Hybrid Code Networks (HCN)
- Jason D. Williams, Hybrid Code Networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning
HCN combines an RNN with domain-specific knowledge encoded as software and system action templates.
4 Major components of HCN are
- RNN
- Domain Specific Software
- Domain Specific Action Template
- Entity Extraction Module
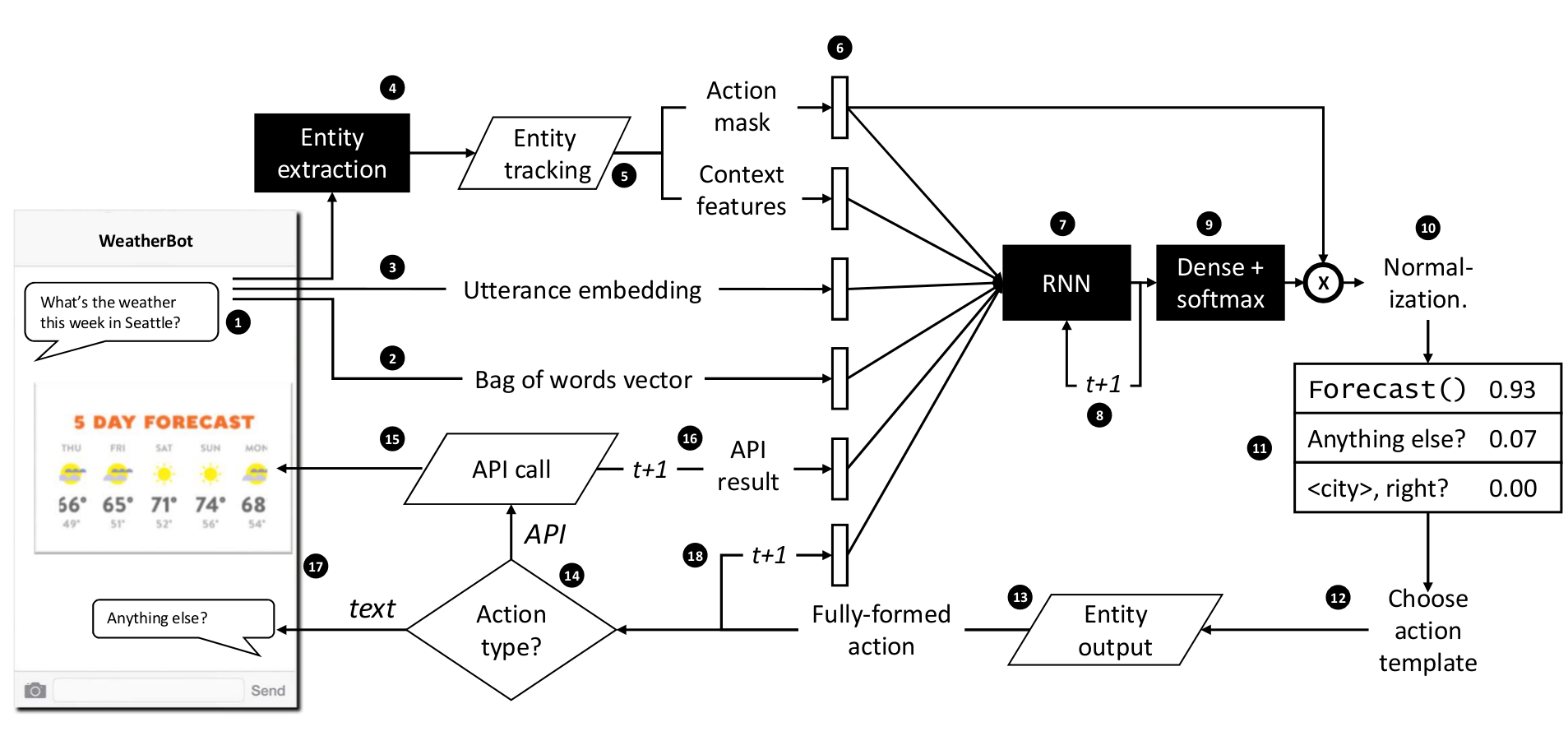
Both the RNN and the developer code maintain dialog state. Each action template can be a textual communicative action or an API call.
- Utterance : The user provides an utterance as text.
- BoW : Bag of words representation of the utterance is done.
- Utterance Embedding : Average word embedding of utterance is calculated. 300 dimensional word2vec is used. The update of the word embeddings is forbidden during training.
- Entity Extraction : Identify entities in the utterance, like name, place, time, etc,; simple string matching approach is proposed in the paper
- Entity Tracking : Map entities in the utterance, to a row in database; override existing entities (in buffer) with new entities.
-
Action Mask : A bit vector representation of which actions are allowed given the context at current timestamp (turn)
- Context Features : Handwritten features extracted from entities that may be useful for distinguishing among actions
- A feature vector is formed based on information extracted from (1) to (5).
- The feature vector is passed to an RNN
- RNN computes and maintains a hidden(internal) state
- Based on the hidden state, an output distribution over the list of distinct system action templates
- The action mask from (6), is applied as elementwise multiplication which should elimante non-permitted actions in the probability distribution over all actions
- An action is selected from the output distribution
- In a supervised learning setting, the action that has the maximum probability is selected
- In a reinforcement learning setting, an action is sampled from the distribution
- Entity Output : Based on the selected action, entities are filled in; fully-formed actions are produced
- Depending on the action,
- An API call is made, which fetches info and provides rich content to user, and depending on dialog state, contributes to the feature vector, to be passed to RNN, during next time step (turn)
- If the action is just text, it is rendered to the user
- The action taken, also contributes to the feature vector.
- LSTM is used in RNN
- AdaDelta optimizer is chosen for training
Once a system operates at a scale, interacting with a large number of users, it is desirable for the system to continue to learn autonomously using reinforcement learning. Policy Gradient method is selected for optimization.
A model
The LSTM in the network, represents the stochastic polity
"better" dialogs receive a positive gradient step, making the actions selected more likely and "worse" dialogs receive a negative gradient step, making the actions selected less likely.
Supervised Learning and Reinforcement Learning can be applied to the same network. After each RL gradient step, we check whether the updated policy reconstructs the training set. If not, we re-run SL gradient steps on the training set until the model reproduces the training set. This allows new training dialogs to be added at any time during RL optimization.
# Given:
# obs_size, action_size, nb_hidden
g = Graph()
g.add_input(
name=’obs’,
input_shape=(None, obs_size)
)
g.add_input(
name=’prev_action’,
input_shape=(None, action_size)
)
g.add_input(
name=’avail_actions’,
input_shape=(None, action_size)
)
g.add_node(
LSTM(
n_hidden,
return_sequences=True,
activation=’tanh’,
),
name=’h1’,
inputs=[
’obs’,
’prev_action’,
’avail_actions’
]
)
g.add_node(
TimeDistributedDense(
action_size,
activation=’softmax’,
),
name=’h2’,
input=’h1’
)
g.add_node(
Activation(
activation=normalize,
),
name=’action’,
inputs=[’h2’,’avail_actions’],
merge_mode=’mul’,
create_output=True
)
g.compile(
optimizer=Adadelta(clipnorm=1.),
sample_weight_modes={
’action’: ’temporal’
},
loss={
’action’:’categorical_crossentropy’
}
)