Partial freezing of the User-Agent string #467
Comments
|
Dear Yoav, Over the past two weeks we have sought evidence to justify this change. We have found none. None of the industry stakeholders we have spoken to were previously aware of the proposal. This means that the usual and necessary protocols of public review are lacking. In its current form this could easily be interpreted as a partisan gerrymandering attempt by the incumbent dominant player in the field, to the disadvantage of other players. In our conversations with other players, most recently at the Westminster Policy Forum, we found that they thought that this was all part of a cookie discussion. Solicitation of feedback from a wide global cross section of stakeholders via a neutral party is now required. The W3C comes to mind as fulfilling exactly that role. This proposal is too radical and has too much potential for disruption to be pushed though quickly, even if you accept the privacy arguments, which we remain unconvinced by. Considering purely the macro issues associated with good governance and controlled change we observe the following:
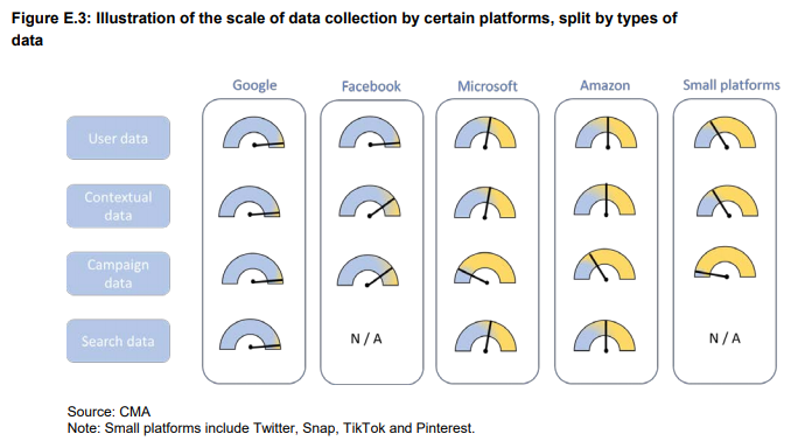
“Google is the platform with the largest dataset collected from its leading consumer-facing services such as YouTube, Google Maps, Gmail, Android, Google Chrome and from partner sites using Google pixel tags, analytical and advertising services. A Google internal document recognises this advantage saying that ‘Google has more data, of more types, from more sources than anyone else’.” The appendix includes the following diagram to illustrate the point.
As just one example the AdCom specification needs to be updated. Only once this is done can all publishers, SSPs, exchanges and DSPs adopt the new schema. If any of these parties do not make the modifications all are disadvantaged. The change needs to be made in lockstep. Many trade bodies and organisations are focused on the implications associated with the publicity concerning 3rd party cookies. They are only just becoming aware of this proposal. We are encouraging them to engage publicly but respect the demands on their time, limited resources and the sensitivities concerning the topic of privacy. There are many more arguments concerning assumptions, insufficient evidence, implementation, control over privacy (who decides?), and the technical impacts of the proposal yet to be resolved. In summary, this is a change that requires careful and widespread consideration, and a significant effort to socialise for it to be recognised by all as legitimately in the public interest. Without mature reflection and appropriate implementation delay it will be perceived as market manipulation by the incumbent player. Regards, James Rosewell - for self and 51Degrees |
|
One specific concern have about this proposal has to do with how "minority browsers" are impacted. Let's consider non-Chrome browsers that are also based on Chromium (as one aspect of browser diversity). It's not clear to me from reading the explainer how you intend non-Chrome browsers based on Chromium to make themselves known through Client Hints. If a hypothetical Chromium-based browser, let's call it Zamzung Zinternet, sends Please note, the TAG's ethical web principles argues that there is an inherent value of having multiple browsers. We should not be introducing a change the web platform that could result in making browser diversity less apparent / less measurable, as this could negatively impact browser diversity. |
|
@torgo, do the examples in https://github.com/WICG/ua-client-hints/blob/master/README.md#should-the-ua-string-really-be-a-set help with your first concern? |
|
As @jyasskin pointed out, the examples there should clarify what we had in mind on that front As for the Zamzung Zinternet case, I'd expect it to send out a set that looks something like Does that help alleviate your concerns? Also, note that there's a discussion on maybe putting more emphasis on the engine vs. the UA brand: WICG/ua-client-hints#52 To me, the Zamzung Zinternet case sounds like a good example in which we should prefer the current spec, over switching over to sending only the engine by default.
Beyond the privacy benefits of this change, it has an explicit goal of discouraging unreliable UA sniffing, as well as problematic UA sniffing patterns such as allow and block lists. So its intent is to discourage patterns that harm browser diversity. |
|
Hi Yoav, First and foremost, thank you for giving the opportunity to members of the community to engage in this discussion. I'm very concerned regarding the reasoning behind this change: bits of entropy. As a small ad network, we use ip and user agent data to combat ad fraud. These same bits of entropy are used when we detect ad fraud. This is virtually impossible to do if all we are getting is a rotating vpn-based ip address and "Chrome 74". At best, we have to wait for another request to get the rest of the UA data (significantly reducing our ad serving speed) or worst case, we will "exceed the user's privacy budget" and be denied this information altogether. Who decides how "the user agent can make reasonable decisions about when to honor requests for detailed user agent hints"? There is absolutely no doubt that your own properties will be ranked high in a hypothetical "trust/privacy" rating. There is nothing stopping you or your successors from abusing this power against smaller players like in the case with Yelp. Just because your organization has hundreds of millions of logged in active users across your various web properties and devices (search, chrome, android, chrome os, youtube, gmail, pixel etc.), it is significantly easier to run ad fraud analysis and protect your own ad network as the rest of us bite the dust. On the github repo it states "Top-level sites a user visits frequently (or installs!) might get more granular data than cross-origin, nested sites, for example". What about smaller sites just starting out? With all the large players (that already have top-level sites a user visits frequently) remaining untouched, you are effectively crippling competition from smaller players. Vast majority of the internet users simply don't care about this change and the handful that do, are probably underestimating the anti-trust issues that this change brings. One would have to be naive to think that there is absolutely no conflict of interest when a company that collects the most amount of data on earth is limiting what other, less frequently visited sites are allowed to see? Reducing bits of entropy is simply not a good enough reason to proceed with the change. I adore chrome and personally use it every day, however, I'd like to point out to the community that this change is not in everyone's best interest. TL;DR: We need the full os and browser version to survive as a small ad network. And more importantly, we need this data as part of every first http request, without being discriminated against for being a less frequently visited / smaller website. Regards, |
Sort of...? But couldn't this just revert over time to being just as messy as the current UA String? And yes, from the PoV of non-dominant browsers, who often need to maintain support for their development by citing usage numbers, I don't think it would be a good thing to suppress the the browser name. I do not think you can engineer a system to 100% eradicate browser sniffing and targeting. Some of this will always have to be tackled through best practice sharing and community pressure. |
It could. I'm hoping a decent application of GREASE can help prevent it.
I agree. But I want us to try and disincentivize negative behavior related to that (e.g. block and allow lists) |
|
Hi @yoavweiss "I want us to try and disincentivize negative behavior related to that" Did you consider removing the installation and Google-specific tracking headers (x-client-data) that Google Chrome is sending to Google properties ? Example: Now, go to https://ad.doubleclick.net/abc - and your browser also sends this magic x-client-data. It's a unique ID to track a specific Chrome instance across all Google properties. Really curious about your opinion, especially after the GDPR explicitly forbidding such tracking. |
|
From HN related to @kiwibrowser 's post: https://www.google.com/chrome/privacy/whitepaper.html
|
This is a misdirect. First, according to the same cited whitepaper, Usage statistics are "enabled by default for Chrome installations of version 54 or later". This means that nearly all Chrome installs will have a very high entropy. And even if a user disables usage statistics, a low entropy seed will very likely still yield a high entropy string since it includes "the state of the installation of Chrome itself, including active variations, as well as server-side experiments that may affect the installation." If you want to use this argument, the equivalent would be allow users to disable their User Agent, but to send it by default. This seems like a much more sane approach. |
|
This thread is already highlighting a set of issues which can be summarised as:
There is no burning problem or "innovation impairment" to justify incomplete engineering, poor governance or risky implementation. National regulators do not require this change – and in fact are actively balancing the needs of privacy, business and fair competition. |
|
Just as a reminder for people who think an "anonymous" ID on a request is fine because the GDPR is only about personally identifiable information: if you attach that random ID to the (most likely fairly unique) configuration of the individual installation and then apply the resulting ID to various requests made by the user, the "anonymous" ID becomes "pseudonymous" as you can infer the user's identity from it, making the resulting data personally-identifiable. Additionally, regardless of the legality and compliance of this, it is clearly a violation of the spirit of information scarcity present in the GDPR and shows a complete disregard for the idea of personal ownership of data and the right to privacy by default. |
|
Google, I think you can do better than this and it might hamr certain US state AG meetings about Google anti-trust issues. Please rethink! |
|
This is scary stuff for those living in oppressive countries who aren’t tech-savvy enough to use a proxy and change these settings.. |
|
I'm just here to read advanced excuses from people thinking that other smart guys reporting the issue here are idiots. You do realize that Chrome is becoming worse plague than Internet Explorer ever was? |
|
You could easily install a Chrome extension for modifying request headers and block the x-client-data header. |
|
@markentingh Privacy shouldn't be reserved for those with the knowledge to modify request headers. |
This comment has been minimized.
This comment has been minimized.
|
you should not have to be tech-savvy to prevent tracking or data gathering, companies should not be able to gather data or track you without CLEAR ad EXPLICIT opt-in and provision to ensure that you at any time can request the removal of all your data they hold. It is unfortunate that the approach of companies is that once you allow them to gather data that the data gather belongs to them. Companies at best have permitted use of data from the user when the opt-in and once cancel so it the permission to use it. if companies want to keep that data when a user opts out, there should be an explicit request from a company to the user if they are permitted to keep using already captured data. All of this should be implemented with the intended user being, a none-tech person and is easy and correctly displayed of information. |
|
As @yoavweiss mentioned above, issue #52 in the UA Client Hints repository attempts to summarize much of the ongoing debate here, particularly around GREASE. My concern with browsers pretending to be other browsers some fixed percentage of the time is twofold:
While we certainly ran into a few sites that blocked the new Edge based on the fact that it had an unknown "Edg" token (web.whatsapp.com was one example), the far more common cause of breakage that we encountered was from sites that started detecting our "Edg" token as a unique browser, but failed to update their per-browser allow lists to include the new Edge. As @mgol mentioned above:
While I admit that exposing engine by default and letting sites opt into receiving brand information using |
|
Do you think that with engines instead of browser brands, website operators will suddenly all become responsible citizens of the web? That is, engines will not just be the new browser brands when it comes to browser identification? If my browser has Again, website operators may exclusively rely on true equivalence classes and everything may be great. But why should anything be different with By the way, as for randomly returning different values (e.g. in 25 % of all cases), I think it’s obvious that this won’t work for the use cases that make |
Nope. I will readily admit that both the My main point is that exposing both brand and engine in a single hint doesn't encourage developers to change their behavior in any way for the better of compatibility. We can provide guidance encouraging them to target true equivalence classes by default, however providing both brand and engine in a single hint feels an awful lot like providing per-browser identifiers in the By only exposing |
|
I agree that the separation of brand and engine is reasonable. It’s just that the hope for better usage by the community in the future is not a strong argument, and responsible developers could already do today what they should do in the future, i.e. rely on engines instead of brands where possible. Turning passive fingerprinting into (detectable) active fingerprinting and offering information selectively is good as well. While most sites will request similar information and there won’t be much variation that could allow you to detect bad actors, this is still the strongest point of the proposal, I’d say. But I really don’t think it will change anything about the complexity and length of strings (or sets), so maybe we should not put too much hope into that and avoid making the proposal more complex to make those dreams possible. It will not work. All in all, it doesn’t appear to be a strong case for this new proposal replacing the current string where both have similar power and will suffer from similar problems. In the end, you will either have to support frozen old values forever or ultimately break backward compatibility. |
|
I have some comments on the proposal in a few different areas. Some of these points have been made already but I nonetheless want to restate them. Lack of industry consultation The User-Agent header has been part of the web since its inception. It has been stable element of the HTTP protocol through all its versions from HTTP 1.0 in 1996 all the way to HTTP/2 in 2015 and thus has inevitably come to be relied upon, even if particular use cases are not apparent, or have have been forgotten about, or its practitioners are not participants in standards groups. The User-Agent string is also likely being used in new ways not contemplated by the original authors of the specification. There was a salutary example of the longevity of standards in a recent Tweet from the author of Envoy, a web proxy server. He has been forced to add elements of HTTP 1.0 to ensure it works in the real world, despite Envoy’s development starting 23 years after HTTP/1.1 was ratified and deliberately opting not to support HTTP 1.0. This is the reality of the web—legacy is forever. Despite this reality, there is no public evidence of any attempt to consult with industry groups to understand the breath and severity of the impact of this proposed change to HTTP. It is a testament to its original design that the HTTP protocol has endured so well despite enormous changes in the internet landscape. Such designs should not be changed lightly. Issues with the stated aim of the proposal In subsequent discussions in the HTTP WG the privacy issues focused on passive fingerprinting, where the User-Agent string could potentially be used by entities for tracking users without their knowledge. What is missing from the discussion is any concrete evidence of the extent or severity of this supposed tracking. Making changes to an open standard that has been in place for over 24 years should require a careful and transparent weighing of the benefits and costs of doing so, not the opinion of some individuals. In this case the benefits are unclear and the central argument is disputed by experts in the field. The costs on the other hand are significant. The burden of proof for making the case that this truly is a problem worth fixing clearly falls on the proposer of the change. If active tracking is the main issue that this proposal seeks to address there are far richer sources of entropy than the User-Agent string. Google themselves have published a paper on a canvas-based tracking technique that can uniquely identify 52M client types with 100% accuracy. Audio fingerprinting, time skew fingerprinting and font-list fingerprinting can be combined to give very high entropy tracking. Timeline of change Move fast and break things is not the correct approach for making changes to an open standard. Narrow review group
All of these constituencies make use of the User-Agent string and must be involved in the discussion for a meaningful consensus to be reached. Obviously you can’t force people to people contribute but my sense is that this proposal is not widely known about amongst these impacted parties. Diversity of web monitisation The proposed change hurts web diversity by disproportionally harming smaller advertising networks that use the OpenRTB protocol. This essentially means most networks outside of Google and Facebook. Why? The User-Agent string is part of the OpenRTB BidRequest object where it is used to help inform bidding decisions, format ads and targeting. Why does it hurt Google less? Because Google is able to maintain a richer set of user data across its dominant web properties (90% market share in search), Chrome browser (69% market share) and Android operating system (74% market share). The web needs diversity of monetisation just as much as it needs diversity in browsers. Dismissive tone in discussions
Entire constituencies of the web should not be dismissed out of hand. This tone has no place in standards setting. Entangling Chrome releases with an open standards process Overstated support Unresolved issues Some closed HTTPWG issues: |
|
Significant time is now being spent by web engineers around the world "second guessing" how Google will proceed. In the interests of good governance and engineering @yoavweiss should now close this issue and the associated Intent at Chromium.org stating it will not be pursued. As many have pointed out the following is needed before it is ready to be debated by the W3C and TAG.
Related to this issue we have written to the Competition and Market Authority concerning Google's control over Chromium and web standards in general. A copy of that letter is available on our website. |
Indeed. Those are all use-cases that we intend to maintain.
The Client Hints infrastructure was thoroughly discussed at the IETF's HTTPWG, as well as its specific application as a replacement to the User Agent string.
There's a lot of independent research on the subject. Panopticlick is one from the EFF.
I'm afraid there's been some confusion. This proposal tries to address passive fingerprinting, by turning it into active fingerprinting that the browser can then keep track of.
Regarding timelines, I updated the intent thread.
The latter 4 are active at the IETF and at the HTTPWG. We've also received a lot of feedback from others on the UA-CH repo.
A few points:
I apologize if this came across as dismissive. That wasn't my intention.
The TAG review process asks for relevant time constraints. I provided them.
I'm not sure what your point is here. These issues were raised (one by me), discussed, resolved and then closed. |
|
Thanks for the response.
I'm saying that there is insufficient industry realisation that this is going on, despite discussions in the HTTPWG. However well-intentioned the discussions are it seems that some web constituents are only vaguely aware of what's being proposed. Obviously this isn't any particular person's fault but it feels like more time or outreach is required for the industry to become aware of the proposal and respond.
With respect, I don't think this answers my concern at all, specifically the extent of this supposed passive tracking. Panopticlick and others like it say what's possible without saying anything about how widespread this tracking actually is, so I don't think that this counts as evidence of passive tracking. Furthermore, Panopticlick mixes both passive and active tracking. If there is independent research on the extent and severity of passive tracking maybe you could cite it here?
No, of course not. And User agents are not obligated to send User-Agent headers either and can say whatever they want in them. But the point is that most user agents have been sending useful User-Agent headers for the last 25 years or so and, for all its imperfection, the web ecosystem has grown up around this consensus, including the advertising industry that helps pay for so much of what we utilise on the web.
Yes, but they get it only on the second request—a significant drawback in an industry where time is everything, especially on mobile devices where connectivity issues are more likely.
Perhaps this is the normal process but the closure felt forced/abrupt. |
|
There is a still a general lack of awareness around this and related Google driven changes to the web. Note: I've edited this post to ensure compliance with the W3C code of conduct. I hope it has - and will - provoked thought. The Economist last week touched on these subjects in a Special Report. In accessing it online one can experience the effects this change is already having on journalisim and access to advertising funded content. Basically you'll have to enter your email address everytime you want to read something, or if that's too much hassle just use Google News where Google will control the revenue for everyone. Small publishers will never get funding and will be commercially unviable. That's not a good thing and takes us a long way from Sir Tim's vision for the web. Here's a link to The Economist article. Who will benefit most from the data economy? And my wider thoughts on the impact. |
|
Last week the European Parliament and Council met to debate repealing legislation concerning Privacy and Electronic Communications regulation. The proposals recognise legitimate interest and the providers of electronic services. It calls out the end user confusion associated with gaining and controlling consent. These are subjects me and others have articulated previously in comments on this proposal. The debate explicitly recognises the use of “metadata can be useful for businesses, consumers and society as a whole”. Legitimate interest includes: • identification of security threads; The debate recognises “providers should be permitted to process an end-user’s electronic communications metadata where it is necessary for the provision of an electronic communications service”. Implementations should be performed in the “least intrusive manner”. The User-Agent meets this criteria. There is an explicit list of the information contained within the end users’ terminal equipment that requires explicit consent. The list does not include metadata such as that contained in the User-Agent. The legitimate interests of businesses are explicitly recognised “taking into consideration the reasonable expectations of the end-user based on her or his relationship with the provider”. The debate advocates placing controls over consent and control within the terminal equipment (or user’s agent) not the removal of such data. The outcome of the debate should inform the W3C, Chromium and other stakeholders. The UK (now no longer part of the EU) is also considering these matters via the Competition and Markets Authority (CMA) investigation and the Information Commissioners Office (ICO). At least two of these three regulatory bodies are publicly progressing in a direction that is not aligned to this proposal. It is not the business of the W3C to help pick winners and losers on the web. This proposal in practice will favour larger businesses. Technically and now regulatorily it looks like a solution looking for a problem. It should be rejected by the W3C at this time. The full text of the EU document is available here. https://data.consilium.europa.eu/doc/document/ST-5979-2020-INIT/en/pdf |
|
Google yesterday recognise the stresses many businesses are already under and are doing their bit to reduce that burden by delaying enhancements to Chromium and Chrome. Here's the short update. "Due to adjusted work schedules at this time, we are pausing upcoming Chrome and Chrome OS releases. Our primary objectives are to ensure Chrome continues to be stable, secure, and work reliably for anyone who depends on them. We’ll continue to prioritize any updates related to security, which will be included in Chrome 80." |
|
@torgo for those that are following this issue please could you add a comment / link on the output from TAG review? There were may related comments concerning the issues associated with removing a standard interface discussed under the Scheme-bound Cookies proposal. Thank you. |
|
We see from this post from Yoav that the proposal has been put off until 2021 at the earliest. At the same time, Client Hints is progressing. We think this state of affairs could allow client hints to mature, both in terms of the spec, and in terms of the implementations and industry adoption. Right now we're going to close this issue to make way for other issues in our workload but we'll be happy to re-open when appropriate. |
|
FYI A pull request has been made on the WICG draft specification to add feedback from those who have used the experiments and considered the specification. |
Should this now be reopened in light of the updated roadmap from the Chromium team? |
|
@ronancremin looks like we will be reviewing in #640 rather than re-opening this issue. |
|
Ah, I had missed #640. That works. |
Goedenavond TAG!
This is not your typical spec review, and is highly related to #320. But, because @torgo asked nicely, I'm opening up a review for a specific application of UA-CH as a replacement for the
User-Agentstring.We've had a lot of feedback on the intent, which resulted in changes to the API we want to ship. It also resulted in many open issues. Most either have pending PRs or will have ones shortly.
The latest summary is:
User-Agentrequest header will be frozen other than its browser's significant version, and unified between different platforms and devices to reduce the amount of passive fingerprinting the browser is sending out by default.navigator.userAgentand friends will be similarly frozen.Sec-CH-UAandSec-CH-UA-Mobileheaders to enable most cases of content negotiation. As those headers are low-entropy, we can afford that trade-off, privacy-wise.Sec-CH-UAis defined as a set, and likely to be GREASEd to avoid current abuse patterns of the User-Agent string.Checkboxes:
Further details:
You should also know that...
[please tell us anything you think is relevant to this review]
We'd prefer the TAG provide feedback as (please delete all but the desired option):
🐛 open issues in our GitHub repo for each point of feedback
The text was updated successfully, but these errors were encountered: