.ts文件里声明一个对@types包的依赖,使用--types命令行选项或在tsconfig.json里指定。使用第三方库时需要引用它的声明文件d.ts才能获得对应的代码补全、接口提示等功能
npm i @types/xxx除了传统的面向对象继承方式,还流行一种通过可重用组件创建类的方式,就是联合另一个简单类的代码。
// Disposable Mixin
+class Disposable {
+ isDisposed: boolean;
+ dispose() {
+ this.isDisposed = true;
+ }
+
+}
+
+// Activatable Mixin
+class Activatable {
+ isActive: boolean;
+ activate() {
+ this.isActive = true;
+ }
+ deactivate() {
+ this.isActive = false;
+ }
+}
+
+class SmartObject implements Disposable, Activatable {
+ constructor() {
+ setInterval(() => console.log(this.isActive + " : " + this.isDisposed), 500);
+ }
+
+ interact() {
+ this.activate();
+ }
+
+ // Disposable
+ isDisposed: boolean = false;
+ dispose: () => void;
+ // Activatable
+ isActive: boolean = false;
+ activate: () => void;
+ deactivate: () => void;
+}
+applyMixins(SmartObject, [Disposable, Activatable]);
+
+let smartObj = new SmartObject();
+setTimeout(() => smartObj.interact(), 1000);
+
+////////////////////////////////////////
+// In your runtime library somewhere
+////////////////////////////////////////
+
+function applyMixins(derivedCtor: any, baseCtors: any[]) {
+ baseCtors.forEach(baseCtor => {
+ Object.getOwnPropertyNames(baseCtor.prototype).forEach(name => {
+ derivedCtor.prototype[name] = baseCtor.prototype[name];
+ });
+ });
+}随着TypeScript和ES6里引入了类,在一些场景下我们需要额外的特性来支持标注或修改类及其成员。 装饰器(Decorators)为我们在类的声明及成员上通过元编程语法添加标注提供了一种方式。
若要启用实验性的装饰器特性,你必须在命令行或tsconfig.json里启用experimentalDecorators编译器选项:
命令行:
tsc --target ES5 --experimentalDecoratorstsconfig.json:
{
+ "compilerOptions": {
+ "target": "ES5",
+ "experimentalDecorators": true
+ }
+}装饰器是一种特殊类型的声明,它能够被附加到类声明,方法, 访问符,属性或参数上。 装饰器使用 @expression这种形式,expression求值后必须为一个函数,它会在运行时被调用,被装饰的声明信息做为参数传入。
const IKun: ClassDecorator = (target) => {
+ console.log(target);
+ target.prototype.name = 'ikun';
+ target.prototype.slogan = () => {
+ console.log('鸡你太美');
+ }
+}
+
+@IKun
+class Person {
+
+}
+
+const person = new Person() as any;
+person.slogan(); // 鸡你太美const IKun = (name: string) => {
+ const decorator: ClassDecorator = (target) => {
+ target.prototype.name = name;
+ target.prototype.slogan = () => {
+ console.log('鸡你太美');
+ }
+ }
+ return decorator
+
+}
+
+@IKun('小黑子')
+class Person {
+
+}
+
+const person = new Person() as any;
+console.log(person.name); // 小黑子
+person.slogan(); // 鸡你太美方法装饰器声明在一个方法的声明之前(紧靠着方法声明)。 它会被应用到方法的 属性描述符上,可以用来监视,修改或者替换方法定义。 方法装饰器不能用在声明文件( .d.ts),重载或者任何外部上下文(比如declare的类)中。
方法装饰器表达式会在运行时当作函数被调用,传入下列3个参数:
如果方法装饰器返回一个值,它会被用作方法的属性描述符。
const logResult = (target: any, propertyKey: string, descriptor: PropertyDescriptor) => {
+ const fn = descriptor.value
+ descriptor.value = function(...rest) {
+ // 使用新的方法来替换原有方法,输出 方法名称 + 输入的参数 实现日志的增强功能
+ const result = fn.apply(this, rest)
+ console.log(propertyKey + ':' + result)
+ return result
+ }
+}
+
+class Person {
+ name: string = ''
+ age: number = 0
+
+ constructor(name: string, age: number) {
+ this.name = name
+ this.age = age
+ }
+
+ @logResult
+ getName() {
+ return this.name
+ }
+
+ @logResult
+ getAge() {
+ return this.age
+ }
+}
+
+const p = new Person('张三', 18)
+p.getName() // getName:张三
+p.getAge() // getAge:18import "reflect-metadata";
+
+const formatMetadataKey = Symbol("format");
+
+function format(formatString: string) {
+ return Reflect.metadata(formatMetadataKey, formatString);
+}
+
+function getFormat(target: any, propertyKey: string) {
+ return Reflect.getMetadata(formatMetadataKey, target, propertyKey);
+}
+
+class Greeter {
+ @format("Hello, %s")
+ greeting: string;
+
+ constructor(message: string) {
+ this.greeting = message;
+ }
+
+ greet() {
+ let formatString = getFormat(this, "greeting");
+ return formatString.replace("%s", this.greeting);
+ }
+}
+
+console.log(new Greeter("world").greet()); // "Hello, world"参数装饰器用于装饰函数参数,参数装饰器接收3个参数:
target: 对于静态成员来说是类的构造函数,对于实例成员是类的原型对象propertyKey: 方法名。paramIndex: 参数所在位置的索引。const paramDecorator = (target: any, propertyKey: string, paramIndex: number) => {
+ console.log(target, propertyKey, paramIndex)
+}
+
+class Person {
+ name: string = ''
+ age: number = 0
+
+ constructor(name: string, age: number) {
+ this.name = name
+ this.age = age
+ }
+
+ setName(@paramDecorator name: string) {
+ this.name = name
+ }
+}
+
+const p = new Person('张三', 18) // Person、setName、0
+p.setName('李四')webpack时前端项目工程化的具体解决方案。webpack的主要功能:提供了友好的前端模块化开发支持、代码压缩混淆、处理浏览器端javascript得兼容性、性能优化等强大的功能。
npm install webpack@version webpack-cli@version -D
webpack.config.js
module.exports = {
+ mode: 'development' //可取值development和production,前者不会压缩和性能优化,打包速度快
+}package.json
"script": {
+ "dev": "webpack"
+}webpack 4.x和5.x版本有如下默认约定
可以在webpack.config.js中
const path = require('path')
+
+module.exports = {
+ entry: path.join(__dirname, './src/index.js'),
+ output: {
+ path: path.join(__dirname, './dist'),
+ filename: 'js/bundle.js'
+ }
+}类似node.js中的nodemon
修改源代码后webpack会自动进行项目打包和构建
npm install webpack-dev-server@version -D
修改package.json的script
"scripts": {
+ "dev": "webpack serve"
+}可以定制index.html内容
npm install html-webpack-plugin@version -D
配置webpack.config.js
const HtmlPlugin = require('html-webpack-plugin')
+
+const htmlPlugin = new HtmlPlugin({
+ template: './src/index.html',//源文件
+ filename: './index.html'//生成的问题
+})
+
+module.exports = {
+ mode: 'development',
+ plugins: [htmlPlugin]
+}每次打包发布自动清理dist目录的旧文件
npm i clean-webpack-plugin@version -D
配置
const { CleanWebpackPlugin } = require('clean-webpack-plugin')
+const cleanPlugin = new CleanWebpackPlugin()
+
+plugins: [htmlPlugin, cleanPlugin]devServer: {
+ open: true,
+ host: 127.0.0.1,
+ port: 80
+}实际开发中,webpack只能打包处理.js模块,其他后缀的模块需要调用loader加载器才能正常打包
loader加载器作用:协助webpack打包处理特定的文件模块,比如:
css-loader可以处理.css文件
npm i style-loader@version css-loader@version -D
webpack.config.js的module->rules数组中添加loader规则
module: {
+ rules: [
+ { test: /\\.css$/, use: ['style-loader', 'css-loader']} //先执行css-loader,从后往前
+ ]
+}less-loader可以处理.less文件
npm i less-loader@version -Dmodule: {
+ rules: [
+ { test: /\\.less$/, use: ['style-loader', 'css-loader', 'less-loader']} //先执行less-loader,从后往前
+ ]
+}babel-loader可以处理webpack无法处理的高级JS语法
npm i babel-loader@version @babel/core@version @babel/plugin-proposal-decorators@version -D
module: {
+ rules: [
+ { test: /\\.js$/, use: 'babel-loader', exclude: /node_modules/} //
+ ]
+}配置babel-loader
在根目录下创建babel.config.js配置文件
module.exports = {
+ plugins: [['@babel@plugin-proposal-decorators'], {legacy: true}]
+}url-loader可以处理样式表中与url路径相关的文件
npm i url-loader@version file-loader@version -D
module: {
+ rules: [
+ /* {
+ test: /\\.jpg|png|gif$/,
+ use: {
+ loader: 'url-loader',
+ options: {
+ limit: 50000, //limit指定图片大小,单位byte,只有小于等于limit的图片才会被转为base64格式
+ outputPath: 'images'
+ }
+ }
+ }
+ */
+ { test: /\\.jpg|png|gif$/, use: 'url-loader?limit=50000&outputPath=images'}
+ ]
+}在package.json的script节点下新增build命令:
"scripts": {
+ "dev": "webpack serve",
+ "build": "webpack --mode production"
+}SourceMap是一个信息文件,里面存着位置信息。也就是说SourceMap文件中存储着压缩混淆后的代码所对应的转换前的位置。
出错的时候除错工具直接显示原始代码,而不是转换后的代码,方便后期调试。
module.exports = {
+ devtool: 'eval-source-map'
+}nosources-source-mapresolve: {
+ alias: {
+ //@代表源码目录
+ '@': path.join(__dirname, './src/')
+ }
+}webpack时前端项目工程化的具体解决方案。webpack的主要功能:提供了友好的前端模块化开发支持、代码压缩混淆、处理浏览器端javascript得兼容性、性能优化等强大的功能。
npm install webpack@version webpack-cli@version -D
webpack.config.js
module.exports = {
+ mode: 'development' //可取值development和production,前者不会压缩和性能优化,打包速度快
+}package.json
"script": {
+ "dev": "webpack"
+}webpack 4.x和5.x版本有如下默认约定
可以在webpack.config.js中
const path = require('path')
+
+module.exports = {
+ entry: path.join(__dirname, './src/index.js'),
+ output: {
+ path: path.join(__dirname, './dist'),
+ filename: 'js/bundle.js'
+ }
+}类似node.js中的nodemon
修改源代码后webpack会自动进行项目打包和构建
npm install webpack-dev-server@version -D
修改package.json的script
"scripts": {
+ "dev": "webpack serve"
+}可以定制index.html内容
npm install html-webpack-plugin@version -D
配置webpack.config.js
const HtmlPlugin = require('html-webpack-plugin')
+
+const htmlPlugin = new HtmlPlugin({
+ template: './src/index.html',//源文件
+ filename: './index.html'//生成的问题
+})
+
+module.exports = {
+ mode: 'development',
+ plugins: [htmlPlugin]
+}每次打包发布自动清理dist目录的旧文件
npm i clean-webpack-plugin@version -D
配置
const { CleanWebpackPlugin } = require('clean-webpack-plugin')
+const cleanPlugin = new CleanWebpackPlugin()
+
+plugins: [htmlPlugin, cleanPlugin]devServer: {
+ open: true,
+ host: 127.0.0.1,
+ port: 80
+}实际开发中,webpack只能打包处理.js模块,其他后缀的模块需要调用loader加载器才能正常打包
loader加载器作用:协助webpack打包处理特定的文件模块,比如:
css-loader可以处理.css文件
npm i style-loader@version css-loader@version -D
webpack.config.js的module->rules数组中添加loader规则
module: {
+ rules: [
+ { test: /\\.css$/, use: ['style-loader', 'css-loader']} //先执行css-loader,从后往前
+ ]
+}less-loader可以处理.less文件
npm i less-loader@version -Dmodule: {
+ rules: [
+ { test: /\\.less$/, use: ['style-loader', 'css-loader', 'less-loader']} //先执行less-loader,从后往前
+ ]
+}babel-loader可以处理webpack无法处理的高级JS语法
npm i babel-loader@version @babel/core@version @babel/plugin-proposal-decorators@version -D
module: {
+ rules: [
+ { test: /\\.js$/, use: 'babel-loader', exclude: /node_modules/} //
+ ]
+}配置babel-loader
在根目录下创建babel.config.js配置文件
module.exports = {
+ plugins: [['@babel@plugin-proposal-decorators'], {legacy: true}]
+}url-loader可以处理样式表中与url路径相关的文件
npm i url-loader@version file-loader@version -D
module: {
+ rules: [
+ /* {
+ test: /\\.jpg|png|gif$/,
+ use: {
+ loader: 'url-loader',
+ options: {
+ limit: 50000, //limit指定图片大小,单位byte,只有小于等于limit的图片才会被转为base64格式
+ outputPath: 'images'
+ }
+ }
+ }
+ */
+ { test: /\\.jpg|png|gif$/, use: 'url-loader?limit=50000&outputPath=images'}
+ ]
+}在package.json的script节点下新增build命令:
"scripts": {
+ "dev": "webpack serve",
+ "build": "webpack --mode production"
+}SourceMap是一个信息文件,里面存着位置信息。也就是说SourceMap文件中存储着压缩混淆后的代码所对应的转换前的位置。
出错的时候除错工具直接显示原始代码,而不是转换后的代码,方便后期调试。
module.exports = {
+ devtool: 'eval-source-map'
+}nosources-source-mapresolve: {
+ alias: {
+ //@代表源码目录
+ '@': path.join(__dirname, './src/')
+ }
+}$是jQuery的别称,也是jQuery的顶级对象,相当于原生JavaScript肿的window,把元素用$包装成jQuery对象,就可以调用jQuery的方法。
$(document).ready(function () {
+ //do something
+});
+$(function () {
+ //do something
+})$对DOM对象包装后产生的对象(伪数组形式存储)$(dom对象)$('div')[index]$('div').get(index)$("选择器")$('li:first')$('li:last')$('li:eq(2)'):索引号等于2$('li:odd'):索引号为奇数$('li:even'):索引号为偶数遍历DOM元素(伪数组形式存储)的过程叫隐式迭代:给匹配到的所有元素进行循环遍历,执行相应的方法,而不用手动进行循环调用
jQuery支持链式编程
jQuery对象.css(属性, 值)jQuery对象.css({"color": "pink", "font-size": "15px"}) (属性可以不用加引号)jQuery对象.css(属性)jQuery对象.addClass(className)jQuery对象.removeClass(className)jQuery对象.toggleClass(className)swing,可用参数linear动画队列停止排队:stop(),必须写在动画的前面
jQuery对象.children("ul").stop().slideToggle()
- jQuery对象.each(function(index, domElement) { } ):遍历匹配的每一个元素,index是索引号,domElement是DOM元素对象,不是jQuery对象
+- $.each(obj, function(index, domElement) { }):遍历指定对象
+- 创建元素:var li = $("<li> </li>")
+- 添加元素
+ - element.append(li):拼接到最后
+ - element.prepend(li):插入到最前
+ - element.before(li):放到元素之后
+ - element.after(li):放到元素之前
+- 删除元素
+ - element.remove():删除匹配的元素
+ - element.empty():删除匹配元素的子节点
+ - element.html(""):等价于empty()
+- offset():设置或返回被选元素相对于文档(document)的偏移坐标,跟父级没有关系
+ - 有两个属性left、top
+ - 修改传递对象{top: 10, left: 30}
+- position():返回被选元素相对**带有定位父级**偏移坐标,如果父级都没有定位,以文档为准
+- scrollTop()/scrollLeft():被卷去的头部/左侧
+ - 可以传递参数直接跳到指定位置element.事件(function(){})element.on(events, [selector], fn)$("div").on({
+ mouseenter: function () {
+ $(this).css("background", "skyblue");
+ },
+ click: function () {
+ $(this).css("background", "red");
+ }
+});
+
+$("div").on("mouseenter mouseleave", function () {
+ $(this).toggleClass("current")
+ }
+);事件绑定在父元素上
$("ul").on("click", "li", function () {
+ alert('111')
+})element.off()解绑所有element.off(事件1,事件2...)解绑指定element.one(事件,fn)
事件被触发,就会有事件对象的产生
element.on(events, [selector], function (event) {
+ console.log(event)
+ event.preventDefault();//阻止默认行为
+ return false; //阻止默认行为
+ event.stopPropagation();//阻止冒泡
+})$.extend([deep], target, object1, [objectN])
deep:true-深拷贝,默认false-浅拷贝
target:目标对象
object:源对象
objectN:第N个源对象,会覆盖前面的相同属性
$统一改为jQuery$.noConflict()/jQuery.noConflict()$.get(url, [data], [callback])
$(function() {
+ $('#btn').on('click', function() {
+ $.get('xxx.com/api/getXxx', 'a=b', function(res) {
+ console.log(res)
+ })
+ })
+})$.post(url, [data], [callback])
$(function() {
+ $('#btn').on('click', function() {
+ $.get('xxx.com/api/getXxx', {"a": "b"}, function(res) {
+ console.log(res)
+ })
+ })
+})$.ajax()
$.ajax({
+ type: '',
+ url: '',
+ data: {},
+ success: function(res) {}
+})$是jQuery的别称,也是jQuery的顶级对象,相当于原生JavaScript肿的window,把元素用$包装成jQuery对象,就可以调用jQuery的方法。
$(document).ready(function () {
+ //do something
+});
+$(function () {
+ //do something
+})$对DOM对象包装后产生的对象(伪数组形式存储)$(dom对象)$('div')[index]$('div').get(index)$("选择器")$('li:first')$('li:last')$('li:eq(2)'):索引号等于2$('li:odd'):索引号为奇数$('li:even'):索引号为偶数遍历DOM元素(伪数组形式存储)的过程叫隐式迭代:给匹配到的所有元素进行循环遍历,执行相应的方法,而不用手动进行循环调用
jQuery支持链式编程
jQuery对象.css(属性, 值)jQuery对象.css({"color": "pink", "font-size": "15px"}) (属性可以不用加引号)jQuery对象.css(属性)jQuery对象.addClass(className)jQuery对象.removeClass(className)jQuery对象.toggleClass(className)swing,可用参数linear动画队列停止排队:stop(),必须写在动画的前面
jQuery对象.children("ul").stop().slideToggle()
- jQuery对象.each(function(index, domElement) { } ):遍历匹配的每一个元素,index是索引号,domElement是DOM元素对象,不是jQuery对象
+- $.each(obj, function(index, domElement) { }):遍历指定对象
+- 创建元素:var li = $("<li> </li>")
+- 添加元素
+ - element.append(li):拼接到最后
+ - element.prepend(li):插入到最前
+ - element.before(li):放到元素之后
+ - element.after(li):放到元素之前
+- 删除元素
+ - element.remove():删除匹配的元素
+ - element.empty():删除匹配元素的子节点
+ - element.html(""):等价于empty()
+- offset():设置或返回被选元素相对于文档(document)的偏移坐标,跟父级没有关系
+ - 有两个属性left、top
+ - 修改传递对象{top: 10, left: 30}
+- position():返回被选元素相对**带有定位父级**偏移坐标,如果父级都没有定位,以文档为准
+- scrollTop()/scrollLeft():被卷去的头部/左侧
+ - 可以传递参数直接跳到指定位置element.事件(function(){})element.on(events, [selector], fn)$("div").on({
+ mouseenter: function () {
+ $(this).css("background", "skyblue");
+ },
+ click: function () {
+ $(this).css("background", "red");
+ }
+});
+
+$("div").on("mouseenter mouseleave", function () {
+ $(this).toggleClass("current")
+ }
+);事件绑定在父元素上
$("ul").on("click", "li", function () {
+ alert('111')
+})element.off()解绑所有element.off(事件1,事件2...)解绑指定element.one(事件,fn)
事件被触发,就会有事件对象的产生
element.on(events, [selector], function (event) {
+ console.log(event)
+ event.preventDefault();//阻止默认行为
+ return false; //阻止默认行为
+ event.stopPropagation();//阻止冒泡
+})$.extend([deep], target, object1, [objectN])
deep:true-深拷贝,默认false-浅拷贝
target:目标对象
object:源对象
objectN:第N个源对象,会覆盖前面的相同属性
$统一改为jQuery$.noConflict()/jQuery.noConflict()$.get(url, [data], [callback])
$(function() {
+ $('#btn').on('click', function() {
+ $.get('xxx.com/api/getXxx', 'a=b', function(res) {
+ console.log(res)
+ })
+ })
+})$.post(url, [data], [callback])
$(function() {
+ $('#btn').on('click', function() {
+ $.get('xxx.com/api/getXxx', {"a": "b"}, function(res) {
+ console.log(res)
+ })
+ })
+})$.ajax()
$.ajax({
+ type: '',
+ url: '',
+ data: {},
+ success: function(res) {}
+})Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。
MVVM是Vue实现数据驱动视图和双向数据绑定的原理。MVVM指的是Model、View和ViewModel。
ViewModel把Model和View连接在一起,同时监听DOM变化和数据源的变化。
<!doctype html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <meta name="viewport"
+ content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
+ <meta http-equiv="X-UA-Compatible" content="ie=edge">
+ <title>Document</title>
+</head>
+<body>
+<div id="app">
+ {{ msg }}
+</div>
+<script src="https://cdn.jsdelivr.net/npm/vue@2/dist/vue.js"></script>
+<script>
+ const vm = new Vue({
+ el: '#app',
+ data: {
+ msg: 'hello world'
+ }
+ })
+</script>
+</body>
+</html>性别
"),a(":把gender值渲染到p标签中,原有的值会被覆盖")])])],-1)),s("li",null,[a(h()+" ",1),s("ul",null,[i[0]||(i[0]=s("li",null,"插值表达式(Mustache),专门用来解决v-text会覆盖默认文本内容的问题,不能用在属性上",-1)),s("li",null,[s("code",null,"性别 "+h(n.gender)+"
",1)]),i[1]||(i[1]=s("li",null,"支持javascript表达式",-1))])]),i[3]||(i[3]=s("li",null,[a("v-html "),s("ul",null,[s("li",null,"把包含HTML标签的字符串渲染为页面的HTML元素")])],-1))]),i[7]||(i[7]=l(`v-bind:属性名:属性名v-on:事件名="函数(param)":v-on:click="add"
简写为:@,例如@click="add"
函数定义在vue实例的methods中
methods: {
+ add: function(param) {
+ console.log(1)
+ }
+}
+---
+ES6写法:
+methods: {
+ add(param) {
+ console.log(1)
+ }
+}不传参数默认参数列表有事件对象e,如果传参可以用$event传递事件对象
事件修饰符
@click.prevent=show():绑定事件并阻止默认行为按键修饰符
控制DOM的显示与隐藏
基于一个数组来循环渲染一个列表结构。v-for指令需要用item in items形式的特殊语法
<li v-for="item in items">姓名是: {{ item.name }}</li>
+
+<li v-for="(item,index) in items">姓名是: {{ item.name }}</li>建议用到v-for指令,要绑定一个:key属性,而且尽量把id作为key
完整语法
<li v-for="(value, key, index) in myObject">
+{{ value }} {{ kye }} {{ index }}
+</li>常用于文本格式化,过滤器可以用在两个地方:插值表达式和v-bind属性绑定,过滤器本质是函数,被定义在vue实例的filters节点下
`,22)),s("ul",null,[s("li",null,[s("code",null,""+h(n.message|n.capitalize)+"
",1),i[4]||(i[4]=a(":调用captitalize过滤器,对message进行格式化"))]),i[5]||(i[5]=s("li",null,[s("code",null,'filters: {
+ capitalize(val) {
+ return val.charAt(0).toUppercase() + var.slice(1)
+ }
+}{{ msg | filterA | filterB(arg1, arg2)}}watch侦听器语序开发者监视数据的变化,从而针对数据的变化做特定的操作。
watch定义在vue实例的watch节点下
方法格式的侦听器
watch: {
+ username(newVal, oldVal) {
+ console.log(newVal, oldVal)
+ }
+}缺点
对象格式的侦听器
watch: {
+ username: {
+ handler(newVal, oldVal) {
+ console.log(newVal, oldVal)
+ },
+ immediate: true,
+ deep: true,
+ 'info.age'(newVal) {
+ console.log(newVal)
+ }
+}可以通过immediate选项让侦听器立即触发
可以通过deep选项开启深度监听,可以监听到对象的任何一个属性变化
如果要侦听的是对象的子属性变化,则必须包裹一层单引号
通过运算得到的属性值,可以被模版结构或methods方法使用。
计算属性放在vue实例的computed节点中
var vm = new Vue({
+ el: '#app',
+ data: {
+ r: 0, g: 0, b: 0
+ },
+ computed: {
+ //计算属性rgb
+ rgb() { return \`rgb(\${this.r}, \${this.g}, \${this.b})\`}
+ //计算属性 allChecked
+ allChecked: {
+ get() {
+ return this.goodsList.every(item => item.goods_state)
+ },
+ set(newVal) {
+ this.goodsList.forEach(item => item.goods_state = newVal)
+ }
+ }
+ },
+ methods: {
+ show() { console.log(this.rgb) }
+ }
+})computed: {
+ allChecked: {
+ get() {
+ return this.goodsList.every(item => item.goods_state)
+ },
+ set(newVal) {
+ this.goodsList.forEach(item => item.goods_state = newVal)
+ }
+ }
+}axios一个专注于网络请求的库
基本语法:
axios({
+ method: '请求类型',
+ // URL中的query参数
+ params: {
+
+ },
+ // body参数
+ data: {
+
+}
+ url: '请求的URL地址',
+}).then((result) => {
+ //.then用来指定成功的回调,result是请求成功后的结果
+})结合async和await使用axios
document.querySelector('#btn').addEventListener('click', async function(){
+ // 如果调用方法返回值是Promise实例,则可以在前面添加await,await只能用在被async“修饰”的方法中
+ // 解构赋值的时候使用:进行重命名
+ const { data: res } = await axios({
+ method: 'POST',
+ url: 'xxx',
+ data: {
+ name: '111'
+ }
+ })
+ console.log(res.data)
+})// main.js
+
+import Vue from 'vue'
+import App from './App.vue'
+import axios from 'axios'
+
+Vue.config.productionTip = false
+
+// 缺点:不利于api接口复用
+// 组件实例中直接用\`this.$http\`使用
+// axios.defaults.baseURL = '请求根路径'
+// Vue.prototype.$http = axios
+
+new Vue({
+ reder: h => h(App)
+}).$mount(#app)单页面应用程序(Single Page Application)简称SPA,指的是一个Web网站中只有唯一的一个HTML页面,所有的功能与交互都在这唯一的一个页面内完成。
vue-cli是Vue.js开发的标准工具。简化了基于webpack创建工程化的Vue项目的过程。
npm install -g @vue/cli
vue create projectName
组件后缀名是.vue,vue组件包括三个组成部分
<!--template是一个虚拟标签,只起到包裹作用,不会被渲染成任何实质性HTML-->
+<template>
+ <div>
+ <!--template中只能有一个根元素-->
+ </div>
+</template><script>
+export default {
+ name: 'xxx',// <keep-alive>实现组件缓存功能,调整工具中看到的标签名称
+ // data必须是一个函数
+ data() {
+ return {
+ xx: xx
+ }
+ },
+ methods: {
+ fun() {
+ // 组件中的this代表当前组件的实例对象
+ console.log(this)
+ this.xx = yy
+ }
+ },
+ watch: {},
+ computed: {}
+ ...
+}
+</script><style lang="less">/* 默认lang="css" */
+
+</style>组件被封装好后,彼此之间是相互独立的,不存在父子关系。
在使用组件时,根据彼此的嵌套关系,形成了父子关系,兄弟关系。
import A from '@/components/A.vueexport default {
+ components: {
+ A //注册名称主要用于 以标签形式把注册的组件 渲染和使用到页面结构之中
+ }
+}<div class="box">
+ <A></A>
+</div>// main.js
+
+import Test from '@/components/Test.vue'
+
+Vue.component('MyTest', Test)props是组件的自定义属性,在封装通用组件的时候,合理的使用props可以极大提高组件的复用性。
<script>
+export default {
+ props: {
+ initCount: {
+ default: 0,//默认值
+ type: Number, //规定属性的值类型,如果传递的值不符合,则会报错
+ required: true //必填项
+ }
+ },
+ data() {
+ return {
+ count: this.initCount
+ }
+ }
+}
+</script>默认情况下,写在组件中的样式会全局生效,原因是:
使用自定义属性:DOM元素增加自定义属性data-v-xxx,使用属性选择器设置样式div[data-v-xxx]
style标签增加scoped属性,会自动为每个标签生成data-v属性
/deep/ 选择器
当使用第三方组件库,如果有修改第三方组件库的默认样式需求,需要用到deep
生命周期是指一个组件从创建->运行->销毁的整个阶段。
//子组件
+methods: {
+ add() {
+ this.count += 1
+ this.$emit('numchange', this.count)
+ }
+}//父组件
+<Son @numchange="getNewCount"></Son>
+
+---
+
+methods: {
+ getNewCount(val) {
+ this.countFromSon = val
+ }
+}//A组件
+import bus from './eventBus.js'
+
+methods: {
+ sendMsg() {
+ bus.$emit('share', this.msg)
+ }
+}
+
+//eventBus.js
+import Vue from 'vue'
+
+export default new Vue()
+
+//兄弟组件B
+import bus from './eventBus.js'
+
+created() {
+ bus.$on('share', val => {
+ this.msgFromSibling = val
+ })
+}ref用来辅助开发者在不依赖jQuery的情况下,获取DOM元素或组件的引用
每个vue组件的实例上,都包含一个$refs对象,里面存储着对应的DOM元素或组件的引用,默认情况下组件的$refs指向一个空对象
<div ref="myDiv"></div>
+
+// methods中访问
+this.$refs.myDiv<Son ref="compSon"></Son>
+
+// methods中访问
+this.$refs.compSon.方法
+this.$refs.compSon.属性组件的$nextTick(callback)方法,会把callback函数会推迟到下一个DOM更新之后执行。
动态组件指的是动态切换组件的显示与隐藏。
is属性 <template>
+ <component :is="componentName"></component>
+</template>
+<script>
+import Left from '@/components/Left.vue'
+import Right from '@/components/Right.vue'
+export default {
+ data() {
+ return {
+ componentName: "Left"
+ }
+ },
+ components: {
+ Left,
+ Right
+ }
+}
+</script>keep-alive标签能把内部的组件进行缓存,而不是销毁组件
<template>
+ <keep-alive>
+ <component :is="componentName"></component>
+ </keep-alive>
+</template>include可以指定哪些组件被缓存,只有名称匹配的组件会被缓存,多个用,分隔
exclude相反
两个属性不能同时使用
<template>
+ <keep-alive include="Left">
+ <component :is="componentName"></component>
+ </keep-alive>
+</template>插槽(Slot)是vue为组件的封装者提供的能力。允许开发者在封装组件时,把不确定的、希望由用户指定的部份定义为插槽。
<!--Left.vue-->
+<template>
+ <slot name="default">
+ 这里可以指定默认内容,会被覆盖
+ </slot>
+</template>渲染Left组件时
<template>
+ <Left>
+ <!--此区域必须在组件中声明插槽才会渲染-->
+ <!--默认情况下 会被填充到名为default的插槽内-->
+ <p>
+ 自定义内容
+ </p>
+ </Left>
+</template>
+
+---
+<template>
+ <Left>
+ <template v-slot:default>
+ <p>
+ 自定义内容
+ </p>
+ </template>
+ </Left>
+</template>
+---
+<template>
+ <Left>
+ <template #default>
+ <p>
+ 自定义内容
+ </p>
+ </template>
+ </Left>
+</template>声明一个插槽区域
每个插槽都要有一个name属性,如果省略,则使用默认名称default
作用域插槽:封装组件时,为预留的slot提供属性对应的值
定义:
+<slot name="content" msg="hello world"></slot>
+--
+使用:
+<template #content="scope">
+ <p>
+ {{ scope.msg }}
+ </p>
+</template>作用域插槽解构赋值
<slot name="content" msg="hello world" :user="user"></slot>
+
+---
+
+<template #content="{msg, user}">
+ <p>
+ {{msg}}
+ </p>
+ <p>
+ {{user}}
+ </p>
+</template>#default在每个vue组件中,可以在directives节点下声明私有自定义指令
当指令第一次被绑定到元素上的时候,会立刻触发bind函数,且只会触发一次
形参el:绑定了此指令的原生的DOM对象
形参binding:传递过来的参数是binding中的value
directives: {
+ color: {
+ bind(el, binding) {
+ el.style.color = binding.value
+ }
+ }
+}第一次不会触发
在DOM更新的时候就会触发update函数
directives: {
+ color: {
+ update(el, binding) {
+ el.style.color = binding.value
+ }
+ }
+}如果bind和update函数的逻辑完全相同,则对象格式的自定义指令可以简写为
directives: {
+ color(el, binding) {
+ el.style.color = binding.value
+ }
+}使用Vue.directive声明
Vue.directive('color', function(el, binding){
+ el.style.color = binding.value
+})
+---
+Vue.directive('color', {
+ binding(el, binding) {
+ el.style.color = binding.value
+ },
+ update(el, binding) {
+ el.style.color = binding.value
+ }
+})hash模式
history模式
publicPath/baseUrl
//vue.config.js
+module.exports = {
+ publicPath: process.env.NODE_ENV === 'production'
+ ? '/production-sub-path/'
+ : '/'
+}createWebHistory(base?)
npm i vue-router@version
在src目录下,新建router/index.js模块
import Vue from 'vue'
+import VueRouter from 'vue-router'
+
+// 调用Vue.use()函数,把VueRouter安装为Vue的插件
+Vue.use(VueRouter)
+
+const router = new VueRouter()
+
+export default routermain.js中挂载路由模块
//main.js
+import ...
+//import router from '@/router/index.js'
+//简写
+import router from '@/router'
+
+new Vue({
+ render: h => h(App),
+ //router: router
+ //属性名 属性值一致 可以简写
+ router
+})router-linkrouter-view,组件在这里展示<template>
+ <div class="container">
+ <a href="#/home">首页</a>
+ <a href="#/movie">电影</a>
+ <a href="#/about">关于</a>
+ <hr/>
+ 可以用router-link标签代替普通a标签,可以省略#
+ <router-link to="#/home">首页</router-link>
+ <router-link to="#/movie">电影</router-link>
+ <router-link to="#/about">关于</router-link>
+
+ <router-view></router-view>
+ </div>
+</template>修改router/index.js
import Vue from 'vue'
+import VueRouter from 'vue-router'
+
+import Home from '@/components/Home.vue'
+import Movie from '@/components/Movie.vue'
+import About from '@/components/About.vue'
+
+// 调用Vue.use()函数,把VueRouter安装为Vue的插件
+Vue.use(VueRouter)
+
+const router = new VueRouter({
+ // routes是一个数组:定义hash地址和组件之间的对应关系
+ routes: [
+ // 路由规则
+ { path: '/', redirect: '/home' }, // 重定向
+ { path: '/home', component: Home },
+ { path: '/movie', component: Movie },
+ { path: '/about', component: About }
+ ]
+})
+
+export default router通过路由实现组件的嵌套展示,叫做嵌套路由
import Vue from 'vue'
+import VueRouter from 'vue-router'
+
+import Home from '@/components/Home.vue'
+import Movie from '@/components/Movie.vue'
+import About from '@/components/About.vue'
+import Tab1 from '@/components/tabs/Tab1.vue'
+import Tab2 from '@/components/tabs/Tab2.vue'
+
+// 调用Vue.use()函数,把VueRouter安装为Vue的插件
+Vue.use(VueRouter)
+
+const router = new VueRouter({
+ // routes是一个数组:定义hash地址和组件之间的对应关系
+ routes: [
+ // 路由规则
+ { path: '/', redirect: '/home' }, // 重定向
+ { path: '/home', component: Home },
+ { path: '/movie', component: Movie },
+ {
+ path: '/about',
+ component: About,
+ children: [
+ { path: 'tab1', component: Tab1 },
+ { path: 'tab2', component: Tab2 }
+ ]
+ }
+ ]
+})
+
+export default routerconst routes = [
+ {
+ path: '/',
+ component: Home,
+ meta: {
+ keepAlive: true,
+ isRecord: true,
+ top: 0
+ }
+ },
+ {
+ path: '/user',
+ component: User
+ }
+]
+
+const router = new VueRouter({
+ routes,
+ scrollBehavior(to, from, savedPosition) {
+ if (savedPosition) {
+ return savedPosition
+ }
+ return {
+ x: 0,
+ y: to.meta.top || 0
+ }
+ }
+})把Hash地址中可变的部分定义为参数项,可以提高路由规则的复用性。
使用:来定义路由的参数项
{ path: '/movie/:id', component: Movie, props: true}$route.params.id获取路径参数(Path Variable)
$route.params.query获取查询参数
$route.params.fullPath:包含路径和参数
$route.params.path:只有路径没有参数
props传餐,在组件中定义props直接获取this.$router.push('hash地址'):跳转到hash地址,增加一条历史记录this.$router.replace('hash地址'):跳转到hash地址,并替换掉当前的历史记录this.$router.go(数值n):可以在浏览历史中前进或后退 this.$router.back()this.$router.forward()可以控制路由的访问权限
每次发生路由导航跳转时,都会触发前置守卫,在前置守卫中,可以对每个路由进行访问权限控制。
const router = new VueRouter({})
+// 每次路由跳转都会触发回调函数
+router.beforeEach((to, from, next) => {
+ // to:将要访问的路由信息对象
+ // from:将要离开的路由信息对象
+ // next:一个函数,调用next()表示放行,允许这次路由导航
+})使用:npm init vite-app projectName
create-vue创建的项目也是基于vite的构建设置
使用:npm create vue@3 或者npm init vue@latest
crete-vue同样支持vue2:npm create vue@2 / npm init vue@2
Vite和Webpack的区别(内容来自ChatGPT):
Vite和Webpack是两种常用的前端构建工具。
- 底层实现不同
Vite使用ES modules(ESM)作为模块系统管理,而Webpack使用CommonJS来管理模块。这意味着,在使用Webpack打包项目时,所有模块都将被打包到一个或多个bundle.js文件中,而Vite将原始文件作为模块提取和处理,并将其以一种非常高效的方式提供给浏览器。
- 开发环境下的性能
Vite在开发环境下启动非常快,不需要等待代码打包时间,并且在修改代码时,也可以直接进行热更新,非常适合在开发阶段使用。而Webpack在开发模式下代码打包速度较慢,启动速度也相对较慢,修改代码后也需要较长的时间来重新打包。
- 生产环境下的性能
在生产环境下,Webpack可以通过代码分割(Code Splitting)和 Tree Shaking来优化代码,减小打包后的文件大小。而Vite在生产环境下目前还不支持代码分割。因此,如果项目需要大量使用Code Splitting和Tree Shaking等技术,使用Webpack可能会更加合适。
- 生态和可定制性
Webpack具有强大的社区和众多的插件和Loader来处理各种文件和场景,可以根据不同的需求进行高度的定制。而Vite的生态和可定制性方面要弱于Webpack,它的插件数量还比较少。
总的来说,Vite是一种专门为现代浏览器设计的前端构建工具,它在开发环境下性能卓越,但在生产环境方面还有一些局限。而Webpack则是一种更加稳健和灵活的构建工具,它可以用于各种复杂的场景和需求,并且有着更强大的生态和定制能力,但需要进行更多的配置。选择使用哪种工具,应该根据具体项目需求和使用场景来进行选择。
create-vue和vue-cli的区别:
- vue-cli基于webpack,而create-vue基于vite
import { createApp } from 'vue'
+
+createApp({
+ data() {
+ return {
+ count: 0
+ }
+ }
+}).mount('#app')vue3的模板中可以有多个根节点
api类型不同,vue2使用选项式api,vue3使用组合式api
定义变量和方法方式不同:vue2定义在data和methods节点中,vue3使用setup()方法,此方法在组件初始化构造的时候触发
从vue引入reactive
使用reactive()方法声明数据为响应式数据const state = reactive({ count: 0 })
<script setup>:顶层的导入和变量声明可在同一组件的模板中直接使用。可以理解为模板中的表达式和 script setup中的代码处在同一个作用域中。
使用ref()定义响应式变量,ref() 将传入参数的值包装为一个带 .value 属性的 ref 对象:
import { ref } from 'vue'
+
+const count = ref(0)和响应式对象的属性类似,ref 的 .value 属性也是响应式的。同时,当值为对象类型时,会用 reactive() 自动转换它的 .value。
一个包含对象类型值的 ref 可以响应式地替换整个对象:
js
const objectRef = ref({ count: 0 })
+
+// 这是响应式的替换
+objectRef.value = { count: 1 }响应式
https://cn.vuejs.org/guide/essentials/reactivity-fundamentals.html
类和样式绑定
生命周期变化
ref()
标注类型
import type { Ref } from 'vue'
+
+const count: Ref<number> = ref(0)当 ref 在模板中作为顶层属性被访问时,它们会被自动“解包”,所以不需要使用 .value。
当一个 ref 被嵌套在一个深层响应式对象中,作为属性被访问或更改时,它会自动解包
Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。
MVVM是Vue实现数据驱动视图和双向数据绑定的原理。MVVM指的是Model、View和ViewModel。
ViewModel把Model和View连接在一起,同时监听DOM变化和数据源的变化。
<!doctype html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <meta name="viewport"
+ content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
+ <meta http-equiv="X-UA-Compatible" content="ie=edge">
+ <title>Document</title>
+</head>
+<body>
+<div id="app">
+ {{ msg }}
+</div>
+<script src="https://cdn.jsdelivr.net/npm/vue@2/dist/vue.js"></script>
+<script>
+ const vm = new Vue({
+ el: '#app',
+ data: {
+ msg: 'hello world'
+ }
+ })
+</script>
+</body>
+</html>性别
"),a(":把gender值渲染到p标签中,原有的值会被覆盖")])])],-1)),s("li",null,[a(h()+" ",1),s("ul",null,[i[0]||(i[0]=s("li",null,"插值表达式(Mustache),专门用来解决v-text会覆盖默认文本内容的问题,不能用在属性上",-1)),s("li",null,[s("code",null,"性别 "+h(n.gender)+"
",1)]),i[1]||(i[1]=s("li",null,"支持javascript表达式",-1))])]),i[3]||(i[3]=s("li",null,[a("v-html "),s("ul",null,[s("li",null,"把包含HTML标签的字符串渲染为页面的HTML元素")])],-1))]),i[7]||(i[7]=l(`v-bind:属性名:属性名v-on:事件名="函数(param)":v-on:click="add"
简写为:@,例如@click="add"
函数定义在vue实例的methods中
methods: {
+ add: function(param) {
+ console.log(1)
+ }
+}
+---
+ES6写法:
+methods: {
+ add(param) {
+ console.log(1)
+ }
+}不传参数默认参数列表有事件对象e,如果传参可以用$event传递事件对象
事件修饰符
@click.prevent=show():绑定事件并阻止默认行为按键修饰符
控制DOM的显示与隐藏
基于一个数组来循环渲染一个列表结构。v-for指令需要用item in items形式的特殊语法
<li v-for="item in items">姓名是: {{ item.name }}</li>
+
+<li v-for="(item,index) in items">姓名是: {{ item.name }}</li>建议用到v-for指令,要绑定一个:key属性,而且尽量把id作为key
完整语法
<li v-for="(value, key, index) in myObject">
+{{ value }} {{ kye }} {{ index }}
+</li>常用于文本格式化,过滤器可以用在两个地方:插值表达式和v-bind属性绑定,过滤器本质是函数,被定义在vue实例的filters节点下
`,22)),s("ul",null,[s("li",null,[s("code",null,""+h(n.message|n.capitalize)+"
",1),i[4]||(i[4]=a(":调用captitalize过滤器,对message进行格式化"))]),i[5]||(i[5]=s("li",null,[s("code",null,'filters: {
+ capitalize(val) {
+ return val.charAt(0).toUppercase() + var.slice(1)
+ }
+}{{ msg | filterA | filterB(arg1, arg2)}}watch侦听器语序开发者监视数据的变化,从而针对数据的变化做特定的操作。
watch定义在vue实例的watch节点下
方法格式的侦听器
watch: {
+ username(newVal, oldVal) {
+ console.log(newVal, oldVal)
+ }
+}缺点
对象格式的侦听器
watch: {
+ username: {
+ handler(newVal, oldVal) {
+ console.log(newVal, oldVal)
+ },
+ immediate: true,
+ deep: true,
+ 'info.age'(newVal) {
+ console.log(newVal)
+ }
+}可以通过immediate选项让侦听器立即触发
可以通过deep选项开启深度监听,可以监听到对象的任何一个属性变化
如果要侦听的是对象的子属性变化,则必须包裹一层单引号
通过运算得到的属性值,可以被模版结构或methods方法使用。
计算属性放在vue实例的computed节点中
var vm = new Vue({
+ el: '#app',
+ data: {
+ r: 0, g: 0, b: 0
+ },
+ computed: {
+ //计算属性rgb
+ rgb() { return \`rgb(\${this.r}, \${this.g}, \${this.b})\`}
+ //计算属性 allChecked
+ allChecked: {
+ get() {
+ return this.goodsList.every(item => item.goods_state)
+ },
+ set(newVal) {
+ this.goodsList.forEach(item => item.goods_state = newVal)
+ }
+ }
+ },
+ methods: {
+ show() { console.log(this.rgb) }
+ }
+})computed: {
+ allChecked: {
+ get() {
+ return this.goodsList.every(item => item.goods_state)
+ },
+ set(newVal) {
+ this.goodsList.forEach(item => item.goods_state = newVal)
+ }
+ }
+}axios一个专注于网络请求的库
基本语法:
axios({
+ method: '请求类型',
+ // URL中的query参数
+ params: {
+
+ },
+ // body参数
+ data: {
+
+}
+ url: '请求的URL地址',
+}).then((result) => {
+ //.then用来指定成功的回调,result是请求成功后的结果
+})结合async和await使用axios
document.querySelector('#btn').addEventListener('click', async function(){
+ // 如果调用方法返回值是Promise实例,则可以在前面添加await,await只能用在被async“修饰”的方法中
+ // 解构赋值的时候使用:进行重命名
+ const { data: res } = await axios({
+ method: 'POST',
+ url: 'xxx',
+ data: {
+ name: '111'
+ }
+ })
+ console.log(res.data)
+})// main.js
+
+import Vue from 'vue'
+import App from './App.vue'
+import axios from 'axios'
+
+Vue.config.productionTip = false
+
+// 缺点:不利于api接口复用
+// 组件实例中直接用\`this.$http\`使用
+// axios.defaults.baseURL = '请求根路径'
+// Vue.prototype.$http = axios
+
+new Vue({
+ reder: h => h(App)
+}).$mount(#app)单页面应用程序(Single Page Application)简称SPA,指的是一个Web网站中只有唯一的一个HTML页面,所有的功能与交互都在这唯一的一个页面内完成。
vue-cli是Vue.js开发的标准工具。简化了基于webpack创建工程化的Vue项目的过程。
npm install -g @vue/cli
vue create projectName
组件后缀名是.vue,vue组件包括三个组成部分
<!--template是一个虚拟标签,只起到包裹作用,不会被渲染成任何实质性HTML-->
+<template>
+ <div>
+ <!--template中只能有一个根元素-->
+ </div>
+</template><script>
+export default {
+ name: 'xxx',// <keep-alive>实现组件缓存功能,调整工具中看到的标签名称
+ // data必须是一个函数
+ data() {
+ return {
+ xx: xx
+ }
+ },
+ methods: {
+ fun() {
+ // 组件中的this代表当前组件的实例对象
+ console.log(this)
+ this.xx = yy
+ }
+ },
+ watch: {},
+ computed: {}
+ ...
+}
+</script><style lang="less">/* 默认lang="css" */
+
+</style>组件被封装好后,彼此之间是相互独立的,不存在父子关系。
在使用组件时,根据彼此的嵌套关系,形成了父子关系,兄弟关系。
import A from '@/components/A.vueexport default {
+ components: {
+ A //注册名称主要用于 以标签形式把注册的组件 渲染和使用到页面结构之中
+ }
+}<div class="box">
+ <A></A>
+</div>// main.js
+
+import Test from '@/components/Test.vue'
+
+Vue.component('MyTest', Test)props是组件的自定义属性,在封装通用组件的时候,合理的使用props可以极大提高组件的复用性。
<script>
+export default {
+ props: {
+ initCount: {
+ default: 0,//默认值
+ type: Number, //规定属性的值类型,如果传递的值不符合,则会报错
+ required: true //必填项
+ }
+ },
+ data() {
+ return {
+ count: this.initCount
+ }
+ }
+}
+</script>默认情况下,写在组件中的样式会全局生效,原因是:
使用自定义属性:DOM元素增加自定义属性data-v-xxx,使用属性选择器设置样式div[data-v-xxx]
style标签增加scoped属性,会自动为每个标签生成data-v属性
/deep/ 选择器
当使用第三方组件库,如果有修改第三方组件库的默认样式需求,需要用到deep
生命周期是指一个组件从创建->运行->销毁的整个阶段。
//子组件
+methods: {
+ add() {
+ this.count += 1
+ this.$emit('numchange', this.count)
+ }
+}//父组件
+<Son @numchange="getNewCount"></Son>
+
+---
+
+methods: {
+ getNewCount(val) {
+ this.countFromSon = val
+ }
+}//A组件
+import bus from './eventBus.js'
+
+methods: {
+ sendMsg() {
+ bus.$emit('share', this.msg)
+ }
+}
+
+//eventBus.js
+import Vue from 'vue'
+
+export default new Vue()
+
+//兄弟组件B
+import bus from './eventBus.js'
+
+created() {
+ bus.$on('share', val => {
+ this.msgFromSibling = val
+ })
+}ref用来辅助开发者在不依赖jQuery的情况下,获取DOM元素或组件的引用
每个vue组件的实例上,都包含一个$refs对象,里面存储着对应的DOM元素或组件的引用,默认情况下组件的$refs指向一个空对象
<div ref="myDiv"></div>
+
+// methods中访问
+this.$refs.myDiv<Son ref="compSon"></Son>
+
+// methods中访问
+this.$refs.compSon.方法
+this.$refs.compSon.属性组件的$nextTick(callback)方法,会把callback函数会推迟到下一个DOM更新之后执行。
动态组件指的是动态切换组件的显示与隐藏。
is属性 <template>
+ <component :is="componentName"></component>
+</template>
+<script>
+import Left from '@/components/Left.vue'
+import Right from '@/components/Right.vue'
+export default {
+ data() {
+ return {
+ componentName: "Left"
+ }
+ },
+ components: {
+ Left,
+ Right
+ }
+}
+</script>keep-alive标签能把内部的组件进行缓存,而不是销毁组件
<template>
+ <keep-alive>
+ <component :is="componentName"></component>
+ </keep-alive>
+</template>include可以指定哪些组件被缓存,只有名称匹配的组件会被缓存,多个用,分隔
exclude相反
两个属性不能同时使用
<template>
+ <keep-alive include="Left">
+ <component :is="componentName"></component>
+ </keep-alive>
+</template>插槽(Slot)是vue为组件的封装者提供的能力。允许开发者在封装组件时,把不确定的、希望由用户指定的部份定义为插槽。
<!--Left.vue-->
+<template>
+ <slot name="default">
+ 这里可以指定默认内容,会被覆盖
+ </slot>
+</template>渲染Left组件时
<template>
+ <Left>
+ <!--此区域必须在组件中声明插槽才会渲染-->
+ <!--默认情况下 会被填充到名为default的插槽内-->
+ <p>
+ 自定义内容
+ </p>
+ </Left>
+</template>
+
+---
+<template>
+ <Left>
+ <template v-slot:default>
+ <p>
+ 自定义内容
+ </p>
+ </template>
+ </Left>
+</template>
+---
+<template>
+ <Left>
+ <template #default>
+ <p>
+ 自定义内容
+ </p>
+ </template>
+ </Left>
+</template>声明一个插槽区域
每个插槽都要有一个name属性,如果省略,则使用默认名称default
作用域插槽:封装组件时,为预留的slot提供属性对应的值
定义:
+<slot name="content" msg="hello world"></slot>
+--
+使用:
+<template #content="scope">
+ <p>
+ {{ scope.msg }}
+ </p>
+</template>作用域插槽解构赋值
<slot name="content" msg="hello world" :user="user"></slot>
+
+---
+
+<template #content="{msg, user}">
+ <p>
+ {{msg}}
+ </p>
+ <p>
+ {{user}}
+ </p>
+</template>#default在每个vue组件中,可以在directives节点下声明私有自定义指令
当指令第一次被绑定到元素上的时候,会立刻触发bind函数,且只会触发一次
形参el:绑定了此指令的原生的DOM对象
形参binding:传递过来的参数是binding中的value
directives: {
+ color: {
+ bind(el, binding) {
+ el.style.color = binding.value
+ }
+ }
+}第一次不会触发
在DOM更新的时候就会触发update函数
directives: {
+ color: {
+ update(el, binding) {
+ el.style.color = binding.value
+ }
+ }
+}如果bind和update函数的逻辑完全相同,则对象格式的自定义指令可以简写为
directives: {
+ color(el, binding) {
+ el.style.color = binding.value
+ }
+}使用Vue.directive声明
Vue.directive('color', function(el, binding){
+ el.style.color = binding.value
+})
+---
+Vue.directive('color', {
+ binding(el, binding) {
+ el.style.color = binding.value
+ },
+ update(el, binding) {
+ el.style.color = binding.value
+ }
+})hash模式
history模式
publicPath/baseUrl
//vue.config.js
+module.exports = {
+ publicPath: process.env.NODE_ENV === 'production'
+ ? '/production-sub-path/'
+ : '/'
+}createWebHistory(base?)
npm i vue-router@version
在src目录下,新建router/index.js模块
import Vue from 'vue'
+import VueRouter from 'vue-router'
+
+// 调用Vue.use()函数,把VueRouter安装为Vue的插件
+Vue.use(VueRouter)
+
+const router = new VueRouter()
+
+export default routermain.js中挂载路由模块
//main.js
+import ...
+//import router from '@/router/index.js'
+//简写
+import router from '@/router'
+
+new Vue({
+ render: h => h(App),
+ //router: router
+ //属性名 属性值一致 可以简写
+ router
+})router-linkrouter-view,组件在这里展示<template>
+ <div class="container">
+ <a href="#/home">首页</a>
+ <a href="#/movie">电影</a>
+ <a href="#/about">关于</a>
+ <hr/>
+ 可以用router-link标签代替普通a标签,可以省略#
+ <router-link to="#/home">首页</router-link>
+ <router-link to="#/movie">电影</router-link>
+ <router-link to="#/about">关于</router-link>
+
+ <router-view></router-view>
+ </div>
+</template>修改router/index.js
import Vue from 'vue'
+import VueRouter from 'vue-router'
+
+import Home from '@/components/Home.vue'
+import Movie from '@/components/Movie.vue'
+import About from '@/components/About.vue'
+
+// 调用Vue.use()函数,把VueRouter安装为Vue的插件
+Vue.use(VueRouter)
+
+const router = new VueRouter({
+ // routes是一个数组:定义hash地址和组件之间的对应关系
+ routes: [
+ // 路由规则
+ { path: '/', redirect: '/home' }, // 重定向
+ { path: '/home', component: Home },
+ { path: '/movie', component: Movie },
+ { path: '/about', component: About }
+ ]
+})
+
+export default router通过路由实现组件的嵌套展示,叫做嵌套路由
import Vue from 'vue'
+import VueRouter from 'vue-router'
+
+import Home from '@/components/Home.vue'
+import Movie from '@/components/Movie.vue'
+import About from '@/components/About.vue'
+import Tab1 from '@/components/tabs/Tab1.vue'
+import Tab2 from '@/components/tabs/Tab2.vue'
+
+// 调用Vue.use()函数,把VueRouter安装为Vue的插件
+Vue.use(VueRouter)
+
+const router = new VueRouter({
+ // routes是一个数组:定义hash地址和组件之间的对应关系
+ routes: [
+ // 路由规则
+ { path: '/', redirect: '/home' }, // 重定向
+ { path: '/home', component: Home },
+ { path: '/movie', component: Movie },
+ {
+ path: '/about',
+ component: About,
+ children: [
+ { path: 'tab1', component: Tab1 },
+ { path: 'tab2', component: Tab2 }
+ ]
+ }
+ ]
+})
+
+export default routerconst routes = [
+ {
+ path: '/',
+ component: Home,
+ meta: {
+ keepAlive: true,
+ isRecord: true,
+ top: 0
+ }
+ },
+ {
+ path: '/user',
+ component: User
+ }
+]
+
+const router = new VueRouter({
+ routes,
+ scrollBehavior(to, from, savedPosition) {
+ if (savedPosition) {
+ return savedPosition
+ }
+ return {
+ x: 0,
+ y: to.meta.top || 0
+ }
+ }
+})把Hash地址中可变的部分定义为参数项,可以提高路由规则的复用性。
使用:来定义路由的参数项
{ path: '/movie/:id', component: Movie, props: true}$route.params.id获取路径参数(Path Variable)
$route.params.query获取查询参数
$route.params.fullPath:包含路径和参数
$route.params.path:只有路径没有参数
props传餐,在组件中定义props直接获取this.$router.push('hash地址'):跳转到hash地址,增加一条历史记录this.$router.replace('hash地址'):跳转到hash地址,并替换掉当前的历史记录this.$router.go(数值n):可以在浏览历史中前进或后退 this.$router.back()this.$router.forward()可以控制路由的访问权限
每次发生路由导航跳转时,都会触发前置守卫,在前置守卫中,可以对每个路由进行访问权限控制。
const router = new VueRouter({})
+// 每次路由跳转都会触发回调函数
+router.beforeEach((to, from, next) => {
+ // to:将要访问的路由信息对象
+ // from:将要离开的路由信息对象
+ // next:一个函数,调用next()表示放行,允许这次路由导航
+})使用:npm init vite-app projectName
create-vue创建的项目也是基于vite的构建设置
使用:npm create vue@3 或者npm init vue@latest
crete-vue同样支持vue2:npm create vue@2 / npm init vue@2
Vite和Webpack的区别(内容来自ChatGPT):
Vite和Webpack是两种常用的前端构建工具。
- 底层实现不同
Vite使用ES modules(ESM)作为模块系统管理,而Webpack使用CommonJS来管理模块。这意味着,在使用Webpack打包项目时,所有模块都将被打包到一个或多个bundle.js文件中,而Vite将原始文件作为模块提取和处理,并将其以一种非常高效的方式提供给浏览器。
- 开发环境下的性能
Vite在开发环境下启动非常快,不需要等待代码打包时间,并且在修改代码时,也可以直接进行热更新,非常适合在开发阶段使用。而Webpack在开发模式下代码打包速度较慢,启动速度也相对较慢,修改代码后也需要较长的时间来重新打包。
- 生产环境下的性能
在生产环境下,Webpack可以通过代码分割(Code Splitting)和 Tree Shaking来优化代码,减小打包后的文件大小。而Vite在生产环境下目前还不支持代码分割。因此,如果项目需要大量使用Code Splitting和Tree Shaking等技术,使用Webpack可能会更加合适。
- 生态和可定制性
Webpack具有强大的社区和众多的插件和Loader来处理各种文件和场景,可以根据不同的需求进行高度的定制。而Vite的生态和可定制性方面要弱于Webpack,它的插件数量还比较少。
总的来说,Vite是一种专门为现代浏览器设计的前端构建工具,它在开发环境下性能卓越,但在生产环境方面还有一些局限。而Webpack则是一种更加稳健和灵活的构建工具,它可以用于各种复杂的场景和需求,并且有着更强大的生态和定制能力,但需要进行更多的配置。选择使用哪种工具,应该根据具体项目需求和使用场景来进行选择。
create-vue和vue-cli的区别:
- vue-cli基于webpack,而create-vue基于vite
import { createApp } from 'vue'
+
+createApp({
+ data() {
+ return {
+ count: 0
+ }
+ }
+}).mount('#app')vue3的模板中可以有多个根节点
api类型不同,vue2使用选项式api,vue3使用组合式api
定义变量和方法方式不同:vue2定义在data和methods节点中,vue3使用setup()方法,此方法在组件初始化构造的时候触发
从vue引入reactive
使用reactive()方法声明数据为响应式数据const state = reactive({ count: 0 })
<script setup>:顶层的导入和变量声明可在同一组件的模板中直接使用。可以理解为模板中的表达式和 script setup中的代码处在同一个作用域中。
使用ref()定义响应式变量,ref() 将传入参数的值包装为一个带 .value 属性的 ref 对象:
import { ref } from 'vue'
+
+const count = ref(0)和响应式对象的属性类似,ref 的 .value 属性也是响应式的。同时,当值为对象类型时,会用 reactive() 自动转换它的 .value。
一个包含对象类型值的 ref 可以响应式地替换整个对象:
js
const objectRef = ref({ count: 0 })
+
+// 这是响应式的替换
+objectRef.value = { count: 1 }响应式
https://cn.vuejs.org/guide/essentials/reactivity-fundamentals.html
类和样式绑定
生命周期变化
ref()
标注类型
import type { Ref } from 'vue'
+
+const count: Ref<number> = ref(0)当 ref 在模板中作为顶层属性被访问时,它们会被自动“解包”,所以不需要使用 .value。
当一个 ref 被嵌套在一个深层响应式对象中,作为属性被访问或更改时,它会自动解包
使用el-upload实现限制上传文件个数、超出数量后后者覆盖前者、自动上传且自行实现上传文件请求,文档写的不清不楚,试了半天都不行,还是看了源码才明白el-upload组件的整个流程。
https://github.com/ElemeFE/element/blob/dev/packages/upload/src/index.vue
https://github.com/ElemeFE/element/blob/dev/packages/upload/src/upload.vue
// index.vue
+render(h) {
+ let uploadList;
+
+ if (this.showFileList) {
+ uploadList = (
+ <UploadList
+ disabled={this.uploadDisabled}
+ listType={this.listType}
+ files={this.uploadFiles}
+ on-remove={this.handleRemove}
+ handlePreview={this.onPreview}>
+ {
+ (props) => {
+ if (this.$scopedSlots.file) {
+ return this.$scopedSlots.file({
+ file: props.file
+ });
+ }
+ }
+ }
+ </UploadList>
+ );
+ }
+
+ const uploadData = {
+ props: {
+ type: this.type,
+ drag: this.drag,
+ action: this.action,
+ multiple: this.multiple,
+ 'before-upload': this.beforeUpload,
+ 'with-credentials': this.withCredentials,
+ headers: this.headers,
+ name: this.name,
+ data: this.data,
+ accept: this.accept,
+ fileList: this.uploadFiles,
+ autoUpload: this.autoUpload,
+ listType: this.listType,
+ disabled: this.uploadDisabled,
+ limit: this.limit,
+ 'on-exceed': this.onExceed,
+ 'on-start': this.handleStart,
+ 'on-progress': this.handleProgress,
+ 'on-success': this.handleSuccess,
+ 'on-error': this.handleError,
+ 'on-preview': this.onPreview,
+ 'on-remove': this.handleRemove,
+ 'http-request': this.httpRequest
+ },
+ ref: 'upload-inner'
+ };
+
+ const trigger = this.$slots.trigger || this.$slots.default;
+ const uploadComponent = <upload {...uploadData}>{trigger}</upload>;
+
+ return (
+ <div>
+ { this.listType === 'picture-card' ? uploadList : ''}
+ {
+ this.$slots.trigger
+ ? [uploadComponent, this.$slots.default]
+ : uploadComponent
+ }
+ {this.$slots.tip}
+ { this.listType !== 'picture-card' ? uploadList : ''}
+ </div>
+ );
+ }// upload.vue
+render(h) {
+ let {
+ handleClick,
+ drag,
+ name,
+ handleChange,
+ multiple,
+ accept,
+ listType,
+ uploadFiles,
+ disabled,
+ handleKeydown
+ } = this;
+ const data = {
+ class: {
+ 'el-upload': true
+ },
+ on: {
+ click: handleClick,
+ keydown: handleKeydown
+ }
+ };
+ data.class[\`el-upload--\${listType}\`] = true;
+ return (
+ <div {...data} tabindex="0" >
+ {
+ drag
+ ? <upload-dragger disabled={disabled} on-file={uploadFiles}>{this.$slots.default}</upload-dragger>
+ : this.$slots.default
+ }
+ <input class="el-upload__input" type="file" ref="input" name={name} on-change={handleChange} multiple={multiple} accept={accept}></input>
+ </div>
+ );
+ }主要关注<input class="el-upload__input" type="file" ref="input" name={name} on-change={handleChange} multiple={multiple} accept={accept}></input>这个jsx代码中绑定了onChange时间,调用函数是handleChange
// upload.vue
+handleChange(ev) {
+ const files = ev.target.files;
+
+ if (!files) return;
+ this.uploadFiles(files);
+}可以看到handleChange直接调用了uploadFiles函数,而uploadFiles函数就是我们要追溯的内容了
uploadFiles(files) {
+ if (this.limit && this.fileList.length + files.length > this.limit) {
+ this.onExceed && this.onExceed(files, this.fileList);
+ return;
+ }
+
+ let postFiles = Array.prototype.slice.call(files);
+ if (!this.multiple) { postFiles = postFiles.slice(0, 1); }
+
+ if (postFiles.length === 0) { return; }
+
+ postFiles.forEach(rawFile => {
+ this.onStart(rawFile);
+ if (this.autoUpload) this.upload(rawFile);
+ });
+},
+upload(rawFile) {
+ this.$refs.input.value = null;
+
+ if (!this.beforeUpload) {
+ return this.post(rawFile);
+ }
+
+ const before = this.beforeUpload(rawFile);
+ if (before && before.then) {
+ before.then(processedFile => {
+ const fileType = Object.prototype.toString.call(processedFile);
+
+ if (fileType === '[object File]' || fileType === '[object Blob]') {
+ if (fileType === '[object Blob]') {
+ processedFile = new File([processedFile], rawFile.name, {
+ type: rawFile.type
+ });
+ }
+ for (const p in rawFile) {
+ if (rawFile.hasOwnProperty(p)) {
+ processedFile[p] = rawFile[p];
+ }
+ }
+ this.post(processedFile);
+ } else {
+ this.post(rawFile);
+ }
+ }, () => {
+ this.onRemove(null, rawFile);
+ });
+ } else if (before !== false) {
+ this.post(rawFile);
+ } else {
+ this.onRemove(null, rawFile);
+ }
+}handleStart(rawFile) {
+ rawFile.uid = Date.now() + this.tempIndex++;
+ let file = {
+ status: 'ready',
+ name: rawFile.name,
+ size: rawFile.size,
+ percentage: 0,
+ uid: rawFile.uid,
+ raw: rawFile
+ };
+
+ if (this.listType === 'picture-card' || this.listType === 'picture') {
+ try {
+ file.url = URL.createObjectURL(rawFile);
+ } catch (err) {
+ console.error('[Element Error][Upload]', err);
+ return;
+ }
+ }
+
+ this.uploadFiles.push(file);
+ this.onChange(file, this.uploadFiles);
+}upload(rawFile) {
+ this.$refs.input.value = null;
+
+ if (!this.beforeUpload) {
+ return this.post(rawFile);
+ }
+
+ const before = this.beforeUpload(rawFile);
+ if (before && before.then) {
+ before.then(processedFile => {
+ const fileType = Object.prototype.toString.call(processedFile);
+
+ if (fileType === '[object File]' || fileType === '[object Blob]') {
+ if (fileType === '[object Blob]') {
+ processedFile = new File([processedFile], rawFile.name, {
+ type: rawFile.type
+ });
+ }
+ for (const p in rawFile) {
+ if (rawFile.hasOwnProperty(p)) {
+ processedFile[p] = rawFile[p];
+ }
+ }
+ this.post(processedFile);
+ } else {
+ this.post(rawFile);
+ }
+ }, () => {
+ this.onRemove(null, rawFile);
+ });
+ } else if (before !== false) {
+ this.post(rawFile);
+ } else {
+ this.onRemove(null, rawFile);
+ }
+}post(rawFile) {
+ const { uid } = rawFile;
+ const options = {
+ headers: this.headers,
+ withCredentials: this.withCredentials,
+ file: rawFile,
+ data: this.data,
+ filename: this.name,
+ action: this.action,
+ onProgress: e => {
+ this.onProgress(e, rawFile);
+ },
+ onSuccess: res => {
+ this.onSuccess(res, rawFile);
+ delete this.reqs[uid];
+ },
+ onError: err => {
+ this.onError(err, rawFile);
+ delete this.reqs[uid];
+ }
+ };
+ const req = this.httpRequest(options);
+ this.reqs[uid] = req;
+ if (req && req.then) {
+ req.then(options.onSuccess, options.onError);
+ }
+},
+handleClick() {
+ if (!this.disabled) {
+ this.$refs.input.value = null;
+ this.$refs.input.click();
+ }
+},
+handleKeydown(e) {
+ if (e.target !== e.currentTarget) return;
+ if (e.keyCode === 13 || e.keyCode === 32) {
+ this.handleClick();
+ }
+}上面分析的是如果没有超过limit限制的情况,而我要实现的就是在超过限制之后依然能够自动上传。
回归到代码,uploadFiles函数在执行了onExceed钩子之后直接就return了,所以下面一直到上传的流程都需要我们自己去调用
uploadFiles(files) {
+ if (this.limit && this.fileList.length + files.length > this.limit) {
+ this.onExceed && this.onExceed(files, this.fileList);
+ return;
+ }
+ //...
+}在回顾下我的目标:限制上传文件个数为一个、超出数量后后者覆盖前者、自动上传且自行实现上传文件请求
所以:终极目标是执行完onExceed后能调用上传的函数,el-upload暴露给我们的函数是submit()
// index.vue
+submit() {
+ this.uploadFiles
+ .filter(file => file.status === 'ready')
+ .forEach(file => {
+ this.$refs['upload-inner'].upload(file.raw);
+ });
+}可以看到这个函数是将uploadFiles中的文件都调用了一次upload,所以我们要在onExceed函数中要做的事:
clearFiles() {
+ this.uploadFiles = [];
+}<template>
+ <el-upload
+ action="#"
+ ref="upload"
+ v-model:file-list="fileList"
+ :limit="Number(1)"
+ :on-exceed="handleExceed"
+ :http-request="handleUpload"
+ list-type="picture-card"
+ :auto-upload="true" >
+ </el-upload>
+</template>
+
+<script setup lang="ts">
+import type { UploadProps, UploadInstance, UploadRawFile } from 'element-plus'
+const upload = ref<UploadInstance>()
+/**
+ * 超过限制后调用的方法
+ * @param files
+ */
+const handleExceed: UploadProps['onExceed'] = (files) => {
+ // 清除所有文件
+ upload.value!.clearFiles()
+ const file = files[0] as UploadRawFile
+ file.uid = genFileId()
+ /**
+ * 调用handleStart把file push到uploadFiles中 -> handleStart会调用onChange方法
+ */
+ upload.value!.handleStart(file)
+ upload.value!.submit()
+}
+</script>使用el-upload实现限制上传文件个数、超出数量后后者覆盖前者、自动上传且自行实现上传文件请求,文档写的不清不楚,试了半天都不行,还是看了源码才明白el-upload组件的整个流程。
https://github.com/ElemeFE/element/blob/dev/packages/upload/src/index.vue
https://github.com/ElemeFE/element/blob/dev/packages/upload/src/upload.vue
// index.vue
+render(h) {
+ let uploadList;
+
+ if (this.showFileList) {
+ uploadList = (
+ <UploadList
+ disabled={this.uploadDisabled}
+ listType={this.listType}
+ files={this.uploadFiles}
+ on-remove={this.handleRemove}
+ handlePreview={this.onPreview}>
+ {
+ (props) => {
+ if (this.$scopedSlots.file) {
+ return this.$scopedSlots.file({
+ file: props.file
+ });
+ }
+ }
+ }
+ </UploadList>
+ );
+ }
+
+ const uploadData = {
+ props: {
+ type: this.type,
+ drag: this.drag,
+ action: this.action,
+ multiple: this.multiple,
+ 'before-upload': this.beforeUpload,
+ 'with-credentials': this.withCredentials,
+ headers: this.headers,
+ name: this.name,
+ data: this.data,
+ accept: this.accept,
+ fileList: this.uploadFiles,
+ autoUpload: this.autoUpload,
+ listType: this.listType,
+ disabled: this.uploadDisabled,
+ limit: this.limit,
+ 'on-exceed': this.onExceed,
+ 'on-start': this.handleStart,
+ 'on-progress': this.handleProgress,
+ 'on-success': this.handleSuccess,
+ 'on-error': this.handleError,
+ 'on-preview': this.onPreview,
+ 'on-remove': this.handleRemove,
+ 'http-request': this.httpRequest
+ },
+ ref: 'upload-inner'
+ };
+
+ const trigger = this.$slots.trigger || this.$slots.default;
+ const uploadComponent = <upload {...uploadData}>{trigger}</upload>;
+
+ return (
+ <div>
+ { this.listType === 'picture-card' ? uploadList : ''}
+ {
+ this.$slots.trigger
+ ? [uploadComponent, this.$slots.default]
+ : uploadComponent
+ }
+ {this.$slots.tip}
+ { this.listType !== 'picture-card' ? uploadList : ''}
+ </div>
+ );
+ }// upload.vue
+render(h) {
+ let {
+ handleClick,
+ drag,
+ name,
+ handleChange,
+ multiple,
+ accept,
+ listType,
+ uploadFiles,
+ disabled,
+ handleKeydown
+ } = this;
+ const data = {
+ class: {
+ 'el-upload': true
+ },
+ on: {
+ click: handleClick,
+ keydown: handleKeydown
+ }
+ };
+ data.class[\`el-upload--\${listType}\`] = true;
+ return (
+ <div {...data} tabindex="0" >
+ {
+ drag
+ ? <upload-dragger disabled={disabled} on-file={uploadFiles}>{this.$slots.default}</upload-dragger>
+ : this.$slots.default
+ }
+ <input class="el-upload__input" type="file" ref="input" name={name} on-change={handleChange} multiple={multiple} accept={accept}></input>
+ </div>
+ );
+ }主要关注<input class="el-upload__input" type="file" ref="input" name={name} on-change={handleChange} multiple={multiple} accept={accept}></input>这个jsx代码中绑定了onChange时间,调用函数是handleChange
// upload.vue
+handleChange(ev) {
+ const files = ev.target.files;
+
+ if (!files) return;
+ this.uploadFiles(files);
+}可以看到handleChange直接调用了uploadFiles函数,而uploadFiles函数就是我们要追溯的内容了
uploadFiles(files) {
+ if (this.limit && this.fileList.length + files.length > this.limit) {
+ this.onExceed && this.onExceed(files, this.fileList);
+ return;
+ }
+
+ let postFiles = Array.prototype.slice.call(files);
+ if (!this.multiple) { postFiles = postFiles.slice(0, 1); }
+
+ if (postFiles.length === 0) { return; }
+
+ postFiles.forEach(rawFile => {
+ this.onStart(rawFile);
+ if (this.autoUpload) this.upload(rawFile);
+ });
+},
+upload(rawFile) {
+ this.$refs.input.value = null;
+
+ if (!this.beforeUpload) {
+ return this.post(rawFile);
+ }
+
+ const before = this.beforeUpload(rawFile);
+ if (before && before.then) {
+ before.then(processedFile => {
+ const fileType = Object.prototype.toString.call(processedFile);
+
+ if (fileType === '[object File]' || fileType === '[object Blob]') {
+ if (fileType === '[object Blob]') {
+ processedFile = new File([processedFile], rawFile.name, {
+ type: rawFile.type
+ });
+ }
+ for (const p in rawFile) {
+ if (rawFile.hasOwnProperty(p)) {
+ processedFile[p] = rawFile[p];
+ }
+ }
+ this.post(processedFile);
+ } else {
+ this.post(rawFile);
+ }
+ }, () => {
+ this.onRemove(null, rawFile);
+ });
+ } else if (before !== false) {
+ this.post(rawFile);
+ } else {
+ this.onRemove(null, rawFile);
+ }
+}handleStart(rawFile) {
+ rawFile.uid = Date.now() + this.tempIndex++;
+ let file = {
+ status: 'ready',
+ name: rawFile.name,
+ size: rawFile.size,
+ percentage: 0,
+ uid: rawFile.uid,
+ raw: rawFile
+ };
+
+ if (this.listType === 'picture-card' || this.listType === 'picture') {
+ try {
+ file.url = URL.createObjectURL(rawFile);
+ } catch (err) {
+ console.error('[Element Error][Upload]', err);
+ return;
+ }
+ }
+
+ this.uploadFiles.push(file);
+ this.onChange(file, this.uploadFiles);
+}upload(rawFile) {
+ this.$refs.input.value = null;
+
+ if (!this.beforeUpload) {
+ return this.post(rawFile);
+ }
+
+ const before = this.beforeUpload(rawFile);
+ if (before && before.then) {
+ before.then(processedFile => {
+ const fileType = Object.prototype.toString.call(processedFile);
+
+ if (fileType === '[object File]' || fileType === '[object Blob]') {
+ if (fileType === '[object Blob]') {
+ processedFile = new File([processedFile], rawFile.name, {
+ type: rawFile.type
+ });
+ }
+ for (const p in rawFile) {
+ if (rawFile.hasOwnProperty(p)) {
+ processedFile[p] = rawFile[p];
+ }
+ }
+ this.post(processedFile);
+ } else {
+ this.post(rawFile);
+ }
+ }, () => {
+ this.onRemove(null, rawFile);
+ });
+ } else if (before !== false) {
+ this.post(rawFile);
+ } else {
+ this.onRemove(null, rawFile);
+ }
+}post(rawFile) {
+ const { uid } = rawFile;
+ const options = {
+ headers: this.headers,
+ withCredentials: this.withCredentials,
+ file: rawFile,
+ data: this.data,
+ filename: this.name,
+ action: this.action,
+ onProgress: e => {
+ this.onProgress(e, rawFile);
+ },
+ onSuccess: res => {
+ this.onSuccess(res, rawFile);
+ delete this.reqs[uid];
+ },
+ onError: err => {
+ this.onError(err, rawFile);
+ delete this.reqs[uid];
+ }
+ };
+ const req = this.httpRequest(options);
+ this.reqs[uid] = req;
+ if (req && req.then) {
+ req.then(options.onSuccess, options.onError);
+ }
+},
+handleClick() {
+ if (!this.disabled) {
+ this.$refs.input.value = null;
+ this.$refs.input.click();
+ }
+},
+handleKeydown(e) {
+ if (e.target !== e.currentTarget) return;
+ if (e.keyCode === 13 || e.keyCode === 32) {
+ this.handleClick();
+ }
+}上面分析的是如果没有超过limit限制的情况,而我要实现的就是在超过限制之后依然能够自动上传。
回归到代码,uploadFiles函数在执行了onExceed钩子之后直接就return了,所以下面一直到上传的流程都需要我们自己去调用
uploadFiles(files) {
+ if (this.limit && this.fileList.length + files.length > this.limit) {
+ this.onExceed && this.onExceed(files, this.fileList);
+ return;
+ }
+ //...
+}在回顾下我的目标:限制上传文件个数为一个、超出数量后后者覆盖前者、自动上传且自行实现上传文件请求
所以:终极目标是执行完onExceed后能调用上传的函数,el-upload暴露给我们的函数是submit()
// index.vue
+submit() {
+ this.uploadFiles
+ .filter(file => file.status === 'ready')
+ .forEach(file => {
+ this.$refs['upload-inner'].upload(file.raw);
+ });
+}可以看到这个函数是将uploadFiles中的文件都调用了一次upload,所以我们要在onExceed函数中要做的事:
clearFiles() {
+ this.uploadFiles = [];
+}<template>
+ <el-upload
+ action="#"
+ ref="upload"
+ v-model:file-list="fileList"
+ :limit="Number(1)"
+ :on-exceed="handleExceed"
+ :http-request="handleUpload"
+ list-type="picture-card"
+ :auto-upload="true" >
+ </el-upload>
+</template>
+
+<script setup lang="ts">
+import type { UploadProps, UploadInstance, UploadRawFile } from 'element-plus'
+const upload = ref<UploadInstance>()
+/**
+ * 超过限制后调用的方法
+ * @param files
+ */
+const handleExceed: UploadProps['onExceed'] = (files) => {
+ // 清除所有文件
+ upload.value!.clearFiles()
+ const file = files[0] as UploadRawFile
+ file.uid = genFileId()
+ /**
+ * 调用handleStart把file push到uploadFiles中 -> handleStart会调用onChange方法
+ */
+ upload.value!.handleStart(file)
+ upload.value!.submit()
+}
+</script>https://www.youtube.com/playlist?list=PLuoeXyslFTuZRi4q4VT6lZKxYbr7so1Mr
struct ContentView: View {
+ @State private var checkAmount = 0.0
+ @State private var numberOfPeople = 0
+ @State private var tipPercentage = 20
+ @FocusState private var amountIsFocused: Bool
+
+ private var totalPerPerson: Double {
+ let peopleCount = Double(numberOfPeople + 2)
+ let tipSelection = Double(tipPercentage)
+ return checkAmount * tipSelection / peopleCount / 100
+ }
+
+ let tipPercentages = [10, 15, 20, 25, 0]
+
+ var body: some View {
+ NavigationView {
+ Form {
+ Section("") {
+ TextField("Amount", value: $checkAmount, format: .currency(code: Locale.current.currencyCode ?? "USD"))
+ .keyboardType(.decimalPad)
+ .focused($amountIsFocused)
+
+ Picker("Number of people", selection: $numberOfPeople) {
+ ForEach(2..<100) {
+ Text("\\($0) people")
+ }
+ }
+ }
+
+ Section {
+ Picker("Tip percentage", selection: $tipPercentage) {
+ ForEach(tipPercentages, id: \\.self) {
+ Text($0, format: .percent)
+ }
+ }
+ .pickerStyle(.segmented)
+ }header: {
+ Text("How much tip do you want to leave")
+ }
+
+ Section {
+ Text(totalPerPerson, format: .currency(code: Locale.current.currencyCode ?? "USD"))
+ }
+ }
+ .navigationTitle("WeSplit")
+ .toolbar {
+ ToolbarItemGroup(placement: .keyboard) {
+ Spacer()
+ Button("Done") {
+ amountIsFocused = false
+ }
+ }
+ }
+ }
+ }
+}Form
TextField & format: .currency(code: Locale.current.currencyCode ?? "USD")
Picker
Section
toolbar修饰符
struct ContentView: View {
+ @State private var showScores = false
+ @State private var scoreTitle = ""
+
+ @State private var scores = 0
+
+ @State private var countries = ["Estonia", "France", "Germany", "Ireland", "Italy", "Nigeria",
+ "Poland", "Russia", "Spain", "UK", "US"].shuffled()
+ @State var correctAnswer = Int.random(in: 0...2)
+
+ var body: some View {
+ ZStack {
+ //AngularGradient(gradient: Gradient(colors: [.red, .yellow, .green,.blue, .purple,.red]), center: .center)
+ RadialGradient(stops: [
+ .init(color: Color(red: 0.1, green: 0.2, blue: 0.45), location: 0.3),
+ .init(color: Color(red: 0.76, green: 0.15, blue: 0.26), location: 0.3)
+ ], center: .top, startRadius: 200, endRadius: 700)
+ .ignoresSafeArea()
+
+ VStack {
+
+ Spacer()
+
+ Text("Guess the flag")
+ .font(.largeTitle.weight(.bold))
+ .foregroundColor(.white)
+
+ VStack(spacing: 15) {
+ VStack{
+ Text("Tap the flag of")
+ .foregroundStyle(.secondary)
+ .font(.subheadline.weight(.heavy))
+ Text(countries[correctAnswer])
+ .font(.largeTitle.weight(.semibold))
+ }
+
+ ForEach(0..<3) {number in
+ Button {
+ flagTapper(number)
+ }label: {
+ Image(countries[number])
+ .renderingMode(.original)
+ .clipShape(Capsule())
+ }
+ }
+ }
+ .frame(maxWidth: .infinity)
+ .padding(.vertical, 20)
+ .background(.regularMaterial)
+ .clipShape(RoundedRectangle(cornerRadius: 20))
+
+ Spacer()
+
+ Text("Score \\(scores)")
+ .foregroundColor(.white)
+ .font(.title.bold())
+ Spacer()
+ }
+ .padding()
+ }
+ .alert(scoreTitle, isPresented: $showScores) {
+ Button("Continue", action: askQuestion)
+ } message: {
+ Text("Your score is \\(scores)")
+ }
+ }
+ func flagTapper(_ number: Int) {
+ if number == correctAnswer {
+ scoreTitle = "Correct"
+ scores += 10
+ } else {
+ scoreTitle = "Wrong"
+ }
+ showScores = true
+ }
+
+ func askQuestion() {
+
+ countries.shuffle()
+ correctAnswer = Int.random(in: 0...2)
+ }
+}
import CoreML
+import SwiftUI
+
+struct ContentView: View {
+ @State private var wakeUp = defaultWakeTime
+ @State private var sleepAmount = 8.0
+ @State private var coffeeAmount = 1
+
+ @State private var alertTitle = ""
+ @State private var alertMessage = ""
+ @State private var showingAlert = false
+
+ static var defaultWakeTime: Date {
+ var components = DateComponents()
+ components.hour = 7
+ components.minute = 0
+ return Calendar.current.date(from: components) ?? Date.now
+ }
+
+ var body: some View {
+ NavigationView {
+ Form {
+ VStack(alignment: .leading, spacing: 0) {
+ Text("When do you want to wake up?")
+ .font(.headline)
+ DatePicker("Please enter atime", selection: $wakeUp, displayedComponents: .hourAndMinute)
+ .labelsHidden()
+ }
+
+
+ VStack(alignment: .leading, spacing: 0) {
+ Text("Desired amount of sleep")
+ .font(.headline)
+ Stepper("\\(sleepAmount.formatted()) hours", value: $sleepAmount, in: 4...12, step: 0.25)
+ }
+
+
+ VStack(alignment: .leading, spacing: 0) {
+ Text("Daily coffee intake")
+ Stepper(coffeeAmount == 1 ? "1 cup" : "\\(coffeeAmount) cups", value: $coffeeAmount, in: 0...20)
+ }
+
+ }
+ .navigationTitle("BetterRest")
+ .toolbar {
+ Button("Calculate", action: calculateBedtime)
+ }
+ .alert(alertTitle, isPresented: $showingAlert) {
+ Button("OK") {}
+ }message: {
+ Text(alertMessage)
+ }
+ }
+
+ }
+
+ func calculateBedtime() {
+ do {
+ let config = MLModelConfiguration()
+ let model = try SleepCalculator(configuration: config)
+ let components = Calendar.current.dateComponents([.hour, .minute], from: wakeUp)
+ let hour = (components.hour ?? 0) * 60 * 60
+ let minute = (components.minute ?? 0) * 60
+
+ let prediction = try model.prediction(wake: Double(hour + minute), estimatedSleep: sleepAmount, coffee: Double(coffeeAmount))
+
+ let sleepTime = wakeUp - prediction.actualSleep
+ alertTitle = "Your ideal bedtime is ..."
+ alertMessage = sleepTime.formatted(date: .omitted, time: .shortened)
+ }catch {
+ alertTitle = "Error"
+ alertMessage = "Sorry, there was a problem calculating your bedtime."
+ }
+
+ showingAlert = true
+ }
+}CoreML机器学习
DateComponents、DatePicker
alert修饰符
Stepper
struct ContentView: View {
+ @State private var usedWords = [String]()
+ @State private var rootWord = ""
+ @State private var newWord = ""
+
+ @State private var errorTitle = ""
+ @State private var errorMessage = ""
+ @State private var showingError = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ Section {
+ TextField("enter your word", text: $newWord)
+ .autocapitalization(.none)
+ }
+
+ Section {
+ ForEach(usedWords, id: \\.self) { word in
+ HStack{
+ Image(systemName: "\\(word.count).circle")
+ Text(word)
+ }
+ }
+ }
+ }
+ .navigationTitle(rootWord)
+ .onSubmit(addNewWord)
+ .onAppear(perform: startGame)
+ .alert(errorTitle, isPresented: $showingError) {
+ Button("OK", role: .cancel) {}
+ }message: {
+ Text(errorMessage)
+ }
+ }
+ }
+
+ func addNewWord() {
+ let answer = newWord.lowercased().trimmingCharacters(in: .whitespacesAndNewlines)
+ guard answer.count > 0 else { return }
+
+ guard isOriginal(word: answer) else {
+ wordError(title: "Word used already", message: "Be more original")
+ return
+ }
+
+ guard isPossible(word: answer) else {
+ wordError(title: "word not possible", message: "you can't spell that word from '\\(rootWord)'")
+ return
+ }
+
+ guard isReal(word: answer) else {
+ wordError(title: "word not recognized", message: "you can't just make them up, you know!")
+ return
+ }
+
+
+ withAnimation{
+ usedWords.insert(answer, at: 0)
+ }
+
+ newWord = ""
+ }
+
+ func startGame() {
+ if let fileURL = Bundle.main.url(forResource: "start", withExtension: "txt") {
+ if let startWords = try? String(contentsOf: fileURL) {
+ let allWords = startWords.components(separatedBy: "\\n")
+ rootWord = allWords.randomElement() ?? "silkworm"
+ return
+ }
+ }
+ fatalError("Could not load start.txt from bundle")
+ }
+
+ func isOriginal(word: String) -> Bool {
+ !usedWords.contains(word)
+ }
+
+ func isPossible(word: String) -> Bool {
+ var tempWord = rootWord
+
+ for letter in word {
+ if let pos = tempWord.firstIndex(of: letter) {
+ tempWord.remove(at: pos)
+ } else {
+ return false
+ }
+ }
+ return true
+ }
+
+ func isReal(word: String) -> Bool {
+ let checker = UITextChecker()
+ let range = NSRange(location: 0, length: word.utf16.count)
+ let misspelledRange = checker.rangeOfMisspelledWord(in: word, range: range, startingAt: 0, wrap: false, language: "en")
+
+ return misspelledRange.location == NSNotFound
+ }
+
+ func wordError(title: String, message: String) {
+ errorTitle = title
+ errorMessage = message
+ showingError = true
+ }
+}TextField("enter your word", text: $newWord).autocapitalization(.none)
onSubmit、onAppear修饰符
读取静态资源
if let fileURL = Bundle.main.url(forResource: "start", withExtension: "txt") {
+ if let startWords = try? String(contentsOf: fileURL) {
+ let allWords = startWords.components(separatedBy: "\\n")
+ rootWord = allWords.randomElement() ?? "silkworm"
+ return
+ }
+ }
+ fatalError("Could not load start.txt from bundle")UITextChecker()
Expenses(ViewModel)
class Expenses: ObservableObject {
+ @Published var items = [ExpenseItem]() {
+ didSet {
+ let encoder = JSONEncoder()
+
+ if let encoded = try? encoder.encode(items) {
+ UserDefaults.standard.set(encoded, forKey: "Items")
+ }
+ }
+ }
+
+ init() {
+ if let itemArr = UserDefaults.standard.data(forKey: "Items") {
+ let decoder = JSONDecoder()
+ if let decodedItems = try? decoder.decode([ExpenseItem].self, from: itemArr) {
+ items = decodedItems
+ return
+ }
+ }
+ items = []
+ }
+}ExpenseItem(Model)
struct ExpenseItem: Identifiable, Codable {
+ let name: String
+ let type: String
+ let amount: Double
+ let id = UUID()
+}AddView
struct AddView: View {
+ @ObservedObject var expenses: Expenses
+
+ @State private var name = ""
+ @State private var type = "Personal"
+ @State private var amount = 0.0
+ @Environment(\\.dismiss) var dismiss
+
+ let types = ["Business", "Personal"]
+
+
+ var body: some View {
+ NavigationView {
+ Form {
+ TextField("Name", text: $name)
+
+ Picker("Type", selection: $type) {
+ ForEach(types, id: \\.self) {
+ Text($0)
+ }
+ }
+
+ TextField("Amount", value: $amount, format: .currency(code: Locale.current.currencyCode ?? "CNY"))
+ .keyboardType(.decimalPad)
+ }
+ .navigationTitle("Add new expense")
+ .toolbar {
+ Button("Save") {
+ let item = ExpenseItem(name: name, type: type, amount: amount)
+ expenses.items.append(item)
+ dismiss()
+ }
+ }
+ }
+ }
+}ContentView
struct ContentView: View {
+ @StateObject var expenses = Expenses()
+ @State private var showingAddExpense = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ ForEach(expenses.items) { item in
+ HStack {
+ VStack(alignment: .leading) {
+ Text(item.name)
+ .font(.headline)
+ Text(item.type)
+ .font(.subheadline)
+ }
+ Spacer()
+ Text(item.amount, format: .currency(code: Locale.current.currencyCode ?? "CNY"))
+ }
+ }
+ .onDelete(perform: removeItems)
+ }
+ .navigationTitle("iExpense")
+ .toolbar {
+ Button {
+ showingAddExpense = true
+ } label: {
+ Image(systemName: "plus")
+ }
+ }
+ .sheet(isPresented: $showingAddExpense) {
+ AddView(expenses: expenses)
+
+ }
+ }
+ }
+
+ func removeItems(at offsets: IndexSet) {
+ expenses.items.remove(atOffsets: offsets)
+ }
+}MVVM
@StateObject、@Published、ObservableObject、@ObservedObject
UserDefaults(存储少量数据,常用于存储Preference)
JSONEncoder、JSONDecoder、Codable
属性观察器(willSet、didSet) 配合 UserDefaults保存数据
onDelete修饰符
sheet修饰符(弹出新页面)
.sheet(isPresented: $showingAddExpense) {
+ AddView(expenses: expenses)
+}@Environment(.dismiss) var dismiss(@Environment(keyPath) 可以读取系统环境数据,dismiss用于关闭当前展示页面)
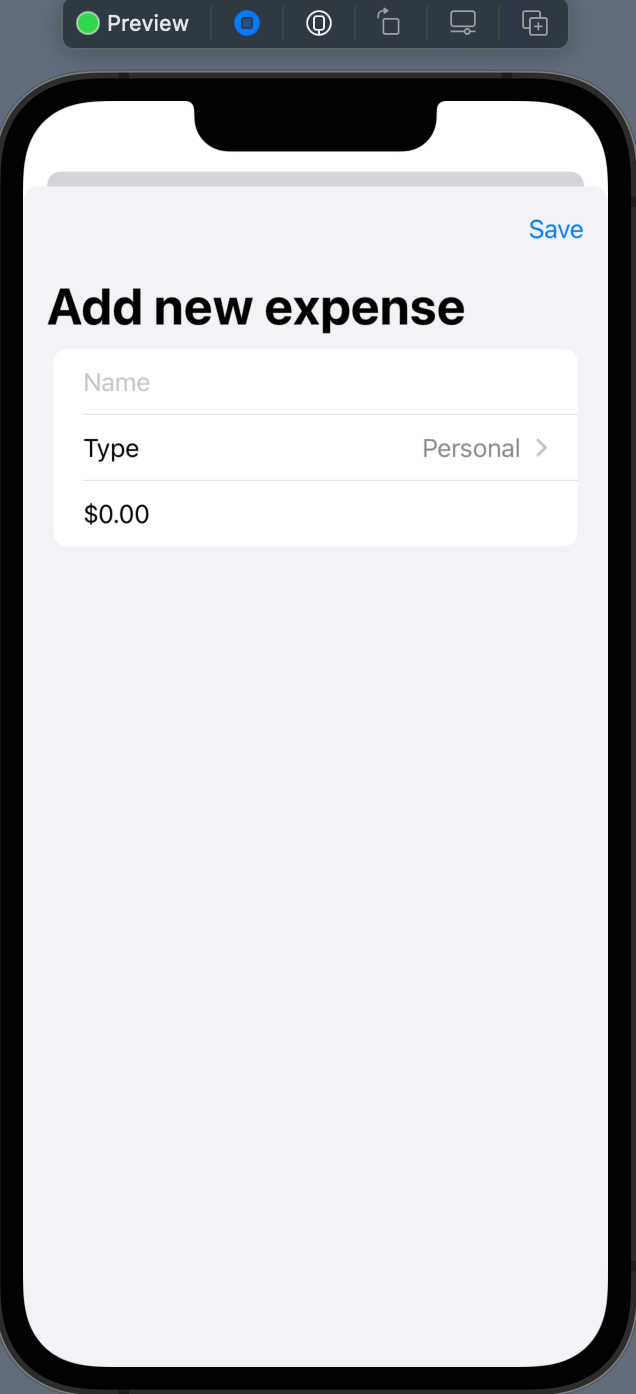
https://www.youtube.com/playlist?list=PLuoeXyslFTuZRi4q4VT6lZKxYbr7so1Mr
struct ContentView: View {
+ @State private var checkAmount = 0.0
+ @State private var numberOfPeople = 0
+ @State private var tipPercentage = 20
+ @FocusState private var amountIsFocused: Bool
+
+ private var totalPerPerson: Double {
+ let peopleCount = Double(numberOfPeople + 2)
+ let tipSelection = Double(tipPercentage)
+ return checkAmount * tipSelection / peopleCount / 100
+ }
+
+ let tipPercentages = [10, 15, 20, 25, 0]
+
+ var body: some View {
+ NavigationView {
+ Form {
+ Section("") {
+ TextField("Amount", value: $checkAmount, format: .currency(code: Locale.current.currencyCode ?? "USD"))
+ .keyboardType(.decimalPad)
+ .focused($amountIsFocused)
+
+ Picker("Number of people", selection: $numberOfPeople) {
+ ForEach(2..<100) {
+ Text("\\($0) people")
+ }
+ }
+ }
+
+ Section {
+ Picker("Tip percentage", selection: $tipPercentage) {
+ ForEach(tipPercentages, id: \\.self) {
+ Text($0, format: .percent)
+ }
+ }
+ .pickerStyle(.segmented)
+ }header: {
+ Text("How much tip do you want to leave")
+ }
+
+ Section {
+ Text(totalPerPerson, format: .currency(code: Locale.current.currencyCode ?? "USD"))
+ }
+ }
+ .navigationTitle("WeSplit")
+ .toolbar {
+ ToolbarItemGroup(placement: .keyboard) {
+ Spacer()
+ Button("Done") {
+ amountIsFocused = false
+ }
+ }
+ }
+ }
+ }
+}Form
TextField & format: .currency(code: Locale.current.currencyCode ?? "USD")
Picker
Section
toolbar修饰符
struct ContentView: View {
+ @State private var showScores = false
+ @State private var scoreTitle = ""
+
+ @State private var scores = 0
+
+ @State private var countries = ["Estonia", "France", "Germany", "Ireland", "Italy", "Nigeria",
+ "Poland", "Russia", "Spain", "UK", "US"].shuffled()
+ @State var correctAnswer = Int.random(in: 0...2)
+
+ var body: some View {
+ ZStack {
+ //AngularGradient(gradient: Gradient(colors: [.red, .yellow, .green,.blue, .purple,.red]), center: .center)
+ RadialGradient(stops: [
+ .init(color: Color(red: 0.1, green: 0.2, blue: 0.45), location: 0.3),
+ .init(color: Color(red: 0.76, green: 0.15, blue: 0.26), location: 0.3)
+ ], center: .top, startRadius: 200, endRadius: 700)
+ .ignoresSafeArea()
+
+ VStack {
+
+ Spacer()
+
+ Text("Guess the flag")
+ .font(.largeTitle.weight(.bold))
+ .foregroundColor(.white)
+
+ VStack(spacing: 15) {
+ VStack{
+ Text("Tap the flag of")
+ .foregroundStyle(.secondary)
+ .font(.subheadline.weight(.heavy))
+ Text(countries[correctAnswer])
+ .font(.largeTitle.weight(.semibold))
+ }
+
+ ForEach(0..<3) {number in
+ Button {
+ flagTapper(number)
+ }label: {
+ Image(countries[number])
+ .renderingMode(.original)
+ .clipShape(Capsule())
+ }
+ }
+ }
+ .frame(maxWidth: .infinity)
+ .padding(.vertical, 20)
+ .background(.regularMaterial)
+ .clipShape(RoundedRectangle(cornerRadius: 20))
+
+ Spacer()
+
+ Text("Score \\(scores)")
+ .foregroundColor(.white)
+ .font(.title.bold())
+ Spacer()
+ }
+ .padding()
+ }
+ .alert(scoreTitle, isPresented: $showScores) {
+ Button("Continue", action: askQuestion)
+ } message: {
+ Text("Your score is \\(scores)")
+ }
+ }
+ func flagTapper(_ number: Int) {
+ if number == correctAnswer {
+ scoreTitle = "Correct"
+ scores += 10
+ } else {
+ scoreTitle = "Wrong"
+ }
+ showScores = true
+ }
+
+ func askQuestion() {
+
+ countries.shuffle()
+ correctAnswer = Int.random(in: 0...2)
+ }
+}
import CoreML
+import SwiftUI
+
+struct ContentView: View {
+ @State private var wakeUp = defaultWakeTime
+ @State private var sleepAmount = 8.0
+ @State private var coffeeAmount = 1
+
+ @State private var alertTitle = ""
+ @State private var alertMessage = ""
+ @State private var showingAlert = false
+
+ static var defaultWakeTime: Date {
+ var components = DateComponents()
+ components.hour = 7
+ components.minute = 0
+ return Calendar.current.date(from: components) ?? Date.now
+ }
+
+ var body: some View {
+ NavigationView {
+ Form {
+ VStack(alignment: .leading, spacing: 0) {
+ Text("When do you want to wake up?")
+ .font(.headline)
+ DatePicker("Please enter atime", selection: $wakeUp, displayedComponents: .hourAndMinute)
+ .labelsHidden()
+ }
+
+
+ VStack(alignment: .leading, spacing: 0) {
+ Text("Desired amount of sleep")
+ .font(.headline)
+ Stepper("\\(sleepAmount.formatted()) hours", value: $sleepAmount, in: 4...12, step: 0.25)
+ }
+
+
+ VStack(alignment: .leading, spacing: 0) {
+ Text("Daily coffee intake")
+ Stepper(coffeeAmount == 1 ? "1 cup" : "\\(coffeeAmount) cups", value: $coffeeAmount, in: 0...20)
+ }
+
+ }
+ .navigationTitle("BetterRest")
+ .toolbar {
+ Button("Calculate", action: calculateBedtime)
+ }
+ .alert(alertTitle, isPresented: $showingAlert) {
+ Button("OK") {}
+ }message: {
+ Text(alertMessage)
+ }
+ }
+
+ }
+
+ func calculateBedtime() {
+ do {
+ let config = MLModelConfiguration()
+ let model = try SleepCalculator(configuration: config)
+ let components = Calendar.current.dateComponents([.hour, .minute], from: wakeUp)
+ let hour = (components.hour ?? 0) * 60 * 60
+ let minute = (components.minute ?? 0) * 60
+
+ let prediction = try model.prediction(wake: Double(hour + minute), estimatedSleep: sleepAmount, coffee: Double(coffeeAmount))
+
+ let sleepTime = wakeUp - prediction.actualSleep
+ alertTitle = "Your ideal bedtime is ..."
+ alertMessage = sleepTime.formatted(date: .omitted, time: .shortened)
+ }catch {
+ alertTitle = "Error"
+ alertMessage = "Sorry, there was a problem calculating your bedtime."
+ }
+
+ showingAlert = true
+ }
+}CoreML机器学习
DateComponents、DatePicker
alert修饰符
Stepper
struct ContentView: View {
+ @State private var usedWords = [String]()
+ @State private var rootWord = ""
+ @State private var newWord = ""
+
+ @State private var errorTitle = ""
+ @State private var errorMessage = ""
+ @State private var showingError = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ Section {
+ TextField("enter your word", text: $newWord)
+ .autocapitalization(.none)
+ }
+
+ Section {
+ ForEach(usedWords, id: \\.self) { word in
+ HStack{
+ Image(systemName: "\\(word.count).circle")
+ Text(word)
+ }
+ }
+ }
+ }
+ .navigationTitle(rootWord)
+ .onSubmit(addNewWord)
+ .onAppear(perform: startGame)
+ .alert(errorTitle, isPresented: $showingError) {
+ Button("OK", role: .cancel) {}
+ }message: {
+ Text(errorMessage)
+ }
+ }
+ }
+
+ func addNewWord() {
+ let answer = newWord.lowercased().trimmingCharacters(in: .whitespacesAndNewlines)
+ guard answer.count > 0 else { return }
+
+ guard isOriginal(word: answer) else {
+ wordError(title: "Word used already", message: "Be more original")
+ return
+ }
+
+ guard isPossible(word: answer) else {
+ wordError(title: "word not possible", message: "you can't spell that word from '\\(rootWord)'")
+ return
+ }
+
+ guard isReal(word: answer) else {
+ wordError(title: "word not recognized", message: "you can't just make them up, you know!")
+ return
+ }
+
+
+ withAnimation{
+ usedWords.insert(answer, at: 0)
+ }
+
+ newWord = ""
+ }
+
+ func startGame() {
+ if let fileURL = Bundle.main.url(forResource: "start", withExtension: "txt") {
+ if let startWords = try? String(contentsOf: fileURL) {
+ let allWords = startWords.components(separatedBy: "\\n")
+ rootWord = allWords.randomElement() ?? "silkworm"
+ return
+ }
+ }
+ fatalError("Could not load start.txt from bundle")
+ }
+
+ func isOriginal(word: String) -> Bool {
+ !usedWords.contains(word)
+ }
+
+ func isPossible(word: String) -> Bool {
+ var tempWord = rootWord
+
+ for letter in word {
+ if let pos = tempWord.firstIndex(of: letter) {
+ tempWord.remove(at: pos)
+ } else {
+ return false
+ }
+ }
+ return true
+ }
+
+ func isReal(word: String) -> Bool {
+ let checker = UITextChecker()
+ let range = NSRange(location: 0, length: word.utf16.count)
+ let misspelledRange = checker.rangeOfMisspelledWord(in: word, range: range, startingAt: 0, wrap: false, language: "en")
+
+ return misspelledRange.location == NSNotFound
+ }
+
+ func wordError(title: String, message: String) {
+ errorTitle = title
+ errorMessage = message
+ showingError = true
+ }
+}TextField("enter your word", text: $newWord).autocapitalization(.none)
onSubmit、onAppear修饰符
读取静态资源
if let fileURL = Bundle.main.url(forResource: "start", withExtension: "txt") {
+ if let startWords = try? String(contentsOf: fileURL) {
+ let allWords = startWords.components(separatedBy: "\\n")
+ rootWord = allWords.randomElement() ?? "silkworm"
+ return
+ }
+ }
+ fatalError("Could not load start.txt from bundle")UITextChecker()
Expenses(ViewModel)
class Expenses: ObservableObject {
+ @Published var items = [ExpenseItem]() {
+ didSet {
+ let encoder = JSONEncoder()
+
+ if let encoded = try? encoder.encode(items) {
+ UserDefaults.standard.set(encoded, forKey: "Items")
+ }
+ }
+ }
+
+ init() {
+ if let itemArr = UserDefaults.standard.data(forKey: "Items") {
+ let decoder = JSONDecoder()
+ if let decodedItems = try? decoder.decode([ExpenseItem].self, from: itemArr) {
+ items = decodedItems
+ return
+ }
+ }
+ items = []
+ }
+}ExpenseItem(Model)
struct ExpenseItem: Identifiable, Codable {
+ let name: String
+ let type: String
+ let amount: Double
+ let id = UUID()
+}AddView
struct AddView: View {
+ @ObservedObject var expenses: Expenses
+
+ @State private var name = ""
+ @State private var type = "Personal"
+ @State private var amount = 0.0
+ @Environment(\\.dismiss) var dismiss
+
+ let types = ["Business", "Personal"]
+
+
+ var body: some View {
+ NavigationView {
+ Form {
+ TextField("Name", text: $name)
+
+ Picker("Type", selection: $type) {
+ ForEach(types, id: \\.self) {
+ Text($0)
+ }
+ }
+
+ TextField("Amount", value: $amount, format: .currency(code: Locale.current.currencyCode ?? "CNY"))
+ .keyboardType(.decimalPad)
+ }
+ .navigationTitle("Add new expense")
+ .toolbar {
+ Button("Save") {
+ let item = ExpenseItem(name: name, type: type, amount: amount)
+ expenses.items.append(item)
+ dismiss()
+ }
+ }
+ }
+ }
+}ContentView
struct ContentView: View {
+ @StateObject var expenses = Expenses()
+ @State private var showingAddExpense = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ ForEach(expenses.items) { item in
+ HStack {
+ VStack(alignment: .leading) {
+ Text(item.name)
+ .font(.headline)
+ Text(item.type)
+ .font(.subheadline)
+ }
+ Spacer()
+ Text(item.amount, format: .currency(code: Locale.current.currencyCode ?? "CNY"))
+ }
+ }
+ .onDelete(perform: removeItems)
+ }
+ .navigationTitle("iExpense")
+ .toolbar {
+ Button {
+ showingAddExpense = true
+ } label: {
+ Image(systemName: "plus")
+ }
+ }
+ .sheet(isPresented: $showingAddExpense) {
+ AddView(expenses: expenses)
+
+ }
+ }
+ }
+
+ func removeItems(at offsets: IndexSet) {
+ expenses.items.remove(atOffsets: offsets)
+ }
+}MVVM
@StateObject、@Published、ObservableObject、@ObservedObject
UserDefaults(存储少量数据,常用于存储Preference)
JSONEncoder、JSONDecoder、Codable
属性观察器(willSet、didSet) 配合 UserDefaults保存数据
onDelete修饰符
sheet修饰符(弹出新页面)
.sheet(isPresented: $showingAddExpense) {
+ AddView(expenses: expenses)
+}@Environment(.dismiss) var dismiss(@Environment(keyPath) 可以读取系统环境数据,dismiss用于关闭当前展示页面)
https://www.youtube.com/playlist?list=PLuoeXyslFTuZRi4q4VT6lZKxYbr7so1Mr
Bundle-Decodable
extension Bundle {
+ func decode<T: Decodable>(_ file: String) -> T {
+ guard let url = self.url(forResource: file, withExtension: nil) else {
+ fatalError("Failed to locate \\(file) in bundle")
+ }
+
+ guard let data = try? Data(contentsOf: url) else {
+ fatalError("Failed to locate \\(file) in bundle")
+ }
+
+ let decoder = JSONDecoder()
+ let formatter = DateFormatter()
+ formatter.dateFormat = "y-MM-dd"
+ decoder.dateDecodingStrategy = .formatted(formatter)
+
+ guard let loaded = try? decoder.decode( T.self, from: data) else {
+ fatalError("Failed to locate \\(file) in bundle")
+ }
+
+ return loaded
+ }
+}Color-Theme
import SwiftUI
+
+extension ShapeStyle where Self == Color {
+ static var darkBackground: Color {
+ Color(red: 0.1, green: 0.1, blue: 0.2)
+ }
+
+ static var lightBackgroud: Color {
+ Color(red: 0.2, green: 0.2, blue: 0.3)
+ }
+}Model
struct Astronaut: Codable, Identifiable {
+ let id: String
+ let name: String
+ let description: String
+}
+
+
+struct Mission: Codable, Identifiable {
+ struct CrewRole: Codable {
+ let name: String
+ let role: String
+ }
+
+ let id: Int
+ let launchDate: Date?
+ let crew: [CrewRole]
+ let description: String
+
+ var displayName: String {
+ "Apollo \\(id)"
+ }
+
+ var image: String {
+ "apollo\\(id)"
+ }
+
+ var formattedLaunchDate: String {
+ launchDate?.formatted(date: .abbreviated, time: .omitted) ?? "N/A"
+ }
+}ContentView
struct ContentView: View {
+ let astronauts: [String: Astronaut] = Bundle.main.decode("astronauts.json")
+ let missions: [Mission] = Bundle.main.decode("missions.json")
+
+ let columns = [
+ GridItem(.adaptive(minimum: 150))
+ ]
+
+ var body: some View {
+ NavigationView {
+ ScrollView {
+ LazyVGrid(columns: columns) {
+ ForEach(missions) { mission in
+ NavigationLink{
+ MissionView(mission: mission, astronauts: astronauts)
+ } label: {
+ VStack{
+ Image(mission.image)
+ .resizable()
+ .scaledToFit()
+ .frame(width: 100, height: 100)
+ VStack {
+ Text(mission.displayName)
+ .font(.headline)
+ .foregroundColor(.white)
+
+ Text(mission.formattedLaunchDate)
+ .font(.subheadline)
+ .foregroundColor(.white.opacity(0.5))
+ }
+ .padding(.vertical)
+ .frame(maxWidth: .infinity)
+ .background(.lightBackgroud)
+ }
+ .clipShape(RoundedRectangle(cornerRadius: 10))
+ .overlay{
+ RoundedRectangle(cornerRadius: 10)
+ .stroke()
+ }
+ }
+ }
+ }
+ .padding([.horizontal, .bottom])
+ }
+ .navigationTitle("Moonshot")
+ .background(.darkBackground)
+ .preferredColorScheme(.dark)
+ }
+ }
+}MissionView
struct MissionView: View {
+ struct CrewMember {
+ let role: String
+ let astronaut: Astronaut
+ }
+
+
+ let mission: Mission
+
+ let crew: [CrewMember]
+
+ var body: some View {
+ GeometryReader { geometry in
+ ScrollView {
+ VStack {
+ Image(mission.image)
+ .resizable()
+ .scaledToFit()
+ .frame(maxWidth: geometry.size.width * 0.6)
+ .padding(.top)
+
+ VStack(alignment: .leading) {
+ Rectangle()
+ .frame(height: 2)
+ .foregroundColor(.lightBackgroud)
+ .padding(.vertical)
+
+ Text("Mission Highlights")
+ .font(.title.bold())
+ .padding(.bottom, 5)
+
+ Text(mission.description)
+ Rectangle()
+ .frame(height: 2)
+ .foregroundColor(.lightBackgroud)
+ .padding(.vertical)
+
+ Text("Crew")
+ .font(.title.bold())
+ .padding(.bottom, 5)
+ }
+ .padding(.horizontal)
+
+
+
+
+
+ ScrollView(.horizontal, showsIndicators: false) {
+ HStack {
+ ForEach(crew, id: \\.role) { crewMember in
+ NavigationLink {
+ AstronautView(astronaut: crewMember.astronaut)
+ }label: {
+ HStack {
+ Image(crewMember.astronaut.id)
+ .resizable()
+ .frame(width: 104, height: 72)
+ .clipShape(Capsule())
+ .overlay{
+ Capsule()
+ .strokeBorder(.white, lineWidth: 1)
+ }
+ VStack(alignment: .leading) {
+ Text(crewMember.astronaut.name)
+ .foregroundColor(.white)
+ .font(.headline)
+
+ Text(crewMember.role)
+ .foregroundColor(.secondary)
+
+ }
+ }
+ }
+ }
+
+ }
+ }
+ .padding(.horizontal)
+ }
+ .padding(.bottom)
+ }
+ .navigationTitle(mission.displayName)
+ .navigationBarTitleDisplayMode(.inline)
+ .background(.darkBackground)
+ }
+
+ }
+
+
+ init(mission: Mission, astronauts: [String: Astronaut]) {
+ self.mission = mission
+
+ self.crew = mission.crew.map { member in
+ if let astronaut = astronauts[member.name] {
+ return CrewMember(role: member.role, astronaut: astronaut)
+ }else {
+ fatalError("Missing \\(member.name)")
+ }
+ }
+ }
+}AstronautView
struct AstronautView: View {
+ let astronaut: Astronaut
+
+ var body: some View {
+ ScrollView {
+ VStack {
+ Image(astronaut.id)
+ .resizable()
+ .scaledToFit()
+
+
+ Text(astronaut.description)
+ .padding()
+
+
+ }
+
+ }
+ .background(.darkBackground)
+ .navigationTitle(astronaut.name)
+ .navigationBarTitleDisplayMode(.inline)
+ }
+}


Order
class Order: ObservableObject, Codable {
+
+ enum CodingKeys: CodingKey {
+ case type, quantity, extraFrosting, addSprinkles, name, streetAddress, city, zip
+ }
+
+ static let types = ["Vanilla", "Strawberry", "Chocolate", "Rainbow"]
+
+ @Published var type = 0
+ @Published var quantity = 3
+ @Published var specialRequestEnabled = false {
+ didSet {
+ if specialRequestEnabled == false {
+ extraFrosting = false
+ addSprinkles = false
+ }
+ }
+ }
+ @Published var extraFrosting = false
+ @Published var addSprinkles = false
+
+
+ @Published var name = ""
+ @Published var streetAddress = ""
+ @Published var city = ""
+ @Published var zip = ""
+
+
+ var hasValidAddress: Bool {
+ if name.isEmpty || streetAddress.isEmpty || city.isEmpty || zip.isEmpty {
+ return false
+ }
+ return true
+ }
+
+
+ var cost: Double {
+ // $2 per cake
+ var cost = Double(quantity) * 2
+
+ // complicated cakes cost more
+ cost += Double(type) / 2
+
+ // $1/cake for extra frosting
+ if extraFrosting {
+ cost += Double(quantity)
+ }
+
+ // $0.5/cake for sprinkles
+ if addSprinkles {
+ cost += Double(quantity) / 2
+ }
+
+ return cost
+ }
+
+ init() {}
+
+
+ func encode(to encoder: Encoder) throws {
+ var container = encoder.container(keyedBy: CodingKeys.self)
+
+ try container.encode(type, forKey: .type)
+ try container.encode(quantity, forKey: .quantity)
+ try container.encode(extraFrosting, forKey: .extraFrosting)
+ try container.encode(addSprinkles, forKey: .addSprinkles)
+ try container.encode(name, forKey: .name)
+ try container.encode(streetAddress, forKey: .streetAddress)
+ try container.encode(city, forKey: .city)
+ try container.encode(zip, forKey: .zip)
+ }
+
+ required init(from decoder: Decoder) throws {
+ let container = try decoder.container(keyedBy: CodingKeys.self)
+
+ type = try container.decode(Int.self, forKey: .type)
+ quantity = try container.decode(Int.self, forKey: .quantity)
+ extraFrosting = try container.decode(Bool.self, forKey: .extraFrosting)
+ addSprinkles = try container.decode(Bool.self, forKey: .addSprinkles)
+ name = try container.decode(String.self, forKey: .name)
+ city = try container.decode(String.self, forKey: .city)
+ streetAddress = try container.decode(String.self, forKey: .streetAddress)
+ zip = try container.decode(String.self, forKey: .zip)
+ }
+}ContentView
struct ContentView: View {
+ @StateObject var order = Order()
+
+ var body: some View {
+ NavigationView{
+ Form {
+ Section {
+ Picker("Select your cake type", selection: $order.type) {
+ ForEach(Order.types.indices, id: \\.self) {
+ Text(Order.types[$0])
+ }
+ }
+ Stepper("Number of cakes: \\(order.quantity)", value: $order.quantity, in: 3...20)
+ }
+
+
+ Section {
+ Toggle("Any special requests?", isOn: $order.specialRequestEnabled.animation())
+
+ if order.specialRequestEnabled {
+ Toggle("Add extra frosting", isOn: $order.extraFrosting)
+ Toggle("Add extra sprinkles", isOn: $order.addSprinkles)
+ }
+ }
+
+ Section {
+ NavigationLink {
+ AddressView(order: order)
+ } label: {
+ Text("Deliver details")
+ }
+ }
+ }
+ .navigationTitle("Cupcake Corner")
+ }
+ }
+}AddressView
struct AddressView: View {
+ @ObservedObject var order: Order
+ var body: some View {
+ Form {
+ Section {
+ TextField("name", text: $order.name)
+ TextField("Street address", text: $order.streetAddress)
+ TextField("City", text: $order.city)
+ TextField("Zip", text: $order.zip)
+ }
+
+ Section {
+ NavigationLink {
+ CheckoutView(order: order)
+ } label: {
+ Text("Check out")
+ }
+ }
+ .disabled(!order.hasValidAddress)
+ }
+ .navigationTitle("Delivery details")
+ .navigationBarTitleDisplayMode(.inline)
+ }
+}CheckoutView
struct CheckoutView: View {
+ @ObservedObject var order: Order
+ @State private var confirmationMessage = ""
+ @State private var showingConfirmation = false
+
+
+ var body: some View {
+ ScrollView {
+
+ VStack {
+ AsyncImage(url: URL(string: "https://hws.dev/img/cupcakes@3x.jpg"), scale: 3) { image in
+ image
+ .resizable()
+ .scaledToFit()
+ } placeholder: {
+ ProgressView()
+ }
+
+
+ Text("Your total is \\(order.cost, format: .currency(code: "USD"))")
+ .font(.title)
+
+ Button("Place Order") {
+ Task {
+ await placeOrder()
+ }
+ }
+ .padding()
+
+ }
+ }
+ .navigationTitle("Check out")
+ .navigationBarTitleDisplayMode(.inline)
+ .alert("Thank you!", isPresented: $showingConfirmation) {
+ Button("OK") {}
+ } message: {
+ Text(confirmationMessage)
+ }
+ }
+
+ func placeOrder() async {
+ guard let encoded = try? JSONEncoder().encode(order) else {
+ print("Failed to encode order")
+ return
+ }
+
+ let url = URL(string: "https://reqres.in/api/cupcakes")!
+ var request = URLRequest(url: url)
+ request.setValue("application/json", forHTTPHeaderField: "Content-Type")
+ request.httpMethod = "POST"
+
+ do {
+ let (data, _) = try await URLSession.shared.upload(for: request, from: encoded)
+ let decodedOrder = try JSONDecoder().decode(Order.self, from: data)
+ confirmationMessage = "Your order for \\(decodedOrder.quantity)x\\(Order.types[decodedOrder.type].lowercased()) cupcakes is on its way !"
+ showingConfirmation = true
+ } catch {
+ print("Check out failed ...")
+ }
+
+ }
+}Codable协议无法处理被@Published等属性包装器修饰的属性,需要额外编码来手动实现Codable协议
Form表单校验使用.disabled()修饰符
异步加载图像AsyncImage,这个View不能像普通Image一样直接使用.resizable()调整大小,需要特殊处理
AsyncImage(url: URL(string: "https://hws.dev/img/cupcakes@3x.jpg"), scale: 3) { image in
+ image
+ .resizable()
+ .scaledToFit()
+ } placeholder: {
+ ProgressView() //加载中loading view
+ }Button的action使用异步方法时需要使用Task
Button("Place Order") {
+ Task {
+ await placeOrder()
+ }
+}使用URLRequest、URLSession发送http请求
异步方法,async,await关键字
BookwormApp
@main
+struct BookwormApp: App {
+
+ @StateObject private var dataController = DataController()
+
+ var body: some Scene {
+ WindowGroup {
+ ContentView()
+ .environment(\\.managedObjectContext, dataController.container.viewContext )
+ }
+ }
+}ContentView
struct ContentView: View {
+ @Environment(\\.managedObjectContext) var moc
+ @FetchRequest(sortDescriptors: [SortDescriptor(\\.title, order: .forward), SortDescriptor(\\.author, order: .forward)]) var books: FetchedResults<Book>
+
+ @State private var showingAddScreen = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ ForEach(books) { book in
+ NavigationLink {
+ DetailView(book: book)
+ } label: {
+ HStack {
+ EmojiRatingView(rating: book.rating)
+ .font(.largeTitle)
+ VStack(alignment: .leading) {
+ Text(book.title ?? "Unknown title")
+ .font(.headline)
+ Text(book.author ?? "Unknown author")
+ .foregroundColor(.secondary)
+ }
+ }
+ }
+ }
+ .onDelete(perform: deleteBooks)
+ }
+ .navigationTitle("Bookworm")
+ .toolbar {
+ ToolbarItem(placement: .navigationBarLeading) {
+ EditButton()
+ }
+
+ ToolbarItem(placement: .navigationBarTrailing) {
+ Button {
+ showingAddScreen.toggle()
+ } label: {
+ Label("Add book", systemImage: "plus")
+ }
+ }
+ }
+ .sheet(isPresented: $showingAddScreen) {
+ AddBookView()
+ }
+ }
+ }
+
+ func deleteBooks(at offsets: IndexSet) {
+ for offset in offsets {
+ let book = books[offset]
+ moc.delete(book)
+ }
+ try? moc.save()
+ }
+}DataController
import CoreData
+
+class DataController: ObservableObject {
+ let container = NSPersistentContainer(name: "Bookworm")
+
+
+ init() {
+ container.loadPersistentStores { description, error in
+ if let error = error {
+ print("Core data failed to load: \\(error.localizedDescription)")
+ }
+
+ }
+ }
+}AddBookView
struct AddBookView: View {
+
+ @Environment(\\.managedObjectContext) var moc
+ @Environment(\\.dismiss) var dismiss
+ @State private var title = ""
+ @State private var author = ""
+ @State private var rating = 3
+ @State private var genre = ""
+ @State private var review = ""
+
+ let genres = ["Fantasy", "Horror", "Kids", "Mystery", "Poetry", "Romance", "Thriller"]
+
+ var body: some View {
+ NavigationView {
+ Form {
+ Section {
+ TextField("Name of book", text: $title)
+ TextField("Author's name", text: $author)
+
+ Picker("Genre", selection: $genre) {
+ ForEach(genres, id: \\.self) {
+ Text($0)
+ }
+ }
+ }
+
+ Section {
+ TextEditor(text: $review)
+
+ RatingView(rating: $rating)
+ } header: {
+ Text("Write a review")
+ }
+
+ Section {
+ Button("Save") {
+ let book = Book(context: moc)
+ book.id = UUID()
+ book.title = self.title
+ book.author = self.author
+ book.genre = self.genre
+ book.review = self.review
+ book.rating = Int16(self.rating)
+ try? moc.save()
+ dismiss()
+ }
+ }
+ }
+ .navigationTitle("Add book")
+ }
+ }
+}RatingView
struct RatingView: View {
+ @Binding var rating: Int
+
+ var label = ""
+ var maxmiumRating = 5
+ var offImage: Image?
+ var onImage = Image(systemName: "star.fill")
+ var offColor = Color.gray
+ var onColor = Color.yellow
+
+
+ var body: some View {
+ HStack {
+ if label.isEmpty == false {
+ Text(label)
+ }
+
+ ForEach(1..<maxmiumRating + 1, id: \\.self) { number in
+ image(for: number)
+ .foregroundColor(number > rating ? offColor : onColor)
+ .onTapGesture {
+ rating = number
+ }
+ }
+ }
+ }
+
+ func image(for number: Int) -> Image {
+ if number > rating {
+ return offImage ?? onImage
+ } else {
+ return onImage
+ }
+ }
+}EmojiRatingView
struct EmojiRatingView: View {
+ let rating: Int16
+
+ var body: some View {
+ switch rating {
+ case 1:
+ return Text("☹️")
+ case 2:
+ return Text("😞")
+ case 3:
+ return Text("😊")
+ case 4:
+ return Text("😍")
+ default:
+ return Text("🤩")
+ }
+ }
+}DetailView
struct DetailView: View {
+ let book: Book
+ @Environment(\\.managedObjectContext) var moc
+ @Environment(\\.dismiss) var dismiss
+ @State private var showingAlert = false
+
+ var body: some View {
+ ScrollView {
+ ZStack(alignment: .bottomTrailing) {
+ Image(book.genre ?? "Fantasy")
+ .resizable()
+ .scaledToFit()
+
+ Text(book.genre?.uppercased() ?? "FANTASY")
+ .font(.caption)
+ .fontWeight(.black)
+ .padding(8)
+ .foregroundColor(.white)
+ .background(.black.opacity(0.75))
+ .clipShape(Capsule())
+ .offset(x: -5, y: -5)
+ }
+
+ Text(book.author ?? "Unknown author")
+ .font(.title)
+ .foregroundColor(.secondary)
+
+ Text(book.review ?? "No review")
+ .padding()
+
+ RatingView(rating: .constant(Int(book.rating)))
+ }
+ .navigationTitle(book.title ?? "Unknown book")
+ .navigationBarTitleDisplayMode(.inline)
+ .alert("Delete this book?", isPresented: $showingAlert) {
+ Button("OK", role: .destructive,action: deleteBook)
+ Button("Cancle", role: .cancel) { }
+ } message: {
+ Text("Are you sure?")
+ }
+ .toolbar {
+ Button {
+ showingAlert = true
+ } label: {
+ Label("Delete this book", systemImage: "trash")
+ }
+ }
+
+ }
+
+
+ func deleteBook() {
+ moc.delete(book)
+
+ try? moc.save()
+
+ dismiss()
+
+ }
+}Bookworm.xcdatamodeld
@Environment(\\.managedObjectContext) var moc
+
+var body: some View {
+ Button("Save") {
+ if moc.hasChanges {
+ try? moc.save()
+ }
+ }
+}Ensuring Core Data objects are unique using constraints
self.container.viewContext.mergePolicy = NSMergePolicy.mergeByPropertyObjectTrumpDynamically filtering @FetchRequest with SwiftUI
struct FilteredList<T: NSManagedOBject, Context: View>: View {
+ @FetchRequest var fetchRequest: FetchedResults<T>
+
+ var body: some View {
+ List(fetchRequest, id:\\.self) { item in
+ self.content(item)
+ }
+ }
+
+ init(filterKey: String, filterValue: String, @ViewBuilder content: @escaping (T) -> Content) {
+ _fetchRequest = FetchRequest<T>(sortDescriptors: [], predicate: NSPredicate(format: "%K BEGINSWITH %@", filterKey, filterValue))
+ self.content = content
+ }
+}https://www.youtube.com/playlist?list=PLuoeXyslFTuZRi4q4VT6lZKxYbr7so1Mr
Bundle-Decodable
extension Bundle {
+ func decode<T: Decodable>(_ file: String) -> T {
+ guard let url = self.url(forResource: file, withExtension: nil) else {
+ fatalError("Failed to locate \\(file) in bundle")
+ }
+
+ guard let data = try? Data(contentsOf: url) else {
+ fatalError("Failed to locate \\(file) in bundle")
+ }
+
+ let decoder = JSONDecoder()
+ let formatter = DateFormatter()
+ formatter.dateFormat = "y-MM-dd"
+ decoder.dateDecodingStrategy = .formatted(formatter)
+
+ guard let loaded = try? decoder.decode( T.self, from: data) else {
+ fatalError("Failed to locate \\(file) in bundle")
+ }
+
+ return loaded
+ }
+}Color-Theme
import SwiftUI
+
+extension ShapeStyle where Self == Color {
+ static var darkBackground: Color {
+ Color(red: 0.1, green: 0.1, blue: 0.2)
+ }
+
+ static var lightBackgroud: Color {
+ Color(red: 0.2, green: 0.2, blue: 0.3)
+ }
+}Model
struct Astronaut: Codable, Identifiable {
+ let id: String
+ let name: String
+ let description: String
+}
+
+
+struct Mission: Codable, Identifiable {
+ struct CrewRole: Codable {
+ let name: String
+ let role: String
+ }
+
+ let id: Int
+ let launchDate: Date?
+ let crew: [CrewRole]
+ let description: String
+
+ var displayName: String {
+ "Apollo \\(id)"
+ }
+
+ var image: String {
+ "apollo\\(id)"
+ }
+
+ var formattedLaunchDate: String {
+ launchDate?.formatted(date: .abbreviated, time: .omitted) ?? "N/A"
+ }
+}ContentView
struct ContentView: View {
+ let astronauts: [String: Astronaut] = Bundle.main.decode("astronauts.json")
+ let missions: [Mission] = Bundle.main.decode("missions.json")
+
+ let columns = [
+ GridItem(.adaptive(minimum: 150))
+ ]
+
+ var body: some View {
+ NavigationView {
+ ScrollView {
+ LazyVGrid(columns: columns) {
+ ForEach(missions) { mission in
+ NavigationLink{
+ MissionView(mission: mission, astronauts: astronauts)
+ } label: {
+ VStack{
+ Image(mission.image)
+ .resizable()
+ .scaledToFit()
+ .frame(width: 100, height: 100)
+ VStack {
+ Text(mission.displayName)
+ .font(.headline)
+ .foregroundColor(.white)
+
+ Text(mission.formattedLaunchDate)
+ .font(.subheadline)
+ .foregroundColor(.white.opacity(0.5))
+ }
+ .padding(.vertical)
+ .frame(maxWidth: .infinity)
+ .background(.lightBackgroud)
+ }
+ .clipShape(RoundedRectangle(cornerRadius: 10))
+ .overlay{
+ RoundedRectangle(cornerRadius: 10)
+ .stroke()
+ }
+ }
+ }
+ }
+ .padding([.horizontal, .bottom])
+ }
+ .navigationTitle("Moonshot")
+ .background(.darkBackground)
+ .preferredColorScheme(.dark)
+ }
+ }
+}MissionView
struct MissionView: View {
+ struct CrewMember {
+ let role: String
+ let astronaut: Astronaut
+ }
+
+
+ let mission: Mission
+
+ let crew: [CrewMember]
+
+ var body: some View {
+ GeometryReader { geometry in
+ ScrollView {
+ VStack {
+ Image(mission.image)
+ .resizable()
+ .scaledToFit()
+ .frame(maxWidth: geometry.size.width * 0.6)
+ .padding(.top)
+
+ VStack(alignment: .leading) {
+ Rectangle()
+ .frame(height: 2)
+ .foregroundColor(.lightBackgroud)
+ .padding(.vertical)
+
+ Text("Mission Highlights")
+ .font(.title.bold())
+ .padding(.bottom, 5)
+
+ Text(mission.description)
+ Rectangle()
+ .frame(height: 2)
+ .foregroundColor(.lightBackgroud)
+ .padding(.vertical)
+
+ Text("Crew")
+ .font(.title.bold())
+ .padding(.bottom, 5)
+ }
+ .padding(.horizontal)
+
+
+
+
+
+ ScrollView(.horizontal, showsIndicators: false) {
+ HStack {
+ ForEach(crew, id: \\.role) { crewMember in
+ NavigationLink {
+ AstronautView(astronaut: crewMember.astronaut)
+ }label: {
+ HStack {
+ Image(crewMember.astronaut.id)
+ .resizable()
+ .frame(width: 104, height: 72)
+ .clipShape(Capsule())
+ .overlay{
+ Capsule()
+ .strokeBorder(.white, lineWidth: 1)
+ }
+ VStack(alignment: .leading) {
+ Text(crewMember.astronaut.name)
+ .foregroundColor(.white)
+ .font(.headline)
+
+ Text(crewMember.role)
+ .foregroundColor(.secondary)
+
+ }
+ }
+ }
+ }
+
+ }
+ }
+ .padding(.horizontal)
+ }
+ .padding(.bottom)
+ }
+ .navigationTitle(mission.displayName)
+ .navigationBarTitleDisplayMode(.inline)
+ .background(.darkBackground)
+ }
+
+ }
+
+
+ init(mission: Mission, astronauts: [String: Astronaut]) {
+ self.mission = mission
+
+ self.crew = mission.crew.map { member in
+ if let astronaut = astronauts[member.name] {
+ return CrewMember(role: member.role, astronaut: astronaut)
+ }else {
+ fatalError("Missing \\(member.name)")
+ }
+ }
+ }
+}AstronautView
struct AstronautView: View {
+ let astronaut: Astronaut
+
+ var body: some View {
+ ScrollView {
+ VStack {
+ Image(astronaut.id)
+ .resizable()
+ .scaledToFit()
+
+
+ Text(astronaut.description)
+ .padding()
+
+
+ }
+
+ }
+ .background(.darkBackground)
+ .navigationTitle(astronaut.name)
+ .navigationBarTitleDisplayMode(.inline)
+ }
+}
Order
class Order: ObservableObject, Codable {
+
+ enum CodingKeys: CodingKey {
+ case type, quantity, extraFrosting, addSprinkles, name, streetAddress, city, zip
+ }
+
+ static let types = ["Vanilla", "Strawberry", "Chocolate", "Rainbow"]
+
+ @Published var type = 0
+ @Published var quantity = 3
+ @Published var specialRequestEnabled = false {
+ didSet {
+ if specialRequestEnabled == false {
+ extraFrosting = false
+ addSprinkles = false
+ }
+ }
+ }
+ @Published var extraFrosting = false
+ @Published var addSprinkles = false
+
+
+ @Published var name = ""
+ @Published var streetAddress = ""
+ @Published var city = ""
+ @Published var zip = ""
+
+
+ var hasValidAddress: Bool {
+ if name.isEmpty || streetAddress.isEmpty || city.isEmpty || zip.isEmpty {
+ return false
+ }
+ return true
+ }
+
+
+ var cost: Double {
+ // $2 per cake
+ var cost = Double(quantity) * 2
+
+ // complicated cakes cost more
+ cost += Double(type) / 2
+
+ // $1/cake for extra frosting
+ if extraFrosting {
+ cost += Double(quantity)
+ }
+
+ // $0.5/cake for sprinkles
+ if addSprinkles {
+ cost += Double(quantity) / 2
+ }
+
+ return cost
+ }
+
+ init() {}
+
+
+ func encode(to encoder: Encoder) throws {
+ var container = encoder.container(keyedBy: CodingKeys.self)
+
+ try container.encode(type, forKey: .type)
+ try container.encode(quantity, forKey: .quantity)
+ try container.encode(extraFrosting, forKey: .extraFrosting)
+ try container.encode(addSprinkles, forKey: .addSprinkles)
+ try container.encode(name, forKey: .name)
+ try container.encode(streetAddress, forKey: .streetAddress)
+ try container.encode(city, forKey: .city)
+ try container.encode(zip, forKey: .zip)
+ }
+
+ required init(from decoder: Decoder) throws {
+ let container = try decoder.container(keyedBy: CodingKeys.self)
+
+ type = try container.decode(Int.self, forKey: .type)
+ quantity = try container.decode(Int.self, forKey: .quantity)
+ extraFrosting = try container.decode(Bool.self, forKey: .extraFrosting)
+ addSprinkles = try container.decode(Bool.self, forKey: .addSprinkles)
+ name = try container.decode(String.self, forKey: .name)
+ city = try container.decode(String.self, forKey: .city)
+ streetAddress = try container.decode(String.self, forKey: .streetAddress)
+ zip = try container.decode(String.self, forKey: .zip)
+ }
+}ContentView
struct ContentView: View {
+ @StateObject var order = Order()
+
+ var body: some View {
+ NavigationView{
+ Form {
+ Section {
+ Picker("Select your cake type", selection: $order.type) {
+ ForEach(Order.types.indices, id: \\.self) {
+ Text(Order.types[$0])
+ }
+ }
+ Stepper("Number of cakes: \\(order.quantity)", value: $order.quantity, in: 3...20)
+ }
+
+
+ Section {
+ Toggle("Any special requests?", isOn: $order.specialRequestEnabled.animation())
+
+ if order.specialRequestEnabled {
+ Toggle("Add extra frosting", isOn: $order.extraFrosting)
+ Toggle("Add extra sprinkles", isOn: $order.addSprinkles)
+ }
+ }
+
+ Section {
+ NavigationLink {
+ AddressView(order: order)
+ } label: {
+ Text("Deliver details")
+ }
+ }
+ }
+ .navigationTitle("Cupcake Corner")
+ }
+ }
+}AddressView
struct AddressView: View {
+ @ObservedObject var order: Order
+ var body: some View {
+ Form {
+ Section {
+ TextField("name", text: $order.name)
+ TextField("Street address", text: $order.streetAddress)
+ TextField("City", text: $order.city)
+ TextField("Zip", text: $order.zip)
+ }
+
+ Section {
+ NavigationLink {
+ CheckoutView(order: order)
+ } label: {
+ Text("Check out")
+ }
+ }
+ .disabled(!order.hasValidAddress)
+ }
+ .navigationTitle("Delivery details")
+ .navigationBarTitleDisplayMode(.inline)
+ }
+}CheckoutView
struct CheckoutView: View {
+ @ObservedObject var order: Order
+ @State private var confirmationMessage = ""
+ @State private var showingConfirmation = false
+
+
+ var body: some View {
+ ScrollView {
+
+ VStack {
+ AsyncImage(url: URL(string: "https://hws.dev/img/cupcakes@3x.jpg"), scale: 3) { image in
+ image
+ .resizable()
+ .scaledToFit()
+ } placeholder: {
+ ProgressView()
+ }
+
+
+ Text("Your total is \\(order.cost, format: .currency(code: "USD"))")
+ .font(.title)
+
+ Button("Place Order") {
+ Task {
+ await placeOrder()
+ }
+ }
+ .padding()
+
+ }
+ }
+ .navigationTitle("Check out")
+ .navigationBarTitleDisplayMode(.inline)
+ .alert("Thank you!", isPresented: $showingConfirmation) {
+ Button("OK") {}
+ } message: {
+ Text(confirmationMessage)
+ }
+ }
+
+ func placeOrder() async {
+ guard let encoded = try? JSONEncoder().encode(order) else {
+ print("Failed to encode order")
+ return
+ }
+
+ let url = URL(string: "https://reqres.in/api/cupcakes")!
+ var request = URLRequest(url: url)
+ request.setValue("application/json", forHTTPHeaderField: "Content-Type")
+ request.httpMethod = "POST"
+
+ do {
+ let (data, _) = try await URLSession.shared.upload(for: request, from: encoded)
+ let decodedOrder = try JSONDecoder().decode(Order.self, from: data)
+ confirmationMessage = "Your order for \\(decodedOrder.quantity)x\\(Order.types[decodedOrder.type].lowercased()) cupcakes is on its way !"
+ showingConfirmation = true
+ } catch {
+ print("Check out failed ...")
+ }
+
+ }
+}Codable协议无法处理被@Published等属性包装器修饰的属性,需要额外编码来手动实现Codable协议
Form表单校验使用.disabled()修饰符
异步加载图像AsyncImage,这个View不能像普通Image一样直接使用.resizable()调整大小,需要特殊处理
AsyncImage(url: URL(string: "https://hws.dev/img/cupcakes@3x.jpg"), scale: 3) { image in
+ image
+ .resizable()
+ .scaledToFit()
+ } placeholder: {
+ ProgressView() //加载中loading view
+ }Button的action使用异步方法时需要使用Task
Button("Place Order") {
+ Task {
+ await placeOrder()
+ }
+}使用URLRequest、URLSession发送http请求
异步方法,async,await关键字
BookwormApp
@main
+struct BookwormApp: App {
+
+ @StateObject private var dataController = DataController()
+
+ var body: some Scene {
+ WindowGroup {
+ ContentView()
+ .environment(\\.managedObjectContext, dataController.container.viewContext )
+ }
+ }
+}ContentView
struct ContentView: View {
+ @Environment(\\.managedObjectContext) var moc
+ @FetchRequest(sortDescriptors: [SortDescriptor(\\.title, order: .forward), SortDescriptor(\\.author, order: .forward)]) var books: FetchedResults<Book>
+
+ @State private var showingAddScreen = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ ForEach(books) { book in
+ NavigationLink {
+ DetailView(book: book)
+ } label: {
+ HStack {
+ EmojiRatingView(rating: book.rating)
+ .font(.largeTitle)
+ VStack(alignment: .leading) {
+ Text(book.title ?? "Unknown title")
+ .font(.headline)
+ Text(book.author ?? "Unknown author")
+ .foregroundColor(.secondary)
+ }
+ }
+ }
+ }
+ .onDelete(perform: deleteBooks)
+ }
+ .navigationTitle("Bookworm")
+ .toolbar {
+ ToolbarItem(placement: .navigationBarLeading) {
+ EditButton()
+ }
+
+ ToolbarItem(placement: .navigationBarTrailing) {
+ Button {
+ showingAddScreen.toggle()
+ } label: {
+ Label("Add book", systemImage: "plus")
+ }
+ }
+ }
+ .sheet(isPresented: $showingAddScreen) {
+ AddBookView()
+ }
+ }
+ }
+
+ func deleteBooks(at offsets: IndexSet) {
+ for offset in offsets {
+ let book = books[offset]
+ moc.delete(book)
+ }
+ try? moc.save()
+ }
+}DataController
import CoreData
+
+class DataController: ObservableObject {
+ let container = NSPersistentContainer(name: "Bookworm")
+
+
+ init() {
+ container.loadPersistentStores { description, error in
+ if let error = error {
+ print("Core data failed to load: \\(error.localizedDescription)")
+ }
+
+ }
+ }
+}AddBookView
struct AddBookView: View {
+
+ @Environment(\\.managedObjectContext) var moc
+ @Environment(\\.dismiss) var dismiss
+ @State private var title = ""
+ @State private var author = ""
+ @State private var rating = 3
+ @State private var genre = ""
+ @State private var review = ""
+
+ let genres = ["Fantasy", "Horror", "Kids", "Mystery", "Poetry", "Romance", "Thriller"]
+
+ var body: some View {
+ NavigationView {
+ Form {
+ Section {
+ TextField("Name of book", text: $title)
+ TextField("Author's name", text: $author)
+
+ Picker("Genre", selection: $genre) {
+ ForEach(genres, id: \\.self) {
+ Text($0)
+ }
+ }
+ }
+
+ Section {
+ TextEditor(text: $review)
+
+ RatingView(rating: $rating)
+ } header: {
+ Text("Write a review")
+ }
+
+ Section {
+ Button("Save") {
+ let book = Book(context: moc)
+ book.id = UUID()
+ book.title = self.title
+ book.author = self.author
+ book.genre = self.genre
+ book.review = self.review
+ book.rating = Int16(self.rating)
+ try? moc.save()
+ dismiss()
+ }
+ }
+ }
+ .navigationTitle("Add book")
+ }
+ }
+}RatingView
struct RatingView: View {
+ @Binding var rating: Int
+
+ var label = ""
+ var maxmiumRating = 5
+ var offImage: Image?
+ var onImage = Image(systemName: "star.fill")
+ var offColor = Color.gray
+ var onColor = Color.yellow
+
+
+ var body: some View {
+ HStack {
+ if label.isEmpty == false {
+ Text(label)
+ }
+
+ ForEach(1..<maxmiumRating + 1, id: \\.self) { number in
+ image(for: number)
+ .foregroundColor(number > rating ? offColor : onColor)
+ .onTapGesture {
+ rating = number
+ }
+ }
+ }
+ }
+
+ func image(for number: Int) -> Image {
+ if number > rating {
+ return offImage ?? onImage
+ } else {
+ return onImage
+ }
+ }
+}EmojiRatingView
struct EmojiRatingView: View {
+ let rating: Int16
+
+ var body: some View {
+ switch rating {
+ case 1:
+ return Text("☹️")
+ case 2:
+ return Text("😞")
+ case 3:
+ return Text("😊")
+ case 4:
+ return Text("😍")
+ default:
+ return Text("🤩")
+ }
+ }
+}DetailView
struct DetailView: View {
+ let book: Book
+ @Environment(\\.managedObjectContext) var moc
+ @Environment(\\.dismiss) var dismiss
+ @State private var showingAlert = false
+
+ var body: some View {
+ ScrollView {
+ ZStack(alignment: .bottomTrailing) {
+ Image(book.genre ?? "Fantasy")
+ .resizable()
+ .scaledToFit()
+
+ Text(book.genre?.uppercased() ?? "FANTASY")
+ .font(.caption)
+ .fontWeight(.black)
+ .padding(8)
+ .foregroundColor(.white)
+ .background(.black.opacity(0.75))
+ .clipShape(Capsule())
+ .offset(x: -5, y: -5)
+ }
+
+ Text(book.author ?? "Unknown author")
+ .font(.title)
+ .foregroundColor(.secondary)
+
+ Text(book.review ?? "No review")
+ .padding()
+
+ RatingView(rating: .constant(Int(book.rating)))
+ }
+ .navigationTitle(book.title ?? "Unknown book")
+ .navigationBarTitleDisplayMode(.inline)
+ .alert("Delete this book?", isPresented: $showingAlert) {
+ Button("OK", role: .destructive,action: deleteBook)
+ Button("Cancle", role: .cancel) { }
+ } message: {
+ Text("Are you sure?")
+ }
+ .toolbar {
+ Button {
+ showingAlert = true
+ } label: {
+ Label("Delete this book", systemImage: "trash")
+ }
+ }
+
+ }
+
+
+ func deleteBook() {
+ moc.delete(book)
+
+ try? moc.save()
+
+ dismiss()
+
+ }
+}Bookworm.xcdatamodeld
@Environment(\\.managedObjectContext) var moc
+
+var body: some View {
+ Button("Save") {
+ if moc.hasChanges {
+ try? moc.save()
+ }
+ }
+}Ensuring Core Data objects are unique using constraints
self.container.viewContext.mergePolicy = NSMergePolicy.mergeByPropertyObjectTrumpDynamically filtering @FetchRequest with SwiftUI
struct FilteredList<T: NSManagedOBject, Context: View>: View {
+ @FetchRequest var fetchRequest: FetchedResults<T>
+
+ var body: some View {
+ List(fetchRequest, id:\\.self) { item in
+ self.content(item)
+ }
+ }
+
+ init(filterKey: String, filterValue: String, @ViewBuilder content: @escaping (T) -> Content) {
+ _fetchRequest = FetchRequest<T>(sortDescriptors: [], predicate: NSPredicate(format: "%K BEGINSWITH %@", filterKey, filterValue))
+ self.content = content
+ }
+}MVVM是一种架构设计范式,把数据和视图分离开,Model和View必须通过ViewModel通信。
数据模型,负责数据和逻辑的处理,独立于UI界面,数据流(data flows)在映射到视图中的过程是只读的
渲染UI界面,展示Model数据,声明式(为UI声明的方法,在任何时候做它们应做的事情)、无状态的(不需要关心任何状态变化)、响应式的(跟随Model数据变化重新渲染)。
执行解释工作(interpreter),绑定View和Model。ViewModel关注Model中的变化(notices changes),然后把Model的数据变更发布出去(publishes changed),订阅了(subsrcbes)某个发布(publication)的View会进行rebuild。
ViewModel没有指向View的指针,不直接与View对话,如果View订阅了某个发布,就会询问ViewModel怎么适应变化,这个过程不会涉及Model,因为ViewModel的作用就是解释Model的变化。
MVVM有一个对应的关联架构,是Model-View-Intent。如果用户意图(intent)做一些操作,那么这些Intent就要进行View到Model这个反向传递过程。而swiftUI还没有进行这个设计,所以我们用下面一系列操作来处理Intent:
对比MVVM的映射过程,多了ViewModel处理View操作,并且修改Model这两个操作。
stacks划分提供给自身的空间,然后把空间分配给内部的视图。优先给least flexible的子视图分配空间。
在给一个视图它需要的空间后,这块空间从可用空间中被移除,然后stack继续给下一个least flexible的视图分配空间。very flexible views最后会平分空间。
在子视图选择了它们的尺寸后,stack会调整自己的size来适应它们,如果有very flexible的子视图,那么这个stack也会变得very flexible
可以使用.layoutPriority(Double)改变获取空间的优先级,默认值为0。.layoutPriority(Double)的优先级要比least flexible更高。
why .leading instead of .left?Stacks会根据语言环境判断对齐方式,例如有些语言(阿拉伯语)的文本是从右向左的。
不会build不可见的视图内容,通常用在ScrollView中
占据所有可用空间,子视图大小根据滚动轴调整
really smart VStacks
Text("hello").backgroup(Rectangle().foregroundColor(.red)),效果类似ZStack(Text在上),但是区别是这个例子中最终的View大小是由Text决定的
Image(systemName: "folder")
+ .font(.system(size: 55, weight: .thin))
+ .overlay(Text("❤️"), alignment: .bottom)视图的大小由Image决定,Text会堆叠在Image上,底部对齐
所有修饰符都会返回一个View
HStack{
+ ForEach(viewModel.cards) { card in
+ CardView(card: card).aspectRatio(2/3, contentMode: .fit)
+ }
+}
+.foregroundColor(.orange)
+.padding(10).padding(10).foregroudColor.aspectRatio.aspectRatio会设置宽度,然后遵循2/3的长宽比设置高度,或者在HStack高度不足时,占据所有高度,然后按2/3设置宽度。.aspectRatio把所有空间提供给CardView总是占据提供给他的所有空间,不绘制任何东西.
分割线,在HStack中绘制垂直的线,VStack中是水平线。
@ViewBuilder是一个参数属性,作用于构造视图的闭包参数上,允许闭包提供多个子视图。
@ViewBuilder
+func front(of card: Card) -> some View {
+ let shape = RoundedRectangle(cornerRadius: 20)
+ shape
+ shape.stroke()
+ Text(card.content)
+}@propertyWrapper
+struct Converter1{
+ let from:String
+ let to:String
+ let rate:Double
+
+ var value:Double
+ var wrappedValue:String{
+ get{
+ "\\(from)\\(value)"
+ }
+ set{
+ value = Double(newValue) ?? -1
+ }
+ }
+
+ var projectedValue:String{
+ return "\\(to)\\(value * rate)"
+ }
+
+ init(initialValue:String,
+ from:String,
+ to:String,
+ rate:Double
+ ) {
+ self.rate = rate
+ self.value = 0
+ self.from = from
+ self.to = to
+ self.wrappedValue = initialValue
+ }
+
+
+}
+
+struct TestWraper {
+ @State var myname = ""
+ @Converter1(initialValue: "100", from: "USD", to: "CNY", rate: 6.88)
+ var usd_cny
+
+ @Converter1(initialValue: "100", from: "CNY", to: "EUR", rate: 0.13)
+ var cny_eur
+
+ func test1(){
+ print("\\(usd_cny)=\\($usd_cny)")
+ print("\\(cny_eur)=\\($cny_eur)")
+ }
+ /*
+ USD100.0=CNY688.0
+ CNY100.0=EUR13.0
+ */
+}wrappedValue的计算属性projectedValue,访问预计值的方式为.$属性名,projectedValue是只读的。lazy、@NSCopying、@NSManaged、weak或unowned修饰视图是只读的
所有视图的struct都是完全、彻底只读的,所以View中只有let和computed(常量和计算属性)才有意义。(被@ObservedObject装饰的属性除外,这种属性必须被标记为var)
为什么
View一直在被创建、丢弃,只有body才会存在很久,所以View不太需要一些需要被修改的属性
don't worry,之所以这样是因为View应该是stateless的,只负责渲染model,不需要自身具有什么状态属性。但是极少数情况下View也是需要状态的(it turns out there are a few rare times when a View needs some state),但这种状态存储总是暂时的(always temporary),所有持久化的状态都存在Model中。
例如:进入编辑模式,需要提前收集数据来为用户修改数据的intent作准备,需要暂时展示其他的View(编辑页面)来收集数据,编辑完后需要一个动画效果来关闭这个编辑页面,所以需要一个"编辑模式状态"的属性来标记何时该关闭。
上述场景中可以使用@State来标记这个临时状态存储变量
@State private var somethingTemporary: SomeType //someType can be any struct这个临时状态变量是private修饰的,是因为只有当前View能访问这个变量。@State变量的变化会导致这个View的body重新渲染。这和@ObservedObject类似,但是@State作用的是一个随机的数据(值语义),而@ObservedObject作用在ViewModel上(对象语义)。
多个视图数据共享和更新时,需要一个数据模型的概念,即多视图的状态可以根据Data-Model进行更新,这种场景下@State就不再适用了。
ObservableObject协议定义了一个数据模型的数据发生变化时发布通知的能力
@ObservedObject这个属性包装器包装的属性可以监听到数据的变化,也可以利用它去更新数据。
@Published这个属性包装器包装的属性,都会被转化为一个publisher(Combine框架的概念),当值发生变化时,会通知系统,然后系统再去更新画面
和@ObservedObject类似,也是修饰对象语义,和@ObservedObject的区别在于,实例是否被创建其的View所持有,其生命周期是否完全可控,@StateObject修饰的属性的生命周期由创建该对象的对象维护(这一点又类似@State)
class DataSource: ObservableObject {
+ @Published var counter = 0
+}
+
+struct Counter: View {
+ @ObservedObject var dataSource = DataSource()
+
+ var body: some View {
+ VStack {
+ Button("Increment counter") {
+ dataSource.counter += 1
+ }
+
+ Text("Count is \\(dataSource.counter)")
+ }
+ }
+}
+
+struct ItemList: View {
+ @State private var items = ["hello", "world"]
+
+ var body: some View {
+ VStack {
+ Button("Append item to list") {
+ items.append("test")
+ }
+
+ List(items, id: \\.self) { name in
+ Text(name)
+ }
+
+ Counter()
+ }
+ }
+}在这个例子中,每次点击Append item to listButton,counter都会被重置,这是因为每次重新渲染,DataSource()都会被重新创建。解决这个问题有两个方法:
将DataSource标记为@StateObject意味着DataSource被实例化后会保存在Counter的外部,当Counter重新渲染时,会直接用这个值。
使用@ObservedObject可以在视图间共享数据、刷新画面,但是必须为需要的视图进行引用的传递。如果视图的层级较多,且各个View和子View使用同一个数据模型,那么@ObservedObject的传递将会变得笨重且易出错。
SwiftUI提供了另一种选择,@EnvironmentObject就是把数据模型引用保存到了一个共同的环境变量中,environment是一个共通的存储区域,保存了app的信息和Views,当然也可以保存自定义数据,包括对observable object的引用。
和@State类似,App也可以响应iOS系统过来的state变化,例如语言环境、字体大小、暗黑模式切换等,为了及时响应这些变化,app可以使用@Environment(KeyPath)来进行获取实时的信息。
@Published属性包装器和ObservableObject的实现定义在Combine框架中。Combine框架中定义了一些协议和数据类型,可以让我们处理数据,当一个代码数据发生变化,可以应用这个框架来通知另外一处代码有新数据可以使用。
这样就会出现两个类型的任务,一个是发布者(publisher),一个是订阅者(subscriber)。发布者决定了数据和错误信息的产生并发给订阅者,订阅者会接受这些信息。
在SwiftUI中,被@Published修饰的属性,会被自动转化为Publisher,ObservableObject协议的实现中,定义了被@Published修饰的属性作为发布者,在属性的值发生变化的时候,发布者将通知订阅者。@ObservedObject和@EnvironmentObject修饰的属性,扮演订阅者的角色。
import Combine
+import Foundation
+
+let myPublisher = Just("55")
+
+let mySubscriber = Subscribers.Sink<String,Never> (receiveCompletion: { completion in
+ if completion == .finished {
+ print("111")
+ }else {
+ print("222")
+ }
+
+}, receiveValue: { value in
+ print(value)
+})
+
+myPublisher.subscribe(mySubscriber)中间发布者
Publishers.Map
Publishers.Filter
...
或Just().操作符
Combine还有一种发布者叫Subjects,实现了Subject协议,可以调用send方法发送数据
import Combine
+import Foundation
+
+enum MyErrors: Error {
+ case wrongValue
+}
+
+let myPublisher = PassthroughSubject<String, MyErrors>()
+//let myPublisher = CurrentValueSubject<String, MyErrors>("100")
+
+let mySubscriber = myPublisher.filter({
+ return $0.count < 5
+}).sink(receiveCompletion: {completion in
+ if completion == .failure(MyErrors.wrongValue) {
+ print("MyErrors.wrongValue")
+ }else {
+ print(completion)
+ }
+
+}, receiveValue: { value in
+ print("value: \\(value)")
+})
+
+
+myPublisher.send("h")SwiftUI中,View协议有一个修饰符.onReceive(Publisher, perform: Closure)把任何View转换成一个订阅者,来接受来自发布者的数据,SwiftUI使UI组件和Combine结合带来了扩展可能。
import SwiftUI
+
+class ContentViewData: ObservableObject {
+ @Published var counter: Int = 0
+ let timePublisher = Timer.publish(every: 2, on: .main, in: .common).autoconnect()
+}
+
+struct ContentView: View {
+ @ObservedObject var contentData = ContentViewData()
+
+ var body: some View {
+ Text("hello, world! \\(self.contentData.counter)")
+ .onReceive(contentData.timePublisher, perform: { value in
+ self.contentData.counter += 1
+ if self.contentData.counter > 20 {
+ self.contentData.timePublisher.upstream.connect().cancel()
+ print("stop")
+ }
+ })
+ }
+}MVVM是一种架构设计范式,把数据和视图分离开,Model和View必须通过ViewModel通信。
数据模型,负责数据和逻辑的处理,独立于UI界面,数据流(data flows)在映射到视图中的过程是只读的
渲染UI界面,展示Model数据,声明式(为UI声明的方法,在任何时候做它们应做的事情)、无状态的(不需要关心任何状态变化)、响应式的(跟随Model数据变化重新渲染)。
执行解释工作(interpreter),绑定View和Model。ViewModel关注Model中的变化(notices changes),然后把Model的数据变更发布出去(publishes changed),订阅了(subsrcbes)某个发布(publication)的View会进行rebuild。
ViewModel没有指向View的指针,不直接与View对话,如果View订阅了某个发布,就会询问ViewModel怎么适应变化,这个过程不会涉及Model,因为ViewModel的作用就是解释Model的变化。
MVVM有一个对应的关联架构,是Model-View-Intent。如果用户意图(intent)做一些操作,那么这些Intent就要进行View到Model这个反向传递过程。而swiftUI还没有进行这个设计,所以我们用下面一系列操作来处理Intent:
对比MVVM的映射过程,多了ViewModel处理View操作,并且修改Model这两个操作。
stacks划分提供给自身的空间,然后把空间分配给内部的视图。优先给least flexible的子视图分配空间。
在给一个视图它需要的空间后,这块空间从可用空间中被移除,然后stack继续给下一个least flexible的视图分配空间。very flexible views最后会平分空间。
在子视图选择了它们的尺寸后,stack会调整自己的size来适应它们,如果有very flexible的子视图,那么这个stack也会变得very flexible
可以使用.layoutPriority(Double)改变获取空间的优先级,默认值为0。.layoutPriority(Double)的优先级要比least flexible更高。
why .leading instead of .left?Stacks会根据语言环境判断对齐方式,例如有些语言(阿拉伯语)的文本是从右向左的。
不会build不可见的视图内容,通常用在ScrollView中
占据所有可用空间,子视图大小根据滚动轴调整
really smart VStacks
Text("hello").backgroup(Rectangle().foregroundColor(.red)),效果类似ZStack(Text在上),但是区别是这个例子中最终的View大小是由Text决定的
Image(systemName: "folder")
+ .font(.system(size: 55, weight: .thin))
+ .overlay(Text("❤️"), alignment: .bottom)视图的大小由Image决定,Text会堆叠在Image上,底部对齐
所有修饰符都会返回一个View
HStack{
+ ForEach(viewModel.cards) { card in
+ CardView(card: card).aspectRatio(2/3, contentMode: .fit)
+ }
+}
+.foregroundColor(.orange)
+.padding(10).padding(10).foregroudColor.aspectRatio.aspectRatio会设置宽度,然后遵循2/3的长宽比设置高度,或者在HStack高度不足时,占据所有高度,然后按2/3设置宽度。.aspectRatio把所有空间提供给CardView总是占据提供给他的所有空间,不绘制任何东西.
分割线,在HStack中绘制垂直的线,VStack中是水平线。
@ViewBuilder是一个参数属性,作用于构造视图的闭包参数上,允许闭包提供多个子视图。
@ViewBuilder
+func front(of card: Card) -> some View {
+ let shape = RoundedRectangle(cornerRadius: 20)
+ shape
+ shape.stroke()
+ Text(card.content)
+}@propertyWrapper
+struct Converter1{
+ let from:String
+ let to:String
+ let rate:Double
+
+ var value:Double
+ var wrappedValue:String{
+ get{
+ "\\(from)\\(value)"
+ }
+ set{
+ value = Double(newValue) ?? -1
+ }
+ }
+
+ var projectedValue:String{
+ return "\\(to)\\(value * rate)"
+ }
+
+ init(initialValue:String,
+ from:String,
+ to:String,
+ rate:Double
+ ) {
+ self.rate = rate
+ self.value = 0
+ self.from = from
+ self.to = to
+ self.wrappedValue = initialValue
+ }
+
+
+}
+
+struct TestWraper {
+ @State var myname = ""
+ @Converter1(initialValue: "100", from: "USD", to: "CNY", rate: 6.88)
+ var usd_cny
+
+ @Converter1(initialValue: "100", from: "CNY", to: "EUR", rate: 0.13)
+ var cny_eur
+
+ func test1(){
+ print("\\(usd_cny)=\\($usd_cny)")
+ print("\\(cny_eur)=\\($cny_eur)")
+ }
+ /*
+ USD100.0=CNY688.0
+ CNY100.0=EUR13.0
+ */
+}wrappedValue的计算属性projectedValue,访问预计值的方式为.$属性名,projectedValue是只读的。lazy、@NSCopying、@NSManaged、weak或unowned修饰视图是只读的
所有视图的struct都是完全、彻底只读的,所以View中只有let和computed(常量和计算属性)才有意义。(被@ObservedObject装饰的属性除外,这种属性必须被标记为var)
为什么
View一直在被创建、丢弃,只有body才会存在很久,所以View不太需要一些需要被修改的属性
don't worry,之所以这样是因为View应该是stateless的,只负责渲染model,不需要自身具有什么状态属性。但是极少数情况下View也是需要状态的(it turns out there are a few rare times when a View needs some state),但这种状态存储总是暂时的(always temporary),所有持久化的状态都存在Model中。
例如:进入编辑模式,需要提前收集数据来为用户修改数据的intent作准备,需要暂时展示其他的View(编辑页面)来收集数据,编辑完后需要一个动画效果来关闭这个编辑页面,所以需要一个"编辑模式状态"的属性来标记何时该关闭。
上述场景中可以使用@State来标记这个临时状态存储变量
@State private var somethingTemporary: SomeType //someType can be any struct这个临时状态变量是private修饰的,是因为只有当前View能访问这个变量。@State变量的变化会导致这个View的body重新渲染。这和@ObservedObject类似,但是@State作用的是一个随机的数据(值语义),而@ObservedObject作用在ViewModel上(对象语义)。
多个视图数据共享和更新时,需要一个数据模型的概念,即多视图的状态可以根据Data-Model进行更新,这种场景下@State就不再适用了。
ObservableObject协议定义了一个数据模型的数据发生变化时发布通知的能力
@ObservedObject这个属性包装器包装的属性可以监听到数据的变化,也可以利用它去更新数据。
@Published这个属性包装器包装的属性,都会被转化为一个publisher(Combine框架的概念),当值发生变化时,会通知系统,然后系统再去更新画面
和@ObservedObject类似,也是修饰对象语义,和@ObservedObject的区别在于,实例是否被创建其的View所持有,其生命周期是否完全可控,@StateObject修饰的属性的生命周期由创建该对象的对象维护(这一点又类似@State)
class DataSource: ObservableObject {
+ @Published var counter = 0
+}
+
+struct Counter: View {
+ @ObservedObject var dataSource = DataSource()
+
+ var body: some View {
+ VStack {
+ Button("Increment counter") {
+ dataSource.counter += 1
+ }
+
+ Text("Count is \\(dataSource.counter)")
+ }
+ }
+}
+
+struct ItemList: View {
+ @State private var items = ["hello", "world"]
+
+ var body: some View {
+ VStack {
+ Button("Append item to list") {
+ items.append("test")
+ }
+
+ List(items, id: \\.self) { name in
+ Text(name)
+ }
+
+ Counter()
+ }
+ }
+}在这个例子中,每次点击Append item to listButton,counter都会被重置,这是因为每次重新渲染,DataSource()都会被重新创建。解决这个问题有两个方法:
将DataSource标记为@StateObject意味着DataSource被实例化后会保存在Counter的外部,当Counter重新渲染时,会直接用这个值。
使用@ObservedObject可以在视图间共享数据、刷新画面,但是必须为需要的视图进行引用的传递。如果视图的层级较多,且各个View和子View使用同一个数据模型,那么@ObservedObject的传递将会变得笨重且易出错。
SwiftUI提供了另一种选择,@EnvironmentObject就是把数据模型引用保存到了一个共同的环境变量中,environment是一个共通的存储区域,保存了app的信息和Views,当然也可以保存自定义数据,包括对observable object的引用。
和@State类似,App也可以响应iOS系统过来的state变化,例如语言环境、字体大小、暗黑模式切换等,为了及时响应这些变化,app可以使用@Environment(KeyPath)来进行获取实时的信息。
@Published属性包装器和ObservableObject的实现定义在Combine框架中。Combine框架中定义了一些协议和数据类型,可以让我们处理数据,当一个代码数据发生变化,可以应用这个框架来通知另外一处代码有新数据可以使用。
这样就会出现两个类型的任务,一个是发布者(publisher),一个是订阅者(subscriber)。发布者决定了数据和错误信息的产生并发给订阅者,订阅者会接受这些信息。
在SwiftUI中,被@Published修饰的属性,会被自动转化为Publisher,ObservableObject协议的实现中,定义了被@Published修饰的属性作为发布者,在属性的值发生变化的时候,发布者将通知订阅者。@ObservedObject和@EnvironmentObject修饰的属性,扮演订阅者的角色。
import Combine
+import Foundation
+
+let myPublisher = Just("55")
+
+let mySubscriber = Subscribers.Sink<String,Never> (receiveCompletion: { completion in
+ if completion == .finished {
+ print("111")
+ }else {
+ print("222")
+ }
+
+}, receiveValue: { value in
+ print(value)
+})
+
+myPublisher.subscribe(mySubscriber)中间发布者
Publishers.Map
Publishers.Filter
...
或Just().操作符
Combine还有一种发布者叫Subjects,实现了Subject协议,可以调用send方法发送数据
import Combine
+import Foundation
+
+enum MyErrors: Error {
+ case wrongValue
+}
+
+let myPublisher = PassthroughSubject<String, MyErrors>()
+//let myPublisher = CurrentValueSubject<String, MyErrors>("100")
+
+let mySubscriber = myPublisher.filter({
+ return $0.count < 5
+}).sink(receiveCompletion: {completion in
+ if completion == .failure(MyErrors.wrongValue) {
+ print("MyErrors.wrongValue")
+ }else {
+ print(completion)
+ }
+
+}, receiveValue: { value in
+ print("value: \\(value)")
+})
+
+
+myPublisher.send("h")SwiftUI中,View协议有一个修饰符.onReceive(Publisher, perform: Closure)把任何View转换成一个订阅者,来接受来自发布者的数据,SwiftUI使UI组件和Combine结合带来了扩展可能。
import SwiftUI
+
+class ContentViewData: ObservableObject {
+ @Published var counter: Int = 0
+ let timePublisher = Timer.publish(every: 2, on: .main, in: .common).autoconnect()
+}
+
+struct ContentView: View {
+ @ObservedObject var contentData = ContentViewData()
+
+ var body: some View {
+ Text("hello, world! \\(self.contentData.counter)")
+ .onReceive(contentData.timePublisher, perform: { value in
+ self.contentData.counter += 1
+ if self.contentData.counter > 20 {
+ self.contentData.timePublisher.upstream.connect().cancel()
+ print("stop")
+ }
+ })
+ }
+}*可选类型(optionals)*来处理值可能缺失的情况。可选类型实际也是一个枚举:
enum Optional<T> {
+ case none
+ case some(T)
+}如果声明一个可选常量或者变量但是没有赋值,它们会自动被设置为nil:
var hello: String? var hello: Optional<String> = .none
+var hello: String? = "hello" var hello: Optional<String> = .some("hello")
+var hello: String? = nil var hello: Optional<String> = .nonevar surveyAnswer: String?
+// surveyAnswer 会被自动设置为 nil -> var surveyAnswer: String? = nillet hello: String? = ...
+print(hello!)等价于
switch hello {
+ case .none: //raise an exception(crash)
+ case .some(let data): print(data)
+}强制解析可能会导致异常,可以使用if let来安全的获取可选类型中的值
if let safehello = hello {
+ print(safehello)
+} else {
+ //do something else
+}等价于
switch hello {
+ case .none: //do something else
+ case .some(let data): print(data)
+}使用可选绑定时后面不能用
&&,可以用,隔开语句
空合运算符(a ?? b)将对可选类型 a 进行空判断,如果 a 包含一个值就进行解包,否则就返回一个默认值 b。表达式 a 必须是 Optional 类型。默认值 b 的类型必须要和 a 存储值的类型保持一致。
空合运算符是对以下代码的简短表达方法:
a != nil ? a! : b例子:
let x: String? = ...
+let y = x ?? z实际等价于上:
switch a {
+ case .none: y = z
+ case .some(let data): y = data
+}可选链式调用是一种可以在当前值可能为 nil 的可选值上请求和调用属性、方法及下标的方法。如果可选值有值,那么调用就会成功;如果可选值是 nil,那么调用将返回 nil。多个调用可以连接在一起形成一个调用链,如果其中任何一个节点为 nil,整个调用链都会失败,即返回 nil。
let x: String = ...
+let y = x?.foo()?.bar?.z等价于
switch x {
+ case .none: y = nil
+ case .some(let xval):
+ switch xval.foo() {
+ case .none: y = nil
+ case .some(let xfooval):
+ switch xfooval.bar {
+ case .none: y = nil
+ case .some(let xfbval): y = xfbval.z
+ }
+ }
+}{ (parameters) -> return_type in
+ statements
+}尾随闭包是一个书写在函数圆括号之后的闭包表达式,函数支持将其作为最后一个参数调用。在使用尾随闭包时,不用写出它的参数标签
例如:
ForEach(modelData.categories.keys.sorted(), id: \\.self) { key in
+ CategoryRow(categoryName: key, items: modelData.categories[key]!)
+}struct SignInView: View {
+ var body: some View {
+ Button {
+ showingProfile.toggle()
+ } label: {
+ Label("User Profile", systemImage: "person.crop.circle")
+ }
+ }
+}结构体和枚举是值类型。默认情况下,值类型的属性不能在它的实例方法中被修改。
如果确实需要在某个特定的方法中修改结构体或者枚举的属性,可以为这个方法选择 可变(mutating)
struct Point {
+ var x = 0.0, y = 0.0
+ mutating func moveBy(x deltaX: Double, y deltaY: Double) {
+ x += deltaX
+ y += deltaY
+ }
+}
+var somePoint = Point(x: 1.0, y: 1.0)
+somePoint.moveBy(x: 2.0, y: 3.0)
+print("The point is now at (\\(somePoint.x), \\(somePoint.y))")
+// 打印“The point is now at (3.0, 4.0)”计算属性不直接存储值,而是提供一个 getter 和一个可选的 setter,来间接获取和设置其他属性或变量的值。
struct Point {
+ var x = 0.0, y = 0.0
+}
+struct Size {
+ var width = 0.0, height = 0.0
+}
+struct Rect {
+ var origin = Point()
+ var size = Size()
+ var center: Point {
+ get {
+ let centerX = origin.x + (size.width / 2)
+ let centerY = origin.y + (size.height / 2)
+ return Point(x: centerX, y: centerY)
+ }
+ set(newCenter) {
+ origin.x = newCenter.x - (size.width / 2)
+ origin.y = newCenter.y - (size.height / 2)
+ }
+ }
+}
+var square = Rect(origin: Point(x: 0.0, y: 0.0),
+ size: Size(width: 10.0, height: 10.0))
+let initialSquareCenter = square.center
+square.center = Point(x: 15.0, y: 15.0)
+print("square.origin is now at (\\(square.origin.x), \\(square.origin.y))")
+// 打印“square.origin is now at (10.0, 10.0)”如果计算属性的 setter 没有定义表示新值的参数名,则可以使用默认名称 newValue。下面是使用了简化 setter 声明的 Rect 结构体代码:
struct AlternativeRect {
+ var origin = Point()
+ var size = Size()
+ var center: Point {
+ get {
+ let centerX = origin.x + (size.width / 2)
+ let centerY = origin.y + (size.height / 2)
+ return Point(x: centerX, y: centerY)
+ }
+ set {
+ origin.x = newValue.x - (size.width / 2)
+ origin.y = newValue.y - (size.height / 2)
+ }
+ }
+}如果整个 getter 是单一表达式,getter 会隐式地返回这个表达式结果。下面是另一个版本的 Rect 结构体,用到了简化的 getter 和 setter 声明:
struct CompactRect {
+ var origin = Point()
+ var size = Size()
+ var center: Point {
+ get {
+ Point(x: origin.x + (size.width / 2),
+ y: origin.y + (size.height / 2))
+ }
+ set {
+ origin.x = newValue.x - (size.width / 2)
+ origin.y = newValue.y - (size.height / 2)
+ }
+ }
+}在 getter 中忽略 return 与在函数中忽略 return 的规则相同.
只有 getter 没有 setter 的计算属性叫只读计算属性。只读计算属性总是返回一个值,可以通过点运算符访问,但不能设置新的值。
注意
必须使用
var关键字定义计算属性,包括只读计算属性,因为它们的值不是固定的。let关键字只用来声明常量属性,表示初始化后再也无法修改的值。
只读计算属性的声明可以去掉 get 关键字和花括号:
struct Cuboid {
+ var width = 0.0, height = 0.0, depth = 0.0
+ var volume: Double {
+ return width * height * depth
+ }
+}
+let fourByFiveByTwo = Cuboid(width: 4.0, height: 5.0, depth: 2.0)
+print("the volume of fourByFiveByTwo is \\(fourByFiveByTwo.volume)")
+// 打印“the volume of fourByFiveByTwo is 40.0”属性观察器监控和响应属性值的变化,每次属性被设置值的时候都会调用属性观察器,即使新值和当前值相同的时候也不例外。
可以在以下位置添加属性观察器:
可以为属性添加其中一个或两个观察器:
willSet 在新的值被设置之前调用didSet 在新的值被设置之后调用willSet 观察器会将新的属性值作为常量参数传入,在 willSet 的实现代码中可以为这个参数指定一个名称,如果不指定则参数仍然可用,这时使用默认名称 newValue 表示。
同样,didSet 观察器会将旧的属性值作为参数传入,可以为该参数指定一个名称或者使用默认参数名 oldValue。如果在 didSet 方法中再次对该属性赋值,那么新值会覆盖旧的值。
在父类初始化方法调用之后,在子类构造器中给父类的属性赋值时,会调用父类属性的
willSet和didSet观察器。而在父类初始化方法调用之前,给子类的属性赋值时不会调用子类属性的观察器。
class StepCounter {
+ var totalSteps: Int = 0 {
+ willSet(newTotalSteps) {
+ print("将 totalSteps 的值设置为 \\(newTotalSteps)")
+ }
+ didSet {
+ if totalSteps > oldValue {
+ print("增加了 \\(totalSteps - oldValue) 步")
+ }
+ }
+ }
+}
+let stepCounter = StepCounter()
+stepCounter.totalSteps = 200
+// 将 totalSteps 的值设置为 200
+// 增加了 200 步
+stepCounter.totalSteps = 360
+// 将 totalSteps 的值设置为 360
+// 增加了 160 步
+stepCounter.totalSteps = 896
+// 将 totalSteps 的值设置为 896
+// 增加了 536 步sort of a "stripped-down" struct/class
有函数和变量,但是没有具体实现,类似interface, 当实现一个协议时,必须实现协议中所有的函数和变量
使用protocol来限制entension:
extension Array where Element: Hashable {...}使用protocol来限制函数:
init(data: Data) where Data: Collection, Data.Element: Identifiable可以通过extension给protocol的func或var添加默认的实现
struct Tesla: Vehicle {
+ //...
+}
+
+extension Vehicle {
+ fun registerWithDMV() { // actual implementation }
+}protocol View {
+ var body: some View
+}extension View {
+ func foregroundColor(_ color: Color) -> some View { /* implementation */ }
+ func font(_ font: Font?) -> some View { /* implementation */ }
+ ...
+}protocol Identifiable {
+ associatedtype ID
+ var id: ID { get }
+}*可选类型(optionals)*来处理值可能缺失的情况。可选类型实际也是一个枚举:
enum Optional<T> {
+ case none
+ case some(T)
+}如果声明一个可选常量或者变量但是没有赋值,它们会自动被设置为nil:
var hello: String? var hello: Optional<String> = .none
+var hello: String? = "hello" var hello: Optional<String> = .some("hello")
+var hello: String? = nil var hello: Optional<String> = .nonevar surveyAnswer: String?
+// surveyAnswer 会被自动设置为 nil -> var surveyAnswer: String? = nillet hello: String? = ...
+print(hello!)等价于
switch hello {
+ case .none: //raise an exception(crash)
+ case .some(let data): print(data)
+}强制解析可能会导致异常,可以使用if let来安全的获取可选类型中的值
if let safehello = hello {
+ print(safehello)
+} else {
+ //do something else
+}等价于
switch hello {
+ case .none: //do something else
+ case .some(let data): print(data)
+}使用可选绑定时后面不能用
&&,可以用,隔开语句
空合运算符(a ?? b)将对可选类型 a 进行空判断,如果 a 包含一个值就进行解包,否则就返回一个默认值 b。表达式 a 必须是 Optional 类型。默认值 b 的类型必须要和 a 存储值的类型保持一致。
空合运算符是对以下代码的简短表达方法:
a != nil ? a! : b例子:
let x: String? = ...
+let y = x ?? z实际等价于上:
switch a {
+ case .none: y = z
+ case .some(let data): y = data
+}可选链式调用是一种可以在当前值可能为 nil 的可选值上请求和调用属性、方法及下标的方法。如果可选值有值,那么调用就会成功;如果可选值是 nil,那么调用将返回 nil。多个调用可以连接在一起形成一个调用链,如果其中任何一个节点为 nil,整个调用链都会失败,即返回 nil。
let x: String = ...
+let y = x?.foo()?.bar?.z等价于
switch x {
+ case .none: y = nil
+ case .some(let xval):
+ switch xval.foo() {
+ case .none: y = nil
+ case .some(let xfooval):
+ switch xfooval.bar {
+ case .none: y = nil
+ case .some(let xfbval): y = xfbval.z
+ }
+ }
+}{ (parameters) -> return_type in
+ statements
+}尾随闭包是一个书写在函数圆括号之后的闭包表达式,函数支持将其作为最后一个参数调用。在使用尾随闭包时,不用写出它的参数标签
例如:
ForEach(modelData.categories.keys.sorted(), id: \\.self) { key in
+ CategoryRow(categoryName: key, items: modelData.categories[key]!)
+}struct SignInView: View {
+ var body: some View {
+ Button {
+ showingProfile.toggle()
+ } label: {
+ Label("User Profile", systemImage: "person.crop.circle")
+ }
+ }
+}结构体和枚举是值类型。默认情况下,值类型的属性不能在它的实例方法中被修改。
如果确实需要在某个特定的方法中修改结构体或者枚举的属性,可以为这个方法选择 可变(mutating)
struct Point {
+ var x = 0.0, y = 0.0
+ mutating func moveBy(x deltaX: Double, y deltaY: Double) {
+ x += deltaX
+ y += deltaY
+ }
+}
+var somePoint = Point(x: 1.0, y: 1.0)
+somePoint.moveBy(x: 2.0, y: 3.0)
+print("The point is now at (\\(somePoint.x), \\(somePoint.y))")
+// 打印“The point is now at (3.0, 4.0)”计算属性不直接存储值,而是提供一个 getter 和一个可选的 setter,来间接获取和设置其他属性或变量的值。
struct Point {
+ var x = 0.0, y = 0.0
+}
+struct Size {
+ var width = 0.0, height = 0.0
+}
+struct Rect {
+ var origin = Point()
+ var size = Size()
+ var center: Point {
+ get {
+ let centerX = origin.x + (size.width / 2)
+ let centerY = origin.y + (size.height / 2)
+ return Point(x: centerX, y: centerY)
+ }
+ set(newCenter) {
+ origin.x = newCenter.x - (size.width / 2)
+ origin.y = newCenter.y - (size.height / 2)
+ }
+ }
+}
+var square = Rect(origin: Point(x: 0.0, y: 0.0),
+ size: Size(width: 10.0, height: 10.0))
+let initialSquareCenter = square.center
+square.center = Point(x: 15.0, y: 15.0)
+print("square.origin is now at (\\(square.origin.x), \\(square.origin.y))")
+// 打印“square.origin is now at (10.0, 10.0)”如果计算属性的 setter 没有定义表示新值的参数名,则可以使用默认名称 newValue。下面是使用了简化 setter 声明的 Rect 结构体代码:
struct AlternativeRect {
+ var origin = Point()
+ var size = Size()
+ var center: Point {
+ get {
+ let centerX = origin.x + (size.width / 2)
+ let centerY = origin.y + (size.height / 2)
+ return Point(x: centerX, y: centerY)
+ }
+ set {
+ origin.x = newValue.x - (size.width / 2)
+ origin.y = newValue.y - (size.height / 2)
+ }
+ }
+}如果整个 getter 是单一表达式,getter 会隐式地返回这个表达式结果。下面是另一个版本的 Rect 结构体,用到了简化的 getter 和 setter 声明:
struct CompactRect {
+ var origin = Point()
+ var size = Size()
+ var center: Point {
+ get {
+ Point(x: origin.x + (size.width / 2),
+ y: origin.y + (size.height / 2))
+ }
+ set {
+ origin.x = newValue.x - (size.width / 2)
+ origin.y = newValue.y - (size.height / 2)
+ }
+ }
+}在 getter 中忽略 return 与在函数中忽略 return 的规则相同.
只有 getter 没有 setter 的计算属性叫只读计算属性。只读计算属性总是返回一个值,可以通过点运算符访问,但不能设置新的值。
注意
必须使用
var关键字定义计算属性,包括只读计算属性,因为它们的值不是固定的。let关键字只用来声明常量属性,表示初始化后再也无法修改的值。
只读计算属性的声明可以去掉 get 关键字和花括号:
struct Cuboid {
+ var width = 0.0, height = 0.0, depth = 0.0
+ var volume: Double {
+ return width * height * depth
+ }
+}
+let fourByFiveByTwo = Cuboid(width: 4.0, height: 5.0, depth: 2.0)
+print("the volume of fourByFiveByTwo is \\(fourByFiveByTwo.volume)")
+// 打印“the volume of fourByFiveByTwo is 40.0”属性观察器监控和响应属性值的变化,每次属性被设置值的时候都会调用属性观察器,即使新值和当前值相同的时候也不例外。
可以在以下位置添加属性观察器:
可以为属性添加其中一个或两个观察器:
willSet 在新的值被设置之前调用didSet 在新的值被设置之后调用willSet 观察器会将新的属性值作为常量参数传入,在 willSet 的实现代码中可以为这个参数指定一个名称,如果不指定则参数仍然可用,这时使用默认名称 newValue 表示。
同样,didSet 观察器会将旧的属性值作为参数传入,可以为该参数指定一个名称或者使用默认参数名 oldValue。如果在 didSet 方法中再次对该属性赋值,那么新值会覆盖旧的值。
在父类初始化方法调用之后,在子类构造器中给父类的属性赋值时,会调用父类属性的
willSet和didSet观察器。而在父类初始化方法调用之前,给子类的属性赋值时不会调用子类属性的观察器。
class StepCounter {
+ var totalSteps: Int = 0 {
+ willSet(newTotalSteps) {
+ print("将 totalSteps 的值设置为 \\(newTotalSteps)")
+ }
+ didSet {
+ if totalSteps > oldValue {
+ print("增加了 \\(totalSteps - oldValue) 步")
+ }
+ }
+ }
+}
+let stepCounter = StepCounter()
+stepCounter.totalSteps = 200
+// 将 totalSteps 的值设置为 200
+// 增加了 200 步
+stepCounter.totalSteps = 360
+// 将 totalSteps 的值设置为 360
+// 增加了 160 步
+stepCounter.totalSteps = 896
+// 将 totalSteps 的值设置为 896
+// 增加了 536 步sort of a "stripped-down" struct/class
有函数和变量,但是没有具体实现,类似interface, 当实现一个协议时,必须实现协议中所有的函数和变量
使用protocol来限制entension:
extension Array where Element: Hashable {...}使用protocol来限制函数:
init(data: Data) where Data: Collection, Data.Element: Identifiable可以通过extension给protocol的func或var添加默认的实现
struct Tesla: Vehicle {
+ //...
+}
+
+extension Vehicle {
+ fun registerWithDMV() { // actual implementation }
+}protocol View {
+ var body: some View
+}extension View {
+ func foregroundColor(_ color: Color) -> some View { /* implementation */ }
+ func font(_ font: Font?) -> some View { /* implementation */ }
+ ...
+}protocol Identifiable {
+ associatedtype ID
+ var id: ID { get }
+}Go Template是一种用于生成文本输出的模板引擎,它是Go语言标准库中内置的一部分。Go Template使用简单而强大的语法来描述要生成的最终文本的结构和内容。
Go Template的语法是基于文本插值的思想,通过在模板文件中插入占位符和控制指令来控制输出的结果。模板可以包含静态文本和动态值,并且可以使用控制指令来迭代、条件判断和执行其他逻辑操作。
<!--test.html-->
+<!DOCTYPE html>
+<html>
+<head>
+ <meta http-equiv="Content-Type" content="text/html; charset=utf-8">
+ <title>Go Web</title>
+</head>
+<body>
+{{ . }}
+</body>
+</html>package main
+
+import (
+ "html/template"
+ "net/http"
+)
+
+func tmpl(w http.ResponseWriter, r *http.Request) {
+ t1, err := template.ParseFiles("test.html")
+ if err != nil {
+ panic(err)
+ }
+ t1.Execute(w, "hello world")
+}
+
+func main() {
+ server := http.Server{
+ Addr: "127.0.0.1:8080",
+ }
+ http.HandleFunc("/", tmpl)
+ server.ListenAndServe()
+}.和作用域 在写template的时候,会经常用到"."。
在template中,点"."代表当前作用域的当前对象。它类似于java/c++的this关键字,类似于perl/python的self。
type Person struct {
+ Name string
+ Age int
+}
+
+func main(){
+ p := Person{"leo",23}
+ tmpl, _ := template.New("test").Parse("Name: {{.Name}}, Age: {{.Age}}")
+ _ = tmpl.Execute(os.Stdout, p)
+}
+// Name: leo, Age: 23但是并非只有一个顶级作用域,range、with、if等内置action都有自己的本地作用域。
package main
+
+import (
+ "os"
+ "text/template"
+)
+
+type Friend struct {
+ Fname string
+}
+type Person struct {
+ UserName string
+ Emails []string
+ Friends []*Friend
+}
+
+func main() {
+ f1 := Friend{Fname: "xiaofang"}
+ f2 := Friend{Fname: "wugui"}
+ t := template.New("test")
+ t = template.Must(t.Parse(
+ \`hello {{.UserName}}!
+{{ range .Emails }}
+an email {{ . }}
+{{- end }}
+{{ with .Friends }}
+{{- range . }}
+my friend name is {{.Fname}}
+{{- end }}
+{{ end }}\`))
+ p := Person{UserName: "test",
+ Emails: []string{"a1@qq.com", "a2@gmail.com"},
+ Friends: []*Friend{&f1, &f2}}
+ t.Execute(os.Stdout, p)
+}输出:
hello test!
+
+an email a1@qq.com
+an email a2@gmail.com
+
+my friend name is xiaofang
+my friend name is wuguitemplate引擎在进行替换的时候,是完全按照文本格式进行替换的。除了需要评估和替换的地方,所有的行分隔符、空格等等空白都原样保留。所以, 对于要解析的内容,不要随意缩进、随意换行。
//可以在\`{{</span>\`符号的后面加上短横线并保留一个或多个空格"- "来去除它前面的空白(包括换行符、制表符、空格等)
+//,即\`{{- xxxx\`。
+//在\`}}\`的前面加上一个或多个空格以及一个短横线"-"来去除它后面的空白,即\`xxxx -}}\`。
+
+{{23}} < {{45}} -> 23 < 45
+{{23}} < {{- 45}} -> 23 <45
+{{23 -}} < {{45}} -> 23< 45
+{{23 -}} < {{- 45}} -> 23<45上面的例子
t.Parse(
+\`hello {{.UserName}}!
+{{ range .Emails }}
+an email {{ . }}
+{{- end }}
+{{ with .Friends }}
+{{- range . }}
+my friend name is {{.Fname}}
+{{- end }}
+{{ end }}\`)注意,上面没有进行缩进。因为缩进的制表符或空格在替换的时候会保留。
注释方式:
{{/* a comment */}}注释后的内容不会被引擎进行替换。但需要注意,注释行在替换的时候也会占用行,所以应该去除前缀和后缀空白,否则会多一空行。
{{- /* a comment without prefix/suffix space */}}
+{{/* a comment without prefix/suffix space */ -}}
+{{- /* a comment without prefix/suffix space */ -}}注意,应该只去除前缀或后缀空白,不要同时都去除,否则会破坏原有的格式。
pipeline是指产生数据的操作。
可以使用管道符号|链接多个命令,用法和unix下的管道类似:|前面的命令将运算结果(或返回值)传递给后一个命令的最后一个位置。
例如:
{{.}} | printf "%s\\n" "abcd"命令可以有超过1个的返回值,这时第二个返回值必须为err类型。
需要注意的是,并非只有使用了|才是pipeline。Go template中,pipeline的概念是传递数据,只要能产生数据的,都是pipeline。这使得某些操作可以作为另一些操作内部的表达式先运行得到结果,就像是Unix下的命令替换一样。
例如,下面的(len "output")是pipeline,它整体先运行。
{{println (len "output")}}下面是Pipeline的几种示例,它们都输出"output":
{{\`"output"\`}}
+{{printf "%q" "output"}}
+{{"output" | printf "%q"}}
+{{printf "%q" (print "out" "put")}}
+{{"put" | printf "%s%s" "out" | printf "%q"}}
+{{"output" | printf "%s" | printf "%q"}}可以在template中定义变量:
// 未定义过的变量
+$var := pipeline
+
+// 已定义过的变量
+$var = pipeline{{- $how_long :=(len "output")}}
+{{- println $how_long}} // 输出6tx := template.Must(template.New("hh").Parse(
+\`{{range $x := . -}}
+{{$y := 333}}
+{{- if (gt $x 33)}}{{println $x $y ($z := 444)}}{{- end}}
+{{- end}}
+\`))
+s := []int{11, 22, 33, 44, 55}
+_ = tx.Execute(os.Stdout, s)
+//44 333 444
+//55 333 444上面的示例中,使用range迭代slice,每个元素都被赋值给变量$x,每次迭代过程中,都新设置一个变量$y ,在内层嵌套的if结构中,可以使用这个两个外层的变量。在if的条件表达式中,使用了一个内置的比较函数gt,如果$x 大于33,则为true。在println的参数中还定义了一个$z,之所以能定义,是因为($z := 444)的过程是一个Pipeline,可以先运行。
需要注意三点:
$,它代表模板的最顶级作用域对象(通俗地理解,是以模板为全局作用域的全局变量),在Execute() 执行的时候进行赋值,且一直不变。例如上面的示例中,$ = [11 22 33 44 55]。再例如,define定义了一个模板t1,则t1中的$ 作用域只属于这个t1。{{if pipeline}} T1 {{end}}
+{{if pipeline}} T1 {{else}} T0 {{end}}
+{{if pipeline}} T1 {{else if pipeline}} T0 {{end}}
+{{if pipeline}} T1 {{else}}{{if pipeline}} T0 {{end}}{{end}}需要注意的是,pipeline为false的情况是各种数据对象的0值:数值0,指针或接口是nil,数组、slice、map或string则是len为0。
有两种迭代表达式
{{range pipeline}} T1 {{end}}
+{{range pipeline}} T1 {{else}} T0 {{end}}range可以迭代slice、数组、map或channel。迭代的时候,会设置"."为当前正在迭代的元素。
对于第一个表达式,当迭代对象的值为0值时,则range直接跳过,就像if一样。对于第二个表达式,则在迭代到0值时执行else语句。
tx := template.Must(template.New("hh").Parse(
+\`{{range $x := . -}}
+{{println $x}}
+{{- end}}
+\`))
+s := []int{11, 22, 33, 44, 55}
+_ = tx.Execute(os.Stdout, s)需注意的是,range的参数部分是pipeline,所以在迭代的过程中是可以进行赋值的。但有两种赋值情况:
{{range $value := .}}
+{{range $key,$value := .}}如果range中只赋值给一个变量,则这个变量是当前正在迭代元素的值。如果赋值给两个变量,则第一个变量是索引值( map/slice是数值,map是key),第二个变量是当前正在迭代元素的值。
with用来设置"."的值。两种格式:
{{with pipeline}} T1 {{end}}
+{{with pipeline}} T1 {{else}} T0 {{end}}对于第一种格式,当pipeline不为0值的时候,点"." 设置为pipeline运算的值,否则跳过。对于第二种格式,当pipeline为0值时,执行else语句块,否则"."设置为pipeline运算的值,并执行T1。
{{with "xx"}}{{println .}}{{end}}上面将输出xx,因为"."已经设置为"xx"。
template定义了一些内置函数,也支持自定义函数
and
+ 返回第一个为空的参数或最后一个参数。可以有任意多个参数。
+ and x y等价于if x then y else x
+
+not
+ 布尔取反。只能一个参数。
+
+or
+ 返回第一个不为空的参数或最后一个参数。可以有任意多个参数。
+ "or x y"等价于"if x then x else y"。
+
+print
+printf
+println
+ 分别等价于fmt包中的Sprint、Sprintf、Sprintln
+
+len
+ 返回参数的length。
+
+index
+ 对可索引对象进行索引取值。第一个参数是索引对象,后面的参数是索引位。
+ "index x 1 2 3"代表的是x[1][2][3]。
+ 可索引对象包括map、slice、array。
+
+call
+ 显式调用函数。第一个参数必须是函数类型,且不是template中的函数,而是外部函数。
+ 例如一个struct中的某个字段是func类型的。
+ "call .X.Y 1 2"表示调用dot.X.Y(1, 2),Y必须是func类型,函数参数是1和2。
+ 函数必须只能有一个或2个返回值,如果有第二个返回值,则必须为error类型。eq arg1 arg2:
+ arg1 == arg2时为true
+ne arg1 arg2:
+ arg1 != arg2时为true
+lt arg1 arg2:
+ arg1 < arg2时为true
+le arg1 arg2:
+ arg1 <= arg2时为true
+gt arg1 arg2:
+ arg1 > arg2时为true
+ge arg1 arg2:
+ arg1 >= arg2时为true对于eq函数,支持多个参数,它们都和第一个参数arg1进行比较。它等价于:
eq arg1 arg2 arg3 arg4...
+arg1==arg2 || arg1==arg3 || arg1==arg4define可以直接在待解析内容中定义一个模板,这个模板会加入到common结构组中,并关联到关联名称上。
定义了模板之后,可以使用template这个action来执行模板。template有两种格式:
{{template "name"}}
+{{template "name" pipeline}}第一种是直接执行名为name的template,点设置为nil。第二种是点"."设置为pipeline的值,并执行名为name的template。可以将template看作是函数:
template("name)
+template("name",pipeline)func main() {
+ t1 := template.New("test1")
+ tmpl, _ := t1.Parse(
+\`{{- define "T1"}}ONE {{println .}}{{end}}
+{{- define "T2"}}TWO {{println .}}{{end}}
+{{- define "T3"}}{{template "T1"}}{{template "T2" "haha"}}{{end}}
+{{- template "T3" -}}
+\`)
+ _ = tmpl.Execute(os.Stdout, "hello world")
+}
+//ONE <nil>
+//TWO haha{{block "name" pipeline}} T1 {{end}}
+ A block is shorthand for defining a template
+ {{define "name"}} T1 {{end}}
+ and then executing it in place
+ {{template "name" pipeline}}
+ The typical use is to define a set of root templates that are
+ then customized by redefining the block templates within.根据官方文档的解释:block等价于define定义一个名为name的模板,并在"有需要"的地方执行这个模板,执行时将"."设置为pipeline的值。
但应该注意,**block的第一个动作是执行名为name的模板,如果不存在,则在此处自动定义这个模板,并执行这个临时定义的模板。换句话说,block可以认为是设置一个默认模板 **。
例如:
{{block "T1" .}} one {{end}}它首先找到T1模板,如果T1存在,则执行找到的T1,如果没找到T1,则临时定义一个,并执行它。
上下文感知的自动转义能让程序更加安全,比如防止XSS攻击(例如在表单中输入带有<script>...</script> 的内容并提交,会使得用户提交的这部分script被执行)。
如果确实不想转义,可以进行类型转换。
type CSS
+type HTML
+type JS
+type URLfunc process(w http.ResponseWriter, r *http.Request) {
+ t, _ := template.ParseFiles("tmpl.html")
+ t.Execute(w, template.HTML(r.FormValue("comment")))
+}Go Template是一种用于生成文本输出的模板引擎,它是Go语言标准库中内置的一部分。Go Template使用简单而强大的语法来描述要生成的最终文本的结构和内容。
Go Template的语法是基于文本插值的思想,通过在模板文件中插入占位符和控制指令来控制输出的结果。模板可以包含静态文本和动态值,并且可以使用控制指令来迭代、条件判断和执行其他逻辑操作。
<!--test.html-->
+<!DOCTYPE html>
+<html>
+<head>
+ <meta http-equiv="Content-Type" content="text/html; charset=utf-8">
+ <title>Go Web</title>
+</head>
+<body>
+{{ . }}
+</body>
+</html>package main
+
+import (
+ "html/template"
+ "net/http"
+)
+
+func tmpl(w http.ResponseWriter, r *http.Request) {
+ t1, err := template.ParseFiles("test.html")
+ if err != nil {
+ panic(err)
+ }
+ t1.Execute(w, "hello world")
+}
+
+func main() {
+ server := http.Server{
+ Addr: "127.0.0.1:8080",
+ }
+ http.HandleFunc("/", tmpl)
+ server.ListenAndServe()
+}.和作用域 在写template的时候,会经常用到"."。
在template中,点"."代表当前作用域的当前对象。它类似于java/c++的this关键字,类似于perl/python的self。
type Person struct {
+ Name string
+ Age int
+}
+
+func main(){
+ p := Person{"leo",23}
+ tmpl, _ := template.New("test").Parse("Name: {{.Name}}, Age: {{.Age}}")
+ _ = tmpl.Execute(os.Stdout, p)
+}
+// Name: leo, Age: 23但是并非只有一个顶级作用域,range、with、if等内置action都有自己的本地作用域。
package main
+
+import (
+ "os"
+ "text/template"
+)
+
+type Friend struct {
+ Fname string
+}
+type Person struct {
+ UserName string
+ Emails []string
+ Friends []*Friend
+}
+
+func main() {
+ f1 := Friend{Fname: "xiaofang"}
+ f2 := Friend{Fname: "wugui"}
+ t := template.New("test")
+ t = template.Must(t.Parse(
+ \`hello {{.UserName}}!
+{{ range .Emails }}
+an email {{ . }}
+{{- end }}
+{{ with .Friends }}
+{{- range . }}
+my friend name is {{.Fname}}
+{{- end }}
+{{ end }}\`))
+ p := Person{UserName: "test",
+ Emails: []string{"a1@qq.com", "a2@gmail.com"},
+ Friends: []*Friend{&f1, &f2}}
+ t.Execute(os.Stdout, p)
+}输出:
hello test!
+
+an email a1@qq.com
+an email a2@gmail.com
+
+my friend name is xiaofang
+my friend name is wuguitemplate引擎在进行替换的时候,是完全按照文本格式进行替换的。除了需要评估和替换的地方,所有的行分隔符、空格等等空白都原样保留。所以, 对于要解析的内容,不要随意缩进、随意换行。
//可以在\`{{</span>\`符号的后面加上短横线并保留一个或多个空格"- "来去除它前面的空白(包括换行符、制表符、空格等)
+//,即\`{{- xxxx\`。
+//在\`}}\`的前面加上一个或多个空格以及一个短横线"-"来去除它后面的空白,即\`xxxx -}}\`。
+
+{{23}} < {{45}} -> 23 < 45
+{{23}} < {{- 45}} -> 23 <45
+{{23 -}} < {{45}} -> 23< 45
+{{23 -}} < {{- 45}} -> 23<45上面的例子
t.Parse(
+\`hello {{.UserName}}!
+{{ range .Emails }}
+an email {{ . }}
+{{- end }}
+{{ with .Friends }}
+{{- range . }}
+my friend name is {{.Fname}}
+{{- end }}
+{{ end }}\`)注意,上面没有进行缩进。因为缩进的制表符或空格在替换的时候会保留。
注释方式:
{{/* a comment */}}注释后的内容不会被引擎进行替换。但需要注意,注释行在替换的时候也会占用行,所以应该去除前缀和后缀空白,否则会多一空行。
{{- /* a comment without prefix/suffix space */}}
+{{/* a comment without prefix/suffix space */ -}}
+{{- /* a comment without prefix/suffix space */ -}}注意,应该只去除前缀或后缀空白,不要同时都去除,否则会破坏原有的格式。
pipeline是指产生数据的操作。
可以使用管道符号|链接多个命令,用法和unix下的管道类似:|前面的命令将运算结果(或返回值)传递给后一个命令的最后一个位置。
例如:
{{.}} | printf "%s\\n" "abcd"命令可以有超过1个的返回值,这时第二个返回值必须为err类型。
需要注意的是,并非只有使用了|才是pipeline。Go template中,pipeline的概念是传递数据,只要能产生数据的,都是pipeline。这使得某些操作可以作为另一些操作内部的表达式先运行得到结果,就像是Unix下的命令替换一样。
例如,下面的(len "output")是pipeline,它整体先运行。
{{println (len "output")}}下面是Pipeline的几种示例,它们都输出"output":
{{\`"output"\`}}
+{{printf "%q" "output"}}
+{{"output" | printf "%q"}}
+{{printf "%q" (print "out" "put")}}
+{{"put" | printf "%s%s" "out" | printf "%q"}}
+{{"output" | printf "%s" | printf "%q"}}可以在template中定义变量:
// 未定义过的变量
+$var := pipeline
+
+// 已定义过的变量
+$var = pipeline{{- $how_long :=(len "output")}}
+{{- println $how_long}} // 输出6tx := template.Must(template.New("hh").Parse(
+\`{{range $x := . -}}
+{{$y := 333}}
+{{- if (gt $x 33)}}{{println $x $y ($z := 444)}}{{- end}}
+{{- end}}
+\`))
+s := []int{11, 22, 33, 44, 55}
+_ = tx.Execute(os.Stdout, s)
+//44 333 444
+//55 333 444上面的示例中,使用range迭代slice,每个元素都被赋值给变量$x,每次迭代过程中,都新设置一个变量$y ,在内层嵌套的if结构中,可以使用这个两个外层的变量。在if的条件表达式中,使用了一个内置的比较函数gt,如果$x 大于33,则为true。在println的参数中还定义了一个$z,之所以能定义,是因为($z := 444)的过程是一个Pipeline,可以先运行。
需要注意三点:
$,它代表模板的最顶级作用域对象(通俗地理解,是以模板为全局作用域的全局变量),在Execute() 执行的时候进行赋值,且一直不变。例如上面的示例中,$ = [11 22 33 44 55]。再例如,define定义了一个模板t1,则t1中的$ 作用域只属于这个t1。{{if pipeline}} T1 {{end}}
+{{if pipeline}} T1 {{else}} T0 {{end}}
+{{if pipeline}} T1 {{else if pipeline}} T0 {{end}}
+{{if pipeline}} T1 {{else}}{{if pipeline}} T0 {{end}}{{end}}需要注意的是,pipeline为false的情况是各种数据对象的0值:数值0,指针或接口是nil,数组、slice、map或string则是len为0。
有两种迭代表达式
{{range pipeline}} T1 {{end}}
+{{range pipeline}} T1 {{else}} T0 {{end}}range可以迭代slice、数组、map或channel。迭代的时候,会设置"."为当前正在迭代的元素。
对于第一个表达式,当迭代对象的值为0值时,则range直接跳过,就像if一样。对于第二个表达式,则在迭代到0值时执行else语句。
tx := template.Must(template.New("hh").Parse(
+\`{{range $x := . -}}
+{{println $x}}
+{{- end}}
+\`))
+s := []int{11, 22, 33, 44, 55}
+_ = tx.Execute(os.Stdout, s)需注意的是,range的参数部分是pipeline,所以在迭代的过程中是可以进行赋值的。但有两种赋值情况:
{{range $value := .}}
+{{range $key,$value := .}}如果range中只赋值给一个变量,则这个变量是当前正在迭代元素的值。如果赋值给两个变量,则第一个变量是索引值( map/slice是数值,map是key),第二个变量是当前正在迭代元素的值。
with用来设置"."的值。两种格式:
{{with pipeline}} T1 {{end}}
+{{with pipeline}} T1 {{else}} T0 {{end}}对于第一种格式,当pipeline不为0值的时候,点"." 设置为pipeline运算的值,否则跳过。对于第二种格式,当pipeline为0值时,执行else语句块,否则"."设置为pipeline运算的值,并执行T1。
{{with "xx"}}{{println .}}{{end}}上面将输出xx,因为"."已经设置为"xx"。
template定义了一些内置函数,也支持自定义函数
and
+ 返回第一个为空的参数或最后一个参数。可以有任意多个参数。
+ and x y等价于if x then y else x
+
+not
+ 布尔取反。只能一个参数。
+
+or
+ 返回第一个不为空的参数或最后一个参数。可以有任意多个参数。
+ "or x y"等价于"if x then x else y"。
+
+print
+printf
+println
+ 分别等价于fmt包中的Sprint、Sprintf、Sprintln
+
+len
+ 返回参数的length。
+
+index
+ 对可索引对象进行索引取值。第一个参数是索引对象,后面的参数是索引位。
+ "index x 1 2 3"代表的是x[1][2][3]。
+ 可索引对象包括map、slice、array。
+
+call
+ 显式调用函数。第一个参数必须是函数类型,且不是template中的函数,而是外部函数。
+ 例如一个struct中的某个字段是func类型的。
+ "call .X.Y 1 2"表示调用dot.X.Y(1, 2),Y必须是func类型,函数参数是1和2。
+ 函数必须只能有一个或2个返回值,如果有第二个返回值,则必须为error类型。eq arg1 arg2:
+ arg1 == arg2时为true
+ne arg1 arg2:
+ arg1 != arg2时为true
+lt arg1 arg2:
+ arg1 < arg2时为true
+le arg1 arg2:
+ arg1 <= arg2时为true
+gt arg1 arg2:
+ arg1 > arg2时为true
+ge arg1 arg2:
+ arg1 >= arg2时为true对于eq函数,支持多个参数,它们都和第一个参数arg1进行比较。它等价于:
eq arg1 arg2 arg3 arg4...
+arg1==arg2 || arg1==arg3 || arg1==arg4define可以直接在待解析内容中定义一个模板,这个模板会加入到common结构组中,并关联到关联名称上。
定义了模板之后,可以使用template这个action来执行模板。template有两种格式:
{{template "name"}}
+{{template "name" pipeline}}第一种是直接执行名为name的template,点设置为nil。第二种是点"."设置为pipeline的值,并执行名为name的template。可以将template看作是函数:
template("name)
+template("name",pipeline)func main() {
+ t1 := template.New("test1")
+ tmpl, _ := t1.Parse(
+\`{{- define "T1"}}ONE {{println .}}{{end}}
+{{- define "T2"}}TWO {{println .}}{{end}}
+{{- define "T3"}}{{template "T1"}}{{template "T2" "haha"}}{{end}}
+{{- template "T3" -}}
+\`)
+ _ = tmpl.Execute(os.Stdout, "hello world")
+}
+//ONE <nil>
+//TWO haha{{block "name" pipeline}} T1 {{end}}
+ A block is shorthand for defining a template
+ {{define "name"}} T1 {{end}}
+ and then executing it in place
+ {{template "name" pipeline}}
+ The typical use is to define a set of root templates that are
+ then customized by redefining the block templates within.根据官方文档的解释:block等价于define定义一个名为name的模板,并在"有需要"的地方执行这个模板,执行时将"."设置为pipeline的值。
但应该注意,**block的第一个动作是执行名为name的模板,如果不存在,则在此处自动定义这个模板,并执行这个临时定义的模板。换句话说,block可以认为是设置一个默认模板 **。
例如:
{{block "T1" .}} one {{end}}它首先找到T1模板,如果T1存在,则执行找到的T1,如果没找到T1,则临时定义一个,并执行它。
上下文感知的自动转义能让程序更加安全,比如防止XSS攻击(例如在表单中输入带有<script>...</script> 的内容并提交,会使得用户提交的这部分script被执行)。
如果确实不想转义,可以进行类型转换。
type CSS
+type HTML
+type JS
+type URLfunc process(w http.ResponseWriter, r *http.Request) {
+ t, _ := template.ParseFiles("tmpl.html")
+ t.Execute(w, template.HTML(r.FormValue("comment")))
+}package main
+
+import "fmt"
+
+func main() {
+ fmt.Println("Hello, World!")
+}package:定义当前源码文件所属的包。import:导入其他包。func:定义函数。var:声明变量。const:声明常量。type:定义类型。struct:定义结构体。interface:定义接口。map:定义映射类型。range:用于循环迭代。select:用于通道操作。defer:延迟执行。go:启动一个新的 goroutine。chan:定义通道类型。default:select 语句中的默认情况。fallthrough:在 switch 语句中贯穿到下一个 case。if:条件语句。else:if 语句中的默认情况。switch:多分支条件语句。case:switch 语句中的分支情况。for:循环语句。break:跳出循环或 switch 语句。continue:结束当前循环,开始下一次循环。return:返回函数结果。panic:抛出异常。package main
+
+import "fmt"
+
+func main() {
+ var a int
+ fmt.Println("a = ", a)
+ fmt.Printf("a的类型是%T\\n", a)
+}
+// a = 0
+// a的类型是intpackage main
+
+import "fmt"
+
+func main() {
+ var a int = 10
+ fmt.Println("a =", a)
+ fmt.Printf("a的类型是%T\\n", a)
+
+ var b string = "hello"
+ fmt.Println("b =", b)
+ fmt.Printf("b的类型是%T\\n", b)
+}
+// a = 10
+// a的类型是int
+// b = hello
+// b的类型是stringpackage main
+
+import "fmt"
+
+func main() {
+ var a = 10
+ fmt.Println("a =", a)
+ fmt.Printf("a的类型是%T\\n", a)
+
+ var b = "hello"
+ fmt.Println("b =", b)
+ fmt.Printf("b的类型是%T\\n", b)
+}
+// a = 10
+// a的类型是int
+// b = hello
+// b的类型是stringpackage main
+
+import "fmt"
+
+func main() {
+ c := "1"
+ fmt.Printf("c = %s, c的类型是%T\\n", c, c)
+}
+// c = 1, c的类型是stringpackage main
+
+func main(){
+ var xx, yy int = 100, 200
+ var kk, wx = 300, "666
+ var (
+ nn int = 100
+ mm bool = true
+ )
+}匿名变量:下划线_,本身就是一个特殊的标识符。可以像其他标识符那样用于变量的声明,任何类型都可以赋值给它,但任何赋值给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用。
和其他静态类型语言不同,可以直接交换变量(python也有这个语法)
package main
+
+import "fmt"
+
+func main() {
+ var (
+ a = 100
+ b = 200
+ )
+
+ a, b = b, a
+
+ fmt.Println(a, b)
+}
+// 200 100package main
+
+import "fmt"
+
+func main(){
+ // 常量(只读属性)
+ const length int = 10
+ // length = 100 // 常量是不允许被修改的
+ fmt.Println("length = ", length)
+}package main
+
+import "fmt"
+
+// const来定义枚举类型
+const (
+ BEIJING = 0
+ SHANGHAI = 1
+ SHENZHEN = 2
+)
+
+func main() {
+ fmt.Println("BEIJING = ", BEIJING) // 0
+ fmt.Println("SHANGHAI = ", SHANGHAI) // 1
+ fmt.Println("SHENZHEN = ", SHENZHEN) // 2
+}iota 是一个常量生成器,用于生成一组相关的枚举值。iota 可以与 const 关键字一起使用,在定义一组枚举时,用来生成连续的值。const 中每新增一行常量声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)
// iota 初始值为 0,每当出现一个新的常量声明时,它的值就会自动加 1,因此 Monday 的值为 1,Tuesday 的值为 2,以此类推。
+const (
+ Sunday = iota // 0
+ Monday // 1
+ Tuesday // 2
+ Wednesday // 3
+ Thursday // 4
+ Friday // 5
+ Saturday // 6
+)
+
+// 在下面的例子中,B 被显式赋值为 3.14,因此接下来的 C 的值为 iota + 1,即 2,而 D 的值也是 iota + 1,所以它的值为 3。
+const (
+ A = iota // 0
+ B = 3.14 // 3.14
+ C = iota // 2
+ D // 3
+)package main
+
+import "fmt"
+
+// 定义递增的步长
+const (
+ BEIJING = iota * 10
+ SHANGHAI
+ SHENZHEN
+)
+
+func main() {
+ fmt.Println("BEIJING = ", BEIJING) // 0
+ fmt.Println("SHANGHAI = ", SHANGHAI) // 10
+ fmt.Println("SHENZHEN = ", SHENZHEN) // 20
+}package main
+
+import (
+ "fmt"
+ "math"
+ "unsafe"
+)
+
+// 有符号整型
+func Integer() {
+ var num8 int8 = 127
+ var num16 int16 = 32767
+ var num32 int32 = math.MaxInt32
+ var num64 int64 = math.MaxInt64
+ var num int = math.MaxInt
+ fmt.Printf("num8的类型是 %T, num8的大小 %d, num8是 %d\\n",
+ num8, unsafe.Sizeof(num8), num8)
+ fmt.Printf("num16的类型是 %T, num16的大小 %d, num16是 %d\\n",
+ num16, unsafe.Sizeof(num16), num16)
+ fmt.Printf("num32的类型是 %T, num32的大小 %d, num32是 %d\\n",
+ num32, unsafe.Sizeof(num32), num32)
+ fmt.Printf("num64的类型是 %T, num64的大小 %d, num64是 %d\\n",
+ num64, unsafe.Sizeof(num64), num64)
+ fmt.Printf("num的类型是 %T, num的大小 %d, num是 %d\\n",
+ num, unsafe.Sizeof(num), num)
+}
+
+// 无符号整型
+func unsignedInteger() {
+ var num8 uint8 = 128
+ var num16 uint16 = 32768
+ var num32 uint32 = math.MaxUint32
+ var num64 uint64 = math.MaxUint64
+ var num uint = math.MaxUint
+ fmt.Printf("num8的类型是 %T, num8的大小 %d, num8是 %d\\n",
+ num8, unsafe.Sizeof(num8), num8)
+ fmt.Printf("num16的类型是 %T, num16的大小 %d, num16是 %d\\n",
+ num16, unsafe.Sizeof(num16), num16)
+ fmt.Printf("num32的类型是 %T, num32的大小 %d, num32是 %d\\n",
+ num32, unsafe.Sizeof(num32), num32)
+ fmt.Printf("num64的类型是 %T, num64的大小 %d, num64是 %d\\n",
+ num64, unsafe.Sizeof(num64), num64)
+ fmt.Printf("num的类型是 %T, num的大小 %d, num是 %d\\n",
+ num, unsafe.Sizeof(num), num)
+}
+
+func main() {
+ Integer()
+ println("---------------------------------------")
+ unsignedInteger()
+}TIP
int 表示整型宽度,在 32 位系统下是 32 位,而在 64 位系统下是 64 位。表示范围:在 32 位系统下是 -2147483648 ~ 2147483647 ,而在 64 位系统是 -9223372036854775808 ~ 9223372036854775807 。int8 , int16 等这些类型后面有跟一个数值的类型来说,它们能表示的数值个数是固定的。所以,在有的时候:例如在二进制传输、读写文件的结构描述(为了保持文件的结构不会受到不同编译目标平台字节长度的影响)等情况下,使用更加精确的 int32 和 int64 是更好的。float32 类型的变量占用 4 个字节的内存,可以表示的数值范围为±1.401298464324817e-45 到±3.4028234663852886e+38,精度约为 7 个十进制位。
float64 类型的变量占用 8 个字节的内存, 可以表示的数值范围为±4.9406564584124654e-324 到±1.7976931348623157e+308,精度约为 15 个十进制位。
Go 语言中的浮点数默认为 float64 类型,如果需要使用 float32 类型,需要显式声明。
package main
+
+import (
+ "fmt"
+ "math"
+)
+
+func showFloat() {
+ var num1 float32 = math.MaxFloat32
+ var num2 float64 = math.MaxFloat64
+ fmt.Printf("num1的类型是%T,num1是%g\\n", num1, num1)
+ fmt.Printf("num2的类型是%T,num1是%g\\n", num2, num2)
+}
+
+func main() {
+ showFloat()
+}
+//num1的类型是float32,num1是3.4028235e+38
+//num2的类型是float64,num1是1.7976931348623157e+308字符串中的每一个元素叫作“字符”,定义字符时使用单引号。Go 语言的字符有两种。
byte类型,占用1个字节,表示 UTF-8 字符串的单个字节的值,表示的是 ASCII 码表中的一个字符,uint8 的别名类型rune类型,占用4个字节,表示单个 unicode 字符,int32 的别名类型package main
+
+import (
+ "fmt"
+ "unsafe"
+)
+
+func showChar() {
+ var x byte = 65
+ var y uint8 = 65
+ z := 'A'
+ fmt.Printf("x = %c\\n", x) // x = A
+ fmt.Printf("y = %c\\n", y) // y = A
+ fmt.Printf("z = %c\\n", z) // z = A
+
+}
+
+func sizeOfChar() {
+ var x byte = 65
+ fmt.Printf("x = %c\\n", x)
+ fmt.Printf("x 占用 %d 个字节\\n", unsafe.Sizeof(x))
+
+ var y rune = 'A'
+ fmt.Printf("y = %c\\n", y)
+ fmt.Printf("y 占用 %d 个字节\\n", unsafe.Sizeof(y))
+}
+
+func main() {
+ showChar()
+ sizeOfChar()
+}字符串在Go语言中是基本数据类型。
var study string // 定义名为str的字符串类型变量
+study = "《123》" // 将变量赋值
+study2 := "《789》" // 以自动推断方式初始化定义多行字符串的方法如下。
package main
+import "fmt"
+
+func main() {
+ var s1 string
+ s1 = \`
+ study := 'Go语言'
+ fmt.Println(study)
+ \`
+ fmt.Println(s1)
+}func showBool(){
+ a := true
+ b := false
+ fmt.Println("a=", a)
+ fmt.Println("b=", b)
+ fmt.Println("true && false = ", a && b)
+ fmt.Println("true || false = ", a || b)
+}
+
+func main() {
+ showBool()
+}| 类 型 | 字 节 数 | 说 明 |
|---|---|---|
| complex64 | 8 | 64 位的复数型,由 float32 类型的实部和虚部联合表示 |
| complex128 | 16 | 128 位的复数型,由 float64 类型的实部和虚部联合表示 |
func showComplex() {
+ // 内置的 complex 函数用于构建复数
+ var x complex64 = complex(1, 2)
+ var y complex128 = complex(3, 4)
+ var z complex128 = complex(5, 6)
+ fmt.Println("x = ", x)
+ fmt.Println("y = ", y)
+ fmt.Println("z = ", z)
+
+ // 内建的 real 和 imag 函数分别返回复数的实部和虚部
+ fmt.Println("real(x) = ", real(x))
+ fmt.Println("imag(x) = ", imag(x))
+ fmt.Println("y * z = ", y*z)
+}
+
+func main() {
+ showComplex()
+}TIP
同样可以用自然方式表示复数
x := 1 + 2i
+y := 3 + 4i
+z := 5 + 6i| 格式 | 含义 |
|---|---|
| %% | 一个%字面量 |
| %b | 一个二进制整数值(基数为 2),或者是一个(高级的)用科学计数法表示的指数为 2 的浮点数 |
| %c | 字符型。可以把输入的数字按照 ASCII 码相应转换为对应的字符 |
| %d | 一个十进制数值(基数为 10) |
| %f | 以标准记数法表示的浮点数或者复数值 |
| %o | 一个以八进制表示的数字(基数为 8) |
| %p | 以十六进制(基数为 16)表示的一个值的地址,前缀为 0x,字母使用小写的 a-f 表示 |
| %q | 使用 Go 语法以及必须时使用转义,以双引号括起来的字符串或者字节切片[]byte,或者是以单引号括起来的数字 |
| %s | 字符串。输出字符串中的字符直至字符串中的空字符(字符串以’\\0‘结尾,这个’\\0’即空字符) |
| %t | 以 true 或者 false 输出的布尔值 |
| %T | 使用 Go 语法输出的值的类型 |
| %x | 以十六进制表示的整型值(基数为十六),数字 a-f 使用小写表示 |
| %X | 以十六进制表示的整型值(基数为十六),数字 A-F 使用小写表示 |
fmt.Print: 将指定的内容打印到标准输出,不换行。
fmt.Println: 将指定的内容打印到标准输出,并在末尾添加换行符。
fmt.Printf: 根据格式字符串将指定的内容格式化后打印到标准输出。
fmt.Sprintf: 根据格式字符串将指定的内容格式化后返回一个格式化的字符串。
fmt.Scan: 从标准输入读取内容,并将其存储到指定的变量中。
fmt.Scanln: 从标准输入按空格分隔读取内容,并将其存储到指定的变量中,遇到换行符停止。
fmt.Scanf: 根据格式字符串从标准输入读取内容,并将其按指定的格式存储到指定的变量中。
fmt.Errorf: 根据格式字符串创建一个新的错误。
+、-、*、/、%、++、--
==、!=、>、<、>=、<=
&&、||、!
&、|、^、<<、>>
Go 中的数组是值类型而不是引用类型。当数组赋值给一个新的变量时,该变量会得到一个原始数组的一个副本。如果对新变量进行更改,不会影响原始数组。
func arrByValue() {
+ arr := [...]string{"123", "456", "789"}
+ copy := arr
+ copy[0] = "Golang"
+ fmt.Println(arr)
+ fmt.Println(copy)
+}var variable_name [SIZE]variable_type
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}如果数组长度不确定,可以使用 ... 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
+或
+balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}如果设置了数组的长度,我们还可以通过指定下标来初始化元素:
// 将索引为 1 和 3 的元素初始化
+balance := [5]float32{1:2.0,3:7.0}初始化数组中 {} 中的元素个数不能大于 [] 中的数字。
如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小:
balance[4] = 50.0数组元素可以通过索引(位置)来读取。格式为数组名后加中括号,中括号中为索引的值。例如:
var salary float32 = balance[9]len(arr)
使用for range循环
func showArr() {
+ arr := [...]string{"123", "456", "789"}
+ for index, value := range arr {
+ fmt.Printf("arr[%d]=%s\\n", index, value)
+ }
+
+ for _, value := range arr {
+ fmt.Printf("value=%s\\n", value)
+ }
+}Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
var identifier []type切片不需要说明长度。
或使用 make() 函数来创建切片:
var slice1 []type = make([]type, len)
+
+也可以简写为
+
+slice1 := make([]type, len)也可以指定容量,其中 capacity 为可选参数。
make([]T, length, capacity)这里 len 是数组的长度并且也是切片的初始长度。
直接初始化切片,[] 表示是切片类型,{1,2,3} 初始化值依次是 1,2,3,其 cap=len=3。
s :=[] int {1,2,3 }初始化切片 s,是数组 arr 的引用。
s := arr[:]将 arr 中从下标 startIndex 到 endIndex-1 下的元素创建为一个新的切片。
s := arr[startIndex:endIndex]默认 endIndex 时将表示一直到arr的最后一个元素。
s := arr[startIndex:]默认 startIndex 时将表示从 arr 的第一个元素开始。
s := arr[:endIndex]通过切片 s 初始化切片 s1。
s1 := s[startIndex:endIndex]通过内置函数 make() 初始化切片s,[]int 标识为其元素类型为 int 的切片。
s :=make([]int,len,cap)
make([]T, length, capacity)用于创建一个指定类型T、长度为length、容量为capacity的切片。其中,length表示切片的实际长度,而capacity则表示切片底层数组的容量。切片的容量可以理解为底层数组能够容纳的元素数量。当切片的容量不足以容纳新添加的元素时,Go 会自动将底层数组扩展一倍,并将原有的元素复制到新的数组中。因此,在预先分配足够容量的情况下,可以避免频繁的内存分配和数据复制操作,提高代码的性能。
需要注意的是,
capacity参数不能小于length参数。如果capacity小于length,则会抛出一个运行时异常。
nilvar numList []int
+fmt.Println(numList == nil) // true== 操作符来判断两个 slice 是否含有全部相等元素。特别注意,如果你需要测试一个 slice 是否是空的,使用 len(s) == 0 来判断,而不应该用 s == nil 来判断。一个 slice 由三个部分构成:指针 、 长度 和 容量 。指针指向第一个 slice 元素对应的底层数组元素的地址,要注意的是 slice 的第一个元素并不一定就是数组的第一个元素。长度对应 slice 中元素的数目;长度不能超过容量,容量一般是从 slice 的开始位置到底层数据的结尾位置。简单的讲,容量就是从创建切片索引开始的底层数组中的元素个数,而长度是切片中的元素个数。
内置的 len 和 cap 函数分别返回 slice 的长度和容量。
s := make([]string, 3, 5)
+fmt.Println(len(s)) // 3
+fmt.Println(cap(s)) // 5切片自己不拥有任何数据。它只是底层数组的一种表示。对切片所做的任何修改都会反映在底层数组中。
func modifySlice() {
+ var arr = [...]string{"123", "456", "789"}
+ s := arr[:] //[0:len(arr)]
+ fmt.Println(arr)
+ fmt.Println(s)
+
+ s[0] = "Go语言"
+ fmt.Println(arr)
+ fmt.Println(s)
+}这里的 arr[:] 没有填入起始值和结束值,默认就是 0 和 len(arr) 。
使用 append 可以将新元素追加到切片上。append 函数的定义是 func append(slice []Type, elems ...Type) []Type 。其中 elems ...Type 在函数定义中表示该函数接受参数 elems 的个数是可变的。这些类型的函数被称为可变参数。
func appendSliceData() {
+ s := []string{"123"}
+ fmt.Println(s)
+ fmt.Println(cap(s))
+
+ s = append(s, "567")
+ fmt.Println(s)
+ fmt.Println(cap(s))
+
+ s = append(s, "789", "0")
+ fmt.Println(s)
+ fmt.Println(cap(s))
+
+ s = append(s, []string{"1", "2"}...)
+ fmt.Println(s)
+ fmt.Println(cap(s))
+}当新的元素被添加到切片时,如果容量不足,会创建一个新的数组。现有数组的元素被复制到这个新数组中,并返回新的引用。现在新切片的容量是旧切片的两倍。
类似于数组,切片也可以有多个维度。
func mSlice() {
+ numList := [][]string{
+ {"1", "123"},
+ {"2", "456"},
+ {"3", "789"},
+ }
+ fmt.Println(numList)
+}在 Go 语言中,map 是散列表(哈希表)的引用。它是一个拥有键值对元素的无序集合,在这个集合中,键是唯一的,可以通过键来获取、更新或移除操作。无论这个散列表有多大,这些操作基本上是通过常量时间完成的。所有可比较的类型,如 整型 ,字符串 等,都可以作为 key 。
使用 make 函数传入键和值的类型,可以创建 map 。具体语法为 make(map[KeyType]ValueType) 。
// 创建一个键类型为 string 值类型为 int 名为 scores 的 map
+scores := make(map[string]int)
+steps := make(map[string]string)字面量创建:
var steps2 map[string]string = map[string]string{
+ "第一步": "123",
+ "第二步": "456",
+ "第三步": "789",
+}
+fmt.Println(steps2)steps3 := map[string]string{
+ "第一步": "123",
+ "第二步": "456",
+ "第三步": "789",
+}
+fmt.Println(steps3)添加元素
// 可以使用 \`map[key] = value\` 向 map 添加元素。
+steps3["第四步"] = "总监"更新元素
// 若 key 已存在,使用 map[key] = value 可以直接更新对应 key 的 value 值。
+steps3["第四步"] = "CTO"获取元素
// 直接使用 map[key] 即可获取对应 key 的 value 值,如果 key不存在,会返回其 value 类型的零值。
+fmt.Println(steps3["第四步"] )删除元素
//使用 delete(map, key)可以删除 map 中的对应 key 键值对,如果 key 不存在,delete 函数会静默处理,不会报错。
+delete(steps3, "第四步")判断 key 是否存在
// 如果我们想知道 map 中的某个 key 是否存在,可以使用下面的语法:value, ok := map[key]
+v3, ok := steps3["第三步"]
+fmt.Println(ok)
+fmt.Println(v3)
+
+v4, ok := steps3["第四步"]
+fmt.Println(ok)
+fmt.Println(v4)这个语句说明 map 的下标读取可以返回两个值,第一个值为当前 key 的 value 值,第二个值表示对应的 key 是否存在,若存在 ok 为 true ,若不存在,则 ok 为 false 。
遍历 map
// 遍历 map 中所有的元素需要用 for range 循环。
+for key, value := range steps3 {
+ fmt.Printf("key: %s, value: %s\\n", key, value)
+}获取 map 长度
// 使用 len 函数可以获取 map 长度
+func createMap() {
+ //...
+ fmt.Println(len(steps3)) // 4
+}当 map 被赋值为一个新变量的时候,它们指向同一个内部数据结构。因此,改变其中一个变量,就会影响到另一变量。
func mapByReference() {
+ steps4 := map[string]string{
+ "第一步": "123",
+ "第二步": "456",
+ "第三步": "789",
+ }
+ fmt.Println("steps4: ", steps4)
+ // steps4: map[第一步:123 第三步:789 第二步:456]
+ newSteps4 := steps4
+ newSteps4["第一步"] = "123-222"
+ newSteps4["第二步"] = "456-222"
+ newSteps4["第三步"] = "789-222"
+ fmt.Println("steps4: ", steps4)
+ // steps4: map[第一步:123-222 第三步:789-222 第二步:456-222]
+ fmt.Println("newSteps4: ", newSteps4)
+ // newSteps4: map[第一步:123-222 第三步:789-222 第二步:456-222]
+}当 map 作为函数参数传递时也会发生同样的情况。
if 条件1 {
+ 逻辑代码1
+} else if 条件2 {
+ 逻辑代码2
+} else if 条件 ... {
+ 逻辑代码 ...
+} else {
+ 逻辑代码 else
+}score := 88
+if score >= 90 {
+ fmt.Println("成绩等级为A")
+} else if score >= 80 {
+ fmt.Println("成绩等级为B")
+} else if score >= 70 {
+ fmt.Println("成绩等级为C")
+} else if score >= 60 {
+ fmt.Println("成绩等级为D")
+} else {
+ fmt.Println("成绩等级为E 成绩不及格")
+}if 还有另外一种写法,它包含一个 statement 可选语句部分,该可选语句在条件判断之前运行。它的语法是:
if statement; condition {
+}
+
+if score := 88; score >= 60 {
+ fmt.Println("成绩及格")
+}switch 表达式 {
+ case 表达式值1:
+ 业务逻辑代码1
+ case 表达式值2:
+ 业务逻辑代码2
+ case 表达式值3:
+ 业务逻辑代码3
+ case 表达式值 ...:
+ 业务逻辑代码 ...
+ default:
+ 业务逻辑代码
+}grade := "B"
+switch grade {
+case "A":
+ fmt.Println("Your score is between 90 and 100.")
+case "B":
+ fmt.Println("Your score is between 80 and 90.")
+case "C":
+ fmt.Println("Your score is between 70 and 80.")
+case "D":
+ fmt.Println("Your score is between 60 and 70.")
+default:
+ fmt.Println("Your score is below 60.")
+}一个 case 多个条件
month := 5
+switch month {
+case 1, 3, 5, 7, 8, 10, 12:
+ fmt.Println("该月份有 31 天")
+case 4, 6, 9, 11:
+ fmt.Println("该月份有 30 天")
+case 2:
+ fmt.Println("该月份闰年为 29 天,非闰年为 28 天")
+default:
+ fmt.Println("输入有误!")
+}switch 还有另外一种写法,它包含一个 statement 可选语句部分,该可选语句在表达式之前运行。它的语法是:
switch statement; expression {
+}
+
+
+switch month := 5; month {
+case 1, 3, 5, 7, 8, 10, 12:
+ fmt.Println("该月份有 31 天")
+case 4, 6, 9, 11:
+ fmt.Println("该月份有 30 天")
+case 2:
+ fmt.Println("该月份闰年为 29 天,非闰年为 28 天")
+default:
+ fmt.Println("输入有误!")
+}这里 month 变量的作用域就仅限于这个 switch 内。
switch 后可接函数
switch 后面可以接一个函数,只要保证 case 后的值类型与函数的返回值一致即可。
package main
+
+import "fmt"
+
+func getResult(args ...int) bool {
+ for _, v := range args {
+ if v < 60 {
+ return false
+ }
+ }
+ return true
+}
+
+func main() {
+ chinese := 88
+ math := 90
+ english := 95
+
+ switch getResult(chinese, math, english) {
+ case true:
+ fmt.Println("考试通过")
+ case false:
+ fmt.Println("考试未通过")
+ }
+}无表达式的 switch
switch 后面的表达式是可选的。如果省略该表达式,则表示这个 switch 语句等同于 switch true ,并且每个 case 表达式都被认定为有效,相应的代码块也会被执行。
score := 88
+switch {
+case score >= 90 && score <= 100:
+ fmt.Println("grade A")
+case score >= 80 && score < 90:
+ fmt.Println("grade B")
+case score >= 70 && score < 80:
+ fmt.Println("grade C")
+case score >= 60 && score < 70:
+ fmt.Println("grade D")
+case score < 60:
+ fmt.Println("grade E")
+}该 switch-case 语句相当于 if-elseif-else 语句。
fallthrough 语句
正常情况下 switch-case 语句在执行时只要有一个 case 满足条件,就会直接退出 switch-case ,如果一个都没有满足,才会执行 default 的代码块。不同于其他语言需要在每个 case 中添加 break 语句才能退出。使用 fallthrough 语句可以在已经执行完成的 case 之后,把控制权转移到下一个 case 的执行代码中。fallthrough 只能穿透一层,不管你有没有匹配上,都要退出了。fallthrough 语句是 case 子句的最后一个语句。如果它出现在了 case 语句的中间,编译会不通过。
s := "123"
+switch {
+case s == "123":
+ fmt.Println("123")
+ fallthrough
+case s == "456":
+ fmt.Println("456")
+case s != "789":
+ fmt.Println("789")
+}循环语句 可以用来重复执行某一段代码。在 C 语言中,循环语句有 for 、 while 和 do while 三种循环。但在 Go 中只有 for 一种循环语句。下面是 for 循环语句的四种基本模型:
// for 接三个表达式
+for initialisation; condition; post {
+ code
+}
+
+// for 接一个条件表达式
+for condition {
+ code
+}
+
+// for 接一个 range 表达式
+for range_expression {
+ code
+}
+
+// for 不接表达式
+for {
+ code
+}接一个条件表达式
num := 0
+for num < 4 {
+ fmt.Println(num)
+ num++
+}接三个表达式
for 后面接的这三个表达式,各有各的用途:
initialisation):初始化控制变量,在整个循环生命周期内,只执行一次;condition):设置循环控制条件,该表达式值为 true 时循环,值为 false 时结束循环;post):每次循环完都会执行此表达式,可以利用其让控制变量增量或减量。这三个表达式,使用 ; 分隔。
for num := 0; num < 4; num++ {
+ fmt.Println(num)
+}接一个 range 表达式
str := "Golang"
+for index, value := range str{
+ fmt.Printf("index %d, value %c\\n", index, value)
+}不接表达式
for 后面不接表达式就相当于无限循环,当然,可以使用 break 语句退出循环
// 第一种写法
+for {
+ code
+}
+// 第二种写法
+for ;; {
+ code
+}break 语句
break 语句用于终止 for 循环,之后程序将执行在 for 循环后的代码。上面的例子已经演示了 break 语句的使用。
continue 语句
continue 语句用来跳出 for 循环中的当前循环。在 continue 语句后的所有的 for 循环语句都不会在本次循环中执行,执行完 continue 语句后将会继续执行一下次循环。下面的程序会打印出 10 以内的奇数。
含有 defer 语句的函数,会在该函数将要返回之前,调用另一个函数。简单点说就是 defer 语句后面跟着的函数会延迟到当前函数执行完后再执行。
package main
+
+import "fmt"
+
+func bookPrint() {
+ fmt.Println("123")
+}
+
+func main() {
+ defer bookPrint()
+ fmt.Println("main函数...")
+}首先,执行 main 函数,因为 bookPrint() 函数前有 defer 关键字,所以会在执行完 main 函数后再执行 bookPrint() 函数,所以先打印出 main函数... ,再执行 bookPrint() 函数打印 123 。
即时求值的变量快照
使用 defer 只是延时调用函数,传递给函数里的变量,不应该受到后续程序的影响。
str := "123"
+defer fmt.Println(str)
+str = "456"
+fmt.Println(str)
+// 456
+// 123延迟方法
defer 不仅能够延迟函数的执行,也能延迟方法的执行。
package main
+
+import "fmt"
+
+type Book struct {
+ bookName, authorName string
+}
+
+func (b Book) printName() {
+ fmt.Printf("%s %s", b.bookName, b.authorName)
+}
+
+func main() {
+ book := Book{"123", "456"}
+ defer book.printName()
+ fmt.Printf("main... ")
+}
+// main... 123 456defer 栈
当一个函数内多次调用 defer 时,Go 会把 defer 调用放入到一个栈中,随后按照 后进先出 的顺序执行。
package main
+
+import "fmt"
+
+func main() {
+ defer fmt.Printf("123")
+ defer fmt.Printf("456")
+ defer fmt.Printf("789")
+ fmt.Printf("main...")
+}
+//main...789456123defer 在 return 后调用
package main
+
+import "fmt"
+
+var s string = "123"
+
+func showLesson() string {
+ defer func() {
+ s = "456"
+ }()
+ fmt.Println("showLesson: s =", s)
+ return s
+}
+
+func main() {
+ lesson := showLesson()
+ fmt.Println("main: s =", s)
+ fmt.Println("main: lesson =", lesson)
+}
+//showLesson: s = 123
+//main: s = 456
+//main: lesson = 123Go 中 defer 和 return 执行的先后顺序
- 多个defer的执行顺序为“后进先出”;
- defer、return、返回值三者的执行逻辑应该是:return最先执行,return负责将结果写入返回值中;接着defer开始执行一些收尾工作;最后函数携带当前返回值退出。
如果函数的返回值是无名的(不带命名返回值),则go语言会在执行return的时候会执行一个类似创建一个临时变量作为保存return值的动作,而有名返回值的函数,由于返回值在函数定义的时候已经将该变量进行定义,在执行return的时候会先执行返回值保存操作,而后续的defer函数会改变这个返回值(虽然defer是在return之后执行的,但是由于使用的函数定义的变量,所以执行defer操作后对该变量的修改会影响到return的值
defer 可以使代码更简洁
如果没有使用 defer ,当在一个操作资源的函数里调用多个 return 时,每次都得释放资源,你可能这样写代码:
func f() {
+ r := getResource() //0,获取资源
+ ......
+ if ... {
+ r.release() //1,释放资源
+ return
+ }
+ ......
+ if ... {
+ r.release() //2,释放资源
+ return
+ }
+ ......
+ if ... {
+ r.release() //3,释放资源
+ return
+ }
+ ......
+ r.release() //4,释放资源
+ return
+}有了 defer 之后,可以简洁地写成下面这样:
func f() {
+ r := getResource() //0,获取资源
+
+ defer r.release() //1,释放资源
+ ......
+ if ... {
+ ...
+ return
+ }
+ ......
+ if ... {
+ ...
+ return
+ }
+ ......
+ if ... {
+ ...
+ return
+ }
+ ......
+ return
+}在 Go 语言中保留 goto 。goto 后面接的是标签,表示下一步要执行哪里的代码。
package main
+
+import "fmt"
+
+func main() {
+ fmt.Println("123")
+ goto label
+ fmt.Println("456")
+label:
+ fmt.Println("789")
+}
+//123
+//789一个指针变量指向了一个值的内存地址。
类似于变量和常量,在使用指针前你需要声明指针。指针声明格式如下:
var var_name *var-typevar-type 为指针类型,var_name 为指针变量名,* 号用于指定变量是作为一个指针。以下是有效的指针声明:
var ip *int /* 指向整型*/
+var fp *float32 /* 指向浮点型 */指针使用流程:
package main
+
+import "fmt"
+
+func main() {
+ var a int= 20 /* 声明实际变量 */
+ var ip *int /* 声明指针变量 */
+
+ ip = &a /* 指针变量的存储地址 */
+
+ fmt.Printf("a 变量的地址是: %x\\n", &a )
+
+ /* 指针变量的存储地址 */
+ fmt.Printf("ip 变量储存的指针地址: %x\\n", ip )
+
+ /* 使用指针访问值 */
+ fmt.Printf("*ip 变量的值: %d\\n", *ip )
+}
+//a 变量的地址是: 20818a220
+//ip 变量储存的指针地址: 20818a220
+//*ip 变量的值: 20当一个指针被定义后没有分配到任何变量时,它的值为 nil。
nil 指针也称为空指针。
nil在概念上和其它语言的null、None、nil、NULL一样,都指代零值或空值。
一个指针变量通常缩写为 ptr。
package main
+
+import "fmt"
+
+func main() {
+ var ptr *int
+
+ fmt.Printf("ptr 的值为 : %x**\\n**", ptr )
+}
+//ptr 的值为 : 0空指针判断
if(ptr != nil) /* ptr 不是空指针 */
+if(ptr == nil) /* ptr 是空指针 */在函数中对指针参数所做的修改,在函数返回后会保存相应的修改。
package main
+
+import (
+ "fmt"
+)
+
+func changeByPointer(value *int) {
+ *value = 200
+}
+
+func main() {
+ x3 := 99
+ p3 := &x3
+ fmt.Println("执行changeByPointer函数之前p3是", *p3)
+ changeByPointer(p3)
+ fmt.Println("执行changeByPointer函数之后p3是", *p3)
+}
+//执行changeByPointer函数之前p3是 99
+//执行changeByPointer函数之后p3是 200切片与指针一样是引用类型,如果我们想通过一个函数改变一个数组的值,可以将该数组的切片当作参数传给函数,也可以将这个数组的指针当作参数传给函数。但 Go 中建议使用第一种方法,即将该数组的切片当作参数传给函数,因为这么写更加简洁易读。
package main
+
+import "fmt"
+
+// 使用切片
+func changeSlice(value []int) {
+ value[0] = 200
+}
+
+// 使用数组指针
+func changeArray(value *[3]int) {
+ (*value)[0] = 200
+}
+
+func main() {
+ x := [3]int{10, 20, 30}
+ changeSlice(x[:])
+ fmt.Println(x) // [200 20 30]
+
+ y := [3]int{100, 200, 300}
+ changeArray(&y)
+ fmt.Println(y) // [200 200 300]
+}Go 语言中数组可以存储同一类型的数据,但在结构体中我们可以为不同项定义不同的数据类型。
结构体是由一系列具有相同类型或不同类型的数据构成的数据集合。Go中没有class的概念,只有struct结构体,所以也没有继承。
type struct_name struct {
+ attribute_name1 attribute_type
+ attribute_name2 attribute_type
+ ...
+}
+
+type Lesson struct {
+ name string //名称
+ target string //学习目标
+ spend int //学习花费时间
+}
+//可以把相同类型的属性声明在同一行,这样可以使结构体变得更加紧凑
+type Lesson2 struct {
+ name, target string
+ spend int
+}上面的结构体称为命名结构体Named Structure。声明结构体时也可以不用声明新类型,这种结构体类型称为匿名结构体Anonymous Structure
var Lesson3 struct {
+ name, target string
+ spend int
+}package main
+
+import "fmt"
+
+type Lesson struct {
+ name, target string
+ spend int
+}
+
+func main() {
+ // 使用字段名创建结构体
+ lesson1 := Lesson{
+ name: "Golang",
+ target: "学习Go语言,并完成一个单体服务",
+ spend: 5,
+ }
+ // 不使用字段名创建结构体,按字段声明顺序初始化
+ lesson2 := Lesson{"Golang", "学习Go语言,并完成一个单体服务", 5}
+
+ fmt.Println("lesson1 ", lesson1)
+ fmt.Println("lesson2 ", lesson2)
+}Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来。
Tag在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
\`key1:"value1" key2:"value2"\`结构体标签由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。键值对之间使用一个空格分隔。 注意事项: 为结构体编写Tag时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在key和value之间添加空格。
例如我们为Student结构体的每个字段定义json序列化时使用的Tag:
//Student 学生
+type Student struct {
+ ID int \`json:"id"\` //通过指定tag实现json序列化该字段时的key
+ Gender string //json序列化是默认使用字段名作为key
+ name string //私有不能被json包访问
+}
+
+func main() {
+ s1 := Student{
+ ID: 1,
+ Gender: "女",
+ name: "pprof",
+ }
+ data, err := json.Marshal(s1)
+ if err != nil {
+ fmt.Println("json marshal failed!")
+ return
+ }
+ fmt.Printf("json str:%s\\n", data) //json str:{"id":1,"Gender":"女"}
+}package main
+
+import "fmt"
+
+func main() {
+ // 创建匿名结构体变量
+ lesson3 := struct {
+ name, target string
+ spend int
+ }{
+ name: "Go语言",
+ target: "掌握GO语言",
+ spend: 3,
+ }
+
+ fmt.Println("lesson3 ", lesson3)
+}当定义好的结构体没有被显式初始化时,结构体的字段将会默认赋为相应类型的零值。
package main
+
+import "fmt"
+
+type Lesson struct {
+ name, target string
+ spend int
+}
+
+func main() {
+ // 不初始化结构体
+ var lesson4 = Lesson{}
+
+ fmt.Println("lesson4 ", lesson4)
+}
+//lesson4 { 0}使用.点操作符访问:lesson.name
使用.也可用与给结构体字段赋值:lesson.name = "test"
package main
+
+import "fmt"
+
+type Lesson struct {
+ name, target string
+ spend int
+}
+
+func main() {
+ lesson8 := &Lesson{"Go语言", "Go语言微服务", 50}
+ fmt.Println("lesson8 name: ", (*lesson8).name)
+ fmt.Println("lesson8 name: ", lesson8.name)
+}lesson8 是一个指向结构体 Lesson 的指针,用 (*lesson8).name 访问 lesson8 的 name 字段, lesson8.name 代替 (*lesson8).name 的解引用访问。
在创建结构体时,字段可以只有类型没有字段名,这种字段称为 匿名字段(Anonymous Field) 。
package main
+
+import "fmt"
+
+type Lesson4 struct {
+ string
+ int
+}
+
+func main() {
+ lesson9 := Lesson4{"Golang", 50}
+ fmt.Println("lesson9 ", lesson9)
+ fmt.Println("lesson9 string: ", lesson9.string)
+ fmt.Println("lesson9 int: ", lesson9.int)
+}上面的程序结构体定义了两个匿名字段,虽然这两个字段没有字段名,但匿名字段的名称默认就是它的类型。所以上面的结构体 Lesoon4 有两个名为 string 和 int 的字段。
结构体的字段也可能是另外一个结构体,这样的结构体称为 嵌套结构体(Nested Structs)
package main
+
+import "fmt"
+
+type Author struct {
+ name string
+ wx string
+}
+
+type Lesson5 struct {
+ name,target string
+ spend int
+ author Author
+}
+
+func main() {
+ lesson10 := Lesson5{
+ name: "Go语言",
+ spend: 50,
+ }
+ lesson10.author = Author{
+ name: "golang",
+ wx: "666",
+ }
+ fmt.Println("lesson10 name:", lesson10.name)
+ fmt.Println("lesson10 spend:", lesson10.spend)
+ fmt.Println("lesson10 author name:", lesson10.author.name)
+ fmt.Println("lesson10 author wx:", lesson10.author.wx)
+}上面的程序 Lesson5 结构体有一个字段 author ,而且它的类型也是一个结构体 Author 。
结构体中如果有匿名的结构体类型字段,则该匿名结构体里的字段就称为 提升字段(Promoted Fields) 。这是因为提升字段就像是属于外部结构体一样,可以用外部结构体直接访问。就像刚刚上面的程序,如果我们把 Lesson 结构体中的字段 author 直接用匿名字段 Author 代替, Author 结构体的字段例如 name 就不用像上面那样使用 lesson10.author.wx 访问,而是使用 lesson10.wx 就能访问 Author 结构体中的 wx 字段。现在结构体 Author 有 name 、 wx 两个字段,访问字段就像在 Lesson 里直接声明的一样,因此我们称之为提升字段。
package main
+
+import "fmt"
+
+type Author struct {
+ name string
+ wx string
+}
+
+type Lesson6 struct {
+ name,target string
+ spend int
+ Author
+}
+
+func main() {
+ lesson10 := Lesson6{
+ name: "Go语言",
+ target: "掌握Go语言",
+ }
+ lesson10.Author = Author{
+ name: "golang",
+ wx: "666",
+ }
+ fmt.Println("lesson10 name:", lesson10.name)
+ fmt.Println("lesson10 target:", lesson10.target)
+ fmt.Println("lesson10 author wx:", lesson10.wx)
+}
+//lesson10 name: Go语言
+//lesson10 target: 掌握Go语言
+//lesson10 author wx: 666如果结构体的全部成员都是可以比较的,那么结构体也是可以比较的,那样的话两个结构体将可以使用 == 或 != 运算符进行比较。可以通过==运算符或 DeeplyEqual()函数比较两个结构相同的类型并包含相同的字段值。因此下面两个比较的表达式是等价的:
package main
+
+import "fmt"
+
+type Lesson struct{
+ name,target string
+ spend int
+}
+
+func main() {
+ lesson11 := Lesson{
+ name: "Go语言",
+ target: "掌握Go语言",
+ }
+ lesson12 := Lesson{
+ name: "Go语言",
+ target: "掌握Go语言",
+ }
+ fmt.Println(lesson11.name == lesson12.name && lesson11.target == lesson12.target) // true
+ fmt.Println(lesson11 == lesson12) // true
+}在 Go 中无法在结构体内部定义方法
package main
+
+import "fmt"
+
+// Lesson 定义一个名为 Lesson 的结构体
+type Lesson struct {
+ name, target string
+ spend int
+}
+
+// ShowLessonInfo 定义一个与 Lesson 的绑定的方法
+func (l Lesson) ShowLessonInfo() {
+ fmt.Println("name:", l.name)
+ fmt.Println("target:", l.target)
+}
+
+func main() {
+ lesson13 := Lesson{
+ name: "Go语言",
+ target: "掌握Go语言",
+ }
+ lesson13.ShowLessonInfo()
+}上面的程序中定义了一个与结构体 Lesson 绑定的方法 ShowLessonInfo() ,其中 ShowLessonInfo 是方法名, (l Lesson) 表示将此方法与 Lesson 的实例绑定,这在 Go 语言中称为接收者,而 l 表示实例本身,相当于 Python 中的 self ,在方法内可以使用 实例本身.属性名称 来访问实例属性。
如果绑定结构体的方法中要改变实例的属性时,必须使用指针作为方法的接收者。
package main
+
+import "fmt"
+
+// Lesson 定义一个名为 Lesson 的结构体
+type Lesson struct {
+ name,target string
+ spend int
+}
+
+// ShowLessonInfo 定义一个与 Lesson 的绑定的方法
+func (l Lesson) ShowLessonInfo() {
+ fmt.Println("name:", l.name)
+ fmt.Println("target:", l.target)
+}
+
+// AddTime 定义一个与 Lesson 的绑定的方法,使 spend 值加 n
+func (l *Lesson) AddTime(n int) {
+ l.spend = l.spend + n
+}
+
+func main() {
+ lesson13 := Lesson{
+ name: "Go语言",
+ target: "掌握Go语言",
+ spend:50,
+ }
+ fmt.Println("添加add方法前")
+ lesson13.ShowLessonInfo()
+ lesson13.AddTime(5)
+ fmt.Println("添加add方法后")
+ lesson13.ShowLessonInfo()
+}函数 是基于功能或逻辑进行封装的可复用的代码结构。将一段功能复杂、很长的一段代码封装成多个代码片段(即函数),有助于提高代码可读性和可维护性。由于 Go 语言是编译型语言,所以函数编写的顺序是无关紧要的。
func function_name(parameter_list) (result_list) {
+ //函数体
+}在参数类型前面加 ... 表示一个切片,用来接收调用者传入的参数。注意,如果该函数下有其他类型的参数,这些其他参数必须放在参数列表的前面,切片必须放在最后。
package main
+
+import "fmt"
+
+func show(args ...string) int {
+ sum := 0
+ for _, item := range args {
+ fmt.Println(item)
+ sum += 1
+ }
+ return sum
+}
+
+func main() {
+ fmt.Println(show("1","2","3"))
+}如果传多个参数的类型都不一样,可以指定类型为 ...interface{} ,然后再遍历。
package main
+
+import "fmt"
+
+func PrintType(args ...interface{}) {
+ for _, arg := range args {
+ switch arg.(type) {
+ case int:
+ fmt.Println(arg, "type is int.")
+ case string:
+ fmt.Println(arg, "type is string.")
+ case float64:
+ fmt.Println(arg, "type is float64.")
+ default:
+ fmt.Println(arg, "is an unknown type.")
+ }
+ }
+}
+
+func main() {
+ PrintType(57, 3.14, "123")
+}使用 ... 可以用来解序列
当函数没有返回值时,函数体可以使用 return 语句返回。在 Go 中一个函数可以返回多个值。
package main
+
+import "fmt"
+
+func showBookInfo(bookName, authorName string) (string, error) {
+ if bookName == "" {
+ return "", errors.New("图书名称为空")
+ }
+ if authorName == "" {
+ return "", errors.New("作者名称为空")
+ }
+ return bookName + ",作者:" + authorName, nil
+}
+
+func main() {
+ bookInfo, err := showBookInfo("123", "45")
+ fmt.Printf("bookInfo = %s, err = %v", bookInfo, err)
+}返回带有变量名的值
func showBookInfo2(bookName, authorName string) (info string, err error) {
+ info = ""
+ if bookName == "" {
+ err = errors.New("图书名称为空")
+ return
+ }
+ if authorName == "" {
+ err = errors.New("作者名称为空")
+ return
+ }
+ // 不使用 := 因为已经在返回值那里声明了
+ info = bookName + ",作者:" + authorName
+ // 直接返回即可
+ return
+}func (parameter_list) (result_list) {
+ body
+}在 Go 语言中,函数名通过首字母大小写实现控制对方法的访问权限。
方法 其实就是一个函数,在 func 这个关键字和方法名中间加入了一个特殊的接收器类型。接收器可以是结构体类型或者是非结构体类型。接收器是可以在方法的内部访问的。
func (t Type) methodName(parameterList) returnList{
+}package main
+
+import "fmt"
+
+// Lesson 定义一个名为 Lesson 的结构体
+type Lesson struct {
+ Name string
+ Target string
+}
+
+// PrintInfo 定义一个与 Lesson 的绑定的方法
+func (lesson Lesson) PrintInfo() {
+ fmt.Println("name:", lesson.Name)
+ fmt.Println("target:", lesson.Target)
+}
+
+
+func main() {
+ l := Lesson{
+ Name: "Go语言",
+ Target: "掌握Go语言",
+ }
+ l.PrintInfo()
+}也可以把上面程序的方法改成一个函数
package main
+
+import "fmt"
+
+type Lesson struct {
+ Name string
+ Target string
+}
+
+func PrintInfo(lesson Lesson) {
+ fmt.Println("name:", lesson.Name)
+ fmt.Println("target:", lesson.Target)
+}
+
+func main() {
+ lesson := Lesson{
+ Name: "Go语言",
+ Target: "掌握Go语言",
+ }
+ PrintInfo(lesson)
+}运行这个程序,也同样会输出上面一样的答案,那么我们为什么还要用方法呢?因为在 Go 中,相同的名字的方法可以定义在不同的类型上,而相同名字的函数是不被允许的。如果你在上面这个程序添加一个同名函数,就会报错。但是在不同的结构体上面定义同名的方法就是可行的。
package main
+
+import "fmt"
+
+type Lesson struct {
+ Name string
+ Target string
+}
+
+func (lesson Lesson) PrintInfo() {
+ fmt.Println("Lesson name:", lesson.Name)
+ fmt.Println("Lesson target:", lesson.Target)
+}
+
+type Author struct {
+ Name string
+}
+
+func (author Author) PrintInfo() {
+ fmt.Println("author name:", author.Name)
+}
+
+func main() {
+ lesson := Lesson{
+ Name: "Go语言",
+ Target: "掌握Go语言",
+ }
+ lesson.PrintInfo()
+ author := Author{"Google"}
+ author.PrintInfo()
+}值接收器和指针接收器之间的区别在于,在指针接收器的方法内部的改变对于调用者是可见的,然而值接收器的方法内部的改变对于调用者是不可见的,所以若要改变实例的属性时,必须使用指针作为方法的接收者。
package main
+
+import "fmt"
+
+// Lesson 定义一个名为 Lesson 的结构体
+type Lesson struct {
+ Name string
+ Target string
+ SpendTime int
+}
+
+// PrintInfo 定义一个与 Lesson 的绑定的方法
+func (lesson Lesson) PrintInfo() {
+ fmt.Println("name:", lesson.Name)
+ fmt.Println("target:", lesson.Target)
+ fmt.Println("spendTime:", lesson.SpendTime)
+}
+
+func (lesson Lesson) ChangeLessonName(name string) {
+ lesson.Name = name
+}
+
+func (lesson *Lesson) AddSpendTime(n int) {
+ lesson.SpendTime = lesson.SpendTime + n
+}
+
+func main() {
+ lesson := Lesson{
+ Name: "Go语言",
+ Target: "掌握Go语言",
+ SpendTime: 1,
+ }
+ fmt.Println("before change")
+ lesson.PrintInfo()
+
+ fmt.Println("after change")
+ lesson.AddSpendTime(2)
+ lesson.ChangeLessonName("Go语言123")
+ lesson.PrintInfo()
+}在上面的程序中, AddSpendTime 使用指针接收器最终能改变实例的 SpendTime 值,然而使用值接收器的 ChangeLessonName 最终没有改变实例 Name 的值。
当一个函数有一个值参数,它只能接受一个值参数。当一个方法有一个值接收器,它可以接受值接收器和指针接收器。
package main
+
+import "fmt"
+
+type Lesson struct {
+ Name string
+}
+
+func (lesson Lesson) PrintInfo() {
+ fmt.Println(lesson.Name)
+}
+
+func PrintInfo(lesson Lesson) {
+ fmt.Println(lesson.Name)
+}
+
+func main() {
+ lesson := Lesson{"Go语言"}
+ PrintInfo(lesson)
+ lesson.PrintInfo()
+
+ bPtr := &lesson
+ //PrintInfo(bPtr) // error
+ bPtr.PrintInfo()
+}在上面的程序中,使用值参数 PrintInfo(lesson) 来调用这个函数是合法的,使用值接收器来调用 lesson.PrintInfo() 也是合法的。
然后在程序中我们创建了一个指向 Lesson 的指针 bPtr ,通过使用指针接收器来调用 bPtr.PrintInfo() 是合法的,但使用值参数调用 PrintInfo(bPtr) 是非法的。
package main
+
+import "fmt"
+
+type myInt int
+
+func (a myInt) add(b myInt) myInt {
+ return a + b
+}
+
+func main() {
+ var x myInt = 50
+ var y myInt = 7
+ fmt.Println(x.add(y)) // 57
+}在 Go 语言中, 接口 就是方法签名(Method Signature)的集合。在面向对象的领域里,接口定义一个对象的行为,接口只指定了对象应该做什么,至于如何实现这个行为,则由对象本身去确定。当一个类型实现了接口中的所有方法,我们称它实现了该接口。接口指定了一个类型应该具有的方法,并由该类型决定如何实现这些方法。
type interface_name interface {
+ method()
+}package main
+
+import "fmt"
+
+type Study interface {
+ learn()
+}
+
+type Student struct {
+ name string
+ book string
+}
+
+func (s Student) learn() {
+ fmt.Printf("%s 在读 %s", s.name, s.book)
+}
+
+func main() {
+ student1 := Student{
+ name: "张三",
+ book: "《Go语言》",
+ }
+ student1.learn()
+}上面的程序定义了一个名为 Study 的接口,接口中有未实现的方法 learn() ,这里还定义了名为 Student 的结构体,其绑定了方法 learn() ,也就隐式实现了 Study 接口,实现的内容是打印语句。
package main
+
+import "fmt"
+
+type Study interface {
+ learn()
+}
+type Student struct {
+ name, book string
+}
+
+func (s Student) learn() {
+ fmt.Printf("%s 在读 %s", s.name, s.book)
+}
+
+type Worker struct {
+ name string
+ book string
+ by string
+}
+
+func (w *Worker) learn() {
+ fmt.Printf("%s 在读 %s,通过方式 %s", w.name, w.book, w.by)
+}
+
+func main() {
+ var s1 Study
+ var s2 Study
+
+ student2 := Student{
+ name: "李四",
+ book: "《Go语言》",
+ }
+ s1 = student2
+ s1.learn()
+
+ student3 := Student{
+ name: "王五",
+ book: "Go语言1",
+ }
+ s1 = &student3
+ s1.learn()
+
+ worker1 := Worker{
+ name: "老王",
+ book: "Go语言2",
+ by: "视频",
+ }
+ // s2 = worker1 // error
+ s2 = &worker1
+ s2.learn()
+}可以把接口的内部看做 (type, value)。type 是接口底层的具体类型(Concrete Type),而 value 是具体类型的值。
package main
+
+import "fmt"
+
+type Study interface {
+ learn()
+}
+type Student struct {
+ name, book string
+}
+
+func (s Student) learn() {
+ fmt.Printf("%s 在读 %s", s.name, s.book)
+}
+func ShowInterface(s Study) {
+ fmt.Printf("接口类型: %T\\n 接口值: %v\\n", s, s)
+}
+
+func main() {
+ var s Study
+ student2 := Student{
+ name: "李四",
+ book: "《Go语言》",
+ }
+ s = student2
+ ShowInterface(s)
+ s.learn()
+}
+//接口类型: main.Student
+//接口值: {李四 《Go语言》}
+//李四 在读 《Go语言》空接口 是特殊形式的接口类型,没有定义任何方法的接口就称为空接口,可以说所有类型都至少实现了空接口,空接口表示为 interface{} 。例如,我们之前的写过的空接口参数函数,可以接受任何类型的参数:
package main
+
+import "fmt"
+
+func ShowType(i interface{}) {
+ fmt.Printf("类型: %T, 值: %v\\n", i, i)
+}
+
+func main() {
+ str := "Go语言"
+ ShowType(str)
+ num := 3.14
+ ShowType(num)
+}通过上面的例子不难发现接口都有两个属性,一个是值,而另一个是类型。对于空接口来说,这两个属性都为 nil
package main
+
+import "fmt"
+
+func main() {
+ var i interface{}
+ fmt.Printf("Type: %T, Value: %v", i, i)
+ // Type: <nil>, Value: <nil>
+}除了上面讲到的使用空接口作为函数参数的用法,空接口还有以下两种用法。
直接使用 interface{} 作为类型声明一个实例,这个实例就能承载任何类型的值:
package main
+
+import "fmt"
+
+func main() {
+ var i interface{}
+
+ i = "Go语言"
+ fmt.Println(i) // Let's go
+
+ i = 3.14
+ fmt.Println(i) // 3.14
+}我们也可以定义一个接收任何类型的 array 、 slice 、 map 、 strcut 。例如:
package main
+
+import "fmt"
+
+func main() {
+ x := make([]interface{}, 3)
+ x[0] = "Go"
+ x[1] = 3.14
+ x[2] = []int{1, 2, 3}
+ for _, value := range x {
+ fmt.Println(value)
+ }
+}空接口可以承载任何值,但是空接口类型的对象是不能赋值给另一个固定类型对象的。
package main
+
+func main() {
+ var num = 1
+ var i interface{} = num
+ var str string = i // error
+}当空接口承载数组和切片后,该对象无法再进行切片。
package main
+
+import "fmt"
+
+func main() {
+ var s = []int{1, 2, 3}
+
+ var i interface{} = s
+
+ var s2 = i[1:2] // error
+ fmt.Println(s2)
+}类型断言用于提取接口的底层值(Underlying Value)。使用 interface.(Type) 可以获取接口的底层值,其中接口 interface 的具体类型是 Type
package main
+
+import "fmt"
+
+func assert(i interface{}) {
+ value, ok := i.(int)
+ fmt.Println(value, ok)
+}
+
+func main() {
+ var x interface{} = 3
+ assert(x)
+ var y interface{} = "Go语言"
+ assert(y)
+}第一次调用 assert(x) 输出 3 true,表示将整数 3 转换为 int 类型成功。
第二次调用 assert(y) 输出 0 false,表示将字符串 "Go语言" 转换为 int 类型失败,因为该字符串无法转换为整数。
package main
+
+import "fmt"
+
+func getTypeValue(i interface{}) {
+ switch i.(type) {
+ case int:
+ fmt.Printf("Type: int, Value: %d\\n", i.(int))
+ case string:
+ fmt.Printf("Type: string, Value: %s\\n", i.(string))
+ default:
+ fmt.Printf("Unknown type\\n")
+ }
+}
+
+func main() {
+ getTypeValue(300)
+ getTypeValue("Go语言")
+ getTypeValue(true)
+}类型或者结构体可以实现多个接口
虽然在 Go 中没有继承机制,但可以通过接口的嵌套实现类似功能。
package main
+
+import "fmt"
+
+// 定义一个简单的读取器接口
+type Reader interface {
+ Read() string
+}
+
+// 定义一个简单的写入器接口
+type Writer interface {
+ Write(data string)
+}
+
+// 定义一个复合接口,嵌套了Reader和Writer接口
+type ReadWriter interface {
+ Reader
+ Writer
+}
+
+// 实现Reader接口
+type MyReader struct{}
+
+func (r MyReader) Read() string {
+ return "Data read from MyReader"
+}
+
+// 实现Writer接口
+type MyWriter struct{}
+
+func (w MyWriter) Write(data string) {
+ fmt.Println("Writing data:", data)
+}
+
+// 实现ReadWriter接口
+type MyReadWriter struct {
+ MyReader
+ MyWriter
+}
+
+// 使用ReadWriter接口作为参数进行函数调用
+func ProcessData(rw ReadWriter) {
+ data := rw.Read()
+ rw.Write(data + " modified")
+}
+
+func main() {
+ // 创建MyReadWriter实例
+ myRW := MyReadWriter{}
+
+ // 调用ProcessData函数,传入myRW作为参数
+ ProcessData(myRW)
+}定义了三个接口:Reader、Writer和ReadWriter。然后,我们实现了这些接口的具体类型:MyReader、MyWriter和MyReadWriter。
MyReadWriter结构体通过嵌套MyReader和MyWriter,同时实现了Reader和Writer接口。这样,MyReadWriter可以以ReadWriter类型的方式使用。
在main函数中,我们创建了一个MyReadWriter实例myRW,然后将其作为参数传递给ProcessData函数。ProcessData函数接收一个ReadWriter类型的参数,并调用其中的方法。
通过接口嵌套,我们可以更灵活地组织和复用代码
包(package) 用于组织 Go 源代码,提供了更好的可重用性与可读性.可以用 go list std命令查看标准包,标准库为大多数的程序提供了必要的基础组件。
先创建一个 book 文件夹,位于该目录下创建一个 book.go 源文件,里面实现自定义的数学加法函数。函数名的首字母要大写。
// Package book
+package book
+
+func ShowBookInfo(bookName, authorName string) (string, error) {
+ if bookName == "" {
+ return "", errors.New("图书名称为空")
+ }
+ if authorName == "" {
+ return "", errors.New("作者名称为空")
+ }
+ return bookName + ",作者:" + authorName, nil
+}使用包之前我们需要导入包,在 GoLand 中会帮你自动导入所需要的包。导入包的语法为 import path ,其中 path 可以是相对于工作区文件夹的相对路径,也可以是绝对路径。
package main
+
+import (
+ "fmt"
+ "learn/book"
+)
+
+func main() {
+ bookName := "《Go语言》"
+ author := "Golang"
+ bookInfo, _ := book.ShowBookInfo(bookName, author)
+ fmt.Println("bookInfo = ", bookInfo)
+}import (
+ "crypto/rand"
+ mrand "math/rand" // 将名称替换为 mrand 避免冲突
+)import . "fmt"
+
+func main() {
+ Println("hello, world")
+}对于一些使用高频的包,例如 fmt 包,每次调用打印函数时都要使用 fmt.Println() 进行调用,很不方便。可以在导入包的时,使用 import . package_path 语法。打印就不用加 fmt 了。
每个包都允许有一个或多个 init 函数, init 函数不应该有任何返回值类型和参数,在代码中也不能显式调用它,当这个包被导入时,就会执行这个包的 init 函数,做初始化任务, init 函数优先于 main 函数执行。该函数形式如下:
func init() {
+}包的初始化顺序:首先初始化 包级别(Package Level) 的变量,紧接着调用 init 函数。包可以有多个 init 函数(在一个文件或分布于多个文件中),它们按照编译器解析它们的顺序进行调用。如果一个包导入了另一个包,会先初始化被导入的包。尽管一个包可能会被导入多次,但是它只会被初始化一次。
导入一个没有使用的包编译会报错。但有时候我们只是想执行包里的 init 函数来执行一些初始化任务,可以使用匿名导入的方法,使用 空白标识符(Blank Identifier) :
import _ "fmt"Go 语言的 协程(Groutine) 是与其他函数或方法一起并发运行的工作方式。协程可以看作是轻量级线程。与线程相比,创建一个协程的成本很小。因此在 Go 应用中,常常会看到会有很多协程并发地运行。
调用函数或者方法时,如果在前面加上关键字 go ,就可以让一个新的 Go 协程并发地运行。
// 定义一个函数
+func functionName(parameterList) {
+ code
+}
+
+// 执行一个函数
+functionName(parameterList)
+
+// 开启一个协程执行这个函数
+go functionName(parameterList)package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func PrintInfo() {
+ fmt.Println("Go语言")
+}
+
+func main() {
+ // 开启一个协程执行 PrintInfo 函数
+ go PrintInfo()
+ // 使主协程休眠 1 秒
+ time.Sleep(1 * time.Second)
+ // 打印 main
+ fmt.Println("main")
+}PrintInfo() 函数与 main() 函数会并发执行,主函数运行在一个特殊的协程上,这个协程称之为 主协程(Main Goroutine) 。
启动一个新的协程时,协程的调用会立即返回。与函数不同,程序控制不会去等待 Go 协程执行完毕。在调用 Go 协程之后,程序控制会立即返回到代码的下一行,忽略该协程的任何返回值。如果 Go 主协程终止,则程序终止,于是其他 Go 协程也会终止。为了让新的协程能继续运行,在 main() 函数添加了 time.Sleep(1 * time.Second) 使主协程休眠 1 秒
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func PrintNum(num int) {
+ for i := 0; i < 3; i++ {
+ fmt.Println(num)
+ // 避免观察不到并发效果 加个休眠
+ time.Sleep(100 * time.Millisecond)
+ }
+}
+
+func main() {
+ // 开启 1 号协程
+ go PrintNum(1)
+ // 开启 2 号协程
+ go PrintNum(2)
+ // 使主协程休眠 1 秒
+ time.Sleep(time.Second)
+}通道(channel) ,就是一个管道,可以想像成 Go 协程之间通信的管道。它是一种队列式的数据结构,遵循先入先出的规则。
每个通道都只能传递一种数据类型的数据,在你声明的时候,我们要指定通道的类型。chan Type 表示 Type 类型的通道。通道的零值为 nil 。
var channel_name chan channel_types
+
+var ch chan string声明完通道后,通道的值为 nil ,我们不能直接使用,必须先使用 make 函数对通道进行初始化操作。
ch = make(chan channel_type)
+
+ch = make(chan string)这样,我们就已经定义好了一个 string 类型的通道 nameChan 。当然,也可以使用简短声明语句一次性定义一个通道:
ch := make(chan string)发送数据:
// 把 data 数据发送到 channel_name 通道中
+// 即把 data 数据写入到 channel_name 通道中
+channel_name <- data接收数据:
// 从 channel_name 通道中接收数据到 value
+// 即从 channel_name 通道中读取数据到 value
+value := <- channel_name通道旁的箭头方向指定了是发送数据还是接收数据。箭头指向通道,代表数据写入到通道中;箭头往通道指向外,代表从通道读数据出去。
package main
+
+import (
+ "fmt"
+)
+
+func PrintChan(c chan string) {
+ // 往通道传入数据
+ c <- "学习Go语言"
+}
+
+func main() {
+ // 创建一个通道
+ ch := make(chan string)
+ // 打印 "学习课程:"
+ fmt.Println("学习课程:")
+ // 开启协程
+ go PrintChan(ch)
+ // 从通道接收数据
+ rec := <- ch
+ // 打印从通道接收到的数据
+ fmt.Println(rec)
+}Tips: 发送与接收默认是阻塞的
close(channel_name)这里要注意,对于一个已经关闭的通道如果再次关闭会导致报错,我们可以在接收数据时,判断通道是否已经关闭,从通道读取数据返回的第二个值表示通道是否没被关闭,如果已经关闭,返回值为 false ;如果还未关闭,返回值为 true 。
value, ok := <- channel_namemake 函数是可以接收两个参数的,同理,创建通道可以传入第二个参数——容量。
0 时,说明通道中不能存放数据,在发送数据时,必须要求立马有人接收,否则会报错。此时的通道称之为无缓冲通道。1 时,说明通道只能缓存一个数据,若通道中已有一个数据,此时再往里发送数据,会造成程序阻塞。利用这点可以利用通道来做锁。1 时,通道中可以存放多个数据,可以用于多个协程之间的通信管道,共享资源。既然通道有容量和长度,那么我们可以通过 cap 函数和 len 函数获取通道的容量和长度。
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ // 创建一个通道
+ c := make(chan int, 3)
+ fmt.Println("初始化后:")
+ fmt.Println("cap =", cap(c))
+ fmt.Println("len =", len(c))
+ c <- 1
+ c <- 2
+ fmt.Println("传入两个数后:")
+ fmt.Println("cap =", cap(c))
+ fmt.Println("len =", len(c))
+ <- c
+ fmt.Println("取出一个数后:")
+ fmt.Println("cap =", cap(c))
+ fmt.Println("len =", len(c))
+}按照是否可缓冲数据可分为:缓冲通道 与 无缓冲通道 。
无缓冲通道在通道里无法存储数据,接收端必须先于发送端准备好,以确保你发送完数据后,有人立马接收数据,否则发送端就会造成阻塞,原因很简单,通道中无法存储数据。也就是说发送端和接收端是同步运行的。
c := make(chan int)
+// 或者
+c := make(chan int, 0)缓冲通道允许通道里存储一个或多个数据,设置缓冲区后,发送端和接收端可以处于异步的状态。
c := make(chan int, 3)到目前为止,上面定义的都是双向通道,既可以发送数据也可以接收数据。例如:
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ // 创建一个通道
+ c := make(chan int)
+
+ // 发送数据
+ go func() {
+ fmt.Println("send: 1")
+ c <- 1
+ }()
+
+ // 接收数据
+ go func() {
+ n := <- c
+ fmt.Println("receive:", n)
+ }()
+
+ // 主协程休眠
+ time.Sleep(time.Millisecond)
+}单向通道只能发送或者接收数据。所以可以具体细分为只读通道和只写通道。
<-chan 表示只读通道:
chan<- 表示只写通道:
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+// Sender 只写通道类型
+type Sender = chan<- string
+
+// Receiver 只读通道类型
+type Receiver = <-chan string
+
+func main() {
+ // 创建一个双向通道
+ var ch = make(chan string)
+
+ // 开启一个协程
+ go func() {
+ // 只能写通道
+ var sender Sender = ch
+ fmt.Println("即将学习:")
+ sender <- "Go语言"
+ }()
+
+ // 开启一个协程
+ go func() {
+ // 只能读通道
+ var receiver Receiver = ch
+ message := <-receiver
+ fmt.Println("开始学习: ", message)
+ }()
+
+ time.Sleep(time.Millisecond)
+}使用 for range 循环可以遍历通道,但在遍历时要确保通道是处于关闭状态,否则循环会被阻塞。
package main
+
+import (
+ "fmt"
+)
+
+func loopPrint(c chan int) {
+ for i := 0; i < 10; i++ {
+ c <- i
+ }
+ // 记得要关闭通道
+ // 否则主协程遍历完不会结束,而会阻塞
+ close(c)
+}
+
+func main() {
+ // 创建一个通道
+ var ch2 = make(chan int, 5)
+ go loopPrint(ch2)
+ for v := range ch2 {
+ fmt.Println(v)
+ }
+}上面讲过,当通道容量为 1 时,说明通道只能缓存一个数据,若通道中已有一个数据,此时再往里发送数据,会造成程序阻塞。例如:
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+// 由于 x = x+1 不是原子操作
+// 所以应避免多个协程对 x 进行操作
+// 使用容量为 1 的通道可以达到锁的效果
+func increment(ch chan bool, x *int) {
+ ch <- true
+ *x = *x + 1
+ <- ch
+}
+
+func main() {
+ ch3 := make(chan bool, 1)
+ var x int
+ for i := 0; i < 10000; i++ {
+ go increment(ch3, &x)
+ }
+ time.Sleep(time.Millisecond)
+ fmt.Println("x =", x)
+}当协程给一个通道发送数据时,照理说会有其他 Go 协程来接收数据。如果没有的话,程序就会在运行时触发 panic ,形成死锁。同理,当有协程等着从一个通道接收数据时,我们期望其他的 Go 协程会向该通道写入数据,要不然程序也会触发 panic 。
package main
+
+func main() {
+ ch := make(chan bool)
+ ch <- true
+}
+//fatal error: all goroutines are asleep - deadlock!package main
+
+import "fmt"
+
+func main() {
+ ch := make(chan bool)
+ ch <- true
+ fmt.Println(<-ch)
+}
+//fatal error: all goroutines are asleep - deadlock!
+//使用 make 函数创建通道时默认不传递第二个参数,通道中不能存放数据,在发送数据时,必须要求立马有人接收,即该通道为无缓冲通道。所以在接收者没有准备好前,发送操作会被阻塞。package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func funcRecieve(c chan bool) {
+ fmt.Println(<-c)
+}
+func main() {
+ ch4 := make(chan bool)
+ go funcRecieve(ch4)
+ ch4 <- true
+ time.Sleep(time.Millisecond)
+}
+
+
+// 或
+
+package main
+
+import "fmt"
+
+func main() {
+ ch6 := make(chan bool, 1)
+ ch6 <- true
+ ch6 <- false
+ fmt.Println(<-ch6)
+}在实际开发中我们并不能保证每个协程执行的时间,如果需要等待多个协程,全部结束任务后,再执行某个业务逻辑。下面我们介绍处理这种情况的方式。
WaitGroup 有几个方法:
Add:初始值为 0 ,这里直接传入子协程的数量,你传入的值会往计数器上加。Done:当某个子协程完成后,可调用此方法,会从计数器上减一,即子协程的数量减一,通常使用 defer 来调用。Wait:阻塞当前协程,直到实例里的计数器归零。信道可以实现多个协程间的通信,于是乎我们可以定义一个信道,在任务执行完成后,往信道中写入 true ,然后在主协程中获取到 true ,就可以认为子协程已经执行完毕。
package main
+
+import "fmt"
+
+func main() {
+ isDone := make(chan bool)
+ go func() {
+ for i := 0; i < 5; i++{
+ fmt.Println(i)
+ }
+ isDone <- true
+ }()
+ <- isDone
+}运行上面的程序,主协程就会等待创建的协程执行完毕后退出。
使用上面的信道方法,虽然可行,但在你程序中使用很多协程的话,你的代码就会看起来很复杂,这里就要介绍一种更好的方法,那就是使用 sync 包中提供的 WaitGroup 类型。WaitGroup 用于等待一批 Go 协程执行结束。程序控制会一直阻塞,直到这些协程全部执行完毕。当然 WaitGroup 也可以用于实现工作池。
WaitGroup 实例化后就能使用:
var name sync.WaitGrouppackage main
+
+import (
+ "fmt"
+ "sync"
+)
+
+func task(taskNum int, wg *sync.WaitGroup) {
+ // 延迟调用 执行完子协程计数器减一
+ defer wg.Done()
+ // 输出任务号
+ for i := 0; i < 3; i++ {
+ fmt.Printf("task %d: %d\\n", taskNum, i)
+ }
+}
+
+func main() {
+ // 实例化 sync.WaitGroup
+ var waitGroup sync.WaitGroup
+ // 传入子协程的数量
+ waitGroup.Add(3)
+ // 开启一个子协程 协程 1 以及 实例 waitGroup
+ go task(1, &waitGroup)
+ // 开启一个子协程 协程 2 以及 实例 waitGroup
+ go task(2, &waitGroup)
+ // 开启一个子协程 协程 3 以及 实例 waitGroup
+ go task(3, &waitGroup)
+ // 实例 waitGroup 阻塞当前协程 等待所有子协程执行完
+ waitGroup.Wait()
+}select 语句用在多个发送/接收通道操作中进行选择。
select 语句会一直阻塞,直到发送/接收操作准备就绪。select 会随机地选取其中之一执行。select 语法如下:
select {
+ case expression1:
+ code
+ case expression2:
+ code
+ default:
+ code
+}package main
+
+import "fmt"
+
+func main() {
+ // 创建3个通道
+ ch1 := make(chan string, 1)
+ ch2 := make(chan string, 1)
+ ch3 := make(chan string, 1)
+ // 往通道 1 发送数据
+ ch1 <- "Go语言1"
+ // 往通道 2 发送数据
+ ch2 <- "Go语言2"
+ // 往通道 3 发送数据
+ ch3 <- "Go语言3"
+
+ select {
+ // 如果从通道 1 收到数据
+ case message1 := <-ch1:
+ fmt.Println("ch1 received:", message1)
+ // 如果从通道 2 收到数据
+ case message2 := <-ch2:
+ fmt.Println("ch2 received:", message2)
+ // 如果从通道 3 收到数据
+ case message3 := <-ch3:
+ fmt.Println("ch3 received:", message3)
+ // 默认输出
+ default:
+ fmt.Println("No data received.")
+ }
+}在执行 select 语句时,如果有机会的话会运行所有表达式,只要其中一个通道接收到数据,那么就会执行对应的 case 代码,然后退出。
每个任务执行的时间不同,使用 select 语句等待相应的通道发出响应。select 会选择首先响应先完成的 task,而忽略其它的响应。使用这种方法,我们可以做多个 task,并给用户返回最快的 task 结果。
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func task1(ch chan string) {
+ time.Sleep(5 * time.Second)
+ ch <- "Go语言1"
+}
+
+func task2(ch chan string) {
+ time.Sleep(7 * time.Second)
+ ch <- "Go语言2"
+}
+
+func task3(ch chan string) {
+ time.Sleep(2 * time.Second)
+ ch <- "Go语言3"
+}
+
+func main() {
+ // 创建三个通道
+ ch1 := make(chan string)
+ ch2 := make(chan string)
+ ch3 := make(chan string)
+ go task1(ch1)
+ go task2(ch2)
+ go task3(ch3)
+
+ select {
+ // 如果从通道 1 收到数据
+ case message1 := <-ch1:
+ fmt.Println("ch1 received:", message1)
+ // 如果从通道 2 收到数据
+ case message2 := <-ch2:
+ fmt.Println("ch2 received:", message2)
+ // 如果从通道 3 收到数据
+ case message3 := <-ch3:
+ fmt.Println("ch3 received:", message3)
+ }
+}上面的程序会发现,没有 default 分支,因为如果加了该默认分支,如果还没从通道接收到数据, select 语句就会直接执行 default 分支然后退出,而不是被阻塞。
如果没有 default 分支, select 就会阻塞,如果一直没有命中其中的某个 case 最后会造成死锁。
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ // 创建两个通道
+ ch1 := make(chan string, 1)
+ ch2 := make(chan string, 1)
+ ch3 := make(chan string, 1)
+
+ select {
+ // 如果从通道 1 收到数据
+ case message1 := <-ch1:
+ fmt.Println("ch1 received:", message1)
+ // 如果从通道 2 收到数据
+ case message2 := <-ch2:
+ fmt.Println("ch2 received:", message2)
+ // 如果从通道 3 收到数据
+ case message3 := <-ch3:
+ fmt.Println("ch3 received:", message3)
+ }
+}
+//fatal error: all goroutines are asleep - deadlock!运行上面的程序会造成死锁。解决该问题的方法是写好 default 分支。
还有另一种情况会导致死锁的发生,那就是使用空 select :
package main
+
+func main() {
+ select {}
+}运行上面的程序会抛出 panic 。
Tips:
switch-case 里面的 case 是顺序执行的,但在 select 里并不是顺序执行的。在上面的第一个例子就可以看出,当 select 由多个 case 准备就绪时,将会随机地选取其中之一去执行。当 case 里的通道始终没有接收到数据时,而且也没有 default 语句时, select 整体就会阻塞,但是有时我们并不希望 select 一直阻塞下去,这时候就可以手动设置一个超时时间。
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func makeTimeout(ch chan bool, t int) {
+ time.Sleep(time.Second * time.Duration(t))
+ ch <- true
+}
+
+func main() {
+ c1 := make(chan string, 1)
+ c2 := make(chan string, 1)
+ c3 := make(chan string, 1)
+ timeout := make(chan bool, 1)
+
+ go makeTimeout(timeout, 2)
+
+ select {
+ case msg1 := <-c1:
+ fmt.Println("c1 received: ", msg1)
+ case msg2 := <-c2:
+ fmt.Println("c2 received: ", msg2)
+ case msg3 := <-c3:
+ fmt.Println("c3 received: ", msg3)
+ case <-timeout:
+ fmt.Println("Timeout, exit.")
+ }
+}select 里的 case 表达式只能对通道进行操作,不管你是往通道写入数据,还是从通道读出数据。
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ c1 := make(chan string, 2)
+
+ c1 <- "Go语言1"
+ select {
+ case c1 <- "Go语言2":
+ fmt.Println("c1 received: ", <-c1)
+ fmt.Println("c1 received: ", <-c1)
+ default:
+ fmt.Println("channel blocking")
+ }
+}
+//c1 received: Go语言1
+//c1 received: Go语言2Go 语言中,经常会遇到并发的问题,当然我们会优先考虑使用通道,同时 Go 语言也给出了传统的解决方式 Mutex(互斥锁) 和 RWMutex(读写锁) 来处理竞争条件。
type Bank struct {
+ balance int
+}
+
+func (b *Bank) Deposit(amount int) {
+ b.balance += amount
+}
+
+func (b *Bank) Balance() int {
+ return b.balance
+}
+
+func main() {
+ b := &Bank{}
+
+ b.Deposit(1000)
+ b.Deposit(1000)
+ b.Deposit(1000)
+
+ fmt.Println(b.Balance()) //3000
+}当程序并发地运行时,多个 Go 协程不应该同时访问那些修改共享资源的代码。这些修改共享资源的代码称为临界区 。
package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+type Bank struct {
+ balance int
+}
+
+func (b *Bank) Deposit(amount int) {
+ b.balance += amount
+}
+
+func (b *Bank) Balance() int {
+ return b.balance
+}
+func main() {
+ var wg sync.WaitGroup
+ b := &Bank{}
+
+ n := 1000
+ wg.Add(n)
+ for i := 1; i <= n; i++ {
+ go func() {
+ b.Deposit(1000)
+ wg.Done()
+ }()
+ }
+ wg.Wait()
+ fmt.Println(b.Balance()) //972000,962000,941000
+}举一个简单的例子,当前变量的值增加 b.balance += amount
当然,对于只有一个协程的程序来说,上面的代码没有任何问题。但是,如果有多个协程并发运行时,就会发生错误,这种情况就称之为数据竞争(data race)。使用下面的互斥锁 Mutex 就能避免这种情况的发生。
互斥锁(Mutex,mutual exclusion) 用于提供一种 加锁机制(Locking Mechanism) ,可确保在某时刻只有一个协程在临界区运行,以防止出现竞争。也是为了来保护一个资源不会因为并发操作而引起冲突导致数据不准确。
Mutex 有两个方法,分别是 Lock() 和 Unlock() ,即对应的加锁和解锁。在 Lock() 和 Unlock() 之间的代码,都只能由一个协程执行,就能避免竞争条件。
如果有一个协程已经持有了锁(Lock),当其他协程试图获得该锁时,这些协程会被阻塞,直到Mutex解除锁定。
package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+type BankV2 struct {
+ balance int
+ m sync.Mutex
+}
+
+func (b *BankV2) Deposit(amount int) {
+ b.m.Lock()
+ b.balance += amount
+ b.m.Unlock()
+}
+
+func (b *BankV2) Balance() int {
+ return b.balance
+}
+
+func main() {
+ var wg sync.WaitGroup
+ b := &BankV2{}
+
+ n := 1000
+ wg.Add(n)
+ for i := 1; i <= n; i++ {
+ go func() {
+ b.Deposit(1000)
+ wg.Done()
+ }()
+ }
+ wg.Wait()
+ fmt.Println(b.Balance()) //1000000
+}要注意同一协程里不要在尚未解锁时再次加锁,也不要对已经解锁的锁再次解锁。
sync.RWMutex 类型实现读写互斥锁,适用于读多写少的场景,它规定了当有人还在读取数据(即读锁占用)时,不允许有人更新这个数据(即写锁会阻塞);为了保证程序的效率,多个人(协程)读取数据(拥有读锁)时,互不影响不会造成阻塞,它不会像 Mutex 那样只允许有一个人(协程)读取同一个数据。读锁与读锁兼容,读锁与写锁互斥,写锁与写锁互斥。
定义一个 RWMuteux 读写锁:
var rwMutex sync.RWMutexRWMutex 里提供了两种锁,每种锁分别对应两个方法,为了避免死锁,两个方法应成对出现,必要时请使用 defer 。
RLock 方法开启锁,调用 RUnlock 释放锁;Lock 方法开启锁,调用 Unlock 释放锁。package main
+
+import (
+ "fmt"
+ "sync"
+ "time"
+)
+
+type BankV3 struct {
+ balance int
+ rwMutex sync.RWMutex // read write lock
+}
+
+func (b *BankV3) Deposit(amount int) {
+ b.rwMutex.Lock() // write lock
+ b.balance += amount
+ b.rwMutex.Unlock() // wirte unlock
+}
+
+func (b *BankV3) Balance() (balance int) {
+ b.rwMutex.RLock() // read lock
+ balance = b.balance
+ b.rwMutex.RUnlock() // read unlock
+ return
+}
+
+func main() {
+ var wg sync.WaitGroup
+ b := &BankV3{}
+
+ n := 1000
+ wg.Add(n)
+ for i := 1; i <= n; i++ {
+ go func() {
+ b.Deposit(1000)
+ wg.Done()
+ }()
+ }
+ wg.Wait()
+ fmt.Println(b.Balance())
+}Cond 实现了一个条件变量,在 Locker 的基础上增加的一个消息通知的功能,保存了一个通知列表,用来唤醒一个或所有因等待条件变量而阻塞的 Go 程,以此来实现多个 Go 程间的同步。
在 Go 中, 错误 使用内建的 error 类型表示。error 类型是一个接口类型,它的定义如下:
type error interface {
+ Error() string
+}error 有了一个签名为 Error() string 的方法。所有实现该接口的类型都可以当作一个错误类型。Error() 方法给出了错误的描述。fmt.Println 在打印错误时,会在内部调用 Error() string 方法来得到该错误的描述。
package main
+
+import (
+ "fmt"
+ "os"
+)
+
+func main() {
+ // 尝试打开文件
+ file, err := os.Open("/a.txt")
+ // 如果打开文件时发生错误 返回一个不等于 nil 的错误
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+ // 如果打开文件成功 返回一个文件句柄 和 一个值为 nil 的错误
+ fmt.Println(file.Name(), "opened successfully")
+}
+// open /a.txt: no such file or directory使用 errors 包中的 New 函数可以创建自定义错误。下面是 errors 包中 New 函数的实现代码:
package errors
+
+func New(text string) error {
+ return &errorString{text}
+}
+
+type errorString struct {
+ s string
+}
+
+func (e *errorString) Error() string {
+ return e.s
+}errorString 是一个结构体类型,只有一个字符串字段 s 。它使用了 errorString 指针接受者,来实现 error 接口的 Error() string 方法。New 函数有一个字符串参数,通过这个参数创建了 errorString 类型的变量,并返回了它的地址。于是它就创建并返回了一个新的错误。
下面是一个简单的自定义错误例子,该例子创建了一个计算矩形面积的函数,当矩形的长和宽两者有一个为负数时,就会返回一个错误:
package main
+
+import (
+ "errors"
+ "fmt"
+)
+
+func area(a, b int) (int, error) {
+ if a < 0 || b < 0 {
+ return 0, errors.New("计算错误, 长度或宽度,不能小于0.")
+ }
+ return a * b, nil
+}
+func main() {
+ a := 100
+ b := -10
+ r, err := area(a, b)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+ fmt.Println("Area =", r)
+}上面的程序能报出我们自定义的错误,但是没有具体说明是哪个数据出了问题,所以下面就来改进一下这个程序,我们使用 fmt 包中的 Errorf 函数,规定错误格式,并返回一个符合该错误的字符串。
package main
+
+import (
+ "fmt"
+)
+
+func area(a, b int) (int, error) {
+ if a < 0 || b < 0 {
+ return 0, fmt.Errorf("计算错误, 长度%d或宽度%d,不能小于0", a, b)
+ }
+ return a * b, nil
+}
+func main() {
+ a := 100
+ b := -10
+ area, err := area(a, b)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+ fmt.Println("Area =", area)
+}给错误添加更多信息还可以 使用结构体类型和字段 实现。下面还是通过改进上面的程序来讲解这种方法的实现:
首先创建一个表示错误的结构体类型,一般错误类型名称都是以 Error 结尾,上面的错误是由于面积计算中长度或宽度错误导致的,所以这里把结构体命名为 areaError :
package main
+
+import (
+ "fmt"
+)
+
+type areaError struct {
+ // 错误信息
+ err string
+ // 错误有关的长度
+ length int
+ // 错误有关的宽度
+ width int
+}
+
+// 使用指针接收者 *areaError 实现了 error 接口的 Error() string 方法
+func (e *areaError) Error() string {
+ // 打印长度和宽度以及错误的描述
+ return fmt.Sprintf("length %d, width %d : %s", e.length, e.width, e.err)
+}
+
+func rectangleArea(a, b int) (int, error) {
+ if a < 0 || b < 0 {
+ return 0, &areaError{"length or width is negative", a, b}
+ }
+ return a * b, nil
+}
+func main() {
+ a := 100
+ b := -10
+ area, err := rectangleArea(a, b)
+ // 检查了错误是否为 nil
+ if err != nil {
+ // 断言 *areaError 类型
+ if err, ok := err.(*areaError); ok {
+ // 如果错误是 *areaError 类型
+ // 用 err.length 和 err.width 来获取错误的长度和宽度 打印出自定义错误的消息
+ fmt.Printf("length %d or width %d is less than zero", err.length, err.width)
+ return
+ }
+ fmt.Println(err)
+ return
+ }
+ fmt.Println("Area =", area)
+}还可以使用 结构体类型的方法 来给错误添加更多信息。下面我们继续完善上面的程序,让程序更加精确的定位是长度引发的错误还是宽度引发的错误。
package main
+
+import (
+ "fmt"
+)
+
+type areaError struct {
+ // 错误信息
+ err string
+ // 长度
+ length int
+ // 宽度
+ width int
+}
+
+// 使用指针接收者 *areaError 实现了 error 接口的 Error() string 方法
+func (e *areaError) Error() string {
+ return e.err
+}
+
+// 长度为负数返回 true
+func (e *areaError) lengthNegative() bool {
+ return e.length < 0
+}
+
+// 宽度为负数返回 true
+func (e *areaError) widthNegative() bool {
+ return e.width < 0
+}
+
+func area(length, width int) (int, error) {
+ err := ""
+ if length < 0 {
+ err += "length is less than zero"
+ }
+ if width < 0 {
+ if err == "" {
+ err = "width is less than zero"
+ } else {
+ err += " and width is less than zero"
+ }
+ }
+ if err != "" {
+ return 0, &areaError{err, length, width}
+ }
+ return length * width, nil
+}
+
+func main() {
+ length := 100
+ width := -10
+ area, err := area(length, width)
+ // 检查了错误是否为 nil
+ if err != nil {
+ // 断言 *areaError 类型
+ if err, ok := err.(*areaError); ok {
+ // 如果错误是 *areaError 类型
+ // 如果长度为负数 打印错误长度具体值
+ if err.lengthNegative() {
+ fmt.Printf("error: 长度 %d 小于0\\n", err.length)
+ }
+ // 如果宽度为负数 打印错误宽度具体值
+ if err.widthNegative() {
+ fmt.Printf("error: 宽度 %d 小于0\\n", err.width)
+ }
+ return
+ }
+ fmt.Println(err)
+ return
+ }
+ fmt.Println("Area =", area)
+}错误和异常是两个不同的概念,非常容易混淆。错误指的是可能出现问题的地方出现了问题;而异常指的是不应该出现问题的地方出现了问题。
在有些情况,当程序发生异常时,无法继续运行。在这种情况下,我们会使用 panic 来终止程序。当函数发生 panic 时,它会终止运行,在执行完所有的延迟函数后,程序返回到该函数的调用方。这样的过程会一直持续下去,直到当前协程的所有函数都返回退出,然后程序会打印出 panic 信息,接着打印出堆栈跟踪,最后程序终止。
我们应该尽可能地使用错误,而不是使用 panic 和 recover 。只有当程序不能继续运行的时候,才应该使用 panic 和 recover 机制。
panic 有两个合理的用例:
panic ,因为如果不能绑定端口,啥也做不了。nil 作为参数调用了它。在这种情况下,我们可以使用 panic ,因为这是一个编程错误:用 nil 参数调用了一个只能接收合法指针的方法。func panic(v interface{})package main
+
+func main() {
+ panic("panic error")
+}上面已经提到了,当函数发生 panic 时,它会终止运行,在执行完所有的延迟函数后,程序返回到该函数的调用方。这样的过程会一直持续下去,直到当前协程的所有函数都返回退出,然后程序会打印出 panic 信息,接着打印出堆栈跟踪,最后程序终止。
package main
+
+import "fmt"
+
+func myTest() {
+ defer fmt.Println("defer myTest")
+ panic("panic myTest")
+}
+func main() {
+ defer fmt.Println("defer main")
+ myTest()
+}
+// defer myTest
+// defer main
+// panic: panic myTestrecover 是一个内建函数,用于重新获得 panic 协程的控制。下面是内建函数 recover 的签名:
func recover() interface{}recover 必须在 defer 函数中才能生效,在其他作用域下,它是不工作的。在延迟函数内调用 recover ,可以取到 panic 的错误信息,并且停止 panic 续发事件,程序运行恢复正常。
package main
+
+import "fmt"
+
+func outOfArray(x int) {
+ defer func() {
+ // recover() 可以将捕获到的 panic 信息打印
+ if err := recover(); err != nil {
+ fmt.Println(err)
+ }
+ }()
+ var array [5]int
+ array[x] = 1
+}
+func main() {
+ // 故意制造数组越界 触发 panic
+ outOfArray(20)
+ // 如果能执行到这句 说明 panic 被捕获了
+ // 后续的程序能继续运行
+ fmt.Println("main...")
+}
+// runtime error: index out of range [20] with length 5
+// main...虽然该程序触发了 panic ,但由于我们使用了 recover() 捕获了 panic 异常,并输出 panic 信息,即使 panic 会导致整个程序退出,但在退出前,有 defer 延迟函数,还是得执行完 defer 。然后程序还会继续执行下去
只有在相同的协程中调用 recover 才管用, recover 不能恢复一个不同协程的 panic。
内置函数 new 分配内存。该函数只接受一个参数,该参数是一个任意类型(包括自定义类型),而不是值,返回指向该类型新分配零值的指针。
// The new built-in function allocates memory. The first argument is a type,
+// not a value, and the value returned is a pointer to a newly
+// allocated zero value of that type.
+func new(Type) *Type使用 new 函数首先会分配内存,并设置类型零值,最后返回指向该类型新分配零值的指针。
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ num := new(int)
+ // 打印出类型的值
+ fmt.Println(*num) // 0
+}内置函数 make 只能分配和初始化类型为 slice 、 map 或 chan 的对象。与 new 一样,第一个参数是类型,而不是值。与 new 不同, make 的返回类型与其参数的类型相同,而不是指向它的指针。结果取决于类型:
slice:size 指定长度。切片的容量等于其长度。可提供第三个参数以指定不同的容量;它不能小于长度。map:为空映射分配足够的空间来容纳指定数量的元素。可以省略大小,在这种情况下,分配一个小的起始大小。chan:使用指定的缓冲区容量初始化通道的缓冲区。如果为零,或者忽略了大小,则通道是无缓冲的。func make(t Type, size ...IntegerType) Type使用make函数必须初始化
// slice
+a := make([]int, 2, 10)
+
+// map
+b := make(map[string]int)
+
+// chan
+c := make(chan int, 10)new:为所有的类型分配内存,并初始化为零值,返回指针。
make:只能为 slice 、 map 、 chan 分配内存,并初始化,返回的是类型。
Go 语言提供了一种机制,能够在运行时更新变量和检查它们的值、调用它们的方法,而不需要在编译时就知道这些变量的具体类型。这种机制被称为 反射 。
在 Go 中 reflect 包实现了运行时反射。reflect 包会帮助识别 interface{} 变量的底层具体类型和具体值。
reflect.Type 表示 interface{} 的具体类型。reflect.TypeOf() 方法返回 reflect.Type
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectType(x interface{}) {
+ obj := reflect.TypeOf(x)
+ fmt.Println(obj)
+}
+
+func main() {
+ var a int64 = 123
+ reflectType(a)
+ var b string = "Go语言"
+ reflectType(b)
+}reflect.Value 表示 interface{} 的具体值。reflect.ValueOf() 方法返回 reflect.Value
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectType(x interface{}) {
+ typeX := reflect.TypeOf(x)
+ valueX := reflect.ValueOf(x)
+ fmt.Println(typeX)
+ fmt.Println(valueX)
+}
+
+func main() {
+ var a int64 = 123
+ reflectType(a)
+ var b string = "Go语言"
+ reflectType(b)
+}relfect.Kind 表示的是种类。在使用反射时,需要理解类型(Type)和种类(Kind)的区别。编程中,使用最多的是类型,但在反射中,当需要区分一个大品种的类型时,就会用到种类(Kind)。
Go 语言程序中的类型(Type)指的是系统原生数据类型,如 int 、 string 、 bool 、 float32 等类型,以及使用 type 关键字定义的类型,这些类型的名称就是其类型本身的名称。例如使用 type A struct{} 定义结构体时,A 就是 struct{} 的类型。
种类(Kind)指的是对象归属的品种,在 reflect 包中有如下定义:
// A Kind represents the specific kind of type that a Type represents.
+// The zero Kind is not a valid kind.
+type Kind uint
+
+const (
+ Invalid Kind = iota
+ Bool
+ Int
+ Int8
+ Int16
+ Int32
+ Int64
+ Uint
+ Uint8
+ Uint16
+ Uint32
+ Uint64
+ Uintptr
+ Float32
+ Float64
+ Complex64
+ Complex128
+ Array
+ Chan
+ Func
+ Interface
+ Map
+ Ptr
+ Slice
+ String
+ Struct
+ UnsafePointer
+)package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectType(x interface{}) {
+ typeX := reflect.TypeOf(x)
+ fmt.Println(typeX.Kind()) // struct
+ fmt.Println(typeX) // main.book
+}
+
+type book struct {
+}
+
+func main() {
+ var b book
+ reflectType(b)
+}relfect.NumField() 方法返回结构体中字段的数量。
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectNumField(x interface{}) {
+ // 检查 x 的类别是 struct
+ if reflect.ValueOf(x).Kind() == reflect.Struct {
+ v := reflect.ValueOf(x)
+ fmt.Println("Number of fields", v.NumField())
+ }
+}
+
+type book struct {
+ name string
+ spend int
+}
+
+func main() {
+ var b book
+ reflectNumField(b)
+}relfect.Field(i int) 方法返回字段 i 的 reflect.Value
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectNumField(x interface{}) {
+ // 检查 x 的类别是 struct
+ if reflect.ValueOf(x).Kind() == reflect.Struct {
+ v := reflect.ValueOf(x)
+ fmt.Println("Number of fields", v.NumField())
+ for i := 0; i < v.NumField(); i++ {
+ fmt.Printf("Field:%d type:%T value:%v\\n", i, v.Field(i), v.Field(i))
+ }
+ }
+}
+
+type book struct {
+ name string
+ spend int
+}
+
+func main() {
+ var b = book{"Go语言", 8}
+ reflectNumField(a)
+}
+// Number of fields 2
+// Field:0 type:reflect.Value value:Go语言
+// Field:1 type:reflect.Value value:8一个接口变量,实际上都是由一 pair 对(type 和 data)组合而成,pair 对中记录着实际变量的值和类型。也就是说在真实世界(反射前环境)里,type 和 value 是合并在一起组成接口变量的。
而在反射的世界(反射后的环境)里,type 和 data 却是分开的,他们分别由 reflect.Type 和 reflect.Value 来表现。
Go语言反射三定律:
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var a interface{} = 3.14
+
+ fmt.Printf("接口变量的类型为 %T ,值为 %v\\n", a, a)
+
+ t := reflect.TypeOf(a)
+ v := reflect.ValueOf(a)
+
+ // 反射第一定律
+ fmt.Printf("从接口变量到反射对象:Type对象类型为 %T\\n", t)
+ fmt.Printf("从接口变量到反射对象:Value对象类型为 %T\\n", v)
+
+ // 反射第二定律
+ i := v.Interface()
+ fmt.Printf("从反射对象到接口变量:对象类型为 %T,值为 %v\\n", i, i)
+ // 使用类型断言进行转换
+ x := v.Interface().(float64)
+ fmt.Printf("x 类型为 %T,值为 %v\\n", x, x)
+}package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var a float64 = 3.14
+ v := reflect.ValueOf(a)
+ fmt.Println("是否可写:", v.CanSet())
+}
+---
+package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var a float64 = 3.14
+ v := reflect.ValueOf(&a)
+ fmt.Println("是否可写:", v.CanSet())
+}
+---
+package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var a float64 = 3.14
+ v := reflect.ValueOf(&a).Elem()
+ fmt.Println("是否可写:", v.CanSet())
+
+ v.SetFloat(2)
+ fmt.Println(v)
+}package main
+
+import "fmt"
+
+func main() {
+ fmt.Println("Hello, World!")
+}package:定义当前源码文件所属的包。import:导入其他包。func:定义函数。var:声明变量。const:声明常量。type:定义类型。struct:定义结构体。interface:定义接口。map:定义映射类型。range:用于循环迭代。select:用于通道操作。defer:延迟执行。go:启动一个新的 goroutine。chan:定义通道类型。default:select 语句中的默认情况。fallthrough:在 switch 语句中贯穿到下一个 case。if:条件语句。else:if 语句中的默认情况。switch:多分支条件语句。case:switch 语句中的分支情况。for:循环语句。break:跳出循环或 switch 语句。continue:结束当前循环,开始下一次循环。return:返回函数结果。panic:抛出异常。package main
+
+import "fmt"
+
+func main() {
+ var a int
+ fmt.Println("a = ", a)
+ fmt.Printf("a的类型是%T\\n", a)
+}
+// a = 0
+// a的类型是intpackage main
+
+import "fmt"
+
+func main() {
+ var a int = 10
+ fmt.Println("a =", a)
+ fmt.Printf("a的类型是%T\\n", a)
+
+ var b string = "hello"
+ fmt.Println("b =", b)
+ fmt.Printf("b的类型是%T\\n", b)
+}
+// a = 10
+// a的类型是int
+// b = hello
+// b的类型是stringpackage main
+
+import "fmt"
+
+func main() {
+ var a = 10
+ fmt.Println("a =", a)
+ fmt.Printf("a的类型是%T\\n", a)
+
+ var b = "hello"
+ fmt.Println("b =", b)
+ fmt.Printf("b的类型是%T\\n", b)
+}
+// a = 10
+// a的类型是int
+// b = hello
+// b的类型是stringpackage main
+
+import "fmt"
+
+func main() {
+ c := "1"
+ fmt.Printf("c = %s, c的类型是%T\\n", c, c)
+}
+// c = 1, c的类型是stringpackage main
+
+func main(){
+ var xx, yy int = 100, 200
+ var kk, wx = 300, "666
+ var (
+ nn int = 100
+ mm bool = true
+ )
+}匿名变量:下划线_,本身就是一个特殊的标识符。可以像其他标识符那样用于变量的声明,任何类型都可以赋值给它,但任何赋值给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用。
和其他静态类型语言不同,可以直接交换变量(python也有这个语法)
package main
+
+import "fmt"
+
+func main() {
+ var (
+ a = 100
+ b = 200
+ )
+
+ a, b = b, a
+
+ fmt.Println(a, b)
+}
+// 200 100package main
+
+import "fmt"
+
+func main(){
+ // 常量(只读属性)
+ const length int = 10
+ // length = 100 // 常量是不允许被修改的
+ fmt.Println("length = ", length)
+}package main
+
+import "fmt"
+
+// const来定义枚举类型
+const (
+ BEIJING = 0
+ SHANGHAI = 1
+ SHENZHEN = 2
+)
+
+func main() {
+ fmt.Println("BEIJING = ", BEIJING) // 0
+ fmt.Println("SHANGHAI = ", SHANGHAI) // 1
+ fmt.Println("SHENZHEN = ", SHENZHEN) // 2
+}iota 是一个常量生成器,用于生成一组相关的枚举值。iota 可以与 const 关键字一起使用,在定义一组枚举时,用来生成连续的值。const 中每新增一行常量声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)
// iota 初始值为 0,每当出现一个新的常量声明时,它的值就会自动加 1,因此 Monday 的值为 1,Tuesday 的值为 2,以此类推。
+const (
+ Sunday = iota // 0
+ Monday // 1
+ Tuesday // 2
+ Wednesday // 3
+ Thursday // 4
+ Friday // 5
+ Saturday // 6
+)
+
+// 在下面的例子中,B 被显式赋值为 3.14,因此接下来的 C 的值为 iota + 1,即 2,而 D 的值也是 iota + 1,所以它的值为 3。
+const (
+ A = iota // 0
+ B = 3.14 // 3.14
+ C = iota // 2
+ D // 3
+)package main
+
+import "fmt"
+
+// 定义递增的步长
+const (
+ BEIJING = iota * 10
+ SHANGHAI
+ SHENZHEN
+)
+
+func main() {
+ fmt.Println("BEIJING = ", BEIJING) // 0
+ fmt.Println("SHANGHAI = ", SHANGHAI) // 10
+ fmt.Println("SHENZHEN = ", SHENZHEN) // 20
+}package main
+
+import (
+ "fmt"
+ "math"
+ "unsafe"
+)
+
+// 有符号整型
+func Integer() {
+ var num8 int8 = 127
+ var num16 int16 = 32767
+ var num32 int32 = math.MaxInt32
+ var num64 int64 = math.MaxInt64
+ var num int = math.MaxInt
+ fmt.Printf("num8的类型是 %T, num8的大小 %d, num8是 %d\\n",
+ num8, unsafe.Sizeof(num8), num8)
+ fmt.Printf("num16的类型是 %T, num16的大小 %d, num16是 %d\\n",
+ num16, unsafe.Sizeof(num16), num16)
+ fmt.Printf("num32的类型是 %T, num32的大小 %d, num32是 %d\\n",
+ num32, unsafe.Sizeof(num32), num32)
+ fmt.Printf("num64的类型是 %T, num64的大小 %d, num64是 %d\\n",
+ num64, unsafe.Sizeof(num64), num64)
+ fmt.Printf("num的类型是 %T, num的大小 %d, num是 %d\\n",
+ num, unsafe.Sizeof(num), num)
+}
+
+// 无符号整型
+func unsignedInteger() {
+ var num8 uint8 = 128
+ var num16 uint16 = 32768
+ var num32 uint32 = math.MaxUint32
+ var num64 uint64 = math.MaxUint64
+ var num uint = math.MaxUint
+ fmt.Printf("num8的类型是 %T, num8的大小 %d, num8是 %d\\n",
+ num8, unsafe.Sizeof(num8), num8)
+ fmt.Printf("num16的类型是 %T, num16的大小 %d, num16是 %d\\n",
+ num16, unsafe.Sizeof(num16), num16)
+ fmt.Printf("num32的类型是 %T, num32的大小 %d, num32是 %d\\n",
+ num32, unsafe.Sizeof(num32), num32)
+ fmt.Printf("num64的类型是 %T, num64的大小 %d, num64是 %d\\n",
+ num64, unsafe.Sizeof(num64), num64)
+ fmt.Printf("num的类型是 %T, num的大小 %d, num是 %d\\n",
+ num, unsafe.Sizeof(num), num)
+}
+
+func main() {
+ Integer()
+ println("---------------------------------------")
+ unsignedInteger()
+}TIP
int 表示整型宽度,在 32 位系统下是 32 位,而在 64 位系统下是 64 位。表示范围:在 32 位系统下是 -2147483648 ~ 2147483647 ,而在 64 位系统是 -9223372036854775808 ~ 9223372036854775807 。int8 , int16 等这些类型后面有跟一个数值的类型来说,它们能表示的数值个数是固定的。所以,在有的时候:例如在二进制传输、读写文件的结构描述(为了保持文件的结构不会受到不同编译目标平台字节长度的影响)等情况下,使用更加精确的 int32 和 int64 是更好的。float32 类型的变量占用 4 个字节的内存,可以表示的数值范围为±1.401298464324817e-45 到±3.4028234663852886e+38,精度约为 7 个十进制位。
float64 类型的变量占用 8 个字节的内存, 可以表示的数值范围为±4.9406564584124654e-324 到±1.7976931348623157e+308,精度约为 15 个十进制位。
Go 语言中的浮点数默认为 float64 类型,如果需要使用 float32 类型,需要显式声明。
package main
+
+import (
+ "fmt"
+ "math"
+)
+
+func showFloat() {
+ var num1 float32 = math.MaxFloat32
+ var num2 float64 = math.MaxFloat64
+ fmt.Printf("num1的类型是%T,num1是%g\\n", num1, num1)
+ fmt.Printf("num2的类型是%T,num1是%g\\n", num2, num2)
+}
+
+func main() {
+ showFloat()
+}
+//num1的类型是float32,num1是3.4028235e+38
+//num2的类型是float64,num1是1.7976931348623157e+308字符串中的每一个元素叫作“字符”,定义字符时使用单引号。Go 语言的字符有两种。
byte类型,占用1个字节,表示 UTF-8 字符串的单个字节的值,表示的是 ASCII 码表中的一个字符,uint8 的别名类型rune类型,占用4个字节,表示单个 unicode 字符,int32 的别名类型package main
+
+import (
+ "fmt"
+ "unsafe"
+)
+
+func showChar() {
+ var x byte = 65
+ var y uint8 = 65
+ z := 'A'
+ fmt.Printf("x = %c\\n", x) // x = A
+ fmt.Printf("y = %c\\n", y) // y = A
+ fmt.Printf("z = %c\\n", z) // z = A
+
+}
+
+func sizeOfChar() {
+ var x byte = 65
+ fmt.Printf("x = %c\\n", x)
+ fmt.Printf("x 占用 %d 个字节\\n", unsafe.Sizeof(x))
+
+ var y rune = 'A'
+ fmt.Printf("y = %c\\n", y)
+ fmt.Printf("y 占用 %d 个字节\\n", unsafe.Sizeof(y))
+}
+
+func main() {
+ showChar()
+ sizeOfChar()
+}字符串在Go语言中是基本数据类型。
var study string // 定义名为str的字符串类型变量
+study = "《123》" // 将变量赋值
+study2 := "《789》" // 以自动推断方式初始化定义多行字符串的方法如下。
package main
+import "fmt"
+
+func main() {
+ var s1 string
+ s1 = \`
+ study := 'Go语言'
+ fmt.Println(study)
+ \`
+ fmt.Println(s1)
+}func showBool(){
+ a := true
+ b := false
+ fmt.Println("a=", a)
+ fmt.Println("b=", b)
+ fmt.Println("true && false = ", a && b)
+ fmt.Println("true || false = ", a || b)
+}
+
+func main() {
+ showBool()
+}| 类 型 | 字 节 数 | 说 明 |
|---|---|---|
| complex64 | 8 | 64 位的复数型,由 float32 类型的实部和虚部联合表示 |
| complex128 | 16 | 128 位的复数型,由 float64 类型的实部和虚部联合表示 |
func showComplex() {
+ // 内置的 complex 函数用于构建复数
+ var x complex64 = complex(1, 2)
+ var y complex128 = complex(3, 4)
+ var z complex128 = complex(5, 6)
+ fmt.Println("x = ", x)
+ fmt.Println("y = ", y)
+ fmt.Println("z = ", z)
+
+ // 内建的 real 和 imag 函数分别返回复数的实部和虚部
+ fmt.Println("real(x) = ", real(x))
+ fmt.Println("imag(x) = ", imag(x))
+ fmt.Println("y * z = ", y*z)
+}
+
+func main() {
+ showComplex()
+}TIP
同样可以用自然方式表示复数
x := 1 + 2i
+y := 3 + 4i
+z := 5 + 6i| 格式 | 含义 |
|---|---|
| %% | 一个%字面量 |
| %b | 一个二进制整数值(基数为 2),或者是一个(高级的)用科学计数法表示的指数为 2 的浮点数 |
| %c | 字符型。可以把输入的数字按照 ASCII 码相应转换为对应的字符 |
| %d | 一个十进制数值(基数为 10) |
| %f | 以标准记数法表示的浮点数或者复数值 |
| %o | 一个以八进制表示的数字(基数为 8) |
| %p | 以十六进制(基数为 16)表示的一个值的地址,前缀为 0x,字母使用小写的 a-f 表示 |
| %q | 使用 Go 语法以及必须时使用转义,以双引号括起来的字符串或者字节切片[]byte,或者是以单引号括起来的数字 |
| %s | 字符串。输出字符串中的字符直至字符串中的空字符(字符串以’\\0‘结尾,这个’\\0’即空字符) |
| %t | 以 true 或者 false 输出的布尔值 |
| %T | 使用 Go 语法输出的值的类型 |
| %x | 以十六进制表示的整型值(基数为十六),数字 a-f 使用小写表示 |
| %X | 以十六进制表示的整型值(基数为十六),数字 A-F 使用小写表示 |
fmt.Print: 将指定的内容打印到标准输出,不换行。
fmt.Println: 将指定的内容打印到标准输出,并在末尾添加换行符。
fmt.Printf: 根据格式字符串将指定的内容格式化后打印到标准输出。
fmt.Sprintf: 根据格式字符串将指定的内容格式化后返回一个格式化的字符串。
fmt.Scan: 从标准输入读取内容,并将其存储到指定的变量中。
fmt.Scanln: 从标准输入按空格分隔读取内容,并将其存储到指定的变量中,遇到换行符停止。
fmt.Scanf: 根据格式字符串从标准输入读取内容,并将其按指定的格式存储到指定的变量中。
fmt.Errorf: 根据格式字符串创建一个新的错误。
+、-、*、/、%、++、--
==、!=、>、<、>=、<=
&&、||、!
&、|、^、<<、>>
Go 中的数组是值类型而不是引用类型。当数组赋值给一个新的变量时,该变量会得到一个原始数组的一个副本。如果对新变量进行更改,不会影响原始数组。
func arrByValue() {
+ arr := [...]string{"123", "456", "789"}
+ copy := arr
+ copy[0] = "Golang"
+ fmt.Println(arr)
+ fmt.Println(copy)
+}var variable_name [SIZE]variable_type
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}如果数组长度不确定,可以使用 ... 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
+或
+balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}如果设置了数组的长度,我们还可以通过指定下标来初始化元素:
// 将索引为 1 和 3 的元素初始化
+balance := [5]float32{1:2.0,3:7.0}初始化数组中 {} 中的元素个数不能大于 [] 中的数字。
如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小:
balance[4] = 50.0数组元素可以通过索引(位置)来读取。格式为数组名后加中括号,中括号中为索引的值。例如:
var salary float32 = balance[9]len(arr)
使用for range循环
func showArr() {
+ arr := [...]string{"123", "456", "789"}
+ for index, value := range arr {
+ fmt.Printf("arr[%d]=%s\\n", index, value)
+ }
+
+ for _, value := range arr {
+ fmt.Printf("value=%s\\n", value)
+ }
+}Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
var identifier []type切片不需要说明长度。
或使用 make() 函数来创建切片:
var slice1 []type = make([]type, len)
+
+也可以简写为
+
+slice1 := make([]type, len)也可以指定容量,其中 capacity 为可选参数。
make([]T, length, capacity)这里 len 是数组的长度并且也是切片的初始长度。
直接初始化切片,[] 表示是切片类型,{1,2,3} 初始化值依次是 1,2,3,其 cap=len=3。
s :=[] int {1,2,3 }初始化切片 s,是数组 arr 的引用。
s := arr[:]将 arr 中从下标 startIndex 到 endIndex-1 下的元素创建为一个新的切片。
s := arr[startIndex:endIndex]默认 endIndex 时将表示一直到arr的最后一个元素。
s := arr[startIndex:]默认 startIndex 时将表示从 arr 的第一个元素开始。
s := arr[:endIndex]通过切片 s 初始化切片 s1。
s1 := s[startIndex:endIndex]通过内置函数 make() 初始化切片s,[]int 标识为其元素类型为 int 的切片。
s :=make([]int,len,cap)
make([]T, length, capacity)用于创建一个指定类型T、长度为length、容量为capacity的切片。其中,length表示切片的实际长度,而capacity则表示切片底层数组的容量。切片的容量可以理解为底层数组能够容纳的元素数量。当切片的容量不足以容纳新添加的元素时,Go 会自动将底层数组扩展一倍,并将原有的元素复制到新的数组中。因此,在预先分配足够容量的情况下,可以避免频繁的内存分配和数据复制操作,提高代码的性能。
需要注意的是,
capacity参数不能小于length参数。如果capacity小于length,则会抛出一个运行时异常。
nilvar numList []int
+fmt.Println(numList == nil) // true== 操作符来判断两个 slice 是否含有全部相等元素。特别注意,如果你需要测试一个 slice 是否是空的,使用 len(s) == 0 来判断,而不应该用 s == nil 来判断。一个 slice 由三个部分构成:指针 、 长度 和 容量 。指针指向第一个 slice 元素对应的底层数组元素的地址,要注意的是 slice 的第一个元素并不一定就是数组的第一个元素。长度对应 slice 中元素的数目;长度不能超过容量,容量一般是从 slice 的开始位置到底层数据的结尾位置。简单的讲,容量就是从创建切片索引开始的底层数组中的元素个数,而长度是切片中的元素个数。
内置的 len 和 cap 函数分别返回 slice 的长度和容量。
s := make([]string, 3, 5)
+fmt.Println(len(s)) // 3
+fmt.Println(cap(s)) // 5切片自己不拥有任何数据。它只是底层数组的一种表示。对切片所做的任何修改都会反映在底层数组中。
func modifySlice() {
+ var arr = [...]string{"123", "456", "789"}
+ s := arr[:] //[0:len(arr)]
+ fmt.Println(arr)
+ fmt.Println(s)
+
+ s[0] = "Go语言"
+ fmt.Println(arr)
+ fmt.Println(s)
+}这里的 arr[:] 没有填入起始值和结束值,默认就是 0 和 len(arr) 。
使用 append 可以将新元素追加到切片上。append 函数的定义是 func append(slice []Type, elems ...Type) []Type 。其中 elems ...Type 在函数定义中表示该函数接受参数 elems 的个数是可变的。这些类型的函数被称为可变参数。
func appendSliceData() {
+ s := []string{"123"}
+ fmt.Println(s)
+ fmt.Println(cap(s))
+
+ s = append(s, "567")
+ fmt.Println(s)
+ fmt.Println(cap(s))
+
+ s = append(s, "789", "0")
+ fmt.Println(s)
+ fmt.Println(cap(s))
+
+ s = append(s, []string{"1", "2"}...)
+ fmt.Println(s)
+ fmt.Println(cap(s))
+}当新的元素被添加到切片时,如果容量不足,会创建一个新的数组。现有数组的元素被复制到这个新数组中,并返回新的引用。现在新切片的容量是旧切片的两倍。
类似于数组,切片也可以有多个维度。
func mSlice() {
+ numList := [][]string{
+ {"1", "123"},
+ {"2", "456"},
+ {"3", "789"},
+ }
+ fmt.Println(numList)
+}在 Go 语言中,map 是散列表(哈希表)的引用。它是一个拥有键值对元素的无序集合,在这个集合中,键是唯一的,可以通过键来获取、更新或移除操作。无论这个散列表有多大,这些操作基本上是通过常量时间完成的。所有可比较的类型,如 整型 ,字符串 等,都可以作为 key 。
使用 make 函数传入键和值的类型,可以创建 map 。具体语法为 make(map[KeyType]ValueType) 。
// 创建一个键类型为 string 值类型为 int 名为 scores 的 map
+scores := make(map[string]int)
+steps := make(map[string]string)字面量创建:
var steps2 map[string]string = map[string]string{
+ "第一步": "123",
+ "第二步": "456",
+ "第三步": "789",
+}
+fmt.Println(steps2)steps3 := map[string]string{
+ "第一步": "123",
+ "第二步": "456",
+ "第三步": "789",
+}
+fmt.Println(steps3)添加元素
// 可以使用 \`map[key] = value\` 向 map 添加元素。
+steps3["第四步"] = "总监"更新元素
// 若 key 已存在,使用 map[key] = value 可以直接更新对应 key 的 value 值。
+steps3["第四步"] = "CTO"获取元素
// 直接使用 map[key] 即可获取对应 key 的 value 值,如果 key不存在,会返回其 value 类型的零值。
+fmt.Println(steps3["第四步"] )删除元素
//使用 delete(map, key)可以删除 map 中的对应 key 键值对,如果 key 不存在,delete 函数会静默处理,不会报错。
+delete(steps3, "第四步")判断 key 是否存在
// 如果我们想知道 map 中的某个 key 是否存在,可以使用下面的语法:value, ok := map[key]
+v3, ok := steps3["第三步"]
+fmt.Println(ok)
+fmt.Println(v3)
+
+v4, ok := steps3["第四步"]
+fmt.Println(ok)
+fmt.Println(v4)这个语句说明 map 的下标读取可以返回两个值,第一个值为当前 key 的 value 值,第二个值表示对应的 key 是否存在,若存在 ok 为 true ,若不存在,则 ok 为 false 。
遍历 map
// 遍历 map 中所有的元素需要用 for range 循环。
+for key, value := range steps3 {
+ fmt.Printf("key: %s, value: %s\\n", key, value)
+}获取 map 长度
// 使用 len 函数可以获取 map 长度
+func createMap() {
+ //...
+ fmt.Println(len(steps3)) // 4
+}当 map 被赋值为一个新变量的时候,它们指向同一个内部数据结构。因此,改变其中一个变量,就会影响到另一变量。
func mapByReference() {
+ steps4 := map[string]string{
+ "第一步": "123",
+ "第二步": "456",
+ "第三步": "789",
+ }
+ fmt.Println("steps4: ", steps4)
+ // steps4: map[第一步:123 第三步:789 第二步:456]
+ newSteps4 := steps4
+ newSteps4["第一步"] = "123-222"
+ newSteps4["第二步"] = "456-222"
+ newSteps4["第三步"] = "789-222"
+ fmt.Println("steps4: ", steps4)
+ // steps4: map[第一步:123-222 第三步:789-222 第二步:456-222]
+ fmt.Println("newSteps4: ", newSteps4)
+ // newSteps4: map[第一步:123-222 第三步:789-222 第二步:456-222]
+}当 map 作为函数参数传递时也会发生同样的情况。
if 条件1 {
+ 逻辑代码1
+} else if 条件2 {
+ 逻辑代码2
+} else if 条件 ... {
+ 逻辑代码 ...
+} else {
+ 逻辑代码 else
+}score := 88
+if score >= 90 {
+ fmt.Println("成绩等级为A")
+} else if score >= 80 {
+ fmt.Println("成绩等级为B")
+} else if score >= 70 {
+ fmt.Println("成绩等级为C")
+} else if score >= 60 {
+ fmt.Println("成绩等级为D")
+} else {
+ fmt.Println("成绩等级为E 成绩不及格")
+}if 还有另外一种写法,它包含一个 statement 可选语句部分,该可选语句在条件判断之前运行。它的语法是:
if statement; condition {
+}
+
+if score := 88; score >= 60 {
+ fmt.Println("成绩及格")
+}switch 表达式 {
+ case 表达式值1:
+ 业务逻辑代码1
+ case 表达式值2:
+ 业务逻辑代码2
+ case 表达式值3:
+ 业务逻辑代码3
+ case 表达式值 ...:
+ 业务逻辑代码 ...
+ default:
+ 业务逻辑代码
+}grade := "B"
+switch grade {
+case "A":
+ fmt.Println("Your score is between 90 and 100.")
+case "B":
+ fmt.Println("Your score is between 80 and 90.")
+case "C":
+ fmt.Println("Your score is between 70 and 80.")
+case "D":
+ fmt.Println("Your score is between 60 and 70.")
+default:
+ fmt.Println("Your score is below 60.")
+}一个 case 多个条件
month := 5
+switch month {
+case 1, 3, 5, 7, 8, 10, 12:
+ fmt.Println("该月份有 31 天")
+case 4, 6, 9, 11:
+ fmt.Println("该月份有 30 天")
+case 2:
+ fmt.Println("该月份闰年为 29 天,非闰年为 28 天")
+default:
+ fmt.Println("输入有误!")
+}switch 还有另外一种写法,它包含一个 statement 可选语句部分,该可选语句在表达式之前运行。它的语法是:
switch statement; expression {
+}
+
+
+switch month := 5; month {
+case 1, 3, 5, 7, 8, 10, 12:
+ fmt.Println("该月份有 31 天")
+case 4, 6, 9, 11:
+ fmt.Println("该月份有 30 天")
+case 2:
+ fmt.Println("该月份闰年为 29 天,非闰年为 28 天")
+default:
+ fmt.Println("输入有误!")
+}这里 month 变量的作用域就仅限于这个 switch 内。
switch 后可接函数
switch 后面可以接一个函数,只要保证 case 后的值类型与函数的返回值一致即可。
package main
+
+import "fmt"
+
+func getResult(args ...int) bool {
+ for _, v := range args {
+ if v < 60 {
+ return false
+ }
+ }
+ return true
+}
+
+func main() {
+ chinese := 88
+ math := 90
+ english := 95
+
+ switch getResult(chinese, math, english) {
+ case true:
+ fmt.Println("考试通过")
+ case false:
+ fmt.Println("考试未通过")
+ }
+}无表达式的 switch
switch 后面的表达式是可选的。如果省略该表达式,则表示这个 switch 语句等同于 switch true ,并且每个 case 表达式都被认定为有效,相应的代码块也会被执行。
score := 88
+switch {
+case score >= 90 && score <= 100:
+ fmt.Println("grade A")
+case score >= 80 && score < 90:
+ fmt.Println("grade B")
+case score >= 70 && score < 80:
+ fmt.Println("grade C")
+case score >= 60 && score < 70:
+ fmt.Println("grade D")
+case score < 60:
+ fmt.Println("grade E")
+}该 switch-case 语句相当于 if-elseif-else 语句。
fallthrough 语句
正常情况下 switch-case 语句在执行时只要有一个 case 满足条件,就会直接退出 switch-case ,如果一个都没有满足,才会执行 default 的代码块。不同于其他语言需要在每个 case 中添加 break 语句才能退出。使用 fallthrough 语句可以在已经执行完成的 case 之后,把控制权转移到下一个 case 的执行代码中。fallthrough 只能穿透一层,不管你有没有匹配上,都要退出了。fallthrough 语句是 case 子句的最后一个语句。如果它出现在了 case 语句的中间,编译会不通过。
s := "123"
+switch {
+case s == "123":
+ fmt.Println("123")
+ fallthrough
+case s == "456":
+ fmt.Println("456")
+case s != "789":
+ fmt.Println("789")
+}循环语句 可以用来重复执行某一段代码。在 C 语言中,循环语句有 for 、 while 和 do while 三种循环。但在 Go 中只有 for 一种循环语句。下面是 for 循环语句的四种基本模型:
// for 接三个表达式
+for initialisation; condition; post {
+ code
+}
+
+// for 接一个条件表达式
+for condition {
+ code
+}
+
+// for 接一个 range 表达式
+for range_expression {
+ code
+}
+
+// for 不接表达式
+for {
+ code
+}接一个条件表达式
num := 0
+for num < 4 {
+ fmt.Println(num)
+ num++
+}接三个表达式
for 后面接的这三个表达式,各有各的用途:
initialisation):初始化控制变量,在整个循环生命周期内,只执行一次;condition):设置循环控制条件,该表达式值为 true 时循环,值为 false 时结束循环;post):每次循环完都会执行此表达式,可以利用其让控制变量增量或减量。这三个表达式,使用 ; 分隔。
for num := 0; num < 4; num++ {
+ fmt.Println(num)
+}接一个 range 表达式
str := "Golang"
+for index, value := range str{
+ fmt.Printf("index %d, value %c\\n", index, value)
+}不接表达式
for 后面不接表达式就相当于无限循环,当然,可以使用 break 语句退出循环
// 第一种写法
+for {
+ code
+}
+// 第二种写法
+for ;; {
+ code
+}break 语句
break 语句用于终止 for 循环,之后程序将执行在 for 循环后的代码。上面的例子已经演示了 break 语句的使用。
continue 语句
continue 语句用来跳出 for 循环中的当前循环。在 continue 语句后的所有的 for 循环语句都不会在本次循环中执行,执行完 continue 语句后将会继续执行一下次循环。下面的程序会打印出 10 以内的奇数。
含有 defer 语句的函数,会在该函数将要返回之前,调用另一个函数。简单点说就是 defer 语句后面跟着的函数会延迟到当前函数执行完后再执行。
package main
+
+import "fmt"
+
+func bookPrint() {
+ fmt.Println("123")
+}
+
+func main() {
+ defer bookPrint()
+ fmt.Println("main函数...")
+}首先,执行 main 函数,因为 bookPrint() 函数前有 defer 关键字,所以会在执行完 main 函数后再执行 bookPrint() 函数,所以先打印出 main函数... ,再执行 bookPrint() 函数打印 123 。
即时求值的变量快照
使用 defer 只是延时调用函数,传递给函数里的变量,不应该受到后续程序的影响。
str := "123"
+defer fmt.Println(str)
+str = "456"
+fmt.Println(str)
+// 456
+// 123延迟方法
defer 不仅能够延迟函数的执行,也能延迟方法的执行。
package main
+
+import "fmt"
+
+type Book struct {
+ bookName, authorName string
+}
+
+func (b Book) printName() {
+ fmt.Printf("%s %s", b.bookName, b.authorName)
+}
+
+func main() {
+ book := Book{"123", "456"}
+ defer book.printName()
+ fmt.Printf("main... ")
+}
+// main... 123 456defer 栈
当一个函数内多次调用 defer 时,Go 会把 defer 调用放入到一个栈中,随后按照 后进先出 的顺序执行。
package main
+
+import "fmt"
+
+func main() {
+ defer fmt.Printf("123")
+ defer fmt.Printf("456")
+ defer fmt.Printf("789")
+ fmt.Printf("main...")
+}
+//main...789456123defer 在 return 后调用
package main
+
+import "fmt"
+
+var s string = "123"
+
+func showLesson() string {
+ defer func() {
+ s = "456"
+ }()
+ fmt.Println("showLesson: s =", s)
+ return s
+}
+
+func main() {
+ lesson := showLesson()
+ fmt.Println("main: s =", s)
+ fmt.Println("main: lesson =", lesson)
+}
+//showLesson: s = 123
+//main: s = 456
+//main: lesson = 123Go 中 defer 和 return 执行的先后顺序
- 多个defer的执行顺序为“后进先出”;
- defer、return、返回值三者的执行逻辑应该是:return最先执行,return负责将结果写入返回值中;接着defer开始执行一些收尾工作;最后函数携带当前返回值退出。
如果函数的返回值是无名的(不带命名返回值),则go语言会在执行return的时候会执行一个类似创建一个临时变量作为保存return值的动作,而有名返回值的函数,由于返回值在函数定义的时候已经将该变量进行定义,在执行return的时候会先执行返回值保存操作,而后续的defer函数会改变这个返回值(虽然defer是在return之后执行的,但是由于使用的函数定义的变量,所以执行defer操作后对该变量的修改会影响到return的值
defer 可以使代码更简洁
如果没有使用 defer ,当在一个操作资源的函数里调用多个 return 时,每次都得释放资源,你可能这样写代码:
func f() {
+ r := getResource() //0,获取资源
+ ......
+ if ... {
+ r.release() //1,释放资源
+ return
+ }
+ ......
+ if ... {
+ r.release() //2,释放资源
+ return
+ }
+ ......
+ if ... {
+ r.release() //3,释放资源
+ return
+ }
+ ......
+ r.release() //4,释放资源
+ return
+}有了 defer 之后,可以简洁地写成下面这样:
func f() {
+ r := getResource() //0,获取资源
+
+ defer r.release() //1,释放资源
+ ......
+ if ... {
+ ...
+ return
+ }
+ ......
+ if ... {
+ ...
+ return
+ }
+ ......
+ if ... {
+ ...
+ return
+ }
+ ......
+ return
+}在 Go 语言中保留 goto 。goto 后面接的是标签,表示下一步要执行哪里的代码。
package main
+
+import "fmt"
+
+func main() {
+ fmt.Println("123")
+ goto label
+ fmt.Println("456")
+label:
+ fmt.Println("789")
+}
+//123
+//789一个指针变量指向了一个值的内存地址。
类似于变量和常量,在使用指针前你需要声明指针。指针声明格式如下:
var var_name *var-typevar-type 为指针类型,var_name 为指针变量名,* 号用于指定变量是作为一个指针。以下是有效的指针声明:
var ip *int /* 指向整型*/
+var fp *float32 /* 指向浮点型 */指针使用流程:
package main
+
+import "fmt"
+
+func main() {
+ var a int= 20 /* 声明实际变量 */
+ var ip *int /* 声明指针变量 */
+
+ ip = &a /* 指针变量的存储地址 */
+
+ fmt.Printf("a 变量的地址是: %x\\n", &a )
+
+ /* 指针变量的存储地址 */
+ fmt.Printf("ip 变量储存的指针地址: %x\\n", ip )
+
+ /* 使用指针访问值 */
+ fmt.Printf("*ip 变量的值: %d\\n", *ip )
+}
+//a 变量的地址是: 20818a220
+//ip 变量储存的指针地址: 20818a220
+//*ip 变量的值: 20当一个指针被定义后没有分配到任何变量时,它的值为 nil。
nil 指针也称为空指针。
nil在概念上和其它语言的null、None、nil、NULL一样,都指代零值或空值。
一个指针变量通常缩写为 ptr。
package main
+
+import "fmt"
+
+func main() {
+ var ptr *int
+
+ fmt.Printf("ptr 的值为 : %x**\\n**", ptr )
+}
+//ptr 的值为 : 0空指针判断
if(ptr != nil) /* ptr 不是空指针 */
+if(ptr == nil) /* ptr 是空指针 */在函数中对指针参数所做的修改,在函数返回后会保存相应的修改。
package main
+
+import (
+ "fmt"
+)
+
+func changeByPointer(value *int) {
+ *value = 200
+}
+
+func main() {
+ x3 := 99
+ p3 := &x3
+ fmt.Println("执行changeByPointer函数之前p3是", *p3)
+ changeByPointer(p3)
+ fmt.Println("执行changeByPointer函数之后p3是", *p3)
+}
+//执行changeByPointer函数之前p3是 99
+//执行changeByPointer函数之后p3是 200切片与指针一样是引用类型,如果我们想通过一个函数改变一个数组的值,可以将该数组的切片当作参数传给函数,也可以将这个数组的指针当作参数传给函数。但 Go 中建议使用第一种方法,即将该数组的切片当作参数传给函数,因为这么写更加简洁易读。
package main
+
+import "fmt"
+
+// 使用切片
+func changeSlice(value []int) {
+ value[0] = 200
+}
+
+// 使用数组指针
+func changeArray(value *[3]int) {
+ (*value)[0] = 200
+}
+
+func main() {
+ x := [3]int{10, 20, 30}
+ changeSlice(x[:])
+ fmt.Println(x) // [200 20 30]
+
+ y := [3]int{100, 200, 300}
+ changeArray(&y)
+ fmt.Println(y) // [200 200 300]
+}Go 语言中数组可以存储同一类型的数据,但在结构体中我们可以为不同项定义不同的数据类型。
结构体是由一系列具有相同类型或不同类型的数据构成的数据集合。Go中没有class的概念,只有struct结构体,所以也没有继承。
type struct_name struct {
+ attribute_name1 attribute_type
+ attribute_name2 attribute_type
+ ...
+}
+
+type Lesson struct {
+ name string //名称
+ target string //学习目标
+ spend int //学习花费时间
+}
+//可以把相同类型的属性声明在同一行,这样可以使结构体变得更加紧凑
+type Lesson2 struct {
+ name, target string
+ spend int
+}上面的结构体称为命名结构体Named Structure。声明结构体时也可以不用声明新类型,这种结构体类型称为匿名结构体Anonymous Structure
var Lesson3 struct {
+ name, target string
+ spend int
+}package main
+
+import "fmt"
+
+type Lesson struct {
+ name, target string
+ spend int
+}
+
+func main() {
+ // 使用字段名创建结构体
+ lesson1 := Lesson{
+ name: "Golang",
+ target: "学习Go语言,并完成一个单体服务",
+ spend: 5,
+ }
+ // 不使用字段名创建结构体,按字段声明顺序初始化
+ lesson2 := Lesson{"Golang", "学习Go语言,并完成一个单体服务", 5}
+
+ fmt.Println("lesson1 ", lesson1)
+ fmt.Println("lesson2 ", lesson2)
+}Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来。
Tag在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
\`key1:"value1" key2:"value2"\`结构体标签由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。键值对之间使用一个空格分隔。 注意事项: 为结构体编写Tag时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在key和value之间添加空格。
例如我们为Student结构体的每个字段定义json序列化时使用的Tag:
//Student 学生
+type Student struct {
+ ID int \`json:"id"\` //通过指定tag实现json序列化该字段时的key
+ Gender string //json序列化是默认使用字段名作为key
+ name string //私有不能被json包访问
+}
+
+func main() {
+ s1 := Student{
+ ID: 1,
+ Gender: "女",
+ name: "pprof",
+ }
+ data, err := json.Marshal(s1)
+ if err != nil {
+ fmt.Println("json marshal failed!")
+ return
+ }
+ fmt.Printf("json str:%s\\n", data) //json str:{"id":1,"Gender":"女"}
+}package main
+
+import "fmt"
+
+func main() {
+ // 创建匿名结构体变量
+ lesson3 := struct {
+ name, target string
+ spend int
+ }{
+ name: "Go语言",
+ target: "掌握GO语言",
+ spend: 3,
+ }
+
+ fmt.Println("lesson3 ", lesson3)
+}当定义好的结构体没有被显式初始化时,结构体的字段将会默认赋为相应类型的零值。
package main
+
+import "fmt"
+
+type Lesson struct {
+ name, target string
+ spend int
+}
+
+func main() {
+ // 不初始化结构体
+ var lesson4 = Lesson{}
+
+ fmt.Println("lesson4 ", lesson4)
+}
+//lesson4 { 0}使用.点操作符访问:lesson.name
使用.也可用与给结构体字段赋值:lesson.name = "test"
package main
+
+import "fmt"
+
+type Lesson struct {
+ name, target string
+ spend int
+}
+
+func main() {
+ lesson8 := &Lesson{"Go语言", "Go语言微服务", 50}
+ fmt.Println("lesson8 name: ", (*lesson8).name)
+ fmt.Println("lesson8 name: ", lesson8.name)
+}lesson8 是一个指向结构体 Lesson 的指针,用 (*lesson8).name 访问 lesson8 的 name 字段, lesson8.name 代替 (*lesson8).name 的解引用访问。
在创建结构体时,字段可以只有类型没有字段名,这种字段称为 匿名字段(Anonymous Field) 。
package main
+
+import "fmt"
+
+type Lesson4 struct {
+ string
+ int
+}
+
+func main() {
+ lesson9 := Lesson4{"Golang", 50}
+ fmt.Println("lesson9 ", lesson9)
+ fmt.Println("lesson9 string: ", lesson9.string)
+ fmt.Println("lesson9 int: ", lesson9.int)
+}上面的程序结构体定义了两个匿名字段,虽然这两个字段没有字段名,但匿名字段的名称默认就是它的类型。所以上面的结构体 Lesoon4 有两个名为 string 和 int 的字段。
结构体的字段也可能是另外一个结构体,这样的结构体称为 嵌套结构体(Nested Structs)
package main
+
+import "fmt"
+
+type Author struct {
+ name string
+ wx string
+}
+
+type Lesson5 struct {
+ name,target string
+ spend int
+ author Author
+}
+
+func main() {
+ lesson10 := Lesson5{
+ name: "Go语言",
+ spend: 50,
+ }
+ lesson10.author = Author{
+ name: "golang",
+ wx: "666",
+ }
+ fmt.Println("lesson10 name:", lesson10.name)
+ fmt.Println("lesson10 spend:", lesson10.spend)
+ fmt.Println("lesson10 author name:", lesson10.author.name)
+ fmt.Println("lesson10 author wx:", lesson10.author.wx)
+}上面的程序 Lesson5 结构体有一个字段 author ,而且它的类型也是一个结构体 Author 。
结构体中如果有匿名的结构体类型字段,则该匿名结构体里的字段就称为 提升字段(Promoted Fields) 。这是因为提升字段就像是属于外部结构体一样,可以用外部结构体直接访问。就像刚刚上面的程序,如果我们把 Lesson 结构体中的字段 author 直接用匿名字段 Author 代替, Author 结构体的字段例如 name 就不用像上面那样使用 lesson10.author.wx 访问,而是使用 lesson10.wx 就能访问 Author 结构体中的 wx 字段。现在结构体 Author 有 name 、 wx 两个字段,访问字段就像在 Lesson 里直接声明的一样,因此我们称之为提升字段。
package main
+
+import "fmt"
+
+type Author struct {
+ name string
+ wx string
+}
+
+type Lesson6 struct {
+ name,target string
+ spend int
+ Author
+}
+
+func main() {
+ lesson10 := Lesson6{
+ name: "Go语言",
+ target: "掌握Go语言",
+ }
+ lesson10.Author = Author{
+ name: "golang",
+ wx: "666",
+ }
+ fmt.Println("lesson10 name:", lesson10.name)
+ fmt.Println("lesson10 target:", lesson10.target)
+ fmt.Println("lesson10 author wx:", lesson10.wx)
+}
+//lesson10 name: Go语言
+//lesson10 target: 掌握Go语言
+//lesson10 author wx: 666如果结构体的全部成员都是可以比较的,那么结构体也是可以比较的,那样的话两个结构体将可以使用 == 或 != 运算符进行比较。可以通过==运算符或 DeeplyEqual()函数比较两个结构相同的类型并包含相同的字段值。因此下面两个比较的表达式是等价的:
package main
+
+import "fmt"
+
+type Lesson struct{
+ name,target string
+ spend int
+}
+
+func main() {
+ lesson11 := Lesson{
+ name: "Go语言",
+ target: "掌握Go语言",
+ }
+ lesson12 := Lesson{
+ name: "Go语言",
+ target: "掌握Go语言",
+ }
+ fmt.Println(lesson11.name == lesson12.name && lesson11.target == lesson12.target) // true
+ fmt.Println(lesson11 == lesson12) // true
+}在 Go 中无法在结构体内部定义方法
package main
+
+import "fmt"
+
+// Lesson 定义一个名为 Lesson 的结构体
+type Lesson struct {
+ name, target string
+ spend int
+}
+
+// ShowLessonInfo 定义一个与 Lesson 的绑定的方法
+func (l Lesson) ShowLessonInfo() {
+ fmt.Println("name:", l.name)
+ fmt.Println("target:", l.target)
+}
+
+func main() {
+ lesson13 := Lesson{
+ name: "Go语言",
+ target: "掌握Go语言",
+ }
+ lesson13.ShowLessonInfo()
+}上面的程序中定义了一个与结构体 Lesson 绑定的方法 ShowLessonInfo() ,其中 ShowLessonInfo 是方法名, (l Lesson) 表示将此方法与 Lesson 的实例绑定,这在 Go 语言中称为接收者,而 l 表示实例本身,相当于 Python 中的 self ,在方法内可以使用 实例本身.属性名称 来访问实例属性。
如果绑定结构体的方法中要改变实例的属性时,必须使用指针作为方法的接收者。
package main
+
+import "fmt"
+
+// Lesson 定义一个名为 Lesson 的结构体
+type Lesson struct {
+ name,target string
+ spend int
+}
+
+// ShowLessonInfo 定义一个与 Lesson 的绑定的方法
+func (l Lesson) ShowLessonInfo() {
+ fmt.Println("name:", l.name)
+ fmt.Println("target:", l.target)
+}
+
+// AddTime 定义一个与 Lesson 的绑定的方法,使 spend 值加 n
+func (l *Lesson) AddTime(n int) {
+ l.spend = l.spend + n
+}
+
+func main() {
+ lesson13 := Lesson{
+ name: "Go语言",
+ target: "掌握Go语言",
+ spend:50,
+ }
+ fmt.Println("添加add方法前")
+ lesson13.ShowLessonInfo()
+ lesson13.AddTime(5)
+ fmt.Println("添加add方法后")
+ lesson13.ShowLessonInfo()
+}函数 是基于功能或逻辑进行封装的可复用的代码结构。将一段功能复杂、很长的一段代码封装成多个代码片段(即函数),有助于提高代码可读性和可维护性。由于 Go 语言是编译型语言,所以函数编写的顺序是无关紧要的。
func function_name(parameter_list) (result_list) {
+ //函数体
+}在参数类型前面加 ... 表示一个切片,用来接收调用者传入的参数。注意,如果该函数下有其他类型的参数,这些其他参数必须放在参数列表的前面,切片必须放在最后。
package main
+
+import "fmt"
+
+func show(args ...string) int {
+ sum := 0
+ for _, item := range args {
+ fmt.Println(item)
+ sum += 1
+ }
+ return sum
+}
+
+func main() {
+ fmt.Println(show("1","2","3"))
+}如果传多个参数的类型都不一样,可以指定类型为 ...interface{} ,然后再遍历。
package main
+
+import "fmt"
+
+func PrintType(args ...interface{}) {
+ for _, arg := range args {
+ switch arg.(type) {
+ case int:
+ fmt.Println(arg, "type is int.")
+ case string:
+ fmt.Println(arg, "type is string.")
+ case float64:
+ fmt.Println(arg, "type is float64.")
+ default:
+ fmt.Println(arg, "is an unknown type.")
+ }
+ }
+}
+
+func main() {
+ PrintType(57, 3.14, "123")
+}使用 ... 可以用来解序列
当函数没有返回值时,函数体可以使用 return 语句返回。在 Go 中一个函数可以返回多个值。
package main
+
+import "fmt"
+
+func showBookInfo(bookName, authorName string) (string, error) {
+ if bookName == "" {
+ return "", errors.New("图书名称为空")
+ }
+ if authorName == "" {
+ return "", errors.New("作者名称为空")
+ }
+ return bookName + ",作者:" + authorName, nil
+}
+
+func main() {
+ bookInfo, err := showBookInfo("123", "45")
+ fmt.Printf("bookInfo = %s, err = %v", bookInfo, err)
+}返回带有变量名的值
func showBookInfo2(bookName, authorName string) (info string, err error) {
+ info = ""
+ if bookName == "" {
+ err = errors.New("图书名称为空")
+ return
+ }
+ if authorName == "" {
+ err = errors.New("作者名称为空")
+ return
+ }
+ // 不使用 := 因为已经在返回值那里声明了
+ info = bookName + ",作者:" + authorName
+ // 直接返回即可
+ return
+}func (parameter_list) (result_list) {
+ body
+}在 Go 语言中,函数名通过首字母大小写实现控制对方法的访问权限。
方法 其实就是一个函数,在 func 这个关键字和方法名中间加入了一个特殊的接收器类型。接收器可以是结构体类型或者是非结构体类型。接收器是可以在方法的内部访问的。
func (t Type) methodName(parameterList) returnList{
+}package main
+
+import "fmt"
+
+// Lesson 定义一个名为 Lesson 的结构体
+type Lesson struct {
+ Name string
+ Target string
+}
+
+// PrintInfo 定义一个与 Lesson 的绑定的方法
+func (lesson Lesson) PrintInfo() {
+ fmt.Println("name:", lesson.Name)
+ fmt.Println("target:", lesson.Target)
+}
+
+
+func main() {
+ l := Lesson{
+ Name: "Go语言",
+ Target: "掌握Go语言",
+ }
+ l.PrintInfo()
+}也可以把上面程序的方法改成一个函数
package main
+
+import "fmt"
+
+type Lesson struct {
+ Name string
+ Target string
+}
+
+func PrintInfo(lesson Lesson) {
+ fmt.Println("name:", lesson.Name)
+ fmt.Println("target:", lesson.Target)
+}
+
+func main() {
+ lesson := Lesson{
+ Name: "Go语言",
+ Target: "掌握Go语言",
+ }
+ PrintInfo(lesson)
+}运行这个程序,也同样会输出上面一样的答案,那么我们为什么还要用方法呢?因为在 Go 中,相同的名字的方法可以定义在不同的类型上,而相同名字的函数是不被允许的。如果你在上面这个程序添加一个同名函数,就会报错。但是在不同的结构体上面定义同名的方法就是可行的。
package main
+
+import "fmt"
+
+type Lesson struct {
+ Name string
+ Target string
+}
+
+func (lesson Lesson) PrintInfo() {
+ fmt.Println("Lesson name:", lesson.Name)
+ fmt.Println("Lesson target:", lesson.Target)
+}
+
+type Author struct {
+ Name string
+}
+
+func (author Author) PrintInfo() {
+ fmt.Println("author name:", author.Name)
+}
+
+func main() {
+ lesson := Lesson{
+ Name: "Go语言",
+ Target: "掌握Go语言",
+ }
+ lesson.PrintInfo()
+ author := Author{"Google"}
+ author.PrintInfo()
+}值接收器和指针接收器之间的区别在于,在指针接收器的方法内部的改变对于调用者是可见的,然而值接收器的方法内部的改变对于调用者是不可见的,所以若要改变实例的属性时,必须使用指针作为方法的接收者。
package main
+
+import "fmt"
+
+// Lesson 定义一个名为 Lesson 的结构体
+type Lesson struct {
+ Name string
+ Target string
+ SpendTime int
+}
+
+// PrintInfo 定义一个与 Lesson 的绑定的方法
+func (lesson Lesson) PrintInfo() {
+ fmt.Println("name:", lesson.Name)
+ fmt.Println("target:", lesson.Target)
+ fmt.Println("spendTime:", lesson.SpendTime)
+}
+
+func (lesson Lesson) ChangeLessonName(name string) {
+ lesson.Name = name
+}
+
+func (lesson *Lesson) AddSpendTime(n int) {
+ lesson.SpendTime = lesson.SpendTime + n
+}
+
+func main() {
+ lesson := Lesson{
+ Name: "Go语言",
+ Target: "掌握Go语言",
+ SpendTime: 1,
+ }
+ fmt.Println("before change")
+ lesson.PrintInfo()
+
+ fmt.Println("after change")
+ lesson.AddSpendTime(2)
+ lesson.ChangeLessonName("Go语言123")
+ lesson.PrintInfo()
+}在上面的程序中, AddSpendTime 使用指针接收器最终能改变实例的 SpendTime 值,然而使用值接收器的 ChangeLessonName 最终没有改变实例 Name 的值。
当一个函数有一个值参数,它只能接受一个值参数。当一个方法有一个值接收器,它可以接受值接收器和指针接收器。
package main
+
+import "fmt"
+
+type Lesson struct {
+ Name string
+}
+
+func (lesson Lesson) PrintInfo() {
+ fmt.Println(lesson.Name)
+}
+
+func PrintInfo(lesson Lesson) {
+ fmt.Println(lesson.Name)
+}
+
+func main() {
+ lesson := Lesson{"Go语言"}
+ PrintInfo(lesson)
+ lesson.PrintInfo()
+
+ bPtr := &lesson
+ //PrintInfo(bPtr) // error
+ bPtr.PrintInfo()
+}在上面的程序中,使用值参数 PrintInfo(lesson) 来调用这个函数是合法的,使用值接收器来调用 lesson.PrintInfo() 也是合法的。
然后在程序中我们创建了一个指向 Lesson 的指针 bPtr ,通过使用指针接收器来调用 bPtr.PrintInfo() 是合法的,但使用值参数调用 PrintInfo(bPtr) 是非法的。
package main
+
+import "fmt"
+
+type myInt int
+
+func (a myInt) add(b myInt) myInt {
+ return a + b
+}
+
+func main() {
+ var x myInt = 50
+ var y myInt = 7
+ fmt.Println(x.add(y)) // 57
+}在 Go 语言中, 接口 就是方法签名(Method Signature)的集合。在面向对象的领域里,接口定义一个对象的行为,接口只指定了对象应该做什么,至于如何实现这个行为,则由对象本身去确定。当一个类型实现了接口中的所有方法,我们称它实现了该接口。接口指定了一个类型应该具有的方法,并由该类型决定如何实现这些方法。
type interface_name interface {
+ method()
+}package main
+
+import "fmt"
+
+type Study interface {
+ learn()
+}
+
+type Student struct {
+ name string
+ book string
+}
+
+func (s Student) learn() {
+ fmt.Printf("%s 在读 %s", s.name, s.book)
+}
+
+func main() {
+ student1 := Student{
+ name: "张三",
+ book: "《Go语言》",
+ }
+ student1.learn()
+}上面的程序定义了一个名为 Study 的接口,接口中有未实现的方法 learn() ,这里还定义了名为 Student 的结构体,其绑定了方法 learn() ,也就隐式实现了 Study 接口,实现的内容是打印语句。
package main
+
+import "fmt"
+
+type Study interface {
+ learn()
+}
+type Student struct {
+ name, book string
+}
+
+func (s Student) learn() {
+ fmt.Printf("%s 在读 %s", s.name, s.book)
+}
+
+type Worker struct {
+ name string
+ book string
+ by string
+}
+
+func (w *Worker) learn() {
+ fmt.Printf("%s 在读 %s,通过方式 %s", w.name, w.book, w.by)
+}
+
+func main() {
+ var s1 Study
+ var s2 Study
+
+ student2 := Student{
+ name: "李四",
+ book: "《Go语言》",
+ }
+ s1 = student2
+ s1.learn()
+
+ student3 := Student{
+ name: "王五",
+ book: "Go语言1",
+ }
+ s1 = &student3
+ s1.learn()
+
+ worker1 := Worker{
+ name: "老王",
+ book: "Go语言2",
+ by: "视频",
+ }
+ // s2 = worker1 // error
+ s2 = &worker1
+ s2.learn()
+}可以把接口的内部看做 (type, value)。type 是接口底层的具体类型(Concrete Type),而 value 是具体类型的值。
package main
+
+import "fmt"
+
+type Study interface {
+ learn()
+}
+type Student struct {
+ name, book string
+}
+
+func (s Student) learn() {
+ fmt.Printf("%s 在读 %s", s.name, s.book)
+}
+func ShowInterface(s Study) {
+ fmt.Printf("接口类型: %T\\n 接口值: %v\\n", s, s)
+}
+
+func main() {
+ var s Study
+ student2 := Student{
+ name: "李四",
+ book: "《Go语言》",
+ }
+ s = student2
+ ShowInterface(s)
+ s.learn()
+}
+//接口类型: main.Student
+//接口值: {李四 《Go语言》}
+//李四 在读 《Go语言》空接口 是特殊形式的接口类型,没有定义任何方法的接口就称为空接口,可以说所有类型都至少实现了空接口,空接口表示为 interface{} 。例如,我们之前的写过的空接口参数函数,可以接受任何类型的参数:
package main
+
+import "fmt"
+
+func ShowType(i interface{}) {
+ fmt.Printf("类型: %T, 值: %v\\n", i, i)
+}
+
+func main() {
+ str := "Go语言"
+ ShowType(str)
+ num := 3.14
+ ShowType(num)
+}通过上面的例子不难发现接口都有两个属性,一个是值,而另一个是类型。对于空接口来说,这两个属性都为 nil
package main
+
+import "fmt"
+
+func main() {
+ var i interface{}
+ fmt.Printf("Type: %T, Value: %v", i, i)
+ // Type: <nil>, Value: <nil>
+}除了上面讲到的使用空接口作为函数参数的用法,空接口还有以下两种用法。
直接使用 interface{} 作为类型声明一个实例,这个实例就能承载任何类型的值:
package main
+
+import "fmt"
+
+func main() {
+ var i interface{}
+
+ i = "Go语言"
+ fmt.Println(i) // Let's go
+
+ i = 3.14
+ fmt.Println(i) // 3.14
+}我们也可以定义一个接收任何类型的 array 、 slice 、 map 、 strcut 。例如:
package main
+
+import "fmt"
+
+func main() {
+ x := make([]interface{}, 3)
+ x[0] = "Go"
+ x[1] = 3.14
+ x[2] = []int{1, 2, 3}
+ for _, value := range x {
+ fmt.Println(value)
+ }
+}空接口可以承载任何值,但是空接口类型的对象是不能赋值给另一个固定类型对象的。
package main
+
+func main() {
+ var num = 1
+ var i interface{} = num
+ var str string = i // error
+}当空接口承载数组和切片后,该对象无法再进行切片。
package main
+
+import "fmt"
+
+func main() {
+ var s = []int{1, 2, 3}
+
+ var i interface{} = s
+
+ var s2 = i[1:2] // error
+ fmt.Println(s2)
+}类型断言用于提取接口的底层值(Underlying Value)。使用 interface.(Type) 可以获取接口的底层值,其中接口 interface 的具体类型是 Type
package main
+
+import "fmt"
+
+func assert(i interface{}) {
+ value, ok := i.(int)
+ fmt.Println(value, ok)
+}
+
+func main() {
+ var x interface{} = 3
+ assert(x)
+ var y interface{} = "Go语言"
+ assert(y)
+}第一次调用 assert(x) 输出 3 true,表示将整数 3 转换为 int 类型成功。
第二次调用 assert(y) 输出 0 false,表示将字符串 "Go语言" 转换为 int 类型失败,因为该字符串无法转换为整数。
package main
+
+import "fmt"
+
+func getTypeValue(i interface{}) {
+ switch i.(type) {
+ case int:
+ fmt.Printf("Type: int, Value: %d\\n", i.(int))
+ case string:
+ fmt.Printf("Type: string, Value: %s\\n", i.(string))
+ default:
+ fmt.Printf("Unknown type\\n")
+ }
+}
+
+func main() {
+ getTypeValue(300)
+ getTypeValue("Go语言")
+ getTypeValue(true)
+}类型或者结构体可以实现多个接口
虽然在 Go 中没有继承机制,但可以通过接口的嵌套实现类似功能。
package main
+
+import "fmt"
+
+// 定义一个简单的读取器接口
+type Reader interface {
+ Read() string
+}
+
+// 定义一个简单的写入器接口
+type Writer interface {
+ Write(data string)
+}
+
+// 定义一个复合接口,嵌套了Reader和Writer接口
+type ReadWriter interface {
+ Reader
+ Writer
+}
+
+// 实现Reader接口
+type MyReader struct{}
+
+func (r MyReader) Read() string {
+ return "Data read from MyReader"
+}
+
+// 实现Writer接口
+type MyWriter struct{}
+
+func (w MyWriter) Write(data string) {
+ fmt.Println("Writing data:", data)
+}
+
+// 实现ReadWriter接口
+type MyReadWriter struct {
+ MyReader
+ MyWriter
+}
+
+// 使用ReadWriter接口作为参数进行函数调用
+func ProcessData(rw ReadWriter) {
+ data := rw.Read()
+ rw.Write(data + " modified")
+}
+
+func main() {
+ // 创建MyReadWriter实例
+ myRW := MyReadWriter{}
+
+ // 调用ProcessData函数,传入myRW作为参数
+ ProcessData(myRW)
+}定义了三个接口:Reader、Writer和ReadWriter。然后,我们实现了这些接口的具体类型:MyReader、MyWriter和MyReadWriter。
MyReadWriter结构体通过嵌套MyReader和MyWriter,同时实现了Reader和Writer接口。这样,MyReadWriter可以以ReadWriter类型的方式使用。
在main函数中,我们创建了一个MyReadWriter实例myRW,然后将其作为参数传递给ProcessData函数。ProcessData函数接收一个ReadWriter类型的参数,并调用其中的方法。
通过接口嵌套,我们可以更灵活地组织和复用代码
包(package) 用于组织 Go 源代码,提供了更好的可重用性与可读性.可以用 go list std命令查看标准包,标准库为大多数的程序提供了必要的基础组件。
先创建一个 book 文件夹,位于该目录下创建一个 book.go 源文件,里面实现自定义的数学加法函数。函数名的首字母要大写。
// Package book
+package book
+
+func ShowBookInfo(bookName, authorName string) (string, error) {
+ if bookName == "" {
+ return "", errors.New("图书名称为空")
+ }
+ if authorName == "" {
+ return "", errors.New("作者名称为空")
+ }
+ return bookName + ",作者:" + authorName, nil
+}使用包之前我们需要导入包,在 GoLand 中会帮你自动导入所需要的包。导入包的语法为 import path ,其中 path 可以是相对于工作区文件夹的相对路径,也可以是绝对路径。
package main
+
+import (
+ "fmt"
+ "learn/book"
+)
+
+func main() {
+ bookName := "《Go语言》"
+ author := "Golang"
+ bookInfo, _ := book.ShowBookInfo(bookName, author)
+ fmt.Println("bookInfo = ", bookInfo)
+}import (
+ "crypto/rand"
+ mrand "math/rand" // 将名称替换为 mrand 避免冲突
+)import . "fmt"
+
+func main() {
+ Println("hello, world")
+}对于一些使用高频的包,例如 fmt 包,每次调用打印函数时都要使用 fmt.Println() 进行调用,很不方便。可以在导入包的时,使用 import . package_path 语法。打印就不用加 fmt 了。
每个包都允许有一个或多个 init 函数, init 函数不应该有任何返回值类型和参数,在代码中也不能显式调用它,当这个包被导入时,就会执行这个包的 init 函数,做初始化任务, init 函数优先于 main 函数执行。该函数形式如下:
func init() {
+}包的初始化顺序:首先初始化 包级别(Package Level) 的变量,紧接着调用 init 函数。包可以有多个 init 函数(在一个文件或分布于多个文件中),它们按照编译器解析它们的顺序进行调用。如果一个包导入了另一个包,会先初始化被导入的包。尽管一个包可能会被导入多次,但是它只会被初始化一次。
导入一个没有使用的包编译会报错。但有时候我们只是想执行包里的 init 函数来执行一些初始化任务,可以使用匿名导入的方法,使用 空白标识符(Blank Identifier) :
import _ "fmt"Go 语言的 协程(Groutine) 是与其他函数或方法一起并发运行的工作方式。协程可以看作是轻量级线程。与线程相比,创建一个协程的成本很小。因此在 Go 应用中,常常会看到会有很多协程并发地运行。
调用函数或者方法时,如果在前面加上关键字 go ,就可以让一个新的 Go 协程并发地运行。
// 定义一个函数
+func functionName(parameterList) {
+ code
+}
+
+// 执行一个函数
+functionName(parameterList)
+
+// 开启一个协程执行这个函数
+go functionName(parameterList)package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func PrintInfo() {
+ fmt.Println("Go语言")
+}
+
+func main() {
+ // 开启一个协程执行 PrintInfo 函数
+ go PrintInfo()
+ // 使主协程休眠 1 秒
+ time.Sleep(1 * time.Second)
+ // 打印 main
+ fmt.Println("main")
+}PrintInfo() 函数与 main() 函数会并发执行,主函数运行在一个特殊的协程上,这个协程称之为 主协程(Main Goroutine) 。
启动一个新的协程时,协程的调用会立即返回。与函数不同,程序控制不会去等待 Go 协程执行完毕。在调用 Go 协程之后,程序控制会立即返回到代码的下一行,忽略该协程的任何返回值。如果 Go 主协程终止,则程序终止,于是其他 Go 协程也会终止。为了让新的协程能继续运行,在 main() 函数添加了 time.Sleep(1 * time.Second) 使主协程休眠 1 秒
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func PrintNum(num int) {
+ for i := 0; i < 3; i++ {
+ fmt.Println(num)
+ // 避免观察不到并发效果 加个休眠
+ time.Sleep(100 * time.Millisecond)
+ }
+}
+
+func main() {
+ // 开启 1 号协程
+ go PrintNum(1)
+ // 开启 2 号协程
+ go PrintNum(2)
+ // 使主协程休眠 1 秒
+ time.Sleep(time.Second)
+}通道(channel) ,就是一个管道,可以想像成 Go 协程之间通信的管道。它是一种队列式的数据结构,遵循先入先出的规则。
每个通道都只能传递一种数据类型的数据,在你声明的时候,我们要指定通道的类型。chan Type 表示 Type 类型的通道。通道的零值为 nil 。
var channel_name chan channel_types
+
+var ch chan string声明完通道后,通道的值为 nil ,我们不能直接使用,必须先使用 make 函数对通道进行初始化操作。
ch = make(chan channel_type)
+
+ch = make(chan string)这样,我们就已经定义好了一个 string 类型的通道 nameChan 。当然,也可以使用简短声明语句一次性定义一个通道:
ch := make(chan string)发送数据:
// 把 data 数据发送到 channel_name 通道中
+// 即把 data 数据写入到 channel_name 通道中
+channel_name <- data接收数据:
// 从 channel_name 通道中接收数据到 value
+// 即从 channel_name 通道中读取数据到 value
+value := <- channel_name通道旁的箭头方向指定了是发送数据还是接收数据。箭头指向通道,代表数据写入到通道中;箭头往通道指向外,代表从通道读数据出去。
package main
+
+import (
+ "fmt"
+)
+
+func PrintChan(c chan string) {
+ // 往通道传入数据
+ c <- "学习Go语言"
+}
+
+func main() {
+ // 创建一个通道
+ ch := make(chan string)
+ // 打印 "学习课程:"
+ fmt.Println("学习课程:")
+ // 开启协程
+ go PrintChan(ch)
+ // 从通道接收数据
+ rec := <- ch
+ // 打印从通道接收到的数据
+ fmt.Println(rec)
+}Tips: 发送与接收默认是阻塞的
close(channel_name)这里要注意,对于一个已经关闭的通道如果再次关闭会导致报错,我们可以在接收数据时,判断通道是否已经关闭,从通道读取数据返回的第二个值表示通道是否没被关闭,如果已经关闭,返回值为 false ;如果还未关闭,返回值为 true 。
value, ok := <- channel_namemake 函数是可以接收两个参数的,同理,创建通道可以传入第二个参数——容量。
0 时,说明通道中不能存放数据,在发送数据时,必须要求立马有人接收,否则会报错。此时的通道称之为无缓冲通道。1 时,说明通道只能缓存一个数据,若通道中已有一个数据,此时再往里发送数据,会造成程序阻塞。利用这点可以利用通道来做锁。1 时,通道中可以存放多个数据,可以用于多个协程之间的通信管道,共享资源。既然通道有容量和长度,那么我们可以通过 cap 函数和 len 函数获取通道的容量和长度。
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ // 创建一个通道
+ c := make(chan int, 3)
+ fmt.Println("初始化后:")
+ fmt.Println("cap =", cap(c))
+ fmt.Println("len =", len(c))
+ c <- 1
+ c <- 2
+ fmt.Println("传入两个数后:")
+ fmt.Println("cap =", cap(c))
+ fmt.Println("len =", len(c))
+ <- c
+ fmt.Println("取出一个数后:")
+ fmt.Println("cap =", cap(c))
+ fmt.Println("len =", len(c))
+}按照是否可缓冲数据可分为:缓冲通道 与 无缓冲通道 。
无缓冲通道在通道里无法存储数据,接收端必须先于发送端准备好,以确保你发送完数据后,有人立马接收数据,否则发送端就会造成阻塞,原因很简单,通道中无法存储数据。也就是说发送端和接收端是同步运行的。
c := make(chan int)
+// 或者
+c := make(chan int, 0)缓冲通道允许通道里存储一个或多个数据,设置缓冲区后,发送端和接收端可以处于异步的状态。
c := make(chan int, 3)到目前为止,上面定义的都是双向通道,既可以发送数据也可以接收数据。例如:
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func main() {
+ // 创建一个通道
+ c := make(chan int)
+
+ // 发送数据
+ go func() {
+ fmt.Println("send: 1")
+ c <- 1
+ }()
+
+ // 接收数据
+ go func() {
+ n := <- c
+ fmt.Println("receive:", n)
+ }()
+
+ // 主协程休眠
+ time.Sleep(time.Millisecond)
+}单向通道只能发送或者接收数据。所以可以具体细分为只读通道和只写通道。
<-chan 表示只读通道:
chan<- 表示只写通道:
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+// Sender 只写通道类型
+type Sender = chan<- string
+
+// Receiver 只读通道类型
+type Receiver = <-chan string
+
+func main() {
+ // 创建一个双向通道
+ var ch = make(chan string)
+
+ // 开启一个协程
+ go func() {
+ // 只能写通道
+ var sender Sender = ch
+ fmt.Println("即将学习:")
+ sender <- "Go语言"
+ }()
+
+ // 开启一个协程
+ go func() {
+ // 只能读通道
+ var receiver Receiver = ch
+ message := <-receiver
+ fmt.Println("开始学习: ", message)
+ }()
+
+ time.Sleep(time.Millisecond)
+}使用 for range 循环可以遍历通道,但在遍历时要确保通道是处于关闭状态,否则循环会被阻塞。
package main
+
+import (
+ "fmt"
+)
+
+func loopPrint(c chan int) {
+ for i := 0; i < 10; i++ {
+ c <- i
+ }
+ // 记得要关闭通道
+ // 否则主协程遍历完不会结束,而会阻塞
+ close(c)
+}
+
+func main() {
+ // 创建一个通道
+ var ch2 = make(chan int, 5)
+ go loopPrint(ch2)
+ for v := range ch2 {
+ fmt.Println(v)
+ }
+}上面讲过,当通道容量为 1 时,说明通道只能缓存一个数据,若通道中已有一个数据,此时再往里发送数据,会造成程序阻塞。例如:
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+// 由于 x = x+1 不是原子操作
+// 所以应避免多个协程对 x 进行操作
+// 使用容量为 1 的通道可以达到锁的效果
+func increment(ch chan bool, x *int) {
+ ch <- true
+ *x = *x + 1
+ <- ch
+}
+
+func main() {
+ ch3 := make(chan bool, 1)
+ var x int
+ for i := 0; i < 10000; i++ {
+ go increment(ch3, &x)
+ }
+ time.Sleep(time.Millisecond)
+ fmt.Println("x =", x)
+}当协程给一个通道发送数据时,照理说会有其他 Go 协程来接收数据。如果没有的话,程序就会在运行时触发 panic ,形成死锁。同理,当有协程等着从一个通道接收数据时,我们期望其他的 Go 协程会向该通道写入数据,要不然程序也会触发 panic 。
package main
+
+func main() {
+ ch := make(chan bool)
+ ch <- true
+}
+//fatal error: all goroutines are asleep - deadlock!package main
+
+import "fmt"
+
+func main() {
+ ch := make(chan bool)
+ ch <- true
+ fmt.Println(<-ch)
+}
+//fatal error: all goroutines are asleep - deadlock!
+//使用 make 函数创建通道时默认不传递第二个参数,通道中不能存放数据,在发送数据时,必须要求立马有人接收,即该通道为无缓冲通道。所以在接收者没有准备好前,发送操作会被阻塞。package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func funcRecieve(c chan bool) {
+ fmt.Println(<-c)
+}
+func main() {
+ ch4 := make(chan bool)
+ go funcRecieve(ch4)
+ ch4 <- true
+ time.Sleep(time.Millisecond)
+}
+
+
+// 或
+
+package main
+
+import "fmt"
+
+func main() {
+ ch6 := make(chan bool, 1)
+ ch6 <- true
+ ch6 <- false
+ fmt.Println(<-ch6)
+}在实际开发中我们并不能保证每个协程执行的时间,如果需要等待多个协程,全部结束任务后,再执行某个业务逻辑。下面我们介绍处理这种情况的方式。
WaitGroup 有几个方法:
Add:初始值为 0 ,这里直接传入子协程的数量,你传入的值会往计数器上加。Done:当某个子协程完成后,可调用此方法,会从计数器上减一,即子协程的数量减一,通常使用 defer 来调用。Wait:阻塞当前协程,直到实例里的计数器归零。信道可以实现多个协程间的通信,于是乎我们可以定义一个信道,在任务执行完成后,往信道中写入 true ,然后在主协程中获取到 true ,就可以认为子协程已经执行完毕。
package main
+
+import "fmt"
+
+func main() {
+ isDone := make(chan bool)
+ go func() {
+ for i := 0; i < 5; i++{
+ fmt.Println(i)
+ }
+ isDone <- true
+ }()
+ <- isDone
+}运行上面的程序,主协程就会等待创建的协程执行完毕后退出。
使用上面的信道方法,虽然可行,但在你程序中使用很多协程的话,你的代码就会看起来很复杂,这里就要介绍一种更好的方法,那就是使用 sync 包中提供的 WaitGroup 类型。WaitGroup 用于等待一批 Go 协程执行结束。程序控制会一直阻塞,直到这些协程全部执行完毕。当然 WaitGroup 也可以用于实现工作池。
WaitGroup 实例化后就能使用:
var name sync.WaitGrouppackage main
+
+import (
+ "fmt"
+ "sync"
+)
+
+func task(taskNum int, wg *sync.WaitGroup) {
+ // 延迟调用 执行完子协程计数器减一
+ defer wg.Done()
+ // 输出任务号
+ for i := 0; i < 3; i++ {
+ fmt.Printf("task %d: %d\\n", taskNum, i)
+ }
+}
+
+func main() {
+ // 实例化 sync.WaitGroup
+ var waitGroup sync.WaitGroup
+ // 传入子协程的数量
+ waitGroup.Add(3)
+ // 开启一个子协程 协程 1 以及 实例 waitGroup
+ go task(1, &waitGroup)
+ // 开启一个子协程 协程 2 以及 实例 waitGroup
+ go task(2, &waitGroup)
+ // 开启一个子协程 协程 3 以及 实例 waitGroup
+ go task(3, &waitGroup)
+ // 实例 waitGroup 阻塞当前协程 等待所有子协程执行完
+ waitGroup.Wait()
+}select 语句用在多个发送/接收通道操作中进行选择。
select 语句会一直阻塞,直到发送/接收操作准备就绪。select 会随机地选取其中之一执行。select 语法如下:
select {
+ case expression1:
+ code
+ case expression2:
+ code
+ default:
+ code
+}package main
+
+import "fmt"
+
+func main() {
+ // 创建3个通道
+ ch1 := make(chan string, 1)
+ ch2 := make(chan string, 1)
+ ch3 := make(chan string, 1)
+ // 往通道 1 发送数据
+ ch1 <- "Go语言1"
+ // 往通道 2 发送数据
+ ch2 <- "Go语言2"
+ // 往通道 3 发送数据
+ ch3 <- "Go语言3"
+
+ select {
+ // 如果从通道 1 收到数据
+ case message1 := <-ch1:
+ fmt.Println("ch1 received:", message1)
+ // 如果从通道 2 收到数据
+ case message2 := <-ch2:
+ fmt.Println("ch2 received:", message2)
+ // 如果从通道 3 收到数据
+ case message3 := <-ch3:
+ fmt.Println("ch3 received:", message3)
+ // 默认输出
+ default:
+ fmt.Println("No data received.")
+ }
+}在执行 select 语句时,如果有机会的话会运行所有表达式,只要其中一个通道接收到数据,那么就会执行对应的 case 代码,然后退出。
每个任务执行的时间不同,使用 select 语句等待相应的通道发出响应。select 会选择首先响应先完成的 task,而忽略其它的响应。使用这种方法,我们可以做多个 task,并给用户返回最快的 task 结果。
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func task1(ch chan string) {
+ time.Sleep(5 * time.Second)
+ ch <- "Go语言1"
+}
+
+func task2(ch chan string) {
+ time.Sleep(7 * time.Second)
+ ch <- "Go语言2"
+}
+
+func task3(ch chan string) {
+ time.Sleep(2 * time.Second)
+ ch <- "Go语言3"
+}
+
+func main() {
+ // 创建三个通道
+ ch1 := make(chan string)
+ ch2 := make(chan string)
+ ch3 := make(chan string)
+ go task1(ch1)
+ go task2(ch2)
+ go task3(ch3)
+
+ select {
+ // 如果从通道 1 收到数据
+ case message1 := <-ch1:
+ fmt.Println("ch1 received:", message1)
+ // 如果从通道 2 收到数据
+ case message2 := <-ch2:
+ fmt.Println("ch2 received:", message2)
+ // 如果从通道 3 收到数据
+ case message3 := <-ch3:
+ fmt.Println("ch3 received:", message3)
+ }
+}上面的程序会发现,没有 default 分支,因为如果加了该默认分支,如果还没从通道接收到数据, select 语句就会直接执行 default 分支然后退出,而不是被阻塞。
如果没有 default 分支, select 就会阻塞,如果一直没有命中其中的某个 case 最后会造成死锁。
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ // 创建两个通道
+ ch1 := make(chan string, 1)
+ ch2 := make(chan string, 1)
+ ch3 := make(chan string, 1)
+
+ select {
+ // 如果从通道 1 收到数据
+ case message1 := <-ch1:
+ fmt.Println("ch1 received:", message1)
+ // 如果从通道 2 收到数据
+ case message2 := <-ch2:
+ fmt.Println("ch2 received:", message2)
+ // 如果从通道 3 收到数据
+ case message3 := <-ch3:
+ fmt.Println("ch3 received:", message3)
+ }
+}
+//fatal error: all goroutines are asleep - deadlock!运行上面的程序会造成死锁。解决该问题的方法是写好 default 分支。
还有另一种情况会导致死锁的发生,那就是使用空 select :
package main
+
+func main() {
+ select {}
+}运行上面的程序会抛出 panic 。
Tips:
switch-case 里面的 case 是顺序执行的,但在 select 里并不是顺序执行的。在上面的第一个例子就可以看出,当 select 由多个 case 准备就绪时,将会随机地选取其中之一去执行。当 case 里的通道始终没有接收到数据时,而且也没有 default 语句时, select 整体就会阻塞,但是有时我们并不希望 select 一直阻塞下去,这时候就可以手动设置一个超时时间。
package main
+
+import (
+ "fmt"
+ "time"
+)
+
+func makeTimeout(ch chan bool, t int) {
+ time.Sleep(time.Second * time.Duration(t))
+ ch <- true
+}
+
+func main() {
+ c1 := make(chan string, 1)
+ c2 := make(chan string, 1)
+ c3 := make(chan string, 1)
+ timeout := make(chan bool, 1)
+
+ go makeTimeout(timeout, 2)
+
+ select {
+ case msg1 := <-c1:
+ fmt.Println("c1 received: ", msg1)
+ case msg2 := <-c2:
+ fmt.Println("c2 received: ", msg2)
+ case msg3 := <-c3:
+ fmt.Println("c3 received: ", msg3)
+ case <-timeout:
+ fmt.Println("Timeout, exit.")
+ }
+}select 里的 case 表达式只能对通道进行操作,不管你是往通道写入数据,还是从通道读出数据。
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ c1 := make(chan string, 2)
+
+ c1 <- "Go语言1"
+ select {
+ case c1 <- "Go语言2":
+ fmt.Println("c1 received: ", <-c1)
+ fmt.Println("c1 received: ", <-c1)
+ default:
+ fmt.Println("channel blocking")
+ }
+}
+//c1 received: Go语言1
+//c1 received: Go语言2Go 语言中,经常会遇到并发的问题,当然我们会优先考虑使用通道,同时 Go 语言也给出了传统的解决方式 Mutex(互斥锁) 和 RWMutex(读写锁) 来处理竞争条件。
type Bank struct {
+ balance int
+}
+
+func (b *Bank) Deposit(amount int) {
+ b.balance += amount
+}
+
+func (b *Bank) Balance() int {
+ return b.balance
+}
+
+func main() {
+ b := &Bank{}
+
+ b.Deposit(1000)
+ b.Deposit(1000)
+ b.Deposit(1000)
+
+ fmt.Println(b.Balance()) //3000
+}当程序并发地运行时,多个 Go 协程不应该同时访问那些修改共享资源的代码。这些修改共享资源的代码称为临界区 。
package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+type Bank struct {
+ balance int
+}
+
+func (b *Bank) Deposit(amount int) {
+ b.balance += amount
+}
+
+func (b *Bank) Balance() int {
+ return b.balance
+}
+func main() {
+ var wg sync.WaitGroup
+ b := &Bank{}
+
+ n := 1000
+ wg.Add(n)
+ for i := 1; i <= n; i++ {
+ go func() {
+ b.Deposit(1000)
+ wg.Done()
+ }()
+ }
+ wg.Wait()
+ fmt.Println(b.Balance()) //972000,962000,941000
+}举一个简单的例子,当前变量的值增加 b.balance += amount
当然,对于只有一个协程的程序来说,上面的代码没有任何问题。但是,如果有多个协程并发运行时,就会发生错误,这种情况就称之为数据竞争(data race)。使用下面的互斥锁 Mutex 就能避免这种情况的发生。
互斥锁(Mutex,mutual exclusion) 用于提供一种 加锁机制(Locking Mechanism) ,可确保在某时刻只有一个协程在临界区运行,以防止出现竞争。也是为了来保护一个资源不会因为并发操作而引起冲突导致数据不准确。
Mutex 有两个方法,分别是 Lock() 和 Unlock() ,即对应的加锁和解锁。在 Lock() 和 Unlock() 之间的代码,都只能由一个协程执行,就能避免竞争条件。
如果有一个协程已经持有了锁(Lock),当其他协程试图获得该锁时,这些协程会被阻塞,直到Mutex解除锁定。
package main
+
+import (
+ "fmt"
+ "sync"
+)
+
+type BankV2 struct {
+ balance int
+ m sync.Mutex
+}
+
+func (b *BankV2) Deposit(amount int) {
+ b.m.Lock()
+ b.balance += amount
+ b.m.Unlock()
+}
+
+func (b *BankV2) Balance() int {
+ return b.balance
+}
+
+func main() {
+ var wg sync.WaitGroup
+ b := &BankV2{}
+
+ n := 1000
+ wg.Add(n)
+ for i := 1; i <= n; i++ {
+ go func() {
+ b.Deposit(1000)
+ wg.Done()
+ }()
+ }
+ wg.Wait()
+ fmt.Println(b.Balance()) //1000000
+}要注意同一协程里不要在尚未解锁时再次加锁,也不要对已经解锁的锁再次解锁。
sync.RWMutex 类型实现读写互斥锁,适用于读多写少的场景,它规定了当有人还在读取数据(即读锁占用)时,不允许有人更新这个数据(即写锁会阻塞);为了保证程序的效率,多个人(协程)读取数据(拥有读锁)时,互不影响不会造成阻塞,它不会像 Mutex 那样只允许有一个人(协程)读取同一个数据。读锁与读锁兼容,读锁与写锁互斥,写锁与写锁互斥。
定义一个 RWMuteux 读写锁:
var rwMutex sync.RWMutexRWMutex 里提供了两种锁,每种锁分别对应两个方法,为了避免死锁,两个方法应成对出现,必要时请使用 defer 。
RLock 方法开启锁,调用 RUnlock 释放锁;Lock 方法开启锁,调用 Unlock 释放锁。package main
+
+import (
+ "fmt"
+ "sync"
+ "time"
+)
+
+type BankV3 struct {
+ balance int
+ rwMutex sync.RWMutex // read write lock
+}
+
+func (b *BankV3) Deposit(amount int) {
+ b.rwMutex.Lock() // write lock
+ b.balance += amount
+ b.rwMutex.Unlock() // wirte unlock
+}
+
+func (b *BankV3) Balance() (balance int) {
+ b.rwMutex.RLock() // read lock
+ balance = b.balance
+ b.rwMutex.RUnlock() // read unlock
+ return
+}
+
+func main() {
+ var wg sync.WaitGroup
+ b := &BankV3{}
+
+ n := 1000
+ wg.Add(n)
+ for i := 1; i <= n; i++ {
+ go func() {
+ b.Deposit(1000)
+ wg.Done()
+ }()
+ }
+ wg.Wait()
+ fmt.Println(b.Balance())
+}Cond 实现了一个条件变量,在 Locker 的基础上增加的一个消息通知的功能,保存了一个通知列表,用来唤醒一个或所有因等待条件变量而阻塞的 Go 程,以此来实现多个 Go 程间的同步。
在 Go 中, 错误 使用内建的 error 类型表示。error 类型是一个接口类型,它的定义如下:
type error interface {
+ Error() string
+}error 有了一个签名为 Error() string 的方法。所有实现该接口的类型都可以当作一个错误类型。Error() 方法给出了错误的描述。fmt.Println 在打印错误时,会在内部调用 Error() string 方法来得到该错误的描述。
package main
+
+import (
+ "fmt"
+ "os"
+)
+
+func main() {
+ // 尝试打开文件
+ file, err := os.Open("/a.txt")
+ // 如果打开文件时发生错误 返回一个不等于 nil 的错误
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+ // 如果打开文件成功 返回一个文件句柄 和 一个值为 nil 的错误
+ fmt.Println(file.Name(), "opened successfully")
+}
+// open /a.txt: no such file or directory使用 errors 包中的 New 函数可以创建自定义错误。下面是 errors 包中 New 函数的实现代码:
package errors
+
+func New(text string) error {
+ return &errorString{text}
+}
+
+type errorString struct {
+ s string
+}
+
+func (e *errorString) Error() string {
+ return e.s
+}errorString 是一个结构体类型,只有一个字符串字段 s 。它使用了 errorString 指针接受者,来实现 error 接口的 Error() string 方法。New 函数有一个字符串参数,通过这个参数创建了 errorString 类型的变量,并返回了它的地址。于是它就创建并返回了一个新的错误。
下面是一个简单的自定义错误例子,该例子创建了一个计算矩形面积的函数,当矩形的长和宽两者有一个为负数时,就会返回一个错误:
package main
+
+import (
+ "errors"
+ "fmt"
+)
+
+func area(a, b int) (int, error) {
+ if a < 0 || b < 0 {
+ return 0, errors.New("计算错误, 长度或宽度,不能小于0.")
+ }
+ return a * b, nil
+}
+func main() {
+ a := 100
+ b := -10
+ r, err := area(a, b)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+ fmt.Println("Area =", r)
+}上面的程序能报出我们自定义的错误,但是没有具体说明是哪个数据出了问题,所以下面就来改进一下这个程序,我们使用 fmt 包中的 Errorf 函数,规定错误格式,并返回一个符合该错误的字符串。
package main
+
+import (
+ "fmt"
+)
+
+func area(a, b int) (int, error) {
+ if a < 0 || b < 0 {
+ return 0, fmt.Errorf("计算错误, 长度%d或宽度%d,不能小于0", a, b)
+ }
+ return a * b, nil
+}
+func main() {
+ a := 100
+ b := -10
+ area, err := area(a, b)
+ if err != nil {
+ fmt.Println(err)
+ return
+ }
+ fmt.Println("Area =", area)
+}给错误添加更多信息还可以 使用结构体类型和字段 实现。下面还是通过改进上面的程序来讲解这种方法的实现:
首先创建一个表示错误的结构体类型,一般错误类型名称都是以 Error 结尾,上面的错误是由于面积计算中长度或宽度错误导致的,所以这里把结构体命名为 areaError :
package main
+
+import (
+ "fmt"
+)
+
+type areaError struct {
+ // 错误信息
+ err string
+ // 错误有关的长度
+ length int
+ // 错误有关的宽度
+ width int
+}
+
+// 使用指针接收者 *areaError 实现了 error 接口的 Error() string 方法
+func (e *areaError) Error() string {
+ // 打印长度和宽度以及错误的描述
+ return fmt.Sprintf("length %d, width %d : %s", e.length, e.width, e.err)
+}
+
+func rectangleArea(a, b int) (int, error) {
+ if a < 0 || b < 0 {
+ return 0, &areaError{"length or width is negative", a, b}
+ }
+ return a * b, nil
+}
+func main() {
+ a := 100
+ b := -10
+ area, err := rectangleArea(a, b)
+ // 检查了错误是否为 nil
+ if err != nil {
+ // 断言 *areaError 类型
+ if err, ok := err.(*areaError); ok {
+ // 如果错误是 *areaError 类型
+ // 用 err.length 和 err.width 来获取错误的长度和宽度 打印出自定义错误的消息
+ fmt.Printf("length %d or width %d is less than zero", err.length, err.width)
+ return
+ }
+ fmt.Println(err)
+ return
+ }
+ fmt.Println("Area =", area)
+}还可以使用 结构体类型的方法 来给错误添加更多信息。下面我们继续完善上面的程序,让程序更加精确的定位是长度引发的错误还是宽度引发的错误。
package main
+
+import (
+ "fmt"
+)
+
+type areaError struct {
+ // 错误信息
+ err string
+ // 长度
+ length int
+ // 宽度
+ width int
+}
+
+// 使用指针接收者 *areaError 实现了 error 接口的 Error() string 方法
+func (e *areaError) Error() string {
+ return e.err
+}
+
+// 长度为负数返回 true
+func (e *areaError) lengthNegative() bool {
+ return e.length < 0
+}
+
+// 宽度为负数返回 true
+func (e *areaError) widthNegative() bool {
+ return e.width < 0
+}
+
+func area(length, width int) (int, error) {
+ err := ""
+ if length < 0 {
+ err += "length is less than zero"
+ }
+ if width < 0 {
+ if err == "" {
+ err = "width is less than zero"
+ } else {
+ err += " and width is less than zero"
+ }
+ }
+ if err != "" {
+ return 0, &areaError{err, length, width}
+ }
+ return length * width, nil
+}
+
+func main() {
+ length := 100
+ width := -10
+ area, err := area(length, width)
+ // 检查了错误是否为 nil
+ if err != nil {
+ // 断言 *areaError 类型
+ if err, ok := err.(*areaError); ok {
+ // 如果错误是 *areaError 类型
+ // 如果长度为负数 打印错误长度具体值
+ if err.lengthNegative() {
+ fmt.Printf("error: 长度 %d 小于0\\n", err.length)
+ }
+ // 如果宽度为负数 打印错误宽度具体值
+ if err.widthNegative() {
+ fmt.Printf("error: 宽度 %d 小于0\\n", err.width)
+ }
+ return
+ }
+ fmt.Println(err)
+ return
+ }
+ fmt.Println("Area =", area)
+}错误和异常是两个不同的概念,非常容易混淆。错误指的是可能出现问题的地方出现了问题;而异常指的是不应该出现问题的地方出现了问题。
在有些情况,当程序发生异常时,无法继续运行。在这种情况下,我们会使用 panic 来终止程序。当函数发生 panic 时,它会终止运行,在执行完所有的延迟函数后,程序返回到该函数的调用方。这样的过程会一直持续下去,直到当前协程的所有函数都返回退出,然后程序会打印出 panic 信息,接着打印出堆栈跟踪,最后程序终止。
我们应该尽可能地使用错误,而不是使用 panic 和 recover 。只有当程序不能继续运行的时候,才应该使用 panic 和 recover 机制。
panic 有两个合理的用例:
panic ,因为如果不能绑定端口,啥也做不了。nil 作为参数调用了它。在这种情况下,我们可以使用 panic ,因为这是一个编程错误:用 nil 参数调用了一个只能接收合法指针的方法。func panic(v interface{})package main
+
+func main() {
+ panic("panic error")
+}上面已经提到了,当函数发生 panic 时,它会终止运行,在执行完所有的延迟函数后,程序返回到该函数的调用方。这样的过程会一直持续下去,直到当前协程的所有函数都返回退出,然后程序会打印出 panic 信息,接着打印出堆栈跟踪,最后程序终止。
package main
+
+import "fmt"
+
+func myTest() {
+ defer fmt.Println("defer myTest")
+ panic("panic myTest")
+}
+func main() {
+ defer fmt.Println("defer main")
+ myTest()
+}
+// defer myTest
+// defer main
+// panic: panic myTestrecover 是一个内建函数,用于重新获得 panic 协程的控制。下面是内建函数 recover 的签名:
func recover() interface{}recover 必须在 defer 函数中才能生效,在其他作用域下,它是不工作的。在延迟函数内调用 recover ,可以取到 panic 的错误信息,并且停止 panic 续发事件,程序运行恢复正常。
package main
+
+import "fmt"
+
+func outOfArray(x int) {
+ defer func() {
+ // recover() 可以将捕获到的 panic 信息打印
+ if err := recover(); err != nil {
+ fmt.Println(err)
+ }
+ }()
+ var array [5]int
+ array[x] = 1
+}
+func main() {
+ // 故意制造数组越界 触发 panic
+ outOfArray(20)
+ // 如果能执行到这句 说明 panic 被捕获了
+ // 后续的程序能继续运行
+ fmt.Println("main...")
+}
+// runtime error: index out of range [20] with length 5
+// main...虽然该程序触发了 panic ,但由于我们使用了 recover() 捕获了 panic 异常,并输出 panic 信息,即使 panic 会导致整个程序退出,但在退出前,有 defer 延迟函数,还是得执行完 defer 。然后程序还会继续执行下去
只有在相同的协程中调用 recover 才管用, recover 不能恢复一个不同协程的 panic。
内置函数 new 分配内存。该函数只接受一个参数,该参数是一个任意类型(包括自定义类型),而不是值,返回指向该类型新分配零值的指针。
// The new built-in function allocates memory. The first argument is a type,
+// not a value, and the value returned is a pointer to a newly
+// allocated zero value of that type.
+func new(Type) *Type使用 new 函数首先会分配内存,并设置类型零值,最后返回指向该类型新分配零值的指针。
package main
+
+import (
+ "fmt"
+)
+
+func main() {
+ num := new(int)
+ // 打印出类型的值
+ fmt.Println(*num) // 0
+}内置函数 make 只能分配和初始化类型为 slice 、 map 或 chan 的对象。与 new 一样,第一个参数是类型,而不是值。与 new 不同, make 的返回类型与其参数的类型相同,而不是指向它的指针。结果取决于类型:
slice:size 指定长度。切片的容量等于其长度。可提供第三个参数以指定不同的容量;它不能小于长度。map:为空映射分配足够的空间来容纳指定数量的元素。可以省略大小,在这种情况下,分配一个小的起始大小。chan:使用指定的缓冲区容量初始化通道的缓冲区。如果为零,或者忽略了大小,则通道是无缓冲的。func make(t Type, size ...IntegerType) Type使用make函数必须初始化
// slice
+a := make([]int, 2, 10)
+
+// map
+b := make(map[string]int)
+
+// chan
+c := make(chan int, 10)new:为所有的类型分配内存,并初始化为零值,返回指针。
make:只能为 slice 、 map 、 chan 分配内存,并初始化,返回的是类型。
Go 语言提供了一种机制,能够在运行时更新变量和检查它们的值、调用它们的方法,而不需要在编译时就知道这些变量的具体类型。这种机制被称为 反射 。
在 Go 中 reflect 包实现了运行时反射。reflect 包会帮助识别 interface{} 变量的底层具体类型和具体值。
reflect.Type 表示 interface{} 的具体类型。reflect.TypeOf() 方法返回 reflect.Type
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectType(x interface{}) {
+ obj := reflect.TypeOf(x)
+ fmt.Println(obj)
+}
+
+func main() {
+ var a int64 = 123
+ reflectType(a)
+ var b string = "Go语言"
+ reflectType(b)
+}reflect.Value 表示 interface{} 的具体值。reflect.ValueOf() 方法返回 reflect.Value
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectType(x interface{}) {
+ typeX := reflect.TypeOf(x)
+ valueX := reflect.ValueOf(x)
+ fmt.Println(typeX)
+ fmt.Println(valueX)
+}
+
+func main() {
+ var a int64 = 123
+ reflectType(a)
+ var b string = "Go语言"
+ reflectType(b)
+}relfect.Kind 表示的是种类。在使用反射时,需要理解类型(Type)和种类(Kind)的区别。编程中,使用最多的是类型,但在反射中,当需要区分一个大品种的类型时,就会用到种类(Kind)。
Go 语言程序中的类型(Type)指的是系统原生数据类型,如 int 、 string 、 bool 、 float32 等类型,以及使用 type 关键字定义的类型,这些类型的名称就是其类型本身的名称。例如使用 type A struct{} 定义结构体时,A 就是 struct{} 的类型。
种类(Kind)指的是对象归属的品种,在 reflect 包中有如下定义:
// A Kind represents the specific kind of type that a Type represents.
+// The zero Kind is not a valid kind.
+type Kind uint
+
+const (
+ Invalid Kind = iota
+ Bool
+ Int
+ Int8
+ Int16
+ Int32
+ Int64
+ Uint
+ Uint8
+ Uint16
+ Uint32
+ Uint64
+ Uintptr
+ Float32
+ Float64
+ Complex64
+ Complex128
+ Array
+ Chan
+ Func
+ Interface
+ Map
+ Ptr
+ Slice
+ String
+ Struct
+ UnsafePointer
+)package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectType(x interface{}) {
+ typeX := reflect.TypeOf(x)
+ fmt.Println(typeX.Kind()) // struct
+ fmt.Println(typeX) // main.book
+}
+
+type book struct {
+}
+
+func main() {
+ var b book
+ reflectType(b)
+}relfect.NumField() 方法返回结构体中字段的数量。
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectNumField(x interface{}) {
+ // 检查 x 的类别是 struct
+ if reflect.ValueOf(x).Kind() == reflect.Struct {
+ v := reflect.ValueOf(x)
+ fmt.Println("Number of fields", v.NumField())
+ }
+}
+
+type book struct {
+ name string
+ spend int
+}
+
+func main() {
+ var b book
+ reflectNumField(b)
+}relfect.Field(i int) 方法返回字段 i 的 reflect.Value
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func reflectNumField(x interface{}) {
+ // 检查 x 的类别是 struct
+ if reflect.ValueOf(x).Kind() == reflect.Struct {
+ v := reflect.ValueOf(x)
+ fmt.Println("Number of fields", v.NumField())
+ for i := 0; i < v.NumField(); i++ {
+ fmt.Printf("Field:%d type:%T value:%v\\n", i, v.Field(i), v.Field(i))
+ }
+ }
+}
+
+type book struct {
+ name string
+ spend int
+}
+
+func main() {
+ var b = book{"Go语言", 8}
+ reflectNumField(a)
+}
+// Number of fields 2
+// Field:0 type:reflect.Value value:Go语言
+// Field:1 type:reflect.Value value:8一个接口变量,实际上都是由一 pair 对(type 和 data)组合而成,pair 对中记录着实际变量的值和类型。也就是说在真实世界(反射前环境)里,type 和 value 是合并在一起组成接口变量的。
而在反射的世界(反射后的环境)里,type 和 data 却是分开的,他们分别由 reflect.Type 和 reflect.Value 来表现。
Go语言反射三定律:
package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var a interface{} = 3.14
+
+ fmt.Printf("接口变量的类型为 %T ,值为 %v\\n", a, a)
+
+ t := reflect.TypeOf(a)
+ v := reflect.ValueOf(a)
+
+ // 反射第一定律
+ fmt.Printf("从接口变量到反射对象:Type对象类型为 %T\\n", t)
+ fmt.Printf("从接口变量到反射对象:Value对象类型为 %T\\n", v)
+
+ // 反射第二定律
+ i := v.Interface()
+ fmt.Printf("从反射对象到接口变量:对象类型为 %T,值为 %v\\n", i, i)
+ // 使用类型断言进行转换
+ x := v.Interface().(float64)
+ fmt.Printf("x 类型为 %T,值为 %v\\n", x, x)
+}package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var a float64 = 3.14
+ v := reflect.ValueOf(a)
+ fmt.Println("是否可写:", v.CanSet())
+}
+---
+package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var a float64 = 3.14
+ v := reflect.ValueOf(&a)
+ fmt.Println("是否可写:", v.CanSet())
+}
+---
+package main
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func main() {
+ var a float64 = 3.14
+ v := reflect.ValueOf(&a).Elem()
+ fmt.Println("是否可写:", v.CanSet())
+
+ v.SetFloat(2)
+ fmt.Println(v)
+}Cobra是一个能够快速构建cli工具的库,相比于之前用过的Python的argparser模块,Cobra更加强大、灵活,还有自动生成文档等功能。
https://github.com/spf13/cobra/blob/main/site/content/user_guide.md
go get -u github.com/spf13/cobra@latest
go install github.com/spf13/cobra-cli@latest
cobra-cli会被安装到GOPATH的bin目录
cd cobra-learn
+cobra-cli init
+// Your Cobra application is ready at
+// /Users/story/Developer/go/src/cobra-learn生成的目录结构:
├── LICENSE
+├── cmd
+│ └── root.go
+├── go.mod
+├── go.sum
+└── main.go// main.go
+package main
+
+import "cobra-learn/cmd"
+
+func main() {
+ cmd.Execute()
+}// root.go
+package cmd
+
+import (
+ "os"
+
+ "github.com/spf13/cobra"
+)
+
+
+
+// rootCmd represents the base command when called without any subcommands
+var rootCmd = &cobra.Command{
+ Use: "cobra-learn",
+ Short: "A brief description of your application",
+ Long: \`A longer description that spans multiple lines and likely contains
+examples and usage of using your application. For example:
+
+Cobra is a CLI library for Go that empowers applications.
+This application is a tool to generate the needed files
+to quickly create a Cobra application.\`,
+ // Uncomment the following line if your bare application
+ // has an action associated with it:
+ // Run: func(cmd *cobra.Command, args []string) { },
+}
+
+// Execute adds all child commands to the root command and sets flags appropriately.
+// This is called by main.main(). It only needs to happen once to the rootCmd.
+func Execute() {
+ err := rootCmd.Execute()
+ if err != nil {
+ os.Exit(1)
+ }
+}
+
+func init() {
+ // Here you will define your flags and configuration settings.
+ // Cobra supports persistent flags, which, if defined here,
+ // will be global for your application.
+
+ // rootCmd.PersistentFlags().StringVar(&cfgFile, "config", "", "config file (default is $HOME/.cobra-learn.yaml)")
+
+ // Cobra also supports local flags, which will only run
+ // when this action is called directly.
+ rootCmd.Flags().BoolP("toggle", "t", false, "Help message for toggle")
+}执行命令go run main.go会输出定义的详细描述
➜ cobra-learn go run main.go
+A longer description that spans multiple lines and likely contains
+examples and usage of using your application. For example:
+
+Cobra is a CLI library for Go that empowers applications.
+This application is a tool to generate the needed files
+to quickly create a Cobra application.➜ cobra-learn cobra-cli add version
+version created at /Users/story/Developer/go/src/cobra-learn目录结构:
├── LICENSE
+├── cmd
+│ ├── root.go
+│ └── version.go
+├── go.mod
+├── go.sum
+└── main.go// version.go
+package cmd
+
+import (
+ "fmt"
+
+ "github.com/spf13/cobra"
+)
+
+// versionCmd represents the version command
+var versionCmd = &cobra.Command{
+ Use: "version",
+ Short: "A brief description of your command",
+ Long: \`A longer description that spans multiple lines and likely contains examples
+and usage of using your command. For example:
+
+Cobra is a CLI library for Go that empowers applications.
+This application is a tool to generate the needed files
+to quickly create a Cobra application.\`,
+ Run: func(cmd *cobra.Command, args []string) {
+ fmt.Println("version called")
+ },
+}
+
+func init() {
+ rootCmd.AddCommand(versionCmd)
+
+ // Here you will define your flags and configuration settings.
+
+ // Cobra supports Persistent Flags which will work for this command
+ // and all subcommands, e.g.:
+ // versionCmd.PersistentFlags().String("foo", "", "A help for foo")
+
+ // Cobra supports local flags which will only run when this command
+ // is called directly, e.g.:
+ // versionCmd.Flags().BoolP("toggle", "t", false, "Help message for toggle")
+}执行go build编译项目,会在项目根目录生成二进制文件cobra-learn执行该命令:
➜ cobra-learn ./cobra-learn
+A longer description that spans multiple lines and likely contains
+examples and usage of using your application. For example:
+
+Cobra is a CLI library for Go that empowers applications.
+This application is a tool to generate the needed files
+to quickly create a Cobra application.
+
+Usage:
+ cobra-learn [command]
+
+Available Commands:
+ completion Generate the autocompletion script for the specified shell
+ help Help about any command
+ version A brief description of your command
+
+Flags:
+ -h, --help help for cobra-learn
+ -t, --toggle Help message for toggle
+
+Use "cobra-learn [command] --help" for more information about a command.执行cobra-learn version:
➜ cobra-learn ./cobra-learn version
+version called可以看到调用命令执行的就是Run属性对应的函数
func init() {
+ rootCmd.AddCommand(versionCmd)
+
+ // Here you will define your flags and configuration settings.
+
+ // Cobra supports Persistent Flags which will work for this command
+ // and all subcommands, e.g.:
+ // versionCmd.PersistentFlags().String("foo", "", "A help for foo")
+
+ // Cobra supports local flags which will only run when this command
+ // is called directly, e.g.:
+ versionCmd.Flags().StringP("ver", "v", "1.0", "版本号")
+}➜ cobra-learn go build
+➜ cobra-learn ./cobra-learn version
+Usage:
+ cobra-learn version [flags]
+
+Flags:
+ -h, --help help for version
+ -v, --ver string 版本号 (default "1.0")在Run函数中获取flag
Run: func(cmd *cobra.Command, args []string) {
+ ver, _ := cmd.Flags().GetString("ver")
+ fmt.Println(ver)
+}➜ cobra-learn go build
+➜ cobra-learn ./cobra-learn version --ver 123
+123 # 使用name
+➜ cobra-learn ./cobra-learn version -v 1234
+1234 # 使用shorthand
+➜ cobra-learn ./cobra-learn version
+1.0 # 不带flag 使用默认值可以看到上面输出的./cobra-learn version的uage信息是默认的
Usage:
+ cobra-learn version [flags]我们可以通过SetUsageTemplate或SetUsageFunc自定义这一内容:
func init() {
+ rootCmd.AddCommand(versionCmd)
+ rootCmd.AddCommand(versionCmd)
+ versionCmd.SetUsageTemplate(
+ \`Usage: story version [options] <ver>\` + "\\n" +
+ \`版本号\` + "\\n" +
+ \`Options:\` + "\\n" +
+ \` -h, --help help for version\` + "\\n",
+ )
+}➜ cobra-learn go build
+➜ cobra-learn ./cobra-learn version
+Error: accepts 1 arg(s), received 0
+Usage: story version [options] <ver>
+版本号
+Options:
+ -h, --help help for versionfunc init() {
+ rootCmd.AddCommand(versionCmd)
+ versionCmd.SetUsageFunc(func(cmd *cobra.Command) error {
+ fmt.Println("Usage: story version")
+ return nil
+ })
+}➜ cobra-learn go build
+➜ cobra-learn ./cobra-learn version
+Usage: story versionNumber of arguments:
NoArgs - report an error if there are any positional args.ArbitraryArgs - accept any number of args.MinimumNArgs(int) - report an error if less than N positional args are provided.MaximumNArgs(int) - report an error if more than N positional args are provided.ExactArgs(int) - report an error if there are not exactly N positional args.RangeArgs(min, max) - report an error if the number of args is not between min and max.Content of the arguments:
OnlyValidArgs - report an error if there are any positional args not specified in the ValidArgs field of Command, which can optionally be set to a list of valid values for positional args.例:Args: cobra.ExactArgs(1)
执行不带参数时:
➜ cobra-learn ./cobra-learn version
+Error: accepts 1 arg(s), received 0 # 提示需要提供一个参数
+Usage: story versionCobra是一个能够快速构建cli工具的库,相比于之前用过的Python的argparser模块,Cobra更加强大、灵活,还有自动生成文档等功能。
https://github.com/spf13/cobra/blob/main/site/content/user_guide.md
go get -u github.com/spf13/cobra@latest
go install github.com/spf13/cobra-cli@latest
cobra-cli会被安装到GOPATH的bin目录
cd cobra-learn
+cobra-cli init
+// Your Cobra application is ready at
+// /Users/story/Developer/go/src/cobra-learn生成的目录结构:
├── LICENSE
+├── cmd
+│ └── root.go
+├── go.mod
+├── go.sum
+└── main.go// main.go
+package main
+
+import "cobra-learn/cmd"
+
+func main() {
+ cmd.Execute()
+}// root.go
+package cmd
+
+import (
+ "os"
+
+ "github.com/spf13/cobra"
+)
+
+
+
+// rootCmd represents the base command when called without any subcommands
+var rootCmd = &cobra.Command{
+ Use: "cobra-learn",
+ Short: "A brief description of your application",
+ Long: \`A longer description that spans multiple lines and likely contains
+examples and usage of using your application. For example:
+
+Cobra is a CLI library for Go that empowers applications.
+This application is a tool to generate the needed files
+to quickly create a Cobra application.\`,
+ // Uncomment the following line if your bare application
+ // has an action associated with it:
+ // Run: func(cmd *cobra.Command, args []string) { },
+}
+
+// Execute adds all child commands to the root command and sets flags appropriately.
+// This is called by main.main(). It only needs to happen once to the rootCmd.
+func Execute() {
+ err := rootCmd.Execute()
+ if err != nil {
+ os.Exit(1)
+ }
+}
+
+func init() {
+ // Here you will define your flags and configuration settings.
+ // Cobra supports persistent flags, which, if defined here,
+ // will be global for your application.
+
+ // rootCmd.PersistentFlags().StringVar(&cfgFile, "config", "", "config file (default is $HOME/.cobra-learn.yaml)")
+
+ // Cobra also supports local flags, which will only run
+ // when this action is called directly.
+ rootCmd.Flags().BoolP("toggle", "t", false, "Help message for toggle")
+}执行命令go run main.go会输出定义的详细描述
➜ cobra-learn go run main.go
+A longer description that spans multiple lines and likely contains
+examples and usage of using your application. For example:
+
+Cobra is a CLI library for Go that empowers applications.
+This application is a tool to generate the needed files
+to quickly create a Cobra application.➜ cobra-learn cobra-cli add version
+version created at /Users/story/Developer/go/src/cobra-learn目录结构:
├── LICENSE
+├── cmd
+│ ├── root.go
+│ └── version.go
+├── go.mod
+├── go.sum
+└── main.go// version.go
+package cmd
+
+import (
+ "fmt"
+
+ "github.com/spf13/cobra"
+)
+
+// versionCmd represents the version command
+var versionCmd = &cobra.Command{
+ Use: "version",
+ Short: "A brief description of your command",
+ Long: \`A longer description that spans multiple lines and likely contains examples
+and usage of using your command. For example:
+
+Cobra is a CLI library for Go that empowers applications.
+This application is a tool to generate the needed files
+to quickly create a Cobra application.\`,
+ Run: func(cmd *cobra.Command, args []string) {
+ fmt.Println("version called")
+ },
+}
+
+func init() {
+ rootCmd.AddCommand(versionCmd)
+
+ // Here you will define your flags and configuration settings.
+
+ // Cobra supports Persistent Flags which will work for this command
+ // and all subcommands, e.g.:
+ // versionCmd.PersistentFlags().String("foo", "", "A help for foo")
+
+ // Cobra supports local flags which will only run when this command
+ // is called directly, e.g.:
+ // versionCmd.Flags().BoolP("toggle", "t", false, "Help message for toggle")
+}执行go build编译项目,会在项目根目录生成二进制文件cobra-learn执行该命令:
➜ cobra-learn ./cobra-learn
+A longer description that spans multiple lines and likely contains
+examples and usage of using your application. For example:
+
+Cobra is a CLI library for Go that empowers applications.
+This application is a tool to generate the needed files
+to quickly create a Cobra application.
+
+Usage:
+ cobra-learn [command]
+
+Available Commands:
+ completion Generate the autocompletion script for the specified shell
+ help Help about any command
+ version A brief description of your command
+
+Flags:
+ -h, --help help for cobra-learn
+ -t, --toggle Help message for toggle
+
+Use "cobra-learn [command] --help" for more information about a command.执行cobra-learn version:
➜ cobra-learn ./cobra-learn version
+version called可以看到调用命令执行的就是Run属性对应的函数
func init() {
+ rootCmd.AddCommand(versionCmd)
+
+ // Here you will define your flags and configuration settings.
+
+ // Cobra supports Persistent Flags which will work for this command
+ // and all subcommands, e.g.:
+ // versionCmd.PersistentFlags().String("foo", "", "A help for foo")
+
+ // Cobra supports local flags which will only run when this command
+ // is called directly, e.g.:
+ versionCmd.Flags().StringP("ver", "v", "1.0", "版本号")
+}➜ cobra-learn go build
+➜ cobra-learn ./cobra-learn version
+Usage:
+ cobra-learn version [flags]
+
+Flags:
+ -h, --help help for version
+ -v, --ver string 版本号 (default "1.0")在Run函数中获取flag
Run: func(cmd *cobra.Command, args []string) {
+ ver, _ := cmd.Flags().GetString("ver")
+ fmt.Println(ver)
+}➜ cobra-learn go build
+➜ cobra-learn ./cobra-learn version --ver 123
+123 # 使用name
+➜ cobra-learn ./cobra-learn version -v 1234
+1234 # 使用shorthand
+➜ cobra-learn ./cobra-learn version
+1.0 # 不带flag 使用默认值可以看到上面输出的./cobra-learn version的uage信息是默认的
Usage:
+ cobra-learn version [flags]我们可以通过SetUsageTemplate或SetUsageFunc自定义这一内容:
func init() {
+ rootCmd.AddCommand(versionCmd)
+ rootCmd.AddCommand(versionCmd)
+ versionCmd.SetUsageTemplate(
+ \`Usage: story version [options] <ver>\` + "\\n" +
+ \`版本号\` + "\\n" +
+ \`Options:\` + "\\n" +
+ \` -h, --help help for version\` + "\\n",
+ )
+}➜ cobra-learn go build
+➜ cobra-learn ./cobra-learn version
+Error: accepts 1 arg(s), received 0
+Usage: story version [options] <ver>
+版本号
+Options:
+ -h, --help help for versionfunc init() {
+ rootCmd.AddCommand(versionCmd)
+ versionCmd.SetUsageFunc(func(cmd *cobra.Command) error {
+ fmt.Println("Usage: story version")
+ return nil
+ })
+}➜ cobra-learn go build
+➜ cobra-learn ./cobra-learn version
+Usage: story versionNumber of arguments:
NoArgs - report an error if there are any positional args.ArbitraryArgs - accept any number of args.MinimumNArgs(int) - report an error if less than N positional args are provided.MaximumNArgs(int) - report an error if more than N positional args are provided.ExactArgs(int) - report an error if there are not exactly N positional args.RangeArgs(min, max) - report an error if the number of args is not between min and max.Content of the arguments:
OnlyValidArgs - report an error if there are any positional args not specified in the ValidArgs field of Command, which can optionally be set to a list of valid values for positional args.例:Args: cobra.ExactArgs(1)
执行不带参数时:
➜ cobra-learn ./cobra-learn version
+Error: accepts 1 arg(s), received 0 # 提示需要提供一个参数
+Usage: story versionpackage main
+
+import (
+ "context"
+ "fmt"
+ "github.com/redis/go-redis/v9"
+ "log"
+)
+
+func main() {
+ ctx := context.Background()
+ // 创建Redis客户端
+ client := redis.NewClient(&redis.Options{
+ Addr: "localhost:6379",
+ DB: 1,
+ })
+
+ // 定义匹配模式和批量处理大小
+ matchPattern := "*"
+ batchSize := 1000
+
+ // 设置游标初始值和删除计数器
+ startCursor := uint64(0)
+ keysDeleted := 0
+ memSaved := 0
+
+ for {
+ // 扫描Redis中的key
+ keys, cursor, err := client.Scan(ctx, startCursor, matchPattern, int64(batchSize)).Result()
+
+ if err != nil {
+ log.Fatal(err)
+ }
+
+ // 检查每个key的过期时间并删除符合条件的键
+ for _, key := range keys {
+ ttl, err := client.TTL(ctx, key).Result()
+ if err != nil {
+ log.Fatal(err)
+ }
+
+ // 如果过期时间大于15年,则删除该键
+ if ttl.Hours() > 24*365*10 {
+ mem, err := client.MemoryUsage(ctx, key).Result()
+ if err != nil {
+ log.Fatal(err)
+ }
+ err = client.Del(ctx, key).Err()
+ if err != nil {
+ log.Fatal(err)
+ }
+ memSaved += int(mem)
+ keysDeleted++
+ }
+ }
+
+ // 如果游标为0,则表示已完成遍历
+ if cursor == 0 {
+ break
+ }
+ startCursor = cursor
+ }
+
+ fmt.Printf("已删除 %d 个过期时间大于10年的键\\n", keysDeleted)
+ fmt.Printf("已释放 %d MB内存\\n", memSaved/1024/1024)
+
+ // 关闭Redis客户端连接
+ err := client.Close()
+ if err != nil {
+ log.Fatal(err)
+ }
+}package main
+
+import (
+ "context"
+ "fmt"
+ "github.com/redis/go-redis/v9"
+ "log"
+)
+
+func main() {
+ ctx := context.Background()
+ // 创建Redis客户端
+ client := redis.NewClient(&redis.Options{
+ Addr: "localhost:6379",
+ DB: 1,
+ })
+
+ // 定义匹配模式和批量处理大小
+ matchPattern := "*"
+ batchSize := 1000
+
+ // 设置游标初始值和删除计数器
+ startCursor := uint64(0)
+ keysDeleted := 0
+ memSaved := 0
+
+ for {
+ // 扫描Redis中的key
+ keys, cursor, err := client.Scan(ctx, startCursor, matchPattern, int64(batchSize)).Result()
+
+ if err != nil {
+ log.Fatal(err)
+ }
+
+ // 检查每个key的过期时间并删除符合条件的键
+ for _, key := range keys {
+ ttl, err := client.TTL(ctx, key).Result()
+ if err != nil {
+ log.Fatal(err)
+ }
+
+ // 如果过期时间大于15年,则删除该键
+ if ttl.Hours() > 24*365*10 {
+ mem, err := client.MemoryUsage(ctx, key).Result()
+ if err != nil {
+ log.Fatal(err)
+ }
+ err = client.Del(ctx, key).Err()
+ if err != nil {
+ log.Fatal(err)
+ }
+ memSaved += int(mem)
+ keysDeleted++
+ }
+ }
+
+ // 如果游标为0,则表示已完成遍历
+ if cursor == 0 {
+ break
+ }
+ startCursor = cursor
+ }
+
+ fmt.Printf("已删除 %d 个过期时间大于10年的键\\n", keysDeleted)
+ fmt.Printf("已释放 %d MB内存\\n", memSaved/1024/1024)
+
+ // 关闭Redis客户端连接
+ err := client.Close()
+ if err != nil {
+ log.Fatal(err)
+ }
+}Gin is a HTTP web framework written in Go (Golang). It features a Martini-like API with much better performance -- up to 40 times faster. If you need smashing performance, get yourself some Gin.
go get -u github.com/gin-gonic/gin
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ ginServer.Use(favicon.New("./favicon.ico"))
+ ginServer.GET("/", func(c *gin.Context) {
+ c.String(200, "Hello World!")
+ })
+ ginServer.POST("/post", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "POST Data",
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+
+}curl -X GET http://localhost:8080
Hello World!curl -X POST http://localhost:8080/post
{"message":"POST Data"}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ // 设置favicon
+ ginServer.Use(favicon.New("./favicon.ico"))
+
+ // 加载静态页
+ ginServer.LoadHTMLGlob("templates/*")
+ // 响应页面给前端
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(200, "index.html", gin.H{
+ "title": "Main website",
+ })
+ })
+ _ = ginServer.Run(":8080")
+}访问localhost:8080或localhost:8080/index
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ // 设置favicon
+ ginServer.Use(favicon.New("./favicon.ico"))
+
+ // 加载静态页
+ ginServer.LoadHTMLGlob("templates/*")
+ // 响应页面给前端
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(200, "index.html", gin.H{
+ "title": "Main website",
+ })
+ })
+ _ = ginServer.Run(":8080")
+}
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+
+ ginServer.GET("/user/info", func(context *gin.Context) {
+ userId := context.Query("userId")
+ userName := context.Query("userName")
+ context.JSON(http.StatusOK, gin.H{
+ "userId": userId,
+ "userName": userName,
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}curl -X GET 'http://localhost:8080/user/info?userId=123&userName=小明'{"userId":"123","userName":"小明"}package main
+
+import (
+ "encoding/json"
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.POST("/user", func(context *gin.Context) {
+ // request body []byte, err
+ body, _ := context.GetRawData()
+ // 包装为map类型
+ var m map[string]interface{}
+ _ = json.Unmarshal(body, &m)
+
+ context.JSON(http.StatusOK, m)
+ })
+
+ _ = ginServer.Run(":8080")
+}curl -X POST 'http://127.0.0.1:8080/user' --header 'Content-Type: application/json' --data '{"userName": "张三"}'{"userName":"张三"}<!DOCTYPE html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <title>Title</title>
+ <link rel="stylesheet" href="/static/base.css">
+</head>
+<body>
+<h1>Hello World!</h1>
+
+<form action="/user/add" method="post">
+ <input type="text" name="username">
+ <input type="password" name="password">
+
+ <button type="submit">提交</button>
+</form>
+<script src="/static/base.js"></script>
+</body>
+</html>package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.LoadHTMLGlob("templates/*")
+
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(http.StatusOK, "index.html", gin.H{
+ "title": "Hello World",
+ })
+ })
+
+ ginServer.POST("/user/add", func(context *gin.Context) {
+ username := context.PostForm("username")
+ password := context.PostForm("password")
+
+ context.JSON(http.StatusOK, gin.H{
+ "msg": "success",
+ "data": gin.H{
+ "username": username,
+ "password": password,
+ },
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.LoadHTMLGlob("templates/*")
+ // 重定向到首页
+ ginServer.GET("/", func(context *gin.Context) {
+ context.Redirect(http.StatusMovedPermanently, "/index")
+ })
+
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(http.StatusOK, "index.html", gin.H{
+ "title": "Hello World",
+ })
+ })
+ // 404页面
+ ginServer.NoRoute(func(context *gin.Context) {
+ context.HTML(http.StatusNotFound, "404.html", gin.H{
+ "title": "404",
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ userGroup := ginServer.Group("/user")
+ {
+ userGroup.GET("/get", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "get user",
+ })
+ })
+ userGroup.POST("/post", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "post user",
+ })
+ })
+ }
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "log"
+)
+
+func myHandler() gin.HandlerFunc {
+ return func(context *gin.Context) {
+ // do something
+ context.Set("name", "zhangsan")
+ context.Next() // 放行
+ // context.Abort() 阻止
+ }
+}
+
+func main() {
+ ginServer := gin.Default()
+
+ userGroup := ginServer.Group("/user")
+ {
+ userGroup.GET("/get", myHandler(), func(c *gin.Context) {
+ // 获取拦截器里设置的值
+ name := c.MustGet("name").(string)
+ log.Println(name)
+ c.JSON(200, gin.H{
+ "message": "get user",
+ })
+ })
+ }
+
+ _ = ginServer.Run(":8080")
+}
+// 2023/07/01 21:36:53 zhangsanGin is a HTTP web framework written in Go (Golang). It features a Martini-like API with much better performance -- up to 40 times faster. If you need smashing performance, get yourself some Gin.
go get -u github.com/gin-gonic/gin
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ ginServer.Use(favicon.New("./favicon.ico"))
+ ginServer.GET("/", func(c *gin.Context) {
+ c.String(200, "Hello World!")
+ })
+ ginServer.POST("/post", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "POST Data",
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+
+}curl -X GET http://localhost:8080
Hello World!curl -X POST http://localhost:8080/post
{"message":"POST Data"}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ // 设置favicon
+ ginServer.Use(favicon.New("./favicon.ico"))
+
+ // 加载静态页
+ ginServer.LoadHTMLGlob("templates/*")
+ // 响应页面给前端
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(200, "index.html", gin.H{
+ "title": "Main website",
+ })
+ })
+ _ = ginServer.Run(":8080")
+}访问localhost:8080或localhost:8080/index
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ // 设置favicon
+ ginServer.Use(favicon.New("./favicon.ico"))
+
+ // 加载静态页
+ ginServer.LoadHTMLGlob("templates/*")
+ // 响应页面给前端
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(200, "index.html", gin.H{
+ "title": "Main website",
+ })
+ })
+ _ = ginServer.Run(":8080")
+}
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+
+ ginServer.GET("/user/info", func(context *gin.Context) {
+ userId := context.Query("userId")
+ userName := context.Query("userName")
+ context.JSON(http.StatusOK, gin.H{
+ "userId": userId,
+ "userName": userName,
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}curl -X GET 'http://localhost:8080/user/info?userId=123&userName=小明'{"userId":"123","userName":"小明"}package main
+
+import (
+ "encoding/json"
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.POST("/user", func(context *gin.Context) {
+ // request body []byte, err
+ body, _ := context.GetRawData()
+ // 包装为map类型
+ var m map[string]interface{}
+ _ = json.Unmarshal(body, &m)
+
+ context.JSON(http.StatusOK, m)
+ })
+
+ _ = ginServer.Run(":8080")
+}curl -X POST 'http://127.0.0.1:8080/user' --header 'Content-Type: application/json' --data '{"userName": "张三"}'{"userName":"张三"}<!DOCTYPE html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <title>Title</title>
+ <link rel="stylesheet" href="/static/base.css">
+</head>
+<body>
+<h1>Hello World!</h1>
+
+<form action="/user/add" method="post">
+ <input type="text" name="username">
+ <input type="password" name="password">
+
+ <button type="submit">提交</button>
+</form>
+<script src="/static/base.js"></script>
+</body>
+</html>package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.LoadHTMLGlob("templates/*")
+
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(http.StatusOK, "index.html", gin.H{
+ "title": "Hello World",
+ })
+ })
+
+ ginServer.POST("/user/add", func(context *gin.Context) {
+ username := context.PostForm("username")
+ password := context.PostForm("password")
+
+ context.JSON(http.StatusOK, gin.H{
+ "msg": "success",
+ "data": gin.H{
+ "username": username,
+ "password": password,
+ },
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.LoadHTMLGlob("templates/*")
+ // 重定向到首页
+ ginServer.GET("/", func(context *gin.Context) {
+ context.Redirect(http.StatusMovedPermanently, "/index")
+ })
+
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(http.StatusOK, "index.html", gin.H{
+ "title": "Hello World",
+ })
+ })
+ // 404页面
+ ginServer.NoRoute(func(context *gin.Context) {
+ context.HTML(http.StatusNotFound, "404.html", gin.H{
+ "title": "404",
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ userGroup := ginServer.Group("/user")
+ {
+ userGroup.GET("/get", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "get user",
+ })
+ })
+ userGroup.POST("/post", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "post user",
+ })
+ })
+ }
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "log"
+)
+
+func myHandler() gin.HandlerFunc {
+ return func(context *gin.Context) {
+ // do something
+ context.Set("name", "zhangsan")
+ context.Next() // 放行
+ // context.Abort() 阻止
+ }
+}
+
+func main() {
+ ginServer := gin.Default()
+
+ userGroup := ginServer.Group("/user")
+ {
+ userGroup.GET("/get", myHandler(), func(c *gin.Context) {
+ // 获取拦截器里设置的值
+ name := c.MustGet("name").(string)
+ log.Println(name)
+ c.JSON(200, gin.H{
+ "message": "get user",
+ })
+ })
+ }
+
+ _ = ginServer.Run(":8080")
+}
+// 2023/07/01 21:36:53 zhangsanHashMap是开发中最常用的容器之一,它也是Java集合框架中极为重要的组成部分,HashMap实现了Map接口,并继承 AbstractMap 抽象类
public class HashMap<K,V> extends AbstractMap<K,V>
+ implements Map<K,V>, Cloneable, Serializable {
+ ***
+}首先了解下HashMap的几个字段
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的初始容量
+static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量
+static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认负载因子
+transient Node<K,V>[] table; //哈希桶数组
+transient int size; //容器中键值对的个数
+transient int modCount; //容器内部结构发生变化的次数,主要用于迭代的快速失败
+int threshold; //阈值 table * loadFactor size超过这个值就会扩容
+final float loadFactor; //负载因子 默认0.75Node的结构
static class Node<K,V> implements Map.Entry<K,V> {
+ final int hash;
+ final K key;
+ V value;
+ Node<K,V> next;
+
+ Node(int hash, K key, V value, Node<K,V> next) {
+ this.hash = hash;
+ this.key = key;
+ this.value = value;
+ this.next = next;
+ }
+
+ public final K getKey() { return key; }
+ public final V getValue() { return value; }
+ public final String toString() { return key + "=" + value; }
+
+ public final int hashCode() {
+ return Objects.hashCode(key) ^ Objects.hashCode(value);
+ }
+
+ public final V setValue(V newValue) {
+ V oldValue = value;
+ value = newValue;
+ return oldValue;
+ }
+
+ public final boolean equals(Object o) {
+ if (o == this)
+ return true;
+ if (o instanceof Map.Entry) {
+ Map.Entry<?,?> e = (Map.Entry<?,?>)o;
+ if (Objects.equals(key, e.getKey()) &&
+ Objects.equals(value, e.getValue()))
+ return true;
+ }
+ return false;
+ }
+}Node(JDK1.8之前叫Entry)是HashMap的静态内部类,实现了Map.Entry接口,包括了hash,key,value和下一节点next四个属性,是构成哈希表的基石,是哈希表存储的元素的具体形式。
public HashMap(int initialCapacity, float loadFactor) {
+ if (initialCapacity < 0)
+ throw new IllegalArgumentException("Illegal initial capacity: " +
+ initialCapacity);
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ if (loadFactor <= 0 || Float.isNaN(loadFactor))
+ throw new IllegalArgumentException("Illegal load factor: " +
+ loadFactor);
+ this.loadFactor = loadFactor;
+ this.threshold = tableSizeFor(initialCapacity);
+}
+=====================================================================
+public HashMap(int initialCapacity) {
+ this(initialCapacity, DEFAULT_LOAD_FACTOR);
+}
+=====================================================================
+public HashMap() {
+ this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
+}
+=====================================================================
+public HashMap(Map<? extends K, ? extends V> m) {
+ this.loadFactor = DEFAULT_LOAD_FACTOR;
+ putMapEntries(m, false);
+}HashMap的初始容量和负载因子是影响map性能的关键参数,容量指的是table数组的大小,负载因子是衡量哈希表使用程度的一个尺度,负载因子越小,那哈希表空间的利用率就越低,造成的空间浪费就越严重。而如果负载因子越大,哈希表的利用率越高,带来的问题就是查找效率的下降。0.75是对空间和时间成本的折衷选择,一般情况下无需修改。
hash的概念:把任意长度的输入,通过hash算法,转换成相同长度的输出(通常为整型)。
HashMap的数据结构:
HashMap的底层数据结构结合了数组和链表(JDK1.8之前),实际上就是一个链表数组,也就是上文提到的Node<K,V> table[]。我们都知道数组的优势是查找快,增删慢,而链表则是增删快,查找慢,而这种链表数组——拉链法,结合了二者的优势,查找快,增删也快。查找元素的时间复杂度为O(1+n),n为链表的长度。在JDK1.8之后,为了解决哈希冲突频繁的问题,在原来的基础上又引入了红黑树,当链表长度超过8时,链表便会转化为红黑树结构,查找的时间复杂度从O(1+n)变成了O(1+lgn),大大提高了查询效率,不必再遍历链表。
JDK1.8之前的HashMap结构 
JDK1.8的HashMap结构 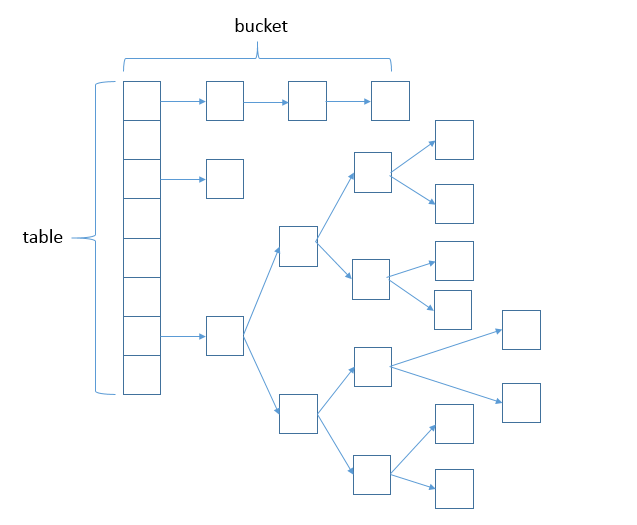
HashMap中的方法很多,这里主要从hash,put,get,resize几个点深入研究
static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}首先,我们可以发现HashMap是允许null键的,而HashTable则不支持。
hash方法的本质是对key.hashCode()和key.hashCode()>>>16进行异或运算,>>>为无符号右移运算符,就是将补码右移后高位补0。^异或是参与运算的数每一位上的数字对比,相同结果为0,不同结果为1。
所以hash方法的功能就是对高16bit和低16bit进行异或运算来减少碰撞。
public V put(K key, V value) {
+ return putVal(hash(key), key, value, false, true);
+}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
+ boolean evict) {
+ Node<K,V>[] tab; Node<K,V> p; int n, i;
+ //如果table为空或者为初始化则进行初始化
+ if ((tab = table) == null || (n = tab.length) == 0)
+ n = (tab = resize()).length;
+ //计算插入的索引值(n- 1) & hash,如果数组中这个索引位置为空 则直接插入,next指针指向为null
+ if ((p = tab[i = (n - 1) & hash]) == null)
+ tab[i] = newNode(hash, key, value, null);
+ else {
+ //如果key已经存在了,直接覆盖value
+ Node<K,V> e; K k;
+ if (p.hash == hash &&
+ ((k = p.key) == key || (key != null && key.equals(k))))
+ //把第一个元素赋值给e记录
+ e = p;
+ //如果是红黑树
+ else if (p instanceof TreeNode)
+ //插入红黑树
+ e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
+ else {
+ //如果为链表,进行遍历直到下一个节点为null或者key存在
+ for (int binCount = 0; ; ++binCount) {
+ if ((e = p.next) == null) {
+ //插入链表最末端
+ p.next = newNode(hash, key, value, null);
+ //如果链表长度达到阈值 转换为红黑树
+ if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
+ treeifyBin(tab, hash);
+ break;
+ }
+ //判断链表中的节点key与即将插入的key是否相同
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ break;
+ //和前面的e = p.next对应 用来遍历链表
+ p = e;
+ }
+ }
+ //如果key存在,则覆盖原来的value,返回oldValue
+ if (e != null) { // existing mapping for key
+ V oldValue = e.value;
+ if (!onlyIfAbsent || oldValue == null)
+ e.value = value;
+ //访问后的回调函数
+ afterNodeAccess(e);
+ return oldValue;
+ }
+ }
+ //记录结构修改
+ ++modCount;
+ //如果哈希表中的键值对数量达到阈值,进行扩容
+ if (++size > threshold)
+ resize();
+ //插入后的回调函数
+ afterNodeInsertion(evict);
+ return null;
+}流程梳理:
计算key的hash值 (h = key.hashCode() ^ h >>> 16)
根据hash值和table数组的长度n计算插入table数组的索引,(n - 1) & hash。由于n始终是2的n次方(为什么后面会介绍),所以(n - 1) & hash 相等于 hash % n ,但是位运算要比取模效率更高
多种情况
如果该位置没有数据,新生成一个节点保存新数据,返回null
如果该位置有数据且是红黑树结构,那么执行相应的插入 / 更新操作;
如果该位置有数据且是链表
流程图: 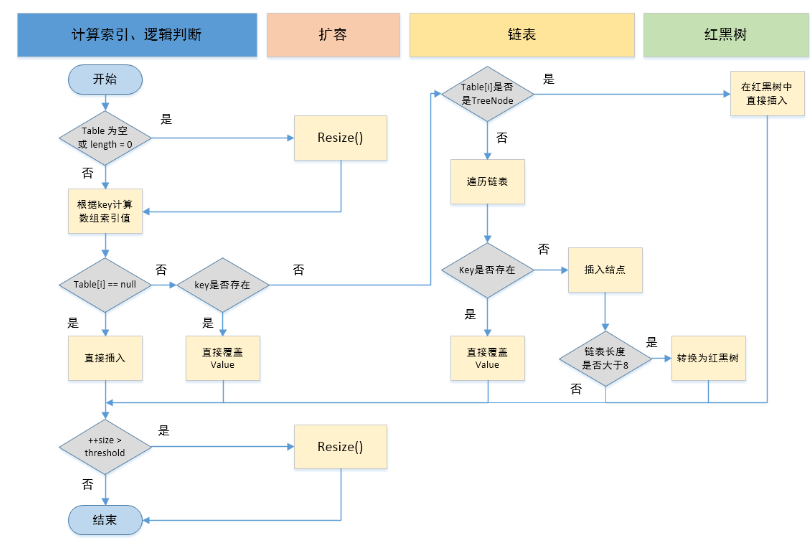
public V get(Object key) {
+ Node<K,V> e;
+ return (e = getNode(hash(key), key)) == null ? null : e.value;
+}
+
+final Node<K,V> getNode(int hash, Object key) {
+ Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
+ // 1. 定位键值对所在桶的位置
+ if ((tab = table) != null && (n = tab.length) > 0 &&
+ (first = tab[(n - 1) & hash]) != null) {
+ if (first.hash == hash && // always check first node
+ ((k = first.key) == key || (key != null && key.equals(k))))
+ return first;
+ if ((e = first.next) != null) {
+ // 2. 如果 first 是 TreeNode 类型,则调用黑红树查找方法
+ if (first instanceof TreeNode)
+ return ((TreeNode<K,V>)first).getTreeNode(hash, key);
+
+ // 2. 对链表进行查找
+ do {
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ return e;
+ } while ((e = e.next) != null);
+ }
+ }
+ return null;
+} final Node<K,V>[] resize() {
+ //oldTable指向当前hash桶数组
+ Node<K,V>[] oldTab = table;
+ int oldCap = (oldTab == null) ? 0 : oldTab.length;
+ int oldThr = threshold;
+ int newCap, newThr = 0;
+ if (oldCap > 0) {//如果旧的hash桶不为空
+ if (oldCap >= MAXIMUM_CAPACITY) {
+ //如果大于最大容量,则阈值设置为最大整数的值
+ threshold = Integer.MAX_VALUE;
+ return oldTab;
+ }
+ else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
+ oldCap >= DEFAULT_INITIAL_CAPACITY)
+ //如果旧的hash桶容量扩容一次(左移1位)后小于最大值,并且旧的桶容量大于默认值16
+ //新桶容量 = 旧桶容量*2
+ newThr = oldThr << 1; // double threshold
+ }
+ else if (oldThr > 0) // initial capacity was placed in threshold
+ newCap = oldThr;
+ else { // zero initial threshold signifies using defaults
+ //初始化
+ newCap = DEFAULT_INITIAL_CAPACITY;
+ newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
+ }
+ if (newThr == 0) {
+ float ft = (float)newCap * loadFactor;
+ newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
+ (int)ft : Integer.MAX_VALUE);
+ }
+ threshold = newThr;
+ @SuppressWarnings({"rawtypes","unchecked"})
+ //初始化一个容量为newCap的新hash桶数组
+ Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
+ //将新桶复制给旧的hash桶数组
+ table = newTab;
+ if (oldTab != null) {
+ //如果旧的hash桶不为空,则开始扩容操作
+ for (int j = 0; j < oldCap; ++j) {
+ Node<K,V> e;
+ if ((e = oldTab[j]) != null) {//旧桶j处节点值赋值给e,如果不为空,将旧桶j节点设置为空
+ oldTab[j] = null;
+ if (e.next == null)//如果e后面没有节点
+ newTab[e.hash & (newCap - 1)] = e;//直接对e的hash值对新数组长度求模获得hash桶中存储位置
+ else if (e instanceof TreeNode)//如果e为红黑树节点,将e添加到红黑树中
+ ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
+ else { // preserve order //如果是链表
+ Node<K,V> loHead = null, loTail = null;
+ Node<K,V> hiHead = null, hiTail = null;
+ Node<K,V> next;
+ do {
+ next = e.next;//将e的下一节点赋值给next
+ if ((e.hash & oldCap) == 0) {//如果e的hash值对旧桶长度求模为0
+ if (loTail == null)
+ loHead = e;//如果loTail为null,将e赋给loHead
+ else
+ loTail.next = e;//非则将e赋值给loTail的next节点
+ loTail = e;//将e赋值给loTail节点
+ }
+ else {//如果e的hash值对旧桶长度取模不为0
+ if (hiTail == null)
+ hiHead = e;//hiHead为null,将e赋值给hiHead
+ else
+ hiTail.next = e;//否则e赋值给hiTail.next
+ hiTail = e;//将e赋值给hiTail
+ }
+ } while ((e = next) != null);//直到e为空
+ if (loTail != null) {
+ //如果loTail不为空,将loTail的下一节点设置为null
+ loTail.next = null;
+ //将loHead赋值给新桶的j处
+ newTab[j] = loHead;
+ }
+ if (hiTail != null) {
+ //如果hiTail不为空,将hiTail的下一节点设置为null
+ hiTail.next = null;
+ //hiHead赋值给新桶的j+旧桶数组长度处
+ newTab[j + oldCap] = hiHead;
+ }
+ }
+ }
+ }
+ }
+ return newTab;
+ } static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ n |= n >>> 2;
+ n |= n >>> 4;
+ n |= n >>> 8;
+ n |= n >>> 16;
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }测试类
public class Test {
+ public static void main(String[] args) {
+
+ int cap = 65538;
+ System.out.println(Integer.toBinaryString(cap));
+ System.out.println(Integer.toBinaryString(cap-1));
+ int i = tableSizeFor(cap);
+ System.out.println(Integer.toBinaryString(i));
+ }
+
+ static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 2;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 4;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 8;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 16;
+ System.out.println(Integer.toBinaryString(n));
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }
+}运行结果
010000000000000010
+010000000000000001
+011000000000000001
+011110000000000001
+011111111000000001
+011111111111111111
+011111111111111111
+100000000000000000HashMap是开发中最常用的容器之一,它也是Java集合框架中极为重要的组成部分,HashMap实现了Map接口,并继承 AbstractMap 抽象类
public class HashMap<K,V> extends AbstractMap<K,V>
+ implements Map<K,V>, Cloneable, Serializable {
+ ***
+}首先了解下HashMap的几个字段
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的初始容量
+static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量
+static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认负载因子
+transient Node<K,V>[] table; //哈希桶数组
+transient int size; //容器中键值对的个数
+transient int modCount; //容器内部结构发生变化的次数,主要用于迭代的快速失败
+int threshold; //阈值 table * loadFactor size超过这个值就会扩容
+final float loadFactor; //负载因子 默认0.75Node的结构
static class Node<K,V> implements Map.Entry<K,V> {
+ final int hash;
+ final K key;
+ V value;
+ Node<K,V> next;
+
+ Node(int hash, K key, V value, Node<K,V> next) {
+ this.hash = hash;
+ this.key = key;
+ this.value = value;
+ this.next = next;
+ }
+
+ public final K getKey() { return key; }
+ public final V getValue() { return value; }
+ public final String toString() { return key + "=" + value; }
+
+ public final int hashCode() {
+ return Objects.hashCode(key) ^ Objects.hashCode(value);
+ }
+
+ public final V setValue(V newValue) {
+ V oldValue = value;
+ value = newValue;
+ return oldValue;
+ }
+
+ public final boolean equals(Object o) {
+ if (o == this)
+ return true;
+ if (o instanceof Map.Entry) {
+ Map.Entry<?,?> e = (Map.Entry<?,?>)o;
+ if (Objects.equals(key, e.getKey()) &&
+ Objects.equals(value, e.getValue()))
+ return true;
+ }
+ return false;
+ }
+}Node(JDK1.8之前叫Entry)是HashMap的静态内部类,实现了Map.Entry接口,包括了hash,key,value和下一节点next四个属性,是构成哈希表的基石,是哈希表存储的元素的具体形式。
public HashMap(int initialCapacity, float loadFactor) {
+ if (initialCapacity < 0)
+ throw new IllegalArgumentException("Illegal initial capacity: " +
+ initialCapacity);
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ if (loadFactor <= 0 || Float.isNaN(loadFactor))
+ throw new IllegalArgumentException("Illegal load factor: " +
+ loadFactor);
+ this.loadFactor = loadFactor;
+ this.threshold = tableSizeFor(initialCapacity);
+}
+=====================================================================
+public HashMap(int initialCapacity) {
+ this(initialCapacity, DEFAULT_LOAD_FACTOR);
+}
+=====================================================================
+public HashMap() {
+ this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
+}
+=====================================================================
+public HashMap(Map<? extends K, ? extends V> m) {
+ this.loadFactor = DEFAULT_LOAD_FACTOR;
+ putMapEntries(m, false);
+}HashMap的初始容量和负载因子是影响map性能的关键参数,容量指的是table数组的大小,负载因子是衡量哈希表使用程度的一个尺度,负载因子越小,那哈希表空间的利用率就越低,造成的空间浪费就越严重。而如果负载因子越大,哈希表的利用率越高,带来的问题就是查找效率的下降。0.75是对空间和时间成本的折衷选择,一般情况下无需修改。
hash的概念:把任意长度的输入,通过hash算法,转换成相同长度的输出(通常为整型)。
HashMap的数据结构:
HashMap的底层数据结构结合了数组和链表(JDK1.8之前),实际上就是一个链表数组,也就是上文提到的Node<K,V> table[]。我们都知道数组的优势是查找快,增删慢,而链表则是增删快,查找慢,而这种链表数组——拉链法,结合了二者的优势,查找快,增删也快。查找元素的时间复杂度为O(1+n),n为链表的长度。在JDK1.8之后,为了解决哈希冲突频繁的问题,在原来的基础上又引入了红黑树,当链表长度超过8时,链表便会转化为红黑树结构,查找的时间复杂度从O(1+n)变成了O(1+lgn),大大提高了查询效率,不必再遍历链表。
JDK1.8之前的HashMap结构
JDK1.8的HashMap结构
HashMap中的方法很多,这里主要从hash,put,get,resize几个点深入研究
static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}首先,我们可以发现HashMap是允许null键的,而HashTable则不支持。
hash方法的本质是对key.hashCode()和key.hashCode()>>>16进行异或运算,>>>为无符号右移运算符,就是将补码右移后高位补0。^异或是参与运算的数每一位上的数字对比,相同结果为0,不同结果为1。
所以hash方法的功能就是对高16bit和低16bit进行异或运算来减少碰撞。
public V put(K key, V value) {
+ return putVal(hash(key), key, value, false, true);
+}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
+ boolean evict) {
+ Node<K,V>[] tab; Node<K,V> p; int n, i;
+ //如果table为空或者为初始化则进行初始化
+ if ((tab = table) == null || (n = tab.length) == 0)
+ n = (tab = resize()).length;
+ //计算插入的索引值(n- 1) & hash,如果数组中这个索引位置为空 则直接插入,next指针指向为null
+ if ((p = tab[i = (n - 1) & hash]) == null)
+ tab[i] = newNode(hash, key, value, null);
+ else {
+ //如果key已经存在了,直接覆盖value
+ Node<K,V> e; K k;
+ if (p.hash == hash &&
+ ((k = p.key) == key || (key != null && key.equals(k))))
+ //把第一个元素赋值给e记录
+ e = p;
+ //如果是红黑树
+ else if (p instanceof TreeNode)
+ //插入红黑树
+ e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
+ else {
+ //如果为链表,进行遍历直到下一个节点为null或者key存在
+ for (int binCount = 0; ; ++binCount) {
+ if ((e = p.next) == null) {
+ //插入链表最末端
+ p.next = newNode(hash, key, value, null);
+ //如果链表长度达到阈值 转换为红黑树
+ if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
+ treeifyBin(tab, hash);
+ break;
+ }
+ //判断链表中的节点key与即将插入的key是否相同
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ break;
+ //和前面的e = p.next对应 用来遍历链表
+ p = e;
+ }
+ }
+ //如果key存在,则覆盖原来的value,返回oldValue
+ if (e != null) { // existing mapping for key
+ V oldValue = e.value;
+ if (!onlyIfAbsent || oldValue == null)
+ e.value = value;
+ //访问后的回调函数
+ afterNodeAccess(e);
+ return oldValue;
+ }
+ }
+ //记录结构修改
+ ++modCount;
+ //如果哈希表中的键值对数量达到阈值,进行扩容
+ if (++size > threshold)
+ resize();
+ //插入后的回调函数
+ afterNodeInsertion(evict);
+ return null;
+}流程梳理:
计算key的hash值 (h = key.hashCode() ^ h >>> 16)
根据hash值和table数组的长度n计算插入table数组的索引,(n - 1) & hash。由于n始终是2的n次方(为什么后面会介绍),所以(n - 1) & hash 相等于 hash % n ,但是位运算要比取模效率更高
多种情况
如果该位置没有数据,新生成一个节点保存新数据,返回null
如果该位置有数据且是红黑树结构,那么执行相应的插入 / 更新操作;
如果该位置有数据且是链表
流程图:
public V get(Object key) {
+ Node<K,V> e;
+ return (e = getNode(hash(key), key)) == null ? null : e.value;
+}
+
+final Node<K,V> getNode(int hash, Object key) {
+ Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
+ // 1. 定位键值对所在桶的位置
+ if ((tab = table) != null && (n = tab.length) > 0 &&
+ (first = tab[(n - 1) & hash]) != null) {
+ if (first.hash == hash && // always check first node
+ ((k = first.key) == key || (key != null && key.equals(k))))
+ return first;
+ if ((e = first.next) != null) {
+ // 2. 如果 first 是 TreeNode 类型,则调用黑红树查找方法
+ if (first instanceof TreeNode)
+ return ((TreeNode<K,V>)first).getTreeNode(hash, key);
+
+ // 2. 对链表进行查找
+ do {
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ return e;
+ } while ((e = e.next) != null);
+ }
+ }
+ return null;
+} final Node<K,V>[] resize() {
+ //oldTable指向当前hash桶数组
+ Node<K,V>[] oldTab = table;
+ int oldCap = (oldTab == null) ? 0 : oldTab.length;
+ int oldThr = threshold;
+ int newCap, newThr = 0;
+ if (oldCap > 0) {//如果旧的hash桶不为空
+ if (oldCap >= MAXIMUM_CAPACITY) {
+ //如果大于最大容量,则阈值设置为最大整数的值
+ threshold = Integer.MAX_VALUE;
+ return oldTab;
+ }
+ else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
+ oldCap >= DEFAULT_INITIAL_CAPACITY)
+ //如果旧的hash桶容量扩容一次(左移1位)后小于最大值,并且旧的桶容量大于默认值16
+ //新桶容量 = 旧桶容量*2
+ newThr = oldThr << 1; // double threshold
+ }
+ else if (oldThr > 0) // initial capacity was placed in threshold
+ newCap = oldThr;
+ else { // zero initial threshold signifies using defaults
+ //初始化
+ newCap = DEFAULT_INITIAL_CAPACITY;
+ newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
+ }
+ if (newThr == 0) {
+ float ft = (float)newCap * loadFactor;
+ newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
+ (int)ft : Integer.MAX_VALUE);
+ }
+ threshold = newThr;
+ @SuppressWarnings({"rawtypes","unchecked"})
+ //初始化一个容量为newCap的新hash桶数组
+ Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
+ //将新桶复制给旧的hash桶数组
+ table = newTab;
+ if (oldTab != null) {
+ //如果旧的hash桶不为空,则开始扩容操作
+ for (int j = 0; j < oldCap; ++j) {
+ Node<K,V> e;
+ if ((e = oldTab[j]) != null) {//旧桶j处节点值赋值给e,如果不为空,将旧桶j节点设置为空
+ oldTab[j] = null;
+ if (e.next == null)//如果e后面没有节点
+ newTab[e.hash & (newCap - 1)] = e;//直接对e的hash值对新数组长度求模获得hash桶中存储位置
+ else if (e instanceof TreeNode)//如果e为红黑树节点,将e添加到红黑树中
+ ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
+ else { // preserve order //如果是链表
+ Node<K,V> loHead = null, loTail = null;
+ Node<K,V> hiHead = null, hiTail = null;
+ Node<K,V> next;
+ do {
+ next = e.next;//将e的下一节点赋值给next
+ if ((e.hash & oldCap) == 0) {//如果e的hash值对旧桶长度求模为0
+ if (loTail == null)
+ loHead = e;//如果loTail为null,将e赋给loHead
+ else
+ loTail.next = e;//非则将e赋值给loTail的next节点
+ loTail = e;//将e赋值给loTail节点
+ }
+ else {//如果e的hash值对旧桶长度取模不为0
+ if (hiTail == null)
+ hiHead = e;//hiHead为null,将e赋值给hiHead
+ else
+ hiTail.next = e;//否则e赋值给hiTail.next
+ hiTail = e;//将e赋值给hiTail
+ }
+ } while ((e = next) != null);//直到e为空
+ if (loTail != null) {
+ //如果loTail不为空,将loTail的下一节点设置为null
+ loTail.next = null;
+ //将loHead赋值给新桶的j处
+ newTab[j] = loHead;
+ }
+ if (hiTail != null) {
+ //如果hiTail不为空,将hiTail的下一节点设置为null
+ hiTail.next = null;
+ //hiHead赋值给新桶的j+旧桶数组长度处
+ newTab[j + oldCap] = hiHead;
+ }
+ }
+ }
+ }
+ }
+ return newTab;
+ } static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ n |= n >>> 2;
+ n |= n >>> 4;
+ n |= n >>> 8;
+ n |= n >>> 16;
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }测试类
public class Test {
+ public static void main(String[] args) {
+
+ int cap = 65538;
+ System.out.println(Integer.toBinaryString(cap));
+ System.out.println(Integer.toBinaryString(cap-1));
+ int i = tableSizeFor(cap);
+ System.out.println(Integer.toBinaryString(i));
+ }
+
+ static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 2;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 4;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 8;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 16;
+ System.out.println(Integer.toBinaryString(n));
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }
+}运行结果
010000000000000010
+010000000000000001
+011000000000000001
+011110000000000001
+011111111000000001
+011111111111111111
+011111111111111111
+100000000000000000Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)
(parameters) -> expression
+或
+(parameters) ->{ statements; }以下是lambda表达式的重要特征:
// 1. 不需要参数,返回值为 5
+() -> 5
+
+// 2. 接收一个参数(数字类型),返回其2倍的值
+x -> 2 * x
+
+// 3. 接受2个参数(数字),并返回他们的差值
+(x, y) -> x – y
+
+// 4. 接收2个int型整数,返回他们的和
+(int x, int y) -> x + y
+
+// 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void)
+(String s) -> System.out.print(s)第一点:所需类型不同
匿名内部类:可以是接口,也可以是抽象类,还可以是具体类。 **Lambda表达式:**只能是接口。
第二点:使用限制不同
1,如果接口中有且仅有一个抽象方法,可以使用Lambda表达式,也可以使用匿名内部类。 2,如果接口中有多于一个抽象方法,只能使用匿名内部类,不可以使用Lambda表达式。
第三点:实现原理不同
匿名内部类:编译之后会产生一个单独的.class字节码文件。 Lambda表达式:编译之后没有产生一个单独的.class字节码文件,对应的字节码文件会在运行的时候动态生成。
函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
函数式接口可以被隐式转换为 lambda 表达式。
Lambda 表达式和方法引用(实际上也可认为是Lambda表达式)上。
@FunctionalInterface
+interface GreetingService
+{
+ void sayMessage(String message);
+}
+
+---
+
+GreetingService greetService1 = message -> System.out.println("Hello " + message);Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
+--------------------+ +------+ +------+ +---+ +-------+
+| stream of elements +-----> |filter+-> |sorted+-> |map+-> |collect|
++--------------------+ +------+ +------+ +---+ +-------+以上的流程转换为 Java 代码为:
List<Integer> transactionsIds =
+widgets.stream()
+ .filter(b -> b.getColor() == RED)
+ .sorted((x,y) -> x.getWeight() - y.getWeight())
+ .mapToInt(Widget::getWeight)
+ .sum();Stream(流)是一个来自数据源的元素队列并支持聚合操作
和以前的Collection操作不同, Stream操作还有两个基础的特征:
stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果;
stream不会改变数据源,通常情况下会产生一个新的集合;
stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
对stream操作分为终端操作和中间操作,那么这两者分别代表什么呢? 终端操作:会消费流,这种操作会产生一个结果的,如果一个流被消费过了,那它就不能被重用的。 中间操作:中间操作会产生另一个流。因此中间操作可以用来创建执行一系列动作的管道。一个特别需要注意的点是: 中间操作不是立即发生的。相反,当在中间操作创建的新流上执行完终端操作后,中间操作指定的操作才会发生。所以中间操作是延迟发生的,中间操作的延迟行为主要是让流API能够更加高效地执行。
stream不可复用,对一个已经进行过终端操作的流再次调用,会抛出异常。
集合创建流:
数组创建流:
Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional 类的引入很好的解决空指针异常。
public class Java8Tester {
+ public static void main(String args[]){
+
+ Java8Tester java8Tester = new Java8Tester();
+ Integer value1 = null;
+ Integer value2 = new Integer(10);
+
+ // Optional.ofNullable - 允许传递为 null 参数
+ Optional<Integer> a = Optional.ofNullable(value1);
+
+ // Optional.of - 如果传递的参数是 null,抛出异常 NullPointerException
+ Optional<Integer> b = Optional.of(value2);
+ System.out.println(java8Tester.sum(a,b));
+ }
+
+ public Integer sum(Optional<Integer> a, Optional<Integer> b){
+
+ // Optional.isPresent - 判断值是否存在
+
+ System.out.println("第一个参数值存在: " + a.isPresent());
+ System.out.println("第二个参数值存在: " + b.isPresent());
+
+ // Optional.orElse - 如果值存在,返回它,否则返回默认值
+ Integer value1 = a.orElse(new Integer(0));
+
+ //Optional.get - 获取值,值需要存在
+ Integer value2 = b.get();
+ return value1 + value2;
+ }
+}
+
+---
+
+
+第一个参数值存在: false
+第二个参数值存在: true
+10Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)
(parameters) -> expression
+或
+(parameters) ->{ statements; }以下是lambda表达式的重要特征:
// 1. 不需要参数,返回值为 5
+() -> 5
+
+// 2. 接收一个参数(数字类型),返回其2倍的值
+x -> 2 * x
+
+// 3. 接受2个参数(数字),并返回他们的差值
+(x, y) -> x – y
+
+// 4. 接收2个int型整数,返回他们的和
+(int x, int y) -> x + y
+
+// 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void)
+(String s) -> System.out.print(s)第一点:所需类型不同
匿名内部类:可以是接口,也可以是抽象类,还可以是具体类。 **Lambda表达式:**只能是接口。
第二点:使用限制不同
1,如果接口中有且仅有一个抽象方法,可以使用Lambda表达式,也可以使用匿名内部类。 2,如果接口中有多于一个抽象方法,只能使用匿名内部类,不可以使用Lambda表达式。
第三点:实现原理不同
匿名内部类:编译之后会产生一个单独的.class字节码文件。 Lambda表达式:编译之后没有产生一个单独的.class字节码文件,对应的字节码文件会在运行的时候动态生成。
函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
函数式接口可以被隐式转换为 lambda 表达式。
Lambda 表达式和方法引用(实际上也可认为是Lambda表达式)上。
@FunctionalInterface
+interface GreetingService
+{
+ void sayMessage(String message);
+}
+
+---
+
+GreetingService greetService1 = message -> System.out.println("Hello " + message);Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
+--------------------+ +------+ +------+ +---+ +-------+
+| stream of elements +-----> |filter+-> |sorted+-> |map+-> |collect|
++--------------------+ +------+ +------+ +---+ +-------+以上的流程转换为 Java 代码为:
List<Integer> transactionsIds =
+widgets.stream()
+ .filter(b -> b.getColor() == RED)
+ .sorted((x,y) -> x.getWeight() - y.getWeight())
+ .mapToInt(Widget::getWeight)
+ .sum();Stream(流)是一个来自数据源的元素队列并支持聚合操作
和以前的Collection操作不同, Stream操作还有两个基础的特征:
stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果;
stream不会改变数据源,通常情况下会产生一个新的集合;
stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
对stream操作分为终端操作和中间操作,那么这两者分别代表什么呢? 终端操作:会消费流,这种操作会产生一个结果的,如果一个流被消费过了,那它就不能被重用的。 中间操作:中间操作会产生另一个流。因此中间操作可以用来创建执行一系列动作的管道。一个特别需要注意的点是: 中间操作不是立即发生的。相反,当在中间操作创建的新流上执行完终端操作后,中间操作指定的操作才会发生。所以中间操作是延迟发生的,中间操作的延迟行为主要是让流API能够更加高效地执行。
stream不可复用,对一个已经进行过终端操作的流再次调用,会抛出异常。
集合创建流:
数组创建流:
Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional 类的引入很好的解决空指针异常。
public class Java8Tester {
+ public static void main(String args[]){
+
+ Java8Tester java8Tester = new Java8Tester();
+ Integer value1 = null;
+ Integer value2 = new Integer(10);
+
+ // Optional.ofNullable - 允许传递为 null 参数
+ Optional<Integer> a = Optional.ofNullable(value1);
+
+ // Optional.of - 如果传递的参数是 null,抛出异常 NullPointerException
+ Optional<Integer> b = Optional.of(value2);
+ System.out.println(java8Tester.sum(a,b));
+ }
+
+ public Integer sum(Optional<Integer> a, Optional<Integer> b){
+
+ // Optional.isPresent - 判断值是否存在
+
+ System.out.println("第一个参数值存在: " + a.isPresent());
+ System.out.println("第二个参数值存在: " + b.isPresent());
+
+ // Optional.orElse - 如果值存在,返回它,否则返回默认值
+ Integer value1 = a.orElse(new Integer(0));
+
+ //Optional.get - 获取值,值需要存在
+ Integer value2 = b.get();
+ return value1 + value2;
+ }
+}
+
+---
+
+
+第一个参数值存在: false
+第二个参数值存在: true
+10public final class String
+ implements java.io.Serializable, Comparable<String>, CharSequence {
+ /** The value is used for character storage. */
+ private final char value[];
+ ...
+}String对象被创建后就无法更改指的是常规方法无法更改,因为String类是由char型数组实现的,而这个数组value也是一个引用,我们可以通过暴力反射setAccessible(true),来修改value数组的内容。
1.String str = new String();构造一个空字符串
public String() {
+ this.value = "".value;
+}2.String str = new String(String string)根据指定的字符串来构造新的String对象
public String(String original) {
+ this.value = original.value;
+ this.hash = original.hash;
+}3.String str = new String(char[] value)通过指定字符数组来构造新的String对象
public String(char value[]) {
+ this.value = Arrays.copyOf(value, value.length);
+}当然,还有我们最常用的String str = "123",不过这种通过字面量形式构造对象的方式完全等同于上述的第三种形式,实际上它的实现是:
char[] chars = {'1','2','3'};
+String str = new String(chars);String a = "123";是否创建了对象要看字符串常量池中,是否已经有了"123"这个对象,如果有,那么这句代码就没有创建对象,如果没有,那么就在字符串常量池中创建了一个"123"对象.
String a = new String("123"),无论字符串常量池是否有"123"这个对象,这句代码都会创建对象,区别就在于创建了一个还是两个.假如常量池中没有,那么就分别在常量池和堆区都分别创建了"123"对象。如果常量池中有该对象,那么就只在堆区中创建一个"123"对象。
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能
JVM为了提高性能和减少内存开销,为字符串开辟一个字符串常量池,类似于缓存区,创建字符串常量时,首先判断字符串常量池是否存在该字符串.如果存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中
实现的基础:字符串不可变
字符串常量池在JDK1.6之前是存放在Perm区的(永久代),也就是我们常说的方法区,而在JDK1.7之后,字符串常量池已经被移到了Heap区(堆区)存放,而在JDK1.8,Perm区已经被移除了,取而代之是元空间。
我们常说的方法区,其实是JVM中提出的规范,永久代和方法区的关系,类似我们Java中的类与接口,方法区是一个接口,制定了规范,而永久代是HotSpot虚拟机对这个规范的实现
并且,字符串常量池相较其他常量池有着特殊性:
直接使用字面量声明的String对象,如果在常量池中不存在,那么就会直接存储在字符串常量池中,如果存在,那么就会直接指向字符串常量池中的对象
而通过new关键字创建的String对象,如果在常量池中不存在,可以通过native方法intern手动入池。而即使常量池中存在这个字符串,这个方法就不会生效.
能否入池,都取决于字符串常量池中是否存在该字符串。
很重要的一点:
由于JDK对于字符串常量池的改动,在JDK1.7和之后的版本,字符串常量池都在堆区中了,而且,使用intern方法入池的字符串,不会再在字符串常量池中创建一个对象,而是保存调用intern方法的这个字符串的引用。
众所周知,在Java中,运算符+在和字符串一起使用时的作用是拼接,而非运算,那么到底是什么原因呢,其实底层就是StringBuffer(JDK1.0)和StringBuilder(JDK1.5之后)实现的。
看了API就会发现,StringBuilder和StringBuffer都是可变字符序列,而且两者的方法是完全一样的,唯一的区别就是线程安全问题,StringBuilder是线程不安全的,而StringBuffer是线程安全的,而StringBuffer始于JDK1.0,StringBuilder始于JDK1.5,也就是说,StringBuilder的出现,就是为了在单线程条件下替换StringBuffer,也就意味着,在不考虑线程安全问题的情况下,我们通常都会使用StringBuilder,因为没有线程问题的影响,StringBuilder的速度更快。
再说回字符串拼接的问题,
String a = "1";
+String b = "2";
+String c = "3";
+String d = a+b+c;
+System.out.print(d);//"123"上面这个代码片段的底层实现,其实是:
String d = (new StringBuilder(String.valueof(a))).append(b).append(c).toString();换言之,字符串拼接,其实是创建了一个新的StringBuilder的对象,来调用append方法进行拼接,拼接完成后再调用toString方法来返回一个新的字符串.
因此,
String a = "Hello";
+String b = "World";
+String c = a+b;
+String d = a+b;
+System.out.println(c);
+System.out.println(d);
+System.out.println(c==d);这个代码片段的结果是HelloWorld,HelloWorld,false。
原因是StringBuilder的toString方法每次都会返回一个new出来的String对象。源码如下:
//StringBuilder类重写的toString方法
+@Override
+ public String toString() {
+ // Create a copy, don't share the array
+ return new String(value, 0, count);
+ }答:
1.假如字符串常量池中没有"123"这个字符串,那么这条代码就创建了两个对象,第一个是在字符串常量池中创建了字符串对象"123",然后在堆区创建了一个字符串对象"123",接着会把堆区这个"123"的引用地址值赋给在栈区声明的str。
2.假如字符串常量池中有"123"这个字符串,那么就只创建了一个对象,就是在堆区中创建了对象"123",然后把地址值赋给str.
代码片段1:
String s1 = new String("1");
+s.intern();
+String s2 = "1";
+System.out.println(s == s2);
+
+String s3 = new String("1") + new String("1");
+s3.intern();
+String s4 = "11";
+System.out.println(s3 == s4);在JDK1.6中:结果是false false
在JDK1.7中:结果是 false true
分析:
String s1 = new String("1")首先在字符串常量池中创建了对象"1",然后在堆区创建对象"1",s1的引用指向的是堆区的对象;
s1.intern()方法,会查找字符串常量池中是否有"1"这个对象,结果里面有,所以这个方法没有生效,等于没写.
String s2 = "1",因为常量池中已经有"1"这个字符串了,所以s2指向了常量池中"1"
s1指向堆区,s2指向永久代,显然二者地址不同,结果为false
String s3 = new String("1") + new String("1");这句代码在堆区创建了两个匿名"1"对象,拼接后的等于在堆区中创建了字符串"11"对象
s3.intern()方法将"11"对象保存在了字符串常量池中
String s4 = "11",指向的是字符串常量池中"11"对象
s3指向堆区,s4指向永久代,结果为false
s1在常量池和堆区分别创建了对象"1",s1指向的是堆区的"1"对象,s.intern()方法无效,s2指向的是常量池中的"1"对象,s1和s2指向地址不同,所以是false;
s3在堆区创建了对象"11",s3.intern()将堆区对象存在常量池中,但是!!! 这里的存是将堆区中"11"的引用存在了常量池,而非创建对象.
所以s4指向常量池中的引用,其实就是s3的引用,所以s3==s4为true。
代码片段2:
String s1 = new String("1");
+String s2 = "1";
+s1.intern();
+System.out.println(s == s2);
+
+String s3 = new String("1") + new String("1");
+String s4 = "11";
+s3.intern();
+System.out.println(s3 == s4);JDK1.6结果:false false
JDK1.7结果:false false
分析:
s1在常量池和堆区分别创建了对象"1",s1指堆区的对象"1";
s2指向的是常量池的对象"1"
因为常量池中有"1"这个对象,所以s1.intern()无效
s1,s2二者指向地址不同,所以是false.
s3在堆区创建了对象"11"
s4在常量池创建了对象"11",并指向了常量池中的"11"对象
常量池中已经有了对象"11",s3.intern()无效
s3,s4指向不同,所以false
s1在常量池和堆区分别创建了对象"1",s1指堆区的对象"1";
s2指向的是常量池的对象"1"
因为常量池中有"1"这个对象,所以s1.intern()无效
s1,s2二者指向地址不同,所以是false.
s3在堆区创建了对象"11"
s4在常量池创建了对象"11",并指向了常量池中的"11"对象
常量池中已经有了对象"11",s3.intern()无效
s3,s4指向不同,所以false
`,92)]))}const o=i(h,[["render",l]]);export{d as __pageData,o as default}; diff --git "a/assets/java_base_String\347\261\273\347\232\204\346\267\261\345\205\245\345\255\246\344\271\240.md.YLdbQYeJ.lean.js" "b/assets/java_base_String\347\261\273\347\232\204\346\267\261\345\205\245\345\255\246\344\271\240.md.YLdbQYeJ.lean.js" new file mode 100644 index 00000000..c689894f --- /dev/null +++ "b/assets/java_base_String\347\261\273\347\232\204\346\267\261\345\205\245\345\255\246\344\271\240.md.YLdbQYeJ.lean.js" @@ -0,0 +1,45 @@ +import{_ as i,c as a,a2 as t,o as n}from"./chunks/framework.BjcrtTwI.js";const d=JSON.parse('{"title":"String类的深入学习","description":"","frontmatter":{},"headers":[],"relativePath":"java/base/String类的深入学习.md","filePath":"java/base/String类的深入学习.md","lastUpdated":1729217313000}'),h={name:"java/base/String类的深入学习.md"};function l(p,s,k,e,r,E){return n(),a("div",null,s[0]||(s[0]=[t(`public final class String
+ implements java.io.Serializable, Comparable<String>, CharSequence {
+ /** The value is used for character storage. */
+ private final char value[];
+ ...
+}String对象被创建后就无法更改指的是常规方法无法更改,因为String类是由char型数组实现的,而这个数组value也是一个引用,我们可以通过暴力反射setAccessible(true),来修改value数组的内容。
1.String str = new String();构造一个空字符串
public String() {
+ this.value = "".value;
+}2.String str = new String(String string)根据指定的字符串来构造新的String对象
public String(String original) {
+ this.value = original.value;
+ this.hash = original.hash;
+}3.String str = new String(char[] value)通过指定字符数组来构造新的String对象
public String(char value[]) {
+ this.value = Arrays.copyOf(value, value.length);
+}当然,还有我们最常用的String str = "123",不过这种通过字面量形式构造对象的方式完全等同于上述的第三种形式,实际上它的实现是:
char[] chars = {'1','2','3'};
+String str = new String(chars);String a = "123";是否创建了对象要看字符串常量池中,是否已经有了"123"这个对象,如果有,那么这句代码就没有创建对象,如果没有,那么就在字符串常量池中创建了一个"123"对象.
String a = new String("123"),无论字符串常量池是否有"123"这个对象,这句代码都会创建对象,区别就在于创建了一个还是两个.假如常量池中没有,那么就分别在常量池和堆区都分别创建了"123"对象。如果常量池中有该对象,那么就只在堆区中创建一个"123"对象。
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能
JVM为了提高性能和减少内存开销,为字符串开辟一个字符串常量池,类似于缓存区,创建字符串常量时,首先判断字符串常量池是否存在该字符串.如果存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中
实现的基础:字符串不可变
字符串常量池在JDK1.6之前是存放在Perm区的(永久代),也就是我们常说的方法区,而在JDK1.7之后,字符串常量池已经被移到了Heap区(堆区)存放,而在JDK1.8,Perm区已经被移除了,取而代之是元空间。
我们常说的方法区,其实是JVM中提出的规范,永久代和方法区的关系,类似我们Java中的类与接口,方法区是一个接口,制定了规范,而永久代是HotSpot虚拟机对这个规范的实现
并且,字符串常量池相较其他常量池有着特殊性:
直接使用字面量声明的String对象,如果在常量池中不存在,那么就会直接存储在字符串常量池中,如果存在,那么就会直接指向字符串常量池中的对象
而通过new关键字创建的String对象,如果在常量池中不存在,可以通过native方法intern手动入池。而即使常量池中存在这个字符串,这个方法就不会生效.
能否入池,都取决于字符串常量池中是否存在该字符串。
很重要的一点:
由于JDK对于字符串常量池的改动,在JDK1.7和之后的版本,字符串常量池都在堆区中了,而且,使用intern方法入池的字符串,不会再在字符串常量池中创建一个对象,而是保存调用intern方法的这个字符串的引用。
众所周知,在Java中,运算符+在和字符串一起使用时的作用是拼接,而非运算,那么到底是什么原因呢,其实底层就是StringBuffer(JDK1.0)和StringBuilder(JDK1.5之后)实现的。
看了API就会发现,StringBuilder和StringBuffer都是可变字符序列,而且两者的方法是完全一样的,唯一的区别就是线程安全问题,StringBuilder是线程不安全的,而StringBuffer是线程安全的,而StringBuffer始于JDK1.0,StringBuilder始于JDK1.5,也就是说,StringBuilder的出现,就是为了在单线程条件下替换StringBuffer,也就意味着,在不考虑线程安全问题的情况下,我们通常都会使用StringBuilder,因为没有线程问题的影响,StringBuilder的速度更快。
再说回字符串拼接的问题,
String a = "1";
+String b = "2";
+String c = "3";
+String d = a+b+c;
+System.out.print(d);//"123"上面这个代码片段的底层实现,其实是:
String d = (new StringBuilder(String.valueof(a))).append(b).append(c).toString();换言之,字符串拼接,其实是创建了一个新的StringBuilder的对象,来调用append方法进行拼接,拼接完成后再调用toString方法来返回一个新的字符串.
因此,
String a = "Hello";
+String b = "World";
+String c = a+b;
+String d = a+b;
+System.out.println(c);
+System.out.println(d);
+System.out.println(c==d);这个代码片段的结果是HelloWorld,HelloWorld,false。
原因是StringBuilder的toString方法每次都会返回一个new出来的String对象。源码如下:
//StringBuilder类重写的toString方法
+@Override
+ public String toString() {
+ // Create a copy, don't share the array
+ return new String(value, 0, count);
+ }答:
1.假如字符串常量池中没有"123"这个字符串,那么这条代码就创建了两个对象,第一个是在字符串常量池中创建了字符串对象"123",然后在堆区创建了一个字符串对象"123",接着会把堆区这个"123"的引用地址值赋给在栈区声明的str。
2.假如字符串常量池中有"123"这个字符串,那么就只创建了一个对象,就是在堆区中创建了对象"123",然后把地址值赋给str.
代码片段1:
String s1 = new String("1");
+s.intern();
+String s2 = "1";
+System.out.println(s == s2);
+
+String s3 = new String("1") + new String("1");
+s3.intern();
+String s4 = "11";
+System.out.println(s3 == s4);在JDK1.6中:结果是false false
在JDK1.7中:结果是 false true
分析:
String s1 = new String("1")首先在字符串常量池中创建了对象"1",然后在堆区创建对象"1",s1的引用指向的是堆区的对象;
s1.intern()方法,会查找字符串常量池中是否有"1"这个对象,结果里面有,所以这个方法没有生效,等于没写.
String s2 = "1",因为常量池中已经有"1"这个字符串了,所以s2指向了常量池中"1"
s1指向堆区,s2指向永久代,显然二者地址不同,结果为false
String s3 = new String("1") + new String("1");这句代码在堆区创建了两个匿名"1"对象,拼接后的等于在堆区中创建了字符串"11"对象
s3.intern()方法将"11"对象保存在了字符串常量池中
String s4 = "11",指向的是字符串常量池中"11"对象
s3指向堆区,s4指向永久代,结果为false
s1在常量池和堆区分别创建了对象"1",s1指向的是堆区的"1"对象,s.intern()方法无效,s2指向的是常量池中的"1"对象,s1和s2指向地址不同,所以是false;
s3在堆区创建了对象"11",s3.intern()将堆区对象存在常量池中,但是!!! 这里的存是将堆区中"11"的引用存在了常量池,而非创建对象.
所以s4指向常量池中的引用,其实就是s3的引用,所以s3==s4为true。
代码片段2:
String s1 = new String("1");
+String s2 = "1";
+s1.intern();
+System.out.println(s == s2);
+
+String s3 = new String("1") + new String("1");
+String s4 = "11";
+s3.intern();
+System.out.println(s3 == s4);JDK1.6结果:false false
JDK1.7结果:false false
分析:
s1在常量池和堆区分别创建了对象"1",s1指堆区的对象"1";
s2指向的是常量池的对象"1"
因为常量池中有"1"这个对象,所以s1.intern()无效
s1,s2二者指向地址不同,所以是false.
s3在堆区创建了对象"11"
s4在常量池创建了对象"11",并指向了常量池中的"11"对象
常量池中已经有了对象"11",s3.intern()无效
s3,s4指向不同,所以false
s1在常量池和堆区分别创建了对象"1",s1指堆区的对象"1";
s2指向的是常量池的对象"1"
因为常量池中有"1"这个对象,所以s1.intern()无效
s1,s2二者指向地址不同,所以是false.
s3在堆区创建了对象"11"
s4在常量池创建了对象"11",并指向了常量池中的"11"对象
常量池中已经有了对象"11",s3.intern()无效
s3,s4指向不同,所以false
`,92)]))}const o=i(h,[["render",l]]);export{d as __pageData,o as default}; diff --git "a/assets/java_database_MySql\347\264\242\345\274\225.md.CBLpW-KH.js" "b/assets/java_database_MySql\347\264\242\345\274\225.md.CBLpW-KH.js" new file mode 100644 index 00000000..c00c34a3 --- /dev/null +++ "b/assets/java_database_MySql\347\264\242\345\274\225.md.CBLpW-KH.js" @@ -0,0 +1,12 @@ +import{_ as i,c as a,a2 as l,o as e}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"MySql索引","description":"","frontmatter":{},"headers":[],"relativePath":"java/database/MySql索引.md","filePath":"java/database/MySql索引.md","lastUpdated":1729217313000}'),h={name:"java/database/MySql索引.md"};function n(t,s,p,k,r,d){return e(),a("div",null,s[0]||(s[0]=[l(`本篇内容基于MySQL的InnoDB存储引擎。
索引是一个单独的、存储在磁盘上的数据库结构,它们包含着对数据表里所有记录的引用指针。使用索引用于快速找出在某个或多个列中有一特定值的行,所有MySQL列类型都可以被索引,==对相关列使用索引是提高查询操作速度的最佳途径==。
InnoDB存储引擎中的索引都是指BTree索引,MySQL中还有Hash索引,详见官网存储引擎索引类型
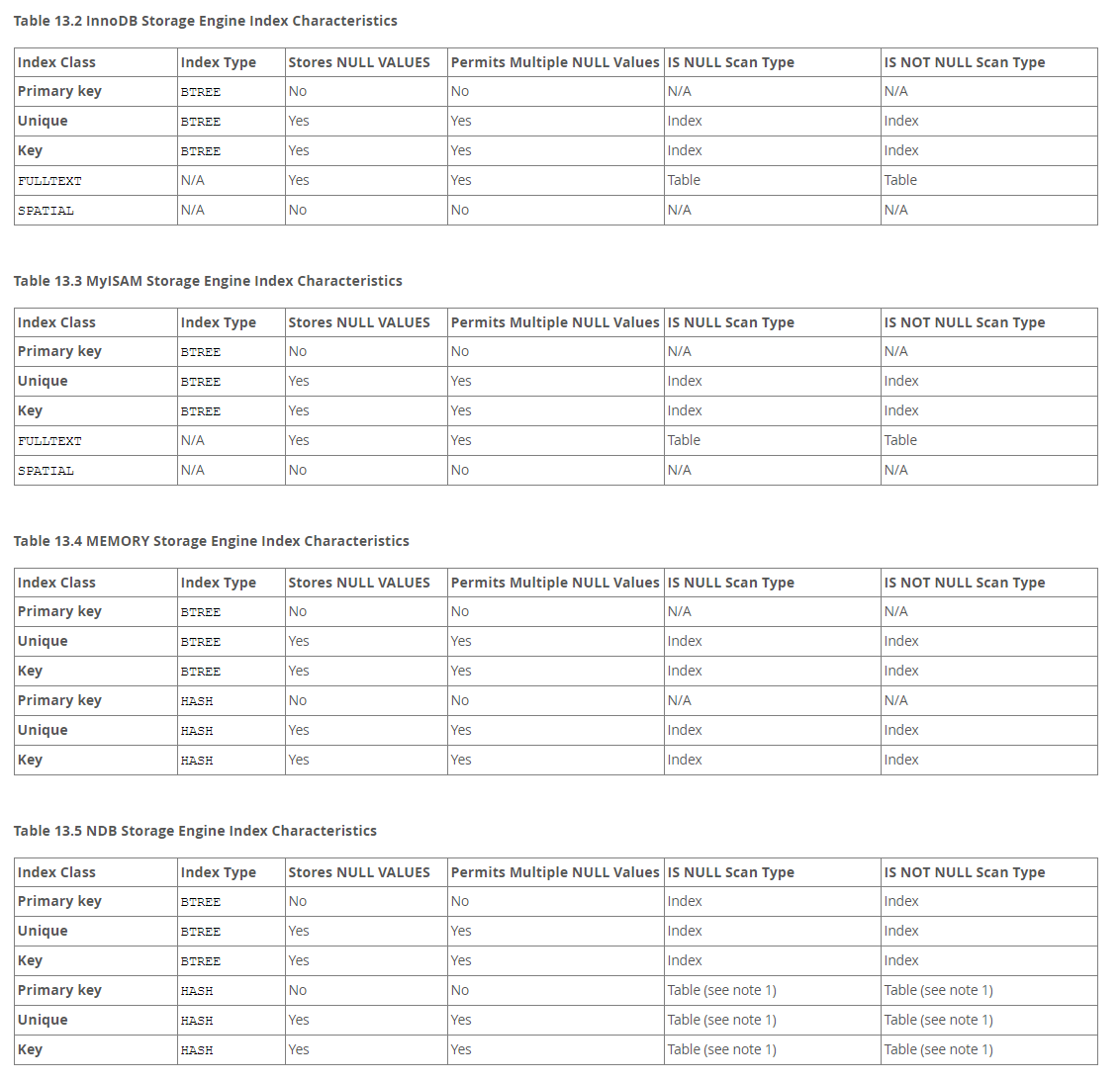
内容引用自美团技术团队发表的文章MySQL索引原理及慢查询优化
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我想找到m开头的单词呢?或者ze开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?
数据库的索引结构需要做的事:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
b+树性质
1.通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
主键索引是一种特殊的唯一索引,这个时候需要一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引
InnoDB存储引擎的表,如果建表的时候没有指定主键,则会使用第一非空的唯一索引作为聚集索引,如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,该列的值会随着数据的插入自增。
在其他存储引擎或其他数据库中主键索引不一定就是聚集索引
唯一索引列的值必须是唯一的,但允许有空值,如果是组合索引,则列值的组合必须是唯一的。
CREATE UNIQUE index 索引名 on 表名(列名)MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值
CREATE index 索引名 on 表名(列名)指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀原则
CREATE index 索引名 on 表名(列名,列名...)全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON 表名(列名)DROP INDEX [indexName] ON 表名;SHOW INDEX FROM 表名-- 有四种方式来添加数据表的索引:
+ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
+
+ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
+
+ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
+
+ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。频繁更新的字段
where条件中用不到的字段
表记录很少
重复记录非常多的表
数据区分不明显的字段,例如性别栏位
全值匹配的查询,例如根据订单id查询select * from t_order where order_id = '9999676623'
匹配范围值的查询,例如 where id > '123456'
最左匹配原则,如user表的username pwd创建了组合索引那么以下几种都可以命中索引
select username from user where username='zhangsan' and pwd ='axsedf1sd'
+
+select username from user where pwd ='axsedf1sd' and username='zhangsan'
+
+select username from user where username='zhangsan'而
select username from user where pwd ='axsedf1sd'不能命中索引
非前导模糊查询, 例如 where name like 'xiaoming%'
本篇内容基于MySQL的InnoDB存储引擎。
索引是一个单独的、存储在磁盘上的数据库结构,它们包含着对数据表里所有记录的引用指针。使用索引用于快速找出在某个或多个列中有一特定值的行,所有MySQL列类型都可以被索引,==对相关列使用索引是提高查询操作速度的最佳途径==。
InnoDB存储引擎中的索引都是指BTree索引,MySQL中还有Hash索引,详见官网存储引擎索引类型
内容引用自美团技术团队发表的文章MySQL索引原理及慢查询优化
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我想找到m开头的单词呢?或者ze开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?
数据库的索引结构需要做的事:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
b+树性质
1.通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
主键索引是一种特殊的唯一索引,这个时候需要一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引
InnoDB存储引擎的表,如果建表的时候没有指定主键,则会使用第一非空的唯一索引作为聚集索引,如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,该列的值会随着数据的插入自增。
在其他存储引擎或其他数据库中主键索引不一定就是聚集索引
唯一索引列的值必须是唯一的,但允许有空值,如果是组合索引,则列值的组合必须是唯一的。
CREATE UNIQUE index 索引名 on 表名(列名)MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值
CREATE index 索引名 on 表名(列名)指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀原则
CREATE index 索引名 on 表名(列名,列名...)全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON 表名(列名)DROP INDEX [indexName] ON 表名;SHOW INDEX FROM 表名-- 有四种方式来添加数据表的索引:
+ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
+
+ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
+
+ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
+
+ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。频繁更新的字段
where条件中用不到的字段
表记录很少
重复记录非常多的表
数据区分不明显的字段,例如性别栏位
全值匹配的查询,例如根据订单id查询select * from t_order where order_id = '9999676623'
匹配范围值的查询,例如 where id > '123456'
最左匹配原则,如user表的username pwd创建了组合索引那么以下几种都可以命中索引
select username from user where username='zhangsan' and pwd ='axsedf1sd'
+
+select username from user where pwd ='axsedf1sd' and username='zhangsan'
+
+select username from user where username='zhangsan'而
select username from user where pwd ='axsedf1sd'不能命中索引
非前导模糊查询, 例如 where name like 'xiaoming%'
otter是一款基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统
仓库地址:https://github.com/alibaba/otter
源库开启binlog,并且必须是ROW模式
需要启动zookeeper
otter是基于canal的,但是otter项目本身内嵌了canal,所以无需独立启动canal-server
初始化otter数据库
CREATE DATABASE /!32312 IF NOT EXISTS/ otter /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;
USE otter;
SET sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
CREATE TABLE ALARM_RULE ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, MONITOR_NAME varchar(1024) DEFAULT NULL, RECEIVER_KEY varchar(1024) DEFAULT NULL, STATUS varchar(32) DEFAULT NULL, PIPELINE_ID bigint(20) NOT NULL, DESCRIPTION varchar(256) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, MATCH_VALUE varchar(1024) DEFAULT NULL, PARAMETERS text DEFAULT NULL, PRIMARY KEY (ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE AUTOKEEPER_CLUSTER ( ID bigint(20) NOT NULL AUTO_INCREMENT, CLUSTER_NAME varchar(200) NOT NULL, SERVER_LIST varchar(1024) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE CANAL ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, NAME varchar(200) DEFAULT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY CANALUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE CHANNEL ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY CHANNELUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE COLUMN_PAIR ( ID bigint(20) NOT NULL AUTO_INCREMENT, SOURCE_COLUMN varchar(200) DEFAULT NULL, TARGET_COLUMN varchar(200) DEFAULT NULL, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID (DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE COLUMN_PAIR_GROUP ( ID bigint(20) NOT NULL AUTO_INCREMENT, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, COLUMN_PAIR_CONTENT text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID (DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, NAMESPACE varchar(200) NOT NULL, PROPERTIES varchar(1000) NOT NULL, DATA_MEDIA_SOURCE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY DATAMEDIAUNIQUE (NAME,NAMESPACE,DATA_MEDIA_SOURCE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA_PAIR ( ID bigint(20) NOT NULL AUTO_INCREMENT, PULLWEIGHT bigint(20) DEFAULT NULL, PUSHWEIGHT bigint(20) DEFAULT NULL, RESOLVER text DEFAULT NULL, FILTER text DEFAULT NULL, SOURCE_DATA_MEDIA_ID bigint(20) DEFAULT NULL, TARGET_DATA_MEDIA_ID bigint(20) DEFAULT NULL, PIPELINE_ID bigint(20) NOT NULL, COLUMN_PAIR_MODE varchar(20) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID (PIPELINE_ID,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA_SOURCE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, TYPE varchar(20) NOT NULL, PROPERTIES varchar(1000) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY DATAMEDIASOURCEUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DELAY_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, DELAY_TIME bigint(20) NOT NULL, DELAY_NUMBER bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_GmtModified_ID (PIPELINE_ID,GMT_MODIFIED,ID), KEY idx_Pipeline_GmtCreate (PIPELINE_ID,GMT_CREATE), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE LOG_RECORD ( ID bigint(20) NOT NULL AUTO_INCREMENT, NID varchar(200) DEFAULT NULL, CHANNEL_ID varchar(200) NOT NULL, PIPELINE_ID varchar(200) NOT NULL, TITLE varchar(1000) DEFAULT NULL, MESSAGE text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY logRecord_pipelineId (PIPELINE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE NODE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, IP varchar(200) NOT NULL, PORT bigint(20) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY NODEUNIQUE (NAME,IP) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE PIPELINE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, CHANNEL_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY PIPELINEUNIQUE (NAME,CHANNEL_ID), KEY idx_ChannelID (CHANNEL_ID,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE PIPELINE_NODE_RELATION ( ID bigint(20) NOT NULL AUTO_INCREMENT, NODE_ID bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, LOCATION varchar(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID (PIPELINE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE SYSTEM_PARAMETER ( ID bigint(20) unsigned NOT NULL, VALUE text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE TABLE_HISTORY_STAT ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, FILE_SIZE bigint(20) DEFAULT NULL, FILE_COUNT bigint(20) DEFAULT NULL, INSERT_COUNT bigint(20) DEFAULT NULL, UPDATE_COUNT bigint(20) DEFAULT NULL, DELETE_COUNT bigint(20) DEFAULT NULL, DATA_MEDIA_PAIR_ID bigint(20) DEFAULT NULL, PIPELINE_ID bigint(20) DEFAULT NULL, START_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', END_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID_END_TIME (DATA_MEDIA_PAIR_ID,END_TIME), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE TABLE_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, FILE_SIZE bigint(20) NOT NULL, FILE_COUNT bigint(20) NOT NULL, INSERT_COUNT bigint(20) NOT NULL, UPDATE_COUNT bigint(20) NOT NULL, DELETE_COUNT bigint(20) NOT NULL, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_DataMediaPairID (PIPELINE_ID,DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE THROUGHPUT_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, TYPE varchar(20) NOT NULL, NUMBER bigint(20) NOT NULL, SIZE bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, START_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', END_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_Type_GmtCreate_ID (PIPELINE_ID,TYPE,GMT_CREATE,ID), KEY idx_PipelineID_Type_EndTime_ID (PIPELINE_ID,TYPE,END_TIME,ID), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE USER ( ID bigint(20) NOT NULL AUTO_INCREMENT, USERNAME varchar(20) NOT NULL, PASSWORD varchar(20) NOT NULL, AUTHORIZETYPE varchar(20) NOT NULL, DEPARTMENT varchar(20) NOT NULL, REALNAME varchar(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY USERUNIQUE (USERNAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MATRIX ( ID bigint(20) NOT NULL AUTO_INCREMENT, GROUP_KEY varchar(200) DEFAULT NULL, MASTER varchar(200) DEFAULT NULL, SLAVE varchar(200) DEFAULT NULL, DESCRIPTION varchar(200) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY GROUPKEY (GROUP_KEY) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS meta_history ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', gmt_create datetime NOT NULL COMMENT '创建时间', gmt_modified datetime NOT NULL COMMENT '修改时间', destination varchar(128) DEFAULT NULL COMMENT '通道名称', binlog_file varchar(64) DEFAULT NULL COMMENT 'binlog文件名', binlog_offest bigint(20) DEFAULT NULL COMMENT 'binlog偏移量', binlog_master_id varchar(64) DEFAULT NULL COMMENT 'binlog节点id', binlog_timestamp bigint(20) DEFAULT NULL COMMENT 'binlog应用的时间戳', use_schema varchar(1024) DEFAULT NULL COMMENT '执行sql时对应的schema', sql_schema varchar(1024) DEFAULT NULL COMMENT '对应的schema', sql_table varchar(1024) DEFAULT NULL COMMENT '对应的table', sql_text longtext DEFAULT NULL COMMENT '执行的sql', sql_type varchar(256) DEFAULT NULL COMMENT 'sql类型', extra text DEFAULT NULL COMMENT '额外的扩展信息', PRIMARY KEY (id), UNIQUE KEY binlog_file_offest(destination,binlog_master_id,binlog_file,binlog_offest), KEY destination (destination), KEY destination_timestamp (destination,binlog_timestamp), KEY gmt_modified (gmt_modified) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='表结构变化明细表';
CREATE TABLE IF NOT EXISTS meta_snapshot ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', gmt_create datetime NOT NULL COMMENT '创建时间', gmt_modified datetime NOT NULL COMMENT '修改时间', destination varchar(128) DEFAULT NULL COMMENT '通道名称', binlog_file varchar(64) DEFAULT NULL COMMENT 'binlog文件名', binlog_offest bigint(20) DEFAULT NULL COMMENT 'binlog偏移量', binlog_master_id varchar(64) DEFAULT NULL COMMENT 'binlog节点id', binlog_timestamp bigint(20) DEFAULT NULL COMMENT 'binlog应用的时间戳', data longtext DEFAULT NULL COMMENT '表结构数据', extra text DEFAULT NULL COMMENT '额外的扩展信息', PRIMARY KEY (id), UNIQUE KEY binlog_file_offest(destination,binlog_master_id,binlog_file,binlog_offest), KEY destination (destination), KEY destination_timestamp (destination,binlog_timestamp), KEY gmt_modified (gmt_modified) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='表结构记录表快照表';
insert into USER(ID,USERNAME,PASSWORD,AUTHORIZETYPE,DEPARTMENT,REALNAME,GMT_CREATE,GMT_MODIFIED) values(null,'admin','801fc357a5a74743894a','ADMIN','admin','admin',now(),now()); insert into USER(ID,USERNAME,PASSWORD,AUTHORIZETYPE,DEPARTMENT,REALNAME,GMT_CREATE,GMT_MODIFIED) values(null,'guest','471e02a154a2121dc577','OPERATOR','guest','guest',now(),now());
## otter manager domain name
+otter.domainName = xxx.com
+## otter manager http port
+otter.port =
+
+## otter manager database config
+otter.database.driver.class.name = com.mysql.jdbc.Driver
+otter.database.driver.url = jdbc:mysql://127.0.0.1:3306/otter?useUnicode=true&characterEncoding=UTF-8&useSSL=false
+otter.database.driver.username =
+otter.database.driver.password =
+
+## otter communication port
+otter.communication.manager.port = 1099
+## default zookeeper address
+otter.zookeeper.cluster.default = 127.0.0.1:2181修改完关键配置后即可执行bin/startup.sh启动manager服务,webUI访问时默认是游客,admin密码默认为admin ,otter没有提供权限控制,游客用户也能看到所有配置信息,因此不能暴露在公网。
坑:startup.sh中的java启动参数-Xss(单个线程栈内存)值都设置的是256k,使用jdk1.8是无法启动的,需要调成大一点例如512k
The stack size specified is too small, Specify at least 384k
切换到admin用户后需要配置zookeeper & node信息,这个node的id为1

在node/conf下执行echo 1 > nid,调整node配置后启动node,看到node状态为已启动即可
配置两个数据源,一个作为源库,一个作为目标库
表明可以用模糊匹配,也可以指定具体的表
监听源库,开启tsdb监控表结构变化
基于日志变更、行记录模式
select和load机器直接选node,同步数据来源的canal选择刚才配置的
添加源表和目标表的映射,视图模式的include/exclude分别代表选中的字段同步/选中的字段排除(不同步),配置好映射关系后保存
批量添加
schema1,table1,sourceId1,schema2,table2,sourceId2
schema1,table1,sourceId1为源表信息
schema2,table2,sourceId2为目标表信息
sourceId是数据源的id,在数据源配置页面可以找到
映射权重 (对应的数字越大,同步会越后面得到同步,优先同步权重小的数据)
启动channel即可测试源库源表的数据变更后,目标库的目标表是否跟着一起更新。
上述介绍的是增量同步数据的基本操作,但是往往源表中已经有了大量的存量数据需要全量同步一次。
Otter官方提供了一种叫自由门的方案可以用于:
原理是基于otter系统表retl_buffer,插入特定数据,otter系统感知后回根据表明和pk提取对应记录和正常增量同步数据一起同步到目标库
/*
+供 otter 使用, otter 需要对 retl.* 的读写权限,以及对业务表的读写权限
+1. 创建database retl
+*/
+CREATE DATABASE retl;
+
+/* 2. 用户授权 给同步用户授权 */
+CREATE USER retl@'%' IDENTIFIED BY 'retl';
+GRANT USAGE ON *.* TO \`retl\`@'%';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO \`retl\`@'%';
+GRANT SELECT, INSERT, UPDATE, DELETE, EXECUTE ON \`retl\`.* TO \`retl\`@'%';
+/* 业务表授权,这里可以限定只授权同步业务的表 */
+GRANT SELECT, INSERT, UPDATE, DELETE ON *.* TO \`retl\`@'%';
+
+/* 3. 创建系统表 */
+USE retl;
+DROP TABLE IF EXISTS retl.retl_buffer;
+DROP TABLE IF EXISTS retl.retl_mark;
+DROP TABLE IF EXISTS retl.xdual;
+
+CREATE TABLE retl_buffer
+(
+ ID BIGINT(20) AUTO_INCREMENT,
+ TABLE_ID INT(11) NOT NULL,
+ FULL_NAME varchar(512),
+ TYPE CHAR(1) NOT NULL,
+ PK_DATA VARCHAR(256) NOT NULL,
+ GMT_CREATE TIMESTAMP NOT NULL,
+ GMT_MODIFIED TIMESTAMP NOT NULL,
+ CONSTRAINT RETL_BUFFER_ID PRIMARY KEY (ID)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+
+CREATE TABLE retl_mark
+(
+ ID BIGINT AUTO_INCREMENT,
+ CHANNEL_ID INT(11),
+ CHANNEL_INFO varchar(128),
+ CONSTRAINT RETL_MARK_ID PRIMARY KEY (ID)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
+
+CREATE TABLE xdual (
+ ID BIGINT(20) NOT NULL AUTO_INCREMENT,
+ X timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
+ PRIMARY KEY (ID)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
+
+/* 4. 插入初始化数据 */
+INSERT INTO retl.xdual(id, x) VALUES (1,now()) ON DUPLICATE KEY UPDATE x = now();insert into retl.retl_buffer(ID,TABLE_ID, FULL_NAME,TYPE,PK_DATA,GMT_CREATE,GMT_MODIFIED) (select null,0,'$schema.table$','I',id,now(),now() from $schema.table$);例如:insert into retl.retl_buffer(ID,TABLE_ID, FULL_NAME,TYPE,PK_DATA,GMT_CREATE,GMT_MODIFIED) (select null,0,'test.user','I',id,now(),now() from test.user);
上述基于数据库插入记录触发otter同步的方案,如果数据量大会比较耗时。也可以直接把源表数据导出并记录导出时binlog的position,先将全量数据导入一次目标表,再基于导出数据时的binlog的position进行增量同步。
mysqldump -uxxx -pxxx --single-transaction --master-data=2 --databases xxx --tables xxx > data.sql
这样,导出的data.sql文件中会有一行信息,记录导出时的binlog文件和position

在目标库执行导入sql
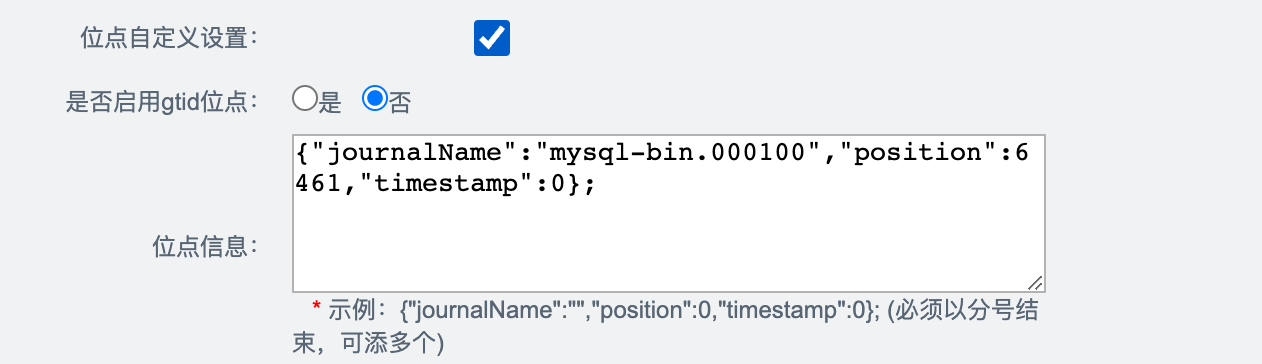
后续新建channel的操作和普通增量同步一样即可。
更换zookeeper后,manager管理页面无法进入,报错内容类似org.I0Itec.zkclient.exception.ZkNoNodeException: org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /otter/channel/3/3/process 。原因是otter会在zookepper中存储一些节点信息,更换zookeeper后,需要复制节点数据,或者删除数据库中的channel、pipeline等表的数据内容 或者访问 http://域名:端口/system_reduction.htm,点击一键修复即可。
show master logsshow binlog events in 'binlog.000048' from 1226 limit 4; 更新canal中的位点配置重新启动
低权限用户需要授权,否则无法读取binlogGRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'xxx'@'%' IDENTIFIED BY '';
log_slave_updates=1,将主库binlog中的操作写入到从库的binlog中,默认是关闭的,虽然数据可以同步,但是从库binlog没有记录这些内容。otter是一款基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统
仓库地址:https://github.com/alibaba/otter
源库开启binlog,并且必须是ROW模式
需要启动zookeeper
otter是基于canal的,但是otter项目本身内嵌了canal,所以无需独立启动canal-server
初始化otter数据库
CREATE DATABASE /!32312 IF NOT EXISTS/ otter /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;
USE otter;
SET sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
CREATE TABLE ALARM_RULE ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, MONITOR_NAME varchar(1024) DEFAULT NULL, RECEIVER_KEY varchar(1024) DEFAULT NULL, STATUS varchar(32) DEFAULT NULL, PIPELINE_ID bigint(20) NOT NULL, DESCRIPTION varchar(256) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, MATCH_VALUE varchar(1024) DEFAULT NULL, PARAMETERS text DEFAULT NULL, PRIMARY KEY (ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE AUTOKEEPER_CLUSTER ( ID bigint(20) NOT NULL AUTO_INCREMENT, CLUSTER_NAME varchar(200) NOT NULL, SERVER_LIST varchar(1024) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE CANAL ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, NAME varchar(200) DEFAULT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY CANALUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE CHANNEL ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY CHANNELUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE COLUMN_PAIR ( ID bigint(20) NOT NULL AUTO_INCREMENT, SOURCE_COLUMN varchar(200) DEFAULT NULL, TARGET_COLUMN varchar(200) DEFAULT NULL, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID (DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE COLUMN_PAIR_GROUP ( ID bigint(20) NOT NULL AUTO_INCREMENT, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, COLUMN_PAIR_CONTENT text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID (DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, NAMESPACE varchar(200) NOT NULL, PROPERTIES varchar(1000) NOT NULL, DATA_MEDIA_SOURCE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY DATAMEDIAUNIQUE (NAME,NAMESPACE,DATA_MEDIA_SOURCE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA_PAIR ( ID bigint(20) NOT NULL AUTO_INCREMENT, PULLWEIGHT bigint(20) DEFAULT NULL, PUSHWEIGHT bigint(20) DEFAULT NULL, RESOLVER text DEFAULT NULL, FILTER text DEFAULT NULL, SOURCE_DATA_MEDIA_ID bigint(20) DEFAULT NULL, TARGET_DATA_MEDIA_ID bigint(20) DEFAULT NULL, PIPELINE_ID bigint(20) NOT NULL, COLUMN_PAIR_MODE varchar(20) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID (PIPELINE_ID,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA_SOURCE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, TYPE varchar(20) NOT NULL, PROPERTIES varchar(1000) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY DATAMEDIASOURCEUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DELAY_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, DELAY_TIME bigint(20) NOT NULL, DELAY_NUMBER bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_GmtModified_ID (PIPELINE_ID,GMT_MODIFIED,ID), KEY idx_Pipeline_GmtCreate (PIPELINE_ID,GMT_CREATE), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE LOG_RECORD ( ID bigint(20) NOT NULL AUTO_INCREMENT, NID varchar(200) DEFAULT NULL, CHANNEL_ID varchar(200) NOT NULL, PIPELINE_ID varchar(200) NOT NULL, TITLE varchar(1000) DEFAULT NULL, MESSAGE text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY logRecord_pipelineId (PIPELINE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE NODE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, IP varchar(200) NOT NULL, PORT bigint(20) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY NODEUNIQUE (NAME,IP) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE PIPELINE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, CHANNEL_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY PIPELINEUNIQUE (NAME,CHANNEL_ID), KEY idx_ChannelID (CHANNEL_ID,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE PIPELINE_NODE_RELATION ( ID bigint(20) NOT NULL AUTO_INCREMENT, NODE_ID bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, LOCATION varchar(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID (PIPELINE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE SYSTEM_PARAMETER ( ID bigint(20) unsigned NOT NULL, VALUE text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE TABLE_HISTORY_STAT ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, FILE_SIZE bigint(20) DEFAULT NULL, FILE_COUNT bigint(20) DEFAULT NULL, INSERT_COUNT bigint(20) DEFAULT NULL, UPDATE_COUNT bigint(20) DEFAULT NULL, DELETE_COUNT bigint(20) DEFAULT NULL, DATA_MEDIA_PAIR_ID bigint(20) DEFAULT NULL, PIPELINE_ID bigint(20) DEFAULT NULL, START_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', END_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID_END_TIME (DATA_MEDIA_PAIR_ID,END_TIME), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE TABLE_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, FILE_SIZE bigint(20) NOT NULL, FILE_COUNT bigint(20) NOT NULL, INSERT_COUNT bigint(20) NOT NULL, UPDATE_COUNT bigint(20) NOT NULL, DELETE_COUNT bigint(20) NOT NULL, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_DataMediaPairID (PIPELINE_ID,DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE THROUGHPUT_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, TYPE varchar(20) NOT NULL, NUMBER bigint(20) NOT NULL, SIZE bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, START_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', END_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_Type_GmtCreate_ID (PIPELINE_ID,TYPE,GMT_CREATE,ID), KEY idx_PipelineID_Type_EndTime_ID (PIPELINE_ID,TYPE,END_TIME,ID), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE USER ( ID bigint(20) NOT NULL AUTO_INCREMENT, USERNAME varchar(20) NOT NULL, PASSWORD varchar(20) NOT NULL, AUTHORIZETYPE varchar(20) NOT NULL, DEPARTMENT varchar(20) NOT NULL, REALNAME varchar(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY USERUNIQUE (USERNAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MATRIX ( ID bigint(20) NOT NULL AUTO_INCREMENT, GROUP_KEY varchar(200) DEFAULT NULL, MASTER varchar(200) DEFAULT NULL, SLAVE varchar(200) DEFAULT NULL, DESCRIPTION varchar(200) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY GROUPKEY (GROUP_KEY) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS meta_history ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', gmt_create datetime NOT NULL COMMENT '创建时间', gmt_modified datetime NOT NULL COMMENT '修改时间', destination varchar(128) DEFAULT NULL COMMENT '通道名称', binlog_file varchar(64) DEFAULT NULL COMMENT 'binlog文件名', binlog_offest bigint(20) DEFAULT NULL COMMENT 'binlog偏移量', binlog_master_id varchar(64) DEFAULT NULL COMMENT 'binlog节点id', binlog_timestamp bigint(20) DEFAULT NULL COMMENT 'binlog应用的时间戳', use_schema varchar(1024) DEFAULT NULL COMMENT '执行sql时对应的schema', sql_schema varchar(1024) DEFAULT NULL COMMENT '对应的schema', sql_table varchar(1024) DEFAULT NULL COMMENT '对应的table', sql_text longtext DEFAULT NULL COMMENT '执行的sql', sql_type varchar(256) DEFAULT NULL COMMENT 'sql类型', extra text DEFAULT NULL COMMENT '额外的扩展信息', PRIMARY KEY (id), UNIQUE KEY binlog_file_offest(destination,binlog_master_id,binlog_file,binlog_offest), KEY destination (destination), KEY destination_timestamp (destination,binlog_timestamp), KEY gmt_modified (gmt_modified) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='表结构变化明细表';
CREATE TABLE IF NOT EXISTS meta_snapshot ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', gmt_create datetime NOT NULL COMMENT '创建时间', gmt_modified datetime NOT NULL COMMENT '修改时间', destination varchar(128) DEFAULT NULL COMMENT '通道名称', binlog_file varchar(64) DEFAULT NULL COMMENT 'binlog文件名', binlog_offest bigint(20) DEFAULT NULL COMMENT 'binlog偏移量', binlog_master_id varchar(64) DEFAULT NULL COMMENT 'binlog节点id', binlog_timestamp bigint(20) DEFAULT NULL COMMENT 'binlog应用的时间戳', data longtext DEFAULT NULL COMMENT '表结构数据', extra text DEFAULT NULL COMMENT '额外的扩展信息', PRIMARY KEY (id), UNIQUE KEY binlog_file_offest(destination,binlog_master_id,binlog_file,binlog_offest), KEY destination (destination), KEY destination_timestamp (destination,binlog_timestamp), KEY gmt_modified (gmt_modified) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='表结构记录表快照表';
insert into USER(ID,USERNAME,PASSWORD,AUTHORIZETYPE,DEPARTMENT,REALNAME,GMT_CREATE,GMT_MODIFIED) values(null,'admin','801fc357a5a74743894a','ADMIN','admin','admin',now(),now()); insert into USER(ID,USERNAME,PASSWORD,AUTHORIZETYPE,DEPARTMENT,REALNAME,GMT_CREATE,GMT_MODIFIED) values(null,'guest','471e02a154a2121dc577','OPERATOR','guest','guest',now(),now());
## otter manager domain name
+otter.domainName = xxx.com
+## otter manager http port
+otter.port =
+
+## otter manager database config
+otter.database.driver.class.name = com.mysql.jdbc.Driver
+otter.database.driver.url = jdbc:mysql://127.0.0.1:3306/otter?useUnicode=true&characterEncoding=UTF-8&useSSL=false
+otter.database.driver.username =
+otter.database.driver.password =
+
+## otter communication port
+otter.communication.manager.port = 1099
+## default zookeeper address
+otter.zookeeper.cluster.default = 127.0.0.1:2181修改完关键配置后即可执行bin/startup.sh启动manager服务,webUI访问时默认是游客,admin密码默认为admin ,otter没有提供权限控制,游客用户也能看到所有配置信息,因此不能暴露在公网。
坑:startup.sh中的java启动参数-Xss(单个线程栈内存)值都设置的是256k,使用jdk1.8是无法启动的,需要调成大一点例如512k
The stack size specified is too small, Specify at least 384k
切换到admin用户后需要配置zookeeper & node信息,这个node的id为1
在node/conf下执行echo 1 > nid,调整node配置后启动node,看到node状态为已启动即可
配置两个数据源,一个作为源库,一个作为目标库
表明可以用模糊匹配,也可以指定具体的表
监听源库,开启tsdb监控表结构变化
基于日志变更、行记录模式
select和load机器直接选node,同步数据来源的canal选择刚才配置的
添加源表和目标表的映射,视图模式的include/exclude分别代表选中的字段同步/选中的字段排除(不同步),配置好映射关系后保存
批量添加
schema1,table1,sourceId1,schema2,table2,sourceId2
schema1,table1,sourceId1为源表信息
schema2,table2,sourceId2为目标表信息
sourceId是数据源的id,在数据源配置页面可以找到
映射权重 (对应的数字越大,同步会越后面得到同步,优先同步权重小的数据)
启动channel即可测试源库源表的数据变更后,目标库的目标表是否跟着一起更新。
上述介绍的是增量同步数据的基本操作,但是往往源表中已经有了大量的存量数据需要全量同步一次。
Otter官方提供了一种叫自由门的方案可以用于:
原理是基于otter系统表retl_buffer,插入特定数据,otter系统感知后回根据表明和pk提取对应记录和正常增量同步数据一起同步到目标库
/*
+供 otter 使用, otter 需要对 retl.* 的读写权限,以及对业务表的读写权限
+1. 创建database retl
+*/
+CREATE DATABASE retl;
+
+/* 2. 用户授权 给同步用户授权 */
+CREATE USER retl@'%' IDENTIFIED BY 'retl';
+GRANT USAGE ON *.* TO \`retl\`@'%';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO \`retl\`@'%';
+GRANT SELECT, INSERT, UPDATE, DELETE, EXECUTE ON \`retl\`.* TO \`retl\`@'%';
+/* 业务表授权,这里可以限定只授权同步业务的表 */
+GRANT SELECT, INSERT, UPDATE, DELETE ON *.* TO \`retl\`@'%';
+
+/* 3. 创建系统表 */
+USE retl;
+DROP TABLE IF EXISTS retl.retl_buffer;
+DROP TABLE IF EXISTS retl.retl_mark;
+DROP TABLE IF EXISTS retl.xdual;
+
+CREATE TABLE retl_buffer
+(
+ ID BIGINT(20) AUTO_INCREMENT,
+ TABLE_ID INT(11) NOT NULL,
+ FULL_NAME varchar(512),
+ TYPE CHAR(1) NOT NULL,
+ PK_DATA VARCHAR(256) NOT NULL,
+ GMT_CREATE TIMESTAMP NOT NULL,
+ GMT_MODIFIED TIMESTAMP NOT NULL,
+ CONSTRAINT RETL_BUFFER_ID PRIMARY KEY (ID)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+
+CREATE TABLE retl_mark
+(
+ ID BIGINT AUTO_INCREMENT,
+ CHANNEL_ID INT(11),
+ CHANNEL_INFO varchar(128),
+ CONSTRAINT RETL_MARK_ID PRIMARY KEY (ID)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
+
+CREATE TABLE xdual (
+ ID BIGINT(20) NOT NULL AUTO_INCREMENT,
+ X timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
+ PRIMARY KEY (ID)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
+
+/* 4. 插入初始化数据 */
+INSERT INTO retl.xdual(id, x) VALUES (1,now()) ON DUPLICATE KEY UPDATE x = now();insert into retl.retl_buffer(ID,TABLE_ID, FULL_NAME,TYPE,PK_DATA,GMT_CREATE,GMT_MODIFIED) (select null,0,'$schema.table$','I',id,now(),now() from $schema.table$);例如:insert into retl.retl_buffer(ID,TABLE_ID, FULL_NAME,TYPE,PK_DATA,GMT_CREATE,GMT_MODIFIED) (select null,0,'test.user','I',id,now(),now() from test.user);
上述基于数据库插入记录触发otter同步的方案,如果数据量大会比较耗时。也可以直接把源表数据导出并记录导出时binlog的position,先将全量数据导入一次目标表,再基于导出数据时的binlog的position进行增量同步。
mysqldump -uxxx -pxxx --single-transaction --master-data=2 --databases xxx --tables xxx > data.sql
这样,导出的data.sql文件中会有一行信息,记录导出时的binlog文件和position
在目标库执行导入sql
后续新建channel的操作和普通增量同步一样即可。
更换zookeeper后,manager管理页面无法进入,报错内容类似org.I0Itec.zkclient.exception.ZkNoNodeException: org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /otter/channel/3/3/process 。原因是otter会在zookepper中存储一些节点信息,更换zookeeper后,需要复制节点数据,或者删除数据库中的channel、pipeline等表的数据内容 或者访问 http://域名:端口/system_reduction.htm,点击一键修复即可。
show master logsshow binlog events in 'binlog.000048' from 1226 limit 4; 更新canal中的位点配置重新启动
低权限用户需要授权,否则无法读取binlogGRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'xxx'@'%' IDENTIFIED BY '';
log_slave_updates=1,将主库binlog中的操作写入到从库的binlog中,默认是关闭的,虽然数据可以同步,但是从库binlog没有记录这些内容。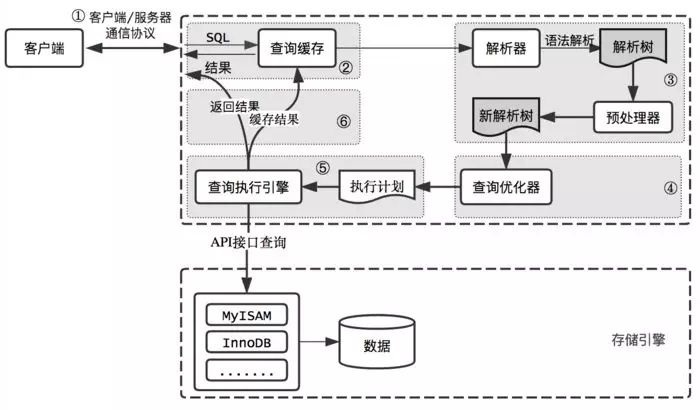
show processlist命令可以查看mysql连接的状态,以我自己的阿里云服务器为例
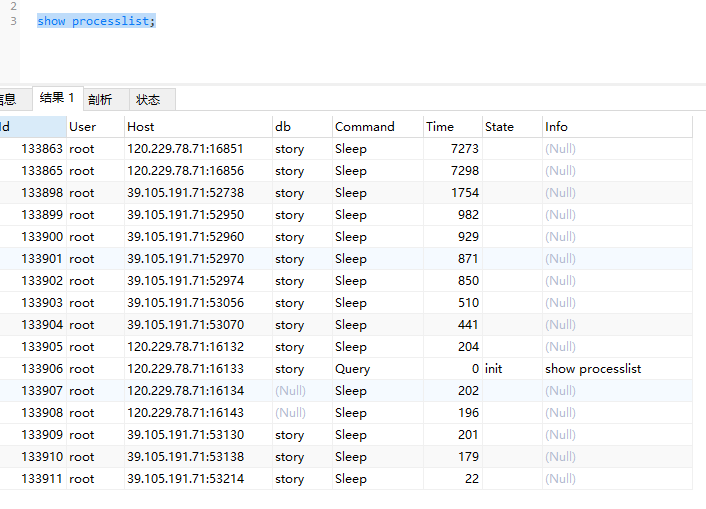
常见的状态:
完整状态列表说明请见官网地址
在解析一个查询语句之前,==如果查询缓存是打开的==(默认是关闭的,浪费性能),那么MySQL会优先检查这个查询是否命中查询缓存中的数据,如果命中缓存直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
可以使用show variables like 'query_cache%'来查看缓存的设置情况
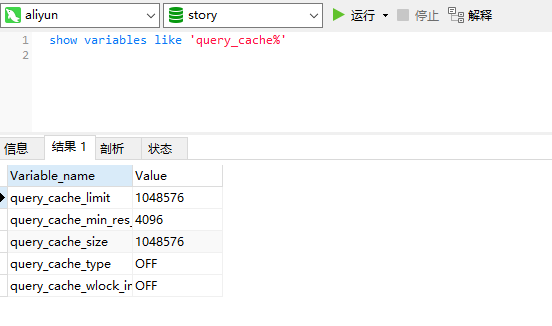 如图,
如图,query_cache_type一栏时OFF关闭状态,如要开启可以修改my.cnf文件设置query_cache_type=1
query_cache_type=0时表示关闭,1时表示打开,2表示只要select 中明确指定SQL_CACHE才缓存。
MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用MySQL语法规则验证和解析查询。语法树被校验合法后由优化器转成查询计划,一条语句可以有很多种执行方式,最后返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
执行计划可以用==explain==命令查看,详见后文。
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。最常使用的也是比较最多的引擎是MyISAM引擎和InnoDB引擎。mysql5.5开始的默认存储引擎已经变更为innodb。
可以使用show variable like 'long_query_time'命令来查看慢查询的时间
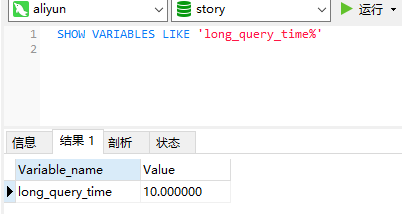
可以看到MySQL中默认的慢查询为10s,然而这个时间属于根本无法接受的地步了,可以将这个时间设置为业务可以接受的范围.
一般的慢SQL定位:业务驱动,测试驱动,慢查询日志
使用SHOW VARIABLES LIKE 'SLOW_QUERY_LOG'命令查看是否开启了慢查询日志保存
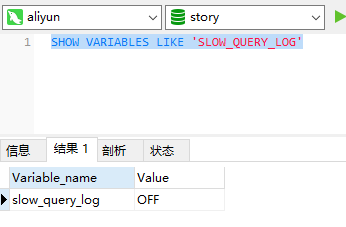
可以看到默认是没有开启的
可以使用以下命令开启保存慢查询日志(==重启mysql后会失效==)
set global slow_query_log = on //-- 打开慢日志
+set global slow_query_log_file = '/var/lib/mysql/test-slow.log' //--慢日志保存位置
+set global log_queries_not_using_indexes = on //-- 没有命中索引的是否要记录慢日志
+set global long_query_time = 2 (秒) //-- 执行时间超过多少为慢日志或者直接修改my.cnf文件添加相应配置后重启mysql(==永久生效==)
EXPLAIN可以帮助开发人员分析SQL问题,EXPLAIN显示了MySQL如何使用使用SQL执行计划,可以帮助开发人员写出更优化的查询语句。使用方法,在select语句前加上Explain就可以了
例如:EXPLAIN SELECT * FROM ARTICLE WHERE ARTICLE_ID = '1'
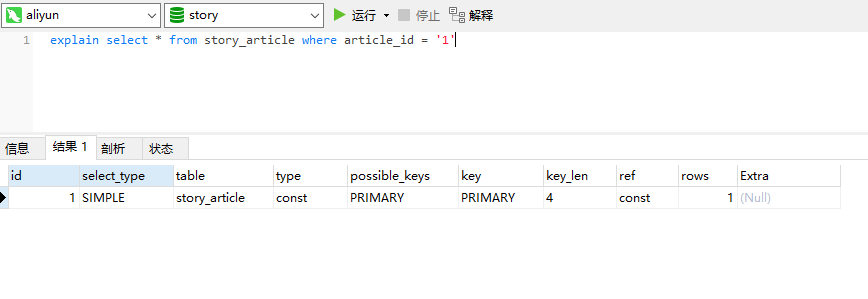 结果列说明:
结果列说明:
这是SELECT的查询序列号,表示查询中执行select子句或操作表的顺序,id相同,执行顺序从上到下,id不同,id值越大执行优先级越高
表示SELECT语句的类型
SIMPLE:简单的select查询(不使用连接查询或者子查询)
PRIMARY:表示主查询,或者是最外层的查询语句,最外层查询为PRIMARY,也就是最后加载的就是PRIMARY
UNION:表示连接查询的第二个或者后面的查询语句,不依赖外部查询的结果集
DEPENDENT UNION:union中的第二个或后面的select语句,取决于外面的查询。
UNION RESULT:连接查询的结果;
SUBQUERY:子查询中的第1个SELECT语句;不依赖于外部查询的结果集
DEPENDENT SUBQUERY:子查询中的第1个SELECT,依赖于外面的查询;
DERIVED:导出表的SELECT(FROM子句的子查询),MySQL会递归执行这些子查询,把结果放在临时表里
DEPENDENT DERIVED:派生表依赖于另一个表
MATERIALIZED:物化子查询
UNCACHEABLE SUBQUERY:子查询,其结果无法缓存,必须针对外部查询的每一行重新进行评估
UNCACHEABLE UNION:UNION中的第二个或随后的 select 查询,属于不可缓存的子查询
表示查询的表
表示表的连接类型,从最好到最差的连接类型为
system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system:表仅有一行,这是const类型的特列,平时不会出现,这个也可以忽略不计。
const:数据表最多只有一个匹配行,因为只匹配一行数据,所以很快
eq_ref:mysql手册是这样说的:"对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY"。eq_ref可以用于使用=比较带索引的列。
ref:查询条件索引既不是UNIQUE也不是PRIMARY KEY的情况。ref可用于=或<或>操作符的带索引的列。
ref_or_null:该连接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
index_merge:该连接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
unique_subquery:该类型替换了下面形式的IN子查询的ref: value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
index_subquery:该连接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引: value IN (SELECT key_column FROM single_table WHERE some_expr)
range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符用常量比较关键字列时,类型为range
index:该连接类型与ALL相同,除了只有索引树被扫描。通常比ALL快,因为索引文件通常比数据文件小。
这个类型发生在这两种方式:
**1)**如果索引是查询的覆盖索引,并且可用于满足表中所需的所有数据,则仅扫描索引树。在这种情况下,Extra列显示为 Using index
**2)**使用对索引的读取执行全表扫描,以按索引顺序查找数据行。 Uses index没有出现在 Extra列中。
ALL:对于每个来自于先前的表的行组合,进行完整的表扫描。(性能最差)
指MySQL能使用哪个索引在该表中找到行。如果为空,没有相关的索引。这时如果要提升性能,可以通过检验WHERE子句,看它是否引用某些列或适合索引的列来提高查询性能。如果是这样,可以创建适合的索引来提高查询的性能。
表示查询实际使用的索引,如果没有选择索引,该列的值是NULL。如果为primary的话,表示使用了主键。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX
表示MySQL选择的索引字段按字节计算的长度,若键是NULL,则长度为NULL。通过key_len值可以确定MySQL将实际使用一个多列索引中的几个字段
表示使用哪个列或常数与索引一起来查询记录。
显示MySQL在表中进行查询时必须检查的行数。
表示MySQL在处理查询时的详细信息
贴一个美团技术团队的文章:MySQL索引原理及慢查询优化,以下内容引用自该文章
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析
`,75)]))}const k=e(t,[["render",n]]);export{g as __pageData,k as default}; diff --git "a/assets/java_database_SQL\344\274\230\345\214\226\345\255\246\344\271\240.md.C7T3bFPf.lean.js" "b/assets/java_database_SQL\344\274\230\345\214\226\345\255\246\344\271\240.md.C7T3bFPf.lean.js" new file mode 100644 index 00000000..18eb1a5e --- /dev/null +++ "b/assets/java_database_SQL\344\274\230\345\214\226\345\255\246\344\271\240.md.C7T3bFPf.lean.js" @@ -0,0 +1,4 @@ +import{_ as e,c as i,a2 as s,o as l}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"SQL优化学习","description":"","frontmatter":{},"headers":[],"relativePath":"java/database/SQL优化学习.md","filePath":"java/database/SQL优化学习.md","lastUpdated":1729217313000}'),t={name:"java/database/SQL优化学习.md"};function n(p,a,r,o,h,d){return l(),i("div",null,a[0]||(a[0]=[s(`
show processlist命令可以查看mysql连接的状态,以我自己的阿里云服务器为例
常见的状态:
完整状态列表说明请见官网地址
在解析一个查询语句之前,==如果查询缓存是打开的==(默认是关闭的,浪费性能),那么MySQL会优先检查这个查询是否命中查询缓存中的数据,如果命中缓存直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
可以使用show variables like 'query_cache%'来查看缓存的设置情况
如图,query_cache_type一栏时OFF关闭状态,如要开启可以修改my.cnf文件设置query_cache_type=1
query_cache_type=0时表示关闭,1时表示打开,2表示只要select 中明确指定SQL_CACHE才缓存。
MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用MySQL语法规则验证和解析查询。语法树被校验合法后由优化器转成查询计划,一条语句可以有很多种执行方式,最后返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
执行计划可以用==explain==命令查看,详见后文。
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。最常使用的也是比较最多的引擎是MyISAM引擎和InnoDB引擎。mysql5.5开始的默认存储引擎已经变更为innodb。
可以使用show variable like 'long_query_time'命令来查看慢查询的时间
可以看到MySQL中默认的慢查询为10s,然而这个时间属于根本无法接受的地步了,可以将这个时间设置为业务可以接受的范围.
一般的慢SQL定位:业务驱动,测试驱动,慢查询日志
使用SHOW VARIABLES LIKE 'SLOW_QUERY_LOG'命令查看是否开启了慢查询日志保存
可以看到默认是没有开启的
可以使用以下命令开启保存慢查询日志(==重启mysql后会失效==)
set global slow_query_log = on //-- 打开慢日志
+set global slow_query_log_file = '/var/lib/mysql/test-slow.log' //--慢日志保存位置
+set global log_queries_not_using_indexes = on //-- 没有命中索引的是否要记录慢日志
+set global long_query_time = 2 (秒) //-- 执行时间超过多少为慢日志或者直接修改my.cnf文件添加相应配置后重启mysql(==永久生效==)
EXPLAIN可以帮助开发人员分析SQL问题,EXPLAIN显示了MySQL如何使用使用SQL执行计划,可以帮助开发人员写出更优化的查询语句。使用方法,在select语句前加上Explain就可以了
例如:EXPLAIN SELECT * FROM ARTICLE WHERE ARTICLE_ID = '1'
结果列说明:
这是SELECT的查询序列号,表示查询中执行select子句或操作表的顺序,id相同,执行顺序从上到下,id不同,id值越大执行优先级越高
表示SELECT语句的类型
SIMPLE:简单的select查询(不使用连接查询或者子查询)
PRIMARY:表示主查询,或者是最外层的查询语句,最外层查询为PRIMARY,也就是最后加载的就是PRIMARY
UNION:表示连接查询的第二个或者后面的查询语句,不依赖外部查询的结果集
DEPENDENT UNION:union中的第二个或后面的select语句,取决于外面的查询。
UNION RESULT:连接查询的结果;
SUBQUERY:子查询中的第1个SELECT语句;不依赖于外部查询的结果集
DEPENDENT SUBQUERY:子查询中的第1个SELECT,依赖于外面的查询;
DERIVED:导出表的SELECT(FROM子句的子查询),MySQL会递归执行这些子查询,把结果放在临时表里
DEPENDENT DERIVED:派生表依赖于另一个表
MATERIALIZED:物化子查询
UNCACHEABLE SUBQUERY:子查询,其结果无法缓存,必须针对外部查询的每一行重新进行评估
UNCACHEABLE UNION:UNION中的第二个或随后的 select 查询,属于不可缓存的子查询
表示查询的表
表示表的连接类型,从最好到最差的连接类型为
system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system:表仅有一行,这是const类型的特列,平时不会出现,这个也可以忽略不计。
const:数据表最多只有一个匹配行,因为只匹配一行数据,所以很快
eq_ref:mysql手册是这样说的:"对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY"。eq_ref可以用于使用=比较带索引的列。
ref:查询条件索引既不是UNIQUE也不是PRIMARY KEY的情况。ref可用于=或<或>操作符的带索引的列。
ref_or_null:该连接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
index_merge:该连接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
unique_subquery:该类型替换了下面形式的IN子查询的ref: value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
index_subquery:该连接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引: value IN (SELECT key_column FROM single_table WHERE some_expr)
range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符用常量比较关键字列时,类型为range
index:该连接类型与ALL相同,除了只有索引树被扫描。通常比ALL快,因为索引文件通常比数据文件小。
这个类型发生在这两种方式:
**1)**如果索引是查询的覆盖索引,并且可用于满足表中所需的所有数据,则仅扫描索引树。在这种情况下,Extra列显示为 Using index
**2)**使用对索引的读取执行全表扫描,以按索引顺序查找数据行。 Uses index没有出现在 Extra列中。
ALL:对于每个来自于先前的表的行组合,进行完整的表扫描。(性能最差)
指MySQL能使用哪个索引在该表中找到行。如果为空,没有相关的索引。这时如果要提升性能,可以通过检验WHERE子句,看它是否引用某些列或适合索引的列来提高查询性能。如果是这样,可以创建适合的索引来提高查询的性能。
表示查询实际使用的索引,如果没有选择索引,该列的值是NULL。如果为primary的话,表示使用了主键。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX
表示MySQL选择的索引字段按字节计算的长度,若键是NULL,则长度为NULL。通过key_len值可以确定MySQL将实际使用一个多列索引中的几个字段
表示使用哪个列或常数与索引一起来查询记录。
显示MySQL在表中进行查询时必须检查的行数。
表示MySQL在处理查询时的详细信息
贴一个美团技术团队的文章:MySQL索引原理及慢查询优化,以下内容引用自该文章
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析
`,75)]))}const k=e(t,[["render",n]]);export{g as __pageData,k as default}; diff --git "a/assets/java_devtool_Maven\347\232\204\347\224\237\345\221\275\345\221\250\346\234\237.md.D3xP1y_T.js" "b/assets/java_devtool_Maven\347\232\204\347\224\237\345\221\275\345\221\250\346\234\237.md.D3xP1y_T.js" new file mode 100644 index 00000000..9dda7b0d --- /dev/null +++ "b/assets/java_devtool_Maven\347\232\204\347\224\237\345\221\275\345\221\250\346\234\237.md.D3xP1y_T.js" @@ -0,0 +1 @@ +import{_ as e,c as a,a2 as l,o as n}from"./chunks/framework.BjcrtTwI.js";const h=JSON.parse('{"title":"Maven的生命周期","description":"","frontmatter":{},"headers":[],"relativePath":"java/devtool/Maven的生命周期.md","filePath":"java/devtool/Maven的生命周期.md","lastUpdated":1729217313000}'),i={name:"java/devtool/Maven的生命周期.md"};function s(d,t,p,r,o,c){return n(),a("div",null,t[0]||(t[0]=[l('maven共有三个标准生命周期:
clean:项目清理的处理
default:项目部署的处理
site:站点文件生成的处理
| 阶段 | 处理 | 描述 |
|---|---|---|
| 验证 validate | 验证项目 | 验证项目是否正确且所有必须信息是可用的 |
| 编译 compile | 执行编译 | 源代码编译在此阶段完成 |
| 测试 Test | 测试 | 使用适当的单元测试框架(例如JUnit)运行测试。 |
| 包装 package | 打包 | 创建JAR/WAR包如在 pom.xml 中定义提及的包 |
| 检查 verify | 检查 | 对集成测试的结果进行检查,以保证质量达标 |
| 安装 install | 安装 | 安装打包的项目到本地仓库,以供其他项目使用 |
| 部署 deploy | 部署 | 拷贝最终的工程包到远程仓库中,以共享给其他开发人员和工程 |
平常用到最多的是mvn clean package或者mvn install,两者都会在target生成最终的jar或war文件,区别在于install命令还会将生成的jar或war包安装至本地仓库。而当需要跨项目引用jar包时,我们需要把自己的jar包上传至maven私服(远程仓库)中,之前还傻傻的直接动手去maven私服手动上传jar包,不过相比于mvn deploy肯定是麻烦很多的,maven的deploy可以很方便的将我们工程中的jar发布至maven私服中方便团队间的jar包共享。
TIP
当deploy快照版本时,maven会给快照打上时间戳以区分快照的版本,因为快照可能会频繁变更。maven会以包名是否包含SNAPSHOT来判断是否快照。
当我们执行 mvn post-clean 命令时,Maven 调用 clean 生命周期,它包含以下阶段:
mvn clean 中的 clean 就是上面的 clean,在一个生命周期中,运行某个阶段的时候,它之前的所有阶段都会被运行,也就是说,如果执行 mvn clean 将运行以下两个生命周期阶段:
pre-clean, clean如果我们运行 mvn post-clean ,则运行以下三个生命周期阶段:
pre-clean, clean, post-cleanMaven Site 插件一般用来创建新的报告文档、部署站点等。
maven共有三个标准生命周期:
clean:项目清理的处理
default:项目部署的处理
site:站点文件生成的处理
| 阶段 | 处理 | 描述 |
|---|---|---|
| 验证 validate | 验证项目 | 验证项目是否正确且所有必须信息是可用的 |
| 编译 compile | 执行编译 | 源代码编译在此阶段完成 |
| 测试 Test | 测试 | 使用适当的单元测试框架(例如JUnit)运行测试。 |
| 包装 package | 打包 | 创建JAR/WAR包如在 pom.xml 中定义提及的包 |
| 检查 verify | 检查 | 对集成测试的结果进行检查,以保证质量达标 |
| 安装 install | 安装 | 安装打包的项目到本地仓库,以供其他项目使用 |
| 部署 deploy | 部署 | 拷贝最终的工程包到远程仓库中,以共享给其他开发人员和工程 |
平常用到最多的是mvn clean package或者mvn install,两者都会在target生成最终的jar或war文件,区别在于install命令还会将生成的jar或war包安装至本地仓库。而当需要跨项目引用jar包时,我们需要把自己的jar包上传至maven私服(远程仓库)中,之前还傻傻的直接动手去maven私服手动上传jar包,不过相比于mvn deploy肯定是麻烦很多的,maven的deploy可以很方便的将我们工程中的jar发布至maven私服中方便团队间的jar包共享。
TIP
当deploy快照版本时,maven会给快照打上时间戳以区分快照的版本,因为快照可能会频繁变更。maven会以包名是否包含SNAPSHOT来判断是否快照。
当我们执行 mvn post-clean 命令时,Maven 调用 clean 生命周期,它包含以下阶段:
mvn clean 中的 clean 就是上面的 clean,在一个生命周期中,运行某个阶段的时候,它之前的所有阶段都会被运行,也就是说,如果执行 mvn clean 将运行以下两个生命周期阶段:
pre-clean, clean如果我们运行 mvn post-clean ,则运行以下三个生命周期阶段:
pre-clean, clean, post-cleanMaven Site 插件一般用来创建新的报告文档、部署站点等。
maven私服突然无法下载依赖,在idea中使用命令查看下详细错误信息mvn clean install -U -e -X
Client报错信息:
Caused by: org.eclipse.aether.transfer.ArtifactTransferException: Could not transfer artifact org.springframework.boot:spring-boot:jar:2.4.1 from/to nexus (xxxxxxxxxxxxxxxxxxxxxxxxx): GET request of: org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar from nexus failedCould not transfer artifact org.springframework.boot:spring-boot:jar:2.4.1 from/to nexus (xxxxxxxxxxxxxxxxxxxxxx): GET request of: org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar from nexus failed: Premature end of Content-Length delimited message body (expected: 1,302,347; received: 76,515) -> [Help 1]服务端错误日志:
2022-04-10 16:51:14,488+0800 INFO [qtp1752276351-145] *UNKNOWN org.apache.shiro.session.mgt.AbstractValidatingSessionManager - Enabling session validation scheduler...
+2022-04-10 16:51:14,502+0800 INFO [qtp1752276351-51] *UNKNOWN org.sonatype.nexus.internal.security.anonymous.AnonymousManagerImpl - Loaded configuration: AnonymousConfiguration{enabled=false, userId='anonymous', realmName='NexusAuthorizingRealm'}
+2022-04-10 16:51:15,233+0800 WARN [qtp1752276351-48] deployment org.sonatype.nexus.repository.httpbridge.internal.ViewServlet - Failure servicing: GET /repository/maven-public/org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar
+org.eclipse.jetty.io.EofException: null
+ at org.eclipse.jetty.io.ChannelEndPoint.flush(ChannelEndPoint.java:284)
+ at org.eclipse.jetty.io.WriteFlusher.flush(WriteFlusher.java:393)
+ at org.eclipse.jetty.io.WriteFlusher.write(WriteFlusher.java:277)
+ at org.eclipse.jetty.io.AbstractEndPoint.write(AbstractEndPoint.java:380)
+ at org.eclipse.jetty.server.HttpConnection$SendCallback.process(HttpConnection.java:826)
+ at org.eclipse.jetty.util.IteratingCallback.processing(IteratingCallback.java:241)
+ at org.eclipse.jetty.util.IteratingCallback.iterate(IteratingCallback.java:224)
+ at org.eclipse.jetty.server.HttpConnection.send(HttpConnection.java:550)
+ at org.eclipse.jetty.server.HttpChannel.sendResponse(HttpChannel.java:850)
+ at org.eclipse.jetty.server.HttpChannel.write(HttpChannel.java:921)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:249)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:225)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:524)
+ at com.google.common.io.ByteStreams.copy(ByteStreams.java:113)
+ at org.sonatype.nexus.repository.view.Payload.copy(Payload.java:61)
+ at org.sonatype.nexus.repository.view.Content.copy(Content.java:116)
+ at org.sonatype.nexus.repository.httpbridge.internal.DefaultHttpResponseSender.send(DefaultHttpResponseSender.java:81)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.dispatchAndSend(ViewServlet.java:228)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.doService(ViewServlet.java:174)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.service(ViewServlet.java:126)
+ at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
+ at com.google.inject.servlet.ServletDefinition.doServiceImpl(ServletDefinition.java:286)
+ at com.google.inject.servlet.ServletDefinition.doService(ServletDefinition.java:276)
+ at com.google.inject.servlet.ServletDefinition.service(ServletDefinition.java:181)
+ at com.google.inject.servlet.DynamicServletPipeline.service(DynamicServletPipeline.java:71)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:85)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:112)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:61)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter.executeChain(AbstractShiroFilter.java:449)
+ at org.sonatype.nexus.security.SecurityFilter.executeChain(SecurityFilter.java:85)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter$1.call(AbstractShiroFilter.java:365)
+ at org.apache.shiro.subject.support.SubjectCallable.doCall(SubjectCallable.java:90)
+ at org.apache.shiro.subject.support.SubjectCallable.call(SubjectCallable.java:83)
+ at org.apache.shiro.subject.support.DelegatingSubject.execute(DelegatingSubject.java:383)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter.doFilterInternal(AbstractShiroFilter.java:362)
+ at org.sonatype.nexus.security.SecurityFilter.doFilterInternal(SecurityFilter.java:101)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.repository.httpbridge.internal.ExhaustRequestFilter.doFilter(ExhaustRequestFilter.java:80)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.sonatype.nexus.licensing.internal.LicensingRedirectFilter.doFilter(LicensingRedirectFilter.java:114)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.codahale.metrics.servlet.AbstractInstrumentedFilter.doFilter(AbstractInstrumentedFilter.java:112)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.ErrorPageFilter.doFilter(ErrorPageFilter.java:79)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.EnvironmentFilter.doFilter(EnvironmentFilter.java:101)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.HeaderPatternFilter.doFilter(HeaderPatternFilter.java:98)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.google.inject.servlet.DynamicFilterPipeline.dispatch(DynamicFilterPipeline.java:104)
+ at com.google.inject.servlet.GuiceFilter.doFilter(GuiceFilter.java:135)
+ at org.sonatype.nexus.bootstrap.osgi.DelegatingFilter.doFilter(DelegatingFilter.java:73)
+ at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1602)
+ at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:540)
+ at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:146)
+ at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:548)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextHandle(ScopedHandler.java:257)
+ at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:1700)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextHandle(ScopedHandler.java:255)
+ at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1345)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:203)
+ at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:480)
+ at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:1667)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:201)
+ at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1247)
+ at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:144)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at com.codahale.metrics.jetty9.InstrumentedHandler.handle(InstrumentedHandler.java:239)
+ at org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:152)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at org.eclipse.jetty.server.Server.handle(Server.java:505)
+ at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:370)
+ at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:267)
+ at org.eclipse.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:305)
+ at org.eclipse.jetty.io.FillInterest.fillable(FillInterest.java:103)
+ at org.eclipse.jetty.io.ChannelEndPoint$2.run(ChannelEndPoint.java:117)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.runTask(EatWhatYouKill.java:333)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.doProduce(EatWhatYouKill.java:310)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.tryProduce(EatWhatYouKill.java:168)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.run(EatWhatYouKill.java:126)
+ at org.eclipse.jetty.util.thread.ReservedThreadExecutor$ReservedThread.run(ReservedThreadExecutor.java:366)
+ at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:698)
+ at org.eclipse.jetty.util.thread.QueuedThreadPool$Runner.run(QueuedThreadPool.java:804)
+ at java.lang.Thread.run(Thread.java:748)
+Caused by: java.io.IOException: Connection reset by peer
+ at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
+ at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)
+ at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
+ at sun.nio.ch.IOUtil.write(IOUtil.java:51)
+ at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471)
+ at org.eclipse.jetty.io.ChannelEndPoint.flush(ChannelEndPoint.java:262)
+ ... 102 common frames omitted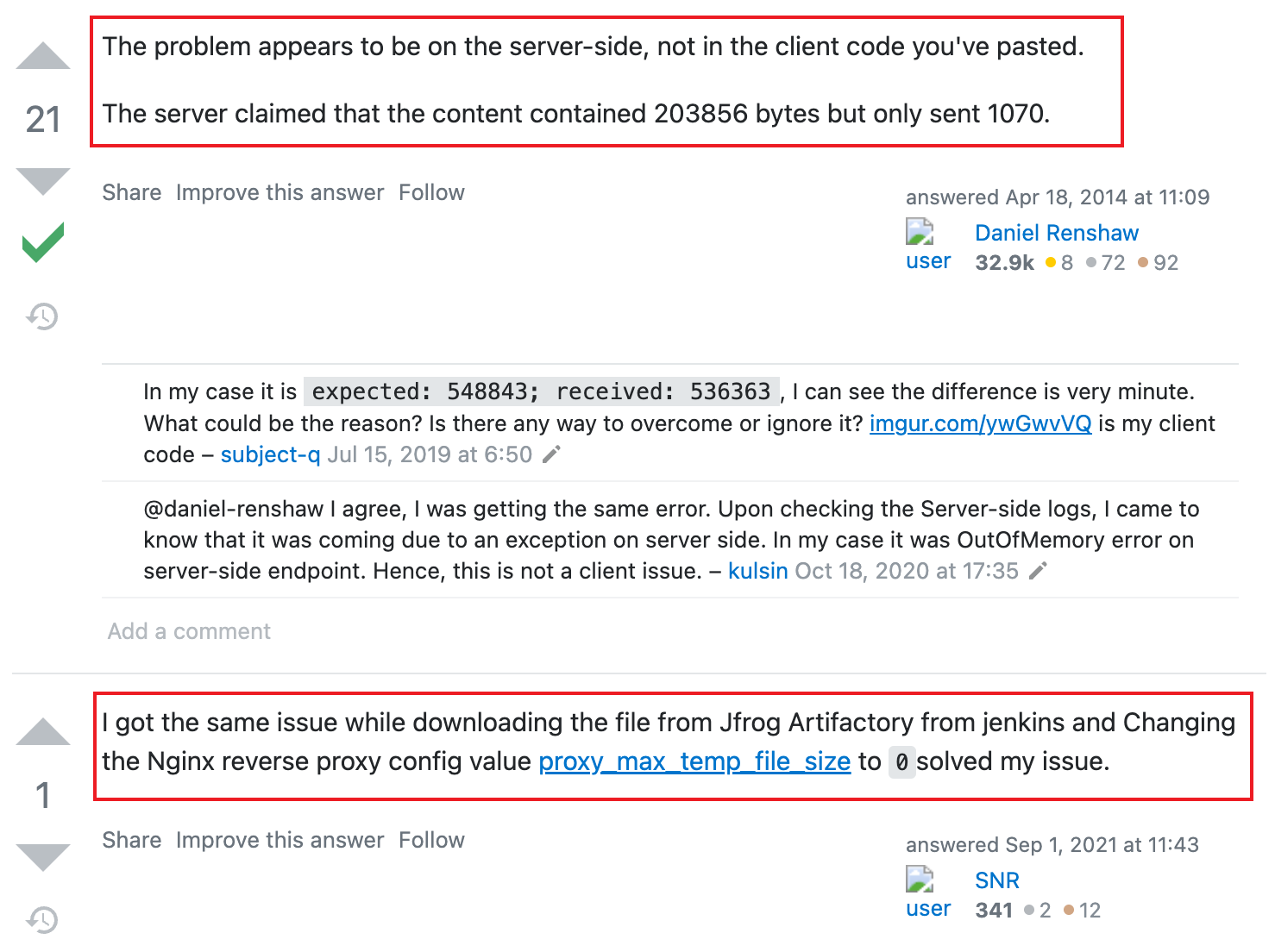
在nginx的location配置中增加proxy_max_temp_file_size 0;
maven私服突然无法下载依赖,在idea中使用命令查看下详细错误信息mvn clean install -U -e -X
Client报错信息:
Caused by: org.eclipse.aether.transfer.ArtifactTransferException: Could not transfer artifact org.springframework.boot:spring-boot:jar:2.4.1 from/to nexus (xxxxxxxxxxxxxxxxxxxxxxxxx): GET request of: org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar from nexus failedCould not transfer artifact org.springframework.boot:spring-boot:jar:2.4.1 from/to nexus (xxxxxxxxxxxxxxxxxxxxxx): GET request of: org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar from nexus failed: Premature end of Content-Length delimited message body (expected: 1,302,347; received: 76,515) -> [Help 1]服务端错误日志:
2022-04-10 16:51:14,488+0800 INFO [qtp1752276351-145] *UNKNOWN org.apache.shiro.session.mgt.AbstractValidatingSessionManager - Enabling session validation scheduler...
+2022-04-10 16:51:14,502+0800 INFO [qtp1752276351-51] *UNKNOWN org.sonatype.nexus.internal.security.anonymous.AnonymousManagerImpl - Loaded configuration: AnonymousConfiguration{enabled=false, userId='anonymous', realmName='NexusAuthorizingRealm'}
+2022-04-10 16:51:15,233+0800 WARN [qtp1752276351-48] deployment org.sonatype.nexus.repository.httpbridge.internal.ViewServlet - Failure servicing: GET /repository/maven-public/org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar
+org.eclipse.jetty.io.EofException: null
+ at org.eclipse.jetty.io.ChannelEndPoint.flush(ChannelEndPoint.java:284)
+ at org.eclipse.jetty.io.WriteFlusher.flush(WriteFlusher.java:393)
+ at org.eclipse.jetty.io.WriteFlusher.write(WriteFlusher.java:277)
+ at org.eclipse.jetty.io.AbstractEndPoint.write(AbstractEndPoint.java:380)
+ at org.eclipse.jetty.server.HttpConnection$SendCallback.process(HttpConnection.java:826)
+ at org.eclipse.jetty.util.IteratingCallback.processing(IteratingCallback.java:241)
+ at org.eclipse.jetty.util.IteratingCallback.iterate(IteratingCallback.java:224)
+ at org.eclipse.jetty.server.HttpConnection.send(HttpConnection.java:550)
+ at org.eclipse.jetty.server.HttpChannel.sendResponse(HttpChannel.java:850)
+ at org.eclipse.jetty.server.HttpChannel.write(HttpChannel.java:921)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:249)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:225)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:524)
+ at com.google.common.io.ByteStreams.copy(ByteStreams.java:113)
+ at org.sonatype.nexus.repository.view.Payload.copy(Payload.java:61)
+ at org.sonatype.nexus.repository.view.Content.copy(Content.java:116)
+ at org.sonatype.nexus.repository.httpbridge.internal.DefaultHttpResponseSender.send(DefaultHttpResponseSender.java:81)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.dispatchAndSend(ViewServlet.java:228)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.doService(ViewServlet.java:174)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.service(ViewServlet.java:126)
+ at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
+ at com.google.inject.servlet.ServletDefinition.doServiceImpl(ServletDefinition.java:286)
+ at com.google.inject.servlet.ServletDefinition.doService(ServletDefinition.java:276)
+ at com.google.inject.servlet.ServletDefinition.service(ServletDefinition.java:181)
+ at com.google.inject.servlet.DynamicServletPipeline.service(DynamicServletPipeline.java:71)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:85)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:112)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:61)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter.executeChain(AbstractShiroFilter.java:449)
+ at org.sonatype.nexus.security.SecurityFilter.executeChain(SecurityFilter.java:85)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter$1.call(AbstractShiroFilter.java:365)
+ at org.apache.shiro.subject.support.SubjectCallable.doCall(SubjectCallable.java:90)
+ at org.apache.shiro.subject.support.SubjectCallable.call(SubjectCallable.java:83)
+ at org.apache.shiro.subject.support.DelegatingSubject.execute(DelegatingSubject.java:383)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter.doFilterInternal(AbstractShiroFilter.java:362)
+ at org.sonatype.nexus.security.SecurityFilter.doFilterInternal(SecurityFilter.java:101)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.repository.httpbridge.internal.ExhaustRequestFilter.doFilter(ExhaustRequestFilter.java:80)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.sonatype.nexus.licensing.internal.LicensingRedirectFilter.doFilter(LicensingRedirectFilter.java:114)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.codahale.metrics.servlet.AbstractInstrumentedFilter.doFilter(AbstractInstrumentedFilter.java:112)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.ErrorPageFilter.doFilter(ErrorPageFilter.java:79)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.EnvironmentFilter.doFilter(EnvironmentFilter.java:101)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.HeaderPatternFilter.doFilter(HeaderPatternFilter.java:98)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.google.inject.servlet.DynamicFilterPipeline.dispatch(DynamicFilterPipeline.java:104)
+ at com.google.inject.servlet.GuiceFilter.doFilter(GuiceFilter.java:135)
+ at org.sonatype.nexus.bootstrap.osgi.DelegatingFilter.doFilter(DelegatingFilter.java:73)
+ at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1602)
+ at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:540)
+ at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:146)
+ at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:548)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextHandle(ScopedHandler.java:257)
+ at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:1700)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextHandle(ScopedHandler.java:255)
+ at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1345)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:203)
+ at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:480)
+ at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:1667)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:201)
+ at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1247)
+ at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:144)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at com.codahale.metrics.jetty9.InstrumentedHandler.handle(InstrumentedHandler.java:239)
+ at org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:152)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at org.eclipse.jetty.server.Server.handle(Server.java:505)
+ at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:370)
+ at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:267)
+ at org.eclipse.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:305)
+ at org.eclipse.jetty.io.FillInterest.fillable(FillInterest.java:103)
+ at org.eclipse.jetty.io.ChannelEndPoint$2.run(ChannelEndPoint.java:117)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.runTask(EatWhatYouKill.java:333)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.doProduce(EatWhatYouKill.java:310)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.tryProduce(EatWhatYouKill.java:168)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.run(EatWhatYouKill.java:126)
+ at org.eclipse.jetty.util.thread.ReservedThreadExecutor$ReservedThread.run(ReservedThreadExecutor.java:366)
+ at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:698)
+ at org.eclipse.jetty.util.thread.QueuedThreadPool$Runner.run(QueuedThreadPool.java:804)
+ at java.lang.Thread.run(Thread.java:748)
+Caused by: java.io.IOException: Connection reset by peer
+ at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
+ at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)
+ at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
+ at sun.nio.ch.IOUtil.write(IOUtil.java:51)
+ at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471)
+ at org.eclipse.jetty.io.ChannelEndPoint.flush(ChannelEndPoint.java:262)
+ ... 102 common frames omitted
在nginx的location配置中增加proxy_max_temp_file_size 0;
@ConfigurationProperties注解可以从外部获取配置信息,并将其绑定到JavaBean中。
SpringBoot可以让配置信息外部化,支持的配置有多种,最常见的.properties、.yaml文件,启动时命令行参数--xxx、系统环境变量、Java系统属性(System.getProperties())...
@ConfigurationProperties注解的功能由ConfigurationPropertiesBindingPostProcessor这个后置处理器实现,spring容器中的enviroment.propertySources记录着外部的属性值,properties后置处理器会从中找到匹配的值绑定到JavaBean中。
属性的绑定是会被覆盖的,排序靠后的会覆盖靠前的,即越靠后的优先级越高。(os环境变量可以覆盖application.properties,java系统属性可以覆盖系统环境变量,命令行参数可以覆盖java系统属性...)
这些配置的方式和可以参照spring boot官方文档:
2. Externalized Configuration
Spring Boot lets you externalize your configuration so that you can work with the same application code in different environments. You can use a variety of external configuration sources, include Java properties files, YAML files, environment variables, and command-line arguments.
Property values can be injected directly into your beans by using the
@Valueannotation, accessed through Spring’sEnvironmentabstraction, or be bound to structured objects through@ConfigurationProperties.Spring Boot uses a very particular
PropertySourceorder that is designed to allow sensible overriding of values. Properties are considered in the following order (with values from lower items overriding earlier ones):
- Default properties (specified by setting
SpringApplication.setDefaultProperties).@PropertySourceannotations on your@Configurationclasses. Please note that such property sources are not added to theEnvironmentuntil the application context is being refreshed. This is too late to configure certain properties such aslogging.*andspring.main.*which are read before refresh begins.- Config data (such as
application.propertiesfiles).- A
RandomValuePropertySourcethat has properties only inrandom.*.- OS environment variables.
- Java System properties (
System.getProperties()).- JNDI attributes from
java:comp/env.ServletContextinit parameters.ServletConfiginit parameters.- Properties from
SPRING_APPLICATION_JSON(inline JSON embedded in an environment variable or system property).- Command line arguments.
propertiesattribute on your tests. Available on@SpringBootTestand the test annotations for testing a particular slice of your application.@TestPropertySourceannotations on your tests.- Devtools global settings properties in the
$HOME/.config/spring-bootdirectory when devtools is active.Config data files are considered in the following order:
- Application properties packaged inside your jar (
application.propertiesand YAML variants).- Profile-specific application properties packaged inside your jar (
application-{profile}.propertiesand YAML variants).- Application properties outside of your packaged jar (
application.propertiesand YAML variants).- Profile-specific application properties outside of your packaged jar (
application-{profile}.propertiesand YAML variants).
这里通过系统环境变量的绑定方式大致记录下,因为java应用的docker镜像通常使用这种方式,例如docker启动指令里加上-e xxx=xxx,就是在指定docker容器的系统环境变量。比较常见的-e JAVA_OPTS=xxx ,因为java应用的镜像通常entrypoint都是sh -c java $JAVA_OPTS xxx.jar。
上文中enviroment.propertySources会读取外部的配置,系统环境变量是通过System.getenv()获取的,通过docker指令给镜像添加了系统环境变量后,就会通过这种方式绑定到java应用的配置类中。
通过docker指令配置系统环境变量的方式,参数的命名需要做对应的调整,例如:
@ConfigurationProperties(prefix="user")
+public class Test{
+ private String name;
+}如果是通过.properties文件来配置那么文件中应该是user.name=xxx,如果是通过linux系统环境变量的方式,则环境变量中应该是USER_NAME=xxx.这是因为不同操作系统对环境变量的命名规则都有严格的要求,spring boot的宽松绑定规则要尽可能兼容不同系统的限制.
linux shell变量的命名规则:可以a-zA-Z0-9,可以下划线_,按照惯例,变量名都是大写的。所以,通过环境变量读取java配置时,应该遵循的原则
将.替换为_
删除所有破折号-
变量名转为大写
例:spring.main.log-startup-info -> SPRING_MAIN_LOGSTARTUPINFO
`,19)]))}const g=o(a,[["render",n]]);export{u as __pageData,g as default}; diff --git "a/assets/java_framework_ConfigurationProperties\346\263\250\350\247\243.md.CW5yTckq.lean.js" "b/assets/java_framework_ConfigurationProperties\346\263\250\350\247\243.md.CW5yTckq.lean.js" new file mode 100644 index 00000000..5bcec658 --- /dev/null +++ "b/assets/java_framework_ConfigurationProperties\346\263\250\350\247\243.md.CW5yTckq.lean.js" @@ -0,0 +1,4 @@ +import{_ as o,c as r,a2 as i,o as t}from"./chunks/framework.BjcrtTwI.js";const u=JSON.parse('{"title":"ConfigurationProperties注解","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/ConfigurationProperties注解.md","filePath":"java/framework/ConfigurationProperties注解.md","lastUpdated":1729217313000}'),a={name:"java/framework/ConfigurationProperties注解.md"};function n(s,e,c,l,p,d){return t(),r("div",null,e[0]||(e[0]=[i(`Binding from Environment Variables
Most operating systems impose strict rules around the names that can be used for environment variables. For example, Linux shell variables can contain only letters (
atozorAtoZ), numbers (0to9) or the underscore character (_). By convention, Unix shell variables will also have their names in UPPERCASE.Spring Boot’s relaxed binding rules are, as much as possible, designed to be compatible with these naming restrictions.
To convert a property name in the canonical-form to an environment variable name you can follow these rules:
- Replace dots (
.) with underscores (_).- Remove any dashes (
-).- Convert to uppercase.
For example, the configuration property
spring.main.log-startup-infowould be an environment variable namedSPRING_MAIN_LOGSTARTUPINFO.Environment variables can also be used when binding to object lists. To bind to a
List, the element number should be surrounded with underscores in the variable name.For example, the configuration property
my.service[0].otherwould use an environment variable namedMY_SERVICE_0_OTHER.
@ConfigurationProperties注解可以从外部获取配置信息,并将其绑定到JavaBean中。
SpringBoot可以让配置信息外部化,支持的配置有多种,最常见的.properties、.yaml文件,启动时命令行参数--xxx、系统环境变量、Java系统属性(System.getProperties())...
@ConfigurationProperties注解的功能由ConfigurationPropertiesBindingPostProcessor这个后置处理器实现,spring容器中的enviroment.propertySources记录着外部的属性值,properties后置处理器会从中找到匹配的值绑定到JavaBean中。
属性的绑定是会被覆盖的,排序靠后的会覆盖靠前的,即越靠后的优先级越高。(os环境变量可以覆盖application.properties,java系统属性可以覆盖系统环境变量,命令行参数可以覆盖java系统属性...)
这些配置的方式和可以参照spring boot官方文档:
2. Externalized Configuration
Spring Boot lets you externalize your configuration so that you can work with the same application code in different environments. You can use a variety of external configuration sources, include Java properties files, YAML files, environment variables, and command-line arguments.
Property values can be injected directly into your beans by using the
@Valueannotation, accessed through Spring’sEnvironmentabstraction, or be bound to structured objects through@ConfigurationProperties.Spring Boot uses a very particular
PropertySourceorder that is designed to allow sensible overriding of values. Properties are considered in the following order (with values from lower items overriding earlier ones):
- Default properties (specified by setting
SpringApplication.setDefaultProperties).@PropertySourceannotations on your@Configurationclasses. Please note that such property sources are not added to theEnvironmentuntil the application context is being refreshed. This is too late to configure certain properties such aslogging.*andspring.main.*which are read before refresh begins.- Config data (such as
application.propertiesfiles).- A
RandomValuePropertySourcethat has properties only inrandom.*.- OS environment variables.
- Java System properties (
System.getProperties()).- JNDI attributes from
java:comp/env.ServletContextinit parameters.ServletConfiginit parameters.- Properties from
SPRING_APPLICATION_JSON(inline JSON embedded in an environment variable or system property).- Command line arguments.
propertiesattribute on your tests. Available on@SpringBootTestand the test annotations for testing a particular slice of your application.@TestPropertySourceannotations on your tests.- Devtools global settings properties in the
$HOME/.config/spring-bootdirectory when devtools is active.Config data files are considered in the following order:
- Application properties packaged inside your jar (
application.propertiesand YAML variants).- Profile-specific application properties packaged inside your jar (
application-{profile}.propertiesand YAML variants).- Application properties outside of your packaged jar (
application.propertiesand YAML variants).- Profile-specific application properties outside of your packaged jar (
application-{profile}.propertiesand YAML variants).
这里通过系统环境变量的绑定方式大致记录下,因为java应用的docker镜像通常使用这种方式,例如docker启动指令里加上-e xxx=xxx,就是在指定docker容器的系统环境变量。比较常见的-e JAVA_OPTS=xxx ,因为java应用的镜像通常entrypoint都是sh -c java $JAVA_OPTS xxx.jar。
上文中enviroment.propertySources会读取外部的配置,系统环境变量是通过System.getenv()获取的,通过docker指令给镜像添加了系统环境变量后,就会通过这种方式绑定到java应用的配置类中。
通过docker指令配置系统环境变量的方式,参数的命名需要做对应的调整,例如:
@ConfigurationProperties(prefix="user")
+public class Test{
+ private String name;
+}如果是通过.properties文件来配置那么文件中应该是user.name=xxx,如果是通过linux系统环境变量的方式,则环境变量中应该是USER_NAME=xxx.这是因为不同操作系统对环境变量的命名规则都有严格的要求,spring boot的宽松绑定规则要尽可能兼容不同系统的限制.
linux shell变量的命名规则:可以a-zA-Z0-9,可以下划线_,按照惯例,变量名都是大写的。所以,通过环境变量读取java配置时,应该遵循的原则
将.替换为_
删除所有破折号-
变量名转为大写
例:spring.main.log-startup-info -> SPRING_MAIN_LOGSTARTUPINFO
`,19)]))}const g=o(a,[["render",n]]);export{u as __pageData,g as default}; diff --git "a/assets/java_framework_JavaSPI\346\234\272\345\210\266\345\222\214Springboot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md.BtT47OM2.js" "b/assets/java_framework_JavaSPI\346\234\272\345\210\266\345\222\214Springboot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md.BtT47OM2.js" new file mode 100644 index 00000000..c13ecdff --- /dev/null +++ "b/assets/java_framework_JavaSPI\346\234\272\345\210\266\345\222\214Springboot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md.BtT47OM2.js" @@ -0,0 +1 @@ +import{_ as i,c as r,a2 as o,o as e}from"./chunks/framework.BjcrtTwI.js";const d=JSON.parse('{"title":"JavaSPI机制和Springboot自动装配原理","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/JavaSPI机制和Springboot自动装配原理.md","filePath":"java/framework/JavaSPI机制和Springboot自动装配原理.md","lastUpdated":1729217313000}'),t={name:"java/framework/JavaSPI机制和Springboot自动装配原理.md"};function s(l,a,p,n,c,g){return e(),r("div",null,a[0]||(a[0]=[o('Binding from Environment Variables
Most operating systems impose strict rules around the names that can be used for environment variables. For example, Linux shell variables can contain only letters (
atozorAtoZ), numbers (0to9) or the underscore character (_). By convention, Unix shell variables will also have their names in UPPERCASE.Spring Boot’s relaxed binding rules are, as much as possible, designed to be compatible with these naming restrictions.
To convert a property name in the canonical-form to an environment variable name you can follow these rules:
- Replace dots (
.) with underscores (_).- Remove any dashes (
-).- Convert to uppercase.
For example, the configuration property
spring.main.log-startup-infowould be an environment variable namedSPRING_MAIN_LOGSTARTUPINFO.Environment variables can also be used when binding to object lists. To bind to a
List, the element number should be surrounded with underscores in the variable name.For example, the configuration property
my.service[0].otherwould use an environment variable namedMY_SERVICE_0_OTHER.
SPI(Service Provider Interface)是一种服务发现机制,提供服务接口,且为该接口寻找服务的实现。
从Java6开始引入,是一种基于ClassLoader类加载器发现并加载服务的机制。
标准的SPI构成:
SPI在JDBC中的应用:JDBC要求Driver实现类在类加载的时候将自身的实例注册到DriverManager中,从而加载数据库驱动,在SPI出现之前,加载数据库驱动时要执行Class.forName("com.mysql.jdbc.Driver"), 在SPI出现后,只需要引入对应依赖的JAR包后,ServiceLoader会自动去约定的路径下寻找需要加载的类。
配置文件
无参构造器
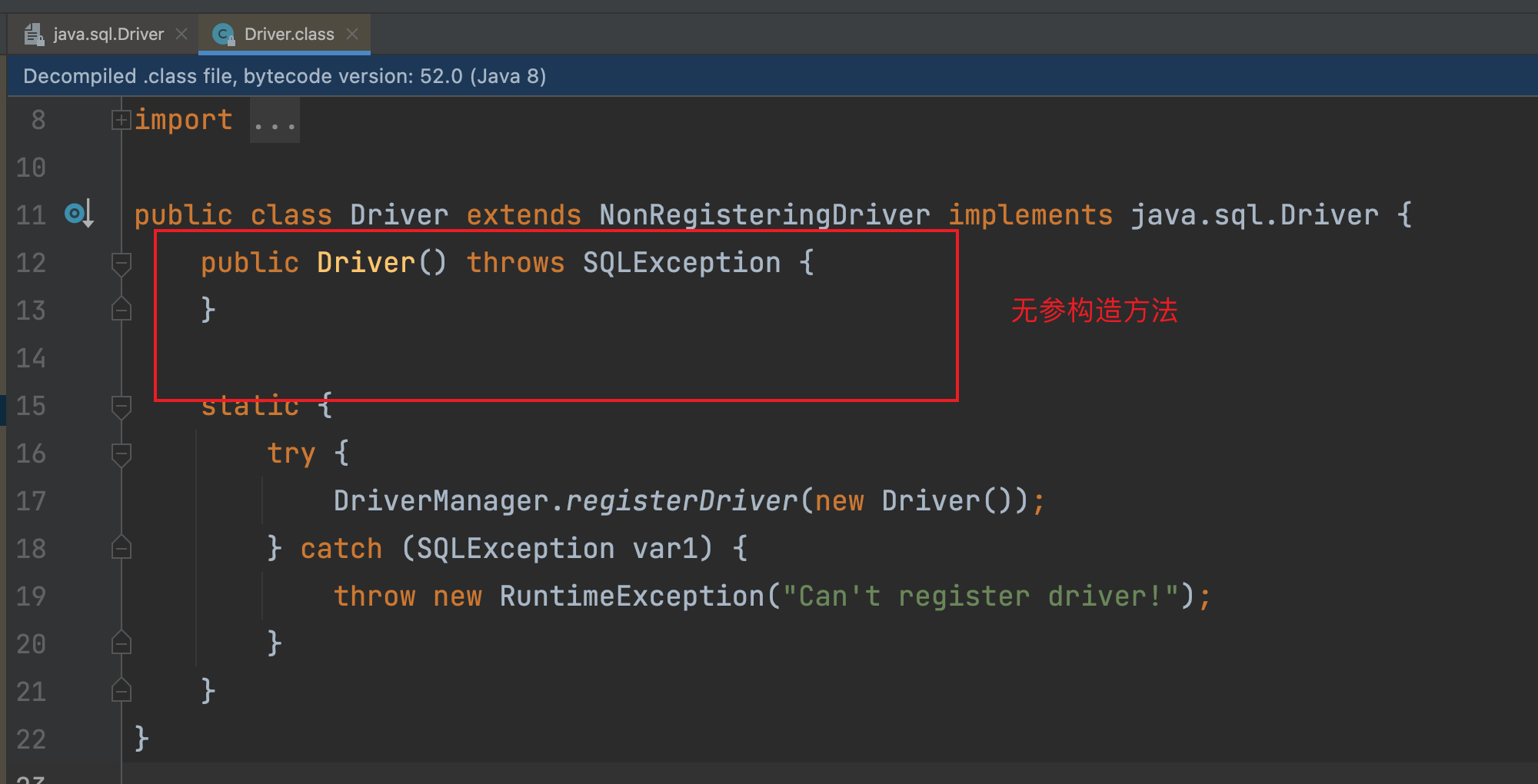
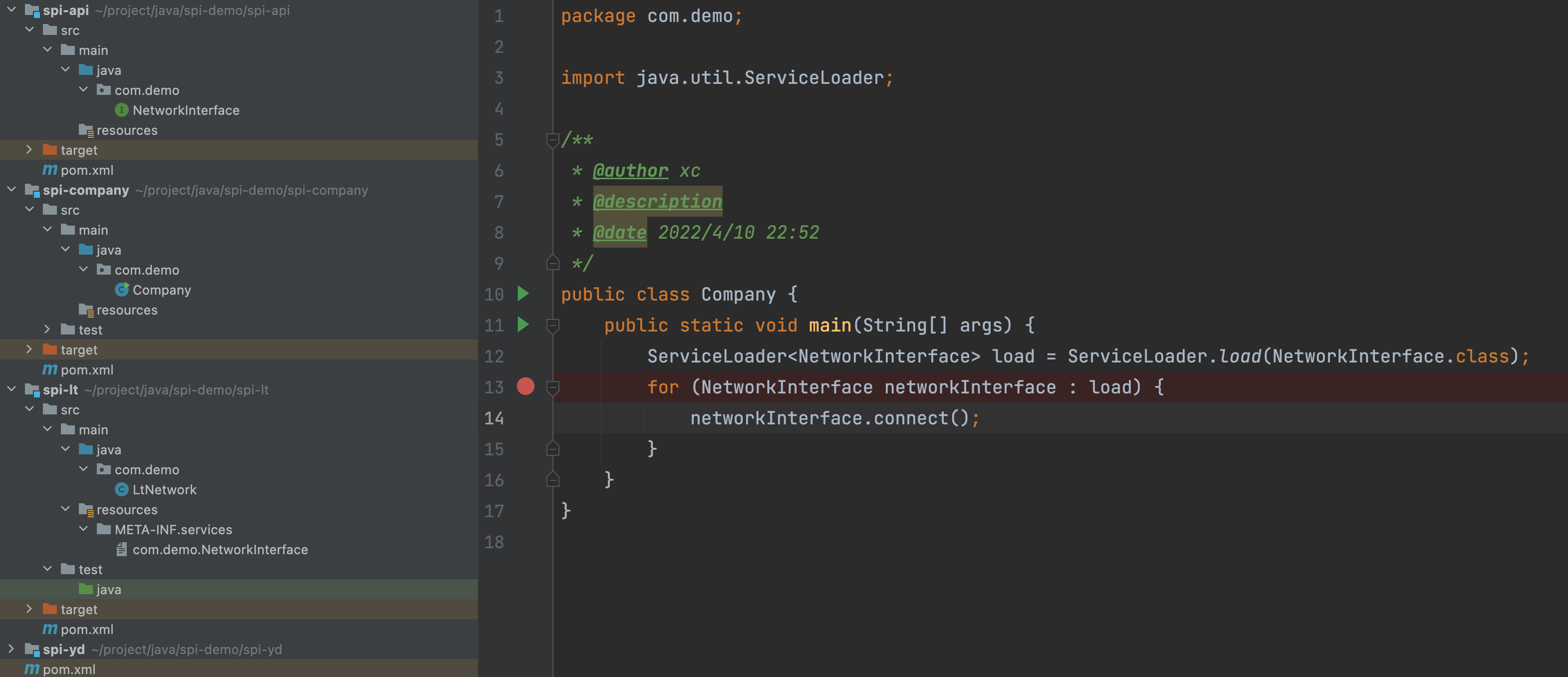
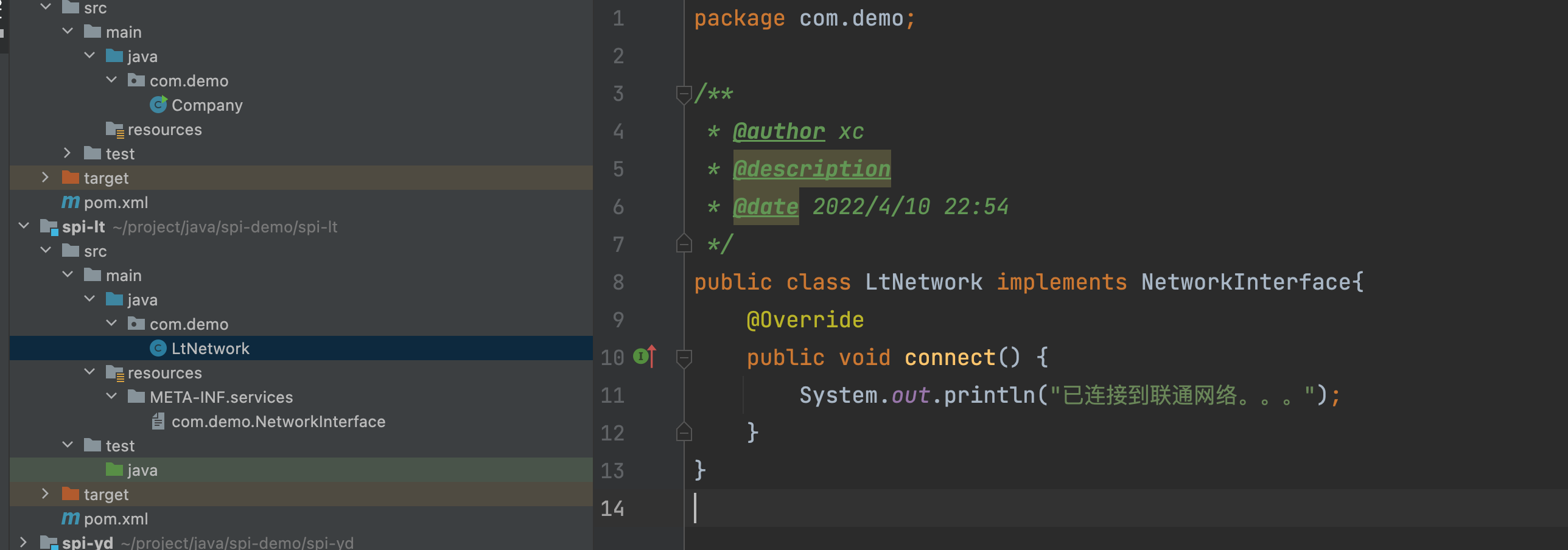
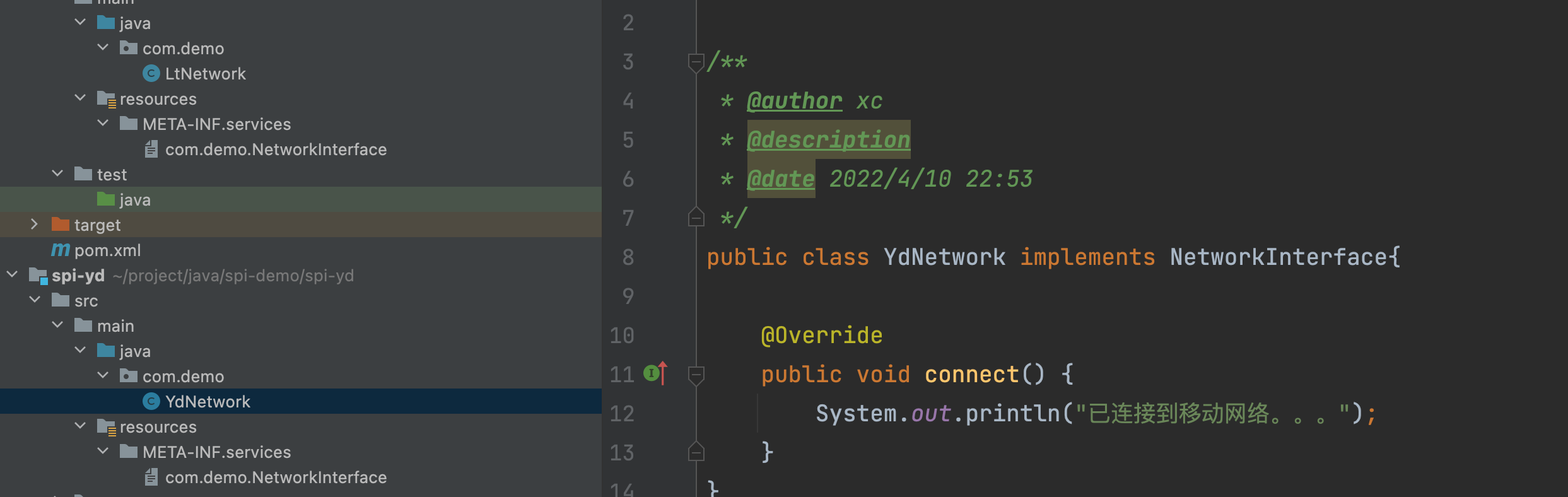
当spi-company依赖spi-lt时运行main方法:
当spi-company依赖spi-yd时运行main方法:
自动装配,即auto-configuration,是基于引入的依赖jar包对springboot应用进行自动配置,提供自动配置的jar包通常以starter结尾,比如mybatis-spring-boot-starter等等。
springboot默认会扫描项目下所有的配置类并注入到ioc容器中,但集成到其他框架并不能直接注入。为了实现真正的auto configuration,springboot的自动装配也采用了和spi类似的设计思想:
使用约定的配置文件:自动装配的配置文件为META-INF/spring.factories,文件内容为org.springframework.boot.autoconfigure.EnableAutoConfiguration=class1,class2,..classN,class是自动配置类的类名
例如mybatis-spring-boot-starter的包结构:

springboot的自动装配核心流程:springboot程序启动,通过spring factories机制加载classpath下的META-INF/spring.factories文件,筛选出所有EnableAutoConfiguration的配置类,反射实例化后注入到springIOC容器中。
todo:实现一个自定义springboot-starter
',34)]))}const h=i(t,[["render",s]]);export{d as __pageData,h as default}; diff --git "a/assets/java_framework_JavaSPI\346\234\272\345\210\266\345\222\214Springboot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md.BtT47OM2.lean.js" "b/assets/java_framework_JavaSPI\346\234\272\345\210\266\345\222\214Springboot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md.BtT47OM2.lean.js" new file mode 100644 index 00000000..c13ecdff --- /dev/null +++ "b/assets/java_framework_JavaSPI\346\234\272\345\210\266\345\222\214Springboot\350\207\252\345\212\250\350\243\205\351\205\215\345\216\237\347\220\206.md.BtT47OM2.lean.js" @@ -0,0 +1 @@ +import{_ as i,c as r,a2 as o,o as e}from"./chunks/framework.BjcrtTwI.js";const d=JSON.parse('{"title":"JavaSPI机制和Springboot自动装配原理","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/JavaSPI机制和Springboot自动装配原理.md","filePath":"java/framework/JavaSPI机制和Springboot自动装配原理.md","lastUpdated":1729217313000}'),t={name:"java/framework/JavaSPI机制和Springboot自动装配原理.md"};function s(l,a,p,n,c,g){return e(),r("div",null,a[0]||(a[0]=[o('SPI(Service Provider Interface)是一种服务发现机制,提供服务接口,且为该接口寻找服务的实现。
从Java6开始引入,是一种基于ClassLoader类加载器发现并加载服务的机制。
标准的SPI构成:
SPI在JDBC中的应用:JDBC要求Driver实现类在类加载的时候将自身的实例注册到DriverManager中,从而加载数据库驱动,在SPI出现之前,加载数据库驱动时要执行Class.forName("com.mysql.jdbc.Driver"), 在SPI出现后,只需要引入对应依赖的JAR包后,ServiceLoader会自动去约定的路径下寻找需要加载的类。
配置文件
无参构造器
当spi-company依赖spi-lt时运行main方法:
当spi-company依赖spi-yd时运行main方法:
自动装配,即auto-configuration,是基于引入的依赖jar包对springboot应用进行自动配置,提供自动配置的jar包通常以starter结尾,比如mybatis-spring-boot-starter等等。
springboot默认会扫描项目下所有的配置类并注入到ioc容器中,但集成到其他框架并不能直接注入。为了实现真正的auto configuration,springboot的自动装配也采用了和spi类似的设计思想:
使用约定的配置文件:自动装配的配置文件为META-INF/spring.factories,文件内容为org.springframework.boot.autoconfigure.EnableAutoConfiguration=class1,class2,..classN,class是自动配置类的类名
例如mybatis-spring-boot-starter的包结构:
springboot的自动装配核心流程:springboot程序启动,通过spring factories机制加载classpath下的META-INF/spring.factories文件,筛选出所有EnableAutoConfiguration的配置类,反射实例化后注入到springIOC容器中。
todo:实现一个自定义springboot-starter
',34)]))}const h=i(t,[["render",s]]);export{d as __pageData,h as default}; diff --git "a/assets/java_framework_Java\346\227\245\345\277\227\345\217\221\345\261\225\345\216\206\345\217\262.md.CM2LZUCH.js" "b/assets/java_framework_Java\346\227\245\345\277\227\345\217\221\345\261\225\345\216\206\345\217\262.md.CM2LZUCH.js" new file mode 100644 index 00000000..b8ddb5fa --- /dev/null +++ "b/assets/java_framework_Java\346\227\245\345\277\227\345\217\221\345\261\225\345\216\206\345\217\262.md.CM2LZUCH.js" @@ -0,0 +1 @@ +import{_ as o,c as e,a2 as l,o as t}from"./chunks/framework.BjcrtTwI.js";const b=JSON.parse('{"title":"Java日志发展历史","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/Java日志发展历史.md","filePath":"java/framework/Java日志发展历史.md","lastUpdated":1729217313000}'),r={name:"java/framework/Java日志发展历史.md"};function i(c,a,p,h,d,n){return t(),e("div",null,a[0]||(a[0]=[l('最近java社区被log4j2的远程代码执行漏洞引爆了,不过还好我们公司的日志主要用的logback,只有少数几个服务用的log4j2,不过还是因为这个加了会班=.=。而java日志有很多乱七八糟的log4j,log4j2,logback,slf4j,jul。。。
2001年以前,java是没有日志库的,打印日志全靠
System.out,System.err
缺点:
1.产生大量的io操作
2.输出的内容不能保存到文件
3.只能打印在控制台,打印完就看不到了
4.无法定制化,且粒度不够细
大佬Ceki Gülcü在2001年开发出了日志库Log4j,后来Log4j成为了Apache项目,Ceki大佬也加入了Apache组织
Apache曾经还建议过SUN公司引入Log4j到java标准库中,但被拒绝了
2002年2月JDK1.4发布,SUN推出了自己的日志标准库JUL(Java Util Logging),其实是照着log4j抄的,但是没抄好,在JDK1.5之后性能和可用性才有所提升
由于Log4j比JUL好用,并且比较成熟,所以Log4j更具优势
2002年8月Apache推出了JCL(Jakarta Commons Logging),也就是日志抽象层,支持运行时动态加载日志组件的实现,也提供了一个默认实现的Simple Log。
(在ClassLoader中进行查找,如果能找到Log4j就默认使用Log4j的实现,如果没有则使用JUL实现,再没有则使用JCL内部提供的Simple Log实现)
但是JCL有三个缺点:
2006年大佬Ceki Gülcü(Log4j)因为一些原因离开了Apache,之后Ceki觉得JCL不好用,自己重新开发了一套新的日志标准接口规范Slf4j(Simple Logging Facade for Java),也可称为日志门面,很明显Slf4j是为了对标JCL,后面也证明了Slf4j比JCL更加优秀
大佬Ceki提供了一系列的桥接包来帮助Slf4j接口与其他日志库建立关系,这种方式称为桥接设置模式。
代码使用Slf4j接口,就可以实现日志的统一标准化,后续如果想要更换日志的实现,只需要引入Slf4j和相关的桥接包,再引入具体的日志标准库即可。
Ceki大佬觉得市场上的日志标准库都是间接实现Slf4j接口,每次都需要配合桥接包,因此在2016年,Ceki大佬基于Slf4j接口开发出了Logback日志标准库作为Slf4j的默认实现,Logback也十分给力,在功能的完整度和性能上超越了所有已有的日志标准库
2012年,Apache推出新项目Log4j2(不兼容Log4j),Log4j2全面借鉴了Slf4j+Logback,虽然log4j2有明显抄袭嫌疑,但是汲取了logback优秀的设计,还解决了一些问题,性能有了极大提升,官方测试是18倍
Log4j2不仅具有Logback的所有特性,还做了分离设计,分为log4j-api和log4j-core,api是日志接口,core是日志标准库,而且Apache也为Log4j2提供了各种桥接包
',29)]))}const k=o(r,[["render",i]]);export{b as __pageData,k as default}; diff --git "a/assets/java_framework_Java\346\227\245\345\277\227\345\217\221\345\261\225\345\216\206\345\217\262.md.CM2LZUCH.lean.js" "b/assets/java_framework_Java\346\227\245\345\277\227\345\217\221\345\261\225\345\216\206\345\217\262.md.CM2LZUCH.lean.js" new file mode 100644 index 00000000..b8ddb5fa --- /dev/null +++ "b/assets/java_framework_Java\346\227\245\345\277\227\345\217\221\345\261\225\345\216\206\345\217\262.md.CM2LZUCH.lean.js" @@ -0,0 +1 @@ +import{_ as o,c as e,a2 as l,o as t}from"./chunks/framework.BjcrtTwI.js";const b=JSON.parse('{"title":"Java日志发展历史","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/Java日志发展历史.md","filePath":"java/framework/Java日志发展历史.md","lastUpdated":1729217313000}'),r={name:"java/framework/Java日志发展历史.md"};function i(c,a,p,h,d,n){return t(),e("div",null,a[0]||(a[0]=[l('最近java社区被log4j2的远程代码执行漏洞引爆了,不过还好我们公司的日志主要用的logback,只有少数几个服务用的log4j2,不过还是因为这个加了会班=.=。而java日志有很多乱七八糟的log4j,log4j2,logback,slf4j,jul。。。
2001年以前,java是没有日志库的,打印日志全靠
System.out,System.err
缺点:
1.产生大量的io操作
2.输出的内容不能保存到文件
3.只能打印在控制台,打印完就看不到了
4.无法定制化,且粒度不够细
大佬Ceki Gülcü在2001年开发出了日志库Log4j,后来Log4j成为了Apache项目,Ceki大佬也加入了Apache组织
Apache曾经还建议过SUN公司引入Log4j到java标准库中,但被拒绝了
2002年2月JDK1.4发布,SUN推出了自己的日志标准库JUL(Java Util Logging),其实是照着log4j抄的,但是没抄好,在JDK1.5之后性能和可用性才有所提升
由于Log4j比JUL好用,并且比较成熟,所以Log4j更具优势
2002年8月Apache推出了JCL(Jakarta Commons Logging),也就是日志抽象层,支持运行时动态加载日志组件的实现,也提供了一个默认实现的Simple Log。
(在ClassLoader中进行查找,如果能找到Log4j就默认使用Log4j的实现,如果没有则使用JUL实现,再没有则使用JCL内部提供的Simple Log实现)
但是JCL有三个缺点:
2006年大佬Ceki Gülcü(Log4j)因为一些原因离开了Apache,之后Ceki觉得JCL不好用,自己重新开发了一套新的日志标准接口规范Slf4j(Simple Logging Facade for Java),也可称为日志门面,很明显Slf4j是为了对标JCL,后面也证明了Slf4j比JCL更加优秀
大佬Ceki提供了一系列的桥接包来帮助Slf4j接口与其他日志库建立关系,这种方式称为桥接设置模式。
代码使用Slf4j接口,就可以实现日志的统一标准化,后续如果想要更换日志的实现,只需要引入Slf4j和相关的桥接包,再引入具体的日志标准库即可。
Ceki大佬觉得市场上的日志标准库都是间接实现Slf4j接口,每次都需要配合桥接包,因此在2016年,Ceki大佬基于Slf4j接口开发出了Logback日志标准库作为Slf4j的默认实现,Logback也十分给力,在功能的完整度和性能上超越了所有已有的日志标准库
2012年,Apache推出新项目Log4j2(不兼容Log4j),Log4j2全面借鉴了Slf4j+Logback,虽然log4j2有明显抄袭嫌疑,但是汲取了logback优秀的设计,还解决了一些问题,性能有了极大提升,官方测试是18倍
Log4j2不仅具有Logback的所有特性,还做了分离设计,分为log4j-api和log4j-core,api是日志接口,core是日志标准库,而且Apache也为Log4j2提供了各种桥接包
',29)]))}const k=o(r,[["render",i]]);export{b as __pageData,k as default}; diff --git "a/assets/java_framework_Mybatis Generator\351\205\215\347\275\256.md.BSx7_gyv.js" "b/assets/java_framework_Mybatis Generator\351\205\215\347\275\256.md.BSx7_gyv.js" new file mode 100644 index 00000000..956fa087 --- /dev/null +++ "b/assets/java_framework_Mybatis Generator\351\205\215\347\275\256.md.BSx7_gyv.js" @@ -0,0 +1,369 @@ +import{_ as i,c as a,a2 as n,o as h}from"./chunks/framework.BjcrtTwI.js";const y=JSON.parse('{"title":"Mybatis Generator配置","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/Mybatis Generator配置.md","filePath":"java/framework/Mybatis Generator配置.md","lastUpdated":1729217313000}'),l={name:"java/framework/Mybatis Generator配置.md"};function k(t,s,p,e,E,r){return h(),a("div",null,s[0]||(s[0]=[n(`mbg逆向工程能快速生成实体类和mapper文件以及xml,提升开发效率。记录下不同持久层框架对应的mbg配置备忘。
mbg的context标签可以自定义targetRuntime,具体的区别可以在http://mybatis.org/generator/quickstart.html#target-runtime-information-and-samples查看。MyBatis3,生成的代码量比较大,会有byExample和selective相关的代码生成。MyBatis3Simple生成的代码量比较小,不会有byExample和selective方法生成。
常用运行方式(还包含 ant、命令行、eclipse)
maven依赖
<dependency>
+ <groupId>org.mybatis.generator</groupId>
+ <artifactId>mybatis-generator-core</artifactId>
+ <version>1.3.5</version>
+</dependency>
+<dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.16</version>
+</dependency>使用maven插件时
<build>
+ <plugins>
+ <plugin>
+ <groupId>org.mybatis.generator</groupId>
+ <artifactId>mybatis-generator-maven-plugin</artifactId>
+ <version>1.3.5</version>
+ <configuration>
+ <!-- 在控制台打印执行日志 -->
+ <verbose>true</verbose>
+ <!-- 重复生成时会覆盖之前的文件-->
+ <overwrite>true</overwrite>
+ <configurationFile>src/main/resources/generatorConfig.xml</configurationFile>
+ </configuration>
+ <dependencies>
+ <dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.16</version>
+ </dependency>
+ </dependencies>
+ </plugin>
+ </plugins>
+ </build><?xml version="1.0" encoding="UTF-8"?>
+<!DOCTYPE generatorConfiguration
+ PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
+ "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
+
+<generatorConfiguration>
+
+ <context id="Mysql" targetRuntime="MyBatis3Simple"
+ defaultModelType="flat">
+
+ <!--property*,-->
+ <property name="beginningDelimiter" value="\`"/>
+ <property name="endingDelimiter" value="\`"/>
+
+ <!--plugin*,-->
+ <!-- 为继承的BaseMapper接口添加对应的实现类 -->
+ <plugin type="tk.mybatis.mapper.generator.MapperPlugin">
+ <property name="mappers" value="cn.xxx.CustomBaseMapper"/>
+ </plugin>
+
+ <!--commentGenerator?,-->
+ <!--<commentGenerator type="mybatis.generator.MyCommentGenerator"></commentGenerator>-->
+
+ <!--jdbcConnection,-->
+ <jdbcConnection driverClass="com.mysql.jdbc.Driver"
+ connectionURL="jdbc:mysql://xxx.xxx.xxx/xxx?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&useSSL=false"
+ userId=""
+ password="">
+ </jdbcConnection>
+
+ <!--javaTypeResolver?, 自定义jdbcType和javaType的映射关系,比如默认的TINYINT会对应Java的Byte类型,如果我们想让TINYINT对应JavaType为Integer就需要在解析类中自定义,这种方式适合源码方式运行mbg,使用maven plugin会比较麻烦-->
+ <javaTypeResolver type="mybatis.generator.MyJavaTypeResolver"></javaTypeResolver>
+
+ <!--javaModelGenerator,-->
+ <javaModelGenerator targetPackage="cn.xxx.dao.entity"
+ targetProject="/Users/story/project/xx/src/main/java">
+ <!--<property name="rootClass" value="xx.BaseEntity"/> entity会继承的类-->
+ </javaModelGenerator>
+
+ <!--sqlMapGenerator?,-->
+ <sqlMapGenerator targetPackage="mapper"
+ targetProject="/Users/story/project/xx/src/main/resources"/>
+
+ <!--javaClientGenerator?,-->
+ <javaClientGenerator targetPackage="cn.xxx.app.wechat.dao.mapper"
+ targetProject="/Users/story/project/xxx/src/main/java"
+ type="XMLMAPPER"/>
+
+ <!--table+-->
+ <table tableName="tb_xx" domainObjectName="XxEntity">
+ <generatedKey column="id" sqlStatement="Mysql" identity="true"/>
+ </table>
+
+ </context>
+
+</generatorConfiguration>public interface CustomBaseMapper<T> extends tk.mybatis.mapper.common.BaseMapper<T>, MySqlMapper<T> {
+
+}public class MyJavaTypeResolver implements JavaTypeResolver {
+
+ protected List<String> warnings;
+
+ protected Properties properties;
+
+ protected Context context;
+
+ protected boolean forceBigDecimals;
+
+ protected Map<Integer, JavaTypeResolverDefaultImpl.JdbcTypeInformation> typeMap;
+
+ public MyJavaTypeResolver() {
+ super();
+ properties = new Properties();
+ typeMap = new HashMap<Integer, JavaTypeResolverDefaultImpl.JdbcTypeInformation>();
+
+ typeMap.put(Types.ARRAY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("ARRAY", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.BIGINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BIGINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Long.class.getName())));
+ typeMap.put(Types.BINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.BIT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BIT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Boolean.class.getName())));
+ typeMap.put(Types.BLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.BOOLEAN, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BOOLEAN", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Boolean.class.getName())));
+ typeMap.put(Types.CHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("CHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.CLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("CLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.DATALINK, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DATALINK", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.DATE, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DATE", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+ typeMap.put(Types.DISTINCT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DISTINCT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.DOUBLE, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DOUBLE", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Double.class.getName())));
+ typeMap.put(Types.FLOAT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("FLOAT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Double.class.getName())));
+ typeMap.put(Types.INTEGER, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("INTEGER", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+ typeMap.put(Types.JAVA_OBJECT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("JAVA_OBJECT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Jdbc4Types.LONGNVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("LONGNVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.LONGVARBINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation(
+ "LONGVARBINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.LONGVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("LONGVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NCLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NCLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.NULL, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NULL", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.OTHER, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("OTHER", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.REAL, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("REAL", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Float.class.getName())));
+ typeMap.put(Types.REF, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("REF", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.SMALLINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("SMALLINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+ typeMap.put(Types.STRUCT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("STRUCT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.TIME, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TIME", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+ typeMap.put(Types.TIMESTAMP, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TIMESTAMP", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+
+ typeMap.put(Types.TINYINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TINYINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+
+ typeMap.put(Types.VARBINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("VARBINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.VARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("VARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+
+ }
+
+ @Override
+ public void addConfigurationProperties(Properties properties) {
+ this.properties.putAll(properties);
+ forceBigDecimals = StringUtility.isTrue(properties.getProperty(PropertyRegistry.TYPE_RESOLVER_FORCE_BIG_DECIMALS));
+ }
+
+ @Override
+ public FullyQualifiedJavaType calculateJavaType(
+ IntrospectedColumn introspectedColumn) {
+ FullyQualifiedJavaType answer;
+ JavaTypeResolverDefaultImpl.JdbcTypeInformation jdbcTypeInformation = typeMap
+ .get(introspectedColumn.getJdbcType());
+
+ if (jdbcTypeInformation == null) {
+ switch (introspectedColumn.getJdbcType()) {
+ case Types.DECIMAL:
+ case Types.NUMERIC:
+ if (introspectedColumn.getScale() > 0
+ || introspectedColumn.getLength() > 18
+ || forceBigDecimals) {
+ answer = new FullyQualifiedJavaType(BigDecimal.class
+ .getName());
+ } else if (introspectedColumn.getLength() > 9) {
+ answer = new FullyQualifiedJavaType(Long.class.getName());
+ } else if (introspectedColumn.getLength() > 4) {
+ answer = new FullyQualifiedJavaType(Integer.class.getName());
+ } else {
+ answer = new FullyQualifiedJavaType(Short.class.getName());
+ }
+ break;
+
+ default:
+ answer = null;
+ break;
+ }
+ } else {
+ answer = jdbcTypeInformation.getFullyQualifiedJavaType();
+ }
+
+ return answer;
+ }
+
+ @Override
+ public String calculateJdbcTypeName(IntrospectedColumn introspectedColumn) {
+ String answer;
+ JavaTypeResolverDefaultImpl.JdbcTypeInformation jdbcTypeInformation = typeMap
+ .get(introspectedColumn.getJdbcType());
+
+ if (jdbcTypeInformation == null) {
+ switch (introspectedColumn.getJdbcType()) {
+ case Types.DECIMAL:
+ answer = "DECIMAL"; //$NON-NLS-1$
+ break;
+ case Types.NUMERIC:
+ answer = "NUMERIC"; //$NON-NLS-1$
+ break;
+ default:
+ answer = null;
+ break;
+ }
+ } else {
+ answer = jdbcTypeInformation.getJdbcTypeName();
+ }
+
+ return answer;
+ }
+
+ @Override
+ public void setWarnings(List<String> warnings) {
+ this.warnings = warnings;
+ }
+
+ @Override
+ public void setContext(Context context) {
+ this.context = context;
+ }
+
+ public static class JdbcTypeInformation {
+ private String jdbcTypeName;
+
+ private FullyQualifiedJavaType fullyQualifiedJavaType;
+
+ public JdbcTypeInformation(String jdbcTypeName,
+ FullyQualifiedJavaType fullyQualifiedJavaType) {
+ this.jdbcTypeName = jdbcTypeName;
+ this.fullyQualifiedJavaType = fullyQualifiedJavaType;
+ }
+
+ public String getJdbcTypeName() {
+ return jdbcTypeName;
+ }
+
+ public FullyQualifiedJavaType getFullyQualifiedJavaType() {
+ return fullyQualifiedJavaType;
+ }
+ }
+}public class MyBatisGeneratorTool {
+ public static void main(String[] args) {
+
+ URL resource = Thread.currentThread().getContextClassLoader().getResource("");
+
+ System.out.println(resource.getPath());
+
+ List<String> warnings = new ArrayList<String>();
+ boolean overwrite = true;
+ File configFile = new File(resource.getPath() + "../../src/test/resources/generator/generatorConfig.xml");
+ ConfigurationParser cp = new ConfigurationParser(warnings);
+ Configuration config = null;
+
+ try {
+ config = cp.parseConfiguration(configFile);
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (XMLParserException e) {
+ e.printStackTrace();
+ }
+
+ DefaultShellCallback callback = new DefaultShellCallback(overwrite);
+ MyBatisGenerator myBatisGenerator = null;
+
+ try {
+ myBatisGenerator = new MyBatisGenerator(config, callback, warnings);
+ } catch (InvalidConfigurationException e) {
+ e.printStackTrace();
+ }
+
+ try {
+ myBatisGenerator.generate(null);
+ } catch (SQLException e) {
+ e.printStackTrace();
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+}
<?xml version="1.0" encoding="UTF-8"?>
+<!DOCTYPE generatorConfiguration
+ PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
+ "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
+<generatorConfiguration>
+ <!-- context 是逆向工程的主要配置信息 -->
+ <!-- id:起个名字 -->
+ <!-- targetRuntime:设置生成的文件适用于那个 mybatis 版本 -->
+ <context id="default" targetRuntime="MyBatis3">
+ <!--optional,指在创建class时,对注释进行控制-->
+ <commentGenerator>
+ <property name="suppressDate" value="true"/>
+ <!-- 是否去除自动生成的注释 true:是 : false:否 -->
+ <property name="suppressAllComments" value="true"/>
+ </commentGenerator>
+ <!--jdbc的数据库连接 wg_insert 为数据库名字-->
+ <jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
+ connectionURL="jdbc:mysql://xxx/xx?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&useSSL=false&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true"
+ userId=""
+ password="">
+ </jdbcConnection>
+ <!--非必须,类型处理器,在数据库类型和java类型之间的转换控制-->
+ <javaTypeResolver>
+ <!-- 默认情况下数据库中的 decimal,bigInt 在 Java 对应是 sql 下的 BigDecimal 类 -->
+ <!-- 不是 double 和 long 类型 -->
+ <!-- 使用常用的基本类型代替 sql 包下的引用类型 -->
+ <property name="forceBigDecimals" value="false"/>
+ </javaTypeResolver>
+ <!-- targetPackage:生成的实体类所在的包 -->
+ <!-- targetProject:生成的实体类所在的硬盘位置 -->
+ <javaModelGenerator targetPackage="xxx"
+ targetProject="/Users/story/project/xxx/src/main/java">
+ <!-- 是否允许子包 -->
+ <property name="enableSubPackages" value="false"/>
+ <!-- 是否对modal添加构造函数 -->
+ <!-- <property name="constructorBased" value="true"/>-->
+ <!-- 是否清理从数据库中查询出的字符串左右两边的空白字符 -->
+ <!-- <property name="trimStrings" value="true"/>-->
+ <!-- 建立modal对象是否不可改变 即生成的modal对象不会有setter方法,只有构造方法 -->
+ <!-- <property name="immutable" value="false"/>-->
+ </javaModelGenerator>
+ <!-- targetPackage 和 targetProject:生成的 mapper 文件的包和位置 -->
+ <sqlMapGenerator targetPackage="xx"
+ targetProject="/Users/story/project/xx/src/main/resources">
+ <!-- 针对数据库的一个配置,是否把 schema 作为字包名 -->
+ <property name="enableSubPackages" value="false"/>
+ </sqlMapGenerator>
+ <!-- targetPackage 和 targetProject:生成的 interface 文件的包和位置 -->
+ <javaClientGenerator type="XMLMAPPER"
+ targetPackage="xx" targetProject="/Users/story/project/xxx/src/main/java">
+ <!-- 针对 oracle 数据库的一个配置,是否把 schema 作为字包名 -->
+ <property name="enableSubPackages" value="false"/>
+ </javaClientGenerator>
+ <!-- tableName是数据库中的表名,domainObjectName是生成的JAVA模型名,后面的参数不用改,要生成更多的表就在下面继续加table标签 -->
+ <table tableName="xxx" domainObjectName="XxxEntity">
+ </table>
+ </context>
+</generatorConfiguration>
mbg逆向工程能快速生成实体类和mapper文件以及xml,提升开发效率。记录下不同持久层框架对应的mbg配置备忘。
mbg的context标签可以自定义targetRuntime,具体的区别可以在http://mybatis.org/generator/quickstart.html#target-runtime-information-and-samples查看。MyBatis3,生成的代码量比较大,会有byExample和selective相关的代码生成。MyBatis3Simple生成的代码量比较小,不会有byExample和selective方法生成。
常用运行方式(还包含 ant、命令行、eclipse)
maven依赖
<dependency>
+ <groupId>org.mybatis.generator</groupId>
+ <artifactId>mybatis-generator-core</artifactId>
+ <version>1.3.5</version>
+</dependency>
+<dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.16</version>
+</dependency>使用maven插件时
<build>
+ <plugins>
+ <plugin>
+ <groupId>org.mybatis.generator</groupId>
+ <artifactId>mybatis-generator-maven-plugin</artifactId>
+ <version>1.3.5</version>
+ <configuration>
+ <!-- 在控制台打印执行日志 -->
+ <verbose>true</verbose>
+ <!-- 重复生成时会覆盖之前的文件-->
+ <overwrite>true</overwrite>
+ <configurationFile>src/main/resources/generatorConfig.xml</configurationFile>
+ </configuration>
+ <dependencies>
+ <dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.16</version>
+ </dependency>
+ </dependencies>
+ </plugin>
+ </plugins>
+ </build><?xml version="1.0" encoding="UTF-8"?>
+<!DOCTYPE generatorConfiguration
+ PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
+ "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
+
+<generatorConfiguration>
+
+ <context id="Mysql" targetRuntime="MyBatis3Simple"
+ defaultModelType="flat">
+
+ <!--property*,-->
+ <property name="beginningDelimiter" value="\`"/>
+ <property name="endingDelimiter" value="\`"/>
+
+ <!--plugin*,-->
+ <!-- 为继承的BaseMapper接口添加对应的实现类 -->
+ <plugin type="tk.mybatis.mapper.generator.MapperPlugin">
+ <property name="mappers" value="cn.xxx.CustomBaseMapper"/>
+ </plugin>
+
+ <!--commentGenerator?,-->
+ <!--<commentGenerator type="mybatis.generator.MyCommentGenerator"></commentGenerator>-->
+
+ <!--jdbcConnection,-->
+ <jdbcConnection driverClass="com.mysql.jdbc.Driver"
+ connectionURL="jdbc:mysql://xxx.xxx.xxx/xxx?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&useSSL=false"
+ userId=""
+ password="">
+ </jdbcConnection>
+
+ <!--javaTypeResolver?, 自定义jdbcType和javaType的映射关系,比如默认的TINYINT会对应Java的Byte类型,如果我们想让TINYINT对应JavaType为Integer就需要在解析类中自定义,这种方式适合源码方式运行mbg,使用maven plugin会比较麻烦-->
+ <javaTypeResolver type="mybatis.generator.MyJavaTypeResolver"></javaTypeResolver>
+
+ <!--javaModelGenerator,-->
+ <javaModelGenerator targetPackage="cn.xxx.dao.entity"
+ targetProject="/Users/story/project/xx/src/main/java">
+ <!--<property name="rootClass" value="xx.BaseEntity"/> entity会继承的类-->
+ </javaModelGenerator>
+
+ <!--sqlMapGenerator?,-->
+ <sqlMapGenerator targetPackage="mapper"
+ targetProject="/Users/story/project/xx/src/main/resources"/>
+
+ <!--javaClientGenerator?,-->
+ <javaClientGenerator targetPackage="cn.xxx.app.wechat.dao.mapper"
+ targetProject="/Users/story/project/xxx/src/main/java"
+ type="XMLMAPPER"/>
+
+ <!--table+-->
+ <table tableName="tb_xx" domainObjectName="XxEntity">
+ <generatedKey column="id" sqlStatement="Mysql" identity="true"/>
+ </table>
+
+ </context>
+
+</generatorConfiguration>public interface CustomBaseMapper<T> extends tk.mybatis.mapper.common.BaseMapper<T>, MySqlMapper<T> {
+
+}public class MyJavaTypeResolver implements JavaTypeResolver {
+
+ protected List<String> warnings;
+
+ protected Properties properties;
+
+ protected Context context;
+
+ protected boolean forceBigDecimals;
+
+ protected Map<Integer, JavaTypeResolverDefaultImpl.JdbcTypeInformation> typeMap;
+
+ public MyJavaTypeResolver() {
+ super();
+ properties = new Properties();
+ typeMap = new HashMap<Integer, JavaTypeResolverDefaultImpl.JdbcTypeInformation>();
+
+ typeMap.put(Types.ARRAY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("ARRAY", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.BIGINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BIGINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Long.class.getName())));
+ typeMap.put(Types.BINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.BIT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BIT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Boolean.class.getName())));
+ typeMap.put(Types.BLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.BOOLEAN, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BOOLEAN", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Boolean.class.getName())));
+ typeMap.put(Types.CHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("CHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.CLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("CLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.DATALINK, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DATALINK", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.DATE, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DATE", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+ typeMap.put(Types.DISTINCT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DISTINCT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.DOUBLE, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DOUBLE", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Double.class.getName())));
+ typeMap.put(Types.FLOAT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("FLOAT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Double.class.getName())));
+ typeMap.put(Types.INTEGER, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("INTEGER", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+ typeMap.put(Types.JAVA_OBJECT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("JAVA_OBJECT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Jdbc4Types.LONGNVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("LONGNVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.LONGVARBINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation(
+ "LONGVARBINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.LONGVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("LONGVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NCLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NCLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.NULL, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NULL", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.OTHER, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("OTHER", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.REAL, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("REAL", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Float.class.getName())));
+ typeMap.put(Types.REF, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("REF", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.SMALLINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("SMALLINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+ typeMap.put(Types.STRUCT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("STRUCT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.TIME, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TIME", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+ typeMap.put(Types.TIMESTAMP, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TIMESTAMP", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+
+ typeMap.put(Types.TINYINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TINYINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+
+ typeMap.put(Types.VARBINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("VARBINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.VARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("VARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+
+ }
+
+ @Override
+ public void addConfigurationProperties(Properties properties) {
+ this.properties.putAll(properties);
+ forceBigDecimals = StringUtility.isTrue(properties.getProperty(PropertyRegistry.TYPE_RESOLVER_FORCE_BIG_DECIMALS));
+ }
+
+ @Override
+ public FullyQualifiedJavaType calculateJavaType(
+ IntrospectedColumn introspectedColumn) {
+ FullyQualifiedJavaType answer;
+ JavaTypeResolverDefaultImpl.JdbcTypeInformation jdbcTypeInformation = typeMap
+ .get(introspectedColumn.getJdbcType());
+
+ if (jdbcTypeInformation == null) {
+ switch (introspectedColumn.getJdbcType()) {
+ case Types.DECIMAL:
+ case Types.NUMERIC:
+ if (introspectedColumn.getScale() > 0
+ || introspectedColumn.getLength() > 18
+ || forceBigDecimals) {
+ answer = new FullyQualifiedJavaType(BigDecimal.class
+ .getName());
+ } else if (introspectedColumn.getLength() > 9) {
+ answer = new FullyQualifiedJavaType(Long.class.getName());
+ } else if (introspectedColumn.getLength() > 4) {
+ answer = new FullyQualifiedJavaType(Integer.class.getName());
+ } else {
+ answer = new FullyQualifiedJavaType(Short.class.getName());
+ }
+ break;
+
+ default:
+ answer = null;
+ break;
+ }
+ } else {
+ answer = jdbcTypeInformation.getFullyQualifiedJavaType();
+ }
+
+ return answer;
+ }
+
+ @Override
+ public String calculateJdbcTypeName(IntrospectedColumn introspectedColumn) {
+ String answer;
+ JavaTypeResolverDefaultImpl.JdbcTypeInformation jdbcTypeInformation = typeMap
+ .get(introspectedColumn.getJdbcType());
+
+ if (jdbcTypeInformation == null) {
+ switch (introspectedColumn.getJdbcType()) {
+ case Types.DECIMAL:
+ answer = "DECIMAL"; //$NON-NLS-1$
+ break;
+ case Types.NUMERIC:
+ answer = "NUMERIC"; //$NON-NLS-1$
+ break;
+ default:
+ answer = null;
+ break;
+ }
+ } else {
+ answer = jdbcTypeInformation.getJdbcTypeName();
+ }
+
+ return answer;
+ }
+
+ @Override
+ public void setWarnings(List<String> warnings) {
+ this.warnings = warnings;
+ }
+
+ @Override
+ public void setContext(Context context) {
+ this.context = context;
+ }
+
+ public static class JdbcTypeInformation {
+ private String jdbcTypeName;
+
+ private FullyQualifiedJavaType fullyQualifiedJavaType;
+
+ public JdbcTypeInformation(String jdbcTypeName,
+ FullyQualifiedJavaType fullyQualifiedJavaType) {
+ this.jdbcTypeName = jdbcTypeName;
+ this.fullyQualifiedJavaType = fullyQualifiedJavaType;
+ }
+
+ public String getJdbcTypeName() {
+ return jdbcTypeName;
+ }
+
+ public FullyQualifiedJavaType getFullyQualifiedJavaType() {
+ return fullyQualifiedJavaType;
+ }
+ }
+}public class MyBatisGeneratorTool {
+ public static void main(String[] args) {
+
+ URL resource = Thread.currentThread().getContextClassLoader().getResource("");
+
+ System.out.println(resource.getPath());
+
+ List<String> warnings = new ArrayList<String>();
+ boolean overwrite = true;
+ File configFile = new File(resource.getPath() + "../../src/test/resources/generator/generatorConfig.xml");
+ ConfigurationParser cp = new ConfigurationParser(warnings);
+ Configuration config = null;
+
+ try {
+ config = cp.parseConfiguration(configFile);
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (XMLParserException e) {
+ e.printStackTrace();
+ }
+
+ DefaultShellCallback callback = new DefaultShellCallback(overwrite);
+ MyBatisGenerator myBatisGenerator = null;
+
+ try {
+ myBatisGenerator = new MyBatisGenerator(config, callback, warnings);
+ } catch (InvalidConfigurationException e) {
+ e.printStackTrace();
+ }
+
+ try {
+ myBatisGenerator.generate(null);
+ } catch (SQLException e) {
+ e.printStackTrace();
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+}
<?xml version="1.0" encoding="UTF-8"?>
+<!DOCTYPE generatorConfiguration
+ PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
+ "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
+<generatorConfiguration>
+ <!-- context 是逆向工程的主要配置信息 -->
+ <!-- id:起个名字 -->
+ <!-- targetRuntime:设置生成的文件适用于那个 mybatis 版本 -->
+ <context id="default" targetRuntime="MyBatis3">
+ <!--optional,指在创建class时,对注释进行控制-->
+ <commentGenerator>
+ <property name="suppressDate" value="true"/>
+ <!-- 是否去除自动生成的注释 true:是 : false:否 -->
+ <property name="suppressAllComments" value="true"/>
+ </commentGenerator>
+ <!--jdbc的数据库连接 wg_insert 为数据库名字-->
+ <jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
+ connectionURL="jdbc:mysql://xxx/xx?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&useSSL=false&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true"
+ userId=""
+ password="">
+ </jdbcConnection>
+ <!--非必须,类型处理器,在数据库类型和java类型之间的转换控制-->
+ <javaTypeResolver>
+ <!-- 默认情况下数据库中的 decimal,bigInt 在 Java 对应是 sql 下的 BigDecimal 类 -->
+ <!-- 不是 double 和 long 类型 -->
+ <!-- 使用常用的基本类型代替 sql 包下的引用类型 -->
+ <property name="forceBigDecimals" value="false"/>
+ </javaTypeResolver>
+ <!-- targetPackage:生成的实体类所在的包 -->
+ <!-- targetProject:生成的实体类所在的硬盘位置 -->
+ <javaModelGenerator targetPackage="xxx"
+ targetProject="/Users/story/project/xxx/src/main/java">
+ <!-- 是否允许子包 -->
+ <property name="enableSubPackages" value="false"/>
+ <!-- 是否对modal添加构造函数 -->
+ <!-- <property name="constructorBased" value="true"/>-->
+ <!-- 是否清理从数据库中查询出的字符串左右两边的空白字符 -->
+ <!-- <property name="trimStrings" value="true"/>-->
+ <!-- 建立modal对象是否不可改变 即生成的modal对象不会有setter方法,只有构造方法 -->
+ <!-- <property name="immutable" value="false"/>-->
+ </javaModelGenerator>
+ <!-- targetPackage 和 targetProject:生成的 mapper 文件的包和位置 -->
+ <sqlMapGenerator targetPackage="xx"
+ targetProject="/Users/story/project/xx/src/main/resources">
+ <!-- 针对数据库的一个配置,是否把 schema 作为字包名 -->
+ <property name="enableSubPackages" value="false"/>
+ </sqlMapGenerator>
+ <!-- targetPackage 和 targetProject:生成的 interface 文件的包和位置 -->
+ <javaClientGenerator type="XMLMAPPER"
+ targetPackage="xx" targetProject="/Users/story/project/xxx/src/main/java">
+ <!-- 针对 oracle 数据库的一个配置,是否把 schema 作为字包名 -->
+ <property name="enableSubPackages" value="false"/>
+ </javaClientGenerator>
+ <!-- tableName是数据库中的表名,domainObjectName是生成的JAVA模型名,后面的参数不用改,要生成更多的表就在下面继续加table标签 -->
+ <table tableName="xxx" domainObjectName="XxxEntity">
+ </table>
+ </context>
+</generatorConfiguration>
传统的POI用户模式解析Excel为我们操作提供了丰富的API,用起来很方便,但是这种模式是一次性将Excel中的数据全部写入内存,并且要还封装结构,使得内存的占用远远超过原本Excel文件的大小,稍微大一点的文件采用用户模式进行解析都会内存溢出,由于现在做的项目要处理的Excel数据量普遍都很大,而且业务对导入功能的使用尤其频繁,所以必须采用事件模式的解析方式来实现业务需求.
事件模式避免内存溢出的原理很简单,就是采用SAX方式解析Excel文件底层的XML文件,这样逐行读取,逐行处理的方式可以完美解决内存占用的问题.
简单的入门程序可以从POI官网找到,下面是根据官方demo封装的一个比较完善的类,只需要创建一个类继承该抽象类然后实现抽象方法rowHandler,然后在rowHandler里进行我们需要的业务操作即可.
关于事件模式解析Excel的代码执行具体流程以后有时间再写篇文章进行总结~
/**
+ * @author storyxc
+ * @description POI事件模式读取Excel抽象类
+ * @createdTime 2020/6/18 14:27
+ */
+public abstract class POIEventModeHandler extends DefaultHandler {
+
+ /**
+ * 构造方法
+ *
+ * @param parseCellValueStringFlag 是否将单元格值解析成字符串
+ * @param ignoreFirstRow 是否忽略首行(一般是表头)
+ */
+ public POIEventModeHandler(final boolean parseCellValueStringFlag, final boolean ignoreFirstRow) {
+ this.parseCellValueStringFlag = parseCellValueStringFlag;
+ this.ignoreFirstRow = ignoreFirstRow;
+ }
+
+ /**
+ * 构造方法
+ *
+ * @param parseCellValueStringFlag 将单元格值解析成字符串
+ * @param ignoreFirstRow 忽略首行
+ * @param dataFormatStyle 指定日期类型解析格式 默认yyyy-MM-dd
+ */
+ public POIEventModeHandler(final boolean parseCellValueStringFlag, final boolean ignoreFirstRow, final String dataFormatStyle) {
+ this.parseCellValueStringFlag = parseCellValueStringFlag;
+ this.ignoreFirstRow = ignoreFirstRow;
+ this.dateFormatStyle = dataFormatStyle;
+ }
+
+ /**
+ * 单元格类型索引
+ */
+ protected enum CellDataType {
+ /**
+ * 布尔值
+ */
+ BOOL("b"),
+ /**
+ * 异常错误
+ */
+ ERROR("e"),
+ /**
+ * 公式
+ */
+ FORMULA("str"),
+ /**
+ * 字符
+ */
+ INLINESTR("inlineStr"),
+ /**
+ * 共享字符表
+ */
+ SSTINDEX("s"),
+ /**
+ * 数值
+ */
+ NUMBER("n"),
+ /**
+ * 空
+ */
+ NULL("null");
+
+ private final String cellType;
+
+ String getCellType() {
+ return this.cellType;
+ }
+
+ CellDataType(final String cellType) {
+ this.cellType = cellType;
+ }
+
+ static CellDataType getCellTypeEnum(final String cellType) {
+ for (final CellDataType cellDataType : CellDataType.values()) {
+ //数字类型时c标签没有t属性
+ if (cellType == null) {
+ return NUMBER;
+ } else if (StringUtils.equals(cellDataType.getCellType(), cellType)) {
+ return cellDataType;
+ }
+ }
+ return null;
+ }
+ }
+
+ /**
+ * sheet样式
+ */
+ @Data
+ @EqualsAndHashCode(callSuper = false)
+ protected class SheetStyle {
+ /**
+ * sheet顺序索引
+ */
+ private int sheetId;
+ /**
+ * sheet名称
+ */
+ private String sheetName;
+ /**
+ * 缩放百分比
+ */
+ private double zoomPercent;
+ /**
+ * 自适应
+ */
+ private boolean fitToPage = false;
+ /**
+ * 是否显示网格线
+ */
+ private boolean showGridLines = true;
+ /**
+ * 默认行高
+ */
+ private double defaultRowHeight;
+ /**
+ * sheet中每一列的样式
+ */
+ Map<String, ColumnStyle> columnStyles;
+ /**
+ * 合并单元格
+ */
+ private List<Integer[]> mergeCells;
+ /* 打印属性 */
+ /**
+ * 上边距
+ */
+ private double topMargin = 0.75;
+ /**
+ * 下边距
+ */
+ private double bottomMargin = 0.75;
+ /**
+ * 左边距
+ */
+ private double leftMargin = 0.7;
+ /**
+ * 右边距
+ */
+ private double rightMargin = 0.7;
+ /**
+ * 页脚边距
+ */
+ private double footerMargin = 0.3;
+ /**
+ * 页头边距
+ */
+ private double headerMargin = 0.3;
+ /**
+ * 缩放比例
+ */
+ private short scale = 100;
+ /**
+ * 页宽
+ */
+ private short fitWidth = 1;
+ /**
+ * 页高
+ */
+ private short fitHeight = 1;
+ /**
+ * 纸张设置
+ */
+ private short pageSize = PrintSetup.A4_PAPERSIZE;
+ /**
+ * 垂直居中
+ */
+ private boolean verticallyCenter;
+ /**
+ * 水平居中
+ */
+ private boolean horizontallyCenter;
+ /**
+ * 横向打印
+ */
+ private boolean landscape;
+ /**
+ * 网格线
+ */
+ private boolean printGridlines;
+ /**
+ * 行号列标
+ */
+ private boolean printHeadings;
+ /**
+ * 草稿品质
+ */
+ private boolean draft;
+ /**
+ * 单色打印
+ */
+ private boolean noColor;
+ /**
+ * 打印顺序 true:先行后列 false:先列后行
+ */
+ private boolean leftToRigh;
+ /**
+ * 起始页页码自动
+ */
+ private boolean usePage;
+ /**
+ * 起始页码
+ */
+ private short pageStart = 1;
+ /**
+ * 页眉页脚与页边距对齐
+ */
+ private boolean alignWithMargins = true;
+ }
+
+ /**
+ * 列样式
+ */
+ @Data
+ @EqualsAndHashCode(callSuper = false)
+ protected class ColumnStyle {
+ /**
+ * 列宽度
+ */
+ private double columnWidth;
+ /**
+ * 列是否隐藏
+ */
+ private boolean isHidden;
+ /**
+ * 默认的列样式
+ */
+ private int defaultColumnStyleIndex;
+ }
+
+ /**
+ * 行数据
+ */
+ @Data
+ @EqualsAndHashCode(callSuper = false)
+ protected class RowData {
+ /**
+ * 当前行高
+ */
+ private double rowHeight;
+ /**
+ * 当前行数据
+ */
+ private List<Object> cellDataValues;
+ /**
+ * 当前行单元格样式索引
+ */
+ private List<Integer> cellStyles;
+ /**
+ * 当前行单元格数据类型
+ */
+ private List<CellDataType> cellDataTypes;
+ /**
+ * 单元格公式
+ */
+ private List<String> cellFormula;
+
+ RowData() {
+ this.cellDataValues = new ArrayList<>();
+ this.cellStyles = new ArrayList<>();
+ this.cellDataTypes = new ArrayList<>();
+ this.cellFormula = new ArrayList<>();
+ }
+ }
+
+ /**
+ * sheet打印区域
+ */
+ @Data
+ @EqualsAndHashCode(callSuper = false)
+ protected class SheetPrint {
+ private String sheetName;
+ private String sheetIndex;
+ private String printArea;
+ private String printTitleRows;
+ private String printTitleColumns;
+ }
+
+ /**
+ * 共享字符表
+ */
+ protected SharedStringsTable sst;
+ /**
+ * 单元格样式
+ */
+ private StylesTable stylesTable;
+ /**
+ * sheet游标
+ */
+ private int sheetIndex = 0;
+ /**
+ * 行游标
+ */
+ private int rowIndex;
+ /**
+ * 列坐标
+ */
+ private int colIndex;
+ /**
+ * 最大行数量
+ */
+ protected int rowMax;
+ /**
+ * 最大列数量
+ */
+ protected int colMax;
+ /**
+ * 是否为有效数据
+ */
+ private boolean valueFlag;
+ /**
+ * T
+ */
+ private boolean isTElement = false;
+ /**
+ * 记录当前值
+ */
+ private StringBuilder cellBuilder;
+ /**
+ * 是否过滤首行
+ */
+ protected boolean ignoreFirstRow = false;
+ /**
+ * 格式化日期样式
+ */
+ protected String dateFormatStyle = "yyyy-MM-dd";
+ /**
+ * 格式化样式
+ */
+ protected Map<Short, String> formatStyleMap = new HashMap<>();
+ /**
+ * 数据格式化formatter
+ */
+ private final DataFormatter dataFormatter = new DataFormatter();
+ /**
+ * 当前sheet样式
+ */
+ private SheetStyle sheetStyle;
+ /**
+ * 行数据
+ */
+ private RowData rowData;
+ /**
+ * sheet打印区域 key:sheetIndex
+ */
+ protected final Map<String, SheetPrint> sheetPrintMap = new HashMap<>();
+ /**
+ * 所有sheetName,key:sheetIndex
+ */
+ private final Map<String, String> sheetNameMap = new HashMap<>();
+ /**
+ * 当前打印标签的sheetIndex
+ */
+ private String localSheetId;
+ /**
+ * 辨别是否打印区域数据
+ */
+ private boolean printFlag;
+ /**
+ * 是否解析成String
+ */
+ private final boolean parseCellValueStringFlag;
+ /**
+ * 是否读取公式
+ */
+ protected boolean isReadFormula = false;
+ /**
+ * 是否共享公式
+ */
+ private boolean isSharedFormula;
+ /**
+ * 共享公式存放
+ */
+ private final Map<String, String> sharedFormulaMap = new HashMap<>();
+ /**
+ * 共享公式插值
+ */
+ private final Map<String, List<Integer>> diffMap = new HashMap<>();
+ /**
+ * 共享公式存放key
+ */
+ private String si;
+
+ /**
+ * 核心抽象方法,读取一行后的操作,将业务逻辑在该方法中实现
+ *
+ * @param sheetIndex
+ * @param rowIndex
+ * @param rowData
+ */
+ protected abstract void rowHandler(final int sheetIndex, final int rowIndex, final RowData rowData);
+
+ /**
+ * sheet处理完后调用的方法
+ *
+ * @param sheetIndex
+ * @param sheetStyle
+ */
+ protected void sheetOver(final int sheetIndex, final SheetStyle sheetStyle) {
+ return;
+ }
+
+ /**
+ * 整个工作簿处理完后调用
+ */
+ protected void workbookOver() {
+ return;
+ }
+
+ /**
+ * 处理完整的Excel
+ *
+ * @param filePath
+ * @throws OpenXML4JException
+ * @throws IOException
+ * @throws SAXException
+ */
+ public void handleExcel(final String filePath) throws OpenXML4JException, IOException, SAXException {
+ OPCPackage opcPackage = null;
+ try {
+ opcPackage = OPCPackage.open(filePath);
+ final XMLReader parser = fetchSheetParser();
+ final XSSFReader.SheetIterator sheets = parseSheet(opcPackage, parser);
+ while (sheets.hasNext()) {
+ final InputStream sheet = sheets.next();
+ sheetStyle = new SheetStyle();
+ sheetStyle.setSheetName(sheets.getSheetName());
+ final InputSource sheetSource = new InputSource(sheet);
+ parser.parse(sheetSource);
+ sheet.close();
+ }
+ } finally {
+ if (opcPackage != null) {
+ opcPackage.close();
+ }
+ }
+ workbookOver();
+ }
+
+ /**
+ * 处理指定的sheet页
+ * @param filePath
+ * @param sheetIdx
+ * @throws OpenXML4JException
+ * @throws SAXException
+ * @throws IOException
+ */
+ public void handleExcel(final String filePath, final int sheetIdx) throws OpenXML4JException, SAXException, IOException {
+ OPCPackage opcPackage = null;
+ try {
+ opcPackage = OPCPackage.open(filePath);
+ final XMLReader parser = fetchSheetParser();
+ final XSSFReader.SheetIterator sheets = parseSheet(opcPackage, parser);
+ while (sheets.hasNext()) {
+ final InputStream sheet = sheets.next();
+ if (sheetIndex + 1 != sheetIdx) {
+ continue;
+ }
+ sheetStyle = new SheetStyle();
+ sheetStyle.setSheetName(sheets.getSheetName());
+ final InputSource sheetSource = new InputSource(sheet);
+ parser.parse(sheetSource);
+ sheet.close();
+ }
+ } finally {
+ if (opcPackage != null) {
+ opcPackage.close();
+ }
+ }
+ workbookOver();
+ }
+
+ private XSSFReader.SheetIterator parseSheet(OPCPackage opcPackage, XMLReader parser) throws IOException, OpenXML4JException, SAXException {
+ final XSSFReader reader = new XSSFReader(opcPackage);
+ sst = reader.getSharedStringsTable();
+ stylesTable = reader.getStylesTable();
+ final XSSFReader.SheetIterator sheets = (XSSFReader.SheetIterator) reader.getSheetsData();
+ //读取工作簿内容
+ final InputStream workbookData = reader.getWorkbookData();
+ final InputSource workbookDataSource = new InputSource(workbookData);
+ parser.parse(workbookDataSource);
+ workbookData.close();
+ //读取单元格样式
+ final InputStream stylesData = reader.getStylesData();
+ final InputSource stylesDataSource = new InputSource(stylesData);
+ parser.parse(stylesDataSource);
+ stylesData.close();
+ return sheets;
+
+ }
+
+ private XMLReader fetchSheetParser() throws SAXException {
+ final XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
+ parser.setContentHandler(this);
+ return parser;
+ }
+
+
+ /**
+ * 读取每对标签的开始标签时调用的方法
+ *
+ * @param uri
+ * @param localName
+ * @param name 当前标签名
+ * @param attributes 当前标签上的属性
+ */
+ @Override
+ public void startElement(final String uri, final String localName,
+ final String name, final Attributes attributes) {
+ if ("numFmt".equals(name)) {
+ final short numFmtId = Short.parseShort(attributes.getValue("numFmtId"));
+ final String formatCode = attributes.getValue("formatCode");
+ formatStyleMap.put(numFmtId, formatCode);
+ } else if ("mergeCells".equals(name)) {
+ sheetStyle.setMergeCells(new ArrayList<Integer[]>());
+ } else if ("mergeCell".equals(name)) {
+ final String[] range = attributes.getValue("ref").split(":");
+ final Integer[] positionDx = new Integer[4];
+ final int[] start = parsePosition(range[0]);
+ final int[] end = parsePosition(range[1]);
+ positionDx[0] = start[1];
+ positionDx[1] = end[1];
+ positionDx[2] = start[0] - 1;
+ positionDx[3] = end[0] - 1;
+ sheetStyle.getMergeCells().add(positionDx);
+ } else if ("pageSetUpPr".equals(name)) {
+ if (attributes.getValue("fitToPage") != null && attributes.getValue("fitToPage").equals("1")) {
+ sheetStyle.setFitToPage(true);
+ }
+ } else if ("sheetView".equals(name)) {
+ if (attributes.getValue("showGridLines") != null && attributes.getValue("showGridLines").equals("0")) {
+ sheetStyle.setShowGridLines(false);
+ }
+ if (attributes.getValue("zoomScale") != null) {
+ sheetStyle.setZoomPercent((int) Double.parseDouble(attributes.getValue("zoomScale")));
+ }
+ } else if ("sheetFormatPr".equals(name)) {
+ if (attributes.getValue("defaultRowHeight") != null) {
+ sheetStyle.setDefaultRowHeight(Double.parseDouble(attributes.getValue("defaultRowHeight")));
+ }
+ } else if ("sheetData".equals(name)) {
+ //开始读取sheet页数据
+ sheetIndex++;
+ rowIndex = 1;
+ cellBuilder = new StringBuilder();
+ rowData = new RowData();
+ sheetHandler(sheetIndex, sheetStyle);
+ } else if ("dimension".equals(name)) {
+ handleMax(attributes.getValue("ref"));
+ sheetStyle.setColumnStyles(new HashMap<String, ColumnStyle>());
+ } else if ("col".equals(name)) {
+ final int startColIndex = Integer.parseInt(attributes.getValue("min"));
+ final int endColIndex = Integer.parseInt(attributes.getValue("max"));
+ final double columnWidth = Double.parseDouble(attributes.getValue("width"));
+ int defaultColumnStyleIndex = 0;
+ boolean hidden = false;
+ if (attributes.getValue("style") != null) {
+ defaultColumnStyleIndex = Integer.parseInt(attributes.getValue("style"));
+ }
+ if (attributes.getValue("hidden") != null && (attributes.getValue("hidden").equals("true") || attributes.getValue("hidden").equals("1"))) {
+ hidden = true;
+ }
+ final ColumnStyle columnStyle = new ColumnStyle();
+ columnStyle.setDefaultColumnStyleIndex(defaultColumnStyleIndex);
+ columnStyle.setHidden(hidden);
+ columnStyle.setColumnWidth(columnWidth);
+ sheetStyle.getColumnStyles().put(Integer.toString(startColIndex) + ":" + Integer.toString(endColIndex), columnStyle);
+ } else if ("row".equals(name)) {
+ //开始读取行数据
+ rowIndex = Integer.parseInt(attributes.getValue("r"));
+ adjustRowMax(rowIndex);
+ //清空数据容器中保留的上一行的数据
+ rowData.getCellDataValues().clear();
+ rowData.getCellStyles().clear();
+ rowData.getCellDataTypes().clear();
+ rowData.getCellFormula().clear();
+ colIndex = 1;
+ if (attributes.getValue("ht") != null) {
+ rowData.setRowHeight(Double.parseDouble(attributes.getValue("ht")));
+ }
+ } else if ("c".equals(name)) {
+ //读取单元格内容
+ final String position = attributes.getValue("r");
+ if (position != null) {
+ colIndex = parsePosition(position)[0];
+ adjustColMax(colIndex);
+ for (int idx = rowData.getCellStyles().size() + 1; idx < colIndex; idx++) {
+ rowData.getCellStyles().add(null);
+ }
+ for (int idx = rowData.getCellDataValues().size() + 1; idx < colIndex; idx++) {
+ rowData.getCellDataValues().add(null);
+ }
+ for (int idx = rowData.getCellDataTypes().size() + 1; idx < colIndex; idx++) {
+ rowData.getCellDataTypes().add(null);
+ }
+ for (int idx = rowData.getCellFormula().size() + 1; idx < colIndex; idx++) {
+ rowData.getCellFormula().add(null);
+ }
+ }
+ if (attributes.getValue("s") != null) {
+ rowData.getCellStyles().add(Integer.parseInt(attributes.getValue("s")));
+ } else {
+ rowData.getCellStyles().add(null);
+ }
+ rowData.getCellDataTypes().add(CellDataType.getCellTypeEnum(attributes.getValue("t")));
+ } else if ("v".equals(name)) {
+ //单元格数据
+ valueFlag = true;
+ } else if ("t".equals(name)) {
+ isTElement = true;
+ valueFlag = true;
+ } else if ("definedName".equals(name) && StringUtils.isNotBlank(attributes.getValue("localSheetId"))) {
+ final String value = attributes.getValue("name");
+ if ("_xlnm.Print_Area".equals(value) || "_xlnm.Print_Titles".equals(value)) {
+ valueFlag = true;
+ printFlag = true;
+ localSheetId = attributes.getValue("localSheetId");
+ cellBuilder = new StringBuilder();
+ }
+ } else if ("sheet".equals(name)) {
+ sheetNameMap.put(attributes.getValue("r:id"), attributes.getValue("name"));
+ } else if ("pageMargins".equals(name)) {
+ //页边距
+
+ } else if ("pageSetup".equals(name)) {
+ //页面设置
+
+ } else if ("printOptions".equals(name)) {
+ //打印选项
+
+ } else if ("headerFooter".equals(name)) {
+ //页眉页脚
+
+ } else if (isReadFormula && "f".equals(name)) {
+ //公式
+ valueFlag = true;
+ if ("shared".equals(attributes.getValue("t"))) {
+ //共享公式
+ isSharedFormula = true;
+ si = attributes.getValue("si");
+ }
+ }
+ }
+
+ /**
+ * 读取每对标签的结束标签时调用
+ *
+ * @param uri
+ * @param localName
+ * @param name
+ */
+ @Override
+ public void endElement(final String uri, final String localName, final String name) {
+ Object result;
+ if ("worksheet".equals(name)) {
+ //一个sheet读取完毕
+ cellBuilder = null;
+ rowIndex = 0;
+ sheetOver(sheetIndex, sheetStyle);
+ } else if ("row".equals(name)) {
+ //一行数据读取完毕
+ if (rowIndex == 1 && ignoreFirstRow) {
+ //过滤首行数据 一般为表头
+ return;
+ }
+ //调用实现的业务逻辑方法处理当前行数据
+ rowHandler(sheetIndex, rowIndex, rowData);
+ rowIndex++;
+ rowData.setRowHeight(0);
+ } else if ("v".equals(name)) {
+ //读取到单元格的数据标签
+ final CellDataType cellDataType = rowData.getCellDataTypes().get(colIndex - 1);
+ switch (cellDataType) {
+ case BOOL:
+ final char firstFlag = cellBuilder.toString().charAt(0);
+ if (parseCellValueStringFlag) {
+ result = firstFlag == '0' ? "false" : "true";
+ } else {
+ result = firstFlag != '0';
+ }
+ break;
+ case ERROR:
+ result = "\\"ERROR:" + cellBuilder.toString() + "\\"";
+ break;
+ case FORMULA:
+ if (parseCellValueStringFlag) {
+ result = cellBuilder.toString();
+ } else {
+ try {
+ result = Double.parseDouble(cellBuilder.toString());
+ } catch (Exception e) {
+ result = cellBuilder.toString();
+ }
+ }
+ break;
+ case INLINESTR:
+ result = new XSSFRichTextString(cellBuilder.toString());
+ break;
+ case SSTINDEX:
+ //共享字符需要从共享字符表中取
+ final int idx = Integer.parseInt(cellBuilder.toString());
+ result = new XSSFRichTextString(sst.getEntryAt(idx));
+ break;
+ case NUMBER:
+ if (parseCellValueStringFlag) {
+ final Integer styleAt = rowData.getCellStyles().get(colIndex - 1);
+ if (styleAt != null) {
+ final XSSFCellStyle cellStyle = stylesTable.getStyleAt(styleAt);
+ final short formatIndex = cellStyle.getDataFormat();
+ final String formatString = cellStyle.getDataFormatString();
+ if (formatString == null) {
+ result = cellBuilder.toString();
+ } else if (formatString.contains("m/dd/yy")
+ || formatString.contains("m/d/yy")
+ || formatString.contains("yyyy/mm/dd")
+ || formatString.contains("yyyy/m/d")) {
+ result = dataFormatter.formatRawCellContents(
+ Double.parseDouble(cellBuilder.toString()),
+ formatIndex, dateFormatStyle).replace("T", "");
+ } else {
+ result = dataFormatter.formatRawCellContents(Double.parseDouble(cellBuilder.toString()),
+ formatIndex, formatString).replace("_", "").trim();
+ }
+ } else {
+ result = cellBuilder.toString();
+ }
+ } else {
+ result = Double.parseDouble(cellBuilder.toString());
+ }
+ break;
+ default:
+ result = null;
+ }
+ writeColData(result);
+ valueFlag = false;
+ } else if ("c".equals(name)) {
+ colIndex++;
+ } else if ("f".equals(name)) {
+ if (isReadFormula) {
+ rowData.getCellDataTypes().set(colIndex - 1, CellDataType.FORMULA);
+ writeColData(cellBuilder);
+ valueFlag = false;
+ }
+ cellBuilder.delete(0, cellBuilder.length());
+ } else if (isTElement) {
+ result = cellBuilder.toString().trim();
+ writeColData(result);
+ isTElement = false;
+ valueFlag = false;
+ } else if (printFlag && "definedName".equals(name)) {
+ result = cellBuilder.toString();
+ writePrint(result);
+ valueFlag = false;
+ printFlag = false;
+ cellBuilder.delete(0, cellBuilder.length());
+ }
+ }
+
+ /**
+ * 写sheet打印区域和打印标题
+ *
+ * @param result
+ */
+ private void writePrint(Object result) {
+ final String res = result.toString();
+ if (StringUtils.isBlank(localSheetId) || StringUtils.equals(res, "#REF!") || StringUtils.isBlank(res)) {
+ return;
+ }
+ final String rId = "rId" + (Integer.parseInt(localSheetId) + 1);
+ final String sheetName = sheetNameMap.get(rId);
+ final SheetPrint sheetPrint = sheetPrintMap.containsKey(sheetName) ? sheetPrintMap.get(sheetName) : new SheetPrint();
+ sheetPrint.setSheetName(sheetName);
+ sheetPrint.setSheetIndex(localSheetId);
+ for (String str : res.split(",")) {
+ final int i = isArea(str.split("!")[1]);
+ if (i == 1) {
+ sheetPrint.setPrintArea(res);
+ } else if (i == 2) {
+ sheetPrint.setPrintTitleRows(str);
+ } else if (i == 3) {
+ sheetPrint.setPrintTitleColumns(str);
+ }
+ }
+ sheetPrintMap.put(sheetName, sheetPrint);
+ localSheetId = null;
+ }
+
+ /**
+ * @param str
+ * @return 1-区域 2-顶端 3-左端 0-判断错误
+ */
+ private int isArea(String str) {
+ String split = str.split(":")[0];
+ int countMatches = StringUtils.countMatches(split, "$");
+ if (countMatches == 2) {
+ return 1;
+ } else if (countMatches == 1) {
+ String substr = split.substring(split.length() - 1);
+ char charAt = substr.charAt(0);
+ Pattern pattern = Pattern.compile("[0-9]*");
+ if (pattern.matcher(substr).matches()) {
+ return 2;
+ } else if ((charAt >= 'a' && charAt <= 'z') || (charAt >= 'A' && charAt <= 'Z')) {
+ return 3;
+ }
+ }
+ return 0;
+
+ }
+
+ /**
+ * 计算当前的最大行和列数
+ *
+ * @param ref
+ */
+ private void handleMax(String ref) {
+ final String[] range = ref.split(":");
+ String maxStr;
+ if (range.length == 1) {
+ maxStr = range[0];
+ } else {
+ maxStr = range[1];
+ }
+ final int[] maxPosition = parsePosition(maxStr);
+ rowMax = maxPosition[1];
+ colMax = maxPosition[0];
+ }
+
+ /**
+ * 把单元格数据添加到当前行的数据容器中
+ *
+ * @param result
+ */
+ private void writeColData(final Object result) {
+ rowData.getCellDataValues().add(result);
+ cellBuilder.delete(0, cellBuilder.length());
+ }
+
+ /**
+ * 数据append到cellBuilder中
+ *
+ * @param ch
+ * @param start
+ * @param length
+ */
+ @Override
+ public void characters(final char[] ch, final int start, final int length) {
+ if (valueFlag) {
+ cellBuilder.append(ch, start, length);
+ }
+ }
+
+ /**
+ * sheet处理
+ *
+ * @param sheetIndex
+ * @param sheetStyle
+ */
+ private void sheetHandler(int sheetIndex, SheetStyle sheetStyle) {
+
+ }
+
+ /**
+ * 获取position坐标的实际坐标数据
+ *
+ * @param position
+ * @return
+ */
+ private int[] parsePosition(String position) {
+ final int[] result = new int[2];
+ final String amPosition = position.replaceAll("[0-9]", "");
+ final char[] chars = amPosition.toUpperCase().toCharArray();
+ int ret = 0;
+ for (int i = 0; i < chars.length; i++) {
+ ret += (chars[i] - 'A' + 1) * Math.pow(26, chars.length - i - 1);
+ }
+ result[0] = ret;
+ result[1] = Integer.parseInt(position.replaceAll("[A-Z]", ""));
+ return result;
+ }
+
+ /**
+ * 调整列最大值
+ *
+ * @param colIndex
+ */
+ private void adjustColMax(final int colIndex) {
+ if (colIndex > colMax) {
+ colMax = colIndex;
+ }
+ }
+
+ /**
+ * 调整行最大值
+ *
+ * @param rowIndex
+ */
+ private void adjustRowMax(final int rowIndex) {
+ if (rowIndex > rowMax) {
+ rowMax = rowIndex;
+ }
+ }
+}传统的POI用户模式解析Excel为我们操作提供了丰富的API,用起来很方便,但是这种模式是一次性将Excel中的数据全部写入内存,并且要还封装结构,使得内存的占用远远超过原本Excel文件的大小,稍微大一点的文件采用用户模式进行解析都会内存溢出,由于现在做的项目要处理的Excel数据量普遍都很大,而且业务对导入功能的使用尤其频繁,所以必须采用事件模式的解析方式来实现业务需求.
事件模式避免内存溢出的原理很简单,就是采用SAX方式解析Excel文件底层的XML文件,这样逐行读取,逐行处理的方式可以完美解决内存占用的问题.
简单的入门程序可以从POI官网找到,下面是根据官方demo封装的一个比较完善的类,只需要创建一个类继承该抽象类然后实现抽象方法rowHandler,然后在rowHandler里进行我们需要的业务操作即可.
关于事件模式解析Excel的代码执行具体流程以后有时间再写篇文章进行总结~
/**
+ * @author storyxc
+ * @description POI事件模式读取Excel抽象类
+ * @createdTime 2020/6/18 14:27
+ */
+public abstract class POIEventModeHandler extends DefaultHandler {
+
+ /**
+ * 构造方法
+ *
+ * @param parseCellValueStringFlag 是否将单元格值解析成字符串
+ * @param ignoreFirstRow 是否忽略首行(一般是表头)
+ */
+ public POIEventModeHandler(final boolean parseCellValueStringFlag, final boolean ignoreFirstRow) {
+ this.parseCellValueStringFlag = parseCellValueStringFlag;
+ this.ignoreFirstRow = ignoreFirstRow;
+ }
+
+ /**
+ * 构造方法
+ *
+ * @param parseCellValueStringFlag 将单元格值解析成字符串
+ * @param ignoreFirstRow 忽略首行
+ * @param dataFormatStyle 指定日期类型解析格式 默认yyyy-MM-dd
+ */
+ public POIEventModeHandler(final boolean parseCellValueStringFlag, final boolean ignoreFirstRow, final String dataFormatStyle) {
+ this.parseCellValueStringFlag = parseCellValueStringFlag;
+ this.ignoreFirstRow = ignoreFirstRow;
+ this.dateFormatStyle = dataFormatStyle;
+ }
+
+ /**
+ * 单元格类型索引
+ */
+ protected enum CellDataType {
+ /**
+ * 布尔值
+ */
+ BOOL("b"),
+ /**
+ * 异常错误
+ */
+ ERROR("e"),
+ /**
+ * 公式
+ */
+ FORMULA("str"),
+ /**
+ * 字符
+ */
+ INLINESTR("inlineStr"),
+ /**
+ * 共享字符表
+ */
+ SSTINDEX("s"),
+ /**
+ * 数值
+ */
+ NUMBER("n"),
+ /**
+ * 空
+ */
+ NULL("null");
+
+ private final String cellType;
+
+ String getCellType() {
+ return this.cellType;
+ }
+
+ CellDataType(final String cellType) {
+ this.cellType = cellType;
+ }
+
+ static CellDataType getCellTypeEnum(final String cellType) {
+ for (final CellDataType cellDataType : CellDataType.values()) {
+ //数字类型时c标签没有t属性
+ if (cellType == null) {
+ return NUMBER;
+ } else if (StringUtils.equals(cellDataType.getCellType(), cellType)) {
+ return cellDataType;
+ }
+ }
+ return null;
+ }
+ }
+
+ /**
+ * sheet样式
+ */
+ @Data
+ @EqualsAndHashCode(callSuper = false)
+ protected class SheetStyle {
+ /**
+ * sheet顺序索引
+ */
+ private int sheetId;
+ /**
+ * sheet名称
+ */
+ private String sheetName;
+ /**
+ * 缩放百分比
+ */
+ private double zoomPercent;
+ /**
+ * 自适应
+ */
+ private boolean fitToPage = false;
+ /**
+ * 是否显示网格线
+ */
+ private boolean showGridLines = true;
+ /**
+ * 默认行高
+ */
+ private double defaultRowHeight;
+ /**
+ * sheet中每一列的样式
+ */
+ Map<String, ColumnStyle> columnStyles;
+ /**
+ * 合并单元格
+ */
+ private List<Integer[]> mergeCells;
+ /* 打印属性 */
+ /**
+ * 上边距
+ */
+ private double topMargin = 0.75;
+ /**
+ * 下边距
+ */
+ private double bottomMargin = 0.75;
+ /**
+ * 左边距
+ */
+ private double leftMargin = 0.7;
+ /**
+ * 右边距
+ */
+ private double rightMargin = 0.7;
+ /**
+ * 页脚边距
+ */
+ private double footerMargin = 0.3;
+ /**
+ * 页头边距
+ */
+ private double headerMargin = 0.3;
+ /**
+ * 缩放比例
+ */
+ private short scale = 100;
+ /**
+ * 页宽
+ */
+ private short fitWidth = 1;
+ /**
+ * 页高
+ */
+ private short fitHeight = 1;
+ /**
+ * 纸张设置
+ */
+ private short pageSize = PrintSetup.A4_PAPERSIZE;
+ /**
+ * 垂直居中
+ */
+ private boolean verticallyCenter;
+ /**
+ * 水平居中
+ */
+ private boolean horizontallyCenter;
+ /**
+ * 横向打印
+ */
+ private boolean landscape;
+ /**
+ * 网格线
+ */
+ private boolean printGridlines;
+ /**
+ * 行号列标
+ */
+ private boolean printHeadings;
+ /**
+ * 草稿品质
+ */
+ private boolean draft;
+ /**
+ * 单色打印
+ */
+ private boolean noColor;
+ /**
+ * 打印顺序 true:先行后列 false:先列后行
+ */
+ private boolean leftToRigh;
+ /**
+ * 起始页页码自动
+ */
+ private boolean usePage;
+ /**
+ * 起始页码
+ */
+ private short pageStart = 1;
+ /**
+ * 页眉页脚与页边距对齐
+ */
+ private boolean alignWithMargins = true;
+ }
+
+ /**
+ * 列样式
+ */
+ @Data
+ @EqualsAndHashCode(callSuper = false)
+ protected class ColumnStyle {
+ /**
+ * 列宽度
+ */
+ private double columnWidth;
+ /**
+ * 列是否隐藏
+ */
+ private boolean isHidden;
+ /**
+ * 默认的列样式
+ */
+ private int defaultColumnStyleIndex;
+ }
+
+ /**
+ * 行数据
+ */
+ @Data
+ @EqualsAndHashCode(callSuper = false)
+ protected class RowData {
+ /**
+ * 当前行高
+ */
+ private double rowHeight;
+ /**
+ * 当前行数据
+ */
+ private List<Object> cellDataValues;
+ /**
+ * 当前行单元格样式索引
+ */
+ private List<Integer> cellStyles;
+ /**
+ * 当前行单元格数据类型
+ */
+ private List<CellDataType> cellDataTypes;
+ /**
+ * 单元格公式
+ */
+ private List<String> cellFormula;
+
+ RowData() {
+ this.cellDataValues = new ArrayList<>();
+ this.cellStyles = new ArrayList<>();
+ this.cellDataTypes = new ArrayList<>();
+ this.cellFormula = new ArrayList<>();
+ }
+ }
+
+ /**
+ * sheet打印区域
+ */
+ @Data
+ @EqualsAndHashCode(callSuper = false)
+ protected class SheetPrint {
+ private String sheetName;
+ private String sheetIndex;
+ private String printArea;
+ private String printTitleRows;
+ private String printTitleColumns;
+ }
+
+ /**
+ * 共享字符表
+ */
+ protected SharedStringsTable sst;
+ /**
+ * 单元格样式
+ */
+ private StylesTable stylesTable;
+ /**
+ * sheet游标
+ */
+ private int sheetIndex = 0;
+ /**
+ * 行游标
+ */
+ private int rowIndex;
+ /**
+ * 列坐标
+ */
+ private int colIndex;
+ /**
+ * 最大行数量
+ */
+ protected int rowMax;
+ /**
+ * 最大列数量
+ */
+ protected int colMax;
+ /**
+ * 是否为有效数据
+ */
+ private boolean valueFlag;
+ /**
+ * T
+ */
+ private boolean isTElement = false;
+ /**
+ * 记录当前值
+ */
+ private StringBuilder cellBuilder;
+ /**
+ * 是否过滤首行
+ */
+ protected boolean ignoreFirstRow = false;
+ /**
+ * 格式化日期样式
+ */
+ protected String dateFormatStyle = "yyyy-MM-dd";
+ /**
+ * 格式化样式
+ */
+ protected Map<Short, String> formatStyleMap = new HashMap<>();
+ /**
+ * 数据格式化formatter
+ */
+ private final DataFormatter dataFormatter = new DataFormatter();
+ /**
+ * 当前sheet样式
+ */
+ private SheetStyle sheetStyle;
+ /**
+ * 行数据
+ */
+ private RowData rowData;
+ /**
+ * sheet打印区域 key:sheetIndex
+ */
+ protected final Map<String, SheetPrint> sheetPrintMap = new HashMap<>();
+ /**
+ * 所有sheetName,key:sheetIndex
+ */
+ private final Map<String, String> sheetNameMap = new HashMap<>();
+ /**
+ * 当前打印标签的sheetIndex
+ */
+ private String localSheetId;
+ /**
+ * 辨别是否打印区域数据
+ */
+ private boolean printFlag;
+ /**
+ * 是否解析成String
+ */
+ private final boolean parseCellValueStringFlag;
+ /**
+ * 是否读取公式
+ */
+ protected boolean isReadFormula = false;
+ /**
+ * 是否共享公式
+ */
+ private boolean isSharedFormula;
+ /**
+ * 共享公式存放
+ */
+ private final Map<String, String> sharedFormulaMap = new HashMap<>();
+ /**
+ * 共享公式插值
+ */
+ private final Map<String, List<Integer>> diffMap = new HashMap<>();
+ /**
+ * 共享公式存放key
+ */
+ private String si;
+
+ /**
+ * 核心抽象方法,读取一行后的操作,将业务逻辑在该方法中实现
+ *
+ * @param sheetIndex
+ * @param rowIndex
+ * @param rowData
+ */
+ protected abstract void rowHandler(final int sheetIndex, final int rowIndex, final RowData rowData);
+
+ /**
+ * sheet处理完后调用的方法
+ *
+ * @param sheetIndex
+ * @param sheetStyle
+ */
+ protected void sheetOver(final int sheetIndex, final SheetStyle sheetStyle) {
+ return;
+ }
+
+ /**
+ * 整个工作簿处理完后调用
+ */
+ protected void workbookOver() {
+ return;
+ }
+
+ /**
+ * 处理完整的Excel
+ *
+ * @param filePath
+ * @throws OpenXML4JException
+ * @throws IOException
+ * @throws SAXException
+ */
+ public void handleExcel(final String filePath) throws OpenXML4JException, IOException, SAXException {
+ OPCPackage opcPackage = null;
+ try {
+ opcPackage = OPCPackage.open(filePath);
+ final XMLReader parser = fetchSheetParser();
+ final XSSFReader.SheetIterator sheets = parseSheet(opcPackage, parser);
+ while (sheets.hasNext()) {
+ final InputStream sheet = sheets.next();
+ sheetStyle = new SheetStyle();
+ sheetStyle.setSheetName(sheets.getSheetName());
+ final InputSource sheetSource = new InputSource(sheet);
+ parser.parse(sheetSource);
+ sheet.close();
+ }
+ } finally {
+ if (opcPackage != null) {
+ opcPackage.close();
+ }
+ }
+ workbookOver();
+ }
+
+ /**
+ * 处理指定的sheet页
+ * @param filePath
+ * @param sheetIdx
+ * @throws OpenXML4JException
+ * @throws SAXException
+ * @throws IOException
+ */
+ public void handleExcel(final String filePath, final int sheetIdx) throws OpenXML4JException, SAXException, IOException {
+ OPCPackage opcPackage = null;
+ try {
+ opcPackage = OPCPackage.open(filePath);
+ final XMLReader parser = fetchSheetParser();
+ final XSSFReader.SheetIterator sheets = parseSheet(opcPackage, parser);
+ while (sheets.hasNext()) {
+ final InputStream sheet = sheets.next();
+ if (sheetIndex + 1 != sheetIdx) {
+ continue;
+ }
+ sheetStyle = new SheetStyle();
+ sheetStyle.setSheetName(sheets.getSheetName());
+ final InputSource sheetSource = new InputSource(sheet);
+ parser.parse(sheetSource);
+ sheet.close();
+ }
+ } finally {
+ if (opcPackage != null) {
+ opcPackage.close();
+ }
+ }
+ workbookOver();
+ }
+
+ private XSSFReader.SheetIterator parseSheet(OPCPackage opcPackage, XMLReader parser) throws IOException, OpenXML4JException, SAXException {
+ final XSSFReader reader = new XSSFReader(opcPackage);
+ sst = reader.getSharedStringsTable();
+ stylesTable = reader.getStylesTable();
+ final XSSFReader.SheetIterator sheets = (XSSFReader.SheetIterator) reader.getSheetsData();
+ //读取工作簿内容
+ final InputStream workbookData = reader.getWorkbookData();
+ final InputSource workbookDataSource = new InputSource(workbookData);
+ parser.parse(workbookDataSource);
+ workbookData.close();
+ //读取单元格样式
+ final InputStream stylesData = reader.getStylesData();
+ final InputSource stylesDataSource = new InputSource(stylesData);
+ parser.parse(stylesDataSource);
+ stylesData.close();
+ return sheets;
+
+ }
+
+ private XMLReader fetchSheetParser() throws SAXException {
+ final XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
+ parser.setContentHandler(this);
+ return parser;
+ }
+
+
+ /**
+ * 读取每对标签的开始标签时调用的方法
+ *
+ * @param uri
+ * @param localName
+ * @param name 当前标签名
+ * @param attributes 当前标签上的属性
+ */
+ @Override
+ public void startElement(final String uri, final String localName,
+ final String name, final Attributes attributes) {
+ if ("numFmt".equals(name)) {
+ final short numFmtId = Short.parseShort(attributes.getValue("numFmtId"));
+ final String formatCode = attributes.getValue("formatCode");
+ formatStyleMap.put(numFmtId, formatCode);
+ } else if ("mergeCells".equals(name)) {
+ sheetStyle.setMergeCells(new ArrayList<Integer[]>());
+ } else if ("mergeCell".equals(name)) {
+ final String[] range = attributes.getValue("ref").split(":");
+ final Integer[] positionDx = new Integer[4];
+ final int[] start = parsePosition(range[0]);
+ final int[] end = parsePosition(range[1]);
+ positionDx[0] = start[1];
+ positionDx[1] = end[1];
+ positionDx[2] = start[0] - 1;
+ positionDx[3] = end[0] - 1;
+ sheetStyle.getMergeCells().add(positionDx);
+ } else if ("pageSetUpPr".equals(name)) {
+ if (attributes.getValue("fitToPage") != null && attributes.getValue("fitToPage").equals("1")) {
+ sheetStyle.setFitToPage(true);
+ }
+ } else if ("sheetView".equals(name)) {
+ if (attributes.getValue("showGridLines") != null && attributes.getValue("showGridLines").equals("0")) {
+ sheetStyle.setShowGridLines(false);
+ }
+ if (attributes.getValue("zoomScale") != null) {
+ sheetStyle.setZoomPercent((int) Double.parseDouble(attributes.getValue("zoomScale")));
+ }
+ } else if ("sheetFormatPr".equals(name)) {
+ if (attributes.getValue("defaultRowHeight") != null) {
+ sheetStyle.setDefaultRowHeight(Double.parseDouble(attributes.getValue("defaultRowHeight")));
+ }
+ } else if ("sheetData".equals(name)) {
+ //开始读取sheet页数据
+ sheetIndex++;
+ rowIndex = 1;
+ cellBuilder = new StringBuilder();
+ rowData = new RowData();
+ sheetHandler(sheetIndex, sheetStyle);
+ } else if ("dimension".equals(name)) {
+ handleMax(attributes.getValue("ref"));
+ sheetStyle.setColumnStyles(new HashMap<String, ColumnStyle>());
+ } else if ("col".equals(name)) {
+ final int startColIndex = Integer.parseInt(attributes.getValue("min"));
+ final int endColIndex = Integer.parseInt(attributes.getValue("max"));
+ final double columnWidth = Double.parseDouble(attributes.getValue("width"));
+ int defaultColumnStyleIndex = 0;
+ boolean hidden = false;
+ if (attributes.getValue("style") != null) {
+ defaultColumnStyleIndex = Integer.parseInt(attributes.getValue("style"));
+ }
+ if (attributes.getValue("hidden") != null && (attributes.getValue("hidden").equals("true") || attributes.getValue("hidden").equals("1"))) {
+ hidden = true;
+ }
+ final ColumnStyle columnStyle = new ColumnStyle();
+ columnStyle.setDefaultColumnStyleIndex(defaultColumnStyleIndex);
+ columnStyle.setHidden(hidden);
+ columnStyle.setColumnWidth(columnWidth);
+ sheetStyle.getColumnStyles().put(Integer.toString(startColIndex) + ":" + Integer.toString(endColIndex), columnStyle);
+ } else if ("row".equals(name)) {
+ //开始读取行数据
+ rowIndex = Integer.parseInt(attributes.getValue("r"));
+ adjustRowMax(rowIndex);
+ //清空数据容器中保留的上一行的数据
+ rowData.getCellDataValues().clear();
+ rowData.getCellStyles().clear();
+ rowData.getCellDataTypes().clear();
+ rowData.getCellFormula().clear();
+ colIndex = 1;
+ if (attributes.getValue("ht") != null) {
+ rowData.setRowHeight(Double.parseDouble(attributes.getValue("ht")));
+ }
+ } else if ("c".equals(name)) {
+ //读取单元格内容
+ final String position = attributes.getValue("r");
+ if (position != null) {
+ colIndex = parsePosition(position)[0];
+ adjustColMax(colIndex);
+ for (int idx = rowData.getCellStyles().size() + 1; idx < colIndex; idx++) {
+ rowData.getCellStyles().add(null);
+ }
+ for (int idx = rowData.getCellDataValues().size() + 1; idx < colIndex; idx++) {
+ rowData.getCellDataValues().add(null);
+ }
+ for (int idx = rowData.getCellDataTypes().size() + 1; idx < colIndex; idx++) {
+ rowData.getCellDataTypes().add(null);
+ }
+ for (int idx = rowData.getCellFormula().size() + 1; idx < colIndex; idx++) {
+ rowData.getCellFormula().add(null);
+ }
+ }
+ if (attributes.getValue("s") != null) {
+ rowData.getCellStyles().add(Integer.parseInt(attributes.getValue("s")));
+ } else {
+ rowData.getCellStyles().add(null);
+ }
+ rowData.getCellDataTypes().add(CellDataType.getCellTypeEnum(attributes.getValue("t")));
+ } else if ("v".equals(name)) {
+ //单元格数据
+ valueFlag = true;
+ } else if ("t".equals(name)) {
+ isTElement = true;
+ valueFlag = true;
+ } else if ("definedName".equals(name) && StringUtils.isNotBlank(attributes.getValue("localSheetId"))) {
+ final String value = attributes.getValue("name");
+ if ("_xlnm.Print_Area".equals(value) || "_xlnm.Print_Titles".equals(value)) {
+ valueFlag = true;
+ printFlag = true;
+ localSheetId = attributes.getValue("localSheetId");
+ cellBuilder = new StringBuilder();
+ }
+ } else if ("sheet".equals(name)) {
+ sheetNameMap.put(attributes.getValue("r:id"), attributes.getValue("name"));
+ } else if ("pageMargins".equals(name)) {
+ //页边距
+
+ } else if ("pageSetup".equals(name)) {
+ //页面设置
+
+ } else if ("printOptions".equals(name)) {
+ //打印选项
+
+ } else if ("headerFooter".equals(name)) {
+ //页眉页脚
+
+ } else if (isReadFormula && "f".equals(name)) {
+ //公式
+ valueFlag = true;
+ if ("shared".equals(attributes.getValue("t"))) {
+ //共享公式
+ isSharedFormula = true;
+ si = attributes.getValue("si");
+ }
+ }
+ }
+
+ /**
+ * 读取每对标签的结束标签时调用
+ *
+ * @param uri
+ * @param localName
+ * @param name
+ */
+ @Override
+ public void endElement(final String uri, final String localName, final String name) {
+ Object result;
+ if ("worksheet".equals(name)) {
+ //一个sheet读取完毕
+ cellBuilder = null;
+ rowIndex = 0;
+ sheetOver(sheetIndex, sheetStyle);
+ } else if ("row".equals(name)) {
+ //一行数据读取完毕
+ if (rowIndex == 1 && ignoreFirstRow) {
+ //过滤首行数据 一般为表头
+ return;
+ }
+ //调用实现的业务逻辑方法处理当前行数据
+ rowHandler(sheetIndex, rowIndex, rowData);
+ rowIndex++;
+ rowData.setRowHeight(0);
+ } else if ("v".equals(name)) {
+ //读取到单元格的数据标签
+ final CellDataType cellDataType = rowData.getCellDataTypes().get(colIndex - 1);
+ switch (cellDataType) {
+ case BOOL:
+ final char firstFlag = cellBuilder.toString().charAt(0);
+ if (parseCellValueStringFlag) {
+ result = firstFlag == '0' ? "false" : "true";
+ } else {
+ result = firstFlag != '0';
+ }
+ break;
+ case ERROR:
+ result = "\\"ERROR:" + cellBuilder.toString() + "\\"";
+ break;
+ case FORMULA:
+ if (parseCellValueStringFlag) {
+ result = cellBuilder.toString();
+ } else {
+ try {
+ result = Double.parseDouble(cellBuilder.toString());
+ } catch (Exception e) {
+ result = cellBuilder.toString();
+ }
+ }
+ break;
+ case INLINESTR:
+ result = new XSSFRichTextString(cellBuilder.toString());
+ break;
+ case SSTINDEX:
+ //共享字符需要从共享字符表中取
+ final int idx = Integer.parseInt(cellBuilder.toString());
+ result = new XSSFRichTextString(sst.getEntryAt(idx));
+ break;
+ case NUMBER:
+ if (parseCellValueStringFlag) {
+ final Integer styleAt = rowData.getCellStyles().get(colIndex - 1);
+ if (styleAt != null) {
+ final XSSFCellStyle cellStyle = stylesTable.getStyleAt(styleAt);
+ final short formatIndex = cellStyle.getDataFormat();
+ final String formatString = cellStyle.getDataFormatString();
+ if (formatString == null) {
+ result = cellBuilder.toString();
+ } else if (formatString.contains("m/dd/yy")
+ || formatString.contains("m/d/yy")
+ || formatString.contains("yyyy/mm/dd")
+ || formatString.contains("yyyy/m/d")) {
+ result = dataFormatter.formatRawCellContents(
+ Double.parseDouble(cellBuilder.toString()),
+ formatIndex, dateFormatStyle).replace("T", "");
+ } else {
+ result = dataFormatter.formatRawCellContents(Double.parseDouble(cellBuilder.toString()),
+ formatIndex, formatString).replace("_", "").trim();
+ }
+ } else {
+ result = cellBuilder.toString();
+ }
+ } else {
+ result = Double.parseDouble(cellBuilder.toString());
+ }
+ break;
+ default:
+ result = null;
+ }
+ writeColData(result);
+ valueFlag = false;
+ } else if ("c".equals(name)) {
+ colIndex++;
+ } else if ("f".equals(name)) {
+ if (isReadFormula) {
+ rowData.getCellDataTypes().set(colIndex - 1, CellDataType.FORMULA);
+ writeColData(cellBuilder);
+ valueFlag = false;
+ }
+ cellBuilder.delete(0, cellBuilder.length());
+ } else if (isTElement) {
+ result = cellBuilder.toString().trim();
+ writeColData(result);
+ isTElement = false;
+ valueFlag = false;
+ } else if (printFlag && "definedName".equals(name)) {
+ result = cellBuilder.toString();
+ writePrint(result);
+ valueFlag = false;
+ printFlag = false;
+ cellBuilder.delete(0, cellBuilder.length());
+ }
+ }
+
+ /**
+ * 写sheet打印区域和打印标题
+ *
+ * @param result
+ */
+ private void writePrint(Object result) {
+ final String res = result.toString();
+ if (StringUtils.isBlank(localSheetId) || StringUtils.equals(res, "#REF!") || StringUtils.isBlank(res)) {
+ return;
+ }
+ final String rId = "rId" + (Integer.parseInt(localSheetId) + 1);
+ final String sheetName = sheetNameMap.get(rId);
+ final SheetPrint sheetPrint = sheetPrintMap.containsKey(sheetName) ? sheetPrintMap.get(sheetName) : new SheetPrint();
+ sheetPrint.setSheetName(sheetName);
+ sheetPrint.setSheetIndex(localSheetId);
+ for (String str : res.split(",")) {
+ final int i = isArea(str.split("!")[1]);
+ if (i == 1) {
+ sheetPrint.setPrintArea(res);
+ } else if (i == 2) {
+ sheetPrint.setPrintTitleRows(str);
+ } else if (i == 3) {
+ sheetPrint.setPrintTitleColumns(str);
+ }
+ }
+ sheetPrintMap.put(sheetName, sheetPrint);
+ localSheetId = null;
+ }
+
+ /**
+ * @param str
+ * @return 1-区域 2-顶端 3-左端 0-判断错误
+ */
+ private int isArea(String str) {
+ String split = str.split(":")[0];
+ int countMatches = StringUtils.countMatches(split, "$");
+ if (countMatches == 2) {
+ return 1;
+ } else if (countMatches == 1) {
+ String substr = split.substring(split.length() - 1);
+ char charAt = substr.charAt(0);
+ Pattern pattern = Pattern.compile("[0-9]*");
+ if (pattern.matcher(substr).matches()) {
+ return 2;
+ } else if ((charAt >= 'a' && charAt <= 'z') || (charAt >= 'A' && charAt <= 'Z')) {
+ return 3;
+ }
+ }
+ return 0;
+
+ }
+
+ /**
+ * 计算当前的最大行和列数
+ *
+ * @param ref
+ */
+ private void handleMax(String ref) {
+ final String[] range = ref.split(":");
+ String maxStr;
+ if (range.length == 1) {
+ maxStr = range[0];
+ } else {
+ maxStr = range[1];
+ }
+ final int[] maxPosition = parsePosition(maxStr);
+ rowMax = maxPosition[1];
+ colMax = maxPosition[0];
+ }
+
+ /**
+ * 把单元格数据添加到当前行的数据容器中
+ *
+ * @param result
+ */
+ private void writeColData(final Object result) {
+ rowData.getCellDataValues().add(result);
+ cellBuilder.delete(0, cellBuilder.length());
+ }
+
+ /**
+ * 数据append到cellBuilder中
+ *
+ * @param ch
+ * @param start
+ * @param length
+ */
+ @Override
+ public void characters(final char[] ch, final int start, final int length) {
+ if (valueFlag) {
+ cellBuilder.append(ch, start, length);
+ }
+ }
+
+ /**
+ * sheet处理
+ *
+ * @param sheetIndex
+ * @param sheetStyle
+ */
+ private void sheetHandler(int sheetIndex, SheetStyle sheetStyle) {
+
+ }
+
+ /**
+ * 获取position坐标的实际坐标数据
+ *
+ * @param position
+ * @return
+ */
+ private int[] parsePosition(String position) {
+ final int[] result = new int[2];
+ final String amPosition = position.replaceAll("[0-9]", "");
+ final char[] chars = amPosition.toUpperCase().toCharArray();
+ int ret = 0;
+ for (int i = 0; i < chars.length; i++) {
+ ret += (chars[i] - 'A' + 1) * Math.pow(26, chars.length - i - 1);
+ }
+ result[0] = ret;
+ result[1] = Integer.parseInt(position.replaceAll("[A-Z]", ""));
+ return result;
+ }
+
+ /**
+ * 调整列最大值
+ *
+ * @param colIndex
+ */
+ private void adjustColMax(final int colIndex) {
+ if (colIndex > colMax) {
+ colMax = colIndex;
+ }
+ }
+
+ /**
+ * 调整行最大值
+ *
+ * @param rowIndex
+ */
+ private void adjustRowMax(final int rowIndex) {
+ if (rowIndex > rowMax) {
+ rowMax = rowIndex;
+ }
+ }
+}微服务配置中心能帮助统一管理多个环境、多个应用程序的外部化配置,不需要在某个配置有改动或新增某个配置项时去多个节点上一个个修改,做到了一次改动,处处使用。这里和Eureka注册中心配合使用。
SpringCloud子项目,提供了分布式系统中外部配置管理的能力,分为server和client 两部分。官网地址
建立一个git仓库,将配置文件放在仓库里,配置文件格式应用名-profile.properties(yml) ,多服务的情况包名可根据服务前缀命名,在配置中心server端配置中增加search-path配置即可,比如多个包名app-1/app-2,可以配置search-path:app-*
+<dependencies>
+ <dependency>
+ <groupId>org.springframework.cloud</groupId>
+ <artifactId>spring-cloud-config-server</artifactId>
+ </dependency>
+ <dependency>
+ <groupId>org.springframework.cloud</groupId>
+ <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
+ </dependency>
+</dependencies>server:
+ port: 8077
+spring:
+ application:
+ name: spring-cloud-config-center
+ cloud:
+ config:
+ server:
+ git:
+ uri: git仓库地址
+ username: 账号
+ password: 密码
+ search-paths: app-* #搜索路径,使用通配符
+
+eureka:
+ client:
+ service-url:
+ defaultZone: http://admin:admin@127.0.0.1:19991/eureka/
+ fetch-registry-interval-seconds: 5
+
+ instance:
+ prefer-ip-address: true
+ lease-expiration-duration-in-seconds: 30
+ lease-renewal-interval-in-seconds: 10@SpringBootApplication
+@EnableEurekaClient
+@EnableConfigServer
+public class ConfigCenterApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(ConfigCenterApplication.class, args);
+ }
+}<!--springcloud config客户端-->
+<dependency>
+ <groupId>org.springframework.cloud</groupId>
+ <artifactId>spring-cloud-config-client</artifactId>
+</dependency>spring:
+ application:
+ name: app-1
+ cloud:
+ config:
+ profile: @spring.profiles.active@
+ label: master
+ discovery:
+ enabled: true
+ service-id: spring-cloud-config-center
+eureka:
+ client:
+ service-url:
+ defaultZone: http://admin:admin@127.0.0.1:19991/eureka/TIP
SpringCloudConfig配合服务发现使用时,必须在bootstrap.yaml(或环境变量) 开启服务发现spring.cloud.config.discovery.enabled=true,并且要配置注册中心的地址eureka.client.serviceUrl.defaultZone ,服务启动时会首先去注册中心找到配置中心server。
The HTTP service has resources in the following form:
/{application}/{profile}[/{label}]
+/{application}-{profile}.yml
+/{label}/{application}-{profile}.yml
+/{application}-{profile}.properties
+/{label}/{application}-{profile}.propertiesDiscovery First Bootstrap
If you use a
DiscoveryClientimplementation, such as Spring Cloud Netflix and Eureka Service Discovery or Spring Cloud Consul, you can have the Config Server register with the Discovery Service. However, in the default “Config First” mode, clients cannot take advantage of the registration.If you prefer to use
DiscoveryClientto locate the Config Server, you can do so by settingspring.cloud.config.discovery.enabled=true(the default isfalse). The net result of doing so is that client applications all need abootstrap.yml(or an environment variable) with the appropriate discovery configuration. For example, with Spring Cloud Netflix, you need to define the Eureka server address (for example, ineureka.client.serviceUrl.defaultZone). The price for using this option is an extra network round trip on startup, to locate the service registration. The benefit is that, as long as the Discovery Service is a fixed point, the Config Server can change its coordinates. The default service ID isconfigserver, but you can change that on the client by settingspring.cloud.config.discovery.serviceId(and on the server, in the usual way for a service, such as by settingspring.application.name).
配置中心启动后,其他服务向配置中心获取配置文件时,配置中心会去git上拉配置并缓存在本地的临时目录。
默认情况下,它们被放在带有config-repo-前缀的系统临时目录中。例如,在linux上,它可以是/tmp/config-repo-<randomid> 。一些操作系统会定期清理临时目录,导致意料之外的情况发生,例如丢失属性。需要在配置文件中增加配置spring.cloud.config.server.git.basedir 或spring.cloud.config.server.svn.basedir来指定一个不在系统临时路径下的目录。
微服务配置中心能帮助统一管理多个环境、多个应用程序的外部化配置,不需要在某个配置有改动或新增某个配置项时去多个节点上一个个修改,做到了一次改动,处处使用。这里和Eureka注册中心配合使用。
SpringCloud子项目,提供了分布式系统中外部配置管理的能力,分为server和client 两部分。官网地址
建立一个git仓库,将配置文件放在仓库里,配置文件格式应用名-profile.properties(yml) ,多服务的情况包名可根据服务前缀命名,在配置中心server端配置中增加search-path配置即可,比如多个包名app-1/app-2,可以配置search-path:app-*
+<dependencies>
+ <dependency>
+ <groupId>org.springframework.cloud</groupId>
+ <artifactId>spring-cloud-config-server</artifactId>
+ </dependency>
+ <dependency>
+ <groupId>org.springframework.cloud</groupId>
+ <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
+ </dependency>
+</dependencies>server:
+ port: 8077
+spring:
+ application:
+ name: spring-cloud-config-center
+ cloud:
+ config:
+ server:
+ git:
+ uri: git仓库地址
+ username: 账号
+ password: 密码
+ search-paths: app-* #搜索路径,使用通配符
+
+eureka:
+ client:
+ service-url:
+ defaultZone: http://admin:admin@127.0.0.1:19991/eureka/
+ fetch-registry-interval-seconds: 5
+
+ instance:
+ prefer-ip-address: true
+ lease-expiration-duration-in-seconds: 30
+ lease-renewal-interval-in-seconds: 10@SpringBootApplication
+@EnableEurekaClient
+@EnableConfigServer
+public class ConfigCenterApplication {
+ public static void main(String[] args) {
+ SpringApplication.run(ConfigCenterApplication.class, args);
+ }
+}<!--springcloud config客户端-->
+<dependency>
+ <groupId>org.springframework.cloud</groupId>
+ <artifactId>spring-cloud-config-client</artifactId>
+</dependency>spring:
+ application:
+ name: app-1
+ cloud:
+ config:
+ profile: @spring.profiles.active@
+ label: master
+ discovery:
+ enabled: true
+ service-id: spring-cloud-config-center
+eureka:
+ client:
+ service-url:
+ defaultZone: http://admin:admin@127.0.0.1:19991/eureka/TIP
SpringCloudConfig配合服务发现使用时,必须在bootstrap.yaml(或环境变量) 开启服务发现spring.cloud.config.discovery.enabled=true,并且要配置注册中心的地址eureka.client.serviceUrl.defaultZone ,服务启动时会首先去注册中心找到配置中心server。
The HTTP service has resources in the following form:
/{application}/{profile}[/{label}]
+/{application}-{profile}.yml
+/{label}/{application}-{profile}.yml
+/{application}-{profile}.properties
+/{label}/{application}-{profile}.propertiesDiscovery First Bootstrap
If you use a
DiscoveryClientimplementation, such as Spring Cloud Netflix and Eureka Service Discovery or Spring Cloud Consul, you can have the Config Server register with the Discovery Service. However, in the default “Config First” mode, clients cannot take advantage of the registration.If you prefer to use
DiscoveryClientto locate the Config Server, you can do so by settingspring.cloud.config.discovery.enabled=true(the default isfalse). The net result of doing so is that client applications all need abootstrap.yml(or an environment variable) with the appropriate discovery configuration. For example, with Spring Cloud Netflix, you need to define the Eureka server address (for example, ineureka.client.serviceUrl.defaultZone). The price for using this option is an extra network round trip on startup, to locate the service registration. The benefit is that, as long as the Discovery Service is a fixed point, the Config Server can change its coordinates. The default service ID isconfigserver, but you can change that on the client by settingspring.cloud.config.discovery.serviceId(and on the server, in the usual way for a service, such as by settingspring.application.name).
配置中心启动后,其他服务向配置中心获取配置文件时,配置中心会去git上拉配置并缓存在本地的临时目录。
默认情况下,它们被放在带有config-repo-前缀的系统临时目录中。例如,在linux上,它可以是/tmp/config-repo-<randomid> 。一些操作系统会定期清理临时目录,导致意料之外的情况发生,例如丢失属性。需要在配置文件中增加配置spring.cloud.config.server.git.basedir 或spring.cloud.config.server.svn.basedir来指定一个不在系统临时路径下的目录。
一个常见的面试/笔试题: SpringMVC的执行流程
答:
1、前端请求到核心前端控制器DispatcherServlet
2、DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3、处理器映射器找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4、 DispatcherServlet调用HandlerAdapter处理器适配器。
5、HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
6、Controller执行完成返回ModelAndView。
7、HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
8、DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9、ViewReslover解析后返回具体View.
10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
11、DispatcherServlet响应用户。
为了应付面试相信很多人和我一样死记硬背过,今天就来看下源码,看看这个流程的庐山真面目。
首先找到DispatcherServlet类,看看它的继承关系 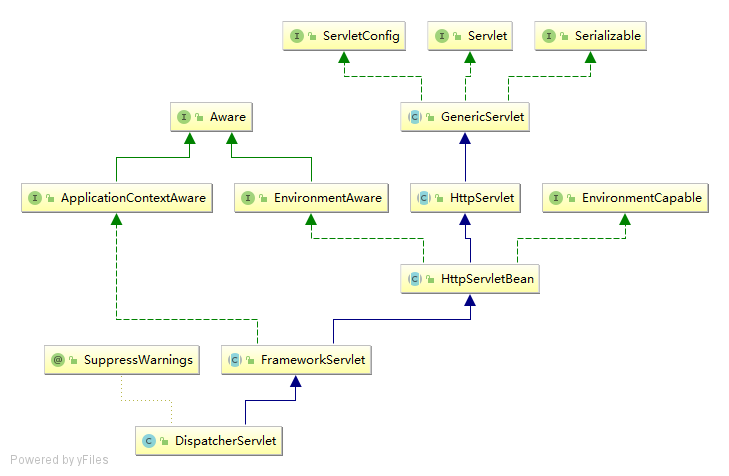
过程图 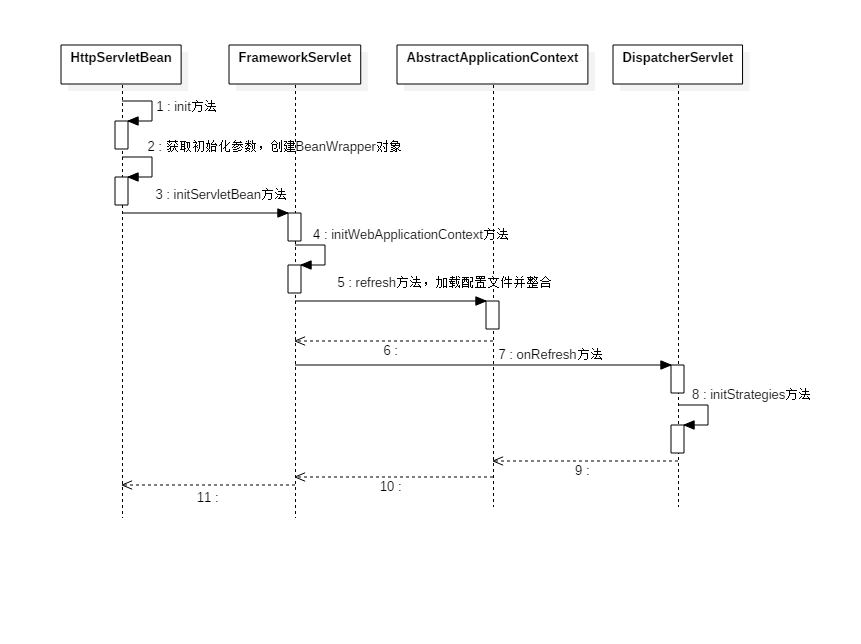
初始化方法
/**
+ * This implementation calls {@link #initStrategies}.
+ */
+ @Override
+ protected void onRefresh(ApplicationContext context) {
+ initStrategies(context);
+ }
+
+ /**
+ * Initialize the strategy objects that this servlet uses.
+ * <p>May be overridden in subclasses in order to initialize further strategy objects.
+ */
+ protected void initStrategies(ApplicationContext context) {
+ initMultipartResolver(context);
+ initLocaleResolver(context);
+ initThemeResolver(context);
+ initHandlerMappings(context);
+ initHandlerAdapters(context);
+ initHandlerExceptionResolvers(context);
+ initRequestToViewNameTranslator(context);
+ initViewResolvers(context);
+ initFlashMapManager(context);
+ }可以看到initStrategies方法初始化了9个组件,其中不乏文章开头中问题涉及到的组件
这九个初始化方法做的事情如下:
首先要明确DispatcherServlet也是一个Servlet,也要遵守servlet接口的规范,servlet通过service方法来根据不同的请求方式来执行doGet,doPost等方法。而FrameworkServlet重写了service方法,并调用了processRequest方法,processRequest方法中又调用了抽象方法doService,DispatcherServlet实现了doService方法,并在该方法中调用了doDispatch方法,doDispatch方法就是具体的请求处理过程
过程图: 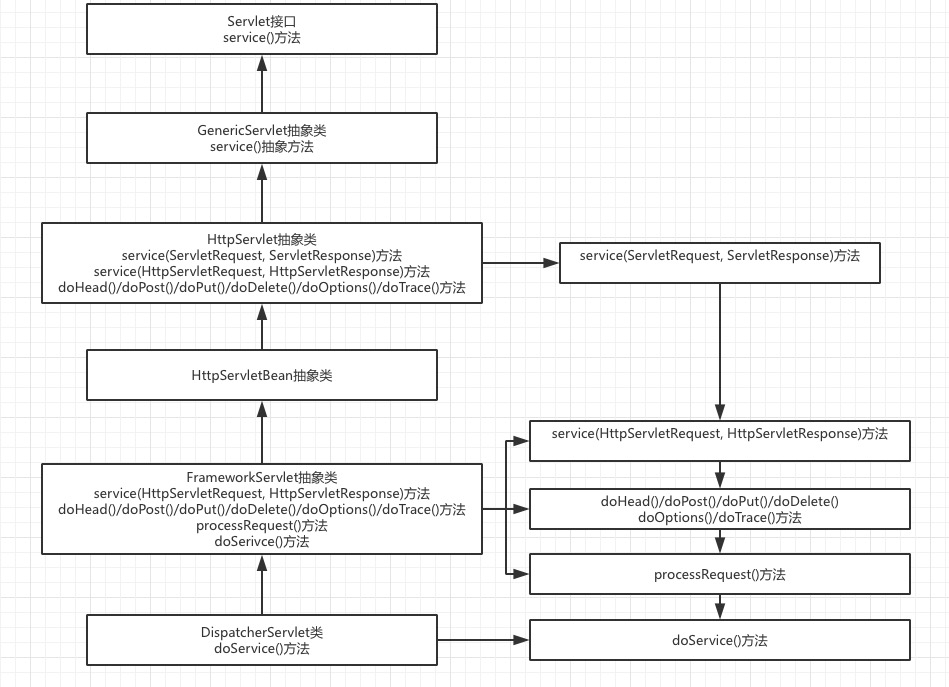
/**
+ * Process the actual dispatching to the handler.
+ * <p>The handler will be obtained by applying the servlet's HandlerMappings in order.
+ * The HandlerAdapter will be obtained by querying the servlet's installed HandlerAdapters
+ * to find the first that supports the handler class.
+ * <p>All HTTP methods are handled by this method. It's up to HandlerAdapters or handlers
+ * themselves to decide which methods are acceptable.
+ * @param request current HTTP request
+ * @param response current HTTP response
+ * @throws Exception in case of any kind of processing failure
+ */
+ protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
+ HttpServletRequest processedRequest = request;
+ HandlerExecutionChain mappedHandler = null;
+ boolean multipartRequestParsed = false;
+
+ WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
+
+ try {
+ ModelAndView mv = null;
+ Exception dispatchException = null;
+
+ try {
+ //判断是否为上传文件的请求,如果不是就返回原始的request,否则做相应的处理
+ processedRequest = checkMultipart(request);
+ multipartRequestParsed = (processedRequest != request);
+
+ // Determine handler for the current request.
+ //找到当前请求对应的处理器,返回的是对应的处理器及拦截器集合
+ mappedHandler = getHandler(processedRequest);
+ if (mappedHandler == null) {
+ noHandlerFound(processedRequest, response);
+ return;
+ }
+
+ // Determine handler adapter for the current request.
+ //根据上一步找到的处理器,再找到对应的处理器适配器
+ HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
+
+ // Process last-modified header, if supported by the handler.
+ String method = request.getMethod();
+ boolean isGet = "GET".equals(method);
+ if (isGet || "HEAD".equals(method)) {
+ long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
+ if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
+ return;
+ }
+ }
+ //这里执行了所有的拦截器中的preHandle方法 也就是为什么拦截器总在controller前先执行
+ if (!mappedHandler.applyPreHandle(processedRequest, response)) {
+ return;
+ }
+
+ // Actually invoke the handler.
+ //调用处理器的处理方法
+ mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
+
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ return;
+ }
+ //设置modelAndView的默认名
+ applyDefaultViewName(processedRequest, mv);
+ //执行拦截器的postHanle方法
+ mappedHandler.applyPostHandle(processedRequest, response, mv);
+ }
+ catch (Exception ex) {
+ dispatchException = ex;
+ }
+ catch (Throwable err) {
+ // As of 4.3, we're processing Errors thrown from handler methods as well,
+ // making them available for @ExceptionHandler methods and other scenarios.
+ dispatchException = new NestedServletException("Handler dispatch failed", err);
+ }
+ //处理modelAndView并渲染
+ processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
+ }
+ catch (Exception ex) {
+ triggerAfterCompletion(processedRequest, response, mappedHandler, ex);
+ }
+ catch (Throwable err) {
+ triggerAfterCompletion(processedRequest, response, mappedHandler,
+ new NestedServletException("Handler processing failed", err));
+ }
+ finally {
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ // Instead of postHandle and afterCompletion
+ if (mappedHandler != null) {
+ mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response);
+ }
+ }
+ else {
+ // Clean up any resources used by a multipart request.
+ if (multipartRequestParsed) {
+ cleanupMultipart(processedRequest);
+ }
+ }
+ }
+ }该方法返回的是HandlerExecutionChain对象,其中包含了处理器和过滤器的集合,这里调用了handlerMapping的getHandler方法,该方法主要调用了getHandlerExecutionChain方法,handlerMapping的集合是在初始化dispatchServlet的时候从beanFactory中查找并封装的,具体的handlerMappings初始化细节可以看initHandlerMappings方法,handlerMapping有多种类型,对应不同的请求,比如请求静态资源的和请求接口的等,此处我们以请求一个查询接口为例
protected HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
+ if (this.handlerMappings != null) {
+ //循环所有的handlerMapping,直到找到对应的handler
+ for (HandlerMapping mapping : this.handlerMappings) {
+ HandlerExecutionChain handler = mapping.getHandler(request);
+ if (handler != null) {
+ return handler;
+ }
+ }
+ }
+ return null;
+}getHandlerExecutionChain方法这里调用的是AbstractHandlerMethodMapping的getHandlerInternal方法,该方法又调用了同一个类中的lookupHandlerMethod方法
lookupHandlerMethod方法会根据请求的uri在mappingRegistry中查询已经注册了的请求路径(requestMapping注解中的路径),如果能直接从map中get到非空的list,就直接根据list匹配对应的HandleMethod对象,如果mappingRegistry中get不到,就尝试使用uri路径匹配,例如带有url参数的这种格式/test/{username}的格式,{username}会被替换为.*的正则表达式去进行匹配,匹配到后返回;
getHandlerExecutionChain方法则是根据请求的路径匹配拦截器的路径,如果有匹配到的,就添加到执行链当中
public final HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
+ //根据request找到对应的handler
+ Object handler = getHandlerInternal(request);
+ if (handler == null) {
+ handler = getDefaultHandler();
+ }
+ if (handler == null) {
+ return null;
+ }
+ // Bean name or resolved handler?
+ if (handler instanceof String) {
+ String handlerName = (String) handler;
+ handler = obtainApplicationContext().getBean(handlerName);
+ }
+
+ HandlerExecutionChain executionChain = getHandlerExecutionChain(handler, request);
+
+ if (logger.isTraceEnabled()) {
+ logger.trace("Mapped to " + handler);
+ }
+ else if (logger.isDebugEnabled() && !request.getDispatcherType().equals(DispatcherType.ASYNC)) {
+ logger.debug("Mapped to " + executionChain.getHandler());
+ }
+
+ if (CorsUtils.isCorsRequest(request)) {
+ CorsConfiguration globalConfig = this.corsConfigurationSource.getCorsConfiguration(request);
+ CorsConfiguration handlerConfig = getCorsConfiguration(handler, request);
+ CorsConfiguration config = (globalConfig != null ? globalConfig.combine(handlerConfig) : handlerConfig);
+ executionChain = getCorsHandlerExecutionChain(request, executionChain, config);
+ }
+
+ return executionChain;
+ }
+
+
+
+protected HandlerExecutionChain getHandlerExecutionChain(Object handler, HttpServletRequest request) {
+ HandlerExecutionChain chain = (handler instanceof HandlerExecutionChain ?
+ (HandlerExecutionChain) handler : new HandlerExecutionChain(handler));
+
+ String lookupPath = this.urlPathHelper.getLookupPathForRequest(request);
+ for (HandlerInterceptor interceptor : this.adaptedInterceptors) {
+ if (interceptor instanceof MappedInterceptor) {
+ MappedInterceptor mappedInterceptor = (MappedInterceptor) interceptor;
+ if (mappedInterceptor.matches(lookupPath, this.pathMatcher)) {
+ chain.addInterceptor(mappedInterceptor.getInterceptor());
+ }
+ }
+ else {
+ chain.addInterceptor(interceptor);
+ }
+ }
+ return chain;
+ }这个方法比较简单,就是从handlerAdapter集合中遍历找到支持当前请求的处理器适配器,用到了handlerAdapter的supports方法,测试的接口请求会调用AbstractHandlerMethodAdapter这个类的supports方法
/**
+ * This implementation expects the handler to be an {@link HandlerMethod}.
+ * @param handler the handler instance to check
+ * @return whether or not this adapter can adapt the given handler
+ */
+@Override
+public final boolean supports(Object handler) {
+ return (handler instanceof HandlerMethod && supportsInternal((HandlerMethod) handler));
+}在找到对应的处理器适配器后,会执行拦截器的preHandle方法,然后执行处理器适配器的handle方法,这个就是实际上调用我们所写的controller了,该方法有几个实现  这里调用的是AbstractHandlerMethodAdapter的方法,该方法调用了抽象方法
这里调用的是AbstractHandlerMethodAdapter的方法,该方法调用了抽象方法handleInternal,它的实现在RequestMappingHandlerAdapter类中
protected ModelAndView handleInternal(HttpServletRequest request,
+ HttpServletResponse response, HandlerMethod handlerMethod) throws Exception {
+
+ ModelAndView mav;
+ checkRequest(request);
+
+ // Execute invokeHandlerMethod in synchronized block if required.
+ if (this.synchronizeOnSession) {
+ HttpSession session = request.getSession(false);
+ if (session != null) {
+ Object mutex = WebUtils.getSessionMutex(session);
+ synchronized (mutex) {
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+ }
+ else {
+ // No HttpSession available -> no mutex necessary
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+ }
+ else {
+ // No synchronization on session demanded at all...
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+
+ if (!response.containsHeader(HEADER_CACHE_CONTROL)) {
+ if (getSessionAttributesHandler(handlerMethod).hasSessionAttributes()) {
+ applyCacheSeconds(response, this.cacheSecondsForSessionAttributeHandlers);
+ }
+ else {
+ prepareResponse(response);
+ }
+ }
+
+ return mav;
+}其中重点在invokeHandlerMethod方法,这个方法首先初始化了一个新的handlerMethod对象,添加了相关的解析组件,返回值处理器等等,然后执行了invokeAndHandle方法,然后最终调用了InvocableHandlerMethod类中的doInvoke方法
protected ModelAndView invokeHandlerMethod(HttpServletRequest request,
+ HttpServletResponse response, HandlerMethod handlerMethod) throws Exception {
+ ServletWebRequest webRequest = new ServletWebRequest(request, response);
+ try {
+ WebDataBinderFactory binderFactory = getDataBinderFactory(handlerMethod);
+ ModelFactory modelFactory = getModelFactory(handlerMethod, binderFactory);
+
+ ServletInvocableHandlerMethod invocableMethod = createInvocableHandlerMethod(handlerMethod);
+ if (this.argumentResolvers != null) {
+ invocableMethod.setHandlerMethodArgumentResolvers(this.argumentResolvers);
+ }
+ if (this.returnValueHandlers != null) {
+ invocableMethod.setHandlerMethodReturnValueHandlers(this.returnValueHandlers);
+ }
+ invocableMethod.setDataBinderFactory(binderFactory);
+ invocableMethod.setParameterNameDiscoverer(this.parameterNameDiscoverer);
+
+ ModelAndViewContainer mavContainer = new ModelAndViewContainer();
+ mavContainer.addAllAttributes(RequestContextUtils.getInputFlashMap(request));
+ modelFactory.initModel(webRequest, mavContainer, invocableMethod);
+ mavContainer.setIgnoreDefaultModelOnRedirect(this.ignoreDefaultModelOnRedirect);
+
+ AsyncWebRequest asyncWebRequest = WebAsyncUtils.createAsyncWebRequest(request, response);
+ asyncWebRequest.setTimeout(this.asyncRequestTimeout);
+
+ WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
+ asyncManager.setTaskExecutor(this.taskExecutor);
+ asyncManager.setAsyncWebRequest(asyncWebRequest);
+ asyncManager.registerCallableInterceptors(this.callableInterceptors);
+ asyncManager.registerDeferredResultInterceptors(this.deferredResultInterceptors);
+
+ if (asyncManager.hasConcurrentResult()) {
+ Object result = asyncManager.getConcurrentResult();
+ mavContainer = (ModelAndViewContainer) asyncManager.getConcurrentResultContext()[0];
+ asyncManager.clearConcurrentResult();
+ LogFormatUtils.traceDebug(logger, traceOn -> {
+ String formatted = LogFormatUtils.formatValue(result, !traceOn);
+ return "Resume with async result [" + formatted + "]";
+ });
+ invocableMethod = invocableMethod.wrapConcurrentResult(result);
+ }
+
+ invocableMethod.invokeAndHandle(webRequest, mavContainer);
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ return null;
+ }
+
+ return getModelAndView(mavContainer, modelFactory, webRequest);
+ }
+ finally {
+ webRequest.requestCompleted();
+ }
+}这里就比较明显了,首先利用暴力反射将方法设置为可访问的,然后直接反射调用并返回结果
/**
+ * Invoke the handler method with the given argument values.
+ */
+@Nullable
+protected Object doInvoke(Object... args) throws Exception {
+ ReflectionUtils.makeAccessible(getBridgedMethod());
+ try {
+ return getBridgedMethod().invoke(getBean(), args);
+ }
+ catch (IllegalArgumentException ex) {
+ assertTargetBean(getBridgedMethod(), getBean(), args);
+ String text = (ex.getMessage() != null ? ex.getMessage() : "Illegal argument");
+ throw new IllegalStateException(formatInvokeError(text, args), ex);
+ }
+ catch (InvocationTargetException ex) {
+ // Unwrap for HandlerExceptionResolvers ...
+ Throwable targetException = ex.getTargetException();
+ if (targetException instanceof RuntimeException) {
+ throw (RuntimeException) targetException;
+ }
+ else if (targetException instanceof Error) {
+ throw (Error) targetException;
+ }
+ else if (targetException instanceof Exception) {
+ throw (Exception) targetException;
+ }
+ else {
+ throw new IllegalStateException(formatInvokeError("Invocation failure", args), targetException);
+ }
+ }
+}返回modelAndview对象后就是渲染的一些操作
`,48)]))}const y=i(l,[["render",h]]);export{g as __pageData,y as default}; diff --git "a/assets/java_framework_SpringMVC\347\232\204\346\211\247\350\241\214\346\265\201\347\250\213\346\272\220\347\240\201\345\210\206\346\236\220.md.DKZqyyEM.lean.js" "b/assets/java_framework_SpringMVC\347\232\204\346\211\247\350\241\214\346\265\201\347\250\213\346\272\220\347\240\201\345\210\206\346\236\220.md.DKZqyyEM.lean.js" new file mode 100644 index 00000000..d2783a66 --- /dev/null +++ "b/assets/java_framework_SpringMVC\347\232\204\346\211\247\350\241\214\346\265\201\347\250\213\346\272\220\347\240\201\345\210\206\346\236\220.md.DKZqyyEM.lean.js" @@ -0,0 +1,309 @@ +import{_ as i,c as a,a2 as n,o as t}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"SpringMVC的执行流程源码分析","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/SpringMVC的执行流程源码分析.md","filePath":"java/framework/SpringMVC的执行流程源码分析.md","lastUpdated":1729217313000}'),l={name:"java/framework/SpringMVC的执行流程源码分析.md"};function h(p,s,e,k,r,E){return t(),a("div",null,s[0]||(s[0]=[n(`一个常见的面试/笔试题: SpringMVC的执行流程
答:
1、前端请求到核心前端控制器DispatcherServlet
2、DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3、处理器映射器找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4、 DispatcherServlet调用HandlerAdapter处理器适配器。
5、HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
6、Controller执行完成返回ModelAndView。
7、HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
8、DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9、ViewReslover解析后返回具体View.
10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
11、DispatcherServlet响应用户。
为了应付面试相信很多人和我一样死记硬背过,今天就来看下源码,看看这个流程的庐山真面目。
首先找到DispatcherServlet类,看看它的继承关系
过程图
初始化方法
/**
+ * This implementation calls {@link #initStrategies}.
+ */
+ @Override
+ protected void onRefresh(ApplicationContext context) {
+ initStrategies(context);
+ }
+
+ /**
+ * Initialize the strategy objects that this servlet uses.
+ * <p>May be overridden in subclasses in order to initialize further strategy objects.
+ */
+ protected void initStrategies(ApplicationContext context) {
+ initMultipartResolver(context);
+ initLocaleResolver(context);
+ initThemeResolver(context);
+ initHandlerMappings(context);
+ initHandlerAdapters(context);
+ initHandlerExceptionResolvers(context);
+ initRequestToViewNameTranslator(context);
+ initViewResolvers(context);
+ initFlashMapManager(context);
+ }可以看到initStrategies方法初始化了9个组件,其中不乏文章开头中问题涉及到的组件
这九个初始化方法做的事情如下:
首先要明确DispatcherServlet也是一个Servlet,也要遵守servlet接口的规范,servlet通过service方法来根据不同的请求方式来执行doGet,doPost等方法。而FrameworkServlet重写了service方法,并调用了processRequest方法,processRequest方法中又调用了抽象方法doService,DispatcherServlet实现了doService方法,并在该方法中调用了doDispatch方法,doDispatch方法就是具体的请求处理过程
过程图:
/**
+ * Process the actual dispatching to the handler.
+ * <p>The handler will be obtained by applying the servlet's HandlerMappings in order.
+ * The HandlerAdapter will be obtained by querying the servlet's installed HandlerAdapters
+ * to find the first that supports the handler class.
+ * <p>All HTTP methods are handled by this method. It's up to HandlerAdapters or handlers
+ * themselves to decide which methods are acceptable.
+ * @param request current HTTP request
+ * @param response current HTTP response
+ * @throws Exception in case of any kind of processing failure
+ */
+ protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
+ HttpServletRequest processedRequest = request;
+ HandlerExecutionChain mappedHandler = null;
+ boolean multipartRequestParsed = false;
+
+ WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
+
+ try {
+ ModelAndView mv = null;
+ Exception dispatchException = null;
+
+ try {
+ //判断是否为上传文件的请求,如果不是就返回原始的request,否则做相应的处理
+ processedRequest = checkMultipart(request);
+ multipartRequestParsed = (processedRequest != request);
+
+ // Determine handler for the current request.
+ //找到当前请求对应的处理器,返回的是对应的处理器及拦截器集合
+ mappedHandler = getHandler(processedRequest);
+ if (mappedHandler == null) {
+ noHandlerFound(processedRequest, response);
+ return;
+ }
+
+ // Determine handler adapter for the current request.
+ //根据上一步找到的处理器,再找到对应的处理器适配器
+ HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
+
+ // Process last-modified header, if supported by the handler.
+ String method = request.getMethod();
+ boolean isGet = "GET".equals(method);
+ if (isGet || "HEAD".equals(method)) {
+ long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
+ if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
+ return;
+ }
+ }
+ //这里执行了所有的拦截器中的preHandle方法 也就是为什么拦截器总在controller前先执行
+ if (!mappedHandler.applyPreHandle(processedRequest, response)) {
+ return;
+ }
+
+ // Actually invoke the handler.
+ //调用处理器的处理方法
+ mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
+
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ return;
+ }
+ //设置modelAndView的默认名
+ applyDefaultViewName(processedRequest, mv);
+ //执行拦截器的postHanle方法
+ mappedHandler.applyPostHandle(processedRequest, response, mv);
+ }
+ catch (Exception ex) {
+ dispatchException = ex;
+ }
+ catch (Throwable err) {
+ // As of 4.3, we're processing Errors thrown from handler methods as well,
+ // making them available for @ExceptionHandler methods and other scenarios.
+ dispatchException = new NestedServletException("Handler dispatch failed", err);
+ }
+ //处理modelAndView并渲染
+ processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
+ }
+ catch (Exception ex) {
+ triggerAfterCompletion(processedRequest, response, mappedHandler, ex);
+ }
+ catch (Throwable err) {
+ triggerAfterCompletion(processedRequest, response, mappedHandler,
+ new NestedServletException("Handler processing failed", err));
+ }
+ finally {
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ // Instead of postHandle and afterCompletion
+ if (mappedHandler != null) {
+ mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response);
+ }
+ }
+ else {
+ // Clean up any resources used by a multipart request.
+ if (multipartRequestParsed) {
+ cleanupMultipart(processedRequest);
+ }
+ }
+ }
+ }该方法返回的是HandlerExecutionChain对象,其中包含了处理器和过滤器的集合,这里调用了handlerMapping的getHandler方法,该方法主要调用了getHandlerExecutionChain方法,handlerMapping的集合是在初始化dispatchServlet的时候从beanFactory中查找并封装的,具体的handlerMappings初始化细节可以看initHandlerMappings方法,handlerMapping有多种类型,对应不同的请求,比如请求静态资源的和请求接口的等,此处我们以请求一个查询接口为例
protected HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
+ if (this.handlerMappings != null) {
+ //循环所有的handlerMapping,直到找到对应的handler
+ for (HandlerMapping mapping : this.handlerMappings) {
+ HandlerExecutionChain handler = mapping.getHandler(request);
+ if (handler != null) {
+ return handler;
+ }
+ }
+ }
+ return null;
+}getHandlerExecutionChain方法这里调用的是AbstractHandlerMethodMapping的getHandlerInternal方法,该方法又调用了同一个类中的lookupHandlerMethod方法
lookupHandlerMethod方法会根据请求的uri在mappingRegistry中查询已经注册了的请求路径(requestMapping注解中的路径),如果能直接从map中get到非空的list,就直接根据list匹配对应的HandleMethod对象,如果mappingRegistry中get不到,就尝试使用uri路径匹配,例如带有url参数的这种格式/test/{username}的格式,{username}会被替换为.*的正则表达式去进行匹配,匹配到后返回;
getHandlerExecutionChain方法则是根据请求的路径匹配拦截器的路径,如果有匹配到的,就添加到执行链当中
public final HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
+ //根据request找到对应的handler
+ Object handler = getHandlerInternal(request);
+ if (handler == null) {
+ handler = getDefaultHandler();
+ }
+ if (handler == null) {
+ return null;
+ }
+ // Bean name or resolved handler?
+ if (handler instanceof String) {
+ String handlerName = (String) handler;
+ handler = obtainApplicationContext().getBean(handlerName);
+ }
+
+ HandlerExecutionChain executionChain = getHandlerExecutionChain(handler, request);
+
+ if (logger.isTraceEnabled()) {
+ logger.trace("Mapped to " + handler);
+ }
+ else if (logger.isDebugEnabled() && !request.getDispatcherType().equals(DispatcherType.ASYNC)) {
+ logger.debug("Mapped to " + executionChain.getHandler());
+ }
+
+ if (CorsUtils.isCorsRequest(request)) {
+ CorsConfiguration globalConfig = this.corsConfigurationSource.getCorsConfiguration(request);
+ CorsConfiguration handlerConfig = getCorsConfiguration(handler, request);
+ CorsConfiguration config = (globalConfig != null ? globalConfig.combine(handlerConfig) : handlerConfig);
+ executionChain = getCorsHandlerExecutionChain(request, executionChain, config);
+ }
+
+ return executionChain;
+ }
+
+
+
+protected HandlerExecutionChain getHandlerExecutionChain(Object handler, HttpServletRequest request) {
+ HandlerExecutionChain chain = (handler instanceof HandlerExecutionChain ?
+ (HandlerExecutionChain) handler : new HandlerExecutionChain(handler));
+
+ String lookupPath = this.urlPathHelper.getLookupPathForRequest(request);
+ for (HandlerInterceptor interceptor : this.adaptedInterceptors) {
+ if (interceptor instanceof MappedInterceptor) {
+ MappedInterceptor mappedInterceptor = (MappedInterceptor) interceptor;
+ if (mappedInterceptor.matches(lookupPath, this.pathMatcher)) {
+ chain.addInterceptor(mappedInterceptor.getInterceptor());
+ }
+ }
+ else {
+ chain.addInterceptor(interceptor);
+ }
+ }
+ return chain;
+ }这个方法比较简单,就是从handlerAdapter集合中遍历找到支持当前请求的处理器适配器,用到了handlerAdapter的supports方法,测试的接口请求会调用AbstractHandlerMethodAdapter这个类的supports方法
/**
+ * This implementation expects the handler to be an {@link HandlerMethod}.
+ * @param handler the handler instance to check
+ * @return whether or not this adapter can adapt the given handler
+ */
+@Override
+public final boolean supports(Object handler) {
+ return (handler instanceof HandlerMethod && supportsInternal((HandlerMethod) handler));
+}在找到对应的处理器适配器后,会执行拦截器的preHandle方法,然后执行处理器适配器的handle方法,这个就是实际上调用我们所写的controller了,该方法有几个实现 这里调用的是AbstractHandlerMethodAdapter的方法,该方法调用了抽象方法handleInternal,它的实现在RequestMappingHandlerAdapter类中
protected ModelAndView handleInternal(HttpServletRequest request,
+ HttpServletResponse response, HandlerMethod handlerMethod) throws Exception {
+
+ ModelAndView mav;
+ checkRequest(request);
+
+ // Execute invokeHandlerMethod in synchronized block if required.
+ if (this.synchronizeOnSession) {
+ HttpSession session = request.getSession(false);
+ if (session != null) {
+ Object mutex = WebUtils.getSessionMutex(session);
+ synchronized (mutex) {
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+ }
+ else {
+ // No HttpSession available -> no mutex necessary
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+ }
+ else {
+ // No synchronization on session demanded at all...
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+
+ if (!response.containsHeader(HEADER_CACHE_CONTROL)) {
+ if (getSessionAttributesHandler(handlerMethod).hasSessionAttributes()) {
+ applyCacheSeconds(response, this.cacheSecondsForSessionAttributeHandlers);
+ }
+ else {
+ prepareResponse(response);
+ }
+ }
+
+ return mav;
+}其中重点在invokeHandlerMethod方法,这个方法首先初始化了一个新的handlerMethod对象,添加了相关的解析组件,返回值处理器等等,然后执行了invokeAndHandle方法,然后最终调用了InvocableHandlerMethod类中的doInvoke方法
protected ModelAndView invokeHandlerMethod(HttpServletRequest request,
+ HttpServletResponse response, HandlerMethod handlerMethod) throws Exception {
+ ServletWebRequest webRequest = new ServletWebRequest(request, response);
+ try {
+ WebDataBinderFactory binderFactory = getDataBinderFactory(handlerMethod);
+ ModelFactory modelFactory = getModelFactory(handlerMethod, binderFactory);
+
+ ServletInvocableHandlerMethod invocableMethod = createInvocableHandlerMethod(handlerMethod);
+ if (this.argumentResolvers != null) {
+ invocableMethod.setHandlerMethodArgumentResolvers(this.argumentResolvers);
+ }
+ if (this.returnValueHandlers != null) {
+ invocableMethod.setHandlerMethodReturnValueHandlers(this.returnValueHandlers);
+ }
+ invocableMethod.setDataBinderFactory(binderFactory);
+ invocableMethod.setParameterNameDiscoverer(this.parameterNameDiscoverer);
+
+ ModelAndViewContainer mavContainer = new ModelAndViewContainer();
+ mavContainer.addAllAttributes(RequestContextUtils.getInputFlashMap(request));
+ modelFactory.initModel(webRequest, mavContainer, invocableMethod);
+ mavContainer.setIgnoreDefaultModelOnRedirect(this.ignoreDefaultModelOnRedirect);
+
+ AsyncWebRequest asyncWebRequest = WebAsyncUtils.createAsyncWebRequest(request, response);
+ asyncWebRequest.setTimeout(this.asyncRequestTimeout);
+
+ WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
+ asyncManager.setTaskExecutor(this.taskExecutor);
+ asyncManager.setAsyncWebRequest(asyncWebRequest);
+ asyncManager.registerCallableInterceptors(this.callableInterceptors);
+ asyncManager.registerDeferredResultInterceptors(this.deferredResultInterceptors);
+
+ if (asyncManager.hasConcurrentResult()) {
+ Object result = asyncManager.getConcurrentResult();
+ mavContainer = (ModelAndViewContainer) asyncManager.getConcurrentResultContext()[0];
+ asyncManager.clearConcurrentResult();
+ LogFormatUtils.traceDebug(logger, traceOn -> {
+ String formatted = LogFormatUtils.formatValue(result, !traceOn);
+ return "Resume with async result [" + formatted + "]";
+ });
+ invocableMethod = invocableMethod.wrapConcurrentResult(result);
+ }
+
+ invocableMethod.invokeAndHandle(webRequest, mavContainer);
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ return null;
+ }
+
+ return getModelAndView(mavContainer, modelFactory, webRequest);
+ }
+ finally {
+ webRequest.requestCompleted();
+ }
+}这里就比较明显了,首先利用暴力反射将方法设置为可访问的,然后直接反射调用并返回结果
/**
+ * Invoke the handler method with the given argument values.
+ */
+@Nullable
+protected Object doInvoke(Object... args) throws Exception {
+ ReflectionUtils.makeAccessible(getBridgedMethod());
+ try {
+ return getBridgedMethod().invoke(getBean(), args);
+ }
+ catch (IllegalArgumentException ex) {
+ assertTargetBean(getBridgedMethod(), getBean(), args);
+ String text = (ex.getMessage() != null ? ex.getMessage() : "Illegal argument");
+ throw new IllegalStateException(formatInvokeError(text, args), ex);
+ }
+ catch (InvocationTargetException ex) {
+ // Unwrap for HandlerExceptionResolvers ...
+ Throwable targetException = ex.getTargetException();
+ if (targetException instanceof RuntimeException) {
+ throw (RuntimeException) targetException;
+ }
+ else if (targetException instanceof Error) {
+ throw (Error) targetException;
+ }
+ else if (targetException instanceof Exception) {
+ throw (Exception) targetException;
+ }
+ else {
+ throw new IllegalStateException(formatInvokeError("Invocation failure", args), targetException);
+ }
+ }
+}返回modelAndview对象后就是渲染的一些操作
`,48)]))}const y=i(l,[["render",h]]);export{g as __pageData,y as default}; diff --git "a/assets/java_framework_Spring\351\205\215\347\275\256\345\222\214\346\235\241\344\273\266\345\214\226\347\273\204\344\273\266\345\212\240\350\275\275\346\263\250\350\247\243.md.Ch4Ic-d9.js" "b/assets/java_framework_Spring\351\205\215\347\275\256\345\222\214\346\235\241\344\273\266\345\214\226\347\273\204\344\273\266\345\212\240\350\275\275\346\263\250\350\247\243.md.Ch4Ic-d9.js" new file mode 100644 index 00000000..191e88d9 --- /dev/null +++ "b/assets/java_framework_Spring\351\205\215\347\275\256\345\222\214\346\235\241\344\273\266\345\214\226\347\273\204\344\273\266\345\212\240\350\275\275\346\263\250\350\247\243.md.Ch4Ic-d9.js" @@ -0,0 +1 @@ +import{_ as o,c as e,a2 as n,o as a}from"./chunks/framework.BjcrtTwI.js";const f=JSON.parse('{"title":"Spring配置和条件化组件加载注解","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/Spring配置和条件化组件加载注解.md","filePath":"java/framework/Spring配置和条件化组件加载注解.md","lastUpdated":1729217313000}'),r={name:"java/framework/Spring配置和条件化组件加载注解.md"};function l(p,i,t,d,c,s){return a(),e("div",null,i[0]||(i[0]=[n('@ConditionalOnProperty:该注解用于根据配置属性的值来决定是否启用或禁用特定的配置项。通过指定属性名称和值,可以在配置文件中动态地控制应用程序的行为。
@ConditionalOnClass:该注解在类路径中存在特定的类时才会生效。它可以用来根据是否引入了某个类来决定是否加载或配置相关的组件。
@EnableConfigurationProperties:该注解用于启用特定的配置属性绑定功能。它通常与 @ConfigurationProperties 注解一起使用,用于将配置文件中的属性值绑定到对应的 Java 对象中。
@ConfigurationProperties:将配置文件中的属性值映射到指定的Java类。
@ConditionalOnBean:根据指定的bean的存在与否,有条件地加载一个组件。
@Conditional:根据指定的条件,有条件地加载一个组件。可以使用自定义条件类。
@ConditionalOnMissingBean:如果指定的bean不存在,则有条件地加载一个组件。
@ConditionalOnMissingClass:如果类路径中缺少指定的类,则有条件地加载一个组件。
@AutoConfigureBefore:用于指定某个自动配置类在另一个指定的自动配置类之前生效。它可以控制自动配置类的加载顺序,确保特定的自动配置类在其他自动配置之前被应用。
@ConditionalOnExpression:根据指定的SpEL表达式,有条件地加载一个组件。
@ConditionalOnWebApplication:根据应用程序是否为Web应用程序,有条件地加载一个组件。
@ConditionalOnResource:根据指定资源的存在与否,有条件地加载一个组件。
@ConditionalOnProperty:该注解用于根据配置属性的值来决定是否启用或禁用特定的配置项。通过指定属性名称和值,可以在配置文件中动态地控制应用程序的行为。
@ConditionalOnClass:该注解在类路径中存在特定的类时才会生效。它可以用来根据是否引入了某个类来决定是否加载或配置相关的组件。
@EnableConfigurationProperties:该注解用于启用特定的配置属性绑定功能。它通常与 @ConfigurationProperties 注解一起使用,用于将配置文件中的属性值绑定到对应的 Java 对象中。
@ConfigurationProperties:将配置文件中的属性值映射到指定的Java类。
@ConditionalOnBean:根据指定的bean的存在与否,有条件地加载一个组件。
@Conditional:根据指定的条件,有条件地加载一个组件。可以使用自定义条件类。
@ConditionalOnMissingBean:如果指定的bean不存在,则有条件地加载一个组件。
@ConditionalOnMissingClass:如果类路径中缺少指定的类,则有条件地加载一个组件。
@AutoConfigureBefore:用于指定某个自动配置类在另一个指定的自动配置类之前生效。它可以控制自动配置类的加载顺序,确保特定的自动配置类在其他自动配置之前被应用。
@ConditionalOnExpression:根据指定的SpEL表达式,有条件地加载一个组件。
@ConditionalOnWebApplication:根据应用程序是否为Web应用程序,有条件地加载一个组件。
@ConditionalOnResource:根据指定资源的存在与否,有条件地加载一个组件。
最近在跟第三方公司对接商城的账单数据,按对账单维度直接推送所有订单和明细,在测试大批量数据时出现了接口超时情况。原因是provider和consumer的超时时间都设置的比较短,因此要把这个接口超时时间调整更大一些。
dubbo的服务超时时间有三个范围,分别是接口方法、接口类、全局。优先级接口方法>接口类>全局。而consumer服务和provider服务又分别可以配置这些超时时间。优先级为consumer>provider。因此完整的dubbo服务超时配置优先级为消费方method >提供方method>消费方reference>提供方service>消费方全局配置provider>提供方全局配置consumer
provider:
@Service(timeout=60000)//alibaba包中的service,包含了spring framework的@Service功能和暴露服务功能,timeout单位mscosumer:
@Reference(timeout=60000)//单位ms<dubbo:provider timeout=“5000”/> 全局配置
+
+<dubbo:service timeout=“4000” …/> 接口类配置
+
+<dubbo:method timeout=“3000” …> 方法配置<?xml version="1.0" encoding="UTF-8"?>
+<beans xmlns="http://www.springframework.org/schema/beans"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
+ xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
+
+ <!-- 提供方应用信息,用于计算依赖关系 -->
+ <dubbo:application name="user-service-provider" />
+
+ <!-- 使用zookeeper广播注册中心暴露服务地址 -->
+ <dubbo:registry address="zookeeper://192.168.0.126:2181" />
+
+ <!-- 用dubbo协议在20880端口暴露服务 -->
+ <dubbo:protocol name="dubbo" port="20880" />
+
+ <!-- 和本地bean一样实现服务 -->
+ <bean id="userService" class="com.storyxc.service.impl.UserServiceImpl" />
+
+ <!-- 声明需要暴露的服务接口 timeout 接口类中全部方法超时配置 优先级2 -->
+ <dubbo:service interface="com.storyxc.service.UserService" ref="userService" timeout="4000" >
+ <!-- 单个方法超时配置优先级最高1 -->
+ <dubbo:method name="queryAllUserAddress" timeout="3000"></dubbo:method>
+ </dubbo:service>
+
+ <!-- 服务提供者全局超时时间配置优先级最低 -->
+ <dubbo:provider timeout="5000"></dubbo:provider>
+
+</beans><dubbo:consumer timeout=“4000” > 全局配置
+
+<dubbo:reference timeout=“3000” …> 接口类配置
+
+<dubbo:method timeout=“2000” …> 方法配置<?xml version="1.0" encoding="UTF-8"?>
+<beans xmlns="http://www.springframework.org/schema/beans"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
+ xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
+
+ <!-- 提供方应用信息,用于计算依赖关系 -->
+ <dubbo:application name="order-service-consumer" />
+
+ <!-- 使用zookeeper广播注册中心暴露服务地址 -->
+ <dubbo:registry address="zookeeper://192.168.0.126:2181" />
+
+ <!-- 引用配置: 创建一个远程服务代理,一个引用可以指向多个注册中心 -->
+ <dubbo:reference id="userService" timeout="3000" interface="com.storyxc.service.UserService">
+ <dubbo:method name="queryAllUserAddress" timeout="2000"></dubbo:method>
+ </dubbo:reference>
+
+ <!-- orderService -->
+ <bean class="com.storyxc.service.impl.OrderServiceImpl">
+ <property name="userService" ref="userService"></property>
+ </bean>
+
+ <!-- 超时全局配置 -->
+ <dubbo:consumer timeout="4000"></dubbo:consumer>
+</beans>最近在跟第三方公司对接商城的账单数据,按对账单维度直接推送所有订单和明细,在测试大批量数据时出现了接口超时情况。原因是provider和consumer的超时时间都设置的比较短,因此要把这个接口超时时间调整更大一些。
dubbo的服务超时时间有三个范围,分别是接口方法、接口类、全局。优先级接口方法>接口类>全局。而consumer服务和provider服务又分别可以配置这些超时时间。优先级为consumer>provider。因此完整的dubbo服务超时配置优先级为消费方method >提供方method>消费方reference>提供方service>消费方全局配置provider>提供方全局配置consumer
provider:
@Service(timeout=60000)//alibaba包中的service,包含了spring framework的@Service功能和暴露服务功能,timeout单位mscosumer:
@Reference(timeout=60000)//单位ms<dubbo:provider timeout=“5000”/> 全局配置
+
+<dubbo:service timeout=“4000” …/> 接口类配置
+
+<dubbo:method timeout=“3000” …> 方法配置<?xml version="1.0" encoding="UTF-8"?>
+<beans xmlns="http://www.springframework.org/schema/beans"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
+ xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
+
+ <!-- 提供方应用信息,用于计算依赖关系 -->
+ <dubbo:application name="user-service-provider" />
+
+ <!-- 使用zookeeper广播注册中心暴露服务地址 -->
+ <dubbo:registry address="zookeeper://192.168.0.126:2181" />
+
+ <!-- 用dubbo协议在20880端口暴露服务 -->
+ <dubbo:protocol name="dubbo" port="20880" />
+
+ <!-- 和本地bean一样实现服务 -->
+ <bean id="userService" class="com.storyxc.service.impl.UserServiceImpl" />
+
+ <!-- 声明需要暴露的服务接口 timeout 接口类中全部方法超时配置 优先级2 -->
+ <dubbo:service interface="com.storyxc.service.UserService" ref="userService" timeout="4000" >
+ <!-- 单个方法超时配置优先级最高1 -->
+ <dubbo:method name="queryAllUserAddress" timeout="3000"></dubbo:method>
+ </dubbo:service>
+
+ <!-- 服务提供者全局超时时间配置优先级最低 -->
+ <dubbo:provider timeout="5000"></dubbo:provider>
+
+</beans><dubbo:consumer timeout=“4000” > 全局配置
+
+<dubbo:reference timeout=“3000” …> 接口类配置
+
+<dubbo:method timeout=“2000” …> 方法配置<?xml version="1.0" encoding="UTF-8"?>
+<beans xmlns="http://www.springframework.org/schema/beans"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
+ xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
+
+ <!-- 提供方应用信息,用于计算依赖关系 -->
+ <dubbo:application name="order-service-consumer" />
+
+ <!-- 使用zookeeper广播注册中心暴露服务地址 -->
+ <dubbo:registry address="zookeeper://192.168.0.126:2181" />
+
+ <!-- 引用配置: 创建一个远程服务代理,一个引用可以指向多个注册中心 -->
+ <dubbo:reference id="userService" timeout="3000" interface="com.storyxc.service.UserService">
+ <dubbo:method name="queryAllUserAddress" timeout="2000"></dubbo:method>
+ </dubbo:reference>
+
+ <!-- orderService -->
+ <bean class="com.storyxc.service.impl.OrderServiceImpl">
+ <property name="userService" ref="userService"></property>
+ </bean>
+
+ <!-- 超时全局配置 -->
+ <dubbo:consumer timeout="4000"></dubbo:consumer>
+</beans>可以通过自定义全局拦截器通过MDC存储数据,在logback配置文件中直接通过%X{变量名} 读取变量。
/**
+ * @author xc
+ * @description 全局拦截器
+ * @date 2023/5/11 16:13
+ */
+@Component
+@Slf4j
+public class GlobalInterceptor implements HandlerInterceptor {
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
+ // 获取当前登录用户信息
+ LoginSession loginSession = LoginContext.getLoginSession();
+ if (loginSession != null) {
+ MDC.put("operator", loginSession.getUserName());
+ }else {
+ MDC.put("operator", "anonymous");
+ }
+ return true;
+ }
+}<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
+ <!--日志文件输出格式-->
+ <!--%X{operator}可以直接获取当前线程MDC中的operator参数输出到日志中-->
+ <encoder>
+ <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} %X{operator} %msg%n</pattern>
+ <charset>UTF-8</charset>
+ </encoder>
+ ...
+</appender>通过自定义转换器来对日志输出的内容进行自定义处理
/**
+ * @author xc
+ * @description
+ * @date 2023/5/23 15:39
+ */
+public class OperatorConverter extends ClassicConverter {
+ @Override
+ public String convert(ILoggingEvent event) {
+ String operator = event.getMDCPropertyMap().get("operator");
+ return StrUtil.isNotBlank(operator) ? "- " + operator + " - " : "";
+ }
+}<configuration scan="true" scanPeriod="10 seconds">
+
+ <!--先声明一个转换器-->
+ <conversionRule conversionWord="operator" converterClass="com.storyxc.config.logback.converter.OperatorConverter" />
+ <!--在输出的pattern中直接使用,此时就不需要用%X{变量}了,直接%conversionWord即可-->
+ <!--此时如果MDC中没有operator变量时%operator会输出空串,否则会输出 "- 操作人姓名 - "-->
+ <appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
+ <!--日志文件输出格式-->
+ <encoder>
+ <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} %operator%msg%n</pattern>
+ <charset>UTF-8</charset>
+ </encoder>
+ ...
+</appender>
+</configuration>/**
+ * @author xc
+ * @description logback日志过滤器:开发环境下只打印本项目路径下的debug & debug以上级别的日志
+ * @date 2023/5/16 20:15
+ */
+public class LogBackDebugPackageFilter extends AbstractMatcherFilter<ILoggingEvent> {
+ private static final String PROJECT_BASE_PACKAGE = "com.storyxc";
+
+ @Override
+ public FilterReply decide(ILoggingEvent event) {
+ if (!isStarted()) {
+ return FilterReply.NEUTRAL;
+ }
+ Level level = event.getLevel();
+ if (level.isGreaterOrEqual(Level.DEBUG)) {
+ String loggerName = event.getLoggerName();
+ if (level.equals(Level.DEBUG)) {
+ if (loggerName != null && loggerName.startsWith(PROJECT_BASE_PACKAGE)) {
+ return FilterReply.ACCEPT;
+ } else {
+ return FilterReply.DENY;
+ }
+ }else {
+ return FilterReply.ACCEPT;
+ }
+ } else {
+ return FilterReply.NEUTRAL;
+ }
+ }
+}<!--输出到控制台-->
+<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
+ <filter class="com.storyxc.config.logback.LogBackDebugPackageFilter">
+ </filter>
+ <encoder>
+ <Pattern>\${CONSOLE_LOG_PATTERN}</Pattern>
+ <!-- 设置字符集 -->
+ <charset>UTF-8</charset>
+ </encoder>
+</appender>可以通过自定义全局拦截器通过MDC存储数据,在logback配置文件中直接通过%X{变量名} 读取变量。
/**
+ * @author xc
+ * @description 全局拦截器
+ * @date 2023/5/11 16:13
+ */
+@Component
+@Slf4j
+public class GlobalInterceptor implements HandlerInterceptor {
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
+ // 获取当前登录用户信息
+ LoginSession loginSession = LoginContext.getLoginSession();
+ if (loginSession != null) {
+ MDC.put("operator", loginSession.getUserName());
+ }else {
+ MDC.put("operator", "anonymous");
+ }
+ return true;
+ }
+}<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
+ <!--日志文件输出格式-->
+ <!--%X{operator}可以直接获取当前线程MDC中的operator参数输出到日志中-->
+ <encoder>
+ <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} %X{operator} %msg%n</pattern>
+ <charset>UTF-8</charset>
+ </encoder>
+ ...
+</appender>通过自定义转换器来对日志输出的内容进行自定义处理
/**
+ * @author xc
+ * @description
+ * @date 2023/5/23 15:39
+ */
+public class OperatorConverter extends ClassicConverter {
+ @Override
+ public String convert(ILoggingEvent event) {
+ String operator = event.getMDCPropertyMap().get("operator");
+ return StrUtil.isNotBlank(operator) ? "- " + operator + " - " : "";
+ }
+}<configuration scan="true" scanPeriod="10 seconds">
+
+ <!--先声明一个转换器-->
+ <conversionRule conversionWord="operator" converterClass="com.storyxc.config.logback.converter.OperatorConverter" />
+ <!--在输出的pattern中直接使用,此时就不需要用%X{变量}了,直接%conversionWord即可-->
+ <!--此时如果MDC中没有operator变量时%operator会输出空串,否则会输出 "- 操作人姓名 - "-->
+ <appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
+ <!--日志文件输出格式-->
+ <encoder>
+ <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} %operator%msg%n</pattern>
+ <charset>UTF-8</charset>
+ </encoder>
+ ...
+</appender>
+</configuration>/**
+ * @author xc
+ * @description logback日志过滤器:开发环境下只打印本项目路径下的debug & debug以上级别的日志
+ * @date 2023/5/16 20:15
+ */
+public class LogBackDebugPackageFilter extends AbstractMatcherFilter<ILoggingEvent> {
+ private static final String PROJECT_BASE_PACKAGE = "com.storyxc";
+
+ @Override
+ public FilterReply decide(ILoggingEvent event) {
+ if (!isStarted()) {
+ return FilterReply.NEUTRAL;
+ }
+ Level level = event.getLevel();
+ if (level.isGreaterOrEqual(Level.DEBUG)) {
+ String loggerName = event.getLoggerName();
+ if (level.equals(Level.DEBUG)) {
+ if (loggerName != null && loggerName.startsWith(PROJECT_BASE_PACKAGE)) {
+ return FilterReply.ACCEPT;
+ } else {
+ return FilterReply.DENY;
+ }
+ }else {
+ return FilterReply.ACCEPT;
+ }
+ } else {
+ return FilterReply.NEUTRAL;
+ }
+ }
+}<!--输出到控制台-->
+<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
+ <filter class="com.storyxc.config.logback.LogBackDebugPackageFilter">
+ </filter>
+ <encoder>
+ <Pattern>\${CONSOLE_LOG_PATTERN}</Pattern>
+ <!-- 设置字符集 -->
+ <charset>UTF-8</charset>
+ </encoder>
+</appender>大致思路:
后台:
@Component
+public class ServerStarter implements ApplicationListener<ContextRefreshedEvent> {
+
+ @Override
+ public void onApplicationEvent(ContextRefreshedEvent event) {
+ if (event.getApplicationContext().getParent() == null ){
+ try {
+ new IMServer().start();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:23
+ */
+public class IMServer {
+ Logger logger = LoggerFactory.getLogger(IMServer.class);
+
+ public void start() throws InterruptedException {
+ NioEventLoopGroup boss = new NioEventLoopGroup();
+ NioEventLoopGroup worker = new NioEventLoopGroup();
+ ServerBootstrap serverBootstrap = new ServerBootstrap();
+ serverBootstrap.group(boss,worker)
+ .channel(NioServerSocketChannel.class)
+ .localAddress(8000)
+ //自定义初始化器
+ .childHandler(new IMStoryInitializer());
+ ChannelFuture future = serverBootstrap.bind();
+ future.addListener(new ChannelFutureListener() {
+ @Override
+ public void operationComplete(ChannelFuture future) throws Exception {
+ logger.info("server start on 8000");
+ }
+ });
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:28
+ */
+public class IMStoryInitializer extends ChannelInitializer<SocketChannel> {
+
+ @Override
+ protected void initChannel(SocketChannel ch) throws Exception {
+ ChannelPipeline pipeline = ch.pipeline();
+ //http编解码器
+ pipeline.addLast(new HttpServerCodec());
+ //以块写数据
+ pipeline.addLast(new ChunkedWriteHandler());
+ //聚合器
+ pipeline.addLast(new HttpObjectAggregator(64*1024));
+
+ //websocket
+ pipeline.addLast(new WebSocketServerProtocolHandler("/ws"));
+ //自定义handler
+ pipeline.addLast(new ChatHandler());
+
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:34
+ */
+public class ChatHandler extends SimpleChannelInboundHandler<TextWebSocketFrame> {
+
+ /**
+ * 管理所有channel
+ */
+ public static ChannelGroup channels = new DefaultChannelGroup(GlobalEventExecutor.INSTANCE);
+
+ @Override
+ protected void channelRead0(ChannelHandlerContext ctx, TextWebSocketFrame msg) throws Exception {
+ //客户端发过来的消息
+ String content = msg.text();
+ //当前通道
+ Channel channel = ctx.channel();
+
+ Message message = JSON.parseObject(content, Message.class);
+
+ String data = message.getMsg();
+
+ String fromUser = message.getFromUser();
+ //客户端建立连接后先发送一条init消息,后台保存这个通道和用户信息的映射
+ if (StringUtils.equals(message.getAction(), "init")) {
+ ChannelUserContext.put(fromUser,channel);
+ } else if (StringUtils.equals(message.getAction(),"chat")){
+ Channel toChannel = ChannelUserContext.get(message.getToUser());
+ if (toChannel != null) {
+ //消息接收方在线
+ toChannel.writeAndFlush(new TextWebSocketFrame(JSON.toJSONString(message.getFromUser() + " : " + message.getMsg())));
+ } else {
+ //接收方不在线 离线消息推送
+ }
+
+ }
+
+ }
+
+ @Override
+ public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
+ channels.add(ctx.channel());
+ }
+
+ @Override
+ public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
+ channels.remove(ctx.channel());
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:46
+ */
+public class ChannelUserContext {
+
+ private static ConcurrentHashMap<String, Channel> userChannelMap;
+
+ static{
+ userChannelMap = new ConcurrentHashMap<>();
+ }
+
+ public static void put(String user, Channel channel){
+ userChannelMap.put(user,channel);
+ }
+
+ public static Channel get(String user) {
+ return userChannelMap.get(user);
+ }
+
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:38
+ */
+@Data
+public class Message implements Serializable {
+ private static final long serialVersionUID = 301234912340234L;
+ private String msg;
+ private String fromUser;
+ private String toUser;
+ private String action;
+}前台页面1
<!DOCTYPE html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <title>WebSocket客户端</title>
+</head>
+<body>
+<script type="text/javascript">
+ var socket;
+
+ //如果浏览器支持WebSocket
+ if(window.WebSocket){
+ //参数就是与服务器连接的地址
+ socket = new WebSocket("ws://localhost:8000/ws");
+
+ //客户端收到服务器消息的时候就会执行这个回调方法
+ socket.onmessage = function (event) {
+ console.log(event);
+ var ta = document.getElementById("responseText");
+ ta.value = ta.value + "\\n"+event.data;
+ }
+
+ //连接建立的回调函数
+ socket.onopen = function(event){
+ var ta = document.getElementById("responseText");
+
+ ta.value = "连接开启";
+ var message = '{"action":"init","msg":"test","fromUser":"张三","toUser":"李四"}';
+ socket.send(message);
+ }
+
+ //连接断掉的回调函数
+ socket.onclose = function (event) {
+ var ta = document.getElementById("responseText");
+ ta.value = ta.value +"\\n"+"连接关闭";
+ }
+ }else{
+ alert("浏览器不支持WebSocket!");
+ }
+
+ //发送数据
+ function send(message){
+ if(!window.WebSocket){
+ return;
+ }
+
+ //当websocket状态打开
+ if(socket.readyState == WebSocket.OPEN){
+ message = '{"action":"chat","msg":"'+ message +'","fromUser":"张三","toUser":"李四"}';
+ socket.send(message);
+ }else{
+ alert("连接没有开启");
+ }
+ }
+</script>
+<form onsubmit="return false">
+ <textarea name = "message" style="width: 400px;height: 200px"></textarea>
+
+ <input type ="button" value="张三:发送数据" onclick="send(this.form.message.value);">
+
+ <h3>服务器输出:</h3>
+
+ <textarea id ="responseText" style="width: 400px;height: 300px;"></textarea>
+
+ <input type="button" onclick="javascript:document.getElementById('responseText').value=''" value="清空数据">
+</form>
+</body>
+</html>页面二就是对这个页面稍微改一下
启动后台后打开两个页面,即可开始进行通讯 
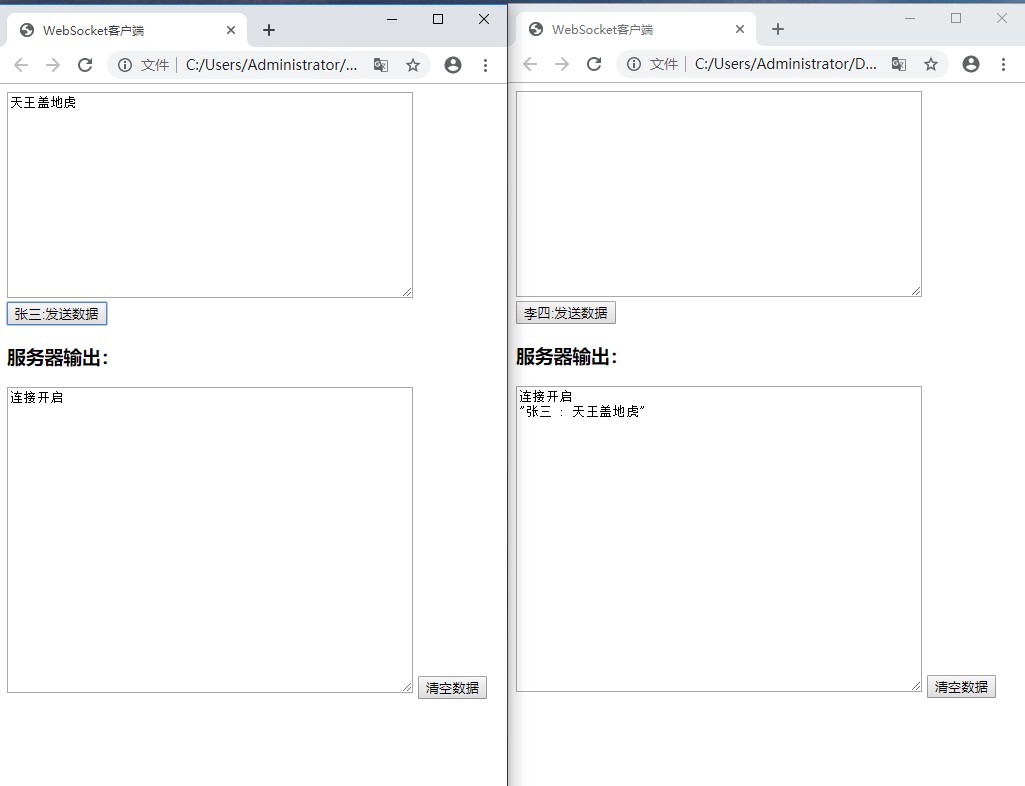
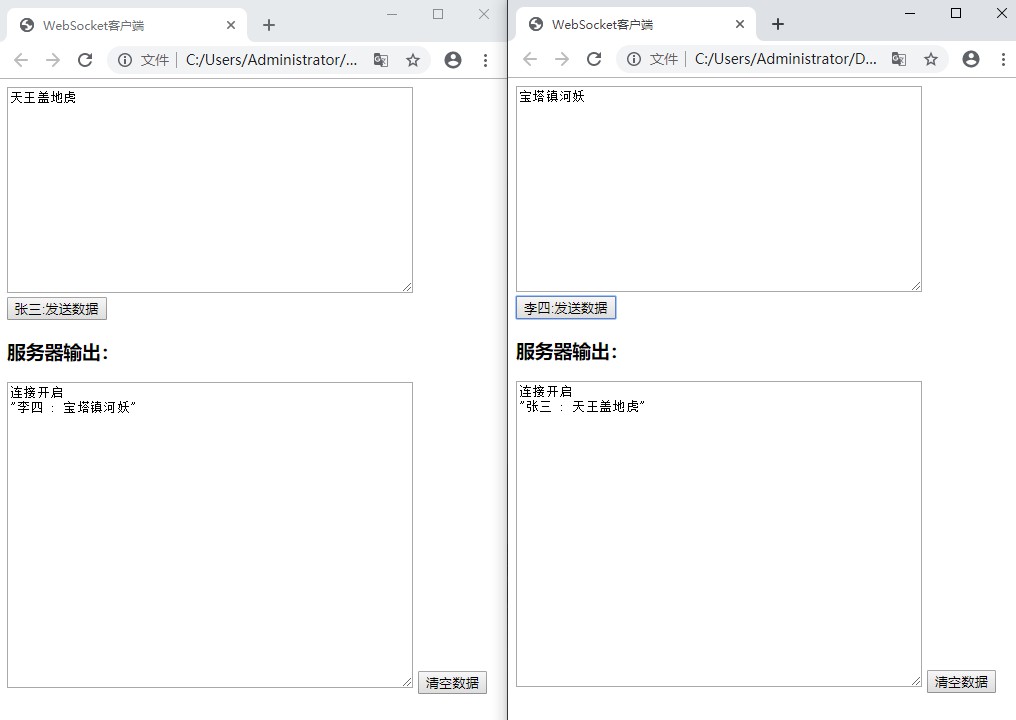
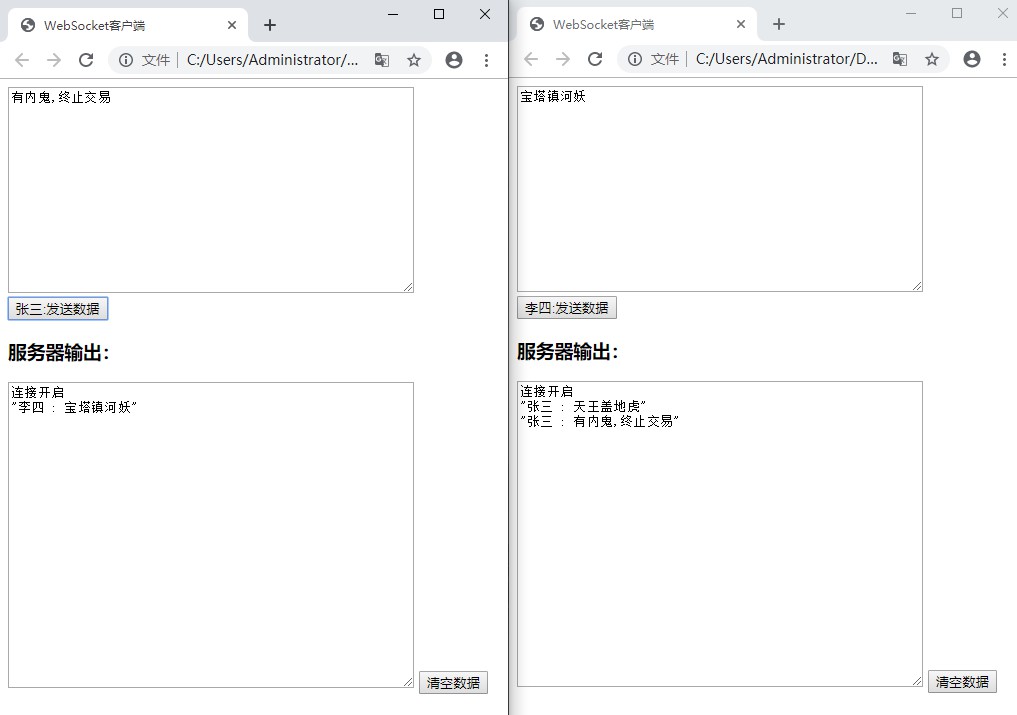
大致思路:
后台:
@Component
+public class ServerStarter implements ApplicationListener<ContextRefreshedEvent> {
+
+ @Override
+ public void onApplicationEvent(ContextRefreshedEvent event) {
+ if (event.getApplicationContext().getParent() == null ){
+ try {
+ new IMServer().start();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:23
+ */
+public class IMServer {
+ Logger logger = LoggerFactory.getLogger(IMServer.class);
+
+ public void start() throws InterruptedException {
+ NioEventLoopGroup boss = new NioEventLoopGroup();
+ NioEventLoopGroup worker = new NioEventLoopGroup();
+ ServerBootstrap serverBootstrap = new ServerBootstrap();
+ serverBootstrap.group(boss,worker)
+ .channel(NioServerSocketChannel.class)
+ .localAddress(8000)
+ //自定义初始化器
+ .childHandler(new IMStoryInitializer());
+ ChannelFuture future = serverBootstrap.bind();
+ future.addListener(new ChannelFutureListener() {
+ @Override
+ public void operationComplete(ChannelFuture future) throws Exception {
+ logger.info("server start on 8000");
+ }
+ });
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:28
+ */
+public class IMStoryInitializer extends ChannelInitializer<SocketChannel> {
+
+ @Override
+ protected void initChannel(SocketChannel ch) throws Exception {
+ ChannelPipeline pipeline = ch.pipeline();
+ //http编解码器
+ pipeline.addLast(new HttpServerCodec());
+ //以块写数据
+ pipeline.addLast(new ChunkedWriteHandler());
+ //聚合器
+ pipeline.addLast(new HttpObjectAggregator(64*1024));
+
+ //websocket
+ pipeline.addLast(new WebSocketServerProtocolHandler("/ws"));
+ //自定义handler
+ pipeline.addLast(new ChatHandler());
+
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:34
+ */
+public class ChatHandler extends SimpleChannelInboundHandler<TextWebSocketFrame> {
+
+ /**
+ * 管理所有channel
+ */
+ public static ChannelGroup channels = new DefaultChannelGroup(GlobalEventExecutor.INSTANCE);
+
+ @Override
+ protected void channelRead0(ChannelHandlerContext ctx, TextWebSocketFrame msg) throws Exception {
+ //客户端发过来的消息
+ String content = msg.text();
+ //当前通道
+ Channel channel = ctx.channel();
+
+ Message message = JSON.parseObject(content, Message.class);
+
+ String data = message.getMsg();
+
+ String fromUser = message.getFromUser();
+ //客户端建立连接后先发送一条init消息,后台保存这个通道和用户信息的映射
+ if (StringUtils.equals(message.getAction(), "init")) {
+ ChannelUserContext.put(fromUser,channel);
+ } else if (StringUtils.equals(message.getAction(),"chat")){
+ Channel toChannel = ChannelUserContext.get(message.getToUser());
+ if (toChannel != null) {
+ //消息接收方在线
+ toChannel.writeAndFlush(new TextWebSocketFrame(JSON.toJSONString(message.getFromUser() + " : " + message.getMsg())));
+ } else {
+ //接收方不在线 离线消息推送
+ }
+
+ }
+
+ }
+
+ @Override
+ public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
+ channels.add(ctx.channel());
+ }
+
+ @Override
+ public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
+ channels.remove(ctx.channel());
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:46
+ */
+public class ChannelUserContext {
+
+ private static ConcurrentHashMap<String, Channel> userChannelMap;
+
+ static{
+ userChannelMap = new ConcurrentHashMap<>();
+ }
+
+ public static void put(String user, Channel channel){
+ userChannelMap.put(user,channel);
+ }
+
+ public static Channel get(String user) {
+ return userChannelMap.get(user);
+ }
+
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:38
+ */
+@Data
+public class Message implements Serializable {
+ private static final long serialVersionUID = 301234912340234L;
+ private String msg;
+ private String fromUser;
+ private String toUser;
+ private String action;
+}前台页面1
<!DOCTYPE html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <title>WebSocket客户端</title>
+</head>
+<body>
+<script type="text/javascript">
+ var socket;
+
+ //如果浏览器支持WebSocket
+ if(window.WebSocket){
+ //参数就是与服务器连接的地址
+ socket = new WebSocket("ws://localhost:8000/ws");
+
+ //客户端收到服务器消息的时候就会执行这个回调方法
+ socket.onmessage = function (event) {
+ console.log(event);
+ var ta = document.getElementById("responseText");
+ ta.value = ta.value + "\\n"+event.data;
+ }
+
+ //连接建立的回调函数
+ socket.onopen = function(event){
+ var ta = document.getElementById("responseText");
+
+ ta.value = "连接开启";
+ var message = '{"action":"init","msg":"test","fromUser":"张三","toUser":"李四"}';
+ socket.send(message);
+ }
+
+ //连接断掉的回调函数
+ socket.onclose = function (event) {
+ var ta = document.getElementById("responseText");
+ ta.value = ta.value +"\\n"+"连接关闭";
+ }
+ }else{
+ alert("浏览器不支持WebSocket!");
+ }
+
+ //发送数据
+ function send(message){
+ if(!window.WebSocket){
+ return;
+ }
+
+ //当websocket状态打开
+ if(socket.readyState == WebSocket.OPEN){
+ message = '{"action":"chat","msg":"'+ message +'","fromUser":"张三","toUser":"李四"}';
+ socket.send(message);
+ }else{
+ alert("连接没有开启");
+ }
+ }
+</script>
+<form onsubmit="return false">
+ <textarea name = "message" style="width: 400px;height: 200px"></textarea>
+
+ <input type ="button" value="张三:发送数据" onclick="send(this.form.message.value);">
+
+ <h3>服务器输出:</h3>
+
+ <textarea id ="responseText" style="width: 400px;height: 300px;"></textarea>
+
+ <input type="button" onclick="javascript:document.getElementById('responseText').value=''" value="清空数据">
+</form>
+</body>
+</html>页面二就是对这个页面稍微改一下
启动后台后打开两个页面,即可开始进行通讯
系统后台登录使用的是图片验证码,生成验证码接口会把验证码放在session中,登录时前端会携带账号密码的密文和验证码到后台,后台再用session中的验证码和前端带过来的进行校验。利用单机的session存储信息有个显而易见的问题,集群环境下这个功能是不可用的,因此要对这个过程进行改造,实现集群共享session,这里采用的是spring-session + redis的方案。
spring-session和springboot的集成非常简单,如果项目使用的是springboot只需要引入依赖,再添加几个简单的配置类即可。如果是ssm那就要稍微麻烦点,要写xml的配置文件。本文是springboot的集成方案,详细内容可以下载spring-session官方sample查看。
<dependencies>
+ <!--spring-session-->
+ <dependency>
+ <groupId>org.springframework.session</groupId>
+ <artifactId>spring-session-data-redis</artifactId>
+ <version>2.0.3.RELEASE</version>
+ </dependency>
+</dependencies>import org.springframework.session.web.context.AbstractHttpSessionApplicationInitializer;
+
+public class Initializer extends AbstractHttpSessionApplicationInitializer {
+
+ public Initializer() {
+ super(Config.class);
+ }
+
+}import org.springframework.context.annotation.Import;
+import org.springframework.session.data.redis.config.annotation.web.http.EnableRedisHttpSession;
+
+@Import(EmbeddedRedisConfig.class)
+@EnableRedisHttpSession
+public class Config {
+
+}import lombok.extern.slf4j.Slf4j;
+import org.springframework.beans.factory.annotation.Value;
+import org.springframework.context.annotation.Bean;
+import org.springframework.context.annotation.Configuration;
+import org.springframework.data.redis.connection.RedisConnectionFactory;
+import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
+import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
+
+@Configuration
+@Slf4j
+public class EmbeddedRedisConfig {
+
+ @Value("\${session.share.redis.ip}")
+ private String ip;
+ @Value("\${session.share.redis.db}")
+ private String db;
+
+
+ @Bean
+ public RedisConnectionFactory redisConnectionFactory() {
+ log.info("session redis ip :{}, db:{}",ip,db);
+ RedisStandaloneConfiguration redisConfig = new RedisStandaloneConfiguration();
+ redisConfig.setHostName(ip);
+ redisConfig.setPort(6379);
+ //指定database
+ redisConfig.setDatabase(Integer.parseInt(db));
+ return new JedisConnectionFactory(redisConfig);
+ }
+
+}这里就省略了,思路很简单,就是用session_id作为key存储登录验证码,从而实现不论登录请求落到集群的哪个服务器都能从redis中获取到正确的验证码。
不得不感慨下spring生态的强大,毫不费力的就集成了一个功能。spring-session使用redis共享session的原理是通过RedisHttpSessionConfiguration配置类,生成一个过滤器SessionRepositoryFilter并且加入到过滤器链中,而且这个过滤器优先级是最高的,然后在SessionRepositoryFilter的doFilter方法中使用HttpServletRequest和HttpServletResponse的包装类把原始的request、response对象包装一下传递到其他过滤器中,在doFilter的final代码段里通过commitSession实现session到redis的持久化。简单的说就是spring-session使用redis存储的session替换了tomcat的httpsession实现。
`,15)]))}const g=i(p,[["render",e]]);export{o as __pageData,g as default}; diff --git "a/assets/java_framework_spring-session\345\256\236\347\216\260\351\233\206\347\276\244session\345\205\261\344\272\253.md.CD90A0jO.lean.js" "b/assets/java_framework_spring-session\345\256\236\347\216\260\351\233\206\347\276\244session\345\205\261\344\272\253.md.CD90A0jO.lean.js" new file mode 100644 index 00000000..12ec30c6 --- /dev/null +++ "b/assets/java_framework_spring-session\345\256\236\347\216\260\351\233\206\347\276\244session\345\205\261\344\272\253.md.CD90A0jO.lean.js" @@ -0,0 +1,52 @@ +import{_ as i,c as a,a2 as n,o as t}from"./chunks/framework.BjcrtTwI.js";const o=JSON.parse('{"title":"spring-session实现集群session共享","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/spring-session实现集群session共享.md","filePath":"java/framework/spring-session实现集群session共享.md","lastUpdated":1729217313000}'),p={name:"java/framework/spring-session实现集群session共享.md"};function e(l,s,h,k,r,E){return t(),a("div",null,s[0]||(s[0]=[n(`系统后台登录使用的是图片验证码,生成验证码接口会把验证码放在session中,登录时前端会携带账号密码的密文和验证码到后台,后台再用session中的验证码和前端带过来的进行校验。利用单机的session存储信息有个显而易见的问题,集群环境下这个功能是不可用的,因此要对这个过程进行改造,实现集群共享session,这里采用的是spring-session + redis的方案。
spring-session和springboot的集成非常简单,如果项目使用的是springboot只需要引入依赖,再添加几个简单的配置类即可。如果是ssm那就要稍微麻烦点,要写xml的配置文件。本文是springboot的集成方案,详细内容可以下载spring-session官方sample查看。
<dependencies>
+ <!--spring-session-->
+ <dependency>
+ <groupId>org.springframework.session</groupId>
+ <artifactId>spring-session-data-redis</artifactId>
+ <version>2.0.3.RELEASE</version>
+ </dependency>
+</dependencies>import org.springframework.session.web.context.AbstractHttpSessionApplicationInitializer;
+
+public class Initializer extends AbstractHttpSessionApplicationInitializer {
+
+ public Initializer() {
+ super(Config.class);
+ }
+
+}import org.springframework.context.annotation.Import;
+import org.springframework.session.data.redis.config.annotation.web.http.EnableRedisHttpSession;
+
+@Import(EmbeddedRedisConfig.class)
+@EnableRedisHttpSession
+public class Config {
+
+}import lombok.extern.slf4j.Slf4j;
+import org.springframework.beans.factory.annotation.Value;
+import org.springframework.context.annotation.Bean;
+import org.springframework.context.annotation.Configuration;
+import org.springframework.data.redis.connection.RedisConnectionFactory;
+import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
+import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
+
+@Configuration
+@Slf4j
+public class EmbeddedRedisConfig {
+
+ @Value("\${session.share.redis.ip}")
+ private String ip;
+ @Value("\${session.share.redis.db}")
+ private String db;
+
+
+ @Bean
+ public RedisConnectionFactory redisConnectionFactory() {
+ log.info("session redis ip :{}, db:{}",ip,db);
+ RedisStandaloneConfiguration redisConfig = new RedisStandaloneConfiguration();
+ redisConfig.setHostName(ip);
+ redisConfig.setPort(6379);
+ //指定database
+ redisConfig.setDatabase(Integer.parseInt(db));
+ return new JedisConnectionFactory(redisConfig);
+ }
+
+}这里就省略了,思路很简单,就是用session_id作为key存储登录验证码,从而实现不论登录请求落到集群的哪个服务器都能从redis中获取到正确的验证码。
不得不感慨下spring生态的强大,毫不费力的就集成了一个功能。spring-session使用redis共享session的原理是通过RedisHttpSessionConfiguration配置类,生成一个过滤器SessionRepositoryFilter并且加入到过滤器链中,而且这个过滤器优先级是最高的,然后在SessionRepositoryFilter的doFilter方法中使用HttpServletRequest和HttpServletResponse的包装类把原始的request、response对象包装一下传递到其他过滤器中,在doFilter的final代码段里通过commitSession实现session到redis的持久化。简单的说就是spring-session使用redis存储的session替换了tomcat的httpsession实现。
`,15)]))}const g=i(p,[["render",e]]);export{o as __pageData,g as default}; diff --git "a/assets/java_framework_springcloud\344\274\230\351\233\205\344\270\213\347\272\277\346\234\215\345\212\241.md.DSbcRUyZ.js" "b/assets/java_framework_springcloud\344\274\230\351\233\205\344\270\213\347\272\277\346\234\215\345\212\241.md.DSbcRUyZ.js" new file mode 100644 index 00000000..3c905cc3 --- /dev/null +++ "b/assets/java_framework_springcloud\344\274\230\351\233\205\344\270\213\347\272\277\346\234\215\345\212\241.md.DSbcRUyZ.js" @@ -0,0 +1,129 @@ +import{_ as i,c as a,a2 as t,o as n}from"./chunks/framework.BjcrtTwI.js";const d=JSON.parse('{"title":"springcloud优雅下线服务","description":"","frontmatter":{},"headers":[],"relativePath":"java/framework/springcloud优雅下线服务.md","filePath":"java/framework/springcloud优雅下线服务.md","lastUpdated":1729217313000}'),h={name:"java/framework/springcloud优雅下线服务.md"};function l(k,s,p,E,e,r){return n(),a("div",null,s[0]||(s[0]=[t(`线上问题需要紧急修复部署,但是服务一直在跑,网关还会一直往服务中路由请求进行处理,如果直接停掉服务,客户端会出现业务中断的问题。因此需要在替换更新前先手动下线服务,这样用户请求不会被分发到下线的节点上,就可以直接进行更新而不影响用户体验。
curl -X GET -u eureka_username:eureka_password http://eureka_ip:eureka_port/eureka/apps/服务名称/实例ip:实例名称:实例port例如
curl -X GET -u admin:admin123 http://127.0.0.1:19991/eureka/apps/app-platform/127.0.0.1:app-platform-1.0.0-SNAPSHOT:8001
+<instance>
+ <instanceId>127.0.0.1:app-platform-2.0.0-SNAPSHOT:8001</instanceId>
+ <hostName>127.0.0.1</hostName>
+ <app>app-platform</app>
+ <ipAddr>127.0.0.1</ipAddr>
+ <status>UP</status>
+ # 状态为在线
+ <overriddenstatus>UNKNOWN</overriddenstatus>
+ # 重写状态为空
+ <port enabled="true">8001</port>
+ <securePort enabled="false">443</securePort>
+ <countryId>1</countryId>
+ <dataCenterInfo class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
+ <name>MyOwn</name>
+ </dataCenterInfo>
+ <leaseInfo>
+ <renewalIntervalInSecs>10</renewalIntervalInSecs>
+ <durationInSecs>30</durationInSecs>
+ <registrationTimestamp>1636639654493</registrationTimestamp>
+ <lastRenewalTimestamp>1636961178498</lastRenewalTimestamp>
+ <evictionTimestamp>0</evictionTimestamp>
+ <serviceUpTimestamp>1636639654493</serviceUpTimestamp>
+ </leaseInfo>
+ <metadata>
+ <management.port>8001</management.port>
+ <nodeId>127.0.0.1_kkg</nodeId>
+ </metadata>
+ <homePageUrl>http://127.0.0.1:8001/</homePageUrl>
+ <statusPageUrl>http://127.0.0.1:8001/actuator/info</statusPageUrl>
+ <healthCheckUrl>http://127.0.0.1:8001/actuator/health</healthCheckUrl>
+ <vipAddress>app-platform</vipAddress>
+ <secureVipAddress>app-platform</secureVipAddress>
+ <isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
+ <lastUpdatedTimestamp>1636639654493</lastUpdatedTimestamp>
+ <lastDirtyTimestamp>1636639654480</lastDirtyTimestamp>
+ <actionType>ADDED</actionType>
+</instance>curl -i -X PUT -u eureka_username:eureka_password http://eureka_ip:eureka_port/eureka/apps/服务名称/实例ip:实例名称:实例port/status?value=OUT_OF_SERVICE例如:
curl -i -X PUT admin:admin123 http://127.0.0.1:19991/eureka/apps/app-platform/127.0.0.1:app-platform-1.0.0-SNAPSHOT:8001/status?value=OUT_OF_SERVICEHTTP/1.1 200 # 请求成功
+X-Content-Type-Options: nosniff
+X-XSS-Protection: 1; mode=block
+Cache-Control: no-cache, no-store, max-age=0, must-revalidate
+Pragma: no-cache
+Expires: 0
+X-Frame-Options: DENY
+Content-Type: application/xml
+Content-Length: 0
+Date: Mon, 15 Nov 2021 07:30:32 GMT
+<instance>
+ <instanceId>127.0.0.1:app-platform-2.0.0-SNAPSHOT:8001</instanceId>
+ <hostName>127.0.0.1</hostName>
+ <app>app-platform</app>
+ <ipAddr>127.0.0.1</ipAddr>
+ <status>OUT_OF_SERVICE</status>
+ # 服务状态-已下线
+ <overriddenstatus>OUT_OF_SERVICE</overriddenstatus>
+ # 重写状态为已下线
+ <port enabled="true">8001</port>
+ <securePort enabled="false">443</securePort>
+ <countryId>1</countryId>
+ <dataCenterInfo class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
+ <name>MyOwn</name>
+ </dataCenterInfo>
+ <leaseInfo>
+ <renewalIntervalInSecs>10</renewalIntervalInSecs>
+ <durationInSecs>30</durationInSecs>
+ <registrationTimestamp>1636639654493</registrationTimestamp>
+ <lastRenewalTimestamp>1636961468691</lastRenewalTimestamp>
+ <evictionTimestamp>0</evictionTimestamp>
+ <serviceUpTimestamp>1636639654493</serviceUpTimestamp>
+ </leaseInfo>
+ <metadata>
+ <management.port>8001</management.port>
+ <nodeId>127.0.0.1_kkg</nodeId>
+ </metadata>
+ <homePageUrl>http://127.0.0.1:8001/</homePageUrl>
+ <statusPageUrl>http://127.0.0.1:8001/actuator/info</statusPageUrl>
+ <healthCheckUrl>http://127.0.0.1:8001/actuator/health</healthCheckUrl>
+ <vipAddress>app-platform</vipAddress>
+ <secureVipAddress>app-platform</secureVipAddress>
+ <isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
+ <lastUpdatedTimestamp>1636961432181</lastUpdatedTimestamp>
+ <lastDirtyTimestamp>1636639654480</lastDirtyTimestamp>
+ <actionType>MODIFIED</actionType>
+</instance>可以看到此时,服务状态为已经下线,不过还是要等到网关服务不再路由请求到该服务时再停掉服务。
curl -i -X DELETE -u eureka_username:eureka_password http://eureka_ip:eureka_port/eureka/apps/服务名称/实例ip:实例名称:实例port/status例如:
curl -i -X DELETE -u admin:admin123 http://127.0.0.1:19991/eureka/apps/app-platform/127.0.0.1:app-platform-1.0.0-SNAPSHOT:8001/statusHTTP/1.1 200 # 请求成功
+X-Content-Type-Options: nosniff
+X-XSS-Protection: 1; mode=block
+Cache-Control: no-cache, no-store, max-age=0, must-revalidate
+Pragma: no-cache
+Expires: 0
+X-Frame-Options: DENY
+Content-Type: application/xml
+Content-Length: 0
+Date: Mon, 15 Nov 2021 07:37:11 GMT
+<instance>
+ <instanceId>127.0.0.1:app-platform-2.0.0-SNAPSHOT:8001</instanceId>
+ <hostName>127.0.0.1</hostName>
+ <app>app-platform</app>
+ <ipAddr>127.0.0.1</ipAddr>
+ <status>UP</status>
+ # 此时服务已上线 如果通知后立刻查询,状态可能会是unknown,隔一段时间再查询即可
+ <overriddenstatus>UNKNOWN</overriddenstatus>
+ <port enabled="true">8001</port>
+ <securePort enabled="false">443</securePort>
+ <countryId>1</countryId>
+ <dataCenterInfo class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
+ <name>MyOwn</name>
+ </dataCenterInfo>
+ <leaseInfo>
+ <renewalIntervalInSecs>10</renewalIntervalInSecs>
+ <durationInSecs>30</durationInSecs>
+ <registrationTimestamp>1636961828894</registrationTimestamp>
+ <lastRenewalTimestamp>1636961861799</lastRenewalTimestamp>
+ <evictionTimestamp>0</evictionTimestamp>
+ <serviceUpTimestamp>1636639654493</serviceUpTimestamp>
+ </leaseInfo>
+ <metadata>
+ <management.port>8001</management.port>
+ <nodeId>127.0.0.1_kkg</nodeId>
+ </metadata>
+ <homePageUrl>http://127.0.0.1:8001/</homePageUrl>
+ <statusPageUrl>http://127.0.0.1:8001/actuator/info</statusPageUrl>
+ <healthCheckUrl>http://127.0.0.1:8001/actuator/health</healthCheckUrl>
+ <vipAddress>app-platform</vipAddress>
+ <secureVipAddress>app-platform</secureVipAddress>
+ <isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
+ <lastUpdatedTimestamp>1636961828894</lastUpdatedTimestamp>
+ <lastDirtyTimestamp>1636961828889</lastDirtyTimestamp>
+ <actionType>ADDED</actionType>
+</instance>线上问题需要紧急修复部署,但是服务一直在跑,网关还会一直往服务中路由请求进行处理,如果直接停掉服务,客户端会出现业务中断的问题。因此需要在替换更新前先手动下线服务,这样用户请求不会被分发到下线的节点上,就可以直接进行更新而不影响用户体验。
curl -X GET -u eureka_username:eureka_password http://eureka_ip:eureka_port/eureka/apps/服务名称/实例ip:实例名称:实例port例如
curl -X GET -u admin:admin123 http://127.0.0.1:19991/eureka/apps/app-platform/127.0.0.1:app-platform-1.0.0-SNAPSHOT:8001
+<instance>
+ <instanceId>127.0.0.1:app-platform-2.0.0-SNAPSHOT:8001</instanceId>
+ <hostName>127.0.0.1</hostName>
+ <app>app-platform</app>
+ <ipAddr>127.0.0.1</ipAddr>
+ <status>UP</status>
+ # 状态为在线
+ <overriddenstatus>UNKNOWN</overriddenstatus>
+ # 重写状态为空
+ <port enabled="true">8001</port>
+ <securePort enabled="false">443</securePort>
+ <countryId>1</countryId>
+ <dataCenterInfo class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
+ <name>MyOwn</name>
+ </dataCenterInfo>
+ <leaseInfo>
+ <renewalIntervalInSecs>10</renewalIntervalInSecs>
+ <durationInSecs>30</durationInSecs>
+ <registrationTimestamp>1636639654493</registrationTimestamp>
+ <lastRenewalTimestamp>1636961178498</lastRenewalTimestamp>
+ <evictionTimestamp>0</evictionTimestamp>
+ <serviceUpTimestamp>1636639654493</serviceUpTimestamp>
+ </leaseInfo>
+ <metadata>
+ <management.port>8001</management.port>
+ <nodeId>127.0.0.1_kkg</nodeId>
+ </metadata>
+ <homePageUrl>http://127.0.0.1:8001/</homePageUrl>
+ <statusPageUrl>http://127.0.0.1:8001/actuator/info</statusPageUrl>
+ <healthCheckUrl>http://127.0.0.1:8001/actuator/health</healthCheckUrl>
+ <vipAddress>app-platform</vipAddress>
+ <secureVipAddress>app-platform</secureVipAddress>
+ <isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
+ <lastUpdatedTimestamp>1636639654493</lastUpdatedTimestamp>
+ <lastDirtyTimestamp>1636639654480</lastDirtyTimestamp>
+ <actionType>ADDED</actionType>
+</instance>curl -i -X PUT -u eureka_username:eureka_password http://eureka_ip:eureka_port/eureka/apps/服务名称/实例ip:实例名称:实例port/status?value=OUT_OF_SERVICE例如:
curl -i -X PUT admin:admin123 http://127.0.0.1:19991/eureka/apps/app-platform/127.0.0.1:app-platform-1.0.0-SNAPSHOT:8001/status?value=OUT_OF_SERVICEHTTP/1.1 200 # 请求成功
+X-Content-Type-Options: nosniff
+X-XSS-Protection: 1; mode=block
+Cache-Control: no-cache, no-store, max-age=0, must-revalidate
+Pragma: no-cache
+Expires: 0
+X-Frame-Options: DENY
+Content-Type: application/xml
+Content-Length: 0
+Date: Mon, 15 Nov 2021 07:30:32 GMT
+<instance>
+ <instanceId>127.0.0.1:app-platform-2.0.0-SNAPSHOT:8001</instanceId>
+ <hostName>127.0.0.1</hostName>
+ <app>app-platform</app>
+ <ipAddr>127.0.0.1</ipAddr>
+ <status>OUT_OF_SERVICE</status>
+ # 服务状态-已下线
+ <overriddenstatus>OUT_OF_SERVICE</overriddenstatus>
+ # 重写状态为已下线
+ <port enabled="true">8001</port>
+ <securePort enabled="false">443</securePort>
+ <countryId>1</countryId>
+ <dataCenterInfo class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
+ <name>MyOwn</name>
+ </dataCenterInfo>
+ <leaseInfo>
+ <renewalIntervalInSecs>10</renewalIntervalInSecs>
+ <durationInSecs>30</durationInSecs>
+ <registrationTimestamp>1636639654493</registrationTimestamp>
+ <lastRenewalTimestamp>1636961468691</lastRenewalTimestamp>
+ <evictionTimestamp>0</evictionTimestamp>
+ <serviceUpTimestamp>1636639654493</serviceUpTimestamp>
+ </leaseInfo>
+ <metadata>
+ <management.port>8001</management.port>
+ <nodeId>127.0.0.1_kkg</nodeId>
+ </metadata>
+ <homePageUrl>http://127.0.0.1:8001/</homePageUrl>
+ <statusPageUrl>http://127.0.0.1:8001/actuator/info</statusPageUrl>
+ <healthCheckUrl>http://127.0.0.1:8001/actuator/health</healthCheckUrl>
+ <vipAddress>app-platform</vipAddress>
+ <secureVipAddress>app-platform</secureVipAddress>
+ <isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
+ <lastUpdatedTimestamp>1636961432181</lastUpdatedTimestamp>
+ <lastDirtyTimestamp>1636639654480</lastDirtyTimestamp>
+ <actionType>MODIFIED</actionType>
+</instance>可以看到此时,服务状态为已经下线,不过还是要等到网关服务不再路由请求到该服务时再停掉服务。
curl -i -X DELETE -u eureka_username:eureka_password http://eureka_ip:eureka_port/eureka/apps/服务名称/实例ip:实例名称:实例port/status例如:
curl -i -X DELETE -u admin:admin123 http://127.0.0.1:19991/eureka/apps/app-platform/127.0.0.1:app-platform-1.0.0-SNAPSHOT:8001/statusHTTP/1.1 200 # 请求成功
+X-Content-Type-Options: nosniff
+X-XSS-Protection: 1; mode=block
+Cache-Control: no-cache, no-store, max-age=0, must-revalidate
+Pragma: no-cache
+Expires: 0
+X-Frame-Options: DENY
+Content-Type: application/xml
+Content-Length: 0
+Date: Mon, 15 Nov 2021 07:37:11 GMT
+<instance>
+ <instanceId>127.0.0.1:app-platform-2.0.0-SNAPSHOT:8001</instanceId>
+ <hostName>127.0.0.1</hostName>
+ <app>app-platform</app>
+ <ipAddr>127.0.0.1</ipAddr>
+ <status>UP</status>
+ # 此时服务已上线 如果通知后立刻查询,状态可能会是unknown,隔一段时间再查询即可
+ <overriddenstatus>UNKNOWN</overriddenstatus>
+ <port enabled="true">8001</port>
+ <securePort enabled="false">443</securePort>
+ <countryId>1</countryId>
+ <dataCenterInfo class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
+ <name>MyOwn</name>
+ </dataCenterInfo>
+ <leaseInfo>
+ <renewalIntervalInSecs>10</renewalIntervalInSecs>
+ <durationInSecs>30</durationInSecs>
+ <registrationTimestamp>1636961828894</registrationTimestamp>
+ <lastRenewalTimestamp>1636961861799</lastRenewalTimestamp>
+ <evictionTimestamp>0</evictionTimestamp>
+ <serviceUpTimestamp>1636639654493</serviceUpTimestamp>
+ </leaseInfo>
+ <metadata>
+ <management.port>8001</management.port>
+ <nodeId>127.0.0.1_kkg</nodeId>
+ </metadata>
+ <homePageUrl>http://127.0.0.1:8001/</homePageUrl>
+ <statusPageUrl>http://127.0.0.1:8001/actuator/info</statusPageUrl>
+ <healthCheckUrl>http://127.0.0.1:8001/actuator/health</healthCheckUrl>
+ <vipAddress>app-platform</vipAddress>
+ <secureVipAddress>app-platform</secureVipAddress>
+ <isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
+ <lastUpdatedTimestamp>1636961828894</lastUpdatedTimestamp>
+ <lastDirtyTimestamp>1636961828889</lastDirtyTimestamp>
+ <actionType>ADDED</actionType>
+</instance><dependencies>
+ <dependency>
+ <groupId>io.springfox</groupId>
+ <artifactId>springfox-boot-starter</artifactId>
+ <version>3.0.0</version>
+ </dependency>
+ <dependency>
+ <groupId>com.github.xiaoymin</groupId>
+ <artifactId>knife4j-spring-boot-starter</artifactId>
+ <version>3.0.2</version>
+ </dependency>
+</dependencies>// swagger config
+@Configuration
+@EnableOpenApi
+@EnableKnife4j
+public class SwaggerConfig {
+
+ @Bean
+ public Docket createRestApi() {
+ // 返回文档摘要信息
+ return new Docket(DocumentationType.OAS_30)
+ .apiInfo(apiInfo())
+ .enable(true)
+ .select()
+ // .apis(RequestHandlerSelectors.withMethodAnnotation(Operation.class))
+ .apis(RequestHandlerSelectors.basePackage("com.storyxc"))
+ .paths(PathSelectors.any())
+ .build();
+ .globalRequestParameters(getGlobalRequestParameters())
+ .globalResponses(HttpMethod.GET, getGlobalResponseMessage())
+ .globalResponses(HttpMethod.POST, getGlobalResponseMessage());
+ }
+
+ /**
+ * 生成接口信息,包括标题、联系人等
+ */
+ private ApiInfo apiInfo() {
+ return new ApiInfoBuilder()
+ .title("接口文档")
+ .description("如有雷同,纯属故意")
+ .contact(new Contact("storyxc", "", "storyxc@163.com"))
+ .version("1.0")
+ .build();
+ }
+
+ /**
+ * 封装全局通用参数
+ */
+ private List<RequestParameter> getGlobalRequestParameters() {
+ List<RequestParameter> parameters = new ArrayList<>();
+ parameters.add(new RequestParameterBuilder()
+ .name("token")
+ .description("token")
+ .required(true)
+ .in(ParameterType.QUERY)
+ .query(q -> q.model(m -> m.scalarModel(ScalarType.STRING)))
+ .required(false)
+ .build());
+ return parameters;
+ }
+
+ /**
+ * 封装通用响应信息
+ */
+ private List<Response> getGlobalResponseMessage() {
+ List<Response> responseList = new ArrayList<>();
+ responseList.add(new ResponseBuilder().code("404").description("未找到资源").build());
+ return responseList;
+ }
+}@Configuration
+@RequiredArgsConstructor
+public class WebMvcConfiguration implements WebMvcConfigurer {
+ private final TokenInterceptor tokenInterceptor;
+
+ @Override
+ public void addCorsMappings(CorsRegistry registry) {
+ registry.addMapping("/**").allowedOriginPatterns("*").allowedMethods("*").allowCredentials(true).maxAge(3600);
+ }
+
+ @Override
+ public void addInterceptors(InterceptorRegistry registry) {
+ String[] ignore = {
+ "/doc.html**",
+ "/webjars/js/**",
+ "/webjars/css/**",
+ "/swagger-ui/**",
+ "/swagger-resources/**",
+ "/v3/**"
+ };
+ registry.addInterceptor(tokenInterceptor).addPathPatterns("/**").excludePathPatterns(ignore);
+ }
+}@Api:定义接口分组名称@ApiImplicitParam: 单个参数注释@ApiImplicitParams:多个参数注释@ApiModel:实体类定义@ApiModelProperty:实体属性定义@ApiOperation:接口定义@ApiParam:参数注释@ApiResponse:响应码@ApiResponses:多个响应码<dependencies>
+ <dependency>
+ <groupId>com.github.xiaoymin</groupId>
+ <artifactId>knife4j-openapi3-spring-boot-starter</artifactId>
+ <version>4.1.0</version>
+ </dependency>
+</dependencies>@Configuration
+public class Swagger3Config {
+ @Bean
+ public GlobalOpenApiCustomizer orderGlobalOpenApiCustomizer() {
+ return openApi -> {
+ Info info = openApi.getInfo();
+ // 可以覆写信息
+ info.title("API");
+ info.version("1.0");
+ };
+ }
+
+ @Bean
+ public GroupedOpenApi opcenterApi() {
+ String[] packagedToMatch = {"com.storyxc.controller.wallpaper"};
+ return GroupedOpenApi.builder().group("wallpaper")
+ // token header
+ .addOperationCustomizer(((operation, handlerMethod) -> operation.addParametersItem(
+ new HeaderParameter()
+ .name("token")
+ .description("token")
+ .required(true)
+ .schema(new io.swagger.v3.oas.models.media.StringSchema())
+ .allowEmptyValue(false)
+ )))
+ .packagesToScan(packagedToMatch).build();
+ }
+
+ @Bean
+ public GroupedOpenApi adminApi() {
+ return GroupedOpenApi.builder()
+ .group("admin")
+ .packagesToScan("com.storyxc.controller.admin")
+ .build();
+ }
+
+ @Bean
+ public OpenAPI customOpenAPI() {
+ return new OpenAPI()
+ .info(new Info()
+ .title("story")
+ .version("1.0")
+ .description("API服务")
+ .termsOfService("https://storyxc.com")
+ .license(new License().name("GPLv3")
+ .url("https://www.gnu.org/licenses/gpl-3.0.html"))
+ .contact(new Contact().name("storyxc").email("storyxc@163.cn").url("https://storyxc.com"))
+ .summary("API服务")
+ );
+ }
+}@Configuration
+@RequiredArgsConstructor
+public class WebMvcConfiguration implements WebMvcConfigurer {
+ private final TokenInterceptor tokenInterceptor;
+
+ @Override
+ public void addCorsMappings(CorsRegistry registry) {
+ registry.addMapping("/**")
+ .allowedOriginPatterns("*")
+ .allowedMethods("*")
+ .allowCredentials(true)
+ .maxAge(3600);
+ }
+
+ @Override
+ public void addInterceptors(InterceptorRegistry registry) {
+ String[] ignore = {
+ "/doc.html**",
+ "/webjars/js/**",
+ "/webjars/css/**",
+ "/swagger-ui/**",
+ "/swagger-resources/**",
+ "/v3/**"
+ };
+ registry.addInterceptor(tokenInterceptor).addPathPatterns("/**").excludePathPatterns(ignore);
+ }
+}springdoc:
+ api-docs:
+ enabled: true
+
+knife4j:
+ enable: true #增强模式
+ production: false #是否生产,生产会关闭knife4j 需要开启增强模式生效
+ setting:
+ swagger-model-name: 模型
+ documents:
+ - name: 项目文档
+ locations: classpath:doc/*
+ group: wallpaper
+ - name: sql
+ locations: classpath:sql/*
+ group: sql| Swagger3 | 注解说明 |
|---|---|
| @Tag(name = “接口类描述”) | Controller 类 |
| @Operation(summary =“接口方法描述”) | Controller 方法 |
| @Parameters | Controller 方法 |
| @Parameter(description=“参数描述”) | Controller 方法上 @Parameters 里Controller 方法的参数 |
| @Parameter(hidden = true) 、@Operation(hidden = true)@Hidden | 排除或隐藏api |
| @Schema | DTO实体DTO实体属性 |
<dependencies>
+ <dependency>
+ <groupId>io.springfox</groupId>
+ <artifactId>springfox-boot-starter</artifactId>
+ <version>3.0.0</version>
+ </dependency>
+ <dependency>
+ <groupId>com.github.xiaoymin</groupId>
+ <artifactId>knife4j-spring-boot-starter</artifactId>
+ <version>3.0.2</version>
+ </dependency>
+</dependencies>// swagger config
+@Configuration
+@EnableOpenApi
+@EnableKnife4j
+public class SwaggerConfig {
+
+ @Bean
+ public Docket createRestApi() {
+ // 返回文档摘要信息
+ return new Docket(DocumentationType.OAS_30)
+ .apiInfo(apiInfo())
+ .enable(true)
+ .select()
+ // .apis(RequestHandlerSelectors.withMethodAnnotation(Operation.class))
+ .apis(RequestHandlerSelectors.basePackage("com.storyxc"))
+ .paths(PathSelectors.any())
+ .build();
+ .globalRequestParameters(getGlobalRequestParameters())
+ .globalResponses(HttpMethod.GET, getGlobalResponseMessage())
+ .globalResponses(HttpMethod.POST, getGlobalResponseMessage());
+ }
+
+ /**
+ * 生成接口信息,包括标题、联系人等
+ */
+ private ApiInfo apiInfo() {
+ return new ApiInfoBuilder()
+ .title("接口文档")
+ .description("如有雷同,纯属故意")
+ .contact(new Contact("storyxc", "", "storyxc@163.com"))
+ .version("1.0")
+ .build();
+ }
+
+ /**
+ * 封装全局通用参数
+ */
+ private List<RequestParameter> getGlobalRequestParameters() {
+ List<RequestParameter> parameters = new ArrayList<>();
+ parameters.add(new RequestParameterBuilder()
+ .name("token")
+ .description("token")
+ .required(true)
+ .in(ParameterType.QUERY)
+ .query(q -> q.model(m -> m.scalarModel(ScalarType.STRING)))
+ .required(false)
+ .build());
+ return parameters;
+ }
+
+ /**
+ * 封装通用响应信息
+ */
+ private List<Response> getGlobalResponseMessage() {
+ List<Response> responseList = new ArrayList<>();
+ responseList.add(new ResponseBuilder().code("404").description("未找到资源").build());
+ return responseList;
+ }
+}@Configuration
+@RequiredArgsConstructor
+public class WebMvcConfiguration implements WebMvcConfigurer {
+ private final TokenInterceptor tokenInterceptor;
+
+ @Override
+ public void addCorsMappings(CorsRegistry registry) {
+ registry.addMapping("/**").allowedOriginPatterns("*").allowedMethods("*").allowCredentials(true).maxAge(3600);
+ }
+
+ @Override
+ public void addInterceptors(InterceptorRegistry registry) {
+ String[] ignore = {
+ "/doc.html**",
+ "/webjars/js/**",
+ "/webjars/css/**",
+ "/swagger-ui/**",
+ "/swagger-resources/**",
+ "/v3/**"
+ };
+ registry.addInterceptor(tokenInterceptor).addPathPatterns("/**").excludePathPatterns(ignore);
+ }
+}@Api:定义接口分组名称@ApiImplicitParam: 单个参数注释@ApiImplicitParams:多个参数注释@ApiModel:实体类定义@ApiModelProperty:实体属性定义@ApiOperation:接口定义@ApiParam:参数注释@ApiResponse:响应码@ApiResponses:多个响应码<dependencies>
+ <dependency>
+ <groupId>com.github.xiaoymin</groupId>
+ <artifactId>knife4j-openapi3-spring-boot-starter</artifactId>
+ <version>4.1.0</version>
+ </dependency>
+</dependencies>@Configuration
+public class Swagger3Config {
+ @Bean
+ public GlobalOpenApiCustomizer orderGlobalOpenApiCustomizer() {
+ return openApi -> {
+ Info info = openApi.getInfo();
+ // 可以覆写信息
+ info.title("API");
+ info.version("1.0");
+ };
+ }
+
+ @Bean
+ public GroupedOpenApi opcenterApi() {
+ String[] packagedToMatch = {"com.storyxc.controller.wallpaper"};
+ return GroupedOpenApi.builder().group("wallpaper")
+ // token header
+ .addOperationCustomizer(((operation, handlerMethod) -> operation.addParametersItem(
+ new HeaderParameter()
+ .name("token")
+ .description("token")
+ .required(true)
+ .schema(new io.swagger.v3.oas.models.media.StringSchema())
+ .allowEmptyValue(false)
+ )))
+ .packagesToScan(packagedToMatch).build();
+ }
+
+ @Bean
+ public GroupedOpenApi adminApi() {
+ return GroupedOpenApi.builder()
+ .group("admin")
+ .packagesToScan("com.storyxc.controller.admin")
+ .build();
+ }
+
+ @Bean
+ public OpenAPI customOpenAPI() {
+ return new OpenAPI()
+ .info(new Info()
+ .title("story")
+ .version("1.0")
+ .description("API服务")
+ .termsOfService("https://storyxc.com")
+ .license(new License().name("GPLv3")
+ .url("https://www.gnu.org/licenses/gpl-3.0.html"))
+ .contact(new Contact().name("storyxc").email("storyxc@163.cn").url("https://storyxc.com"))
+ .summary("API服务")
+ );
+ }
+}@Configuration
+@RequiredArgsConstructor
+public class WebMvcConfiguration implements WebMvcConfigurer {
+ private final TokenInterceptor tokenInterceptor;
+
+ @Override
+ public void addCorsMappings(CorsRegistry registry) {
+ registry.addMapping("/**")
+ .allowedOriginPatterns("*")
+ .allowedMethods("*")
+ .allowCredentials(true)
+ .maxAge(3600);
+ }
+
+ @Override
+ public void addInterceptors(InterceptorRegistry registry) {
+ String[] ignore = {
+ "/doc.html**",
+ "/webjars/js/**",
+ "/webjars/css/**",
+ "/swagger-ui/**",
+ "/swagger-resources/**",
+ "/v3/**"
+ };
+ registry.addInterceptor(tokenInterceptor).addPathPatterns("/**").excludePathPatterns(ignore);
+ }
+}springdoc:
+ api-docs:
+ enabled: true
+
+knife4j:
+ enable: true #增强模式
+ production: false #是否生产,生产会关闭knife4j 需要开启增强模式生效
+ setting:
+ swagger-model-name: 模型
+ documents:
+ - name: 项目文档
+ locations: classpath:doc/*
+ group: wallpaper
+ - name: sql
+ locations: classpath:sql/*
+ group: sql| Swagger3 | 注解说明 |
|---|---|
| @Tag(name = “接口类描述”) | Controller 类 |
| @Operation(summary =“接口方法描述”) | Controller 方法 |
| @Parameters | Controller 方法 |
| @Parameter(description=“参数描述”) | Controller 方法上 @Parameters 里Controller 方法的参数 |
| @Parameter(hidden = true) 、@Operation(hidden = true)@Hidden | 排除或隐藏api |
| @Schema | DTO实体DTO实体属性 |
本来一直在用easypoi,但是发现多sheet导出easyexcel的支持更好一点,遂切换
<dependency>
+ <groupId>com.alibaba</groupId>
+ <artifactId>easyexcel</artifactId>
+ <version>2.2.7</version>
+</dependency>public void export(X param, HttpServletResponse response) {
+ String templatePath = "xxx"
+ OutputStream fos = null;
+ ExcelWriter excelWriter;
+ try {
+ fos = response.getOutputStream();
+ response.setContentType("application/vnd.ms-excel");
+ SimpleDateFormat yyyyMMdd = new SimpleDateFormat("yyyyMMddHHmmss");
+ String date = yyyyMMdd.format(new Date());
+ String fileName = "xxx" + date;
+ fileName = new String(fileName.getBytes(StandardCharsets.UTF_8), "ISO8859-1");
+ response.setHeader("Content-Disposition", "attachment;filename=" + fileName + ".xls");
+
+ excelWriter = EasyExcel.write(fos).withTemplate(templatePath).build();
+ WriteSheet sheet0 = EasyExcel.writerSheet(0, "xxx").build();
+ WriteSheet sheet1 = EasyExcel.writerSheet(1, "xxx").build();
+
+ FillConfig fillConfig = FillConfig.builder().forceNewRow(Boolean.FALSE).build();
+ //遍历:模版文件 {t.属性}
+ excelWriter.fill(new FillWrapper("t", xxx), fillConfig, sheet0);//.fill(exportDate, writeSheet0); 填充单独属性
+ excelWriter.fill(new FillWrapper("t", xxx), fillConfig, sheet1);
+ excelWriter.finish();
+ } catch (Exception e) {
+ log.info("xxx");
+ } finally {
+ if (fos != null) {
+ try {
+ fos.close();
+ } catch (IOException e) {
+ log.error("xxxx");
+ }
+ }
+ }
+ }本来一直在用easypoi,但是发现多sheet导出easyexcel的支持更好一点,遂切换
<dependency>
+ <groupId>com.alibaba</groupId>
+ <artifactId>easyexcel</artifactId>
+ <version>2.2.7</version>
+</dependency>public void export(X param, HttpServletResponse response) {
+ String templatePath = "xxx"
+ OutputStream fos = null;
+ ExcelWriter excelWriter;
+ try {
+ fos = response.getOutputStream();
+ response.setContentType("application/vnd.ms-excel");
+ SimpleDateFormat yyyyMMdd = new SimpleDateFormat("yyyyMMddHHmmss");
+ String date = yyyyMMdd.format(new Date());
+ String fileName = "xxx" + date;
+ fileName = new String(fileName.getBytes(StandardCharsets.UTF_8), "ISO8859-1");
+ response.setHeader("Content-Disposition", "attachment;filename=" + fileName + ".xls");
+
+ excelWriter = EasyExcel.write(fos).withTemplate(templatePath).build();
+ WriteSheet sheet0 = EasyExcel.writerSheet(0, "xxx").build();
+ WriteSheet sheet1 = EasyExcel.writerSheet(1, "xxx").build();
+
+ FillConfig fillConfig = FillConfig.builder().forceNewRow(Boolean.FALSE).build();
+ //遍历:模版文件 {t.属性}
+ excelWriter.fill(new FillWrapper("t", xxx), fillConfig, sheet0);//.fill(exportDate, writeSheet0); 填充单独属性
+ excelWriter.fill(new FillWrapper("t", xxx), fillConfig, sheet1);
+ excelWriter.finish();
+ } catch (Exception e) {
+ log.info("xxx");
+ } finally {
+ if (fos != null) {
+ try {
+ fos.close();
+ } catch (IOException e) {
+ log.error("xxxx");
+ }
+ }
+ }
+ }后台的参数校验如果全写在业务代码里会导致代码很臃肿,此时可以引入Spring Validation来进行参数校验,还可以自定义校验规则,自定义参数校验异常等
<dependency>
+ <groupId>org.hibernate</groupId>
+ <artifactId>hibernate-validator</artifactId>
+</dependency>
+<dependency>
+ <groupId>com.fasterxml.jackson.core</groupId>
+ <artifactId>jackson-databind</artifactId>
+</dependency>在需要校验的对象前,加上@Validated注解,在对象字段上使用具体校验规则的注解即可。如果是嵌套对象,则在嵌套的对象上使用@Valid注解表明需要嵌套校验
public String receive(@RequestBody @Validated StatementDto dto, BindingResult result) {
+ if (result.hasErrors()) {
+ throw new ParameterNotValidException(result);
+ }
+ return "test";
+ }public class QchjcCustomerStatementDto implements Serializable {
+
+ @NotEmpty(message = "不能为空")
+ @Valid
+ private List<OrderDto> order;
+
+ @DecimalMin(value = "0",message = "金额需大于等于0.00")
+ private BigDecimal amount;
+}TIP
@Validated注解标记的参数会被spring进行校验,校验的信息会存放到其后的BindingResult中,如果有多个参数需要校验可以采用如下形式:(@Validated Person person, BindingResult fooBindingResult ,@Validated Bar bar, BindingResult barBindingResult);即一个校验类对应一个校验结果。
JSR303/JSR-349: JSR303是一项标准,只提供规范不提供实现,规定一些校验规范即校验注解,如@Null,@NotNull,@Pattern,位于javax.validation.constraints包下。JSR-349是其的升级版本,添加了一些新特性。
@Null 被注释的元素必须为null
@NotNull 被注释的元素必须不为null
@AssertTrue 被注释的元素必须为true
@AssertFalse 被注释的元素必须为false
@Min(value) 被注释的元素必须是一个数字,其值必须大于等于指定的最小值
@Max(value) 被注释的元素必须是一个数字,其值必须小于等于指定的最大值
@DecimalMin(value) 被注释的元素必须是一个数字,其值必须大于等于指定
最小值
@DecimalMax(value) 被注释的元素必须是一个数字,其值必须小于等于指定
最大值
@Size(max, min) 被注释的元素的大小必须在指定的范围内
@Digits (integer, fraction) 被注释的元素必须是一个数字,其值必须在可接受的范围内
@Past 被注释的元素必须是一个过去的日期
@Future 被注释的元素必须是一个将来的日期
@Pattern(value) 被注释的元素必须符合指定的正则表达式
hibernate validation:hibernate validation是对这个规范的实现,并增加了一些其他校验注解,如@Email,@Length,@Range等等
spring validation:spring validation对hibernate validation进行了二次封装,在springmvc模块中添加了自动校验,并将校验信息封装进了特定的类中
如果方法参数中不声明BindingResult,那么spring校验不通过后会直接抛出BindException,体验很不好。因此我们可以进行自定义异常处理。
public class ParameterNotValidException extends RuntimeException{
+ private static final long serialVersionUID = 1L;
+ private BindingResult bindingResult;
+
+ public ParameterNotValidException(BindingResult bindingResult) {
+ this.bindingResult = bindingResult;
+ }
+
+ public BindingResult getBindingResult() {
+ return bindingResult;
+ }
+
+ @Override
+ public String getMessage() {
+ return "参数校验不通过";
+ }
+}@ControllerAdvice
+public class ExceptionHandler {
+ /**
+ * 方法参数校验异常处理
+ */
+ @ExceptionHandler(ParameterNotValidException.class)
+ @ResponseBody
+ public O handleMethodArgumentNotValidException(ParameterNotValidException e) {
+ BindingResult bindingResult = e.getBindingResult();
+ FieldError fieldError = bindingResult.getFieldError();
+ String field = fieldError.getField();
+ String defaultMessage = fieldError.getDefaultMessage();
+ O o = new O();
+ o.setResultCode(500);
+ o.setSuccess(false);
+ o.setResultMessage(field + ":" + defaultMessage);
+ return o;
+ }
+}例如,我们需要新增一个校验规则,数字类型必须大于0
新建校验注解
@Target(ElementType.FIELD)
+@Retention(RetentionPolicy.RUNTIME)
+@Constraint(validatedBy = GreaterThanZeroValidator.class)//标注校验由哪些类执行,可以是多个
+public @interface GreaterThanZero {
+ String message();
+
+ Class<?>[] groups() default {};//在不同接口中参数可能校验的规则不同,可以创建不同的组,并在校验规则标记组,在controller层也标记组,这样就可以不同接口实现不同校验规则
+
+ Class<?>[] payload() default {};
+}一个标注(annotation) 是通过
@interface关键字来定义的. 这个标注中的属性是声明成类似方法的样式的. 根据Bean Validation API 规范的要求
message属性, 这个属性被用来定义默认得消息模版, 当这个约束条件被验证失败的时候,通过此属性来输出错误信息.
groups 属性, 用于指定这个约束条件属于哪(些)个校验组.这个的默认值必须是
Class<?>类型到空到数组.
payload属性, Bean Validation API 的使用者可以通过此属性来给约束条件指定严重级别. 这个属性并不被API自身所使用.javapublic class Severity { + public static class Info extends Payload {}; + public static class Error extends Payload {}; +} + +public class ContactDetails { + @NotNull(message="Name is mandatory", payload=Severity.Error.class) + private String name; + + @NotNull(message="Phone number not specified, but not mandatory", payload=Severity.Info.class) + private String phoneNumber; + + // ... +}这样, 在校验完一个
ContactDetails的示例之后, 你就可以通过调用ConstraintViolation.getConstraintDescriptor().getPayload()来得到之前指定到错误级别了,并且可以根据这个信息来决定接下来到行为.
校验规则类
public class GreaterThanZeroValidator implements ConstraintValidator<GreaterThanZero, Object> {
+ @Override
+ public boolean isValid(Object o, ConstraintValidatorContext constraintValidatorContext) {
+ if (o == null) {
+ return false;
+ }
+ if (o instanceof Number) {
+ return ((Number) o).intValue() > 0;
+ }
+
+ return false;
+ }
+}ConstraintValidator定义了两个泛型参数, 第一个是这个校验器所服务到标注类型, 第二个这个校验器所支持到被校验元素到类型.如果一个约束标注支持多种类型到被校验元素的话, 那么需要为每个所支持的类型定义一个ConstraintValidator,并且注册到约束标注中.这个验证器的实现就很平常了initialize() 方法传进来一个所要验证的标注类型的实例isValid()是实现真正的校验逻辑的地方后台的参数校验如果全写在业务代码里会导致代码很臃肿,此时可以引入Spring Validation来进行参数校验,还可以自定义校验规则,自定义参数校验异常等
<dependency>
+ <groupId>org.hibernate</groupId>
+ <artifactId>hibernate-validator</artifactId>
+</dependency>
+<dependency>
+ <groupId>com.fasterxml.jackson.core</groupId>
+ <artifactId>jackson-databind</artifactId>
+</dependency>在需要校验的对象前,加上@Validated注解,在对象字段上使用具体校验规则的注解即可。如果是嵌套对象,则在嵌套的对象上使用@Valid注解表明需要嵌套校验
public String receive(@RequestBody @Validated StatementDto dto, BindingResult result) {
+ if (result.hasErrors()) {
+ throw new ParameterNotValidException(result);
+ }
+ return "test";
+ }public class QchjcCustomerStatementDto implements Serializable {
+
+ @NotEmpty(message = "不能为空")
+ @Valid
+ private List<OrderDto> order;
+
+ @DecimalMin(value = "0",message = "金额需大于等于0.00")
+ private BigDecimal amount;
+}TIP
@Validated注解标记的参数会被spring进行校验,校验的信息会存放到其后的BindingResult中,如果有多个参数需要校验可以采用如下形式:(@Validated Person person, BindingResult fooBindingResult ,@Validated Bar bar, BindingResult barBindingResult);即一个校验类对应一个校验结果。
JSR303/JSR-349: JSR303是一项标准,只提供规范不提供实现,规定一些校验规范即校验注解,如@Null,@NotNull,@Pattern,位于javax.validation.constraints包下。JSR-349是其的升级版本,添加了一些新特性。
@Null 被注释的元素必须为null
@NotNull 被注释的元素必须不为null
@AssertTrue 被注释的元素必须为true
@AssertFalse 被注释的元素必须为false
@Min(value) 被注释的元素必须是一个数字,其值必须大于等于指定的最小值
@Max(value) 被注释的元素必须是一个数字,其值必须小于等于指定的最大值
@DecimalMin(value) 被注释的元素必须是一个数字,其值必须大于等于指定
最小值
@DecimalMax(value) 被注释的元素必须是一个数字,其值必须小于等于指定
最大值
@Size(max, min) 被注释的元素的大小必须在指定的范围内
@Digits (integer, fraction) 被注释的元素必须是一个数字,其值必须在可接受的范围内
@Past 被注释的元素必须是一个过去的日期
@Future 被注释的元素必须是一个将来的日期
@Pattern(value) 被注释的元素必须符合指定的正则表达式
hibernate validation:hibernate validation是对这个规范的实现,并增加了一些其他校验注解,如@Email,@Length,@Range等等
spring validation:spring validation对hibernate validation进行了二次封装,在springmvc模块中添加了自动校验,并将校验信息封装进了特定的类中
如果方法参数中不声明BindingResult,那么spring校验不通过后会直接抛出BindException,体验很不好。因此我们可以进行自定义异常处理。
public class ParameterNotValidException extends RuntimeException{
+ private static final long serialVersionUID = 1L;
+ private BindingResult bindingResult;
+
+ public ParameterNotValidException(BindingResult bindingResult) {
+ this.bindingResult = bindingResult;
+ }
+
+ public BindingResult getBindingResult() {
+ return bindingResult;
+ }
+
+ @Override
+ public String getMessage() {
+ return "参数校验不通过";
+ }
+}@ControllerAdvice
+public class ExceptionHandler {
+ /**
+ * 方法参数校验异常处理
+ */
+ @ExceptionHandler(ParameterNotValidException.class)
+ @ResponseBody
+ public O handleMethodArgumentNotValidException(ParameterNotValidException e) {
+ BindingResult bindingResult = e.getBindingResult();
+ FieldError fieldError = bindingResult.getFieldError();
+ String field = fieldError.getField();
+ String defaultMessage = fieldError.getDefaultMessage();
+ O o = new O();
+ o.setResultCode(500);
+ o.setSuccess(false);
+ o.setResultMessage(field + ":" + defaultMessage);
+ return o;
+ }
+}例如,我们需要新增一个校验规则,数字类型必须大于0
新建校验注解
@Target(ElementType.FIELD)
+@Retention(RetentionPolicy.RUNTIME)
+@Constraint(validatedBy = GreaterThanZeroValidator.class)//标注校验由哪些类执行,可以是多个
+public @interface GreaterThanZero {
+ String message();
+
+ Class<?>[] groups() default {};//在不同接口中参数可能校验的规则不同,可以创建不同的组,并在校验规则标记组,在controller层也标记组,这样就可以不同接口实现不同校验规则
+
+ Class<?>[] payload() default {};
+}一个标注(annotation) 是通过
@interface关键字来定义的. 这个标注中的属性是声明成类似方法的样式的. 根据Bean Validation API 规范的要求
message属性, 这个属性被用来定义默认得消息模版, 当这个约束条件被验证失败的时候,通过此属性来输出错误信息.
groups 属性, 用于指定这个约束条件属于哪(些)个校验组.这个的默认值必须是
Class<?>类型到空到数组.
payload属性, Bean Validation API 的使用者可以通过此属性来给约束条件指定严重级别. 这个属性并不被API自身所使用.javapublic class Severity { + public static class Info extends Payload {}; + public static class Error extends Payload {}; +} + +public class ContactDetails { + @NotNull(message="Name is mandatory", payload=Severity.Error.class) + private String name; + + @NotNull(message="Phone number not specified, but not mandatory", payload=Severity.Info.class) + private String phoneNumber; + + // ... +}这样, 在校验完一个
ContactDetails的示例之后, 你就可以通过调用ConstraintViolation.getConstraintDescriptor().getPayload()来得到之前指定到错误级别了,并且可以根据这个信息来决定接下来到行为.
校验规则类
public class GreaterThanZeroValidator implements ConstraintValidator<GreaterThanZero, Object> {
+ @Override
+ public boolean isValid(Object o, ConstraintValidatorContext constraintValidatorContext) {
+ if (o == null) {
+ return false;
+ }
+ if (o instanceof Number) {
+ return ((Number) o).intValue() > 0;
+ }
+
+ return false;
+ }
+}ConstraintValidator定义了两个泛型参数, 第一个是这个校验器所服务到标注类型, 第二个这个校验器所支持到被校验元素到类型.如果一个约束标注支持多种类型到被校验元素的话, 那么需要为每个所支持的类型定义一个ConstraintValidator,并且注册到约束标注中.这个验证器的实现就很平常了initialize() 方法传进来一个所要验证的标注类型的实例isValid()是实现真正的校验逻辑的地方今天领导让我了解下分布式定时任务的内容,对项目中目前的定时任务改造一下,公司目前项目中封装的定时任务注解是基于spring的scheduler的,单机环境下没问题,但是为了服务的高可用生产都是集群部署的,会导致任务多次运行的问题,上家公司用的ssm,定时任务选型是Quartz,生产上采用的quartz的集群部署,quartz集群是不会出现任务重复执行的,原理跟下文讲到的xxl-job一样都是通过数据库表来加锁实现
Xxl-job官网:https://www.xuxueli.com/xxl-job/
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
选择xxl-job的原因有以下几点:
使用流程:
执行doc中的sql脚本,建相关的库表,具体表的作用可阅读帮助文档
修改xxl-job-admin配置文件后可以直接启动admin应用
修改执行器应用中配置文件,注意匹配admin的相关信息
copy一份示例执行器的代码 修改应用端口和执行端口
启动两个示例执行器应用(模拟集群)
打开控制台可以看到已经注册上了两个节点 
在控制台任务管理中修改任务的相关信息,这里只试个最简单的,更多高级配置请看使用文档
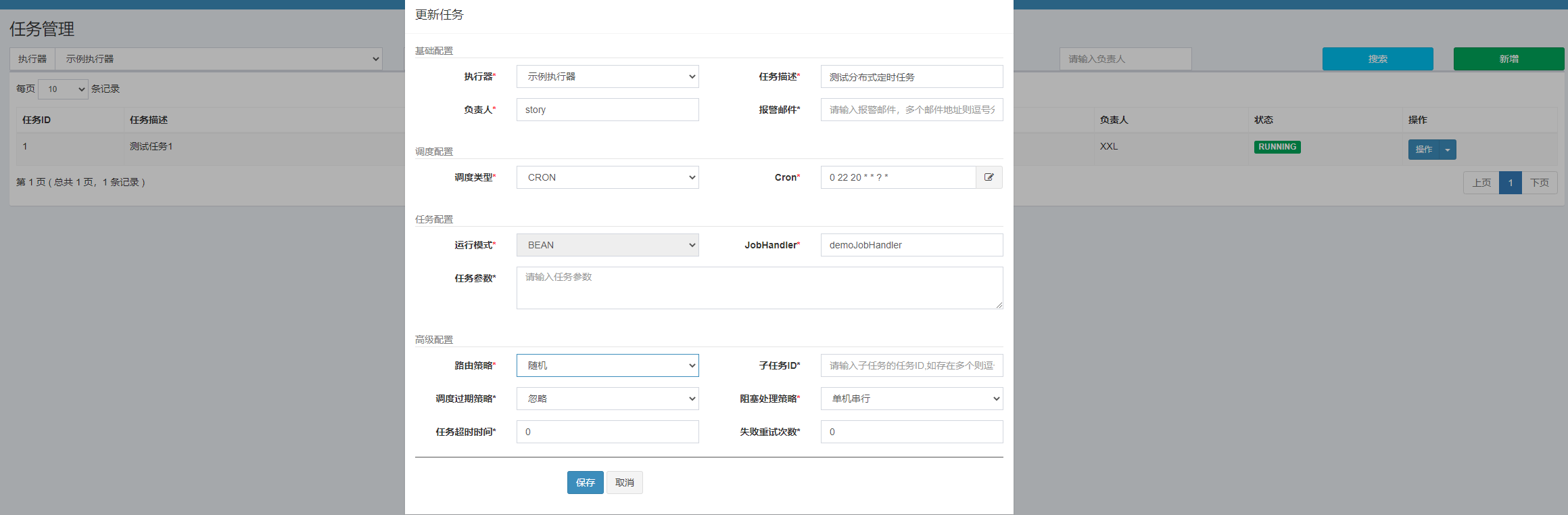

可以在控制台的调度记录中看到,集群模式下任务也只执行了一次.
除了cron任务,xxl-job中还支持周期性的任务,shell任务等.路由策略还支持轮询,一致性哈希,故障转移等,在admin中配置好java.mail信息,在控制配置任务时添加告警邮件,在任务调度出现异常时还会邮件告警
集成到微服务系统的思路:
今天领导让我了解下分布式定时任务的内容,对项目中目前的定时任务改造一下,公司目前项目中封装的定时任务注解是基于spring的scheduler的,单机环境下没问题,但是为了服务的高可用生产都是集群部署的,会导致任务多次运行的问题,上家公司用的ssm,定时任务选型是Quartz,生产上采用的quartz的集群部署,quartz集群是不会出现任务重复执行的,原理跟下文讲到的xxl-job一样都是通过数据库表来加锁实现
Xxl-job官网:https://www.xuxueli.com/xxl-job/
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
选择xxl-job的原因有以下几点:
使用流程:
执行doc中的sql脚本,建相关的库表,具体表的作用可阅读帮助文档
修改xxl-job-admin配置文件后可以直接启动admin应用
修改执行器应用中配置文件,注意匹配admin的相关信息
copy一份示例执行器的代码 修改应用端口和执行端口
启动两个示例执行器应用(模拟集群)
打开控制台可以看到已经注册上了两个节点
在控制台任务管理中修改任务的相关信息,这里只试个最简单的,更多高级配置请看使用文档
可以在控制台的调度记录中看到,集群模式下任务也只执行了一次.
除了cron任务,xxl-job中还支持周期性的任务,shell任务等.路由策略还支持轮询,一致性哈希,故障转移等,在admin中配置好java.mail信息,在控制配置任务时添加告警邮件,在任务调度出现异常时还会邮件告警
集成到微服务系统的思路:
@Configuration
+public class CorsFilterConfig {
+ @Bean
+ public CorsFilter corsFilter() {
+ UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
+ CorsConfiguration corsConfiguration = new CorsConfiguration();
+ corsConfiguration.setAllowCredentials(true);
+ corsConfiguration.addAllowedOriginPattern("*");
+ corsConfiguration.addAllowedHeader("*");
+ corsConfiguration.addAllowedMethod("*");
+ corsConfiguration.setMaxAge(10000L);
+ source.registerCorsConfiguration("/**", corsConfiguration);
+ return new CorsFilter(source);
+ }
+
+}@Configuration
+@RequiredArgsConstructor
+public class WebMvcConfiguration implements WebMvcConfigurer {
+ @Override
+ public void addCorsMappings(CorsRegistry registry) {
+ registry.addMapping("/**")
+ .allowedOriginPatterns("*")
+ .allowedMethods("*")
+ .allowCredentials(true)
+ .allowedHeaders("*")
+ .maxAge(3600);
+ }
+}@Configuration
+public class CorsFilterConfig {
+ @Bean
+ public CorsFilter corsFilter() {
+ UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
+ CorsConfiguration corsConfiguration = new CorsConfiguration();
+ corsConfiguration.setAllowCredentials(true);
+ corsConfiguration.addAllowedOriginPattern("*");
+ corsConfiguration.addAllowedHeader("*");
+ corsConfiguration.addAllowedMethod("*");
+ corsConfiguration.setMaxAge(10000L);
+ source.registerCorsConfiguration("/**", corsConfiguration);
+ return new CorsFilter(source);
+ }
+
+}@Configuration
+@RequiredArgsConstructor
+public class WebMvcConfiguration implements WebMvcConfigurer {
+ @Override
+ public void addCorsMappings(CorsRegistry registry) {
+ registry.addMapping("/**")
+ .allowedOriginPatterns("*")
+ .allowedMethods("*")
+ .allowCredentials(true)
+ .allowedHeaders("*")
+ .maxAge(3600);
+ }
+}import cn.hutool.core.util.StrUtil;
+import com.baomidou.mybatisplus.annotation.DbType;
+import com.baomidou.mybatisplus.annotation.IdType;
+import com.baomidou.mybatisplus.core.toolkit.StringPool;
+import com.baomidou.mybatisplus.generator.AutoGenerator;
+import com.baomidou.mybatisplus.generator.InjectionConfig;
+import com.baomidou.mybatisplus.generator.config.*;
+import com.baomidou.mybatisplus.generator.config.po.TableInfo;
+import com.baomidou.mybatisplus.generator.config.rules.DateType;
+import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
+import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * @author xc
+ * @description
+ * @date 2023/5/19 09:20
+ */
+public class MybatisPlusCodeGenerator {
+
+ private static final String projectPath = System.getProperty("user.dir");
+
+ public static void main(String[] args) {
+ //====================配置变量区域=====================//
+ String author = "storyxc";// 生成文件的作者,可以不填
+ String rootPackage = "com.storyxc";// 生成的entity、controller、service等包所在的公共上一级包路径全限定名
+ String modelModuleName = "storyxc-model";
+ String serviceModuleName = "storyxc-web";
+ String controllerModuleName = "storyxc-web";
+ // 数据库配置
+ String url="jdbc:mysql://127.0.0.1/story?useUnicode=true&characterEncoding=UTF-8&useSSL=false";
+ String driverClassName = "com.mysql.cj.jdbc.Driver";// 或者com.mysql.cj.jdbc.Driver
+ String username = "root";
+ String password = "root";
+
+ String[] tableNames = new String[]{""};
+ String pkgName = "";
+ //====================配置变量区域=====================//
+ String[] tablePrefix = new String[]{""};
+ // 代码生成器
+ AutoGenerator generator = new AutoGenerator();
+ // 全局配置
+ GlobalConfig globalConfig = new GlobalConfig();
+ globalConfig.setOutputDir(projectPath + "/" + modelModuleName + "/src/main/java");// 生成文件的输出目录
+ globalConfig.setFileOverride(false);// 是否覆盖已有文件,默认false
+ globalConfig.setOpen(false);// 是否打开输出目录
+ globalConfig.setAuthor(author);
+ globalConfig.setServiceName("%sService");// 去掉service接口的首字母I
+ globalConfig.setBaseResultMap(true);// 开启 BaseResultMap
+ globalConfig.setDateType(DateType.ONLY_DATE);// 只使用 java.util.date代替
+ globalConfig.setIdType(IdType.ASSIGN_ID);// 分配ID (主键类型为number或string)
+ generator.setGlobalConfig(globalConfig);
+
+ // 数据源配置
+ DataSourceConfig dataSourceConfig = new DataSourceConfig();
+ dataSourceConfig.setUrl(url);
+ dataSourceConfig.setDbType(DbType.MYSQL);// 数据库类型
+ dataSourceConfig.setDriverName(driverClassName);
+ dataSourceConfig.setUsername(username);
+ dataSourceConfig.setPassword(password);
+ generator.setDataSource(dataSourceConfig);
+
+ // 包配置
+ PackageConfig packageConfig = new PackageConfig();
+ //packageConfig.setModuleName(scanner("模块名"));
+ packageConfig.setParent(rootPackage);
+ packageConfig.setController("controller" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName : ""));
+ packageConfig.setService("service" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName : ""));
+ packageConfig.setServiceImpl("service" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName + ".impl" : ".impl"));
+ packageConfig.setEntity("dao.entity" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName : ""));
+ packageConfig.setMapper("dao.mapper" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName : ""));
+
+ //packageConfig.setXml("dao.mapper.xml");
+ generator.setPackageInfo(packageConfig);
+
+ // 注意:模板引擎在mybatisplus依赖中的templates目录下,可以依照此默认模板进行自定义
+
+ // 策略配置:配置根据哪张表生成代码
+ StrategyConfig strategy = new StrategyConfig();
+ strategy.setInclude(tableNames);// 表名,多个英文逗号分割(与exclude二选一配置)
+ strategy.setNaming(NamingStrategy.underline_to_camel);
+ strategy.setColumnNaming(NamingStrategy.underline_to_camel);
+ // strategy.setSuperEntityClass("你自己的父类实体,没有就不用设置!");
+ strategy.setEntityLombokModel(true);// lombok模型,@Accessors(chain = true)setter链式操作
+ strategy.setRestControllerStyle(true);// controller生成@RestController
+ strategy.setEntityTableFieldAnnotationEnable(true);// 是否生成实体时,生成字段注解
+ // strategy.setEntityColumnConstant(true);// 是否生成字段常量(默认 false)
+ strategy.setTablePrefix(tablePrefix);// 生成实体时去掉表前缀
+
+ TemplateConfig templateConfig = new TemplateConfig();
+ templateConfig.setController(null);
+ templateConfig.setService(null);
+ templateConfig.setServiceImpl(null);
+ templateConfig.setXml(null);
+ templateConfig.setMapper(null);
+ templateConfig.setEntity(null);
+ generator.setTemplate(templateConfig);
+
+
+ generator.setStrategy(strategy);
+ generator.setTemplateEngine(new FreemarkerTemplateEngine());
+
+ /**
+ * 自定义输出路径
+ */
+ // controller
+ List<FileOutConfig> focList = new ArrayList<>();
+
+ // mapper.xml
+ focList.add(new FileOutConfig("/templates/story-entity.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ // 自定义输出文件名 , 如果你 Entity 设置了前后缀、此处注意 xml 的名称会跟着发生变化!!
+ return projectPath + "/" + modelModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/dao/entity/" + pkgName + "/" + tableInfo.getEntityName() + StringPool.DOT_JAVA;
+ }
+ });
+
+ focList.add(new FileOutConfig("/templates/story-controller.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ return projectPath + "/" + controllerModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/controller/" + pkgName + "/" + tableInfo.getEntityName() + "Controller" + StringPool.DOT_JAVA;
+ }
+ });
+ // service
+ focList.add(new FileOutConfig("/templates/service.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ return projectPath + "/" + serviceModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/service/" + pkgName + "/" + tableInfo.getEntityName() + "Service" + StringPool.DOT_JAVA;
+ }
+ });
+
+ // serviceImpl
+ focList.add(new FileOutConfig("/templates/story-serviceImpl.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ return projectPath + "/" + serviceModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/service/" + pkgName + "/impl/" + tableInfo.getEntityName() + "ServiceImpl" + StringPool.DOT_JAVA;
+ }
+ });
+
+ // mapper.java
+ // service
+ focList.add(new FileOutConfig("/templates/story-mapper.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ return projectPath + "/" + modelModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/dao/mapper/" + pkgName + "/" + tableInfo.getEntityName() + "Mapper" + StringPool.DOT_JAVA;
+ }
+ });
+
+ // mapper.xml
+ focList.add(new FileOutConfig("/templates/mapper.xml.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ // 自定义输出文件名 , 如果你 Entity 设置了前后缀、此处注意 xml 的名称会跟着发生变化!!
+ return projectPath + "/" + modelModuleName + "/src/main/resources/mapper/" + pkgName + "/" + tableInfo.getEntityName() + "Mapper" + StringPool.DOT_XML;
+ }
+ });
+
+ InjectionConfig injectionConfig = new InjectionConfig() {
+ @Override
+ public void initMap() { }
+ };
+ injectionConfig.setFileOutConfigList(focList);
+
+ generator.setCfg(injectionConfig);
+ generator.execute();
+ }
+}WARNING
模板不能使用IDE格式化,否则生成的文件缩进会有问题
package \${package.Entity};
+
+<#list table.importPackages as pkg>
+ import \${pkg};
+ </#list>
+<#if swagger2>
+ import io.swagger.annotations.ApiModel;
+ import io.swagger.annotations.ApiModelProperty;
+ </#if>
+<#if entityLombokModel>
+ import lombok.Data;
+ import lombok.EqualsAndHashCode;
+<#if chainModel>
+ import lombok.experimental.Accessors;
+ </#if>
+ </#if>
+ import io.swagger.v3.oas.annotations.media.Schema;
+ import lombok.experimental.FieldNameConstants;
+
+ /**
+ * \${table.comment!}
+ *
+ * @author \${author}
+ * @since \${date}
+ */
+<#if entityLombokModel>
+ @Data
+<#if superEntityClass??>
+ @EqualsAndHashCode(callSuper = true)
+<#else>
+ @EqualsAndHashCode(callSuper = false)
+ </#if>
+<#if chainModel>
+ @Accessors(chain = true)
+ </#if>
+ </#if>
+<#if table.convert>
+ @TableName("\${table.name}")
+ </#if>
+<#if swagger2>
+ @ApiModel(value="\${entity}对象", description="\${table.comment!}")
+ </#if>
+ @FieldNameConstants
+<#if superEntityClass??>
+ public class \${entity} extends \${superEntityClass}<#if activeRecord><\${entity}></#if> {
+<#elseif activeRecord>
+ public class \${entity} extends Model<\${entity}> {
+<#else>
+ public class \${entity} implements Serializable {
+ </#if>
+
+<#if entitySerialVersionUID>
+ private static final long serialVersionUID = 1L;
+ </#if>
+<#-- ---------- BEGIN 字段循环遍历 ---------->
+<#list table.fields as field>
+<#if field.keyFlag>
+<#assign keyPropertyName="\${field.propertyName}"/>
+ </#if>
+
+ @Schema(description = "\${field.comment}")
+<#if field.keyFlag>
+<#-- 主键 -->
+<#if field.keyIdentityFlag>
+ @TableId(value = "\${field.annotationColumnName}", type = IdType.AUTO)
+<#elseif idType??>
+ @TableId(value = "\${field.annotationColumnName}", type = IdType.\${idType})
+<#elseif field.convert>
+ @TableId("\${field.annotationColumnName}")
+ </#if>
+<#-- 普通字段 -->
+<#elseif field.fill??>
+<#-- ----- 存在字段填充设置 ----->
+<#if field.convert>
+ @TableField(value = "\${field.annotationColumnName}", fill = FieldFill.\${field.fill})
+<#else>
+ @TableField(fill = FieldFill.\${field.fill})
+ </#if>
+<#elseif field.convert>
+ @TableField("\${field.annotationColumnName}")
+ </#if>
+<#-- 乐观锁注解 -->
+<#if (versionFieldName!"") == field.name>
+ @Version
+ </#if>
+<#-- 逻辑删除注解 -->
+<#if (logicDeleteFieldName!"") == field.name>
+ @TableLogic
+ </#if>
+ private \${field.propertyType} \${field.propertyName};
+ </#list>
+<#------------ END 字段循环遍历 ---------->
+
+<#if !entityLombokModel>
+<#list table.fields as field>
+<#if field.propertyType == "boolean">
+<#assign getprefix="is"/>
+<#else>
+<#assign getprefix="get"/>
+ </#if>
+ public \${field.propertyType} \${getprefix}\${field.capitalName}() {
+ return \${field.propertyName};
+ }
+
+<#if chainModel>
+ public \${entity} set\${field.capitalName}(\${field.propertyType} \${field.propertyName}) {
+<#else>
+ public void set\${field.capitalName}(\${field.propertyType} \${field.propertyName}) {
+ </#if>
+ this.\${field.propertyName} = \${field.propertyName};
+<#if chainModel>
+ return this;
+ </#if>
+ }
+ </#list>
+ </#if>
+
+<#if entityColumnConstant>
+<#list table.fields as field>
+ public static final String \${field.name?upper_case} = "\${field.name}";
+
+ </#list>
+ </#if>
+<#if activeRecord>
+ @Override
+ protected Serializable pkVal() {
+<#if keyPropertyName??>
+ return this.\${keyPropertyName};
+<#else>
+ return null;
+ </#if>
+ }
+
+ </#if>
+<#if !entityLombokModel>
+ @Override
+ public String toString() {
+ return "\${entity}{" +
+<#list table.fields as field>
+<#if field_index==0>
+ "\${field.propertyName}=" + \${field.propertyName} +
+<#else>
+ ", \${field.propertyName}=" + \${field.propertyName} +
+ </#if>
+ </#list>
+ "}";
+ }
+ </#if>
+ }package \${package.Controller};
+
+ import \${package.Service}.\${table.serviceName};
+ import org.springframework.web.bind.annotation.RequestMapping;
+<#if restControllerStyle>
+ import org.springframework.web.bind.annotation.RestController;
+<#else>
+ import org.springframework.stereotype.Controller;
+ </#if>
+<#if superControllerClassPackage??>
+ import \${superControllerClassPackage};
+ </#if>
+ import io.swagger.v3.oas.annotations.tags.Tag;
+ import lombok.RequiredArgsConstructor;
+ import lombok.extern.slf4j.Slf4j;
+
+ /**
+ * \${table.comment!} 前端控制器
+ *
+ * @author \${author}
+ * @since \${date}
+ */
+ @Tag(name = "")
+ @Slf4j
+ @RequiredArgsConstructor
+<#if restControllerStyle>
+ @RestController
+<#else>
+ @Controller
+ </#if>
+ @RequestMapping("<#if package.ModuleName?? && package.ModuleName != "">/\${package.ModuleName}</#if>/<#if controllerMappingHyphenStyle??>\${controllerMappingHyphen}<#else>\${table.entityPath}</#if>")
+<#if kotlin>
+ class \${table.controllerName}<#if superControllerClass??> : \${superControllerClass}()</#if>
+<#else>
+<#if superControllerClass??>
+ public class \${table.controllerName} extends \${superControllerClass} {
+<#else>
+ public class \${table.controllerName} {
+ </#if>
+ private final \${table.serviceName} \${table.serviceName?uncap_first};
+
+ }
+ </#if>package \${package.ServiceImpl};
+
+ import \${package.Entity}.\${entity};
+ import \${package.Mapper}.\${table.mapperName};
+ import \${package.Service}.\${table.serviceName};
+ import \${superServiceImplClassPackage};
+ import org.springframework.stereotype.Service;
+ import lombok.RequiredArgsConstructor;
+ import lombok.extern.slf4j.Slf4j;
+
+ /**
+ * \${table.comment!} 服务实现类
+ *
+ * @author \${author}
+ * @since \${date}
+ */
+ @Slf4j
+ @RequiredArgsConstructor
+ @Service
+<#if kotlin>
+ open class \${table.serviceImplName} : \${superServiceImplClass}<\${table.mapperName}, \${entity}>(), \${table.serviceName} {
+
+ }
+<#else>
+ public class \${table.serviceImplName} extends \${superServiceImplClass}<\${table.mapperName}, \${entity}> implements \${table.serviceName} {
+
+ }
+ </#if>package \${package.Mapper};
+
+import \${package.Entity}.\${entity};
+import \${superMapperClassPackage};
+import org.apache.ibatis.annotations.Mapper;
+
+/**
+ * <p>
+ * \${table.comment!} Mapper 接口
+ * </p>
+ *
+ * @author \${author}
+ * @since \${date}
+ */
+<#if kotlin>
+interface ${table.mapperName} : \${superMapperClass}<\${entity}>
+<#else>
+@Mapper
+public interface ${table.mapperName} extends \${superMapperClass}<\${entity}> {
+
+}
+</#if>import cn.hutool.core.util.StrUtil;
+import com.baomidou.mybatisplus.generator.FastAutoGenerator;
+import com.baomidou.mybatisplus.generator.config.OutputFile;
+import com.baomidou.mybatisplus.generator.config.rules.DateType;
+import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
+
+import java.util.Collections;
+
+// 执行 main 方法,控制台输入模块表名,回车自动生成对应项目目录中
+public class MybatisPlusCodeGenerator {
+
+ public static void main(String[] args) {
+ //====================配置变量区域=====================//
+ String author = "xc";// 生成文件的作者,可以不填
+ String rootPackage = "com.story.test";// 生成的entity、controller、service等包所在的公共上一级包路径全限定名
+ String module = "modules/moduleA";
+ String folder = "subFolder";
+ // 数据库配置
+ String url = "jdbc:mysql://ip:port/database?useUnicode=true&characterEncoding=UTF-8&useSSL=false";
+ String username = "";
+ String password = "";
+
+ String[] tableNames = new String[]{"tb_table_name"};
+ String[] tablePrefix = new String[]{"tb_"};
+
+ FastAutoGenerator.create(
+ // 数据源配置
+ url,
+ username,
+ password)
+ // 全局配置
+ .globalConfig(builder -> {
+ builder.author(author)
+ .outputDir(System.getProperty("user.dir") + "/" + module + "/src/main/java")
+ .disableOpenDir()
+ .dateType(DateType.ONLY_DATE);
+ })
+ // 包配置
+ .packageConfig(builder -> {
+ builder.parent(rootPackage)
+ .entity("dao.entity" + (StrUtil.isBlank(folder) ? "" : "." + folder))
+ .mapper("dao.mapper" + (StrUtil.isBlank(folder) ? "" : "." + folder))
+ .service("service" + (StrUtil.isBlank(folder) ? "" : "." + folder))
+ .serviceImpl("service.impl" + (StrUtil.isBlank(folder) ? "" : "." + folder))
+ .pathInfo(Collections.singletonMap(
+ OutputFile.xml, System.getProperty("user.dir") + "/" + module + "/src/main/resources/mapper" + (StrUtil.isBlank(folder) ? "" : "/" + folder)
+ ))
+ ;
+
+ })
+ // 模版配置
+ .templateConfig(builder -> {
+ builder
+ // .controller("/templates/controller.java")
+ .controller("")
+ .serviceImpl("/templates/serviceImpl.java")
+ // .service("")
+ // .serviceImpl("")
+ .mapper("/templates/mapper.java")
+ .entity("/templates/entity.java");
+ })
+ // 策略配置
+ .strategyConfig(builder -> {
+ builder.addInclude(tableNames)
+ .addTablePrefix(tablePrefix)
+ .controllerBuilder().enableRestStyle()
+ .entityBuilder().enableLombok()
+ .entityBuilder().enableTableFieldAnnotation()
+ .serviceBuilder().formatServiceFileName("%sService")
+ .mapperBuilder().enableBaseResultMap();
+
+
+ })
+ .templateEngine(new FreemarkerTemplateEngine())
+ .execute();
+
+ }
+}import cn.hutool.core.util.StrUtil;
+import com.baomidou.mybatisplus.annotation.DbType;
+import com.baomidou.mybatisplus.annotation.IdType;
+import com.baomidou.mybatisplus.core.toolkit.StringPool;
+import com.baomidou.mybatisplus.generator.AutoGenerator;
+import com.baomidou.mybatisplus.generator.InjectionConfig;
+import com.baomidou.mybatisplus.generator.config.*;
+import com.baomidou.mybatisplus.generator.config.po.TableInfo;
+import com.baomidou.mybatisplus.generator.config.rules.DateType;
+import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
+import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
+
+import java.util.ArrayList;
+import java.util.List;
+
+/**
+ * @author xc
+ * @description
+ * @date 2023/5/19 09:20
+ */
+public class MybatisPlusCodeGenerator {
+
+ private static final String projectPath = System.getProperty("user.dir");
+
+ public static void main(String[] args) {
+ //====================配置变量区域=====================//
+ String author = "storyxc";// 生成文件的作者,可以不填
+ String rootPackage = "com.storyxc";// 生成的entity、controller、service等包所在的公共上一级包路径全限定名
+ String modelModuleName = "storyxc-model";
+ String serviceModuleName = "storyxc-web";
+ String controllerModuleName = "storyxc-web";
+ // 数据库配置
+ String url="jdbc:mysql://127.0.0.1/story?useUnicode=true&characterEncoding=UTF-8&useSSL=false";
+ String driverClassName = "com.mysql.cj.jdbc.Driver";// 或者com.mysql.cj.jdbc.Driver
+ String username = "root";
+ String password = "root";
+
+ String[] tableNames = new String[]{""};
+ String pkgName = "";
+ //====================配置变量区域=====================//
+ String[] tablePrefix = new String[]{""};
+ // 代码生成器
+ AutoGenerator generator = new AutoGenerator();
+ // 全局配置
+ GlobalConfig globalConfig = new GlobalConfig();
+ globalConfig.setOutputDir(projectPath + "/" + modelModuleName + "/src/main/java");// 生成文件的输出目录
+ globalConfig.setFileOverride(false);// 是否覆盖已有文件,默认false
+ globalConfig.setOpen(false);// 是否打开输出目录
+ globalConfig.setAuthor(author);
+ globalConfig.setServiceName("%sService");// 去掉service接口的首字母I
+ globalConfig.setBaseResultMap(true);// 开启 BaseResultMap
+ globalConfig.setDateType(DateType.ONLY_DATE);// 只使用 java.util.date代替
+ globalConfig.setIdType(IdType.ASSIGN_ID);// 分配ID (主键类型为number或string)
+ generator.setGlobalConfig(globalConfig);
+
+ // 数据源配置
+ DataSourceConfig dataSourceConfig = new DataSourceConfig();
+ dataSourceConfig.setUrl(url);
+ dataSourceConfig.setDbType(DbType.MYSQL);// 数据库类型
+ dataSourceConfig.setDriverName(driverClassName);
+ dataSourceConfig.setUsername(username);
+ dataSourceConfig.setPassword(password);
+ generator.setDataSource(dataSourceConfig);
+
+ // 包配置
+ PackageConfig packageConfig = new PackageConfig();
+ //packageConfig.setModuleName(scanner("模块名"));
+ packageConfig.setParent(rootPackage);
+ packageConfig.setController("controller" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName : ""));
+ packageConfig.setService("service" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName : ""));
+ packageConfig.setServiceImpl("service" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName + ".impl" : ".impl"));
+ packageConfig.setEntity("dao.entity" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName : ""));
+ packageConfig.setMapper("dao.mapper" + (StrUtil.isNotBlank(pkgName) ? "." + pkgName : ""));
+
+ //packageConfig.setXml("dao.mapper.xml");
+ generator.setPackageInfo(packageConfig);
+
+ // 注意:模板引擎在mybatisplus依赖中的templates目录下,可以依照此默认模板进行自定义
+
+ // 策略配置:配置根据哪张表生成代码
+ StrategyConfig strategy = new StrategyConfig();
+ strategy.setInclude(tableNames);// 表名,多个英文逗号分割(与exclude二选一配置)
+ strategy.setNaming(NamingStrategy.underline_to_camel);
+ strategy.setColumnNaming(NamingStrategy.underline_to_camel);
+ // strategy.setSuperEntityClass("你自己的父类实体,没有就不用设置!");
+ strategy.setEntityLombokModel(true);// lombok模型,@Accessors(chain = true)setter链式操作
+ strategy.setRestControllerStyle(true);// controller生成@RestController
+ strategy.setEntityTableFieldAnnotationEnable(true);// 是否生成实体时,生成字段注解
+ // strategy.setEntityColumnConstant(true);// 是否生成字段常量(默认 false)
+ strategy.setTablePrefix(tablePrefix);// 生成实体时去掉表前缀
+
+ TemplateConfig templateConfig = new TemplateConfig();
+ templateConfig.setController(null);
+ templateConfig.setService(null);
+ templateConfig.setServiceImpl(null);
+ templateConfig.setXml(null);
+ templateConfig.setMapper(null);
+ templateConfig.setEntity(null);
+ generator.setTemplate(templateConfig);
+
+
+ generator.setStrategy(strategy);
+ generator.setTemplateEngine(new FreemarkerTemplateEngine());
+
+ /**
+ * 自定义输出路径
+ */
+ // controller
+ List<FileOutConfig> focList = new ArrayList<>();
+
+ // mapper.xml
+ focList.add(new FileOutConfig("/templates/story-entity.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ // 自定义输出文件名 , 如果你 Entity 设置了前后缀、此处注意 xml 的名称会跟着发生变化!!
+ return projectPath + "/" + modelModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/dao/entity/" + pkgName + "/" + tableInfo.getEntityName() + StringPool.DOT_JAVA;
+ }
+ });
+
+ focList.add(new FileOutConfig("/templates/story-controller.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ return projectPath + "/" + controllerModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/controller/" + pkgName + "/" + tableInfo.getEntityName() + "Controller" + StringPool.DOT_JAVA;
+ }
+ });
+ // service
+ focList.add(new FileOutConfig("/templates/service.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ return projectPath + "/" + serviceModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/service/" + pkgName + "/" + tableInfo.getEntityName() + "Service" + StringPool.DOT_JAVA;
+ }
+ });
+
+ // serviceImpl
+ focList.add(new FileOutConfig("/templates/story-serviceImpl.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ return projectPath + "/" + serviceModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/service/" + pkgName + "/impl/" + tableInfo.getEntityName() + "ServiceImpl" + StringPool.DOT_JAVA;
+ }
+ });
+
+ // mapper.java
+ // service
+ focList.add(new FileOutConfig("/templates/story-mapper.java.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ return projectPath + "/" + modelModuleName + "/src/main/java/" + rootPackage.replace(".", "/") + "/dao/mapper/" + pkgName + "/" + tableInfo.getEntityName() + "Mapper" + StringPool.DOT_JAVA;
+ }
+ });
+
+ // mapper.xml
+ focList.add(new FileOutConfig("/templates/mapper.xml.ftl") {
+ @Override
+ public String outputFile(TableInfo tableInfo) {
+ // 自定义输出文件名 , 如果你 Entity 设置了前后缀、此处注意 xml 的名称会跟着发生变化!!
+ return projectPath + "/" + modelModuleName + "/src/main/resources/mapper/" + pkgName + "/" + tableInfo.getEntityName() + "Mapper" + StringPool.DOT_XML;
+ }
+ });
+
+ InjectionConfig injectionConfig = new InjectionConfig() {
+ @Override
+ public void initMap() { }
+ };
+ injectionConfig.setFileOutConfigList(focList);
+
+ generator.setCfg(injectionConfig);
+ generator.execute();
+ }
+}WARNING
模板不能使用IDE格式化,否则生成的文件缩进会有问题
package \${package.Entity};
+
+<#list table.importPackages as pkg>
+ import \${pkg};
+ </#list>
+<#if swagger2>
+ import io.swagger.annotations.ApiModel;
+ import io.swagger.annotations.ApiModelProperty;
+ </#if>
+<#if entityLombokModel>
+ import lombok.Data;
+ import lombok.EqualsAndHashCode;
+<#if chainModel>
+ import lombok.experimental.Accessors;
+ </#if>
+ </#if>
+ import io.swagger.v3.oas.annotations.media.Schema;
+ import lombok.experimental.FieldNameConstants;
+
+ /**
+ * \${table.comment!}
+ *
+ * @author \${author}
+ * @since \${date}
+ */
+<#if entityLombokModel>
+ @Data
+<#if superEntityClass??>
+ @EqualsAndHashCode(callSuper = true)
+<#else>
+ @EqualsAndHashCode(callSuper = false)
+ </#if>
+<#if chainModel>
+ @Accessors(chain = true)
+ </#if>
+ </#if>
+<#if table.convert>
+ @TableName("\${table.name}")
+ </#if>
+<#if swagger2>
+ @ApiModel(value="\${entity}对象", description="\${table.comment!}")
+ </#if>
+ @FieldNameConstants
+<#if superEntityClass??>
+ public class \${entity} extends \${superEntityClass}<#if activeRecord><\${entity}></#if> {
+<#elseif activeRecord>
+ public class \${entity} extends Model<\${entity}> {
+<#else>
+ public class \${entity} implements Serializable {
+ </#if>
+
+<#if entitySerialVersionUID>
+ private static final long serialVersionUID = 1L;
+ </#if>
+<#-- ---------- BEGIN 字段循环遍历 ---------->
+<#list table.fields as field>
+<#if field.keyFlag>
+<#assign keyPropertyName="\${field.propertyName}"/>
+ </#if>
+
+ @Schema(description = "\${field.comment}")
+<#if field.keyFlag>
+<#-- 主键 -->
+<#if field.keyIdentityFlag>
+ @TableId(value = "\${field.annotationColumnName}", type = IdType.AUTO)
+<#elseif idType??>
+ @TableId(value = "\${field.annotationColumnName}", type = IdType.\${idType})
+<#elseif field.convert>
+ @TableId("\${field.annotationColumnName}")
+ </#if>
+<#-- 普通字段 -->
+<#elseif field.fill??>
+<#-- ----- 存在字段填充设置 ----->
+<#if field.convert>
+ @TableField(value = "\${field.annotationColumnName}", fill = FieldFill.\${field.fill})
+<#else>
+ @TableField(fill = FieldFill.\${field.fill})
+ </#if>
+<#elseif field.convert>
+ @TableField("\${field.annotationColumnName}")
+ </#if>
+<#-- 乐观锁注解 -->
+<#if (versionFieldName!"") == field.name>
+ @Version
+ </#if>
+<#-- 逻辑删除注解 -->
+<#if (logicDeleteFieldName!"") == field.name>
+ @TableLogic
+ </#if>
+ private \${field.propertyType} \${field.propertyName};
+ </#list>
+<#------------ END 字段循环遍历 ---------->
+
+<#if !entityLombokModel>
+<#list table.fields as field>
+<#if field.propertyType == "boolean">
+<#assign getprefix="is"/>
+<#else>
+<#assign getprefix="get"/>
+ </#if>
+ public \${field.propertyType} \${getprefix}\${field.capitalName}() {
+ return \${field.propertyName};
+ }
+
+<#if chainModel>
+ public \${entity} set\${field.capitalName}(\${field.propertyType} \${field.propertyName}) {
+<#else>
+ public void set\${field.capitalName}(\${field.propertyType} \${field.propertyName}) {
+ </#if>
+ this.\${field.propertyName} = \${field.propertyName};
+<#if chainModel>
+ return this;
+ </#if>
+ }
+ </#list>
+ </#if>
+
+<#if entityColumnConstant>
+<#list table.fields as field>
+ public static final String \${field.name?upper_case} = "\${field.name}";
+
+ </#list>
+ </#if>
+<#if activeRecord>
+ @Override
+ protected Serializable pkVal() {
+<#if keyPropertyName??>
+ return this.\${keyPropertyName};
+<#else>
+ return null;
+ </#if>
+ }
+
+ </#if>
+<#if !entityLombokModel>
+ @Override
+ public String toString() {
+ return "\${entity}{" +
+<#list table.fields as field>
+<#if field_index==0>
+ "\${field.propertyName}=" + \${field.propertyName} +
+<#else>
+ ", \${field.propertyName}=" + \${field.propertyName} +
+ </#if>
+ </#list>
+ "}";
+ }
+ </#if>
+ }package \${package.Controller};
+
+ import \${package.Service}.\${table.serviceName};
+ import org.springframework.web.bind.annotation.RequestMapping;
+<#if restControllerStyle>
+ import org.springframework.web.bind.annotation.RestController;
+<#else>
+ import org.springframework.stereotype.Controller;
+ </#if>
+<#if superControllerClassPackage??>
+ import \${superControllerClassPackage};
+ </#if>
+ import io.swagger.v3.oas.annotations.tags.Tag;
+ import lombok.RequiredArgsConstructor;
+ import lombok.extern.slf4j.Slf4j;
+
+ /**
+ * \${table.comment!} 前端控制器
+ *
+ * @author \${author}
+ * @since \${date}
+ */
+ @Tag(name = "")
+ @Slf4j
+ @RequiredArgsConstructor
+<#if restControllerStyle>
+ @RestController
+<#else>
+ @Controller
+ </#if>
+ @RequestMapping("<#if package.ModuleName?? && package.ModuleName != "">/\${package.ModuleName}</#if>/<#if controllerMappingHyphenStyle??>\${controllerMappingHyphen}<#else>\${table.entityPath}</#if>")
+<#if kotlin>
+ class \${table.controllerName}<#if superControllerClass??> : \${superControllerClass}()</#if>
+<#else>
+<#if superControllerClass??>
+ public class \${table.controllerName} extends \${superControllerClass} {
+<#else>
+ public class \${table.controllerName} {
+ </#if>
+ private final \${table.serviceName} \${table.serviceName?uncap_first};
+
+ }
+ </#if>package \${package.ServiceImpl};
+
+ import \${package.Entity}.\${entity};
+ import \${package.Mapper}.\${table.mapperName};
+ import \${package.Service}.\${table.serviceName};
+ import \${superServiceImplClassPackage};
+ import org.springframework.stereotype.Service;
+ import lombok.RequiredArgsConstructor;
+ import lombok.extern.slf4j.Slf4j;
+
+ /**
+ * \${table.comment!} 服务实现类
+ *
+ * @author \${author}
+ * @since \${date}
+ */
+ @Slf4j
+ @RequiredArgsConstructor
+ @Service
+<#if kotlin>
+ open class \${table.serviceImplName} : \${superServiceImplClass}<\${table.mapperName}, \${entity}>(), \${table.serviceName} {
+
+ }
+<#else>
+ public class \${table.serviceImplName} extends \${superServiceImplClass}<\${table.mapperName}, \${entity}> implements \${table.serviceName} {
+
+ }
+ </#if>package \${package.Mapper};
+
+import \${package.Entity}.\${entity};
+import \${superMapperClassPackage};
+import org.apache.ibatis.annotations.Mapper;
+
+/**
+ * <p>
+ * \${table.comment!} Mapper 接口
+ * </p>
+ *
+ * @author \${author}
+ * @since \${date}
+ */
+<#if kotlin>
+interface ${table.mapperName} : \${superMapperClass}<\${entity}>
+<#else>
+@Mapper
+public interface ${table.mapperName} extends \${superMapperClass}<\${entity}> {
+
+}
+</#if>import cn.hutool.core.util.StrUtil;
+import com.baomidou.mybatisplus.generator.FastAutoGenerator;
+import com.baomidou.mybatisplus.generator.config.OutputFile;
+import com.baomidou.mybatisplus.generator.config.rules.DateType;
+import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
+
+import java.util.Collections;
+
+// 执行 main 方法,控制台输入模块表名,回车自动生成对应项目目录中
+public class MybatisPlusCodeGenerator {
+
+ public static void main(String[] args) {
+ //====================配置变量区域=====================//
+ String author = "xc";// 生成文件的作者,可以不填
+ String rootPackage = "com.story.test";// 生成的entity、controller、service等包所在的公共上一级包路径全限定名
+ String module = "modules/moduleA";
+ String folder = "subFolder";
+ // 数据库配置
+ String url = "jdbc:mysql://ip:port/database?useUnicode=true&characterEncoding=UTF-8&useSSL=false";
+ String username = "";
+ String password = "";
+
+ String[] tableNames = new String[]{"tb_table_name"};
+ String[] tablePrefix = new String[]{"tb_"};
+
+ FastAutoGenerator.create(
+ // 数据源配置
+ url,
+ username,
+ password)
+ // 全局配置
+ .globalConfig(builder -> {
+ builder.author(author)
+ .outputDir(System.getProperty("user.dir") + "/" + module + "/src/main/java")
+ .disableOpenDir()
+ .dateType(DateType.ONLY_DATE);
+ })
+ // 包配置
+ .packageConfig(builder -> {
+ builder.parent(rootPackage)
+ .entity("dao.entity" + (StrUtil.isBlank(folder) ? "" : "." + folder))
+ .mapper("dao.mapper" + (StrUtil.isBlank(folder) ? "" : "." + folder))
+ .service("service" + (StrUtil.isBlank(folder) ? "" : "." + folder))
+ .serviceImpl("service.impl" + (StrUtil.isBlank(folder) ? "" : "." + folder))
+ .pathInfo(Collections.singletonMap(
+ OutputFile.xml, System.getProperty("user.dir") + "/" + module + "/src/main/resources/mapper" + (StrUtil.isBlank(folder) ? "" : "/" + folder)
+ ))
+ ;
+
+ })
+ // 模版配置
+ .templateConfig(builder -> {
+ builder
+ // .controller("/templates/controller.java")
+ .controller("")
+ .serviceImpl("/templates/serviceImpl.java")
+ // .service("")
+ // .serviceImpl("")
+ .mapper("/templates/mapper.java")
+ .entity("/templates/entity.java");
+ })
+ // 策略配置
+ .strategyConfig(builder -> {
+ builder.addInclude(tableNames)
+ .addTablePrefix(tablePrefix)
+ .controllerBuilder().enableRestStyle()
+ .entityBuilder().enableLombok()
+ .entityBuilder().enableTableFieldAnnotation()
+ .serviceBuilder().formatServiceFileName("%sService")
+ .mapperBuilder().enableBaseResultMap();
+
+
+ })
+ .templateEngine(new FreemarkerTemplateEngine())
+ .execute();
+
+ }
+}新公司用的消息中间件是kafka,此前没有接触过,先大致了解下内容,后续再补充
Kafka is a distributed,partitioned,replicated commit logservice。
Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka 适合离线和在线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
相关术语:
broker:kafka集群中的每一台server称为一个kafka实例,也叫broker
topic:主题,一个topic中保存同一类消息,相当于对消息的分类
partition:分区,每个topic都可以分成多个partition,每个partition的存储层面都是append log文件.任何发布到该partition的消息都会被追加到log文件尾部.
分区的根本原因:kafka基于文件进行存储,当文件内容达到一定程度很容易达到单个磁盘的上限,因此采取分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同server上,另外也可以负载均衡,容纳更多消费者
offset:偏移量,一个分区对应一个磁盘上的文件,而消息在文件中的位置就是offset偏移量,offset为一个long型数字,可以唯一标记一条消息,kafka没有提供其他额外的索引机制来存储offset,所以只能顺序读写,在kafka中几乎不允许对消息进行"随机读写"
总结:
一个topic对应的多个partition分散存储到集群的多个broker上,存储方式是一个partition对应一个文件,每个broker负责存储在自己机器上的partition中的消息读写
kafka可以配置partitions需要备份的个数(replicas),每个partition将会备份到多台机器上,以提高可用性.既然有副本,就涉及到对同一个文件的多个备份如何进行管理调度,kafka的方案是每个partition选举一个server作为leader,由leader负责所有对该分区的读写,其他server作为follower只需要简单的与leader同步,如果原来的leader失效,会重新选举由其他的follower来成为新的leader
如何选举leader:kafka使用zookeeper在broker中选出一个controller,用于partition的分配和leader选举
另外,作为leader的server承担了该分区所有的读写,所以压力较大,从整体考虑,有多少个partition就有多少个leader,kafka会将leader分散到不同的broker上,确保整体负载均衡
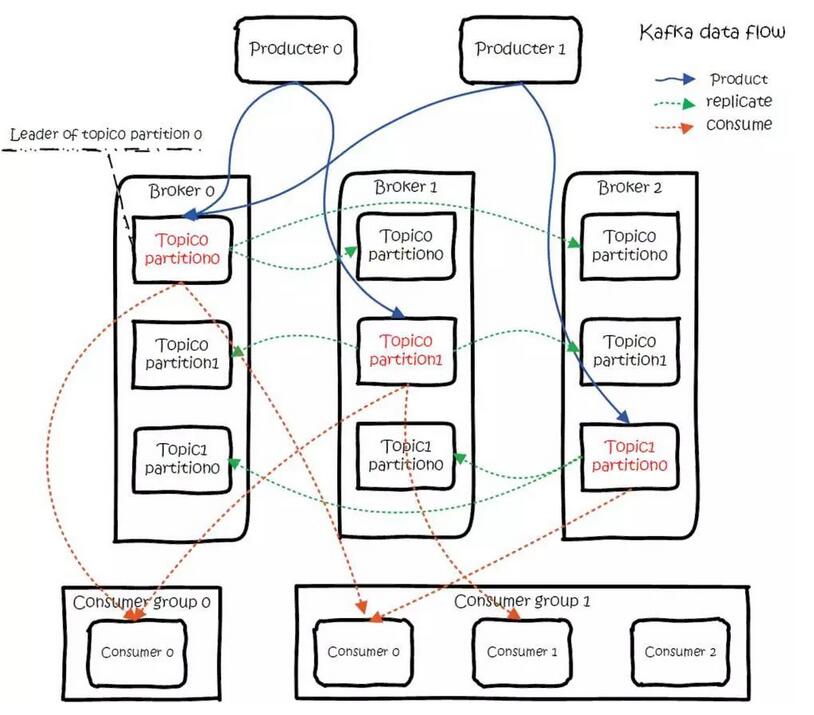
生产者写入的消息,可以指定四个参数:topic、partition、key、value其中topic和value是必须指定的,key和partition是可选的。
对于一条记录,先对其进行序列化,然后按照topic和partition,放进对应的发送队列中。如果partition没有指定,那么情况如下:a、Key有填,按照key进行hash,相同的key去一个partition
b、key没填,round-robin轮询来选partition 
producer会和topic下的所有partition leader保持socket连接,消息经过producer直接通过socket发送至broker。其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper客户端已经注册了watch监听partition leader的变更事件,因此可以准确的知道谁是当前leader。
producer端采用异步发送,多条消息暂且在客户端buffer起来,并将他们批量发送到broker,小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率
消费者不是以单独形式存在,每一个消费者属于一个consumer group消费者组,一个group包含多个consumer。订阅topic是以一个消费组来订阅的,发送到topic的消息,只会被订阅此topic的每个group中的consumer消费。
如果所有的consumer都具有相同group,那么就像一个点对点的消息系统,如果每个consumer都具有不同的group,那消息就会广播给所有消费者。
具体说来,这实际上是根据partition来分的,==一个partition只能被消费组里的一个消费者消费,但是可以被多个消费组消费==,消费组里的每个消费者是关联到一个partition的,因此有这样的说法:对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则意味着某些消费者无法得到消息
同一个消费组的两个消费者不会同时消费一个partition.
在kafka中,采用了pull的方式,即consumer和broker建立连接之后,主动去pull(或者说fetch)消息,首先consumer端可以根据自己的消费能力适时去fetch消息并处理,且可以控制消息消费的进度(offset)。
partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,所以kafka的broker端很轻量级。当消息被consumer接受之后,需要保存offset记录消费到哪,以前保存在zk中,由于zk的性能瓶颈,以前的解决方案是consumer一分钟上报一次,在0.10版本后kafka把offset保存,从zk中剥离,保存在consumeroffsets topic的topic中,由此可见,consumer客户端也很轻量级
kafka支持三种消息投递语义,在业务中通常使用At least once模型
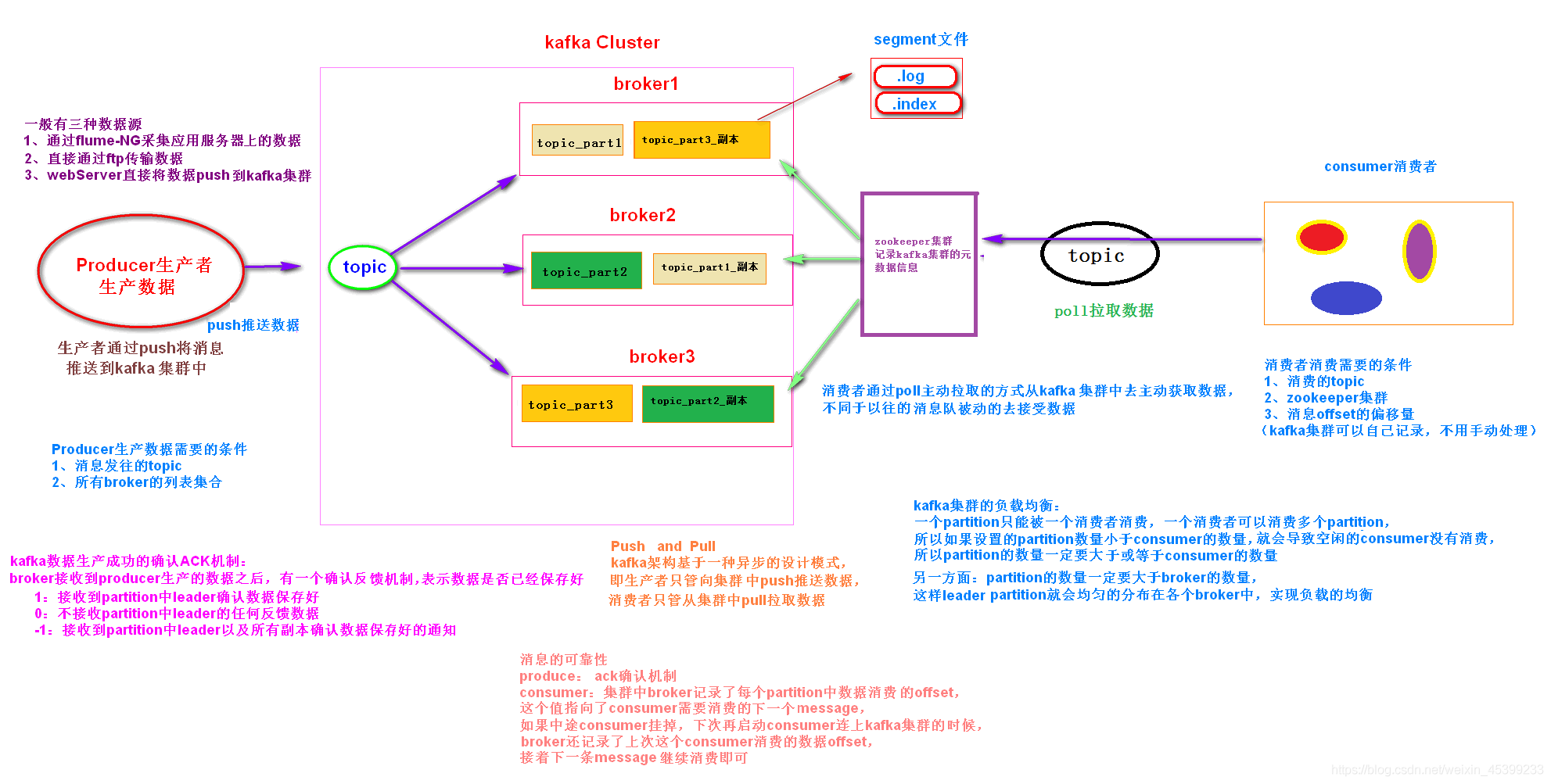
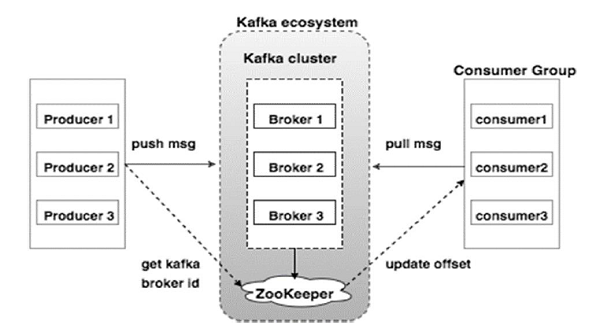
新公司用的消息中间件是kafka,此前没有接触过,先大致了解下内容,后续再补充
Kafka is a distributed,partitioned,replicated commit logservice。
Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka 适合离线和在线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
相关术语:
broker:kafka集群中的每一台server称为一个kafka实例,也叫broker
topic:主题,一个topic中保存同一类消息,相当于对消息的分类
partition:分区,每个topic都可以分成多个partition,每个partition的存储层面都是append log文件.任何发布到该partition的消息都会被追加到log文件尾部.
分区的根本原因:kafka基于文件进行存储,当文件内容达到一定程度很容易达到单个磁盘的上限,因此采取分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同server上,另外也可以负载均衡,容纳更多消费者
offset:偏移量,一个分区对应一个磁盘上的文件,而消息在文件中的位置就是offset偏移量,offset为一个long型数字,可以唯一标记一条消息,kafka没有提供其他额外的索引机制来存储offset,所以只能顺序读写,在kafka中几乎不允许对消息进行"随机读写"
总结:
一个topic对应的多个partition分散存储到集群的多个broker上,存储方式是一个partition对应一个文件,每个broker负责存储在自己机器上的partition中的消息读写
kafka可以配置partitions需要备份的个数(replicas),每个partition将会备份到多台机器上,以提高可用性.既然有副本,就涉及到对同一个文件的多个备份如何进行管理调度,kafka的方案是每个partition选举一个server作为leader,由leader负责所有对该分区的读写,其他server作为follower只需要简单的与leader同步,如果原来的leader失效,会重新选举由其他的follower来成为新的leader
如何选举leader:kafka使用zookeeper在broker中选出一个controller,用于partition的分配和leader选举
另外,作为leader的server承担了该分区所有的读写,所以压力较大,从整体考虑,有多少个partition就有多少个leader,kafka会将leader分散到不同的broker上,确保整体负载均衡
生产者写入的消息,可以指定四个参数:topic、partition、key、value其中topic和value是必须指定的,key和partition是可选的。
对于一条记录,先对其进行序列化,然后按照topic和partition,放进对应的发送队列中。如果partition没有指定,那么情况如下:a、Key有填,按照key进行hash,相同的key去一个partition
b、key没填,round-robin轮询来选partition
producer会和topic下的所有partition leader保持socket连接,消息经过producer直接通过socket发送至broker。其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper客户端已经注册了watch监听partition leader的变更事件,因此可以准确的知道谁是当前leader。
producer端采用异步发送,多条消息暂且在客户端buffer起来,并将他们批量发送到broker,小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率
消费者不是以单独形式存在,每一个消费者属于一个consumer group消费者组,一个group包含多个consumer。订阅topic是以一个消费组来订阅的,发送到topic的消息,只会被订阅此topic的每个group中的consumer消费。
如果所有的consumer都具有相同group,那么就像一个点对点的消息系统,如果每个consumer都具有不同的group,那消息就会广播给所有消费者。
具体说来,这实际上是根据partition来分的,==一个partition只能被消费组里的一个消费者消费,但是可以被多个消费组消费==,消费组里的每个消费者是关联到一个partition的,因此有这样的说法:对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则意味着某些消费者无法得到消息
同一个消费组的两个消费者不会同时消费一个partition.
在kafka中,采用了pull的方式,即consumer和broker建立连接之后,主动去pull(或者说fetch)消息,首先consumer端可以根据自己的消费能力适时去fetch消息并处理,且可以控制消息消费的进度(offset)。
partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,所以kafka的broker端很轻量级。当消息被consumer接受之后,需要保存offset记录消费到哪,以前保存在zk中,由于zk的性能瓶颈,以前的解决方案是consumer一分钟上报一次,在0.10版本后kafka把offset保存,从zk中剥离,保存在consumeroffsets topic的topic中,由此可见,consumer客户端也很轻量级
kafka支持三种消息投递语义,在业务中通常使用At least once模型
环境信息:MacOS 13.4.1
Kafka版本:Homebrew Kafka_3.4.0
kafka-topics --create --topic topic-name --partitions 4 --replication-factor 2 --bootstrap-server localhost:9092
kafka-topics --bootstrap-server 127.0.0.1:9092 --list
kafka-topics --bootstrap-server 127.0.0.1:9092 --describe --topic topic-name
kafka-topics --bootstrap-server 127.0.0.1:9092 --alter --partitions 2 --topic topic-name
kafka-topics --bootstrap-server 127.0.0.1:9092 --delete --topic topic-name
给topic保留消息时间改为1s,然后等topic中的消息被自动删除,再删除该配置
删除topic也可以实现清空消息
kafka-configs --bootstrap-server 127.0.0.1:9092 --entity-type topics --alter --entity-name example --add-config retention.ms=1000
kafka-configs --bootstrap-server 127.0.0.1:9092 --entity-type topics --alter --entity-name example --delete-config retention.ms
kafka-consumer-groups --bootstrap-server 127.0.0.1:9092 --list
kafka-consumer-groups --bootstrap-server 127.0.0.1:9092 --describe --group topic-name
kafka-consumer-groups --bootstrap-server 127.0.0.1:9092 --describe --members --group topic-name
kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic topic-name --from-beginning
kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic topic-name --partition 0 --offset 1
环境信息:MacOS 13.4.1
Kafka版本:Homebrew Kafka_3.4.0
kafka-topics --create --topic topic-name --partitions 4 --replication-factor 2 --bootstrap-server localhost:9092
kafka-topics --bootstrap-server 127.0.0.1:9092 --list
kafka-topics --bootstrap-server 127.0.0.1:9092 --describe --topic topic-name
kafka-topics --bootstrap-server 127.0.0.1:9092 --alter --partitions 2 --topic topic-name
kafka-topics --bootstrap-server 127.0.0.1:9092 --delete --topic topic-name
给topic保留消息时间改为1s,然后等topic中的消息被自动删除,再删除该配置
删除topic也可以实现清空消息
kafka-configs --bootstrap-server 127.0.0.1:9092 --entity-type topics --alter --entity-name example --add-config retention.ms=1000
kafka-configs --bootstrap-server 127.0.0.1:9092 --entity-type topics --alter --entity-name example --delete-config retention.ms
kafka-consumer-groups --bootstrap-server 127.0.0.1:9092 --list
kafka-consumer-groups --bootstrap-server 127.0.0.1:9092 --describe --group topic-name
kafka-consumer-groups --bootstrap-server 127.0.0.1:9092 --describe --members --group topic-name
kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic topic-name --from-beginning
kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic topic-name --partition 0 --offset 1
官方地址:https://kafka.apache.org/downloads.html
官方文档:http://kafka.apache.org/quickstart
TIP
强烈建议新学习一项新内容的时候尽量阅读英文原版文档
使用kafka自带的zookeeper启动
tar -xzf kafka_2.13-2.8.0.tgz
+cd kafka_2.13-2.8.0
+bin/zookeeper-server-start.sh config/zookeeper.properties & #后台启动在kafka0.5x版本后已经自带了zookeeper, 而在最新的kafka2.8版本中,不再需要zookeeper服务,官网把这种称之为KRaft模式
bin/kafka-server-start.sh config/server.properties等所有服务等启动完毕,kafka就已经是可用的了
创建一个名为quickstart-events的topic,只有一个分区和一个备份
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic quickstart-events
+
+查看已创建的topic信息
+
+\`\`\`bash
+[root@localhost kafka_2.13-2.8.0]# bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
+Topic: quickstart-events TopicId: iOM06pJVQV-y_A6QkmfeHw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
+ Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0kafka提供了一个命令行工具,可以从输入文件或命令行中读取消息并发送给kafka集群,每一行是一条消息.运行producer(生产者) ,然后再控制台输入几条消息到服务器
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092输入此命令后进入交互模式,便可以开始发送消息到topic
>hello
+>hello world
+>this is first kafka message
+>可以使用Ctrl+C退出交互模式
打开另外一个终端窗口运行命令
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092可以看到输出了刚才我们通过生产者终端发送的消息
hello
+hello world
+this is first kafka message此时如果我们再在生产者终端发送消息,消费者终端也能实时进行消费,同样可以使用Ctrl+C 退出消费者的交互模式,消息会被持久化到kafka中,所以消息可以被消费多次以及被多个消费者消费,比如我们再打开一个窗口,执行消费的命令
[root@localhost kafka_2.13-2.8.0]# bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
+hello
+hello world
+this is first kafka message
+
+可以看到,新的消费者又消费到了刚才的消息
+<dependency>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter</artifactId>
+</dependency>
+<dependency>
+<groupId>org.apache.kafka</groupId>
+<artifactId>kafka-streams</artifactId>
+</dependency>
+<dependency>
+<groupId>org.springframework.kafka</groupId>
+<artifactId>spring-kafka</artifactId>
+</dependency>
+
+<dependency>
+<groupId>org.springframework.boot</groupId>
+<artifactId>spring-boot-starter-test</artifactId>
+<scope>test</scope>
+</dependency>
+<dependency>
+<groupId>org.springframework.kafka</groupId>
+<artifactId>spring-kafka-test</artifactId>
+<scope>test</scope>
+</dependency>修改config/server.properties
+listeners=PLAINTEXT://0.0.0.0:9092
+advertised.listeners=PLAINTEXT://192.168.174.130:9092firewall-cmd --zone=public --add-port=9092/tcp --permanent
firewall-cmd --reload
/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 23:58
+ */
+public class KafkaProducerTests {
+ @Test
+ void kafkaProducerTest() {
+ Properties properties = new Properties();
+ properties.put("bootstrap.servers", "192.168.174.130:9092");
+ properties.put("acks", "all");
+ properties.put("retries", 0);
+ properties.put("batch.size", 16384);
+ properties.put("linger.ms", 1);
+ properties.put("buffer.memory", 33554432);
+ properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+ properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+
+ KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
+ for (int i = 0; i < 100; i++) {
+ producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), "Kafka message " + i));
+ System.out.println("发送了消息");
+ }
+ producer.close();
+
+ }
+}send()方法是异步的,添加消息到缓冲区等待发送并立即return,生产者会将单个消息批量在一起进行发送
ack是判断是否发送成功的,all将会阻塞消息,这种性能是最低的,但是是最可靠的
retries,如果请求失败,生产者会自动重试,如果启用重试,可能会产生重复消息
producer缓存每个分区未发送的消息,缓存的大小通过batch.size配置指定,数值较大会产生更大的批次并需要更大的内存
默认缓冲可立即发送,即使缓存空间没有满,但是如果想减少请求的数量,可设置linger.ms大于0,这将让生产者在发送请求前等待一会儿,希望更多的消息来填补到缓冲区中
buffer.memory 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽缓存空间,当缓存空间耗尽时,其他发送调用将会被阻塞,阻塞实践的阈值通过max.block.ms 设定,之后它将抛出一个TimeoutException
key.serializer和value.serializer将用户提供的key和value对象ProducerRecord转换成字节,可以使用附带 的* *ByteArraySerializer或StringSeriializer**处理byte或string类型
/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 23:59
+ */
+public class KafkaConsumerTests {
+ @Test
+ void kafkaConsumerTest(){
+ Properties props = new Properties();
+ props.setProperty("bootstrap.servers", "192.168.174.130:9092");
+ props.setProperty("group.id", "test");
+ props.setProperty("enable.auto.commit", "true");
+ props.setProperty("auto.commit.interval.ms", "1000");
+ props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+ props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+ KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
+ consumer.subscribe(Collections.singletonList("test"));
+ while (true) {
+ ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
+ for (ConsumerRecord<String, String> record : records)
+ System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
+ }
+ }
+}enable.auto.commit自动提交偏移量,auto.commit.interval.ms控制提交的频率test的topic,消费者组叫testbroker通过心跳检测test消费组中的进程,消费者会自动ping集群,告诉集群他还活着,只要消费者停止心跳的时间超过了session.timeout.ms 就会被认定为故障,它的分区将会被分配到别的进程
先启动消费者,后启动生产者,可以看到消费者的终端输出了
offset = 502, key = 0, value = Kafka message 0
+offset = 503, key = 1, value = Kafka message 1
+offset = 504, key = 2, value = Kafka message 2
+offset = 505, key = 3, value = Kafka message 3
+offset = 506, key = 4, value = Kafka message 4
+offset = 507, key = 5, value = Kafka message 5
+offset = 508, key = 6, value = Kafka message 6
+offset = 509, key = 7, value = Kafka message 7
+offset = 510, key = 8, value = Kafka message 8
+offset = 511, key = 9, value = Kafka message 9
+offset = 512, key = 10, value = Kafka message 10
+offset = 513, key = 11, value = Kafka message 11
+offset = 514, key = 12, value = Kafka message 12
+offset = 515, key = 13, value = Kafka message 13
+offset = 516, key = 14, value = Kafka message 14
+offset = 517, key = 15, value = Kafka message 15
+offset = 518, key = 16, value = Kafka message 16
+offset = 519, key = 17, value = Kafka message 17
+offset = 520, key = 18, value = Kafka message 18
+offset = 521, key = 19, value = Kafka message 19
+offset = 522, key = 20, value = Kafka message 20
+......
+<dependency>
+ <groupId>org.springframework.kafka</groupId>
+ <artifactId>spring-kafka</artifactId>
+</dependency>/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 21:49
+ */
+@RestController
+@RequestMapping("/kafka")
+public class KafkaDemoProducer {
+
+ @Autowired
+ private KafkaTemplate kafkaTemplate;
+
+ @GetMapping("/send/{msg}")
+ public String sendMessage(@PathVariable String msg) {
+ ListenableFuture send = kafkaTemplate.send("springboot-kafka", "测试发送:" + msg + "-" + System.currentTimeMillis());
+ System.out.println(send);
+ return "发送成功";
+ }
+}/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/15 23:55
+ */
+@Component
+public class KafkaDemoConsumer {
+
+
+ @KafkaListener(topics = {"springboot-kafka"})
+ public void onReceive(ConsumerRecord<?, ?> record) {
+ System.out.println("接收消息:" + record.topic() + "-" + record.partition() + "-" + record.value());
+ }
+}启动应用
发送消息
日志
2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka version: 2.6.0
+2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka commitId: 62abe01bee039651
+2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka startTimeMs: 1621151778430
+2021-05-16 15:56:18.435 INFO 10808 --- [ad | producer-1] org.apache.kafka.clients.Metadata : [Producer clientId=producer-1] Cluster ID: t54vUJ_qTWm-o8WmD-dfag
+org.springframework.util.concurrent.SettableListenableFuture@2a59dc33
+接收消息:springboot-kafka-0-测试发送:hello-1621151778418官方地址:https://kafka.apache.org/downloads.html
官方文档:http://kafka.apache.org/quickstart
TIP
强烈建议新学习一项新内容的时候尽量阅读英文原版文档
使用kafka自带的zookeeper启动
tar -xzf kafka_2.13-2.8.0.tgz
+cd kafka_2.13-2.8.0
+bin/zookeeper-server-start.sh config/zookeeper.properties & #后台启动在kafka0.5x版本后已经自带了zookeeper, 而在最新的kafka2.8版本中,不再需要zookeeper服务,官网把这种称之为KRaft模式
bin/kafka-server-start.sh config/server.properties等所有服务等启动完毕,kafka就已经是可用的了
创建一个名为quickstart-events的topic,只有一个分区和一个备份
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic quickstart-events
+
+查看已创建的topic信息
+
+\`\`\`bash
+[root@localhost kafka_2.13-2.8.0]# bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
+Topic: quickstart-events TopicId: iOM06pJVQV-y_A6QkmfeHw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
+ Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0kafka提供了一个命令行工具,可以从输入文件或命令行中读取消息并发送给kafka集群,每一行是一条消息.运行producer(生产者) ,然后再控制台输入几条消息到服务器
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092输入此命令后进入交互模式,便可以开始发送消息到topic
>hello
+>hello world
+>this is first kafka message
+>可以使用Ctrl+C退出交互模式
打开另外一个终端窗口运行命令
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092可以看到输出了刚才我们通过生产者终端发送的消息
hello
+hello world
+this is first kafka message此时如果我们再在生产者终端发送消息,消费者终端也能实时进行消费,同样可以使用Ctrl+C 退出消费者的交互模式,消息会被持久化到kafka中,所以消息可以被消费多次以及被多个消费者消费,比如我们再打开一个窗口,执行消费的命令
[root@localhost kafka_2.13-2.8.0]# bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
+hello
+hello world
+this is first kafka message
+
+可以看到,新的消费者又消费到了刚才的消息
+<dependency>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter</artifactId>
+</dependency>
+<dependency>
+<groupId>org.apache.kafka</groupId>
+<artifactId>kafka-streams</artifactId>
+</dependency>
+<dependency>
+<groupId>org.springframework.kafka</groupId>
+<artifactId>spring-kafka</artifactId>
+</dependency>
+
+<dependency>
+<groupId>org.springframework.boot</groupId>
+<artifactId>spring-boot-starter-test</artifactId>
+<scope>test</scope>
+</dependency>
+<dependency>
+<groupId>org.springframework.kafka</groupId>
+<artifactId>spring-kafka-test</artifactId>
+<scope>test</scope>
+</dependency>修改config/server.properties
+listeners=PLAINTEXT://0.0.0.0:9092
+advertised.listeners=PLAINTEXT://192.168.174.130:9092firewall-cmd --zone=public --add-port=9092/tcp --permanent
firewall-cmd --reload
/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 23:58
+ */
+public class KafkaProducerTests {
+ @Test
+ void kafkaProducerTest() {
+ Properties properties = new Properties();
+ properties.put("bootstrap.servers", "192.168.174.130:9092");
+ properties.put("acks", "all");
+ properties.put("retries", 0);
+ properties.put("batch.size", 16384);
+ properties.put("linger.ms", 1);
+ properties.put("buffer.memory", 33554432);
+ properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+ properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+
+ KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
+ for (int i = 0; i < 100; i++) {
+ producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), "Kafka message " + i));
+ System.out.println("发送了消息");
+ }
+ producer.close();
+
+ }
+}send()方法是异步的,添加消息到缓冲区等待发送并立即return,生产者会将单个消息批量在一起进行发送
ack是判断是否发送成功的,all将会阻塞消息,这种性能是最低的,但是是最可靠的
retries,如果请求失败,生产者会自动重试,如果启用重试,可能会产生重复消息
producer缓存每个分区未发送的消息,缓存的大小通过batch.size配置指定,数值较大会产生更大的批次并需要更大的内存
默认缓冲可立即发送,即使缓存空间没有满,但是如果想减少请求的数量,可设置linger.ms大于0,这将让生产者在发送请求前等待一会儿,希望更多的消息来填补到缓冲区中
buffer.memory 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽缓存空间,当缓存空间耗尽时,其他发送调用将会被阻塞,阻塞实践的阈值通过max.block.ms 设定,之后它将抛出一个TimeoutException
key.serializer和value.serializer将用户提供的key和value对象ProducerRecord转换成字节,可以使用附带 的* *ByteArraySerializer或StringSeriializer**处理byte或string类型
/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 23:59
+ */
+public class KafkaConsumerTests {
+ @Test
+ void kafkaConsumerTest(){
+ Properties props = new Properties();
+ props.setProperty("bootstrap.servers", "192.168.174.130:9092");
+ props.setProperty("group.id", "test");
+ props.setProperty("enable.auto.commit", "true");
+ props.setProperty("auto.commit.interval.ms", "1000");
+ props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+ props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+ KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
+ consumer.subscribe(Collections.singletonList("test"));
+ while (true) {
+ ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
+ for (ConsumerRecord<String, String> record : records)
+ System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
+ }
+ }
+}enable.auto.commit自动提交偏移量,auto.commit.interval.ms控制提交的频率test的topic,消费者组叫testbroker通过心跳检测test消费组中的进程,消费者会自动ping集群,告诉集群他还活着,只要消费者停止心跳的时间超过了session.timeout.ms 就会被认定为故障,它的分区将会被分配到别的进程
先启动消费者,后启动生产者,可以看到消费者的终端输出了
offset = 502, key = 0, value = Kafka message 0
+offset = 503, key = 1, value = Kafka message 1
+offset = 504, key = 2, value = Kafka message 2
+offset = 505, key = 3, value = Kafka message 3
+offset = 506, key = 4, value = Kafka message 4
+offset = 507, key = 5, value = Kafka message 5
+offset = 508, key = 6, value = Kafka message 6
+offset = 509, key = 7, value = Kafka message 7
+offset = 510, key = 8, value = Kafka message 8
+offset = 511, key = 9, value = Kafka message 9
+offset = 512, key = 10, value = Kafka message 10
+offset = 513, key = 11, value = Kafka message 11
+offset = 514, key = 12, value = Kafka message 12
+offset = 515, key = 13, value = Kafka message 13
+offset = 516, key = 14, value = Kafka message 14
+offset = 517, key = 15, value = Kafka message 15
+offset = 518, key = 16, value = Kafka message 16
+offset = 519, key = 17, value = Kafka message 17
+offset = 520, key = 18, value = Kafka message 18
+offset = 521, key = 19, value = Kafka message 19
+offset = 522, key = 20, value = Kafka message 20
+......
+<dependency>
+ <groupId>org.springframework.kafka</groupId>
+ <artifactId>spring-kafka</artifactId>
+</dependency>/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 21:49
+ */
+@RestController
+@RequestMapping("/kafka")
+public class KafkaDemoProducer {
+
+ @Autowired
+ private KafkaTemplate kafkaTemplate;
+
+ @GetMapping("/send/{msg}")
+ public String sendMessage(@PathVariable String msg) {
+ ListenableFuture send = kafkaTemplate.send("springboot-kafka", "测试发送:" + msg + "-" + System.currentTimeMillis());
+ System.out.println(send);
+ return "发送成功";
+ }
+}/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/15 23:55
+ */
+@Component
+public class KafkaDemoConsumer {
+
+
+ @KafkaListener(topics = {"springboot-kafka"})
+ public void onReceive(ConsumerRecord<?, ?> record) {
+ System.out.println("接收消息:" + record.topic() + "-" + record.partition() + "-" + record.value());
+ }
+}启动应用
发送消息
日志
2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka version: 2.6.0
+2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka commitId: 62abe01bee039651
+2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka startTimeMs: 1621151778430
+2021-05-16 15:56:18.435 INFO 10808 --- [ad | producer-1] org.apache.kafka.clients.Metadata : [Producer clientId=producer-1] Cluster ID: t54vUJ_qTWm-o8WmD-dfag
+org.springframework.util.concurrent.SettableListenableFuture@2a59dc33
+接收消息:springboot-kafka-0-测试发送:hello-1621151778418最近在支援开发公司的财务对账系统,其中涉及一个功能点是某个对账单创建开票申请后,需要更新对账单的开票申请状态(未申请,部分申请,全部申请),这里使用了kafka,当创建开票申请后生产者即发送一条消息,消费者再去进行消费。
然后就碰到个问题,生产者这里是有事务的,因此会出现事务还没提交,开票申请数据还没有写入到数据库中,但是消息已经发送到kafka了,此时消费者直接消费消息时是查询不到这批开票申请数据的,就会出现创建开票申请业务实际成功了,但是对账单的开票申请状态仍为未申请。所以用了一个笨方法解决这个问题,在消费者线程中sleep(5000),来确保消费到消息时生产者的事务已经提交。
在测试环境测试少量账单&开票申请数据时是完全没有问题的,但是上了生产之后会有批量的账单数据推送过来,创建了大量的开票申请。这时候就发现异常情况了:消息队列中堆积了大量的消息,虽然日志一直还在正常跑,但是offset一直没变,并且过一段时间还会重复消费已经跑过日志的消息。
消费重复消费的根本原因都是:已经消费了数据,但是offset并没有提交。
网上找到的资料里有一段这么写的:
kafka消息重复消费很大一部分原因在于发生了再均衡。
1)消费者宕机、重启等。导致消息已经消费但是没有提交offset。
2)消费者使用自动提交offset,但当还没有提交的时候,有新的消费者加入或者移除,发生了rebalance。再次消费的时候,消费者会根据提交的偏移量来,于是重复消费了数据。
3)消息处理耗时,或者消费者拉取的消息量太多,处理耗时,超过了max.poll.interval.ms的配置时间,导致认为当前消费者已经死掉,触发再均衡。
日志:
This member will leave the group because consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.这里我碰到的情况就是第三种,因为消费者consumer每次拉取的消息较多,且有线程sleep的操作,所以导致处理超时了,超过max.poll.interval.ms的时间就会触发rebalance,然后就会重新分配消费者再次消费上次拉取的那批数据,这就是重复消费的原因。
了解了超时的原因,就好解决了,根据日志中的提示,我们可以调整max.poll.interval.ms和max.poll.records两个参数
max.poll.interval.ms的值,默认值为300000,单位是ms,即5分钟,可以调整为10分钟max.poll.records的值,默认是500,可以调整为100参考资料:
',18)]))}const u=a(t,[["render",s]]);export{h as __pageData,u as default}; diff --git "a/assets/java_middleware_kakfa\351\207\215\345\244\215\346\266\210\350\264\271\351\227\256\351\242\230\345\244\204\347\220\206.md.BAMDmOGh.lean.js" "b/assets/java_middleware_kakfa\351\207\215\345\244\215\346\266\210\350\264\271\351\227\256\351\242\230\345\244\204\347\220\206.md.BAMDmOGh.lean.js" new file mode 100644 index 00000000..975bcf61 --- /dev/null +++ "b/assets/java_middleware_kakfa\351\207\215\345\244\215\346\266\210\350\264\271\351\227\256\351\242\230\345\244\204\347\220\206.md.BAMDmOGh.lean.js" @@ -0,0 +1 @@ +import{_ as a,c as o,a2 as p,o as l}from"./chunks/framework.BjcrtTwI.js";const h=JSON.parse('{"title":"kafka重复消费问题处理","description":"","frontmatter":{},"headers":[],"relativePath":"java/middleware/kakfa重复消费问题处理.md","filePath":"java/middleware/kakfa重复消费问题处理.md","lastUpdated":1729217313000}'),t={name:"java/middleware/kakfa重复消费问题处理.md"};function s(n,e,r,i,c,m){return l(),o("div",null,e[0]||(e[0]=[p('Kafka知识回顾
1、消费者常见参数
①:fetch.min.bytes,配置Consumer一次拉取请求中能从Kafka中拉取的最小数据量,默认为1B,如果小于这个参数配置的值,就需要进行等待,直到数据量满足这个参数的配置大小。调大可以提交吞吐量,但也会造成延迟
②:fetch.max.bytes,一次拉取数据的最大数据量,默认为52428800B,也就是50M,但是如果设置的值过小,甚至小于每条消息的值,实际上也是能消费成功的
③:fetch.wait.max.ms,若是不满足fetch.min.bytes时,等待消费端请求的最长等待时间,默认是500ms
④:max.poll.records,单次poll调用返回的最大消息记录数,如果处理逻辑很轻量,可以适当提高该值。一次从kafka中poll出来的数据条数,max.poll.records条数据需要在在session.timeout.ms这个时间内处理完,默认值为500
⑤:consumer.poll(100) ,100 毫秒是一个超时时间,一旦拿到足够多的数据(fetch.min.bytes 参数设置),consumer.poll(100)会立即返回 ConsumerRecords<String, String> records。如果没有拿到足够多的数据,会阻塞100ms,但不会超过100ms就会返回
⑥:session. timeout. ms ,默认值是10s,该参数是 Consumer Group 主动检测 (组内成员comsummer)崩溃的时间间隔。若超过这个时间内没有收到心跳报文,则认为此消费者已经下线。将触发再均衡操作
⑦:max.poll.interval.ms,两次拉取消息的间隔,默认5分钟;通过消费组管理消费者时,该配置指定拉取消息线程最长空闲时间,若超过这个时间间隔没有发起poll操作,则消费组认为该消费者已离开了消费组,将进行再均衡操作(将分区分配给组内其他消费者成员)
若超过这个时间则报如下异常:
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.即:无法完成提交,因为组已经重新平衡并将分区分配给另一个成员。这意味着对poll()的后续调用之间的时间比配置的max.poll.interval.ms长,这通常意味着poll循环花费了太多的时间来处理消息。
可以通过增加max.poll.interval.ms来解决这个问题,也可以通过减少在poll()中使用max.poll.records返回的批的最大大小来解决这个问题
2、poll机制
①:每次poll的消息处理完成之后再进行下一次poll,是同步操作
②:每次poll之前检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移
③:每次poll时,consumer都将尝试使用上次消费的offset作为起始offset,然后依次拉取消息
④:poll(long timeout),timeout指等待轮询缓冲区的数据所花费的时间,单位是毫秒
3、再均衡 rebalance
将分区的所有权从一个消费者转移到其他消费者的行为称为再均衡(重平衡,rebalance)。
消费者通过向组织协调者(kafka broker)发送心跳来维护自己是消费者组的一员并确认其拥有的分区。对于不同不的消费群体来说,其组织协调者可以是不同的。只要消费者定期发送心跳,就会认为 消费者是存活的并处理其分区中的消息。当消费者检索记录或者提交它所消费的记录时就会发送心跳。
如果过了一段时间Kafka停止发送心跳了,会话(session)就会过期,组织协调者就会认为这个consumer已经死亡,就会触发一次重平衡。如果消费者宕机并且停止发送消息,组织协调者会等待几秒钟,确认它死亡了才会触发重平衡。在这段时间里,死亡的消费者将不处理任何消息。在清理消费者时,消费者将通知协调者它要离开群组,组织协调者会触发一次重平衡,尽量降低处理停顿。
重平衡是一把双刃剑,它为消费者群组带来高可用性和伸缩性的同时,还有有一些明显的缺点(bug),而这些 bug 到现在社区还无法修改。也就是说,在重平衡期间,消费者组中的消费者实例都会停止消费(Stop The World),等待重平衡的完成。而且重平衡这个过程很慢。
触发再均衡的情况:
①:有新的消费者加入消费组、或已有消费者主动离开组
②:消费者超过session时间未发送心跳(已有 consumer 崩溃了)
③:一次poll()之后的消息处理时间超过了max.poll.interval.ms的配置时间,因为一次poll()处理完才会触发下次poll() (已有 consumer 崩溃了)
④:订阅主题数发生变更
⑤:订阅主题的分区数发生变更
三、重复消费的解决方案
由于网络问题,重复消费不可避免,因此,消费者需要实现消费幂等。
方案:
①:消息表
②:数据库唯一索引
③:缓存消费过的消息id
四、项目kafka重复消费的排查
重复消费问题1:
每次拉取的消息记录数max.poll.records为100,poll最大拉取间隔max.poll.interval.ms为 300s,消息处理过于耗时导致时长大于了这个值,导致再均衡发生重复消费
解决办法:
①:减少每次拉取的消息记录数和增大poll之间的时间间隔
②:拉取到消息之后异步处理(保证成功消费)
最近在支援开发公司的财务对账系统,其中涉及一个功能点是某个对账单创建开票申请后,需要更新对账单的开票申请状态(未申请,部分申请,全部申请),这里使用了kafka,当创建开票申请后生产者即发送一条消息,消费者再去进行消费。
然后就碰到个问题,生产者这里是有事务的,因此会出现事务还没提交,开票申请数据还没有写入到数据库中,但是消息已经发送到kafka了,此时消费者直接消费消息时是查询不到这批开票申请数据的,就会出现创建开票申请业务实际成功了,但是对账单的开票申请状态仍为未申请。所以用了一个笨方法解决这个问题,在消费者线程中sleep(5000),来确保消费到消息时生产者的事务已经提交。
在测试环境测试少量账单&开票申请数据时是完全没有问题的,但是上了生产之后会有批量的账单数据推送过来,创建了大量的开票申请。这时候就发现异常情况了:消息队列中堆积了大量的消息,虽然日志一直还在正常跑,但是offset一直没变,并且过一段时间还会重复消费已经跑过日志的消息。
消费重复消费的根本原因都是:已经消费了数据,但是offset并没有提交。
网上找到的资料里有一段这么写的:
kafka消息重复消费很大一部分原因在于发生了再均衡。
1)消费者宕机、重启等。导致消息已经消费但是没有提交offset。
2)消费者使用自动提交offset,但当还没有提交的时候,有新的消费者加入或者移除,发生了rebalance。再次消费的时候,消费者会根据提交的偏移量来,于是重复消费了数据。
3)消息处理耗时,或者消费者拉取的消息量太多,处理耗时,超过了max.poll.interval.ms的配置时间,导致认为当前消费者已经死掉,触发再均衡。
日志:
This member will leave the group because consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.这里我碰到的情况就是第三种,因为消费者consumer每次拉取的消息较多,且有线程sleep的操作,所以导致处理超时了,超过max.poll.interval.ms的时间就会触发rebalance,然后就会重新分配消费者再次消费上次拉取的那批数据,这就是重复消费的原因。
了解了超时的原因,就好解决了,根据日志中的提示,我们可以调整max.poll.interval.ms和max.poll.records两个参数
max.poll.interval.ms的值,默认值为300000,单位是ms,即5分钟,可以调整为10分钟max.poll.records的值,默认是500,可以调整为100参考资料:
',18)]))}const u=a(t,[["render",s]]);export{h as __pageData,u as default}; diff --git "a/assets/java_middleware_\345\205\263\344\272\216\346\266\210\346\201\257\344\270\255\351\227\264\344\273\266MQ.md.BLbr6QFI.js" "b/assets/java_middleware_\345\205\263\344\272\216\346\266\210\346\201\257\344\270\255\351\227\264\344\273\266MQ.md.BLbr6QFI.js" new file mode 100644 index 00000000..616f7476 --- /dev/null +++ "b/assets/java_middleware_\345\205\263\344\272\216\346\266\210\346\201\257\344\270\255\351\227\264\344\273\266MQ.md.BLbr6QFI.js" @@ -0,0 +1,30 @@ +import{_ as i,c as a,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"关于消息中间件MQ","description":"","frontmatter":{},"headers":[],"relativePath":"java/middleware/关于消息中间件MQ.md","filePath":"java/middleware/关于消息中间件MQ.md","lastUpdated":1729217313000}'),p={name:"java/middleware/关于消息中间件MQ.md"};function h(t,s,e,k,r,d){return l(),a("div",null,s[0]||(s[0]=[n(`Kafka知识回顾
1、消费者常见参数
①:fetch.min.bytes,配置Consumer一次拉取请求中能从Kafka中拉取的最小数据量,默认为1B,如果小于这个参数配置的值,就需要进行等待,直到数据量满足这个参数的配置大小。调大可以提交吞吐量,但也会造成延迟
②:fetch.max.bytes,一次拉取数据的最大数据量,默认为52428800B,也就是50M,但是如果设置的值过小,甚至小于每条消息的值,实际上也是能消费成功的
③:fetch.wait.max.ms,若是不满足fetch.min.bytes时,等待消费端请求的最长等待时间,默认是500ms
④:max.poll.records,单次poll调用返回的最大消息记录数,如果处理逻辑很轻量,可以适当提高该值。一次从kafka中poll出来的数据条数,max.poll.records条数据需要在在session.timeout.ms这个时间内处理完,默认值为500
⑤:consumer.poll(100) ,100 毫秒是一个超时时间,一旦拿到足够多的数据(fetch.min.bytes 参数设置),consumer.poll(100)会立即返回 ConsumerRecords<String, String> records。如果没有拿到足够多的数据,会阻塞100ms,但不会超过100ms就会返回
⑥:session. timeout. ms ,默认值是10s,该参数是 Consumer Group 主动检测 (组内成员comsummer)崩溃的时间间隔。若超过这个时间内没有收到心跳报文,则认为此消费者已经下线。将触发再均衡操作
⑦:max.poll.interval.ms,两次拉取消息的间隔,默认5分钟;通过消费组管理消费者时,该配置指定拉取消息线程最长空闲时间,若超过这个时间间隔没有发起poll操作,则消费组认为该消费者已离开了消费组,将进行再均衡操作(将分区分配给组内其他消费者成员)
若超过这个时间则报如下异常:
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.即:无法完成提交,因为组已经重新平衡并将分区分配给另一个成员。这意味着对poll()的后续调用之间的时间比配置的max.poll.interval.ms长,这通常意味着poll循环花费了太多的时间来处理消息。
可以通过增加max.poll.interval.ms来解决这个问题,也可以通过减少在poll()中使用max.poll.records返回的批的最大大小来解决这个问题
2、poll机制
①:每次poll的消息处理完成之后再进行下一次poll,是同步操作
②:每次poll之前检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移
③:每次poll时,consumer都将尝试使用上次消费的offset作为起始offset,然后依次拉取消息
④:poll(long timeout),timeout指等待轮询缓冲区的数据所花费的时间,单位是毫秒
3、再均衡 rebalance
将分区的所有权从一个消费者转移到其他消费者的行为称为再均衡(重平衡,rebalance)。
消费者通过向组织协调者(kafka broker)发送心跳来维护自己是消费者组的一员并确认其拥有的分区。对于不同不的消费群体来说,其组织协调者可以是不同的。只要消费者定期发送心跳,就会认为 消费者是存活的并处理其分区中的消息。当消费者检索记录或者提交它所消费的记录时就会发送心跳。
如果过了一段时间Kafka停止发送心跳了,会话(session)就会过期,组织协调者就会认为这个consumer已经死亡,就会触发一次重平衡。如果消费者宕机并且停止发送消息,组织协调者会等待几秒钟,确认它死亡了才会触发重平衡。在这段时间里,死亡的消费者将不处理任何消息。在清理消费者时,消费者将通知协调者它要离开群组,组织协调者会触发一次重平衡,尽量降低处理停顿。
重平衡是一把双刃剑,它为消费者群组带来高可用性和伸缩性的同时,还有有一些明显的缺点(bug),而这些 bug 到现在社区还无法修改。也就是说,在重平衡期间,消费者组中的消费者实例都会停止消费(Stop The World),等待重平衡的完成。而且重平衡这个过程很慢。
触发再均衡的情况:
①:有新的消费者加入消费组、或已有消费者主动离开组
②:消费者超过session时间未发送心跳(已有 consumer 崩溃了)
③:一次poll()之后的消息处理时间超过了max.poll.interval.ms的配置时间,因为一次poll()处理完才会触发下次poll() (已有 consumer 崩溃了)
④:订阅主题数发生变更
⑤:订阅主题的分区数发生变更
三、重复消费的解决方案
由于网络问题,重复消费不可避免,因此,消费者需要实现消费幂等。
方案:
①:消息表
②:数据库唯一索引
③:缓存消费过的消息id
四、项目kafka重复消费的排查
重复消费问题1:
每次拉取的消息记录数max.poll.records为100,poll最大拉取间隔max.poll.interval.ms为 300s,消息处理过于耗时导致时长大于了这个值,导致再均衡发生重复消费
解决办法:
①:减少每次拉取的消息记录数和增大poll之间的时间间隔
②:拉取到消息之后异步处理(保证成功消费)
本文以RabbitMQ为例
这个问题也可以理解为MQ的作用,MQ的作用:
优点:
缺点:
系统复杂度提高。需要考虑MQ的各种情况,如消息丢失,重复消费,顺序消费等
一致性问题。如A系统返回了成功的结果,BC系统成功了但D系统失败了
系统可用性问题。如果MQ宕机,可能会导致系统的崩溃
RabbitMQ有三种模式:单机、普通集群、镜像集群
**普通集群:**就是在多台服务器上启动多个rabbitmq实例,但是创建的队列只会放在一个rabbitmq实例中,其他的实例会同步这个队列的元数据。消费的时候如果连接了另一个实例,也会从拥有队列的那个实例获取消息然后返回。
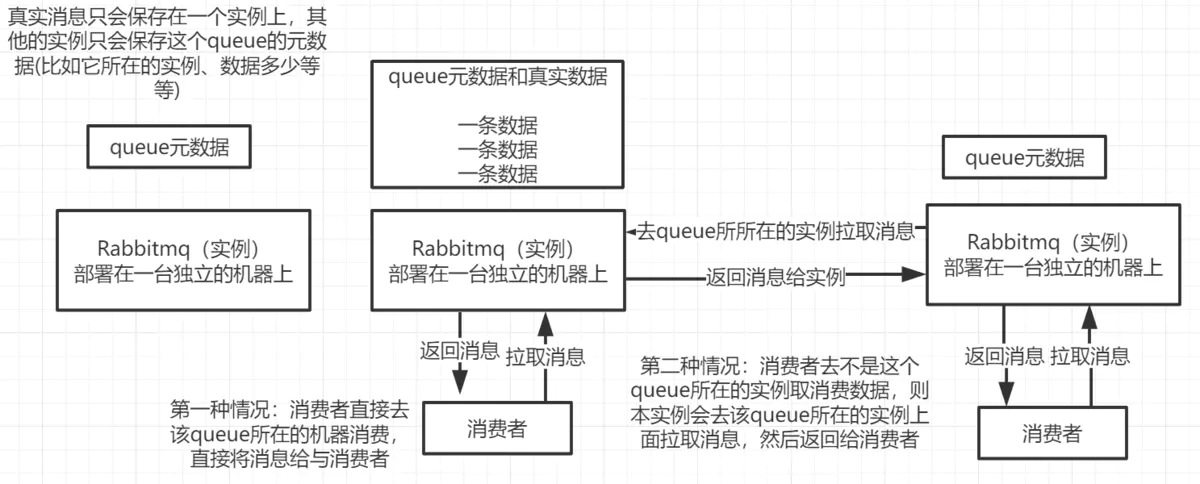
这种方案并不能做到高可用
**镜像集群:**真正的高可用模式,创建的queue无论元数据还是消息数据都存放在多个实例中,每次写消息到queue时,都会自动把消息同步到多个queue中。
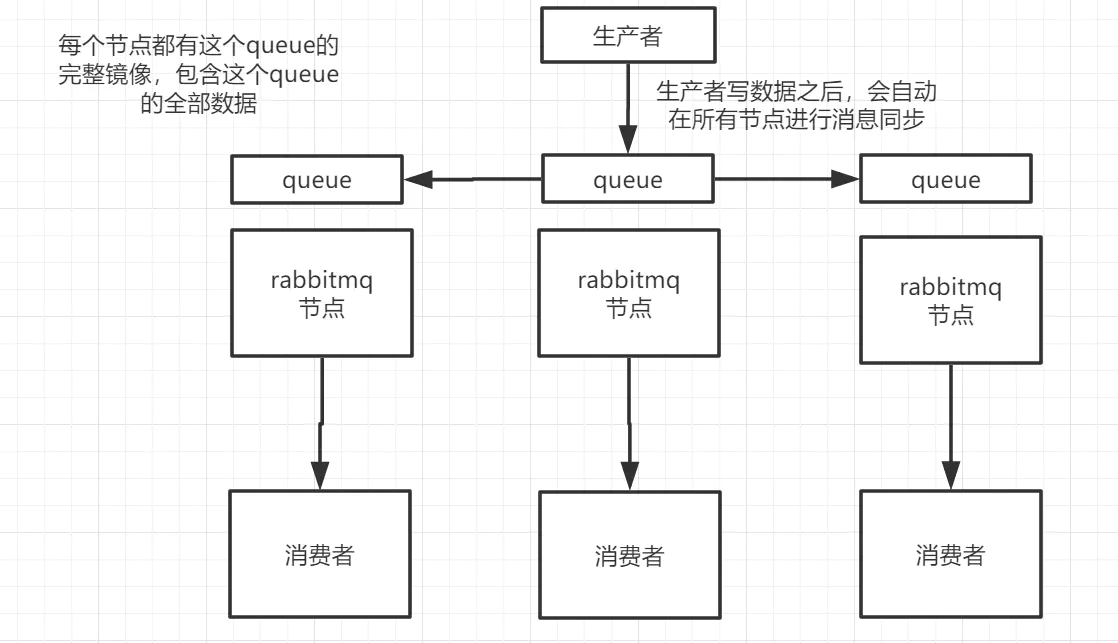
优点:实现了高可用,任何一台机器宕机,其他机器能继续使用
缺点:1、性能消耗较大,所有机器都要进行消息同步 2、没有扩展性,如果有一个queue负载很重,就算增加机器,新增的机器也包含这个queue的全部数据,
保证消费的幂等性,让每条消息带一个全局唯一的bizId,具体过程:
1、消费者获取消息后先根据redis/db是否有该消息
2、如果不存在,则正常消费,消费完毕后写入redis/db
3、如果已经存在,证明已经消费过,直接丢弃
原则:数据不能多也不能少,不能多是指不重复消费,不能少是指不能丢数据
丢失数据场景:
解决方案:
针对生产者丢失数据:
channel.txSelect();
+try{
+ //发送消息
+}catch(Exception e){
+ channel.rollback();
+ //重新发送
+}**缺点:**开启事务会变成阻塞操作,造成生产者的性能和吞吐量的下降
//开启confirm模式
+channel.confirm();
+//发送消息
+
+在生产者服务提供一个回调接口的实现
+
+public void ack(String messageId){
+ //已经收到消息
+}
+
+public void nack(String messageId){
+ //重发消息
+}**针对mq丢失数据:**开启mq的持久化,将交换机/队列的durable设置为true,表示交换机/队列时持久化的,在服务崩溃或重启后无需重新创建
@RabbitListener(
+ bindings = {
+ @QueueBinding(
+ value = @Queue(value = "dynamicQueue", autoDelete = "false", durable = "true"),
+ exchange = @Exchange(value = "exchange", durable = "true", type = ExchangeTypes.DIRECT),
+ key = "routingKey"
+ )
+ }
+)
+public void dynamicQueue(Message message, Channel channel) {
+ System.out.println("接收消息:" + new String(message.getBody()));
+}如果消息想从rabbitmq崩溃中回复,消息必须实现:
针对消费者丢失数据:关闭消费者的autoAck机制,然后每次处理完一条消息,主动发送ack给rabbitmq,如果此时还没发送ack就宕机,mq没有收到ack消息,就会重新将消息重新分配给其他
强制消费者手动确认:
spring.rabbitmq.listener.simple.acknowledge-mode: manual消费者手动ack:
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);一个queue一个consumer
1.先修复consumer的问题,确保恢复消费速度,然后停掉所有consumer
2.临时建立数十倍的queue
3.写一个临时分发的consumer程序,部署上去消费积压的消息,消费不做处理,直接轮询写入上一步建好的queue中
4.重新部署consumer(机器加倍),每一批consumer消费一个临时queue
`,51)]))}const c=i(p,[["render",h]]);export{g as __pageData,c as default}; diff --git "a/assets/java_middleware_\345\205\263\344\272\216\346\266\210\346\201\257\344\270\255\351\227\264\344\273\266MQ.md.BLbr6QFI.lean.js" "b/assets/java_middleware_\345\205\263\344\272\216\346\266\210\346\201\257\344\270\255\351\227\264\344\273\266MQ.md.BLbr6QFI.lean.js" new file mode 100644 index 00000000..616f7476 --- /dev/null +++ "b/assets/java_middleware_\345\205\263\344\272\216\346\266\210\346\201\257\344\270\255\351\227\264\344\273\266MQ.md.BLbr6QFI.lean.js" @@ -0,0 +1,30 @@ +import{_ as i,c as a,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"关于消息中间件MQ","description":"","frontmatter":{},"headers":[],"relativePath":"java/middleware/关于消息中间件MQ.md","filePath":"java/middleware/关于消息中间件MQ.md","lastUpdated":1729217313000}'),p={name:"java/middleware/关于消息中间件MQ.md"};function h(t,s,e,k,r,d){return l(),a("div",null,s[0]||(s[0]=[n(`本文以RabbitMQ为例
这个问题也可以理解为MQ的作用,MQ的作用:
优点:
缺点:
系统复杂度提高。需要考虑MQ的各种情况,如消息丢失,重复消费,顺序消费等
一致性问题。如A系统返回了成功的结果,BC系统成功了但D系统失败了
系统可用性问题。如果MQ宕机,可能会导致系统的崩溃
RabbitMQ有三种模式:单机、普通集群、镜像集群
**普通集群:**就是在多台服务器上启动多个rabbitmq实例,但是创建的队列只会放在一个rabbitmq实例中,其他的实例会同步这个队列的元数据。消费的时候如果连接了另一个实例,也会从拥有队列的那个实例获取消息然后返回。
这种方案并不能做到高可用
**镜像集群:**真正的高可用模式,创建的queue无论元数据还是消息数据都存放在多个实例中,每次写消息到queue时,都会自动把消息同步到多个queue中。
优点:实现了高可用,任何一台机器宕机,其他机器能继续使用
缺点:1、性能消耗较大,所有机器都要进行消息同步 2、没有扩展性,如果有一个queue负载很重,就算增加机器,新增的机器也包含这个queue的全部数据,
保证消费的幂等性,让每条消息带一个全局唯一的bizId,具体过程:
1、消费者获取消息后先根据redis/db是否有该消息
2、如果不存在,则正常消费,消费完毕后写入redis/db
3、如果已经存在,证明已经消费过,直接丢弃
原则:数据不能多也不能少,不能多是指不重复消费,不能少是指不能丢数据
丢失数据场景:
解决方案:
针对生产者丢失数据:
channel.txSelect();
+try{
+ //发送消息
+}catch(Exception e){
+ channel.rollback();
+ //重新发送
+}**缺点:**开启事务会变成阻塞操作,造成生产者的性能和吞吐量的下降
//开启confirm模式
+channel.confirm();
+//发送消息
+
+在生产者服务提供一个回调接口的实现
+
+public void ack(String messageId){
+ //已经收到消息
+}
+
+public void nack(String messageId){
+ //重发消息
+}**针对mq丢失数据:**开启mq的持久化,将交换机/队列的durable设置为true,表示交换机/队列时持久化的,在服务崩溃或重启后无需重新创建
@RabbitListener(
+ bindings = {
+ @QueueBinding(
+ value = @Queue(value = "dynamicQueue", autoDelete = "false", durable = "true"),
+ exchange = @Exchange(value = "exchange", durable = "true", type = ExchangeTypes.DIRECT),
+ key = "routingKey"
+ )
+ }
+)
+public void dynamicQueue(Message message, Channel channel) {
+ System.out.println("接收消息:" + new String(message.getBody()));
+}如果消息想从rabbitmq崩溃中回复,消息必须实现:
针对消费者丢失数据:关闭消费者的autoAck机制,然后每次处理完一条消息,主动发送ack给rabbitmq,如果此时还没发送ack就宕机,mq没有收到ack消息,就会重新将消息重新分配给其他
强制消费者手动确认:
spring.rabbitmq.listener.simple.acknowledge-mode: manual消费者手动ack:
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);一个queue一个consumer
1.先修复consumer的问题,确保恢复消费速度,然后停掉所有consumer
2.临时建立数十倍的queue
3.写一个临时分发的consumer程序,部署上去消费积压的消息,消费不做处理,直接轮询写入上一步建好的queue中
4.重新部署consumer(机器加倍),每一批consumer消费一个临时queue
`,51)]))}const c=i(p,[["render",h]]);export{g as __pageData,c as default}; diff --git "a/assets/java_middleware_\345\210\206\345\270\203\345\274\217\351\224\201\350\247\243\345\206\263\346\226\271\346\241\210.md.DN1P49hz.js" "b/assets/java_middleware_\345\210\206\345\270\203\345\274\217\351\224\201\350\247\243\345\206\263\346\226\271\346\241\210.md.DN1P49hz.js" new file mode 100644 index 00000000..81a4af10 --- /dev/null +++ "b/assets/java_middleware_\345\210\206\345\270\203\345\274\217\351\224\201\350\247\243\345\206\263\346\226\271\346\241\210.md.DN1P49hz.js" @@ -0,0 +1,72 @@ +import{_ as i,c as a,a2 as n,o as h}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"分布式锁解决方案","description":"","frontmatter":{},"headers":[],"relativePath":"java/middleware/分布式锁解决方案.md","filePath":"java/middleware/分布式锁解决方案.md","lastUpdated":1729217313000}'),l={name:"java/middleware/分布式锁解决方案.md"};function k(t,s,p,e,E,r){return h(),a("div",null,s[0]||(s[0]=[n(`在单体应用中,对于并发处理公共资源时例如卖票,减商品库存这类操作,可以简单的加锁实现同步.但当单体应用服务化后,在分布式场景下,简单的加锁操作就无法实现需求了.这时就需要借助第三方组件来达到多进程多线程之间的同步操作.
分布式锁:在分布式环境下,多个程序/线程都需要对某一份(有限份)数据进行修改时,针对程序进行控制,保证在同一时间节点下,只有一个程序/线程对数据进行操作的技术
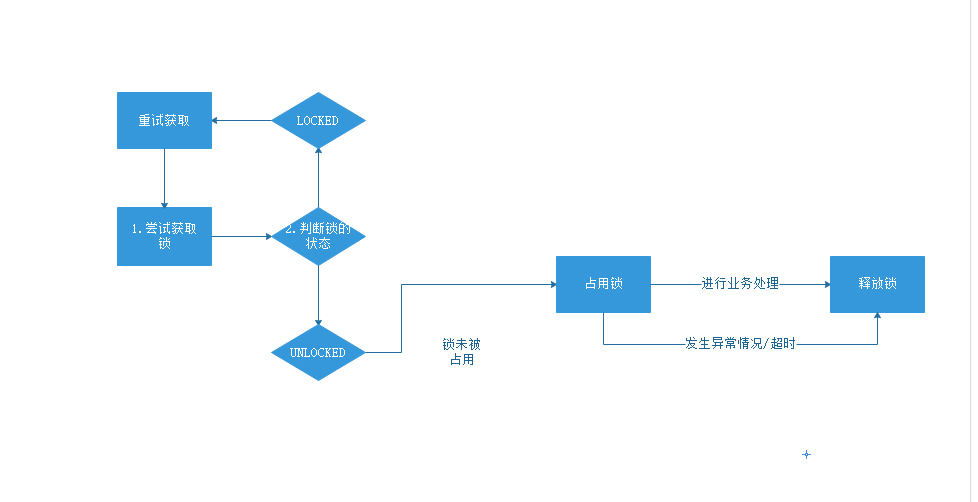
EX NX参数步骤:
1.创建一张表,表中要有唯一索引的字段用于记录当前哪个程序在进行操作
2.程序访问时,将程序的编号insert到这张表中(保证这个编号符合规则可以区分)
3.insert操作成功则代表该程序获得了锁,可以执行业务逻辑
4.当其他相同编号的程序进行insert时,由于唯一索引的限制会失败,则代表获取锁失败
5.当占用锁的程序业务逻辑执行完毕后删除该数据,代表释放锁
以mysql为例的innodb引擎为例,可以使用for update语句来给数据库表加排他锁,当一个线程执行了for update操作给一条记录加锁后,其他线程无法再在该记录上增加排他锁
步骤:
1.开启事务
2.在查询语句后跟for update 例如 select * from tb_goods where id=1 for update
3.成功获取排他锁的线程即获得了分布式锁,可以执行业务逻辑
4.执行完毕后需要commit提交事务来释放锁
==这种方式需要关闭数据库事务的自动提交==
以上两种通过数据库来实现分布式锁的方案比较==简单方便,可以快速实现==,但是基于数据库的操作,开销非常大,对服务的性能存在影响
redis实现分布式锁最核心的方法setnx,setnx的含义就是set if not exists,其中有两个参数setnx(key,value).该方法是原子的,如果key不存在,则设置当前key成功,返回1,如果key已存在,则设置当前key失败,返回0;
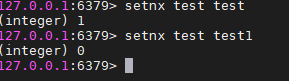
理想情况下,当某个程序抢占了锁后,处理完业务流程应该删除对应的key,如果这个过程中发生了问题,导致锁超时或者出现了异常,没有办法释放锁,就会产生死锁问题.
redis提供的另一个指令EXPIRE,来设置锁的过期时间EXPIRE KEY seconds来设置key的生存时间,如图
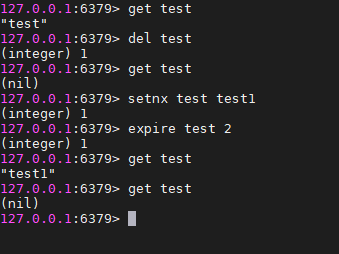
两秒以后key就被自动删除了.
但是程序里我们也不能写成如下的代码
public static void wrongGetLock1(Jedis jedis, String lockKey, String requestId, int expireTime) {
+
+ Long result = jedis.setnx(lockKey, requestId);
+ if (result == 1) {
+ jedis.expire(lockKey, expireTime);
+ doSomething();
+ }
+}因为setnx和expire两个指令是两条命令并不具有原子性,如果在执行setnx后程序突然崩溃,没有设置过期时间就会发生死锁.
在redis2.6.12版本后,又提供了一个新的方案
SET key value [EX seconds] [PX millisecounds] [NX|XX] EX seconds:设置键的过期时间为second秒 PX millisecounds:设置键的过期时间为millisecounds 毫秒 NX:只在键不存在的时候,才对键进行设置操作 XX:只在键已经存在的时候,才对键进行设置操作 SET操作成功后,返回的是OK,失败返回NIL
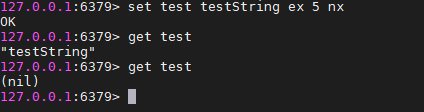
释放锁的时候很容易联想到del指令,可是这个指令如果直接在代码中使用,会产生一个很严重的问题,拥有超时锁的线程会释放掉当前拥有锁的那个线程的锁
(删了不属于自己的锁)
场景:
所以,我们要在set键值对的时候,保证可以区分开当前锁是否属于执行指令的这个线程,value我们可以设置为当前的requestID或线程的id
而这些步骤如果直接用代码控制则会显得较为繁琐,可以引入lua脚本
if redis.call('get', KEYS[1]) == ARGV[1]
+ then
+ return redis.call('del', KEYS[1])
+ else
+ return 0
+end上述lua脚本用于比较KEYS[1]对应的VALUE和ARG[1]的值是否一直,即当前锁是否属于当前线程,如果是true则删除锁,返回del结果,否则直接返回0
执行脚本可以使用redis的eval指令
jedis.eval(String script, List<String> kyes,List<String>args);存在的问题:上面讨论的是单机redis的场景,如果是分布式下的redis哨兵集群会存在问题,如果线程1的锁加在了主库,这时候主库直接宕机,redis还没来得及将这个锁的数据同步至从节点,sentinel就将从库中的一台选举为主库了,这时候另一个线程也来进行加锁,也会成功,这时候便有两个线程同时获得了锁
这种情况可以使用Redisson redlock
javaConfig config = new Config(); +config.useSentinelServers().addSentinelAddress("127.0.0.1:6369","127.0.0.1:6379", "127.0.0.1:6389") + .setMasterName("masterName") + .setPassword("password").setDatabase(0); +RedissonClient redissonClient = Redisson.create(config); +RLock redLock = redissonClient.getLock("REDLOCK_KEY"); +boolean isLock; +try { + isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS); + if (isLock) { + //TODO if get lock success, do something; + } +} catch (Exception e) { +} finally { + redLock.unlock(); +}由于 redisson 包的实现中,通过 lua 脚本校验了解锁时的 client 身份,所以我们无需再在 finally 中去判断是否加锁成功,也无需做额外的身份校验,可以说已经达到开箱即用的程度了。
zookeeper一般有多个节点构成(单数个),采用zab一致性协议,所以可以将zk看成一个单点结构,对其修改数据其内部会自动将所有节点进行修改才提供查询服务
zookeeper的数据是目录树的方式存储的,每个目录称为znode,znode可以存储数据,还可以在其中增加子节点
子节点有三种类型
Watch机制,客户端可以监控每个节点的变化,产生变化时会给客户端产生一个事件
获取锁的流程:
1.先有一个锁根节点,lockRootNode,可以是一个永久节点
2.客户端获取锁,先在lockRootNode下创建一个顺序的临时节点
3.调用lockRootNode节点的getChildren()方法获取所有节点,并从小到大排序,如果创建的最小的节点是当前节点,则返回true,获取锁成功,否则,watch比自己序号小的节点的释放动作(exist watch),这也可以保证每个客户端只需要watch一个节点
4.如果有节点释放操作,重复第3步
代码中可以使用Apache Curator来实现基于临时节点的分布式锁
public class CuratorDistrLockTest {
+
+ /** Zookeeper info */
+ private static final String ZK_ADDRESS = "192.168.1.100:2181";
+ private static final String ZK_LOCK_PATH = "/lockRootNode";
+
+ public static void main(String[] args) throws InterruptedException {
+ // 1.Connect to zk
+ CuratorFramework client = CuratorFrameworkFactory.newClient(
+ ZK_ADDRESS,
+ new RetryNTimes(10, 5000)
+ );
+ client.start();
+ System.out.println("zk client start successfully!");
+
+ Thread t1 = new Thread(() -> {
+ doWithLock(client);
+ }, "t1");
+ Thread t2 = new Thread(() -> {
+ doWithLock(client);
+ }, "t2");
+
+ t1.start();
+ t2.start();
+ }
+
+ private static void doWithLock(CuratorFramework client) {
+ InterProcessMutex lock = new InterProcessMutex(client, ZK_LOCK_PATH);
+ try {
+ if (lock.acquire(10 * 1000, TimeUnit.SECONDS)) {
+ System.out.println(Thread.currentThread().getName() + " hold lock");
+ Thread.sleep(5000L);
+ System.out.println(Thread.currentThread().getName() + " release lock");
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ try {
+ lock.release();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+ }
+}优缺点:
优点:
缺点:
在单体应用中,对于并发处理公共资源时例如卖票,减商品库存这类操作,可以简单的加锁实现同步.但当单体应用服务化后,在分布式场景下,简单的加锁操作就无法实现需求了.这时就需要借助第三方组件来达到多进程多线程之间的同步操作.
分布式锁:在分布式环境下,多个程序/线程都需要对某一份(有限份)数据进行修改时,针对程序进行控制,保证在同一时间节点下,只有一个程序/线程对数据进行操作的技术
EX NX参数步骤:
1.创建一张表,表中要有唯一索引的字段用于记录当前哪个程序在进行操作
2.程序访问时,将程序的编号insert到这张表中(保证这个编号符合规则可以区分)
3.insert操作成功则代表该程序获得了锁,可以执行业务逻辑
4.当其他相同编号的程序进行insert时,由于唯一索引的限制会失败,则代表获取锁失败
5.当占用锁的程序业务逻辑执行完毕后删除该数据,代表释放锁
以mysql为例的innodb引擎为例,可以使用for update语句来给数据库表加排他锁,当一个线程执行了for update操作给一条记录加锁后,其他线程无法再在该记录上增加排他锁
步骤:
1.开启事务
2.在查询语句后跟for update 例如 select * from tb_goods where id=1 for update
3.成功获取排他锁的线程即获得了分布式锁,可以执行业务逻辑
4.执行完毕后需要commit提交事务来释放锁
==这种方式需要关闭数据库事务的自动提交==
以上两种通过数据库来实现分布式锁的方案比较==简单方便,可以快速实现==,但是基于数据库的操作,开销非常大,对服务的性能存在影响
redis实现分布式锁最核心的方法setnx,setnx的含义就是set if not exists,其中有两个参数setnx(key,value).该方法是原子的,如果key不存在,则设置当前key成功,返回1,如果key已存在,则设置当前key失败,返回0;
理想情况下,当某个程序抢占了锁后,处理完业务流程应该删除对应的key,如果这个过程中发生了问题,导致锁超时或者出现了异常,没有办法释放锁,就会产生死锁问题.
redis提供的另一个指令EXPIRE,来设置锁的过期时间EXPIRE KEY seconds来设置key的生存时间,如图
两秒以后key就被自动删除了.
但是程序里我们也不能写成如下的代码
public static void wrongGetLock1(Jedis jedis, String lockKey, String requestId, int expireTime) {
+
+ Long result = jedis.setnx(lockKey, requestId);
+ if (result == 1) {
+ jedis.expire(lockKey, expireTime);
+ doSomething();
+ }
+}因为setnx和expire两个指令是两条命令并不具有原子性,如果在执行setnx后程序突然崩溃,没有设置过期时间就会发生死锁.
在redis2.6.12版本后,又提供了一个新的方案
SET key value [EX seconds] [PX millisecounds] [NX|XX] EX seconds:设置键的过期时间为second秒 PX millisecounds:设置键的过期时间为millisecounds 毫秒 NX:只在键不存在的时候,才对键进行设置操作 XX:只在键已经存在的时候,才对键进行设置操作 SET操作成功后,返回的是OK,失败返回NIL
释放锁的时候很容易联想到del指令,可是这个指令如果直接在代码中使用,会产生一个很严重的问题,拥有超时锁的线程会释放掉当前拥有锁的那个线程的锁
(删了不属于自己的锁)
场景:
所以,我们要在set键值对的时候,保证可以区分开当前锁是否属于执行指令的这个线程,value我们可以设置为当前的requestID或线程的id
而这些步骤如果直接用代码控制则会显得较为繁琐,可以引入lua脚本
if redis.call('get', KEYS[1]) == ARGV[1]
+ then
+ return redis.call('del', KEYS[1])
+ else
+ return 0
+end上述lua脚本用于比较KEYS[1]对应的VALUE和ARG[1]的值是否一直,即当前锁是否属于当前线程,如果是true则删除锁,返回del结果,否则直接返回0
执行脚本可以使用redis的eval指令
jedis.eval(String script, List<String> kyes,List<String>args);存在的问题:上面讨论的是单机redis的场景,如果是分布式下的redis哨兵集群会存在问题,如果线程1的锁加在了主库,这时候主库直接宕机,redis还没来得及将这个锁的数据同步至从节点,sentinel就将从库中的一台选举为主库了,这时候另一个线程也来进行加锁,也会成功,这时候便有两个线程同时获得了锁
这种情况可以使用Redisson redlock
javaConfig config = new Config(); +config.useSentinelServers().addSentinelAddress("127.0.0.1:6369","127.0.0.1:6379", "127.0.0.1:6389") + .setMasterName("masterName") + .setPassword("password").setDatabase(0); +RedissonClient redissonClient = Redisson.create(config); +RLock redLock = redissonClient.getLock("REDLOCK_KEY"); +boolean isLock; +try { + isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS); + if (isLock) { + //TODO if get lock success, do something; + } +} catch (Exception e) { +} finally { + redLock.unlock(); +}由于 redisson 包的实现中,通过 lua 脚本校验了解锁时的 client 身份,所以我们无需再在 finally 中去判断是否加锁成功,也无需做额外的身份校验,可以说已经达到开箱即用的程度了。
zookeeper一般有多个节点构成(单数个),采用zab一致性协议,所以可以将zk看成一个单点结构,对其修改数据其内部会自动将所有节点进行修改才提供查询服务
zookeeper的数据是目录树的方式存储的,每个目录称为znode,znode可以存储数据,还可以在其中增加子节点
子节点有三种类型
Watch机制,客户端可以监控每个节点的变化,产生变化时会给客户端产生一个事件
获取锁的流程:
1.先有一个锁根节点,lockRootNode,可以是一个永久节点
2.客户端获取锁,先在lockRootNode下创建一个顺序的临时节点
3.调用lockRootNode节点的getChildren()方法获取所有节点,并从小到大排序,如果创建的最小的节点是当前节点,则返回true,获取锁成功,否则,watch比自己序号小的节点的释放动作(exist watch),这也可以保证每个客户端只需要watch一个节点
4.如果有节点释放操作,重复第3步
代码中可以使用Apache Curator来实现基于临时节点的分布式锁
public class CuratorDistrLockTest {
+
+ /** Zookeeper info */
+ private static final String ZK_ADDRESS = "192.168.1.100:2181";
+ private static final String ZK_LOCK_PATH = "/lockRootNode";
+
+ public static void main(String[] args) throws InterruptedException {
+ // 1.Connect to zk
+ CuratorFramework client = CuratorFrameworkFactory.newClient(
+ ZK_ADDRESS,
+ new RetryNTimes(10, 5000)
+ );
+ client.start();
+ System.out.println("zk client start successfully!");
+
+ Thread t1 = new Thread(() -> {
+ doWithLock(client);
+ }, "t1");
+ Thread t2 = new Thread(() -> {
+ doWithLock(client);
+ }, "t2");
+
+ t1.start();
+ t2.start();
+ }
+
+ private static void doWithLock(CuratorFramework client) {
+ InterProcessMutex lock = new InterProcessMutex(client, ZK_LOCK_PATH);
+ try {
+ if (lock.acquire(10 * 1000, TimeUnit.SECONDS)) {
+ System.out.println(Thread.currentThread().getName() + " hold lock");
+ Thread.sleep(5000L);
+ System.out.println(Thread.currentThread().getName() + " release lock");
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ try {
+ lock.release();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+ }
+}优缺点:
优点:
缺点:
前几天做一个大批量数据异步的导入,采用的是之前用过的事件模式处理,大致流程是用户上传excel文件后,主线程对excel表头进行校验,如果通过校验,则开辟子线程进行业务处理,主线程返回响应.
整个导入流程和原来做的没什么区别,就是这次整个业务流程都放在子线程中进行处理,原来做的那个导入是只是主线程读数据,读到设定的阈值时则新开线程进行数据的持久化.
之前的那个系统做的功能是没有什么问题的,只是前台需要等待主线程读取完数据,后台在异步的分批插入数据到db,主线程读取数据这个过程前端页面一直在loading,体验不是很好. 这次为了优化用户体验,整个读取和业务流程操作都放在子线程中,并且新增了进度条展示,但是出现了标题的Zip File is closed异常,但不能完全重现,时而出现,时而正常.完整堆栈信息如下:
Exception in thread "main" java.lang.IllegalStateException: Zip File is closed
+ at org.apache.poi.openxml4j.util.ZipFileZipEntrySource.getEntries(ZipFileZipEntrySource.java:45)
+ at org.apache.poi.openxml4j.opc.ZipPackage.getPartsImpl(ZipPackage.java:161)
+ at org.apache.poi.openxml4j.opc.OPCPackage.getParts(OPCPackage.java:662)
+ at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:223)
+ at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:186)
+ at com.test.util.POIEventModeHandler.handleExcel(POIEventModeHandler.java:482)
+ at com.test.util.Test.main(Test.java:20)追踪源码后发现,出现这个异常时,读取的zipentry为null,简单点说就是读了个不存在的文件.
然后我才想起来项目里文件上传有个对应的拦截器,请求过来之后,拦截器会把前台传的文件先保存在服务器的临时目录中,我们的controller里拿到的文件路径封装的是服务器上的临时文件目录,而不是前台那个MultipartFile的,在controller响应的时候,这个拦截器又把临时文件删除了.所以我这个问题就是线程执行的随机性导致的,正常的时候先执行了子线程中读取临时文件的方法,此时再切换到主线程返回响应时,拦截器无法删除这个文件,而如果一直先执行的是主线程,拦截器会先把文件删掉,这个时候子线程执行open那个临时文件就会出现zip file is closed的异常.
由于拦截器是公用的,而且原来的逻辑是响应后删除临时文件避免服务器磁盘占用,所以处理方案就是主线程在新建子线程任务之前把这个临时文件再copy一份让子线程去读取这个copy,子线程的finally中再把这个copy的文件删除即可.
前几天做一个大批量数据异步的导入,采用的是之前用过的事件模式处理,大致流程是用户上传excel文件后,主线程对excel表头进行校验,如果通过校验,则开辟子线程进行业务处理,主线程返回响应.
整个导入流程和原来做的没什么区别,就是这次整个业务流程都放在子线程中进行处理,原来做的那个导入是只是主线程读数据,读到设定的阈值时则新开线程进行数据的持久化.
之前的那个系统做的功能是没有什么问题的,只是前台需要等待主线程读取完数据,后台在异步的分批插入数据到db,主线程读取数据这个过程前端页面一直在loading,体验不是很好. 这次为了优化用户体验,整个读取和业务流程操作都放在子线程中,并且新增了进度条展示,但是出现了标题的Zip File is closed异常,但不能完全重现,时而出现,时而正常.完整堆栈信息如下:
Exception in thread "main" java.lang.IllegalStateException: Zip File is closed
+ at org.apache.poi.openxml4j.util.ZipFileZipEntrySource.getEntries(ZipFileZipEntrySource.java:45)
+ at org.apache.poi.openxml4j.opc.ZipPackage.getPartsImpl(ZipPackage.java:161)
+ at org.apache.poi.openxml4j.opc.OPCPackage.getParts(OPCPackage.java:662)
+ at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:223)
+ at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:186)
+ at com.test.util.POIEventModeHandler.handleExcel(POIEventModeHandler.java:482)
+ at com.test.util.Test.main(Test.java:20)追踪源码后发现,出现这个异常时,读取的zipentry为null,简单点说就是读了个不存在的文件.
然后我才想起来项目里文件上传有个对应的拦截器,请求过来之后,拦截器会把前台传的文件先保存在服务器的临时目录中,我们的controller里拿到的文件路径封装的是服务器上的临时文件目录,而不是前台那个MultipartFile的,在controller响应的时候,这个拦截器又把临时文件删除了.所以我这个问题就是线程执行的随机性导致的,正常的时候先执行了子线程中读取临时文件的方法,此时再切换到主线程返回响应时,拦截器无法删除这个文件,而如果一直先执行的是主线程,拦截器会先把文件删掉,这个时候子线程执行open那个临时文件就会出现zip file is closed的异常.
由于拦截器是公用的,而且原来的逻辑是响应后删除临时文件避免服务器磁盘占用,所以处理方案就是主线程在新建子线程任务之前把这个临时文件再copy一份让子线程去读取这个copy,子线程的finally中再把这个copy的文件删除即可.
1.top命令找出cpu占用率高的进程pid
2.top -H -p pid 找出cpu占用率高的线程tid
3.printf "%x" tid命令打印出tid的十六进制形式
4.jstack pid | grep 十六进制tid -A 行数打印堆栈信息 或者 jstack pid >> log.txt将堆栈信息保存在文件中,再从文件中查找对应线程的信息
5.jstat -gcutil pid 5000 每隔5秒打印一次gc情况
S0:幸存1区当前使用比例
+S1:幸存2区当前使用比例
+E:伊甸园区使用比例
+O:老年代使用比例
+M:元数据区使用比例
+CCS:压缩使用比例
+YGC:年轻代垃圾回收次数
+FGC:老年代垃圾回收次数
+FGCT:老年代垃圾回收消耗时间
+GCT:垃圾回收消耗总时间6.jmap -heap pid 查看堆内存详细信息
7.jmap -histo pid > xxx.log 输出gc日志到文件
1.top命令找出cpu占用率高的进程pid
2.top -H -p pid 找出cpu占用率高的线程tid
3.printf "%x" tid命令打印出tid的十六进制形式
4.jstack pid | grep 十六进制tid -A 行数打印堆栈信息 或者 jstack pid >> log.txt将堆栈信息保存在文件中,再从文件中查找对应线程的信息
5.jstat -gcutil pid 5000 每隔5秒打印一次gc情况
S0:幸存1区当前使用比例
+S1:幸存2区当前使用比例
+E:伊甸园区使用比例
+O:老年代使用比例
+M:元数据区使用比例
+CCS:压缩使用比例
+YGC:年轻代垃圾回收次数
+FGC:老年代垃圾回收次数
+FGCT:老年代垃圾回收消耗时间
+GCT:垃圾回收消耗总时间6.jmap -heap pid 查看堆内存详细信息
7.jmap -histo pid > xxx.log 输出gc日志到文件
有个功能需要做ip的判断,区分请求是来自用户端还是来自其他服务的feign调用,其中有个一个服务发起的feign调用,一直无法获取到真实的服务器ip,而一直是用户端的ip。
public static String getIpAddr(HttpServletRequest request) {
+ String ipAddress = request.getHeader("x-forwarded-for");
+ if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
+ ipAddress = request.getHeader("Proxy-Client-IP");
+ }
+ if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
+ ipAddress = request.getHeader("WL-Proxy-Client-IP");
+ }
+ if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
+ ipAddress = request.getRemoteAddr();
+ if (ipAddress.equals("127.0.0.1") || ipAddress.equals("0:0:0:0:0:0:0:1")) {
+ //根据网卡取本机配置的IP
+ InetAddress inet = null;
+ try {
+ inet = InetAddress.getLocalHost();
+ } catch (UnknownHostException e) {
+ e.printStackTrace();
+ }
+ ipAddress = inet.getHostAddress();
+ }
+ }
+ //对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
+ if (ipAddress != null && ipAddress.length() > 15) { //"***.***.***.***".length() = 15
+ if (ipAddress.indexOf(",") > 0) {
+ ipAddress = ipAddress.substring(0, ipAddress.indexOf(","));
+ }
+ }
+ return ipAddress;
+ }@Bean
+ public Feign.Builder feignBuilder() {
+ return Feign.builder().requestInterceptor(new RequestInterceptor() {
+ @Override
+ public void apply(RequestTemplate requestTemplate) {
+ Map<String, String> customHeaders = WebUtils.getCustomHeaders();
+ customHeaders.forEach((k, v) -> {
+ requestTemplate.header(k, v);
+ });
+ }
+ });
+ }
+
+---
+
+public static Map<String, String> getCustomHeaders() {
+ Map<String, String> headers = new HashMap();
+ HttpServletRequest request = RequestContextHelper.getRequest();
+ Enumeration<String> headerNames = request.getHeaderNames();
+
+ while(headerNames.hasMoreElements()) {
+ String headerName = ((String)headerNames.nextElement()).toLowerCase();
+ if (headerName.startsWith("x-")) {
+ String headerValue = request.getHeader(headerName);
+ if (headerValue != null) {
+ headers.put(headerName, headerValue);
+ }
+ }
+ }
+
+ headers.put("x-invoker-ip", IpUtils.getLocalIpAddr());
+ if (!headers.containsKey("x-auth-token")) {
+ headers.put("x-auth-token", TokenGenerator.generateWithSign());
+ }
+
+ return headers;
+ }至此,问题解决,x-forwarded-for被放在了feign请求头中,导致了上述问题,这里把x-forwarded-for请求头排除即可。
分析:
请求流程: 用户->nginx->网关服务->a服务->feign调用->b服务
用户的请求通过nignx后代理ip就会被添加到x-forwarded-for请求头中,此时x-forwarded-for请求头为:用户ip,nginx服务器的ip,后请求从网关路由到a服务,a服务通过feign.buider的添加拦截器方法,增加了一个添加指定请求头到feign的请求中的拦截器,导致原来的x-forwarded-for被原封不动的传到了b服务,b服务根据这个请求头获取ip时,就拿到了原始用户的ip。
有个功能需要做ip的判断,区分请求是来自用户端还是来自其他服务的feign调用,其中有个一个服务发起的feign调用,一直无法获取到真实的服务器ip,而一直是用户端的ip。
public static String getIpAddr(HttpServletRequest request) {
+ String ipAddress = request.getHeader("x-forwarded-for");
+ if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
+ ipAddress = request.getHeader("Proxy-Client-IP");
+ }
+ if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
+ ipAddress = request.getHeader("WL-Proxy-Client-IP");
+ }
+ if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
+ ipAddress = request.getRemoteAddr();
+ if (ipAddress.equals("127.0.0.1") || ipAddress.equals("0:0:0:0:0:0:0:1")) {
+ //根据网卡取本机配置的IP
+ InetAddress inet = null;
+ try {
+ inet = InetAddress.getLocalHost();
+ } catch (UnknownHostException e) {
+ e.printStackTrace();
+ }
+ ipAddress = inet.getHostAddress();
+ }
+ }
+ //对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
+ if (ipAddress != null && ipAddress.length() > 15) { //"***.***.***.***".length() = 15
+ if (ipAddress.indexOf(",") > 0) {
+ ipAddress = ipAddress.substring(0, ipAddress.indexOf(","));
+ }
+ }
+ return ipAddress;
+ }@Bean
+ public Feign.Builder feignBuilder() {
+ return Feign.builder().requestInterceptor(new RequestInterceptor() {
+ @Override
+ public void apply(RequestTemplate requestTemplate) {
+ Map<String, String> customHeaders = WebUtils.getCustomHeaders();
+ customHeaders.forEach((k, v) -> {
+ requestTemplate.header(k, v);
+ });
+ }
+ });
+ }
+
+---
+
+public static Map<String, String> getCustomHeaders() {
+ Map<String, String> headers = new HashMap();
+ HttpServletRequest request = RequestContextHelper.getRequest();
+ Enumeration<String> headerNames = request.getHeaderNames();
+
+ while(headerNames.hasMoreElements()) {
+ String headerName = ((String)headerNames.nextElement()).toLowerCase();
+ if (headerName.startsWith("x-")) {
+ String headerValue = request.getHeader(headerName);
+ if (headerValue != null) {
+ headers.put(headerName, headerValue);
+ }
+ }
+ }
+
+ headers.put("x-invoker-ip", IpUtils.getLocalIpAddr());
+ if (!headers.containsKey("x-auth-token")) {
+ headers.put("x-auth-token", TokenGenerator.generateWithSign());
+ }
+
+ return headers;
+ }至此,问题解决,x-forwarded-for被放在了feign请求头中,导致了上述问题,这里把x-forwarded-for请求头排除即可。
分析:
请求流程: 用户->nginx->网关服务->a服务->feign调用->b服务
用户的请求通过nignx后代理ip就会被添加到x-forwarded-for请求头中,此时x-forwarded-for请求头为:用户ip,nginx服务器的ip,后请求从网关路由到a服务,a服务通过feign.buider的添加拦截器方法,增加了一个添加指定请求头到feign的请求中的拦截器,导致原来的x-forwarded-for被原封不动的传到了b服务,b服务根据这个请求头获取ip时,就拿到了原始用户的ip。
最近公司项目需要做一个在线预览Office文件的功能,尝试了使用OpenOffice把Office文档转化成PDF格式和HTML格式的文件再由前端解析PDF或者直接通过iFrame访问HTML文件的方案,windows系统直接下载安装后cmd运行命令就可以启动openoffice的服务了.服务器就稍微麻烦一点,本文记录了我在自己的阿里云服务器上安装OpenOffice遇到的坑和解决的办法. 解压安装OpenOffice,这个网上搜一下有很多,不再详细记录.可以参考 linux环境下安装 openOffice 并启动服务
yum install openjdk 1.8重新配置了JAVA_HOME后解决了这个报错yum install libXext.X86_64. 这个是64位linux的版本,32位的系统需要改成对应的版本yum groupinstall "X Window System",我在运行这个命令的时候,又碰到了另一个报错:no packages in any requested group available to install or update, 这里命令后面要加上一些参数,执行yum groupinstall "X Window System" --setoptgroup_package_type=mandatory.default.optional解决报错后,再重新执行启动服务的命令 nohup ./soffice -headless -accept="socket,host=127.0.0.1,port=8100;urp;" -nofirststartwizard &
执行后可以使用netstat命令查看8100端口的占用情况net stat -lnp|grep 8100 可以看到soffice.bin就说明服务成功启动了
然后启动测试的demo后发现,office文件转换成PDF后中文出现乱码,这是因为服务器上没有中文字体,用ftp工具把windows的中文字体直接传到服务器上的/usr/share/fonts文件夹中,清除缓存后重新启动openoffice服务后就能正确显示中文了.
',8)]))}const O=o(n,[["render",r]]);export{u as __pageData,O as default}; diff --git "a/assets/java_others_linux\346\234\215\345\212\241\345\231\250\345\256\211\350\243\205OpenOffice\350\270\251\345\235\221.md.B-zHeOTT.lean.js" "b/assets/java_others_linux\346\234\215\345\212\241\345\231\250\345\256\211\350\243\205OpenOffice\350\270\251\345\235\221.md.B-zHeOTT.lean.js" new file mode 100644 index 00000000..32ff1299 --- /dev/null +++ "b/assets/java_others_linux\346\234\215\345\212\241\345\231\250\345\256\211\350\243\205OpenOffice\350\270\251\345\235\221.md.B-zHeOTT.lean.js" @@ -0,0 +1 @@ +import{_ as o,c as t,a2 as a,o as i}from"./chunks/framework.BjcrtTwI.js";const u=JSON.parse('{"title":"linux服务器安装OpenOffice踩坑","description":"","frontmatter":{},"headers":[],"relativePath":"java/others/linux服务器安装OpenOffice踩坑.md","filePath":"java/others/linux服务器安装OpenOffice踩坑.md","lastUpdated":1729217313000}'),n={name:"java/others/linux服务器安装OpenOffice踩坑.md"};function r(l,e,f,c,p,s){return i(),t("div",null,e[0]||(e[0]=[a('最近公司项目需要做一个在线预览Office文件的功能,尝试了使用OpenOffice把Office文档转化成PDF格式和HTML格式的文件再由前端解析PDF或者直接通过iFrame访问HTML文件的方案,windows系统直接下载安装后cmd运行命令就可以启动openoffice的服务了.服务器就稍微麻烦一点,本文记录了我在自己的阿里云服务器上安装OpenOffice遇到的坑和解决的办法. 解压安装OpenOffice,这个网上搜一下有很多,不再详细记录.可以参考 linux环境下安装 openOffice 并启动服务
yum install openjdk 1.8重新配置了JAVA_HOME后解决了这个报错yum install libXext.X86_64. 这个是64位linux的版本,32位的系统需要改成对应的版本yum groupinstall "X Window System",我在运行这个命令的时候,又碰到了另一个报错:no packages in any requested group available to install or update, 这里命令后面要加上一些参数,执行yum groupinstall "X Window System" --setoptgroup_package_type=mandatory.default.optional解决报错后,再重新执行启动服务的命令 nohup ./soffice -headless -accept="socket,host=127.0.0.1,port=8100;urp;" -nofirststartwizard &
执行后可以使用netstat命令查看8100端口的占用情况net stat -lnp|grep 8100 可以看到soffice.bin就说明服务成功启动了
然后启动测试的demo后发现,office文件转换成PDF后中文出现乱码,这是因为服务器上没有中文字体,用ftp工具把windows的中文字体直接传到服务器上的/usr/share/fonts文件夹中,清除缓存后重新启动openoffice服务后就能正确显示中文了.
',8)]))}const O=o(n,[["render",r]]);export{u as __pageData,O as default}; diff --git "a/assets/java_others_mybatis\347\232\204classpath\351\205\215\347\275\256\345\257\274\350\207\264\347\232\204jar\345\214\205\350\257\273\345\217\226\351\227\256\351\242\230.md.NR2hJvkt.js" "b/assets/java_others_mybatis\347\232\204classpath\351\205\215\347\275\256\345\257\274\350\207\264\347\232\204jar\345\214\205\350\257\273\345\217\226\351\227\256\351\242\230.md.NR2hJvkt.js" new file mode 100644 index 00000000..a1047d7f --- /dev/null +++ "b/assets/java_others_mybatis\347\232\204classpath\351\205\215\347\275\256\345\257\274\350\207\264\347\232\204jar\345\214\205\350\257\273\345\217\226\351\227\256\351\242\230.md.NR2hJvkt.js" @@ -0,0 +1 @@ +import{_ as s,c as t,a2 as e,o as c}from"./chunks/framework.BjcrtTwI.js";const _=JSON.parse('{"title":"mybatis的classpath配置导致的jar包读取问题","description":"","frontmatter":{},"headers":[],"relativePath":"java/others/mybatis的classpath配置导致的jar包读取问题.md","filePath":"java/others/mybatis的classpath配置导致的jar包读取问题.md","lastUpdated":1729217313000}'),r={name:"java/others/mybatis的classpath配置导致的jar包读取问题.md"};function p(l,a,o,i,h,d){return c(),t("div",null,a[0]||(a[0]=[e('今天同事碰到个问题,在服务中引入了另一个服务的mapper文件后找不到其中配置的resultMap引发报错。后经排查是因为配置文件中classpath的配置问题引起的。
classpath:: 只会从当前服务的class目录下寻找文件
classpath*:: 会从class目录下寻找文件,还会从引入的依赖(打包后lib文件夹中的jar包)中寻找文件
所以当把mybatis的classpath配置从classpath:改为classpath*:后问题能解决了
今天同事碰到个问题,在服务中引入了另一个服务的mapper文件后找不到其中配置的resultMap引发报错。后经排查是因为配置文件中classpath的配置问题引起的。
classpath:: 只会从当前服务的class目录下寻找文件
classpath*:: 会从class目录下寻找文件,还会从引入的依赖(打包后lib文件夹中的jar包)中寻找文件
所以当把mybatis的classpath配置从classpath:改为classpath*:后问题能解决了
ribbon有个参数可以用来调整刷新server list的时间间隔参数。
ribbon-loadbalancer-2.2.0-sources.jar!/com/netflix/client/config/CommonClientConfigKey.java
public static final IClientConfigKey<Integer> ServerListRefreshInterval = new CommonClientConfigKey<Integer>("ServerListRefreshInterval"){};ribbon-loadbalancer-2.2.0-sources.jar!/com/netflix/loadbalancer/PollingServerListUpdater.java
private static long getRefreshIntervalMs(IClientConfig clientConfig) {
+ return clientConfig.get(CommonClientConfigKey.ServerListRefreshInterval, LISTOFSERVERS_CACHE_REPEAT_INTERVAL);
+ }
+
+ @Override
+ public synchronized void start(final UpdateAction updateAction) {
+ if (isActive.compareAndSet(false, true)) {
+ final Runnable wrapperRunnable = new Runnable() {
+ @Override
+ public void run() {
+ if (!isActive.get()) {
+ if (scheduledFuture != null) {
+ scheduledFuture.cancel(true);
+ }
+ return;
+ }
+ try {
+ updateAction.doUpdate();
+ lastUpdated = System.currentTimeMillis();
+ } catch (Exception e) {
+ logger.warn("Failed one update cycle", e);
+ }
+ }
+ };
+
+ scheduledFuture = getRefreshExecutor().scheduleWithFixedDelay(
+ wrapperRunnable,
+ initialDelayMs,
+ refreshIntervalMs,
+ TimeUnit.MILLISECONDS
+ );
+ } else {
+ logger.info("Already active, no-op");
+ }
+ }可以看到有个定时线程,每隔一定时间会去刷新服务的列表,因此,这个时间不要改的太长,默认应该是30s,公司的测试环境不知道是哪位大佬出于什么考虑改的,我反正已经改回去了 = =.
公司用canal主要是因为有新旧两个系统,两个系统同时在运转,目前还没有完全迁移,因此用canal保证新旧系统数据的一致性,这次主要是修复一个楼层信息不同步的bug,问题是更新的时候有个状态字段被写死了,没有用kafka里消息体里的数据更新,这个小问题上周就修复了,自测通过了的,这周测试复测结果发现什么操作都同步不了.这使我一度陷入了自我怀疑.... 然后去看监控的服务日志,发现确实是什么数据库的变更都检测不到了,因为不熟悉这套东西,看了半天也没看出来问题,只能求助我们头儿,然后据他说这个问题经常出现,然后就删了canal实例里面的meta.bat文件,然后运行./restart.sh,重启之后果然恢复正常了,具体啥原因我还没搞懂,日后研究明白了再补充
后续:canal提供了tsdb时序数据库,上次碰到的canal报错问题,是因为监控表的元数据跟现有数据不一致导致的,tsdb中会记录所有对监控的表的操作记录,但是有一张表加了两个字段(57+2)后,这两条alter语句不知道什么情况没有被记录到tsdb的history表中,导致监控到的表的列数不匹配,canal认为还是57列,实际为59,由于是测试环境,所以直接把这张表copy了一份然后把原表删了,再把copy的表改个名字就ok了
`,12)]))}const c=i(h,[["render",t]]);export{g as __pageData,c as default}; diff --git "a/assets/java_others_ribbon\345\210\267\346\226\260\346\234\215\345\212\241\345\210\227\350\241\250\351\227\264\351\232\224\345\222\214canal\347\232\204\345\235\221.md.B7WtS0xJ.lean.js" "b/assets/java_others_ribbon\345\210\267\346\226\260\346\234\215\345\212\241\345\210\227\350\241\250\351\227\264\351\232\224\345\222\214canal\347\232\204\345\235\221.md.B7WtS0xJ.lean.js" new file mode 100644 index 00000000..05e00123 --- /dev/null +++ "b/assets/java_others_ribbon\345\210\267\346\226\260\346\234\215\345\212\241\345\210\227\350\241\250\351\227\264\351\232\224\345\222\214canal\347\232\204\345\235\221.md.B7WtS0xJ.lean.js" @@ -0,0 +1,35 @@ +import{_ as i,c as a,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"ribbon刷新服务列表间隔和canal的坑","description":"","frontmatter":{},"headers":[],"relativePath":"java/others/ribbon刷新服务列表间隔和canal的坑.md","filePath":"java/others/ribbon刷新服务列表间隔和canal的坑.md","lastUpdated":1729217313000}'),h={name:"java/others/ribbon刷新服务列表间隔和canal的坑.md"};function t(e,s,p,k,r,E){return l(),a("div",null,s[0]||(s[0]=[n(`ribbon有个参数可以用来调整刷新server list的时间间隔参数。
ribbon-loadbalancer-2.2.0-sources.jar!/com/netflix/client/config/CommonClientConfigKey.java
public static final IClientConfigKey<Integer> ServerListRefreshInterval = new CommonClientConfigKey<Integer>("ServerListRefreshInterval"){};ribbon-loadbalancer-2.2.0-sources.jar!/com/netflix/loadbalancer/PollingServerListUpdater.java
private static long getRefreshIntervalMs(IClientConfig clientConfig) {
+ return clientConfig.get(CommonClientConfigKey.ServerListRefreshInterval, LISTOFSERVERS_CACHE_REPEAT_INTERVAL);
+ }
+
+ @Override
+ public synchronized void start(final UpdateAction updateAction) {
+ if (isActive.compareAndSet(false, true)) {
+ final Runnable wrapperRunnable = new Runnable() {
+ @Override
+ public void run() {
+ if (!isActive.get()) {
+ if (scheduledFuture != null) {
+ scheduledFuture.cancel(true);
+ }
+ return;
+ }
+ try {
+ updateAction.doUpdate();
+ lastUpdated = System.currentTimeMillis();
+ } catch (Exception e) {
+ logger.warn("Failed one update cycle", e);
+ }
+ }
+ };
+
+ scheduledFuture = getRefreshExecutor().scheduleWithFixedDelay(
+ wrapperRunnable,
+ initialDelayMs,
+ refreshIntervalMs,
+ TimeUnit.MILLISECONDS
+ );
+ } else {
+ logger.info("Already active, no-op");
+ }
+ }可以看到有个定时线程,每隔一定时间会去刷新服务的列表,因此,这个时间不要改的太长,默认应该是30s,公司的测试环境不知道是哪位大佬出于什么考虑改的,我反正已经改回去了 = =.
公司用canal主要是因为有新旧两个系统,两个系统同时在运转,目前还没有完全迁移,因此用canal保证新旧系统数据的一致性,这次主要是修复一个楼层信息不同步的bug,问题是更新的时候有个状态字段被写死了,没有用kafka里消息体里的数据更新,这个小问题上周就修复了,自测通过了的,这周测试复测结果发现什么操作都同步不了.这使我一度陷入了自我怀疑.... 然后去看监控的服务日志,发现确实是什么数据库的变更都检测不到了,因为不熟悉这套东西,看了半天也没看出来问题,只能求助我们头儿,然后据他说这个问题经常出现,然后就删了canal实例里面的meta.bat文件,然后运行./restart.sh,重启之后果然恢复正常了,具体啥原因我还没搞懂,日后研究明白了再补充
后续:canal提供了tsdb时序数据库,上次碰到的canal报错问题,是因为监控表的元数据跟现有数据不一致导致的,tsdb中会记录所有对监控的表的操作记录,但是有一张表加了两个字段(57+2)后,这两条alter语句不知道什么情况没有被记录到tsdb的history表中,导致监控到的表的列数不匹配,canal认为还是57列,实际为59,由于是测试环境,所以直接把这张表copy了一份然后把原表删了,再把copy的表改个名字就ok了
`,12)]))}const c=i(h,[["render",t]]);export{g as __pageData,c as default}; diff --git "a/assets/java_others_\345\276\256\344\277\241\345\260\217\347\250\213\345\272\217\345\212\240\345\257\206\346\225\260\346\215\256\345\257\271\347\247\260\350\247\243\345\257\206\345\267\245\345\205\267\347\261\273.md.Cl-o3PFv.js" "b/assets/java_others_\345\276\256\344\277\241\345\260\217\347\250\213\345\272\217\345\212\240\345\257\206\346\225\260\346\215\256\345\257\271\347\247\260\350\247\243\345\257\206\345\267\245\345\205\267\347\261\273.md.Cl-o3PFv.js" new file mode 100644 index 00000000..db8ea853 --- /dev/null +++ "b/assets/java_others_\345\276\256\344\277\241\345\260\217\347\250\213\345\272\217\345\212\240\345\257\206\346\225\260\346\215\256\345\257\271\347\247\260\350\247\243\345\257\206\345\267\245\345\205\267\347\261\273.md.Cl-o3PFv.js" @@ -0,0 +1,66 @@ +import{_ as i,c as a,a2 as n,o as h}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"微信小程序加密数据对称解密工具类","description":"","frontmatter":{},"headers":[],"relativePath":"java/others/微信小程序加密数据对称解密工具类.md","filePath":"java/others/微信小程序加密数据对称解密工具类.md","lastUpdated":1729217313000}'),k={name:"java/others/微信小程序加密数据对称解密工具类.md"};function p(t,s,l,e,E,r){return h(),a("div",null,s[0]||(s[0]=[n(`小程序授权登录获取用户手机号功能
<dependency>
+ <groupId>org.bouncycastle</groupId>
+ <artifactId>bcprov-jdk16</artifactId>
+ <version>1.46</version>
+</dependency>
+
+ <dependency>
+ <groupId>commons-codec</groupId>
+ <artifactId>commons-codec</artifactId>
+ <version>1.4</version>
+</dependency>import com.alibaba.fastjson.JSON;
+import org.apache.commons.codec.binary.Base64;
+import org.bouncycastle.jce.provider.BouncyCastleProvider;
+
+import javax.crypto.Cipher;
+import javax.crypto.spec.IvParameterSpec;
+import javax.crypto.spec.SecretKeySpec;
+import java.security.Security;
+import java.security.spec.AlgorithmParameterSpec;
+import java.util.Map;
+
+/**
+ * @author storyxc
+ * @description 微信敏感数据对称解密工具类
+ * @create 2021/4/30 15:32
+ */
+public class WeixinDecryptUtils {
+
+
+ /**
+ * 微信加密数据对称解密
+ * @param appId 公众号/小程序id
+ * @param encryptData 加密数据
+ * @param iv 加密初始向量
+ * @param sessionKey 会话密钥
+ * @return 解密数据
+ */
+ public static Map<String,Object> decrypt(String appId,String sessionKey,String encryptData,String iv)
+ throws Exception{
+ byte[] decodeEncryptData = Base64.decodeBase64(encryptData);
+ byte[] decodeIv = Base64.decodeBase64(iv);
+ byte[] decodeSessionKey = Base64.decodeBase64(sessionKey);
+ Security.addProvider(new BouncyCastleProvider());
+ AlgorithmParameterSpec ivSpec = new IvParameterSpec(decodeIv);
+ Cipher cipher = Cipher.getInstance("AES/CBC/PKCS7Padding","BC");
+ SecretKeySpec keySpec = new SecretKeySpec(decodeSessionKey, "AES");
+ cipher.init(Cipher.DECRYPT_MODE, keySpec, ivSpec);
+ byte[] doFinal = cipher.doFinal(decodeEncryptData);
+ String str = new String(doFinal);
+ Map map = JSON.parseObject(str, Map.class);
+ Map<String,Object> watermark = (Map<String, Object>) map.get("watermark");
+ if (watermark != null && !appId.equals(watermark.get("appid"))) {
+ throw new RunException(500,"Invalid encrpytedData watermark appId "+appId+",parsed appID " +(String)watermark.get("appid"));
+ }
+ return map;
+ }
+
+ public static void main(String[] args) throws Exception{
+ String appId = "wx4f4bc4dec97d474b";
+ String sessionKey = "tiihtNczf5v6AKRyjwEUhQ==";
+ String encryptedData = "CiyLU1Aw2KjvrjMdj8YKliAjtP4gsMZMQmRzooG2xrDcvSnxIMXFufNstNGTyaGS9uT5geRa0W4oTOb1WT7fJlAC+oNPdbB+3hVbJSRgv+4lGOETKUQz6OYStslQ142dNCuabNPGBzlooOmB231qMM85d2/fV6ChevvXvQP8Hkue1poOFtnEtpyxVLW1zAo6/1Xx1COxFvrc2d7UL/lmHInNlxuacJXwu0fjpXfz/YqYzBIBzD6WUfTIF9GRHpOn/Hz7saL8xz+W//FRAUid1OksQaQx4CMs8LOddcQhULW4ucetDf96JcR3g0gfRK4PC7E/r7Z6xNrXd2UIeorGj5Ef7b1pJAYB6Y5anaHqZ9J6nKEBvB4DnNLIVWSgARns/8wR2SiRS7MNACwTyrGvt9ts8p12PKFdlqYTopNHR1Vf7XjfhQlVsAJdNiKdYmYVoKlaRv85IfVunYzO0IKXsyl7JCUjCpoG20f0a04COwfneQAGGwd5oa+T8yO5hzuyDb/XcxxmK01EpqOyuxINew==";
+ String iv = "r7BXXKkLb8qrSNn05n0qiA==";
+ Map<String, Object> decode = decrypt(appId, sessionKey, encryptedData, iv);
+ System.out.println(JSON.toJSONString(decode));
+ }
+}小程序授权登录获取用户手机号功能
<dependency>
+ <groupId>org.bouncycastle</groupId>
+ <artifactId>bcprov-jdk16</artifactId>
+ <version>1.46</version>
+</dependency>
+
+ <dependency>
+ <groupId>commons-codec</groupId>
+ <artifactId>commons-codec</artifactId>
+ <version>1.4</version>
+</dependency>import com.alibaba.fastjson.JSON;
+import org.apache.commons.codec.binary.Base64;
+import org.bouncycastle.jce.provider.BouncyCastleProvider;
+
+import javax.crypto.Cipher;
+import javax.crypto.spec.IvParameterSpec;
+import javax.crypto.spec.SecretKeySpec;
+import java.security.Security;
+import java.security.spec.AlgorithmParameterSpec;
+import java.util.Map;
+
+/**
+ * @author storyxc
+ * @description 微信敏感数据对称解密工具类
+ * @create 2021/4/30 15:32
+ */
+public class WeixinDecryptUtils {
+
+
+ /**
+ * 微信加密数据对称解密
+ * @param appId 公众号/小程序id
+ * @param encryptData 加密数据
+ * @param iv 加密初始向量
+ * @param sessionKey 会话密钥
+ * @return 解密数据
+ */
+ public static Map<String,Object> decrypt(String appId,String sessionKey,String encryptData,String iv)
+ throws Exception{
+ byte[] decodeEncryptData = Base64.decodeBase64(encryptData);
+ byte[] decodeIv = Base64.decodeBase64(iv);
+ byte[] decodeSessionKey = Base64.decodeBase64(sessionKey);
+ Security.addProvider(new BouncyCastleProvider());
+ AlgorithmParameterSpec ivSpec = new IvParameterSpec(decodeIv);
+ Cipher cipher = Cipher.getInstance("AES/CBC/PKCS7Padding","BC");
+ SecretKeySpec keySpec = new SecretKeySpec(decodeSessionKey, "AES");
+ cipher.init(Cipher.DECRYPT_MODE, keySpec, ivSpec);
+ byte[] doFinal = cipher.doFinal(decodeEncryptData);
+ String str = new String(doFinal);
+ Map map = JSON.parseObject(str, Map.class);
+ Map<String,Object> watermark = (Map<String, Object>) map.get("watermark");
+ if (watermark != null && !appId.equals(watermark.get("appid"))) {
+ throw new RunException(500,"Invalid encrpytedData watermark appId "+appId+",parsed appID " +(String)watermark.get("appid"));
+ }
+ return map;
+ }
+
+ public static void main(String[] args) throws Exception{
+ String appId = "wx4f4bc4dec97d474b";
+ String sessionKey = "tiihtNczf5v6AKRyjwEUhQ==";
+ String encryptedData = "CiyLU1Aw2KjvrjMdj8YKliAjtP4gsMZMQmRzooG2xrDcvSnxIMXFufNstNGTyaGS9uT5geRa0W4oTOb1WT7fJlAC+oNPdbB+3hVbJSRgv+4lGOETKUQz6OYStslQ142dNCuabNPGBzlooOmB231qMM85d2/fV6ChevvXvQP8Hkue1poOFtnEtpyxVLW1zAo6/1Xx1COxFvrc2d7UL/lmHInNlxuacJXwu0fjpXfz/YqYzBIBzD6WUfTIF9GRHpOn/Hz7saL8xz+W//FRAUid1OksQaQx4CMs8LOddcQhULW4ucetDf96JcR3g0gfRK4PC7E/r7Z6xNrXd2UIeorGj5Ef7b1pJAYB6Y5anaHqZ9J6nKEBvB4DnNLIVWSgARns/8wR2SiRS7MNACwTyrGvt9ts8p12PKFdlqYTopNHR1Vf7XjfhQlVsAJdNiKdYmYVoKlaRv85IfVunYzO0IKXsyl7JCUjCpoG20f0a04COwfneQAGGwd5oa+T8yO5hzuyDb/XcxxmK01EpqOyuxINew==";
+ String iv = "r7BXXKkLb8qrSNn05n0qiA==";
+ Map<String, Object> decode = decrypt(appId, sessionKey, encryptedData, iv);
+ System.out.println(JSON.toJSONString(decode));
+ }
+}同事手抖在测试环境数据库执行了delete from tb_xxx没加where语句,数据库是单机版且没有备份,且binlog不完整。
鉴于以上条件,只能通过找出执行的删除语句的binlog,找出来之后将删除语句反向执行了。
查看binlog文件:SHOW BINARY LOGS;
刷新binlog文件:flush logs;将binlog截断
查看binlog内容:show binlog events in mysql-bin.xxxx
找到具体删除语句在那个位置/时间后可以将binlog内容导出到文件中
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-position=xxx --stop-position=xxx --database=xxx /path/to/binlog.0001 > ~/partial_binlog.sql
如果知道具体执行的时间,也可以将开始/结束位点改为开始/结束时间:
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-datetime="2024-05-29 14:45:45" --stop-datetime="2024-05-29 14:50:00" --database=xxx /path/to/binlog.0001 > ~/partial_binlog.sql
来自chatgpt的解释
参数解释
mysqlbinlog:这是MySQL提供的一个工具,用于读取二进制日志文件并将其转换为文本格式。--no-defaults:此选项告诉mysqlbinlog工具忽略配置文件中的默认设置,确保命令仅使用显式提供的参数。--base64-output=decode-rows:此选项指示mysqlbinlog工具将以 Base64 编码存储的行事件解码为可读的格式。这样可以更好地查看DELETE、INSERT和UPDATE语句中的具体数据。-v或--verbose:此选项启用详细输出模式,会显示更多的信息,包括解码后的行事件的具体内容。--start-position=xxx:指定从二进制日志文件的哪个位置开始读取事件。xxx应替换为实际的开始位置。--stop-position=xxx:指定读取到二进制日志文件的哪个位置结束。xxx应替换为实际的结束位置。--database=xxx:指定只输出与某个数据库相关的事件。xxx应替换为实际的数据库名称。/path/to/binlog.0001:指定要读取的二进制日志文件的路径和名称。需要替换为实际的文件路径。> ~/partial_binlog.sql:将输出重定向到指定的文件~/partial_binlog.sql中。作用总结
这条命令会:
- 从指定的二进制日志文件 (
/path/to/binlog.0001) 中读取日志事件。- 仅提取与指定数据库 (
--database=xxx) 相关的事件。- 从指定的开始位置 (
--start-position=xxx) 到结束位置 (--stop-position=xxx) 之间的日志事件。- 将日志事件解码为可读的SQL语句,并将输出写入到文件
~/partial_binlog.sql中。此命令常用于从二进制日志中恢复特定时间范围内的数据库操作,特别是用于数据恢复或审计操作。
执行结束后会在文件最后部份注释中输出解码后的DELETE语句内容,这里直接通过python脚本处理一下,把DELETE替换成INSERT语句,回到数据库中执行即可。(需要稍微调整下细节)
脚本:
if __name__ == '__main__':
+ # 打开原始binlog日志文件和目标SQL文件
+ input_file = "partial_binlog.sql"
+ output_file = "ok.sql"
+
+ # 读取原始binlog文件内容
+ with open(input_file, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ # 替换DELETE为INSERT,使用正则表达式进行复杂替换
+ import re
+
+ content = re.sub(r'### DELETE FROM', ';INSERT INTO', content)
+ content = re.sub(r'### WHERE', 'SELECT', content)
+ content = re.sub(r'###', '', content)
+ content = re.sub(r'@1=', '', content)
+ content = re.sub(r'@[1-9]=', ',', content)
+ content = re.sub(r'@[1-9][0-9]=', ',', content)
+ content = re.sub(r'@[1-9][0-9][0-9]=', ',', content)
+
+ # 将处理后的内容写入目标SQL文件
+ with open(output_file, "w", encoding="utf-8") as f:
+ f.write(content)
+
+ print("转换完成:", output_file)同事手抖在测试环境数据库执行了delete from tb_xxx没加where语句,数据库是单机版且没有备份,且binlog不完整。
鉴于以上条件,只能通过找出执行的删除语句的binlog,找出来之后将删除语句反向执行了。
查看binlog文件:SHOW BINARY LOGS;
刷新binlog文件:flush logs;将binlog截断
查看binlog内容:show binlog events in mysql-bin.xxxx
找到具体删除语句在那个位置/时间后可以将binlog内容导出到文件中
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-position=xxx --stop-position=xxx --database=xxx /path/to/binlog.0001 > ~/partial_binlog.sql
如果知道具体执行的时间,也可以将开始/结束位点改为开始/结束时间:
mysqlbinlog --no-defaults --base64-output=decode-rows -v --start-datetime="2024-05-29 14:45:45" --stop-datetime="2024-05-29 14:50:00" --database=xxx /path/to/binlog.0001 > ~/partial_binlog.sql
来自chatgpt的解释
参数解释
mysqlbinlog:这是MySQL提供的一个工具,用于读取二进制日志文件并将其转换为文本格式。--no-defaults:此选项告诉mysqlbinlog工具忽略配置文件中的默认设置,确保命令仅使用显式提供的参数。--base64-output=decode-rows:此选项指示mysqlbinlog工具将以 Base64 编码存储的行事件解码为可读的格式。这样可以更好地查看DELETE、INSERT和UPDATE语句中的具体数据。-v或--verbose:此选项启用详细输出模式,会显示更多的信息,包括解码后的行事件的具体内容。--start-position=xxx:指定从二进制日志文件的哪个位置开始读取事件。xxx应替换为实际的开始位置。--stop-position=xxx:指定读取到二进制日志文件的哪个位置结束。xxx应替换为实际的结束位置。--database=xxx:指定只输出与某个数据库相关的事件。xxx应替换为实际的数据库名称。/path/to/binlog.0001:指定要读取的二进制日志文件的路径和名称。需要替换为实际的文件路径。> ~/partial_binlog.sql:将输出重定向到指定的文件~/partial_binlog.sql中。作用总结
这条命令会:
- 从指定的二进制日志文件 (
/path/to/binlog.0001) 中读取日志事件。- 仅提取与指定数据库 (
--database=xxx) 相关的事件。- 从指定的开始位置 (
--start-position=xxx) 到结束位置 (--stop-position=xxx) 之间的日志事件。- 将日志事件解码为可读的SQL语句,并将输出写入到文件
~/partial_binlog.sql中。此命令常用于从二进制日志中恢复特定时间范围内的数据库操作,特别是用于数据恢复或审计操作。
执行结束后会在文件最后部份注释中输出解码后的DELETE语句内容,这里直接通过python脚本处理一下,把DELETE替换成INSERT语句,回到数据库中执行即可。(需要稍微调整下细节)
脚本:
if __name__ == '__main__':
+ # 打开原始binlog日志文件和目标SQL文件
+ input_file = "partial_binlog.sql"
+ output_file = "ok.sql"
+
+ # 读取原始binlog文件内容
+ with open(input_file, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ # 替换DELETE为INSERT,使用正则表达式进行复杂替换
+ import re
+
+ content = re.sub(r'### DELETE FROM', ';INSERT INTO', content)
+ content = re.sub(r'### WHERE', 'SELECT', content)
+ content = re.sub(r'###', '', content)
+ content = re.sub(r'@1=', '', content)
+ content = re.sub(r'@[1-9]=', ',', content)
+ content = re.sub(r'@[1-9][0-9]=', ',', content)
+ content = re.sub(r'@[1-9][0-9][0-9]=', ',', content)
+
+ # 将处理后的内容写入目标SQL文件
+ with open(output_file, "w", encoding="utf-8") as f:
+ f.write(content)
+
+ print("转换完成:", output_file)canal官方仓库:https://github.com/alibaba/canal/
wiki:https://github.com/alibaba/canal/wiki
canal的用途是基于mysql的binlog日志解析,提供增量数据的订阅和消费。简单的场景:通过canal监控mysql数据变更从而及时更新redis中对应的缓存或更新es中的文档内容
本文主要介绍canal在服务器端的部署,包括canal-admin,canal-tsdb配置以及instance配置。mysql版本为5.7,系统为macOS14.2.1。
首先需要下载canal的发行版,下载地址:https://github.com/alibaba/canal/releases,可自行选择版本,这里选择1.1.4。
自建MySQL,需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
+log-bin=mysql-bin # 开启 binlog
+binlog-format=ROW # 选择 ROW 模式
+server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复mkdir -p ~/Downloads/canal/admin && tar -zxvf canal.admin-1.1.4.tar.gz -C ~/Downloads/canal/admin执行conf文件夹中的canal_manager.sql建表
mysql -uroot -p < ~/Downloads/canal/admin/conf/canal_manager.sql
创建canal用户并授权canal链接 MySQL 账号具有作为 MySQL slave 的权限
CREATE USER canal IDENTIFIED BY 'canal';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
+-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
+FLUSH PRIVILEGES;修改conf文件夹中的application.yml
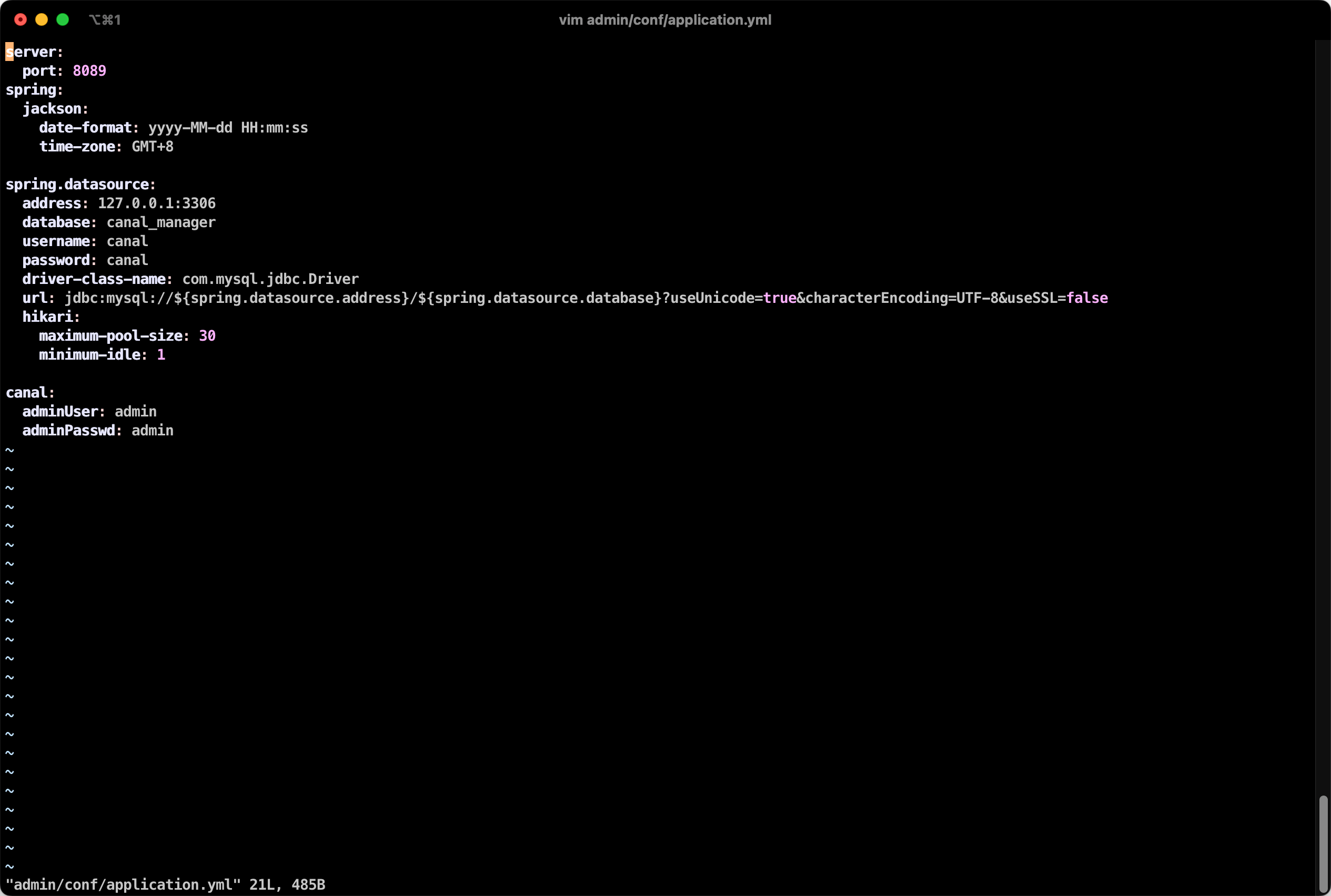
执行admin/bin目录的startup.sh
访问8089端口
使用默认账号密码 admin/123456即可登录
TIP
application.yml中的canal.adminUser和canal.adminPasswd并非WebUI的登录用户名和密码,而是和canal-server交互用的

canal-admin的核心模型主要有:
- instance,对应canal-server里的instance,一个最小的订阅mysql的队列
- server,对应canal-server,一个server里可以包含多个instance
- 集群,对应一组canal-server,组合在一起面向高可用HA的运维
简单解释:
- instance是最原始的业务订阅诉求,它会和 server/集群 这两个面向资源服务属性的进行关联,比如instance A绑定到server A上或者集群 A上,
- 有了任务和资源的绑定关系后,对应的资源服务就会接收到这个任务配置,在对应的资源上动态加载instance,并提供服务
- 将server抽象成资源之后,原本canal-server运行所需要的canal.properties/instance.properties配置文件就需要在web ui上进行统一运维,每个server只需要以最基本的启动配置 (比如知道一下canal-admin的manager地址,以及访问配置的账号、密码即可)
新建server,按照图中配置即可
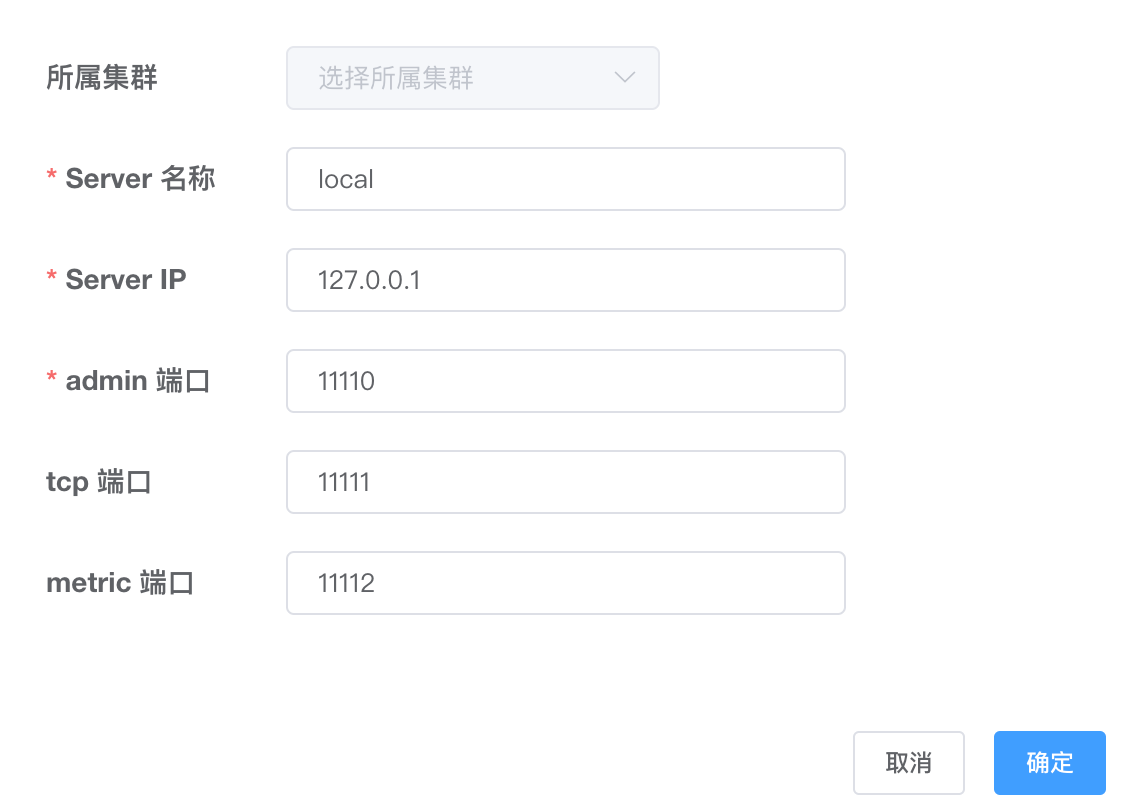
配置项:
- 所属集群,可以选择为单机 或者 集群。一般单机Server的模式主要用于一次性的任务或者测试任务
- Server名称,唯一即可,方便自己记忆
- Server Ip,机器ip
- admin端口,canal 1.1.4版本新增的能力,会在canal-server上提供远程管理操作,默认值11110
- tcp端口,canal提供netty数据订阅服务的端口
- metric端口, promethues的exporter监控数据端口 (未来会对接监控)
#################################################
+######### common argument #############
+#################################################
+# tcp bind ip
+canal.ip =
+# register ip to zookeeper
+canal.register.ip =
+canal.port = 11111
+canal.metrics.pull.port = 11112
+# canal instance user/passwd
+canal.user = canal
+canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
+
+# canal admin config
+canal.admin.manager = 127.0.0.1:8089
+canal.admin.port = 11110
+canal.admin.user = admin
+canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
+
+canal.zkServers =
+# flush data to zk
+canal.zookeeper.flush.period = 1000
+canal.withoutNetty = false
+# tcp, kafka, RocketMQ
+canal.serverMode = kafka
+# flush meta cursor/parse position to file
+canal.file.data.dir = \${canal.conf.dir}
+canal.file.flush.period = 1000
+## memory store RingBuffer size, should be Math.pow(2,n)
+canal.instance.memory.buffer.size = 16384
+## memory store RingBuffer used memory unit size , default 1kb
+canal.instance.memory.buffer.memunit = 1024
+## meory store gets mode used MEMSIZE or ITEMSIZE
+canal.instance.memory.batch.mode = MEMSIZE
+canal.instance.memory.rawEntry = true
+
+## detecing config
+canal.instance.detecting.enable = false
+#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
+canal.instance.detecting.sql = select 1
+canal.instance.detecting.interval.time = 3
+canal.instance.detecting.retry.threshold = 3
+canal.instance.detecting.heartbeatHaEnable = false
+
+# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
+canal.instance.transaction.size = 1024
+# mysql fallback connected to new master should fallback times
+canal.instance.fallbackIntervalInSeconds = 60
+
+# network config
+canal.instance.network.receiveBufferSize = 16384
+canal.instance.network.sendBufferSize = 16384
+canal.instance.network.soTimeout = 30
+
+# binlog filter config
+canal.instance.filter.druid.ddl = true
+canal.instance.filter.query.dcl = false
+canal.instance.filter.query.dml = false
+canal.instance.filter.query.ddl = false
+canal.instance.filter.table.error = false
+canal.instance.filter.rows = false
+canal.instance.filter.transaction.entry = false
+
+# binlog format/image check
+canal.instance.binlog.format = ROW,STATEMENT,MIXED
+canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
+
+# binlog ddl isolation
+canal.instance.get.ddl.isolation = false
+
+# parallel parser config
+canal.instance.parser.parallel = true
+## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
+#canal.instance.parser.parallelThreadSize = 16
+## disruptor ringbuffer size, must be power of 2
+canal.instance.parser.parallelBufferSize = 256
+
+# table meta tsdb info
+canal.instance.tsdb.enable = true
+#canal.instance.tsdb.dir = \${canal.file.data.dir:../conf}/\${canal.instance.destination:}
+#canal.instance.tsdb.url = jdbc:h2:\${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
+canal.instance.tsdb.dbUsername = canal
+canal.instance.tsdb.dbPassword = canal
+# dump snapshot interval, default 24 hour
+canal.instance.tsdb.snapshot.interval = 24
+# purge snapshot expire , default 360 hour(15 days)
+canal.instance.tsdb.snapshot.expire = 360
+
+# aliyun ak/sk , support rds/mq
+canal.aliyun.accessKey =
+canal.aliyun.secretKey =
+
+#################################################
+######### destinations #############
+#################################################
+canal.destinations =
+# conf root dir
+canal.conf.dir = ../conf
+# auto scan instance dir add/remove and start/stop instance
+canal.auto.scan = true
+canal.auto.scan.interval = 5
+
+#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
+canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
+
+canal.instance.global.mode = manager
+canal.instance.global.lazy = false
+canal.instance.global.manager.address = \${canal.admin.manager}
+#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
+canal.instance.global.spring.xml = classpath:spring/file-instance.xml
+#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
+
+##################################################
+######### MQ #############
+##################################################
+canal.mq.servers = 127.0.0.1:9092
+canal.mq.retries = 0
+canal.mq.batchSize = 16384
+canal.mq.maxRequestSize = 1048576
+canal.mq.lingerMs = 100
+canal.mq.bufferMemory = 33554432
+canal.mq.canalBatchSize = 50
+canal.mq.canalGetTimeout = 100
+canal.mq.flatMessage = true
+canal.mq.compressionType = none
+canal.mq.acks = all
+#canal.mq.properties. =
+canal.mq.producerGroup = canal-test
+# Set this value to "cloud", if you want open message trace feature in aliyun.
+canal.mq.accessChannel = local
+# aliyun mq namespace
+#canal.mq.namespace =
+
+##################################################
+######### Kafka Kerberos Info #############
+##################################################
+canal.mq.kafka.kerberos.enable = false
+canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
+canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"TIP
canal.auto.scan如果设置为true,canal.destinations可以不填写,server会自动扫描instance然后启动
// CanalController
+// 初始化monitor机制
+autoScan = BooleanUtils.toBoolean(getProperty(properties, CanalConstants.CANAL_AUTO_SCAN));
+if (autoScan) {
+ defaultAction = new InstanceAction() {
+ public void start(String destination) {
+ InstanceConfig config = instanceConfigs.get(destination);
+ if (config == null) {
+ // 重新读取一下instance config
+ config = parseInstanceConfig(properties, destination);
+ instanceConfigs.put(destination, config);
+ }
+ if (!embededCanalServer.isStart(destination)) {
+ // HA机制启动
+ ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
+ if (!config.getLazy() && !runningMonitor.isStart()) {
+ runningMonitor.start();
+ }
+ }
+ logger.info("auto notify start {} successful.", destination);
+ }
+ //...
+ }
+}
+
+instanceConfigMonitors = MigrateMap.makeComputingMap(new Function<InstanceMode, InstanceConfigMonitor>() {
+
+ public InstanceConfigMonitor apply(InstanceMode mode) {
+ int scanInterval = Integer.valueOf(getProperty(properties,
+ CanalConstants.CANAL_AUTO_SCAN_INTERVAL,
+ "5"));
+
+ if (mode.isSpring()) {
+ SpringInstanceConfigMonitor monitor = new SpringInstanceConfigMonitor();
+ monitor.setScanIntervalInSecond(scanInterval);
+ monitor.setDefaultAction(defaultAction);
+ // 设置conf目录,默认是user.dir + conf目录组成
+ String rootDir = getProperty(properties, CanalConstants.CANAL_CONF_DIR);
+ if (StringUtils.isEmpty(rootDir)) {
+ rootDir = "../conf";
+ }
+
+ if (StringUtils.equals("otter-canal", System.getProperty("appName"))) {
+ monitor.setRootConf(rootDir);
+ } else {
+ // eclipse debug模式
+ monitor.setRootConf("src/main/resources/");
+ }
+ return monitor;
+ } else if (mode.isManager()) {
+ ManagerInstanceConfigMonitor monitor = new ManagerInstanceConfigMonitor();
+ monitor.setScanIntervalInSecond(scanInterval);
+ monitor.setDefaultAction(defaultAction);
+ String managerAddress = getProperty(properties, CanalConstants.CANAL_ADMIN_MANAGER);
+ monitor.setConfigClient(getManagerClient(managerAddress));
+ return monitor;
+ } else {
+ throw new UnsupportedOperationException("unknow mode :" + mode + " for monitor");
+ }
+ }
+});
+
+
+// CanalController.start()
+public void start() throws Throwable {
+ // ...
+ // 尝试启动一下非lazy状态的通道
+ for (Map.Entry<String, InstanceConfig> entry : instanceConfigs.entrySet()) {
+ final String destination = entry.getKey();
+ InstanceConfig config = entry.getValue();
+ // 创建destination的工作节点
+ if (!embededCanalServer.isStart(destination)) {
+ // HA机制启动
+ ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
+ if (!config.getLazy() && !runningMonitor.isStart()) {
+ runningMonitor.start();
+ }
+ }
+
+ if (autoScan) {
+ instanceConfigMonitors.get(config.getMode()).register(destination, defaultAction);
+ }
+ }
+
+ if (autoScan) {
+ instanceConfigMonitors.get(globalInstanceConfig.getMode()).start();
+ for (InstanceConfigMonitor monitor : instanceConfigMonitors.values()) {
+ if (!monitor.isStart()) {
+ monitor.start();
+ }
+ }
+ }
+ // ...
+}
+
+// 然后会调用ManagerInstanceConfigMonitor的start方法,start方法会启动一个定时任务,每隔scanInterval秒调用scan方法
+public void start() {
+ super.start();
+ executor.scheduleWithFixedDelay(new Runnable() {
+
+ public void run() {
+ try {
+ scan();
+ if (isFirst) {
+ isFirst = false;
+ }
+ } catch (Throwable e) {
+ logger.error("scan failed", e);
+ }
+ }
+
+ }, 0, scanIntervalInSecond, TimeUnit.SECONDS);
+}
+
+// scan方法中会通过configClient调用canal-admin的接口获取instance的配置信息,
+// 最后对instance进行stop/reload/start操作
+
+private void scan() {
+ String instances = configClient.findInstances(null);
+ final List<String> is = Lists.newArrayList(StringUtils.split(instances, ','));
+ List<String> start = Lists.newArrayList();
+ List<String> stop = Lists.newArrayList();
+ List<String> restart = Lists.newArrayList();
+ for (String instance : is) {
+ if (!configs.containsKey(instance)) {
+ PlainCanal newPlainCanal = configClient.findInstance(instance, null);
+ if (newPlainCanal != null) {
+ configs.put(instance, newPlainCanal);
+ start.add(instance);
+ }
+ } else {
+ PlainCanal plainCanal = configs.get(instance);
+ PlainCanal newPlainCanal = configClient.findInstance(instance, plainCanal.getMd5());
+ if (newPlainCanal != null) {
+ // 配置有变化
+ restart.add(instance);
+ configs.put(instance, newPlainCanal);
+ }
+ }
+ }
+
+ configs.forEach((instance, plainCanal) -> {
+ if (!is.contains(instance)) {
+ stop.add(instance);
+ }
+ });
+
+ stop.forEach(instance -> {
+ notifyStop(instance);
+ });
+
+ restart.forEach(instance -> {
+ notifyReload(instance);
+ });
+
+ start.forEach(instance -> {
+ notifyStart(instance);
+ });
+
+}mkdir -p ~/Downloads/canal/deployer && tar -zxvf canal.deployer-1.1.4.tar.gz -C ~/Downloads/canal/deployer用conf目录下的canal_local.properties替换canal.properties
修改配置
# canal.ip
+canal.ip = 127.0.0.1
+# register ip
+canal.register.ip = 127.0.0.1TIP
注意ip前后不能有空格,不然会无法启动netty server从而无法启动canal server,应该是后台没做trim
如果不填写canal.ip和canal.register.ip两个配置项,代码中将通过AddressUtils.getHostIp()获取本机的ip地址,如果本地有docker/orbstack等创建的虚拟网络设备会导致启动canal-server后识别到多个server且是不同的ip(docker0网桥或orbstack容器等的ip),比较膈应人。(#issue47)
源码:
// CanalController.java
+
+if (StringUtils.isEmpty(ip) && StringUtils.isEmpty(registerIp)) {
+ ip = registerIp = AddressUtils.getHostIp();
+}
+
+if (StringUtils.isEmpty(ip)) {
+ ip = AddressUtils.getHostIp();
+}
+
+if (StringUtils.isEmpty(registerIp)) {
+ registerIp = ip; // 兼容以前配置
+}执行bin目录下的startup.sh
直接在canal admin的webUI界面中配置instance,等待启动即可,如有问题查看deploy/logs/story/story.log
具体配置项参见wiki
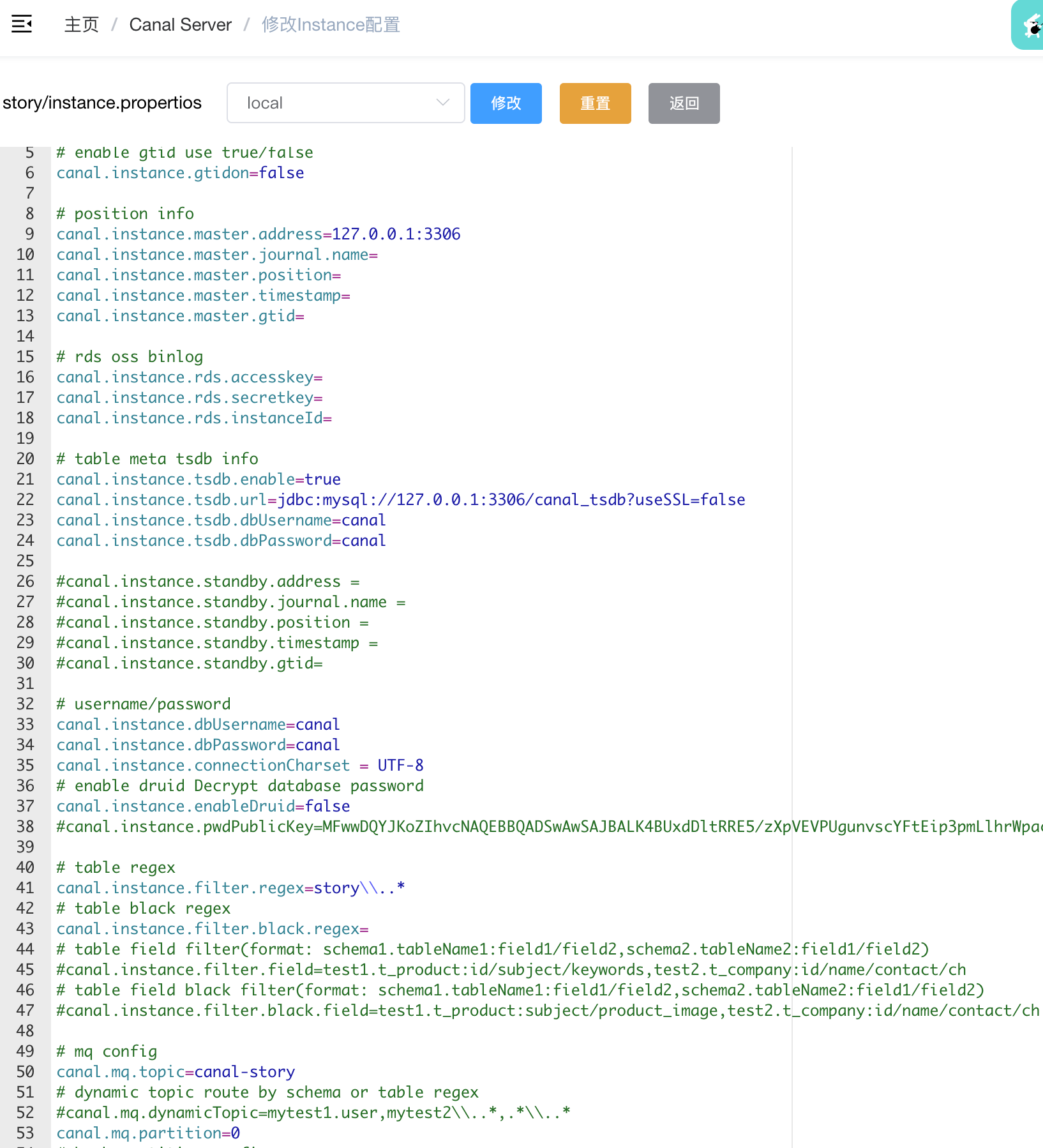
TIP
如果在server的配置文件中填了相同的配置项,那么instance中的配置会被server中的覆盖,例如canal.instance.tsdb.url配置(#issue4669)
此时我们的实例story已经开始监听story数据库下面的操作,如果有变更,就会推送至kafka的canal-story这个topic中
之后就需要通过业务端根据情况监听队列中的数据变化,做相应的操作。
`,35)]))}const c=i(p,[["render",h]]);export{g as __pageData,c as default}; diff --git "a/assets/linux_applications_Canal\351\203\250\347\275\262.md.CUZy4JDl.lean.js" "b/assets/linux_applications_Canal\351\203\250\347\275\262.md.CUZy4JDl.lean.js" new file mode 100644 index 00000000..7a2eb3c6 --- /dev/null +++ "b/assets/linux_applications_Canal\351\203\250\347\275\262.md.CUZy4JDl.lean.js" @@ -0,0 +1,319 @@ +import{_ as i,c as a,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"canal部署","description":"","frontmatter":{},"headers":[],"relativePath":"linux/applications/Canal部署.md","filePath":"linux/applications/Canal部署.md","lastUpdated":1729217313000}'),p={name:"linux/applications/Canal部署.md"};function h(t,s,k,e,E,r){return l(),a("div",null,s[0]||(s[0]=[n(`canal官方仓库:https://github.com/alibaba/canal/
wiki:https://github.com/alibaba/canal/wiki
canal的用途是基于mysql的binlog日志解析,提供增量数据的订阅和消费。简单的场景:通过canal监控mysql数据变更从而及时更新redis中对应的缓存或更新es中的文档内容
本文主要介绍canal在服务器端的部署,包括canal-admin,canal-tsdb配置以及instance配置。mysql版本为5.7,系统为macOS14.2.1。
首先需要下载canal的发行版,下载地址:https://github.com/alibaba/canal/releases,可自行选择版本,这里选择1.1.4。
自建MySQL,需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
+log-bin=mysql-bin # 开启 binlog
+binlog-format=ROW # 选择 ROW 模式
+server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复mkdir -p ~/Downloads/canal/admin && tar -zxvf canal.admin-1.1.4.tar.gz -C ~/Downloads/canal/admin执行conf文件夹中的canal_manager.sql建表
mysql -uroot -p < ~/Downloads/canal/admin/conf/canal_manager.sql
创建canal用户并授权canal链接 MySQL 账号具有作为 MySQL slave 的权限
CREATE USER canal IDENTIFIED BY 'canal';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
+-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
+FLUSH PRIVILEGES;修改conf文件夹中的application.yml
执行admin/bin目录的startup.sh
访问8089端口
使用默认账号密码 admin/123456即可登录
TIP
application.yml中的canal.adminUser和canal.adminPasswd并非WebUI的登录用户名和密码,而是和canal-server交互用的
canal-admin的核心模型主要有:
- instance,对应canal-server里的instance,一个最小的订阅mysql的队列
- server,对应canal-server,一个server里可以包含多个instance
- 集群,对应一组canal-server,组合在一起面向高可用HA的运维
简单解释:
- instance是最原始的业务订阅诉求,它会和 server/集群 这两个面向资源服务属性的进行关联,比如instance A绑定到server A上或者集群 A上,
- 有了任务和资源的绑定关系后,对应的资源服务就会接收到这个任务配置,在对应的资源上动态加载instance,并提供服务
- 将server抽象成资源之后,原本canal-server运行所需要的canal.properties/instance.properties配置文件就需要在web ui上进行统一运维,每个server只需要以最基本的启动配置 (比如知道一下canal-admin的manager地址,以及访问配置的账号、密码即可)
新建server,按照图中配置即可
配置项:
- 所属集群,可以选择为单机 或者 集群。一般单机Server的模式主要用于一次性的任务或者测试任务
- Server名称,唯一即可,方便自己记忆
- Server Ip,机器ip
- admin端口,canal 1.1.4版本新增的能力,会在canal-server上提供远程管理操作,默认值11110
- tcp端口,canal提供netty数据订阅服务的端口
- metric端口, promethues的exporter监控数据端口 (未来会对接监控)
#################################################
+######### common argument #############
+#################################################
+# tcp bind ip
+canal.ip =
+# register ip to zookeeper
+canal.register.ip =
+canal.port = 11111
+canal.metrics.pull.port = 11112
+# canal instance user/passwd
+canal.user = canal
+canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
+
+# canal admin config
+canal.admin.manager = 127.0.0.1:8089
+canal.admin.port = 11110
+canal.admin.user = admin
+canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
+
+canal.zkServers =
+# flush data to zk
+canal.zookeeper.flush.period = 1000
+canal.withoutNetty = false
+# tcp, kafka, RocketMQ
+canal.serverMode = kafka
+# flush meta cursor/parse position to file
+canal.file.data.dir = \${canal.conf.dir}
+canal.file.flush.period = 1000
+## memory store RingBuffer size, should be Math.pow(2,n)
+canal.instance.memory.buffer.size = 16384
+## memory store RingBuffer used memory unit size , default 1kb
+canal.instance.memory.buffer.memunit = 1024
+## meory store gets mode used MEMSIZE or ITEMSIZE
+canal.instance.memory.batch.mode = MEMSIZE
+canal.instance.memory.rawEntry = true
+
+## detecing config
+canal.instance.detecting.enable = false
+#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
+canal.instance.detecting.sql = select 1
+canal.instance.detecting.interval.time = 3
+canal.instance.detecting.retry.threshold = 3
+canal.instance.detecting.heartbeatHaEnable = false
+
+# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
+canal.instance.transaction.size = 1024
+# mysql fallback connected to new master should fallback times
+canal.instance.fallbackIntervalInSeconds = 60
+
+# network config
+canal.instance.network.receiveBufferSize = 16384
+canal.instance.network.sendBufferSize = 16384
+canal.instance.network.soTimeout = 30
+
+# binlog filter config
+canal.instance.filter.druid.ddl = true
+canal.instance.filter.query.dcl = false
+canal.instance.filter.query.dml = false
+canal.instance.filter.query.ddl = false
+canal.instance.filter.table.error = false
+canal.instance.filter.rows = false
+canal.instance.filter.transaction.entry = false
+
+# binlog format/image check
+canal.instance.binlog.format = ROW,STATEMENT,MIXED
+canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
+
+# binlog ddl isolation
+canal.instance.get.ddl.isolation = false
+
+# parallel parser config
+canal.instance.parser.parallel = true
+## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
+#canal.instance.parser.parallelThreadSize = 16
+## disruptor ringbuffer size, must be power of 2
+canal.instance.parser.parallelBufferSize = 256
+
+# table meta tsdb info
+canal.instance.tsdb.enable = true
+#canal.instance.tsdb.dir = \${canal.file.data.dir:../conf}/\${canal.instance.destination:}
+#canal.instance.tsdb.url = jdbc:h2:\${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
+canal.instance.tsdb.dbUsername = canal
+canal.instance.tsdb.dbPassword = canal
+# dump snapshot interval, default 24 hour
+canal.instance.tsdb.snapshot.interval = 24
+# purge snapshot expire , default 360 hour(15 days)
+canal.instance.tsdb.snapshot.expire = 360
+
+# aliyun ak/sk , support rds/mq
+canal.aliyun.accessKey =
+canal.aliyun.secretKey =
+
+#################################################
+######### destinations #############
+#################################################
+canal.destinations =
+# conf root dir
+canal.conf.dir = ../conf
+# auto scan instance dir add/remove and start/stop instance
+canal.auto.scan = true
+canal.auto.scan.interval = 5
+
+#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
+canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
+
+canal.instance.global.mode = manager
+canal.instance.global.lazy = false
+canal.instance.global.manager.address = \${canal.admin.manager}
+#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
+canal.instance.global.spring.xml = classpath:spring/file-instance.xml
+#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
+
+##################################################
+######### MQ #############
+##################################################
+canal.mq.servers = 127.0.0.1:9092
+canal.mq.retries = 0
+canal.mq.batchSize = 16384
+canal.mq.maxRequestSize = 1048576
+canal.mq.lingerMs = 100
+canal.mq.bufferMemory = 33554432
+canal.mq.canalBatchSize = 50
+canal.mq.canalGetTimeout = 100
+canal.mq.flatMessage = true
+canal.mq.compressionType = none
+canal.mq.acks = all
+#canal.mq.properties. =
+canal.mq.producerGroup = canal-test
+# Set this value to "cloud", if you want open message trace feature in aliyun.
+canal.mq.accessChannel = local
+# aliyun mq namespace
+#canal.mq.namespace =
+
+##################################################
+######### Kafka Kerberos Info #############
+##################################################
+canal.mq.kafka.kerberos.enable = false
+canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
+canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"TIP
canal.auto.scan如果设置为true,canal.destinations可以不填写,server会自动扫描instance然后启动
// CanalController
+// 初始化monitor机制
+autoScan = BooleanUtils.toBoolean(getProperty(properties, CanalConstants.CANAL_AUTO_SCAN));
+if (autoScan) {
+ defaultAction = new InstanceAction() {
+ public void start(String destination) {
+ InstanceConfig config = instanceConfigs.get(destination);
+ if (config == null) {
+ // 重新读取一下instance config
+ config = parseInstanceConfig(properties, destination);
+ instanceConfigs.put(destination, config);
+ }
+ if (!embededCanalServer.isStart(destination)) {
+ // HA机制启动
+ ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
+ if (!config.getLazy() && !runningMonitor.isStart()) {
+ runningMonitor.start();
+ }
+ }
+ logger.info("auto notify start {} successful.", destination);
+ }
+ //...
+ }
+}
+
+instanceConfigMonitors = MigrateMap.makeComputingMap(new Function<InstanceMode, InstanceConfigMonitor>() {
+
+ public InstanceConfigMonitor apply(InstanceMode mode) {
+ int scanInterval = Integer.valueOf(getProperty(properties,
+ CanalConstants.CANAL_AUTO_SCAN_INTERVAL,
+ "5"));
+
+ if (mode.isSpring()) {
+ SpringInstanceConfigMonitor monitor = new SpringInstanceConfigMonitor();
+ monitor.setScanIntervalInSecond(scanInterval);
+ monitor.setDefaultAction(defaultAction);
+ // 设置conf目录,默认是user.dir + conf目录组成
+ String rootDir = getProperty(properties, CanalConstants.CANAL_CONF_DIR);
+ if (StringUtils.isEmpty(rootDir)) {
+ rootDir = "../conf";
+ }
+
+ if (StringUtils.equals("otter-canal", System.getProperty("appName"))) {
+ monitor.setRootConf(rootDir);
+ } else {
+ // eclipse debug模式
+ monitor.setRootConf("src/main/resources/");
+ }
+ return monitor;
+ } else if (mode.isManager()) {
+ ManagerInstanceConfigMonitor monitor = new ManagerInstanceConfigMonitor();
+ monitor.setScanIntervalInSecond(scanInterval);
+ monitor.setDefaultAction(defaultAction);
+ String managerAddress = getProperty(properties, CanalConstants.CANAL_ADMIN_MANAGER);
+ monitor.setConfigClient(getManagerClient(managerAddress));
+ return monitor;
+ } else {
+ throw new UnsupportedOperationException("unknow mode :" + mode + " for monitor");
+ }
+ }
+});
+
+
+// CanalController.start()
+public void start() throws Throwable {
+ // ...
+ // 尝试启动一下非lazy状态的通道
+ for (Map.Entry<String, InstanceConfig> entry : instanceConfigs.entrySet()) {
+ final String destination = entry.getKey();
+ InstanceConfig config = entry.getValue();
+ // 创建destination的工作节点
+ if (!embededCanalServer.isStart(destination)) {
+ // HA机制启动
+ ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
+ if (!config.getLazy() && !runningMonitor.isStart()) {
+ runningMonitor.start();
+ }
+ }
+
+ if (autoScan) {
+ instanceConfigMonitors.get(config.getMode()).register(destination, defaultAction);
+ }
+ }
+
+ if (autoScan) {
+ instanceConfigMonitors.get(globalInstanceConfig.getMode()).start();
+ for (InstanceConfigMonitor monitor : instanceConfigMonitors.values()) {
+ if (!monitor.isStart()) {
+ monitor.start();
+ }
+ }
+ }
+ // ...
+}
+
+// 然后会调用ManagerInstanceConfigMonitor的start方法,start方法会启动一个定时任务,每隔scanInterval秒调用scan方法
+public void start() {
+ super.start();
+ executor.scheduleWithFixedDelay(new Runnable() {
+
+ public void run() {
+ try {
+ scan();
+ if (isFirst) {
+ isFirst = false;
+ }
+ } catch (Throwable e) {
+ logger.error("scan failed", e);
+ }
+ }
+
+ }, 0, scanIntervalInSecond, TimeUnit.SECONDS);
+}
+
+// scan方法中会通过configClient调用canal-admin的接口获取instance的配置信息,
+// 最后对instance进行stop/reload/start操作
+
+private void scan() {
+ String instances = configClient.findInstances(null);
+ final List<String> is = Lists.newArrayList(StringUtils.split(instances, ','));
+ List<String> start = Lists.newArrayList();
+ List<String> stop = Lists.newArrayList();
+ List<String> restart = Lists.newArrayList();
+ for (String instance : is) {
+ if (!configs.containsKey(instance)) {
+ PlainCanal newPlainCanal = configClient.findInstance(instance, null);
+ if (newPlainCanal != null) {
+ configs.put(instance, newPlainCanal);
+ start.add(instance);
+ }
+ } else {
+ PlainCanal plainCanal = configs.get(instance);
+ PlainCanal newPlainCanal = configClient.findInstance(instance, plainCanal.getMd5());
+ if (newPlainCanal != null) {
+ // 配置有变化
+ restart.add(instance);
+ configs.put(instance, newPlainCanal);
+ }
+ }
+ }
+
+ configs.forEach((instance, plainCanal) -> {
+ if (!is.contains(instance)) {
+ stop.add(instance);
+ }
+ });
+
+ stop.forEach(instance -> {
+ notifyStop(instance);
+ });
+
+ restart.forEach(instance -> {
+ notifyReload(instance);
+ });
+
+ start.forEach(instance -> {
+ notifyStart(instance);
+ });
+
+}mkdir -p ~/Downloads/canal/deployer && tar -zxvf canal.deployer-1.1.4.tar.gz -C ~/Downloads/canal/deployer用conf目录下的canal_local.properties替换canal.properties
修改配置
# canal.ip
+canal.ip = 127.0.0.1
+# register ip
+canal.register.ip = 127.0.0.1TIP
注意ip前后不能有空格,不然会无法启动netty server从而无法启动canal server,应该是后台没做trim
如果不填写canal.ip和canal.register.ip两个配置项,代码中将通过AddressUtils.getHostIp()获取本机的ip地址,如果本地有docker/orbstack等创建的虚拟网络设备会导致启动canal-server后识别到多个server且是不同的ip(docker0网桥或orbstack容器等的ip),比较膈应人。(#issue47)
源码:
// CanalController.java
+
+if (StringUtils.isEmpty(ip) && StringUtils.isEmpty(registerIp)) {
+ ip = registerIp = AddressUtils.getHostIp();
+}
+
+if (StringUtils.isEmpty(ip)) {
+ ip = AddressUtils.getHostIp();
+}
+
+if (StringUtils.isEmpty(registerIp)) {
+ registerIp = ip; // 兼容以前配置
+}执行bin目录下的startup.sh
直接在canal admin的webUI界面中配置instance,等待启动即可,如有问题查看deploy/logs/story/story.log
具体配置项参见wiki
TIP
如果在server的配置文件中填了相同的配置项,那么instance中的配置会被server中的覆盖,例如canal.instance.tsdb.url配置(#issue4669)
此时我们的实例story已经开始监听story数据库下面的操作,如果有变更,就会推送至kafka的canal-story这个topic中
之后就需要通过业务端根据情况监听队列中的数据变化,做相应的操作。
`,35)]))}const c=i(p,[["render",h]]);export{g as __pageData,c as default}; diff --git a/assets/linux_applications_Clash.md.DYXGc4Nj.js b/assets/linux_applications_Clash.md.DYXGc4Nj.js new file mode 100644 index 00000000..efce7bc6 --- /dev/null +++ b/assets/linux_applications_Clash.md.DYXGc4Nj.js @@ -0,0 +1,330 @@ +import{_ as i,c as a,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"Clash","description":"","frontmatter":{},"headers":[],"relativePath":"linux/applications/Clash.md","filePath":"linux/applications/Clash.md","lastUpdated":1729217313000}'),p={name:"linux/applications/Clash.md"};function h(k,s,t,e,E,r){return l(),a("div",null,s[0]||(s[0]=[n(`Repo:https://github.com/Dreamacro/clash
Premium Binary:https://github.com/Dreamacro/clash/releases/tag/premium
Configuration:https://dreamacro.github.io/clash/configuration/configuration-reference.html
下载最新版的premium内核二进制文件
编写配置文件
# /root/.config/clash/config.yaml
+
+# (HTTP and SOCKS5 in one port)
+mixed-port: 7890
+# RESTful API for clash
+external-controller: 127.0.0.1:9090
+secret: 123456
+allow-lan: false
+mode: rule
+log-level: warning
+
+tun:
+ enable: true
+ stack: system # system gvisor
+ auto-route: true
+ auto-detect-interface: true
+ dns-hijack:
+ - any:53 # DNS hijacking might result in a failure, if the system DNS is at a private IP address (since auto-route does not capture private network traffic).
+
+dns:
+ enable: true
+ listen: 0.0.0.0:7874
+ ipv6: false
+ default-nameserver:
+ - 114.114.114.114
+ nameserver:
+ - 119.29.29.29
+ - 223.5.5.5
+ - 8.8.8.8
+ fallback:
+ - https://dns.cloudflare.com/dns-query
+ - tls://dns.google:853
+ - https://1.1.1.1/dns-query
+ enhanced-mode: fake-ip # fake-ip redir-host
+ fake-ip-range: 198.18.0.1/16
+ fake-ip-filter:
+ - "*.lan"
+ - "*.localdomain"
+ - "*.example"
+ - "*.invalid"
+ - "*.localhost"
+ - "*.test"
+ - "*.local"
+ - "*.home.arpa"
+ - time.*.com
+ - time.*.gov
+ - time.*.edu.cn
+ - time.*.apple.com
+ - time-ios.apple.com
+ - time1.*.com
+ - time2.*.com
+ - time3.*.com
+ - time4.*.com
+ - time5.*.com
+ - time6.*.com
+ - time7.*.com
+ - ntp.*.com
+ - ntp1.*.com
+ - ntp2.*.com
+ - ntp3.*.com
+ - ntp4.*.com
+ - ntp5.*.com
+ - ntp6.*.com
+ - ntp7.*.com
+ - "*.time.edu.cn"
+ - "*.ntp.org.cn"
+ - "+.pool.ntp.org"
+ - time1.cloud.tencent.com
+ - music.163.com
+ - "*.music.163.com"
+ - "*.126.net"
+ - musicapi.taihe.com
+ - music.taihe.com
+ - songsearch.kugou.com
+ - trackercdn.kugou.com
+ - "*.kuwo.cn"
+ - api-jooxtt.sanook.com
+ - api.joox.com
+ - joox.com
+ - y.qq.com
+ - "*.y.qq.com"
+ - streamoc.music.tc.qq.com
+ - mobileoc.music.tc.qq.com
+ - isure.stream.qqmusic.qq.com
+ - dl.stream.qqmusic.qq.com
+ - aqqmusic.tc.qq.com
+ - amobile.music.tc.qq.com
+ - "*.xiami.com"
+ - "*.music.migu.cn"
+ - music.migu.cn
+ - "+.msftconnecttest.com"
+ - "+.msftncsi.com"
+ - localhost.ptlogin2.qq.com
+ - localhost.sec.qq.com
+ - "+.qq.com"
+ - "+.tencent.com"
+ - "+.srv.nintendo.net"
+ - "*.n.n.srv.nintendo.net"
+ - "+.stun.playstation.net"
+ - xbox.*.*.microsoft.com
+ - "*.*.xboxlive.com"
+ - xbox.*.microsoft.com
+ - xnotify.xboxlive.com
+ - "+.battlenet.com.cn"
+ - "+.wotgame.cn"
+ - "+.wggames.cn"
+ - "+.wowsgame.cn"
+ - "+.wargaming.net"
+ - proxy.golang.org
+ - stun.*.*
+ - stun.*.*.*
+ - "+.stun.*.*"
+ - "+.stun.*.*.*"
+ - "+.stun.*.*.*.*"
+ - "+.stun.*.*.*.*.*"
+ - heartbeat.belkin.com
+ - "*.linksys.com"
+ - "*.linksyssmartwifi.com"
+ - mobileoc.music.tc.qq.com
+ - isure.stream.qqmusic.qq.com
+ - dl.stream.qqmusic.qq.com
+ - aqqmusic.tc.qq.com
+ - amobile.music.tc.qq.com
+ - "*.xiami.com"
+ - "*.music.migu.cn"
+ - music.migu.cn
+ - "+.msftconnecttest.com"
+ - "+.msftncsi.com"
+ - localhost.ptlogin2.qq.com
+ - localhost.sec.qq.com
+ - "+.qq.com"
+ - "+.tencent.com"
+ - "+.srv.nintendo.net"
+ - "*.n.n.srv.nintendo.net"
+ - "+.stun.playstation.net"
+ - xbox.*.*.microsoft.com
+ - "*.*.xboxlive.com"
+ - xbox.*.microsoft.com
+ - xnotify.xboxlive.com
+ - "+.battlenet.com.cn"
+ - "+.wotgame.cn"
+ - "+.wggames.cn"
+ - "+.wowsgame.cn"
+ - "+.wargaming.net"
+ - proxy.golang.org
+ - stun.*.*
+ - stun.*.*.*
+ - "+.stun.*.*"
+ - "+.stun.*.*.*"
+ - "+.stun.*.*.*.*"
+ - "+.stun.*.*.*.*.*"
+ - heartbeat.belkin.com
+ - "*.linksys.com"
+ - "*.linksyssmartwifi.com"
+ - "*.router.asus.com"
+ - mesu.apple.com
+ - swscan.apple.com
+ - swquery.apple.com
+ - swdownload.apple.com
+ - swcdn.apple.com
+ - swdist.apple.com
+ - lens.l.google.com
+ - stun.l.google.com
+ - "+.nflxvideo.net"
+ - "*.square-enix.com"
+ - "*.finalfantasyxiv.com"
+ - "*.ffxiv.com"
+ - "*.ff14.sdo.com"
+ - ff.dorado.sdo.com
+ - "*.mcdn.bilivideo.cn"
+ - "+.media.dssott.com"
+ - shark007.net
+ - Mijia Cloud
+ - "+.cmbchina.com"
+ - "+.cmbimg.com"
+ - local.adguard.org
+ - "+.sandai.net"
+ - "+.n0808.com"
+
+proxy-providers:
+ provider:
+ type: http
+ path: ./profile/provider.yaml
+ url: subscription.url
+ interval: 36000
+ health-check:
+ enable: true
+ url: http://www.gstatic.com/generate_204
+ interval: 3600
+
+proxy-groups:
+ - name: PROXY
+ type: select
+ use:
+ - provider
+
+rule-providers:
+ reject:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/reject.txt"
+ path: ./ruleset/reject.yaml
+ interval: 86400
+
+ icloud:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/icloud.txt"
+ path: ./ruleset/icloud.yaml
+ interval: 86400
+
+ apple:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/apple.txt"
+ path: ./ruleset/apple.yaml
+ interval: 86400
+
+ # google:
+ # type: http
+ # behavior: domain
+ # url: "https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/google.txt"
+ # path: ./ruleset/google.yaml
+ # interval: 86400
+
+ proxy:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/proxy.txt"
+ path: ./ruleset/proxy.yaml
+ interval: 86400
+
+ direct:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/direct.txt"
+ path: ./ruleset/direct.yaml
+ interval: 86400
+ private:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/private.txt"
+ path: ./ruleset/private.yaml
+ interval: 86400
+
+ gfw:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/gfw.txt"
+ path: ./ruleset/gfw.yaml
+ interval: 86400
+
+ tld-not-cn:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/tld-not-cn.txt"
+ path: ./ruleset/tld-not-cn.yaml
+ interval: 86400
+
+ telegramcidr:
+ type: http
+ behavior: ipcidr
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/telegramcidr.txt"
+ path: ./ruleset/telegramcidr.yaml
+ interval: 86400
+
+ cncidr:
+ type: http
+ behavior: ipcidr
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/cncidr.txt"
+ path: ./ruleset/cncidr.yaml
+ interval: 86400
+
+ lancidr:
+ type: http
+ behavior: ipcidr
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/lancidr.txt"
+ path: ./ruleset/lancidr.yaml
+ interval: 86400
+
+ applications:
+ type: http
+ behavior: classical
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/applications.txt"
+ path: ./ruleset/applications.yaml
+ interval: 86400
+
+
+# Script Shortcuts enables the use of script in rules mode. By default, DNS resolution takes place for SCRIPT rules. no-resolve can be appended to the rule to prevent the resolution. (i.e.: SCRIPT,quic,DIRECT,no-resolve)
+script:
+ engine: expr # or starlark (10x to 20x slower)
+ shortcuts:
+ quic: network == 'udp' and dst_port == 443
+ curl: resolve_process_name() == 'curl'
+ # curl: resolve_process_path() == '/usr/bin/curl'
+ not_common_port: dst_port not in [21, 22, 23, 53, 80, 123, 143, 194, 443, 465, 587, 853, 993, 995, 998, 2052, 2053, 2082, 2083, 2086, 2095, 2096, 5222, 5228, 5229, 5230, 8080, 8443, 8880, 8888, 8889]
+
+
+rules:
+ - SCRIPT,not_common_port,DIRECT # 只代理常规端口,常用于防止PT、BT的流量走代理
+ - SCRIPT,quic,REJECT
+ - DST-PORT,22,DIRECT
+ - RULE-SET,applications,DIRECT
+ - DOMAIN,clash.razord.top,DIRECT
+ - DOMAIN,yacd.haishan.me,DIRECT
+ - RULE-SET,private,DIRECT
+ - RULE-SET,reject,REJECT
+ - RULE-SET,icloud,DIRECT
+ - RULE-SET,apple,DIRECT
+ # - RULE-SET,google,DIRECT
+ - RULE-SET,proxy,PROXY
+ - RULE-SET,direct,DIRECT
+ - RULE-SET,lancidr,DIRECT
+ - RULE-SET,cncidr,DIRECT
+ - RULE-SET,telegramcidr,PROXY
+ - GEOIP,LAN,DIRECT
+ - GEOIP,CN,DIRECT
+ - MATCH,PROXYcat > /etc/systemd/system/clash.service <<EOF
+[Unit]
+Description=clash
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/bin/clash -d /root/.config/clash
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF
+
+# systemctl daemon-reloadcurl -X GET http://127.0.0.1:9090/proxies --header 'Authorization: Bearer 123456'curl -X GET http://127.0.0.1:9090/proxies/{proxyGroupName} --header 'Authorization: Bearer 123456'curl -X PUT http://127.0.0.1:9090/proxies/{proxyGroupName} --header 'Authorization: Bearer 123456' --header "Content-Type: application/json" -d '{"name": "代理节点名称"}'Repo:https://github.com/Dreamacro/clash
Premium Binary:https://github.com/Dreamacro/clash/releases/tag/premium
Configuration:https://dreamacro.github.io/clash/configuration/configuration-reference.html
下载最新版的premium内核二进制文件
编写配置文件
# /root/.config/clash/config.yaml
+
+# (HTTP and SOCKS5 in one port)
+mixed-port: 7890
+# RESTful API for clash
+external-controller: 127.0.0.1:9090
+secret: 123456
+allow-lan: false
+mode: rule
+log-level: warning
+
+tun:
+ enable: true
+ stack: system # system gvisor
+ auto-route: true
+ auto-detect-interface: true
+ dns-hijack:
+ - any:53 # DNS hijacking might result in a failure, if the system DNS is at a private IP address (since auto-route does not capture private network traffic).
+
+dns:
+ enable: true
+ listen: 0.0.0.0:7874
+ ipv6: false
+ default-nameserver:
+ - 114.114.114.114
+ nameserver:
+ - 119.29.29.29
+ - 223.5.5.5
+ - 8.8.8.8
+ fallback:
+ - https://dns.cloudflare.com/dns-query
+ - tls://dns.google:853
+ - https://1.1.1.1/dns-query
+ enhanced-mode: fake-ip # fake-ip redir-host
+ fake-ip-range: 198.18.0.1/16
+ fake-ip-filter:
+ - "*.lan"
+ - "*.localdomain"
+ - "*.example"
+ - "*.invalid"
+ - "*.localhost"
+ - "*.test"
+ - "*.local"
+ - "*.home.arpa"
+ - time.*.com
+ - time.*.gov
+ - time.*.edu.cn
+ - time.*.apple.com
+ - time-ios.apple.com
+ - time1.*.com
+ - time2.*.com
+ - time3.*.com
+ - time4.*.com
+ - time5.*.com
+ - time6.*.com
+ - time7.*.com
+ - ntp.*.com
+ - ntp1.*.com
+ - ntp2.*.com
+ - ntp3.*.com
+ - ntp4.*.com
+ - ntp5.*.com
+ - ntp6.*.com
+ - ntp7.*.com
+ - "*.time.edu.cn"
+ - "*.ntp.org.cn"
+ - "+.pool.ntp.org"
+ - time1.cloud.tencent.com
+ - music.163.com
+ - "*.music.163.com"
+ - "*.126.net"
+ - musicapi.taihe.com
+ - music.taihe.com
+ - songsearch.kugou.com
+ - trackercdn.kugou.com
+ - "*.kuwo.cn"
+ - api-jooxtt.sanook.com
+ - api.joox.com
+ - joox.com
+ - y.qq.com
+ - "*.y.qq.com"
+ - streamoc.music.tc.qq.com
+ - mobileoc.music.tc.qq.com
+ - isure.stream.qqmusic.qq.com
+ - dl.stream.qqmusic.qq.com
+ - aqqmusic.tc.qq.com
+ - amobile.music.tc.qq.com
+ - "*.xiami.com"
+ - "*.music.migu.cn"
+ - music.migu.cn
+ - "+.msftconnecttest.com"
+ - "+.msftncsi.com"
+ - localhost.ptlogin2.qq.com
+ - localhost.sec.qq.com
+ - "+.qq.com"
+ - "+.tencent.com"
+ - "+.srv.nintendo.net"
+ - "*.n.n.srv.nintendo.net"
+ - "+.stun.playstation.net"
+ - xbox.*.*.microsoft.com
+ - "*.*.xboxlive.com"
+ - xbox.*.microsoft.com
+ - xnotify.xboxlive.com
+ - "+.battlenet.com.cn"
+ - "+.wotgame.cn"
+ - "+.wggames.cn"
+ - "+.wowsgame.cn"
+ - "+.wargaming.net"
+ - proxy.golang.org
+ - stun.*.*
+ - stun.*.*.*
+ - "+.stun.*.*"
+ - "+.stun.*.*.*"
+ - "+.stun.*.*.*.*"
+ - "+.stun.*.*.*.*.*"
+ - heartbeat.belkin.com
+ - "*.linksys.com"
+ - "*.linksyssmartwifi.com"
+ - mobileoc.music.tc.qq.com
+ - isure.stream.qqmusic.qq.com
+ - dl.stream.qqmusic.qq.com
+ - aqqmusic.tc.qq.com
+ - amobile.music.tc.qq.com
+ - "*.xiami.com"
+ - "*.music.migu.cn"
+ - music.migu.cn
+ - "+.msftconnecttest.com"
+ - "+.msftncsi.com"
+ - localhost.ptlogin2.qq.com
+ - localhost.sec.qq.com
+ - "+.qq.com"
+ - "+.tencent.com"
+ - "+.srv.nintendo.net"
+ - "*.n.n.srv.nintendo.net"
+ - "+.stun.playstation.net"
+ - xbox.*.*.microsoft.com
+ - "*.*.xboxlive.com"
+ - xbox.*.microsoft.com
+ - xnotify.xboxlive.com
+ - "+.battlenet.com.cn"
+ - "+.wotgame.cn"
+ - "+.wggames.cn"
+ - "+.wowsgame.cn"
+ - "+.wargaming.net"
+ - proxy.golang.org
+ - stun.*.*
+ - stun.*.*.*
+ - "+.stun.*.*"
+ - "+.stun.*.*.*"
+ - "+.stun.*.*.*.*"
+ - "+.stun.*.*.*.*.*"
+ - heartbeat.belkin.com
+ - "*.linksys.com"
+ - "*.linksyssmartwifi.com"
+ - "*.router.asus.com"
+ - mesu.apple.com
+ - swscan.apple.com
+ - swquery.apple.com
+ - swdownload.apple.com
+ - swcdn.apple.com
+ - swdist.apple.com
+ - lens.l.google.com
+ - stun.l.google.com
+ - "+.nflxvideo.net"
+ - "*.square-enix.com"
+ - "*.finalfantasyxiv.com"
+ - "*.ffxiv.com"
+ - "*.ff14.sdo.com"
+ - ff.dorado.sdo.com
+ - "*.mcdn.bilivideo.cn"
+ - "+.media.dssott.com"
+ - shark007.net
+ - Mijia Cloud
+ - "+.cmbchina.com"
+ - "+.cmbimg.com"
+ - local.adguard.org
+ - "+.sandai.net"
+ - "+.n0808.com"
+
+proxy-providers:
+ provider:
+ type: http
+ path: ./profile/provider.yaml
+ url: subscription.url
+ interval: 36000
+ health-check:
+ enable: true
+ url: http://www.gstatic.com/generate_204
+ interval: 3600
+
+proxy-groups:
+ - name: PROXY
+ type: select
+ use:
+ - provider
+
+rule-providers:
+ reject:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/reject.txt"
+ path: ./ruleset/reject.yaml
+ interval: 86400
+
+ icloud:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/icloud.txt"
+ path: ./ruleset/icloud.yaml
+ interval: 86400
+
+ apple:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/apple.txt"
+ path: ./ruleset/apple.yaml
+ interval: 86400
+
+ # google:
+ # type: http
+ # behavior: domain
+ # url: "https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/google.txt"
+ # path: ./ruleset/google.yaml
+ # interval: 86400
+
+ proxy:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/proxy.txt"
+ path: ./ruleset/proxy.yaml
+ interval: 86400
+
+ direct:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/direct.txt"
+ path: ./ruleset/direct.yaml
+ interval: 86400
+ private:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/private.txt"
+ path: ./ruleset/private.yaml
+ interval: 86400
+
+ gfw:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/gfw.txt"
+ path: ./ruleset/gfw.yaml
+ interval: 86400
+
+ tld-not-cn:
+ type: http
+ behavior: domain
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/tld-not-cn.txt"
+ path: ./ruleset/tld-not-cn.yaml
+ interval: 86400
+
+ telegramcidr:
+ type: http
+ behavior: ipcidr
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/telegramcidr.txt"
+ path: ./ruleset/telegramcidr.yaml
+ interval: 86400
+
+ cncidr:
+ type: http
+ behavior: ipcidr
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/cncidr.txt"
+ path: ./ruleset/cncidr.yaml
+ interval: 86400
+
+ lancidr:
+ type: http
+ behavior: ipcidr
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/lancidr.txt"
+ path: ./ruleset/lancidr.yaml
+ interval: 86400
+
+ applications:
+ type: http
+ behavior: classical
+ url: "https://raw.githubusercontent.com/Loyalsoldier/clash-rules/release/applications.txt"
+ path: ./ruleset/applications.yaml
+ interval: 86400
+
+
+# Script Shortcuts enables the use of script in rules mode. By default, DNS resolution takes place for SCRIPT rules. no-resolve can be appended to the rule to prevent the resolution. (i.e.: SCRIPT,quic,DIRECT,no-resolve)
+script:
+ engine: expr # or starlark (10x to 20x slower)
+ shortcuts:
+ quic: network == 'udp' and dst_port == 443
+ curl: resolve_process_name() == 'curl'
+ # curl: resolve_process_path() == '/usr/bin/curl'
+ not_common_port: dst_port not in [21, 22, 23, 53, 80, 123, 143, 194, 443, 465, 587, 853, 993, 995, 998, 2052, 2053, 2082, 2083, 2086, 2095, 2096, 5222, 5228, 5229, 5230, 8080, 8443, 8880, 8888, 8889]
+
+
+rules:
+ - SCRIPT,not_common_port,DIRECT # 只代理常规端口,常用于防止PT、BT的流量走代理
+ - SCRIPT,quic,REJECT
+ - DST-PORT,22,DIRECT
+ - RULE-SET,applications,DIRECT
+ - DOMAIN,clash.razord.top,DIRECT
+ - DOMAIN,yacd.haishan.me,DIRECT
+ - RULE-SET,private,DIRECT
+ - RULE-SET,reject,REJECT
+ - RULE-SET,icloud,DIRECT
+ - RULE-SET,apple,DIRECT
+ # - RULE-SET,google,DIRECT
+ - RULE-SET,proxy,PROXY
+ - RULE-SET,direct,DIRECT
+ - RULE-SET,lancidr,DIRECT
+ - RULE-SET,cncidr,DIRECT
+ - RULE-SET,telegramcidr,PROXY
+ - GEOIP,LAN,DIRECT
+ - GEOIP,CN,DIRECT
+ - MATCH,PROXYcat > /etc/systemd/system/clash.service <<EOF
+[Unit]
+Description=clash
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/bin/clash -d /root/.config/clash
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF
+
+# systemctl daemon-reloadcurl -X GET http://127.0.0.1:9090/proxies --header 'Authorization: Bearer 123456'curl -X GET http://127.0.0.1:9090/proxies/{proxyGroupName} --header 'Authorization: Bearer 123456'curl -X PUT http://127.0.0.1:9090/proxies/{proxyGroupName} --header 'Authorization: Bearer 123456' --header "Content-Type: application/json" -d '{"name": "代理节点名称"}'FFmpeg: A complete, cross-platform solution to record, convert and stream audio and video.
ffmpeg -i input.mp4 -vn -acodec libmp3lame -q:a 0 ~/Downloads/output.mp3-vn:禁用复制视频流,只提取音频流-acodec libmp3lame:指定输出使用 LAME MP3 编码器进行编码。-q:a 0:设置输出音频的质量。0 表示最高品质。yt-dlp -f bestaudio "https://www.youtube.com/watch?v=xxx" -o - | ffmpeg -i pipe:0 -vn -acodec libmp3lame -q:a 0 ~/downloads/output.mp3yt-dlp -f bestvideo+bestaudio "https://www.youtube.com/watch?v=example" -o ~/Downloads/output.mp4 --recode-video mp4FFmpeg: A complete, cross-platform solution to record, convert and stream audio and video.
ffmpeg -i input.mp4 -vn -acodec libmp3lame -q:a 0 ~/Downloads/output.mp3-vn:禁用复制视频流,只提取音频流-acodec libmp3lame:指定输出使用 LAME MP3 编码器进行编码。-q:a 0:设置输出音频的质量。0 表示最高品质。yt-dlp -f bestaudio "https://www.youtube.com/watch?v=xxx" -o - | ffmpeg -i pipe:0 -vn -acodec libmp3lame -q:a 0 ~/downloads/output.mp3yt-dlp -f bestvideo+bestaudio "https://www.youtube.com/watch?v=example" -o ~/Downloads/output.mp4 --recode-video mp4grafana的告警可以使用Go Template语法来读取内置的变量数据并输出到告警邮件中
比如alert query从Loki日志中查询,可以同时从日志中提取出自己需要的关键属性作为标签:
count_over_time({job="wechat"} |= \`订单申请退款失败\` | pattern \`<_> orderNo=<orderNo> refundNo=<refundNo>\` [1m])上面的查询提取了订单号、退款单号的数据,标签会存在_value_string_中,可以使用$values访问,在Summary中填写以下模板:
{{ with $values }}
+{{ range $k, $v := . }}
+ 订单编号: {{$v.Labels.orderNo}}
+ 退款单号: {{$v.Labels.refundNo}}
+ 服务器实例: {{$v.Labels.instance}}
+{{ end }}
+{{ end }}https://community.grafana.com/t/how-to-use-alert-message-templates-in-grafana/67537/3
Guest# grafana.ini
+
+[auth.anonymous]
+# enable anonymous access
+enabled = true
+# specify organization name that should be used for unauthenticated users
+org_name = Guest
+# specify role for unauthenticated users
+org_role = Viewer
+
+# mask the Grafana version number for unauthenticated users
+hide_version = truegrafana的告警可以使用Go Template语法来读取内置的变量数据并输出到告警邮件中
比如alert query从Loki日志中查询,可以同时从日志中提取出自己需要的关键属性作为标签:
count_over_time({job="wechat"} |= \`订单申请退款失败\` | pattern \`<_> orderNo=<orderNo> refundNo=<refundNo>\` [1m])上面的查询提取了订单号、退款单号的数据,标签会存在_value_string_中,可以使用$values访问,在Summary中填写以下模板:
{{ with $values }}
+{{ range $k, $v := . }}
+ 订单编号: {{$v.Labels.orderNo}}
+ 退款单号: {{$v.Labels.refundNo}}
+ 服务器实例: {{$v.Labels.instance}}
+{{ end }}
+{{ end }}https://community.grafana.com/t/how-to-use-alert-message-templates-in-grafana/67537/3
Guest# grafana.ini
+
+[auth.anonymous]
+# enable anonymous access
+enabled = true
+# specify organization name that should be used for unauthenticated users
+org_name = Guest
+# specify role for unauthenticated users
+org_role = Viewer
+
+# mask the Grafana version number for unauthenticated users
+hide_version = truewget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
yum install google-chrome-stable_current_x86_64.rpm
yum install mesa-libOSMesa-devel gnu-free-sans-fonts wqy-zenhei-fonts
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.debsudo dpkg -i google-chrome-stable_current_amd64.deb
安装报错
dpkg: error processing package google-chrome-stable (--install): dependency problems - leaving unconfigured Processing triggers for mime-support (3.64ubuntu1) ... Processing triggers for man-db (2.9.1-1) ... Errors were encountered while processing: google-chrome-stable
使用sudo apt-get install -f修复依赖关系,
如果系统中有某个软件包不满足依赖条件,这个命令就会自动修复,将要安装那个软件包依赖的软件包。
淘宝源地址:http://npm.taobao.org/mirrors/chromedriver/
需要根据不同版本的chrome进行选择下载,比如我安装的chrome是96版本的,那么chromedriver就需要找对应的96版本
这里选择一个最近更新的即可

这里下载linux版本,下载后解压,把解压后的chromedriver可执行文件移动到path下,例如/usr/bin
wget http://npm.taobao.org/mirrors/chromedriver/96.0.4664.45/chromedriver_linux64.zip
+
+unzip chromedriver_linux64.zip
+
+mv chromedriver /usr/bin
+
+chmod +x /usr/bin/chromedriverlinux下无头浏览器模式:
from selenium import webdriver
+from selenium.webdriver.chrome.options import Options
+
+chrome_options = Options()
+chrome_options.add_argument('--headless')
+chrome_options.add_argument('--no-sandbox')
+chrome_options.add_argument('--disable-gpu')
+chrome_options.add_argument('--disable-dev-shm-usage')
+driver = webdriver.Chrome(chrome_options=chrome_options)
+driver.get("https://www.baidu.com")
+
+with open("./baidu.html", "w", encoding="utf-8") as fp:
+ fp.write(driver.page_source)wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
yum install google-chrome-stable_current_x86_64.rpm
yum install mesa-libOSMesa-devel gnu-free-sans-fonts wqy-zenhei-fonts
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.debsudo dpkg -i google-chrome-stable_current_amd64.deb
安装报错
dpkg: error processing package google-chrome-stable (--install): dependency problems - leaving unconfigured Processing triggers for mime-support (3.64ubuntu1) ... Processing triggers for man-db (2.9.1-1) ... Errors were encountered while processing: google-chrome-stable
使用sudo apt-get install -f修复依赖关系,
如果系统中有某个软件包不满足依赖条件,这个命令就会自动修复,将要安装那个软件包依赖的软件包。
淘宝源地址:http://npm.taobao.org/mirrors/chromedriver/
需要根据不同版本的chrome进行选择下载,比如我安装的chrome是96版本的,那么chromedriver就需要找对应的96版本
这里选择一个最近更新的即可
这里下载linux版本,下载后解压,把解压后的chromedriver可执行文件移动到path下,例如/usr/bin
wget http://npm.taobao.org/mirrors/chromedriver/96.0.4664.45/chromedriver_linux64.zip
+
+unzip chromedriver_linux64.zip
+
+mv chromedriver /usr/bin
+
+chmod +x /usr/bin/chromedriverlinux下无头浏览器模式:
from selenium import webdriver
+from selenium.webdriver.chrome.options import Options
+
+chrome_options = Options()
+chrome_options.add_argument('--headless')
+chrome_options.add_argument('--no-sandbox')
+chrome_options.add_argument('--disable-gpu')
+chrome_options.add_argument('--disable-dev-shm-usage')
+driver = webdriver.Chrome(chrome_options=chrome_options)
+driver.get("https://www.baidu.com")
+
+with open("./baidu.html", "w", encoding="utf-8") as fp:
+ fp.write(driver.page_source)记录常用、踩坑的nginx配置内容
upstream指令主要用于负载均衡,设置一系列的后端服务器
server块的指令主要用于指定主机和端口
监听的端口号
default_server:定义默认的 server 处理没有成功匹配 server_name 的请求,如果没有显式定义,则会选取第一个定义的server作为default_server。
显式定义:listen 80 default_server
隐式定义
http {
+ # 如果没有显式声明 default server 则第一个 server 会被隐式的设为 default server
+ server {
+ listen 80;
+ server_name _; # _ 并不是重点 __ 也可以 ___也可以
+ return 403; # 403 forbidden
+ }
+
+ server {
+ listen 80;
+ server_name www.a.com;
+ ...
+ }
+}server_name storyxc.com:完整匹配
server_name *.storyxc.com:*开始的通配符匹配
.storyxc.com能同时匹配storyxc.com和*.storyxc.comA wildcard name may contain an asterisk only on the name’s start or end, and only on a dot border. The names “
www.*.example.org” and “w*.example.org” are invalid. However, these names can be specified using regular expressions, for example, “~^www\\..+\\.example\\.org$” and “~^w.*\\.example\\.org$”. An asterisk can match several name parts. The name “*.example.org” matches not onlywww.example.orgbutwww.sub.example.orgas well.A special wildcard name in the form “
.example.org” can be used to match both the exact name “example.org” and the wildcard name “*.example.org”.
server_name mail.* :*结尾的通配符匹配
server_name ~^(?<user>.+)\\.storyxc\\.com$第一个匹配的正则表达式(按照配置文件中出现的顺序)
server_name _:通常使用_作为default server的server_name
location块用于匹配网页位置
location支持正则表达式匹配,也支持条件判断匹配
语法规则: location [=|~|~*|^~] /uri/ { … }
=:完全精确匹配^~:表示uri以某个常规字符串开头,理解为匹配url路径即可,nginx不对url进行编码~:表示区分大小写的正则匹配~*:表示不区分大小写的正则匹配!~:区分大小写不匹配!~*:不区分大小写不匹配/:通用匹配,优先级最低匹配顺序:=最高,正则匹配其次(按照规则顺序),通用匹配/最低,匹配成功时停止匹配按照当前规则处理请求
location ~ .*\\.(gif|jpg|jpeg|png|bmp|swf)$ {
+ # 匹配所有扩展名以.gif、.jpg、.jpeg、.png、.bmp、.swf结尾的静态文件
+ root /wwwroot/xxx;
+ # expires用来指定静态文件的过期时间,这里是30天
+ expires 30d;
+}location ~ ^/(upload|html)/ {
+ # 匹配所有/upload /html
+ root /web/wwwroot/www.cszhi.com;
+ expires 30d;
+}/的影响 | Case # | Nginx location | proxy_pass URL | Test URL | Path received |
|---|---|---|---|---|
| 01 | /test01 | http://127.0.0.1:8080 | /test01/abc/test | /test01/abc/test |
| 02 | /test02 | http://127.0.0.1:8080/ | /test02/abc/test | //abc/test |
| 03 | /test03/ | http://127.0.0.1:8080 | /test03/abc/test | /test03/abc/test |
| 04 | /test04/ | http://127.0.0.1:8080/ | /test04/abc/test | /abc/test |
| 05 | /test05 | http://127.0.0.1:8080/app1 | /test05/abc/test | /app1/abc/test |
| 06 | /test06 | http://127.0.0.1:8080/app1/ | /test06/abc/test | /app1//abc/test |
| 07 | /test07/ | http://127.0.0.1:8080/app1 | /test07/abc/test | /app1abc/test |
| 08 | /test08/ | http://127.0.0.1:8080/app1/ | /test08/abc/test | /app1/abc/test |
| 09 | / | http://127.0.0.1:8080 | /test09/abc/test | /test09/abc/test |
| 10 | / | http://127.0.0.1:8080/ | /test10/abc/test | /test10/abc/test |
| 11 | / | http://127.0.0.1:8080/app1 | /test11/abc/test | /app1test11/abc/test |
| 12 | / | http://127.0.0.1:8080/app2/ | /test12/abc/test | /app2/test12/abc/test |
/,否则就会访问失败location /abc {
+ root /wwwroot/aaa;
+ # 此规则匹配的最终资源路径为/wwwroot/aaa/abc/
+ # 如果访问的是/abc/a.html,则最终访问的资源是服务器中的/wwwroot/aaa/abc/a.html
+ index index.html;
+}
+
+location /abc {
+ alias /wwwroot/aaa/;
+ # 此规则匹配的最终资源路径为/wwwroot/aaa/
+ # 如果访问的是/abc/b.txt,则最终访问的资源是/wwwroot/aaa/b.txt
+ index index.html;
+}当nginx监听的不是80端口时,访问文件夹且末尾不是/,则nginx会进行301永久重定向,此时会丢掉客户端访问时的端口号,可以通过以下配置解决,作用是将不以 / 结尾的目录 URL 重定向至以 / 结尾的目录 URL。使用 -d 判断 $request_filename 是否为一个目录,如果是,则使用 rewrite 指令进行重写。其中,[^/]$ 表示匹配不以 / 结尾的 URL,即目录 URL,$scheme://$http_host$uri/ 表示重定向目标 URL,其中使用了 $scheme 变量表示客户端请求所使用的协议(HTTP 或 HTTPS)、$http_host 变量表示客户端请求的 HOST 头部信息、$uri 变量表示客户端请求的 URI。
location / {
+ if (-d $request_filename) {
+ rewrite [^/]$ $scheme://$http_host$uri/ permanent;
+ }
+ try_files $uri $uri/ /index.html;
+}| 变量名 | 作用 |
|---|---|
| $scheme | 请求使用的协议 (http 或 https) |
| $host | 当前请求的主机名,不包括端口号。 |
| $http_host | 完整的HTTP主机头,包括主机名和端口号。 |
| $request_uri | 完整的请求 URI,包括查询字符串 |
| $uri | 当前请求的 URI (不包含请求参数) |
| $args | 当前请求的参数部分,不包括问号 |
| $request_method | 当前请求的方法 (GET、POST 等) |
| $remote_addr | 客户端 IP 地址 |
| $server_addr | 服务器 IP 地址 |
| $server_name | 当前请求的服务器名称 |
| $server_protocol | 服务器使用的协议版本 |
| $request_filename | 当前请求的文件路径和名称 |
| $document_root | 当前请求的根目录 |
| $is_args | 如果请求包含参数部分,值为 ?,否则为空字符串 |
| $query_string | 当前请求的查询字符串部分,包括问号(?) |
| $http_user_agent | 客户端发送的 User-Agent 头部信息 |
| $http_referer | 客户端发送的 Referer 头部信息 |
| $http_cookie | 客户端发送的 Cookie 头部信息 |
| $remote_port | 客户端端口号 |
| $server_port | 服务器端口号 |
| $realpath_root | 请求根目录的实际路径 |
| $content_type | 请求的内容类型 |
| $content_length | 请求的内容长度 |
| $request_body | 请求的主体内容 |
| 配置指令 | 作用 |
|---|---|
proxy_set_header Host $host; | 设置代理请求的主机头,通常用于传递客户端的原始主机头。$http_host传递包含端口号。 |
proxy_set_header X-Real-IP $remote_addr; | 设置代理请求的客户端真实IP地址,用于传递客户端的真实IP地址给后端服务器。 |
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; | 用于将客户端的原始IP地址添加到X-Forwarded-For头中,以便后端服务器知道请求的真实来源。 |
proxy_set_header X-Forwarded-Proto $scheme; | 设置代理请求的协议(HTTP或HTTPS),以便后端服务器知道请求的协议类型。 |
proxy_set_header User-Agent $http_user_agent; | 传递客户端的User-Agent头,用于识别客户端的浏览器或应用程序。 |
proxy_set_header Referer $http_referer; | 传递客户端的Referer头,通常用于跟踪页面来源。 |
proxy_set_header Cookie $http_cookie; | 传递客户端的Cookie头,以便后端服务器可以访问客户端的Cookie数据。 |
proxy_set_header Connection ""; | 清除代理请求的Connection头,通常用于避免代理干扰连接的管理。 |
proxy_set_header Upgrade $http_upgrade; | 用于处理WebSocket连接的Upgrade头,通常与WebSocket代理一起使用。 |
proxy_set_header X-Frame-Options SAMEORIGIN; | 用于设置X-Frame-Options头,控制网页是否可以嵌套在其他网页中显示。 |
记录常用、踩坑的nginx配置内容
upstream指令主要用于负载均衡,设置一系列的后端服务器
server块的指令主要用于指定主机和端口
监听的端口号
default_server:定义默认的 server 处理没有成功匹配 server_name 的请求,如果没有显式定义,则会选取第一个定义的server作为default_server。
显式定义:listen 80 default_server
隐式定义
http {
+ # 如果没有显式声明 default server 则第一个 server 会被隐式的设为 default server
+ server {
+ listen 80;
+ server_name _; # _ 并不是重点 __ 也可以 ___也可以
+ return 403; # 403 forbidden
+ }
+
+ server {
+ listen 80;
+ server_name www.a.com;
+ ...
+ }
+}server_name storyxc.com:完整匹配
server_name *.storyxc.com:*开始的通配符匹配
.storyxc.com能同时匹配storyxc.com和*.storyxc.comA wildcard name may contain an asterisk only on the name’s start or end, and only on a dot border. The names “
www.*.example.org” and “w*.example.org” are invalid. However, these names can be specified using regular expressions, for example, “~^www\\..+\\.example\\.org$” and “~^w.*\\.example\\.org$”. An asterisk can match several name parts. The name “*.example.org” matches not onlywww.example.orgbutwww.sub.example.orgas well.A special wildcard name in the form “
.example.org” can be used to match both the exact name “example.org” and the wildcard name “*.example.org”.
server_name mail.* :*结尾的通配符匹配
server_name ~^(?<user>.+)\\.storyxc\\.com$第一个匹配的正则表达式(按照配置文件中出现的顺序)
server_name _:通常使用_作为default server的server_name
location块用于匹配网页位置
location支持正则表达式匹配,也支持条件判断匹配
语法规则: location [=|~|~*|^~] /uri/ { … }
=:完全精确匹配^~:表示uri以某个常规字符串开头,理解为匹配url路径即可,nginx不对url进行编码~:表示区分大小写的正则匹配~*:表示不区分大小写的正则匹配!~:区分大小写不匹配!~*:不区分大小写不匹配/:通用匹配,优先级最低匹配顺序:=最高,正则匹配其次(按照规则顺序),通用匹配/最低,匹配成功时停止匹配按照当前规则处理请求
location ~ .*\\.(gif|jpg|jpeg|png|bmp|swf)$ {
+ # 匹配所有扩展名以.gif、.jpg、.jpeg、.png、.bmp、.swf结尾的静态文件
+ root /wwwroot/xxx;
+ # expires用来指定静态文件的过期时间,这里是30天
+ expires 30d;
+}location ~ ^/(upload|html)/ {
+ # 匹配所有/upload /html
+ root /web/wwwroot/www.cszhi.com;
+ expires 30d;
+}/的影响 | Case # | Nginx location | proxy_pass URL | Test URL | Path received |
|---|---|---|---|---|
| 01 | /test01 | http://127.0.0.1:8080 | /test01/abc/test | /test01/abc/test |
| 02 | /test02 | http://127.0.0.1:8080/ | /test02/abc/test | //abc/test |
| 03 | /test03/ | http://127.0.0.1:8080 | /test03/abc/test | /test03/abc/test |
| 04 | /test04/ | http://127.0.0.1:8080/ | /test04/abc/test | /abc/test |
| 05 | /test05 | http://127.0.0.1:8080/app1 | /test05/abc/test | /app1/abc/test |
| 06 | /test06 | http://127.0.0.1:8080/app1/ | /test06/abc/test | /app1//abc/test |
| 07 | /test07/ | http://127.0.0.1:8080/app1 | /test07/abc/test | /app1abc/test |
| 08 | /test08/ | http://127.0.0.1:8080/app1/ | /test08/abc/test | /app1/abc/test |
| 09 | / | http://127.0.0.1:8080 | /test09/abc/test | /test09/abc/test |
| 10 | / | http://127.0.0.1:8080/ | /test10/abc/test | /test10/abc/test |
| 11 | / | http://127.0.0.1:8080/app1 | /test11/abc/test | /app1test11/abc/test |
| 12 | / | http://127.0.0.1:8080/app2/ | /test12/abc/test | /app2/test12/abc/test |
/,否则就会访问失败location /abc {
+ root /wwwroot/aaa;
+ # 此规则匹配的最终资源路径为/wwwroot/aaa/abc/
+ # 如果访问的是/abc/a.html,则最终访问的资源是服务器中的/wwwroot/aaa/abc/a.html
+ index index.html;
+}
+
+location /abc {
+ alias /wwwroot/aaa/;
+ # 此规则匹配的最终资源路径为/wwwroot/aaa/
+ # 如果访问的是/abc/b.txt,则最终访问的资源是/wwwroot/aaa/b.txt
+ index index.html;
+}当nginx监听的不是80端口时,访问文件夹且末尾不是/,则nginx会进行301永久重定向,此时会丢掉客户端访问时的端口号,可以通过以下配置解决,作用是将不以 / 结尾的目录 URL 重定向至以 / 结尾的目录 URL。使用 -d 判断 $request_filename 是否为一个目录,如果是,则使用 rewrite 指令进行重写。其中,[^/]$ 表示匹配不以 / 结尾的 URL,即目录 URL,$scheme://$http_host$uri/ 表示重定向目标 URL,其中使用了 $scheme 变量表示客户端请求所使用的协议(HTTP 或 HTTPS)、$http_host 变量表示客户端请求的 HOST 头部信息、$uri 变量表示客户端请求的 URI。
location / {
+ if (-d $request_filename) {
+ rewrite [^/]$ $scheme://$http_host$uri/ permanent;
+ }
+ try_files $uri $uri/ /index.html;
+}| 变量名 | 作用 |
|---|---|
| $scheme | 请求使用的协议 (http 或 https) |
| $host | 当前请求的主机名,不包括端口号。 |
| $http_host | 完整的HTTP主机头,包括主机名和端口号。 |
| $request_uri | 完整的请求 URI,包括查询字符串 |
| $uri | 当前请求的 URI (不包含请求参数) |
| $args | 当前请求的参数部分,不包括问号 |
| $request_method | 当前请求的方法 (GET、POST 等) |
| $remote_addr | 客户端 IP 地址 |
| $server_addr | 服务器 IP 地址 |
| $server_name | 当前请求的服务器名称 |
| $server_protocol | 服务器使用的协议版本 |
| $request_filename | 当前请求的文件路径和名称 |
| $document_root | 当前请求的根目录 |
| $is_args | 如果请求包含参数部分,值为 ?,否则为空字符串 |
| $query_string | 当前请求的查询字符串部分,包括问号(?) |
| $http_user_agent | 客户端发送的 User-Agent 头部信息 |
| $http_referer | 客户端发送的 Referer 头部信息 |
| $http_cookie | 客户端发送的 Cookie 头部信息 |
| $remote_port | 客户端端口号 |
| $server_port | 服务器端口号 |
| $realpath_root | 请求根目录的实际路径 |
| $content_type | 请求的内容类型 |
| $content_length | 请求的内容长度 |
| $request_body | 请求的主体内容 |
| 配置指令 | 作用 |
|---|---|
proxy_set_header Host $host; | 设置代理请求的主机头,通常用于传递客户端的原始主机头。$http_host传递包含端口号。 |
proxy_set_header X-Real-IP $remote_addr; | 设置代理请求的客户端真实IP地址,用于传递客户端的真实IP地址给后端服务器。 |
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; | 用于将客户端的原始IP地址添加到X-Forwarded-For头中,以便后端服务器知道请求的真实来源。 |
proxy_set_header X-Forwarded-Proto $scheme; | 设置代理请求的协议(HTTP或HTTPS),以便后端服务器知道请求的协议类型。 |
proxy_set_header User-Agent $http_user_agent; | 传递客户端的User-Agent头,用于识别客户端的浏览器或应用程序。 |
proxy_set_header Referer $http_referer; | 传递客户端的Referer头,通常用于跟踪页面来源。 |
proxy_set_header Cookie $http_cookie; | 传递客户端的Cookie头,以便后端服务器可以访问客户端的Cookie数据。 |
proxy_set_header Connection ""; | 清除代理请求的Connection头,通常用于避免代理干扰连接的管理。 |
proxy_set_header Upgrade $http_upgrade; | 用于处理WebSocket连接的Upgrade头,通常与WebSocket代理一起使用。 |
proxy_set_header X-Frame-Options SAMEORIGIN; | 用于设置X-Frame-Options头,控制网页是否可以嵌套在其他网页中显示。 |
rclone 作为文件和对象存储的管理工具, 经过近些年的发展已经完好的支持各种存储协议, 比如 HDFS, FTP, SFTP, GCS 和 S3(兼容 aws, 金山云, 腾讯云, 阿里云等)等, 逐渐有统一管理云存储之势, 从 rclone-github 来看, 各大云厂商也逐渐将各自的存储协议合并到了 rclone 中. 这在对象存储统一管理, 尤其是多云管理的场景中带来了很大的便利, 也便于我们实现诸如统一运维管理的目标.
两种方式:
apt install rclonecurl https://rclone.org/install.sh | sudo bashrclone config
+2023/10/20 16:58:06 NOTICE: Config file "/root/.config/rclone/rclone.conf" not found - using defaults
+No remotes found - make a new one
+n) New remote
+s) Set configuration password
+q) Quit config
+n/s/q>n
+name>alist
+Type of storage to configure.
+Enter a string value. Press Enter for the default ("").
+Choose a number from below, or type in your own value
+ 1 / 1Fichier
+ \\ "fichier"
+ 2 / Alias for an existing remote
+ \\ "alias"
+ 3 / Amazon Drive
+ \\ "amazon cloud drive"
+ 4 / Amazon S3 Compliant Storage Provider (AWS, Alibaba, Ceph, Digital Ocean, Dreamhost, IBM COS, Minio, Tencent COS, etc)
+ \\ "s3"
+ 5 / Backblaze B2
+ \\ "b2"
+ 6 / Box
+ \\ "box"
+ 7 / Cache a remote
+ \\ "cache"
+ 8 / Citrix Sharefile
+ \\ "sharefile"
+ 9 / Dropbox
+ \\ "dropbox"
+10 / Encrypt/Decrypt a remote
+ \\ "crypt"
+11 / FTP Connection
+ \\ "ftp"
+12 / Google Cloud Storage (this is not Google Drive)
+ \\ "google cloud storage"
+13 / Google Drive
+ \\ "drive"
+14 / Google Photos
+ \\ "google photos"
+15 / Hubic
+ \\ "hubic"
+16 / In memory object storage system.
+ \\ "memory"
+17 / Jottacloud
+ \\ "jottacloud"
+18 / Koofr
+ \\ "koofr"
+19 / Local Disk
+ \\ "local"
+20 / Mail.ru Cloud
+ \\ "mailru"
+21 / Microsoft Azure Blob Storage
+ \\ "azureblob"
+22 / Microsoft OneDrive
+ \\ "onedrive"
+23 / OpenDrive
+ \\ "opendrive"
+24 / OpenStack Swift (Rackspace Cloud Files, Memset Memstore, OVH)
+ \\ "swift"
+25 / Pcloud
+ \\ "pcloud"
+26 / Put.io
+ \\ "putio"
+27 / SSH/SFTP Connection
+ \\ "sftp"
+28 / Sugarsync
+ \\ "sugarsync"
+29 / Transparently chunk/split large files
+ \\ "chunker"
+30 / Union merges the contents of several upstream fs
+ \\ "union"
+31 / Webdav
+ \\ "webdav"
+32 / Yandex Disk
+ \\ "yandex"
+33 / http Connection
+ \\ "http"
+34 / premiumize.me
+ \\ "premiumizeme"
+35 / seafile
+ \\ "seafile"
+Storage> 31
+** See help for webdav backend at: https://rclone.org/webdav/ **
+
+URL of http host to connect to
+Enter a string value. Press Enter for the default ("").
+Choose a number from below, or type in your own value
+ 1 / Connect to example.com
+ \\ "https://example.com"
+url> https://ip:port/dav
+Name of the Webdav site/service/software you are using
+Enter a string value. Press Enter for the default ("").
+Choose a number from below, or type in your own value
+ 1 / Nextcloud
+ \\ "nextcloud"
+ 2 / Owncloud
+ \\ "owncloud"
+ 3 / Sharepoint
+ \\ "sharepoint"
+ 4 / Other site/service or software
+ \\ "other"
+vendor> 4
+User name
+Enter a string value. Press Enter for the default ("").
+user>
+Password.
+y) Yes type in my own password
+g) Generate random password
+n) No leave this optional password blank (default)
+y/g/n> n
+Enter the password:
+password:
+Confirm the password:
+password:
+Bearer token instead of user/pass (eg a Macaroon)
+Enter a string value. Press Enter for the default ("").
+bearer_token>
+Edit advanced config? (y/n)
+y) Yes
+n) No (default)
+y/n> n
+Remote config
+--------------------
+[alist]
+url =
+vendor = other
+user =
+pass = *** ENCRYPTED ***
+--------------------
+y) Yes this is OK (default)
+e) Edit this remote
+d) Delete this remote
+y/e/d> y
+
+Current remotes:
+
+Name Type
+==== ====
+alist webdav
+
+e) Edit existing remote
+n) New remote
+d) Delete remote
+r) Rename remote
+c) Copy remote
+s) Set configuration password
+q) Quit config
+e/n/d/r/c/s/q> qmkdir /alist
+#将后面修改成你上面手动运行命令中,除了rclone的全部参数
+command="mount alist:/ /alist --cache-dir /tmp --allow-other --vfs-cache-mode writes --allow-non-empty"
+#以下是一整条命令,一起复制到SSH客户端运行
+cat > /etc/systemd/system/rclone.service <<EOF
+[Unit]
+Description=Rclone
+# 在网络和docker服务之后启动,因为要先启动阿里云盘的webdav服务容器
+After=network-online.target docker.service
+[Service]
+Type=simple
+ExecStart=$(command -v rclone) \${command}
+Restart=on-abort
+User=root
+[Install]
+WantedBy=default.target
+EOF启动:
systemctl start rclone开机自启动:
systemctl enable rclonerclone 作为文件和对象存储的管理工具, 经过近些年的发展已经完好的支持各种存储协议, 比如 HDFS, FTP, SFTP, GCS 和 S3(兼容 aws, 金山云, 腾讯云, 阿里云等)等, 逐渐有统一管理云存储之势, 从 rclone-github 来看, 各大云厂商也逐渐将各自的存储协议合并到了 rclone 中. 这在对象存储统一管理, 尤其是多云管理的场景中带来了很大的便利, 也便于我们实现诸如统一运维管理的目标.
两种方式:
apt install rclonecurl https://rclone.org/install.sh | sudo bashrclone config
+2023/10/20 16:58:06 NOTICE: Config file "/root/.config/rclone/rclone.conf" not found - using defaults
+No remotes found - make a new one
+n) New remote
+s) Set configuration password
+q) Quit config
+n/s/q>n
+name>alist
+Type of storage to configure.
+Enter a string value. Press Enter for the default ("").
+Choose a number from below, or type in your own value
+ 1 / 1Fichier
+ \\ "fichier"
+ 2 / Alias for an existing remote
+ \\ "alias"
+ 3 / Amazon Drive
+ \\ "amazon cloud drive"
+ 4 / Amazon S3 Compliant Storage Provider (AWS, Alibaba, Ceph, Digital Ocean, Dreamhost, IBM COS, Minio, Tencent COS, etc)
+ \\ "s3"
+ 5 / Backblaze B2
+ \\ "b2"
+ 6 / Box
+ \\ "box"
+ 7 / Cache a remote
+ \\ "cache"
+ 8 / Citrix Sharefile
+ \\ "sharefile"
+ 9 / Dropbox
+ \\ "dropbox"
+10 / Encrypt/Decrypt a remote
+ \\ "crypt"
+11 / FTP Connection
+ \\ "ftp"
+12 / Google Cloud Storage (this is not Google Drive)
+ \\ "google cloud storage"
+13 / Google Drive
+ \\ "drive"
+14 / Google Photos
+ \\ "google photos"
+15 / Hubic
+ \\ "hubic"
+16 / In memory object storage system.
+ \\ "memory"
+17 / Jottacloud
+ \\ "jottacloud"
+18 / Koofr
+ \\ "koofr"
+19 / Local Disk
+ \\ "local"
+20 / Mail.ru Cloud
+ \\ "mailru"
+21 / Microsoft Azure Blob Storage
+ \\ "azureblob"
+22 / Microsoft OneDrive
+ \\ "onedrive"
+23 / OpenDrive
+ \\ "opendrive"
+24 / OpenStack Swift (Rackspace Cloud Files, Memset Memstore, OVH)
+ \\ "swift"
+25 / Pcloud
+ \\ "pcloud"
+26 / Put.io
+ \\ "putio"
+27 / SSH/SFTP Connection
+ \\ "sftp"
+28 / Sugarsync
+ \\ "sugarsync"
+29 / Transparently chunk/split large files
+ \\ "chunker"
+30 / Union merges the contents of several upstream fs
+ \\ "union"
+31 / Webdav
+ \\ "webdav"
+32 / Yandex Disk
+ \\ "yandex"
+33 / http Connection
+ \\ "http"
+34 / premiumize.me
+ \\ "premiumizeme"
+35 / seafile
+ \\ "seafile"
+Storage> 31
+** See help for webdav backend at: https://rclone.org/webdav/ **
+
+URL of http host to connect to
+Enter a string value. Press Enter for the default ("").
+Choose a number from below, or type in your own value
+ 1 / Connect to example.com
+ \\ "https://example.com"
+url> https://ip:port/dav
+Name of the Webdav site/service/software you are using
+Enter a string value. Press Enter for the default ("").
+Choose a number from below, or type in your own value
+ 1 / Nextcloud
+ \\ "nextcloud"
+ 2 / Owncloud
+ \\ "owncloud"
+ 3 / Sharepoint
+ \\ "sharepoint"
+ 4 / Other site/service or software
+ \\ "other"
+vendor> 4
+User name
+Enter a string value. Press Enter for the default ("").
+user>
+Password.
+y) Yes type in my own password
+g) Generate random password
+n) No leave this optional password blank (default)
+y/g/n> n
+Enter the password:
+password:
+Confirm the password:
+password:
+Bearer token instead of user/pass (eg a Macaroon)
+Enter a string value. Press Enter for the default ("").
+bearer_token>
+Edit advanced config? (y/n)
+y) Yes
+n) No (default)
+y/n> n
+Remote config
+--------------------
+[alist]
+url =
+vendor = other
+user =
+pass = *** ENCRYPTED ***
+--------------------
+y) Yes this is OK (default)
+e) Edit this remote
+d) Delete this remote
+y/e/d> y
+
+Current remotes:
+
+Name Type
+==== ====
+alist webdav
+
+e) Edit existing remote
+n) New remote
+d) Delete remote
+r) Rename remote
+c) Copy remote
+s) Set configuration password
+q) Quit config
+e/n/d/r/c/s/q> qmkdir /alist
+#将后面修改成你上面手动运行命令中,除了rclone的全部参数
+command="mount alist:/ /alist --cache-dir /tmp --allow-other --vfs-cache-mode writes --allow-non-empty"
+#以下是一整条命令,一起复制到SSH客户端运行
+cat > /etc/systemd/system/rclone.service <<EOF
+[Unit]
+Description=Rclone
+# 在网络和docker服务之后启动,因为要先启动阿里云盘的webdav服务容器
+After=network-online.target docker.service
+[Service]
+Type=simple
+ExecStart=$(command -v rclone) \${command}
+Restart=on-abort
+User=root
+[Install]
+WantedBy=default.target
+EOF启动:
systemctl start rclone开机自启动:
systemctl enable rclone服务商目前都停止了签发1年有效期的SSL证书,有效期都缩短至3个月,这给多个域名管理带来极大不便。
acme.sh项目是一个纯shell脚本的ACME(Automatic Certificate Management Environment)客户端协议实现,能够帮助我们自动签发以及更新证书。
curl https://get.acme.sh | sh -s email=my@example.com
https://github.com/acmesh-official/acme.sh/wiki/How-to-issue-a-cert
ACME-challenge
ACME-challenge 是 ACME 协议中的一部分,旨在验证用户对某个域名的控制权。ACME 协议支持多种验证方式,其中 HTTP-01 是最常用的一种,涉及到 .well-known/acme-challenge。
当用户请求证书时,证书颁发机构 (CA) 需要确认申请人对该域名的控制权。这是通过向 CA 提供某种形式的“挑战”并成功响应它来完成的。ACME-challenge 验证方式包括:
1.HTTP-01 验证:通过 HTTP 请求验证域名的所有权。
2.DNS-01 验证:通过 DNS 记录验证域名的所有权。
3.TLS-ALPN-01 验证:通过特定的 TLS 握手协议验证域名的所有权。
其中最常用的是 HTTP-01 验证,通过 .well-known/acme-challenge 目录进行。
•HTTP-01 验证要求服务器通过 HTTP(端口 80)公开访问验证文件,因此服务器需要监听 HTTP 请求。如果所有流量都强制重定向到 HTTPS,可能会导致验证失败。你可以专门为验证请求保留对 HTTP 的访问权限(即通过 Nginx 配置保留 .well-known/acme-challenge/ 目录的请求)。
•验证文件只能通过 HTTP 访问,不能通过 HTTPS,因此确保 .well-known/acme-challenge 路径上的请求不会被重定向。
acme.sh --issue -d example.com --nginx
acme.sh --issue -d example.com --nginx /etc/nginx/nginx.conf
acme.sh --issue -d example.com --nginx /etc/nginx/conf.d/example.com.conf
如果配置了强制https,需要修改vhost的配置
server {
+ listen 80;
+ listen [::]:80;
+ server_name domain.com;
+
+ return 301 https://$host$request_uri;
+}
+为
+server {
+ listen 80;
+ listen [::]:80;
+ server_name domain.com;
+
+ location / {
+ return 301 https://$host$request_uri;
+ }
+}随后,acme.sh会自动在server配置上增加关于.well-knwon/acme-challenge的location配置,验证完成后自动恢复原本的配置文件
# HTTP redirect
+server {
+ listen 80;
+ listen [::]:80;
+ server_name domain.com;
+#ACME_NGINX_START
+location ~ "^/\\.well-known/acme-challenge/([-_a-zA-Z0-9]+)$" {
+ default_type text/plain;
+ return 200 "xxxxxxxxxxxxxx";
+}
+#NGINX_START
+
+
+ # 其他请求仍然重定向到 HTTPS
+ location / {
+ return 301 https://$host$request_uri;
+ }
+}以我用的dnspod为例
export DP_Id="123"
+export DP_Key="abcd"
+acme.sh --issue --dns dns_dp -d domain.comacme.sh --install-cert -d domain.com \\
+--key-file /etc/nginx/ssl/domain.key \\
+--fullchain-file /etc/nginx/ssl/domain.crt \\
+--reloadcmd "systemctl reload nginx"acme.sh --install-cert -d domain.com \\
+--key-file /path/domain.key \\
+--fullchain-file /path/domain.crt \\
+--reloadcmd "docker restart docker-nginx"在执行安装脚本时,脚本会自动创建crontab任务
30 1 * * * "/root/.acme.sh"/acme.sh --cron --home "/root/.acme.sh" > /dev/null
当证书剩余有效期少于 30 天时,acme.sh 会尝试更新证书。
acme.sh --upgrade --auto-upgrade
acme.sh --upgrade --auto-upgrade 0
acme.sh --upgrade
服务商目前都停止了签发1年有效期的SSL证书,有效期都缩短至3个月,这给多个域名管理带来极大不便。
acme.sh项目是一个纯shell脚本的ACME(Automatic Certificate Management Environment)客户端协议实现,能够帮助我们自动签发以及更新证书。
curl https://get.acme.sh | sh -s email=my@example.com
https://github.com/acmesh-official/acme.sh/wiki/How-to-issue-a-cert
ACME-challenge
ACME-challenge 是 ACME 协议中的一部分,旨在验证用户对某个域名的控制权。ACME 协议支持多种验证方式,其中 HTTP-01 是最常用的一种,涉及到 .well-known/acme-challenge。
当用户请求证书时,证书颁发机构 (CA) 需要确认申请人对该域名的控制权。这是通过向 CA 提供某种形式的“挑战”并成功响应它来完成的。ACME-challenge 验证方式包括:
1.HTTP-01 验证:通过 HTTP 请求验证域名的所有权。
2.DNS-01 验证:通过 DNS 记录验证域名的所有权。
3.TLS-ALPN-01 验证:通过特定的 TLS 握手协议验证域名的所有权。
其中最常用的是 HTTP-01 验证,通过 .well-known/acme-challenge 目录进行。
•HTTP-01 验证要求服务器通过 HTTP(端口 80)公开访问验证文件,因此服务器需要监听 HTTP 请求。如果所有流量都强制重定向到 HTTPS,可能会导致验证失败。你可以专门为验证请求保留对 HTTP 的访问权限(即通过 Nginx 配置保留 .well-known/acme-challenge/ 目录的请求)。
•验证文件只能通过 HTTP 访问,不能通过 HTTPS,因此确保 .well-known/acme-challenge 路径上的请求不会被重定向。
acme.sh --issue -d example.com --nginx
acme.sh --issue -d example.com --nginx /etc/nginx/nginx.conf
acme.sh --issue -d example.com --nginx /etc/nginx/conf.d/example.com.conf
如果配置了强制https,需要修改vhost的配置
server {
+ listen 80;
+ listen [::]:80;
+ server_name domain.com;
+
+ return 301 https://$host$request_uri;
+}
+为
+server {
+ listen 80;
+ listen [::]:80;
+ server_name domain.com;
+
+ location / {
+ return 301 https://$host$request_uri;
+ }
+}随后,acme.sh会自动在server配置上增加关于.well-knwon/acme-challenge的location配置,验证完成后自动恢复原本的配置文件
# HTTP redirect
+server {
+ listen 80;
+ listen [::]:80;
+ server_name domain.com;
+#ACME_NGINX_START
+location ~ "^/\\.well-known/acme-challenge/([-_a-zA-Z0-9]+)$" {
+ default_type text/plain;
+ return 200 "xxxxxxxxxxxxxx";
+}
+#NGINX_START
+
+
+ # 其他请求仍然重定向到 HTTPS
+ location / {
+ return 301 https://$host$request_uri;
+ }
+}以我用的dnspod为例
export DP_Id="123"
+export DP_Key="abcd"
+acme.sh --issue --dns dns_dp -d domain.comacme.sh --install-cert -d domain.com \\
+--key-file /etc/nginx/ssl/domain.key \\
+--fullchain-file /etc/nginx/ssl/domain.crt \\
+--reloadcmd "systemctl reload nginx"acme.sh --install-cert -d domain.com \\
+--key-file /path/domain.key \\
+--fullchain-file /path/domain.crt \\
+--reloadcmd "docker restart docker-nginx"在执行安装脚本时,脚本会自动创建crontab任务
30 1 * * * "/root/.acme.sh"/acme.sh --cron --home "/root/.acme.sh" > /dev/null
当证书剩余有效期少于 30 天时,acme.sh 会尝试更新证书。
acme.sh --upgrade --auto-upgrade
acme.sh --upgrade --auto-upgrade 0
acme.sh --upgrade
iptables是一个用户级程序,用于操作内核级的网络模块netfilter
iptables的功能由表的形式呈现,每张表由若干个链组成,每个链可以分配一组规则
iptables有五张内建表,按照优先级高到底分别是:Raw、Mangle、NAT、Filter、Security
此表负责数据包标记,决定数据包是否被状态跟踪机制处理,Raw表有2个内建链
此表负责更改数据包内容,Mangle表有5个内建链
此表负责数据包的ip地址转换,NAT表有3种内建链
此表负责过滤数据包,iptables的默认表,具有3种内建链
新加入的特性,用于强制访问控制(MAC)网络规则,有3种内建链
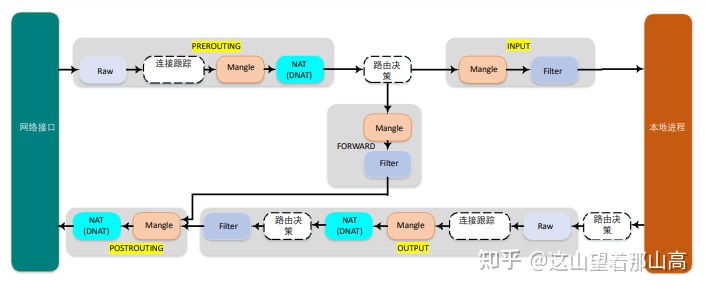
iptables [-t 表名] 命令选项 [链名] [匹配条件] [-j 策略]
iptables命令包含五个部分
表名:要操作的表,不指定时默认操作Filter表
链名:要操作的链,不指定链时默认表内所有链
命令选项:要进行的操作
匹配条件:定义规则适用哪些数据包(匹配哪些数据包)
策略:匹配数据的目标执行的操作,说白了就是packet匹配上规则后该干嘛
ACCEPT:允许数据包通过。
DROP:直接丢弃数据包,不给任何回应信息,这时候客户端会感觉自己的请求泥牛入海了,过了超时时间才会有反应。
REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息。
SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题。
MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的ip上。
DNAT:目标地址转换。
REDIRECT:在本机做端口映射。
iptables -A INPUT -s 127.0.0.1 -p tcp --dport 3306 -j ACCEPTiptables -I INPUT -p tcp -j ACCEPT或iptables -I INPUT 2 -p tcp -j ACCEPT-L:列出所有规则
-n:以数字形式显示地址、端口等信息
-v:显示更详细规则信息
--line-numbers:显示规则序号
删除nat表INPUT链的第三条规则:iptables -t nat -D INPUT 3
清空nat表所有规则:iptables -t nat -F
iptables -t filter -P FORWARD DROP多端口匹配 -m multiport --sport 源端口列表 -m multiport --dport 目的端口列表 IP范围匹配 -m iprange --src-range IP范围 MAC地址匹配 -m mac –mac1-source MAC地址 状态匹配 -m state --state 连接状态
iptables -A INPUT -p tcp -m multiport --dport 25,80,110,143 -j ACCEPT
+iptables -A FORWARD -p tcp -m iprange --src-range 192.168.4.21-192.168.4.28 -j ACCEPT
+iptables -A INPUT -m mac --mac-source 00:0c:29:c0:55:3f -j DROP
+iptables -P INPUT DROP
+iptables -I INPUT -p tcp -m multiport --dport 80-82,85 -j ACCEPT
+iptables -I INPUT -p tcp -m state --state NEW,ESTABLISHED,RELATED -j ACCEPTiptables是一个用户级程序,用于操作内核级的网络模块netfilter
iptables的功能由表的形式呈现,每张表由若干个链组成,每个链可以分配一组规则
iptables有五张内建表,按照优先级高到底分别是:Raw、Mangle、NAT、Filter、Security
此表负责数据包标记,决定数据包是否被状态跟踪机制处理,Raw表有2个内建链
此表负责更改数据包内容,Mangle表有5个内建链
此表负责数据包的ip地址转换,NAT表有3种内建链
此表负责过滤数据包,iptables的默认表,具有3种内建链
新加入的特性,用于强制访问控制(MAC)网络规则,有3种内建链
iptables [-t 表名] 命令选项 [链名] [匹配条件] [-j 策略]
iptables命令包含五个部分
表名:要操作的表,不指定时默认操作Filter表
链名:要操作的链,不指定链时默认表内所有链
命令选项:要进行的操作
匹配条件:定义规则适用哪些数据包(匹配哪些数据包)
策略:匹配数据的目标执行的操作,说白了就是packet匹配上规则后该干嘛
ACCEPT:允许数据包通过。
DROP:直接丢弃数据包,不给任何回应信息,这时候客户端会感觉自己的请求泥牛入海了,过了超时时间才会有反应。
REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息。
SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题。
MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的ip上。
DNAT:目标地址转换。
REDIRECT:在本机做端口映射。
iptables -A INPUT -s 127.0.0.1 -p tcp --dport 3306 -j ACCEPTiptables -I INPUT -p tcp -j ACCEPT或iptables -I INPUT 2 -p tcp -j ACCEPT-L:列出所有规则
-n:以数字形式显示地址、端口等信息
-v:显示更详细规则信息
--line-numbers:显示规则序号
删除nat表INPUT链的第三条规则:iptables -t nat -D INPUT 3
清空nat表所有规则:iptables -t nat -F
iptables -t filter -P FORWARD DROP多端口匹配 -m multiport --sport 源端口列表 -m multiport --dport 目的端口列表 IP范围匹配 -m iprange --src-range IP范围 MAC地址匹配 -m mac –mac1-source MAC地址 状态匹配 -m state --state 连接状态
iptables -A INPUT -p tcp -m multiport --dport 25,80,110,143 -j ACCEPT
+iptables -A FORWARD -p tcp -m iprange --src-range 192.168.4.21-192.168.4.28 -j ACCEPT
+iptables -A INPUT -m mac --mac-source 00:0c:29:c0:55:3f -j DROP
+iptables -P INPUT DROP
+iptables -I INPUT -p tcp -m multiport --dport 80-82,85 -j ACCEPT
+iptables -I INPUT -p tcp -m state --state NEW,ESTABLISHED,RELATED -j ACCEPTscreen -dmS <name>
screen -S <name> -X stuff <text>
例如:screen -S <name> -X stuff abc,当attach之后,窗口中已经有了abc
如果想执行命令:
screen -S <name> -X stuff "<command> \\n"
+screen -S <name> -X stuff "<command> \\r"
+---
+screen -S centos -X stuff $'<command> \\n'
+---
+screen -S new_screen -X stuff "cd /dir
+"screen -S <name> -X quit
screen -dmS <name>
screen -S <name> -X stuff <text>
例如:screen -S <name> -X stuff abc,当attach之后,窗口中已经有了abc
如果想执行命令:
screen -S <name> -X stuff "<command> \\n"
+screen -S <name> -X stuff "<command> \\r"
+---
+screen -S centos -X stuff $'<command> \\n'
+---
+screen -S new_screen -X stuff "cd /dir
+"screen -S <name> -X quit
禁用Secure Boot
ip add查看当前ip
passwd修改密码
reflector -c China --sort rate --save /etc/pacman.d/mirrorlist
+reflector -c China --sort rate --save /mnt/etc/pacman.d/mirrorlist查看磁盘设备情况fdisk -l 或 lsblk,以rom、loop、airoot结尾的设备可以忽略
arch linux推荐的分区表设置
| 挂载点 | 分区 | 分区类型 | 建议大小 |
|---|---|---|---|
/mnt/boot | /dev/efi_system_partition | EFI system partition | At least 300 MiB. If multiple kernels will be installed, then no less than 1 GiB. |
[SWAP] | /dev/*swap_partition | Linux swap | More than 512 MiB |
/mnt | /dev/root_partition | Linux x86-64 root (/) | Remainder of the device |
fdisk /dev/sda
+
+g # 将磁盘分区表设置为GPT格式
+
+n # 新增一个分区,分区号默认会递增,直接回车,起始扇区直接回车按默认值,结束输入+300M并回车,标识分区大小为300M
+# 重复新建分区操作,创建好3个空间大小分别为300M、1G、剩余全部空间的三个分区
+
+t # 更改分区类型
+# 重复t操作 把1、2、3分区分别改为1(EFI System Partition)、19(SWAP)、23(linux x86-64 root)
+
+w # 写入保存分区表mkfs.fat -F 32 /dev/sda1
+mkswap /dev/sda2
+mkfs.ext4 /dev/sda3mount /dev/sda3 /mnt
+mkdir -p /mnt/boot && mount /dev/sda1 /mnt/boot #创建/mnt/boot目录供挂载
+swapon /dev/sda2 # 挂载swappacstrap -K /mnt base linux linux-firmware
+pacman -Sy
+pacman -S vimgenfstab -U /mnt >> /mnt/etc/fstab && cat /mnt/etc/fstabarch-chroot /mntln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime # 切换时区到东8区 或者timedatectl set-timezone Asia/Shanghai
+
+hwclock --systohc # 将系统时间同步到硬件时钟 生成/etc/adjtime文件vim /etc/locale.gen
+# 将en_US.UTF-8和zh_CN.UTF-8注释去掉
+# 保存
+locale-gen创建/etc/locale.conf文件并编辑
#/etc/locale.conf
+LANG=en_US.UTF-8echo "archlinux" >> /etc/hostnamepasswdpacman -S dosfstools grub efibootmgr # 安装引导程序
+grub-install --target=x86_64-efi --efi-directory=/boot --recheck # 将grub安装至EFI分区
+grub-mkconfig -o /boot/grub/grub.cfg # 生成grub配置pacman -S networkmanager network-manager-applet dhcpcd dialog os-prober mtools ntfs-3g base-devel linux-headers reflector git net-tools dnsutils inetutils iproute2exit # 返回至arch-chroot之前的环境
+
+# 卸载
+umount /mnt/boot
+umount /mnt
+reboot # 重启systemctl start dhcpcd
+systemctl enable dhcpcd # dhcpcd开机自启
+
+systemctl start sshd
+systemctl enable sshd # sshd开机自启# /etc/ssh/sshd_config
+PermitRootLogin yes
+PasswordAuthentication yessystemctl restart sshd
# /etc/dhcpcd.conf
+interface eth0
+static ip_address=192.168.2.67/24
+static routers=192.168.2.1
+static domain_name_servers=192.168.2.1`,55)]))}const g=i(l,[["render",n]]);export{c as __pageData,g as default}; diff --git "a/assets/linux_env_ArchLinux\345\256\211\350\243\205.md.D-wbzdid.lean.js" "b/assets/linux_env_ArchLinux\345\256\211\350\243\205.md.D-wbzdid.lean.js" new file mode 100644 index 00000000..6c2bc288 --- /dev/null +++ "b/assets/linux_env_ArchLinux\345\256\211\350\243\205.md.D-wbzdid.lean.js" @@ -0,0 +1,41 @@ +import{_ as i,c as a,a2 as t,o as e}from"./chunks/framework.BjcrtTwI.js";const c=JSON.parse('{"title":"ArchLinux安装","description":"","frontmatter":{},"headers":[],"relativePath":"linux/env/ArchLinux安装.md","filePath":"linux/env/ArchLinux安装.md","lastUpdated":1729217313000}'),l={name:"linux/env/ArchLinux安装.md"};function n(h,s,p,k,r,d){return e(),a("div",null,s[0]||(s[0]=[t(`
禁用Secure Boot
ip add查看当前ip
passwd修改密码
reflector -c China --sort rate --save /etc/pacman.d/mirrorlist
+reflector -c China --sort rate --save /mnt/etc/pacman.d/mirrorlist查看磁盘设备情况fdisk -l 或 lsblk,以rom、loop、airoot结尾的设备可以忽略
arch linux推荐的分区表设置
| 挂载点 | 分区 | 分区类型 | 建议大小 |
|---|---|---|---|
/mnt/boot | /dev/efi_system_partition | EFI system partition | At least 300 MiB. If multiple kernels will be installed, then no less than 1 GiB. |
[SWAP] | /dev/*swap_partition | Linux swap | More than 512 MiB |
/mnt | /dev/root_partition | Linux x86-64 root (/) | Remainder of the device |
fdisk /dev/sda
+
+g # 将磁盘分区表设置为GPT格式
+
+n # 新增一个分区,分区号默认会递增,直接回车,起始扇区直接回车按默认值,结束输入+300M并回车,标识分区大小为300M
+# 重复新建分区操作,创建好3个空间大小分别为300M、1G、剩余全部空间的三个分区
+
+t # 更改分区类型
+# 重复t操作 把1、2、3分区分别改为1(EFI System Partition)、19(SWAP)、23(linux x86-64 root)
+
+w # 写入保存分区表mkfs.fat -F 32 /dev/sda1
+mkswap /dev/sda2
+mkfs.ext4 /dev/sda3mount /dev/sda3 /mnt
+mkdir -p /mnt/boot && mount /dev/sda1 /mnt/boot #创建/mnt/boot目录供挂载
+swapon /dev/sda2 # 挂载swappacstrap -K /mnt base linux linux-firmware
+pacman -Sy
+pacman -S vimgenfstab -U /mnt >> /mnt/etc/fstab && cat /mnt/etc/fstabarch-chroot /mntln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime # 切换时区到东8区 或者timedatectl set-timezone Asia/Shanghai
+
+hwclock --systohc # 将系统时间同步到硬件时钟 生成/etc/adjtime文件vim /etc/locale.gen
+# 将en_US.UTF-8和zh_CN.UTF-8注释去掉
+# 保存
+locale-gen创建/etc/locale.conf文件并编辑
#/etc/locale.conf
+LANG=en_US.UTF-8echo "archlinux" >> /etc/hostnamepasswdpacman -S dosfstools grub efibootmgr # 安装引导程序
+grub-install --target=x86_64-efi --efi-directory=/boot --recheck # 将grub安装至EFI分区
+grub-mkconfig -o /boot/grub/grub.cfg # 生成grub配置pacman -S networkmanager network-manager-applet dhcpcd dialog os-prober mtools ntfs-3g base-devel linux-headers reflector git net-tools dnsutils inetutils iproute2exit # 返回至arch-chroot之前的环境
+
+# 卸载
+umount /mnt/boot
+umount /mnt
+reboot # 重启systemctl start dhcpcd
+systemctl enable dhcpcd # dhcpcd开机自启
+
+systemctl start sshd
+systemctl enable sshd # sshd开机自启# /etc/ssh/sshd_config
+PermitRootLogin yes
+PasswordAuthentication yessystemctl restart sshd
# /etc/dhcpcd.conf
+interface eth0
+static ip_address=192.168.2.67/24
+static routers=192.168.2.1
+static domain_name_servers=192.168.2.1`,55)]))}const g=i(l,[["render",n]]);export{c as __pageData,g as default}; diff --git "a/assets/linux_env_Centos7\345\256\211\350\243\205Python3\347\216\257\345\242\203.md.ClPs2Q6l.js" "b/assets/linux_env_Centos7\345\256\211\350\243\205Python3\347\216\257\345\242\203.md.ClPs2Q6l.js" new file mode 100644 index 00000000..06582c85 --- /dev/null +++ "b/assets/linux_env_Centos7\345\256\211\350\243\205Python3\347\216\257\345\242\203.md.ClPs2Q6l.js" @@ -0,0 +1,11 @@ +import{_ as i,c as a,a2 as t,o as l}from"./chunks/framework.BjcrtTwI.js";const r=JSON.parse('{"title":"Centos7安装Python3环境","description":"","frontmatter":{},"headers":[],"relativePath":"linux/env/Centos7安装Python3环境.md","filePath":"linux/env/Centos7安装Python3环境.md","lastUpdated":1729217313000}'),n={name:"linux/env/Centos7安装Python3环境.md"};function h(p,s,e,k,F,d){return l(),a("div",null,s[0]||(s[0]=[t(`
yum -y groupinstall "Development tools"
+yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
+yum install -y libffi-devel zlib1g-dev
+yum install zlib* -ywget https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz这一步骤提示我wget命令找不到,所以要先安装wget
yum -y install wget再次执行下载安装包的命令
mkdir /usr/local/python3
+tar -xvf Python-3.7.2.tar.xz
+cd Python-3.7.2
+# 指定安装位置 提高运行速度 第三个是为了解决pip需要用到ssl
+./configure --prefix=/usr/local/python3 --with-ssl
+make && make install./configure --prefix=/usr/local/python3 --enable-optimizations --with-ssl --enable-optimizations参数可能在低版本gcc导致编译报错 去掉即可
ln -s /usr/local/python3/bin/python3 /usr/local/bin/python3
+ln -s /usr/local/python3/bin/pip3 /usr/local/bin/pip3python3 -v
+pip3 -vyum -y groupinstall "Development tools"
+yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
+yum install -y libffi-devel zlib1g-dev
+yum install zlib* -ywget https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz这一步骤提示我wget命令找不到,所以要先安装wget
yum -y install wget再次执行下载安装包的命令
mkdir /usr/local/python3
+tar -xvf Python-3.7.2.tar.xz
+cd Python-3.7.2
+# 指定安装位置 提高运行速度 第三个是为了解决pip需要用到ssl
+./configure --prefix=/usr/local/python3 --with-ssl
+make && make install./configure --prefix=/usr/local/python3 --enable-optimizations --with-ssl --enable-optimizations参数可能在低版本gcc导致编译报错 去掉即可
ln -s /usr/local/python3/bin/python3 /usr/local/bin/python3
+ln -s /usr/local/python3/bin/pip3 /usr/local/bin/pip3python3 -v
+pip3 -v# 查看当前时间、时区
+date
+# 列出可用时区
+timedatectl list-timezones
+# 设置时区
+timedatectl set-timezone Asia/Shanghai
+# 确认已经更改
+timedatectl# 查看主机信息
+hostnamectl
+# 修改主机名
+hostnamectl set-hostname newhostname# 查看当前时间、时区
+date
+# 列出可用时区
+timedatectl list-timezones
+# 设置时区
+timedatectl set-timezone Asia/Shanghai
+# 确认已经更改
+timedatectl# 查看主机信息
+hostnamectl
+# 修改主机名
+hostnamectl set-hostname newhostname使用场景:由于公司没有单独的文件服务器/nas之类的共享存储,图片之类的也没有上云,目前业务中上传的文件也是放在应用服务器当中的。生产环境都是高可用的多节点部署,这样就会产生问题。比如用户上传一张图片,请求被分发到A服务器中,由于图片访问的域名是统一的B服务器域名,上传完成后用B服务器的域名去访问静态文件就会404。后续我们考虑搭建fastdfs来统一管理文件。目前的临时解决方案是通过配置服务器共享目录来实现文件在多个节点服务器间的同步。
环境:CentOS 7.6
分别在A、B两台服务器上安装nfs和rpcbind
yum install nfs-utils rpcbind比如我们的静态资源存储在B服务器,则需要把B服务器的目录暴露出来,共享给A服务器,让A服务器挂载该目录。
在B服务器(提供资源的服务器)上修改/etc/exports文件,把指定的目录暴露给A服务器并分配权限
# /需要暴露的目录 A服务器IP(rw,async,no_root_squash)
+/data/images 192.168.111.1(rw,async,no_root_squash)修改完后需要使配置立即生效,执行exportfs -arv命令
关闭防火墙/端口111(tcp/udp)、2049(tcp)、4046(udp)向指定ip开放
service rpcbind startservice nfs start执行命令:mount -o rw -t nfs B服务器IP:/B服务器暴露的路径 /要映射的本机(A服务器)的路径
例如:mount -o rw -t nfs 192.168.111.2:/data/images /data/images
可以在A服务器的/data/images下上传一些文件,然后看B服务器中的/data/images目录中是否同步,如果同步了则说明挂载成功,共享目录就配置完成了。
`,14)]))}const k=i(n,[["render",l]]);export{u as __pageData,k as default}; diff --git "a/assets/linux_env_Linux\346\234\215\345\212\241\345\231\250\346\226\207\344\273\266\347\233\256\345\275\225\345\205\261\344\272\253\346\230\240\345\260\204\351\205\215\347\275\256.md.BFYRLipg.lean.js" "b/assets/linux_env_Linux\346\234\215\345\212\241\345\231\250\346\226\207\344\273\266\347\233\256\345\275\225\345\205\261\344\272\253\346\230\240\345\260\204\351\205\215\347\275\256.md.BFYRLipg.lean.js" new file mode 100644 index 00000000..4dfc975b --- /dev/null +++ "b/assets/linux_env_Linux\346\234\215\345\212\241\345\231\250\346\226\207\344\273\266\347\233\256\345\275\225\345\205\261\344\272\253\346\230\240\345\260\204\351\205\215\347\275\256.md.BFYRLipg.lean.js" @@ -0,0 +1,2 @@ +import{_ as i,c as e,a2 as s,o as t}from"./chunks/framework.BjcrtTwI.js";const u=JSON.parse('{"title":"Linux服务器文件目录共享映射配置","description":"","frontmatter":{},"headers":[],"relativePath":"linux/env/Linux服务器文件目录共享映射配置.md","filePath":"linux/env/Linux服务器文件目录共享映射配置.md","lastUpdated":1729217313000}'),n={name:"linux/env/Linux服务器文件目录共享映射配置.md"};function l(r,a,o,d,p,c){return t(),e("div",null,a[0]||(a[0]=[s(`使用场景:由于公司没有单独的文件服务器/nas之类的共享存储,图片之类的也没有上云,目前业务中上传的文件也是放在应用服务器当中的。生产环境都是高可用的多节点部署,这样就会产生问题。比如用户上传一张图片,请求被分发到A服务器中,由于图片访问的域名是统一的B服务器域名,上传完成后用B服务器的域名去访问静态文件就会404。后续我们考虑搭建fastdfs来统一管理文件。目前的临时解决方案是通过配置服务器共享目录来实现文件在多个节点服务器间的同步。
环境:CentOS 7.6
分别在A、B两台服务器上安装nfs和rpcbind
yum install nfs-utils rpcbind比如我们的静态资源存储在B服务器,则需要把B服务器的目录暴露出来,共享给A服务器,让A服务器挂载该目录。
在B服务器(提供资源的服务器)上修改/etc/exports文件,把指定的目录暴露给A服务器并分配权限
# /需要暴露的目录 A服务器IP(rw,async,no_root_squash)
+/data/images 192.168.111.1(rw,async,no_root_squash)修改完后需要使配置立即生效,执行exportfs -arv命令
关闭防火墙/端口111(tcp/udp)、2049(tcp)、4046(udp)向指定ip开放
service rpcbind startservice nfs start执行命令:mount -o rw -t nfs B服务器IP:/B服务器暴露的路径 /要映射的本机(A服务器)的路径
例如:mount -o rw -t nfs 192.168.111.2:/data/images /data/images
可以在A服务器的/data/images下上传一些文件,然后看B服务器中的/data/images目录中是否同步,如果同步了则说明挂载成功,共享目录就配置完成了。
`,14)]))}const k=i(n,[["render",l]]);export{u as __pageData,k as default}; diff --git "a/assets/linux_env_Linux\347\247\201\351\222\245\347\231\273\351\231\206\346\217\220\347\244\272server refused our key.md.DcR0H7e3.js" "b/assets/linux_env_Linux\347\247\201\351\222\245\347\231\273\351\231\206\346\217\220\347\244\272server refused our key.md.DcR0H7e3.js" new file mode 100644 index 00000000..1ac1c511 --- /dev/null +++ "b/assets/linux_env_Linux\347\247\201\351\222\245\347\231\273\351\231\206\346\217\220\347\244\272server refused our key.md.DcR0H7e3.js" @@ -0,0 +1,8 @@ +import{_ as e,c as a,a2 as i,o as n}from"./chunks/framework.BjcrtTwI.js";const c=JSON.parse('{"title":"Linux私钥登陆提示server refused our key","description":"","frontmatter":{},"headers":[],"relativePath":"linux/env/Linux私钥登陆提示server refused our key.md","filePath":"linux/env/Linux私钥登陆提示server refused our key.md","lastUpdated":1729217313000}'),t={name:"linux/env/Linux私钥登陆提示server refused our key.md"};function r(l,s,h,p,o,d){return n(),a("div",null,s[0]||(s[0]=[i(`家庭内网装了个物理机的Ubuntu server,用的最新版本的22.04,然后用windows端的mobaxterm和navicat使用ssh私钥连接内网服务器时返回了Server refused our key的异常
openssh 8.8开始默认禁用了使用SHA-1哈希算法的RSA签名,看了一下ubuntu server 22.04的默认openssh版本:
➜ ~ ssh -V
+OpenSSH_8.9p1 Ubuntu-3, OpenSSL 3.0.2 15 Mar 2022https://www.openssh.com/txt/release-8.8
This release disables RSA signatures using the SHA-1 hash algorithm by default. This change has been made as the SHA-1 hash algorithm is cryptographically broken, and it is possible to create chosen-prefix hash collisions for <USD$50K [1]
vim /etc/ssh/sshd_config
+
+# 添加配置
+PubkeyAcceptedKeyTypes +ssh-rsa
+
+
+systemctl restart sshd家庭内网装了个物理机的Ubuntu server,用的最新版本的22.04,然后用windows端的mobaxterm和navicat使用ssh私钥连接内网服务器时返回了Server refused our key的异常
openssh 8.8开始默认禁用了使用SHA-1哈希算法的RSA签名,看了一下ubuntu server 22.04的默认openssh版本:
➜ ~ ssh -V
+OpenSSH_8.9p1 Ubuntu-3, OpenSSL 3.0.2 15 Mar 2022https://www.openssh.com/txt/release-8.8
This release disables RSA signatures using the SHA-1 hash algorithm by default. This change has been made as the SHA-1 hash algorithm is cryptographically broken, and it is possible to create chosen-prefix hash collisions for <USD$50K [1]
vim /etc/ssh/sshd_config
+
+# 添加配置
+PubkeyAcceptedKeyTypes +ssh-rsa
+
+
+systemctl restart sshd服务器上日常运行着静态博客+云笔记+jenkins的容器,jenkins用于gitee上托管的博客repo的ci/cd。当jenkins进行构建时,内存占用率会急剧升高,轻则容器宕机,重则服务器跟着一起boom。因此需要设置swap来缓解jenkins内存占用瞬时升高的状况。
df -h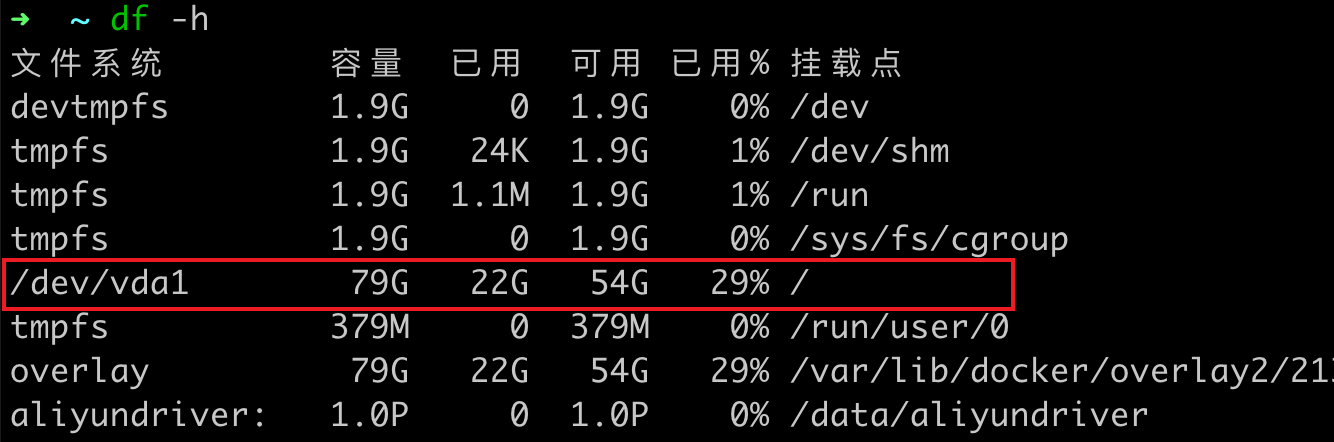
Filesystem中/dev/vda1挂载点为/的就是我们的磁盘
一般来说swap大小设置规则:
4G以内RAM,Swap设置为2倍RAM
4G-8GRAM,Swap设置等于内存大小
8G-64G,Swap设置为8G
64G-256G,Swap设置为16G
我这个是腾讯云4c 4G 80G的机器,这里swap设置为4G:fallocate -l 4G /swap
修改权限使文件只能root访问:chmod 600 /swap
将文件标记为swap空间:mkswap /swap
启用swap文件:swapon /swap
验证交换是否可用:swapon --show
备份fstab:cp /etc/fstab /etc/fstab.bak
添加一条记录: echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
调整Swappiness参数,该参数主要配置系统将数据从RAM交换到交换空间的频率。该参数的值是介于0和100之间的百分比。范围在0到100之间。 低参数值会让内核尽量少用交换,更高参数值会使内核更多的去使用交换空间。
查看当前swappiness值:cat /proc/sys/vm/swappiness
临时修改,重启失效:sysctl vm.swappiness=10
永久设置:vim /etc/sysctl.conf,最后一行加上vm.swappiness=10,保存并退出。sysctl -p 立即生效
cat /proc/sys/vm/vfs_cache_pressure 缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache。vim /etc/sysctl.conf,最后一行加上vm.vfs_cache_pressure=50
服务器上日常运行着静态博客+云笔记+jenkins的容器,jenkins用于gitee上托管的博客repo的ci/cd。当jenkins进行构建时,内存占用率会急剧升高,轻则容器宕机,重则服务器跟着一起boom。因此需要设置swap来缓解jenkins内存占用瞬时升高的状况。
df -h
Filesystem中/dev/vda1挂载点为/的就是我们的磁盘
一般来说swap大小设置规则:
4G以内RAM,Swap设置为2倍RAM
4G-8GRAM,Swap设置等于内存大小
8G-64G,Swap设置为8G
64G-256G,Swap设置为16G
我这个是腾讯云4c 4G 80G的机器,这里swap设置为4G:fallocate -l 4G /swap
修改权限使文件只能root访问:chmod 600 /swap
将文件标记为swap空间:mkswap /swap
启用swap文件:swapon /swap
验证交换是否可用:swapon --show
备份fstab:cp /etc/fstab /etc/fstab.bak
添加一条记录: echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
调整Swappiness参数,该参数主要配置系统将数据从RAM交换到交换空间的频率。该参数的值是介于0和100之间的百分比。范围在0到100之间。 低参数值会让内核尽量少用交换,更高参数值会使内核更多的去使用交换空间。
查看当前swappiness值:cat /proc/sys/vm/swappiness
临时修改,重启失效:sysctl vm.swappiness=10
永久设置:vim /etc/sysctl.conf,最后一行加上vm.swappiness=10,保存并退出。sysctl -p 立即生效
cat /proc/sys/vm/vfs_cache_pressure 缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache。vim /etc/sysctl.conf,最后一行加上vm.vfs_cache_pressure=50
ACL即Access Control List,访问控制列表,POSIX 1003.1e/1003.2c标准中定义的权限管理方式。详细内容可以参考POSIX Access Control Lists on Linux这篇文章。
POSIX:POSIX是可移植操作系统接口(Portable Operating System Interface of UNIX)的缩写,POSIX标准定义了操作系统应该为应用程序提供的接口标准,是在各种UNIX操作系统上运行的软件的一系列API标准的总称。POSIX标准意在期望获得源代码级别的软件可移植性。换句话说,为一个POSIX兼容的操作系统编写的程序,应该可以在任何其它的POSIX操作系统(即使是来自另一个厂商)上编译执行。
经典的Unix权限模型中每个文件系统对象都定义了三组权限,owner、group和other。也就是常用的chmod命令中修改的权限,包括读(r)、写入(w)和执行(x)。但是如果我们想更细颗粒度的控制某些用户的权限时,使用chmod、chown就很难办了。这就需要ACL来针对单一用户、单一文件或目录来进行权限控制。
ACL由一系列Access Entry组成,Access Entry又包括三个部分:Entry type,qualifier(非必须)、权限
Entry type有以下类型:
Owner/ACL_USER_OBJ : 相当于Linux里file_owner的权限
Named user/ACL_USER: 定义了额外的用户可以对此文件拥有的权限
Owning group/ACL_GROUP_OBJ: 相当于Linux里group的权限
Named group/ACL_GROUP: 定义了额外的组可以对此文件拥有的权限
Mask/ACL_MASK: 定义了ACL_USER, ACL_GROUP_OBJ和ACL_GROUP的最大权限
Others/ACL_OTHER: 相当于Linux里other的权限
进程请求访问文件系统对象。执行两个步骤。第一步选择与请求进程最匹配的 ACL 条目。ACL 条目按以下顺序查看:所有者、命名用户、(拥有或命名)组、其他。只有一个条目决定访问。第二步检查匹配条目是否包含足够的权限。
一个进程可以是多个组中的成员,因此可以匹配多个组条目。如果这些匹配的组条目中的任何一个包含请求的权限,则选择包含请求的权限的条目(无论选择哪个条目,结果都是相同的)。如果没有匹配的组条目包含请求的权限,则无论选择哪个条目都将拒绝访问。
访问检查算法可以用伪代码描述如下。
if
进程的用户ID是所有者,所有者条目决定访问权限
else if
进程的用户 ID 与指定用户条目之一中的限定符匹配,此条目确定访问权限
else if
进程的组 ID 之一与所属组匹配,并且所属组条目包含请求的权限,此条目确定访问权限
else if
进程的组 ID 之一与命名组条目之一的限定符匹配,并且此条目包含请求的权限,此条目确定访问权限
else if
进程的组 ID 之一与所属组或任何命名组条目匹配,但所属组条目或任何匹配命名组条目均不包含请求的权限,这确定访问被拒绝
else
另一个条目决定访问。
if
此选择产生的匹配条目是所有者或其他条目,并且它包含请求的权限,授予访问权限
else if
匹配条目是命名用户、拥有组或命名组条目,并且此条目包含请求的权限,并且掩码条目也包含请求的权限(或没有掩码条目),授予访问权限
else
访问被拒绝。
The access check algorithm can be described in pseudo-code as follows.
If
the user ID of the process is the owner, the owner entry determines access
else if
the user ID of the process matches the qualifier in one of the named user entries, this entry determines access
else if
one of the group IDs of the process matches the owning group and the owning group entry contains the requested permissions, this entry determines access
else if
one of the group IDs of the process matches the qualifier of one of the named group entries and this entry contains the requested permissions, this entry determines access
else if
one of the group IDs of the process matches the owning group or any of the named group entries, but neither the owning group entry nor any of the matching named group entries contains the requested permissions, this determines that access is denied
else
the other entry determines access.
If
the matching entry resulting from this selection is the owner or other entry and it contains the requested permissions, access is granted
else if
the matching entry is a named user, owning group, or named group entry and this entry contains the requested permissions and the mask entry also contains the requested permissions (or there is no mask entry), access is granted
else
access is denied.
getfacl:查看某个文件/目录的ACL权限
setfacl:设置某个文件/目录的ACL权限
setfacl -m u:user1:rx /test:给user1用户设置/test目录的rx(r-x)权限setfacl -m g:group1:rx /test:给group1组设置/test目录的rx(r-x)权限setfacl -m o:--x /test:给other设置x(--x)权限(chmod o+x /test)默认权限下新建的子目录会继承父目录的权限,只有目录才能给默认权限,不是目录的对象仅继承父目录的默认 ACL 作为其访问 ACL。
setfacl -m d:u:user1:rx /test:给user1用户设置/test目录的默认rx权限setfacl -m d:g:group1:rx /test:给group1组设置/test目录的默认rx权限setfacl -m d:o:--x /test:给other设置/test目录的默认x权限如上文所描述的,mask定义了ACL_USER, ACL_GROUP_OBJ和ACL_GROUP的最大权限。例如,mask权限为r--,此时不管ACL_USER的权限为多大,就算是``rwx,最终生效的都只会是r--`。概括来说:用户和用户组的权限必须在mask权限的范围之内才能生效,mask权限就是最大有效权限。
setfacl -m m:rx /test:设置mask权限为r-x,使用setfacl -m m:权限 路径
setfacl -b /test
setfacl -x u:user1 /test
ACL即Access Control List,访问控制列表,POSIX 1003.1e/1003.2c标准中定义的权限管理方式。详细内容可以参考POSIX Access Control Lists on Linux这篇文章。
POSIX:POSIX是可移植操作系统接口(Portable Operating System Interface of UNIX)的缩写,POSIX标准定义了操作系统应该为应用程序提供的接口标准,是在各种UNIX操作系统上运行的软件的一系列API标准的总称。POSIX标准意在期望获得源代码级别的软件可移植性。换句话说,为一个POSIX兼容的操作系统编写的程序,应该可以在任何其它的POSIX操作系统(即使是来自另一个厂商)上编译执行。
经典的Unix权限模型中每个文件系统对象都定义了三组权限,owner、group和other。也就是常用的chmod命令中修改的权限,包括读(r)、写入(w)和执行(x)。但是如果我们想更细颗粒度的控制某些用户的权限时,使用chmod、chown就很难办了。这就需要ACL来针对单一用户、单一文件或目录来进行权限控制。
ACL由一系列Access Entry组成,Access Entry又包括三个部分:Entry type,qualifier(非必须)、权限
Entry type有以下类型:
Owner/ACL_USER_OBJ : 相当于Linux里file_owner的权限
Named user/ACL_USER: 定义了额外的用户可以对此文件拥有的权限
Owning group/ACL_GROUP_OBJ: 相当于Linux里group的权限
Named group/ACL_GROUP: 定义了额外的组可以对此文件拥有的权限
Mask/ACL_MASK: 定义了ACL_USER, ACL_GROUP_OBJ和ACL_GROUP的最大权限
Others/ACL_OTHER: 相当于Linux里other的权限
进程请求访问文件系统对象。执行两个步骤。第一步选择与请求进程最匹配的 ACL 条目。ACL 条目按以下顺序查看:所有者、命名用户、(拥有或命名)组、其他。只有一个条目决定访问。第二步检查匹配条目是否包含足够的权限。
一个进程可以是多个组中的成员,因此可以匹配多个组条目。如果这些匹配的组条目中的任何一个包含请求的权限,则选择包含请求的权限的条目(无论选择哪个条目,结果都是相同的)。如果没有匹配的组条目包含请求的权限,则无论选择哪个条目都将拒绝访问。
访问检查算法可以用伪代码描述如下。
if
进程的用户ID是所有者,所有者条目决定访问权限
else if
进程的用户 ID 与指定用户条目之一中的限定符匹配,此条目确定访问权限
else if
进程的组 ID 之一与所属组匹配,并且所属组条目包含请求的权限,此条目确定访问权限
else if
进程的组 ID 之一与命名组条目之一的限定符匹配,并且此条目包含请求的权限,此条目确定访问权限
else if
进程的组 ID 之一与所属组或任何命名组条目匹配,但所属组条目或任何匹配命名组条目均不包含请求的权限,这确定访问被拒绝
else
另一个条目决定访问。
if
此选择产生的匹配条目是所有者或其他条目,并且它包含请求的权限,授予访问权限
else if
匹配条目是命名用户、拥有组或命名组条目,并且此条目包含请求的权限,并且掩码条目也包含请求的权限(或没有掩码条目),授予访问权限
else
访问被拒绝。
The access check algorithm can be described in pseudo-code as follows.
If
the user ID of the process is the owner, the owner entry determines access
else if
the user ID of the process matches the qualifier in one of the named user entries, this entry determines access
else if
one of the group IDs of the process matches the owning group and the owning group entry contains the requested permissions, this entry determines access
else if
one of the group IDs of the process matches the qualifier of one of the named group entries and this entry contains the requested permissions, this entry determines access
else if
one of the group IDs of the process matches the owning group or any of the named group entries, but neither the owning group entry nor any of the matching named group entries contains the requested permissions, this determines that access is denied
else
the other entry determines access.
If
the matching entry resulting from this selection is the owner or other entry and it contains the requested permissions, access is granted
else if
the matching entry is a named user, owning group, or named group entry and this entry contains the requested permissions and the mask entry also contains the requested permissions (or there is no mask entry), access is granted
else
access is denied.
getfacl:查看某个文件/目录的ACL权限
setfacl:设置某个文件/目录的ACL权限
setfacl -m u:user1:rx /test:给user1用户设置/test目录的rx(r-x)权限setfacl -m g:group1:rx /test:给group1组设置/test目录的rx(r-x)权限setfacl -m o:--x /test:给other设置x(--x)权限(chmod o+x /test)默认权限下新建的子目录会继承父目录的权限,只有目录才能给默认权限,不是目录的对象仅继承父目录的默认 ACL 作为其访问 ACL。
setfacl -m d:u:user1:rx /test:给user1用户设置/test目录的默认rx权限setfacl -m d:g:group1:rx /test:给group1组设置/test目录的默认rx权限setfacl -m d:o:--x /test:给other设置/test目录的默认x权限如上文所描述的,mask定义了ACL_USER, ACL_GROUP_OBJ和ACL_GROUP的最大权限。例如,mask权限为r--,此时不管ACL_USER的权限为多大,就算是``rwx,最终生效的都只会是r--`。概括来说:用户和用户组的权限必须在mask权限的范围之内才能生效,mask权限就是最大有效权限。
setfacl -m m:rx /test:设置mask权限为r-x,使用setfacl -m m:权限 路径
setfacl -b /test
setfacl -x u:user1 /test
chmod -x /etc/update-motd.d/*
vim /etc/default/motd-news 将enabled改为0
apt remove landscape-common landscape-client
# 1.备份数据
+# 2.制作一个linux启动盘 例如live server的
+# 3.连接原启动盘和需要迁移到的目标盘
+# 4.U盘启动直接进入shell
+# 5.查看磁盘信息
+lsblk
+# 6.dd命令直接全盘迁移
+dd if=/dev/sda of=/dev/sdb bs=4096 conv=sync,noerror
+# 7.拷贝完成后使用新磁盘启动
+# 8.删除旧分区&resize
+fdisk /dev/sdX
+d #删除磁盘最后一个分区
+n #新建一个分区,扇区开始结束都用默认即可
+w #写盘保存
+
+partprobe #重新读取分区表并更新分区信息
+
+resize2fs /dev/sdXX #调整文件系统的大小最近打算给home server换一块瑞昱的2.5G网卡(8125b芯片),所以想提前安装下网卡驱动,执行官网那个autorun.sh脚本前也没仔细看, 结果脚本直接把原来的8169网卡驱动卸载了,导致机器直接失联。还好脚本里有备份,所以只需要恢复回去就行了。
shell#!/bin/sh +# SPDX-License-Identifier: GPL-2.0-only + +# invoke insmod with all arguments we got +# and use a pathname, as insmod doesn't look in . by default + +TARGET_PATH=$(find /lib/modules/$(uname -r)/kernel/drivers/net/ethernet -name realtek -type d) +if [ "$TARGET_PATH" = "" ]; then + TARGET_PATH=$(find /lib/modules/$(uname -r)/kernel/drivers/net -name realtek -type d) +fi +if [ "$TARGET_PATH" = "" ]; then + TARGET_PATH=/lib/modules/$(uname -r)/kernel/drivers/net +fi +echo +echo "Check old driver and unload it." +check=\`lsmod | grep r8169\` +if [ "$check" != "" ]; then + echo "rmmod r8169" + /sbin/rmmod r8169 +fi + +check=\`lsmod | grep r8125\` +if [ "$check" != "" ]; then + echo "rmmod r8125" + /sbin/rmmod r8125 +fi + +echo "Build the module and install" +echo "-------------------------------" >> log.txt +date 1>>log.txt +make $@ all 1>>log.txt || exit 1 +module=\`ls src/*.ko\` +module=\${module#src/} +module=\${module%.ko} + +if [ "$module" = "" ]; then + echo "No driver exists!!!" + exit 1 +elif [ "$module" != "r8169" ]; then + if test -e $TARGET_PATH/r8169.ko ; then + echo "Backup r8169.ko" + if test -e $TARGET_PATH/r8169.bak ; then + i=0 + while test -e $TARGET_PATH/r8169.bak$i + do + i=$(($i+1)) + done + echo "rename r8169.ko to r8169.bak$i" + mv $TARGET_PATH/r8169.ko $TARGET_PATH/r8169.bak$i + else + echo "rename r8169.ko to r8169.bak" + mv $TARGET_PATH/r8169.ko $TARGET_PATH/r8169.bak + fi + fi +fi + +echo "DEPMOD $(uname -r)" +depmod \`uname -r\` +echo "load module $module" +modprobe $module + +is_update_initramfs=n +distrib_list="ubuntu debian" + +if [ -r /etc/debian_version ]; then + is_update_initramfs=y +elif [ -r /etc/lsb-release ]; then + for distrib in $distrib_list + do + /bin/grep -i "$distrib" /etc/lsb-release 2>&1 /dev/null && \\ + is_update_initramfs=y && break + done +fi + +if [ "$is_update_initramfs" = "y" ]; then + if which update-initramfs >/dev/null ; then + echo "Updating initramfs. Please wait." + update-initramfs -u -k $(uname -r) + else + echo "update-initramfs: command not found" + exit 1 + fi +fi + +echo "Completed." +exit 0
# 进入网卡驱动目录
+cd /lib/modules/$(uname -r)//kernel/drivers/net/ethernet/realtek
+# 恢复备份
+mv r8169.bak r8169.ko
+# 加载模块
+insmod r8169.ko
+# 验证是否加载
+lsmod | grep r8169
+# 更新模块依赖关系
+depmod \`uname -r\`
+# 更新initramfs
+update-initramfs -u -k $(uname -r)A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. https://github.com/awesometic/realtek-r8125-dkms
sudo add-apt-repository ppa:awesometic/ppa
sudo apt install realtek-r8125-dkms
sudo tee -a /etc/modprobe.d/blacklist-r8169.conf > /dev/null <<EOT
+# To use r8125 driver explicitly
+blacklist r8169
+EOTsudo update-initramfs -u
vim /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
+network:
+ ethernets:
+ enp1s0: # 根据ifconfig -a找到2.5G网卡设备的名称
+ dhcp4: true
+ version: 2netplan apply
reboot
`,16)]))}const E=i(l,[["render",k]]);export{g as __pageData,E as default}; diff --git a/assets/linux_env_Ubuntu-server.md.CIYKI1NW.lean.js b/assets/linux_env_Ubuntu-server.md.CIYKI1NW.lean.js new file mode 100644 index 00000000..208f1d39 --- /dev/null +++ b/assets/linux_env_Ubuntu-server.md.CIYKI1NW.lean.js @@ -0,0 +1,122 @@ +import{_ as i,c as a,a2 as n,o as h}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"Ubuntu-server","description":"","frontmatter":{},"headers":[],"relativePath":"linux/env/Ubuntu-server.md","filePath":"linux/env/Ubuntu-server.md","lastUpdated":1729217313000}'),l={name:"linux/env/Ubuntu-server.md"};function k(t,s,p,e,r,d){return h(),a("div",null,s[0]||(s[0]=[n(`内核更新后重新安装:
apt install ./realtek-r8125-9.012.04-1_amd64.deb --reinstall
chmod -x /etc/update-motd.d/*
vim /etc/default/motd-news 将enabled改为0
apt remove landscape-common landscape-client
# 1.备份数据
+# 2.制作一个linux启动盘 例如live server的
+# 3.连接原启动盘和需要迁移到的目标盘
+# 4.U盘启动直接进入shell
+# 5.查看磁盘信息
+lsblk
+# 6.dd命令直接全盘迁移
+dd if=/dev/sda of=/dev/sdb bs=4096 conv=sync,noerror
+# 7.拷贝完成后使用新磁盘启动
+# 8.删除旧分区&resize
+fdisk /dev/sdX
+d #删除磁盘最后一个分区
+n #新建一个分区,扇区开始结束都用默认即可
+w #写盘保存
+
+partprobe #重新读取分区表并更新分区信息
+
+resize2fs /dev/sdXX #调整文件系统的大小最近打算给home server换一块瑞昱的2.5G网卡(8125b芯片),所以想提前安装下网卡驱动,执行官网那个autorun.sh脚本前也没仔细看, 结果脚本直接把原来的8169网卡驱动卸载了,导致机器直接失联。还好脚本里有备份,所以只需要恢复回去就行了。
shell#!/bin/sh +# SPDX-License-Identifier: GPL-2.0-only + +# invoke insmod with all arguments we got +# and use a pathname, as insmod doesn't look in . by default + +TARGET_PATH=$(find /lib/modules/$(uname -r)/kernel/drivers/net/ethernet -name realtek -type d) +if [ "$TARGET_PATH" = "" ]; then + TARGET_PATH=$(find /lib/modules/$(uname -r)/kernel/drivers/net -name realtek -type d) +fi +if [ "$TARGET_PATH" = "" ]; then + TARGET_PATH=/lib/modules/$(uname -r)/kernel/drivers/net +fi +echo +echo "Check old driver and unload it." +check=\`lsmod | grep r8169\` +if [ "$check" != "" ]; then + echo "rmmod r8169" + /sbin/rmmod r8169 +fi + +check=\`lsmod | grep r8125\` +if [ "$check" != "" ]; then + echo "rmmod r8125" + /sbin/rmmod r8125 +fi + +echo "Build the module and install" +echo "-------------------------------" >> log.txt +date 1>>log.txt +make $@ all 1>>log.txt || exit 1 +module=\`ls src/*.ko\` +module=\${module#src/} +module=\${module%.ko} + +if [ "$module" = "" ]; then + echo "No driver exists!!!" + exit 1 +elif [ "$module" != "r8169" ]; then + if test -e $TARGET_PATH/r8169.ko ; then + echo "Backup r8169.ko" + if test -e $TARGET_PATH/r8169.bak ; then + i=0 + while test -e $TARGET_PATH/r8169.bak$i + do + i=$(($i+1)) + done + echo "rename r8169.ko to r8169.bak$i" + mv $TARGET_PATH/r8169.ko $TARGET_PATH/r8169.bak$i + else + echo "rename r8169.ko to r8169.bak" + mv $TARGET_PATH/r8169.ko $TARGET_PATH/r8169.bak + fi + fi +fi + +echo "DEPMOD $(uname -r)" +depmod \`uname -r\` +echo "load module $module" +modprobe $module + +is_update_initramfs=n +distrib_list="ubuntu debian" + +if [ -r /etc/debian_version ]; then + is_update_initramfs=y +elif [ -r /etc/lsb-release ]; then + for distrib in $distrib_list + do + /bin/grep -i "$distrib" /etc/lsb-release 2>&1 /dev/null && \\ + is_update_initramfs=y && break + done +fi + +if [ "$is_update_initramfs" = "y" ]; then + if which update-initramfs >/dev/null ; then + echo "Updating initramfs. Please wait." + update-initramfs -u -k $(uname -r) + else + echo "update-initramfs: command not found" + exit 1 + fi +fi + +echo "Completed." +exit 0
# 进入网卡驱动目录
+cd /lib/modules/$(uname -r)//kernel/drivers/net/ethernet/realtek
+# 恢复备份
+mv r8169.bak r8169.ko
+# 加载模块
+insmod r8169.ko
+# 验证是否加载
+lsmod | grep r8169
+# 更新模块依赖关系
+depmod \`uname -r\`
+# 更新initramfs
+update-initramfs -u -k $(uname -r)A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. https://github.com/awesometic/realtek-r8125-dkms
sudo add-apt-repository ppa:awesometic/ppa
sudo apt install realtek-r8125-dkms
sudo tee -a /etc/modprobe.d/blacklist-r8169.conf > /dev/null <<EOT
+# To use r8125 driver explicitly
+blacklist r8169
+EOTsudo update-initramfs -u
vim /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
+network:
+ ethernets:
+ enp1s0: # 根据ifconfig -a找到2.5G网卡设备的名称
+ dhcp4: true
+ version: 2netplan apply
reboot
`,16)]))}const E=i(l,[["render",k]]);export{g as __pageData,E as default}; diff --git "a/assets/linux_env_bash\345\270\270\347\224\250\347\232\204\345\277\253\346\215\267\351\224\256.md.DvljKhg5.js" "b/assets/linux_env_bash\345\270\270\347\224\250\347\232\204\345\277\253\346\215\267\351\224\256.md.DvljKhg5.js" new file mode 100644 index 00000000..585913f5 --- /dev/null +++ "b/assets/linux_env_bash\345\270\270\347\224\250\347\232\204\345\277\253\346\215\267\351\224\256.md.DvljKhg5.js" @@ -0,0 +1 @@ +import{_ as t,c as i,a2 as a,o as r}from"./chunks/framework.BjcrtTwI.js";const p=JSON.parse('{"title":"bash常用的快捷键","description":"","frontmatter":{},"headers":[],"relativePath":"linux/env/bash常用的快捷键.md","filePath":"linux/env/bash常用的快捷键.md","lastUpdated":1729217313000}'),e={name:"linux/env/bash常用的快捷键.md"};function c(s,l,n,o,h,d){return r(),i("div",null,l[0]||(l[0]=[a('内核更新后重新安装:
apt install ./realtek-r8125-9.012.04-1_amd64.deb --reinstall
centos7.0以上的版本默认为firewalld,以下是iptables,整理一下命令备用。
firewall-cmd --statefirewall-cmd --list-allfirewall-cmd --reloadsystemctl stop firewalld.service
+systemctl start firewalld.servicefirewall-cmd --zone=public --add-port=5672/tcp --permanentfirewall-cmd --zone=public --remove-port=5672/tcp --permanentsystemctl start iptables.service
+systemctl stop iptables.servicesystemctl status iptables.service1.命令
iptables -I INPUT -p tcp --dport 8000 -j ACCEPT2.直接修改/etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp --dport 8000 -j ACCEPT
service iptables restartcentos7.0以上的版本默认为firewalld,以下是iptables,整理一下命令备用。
firewall-cmd --statefirewall-cmd --list-allfirewall-cmd --reloadsystemctl stop firewalld.service
+systemctl start firewalld.servicefirewall-cmd --zone=public --add-port=5672/tcp --permanentfirewall-cmd --zone=public --remove-port=5672/tcp --permanentsystemctl start iptables.service
+systemctl stop iptables.servicesystemctl status iptables.service1.命令
iptables -I INPUT -p tcp --dport 8000 -j ACCEPT2.直接修改/etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp --dport 8000 -j ACCEPT
service iptables restartCentOS7-1908版本
http://vault.centos.org/7.7.1908/isos/x86_64/CentOS-7-x86_64-DVD-1908.torrent
ifconfig
yum search ifconfigyum install net-tools.x86_64lsb_release
yum install -y redhat-lsbyum提示没有可用镜像
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repowget
yum install wgetdns
vi /etc/sysconfig/network-scripts/ifcfg-ens33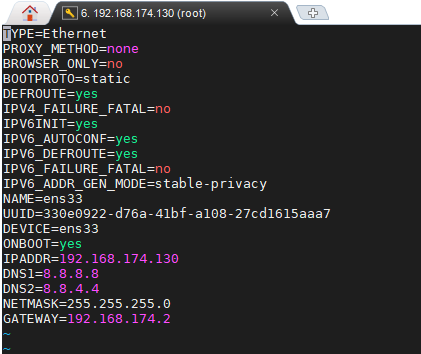
真机的ip信息
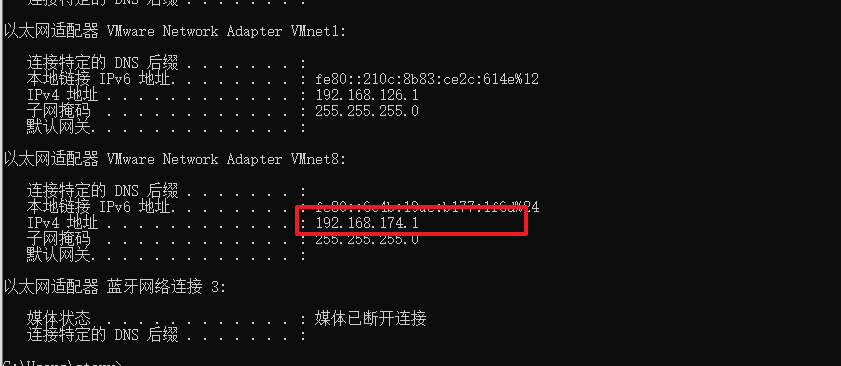
JDK1.8
oracle官网下载jdk后上传虚拟机
解压并配置环境变量,比如我下载的是jre1.8.0_202
vi /etc/profile/
JAVA_HOME=/usr/local/java/jre1.8.0_202
+PATH=$JAVA_HOME/bin:$PATH
+CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
+export JAVA_HOME
+export CLASSPATH
+export PATHsource /etc/profile或重启虚拟机使环境变量生效
python3
mysql 5.7
下载并安装mysql官方的yum repository: wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.41-1.el7.x86_64.rpm-bundle.tar
解压包:tar -xvf mysql-5.7.41-1.el7.x86_64.rpm-bundle.tar
yum -y install mysql-community-common-5.7.41-1.el7.x86_64.rpm mysql-community-libs-5.7.41-1.el7.x86_64.rpm mysql-community-client-5.7.41-1.el7.x86_64.rpm mysql-community-server-5.7.41-1.el7.x86_64.rpm
启动systemctl enable mysqld && systemctl start mysqld
临时密码 grep 'temporary password' /var/log/mysqld.log
根据临时密码登入mysql
改密码 ALTER USER 'root'@'localhost' IDENTIFIED BY 'new pwd';
更改密码弱口令设置,设置简单密码:
set global validate_password_policy=0;
set global validate_password_length=1;
配置远程登陆
grant all on *.* to 'root'@'%' identified by 'pwd';
立即生效: flush privileges;
创建用户&授权
-- 创建用户
+CREATE USER '用户名'@'localhost' IDENTIFIED BY '密码';
+CREATE USER '用户名'@'%' IDENTIFIED BY '密码';
+-- 授权全部
+grant all privileges on 数据库名称.* to '用户名'@'localhost' identified by '密码'; #本地授权
+grant all privileges on 数据库名称.* to '用户名'@'%' identified by '密码'; #远程授权
+flush privileges; #刷新系统权限表
+-- 授权指定
+grant select,update,delete,insert on 数据库名称.* to '用户'@'localhost' identified by '密码';
+flush privileges; #刷新系统权限表
+-- 删除用户
+Delete FROM mysql.user Where User='用户名' and Host='localhost'; #删除本地用户
+Delete FROM mysql.user Where User='用户名' and Host='%'; #删除远程用户
+flush privileges; #刷新系统权限表
+-- 删除用户及权限
+DROP USER 'username'@'localhost';
+DROP USER 'username'@'%';
+-- 查看当前用户权限
+show grants;
+-- 查看指定用户权限
+show grants for username@localhost;mysql 8.0
-- 修改root密码
+UPDATE mysql.user SET authentication_string=null WHERE User='root';
+FLUSH PRIVILEGES;
+
+ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'new_password';
+FLUSH PRIVILEGES;
+
+
+CREATE USER ''@'' IDENTIFIED BY '';
+
+GRANT ALL PRIVILEGES ON *.* TO ''@'';nginx
依赖
yum -y install gcc pcre pcre-devel zlib zlib-devel openssl openssl-develapt install libpcre3 libpcre3-dev openssl libssl-dev下载安装包 wget http://nginx.org/download/nginx-1.9.9.tar.gz
解压到指定目录 tar -xzvf nginx-1.9.9.tar.gz -C /usr/local/nginx/
切换到nginx的目录执行 cd /usr/local/nginx/nginx-1.9.9
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module #配置ssl模块
+
+make
+
+make install安装后切换到/usr/local/nginx/sbin启动nginx并访问
开机自启nginx
vi /etc/init.d/nginx
#!/bin/bash
+#
+# nginx - this script starts and stops the nginx daemon
+#
+# chkconfig: - 85 15
+# description: NGINX is an HTTP(S) server, HTTP(S) reverse \\
+# proxy and IMAP/POP3 proxy server
+# processname: nginx
+# config: /etc/nginx/nginx.conf
+# config: /etc/sysconfig/nginx
+# pidfile: /var/run/nginx.pid
+
+# Source function library.
+. /etc/rc.d/init.d/functions
+
+# Source networking configuration.
+. /etc/sysconfig/network
+
+# Check that networking is up.
+[ "$NETWORKING" = "no" ] && exit 0
+
+nginx="/usr/local/nginx/sbin/nginx"
+prog=$(basename $nginx)
+
+NGINX_CONF_FILE="/usr/local/nginx/conf/nginx.conf"
+
+[ -f /etc/sysconfig/nginx ] && . /etc/sysconfig/nginx
+
+lockfile=/var/lock/subsys/nginx
+
+make_dirs() {
+ # make required directories
+ user=\`$nginx -V 2>&1 | grep "configure arguments:.*--user=" | sed 's/[^*]*--user=\\([^ ]*\\).*/\\1/g' -\`
+ if [ -n "$user" ]; then
+ if [ -z "\`grep $user /etc/passwd\`" ]; then
+ useradd -M -s /bin/nologin $user
+ fi
+ options=\`$nginx -V 2>&1 | grep 'configure arguments:'\`
+ for opt in $options; do
+ if [ \`echo $opt | grep '.*-temp-path'\` ]; then
+ value=\`echo $opt | cut -d "=" -f 2\`
+ if [ ! -d "$value" ]; then
+ # echo "creating" $value
+ mkdir -p $value && chown -R $user $value
+ fi
+ fi
+ done
+ fi
+}
+
+start() {
+ [ -x $nginx ] || exit 5
+ [ -f $NGINX_CONF_FILE ] || exit 6
+ make_dirs
+ echo -n $"Starting $prog: "
+ daemon $nginx -c $NGINX_CONF_FILE
+ retval=$?
+ echo
+ [ $retval -eq 0 ] && touch $lockfile
+ return $retval
+}
+
+stop() {
+ echo -n $"Stopping $prog: "
+ killproc $prog -QUIT
+ retval=$?
+ echo
+ [ $retval -eq 0 ] && rm -f $lockfile
+ return $retval
+}
+
+restart() {
+ configtest || return $?
+ stop
+ sleep 1
+ start
+}
+
+reload() {
+ configtest || return $?
+ echo -n $"Reloading $prog: "
+ killproc $nginx -HUP
+ RETVAL=$?
+ echo
+}
+
+force_reload() {
+ restart
+}
+
+configtest() {
+ $nginx -t -c $NGINX_CONF_FILE
+}
+
+rh_status() {
+ status $prog
+}
+
+rh_status_q() {
+ rh_status >/dev/null 2>&1
+}
+
+case "$1" in
+ start)
+ rh_status_q && exit 0
+ $1
+ ;;
+ stop)
+ rh_status_q || exit 0
+ $1
+ ;;
+ restart|configtest)
+ $1
+ ;;
+ reload)
+ rh_status_q || exit 7
+ $1
+ ;;
+ force-reload)
+ force_reload
+ ;;
+ status)
+ rh_status
+ ;;
+ condrestart|try-restart)
+ rh_status_q || exit 0
+ ;;
+ *)
+ echo $"Usage: $0 {start|stop|status|restart|reload|configtest}"
+ exit 2
+esacchmod 777 /etc/init.d/nginxchkconfig nginx on开放端口
firewall-cmd --list-portsfirewall-cmd --zone=public --add-port=80/tcp --permanentfirewall-cmd --reload #重启firewallsystemctl stop firewalld.service #停止firewallsystemctl disable firewalld.service #禁止firewall开机启动firewall-cmd --state #查看默认防火墙状态redis
下载安装包wget http://download.redis.io/releases/redis-5.0.7.tar.gz
tar -zxvf redis-5.0.7.tar.gz
mv /root/redis-5.0.7 /usr/local/redis
cd /usr/local/redis/redis-5.0.7
make && make PREFIX=/usr/local/redis install
可能会报错,因为centos自带的gcc版本太低
执行命令
yum -y install centos-release-scl devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
+# scl enable devtoolset-9 bash #临时启用新版本的gcc
+echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile # 永久启用新版gcc开机自启redis
vi /etc/init.d/redis#!/bin/sh
+# chkconfig: 2345 10 90
+# description: Start and Stop redis
+
+REDISPORT=6379
+EXEC=/usr/local/redis/bin/redis-server
+CLIEXEC=/usr/local/redis/bin/redis-cli
+
+PIDFILE=/var/run/redis_\${REDISPORT}.pid
+CONF="/usr/local/redis/redis.conf"
+
+case "$1" in
+ start)
+ if [ -f $PIDFILE ]
+ then
+ echo "$PIDFILE exists, process is already running or crashed"
+ else
+ echo "Starting Redis server..."
+ $EXEC $CONF &
+ fi
+ ;;
+ stop)
+ if [ ! -f $PIDFILE ]
+ then
+ echo "$PIDFILE does not exist, process is not running"
+ else
+ PID=$(cat $PIDFILE)
+ echo "Stopping ..."
+ $CLIEXEC -p $REDISPORT shutdown
+ while [ -x /proc/\${PID} ]
+ do
+ echo "Waiting for Redis to shutdown ..."
+ sleep 1
+ done
+ echo "Redis stopped"
+ fi
+ ;;
+ restart)
+ "$0" stop
+ sleep 3
+ "$0" start
+ ;;
+ *)
+ echo "Please use start or stop or restart as first argument"
+ ;;
+esacvim /usr/local/redis/redis.conf
+修改
+bind 0.0.0.0 #所有ipv4端口
+protected-mode no # 关闭保护模式
+daemonize yes # 守护进程
+requirepass password #需要密码登录
+pidfile /var/run/redis_6379.pid #pid文件# 授权
+chmod 777 /etc/init.d/redis# 开机启动
+chkconfig redis on# 创建客户端软链接
+ln -s /usr/local/redis/bin/redis-cli /usr/local/bin/redis-clidocker
卸载旧版本
sudo yum remove docker \\
+ docker-client \\
+ docker-client-latest \\
+ docker-common \\
+ docker-latest \\
+ docker-latest-logrotate \\
+ docker-logrotate \\
+ docker-engine使用docker repository安装
# set up repository
+sudo yum install -y yum-utils
+
+sudo yum-config-manager \\
+ --add-repo \\
+ https://download.docker.com/linux/centos/docker-ce.repo
+
+
+# install docker engine
+sudo yum install docker-ce docker-ce-cli containerd.io
+
+# start docker engine
+sudo systemctl start dockerCentOS7-1908版本
http://vault.centos.org/7.7.1908/isos/x86_64/CentOS-7-x86_64-DVD-1908.torrent
ifconfig
yum search ifconfigyum install net-tools.x86_64lsb_release
yum install -y redhat-lsbyum提示没有可用镜像
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repowget
yum install wgetdns
vi /etc/sysconfig/network-scripts/ifcfg-ens33
真机的ip信息
JDK1.8
oracle官网下载jdk后上传虚拟机
解压并配置环境变量,比如我下载的是jre1.8.0_202
vi /etc/profile/
JAVA_HOME=/usr/local/java/jre1.8.0_202
+PATH=$JAVA_HOME/bin:$PATH
+CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
+export JAVA_HOME
+export CLASSPATH
+export PATHsource /etc/profile或重启虚拟机使环境变量生效
python3
mysql 5.7
下载并安装mysql官方的yum repository: wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.41-1.el7.x86_64.rpm-bundle.tar
解压包:tar -xvf mysql-5.7.41-1.el7.x86_64.rpm-bundle.tar
yum -y install mysql-community-common-5.7.41-1.el7.x86_64.rpm mysql-community-libs-5.7.41-1.el7.x86_64.rpm mysql-community-client-5.7.41-1.el7.x86_64.rpm mysql-community-server-5.7.41-1.el7.x86_64.rpm
启动systemctl enable mysqld && systemctl start mysqld
临时密码 grep 'temporary password' /var/log/mysqld.log
根据临时密码登入mysql
改密码 ALTER USER 'root'@'localhost' IDENTIFIED BY 'new pwd';
更改密码弱口令设置,设置简单密码:
set global validate_password_policy=0;
set global validate_password_length=1;
配置远程登陆
grant all on *.* to 'root'@'%' identified by 'pwd';
立即生效: flush privileges;
创建用户&授权
-- 创建用户
+CREATE USER '用户名'@'localhost' IDENTIFIED BY '密码';
+CREATE USER '用户名'@'%' IDENTIFIED BY '密码';
+-- 授权全部
+grant all privileges on 数据库名称.* to '用户名'@'localhost' identified by '密码'; #本地授权
+grant all privileges on 数据库名称.* to '用户名'@'%' identified by '密码'; #远程授权
+flush privileges; #刷新系统权限表
+-- 授权指定
+grant select,update,delete,insert on 数据库名称.* to '用户'@'localhost' identified by '密码';
+flush privileges; #刷新系统权限表
+-- 删除用户
+Delete FROM mysql.user Where User='用户名' and Host='localhost'; #删除本地用户
+Delete FROM mysql.user Where User='用户名' and Host='%'; #删除远程用户
+flush privileges; #刷新系统权限表
+-- 删除用户及权限
+DROP USER 'username'@'localhost';
+DROP USER 'username'@'%';
+-- 查看当前用户权限
+show grants;
+-- 查看指定用户权限
+show grants for username@localhost;mysql 8.0
-- 修改root密码
+UPDATE mysql.user SET authentication_string=null WHERE User='root';
+FLUSH PRIVILEGES;
+
+ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'new_password';
+FLUSH PRIVILEGES;
+
+
+CREATE USER ''@'' IDENTIFIED BY '';
+
+GRANT ALL PRIVILEGES ON *.* TO ''@'';nginx
依赖
yum -y install gcc pcre pcre-devel zlib zlib-devel openssl openssl-develapt install libpcre3 libpcre3-dev openssl libssl-dev下载安装包 wget http://nginx.org/download/nginx-1.9.9.tar.gz
解压到指定目录 tar -xzvf nginx-1.9.9.tar.gz -C /usr/local/nginx/
切换到nginx的目录执行 cd /usr/local/nginx/nginx-1.9.9
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module #配置ssl模块
+
+make
+
+make install安装后切换到/usr/local/nginx/sbin启动nginx并访问
开机自启nginx
vi /etc/init.d/nginx
#!/bin/bash
+#
+# nginx - this script starts and stops the nginx daemon
+#
+# chkconfig: - 85 15
+# description: NGINX is an HTTP(S) server, HTTP(S) reverse \\
+# proxy and IMAP/POP3 proxy server
+# processname: nginx
+# config: /etc/nginx/nginx.conf
+# config: /etc/sysconfig/nginx
+# pidfile: /var/run/nginx.pid
+
+# Source function library.
+. /etc/rc.d/init.d/functions
+
+# Source networking configuration.
+. /etc/sysconfig/network
+
+# Check that networking is up.
+[ "$NETWORKING" = "no" ] && exit 0
+
+nginx="/usr/local/nginx/sbin/nginx"
+prog=$(basename $nginx)
+
+NGINX_CONF_FILE="/usr/local/nginx/conf/nginx.conf"
+
+[ -f /etc/sysconfig/nginx ] && . /etc/sysconfig/nginx
+
+lockfile=/var/lock/subsys/nginx
+
+make_dirs() {
+ # make required directories
+ user=\`$nginx -V 2>&1 | grep "configure arguments:.*--user=" | sed 's/[^*]*--user=\\([^ ]*\\).*/\\1/g' -\`
+ if [ -n "$user" ]; then
+ if [ -z "\`grep $user /etc/passwd\`" ]; then
+ useradd -M -s /bin/nologin $user
+ fi
+ options=\`$nginx -V 2>&1 | grep 'configure arguments:'\`
+ for opt in $options; do
+ if [ \`echo $opt | grep '.*-temp-path'\` ]; then
+ value=\`echo $opt | cut -d "=" -f 2\`
+ if [ ! -d "$value" ]; then
+ # echo "creating" $value
+ mkdir -p $value && chown -R $user $value
+ fi
+ fi
+ done
+ fi
+}
+
+start() {
+ [ -x $nginx ] || exit 5
+ [ -f $NGINX_CONF_FILE ] || exit 6
+ make_dirs
+ echo -n $"Starting $prog: "
+ daemon $nginx -c $NGINX_CONF_FILE
+ retval=$?
+ echo
+ [ $retval -eq 0 ] && touch $lockfile
+ return $retval
+}
+
+stop() {
+ echo -n $"Stopping $prog: "
+ killproc $prog -QUIT
+ retval=$?
+ echo
+ [ $retval -eq 0 ] && rm -f $lockfile
+ return $retval
+}
+
+restart() {
+ configtest || return $?
+ stop
+ sleep 1
+ start
+}
+
+reload() {
+ configtest || return $?
+ echo -n $"Reloading $prog: "
+ killproc $nginx -HUP
+ RETVAL=$?
+ echo
+}
+
+force_reload() {
+ restart
+}
+
+configtest() {
+ $nginx -t -c $NGINX_CONF_FILE
+}
+
+rh_status() {
+ status $prog
+}
+
+rh_status_q() {
+ rh_status >/dev/null 2>&1
+}
+
+case "$1" in
+ start)
+ rh_status_q && exit 0
+ $1
+ ;;
+ stop)
+ rh_status_q || exit 0
+ $1
+ ;;
+ restart|configtest)
+ $1
+ ;;
+ reload)
+ rh_status_q || exit 7
+ $1
+ ;;
+ force-reload)
+ force_reload
+ ;;
+ status)
+ rh_status
+ ;;
+ condrestart|try-restart)
+ rh_status_q || exit 0
+ ;;
+ *)
+ echo $"Usage: $0 {start|stop|status|restart|reload|configtest}"
+ exit 2
+esacchmod 777 /etc/init.d/nginxchkconfig nginx on开放端口
firewall-cmd --list-portsfirewall-cmd --zone=public --add-port=80/tcp --permanentfirewall-cmd --reload #重启firewallsystemctl stop firewalld.service #停止firewallsystemctl disable firewalld.service #禁止firewall开机启动firewall-cmd --state #查看默认防火墙状态redis
下载安装包wget http://download.redis.io/releases/redis-5.0.7.tar.gz
tar -zxvf redis-5.0.7.tar.gz
mv /root/redis-5.0.7 /usr/local/redis
cd /usr/local/redis/redis-5.0.7
make && make PREFIX=/usr/local/redis install
可能会报错,因为centos自带的gcc版本太低
执行命令
yum -y install centos-release-scl devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
+# scl enable devtoolset-9 bash #临时启用新版本的gcc
+echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile # 永久启用新版gcc开机自启redis
vi /etc/init.d/redis#!/bin/sh
+# chkconfig: 2345 10 90
+# description: Start and Stop redis
+
+REDISPORT=6379
+EXEC=/usr/local/redis/bin/redis-server
+CLIEXEC=/usr/local/redis/bin/redis-cli
+
+PIDFILE=/var/run/redis_\${REDISPORT}.pid
+CONF="/usr/local/redis/redis.conf"
+
+case "$1" in
+ start)
+ if [ -f $PIDFILE ]
+ then
+ echo "$PIDFILE exists, process is already running or crashed"
+ else
+ echo "Starting Redis server..."
+ $EXEC $CONF &
+ fi
+ ;;
+ stop)
+ if [ ! -f $PIDFILE ]
+ then
+ echo "$PIDFILE does not exist, process is not running"
+ else
+ PID=$(cat $PIDFILE)
+ echo "Stopping ..."
+ $CLIEXEC -p $REDISPORT shutdown
+ while [ -x /proc/\${PID} ]
+ do
+ echo "Waiting for Redis to shutdown ..."
+ sleep 1
+ done
+ echo "Redis stopped"
+ fi
+ ;;
+ restart)
+ "$0" stop
+ sleep 3
+ "$0" start
+ ;;
+ *)
+ echo "Please use start or stop or restart as first argument"
+ ;;
+esacvim /usr/local/redis/redis.conf
+修改
+bind 0.0.0.0 #所有ipv4端口
+protected-mode no # 关闭保护模式
+daemonize yes # 守护进程
+requirepass password #需要密码登录
+pidfile /var/run/redis_6379.pid #pid文件# 授权
+chmod 777 /etc/init.d/redis# 开机启动
+chkconfig redis on# 创建客户端软链接
+ln -s /usr/local/redis/bin/redis-cli /usr/local/bin/redis-clidocker
卸载旧版本
sudo yum remove docker \\
+ docker-client \\
+ docker-client-latest \\
+ docker-common \\
+ docker-latest \\
+ docker-latest-logrotate \\
+ docker-logrotate \\
+ docker-engine使用docker repository安装
# set up repository
+sudo yum install -y yum-utils
+
+sudo yum-config-manager \\
+ --add-repo \\
+ https://download.docker.com/linux/centos/docker-ce.repo
+
+
+# install docker engine
+sudo yum install docker-ce docker-ce-cli containerd.io
+
+# start docker engine
+sudo systemctl start dockerThere were 89 failed login attempts since the last successful login.
最近登录阿里云服务器,总是发现有人恶意尝试登录,虽然密码强度很高,但是看着就闹心,索性把密码登录给ban掉改用密钥登录。
cd ~/.ssh
+ssh-keygen -t rsa -C "邮箱地址"此时会在/root/.ssh下生成id_rsa和id_rsa.pub的私钥和公钥
使用ssh-copy-id命令将公钥拷贝到服务器上
把本地的ssh公钥文件安装到远程主机对应的账户下,ssh-copy-id命令 可以把本地主机的公钥复制到远程主机的authorized_keys文件上,ssh-copy-id命令也会给远程主机的用户主目录(home)和~/.ssh, 和~/.ssh/authorized_keys设置合适的权限。 ssh-copy-id 用来将本地公钥复制到远程主机。如果不传入 -i 参数,ssh-copy-id 使用默认 ~/.ssh/identity.pub 作为默认公钥。如果多次运行 ssh-copy-id ,该命令不会检查重复,会在远程主机中多次写入 authorized_keys 。
ssh-copy-id [-i identify_file] [user@]hostvim /etc/ssh/sshd_config
+
+RSAAuthentication yes
+PubkeyAuthentication yes
+AuthorizedKeysFile .ssh/authorized_keys
+PasswordAuthentication yes #密码登录 此时不要关闭修改并保存,重启sshd服务systemctl restart sshd
id_rsa文件权限需要调整,否则使用密钥登录会因为私钥文件权限问题被拒绝。
一般来说: .ssh目录设置700权限 id_rsa,authorized_keys文件设置600权限 id_rsa.pub,known_hosts文件设置644权限
登录使用ssh -i "私钥文件全路径" root@xxx.xxx.xxx.xxx
登录成功
密钥登录成功后即可关闭服务器的密码登录
vim /etc/ssh/sshd_config
+
+PasswordAuthentication no #关闭密码登录保存后重启sshd服务systemctl restart sshd
可以看到密码登录已经被关闭
adduser username
+
+mkdir /home/username/.ssh
+# 编辑authorized_keys文件,将生成的公钥添加进去
+vim /home/username/.ssh/authorized_keys
+
+chown -R username:username /home/username.ssh
+chmod 700 /home/username/.ssh
+chmod 600 /home/username/.ssh/authorized_keysThere were 89 failed login attempts since the last successful login.
最近登录阿里云服务器,总是发现有人恶意尝试登录,虽然密码强度很高,但是看着就闹心,索性把密码登录给ban掉改用密钥登录。
cd ~/.ssh
+ssh-keygen -t rsa -C "邮箱地址"此时会在/root/.ssh下生成id_rsa和id_rsa.pub的私钥和公钥
使用ssh-copy-id命令将公钥拷贝到服务器上
把本地的ssh公钥文件安装到远程主机对应的账户下,ssh-copy-id命令 可以把本地主机的公钥复制到远程主机的authorized_keys文件上,ssh-copy-id命令也会给远程主机的用户主目录(home)和~/.ssh, 和~/.ssh/authorized_keys设置合适的权限。 ssh-copy-id 用来将本地公钥复制到远程主机。如果不传入 -i 参数,ssh-copy-id 使用默认 ~/.ssh/identity.pub 作为默认公钥。如果多次运行 ssh-copy-id ,该命令不会检查重复,会在远程主机中多次写入 authorized_keys 。
ssh-copy-id [-i identify_file] [user@]hostvim /etc/ssh/sshd_config
+
+RSAAuthentication yes
+PubkeyAuthentication yes
+AuthorizedKeysFile .ssh/authorized_keys
+PasswordAuthentication yes #密码登录 此时不要关闭修改并保存,重启sshd服务systemctl restart sshd
id_rsa文件权限需要调整,否则使用密钥登录会因为私钥文件权限问题被拒绝。
一般来说: .ssh目录设置700权限 id_rsa,authorized_keys文件设置600权限 id_rsa.pub,known_hosts文件设置644权限
登录使用ssh -i "私钥文件全路径" root@xxx.xxx.xxx.xxx
登录成功
密钥登录成功后即可关闭服务器的密码登录
vim /etc/ssh/sshd_config
+
+PasswordAuthentication no #关闭密码登录保存后重启sshd服务systemctl restart sshd
可以看到密码登录已经被关闭
adduser username
+
+mkdir /home/username/.ssh
+# 编辑authorized_keys文件,将生成的公钥添加进去
+vim /home/username/.ssh/authorized_keys
+
+chown -R username:username /home/username.ssh
+chmod 700 /home/username/.ssh
+chmod 600 /home/username/.ssh/authorized_keysln: link,链接,类似windows中的快捷方式的概念,主要针对路径比较长的文件夹,建立一个链接,让访问更加方便,分为软链接(-s)和硬链接
alias:别名,主要是针对某个命令,如果命令的路径比较长、比较复杂,那么起个别名会更方便
ln: link,链接,类似windows中的快捷方式的概念,主要针对路径比较长的文件夹,建立一个链接,让访问更加方便,分为软链接(-s)和硬链接
alias:别名,主要是针对某个命令,如果命令的路径比较长、比较复杂,那么起个别名会更方便
fdisk -l:查看硬盘个数、分区情况
fdisk /dev/sdx:磁盘分区,只能分小容量(2T以内),mbr分区表
parted /dev/sdx:磁盘分区,gpt分区表
多个分区需要注意4k对齐,4k对齐内容介绍见下文引用的disk genius的文章
根据自己需求的文件格式选择,例如常见的ext4文件系统
mkfs.ext4 [-b block-size] [-C cluster-size] [-i bytes-per-inode] [-I inode-size] [-N number-of-inodes] [-t fs-type] [-T usage-type ] device
可以指定inode的个数和占用的空间和多少字节一个inode,需要注意inode如果过小,当inode使用完后,即使磁盘有空间也无法再写入数据。/etc/mke2fs.conf文件中定义了一些默认的类型配置,usage-type根据文件系统的主要用途对应的类型,例如largefile类型为1M一个inode,还有largefile4为4M一个inode,这样可以减少inode的占用空间和个数,用于存储大文件,但是实际上inode占用的空间对于大容量硬盘来说很少。
ext2/3/4文件系统会预留5%空间用于紧急情况,保障在硬盘快满的时候不至于crash,但是一个16T的硬盘的5%将近800G,实在是浪费。可以通过tune2fs命令来减少预留空间
tune2fs -m 1 /dev/sdx:将设备的预留空间调整为1%,也可以改成0,但不建议。
手动挂载(重启失效):mount /dev/sdx /path
自动挂载(开机自动挂载):
blkid /dev/sdx记录需要挂载设备的uuidvim /etc/fstab添加一条记录,例如UUID=506ed1d0-bc35-4585-8496-1ff4de100982 /repo ext4 defaults 0 0
+# 第一项为设备uuid 第二项为挂载点即挂载目录 第三项为文件系统类型 第四项为挂载的状态例如ro(只读)或defaults(包含了读写rw,exec,async等)
+# 第五项为DUMP选项 默认0 第六项为被fsck命令决定启动时被扫描的文件系统顺序 仓库盘可以填0不需要扫描,系统盘1,其他可2
+# 使用\`parted /dev/sda\`
+GNU Parted 3.4
+Using /dev/sda
+Welcome to GNU Parted! Type 'help' to view a list of commands.
+
+# \`p\`输出信息
+# 扩容前:
+(parted) p
+Model: ATA QEMU HARDDISK (scsi)
+Disk /dev/sda: 859GB
+Sector size (logical/physical): 512B/512B
+Partition Table: gpt
+Disk Flags:
+
+Number Start End Size File system Name Flags
+ 1 1049kB 2097kB 1049kB bios_grub
+ 2 2097kB 537GB 537GB ext4
+
+# 使用\`resizepart 2 -1\`
+
+# 扩容后
+(parted) p
+Model: ATA QEMU HARDDISK (scsi)
+Disk /dev/sda: 859GB
+Sector size (logical/physical): 512B/512B
+Partition Table: gpt
+Disk Flags:
+
+Number Start End Size File system Name Flags
+ 1 1049kB 2097kB 1049kB bios_grub
+ 2 2097kB 859GB 859GB ext4
resizepart partition end:end参数填分区结束扇区号,直接使用resizepart 2 -1可以自动扩展到可用空间的末尾- 或者使用fdisk扩容,先删除再新增
`,24)]))}const o=i(l,[["render",h]]);export{g as __pageData,o as default}; diff --git "a/assets/linux_hardware_linux\347\243\201\347\233\230\346\223\215\344\275\234\347\233\270\345\205\263.md.CcwkAL_X.lean.js" "b/assets/linux_hardware_linux\347\243\201\347\233\230\346\223\215\344\275\234\347\233\270\345\205\263.md.CcwkAL_X.lean.js" new file mode 100644 index 00000000..751bfc64 --- /dev/null +++ "b/assets/linux_hardware_linux\347\243\201\347\233\230\346\223\215\344\275\234\347\233\270\345\205\263.md.CcwkAL_X.lean.js" @@ -0,0 +1,34 @@ +import{_ as i,c as a,a2 as n,o as e}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"linux磁盘操作相关","description":"","frontmatter":{},"headers":[],"relativePath":"linux/hardware/linux磁盘操作相关.md","filePath":"linux/hardware/linux磁盘操作相关.md","lastUpdated":1729217313000}'),l={name:"linux/hardware/linux磁盘操作相关.md"};function h(p,s,t,k,r,d){return e(),a("div",null,s[0]||(s[0]=[n(`内容引用自
disk genius文章:分区4K对齐那些事,你想知道的都在这里物理扇区的概念
分区对齐,是指将分区起始位置对齐到一定的扇区。我们要先了解对齐和扇区的关系。我们知道,硬盘的基本读写单位是“扇区”。对于硬盘的读写操作,每次读写都是以扇区为单位进行的,最少一个扇区,通常是512个字节。由于硬盘数据存储结构的限制,单独读写1个或几个字节是不可能的。通过系统提供的接口读写文件数据时,看起来可以单独读写少量字节,实际上是经过了操作系统的转换才实现的。硬盘实际执行时读写的仍然是整个扇区。
近年来,随着对硬盘容量的要求不断增加,为了提高数据记录密度,硬盘厂商往往采用增大扇区大小的方法,于是出现了扇区大小为4096字节的硬盘。我们将这样的扇区称之为“物理扇区”。但是这样的大扇区会有兼容性问题,有的系统或软件无法适应。为了解决这个问题,硬盘内部将物理扇区在逻辑上划分为多个扇区片段并将其作为普通的扇区(一般为512字节大小)报告给操作系统及应用软件。这样的扇区片段我们称之为“逻辑扇区”。实际读写时由硬盘内的程序(固件)负责在逻辑扇区与物理扇区之间进行转换,上层程序“感觉”不到物理扇区的存在。
逻辑扇区是硬盘可以接受读写指令的最小操作单元,是操作系统及应用程序可以访问的扇区,多数情况下其大小为512字节。我们通常所说的扇区一般就是指的逻辑扇区。物理扇区是硬盘底层硬件意义上的扇区,是实际执行读写操作的最小单元。是只能由硬盘直接访问的扇区,操作系统及应用程序一般无法直接访问物理扇区。一个物理扇区可以包含一个或多个逻辑扇区(比如多数硬盘的物理扇区包含了8个逻辑扇区)。当要读写某个逻辑扇区时,硬盘底层在实际操作时都会读写逻辑扇区所在的整个物理扇区。
这里说的“硬盘”及其“扇区”的概念,同样适用于存储卡、固态硬盘(SSD)。接下来我们统称其为“磁盘”。它们在使用上的基本原理是一致的。其中固态硬盘在实现上更加复杂,它有“页”和“块”的概念,为了便于理解,我们可以简单的将其视同为逻辑扇区和物理扇区。另外固态硬盘在写入数据之前必须先执行擦除操作,不能直接写入到已存有数据的块,必须先擦除再写入。所以固态硬盘(SSD)对分区4K对齐的要求更高。如果没有对齐,额外的动作会增加更多,造成读写性能下降。
分区及其格式化
磁盘在使用之前必须要先分区并格式化。简单的理解,分区就是指从磁盘上划分出来的一大片连续的扇区。格式化则是对分区范围内扇区的使用进行规划。比如文件数据的储存如何安排、文件属性储存在哪里、目录结构如何存储等等。分区经过格式化后,就可以存储文件了。格式化程序会将分区里面的所有扇区从头至尾进行分组,划分为固定大小的“簇”,并按顺序进行编号。每个“簇”可固定包含一个或多个扇区,其扇区个数总是2的n次方。格式化以后,分区就会以“簇”为最小单位进行读写。文件的数据、属性等等信息都要保存到“簇”里面。
为什么要分区对齐
为磁盘划分分区时,是以逻辑扇区为单位进行划分的,分区可以从任意编号的逻辑扇区开始。如果分区的起始位置没有对齐到某个物理扇区的边缘,格式化后,所有的“簇”也将无法对齐到物理扇区的边缘。如下图所示,每个物理扇区由4个逻辑扇区组成。分区是从3号扇区开始的。格式化后,每个簇占用了4个扇区,这些簇都没有对齐到物理扇区的边缘,也就是说,每个簇都跨越了2个物理扇区。
由于磁盘总是以物理扇区为单位进行读写,在这样的分区情况下,当要读取某个簇时,实际上总是需要多读取一个物理扇区的数据。比如要读取0号簇共4个逻辑扇区的数据,磁盘实际执行时,必须要读取0号和1号两个物理扇区共8个逻辑扇区的数据。同理,对“簇”的写入操作也是这样。显而易见,这样会造成读写性能的严重下降。
下面再看对齐的情况。如下图所示,分区从4号扇区开始,刚好对齐到了物理扇区1的边缘,格式化后,每个簇同样占用了4个扇区,而且这些簇都对齐到了物理扇区的边缘。
在这样对齐的情况下,当要读取某个簇,磁盘实际执行时并不需要额外读取任何扇区,可以充分发挥磁盘的读写性能。显然这正是我们需要的。
由此可见,对于物理扇区大小与逻辑扇区大小不一致的磁盘,分区4K对齐才能充分发挥磁盘的读写性能。而不对齐就会造成磁盘读写性能的下降。
如何才能对齐
通过前述图示的两个例子可以看到,只要将分区的起始位置对齐到物理扇区的边缘,格式化程序就会将每个簇也对齐到物理扇区的边缘,这样就实现了分区的对齐。其实对齐很简单。
如何检测物理扇区大小
划分分区时,要想实现4K对齐,必须首先知道磁盘物理扇区的大小。那么如何查询呢?
打开DiskGenius软件,点击要检测的磁盘,在软件界面右侧的磁盘参数表中,可以找到“扇区大小”和“物理扇区大小”。其中“扇区大小”指的是逻辑扇区的大小。如图所示,这个磁盘的物理扇区大小为4096字节,通过计算得知,它包含了8个逻辑扇区。
对齐到多少个扇区才正确
知道了“扇区大小”和“物理扇区大小”,用“物理扇区大小”除以“扇区大小”就能得到每个物理扇区所包含的逻辑扇区个数。这个数值就是我们要对齐的扇区个数的最小值。只要将分区起始位置对齐到这个数值的整数倍就可以了。举个例子,比如物理扇区大小是4096字节,逻辑扇区大小是512字节,那么4096除以512,等于8。我们只要将分区起始位置对齐到8的整数倍扇区就能满足分区对齐的要求。比如对齐到8、16、24、32、... 1024、2048等等。只要这个起始扇区号能够被8整除就都可以。并不是这个除数数值越大越好。Windows系统默认对齐的扇区数是2048。这个数值基本上能满足几乎所有磁盘的4K对齐要求了。
为什么大家都说4K对齐
习惯而已。因为开始出现物理扇区的概念时,多数磁盘的物理扇区大小都是4096即4K字节,习惯了就俗称4K对齐了。实际划分分区时还是要检测一下物理扇区大小,因为有些磁盘的物理扇区可能包含4个、8个、16个或者更多个逻辑扇区(总是2的n次方)。知道物理扇区大小后,再按照刚才说的计算方法,以物理扇区包含的逻辑扇区个数为基准,对齐到实际的物理扇区大小才是正确的。如果物理扇区大小是8192字节,那就要按照8192字节来对齐,严格来讲,这就不能叫4K对齐了。
划分分区时如何具体操作分区对齐
以DiskGenius软件为例,建立新分区时,在“建立新分区”对话框中勾选“对齐到下列扇区数的整数倍”,然后选择需要对齐的扇区数目,点“确定”后建立的分区就是对齐的了。
软件在“扇区数目”下拉框中列出了很多的选项,从中选择任意一个大于物理扇区大小的扇区数都是可以的,都能满足对齐要求。软件列出那么多的扇区数选项只是增加了选择的自由度,并不是数值越大越好。使用过大的数值可能会造成磁盘空间的浪费。软件默认的设置已经能够满足几乎所有磁盘的 4K对齐要求。
除了“建立新分区”对话框,DiskGenius软件还有一个“快速分区”功能,其中也有相同的对齐设置。如下图所示:
如何检测是否对齐
作为一款强大的分区管理软件,DiskGenius同样提供了分区4K对齐检测的功能。你可以用它检测一下自己硬盘的分区是否对齐了。使用方法很简单,打开软件后,首先在软件左侧选中要检测的磁盘,然后选择“工具”菜单中的“分区4KB扇区对齐检测”,软件立即显示检测结果,如下图所示:
最右侧“对齐”一栏是“Y”的分区就是对齐的分区,否则就是没有对齐。没有对齐的分区会用红色字体显示。
fdisk -l:查看硬盘个数、分区情况
fdisk /dev/sdx:磁盘分区,只能分小容量(2T以内),mbr分区表
parted /dev/sdx:磁盘分区,gpt分区表
多个分区需要注意4k对齐,4k对齐内容介绍见下文引用的disk genius的文章
根据自己需求的文件格式选择,例如常见的ext4文件系统
mkfs.ext4 [-b block-size] [-C cluster-size] [-i bytes-per-inode] [-I inode-size] [-N number-of-inodes] [-t fs-type] [-T usage-type ] device
可以指定inode的个数和占用的空间和多少字节一个inode,需要注意inode如果过小,当inode使用完后,即使磁盘有空间也无法再写入数据。/etc/mke2fs.conf文件中定义了一些默认的类型配置,usage-type根据文件系统的主要用途对应的类型,例如largefile类型为1M一个inode,还有largefile4为4M一个inode,这样可以减少inode的占用空间和个数,用于存储大文件,但是实际上inode占用的空间对于大容量硬盘来说很少。
ext2/3/4文件系统会预留5%空间用于紧急情况,保障在硬盘快满的时候不至于crash,但是一个16T的硬盘的5%将近800G,实在是浪费。可以通过tune2fs命令来减少预留空间
tune2fs -m 1 /dev/sdx:将设备的预留空间调整为1%,也可以改成0,但不建议。
手动挂载(重启失效):mount /dev/sdx /path
自动挂载(开机自动挂载):
blkid /dev/sdx记录需要挂载设备的uuidvim /etc/fstab添加一条记录,例如UUID=506ed1d0-bc35-4585-8496-1ff4de100982 /repo ext4 defaults 0 0
+# 第一项为设备uuid 第二项为挂载点即挂载目录 第三项为文件系统类型 第四项为挂载的状态例如ro(只读)或defaults(包含了读写rw,exec,async等)
+# 第五项为DUMP选项 默认0 第六项为被fsck命令决定启动时被扫描的文件系统顺序 仓库盘可以填0不需要扫描,系统盘1,其他可2
+# 使用\`parted /dev/sda\`
+GNU Parted 3.4
+Using /dev/sda
+Welcome to GNU Parted! Type 'help' to view a list of commands.
+
+# \`p\`输出信息
+# 扩容前:
+(parted) p
+Model: ATA QEMU HARDDISK (scsi)
+Disk /dev/sda: 859GB
+Sector size (logical/physical): 512B/512B
+Partition Table: gpt
+Disk Flags:
+
+Number Start End Size File system Name Flags
+ 1 1049kB 2097kB 1049kB bios_grub
+ 2 2097kB 537GB 537GB ext4
+
+# 使用\`resizepart 2 -1\`
+
+# 扩容后
+(parted) p
+Model: ATA QEMU HARDDISK (scsi)
+Disk /dev/sda: 859GB
+Sector size (logical/physical): 512B/512B
+Partition Table: gpt
+Disk Flags:
+
+Number Start End Size File system Name Flags
+ 1 1049kB 2097kB 1049kB bios_grub
+ 2 2097kB 859GB 859GB ext4
resizepart partition end:end参数填分区结束扇区号,直接使用resizepart 2 -1可以自动扩展到可用空间的末尾- 或者使用fdisk扩容,先删除再新增
`,24)]))}const o=i(l,[["render",h]]);export{g as __pageData,o as default}; diff --git a/assets/linux_index.md.VpdZKrBe.js b/assets/linux_index.md.VpdZKrBe.js new file mode 100644 index 00000000..b9efaaa9 --- /dev/null +++ b/assets/linux_index.md.VpdZKrBe.js @@ -0,0 +1 @@ +import{_ as t,c as n,m as e,a as i,o as l}from"./chunks/framework.BjcrtTwI.js";const m=JSON.parse('{"title":"Linux","description":"","frontmatter":{},"headers":[],"relativePath":"linux/index.md","filePath":"linux/index.md","lastUpdated":1729217313000}'),o={name:"linux/index.md"};function r(s,a,d,c,x,u){return l(),n("div",null,a[0]||(a[0]=[e("h1",{id:"linux",tabindex:"-1"},[i("Linux "),e("a",{class:"header-anchor",href:"#linux","aria-label":'Permalink to "Linux"'},"")],-1),e("blockquote",null,[e("p",null,"Talk is cheap,show me the code。")],-1)]))}const f=t(o,[["render",r]]);export{m as __pageData,f as default}; diff --git a/assets/linux_index.md.VpdZKrBe.lean.js b/assets/linux_index.md.VpdZKrBe.lean.js new file mode 100644 index 00000000..b9efaaa9 --- /dev/null +++ b/assets/linux_index.md.VpdZKrBe.lean.js @@ -0,0 +1 @@ +import{_ as t,c as n,m as e,a as i,o as l}from"./chunks/framework.BjcrtTwI.js";const m=JSON.parse('{"title":"Linux","description":"","frontmatter":{},"headers":[],"relativePath":"linux/index.md","filePath":"linux/index.md","lastUpdated":1729217313000}'),o={name:"linux/index.md"};function r(s,a,d,c,x,u){return l(),n("div",null,a[0]||(a[0]=[e("h1",{id:"linux",tabindex:"-1"},[i("Linux "),e("a",{class:"header-anchor",href:"#linux","aria-label":'Permalink to "Linux"'},"")],-1),e("blockquote",null,[e("p",null,"Talk is cheap,show me the code。")],-1)]))}const f=t(o,[["render",r]]);export{m as __pageData,f as default}; diff --git a/assets/python_base_Poetry.md.DamgIOGc.js b/assets/python_base_Poetry.md.DamgIOGc.js new file mode 100644 index 00000000..1947403d --- /dev/null +++ b/assets/python_base_Poetry.md.DamgIOGc.js @@ -0,0 +1,9 @@ +import{_ as i,c as o,a2 as s,o as t}from"./chunks/framework.BjcrtTwI.js";const k=JSON.parse('{"title":"Poetry","description":"","frontmatter":{},"headers":[],"relativePath":"python/base/Poetry.md","filePath":"python/base/Poetry.md","lastUpdated":1729217313000}'),l={name:"python/base/Poetry.md"};function a(p,e,n,r,d,c){return t(),o("div",null,e[0]||(e[0]=[s(`内容引用自
disk genius文章:分区4K对齐那些事,你想知道的都在这里物理扇区的概念
分区对齐,是指将分区起始位置对齐到一定的扇区。我们要先了解对齐和扇区的关系。我们知道,硬盘的基本读写单位是“扇区”。对于硬盘的读写操作,每次读写都是以扇区为单位进行的,最少一个扇区,通常是512个字节。由于硬盘数据存储结构的限制,单独读写1个或几个字节是不可能的。通过系统提供的接口读写文件数据时,看起来可以单独读写少量字节,实际上是经过了操作系统的转换才实现的。硬盘实际执行时读写的仍然是整个扇区。
近年来,随着对硬盘容量的要求不断增加,为了提高数据记录密度,硬盘厂商往往采用增大扇区大小的方法,于是出现了扇区大小为4096字节的硬盘。我们将这样的扇区称之为“物理扇区”。但是这样的大扇区会有兼容性问题,有的系统或软件无法适应。为了解决这个问题,硬盘内部将物理扇区在逻辑上划分为多个扇区片段并将其作为普通的扇区(一般为512字节大小)报告给操作系统及应用软件。这样的扇区片段我们称之为“逻辑扇区”。实际读写时由硬盘内的程序(固件)负责在逻辑扇区与物理扇区之间进行转换,上层程序“感觉”不到物理扇区的存在。
逻辑扇区是硬盘可以接受读写指令的最小操作单元,是操作系统及应用程序可以访问的扇区,多数情况下其大小为512字节。我们通常所说的扇区一般就是指的逻辑扇区。物理扇区是硬盘底层硬件意义上的扇区,是实际执行读写操作的最小单元。是只能由硬盘直接访问的扇区,操作系统及应用程序一般无法直接访问物理扇区。一个物理扇区可以包含一个或多个逻辑扇区(比如多数硬盘的物理扇区包含了8个逻辑扇区)。当要读写某个逻辑扇区时,硬盘底层在实际操作时都会读写逻辑扇区所在的整个物理扇区。
这里说的“硬盘”及其“扇区”的概念,同样适用于存储卡、固态硬盘(SSD)。接下来我们统称其为“磁盘”。它们在使用上的基本原理是一致的。其中固态硬盘在实现上更加复杂,它有“页”和“块”的概念,为了便于理解,我们可以简单的将其视同为逻辑扇区和物理扇区。另外固态硬盘在写入数据之前必须先执行擦除操作,不能直接写入到已存有数据的块,必须先擦除再写入。所以固态硬盘(SSD)对分区4K对齐的要求更高。如果没有对齐,额外的动作会增加更多,造成读写性能下降。
分区及其格式化
磁盘在使用之前必须要先分区并格式化。简单的理解,分区就是指从磁盘上划分出来的一大片连续的扇区。格式化则是对分区范围内扇区的使用进行规划。比如文件数据的储存如何安排、文件属性储存在哪里、目录结构如何存储等等。分区经过格式化后,就可以存储文件了。格式化程序会将分区里面的所有扇区从头至尾进行分组,划分为固定大小的“簇”,并按顺序进行编号。每个“簇”可固定包含一个或多个扇区,其扇区个数总是2的n次方。格式化以后,分区就会以“簇”为最小单位进行读写。文件的数据、属性等等信息都要保存到“簇”里面。
为什么要分区对齐
为磁盘划分分区时,是以逻辑扇区为单位进行划分的,分区可以从任意编号的逻辑扇区开始。如果分区的起始位置没有对齐到某个物理扇区的边缘,格式化后,所有的“簇”也将无法对齐到物理扇区的边缘。如下图所示,每个物理扇区由4个逻辑扇区组成。分区是从3号扇区开始的。格式化后,每个簇占用了4个扇区,这些簇都没有对齐到物理扇区的边缘,也就是说,每个簇都跨越了2个物理扇区。
由于磁盘总是以物理扇区为单位进行读写,在这样的分区情况下,当要读取某个簇时,实际上总是需要多读取一个物理扇区的数据。比如要读取0号簇共4个逻辑扇区的数据,磁盘实际执行时,必须要读取0号和1号两个物理扇区共8个逻辑扇区的数据。同理,对“簇”的写入操作也是这样。显而易见,这样会造成读写性能的严重下降。
下面再看对齐的情况。如下图所示,分区从4号扇区开始,刚好对齐到了物理扇区1的边缘,格式化后,每个簇同样占用了4个扇区,而且这些簇都对齐到了物理扇区的边缘。
在这样对齐的情况下,当要读取某个簇,磁盘实际执行时并不需要额外读取任何扇区,可以充分发挥磁盘的读写性能。显然这正是我们需要的。
由此可见,对于物理扇区大小与逻辑扇区大小不一致的磁盘,分区4K对齐才能充分发挥磁盘的读写性能。而不对齐就会造成磁盘读写性能的下降。
如何才能对齐
通过前述图示的两个例子可以看到,只要将分区的起始位置对齐到物理扇区的边缘,格式化程序就会将每个簇也对齐到物理扇区的边缘,这样就实现了分区的对齐。其实对齐很简单。
如何检测物理扇区大小
划分分区时,要想实现4K对齐,必须首先知道磁盘物理扇区的大小。那么如何查询呢?
打开DiskGenius软件,点击要检测的磁盘,在软件界面右侧的磁盘参数表中,可以找到“扇区大小”和“物理扇区大小”。其中“扇区大小”指的是逻辑扇区的大小。如图所示,这个磁盘的物理扇区大小为4096字节,通过计算得知,它包含了8个逻辑扇区。
对齐到多少个扇区才正确
知道了“扇区大小”和“物理扇区大小”,用“物理扇区大小”除以“扇区大小”就能得到每个物理扇区所包含的逻辑扇区个数。这个数值就是我们要对齐的扇区个数的最小值。只要将分区起始位置对齐到这个数值的整数倍就可以了。举个例子,比如物理扇区大小是4096字节,逻辑扇区大小是512字节,那么4096除以512,等于8。我们只要将分区起始位置对齐到8的整数倍扇区就能满足分区对齐的要求。比如对齐到8、16、24、32、... 1024、2048等等。只要这个起始扇区号能够被8整除就都可以。并不是这个除数数值越大越好。Windows系统默认对齐的扇区数是2048。这个数值基本上能满足几乎所有磁盘的4K对齐要求了。
为什么大家都说4K对齐
习惯而已。因为开始出现物理扇区的概念时,多数磁盘的物理扇区大小都是4096即4K字节,习惯了就俗称4K对齐了。实际划分分区时还是要检测一下物理扇区大小,因为有些磁盘的物理扇区可能包含4个、8个、16个或者更多个逻辑扇区(总是2的n次方)。知道物理扇区大小后,再按照刚才说的计算方法,以物理扇区包含的逻辑扇区个数为基准,对齐到实际的物理扇区大小才是正确的。如果物理扇区大小是8192字节,那就要按照8192字节来对齐,严格来讲,这就不能叫4K对齐了。
划分分区时如何具体操作分区对齐
以DiskGenius软件为例,建立新分区时,在“建立新分区”对话框中勾选“对齐到下列扇区数的整数倍”,然后选择需要对齐的扇区数目,点“确定”后建立的分区就是对齐的了。
软件在“扇区数目”下拉框中列出了很多的选项,从中选择任意一个大于物理扇区大小的扇区数都是可以的,都能满足对齐要求。软件列出那么多的扇区数选项只是增加了选择的自由度,并不是数值越大越好。使用过大的数值可能会造成磁盘空间的浪费。软件默认的设置已经能够满足几乎所有磁盘的 4K对齐要求。
除了“建立新分区”对话框,DiskGenius软件还有一个“快速分区”功能,其中也有相同的对齐设置。如下图所示:
如何检测是否对齐
作为一款强大的分区管理软件,DiskGenius同样提供了分区4K对齐检测的功能。你可以用它检测一下自己硬盘的分区是否对齐了。使用方法很简单,打开软件后,首先在软件左侧选中要检测的磁盘,然后选择“工具”菜单中的“分区4KB扇区对齐检测”,软件立即显示检测结果,如下图所示:
最右侧“对齐”一栏是“Y”的分区就是对齐的分区,否则就是没有对齐。没有对齐的分区会用红色字体显示。
Poetry: PYTHON PACKAGING AND DEPENDENCY MANAGEMENT MADE EASY
Poetry是一个Python包管理工具,类似于pip,但是远比pip强大,除了依赖管理外,还能自动解析依赖的关系,还可以管理项目的虚拟环境,打包、发布。
pip的缺陷:移除依赖时不能自动解析依赖的关系
如果执行pip install flask,pip会自动安装flask所依赖的包,但是如果执行pip uninstall flask,pip只会移除flask包,而不会移除flask依赖的包,这样就会导致项目中存在无用的包,只能我们手动移除。但是手动移除包是很危险的,因为一不小心可能会把其他包依赖的包删除了导致项目不能正常运行。
Poetry使用了PEP 518提出的pyproject.toml配置文件,在依赖管理方面替代了传统的requirements.txt,在构建方面替换了传统的setup.py,更加清晰、灵活。
https://python-poetry.org/docs/#installing-with-the-official-installer
Poetry在各个操作系统的默认安装路径:
~/Library/Application Support/pypoetry on MacOS.~/.local/share/pypoetry on Linux/Unix.%APPDATA%\\pypoetry on Windows.在安装时指定POETRY_HOME环境变量:
curl -sSL https://install.python-poetry.org | POETRY_HOME=/etc/poetry python3 -将$POETRY_HOME/bin添加到PATH
查看版本:poetry --version
更新版本:poetry self update
命令补全:
mkdir $ZSH_CUSTOM/plugins/poetry
+poetry completions zsh > $ZSH_CUSTOM/plugins/poetry/_poetr# .zshrc
+plugins=(
+ git
+ zsh-autosuggestions
+ zsh-syntax-highlighting
+ poetry
+ ...
+)poetry initpoetry config virtualenvs.in-project true默认的情况poetry会将虚拟环境生成到特定目录(根据操作系统有不同),命名规则为项目名-random-python版本,这样并不方便管理,所以改为在项目目录下生成虚拟环境,更符合使用习惯,修改后生成的虚拟环境在项目路径下的.venv
poetry env use python取决于python在PATH中link的版本,也可以改为poetry env use python3.11
poetry shellexitpoetry add执行poetry add后会自动将add的包信息和版本添加到pyproject.toml中(不会记录该包依赖的其他包),这样就可以区分出主动安装的是什么包,和基于依赖关系安装的是什么包。
除了pyproject.toml,项目中还会生成一个poetry.lock文件(类似npm的lock文件或原来的requirements.txt),记录安装的所有依赖和对应版本
指定版本新增依赖:
^:表示匹配指定版本的最新次版本(minor version)和补丁版本(patch version),但不改变主版本(major version)。 poetry add Django@^2.1.0 表示匹配2.x.x中最新的版本不包括3.0.0。~:表示匹配指定版本的最新补丁版本,不改变主版本和次版本。 poetry add Django@~1.2.3表示匹配1.2.x中最新的版本,但不包括1.3.0。>=:表示匹配指定版本或更高版本,不限制最后一位的变化。 poetry add Django>=3.2.0表示匹配Django3.2版本及其更高版本。==:表示严格匹配指定版本。 poetry add numpy==1.21.3表示只匹配精确版本号为1.21.3。新增依赖到dev-dependencies:poetry add xxx -D或poetry add xxx --dev
手动更新依赖版本:
pyproject.toml中的依赖版本poetry lockpoetry installpoetry install
pyproject.toml文件中的[tool.poetry.dependencies]部分,并根据其中的规范(例如包的名称和版本要求)来安装依赖项。poetry.lock文件,poetry install会生成poetry.lock文件。这个锁文件包含了确切的依赖项版本,确保在不同的环境中使用相同的软件包版本。poetry.lock文件,poetry install将首先检查锁文件并使用其中的版本信息,而不是重新计算依赖关系。这有助于提高依赖项安装的速度。poetry install会自动创建一个虚拟环境,并将依赖项安装到该虚拟环境中。如果已经存在虚拟环境,将会使用现有的虚拟环境。更新依赖:poetry update
列出依赖:poetry show
poetry show --tree移除依赖:poetry remove
输出requirements.txt:poetry export
poetry export -f requirements.txt -o requirements.txt --without-hashes打包:poetry build
poetry build -f wheel发布:poetry publish
需要配置仓库
Poetry: PYTHON PACKAGING AND DEPENDENCY MANAGEMENT MADE EASY
Poetry是一个Python包管理工具,类似于pip,但是远比pip强大,除了依赖管理外,还能自动解析依赖的关系,还可以管理项目的虚拟环境,打包、发布。
pip的缺陷:移除依赖时不能自动解析依赖的关系
如果执行pip install flask,pip会自动安装flask所依赖的包,但是如果执行pip uninstall flask,pip只会移除flask包,而不会移除flask依赖的包,这样就会导致项目中存在无用的包,只能我们手动移除。但是手动移除包是很危险的,因为一不小心可能会把其他包依赖的包删除了导致项目不能正常运行。
Poetry使用了PEP 518提出的pyproject.toml配置文件,在依赖管理方面替代了传统的requirements.txt,在构建方面替换了传统的setup.py,更加清晰、灵活。
https://python-poetry.org/docs/#installing-with-the-official-installer
Poetry在各个操作系统的默认安装路径:
~/Library/Application Support/pypoetry on MacOS.~/.local/share/pypoetry on Linux/Unix.%APPDATA%\\pypoetry on Windows.在安装时指定POETRY_HOME环境变量:
curl -sSL https://install.python-poetry.org | POETRY_HOME=/etc/poetry python3 -将$POETRY_HOME/bin添加到PATH
查看版本:poetry --version
更新版本:poetry self update
命令补全:
mkdir $ZSH_CUSTOM/plugins/poetry
+poetry completions zsh > $ZSH_CUSTOM/plugins/poetry/_poetr# .zshrc
+plugins=(
+ git
+ zsh-autosuggestions
+ zsh-syntax-highlighting
+ poetry
+ ...
+)poetry initpoetry config virtualenvs.in-project true默认的情况poetry会将虚拟环境生成到特定目录(根据操作系统有不同),命名规则为项目名-random-python版本,这样并不方便管理,所以改为在项目目录下生成虚拟环境,更符合使用习惯,修改后生成的虚拟环境在项目路径下的.venv
poetry env use python取决于python在PATH中link的版本,也可以改为poetry env use python3.11
poetry shellexitpoetry add执行poetry add后会自动将add的包信息和版本添加到pyproject.toml中(不会记录该包依赖的其他包),这样就可以区分出主动安装的是什么包,和基于依赖关系安装的是什么包。
除了pyproject.toml,项目中还会生成一个poetry.lock文件(类似npm的lock文件或原来的requirements.txt),记录安装的所有依赖和对应版本
指定版本新增依赖:
^:表示匹配指定版本的最新次版本(minor version)和补丁版本(patch version),但不改变主版本(major version)。 poetry add Django@^2.1.0 表示匹配2.x.x中最新的版本不包括3.0.0。~:表示匹配指定版本的最新补丁版本,不改变主版本和次版本。 poetry add Django@~1.2.3表示匹配1.2.x中最新的版本,但不包括1.3.0。>=:表示匹配指定版本或更高版本,不限制最后一位的变化。 poetry add Django>=3.2.0表示匹配Django3.2版本及其更高版本。==:表示严格匹配指定版本。 poetry add numpy==1.21.3表示只匹配精确版本号为1.21.3。新增依赖到dev-dependencies:poetry add xxx -D或poetry add xxx --dev
手动更新依赖版本:
pyproject.toml中的依赖版本poetry lockpoetry installpoetry install
pyproject.toml文件中的[tool.poetry.dependencies]部分,并根据其中的规范(例如包的名称和版本要求)来安装依赖项。poetry.lock文件,poetry install会生成poetry.lock文件。这个锁文件包含了确切的依赖项版本,确保在不同的环境中使用相同的软件包版本。poetry.lock文件,poetry install将首先检查锁文件并使用其中的版本信息,而不是重新计算依赖关系。这有助于提高依赖项安装的速度。poetry install会自动创建一个虚拟环境,并将依赖项安装到该虚拟环境中。如果已经存在虚拟环境,将会使用现有的虚拟环境。更新依赖:poetry update
列出依赖:poetry show
poetry show --tree移除依赖:poetry remove
输出requirements.txt:poetry export
poetry export -f requirements.txt -o requirements.txt --without-hashes打包:poetry build
poetry build -f wheel发布:poetry publish
需要配置仓库
print('hello world')_python3中支持中文变量名
import keyword
+
+
+print(keyword.kwlist)
+
+
+['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']python中单行注释#
多行注释可以多个#或者三单引号'''和三双引号"""
python使用缩进来表示代码块,而不是像Java一样的{},目前还很不习惯。。
if True:
+ print('true')
+else:
+ print('false')python一般一行写一条一句,特殊情况可以使用反斜杠\\实现多行语句
total = item_one + \\
+ item_two + \\
+ item_three在[],{},()中的多行语句不需要\\
python中的数字有四种类型:
\\函数之间或类之间用空行分隔,一般是两个空行,以分隔两段不同功能或含义的代码
同一行显示多条语句
使用;分隔(ps,python的语句后面不用每行加分号,好不习惯。。。)
缩进相同的一组语句构成一个代码块,我们称首行及后面的代码称为一个子句(clause)
print输出类似java中的println,默认是换行的,如果不想换行在print函数中加入参数ene=''
例如 print('x', end ='' )
python中的变量不需要声明(但python是强类型语言),使用变量前必须赋值,赋值以后变量才会创建。
在python中,变量就是变量,没有类型。我们所说的类型是变量所指的内存中对象的数据类型
a = b = c = 1以上实例,创建一个整型对象1,从后向前赋值,三个变量被赋予相同的值
a, b, c = 1, 2, 'noob'以上实例,两个整型对象1,2分配给a和b,字符串对象noob分配给变量c
python3中有六个标准数据类型
其中
type()函数或者isinstance()函数
区别:
特殊:
//除法,得到一个整数%取余数(取模)python的字符串用单引号或双引号括起来
定义字符串时 加前缀 u/b/r/f
字符串截取语法:变量[头下标:尾下标] 前闭后开
字符串的切片:
str = 'Runoob'
+
+print (str) # 输出字符串
+print (str[0:-1]) # 输出第一个到倒数第二个的所有字符
+print (str[0]) # 输出字符串第一个字符
+print (str[2:5]) # 输出从第三个开始到第五个的字符
+print (str[2:]) # 输出从第三个开始的后的所有字符
+print (str * 2) # 输出字符串两次,也可以写成 print (2 * str)
+print (str + "TEST") # 连接字符串
+
+结果:
+Runoob
+Runoo
+R
+noo
+noob
+RunoobRunoob
+RunoobTESTList是python中使用最频繁的数据类型
列表是写在方括号[]之间、用逗号分隔开的元素列表
和字符串一样,列表可以被索引和截取,列表被截取后返回一个新列表
注意:
+进行拼接tuple和列表类似,但是是由()括起来的,且不可变数据类型
元素一样可以被索引和截取,元组也可以使用+进行拼接
set可以使用大括号{}或者set()函数创建集合,创建一个空集合时必须使用set()函数而非{ },因为{ }被用来创建一个空字典
set和java中的set集合一样存储的数据都是不重复的
字典(dictionary)是Python中另一个非常有用的内置数据类型。 类似java的Map
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
| 语法 | 作用 |
|---|---|
| [int(x ,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| [complex(real ,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 31 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 |
| / | 除 - x 除以 y | b / a 输出结果 2.1 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 1 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的21次方 |
| // | 取整除 - 向下取接近商的整数 | >>> 9//2 4 >>> -9//2 -5 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写。 | (a < b) 返回 True。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 True。 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。 | 在这个示例中,赋值表达式可以避免调用 len() 两次:if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)")(这个特性java中默认就有) |
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
python的条件控控制语法上和格式上和java一些区别
if condition_1:
+ statement_block_1
+elif condition_2:
+ statement_block_2
+else:
+ statement_block_3Python 中用 elif 代替了 else if,所以if语句的关键字为:if – elif – else。
注意:
如果if后面的条件是数字,只要这个数字不是0,python都会把它当做True处理
如果if后面跟的是字符串,则只要这个字符串不为空串,python就把它看作True
同样的如果if后跟元组,list,set,字典 只要不为空就是true
和java中的三元运算类似
语法: 变量 = 表达式1 if 条件 else 表达式2
例如
a = 1;
+b = a + 1 if a == 1 else a + 2;
+print(b)
+
+结果:2python中的循环有for和while两种
while 判断条件(condition):
+ 执行语句(statements)……while...else在条件语句为false时执行else的代码块
while expr:
+ statement1
+else:
+ statement2for 循环可以遍历任何可选代对象,如一个列表或者一个字符串。
for循环的一般格式如下:
for <variable> in <sequence>:
+ <statements>
+else:
+ <statements>用法和java一样
break区别:
例如:
_list = [1, 2, 3, 4, 5]
+
+for i in _list:
+ if i == 3:
+ print('33333333')
+else:
+ print('循环完毕')
+
+执行结果:
+33333333
+循环完毕而当循环是break终止的时候,else代码块不会执行:
_list = [1, 2, 3, 4, 5]
+
+for i in _list:
+ if i == 3:
+ print('333')
+ break
+else:
+ print('循环完毕')
+
+执行结果:
+333Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句
例如:
class MyTestClass:
+ pass
+
+
+def my_func():
+ pass
+
+
+if expr:
+ pass迭代器是python中访问集合元素的一种方式,有两个基本方法iter()和next()
字符串、列表或元组对象都可以创建迭代器
_list = [1,2,3,4]
+it = iter(_list)
+print(next(it))
+print(next(it))
+
+结果:
+1
+2迭代器对象可以使用常规for语句进行遍历:
_list = [1, 2, 3, 4]
+it = iter(_list)
+for x in it:
+ print(x, end=" ")
+
+结果:
+1 2 3 4在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
def gen_fun():
+ print('11111111111')
+ yield 1
+ print('22222222222')
+ yield 2
+ yield 3
+obj = gen_fun()
+print(obj)
+for i in obj:
+ print(i)
+#res
+<generator object gen_fun at 0x0000029394291AC0>
+11111111111
+1
+22222222222
+2
+3上面的代码可以看到在调用函数过程中,'111111'和'222222222'并没有打印出来,而是在for循环中才执行,这就是因为yield导致了函数的暂停,而for循环实际底层是迭代器实现,所以才恢复到print语句的位置继续执行
对应java中的方法
一般格式:
def 函数名(参数列表):
+ 函数体默认情况下,参数值和名称是按声明的顺序匹配的
由于python中的变量没有类型,所以不像java的参数列表都是有类型声明的
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
以下是调用函数时可使用的正式参数类型:
按照正确顺序传入参数,调用的数量和声明的数量必须一致
调用使用关键字参数来确定传入的参数值,使用关键字参数允许调用时与声明时的顺序不一致,因为python解释器能用参数名匹配参数值
def print_me(str):
+ print(str)
+
+#调用
+print_me(str = 'tom')
+
+结果:
+tom
+
+
+def printinfo( name, age ):
+ "打印任何传入的字符串"
+ print ("名字: ", name)
+ print ("年龄: ", age)
+ return
+
+#调用printinfo函数
+printinfo( age=50, name="mike" )
+结果:
+名字: mike
+年龄: 50调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值
def printinfo( name, age = 35 ):
+ print ("名字: ", name)
+ print ("年龄: ", age)
+ return
+
+#调用printinfo函数
+printinfo( age=50, name="tom" )
+print ("------------------------")
+printinfo( name="tom" )
+
+结果:
+名字: tom
+年龄: 50
+------------------------
+名字: tom
+年龄: 35你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。
*args就是就是传递一个可变参数列表给函数实参,这个参数列表的数目未知,甚至长度可以为0。下面这段代码演示了如何使用args
def test_args(first, *args):
+ print('Required argument: ', first)
+ print(type(args))
+ for v in args:
+ print ('Optional argument: ', v)
+
+test_args(1, 2, 3, 4)
+
+结果:
+Required argument: 1
+<class 'tuple'>
+Optional argument: 2
+Optional argument: 3
+Optional argument: 4而**kwargs则是将一个可变的关键字参数的字典传给函数实参,同样参数列表长度可以为0或为其他值。下面这段代码演示了如何使用kwargs
def test_kwargs(first, *args, **kwargs):
+ print('Required argument: ', first)
+ print(type(kwargs))
+ for v in args:
+ print ('Optional argument (args): ', v)
+ for k, v in kwargs.items():
+ print ('Optional argument %s (kwargs): %s' % (k, v))
+
+test_kwargs(1, 2, 3, 4, k1=5, k2=6)
+
+结果:
+Required argument: 1
+<class 'dict'>
+Optional argument (args): 2
+Optional argument (args): 3
+Optional argument (args): 4
+Optional argument k2 (kwargs): 6
+Optional argument k1 (kwargs): 5声明函数时,参数中星号 * 可以单独出现,例如:
参数列表里的 * 星号,标志着位置参数的就此终结,之后的那些参数,都只能以关键字形式来指定。
def f(a,b,*,c):
+ return a+b+c
+
+# f(1,2,3)->会报错
+# f(1,2,c=3) -> 正常args和kwargs不仅可以在函数定义中使用,还可以在函数调用中使用。在函数定义时使用就相当于pack(打包),在函数调用时就相当于unpack(解包)。
首先来看一下使用args来解包调用函数的代码,
def test_args_kwargs(arg1, arg2, arg3):
+ print("arg1:", arg1)
+ print("arg2:", arg2)
+ print("arg3:", arg3)
+
+args = ("two", 3, 5)
+test_args_kwargs(*args)
+
+结果:
+arg1: two
+arg2: 3
+arg3: 5kwargs的用法类似:
kwargs = {"arg3": 3, "arg2": "two", "arg1": 5}
+test_args_kwargs(**kwargs)
+
+#result
+arg1: 5
+arg2: two
+arg3: 3python中使用lambda来创建匿名函数
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
lambda [arg1 [,arg2,.....argn]]:expression例子:
sum = lambda arg1, arg2: arg1 + arg2
+
+# 调用sum函数
+print ("相加后的值为 : ", sum( 10, 20 ))
+print ("相加后的值为 : ", sum( 20, 20 ))
+
+相加后的值为 : 30
+相加后的值为 : 40作用:快速生成列表
语法:
变量 = [生成规则 for 临时变量 in 集合]每循环一次就会生成一个符合生成规则的数据添加到列表中
例如:
my_list = [i for i in range(5)]
+print(my_list)
+
+#res
+[0,1,2,3,4,5]Python3.8 新增了一个函数形参语法 / 用来指明函数形参必须使用指定位置参数,不能使用关键字参数的形式。
在以下的例子中,形参 a 和 b 必须使用指定位置参数,c 或 d 可以是位置形参或关键字形参,而 e 或 f 要求为关键字形参:
def f(a, b, /, c, d, *, e, f):
+ print(a, b, c, d, e, f)正确:
f(10, 20, 30, d=40, e=50, f=60)错误:
f(10, b=20, c=30, d=40, e=50, f=60) # b 不能使用关键字参数的形式
+f(10, 20, 30, 40, 50, f=60) # e 必须使用关键字参数的形式import module1[, module2[,... moduleN]
+from modname import name1[, name2[, ... nameN]]
+from modname import *一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
if __name__ == '__main__':
+ print('程序自身在运行')
+else:
+ print('我来自另一模块')说明: 每个模块都有一个__name__属性,当其值是'main'时,表明该模块自身在运行,否则是被引入。
说明:name 与 main 底下是双下划线
dir(sys)
+['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__',
+ '__package__', '__stderr__', '__stdin__', '__stdout__',
+ '_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe',
+ '_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv',
+ 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder',
+ 'call_tracing', 'callstats', 'copyright', 'displayhook',
+ 'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix',
+ 'executable', 'exit', 'flags', 'float_info', 'float_repr_style',
+ 'getcheckinterval', 'getdefaultencoding', 'getdlopenflags',
+ 'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit',
+ 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount',
+ 'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
+ 'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path',
+ 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1',
+ 'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit',
+ 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout',
+ 'thread_info', 'version', 'version_info', 'warnoptions']自定义模块名不要和系统中要使用的模块名字一样
模块搜索顺序->当前目录->系统目录(sys.path)-> 程序报错
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。采用点模块名称这种形式也不用担心不同库之间的模块重名的情况
sound/ 顶层包
+ __init__.py 初始化 sound 包
+ formats/ 文件格式转换子包
+ __init__.py
+ wavread.py
+ wavwrite.py
+ aiffread.py
+ aiffwrite.py
+ auread.py
+ auwrite.py
+ ...
+ effects/ 声音效果子包
+ __init__.py
+ echo.py
+ surround.py
+ reverse.py
+ ...
+ filters/ filters 子包
+ __init__.py
+ equalizer.py
+ vocoder.py
+ karaoke.py
+ ...在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
最简单的情况,放一个空的 :file:__init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为(将在后面介绍的) __all__变量赋值。
用户可以每次只导入一个包里面的特定模块,比如:
import sound.effects.echo这将会导入子模块:sound.effects.echo。 他必须使用全名去访问:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)还有一种导入子模块的方法是:
from sound.effects import echo这同样会导入子模块: echo,并且他不需要那些冗长的前缀,所以他可以这样使用:
echo.echofilter(input, output, delay=0.7, atten=4)还有一种变化就是直接导入一个函数或者变量:
from sound.effects.echo import echofilter同样的,这种方法会导入子模块: echo,并且可以直接使用他的 echofilter() 函数:
echofilter(input, output, delay=0.7, atten=4)注意当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import 语法会首先把 item 当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,抛出一个 :exc:ImportError 异常。
反之,如果使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
from sound.effects import * : Python 会进入文件系统,找到这个包里面所有的子模块,然后一个一个的把它们都导入进来。
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 all 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
以下实例在 file:sounds/effects/_init_.py 中包含如下代码:
__all__ = ["echo", "surround", "reverse"]这表示当你使用from sound.effects import *这种用法时,你只会导入包里面这三个子模块。
如果 __all__ 真的没有定义,那么使用**from sound.effects import ***这种语法的时候,就不会导入包 sound.effects 里的任何子模块。他只是把包sound.effects和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。
这会把__init__.py里面定义的所有名字导入进来。并且他不会破坏掉我们在这句话之前导入的所有明确指定的模块。看下这部分代码:
import sound.effects.echo
+import sound.effects.surround
+from sound.effects import *这个例子中,在执行 from...import 前,包 sound.effects 中的 echo 和 surround 模块都被导入到当前的命名空间中了。(当然如果定义了 __all__ 就更没问题了)
python的io操作相比java的IO流简单太多了,直接就是一个open()函数
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
**注意:**使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)参数说明:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 方法及描述 |
|---|
| file.close()关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| [file.read(size])从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| [file.readline(size])读取整行,包括 "\\n" 字符。 |
| [file.readlines(sizeint])读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| [file.seek(offset, whence])移动文件读取指针到指定位置 |
| file.tell()返回文件当前位置。 |
| [file.truncate(size])从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 |
| file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
import os #导入os模块
+
+#修改文件名
+os.rename(原文件名,新文件名)
+#删除文件
+os.remove(文件名)
+#创建文件夹
+os.mkdir(名称)
+#获取当前目录
+os.getcwd()
+#改变默认目录
+os.chdir(路径)
+#获取目录列表
+os.listdir(路径)
+#删除文件夹
+os.rmdir(路径)类名遵循大驼峰规则
"""
+新式类:直接或间接继承object,py3中所有类都是object的子类(same as java)
+"""
+class Demo(object):
+ pass
+"""
+旧式类:已过时
+"""
+class Demo1():
+ pass
+
+class Demo2:
+ passclass Dog(Object):
+ def eat(self):
+ print('吃')创建对象语法:
class Dog(Object):
+ def eat(self):
+ print('吃')
+
+
+dog1 = Dog()
+dog1.eat()
+#res
+吃给对象添加属性:对象.属性名 = 属性值
获取对象的属性变量 = 对象.属性名
修改:和添加一样,添加存在的属性就是修改
python的类中,有一类方法,以\`两个下划线开头\`和\`两个下划线结尾\`,并在满足\`某个特定条件下会自动调用\`,这类方法,称为\`魔法方法\` magic method__init__
在创建对象之后自动调用
作用:
注意点:
__init__方法出现了self之外的形参,在创建对象的时候,需要给额外的形参传值类名(实参) 这个类似java中的构造方法的有参构造class Dog(object):
+ def __init__(self,name):
+ self.name = name
+ print('init方法执行了')
+
+dog = Dog('大黄')
+print(dog.name)
+#res
+init方法执行了
+大黄__str__
类似java的toString:
__str__方法,打印的结果是__str__方法的返回值str(对象)将自定义类型转换为字符串的时候,会自动调用__str__方法时,这个返回值是对象的地址注意点:
__del__
对象在内存当中被销毁的时候调用:
del 变量语句删除,将这个对象的引用计数变为0,会自动调用引用计数:python内存管理的机制,指一块内存有多少变量在引用
Java中JVM为了避免对象间存在循环依赖导致对象无法被回收,JVM的垃圾回收算法采用的是可达性分析算法,通过gc roots对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到gc roots没有任何引用链相连时,则证明此对象是不可用的
通过self操作:
self指的是当前实例(类似java中的this),作为类中方法的第一个形参,在通过对象调用方法的时候,不需要手动传参
python解释器会自动把调用方法的对象传递给self形参
self也可以改成其他的形参名,但一般不修改这个名字,默认为self
class Dog(object):
+ def play(self):
+ print(f'{self.name}在玩耍')
+
+dog = Dog()
+dog.name = '大黄'
+dog.play()
+
+#res
+大黄在玩耍class Animal(object):
+ pass
+
+class Dog(Animal):
+ passclass 马(object):
+ pass
+
+class 驴(object):
+ pass
+
+class 骡子(马,驴):
+ pass 需要注意:
多继承中圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
和java一样,子类重写父类中的同名方法,通过子类独对象调用方法时调用的是子类自己的方法
java中调用父类就用super,python有以下几种方式
父类名.方法名(self,其他参数)
super(类A,self).方法名(参数),会调用类A的父类中的方法
super().方法名(参数)=>super(当前类,self).方法名(参数) 是第二中的简写,调用当前类的父类
子类重写父类的init方法:在子类的init方法需要调用父类的init方法(和java也一样),给对象添加从父类继承的属性
注意:子类init方法的形参,一般先写父类的形参,再写自己独有的形参
class Dog(object):
+ def __init__(self,name):
+ self.name = name
+ self.age = 1
+
+ def __str__(self):
+ return f'名字为{self.name},年龄为{self.age}'
+
+class MyDog(Dog):
+ def __init__(self,name,color):
+ super().__init__(name)
+ self.color = color
+
+ def __str__(self):
+ return f'名字为{self.name},年龄为{self.age},颜色为{self.color}'
+
+
+dog = MyDog('大黄','黄色')
+print(dog)
+#res
+名字为大黄,年龄为1,颜色为黄色封装的意义:
python没有java中的权限修饰符public/private之类的,私有的属性或者方法都由两个下划线开头
普通的属性前面加两个下划线就是私有属性
方法名前面加两个下划线就是私有方法
和java一样私有属性不能被继承,私有方法不能在类外部访问,可以提供共有方法访问私有属性或私有方法
类似java中的静态变量
访问:类名.类属性
修改:类名.类属性 = 属性值
类方法:使用@classmethod装饰的方法称为类方法,第一个参数是cls,代表类对象自己
注意:
何时定义类方法:
调用:
使用@staticmethod装饰的方法称为静态方法,对参数没有特殊要求,可以有,可以没有
何时定义:
调用:
由于python不需要声明变量类型,因此多态体现的不是那么直观,思想和java一样,可以使用父类的地方,也可以使用子类,使用多态的意义在于提高应用的扩展性
try:
+ statement1
+except 异常名:
+ statement2try:
+ statement1
+except (异常1,异常2,...):
+ statement2
+
+try:
+ statement1
+except 异常1:
+ statement2
+except 异常2:
+ statement3try:
+ statement1
+except (异常1,异常2,...) as 变量名:
+ print(变量名)try:
+ statement1
+except: #缺点 不能获取异常信息
+ statement2
+
+try:
+ statement1
+except Exception as 变量名:
+ print(变量名)try:
+ statement1
+except Exception as e:
+ print(e)
+else:
+ 代码没有发生异常会执行的代码块
+finally:
+ 不管有没有异常都会执行的代码块raise 异常对象
+
+
+
+异常对象 = 异常类(参数)
+
+
+抛出自定义异常:
+ 1.自定义异常类,继承Exception或者BaseException
+ 2.选择性定义__init__方法,__str__方法
+ 3.抛出print('hello world')_python3中支持中文变量名
import keyword
+
+
+print(keyword.kwlist)
+
+
+['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']python中单行注释#
多行注释可以多个#或者三单引号'''和三双引号"""
python使用缩进来表示代码块,而不是像Java一样的{},目前还很不习惯。。
if True:
+ print('true')
+else:
+ print('false')python一般一行写一条一句,特殊情况可以使用反斜杠\\实现多行语句
total = item_one + \\
+ item_two + \\
+ item_three在[],{},()中的多行语句不需要\\
python中的数字有四种类型:
\\函数之间或类之间用空行分隔,一般是两个空行,以分隔两段不同功能或含义的代码
同一行显示多条语句
使用;分隔(ps,python的语句后面不用每行加分号,好不习惯。。。)
缩进相同的一组语句构成一个代码块,我们称首行及后面的代码称为一个子句(clause)
print输出类似java中的println,默认是换行的,如果不想换行在print函数中加入参数ene=''
例如 print('x', end ='' )
python中的变量不需要声明(但python是强类型语言),使用变量前必须赋值,赋值以后变量才会创建。
在python中,变量就是变量,没有类型。我们所说的类型是变量所指的内存中对象的数据类型
a = b = c = 1以上实例,创建一个整型对象1,从后向前赋值,三个变量被赋予相同的值
a, b, c = 1, 2, 'noob'以上实例,两个整型对象1,2分配给a和b,字符串对象noob分配给变量c
python3中有六个标准数据类型
其中
type()函数或者isinstance()函数
区别:
特殊:
//除法,得到一个整数%取余数(取模)python的字符串用单引号或双引号括起来
定义字符串时 加前缀 u/b/r/f
字符串截取语法:变量[头下标:尾下标] 前闭后开
字符串的切片:
str = 'Runoob'
+
+print (str) # 输出字符串
+print (str[0:-1]) # 输出第一个到倒数第二个的所有字符
+print (str[0]) # 输出字符串第一个字符
+print (str[2:5]) # 输出从第三个开始到第五个的字符
+print (str[2:]) # 输出从第三个开始的后的所有字符
+print (str * 2) # 输出字符串两次,也可以写成 print (2 * str)
+print (str + "TEST") # 连接字符串
+
+结果:
+Runoob
+Runoo
+R
+noo
+noob
+RunoobRunoob
+RunoobTESTList是python中使用最频繁的数据类型
列表是写在方括号[]之间、用逗号分隔开的元素列表
和字符串一样,列表可以被索引和截取,列表被截取后返回一个新列表
注意:
+进行拼接tuple和列表类似,但是是由()括起来的,且不可变数据类型
元素一样可以被索引和截取,元组也可以使用+进行拼接
set可以使用大括号{}或者set()函数创建集合,创建一个空集合时必须使用set()函数而非{ },因为{ }被用来创建一个空字典
set和java中的set集合一样存储的数据都是不重复的
字典(dictionary)是Python中另一个非常有用的内置数据类型。 类似java的Map
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
| 语法 | 作用 |
|---|---|
| [int(x ,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| [complex(real ,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 31 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 |
| / | 除 - x 除以 y | b / a 输出结果 2.1 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 1 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的21次方 |
| // | 取整除 - 向下取接近商的整数 | >>> 9//2 4 >>> -9//2 -5 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写。 | (a < b) 返回 True。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 True。 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。 | 在这个示例中,赋值表达式可以避免调用 len() 两次:if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)")(这个特性java中默认就有) |
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
python的条件控控制语法上和格式上和java一些区别
if condition_1:
+ statement_block_1
+elif condition_2:
+ statement_block_2
+else:
+ statement_block_3Python 中用 elif 代替了 else if,所以if语句的关键字为:if – elif – else。
注意:
如果if后面的条件是数字,只要这个数字不是0,python都会把它当做True处理
如果if后面跟的是字符串,则只要这个字符串不为空串,python就把它看作True
同样的如果if后跟元组,list,set,字典 只要不为空就是true
和java中的三元运算类似
语法: 变量 = 表达式1 if 条件 else 表达式2
例如
a = 1;
+b = a + 1 if a == 1 else a + 2;
+print(b)
+
+结果:2python中的循环有for和while两种
while 判断条件(condition):
+ 执行语句(statements)……while...else在条件语句为false时执行else的代码块
while expr:
+ statement1
+else:
+ statement2for 循环可以遍历任何可选代对象,如一个列表或者一个字符串。
for循环的一般格式如下:
for <variable> in <sequence>:
+ <statements>
+else:
+ <statements>用法和java一样
break区别:
例如:
_list = [1, 2, 3, 4, 5]
+
+for i in _list:
+ if i == 3:
+ print('33333333')
+else:
+ print('循环完毕')
+
+执行结果:
+33333333
+循环完毕而当循环是break终止的时候,else代码块不会执行:
_list = [1, 2, 3, 4, 5]
+
+for i in _list:
+ if i == 3:
+ print('333')
+ break
+else:
+ print('循环完毕')
+
+执行结果:
+333Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句
例如:
class MyTestClass:
+ pass
+
+
+def my_func():
+ pass
+
+
+if expr:
+ pass迭代器是python中访问集合元素的一种方式,有两个基本方法iter()和next()
字符串、列表或元组对象都可以创建迭代器
_list = [1,2,3,4]
+it = iter(_list)
+print(next(it))
+print(next(it))
+
+结果:
+1
+2迭代器对象可以使用常规for语句进行遍历:
_list = [1, 2, 3, 4]
+it = iter(_list)
+for x in it:
+ print(x, end=" ")
+
+结果:
+1 2 3 4在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
def gen_fun():
+ print('11111111111')
+ yield 1
+ print('22222222222')
+ yield 2
+ yield 3
+obj = gen_fun()
+print(obj)
+for i in obj:
+ print(i)
+#res
+<generator object gen_fun at 0x0000029394291AC0>
+11111111111
+1
+22222222222
+2
+3上面的代码可以看到在调用函数过程中,'111111'和'222222222'并没有打印出来,而是在for循环中才执行,这就是因为yield导致了函数的暂停,而for循环实际底层是迭代器实现,所以才恢复到print语句的位置继续执行
对应java中的方法
一般格式:
def 函数名(参数列表):
+ 函数体默认情况下,参数值和名称是按声明的顺序匹配的
由于python中的变量没有类型,所以不像java的参数列表都是有类型声明的
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
以下是调用函数时可使用的正式参数类型:
按照正确顺序传入参数,调用的数量和声明的数量必须一致
调用使用关键字参数来确定传入的参数值,使用关键字参数允许调用时与声明时的顺序不一致,因为python解释器能用参数名匹配参数值
def print_me(str):
+ print(str)
+
+#调用
+print_me(str = 'tom')
+
+结果:
+tom
+
+
+def printinfo( name, age ):
+ "打印任何传入的字符串"
+ print ("名字: ", name)
+ print ("年龄: ", age)
+ return
+
+#调用printinfo函数
+printinfo( age=50, name="mike" )
+结果:
+名字: mike
+年龄: 50调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值
def printinfo( name, age = 35 ):
+ print ("名字: ", name)
+ print ("年龄: ", age)
+ return
+
+#调用printinfo函数
+printinfo( age=50, name="tom" )
+print ("------------------------")
+printinfo( name="tom" )
+
+结果:
+名字: tom
+年龄: 50
+------------------------
+名字: tom
+年龄: 35你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。
*args就是就是传递一个可变参数列表给函数实参,这个参数列表的数目未知,甚至长度可以为0。下面这段代码演示了如何使用args
def test_args(first, *args):
+ print('Required argument: ', first)
+ print(type(args))
+ for v in args:
+ print ('Optional argument: ', v)
+
+test_args(1, 2, 3, 4)
+
+结果:
+Required argument: 1
+<class 'tuple'>
+Optional argument: 2
+Optional argument: 3
+Optional argument: 4而**kwargs则是将一个可变的关键字参数的字典传给函数实参,同样参数列表长度可以为0或为其他值。下面这段代码演示了如何使用kwargs
def test_kwargs(first, *args, **kwargs):
+ print('Required argument: ', first)
+ print(type(kwargs))
+ for v in args:
+ print ('Optional argument (args): ', v)
+ for k, v in kwargs.items():
+ print ('Optional argument %s (kwargs): %s' % (k, v))
+
+test_kwargs(1, 2, 3, 4, k1=5, k2=6)
+
+结果:
+Required argument: 1
+<class 'dict'>
+Optional argument (args): 2
+Optional argument (args): 3
+Optional argument (args): 4
+Optional argument k2 (kwargs): 6
+Optional argument k1 (kwargs): 5声明函数时,参数中星号 * 可以单独出现,例如:
参数列表里的 * 星号,标志着位置参数的就此终结,之后的那些参数,都只能以关键字形式来指定。
def f(a,b,*,c):
+ return a+b+c
+
+# f(1,2,3)->会报错
+# f(1,2,c=3) -> 正常args和kwargs不仅可以在函数定义中使用,还可以在函数调用中使用。在函数定义时使用就相当于pack(打包),在函数调用时就相当于unpack(解包)。
首先来看一下使用args来解包调用函数的代码,
def test_args_kwargs(arg1, arg2, arg3):
+ print("arg1:", arg1)
+ print("arg2:", arg2)
+ print("arg3:", arg3)
+
+args = ("two", 3, 5)
+test_args_kwargs(*args)
+
+结果:
+arg1: two
+arg2: 3
+arg3: 5kwargs的用法类似:
kwargs = {"arg3": 3, "arg2": "two", "arg1": 5}
+test_args_kwargs(**kwargs)
+
+#result
+arg1: 5
+arg2: two
+arg3: 3python中使用lambda来创建匿名函数
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
lambda [arg1 [,arg2,.....argn]]:expression例子:
sum = lambda arg1, arg2: arg1 + arg2
+
+# 调用sum函数
+print ("相加后的值为 : ", sum( 10, 20 ))
+print ("相加后的值为 : ", sum( 20, 20 ))
+
+相加后的值为 : 30
+相加后的值为 : 40作用:快速生成列表
语法:
变量 = [生成规则 for 临时变量 in 集合]每循环一次就会生成一个符合生成规则的数据添加到列表中
例如:
my_list = [i for i in range(5)]
+print(my_list)
+
+#res
+[0,1,2,3,4,5]Python3.8 新增了一个函数形参语法 / 用来指明函数形参必须使用指定位置参数,不能使用关键字参数的形式。
在以下的例子中,形参 a 和 b 必须使用指定位置参数,c 或 d 可以是位置形参或关键字形参,而 e 或 f 要求为关键字形参:
def f(a, b, /, c, d, *, e, f):
+ print(a, b, c, d, e, f)正确:
f(10, 20, 30, d=40, e=50, f=60)错误:
f(10, b=20, c=30, d=40, e=50, f=60) # b 不能使用关键字参数的形式
+f(10, 20, 30, 40, 50, f=60) # e 必须使用关键字参数的形式import module1[, module2[,... moduleN]
+from modname import name1[, name2[, ... nameN]]
+from modname import *一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
if __name__ == '__main__':
+ print('程序自身在运行')
+else:
+ print('我来自另一模块')说明: 每个模块都有一个__name__属性,当其值是'main'时,表明该模块自身在运行,否则是被引入。
说明:name 与 main 底下是双下划线
dir(sys)
+['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__',
+ '__package__', '__stderr__', '__stdin__', '__stdout__',
+ '_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe',
+ '_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv',
+ 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder',
+ 'call_tracing', 'callstats', 'copyright', 'displayhook',
+ 'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix',
+ 'executable', 'exit', 'flags', 'float_info', 'float_repr_style',
+ 'getcheckinterval', 'getdefaultencoding', 'getdlopenflags',
+ 'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit',
+ 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount',
+ 'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
+ 'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path',
+ 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1',
+ 'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit',
+ 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout',
+ 'thread_info', 'version', 'version_info', 'warnoptions']自定义模块名不要和系统中要使用的模块名字一样
模块搜索顺序->当前目录->系统目录(sys.path)-> 程序报错
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。采用点模块名称这种形式也不用担心不同库之间的模块重名的情况
sound/ 顶层包
+ __init__.py 初始化 sound 包
+ formats/ 文件格式转换子包
+ __init__.py
+ wavread.py
+ wavwrite.py
+ aiffread.py
+ aiffwrite.py
+ auread.py
+ auwrite.py
+ ...
+ effects/ 声音效果子包
+ __init__.py
+ echo.py
+ surround.py
+ reverse.py
+ ...
+ filters/ filters 子包
+ __init__.py
+ equalizer.py
+ vocoder.py
+ karaoke.py
+ ...在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
最简单的情况,放一个空的 :file:__init__.py就可以了。当然这个文件中也可以包含一些初始化代码或者为(将在后面介绍的) __all__变量赋值。
用户可以每次只导入一个包里面的特定模块,比如:
import sound.effects.echo这将会导入子模块:sound.effects.echo。 他必须使用全名去访问:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)还有一种导入子模块的方法是:
from sound.effects import echo这同样会导入子模块: echo,并且他不需要那些冗长的前缀,所以他可以这样使用:
echo.echofilter(input, output, delay=0.7, atten=4)还有一种变化就是直接导入一个函数或者变量:
from sound.effects.echo import echofilter同样的,这种方法会导入子模块: echo,并且可以直接使用他的 echofilter() 函数:
echofilter(input, output, delay=0.7, atten=4)注意当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import 语法会首先把 item 当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,抛出一个 :exc:ImportError 异常。
反之,如果使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
from sound.effects import * : Python 会进入文件系统,找到这个包里面所有的子模块,然后一个一个的把它们都导入进来。
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 all 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
以下实例在 file:sounds/effects/_init_.py 中包含如下代码:
__all__ = ["echo", "surround", "reverse"]这表示当你使用from sound.effects import *这种用法时,你只会导入包里面这三个子模块。
如果 __all__ 真的没有定义,那么使用**from sound.effects import ***这种语法的时候,就不会导入包 sound.effects 里的任何子模块。他只是把包sound.effects和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。
这会把__init__.py里面定义的所有名字导入进来。并且他不会破坏掉我们在这句话之前导入的所有明确指定的模块。看下这部分代码:
import sound.effects.echo
+import sound.effects.surround
+from sound.effects import *这个例子中,在执行 from...import 前,包 sound.effects 中的 echo 和 surround 模块都被导入到当前的命名空间中了。(当然如果定义了 __all__ 就更没问题了)
python的io操作相比java的IO流简单太多了,直接就是一个open()函数
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
**注意:**使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)参数说明:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 方法及描述 |
|---|
| file.close()关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| [file.read(size])从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| [file.readline(size])读取整行,包括 "\\n" 字符。 |
| [file.readlines(sizeint])读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| [file.seek(offset, whence])移动文件读取指针到指定位置 |
| file.tell()返回文件当前位置。 |
| [file.truncate(size])从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 |
| file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
import os #导入os模块
+
+#修改文件名
+os.rename(原文件名,新文件名)
+#删除文件
+os.remove(文件名)
+#创建文件夹
+os.mkdir(名称)
+#获取当前目录
+os.getcwd()
+#改变默认目录
+os.chdir(路径)
+#获取目录列表
+os.listdir(路径)
+#删除文件夹
+os.rmdir(路径)类名遵循大驼峰规则
"""
+新式类:直接或间接继承object,py3中所有类都是object的子类(same as java)
+"""
+class Demo(object):
+ pass
+"""
+旧式类:已过时
+"""
+class Demo1():
+ pass
+
+class Demo2:
+ passclass Dog(Object):
+ def eat(self):
+ print('吃')创建对象语法:
class Dog(Object):
+ def eat(self):
+ print('吃')
+
+
+dog1 = Dog()
+dog1.eat()
+#res
+吃给对象添加属性:对象.属性名 = 属性值
获取对象的属性变量 = 对象.属性名
修改:和添加一样,添加存在的属性就是修改
python的类中,有一类方法,以\`两个下划线开头\`和\`两个下划线结尾\`,并在满足\`某个特定条件下会自动调用\`,这类方法,称为\`魔法方法\` magic method__init__
在创建对象之后自动调用
作用:
注意点:
__init__方法出现了self之外的形参,在创建对象的时候,需要给额外的形参传值类名(实参) 这个类似java中的构造方法的有参构造class Dog(object):
+ def __init__(self,name):
+ self.name = name
+ print('init方法执行了')
+
+dog = Dog('大黄')
+print(dog.name)
+#res
+init方法执行了
+大黄__str__
类似java的toString:
__str__方法,打印的结果是__str__方法的返回值str(对象)将自定义类型转换为字符串的时候,会自动调用__str__方法时,这个返回值是对象的地址注意点:
__del__
对象在内存当中被销毁的时候调用:
del 变量语句删除,将这个对象的引用计数变为0,会自动调用引用计数:python内存管理的机制,指一块内存有多少变量在引用
Java中JVM为了避免对象间存在循环依赖导致对象无法被回收,JVM的垃圾回收算法采用的是可达性分析算法,通过gc roots对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到gc roots没有任何引用链相连时,则证明此对象是不可用的
通过self操作:
self指的是当前实例(类似java中的this),作为类中方法的第一个形参,在通过对象调用方法的时候,不需要手动传参
python解释器会自动把调用方法的对象传递给self形参
self也可以改成其他的形参名,但一般不修改这个名字,默认为self
class Dog(object):
+ def play(self):
+ print(f'{self.name}在玩耍')
+
+dog = Dog()
+dog.name = '大黄'
+dog.play()
+
+#res
+大黄在玩耍class Animal(object):
+ pass
+
+class Dog(Animal):
+ passclass 马(object):
+ pass
+
+class 驴(object):
+ pass
+
+class 骡子(马,驴):
+ pass 需要注意:
多继承中圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
和java一样,子类重写父类中的同名方法,通过子类独对象调用方法时调用的是子类自己的方法
java中调用父类就用super,python有以下几种方式
父类名.方法名(self,其他参数)
super(类A,self).方法名(参数),会调用类A的父类中的方法
super().方法名(参数)=>super(当前类,self).方法名(参数) 是第二中的简写,调用当前类的父类
子类重写父类的init方法:在子类的init方法需要调用父类的init方法(和java也一样),给对象添加从父类继承的属性
注意:子类init方法的形参,一般先写父类的形参,再写自己独有的形参
class Dog(object):
+ def __init__(self,name):
+ self.name = name
+ self.age = 1
+
+ def __str__(self):
+ return f'名字为{self.name},年龄为{self.age}'
+
+class MyDog(Dog):
+ def __init__(self,name,color):
+ super().__init__(name)
+ self.color = color
+
+ def __str__(self):
+ return f'名字为{self.name},年龄为{self.age},颜色为{self.color}'
+
+
+dog = MyDog('大黄','黄色')
+print(dog)
+#res
+名字为大黄,年龄为1,颜色为黄色封装的意义:
python没有java中的权限修饰符public/private之类的,私有的属性或者方法都由两个下划线开头
普通的属性前面加两个下划线就是私有属性
方法名前面加两个下划线就是私有方法
和java一样私有属性不能被继承,私有方法不能在类外部访问,可以提供共有方法访问私有属性或私有方法
类似java中的静态变量
访问:类名.类属性
修改:类名.类属性 = 属性值
类方法:使用@classmethod装饰的方法称为类方法,第一个参数是cls,代表类对象自己
注意:
何时定义类方法:
调用:
使用@staticmethod装饰的方法称为静态方法,对参数没有特殊要求,可以有,可以没有
何时定义:
调用:
由于python不需要声明变量类型,因此多态体现的不是那么直观,思想和java一样,可以使用父类的地方,也可以使用子类,使用多态的意义在于提高应用的扩展性
try:
+ statement1
+except 异常名:
+ statement2try:
+ statement1
+except (异常1,异常2,...):
+ statement2
+
+try:
+ statement1
+except 异常1:
+ statement2
+except 异常2:
+ statement3try:
+ statement1
+except (异常1,异常2,...) as 变量名:
+ print(变量名)try:
+ statement1
+except: #缺点 不能获取异常信息
+ statement2
+
+try:
+ statement1
+except Exception as 变量名:
+ print(变量名)try:
+ statement1
+except Exception as e:
+ print(e)
+else:
+ 代码没有发生异常会执行的代码块
+finally:
+ 不管有没有异常都会执行的代码块raise 异常对象
+
+
+
+异常对象 = 异常类(参数)
+
+
+抛出自定义异常:
+ 1.自定义异常类,继承Exception或者BaseException
+ 2.选择性定义__init__方法,__str__方法
+ 3.抛出多线程:threading,利用CPU运算和IO可以同时执行,让CPU不会干巴巴等待IO完成
多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务
异步IO:asyncio,在单线程中利用CPU和IO同时执行的原理,实现函数异步执行
使用Lock对资源加锁,防止冲突访问
使用Queue实现不同线程、进程之间的数据通信,实现生产者消费者模式
使用线程池Pool、进程池Pool,简化线程、进程任务的提交、等待结束、获取结果
使用subprocess启动外部程序的进程,并进行输出交互
CPU密集型计算:也叫计算密集型,指I/O很短时间内就完成,CPU需要大量计算和处理,特点是CPU占用率很高,例如解压缩,加密解密,正则匹配等。
I/O密集型计算:硬盘、内存、网络的读写操作,例如文件处理、网络爬虫、读写数据库等。
多进程Process(multiprocessing):
多线程Thread(threading):
一个进程中可以启动多个线程
相比进程更轻量级,占用资源更少。但只能单CPU并发执行,不能利用多CPU(GIL,全局解释器锁)
相比协程,线程启动数目有限制,占用内存资源,有线程切换的开销
适用于:IO密集型任务,同时运行的任务数目要求不高
多协程Coroutine(asyncio):
一个线程中可以启动多个协程
优点:内存开销最小,启动数量最多
缺点:支持的库有限(aiohttp vs requests),代码实现较为复杂
适用于:I/O密集型任务,需要超多任务运行且有现有库支持的场景
import time
+import threading
+
+
+import requests
+import threading
+import time
+
+urls = [f'https://www.cnblogs.com/#p{i}' for i in range(1, 50)]
+
+
+def craw(url):
+ r = requests.get(url)
+ time.sleep(1)
+ print(url, len(r.text))
+
+
+if __name__ == '__main__':
+ start = time.time()
+ t = threading.Thread(target=craw, args=(urls[0],))
+ t.start()
+ t.join()
+ print(f'cost {start - time.time()}s')import requests
+import time
+import threading
+from blog_spider import urls
+
+
+class MyThread(threading.Thread):
+ def __init__(self, url):
+ super().__init__()
+ self.url = url
+
+ def run(self):
+ r = requests.get(self.url)
+ time.sleep(1)
+ print(self.url, len(r.text))
+
+
+if __name__ == '__main__':
+ start = time.time()
+ t = MyThread(urls[0])
+ t.start()
+ t.join()
+ print(time.time() - start)import threading
+import time
+
+
+class MyThread(threading.Thread):
+ def __init__(self, thread_id, name, counter):
+ super().__init__(name=name)
+ self.name = name
+ self.thread_id = thread_id
+ self.counter = counter
+
+ def run(self):
+ print("开启线程: " + self.name)
+ # 获取锁.用于线程同步
+ my_lock.acquire()
+ print_time(self.name, self.counter, 3)
+ # 释放锁
+ my_lock.release()
+
+
+def print_time(thread_name, delay, counter):
+ while counter:
+ time.sleep(delay)
+ print(f"#{thread_name}: {time.ctime(time.time())}")
+ counter -= 1
+
+
+my_lock = threading.Lock()
+threads = []
+# 创建新线程
+thread1 = MyThread(1, "Thread-1", 1)
+thread2 = MyThread(2, "Thread-2", 2)
+thread1.start()
+thread2.start()
+# 添加到线程列表
+threads.append(thread1)
+threads.append(thread2)
+
+for t in threads:
+ t.join()
+print("退出主线程")结果:
开启线程: Thread-1
+开启线程: Thread-2
+#Thread-1: Mon Apr 12 21:54:42 2021
+#Thread-1: Mon Apr 12 21:54:43 2021
+#Thread-1: Mon Apr 12 21:54:44 2021
+#Thread-2: Mon Apr 12 21:54:46 2021
+#Thread-2: Mon Apr 12 21:54:48 2021
+#Thread-2: Mon Apr 12 21:54:50 2021
+退出主线程1.try-finally模式
import threading
+
+lock = threading.lock()
+lock.acquire()
+try:
+ #do something
+finally:
+ lock.release()import threading
+
+lock = threading.lock()
+
+with lock:
+ # do somethingimport requests
+from bs4 import BeautifulSoup
+
+urls = [f'https://www.cnblogs.com/#p{i}' for i in range(1, 50)]
+
+
+def craw(url):
+ r = requests.get(url)
+ return r.text
+
+
+def parse(html):
+ soup = BeautifulSoup(html, 'html.parser')
+ links = soup.find_all('a', class_='post-item-title')
+ return [(link.get('href'), link.get_text()) for link in links]import queue
+import threading
+import time
+import random
+
+import blog_spider
+
+
+def do_crawl(url_queue: queue.Queue, html_queue: queue.Queue):
+ while True:
+ url = url_queue.get()
+ html = blog_spider.craw(url)
+ html_queue.put(html)
+
+
+def do_parse(html_queue: queue.Queue, fout):
+ while True:
+ html = html_queue.get()
+ results = blog_spider.parse(html)
+ for result in results:
+ fout.write(str(result) + '\\n')
+ time.sleep(1)
+
+
+if __name__ == '__main__':
+ url_queue = queue.Queue()
+ html_queue = queue.Queue()
+ for url in blog_spider.urls:
+ url_queue.put(url)
+
+ for i in range(3):
+ t = threading.Thread(target=do_crawl, args=(url_queue, html_queue), name='crawl-{}'.format(i))
+ t.start()
+
+ fout = open('results.txt', 'w')
+ for i in range(3):
+ t = threading.Thread(target=do_parse, args=(html_queue, fout), name='parse-{}'.format(i))
+ t.start()import queue
+import threading
+import time
+
+exitFlag = 0
+
+
+class MyThread(threading.Thread):
+ def __init__(self, thread_id, name, q):
+ super().__init__(name=name)
+ self.threadId = thread_id
+ self.name = name
+ self.q = q
+
+ def run(self):
+ print("开启线程: " + self.name)
+ process_data(self.name, self.q)
+ print("退出线程: " + self.name)
+
+
+def process_data(name, q):
+ while not exitFlag:
+ queueLock.acquire()
+ if not workQueue.empty():
+ data = q.get()
+ queueLock.release()
+ print(f"{name} processing {data}")
+ else:
+ queueLock.release()
+ time.sleep(1)
+
+
+threadList = ["Thread-1", "Thread-2", "Thread-3"]
+queueLock = threading.Lock()
+nameList = ["ONE", "TWO", "THREE", "FOUR", "FIVE"]
+workQueue = queue.Queue(10)
+threads = []
+threadId = 1
+
+for tname in threadList:
+ thread = MyThread(threadId, tname, workQueue)
+ thread.start()
+ threads.append(thread)
+ threadId += 1
+
+queueLock.acquire()
+for name in nameList:
+ workQueue.put(name)
+queueLock.release()
+
+while not workQueue.empty():
+ pass
+
+exitFlag = 1
+
+for t in threads:
+ t.join()
+
+print("主线程退出")运行结果:
开启线程: Thread-1
+开启线程: Thread-2
+开启线程: Thread-3
+Thread-1 processing ONE
+Thread-2 processing TWO
+Thread-3 processing THREE
+Thread-2 processing FOUR
+Thread-1 processing FIVE
+退出线程: Thread-2
+退出线程: Thread-1
+退出线程: Thread-3
+主线程退出from concurrent.futures import ThreadPoolExecutor, as_completed
+import time
+
+
+def get_data(times):
+ time.sleep(times)
+ print("get data {} success".format(times))
+
+
+thread_pool = ThreadPoolExecutor(max_workers=2)
+task1 = thread_pool.submit(get_data, 3)
+task2 = thread_pool.submit(get_data, 2)
+
+datas = [1, 2, 3]
+# submit后直接返回
+all_tasks = [thread_pool.submit(get_data, data) for data in datas]
+# as_complete底层是生成器
+# for future in as_completed(all_tasks):
+# res = future.result()
+# print(res)
+for data in thread_pool.map(get_data, datas):
+ print("get {} data ".format(data))as_complete使用,这种方式是按任务完成顺序返回。对于io操作来说,使用多线程
对于耗cpu的操作,用多进程
from concurrent.futures import ProcessPoolExecutor
+import multiprocessing
+import time
+
+
+# 多进程编程
+def get_html(n):
+ time.sleep(n)
+ return n
+
+
+if __name__ == '__main__':
+ # progress = multiprocessing.Process(target=get_html, args=(2,))
+ # print(progress.pid)
+ # progress.start()
+ # print(progress.pid)
+ # progress.join()
+ # print('main progress end')
+
+ # 使用进程池
+ pool = multiprocessing.Pool(multiprocessing.cpu_count())
+ # res = pool.apply_async(get_html, args=(3,))
+ # 不再接受任务
+ # pool.close()
+ # 等待所有任务完成
+ # pool.join()
+ # print(res)
+ # print(res.get())
+
+ # imap 按顺序
+ # for res in pool.imap(get_html, [1, 5, 3]):
+ # print("{} sleep success".format(res))
+ # imap_unordered 按完成时间
+ for res in pool.imap_unordered(get_html, [1, 5, 3]):
+ print("{} sleep success".format(res))
协程,又称微线程,纤程。英文名Coroutine。是一种用户态的上下文切换技术。协程的作用是在执行函数A时可以随时中断去执行函数B,然后中断函数B继续执行函数A(可以自由切换)。但这一过程并不是函数调用,这一整个过程看似像多线程,然而协程只有一个线程执行。
协程可以处理IO密集型程序的效率问题,但是CPU密集型不是它的长处,要充分发挥CPU的利用率可以结合多进程+协程
实现协程的方式:
asyncio模块中,每一个进程都有一个事件循环。把一些函数注册到事件循环上,当满足事件发生的时候,调用相应的协程函数
事件循环的作用是管理所有的事件,在整个程序运行过程中不断循环执行,追踪事件发生的顺序将它们放到队列中,当主线程空闲的时候,调用相应的事件处理者处理事件。
伪代码:
任务列表 = [任务1,任务2,任务3...]
+
+while true:
+ 可执行的任务列表,已完成的任务列表 = 检查所有任务,将可执行的和已完成的任务返回
+ for 就绪任务 in 可执行的任务:
+ 执行就绪任务
+
+ for 已完成的任务 in 已完成的任务:
+ 剔除已完成的任务
+
+ 如果任务列表的全部任务都已完成,终止循环import asyncio
+
+
+# 生成或获取一个事件循环
+loop = asyncio.get_event_loop()
+# 将任务放到任务列表
+loop.run_until_complete(任务)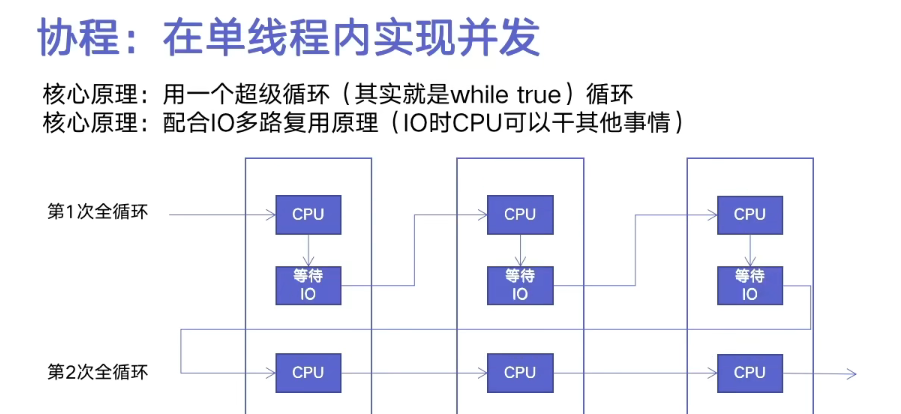
定义函数时,如果是async def 函数的函数,就是一个协程函数
执行协程函数得到的对象
TIP
执行协程函数创建协程对象,函数内部代码不会立即执行
如果想运行协程函数内部代码,必须将协程对象交给事件循环处理
import asyncio
+
+
+# 定义一个协程函数
+async def func():
+ print("异步编程")
+
+
+# 生成一个事件循环
+loop = asyncio.get_event_loop()
+# 得到协程对象
+res = func()
+# 将协程对象交给事件循环
+loop.run_until_complete(res)
+# asyncio.run(res)
+
+res:
+异步编程如果不把协程对象放入事件循环
import asyncio
+
+
+# 定义一个协程函数
+async def func():
+ print("异步编程")
+
+
+# 生成一个事件循环
+loop = asyncio.get_event_loop()
+# 得到协程对象
+res = func()
+
+res:
+sys:1: RuntimeWarning: coroutine 'func' was never awaitedimport asyncio
+# 获取事件循环
+loop = asyncio.get_event_loop()
+
+# 定义协程函数
+async def hello(count):
+ print(f"Hello World! {count}")
+ await asyncio.sleep(1)
+
+# 创建task列表
+tasks = [loop.create_task(hello(count)) for count in range(10)]
+# 执行事件列表
+loop.run_until_complete(asyncio.wait(tasks))import asyncio
+import aiohttp
+import blog_spider
+import time
+
+async def async_craw(url):
+ print('开始爬取:', url)
+ async with aiohttp.ClientSession() as session:
+ async with session.get(url) as response:
+ result = await response.text()
+ print('爬取结束:', url, len(result))
+
+
+loop = asyncio.get_event_loop()
+
+tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
+
+start = time.time()
+loop.run_until_complete(asyncio.wait(tasks))
+print('耗时:', time.time() - start)
+
+---sem = asyncio.Semaphore(10)
+
+async with sem:
+ # work with shared resource
+-----------------------------------
+
+sem = asyncio.Semaphore(10)
+
+await sem.acquire()
+try:
+ # work with shared resource
+finally:
+ sem.release()import asyncio
+import aiohttp
+import blog_spider
+
+sem = asyncio.Semaphore(10)
+
+async def async_craw(url):
+ print('开始爬取:', url)
+ async with sem:
+ async with aiohttp.ClientSession() as session:
+ async with session.get(url) as response:
+ result = await response.text()
+ print('爬取结束:', url, len(result))
+
+
+loop = asyncio.get_event_loop()
+
+tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
+import time
+start = time.time()
+loop.run_until_complete(asyncio.wait(tasks))
+print('耗时:', time.time() - start)使用asyncio.run()代替原来创建事件循环,使用事件循环执行函数的操作
import asyncio
+import blog_spider
+
+# async def 定义协程函数
+async def async_craw(url):
+ print('开始爬取:', url)
+ # 触发io操作,调用其他协程
+ await asyncio.sleep(0)
+ print('爬取完成:', url)
+
+
+async def main():
+ # 创建协程列表
+ tasks = [async_craw(url) for url in blog_spider.urls]
+ # asyncio.gather(*task)表示协同执行tasks列表里的所有协程
+ await asyncio.gather(*tasks)
+#
+asyncio.run(main())asyncio.wait 和 asyncio.gather 实现的效果是相同的,都是把所有 Task 任务结果收集起来。asyncio.wait 会返回两个值:done 和 pending,done 为已完成的协程 Task,pending 为超时未完成的协程 Task,需通过 future.result 调用 Task 的 result;而asyncio.gather 返回的是所有已完成 Task 的 result,不需要再进行调用或其他操作,就可以得到全部结果。await + 可等待的对象(协程对象、Future对象、Task对象 -> io等待)
import asyncio
+
+
+async def func():
+ print('异步编程')
+ response = await asyncio.sleep(2)
+ print("结束",response)
+
+asyncio.run(func())示例:
import asyncio
+
+
+async def others():
+ print('start')
+ await asyncio.sleep(2)
+ print('end')
+ return '返回值'
+
+
+async def func():
+ print('执行协程函数内部代码')
+ # 遇到IO操作挂起当前协程,等到IO完成后继续运行,当前协程挂起时,事件循环可以执行其他协程
+ response = await others()
+ print(f'IO的结果是:{response} ')
+
+asyncio.run(func())
+
+res:
+执行协程函数内部代码
+start
+end
+IO的结果是:返回值Tasks用于并发调度协程,是对协程对象的一种封装,其中包含了任务的各个状态。通过asyncio.create_task()函数创建Task对象,这样可以让协程加入事件循环中等待调度执行。还可以使用低层级的loop.create_task()或asyncio.ensure_future()函数。不建议手动实例化Task对象。
示例1:
import asyncio
+
+
+async def func():
+ print(1)
+ await asyncio.sleep(2)
+ print(2)
+ return '返回值'
+
+
+async def main():
+ print('main函数开始')
+
+ # 创建task对象,将当前执行func函数的任务添加到事件循环
+ task1 = asyncio.create_task(func())
+
+ task2 = asyncio.create_task(func())
+
+ print('main函数结束')
+
+ # 当执行某协程遇到IO操作,会自动切换执行其他任务
+ res1 = await task1
+ res2 = await task2
+ print(res1, res2)
+
+
+asyncio.run(main())
+
+res:
+main函数开始
+main函数结束
+1
+1
+2
+2
+返回值 返回值示例2:
import asyncio
+
+
+async def func():
+ print(1)
+ await asyncio.sleep(2)
+ print(2)
+ return '返回值'
+
+
+async def main():
+ print('main函数开始')
+
+
+ task_list = [
+ asyncio.create_task(func()),
+ asyncio.create_task(func())
+ ]
+ print('main函数结束')
+ done,pending = await asyncio.wait(task_list,timeout=None)
+ print(done)
+asyncio.run(main())Task继承了Future,Task对象内部await的结果的处理基于Future对象
async def main():
+ loop = asyncio.get_running_loop()
+ _future = loop.create_future()
+ await _future
+asyncio.run(main())使用线程池/进程池实现异步操作时用到的对象
import time
+from concurrent.futures import Future
+from concurrent.futures.thread import ThreadPoolExecutor
+
+def func(value):
+ time.sleep(1)
+ print(value)
+ return 123
+
+pool = ThreadPoolExecutory(max_workers=5)
+for i in range(5)
+ fut = pool.submit(func,1)
+ print(fut)多线程:threading,利用CPU运算和IO可以同时执行,让CPU不会干巴巴等待IO完成
多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务
异步IO:asyncio,在单线程中利用CPU和IO同时执行的原理,实现函数异步执行
使用Lock对资源加锁,防止冲突访问
使用Queue实现不同线程、进程之间的数据通信,实现生产者消费者模式
使用线程池Pool、进程池Pool,简化线程、进程任务的提交、等待结束、获取结果
使用subprocess启动外部程序的进程,并进行输出交互
CPU密集型计算:也叫计算密集型,指I/O很短时间内就完成,CPU需要大量计算和处理,特点是CPU占用率很高,例如解压缩,加密解密,正则匹配等。
I/O密集型计算:硬盘、内存、网络的读写操作,例如文件处理、网络爬虫、读写数据库等。
多进程Process(multiprocessing):
多线程Thread(threading):
一个进程中可以启动多个线程
相比进程更轻量级,占用资源更少。但只能单CPU并发执行,不能利用多CPU(GIL,全局解释器锁)
相比协程,线程启动数目有限制,占用内存资源,有线程切换的开销
适用于:IO密集型任务,同时运行的任务数目要求不高
多协程Coroutine(asyncio):
一个线程中可以启动多个协程
优点:内存开销最小,启动数量最多
缺点:支持的库有限(aiohttp vs requests),代码实现较为复杂
适用于:I/O密集型任务,需要超多任务运行且有现有库支持的场景
import time
+import threading
+
+
+import requests
+import threading
+import time
+
+urls = [f'https://www.cnblogs.com/#p{i}' for i in range(1, 50)]
+
+
+def craw(url):
+ r = requests.get(url)
+ time.sleep(1)
+ print(url, len(r.text))
+
+
+if __name__ == '__main__':
+ start = time.time()
+ t = threading.Thread(target=craw, args=(urls[0],))
+ t.start()
+ t.join()
+ print(f'cost {start - time.time()}s')import requests
+import time
+import threading
+from blog_spider import urls
+
+
+class MyThread(threading.Thread):
+ def __init__(self, url):
+ super().__init__()
+ self.url = url
+
+ def run(self):
+ r = requests.get(self.url)
+ time.sleep(1)
+ print(self.url, len(r.text))
+
+
+if __name__ == '__main__':
+ start = time.time()
+ t = MyThread(urls[0])
+ t.start()
+ t.join()
+ print(time.time() - start)import threading
+import time
+
+
+class MyThread(threading.Thread):
+ def __init__(self, thread_id, name, counter):
+ super().__init__(name=name)
+ self.name = name
+ self.thread_id = thread_id
+ self.counter = counter
+
+ def run(self):
+ print("开启线程: " + self.name)
+ # 获取锁.用于线程同步
+ my_lock.acquire()
+ print_time(self.name, self.counter, 3)
+ # 释放锁
+ my_lock.release()
+
+
+def print_time(thread_name, delay, counter):
+ while counter:
+ time.sleep(delay)
+ print(f"#{thread_name}: {time.ctime(time.time())}")
+ counter -= 1
+
+
+my_lock = threading.Lock()
+threads = []
+# 创建新线程
+thread1 = MyThread(1, "Thread-1", 1)
+thread2 = MyThread(2, "Thread-2", 2)
+thread1.start()
+thread2.start()
+# 添加到线程列表
+threads.append(thread1)
+threads.append(thread2)
+
+for t in threads:
+ t.join()
+print("退出主线程")结果:
开启线程: Thread-1
+开启线程: Thread-2
+#Thread-1: Mon Apr 12 21:54:42 2021
+#Thread-1: Mon Apr 12 21:54:43 2021
+#Thread-1: Mon Apr 12 21:54:44 2021
+#Thread-2: Mon Apr 12 21:54:46 2021
+#Thread-2: Mon Apr 12 21:54:48 2021
+#Thread-2: Mon Apr 12 21:54:50 2021
+退出主线程1.try-finally模式
import threading
+
+lock = threading.lock()
+lock.acquire()
+try:
+ #do something
+finally:
+ lock.release()import threading
+
+lock = threading.lock()
+
+with lock:
+ # do somethingimport requests
+from bs4 import BeautifulSoup
+
+urls = [f'https://www.cnblogs.com/#p{i}' for i in range(1, 50)]
+
+
+def craw(url):
+ r = requests.get(url)
+ return r.text
+
+
+def parse(html):
+ soup = BeautifulSoup(html, 'html.parser')
+ links = soup.find_all('a', class_='post-item-title')
+ return [(link.get('href'), link.get_text()) for link in links]import queue
+import threading
+import time
+import random
+
+import blog_spider
+
+
+def do_crawl(url_queue: queue.Queue, html_queue: queue.Queue):
+ while True:
+ url = url_queue.get()
+ html = blog_spider.craw(url)
+ html_queue.put(html)
+
+
+def do_parse(html_queue: queue.Queue, fout):
+ while True:
+ html = html_queue.get()
+ results = blog_spider.parse(html)
+ for result in results:
+ fout.write(str(result) + '\\n')
+ time.sleep(1)
+
+
+if __name__ == '__main__':
+ url_queue = queue.Queue()
+ html_queue = queue.Queue()
+ for url in blog_spider.urls:
+ url_queue.put(url)
+
+ for i in range(3):
+ t = threading.Thread(target=do_crawl, args=(url_queue, html_queue), name='crawl-{}'.format(i))
+ t.start()
+
+ fout = open('results.txt', 'w')
+ for i in range(3):
+ t = threading.Thread(target=do_parse, args=(html_queue, fout), name='parse-{}'.format(i))
+ t.start()import queue
+import threading
+import time
+
+exitFlag = 0
+
+
+class MyThread(threading.Thread):
+ def __init__(self, thread_id, name, q):
+ super().__init__(name=name)
+ self.threadId = thread_id
+ self.name = name
+ self.q = q
+
+ def run(self):
+ print("开启线程: " + self.name)
+ process_data(self.name, self.q)
+ print("退出线程: " + self.name)
+
+
+def process_data(name, q):
+ while not exitFlag:
+ queueLock.acquire()
+ if not workQueue.empty():
+ data = q.get()
+ queueLock.release()
+ print(f"{name} processing {data}")
+ else:
+ queueLock.release()
+ time.sleep(1)
+
+
+threadList = ["Thread-1", "Thread-2", "Thread-3"]
+queueLock = threading.Lock()
+nameList = ["ONE", "TWO", "THREE", "FOUR", "FIVE"]
+workQueue = queue.Queue(10)
+threads = []
+threadId = 1
+
+for tname in threadList:
+ thread = MyThread(threadId, tname, workQueue)
+ thread.start()
+ threads.append(thread)
+ threadId += 1
+
+queueLock.acquire()
+for name in nameList:
+ workQueue.put(name)
+queueLock.release()
+
+while not workQueue.empty():
+ pass
+
+exitFlag = 1
+
+for t in threads:
+ t.join()
+
+print("主线程退出")运行结果:
开启线程: Thread-1
+开启线程: Thread-2
+开启线程: Thread-3
+Thread-1 processing ONE
+Thread-2 processing TWO
+Thread-3 processing THREE
+Thread-2 processing FOUR
+Thread-1 processing FIVE
+退出线程: Thread-2
+退出线程: Thread-1
+退出线程: Thread-3
+主线程退出from concurrent.futures import ThreadPoolExecutor, as_completed
+import time
+
+
+def get_data(times):
+ time.sleep(times)
+ print("get data {} success".format(times))
+
+
+thread_pool = ThreadPoolExecutor(max_workers=2)
+task1 = thread_pool.submit(get_data, 3)
+task2 = thread_pool.submit(get_data, 2)
+
+datas = [1, 2, 3]
+# submit后直接返回
+all_tasks = [thread_pool.submit(get_data, data) for data in datas]
+# as_complete底层是生成器
+# for future in as_completed(all_tasks):
+# res = future.result()
+# print(res)
+for data in thread_pool.map(get_data, datas):
+ print("get {} data ".format(data))as_complete使用,这种方式是按任务完成顺序返回。对于io操作来说,使用多线程
对于耗cpu的操作,用多进程
from concurrent.futures import ProcessPoolExecutor
+import multiprocessing
+import time
+
+
+# 多进程编程
+def get_html(n):
+ time.sleep(n)
+ return n
+
+
+if __name__ == '__main__':
+ # progress = multiprocessing.Process(target=get_html, args=(2,))
+ # print(progress.pid)
+ # progress.start()
+ # print(progress.pid)
+ # progress.join()
+ # print('main progress end')
+
+ # 使用进程池
+ pool = multiprocessing.Pool(multiprocessing.cpu_count())
+ # res = pool.apply_async(get_html, args=(3,))
+ # 不再接受任务
+ # pool.close()
+ # 等待所有任务完成
+ # pool.join()
+ # print(res)
+ # print(res.get())
+
+ # imap 按顺序
+ # for res in pool.imap(get_html, [1, 5, 3]):
+ # print("{} sleep success".format(res))
+ # imap_unordered 按完成时间
+ for res in pool.imap_unordered(get_html, [1, 5, 3]):
+ print("{} sleep success".format(res))
协程,又称微线程,纤程。英文名Coroutine。是一种用户态的上下文切换技术。协程的作用是在执行函数A时可以随时中断去执行函数B,然后中断函数B继续执行函数A(可以自由切换)。但这一过程并不是函数调用,这一整个过程看似像多线程,然而协程只有一个线程执行。
协程可以处理IO密集型程序的效率问题,但是CPU密集型不是它的长处,要充分发挥CPU的利用率可以结合多进程+协程
实现协程的方式:
asyncio模块中,每一个进程都有一个事件循环。把一些函数注册到事件循环上,当满足事件发生的时候,调用相应的协程函数
事件循环的作用是管理所有的事件,在整个程序运行过程中不断循环执行,追踪事件发生的顺序将它们放到队列中,当主线程空闲的时候,调用相应的事件处理者处理事件。
伪代码:
任务列表 = [任务1,任务2,任务3...]
+
+while true:
+ 可执行的任务列表,已完成的任务列表 = 检查所有任务,将可执行的和已完成的任务返回
+ for 就绪任务 in 可执行的任务:
+ 执行就绪任务
+
+ for 已完成的任务 in 已完成的任务:
+ 剔除已完成的任务
+
+ 如果任务列表的全部任务都已完成,终止循环import asyncio
+
+
+# 生成或获取一个事件循环
+loop = asyncio.get_event_loop()
+# 将任务放到任务列表
+loop.run_until_complete(任务)
定义函数时,如果是async def 函数的函数,就是一个协程函数
执行协程函数得到的对象
TIP
执行协程函数创建协程对象,函数内部代码不会立即执行
如果想运行协程函数内部代码,必须将协程对象交给事件循环处理
import asyncio
+
+
+# 定义一个协程函数
+async def func():
+ print("异步编程")
+
+
+# 生成一个事件循环
+loop = asyncio.get_event_loop()
+# 得到协程对象
+res = func()
+# 将协程对象交给事件循环
+loop.run_until_complete(res)
+# asyncio.run(res)
+
+res:
+异步编程如果不把协程对象放入事件循环
import asyncio
+
+
+# 定义一个协程函数
+async def func():
+ print("异步编程")
+
+
+# 生成一个事件循环
+loop = asyncio.get_event_loop()
+# 得到协程对象
+res = func()
+
+res:
+sys:1: RuntimeWarning: coroutine 'func' was never awaitedimport asyncio
+# 获取事件循环
+loop = asyncio.get_event_loop()
+
+# 定义协程函数
+async def hello(count):
+ print(f"Hello World! {count}")
+ await asyncio.sleep(1)
+
+# 创建task列表
+tasks = [loop.create_task(hello(count)) for count in range(10)]
+# 执行事件列表
+loop.run_until_complete(asyncio.wait(tasks))import asyncio
+import aiohttp
+import blog_spider
+import time
+
+async def async_craw(url):
+ print('开始爬取:', url)
+ async with aiohttp.ClientSession() as session:
+ async with session.get(url) as response:
+ result = await response.text()
+ print('爬取结束:', url, len(result))
+
+
+loop = asyncio.get_event_loop()
+
+tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
+
+start = time.time()
+loop.run_until_complete(asyncio.wait(tasks))
+print('耗时:', time.time() - start)
+
+---sem = asyncio.Semaphore(10)
+
+async with sem:
+ # work with shared resource
+-----------------------------------
+
+sem = asyncio.Semaphore(10)
+
+await sem.acquire()
+try:
+ # work with shared resource
+finally:
+ sem.release()import asyncio
+import aiohttp
+import blog_spider
+
+sem = asyncio.Semaphore(10)
+
+async def async_craw(url):
+ print('开始爬取:', url)
+ async with sem:
+ async with aiohttp.ClientSession() as session:
+ async with session.get(url) as response:
+ result = await response.text()
+ print('爬取结束:', url, len(result))
+
+
+loop = asyncio.get_event_loop()
+
+tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
+import time
+start = time.time()
+loop.run_until_complete(asyncio.wait(tasks))
+print('耗时:', time.time() - start)使用asyncio.run()代替原来创建事件循环,使用事件循环执行函数的操作
import asyncio
+import blog_spider
+
+# async def 定义协程函数
+async def async_craw(url):
+ print('开始爬取:', url)
+ # 触发io操作,调用其他协程
+ await asyncio.sleep(0)
+ print('爬取完成:', url)
+
+
+async def main():
+ # 创建协程列表
+ tasks = [async_craw(url) for url in blog_spider.urls]
+ # asyncio.gather(*task)表示协同执行tasks列表里的所有协程
+ await asyncio.gather(*tasks)
+#
+asyncio.run(main())asyncio.wait 和 asyncio.gather 实现的效果是相同的,都是把所有 Task 任务结果收集起来。asyncio.wait 会返回两个值:done 和 pending,done 为已完成的协程 Task,pending 为超时未完成的协程 Task,需通过 future.result 调用 Task 的 result;而asyncio.gather 返回的是所有已完成 Task 的 result,不需要再进行调用或其他操作,就可以得到全部结果。await + 可等待的对象(协程对象、Future对象、Task对象 -> io等待)
import asyncio
+
+
+async def func():
+ print('异步编程')
+ response = await asyncio.sleep(2)
+ print("结束",response)
+
+asyncio.run(func())示例:
import asyncio
+
+
+async def others():
+ print('start')
+ await asyncio.sleep(2)
+ print('end')
+ return '返回值'
+
+
+async def func():
+ print('执行协程函数内部代码')
+ # 遇到IO操作挂起当前协程,等到IO完成后继续运行,当前协程挂起时,事件循环可以执行其他协程
+ response = await others()
+ print(f'IO的结果是:{response} ')
+
+asyncio.run(func())
+
+res:
+执行协程函数内部代码
+start
+end
+IO的结果是:返回值Tasks用于并发调度协程,是对协程对象的一种封装,其中包含了任务的各个状态。通过asyncio.create_task()函数创建Task对象,这样可以让协程加入事件循环中等待调度执行。还可以使用低层级的loop.create_task()或asyncio.ensure_future()函数。不建议手动实例化Task对象。
示例1:
import asyncio
+
+
+async def func():
+ print(1)
+ await asyncio.sleep(2)
+ print(2)
+ return '返回值'
+
+
+async def main():
+ print('main函数开始')
+
+ # 创建task对象,将当前执行func函数的任务添加到事件循环
+ task1 = asyncio.create_task(func())
+
+ task2 = asyncio.create_task(func())
+
+ print('main函数结束')
+
+ # 当执行某协程遇到IO操作,会自动切换执行其他任务
+ res1 = await task1
+ res2 = await task2
+ print(res1, res2)
+
+
+asyncio.run(main())
+
+res:
+main函数开始
+main函数结束
+1
+1
+2
+2
+返回值 返回值示例2:
import asyncio
+
+
+async def func():
+ print(1)
+ await asyncio.sleep(2)
+ print(2)
+ return '返回值'
+
+
+async def main():
+ print('main函数开始')
+
+
+ task_list = [
+ asyncio.create_task(func()),
+ asyncio.create_task(func())
+ ]
+ print('main函数结束')
+ done,pending = await asyncio.wait(task_list,timeout=None)
+ print(done)
+asyncio.run(main())Task继承了Future,Task对象内部await的结果的处理基于Future对象
async def main():
+ loop = asyncio.get_running_loop()
+ _future = loop.create_future()
+ await _future
+asyncio.run(main())使用线程池/进程池实现异步操作时用到的对象
import time
+from concurrent.futures import Future
+from concurrent.futures.thread import ThreadPoolExecutor
+
+def func(value):
+ time.sleep(1)
+ print(value)
+ return 123
+
+pool = ThreadPoolExecutory(max_workers=5)
+for i in range(5)
+ fut = pool.submit(func,1)
+ print(fut)如果在一个外部函数中定义一个内部函数,内部函数对外部作用域(但不是在全局作用域)的变量进行引用,外部函数的返回值是内部函数,这样的函数就被认为是闭包(closure)。
python装饰器实质上也是一个闭包函数,目的是在不改变原函数的情况下实现对原函数功能的增强。(类似Spring中的AOP)
@装饰器函数名
@装饰器类名
@装饰器函数名(param)
@装饰器类名(param)
这里的不带参数是指
@装饰器后没有(参数)而非装饰器函数没有参数
例如下面的record函数就是一个简单装饰器,作用是记录被装饰函数的执行耗时
import time
+
+
+def record(func):
+ def decorator(*args, **kwargs):
+ print('====start====')
+ start = time.time()
+ func(*args, **kwargs)
+ print(f'===end cost : {time.time() - start} seconds===')
+
+ return decorator
+
+
+@record # 不带参数
+def test(name, age):
+ time.sleep(1)
+ print(f'my name is {name}, {age} years old')
+
+
+test('tom', 18)
+
+
+
+====start====
+my name is tom, 18 years old
+===end cost : 1.0049748420715332 seconds===在上述不带参数的装饰器函数例子中,14行@record实质上等于test = record(test),最终调用test('tom',18)的伪代码:
print('====start====')
+start = time.time()
+
+# func(*args, **kwargs)
+time.sleep(1) # -> 原始的test('tom',18)
+print(f'my name is {name}, {age} years old') # -> 原始的test('tom',18)
+
+print(f'===end cost : {time.time() - start} seconds===')python中一切皆对象,如果在对象后跟()即是执行调用的意思,例如函数,类,类里的函数,实现了__call__方法的对象都可以被调用,因为这些对象是callable对象。还是刚才的例子,@装饰器(参数)语法,实际上是在不带参数的装饰器函数基础上包了一层,由test = record(test)变成了decorator = record(count); test = decorator(test)。
例子如下
import time
+
+def record(count):
+ def decorator(func):
+ def wrapper(*args, **kwargs):
+ print('====start====')
+ start = time.time()
+ for _num in range(count):
+ func(*args, **kwargs)
+ print(f'===end cost : {time.time() - start} seconds===')
+ return wrapper
+
+ return decorator
+
+
+@record(5)
+def test(name, age):
+ time.sleep(1)
+ print(f'my name is {name}, {age} years old')
+
+
+test('tom', 18)
+
+---
+====start====
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+===end cost : 5.020708799362183 seconds===带参数的装饰器,实际就是加了一层函数的嵌套,可以把这种装饰器拆成两步分析,第一步执行record(5)返回了函数decorator,@decorator这样就是不带参数的装饰器形式了。
装饰器返回的是一个全新的函数,对函数的装饰方法(常写成wrapper)的参数列表为了兼容性可以写为(*args, **kwargs),但是这个函数的参数实际可以写为任意形式(只要该参数包含被装饰函数的参数列表即可),回归到定义上来说就是不修改已有函数的调用方式即可。网上教程中通常把wrapper的参数写成和被装饰函数一致,很容易让人误以为这两者的参数列表必须保持一致。
例子:
import time
+from dataclasses import dataclass
+
+
+@dataclass
+class User(object):
+ name: str
+ info: tuple = ()
+
+
+def record(count):
+ def decorator(func):
+ def wrapper(user):
+ print('====start====')
+ start = time.time()
+ for _num in range(count):
+ func(*user.info)
+
+ print(f'===end cost : {time.time() - start} seconds===')
+ return wrapper
+
+ return decorator
+
+
+@record(5)
+def test(name, age):
+ time.sleep(1)
+ print(f'my name is {name}, {age} years old')
+
+
+# test('tom', 18)
+print(test.__name__)
+tom = User('tom', info=('tom', 18))
+test(tom)
+
+---
+
+wrapper
+====start====
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+===end cost : 5.013930797576904 seconds===可以看到,test函数的name为wrapper,也就是装饰功能的函数的名字,而且这里test函数的参数列表也已经变成了(user),也就是这里实际上test = wrapper(user)。如果使用装饰器后,想保留原函数的名称,可以使用@functools.wraps来装饰wrapper函数。
例子:
import functools
+import time
+from dataclasses import dataclass
+
+
+@dataclass
+class User(object):
+ name: str
+ info: tuple = ()
+
+
+def record(count):
+ def decorator(func):
+ @functools.wraps(func)
+ def wrapper(user):
+ print('====start====')
+ start = time.time()
+ for _num in range(count):
+ func(*user.info)
+
+ print(f'===end cost : {time.time() - start} seconds===')
+ return wrapper
+
+ return decorator
+
+
+@record(5)
+def test(name, age):
+ time.sleep(1)
+ print(f'my name is {name}, {age} years old')
+
+
+# test('tom', 18)
+print(test.__name__)
+tom = User('tom', info=('tom', 18))
+test(tom)
+
+---
+
+test
+====start====
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+===end cost : 5.015993118286133 seconds===可以看到,在对test进行了装饰后,返回的新的函数名称还是保持为test
类也可以作为装饰器使用,需要实现__init__函数和__call__函数,例子:
import time
+
+
+class Timer(object):
+
+ def __init__(self, func):
+ self.func = func
+
+ def __call__(self, *args, **kwargs):
+ start = time.time()
+ ret = self.func(*args, **kwargs)
+ print(f'Time : {time.time() - start}')
+ return ret
+
+
+@Timer
+def add(a, b):
+ return a + b
+
+# 等价于 add = Timer(add)
+
+print(add(2, 3))类似带参数的装饰器函数,带参数的装饰器类需要在__call__函数内部,再包一层
import time
+
+
+class Timer(object):
+
+ def __init__(self, pre_fix):
+ self.pre_fix = pre_fix
+
+ def __call__(self, func):
+ def wrapper(*args, **kwargs):
+ start = time.time()
+ ret = func(*args, **kwargs)
+ print(f'{self.pre_fix}: {time.time() - start}')
+ return ret
+
+ return wrapper
+
+
+@Timer(pre_fix='current_time')
+def add(a, b):
+ return a + b
+
+
+print(add(2, 3))函数也可以装饰类,下面的例子中,add_str是一个参数为class,返回值也是class的函数,装饰了MyObj类,作用是把被装饰类的__str__函数替换为打印self.__dict__
def add_str(cls):
+ def __str__(self):
+ return str(self.__dict__)
+
+ cls.__str__ = __str__
+ return cls
+
+
+@add_str
+class MyObj(object):
+ def __init__(self, a, b):
+ self.a = a
+ self.b = b
+
+
+print(MyObj(1, 2))
+
+---
+
+{'a': 1, 'b': 2}def add_str(time):
+ def _cls(cls):
+ def __str__(self):
+ return f'调用时间 {time} 点 == ' + str(self.__dict__)
+
+ cls.__str__ = __str__
+
+ return cls
+
+ return _cls
+
+
+@add_str(time='19')
+class MyObj(object):
+ def __init__(self, a, b):
+ self.a = a
+ self.b = b
+
+
+print(MyObj(1, 2))
+
+---
+
+调用时间 19 点 == {'a': 1, 'b': 2}没什么意义
`,52)]))}const g=i(k,[["render",l]]);export{y as __pageData,g as default}; diff --git "a/assets/python_base_\350\243\205\351\245\260\345\231\250\346\267\261\345\205\245.md.CONqcDBx.lean.js" "b/assets/python_base_\350\243\205\351\245\260\345\231\250\346\267\261\345\205\245.md.CONqcDBx.lean.js" new file mode 100644 index 00000000..65eea7cf --- /dev/null +++ "b/assets/python_base_\350\243\205\351\245\260\345\231\250\346\267\261\345\205\245.md.CONqcDBx.lean.js" @@ -0,0 +1,239 @@ +import{_ as i,c as a,a2 as n,o as h}from"./chunks/framework.BjcrtTwI.js";const y=JSON.parse('{"title":"装饰器深入","description":"","frontmatter":{},"headers":[],"relativePath":"python/base/装饰器深入.md","filePath":"python/base/装饰器深入.md","lastUpdated":1729217313000}'),k={name:"python/base/装饰器深入.md"};function l(p,s,t,e,E,r){return h(),a("div",null,s[0]||(s[0]=[n(`如果在一个外部函数中定义一个内部函数,内部函数对外部作用域(但不是在全局作用域)的变量进行引用,外部函数的返回值是内部函数,这样的函数就被认为是闭包(closure)。
python装饰器实质上也是一个闭包函数,目的是在不改变原函数的情况下实现对原函数功能的增强。(类似Spring中的AOP)
@装饰器函数名
@装饰器类名
@装饰器函数名(param)
@装饰器类名(param)
这里的不带参数是指
@装饰器后没有(参数)而非装饰器函数没有参数
例如下面的record函数就是一个简单装饰器,作用是记录被装饰函数的执行耗时
import time
+
+
+def record(func):
+ def decorator(*args, **kwargs):
+ print('====start====')
+ start = time.time()
+ func(*args, **kwargs)
+ print(f'===end cost : {time.time() - start} seconds===')
+
+ return decorator
+
+
+@record # 不带参数
+def test(name, age):
+ time.sleep(1)
+ print(f'my name is {name}, {age} years old')
+
+
+test('tom', 18)
+
+
+
+====start====
+my name is tom, 18 years old
+===end cost : 1.0049748420715332 seconds===在上述不带参数的装饰器函数例子中,14行@record实质上等于test = record(test),最终调用test('tom',18)的伪代码:
print('====start====')
+start = time.time()
+
+# func(*args, **kwargs)
+time.sleep(1) # -> 原始的test('tom',18)
+print(f'my name is {name}, {age} years old') # -> 原始的test('tom',18)
+
+print(f'===end cost : {time.time() - start} seconds===')python中一切皆对象,如果在对象后跟()即是执行调用的意思,例如函数,类,类里的函数,实现了__call__方法的对象都可以被调用,因为这些对象是callable对象。还是刚才的例子,@装饰器(参数)语法,实际上是在不带参数的装饰器函数基础上包了一层,由test = record(test)变成了decorator = record(count); test = decorator(test)。
例子如下
import time
+
+def record(count):
+ def decorator(func):
+ def wrapper(*args, **kwargs):
+ print('====start====')
+ start = time.time()
+ for _num in range(count):
+ func(*args, **kwargs)
+ print(f'===end cost : {time.time() - start} seconds===')
+ return wrapper
+
+ return decorator
+
+
+@record(5)
+def test(name, age):
+ time.sleep(1)
+ print(f'my name is {name}, {age} years old')
+
+
+test('tom', 18)
+
+---
+====start====
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+===end cost : 5.020708799362183 seconds===带参数的装饰器,实际就是加了一层函数的嵌套,可以把这种装饰器拆成两步分析,第一步执行record(5)返回了函数decorator,@decorator这样就是不带参数的装饰器形式了。
装饰器返回的是一个全新的函数,对函数的装饰方法(常写成wrapper)的参数列表为了兼容性可以写为(*args, **kwargs),但是这个函数的参数实际可以写为任意形式(只要该参数包含被装饰函数的参数列表即可),回归到定义上来说就是不修改已有函数的调用方式即可。网上教程中通常把wrapper的参数写成和被装饰函数一致,很容易让人误以为这两者的参数列表必须保持一致。
例子:
import time
+from dataclasses import dataclass
+
+
+@dataclass
+class User(object):
+ name: str
+ info: tuple = ()
+
+
+def record(count):
+ def decorator(func):
+ def wrapper(user):
+ print('====start====')
+ start = time.time()
+ for _num in range(count):
+ func(*user.info)
+
+ print(f'===end cost : {time.time() - start} seconds===')
+ return wrapper
+
+ return decorator
+
+
+@record(5)
+def test(name, age):
+ time.sleep(1)
+ print(f'my name is {name}, {age} years old')
+
+
+# test('tom', 18)
+print(test.__name__)
+tom = User('tom', info=('tom', 18))
+test(tom)
+
+---
+
+wrapper
+====start====
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+===end cost : 5.013930797576904 seconds===可以看到,test函数的name为wrapper,也就是装饰功能的函数的名字,而且这里test函数的参数列表也已经变成了(user),也就是这里实际上test = wrapper(user)。如果使用装饰器后,想保留原函数的名称,可以使用@functools.wraps来装饰wrapper函数。
例子:
import functools
+import time
+from dataclasses import dataclass
+
+
+@dataclass
+class User(object):
+ name: str
+ info: tuple = ()
+
+
+def record(count):
+ def decorator(func):
+ @functools.wraps(func)
+ def wrapper(user):
+ print('====start====')
+ start = time.time()
+ for _num in range(count):
+ func(*user.info)
+
+ print(f'===end cost : {time.time() - start} seconds===')
+ return wrapper
+
+ return decorator
+
+
+@record(5)
+def test(name, age):
+ time.sleep(1)
+ print(f'my name is {name}, {age} years old')
+
+
+# test('tom', 18)
+print(test.__name__)
+tom = User('tom', info=('tom', 18))
+test(tom)
+
+---
+
+test
+====start====
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+my name is tom, 18 years old
+===end cost : 5.015993118286133 seconds===可以看到,在对test进行了装饰后,返回的新的函数名称还是保持为test
类也可以作为装饰器使用,需要实现__init__函数和__call__函数,例子:
import time
+
+
+class Timer(object):
+
+ def __init__(self, func):
+ self.func = func
+
+ def __call__(self, *args, **kwargs):
+ start = time.time()
+ ret = self.func(*args, **kwargs)
+ print(f'Time : {time.time() - start}')
+ return ret
+
+
+@Timer
+def add(a, b):
+ return a + b
+
+# 等价于 add = Timer(add)
+
+print(add(2, 3))类似带参数的装饰器函数,带参数的装饰器类需要在__call__函数内部,再包一层
import time
+
+
+class Timer(object):
+
+ def __init__(self, pre_fix):
+ self.pre_fix = pre_fix
+
+ def __call__(self, func):
+ def wrapper(*args, **kwargs):
+ start = time.time()
+ ret = func(*args, **kwargs)
+ print(f'{self.pre_fix}: {time.time() - start}')
+ return ret
+
+ return wrapper
+
+
+@Timer(pre_fix='current_time')
+def add(a, b):
+ return a + b
+
+
+print(add(2, 3))函数也可以装饰类,下面的例子中,add_str是一个参数为class,返回值也是class的函数,装饰了MyObj类,作用是把被装饰类的__str__函数替换为打印self.__dict__
def add_str(cls):
+ def __str__(self):
+ return str(self.__dict__)
+
+ cls.__str__ = __str__
+ return cls
+
+
+@add_str
+class MyObj(object):
+ def __init__(self, a, b):
+ self.a = a
+ self.b = b
+
+
+print(MyObj(1, 2))
+
+---
+
+{'a': 1, 'b': 2}def add_str(time):
+ def _cls(cls):
+ def __str__(self):
+ return f'调用时间 {time} 点 == ' + str(self.__dict__)
+
+ cls.__str__ = __str__
+
+ return cls
+
+ return _cls
+
+
+@add_str(time='19')
+class MyObj(object):
+ def __init__(self, a, b):
+ self.a = a
+ self.b = b
+
+
+print(MyObj(1, 2))
+
+---
+
+调用时间 19 点 == {'a': 1, 'b': 2}没什么意义
`,52)]))}const g=i(k,[["render",l]]);export{y as __pageData,g as default}; diff --git "a/assets/python_crawler_CrawlSpider\345\205\250\347\253\231\347\210\254\345\217\226.md.C49jCNuk.js" "b/assets/python_crawler_CrawlSpider\345\205\250\347\253\231\347\210\254\345\217\226.md.C49jCNuk.js" new file mode 100644 index 00000000..c7dbb9e2 --- /dev/null +++ "b/assets/python_crawler_CrawlSpider\345\205\250\347\253\231\347\210\254\345\217\226.md.C49jCNuk.js" @@ -0,0 +1,115 @@ +import{_ as i,c as a,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const y=JSON.parse('{"title":"CrawlSpider全站爬取","description":"","frontmatter":{},"headers":[],"relativePath":"python/crawler/CrawlSpider全站爬取.md","filePath":"python/crawler/CrawlSpider全站爬取.md","lastUpdated":1729217313000}'),h={name:"python/crawler/CrawlSpider全站爬取.md"};function p(k,s,t,e,E,r){return l(),a("div",null,s[0]||(s[0]=[n(`CrawlSpider是Spider的一个子类,具有提取指定规则链接的功能
CrawlSpider的作用:
scrapy startproject crawl_spidercd crawl_spiderscrapy genspider -t crawl storyxc xxx.com 相比普通的增加了-t crawl参数根据指定规则(allow=‘正则表达式“)提取符合要求的所有url
link = LinkExtractor(allow=r'id=1&page=\\d+')将链接提取器提取到的链接进行指定规则(callback)的解析
rules = (
+ Rule(link, callback='parse_item', follow=True),
+)from scrapy.linkextractors import LinkExtractor
+from scrapy.spiders import CrawlSpider, Rule
+from crawl_spider.items import CrawlSpiderItem,DetailItem
+
+
+class StoryxcSpider(CrawlSpider):
+ name = 'storyxc'
+ start_urls = ['http://wz.sun0769.com/political/index/politicsNewest']
+
+ # 链接提取器,符合正则表达式的链接都会被提取
+ link = LinkExtractor(allow=r'id=1&page=\\d+')
+ detail_link = LinkExtractor(allow=r'\\/political\\/politics\\/index\\?id=\\d+')
+
+ rules = (
+ Rule(link, callback='parse_item', follow=True),
+ Rule(detail_link, callback='parse_detail'),
+ )
+
+ def parse_item(self, response):
+ li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
+ for li in li_list:
+ wz_id = li.xpath('./span[1]/text()').extract_first()
+ wz_title = li.xpath('./span[3]/a/text()').extract_first()
+ item = CrawlSpiderItem()
+ item['num'] = wz_id
+ item['title'] = wz_title
+ yield item
+
+ def parse_detail(self, response):
+ id = response.xpath('/html/body/div[3]/div[2]/div[2]/div[1]/span[4]/text()').extract_first()
+ id = id.replace('编号:','')
+ content = ''.join(response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract())
+ item = DetailItem()
+ item['num'] = id
+ item['content'] = content
+ yield item# Define here the models for your scraped items
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/items.html
+
+import scrapy
+
+
+class CrawlSpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ title =scrapy.Field()
+ num = scrapy.Field()
+
+class DetailItem(scrapy.Item):
+ num = scrapy.Field()
+ content = scrapy.Field()# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+
+
+# useful for handling different item types with a single interface
+from itemadapter import ItemAdapter
+from crawl_spider.items import CrawlSpiderItem, DetailItem
+import pymysql
+
+
+class CrawlSpiderPipeline:
+ def process_item(self, item, spider):
+ if item.__class__.__name__ == 'DetailItem':
+ with Mysql() as conn:
+ cursor = conn.cursor()
+ try:
+ cursor.execute(
+ 'insert into tb_wz_content(id,content) values("%s","%s")' % (
+ item['num'],item['content']))
+ conn.commit()
+ except:
+ print('插入问政内容失败!')
+ conn.rollback()
+
+
+ else:
+ with Mysql() as conn:
+ cursor = conn.cursor()
+ try:
+ cursor.execute(
+ 'insert into tb_wz_title(id,title) values("%s","%s")' % (item['num'],item['title']))
+ conn.commit()
+ except:
+ print('插入问政标题失败!')
+ conn.rollback()
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()BOT_NAME = 'crawl_spider'
+
+SPIDER_MODULES = ['crawl_spider.spiders']
+NEWSPIDER_MODULE = 'crawl_spider.spiders'
+
+
+# Crawl responsibly by identifying yourself (and your website) on the user-agent
+USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+# Obey robots.txt rules
+ROBOTSTXT_OBEY = False
+
+
+
+ITEM_PIPELINES = {
+ 'crawl_spider.pipelines.CrawlSpiderPipeline': 300,
+}启动爬虫:
数据库会新增数据
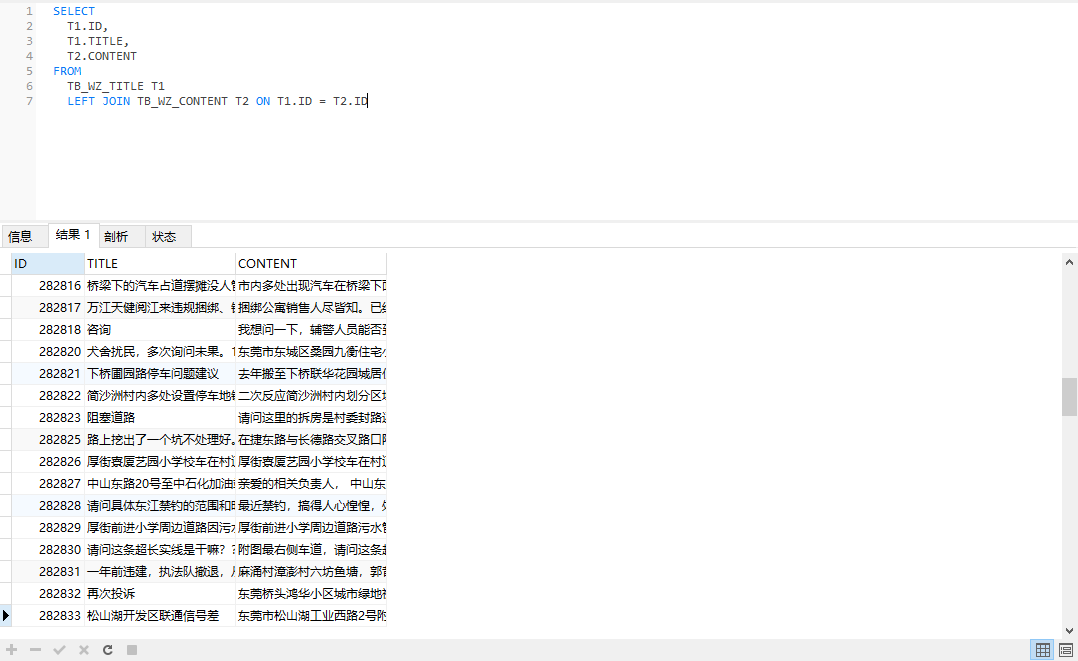
CrawlSpider是Spider的一个子类,具有提取指定规则链接的功能
CrawlSpider的作用:
scrapy startproject crawl_spidercd crawl_spiderscrapy genspider -t crawl storyxc xxx.com 相比普通的增加了-t crawl参数根据指定规则(allow=‘正则表达式“)提取符合要求的所有url
link = LinkExtractor(allow=r'id=1&page=\\d+')将链接提取器提取到的链接进行指定规则(callback)的解析
rules = (
+ Rule(link, callback='parse_item', follow=True),
+)from scrapy.linkextractors import LinkExtractor
+from scrapy.spiders import CrawlSpider, Rule
+from crawl_spider.items import CrawlSpiderItem,DetailItem
+
+
+class StoryxcSpider(CrawlSpider):
+ name = 'storyxc'
+ start_urls = ['http://wz.sun0769.com/political/index/politicsNewest']
+
+ # 链接提取器,符合正则表达式的链接都会被提取
+ link = LinkExtractor(allow=r'id=1&page=\\d+')
+ detail_link = LinkExtractor(allow=r'\\/political\\/politics\\/index\\?id=\\d+')
+
+ rules = (
+ Rule(link, callback='parse_item', follow=True),
+ Rule(detail_link, callback='parse_detail'),
+ )
+
+ def parse_item(self, response):
+ li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
+ for li in li_list:
+ wz_id = li.xpath('./span[1]/text()').extract_first()
+ wz_title = li.xpath('./span[3]/a/text()').extract_first()
+ item = CrawlSpiderItem()
+ item['num'] = wz_id
+ item['title'] = wz_title
+ yield item
+
+ def parse_detail(self, response):
+ id = response.xpath('/html/body/div[3]/div[2]/div[2]/div[1]/span[4]/text()').extract_first()
+ id = id.replace('编号:','')
+ content = ''.join(response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract())
+ item = DetailItem()
+ item['num'] = id
+ item['content'] = content
+ yield item# Define here the models for your scraped items
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/items.html
+
+import scrapy
+
+
+class CrawlSpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ title =scrapy.Field()
+ num = scrapy.Field()
+
+class DetailItem(scrapy.Item):
+ num = scrapy.Field()
+ content = scrapy.Field()# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+
+
+# useful for handling different item types with a single interface
+from itemadapter import ItemAdapter
+from crawl_spider.items import CrawlSpiderItem, DetailItem
+import pymysql
+
+
+class CrawlSpiderPipeline:
+ def process_item(self, item, spider):
+ if item.__class__.__name__ == 'DetailItem':
+ with Mysql() as conn:
+ cursor = conn.cursor()
+ try:
+ cursor.execute(
+ 'insert into tb_wz_content(id,content) values("%s","%s")' % (
+ item['num'],item['content']))
+ conn.commit()
+ except:
+ print('插入问政内容失败!')
+ conn.rollback()
+
+
+ else:
+ with Mysql() as conn:
+ cursor = conn.cursor()
+ try:
+ cursor.execute(
+ 'insert into tb_wz_title(id,title) values("%s","%s")' % (item['num'],item['title']))
+ conn.commit()
+ except:
+ print('插入问政标题失败!')
+ conn.rollback()
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()BOT_NAME = 'crawl_spider'
+
+SPIDER_MODULES = ['crawl_spider.spiders']
+NEWSPIDER_MODULE = 'crawl_spider.spiders'
+
+
+# Crawl responsibly by identifying yourself (and your website) on the user-agent
+USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+# Obey robots.txt rules
+ROBOTSTXT_OBEY = False
+
+
+
+ITEM_PIPELINES = {
+ 'crawl_spider.pipelines.CrawlSpiderPipeline': 300,
+}启动爬虫:
数据库会新增数据
直接上代码
TIP
需要提前下载ffmpeg并配置环境变量,ffmpeg下载地址:http://www.ffmpeg.org/download.html
import requests
+import re
+import json
+import os
+import subprocess
+
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
+ 'Referer': 'https://www.bilibili.com'
+}
+
+"""
+ requests获取页面源码
+"""
+
+
+def send_request(b_url):
+ data = requests.get(url=b_url, headers=headers).text
+ return data
+
+
+"""
+ 正则匹配视频和音频的真实地址
+"""
+
+
+def get_play_info(data):
+ json_data = json.loads(re.findall('<script>window\\.__playinfo__=(.*?)</script>', data)[0])
+ video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
+ audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
+ return video_url, audio_url
+
+
+"""
+ 分别下载视频和音频文件后利用ffmpeg合并
+"""
+
+
+def download(info_list, info):
+ print(f'开始下载: {info}')
+ video_data = requests.get(url=info_list[0], headers=headers).content
+ audio_data = requests.get(url=info_list[1], headers=headers).content
+ desktop = os.path.join(os.path.expanduser("~"), 'Desktop')
+ video_path = desktop + '\\\\' + info
+ audio_path = desktop + '\\\\' + info + '_.mp3'
+ # 如果视频名称中有'-' 执行ffmpeg合并的时候会报错
+ video_path = video_path.replace('-',' ')
+ audio_path = audio_path.replace('-',' ')
+ with open(video_path + '_temp.mp4', 'wb') as f:
+ f.write(video_data)
+ with open(audio_path, 'wb') as f:
+ f.write(audio_data)
+ cmd = 'ffmpeg -y -i ' + video_path + '_temp.mp4' + ' -i ' \\
+ + audio_path + ' -c:v copy -c:a aac -strict experimental ' + video_path + '.mp4'
+ print(cmd)
+ subprocess.Popen(cmd, shell=True)
+ # os.system(cmd)
+ print('下载完成')
+
+
+if __name__ == '__main__':
+ url = input('请输入要下载的b站视频链接:')
+ page_data = send_request(url)
+ # 解析视频的名称
+ title = re.findall('<h1 title=\\"(.*?)\\" class=\\"video-title', page_data)[0]
+ play_info_list = get_play_info(page_data)
+ download(play_info_list, title)直接上代码
TIP
需要提前下载ffmpeg并配置环境变量,ffmpeg下载地址:http://www.ffmpeg.org/download.html
import requests
+import re
+import json
+import os
+import subprocess
+
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
+ 'Referer': 'https://www.bilibili.com'
+}
+
+"""
+ requests获取页面源码
+"""
+
+
+def send_request(b_url):
+ data = requests.get(url=b_url, headers=headers).text
+ return data
+
+
+"""
+ 正则匹配视频和音频的真实地址
+"""
+
+
+def get_play_info(data):
+ json_data = json.loads(re.findall('<script>window\\.__playinfo__=(.*?)</script>', data)[0])
+ video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
+ audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
+ return video_url, audio_url
+
+
+"""
+ 分别下载视频和音频文件后利用ffmpeg合并
+"""
+
+
+def download(info_list, info):
+ print(f'开始下载: {info}')
+ video_data = requests.get(url=info_list[0], headers=headers).content
+ audio_data = requests.get(url=info_list[1], headers=headers).content
+ desktop = os.path.join(os.path.expanduser("~"), 'Desktop')
+ video_path = desktop + '\\\\' + info
+ audio_path = desktop + '\\\\' + info + '_.mp3'
+ # 如果视频名称中有'-' 执行ffmpeg合并的时候会报错
+ video_path = video_path.replace('-',' ')
+ audio_path = audio_path.replace('-',' ')
+ with open(video_path + '_temp.mp4', 'wb') as f:
+ f.write(video_data)
+ with open(audio_path, 'wb') as f:
+ f.write(audio_data)
+ cmd = 'ffmpeg -y -i ' + video_path + '_temp.mp4' + ' -i ' \\
+ + audio_path + ' -c:v copy -c:a aac -strict experimental ' + video_path + '.mp4'
+ print(cmd)
+ subprocess.Popen(cmd, shell=True)
+ # os.system(cmd)
+ print('下载完成')
+
+
+if __name__ == '__main__':
+ url = input('请输入要下载的b站视频链接:')
+ page_data = send_request(url)
+ # 解析视频的名称
+ title = re.findall('<h1 title=\\"(.*?)\\" class=\\"video-title', page_data)[0]
+ play_info_list = get_play_info(page_data)
+ download(play_info_list, title)requests模块是python中原生的一款基于网络请求的模块,功能强大,简单便捷,效率极高。
作用:模拟浏览器发请求
环境安装:pip install requests
import requests
+
+# 爬取搜狗首页的数据
+
+if __name__ == '__main__':
+ url = "https://www.sogou.com"
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+
+ response = requests.get(url,headers)
+ page_text = response.text
+ print(page_text)
+ with open("./sogou.html", "w", encoding="utf-8") as fp:
+ fp.write(page_text)
+ print("爬取结束")WARNING
坑1:ValueError:requests check_hostname requires server_hostname
坑2:requests.exceptions.SSLError: hostname '127.0.0.1' doesn't match None of。。
网上有说降低requests版本的,有安装乱七八糟东西的,最后是降低了urllib3的版本解决的,据说是高版本的urllib有个bug
pip install urllib3==1.25.8
import requests
+
+if __name__ == '__main__':
+ url = 'https://www.sogou.com/web'
+ keyword = input('enter your keyword: ')
+ # UA伪装
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
+ }
+ param = {
+ 'query': keyword
+ }
+ response = requests.get(url, params=param,headers=headers)
+ resp = response.text
+ file_name = keyword + '.html'
+ with open(file_name, 'w', encoding='utf-8') as f:
+ f.write(resp)
+ print(file_name, '保存成功')import requests
+import json
+
+if __name__ == '__main__':
+ url = 'https://fanyi.baidu.com/sug'
+ keyword = {
+ 'kw': 'dog'
+ }
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ response = requests.post(url=url, data=keyword, headers=headers)
+ _json = response.json()
+ file_name = keyword.get('kw') + '.json'
+ with open(file_name, 'w', encoding='utf-8') as f:
+ json.dump(_json,f,ensure_ascii=False)
+ print('json存储成功')结果:
{
+ "errno": 0,
+ "data": [
+ {
+ "k": "dog",
+ "v": "n. 狗; 蹩脚货; 丑女人; 卑鄙小人 v. 困扰; 跟踪"
+ },
+ {
+ "k": "DOG",
+ "v": "abbr. Data Output Gate 数据输出门"
+ },
+ {
+ "k": "doge",
+ "v": "n. 共和国总督"
+ },
+ {
+ "k": "dogm",
+ "v": "abbr. dogmatic 教条的; 独断的; dogmatism 教条主义; dogmatist"
+ },
+ {
+ "k": "Dogo",
+ "v": "[地名] [马里、尼日尔、乍得] 多戈; [地名] [韩国] 道高"
+ }
+ ]
+}import requests
+import json
+
+if __name__ == '__main__':
+ url = 'https://movie.douban.com/j/chart/top_list'
+ total = 748
+ limit = 20
+ start = 0
+ params = {
+ 'type': 11,
+ 'interval_id': '100:90',
+ 'action': '',
+ 'start': start,
+ 'limit': limit
+ }
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ result = total // limit
+ res_list = []
+ if result:
+ for i in range(result if total // limit == 0 else result + 1):
+ start += 20
+ res = requests.get(url=url, params=params, headers=headers)
+ res_json = res.json()
+ res_list.append(res_json)
+ with open('douban_movie.json', 'w', encoding='utf-8') as f:
+ json.dump(res_list, f, ensure_ascii=False)
+
+ print('over')import requests
+import json
+
+if __name__ == '__main__':
+ # 列表页ajax
+ url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
+ # 详情页ajax
+ detail_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
+
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ params = {
+ 'on': True,
+ 'page': 1,
+ 'pageSize': 15,
+ 'productName': '',
+ 'conditionType': 1,
+ 'applyname': '',
+ 'applysn': ''
+ }
+
+ detail_params = {
+ 'id': ''
+ }
+ # 数据容器
+ data_list = []
+ # 列表页响应
+ response = requests.post(url=url, params=params, headers=headers)
+ res_obj = response.json()
+ # 提取列表信息遍历
+ res_list = res_obj.get('list')
+ for data in res_list:
+ # id是详情页请求的参数
+ detail_id = data.get('ID')
+ detail_params['id'] = detail_id
+ # 详情页响应
+ resp = requests.post(url=detail_url, params=detail_params, headers=headers)
+ res_obj = resp.json()
+ # 容器保存
+ data_list.append(res_obj)
+ # 持久化存储
+ with open('make_up_xkz.json', 'a', encoding='utf-8') as f:
+ json.dump(data_list, f, ensure_ascii=False)
+ print('over')import requests
+import re
+
+if __name__ == '__main__':
+ for i in range(13):
+ page_no = str(i + 1)
+ url = 'https://www.qiushibaike.com/imgrank/page/%d'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ url = format(url % page_no)
+ page_txt = requests.get(url=url, headers=headers).text
+ exp = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
+ src_list = re.findall(exp, page_txt, re.S)
+ # print(src_list)
+ for src in src_list:
+ url = 'https:' + src
+ # 向图片url发请求保存
+ stream = requests.get(url=url, headers=headers).content
+ # 文件名
+ src = src.split('/')[-1]
+ img_path = './img/' + src
+ f = open(img_path, 'wb')
+ f.write(stream)
+ print(img_path, '下载成功')from lxml import etree
+import requests
+
+if __name__ == '__main__':
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ url = 'https://bj.58.com/ershoufang/'
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ div_list = tree.xpath('//div[@class="property"]')
+ with open('58.txt', 'w', encoding='utf-8') as f:
+ for div in div_list:
+ title = div.xpath('.//h3[@class="property-content-title-name"]/text()')
+ f.write(title[0]+'\\r\\n')import requests
+from lxml import etree
+import os
+from concurrent.futures import ThreadPoolExecutor
+
+
+def download_pic(page_no, real_url, first_page_url, ):
+ print('=============开始下载第 ' + str(page_no) + ' 页=================')
+ if not page_no == 1:
+ pattern = '_' + str(page_no)
+ init_url = format(real_url % pattern)
+ else:
+ init_url = first_page_url
+ down_page_text = requests.get(url=init_url, headers=headers).text
+ down_tree = etree.HTML(down_page_text)
+ li_list = down_tree.xpath('//div[@class="slist"]//li')
+ for li in li_list:
+ img_url = 'https://pic.netbian.com' + li.xpath('.//img/@src')[0]
+ img_name = li.xpath('.//img/@alt')[0] + '.jpg'
+ img_name = img_name.encode('iso-8859-1').decode('gbk')
+ with open('./beauty/' + img_name, 'wb') as f:
+ stream = requests.get(url=img_url, headers=headers).content
+ f.write(stream)
+ print(img_name, ' 下载成功')
+
+
+if __name__ == '__main__':
+ url = 'https://pic.netbian.com/4kmeinv/index.html'
+ next_url = 'https://pic.netbian.com/4kmeinv/index%s.html'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+
+ if not os.path.exists('./beauty'):
+ os.mkdir('./beauty')
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ page_info = tree.xpath('//div[@class="page"]/a[7]/text()')
+ total_page_no = int(page_info[0])
+ thread_pool = ThreadPoolExecutor(max_workers=60)
+ for i in range(total_page_no):
+ i += 1
+ thread_pool.submit(download_pic, i, next_url, url)import requests
+from lxml import etree
+
+if __name__ == '__main__':
+ url = 'https://www.aqistudy.cn/historydata'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ cities = tree.xpath('//div[@class="bottom"]/ul//li/a/text()')
+ print(len(cities))requests模块是python中原生的一款基于网络请求的模块,功能强大,简单便捷,效率极高。
作用:模拟浏览器发请求
环境安装:pip install requests
import requests
+
+# 爬取搜狗首页的数据
+
+if __name__ == '__main__':
+ url = "https://www.sogou.com"
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+
+ response = requests.get(url,headers)
+ page_text = response.text
+ print(page_text)
+ with open("./sogou.html", "w", encoding="utf-8") as fp:
+ fp.write(page_text)
+ print("爬取结束")WARNING
坑1:ValueError:requests check_hostname requires server_hostname
坑2:requests.exceptions.SSLError: hostname '127.0.0.1' doesn't match None of。。
网上有说降低requests版本的,有安装乱七八糟东西的,最后是降低了urllib3的版本解决的,据说是高版本的urllib有个bug
pip install urllib3==1.25.8
import requests
+
+if __name__ == '__main__':
+ url = 'https://www.sogou.com/web'
+ keyword = input('enter your keyword: ')
+ # UA伪装
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
+ }
+ param = {
+ 'query': keyword
+ }
+ response = requests.get(url, params=param,headers=headers)
+ resp = response.text
+ file_name = keyword + '.html'
+ with open(file_name, 'w', encoding='utf-8') as f:
+ f.write(resp)
+ print(file_name, '保存成功')import requests
+import json
+
+if __name__ == '__main__':
+ url = 'https://fanyi.baidu.com/sug'
+ keyword = {
+ 'kw': 'dog'
+ }
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ response = requests.post(url=url, data=keyword, headers=headers)
+ _json = response.json()
+ file_name = keyword.get('kw') + '.json'
+ with open(file_name, 'w', encoding='utf-8') as f:
+ json.dump(_json,f,ensure_ascii=False)
+ print('json存储成功')结果:
{
+ "errno": 0,
+ "data": [
+ {
+ "k": "dog",
+ "v": "n. 狗; 蹩脚货; 丑女人; 卑鄙小人 v. 困扰; 跟踪"
+ },
+ {
+ "k": "DOG",
+ "v": "abbr. Data Output Gate 数据输出门"
+ },
+ {
+ "k": "doge",
+ "v": "n. 共和国总督"
+ },
+ {
+ "k": "dogm",
+ "v": "abbr. dogmatic 教条的; 独断的; dogmatism 教条主义; dogmatist"
+ },
+ {
+ "k": "Dogo",
+ "v": "[地名] [马里、尼日尔、乍得] 多戈; [地名] [韩国] 道高"
+ }
+ ]
+}import requests
+import json
+
+if __name__ == '__main__':
+ url = 'https://movie.douban.com/j/chart/top_list'
+ total = 748
+ limit = 20
+ start = 0
+ params = {
+ 'type': 11,
+ 'interval_id': '100:90',
+ 'action': '',
+ 'start': start,
+ 'limit': limit
+ }
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ result = total // limit
+ res_list = []
+ if result:
+ for i in range(result if total // limit == 0 else result + 1):
+ start += 20
+ res = requests.get(url=url, params=params, headers=headers)
+ res_json = res.json()
+ res_list.append(res_json)
+ with open('douban_movie.json', 'w', encoding='utf-8') as f:
+ json.dump(res_list, f, ensure_ascii=False)
+
+ print('over')import requests
+import json
+
+if __name__ == '__main__':
+ # 列表页ajax
+ url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
+ # 详情页ajax
+ detail_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
+
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ params = {
+ 'on': True,
+ 'page': 1,
+ 'pageSize': 15,
+ 'productName': '',
+ 'conditionType': 1,
+ 'applyname': '',
+ 'applysn': ''
+ }
+
+ detail_params = {
+ 'id': ''
+ }
+ # 数据容器
+ data_list = []
+ # 列表页响应
+ response = requests.post(url=url, params=params, headers=headers)
+ res_obj = response.json()
+ # 提取列表信息遍历
+ res_list = res_obj.get('list')
+ for data in res_list:
+ # id是详情页请求的参数
+ detail_id = data.get('ID')
+ detail_params['id'] = detail_id
+ # 详情页响应
+ resp = requests.post(url=detail_url, params=detail_params, headers=headers)
+ res_obj = resp.json()
+ # 容器保存
+ data_list.append(res_obj)
+ # 持久化存储
+ with open('make_up_xkz.json', 'a', encoding='utf-8') as f:
+ json.dump(data_list, f, ensure_ascii=False)
+ print('over')import requests
+import re
+
+if __name__ == '__main__':
+ for i in range(13):
+ page_no = str(i + 1)
+ url = 'https://www.qiushibaike.com/imgrank/page/%d'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ url = format(url % page_no)
+ page_txt = requests.get(url=url, headers=headers).text
+ exp = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
+ src_list = re.findall(exp, page_txt, re.S)
+ # print(src_list)
+ for src in src_list:
+ url = 'https:' + src
+ # 向图片url发请求保存
+ stream = requests.get(url=url, headers=headers).content
+ # 文件名
+ src = src.split('/')[-1]
+ img_path = './img/' + src
+ f = open(img_path, 'wb')
+ f.write(stream)
+ print(img_path, '下载成功')from lxml import etree
+import requests
+
+if __name__ == '__main__':
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ url = 'https://bj.58.com/ershoufang/'
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ div_list = tree.xpath('//div[@class="property"]')
+ with open('58.txt', 'w', encoding='utf-8') as f:
+ for div in div_list:
+ title = div.xpath('.//h3[@class="property-content-title-name"]/text()')
+ f.write(title[0]+'\\r\\n')import requests
+from lxml import etree
+import os
+from concurrent.futures import ThreadPoolExecutor
+
+
+def download_pic(page_no, real_url, first_page_url, ):
+ print('=============开始下载第 ' + str(page_no) + ' 页=================')
+ if not page_no == 1:
+ pattern = '_' + str(page_no)
+ init_url = format(real_url % pattern)
+ else:
+ init_url = first_page_url
+ down_page_text = requests.get(url=init_url, headers=headers).text
+ down_tree = etree.HTML(down_page_text)
+ li_list = down_tree.xpath('//div[@class="slist"]//li')
+ for li in li_list:
+ img_url = 'https://pic.netbian.com' + li.xpath('.//img/@src')[0]
+ img_name = li.xpath('.//img/@alt')[0] + '.jpg'
+ img_name = img_name.encode('iso-8859-1').decode('gbk')
+ with open('./beauty/' + img_name, 'wb') as f:
+ stream = requests.get(url=img_url, headers=headers).content
+ f.write(stream)
+ print(img_name, ' 下载成功')
+
+
+if __name__ == '__main__':
+ url = 'https://pic.netbian.com/4kmeinv/index.html'
+ next_url = 'https://pic.netbian.com/4kmeinv/index%s.html'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+
+ if not os.path.exists('./beauty'):
+ os.mkdir('./beauty')
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ page_info = tree.xpath('//div[@class="page"]/a[7]/text()')
+ total_page_no = int(page_info[0])
+ thread_pool = ThreadPoolExecutor(max_workers=60)
+ for i in range(total_page_no):
+ i += 1
+ thread_pool.submit(download_pic, i, next_url, url)import requests
+from lxml import etree
+
+if __name__ == '__main__':
+ url = 'https://www.aqistudy.cn/historydata'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ cities = tree.xpath('//div[@class="bottom"]/ul//li/a/text()')
+ print(len(cities))高性能的持久化存储,高性能的数据解析,分布式。
pip install scrapyscrapy startproject yourProjectNamestory_spider/
+ scrapy.cfg # 部署配置文件
+
+ story_spider/ # Python模块,代码写在这个目录下
+ __init__.py
+
+ items.py # 项目项定义文件
+
+ pipelines.py # 项目管道文件
+
+ settings.py # 项目设置文件
+
+ spiders/ # 我们的爬虫/蜘蛛 目录
+ __init__.py在spiders目录中创建一个爬虫文件
cd 项目目录(spriders文件夹所在的目录)scrapy genspider storyxc storyxc.com爬虫文件内容
import scrapy
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://www.storyxc.com/', 'http://blog.storyxc.com']
+
+ # 用作数据解析:response参数表示的是请求成功后的响应对象
+ def parse(self, response):
+ print(response)修改settings.py中的ROBOTSTXT_OBEY = False
执行工程命令后可以加 --nolog
也可以在setting.py中添加:
#显示指定级别的日志信息 +LOG_LEVEL = 'ERROR'
执行工程scrapy crawl storyxc,日志信息
<200 https://www.storyxc.com/>
+<200 https://blog.storyxc.com/>解析糗事百科段子的作者和段子内容
import scrapy
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://www.qiushibaike.com/text/']
+
+ # 用作数据解析:response参数表示的是请求成功后的响应对象
+ def parse(self, response):
+ # 解析:作者的名称+段子内容
+ div_list = response.xpath('//div[@id="content"]/div/div[2]/div')
+ for div in div_list:
+ # extract()方法可以提取Selector对象中的data参数字符串
+ # extract_first()提取的是list数组里面的第一个字符串,
+ author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
+ # 列表调用了extract()表示将每一个Selector对象中的data字符串提取出来
+ content = ''.join(div.xpath('./a[1]/div[1]/span//text()').extract())
+ print(author,content)代码改造:
import scrapy
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://www.qiushibaike.com/text/']
+
+ # 用作数据解析:response参数表示的是请求成功后的响应对象
+ def parse(self, response):
+ # 解析:作者的名称+段子内容
+ div_list = response.xpath('//div[@id="content"]/div/div[2]/div')
+ data_list = []
+ for div in div_list:
+ # extract()方法可以提取Selector对象中的data参数字符串
+ # extract_first()提取的是list数组里面的第一个字符串,
+ author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
+ # 列表调用了extract()表示将每一个Selector对象中的data字符串提取出来
+ content = ''.join(div.xpath('./a[1]/div[1]/span//text()').extract())
+ dict = {
+ 'author':author,
+ 'content':content
+ }
+ data_list.append(dict)
+ return data_listscrapy crawl xxx -o path流程:
数据解析
在item类中定义相关的属性
将解析的数据封装存储到Item类型的对象中
将item类型的对象提交给管道进行持久化存储的操作
在管道类的process_item函数中要将其接受到的item对象中存储的数据进行持久化操作
在settings.py中开启管道
import scrapy
+from story_spider.items import StorySpiderItem
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://www.qiushibaike.com/text/']
+
+ # 用作数据解析:response参数表示的是请求成功后的响应对象
+ def parse(self, response):
+ # 解析:作者的名称+段子内容
+ div_list = response.xpath('//div[@id="content"]/div/div[2]/div')
+ data_list = []
+ for div in div_list:
+ # extract()方法可以提取Selector对象中的data参数字符串
+ # extract_first()提取的是list数组里面的第一个字符串,
+ author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
+ # 列表调用了extract()表示将每一个Selector对象中的data字符串提取出来
+ content = ''.join(div.xpath('./a[1]/div[1]/span//text()').extract())
+ item = StorySpiderItem()
+ item['author'] = author
+ item['content'] = content
+ yield itemimport scrapy
+
+
+class StorySpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ author = scrapy.Field()
+ content = scrapy.Field()class StorySpiderPipeline:
+ fp = None
+
+ # open_spider方法只会在爬虫开始时调用一次,可以用于数据初始化操作
+ def open_spider(self, spider):
+ print('开始执行爬虫...')
+ self.fp = open('./qiubai.txt', 'w', encoding='utf-8')
+
+ # close_spider会在结束时调用一次
+ def close_spider(self, spider):
+ print('爬虫执行结束...')
+ self.fp.close()
+
+ # 专门用来处理item对象
+ # 该方法可以接收爬虫文件提交的item对象
+ def process_item(self, item, spider):
+ author = item['author']
+ content = item['content']
+ self.fp.write(author + ':' + content + '\\n')
+ return itemTIP
return item可以使item继续传递到下一个即将被执行的管道类中,以此可以实现多个管道类的操作,比如一份数据持久化到文件,一份数据持久化到数据库
settings.py中修改
# Configure item pipelines
+# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+ITEM_PIPELINES = {
+ # 300表示优先级,数值越小,优先级越高
+ 'story_spider.pipelines.StorySpiderPipeline': 300,
+}scrapy crawl storyxc
+开始执行爬虫...
+爬虫执行结束...
+目录下生成了qiubai.txt高性能的持久化存储,高性能的数据解析,分布式。
pip install scrapyscrapy startproject yourProjectNamestory_spider/
+ scrapy.cfg # 部署配置文件
+
+ story_spider/ # Python模块,代码写在这个目录下
+ __init__.py
+
+ items.py # 项目项定义文件
+
+ pipelines.py # 项目管道文件
+
+ settings.py # 项目设置文件
+
+ spiders/ # 我们的爬虫/蜘蛛 目录
+ __init__.py在spiders目录中创建一个爬虫文件
cd 项目目录(spriders文件夹所在的目录)scrapy genspider storyxc storyxc.com爬虫文件内容
import scrapy
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://www.storyxc.com/', 'http://blog.storyxc.com']
+
+ # 用作数据解析:response参数表示的是请求成功后的响应对象
+ def parse(self, response):
+ print(response)修改settings.py中的ROBOTSTXT_OBEY = False
执行工程命令后可以加 --nolog
也可以在setting.py中添加:
#显示指定级别的日志信息 +LOG_LEVEL = 'ERROR'
执行工程scrapy crawl storyxc,日志信息
<200 https://www.storyxc.com/>
+<200 https://blog.storyxc.com/>解析糗事百科段子的作者和段子内容
import scrapy
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://www.qiushibaike.com/text/']
+
+ # 用作数据解析:response参数表示的是请求成功后的响应对象
+ def parse(self, response):
+ # 解析:作者的名称+段子内容
+ div_list = response.xpath('//div[@id="content"]/div/div[2]/div')
+ for div in div_list:
+ # extract()方法可以提取Selector对象中的data参数字符串
+ # extract_first()提取的是list数组里面的第一个字符串,
+ author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
+ # 列表调用了extract()表示将每一个Selector对象中的data字符串提取出来
+ content = ''.join(div.xpath('./a[1]/div[1]/span//text()').extract())
+ print(author,content)代码改造:
import scrapy
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://www.qiushibaike.com/text/']
+
+ # 用作数据解析:response参数表示的是请求成功后的响应对象
+ def parse(self, response):
+ # 解析:作者的名称+段子内容
+ div_list = response.xpath('//div[@id="content"]/div/div[2]/div')
+ data_list = []
+ for div in div_list:
+ # extract()方法可以提取Selector对象中的data参数字符串
+ # extract_first()提取的是list数组里面的第一个字符串,
+ author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
+ # 列表调用了extract()表示将每一个Selector对象中的data字符串提取出来
+ content = ''.join(div.xpath('./a[1]/div[1]/span//text()').extract())
+ dict = {
+ 'author':author,
+ 'content':content
+ }
+ data_list.append(dict)
+ return data_listscrapy crawl xxx -o path流程:
数据解析
在item类中定义相关的属性
将解析的数据封装存储到Item类型的对象中
将item类型的对象提交给管道进行持久化存储的操作
在管道类的process_item函数中要将其接受到的item对象中存储的数据进行持久化操作
在settings.py中开启管道
import scrapy
+from story_spider.items import StorySpiderItem
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://www.qiushibaike.com/text/']
+
+ # 用作数据解析:response参数表示的是请求成功后的响应对象
+ def parse(self, response):
+ # 解析:作者的名称+段子内容
+ div_list = response.xpath('//div[@id="content"]/div/div[2]/div')
+ data_list = []
+ for div in div_list:
+ # extract()方法可以提取Selector对象中的data参数字符串
+ # extract_first()提取的是list数组里面的第一个字符串,
+ author = div.xpath('./div[1]/a[2]/h2/text()').extract_first()
+ # 列表调用了extract()表示将每一个Selector对象中的data字符串提取出来
+ content = ''.join(div.xpath('./a[1]/div[1]/span//text()').extract())
+ item = StorySpiderItem()
+ item['author'] = author
+ item['content'] = content
+ yield itemimport scrapy
+
+
+class StorySpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ author = scrapy.Field()
+ content = scrapy.Field()class StorySpiderPipeline:
+ fp = None
+
+ # open_spider方法只会在爬虫开始时调用一次,可以用于数据初始化操作
+ def open_spider(self, spider):
+ print('开始执行爬虫...')
+ self.fp = open('./qiubai.txt', 'w', encoding='utf-8')
+
+ # close_spider会在结束时调用一次
+ def close_spider(self, spider):
+ print('爬虫执行结束...')
+ self.fp.close()
+
+ # 专门用来处理item对象
+ # 该方法可以接收爬虫文件提交的item对象
+ def process_item(self, item, spider):
+ author = item['author']
+ content = item['content']
+ self.fp.write(author + ':' + content + '\\n')
+ return itemTIP
return item可以使item继续传递到下一个即将被执行的管道类中,以此可以实现多个管道类的操作,比如一份数据持久化到文件,一份数据持久化到数据库
settings.py中修改
# Configure item pipelines
+# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+ITEM_PIPELINES = {
+ # 300表示优先级,数值越小,优先级越高
+ 'story_spider.pipelines.StorySpiderPipeline': 300,
+}scrapy crawl storyxc
+开始执行爬虫...
+爬虫执行结束...
+目录下生成了qiubai.txt将网站中某板块下的全部页码对应页面数据进行爬取
实现方式
将所有页面url添加到start_urls列表
手动进行请求发送
import scrapy
+from story_spider.items import StorySpiderItem
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['http://www.521609.com/meinvxiaohua/']
+ url_template = 'http://www.521609.com/meinvxiaohua/list12%d.html'
+ page_num = 2
+
+ def parse(self, response):
+ li_list = response.xpath('//div[@id="content"]/div[2]/div[2]/ul/li')
+ for li in li_list:
+ img_name = li.xpath('./a[2]//text()').extract_first()
+ print(img_name)
+ if self.page_num <= 11:
+ next_url = format(self.url_template % self.page_num)
+ self.page_num += 1
+ # 手动请求发送:yield scrapy.Request(url,callback)
+ # callback专门用作数据解析
+ yield scrapy.Request(url=next_url, callback=self.parse)流程:
spider中产生url,对url进行请求发送
url会被封装成请求对象交给引擎,引擎把请求给调度器
调度器会使用过滤器将引擎提交的请求去重,将去重后的请求对象放入队列
调度器会把请求对象从队列中调度给引擎,引擎把请求交给下载器
下载器去互联网中进行数据下载,将数据封装在response里返回给引擎
引擎将response返回给spider,spider对数据进行解析,将数据封装到item当中,交给引擎
引擎把item交给管道
管道进行持久化存储
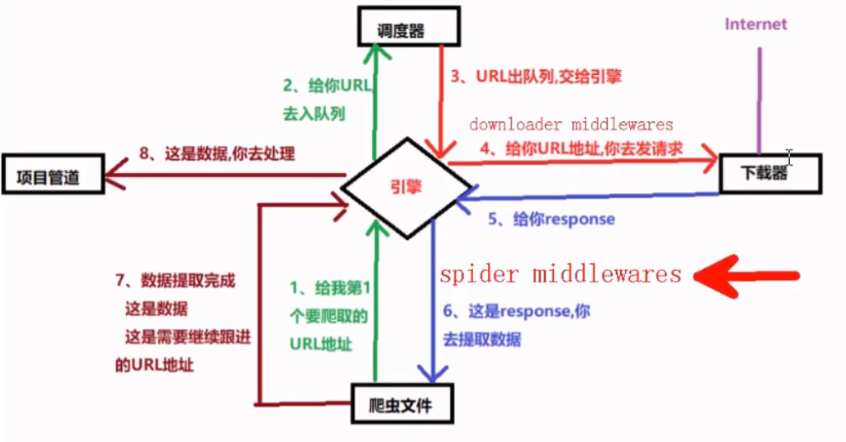
使用场景:如果爬取解析的数据不再同一张页面中(深度爬取)
yield scrapy.Request(url,callback,meta= {'item':item})
只需要解析出img的src属性进行解析并提交到管道,管道就会对图片的src进行请求发送获取二进制数据
import scrapy
+from story_spider.items import StorySpiderItem
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['http://sc.chinaz.com/tupian/']
+
+ def parse(self, response):
+ div_list = response.xpath('//div[@id="container"]/div')
+ for div in div_list:
+ # 该网站有懒加载,要使用伪属性
+ src = div.xpath('./div/a/img/@src2').extract_first()
+ real_src = 'https:' + src
+ # print(real_src)
+ item = StorySpiderItem()
+ item['src'] = real_src
+ yield item# Define here the models for your scraped items
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/items.html
+
+import scrapy
+
+
+class StorySpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ src = scrapy.Field()# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+
+
+# useful for handling different item types with a single interface
+
+from scrapy.pipelines.images import ImagesPipeline
+import scrapy
+
+
+class ImagePipeline(ImagesPipeline):
+ # 根据图片地址进行图片数据的请求
+ def get_media_requests(self, item, info):
+ print(item['src'])
+ yield scrapy.Request(item['src'])
+
+ def file_path(self, request, response=None, info=None, *, item=None):
+ # 指定图片存储路径
+ imageName = request.url.split('/')[-1]
+ return imageName
+
+ def item_completed(self, results, item, info):
+ return item # 返回给下一个被执行的管道类# 保存的文件夹
+IMAGES_STORE = './imgs'
+# 启用管道
+ITEM_PIPELINES = {
+ # 300表示优先级,数值越小,优先级越高
+ 'story_spider.pipelines.ImagePipeline': 300
+}DANGER
这里直接运行不会报错,但是会发现也没有下载成功,但是实际上url已经能拿到了,把日志的级别放开后,查看日志信息会发现有一句 2021-05-01 13:22:48 [scrapy.middleware] WARNING: Disabled ImgsPipeline: ImagesPipeline requires installing Pillow 4.0.0 or later
提示使用ImagesPipeline还需要安装下pillow :pip install pillow
这个很坑,不仔细看找不到,排查了半天才解决
安装完pillow后启动爬虫,可以看到图片已经下载完成
def process_request(self, request, spider):
+ # UA 伪装,也可以设置ua池,随机设置
+ request.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+ # 设置代理
+ request.meta['proxy'] = 'https://ip:port'
+ return None
+
+ def process_response(self, request, response, spider):
+ # Called with the response returned from the downloader.
+
+ # Must either;
+ # - return a Response object
+ # - return a Request object
+ # - or raise IgnoreRequest
+ return response
+
+ def process_exception(self, request, exception, spider):
+
+ # Called when a download handler or a process_request()
+ # (from other downloader middleware) raises an exception.
+ # 发生异常的请求切换代理 也可以实现代理池,指定切换逻辑
+ request.meta['proxy'] = 'https://ip:port'
+
+ # Must either:
+ # - return None: continue processing this exception
+ # - return a Response object: stops process_exception() chain
+ # - return a Request object: stops process_exception() chain
+ return request #将修正后的request重新进行发送import scrapy
+from story_spider.items import StorySpiderItem
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://news.163.com/']
+ module_urls = []
+
+ def __init__(self):
+ super().__init__(self)
+ from selenium import webdriver
+ self.browser = webdriver.Chrome()
+
+ def parse(self, response):
+
+ li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
+ need_index = [3, 4, 6]
+ for index in need_index:
+ module_url = li_list[index].xpath('./a/@href').extract_first()
+ self.module_urls.append(module_url)
+
+ for url in self.module_urls:
+ yield scrapy.Request(url, callback=self.parse_module)
+
+ # 解析篡改过的 已经添加了动态加载数据的响应信息
+ def parse_module(self, response):
+ div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div')
+ for div in div_list:
+ # news_title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
+ detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
+
+ yield scrapy.Request(url=detail_url,callback=self.parse_detail)
+
+
+ # 解析新闻详情页
+ def parse_detail(self, response):
+ title = response.xpath('//*[@id="container"]/div[1]/h1/text()').extract_first()
+ detail_text = response.xpath('//*[@id="content"]/div[2]//text()').extract()
+ detail_text = ''.join(detail_text)
+ item = StorySpiderItem()
+ item['title'] = title
+ item['content'] = detail_text
+ yield item
+
+ def closed(self,spider):
+ self.browser.quit()只展示了下载中间件
class StorySpiderDownloaderMiddleware:
+
+ def process_request(self, request, spider):
+
+ return None
+
+ # 拦截模块对应的响应对象,进行篡改
+ # 由于是动态加载的内容,使用selenium
+ def process_response(self, request, response, spider):
+ # 过滤指定的响应对象
+ urls = spider.module_urls
+ bro = spider.browser
+ from scrapy.http import HtmlResponse
+ from time import sleep
+ # 只有指定模块url的数据才使用selenium请求并进行篡改数据
+ if request.url in urls:
+ bro.get(request.url) # selenium请求详情页
+ sleep(3)
+ page_data = bro.page_source # 包含了动态加载的新闻数据
+ # 要爬取的指定模块的响应内容
+ # 实例化一个新的响应对象 (包含动态加载的新闻数据),替代原来的响应对象
+ new_res = HtmlResponse(url=request.url,body=page_data,encoding='utf-8',request=request)
+ return new_res
+
+ return response
+
+ def process_exception(self, request, exception, spider):
+
+ return request #将修正后的request重新进行发送import scrapy
+
+
+class StorySpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ title = scrapy.Field()
+ content = scrapy.Field()class StroyxcPipeline(object):
+ fp = None
+
+ def open_spider(self, spider):
+ self.fp = open('./163news.txt', 'w', encoding='utf-8')
+
+ def process_item(self, item, spider):
+ self.fp.write(item['title'] + ':' + item['content'] + '\\n')
+ return item
+
+ def close_spider(self, spider):
+ self.fp.close()BOT_NAME = 'story_spider'
+
+SPIDER_MODULES = ['story_spider.spiders']
+NEWSPIDER_MODULE = 'story_spider.spiders'
+
+# Crawl responsibly by identifying yourself (and your website) on the user-agent
+USER_AGENT = {
+ 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
+}
+
+# Obey robots.txt rules
+ROBOTSTXT_OBEY = False
+
+
+# Enable or disable downloader middlewares
+# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
+DOWNLOADER_MIDDLEWARES = {
+ 'story_spider.middlewares.StorySpiderDownloaderMiddleware': 543,
+}
+
+# Configure item pipelines
+# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+ITEM_PIPELINES = {
+ # 300表示优先级,数值越小,优先级越高
+ 'story_spider.pipelines.StroyxcPipeline': 300
+}运行结果:
pycharm中编辑运行/debug配置
点击加号添加一个新的配置,选择python,给配置命个名,比如scrapy
script path选择python目录下的Lib/site-packages/scrapycmdline.py
parameter填crawl yourSpiderName
working directory填写爬虫项目路径
保存,再debug运行scrapy这个配置就行
例如:
将网站中某板块下的全部页码对应页面数据进行爬取
实现方式
将所有页面url添加到start_urls列表
手动进行请求发送
import scrapy
+from story_spider.items import StorySpiderItem
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['http://www.521609.com/meinvxiaohua/']
+ url_template = 'http://www.521609.com/meinvxiaohua/list12%d.html'
+ page_num = 2
+
+ def parse(self, response):
+ li_list = response.xpath('//div[@id="content"]/div[2]/div[2]/ul/li')
+ for li in li_list:
+ img_name = li.xpath('./a[2]//text()').extract_first()
+ print(img_name)
+ if self.page_num <= 11:
+ next_url = format(self.url_template % self.page_num)
+ self.page_num += 1
+ # 手动请求发送:yield scrapy.Request(url,callback)
+ # callback专门用作数据解析
+ yield scrapy.Request(url=next_url, callback=self.parse)流程:
spider中产生url,对url进行请求发送
url会被封装成请求对象交给引擎,引擎把请求给调度器
调度器会使用过滤器将引擎提交的请求去重,将去重后的请求对象放入队列
调度器会把请求对象从队列中调度给引擎,引擎把请求交给下载器
下载器去互联网中进行数据下载,将数据封装在response里返回给引擎
引擎将response返回给spider,spider对数据进行解析,将数据封装到item当中,交给引擎
引擎把item交给管道
管道进行持久化存储
使用场景:如果爬取解析的数据不再同一张页面中(深度爬取)
yield scrapy.Request(url,callback,meta= {'item':item})
只需要解析出img的src属性进行解析并提交到管道,管道就会对图片的src进行请求发送获取二进制数据
import scrapy
+from story_spider.items import StorySpiderItem
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['http://sc.chinaz.com/tupian/']
+
+ def parse(self, response):
+ div_list = response.xpath('//div[@id="container"]/div')
+ for div in div_list:
+ # 该网站有懒加载,要使用伪属性
+ src = div.xpath('./div/a/img/@src2').extract_first()
+ real_src = 'https:' + src
+ # print(real_src)
+ item = StorySpiderItem()
+ item['src'] = real_src
+ yield item# Define here the models for your scraped items
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/items.html
+
+import scrapy
+
+
+class StorySpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ src = scrapy.Field()# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+
+
+# useful for handling different item types with a single interface
+
+from scrapy.pipelines.images import ImagesPipeline
+import scrapy
+
+
+class ImagePipeline(ImagesPipeline):
+ # 根据图片地址进行图片数据的请求
+ def get_media_requests(self, item, info):
+ print(item['src'])
+ yield scrapy.Request(item['src'])
+
+ def file_path(self, request, response=None, info=None, *, item=None):
+ # 指定图片存储路径
+ imageName = request.url.split('/')[-1]
+ return imageName
+
+ def item_completed(self, results, item, info):
+ return item # 返回给下一个被执行的管道类# 保存的文件夹
+IMAGES_STORE = './imgs'
+# 启用管道
+ITEM_PIPELINES = {
+ # 300表示优先级,数值越小,优先级越高
+ 'story_spider.pipelines.ImagePipeline': 300
+}DANGER
这里直接运行不会报错,但是会发现也没有下载成功,但是实际上url已经能拿到了,把日志的级别放开后,查看日志信息会发现有一句 2021-05-01 13:22:48 [scrapy.middleware] WARNING: Disabled ImgsPipeline: ImagesPipeline requires installing Pillow 4.0.0 or later
提示使用ImagesPipeline还需要安装下pillow :pip install pillow
这个很坑,不仔细看找不到,排查了半天才解决
安装完pillow后启动爬虫,可以看到图片已经下载完成
def process_request(self, request, spider):
+ # UA 伪装,也可以设置ua池,随机设置
+ request.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+ # 设置代理
+ request.meta['proxy'] = 'https://ip:port'
+ return None
+
+ def process_response(self, request, response, spider):
+ # Called with the response returned from the downloader.
+
+ # Must either;
+ # - return a Response object
+ # - return a Request object
+ # - or raise IgnoreRequest
+ return response
+
+ def process_exception(self, request, exception, spider):
+
+ # Called when a download handler or a process_request()
+ # (from other downloader middleware) raises an exception.
+ # 发生异常的请求切换代理 也可以实现代理池,指定切换逻辑
+ request.meta['proxy'] = 'https://ip:port'
+
+ # Must either:
+ # - return None: continue processing this exception
+ # - return a Response object: stops process_exception() chain
+ # - return a Request object: stops process_exception() chain
+ return request #将修正后的request重新进行发送import scrapy
+from story_spider.items import StorySpiderItem
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://news.163.com/']
+ module_urls = []
+
+ def __init__(self):
+ super().__init__(self)
+ from selenium import webdriver
+ self.browser = webdriver.Chrome()
+
+ def parse(self, response):
+
+ li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
+ need_index = [3, 4, 6]
+ for index in need_index:
+ module_url = li_list[index].xpath('./a/@href').extract_first()
+ self.module_urls.append(module_url)
+
+ for url in self.module_urls:
+ yield scrapy.Request(url, callback=self.parse_module)
+
+ # 解析篡改过的 已经添加了动态加载数据的响应信息
+ def parse_module(self, response):
+ div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div')
+ for div in div_list:
+ # news_title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
+ detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
+
+ yield scrapy.Request(url=detail_url,callback=self.parse_detail)
+
+
+ # 解析新闻详情页
+ def parse_detail(self, response):
+ title = response.xpath('//*[@id="container"]/div[1]/h1/text()').extract_first()
+ detail_text = response.xpath('//*[@id="content"]/div[2]//text()').extract()
+ detail_text = ''.join(detail_text)
+ item = StorySpiderItem()
+ item['title'] = title
+ item['content'] = detail_text
+ yield item
+
+ def closed(self,spider):
+ self.browser.quit()只展示了下载中间件
class StorySpiderDownloaderMiddleware:
+
+ def process_request(self, request, spider):
+
+ return None
+
+ # 拦截模块对应的响应对象,进行篡改
+ # 由于是动态加载的内容,使用selenium
+ def process_response(self, request, response, spider):
+ # 过滤指定的响应对象
+ urls = spider.module_urls
+ bro = spider.browser
+ from scrapy.http import HtmlResponse
+ from time import sleep
+ # 只有指定模块url的数据才使用selenium请求并进行篡改数据
+ if request.url in urls:
+ bro.get(request.url) # selenium请求详情页
+ sleep(3)
+ page_data = bro.page_source # 包含了动态加载的新闻数据
+ # 要爬取的指定模块的响应内容
+ # 实例化一个新的响应对象 (包含动态加载的新闻数据),替代原来的响应对象
+ new_res = HtmlResponse(url=request.url,body=page_data,encoding='utf-8',request=request)
+ return new_res
+
+ return response
+
+ def process_exception(self, request, exception, spider):
+
+ return request #将修正后的request重新进行发送import scrapy
+
+
+class StorySpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ title = scrapy.Field()
+ content = scrapy.Field()class StroyxcPipeline(object):
+ fp = None
+
+ def open_spider(self, spider):
+ self.fp = open('./163news.txt', 'w', encoding='utf-8')
+
+ def process_item(self, item, spider):
+ self.fp.write(item['title'] + ':' + item['content'] + '\\n')
+ return item
+
+ def close_spider(self, spider):
+ self.fp.close()BOT_NAME = 'story_spider'
+
+SPIDER_MODULES = ['story_spider.spiders']
+NEWSPIDER_MODULE = 'story_spider.spiders'
+
+# Crawl responsibly by identifying yourself (and your website) on the user-agent
+USER_AGENT = {
+ 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
+}
+
+# Obey robots.txt rules
+ROBOTSTXT_OBEY = False
+
+
+# Enable or disable downloader middlewares
+# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
+DOWNLOADER_MIDDLEWARES = {
+ 'story_spider.middlewares.StorySpiderDownloaderMiddleware': 543,
+}
+
+# Configure item pipelines
+# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+ITEM_PIPELINES = {
+ # 300表示优先级,数值越小,优先级越高
+ 'story_spider.pipelines.StroyxcPipeline': 300
+}运行结果:
pycharm中编辑运行/debug配置
点击加号添加一个新的配置,选择python,给配置命个名,比如scrapy
script path选择python目录下的Lib/site-packages/scrapycmdline.py
parameter填crawl yourSpiderName
working directory填写爬虫项目路径
保存,再debug运行scrapy这个配置就行
例如:
selenium是一个用于web应用程序测试的工具,selenium测试直接运行在浏览器中,就像真正的用户在操作一样
selenium在爬虫中的应用:
selenium模块:
pip install seleniumfrom selenium import webdriver
+from lxml import etree
+import time
+
+# 实例化一个浏览器对象
+browser = webdriver.Chrome(executable_path=r'D:\\install\\tools\\chromedriver\\chromedriver.exe')
+# 访问url
+browser.get('https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=')
+# 获取页面源码内容
+page_text = browser.page_source
+
+tree = etree.HTML(page_text)
+span_list = tree.xpath('//div[@class="movie-content"]/div[1]/div[1]/span[1]')
+for span in span_list:
+ name = span.xpath('.//a/text()')
+ print(name)
+time.sleep(5)
+# 退出
+browser.quit()
+
+res:
+['肖申克的救赎']
+['霸王别姬']
+['控方证人']
+['伊丽莎白']
+['阿甘正传']
+['美丽人生']
+['辛德勒的名单']
+['茶馆']
+['控方证人']
+['十二怒汉(电视版)']
+['这个杀手不太冷']
+['千与千寻']
+['泰坦尼克号']
+['忠犬八公的故事']
+['十二怒汉']
+['泰坦尼克号 3D版']
+['背靠背,脸对脸']
+['灿烂人生']
+['横空出世']
+['遥望南方的童年']from selenium import webdriver
+from time import sleep
+
+bro = webdriver.Chrome(executable_path=r'D:\\install\\tools\\chromedriver\\chromedriver.exe')
+bro.get('https://www.taobao.com/')
+# 找到搜索框
+input_ = bro.find_element_by_id('q')
+# 输入值
+input_.send_keys('macbook')
+# 执行js
+bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
+sleep(2)
+# 点击搜索按钮
+btn = bro.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button')
+btn.click()
+
+sleep(2)
+
+bro.get('https://www.baidu.com')
+sleep(1)
+# 后退
+bro.back()
+
+sleep(1)
+# 前进
+bro.forward()
+sleep(1)
+bro.quit()switch_to.frame(id)from selenium import webdriver
+import time
+
+url = 'https://qzone.qq.com/'
+browser = webdriver.Chrome()
+browser.get(url)
+browser.switch_to.frame('login_frame')
+btn = browser.find_element_by_id('switcher_plogin')
+btn.click()
+uname_input = browser.find_element_by_id('u')
+pwd_input = browser.find_element_by_id('p')
+uname_input.send_keys('1234')
+pwd_input.send_keys('123411234')
+login_btn = browser.find_element_by_id('login_button')
+login_btn.click()
+time.sleep(5)
+browser.quit()from selenium import webdriver
+from selenium.webdriver.chrome.options import Options
+from selenium.webdriver import ChromeOptions
+from time import sleep
+
+# 实现无可视化节目(无头浏览器)
+chrome_options = Options()
+chrome_options.add_argument('--headless')
+chrome_options.add_argument('--disable-gpu')
+# 实现规避检测
+option = ChromeOptions()
+option.add_experimental_option('excludeSwitches', ['enable-automation'])
+bro = webdriver.Chrome(chrome_options=chrome_options, options=option)
+bro.get('https://www.baidu.com')
+print(bro.page_source)
+sleep(2)
+bro.quit()from selenium import webdriver
+from time import sleep
+from story.code import StoryClient
+from PIL import Image
+from selenium.webdriver import ActionChains
+from selenium.webdriver import ChromeOptions
+
+option = ChromeOptions()
+option.add_experimental_option('excludeSwitches', ['enable-automation'])
+# 访问12306
+url = 'https://www.12306.cn/index/index.html'
+bro = webdriver.Chrome(options=option)
+bro.get(url)
+script = 'Object.defineProperty(navigator,"webdriver",{get:()=>undefined,});'
+bro.execute_script(script)
+# 点击登录标签
+sleep(5)
+a_btn = bro.find_element_by_xpath('/html/body/div[2]/div/div[1]/div/div/ul/li[5]/a[1]')
+a_btn.click()
+sleep(2)
+# 点击账号登录按钮
+account_login = bro.find_element_by_xpath('/html/body/div[2]/div[2]/ul/li[2]/a')
+account_login.click()
+sleep(5)
+# 保存页面截图
+bro.save_screenshot('page.png')
+# 确定验证码图片对应的左上角和右下角的坐标,进行裁剪
+code_element = bro.find_element_by_id('J-loginImgArea')
+location = code_element.location # 左上角坐标(x,y)
+size = code_element.size # 验证码图片的长和宽
+rangle = (
+int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
+# 截取验证码图片
+image = Image.open('./page.png')
+frame = image.crop(rangle)
+print(rangle)
+frame.save('./code.png')
+# 超级鹰识别验证码
+client = StoryClient()
+im = open('./code.png', 'rb').read()
+res = client.post_pic(im, 9004)['pic_str']
+print(res)
+# 输入用户名和密码
+uname_input = bro.find_element_by_id('J-userName')
+pwd_input = bro.find_element_by_id('J-password')
+uname_input.send_keys('aaaaaaaaaaaa')
+pwd_input.send_keys('bbbbbbbbbbb')
+sleep(5)
+# 处理识别结果
+all_position_list = [] # 即将被点击的坐标
+if '|' in res:
+ list_1 = res.split('|')
+ count_1 = len(list_1)
+ for i in range(count_1):
+ xy_list = []
+ x = int(list_1[i].split(',')[0])
+ y = int(list_1[i].split(',')[1])
+ xy_list.append(x)
+ xy_list.append(y)
+ all_position_list.append(xy_list)
+else:
+ x = int(res.split(',')[0])
+ y = int(res.split(',')[1])
+ xy_list = []
+ xy_list.append(x)
+ xy_list.append(y)
+ all_position_list.append(xy_list)
+
+print(all_position_list)
+# 使用动作链点击验证码
+for l in all_position_list:
+ x = l[0]
+ y = l[1]
+ # 参照物是截取的验证码区域
+ ActionChains(bro).move_to_element_with_offset(code_element, x, y).click().perform()
+sleep(5)
+login_btn = bro.find_element_by_id('J-login')
+login_btn.click()
+sleep(2)
+#滑动验证码
+span = bro.find_element_by_xpath('//*[@id="nc_1_n1z"]')
+# 对div_tag进行滑动操作
+action = ActionChains(bro)
+action.click_and_hold(span).perform()
+action.drag_and_drop_by_offset(span, 400, 0).perform()
+action.release()
+
+sleep(10)
+bro.quit()最后一步滑块验证码无法通过,还需要优化
`,22)]))}const y=i(l,[["render",k]]);export{g as __pageData,y as default}; diff --git "a/assets/python_crawler_selenium\346\250\241\345\235\227.md.Dw7Y3Oty.lean.js" "b/assets/python_crawler_selenium\346\250\241\345\235\227.md.Dw7Y3Oty.lean.js" new file mode 100644 index 00000000..dc36fe36 --- /dev/null +++ "b/assets/python_crawler_selenium\346\250\241\345\235\227.md.Dw7Y3Oty.lean.js" @@ -0,0 +1,188 @@ +import{_ as i,c as a,a2 as n,o as h}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"selenium模块","description":"","frontmatter":{},"headers":[],"relativePath":"python/crawler/selenium模块.md","filePath":"python/crawler/selenium模块.md","lastUpdated":1729217313000}'),l={name:"python/crawler/selenium模块.md"};function k(p,s,t,E,e,r){return h(),a("div",null,s[0]||(s[0]=[n(`selenium是一个用于web应用程序测试的工具,selenium测试直接运行在浏览器中,就像真正的用户在操作一样
selenium在爬虫中的应用:
selenium模块:
pip install seleniumfrom selenium import webdriver
+from lxml import etree
+import time
+
+# 实例化一个浏览器对象
+browser = webdriver.Chrome(executable_path=r'D:\\install\\tools\\chromedriver\\chromedriver.exe')
+# 访问url
+browser.get('https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=')
+# 获取页面源码内容
+page_text = browser.page_source
+
+tree = etree.HTML(page_text)
+span_list = tree.xpath('//div[@class="movie-content"]/div[1]/div[1]/span[1]')
+for span in span_list:
+ name = span.xpath('.//a/text()')
+ print(name)
+time.sleep(5)
+# 退出
+browser.quit()
+
+res:
+['肖申克的救赎']
+['霸王别姬']
+['控方证人']
+['伊丽莎白']
+['阿甘正传']
+['美丽人生']
+['辛德勒的名单']
+['茶馆']
+['控方证人']
+['十二怒汉(电视版)']
+['这个杀手不太冷']
+['千与千寻']
+['泰坦尼克号']
+['忠犬八公的故事']
+['十二怒汉']
+['泰坦尼克号 3D版']
+['背靠背,脸对脸']
+['灿烂人生']
+['横空出世']
+['遥望南方的童年']from selenium import webdriver
+from time import sleep
+
+bro = webdriver.Chrome(executable_path=r'D:\\install\\tools\\chromedriver\\chromedriver.exe')
+bro.get('https://www.taobao.com/')
+# 找到搜索框
+input_ = bro.find_element_by_id('q')
+# 输入值
+input_.send_keys('macbook')
+# 执行js
+bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
+sleep(2)
+# 点击搜索按钮
+btn = bro.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button')
+btn.click()
+
+sleep(2)
+
+bro.get('https://www.baidu.com')
+sleep(1)
+# 后退
+bro.back()
+
+sleep(1)
+# 前进
+bro.forward()
+sleep(1)
+bro.quit()switch_to.frame(id)from selenium import webdriver
+import time
+
+url = 'https://qzone.qq.com/'
+browser = webdriver.Chrome()
+browser.get(url)
+browser.switch_to.frame('login_frame')
+btn = browser.find_element_by_id('switcher_plogin')
+btn.click()
+uname_input = browser.find_element_by_id('u')
+pwd_input = browser.find_element_by_id('p')
+uname_input.send_keys('1234')
+pwd_input.send_keys('123411234')
+login_btn = browser.find_element_by_id('login_button')
+login_btn.click()
+time.sleep(5)
+browser.quit()from selenium import webdriver
+from selenium.webdriver.chrome.options import Options
+from selenium.webdriver import ChromeOptions
+from time import sleep
+
+# 实现无可视化节目(无头浏览器)
+chrome_options = Options()
+chrome_options.add_argument('--headless')
+chrome_options.add_argument('--disable-gpu')
+# 实现规避检测
+option = ChromeOptions()
+option.add_experimental_option('excludeSwitches', ['enable-automation'])
+bro = webdriver.Chrome(chrome_options=chrome_options, options=option)
+bro.get('https://www.baidu.com')
+print(bro.page_source)
+sleep(2)
+bro.quit()from selenium import webdriver
+from time import sleep
+from story.code import StoryClient
+from PIL import Image
+from selenium.webdriver import ActionChains
+from selenium.webdriver import ChromeOptions
+
+option = ChromeOptions()
+option.add_experimental_option('excludeSwitches', ['enable-automation'])
+# 访问12306
+url = 'https://www.12306.cn/index/index.html'
+bro = webdriver.Chrome(options=option)
+bro.get(url)
+script = 'Object.defineProperty(navigator,"webdriver",{get:()=>undefined,});'
+bro.execute_script(script)
+# 点击登录标签
+sleep(5)
+a_btn = bro.find_element_by_xpath('/html/body/div[2]/div/div[1]/div/div/ul/li[5]/a[1]')
+a_btn.click()
+sleep(2)
+# 点击账号登录按钮
+account_login = bro.find_element_by_xpath('/html/body/div[2]/div[2]/ul/li[2]/a')
+account_login.click()
+sleep(5)
+# 保存页面截图
+bro.save_screenshot('page.png')
+# 确定验证码图片对应的左上角和右下角的坐标,进行裁剪
+code_element = bro.find_element_by_id('J-loginImgArea')
+location = code_element.location # 左上角坐标(x,y)
+size = code_element.size # 验证码图片的长和宽
+rangle = (
+int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
+# 截取验证码图片
+image = Image.open('./page.png')
+frame = image.crop(rangle)
+print(rangle)
+frame.save('./code.png')
+# 超级鹰识别验证码
+client = StoryClient()
+im = open('./code.png', 'rb').read()
+res = client.post_pic(im, 9004)['pic_str']
+print(res)
+# 输入用户名和密码
+uname_input = bro.find_element_by_id('J-userName')
+pwd_input = bro.find_element_by_id('J-password')
+uname_input.send_keys('aaaaaaaaaaaa')
+pwd_input.send_keys('bbbbbbbbbbb')
+sleep(5)
+# 处理识别结果
+all_position_list = [] # 即将被点击的坐标
+if '|' in res:
+ list_1 = res.split('|')
+ count_1 = len(list_1)
+ for i in range(count_1):
+ xy_list = []
+ x = int(list_1[i].split(',')[0])
+ y = int(list_1[i].split(',')[1])
+ xy_list.append(x)
+ xy_list.append(y)
+ all_position_list.append(xy_list)
+else:
+ x = int(res.split(',')[0])
+ y = int(res.split(',')[1])
+ xy_list = []
+ xy_list.append(x)
+ xy_list.append(y)
+ all_position_list.append(xy_list)
+
+print(all_position_list)
+# 使用动作链点击验证码
+for l in all_position_list:
+ x = l[0]
+ y = l[1]
+ # 参照物是截取的验证码区域
+ ActionChains(bro).move_to_element_with_offset(code_element, x, y).click().perform()
+sleep(5)
+login_btn = bro.find_element_by_id('J-login')
+login_btn.click()
+sleep(2)
+#滑动验证码
+span = bro.find_element_by_xpath('//*[@id="nc_1_n1z"]')
+# 对div_tag进行滑动操作
+action = ActionChains(bro)
+action.click_and_hold(span).perform()
+action.drag_and_drop_by_offset(span, 400, 0).perform()
+action.release()
+
+sleep(10)
+bro.quit()最后一步滑块验证码无法通过,还需要优化
`,22)]))}const y=i(l,[["render",k]]);export{g as __pageData,y as default}; diff --git "a/assets/python_crawler_\345\210\206\345\270\203\345\274\217\347\210\254\350\231\253\345\222\214\345\242\236\351\207\217\345\274\217\347\210\254\350\231\253.md.DQdHgyJv.js" "b/assets/python_crawler_\345\210\206\345\270\203\345\274\217\347\210\254\350\231\253\345\222\214\345\242\236\351\207\217\345\274\217\347\210\254\350\231\253.md.DQdHgyJv.js" new file mode 100644 index 00000000..6ac194df --- /dev/null +++ "b/assets/python_crawler_\345\210\206\345\270\203\345\274\217\347\210\254\350\231\253\345\222\214\345\242\236\351\207\217\345\274\217\347\210\254\350\231\253.md.DQdHgyJv.js" @@ -0,0 +1,8 @@ +import{_ as s,c as a,a2 as l,o as e}from"./chunks/framework.BjcrtTwI.js";const k=JSON.parse('{"title":"分布式爬虫和增量式爬虫","description":"","frontmatter":{},"headers":[],"relativePath":"python/crawler/分布式爬虫和增量式爬虫.md","filePath":"python/crawler/分布式爬虫和增量式爬虫.md","lastUpdated":1729217313000}'),p={name:"python/crawler/分布式爬虫和增量式爬虫.md"};function t(r,i,n,h,d,o){return e(),a("div",null,i[0]||(i[0]=[l(`搭建集群,让集群对一组资源进行联合爬取
提升爬取数据效率
安装scrapy-redis组件
原生scrapy无法实现分布式爬虫
scrapy-redis组件作用
实现流程
创建工程
创建一个基于CrawlSpider的爬虫
修改爬虫文件
爬虫文件添加from scrapy_redis.spiders import RedisCrawlSpider
注释掉start_urls和allowed_domains
新增属性redis_key = 'story',代表被共享的调度器队列的名称
编写数据解析操作
将当前爬虫类的父类修改成RedisCrawlSpider
settings配置新增
指定使用可以共享的管道
ITEM_PIPELINES = {
+ 'scrapy_redis.pipelines.RedisPipeline' : 400
+}指定可以共享的调度器
# 增加一个去重容器的配置,使用redis的set来存储请求数据,实现请求去重持久化
+DUPEFLTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
+# 使用scrapy-redis组件自己的调度器
+SCHEDULER = "scrapy_redis.scheduler.Scheduler"
+# 配置调度器是否要持久化-爬虫结束要不要清空redis请求队列和去重的set
+SCHEDULER_PERSIST = True配置redis的配置文件
bind 127.0.0.1注释掉protected-mode 改为no启动redis
启动工程,进入到爬虫文件的目录后scrapy runspider xxx
向调度器队列中放入起始url
lpush redis_key url检测网站数据更新情况,只会爬取网站最新更新的数据
搭建集群,让集群对一组资源进行联合爬取
提升爬取数据效率
安装scrapy-redis组件
原生scrapy无法实现分布式爬虫
scrapy-redis组件作用
实现流程
创建工程
创建一个基于CrawlSpider的爬虫
修改爬虫文件
爬虫文件添加from scrapy_redis.spiders import RedisCrawlSpider
注释掉start_urls和allowed_domains
新增属性redis_key = 'story',代表被共享的调度器队列的名称
编写数据解析操作
将当前爬虫类的父类修改成RedisCrawlSpider
settings配置新增
指定使用可以共享的管道
ITEM_PIPELINES = {
+ 'scrapy_redis.pipelines.RedisPipeline' : 400
+}指定可以共享的调度器
# 增加一个去重容器的配置,使用redis的set来存储请求数据,实现请求去重持久化
+DUPEFLTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
+# 使用scrapy-redis组件自己的调度器
+SCHEDULER = "scrapy_redis.scheduler.Scheduler"
+# 配置调度器是否要持久化-爬虫结束要不要清空redis请求队列和去重的set
+SCHEDULER_PERSIST = True配置redis的配置文件
bind 127.0.0.1注释掉protected-mode 改为no启动redis
启动工程,进入到爬虫文件的目录后scrapy runspider xxx
向调度器队列中放入起始url
lpush redis_key url检测网站数据更新情况,只会爬取网站最新更新的数据
增量式爬取指定的up主的所有投稿作品,即实现一个增量式爬虫。
这次示范的up主是个妹子😏kototo使用了scrapy框架,主要是为了练手,不使用框架反而会更简单一些。
python模块:scrapy、selenium、requests、pymysql
其他环境:ffmpeg、mysql
scrapy startproject kototo
+cd kototo
+scrapy genspider kototo bilibili.comimport scrapy
+from selenium import webdriver
+import re
+import json
+import requests
+import os
+from kototo.items import KototoItem
+import pymysql
+
+
+class KototoSpider(scrapy.Spider):
+ name = 'kototo'
+ start_urls = []
+
+ def __init__(self):
+ """
+ 构造器,主要初始化了selenium对象并实现无头浏览器,以及
+ 初始化需要爬取的url地址,因为b站的翻页是js实现的,所以要手动处理一下
+ """
+ super().__init__()
+ # 构造无头浏览器
+ from selenium.webdriver.chrome.options import Options
+ chrome_options = Options()
+ chrome_options.add_argument('--headless')
+ chrome_options.add_argument('--disable-gpu')
+ self.bro = webdriver.Chrome(chrome_options=chrome_options)
+ # 指定的up主的投稿页面,可以提到外面使用input输入
+ space_url = 'https://space.bilibili.com/17485141/video'
+ # 初始化需要爬取的列表页
+ self.init_start_urls(self.start_urls, space_url)
+ # 创建桌面文件夹
+ self.desktop_path = os.path.join(os.path.expanduser('~'), 'Desktop\\\\' + self.name + '\\\\')
+ if not os.path.exists(self.desktop_path):
+ os.mkdir(self.desktop_path)
+
+ def parse(self, response):
+ """
+ 解析方法,解析列表页的视频li,拿到标题和详情页,然后主动请求详情页
+ :param response:
+ :return:
+ """
+ li_list = response.xpath('//*[@id="submit-video-list"]/ul[2]/li')
+ for li in li_list:
+ print(li.xpath('./a[2]/@title').extract_first())
+ print(detail_url := 'https://' + li.xpath('./a[2]/@href').extract_first()[2:])
+ yield scrapy.Request(url=detail_url, callback=self.parse_detail)
+
+ def parse_detail(self, response):
+ """
+ 增量爬取: 解析详情页的音视频地址并交给管道处理
+ 使用mysql实现
+ :param response:
+ :return:
+ """
+ title = response.xpath('//*[@id="viewbox_report"]/h1/@title').extract_first()
+ # 替换掉视频名称中无法用在文件名中或会导致cmd命令出错的字符
+ title = title.replace('-', '').replace(' ', '').replace('/', '').replace('|', '')
+ play_info_list = self.get_play_info(response)
+ # 这里使用mysql的唯一索引实现增量爬取,如果是服务器上跑也可以用redis
+ if self.insert_info(title, play_info_list[1]):
+ video_temp_path = (self.desktop_path + title + '_temp.mp4').replace('-', '')
+ video_path = self.desktop_path + title + '.mp4'
+ audio_path = self.desktop_path + title + '.mp3'
+ item = KototoItem()
+ item['video_url'] = play_info_list[0]
+ item['audio_url'] = play_info_list[1]
+ item['video_path'] = video_path
+ item['audio_path'] = audio_path
+ item['video_temp_path'] = video_temp_path
+ yield item
+ else:
+ print(title + ': 已经下载过了!')
+
+ def insert_info(self, vtitle, vurl):
+ """
+ mysql持久化存储爬取过的视频内容信息
+ :param vtitle: 标题
+ :param vurl: 视频链接
+ :return:
+ """
+ with Mysql() as conn:
+ cursor = conn.cursor(pymysql.cursors.DictCursor)
+ try:
+ sql = 'insert into tb_kototo(title,url) values("%s","%s")' % (vtitle, vurl)
+ res = cursor.execute(sql)
+ conn.commit()
+ if res == 1:
+ return True
+ else:
+ return False
+ except:
+ return False
+
+ def get_play_info(self, resp):
+ """
+ 解析详情页的源代码,提取其中的视频和文件真实地址
+ :param resp:
+ :return:
+ """
+ json_data = json.loads(re.findall('<script>window\\.__playinfo__=(.*?)</script>', resp.text)[0])
+ # 拿到视频和音频的真实链接地址
+ video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
+ audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
+ return video_url, audio_url
+
+ def init_start_urls(self, url_list, person_page):
+ """
+ 初始化需要爬取的列表页,由于b站使用js翻页,无法在源码中找到翻页地址,
+ 需要自己手动实现解析翻页url的操作
+ :param url_list:
+ :param person_page:
+ :return:
+ """
+ mid = re.findall('https://space.bilibili.com/(.*?)/video\\w*', person_page)[0]
+ url = 'https://api.bilibili.com/x/space/arc/search?mid=' + mid + '&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
+ 'Referer': 'https://www.bilibili.com'
+ }
+ json_data = requests.get(url=url, headers=headers).json()
+ total_count = json_data['data']['page']['count']
+ page_size = json_data['data']['page']['ps']
+ if total_count <= page_size:
+ page_count = 1
+ elif total_count % page_size == 0:
+ page_count = total_count / page_size
+ else:
+ page_count = total_count // page_size + 1
+
+ url_template = 'https://space.bilibili.com/' + mid + '/video?tid=0&page=' + '%d' + '&keyword=&order=pubdate'
+ for i in range(page_count):
+ page_no = i + 1
+ url_list.append(url_template % page_no)
+
+ def closed(self, spider):
+ """
+ 爬虫结束关闭selenium窗口
+ :param spider:
+ :return:
+ """
+ self.bro.quit()
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()# Define here the models for your spider middleware
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
+
+from scrapy import signals
+
+# useful for handling different item types with a single interface
+from itemadapter import is_item, ItemAdapter
+
+
+class KototoSpiderMiddleware:
+ # Not all methods need to be defined. If a method is not defined,
+ # scrapy acts as if the spider middleware does not modify the
+ # passed objects.
+
+ @classmethod
+ def from_crawler(cls, crawler):
+ # This method is used by Scrapy to create your spiders.
+ s = cls()
+ crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
+ return s
+
+ def process_spider_input(self, response, spider):
+ # Called for each response that goes through the spider
+ # middleware and into the spider.
+
+ # Should return None or raise an exception.
+ return None
+
+ def process_spider_output(self, response, result, spider):
+ # Called with the results returned from the Spider, after
+ # it has processed the response.
+
+ # Must return an iterable of Request, or item objects.
+ for i in result:
+ yield i
+
+ def process_spider_exception(self, response, exception, spider):
+ # Called when a spider or process_spider_input() method
+ # (from other spider middleware) raises an exception.
+
+ # Should return either None or an iterable of Request or item objects.
+ pass
+
+ def process_start_requests(self, start_requests, spider):
+ # Called with the start requests of the spider, and works
+ # similarly to the process_spider_output() method, except
+ # that it doesn’t have a response associated.
+
+ # Must return only requests (not items).
+ for r in start_requests:
+ yield r
+
+ def spider_opened(self, spider):
+ spider.logger.info('Spider opened: %s' % spider.name)
+
+
+class KototoDownloaderMiddleware:
+
+ def process_request(self, request, spider):
+ return None
+
+ def process_response(self, request, response, spider):
+ """
+ 篡改列表页的响应数据:
+ 视频列表是通过ajax请求动态加载的,因此要通过selenium去加载这部分数据
+ 并篡改响应内容
+ :param request:
+ :param response:
+ :param spider:
+ :return:
+ """
+ urls = spider.start_urls
+ bro = spider.bro
+ from scrapy.http import HtmlResponse
+ from time import sleep
+ if request.url in urls:
+ """
+ 如果是列表页就进行响应篡改操作
+ """
+ bro.get(request.url)
+ sleep(3)
+ page_data = bro.page_source
+ new_response = HtmlResponse(url=request.url, body=page_data, encoding='utf-8', request=request)
+ # 返回篡改过的响应对象
+ return new_response
+ return response
+
+ def process_exception(self, request, exception, spider):
+ passimport scrapy
+
+
+class KototoItem(scrapy.Item):
+ video_path = scrapy.Field()
+ video_url = scrapy.Field()
+ audio_path = scrapy.Field()
+ audio_url = scrapy.Field()
+ video_temp_path = scrapy.Field()import requests
+import os
+
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
+ 'Referer': 'https://www.bilibili.com'
+}
+
+
+class KototoPipeline(object):
+ def process_item(self, item, spider):
+ video = item['video_url']
+ audio = item['audio_url']
+ video_temp_path = item['video_temp_path']
+ audio_path = item['audio_path']
+ video_data = requests.get(url=video, headers=headers).content
+ audio_data = requests.get(url=audio, headers=headers).content
+ with open(video_temp_path, 'wb') as f:
+ f.write(video_data)
+ with open(audio_path, 'wb') as f:
+ f.write(audio_data)
+ return item
+
+
+class MergePipeline(object):
+ """
+ 删除临时文件
+ """
+
+ def process_item(self, item, spider):
+ video_temp_path = item['video_temp_path']
+ audio_path = item['audio_path']
+ video_path = item['video_path']
+ cmd = 'ffmpeg -y -i ' + video_temp_path + ' -i ' \\
+ + audio_path + ' -c:v copy -c:a aac -strict experimental ' + video_path
+ print(cmd)
+ # subprocess.Popen(cmd, shell=True)
+ os.system(cmd)
+ os.remove(video_temp_path)
+ os.remove(audio_path)
+ print(video_path, '下载完成')
+ return itemBOT_NAME = 'kototo'
+
+SPIDER_MODULES = ['kototo.spiders']
+NEWSPIDER_MODULE = 'kototo.spiders'
+
+
+USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+
+ROBOTSTXT_OBEY = False
+
+
+DEFAULT_REQUEST_HEADERS = {
+ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
+ 'Referer': 'https://space.bilibili.com/17485141/video',
+ 'Origin': 'https://space.bilibili.com'
+}
+FILES_STORE = './files'
+DOWNLOADER_MIDDLEWARES = {
+ 'kototo.middlewares.KototoDownloaderMiddleware': 543,
+}
+
+ITEM_PIPELINES = {
+ # 下载
+ 'kototo.pipelines.KototoPipeline': 1,
+ # 合并
+ 'kototo.pipelines.MergePipeline': 2,
+}命令启动:scrapy crawl kototo
配置pycharm启动(推荐)
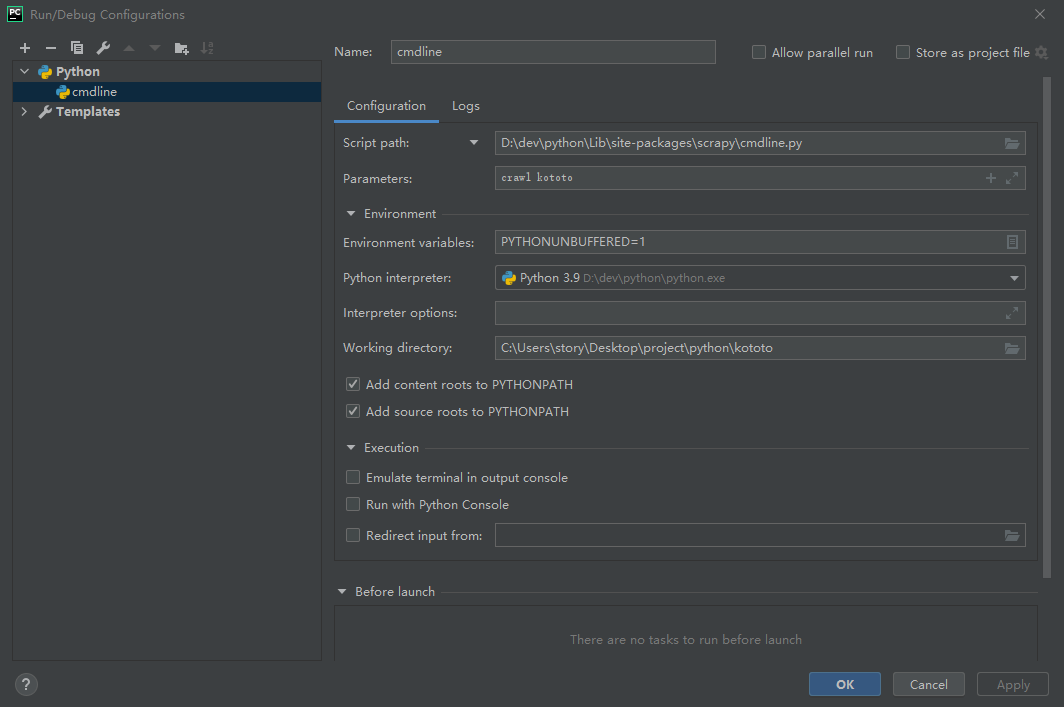
已经爬取过的资源会提示已经下载过,只会处理更新的内容。
`,27)]))}const y=i(p,[["render",l]]);export{g as __pageData,y as default}; diff --git "a/assets/python_crawler_\345\242\236\351\207\217\345\274\217\347\210\254\350\231\253\345\256\236\350\267\265\346\241\210\344\276\213 \344\270\213\350\275\275\346\214\207\345\256\232b\347\253\231up\344\270\273\347\232\204\346\211\200\346\234\211\344\275\234\345\223\201.md.CPSR9gdM.lean.js" "b/assets/python_crawler_\345\242\236\351\207\217\345\274\217\347\210\254\350\231\253\345\256\236\350\267\265\346\241\210\344\276\213 \344\270\213\350\275\275\346\214\207\345\256\232b\347\253\231up\344\270\273\347\232\204\346\211\200\346\234\211\344\275\234\345\223\201.md.CPSR9gdM.lean.js" new file mode 100644 index 00000000..2b8c20d6 --- /dev/null +++ "b/assets/python_crawler_\345\242\236\351\207\217\345\274\217\347\210\254\350\231\253\345\256\236\350\267\265\346\241\210\344\276\213 \344\270\213\350\275\275\346\214\207\345\256\232b\347\253\231up\344\270\273\347\232\204\346\211\200\346\234\211\344\275\234\345\223\201.md.CPSR9gdM.lean.js" @@ -0,0 +1,318 @@ +import{_ as i,c as a,a2 as n,o as h}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"增量式爬虫实践案例 下载指定b站up主的所有作品","description":"","frontmatter":{},"headers":[],"relativePath":"python/crawler/增量式爬虫实践案例 下载指定b站up主的所有作品.md","filePath":"python/crawler/增量式爬虫实践案例 下载指定b站up主的所有作品.md","lastUpdated":1729217313000}'),p={name:"python/crawler/增量式爬虫实践案例 下载指定b站up主的所有作品.md"};function l(k,s,t,e,E,r){return h(),a("div",null,s[0]||(s[0]=[n(`增量式爬取指定的up主的所有投稿作品,即实现一个增量式爬虫。
这次示范的up主是个妹子😏kototo使用了scrapy框架,主要是为了练手,不使用框架反而会更简单一些。
python模块:scrapy、selenium、requests、pymysql
其他环境:ffmpeg、mysql
scrapy startproject kototo
+cd kototo
+scrapy genspider kototo bilibili.comimport scrapy
+from selenium import webdriver
+import re
+import json
+import requests
+import os
+from kototo.items import KototoItem
+import pymysql
+
+
+class KototoSpider(scrapy.Spider):
+ name = 'kototo'
+ start_urls = []
+
+ def __init__(self):
+ """
+ 构造器,主要初始化了selenium对象并实现无头浏览器,以及
+ 初始化需要爬取的url地址,因为b站的翻页是js实现的,所以要手动处理一下
+ """
+ super().__init__()
+ # 构造无头浏览器
+ from selenium.webdriver.chrome.options import Options
+ chrome_options = Options()
+ chrome_options.add_argument('--headless')
+ chrome_options.add_argument('--disable-gpu')
+ self.bro = webdriver.Chrome(chrome_options=chrome_options)
+ # 指定的up主的投稿页面,可以提到外面使用input输入
+ space_url = 'https://space.bilibili.com/17485141/video'
+ # 初始化需要爬取的列表页
+ self.init_start_urls(self.start_urls, space_url)
+ # 创建桌面文件夹
+ self.desktop_path = os.path.join(os.path.expanduser('~'), 'Desktop\\\\' + self.name + '\\\\')
+ if not os.path.exists(self.desktop_path):
+ os.mkdir(self.desktop_path)
+
+ def parse(self, response):
+ """
+ 解析方法,解析列表页的视频li,拿到标题和详情页,然后主动请求详情页
+ :param response:
+ :return:
+ """
+ li_list = response.xpath('//*[@id="submit-video-list"]/ul[2]/li')
+ for li in li_list:
+ print(li.xpath('./a[2]/@title').extract_first())
+ print(detail_url := 'https://' + li.xpath('./a[2]/@href').extract_first()[2:])
+ yield scrapy.Request(url=detail_url, callback=self.parse_detail)
+
+ def parse_detail(self, response):
+ """
+ 增量爬取: 解析详情页的音视频地址并交给管道处理
+ 使用mysql实现
+ :param response:
+ :return:
+ """
+ title = response.xpath('//*[@id="viewbox_report"]/h1/@title').extract_first()
+ # 替换掉视频名称中无法用在文件名中或会导致cmd命令出错的字符
+ title = title.replace('-', '').replace(' ', '').replace('/', '').replace('|', '')
+ play_info_list = self.get_play_info(response)
+ # 这里使用mysql的唯一索引实现增量爬取,如果是服务器上跑也可以用redis
+ if self.insert_info(title, play_info_list[1]):
+ video_temp_path = (self.desktop_path + title + '_temp.mp4').replace('-', '')
+ video_path = self.desktop_path + title + '.mp4'
+ audio_path = self.desktop_path + title + '.mp3'
+ item = KototoItem()
+ item['video_url'] = play_info_list[0]
+ item['audio_url'] = play_info_list[1]
+ item['video_path'] = video_path
+ item['audio_path'] = audio_path
+ item['video_temp_path'] = video_temp_path
+ yield item
+ else:
+ print(title + ': 已经下载过了!')
+
+ def insert_info(self, vtitle, vurl):
+ """
+ mysql持久化存储爬取过的视频内容信息
+ :param vtitle: 标题
+ :param vurl: 视频链接
+ :return:
+ """
+ with Mysql() as conn:
+ cursor = conn.cursor(pymysql.cursors.DictCursor)
+ try:
+ sql = 'insert into tb_kototo(title,url) values("%s","%s")' % (vtitle, vurl)
+ res = cursor.execute(sql)
+ conn.commit()
+ if res == 1:
+ return True
+ else:
+ return False
+ except:
+ return False
+
+ def get_play_info(self, resp):
+ """
+ 解析详情页的源代码,提取其中的视频和文件真实地址
+ :param resp:
+ :return:
+ """
+ json_data = json.loads(re.findall('<script>window\\.__playinfo__=(.*?)</script>', resp.text)[0])
+ # 拿到视频和音频的真实链接地址
+ video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
+ audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
+ return video_url, audio_url
+
+ def init_start_urls(self, url_list, person_page):
+ """
+ 初始化需要爬取的列表页,由于b站使用js翻页,无法在源码中找到翻页地址,
+ 需要自己手动实现解析翻页url的操作
+ :param url_list:
+ :param person_page:
+ :return:
+ """
+ mid = re.findall('https://space.bilibili.com/(.*?)/video\\w*', person_page)[0]
+ url = 'https://api.bilibili.com/x/space/arc/search?mid=' + mid + '&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
+ 'Referer': 'https://www.bilibili.com'
+ }
+ json_data = requests.get(url=url, headers=headers).json()
+ total_count = json_data['data']['page']['count']
+ page_size = json_data['data']['page']['ps']
+ if total_count <= page_size:
+ page_count = 1
+ elif total_count % page_size == 0:
+ page_count = total_count / page_size
+ else:
+ page_count = total_count // page_size + 1
+
+ url_template = 'https://space.bilibili.com/' + mid + '/video?tid=0&page=' + '%d' + '&keyword=&order=pubdate'
+ for i in range(page_count):
+ page_no = i + 1
+ url_list.append(url_template % page_no)
+
+ def closed(self, spider):
+ """
+ 爬虫结束关闭selenium窗口
+ :param spider:
+ :return:
+ """
+ self.bro.quit()
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()# Define here the models for your spider middleware
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
+
+from scrapy import signals
+
+# useful for handling different item types with a single interface
+from itemadapter import is_item, ItemAdapter
+
+
+class KototoSpiderMiddleware:
+ # Not all methods need to be defined. If a method is not defined,
+ # scrapy acts as if the spider middleware does not modify the
+ # passed objects.
+
+ @classmethod
+ def from_crawler(cls, crawler):
+ # This method is used by Scrapy to create your spiders.
+ s = cls()
+ crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
+ return s
+
+ def process_spider_input(self, response, spider):
+ # Called for each response that goes through the spider
+ # middleware and into the spider.
+
+ # Should return None or raise an exception.
+ return None
+
+ def process_spider_output(self, response, result, spider):
+ # Called with the results returned from the Spider, after
+ # it has processed the response.
+
+ # Must return an iterable of Request, or item objects.
+ for i in result:
+ yield i
+
+ def process_spider_exception(self, response, exception, spider):
+ # Called when a spider or process_spider_input() method
+ # (from other spider middleware) raises an exception.
+
+ # Should return either None or an iterable of Request or item objects.
+ pass
+
+ def process_start_requests(self, start_requests, spider):
+ # Called with the start requests of the spider, and works
+ # similarly to the process_spider_output() method, except
+ # that it doesn’t have a response associated.
+
+ # Must return only requests (not items).
+ for r in start_requests:
+ yield r
+
+ def spider_opened(self, spider):
+ spider.logger.info('Spider opened: %s' % spider.name)
+
+
+class KototoDownloaderMiddleware:
+
+ def process_request(self, request, spider):
+ return None
+
+ def process_response(self, request, response, spider):
+ """
+ 篡改列表页的响应数据:
+ 视频列表是通过ajax请求动态加载的,因此要通过selenium去加载这部分数据
+ 并篡改响应内容
+ :param request:
+ :param response:
+ :param spider:
+ :return:
+ """
+ urls = spider.start_urls
+ bro = spider.bro
+ from scrapy.http import HtmlResponse
+ from time import sleep
+ if request.url in urls:
+ """
+ 如果是列表页就进行响应篡改操作
+ """
+ bro.get(request.url)
+ sleep(3)
+ page_data = bro.page_source
+ new_response = HtmlResponse(url=request.url, body=page_data, encoding='utf-8', request=request)
+ # 返回篡改过的响应对象
+ return new_response
+ return response
+
+ def process_exception(self, request, exception, spider):
+ passimport scrapy
+
+
+class KototoItem(scrapy.Item):
+ video_path = scrapy.Field()
+ video_url = scrapy.Field()
+ audio_path = scrapy.Field()
+ audio_url = scrapy.Field()
+ video_temp_path = scrapy.Field()import requests
+import os
+
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
+ 'Referer': 'https://www.bilibili.com'
+}
+
+
+class KototoPipeline(object):
+ def process_item(self, item, spider):
+ video = item['video_url']
+ audio = item['audio_url']
+ video_temp_path = item['video_temp_path']
+ audio_path = item['audio_path']
+ video_data = requests.get(url=video, headers=headers).content
+ audio_data = requests.get(url=audio, headers=headers).content
+ with open(video_temp_path, 'wb') as f:
+ f.write(video_data)
+ with open(audio_path, 'wb') as f:
+ f.write(audio_data)
+ return item
+
+
+class MergePipeline(object):
+ """
+ 删除临时文件
+ """
+
+ def process_item(self, item, spider):
+ video_temp_path = item['video_temp_path']
+ audio_path = item['audio_path']
+ video_path = item['video_path']
+ cmd = 'ffmpeg -y -i ' + video_temp_path + ' -i ' \\
+ + audio_path + ' -c:v copy -c:a aac -strict experimental ' + video_path
+ print(cmd)
+ # subprocess.Popen(cmd, shell=True)
+ os.system(cmd)
+ os.remove(video_temp_path)
+ os.remove(audio_path)
+ print(video_path, '下载完成')
+ return itemBOT_NAME = 'kototo'
+
+SPIDER_MODULES = ['kototo.spiders']
+NEWSPIDER_MODULE = 'kototo.spiders'
+
+
+USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+
+ROBOTSTXT_OBEY = False
+
+
+DEFAULT_REQUEST_HEADERS = {
+ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
+ 'Referer': 'https://space.bilibili.com/17485141/video',
+ 'Origin': 'https://space.bilibili.com'
+}
+FILES_STORE = './files'
+DOWNLOADER_MIDDLEWARES = {
+ 'kototo.middlewares.KototoDownloaderMiddleware': 543,
+}
+
+ITEM_PIPELINES = {
+ # 下载
+ 'kototo.pipelines.KototoPipeline': 1,
+ # 合并
+ 'kototo.pipelines.MergePipeline': 2,
+}命令启动:scrapy crawl kototo
配置pycharm启动(推荐)
已经爬取过的资源会提示已经下载过,只会处理更新的内容。
`,27)]))}const y=i(p,[["render",l]]);export{g as __pageData,y as default}; diff --git "a/assets/python_crawler_\345\244\232\347\272\277\347\250\213\347\210\254\345\217\226\346\242\250\350\247\206\351\242\221\347\275\221\347\253\231\347\232\204\347\203\255\351\227\250\350\247\206\351\242\221.md.sevaMktl.js" "b/assets/python_crawler_\345\244\232\347\272\277\347\250\213\347\210\254\345\217\226\346\242\250\350\247\206\351\242\221\347\275\221\347\253\231\347\232\204\347\203\255\351\227\250\350\247\206\351\242\221.md.sevaMktl.js" new file mode 100644 index 00000000..f92434f5 --- /dev/null +++ "b/assets/python_crawler_\345\244\232\347\272\277\347\250\213\347\210\254\345\217\226\346\242\250\350\247\206\351\242\221\347\275\221\347\253\231\347\232\204\347\203\255\351\227\250\350\247\206\351\242\221.md.sevaMktl.js" @@ -0,0 +1,76 @@ +import{_ as i,c as a,a2 as n,o as h}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"多线程爬取梨视频网站的热门视频","description":"","frontmatter":{},"headers":[],"relativePath":"python/crawler/多线程爬取梨视频网站的热门视频.md","filePath":"python/crawler/多线程爬取梨视频网站的热门视频.md","lastUpdated":1729217313000}'),k={name:"python/crawler/多线程爬取梨视频网站的热门视频.md"};function l(p,s,t,e,E,r){return h(),a("div",null,s[0]||(s[0]=[n(`from multiprocessing.dummy import Pool
+import requests
+from lxml import etree
+import random
+import os
+
+
+# 体育分类视频url地址
+url = 'https://www.pearvideo.com/category_9'
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+}
+
+
+def get_videos():
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ li_list = tree.xpath('//ul[@id="listvideoListUl"]/li')
+ if not os.path.exists('./video'):
+ os.mkdir('./video')
+ # 存储所有的视频真实地址和名称信息
+ video_url_list = []
+ for li in li_list:
+ # 视频id
+ video_id = li.xpath('.//a/@href')[0].split('_')[1]
+ # 视频名称
+ name = li.xpath('.//div[@class="vervideo-title"]/text()')[0] + '.mp4'
+ # 梨视频的video标签是动态加载的,通过请求抓包获取到的ajax地址
+ ajax_url = 'https://www.pearvideo.com/videoStatus.jsp'
+ query_param = {
+ 'contId': video_id,
+ 'mrd': str(random.random())
+ }
+ # 梨视频有Referer 防盗链验证
+ # 需要在普通的ua伪装中加入Referer请求头,否则会一直提示文章已下线
+ ajax_headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
+ 'Referer': 'https://www.pearvideo.com/video_' + video_id
+ }
+ json_obj = requests.get(url=ajax_url, headers=ajax_headers, params=query_param).json()
+ # 响应的地址:https://video.pearvideo.com/mp4/adshort/20210419/1618849825266-15658816_adpkg-ad_hd.mp4
+ # 实际的地址:https://video.pearvideo.com/mp4/adshort/20210419/cont-1727112-15658816_adpkg-ad_hd.mp4
+ # 实际地址中cont-后是视频id 因此要把这串字符串处理掉
+ temp_url = json_obj['videoInfo']['videos']['srcUrl']
+ last_index = temp_url.rfind('/')
+ # 最后一个/前的内容 https://video.pearvideo.com/mp4/adshort/20210419
+ real_video_url = temp_url[:last_index]
+ # 最后一个/后的内容根据-切片(不包含) 1618849825266-15658816_adpkg-ad_hd.mp4
+ str_list = temp_url[last_index + 1:].split('-')
+ for i in range(0, len(str_list)):
+ if i == 0:
+ real_video_url = real_video_url + '/cont-' + video_id + '-'
+ elif i == len(str_list) - 1:
+ real_video_url = real_video_url + str_list[i]
+ else:
+ real_video_url = real_video_url + str_list[i] + '-'
+ # 字典存储视频信息
+ video_dict = {'name': name, "url": real_video_url}
+ video_url_list.append(video_dict)
+ return video_url_list
+
+
+# io操作较耗时,采用多线程进行
+def download_video(dict):
+ video_name = dict['name']
+ video_url = dict['url']
+ video_stream = requests.get(url=video_url, headers=headers).content
+ with open('./video/' + video_name, 'wb') as f:
+ f.write(video_stream)
+ print(f'============={video_name}下载完毕===============')
+
+
+if __name__ == '__main__':
+ # 多线程执行下载任务
+ pool = Pool(4)
+ pool.map(download_video, get_videos())根据主链接拿到最热视频的视频id和视频名称
通过抓包拿到请求视频真实地址的ajax请求地址,修改参数,添加Referer请求头解决防盗链问题
通过ajax请求拿到响应的json对象,解析出我们需要的视频地址
通过对比可以得知视频地址是经过了字符串替换的,通过字符串操作得到真实的视频地址
将解析出来的视频信息字典统一存在列表,再定义一个持久化方法
通过多线程进行持久化操作
from multiprocessing.dummy import Pool
+import requests
+from lxml import etree
+import random
+import os
+
+
+# 体育分类视频url地址
+url = 'https://www.pearvideo.com/category_9'
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+}
+
+
+def get_videos():
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ li_list = tree.xpath('//ul[@id="listvideoListUl"]/li')
+ if not os.path.exists('./video'):
+ os.mkdir('./video')
+ # 存储所有的视频真实地址和名称信息
+ video_url_list = []
+ for li in li_list:
+ # 视频id
+ video_id = li.xpath('.//a/@href')[0].split('_')[1]
+ # 视频名称
+ name = li.xpath('.//div[@class="vervideo-title"]/text()')[0] + '.mp4'
+ # 梨视频的video标签是动态加载的,通过请求抓包获取到的ajax地址
+ ajax_url = 'https://www.pearvideo.com/videoStatus.jsp'
+ query_param = {
+ 'contId': video_id,
+ 'mrd': str(random.random())
+ }
+ # 梨视频有Referer 防盗链验证
+ # 需要在普通的ua伪装中加入Referer请求头,否则会一直提示文章已下线
+ ajax_headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
+ 'Referer': 'https://www.pearvideo.com/video_' + video_id
+ }
+ json_obj = requests.get(url=ajax_url, headers=ajax_headers, params=query_param).json()
+ # 响应的地址:https://video.pearvideo.com/mp4/adshort/20210419/1618849825266-15658816_adpkg-ad_hd.mp4
+ # 实际的地址:https://video.pearvideo.com/mp4/adshort/20210419/cont-1727112-15658816_adpkg-ad_hd.mp4
+ # 实际地址中cont-后是视频id 因此要把这串字符串处理掉
+ temp_url = json_obj['videoInfo']['videos']['srcUrl']
+ last_index = temp_url.rfind('/')
+ # 最后一个/前的内容 https://video.pearvideo.com/mp4/adshort/20210419
+ real_video_url = temp_url[:last_index]
+ # 最后一个/后的内容根据-切片(不包含) 1618849825266-15658816_adpkg-ad_hd.mp4
+ str_list = temp_url[last_index + 1:].split('-')
+ for i in range(0, len(str_list)):
+ if i == 0:
+ real_video_url = real_video_url + '/cont-' + video_id + '-'
+ elif i == len(str_list) - 1:
+ real_video_url = real_video_url + str_list[i]
+ else:
+ real_video_url = real_video_url + str_list[i] + '-'
+ # 字典存储视频信息
+ video_dict = {'name': name, "url": real_video_url}
+ video_url_list.append(video_dict)
+ return video_url_list
+
+
+# io操作较耗时,采用多线程进行
+def download_video(dict):
+ video_name = dict['name']
+ video_url = dict['url']
+ video_stream = requests.get(url=video_url, headers=headers).content
+ with open('./video/' + video_name, 'wb') as f:
+ f.write(video_stream)
+ print(f'============={video_name}下载完毕===============')
+
+
+if __name__ == '__main__':
+ # 多线程执行下载任务
+ pool = Pool(4)
+ pool.map(download_video, get_videos())根据主链接拿到最热视频的视频id和视频名称
通过抓包拿到请求视频真实地址的ajax请求地址,修改参数,添加Referer请求头解决防盗链问题
通过ajax请求拿到响应的json对象,解析出我们需要的视频地址
通过对比可以得知视频地址是经过了字符串替换的,通过字符串操作得到真实的视频地址
将解析出来的视频信息字典统一存在列表,再定义一个持久化方法
通过多线程进行持久化操作
地址:https://www.chaojiying.com/
使用方法:
import requests
+from lxml import etree
+from story.code import StoryClient
+import os
+
+
+if __name__ == '__main__':
+ url = 'https://so.gushiwen.cn/user/login.aspx'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ # 验证码url地址
+ code_url = 'https://so.gushiwen.cn' + tree.xpath('//*[@id="imgCode"]/@src')[0]
+ img_data = requests.get(url=code_url, headers=headers).content
+ if not os.path.exists('./img'):
+ os.mkdir('./img')
+ with open('./img/code.jpg', 'wb') as f:
+ f.write(img_data)
+ client = StoryClient()
+ with open('./img/code.jpp','rb') as f:
+ im = f.read()
+ res = client.post_pic(im,1902)['pic_str']
+ print(res)这里我微调了一下,把用户信息在代码里写死了,可以根据自己情况调整
import requests
+from hashlib import md5
+
+
+class StoryClient(object):
+
+ def __init__(self):
+ self.username = '超级鹰用户名'
+ password = '超级鹰密码'.encode('utf8')
+ self.password = md5(password).hexdigest()
+ self.soft_id = '超级鹰软件ID'
+ self.base_params = {
+ 'user': self.username,
+ 'pass2': self.password,
+ 'softid': self.soft_id,
+ }
+ self.headers = {
+ 'Connection': 'Keep-Alive',
+ 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
+ }
+
+ def post_pic(self, im, codetype):
+ """
+ im: 图片字节
+ codetype: 题目类型 参考 http://www.chaojiying.com/price.html
+ """
+ params = {
+ 'codetype': codetype,
+ }
+ params.update(self.base_params)
+ files = {'userfile': ('ccc.jpg', im)}
+ r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
+ headers=self.headers)
+ return r.json()
+
+ def ReportError(self, im_id):
+ """
+ im_id:报错题目的图片ID
+ """
+ params = {
+ 'id': im_id,
+ }
+ params.update(self.base_params)
+ r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
+ return r.json()
+
+
+if __name__ == '__main__':
+ client = StoryClient()
+ im = open('a.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
+ print(client.post_pic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()import requests
+from lxml import etree
+from story.code import StoryClient
+
+if __name__ == '__main__':
+ url = 'http://www.renren.com/SysHome.do'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ # 使用session发送请求
+ session = requests.session()
+ # page_text = requests.get(url=url, headers=headers).text
+ page_text = session.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ code_url = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
+ code_img_data = requests.get(url=code_url, headers=headers).content
+ path = './img/code.jpg'
+ with open(path, 'wb') as f:
+ f.write(code_img_data)
+ # 超级鹰客户端
+ client = StoryClient()
+ with open(path, 'rb') as r:
+ im = r.read()
+ code = client.post_pic(im, 1902)['pic_str']
+ login_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2021312240804'
+ data = {
+ 'email': '人人网用户名',
+ 'icode': code,
+ 'origURL': 'http://www.renren.com/home',
+ 'domain': 'renren.com',
+ 'key_id': 1,
+ 'captcha_type': 'web_login',
+ 'password': '人人网密码',
+ 'rkey': 'asdfasdf',
+ 'f': ''
+ }
+ #response = requests.post(url=login_url, headers=headers, data=data)
+ # 使用session
+ response = session.post(url=login_url, headers=headers, data=data)
+ print(response.status_code)
+ login_page_data = response.text
+ with open('renren.html', 'w', encoding='utf-8') as f:
+ f.write(login_page_data)
+
+ detail_url = 'http://www.renren.com/6666666/profile'
+ # detail_text = requests.get(url=detail_url,headers=headers).text
+ # 使用session
+ detail_text = session.get(url=detail_url,headers=headers).text
+ with open('./detail.html','w',encoding='utf-8') as dw:
+ dw.write(detail_text)地址:https://www.chaojiying.com/
使用方法:
import requests
+from lxml import etree
+from story.code import StoryClient
+import os
+
+
+if __name__ == '__main__':
+ url = 'https://so.gushiwen.cn/user/login.aspx'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ page_text = requests.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ # 验证码url地址
+ code_url = 'https://so.gushiwen.cn' + tree.xpath('//*[@id="imgCode"]/@src')[0]
+ img_data = requests.get(url=code_url, headers=headers).content
+ if not os.path.exists('./img'):
+ os.mkdir('./img')
+ with open('./img/code.jpg', 'wb') as f:
+ f.write(img_data)
+ client = StoryClient()
+ with open('./img/code.jpp','rb') as f:
+ im = f.read()
+ res = client.post_pic(im,1902)['pic_str']
+ print(res)这里我微调了一下,把用户信息在代码里写死了,可以根据自己情况调整
import requests
+from hashlib import md5
+
+
+class StoryClient(object):
+
+ def __init__(self):
+ self.username = '超级鹰用户名'
+ password = '超级鹰密码'.encode('utf8')
+ self.password = md5(password).hexdigest()
+ self.soft_id = '超级鹰软件ID'
+ self.base_params = {
+ 'user': self.username,
+ 'pass2': self.password,
+ 'softid': self.soft_id,
+ }
+ self.headers = {
+ 'Connection': 'Keep-Alive',
+ 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
+ }
+
+ def post_pic(self, im, codetype):
+ """
+ im: 图片字节
+ codetype: 题目类型 参考 http://www.chaojiying.com/price.html
+ """
+ params = {
+ 'codetype': codetype,
+ }
+ params.update(self.base_params)
+ files = {'userfile': ('ccc.jpg', im)}
+ r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
+ headers=self.headers)
+ return r.json()
+
+ def ReportError(self, im_id):
+ """
+ im_id:报错题目的图片ID
+ """
+ params = {
+ 'id': im_id,
+ }
+ params.update(self.base_params)
+ r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
+ return r.json()
+
+
+if __name__ == '__main__':
+ client = StoryClient()
+ im = open('a.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
+ print(client.post_pic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()import requests
+from lxml import etree
+from story.code import StoryClient
+
+if __name__ == '__main__':
+ url = 'http://www.renren.com/SysHome.do'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+ }
+ # 使用session发送请求
+ session = requests.session()
+ # page_text = requests.get(url=url, headers=headers).text
+ page_text = session.get(url=url, headers=headers).text
+ tree = etree.HTML(page_text)
+ code_url = tree.xpath('//*[@id="verifyPic_login"]/@src')[0]
+ code_img_data = requests.get(url=code_url, headers=headers).content
+ path = './img/code.jpg'
+ with open(path, 'wb') as f:
+ f.write(code_img_data)
+ # 超级鹰客户端
+ client = StoryClient()
+ with open(path, 'rb') as r:
+ im = r.read()
+ code = client.post_pic(im, 1902)['pic_str']
+ login_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2021312240804'
+ data = {
+ 'email': '人人网用户名',
+ 'icode': code,
+ 'origURL': 'http://www.renren.com/home',
+ 'domain': 'renren.com',
+ 'key_id': 1,
+ 'captcha_type': 'web_login',
+ 'password': '人人网密码',
+ 'rkey': 'asdfasdf',
+ 'f': ''
+ }
+ #response = requests.post(url=login_url, headers=headers, data=data)
+ # 使用session
+ response = session.post(url=login_url, headers=headers, data=data)
+ print(response.status_code)
+ login_page_data = response.text
+ with open('renren.html', 'w', encoding='utf-8') as f:
+ f.write(login_page_data)
+
+ detail_url = 'http://www.renren.com/6666666/profile'
+ # detail_text = requests.get(url=detail_url,headers=headers).text
+ # 使用session
+ detail_text = session.get(url=detail_url,headers=headers).text
+ with open('./detail.html','w',encoding='utf-8') as dw:
+ dw.write(detail_text)import sys
+import subprocess
+import re
+import os
+
+_pattern = r'[^A-Za-z0-9_\\-.,:+\\/@\\n]'
+
+
+def replace_func(match_obj):
+ return '\\\\' + match_obj.group(0)
+
+
+def shell_escape(str_param):
+ return re.sub(_pattern, replace_func, str_param)
+
+
+if __name__ == '__main__':
+ if os.path.exists(sys.argv[1]):
+ file_path = shell_escape(sys.argv[1])
+ editor = shell_escape(sys.argv[2])
+ command = f"open -a {editor} {file_path}"
+ subprocess.Popen(command, shell=True)repository:https://github.com/storyxc/Alfred-open-with-editor/releases/tag/Alfred
import sys
+import subprocess
+import re
+import os
+
+_pattern = r'[^A-Za-z0-9_\\-.,:+\\/@\\n]'
+
+
+def replace_func(match_obj):
+ return '\\\\' + match_obj.group(0)
+
+
+def shell_escape(str_param):
+ return re.sub(_pattern, replace_func, str_param)
+
+
+if __name__ == '__main__':
+ if os.path.exists(sys.argv[1]):
+ file_path = shell_escape(sys.argv[1])
+ editor = shell_escape(sys.argv[2])
+ command = f"open -a {editor} {file_path}"
+ subprocess.Popen(command, shell=True)repository:https://github.com/storyxc/Alfred-open-with-editor/releases/tag/Alfred
学习如何使用python编写一个命令行程序。
argparse 模块可以让人轻松编写用户友好的命令行接口。程序定义它需要的参数,然后 argparse 将弄清如何从 sys.argv 解析出那些参数。 argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。
官方文档地址:https://docs.python.org/zh-cn/3/library/argparse.html#upgrading-optparse-code
import argparse
+parser = argparse.ArgumentParser()
+parser.parse_args()使用命令行运行这个程序
$ python main.py
+
+
+$ python main.py --help
+usage: main.py [-h]
+
+optional arguments:
+ -h, --help show this help message and exit
+
+
+$ python main.py story
+usage: main.py [-h]
+main.py: error: unrecognized arguments: story程序运行情况:
--help可以缩写为-h,是唯一一个可以直接使用的选项,指定任何没有定义的内容都会报错,但是也会给出提示import argparse
+parser = argparse.ArgumentParser()
+parser.add_argument('print')
+args = parser.parse_args()
+print(args.print)运行
$ python main.py
+usage: main.py [-h] print
+main.py: error: the following arguments are required: print
+
+$ python main.py --help
+usage: main.py [-h] print
+
+positional arguments:
+ print
+
+optional arguments:
+ -h, --help show this help message and exit
+
+
+$ python main.py test
+test程序运行情况:
add_argument()方法,该方法指定程序能够接受哪些命令行选项。在例子中使用了print作为选项名add_argument方法还可以添加提示信息
比如修改上面的代码再次运行:
parser.add_argument('print',help='print the string you typed')
$ python main.py --help
+usage: main.py [-h] print
+
+positional arguments:
+ print print the string you typed
+
+optional arguments:
+ -h, --help show this help message and exit还可以指定输入的值的类型,否则argparse会把一切输入都当作字符串
parser.add_argument('print',help='print the number you typed',type=int)
运行:
$ python main.py 1
+1
+
+$ python main.py two
+usage: main.py [-h] print
+main.py: error: argument print: invalid int value: 'two'import argparse
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--verbosity', help='increase output verbosity')
+args = parser.parse_args()
+if args.verbosity:
+ print('verbosity turn on')运行:
$ python main.py
+
+$ python main.py --verbosity test
+verbosity turn on
+
+$ python main.py -h
+usage: main.py [-h] [--verbosity VERBOSITY]
+
+optional arguments:
+ -h, --help show this help message and exit
+ --verbosity VERBOSITY
+ increase output verbosity
+
+$ python main.py --verbosity
+usage: main.py [-h] [--verbosity VERBOSITY]
+main.py: error: argument --verbosity: expected one argument运行结果:
当指定了--verbosity时打印turn on,否则不打印
不添加这选项时不会报错,说明是可选参数,当一个可选参数没有被使用,对应的变量会被赋值为None,因此args.verbosity在if中被判断为逻辑假
帮助信息多了VERBOSITY
使用--verbosity选项时必须指定一个值,否则会报错
修改代码:
import argparse
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--verbose', help='increase output verbosity',
+ action='store_true')
+args = parser.parse_args()
+if args.verbose:
+ print('verbosity turn on')运行:
$ python main.py
+
+
+$ python main.py --verbose
+verbosity turn on
+
+$ python main.py --help
+usage: main.py [-h] [--verbose]
+
+$ python main.py --verbose test
+usage: main.py [-h] [--verbose]
+main.py: error: unrecognized arguments: test
+
+
+optional arguments:
+ -h, --help show this help message and exit
+ --verbose increase output verbosity运行结果:
store_true,意味着,当这一选项存在时,为args.verbose赋值为True,没有指定该选项时为False我们能注意到-h和--help是功能相同的,我们也可以给自定义的参数指定简短的形式
import argparse
+
+parser = argparse.ArgumentParser()
+parser.add_argument('-v', '--verbose', help='increase output verbosity',
+ action='store_true')
+parser.add_argument('-s', '--square', type=int, help='display a square of a given number')
+args = parser.parse_args()
+answer = args.square ** 2 # **运算符为计算arg1的arg2次幂
+if args.verbose:
+ print('the square of {} is {}'.format(args.square, answer))
+else:
+ print(answer)运行:
$ python main.py -s -v 1
+usage: main.py [-h] [-v] [-s SQUARE]
+main.py: error: argument -s/--square: expected one argument
+
+$ python main.py -s 2 -v
+the square of 2 is 4
+
+$ python main.py -s 2
+4运行结果:
修改代码:
import argparse
+
+parser = argparse.ArgumentParser()
+parser.add_argument('-v', '--verbose', type=int,help='increase output verbosity')
+parser.add_argument('-s', '--square', type=int, help='display a square of a given number')
+args = parser.parse_args()
+answer = args.square ** 2 # **运算符为计算arg1的arg2次幂
+if args.verbose == 1:
+ print('the square of {} is {}'.format(args.square, answer))
+elif args.verbose == 2:
+ print('{}^2 is {}'.format(args.square, answer))
+else:
+ print(answer)运行结果:
$ python main.py -s 2 -v 1
+the square of 2 is 4
+
+$ python main.py -s 2 -v 2
+2^2 is 4
+
+$ python main.py -s 2 -v 3
+4显然,用户指定-v的值是3是我们不愿意看见的,因此我们可以限定-v的取值范围
修改
parser.add_argument('-v', '--verbose', type=int,help='increase output verbosity',
+ choices=[1,2])再次运行:
$ python main.py -s 2 -v 3
+usage: main.py [-h] [-v {1,2}] [-s SQUARE]
+main.py: error: argument -v/--verbose: invalid choice: 3 (choose from 1, 2)
+
+$ python main.py -h
+usage: main.py [-h] [-v {1,2}] [-s SQUARE]
+
+optional arguments:
+ -h, --help show this help message and exit
+ -v {1,2}, --verbose {1,2}
+ increase output verbosity
+ -s SQUARE, --square SQUARE
+ display a square of a given numberadd_mutually_exclusive_group()方法允许指定彼此冲突的选项
import argparse
+
+parser = argparse.ArgumentParser()
+group = parser.add_mutually_exclusive_group()
+group.add_argument("-v", "--verbose", action="store_true")
+group.add_argument("-q", "--quiet", action="store_true")
+parser.add_argument("x", type=int, help="the base")
+parser.add_argument("y", type=int, help="the exponent")
+args = parser.parse_args()
+answer = args.x**args.y
+
+if args.quiet:
+ print(answer)
+elif args.verbose:
+ print("{} to the power {} equals {}".format(args.x, args.y, answer))
+else:
+ print("{}^{} == {}".format(args.x, args.y, answer))运行:
$ python main.py 4 2
+4^2 == 16
+
+$ python main.py 4 2 -v
+4 to the power 2 equals 16
+
+$ python main.py 4 2 -q
+16
+
+$ python main.py -h
+usage: main.py [-h] [-v | -q] x y
+
+calculate X to the power of Y
+
+positional arguments:
+ x the base
+ y the exponent
+
+optional arguments:
+ -h, --help show this help message and exit
+ -v, --verbose
+ -q, --quiet运行结果:
根据指定-v还是-q,可以得到不同输出,实现不同功能
usage: main.py [-h] [-v | -q] x y中[-v|-q]代表可选其一,而不是使用两者
如果同时使用会报错:
$ python main.py 4 2 -v -q
+usage: main.py [-h] [-v | -q] x y
+main.py: error: argument -q/--quiet: not allowed with argument -v/--verbose学习如何使用python编写一个命令行程序。
argparse 模块可以让人轻松编写用户友好的命令行接口。程序定义它需要的参数,然后 argparse 将弄清如何从 sys.argv 解析出那些参数。 argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。
官方文档地址:https://docs.python.org/zh-cn/3/library/argparse.html#upgrading-optparse-code
import argparse
+parser = argparse.ArgumentParser()
+parser.parse_args()使用命令行运行这个程序
$ python main.py
+
+
+$ python main.py --help
+usage: main.py [-h]
+
+optional arguments:
+ -h, --help show this help message and exit
+
+
+$ python main.py story
+usage: main.py [-h]
+main.py: error: unrecognized arguments: story程序运行情况:
--help可以缩写为-h,是唯一一个可以直接使用的选项,指定任何没有定义的内容都会报错,但是也会给出提示import argparse
+parser = argparse.ArgumentParser()
+parser.add_argument('print')
+args = parser.parse_args()
+print(args.print)运行
$ python main.py
+usage: main.py [-h] print
+main.py: error: the following arguments are required: print
+
+$ python main.py --help
+usage: main.py [-h] print
+
+positional arguments:
+ print
+
+optional arguments:
+ -h, --help show this help message and exit
+
+
+$ python main.py test
+test程序运行情况:
add_argument()方法,该方法指定程序能够接受哪些命令行选项。在例子中使用了print作为选项名add_argument方法还可以添加提示信息
比如修改上面的代码再次运行:
parser.add_argument('print',help='print the string you typed')
$ python main.py --help
+usage: main.py [-h] print
+
+positional arguments:
+ print print the string you typed
+
+optional arguments:
+ -h, --help show this help message and exit还可以指定输入的值的类型,否则argparse会把一切输入都当作字符串
parser.add_argument('print',help='print the number you typed',type=int)
运行:
$ python main.py 1
+1
+
+$ python main.py two
+usage: main.py [-h] print
+main.py: error: argument print: invalid int value: 'two'import argparse
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--verbosity', help='increase output verbosity')
+args = parser.parse_args()
+if args.verbosity:
+ print('verbosity turn on')运行:
$ python main.py
+
+$ python main.py --verbosity test
+verbosity turn on
+
+$ python main.py -h
+usage: main.py [-h] [--verbosity VERBOSITY]
+
+optional arguments:
+ -h, --help show this help message and exit
+ --verbosity VERBOSITY
+ increase output verbosity
+
+$ python main.py --verbosity
+usage: main.py [-h] [--verbosity VERBOSITY]
+main.py: error: argument --verbosity: expected one argument运行结果:
当指定了--verbosity时打印turn on,否则不打印
不添加这选项时不会报错,说明是可选参数,当一个可选参数没有被使用,对应的变量会被赋值为None,因此args.verbosity在if中被判断为逻辑假
帮助信息多了VERBOSITY
使用--verbosity选项时必须指定一个值,否则会报错
修改代码:
import argparse
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--verbose', help='increase output verbosity',
+ action='store_true')
+args = parser.parse_args()
+if args.verbose:
+ print('verbosity turn on')运行:
$ python main.py
+
+
+$ python main.py --verbose
+verbosity turn on
+
+$ python main.py --help
+usage: main.py [-h] [--verbose]
+
+$ python main.py --verbose test
+usage: main.py [-h] [--verbose]
+main.py: error: unrecognized arguments: test
+
+
+optional arguments:
+ -h, --help show this help message and exit
+ --verbose increase output verbosity运行结果:
store_true,意味着,当这一选项存在时,为args.verbose赋值为True,没有指定该选项时为False我们能注意到-h和--help是功能相同的,我们也可以给自定义的参数指定简短的形式
import argparse
+
+parser = argparse.ArgumentParser()
+parser.add_argument('-v', '--verbose', help='increase output verbosity',
+ action='store_true')
+parser.add_argument('-s', '--square', type=int, help='display a square of a given number')
+args = parser.parse_args()
+answer = args.square ** 2 # **运算符为计算arg1的arg2次幂
+if args.verbose:
+ print('the square of {} is {}'.format(args.square, answer))
+else:
+ print(answer)运行:
$ python main.py -s -v 1
+usage: main.py [-h] [-v] [-s SQUARE]
+main.py: error: argument -s/--square: expected one argument
+
+$ python main.py -s 2 -v
+the square of 2 is 4
+
+$ python main.py -s 2
+4运行结果:
修改代码:
import argparse
+
+parser = argparse.ArgumentParser()
+parser.add_argument('-v', '--verbose', type=int,help='increase output verbosity')
+parser.add_argument('-s', '--square', type=int, help='display a square of a given number')
+args = parser.parse_args()
+answer = args.square ** 2 # **运算符为计算arg1的arg2次幂
+if args.verbose == 1:
+ print('the square of {} is {}'.format(args.square, answer))
+elif args.verbose == 2:
+ print('{}^2 is {}'.format(args.square, answer))
+else:
+ print(answer)运行结果:
$ python main.py -s 2 -v 1
+the square of 2 is 4
+
+$ python main.py -s 2 -v 2
+2^2 is 4
+
+$ python main.py -s 2 -v 3
+4显然,用户指定-v的值是3是我们不愿意看见的,因此我们可以限定-v的取值范围
修改
parser.add_argument('-v', '--verbose', type=int,help='increase output verbosity',
+ choices=[1,2])再次运行:
$ python main.py -s 2 -v 3
+usage: main.py [-h] [-v {1,2}] [-s SQUARE]
+main.py: error: argument -v/--verbose: invalid choice: 3 (choose from 1, 2)
+
+$ python main.py -h
+usage: main.py [-h] [-v {1,2}] [-s SQUARE]
+
+optional arguments:
+ -h, --help show this help message and exit
+ -v {1,2}, --verbose {1,2}
+ increase output verbosity
+ -s SQUARE, --square SQUARE
+ display a square of a given numberadd_mutually_exclusive_group()方法允许指定彼此冲突的选项
import argparse
+
+parser = argparse.ArgumentParser()
+group = parser.add_mutually_exclusive_group()
+group.add_argument("-v", "--verbose", action="store_true")
+group.add_argument("-q", "--quiet", action="store_true")
+parser.add_argument("x", type=int, help="the base")
+parser.add_argument("y", type=int, help="the exponent")
+args = parser.parse_args()
+answer = args.x**args.y
+
+if args.quiet:
+ print(answer)
+elif args.verbose:
+ print("{} to the power {} equals {}".format(args.x, args.y, answer))
+else:
+ print("{}^{} == {}".format(args.x, args.y, answer))运行:
$ python main.py 4 2
+4^2 == 16
+
+$ python main.py 4 2 -v
+4 to the power 2 equals 16
+
+$ python main.py 4 2 -q
+16
+
+$ python main.py -h
+usage: main.py [-h] [-v | -q] x y
+
+calculate X to the power of Y
+
+positional arguments:
+ x the base
+ y the exponent
+
+optional arguments:
+ -h, --help show this help message and exit
+ -v, --verbose
+ -q, --quiet运行结果:
根据指定-v还是-q,可以得到不同输出,实现不同功能
usage: main.py [-h] [-v | -q] x y中[-v|-q]代表可选其一,而不是使用两者
如果同时使用会报错:
$ python main.py 4 2 -v -q
+usage: main.py [-h] [-v | -q] x y
+main.py: error: argument -q/--quiet: not allowed with argument -v/--verbose安装google-api-python-client包,github仓库:https://github.com/googleapis/google-api-python-client
安装oauth2client包,github仓库:https://github.com/googleapis/oauth2client
google cloud创建应用
youtube data api v3并启用client_secrets.json中(要和上传的python脚本文件在相同目录){
+ "web": {
+ "client_id": "[[INSERT CLIENT ID HERE]]",
+ "client_secret": "[[INSERT CLIENT SECRET HERE]]",
+ "redirect_uris": [],
+ "auth_uri": "https://accounts.google.com/o/oauth2/auth",
+ "token_uri": "https://accounts.google.com/o/oauth2/token"
+ }
+}python3 upload_video.py --file="/tmp/test_video_file.flv"
+ --title="Summer vacation in California"
+ --description="Had fun surfing in Santa Cruz"
+ --keywords="surfing,Santa Cruz"
+ --category="22"
+ --privacyStatus="private"代码源自YouTube Data API,给的例子比较老旧,是python2的代码,还有没法用的httplib包,下面代码针对这些做了删改调整可以直接使用。
#!/usr/bin/python
+
+
+import httplib2
+import os
+import random
+import sys
+import time
+
+from apiclient.discovery import build
+from apiclient.errors import HttpError
+from apiclient.http import MediaFileUpload
+from oauth2client.client import flow_from_clientsecrets
+from oauth2client.file import Storage
+from oauth2client.tools import argparser, run_flow
+
+
+# Explicitly tell the underlying HTTP transport library not to retry, since
+# we are handling retry logic ourselves.
+httplib2.RETRIES = 1
+
+# Maximum number of times to retry before giving up.
+MAX_RETRIES = 10
+
+# Always retry when these exceptions are raised.
+RETRIABLE_EXCEPTIONS = (httplib2.HttpLib2Error, IOError)
+
+# Always retry when an apiclient.errors.HttpError with one of these status
+# codes is raised.
+RETRIABLE_STATUS_CODES = [500, 502, 503, 504]
+
+# The CLIENT_SECRETS_FILE variable specifies the name of a file that contains
+# the OAuth 2.0 information for this application, including its client_id and
+# client_secret. You can acquire an OAuth 2.0 client ID and client secret from
+# the Google API Console at
+# https://console.developers.google.com/.
+# Please ensure that you have enabled the YouTube Data API for your project.
+# For more information about using OAuth2 to access the YouTube Data API, see:
+# https://developers.google.com/youtube/v3/guides/authentication
+# For more information about the client_secrets.json file format, see:
+# https://developers.google.com/api-client-library/python/guide/aaa_client_secrets
+CLIENT_SECRETS_FILE = "client_secrets.json"
+
+# This OAuth 2.0 access scope allows an application to upload files to the
+# authenticated user's YouTube channel, but doesn't allow other types of access.
+YOUTUBE_UPLOAD_SCOPE = "https://www.googleapis.com/auth/youtube.upload"
+YOUTUBE_API_SERVICE_NAME = "youtube"
+YOUTUBE_API_VERSION = "v3"
+
+# This variable defines a message to display if the CLIENT_SECRETS_FILE is
+# missing.
+MISSING_CLIENT_SECRETS_MESSAGE = """
+WARNING: Please configure OAuth 2.0
+
+To make this sample run you will need to populate the client_secrets.json file
+found at:
+
+ %s
+
+with information from the API Console
+https://console.developers.google.com/
+
+For more information about the client_secrets.json file format, please visit:
+https://developers.google.com/api-client-library/python/guide/aaa_client_secrets
+""" % os.path.abspath(os.path.join(os.path.dirname(__file__),
+ CLIENT_SECRETS_FILE))
+
+VALID_PRIVACY_STATUSES = ("public", "private", "unlisted")
+
+
+def get_authenticated_service(args):
+ flow = flow_from_clientsecrets(CLIENT_SECRETS_FILE,
+ scope=YOUTUBE_UPLOAD_SCOPE,
+ message=MISSING_CLIENT_SECRETS_MESSAGE)
+
+ storage = Storage("%s-oauth2.json" % sys.argv[0])
+ credentials = storage.get()
+
+ if credentials is None or credentials.invalid:
+ credentials = run_flow(flow, storage, args)
+
+ return build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION,
+ http=credentials.authorize(httplib2.Http()))
+
+def initialize_upload(youtube, options):
+ tags = None
+ if options.keywords:
+ tags = options.keywords.split(",")
+
+ body=dict(
+ snippet=dict(
+ title=options.title,
+ description=options.description,
+ tags=tags,
+ categoryId=options.category
+ ),
+ status=dict(
+ privacyStatus=options.privacyStatus
+ )
+ )
+
+ # Call the API's videos.insert method to create and upload the video.
+ insert_request = youtube.videos().insert(
+ part=",".join(body.keys()),
+ body=body,
+ # The chunksize parameter specifies the size of each chunk of data, in
+ # bytes, that will be uploaded at a time. Set a higher value for
+ # reliable connections as fewer chunks lead to faster uploads. Set a lower
+ # value for better recovery on less reliable connections.
+ #
+ # Setting "chunksize" equal to -1 in the code below means that the entire
+ # file will be uploaded in a single HTTP request. (If the upload fails,
+ # it will still be retried where it left off.) This is usually a best
+ # practice, but if you're using Python older than 2.6 or if you're
+ # running on App Engine, you should set the chunksize to something like
+ # 1024 * 1024 (1 megabyte).
+ media_body=MediaFileUpload(options.file, chunksize=-1, resumable=True)
+ )
+
+ resumable_upload(insert_request)
+
+# This method implements an exponential backoff strategy to resume a
+# failed upload.
+def resumable_upload(insert_request):
+ response = None
+ error = None
+ retry = 0
+ while response is None:
+ try:
+ print("Uploading file...")
+ status, response = insert_request.next_chunk()
+ if response is not None:
+ if 'id' in response:
+ print("Video id '%s' was successfully uploaded." % response['id'])
+ else:
+ exit("The upload failed with an unexpected response: %s" % response)
+ except HttpError as e:
+ if e.resp.status in RETRIABLE_STATUS_CODES:
+ error = "A retriable HTTP error %d occurred:\\n%s" % (e.resp.status,
+ e.content)
+ else:
+ raise
+ except RETRIABLE_EXCEPTIONS as e:
+ error = "A retriable error occurred: %s" % e
+
+ if error is not None:
+ print(error)
+ retry += 1
+ if retry > MAX_RETRIES:
+ exit("No longer attempting to retry.")
+
+ max_sleep = 2 ** retry
+ sleep_seconds = random.random() * max_sleep
+ print("Sleeping %f seconds and then retrying..." % sleep_seconds)
+ time.sleep(sleep_seconds)
+
+if __name__ == '__main__':
+ argparser.add_argument("--file", required=True, help="Video file to upload")
+ argparser.add_argument("--title", help="Video title", default="Test Title")
+ argparser.add_argument("--description", help="Video description",
+ default="Test Description")
+ argparser.add_argument("--category", default="22",
+ help="Numeric video category. " +
+ "See https://developers.google.com/youtube/v3/docs/videoCategories/list")
+ argparser.add_argument("--keywords", help="Video keywords, comma separated",
+ default="")
+ argparser.add_argument("--privacyStatus", choices=VALID_PRIVACY_STATUSES,
+ default=VALID_PRIVACY_STATUSES[0], help="Video privacy status.")
+ args = argparser.parse_args()
+
+ if not os.path.exists(args.file):
+ exit("Please specify a valid file using the --file= parameter.")
+
+ youtube = get_authenticated_service(args)
+ try:
+ initialize_upload(youtube, args)
+ except HttpError as e:
+ print("An HTTP error %d occurred:\\n%s" % (e.resp.status, e.content))安装google-api-python-client包,github仓库:https://github.com/googleapis/google-api-python-client
安装oauth2client包,github仓库:https://github.com/googleapis/oauth2client
google cloud创建应用
youtube data api v3并启用client_secrets.json中(要和上传的python脚本文件在相同目录){
+ "web": {
+ "client_id": "[[INSERT CLIENT ID HERE]]",
+ "client_secret": "[[INSERT CLIENT SECRET HERE]]",
+ "redirect_uris": [],
+ "auth_uri": "https://accounts.google.com/o/oauth2/auth",
+ "token_uri": "https://accounts.google.com/o/oauth2/token"
+ }
+}python3 upload_video.py --file="/tmp/test_video_file.flv"
+ --title="Summer vacation in California"
+ --description="Had fun surfing in Santa Cruz"
+ --keywords="surfing,Santa Cruz"
+ --category="22"
+ --privacyStatus="private"代码源自YouTube Data API,给的例子比较老旧,是python2的代码,还有没法用的httplib包,下面代码针对这些做了删改调整可以直接使用。
#!/usr/bin/python
+
+
+import httplib2
+import os
+import random
+import sys
+import time
+
+from apiclient.discovery import build
+from apiclient.errors import HttpError
+from apiclient.http import MediaFileUpload
+from oauth2client.client import flow_from_clientsecrets
+from oauth2client.file import Storage
+from oauth2client.tools import argparser, run_flow
+
+
+# Explicitly tell the underlying HTTP transport library not to retry, since
+# we are handling retry logic ourselves.
+httplib2.RETRIES = 1
+
+# Maximum number of times to retry before giving up.
+MAX_RETRIES = 10
+
+# Always retry when these exceptions are raised.
+RETRIABLE_EXCEPTIONS = (httplib2.HttpLib2Error, IOError)
+
+# Always retry when an apiclient.errors.HttpError with one of these status
+# codes is raised.
+RETRIABLE_STATUS_CODES = [500, 502, 503, 504]
+
+# The CLIENT_SECRETS_FILE variable specifies the name of a file that contains
+# the OAuth 2.0 information for this application, including its client_id and
+# client_secret. You can acquire an OAuth 2.0 client ID and client secret from
+# the Google API Console at
+# https://console.developers.google.com/.
+# Please ensure that you have enabled the YouTube Data API for your project.
+# For more information about using OAuth2 to access the YouTube Data API, see:
+# https://developers.google.com/youtube/v3/guides/authentication
+# For more information about the client_secrets.json file format, see:
+# https://developers.google.com/api-client-library/python/guide/aaa_client_secrets
+CLIENT_SECRETS_FILE = "client_secrets.json"
+
+# This OAuth 2.0 access scope allows an application to upload files to the
+# authenticated user's YouTube channel, but doesn't allow other types of access.
+YOUTUBE_UPLOAD_SCOPE = "https://www.googleapis.com/auth/youtube.upload"
+YOUTUBE_API_SERVICE_NAME = "youtube"
+YOUTUBE_API_VERSION = "v3"
+
+# This variable defines a message to display if the CLIENT_SECRETS_FILE is
+# missing.
+MISSING_CLIENT_SECRETS_MESSAGE = """
+WARNING: Please configure OAuth 2.0
+
+To make this sample run you will need to populate the client_secrets.json file
+found at:
+
+ %s
+
+with information from the API Console
+https://console.developers.google.com/
+
+For more information about the client_secrets.json file format, please visit:
+https://developers.google.com/api-client-library/python/guide/aaa_client_secrets
+""" % os.path.abspath(os.path.join(os.path.dirname(__file__),
+ CLIENT_SECRETS_FILE))
+
+VALID_PRIVACY_STATUSES = ("public", "private", "unlisted")
+
+
+def get_authenticated_service(args):
+ flow = flow_from_clientsecrets(CLIENT_SECRETS_FILE,
+ scope=YOUTUBE_UPLOAD_SCOPE,
+ message=MISSING_CLIENT_SECRETS_MESSAGE)
+
+ storage = Storage("%s-oauth2.json" % sys.argv[0])
+ credentials = storage.get()
+
+ if credentials is None or credentials.invalid:
+ credentials = run_flow(flow, storage, args)
+
+ return build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION,
+ http=credentials.authorize(httplib2.Http()))
+
+def initialize_upload(youtube, options):
+ tags = None
+ if options.keywords:
+ tags = options.keywords.split(",")
+
+ body=dict(
+ snippet=dict(
+ title=options.title,
+ description=options.description,
+ tags=tags,
+ categoryId=options.category
+ ),
+ status=dict(
+ privacyStatus=options.privacyStatus
+ )
+ )
+
+ # Call the API's videos.insert method to create and upload the video.
+ insert_request = youtube.videos().insert(
+ part=",".join(body.keys()),
+ body=body,
+ # The chunksize parameter specifies the size of each chunk of data, in
+ # bytes, that will be uploaded at a time. Set a higher value for
+ # reliable connections as fewer chunks lead to faster uploads. Set a lower
+ # value for better recovery on less reliable connections.
+ #
+ # Setting "chunksize" equal to -1 in the code below means that the entire
+ # file will be uploaded in a single HTTP request. (If the upload fails,
+ # it will still be retried where it left off.) This is usually a best
+ # practice, but if you're using Python older than 2.6 or if you're
+ # running on App Engine, you should set the chunksize to something like
+ # 1024 * 1024 (1 megabyte).
+ media_body=MediaFileUpload(options.file, chunksize=-1, resumable=True)
+ )
+
+ resumable_upload(insert_request)
+
+# This method implements an exponential backoff strategy to resume a
+# failed upload.
+def resumable_upload(insert_request):
+ response = None
+ error = None
+ retry = 0
+ while response is None:
+ try:
+ print("Uploading file...")
+ status, response = insert_request.next_chunk()
+ if response is not None:
+ if 'id' in response:
+ print("Video id '%s' was successfully uploaded." % response['id'])
+ else:
+ exit("The upload failed with an unexpected response: %s" % response)
+ except HttpError as e:
+ if e.resp.status in RETRIABLE_STATUS_CODES:
+ error = "A retriable HTTP error %d occurred:\\n%s" % (e.resp.status,
+ e.content)
+ else:
+ raise
+ except RETRIABLE_EXCEPTIONS as e:
+ error = "A retriable error occurred: %s" % e
+
+ if error is not None:
+ print(error)
+ retry += 1
+ if retry > MAX_RETRIES:
+ exit("No longer attempting to retry.")
+
+ max_sleep = 2 ** retry
+ sleep_seconds = random.random() * max_sleep
+ print("Sleeping %f seconds and then retrying..." % sleep_seconds)
+ time.sleep(sleep_seconds)
+
+if __name__ == '__main__':
+ argparser.add_argument("--file", required=True, help="Video file to upload")
+ argparser.add_argument("--title", help="Video title", default="Test Title")
+ argparser.add_argument("--description", help="Video description",
+ default="Test Description")
+ argparser.add_argument("--category", default="22",
+ help="Numeric video category. " +
+ "See https://developers.google.com/youtube/v3/docs/videoCategories/list")
+ argparser.add_argument("--keywords", help="Video keywords, comma separated",
+ default="")
+ argparser.add_argument("--privacyStatus", choices=VALID_PRIVACY_STATUSES,
+ default=VALID_PRIVACY_STATUSES[0], help="Video privacy status.")
+ args = argparser.parse_args()
+
+ if not os.path.exists(args.file):
+ exit("Please specify a valid file using the --file= parameter.")
+
+ youtube = get_authenticated_service(args)
+ try:
+ initialize_upload(youtube, args)
+ except HttpError as e:
+ print("An HTTP error %d occurred:\\n%s" % (e.resp.status, e.content))以csv/txt文件为例
pd.read_csv():返回一个DataFrame或TextFileReader
header指定具体表头行数,如果没有则header=None,第一行是表头则header=0,header还可以是一个列表例如header=[0,1,3],此时会有多个标题,且1和3之间的行会被忽略掉
seq指定分割符,默认为','
skiprows跳过某一行,行号从0开始,例如skiprows=2或skiprows=[0,1,200]
nrows指定需要读取的行数,从第一行开始,例如nrows=1000
na_values空值置换,会把指定的值替换为空值例如na_values=['\\N', 15]会把字符串\\N和数字15替换为空值NaN
na_values={'Age':0,'Comment':'该用户没有评价'}iterator: True时返回一个TextFileReader,用于大文件处理,可以逐块处理文件
chunksize:指定文件块大小,返回一个TextFileReader
encoding:指定编码
index_col:读取时指定索引列,和df.set_index效果相同
names:文件中没有表头,手动指定表头,需要和header配合使用
names和header的使用场景主要如下:
- csv文件有表头并且是第一行,那么names和header都无需指定;
- csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;
- csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;
- csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,其实就等价于将数据读取进来之后再对列名进行rename;
多行多列的二维数组、整个表格、多行多列
一维数据、一行或一列
对应纵向上的行
替换索引为某一列的值:df.set_index('xxx', inplace=True)
对应横向上的列
df.loc,根据行、列的标签值查询(既能查询又能覆盖写入)
行根据行标签,也就是索引筛选,列根据列标签,列名筛选
如果选取的是所有行或者所有列,可以用:代替
行标签选取的时候,两端都包含,比如[0:5]指的是0,1,2,3,4,5
df.iloc,根据行、列的数字位置查询
iloc基于位置索引,简言之,就是第几行第几列,只不过这里的行列都是从0开始的。
iloc的0:X中不包括X,只能到X-1.
df.where
df.query
使用单个label值查询
查找并替换某一列的值&转换数据类型:df.loc[:, 'x'] = df['x'].str.replace('X','').astype('int32')
查询单个值:df.loc['index', 'column']
得到一个Series:df.loc['index', ['column1', 'column2']]
使用值列表批量查询
使用数值区间进行范围查询(包含区间的开始和结尾)
使用条件表达式查询
调用函数查询
lambda表达式:df.loc[lambda df: df['age'] > 18, :]
调用函数:
def query_adult(x):
+ return df['age'] > 18
+
+df.loc[query_adult, :]直接赋值
df.apply
apply赋值 基于 0-'index' 1-'columns' 操作跨行/跨列
def get_is_adult(x):
+ if x['age'] >= 18:
+ return '成年'
+ else:
+ return '未成年'
+
+df.loc[:, 'isAdult'] = df.apply(get_is_adult, axis=1)df.assign
按条件选择分组并分别赋值
按字段分组查看数量: df['tempDiff'].value_counts()
df_list = [df]
+df2 = pd.concat(df_list)
+
+if not os.path.exists('../resources/data1.csv'):
+ df2.to_csv('../resources/data1.csv', mode='a', index=False, header=True)
+else:
+ df2.to_csv('../resources/data1.csv', mode='a', index=False, header=False)pandas的axis参数:指的是跨该axis,例如指定columns 则是跨列,也就是沿着列名水平方向执行
跨列操作:在横向上遍历每行,对每行的数据进行操作
跨行操作:在水平方向遍历每列,对每列数据进行操作
以csv/txt文件为例
pd.read_csv():返回一个DataFrame或TextFileReader
header指定具体表头行数,如果没有则header=None,第一行是表头则header=0,header还可以是一个列表例如header=[0,1,3],此时会有多个标题,且1和3之间的行会被忽略掉
seq指定分割符,默认为','
skiprows跳过某一行,行号从0开始,例如skiprows=2或skiprows=[0,1,200]
nrows指定需要读取的行数,从第一行开始,例如nrows=1000
na_values空值置换,会把指定的值替换为空值例如na_values=['\\N', 15]会把字符串\\N和数字15替换为空值NaN
na_values={'Age':0,'Comment':'该用户没有评价'}iterator: True时返回一个TextFileReader,用于大文件处理,可以逐块处理文件
chunksize:指定文件块大小,返回一个TextFileReader
encoding:指定编码
index_col:读取时指定索引列,和df.set_index效果相同
names:文件中没有表头,手动指定表头,需要和header配合使用
names和header的使用场景主要如下:
- csv文件有表头并且是第一行,那么names和header都无需指定;
- csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;
- csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;
- csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,其实就等价于将数据读取进来之后再对列名进行rename;
多行多列的二维数组、整个表格、多行多列
一维数据、一行或一列
对应纵向上的行
替换索引为某一列的值:df.set_index('xxx', inplace=True)
对应横向上的列
df.loc,根据行、列的标签值查询(既能查询又能覆盖写入)
行根据行标签,也就是索引筛选,列根据列标签,列名筛选
如果选取的是所有行或者所有列,可以用:代替
行标签选取的时候,两端都包含,比如[0:5]指的是0,1,2,3,4,5
df.iloc,根据行、列的数字位置查询
iloc基于位置索引,简言之,就是第几行第几列,只不过这里的行列都是从0开始的。
iloc的0:X中不包括X,只能到X-1.
df.where
df.query
使用单个label值查询
查找并替换某一列的值&转换数据类型:df.loc[:, 'x'] = df['x'].str.replace('X','').astype('int32')
查询单个值:df.loc['index', 'column']
得到一个Series:df.loc['index', ['column1', 'column2']]
使用值列表批量查询
使用数值区间进行范围查询(包含区间的开始和结尾)
使用条件表达式查询
调用函数查询
lambda表达式:df.loc[lambda df: df['age'] > 18, :]
调用函数:
def query_adult(x):
+ return df['age'] > 18
+
+df.loc[query_adult, :]直接赋值
df.apply
apply赋值 基于 0-'index' 1-'columns' 操作跨行/跨列
def get_is_adult(x):
+ if x['age'] >= 18:
+ return '成年'
+ else:
+ return '未成年'
+
+df.loc[:, 'isAdult'] = df.apply(get_is_adult, axis=1)df.assign
按条件选择分组并分别赋值
按字段分组查看数量: df['tempDiff'].value_counts()
df_list = [df]
+df2 = pd.concat(df_list)
+
+if not os.path.exists('../resources/data1.csv'):
+ df2.to_csv('../resources/data1.csv', mode='a', index=False, header=True)
+else:
+ df2.to_csv('../resources/data1.csv', mode='a', index=False, header=False)pandas的axis参数:指的是跨该axis,例如指定columns 则是跨列,也就是沿着列名水平方向执行
跨列操作:在横向上遍历每行,对每行的数据进行操作
跨行操作:在水平方向遍历每列,对每列数据进行操作
+import winreg
+
+INTERNET_SETTINGS = winreg.OpenKey(winreg.HKEY_CURRENT_USER,
+ r'Software\\Microsoft\\Windows\\CurrentVersion\\Internet Settings',
+ 0, winreg.KEY_ALL_ACCESS)
+name = 'ProxyEnable'
+
+def toggle_proxy():
+ _, reg_type = get_key()
+ winreg.SetValueEx(INTERNET_SETTINGS, name, 0, reg_type, 1 if _ == 0 else 0)
+
+def get_key():
+ return winreg.QueryValueEx(INTERNET_SETTINGS,name)
+
+toggle_proxy()
+import winreg
+
+INTERNET_SETTINGS = winreg.OpenKey(winreg.HKEY_CURRENT_USER,
+ r'Software\\Microsoft\\Windows\\CurrentVersion\\Internet Settings',
+ 0, winreg.KEY_ALL_ACCESS)
+name = 'ProxyEnable'
+
+def toggle_proxy():
+ _, reg_type = get_key()
+ winreg.SetValueEx(INTERNET_SETTINGS, name, 0, reg_type, 1 if _ == 0 else 0)
+
+def get_key():
+ return winreg.QueryValueEx(INTERNET_SETTINGS,name)
+
+toggle_proxy()import pymysql
+from sshtunnel import SSHTunnelForwarder
+import pymysql.cursors
+import xlrd
+
+
+def querySQL(ssh_config, db_config, sql):
+ with SSHTunnelForwarder(
+ (ssh_config['host'], ssh_config['port']),
+ ssh_password=ssh_config['password'],
+ ssh_username=ssh_config['username'],
+ remote_bind_address=(db_config['host'], db_config['port'])
+ ) as server:
+ db = pymysql.connect(
+ host='127.0.0.1',
+ port=server.local_bind_port,
+ user=db_config['username'],
+ passwd=db_config['password'],
+ db=db_config['db_name'],
+ charset="utf8",
+ cursorclass=pymysql.cursors.DictCursor)
+
+ cursor = db.cursor()
+ data = {}
+ try:
+ cursor.execute(sql)
+ data = cursor.fetchone()
+ db.commit()
+ except:
+ db.rollback()
+
+ db.close()
+ cursor.close()
+ return data
+
+
+class ExcelData(object):
+ def __init__(self, data_path, sheetname):
+ self.data_path = data_path # excle表格路径,需传入绝对路径
+ self.sheetname = sheetname # excle表格内sheet名
+ self.data = xlrd.open_workbook(self.data_path) # 打开excel表格
+ self.table = self.data.sheet_by_name(self.sheetname) # 切换到相应sheet
+ self.keys = self.table.row_values(0) # 第一行作为key值
+ self.rowNum = self.table.nrows # 获取表格行数
+ self.colNum = self.table.ncols # 获取表格列数
+
+ def readExcel(self):
+ if self.rowNum < 2:
+ print("excle内数据行数小于2")
+ else:
+ L = [] # 列表L存放取出的数据
+ for i in range(1, self.rowNum): # 从第二行(数据行)开始取数据
+ sheet_data = {} # 定义一个字典用来存放对应数据
+ for j in range(self.colNum): # j对应列值
+ sheet_data[self.keys[j]] = self.table.row_values(i)[j] # 把第i行第j列的值取出赋给第j列的键值,构成字典
+ L.append(sheet_data) # 一行值取完之后(一个字典),追加到L列表中
+ # print(type(L))
+ return L
+
+
+if __name__ == "__main__":
+ # 远程登录配置信息
+ ssh_config = {
+ 'host': '',
+ 'port': 22,
+ 'username': '',
+ 'password': ''
+ }
+ # 数据库配置信息
+ db_config = {
+ 'host': '',
+ 'port': 3306,
+ 'username': '',
+ 'password': '',
+ 'db_name': ''
+ }
+
+ path = ""
+ sheetname = ""
+ get_data = ExcelData(path, sheetname)
+ dataList = get_data.readExcel()
+ process_result = []
+ with open('./res.txt', 'w') as f:
+ for data in dataList:
+ # 查询语句
+ try:
+ sql = ''
+
+ # 查询
+ res = querySQL(ssh_config, db_config, sql)
+
+ update_sql = ""
+ f.write(update_sql + '\\n')
+ # print(res)
+ except Exception as e:
+ error = '... 处理失败'
+ process_result.append(error)
+ print(process_result)import pymysql
+from sshtunnel import SSHTunnelForwarder
+import pymysql.cursors
+import xlrd
+
+
+def querySQL(ssh_config, db_config, sql):
+ with SSHTunnelForwarder(
+ (ssh_config['host'], ssh_config['port']),
+ ssh_password=ssh_config['password'],
+ ssh_username=ssh_config['username'],
+ remote_bind_address=(db_config['host'], db_config['port'])
+ ) as server:
+ db = pymysql.connect(
+ host='127.0.0.1',
+ port=server.local_bind_port,
+ user=db_config['username'],
+ passwd=db_config['password'],
+ db=db_config['db_name'],
+ charset="utf8",
+ cursorclass=pymysql.cursors.DictCursor)
+
+ cursor = db.cursor()
+ data = {}
+ try:
+ cursor.execute(sql)
+ data = cursor.fetchone()
+ db.commit()
+ except:
+ db.rollback()
+
+ db.close()
+ cursor.close()
+ return data
+
+
+class ExcelData(object):
+ def __init__(self, data_path, sheetname):
+ self.data_path = data_path # excle表格路径,需传入绝对路径
+ self.sheetname = sheetname # excle表格内sheet名
+ self.data = xlrd.open_workbook(self.data_path) # 打开excel表格
+ self.table = self.data.sheet_by_name(self.sheetname) # 切换到相应sheet
+ self.keys = self.table.row_values(0) # 第一行作为key值
+ self.rowNum = self.table.nrows # 获取表格行数
+ self.colNum = self.table.ncols # 获取表格列数
+
+ def readExcel(self):
+ if self.rowNum < 2:
+ print("excle内数据行数小于2")
+ else:
+ L = [] # 列表L存放取出的数据
+ for i in range(1, self.rowNum): # 从第二行(数据行)开始取数据
+ sheet_data = {} # 定义一个字典用来存放对应数据
+ for j in range(self.colNum): # j对应列值
+ sheet_data[self.keys[j]] = self.table.row_values(i)[j] # 把第i行第j列的值取出赋给第j列的键值,构成字典
+ L.append(sheet_data) # 一行值取完之后(一个字典),追加到L列表中
+ # print(type(L))
+ return L
+
+
+if __name__ == "__main__":
+ # 远程登录配置信息
+ ssh_config = {
+ 'host': '',
+ 'port': 22,
+ 'username': '',
+ 'password': ''
+ }
+ # 数据库配置信息
+ db_config = {
+ 'host': '',
+ 'port': 3306,
+ 'username': '',
+ 'password': '',
+ 'db_name': ''
+ }
+
+ path = ""
+ sheetname = ""
+ get_data = ExcelData(path, sheetname)
+ dataList = get_data.readExcel()
+ process_result = []
+ with open('./res.txt', 'w') as f:
+ for data in dataList:
+ # 查询语句
+ try:
+ sql = ''
+
+ # 查询
+ res = querySQL(ssh_config, db_config, sql)
+
+ update_sql = ""
+ f.write(update_sql + '\\n')
+ # print(res)
+ except Exception as e:
+ error = '... 处理失败'
+ process_result.append(error)
+ print(process_result)Django 是一个由 Python 编写的一个开放源代码的 Web 应用框架。
使用 Django,只要很少的代码,Python 的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的 Web 服务 Django 本身基于 MVC 模型,即 Model(模型)+ View(视图)+ Controller(控制器)设计模式,MVC 模式使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。
MVC 优势:
Django 采用了 MVT 的软件设计模式,即模型(Model),视图(View)和模板(Template)。
Django 的 MTV 模式本质上和 MVC 是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django 的 MTV 分别是指:
除了以上三层之外,还需要一个 URL 分发器,它的作用是将一个个 URL 的页面请求分发给不同的 View 处理,View 再调用相应的 Model 和 Template,MTV 的响应模式如下所示:
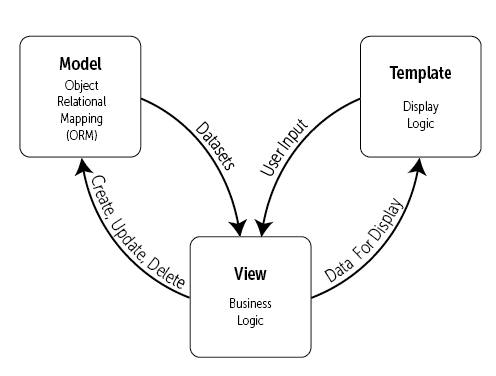
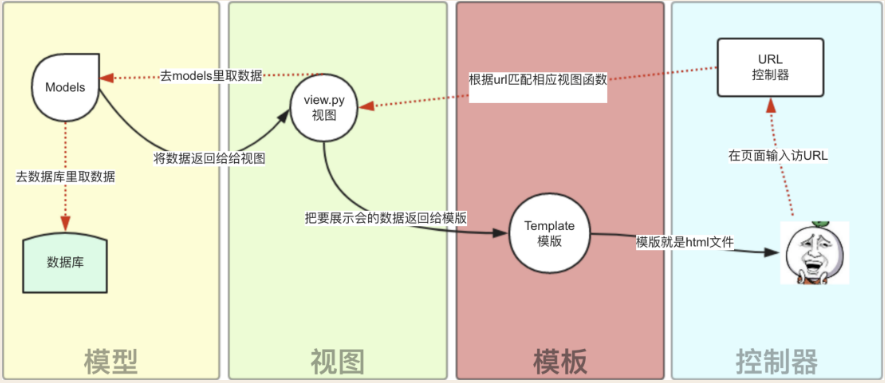
解析:
用户通过浏览器向我们的服务器发起一个请求(request),这个请求会去访问视图函数:
视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
安装:pip install Django
创建Django项目:
django-admin startproject 项目名称项目结构
启动:python manage.py runserver 8001
# django的1.x和2.x不同
+# 1.x : url(正则表达式,views视图函数,参数,别名)
+# 2.x : path,re_path(原来的url)
+from django.contrib import admin
+from django.urls import path
+
+urlpatterns = [
+ path('admin/', admin.site.urls),
+]from django.contrib import admin
+from django.urls import path
+from storyxc.views import index
+urlpatterns = [
+ path('admin/', admin.site.urls),
+ path('',index,{'param':'story'})
+]from django.shortcuts import HttpResponse
+
+
+def index(request,param):
+ print(param)
+ return HttpResponse('ok')启动应用后访问localhost:8000

控制台:
[30/Apr/2021 00:31:21] "GET / HTTP/1.1" 200 2
+storypython3 manage.py startapp demo
djangoProject
+├── demo
+│ ├── __init__.py
+│ ├── admin.py
+│ ├── apps.py
+│ ├── migrations
+│ │ └── __init__.py
+│ ├── models.py
+│ ├── tests.py
+│ └── views.py
+├── djangoProject
+│ ├── __init__.py
+│ ├── __pycache__
+│ │ ├── __init__.cpython-311.pyc
+│ │ └── settings.cpython-311.pyc
+│ ├── asgi.py
+│ ├── settings.py
+│ ├── urls.py
+│ └── wsgi.py
+├── manage.py
+└── templates# djangoProject/settings.py
+
+# Application definition
+
+INSTALLED_APPS = [
+ 'django.contrib.admin',
+ 'django.contrib.auth',
+ 'django.contrib.contenttypes',
+ 'django.contrib.sessions',
+ 'django.contrib.messages',
+ 'django.contrib.staticfiles',
+ # 新增注册app
+ 'demo.apps.DemoConfig'
+]
+# 可以配置可访问域名
+ALLOWED_HOSTS = ["192.168.2.2"]Django 是一个由 Python 编写的一个开放源代码的 Web 应用框架。
使用 Django,只要很少的代码,Python 的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的 Web 服务 Django 本身基于 MVC 模型,即 Model(模型)+ View(视图)+ Controller(控制器)设计模式,MVC 模式使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。
MVC 优势:
Django 采用了 MVT 的软件设计模式,即模型(Model),视图(View)和模板(Template)。
Django 的 MTV 模式本质上和 MVC 是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django 的 MTV 分别是指:
除了以上三层之外,还需要一个 URL 分发器,它的作用是将一个个 URL 的页面请求分发给不同的 View 处理,View 再调用相应的 Model 和 Template,MTV 的响应模式如下所示:
解析:
用户通过浏览器向我们的服务器发起一个请求(request),这个请求会去访问视图函数:
视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
安装:pip install Django
创建Django项目:
django-admin startproject 项目名称项目结构
启动:python manage.py runserver 8001
# django的1.x和2.x不同
+# 1.x : url(正则表达式,views视图函数,参数,别名)
+# 2.x : path,re_path(原来的url)
+from django.contrib import admin
+from django.urls import path
+
+urlpatterns = [
+ path('admin/', admin.site.urls),
+]from django.contrib import admin
+from django.urls import path
+from storyxc.views import index
+urlpatterns = [
+ path('admin/', admin.site.urls),
+ path('',index,{'param':'story'})
+]from django.shortcuts import HttpResponse
+
+
+def index(request,param):
+ print(param)
+ return HttpResponse('ok')启动应用后访问localhost:8000
控制台:
[30/Apr/2021 00:31:21] "GET / HTTP/1.1" 200 2
+storypython3 manage.py startapp demo
djangoProject
+├── demo
+│ ├── __init__.py
+│ ├── admin.py
+│ ├── apps.py
+│ ├── migrations
+│ │ └── __init__.py
+│ ├── models.py
+│ ├── tests.py
+│ └── views.py
+├── djangoProject
+│ ├── __init__.py
+│ ├── __pycache__
+│ │ ├── __init__.cpython-311.pyc
+│ │ └── settings.cpython-311.pyc
+│ ├── asgi.py
+│ ├── settings.py
+│ ├── urls.py
+│ └── wsgi.py
+├── manage.py
+└── templates# djangoProject/settings.py
+
+# Application definition
+
+INSTALLED_APPS = [
+ 'django.contrib.admin',
+ 'django.contrib.auth',
+ 'django.contrib.contenttypes',
+ 'django.contrib.sessions',
+ 'django.contrib.messages',
+ 'django.contrib.staticfiles',
+ # 新增注册app
+ 'demo.apps.DemoConfig'
+]
+# 可以配置可访问域名
+ALLOWED_HOSTS = ["192.168.2.2"]安装:pip install pymysql
代码:
import pymysql
+
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor(cursor=pymysql.cursors.DictCursor)
+cursor.execute('select * from tb_student')
+print(cursor.fetchall())
+connection.close()
+
+res:
+[{'id': 1, 'name': 'tom', 'age': 18}, {'id': 2, 'name': 'rose', 'age': 17}]connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+cursor.execute('update tb_student set name = "jack" where id = 1')
+connection.commit()
+connection.close()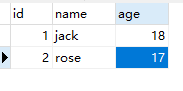
import pymysql
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+try:
+ cursor.execute('delete from tb_student where id = 2')
+ connection.commit()
+except Exception as e:
+ connection.rollback()
+connection.close()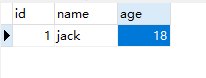
import pymysql
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+try:
+ # 方式1
+ cursor.execute('insert into tb_student(name,age) values("mike",20)')
+ # 方式2
+ cursor.execute('insert into tb_student(name,age) values("%s",%s)' % ('mike',21))
+ connection.commit()
+except Exception as e:
+ connection.rollback()
+connection.close()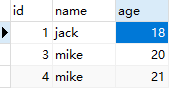
import pymysql
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()
+
+
+if __name__ == '__main__':
+ with Mysql() as conn:
+ cursor = conn.cursor(pymysql.cursors.DictCursor)
+ try:
+ sql = "select * from tb_student"
+ cursor.execute(sql)
+ res = cursor.fetchall()
+ print(res)
+ except:
+ print('error')安装:pip install pymysql
代码:
import pymysql
+
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor(cursor=pymysql.cursors.DictCursor)
+cursor.execute('select * from tb_student')
+print(cursor.fetchall())
+connection.close()
+
+res:
+[{'id': 1, 'name': 'tom', 'age': 18}, {'id': 2, 'name': 'rose', 'age': 17}]connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+cursor.execute('update tb_student set name = "jack" where id = 1')
+connection.commit()
+connection.close()
import pymysql
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+try:
+ cursor.execute('delete from tb_student where id = 2')
+ connection.commit()
+except Exception as e:
+ connection.rollback()
+connection.close()
import pymysql
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+try:
+ # 方式1
+ cursor.execute('insert into tb_student(name,age) values("mike",20)')
+ # 方式2
+ cursor.execute('insert into tb_student(name,age) values("%s",%s)' % ('mike',21))
+ connection.commit()
+except Exception as e:
+ connection.rollback()
+connection.close()
import pymysql
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()
+
+
+if __name__ == '__main__':
+ with Mysql() as conn:
+ cursor = conn.cursor(pymysql.cursors.DictCursor)
+ try:
+ sql = "select * from tb_student"
+ cursor.execute(sql)
+ res = cursor.fetchall()
+ print(res)
+ except:
+ print('error')家庭服务器由于是移动宽带(大内网),没有办法申请公网ip,这样不在家的时候就无法进行服务器管理了。如果有公网ip,可以使用ddns,也可以用花生壳这类内网穿透工具。或者自己有一台有公网ip的云主机,可以通过frp应用来实现内网穿透。frp仓库地址:https://github.com/fatedier/frp
具体使用可以查看frp使用文档,这里介绍下我用的场景:带sk校验的安全的ssh连接
在云主机上部署fprs,配置如下:
[common]
+bind_addr = 0.0.0.0
+bind_port = 7000
+
+token = xxxcat > /etc/systemd/system/frps.service <<EOF
+[Unit]
+Description=frps
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/bin/frps -c /etc/frps/frps.ini
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF[common]
+server_addr = x.x.x.x
+server_port = 7000
+token = xxx
+
+[ssh]
+type = tcp
+local_ip = 127.0.0.1
+local_port = 22
+remote_port = 6001
+
+[secret_ssh]
+type = stcp
+# 只有 sk 一致的用户才能访问到此服务
+sk = abcdefg
+local_ip = 127.0.0.1
+local_port = 22在需要访问内网的机器上执行命令连接内网服务,例如用户为root
ssh -oPort=6001 root@x.x.x.x
[common]
+server_addr = x.x.x.x
+server_port = 7000
+token = xxx
+
+[secret_ssh_visitor]
+type = stcp
+# stcp 的访问者
+role = visitor
+# 要访问的 stcp 代理的名字
+server_name = secret_ssh
+sk = abcdefg
+# 绑定本地端口用于访问 SSH 服务
+bind_addr = 127.0.0.1
+bind_port = 6000在需要访问内网的机器上执行命令连接内网服务,例如用户为root
ssh -oPort 6000 root@127.0.0.1
如果内网机器开启了密钥登录,则需要指定内网服务器的私钥文件
ssh -oPort 6000 -i identityFile root@127.0.0.1
家庭服务器由于是移动宽带(大内网),没有办法申请公网ip,这样不在家的时候就无法进行服务器管理了。如果有公网ip,可以使用ddns,也可以用花生壳这类内网穿透工具。或者自己有一台有公网ip的云主机,可以通过frp应用来实现内网穿透。frp仓库地址:https://github.com/fatedier/frp
具体使用可以查看frp使用文档,这里介绍下我用的场景:带sk校验的安全的ssh连接
在云主机上部署fprs,配置如下:
[common]
+bind_addr = 0.0.0.0
+bind_port = 7000
+
+token = xxxcat > /etc/systemd/system/frps.service <<EOF
+[Unit]
+Description=frps
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/bin/frps -c /etc/frps/frps.ini
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF[common]
+server_addr = x.x.x.x
+server_port = 7000
+token = xxx
+
+[ssh]
+type = tcp
+local_ip = 127.0.0.1
+local_port = 22
+remote_port = 6001
+
+[secret_ssh]
+type = stcp
+# 只有 sk 一致的用户才能访问到此服务
+sk = abcdefg
+local_ip = 127.0.0.1
+local_port = 22在需要访问内网的机器上执行命令连接内网服务,例如用户为root
ssh -oPort=6001 root@x.x.x.x
[common]
+server_addr = x.x.x.x
+server_port = 7000
+token = xxx
+
+[secret_ssh_visitor]
+type = stcp
+# stcp 的访问者
+role = visitor
+# 要访问的 stcp 代理的名字
+server_name = secret_ssh
+sk = abcdefg
+# 绑定本地端口用于访问 SSH 服务
+bind_addr = 127.0.0.1
+bind_port = 6000在需要访问内网的机器上执行命令连接内网服务,例如用户为root
ssh -oPort 6000 root@127.0.0.1
如果内网机器开启了密钥登录,则需要指定内网服务器的私钥文件
ssh -oPort 6000 -i identityFile root@127.0.0.1
一直想搞一台nas玩玩儿,但是看了群晖、威联通这些成品nas低到令人发指的性价比,我最终还是决定diy一台小主机来实现自己的需求。
PC上还有块4T的希捷酷鹰,再添3块4T紫盘组raid5阵列。机箱的盘位就至少需要4个以上,挑了一圈就乔思伯N1(5盘位)和万由的810A(8盘位)能看的过去,虽然万由盘位多但是价格比n1高了大几百,目前也用不到这么多盘位,因此机箱确定了n1,主板也要买itx版型。
要跑的docker容器比较多,下载器服务、阿里云的webdav容器、直播录制程序容器等等。。。因此内存需要32G以上。
确定使用的系统是个比较复杂的过程,因为有过PVE虚拟机翻车的经历,这个服务器又主要承载了数据存储功能,所以要追求稳定,因此首先排除PVE和ESXi这些虚拟机系统,直接物理机装系统。然后我在虚拟机上装了最新版的Truenas scale体验了一下,这个系统是基于debian用python开发的,交互上倒没什么问题,但是因为是个纯nas系统,对主系统限制较多,自由度不高(不能直接装软件),因此也被pass,黑群晖这些就不说了,在我看来还不如truenas。一圈排除下来就只能直接装linux server了。去V2EX论坛问了老哥们的意见,推荐debian的很多,也有建议用最熟悉的系统的, 最后我选择了后者,选了比较有把握的ubuntu server,正好ubuntu的22.04发行版刚出,就直接安排上了。 2024年还是换成了debian,ubuntu server更新太频繁经常重启,有点难顶。
经过了好几天的挑选,最终敲定了这套配置
cpu:i3-10100散片
+主板:七彩虹cvn b460i frozen
+内存:金士顿16g*2 2666
+固态:七彩虹 ssd sata3 128g
+cpu散热:超频3刀锋
+机械硬盘:西数海康oem紫盘4t*3
+电源:tt 350w sfx电源
+机箱+线材:乔思伯n1
+扩展卡:乐扩m2转sata3接口扩展卡其中散热、固态是在公司的福利商城购买,cpu、机械硬盘、机箱、扩展卡在淘宝购买,主板、电源在京东购买,内存在咸鱼淘的。不算硬盘花费是2480,加上硬盘3755。
组装完成后:



跟其他工业风机箱比起来,乔思伯n1这款颜值还是很不错的。
ubuntu官网下载最新版的ubuntu-server-22.04,然后rufus刷写到U盘中,使用U盘引导启动。
安装过程不再赘述,这里记录几个重点步骤:
在配置Ubuntu安装镜像这一步最好选择国内的企业/大学镜像站,不然后面安装可能会在下载时卡住。网易镜像源http://mirrors.163.com/ubuntu/,阿里云镜像源https://mirrors.aliyun.com/ubuntu/,清华源https://mirrors.tuna.tsinghua.edu.cn/ubuntu/
/和/boot 两个区,然后四块4T机械组了raid5。(ubuntu在建立阵列后会立刻进入重建过程,阵列中会有一个分区状态为spare rebuilding ,其他分区为active sync。这个重建过程很久,我4块4T重建总共用了十几个小时,重建完成后阵列下所有分区都会变为active sync 状态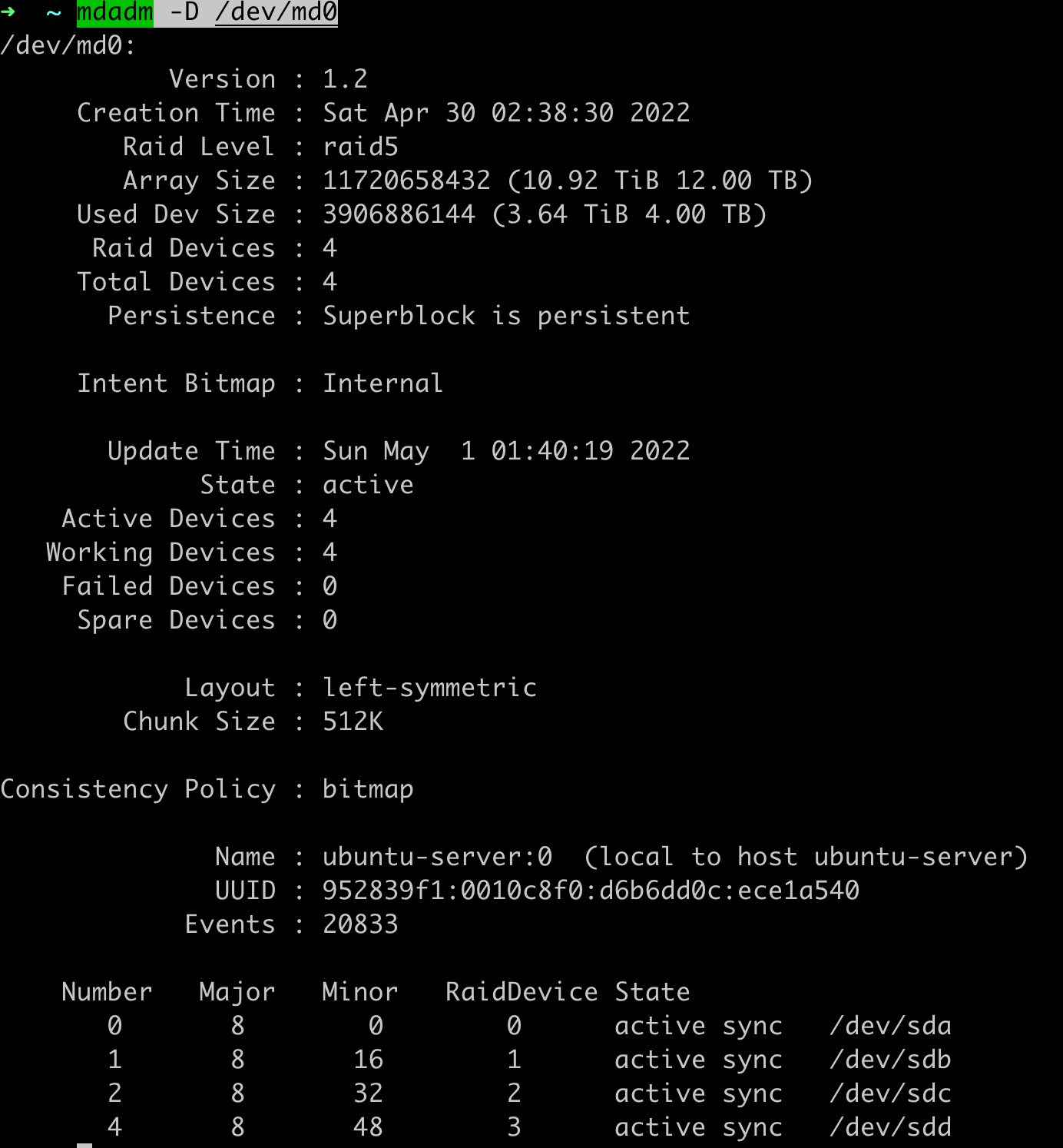
开启root登陆
sudo vim /etc/ssh/sshd_config
+
+# 添加配置
+PermitRootLogin yes
+
+# 给root修改密码
+sudo passwd root
+
+systemctl restart sshd启用密钥登陆
见另一篇博客 阿里云服务器启用密钥登陆并禁用密码登陆
时区同步
sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
这个部分长期更新XD,一点点补上吧。
# 安装samba
+sudo apt install samba
+# 启动smb
+systemctl start smb
+# 开机自启
+systemctl enable smb
+
+# 创建共享文件夹 设置权限770
+mkdir /mnt/data
+sudo chmod 770 /mnt/data
+
+# 添加用户和密码
+sudo smbpasswd -a 用户名
+
+# 修改配置文件,在文件最后添加共享资源设置
+sudo vim /etc/samba/smb.conf
+
+[data]
+path = /mnt/data
+available = yes
+browseable = yes
+public = no
+writable = yes
+valid users = storysamba共享配置详解
[temp] #共享资源名称
comment = Temporary file space #简单的解释,内容无关紧要
path = /tmp #实际的共享目录
writable = yes #设置为可写入
browseable = yes #可以被所有用户浏览到资源名称,
guest ok = yes #可以让用户随意登录
public = yes #允许匿名查看
valid users = 用户名 #设置访问用户
valid users = @组名 #设置访问组
readonly = yes #只读
readonly = no #读写
hosts deny = 192.168.0.0 #表示禁止所有来自192.168.0.0/24 网段的IP 地址访问
hosts allow = 192.168.0.24 #表示允许192.168.0.24 这个IP 地址访问
[homes]为特殊共享目录,表示用户主目录。
[printers]表示共享打印机。
原文链接:https://blog.csdn.net/l1593572468/article/details/121444812
# Uninstall old versions
+sudo apt-get remove docker docker-engine docker.io containerd runc
+
+# Update the apt package index and install packages to allow apt to use a repository over HTTPS:
+sudo apt-get update
+sudo apt-get install \\
+ ca-certificates \\
+ curl \\
+ gnupg \\
+ lsb-release
+# Add Docker’s official GPG key:
+curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
+
+# Use the following command to set up the stable repository.
+echo \\
+ "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \\
+ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
+
+# Install Docker Engine
+sudo apt-get update
+sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
+
+
+systemctl enable docker参考另一篇博客挂载阿里云盘+开机自动挂载
docker run -d \\
+ --name=transmission \\
+ -e TRANSMISSION_WEB_HOME=/transmission-web-control/ \\
+ -e PUID=1000 \\
+ -e PGID=1000 \\
+ -e TZ=Asia/Shanghai \\
+ -e USER=<user> \\
+ -e PASS=<pass> \\
+ -p 19091:9091 \\
+ -p 51413:51413 \\
+ -p 51413:51413/udp \\
+ -v /mnt/data/docker/transmission/data:/config \\
+ -v /mnt/data/downloads/others:/downloads/others \\
+ -v /mnt/data/downloads/tvseries:/downloads/tvseries \\
+ -v /mnt/data/docker/transmission/watch/folder:/watch \\
+ -v /mnt/data/downloads/movies:/downloads/movies \\
+ --restart=always \\
+ linuxserver/transmissionversion: "3.2"
+
+services:
+ qbittorrent:
+ image: nevinee/qbittorrent:4.3.9
+ container_name: qbittorrent
+ environment:
+ - PUID=0
+ - PGID=0
+ - TZ=Asia/Shanghai
+ - WEBUI_PORT=18080
+ - BT_PORT=55555
+ volumes:
+ - /mnt/data/docker/qbittorrent/config:/data
+ - /repo:/downloads
+ network_mode: host
+ restart: unless-stoppeddocker run -d \\
+ --name aria2 \\
+ --restart always \\
+ --log-opt max-size=1m \\
+ -e TZ=Asia/Shanghai \\
+ -e PUID=$UID \\
+ -e PGID=$GID \\
+ -e UMASK_SET=022 \\
+ -e RPC_SECRET=<secret> \\
+ -e RPC_PORT=16800 \\
+ -p 16800:16800 \\
+ -e LISTEN_PORT=16888 \\
+ -p 16888:16888 \\
+ -p 16888:16888/udp \\
+ -v /mnt/data/docker/aria2/config:/config \\
+ -v /mnt/data/downloads/tvseries:/downloads/tvseries \\
+ -v /mnt/data/downloads/movies:/downloads/movies \\
+ -v /mnt/data/downloads/others:/downloads/others \\
+ p3terx/aria2-proversion: "3.2"
+
+services:
+ jenkins:
+ image: jenkins/jenkins:2.332.3-jdk11
+ container_name: jenkins
+ environment:
+ - TZ=Asia/Shanghai
+ user: root
+ volumes:
+ - /story/dist:/story/dist
+ - /mnt/data/docker/jenkins/jenkins_data:/var/jenkins_home
+ - /etc/localtime:/etc/localtime:ro
+ ports:
+ - "8099:8080"
+ restart: unless-stoppedversion: "3.2"
+services:
+ jellyfin:
+ image: linuxserver/jellyfin
+ container_name: jellyfin
+ environment:
+ - PUID=0
+ - PGID=0
+ - TZ=Asia/Shanghai
+ volumes:
+ - /mnt/data/docker/jellyfin/library:/config
+ - /tvshows:/data/tvshows
+ - /movies:/data/movies
+ devices:
+ - /dev/dri:/dev/dri
+ network_mode: host
+ restart: unless-stopped# 安装驱动
+apt install intel-media-va-driver
+# 解码支持确认
+/usr/lib/jellyfin-ffmpeg/vainfo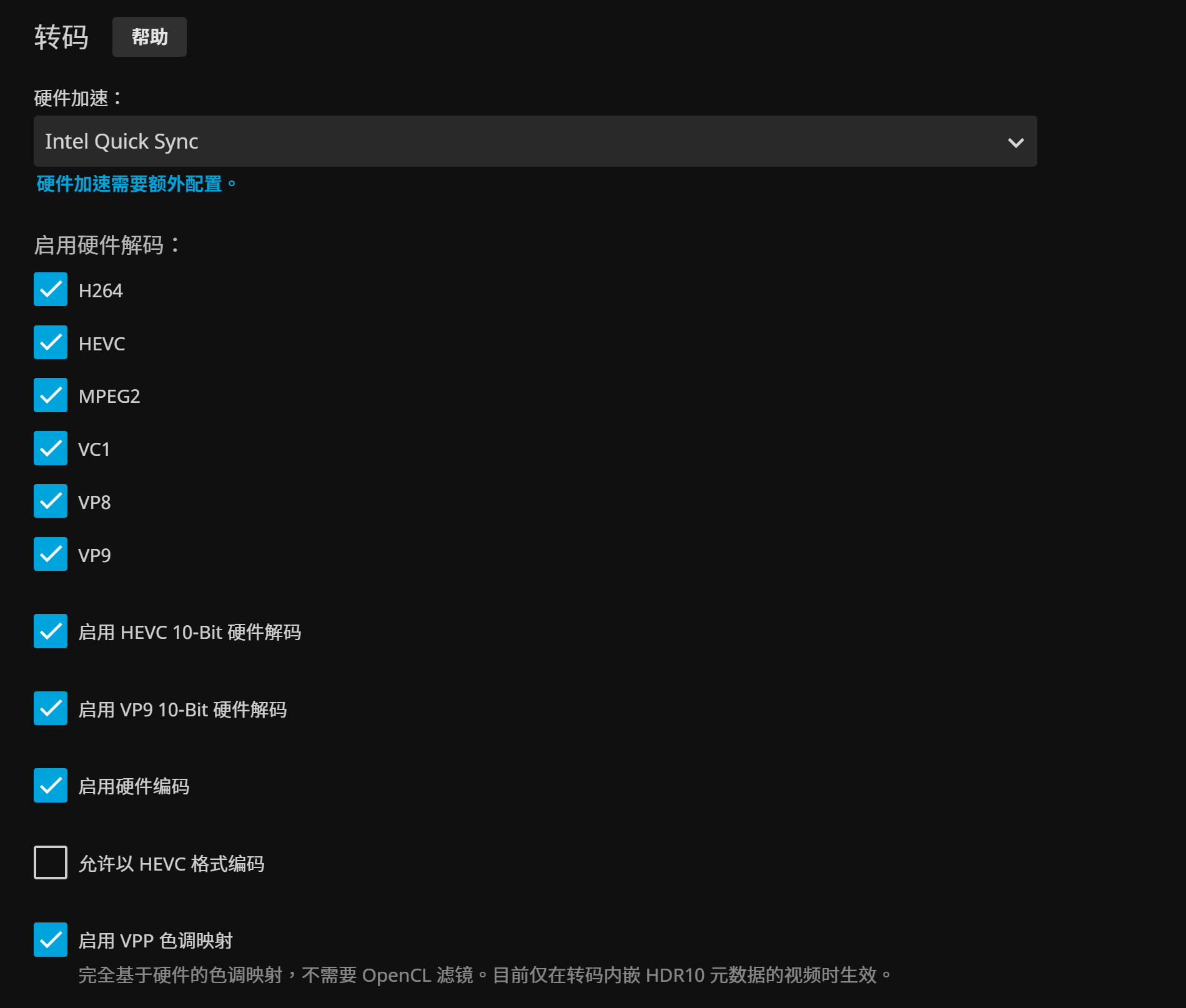
wget https://downloads.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz
+ tar -xzvf kafka_2.13-3.6.1.tgz -C /usr/localzookeeper.service
[Unit]
+Description=zookeeper
+
+[Service]
+Type=forking
+Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
+ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh -daemon /usr/local/kafka/config/zookeeper.properties
+ExecStop=/usr/local/kafka/bin/zookeeper-server-start.sh stop
+SyslogIdentifier=zookeeper
+
+[Install]
+WantedBy=multi-user.targetkafka.service
[Unit]
+Description=kafka
+After=zookeeper.service
+
+[Service]
+Type=forking
+Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
+ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
+ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
+
+[Install]
+WantedBy=multi-user.targetdocker run -d \\
+ --name onedev \\
+ -v /var/run/docker.sock:/var/run/docker.sock \\
+ -v /mnt/data/docker/onedev:/opt/onedev \\
+ -p 6610:6610 \\ # http
+ -p 6611:6611 \\ # ssh
+ --restart=always \\
+ 1dev/server:latestsudo apt install rabbitmq-server
+
+cd /usr/lib/rabbitmq/bin
+# 开启rabbit网页控制台 默认端口号15672,重启rabbitmq服务
+ ./rabbitmq-plugins enable rabbitmq_management
+
+# rabbitmq默认用户guest不允许远程登陆,且systemd默认的启动用户为rabbitmq,可以改为root
+cd /lib/systemd/system
+vim rabbitmq-server.service
+
+# 新建rabbitmq用户
+cd /usr/lib/rabbitmq/bin
+./rabbitmqctl add_user username password
+# 授权
+./rabbitmqctl set_user_tags username administrator
+./rabbitmqctl set_permissions -p "/" username ".*" ".*" ".*"
+
+# 查看、删除、修改密码
+./rabbitmqctl list_users
+./rabbitmqctl delete_user username
+./rabbitmqctl change_password username newpasswordversion: "3"
+
+networks:
+ gitea:
+ external: false
+
+volumes:
+ gitea:
+ driver: local
+
+services:
+ server:
+ image: gitea/gitea:1.16.7
+ container_name: gitea
+ environment:
+ - DOMAIN=192.168.2.66
+ - HTTP_PORT=6610
+ - SSH_PORT=6611
+ - SSH_LISTEN_PORT=6611
+ restart: always
+ networks:
+ - gitea
+ volumes:
+ - gitea:/data
+ - /etc/timezone:/etc/timezone:ro
+ - /etc/localtime:/etc/localtime:ro
+ ports:
+ - "6610:6610"
+ - "6611:6611"/var/lib/docker/volumes/gitea_gitea/_data/gitea/conf/app.ini
+
+# add the following lines to the end of the file
+[webhook]
+ALLOWED_HOST_LIST = 192.168.2.66In Jenkins: on the job settings page set "Source Code Management" option to "Git", provide URL to your repo (http://gitea-url.your.org/username/repo.git), and in "Poll triggers" section check "Poll SCM" option with no schedule defined. This setup basically tells Jenkins to poll your Gitea repo only when requested via the webhook.
In Gitea: under repo -> Settings -> Webhooks, add new webhook, set the URL to http://jenkins_url.your.org/gitea-webhook/post, and clear the secret (leave it blank).
At this point clicking on "Test Delivery" button should produce a successful delivery attempt (green checkmark).
docker run -d --name kafkaui -p 9000:9000 \\
+ -e KAFKA_BROKERCONNECT="192.168.2.66:9092"\\
+ -e JVM_OPTS="-Xms32M -Xmx64M" \\
+ -e SERVER_SERVLET_CONTEXTPATH="/" \\
+ obsidiandynamics/kafdropversion: '3'
+
+services:
+ cadvisor:
+ image: gcr.io/cadvisor/cadvisor:v0.47.2
+ container_name: cadvisor
+ volumes:
+ - /:/rootfs:ro
+ - /var/run:/var/run:ro
+ - /sys:/sys:ro
+ - /var/lib/docker/:/var/lib/docker:ro
+ - /dev/disk/:/dev/disk:ro
+ ports:
+ - "28080:8080"
+ privileged: true
+ restart: unless-stopped
+ devices:
+ - /dev/kmsgwget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gztar -zxvf node_exporter-1.6.1.linux-amd64.tar.gz && mv node_exporter-1.6.1.linux-amd64/node_exporter /usr/local/bin # 编写systemd服务
+cat > /etc/systemd/system/node_exporter.service <<EOF
+[Unit]
+Description=node_exporeter
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/local/bin/node_exporter
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF
+
+# 更新内核并启动,自启动
+systemctl daemon-reload && systemctl start node_exporter && systemctl enable node_exporter && systemctl status node_exporter# openwrt要使用init.d
+# /etc/init.d/node_exporter
+#!/bin/sh /etc/rc.common
+
+START=99
+STOP=10
+
+start() {
+ echo "Starting Node Exporter..."
+ /usr/bin/node_exporter --web.listen-address=":9100" > /dev/null 2>&1 &
+}
+
+stop() {
+ echo "Stopping Node Exporter..."
+ killall node_exporter
+}
+
+restart() {
+ stop
+ sleep 1
+ start
+}/etc/init.d/node_exporter enable && /etc/init.d/node_exporter start
wget https://github.com/oliver006/redis_exporter/releases/download/v1.46.0/redis_exporter-v1.46.0.linux-amd64.tar.gztar -xvf redis_exporter-v1.46.0.linux-amd64.tar.gz && mv redis_exporter-v1.46.0.linux-amd64/redis_exporter /usr/local/bin# 编写systemd服务
+cat > /etc/systemd/system/redis_exporter.service <<EOF
+[Unit]
+Description=redis_exporter
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/local/bin/redis_exporter -redis.addr ip:port
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF
+
+# 更新内核并启动,自启动
+systemctl daemon-reload && systemctl start redis_exporter && systemctl enable redis_exporter && systemctl status redis_exporter# docker-compose.yml
+
+version: "3"
+
+
+services:
+ grafana:
+ image: grafana/grafana
+ container_name: grafana
+ restart: unless-stopped
+ ports:
+ - 3000:3000
+ user: root
+ volumes:
+ - /mnt/data/docker/monitor/grafana/conf/grafana.ini:/etc/grafana/grafana.ini
+ - /mnt/data/docker/monitor/grafana/data:/var/lib/grafana
+ - /mnt/data/docker/monitor/grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards
+ - /mnt/data/docker/monitor/grafana/provisioning/datasources:/etc/grafana/provisioning/datasources
+ environment:
+ - TZ=Asia/shanghai
+ prometheus:
+ image: prom/prometheus
+ container_name: prometheus
+ restart: unless-stopped
+ ports:
+ - 9090:9090
+ volumes:
+ - /mnt/data/docker/monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
+ - prometheus_data:/prometheus
+ environment:
+ - TZ=Asia/shanghai
+
+volumes:
+ prometheus_data:prometheus.yml
global:
+ scrape_interval: 15s
+ evaluation_interval: 15s
+
+
+scrape_configs:
+ - job_name: "linux"
+ scrape_interval: 5s
+ static_configs:
+ - targets: [ "192.168.2.66:9100" ]
+ labels:
+ instance: home-server-ubuntu
+ - job_name: "redis"
+ scrape_interval: 5s
+ static_configs:
+ - targets: [ "192.168.2.66:9121" ]
+ labels:
+ instance: home-server-ubuntu
+ - job_name: "cadvisor"
+ static_configs:
+ - targets: [ "192.168.2.66:28080" ]
+ labels:
+ instance: home-server-ubuntudocker cp grafana:/etc/grafana.ini ~/grafana监控大盘模板
配置域名解析,Bitwarden默认使用80和443端口,可以执行安装后在bwdata/config.yaml修改端口
http_prt: 80
+https_port: 443修改完
bwdata/config.yaml后需要执行./bitwarden.sh rebuild
curl -fsSL https://get.docker.com | sudo sh
sudo adduser bitwarden
+sudo passwd bitwarden
+sudo groupadd docker
+sudo usermod -aG docker bitwarden
+sudo mkdir /opt/bitwarden
+sudo chmod -R 700 /opt/bitwarden
+sudo chown -R bitwarden:bitwarden /opt/bitwarden**](https://bitwarden.com/host/) for use in installation.
For more information, see What are my installation id and installation key used for?
curl -Lso bitwarden.sh "https://func.bitwarden.com/api/dl/?app=self-host&platform=linux" && chmod 700 bitwarden.sh
+
+./bitwarden.sh install./bwdata/env/global.override.env. globalSettings__mail__replyToEmail=email@example.com
+globalSettings__mail__smtp__host=smtp.qq.com
+globalSettings__mail__smtp__port=465
+globalSettings__mail__smtp__ssl=true
+globalSettings__mail__smtp__username=email@example.com
+globalSettings__mail__smtp__password=password
+
+globalSettings__disableUserRegistration=true # 禁止注册修改完后执行
./bitwarden.sh restart
./bitwarden.sh start
backup bwdata folder
https://bitwarden.com/help/migration/
如果低版本迁移到高版本,覆盖bwdata后,先执行./bitwarden.sh update
https://bitwarden.com/download
version: '3.8'
+
+services:
+ hoppscotch:
+ container_name: hoppscotch
+ image: hoppscotch/hoppscotch
+ ports:
+ - "53000:3000"
+ - "53100:3100"
+ - "53170:3170"
+ env_file: .env
+ restart: unless-stopped
+ links:
+ - postgresql
+ depends_on:
+ - postgresql
+ networks:
+ - hoppscotch
+ postgresql:
+ container_name: postgresql
+ image: postgres
+ environment:
+ POSTGRES_DB: db
+ POSTGRES_USER: user
+ POSTGRES_PASSWORD: passwd
+ ports:
+ - "5432:5432"
+ volumes:
+ - postgres_data:/var/lib/postgresql/data
+ restart: unless-stopped
+ networks:
+ - hoppscotch
+
+volumes:
+ postgres_data:
+
+networks:
+ hoppscotch:#-----------------------Backend Config------------------------------#
+# Prisma Config
+DATABASE_URL=postgresql://user:passwd@postgresql:5432/db
+
+# Auth Tokens Config
+JWT_SECRET="xxx"
+TOKEN_SALT_COMPLEXITY=10
+MAGIC_LINK_TOKEN_VALIDITY= 3
+REFRESH_TOKEN_VALIDITY="604800000" # Default validity is 7 days (604800000 ms) in ms
+ACCESS_TOKEN_VALIDITY="86400000" # Default validity is 1 day (86400000 ms) in ms
+SESSION_SECRET='xxx'
+
+# Hoppscotch App Domain Config
+REDIRECT_URL="https://hoppscotch.example.com"
+WHITELISTED_ORIGINS="https://hoppscotch.example.com/backend,https://hoppscotch.example.com,https://hoppadmin.example.com"
+VITE_ALLOWED_AUTH_PROVIDERS=GITHUB
+
+# Google Auth Config
+#GOOGLE_CLIENT_ID="************************************************"
+#GOOGLE_CLIENT_SECRET="************************************************"
+#GOOGLE_CALLBACK_URL="http://hoppscotch.example.com:3170/v1/auth/google/callback"
+#GOOGLE_SCOPE="email,profilstoryxc
+
+# Github Auth Config
+GITHUB_CLIENT_ID="xxx"
+GITHUB_CLIENT_SECRET="xxx"
+GITHUB_CALLBACK_URL="https://hoppscotch.example.com/backend/v1/auth/github/callback"
+GITHUB_SCOPE="user:email"
+
+# Microsoft Auth Config
+#MICROSOFT_CLIENT_ID="************************************************"
+#MICROSOFT_CLIENT_SECRET="************************************************"
+#MICROSOFT_CALLBACK_URL="http://hoppscotch.example.com:3170/v1/auth/microsoft/callback"
+#MICROSOFT_SCOPE="user.read"
+#MICROSOFT_TENANT="common"
+
+# Mailer config
+MAILER_SMTP_URL="smtps://user@domain.com:passwd@smtp.domain.com"
+MAILER_ADDRESS_FROM="user@domain.com"
+
+# Rate Limit Config
+RATE_LIMIT_TTL=60 # In seconds
+RATE_LIMIT_MAX=100 # Max requests per IP
+
+
+#-----------------------Frontend Config------------------------------#
+
+
+# Base URLs
+VITE_BASE_URL=https://hoppscotch.example.com
+VITE_SHORTCODE_BASE_URL=https://hoppscotch.example.com
+VITE_ADMIN_URL=https://hoppadmin.example.com
+
+# Backend URLs
+VITE_BACKEND_GQL_URL=https://hoppscotch.example.com/backend/graphql
+VITE_BACKEND_WS_URL=wss://hoppscotch.example.com/backend/ws/graphql
+VITE_BACKEND_API_URL=https://hoppscotch.example.com/backend/v1
+
+# Terms Of Service And Privacy Policy Links (Optional)
+VITE_APP_TOS_LINK=https://docs.hoppscotch.io/support/terms
+VITE_APP_PRIVACY_POLICY_LINK=https://docs.hoppscotch.io/support/privacyserver {
+ listen 443 ssl;
+ listen [::]:443 ssl;
+ server_name hoppscotch.example.com;
+
+ # SSL
+ ssl_certificate /etc/nginx/ssl/hoppscotch.example.com.crt;
+ ssl_certificate_key /etc/nginx/ssl/hoppscotch.example.com.key;
+ ssl_session_timeout 5m;
+ #请按照以下协议配置
+ ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
+ #表示使用的加密套件的类型。
+ ssl_protocols TLSv1.1 TLSv1.2;
+
+ # security
+
+ # logging
+ access_log /var/log/nginx/access.log combined buffer=512k flush=1m;
+ error_log /var/log/nginx/error.log warn;
+
+ # additional config
+
+ location /backend/ws/ {
+ proxy_pass http://127.0.0.1:53170/;
+ proxy_set_header Upgrade $http_upgrade;
+ proxy_set_header Connection "Upgrade";
+ proxy_set_header X-Real-IP $remote_addr;
+ }
+
+ location /backend/ {
+ proxy_pass http://127.0.0.1:53170/;
+ }
+
+ location / {
+ proxy_pass http://127.0.0.1:53000/;
+ }
+}
+
+# HTTP redirect
+server {
+ listen 80;
+ listen [::]:80;
+ server_name hoppscotch.example.com;
+ return 301 https://hoppscotch.example.com$request_uri;
+}version: "3"
+
+services:
+ kutt:
+ image: kutt/kutt
+ depends_on:
+ - postgres
+ - redis
+ command: [ "./wait-for-it.sh", "postgres:5432", "--", "npm", "start" ]
+ ports:
+ - "3000:3000"
+ env_file:
+ - .env
+ environment:
+ DB_HOST: postgres
+ DB_NAME: kutt
+ DB_USER: user
+ DB_PASSWORD: passwd
+ REDIS_HOST: redis
+
+ redis:
+ image: redis:6.0-alpine
+ volumes:
+ - redis_data:/data
+
+ postgres:
+ image: postgres:12-alpine
+ environment:
+ POSTGRES_USER: user
+ POSTGRES_PASSWORD: passwd
+ POSTGRES_DB: kutt
+ volumes:
+ - postgres_data:/var/lib/postgresql/data
+
+volumes:
+ redis_data:
+ postgres_data:# App port to run on
+PORT=3000
+
+# The name of the site where Kutt is hosted
+SITE_NAME=Kutt
+
+# The domain that this website is on
+DEFAULT_DOMAIN=kutt.domain.com
+
+# Generated link length
+LINK_LENGTH=5
+
+# Postgres database credential details
+DB_HOST=postgres
+DB_PORT=5432
+DB_NAME=postgres
+DB_USER=user
+DB_PASSWORD=passwd
+DB_SSL=false
+
+# Redis host and port
+REDIS_HOST=redis
+REDIS_PORT=6379
+REDIS_PASSWORD=
+REDIS_DB=
+
+# Disable registration
+DISALLOW_REGISTRATION=true
+
+# Disable anonymous link creation
+DISALLOW_ANONYMOUS_LINKS=true
+
+# The daily limit for each user
+USER_LIMIT_PER_DAY=50
+
+# Create a cooldown for non-logged in users in minutes
+# Set 0 to disable
+NON_USER_COOLDOWN=0
+
+# Max number of visits for each link to have detailed stats
+DEFAULT_MAX_STATS_PER_LINK=5000
+
+# Use HTTPS for links with custom domain
+CUSTOM_DOMAIN_USE_HTTPS=false
+
+# A passphrase to encrypt JWT. Use a long and secure key.
+JWT_SECRET=xxx
+
+# Admin emails so they can access admin actions on settings page
+# Comma seperated
+ADMIN_EMAILS=user@domain.com
+
+# Invisible reCaptcha secret key
+# Create one in https://www.google.com/recaptcha/intro/
+RECAPTCHA_SITE_KEY=
+RECAPTCHA_SECRET_KEY=
+
+# Google Cloud API to prevent from users from submitting malware URLs.
+# Get it from https://developers.google.com/safe-browsing/v4/get-started
+GOOGLE_SAFE_BROWSING_KEY=
+
+# Your email host details to use to send verification emails.
+# More info on http://nodemailer.com/
+# Mail from example "Kutt <support@kutt.it>". Leave empty to use MAIL_USER
+MAIL_HOST=smtp.domain.com
+MAIL_PORT=465
+MAIL_SECURE=true
+MAIL_USER=user@domain.com
+MAIL_FROM=user@domain.com
+MAIL_PASSWORD=passwd
+
+# The email address that will receive submitted reports.
+REPORT_EMAIL=
+
+# Support email to show on the app
+CONTACT_EMAIL=server {
+ listen 443 ssl;
+ listen [::]:443 ssl;
+ server_name kutt.domain.com;
+
+ # SSL
+ ssl_certificate /etc/nginx/ssl/kutt.domain.com.crt;
+ ssl_certificate_key /etc/nginx/ssl/kutt.domain.com.key;
+ ssl_session_timeout 5m;
+ #请按照以下协议配置
+ ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
+ #表示使用的加密套件的类型。
+ ssl_protocols TLSv1.1 TLSv1.2;
+
+ # security
+ include nginxconfig.io/security.conf;
+
+ # logging
+ access_log /var/log/nginx/access_kutt.log combined buffer=512k flush=1m;
+ error_log /var/log/nginx/error_kutt.log warn;
+
+ # additional config
+ #include nginxconfig.io/general.conf;
+ location / {
+ proxy_pass http://127.0.0.1:3000;
+ proxy_set_header Host $host;
+ proxy_set_header X-Real-IP $remote_addr;
+ proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
+ }
+
+}
+
+
+# HTTP redirect
+server {
+ listen 80;
+ listen [::]:80;
+ server_name .kutt.domain.com;
+ return 301 https://kutt.domain.com$request_uri;
+}version: "3"
+services:
+ nas-tools:
+ image: nastool/nas-tools:latest
+ ports:
+ - 3000:3000 # 默认的webui控制端口
+ volumes:
+ - ./config:/config # 冒号左边请修改为你想保存配置的路径
+ - /repo/others:/repo/others # 媒体目录,多个目录需要分别映射进来,需要满足配置文件说明中的要求
+ - /repo/movies:/repo/movies
+ - /repo/tvseries:/repo/tvseries
+ - /repo/resources/link:/repo/resources/link
+ environment:
+ - PUID=1000 # 想切换为哪个用户来运行程序,该用户的uid
+ - PGID=1000 # 想切换为哪个用户来运行程序,该用户的gid
+ - UMASK=022 # 掩码权限,默认000,可以考虑设置为022
+ - NASTOOL_AUTO_UPDATE=false # 如需在启动容器时自动升级程程序请设置为true
+ - NASTOOL_CN_UPDATE=false # 如果开启了容器启动自动升级程序,并且网络不太友好时,可以设置为true,会使用国内源进行软件更新
+ #- REPO_URL=https://ghproxy.com/https://github.com/NAStool/nas-tools.git # 当你访问github网络很差时,可以考虑解释本行注释
+ restart: always
+ network_mode: bridge
+ hostname: nas-tools
+ container_name: nastoolhttps://core.telegram.org/api/obtaining_api_id
repo:
https://github.com/tdlib/telegram-bot-apigenerator:
https://tdlib.github.io/telegram-bot-api/build.htmlshellapt-get update +apt-get upgrade +apt-get install make git zlib1g-dev libssl-dev gperf cmake g++ +git clone --recursive https://github.com/tdlib/telegram-bot-api.git +cd telegram-bot-api +rm -rf build +mkdir build +cd build +cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX:PATH=/usr/local .. +cmake --build . --target install +cd ../.. +ls -l /usr/local/bin/telegram-bot-api*
systemctl edit --force --full tgbot-api.service
[Unit]
+Description=telegram bot api
+After=network.target
+[Service]
+Environment="TELEGRAM_API_ID=xxx"
+Environment="TELEGRAM_API_HASH=xxx"
+ExecStart=/usr/local/bin/telegram-bot-api --http-port=16666 --local --log=/var/log/telegram-bot-api/tg-bot-api.log
+[Install]
+WantedBy=multi-user.target[Unit]
+Description=uwsgi
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/bin/uwsgi --emperor /opt/uwsgi
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target[uwsgi]
+; 套接字文件的位置,可以是Unix socket或TCP地址
+http-socket = ip:port
+
+; Django项目根目录
+chdir = /root/project/home
+
+; 加载Django应用
+module = home.wsgi:application
+
+; 启用主线程
+master = true
+
+; 进程数量
+processes = 1
+
+; 每个进程的线程数
+threads = 1
+
+; 启用文件监控,代码改动自动重载
+py-autoreload = 1
+
+; 设置虚拟环境
+virtualenv = /root/project/home/venv
+
+; python搜索路径
+pythonpath = /root/project/home/venv/lib/python3.10/site-packages
+
+
+; 日志目录
+logto = /var/log/uwsgi/%n.log
+
+plugins = python3
+
+buffer-size = 65536apt install vsftpdvim /etc/vsftpd.conf
listen=NO
+listen_ipv6=YES
+# 禁止匿名用户登录
+anonymous_enable=NO
+# 允许本地用户登录
+local_enable=YES
+# 允许本地用户进行写操作
+write_enable=YES
+# 将所有本地用户限制在其主目录中
+chroot_local_user=YES
+# 允许在受限目录中有写权限
+allow_writeable_chroot=YES重启systemctl restart vsftpd
usergroup add ftpuser
+# 创建用户 指定用户组、家目录、禁止用户通过ssh/控制台登录
+useradd -g ftpuser -d /home/ftpuser -s /usr/sbin/nologin newftpuser
+# 设置密码
+passwd newftpuservim /etc/shells,最后一行添加/usr/sbin/nologin
`,163)]))}const o=i(p,[["render",h]]);export{g as __pageData,o as default}; diff --git "a/assets/tinker_network_home server\346\220\255\345\273\272.md.DL0brMy8.lean.js" "b/assets/tinker_network_home server\346\220\255\345\273\272.md.DL0brMy8.lean.js" new file mode 100644 index 00000000..0c62727b --- /dev/null +++ "b/assets/tinker_network_home server\346\220\255\345\273\272.md.DL0brMy8.lean.js" @@ -0,0 +1,760 @@ +import{_ as i,c as a,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"家庭服务器home server搭建","description":"","frontmatter":{},"headers":[],"relativePath":"tinker/network/home server搭建.md","filePath":"tinker/network/home server搭建.md","lastUpdated":1729217313000}'),p={name:"tinker/network/home server搭建.md"};function h(t,s,e,k,r,d){return l(),a("div",null,s[0]||(s[0]=[n(`在 /etc/shells 文件中添加 /usr/sbin/nologin 的作用是允许系统中某些服务(如 FTP)将使用 /usr/sbin/nologin 作为登录 shell 的用户视为合法用户。
允许通过特定服务登录:一些服务(如 FTP 服务器、邮件服务器等)会检查用户的登录 shell 是否在 /etc/shells 列表中,以决定是否允许用户登录。 将 /usr/sbin/nologin 添加到 /etc/shells 文件后,配置了这个 shell 的用户将被这些服务视为合法用户,允许通过这些服务登录。
阻止用户获得交互式 shell: 即使 /usr/sbin/nologin 被添加到 /etc/shells 中,用户仍然无法通过 SSH、控制台等方式获得交互式 shell。/usr/sbin/nologin 会立即终止会话并显示一条消息,通常是“此账户当前不可用”。
一直想搞一台nas玩玩儿,但是看了群晖、威联通这些成品nas低到令人发指的性价比,我最终还是决定diy一台小主机来实现自己的需求。
PC上还有块4T的希捷酷鹰,再添3块4T紫盘组raid5阵列。机箱的盘位就至少需要4个以上,挑了一圈就乔思伯N1(5盘位)和万由的810A(8盘位)能看的过去,虽然万由盘位多但是价格比n1高了大几百,目前也用不到这么多盘位,因此机箱确定了n1,主板也要买itx版型。
要跑的docker容器比较多,下载器服务、阿里云的webdav容器、直播录制程序容器等等。。。因此内存需要32G以上。
确定使用的系统是个比较复杂的过程,因为有过PVE虚拟机翻车的经历,这个服务器又主要承载了数据存储功能,所以要追求稳定,因此首先排除PVE和ESXi这些虚拟机系统,直接物理机装系统。然后我在虚拟机上装了最新版的Truenas scale体验了一下,这个系统是基于debian用python开发的,交互上倒没什么问题,但是因为是个纯nas系统,对主系统限制较多,自由度不高(不能直接装软件),因此也被pass,黑群晖这些就不说了,在我看来还不如truenas。一圈排除下来就只能直接装linux server了。去V2EX论坛问了老哥们的意见,推荐debian的很多,也有建议用最熟悉的系统的, 最后我选择了后者,选了比较有把握的ubuntu server,正好ubuntu的22.04发行版刚出,就直接安排上了。 2024年还是换成了debian,ubuntu server更新太频繁经常重启,有点难顶。
经过了好几天的挑选,最终敲定了这套配置
cpu:i3-10100散片
+主板:七彩虹cvn b460i frozen
+内存:金士顿16g*2 2666
+固态:七彩虹 ssd sata3 128g
+cpu散热:超频3刀锋
+机械硬盘:西数海康oem紫盘4t*3
+电源:tt 350w sfx电源
+机箱+线材:乔思伯n1
+扩展卡:乐扩m2转sata3接口扩展卡其中散热、固态是在公司的福利商城购买,cpu、机械硬盘、机箱、扩展卡在淘宝购买,主板、电源在京东购买,内存在咸鱼淘的。不算硬盘花费是2480,加上硬盘3755。
组装完成后:
跟其他工业风机箱比起来,乔思伯n1这款颜值还是很不错的。
ubuntu官网下载最新版的ubuntu-server-22.04,然后rufus刷写到U盘中,使用U盘引导启动。
安装过程不再赘述,这里记录几个重点步骤:
在配置Ubuntu安装镜像这一步最好选择国内的企业/大学镜像站,不然后面安装可能会在下载时卡住。网易镜像源http://mirrors.163.com/ubuntu/,阿里云镜像源https://mirrors.aliyun.com/ubuntu/,清华源https://mirrors.tuna.tsinghua.edu.cn/ubuntu/
/和/boot 两个区,然后四块4T机械组了raid5。(ubuntu在建立阵列后会立刻进入重建过程,阵列中会有一个分区状态为spare rebuilding ,其他分区为active sync。这个重建过程很久,我4块4T重建总共用了十几个小时,重建完成后阵列下所有分区都会变为active sync 状态
开启root登陆
sudo vim /etc/ssh/sshd_config
+
+# 添加配置
+PermitRootLogin yes
+
+# 给root修改密码
+sudo passwd root
+
+systemctl restart sshd启用密钥登陆
见另一篇博客 阿里云服务器启用密钥登陆并禁用密码登陆
时区同步
sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
这个部分长期更新XD,一点点补上吧。
# 安装samba
+sudo apt install samba
+# 启动smb
+systemctl start smb
+# 开机自启
+systemctl enable smb
+
+# 创建共享文件夹 设置权限770
+mkdir /mnt/data
+sudo chmod 770 /mnt/data
+
+# 添加用户和密码
+sudo smbpasswd -a 用户名
+
+# 修改配置文件,在文件最后添加共享资源设置
+sudo vim /etc/samba/smb.conf
+
+[data]
+path = /mnt/data
+available = yes
+browseable = yes
+public = no
+writable = yes
+valid users = storysamba共享配置详解
[temp] #共享资源名称
comment = Temporary file space #简单的解释,内容无关紧要
path = /tmp #实际的共享目录
writable = yes #设置为可写入
browseable = yes #可以被所有用户浏览到资源名称,
guest ok = yes #可以让用户随意登录
public = yes #允许匿名查看
valid users = 用户名 #设置访问用户
valid users = @组名 #设置访问组
readonly = yes #只读
readonly = no #读写
hosts deny = 192.168.0.0 #表示禁止所有来自192.168.0.0/24 网段的IP 地址访问
hosts allow = 192.168.0.24 #表示允许192.168.0.24 这个IP 地址访问
[homes]为特殊共享目录,表示用户主目录。
[printers]表示共享打印机。
原文链接:https://blog.csdn.net/l1593572468/article/details/121444812
# Uninstall old versions
+sudo apt-get remove docker docker-engine docker.io containerd runc
+
+# Update the apt package index and install packages to allow apt to use a repository over HTTPS:
+sudo apt-get update
+sudo apt-get install \\
+ ca-certificates \\
+ curl \\
+ gnupg \\
+ lsb-release
+# Add Docker’s official GPG key:
+curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
+
+# Use the following command to set up the stable repository.
+echo \\
+ "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \\
+ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
+
+# Install Docker Engine
+sudo apt-get update
+sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
+
+
+systemctl enable docker参考另一篇博客挂载阿里云盘+开机自动挂载
docker run -d \\
+ --name=transmission \\
+ -e TRANSMISSION_WEB_HOME=/transmission-web-control/ \\
+ -e PUID=1000 \\
+ -e PGID=1000 \\
+ -e TZ=Asia/Shanghai \\
+ -e USER=<user> \\
+ -e PASS=<pass> \\
+ -p 19091:9091 \\
+ -p 51413:51413 \\
+ -p 51413:51413/udp \\
+ -v /mnt/data/docker/transmission/data:/config \\
+ -v /mnt/data/downloads/others:/downloads/others \\
+ -v /mnt/data/downloads/tvseries:/downloads/tvseries \\
+ -v /mnt/data/docker/transmission/watch/folder:/watch \\
+ -v /mnt/data/downloads/movies:/downloads/movies \\
+ --restart=always \\
+ linuxserver/transmissionversion: "3.2"
+
+services:
+ qbittorrent:
+ image: nevinee/qbittorrent:4.3.9
+ container_name: qbittorrent
+ environment:
+ - PUID=0
+ - PGID=0
+ - TZ=Asia/Shanghai
+ - WEBUI_PORT=18080
+ - BT_PORT=55555
+ volumes:
+ - /mnt/data/docker/qbittorrent/config:/data
+ - /repo:/downloads
+ network_mode: host
+ restart: unless-stoppeddocker run -d \\
+ --name aria2 \\
+ --restart always \\
+ --log-opt max-size=1m \\
+ -e TZ=Asia/Shanghai \\
+ -e PUID=$UID \\
+ -e PGID=$GID \\
+ -e UMASK_SET=022 \\
+ -e RPC_SECRET=<secret> \\
+ -e RPC_PORT=16800 \\
+ -p 16800:16800 \\
+ -e LISTEN_PORT=16888 \\
+ -p 16888:16888 \\
+ -p 16888:16888/udp \\
+ -v /mnt/data/docker/aria2/config:/config \\
+ -v /mnt/data/downloads/tvseries:/downloads/tvseries \\
+ -v /mnt/data/downloads/movies:/downloads/movies \\
+ -v /mnt/data/downloads/others:/downloads/others \\
+ p3terx/aria2-proversion: "3.2"
+
+services:
+ jenkins:
+ image: jenkins/jenkins:2.332.3-jdk11
+ container_name: jenkins
+ environment:
+ - TZ=Asia/Shanghai
+ user: root
+ volumes:
+ - /story/dist:/story/dist
+ - /mnt/data/docker/jenkins/jenkins_data:/var/jenkins_home
+ - /etc/localtime:/etc/localtime:ro
+ ports:
+ - "8099:8080"
+ restart: unless-stoppedversion: "3.2"
+services:
+ jellyfin:
+ image: linuxserver/jellyfin
+ container_name: jellyfin
+ environment:
+ - PUID=0
+ - PGID=0
+ - TZ=Asia/Shanghai
+ volumes:
+ - /mnt/data/docker/jellyfin/library:/config
+ - /tvshows:/data/tvshows
+ - /movies:/data/movies
+ devices:
+ - /dev/dri:/dev/dri
+ network_mode: host
+ restart: unless-stopped# 安装驱动
+apt install intel-media-va-driver
+# 解码支持确认
+/usr/lib/jellyfin-ffmpeg/vainfo
wget https://downloads.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz
+ tar -xzvf kafka_2.13-3.6.1.tgz -C /usr/localzookeeper.service
[Unit]
+Description=zookeeper
+
+[Service]
+Type=forking
+Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
+ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh -daemon /usr/local/kafka/config/zookeeper.properties
+ExecStop=/usr/local/kafka/bin/zookeeper-server-start.sh stop
+SyslogIdentifier=zookeeper
+
+[Install]
+WantedBy=multi-user.targetkafka.service
[Unit]
+Description=kafka
+After=zookeeper.service
+
+[Service]
+Type=forking
+Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
+ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
+ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
+
+[Install]
+WantedBy=multi-user.targetdocker run -d \\
+ --name onedev \\
+ -v /var/run/docker.sock:/var/run/docker.sock \\
+ -v /mnt/data/docker/onedev:/opt/onedev \\
+ -p 6610:6610 \\ # http
+ -p 6611:6611 \\ # ssh
+ --restart=always \\
+ 1dev/server:latestsudo apt install rabbitmq-server
+
+cd /usr/lib/rabbitmq/bin
+# 开启rabbit网页控制台 默认端口号15672,重启rabbitmq服务
+ ./rabbitmq-plugins enable rabbitmq_management
+
+# rabbitmq默认用户guest不允许远程登陆,且systemd默认的启动用户为rabbitmq,可以改为root
+cd /lib/systemd/system
+vim rabbitmq-server.service
+
+# 新建rabbitmq用户
+cd /usr/lib/rabbitmq/bin
+./rabbitmqctl add_user username password
+# 授权
+./rabbitmqctl set_user_tags username administrator
+./rabbitmqctl set_permissions -p "/" username ".*" ".*" ".*"
+
+# 查看、删除、修改密码
+./rabbitmqctl list_users
+./rabbitmqctl delete_user username
+./rabbitmqctl change_password username newpasswordversion: "3"
+
+networks:
+ gitea:
+ external: false
+
+volumes:
+ gitea:
+ driver: local
+
+services:
+ server:
+ image: gitea/gitea:1.16.7
+ container_name: gitea
+ environment:
+ - DOMAIN=192.168.2.66
+ - HTTP_PORT=6610
+ - SSH_PORT=6611
+ - SSH_LISTEN_PORT=6611
+ restart: always
+ networks:
+ - gitea
+ volumes:
+ - gitea:/data
+ - /etc/timezone:/etc/timezone:ro
+ - /etc/localtime:/etc/localtime:ro
+ ports:
+ - "6610:6610"
+ - "6611:6611"/var/lib/docker/volumes/gitea_gitea/_data/gitea/conf/app.ini
+
+# add the following lines to the end of the file
+[webhook]
+ALLOWED_HOST_LIST = 192.168.2.66In Jenkins: on the job settings page set "Source Code Management" option to "Git", provide URL to your repo (http://gitea-url.your.org/username/repo.git), and in "Poll triggers" section check "Poll SCM" option with no schedule defined. This setup basically tells Jenkins to poll your Gitea repo only when requested via the webhook.
In Gitea: under repo -> Settings -> Webhooks, add new webhook, set the URL to http://jenkins_url.your.org/gitea-webhook/post, and clear the secret (leave it blank).
At this point clicking on "Test Delivery" button should produce a successful delivery attempt (green checkmark).
docker run -d --name kafkaui -p 9000:9000 \\
+ -e KAFKA_BROKERCONNECT="192.168.2.66:9092"\\
+ -e JVM_OPTS="-Xms32M -Xmx64M" \\
+ -e SERVER_SERVLET_CONTEXTPATH="/" \\
+ obsidiandynamics/kafdropversion: '3'
+
+services:
+ cadvisor:
+ image: gcr.io/cadvisor/cadvisor:v0.47.2
+ container_name: cadvisor
+ volumes:
+ - /:/rootfs:ro
+ - /var/run:/var/run:ro
+ - /sys:/sys:ro
+ - /var/lib/docker/:/var/lib/docker:ro
+ - /dev/disk/:/dev/disk:ro
+ ports:
+ - "28080:8080"
+ privileged: true
+ restart: unless-stopped
+ devices:
+ - /dev/kmsgwget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gztar -zxvf node_exporter-1.6.1.linux-amd64.tar.gz && mv node_exporter-1.6.1.linux-amd64/node_exporter /usr/local/bin # 编写systemd服务
+cat > /etc/systemd/system/node_exporter.service <<EOF
+[Unit]
+Description=node_exporeter
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/local/bin/node_exporter
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF
+
+# 更新内核并启动,自启动
+systemctl daemon-reload && systemctl start node_exporter && systemctl enable node_exporter && systemctl status node_exporter# openwrt要使用init.d
+# /etc/init.d/node_exporter
+#!/bin/sh /etc/rc.common
+
+START=99
+STOP=10
+
+start() {
+ echo "Starting Node Exporter..."
+ /usr/bin/node_exporter --web.listen-address=":9100" > /dev/null 2>&1 &
+}
+
+stop() {
+ echo "Stopping Node Exporter..."
+ killall node_exporter
+}
+
+restart() {
+ stop
+ sleep 1
+ start
+}/etc/init.d/node_exporter enable && /etc/init.d/node_exporter start
wget https://github.com/oliver006/redis_exporter/releases/download/v1.46.0/redis_exporter-v1.46.0.linux-amd64.tar.gztar -xvf redis_exporter-v1.46.0.linux-amd64.tar.gz && mv redis_exporter-v1.46.0.linux-amd64/redis_exporter /usr/local/bin# 编写systemd服务
+cat > /etc/systemd/system/redis_exporter.service <<EOF
+[Unit]
+Description=redis_exporter
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/local/bin/redis_exporter -redis.addr ip:port
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF
+
+# 更新内核并启动,自启动
+systemctl daemon-reload && systemctl start redis_exporter && systemctl enable redis_exporter && systemctl status redis_exporter# docker-compose.yml
+
+version: "3"
+
+
+services:
+ grafana:
+ image: grafana/grafana
+ container_name: grafana
+ restart: unless-stopped
+ ports:
+ - 3000:3000
+ user: root
+ volumes:
+ - /mnt/data/docker/monitor/grafana/conf/grafana.ini:/etc/grafana/grafana.ini
+ - /mnt/data/docker/monitor/grafana/data:/var/lib/grafana
+ - /mnt/data/docker/monitor/grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards
+ - /mnt/data/docker/monitor/grafana/provisioning/datasources:/etc/grafana/provisioning/datasources
+ environment:
+ - TZ=Asia/shanghai
+ prometheus:
+ image: prom/prometheus
+ container_name: prometheus
+ restart: unless-stopped
+ ports:
+ - 9090:9090
+ volumes:
+ - /mnt/data/docker/monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
+ - prometheus_data:/prometheus
+ environment:
+ - TZ=Asia/shanghai
+
+volumes:
+ prometheus_data:prometheus.yml
global:
+ scrape_interval: 15s
+ evaluation_interval: 15s
+
+
+scrape_configs:
+ - job_name: "linux"
+ scrape_interval: 5s
+ static_configs:
+ - targets: [ "192.168.2.66:9100" ]
+ labels:
+ instance: home-server-ubuntu
+ - job_name: "redis"
+ scrape_interval: 5s
+ static_configs:
+ - targets: [ "192.168.2.66:9121" ]
+ labels:
+ instance: home-server-ubuntu
+ - job_name: "cadvisor"
+ static_configs:
+ - targets: [ "192.168.2.66:28080" ]
+ labels:
+ instance: home-server-ubuntudocker cp grafana:/etc/grafana.ini ~/grafana监控大盘模板
配置域名解析,Bitwarden默认使用80和443端口,可以执行安装后在bwdata/config.yaml修改端口
http_prt: 80
+https_port: 443修改完
bwdata/config.yaml后需要执行./bitwarden.sh rebuild
curl -fsSL https://get.docker.com | sudo sh
sudo adduser bitwarden
+sudo passwd bitwarden
+sudo groupadd docker
+sudo usermod -aG docker bitwarden
+sudo mkdir /opt/bitwarden
+sudo chmod -R 700 /opt/bitwarden
+sudo chown -R bitwarden:bitwarden /opt/bitwarden**](https://bitwarden.com/host/) for use in installation.
For more information, see What are my installation id and installation key used for?
curl -Lso bitwarden.sh "https://func.bitwarden.com/api/dl/?app=self-host&platform=linux" && chmod 700 bitwarden.sh
+
+./bitwarden.sh install./bwdata/env/global.override.env. globalSettings__mail__replyToEmail=email@example.com
+globalSettings__mail__smtp__host=smtp.qq.com
+globalSettings__mail__smtp__port=465
+globalSettings__mail__smtp__ssl=true
+globalSettings__mail__smtp__username=email@example.com
+globalSettings__mail__smtp__password=password
+
+globalSettings__disableUserRegistration=true # 禁止注册修改完后执行
./bitwarden.sh restart
./bitwarden.sh start
backup bwdata folder
https://bitwarden.com/help/migration/
如果低版本迁移到高版本,覆盖bwdata后,先执行./bitwarden.sh update
https://bitwarden.com/download
version: '3.8'
+
+services:
+ hoppscotch:
+ container_name: hoppscotch
+ image: hoppscotch/hoppscotch
+ ports:
+ - "53000:3000"
+ - "53100:3100"
+ - "53170:3170"
+ env_file: .env
+ restart: unless-stopped
+ links:
+ - postgresql
+ depends_on:
+ - postgresql
+ networks:
+ - hoppscotch
+ postgresql:
+ container_name: postgresql
+ image: postgres
+ environment:
+ POSTGRES_DB: db
+ POSTGRES_USER: user
+ POSTGRES_PASSWORD: passwd
+ ports:
+ - "5432:5432"
+ volumes:
+ - postgres_data:/var/lib/postgresql/data
+ restart: unless-stopped
+ networks:
+ - hoppscotch
+
+volumes:
+ postgres_data:
+
+networks:
+ hoppscotch:#-----------------------Backend Config------------------------------#
+# Prisma Config
+DATABASE_URL=postgresql://user:passwd@postgresql:5432/db
+
+# Auth Tokens Config
+JWT_SECRET="xxx"
+TOKEN_SALT_COMPLEXITY=10
+MAGIC_LINK_TOKEN_VALIDITY= 3
+REFRESH_TOKEN_VALIDITY="604800000" # Default validity is 7 days (604800000 ms) in ms
+ACCESS_TOKEN_VALIDITY="86400000" # Default validity is 1 day (86400000 ms) in ms
+SESSION_SECRET='xxx'
+
+# Hoppscotch App Domain Config
+REDIRECT_URL="https://hoppscotch.example.com"
+WHITELISTED_ORIGINS="https://hoppscotch.example.com/backend,https://hoppscotch.example.com,https://hoppadmin.example.com"
+VITE_ALLOWED_AUTH_PROVIDERS=GITHUB
+
+# Google Auth Config
+#GOOGLE_CLIENT_ID="************************************************"
+#GOOGLE_CLIENT_SECRET="************************************************"
+#GOOGLE_CALLBACK_URL="http://hoppscotch.example.com:3170/v1/auth/google/callback"
+#GOOGLE_SCOPE="email,profilstoryxc
+
+# Github Auth Config
+GITHUB_CLIENT_ID="xxx"
+GITHUB_CLIENT_SECRET="xxx"
+GITHUB_CALLBACK_URL="https://hoppscotch.example.com/backend/v1/auth/github/callback"
+GITHUB_SCOPE="user:email"
+
+# Microsoft Auth Config
+#MICROSOFT_CLIENT_ID="************************************************"
+#MICROSOFT_CLIENT_SECRET="************************************************"
+#MICROSOFT_CALLBACK_URL="http://hoppscotch.example.com:3170/v1/auth/microsoft/callback"
+#MICROSOFT_SCOPE="user.read"
+#MICROSOFT_TENANT="common"
+
+# Mailer config
+MAILER_SMTP_URL="smtps://user@domain.com:passwd@smtp.domain.com"
+MAILER_ADDRESS_FROM="user@domain.com"
+
+# Rate Limit Config
+RATE_LIMIT_TTL=60 # In seconds
+RATE_LIMIT_MAX=100 # Max requests per IP
+
+
+#-----------------------Frontend Config------------------------------#
+
+
+# Base URLs
+VITE_BASE_URL=https://hoppscotch.example.com
+VITE_SHORTCODE_BASE_URL=https://hoppscotch.example.com
+VITE_ADMIN_URL=https://hoppadmin.example.com
+
+# Backend URLs
+VITE_BACKEND_GQL_URL=https://hoppscotch.example.com/backend/graphql
+VITE_BACKEND_WS_URL=wss://hoppscotch.example.com/backend/ws/graphql
+VITE_BACKEND_API_URL=https://hoppscotch.example.com/backend/v1
+
+# Terms Of Service And Privacy Policy Links (Optional)
+VITE_APP_TOS_LINK=https://docs.hoppscotch.io/support/terms
+VITE_APP_PRIVACY_POLICY_LINK=https://docs.hoppscotch.io/support/privacyserver {
+ listen 443 ssl;
+ listen [::]:443 ssl;
+ server_name hoppscotch.example.com;
+
+ # SSL
+ ssl_certificate /etc/nginx/ssl/hoppscotch.example.com.crt;
+ ssl_certificate_key /etc/nginx/ssl/hoppscotch.example.com.key;
+ ssl_session_timeout 5m;
+ #请按照以下协议配置
+ ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
+ #表示使用的加密套件的类型。
+ ssl_protocols TLSv1.1 TLSv1.2;
+
+ # security
+
+ # logging
+ access_log /var/log/nginx/access.log combined buffer=512k flush=1m;
+ error_log /var/log/nginx/error.log warn;
+
+ # additional config
+
+ location /backend/ws/ {
+ proxy_pass http://127.0.0.1:53170/;
+ proxy_set_header Upgrade $http_upgrade;
+ proxy_set_header Connection "Upgrade";
+ proxy_set_header X-Real-IP $remote_addr;
+ }
+
+ location /backend/ {
+ proxy_pass http://127.0.0.1:53170/;
+ }
+
+ location / {
+ proxy_pass http://127.0.0.1:53000/;
+ }
+}
+
+# HTTP redirect
+server {
+ listen 80;
+ listen [::]:80;
+ server_name hoppscotch.example.com;
+ return 301 https://hoppscotch.example.com$request_uri;
+}version: "3"
+
+services:
+ kutt:
+ image: kutt/kutt
+ depends_on:
+ - postgres
+ - redis
+ command: [ "./wait-for-it.sh", "postgres:5432", "--", "npm", "start" ]
+ ports:
+ - "3000:3000"
+ env_file:
+ - .env
+ environment:
+ DB_HOST: postgres
+ DB_NAME: kutt
+ DB_USER: user
+ DB_PASSWORD: passwd
+ REDIS_HOST: redis
+
+ redis:
+ image: redis:6.0-alpine
+ volumes:
+ - redis_data:/data
+
+ postgres:
+ image: postgres:12-alpine
+ environment:
+ POSTGRES_USER: user
+ POSTGRES_PASSWORD: passwd
+ POSTGRES_DB: kutt
+ volumes:
+ - postgres_data:/var/lib/postgresql/data
+
+volumes:
+ redis_data:
+ postgres_data:# App port to run on
+PORT=3000
+
+# The name of the site where Kutt is hosted
+SITE_NAME=Kutt
+
+# The domain that this website is on
+DEFAULT_DOMAIN=kutt.domain.com
+
+# Generated link length
+LINK_LENGTH=5
+
+# Postgres database credential details
+DB_HOST=postgres
+DB_PORT=5432
+DB_NAME=postgres
+DB_USER=user
+DB_PASSWORD=passwd
+DB_SSL=false
+
+# Redis host and port
+REDIS_HOST=redis
+REDIS_PORT=6379
+REDIS_PASSWORD=
+REDIS_DB=
+
+# Disable registration
+DISALLOW_REGISTRATION=true
+
+# Disable anonymous link creation
+DISALLOW_ANONYMOUS_LINKS=true
+
+# The daily limit for each user
+USER_LIMIT_PER_DAY=50
+
+# Create a cooldown for non-logged in users in minutes
+# Set 0 to disable
+NON_USER_COOLDOWN=0
+
+# Max number of visits for each link to have detailed stats
+DEFAULT_MAX_STATS_PER_LINK=5000
+
+# Use HTTPS for links with custom domain
+CUSTOM_DOMAIN_USE_HTTPS=false
+
+# A passphrase to encrypt JWT. Use a long and secure key.
+JWT_SECRET=xxx
+
+# Admin emails so they can access admin actions on settings page
+# Comma seperated
+ADMIN_EMAILS=user@domain.com
+
+# Invisible reCaptcha secret key
+# Create one in https://www.google.com/recaptcha/intro/
+RECAPTCHA_SITE_KEY=
+RECAPTCHA_SECRET_KEY=
+
+# Google Cloud API to prevent from users from submitting malware URLs.
+# Get it from https://developers.google.com/safe-browsing/v4/get-started
+GOOGLE_SAFE_BROWSING_KEY=
+
+# Your email host details to use to send verification emails.
+# More info on http://nodemailer.com/
+# Mail from example "Kutt <support@kutt.it>". Leave empty to use MAIL_USER
+MAIL_HOST=smtp.domain.com
+MAIL_PORT=465
+MAIL_SECURE=true
+MAIL_USER=user@domain.com
+MAIL_FROM=user@domain.com
+MAIL_PASSWORD=passwd
+
+# The email address that will receive submitted reports.
+REPORT_EMAIL=
+
+# Support email to show on the app
+CONTACT_EMAIL=server {
+ listen 443 ssl;
+ listen [::]:443 ssl;
+ server_name kutt.domain.com;
+
+ # SSL
+ ssl_certificate /etc/nginx/ssl/kutt.domain.com.crt;
+ ssl_certificate_key /etc/nginx/ssl/kutt.domain.com.key;
+ ssl_session_timeout 5m;
+ #请按照以下协议配置
+ ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
+ #表示使用的加密套件的类型。
+ ssl_protocols TLSv1.1 TLSv1.2;
+
+ # security
+ include nginxconfig.io/security.conf;
+
+ # logging
+ access_log /var/log/nginx/access_kutt.log combined buffer=512k flush=1m;
+ error_log /var/log/nginx/error_kutt.log warn;
+
+ # additional config
+ #include nginxconfig.io/general.conf;
+ location / {
+ proxy_pass http://127.0.0.1:3000;
+ proxy_set_header Host $host;
+ proxy_set_header X-Real-IP $remote_addr;
+ proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
+ }
+
+}
+
+
+# HTTP redirect
+server {
+ listen 80;
+ listen [::]:80;
+ server_name .kutt.domain.com;
+ return 301 https://kutt.domain.com$request_uri;
+}version: "3"
+services:
+ nas-tools:
+ image: nastool/nas-tools:latest
+ ports:
+ - 3000:3000 # 默认的webui控制端口
+ volumes:
+ - ./config:/config # 冒号左边请修改为你想保存配置的路径
+ - /repo/others:/repo/others # 媒体目录,多个目录需要分别映射进来,需要满足配置文件说明中的要求
+ - /repo/movies:/repo/movies
+ - /repo/tvseries:/repo/tvseries
+ - /repo/resources/link:/repo/resources/link
+ environment:
+ - PUID=1000 # 想切换为哪个用户来运行程序,该用户的uid
+ - PGID=1000 # 想切换为哪个用户来运行程序,该用户的gid
+ - UMASK=022 # 掩码权限,默认000,可以考虑设置为022
+ - NASTOOL_AUTO_UPDATE=false # 如需在启动容器时自动升级程程序请设置为true
+ - NASTOOL_CN_UPDATE=false # 如果开启了容器启动自动升级程序,并且网络不太友好时,可以设置为true,会使用国内源进行软件更新
+ #- REPO_URL=https://ghproxy.com/https://github.com/NAStool/nas-tools.git # 当你访问github网络很差时,可以考虑解释本行注释
+ restart: always
+ network_mode: bridge
+ hostname: nas-tools
+ container_name: nastoolhttps://core.telegram.org/api/obtaining_api_id
repo:
https://github.com/tdlib/telegram-bot-apigenerator:
https://tdlib.github.io/telegram-bot-api/build.htmlshellapt-get update +apt-get upgrade +apt-get install make git zlib1g-dev libssl-dev gperf cmake g++ +git clone --recursive https://github.com/tdlib/telegram-bot-api.git +cd telegram-bot-api +rm -rf build +mkdir build +cd build +cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX:PATH=/usr/local .. +cmake --build . --target install +cd ../.. +ls -l /usr/local/bin/telegram-bot-api*
systemctl edit --force --full tgbot-api.service
[Unit]
+Description=telegram bot api
+After=network.target
+[Service]
+Environment="TELEGRAM_API_ID=xxx"
+Environment="TELEGRAM_API_HASH=xxx"
+ExecStart=/usr/local/bin/telegram-bot-api --http-port=16666 --local --log=/var/log/telegram-bot-api/tg-bot-api.log
+[Install]
+WantedBy=multi-user.target[Unit]
+Description=uwsgi
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/bin/uwsgi --emperor /opt/uwsgi
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target[uwsgi]
+; 套接字文件的位置,可以是Unix socket或TCP地址
+http-socket = ip:port
+
+; Django项目根目录
+chdir = /root/project/home
+
+; 加载Django应用
+module = home.wsgi:application
+
+; 启用主线程
+master = true
+
+; 进程数量
+processes = 1
+
+; 每个进程的线程数
+threads = 1
+
+; 启用文件监控,代码改动自动重载
+py-autoreload = 1
+
+; 设置虚拟环境
+virtualenv = /root/project/home/venv
+
+; python搜索路径
+pythonpath = /root/project/home/venv/lib/python3.10/site-packages
+
+
+; 日志目录
+logto = /var/log/uwsgi/%n.log
+
+plugins = python3
+
+buffer-size = 65536apt install vsftpdvim /etc/vsftpd.conf
listen=NO
+listen_ipv6=YES
+# 禁止匿名用户登录
+anonymous_enable=NO
+# 允许本地用户登录
+local_enable=YES
+# 允许本地用户进行写操作
+write_enable=YES
+# 将所有本地用户限制在其主目录中
+chroot_local_user=YES
+# 允许在受限目录中有写权限
+allow_writeable_chroot=YES重启systemctl restart vsftpd
usergroup add ftpuser
+# 创建用户 指定用户组、家目录、禁止用户通过ssh/控制台登录
+useradd -g ftpuser -d /home/ftpuser -s /usr/sbin/nologin newftpuser
+# 设置密码
+passwd newftpuservim /etc/shells,最后一行添加/usr/sbin/nologin
`,163)]))}const o=i(p,[["render",h]]);export{g as __pageData,o as default}; diff --git "a/assets/tinker_network_openwrt\345\256\211\350\243\205\345\217\212\351\205\215\347\275\256.md.CO0nBeN9.js" "b/assets/tinker_network_openwrt\345\256\211\350\243\205\345\217\212\351\205\215\347\275\256.md.CO0nBeN9.js" new file mode 100644 index 00000000..9468e1ef --- /dev/null +++ "b/assets/tinker_network_openwrt\345\256\211\350\243\205\345\217\212\351\205\215\347\275\256.md.CO0nBeN9.js" @@ -0,0 +1,12 @@ +import{_ as e,c as s,a2 as n,o as p}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"openwrt安装及配置","description":"","frontmatter":{},"headers":[],"relativePath":"tinker/network/openwrt安装及配置.md","filePath":"tinker/network/openwrt安装及配置.md","lastUpdated":1729217313000}'),t={name:"tinker/network/openwrt安装及配置.md"};function i(l,a,o,r,c,d){return p(),s("div",null,a[0]||(a[0]=[n(`在 /etc/shells 文件中添加 /usr/sbin/nologin 的作用是允许系统中某些服务(如 FTP)将使用 /usr/sbin/nologin 作为登录 shell 的用户视为合法用户。
允许通过特定服务登录:一些服务(如 FTP 服务器、邮件服务器等)会检查用户的登录 shell 是否在 /etc/shells 列表中,以决定是否允许用户登录。 将 /usr/sbin/nologin 添加到 /etc/shells 文件后,配置了这个 shell 的用户将被这些服务视为合法用户,允许通过这些服务登录。
阻止用户获得交互式 shell: 即使 /usr/sbin/nologin 被添加到 /etc/shells 中,用户仍然无法通过 SSH、控制台等方式获得交互式 shell。/usr/sbin/nologin 会立即终止会话并显示一条消息,通常是“此账户当前不可用”。
趁着五一假期把家用服务器装好跑起来了,另外还买了一台J4125工控机来做软路由。工控机的机器今天刚到,下午反复折腾了pve虚拟机安装openwrt和物理机直接安装,目前是用物理机装好配置完毕了,但是看了一眼这监控数据,总感觉有点浪费性能。所以这篇文章写完我还是要换回pve安装(doge),剩下的性能折腾下其他虚拟机。
1. pe工具箱
+2. openwrt编译好的镜像,我用的是esir的固件
+3. 刷写镜像的软件physdiskwrite.exe1. pe工具箱安装到U盘中
+2. 把解压后的x86.img镜像文件和physdiskwrite.exe软件复制到U盘中
+3. 这时候已经可以拔掉硬路由器了,光猫lan口连软路由wan口(要问卖家哪个是wan口,我这个eth1是wan口),pc连软路由lan口(0、2、3),这是为了pc能跟软路由在同一个网段,如果不在则需要手动配置静态ip1. u盘启动工控机
+2. 用pe工具箱自带的diskgenius把装的硬盘格式化即可,注意这里不要进行分区,否则会写盘失败
+3. 打开cmd窗口,执行命令 physdiskwrite.exe -u x86.img,这里可以直接用鼠标把程序拖到cmd窗口,会自动拼出完整路径
+4. 根据终端输出选择要写入的硬盘,比如0是硬盘,1是u盘,就填0,enter即可开始写盘,等待写盘完毕即可
+5. 扩容系统分区,使用diskgenius找到刚刚写入的硬盘,然后再选中上面灰色未使用的分区,右击菜单中选择 “将空间分配给” -> “分区:未格式化(D:)”,然后确认即可
+6. 写盘完毕,选择重启,这时候直接拔出U盘即可
+7. 等待重启后,openwrt系统就已经成功启动了,如果不确定是否安装完,回车一下看看是否有lede的banner输出就行了
+8. openwrt一般ip为192.168.2.1(esir固件是5.1),这个可以看固件wiki或者自己ifconfig看一下
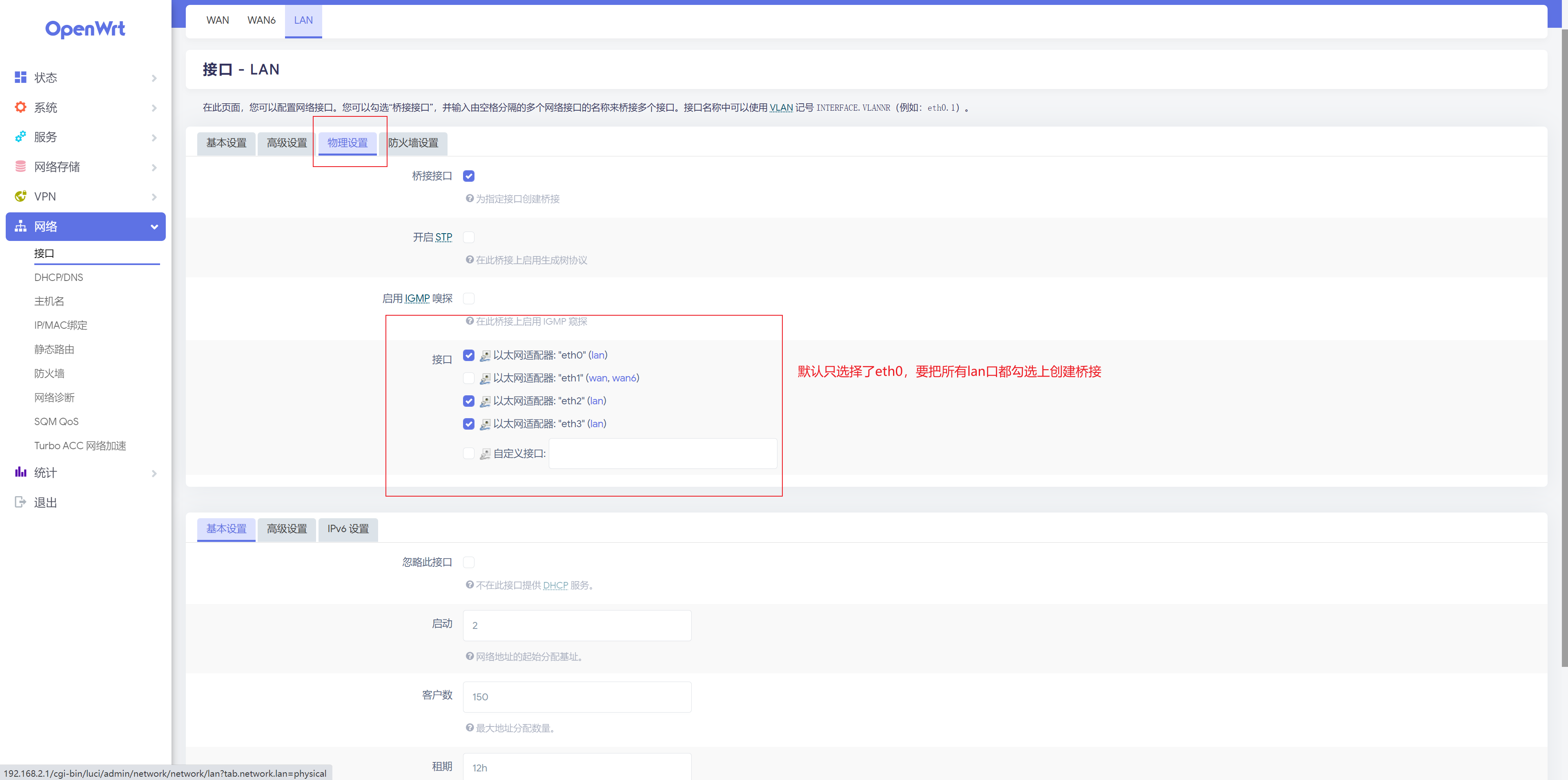
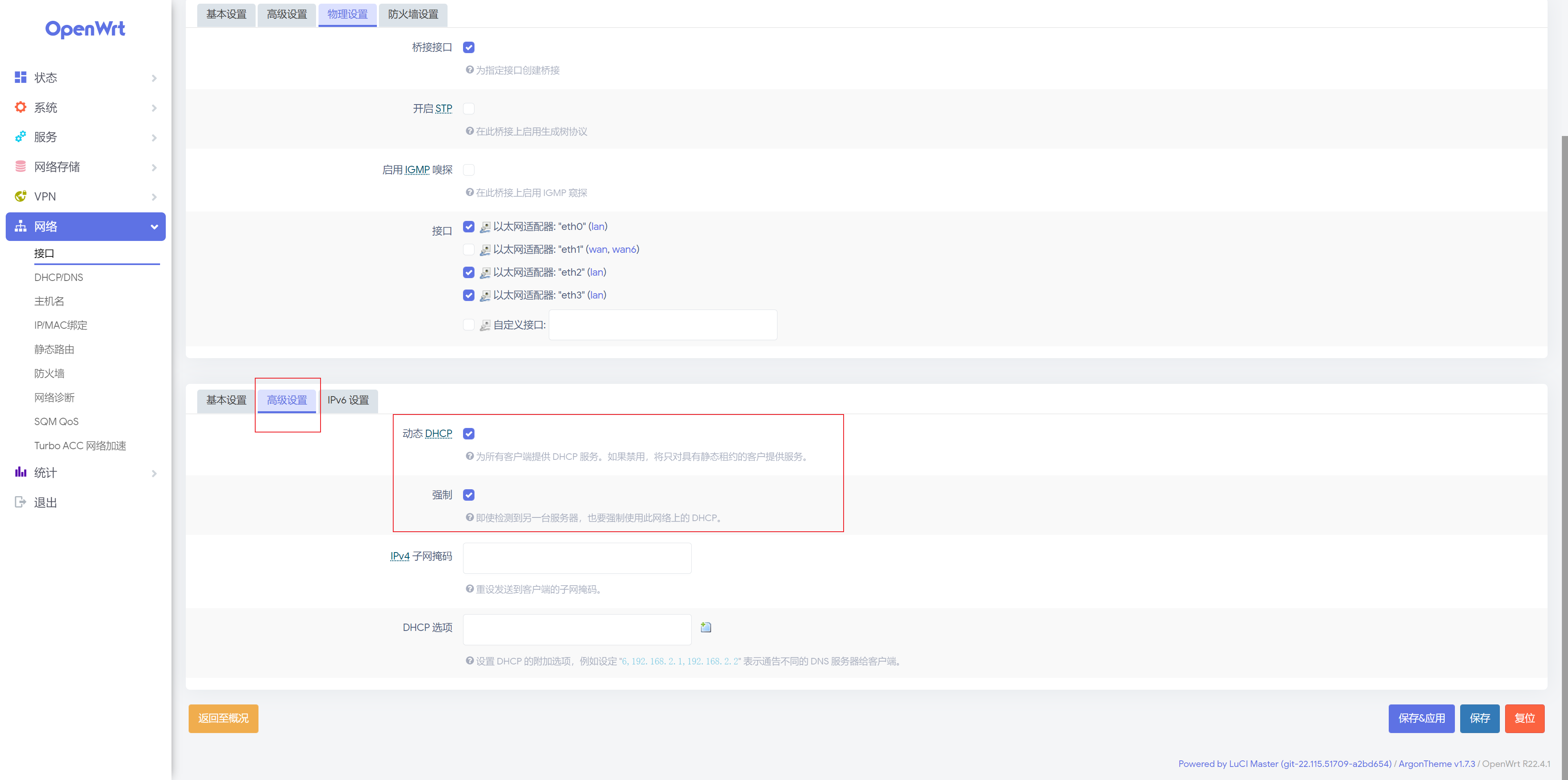
移动光猫改桥接模式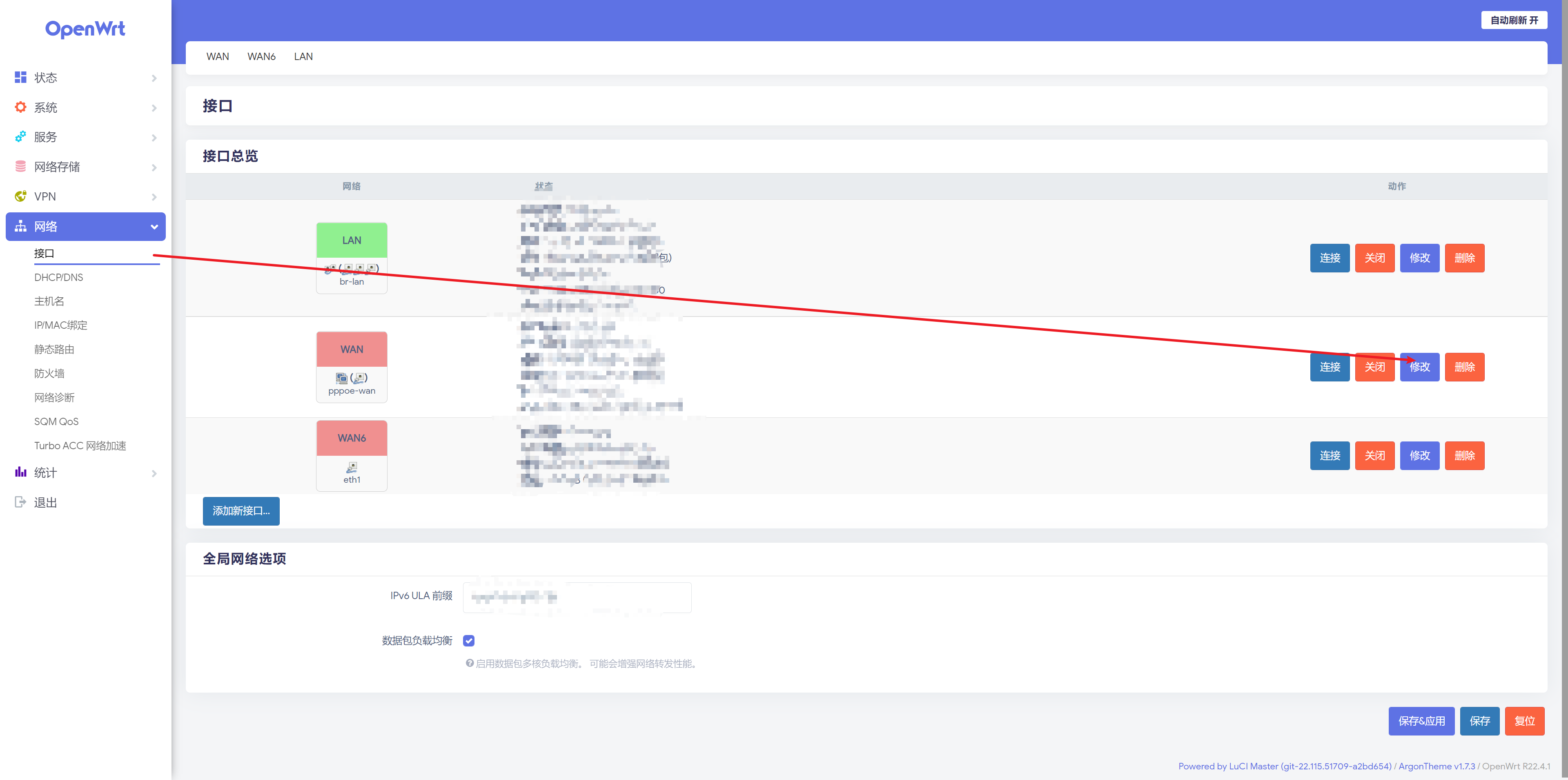
选择PPPoE协议并切换,填上宽带账号密码保存&应用即可
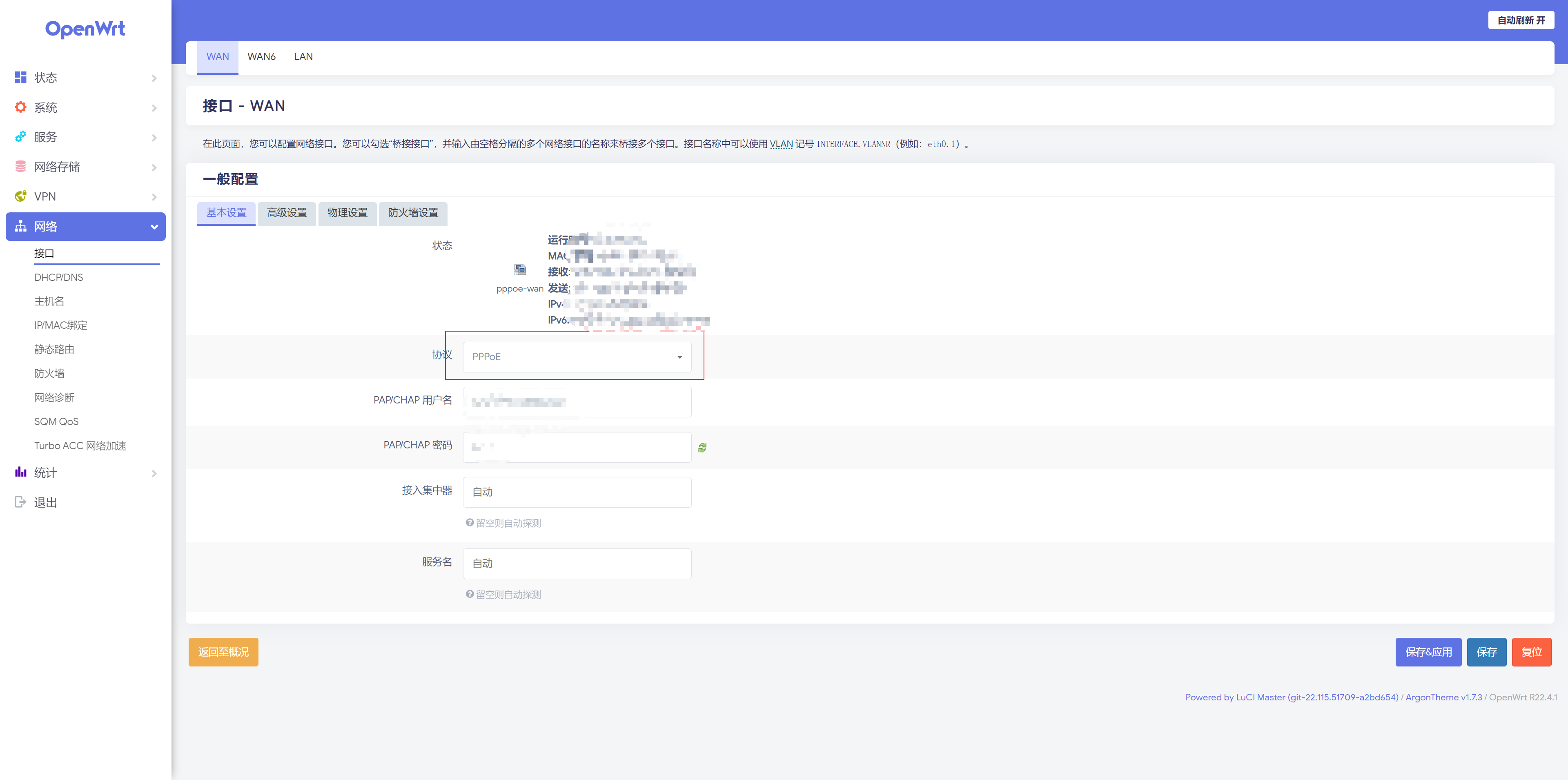
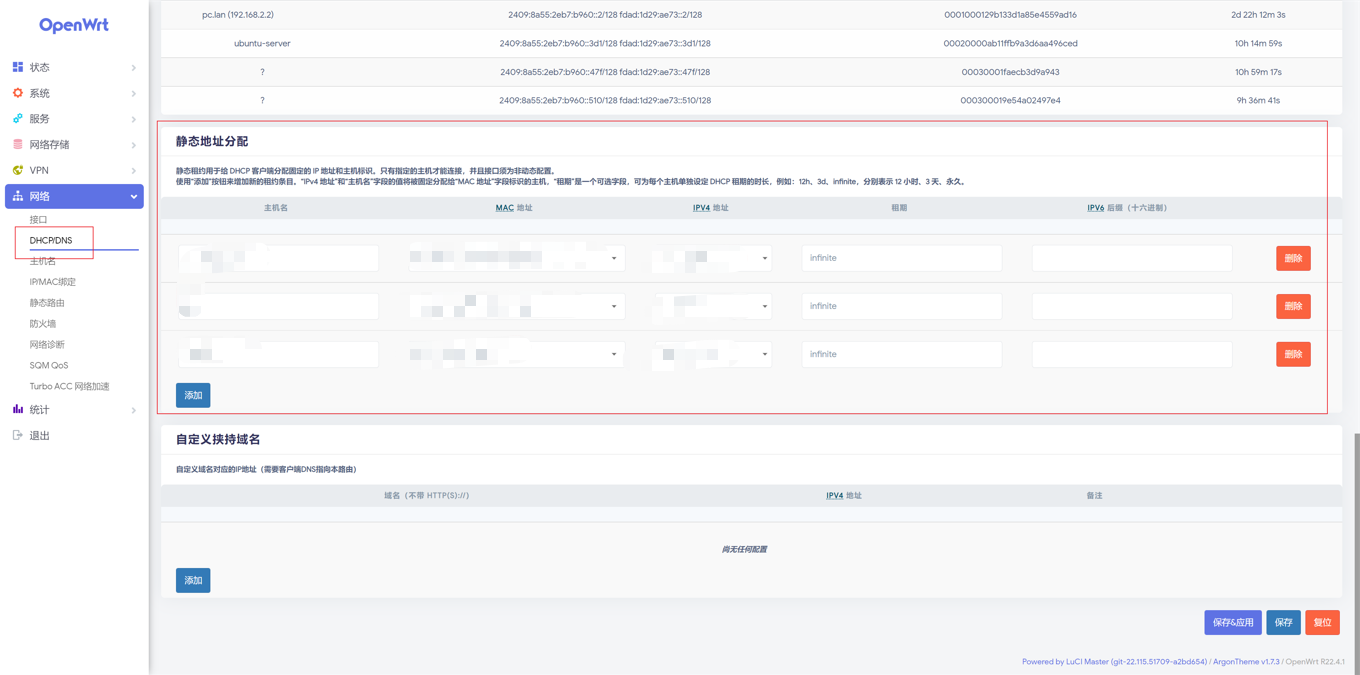
可以根据设备mac地址,自定义主机名和ip,并设置租期,这里一般我们设置静态ip都是永久的,填infinite。保存&应用,然后重启软路由即可。
这里可能重启软路由和设备后也不会让静态ip配置生效,网上找到了一篇文章的分析,跟第一次获取的ip租期未到期有管,可以手动释放旧的租约,然后刷新租约。windows下
ipconfig /release&ipconfig /renew,linux下dhclient -r&dhclient -s 192.168.2.1以下为原文:https://www.csdn.net/tags/NtjakgwsOTY3ODMtYmxvZwO0O0OO0O0O.html
我在使用 Openwrt 时手动分配了新的静态 IP 给我的电脑,但是在保存并应用后并没有立即生效,而且在我分别重启了电脑和路由器后仍然没有生效,为此我花了点时间找出了解决方法。
原因分析
在“DHCP/DNS->静态地址分配”中给电脑配置了静态地址不会立即生效,因为在此之前路由器已经通过 DHCP 分配了 IP 地址给电脑形成租约,在这个租约到期之前不会改变分配给电脑的 IP。通常我们在 Lan 中设置租约时间为 12h(小时),也就意味着要在 12 小时后电脑才会获取到我们设置的静态 IP。
不过我们可以清空路由器上的旧租约,同时将电脑断网重连,以此来使电脑获得新 IP 地址。最简单的方法就是将路由器重启,既清空了旧租约,又使电脑重连。但是为什么我之前重启会不起作用呢?
说实话这锅还真不好甩,我的电脑是 Win10 系统,在我重启路由器后,系统并不是向路由器请求一份新的租约,而是拿着旧的租约想要更新续约。这里你可能认为是路由器就直接续约了,但我认为并不是,OpenWrt 已经设定了静态地址,而电脑请求续约的 IP 不一样,结果是 OpenWrt 不会给续约,但也不会返回新的租约。
最终导致的结果就是电脑租约无法更新,但由于租约也没有到期,所以电脑继续使用旧的,而正好使用旧IP还能正常上网就一直沿用旧租约了。
解决方法
最简单的方法,设置的静态 IP 为原本 DHCP 获取到的 IP 地址,这样就不会存在不生效问题。但一定要更换 IP 的话,保证 OpenWrt 已重启,打开 Windows 命令行或者 Power Shell,输入以下命令执行:ipconfig /release
ipconfig /renew
第一条命令删除旧租约,这样就不会由于 IP 地址错误导致 OpenWrt 无法返回新租约,第二条命令就是手动更新租约。至此,解决了静态 IP 分配不生效的问题。
参考b站up主司波图的教程
`,28)]))}const m=e(t,[["render",i]]);export{g as __pageData,m as default}; diff --git "a/assets/tinker_network_openwrt\345\256\211\350\243\205\345\217\212\351\205\215\347\275\256.md.CO0nBeN9.lean.js" "b/assets/tinker_network_openwrt\345\256\211\350\243\205\345\217\212\351\205\215\347\275\256.md.CO0nBeN9.lean.js" new file mode 100644 index 00000000..9468e1ef --- /dev/null +++ "b/assets/tinker_network_openwrt\345\256\211\350\243\205\345\217\212\351\205\215\347\275\256.md.CO0nBeN9.lean.js" @@ -0,0 +1,12 @@ +import{_ as e,c as s,a2 as n,o as p}from"./chunks/framework.BjcrtTwI.js";const g=JSON.parse('{"title":"openwrt安装及配置","description":"","frontmatter":{},"headers":[],"relativePath":"tinker/network/openwrt安装及配置.md","filePath":"tinker/network/openwrt安装及配置.md","lastUpdated":1729217313000}'),t={name:"tinker/network/openwrt安装及配置.md"};function i(l,a,o,r,c,d){return p(),s("div",null,a[0]||(a[0]=[n(`趁着五一假期把家用服务器装好跑起来了,另外还买了一台J4125工控机来做软路由。工控机的机器今天刚到,下午反复折腾了pve虚拟机安装openwrt和物理机直接安装,目前是用物理机装好配置完毕了,但是看了一眼这监控数据,总感觉有点浪费性能。所以这篇文章写完我还是要换回pve安装(doge),剩下的性能折腾下其他虚拟机。
1. pe工具箱
+2. openwrt编译好的镜像,我用的是esir的固件
+3. 刷写镜像的软件physdiskwrite.exe1. pe工具箱安装到U盘中
+2. 把解压后的x86.img镜像文件和physdiskwrite.exe软件复制到U盘中
+3. 这时候已经可以拔掉硬路由器了,光猫lan口连软路由wan口(要问卖家哪个是wan口,我这个eth1是wan口),pc连软路由lan口(0、2、3),这是为了pc能跟软路由在同一个网段,如果不在则需要手动配置静态ip1. u盘启动工控机
+2. 用pe工具箱自带的diskgenius把装的硬盘格式化即可,注意这里不要进行分区,否则会写盘失败
+3. 打开cmd窗口,执行命令 physdiskwrite.exe -u x86.img,这里可以直接用鼠标把程序拖到cmd窗口,会自动拼出完整路径
+4. 根据终端输出选择要写入的硬盘,比如0是硬盘,1是u盘,就填0,enter即可开始写盘,等待写盘完毕即可
+5. 扩容系统分区,使用diskgenius找到刚刚写入的硬盘,然后再选中上面灰色未使用的分区,右击菜单中选择 “将空间分配给” -> “分区:未格式化(D:)”,然后确认即可
+6. 写盘完毕,选择重启,这时候直接拔出U盘即可
+7. 等待重启后,openwrt系统就已经成功启动了,如果不确定是否安装完,回车一下看看是否有lede的banner输出就行了
+8. openwrt一般ip为192.168.2.1(esir固件是5.1),这个可以看固件wiki或者自己ifconfig看一下
移动光猫改桥接模式
选择PPPoE协议并切换,填上宽带账号密码保存&应用即可
可以根据设备mac地址,自定义主机名和ip,并设置租期,这里一般我们设置静态ip都是永久的,填infinite。保存&应用,然后重启软路由即可。
这里可能重启软路由和设备后也不会让静态ip配置生效,网上找到了一篇文章的分析,跟第一次获取的ip租期未到期有管,可以手动释放旧的租约,然后刷新租约。windows下
ipconfig /release&ipconfig /renew,linux下dhclient -r&dhclient -s 192.168.2.1以下为原文:https://www.csdn.net/tags/NtjakgwsOTY3ODMtYmxvZwO0O0OO0O0O.html
我在使用 Openwrt 时手动分配了新的静态 IP 给我的电脑,但是在保存并应用后并没有立即生效,而且在我分别重启了电脑和路由器后仍然没有生效,为此我花了点时间找出了解决方法。
原因分析
在“DHCP/DNS->静态地址分配”中给电脑配置了静态地址不会立即生效,因为在此之前路由器已经通过 DHCP 分配了 IP 地址给电脑形成租约,在这个租约到期之前不会改变分配给电脑的 IP。通常我们在 Lan 中设置租约时间为 12h(小时),也就意味着要在 12 小时后电脑才会获取到我们设置的静态 IP。
不过我们可以清空路由器上的旧租约,同时将电脑断网重连,以此来使电脑获得新 IP 地址。最简单的方法就是将路由器重启,既清空了旧租约,又使电脑重连。但是为什么我之前重启会不起作用呢?
说实话这锅还真不好甩,我的电脑是 Win10 系统,在我重启路由器后,系统并不是向路由器请求一份新的租约,而是拿着旧的租约想要更新续约。这里你可能认为是路由器就直接续约了,但我认为并不是,OpenWrt 已经设定了静态地址,而电脑请求续约的 IP 不一样,结果是 OpenWrt 不会给续约,但也不会返回新的租约。
最终导致的结果就是电脑租约无法更新,但由于租约也没有到期,所以电脑继续使用旧的,而正好使用旧IP还能正常上网就一直沿用旧租约了。
解决方法
最简单的方法,设置的静态 IP 为原本 DHCP 获取到的 IP 地址,这样就不会存在不生效问题。但一定要更换 IP 的话,保证 OpenWrt 已重启,打开 Windows 命令行或者 Power Shell,输入以下命令执行:ipconfig /release
ipconfig /renew
第一条命令删除旧租约,这样就不会由于 IP 地址错误导致 OpenWrt 无法返回新租约,第二条命令就是手动更新租约。至此,解决了静态 IP 分配不生效的问题。
参考b站up主司波图的教程
`,28)]))}const m=e(t,[["render",i]]);export{g as __pageData,m as default}; diff --git "a/assets/tinker_network_openwrt\345\274\200\345\220\257ipv6.md.BJ0A2qG8.js" "b/assets/tinker_network_openwrt\345\274\200\345\220\257ipv6.md.BJ0A2qG8.js" new file mode 100644 index 00000000..f5eba53b --- /dev/null +++ "b/assets/tinker_network_openwrt\345\274\200\345\220\257ipv6.md.BJ0A2qG8.js" @@ -0,0 +1 @@ +import{_ as e,c as t,a2 as r,o as i}from"./chunks/framework.BjcrtTwI.js";const m=JSON.parse('{"title":"openwrt开启ipv6","description":"","frontmatter":{},"headers":[],"relativePath":"tinker/network/openwrt开启ipv6.md","filePath":"tinker/network/openwrt开启ipv6.md","lastUpdated":1729217313000}'),o={name:"tinker/network/openwrt开启ipv6.md"};function n(p,a,s,l,h,c){return i(),t("div",null,a[0]||(a[0]=[r('由于移动宽带没有公网ip,玩儿pt上传上不去,所以考虑开启ipv6提速
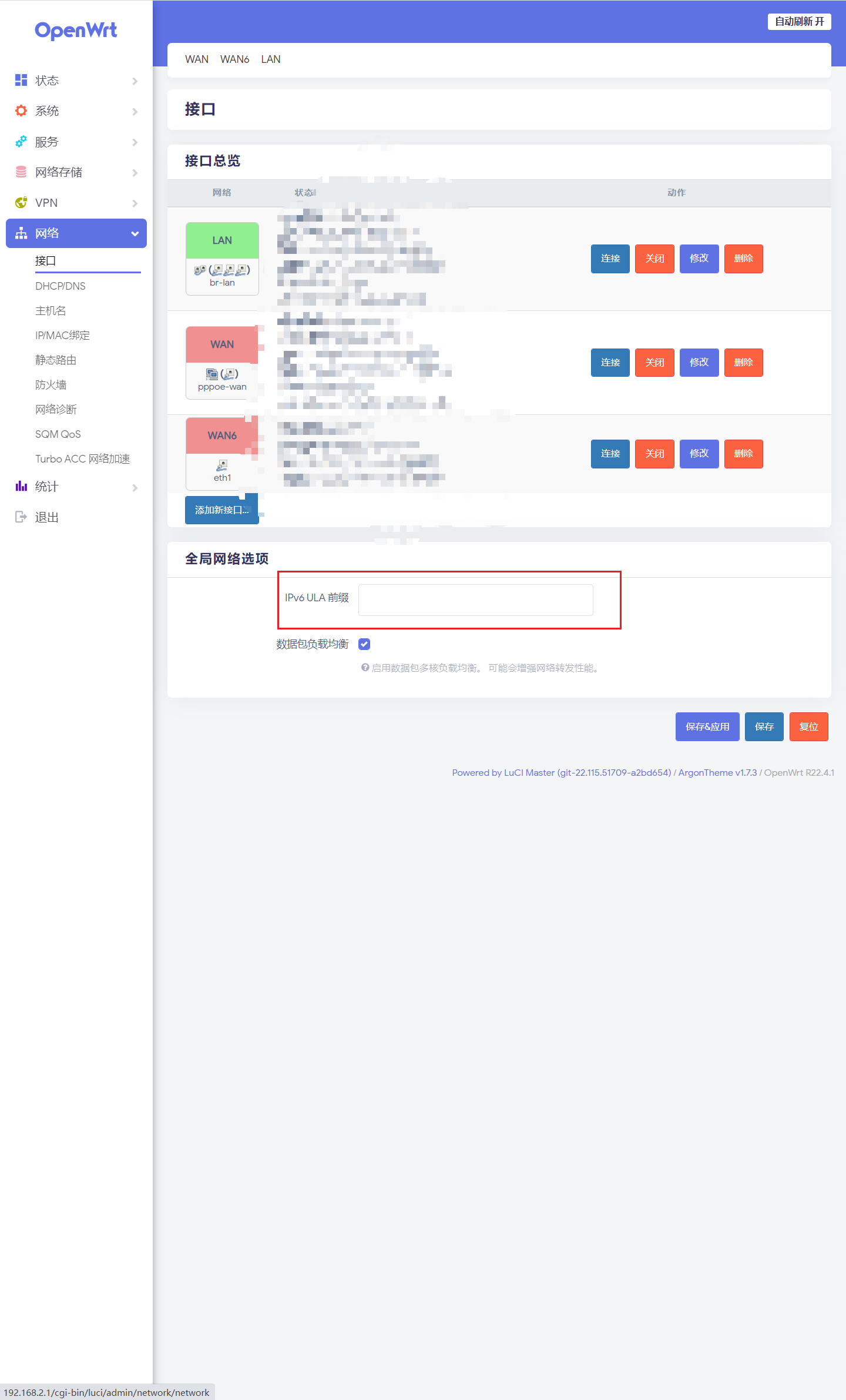

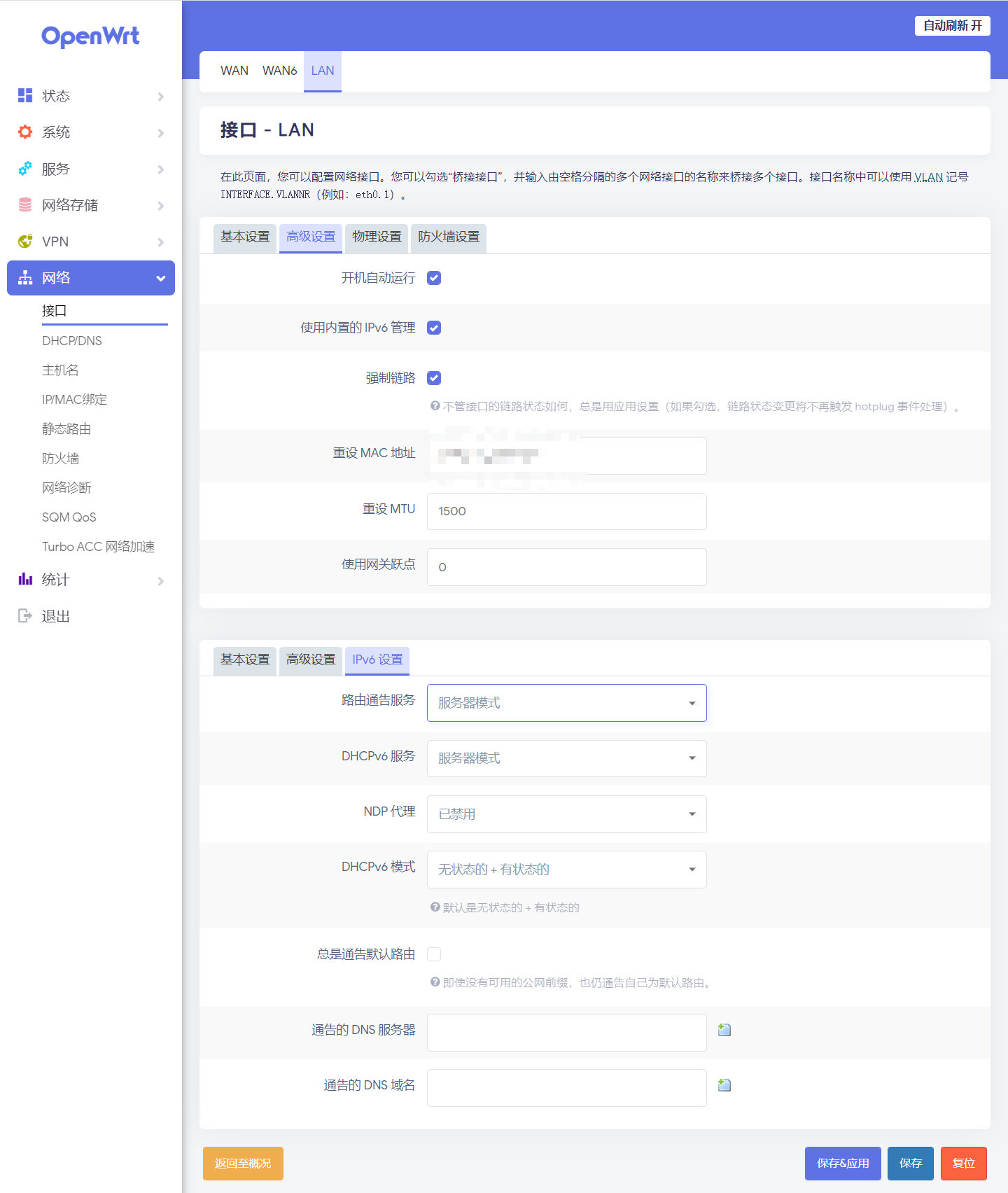
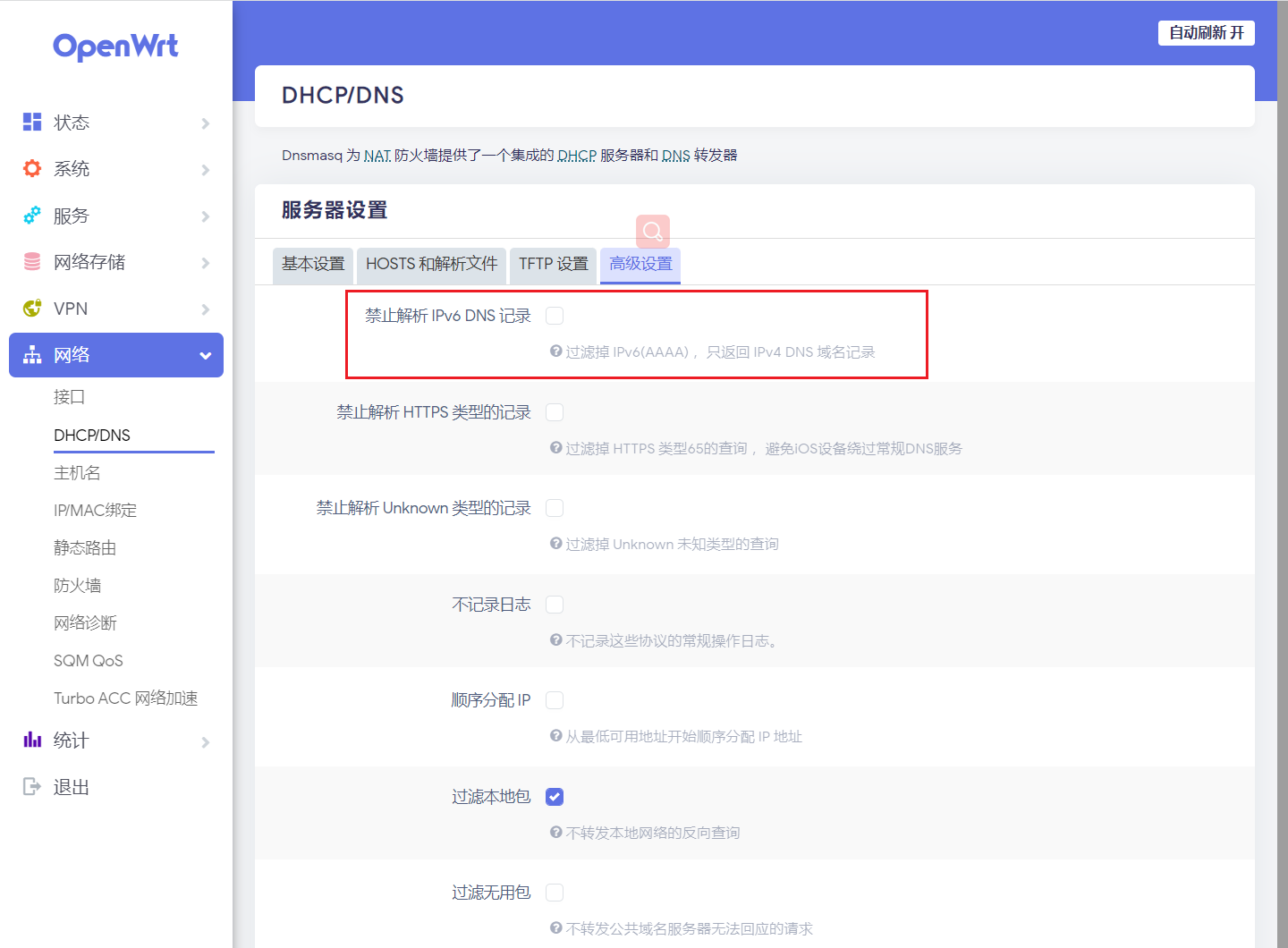
由于移动宽带没有公网ip,玩儿pt上传上不去,所以考虑开启ipv6提速
PT(Private Tracker):是一种基于私有BT Tracker服务器的资源传播形式,经授权的用户使用受允许的客户端进行种子制作与下载,对参与的用户做出流量统计(需要用户完成一定量的上传)。
上面提到PT的关键词:私有、小范围、流量统计。传统的BT则是公有、大范围(整个互联网)、不统计流量。BT是公开的tracker,范围很广,但是有很多人只下载不上传(h&r/hit and run),俗称白嫖,因此无法保证种子的下载速度。PT则解决了这一痛点,强制要求用户上传,换来了高速下载,另外pt站点的资源质量很高,资源更新更快。当然PT的局限就是圈子小,入门门槛高,往往pt站点采用邀请制+捐赠制。
家用pc、nas、服务器、能装下载工具的路由器、各种下载机(玩客云、n1盒子等)均可
越大越好
捐赠入站
通过别人邀请
pt站点开放注册时注册加入
种子:根据 BitTorrent 协议,文件发布者会根据要发布的文件生成提供一个.torrent 文件,即种子文件,也简称为“种子”。种子文件本质上是文本文件,包含 Tracker信息和文件信息两部分。Tracker 信息主要是 BT 下载中需要用到的 Tracker 服务器的地址和针对 Tracker 服务器的设置,文件信息是根据 对目标文件的计算生成的,计算结果根据 BitTorrent 协议内的规则进行编码。它的 主要原理是需要把提供下载的文件虚拟分成大小相等的块,块大小必须为 2k 的整数次方(由于是虚拟分块,硬盘上并不产生各个块文件),并把每个块的索引信息和 Hash 验证码写入种子文件中;所以,种子文件就是被下载文件的“索引”。 下载者要下载文件内容,需要先得到相应的种子文件,然后使用 BT 客户端软件进行下载。下载时,BT 客户端首先解析种子文件得到 Tracker 地址,然后连接 Tracker 服务器。Tracker 服务器回应下载者的请求,提供下载者其他下载者(包括发布者)的 IP。下载者再连接其他 下载者,根据种子文件,两者分别告知对方自己已经有的块,然后交换对方所没有的数据。 此时不需要其他服务器参与,分散了单个线路上的数据流量,因此减轻了服务器负担。 下载者每得到一个块,需要算出下载块的 Hash 验证码与种子文件中的对比,如果一样则说 明块正确,不一样则需要重新下载这个块。这种规定是为了解决下载内容淮确性的问题。 一般的 HTTP与FTP 下载,发布文件仅在某个或某几个服务器,下载的人太多,服务器的带宽 很易不胜负荷,变得很慢。而 BitTorrent 协议下载的特点是,下载的人越多,提供的带宽也 越多,下载速度就越快。同时,拥有完整文件的用户也会越来越多,使文件的“寿命”不断延长。
Tarcker: 收集下载者信息的服务器,并将此信息提供给其他下载者,可以理解为电话总机。
做种:资源下载完毕后不删除任务,保持继续上传的过程
辅种:其他人发布了资源,你手里刚好也有这个资源,那么你下载种子之后。只要数据通过了 hash 校验就会变成做种状态。(部分站点禁止)
上传量:做种时上传的流量
下载量:下载资源的流量
分享率:上传量/下载量
做种率:做种时间/下载时间
魔力值:pt站点的积分,可以通过做种、签到等途径获取
最小做种时间:为了保证种子的活跃度,一些PT站点严禁H&R(Hit and Run、下了就跑),要求用户至少持续做种一段时间
类似游戏的新手区教学,让新手了解PT站点的规则,PT站点还会对新人进行考核,一般考核期为一个月,考核主要从以下几点:
| 考核点 | 说明 | 要求 |
|---|---|---|
| 上传量 | 上传了多少数据 | 30G-100G不等 |
| 下载量 | 下载了多少数据 | 30G-100G不等 |
| 分享率 | 上传量/下载量 | 一般要求分享率>1 |
| 做种率 | 做种时间/下载时间 | 一般要求3-8不等 |
| 魔力值 | 通过签到、做种等途径获取的积分 | 一般要求3000-8000不等 |
老老实实下热门种子并持续做种
对于一些以影视作品为主的网站,尽可能的下载热门种子,这样能更快的获得上传量。可以使用 BT 客户端的 RSS 订阅功能,实现无人值守下载。 对于以小种为主的 PT 站,如 OpenCD 以及大部分教育网站点,则需要通过下载大量小体积种子并长时间做种以换取魔力值,再使用魔力值兑换上传。
保证良好分享率
在种子板块新发布且带有Free标签的种子是不计算下载量的
带有2xFree是不计算下载量且计算双倍上传流量的,一般选这种种子数据会更好看
要注意免费时常。
进到种子页面,看种子的做种者数量和下载者数量,挑做种人少&下载人多的。
无标记为正常计算上传、下载量
带有%50标记为计算50%下载量
带有2x%50为计算%50下载量、计算两倍上传量
不断下载免费种子,多维持一些,种子体积可以挑选大一点的,然后挂机做种提升上传量,在下载量不变的情况下,上传越高分量率就越高。
HDChina瓷器:近 10 年的老站,用户数据继承自原先的 HDWinG 和 HDStar。资源方面,官方制作组(HDCTV 和 HDChina)的 Netflix、HBO 剧集,原盘,录制的电视剧比较多。
TTG:
PT(Private Tracker):是一种基于私有BT Tracker服务器的资源传播形式,经授权的用户使用受允许的客户端进行种子制作与下载,对参与的用户做出流量统计(需要用户完成一定量的上传)。
上面提到PT的关键词:私有、小范围、流量统计。传统的BT则是公有、大范围(整个互联网)、不统计流量。BT是公开的tracker,范围很广,但是有很多人只下载不上传(h&r/hit and run),俗称白嫖,因此无法保证种子的下载速度。PT则解决了这一痛点,强制要求用户上传,换来了高速下载,另外pt站点的资源质量很高,资源更新更快。当然PT的局限就是圈子小,入门门槛高,往往pt站点采用邀请制+捐赠制。
家用pc、nas、服务器、能装下载工具的路由器、各种下载机(玩客云、n1盒子等)均可
越大越好
捐赠入站
通过别人邀请
pt站点开放注册时注册加入
种子:根据 BitTorrent 协议,文件发布者会根据要发布的文件生成提供一个.torrent 文件,即种子文件,也简称为“种子”。种子文件本质上是文本文件,包含 Tracker信息和文件信息两部分。Tracker 信息主要是 BT 下载中需要用到的 Tracker 服务器的地址和针对 Tracker 服务器的设置,文件信息是根据 对目标文件的计算生成的,计算结果根据 BitTorrent 协议内的规则进行编码。它的 主要原理是需要把提供下载的文件虚拟分成大小相等的块,块大小必须为 2k 的整数次方(由于是虚拟分块,硬盘上并不产生各个块文件),并把每个块的索引信息和 Hash 验证码写入种子文件中;所以,种子文件就是被下载文件的“索引”。 下载者要下载文件内容,需要先得到相应的种子文件,然后使用 BT 客户端软件进行下载。下载时,BT 客户端首先解析种子文件得到 Tracker 地址,然后连接 Tracker 服务器。Tracker 服务器回应下载者的请求,提供下载者其他下载者(包括发布者)的 IP。下载者再连接其他 下载者,根据种子文件,两者分别告知对方自己已经有的块,然后交换对方所没有的数据。 此时不需要其他服务器参与,分散了单个线路上的数据流量,因此减轻了服务器负担。 下载者每得到一个块,需要算出下载块的 Hash 验证码与种子文件中的对比,如果一样则说 明块正确,不一样则需要重新下载这个块。这种规定是为了解决下载内容淮确性的问题。 一般的 HTTP与FTP 下载,发布文件仅在某个或某几个服务器,下载的人太多,服务器的带宽 很易不胜负荷,变得很慢。而 BitTorrent 协议下载的特点是,下载的人越多,提供的带宽也 越多,下载速度就越快。同时,拥有完整文件的用户也会越来越多,使文件的“寿命”不断延长。
Tarcker: 收集下载者信息的服务器,并将此信息提供给其他下载者,可以理解为电话总机。
做种:资源下载完毕后不删除任务,保持继续上传的过程
辅种:其他人发布了资源,你手里刚好也有这个资源,那么你下载种子之后。只要数据通过了 hash 校验就会变成做种状态。(部分站点禁止)
上传量:做种时上传的流量
下载量:下载资源的流量
分享率:上传量/下载量
做种率:做种时间/下载时间
魔力值:pt站点的积分,可以通过做种、签到等途径获取
最小做种时间:为了保证种子的活跃度,一些PT站点严禁H&R(Hit and Run、下了就跑),要求用户至少持续做种一段时间
类似游戏的新手区教学,让新手了解PT站点的规则,PT站点还会对新人进行考核,一般考核期为一个月,考核主要从以下几点:
| 考核点 | 说明 | 要求 |
|---|---|---|
| 上传量 | 上传了多少数据 | 30G-100G不等 |
| 下载量 | 下载了多少数据 | 30G-100G不等 |
| 分享率 | 上传量/下载量 | 一般要求分享率>1 |
| 做种率 | 做种时间/下载时间 | 一般要求3-8不等 |
| 魔力值 | 通过签到、做种等途径获取的积分 | 一般要求3000-8000不等 |
老老实实下热门种子并持续做种
对于一些以影视作品为主的网站,尽可能的下载热门种子,这样能更快的获得上传量。可以使用 BT 客户端的 RSS 订阅功能,实现无人值守下载。 对于以小种为主的 PT 站,如 OpenCD 以及大部分教育网站点,则需要通过下载大量小体积种子并长时间做种以换取魔力值,再使用魔力值兑换上传。
保证良好分享率
在种子板块新发布且带有Free标签的种子是不计算下载量的
带有2xFree是不计算下载量且计算双倍上传流量的,一般选这种种子数据会更好看
要注意免费时常。
进到种子页面,看种子的做种者数量和下载者数量,挑做种人少&下载人多的。
无标记为正常计算上传、下载量
带有%50标记为计算50%下载量
带有2x%50为计算%50下载量、计算两倍上传量
不断下载免费种子,多维持一些,种子体积可以挑选大一点的,然后挂机做种提升上传量,在下载量不变的情况下,上传越高分量率就越高。
HDChina瓷器:近 10 年的老站,用户数据继承自原先的 HDWinG 和 HDStar。资源方面,官方制作组(HDCTV 和 HDChina)的 Netflix、HBO 剧集,原盘,录制的电视剧比较多。
TTG:
主板支持WOL(Wake on LAN)功能和来电开机
以七彩虹主板为例
ADVANCED(高级模式)> Power Management Configuration(电源管理配置)> Wake By Lan(网卡唤醒)
+Wake By Lan(网卡唤醒)
+设置网络唤醒功能。
+[Enabled] 当检测到 LAN 设备已激活或有信号输入时,唤醒系统。
+[Disabled] 关闭网络唤醒功能。
+
+
+ADVANCED(高级模式)> Power Management Configuration(电源管理配置)> AC Power Loss(断电开机功能)
+AC Power Loss(断电开机功能)
+设置计算机断电之后,电源再次被接通时计算机的响应状态。
+[Power On] 通电后计算机自动开机。
+[Power Off] 通电后计算机保持关机状态。
+[Last State]] 通电后计算机恢复上次断电前的状态。# 如果没有需要先安装 apt install ethtool
+# 首先使用ifconfig或ip a查看设备名称 我的是enp3s0
+
+ethtool enp3s0 | grep "Wake-on"
+ Supports Wake-on: pumbg
+ Wake-on: d这个信息说明支持pumbg几种唤醒方式,而d表示当前处于禁用状态
"Wake-on" 中的不同字母代表不同的唤醒模式 这些字母分别代表以下内容:
p:代表PHY(物理层)唤醒模式,这种模式是基于物理层的唤醒模式。u:代表UDP数据包唤醒模式,这种模式需要特定的UDP数据包来唤醒设备。m:代表多播唤醒模式,这允许多播数据包来唤醒设备。b:代表广播唤醒模式,这允许广播数据包来唤醒设备。g:代表魔术唤醒帧模式,这是一种常用的唤醒模式,需要特定的魔术唤醒数据包。魔术唤醒数据包(Magic Wake-on-LAN Packet)是一种特殊的数据包,用于远程唤醒计算机或网络设备。它通常用于通过局域网远程唤醒处于休眠或关机状态的设备,以便进行远程管理或访问。这些数据包被称为"魔术",因为它们包含了一些特定的唤醒模式信息,以便网络接口卡能够识别并唤醒目标设备。
魔术唤醒数据包的结构通常包括以下元素:
- 目标设备的MAC地址:这是数据包的目标设备的物理地址,以便网络接口卡知道唤醒哪台设备。
- 以太网帧:数据包以标准的以太网帧格式进行封装。
- 魔术唤醒模式信息:这些信息告诉网络接口卡以特定方式处理数据包,以实现唤醒功能。
ethtool -s enp3s0 wol g
sudo systemctl edit --force --full wol-enable.service可以使用update-alternatives --config editor修改默认编辑器
[Unit]
+Description=Enable Wake-on-LAN
+
+[Service]
+ExecStart=/usr/sbin/ethtool -s enp3s0 wol g
+
+[Install]
+WantedBy=multi-user.targetsystemctl daemon-reload && systemctl enable wol-enable.service && systemctl start wol-enable.service
不同平台都有相对应的唤醒客户端,我主要是从软路由使用这个功能。使用Etherwake选中要唤醒的设备点击唤醒主机即可发送数据包成功唤醒。

可以配合UPS使用实现断电安全关机以及来电自动启动,详情见另一篇关于UPS和NUT的博客。
`,25)]))}const u=a(l,[["render",t]]);export{c as __pageData,u as default}; diff --git "a/assets/tinker_network_ubuntu-server\345\274\200\345\220\257\347\275\221\347\273\234\345\224\244\351\206\222.md.Dp1TwPSn.lean.js" "b/assets/tinker_network_ubuntu-server\345\274\200\345\220\257\347\275\221\347\273\234\345\224\244\351\206\222.md.Dp1TwPSn.lean.js" new file mode 100644 index 00000000..d1325492 --- /dev/null +++ "b/assets/tinker_network_ubuntu-server\345\274\200\345\220\257\347\275\221\347\273\234\345\224\244\351\206\222.md.Dp1TwPSn.lean.js" @@ -0,0 +1,25 @@ +import{_ as a,c as e,a2 as n,o as i}from"./chunks/framework.BjcrtTwI.js";const c=JSON.parse('{"title":"ubuntu-server开启网络唤醒和通电自动启动","description":"","frontmatter":{},"headers":[],"relativePath":"tinker/network/ubuntu-server开启网络唤醒.md","filePath":"tinker/network/ubuntu-server开启网络唤醒.md","lastUpdated":1729217313000}'),l={name:"tinker/network/ubuntu-server开启网络唤醒.md"};function t(p,s,h,o,r,k){return i(),e("div",null,s[0]||(s[0]=[n(`主板支持WOL(Wake on LAN)功能和来电开机
以七彩虹主板为例
ADVANCED(高级模式)> Power Management Configuration(电源管理配置)> Wake By Lan(网卡唤醒)
+Wake By Lan(网卡唤醒)
+设置网络唤醒功能。
+[Enabled] 当检测到 LAN 设备已激活或有信号输入时,唤醒系统。
+[Disabled] 关闭网络唤醒功能。
+
+
+ADVANCED(高级模式)> Power Management Configuration(电源管理配置)> AC Power Loss(断电开机功能)
+AC Power Loss(断电开机功能)
+设置计算机断电之后,电源再次被接通时计算机的响应状态。
+[Power On] 通电后计算机自动开机。
+[Power Off] 通电后计算机保持关机状态。
+[Last State]] 通电后计算机恢复上次断电前的状态。# 如果没有需要先安装 apt install ethtool
+# 首先使用ifconfig或ip a查看设备名称 我的是enp3s0
+
+ethtool enp3s0 | grep "Wake-on"
+ Supports Wake-on: pumbg
+ Wake-on: d这个信息说明支持pumbg几种唤醒方式,而d表示当前处于禁用状态
"Wake-on" 中的不同字母代表不同的唤醒模式 这些字母分别代表以下内容:
p:代表PHY(物理层)唤醒模式,这种模式是基于物理层的唤醒模式。u:代表UDP数据包唤醒模式,这种模式需要特定的UDP数据包来唤醒设备。m:代表多播唤醒模式,这允许多播数据包来唤醒设备。b:代表广播唤醒模式,这允许广播数据包来唤醒设备。g:代表魔术唤醒帧模式,这是一种常用的唤醒模式,需要特定的魔术唤醒数据包。魔术唤醒数据包(Magic Wake-on-LAN Packet)是一种特殊的数据包,用于远程唤醒计算机或网络设备。它通常用于通过局域网远程唤醒处于休眠或关机状态的设备,以便进行远程管理或访问。这些数据包被称为"魔术",因为它们包含了一些特定的唤醒模式信息,以便网络接口卡能够识别并唤醒目标设备。
魔术唤醒数据包的结构通常包括以下元素:
- 目标设备的MAC地址:这是数据包的目标设备的物理地址,以便网络接口卡知道唤醒哪台设备。
- 以太网帧:数据包以标准的以太网帧格式进行封装。
- 魔术唤醒模式信息:这些信息告诉网络接口卡以特定方式处理数据包,以实现唤醒功能。
ethtool -s enp3s0 wol g
sudo systemctl edit --force --full wol-enable.service可以使用update-alternatives --config editor修改默认编辑器
[Unit]
+Description=Enable Wake-on-LAN
+
+[Service]
+ExecStart=/usr/sbin/ethtool -s enp3s0 wol g
+
+[Install]
+WantedBy=multi-user.targetsystemctl daemon-reload && systemctl enable wol-enable.service && systemctl start wol-enable.service
不同平台都有相对应的唤醒客户端,我主要是从软路由使用这个功能。使用Etherwake选中要唤醒的设备点击唤醒主机即可发送数据包成功唤醒。
可以配合UPS使用实现断电安全关机以及来电自动启动,详情见另一篇关于UPS和NUT的博客。
`,25)]))}const u=a(l,[["render",t]]);export{c as __pageData,u as default}; diff --git "a/assets/tinker_network_windows\346\214\202\350\275\275webdav\347\232\204\351\227\256\351\242\230\345\244\204\347\220\206.md.86QqB54I.js" "b/assets/tinker_network_windows\346\214\202\350\275\275webdav\347\232\204\351\227\256\351\242\230\345\244\204\347\220\206.md.86QqB54I.js" new file mode 100644 index 00000000..ff1380a3 --- /dev/null +++ "b/assets/tinker_network_windows\346\214\202\350\275\275webdav\347\232\204\351\227\256\351\242\230\345\244\204\347\220\206.md.86QqB54I.js" @@ -0,0 +1 @@ +import{_ as a,c as o,a2 as d,o as t}from"./chunks/framework.BjcrtTwI.js";const h=JSON.parse('{"title":"windows挂载webdav的问题处理","description":"","frontmatter":{},"headers":[],"relativePath":"tinker/network/windows挂载webdav的问题处理.md","filePath":"tinker/network/windows挂载webdav的问题处理.md","lastUpdated":1729217313000}'),r={name:"tinker/network/windows挂载webdav的问题处理.md"};function i(n,e,s,w,c,l){return t(),o("div",null,e[0]||(e[0]=[d('home server里开着阿里云盘的webdav容器,想要在pc的windows中挂载,之前用的RaiDriver这个软件,但是开机启动总弹广告,遂弃用。用windows原生的挂载方式,直接在资源管理器中右键选择添加一个网络位置,填写http的webdav服务地址+端口后提示输入的文件夹似乎无效。
出现这个提示是因为windows本身的权限控制,可以在注册表中修改相关配置。
具体操作:
修改注册表\\HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\Services\\WebClient\\Parameters下BasicAuthLevel的值为2
在服务中把WebClient启动,并把启动类型改为自动
然后就可以在资源管理器中再次尝试添加网络位置,输入ip+端口即可。
',8)]))}const b=a(r,[["render",i]]);export{h as __pageData,b as default}; diff --git "a/assets/tinker_network_windows\346\214\202\350\275\275webdav\347\232\204\351\227\256\351\242\230\345\244\204\347\220\206.md.86QqB54I.lean.js" "b/assets/tinker_network_windows\346\214\202\350\275\275webdav\347\232\204\351\227\256\351\242\230\345\244\204\347\220\206.md.86QqB54I.lean.js" new file mode 100644 index 00000000..ff1380a3 --- /dev/null +++ "b/assets/tinker_network_windows\346\214\202\350\275\275webdav\347\232\204\351\227\256\351\242\230\345\244\204\347\220\206.md.86QqB54I.lean.js" @@ -0,0 +1 @@ +import{_ as a,c as o,a2 as d,o as t}from"./chunks/framework.BjcrtTwI.js";const h=JSON.parse('{"title":"windows挂载webdav的问题处理","description":"","frontmatter":{},"headers":[],"relativePath":"tinker/network/windows挂载webdav的问题处理.md","filePath":"tinker/network/windows挂载webdav的问题处理.md","lastUpdated":1729217313000}'),r={name:"tinker/network/windows挂载webdav的问题处理.md"};function i(n,e,s,w,c,l){return t(),o("div",null,e[0]||(e[0]=[d('home server里开着阿里云盘的webdav容器,想要在pc的windows中挂载,之前用的RaiDriver这个软件,但是开机启动总弹广告,遂弃用。用windows原生的挂载方式,直接在资源管理器中右键选择添加一个网络位置,填写http的webdav服务地址+端口后提示输入的文件夹似乎无效。
出现这个提示是因为windows本身的权限控制,可以在注册表中修改相关配置。
具体操作:
修改注册表\\HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\Services\\WebClient\\Parameters下BasicAuthLevel的值为2
在服务中把WebClient启动,并把启动类型改为自动
然后就可以在资源管理器中再次尝试添加网络位置,输入ip+端口即可。
',8)]))}const b=a(r,[["render",i]]);export{h as __pageData,b as default}; diff --git "a/assets/tinker_network_\344\275\277\347\224\250https\350\256\277\351\227\256\345\206\205\347\275\221\346\234\215\345\212\241.md.Bl3kww8h.js" "b/assets/tinker_network_\344\275\277\347\224\250https\350\256\277\351\227\256\345\206\205\347\275\221\346\234\215\345\212\241.md.Bl3kww8h.js" new file mode 100644 index 00000000..b84c67ea --- /dev/null +++ "b/assets/tinker_network_\344\275\277\347\224\250https\350\256\277\351\227\256\345\206\205\347\275\221\346\234\215\345\212\241.md.Bl3kww8h.js" @@ -0,0 +1,29 @@ +import{_ as i,c as a,a2 as n,o as l}from"./chunks/framework.BjcrtTwI.js";const o=JSON.parse('{"title":"使用https访问内网服务","description":"","frontmatter":{},"headers":[],"relativePath":"tinker/network/使用https访问内网服务.md","filePath":"tinker/network/使用https访问内网服务.md","lastUpdated":1729217313000}'),h={name:"tinker/network/使用https访问内网服务.md"};function t(p,s,k,e,r,d){return l(),a("div",null,s[0]||(s[0]=[n(`将需要的子域名使用ddns解析到wan口ip
# docker-compose.yml
+
+version: "3"
+services:
+ swag:
+ image: linuxserver/swag:latest
+ container_name: swag
+ cap_add:
+ - NET_ADMIN
+ environment:
+ - PUID=1000
+ - PGID=1000
+ - TZ=Asia/Shanghai # 时区
+ - URL=yourdomain.com # 主域名
+ - VALIDATION=dns # certbot验证的方法,一般选dns
+ - SUBDOMAINS=yoursubdoamin.yourdomain.com
+ - CERTPROVIDER= # 可以填zerossl,默认使用let's encrypt签发证书
+ - DNSPLUGIN=dnspod # 支持aliyun、dnspod、cloudflare等等,详情见官方文档
+ - PROPAGATION= # 选择覆盖dns插件的默认传播时间(以秒为单位)
+ - EMAIL=user@email.com # 邮箱
+ - ONLY_SUBDOMAINS=true # 是否只获取子域名的证书
+ - EXTRA_DOMAINS= # 其他完全限定域名(逗号分隔,无空格)例如 extradomain.com,subdomain.anotherdomain.org
+ - STAGING=false # 设置为 true 以在暂存模式下检索证书。但生成的证书将无法通过浏览器的安全测试。仅用于测试。
+ volumes:
+ - /docker/swag/config:/config
+ ports:
+ - 65111:443 # 映射端口,家宽可以选择高位端口
+# - 80:80 #optional
+ restart: unless-stopped在config/dns-conf目录中找到自己选择的dns插件的配置文件,按要求填写验证信息
在config/nginx/proxy-confs基于给出的模板配置文件修改出自己的虚拟主机配置,将请求反向代理到内网的指定服务
防火墙中配置端口转发规则:将要从外网访问的高位端口(例如65222)转发到上面映射的端口65111
此时即可通过https://subdomain.domain.com:65222来访问对应的内网服务
将需要的子域名使用ddns解析到wan口ip
# docker-compose.yml
+
+version: "3"
+services:
+ swag:
+ image: linuxserver/swag:latest
+ container_name: swag
+ cap_add:
+ - NET_ADMIN
+ environment:
+ - PUID=1000
+ - PGID=1000
+ - TZ=Asia/Shanghai # 时区
+ - URL=yourdomain.com # 主域名
+ - VALIDATION=dns # certbot验证的方法,一般选dns
+ - SUBDOMAINS=yoursubdoamin.yourdomain.com
+ - CERTPROVIDER= # 可以填zerossl,默认使用let's encrypt签发证书
+ - DNSPLUGIN=dnspod # 支持aliyun、dnspod、cloudflare等等,详情见官方文档
+ - PROPAGATION= # 选择覆盖dns插件的默认传播时间(以秒为单位)
+ - EMAIL=user@email.com # 邮箱
+ - ONLY_SUBDOMAINS=true # 是否只获取子域名的证书
+ - EXTRA_DOMAINS= # 其他完全限定域名(逗号分隔,无空格)例如 extradomain.com,subdomain.anotherdomain.org
+ - STAGING=false # 设置为 true 以在暂存模式下检索证书。但生成的证书将无法通过浏览器的安全测试。仅用于测试。
+ volumes:
+ - /docker/swag/config:/config
+ ports:
+ - 65111:443 # 映射端口,家宽可以选择高位端口
+# - 80:80 #optional
+ restart: unless-stopped在config/dns-conf目录中找到自己选择的dns插件的配置文件,按要求填写验证信息
在config/nginx/proxy-confs基于给出的模板配置文件修改出自己的虚拟主机配置,将请求反向代理到内网的指定服务
防火墙中配置端口转发规则:将要从外网访问的高位端口(例如65222)转发到上面映射的端口65111
此时即可通过https://subdomain.domain.com:65222来访问对应的内网服务
搞了7*24小时服务器之后经历了两次突然断电,每次重启磁盘检查都要卡很久,夏天一到用电量骤升,市电断电和跳闸的几率都增加了。万一多来几次突然断电,磁盘阵列可能要挂了,更关键的是数据无价啊,ups还是少不了。
因为不是成品nas系统,想实现自动关机得依靠linux上已有的软件。而我对apcupsd 这款软件有所耳闻,所以第一选择就去看了新款的apc bk650m2-ch ,快下单了才得知新款不支持apcupsd,然后就听网友的建议看了山特的box600和box850 ,山特这个型号有两排插座,一排防雷+不断电,一排是防雷,还省了了插排钱,自带的usb通讯端口可以通过nut 软件进行管理,实现自动关机以及自定义脚本执行等功能,虽然电池容量小了点,但是能省就省吧,最后下单了box600。
ups机器本身没什么可讲的,把附带的rj45接ups,usb线接主机,再把主机电源插在ups的不断电插口上,接着给ups通电即可。主要介绍下nut的使用和配置。
apt install nut
首先可以用lsusb命令查看是否接入了ups,能看到ups即可

然后编辑ups配置文件vim /etc/nut/ups.conf,增加配置如下
maxretry = 3
+[santak]
+ driver = usbhid-ups
+ port = auto
+ desc = "my ups"santak是ups的设备名,可以自定义,后续有些命令这个设备名还会用到
vim /etc/nut/upsd.users新增配置
[ups]
+ password = xxx
+ upsmon masterups为用户名,xxx为密码,upsmon master为运行模式
chown root:nut /etc/nut/upsd.conf /etc/nut/upsd.users
+chmod 0640 /etc/nut/upsd.conf /etc/nut/upsd.usersvim /etc/nut/nut.conf修改模式为单机
MODE=standalone启动upsd服务
/sbin/upsd查看全部
/bin/upsc santak@localhost # 这里的santak就是上面的设备名查看某个信息在后面接信息类别就行,例如查看电量
/bin/upsc santak@127.0.0.1 battery.charge
+
+Init SSL without certificate database
+100nut服务会在UPS发送LOWBATT时通知机器关机,触发时机默认为ups电量剩余20% 。我们需要添加upsmon配置vim /etc/nut/upsmon.conf
在MONITOR监视器部分添加配置
MONITOR santak@localhost 1 ups xxx master
+
+# MONITOR 设备名@ip 1 用户名 密码 节点授权
chown root:nut /etc/nut/upsmon.conf
+chmod 0640 /etc/nut/upsmon.conf启动upsmon
/sbin/upsmon实际上配置完上面的内容已经可以实现断电时安全关机了,但喜欢折腾的还可以自定义触发事件的脚本
vim /etc/nut/upsmon.conf添加内容
NOTIFYCMD /sbin/upssched这个配置的作用是发生事件是运行upssched程序
设置触发条件,三个动作分别是记录日志+通知所有用户发生了事件+执行notifycmd,也就是/sbin/upssched
NOTIFYFLAG ONBATT SYSLOG+WALL+EXECvim /etc/nut/upssched.conf编辑内容
CMDSCRIPT /usr/local/bin/upssched
+PIPEFN /var/run/nut/upssched/upssched.pipe
+LOCKFN /var/run/nut/upssched/upssched.lock
+AT ONBATT * START-TIMER power-off 10
+AT ONLINE * CANCEL-TIMER power-off这段配置通过CMDSCRIPT指定了发生事件时需要执行的脚本,这个脚本可以根据需求自定义,在断电时(ONBATT/电池供电) 会启动一个10秒的timer,之后会执行power-off事件,这里涉及的文件nut用户都需要配置权限
这个可以自定义,例如发邮件等操作,这里展示最基本的脚本格式,例如power-off事件发生时,将断电了 信息写入指定文件,还可以调用ups的指令/sbin/upsmon -c fsd执行立刻关机操作 (FSD = "Forced Shutdown")
#! /bin/sh
+
+case $1 in
+ power-off)
+ echo '$(date +\\%Y-\\%m-\\%d\\ \\%H:\\%M:\\%S) - 断电了 ' >> /var/log/nut/nut.log
+ #/sbin/upsmon -c fsd #立即通知关机
+ ;;
+ *)
+ logger -t upssched "Unrecognized command: $1"
+ ;;
+esac搞了7*24小时服务器之后经历了两次突然断电,每次重启磁盘检查都要卡很久,夏天一到用电量骤升,市电断电和跳闸的几率都增加了。万一多来几次突然断电,磁盘阵列可能要挂了,更关键的是数据无价啊,ups还是少不了。
因为不是成品nas系统,想实现自动关机得依靠linux上已有的软件。而我对apcupsd 这款软件有所耳闻,所以第一选择就去看了新款的apc bk650m2-ch ,快下单了才得知新款不支持apcupsd,然后就听网友的建议看了山特的box600和box850 ,山特这个型号有两排插座,一排防雷+不断电,一排是防雷,还省了了插排钱,自带的usb通讯端口可以通过nut 软件进行管理,实现自动关机以及自定义脚本执行等功能,虽然电池容量小了点,但是能省就省吧,最后下单了box600。
ups机器本身没什么可讲的,把附带的rj45接ups,usb线接主机,再把主机电源插在ups的不断电插口上,接着给ups通电即可。主要介绍下nut的使用和配置。
apt install nut
首先可以用lsusb命令查看是否接入了ups,能看到ups即可
然后编辑ups配置文件vim /etc/nut/ups.conf,增加配置如下
maxretry = 3
+[santak]
+ driver = usbhid-ups
+ port = auto
+ desc = "my ups"santak是ups的设备名,可以自定义,后续有些命令这个设备名还会用到
vim /etc/nut/upsd.users新增配置
[ups]
+ password = xxx
+ upsmon masterups为用户名,xxx为密码,upsmon master为运行模式
chown root:nut /etc/nut/upsd.conf /etc/nut/upsd.users
+chmod 0640 /etc/nut/upsd.conf /etc/nut/upsd.usersvim /etc/nut/nut.conf修改模式为单机
MODE=standalone启动upsd服务
/sbin/upsd查看全部
/bin/upsc santak@localhost # 这里的santak就是上面的设备名查看某个信息在后面接信息类别就行,例如查看电量
/bin/upsc santak@127.0.0.1 battery.charge
+
+Init SSL without certificate database
+100nut服务会在UPS发送LOWBATT时通知机器关机,触发时机默认为ups电量剩余20% 。我们需要添加upsmon配置vim /etc/nut/upsmon.conf
在MONITOR监视器部分添加配置
MONITOR santak@localhost 1 ups xxx master
+
+# MONITOR 设备名@ip 1 用户名 密码 节点授权
chown root:nut /etc/nut/upsmon.conf
+chmod 0640 /etc/nut/upsmon.conf启动upsmon
/sbin/upsmon实际上配置完上面的内容已经可以实现断电时安全关机了,但喜欢折腾的还可以自定义触发事件的脚本
vim /etc/nut/upsmon.conf添加内容
NOTIFYCMD /sbin/upssched这个配置的作用是发生事件是运行upssched程序
设置触发条件,三个动作分别是记录日志+通知所有用户发生了事件+执行notifycmd,也就是/sbin/upssched
NOTIFYFLAG ONBATT SYSLOG+WALL+EXECvim /etc/nut/upssched.conf编辑内容
CMDSCRIPT /usr/local/bin/upssched
+PIPEFN /var/run/nut/upssched/upssched.pipe
+LOCKFN /var/run/nut/upssched/upssched.lock
+AT ONBATT * START-TIMER power-off 10
+AT ONLINE * CANCEL-TIMER power-off这段配置通过CMDSCRIPT指定了发生事件时需要执行的脚本,这个脚本可以根据需求自定义,在断电时(ONBATT/电池供电) 会启动一个10秒的timer,之后会执行power-off事件,这里涉及的文件nut用户都需要配置权限
这个可以自定义,例如发邮件等操作,这里展示最基本的脚本格式,例如power-off事件发生时,将断电了 信息写入指定文件,还可以调用ups的指令/sbin/upsmon -c fsd执行立刻关机操作 (FSD = "Forced Shutdown")
#! /bin/sh
+
+case $1 in
+ power-off)
+ echo '$(date +\\%Y-\\%m-\\%d\\ \\%H:\\%M:\\%S) - 断电了 ' >> /var/log/nut/nut.log
+ #/sbin/upsmon -c fsd #立即通知关机
+ ;;
+ *)
+ logger -t upssched "Unrecognized command: $1"
+ ;;
+esac坐标广东,移动千兆宽带,服务商的光猫是带路由功能的,但是性能极差,且跑不满带宽。然后我就在公司福利商城买了个小米的A4路由器千兆版,但是拨号还是光猫,然后就动手折腾了下,光猫改桥接模式,拨号功能改为路由器执行。这样把光猫和路由器指责剥离开来,光猫就负责光转电,路由器则进行拨号和提供Wi-Fi功能。
从网上找到的:
账号:CMCCAdmin
密码:aDm8H%MdA
这个可能各地不同,如果不行就要找宽带安装师傅或者移动问了。
手机号@139.gd,密码如果不知道可以去移动app上修改宽带密码,输入后点击保存,路由器应该就可以可以进行拨号了TIP
网络上有些教程说的是直接删掉光猫原有的那个路由模式连接配置,千万别这么干,一定要按照我这种方案取消使能和lan口的操作。这样只是相当于把那个连接禁用了,并不会删除,万一自己配置路由拨号不顺利,还可以重新启用原有的连接进行上网。如果删了,自己又没配置好,那就芭比Q了。
坐标广东,移动千兆宽带,服务商的光猫是带路由功能的,但是性能极差,且跑不满带宽。然后我就在公司福利商城买了个小米的A4路由器千兆版,但是拨号还是光猫,然后就动手折腾了下,光猫改桥接模式,拨号功能改为路由器执行。这样把光猫和路由器指责剥离开来,光猫就负责光转电,路由器则进行拨号和提供Wi-Fi功能。
从网上找到的:
账号:CMCCAdmin
密码:aDm8H%MdA
这个可能各地不同,如果不行就要找宽带安装师傅或者移动问了。
手机号@139.gd,密码如果不知道可以去移动app上修改宽带密码,输入后点击保存,路由器应该就可以可以进行拨号了TIP
网络上有些教程说的是直接删掉光猫原有的那个路由模式连接配置,千万别这么干,一定要按照我这种方案取消使能和lan口的操作。这样只是相当于把那个连接禁用了,并不会删除,万一自己配置路由拨号不顺利,还可以重新启用原有的连接进行上网。如果删了,自己又没配置好,那就芭比Q了。
pve虚拟机因为断电异常关机后,会出现重启无法进入系统的问题,并提示磁盘检查相关的异常,例如我碰到的提示
The root filesystem on /dev/mapper/pve-root requires a manual fsck手动执行fsck命令fsck -y /dev/mapper/pve-root即可
pve虚拟机因为断电异常关机后,会出现重启无法进入系统的问题,并提示磁盘检查相关的异常,例如我碰到的提示
The root filesystem on /dev/mapper/pve-root requires a manual fsck手动执行fsck命令fsck -y /dev/mapper/pve-root即可
安装完VMWare后,会自动生成两个虚拟网卡:
桥接模式分为两种模式:
桥接是虚拟机的网卡直接把数据包交给物理机的物理网卡进行处理,虚拟机必须有自己的ip、dns、网关信息

NAT(Network Address Translation),网络地址转换,相当于在虚拟机和物理机之间添加了一个交换机,拥有NAT地址转换功能,能够自动把虚拟机的IP转换为与物理机在同一网段的IP。VMnet8是NAT模式,自带DHCP功能,能给虚拟机分配IP地址。能够实现虚拟机和物理机相互通信,虚拟机和外网通信,但是不能外网到虚拟机通信,如果想让虚拟机作为服务器不能选择该模式。
DHCP(动态主机配置协议)是一个局域网的网络协议。指的是由服务器控制一段IP地址范围,客户机登录服务器时就可以自动获得服务器分配的IP地址和子网掩码。
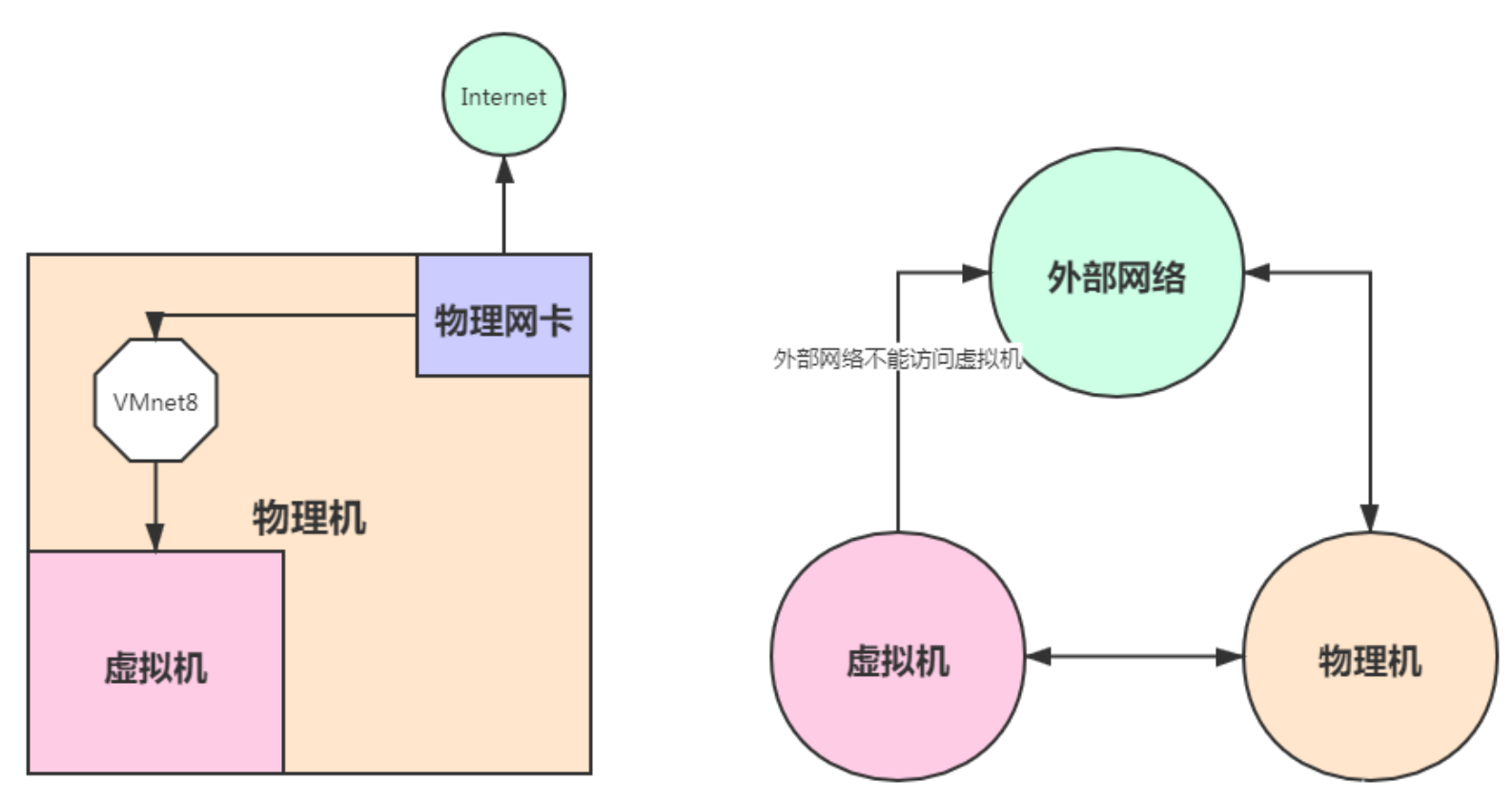
内部虚拟机连接到一个可提供 DHCP 功能的虚拟网卡VMnet1上去,VMnet1相当于一个交换机,将虚拟机发来的数据包转发给物理网卡,但是物理网卡不会将该数据包向外转发。所以仅主机模式只能用于虚拟机与虚拟机之间、虚拟机与物理机之间的通信。
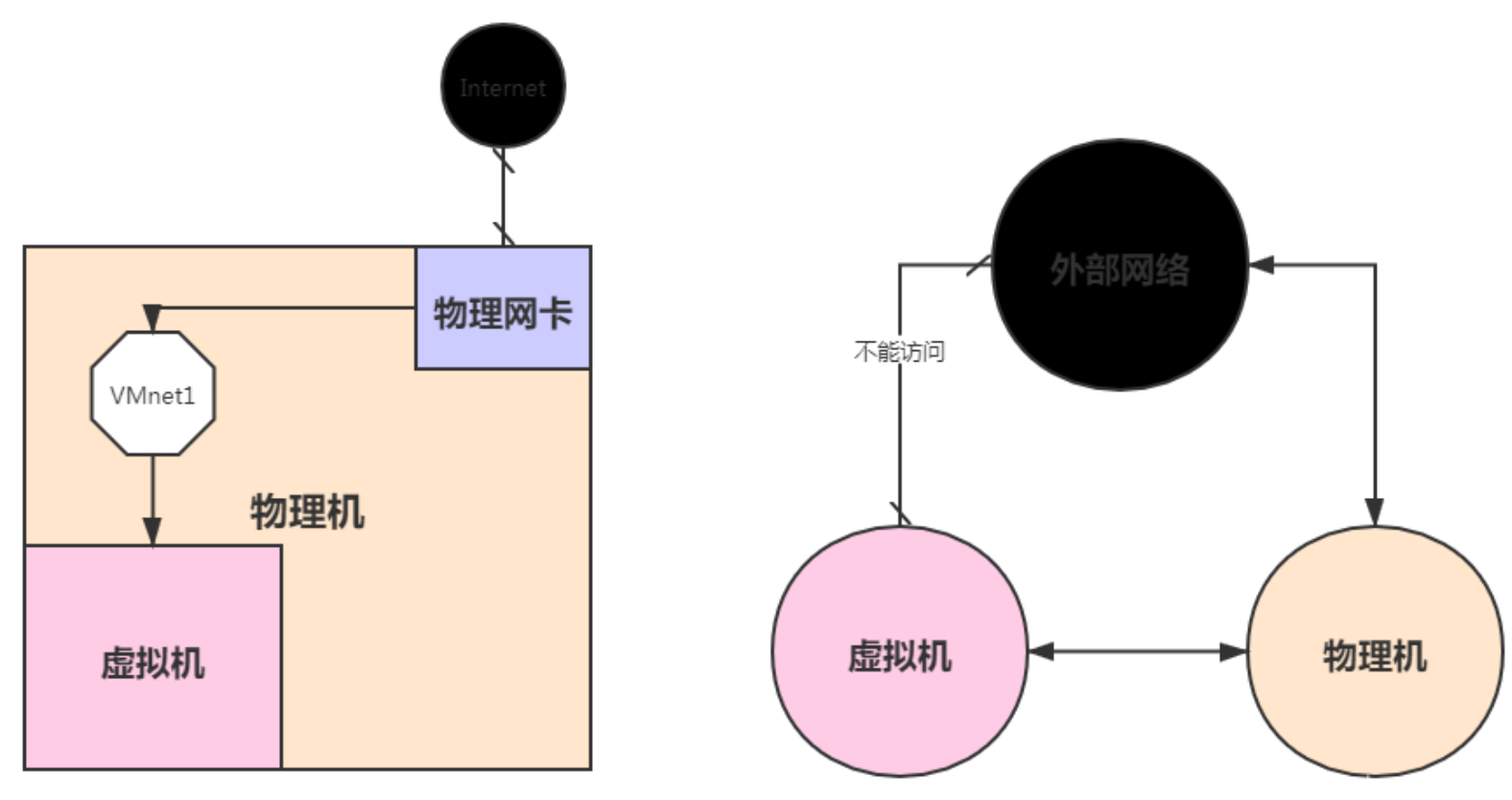
相当于模拟出一个交换机或者集线器出来,把不同虚拟机连接起来,与物理机不进行数据交流,与外网也不进行数据交流,构建一个独立的网络。没有 DHCP 功能,需要手工配置 IP 或者单独配置 DHCP 服务器。
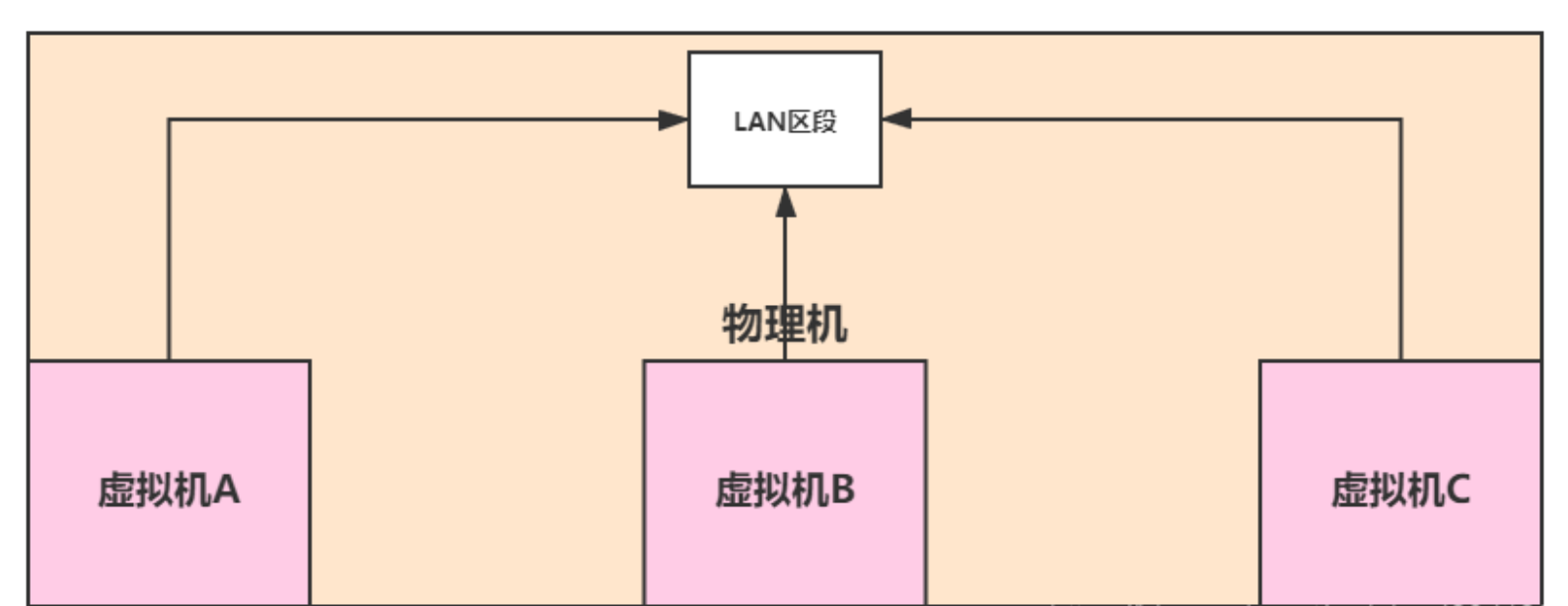
VMware DHCP Service、VMware NAT Service、VMware Workstation Server服务开启,如果处于停止状态则启动,此外,要把VMnet8的ipv4地址和dns设置为自动获取安装完VMWare后,会自动生成两个虚拟网卡:
桥接模式分为两种模式:
桥接是虚拟机的网卡直接把数据包交给物理机的物理网卡进行处理,虚拟机必须有自己的ip、dns、网关信息
NAT(Network Address Translation),网络地址转换,相当于在虚拟机和物理机之间添加了一个交换机,拥有NAT地址转换功能,能够自动把虚拟机的IP转换为与物理机在同一网段的IP。VMnet8是NAT模式,自带DHCP功能,能给虚拟机分配IP地址。能够实现虚拟机和物理机相互通信,虚拟机和外网通信,但是不能外网到虚拟机通信,如果想让虚拟机作为服务器不能选择该模式。
DHCP(动态主机配置协议)是一个局域网的网络协议。指的是由服务器控制一段IP地址范围,客户机登录服务器时就可以自动获得服务器分配的IP地址和子网掩码。
内部虚拟机连接到一个可提供 DHCP 功能的虚拟网卡VMnet1上去,VMnet1相当于一个交换机,将虚拟机发来的数据包转发给物理网卡,但是物理网卡不会将该数据包向外转发。所以仅主机模式只能用于虚拟机与虚拟机之间、虚拟机与物理机之间的通信。
相当于模拟出一个交换机或者集线器出来,把不同虚拟机连接起来,与物理机不进行数据交流,与外网也不进行数据交流,构建一个独立的网络。没有 DHCP 功能,需要手工配置 IP 或者单独配置 DHCP 服务器。
VMware DHCP Service、VMware NAT Service、VMware Workstation Server服务开启,如果处于停止状态则启动,此外,要把VMnet8的ipv4地址和dns设置为自动获取WARNING
一般的系统选择iso镜像模式写入,安装pve需要选择dd镜像模式写入
等待刷写完毕按照正常U盘安装系统流程安装,注意ip网关等配置即可
官网下载truenas scale系统镜像,打开pve的配置地址,点击上传后选择下载好的镜像文件并上传

操作系统选择刚上传的镜像
系统tab页默认即可,磁盘这里要注意总线/设备选择sata0,磁盘大小选择16即可,这里是分了一个虚拟的系统盘,不需要太大,因为truenas系统的系统引导盘和存储是分开的,分的太大在truenas中也无法用于存储
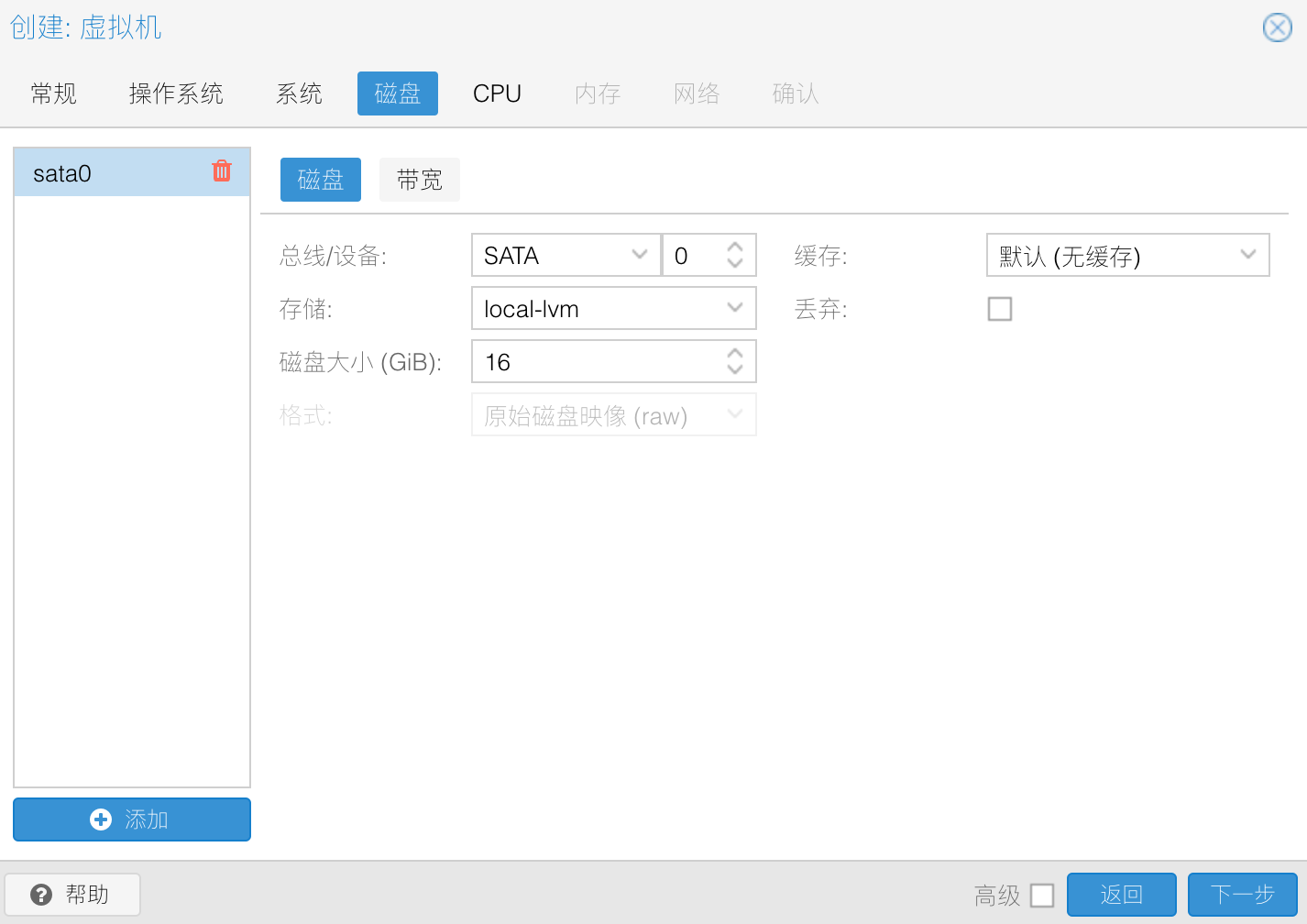
cpu根据情况设置,内存最小8G,建议尽可能大,truenas scale官方建议最好16G,因为truenas的文件系统很依赖内存。
启动刚创建的虚拟机,在选择系统安装盘界面按空格选中刚分配的16G磁盘,选择ok即可
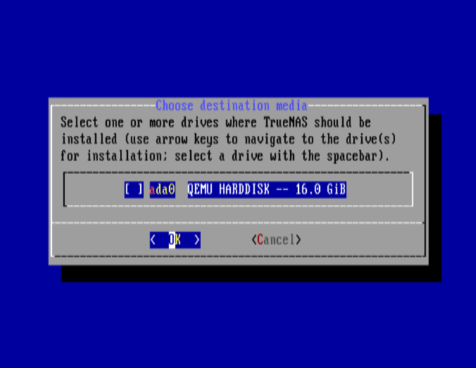
然后输入root密码,安装完后选择3重启
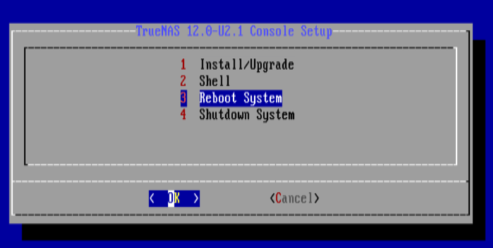
随后等待系统安装完毕
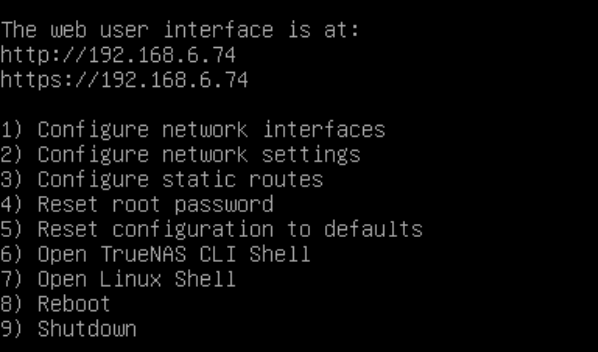
输入9选择关机
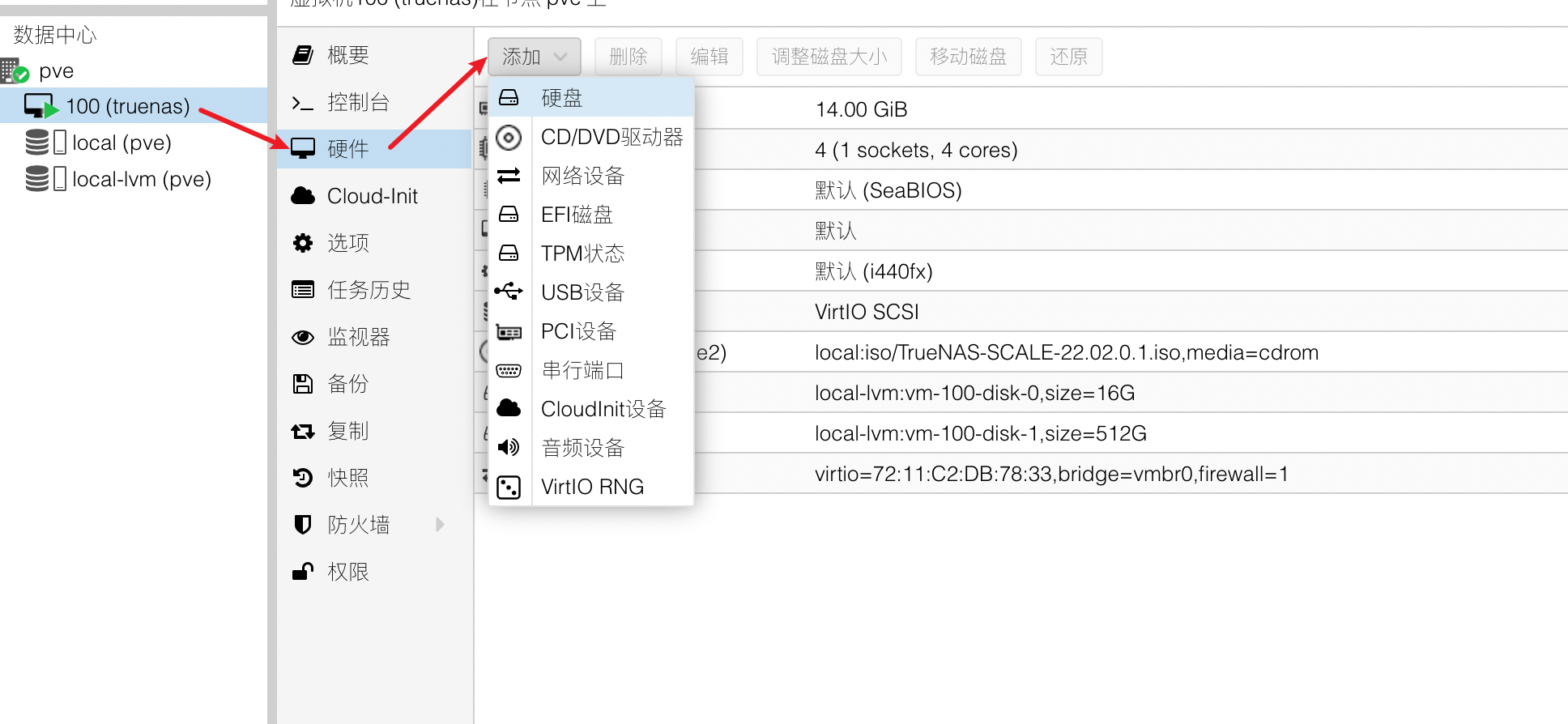
总线这里序号会默认自增,存储选择磁盘,我这里是只有一个固态硬盘,磁盘大小根据实际情况选择即可,添加即完成了虚拟硬盘的添加。
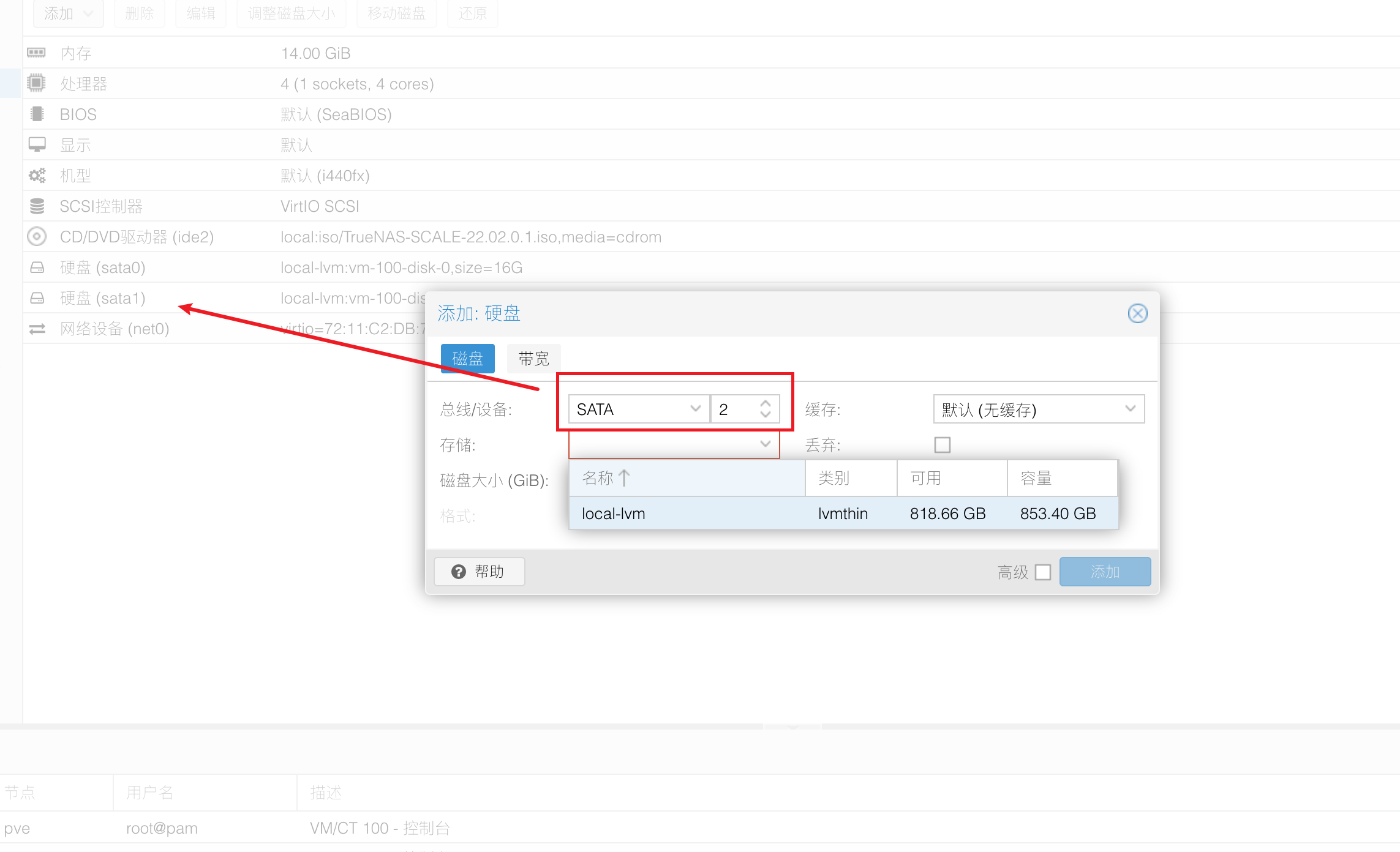
硬盘直通
1)直通单个硬盘
因为我这台测试机器只有一个固态硬盘,pve系统也装在这上面,所以无法用硬盘的直通,如果有多个机械盘,想直通给truenas,可以使用以下命令
ls -l /dev/disk/by-id # 查看硬盘名称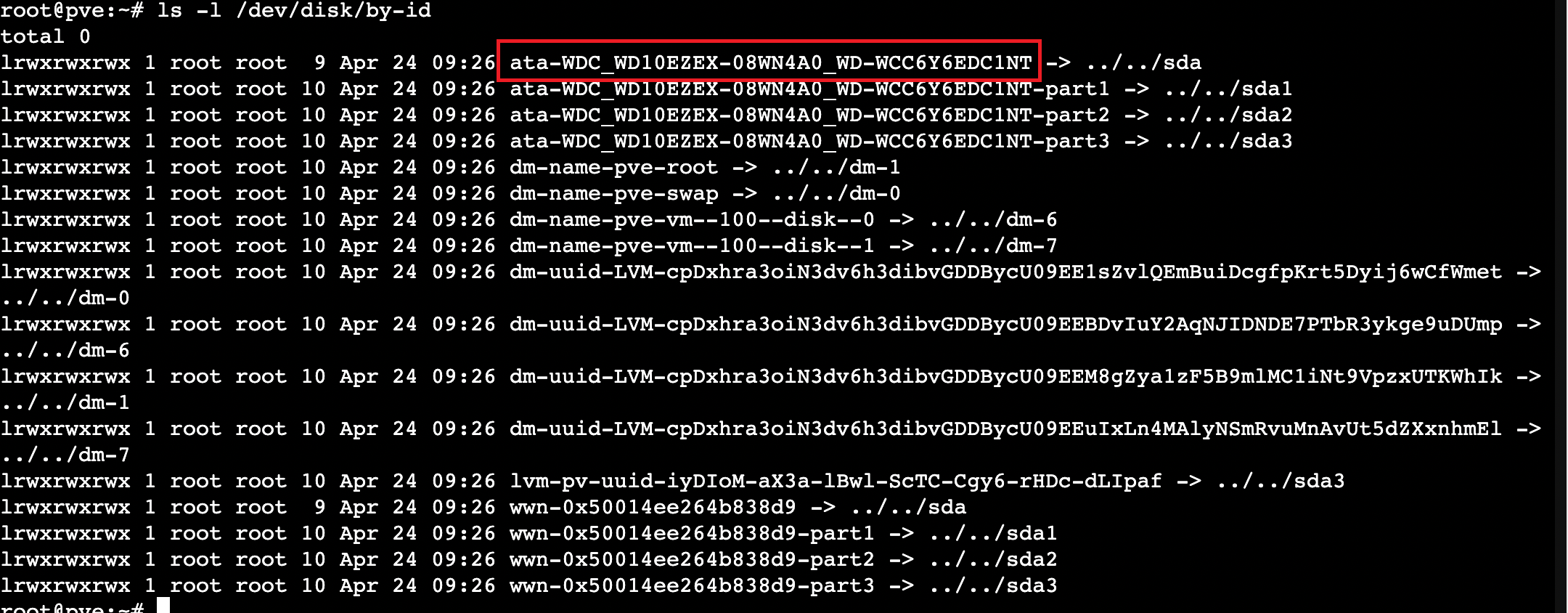
这里sda对应就是我的唯一一个硬盘,后面的sda1、2、3都是分区,可以忽略,记录下磁盘名称ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT,执行命令进行直通
qm set 100 -sata1 /dev/disk/by-id ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT
+---
+返回
+update VM 100: -sata1 /dev/disk/by-id ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT看到这个返回信息即为直通成功,回到虚拟机下面可以看到已经新增了一个sata硬盘
命令拆解:
qm set vm编号 -总线编号 磁盘路径
+- vm编号为pve虚拟机中的编号,例如100,101,102等
+- 总线编号为指定编号下要新增的硬盘总线编号,例如虚拟机下只有一个硬盘sata0,要新增的就是sata1,这里就要填sata1
+- 磁盘路径 就是/dev/disk/by-id/ + 我们上一步保存的硬盘名称2)添加PCI设备,直通sata控制器
Proxmox VE(PVE)系统直通SATA Controller(SATA 控制器),会把整个sata总线全部直通过去,就是直接将南桥或者直接把北桥连接的sata总线直通,那么有些主板sata接口就会全部被直通。
WARNING
如果PVE系统安装在sata硬盘中,会导致PVE无法启动,所以在直通sata控制器前要确认自己的PVE系统安装位置,或者直接安装到NVMe硬盘中
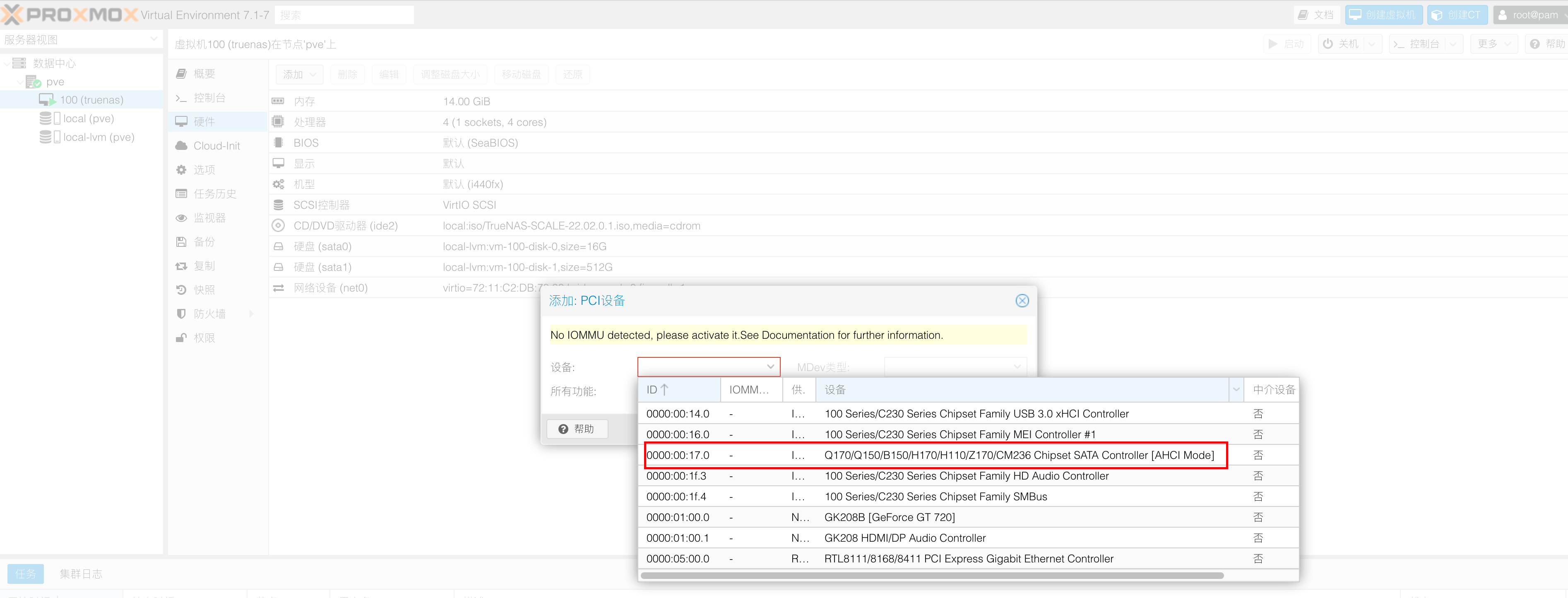
qm set vm编号 -delete 设备名,例如要删除设备ID为100的虚拟机下直通的sata1
那就是qm set 100 -delete sata1
WARNING
一般的系统选择iso镜像模式写入,安装pve需要选择dd镜像模式写入
等待刷写完毕按照正常U盘安装系统流程安装,注意ip网关等配置即可
官网下载truenas scale系统镜像,打开pve的配置地址,点击上传后选择下载好的镜像文件并上传
操作系统选择刚上传的镜像
系统tab页默认即可,磁盘这里要注意总线/设备选择sata0,磁盘大小选择16即可,这里是分了一个虚拟的系统盘,不需要太大,因为truenas系统的系统引导盘和存储是分开的,分的太大在truenas中也无法用于存储
cpu根据情况设置,内存最小8G,建议尽可能大,truenas scale官方建议最好16G,因为truenas的文件系统很依赖内存。
启动刚创建的虚拟机,在选择系统安装盘界面按空格选中刚分配的16G磁盘,选择ok即可
然后输入root密码,安装完后选择3重启
随后等待系统安装完毕
输入9选择关机
总线这里序号会默认自增,存储选择磁盘,我这里是只有一个固态硬盘,磁盘大小根据实际情况选择即可,添加即完成了虚拟硬盘的添加。
硬盘直通
1)直通单个硬盘
因为我这台测试机器只有一个固态硬盘,pve系统也装在这上面,所以无法用硬盘的直通,如果有多个机械盘,想直通给truenas,可以使用以下命令
ls -l /dev/disk/by-id # 查看硬盘名称
这里sda对应就是我的唯一一个硬盘,后面的sda1、2、3都是分区,可以忽略,记录下磁盘名称ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT,执行命令进行直通
qm set 100 -sata1 /dev/disk/by-id ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT
+---
+返回
+update VM 100: -sata1 /dev/disk/by-id ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT看到这个返回信息即为直通成功,回到虚拟机下面可以看到已经新增了一个sata硬盘
命令拆解:
qm set vm编号 -总线编号 磁盘路径
+- vm编号为pve虚拟机中的编号,例如100,101,102等
+- 总线编号为指定编号下要新增的硬盘总线编号,例如虚拟机下只有一个硬盘sata0,要新增的就是sata1,这里就要填sata1
+- 磁盘路径 就是/dev/disk/by-id/ + 我们上一步保存的硬盘名称2)添加PCI设备,直通sata控制器
Proxmox VE(PVE)系统直通SATA Controller(SATA 控制器),会把整个sata总线全部直通过去,就是直接将南桥或者直接把北桥连接的sata总线直通,那么有些主板sata接口就会全部被直通。
WARNING
如果PVE系统安装在sata硬盘中,会导致PVE无法启动,所以在直通sata控制器前要确认自己的PVE系统安装位置,或者直接安装到NVMe硬盘中
qm set vm编号 -delete 设备名,例如要删除设备ID为100的虚拟机下直通的sata1
那就是qm set 100 -delete sata1
Docker可以通过读取Dockerfile中的指令自动构建映像。Dockerfile是一个文本文档,其中包含用户在命令行上调用来组装镜像的所有命令。
# 注释
+INSTRUCTION arguments指令大小写不敏感,所以使用小写也不影响构建,但习惯上都将指令大写用于区分指令和参数。
Dockerfile必须以FROM指令开始(特殊情况:ARG指令)。
dockerfileARG CODE_VERSION=latest +FROM base:${CODE_VERSION} +CMD /code/run-app
ADDCOPYENVEXPOSEFROMLABELSTOPSIGNALUSERVOLUMEWORKDIRONBUILDdockerfileFROM busybox +ENV FOO=/bar +WORKDIR ${FOO} # WORKDIR /bar +ADD . $FOO # ADD . /bar +COPY \$FOO /quux # COPY $FOO /quux
FROM image_name:version as alias1
+# FROM [--platform=<platform>] <image>[:<tag>] [AS <name>] 一个Dockerfile中FROM可以多次出现 用于构建多个镜像或者将一个构建阶段用作另一个构建阶段的依赖项
+MAINTAINER storyxc #维护文档的人,现在用LABEL xxx=xxx代替了
+
+RUN xxx
+# RUN <command> shell格式,默认在linux上使用/bin/sh -c执行,windows上 cmd /S /C执行
+# RUN ['executable', 'param1', 'param2'] exec格式
+
+# Deploy Biliup
+FROM python:3.9 as alias2
+
+ENV TZ=Asia/Shanghai
+# ENV指定环境变量
+
+EXPOSE 19159/tcp
+EXPOSE 19149/udp
+# 注明暴露的端口,只是声明作用,实际没有功能
+
+ADD hom* /mydir/
+# ADD指令用于向镜像内拷贝文件 目录 不仅能复制本机的文件,也能将远程URL的资源复制到镜像中
+# ADD [--chown=<user>:<group>] [--chmod=<perms>] [--checksum=<checksum>] <src>... <dest>
+# ADD [--chown=<user>:<group>] [--chmod=<perms>] ["<src>",... "<dest>"]
+# ADD可以识别压缩格式,把可解压的文件解压为目录,远程URL资源不会被解压
+
+VOLUME /opt
+# 指定创建一个具有指定名称的挂载点 可以使用JSON数组格式 或多个参数纯字符串
+
+COPY --from=alias1 /dir1 /dir2
+# COPY [--chown=<user>:<group>] [--chmod=<perms>] <src>... <dest>
+# COPY [--chown=<user>:<group>] [--chmod=<perms>] ["<src>",... "<dest>"]
+
+WORKDIR /opt
+# WORKDIR指定工作目录,如果没有则会被创建,如果WORKDIR后出现了相对路径,都是相对WORKDIR的
+
+CMD ["param1", "param2"]
+# CMD指令有三种格式
+# CMD ["executable","param1","param2"] exec格式 最常用,不会有变量替换,需要变量替换需要使用shell格式或类似["shell", "-c", "e cho $HOME"]
+# CMD ["param1","param2"] 作为ENTRYPOINT的默认参数,如果是这个用法 那么ENTRYPOINT指令也要用JSON数组的格式书写
+# CMD command param1 param2 shell格式
+# 一个Dockerfile中只能有一个CMD指令,如果写了多个那么只有最后一个生效
+
+ENTRYPOINT ["biliup"]
+# ENTRYPOINT ["executable", "param1", "param2"]
+# ENTRYPOINT command param1 param2
在编程阶段还不清楚类型的变量指定的一个类型
某种程度上来说,void类型像是与any类型相反,它表示没有任何类型。
TypeScript里,undefined和null两者各自有自己的类型分别叫做undefined和null。 和 void相似,它们的本身的类型用处不是很大。
默认情况下null和undefined是所有类型的子类型。 就是说你可以把 null和undefined赋值给number类型的变量。
然而,当指定了--strictNullChecks标记,null和undefined只能赋值给void和它们各自。 这能避免 很多常见的问题。
Object:包含所有类型object:表示非原始类型也就是除number,string,boolean,symbol,null或undefined之外的类型。{}:同new Object(),包含所有类型,但无法修改属性、赋值等typescript中定义对象的方式是用interface,定义一种约束,让数据结构满足约束格式
interface Man extends Person{
+ age?:number
+ [propName:string]:any
+ readonly id:number
+}
+
+interface Person {
+ name:string
+}
+
+let p:Man = {
+ name: 'zs',
+ id: 1,
+ age: 18,
+ a:1,
+ b:2
+}
+
+
+interface Fn {
+ (name:string):number[]
+}
+
+const fn:Fn = function(name:string) {
+ return [1]
+}interface完全一致interface会被合并?readonly[],例如:number[]、string[]Array<number>interfacelet arr:number[][] = [[1], [2]]any[]//返回值
+function add(a:number, b:number): number {
+ return a+b
+}
+//箭头函数和定义返回值
+const add = (a:number,b:number):number => a+b
+
+//默认参数
+function add(a:number = 10, b:number = 20) {
+ return a+b
+}
+//可选参数
+function add(a:number = 10, b?:number): number{
+ return a+b
+}
+//传对象
+interface User {
+ name:string
+ age:nubmer
+}
+
+function add(user: User): User{
+ return user
+}
+console.log(add({ name: "111", age: 18}))
+
+//ts可以定义this的类型,在js中无法使用,必须是第一个参数定义this的类型(有点类似python里面的self?)
+interface Obj {
+ user:number[]
+ add:(this:Obj,num:number)=>void
+}
+
+let obj:Obj = {
+ user:[1,2,3],
+ add(this:Obj,num:number) {
+ this.user.push(num)
+ }
+}
+obj.add(4)
+console.log(obj)
+
+//函数重载
+let user:number[] = [1,2,3]
+
+
+function findNum():number[]
+function findNum(id:number):number[]
+function findNum(add:number[]):number[]
+
+//跟据入参走不同逻辑
+function findNum(ids?:number | number[]):number[] {
+ if(typeof ids == 'number') {
+ return user.filter(v=> v == ids)
+ }else if (Array.isArray(ids)) {
+ user.push(...ids)
+ return user
+ }else {
+ return user
+ }
+}
+console.log(findNum())let phone:number | string = '123456'
+
+//函数使用联合类型
+let fn = function(type:number | boolean):boolean {
+ return !!type
+}TypeScript中的 !!是一个逻辑非(not)操作符的双重否定形式,它可以用于将一个值转换成对应的布尔值。基本上,!!可以将任何值强制转换为对应的布尔值类型。
例如,使用!!可以将下列值转换为布尔类型的值:
!!true // true
!!1 // true
!!"hello" // true
!!undefined // false
!!null // false
!!0 // false
!!"" // false
interface People {
+ name:string,
+ age:string
+}
+
+interface Man {
+ sex:number
+}
+
+const p = (param:People & Man):void => {
+ console.log(man)
+}
+
+p({
+ name:"ikun",
+ age:"两年半",
+ sex:1
+})尖括号写法
let someValue: any = "this is a string";
+
+let strLength: number = (<string>someValue).length;as写法
let someValue: any = "this is a string";
+
+let strLength: number = (someValue as string).length;使用JSX时只允许as写法
Number(1)Date()RegExp(/\w/)Error('wrong')XMLHttpRequestHTML(元素名称)Element / HTMLElement / ElementNodeList / NodeListOf<HTMLDivElement | HTMLElement>StorageLocationPromise//class的基本用法 继承 和类型约束 implements
+interface Options {
+ el: string | HTMLElement;
+}
+interface VueClass {
+ options: Options;
+ init(): void;
+}
+interface Vnode {
+ tag: string;
+ text: string;
+ children?: Vnode[];
+}
+//虚拟dom
+class Dom {
+ //创建dom节点
+ createElement(el: string) {
+ return document.createElement(el);
+ }
+ //填充文本
+ setText(el: HTMLElement, text: string | null) {
+ el.textContent = text;
+ }
+ //渲染函数
+ render(data: Vnode) {
+ let root = this.createElement(data.tag);
+ if (data.children && Array.isArray(data.children)) {
+ data.children.forEach((item) => {
+ let child = this.render(item);
+ root.appendChild(child);
+ });
+ } else {
+ this.setText(root, data.text === undefined ? "" : data.text);
+ }
+ return root;
+ }
+}
+
+class Vue extends Dom implements VueClass {
+ options: Options;
+ constructor(options: Options) {
+ super();
+ this.options = options;
+ this.init();
+ }
+ init(): void {
+ let data: Vnode = {
+ tag: "div",
+ text: '111',
+ children: [
+ {
+ tag: "section",
+ text: "子节点1",
+ },
+ {
+ tag: "section",
+ text: "子节点2",
+ },
+ {
+ tag: "section",
+ text: "子节点3",
+ }
+ ],
+ };
+ let app =
+ typeof this.options.el == "string"
+ ? document.querySelector(this.options.el)
+ : this.options.el;
+ app?.appendChild(this.render(data));
+ }
+}
+
+new Vue({
+ el: "#app"
+});元组类型允许表示一个已知元素数量和类型的数组,各元素的类型不必相同。
// Declare a tuple type
+let x: [string, number];
+// Initialize it
+x = ['hello', 10]; // OK
+// Initialize it incorrectly
+x = [10, 'hello']; // Error当访问一个已知索引的元素,会得到正确的类型:
console.log(x[0].substr(1)); // OK
+console.log(x[1].substr(1)); // Error, 'number' does not have 'substr'当访问一个越界的元素,会使用联合类型替代:
x[3] = 'world'; // OK, 字符串可以赋值给(string | number)类型
+
+console.log(x[5].toString()); // OK, 'string' 和 'number' 都有 toString
+
+x[6] = true; // Error, 布尔不是(string | number)类型enum类型是对JavaScript标准数据类型的一个补充。
enum Color {Red, Green, Blue}
+let c: Color = Color.Green;默认情况下,从0开始为元素编号。 你也可以手动的指定成员的数值。 例如,我们将上面的例子改成从 1开始编号:
enum Color {Red = 1, Green, Blue}
+let c: Color = Color.Green;或者,全部都采用手动赋值:
enum Color {Red = 1, Green = 2, Blue = 4}
+let c: Color = Color.Green;枚举类型提供的一个便利是你可以由枚举的值得到它的名字。 例如,我们知道数值为2,但是不确定它映射到Color里的哪个名字,我们可以查找相应的名字:
enum Color {Red = 1, Green, Blue}
+let colorName: string = Color[2];
+
+console.log(colorName); // 显示'Green'因为上面代码里它的值是2TypeScript里,在有些没有明确指出类型的地方,类型推论会帮助提供类型。
如果没有指出类型 & 没赋值 会被推断成any类型。
type s = string | null
+
+let str:s = 'test'
+
+let str1 = '123'
+type s1 = typeof str1
+
+
+type num = 1 extends number ? 1 : 0
never类型表示的是那些永不存在的值的类型。 例如, never类型是那些总是会抛出异常或根本就不会有返回值的函数表达式或箭头函数表达式的返回值类型; 变量也可能是 never类型,当它们被永不为真的类型保护所约束时。
never类型是任何类型的子类型,也可以赋值给任何类型;然而,没有类型是never的子类型或可以赋值给never类型(除了never本身之外)。 即使 any也不可以赋值给never。
type A = string & number //never
+type A = void | number | never //never会被忽略掉
+
+
+type A = '唱' | '跳' | 'rap'
+
+function kun(value: A) {
+ switch (value) {
+ case '唱':
+ break;
+ case '跳':
+ break;
+ case 'rap':
+ break;
+ default:
+ const check: never = value;
+ break;
+ }
+}let a1:symbol = Symbol(1)
+let a2:symbol = Symbol(2)
+console.log(a1 === a2) // false
+
+//for Symbol 有没有注册过这个key 如果有直接用 没有就创建
+console.log(Symbol.for('1') === Symbol.for('1')) // truefunction* gen() {
+ yield Promise.resovle('111')
+ yield '1'
+ yield '2'
+}
+const g = gen()
+console.log(g.next())
+console.log(g.next())
+console.log(g.next())
+console.log(g.next())
+/*
+{ value: Promise { '111' }, done: false }
+{ value: '1', done: false }
+{ value: '2', done: false }
+{ value: undefined, done: true }
+*/let Set:Set<number> = new Set([1,1,2,3,3,3]) // 1 2 3
+
+let map:Map<any, any> = new Map()
+let arr = [1,2,3]
+map.set(arr, '123')
+
+function args(){
+ console.log(arguments) //伪数组 IArguments
+}
+
+const each = (value:any) => {
+ let It: any = value[Symbol.iterator]()
+ let next: any = { done: false }
+ while (!next.done) {
+ next = It.next()
+ if (!next.done) {
+ console.log(next.value)
+ }
+ }
+}
+each([1,2,3])
+/*
+1
+2
+3
+*/
+
+
+//迭代器语法糖 for of
+//对象不能用 for of语法
+for (let value of map) {
+ console.log(value)
+}
+
+//数组解构 底层原理也是调用iterator
+let a = [4,5,6]
+let copy = [...a]
+console.log(a)
+
+let obj = {
+ max:5,
+ current:0,
+ [Symbol.iterator]() {
+ return {
+ max: this.max,
+ current: this.current,
+ next() {
+ if (this.current == this.max) {
+ return {
+ value: undefined,
+ done:true
+ }
+ }else {
+ return {
+ value: this.current++,
+ done:false
+ }
+ }
+ }
+ }
+ }
+}
+
+for (let value of obj) {
+ console.log(value)
+}
+/*
+0
+1
+2
+3
+4
+*/function fun<T>(a:T, b:T):Array<T> {
+ return [a,b]
+}
+
+type A<T> = string | number | T
+let a:A<boolean> = true
+
+interface Date<T> {
+ msg:T
+}
+let data:Date<number> = {
+ msg:1
+}
+
+function add<T = number,K = number>(a:T,b:K):Array<T | K> {
+ return [a,b]
+}
+add(false, '1')
+
+const axios = {
+ get<T>(url:string) {
+ return new Promise<T>((resolve,reject)=>{
+ let xhr:XMLHttpRequest = new XMLHttpRequest()
+ xhr.open('GET',url)
+ xhr.onreadystatechange = () => {
+ if(xhr.readyState ==4 && xhr.status == 200) {
+ resolve(JSON.parse(xhr.responseText))
+ }
+ }
+ xhr.send(null)
+ })
+ }
+}// extends
+interface Len {
+ length:number
+}
+
+function func<T extends Len)(a:T) {
+ console.log(a.length)
+}
+
+let obj = {
+ name: 'test',
+ sex: 1
+}
+
+// 约束对象的key
+type key = keyof typeof obj // "name" | "sex"
+
+function ob<T extends object, K extends keyof T>(obj:T, key:K) {
+
+}
+
+
+interface Data {
+ name:string
+ age:number
+ sex:string
+}
+
+type Options<T extends object> = {
+ //readonly [Key in keyof T]?:T[Key]
+ [Key in keyof T]?:T[Key]
+}
+
+type B = Options<Data>
+/*
+type B = {
+ name?: string | undefined;
+ age?: number | undefined;
+ sex?: string | undefined;
+}
+type B = {
+ name?: string | undefined;
+ age?: number | undefined;
+ sex?: string | undefined;
+}
+*/通过tsc --init生成
"compilerOptions": {
+ "incremental": true, // TS编译器在第一次编译之后会生成一个存储编译信息的文件,第二次编译会在第一次的基础上进行增量编译,可以提高编译的速度
+ "tsBuildInfoFile": "./buildFile", // 增量编译文件的存储位置
+ "diagnostics": true, // 打印诊断信息
+ "target": "ES5", // 目标语言的版本
+ "module": "CommonJS", // 生成代码的模板标准
+ "outFile": "./app.js", // 将多个相互依赖的文件生成一个文件,可以用在AMD模块中,即开启时应设置"module": "AMD",
+ "lib": ["DOM", "ES2015", "ScriptHost", "ES2019.Array"], // TS需要引用的库,即声明文件,es5 默认引用dom、es5、scripthost,如需要使用es的高级版本特性,通常都需要配置,如es8的数组新特性需要引入"ES2019.Array",
+ "allowJS": true, // 允许编译器编译JS,JSX文件
+ "checkJs": true, // 允许在JS文件中报错,通常与allowJS一起使用
+ "outDir": "./dist", // 指定输出目录
+ "rootDir": "./", // 指定输出文件目录(用于输出),用于控制输出目录结构
+ "declaration": true, // 生成声明文件,开启后会自动生成声明文件
+ "declarationDir": "./file", // 指定生成声明文件存放目录
+ "emitDeclarationOnly": true, // 只生成声明文件,而不会生成js文件
+ "sourceMap": true, // 生成目标文件的sourceMap文件
+ "inlineSourceMap": true, // 生成目标文件的inline SourceMap,inline SourceMap会包含在生成的js文件中
+ "declarationMap": true, // 为声明文件生成sourceMap
+ "typeRoots": [], // 声明文件目录,默认时node_modules/@types
+ "types": [], // 加载的声明文件包
+ "removeComments":true, // 删除注释
+ "noEmit": true, // 不输出文件,即编译后不会生成任何js文件
+ "noEmitOnError": true, // 发送错误时不输出任何文件
+ "noEmitHelpers": true, // 不生成helper函数,减小体积,需要额外安装,常配合importHelpers一起使用
+ "importHelpers": true, // 通过tslib引入helper函数,文件必须是模块
+ "downlevelIteration": true, // 降级遍历器实现,如果目标源是es3/5,那么遍历器会有降级的实现
+ "strict": true, // 开启所有严格的类型检查
+ "alwaysStrict": true, // 在代码中注入'use strict'
+ "noImplicitAny": true, // 不允许隐式的any类型
+ "strictNullChecks": true, // 不允许把null、undefined赋值给其他类型的变量
+ "strictFunctionTypes": true, // 不允许函数参数双向协变
+ "strictPropertyInitialization": true, // 类的实例属性必须初始化
+ "strictBindCallApply": true, // 严格的bind/call/apply检查
+ "noImplicitThis": true, // 不允许this有隐式的any类型
+ "noUnusedLocals": true, // 检查只声明、未使用的局部变量(只提示不报错)
+ "noUnusedParameters": true, // 检查未使用的函数参数(只提示不报错)
+ "noFallthroughCasesInSwitch": true, // 防止switch语句贯穿(即如果没有break语句后面不会执行)
+ "noImplicitReturns": true, //每个分支都会有返回值
+ "esModuleInterop": true, // 允许export=导出,由import from 导入
+ "allowUmdGlobalAccess": true, // 允许在模块中全局变量的方式访问umd模块
+ "moduleResolution": "node", // 模块解析策略,ts默认用node的解析策略,即相对的方式导入
+ "baseUrl": "./", // 解析非相对模块的基地址,默认是当前目录
+ "paths": { // 路径映射,相对于baseUrl
+ // 如使用jq时不想使用默认版本,而需要手动指定版本,可进行如下配置
+ "jquery": ["node_modules/jquery/dist/jquery.min.js"]
+ },
+ "rootDirs": ["src","out"], // 将多个目录放在一个虚拟目录下,用于运行时,即编译后引入文件的位置可能发生变化,这也设置可以虚拟src和out在同一个目录下,不用再去改变路径也不会报错
+ "listEmittedFiles": true, // 打印输出文件
+ "listFiles": true// 打印编译的文件(包括引用的声明文件)
+}
+
+// 指定一个匹配列表(属于自动指定该路径下的所有ts相关文件)
+"include": [
+ "src/**/*"
+],
+// 指定一个排除列表(include的反向操作)
+ "exclude": [
+ "demo.ts"
+],
+// 指定哪些文件使用该配置(属于手动一个个指定文件)
+ "files": [
+ "demo.ts"
+]typescript提供了namespace避免全局变量污染的问题。
任何包含顶级import或export的文件都被当作一个模块。相反的,如果不带,那么它的内容被视为全局可见的。
内部模块,外部模块现在简称为模块。namespace A {
+ export const a = 1
+}
+// 实现:
+"use strict"
+var A;
+(function (A) {
+ A.a = 1;
+})(A || A = {});
+
+// 嵌套命名空间
+namespace A {
+ export namespace C {
+ export const D = 5;
+ }
+}
+
+console.log(A.C.D)
+
+//抽离命名空间
+export namespace V {
+ export const a = 1
+}
+
+import {V} from '../index'
+console.log(V)// {a:1}
+
+
+//简化命名空间
+namespace A {
+ export namespace C {
+ export const D = 5;
+ }
+}
+
+import a = A.C
+console.log(a.D)
+
+//命名空间合并
+namespace A {
+ export const b = 2
+}
+namespace A {
+ export const a = 1
+}
+//等价于
+namespace A {
+ export const b = 2
+ export const a = 1
+}三斜线指令是包含单个XML标签的单行注释。 注释的内容会做为编译器指令使用。
/// <reference path="..." />
+/// <reference path="..." />指令是三斜线指令中最常见的一种。 它用于声明文件间的 依赖。三斜线引用告诉编译器在编译过程中要引入的额外的文件。
/// <reference types="..." />
+与 /// <reference path="..." />指令相似,这个指令是用来声明 依赖的; 一个 /// <reference types="..." />指令则声明了对某个包的依赖。
+
+对这些包的名字的解析与在 import语句里对模块名的解析类似。 可以简单地把三斜线类型引用指令当做 import声明的包。
+
+例如,把 /// <reference types="node" />引入到声明文件,表明这个文件使用了 @types/node/index.d.ts里面声明的名字; 并且,这个包需要在编译阶段与声明文件一起被包含进来。
+
+仅当在你需要写一个d.ts文件时才使用这个指令。
+
+对于那些在编译阶段生成的声明文件,编译器会自动地添加/// <reference types="..." />; 当且仅当结果文件中使用了引用的包里的声明时才会在生成的声明文件里添加/// <reference types="..." />语句。
+
+若要在.ts文件里声明一个对@types包的依赖,使用--types命令行选项或在tsconfig.json里指定。使用第三方库时需要引用它的声明文件d.ts才能获得对应的代码补全、接口提示等功能
npm i @types/xxx除了传统的面向对象继承方式,还流行一种通过可重用组件创建类的方式,就是联合另一个简单类的代码。
// Disposable Mixin
+class Disposable {
+ isDisposed: boolean;
+ dispose() {
+ this.isDisposed = true;
+ }
+
+}
+
+// Activatable Mixin
+class Activatable {
+ isActive: boolean;
+ activate() {
+ this.isActive = true;
+ }
+ deactivate() {
+ this.isActive = false;
+ }
+}
+
+class SmartObject implements Disposable, Activatable {
+ constructor() {
+ setInterval(() => console.log(this.isActive + " : " + this.isDisposed), 500);
+ }
+
+ interact() {
+ this.activate();
+ }
+
+ // Disposable
+ isDisposed: boolean = false;
+ dispose: () => void;
+ // Activatable
+ isActive: boolean = false;
+ activate: () => void;
+ deactivate: () => void;
+}
+applyMixins(SmartObject, [Disposable, Activatable]);
+
+let smartObj = new SmartObject();
+setTimeout(() => smartObj.interact(), 1000);
+
+////////////////////////////////////////
+// In your runtime library somewhere
+////////////////////////////////////////
+
+function applyMixins(derivedCtor: any, baseCtors: any[]) {
+ baseCtors.forEach(baseCtor => {
+ Object.getOwnPropertyNames(baseCtor.prototype).forEach(name => {
+ derivedCtor.prototype[name] = baseCtor.prototype[name];
+ });
+ });
+}随着TypeScript和ES6里引入了类,在一些场景下我们需要额外的特性来支持标注或修改类及其成员。 装饰器(Decorators)为我们在类的声明及成员上通过元编程语法添加标注提供了一种方式。
若要启用实验性的装饰器特性,你必须在命令行或tsconfig.json里启用experimentalDecorators编译器选项:
命令行:
tsc --target ES5 --experimentalDecoratorstsconfig.json:
{
+ "compilerOptions": {
+ "target": "ES5",
+ "experimentalDecorators": true
+ }
+}装饰器是一种特殊类型的声明,它能够被附加到类声明,方法, 访问符,属性或参数上。 装饰器使用 @expression这种形式,expression求值后必须为一个函数,它会在运行时被调用,被装饰的声明信息做为参数传入。
const IKun: ClassDecorator = (target) => {
+ console.log(target);
+ target.prototype.name = 'ikun';
+ target.prototype.slogan = () => {
+ console.log('鸡你太美');
+ }
+}
+
+@IKun
+class Person {
+
+}
+
+const person = new Person() as any;
+person.slogan(); // 鸡你太美const IKun = (name: string) => {
+ const decorator: ClassDecorator = (target) => {
+ target.prototype.name = name;
+ target.prototype.slogan = () => {
+ console.log('鸡你太美');
+ }
+ }
+ return decorator
+
+}
+
+@IKun('小黑子')
+class Person {
+
+}
+
+const person = new Person() as any;
+console.log(person.name); // 小黑子
+person.slogan(); // 鸡你太美方法装饰器声明在一个方法的声明之前(紧靠着方法声明)。 它会被应用到方法的 属性描述符上,可以用来监视,修改或者替换方法定义。 方法装饰器不能用在声明文件( .d.ts),重载或者任何外部上下文(比如declare的类)中。
方法装饰器表达式会在运行时当作函数被调用,传入下列3个参数:
如果方法装饰器返回一个值,它会被用作方法的属性描述符。
const logResult = (target: any, propertyKey: string, descriptor: PropertyDescriptor) => {
+ const fn = descriptor.value
+ descriptor.value = function(...rest) {
+ // 使用新的方法来替换原有方法,输出 方法名称 + 输入的参数 实现日志的增强功能
+ const result = fn.apply(this, rest)
+ console.log(propertyKey + ':' + result)
+ return result
+ }
+}
+
+class Person {
+ name: string = ''
+ age: number = 0
+
+ constructor(name: string, age: number) {
+ this.name = name
+ this.age = age
+ }
+
+ @logResult
+ getName() {
+ return this.name
+ }
+
+ @logResult
+ getAge() {
+ return this.age
+ }
+}
+
+const p = new Person('张三', 18)
+p.getName() // getName:张三
+p.getAge() // getAge:18import "reflect-metadata";
+
+const formatMetadataKey = Symbol("format");
+
+function format(formatString: string) {
+ return Reflect.metadata(formatMetadataKey, formatString);
+}
+
+function getFormat(target: any, propertyKey: string) {
+ return Reflect.getMetadata(formatMetadataKey, target, propertyKey);
+}
+
+class Greeter {
+ @format("Hello, %s")
+ greeting: string;
+
+ constructor(message: string) {
+ this.greeting = message;
+ }
+
+ greet() {
+ let formatString = getFormat(this, "greeting");
+ return formatString.replace("%s", this.greeting);
+ }
+}
+
+console.log(new Greeter("world").greet()); // "Hello, world"参数装饰器用于装饰函数参数,参数装饰器接收3个参数:
target: 对于静态成员来说是类的构造函数,对于实例成员是类的原型对象propertyKey: 方法名。paramIndex: 参数所在位置的索引。const paramDecorator = (target: any, propertyKey: string, paramIndex: number) => {
+ console.log(target, propertyKey, paramIndex)
+}
+
+class Person {
+ name: string = ''
+ age: number = 0
+
+ constructor(name: string, age: number) {
+ this.name = name
+ this.age = age
+ }
+
+ setName(@paramDecorator name: string) {
+ this.name = name
+ }
+}
+
+const p = new Person('张三', 18) // Person、setName、0
+p.setName('李四')https://www.youtube.com/playlist?list=PLuoeXyslFTuZRi4q4VT6lZKxYbr7so1Mr
struct ContentView: View {
+ @State private var checkAmount = 0.0
+ @State private var numberOfPeople = 0
+ @State private var tipPercentage = 20
+ @FocusState private var amountIsFocused: Bool
+
+ private var totalPerPerson: Double {
+ let peopleCount = Double(numberOfPeople + 2)
+ let tipSelection = Double(tipPercentage)
+ return checkAmount * tipSelection / peopleCount / 100
+ }
+
+ let tipPercentages = [10, 15, 20, 25, 0]
+
+ var body: some View {
+ NavigationView {
+ Form {
+ Section("") {
+ TextField("Amount", value: $checkAmount, format: .currency(code: Locale.current.currencyCode ?? "USD"))
+ .keyboardType(.decimalPad)
+ .focused($amountIsFocused)
+
+ Picker("Number of people", selection: $numberOfPeople) {
+ ForEach(2..<100) {
+ Text("\($0) people")
+ }
+ }
+ }
+
+ Section {
+ Picker("Tip percentage", selection: $tipPercentage) {
+ ForEach(tipPercentages, id: \.self) {
+ Text($0, format: .percent)
+ }
+ }
+ .pickerStyle(.segmented)
+ }header: {
+ Text("How much tip do you want to leave")
+ }
+
+ Section {
+ Text(totalPerPerson, format: .currency(code: Locale.current.currencyCode ?? "USD"))
+ }
+ }
+ .navigationTitle("WeSplit")
+ .toolbar {
+ ToolbarItemGroup(placement: .keyboard) {
+ Spacer()
+ Button("Done") {
+ amountIsFocused = false
+ }
+ }
+ }
+ }
+ }
+}Form
TextField & format: .currency(code: Locale.current.currencyCode ?? "USD")
Picker
Section
toolbar修饰符
struct ContentView: View {
+ @State private var showScores = false
+ @State private var scoreTitle = ""
+
+ @State private var scores = 0
+
+ @State private var countries = ["Estonia", "France", "Germany", "Ireland", "Italy", "Nigeria",
+ "Poland", "Russia", "Spain", "UK", "US"].shuffled()
+ @State var correctAnswer = Int.random(in: 0...2)
+
+ var body: some View {
+ ZStack {
+ //AngularGradient(gradient: Gradient(colors: [.red, .yellow, .green,.blue, .purple,.red]), center: .center)
+ RadialGradient(stops: [
+ .init(color: Color(red: 0.1, green: 0.2, blue: 0.45), location: 0.3),
+ .init(color: Color(red: 0.76, green: 0.15, blue: 0.26), location: 0.3)
+ ], center: .top, startRadius: 200, endRadius: 700)
+ .ignoresSafeArea()
+
+ VStack {
+
+ Spacer()
+
+ Text("Guess the flag")
+ .font(.largeTitle.weight(.bold))
+ .foregroundColor(.white)
+
+ VStack(spacing: 15) {
+ VStack{
+ Text("Tap the flag of")
+ .foregroundStyle(.secondary)
+ .font(.subheadline.weight(.heavy))
+ Text(countries[correctAnswer])
+ .font(.largeTitle.weight(.semibold))
+ }
+
+ ForEach(0..<3) {number in
+ Button {
+ flagTapper(number)
+ }label: {
+ Image(countries[number])
+ .renderingMode(.original)
+ .clipShape(Capsule())
+ }
+ }
+ }
+ .frame(maxWidth: .infinity)
+ .padding(.vertical, 20)
+ .background(.regularMaterial)
+ .clipShape(RoundedRectangle(cornerRadius: 20))
+
+ Spacer()
+
+ Text("Score \(scores)")
+ .foregroundColor(.white)
+ .font(.title.bold())
+ Spacer()
+ }
+ .padding()
+ }
+ .alert(scoreTitle, isPresented: $showScores) {
+ Button("Continue", action: askQuestion)
+ } message: {
+ Text("Your score is \(scores)")
+ }
+ }
+ func flagTapper(_ number: Int) {
+ if number == correctAnswer {
+ scoreTitle = "Correct"
+ scores += 10
+ } else {
+ scoreTitle = "Wrong"
+ }
+ showScores = true
+ }
+
+ func askQuestion() {
+
+ countries.shuffle()
+ correctAnswer = Int.random(in: 0...2)
+ }
+}
import CoreML
+import SwiftUI
+
+struct ContentView: View {
+ @State private var wakeUp = defaultWakeTime
+ @State private var sleepAmount = 8.0
+ @State private var coffeeAmount = 1
+
+ @State private var alertTitle = ""
+ @State private var alertMessage = ""
+ @State private var showingAlert = false
+
+ static var defaultWakeTime: Date {
+ var components = DateComponents()
+ components.hour = 7
+ components.minute = 0
+ return Calendar.current.date(from: components) ?? Date.now
+ }
+
+ var body: some View {
+ NavigationView {
+ Form {
+ VStack(alignment: .leading, spacing: 0) {
+ Text("When do you want to wake up?")
+ .font(.headline)
+ DatePicker("Please enter atime", selection: $wakeUp, displayedComponents: .hourAndMinute)
+ .labelsHidden()
+ }
+
+
+ VStack(alignment: .leading, spacing: 0) {
+ Text("Desired amount of sleep")
+ .font(.headline)
+ Stepper("\(sleepAmount.formatted()) hours", value: $sleepAmount, in: 4...12, step: 0.25)
+ }
+
+
+ VStack(alignment: .leading, spacing: 0) {
+ Text("Daily coffee intake")
+ Stepper(coffeeAmount == 1 ? "1 cup" : "\(coffeeAmount) cups", value: $coffeeAmount, in: 0...20)
+ }
+
+ }
+ .navigationTitle("BetterRest")
+ .toolbar {
+ Button("Calculate", action: calculateBedtime)
+ }
+ .alert(alertTitle, isPresented: $showingAlert) {
+ Button("OK") {}
+ }message: {
+ Text(alertMessage)
+ }
+ }
+
+ }
+
+ func calculateBedtime() {
+ do {
+ let config = MLModelConfiguration()
+ let model = try SleepCalculator(configuration: config)
+ let components = Calendar.current.dateComponents([.hour, .minute], from: wakeUp)
+ let hour = (components.hour ?? 0) * 60 * 60
+ let minute = (components.minute ?? 0) * 60
+
+ let prediction = try model.prediction(wake: Double(hour + minute), estimatedSleep: sleepAmount, coffee: Double(coffeeAmount))
+
+ let sleepTime = wakeUp - prediction.actualSleep
+ alertTitle = "Your ideal bedtime is ..."
+ alertMessage = sleepTime.formatted(date: .omitted, time: .shortened)
+ }catch {
+ alertTitle = "Error"
+ alertMessage = "Sorry, there was a problem calculating your bedtime."
+ }
+
+ showingAlert = true
+ }
+}CoreML机器学习
DateComponents、DatePicker
alert修饰符
Stepper
struct ContentView: View {
+ @State private var usedWords = [String]()
+ @State private var rootWord = ""
+ @State private var newWord = ""
+
+ @State private var errorTitle = ""
+ @State private var errorMessage = ""
+ @State private var showingError = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ Section {
+ TextField("enter your word", text: $newWord)
+ .autocapitalization(.none)
+ }
+
+ Section {
+ ForEach(usedWords, id: \.self) { word in
+ HStack{
+ Image(systemName: "\(word.count).circle")
+ Text(word)
+ }
+ }
+ }
+ }
+ .navigationTitle(rootWord)
+ .onSubmit(addNewWord)
+ .onAppear(perform: startGame)
+ .alert(errorTitle, isPresented: $showingError) {
+ Button("OK", role: .cancel) {}
+ }message: {
+ Text(errorMessage)
+ }
+ }
+ }
+
+ func addNewWord() {
+ let answer = newWord.lowercased().trimmingCharacters(in: .whitespacesAndNewlines)
+ guard answer.count > 0 else { return }
+
+ guard isOriginal(word: answer) else {
+ wordError(title: "Word used already", message: "Be more original")
+ return
+ }
+
+ guard isPossible(word: answer) else {
+ wordError(title: "word not possible", message: "you can't spell that word from '\(rootWord)'")
+ return
+ }
+
+ guard isReal(word: answer) else {
+ wordError(title: "word not recognized", message: "you can't just make them up, you know!")
+ return
+ }
+
+
+ withAnimation{
+ usedWords.insert(answer, at: 0)
+ }
+
+ newWord = ""
+ }
+
+ func startGame() {
+ if let fileURL = Bundle.main.url(forResource: "start", withExtension: "txt") {
+ if let startWords = try? String(contentsOf: fileURL) {
+ let allWords = startWords.components(separatedBy: "\n")
+ rootWord = allWords.randomElement() ?? "silkworm"
+ return
+ }
+ }
+ fatalError("Could not load start.txt from bundle")
+ }
+
+ func isOriginal(word: String) -> Bool {
+ !usedWords.contains(word)
+ }
+
+ func isPossible(word: String) -> Bool {
+ var tempWord = rootWord
+
+ for letter in word {
+ if let pos = tempWord.firstIndex(of: letter) {
+ tempWord.remove(at: pos)
+ } else {
+ return false
+ }
+ }
+ return true
+ }
+
+ func isReal(word: String) -> Bool {
+ let checker = UITextChecker()
+ let range = NSRange(location: 0, length: word.utf16.count)
+ let misspelledRange = checker.rangeOfMisspelledWord(in: word, range: range, startingAt: 0, wrap: false, language: "en")
+
+ return misspelledRange.location == NSNotFound
+ }
+
+ func wordError(title: String, message: String) {
+ errorTitle = title
+ errorMessage = message
+ showingError = true
+ }
+}TextField("enter your word", text: $newWord).autocapitalization(.none)
onSubmit、onAppear修饰符
读取静态资源
if let fileURL = Bundle.main.url(forResource: "start", withExtension: "txt") {
+ if let startWords = try? String(contentsOf: fileURL) {
+ let allWords = startWords.components(separatedBy: "\n")
+ rootWord = allWords.randomElement() ?? "silkworm"
+ return
+ }
+ }
+ fatalError("Could not load start.txt from bundle")UITextChecker()
Expenses(ViewModel)
class Expenses: ObservableObject {
+ @Published var items = [ExpenseItem]() {
+ didSet {
+ let encoder = JSONEncoder()
+
+ if let encoded = try? encoder.encode(items) {
+ UserDefaults.standard.set(encoded, forKey: "Items")
+ }
+ }
+ }
+
+ init() {
+ if let itemArr = UserDefaults.standard.data(forKey: "Items") {
+ let decoder = JSONDecoder()
+ if let decodedItems = try? decoder.decode([ExpenseItem].self, from: itemArr) {
+ items = decodedItems
+ return
+ }
+ }
+ items = []
+ }
+}ExpenseItem(Model)
struct ExpenseItem: Identifiable, Codable {
+ let name: String
+ let type: String
+ let amount: Double
+ let id = UUID()
+}AddView
struct AddView: View {
+ @ObservedObject var expenses: Expenses
+
+ @State private var name = ""
+ @State private var type = "Personal"
+ @State private var amount = 0.0
+ @Environment(\.dismiss) var dismiss
+
+ let types = ["Business", "Personal"]
+
+
+ var body: some View {
+ NavigationView {
+ Form {
+ TextField("Name", text: $name)
+
+ Picker("Type", selection: $type) {
+ ForEach(types, id: \.self) {
+ Text($0)
+ }
+ }
+
+ TextField("Amount", value: $amount, format: .currency(code: Locale.current.currencyCode ?? "CNY"))
+ .keyboardType(.decimalPad)
+ }
+ .navigationTitle("Add new expense")
+ .toolbar {
+ Button("Save") {
+ let item = ExpenseItem(name: name, type: type, amount: amount)
+ expenses.items.append(item)
+ dismiss()
+ }
+ }
+ }
+ }
+}ContentView
struct ContentView: View {
+ @StateObject var expenses = Expenses()
+ @State private var showingAddExpense = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ ForEach(expenses.items) { item in
+ HStack {
+ VStack(alignment: .leading) {
+ Text(item.name)
+ .font(.headline)
+ Text(item.type)
+ .font(.subheadline)
+ }
+ Spacer()
+ Text(item.amount, format: .currency(code: Locale.current.currencyCode ?? "CNY"))
+ }
+ }
+ .onDelete(perform: removeItems)
+ }
+ .navigationTitle("iExpense")
+ .toolbar {
+ Button {
+ showingAddExpense = true
+ } label: {
+ Image(systemName: "plus")
+ }
+ }
+ .sheet(isPresented: $showingAddExpense) {
+ AddView(expenses: expenses)
+
+ }
+ }
+ }
+
+ func removeItems(at offsets: IndexSet) {
+ expenses.items.remove(atOffsets: offsets)
+ }
+}MVVM
@StateObject、@Published、ObservableObject、@ObservedObject
UserDefaults(存储少量数据,常用于存储Preference)
JSONEncoder、JSONDecoder、Codable
属性观察器(willSet、didSet) 配合 UserDefaults保存数据
onDelete修饰符
sheet修饰符(弹出新页面)
.sheet(isPresented: $showingAddExpense) {
+ AddView(expenses: expenses)
+}@Environment(.dismiss) var dismiss(@Environment(keyPath) 可以读取系统环境数据,dismiss用于关闭当前展示页面)
https://www.youtube.com/playlist?list=PLuoeXyslFTuZRi4q4VT6lZKxYbr7so1Mr
Bundle-Decodable
extension Bundle {
+ func decode<T: Decodable>(_ file: String) -> T {
+ guard let url = self.url(forResource: file, withExtension: nil) else {
+ fatalError("Failed to locate \(file) in bundle")
+ }
+
+ guard let data = try? Data(contentsOf: url) else {
+ fatalError("Failed to locate \(file) in bundle")
+ }
+
+ let decoder = JSONDecoder()
+ let formatter = DateFormatter()
+ formatter.dateFormat = "y-MM-dd"
+ decoder.dateDecodingStrategy = .formatted(formatter)
+
+ guard let loaded = try? decoder.decode( T.self, from: data) else {
+ fatalError("Failed to locate \(file) in bundle")
+ }
+
+ return loaded
+ }
+}Color-Theme
import SwiftUI
+
+extension ShapeStyle where Self == Color {
+ static var darkBackground: Color {
+ Color(red: 0.1, green: 0.1, blue: 0.2)
+ }
+
+ static var lightBackgroud: Color {
+ Color(red: 0.2, green: 0.2, blue: 0.3)
+ }
+}Model
struct Astronaut: Codable, Identifiable {
+ let id: String
+ let name: String
+ let description: String
+}
+
+
+struct Mission: Codable, Identifiable {
+ struct CrewRole: Codable {
+ let name: String
+ let role: String
+ }
+
+ let id: Int
+ let launchDate: Date?
+ let crew: [CrewRole]
+ let description: String
+
+ var displayName: String {
+ "Apollo \(id)"
+ }
+
+ var image: String {
+ "apollo\(id)"
+ }
+
+ var formattedLaunchDate: String {
+ launchDate?.formatted(date: .abbreviated, time: .omitted) ?? "N/A"
+ }
+}ContentView
struct ContentView: View {
+ let astronauts: [String: Astronaut] = Bundle.main.decode("astronauts.json")
+ let missions: [Mission] = Bundle.main.decode("missions.json")
+
+ let columns = [
+ GridItem(.adaptive(minimum: 150))
+ ]
+
+ var body: some View {
+ NavigationView {
+ ScrollView {
+ LazyVGrid(columns: columns) {
+ ForEach(missions) { mission in
+ NavigationLink{
+ MissionView(mission: mission, astronauts: astronauts)
+ } label: {
+ VStack{
+ Image(mission.image)
+ .resizable()
+ .scaledToFit()
+ .frame(width: 100, height: 100)
+ VStack {
+ Text(mission.displayName)
+ .font(.headline)
+ .foregroundColor(.white)
+
+ Text(mission.formattedLaunchDate)
+ .font(.subheadline)
+ .foregroundColor(.white.opacity(0.5))
+ }
+ .padding(.vertical)
+ .frame(maxWidth: .infinity)
+ .background(.lightBackgroud)
+ }
+ .clipShape(RoundedRectangle(cornerRadius: 10))
+ .overlay{
+ RoundedRectangle(cornerRadius: 10)
+ .stroke()
+ }
+ }
+ }
+ }
+ .padding([.horizontal, .bottom])
+ }
+ .navigationTitle("Moonshot")
+ .background(.darkBackground)
+ .preferredColorScheme(.dark)
+ }
+ }
+}MissionView
struct MissionView: View {
+ struct CrewMember {
+ let role: String
+ let astronaut: Astronaut
+ }
+
+
+ let mission: Mission
+
+ let crew: [CrewMember]
+
+ var body: some View {
+ GeometryReader { geometry in
+ ScrollView {
+ VStack {
+ Image(mission.image)
+ .resizable()
+ .scaledToFit()
+ .frame(maxWidth: geometry.size.width * 0.6)
+ .padding(.top)
+
+ VStack(alignment: .leading) {
+ Rectangle()
+ .frame(height: 2)
+ .foregroundColor(.lightBackgroud)
+ .padding(.vertical)
+
+ Text("Mission Highlights")
+ .font(.title.bold())
+ .padding(.bottom, 5)
+
+ Text(mission.description)
+ Rectangle()
+ .frame(height: 2)
+ .foregroundColor(.lightBackgroud)
+ .padding(.vertical)
+
+ Text("Crew")
+ .font(.title.bold())
+ .padding(.bottom, 5)
+ }
+ .padding(.horizontal)
+
+
+
+
+
+ ScrollView(.horizontal, showsIndicators: false) {
+ HStack {
+ ForEach(crew, id: \.role) { crewMember in
+ NavigationLink {
+ AstronautView(astronaut: crewMember.astronaut)
+ }label: {
+ HStack {
+ Image(crewMember.astronaut.id)
+ .resizable()
+ .frame(width: 104, height: 72)
+ .clipShape(Capsule())
+ .overlay{
+ Capsule()
+ .strokeBorder(.white, lineWidth: 1)
+ }
+ VStack(alignment: .leading) {
+ Text(crewMember.astronaut.name)
+ .foregroundColor(.white)
+ .font(.headline)
+
+ Text(crewMember.role)
+ .foregroundColor(.secondary)
+
+ }
+ }
+ }
+ }
+
+ }
+ }
+ .padding(.horizontal)
+ }
+ .padding(.bottom)
+ }
+ .navigationTitle(mission.displayName)
+ .navigationBarTitleDisplayMode(.inline)
+ .background(.darkBackground)
+ }
+
+ }
+
+
+ init(mission: Mission, astronauts: [String: Astronaut]) {
+ self.mission = mission
+
+ self.crew = mission.crew.map { member in
+ if let astronaut = astronauts[member.name] {
+ return CrewMember(role: member.role, astronaut: astronaut)
+ }else {
+ fatalError("Missing \(member.name)")
+ }
+ }
+ }
+}AstronautView
struct AstronautView: View {
+ let astronaut: Astronaut
+
+ var body: some View {
+ ScrollView {
+ VStack {
+ Image(astronaut.id)
+ .resizable()
+ .scaledToFit()
+
+
+ Text(astronaut.description)
+ .padding()
+
+
+ }
+
+ }
+ .background(.darkBackground)
+ .navigationTitle(astronaut.name)
+ .navigationBarTitleDisplayMode(.inline)
+ }
+}
Order
class Order: ObservableObject, Codable {
+
+ enum CodingKeys: CodingKey {
+ case type, quantity, extraFrosting, addSprinkles, name, streetAddress, city, zip
+ }
+
+ static let types = ["Vanilla", "Strawberry", "Chocolate", "Rainbow"]
+
+ @Published var type = 0
+ @Published var quantity = 3
+ @Published var specialRequestEnabled = false {
+ didSet {
+ if specialRequestEnabled == false {
+ extraFrosting = false
+ addSprinkles = false
+ }
+ }
+ }
+ @Published var extraFrosting = false
+ @Published var addSprinkles = false
+
+
+ @Published var name = ""
+ @Published var streetAddress = ""
+ @Published var city = ""
+ @Published var zip = ""
+
+
+ var hasValidAddress: Bool {
+ if name.isEmpty || streetAddress.isEmpty || city.isEmpty || zip.isEmpty {
+ return false
+ }
+ return true
+ }
+
+
+ var cost: Double {
+ // $2 per cake
+ var cost = Double(quantity) * 2
+
+ // complicated cakes cost more
+ cost += Double(type) / 2
+
+ // $1/cake for extra frosting
+ if extraFrosting {
+ cost += Double(quantity)
+ }
+
+ // $0.5/cake for sprinkles
+ if addSprinkles {
+ cost += Double(quantity) / 2
+ }
+
+ return cost
+ }
+
+ init() {}
+
+
+ func encode(to encoder: Encoder) throws {
+ var container = encoder.container(keyedBy: CodingKeys.self)
+
+ try container.encode(type, forKey: .type)
+ try container.encode(quantity, forKey: .quantity)
+ try container.encode(extraFrosting, forKey: .extraFrosting)
+ try container.encode(addSprinkles, forKey: .addSprinkles)
+ try container.encode(name, forKey: .name)
+ try container.encode(streetAddress, forKey: .streetAddress)
+ try container.encode(city, forKey: .city)
+ try container.encode(zip, forKey: .zip)
+ }
+
+ required init(from decoder: Decoder) throws {
+ let container = try decoder.container(keyedBy: CodingKeys.self)
+
+ type = try container.decode(Int.self, forKey: .type)
+ quantity = try container.decode(Int.self, forKey: .quantity)
+ extraFrosting = try container.decode(Bool.self, forKey: .extraFrosting)
+ addSprinkles = try container.decode(Bool.self, forKey: .addSprinkles)
+ name = try container.decode(String.self, forKey: .name)
+ city = try container.decode(String.self, forKey: .city)
+ streetAddress = try container.decode(String.self, forKey: .streetAddress)
+ zip = try container.decode(String.self, forKey: .zip)
+ }
+}ContentView
struct ContentView: View {
+ @StateObject var order = Order()
+
+ var body: some View {
+ NavigationView{
+ Form {
+ Section {
+ Picker("Select your cake type", selection: $order.type) {
+ ForEach(Order.types.indices, id: \.self) {
+ Text(Order.types[$0])
+ }
+ }
+ Stepper("Number of cakes: \(order.quantity)", value: $order.quantity, in: 3...20)
+ }
+
+
+ Section {
+ Toggle("Any special requests?", isOn: $order.specialRequestEnabled.animation())
+
+ if order.specialRequestEnabled {
+ Toggle("Add extra frosting", isOn: $order.extraFrosting)
+ Toggle("Add extra sprinkles", isOn: $order.addSprinkles)
+ }
+ }
+
+ Section {
+ NavigationLink {
+ AddressView(order: order)
+ } label: {
+ Text("Deliver details")
+ }
+ }
+ }
+ .navigationTitle("Cupcake Corner")
+ }
+ }
+}AddressView
struct AddressView: View {
+ @ObservedObject var order: Order
+ var body: some View {
+ Form {
+ Section {
+ TextField("name", text: $order.name)
+ TextField("Street address", text: $order.streetAddress)
+ TextField("City", text: $order.city)
+ TextField("Zip", text: $order.zip)
+ }
+
+ Section {
+ NavigationLink {
+ CheckoutView(order: order)
+ } label: {
+ Text("Check out")
+ }
+ }
+ .disabled(!order.hasValidAddress)
+ }
+ .navigationTitle("Delivery details")
+ .navigationBarTitleDisplayMode(.inline)
+ }
+}CheckoutView
struct CheckoutView: View {
+ @ObservedObject var order: Order
+ @State private var confirmationMessage = ""
+ @State private var showingConfirmation = false
+
+
+ var body: some View {
+ ScrollView {
+
+ VStack {
+ AsyncImage(url: URL(string: "https://hws.dev/img/cupcakes@3x.jpg"), scale: 3) { image in
+ image
+ .resizable()
+ .scaledToFit()
+ } placeholder: {
+ ProgressView()
+ }
+
+
+ Text("Your total is \(order.cost, format: .currency(code: "USD"))")
+ .font(.title)
+
+ Button("Place Order") {
+ Task {
+ await placeOrder()
+ }
+ }
+ .padding()
+
+ }
+ }
+ .navigationTitle("Check out")
+ .navigationBarTitleDisplayMode(.inline)
+ .alert("Thank you!", isPresented: $showingConfirmation) {
+ Button("OK") {}
+ } message: {
+ Text(confirmationMessage)
+ }
+ }
+
+ func placeOrder() async {
+ guard let encoded = try? JSONEncoder().encode(order) else {
+ print("Failed to encode order")
+ return
+ }
+
+ let url = URL(string: "https://reqres.in/api/cupcakes")!
+ var request = URLRequest(url: url)
+ request.setValue("application/json", forHTTPHeaderField: "Content-Type")
+ request.httpMethod = "POST"
+
+ do {
+ let (data, _) = try await URLSession.shared.upload(for: request, from: encoded)
+ let decodedOrder = try JSONDecoder().decode(Order.self, from: data)
+ confirmationMessage = "Your order for \(decodedOrder.quantity)x\(Order.types[decodedOrder.type].lowercased()) cupcakes is on its way !"
+ showingConfirmation = true
+ } catch {
+ print("Check out failed ...")
+ }
+
+ }
+}Codable协议无法处理被@Published等属性包装器修饰的属性,需要额外编码来手动实现Codable协议
Form表单校验使用.disabled()修饰符
异步加载图像AsyncImage,这个View不能像普通Image一样直接使用.resizable()调整大小,需要特殊处理
AsyncImage(url: URL(string: "https://hws.dev/img/cupcakes@3x.jpg"), scale: 3) { image in
+ image
+ .resizable()
+ .scaledToFit()
+ } placeholder: {
+ ProgressView() //加载中loading view
+ }Button的action使用异步方法时需要使用Task
Button("Place Order") {
+ Task {
+ await placeOrder()
+ }
+}使用URLRequest、URLSession发送http请求
异步方法,async,await关键字
BookwormApp
@main
+struct BookwormApp: App {
+
+ @StateObject private var dataController = DataController()
+
+ var body: some Scene {
+ WindowGroup {
+ ContentView()
+ .environment(\.managedObjectContext, dataController.container.viewContext )
+ }
+ }
+}ContentView
struct ContentView: View {
+ @Environment(\.managedObjectContext) var moc
+ @FetchRequest(sortDescriptors: [SortDescriptor(\.title, order: .forward), SortDescriptor(\.author, order: .forward)]) var books: FetchedResults<Book>
+
+ @State private var showingAddScreen = false
+
+ var body: some View {
+ NavigationView {
+ List {
+ ForEach(books) { book in
+ NavigationLink {
+ DetailView(book: book)
+ } label: {
+ HStack {
+ EmojiRatingView(rating: book.rating)
+ .font(.largeTitle)
+ VStack(alignment: .leading) {
+ Text(book.title ?? "Unknown title")
+ .font(.headline)
+ Text(book.author ?? "Unknown author")
+ .foregroundColor(.secondary)
+ }
+ }
+ }
+ }
+ .onDelete(perform: deleteBooks)
+ }
+ .navigationTitle("Bookworm")
+ .toolbar {
+ ToolbarItem(placement: .navigationBarLeading) {
+ EditButton()
+ }
+
+ ToolbarItem(placement: .navigationBarTrailing) {
+ Button {
+ showingAddScreen.toggle()
+ } label: {
+ Label("Add book", systemImage: "plus")
+ }
+ }
+ }
+ .sheet(isPresented: $showingAddScreen) {
+ AddBookView()
+ }
+ }
+ }
+
+ func deleteBooks(at offsets: IndexSet) {
+ for offset in offsets {
+ let book = books[offset]
+ moc.delete(book)
+ }
+ try? moc.save()
+ }
+}DataController
import CoreData
+
+class DataController: ObservableObject {
+ let container = NSPersistentContainer(name: "Bookworm")
+
+
+ init() {
+ container.loadPersistentStores { description, error in
+ if let error = error {
+ print("Core data failed to load: \(error.localizedDescription)")
+ }
+
+ }
+ }
+}AddBookView
struct AddBookView: View {
+
+ @Environment(\.managedObjectContext) var moc
+ @Environment(\.dismiss) var dismiss
+ @State private var title = ""
+ @State private var author = ""
+ @State private var rating = 3
+ @State private var genre = ""
+ @State private var review = ""
+
+ let genres = ["Fantasy", "Horror", "Kids", "Mystery", "Poetry", "Romance", "Thriller"]
+
+ var body: some View {
+ NavigationView {
+ Form {
+ Section {
+ TextField("Name of book", text: $title)
+ TextField("Author's name", text: $author)
+
+ Picker("Genre", selection: $genre) {
+ ForEach(genres, id: \.self) {
+ Text($0)
+ }
+ }
+ }
+
+ Section {
+ TextEditor(text: $review)
+
+ RatingView(rating: $rating)
+ } header: {
+ Text("Write a review")
+ }
+
+ Section {
+ Button("Save") {
+ let book = Book(context: moc)
+ book.id = UUID()
+ book.title = self.title
+ book.author = self.author
+ book.genre = self.genre
+ book.review = self.review
+ book.rating = Int16(self.rating)
+ try? moc.save()
+ dismiss()
+ }
+ }
+ }
+ .navigationTitle("Add book")
+ }
+ }
+}RatingView
struct RatingView: View {
+ @Binding var rating: Int
+
+ var label = ""
+ var maxmiumRating = 5
+ var offImage: Image?
+ var onImage = Image(systemName: "star.fill")
+ var offColor = Color.gray
+ var onColor = Color.yellow
+
+
+ var body: some View {
+ HStack {
+ if label.isEmpty == false {
+ Text(label)
+ }
+
+ ForEach(1..<maxmiumRating + 1, id: \.self) { number in
+ image(for: number)
+ .foregroundColor(number > rating ? offColor : onColor)
+ .onTapGesture {
+ rating = number
+ }
+ }
+ }
+ }
+
+ func image(for number: Int) -> Image {
+ if number > rating {
+ return offImage ?? onImage
+ } else {
+ return onImage
+ }
+ }
+}EmojiRatingView
struct EmojiRatingView: View {
+ let rating: Int16
+
+ var body: some View {
+ switch rating {
+ case 1:
+ return Text("☹️")
+ case 2:
+ return Text("😞")
+ case 3:
+ return Text("😊")
+ case 4:
+ return Text("😍")
+ default:
+ return Text("🤩")
+ }
+ }
+}DetailView
struct DetailView: View {
+ let book: Book
+ @Environment(\.managedObjectContext) var moc
+ @Environment(\.dismiss) var dismiss
+ @State private var showingAlert = false
+
+ var body: some View {
+ ScrollView {
+ ZStack(alignment: .bottomTrailing) {
+ Image(book.genre ?? "Fantasy")
+ .resizable()
+ .scaledToFit()
+
+ Text(book.genre?.uppercased() ?? "FANTASY")
+ .font(.caption)
+ .fontWeight(.black)
+ .padding(8)
+ .foregroundColor(.white)
+ .background(.black.opacity(0.75))
+ .clipShape(Capsule())
+ .offset(x: -5, y: -5)
+ }
+
+ Text(book.author ?? "Unknown author")
+ .font(.title)
+ .foregroundColor(.secondary)
+
+ Text(book.review ?? "No review")
+ .padding()
+
+ RatingView(rating: .constant(Int(book.rating)))
+ }
+ .navigationTitle(book.title ?? "Unknown book")
+ .navigationBarTitleDisplayMode(.inline)
+ .alert("Delete this book?", isPresented: $showingAlert) {
+ Button("OK", role: .destructive,action: deleteBook)
+ Button("Cancle", role: .cancel) { }
+ } message: {
+ Text("Are you sure?")
+ }
+ .toolbar {
+ Button {
+ showingAlert = true
+ } label: {
+ Label("Delete this book", systemImage: "trash")
+ }
+ }
+
+ }
+
+
+ func deleteBook() {
+ moc.delete(book)
+
+ try? moc.save()
+
+ dismiss()
+
+ }
+}Bookworm.xcdatamodeld
@Environment(\.managedObjectContext) var moc
+
+var body: some View {
+ Button("Save") {
+ if moc.hasChanges {
+ try? moc.save()
+ }
+ }
+}Ensuring Core Data objects are unique using constraints
self.container.viewContext.mergePolicy = NSMergePolicy.mergeByPropertyObjectTrumpDynamically filtering @FetchRequest with SwiftUI
struct FilteredList<T: NSManagedOBject, Context: View>: View {
+ @FetchRequest var fetchRequest: FetchedResults<T>
+
+ var body: some View {
+ List(fetchRequest, id:\.self) { item in
+ self.content(item)
+ }
+ }
+
+ init(filterKey: String, filterValue: String, @ViewBuilder content: @escaping (T) -> Content) {
+ _fetchRequest = FetchRequest<T>(sortDescriptors: [], predicate: NSPredicate(format: "%K BEGINSWITH %@", filterKey, filterValue))
+ self.content = content
+ }
+}Gin is a HTTP web framework written in Go (Golang). It features a Martini-like API with much better performance -- up to 40 times faster. If you need smashing performance, get yourself some Gin.
go get -u github.com/gin-gonic/gin
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ ginServer.Use(favicon.New("./favicon.ico"))
+ ginServer.GET("/", func(c *gin.Context) {
+ c.String(200, "Hello World!")
+ })
+ ginServer.POST("/post", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "POST Data",
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+
+}curl -X GET http://localhost:8080
Hello World!curl -X POST http://localhost:8080/post
{"message":"POST Data"}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ // 设置favicon
+ ginServer.Use(favicon.New("./favicon.ico"))
+
+ // 加载静态页
+ ginServer.LoadHTMLGlob("templates/*")
+ // 响应页面给前端
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(200, "index.html", gin.H{
+ "title": "Main website",
+ })
+ })
+ _ = ginServer.Run(":8080")
+}访问localhost:8080或localhost:8080/index
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/thinkerou/favicon"
+)
+
+func main() {
+ // 创建服务
+ ginServer := gin.Default()
+ // 设置favicon
+ ginServer.Use(favicon.New("./favicon.ico"))
+
+ // 加载静态页
+ ginServer.LoadHTMLGlob("templates/*")
+ // 响应页面给前端
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(200, "index.html", gin.H{
+ "title": "Main website",
+ })
+ })
+ _ = ginServer.Run(":8080")
+}
package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+
+ ginServer.GET("/user/info", func(context *gin.Context) {
+ userId := context.Query("userId")
+ userName := context.Query("userName")
+ context.JSON(http.StatusOK, gin.H{
+ "userId": userId,
+ "userName": userName,
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}curl -X GET 'http://localhost:8080/user/info?userId=123&userName=小明'{"userId":"123","userName":"小明"}package main
+
+import (
+ "encoding/json"
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.POST("/user", func(context *gin.Context) {
+ // request body []byte, err
+ body, _ := context.GetRawData()
+ // 包装为map类型
+ var m map[string]interface{}
+ _ = json.Unmarshal(body, &m)
+
+ context.JSON(http.StatusOK, m)
+ })
+
+ _ = ginServer.Run(":8080")
+}curl -X POST 'http://127.0.0.1:8080/user' --header 'Content-Type: application/json' --data '{"userName": "张三"}'{"userName":"张三"}<!DOCTYPE html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <title>Title</title>
+ <link rel="stylesheet" href="/static/base.css">
+</head>
+<body>
+<h1>Hello World!</h1>
+
+<form action="/user/add" method="post">
+ <input type="text" name="username">
+ <input type="password" name="password">
+
+ <button type="submit">提交</button>
+</form>
+<script src="/static/base.js"></script>
+</body>
+</html>package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.LoadHTMLGlob("templates/*")
+
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(http.StatusOK, "index.html", gin.H{
+ "title": "Hello World",
+ })
+ })
+
+ ginServer.POST("/user/add", func(context *gin.Context) {
+ username := context.PostForm("username")
+ password := context.PostForm("password")
+
+ context.JSON(http.StatusOK, gin.H{
+ "msg": "success",
+ "data": gin.H{
+ "username": username,
+ "password": password,
+ },
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "net/http"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ ginServer.LoadHTMLGlob("templates/*")
+ // 重定向到首页
+ ginServer.GET("/", func(context *gin.Context) {
+ context.Redirect(http.StatusMovedPermanently, "/index")
+ })
+
+ ginServer.GET("/index", func(context *gin.Context) {
+ context.HTML(http.StatusOK, "index.html", gin.H{
+ "title": "Hello World",
+ })
+ })
+ // 404页面
+ ginServer.NoRoute(func(context *gin.Context) {
+ context.HTML(http.StatusNotFound, "404.html", gin.H{
+ "title": "404",
+ })
+ })
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+)
+
+func main() {
+ ginServer := gin.Default()
+
+ userGroup := ginServer.Group("/user")
+ {
+ userGroup.GET("/get", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "get user",
+ })
+ })
+ userGroup.POST("/post", func(c *gin.Context) {
+ c.JSON(200, gin.H{
+ "message": "post user",
+ })
+ })
+ }
+
+ _ = ginServer.Run(":8080")
+}package main
+
+import (
+ "github.com/gin-gonic/gin"
+ "log"
+)
+
+func myHandler() gin.HandlerFunc {
+ return func(context *gin.Context) {
+ // do something
+ context.Set("name", "zhangsan")
+ context.Next() // 放行
+ // context.Abort() 阻止
+ }
+}
+
+func main() {
+ ginServer := gin.Default()
+
+ userGroup := ginServer.Group("/user")
+ {
+ userGroup.GET("/get", myHandler(), func(c *gin.Context) {
+ // 获取拦截器里设置的值
+ name := c.MustGet("name").(string)
+ log.Println(name)
+ c.JSON(200, gin.H{
+ "message": "get user",
+ })
+ })
+ }
+
+ _ = ginServer.Run(":8080")
+}
+// 2023/07/01 21:36:53 zhangsanHashMap是开发中最常用的容器之一,它也是Java集合框架中极为重要的组成部分,HashMap实现了Map接口,并继承 AbstractMap 抽象类
public class HashMap<K,V> extends AbstractMap<K,V>
+ implements Map<K,V>, Cloneable, Serializable {
+ ***
+}首先了解下HashMap的几个字段
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的初始容量
+static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量
+static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认负载因子
+transient Node<K,V>[] table; //哈希桶数组
+transient int size; //容器中键值对的个数
+transient int modCount; //容器内部结构发生变化的次数,主要用于迭代的快速失败
+int threshold; //阈值 table * loadFactor size超过这个值就会扩容
+final float loadFactor; //负载因子 默认0.75Node的结构
static class Node<K,V> implements Map.Entry<K,V> {
+ final int hash;
+ final K key;
+ V value;
+ Node<K,V> next;
+
+ Node(int hash, K key, V value, Node<K,V> next) {
+ this.hash = hash;
+ this.key = key;
+ this.value = value;
+ this.next = next;
+ }
+
+ public final K getKey() { return key; }
+ public final V getValue() { return value; }
+ public final String toString() { return key + "=" + value; }
+
+ public final int hashCode() {
+ return Objects.hashCode(key) ^ Objects.hashCode(value);
+ }
+
+ public final V setValue(V newValue) {
+ V oldValue = value;
+ value = newValue;
+ return oldValue;
+ }
+
+ public final boolean equals(Object o) {
+ if (o == this)
+ return true;
+ if (o instanceof Map.Entry) {
+ Map.Entry<?,?> e = (Map.Entry<?,?>)o;
+ if (Objects.equals(key, e.getKey()) &&
+ Objects.equals(value, e.getValue()))
+ return true;
+ }
+ return false;
+ }
+}Node(JDK1.8之前叫Entry)是HashMap的静态内部类,实现了Map.Entry接口,包括了hash,key,value和下一节点next四个属性,是构成哈希表的基石,是哈希表存储的元素的具体形式。
public HashMap(int initialCapacity, float loadFactor) {
+ if (initialCapacity < 0)
+ throw new IllegalArgumentException("Illegal initial capacity: " +
+ initialCapacity);
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ if (loadFactor <= 0 || Float.isNaN(loadFactor))
+ throw new IllegalArgumentException("Illegal load factor: " +
+ loadFactor);
+ this.loadFactor = loadFactor;
+ this.threshold = tableSizeFor(initialCapacity);
+}
+=====================================================================
+public HashMap(int initialCapacity) {
+ this(initialCapacity, DEFAULT_LOAD_FACTOR);
+}
+=====================================================================
+public HashMap() {
+ this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
+}
+=====================================================================
+public HashMap(Map<? extends K, ? extends V> m) {
+ this.loadFactor = DEFAULT_LOAD_FACTOR;
+ putMapEntries(m, false);
+}HashMap的初始容量和负载因子是影响map性能的关键参数,容量指的是table数组的大小,负载因子是衡量哈希表使用程度的一个尺度,负载因子越小,那哈希表空间的利用率就越低,造成的空间浪费就越严重。而如果负载因子越大,哈希表的利用率越高,带来的问题就是查找效率的下降。0.75是对空间和时间成本的折衷选择,一般情况下无需修改。
hash的概念:把任意长度的输入,通过hash算法,转换成相同长度的输出(通常为整型)。
HashMap的数据结构:
HashMap的底层数据结构结合了数组和链表(JDK1.8之前),实际上就是一个链表数组,也就是上文提到的Node<K,V> table[]。我们都知道数组的优势是查找快,增删慢,而链表则是增删快,查找慢,而这种链表数组——拉链法,结合了二者的优势,查找快,增删也快。查找元素的时间复杂度为O(1+n),n为链表的长度。在JDK1.8之后,为了解决哈希冲突频繁的问题,在原来的基础上又引入了红黑树,当链表长度超过8时,链表便会转化为红黑树结构,查找的时间复杂度从O(1+n)变成了O(1+lgn),大大提高了查询效率,不必再遍历链表。
JDK1.8之前的HashMap结构
JDK1.8的HashMap结构
HashMap中的方法很多,这里主要从hash,put,get,resize几个点深入研究
static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}首先,我们可以发现HashMap是允许null键的,而HashTable则不支持。
hash方法的本质是对key.hashCode()和key.hashCode()>>>16进行异或运算,>>>为无符号右移运算符,就是将补码右移后高位补0。^异或是参与运算的数每一位上的数字对比,相同结果为0,不同结果为1。
所以hash方法的功能就是对高16bit和低16bit进行异或运算来减少碰撞。
public V put(K key, V value) {
+ return putVal(hash(key), key, value, false, true);
+}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
+ boolean evict) {
+ Node<K,V>[] tab; Node<K,V> p; int n, i;
+ //如果table为空或者为初始化则进行初始化
+ if ((tab = table) == null || (n = tab.length) == 0)
+ n = (tab = resize()).length;
+ //计算插入的索引值(n- 1) & hash,如果数组中这个索引位置为空 则直接插入,next指针指向为null
+ if ((p = tab[i = (n - 1) & hash]) == null)
+ tab[i] = newNode(hash, key, value, null);
+ else {
+ //如果key已经存在了,直接覆盖value
+ Node<K,V> e; K k;
+ if (p.hash == hash &&
+ ((k = p.key) == key || (key != null && key.equals(k))))
+ //把第一个元素赋值给e记录
+ e = p;
+ //如果是红黑树
+ else if (p instanceof TreeNode)
+ //插入红黑树
+ e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
+ else {
+ //如果为链表,进行遍历直到下一个节点为null或者key存在
+ for (int binCount = 0; ; ++binCount) {
+ if ((e = p.next) == null) {
+ //插入链表最末端
+ p.next = newNode(hash, key, value, null);
+ //如果链表长度达到阈值 转换为红黑树
+ if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
+ treeifyBin(tab, hash);
+ break;
+ }
+ //判断链表中的节点key与即将插入的key是否相同
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ break;
+ //和前面的e = p.next对应 用来遍历链表
+ p = e;
+ }
+ }
+ //如果key存在,则覆盖原来的value,返回oldValue
+ if (e != null) { // existing mapping for key
+ V oldValue = e.value;
+ if (!onlyIfAbsent || oldValue == null)
+ e.value = value;
+ //访问后的回调函数
+ afterNodeAccess(e);
+ return oldValue;
+ }
+ }
+ //记录结构修改
+ ++modCount;
+ //如果哈希表中的键值对数量达到阈值,进行扩容
+ if (++size > threshold)
+ resize();
+ //插入后的回调函数
+ afterNodeInsertion(evict);
+ return null;
+}流程梳理:
计算key的hash值 (h = key.hashCode() ^ h >>> 16)
根据hash值和table数组的长度n计算插入table数组的索引,(n - 1) & hash。由于n始终是2的n次方(为什么后面会介绍),所以(n - 1) & hash 相等于 hash % n ,但是位运算要比取模效率更高
多种情况
如果该位置没有数据,新生成一个节点保存新数据,返回null
如果该位置有数据且是红黑树结构,那么执行相应的插入 / 更新操作;
如果该位置有数据且是链表
流程图:
public V get(Object key) {
+ Node<K,V> e;
+ return (e = getNode(hash(key), key)) == null ? null : e.value;
+}
+
+final Node<K,V> getNode(int hash, Object key) {
+ Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
+ // 1. 定位键值对所在桶的位置
+ if ((tab = table) != null && (n = tab.length) > 0 &&
+ (first = tab[(n - 1) & hash]) != null) {
+ if (first.hash == hash && // always check first node
+ ((k = first.key) == key || (key != null && key.equals(k))))
+ return first;
+ if ((e = first.next) != null) {
+ // 2. 如果 first 是 TreeNode 类型,则调用黑红树查找方法
+ if (first instanceof TreeNode)
+ return ((TreeNode<K,V>)first).getTreeNode(hash, key);
+
+ // 2. 对链表进行查找
+ do {
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ return e;
+ } while ((e = e.next) != null);
+ }
+ }
+ return null;
+} final Node<K,V>[] resize() {
+ //oldTable指向当前hash桶数组
+ Node<K,V>[] oldTab = table;
+ int oldCap = (oldTab == null) ? 0 : oldTab.length;
+ int oldThr = threshold;
+ int newCap, newThr = 0;
+ if (oldCap > 0) {//如果旧的hash桶不为空
+ if (oldCap >= MAXIMUM_CAPACITY) {
+ //如果大于最大容量,则阈值设置为最大整数的值
+ threshold = Integer.MAX_VALUE;
+ return oldTab;
+ }
+ else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
+ oldCap >= DEFAULT_INITIAL_CAPACITY)
+ //如果旧的hash桶容量扩容一次(左移1位)后小于最大值,并且旧的桶容量大于默认值16
+ //新桶容量 = 旧桶容量*2
+ newThr = oldThr << 1; // double threshold
+ }
+ else if (oldThr > 0) // initial capacity was placed in threshold
+ newCap = oldThr;
+ else { // zero initial threshold signifies using defaults
+ //初始化
+ newCap = DEFAULT_INITIAL_CAPACITY;
+ newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
+ }
+ if (newThr == 0) {
+ float ft = (float)newCap * loadFactor;
+ newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
+ (int)ft : Integer.MAX_VALUE);
+ }
+ threshold = newThr;
+ @SuppressWarnings({"rawtypes","unchecked"})
+ //初始化一个容量为newCap的新hash桶数组
+ Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
+ //将新桶复制给旧的hash桶数组
+ table = newTab;
+ if (oldTab != null) {
+ //如果旧的hash桶不为空,则开始扩容操作
+ for (int j = 0; j < oldCap; ++j) {
+ Node<K,V> e;
+ if ((e = oldTab[j]) != null) {//旧桶j处节点值赋值给e,如果不为空,将旧桶j节点设置为空
+ oldTab[j] = null;
+ if (e.next == null)//如果e后面没有节点
+ newTab[e.hash & (newCap - 1)] = e;//直接对e的hash值对新数组长度求模获得hash桶中存储位置
+ else if (e instanceof TreeNode)//如果e为红黑树节点,将e添加到红黑树中
+ ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
+ else { // preserve order //如果是链表
+ Node<K,V> loHead = null, loTail = null;
+ Node<K,V> hiHead = null, hiTail = null;
+ Node<K,V> next;
+ do {
+ next = e.next;//将e的下一节点赋值给next
+ if ((e.hash & oldCap) == 0) {//如果e的hash值对旧桶长度求模为0
+ if (loTail == null)
+ loHead = e;//如果loTail为null,将e赋给loHead
+ else
+ loTail.next = e;//非则将e赋值给loTail的next节点
+ loTail = e;//将e赋值给loTail节点
+ }
+ else {//如果e的hash值对旧桶长度取模不为0
+ if (hiTail == null)
+ hiHead = e;//hiHead为null,将e赋值给hiHead
+ else
+ hiTail.next = e;//否则e赋值给hiTail.next
+ hiTail = e;//将e赋值给hiTail
+ }
+ } while ((e = next) != null);//直到e为空
+ if (loTail != null) {
+ //如果loTail不为空,将loTail的下一节点设置为null
+ loTail.next = null;
+ //将loHead赋值给新桶的j处
+ newTab[j] = loHead;
+ }
+ if (hiTail != null) {
+ //如果hiTail不为空,将hiTail的下一节点设置为null
+ hiTail.next = null;
+ //hiHead赋值给新桶的j+旧桶数组长度处
+ newTab[j + oldCap] = hiHead;
+ }
+ }
+ }
+ }
+ }
+ return newTab;
+ } static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ n |= n >>> 2;
+ n |= n >>> 4;
+ n |= n >>> 8;
+ n |= n >>> 16;
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }测试类
public class Test {
+ public static void main(String[] args) {
+
+ int cap = 65538;
+ System.out.println(Integer.toBinaryString(cap));
+ System.out.println(Integer.toBinaryString(cap-1));
+ int i = tableSizeFor(cap);
+ System.out.println(Integer.toBinaryString(i));
+ }
+
+ static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 2;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 4;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 8;
+ System.out.println(Integer.toBinaryString(n));
+ n |= n >>> 16;
+ System.out.println(Integer.toBinaryString(n));
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }
+}运行结果
010000000000000010
+010000000000000001
+011000000000000001
+011110000000000001
+011111111000000001
+011111111111111111
+011111111111111111
+100000000000000000本篇内容基于MySQL的InnoDB存储引擎。
索引是一个单独的、存储在磁盘上的数据库结构,它们包含着对数据表里所有记录的引用指针。使用索引用于快速找出在某个或多个列中有一特定值的行,所有MySQL列类型都可以被索引,==对相关列使用索引是提高查询操作速度的最佳途径==。
InnoDB存储引擎中的索引都是指BTree索引,MySQL中还有Hash索引,详见官网存储引擎索引类型
内容引用自美团技术团队发表的文章MySQL索引原理及慢查询优化
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我想找到m开头的单词呢?或者ze开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?
数据库的索引结构需要做的事:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
b+树性质
1.通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
主键索引是一种特殊的唯一索引,这个时候需要一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引
InnoDB存储引擎的表,如果建表的时候没有指定主键,则会使用第一非空的唯一索引作为聚集索引,如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,该列的值会随着数据的插入自增。
在其他存储引擎或其他数据库中主键索引不一定就是聚集索引
唯一索引列的值必须是唯一的,但允许有空值,如果是组合索引,则列值的组合必须是唯一的。
CREATE UNIQUE index 索引名 on 表名(列名)MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值
CREATE index 索引名 on 表名(列名)指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀原则
CREATE index 索引名 on 表名(列名,列名...)全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON 表名(列名)DROP INDEX [indexName] ON 表名;SHOW INDEX FROM 表名-- 有四种方式来添加数据表的索引:
+ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
+
+ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
+
+ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
+
+ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。频繁更新的字段
where条件中用不到的字段
表记录很少
重复记录非常多的表
数据区分不明显的字段,例如性别栏位
全值匹配的查询,例如根据订单id查询select * from t_order where order_id = '9999676623'
匹配范围值的查询,例如 where id > '123456'
最左匹配原则,如user表的username pwd创建了组合索引那么以下几种都可以命中索引
select username from user where username='zhangsan' and pwd ='axsedf1sd'
+
+select username from user where pwd ='axsedf1sd' and username='zhangsan'
+
+select username from user where username='zhangsan'而
select username from user where pwd ='axsedf1sd'不能命中索引
非前导模糊查询, 例如 where name like 'xiaoming%'
otter是一款基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统
仓库地址:https://github.com/alibaba/otter
源库开启binlog,并且必须是ROW模式
需要启动zookeeper
otter是基于canal的,但是otter项目本身内嵌了canal,所以无需独立启动canal-server
初始化otter数据库
CREATE DATABASE /!32312 IF NOT EXISTS/ otter /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */;
USE otter;
SET sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
CREATE TABLE ALARM_RULE ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, MONITOR_NAME varchar(1024) DEFAULT NULL, RECEIVER_KEY varchar(1024) DEFAULT NULL, STATUS varchar(32) DEFAULT NULL, PIPELINE_ID bigint(20) NOT NULL, DESCRIPTION varchar(256) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, MATCH_VALUE varchar(1024) DEFAULT NULL, PARAMETERS text DEFAULT NULL, PRIMARY KEY (ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE AUTOKEEPER_CLUSTER ( ID bigint(20) NOT NULL AUTO_INCREMENT, CLUSTER_NAME varchar(200) NOT NULL, SERVER_LIST varchar(1024) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE CANAL ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, NAME varchar(200) DEFAULT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY CANALUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE CHANNEL ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY CHANNELUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE COLUMN_PAIR ( ID bigint(20) NOT NULL AUTO_INCREMENT, SOURCE_COLUMN varchar(200) DEFAULT NULL, TARGET_COLUMN varchar(200) DEFAULT NULL, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID (DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE COLUMN_PAIR_GROUP ( ID bigint(20) NOT NULL AUTO_INCREMENT, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, COLUMN_PAIR_CONTENT text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID (DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, NAMESPACE varchar(200) NOT NULL, PROPERTIES varchar(1000) NOT NULL, DATA_MEDIA_SOURCE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY DATAMEDIAUNIQUE (NAME,NAMESPACE,DATA_MEDIA_SOURCE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA_PAIR ( ID bigint(20) NOT NULL AUTO_INCREMENT, PULLWEIGHT bigint(20) DEFAULT NULL, PUSHWEIGHT bigint(20) DEFAULT NULL, RESOLVER text DEFAULT NULL, FILTER text DEFAULT NULL, SOURCE_DATA_MEDIA_ID bigint(20) DEFAULT NULL, TARGET_DATA_MEDIA_ID bigint(20) DEFAULT NULL, PIPELINE_ID bigint(20) NOT NULL, COLUMN_PAIR_MODE varchar(20) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID (PIPELINE_ID,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MEDIA_SOURCE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, TYPE varchar(20) NOT NULL, PROPERTIES varchar(1000) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY DATAMEDIASOURCEUNIQUE (NAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DELAY_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, DELAY_TIME bigint(20) NOT NULL, DELAY_NUMBER bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_GmtModified_ID (PIPELINE_ID,GMT_MODIFIED,ID), KEY idx_Pipeline_GmtCreate (PIPELINE_ID,GMT_CREATE), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE LOG_RECORD ( ID bigint(20) NOT NULL AUTO_INCREMENT, NID varchar(200) DEFAULT NULL, CHANNEL_ID varchar(200) NOT NULL, PIPELINE_ID varchar(200) NOT NULL, TITLE varchar(1000) DEFAULT NULL, MESSAGE text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY logRecord_pipelineId (PIPELINE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE NODE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, IP varchar(200) NOT NULL, PORT bigint(20) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY NODEUNIQUE (NAME,IP) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE PIPELINE ( ID bigint(20) NOT NULL AUTO_INCREMENT, NAME varchar(200) NOT NULL, DESCRIPTION varchar(200) DEFAULT NULL, PARAMETERS text DEFAULT NULL, CHANNEL_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY PIPELINEUNIQUE (NAME,CHANNEL_ID), KEY idx_ChannelID (CHANNEL_ID,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE PIPELINE_NODE_RELATION ( ID bigint(20) NOT NULL AUTO_INCREMENT, NODE_ID bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, LOCATION varchar(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID (PIPELINE_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE SYSTEM_PARAMETER ( ID bigint(20) unsigned NOT NULL, VALUE text DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE TABLE_HISTORY_STAT ( ID bigint(20) unsigned NOT NULL AUTO_INCREMENT, FILE_SIZE bigint(20) DEFAULT NULL, FILE_COUNT bigint(20) DEFAULT NULL, INSERT_COUNT bigint(20) DEFAULT NULL, UPDATE_COUNT bigint(20) DEFAULT NULL, DELETE_COUNT bigint(20) DEFAULT NULL, DATA_MEDIA_PAIR_ID bigint(20) DEFAULT NULL, PIPELINE_ID bigint(20) DEFAULT NULL, START_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', END_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_DATA_MEDIA_PAIR_ID_END_TIME (DATA_MEDIA_PAIR_ID,END_TIME), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE TABLE_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, FILE_SIZE bigint(20) NOT NULL, FILE_COUNT bigint(20) NOT NULL, INSERT_COUNT bigint(20) NOT NULL, UPDATE_COUNT bigint(20) NOT NULL, DELETE_COUNT bigint(20) NOT NULL, DATA_MEDIA_PAIR_ID bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_DataMediaPairID (PIPELINE_ID,DATA_MEDIA_PAIR_ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE THROUGHPUT_STAT ( ID bigint(20) NOT NULL AUTO_INCREMENT, TYPE varchar(20) NOT NULL, NUMBER bigint(20) NOT NULL, SIZE bigint(20) NOT NULL, PIPELINE_ID bigint(20) NOT NULL, START_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', END_TIME timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY idx_PipelineID_Type_GmtCreate_ID (PIPELINE_ID,TYPE,GMT_CREATE,ID), KEY idx_PipelineID_Type_EndTime_ID (PIPELINE_ID,TYPE,END_TIME,ID), KEY idx_GmtCreate_id (GMT_CREATE,ID) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE USER ( ID bigint(20) NOT NULL AUTO_INCREMENT, USERNAME varchar(20) NOT NULL, PASSWORD varchar(20) NOT NULL, AUTHORIZETYPE varchar(20) NOT NULL, DEPARTMENT varchar(20) NOT NULL, REALNAME varchar(20) NOT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), UNIQUE KEY USERUNIQUE (USERNAME) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE DATA_MATRIX ( ID bigint(20) NOT NULL AUTO_INCREMENT, GROUP_KEY varchar(200) DEFAULT NULL, MASTER varchar(200) DEFAULT NULL, SLAVE varchar(200) DEFAULT NULL, DESCRIPTION varchar(200) DEFAULT NULL, GMT_CREATE timestamp NOT NULL DEFAULT '0000-00-00 00:00:00', GMT_MODIFIED timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (ID), KEY GROUPKEY (GROUP_KEY) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS meta_history ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', gmt_create datetime NOT NULL COMMENT '创建时间', gmt_modified datetime NOT NULL COMMENT '修改时间', destination varchar(128) DEFAULT NULL COMMENT '通道名称', binlog_file varchar(64) DEFAULT NULL COMMENT 'binlog文件名', binlog_offest bigint(20) DEFAULT NULL COMMENT 'binlog偏移量', binlog_master_id varchar(64) DEFAULT NULL COMMENT 'binlog节点id', binlog_timestamp bigint(20) DEFAULT NULL COMMENT 'binlog应用的时间戳', use_schema varchar(1024) DEFAULT NULL COMMENT '执行sql时对应的schema', sql_schema varchar(1024) DEFAULT NULL COMMENT '对应的schema', sql_table varchar(1024) DEFAULT NULL COMMENT '对应的table', sql_text longtext DEFAULT NULL COMMENT '执行的sql', sql_type varchar(256) DEFAULT NULL COMMENT 'sql类型', extra text DEFAULT NULL COMMENT '额外的扩展信息', PRIMARY KEY (id), UNIQUE KEY binlog_file_offest(destination,binlog_master_id,binlog_file,binlog_offest), KEY destination (destination), KEY destination_timestamp (destination,binlog_timestamp), KEY gmt_modified (gmt_modified) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='表结构变化明细表';
CREATE TABLE IF NOT EXISTS meta_snapshot ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', gmt_create datetime NOT NULL COMMENT '创建时间', gmt_modified datetime NOT NULL COMMENT '修改时间', destination varchar(128) DEFAULT NULL COMMENT '通道名称', binlog_file varchar(64) DEFAULT NULL COMMENT 'binlog文件名', binlog_offest bigint(20) DEFAULT NULL COMMENT 'binlog偏移量', binlog_master_id varchar(64) DEFAULT NULL COMMENT 'binlog节点id', binlog_timestamp bigint(20) DEFAULT NULL COMMENT 'binlog应用的时间戳', data longtext DEFAULT NULL COMMENT '表结构数据', extra text DEFAULT NULL COMMENT '额外的扩展信息', PRIMARY KEY (id), UNIQUE KEY binlog_file_offest(destination,binlog_master_id,binlog_file,binlog_offest), KEY destination (destination), KEY destination_timestamp (destination,binlog_timestamp), KEY gmt_modified (gmt_modified) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='表结构记录表快照表';
insert into USER(ID,USERNAME,PASSWORD,AUTHORIZETYPE,DEPARTMENT,REALNAME,GMT_CREATE,GMT_MODIFIED) values(null,'admin','801fc357a5a74743894a','ADMIN','admin','admin',now(),now()); insert into USER(ID,USERNAME,PASSWORD,AUTHORIZETYPE,DEPARTMENT,REALNAME,GMT_CREATE,GMT_MODIFIED) values(null,'guest','471e02a154a2121dc577','OPERATOR','guest','guest',now(),now());
## otter manager domain name
+otter.domainName = xxx.com
+## otter manager http port
+otter.port =
+
+## otter manager database config
+otter.database.driver.class.name = com.mysql.jdbc.Driver
+otter.database.driver.url = jdbc:mysql://127.0.0.1:3306/otter?useUnicode=true&characterEncoding=UTF-8&useSSL=false
+otter.database.driver.username =
+otter.database.driver.password =
+
+## otter communication port
+otter.communication.manager.port = 1099
+## default zookeeper address
+otter.zookeeper.cluster.default = 127.0.0.1:2181修改完关键配置后即可执行bin/startup.sh启动manager服务,webUI访问时默认是游客,admin密码默认为admin ,otter没有提供权限控制,游客用户也能看到所有配置信息,因此不能暴露在公网。
坑:startup.sh中的java启动参数-Xss(单个线程栈内存)值都设置的是256k,使用jdk1.8是无法启动的,需要调成大一点例如512k
The stack size specified is too small, Specify at least 384k
切换到admin用户后需要配置zookeeper & node信息,这个node的id为1
在node/conf下执行echo 1 > nid,调整node配置后启动node,看到node状态为已启动即可
配置两个数据源,一个作为源库,一个作为目标库
表明可以用模糊匹配,也可以指定具体的表
监听源库,开启tsdb监控表结构变化
基于日志变更、行记录模式
select和load机器直接选node,同步数据来源的canal选择刚才配置的
添加源表和目标表的映射,视图模式的include/exclude分别代表选中的字段同步/选中的字段排除(不同步),配置好映射关系后保存
批量添加
schema1,table1,sourceId1,schema2,table2,sourceId2
schema1,table1,sourceId1为源表信息
schema2,table2,sourceId2为目标表信息
sourceId是数据源的id,在数据源配置页面可以找到
映射权重 (对应的数字越大,同步会越后面得到同步,优先同步权重小的数据)
启动channel即可测试源库源表的数据变更后,目标库的目标表是否跟着一起更新。
上述介绍的是增量同步数据的基本操作,但是往往源表中已经有了大量的存量数据需要全量同步一次。
Otter官方提供了一种叫自由门的方案可以用于:
原理是基于otter系统表retl_buffer,插入特定数据,otter系统感知后回根据表明和pk提取对应记录和正常增量同步数据一起同步到目标库
/*
+供 otter 使用, otter 需要对 retl.* 的读写权限,以及对业务表的读写权限
+1. 创建database retl
+*/
+CREATE DATABASE retl;
+
+/* 2. 用户授权 给同步用户授权 */
+CREATE USER retl@'%' IDENTIFIED BY 'retl';
+GRANT USAGE ON *.* TO `retl`@'%';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO `retl`@'%';
+GRANT SELECT, INSERT, UPDATE, DELETE, EXECUTE ON `retl`.* TO `retl`@'%';
+/* 业务表授权,这里可以限定只授权同步业务的表 */
+GRANT SELECT, INSERT, UPDATE, DELETE ON *.* TO `retl`@'%';
+
+/* 3. 创建系统表 */
+USE retl;
+DROP TABLE IF EXISTS retl.retl_buffer;
+DROP TABLE IF EXISTS retl.retl_mark;
+DROP TABLE IF EXISTS retl.xdual;
+
+CREATE TABLE retl_buffer
+(
+ ID BIGINT(20) AUTO_INCREMENT,
+ TABLE_ID INT(11) NOT NULL,
+ FULL_NAME varchar(512),
+ TYPE CHAR(1) NOT NULL,
+ PK_DATA VARCHAR(256) NOT NULL,
+ GMT_CREATE TIMESTAMP NOT NULL,
+ GMT_MODIFIED TIMESTAMP NOT NULL,
+ CONSTRAINT RETL_BUFFER_ID PRIMARY KEY (ID)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+
+CREATE TABLE retl_mark
+(
+ ID BIGINT AUTO_INCREMENT,
+ CHANNEL_ID INT(11),
+ CHANNEL_INFO varchar(128),
+ CONSTRAINT RETL_MARK_ID PRIMARY KEY (ID)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
+
+CREATE TABLE xdual (
+ ID BIGINT(20) NOT NULL AUTO_INCREMENT,
+ X timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
+ PRIMARY KEY (ID)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
+
+/* 4. 插入初始化数据 */
+INSERT INTO retl.xdual(id, x) VALUES (1,now()) ON DUPLICATE KEY UPDATE x = now();insert into retl.retl_buffer(ID,TABLE_ID, FULL_NAME,TYPE,PK_DATA,GMT_CREATE,GMT_MODIFIED) (select null,0,'$schema.table$','I',id,now(),now() from $schema.table$);例如:insert into retl.retl_buffer(ID,TABLE_ID, FULL_NAME,TYPE,PK_DATA,GMT_CREATE,GMT_MODIFIED) (select null,0,'test.user','I',id,now(),now() from test.user);
上述基于数据库插入记录触发otter同步的方案,如果数据量大会比较耗时。也可以直接把源表数据导出并记录导出时binlog的position,先将全量数据导入一次目标表,再基于导出数据时的binlog的position进行增量同步。
mysqldump -uxxx -pxxx --single-transaction --master-data=2 --databases xxx --tables xxx > data.sql
这样,导出的data.sql文件中会有一行信息,记录导出时的binlog文件和position
在目标库执行导入sql
后续新建channel的操作和普通增量同步一样即可。
更换zookeeper后,manager管理页面无法进入,报错内容类似org.I0Itec.zkclient.exception.ZkNoNodeException: org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /otter/channel/3/3/process 。原因是otter会在zookepper中存储一些节点信息,更换zookeeper后,需要复制节点数据,或者删除数据库中的channel、pipeline等表的数据内容 或者访问 http://域名:端口/system_reduction.htm,点击一键修复即可。
show master logsshow binlog events in 'binlog.000048' from 1226 limit 4; 更新canal中的位点配置重新启动
低权限用户需要授权,否则无法读取binlogGRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'xxx'@'%' IDENTIFIED BY '';
log_slave_updates=1,将主库binlog中的操作写入到从库的binlog中,默认是关闭的,虽然数据可以同步,但是从库binlog没有记录这些内容。
show processlist命令可以查看mysql连接的状态,以我自己的阿里云服务器为例
常见的状态:
完整状态列表说明请见官网地址
在解析一个查询语句之前,==如果查询缓存是打开的==(默认是关闭的,浪费性能),那么MySQL会优先检查这个查询是否命中查询缓存中的数据,如果命中缓存直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
可以使用show variables like 'query_cache%'来查看缓存的设置情况
如图,query_cache_type一栏时OFF关闭状态,如要开启可以修改my.cnf文件设置query_cache_type=1
query_cache_type=0时表示关闭,1时表示打开,2表示只要select 中明确指定SQL_CACHE才缓存。
MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用MySQL语法规则验证和解析查询。语法树被校验合法后由优化器转成查询计划,一条语句可以有很多种执行方式,最后返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
执行计划可以用==explain==命令查看,详见后文。
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。最常使用的也是比较最多的引擎是MyISAM引擎和InnoDB引擎。mysql5.5开始的默认存储引擎已经变更为innodb。
可以使用show variable like 'long_query_time'命令来查看慢查询的时间
可以看到MySQL中默认的慢查询为10s,然而这个时间属于根本无法接受的地步了,可以将这个时间设置为业务可以接受的范围.
一般的慢SQL定位:业务驱动,测试驱动,慢查询日志
使用SHOW VARIABLES LIKE 'SLOW_QUERY_LOG'命令查看是否开启了慢查询日志保存
可以看到默认是没有开启的
可以使用以下命令开启保存慢查询日志(==重启mysql后会失效==)
set global slow_query_log = on //-- 打开慢日志
+set global slow_query_log_file = '/var/lib/mysql/test-slow.log' //--慢日志保存位置
+set global log_queries_not_using_indexes = on //-- 没有命中索引的是否要记录慢日志
+set global long_query_time = 2 (秒) //-- 执行时间超过多少为慢日志或者直接修改my.cnf文件添加相应配置后重启mysql(==永久生效==)
EXPLAIN可以帮助开发人员分析SQL问题,EXPLAIN显示了MySQL如何使用使用SQL执行计划,可以帮助开发人员写出更优化的查询语句。使用方法,在select语句前加上Explain就可以了
例如:EXPLAIN SELECT * FROM ARTICLE WHERE ARTICLE_ID = '1'
结果列说明:
这是SELECT的查询序列号,表示查询中执行select子句或操作表的顺序,id相同,执行顺序从上到下,id不同,id值越大执行优先级越高
表示SELECT语句的类型
SIMPLE:简单的select查询(不使用连接查询或者子查询)
PRIMARY:表示主查询,或者是最外层的查询语句,最外层查询为PRIMARY,也就是最后加载的就是PRIMARY
UNION:表示连接查询的第二个或者后面的查询语句,不依赖外部查询的结果集
DEPENDENT UNION:union中的第二个或后面的select语句,取决于外面的查询。
UNION RESULT:连接查询的结果;
SUBQUERY:子查询中的第1个SELECT语句;不依赖于外部查询的结果集
DEPENDENT SUBQUERY:子查询中的第1个SELECT,依赖于外面的查询;
DERIVED:导出表的SELECT(FROM子句的子查询),MySQL会递归执行这些子查询,把结果放在临时表里
DEPENDENT DERIVED:派生表依赖于另一个表
MATERIALIZED:物化子查询
UNCACHEABLE SUBQUERY:子查询,其结果无法缓存,必须针对外部查询的每一行重新进行评估
UNCACHEABLE UNION:UNION中的第二个或随后的 select 查询,属于不可缓存的子查询
表示查询的表
表示表的连接类型,从最好到最差的连接类型为
system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system:表仅有一行,这是const类型的特列,平时不会出现,这个也可以忽略不计。
const:数据表最多只有一个匹配行,因为只匹配一行数据,所以很快
eq_ref:mysql手册是这样说的:"对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY"。eq_ref可以用于使用=比较带索引的列。
ref:查询条件索引既不是UNIQUE也不是PRIMARY KEY的情况。ref可用于=或<或>操作符的带索引的列。
ref_or_null:该连接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
index_merge:该连接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
unique_subquery:该类型替换了下面形式的IN子查询的ref: value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
index_subquery:该连接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引: value IN (SELECT key_column FROM single_table WHERE some_expr)
range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符用常量比较关键字列时,类型为range
index:该连接类型与ALL相同,除了只有索引树被扫描。通常比ALL快,因为索引文件通常比数据文件小。
这个类型发生在这两种方式:
**1)**如果索引是查询的覆盖索引,并且可用于满足表中所需的所有数据,则仅扫描索引树。在这种情况下,Extra列显示为 Using index
**2)**使用对索引的读取执行全表扫描,以按索引顺序查找数据行。 Uses index没有出现在 Extra列中。
ALL:对于每个来自于先前的表的行组合,进行完整的表扫描。(性能最差)
指MySQL能使用哪个索引在该表中找到行。如果为空,没有相关的索引。这时如果要提升性能,可以通过检验WHERE子句,看它是否引用某些列或适合索引的列来提高查询性能。如果是这样,可以创建适合的索引来提高查询的性能。
表示查询实际使用的索引,如果没有选择索引,该列的值是NULL。如果为primary的话,表示使用了主键。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX
表示MySQL选择的索引字段按字节计算的长度,若键是NULL,则长度为NULL。通过key_len值可以确定MySQL将实际使用一个多列索引中的几个字段
表示使用哪个列或常数与索引一起来查询记录。
显示MySQL在表中进行查询时必须检查的行数。
表示MySQL在处理查询时的详细信息
贴一个美团技术团队的文章:MySQL索引原理及慢查询优化,以下内容引用自该文章
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析
maven私服突然无法下载依赖,在idea中使用命令查看下详细错误信息mvn clean install -U -e -X
Client报错信息:
Caused by: org.eclipse.aether.transfer.ArtifactTransferException: Could not transfer artifact org.springframework.boot:spring-boot:jar:2.4.1 from/to nexus (xxxxxxxxxxxxxxxxxxxxxxxxx): GET request of: org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar from nexus failedCould not transfer artifact org.springframework.boot:spring-boot:jar:2.4.1 from/to nexus (xxxxxxxxxxxxxxxxxxxxxx): GET request of: org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar from nexus failed: Premature end of Content-Length delimited message body (expected: 1,302,347; received: 76,515) -> [Help 1]服务端错误日志:
2022-04-10 16:51:14,488+0800 INFO [qtp1752276351-145] *UNKNOWN org.apache.shiro.session.mgt.AbstractValidatingSessionManager - Enabling session validation scheduler...
+2022-04-10 16:51:14,502+0800 INFO [qtp1752276351-51] *UNKNOWN org.sonatype.nexus.internal.security.anonymous.AnonymousManagerImpl - Loaded configuration: AnonymousConfiguration{enabled=false, userId='anonymous', realmName='NexusAuthorizingRealm'}
+2022-04-10 16:51:15,233+0800 WARN [qtp1752276351-48] deployment org.sonatype.nexus.repository.httpbridge.internal.ViewServlet - Failure servicing: GET /repository/maven-public/org/springframework/boot/spring-boot/2.4.1/spring-boot-2.4.1.jar
+org.eclipse.jetty.io.EofException: null
+ at org.eclipse.jetty.io.ChannelEndPoint.flush(ChannelEndPoint.java:284)
+ at org.eclipse.jetty.io.WriteFlusher.flush(WriteFlusher.java:393)
+ at org.eclipse.jetty.io.WriteFlusher.write(WriteFlusher.java:277)
+ at org.eclipse.jetty.io.AbstractEndPoint.write(AbstractEndPoint.java:380)
+ at org.eclipse.jetty.server.HttpConnection$SendCallback.process(HttpConnection.java:826)
+ at org.eclipse.jetty.util.IteratingCallback.processing(IteratingCallback.java:241)
+ at org.eclipse.jetty.util.IteratingCallback.iterate(IteratingCallback.java:224)
+ at org.eclipse.jetty.server.HttpConnection.send(HttpConnection.java:550)
+ at org.eclipse.jetty.server.HttpChannel.sendResponse(HttpChannel.java:850)
+ at org.eclipse.jetty.server.HttpChannel.write(HttpChannel.java:921)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:249)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:225)
+ at org.eclipse.jetty.server.HttpOutput.write(HttpOutput.java:524)
+ at com.google.common.io.ByteStreams.copy(ByteStreams.java:113)
+ at org.sonatype.nexus.repository.view.Payload.copy(Payload.java:61)
+ at org.sonatype.nexus.repository.view.Content.copy(Content.java:116)
+ at org.sonatype.nexus.repository.httpbridge.internal.DefaultHttpResponseSender.send(DefaultHttpResponseSender.java:81)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.dispatchAndSend(ViewServlet.java:228)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.doService(ViewServlet.java:174)
+ at org.sonatype.nexus.repository.httpbridge.internal.ViewServlet.service(ViewServlet.java:126)
+ at javax.servlet.http.HttpServlet.service(HttpServlet.java:790)
+ at com.google.inject.servlet.ServletDefinition.doServiceImpl(ServletDefinition.java:286)
+ at com.google.inject.servlet.ServletDefinition.doService(ServletDefinition.java:276)
+ at com.google.inject.servlet.ServletDefinition.service(ServletDefinition.java:181)
+ at com.google.inject.servlet.DynamicServletPipeline.service(DynamicServletPipeline.java:71)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:85)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:112)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:61)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
+ at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter.executeChain(AbstractShiroFilter.java:449)
+ at org.sonatype.nexus.security.SecurityFilter.executeChain(SecurityFilter.java:85)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter$1.call(AbstractShiroFilter.java:365)
+ at org.apache.shiro.subject.support.SubjectCallable.doCall(SubjectCallable.java:90)
+ at org.apache.shiro.subject.support.SubjectCallable.call(SubjectCallable.java:83)
+ at org.apache.shiro.subject.support.DelegatingSubject.execute(DelegatingSubject.java:383)
+ at org.apache.shiro.web.servlet.AbstractShiroFilter.doFilterInternal(AbstractShiroFilter.java:362)
+ at org.sonatype.nexus.security.SecurityFilter.doFilterInternal(SecurityFilter.java:101)
+ at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.repository.httpbridge.internal.ExhaustRequestFilter.doFilter(ExhaustRequestFilter.java:80)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.sonatype.nexus.licensing.internal.LicensingRedirectFilter.doFilter(LicensingRedirectFilter.java:114)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.codahale.metrics.servlet.AbstractInstrumentedFilter.doFilter(AbstractInstrumentedFilter.java:112)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.ErrorPageFilter.doFilter(ErrorPageFilter.java:79)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.EnvironmentFilter.doFilter(EnvironmentFilter.java:101)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at org.sonatype.nexus.internal.web.HeaderPatternFilter.doFilter(HeaderPatternFilter.java:98)
+ at com.google.inject.servlet.FilterChainInvocation.doFilter(FilterChainInvocation.java:82)
+ at com.google.inject.servlet.DynamicFilterPipeline.dispatch(DynamicFilterPipeline.java:104)
+ at com.google.inject.servlet.GuiceFilter.doFilter(GuiceFilter.java:135)
+ at org.sonatype.nexus.bootstrap.osgi.DelegatingFilter.doFilter(DelegatingFilter.java:73)
+ at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1602)
+ at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:540)
+ at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:146)
+ at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:548)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextHandle(ScopedHandler.java:257)
+ at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:1700)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextHandle(ScopedHandler.java:255)
+ at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1345)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:203)
+ at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:480)
+ at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:1667)
+ at org.eclipse.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:201)
+ at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1247)
+ at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:144)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at com.codahale.metrics.jetty9.InstrumentedHandler.handle(InstrumentedHandler.java:239)
+ at org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:152)
+ at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:132)
+ at org.eclipse.jetty.server.Server.handle(Server.java:505)
+ at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:370)
+ at org.eclipse.jetty.server.HttpConnection.onFillable(HttpConnection.java:267)
+ at org.eclipse.jetty.io.AbstractConnection$ReadCallback.succeeded(AbstractConnection.java:305)
+ at org.eclipse.jetty.io.FillInterest.fillable(FillInterest.java:103)
+ at org.eclipse.jetty.io.ChannelEndPoint$2.run(ChannelEndPoint.java:117)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.runTask(EatWhatYouKill.java:333)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.doProduce(EatWhatYouKill.java:310)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.tryProduce(EatWhatYouKill.java:168)
+ at org.eclipse.jetty.util.thread.strategy.EatWhatYouKill.run(EatWhatYouKill.java:126)
+ at org.eclipse.jetty.util.thread.ReservedThreadExecutor$ReservedThread.run(ReservedThreadExecutor.java:366)
+ at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:698)
+ at org.eclipse.jetty.util.thread.QueuedThreadPool$Runner.run(QueuedThreadPool.java:804)
+ at java.lang.Thread.run(Thread.java:748)
+Caused by: java.io.IOException: Connection reset by peer
+ at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
+ at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)
+ at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
+ at sun.nio.ch.IOUtil.write(IOUtil.java:51)
+ at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471)
+ at org.eclipse.jetty.io.ChannelEndPoint.flush(ChannelEndPoint.java:262)
+ ... 102 common frames omitted
在nginx的location配置中增加proxy_max_temp_file_size 0;
SPI(Service Provider Interface)是一种服务发现机制,提供服务接口,且为该接口寻找服务的实现。
从Java6开始引入,是一种基于ClassLoader类加载器发现并加载服务的机制。
标准的SPI构成:
SPI在JDBC中的应用:JDBC要求Driver实现类在类加载的时候将自身的实例注册到DriverManager中,从而加载数据库驱动,在SPI出现之前,加载数据库驱动时要执行Class.forName("com.mysql.jdbc.Driver"), 在SPI出现后,只需要引入对应依赖的JAR包后,ServiceLoader会自动去约定的路径下寻找需要加载的类。
配置文件
无参构造器
当spi-company依赖spi-lt时运行main方法:
当spi-company依赖spi-yd时运行main方法:
自动装配,即auto-configuration,是基于引入的依赖jar包对springboot应用进行自动配置,提供自动配置的jar包通常以starter结尾,比如mybatis-spring-boot-starter等等。
springboot默认会扫描项目下所有的配置类并注入到ioc容器中,但集成到其他框架并不能直接注入。为了实现真正的auto configuration,springboot的自动装配也采用了和spi类似的设计思想:
使用约定的配置文件:自动装配的配置文件为META-INF/spring.factories,文件内容为org.springframework.boot.autoconfigure.EnableAutoConfiguration=class1,class2,..classN,class是自动配置类的类名
例如mybatis-spring-boot-starter的包结构:
springboot的自动装配核心流程:springboot程序启动,通过spring factories机制加载classpath下的META-INF/spring.factories文件,筛选出所有EnableAutoConfiguration的配置类,反射实例化后注入到springIOC容器中。
todo:实现一个自定义springboot-starter
mbg逆向工程能快速生成实体类和mapper文件以及xml,提升开发效率。记录下不同持久层框架对应的mbg配置备忘。
mbg的context标签可以自定义targetRuntime,具体的区别可以在http://mybatis.org/generator/quickstart.html#target-runtime-information-and-samples查看。MyBatis3,生成的代码量比较大,会有byExample和selective相关的代码生成。MyBatis3Simple生成的代码量比较小,不会有byExample和selective方法生成。
常用运行方式(还包含 ant、命令行、eclipse)
maven依赖
<dependency>
+ <groupId>org.mybatis.generator</groupId>
+ <artifactId>mybatis-generator-core</artifactId>
+ <version>1.3.5</version>
+</dependency>
+<dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.16</version>
+</dependency>使用maven插件时
<build>
+ <plugins>
+ <plugin>
+ <groupId>org.mybatis.generator</groupId>
+ <artifactId>mybatis-generator-maven-plugin</artifactId>
+ <version>1.3.5</version>
+ <configuration>
+ <!-- 在控制台打印执行日志 -->
+ <verbose>true</verbose>
+ <!-- 重复生成时会覆盖之前的文件-->
+ <overwrite>true</overwrite>
+ <configurationFile>src/main/resources/generatorConfig.xml</configurationFile>
+ </configuration>
+ <dependencies>
+ <dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.16</version>
+ </dependency>
+ </dependencies>
+ </plugin>
+ </plugins>
+ </build><?xml version="1.0" encoding="UTF-8"?>
+<!DOCTYPE generatorConfiguration
+ PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
+ "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
+
+<generatorConfiguration>
+
+ <context id="Mysql" targetRuntime="MyBatis3Simple"
+ defaultModelType="flat">
+
+ <!--property*,-->
+ <property name="beginningDelimiter" value="`"/>
+ <property name="endingDelimiter" value="`"/>
+
+ <!--plugin*,-->
+ <!-- 为继承的BaseMapper接口添加对应的实现类 -->
+ <plugin type="tk.mybatis.mapper.generator.MapperPlugin">
+ <property name="mappers" value="cn.xxx.CustomBaseMapper"/>
+ </plugin>
+
+ <!--commentGenerator?,-->
+ <!--<commentGenerator type="mybatis.generator.MyCommentGenerator"></commentGenerator>-->
+
+ <!--jdbcConnection,-->
+ <jdbcConnection driverClass="com.mysql.jdbc.Driver"
+ connectionURL="jdbc:mysql://xxx.xxx.xxx/xxx?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&useSSL=false"
+ userId=""
+ password="">
+ </jdbcConnection>
+
+ <!--javaTypeResolver?, 自定义jdbcType和javaType的映射关系,比如默认的TINYINT会对应Java的Byte类型,如果我们想让TINYINT对应JavaType为Integer就需要在解析类中自定义,这种方式适合源码方式运行mbg,使用maven plugin会比较麻烦-->
+ <javaTypeResolver type="mybatis.generator.MyJavaTypeResolver"></javaTypeResolver>
+
+ <!--javaModelGenerator,-->
+ <javaModelGenerator targetPackage="cn.xxx.dao.entity"
+ targetProject="/Users/story/project/xx/src/main/java">
+ <!--<property name="rootClass" value="xx.BaseEntity"/> entity会继承的类-->
+ </javaModelGenerator>
+
+ <!--sqlMapGenerator?,-->
+ <sqlMapGenerator targetPackage="mapper"
+ targetProject="/Users/story/project/xx/src/main/resources"/>
+
+ <!--javaClientGenerator?,-->
+ <javaClientGenerator targetPackage="cn.xxx.app.wechat.dao.mapper"
+ targetProject="/Users/story/project/xxx/src/main/java"
+ type="XMLMAPPER"/>
+
+ <!--table+-->
+ <table tableName="tb_xx" domainObjectName="XxEntity">
+ <generatedKey column="id" sqlStatement="Mysql" identity="true"/>
+ </table>
+
+ </context>
+
+</generatorConfiguration>public interface CustomBaseMapper<T> extends tk.mybatis.mapper.common.BaseMapper<T>, MySqlMapper<T> {
+
+}public class MyJavaTypeResolver implements JavaTypeResolver {
+
+ protected List<String> warnings;
+
+ protected Properties properties;
+
+ protected Context context;
+
+ protected boolean forceBigDecimals;
+
+ protected Map<Integer, JavaTypeResolverDefaultImpl.JdbcTypeInformation> typeMap;
+
+ public MyJavaTypeResolver() {
+ super();
+ properties = new Properties();
+ typeMap = new HashMap<Integer, JavaTypeResolverDefaultImpl.JdbcTypeInformation>();
+
+ typeMap.put(Types.ARRAY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("ARRAY", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.BIGINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BIGINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Long.class.getName())));
+ typeMap.put(Types.BINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.BIT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BIT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Boolean.class.getName())));
+ typeMap.put(Types.BLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.BOOLEAN, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("BOOLEAN", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Boolean.class.getName())));
+ typeMap.put(Types.CHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("CHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.CLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("CLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.DATALINK, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DATALINK", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.DATE, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DATE", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+ typeMap.put(Types.DISTINCT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DISTINCT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.DOUBLE, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("DOUBLE", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Double.class.getName())));
+ typeMap.put(Types.FLOAT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("FLOAT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Double.class.getName())));
+ typeMap.put(Types.INTEGER, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("INTEGER", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+ typeMap.put(Types.JAVA_OBJECT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("JAVA_OBJECT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Jdbc4Types.LONGNVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("LONGNVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.LONGVARBINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation(
+ "LONGVARBINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.LONGVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("LONGVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NCLOB, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NCLOB", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Jdbc4Types.NVARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NVARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+ typeMap.put(Types.NULL, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("NULL", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.OTHER, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("OTHER", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.REAL, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("REAL", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Float.class.getName())));
+ typeMap.put(Types.REF, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("REF", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.SMALLINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("SMALLINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+ typeMap.put(Types.STRUCT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("STRUCT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Object.class.getName())));
+ typeMap.put(Types.TIME, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TIME", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+ typeMap.put(Types.TIMESTAMP, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TIMESTAMP", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Date.class.getName())));
+
+ typeMap.put(Types.TINYINT, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("TINYINT", //$NON-NLS-1$
+ new FullyQualifiedJavaType(Integer.class.getName())));
+
+ typeMap.put(Types.VARBINARY, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("VARBINARY", //$NON-NLS-1$
+ new FullyQualifiedJavaType("byte[]"))); //$NON-NLS-1$
+ typeMap.put(Types.VARCHAR, new JavaTypeResolverDefaultImpl.JdbcTypeInformation("VARCHAR", //$NON-NLS-1$
+ new FullyQualifiedJavaType(String.class.getName())));
+
+ }
+
+ @Override
+ public void addConfigurationProperties(Properties properties) {
+ this.properties.putAll(properties);
+ forceBigDecimals = StringUtility.isTrue(properties.getProperty(PropertyRegistry.TYPE_RESOLVER_FORCE_BIG_DECIMALS));
+ }
+
+ @Override
+ public FullyQualifiedJavaType calculateJavaType(
+ IntrospectedColumn introspectedColumn) {
+ FullyQualifiedJavaType answer;
+ JavaTypeResolverDefaultImpl.JdbcTypeInformation jdbcTypeInformation = typeMap
+ .get(introspectedColumn.getJdbcType());
+
+ if (jdbcTypeInformation == null) {
+ switch (introspectedColumn.getJdbcType()) {
+ case Types.DECIMAL:
+ case Types.NUMERIC:
+ if (introspectedColumn.getScale() > 0
+ || introspectedColumn.getLength() > 18
+ || forceBigDecimals) {
+ answer = new FullyQualifiedJavaType(BigDecimal.class
+ .getName());
+ } else if (introspectedColumn.getLength() > 9) {
+ answer = new FullyQualifiedJavaType(Long.class.getName());
+ } else if (introspectedColumn.getLength() > 4) {
+ answer = new FullyQualifiedJavaType(Integer.class.getName());
+ } else {
+ answer = new FullyQualifiedJavaType(Short.class.getName());
+ }
+ break;
+
+ default:
+ answer = null;
+ break;
+ }
+ } else {
+ answer = jdbcTypeInformation.getFullyQualifiedJavaType();
+ }
+
+ return answer;
+ }
+
+ @Override
+ public String calculateJdbcTypeName(IntrospectedColumn introspectedColumn) {
+ String answer;
+ JavaTypeResolverDefaultImpl.JdbcTypeInformation jdbcTypeInformation = typeMap
+ .get(introspectedColumn.getJdbcType());
+
+ if (jdbcTypeInformation == null) {
+ switch (introspectedColumn.getJdbcType()) {
+ case Types.DECIMAL:
+ answer = "DECIMAL"; //$NON-NLS-1$
+ break;
+ case Types.NUMERIC:
+ answer = "NUMERIC"; //$NON-NLS-1$
+ break;
+ default:
+ answer = null;
+ break;
+ }
+ } else {
+ answer = jdbcTypeInformation.getJdbcTypeName();
+ }
+
+ return answer;
+ }
+
+ @Override
+ public void setWarnings(List<String> warnings) {
+ this.warnings = warnings;
+ }
+
+ @Override
+ public void setContext(Context context) {
+ this.context = context;
+ }
+
+ public static class JdbcTypeInformation {
+ private String jdbcTypeName;
+
+ private FullyQualifiedJavaType fullyQualifiedJavaType;
+
+ public JdbcTypeInformation(String jdbcTypeName,
+ FullyQualifiedJavaType fullyQualifiedJavaType) {
+ this.jdbcTypeName = jdbcTypeName;
+ this.fullyQualifiedJavaType = fullyQualifiedJavaType;
+ }
+
+ public String getJdbcTypeName() {
+ return jdbcTypeName;
+ }
+
+ public FullyQualifiedJavaType getFullyQualifiedJavaType() {
+ return fullyQualifiedJavaType;
+ }
+ }
+}public class MyBatisGeneratorTool {
+ public static void main(String[] args) {
+
+ URL resource = Thread.currentThread().getContextClassLoader().getResource("");
+
+ System.out.println(resource.getPath());
+
+ List<String> warnings = new ArrayList<String>();
+ boolean overwrite = true;
+ File configFile = new File(resource.getPath() + "../../src/test/resources/generator/generatorConfig.xml");
+ ConfigurationParser cp = new ConfigurationParser(warnings);
+ Configuration config = null;
+
+ try {
+ config = cp.parseConfiguration(configFile);
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (XMLParserException e) {
+ e.printStackTrace();
+ }
+
+ DefaultShellCallback callback = new DefaultShellCallback(overwrite);
+ MyBatisGenerator myBatisGenerator = null;
+
+ try {
+ myBatisGenerator = new MyBatisGenerator(config, callback, warnings);
+ } catch (InvalidConfigurationException e) {
+ e.printStackTrace();
+ }
+
+ try {
+ myBatisGenerator.generate(null);
+ } catch (SQLException e) {
+ e.printStackTrace();
+ } catch (IOException e) {
+ e.printStackTrace();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+}
<?xml version="1.0" encoding="UTF-8"?>
+<!DOCTYPE generatorConfiguration
+ PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
+ "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
+<generatorConfiguration>
+ <!-- context 是逆向工程的主要配置信息 -->
+ <!-- id:起个名字 -->
+ <!-- targetRuntime:设置生成的文件适用于那个 mybatis 版本 -->
+ <context id="default" targetRuntime="MyBatis3">
+ <!--optional,指在创建class时,对注释进行控制-->
+ <commentGenerator>
+ <property name="suppressDate" value="true"/>
+ <!-- 是否去除自动生成的注释 true:是 : false:否 -->
+ <property name="suppressAllComments" value="true"/>
+ </commentGenerator>
+ <!--jdbc的数据库连接 wg_insert 为数据库名字-->
+ <jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
+ connectionURL="jdbc:mysql://xxx/xx?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&useSSL=false&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true"
+ userId=""
+ password="">
+ </jdbcConnection>
+ <!--非必须,类型处理器,在数据库类型和java类型之间的转换控制-->
+ <javaTypeResolver>
+ <!-- 默认情况下数据库中的 decimal,bigInt 在 Java 对应是 sql 下的 BigDecimal 类 -->
+ <!-- 不是 double 和 long 类型 -->
+ <!-- 使用常用的基本类型代替 sql 包下的引用类型 -->
+ <property name="forceBigDecimals" value="false"/>
+ </javaTypeResolver>
+ <!-- targetPackage:生成的实体类所在的包 -->
+ <!-- targetProject:生成的实体类所在的硬盘位置 -->
+ <javaModelGenerator targetPackage="xxx"
+ targetProject="/Users/story/project/xxx/src/main/java">
+ <!-- 是否允许子包 -->
+ <property name="enableSubPackages" value="false"/>
+ <!-- 是否对modal添加构造函数 -->
+ <!-- <property name="constructorBased" value="true"/>-->
+ <!-- 是否清理从数据库中查询出的字符串左右两边的空白字符 -->
+ <!-- <property name="trimStrings" value="true"/>-->
+ <!-- 建立modal对象是否不可改变 即生成的modal对象不会有setter方法,只有构造方法 -->
+ <!-- <property name="immutable" value="false"/>-->
+ </javaModelGenerator>
+ <!-- targetPackage 和 targetProject:生成的 mapper 文件的包和位置 -->
+ <sqlMapGenerator targetPackage="xx"
+ targetProject="/Users/story/project/xx/src/main/resources">
+ <!-- 针对数据库的一个配置,是否把 schema 作为字包名 -->
+ <property name="enableSubPackages" value="false"/>
+ </sqlMapGenerator>
+ <!-- targetPackage 和 targetProject:生成的 interface 文件的包和位置 -->
+ <javaClientGenerator type="XMLMAPPER"
+ targetPackage="xx" targetProject="/Users/story/project/xxx/src/main/java">
+ <!-- 针对 oracle 数据库的一个配置,是否把 schema 作为字包名 -->
+ <property name="enableSubPackages" value="false"/>
+ </javaClientGenerator>
+ <!-- tableName是数据库中的表名,domainObjectName是生成的JAVA模型名,后面的参数不用改,要生成更多的表就在下面继续加table标签 -->
+ <table tableName="xxx" domainObjectName="XxxEntity">
+ </table>
+ </context>
+</generatorConfiguration>
一个常见的面试/笔试题: SpringMVC的执行流程
答:
1、前端请求到核心前端控制器DispatcherServlet
2、DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3、处理器映射器找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4、 DispatcherServlet调用HandlerAdapter处理器适配器。
5、HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
6、Controller执行完成返回ModelAndView。
7、HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
8、DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9、ViewReslover解析后返回具体View.
10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
11、DispatcherServlet响应用户。
为了应付面试相信很多人和我一样死记硬背过,今天就来看下源码,看看这个流程的庐山真面目。
首先找到DispatcherServlet类,看看它的继承关系
过程图
初始化方法
/**
+ * This implementation calls {@link #initStrategies}.
+ */
+ @Override
+ protected void onRefresh(ApplicationContext context) {
+ initStrategies(context);
+ }
+
+ /**
+ * Initialize the strategy objects that this servlet uses.
+ * <p>May be overridden in subclasses in order to initialize further strategy objects.
+ */
+ protected void initStrategies(ApplicationContext context) {
+ initMultipartResolver(context);
+ initLocaleResolver(context);
+ initThemeResolver(context);
+ initHandlerMappings(context);
+ initHandlerAdapters(context);
+ initHandlerExceptionResolvers(context);
+ initRequestToViewNameTranslator(context);
+ initViewResolvers(context);
+ initFlashMapManager(context);
+ }可以看到initStrategies方法初始化了9个组件,其中不乏文章开头中问题涉及到的组件
这九个初始化方法做的事情如下:
首先要明确DispatcherServlet也是一个Servlet,也要遵守servlet接口的规范,servlet通过service方法来根据不同的请求方式来执行doGet,doPost等方法。而FrameworkServlet重写了service方法,并调用了processRequest方法,processRequest方法中又调用了抽象方法doService,DispatcherServlet实现了doService方法,并在该方法中调用了doDispatch方法,doDispatch方法就是具体的请求处理过程
过程图:
/**
+ * Process the actual dispatching to the handler.
+ * <p>The handler will be obtained by applying the servlet's HandlerMappings in order.
+ * The HandlerAdapter will be obtained by querying the servlet's installed HandlerAdapters
+ * to find the first that supports the handler class.
+ * <p>All HTTP methods are handled by this method. It's up to HandlerAdapters or handlers
+ * themselves to decide which methods are acceptable.
+ * @param request current HTTP request
+ * @param response current HTTP response
+ * @throws Exception in case of any kind of processing failure
+ */
+ protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
+ HttpServletRequest processedRequest = request;
+ HandlerExecutionChain mappedHandler = null;
+ boolean multipartRequestParsed = false;
+
+ WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
+
+ try {
+ ModelAndView mv = null;
+ Exception dispatchException = null;
+
+ try {
+ //判断是否为上传文件的请求,如果不是就返回原始的request,否则做相应的处理
+ processedRequest = checkMultipart(request);
+ multipartRequestParsed = (processedRequest != request);
+
+ // Determine handler for the current request.
+ //找到当前请求对应的处理器,返回的是对应的处理器及拦截器集合
+ mappedHandler = getHandler(processedRequest);
+ if (mappedHandler == null) {
+ noHandlerFound(processedRequest, response);
+ return;
+ }
+
+ // Determine handler adapter for the current request.
+ //根据上一步找到的处理器,再找到对应的处理器适配器
+ HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
+
+ // Process last-modified header, if supported by the handler.
+ String method = request.getMethod();
+ boolean isGet = "GET".equals(method);
+ if (isGet || "HEAD".equals(method)) {
+ long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
+ if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
+ return;
+ }
+ }
+ //这里执行了所有的拦截器中的preHandle方法 也就是为什么拦截器总在controller前先执行
+ if (!mappedHandler.applyPreHandle(processedRequest, response)) {
+ return;
+ }
+
+ // Actually invoke the handler.
+ //调用处理器的处理方法
+ mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
+
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ return;
+ }
+ //设置modelAndView的默认名
+ applyDefaultViewName(processedRequest, mv);
+ //执行拦截器的postHanle方法
+ mappedHandler.applyPostHandle(processedRequest, response, mv);
+ }
+ catch (Exception ex) {
+ dispatchException = ex;
+ }
+ catch (Throwable err) {
+ // As of 4.3, we're processing Errors thrown from handler methods as well,
+ // making them available for @ExceptionHandler methods and other scenarios.
+ dispatchException = new NestedServletException("Handler dispatch failed", err);
+ }
+ //处理modelAndView并渲染
+ processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
+ }
+ catch (Exception ex) {
+ triggerAfterCompletion(processedRequest, response, mappedHandler, ex);
+ }
+ catch (Throwable err) {
+ triggerAfterCompletion(processedRequest, response, mappedHandler,
+ new NestedServletException("Handler processing failed", err));
+ }
+ finally {
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ // Instead of postHandle and afterCompletion
+ if (mappedHandler != null) {
+ mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response);
+ }
+ }
+ else {
+ // Clean up any resources used by a multipart request.
+ if (multipartRequestParsed) {
+ cleanupMultipart(processedRequest);
+ }
+ }
+ }
+ }该方法返回的是HandlerExecutionChain对象,其中包含了处理器和过滤器的集合,这里调用了handlerMapping的getHandler方法,该方法主要调用了getHandlerExecutionChain方法,handlerMapping的集合是在初始化dispatchServlet的时候从beanFactory中查找并封装的,具体的handlerMappings初始化细节可以看initHandlerMappings方法,handlerMapping有多种类型,对应不同的请求,比如请求静态资源的和请求接口的等,此处我们以请求一个查询接口为例
protected HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
+ if (this.handlerMappings != null) {
+ //循环所有的handlerMapping,直到找到对应的handler
+ for (HandlerMapping mapping : this.handlerMappings) {
+ HandlerExecutionChain handler = mapping.getHandler(request);
+ if (handler != null) {
+ return handler;
+ }
+ }
+ }
+ return null;
+}getHandlerExecutionChain方法这里调用的是AbstractHandlerMethodMapping的getHandlerInternal方法,该方法又调用了同一个类中的lookupHandlerMethod方法
lookupHandlerMethod方法会根据请求的uri在mappingRegistry中查询已经注册了的请求路径(requestMapping注解中的路径),如果能直接从map中get到非空的list,就直接根据list匹配对应的HandleMethod对象,如果mappingRegistry中get不到,就尝试使用uri路径匹配,例如带有url参数的这种格式/test/{username}的格式,{username}会被替换为.*的正则表达式去进行匹配,匹配到后返回;
getHandlerExecutionChain方法则是根据请求的路径匹配拦截器的路径,如果有匹配到的,就添加到执行链当中
public final HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
+ //根据request找到对应的handler
+ Object handler = getHandlerInternal(request);
+ if (handler == null) {
+ handler = getDefaultHandler();
+ }
+ if (handler == null) {
+ return null;
+ }
+ // Bean name or resolved handler?
+ if (handler instanceof String) {
+ String handlerName = (String) handler;
+ handler = obtainApplicationContext().getBean(handlerName);
+ }
+
+ HandlerExecutionChain executionChain = getHandlerExecutionChain(handler, request);
+
+ if (logger.isTraceEnabled()) {
+ logger.trace("Mapped to " + handler);
+ }
+ else if (logger.isDebugEnabled() && !request.getDispatcherType().equals(DispatcherType.ASYNC)) {
+ logger.debug("Mapped to " + executionChain.getHandler());
+ }
+
+ if (CorsUtils.isCorsRequest(request)) {
+ CorsConfiguration globalConfig = this.corsConfigurationSource.getCorsConfiguration(request);
+ CorsConfiguration handlerConfig = getCorsConfiguration(handler, request);
+ CorsConfiguration config = (globalConfig != null ? globalConfig.combine(handlerConfig) : handlerConfig);
+ executionChain = getCorsHandlerExecutionChain(request, executionChain, config);
+ }
+
+ return executionChain;
+ }
+
+
+
+protected HandlerExecutionChain getHandlerExecutionChain(Object handler, HttpServletRequest request) {
+ HandlerExecutionChain chain = (handler instanceof HandlerExecutionChain ?
+ (HandlerExecutionChain) handler : new HandlerExecutionChain(handler));
+
+ String lookupPath = this.urlPathHelper.getLookupPathForRequest(request);
+ for (HandlerInterceptor interceptor : this.adaptedInterceptors) {
+ if (interceptor instanceof MappedInterceptor) {
+ MappedInterceptor mappedInterceptor = (MappedInterceptor) interceptor;
+ if (mappedInterceptor.matches(lookupPath, this.pathMatcher)) {
+ chain.addInterceptor(mappedInterceptor.getInterceptor());
+ }
+ }
+ else {
+ chain.addInterceptor(interceptor);
+ }
+ }
+ return chain;
+ }这个方法比较简单,就是从handlerAdapter集合中遍历找到支持当前请求的处理器适配器,用到了handlerAdapter的supports方法,测试的接口请求会调用AbstractHandlerMethodAdapter这个类的supports方法
/**
+ * This implementation expects the handler to be an {@link HandlerMethod}.
+ * @param handler the handler instance to check
+ * @return whether or not this adapter can adapt the given handler
+ */
+@Override
+public final boolean supports(Object handler) {
+ return (handler instanceof HandlerMethod && supportsInternal((HandlerMethod) handler));
+}在找到对应的处理器适配器后,会执行拦截器的preHandle方法,然后执行处理器适配器的handle方法,这个就是实际上调用我们所写的controller了,该方法有几个实现 这里调用的是AbstractHandlerMethodAdapter的方法,该方法调用了抽象方法handleInternal,它的实现在RequestMappingHandlerAdapter类中
protected ModelAndView handleInternal(HttpServletRequest request,
+ HttpServletResponse response, HandlerMethod handlerMethod) throws Exception {
+
+ ModelAndView mav;
+ checkRequest(request);
+
+ // Execute invokeHandlerMethod in synchronized block if required.
+ if (this.synchronizeOnSession) {
+ HttpSession session = request.getSession(false);
+ if (session != null) {
+ Object mutex = WebUtils.getSessionMutex(session);
+ synchronized (mutex) {
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+ }
+ else {
+ // No HttpSession available -> no mutex necessary
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+ }
+ else {
+ // No synchronization on session demanded at all...
+ mav = invokeHandlerMethod(request, response, handlerMethod);
+ }
+
+ if (!response.containsHeader(HEADER_CACHE_CONTROL)) {
+ if (getSessionAttributesHandler(handlerMethod).hasSessionAttributes()) {
+ applyCacheSeconds(response, this.cacheSecondsForSessionAttributeHandlers);
+ }
+ else {
+ prepareResponse(response);
+ }
+ }
+
+ return mav;
+}其中重点在invokeHandlerMethod方法,这个方法首先初始化了一个新的handlerMethod对象,添加了相关的解析组件,返回值处理器等等,然后执行了invokeAndHandle方法,然后最终调用了InvocableHandlerMethod类中的doInvoke方法
protected ModelAndView invokeHandlerMethod(HttpServletRequest request,
+ HttpServletResponse response, HandlerMethod handlerMethod) throws Exception {
+ ServletWebRequest webRequest = new ServletWebRequest(request, response);
+ try {
+ WebDataBinderFactory binderFactory = getDataBinderFactory(handlerMethod);
+ ModelFactory modelFactory = getModelFactory(handlerMethod, binderFactory);
+
+ ServletInvocableHandlerMethod invocableMethod = createInvocableHandlerMethod(handlerMethod);
+ if (this.argumentResolvers != null) {
+ invocableMethod.setHandlerMethodArgumentResolvers(this.argumentResolvers);
+ }
+ if (this.returnValueHandlers != null) {
+ invocableMethod.setHandlerMethodReturnValueHandlers(this.returnValueHandlers);
+ }
+ invocableMethod.setDataBinderFactory(binderFactory);
+ invocableMethod.setParameterNameDiscoverer(this.parameterNameDiscoverer);
+
+ ModelAndViewContainer mavContainer = new ModelAndViewContainer();
+ mavContainer.addAllAttributes(RequestContextUtils.getInputFlashMap(request));
+ modelFactory.initModel(webRequest, mavContainer, invocableMethod);
+ mavContainer.setIgnoreDefaultModelOnRedirect(this.ignoreDefaultModelOnRedirect);
+
+ AsyncWebRequest asyncWebRequest = WebAsyncUtils.createAsyncWebRequest(request, response);
+ asyncWebRequest.setTimeout(this.asyncRequestTimeout);
+
+ WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
+ asyncManager.setTaskExecutor(this.taskExecutor);
+ asyncManager.setAsyncWebRequest(asyncWebRequest);
+ asyncManager.registerCallableInterceptors(this.callableInterceptors);
+ asyncManager.registerDeferredResultInterceptors(this.deferredResultInterceptors);
+
+ if (asyncManager.hasConcurrentResult()) {
+ Object result = asyncManager.getConcurrentResult();
+ mavContainer = (ModelAndViewContainer) asyncManager.getConcurrentResultContext()[0];
+ asyncManager.clearConcurrentResult();
+ LogFormatUtils.traceDebug(logger, traceOn -> {
+ String formatted = LogFormatUtils.formatValue(result, !traceOn);
+ return "Resume with async result [" + formatted + "]";
+ });
+ invocableMethod = invocableMethod.wrapConcurrentResult(result);
+ }
+
+ invocableMethod.invokeAndHandle(webRequest, mavContainer);
+ if (asyncManager.isConcurrentHandlingStarted()) {
+ return null;
+ }
+
+ return getModelAndView(mavContainer, modelFactory, webRequest);
+ }
+ finally {
+ webRequest.requestCompleted();
+ }
+}这里就比较明显了,首先利用暴力反射将方法设置为可访问的,然后直接反射调用并返回结果
/**
+ * Invoke the handler method with the given argument values.
+ */
+@Nullable
+protected Object doInvoke(Object... args) throws Exception {
+ ReflectionUtils.makeAccessible(getBridgedMethod());
+ try {
+ return getBridgedMethod().invoke(getBean(), args);
+ }
+ catch (IllegalArgumentException ex) {
+ assertTargetBean(getBridgedMethod(), getBean(), args);
+ String text = (ex.getMessage() != null ? ex.getMessage() : "Illegal argument");
+ throw new IllegalStateException(formatInvokeError(text, args), ex);
+ }
+ catch (InvocationTargetException ex) {
+ // Unwrap for HandlerExceptionResolvers ...
+ Throwable targetException = ex.getTargetException();
+ if (targetException instanceof RuntimeException) {
+ throw (RuntimeException) targetException;
+ }
+ else if (targetException instanceof Error) {
+ throw (Error) targetException;
+ }
+ else if (targetException instanceof Exception) {
+ throw (Exception) targetException;
+ }
+ else {
+ throw new IllegalStateException(formatInvokeError("Invocation failure", args), targetException);
+ }
+ }
+}返回modelAndview对象后就是渲染的一些操作
大致思路:
后台:
@Component
+public class ServerStarter implements ApplicationListener<ContextRefreshedEvent> {
+
+ @Override
+ public void onApplicationEvent(ContextRefreshedEvent event) {
+ if (event.getApplicationContext().getParent() == null ){
+ try {
+ new IMServer().start();
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+ }/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:23
+ */
+public class IMServer {
+ Logger logger = LoggerFactory.getLogger(IMServer.class);
+
+ public void start() throws InterruptedException {
+ NioEventLoopGroup boss = new NioEventLoopGroup();
+ NioEventLoopGroup worker = new NioEventLoopGroup();
+ ServerBootstrap serverBootstrap = new ServerBootstrap();
+ serverBootstrap.group(boss,worker)
+ .channel(NioServerSocketChannel.class)
+ .localAddress(8000)
+ //自定义初始化器
+ .childHandler(new IMStoryInitializer());
+ ChannelFuture future = serverBootstrap.bind();
+ future.addListener(new ChannelFutureListener() {
+ @Override
+ public void operationComplete(ChannelFuture future) throws Exception {
+ logger.info("server start on 8000");
+ }
+ });
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:28
+ */
+public class IMStoryInitializer extends ChannelInitializer<SocketChannel> {
+
+ @Override
+ protected void initChannel(SocketChannel ch) throws Exception {
+ ChannelPipeline pipeline = ch.pipeline();
+ //http编解码器
+ pipeline.addLast(new HttpServerCodec());
+ //以块写数据
+ pipeline.addLast(new ChunkedWriteHandler());
+ //聚合器
+ pipeline.addLast(new HttpObjectAggregator(64*1024));
+
+ //websocket
+ pipeline.addLast(new WebSocketServerProtocolHandler("/ws"));
+ //自定义handler
+ pipeline.addLast(new ChatHandler());
+
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:34
+ */
+public class ChatHandler extends SimpleChannelInboundHandler<TextWebSocketFrame> {
+
+ /**
+ * 管理所有channel
+ */
+ public static ChannelGroup channels = new DefaultChannelGroup(GlobalEventExecutor.INSTANCE);
+
+ @Override
+ protected void channelRead0(ChannelHandlerContext ctx, TextWebSocketFrame msg) throws Exception {
+ //客户端发过来的消息
+ String content = msg.text();
+ //当前通道
+ Channel channel = ctx.channel();
+
+ Message message = JSON.parseObject(content, Message.class);
+
+ String data = message.getMsg();
+
+ String fromUser = message.getFromUser();
+ //客户端建立连接后先发送一条init消息,后台保存这个通道和用户信息的映射
+ if (StringUtils.equals(message.getAction(), "init")) {
+ ChannelUserContext.put(fromUser,channel);
+ } else if (StringUtils.equals(message.getAction(),"chat")){
+ Channel toChannel = ChannelUserContext.get(message.getToUser());
+ if (toChannel != null) {
+ //消息接收方在线
+ toChannel.writeAndFlush(new TextWebSocketFrame(JSON.toJSONString(message.getFromUser() + " : " + message.getMsg())));
+ } else {
+ //接收方不在线 离线消息推送
+ }
+
+ }
+
+ }
+
+ @Override
+ public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
+ channels.add(ctx.channel());
+ }
+
+ @Override
+ public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
+ channels.remove(ctx.channel());
+ }
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:46
+ */
+public class ChannelUserContext {
+
+ private static ConcurrentHashMap<String, Channel> userChannelMap;
+
+ static{
+ userChannelMap = new ConcurrentHashMap<>();
+ }
+
+ public static void put(String user, Channel channel){
+ userChannelMap.put(user,channel);
+ }
+
+ public static Channel get(String user) {
+ return userChannelMap.get(user);
+ }
+
+}/**
+ * @author Xc
+ * @description
+ * @createdTime 2020/7/9 9:38
+ */
+@Data
+public class Message implements Serializable {
+ private static final long serialVersionUID = 301234912340234L;
+ private String msg;
+ private String fromUser;
+ private String toUser;
+ private String action;
+}前台页面1
<!DOCTYPE html>
+<html lang="en">
+<head>
+ <meta charset="UTF-8">
+ <title>WebSocket客户端</title>
+</head>
+<body>
+<script type="text/javascript">
+ var socket;
+
+ //如果浏览器支持WebSocket
+ if(window.WebSocket){
+ //参数就是与服务器连接的地址
+ socket = new WebSocket("ws://localhost:8000/ws");
+
+ //客户端收到服务器消息的时候就会执行这个回调方法
+ socket.onmessage = function (event) {
+ console.log(event);
+ var ta = document.getElementById("responseText");
+ ta.value = ta.value + "\n"+event.data;
+ }
+
+ //连接建立的回调函数
+ socket.onopen = function(event){
+ var ta = document.getElementById("responseText");
+
+ ta.value = "连接开启";
+ var message = '{"action":"init","msg":"test","fromUser":"张三","toUser":"李四"}';
+ socket.send(message);
+ }
+
+ //连接断掉的回调函数
+ socket.onclose = function (event) {
+ var ta = document.getElementById("responseText");
+ ta.value = ta.value +"\n"+"连接关闭";
+ }
+ }else{
+ alert("浏览器不支持WebSocket!");
+ }
+
+ //发送数据
+ function send(message){
+ if(!window.WebSocket){
+ return;
+ }
+
+ //当websocket状态打开
+ if(socket.readyState == WebSocket.OPEN){
+ message = '{"action":"chat","msg":"'+ message +'","fromUser":"张三","toUser":"李四"}';
+ socket.send(message);
+ }else{
+ alert("连接没有开启");
+ }
+ }
+</script>
+<form onsubmit="return false">
+ <textarea name = "message" style="width: 400px;height: 200px"></textarea>
+
+ <input type ="button" value="张三:发送数据" onclick="send(this.form.message.value);">
+
+ <h3>服务器输出:</h3>
+
+ <textarea id ="responseText" style="width: 400px;height: 300px;"></textarea>
+
+ <input type="button" onclick="javascript:document.getElementById('responseText').value=''" value="清空数据">
+</form>
+</body>
+</html>页面二就是对这个页面稍微改一下
启动后台后打开两个页面,即可开始进行通讯
今天领导让我了解下分布式定时任务的内容,对项目中目前的定时任务改造一下,公司目前项目中封装的定时任务注解是基于spring的scheduler的,单机环境下没问题,但是为了服务的高可用生产都是集群部署的,会导致任务多次运行的问题,上家公司用的ssm,定时任务选型是Quartz,生产上采用的quartz的集群部署,quartz集群是不会出现任务重复执行的,原理跟下文讲到的xxl-job一样都是通过数据库表来加锁实现
Xxl-job官网:https://www.xuxueli.com/xxl-job/
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
选择xxl-job的原因有以下几点:
使用流程:
执行doc中的sql脚本,建相关的库表,具体表的作用可阅读帮助文档
修改xxl-job-admin配置文件后可以直接启动admin应用
修改执行器应用中配置文件,注意匹配admin的相关信息
copy一份示例执行器的代码 修改应用端口和执行端口
启动两个示例执行器应用(模拟集群)
打开控制台可以看到已经注册上了两个节点
在控制台任务管理中修改任务的相关信息,这里只试个最简单的,更多高级配置请看使用文档
可以在控制台的调度记录中看到,集群模式下任务也只执行了一次.
除了cron任务,xxl-job中还支持周期性的任务,shell任务等.路由策略还支持轮询,一致性哈希,故障转移等,在admin中配置好java.mail信息,在控制配置任务时添加告警邮件,在任务调度出现异常时还会邮件告警
集成到微服务系统的思路:
新公司用的消息中间件是kafka,此前没有接触过,先大致了解下内容,后续再补充
Kafka is a distributed,partitioned,replicated commit logservice。
Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka 适合离线和在线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
相关术语:
broker:kafka集群中的每一台server称为一个kafka实例,也叫broker
topic:主题,一个topic中保存同一类消息,相当于对消息的分类
partition:分区,每个topic都可以分成多个partition,每个partition的存储层面都是append log文件.任何发布到该partition的消息都会被追加到log文件尾部.
分区的根本原因:kafka基于文件进行存储,当文件内容达到一定程度很容易达到单个磁盘的上限,因此采取分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同server上,另外也可以负载均衡,容纳更多消费者
offset:偏移量,一个分区对应一个磁盘上的文件,而消息在文件中的位置就是offset偏移量,offset为一个long型数字,可以唯一标记一条消息,kafka没有提供其他额外的索引机制来存储offset,所以只能顺序读写,在kafka中几乎不允许对消息进行"随机读写"
总结:
一个topic对应的多个partition分散存储到集群的多个broker上,存储方式是一个partition对应一个文件,每个broker负责存储在自己机器上的partition中的消息读写
kafka可以配置partitions需要备份的个数(replicas),每个partition将会备份到多台机器上,以提高可用性.既然有副本,就涉及到对同一个文件的多个备份如何进行管理调度,kafka的方案是每个partition选举一个server作为leader,由leader负责所有对该分区的读写,其他server作为follower只需要简单的与leader同步,如果原来的leader失效,会重新选举由其他的follower来成为新的leader
如何选举leader:kafka使用zookeeper在broker中选出一个controller,用于partition的分配和leader选举
另外,作为leader的server承担了该分区所有的读写,所以压力较大,从整体考虑,有多少个partition就有多少个leader,kafka会将leader分散到不同的broker上,确保整体负载均衡
生产者写入的消息,可以指定四个参数:topic、partition、key、value其中topic和value是必须指定的,key和partition是可选的。
对于一条记录,先对其进行序列化,然后按照topic和partition,放进对应的发送队列中。如果partition没有指定,那么情况如下:a、Key有填,按照key进行hash,相同的key去一个partition
b、key没填,round-robin轮询来选partition
producer会和topic下的所有partition leader保持socket连接,消息经过producer直接通过socket发送至broker。其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper客户端已经注册了watch监听partition leader的变更事件,因此可以准确的知道谁是当前leader。
producer端采用异步发送,多条消息暂且在客户端buffer起来,并将他们批量发送到broker,小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率
消费者不是以单独形式存在,每一个消费者属于一个consumer group消费者组,一个group包含多个consumer。订阅topic是以一个消费组来订阅的,发送到topic的消息,只会被订阅此topic的每个group中的consumer消费。
如果所有的consumer都具有相同group,那么就像一个点对点的消息系统,如果每个consumer都具有不同的group,那消息就会广播给所有消费者。
具体说来,这实际上是根据partition来分的,==一个partition只能被消费组里的一个消费者消费,但是可以被多个消费组消费==,消费组里的每个消费者是关联到一个partition的,因此有这样的说法:对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则意味着某些消费者无法得到消息
同一个消费组的两个消费者不会同时消费一个partition.
在kafka中,采用了pull的方式,即consumer和broker建立连接之后,主动去pull(或者说fetch)消息,首先consumer端可以根据自己的消费能力适时去fetch消息并处理,且可以控制消息消费的进度(offset)。
partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,所以kafka的broker端很轻量级。当消息被consumer接受之后,需要保存offset记录消费到哪,以前保存在zk中,由于zk的性能瓶颈,以前的解决方案是consumer一分钟上报一次,在0.10版本后kafka把offset保存,从zk中剥离,保存在consumeroffsets topic的topic中,由此可见,consumer客户端也很轻量级
kafka支持三种消息投递语义,在业务中通常使用At least once模型
官方地址:https://kafka.apache.org/downloads.html
官方文档:http://kafka.apache.org/quickstart
TIP
强烈建议新学习一项新内容的时候尽量阅读英文原版文档
使用kafka自带的zookeeper启动
tar -xzf kafka_2.13-2.8.0.tgz
+cd kafka_2.13-2.8.0
+bin/zookeeper-server-start.sh config/zookeeper.properties & #后台启动在kafka0.5x版本后已经自带了zookeeper, 而在最新的kafka2.8版本中,不再需要zookeeper服务,官网把这种称之为KRaft模式
bin/kafka-server-start.sh config/server.properties等所有服务等启动完毕,kafka就已经是可用的了
创建一个名为quickstart-events的topic,只有一个分区和一个备份
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic quickstart-events
+
+查看已创建的topic信息
+
+```bash
+[root@localhost kafka_2.13-2.8.0]# bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
+Topic: quickstart-events TopicId: iOM06pJVQV-y_A6QkmfeHw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
+ Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0kafka提供了一个命令行工具,可以从输入文件或命令行中读取消息并发送给kafka集群,每一行是一条消息.运行producer(生产者) ,然后再控制台输入几条消息到服务器
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092输入此命令后进入交互模式,便可以开始发送消息到topic
>hello
+>hello world
+>this is first kafka message
+>可以使用Ctrl+C退出交互模式
打开另外一个终端窗口运行命令
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092可以看到输出了刚才我们通过生产者终端发送的消息
hello
+hello world
+this is first kafka message此时如果我们再在生产者终端发送消息,消费者终端也能实时进行消费,同样可以使用Ctrl+C 退出消费者的交互模式,消息会被持久化到kafka中,所以消息可以被消费多次以及被多个消费者消费,比如我们再打开一个窗口,执行消费的命令
[root@localhost kafka_2.13-2.8.0]# bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
+hello
+hello world
+this is first kafka message
+
+可以看到,新的消费者又消费到了刚才的消息
+<dependency>
+ <groupId>org.springframework.boot</groupId>
+ <artifactId>spring-boot-starter</artifactId>
+</dependency>
+<dependency>
+<groupId>org.apache.kafka</groupId>
+<artifactId>kafka-streams</artifactId>
+</dependency>
+<dependency>
+<groupId>org.springframework.kafka</groupId>
+<artifactId>spring-kafka</artifactId>
+</dependency>
+
+<dependency>
+<groupId>org.springframework.boot</groupId>
+<artifactId>spring-boot-starter-test</artifactId>
+<scope>test</scope>
+</dependency>
+<dependency>
+<groupId>org.springframework.kafka</groupId>
+<artifactId>spring-kafka-test</artifactId>
+<scope>test</scope>
+</dependency>修改config/server.properties
+listeners=PLAINTEXT://0.0.0.0:9092
+advertised.listeners=PLAINTEXT://192.168.174.130:9092firewall-cmd --zone=public --add-port=9092/tcp --permanent
firewall-cmd --reload
/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 23:58
+ */
+public class KafkaProducerTests {
+ @Test
+ void kafkaProducerTest() {
+ Properties properties = new Properties();
+ properties.put("bootstrap.servers", "192.168.174.130:9092");
+ properties.put("acks", "all");
+ properties.put("retries", 0);
+ properties.put("batch.size", 16384);
+ properties.put("linger.ms", 1);
+ properties.put("buffer.memory", 33554432);
+ properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+ properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
+
+ KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
+ for (int i = 0; i < 100; i++) {
+ producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), "Kafka message " + i));
+ System.out.println("发送了消息");
+ }
+ producer.close();
+
+ }
+}send()方法是异步的,添加消息到缓冲区等待发送并立即return,生产者会将单个消息批量在一起进行发送
ack是判断是否发送成功的,all将会阻塞消息,这种性能是最低的,但是是最可靠的
retries,如果请求失败,生产者会自动重试,如果启用重试,可能会产生重复消息
producer缓存每个分区未发送的消息,缓存的大小通过batch.size配置指定,数值较大会产生更大的批次并需要更大的内存
默认缓冲可立即发送,即使缓存空间没有满,但是如果想减少请求的数量,可设置linger.ms大于0,这将让生产者在发送请求前等待一会儿,希望更多的消息来填补到缓冲区中
buffer.memory 控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽缓存空间,当缓存空间耗尽时,其他发送调用将会被阻塞,阻塞实践的阈值通过max.block.ms 设定,之后它将抛出一个TimeoutException
key.serializer和value.serializer将用户提供的key和value对象ProducerRecord转换成字节,可以使用附带 的* *ByteArraySerializer或StringSeriializer**处理byte或string类型
/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 23:59
+ */
+public class KafkaConsumerTests {
+ @Test
+ void kafkaConsumerTest(){
+ Properties props = new Properties();
+ props.setProperty("bootstrap.servers", "192.168.174.130:9092");
+ props.setProperty("group.id", "test");
+ props.setProperty("enable.auto.commit", "true");
+ props.setProperty("auto.commit.interval.ms", "1000");
+ props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+ props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
+ KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
+ consumer.subscribe(Collections.singletonList("test"));
+ while (true) {
+ ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
+ for (ConsumerRecord<String, String> record : records)
+ System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
+ }
+ }
+}enable.auto.commit自动提交偏移量,auto.commit.interval.ms控制提交的频率test的topic,消费者组叫testbroker通过心跳检测test消费组中的进程,消费者会自动ping集群,告诉集群他还活着,只要消费者停止心跳的时间超过了session.timeout.ms 就会被认定为故障,它的分区将会被分配到别的进程
先启动消费者,后启动生产者,可以看到消费者的终端输出了
offset = 502, key = 0, value = Kafka message 0
+offset = 503, key = 1, value = Kafka message 1
+offset = 504, key = 2, value = Kafka message 2
+offset = 505, key = 3, value = Kafka message 3
+offset = 506, key = 4, value = Kafka message 4
+offset = 507, key = 5, value = Kafka message 5
+offset = 508, key = 6, value = Kafka message 6
+offset = 509, key = 7, value = Kafka message 7
+offset = 510, key = 8, value = Kafka message 8
+offset = 511, key = 9, value = Kafka message 9
+offset = 512, key = 10, value = Kafka message 10
+offset = 513, key = 11, value = Kafka message 11
+offset = 514, key = 12, value = Kafka message 12
+offset = 515, key = 13, value = Kafka message 13
+offset = 516, key = 14, value = Kafka message 14
+offset = 517, key = 15, value = Kafka message 15
+offset = 518, key = 16, value = Kafka message 16
+offset = 519, key = 17, value = Kafka message 17
+offset = 520, key = 18, value = Kafka message 18
+offset = 521, key = 19, value = Kafka message 19
+offset = 522, key = 20, value = Kafka message 20
+......
+<dependency>
+ <groupId>org.springframework.kafka</groupId>
+ <artifactId>spring-kafka</artifactId>
+</dependency>/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/10 21:49
+ */
+@RestController
+@RequestMapping("/kafka")
+public class KafkaDemoProducer {
+
+ @Autowired
+ private KafkaTemplate kafkaTemplate;
+
+ @GetMapping("/send/{msg}")
+ public String sendMessage(@PathVariable String msg) {
+ ListenableFuture send = kafkaTemplate.send("springboot-kafka", "测试发送:" + msg + "-" + System.currentTimeMillis());
+ System.out.println(send);
+ return "发送成功";
+ }
+}/**
+ * @author xc
+ * @description
+ * @createdTime 2021/5/15 23:55
+ */
+@Component
+public class KafkaDemoConsumer {
+
+
+ @KafkaListener(topics = {"springboot-kafka"})
+ public void onReceive(ConsumerRecord<?, ?> record) {
+ System.out.println("接收消息:" + record.topic() + "-" + record.partition() + "-" + record.value());
+ }
+}启动应用
发送消息
日志
2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka version: 2.6.0
+2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka commitId: 62abe01bee039651
+2021-05-16 15:56:18.430 INFO 10808 --- [nio-8080-exec-1] o.a.kafka.common.utils.AppInfoParser : Kafka startTimeMs: 1621151778430
+2021-05-16 15:56:18.435 INFO 10808 --- [ad | producer-1] org.apache.kafka.clients.Metadata : [Producer clientId=producer-1] Cluster ID: t54vUJ_qTWm-o8WmD-dfag
+org.springframework.util.concurrent.SettableListenableFuture@2a59dc33
+接收消息:springboot-kafka-0-测试发送:hello-1621151778418本文以RabbitMQ为例
这个问题也可以理解为MQ的作用,MQ的作用:
优点:
缺点:
系统复杂度提高。需要考虑MQ的各种情况,如消息丢失,重复消费,顺序消费等
一致性问题。如A系统返回了成功的结果,BC系统成功了但D系统失败了
系统可用性问题。如果MQ宕机,可能会导致系统的崩溃
RabbitMQ有三种模式:单机、普通集群、镜像集群
**普通集群:**就是在多台服务器上启动多个rabbitmq实例,但是创建的队列只会放在一个rabbitmq实例中,其他的实例会同步这个队列的元数据。消费的时候如果连接了另一个实例,也会从拥有队列的那个实例获取消息然后返回。
这种方案并不能做到高可用
**镜像集群:**真正的高可用模式,创建的queue无论元数据还是消息数据都存放在多个实例中,每次写消息到queue时,都会自动把消息同步到多个queue中。
优点:实现了高可用,任何一台机器宕机,其他机器能继续使用
缺点:1、性能消耗较大,所有机器都要进行消息同步 2、没有扩展性,如果有一个queue负载很重,就算增加机器,新增的机器也包含这个queue的全部数据,
保证消费的幂等性,让每条消息带一个全局唯一的bizId,具体过程:
1、消费者获取消息后先根据redis/db是否有该消息
2、如果不存在,则正常消费,消费完毕后写入redis/db
3、如果已经存在,证明已经消费过,直接丢弃
原则:数据不能多也不能少,不能多是指不重复消费,不能少是指不能丢数据
丢失数据场景:
解决方案:
针对生产者丢失数据:
channel.txSelect();
+try{
+ //发送消息
+}catch(Exception e){
+ channel.rollback();
+ //重新发送
+}**缺点:**开启事务会变成阻塞操作,造成生产者的性能和吞吐量的下降
//开启confirm模式
+channel.confirm();
+//发送消息
+
+在生产者服务提供一个回调接口的实现
+
+public void ack(String messageId){
+ //已经收到消息
+}
+
+public void nack(String messageId){
+ //重发消息
+}**针对mq丢失数据:**开启mq的持久化,将交换机/队列的durable设置为true,表示交换机/队列时持久化的,在服务崩溃或重启后无需重新创建
@RabbitListener(
+ bindings = {
+ @QueueBinding(
+ value = @Queue(value = "dynamicQueue", autoDelete = "false", durable = "true"),
+ exchange = @Exchange(value = "exchange", durable = "true", type = ExchangeTypes.DIRECT),
+ key = "routingKey"
+ )
+ }
+)
+public void dynamicQueue(Message message, Channel channel) {
+ System.out.println("接收消息:" + new String(message.getBody()));
+}如果消息想从rabbitmq崩溃中回复,消息必须实现:
针对消费者丢失数据:关闭消费者的autoAck机制,然后每次处理完一条消息,主动发送ack给rabbitmq,如果此时还没发送ack就宕机,mq没有收到ack消息,就会重新将消息重新分配给其他
强制消费者手动确认:
spring.rabbitmq.listener.simple.acknowledge-mode: manual消费者手动ack:
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);一个queue一个consumer
1.先修复consumer的问题,确保恢复消费速度,然后停掉所有consumer
2.临时建立数十倍的queue
3.写一个临时分发的consumer程序,部署上去消费积压的消息,消费不做处理,直接轮询写入上一步建好的queue中
4.重新部署consumer(机器加倍),每一批consumer消费一个临时queue
在单体应用中,对于并发处理公共资源时例如卖票,减商品库存这类操作,可以简单的加锁实现同步.但当单体应用服务化后,在分布式场景下,简单的加锁操作就无法实现需求了.这时就需要借助第三方组件来达到多进程多线程之间的同步操作.
分布式锁:在分布式环境下,多个程序/线程都需要对某一份(有限份)数据进行修改时,针对程序进行控制,保证在同一时间节点下,只有一个程序/线程对数据进行操作的技术
EX NX参数步骤:
1.创建一张表,表中要有唯一索引的字段用于记录当前哪个程序在进行操作
2.程序访问时,将程序的编号insert到这张表中(保证这个编号符合规则可以区分)
3.insert操作成功则代表该程序获得了锁,可以执行业务逻辑
4.当其他相同编号的程序进行insert时,由于唯一索引的限制会失败,则代表获取锁失败
5.当占用锁的程序业务逻辑执行完毕后删除该数据,代表释放锁
以mysql为例的innodb引擎为例,可以使用for update语句来给数据库表加排他锁,当一个线程执行了for update操作给一条记录加锁后,其他线程无法再在该记录上增加排他锁
步骤:
1.开启事务
2.在查询语句后跟for update 例如 select * from tb_goods where id=1 for update
3.成功获取排他锁的线程即获得了分布式锁,可以执行业务逻辑
4.执行完毕后需要commit提交事务来释放锁
==这种方式需要关闭数据库事务的自动提交==
以上两种通过数据库来实现分布式锁的方案比较==简单方便,可以快速实现==,但是基于数据库的操作,开销非常大,对服务的性能存在影响
redis实现分布式锁最核心的方法setnx,setnx的含义就是set if not exists,其中有两个参数setnx(key,value).该方法是原子的,如果key不存在,则设置当前key成功,返回1,如果key已存在,则设置当前key失败,返回0;
理想情况下,当某个程序抢占了锁后,处理完业务流程应该删除对应的key,如果这个过程中发生了问题,导致锁超时或者出现了异常,没有办法释放锁,就会产生死锁问题.
redis提供的另一个指令EXPIRE,来设置锁的过期时间EXPIRE KEY seconds来设置key的生存时间,如图
两秒以后key就被自动删除了.
但是程序里我们也不能写成如下的代码
public static void wrongGetLock1(Jedis jedis, String lockKey, String requestId, int expireTime) {
+
+ Long result = jedis.setnx(lockKey, requestId);
+ if (result == 1) {
+ jedis.expire(lockKey, expireTime);
+ doSomething();
+ }
+}因为setnx和expire两个指令是两条命令并不具有原子性,如果在执行setnx后程序突然崩溃,没有设置过期时间就会发生死锁.
在redis2.6.12版本后,又提供了一个新的方案
SET key value [EX seconds] [PX millisecounds] [NX|XX] EX seconds:设置键的过期时间为second秒 PX millisecounds:设置键的过期时间为millisecounds 毫秒 NX:只在键不存在的时候,才对键进行设置操作 XX:只在键已经存在的时候,才对键进行设置操作 SET操作成功后,返回的是OK,失败返回NIL
释放锁的时候很容易联想到del指令,可是这个指令如果直接在代码中使用,会产生一个很严重的问题,拥有超时锁的线程会释放掉当前拥有锁的那个线程的锁
(删了不属于自己的锁)
场景:
所以,我们要在set键值对的时候,保证可以区分开当前锁是否属于执行指令的这个线程,value我们可以设置为当前的requestID或线程的id
而这些步骤如果直接用代码控制则会显得较为繁琐,可以引入lua脚本
if redis.call('get', KEYS[1]) == ARGV[1]
+ then
+ return redis.call('del', KEYS[1])
+ else
+ return 0
+end上述lua脚本用于比较KEYS[1]对应的VALUE和ARG[1]的值是否一直,即当前锁是否属于当前线程,如果是true则删除锁,返回del结果,否则直接返回0
执行脚本可以使用redis的eval指令
jedis.eval(String script, List<String> kyes,List<String>args);存在的问题:上面讨论的是单机redis的场景,如果是分布式下的redis哨兵集群会存在问题,如果线程1的锁加在了主库,这时候主库直接宕机,redis还没来得及将这个锁的数据同步至从节点,sentinel就将从库中的一台选举为主库了,这时候另一个线程也来进行加锁,也会成功,这时候便有两个线程同时获得了锁
这种情况可以使用Redisson redlock
javaConfig config = new Config(); +config.useSentinelServers().addSentinelAddress("127.0.0.1:6369","127.0.0.1:6379", "127.0.0.1:6389") + .setMasterName("masterName") + .setPassword("password").setDatabase(0); +RedissonClient redissonClient = Redisson.create(config); +RLock redLock = redissonClient.getLock("REDLOCK_KEY"); +boolean isLock; +try { + isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS); + if (isLock) { + //TODO if get lock success, do something; + } +} catch (Exception e) { +} finally { + redLock.unlock(); +}由于 redisson 包的实现中,通过 lua 脚本校验了解锁时的 client 身份,所以我们无需再在 finally 中去判断是否加锁成功,也无需做额外的身份校验,可以说已经达到开箱即用的程度了。
zookeeper一般有多个节点构成(单数个),采用zab一致性协议,所以可以将zk看成一个单点结构,对其修改数据其内部会自动将所有节点进行修改才提供查询服务
zookeeper的数据是目录树的方式存储的,每个目录称为znode,znode可以存储数据,还可以在其中增加子节点
子节点有三种类型
Watch机制,客户端可以监控每个节点的变化,产生变化时会给客户端产生一个事件
获取锁的流程:
1.先有一个锁根节点,lockRootNode,可以是一个永久节点
2.客户端获取锁,先在lockRootNode下创建一个顺序的临时节点
3.调用lockRootNode节点的getChildren()方法获取所有节点,并从小到大排序,如果创建的最小的节点是当前节点,则返回true,获取锁成功,否则,watch比自己序号小的节点的释放动作(exist watch),这也可以保证每个客户端只需要watch一个节点
4.如果有节点释放操作,重复第3步
代码中可以使用Apache Curator来实现基于临时节点的分布式锁
public class CuratorDistrLockTest {
+
+ /** Zookeeper info */
+ private static final String ZK_ADDRESS = "192.168.1.100:2181";
+ private static final String ZK_LOCK_PATH = "/lockRootNode";
+
+ public static void main(String[] args) throws InterruptedException {
+ // 1.Connect to zk
+ CuratorFramework client = CuratorFrameworkFactory.newClient(
+ ZK_ADDRESS,
+ new RetryNTimes(10, 5000)
+ );
+ client.start();
+ System.out.println("zk client start successfully!");
+
+ Thread t1 = new Thread(() -> {
+ doWithLock(client);
+ }, "t1");
+ Thread t2 = new Thread(() -> {
+ doWithLock(client);
+ }, "t2");
+
+ t1.start();
+ t2.start();
+ }
+
+ private static void doWithLock(CuratorFramework client) {
+ InterProcessMutex lock = new InterProcessMutex(client, ZK_LOCK_PATH);
+ try {
+ if (lock.acquire(10 * 1000, TimeUnit.SECONDS)) {
+ System.out.println(Thread.currentThread().getName() + " hold lock");
+ Thread.sleep(5000L);
+ System.out.println(Thread.currentThread().getName() + " release lock");
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
+ } finally {
+ try {
+ lock.release();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+ }
+}优缺点:
优点:
缺点:
使用yum list --showduplicate | grep java-1.8 找出相关的软件版本
yum install 安装图中这两个软件即可
canal官方仓库:https://github.com/alibaba/canal/
wiki:https://github.com/alibaba/canal/wiki
canal的用途是基于mysql的binlog日志解析,提供增量数据的订阅和消费。简单的场景:通过canal监控mysql数据变更从而及时更新redis中对应的缓存或更新es中的文档内容
本文主要介绍canal在服务器端的部署,包括canal-admin,canal-tsdb配置以及instance配置。mysql版本为5.7,系统为macOS14.2.1。
首先需要下载canal的发行版,下载地址:https://github.com/alibaba/canal/releases,可自行选择版本,这里选择1.1.4。
自建MySQL,需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
+log-bin=mysql-bin # 开启 binlog
+binlog-format=ROW # 选择 ROW 模式
+server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复mkdir -p ~/Downloads/canal/admin && tar -zxvf canal.admin-1.1.4.tar.gz -C ~/Downloads/canal/admin执行conf文件夹中的canal_manager.sql建表
mysql -uroot -p < ~/Downloads/canal/admin/conf/canal_manager.sql
创建canal用户并授权canal链接 MySQL 账号具有作为 MySQL slave 的权限
CREATE USER canal IDENTIFIED BY 'canal';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
+-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
+FLUSH PRIVILEGES;修改conf文件夹中的application.yml
执行admin/bin目录的startup.sh
访问8089端口
使用默认账号密码 admin/123456即可登录
TIP
application.yml中的canal.adminUser和canal.adminPasswd并非WebUI的登录用户名和密码,而是和canal-server交互用的
canal-admin的核心模型主要有:
- instance,对应canal-server里的instance,一个最小的订阅mysql的队列
- server,对应canal-server,一个server里可以包含多个instance
- 集群,对应一组canal-server,组合在一起面向高可用HA的运维
简单解释:
- instance是最原始的业务订阅诉求,它会和 server/集群 这两个面向资源服务属性的进行关联,比如instance A绑定到server A上或者集群 A上,
- 有了任务和资源的绑定关系后,对应的资源服务就会接收到这个任务配置,在对应的资源上动态加载instance,并提供服务
- 将server抽象成资源之后,原本canal-server运行所需要的canal.properties/instance.properties配置文件就需要在web ui上进行统一运维,每个server只需要以最基本的启动配置 (比如知道一下canal-admin的manager地址,以及访问配置的账号、密码即可)
新建server,按照图中配置即可
配置项:
- 所属集群,可以选择为单机 或者 集群。一般单机Server的模式主要用于一次性的任务或者测试任务
- Server名称,唯一即可,方便自己记忆
- Server Ip,机器ip
- admin端口,canal 1.1.4版本新增的能力,会在canal-server上提供远程管理操作,默认值11110
- tcp端口,canal提供netty数据订阅服务的端口
- metric端口, promethues的exporter监控数据端口 (未来会对接监控)
#################################################
+######### common argument #############
+#################################################
+# tcp bind ip
+canal.ip =
+# register ip to zookeeper
+canal.register.ip =
+canal.port = 11111
+canal.metrics.pull.port = 11112
+# canal instance user/passwd
+canal.user = canal
+canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
+
+# canal admin config
+canal.admin.manager = 127.0.0.1:8089
+canal.admin.port = 11110
+canal.admin.user = admin
+canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
+
+canal.zkServers =
+# flush data to zk
+canal.zookeeper.flush.period = 1000
+canal.withoutNetty = false
+# tcp, kafka, RocketMQ
+canal.serverMode = kafka
+# flush meta cursor/parse position to file
+canal.file.data.dir = ${canal.conf.dir}
+canal.file.flush.period = 1000
+## memory store RingBuffer size, should be Math.pow(2,n)
+canal.instance.memory.buffer.size = 16384
+## memory store RingBuffer used memory unit size , default 1kb
+canal.instance.memory.buffer.memunit = 1024
+## meory store gets mode used MEMSIZE or ITEMSIZE
+canal.instance.memory.batch.mode = MEMSIZE
+canal.instance.memory.rawEntry = true
+
+## detecing config
+canal.instance.detecting.enable = false
+#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
+canal.instance.detecting.sql = select 1
+canal.instance.detecting.interval.time = 3
+canal.instance.detecting.retry.threshold = 3
+canal.instance.detecting.heartbeatHaEnable = false
+
+# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
+canal.instance.transaction.size = 1024
+# mysql fallback connected to new master should fallback times
+canal.instance.fallbackIntervalInSeconds = 60
+
+# network config
+canal.instance.network.receiveBufferSize = 16384
+canal.instance.network.sendBufferSize = 16384
+canal.instance.network.soTimeout = 30
+
+# binlog filter config
+canal.instance.filter.druid.ddl = true
+canal.instance.filter.query.dcl = false
+canal.instance.filter.query.dml = false
+canal.instance.filter.query.ddl = false
+canal.instance.filter.table.error = false
+canal.instance.filter.rows = false
+canal.instance.filter.transaction.entry = false
+
+# binlog format/image check
+canal.instance.binlog.format = ROW,STATEMENT,MIXED
+canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
+
+# binlog ddl isolation
+canal.instance.get.ddl.isolation = false
+
+# parallel parser config
+canal.instance.parser.parallel = true
+## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
+#canal.instance.parser.parallelThreadSize = 16
+## disruptor ringbuffer size, must be power of 2
+canal.instance.parser.parallelBufferSize = 256
+
+# table meta tsdb info
+canal.instance.tsdb.enable = true
+#canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
+#canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
+canal.instance.tsdb.dbUsername = canal
+canal.instance.tsdb.dbPassword = canal
+# dump snapshot interval, default 24 hour
+canal.instance.tsdb.snapshot.interval = 24
+# purge snapshot expire , default 360 hour(15 days)
+canal.instance.tsdb.snapshot.expire = 360
+
+# aliyun ak/sk , support rds/mq
+canal.aliyun.accessKey =
+canal.aliyun.secretKey =
+
+#################################################
+######### destinations #############
+#################################################
+canal.destinations =
+# conf root dir
+canal.conf.dir = ../conf
+# auto scan instance dir add/remove and start/stop instance
+canal.auto.scan = true
+canal.auto.scan.interval = 5
+
+#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
+canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
+
+canal.instance.global.mode = manager
+canal.instance.global.lazy = false
+canal.instance.global.manager.address = ${canal.admin.manager}
+#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
+canal.instance.global.spring.xml = classpath:spring/file-instance.xml
+#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
+
+##################################################
+######### MQ #############
+##################################################
+canal.mq.servers = 127.0.0.1:9092
+canal.mq.retries = 0
+canal.mq.batchSize = 16384
+canal.mq.maxRequestSize = 1048576
+canal.mq.lingerMs = 100
+canal.mq.bufferMemory = 33554432
+canal.mq.canalBatchSize = 50
+canal.mq.canalGetTimeout = 100
+canal.mq.flatMessage = true
+canal.mq.compressionType = none
+canal.mq.acks = all
+#canal.mq.properties. =
+canal.mq.producerGroup = canal-test
+# Set this value to "cloud", if you want open message trace feature in aliyun.
+canal.mq.accessChannel = local
+# aliyun mq namespace
+#canal.mq.namespace =
+
+##################################################
+######### Kafka Kerberos Info #############
+##################################################
+canal.mq.kafka.kerberos.enable = false
+canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
+canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"TIP
canal.auto.scan如果设置为true,canal.destinations可以不填写,server会自动扫描instance然后启动
// CanalController
+// 初始化monitor机制
+autoScan = BooleanUtils.toBoolean(getProperty(properties, CanalConstants.CANAL_AUTO_SCAN));
+if (autoScan) {
+ defaultAction = new InstanceAction() {
+ public void start(String destination) {
+ InstanceConfig config = instanceConfigs.get(destination);
+ if (config == null) {
+ // 重新读取一下instance config
+ config = parseInstanceConfig(properties, destination);
+ instanceConfigs.put(destination, config);
+ }
+ if (!embededCanalServer.isStart(destination)) {
+ // HA机制启动
+ ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
+ if (!config.getLazy() && !runningMonitor.isStart()) {
+ runningMonitor.start();
+ }
+ }
+ logger.info("auto notify start {} successful.", destination);
+ }
+ //...
+ }
+}
+
+instanceConfigMonitors = MigrateMap.makeComputingMap(new Function<InstanceMode, InstanceConfigMonitor>() {
+
+ public InstanceConfigMonitor apply(InstanceMode mode) {
+ int scanInterval = Integer.valueOf(getProperty(properties,
+ CanalConstants.CANAL_AUTO_SCAN_INTERVAL,
+ "5"));
+
+ if (mode.isSpring()) {
+ SpringInstanceConfigMonitor monitor = new SpringInstanceConfigMonitor();
+ monitor.setScanIntervalInSecond(scanInterval);
+ monitor.setDefaultAction(defaultAction);
+ // 设置conf目录,默认是user.dir + conf目录组成
+ String rootDir = getProperty(properties, CanalConstants.CANAL_CONF_DIR);
+ if (StringUtils.isEmpty(rootDir)) {
+ rootDir = "../conf";
+ }
+
+ if (StringUtils.equals("otter-canal", System.getProperty("appName"))) {
+ monitor.setRootConf(rootDir);
+ } else {
+ // eclipse debug模式
+ monitor.setRootConf("src/main/resources/");
+ }
+ return monitor;
+ } else if (mode.isManager()) {
+ ManagerInstanceConfigMonitor monitor = new ManagerInstanceConfigMonitor();
+ monitor.setScanIntervalInSecond(scanInterval);
+ monitor.setDefaultAction(defaultAction);
+ String managerAddress = getProperty(properties, CanalConstants.CANAL_ADMIN_MANAGER);
+ monitor.setConfigClient(getManagerClient(managerAddress));
+ return monitor;
+ } else {
+ throw new UnsupportedOperationException("unknow mode :" + mode + " for monitor");
+ }
+ }
+});
+
+
+// CanalController.start()
+public void start() throws Throwable {
+ // ...
+ // 尝试启动一下非lazy状态的通道
+ for (Map.Entry<String, InstanceConfig> entry : instanceConfigs.entrySet()) {
+ final String destination = entry.getKey();
+ InstanceConfig config = entry.getValue();
+ // 创建destination的工作节点
+ if (!embededCanalServer.isStart(destination)) {
+ // HA机制启动
+ ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
+ if (!config.getLazy() && !runningMonitor.isStart()) {
+ runningMonitor.start();
+ }
+ }
+
+ if (autoScan) {
+ instanceConfigMonitors.get(config.getMode()).register(destination, defaultAction);
+ }
+ }
+
+ if (autoScan) {
+ instanceConfigMonitors.get(globalInstanceConfig.getMode()).start();
+ for (InstanceConfigMonitor monitor : instanceConfigMonitors.values()) {
+ if (!monitor.isStart()) {
+ monitor.start();
+ }
+ }
+ }
+ // ...
+}
+
+// 然后会调用ManagerInstanceConfigMonitor的start方法,start方法会启动一个定时任务,每隔scanInterval秒调用scan方法
+public void start() {
+ super.start();
+ executor.scheduleWithFixedDelay(new Runnable() {
+
+ public void run() {
+ try {
+ scan();
+ if (isFirst) {
+ isFirst = false;
+ }
+ } catch (Throwable e) {
+ logger.error("scan failed", e);
+ }
+ }
+
+ }, 0, scanIntervalInSecond, TimeUnit.SECONDS);
+}
+
+// scan方法中会通过configClient调用canal-admin的接口获取instance的配置信息,
+// 最后对instance进行stop/reload/start操作
+
+private void scan() {
+ String instances = configClient.findInstances(null);
+ final List<String> is = Lists.newArrayList(StringUtils.split(instances, ','));
+ List<String> start = Lists.newArrayList();
+ List<String> stop = Lists.newArrayList();
+ List<String> restart = Lists.newArrayList();
+ for (String instance : is) {
+ if (!configs.containsKey(instance)) {
+ PlainCanal newPlainCanal = configClient.findInstance(instance, null);
+ if (newPlainCanal != null) {
+ configs.put(instance, newPlainCanal);
+ start.add(instance);
+ }
+ } else {
+ PlainCanal plainCanal = configs.get(instance);
+ PlainCanal newPlainCanal = configClient.findInstance(instance, plainCanal.getMd5());
+ if (newPlainCanal != null) {
+ // 配置有变化
+ restart.add(instance);
+ configs.put(instance, newPlainCanal);
+ }
+ }
+ }
+
+ configs.forEach((instance, plainCanal) -> {
+ if (!is.contains(instance)) {
+ stop.add(instance);
+ }
+ });
+
+ stop.forEach(instance -> {
+ notifyStop(instance);
+ });
+
+ restart.forEach(instance -> {
+ notifyReload(instance);
+ });
+
+ start.forEach(instance -> {
+ notifyStart(instance);
+ });
+
+}mkdir -p ~/Downloads/canal/deployer && tar -zxvf canal.deployer-1.1.4.tar.gz -C ~/Downloads/canal/deployer用conf目录下的canal_local.properties替换canal.properties
修改配置
# canal.ip
+canal.ip = 127.0.0.1
+# register ip
+canal.register.ip = 127.0.0.1TIP
注意ip前后不能有空格,不然会无法启动netty server从而无法启动canal server,应该是后台没做trim
如果不填写canal.ip和canal.register.ip两个配置项,代码中将通过AddressUtils.getHostIp()获取本机的ip地址,如果本地有docker/orbstack等创建的虚拟网络设备会导致启动canal-server后识别到多个server且是不同的ip(docker0网桥或orbstack容器等的ip),比较膈应人。(#issue47)
源码:
// CanalController.java
+
+if (StringUtils.isEmpty(ip) && StringUtils.isEmpty(registerIp)) {
+ ip = registerIp = AddressUtils.getHostIp();
+}
+
+if (StringUtils.isEmpty(ip)) {
+ ip = AddressUtils.getHostIp();
+}
+
+if (StringUtils.isEmpty(registerIp)) {
+ registerIp = ip; // 兼容以前配置
+}执行bin目录下的startup.sh
直接在canal admin的webUI界面中配置instance,等待启动即可,如有问题查看deploy/logs/story/story.log
具体配置项参见wiki
TIP
如果在server的配置文件中填了相同的配置项,那么instance中的配置会被server中的覆盖,例如canal.instance.tsdb.url配置(#issue4669)
此时我们的实例story已经开始监听story数据库下面的操作,如果有变更,就会推送至kafka的canal-story这个topic中
之后就需要通过业务端根据情况监听队列中的数据变化,做相应的操作。
wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
yum install google-chrome-stable_current_x86_64.rpm
yum install mesa-libOSMesa-devel gnu-free-sans-fonts wqy-zenhei-fonts
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.debsudo dpkg -i google-chrome-stable_current_amd64.deb
安装报错
dpkg: error processing package google-chrome-stable (--install): dependency problems - leaving unconfigured Processing triggers for mime-support (3.64ubuntu1) ... Processing triggers for man-db (2.9.1-1) ... Errors were encountered while processing: google-chrome-stable
使用sudo apt-get install -f修复依赖关系,
如果系统中有某个软件包不满足依赖条件,这个命令就会自动修复,将要安装那个软件包依赖的软件包。
淘宝源地址:http://npm.taobao.org/mirrors/chromedriver/
需要根据不同版本的chrome进行选择下载,比如我安装的chrome是96版本的,那么chromedriver就需要找对应的96版本
这里选择一个最近更新的即可
这里下载linux版本,下载后解压,把解压后的chromedriver可执行文件移动到path下,例如/usr/bin
wget http://npm.taobao.org/mirrors/chromedriver/96.0.4664.45/chromedriver_linux64.zip
+
+unzip chromedriver_linux64.zip
+
+mv chromedriver /usr/bin
+
+chmod +x /usr/bin/chromedriverlinux下无头浏览器模式:
from selenium import webdriver
+from selenium.webdriver.chrome.options import Options
+
+chrome_options = Options()
+chrome_options.add_argument('--headless')
+chrome_options.add_argument('--no-sandbox')
+chrome_options.add_argument('--disable-gpu')
+chrome_options.add_argument('--disable-dev-shm-usage')
+driver = webdriver.Chrome(chrome_options=chrome_options)
+driver.get("https://www.baidu.com")
+
+with open("./baidu.html", "w", encoding="utf-8") as fp:
+ fp.write(driver.page_source)iptables是一个用户级程序,用于操作内核级的网络模块netfilter
iptables的功能由表的形式呈现,每张表由若干个链组成,每个链可以分配一组规则
iptables有五张内建表,按照优先级高到底分别是:Raw、Mangle、NAT、Filter、Security
此表负责数据包标记,决定数据包是否被状态跟踪机制处理,Raw表有2个内建链
此表负责更改数据包内容,Mangle表有5个内建链
此表负责数据包的ip地址转换,NAT表有3种内建链
此表负责过滤数据包,iptables的默认表,具有3种内建链
新加入的特性,用于强制访问控制(MAC)网络规则,有3种内建链
iptables [-t 表名] 命令选项 [链名] [匹配条件] [-j 策略]
iptables命令包含五个部分
表名:要操作的表,不指定时默认操作Filter表
链名:要操作的链,不指定链时默认表内所有链
命令选项:要进行的操作
匹配条件:定义规则适用哪些数据包(匹配哪些数据包)
策略:匹配数据的目标执行的操作,说白了就是packet匹配上规则后该干嘛
ACCEPT:允许数据包通过。
DROP:直接丢弃数据包,不给任何回应信息,这时候客户端会感觉自己的请求泥牛入海了,过了超时时间才会有反应。
REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息。
SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题。
MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的ip上。
DNAT:目标地址转换。
REDIRECT:在本机做端口映射。
iptables -A INPUT -s 127.0.0.1 -p tcp --dport 3306 -j ACCEPTiptables -I INPUT -p tcp -j ACCEPT或iptables -I INPUT 2 -p tcp -j ACCEPT-L:列出所有规则
-n:以数字形式显示地址、端口等信息
-v:显示更详细规则信息
--line-numbers:显示规则序号
删除nat表INPUT链的第三条规则:iptables -t nat -D INPUT 3
清空nat表所有规则:iptables -t nat -F
iptables -t filter -P FORWARD DROP多端口匹配 -m multiport --sport 源端口列表 -m multiport --dport 目的端口列表 IP范围匹配 -m iprange --src-range IP范围 MAC地址匹配 -m mac –mac1-source MAC地址 状态匹配 -m state --state 连接状态
iptables -A INPUT -p tcp -m multiport --dport 25,80,110,143 -j ACCEPT
+iptables -A FORWARD -p tcp -m iprange --src-range 192.168.4.21-192.168.4.28 -j ACCEPT
+iptables -A INPUT -m mac --mac-source 00:0c:29:c0:55:3f -j DROP
+iptables -P INPUT DROP
+iptables -I INPUT -p tcp -m multiport --dport 80-82,85 -j ACCEPT
+iptables -I INPUT -p tcp -m state --state NEW,ESTABLISHED,RELATED -j ACCEPT服务器上日常运行着静态博客+云笔记+jenkins的容器,jenkins用于gitee上托管的博客repo的ci/cd。当jenkins进行构建时,内存占用率会急剧升高,轻则容器宕机,重则服务器跟着一起boom。因此需要设置swap来缓解jenkins内存占用瞬时升高的状况。
df -h
Filesystem中/dev/vda1挂载点为/的就是我们的磁盘
一般来说swap大小设置规则:
4G以内RAM,Swap设置为2倍RAM
4G-8GRAM,Swap设置等于内存大小
8G-64G,Swap设置为8G
64G-256G,Swap设置为16G
我这个是腾讯云4c 4G 80G的机器,这里swap设置为4G:fallocate -l 4G /swap
修改权限使文件只能root访问:chmod 600 /swap
将文件标记为swap空间:mkswap /swap
启用swap文件:swapon /swap
验证交换是否可用:swapon --show
备份fstab:cp /etc/fstab /etc/fstab.bak
添加一条记录: echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
调整Swappiness参数,该参数主要配置系统将数据从RAM交换到交换空间的频率。该参数的值是介于0和100之间的百分比。范围在0到100之间。 低参数值会让内核尽量少用交换,更高参数值会使内核更多的去使用交换空间。
查看当前swappiness值:cat /proc/sys/vm/swappiness
临时修改,重启失效:sysctl vm.swappiness=10
永久设置:vim /etc/sysctl.conf,最后一行加上vm.swappiness=10,保存并退出。sysctl -p 立即生效
cat /proc/sys/vm/vfs_cache_pressure 缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache。vim /etc/sysctl.conf,最后一行加上vm.vfs_cache_pressure=50
CentOS7-1908版本
http://vault.centos.org/7.7.1908/isos/x86_64/CentOS-7-x86_64-DVD-1908.torrent
ifconfig
yum search ifconfigyum install net-tools.x86_64lsb_release
yum install -y redhat-lsbyum提示没有可用镜像
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repowget
yum install wgetdns
vi /etc/sysconfig/network-scripts/ifcfg-ens33
真机的ip信息
JDK1.8
oracle官网下载jdk后上传虚拟机
解压并配置环境变量,比如我下载的是jre1.8.0_202
vi /etc/profile/
JAVA_HOME=/usr/local/java/jre1.8.0_202
+PATH=$JAVA_HOME/bin:$PATH
+CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
+export JAVA_HOME
+export CLASSPATH
+export PATHsource /etc/profile或重启虚拟机使环境变量生效
python3
mysql 5.7
下载并安装mysql官方的yum repository: wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.41-1.el7.x86_64.rpm-bundle.tar
解压包:tar -xvf mysql-5.7.41-1.el7.x86_64.rpm-bundle.tar
yum -y install mysql-community-common-5.7.41-1.el7.x86_64.rpm mysql-community-libs-5.7.41-1.el7.x86_64.rpm mysql-community-client-5.7.41-1.el7.x86_64.rpm mysql-community-server-5.7.41-1.el7.x86_64.rpm
启动systemctl enable mysqld && systemctl start mysqld
临时密码 grep 'temporary password' /var/log/mysqld.log
根据临时密码登入mysql
改密码 ALTER USER 'root'@'localhost' IDENTIFIED BY 'new pwd';
更改密码弱口令设置,设置简单密码:
set global validate_password_policy=0;
set global validate_password_length=1;
配置远程登陆
grant all on *.* to 'root'@'%' identified by 'pwd';
立即生效: flush privileges;
创建用户&授权
-- 创建用户
+CREATE USER '用户名'@'localhost' IDENTIFIED BY '密码';
+CREATE USER '用户名'@'%' IDENTIFIED BY '密码';
+-- 授权全部
+grant all privileges on 数据库名称.* to '用户名'@'localhost' identified by '密码'; #本地授权
+grant all privileges on 数据库名称.* to '用户名'@'%' identified by '密码'; #远程授权
+flush privileges; #刷新系统权限表
+-- 授权指定
+grant select,update,delete,insert on 数据库名称.* to '用户'@'localhost' identified by '密码';
+flush privileges; #刷新系统权限表
+-- 删除用户
+Delete FROM mysql.user Where User='用户名' and Host='localhost'; #删除本地用户
+Delete FROM mysql.user Where User='用户名' and Host='%'; #删除远程用户
+flush privileges; #刷新系统权限表
+-- 删除用户及权限
+DROP USER 'username'@'localhost';
+DROP USER 'username'@'%';
+-- 查看当前用户权限
+show grants;
+-- 查看指定用户权限
+show grants for username@localhost;mysql 8.0
-- 修改root密码
+UPDATE mysql.user SET authentication_string=null WHERE User='root';
+FLUSH PRIVILEGES;
+
+ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'new_password';
+FLUSH PRIVILEGES;
+
+
+CREATE USER ''@'' IDENTIFIED BY '';
+
+GRANT ALL PRIVILEGES ON *.* TO ''@'';nginx
依赖
yum -y install gcc pcre pcre-devel zlib zlib-devel openssl openssl-develapt install libpcre3 libpcre3-dev openssl libssl-dev下载安装包 wget http://nginx.org/download/nginx-1.9.9.tar.gz
解压到指定目录 tar -xzvf nginx-1.9.9.tar.gz -C /usr/local/nginx/
切换到nginx的目录执行 cd /usr/local/nginx/nginx-1.9.9
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module #配置ssl模块
+
+make
+
+make install安装后切换到/usr/local/nginx/sbin启动nginx并访问
开机自启nginx
vi /etc/init.d/nginx
#!/bin/bash
+#
+# nginx - this script starts and stops the nginx daemon
+#
+# chkconfig: - 85 15
+# description: NGINX is an HTTP(S) server, HTTP(S) reverse \
+# proxy and IMAP/POP3 proxy server
+# processname: nginx
+# config: /etc/nginx/nginx.conf
+# config: /etc/sysconfig/nginx
+# pidfile: /var/run/nginx.pid
+
+# Source function library.
+. /etc/rc.d/init.d/functions
+
+# Source networking configuration.
+. /etc/sysconfig/network
+
+# Check that networking is up.
+[ "$NETWORKING" = "no" ] && exit 0
+
+nginx="/usr/local/nginx/sbin/nginx"
+prog=$(basename $nginx)
+
+NGINX_CONF_FILE="/usr/local/nginx/conf/nginx.conf"
+
+[ -f /etc/sysconfig/nginx ] && . /etc/sysconfig/nginx
+
+lockfile=/var/lock/subsys/nginx
+
+make_dirs() {
+ # make required directories
+ user=`$nginx -V 2>&1 | grep "configure arguments:.*--user=" | sed 's/[^*]*--user=\([^ ]*\).*/\1/g' -`
+ if [ -n "$user" ]; then
+ if [ -z "`grep $user /etc/passwd`" ]; then
+ useradd -M -s /bin/nologin $user
+ fi
+ options=`$nginx -V 2>&1 | grep 'configure arguments:'`
+ for opt in $options; do
+ if [ `echo $opt | grep '.*-temp-path'` ]; then
+ value=`echo $opt | cut -d "=" -f 2`
+ if [ ! -d "$value" ]; then
+ # echo "creating" $value
+ mkdir -p $value && chown -R $user $value
+ fi
+ fi
+ done
+ fi
+}
+
+start() {
+ [ -x $nginx ] || exit 5
+ [ -f $NGINX_CONF_FILE ] || exit 6
+ make_dirs
+ echo -n $"Starting $prog: "
+ daemon $nginx -c $NGINX_CONF_FILE
+ retval=$?
+ echo
+ [ $retval -eq 0 ] && touch $lockfile
+ return $retval
+}
+
+stop() {
+ echo -n $"Stopping $prog: "
+ killproc $prog -QUIT
+ retval=$?
+ echo
+ [ $retval -eq 0 ] && rm -f $lockfile
+ return $retval
+}
+
+restart() {
+ configtest || return $?
+ stop
+ sleep 1
+ start
+}
+
+reload() {
+ configtest || return $?
+ echo -n $"Reloading $prog: "
+ killproc $nginx -HUP
+ RETVAL=$?
+ echo
+}
+
+force_reload() {
+ restart
+}
+
+configtest() {
+ $nginx -t -c $NGINX_CONF_FILE
+}
+
+rh_status() {
+ status $prog
+}
+
+rh_status_q() {
+ rh_status >/dev/null 2>&1
+}
+
+case "$1" in
+ start)
+ rh_status_q && exit 0
+ $1
+ ;;
+ stop)
+ rh_status_q || exit 0
+ $1
+ ;;
+ restart|configtest)
+ $1
+ ;;
+ reload)
+ rh_status_q || exit 7
+ $1
+ ;;
+ force-reload)
+ force_reload
+ ;;
+ status)
+ rh_status
+ ;;
+ condrestart|try-restart)
+ rh_status_q || exit 0
+ ;;
+ *)
+ echo $"Usage: $0 {start|stop|status|restart|reload|configtest}"
+ exit 2
+esacchmod 777 /etc/init.d/nginxchkconfig nginx on开放端口
firewall-cmd --list-portsfirewall-cmd --zone=public --add-port=80/tcp --permanentfirewall-cmd --reload #重启firewallsystemctl stop firewalld.service #停止firewallsystemctl disable firewalld.service #禁止firewall开机启动firewall-cmd --state #查看默认防火墙状态redis
下载安装包wget http://download.redis.io/releases/redis-5.0.7.tar.gz
tar -zxvf redis-5.0.7.tar.gz
mv /root/redis-5.0.7 /usr/local/redis
cd /usr/local/redis/redis-5.0.7
make && make PREFIX=/usr/local/redis install
可能会报错,因为centos自带的gcc版本太低
执行命令
yum -y install centos-release-scl devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
+# scl enable devtoolset-9 bash #临时启用新版本的gcc
+echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile # 永久启用新版gcc开机自启redis
vi /etc/init.d/redis#!/bin/sh
+# chkconfig: 2345 10 90
+# description: Start and Stop redis
+
+REDISPORT=6379
+EXEC=/usr/local/redis/bin/redis-server
+CLIEXEC=/usr/local/redis/bin/redis-cli
+
+PIDFILE=/var/run/redis_${REDISPORT}.pid
+CONF="/usr/local/redis/redis.conf"
+
+case "$1" in
+ start)
+ if [ -f $PIDFILE ]
+ then
+ echo "$PIDFILE exists, process is already running or crashed"
+ else
+ echo "Starting Redis server..."
+ $EXEC $CONF &
+ fi
+ ;;
+ stop)
+ if [ ! -f $PIDFILE ]
+ then
+ echo "$PIDFILE does not exist, process is not running"
+ else
+ PID=$(cat $PIDFILE)
+ echo "Stopping ..."
+ $CLIEXEC -p $REDISPORT shutdown
+ while [ -x /proc/${PID} ]
+ do
+ echo "Waiting for Redis to shutdown ..."
+ sleep 1
+ done
+ echo "Redis stopped"
+ fi
+ ;;
+ restart)
+ "$0" stop
+ sleep 3
+ "$0" start
+ ;;
+ *)
+ echo "Please use start or stop or restart as first argument"
+ ;;
+esacvim /usr/local/redis/redis.conf
+修改
+bind 0.0.0.0 #所有ipv4端口
+protected-mode no # 关闭保护模式
+daemonize yes # 守护进程
+requirepass password #需要密码登录
+pidfile /var/run/redis_6379.pid #pid文件# 授权
+chmod 777 /etc/init.d/redis# 开机启动
+chkconfig redis on# 创建客户端软链接
+ln -s /usr/local/redis/bin/redis-cli /usr/local/bin/redis-clidocker
卸载旧版本
sudo yum remove docker \
+ docker-client \
+ docker-client-latest \
+ docker-common \
+ docker-latest \
+ docker-latest-logrotate \
+ docker-logrotate \
+ docker-engine使用docker repository安装
# set up repository
+sudo yum install -y yum-utils
+
+sudo yum-config-manager \
+ --add-repo \
+ https://download.docker.com/linux/centos/docker-ce.repo
+
+
+# install docker engine
+sudo yum install docker-ce docker-ce-cli containerd.io
+
+# start docker engine
+sudo systemctl start dockerThere were 89 failed login attempts since the last successful login.
最近登录阿里云服务器,总是发现有人恶意尝试登录,虽然密码强度很高,但是看着就闹心,索性把密码登录给ban掉改用密钥登录。
cd ~/.ssh
+ssh-keygen -t rsa -C "邮箱地址"此时会在/root/.ssh下生成id_rsa和id_rsa.pub的私钥和公钥
使用ssh-copy-id命令将公钥拷贝到服务器上
把本地的ssh公钥文件安装到远程主机对应的账户下,ssh-copy-id命令 可以把本地主机的公钥复制到远程主机的authorized_keys文件上,ssh-copy-id命令也会给远程主机的用户主目录(home)和~/.ssh, 和~/.ssh/authorized_keys设置合适的权限。 ssh-copy-id 用来将本地公钥复制到远程主机。如果不传入 -i 参数,ssh-copy-id 使用默认 ~/.ssh/identity.pub 作为默认公钥。如果多次运行 ssh-copy-id ,该命令不会检查重复,会在远程主机中多次写入 authorized_keys 。
ssh-copy-id [-i identify_file] [user@]hostvim /etc/ssh/sshd_config
+
+RSAAuthentication yes
+PubkeyAuthentication yes
+AuthorizedKeysFile .ssh/authorized_keys
+PasswordAuthentication yes #密码登录 此时不要关闭修改并保存,重启sshd服务systemctl restart sshd
id_rsa文件权限需要调整,否则使用密钥登录会因为私钥文件权限问题被拒绝。
一般来说: .ssh目录设置700权限 id_rsa,authorized_keys文件设置600权限 id_rsa.pub,known_hosts文件设置644权限
登录使用ssh -i "私钥文件全路径" root@xxx.xxx.xxx.xxx
登录成功
密钥登录成功后即可关闭服务器的密码登录
vim /etc/ssh/sshd_config
+
+PasswordAuthentication no #关闭密码登录保存后重启sshd服务systemctl restart sshd
可以看到密码登录已经被关闭
adduser username
+
+mkdir /home/username/.ssh
+# 编辑authorized_keys文件,将生成的公钥添加进去
+vim /home/username/.ssh/authorized_keys
+
+chown -R username:username /home/username.ssh
+chmod 700 /home/username/.ssh
+chmod 600 /home/username/.ssh/authorized_keysfdisk -l:查看硬盘个数、分区情况
fdisk /dev/sdx:磁盘分区,只能分小容量(2T以内),mbr分区表
parted /dev/sdx:磁盘分区,gpt分区表
多个分区需要注意4k对齐,4k对齐内容介绍见下文引用的disk genius的文章
根据自己需求的文件格式选择,例如常见的ext4文件系统
mkfs.ext4 [-b block-size] [-C cluster-size] [-i bytes-per-inode] [-I inode-size] [-N number-of-inodes] [-t fs-type] [-T usage-type ] device
可以指定inode的个数和占用的空间和多少字节一个inode,需要注意inode如果过小,当inode使用完后,即使磁盘有空间也无法再写入数据。/etc/mke2fs.conf文件中定义了一些默认的类型配置,usage-type根据文件系统的主要用途对应的类型,例如largefile类型为1M一个inode,还有largefile4为4M一个inode,这样可以减少inode的占用空间和个数,用于存储大文件,但是实际上inode占用的空间对于大容量硬盘来说很少。
ext2/3/4文件系统会预留5%空间用于紧急情况,保障在硬盘快满的时候不至于crash,但是一个16T的硬盘的5%将近800G,实在是浪费。可以通过tune2fs命令来减少预留空间
tune2fs -m 1 /dev/sdx:将设备的预留空间调整为1%,也可以改成0,但不建议。
手动挂载(重启失效):mount /dev/sdx /path
自动挂载(开机自动挂载):
blkid /dev/sdx记录需要挂载设备的uuidvim /etc/fstab添加一条记录,例如UUID=506ed1d0-bc35-4585-8496-1ff4de100982 /repo ext4 defaults 0 0
+# 第一项为设备uuid 第二项为挂载点即挂载目录 第三项为文件系统类型 第四项为挂载的状态例如ro(只读)或defaults(包含了读写rw,exec,async等)
+# 第五项为DUMP选项 默认0 第六项为被fsck命令决定启动时被扫描的文件系统顺序 仓库盘可以填0不需要扫描,系统盘1,其他可2
+# 使用`parted /dev/sda`
+GNU Parted 3.4
+Using /dev/sda
+Welcome to GNU Parted! Type 'help' to view a list of commands.
+
+# `p`输出信息
+# 扩容前:
+(parted) p
+Model: ATA QEMU HARDDISK (scsi)
+Disk /dev/sda: 859GB
+Sector size (logical/physical): 512B/512B
+Partition Table: gpt
+Disk Flags:
+
+Number Start End Size File system Name Flags
+ 1 1049kB 2097kB 1049kB bios_grub
+ 2 2097kB 537GB 537GB ext4
+
+# 使用`resizepart 2 -1`
+
+# 扩容后
+(parted) p
+Model: ATA QEMU HARDDISK (scsi)
+Disk /dev/sda: 859GB
+Sector size (logical/physical): 512B/512B
+Partition Table: gpt
+Disk Flags:
+
+Number Start End Size File system Name Flags
+ 1 1049kB 2097kB 1049kB bios_grub
+ 2 2097kB 859GB 859GB ext4
resizepart partition end:end参数填分区结束扇区号,直接使用resizepart 2 -1可以自动扩展到可用空间的末尾- 或者使用fdisk扩容,先删除再新增
内容引用自
disk genius文章:分区4K对齐那些事,你想知道的都在这里物理扇区的概念
分区对齐,是指将分区起始位置对齐到一定的扇区。我们要先了解对齐和扇区的关系。我们知道,硬盘的基本读写单位是“扇区”。对于硬盘的读写操作,每次读写都是以扇区为单位进行的,最少一个扇区,通常是512个字节。由于硬盘数据存储结构的限制,单独读写1个或几个字节是不可能的。通过系统提供的接口读写文件数据时,看起来可以单独读写少量字节,实际上是经过了操作系统的转换才实现的。硬盘实际执行时读写的仍然是整个扇区。
近年来,随着对硬盘容量的要求不断增加,为了提高数据记录密度,硬盘厂商往往采用增大扇区大小的方法,于是出现了扇区大小为4096字节的硬盘。我们将这样的扇区称之为“物理扇区”。但是这样的大扇区会有兼容性问题,有的系统或软件无法适应。为了解决这个问题,硬盘内部将物理扇区在逻辑上划分为多个扇区片段并将其作为普通的扇区(一般为512字节大小)报告给操作系统及应用软件。这样的扇区片段我们称之为“逻辑扇区”。实际读写时由硬盘内的程序(固件)负责在逻辑扇区与物理扇区之间进行转换,上层程序“感觉”不到物理扇区的存在。
逻辑扇区是硬盘可以接受读写指令的最小操作单元,是操作系统及应用程序可以访问的扇区,多数情况下其大小为512字节。我们通常所说的扇区一般就是指的逻辑扇区。物理扇区是硬盘底层硬件意义上的扇区,是实际执行读写操作的最小单元。是只能由硬盘直接访问的扇区,操作系统及应用程序一般无法直接访问物理扇区。一个物理扇区可以包含一个或多个逻辑扇区(比如多数硬盘的物理扇区包含了8个逻辑扇区)。当要读写某个逻辑扇区时,硬盘底层在实际操作时都会读写逻辑扇区所在的整个物理扇区。
这里说的“硬盘”及其“扇区”的概念,同样适用于存储卡、固态硬盘(SSD)。接下来我们统称其为“磁盘”。它们在使用上的基本原理是一致的。其中固态硬盘在实现上更加复杂,它有“页”和“块”的概念,为了便于理解,我们可以简单的将其视同为逻辑扇区和物理扇区。另外固态硬盘在写入数据之前必须先执行擦除操作,不能直接写入到已存有数据的块,必须先擦除再写入。所以固态硬盘(SSD)对分区4K对齐的要求更高。如果没有对齐,额外的动作会增加更多,造成读写性能下降。
分区及其格式化
磁盘在使用之前必须要先分区并格式化。简单的理解,分区就是指从磁盘上划分出来的一大片连续的扇区。格式化则是对分区范围内扇区的使用进行规划。比如文件数据的储存如何安排、文件属性储存在哪里、目录结构如何存储等等。分区经过格式化后,就可以存储文件了。格式化程序会将分区里面的所有扇区从头至尾进行分组,划分为固定大小的“簇”,并按顺序进行编号。每个“簇”可固定包含一个或多个扇区,其扇区个数总是2的n次方。格式化以后,分区就会以“簇”为最小单位进行读写。文件的数据、属性等等信息都要保存到“簇”里面。
为什么要分区对齐
为磁盘划分分区时,是以逻辑扇区为单位进行划分的,分区可以从任意编号的逻辑扇区开始。如果分区的起始位置没有对齐到某个物理扇区的边缘,格式化后,所有的“簇”也将无法对齐到物理扇区的边缘。如下图所示,每个物理扇区由4个逻辑扇区组成。分区是从3号扇区开始的。格式化后,每个簇占用了4个扇区,这些簇都没有对齐到物理扇区的边缘,也就是说,每个簇都跨越了2个物理扇区。
由于磁盘总是以物理扇区为单位进行读写,在这样的分区情况下,当要读取某个簇时,实际上总是需要多读取一个物理扇区的数据。比如要读取0号簇共4个逻辑扇区的数据,磁盘实际执行时,必须要读取0号和1号两个物理扇区共8个逻辑扇区的数据。同理,对“簇”的写入操作也是这样。显而易见,这样会造成读写性能的严重下降。
下面再看对齐的情况。如下图所示,分区从4号扇区开始,刚好对齐到了物理扇区1的边缘,格式化后,每个簇同样占用了4个扇区,而且这些簇都对齐到了物理扇区的边缘。
在这样对齐的情况下,当要读取某个簇,磁盘实际执行时并不需要额外读取任何扇区,可以充分发挥磁盘的读写性能。显然这正是我们需要的。
由此可见,对于物理扇区大小与逻辑扇区大小不一致的磁盘,分区4K对齐才能充分发挥磁盘的读写性能。而不对齐就会造成磁盘读写性能的下降。
如何才能对齐
通过前述图示的两个例子可以看到,只要将分区的起始位置对齐到物理扇区的边缘,格式化程序就会将每个簇也对齐到物理扇区的边缘,这样就实现了分区的对齐。其实对齐很简单。
如何检测物理扇区大小
划分分区时,要想实现4K对齐,必须首先知道磁盘物理扇区的大小。那么如何查询呢?
打开DiskGenius软件,点击要检测的磁盘,在软件界面右侧的磁盘参数表中,可以找到“扇区大小”和“物理扇区大小”。其中“扇区大小”指的是逻辑扇区的大小。如图所示,这个磁盘的物理扇区大小为4096字节,通过计算得知,它包含了8个逻辑扇区。
对齐到多少个扇区才正确
知道了“扇区大小”和“物理扇区大小”,用“物理扇区大小”除以“扇区大小”就能得到每个物理扇区所包含的逻辑扇区个数。这个数值就是我们要对齐的扇区个数的最小值。只要将分区起始位置对齐到这个数值的整数倍就可以了。举个例子,比如物理扇区大小是4096字节,逻辑扇区大小是512字节,那么4096除以512,等于8。我们只要将分区起始位置对齐到8的整数倍扇区就能满足分区对齐的要求。比如对齐到8、16、24、32、... 1024、2048等等。只要这个起始扇区号能够被8整除就都可以。并不是这个除数数值越大越好。Windows系统默认对齐的扇区数是2048。这个数值基本上能满足几乎所有磁盘的4K对齐要求了。
为什么大家都说4K对齐
习惯而已。因为开始出现物理扇区的概念时,多数磁盘的物理扇区大小都是4096即4K字节,习惯了就俗称4K对齐了。实际划分分区时还是要检测一下物理扇区大小,因为有些磁盘的物理扇区可能包含4个、8个、16个或者更多个逻辑扇区(总是2的n次方)。知道物理扇区大小后,再按照刚才说的计算方法,以物理扇区包含的逻辑扇区个数为基准,对齐到实际的物理扇区大小才是正确的。如果物理扇区大小是8192字节,那就要按照8192字节来对齐,严格来讲,这就不能叫4K对齐了。
划分分区时如何具体操作分区对齐
以DiskGenius软件为例,建立新分区时,在“建立新分区”对话框中勾选“对齐到下列扇区数的整数倍”,然后选择需要对齐的扇区数目,点“确定”后建立的分区就是对齐的了。
软件在“扇区数目”下拉框中列出了很多的选项,从中选择任意一个大于物理扇区大小的扇区数都是可以的,都能满足对齐要求。软件列出那么多的扇区数选项只是增加了选择的自由度,并不是数值越大越好。使用过大的数值可能会造成磁盘空间的浪费。软件默认的设置已经能够满足几乎所有磁盘的 4K对齐要求。
除了“建立新分区”对话框,DiskGenius软件还有一个“快速分区”功能,其中也有相同的对齐设置。如下图所示:
如何检测是否对齐
作为一款强大的分区管理软件,DiskGenius同样提供了分区4K对齐检测的功能。你可以用它检测一下自己硬盘的分区是否对齐了。使用方法很简单,打开软件后,首先在软件左侧选中要检测的磁盘,然后选择“工具”菜单中的“分区4KB扇区对齐检测”,软件立即显示检测结果,如下图所示:
最右侧“对齐”一栏是“Y”的分区就是对齐的分区,否则就是没有对齐。没有对齐的分区会用红色字体显示。
多线程:threading,利用CPU运算和IO可以同时执行,让CPU不会干巴巴等待IO完成
多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务
异步IO:asyncio,在单线程中利用CPU和IO同时执行的原理,实现函数异步执行
使用Lock对资源加锁,防止冲突访问
使用Queue实现不同线程、进程之间的数据通信,实现生产者消费者模式
使用线程池Pool、进程池Pool,简化线程、进程任务的提交、等待结束、获取结果
使用subprocess启动外部程序的进程,并进行输出交互
CPU密集型计算:也叫计算密集型,指I/O很短时间内就完成,CPU需要大量计算和处理,特点是CPU占用率很高,例如解压缩,加密解密,正则匹配等。
I/O密集型计算:硬盘、内存、网络的读写操作,例如文件处理、网络爬虫、读写数据库等。
多进程Process(multiprocessing):
多线程Thread(threading):
一个进程中可以启动多个线程
相比进程更轻量级,占用资源更少。但只能单CPU并发执行,不能利用多CPU(GIL,全局解释器锁)
相比协程,线程启动数目有限制,占用内存资源,有线程切换的开销
适用于:IO密集型任务,同时运行的任务数目要求不高
多协程Coroutine(asyncio):
一个线程中可以启动多个协程
优点:内存开销最小,启动数量最多
缺点:支持的库有限(aiohttp vs requests),代码实现较为复杂
适用于:I/O密集型任务,需要超多任务运行且有现有库支持的场景
import time
+import threading
+
+
+import requests
+import threading
+import time
+
+urls = [f'https://www.cnblogs.com/#p{i}' for i in range(1, 50)]
+
+
+def craw(url):
+ r = requests.get(url)
+ time.sleep(1)
+ print(url, len(r.text))
+
+
+if __name__ == '__main__':
+ start = time.time()
+ t = threading.Thread(target=craw, args=(urls[0],))
+ t.start()
+ t.join()
+ print(f'cost {start - time.time()}s')import requests
+import time
+import threading
+from blog_spider import urls
+
+
+class MyThread(threading.Thread):
+ def __init__(self, url):
+ super().__init__()
+ self.url = url
+
+ def run(self):
+ r = requests.get(self.url)
+ time.sleep(1)
+ print(self.url, len(r.text))
+
+
+if __name__ == '__main__':
+ start = time.time()
+ t = MyThread(urls[0])
+ t.start()
+ t.join()
+ print(time.time() - start)import threading
+import time
+
+
+class MyThread(threading.Thread):
+ def __init__(self, thread_id, name, counter):
+ super().__init__(name=name)
+ self.name = name
+ self.thread_id = thread_id
+ self.counter = counter
+
+ def run(self):
+ print("开启线程: " + self.name)
+ # 获取锁.用于线程同步
+ my_lock.acquire()
+ print_time(self.name, self.counter, 3)
+ # 释放锁
+ my_lock.release()
+
+
+def print_time(thread_name, delay, counter):
+ while counter:
+ time.sleep(delay)
+ print(f"#{thread_name}: {time.ctime(time.time())}")
+ counter -= 1
+
+
+my_lock = threading.Lock()
+threads = []
+# 创建新线程
+thread1 = MyThread(1, "Thread-1", 1)
+thread2 = MyThread(2, "Thread-2", 2)
+thread1.start()
+thread2.start()
+# 添加到线程列表
+threads.append(thread1)
+threads.append(thread2)
+
+for t in threads:
+ t.join()
+print("退出主线程")结果:
开启线程: Thread-1
+开启线程: Thread-2
+#Thread-1: Mon Apr 12 21:54:42 2021
+#Thread-1: Mon Apr 12 21:54:43 2021
+#Thread-1: Mon Apr 12 21:54:44 2021
+#Thread-2: Mon Apr 12 21:54:46 2021
+#Thread-2: Mon Apr 12 21:54:48 2021
+#Thread-2: Mon Apr 12 21:54:50 2021
+退出主线程1.try-finally模式
import threading
+
+lock = threading.lock()
+lock.acquire()
+try:
+ #do something
+finally:
+ lock.release()import threading
+
+lock = threading.lock()
+
+with lock:
+ # do somethingimport requests
+from bs4 import BeautifulSoup
+
+urls = [f'https://www.cnblogs.com/#p{i}' for i in range(1, 50)]
+
+
+def craw(url):
+ r = requests.get(url)
+ return r.text
+
+
+def parse(html):
+ soup = BeautifulSoup(html, 'html.parser')
+ links = soup.find_all('a', class_='post-item-title')
+ return [(link.get('href'), link.get_text()) for link in links]import queue
+import threading
+import time
+import random
+
+import blog_spider
+
+
+def do_crawl(url_queue: queue.Queue, html_queue: queue.Queue):
+ while True:
+ url = url_queue.get()
+ html = blog_spider.craw(url)
+ html_queue.put(html)
+
+
+def do_parse(html_queue: queue.Queue, fout):
+ while True:
+ html = html_queue.get()
+ results = blog_spider.parse(html)
+ for result in results:
+ fout.write(str(result) + '\n')
+ time.sleep(1)
+
+
+if __name__ == '__main__':
+ url_queue = queue.Queue()
+ html_queue = queue.Queue()
+ for url in blog_spider.urls:
+ url_queue.put(url)
+
+ for i in range(3):
+ t = threading.Thread(target=do_crawl, args=(url_queue, html_queue), name='crawl-{}'.format(i))
+ t.start()
+
+ fout = open('results.txt', 'w')
+ for i in range(3):
+ t = threading.Thread(target=do_parse, args=(html_queue, fout), name='parse-{}'.format(i))
+ t.start()import queue
+import threading
+import time
+
+exitFlag = 0
+
+
+class MyThread(threading.Thread):
+ def __init__(self, thread_id, name, q):
+ super().__init__(name=name)
+ self.threadId = thread_id
+ self.name = name
+ self.q = q
+
+ def run(self):
+ print("开启线程: " + self.name)
+ process_data(self.name, self.q)
+ print("退出线程: " + self.name)
+
+
+def process_data(name, q):
+ while not exitFlag:
+ queueLock.acquire()
+ if not workQueue.empty():
+ data = q.get()
+ queueLock.release()
+ print(f"{name} processing {data}")
+ else:
+ queueLock.release()
+ time.sleep(1)
+
+
+threadList = ["Thread-1", "Thread-2", "Thread-3"]
+queueLock = threading.Lock()
+nameList = ["ONE", "TWO", "THREE", "FOUR", "FIVE"]
+workQueue = queue.Queue(10)
+threads = []
+threadId = 1
+
+for tname in threadList:
+ thread = MyThread(threadId, tname, workQueue)
+ thread.start()
+ threads.append(thread)
+ threadId += 1
+
+queueLock.acquire()
+for name in nameList:
+ workQueue.put(name)
+queueLock.release()
+
+while not workQueue.empty():
+ pass
+
+exitFlag = 1
+
+for t in threads:
+ t.join()
+
+print("主线程退出")运行结果:
开启线程: Thread-1
+开启线程: Thread-2
+开启线程: Thread-3
+Thread-1 processing ONE
+Thread-2 processing TWO
+Thread-3 processing THREE
+Thread-2 processing FOUR
+Thread-1 processing FIVE
+退出线程: Thread-2
+退出线程: Thread-1
+退出线程: Thread-3
+主线程退出from concurrent.futures import ThreadPoolExecutor, as_completed
+import time
+
+
+def get_data(times):
+ time.sleep(times)
+ print("get data {} success".format(times))
+
+
+thread_pool = ThreadPoolExecutor(max_workers=2)
+task1 = thread_pool.submit(get_data, 3)
+task2 = thread_pool.submit(get_data, 2)
+
+datas = [1, 2, 3]
+# submit后直接返回
+all_tasks = [thread_pool.submit(get_data, data) for data in datas]
+# as_complete底层是生成器
+# for future in as_completed(all_tasks):
+# res = future.result()
+# print(res)
+for data in thread_pool.map(get_data, datas):
+ print("get {} data ".format(data))as_complete使用,这种方式是按任务完成顺序返回。对于io操作来说,使用多线程
对于耗cpu的操作,用多进程
from concurrent.futures import ProcessPoolExecutor
+import multiprocessing
+import time
+
+
+# 多进程编程
+def get_html(n):
+ time.sleep(n)
+ return n
+
+
+if __name__ == '__main__':
+ # progress = multiprocessing.Process(target=get_html, args=(2,))
+ # print(progress.pid)
+ # progress.start()
+ # print(progress.pid)
+ # progress.join()
+ # print('main progress end')
+
+ # 使用进程池
+ pool = multiprocessing.Pool(multiprocessing.cpu_count())
+ # res = pool.apply_async(get_html, args=(3,))
+ # 不再接受任务
+ # pool.close()
+ # 等待所有任务完成
+ # pool.join()
+ # print(res)
+ # print(res.get())
+
+ # imap 按顺序
+ # for res in pool.imap(get_html, [1, 5, 3]):
+ # print("{} sleep success".format(res))
+ # imap_unordered 按完成时间
+ for res in pool.imap_unordered(get_html, [1, 5, 3]):
+ print("{} sleep success".format(res))
协程,又称微线程,纤程。英文名Coroutine。是一种用户态的上下文切换技术。协程的作用是在执行函数A时可以随时中断去执行函数B,然后中断函数B继续执行函数A(可以自由切换)。但这一过程并不是函数调用,这一整个过程看似像多线程,然而协程只有一个线程执行。
协程可以处理IO密集型程序的效率问题,但是CPU密集型不是它的长处,要充分发挥CPU的利用率可以结合多进程+协程
实现协程的方式:
asyncio模块中,每一个进程都有一个事件循环。把一些函数注册到事件循环上,当满足事件发生的时候,调用相应的协程函数
事件循环的作用是管理所有的事件,在整个程序运行过程中不断循环执行,追踪事件发生的顺序将它们放到队列中,当主线程空闲的时候,调用相应的事件处理者处理事件。
伪代码:
任务列表 = [任务1,任务2,任务3...]
+
+while true:
+ 可执行的任务列表,已完成的任务列表 = 检查所有任务,将可执行的和已完成的任务返回
+ for 就绪任务 in 可执行的任务:
+ 执行就绪任务
+
+ for 已完成的任务 in 已完成的任务:
+ 剔除已完成的任务
+
+ 如果任务列表的全部任务都已完成,终止循环import asyncio
+
+
+# 生成或获取一个事件循环
+loop = asyncio.get_event_loop()
+# 将任务放到任务列表
+loop.run_until_complete(任务)
定义函数时,如果是async def 函数的函数,就是一个协程函数
执行协程函数得到的对象
TIP
执行协程函数创建协程对象,函数内部代码不会立即执行
如果想运行协程函数内部代码,必须将协程对象交给事件循环处理
import asyncio
+
+
+# 定义一个协程函数
+async def func():
+ print("异步编程")
+
+
+# 生成一个事件循环
+loop = asyncio.get_event_loop()
+# 得到协程对象
+res = func()
+# 将协程对象交给事件循环
+loop.run_until_complete(res)
+# asyncio.run(res)
+
+res:
+异步编程如果不把协程对象放入事件循环
import asyncio
+
+
+# 定义一个协程函数
+async def func():
+ print("异步编程")
+
+
+# 生成一个事件循环
+loop = asyncio.get_event_loop()
+# 得到协程对象
+res = func()
+
+res:
+sys:1: RuntimeWarning: coroutine 'func' was never awaitedimport asyncio
+# 获取事件循环
+loop = asyncio.get_event_loop()
+
+# 定义协程函数
+async def hello(count):
+ print(f"Hello World! {count}")
+ await asyncio.sleep(1)
+
+# 创建task列表
+tasks = [loop.create_task(hello(count)) for count in range(10)]
+# 执行事件列表
+loop.run_until_complete(asyncio.wait(tasks))import asyncio
+import aiohttp
+import blog_spider
+import time
+
+async def async_craw(url):
+ print('开始爬取:', url)
+ async with aiohttp.ClientSession() as session:
+ async with session.get(url) as response:
+ result = await response.text()
+ print('爬取结束:', url, len(result))
+
+
+loop = asyncio.get_event_loop()
+
+tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
+
+start = time.time()
+loop.run_until_complete(asyncio.wait(tasks))
+print('耗时:', time.time() - start)
+
+---sem = asyncio.Semaphore(10)
+
+async with sem:
+ # work with shared resource
+-----------------------------------
+
+sem = asyncio.Semaphore(10)
+
+await sem.acquire()
+try:
+ # work with shared resource
+finally:
+ sem.release()import asyncio
+import aiohttp
+import blog_spider
+
+sem = asyncio.Semaphore(10)
+
+async def async_craw(url):
+ print('开始爬取:', url)
+ async with sem:
+ async with aiohttp.ClientSession() as session:
+ async with session.get(url) as response:
+ result = await response.text()
+ print('爬取结束:', url, len(result))
+
+
+loop = asyncio.get_event_loop()
+
+tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
+import time
+start = time.time()
+loop.run_until_complete(asyncio.wait(tasks))
+print('耗时:', time.time() - start)使用asyncio.run()代替原来创建事件循环,使用事件循环执行函数的操作
import asyncio
+import blog_spider
+
+# async def 定义协程函数
+async def async_craw(url):
+ print('开始爬取:', url)
+ # 触发io操作,调用其他协程
+ await asyncio.sleep(0)
+ print('爬取完成:', url)
+
+
+async def main():
+ # 创建协程列表
+ tasks = [async_craw(url) for url in blog_spider.urls]
+ # asyncio.gather(*task)表示协同执行tasks列表里的所有协程
+ await asyncio.gather(*tasks)
+#
+asyncio.run(main())asyncio.wait 和 asyncio.gather 实现的效果是相同的,都是把所有 Task 任务结果收集起来。asyncio.wait 会返回两个值:done 和 pending,done 为已完成的协程 Task,pending 为超时未完成的协程 Task,需通过 future.result 调用 Task 的 result;而asyncio.gather 返回的是所有已完成 Task 的 result,不需要再进行调用或其他操作,就可以得到全部结果。await + 可等待的对象(协程对象、Future对象、Task对象 -> io等待)
import asyncio
+
+
+async def func():
+ print('异步编程')
+ response = await asyncio.sleep(2)
+ print("结束",response)
+
+asyncio.run(func())示例:
import asyncio
+
+
+async def others():
+ print('start')
+ await asyncio.sleep(2)
+ print('end')
+ return '返回值'
+
+
+async def func():
+ print('执行协程函数内部代码')
+ # 遇到IO操作挂起当前协程,等到IO完成后继续运行,当前协程挂起时,事件循环可以执行其他协程
+ response = await others()
+ print(f'IO的结果是:{response} ')
+
+asyncio.run(func())
+
+res:
+执行协程函数内部代码
+start
+end
+IO的结果是:返回值Tasks用于并发调度协程,是对协程对象的一种封装,其中包含了任务的各个状态。通过asyncio.create_task()函数创建Task对象,这样可以让协程加入事件循环中等待调度执行。还可以使用低层级的loop.create_task()或asyncio.ensure_future()函数。不建议手动实例化Task对象。
示例1:
import asyncio
+
+
+async def func():
+ print(1)
+ await asyncio.sleep(2)
+ print(2)
+ return '返回值'
+
+
+async def main():
+ print('main函数开始')
+
+ # 创建task对象,将当前执行func函数的任务添加到事件循环
+ task1 = asyncio.create_task(func())
+
+ task2 = asyncio.create_task(func())
+
+ print('main函数结束')
+
+ # 当执行某协程遇到IO操作,会自动切换执行其他任务
+ res1 = await task1
+ res2 = await task2
+ print(res1, res2)
+
+
+asyncio.run(main())
+
+res:
+main函数开始
+main函数结束
+1
+1
+2
+2
+返回值 返回值示例2:
import asyncio
+
+
+async def func():
+ print(1)
+ await asyncio.sleep(2)
+ print(2)
+ return '返回值'
+
+
+async def main():
+ print('main函数开始')
+
+
+ task_list = [
+ asyncio.create_task(func()),
+ asyncio.create_task(func())
+ ]
+ print('main函数结束')
+ done,pending = await asyncio.wait(task_list,timeout=None)
+ print(done)
+asyncio.run(main())Task继承了Future,Task对象内部await的结果的处理基于Future对象
async def main():
+ loop = asyncio.get_running_loop()
+ _future = loop.create_future()
+ await _future
+asyncio.run(main())使用线程池/进程池实现异步操作时用到的对象
import time
+from concurrent.futures import Future
+from concurrent.futures.thread import ThreadPoolExecutor
+
+def func(value):
+ time.sleep(1)
+ print(value)
+ return 123
+
+pool = ThreadPoolExecutory(max_workers=5)
+for i in range(5)
+ fut = pool.submit(func,1)
+ print(fut)CrawlSpider是Spider的一个子类,具有提取指定规则链接的功能
CrawlSpider的作用:
scrapy startproject crawl_spidercd crawl_spiderscrapy genspider -t crawl storyxc xxx.com 相比普通的增加了-t crawl参数根据指定规则(allow=‘正则表达式“)提取符合要求的所有url
link = LinkExtractor(allow=r'id=1&page=\d+')将链接提取器提取到的链接进行指定规则(callback)的解析
rules = (
+ Rule(link, callback='parse_item', follow=True),
+)from scrapy.linkextractors import LinkExtractor
+from scrapy.spiders import CrawlSpider, Rule
+from crawl_spider.items import CrawlSpiderItem,DetailItem
+
+
+class StoryxcSpider(CrawlSpider):
+ name = 'storyxc'
+ start_urls = ['http://wz.sun0769.com/political/index/politicsNewest']
+
+ # 链接提取器,符合正则表达式的链接都会被提取
+ link = LinkExtractor(allow=r'id=1&page=\d+')
+ detail_link = LinkExtractor(allow=r'\/political\/politics\/index\?id=\d+')
+
+ rules = (
+ Rule(link, callback='parse_item', follow=True),
+ Rule(detail_link, callback='parse_detail'),
+ )
+
+ def parse_item(self, response):
+ li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
+ for li in li_list:
+ wz_id = li.xpath('./span[1]/text()').extract_first()
+ wz_title = li.xpath('./span[3]/a/text()').extract_first()
+ item = CrawlSpiderItem()
+ item['num'] = wz_id
+ item['title'] = wz_title
+ yield item
+
+ def parse_detail(self, response):
+ id = response.xpath('/html/body/div[3]/div[2]/div[2]/div[1]/span[4]/text()').extract_first()
+ id = id.replace('编号:','')
+ content = ''.join(response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract())
+ item = DetailItem()
+ item['num'] = id
+ item['content'] = content
+ yield item# Define here the models for your scraped items
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/items.html
+
+import scrapy
+
+
+class CrawlSpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ title =scrapy.Field()
+ num = scrapy.Field()
+
+class DetailItem(scrapy.Item):
+ num = scrapy.Field()
+ content = scrapy.Field()# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+
+
+# useful for handling different item types with a single interface
+from itemadapter import ItemAdapter
+from crawl_spider.items import CrawlSpiderItem, DetailItem
+import pymysql
+
+
+class CrawlSpiderPipeline:
+ def process_item(self, item, spider):
+ if item.__class__.__name__ == 'DetailItem':
+ with Mysql() as conn:
+ cursor = conn.cursor()
+ try:
+ cursor.execute(
+ 'insert into tb_wz_content(id,content) values("%s","%s")' % (
+ item['num'],item['content']))
+ conn.commit()
+ except:
+ print('插入问政内容失败!')
+ conn.rollback()
+
+
+ else:
+ with Mysql() as conn:
+ cursor = conn.cursor()
+ try:
+ cursor.execute(
+ 'insert into tb_wz_title(id,title) values("%s","%s")' % (item['num'],item['title']))
+ conn.commit()
+ except:
+ print('插入问政标题失败!')
+ conn.rollback()
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()BOT_NAME = 'crawl_spider'
+
+SPIDER_MODULES = ['crawl_spider.spiders']
+NEWSPIDER_MODULE = 'crawl_spider.spiders'
+
+
+# Crawl responsibly by identifying yourself (and your website) on the user-agent
+USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+# Obey robots.txt rules
+ROBOTSTXT_OBEY = False
+
+
+
+ITEM_PIPELINES = {
+ 'crawl_spider.pipelines.CrawlSpiderPipeline': 300,
+}启动爬虫:
数据库会新增数据
将网站中某板块下的全部页码对应页面数据进行爬取
实现方式
将所有页面url添加到start_urls列表
手动进行请求发送
import scrapy
+from story_spider.items import StorySpiderItem
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['http://www.521609.com/meinvxiaohua/']
+ url_template = 'http://www.521609.com/meinvxiaohua/list12%d.html'
+ page_num = 2
+
+ def parse(self, response):
+ li_list = response.xpath('//div[@id="content"]/div[2]/div[2]/ul/li')
+ for li in li_list:
+ img_name = li.xpath('./a[2]//text()').extract_first()
+ print(img_name)
+ if self.page_num <= 11:
+ next_url = format(self.url_template % self.page_num)
+ self.page_num += 1
+ # 手动请求发送:yield scrapy.Request(url,callback)
+ # callback专门用作数据解析
+ yield scrapy.Request(url=next_url, callback=self.parse)流程:
spider中产生url,对url进行请求发送
url会被封装成请求对象交给引擎,引擎把请求给调度器
调度器会使用过滤器将引擎提交的请求去重,将去重后的请求对象放入队列
调度器会把请求对象从队列中调度给引擎,引擎把请求交给下载器
下载器去互联网中进行数据下载,将数据封装在response里返回给引擎
引擎将response返回给spider,spider对数据进行解析,将数据封装到item当中,交给引擎
引擎把item交给管道
管道进行持久化存储
使用场景:如果爬取解析的数据不再同一张页面中(深度爬取)
yield scrapy.Request(url,callback,meta= {'item':item})
只需要解析出img的src属性进行解析并提交到管道,管道就会对图片的src进行请求发送获取二进制数据
import scrapy
+from story_spider.items import StorySpiderItem
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['http://sc.chinaz.com/tupian/']
+
+ def parse(self, response):
+ div_list = response.xpath('//div[@id="container"]/div')
+ for div in div_list:
+ # 该网站有懒加载,要使用伪属性
+ src = div.xpath('./div/a/img/@src2').extract_first()
+ real_src = 'https:' + src
+ # print(real_src)
+ item = StorySpiderItem()
+ item['src'] = real_src
+ yield item# Define here the models for your scraped items
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/items.html
+
+import scrapy
+
+
+class StorySpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ src = scrapy.Field()# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+
+
+# useful for handling different item types with a single interface
+
+from scrapy.pipelines.images import ImagesPipeline
+import scrapy
+
+
+class ImagePipeline(ImagesPipeline):
+ # 根据图片地址进行图片数据的请求
+ def get_media_requests(self, item, info):
+ print(item['src'])
+ yield scrapy.Request(item['src'])
+
+ def file_path(self, request, response=None, info=None, *, item=None):
+ # 指定图片存储路径
+ imageName = request.url.split('/')[-1]
+ return imageName
+
+ def item_completed(self, results, item, info):
+ return item # 返回给下一个被执行的管道类# 保存的文件夹
+IMAGES_STORE = './imgs'
+# 启用管道
+ITEM_PIPELINES = {
+ # 300表示优先级,数值越小,优先级越高
+ 'story_spider.pipelines.ImagePipeline': 300
+}DANGER
这里直接运行不会报错,但是会发现也没有下载成功,但是实际上url已经能拿到了,把日志的级别放开后,查看日志信息会发现有一句 2021-05-01 13:22:48 [scrapy.middleware] WARNING: Disabled ImgsPipeline: ImagesPipeline requires installing Pillow 4.0.0 or later
提示使用ImagesPipeline还需要安装下pillow :pip install pillow
这个很坑,不仔细看找不到,排查了半天才解决
安装完pillow后启动爬虫,可以看到图片已经下载完成
def process_request(self, request, spider):
+ # UA 伪装,也可以设置ua池,随机设置
+ request.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+ # 设置代理
+ request.meta['proxy'] = 'https://ip:port'
+ return None
+
+ def process_response(self, request, response, spider):
+ # Called with the response returned from the downloader.
+
+ # Must either;
+ # - return a Response object
+ # - return a Request object
+ # - or raise IgnoreRequest
+ return response
+
+ def process_exception(self, request, exception, spider):
+
+ # Called when a download handler or a process_request()
+ # (from other downloader middleware) raises an exception.
+ # 发生异常的请求切换代理 也可以实现代理池,指定切换逻辑
+ request.meta['proxy'] = 'https://ip:port'
+
+ # Must either:
+ # - return None: continue processing this exception
+ # - return a Response object: stops process_exception() chain
+ # - return a Request object: stops process_exception() chain
+ return request #将修正后的request重新进行发送import scrapy
+from story_spider.items import StorySpiderItem
+
+
+# 必须继承scrapy.Spider
+class StoryxcSpider(scrapy.Spider):
+ # 爬虫文件的名称:爬虫源文件的一个唯一标识
+ name = 'storyxc'
+ # 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
+ # allowed_domains = ['storyxc.com']
+ # 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
+ start_urls = ['https://news.163.com/']
+ module_urls = []
+
+ def __init__(self):
+ super().__init__(self)
+ from selenium import webdriver
+ self.browser = webdriver.Chrome()
+
+ def parse(self, response):
+
+ li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
+ need_index = [3, 4, 6]
+ for index in need_index:
+ module_url = li_list[index].xpath('./a/@href').extract_first()
+ self.module_urls.append(module_url)
+
+ for url in self.module_urls:
+ yield scrapy.Request(url, callback=self.parse_module)
+
+ # 解析篡改过的 已经添加了动态加载数据的响应信息
+ def parse_module(self, response):
+ div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div')
+ for div in div_list:
+ # news_title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
+ detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
+
+ yield scrapy.Request(url=detail_url,callback=self.parse_detail)
+
+
+ # 解析新闻详情页
+ def parse_detail(self, response):
+ title = response.xpath('//*[@id="container"]/div[1]/h1/text()').extract_first()
+ detail_text = response.xpath('//*[@id="content"]/div[2]//text()').extract()
+ detail_text = ''.join(detail_text)
+ item = StorySpiderItem()
+ item['title'] = title
+ item['content'] = detail_text
+ yield item
+
+ def closed(self,spider):
+ self.browser.quit()只展示了下载中间件
class StorySpiderDownloaderMiddleware:
+
+ def process_request(self, request, spider):
+
+ return None
+
+ # 拦截模块对应的响应对象,进行篡改
+ # 由于是动态加载的内容,使用selenium
+ def process_response(self, request, response, spider):
+ # 过滤指定的响应对象
+ urls = spider.module_urls
+ bro = spider.browser
+ from scrapy.http import HtmlResponse
+ from time import sleep
+ # 只有指定模块url的数据才使用selenium请求并进行篡改数据
+ if request.url in urls:
+ bro.get(request.url) # selenium请求详情页
+ sleep(3)
+ page_data = bro.page_source # 包含了动态加载的新闻数据
+ # 要爬取的指定模块的响应内容
+ # 实例化一个新的响应对象 (包含动态加载的新闻数据),替代原来的响应对象
+ new_res = HtmlResponse(url=request.url,body=page_data,encoding='utf-8',request=request)
+ return new_res
+
+ return response
+
+ def process_exception(self, request, exception, spider):
+
+ return request #将修正后的request重新进行发送import scrapy
+
+
+class StorySpiderItem(scrapy.Item):
+ # define the fields for your item here like:
+ # name = scrapy.Field()
+ title = scrapy.Field()
+ content = scrapy.Field()class StroyxcPipeline(object):
+ fp = None
+
+ def open_spider(self, spider):
+ self.fp = open('./163news.txt', 'w', encoding='utf-8')
+
+ def process_item(self, item, spider):
+ self.fp.write(item['title'] + ':' + item['content'] + '\n')
+ return item
+
+ def close_spider(self, spider):
+ self.fp.close()BOT_NAME = 'story_spider'
+
+SPIDER_MODULES = ['story_spider.spiders']
+NEWSPIDER_MODULE = 'story_spider.spiders'
+
+# Crawl responsibly by identifying yourself (and your website) on the user-agent
+USER_AGENT = {
+ 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
+}
+
+# Obey robots.txt rules
+ROBOTSTXT_OBEY = False
+
+
+# Enable or disable downloader middlewares
+# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
+DOWNLOADER_MIDDLEWARES = {
+ 'story_spider.middlewares.StorySpiderDownloaderMiddleware': 543,
+}
+
+# Configure item pipelines
+# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+ITEM_PIPELINES = {
+ # 300表示优先级,数值越小,优先级越高
+ 'story_spider.pipelines.StroyxcPipeline': 300
+}运行结果:
pycharm中编辑运行/debug配置
点击加号添加一个新的配置,选择python,给配置命个名,比如scrapy
script path选择python目录下的Lib/site-packages/scrapycmdline.py
parameter填crawl yourSpiderName
working directory填写爬虫项目路径
保存,再debug运行scrapy这个配置就行
例如:
增量式爬取指定的up主的所有投稿作品,即实现一个增量式爬虫。
这次示范的up主是个妹子😏kototo使用了scrapy框架,主要是为了练手,不使用框架反而会更简单一些。
python模块:scrapy、selenium、requests、pymysql
其他环境:ffmpeg、mysql
scrapy startproject kototo
+cd kototo
+scrapy genspider kototo bilibili.comimport scrapy
+from selenium import webdriver
+import re
+import json
+import requests
+import os
+from kototo.items import KototoItem
+import pymysql
+
+
+class KototoSpider(scrapy.Spider):
+ name = 'kototo'
+ start_urls = []
+
+ def __init__(self):
+ """
+ 构造器,主要初始化了selenium对象并实现无头浏览器,以及
+ 初始化需要爬取的url地址,因为b站的翻页是js实现的,所以要手动处理一下
+ """
+ super().__init__()
+ # 构造无头浏览器
+ from selenium.webdriver.chrome.options import Options
+ chrome_options = Options()
+ chrome_options.add_argument('--headless')
+ chrome_options.add_argument('--disable-gpu')
+ self.bro = webdriver.Chrome(chrome_options=chrome_options)
+ # 指定的up主的投稿页面,可以提到外面使用input输入
+ space_url = 'https://space.bilibili.com/17485141/video'
+ # 初始化需要爬取的列表页
+ self.init_start_urls(self.start_urls, space_url)
+ # 创建桌面文件夹
+ self.desktop_path = os.path.join(os.path.expanduser('~'), 'Desktop\\' + self.name + '\\')
+ if not os.path.exists(self.desktop_path):
+ os.mkdir(self.desktop_path)
+
+ def parse(self, response):
+ """
+ 解析方法,解析列表页的视频li,拿到标题和详情页,然后主动请求详情页
+ :param response:
+ :return:
+ """
+ li_list = response.xpath('//*[@id="submit-video-list"]/ul[2]/li')
+ for li in li_list:
+ print(li.xpath('./a[2]/@title').extract_first())
+ print(detail_url := 'https://' + li.xpath('./a[2]/@href').extract_first()[2:])
+ yield scrapy.Request(url=detail_url, callback=self.parse_detail)
+
+ def parse_detail(self, response):
+ """
+ 增量爬取: 解析详情页的音视频地址并交给管道处理
+ 使用mysql实现
+ :param response:
+ :return:
+ """
+ title = response.xpath('//*[@id="viewbox_report"]/h1/@title').extract_first()
+ # 替换掉视频名称中无法用在文件名中或会导致cmd命令出错的字符
+ title = title.replace('-', '').replace(' ', '').replace('/', '').replace('|', '')
+ play_info_list = self.get_play_info(response)
+ # 这里使用mysql的唯一索引实现增量爬取,如果是服务器上跑也可以用redis
+ if self.insert_info(title, play_info_list[1]):
+ video_temp_path = (self.desktop_path + title + '_temp.mp4').replace('-', '')
+ video_path = self.desktop_path + title + '.mp4'
+ audio_path = self.desktop_path + title + '.mp3'
+ item = KototoItem()
+ item['video_url'] = play_info_list[0]
+ item['audio_url'] = play_info_list[1]
+ item['video_path'] = video_path
+ item['audio_path'] = audio_path
+ item['video_temp_path'] = video_temp_path
+ yield item
+ else:
+ print(title + ': 已经下载过了!')
+
+ def insert_info(self, vtitle, vurl):
+ """
+ mysql持久化存储爬取过的视频内容信息
+ :param vtitle: 标题
+ :param vurl: 视频链接
+ :return:
+ """
+ with Mysql() as conn:
+ cursor = conn.cursor(pymysql.cursors.DictCursor)
+ try:
+ sql = 'insert into tb_kototo(title,url) values("%s","%s")' % (vtitle, vurl)
+ res = cursor.execute(sql)
+ conn.commit()
+ if res == 1:
+ return True
+ else:
+ return False
+ except:
+ return False
+
+ def get_play_info(self, resp):
+ """
+ 解析详情页的源代码,提取其中的视频和文件真实地址
+ :param resp:
+ :return:
+ """
+ json_data = json.loads(re.findall('<script>window\.__playinfo__=(.*?)</script>', resp.text)[0])
+ # 拿到视频和音频的真实链接地址
+ video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
+ audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
+ return video_url, audio_url
+
+ def init_start_urls(self, url_list, person_page):
+ """
+ 初始化需要爬取的列表页,由于b站使用js翻页,无法在源码中找到翻页地址,
+ 需要自己手动实现解析翻页url的操作
+ :param url_list:
+ :param person_page:
+ :return:
+ """
+ mid = re.findall('https://space.bilibili.com/(.*?)/video\w*', person_page)[0]
+ url = 'https://api.bilibili.com/x/space/arc/search?mid=' + mid + '&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'
+ headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
+ 'Referer': 'https://www.bilibili.com'
+ }
+ json_data = requests.get(url=url, headers=headers).json()
+ total_count = json_data['data']['page']['count']
+ page_size = json_data['data']['page']['ps']
+ if total_count <= page_size:
+ page_count = 1
+ elif total_count % page_size == 0:
+ page_count = total_count / page_size
+ else:
+ page_count = total_count // page_size + 1
+
+ url_template = 'https://space.bilibili.com/' + mid + '/video?tid=0&page=' + '%d' + '&keyword=&order=pubdate'
+ for i in range(page_count):
+ page_no = i + 1
+ url_list.append(url_template % page_no)
+
+ def closed(self, spider):
+ """
+ 爬虫结束关闭selenium窗口
+ :param spider:
+ :return:
+ """
+ self.bro.quit()
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()# Define here the models for your spider middleware
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
+
+from scrapy import signals
+
+# useful for handling different item types with a single interface
+from itemadapter import is_item, ItemAdapter
+
+
+class KototoSpiderMiddleware:
+ # Not all methods need to be defined. If a method is not defined,
+ # scrapy acts as if the spider middleware does not modify the
+ # passed objects.
+
+ @classmethod
+ def from_crawler(cls, crawler):
+ # This method is used by Scrapy to create your spiders.
+ s = cls()
+ crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
+ return s
+
+ def process_spider_input(self, response, spider):
+ # Called for each response that goes through the spider
+ # middleware and into the spider.
+
+ # Should return None or raise an exception.
+ return None
+
+ def process_spider_output(self, response, result, spider):
+ # Called with the results returned from the Spider, after
+ # it has processed the response.
+
+ # Must return an iterable of Request, or item objects.
+ for i in result:
+ yield i
+
+ def process_spider_exception(self, response, exception, spider):
+ # Called when a spider or process_spider_input() method
+ # (from other spider middleware) raises an exception.
+
+ # Should return either None or an iterable of Request or item objects.
+ pass
+
+ def process_start_requests(self, start_requests, spider):
+ # Called with the start requests of the spider, and works
+ # similarly to the process_spider_output() method, except
+ # that it doesn’t have a response associated.
+
+ # Must return only requests (not items).
+ for r in start_requests:
+ yield r
+
+ def spider_opened(self, spider):
+ spider.logger.info('Spider opened: %s' % spider.name)
+
+
+class KototoDownloaderMiddleware:
+
+ def process_request(self, request, spider):
+ return None
+
+ def process_response(self, request, response, spider):
+ """
+ 篡改列表页的响应数据:
+ 视频列表是通过ajax请求动态加载的,因此要通过selenium去加载这部分数据
+ 并篡改响应内容
+ :param request:
+ :param response:
+ :param spider:
+ :return:
+ """
+ urls = spider.start_urls
+ bro = spider.bro
+ from scrapy.http import HtmlResponse
+ from time import sleep
+ if request.url in urls:
+ """
+ 如果是列表页就进行响应篡改操作
+ """
+ bro.get(request.url)
+ sleep(3)
+ page_data = bro.page_source
+ new_response = HtmlResponse(url=request.url, body=page_data, encoding='utf-8', request=request)
+ # 返回篡改过的响应对象
+ return new_response
+ return response
+
+ def process_exception(self, request, exception, spider):
+ passimport scrapy
+
+
+class KototoItem(scrapy.Item):
+ video_path = scrapy.Field()
+ video_url = scrapy.Field()
+ audio_path = scrapy.Field()
+ audio_url = scrapy.Field()
+ video_temp_path = scrapy.Field()import requests
+import os
+
+headers = {
+ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
+ 'Referer': 'https://www.bilibili.com'
+}
+
+
+class KototoPipeline(object):
+ def process_item(self, item, spider):
+ video = item['video_url']
+ audio = item['audio_url']
+ video_temp_path = item['video_temp_path']
+ audio_path = item['audio_path']
+ video_data = requests.get(url=video, headers=headers).content
+ audio_data = requests.get(url=audio, headers=headers).content
+ with open(video_temp_path, 'wb') as f:
+ f.write(video_data)
+ with open(audio_path, 'wb') as f:
+ f.write(audio_data)
+ return item
+
+
+class MergePipeline(object):
+ """
+ 删除临时文件
+ """
+
+ def process_item(self, item, spider):
+ video_temp_path = item['video_temp_path']
+ audio_path = item['audio_path']
+ video_path = item['video_path']
+ cmd = 'ffmpeg -y -i ' + video_temp_path + ' -i ' \
+ + audio_path + ' -c:v copy -c:a aac -strict experimental ' + video_path
+ print(cmd)
+ # subprocess.Popen(cmd, shell=True)
+ os.system(cmd)
+ os.remove(video_temp_path)
+ os.remove(audio_path)
+ print(video_path, '下载完成')
+ return itemBOT_NAME = 'kototo'
+
+SPIDER_MODULES = ['kototo.spiders']
+NEWSPIDER_MODULE = 'kototo.spiders'
+
+
+USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
+
+
+ROBOTSTXT_OBEY = False
+
+
+DEFAULT_REQUEST_HEADERS = {
+ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
+ 'Referer': 'https://space.bilibili.com/17485141/video',
+ 'Origin': 'https://space.bilibili.com'
+}
+FILES_STORE = './files'
+DOWNLOADER_MIDDLEWARES = {
+ 'kototo.middlewares.KototoDownloaderMiddleware': 543,
+}
+
+ITEM_PIPELINES = {
+ # 下载
+ 'kototo.pipelines.KototoPipeline': 1,
+ # 合并
+ 'kototo.pipelines.MergePipeline': 2,
+}命令启动:scrapy crawl kototo
配置pycharm启动(推荐)
已经爬取过的资源会提示已经下载过,只会处理更新的内容。
import sys
+import subprocess
+import re
+import os
+
+_pattern = r'[^A-Za-z0-9_\-.,:+\/@\n]'
+
+
+def replace_func(match_obj):
+ return '\\' + match_obj.group(0)
+
+
+def shell_escape(str_param):
+ return re.sub(_pattern, replace_func, str_param)
+
+
+if __name__ == '__main__':
+ if os.path.exists(sys.argv[1]):
+ file_path = shell_escape(sys.argv[1])
+ editor = shell_escape(sys.argv[2])
+ command = f"open -a {editor} {file_path}"
+ subprocess.Popen(command, shell=True)repository:https://github.com/storyxc/Alfred-open-with-editor/releases/tag/Alfred
Django 是一个由 Python 编写的一个开放源代码的 Web 应用框架。
使用 Django,只要很少的代码,Python 的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的 Web 服务 Django 本身基于 MVC 模型,即 Model(模型)+ View(视图)+ Controller(控制器)设计模式,MVC 模式使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。
MVC 优势:
Django 采用了 MVT 的软件设计模式,即模型(Model),视图(View)和模板(Template)。
Django 的 MTV 模式本质上和 MVC 是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django 的 MTV 分别是指:
除了以上三层之外,还需要一个 URL 分发器,它的作用是将一个个 URL 的页面请求分发给不同的 View 处理,View 再调用相应的 Model 和 Template,MTV 的响应模式如下所示:
解析:
用户通过浏览器向我们的服务器发起一个请求(request),这个请求会去访问视图函数:
视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
安装:pip install Django
创建Django项目:
django-admin startproject 项目名称项目结构
启动:python manage.py runserver 8001
# django的1.x和2.x不同
+# 1.x : url(正则表达式,views视图函数,参数,别名)
+# 2.x : path,re_path(原来的url)
+from django.contrib import admin
+from django.urls import path
+
+urlpatterns = [
+ path('admin/', admin.site.urls),
+]from django.contrib import admin
+from django.urls import path
+from storyxc.views import index
+urlpatterns = [
+ path('admin/', admin.site.urls),
+ path('',index,{'param':'story'})
+]from django.shortcuts import HttpResponse
+
+
+def index(request,param):
+ print(param)
+ return HttpResponse('ok')启动应用后访问localhost:8000
控制台:
[30/Apr/2021 00:31:21] "GET / HTTP/1.1" 200 2
+storypython3 manage.py startapp demo
djangoProject
+├── demo
+│ ├── __init__.py
+│ ├── admin.py
+│ ├── apps.py
+│ ├── migrations
+│ │ └── __init__.py
+│ ├── models.py
+│ ├── tests.py
+│ └── views.py
+├── djangoProject
+│ ├── __init__.py
+│ ├── __pycache__
+│ │ ├── __init__.cpython-311.pyc
+│ │ └── settings.cpython-311.pyc
+│ ├── asgi.py
+│ ├── settings.py
+│ ├── urls.py
+│ └── wsgi.py
+├── manage.py
+└── templates# djangoProject/settings.py
+
+# Application definition
+
+INSTALLED_APPS = [
+ 'django.contrib.admin',
+ 'django.contrib.auth',
+ 'django.contrib.contenttypes',
+ 'django.contrib.sessions',
+ 'django.contrib.messages',
+ 'django.contrib.staticfiles',
+ # 新增注册app
+ 'demo.apps.DemoConfig'
+]
+# 可以配置可访问域名
+ALLOWED_HOSTS = ["192.168.2.2"]安装:pip install pymysql
代码:
import pymysql
+
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor(cursor=pymysql.cursors.DictCursor)
+cursor.execute('select * from tb_student')
+print(cursor.fetchall())
+connection.close()
+
+res:
+[{'id': 1, 'name': 'tom', 'age': 18}, {'id': 2, 'name': 'rose', 'age': 17}]connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+cursor.execute('update tb_student set name = "jack" where id = 1')
+connection.commit()
+connection.close()
import pymysql
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+try:
+ cursor.execute('delete from tb_student where id = 2')
+ connection.commit()
+except Exception as e:
+ connection.rollback()
+connection.close()
import pymysql
+
+connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+cursor = connection.cursor()
+try:
+ # 方式1
+ cursor.execute('insert into tb_student(name,age) values("mike",20)')
+ # 方式2
+ cursor.execute('insert into tb_student(name,age) values("%s",%s)' % ('mike',21))
+ connection.commit()
+except Exception as e:
+ connection.rollback()
+connection.close()
import pymysql
+
+
+class Mysql(object):
+ def __enter__(self):
+ self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
+ return self.connection
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ self.connection.close()
+
+
+if __name__ == '__main__':
+ with Mysql() as conn:
+ cursor = conn.cursor(pymysql.cursors.DictCursor)
+ try:
+ sql = "select * from tb_student"
+ cursor.execute(sql)
+ res = cursor.fetchall()
+ print(res)
+ except:
+ print('error')一直想搞一台nas玩玩儿,但是看了群晖、威联通这些成品nas低到令人发指的性价比,我最终还是决定diy一台小主机来实现自己的需求。
PC上还有块4T的希捷酷鹰,再添3块4T紫盘组raid5阵列。机箱的盘位就至少需要4个以上,挑了一圈就乔思伯N1(5盘位)和万由的810A(8盘位)能看的过去,虽然万由盘位多但是价格比n1高了大几百,目前也用不到这么多盘位,因此机箱确定了n1,主板也要买itx版型。
要跑的docker容器比较多,下载器服务、阿里云的webdav容器、直播录制程序容器等等。。。因此内存需要32G以上。
确定使用的系统是个比较复杂的过程,因为有过PVE虚拟机翻车的经历,这个服务器又主要承载了数据存储功能,所以要追求稳定,因此首先排除PVE和ESXi这些虚拟机系统,直接物理机装系统。然后我在虚拟机上装了最新版的Truenas scale体验了一下,这个系统是基于debian用python开发的,交互上倒没什么问题,但是因为是个纯nas系统,对主系统限制较多,自由度不高(不能直接装软件),因此也被pass,黑群晖这些就不说了,在我看来还不如truenas。一圈排除下来就只能直接装linux server了。去V2EX论坛问了老哥们的意见,推荐debian的很多,也有建议用最熟悉的系统的, 最后我选择了后者,选了比较有把握的ubuntu server,正好ubuntu的22.04发行版刚出,就直接安排上了。 2024年还是换成了debian,ubuntu server更新太频繁经常重启,有点难顶。
经过了好几天的挑选,最终敲定了这套配置
cpu:i3-10100散片
+主板:七彩虹cvn b460i frozen
+内存:金士顿16g*2 2666
+固态:七彩虹 ssd sata3 128g
+cpu散热:超频3刀锋
+机械硬盘:西数海康oem紫盘4t*3
+电源:tt 350w sfx电源
+机箱+线材:乔思伯n1
+扩展卡:乐扩m2转sata3接口扩展卡其中散热、固态是在公司的福利商城购买,cpu、机械硬盘、机箱、扩展卡在淘宝购买,主板、电源在京东购买,内存在咸鱼淘的。不算硬盘花费是2480,加上硬盘3755。
组装完成后:
跟其他工业风机箱比起来,乔思伯n1这款颜值还是很不错的。
ubuntu官网下载最新版的ubuntu-server-22.04,然后rufus刷写到U盘中,使用U盘引导启动。
安装过程不再赘述,这里记录几个重点步骤:
在配置Ubuntu安装镜像这一步最好选择国内的企业/大学镜像站,不然后面安装可能会在下载时卡住。网易镜像源http://mirrors.163.com/ubuntu/,阿里云镜像源https://mirrors.aliyun.com/ubuntu/,清华源https://mirrors.tuna.tsinghua.edu.cn/ubuntu/
/和/boot 两个区,然后四块4T机械组了raid5。(ubuntu在建立阵列后会立刻进入重建过程,阵列中会有一个分区状态为spare rebuilding ,其他分区为active sync。这个重建过程很久,我4块4T重建总共用了十几个小时,重建完成后阵列下所有分区都会变为active sync 状态
开启root登陆
sudo vim /etc/ssh/sshd_config
+
+# 添加配置
+PermitRootLogin yes
+
+# 给root修改密码
+sudo passwd root
+
+systemctl restart sshd启用密钥登陆
见另一篇博客 阿里云服务器启用密钥登陆并禁用密码登陆
时区同步
sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
这个部分长期更新XD,一点点补上吧。
# 安装samba
+sudo apt install samba
+# 启动smb
+systemctl start smb
+# 开机自启
+systemctl enable smb
+
+# 创建共享文件夹 设置权限770
+mkdir /mnt/data
+sudo chmod 770 /mnt/data
+
+# 添加用户和密码
+sudo smbpasswd -a 用户名
+
+# 修改配置文件,在文件最后添加共享资源设置
+sudo vim /etc/samba/smb.conf
+
+[data]
+path = /mnt/data
+available = yes
+browseable = yes
+public = no
+writable = yes
+valid users = storysamba共享配置详解
[temp] #共享资源名称
comment = Temporary file space #简单的解释,内容无关紧要
path = /tmp #实际的共享目录
writable = yes #设置为可写入
browseable = yes #可以被所有用户浏览到资源名称,
guest ok = yes #可以让用户随意登录
public = yes #允许匿名查看
valid users = 用户名 #设置访问用户
valid users = @组名 #设置访问组
readonly = yes #只读
readonly = no #读写
hosts deny = 192.168.0.0 #表示禁止所有来自192.168.0.0/24 网段的IP 地址访问
hosts allow = 192.168.0.24 #表示允许192.168.0.24 这个IP 地址访问
[homes]为特殊共享目录,表示用户主目录。
[printers]表示共享打印机。
原文链接:https://blog.csdn.net/l1593572468/article/details/121444812
# Uninstall old versions
+sudo apt-get remove docker docker-engine docker.io containerd runc
+
+# Update the apt package index and install packages to allow apt to use a repository over HTTPS:
+sudo apt-get update
+sudo apt-get install \
+ ca-certificates \
+ curl \
+ gnupg \
+ lsb-release
+# Add Docker’s official GPG key:
+curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
+
+# Use the following command to set up the stable repository.
+echo \
+ "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
+ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
+
+# Install Docker Engine
+sudo apt-get update
+sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
+
+
+systemctl enable docker参考另一篇博客挂载阿里云盘+开机自动挂载
docker run -d \
+ --name=transmission \
+ -e TRANSMISSION_WEB_HOME=/transmission-web-control/ \
+ -e PUID=1000 \
+ -e PGID=1000 \
+ -e TZ=Asia/Shanghai \
+ -e USER=<user> \
+ -e PASS=<pass> \
+ -p 19091:9091 \
+ -p 51413:51413 \
+ -p 51413:51413/udp \
+ -v /mnt/data/docker/transmission/data:/config \
+ -v /mnt/data/downloads/others:/downloads/others \
+ -v /mnt/data/downloads/tvseries:/downloads/tvseries \
+ -v /mnt/data/docker/transmission/watch/folder:/watch \
+ -v /mnt/data/downloads/movies:/downloads/movies \
+ --restart=always \
+ linuxserver/transmissionversion: "3.2"
+
+services:
+ qbittorrent:
+ image: nevinee/qbittorrent:4.3.9
+ container_name: qbittorrent
+ environment:
+ - PUID=0
+ - PGID=0
+ - TZ=Asia/Shanghai
+ - WEBUI_PORT=18080
+ - BT_PORT=55555
+ volumes:
+ - /mnt/data/docker/qbittorrent/config:/data
+ - /repo:/downloads
+ network_mode: host
+ restart: unless-stoppeddocker run -d \
+ --name aria2 \
+ --restart always \
+ --log-opt max-size=1m \
+ -e TZ=Asia/Shanghai \
+ -e PUID=$UID \
+ -e PGID=$GID \
+ -e UMASK_SET=022 \
+ -e RPC_SECRET=<secret> \
+ -e RPC_PORT=16800 \
+ -p 16800:16800 \
+ -e LISTEN_PORT=16888 \
+ -p 16888:16888 \
+ -p 16888:16888/udp \
+ -v /mnt/data/docker/aria2/config:/config \
+ -v /mnt/data/downloads/tvseries:/downloads/tvseries \
+ -v /mnt/data/downloads/movies:/downloads/movies \
+ -v /mnt/data/downloads/others:/downloads/others \
+ p3terx/aria2-proversion: "3.2"
+
+services:
+ jenkins:
+ image: jenkins/jenkins:2.332.3-jdk11
+ container_name: jenkins
+ environment:
+ - TZ=Asia/Shanghai
+ user: root
+ volumes:
+ - /story/dist:/story/dist
+ - /mnt/data/docker/jenkins/jenkins_data:/var/jenkins_home
+ - /etc/localtime:/etc/localtime:ro
+ ports:
+ - "8099:8080"
+ restart: unless-stoppedversion: "3.2"
+services:
+ jellyfin:
+ image: linuxserver/jellyfin
+ container_name: jellyfin
+ environment:
+ - PUID=0
+ - PGID=0
+ - TZ=Asia/Shanghai
+ volumes:
+ - /mnt/data/docker/jellyfin/library:/config
+ - /tvshows:/data/tvshows
+ - /movies:/data/movies
+ devices:
+ - /dev/dri:/dev/dri
+ network_mode: host
+ restart: unless-stopped# 安装驱动
+apt install intel-media-va-driver
+# 解码支持确认
+/usr/lib/jellyfin-ffmpeg/vainfo
wget https://downloads.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz
+ tar -xzvf kafka_2.13-3.6.1.tgz -C /usr/localzookeeper.service
[Unit]
+Description=zookeeper
+
+[Service]
+Type=forking
+Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
+ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh -daemon /usr/local/kafka/config/zookeeper.properties
+ExecStop=/usr/local/kafka/bin/zookeeper-server-start.sh stop
+SyslogIdentifier=zookeeper
+
+[Install]
+WantedBy=multi-user.targetkafka.service
[Unit]
+Description=kafka
+After=zookeeper.service
+
+[Service]
+Type=forking
+Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
+ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
+ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
+
+[Install]
+WantedBy=multi-user.targetdocker run -d \
+ --name onedev \
+ -v /var/run/docker.sock:/var/run/docker.sock \
+ -v /mnt/data/docker/onedev:/opt/onedev \
+ -p 6610:6610 \ # http
+ -p 6611:6611 \ # ssh
+ --restart=always \
+ 1dev/server:latestsudo apt install rabbitmq-server
+
+cd /usr/lib/rabbitmq/bin
+# 开启rabbit网页控制台 默认端口号15672,重启rabbitmq服务
+ ./rabbitmq-plugins enable rabbitmq_management
+
+# rabbitmq默认用户guest不允许远程登陆,且systemd默认的启动用户为rabbitmq,可以改为root
+cd /lib/systemd/system
+vim rabbitmq-server.service
+
+# 新建rabbitmq用户
+cd /usr/lib/rabbitmq/bin
+./rabbitmqctl add_user username password
+# 授权
+./rabbitmqctl set_user_tags username administrator
+./rabbitmqctl set_permissions -p "/" username ".*" ".*" ".*"
+
+# 查看、删除、修改密码
+./rabbitmqctl list_users
+./rabbitmqctl delete_user username
+./rabbitmqctl change_password username newpasswordversion: "3"
+
+networks:
+ gitea:
+ external: false
+
+volumes:
+ gitea:
+ driver: local
+
+services:
+ server:
+ image: gitea/gitea:1.16.7
+ container_name: gitea
+ environment:
+ - DOMAIN=192.168.2.66
+ - HTTP_PORT=6610
+ - SSH_PORT=6611
+ - SSH_LISTEN_PORT=6611
+ restart: always
+ networks:
+ - gitea
+ volumes:
+ - gitea:/data
+ - /etc/timezone:/etc/timezone:ro
+ - /etc/localtime:/etc/localtime:ro
+ ports:
+ - "6610:6610"
+ - "6611:6611"/var/lib/docker/volumes/gitea_gitea/_data/gitea/conf/app.ini
+
+# add the following lines to the end of the file
+[webhook]
+ALLOWED_HOST_LIST = 192.168.2.66In Jenkins: on the job settings page set "Source Code Management" option to "Git", provide URL to your repo (http://gitea-url.your.org/username/repo.git), and in "Poll triggers" section check "Poll SCM" option with no schedule defined. This setup basically tells Jenkins to poll your Gitea repo only when requested via the webhook.
In Gitea: under repo -> Settings -> Webhooks, add new webhook, set the URL to http://jenkins_url.your.org/gitea-webhook/post, and clear the secret (leave it blank).
At this point clicking on "Test Delivery" button should produce a successful delivery attempt (green checkmark).
docker run -d --name kafkaui -p 9000:9000 \
+ -e KAFKA_BROKERCONNECT="192.168.2.66:9092"\
+ -e JVM_OPTS="-Xms32M -Xmx64M" \
+ -e SERVER_SERVLET_CONTEXTPATH="/" \
+ obsidiandynamics/kafdropversion: '3'
+
+services:
+ cadvisor:
+ image: gcr.io/cadvisor/cadvisor:v0.47.2
+ container_name: cadvisor
+ volumes:
+ - /:/rootfs:ro
+ - /var/run:/var/run:ro
+ - /sys:/sys:ro
+ - /var/lib/docker/:/var/lib/docker:ro
+ - /dev/disk/:/dev/disk:ro
+ ports:
+ - "28080:8080"
+ privileged: true
+ restart: unless-stopped
+ devices:
+ - /dev/kmsgwget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gztar -zxvf node_exporter-1.6.1.linux-amd64.tar.gz && mv node_exporter-1.6.1.linux-amd64/node_exporter /usr/local/bin # 编写systemd服务
+cat > /etc/systemd/system/node_exporter.service <<EOF
+[Unit]
+Description=node_exporeter
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/local/bin/node_exporter
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF
+
+# 更新内核并启动,自启动
+systemctl daemon-reload && systemctl start node_exporter && systemctl enable node_exporter && systemctl status node_exporter# openwrt要使用init.d
+# /etc/init.d/node_exporter
+#!/bin/sh /etc/rc.common
+
+START=99
+STOP=10
+
+start() {
+ echo "Starting Node Exporter..."
+ /usr/bin/node_exporter --web.listen-address=":9100" > /dev/null 2>&1 &
+}
+
+stop() {
+ echo "Stopping Node Exporter..."
+ killall node_exporter
+}
+
+restart() {
+ stop
+ sleep 1
+ start
+}/etc/init.d/node_exporter enable && /etc/init.d/node_exporter start
wget https://github.com/oliver006/redis_exporter/releases/download/v1.46.0/redis_exporter-v1.46.0.linux-amd64.tar.gztar -xvf redis_exporter-v1.46.0.linux-amd64.tar.gz && mv redis_exporter-v1.46.0.linux-amd64/redis_exporter /usr/local/bin# 编写systemd服务
+cat > /etc/systemd/system/redis_exporter.service <<EOF
+[Unit]
+Description=redis_exporter
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/local/bin/redis_exporter -redis.addr ip:port
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target
+EOF
+
+# 更新内核并启动,自启动
+systemctl daemon-reload && systemctl start redis_exporter && systemctl enable redis_exporter && systemctl status redis_exporter# docker-compose.yml
+
+version: "3"
+
+
+services:
+ grafana:
+ image: grafana/grafana
+ container_name: grafana
+ restart: unless-stopped
+ ports:
+ - 3000:3000
+ user: root
+ volumes:
+ - /mnt/data/docker/monitor/grafana/conf/grafana.ini:/etc/grafana/grafana.ini
+ - /mnt/data/docker/monitor/grafana/data:/var/lib/grafana
+ - /mnt/data/docker/monitor/grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards
+ - /mnt/data/docker/monitor/grafana/provisioning/datasources:/etc/grafana/provisioning/datasources
+ environment:
+ - TZ=Asia/shanghai
+ prometheus:
+ image: prom/prometheus
+ container_name: prometheus
+ restart: unless-stopped
+ ports:
+ - 9090:9090
+ volumes:
+ - /mnt/data/docker/monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
+ - prometheus_data:/prometheus
+ environment:
+ - TZ=Asia/shanghai
+
+volumes:
+ prometheus_data:prometheus.yml
global:
+ scrape_interval: 15s
+ evaluation_interval: 15s
+
+
+scrape_configs:
+ - job_name: "linux"
+ scrape_interval: 5s
+ static_configs:
+ - targets: [ "192.168.2.66:9100" ]
+ labels:
+ instance: home-server-ubuntu
+ - job_name: "redis"
+ scrape_interval: 5s
+ static_configs:
+ - targets: [ "192.168.2.66:9121" ]
+ labels:
+ instance: home-server-ubuntu
+ - job_name: "cadvisor"
+ static_configs:
+ - targets: [ "192.168.2.66:28080" ]
+ labels:
+ instance: home-server-ubuntudocker cp grafana:/etc/grafana.ini ~/grafana监控大盘模板
配置域名解析,Bitwarden默认使用80和443端口,可以执行安装后在bwdata/config.yaml修改端口
http_prt: 80
+https_port: 443修改完
bwdata/config.yaml后需要执行./bitwarden.sh rebuild
curl -fsSL https://get.docker.com | sudo sh
sudo adduser bitwarden
+sudo passwd bitwarden
+sudo groupadd docker
+sudo usermod -aG docker bitwarden
+sudo mkdir /opt/bitwarden
+sudo chmod -R 700 /opt/bitwarden
+sudo chown -R bitwarden:bitwarden /opt/bitwarden**](https://bitwarden.com/host/) for use in installation.
For more information, see What are my installation id and installation key used for?
curl -Lso bitwarden.sh "https://func.bitwarden.com/api/dl/?app=self-host&platform=linux" && chmod 700 bitwarden.sh
+
+./bitwarden.sh install./bwdata/env/global.override.env. globalSettings__mail__replyToEmail=email@example.com
+globalSettings__mail__smtp__host=smtp.qq.com
+globalSettings__mail__smtp__port=465
+globalSettings__mail__smtp__ssl=true
+globalSettings__mail__smtp__username=email@example.com
+globalSettings__mail__smtp__password=password
+
+globalSettings__disableUserRegistration=true # 禁止注册修改完后执行
./bitwarden.sh restart
./bitwarden.sh start
backup bwdata folder
https://bitwarden.com/help/migration/
如果低版本迁移到高版本,覆盖bwdata后,先执行./bitwarden.sh update
https://bitwarden.com/download
version: '3.8'
+
+services:
+ hoppscotch:
+ container_name: hoppscotch
+ image: hoppscotch/hoppscotch
+ ports:
+ - "53000:3000"
+ - "53100:3100"
+ - "53170:3170"
+ env_file: .env
+ restart: unless-stopped
+ links:
+ - postgresql
+ depends_on:
+ - postgresql
+ networks:
+ - hoppscotch
+ postgresql:
+ container_name: postgresql
+ image: postgres
+ environment:
+ POSTGRES_DB: db
+ POSTGRES_USER: user
+ POSTGRES_PASSWORD: passwd
+ ports:
+ - "5432:5432"
+ volumes:
+ - postgres_data:/var/lib/postgresql/data
+ restart: unless-stopped
+ networks:
+ - hoppscotch
+
+volumes:
+ postgres_data:
+
+networks:
+ hoppscotch:#-----------------------Backend Config------------------------------#
+# Prisma Config
+DATABASE_URL=postgresql://user:passwd@postgresql:5432/db
+
+# Auth Tokens Config
+JWT_SECRET="xxx"
+TOKEN_SALT_COMPLEXITY=10
+MAGIC_LINK_TOKEN_VALIDITY= 3
+REFRESH_TOKEN_VALIDITY="604800000" # Default validity is 7 days (604800000 ms) in ms
+ACCESS_TOKEN_VALIDITY="86400000" # Default validity is 1 day (86400000 ms) in ms
+SESSION_SECRET='xxx'
+
+# Hoppscotch App Domain Config
+REDIRECT_URL="https://hoppscotch.example.com"
+WHITELISTED_ORIGINS="https://hoppscotch.example.com/backend,https://hoppscotch.example.com,https://hoppadmin.example.com"
+VITE_ALLOWED_AUTH_PROVIDERS=GITHUB
+
+# Google Auth Config
+#GOOGLE_CLIENT_ID="************************************************"
+#GOOGLE_CLIENT_SECRET="************************************************"
+#GOOGLE_CALLBACK_URL="http://hoppscotch.example.com:3170/v1/auth/google/callback"
+#GOOGLE_SCOPE="email,profilstoryxc
+
+# Github Auth Config
+GITHUB_CLIENT_ID="xxx"
+GITHUB_CLIENT_SECRET="xxx"
+GITHUB_CALLBACK_URL="https://hoppscotch.example.com/backend/v1/auth/github/callback"
+GITHUB_SCOPE="user:email"
+
+# Microsoft Auth Config
+#MICROSOFT_CLIENT_ID="************************************************"
+#MICROSOFT_CLIENT_SECRET="************************************************"
+#MICROSOFT_CALLBACK_URL="http://hoppscotch.example.com:3170/v1/auth/microsoft/callback"
+#MICROSOFT_SCOPE="user.read"
+#MICROSOFT_TENANT="common"
+
+# Mailer config
+MAILER_SMTP_URL="smtps://user@domain.com:passwd@smtp.domain.com"
+MAILER_ADDRESS_FROM="user@domain.com"
+
+# Rate Limit Config
+RATE_LIMIT_TTL=60 # In seconds
+RATE_LIMIT_MAX=100 # Max requests per IP
+
+
+#-----------------------Frontend Config------------------------------#
+
+
+# Base URLs
+VITE_BASE_URL=https://hoppscotch.example.com
+VITE_SHORTCODE_BASE_URL=https://hoppscotch.example.com
+VITE_ADMIN_URL=https://hoppadmin.example.com
+
+# Backend URLs
+VITE_BACKEND_GQL_URL=https://hoppscotch.example.com/backend/graphql
+VITE_BACKEND_WS_URL=wss://hoppscotch.example.com/backend/ws/graphql
+VITE_BACKEND_API_URL=https://hoppscotch.example.com/backend/v1
+
+# Terms Of Service And Privacy Policy Links (Optional)
+VITE_APP_TOS_LINK=https://docs.hoppscotch.io/support/terms
+VITE_APP_PRIVACY_POLICY_LINK=https://docs.hoppscotch.io/support/privacyserver {
+ listen 443 ssl;
+ listen [::]:443 ssl;
+ server_name hoppscotch.example.com;
+
+ # SSL
+ ssl_certificate /etc/nginx/ssl/hoppscotch.example.com.crt;
+ ssl_certificate_key /etc/nginx/ssl/hoppscotch.example.com.key;
+ ssl_session_timeout 5m;
+ #请按照以下协议配置
+ ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
+ #表示使用的加密套件的类型。
+ ssl_protocols TLSv1.1 TLSv1.2;
+
+ # security
+
+ # logging
+ access_log /var/log/nginx/access.log combined buffer=512k flush=1m;
+ error_log /var/log/nginx/error.log warn;
+
+ # additional config
+
+ location /backend/ws/ {
+ proxy_pass http://127.0.0.1:53170/;
+ proxy_set_header Upgrade $http_upgrade;
+ proxy_set_header Connection "Upgrade";
+ proxy_set_header X-Real-IP $remote_addr;
+ }
+
+ location /backend/ {
+ proxy_pass http://127.0.0.1:53170/;
+ }
+
+ location / {
+ proxy_pass http://127.0.0.1:53000/;
+ }
+}
+
+# HTTP redirect
+server {
+ listen 80;
+ listen [::]:80;
+ server_name hoppscotch.example.com;
+ return 301 https://hoppscotch.example.com$request_uri;
+}version: "3"
+
+services:
+ kutt:
+ image: kutt/kutt
+ depends_on:
+ - postgres
+ - redis
+ command: [ "./wait-for-it.sh", "postgres:5432", "--", "npm", "start" ]
+ ports:
+ - "3000:3000"
+ env_file:
+ - .env
+ environment:
+ DB_HOST: postgres
+ DB_NAME: kutt
+ DB_USER: user
+ DB_PASSWORD: passwd
+ REDIS_HOST: redis
+
+ redis:
+ image: redis:6.0-alpine
+ volumes:
+ - redis_data:/data
+
+ postgres:
+ image: postgres:12-alpine
+ environment:
+ POSTGRES_USER: user
+ POSTGRES_PASSWORD: passwd
+ POSTGRES_DB: kutt
+ volumes:
+ - postgres_data:/var/lib/postgresql/data
+
+volumes:
+ redis_data:
+ postgres_data:# App port to run on
+PORT=3000
+
+# The name of the site where Kutt is hosted
+SITE_NAME=Kutt
+
+# The domain that this website is on
+DEFAULT_DOMAIN=kutt.domain.com
+
+# Generated link length
+LINK_LENGTH=5
+
+# Postgres database credential details
+DB_HOST=postgres
+DB_PORT=5432
+DB_NAME=postgres
+DB_USER=user
+DB_PASSWORD=passwd
+DB_SSL=false
+
+# Redis host and port
+REDIS_HOST=redis
+REDIS_PORT=6379
+REDIS_PASSWORD=
+REDIS_DB=
+
+# Disable registration
+DISALLOW_REGISTRATION=true
+
+# Disable anonymous link creation
+DISALLOW_ANONYMOUS_LINKS=true
+
+# The daily limit for each user
+USER_LIMIT_PER_DAY=50
+
+# Create a cooldown for non-logged in users in minutes
+# Set 0 to disable
+NON_USER_COOLDOWN=0
+
+# Max number of visits for each link to have detailed stats
+DEFAULT_MAX_STATS_PER_LINK=5000
+
+# Use HTTPS for links with custom domain
+CUSTOM_DOMAIN_USE_HTTPS=false
+
+# A passphrase to encrypt JWT. Use a long and secure key.
+JWT_SECRET=xxx
+
+# Admin emails so they can access admin actions on settings page
+# Comma seperated
+ADMIN_EMAILS=user@domain.com
+
+# Invisible reCaptcha secret key
+# Create one in https://www.google.com/recaptcha/intro/
+RECAPTCHA_SITE_KEY=
+RECAPTCHA_SECRET_KEY=
+
+# Google Cloud API to prevent from users from submitting malware URLs.
+# Get it from https://developers.google.com/safe-browsing/v4/get-started
+GOOGLE_SAFE_BROWSING_KEY=
+
+# Your email host details to use to send verification emails.
+# More info on http://nodemailer.com/
+# Mail from example "Kutt <support@kutt.it>". Leave empty to use MAIL_USER
+MAIL_HOST=smtp.domain.com
+MAIL_PORT=465
+MAIL_SECURE=true
+MAIL_USER=user@domain.com
+MAIL_FROM=user@domain.com
+MAIL_PASSWORD=passwd
+
+# The email address that will receive submitted reports.
+REPORT_EMAIL=
+
+# Support email to show on the app
+CONTACT_EMAIL=server {
+ listen 443 ssl;
+ listen [::]:443 ssl;
+ server_name kutt.domain.com;
+
+ # SSL
+ ssl_certificate /etc/nginx/ssl/kutt.domain.com.crt;
+ ssl_certificate_key /etc/nginx/ssl/kutt.domain.com.key;
+ ssl_session_timeout 5m;
+ #请按照以下协议配置
+ ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
+ #表示使用的加密套件的类型。
+ ssl_protocols TLSv1.1 TLSv1.2;
+
+ # security
+ include nginxconfig.io/security.conf;
+
+ # logging
+ access_log /var/log/nginx/access_kutt.log combined buffer=512k flush=1m;
+ error_log /var/log/nginx/error_kutt.log warn;
+
+ # additional config
+ #include nginxconfig.io/general.conf;
+ location / {
+ proxy_pass http://127.0.0.1:3000;
+ proxy_set_header Host $host;
+ proxy_set_header X-Real-IP $remote_addr;
+ proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
+ }
+
+}
+
+
+# HTTP redirect
+server {
+ listen 80;
+ listen [::]:80;
+ server_name .kutt.domain.com;
+ return 301 https://kutt.domain.com$request_uri;
+}version: "3"
+services:
+ nas-tools:
+ image: nastool/nas-tools:latest
+ ports:
+ - 3000:3000 # 默认的webui控制端口
+ volumes:
+ - ./config:/config # 冒号左边请修改为你想保存配置的路径
+ - /repo/others:/repo/others # 媒体目录,多个目录需要分别映射进来,需要满足配置文件说明中的要求
+ - /repo/movies:/repo/movies
+ - /repo/tvseries:/repo/tvseries
+ - /repo/resources/link:/repo/resources/link
+ environment:
+ - PUID=1000 # 想切换为哪个用户来运行程序,该用户的uid
+ - PGID=1000 # 想切换为哪个用户来运行程序,该用户的gid
+ - UMASK=022 # 掩码权限,默认000,可以考虑设置为022
+ - NASTOOL_AUTO_UPDATE=false # 如需在启动容器时自动升级程程序请设置为true
+ - NASTOOL_CN_UPDATE=false # 如果开启了容器启动自动升级程序,并且网络不太友好时,可以设置为true,会使用国内源进行软件更新
+ #- REPO_URL=https://ghproxy.com/https://github.com/NAStool/nas-tools.git # 当你访问github网络很差时,可以考虑解释本行注释
+ restart: always
+ network_mode: bridge
+ hostname: nas-tools
+ container_name: nastoolhttps://core.telegram.org/api/obtaining_api_id
repo:
https://github.com/tdlib/telegram-bot-apigenerator:
https://tdlib.github.io/telegram-bot-api/build.htmlshellapt-get update +apt-get upgrade +apt-get install make git zlib1g-dev libssl-dev gperf cmake g++ +git clone --recursive https://github.com/tdlib/telegram-bot-api.git +cd telegram-bot-api +rm -rf build +mkdir build +cd build +cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX:PATH=/usr/local .. +cmake --build . --target install +cd ../.. +ls -l /usr/local/bin/telegram-bot-api*
systemctl edit --force --full tgbot-api.service
[Unit]
+Description=telegram bot api
+After=network.target
+[Service]
+Environment="TELEGRAM_API_ID=xxx"
+Environment="TELEGRAM_API_HASH=xxx"
+ExecStart=/usr/local/bin/telegram-bot-api --http-port=16666 --local --log=/var/log/telegram-bot-api/tg-bot-api.log
+[Install]
+WantedBy=multi-user.target[Unit]
+Description=uwsgi
+After=network.target
+[Service]
+Type=simple
+ExecStart=/usr/bin/uwsgi --emperor /opt/uwsgi
+Restart=on-failure
+[Install]
+WantedBy=multi-user.target[uwsgi]
+; 套接字文件的位置,可以是Unix socket或TCP地址
+http-socket = ip:port
+
+; Django项目根目录
+chdir = /root/project/home
+
+; 加载Django应用
+module = home.wsgi:application
+
+; 启用主线程
+master = true
+
+; 进程数量
+processes = 1
+
+; 每个进程的线程数
+threads = 1
+
+; 启用文件监控,代码改动自动重载
+py-autoreload = 1
+
+; 设置虚拟环境
+virtualenv = /root/project/home/venv
+
+; python搜索路径
+pythonpath = /root/project/home/venv/lib/python3.10/site-packages
+
+
+; 日志目录
+logto = /var/log/uwsgi/%n.log
+
+plugins = python3
+
+buffer-size = 65536apt install vsftpdvim /etc/vsftpd.conf
listen=NO
+listen_ipv6=YES
+# 禁止匿名用户登录
+anonymous_enable=NO
+# 允许本地用户登录
+local_enable=YES
+# 允许本地用户进行写操作
+write_enable=YES
+# 将所有本地用户限制在其主目录中
+chroot_local_user=YES
+# 允许在受限目录中有写权限
+allow_writeable_chroot=YES重启systemctl restart vsftpd
usergroup add ftpuser
+# 创建用户 指定用户组、家目录、禁止用户通过ssh/控制台登录
+useradd -g ftpuser -d /home/ftpuser -s /usr/sbin/nologin newftpuser
+# 设置密码
+passwd newftpuservim /etc/shells,最后一行添加/usr/sbin/nologin
在 /etc/shells 文件中添加 /usr/sbin/nologin 的作用是允许系统中某些服务(如 FTP)将使用 /usr/sbin/nologin 作为登录 shell 的用户视为合法用户。
允许通过特定服务登录:一些服务(如 FTP 服务器、邮件服务器等)会检查用户的登录 shell 是否在 /etc/shells 列表中,以决定是否允许用户登录。 将 /usr/sbin/nologin 添加到 /etc/shells 文件后,配置了这个 shell 的用户将被这些服务视为合法用户,允许通过这些服务登录。
阻止用户获得交互式 shell: 即使 /usr/sbin/nologin 被添加到 /etc/shells 中,用户仍然无法通过 SSH、控制台等方式获得交互式 shell。/usr/sbin/nologin 会立即终止会话并显示一条消息,通常是“此账户当前不可用”。
趁着五一假期把家用服务器装好跑起来了,另外还买了一台J4125工控机来做软路由。工控机的机器今天刚到,下午反复折腾了pve虚拟机安装openwrt和物理机直接安装,目前是用物理机装好配置完毕了,但是看了一眼这监控数据,总感觉有点浪费性能。所以这篇文章写完我还是要换回pve安装(doge),剩下的性能折腾下其他虚拟机。
1. pe工具箱
+2. openwrt编译好的镜像,我用的是esir的固件
+3. 刷写镜像的软件physdiskwrite.exe1. pe工具箱安装到U盘中
+2. 把解压后的x86.img镜像文件和physdiskwrite.exe软件复制到U盘中
+3. 这时候已经可以拔掉硬路由器了,光猫lan口连软路由wan口(要问卖家哪个是wan口,我这个eth1是wan口),pc连软路由lan口(0、2、3),这是为了pc能跟软路由在同一个网段,如果不在则需要手动配置静态ip1. u盘启动工控机
+2. 用pe工具箱自带的diskgenius把装的硬盘格式化即可,注意这里不要进行分区,否则会写盘失败
+3. 打开cmd窗口,执行命令 physdiskwrite.exe -u x86.img,这里可以直接用鼠标把程序拖到cmd窗口,会自动拼出完整路径
+4. 根据终端输出选择要写入的硬盘,比如0是硬盘,1是u盘,就填0,enter即可开始写盘,等待写盘完毕即可
+5. 扩容系统分区,使用diskgenius找到刚刚写入的硬盘,然后再选中上面灰色未使用的分区,右击菜单中选择 “将空间分配给” -> “分区:未格式化(D:)”,然后确认即可
+6. 写盘完毕,选择重启,这时候直接拔出U盘即可
+7. 等待重启后,openwrt系统就已经成功启动了,如果不确定是否安装完,回车一下看看是否有lede的banner输出就行了
+8. openwrt一般ip为192.168.2.1(esir固件是5.1),这个可以看固件wiki或者自己ifconfig看一下
移动光猫改桥接模式
选择PPPoE协议并切换,填上宽带账号密码保存&应用即可
可以根据设备mac地址,自定义主机名和ip,并设置租期,这里一般我们设置静态ip都是永久的,填infinite。保存&应用,然后重启软路由即可。
这里可能重启软路由和设备后也不会让静态ip配置生效,网上找到了一篇文章的分析,跟第一次获取的ip租期未到期有管,可以手动释放旧的租约,然后刷新租约。windows下
ipconfig /release&ipconfig /renew,linux下dhclient -r&dhclient -s 192.168.2.1以下为原文:https://www.csdn.net/tags/NtjakgwsOTY3ODMtYmxvZwO0O0OO0O0O.html
我在使用 Openwrt 时手动分配了新的静态 IP 给我的电脑,但是在保存并应用后并没有立即生效,而且在我分别重启了电脑和路由器后仍然没有生效,为此我花了点时间找出了解决方法。
原因分析
在“DHCP/DNS->静态地址分配”中给电脑配置了静态地址不会立即生效,因为在此之前路由器已经通过 DHCP 分配了 IP 地址给电脑形成租约,在这个租约到期之前不会改变分配给电脑的 IP。通常我们在 Lan 中设置租约时间为 12h(小时),也就意味着要在 12 小时后电脑才会获取到我们设置的静态 IP。
不过我们可以清空路由器上的旧租约,同时将电脑断网重连,以此来使电脑获得新 IP 地址。最简单的方法就是将路由器重启,既清空了旧租约,又使电脑重连。但是为什么我之前重启会不起作用呢?
说实话这锅还真不好甩,我的电脑是 Win10 系统,在我重启路由器后,系统并不是向路由器请求一份新的租约,而是拿着旧的租约想要更新续约。这里你可能认为是路由器就直接续约了,但我认为并不是,OpenWrt 已经设定了静态地址,而电脑请求续约的 IP 不一样,结果是 OpenWrt 不会给续约,但也不会返回新的租约。
最终导致的结果就是电脑租约无法更新,但由于租约也没有到期,所以电脑继续使用旧的,而正好使用旧IP还能正常上网就一直沿用旧租约了。
解决方法
最简单的方法,设置的静态 IP 为原本 DHCP 获取到的 IP 地址,这样就不会存在不生效问题。但一定要更换 IP 的话,保证 OpenWrt 已重启,打开 Windows 命令行或者 Power Shell,输入以下命令执行:ipconfig /release
ipconfig /renew
第一条命令删除旧租约,这样就不会由于 IP 地址错误导致 OpenWrt 无法返回新租约,第二条命令就是手动更新租约。至此,解决了静态 IP 分配不生效的问题。
参考b站up主司波图的教程
主板支持WOL(Wake on LAN)功能和来电开机
以七彩虹主板为例
ADVANCED(高级模式)> Power Management Configuration(电源管理配置)> Wake By Lan(网卡唤醒)
+Wake By Lan(网卡唤醒)
+设置网络唤醒功能。
+[Enabled] 当检测到 LAN 设备已激活或有信号输入时,唤醒系统。
+[Disabled] 关闭网络唤醒功能。
+
+
+ADVANCED(高级模式)> Power Management Configuration(电源管理配置)> AC Power Loss(断电开机功能)
+AC Power Loss(断电开机功能)
+设置计算机断电之后,电源再次被接通时计算机的响应状态。
+[Power On] 通电后计算机自动开机。
+[Power Off] 通电后计算机保持关机状态。
+[Last State]] 通电后计算机恢复上次断电前的状态。# 如果没有需要先安装 apt install ethtool
+# 首先使用ifconfig或ip a查看设备名称 我的是enp3s0
+
+ethtool enp3s0 | grep "Wake-on"
+ Supports Wake-on: pumbg
+ Wake-on: d这个信息说明支持pumbg几种唤醒方式,而d表示当前处于禁用状态
"Wake-on" 中的不同字母代表不同的唤醒模式 这些字母分别代表以下内容:
p:代表PHY(物理层)唤醒模式,这种模式是基于物理层的唤醒模式。u:代表UDP数据包唤醒模式,这种模式需要特定的UDP数据包来唤醒设备。m:代表多播唤醒模式,这允许多播数据包来唤醒设备。b:代表广播唤醒模式,这允许广播数据包来唤醒设备。g:代表魔术唤醒帧模式,这是一种常用的唤醒模式,需要特定的魔术唤醒数据包。魔术唤醒数据包(Magic Wake-on-LAN Packet)是一种特殊的数据包,用于远程唤醒计算机或网络设备。它通常用于通过局域网远程唤醒处于休眠或关机状态的设备,以便进行远程管理或访问。这些数据包被称为"魔术",因为它们包含了一些特定的唤醒模式信息,以便网络接口卡能够识别并唤醒目标设备。
魔术唤醒数据包的结构通常包括以下元素:
- 目标设备的MAC地址:这是数据包的目标设备的物理地址,以便网络接口卡知道唤醒哪台设备。
- 以太网帧:数据包以标准的以太网帧格式进行封装。
- 魔术唤醒模式信息:这些信息告诉网络接口卡以特定方式处理数据包,以实现唤醒功能。
ethtool -s enp3s0 wol g
sudo systemctl edit --force --full wol-enable.service可以使用update-alternatives --config editor修改默认编辑器
[Unit]
+Description=Enable Wake-on-LAN
+
+[Service]
+ExecStart=/usr/sbin/ethtool -s enp3s0 wol g
+
+[Install]
+WantedBy=multi-user.targetsystemctl daemon-reload && systemctl enable wol-enable.service && systemctl start wol-enable.service
不同平台都有相对应的唤醒客户端,我主要是从软路由使用这个功能。使用Etherwake选中要唤醒的设备点击唤醒主机即可发送数据包成功唤醒。
可以配合UPS使用实现断电安全关机以及来电自动启动,详情见另一篇关于UPS和NUT的博客。
搞了7*24小时服务器之后经历了两次突然断电,每次重启磁盘检查都要卡很久,夏天一到用电量骤升,市电断电和跳闸的几率都增加了。万一多来几次突然断电,磁盘阵列可能要挂了,更关键的是数据无价啊,ups还是少不了。
因为不是成品nas系统,想实现自动关机得依靠linux上已有的软件。而我对apcupsd 这款软件有所耳闻,所以第一选择就去看了新款的apc bk650m2-ch ,快下单了才得知新款不支持apcupsd,然后就听网友的建议看了山特的box600和box850 ,山特这个型号有两排插座,一排防雷+不断电,一排是防雷,还省了了插排钱,自带的usb通讯端口可以通过nut 软件进行管理,实现自动关机以及自定义脚本执行等功能,虽然电池容量小了点,但是能省就省吧,最后下单了box600。
ups机器本身没什么可讲的,把附带的rj45接ups,usb线接主机,再把主机电源插在ups的不断电插口上,接着给ups通电即可。主要介绍下nut的使用和配置。
apt install nut
首先可以用lsusb命令查看是否接入了ups,能看到ups即可
然后编辑ups配置文件vim /etc/nut/ups.conf,增加配置如下
maxretry = 3
+[santak]
+ driver = usbhid-ups
+ port = auto
+ desc = "my ups"santak是ups的设备名,可以自定义,后续有些命令这个设备名还会用到
vim /etc/nut/upsd.users新增配置
[ups]
+ password = xxx
+ upsmon masterups为用户名,xxx为密码,upsmon master为运行模式
chown root:nut /etc/nut/upsd.conf /etc/nut/upsd.users
+chmod 0640 /etc/nut/upsd.conf /etc/nut/upsd.usersvim /etc/nut/nut.conf修改模式为单机
MODE=standalone启动upsd服务
/sbin/upsd查看全部
/bin/upsc santak@localhost # 这里的santak就是上面的设备名查看某个信息在后面接信息类别就行,例如查看电量
/bin/upsc santak@127.0.0.1 battery.charge
+
+Init SSL without certificate database
+100nut服务会在UPS发送LOWBATT时通知机器关机,触发时机默认为ups电量剩余20% 。我们需要添加upsmon配置vim /etc/nut/upsmon.conf
在MONITOR监视器部分添加配置
MONITOR santak@localhost 1 ups xxx master
+
+# MONITOR 设备名@ip 1 用户名 密码 节点授权
chown root:nut /etc/nut/upsmon.conf
+chmod 0640 /etc/nut/upsmon.conf启动upsmon
/sbin/upsmon实际上配置完上面的内容已经可以实现断电时安全关机了,但喜欢折腾的还可以自定义触发事件的脚本
vim /etc/nut/upsmon.conf添加内容
NOTIFYCMD /sbin/upssched这个配置的作用是发生事件是运行upssched程序
设置触发条件,三个动作分别是记录日志+通知所有用户发生了事件+执行notifycmd,也就是/sbin/upssched
NOTIFYFLAG ONBATT SYSLOG+WALL+EXECvim /etc/nut/upssched.conf编辑内容
CMDSCRIPT /usr/local/bin/upssched
+PIPEFN /var/run/nut/upssched/upssched.pipe
+LOCKFN /var/run/nut/upssched/upssched.lock
+AT ONBATT * START-TIMER power-off 10
+AT ONLINE * CANCEL-TIMER power-off这段配置通过CMDSCRIPT指定了发生事件时需要执行的脚本,这个脚本可以根据需求自定义,在断电时(ONBATT/电池供电) 会启动一个10秒的timer,之后会执行power-off事件,这里涉及的文件nut用户都需要配置权限
这个可以自定义,例如发邮件等操作,这里展示最基本的脚本格式,例如power-off事件发生时,将断电了 信息写入指定文件,还可以调用ups的指令/sbin/upsmon -c fsd执行立刻关机操作 (FSD = "Forced Shutdown")
#! /bin/sh
+
+case $1 in
+ power-off)
+ echo '$(date +\%Y-\%m-\%d\ \%H:\%M:\%S) - 断电了 ' >> /var/log/nut/nut.log
+ #/sbin/upsmon -c fsd #立即通知关机
+ ;;
+ *)
+ logger -t upssched "Unrecognized command: $1"
+ ;;
+esac安装完VMWare后,会自动生成两个虚拟网卡:
桥接模式分为两种模式:
桥接是虚拟机的网卡直接把数据包交给物理机的物理网卡进行处理,虚拟机必须有自己的ip、dns、网关信息
NAT(Network Address Translation),网络地址转换,相当于在虚拟机和物理机之间添加了一个交换机,拥有NAT地址转换功能,能够自动把虚拟机的IP转换为与物理机在同一网段的IP。VMnet8是NAT模式,自带DHCP功能,能给虚拟机分配IP地址。能够实现虚拟机和物理机相互通信,虚拟机和外网通信,但是不能外网到虚拟机通信,如果想让虚拟机作为服务器不能选择该模式。
DHCP(动态主机配置协议)是一个局域网的网络协议。指的是由服务器控制一段IP地址范围,客户机登录服务器时就可以自动获得服务器分配的IP地址和子网掩码。
内部虚拟机连接到一个可提供 DHCP 功能的虚拟网卡VMnet1上去,VMnet1相当于一个交换机,将虚拟机发来的数据包转发给物理网卡,但是物理网卡不会将该数据包向外转发。所以仅主机模式只能用于虚拟机与虚拟机之间、虚拟机与物理机之间的通信。
相当于模拟出一个交换机或者集线器出来,把不同虚拟机连接起来,与物理机不进行数据交流,与外网也不进行数据交流,构建一个独立的网络。没有 DHCP 功能,需要手工配置 IP 或者单独配置 DHCP 服务器。
VMware DHCP Service、VMware NAT Service、VMware Workstation Server服务开启,如果处于停止状态则启动,此外,要把VMnet8的ipv4地址和dns设置为自动获取WARNING
一般的系统选择iso镜像模式写入,安装pve需要选择dd镜像模式写入
等待刷写完毕按照正常U盘安装系统流程安装,注意ip网关等配置即可
官网下载truenas scale系统镜像,打开pve的配置地址,点击上传后选择下载好的镜像文件并上传
操作系统选择刚上传的镜像
系统tab页默认即可,磁盘这里要注意总线/设备选择sata0,磁盘大小选择16即可,这里是分了一个虚拟的系统盘,不需要太大,因为truenas系统的系统引导盘和存储是分开的,分的太大在truenas中也无法用于存储
cpu根据情况设置,内存最小8G,建议尽可能大,truenas scale官方建议最好16G,因为truenas的文件系统很依赖内存。
启动刚创建的虚拟机,在选择系统安装盘界面按空格选中刚分配的16G磁盘,选择ok即可
然后输入root密码,安装完后选择3重启
随后等待系统安装完毕
输入9选择关机
总线这里序号会默认自增,存储选择磁盘,我这里是只有一个固态硬盘,磁盘大小根据实际情况选择即可,添加即完成了虚拟硬盘的添加。
硬盘直通
1)直通单个硬盘
因为我这台测试机器只有一个固态硬盘,pve系统也装在这上面,所以无法用硬盘的直通,如果有多个机械盘,想直通给truenas,可以使用以下命令
ls -l /dev/disk/by-id # 查看硬盘名称
这里sda对应就是我的唯一一个硬盘,后面的sda1、2、3都是分区,可以忽略,记录下磁盘名称ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT,执行命令进行直通
qm set 100 -sata1 /dev/disk/by-id ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT
+---
+返回
+update VM 100: -sata1 /dev/disk/by-id ata-WDC_WD10EZEX-08WN4A0_WD-WCC6Y6EDC1NT看到这个返回信息即为直通成功,回到虚拟机下面可以看到已经新增了一个sata硬盘
命令拆解:
qm set vm编号 -总线编号 磁盘路径
+- vm编号为pve虚拟机中的编号,例如100,101,102等
+- 总线编号为指定编号下要新增的硬盘总线编号,例如虚拟机下只有一个硬盘sata0,要新增的就是sata1,这里就要填sata1
+- 磁盘路径 就是/dev/disk/by-id/ + 我们上一步保存的硬盘名称2)添加PCI设备,直通sata控制器
Proxmox VE(PVE)系统直通SATA Controller(SATA 控制器),会把整个sata总线全部直通过去,就是直接将南桥或者直接把北桥连接的sata总线直通,那么有些主板sata接口就会全部被直通。
WARNING
如果PVE系统安装在sata硬盘中,会导致PVE无法启动,所以在直通sata控制器前要确认自己的PVE系统安装位置,或者直接安装到NVMe硬盘中
qm set vm编号 -delete 设备名,例如要删除设备ID为100的虚拟机下直通的sata1
那就是qm set 100 -delete sata1