We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
koa 框架是基于 Node.js 下一代的 web server 框架, 舍弃了回调写法, 提高了错误处理效率, 而且其不绑定任何中间件, 核心代码只提供优雅轻量的函数库. 平时经常使用到 koa 框架, 所以希望通过阅读源码学习其思想, 本文是基于 koa2 的源码进行分析.
koa 框架的源码结构非常简单, 在 lib 文件夹下, 只有 4 个文件, 分别是 application.js, context.js, request.js, response.js. 而 application.js 是 koa 框架的入口文件, context.js 的作用是创建网络请求的上下文对象, request.js 是用于包装 koa 的 request 对象的, response.js 则是用于包装 koa 的 response 对象的. 我们这里使用 koa 框架建立一个简单的 node 服务, 以此来逐步了解 koa 内部机理.
const koa = require('koa'); const app = new koa(); app.use(async (ctx, next) { ctx.body = 'Hello World'; }); app.listen(3000);
上面的代码, 先生成了一个 koa 对象, 然后通过使用 use 函数往 server 中添加中间件函数, 最后使用 listen 函数进行对 3000 端口的监听.
由上面的简单代码, 我们会有几个疑问: koa 对象中包含了些什么属性与方法? use 函数对于中间件函数的处理是怎么样的? listen 函数做了什么? 因此我们先来看一下 application.js 的源码:
application.js 暴露了一个 Application 类供我们使用, 也即是说, 我们 new 一个 koa 对象实质上就是新建一个 Application 的实例对象. 而 Application 类是继承 于 EventEmitter (Node.js events 模块)的, 所以我们在 koa 实例对象上可以使用 on, emit 等方法进行事件监听.
constructor() { super(); // 因为继承于 EventEmitter, 这里需要调用 super this.proxy = false; // 代理设置 this.middleware = []; this.subdomainOffset = 2; // 子域名偏移设置 this.env = process.env.NODE_ENV || 'development'; // node 环境变量 this.context = Object.create(context); this.request = Object.create(request); this.response = Object.create(response); }
可以看到在 constructor 函数中, 实例对象会初始化几个重要的属性, proxy 属性是代理设置, middleware 属性是中间件数组, 用于存储中间件函数的, subdomainOffset 属性是子域名偏移量 设置, env 属性保存 node 的环境变量 NODE_ENV 值, context, requets, response 则是 koa 自身的包装的 context 对象, request 对象, response 对象. 这里特别讲解一下 proxy 属性与 subdomainOffset 属性. proxy 属性值是 true 或者 false, 它的作用在于是否获取真正的客户端 ip 地址(详细请看附录的第一点). subdomainOffset 属性会改变获取 subdomain 时返回数组的值, 比如 test.page.example.com 域名, 如果设置 subdomainOffset 为 2, 那么返回的数组值为 ["page", "test"], 如果设置为 3, 那么返回数组值为 ["test"].
use 函数内部仅仅是对 generator 函数利用 koa-convert 库进行转化(将 generator 函数包装成 Promise), 如果不是则不转化, 然后将这个中间件函数 push 进实例对象的 middleware 数组中. 所以, 所谓中间件函数的串联其实就是通过数组来逐个执行的, 至于 koa 是怎么利用 koa-compose 建立起核心的中间件机制的, 这里按下不表, 详细请阅读本人的 理解 koa 中间件机制 博文.
listen 函数的原理其实很简单, 它实际上是一个缩写的函数, 它本质上就是在内部通过 Node 原生的 http 模块建立起一个 http server, 而这个 http server 的回调函数使用的是 koa 中的 callback 函数.
listen(...args) { debug('listen'); const server = http.createServer(this.callback()); return server.listen(...args); }
下面就来讲解一下核心的 callback 函数.
callback() { const fn = compose(this.middleware); // 使用 compose 建立中间件机制, 详情请看 http://zhangxiang958.github.io/2018/03/16/%E7%90%86%E8%A7%A3%20Koa%20%E7%9A%84%E4%B8%AD%E9%97%B4%E4%BB%B6%E6%9C%BA%E5%88%B6/ if (!this.listeners('error').length) this.on('error', this.onerror); // 如果没有对 error 事件进行监听, 那么绑定 error 事件监听处理 // handleRequest 函数相当于 http.creatServer 的回调函数, 有 req, res 两个参数, 代表原生的 request, response 对象. const handleRequest = (req, res) => { const ctx = this.createContext(req, res); // 每次接受一个新的请求就是生成一次全新的 context return this.handleRequest(ctx, fn); }; return handleRequest; } handleRequest(ctx, fnMiddleware) { const res = ctx.res; res.statusCode = 404; const onerror = err => ctx.onerror(err); // 错误处理 const handleResponse = () => respond(ctx); // 响应处理 onFinished(res, onerror); // 为 res 对象添加错误处理响应, 当 res 响应结束时, 执行 context 中的 onerror 函数(这里需要注意区分 context 与 koa 实例中的 onerror) return fnMiddleware(ctx).then(handleResponse).catch(onerror); // 执行中间件数组所有函数, 并结束时调用 respond 函数 }
对于 this.createContext 函数, 它的用于就是生成一个新的 context 对象并建立 koa 中 context, requets, response 属性之间与原生 http 对象的关系的.而 handleRequest 函数只是负责执行 中间件所有的函数, 并在中间件函数执行结束的时候调用 respond. 对于在 koa 中的 context 对象, request 对象, response 对象与 http 模块原生的 req 与 res 之间的关系我并不打算陈列代码, 下面我以图解的形式来帮助阅读:
对于 respond 函数, 其核心就是根据不同类型的数据对 http 的响应头部与响应体 body 做对应的处理.
function respond(ctx) { // allow bypassing koa if (false === ctx.respond) return; const res = ctx.res; // writable 是原生的 response 对象的 writeable 属性, 检查是否是可写流 if (!ctx.writable) return; let body = ctx.body; const code = ctx.status; // ignore body // 如果响应的 statusCode 是属于 body 为空的类型, 例如 204, 205, 304, 将 body 置为 null if (statuses.empty[code]) { // strip headers ctx.body = null; return res.end(); } // 如果是 HEAD 方法 if ('HEAD' == ctx.method) { // headersSent 属性 Node 原生的 response 对象上的, 用于检查 http 响应头部是否已经被发送 // 如果头部未被发送, 那么添加 length 头部 if (!res.headersSent && isJSON(body)) { ctx.length = Buffer.byteLength(JSON.stringify(body)); } return res.end(); } // status body // 如果 body 值为空 if (null == body) { // body 值为 context 中的 message 属性或 code body = ctx.message || String(code); // 修改头部的 type 与 length 属性 if (!res.headersSent) { ctx.type = 'text'; ctx.length = Buffer.byteLength(body); } return res.end(body); } // responses // 对 body 为 buffer 类型的进行处理 if (Buffer.isBuffer(body)) return res.end(body); // 对 body 为字符串类型的进行处理 if ('string' == typeof body) return res.end(body); // 对 body 为流形式的进行处理 if (body instanceof Stream) return body.pipe(res); // body: json // 对 body 为 json 格式的数据进行处理, 1: 将 body 转化为 json 字符串, 2: 添加 length 头部信息 body = JSON.stringify(body); if (!res.headersSent) { ctx.length = Buffer.byteLength(body); } res.end(body); }
在 respond 函数中, 主要是运用 node http 模块中的响应对象中的 end 方法与 koa context 对象中代理的属性进行最终响应对象的设置.
主要是对原生的 http 模块的 requets 对象进行封装, 其实就是对 request 对象某些属性或方法通过重写 getter/setter 函数进行代理, 请看下面的图进行更好的理解:
我们可以看到 request 中有很多 accept 相关的方法, 我们来看看 accept 相关的内容协商的知识: 所谓内容协商, 就是客户端向服务端请求文件, 返回符合某些标准的文件, 而除了服务端将所有版本的文件全部返回由 客户端来决定使用哪个版本这种比较浪费网络资源的方法之外, 我们还可以使用通过请求/响应头部进行交流并返回合适 版本的方法.
使用上面的头部字段就可以达到请求合适的文档类型.而对于客户端与服务端之间可能有多个实体, 比如 CDN, 缓存服务 器等等, 万一中间实体缓存了错误的文件版本, 那么后果就是客户端有可能无法正确地解析该文件.所以需要 vary 响应 头部字段, vary 字段的值类似于这样: vary: user-agent, location. vary 字段是告诉中间实体如何正确判断有效的 缓存文件版本, 比如像上面的值, 那就是利用请求的 user-agent, location 两个头部的字段生成的 hash, 如果再有请 求过来并且请求的 ua 与 location 头部字段生成的 hash 有缓存, 那么就返回对应的缓存文件.
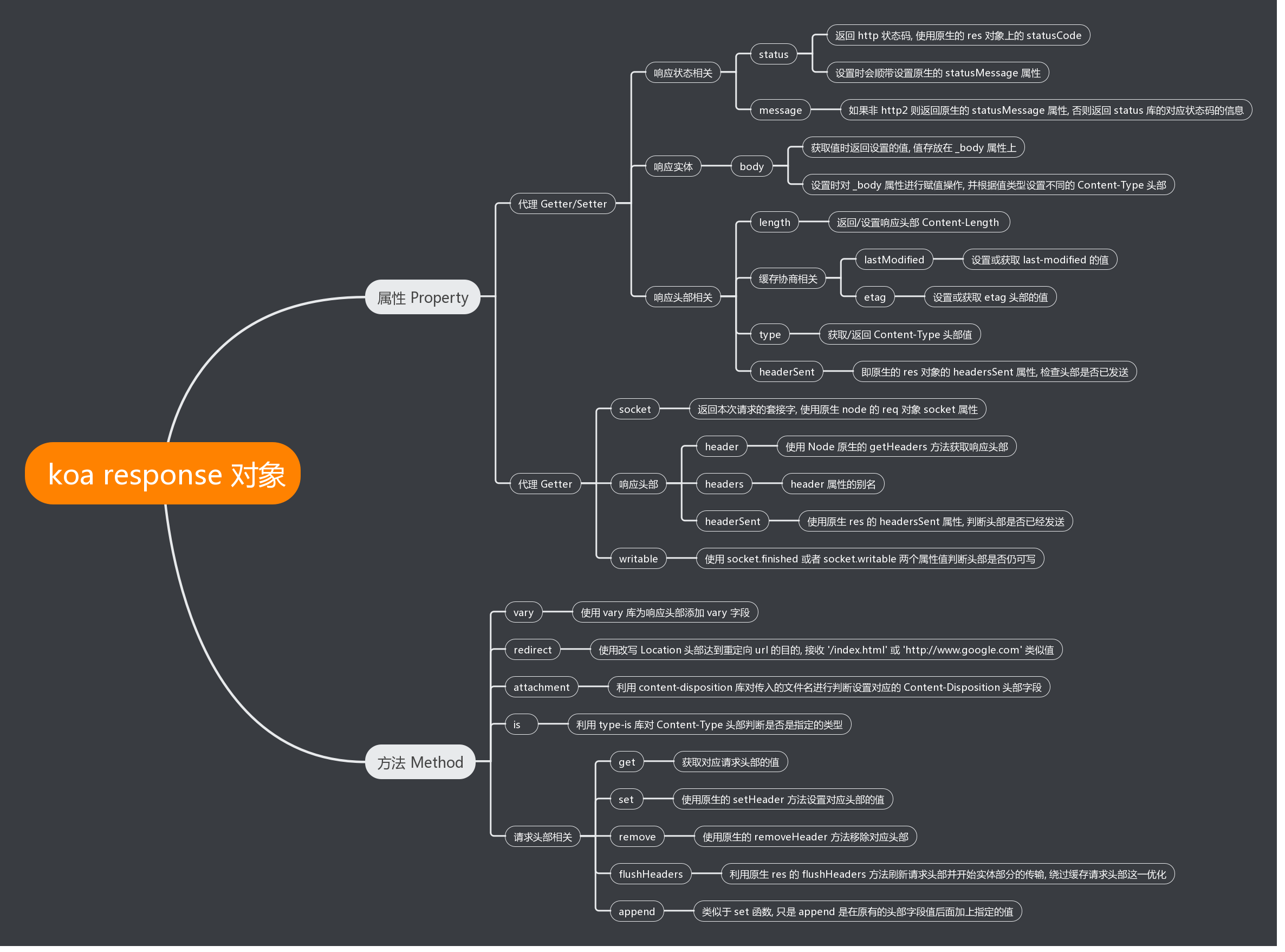
同样的, response 也是对 http 模块的 response 对象进行封装, 通过对 response 对象的某些属性或方法通过重写 getter/setter 函数进行代理, 请看下面的图帮助理解:
在 response 对象的 attachment 方法中, 我们可以看到对 HTTP 头部的 Content-disposition 字段进行了处理, 那么究竟 Content-disposition 字段是做什么用的? Content-disposition 是用于说明这个返回的信息是以什么形式展示的, 例如如果值为 inline, 那么就是以网页的一部分或者整个页面展示, 如果是 attachment 的话, 就是以下载附件的 形式展示:
Content-Disposition: inline; // 网页一部分或者整个网页展示 Content-Disposition: attachment; // 下载网页附件的形式 Content-Disposition: attachment, filename="xxx.ext"; // 还可以使用 filename 来指定文件名
当然, 在 Content-Type 为 multipart/form-data 格式中, Content-Disposition 也会发挥作用, 用于定义表单的键名:
Content-Type: multipart/form; boundry="boundry" --boundry Content-Disposition: form-data; name="field1" value --boundry Content-Disposition: form-data; name="field2" value
在 request 中使用 fresh 字段来判断这个请求需要的内容是否是最新的, 其原理也就是我们熟知的 http 缓存机制, 内部通过 fresh 这个库, 判断请求头部中的 if-modify-since 与 if-match-since 对比于响应头部中的 last-Modified 字段与 ETag 字段.当然, 在检查这两个字段之前, 还需要检查一下请求头部的 Cache-Control 头部, 如果 Cache-Control 头部 是 no-cache, 那么就代表请求信息必须是最新的, 如果不是 no-cache, 接着就需要判断上面说的两个字段.而 last-modified 与 ETag 的检查有没有优先顺序呢? 答案是有的. koa 中先检查 ETag 有没有过期, 手段是通过检查 if-match-since 字段与 Etag 字段是否相同, 然后会检查 last-modified 有没有过期, 手段是通过检查 if-modify-since 与 last-modified 的日期是不是 last-modified 日期时间戳小于 if-modified-since 日期时间戳, 如果是那么说明内容是新鲜的, 如果不是说明内容是旧的.
分析了上面的 request 与 response, context 的分析更为简单了, context 的核心就是通过 delegates 这一个库, 将 request, response 对象上的属性方法代理到 context 对象上. 也就是说例如 this.ctx.headersSent 相当于 this.response.headersSent. request 对象与 response 对象的所有方法与属性都能在 ctx 对象上找到. 这里我们来看一下 delegates 库 的属性代理函数的片段, 借此理解一下 context 是如何代理 request 与 response 上的属性与方法的:
delegate(proto, 'response') .getter('headerSent');
Delegator.prototype.getter = function(name){ // this.proto 指向原型, 这里的 proto 就是上面的 proto, 也就是说 context 对象 var proto = this.proto; // target 是指 'response' 字符串 var target = this.target; // 将 name 加入到 delegator 实例对象的 getters 数组中 this.getters.push(name); // 调用原生的 __defineGetter__ 方法进行 getter 代理, 那么 proto[name] 就相当于 proto[target][name] // 而 context.response 就相当于 response 对象 // 由此实现属性代理 proto.__defineGetter__(name, function(){ return this[target][name]; }); return this; };
在 koa 中, 错误处理分为在 application.js 中的 onerror 处理函数与在 context.js 中的 onerror 处理函数.这两者绑定的位置是不一样的, context 的 onerror 函数是绑定在 中间函数数组生成的 Promise 的 catch 中与 res 对象的 onFinished 函数的回调的, 这里的意图显而易见, 就是为了处理请求或响应中出现的 error 事件的. 而 application.js 中的 onerror 函数是绑定在 koa 实例对象上的, 它监听的是整个对象的 error 事件.
onerror(err) { // don't do anything if there is no error. // this allows you to pass `this.onerror` // to node-style callbacks. // 没有错误则忽略, 不执行下面的逻辑 if (null == err) return; // 将错误转化为 Error 实例 if (!(err instanceof Error)) err = new Error(util.format('non-error thrown: %j', err)); let headerSent = false; if (this.headerSent || !this.writable) { headerSent = err.headerSent = true; } // delegate // 触发 koa 实例对象的 error 事件, application 上的 onerror 函数会执行 this.app.emit('error', err, this); // nothing we can do here other // than delegate to the app-level // handler and log. // 如果响应头部已经发送(或者 socket 不可写), 那么退出函数 if (headerSent) { return; } // 获取 http 原生 res 对象 const { res } = this; // first unset all headers // 根据文档 res.getHeaderNames 函数是 7.7.0 版本后添加的, 这里为了兼容做了一个判断 // 如果出错那么之前中间件或者其他地方设置的 HTTP 头部就无效了, 应该清空设置 if (typeof res.getHeaderNames === 'function') { res.getHeaderNames().forEach(name => res.removeHeader(name)); } else { res._headers = {}; // Node < 7.7 } // then set those specified this.set(err.headers); // force text/plain // 出错后响应类型为 text/plain this.type = 'text'; // ENOENT support // 对 ENOENT 错误进行处理, ENOENT 的错误 message 是文件或者路径不存在, 所以状态码应该是 404 if ('ENOENT' == err.code) err.status = 404; // default to 500 // 默认设置状态码为 500 if ('number' != typeof err.status || !statuses[err.status]) err.status = 500; // respond const code = statuses[err.status]; const msg = err.expose ? err.message : code; // 设置响应状态码 this.status = err.status; // 设置响应 body 长度 this.length = Buffer.byteLength(msg); // 返回 message this.res.end(msg); }
application 中的错误处理是对 koa 实例对象中例如函数执行出错等等内部错误进行处理.
onerror(err) { // 判断 err 是否是 Error 实例 assert(err instanceof Error, `non-error thrown: ${err}`); // 忽略 404 错误 if (404 == err.status || err.expose) return; // 如果有静默设置, 则忽略 if (this.silent) return; // 打印出出错堆栈 const msg = err.stack || err.toString(); console.error(); console.error(msg.replace(/^/gm, ' ')); console.error(); }
这个函数的主要作用就是处理出错函数的堆栈打印, 方便我们进行问题定位.
要知道, 我们在实际运用中, 可能会使用很多的代理服务器, 包括我们常见的正向代理与反向代理, 虽然代理的用处很大, 但是无法避免地我们有时需要知晓真正的客户端的请求 ip, 而其实实际上, 服务器并不知道真正的客户端请求 ip, 即使你使用 socket.remoteAddrss 属性来查看, 因为这个请求是代理服务器转发给服务器的, 幸好代理服务器例如 nginx 提供了一个 HTTP 头部来记录每次代理服务器的源 IP 地址, 也就是 X-Forwarded-For 头部.形式如下:
X-Forwarded-For: 192.168.210.13, 210.112.40.13, 43.56.210.10
如果一个请求跳转了很多代理服务器, 那么 X-Forwarded-For 头部的 ip 地址就会越多, 第一个就是原始的客户端请求 ip, 第二个就是第一个代理服务器 ip, 以此类推. 当然, X-Forwarded-For 并不完全可信, 因为中间的代理服务器可能会"使坏"更改某些 IP. 而 koa 中 proxy 属性的设置就是如果使用 true, 那么就是使用 X-Forwarded-For 头部的第一个 ip 地址, 如果使用 false, 则使用 server 中的 socket.remoteAddress 属性值. 除了 X-Forwarded-For 之外, proxy 还会影响 X-Forwarded-proto 的使用, 和 X-Forwarded-For 一样, X-Forwarded-proto 记录最开始的请求连接使用的协议类型(HTTP/HTTPS), 因为客户端与 服务端之间可能会存在很多层代理服务器, 而代理服务器与服务端之间可能只是使用 HTTP 协议, 并没有使用 HTTPS, 所以 proxy 属性为 true 的话, koa 的 protocol 属性会去取 X-Forwarded-proto 头部 的值(koa 中 protocol 属性会先使用 tlsSocket.encrypted 属性来判断是否是 https 协议, 如果是则直接返回 'https').
~ 运算符是一元运算符, 它的运算逻辑是如下: 例如计算 ~1
1. 将十进制的 1 转化为二进制的 0001 2. 先对 0001 按位取反: 1110 3. 然后我们知道最高位为 1, 所以数字为负数, 然后将除去最高位剩下的三位数字再按位取反得到 001 4. 然后再向 001 加 1 即 001 + 001 得到 010, 转为十进制为数字 2 5. 再加上我们之前最高位为 1, 所以最后数字为负数即 -2 6. 所以 ~1 === -2
用简略的表达式来说明就是 ~ X = -(X + 1).而我们可以看到在 koa 中, length 返回的结果使用了 ~~length 这样的形式, 两次二进制否运算, 这样的目的是为了值得安全输出, 如果 ~ 运算符后面的值 是 NaN, null, 空字符串, 空数组, 非数字字符串的话, 返回值为 -1, 而对于小数, ~ 运算符会向下取整.其实对于小数, ~ 运算会选择忽略小数部分, 对于非整数的值会先执行 Number 类型转化. 所以两次二进制否运算 ~~, 可以使小数向下取整, 让非整数值输出为 0(~-1 === 0).
细心阅读源码会发现, 在 koa 中设置响应的 length 头部信息, 并不是使用字符串的 length 属性来设置的, 而是通过 Buffer.byteLength 方法来计算得到的. 为什么要这么做呢? HTTP Content-length 头部的数值其实是字节数而不是字符数, 对于汉字来说, utf-8 编码模式下一个汉字字符需要 3 个字节, 所以不能使用字符串的 length 属性来赋值 Content-Length 头部.
我们可以在 request 对象中找到, 有 idempotent 属性, 它用于判断请求方法 verb 是不是幂等的. 所谓幂等性, 就是无论这个相同的请求请求多少次, 得到的数据结果是一样的. 而在 HTTP 的方法中, GET, HEAD, PUT, DELETE, TRACK, OPTIONS 请求都是幂等的. 对于 POST 与 PATCH 方法则是不幂等的. 这里特别讲解一下 PUT 的含义, PUT 的定义是 Replace(create or update), 如果存在那么就替换, 如果不存在那么就新增数据.
The text was updated successfully, but these errors were encountered:
No branches or pull requests
koa 框架是基于 Node.js 下一代的 web server 框架, 舍弃了回调写法, 提高了错误处理效率, 而且其不绑定任何中间件, 核心代码只提供优雅轻量的函数库.
平时经常使用到 koa 框架, 所以希望通过阅读源码学习其思想, 本文是基于 koa2 的源码进行分析.
koa 整体架构
koa 框架的源码结构非常简单, 在 lib 文件夹下, 只有 4 个文件, 分别是 application.js, context.js, request.js, response.js.
而 application.js 是 koa 框架的入口文件, context.js 的作用是创建网络请求的上下文对象, request.js 是用于包装 koa 的 request 对象的, response.js
则是用于包装 koa 的 response 对象的. 我们这里使用 koa 框架建立一个简单的 node 服务, 以此来逐步了解 koa 内部机理.
上面的代码, 先生成了一个 koa 对象, 然后通过使用 use 函数往 server 中添加中间件函数, 最后使用 listen 函数进行对 3000 端口的监听.
koa 源码剖析
由上面的简单代码, 我们会有几个疑问: koa 对象中包含了些什么属性与方法? use 函数对于中间件函数的处理是怎么样的? listen 函数做了什么?
因此我们先来看一下 application.js 的源码:
application.js
application.js 暴露了一个 Application 类供我们使用, 也即是说, 我们 new 一个 koa 对象实质上就是新建一个 Application 的实例对象. 而 Application 类是继承
于 EventEmitter (Node.js events 模块)的, 所以我们在 koa 实例对象上可以使用 on, emit 等方法进行事件监听.
生成 application 对象
可以看到在 constructor 函数中, 实例对象会初始化几个重要的属性, proxy 属性是代理设置, middleware 属性是中间件数组, 用于存储中间件函数的, subdomainOffset 属性是子域名偏移量
设置, env 属性保存 node 的环境变量 NODE_ENV 值, context, requets, response 则是 koa 自身的包装的 context 对象, request 对象, response 对象. 这里特别讲解一下 proxy 属性与
subdomainOffset 属性. proxy 属性值是 true 或者 false, 它的作用在于是否获取真正的客户端 ip 地址(详细请看附录的第一点). subdomainOffset 属性会改变获取 subdomain 时返回数组的值,
比如 test.page.example.com 域名, 如果设置 subdomainOffset 为 2, 那么返回的数组值为 ["page", "test"], 如果设置为 3, 那么返回数组值为 ["test"].
use 与中间件
use 函数内部仅仅是对 generator 函数利用 koa-convert 库进行转化(将 generator 函数包装成 Promise), 如果不是则不转化, 然后将这个中间件函数 push 进实例对象的 middleware 数组中.
所以, 所谓中间件函数的串联其实就是通过数组来逐个执行的, 至于 koa 是怎么利用 koa-compose 建立起核心的中间件机制的, 这里按下不表, 详细请阅读本人的 理解 koa 中间件机制 博文.
listen 原理
listen 函数的原理其实很简单, 它实际上是一个缩写的函数, 它本质上就是在内部通过 Node 原生的 http 模块建立起一个 http server, 而这个 http server 的回调函数使用的是 koa 中的 callback 函数.
下面就来讲解一下核心的 callback 函数.
对于 this.createContext 函数, 它的用于就是生成一个新的 context 对象并建立 koa 中 context, requets, response 属性之间与原生 http 对象的关系的.而 handleRequest 函数只是负责执行
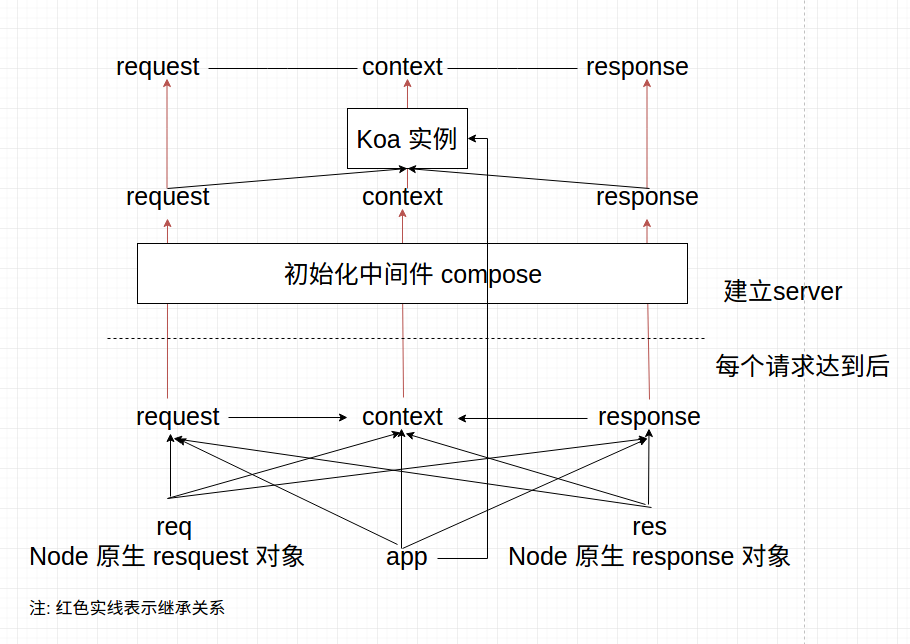
中间件所有的函数, 并在中间件函数执行结束的时候调用 respond.
对于在 koa 中的 context 对象, request 对象, response 对象与 http 模块原生的 req 与 res 之间的关系我并不打算陈列代码, 下面我以图解的形式来帮助阅读:
对请求的响应处理 respond
对于 respond 函数, 其核心就是根据不同类型的数据对 http 的响应头部与响应体 body 做对应的处理.
在 respond 函数中, 主要是运用 node http 模块中的响应对象中的 end 方法与 koa context 对象中代理的属性进行最终响应对象的设置.
request.js
主要是对原生的 http 模块的 requets 对象进行封装, 其实就是对 request 对象某些属性或方法通过重写 getter/setter 函数进行代理, 请看下面的图进行更好的理解:

内容协商
我们可以看到 request 中有很多 accept 相关的方法, 我们来看看 accept 相关的内容协商的知识:
所谓内容协商, 就是客户端向服务端请求文件, 返回符合某些标准的文件, 而除了服务端将所有版本的文件全部返回由
客户端来决定使用哪个版本这种比较浪费网络资源的方法之外, 我们还可以使用通过请求/响应头部进行交流并返回合适
版本的方法.
使用上面的头部字段就可以达到请求合适的文档类型.而对于客户端与服务端之间可能有多个实体, 比如 CDN, 缓存服务
器等等, 万一中间实体缓存了错误的文件版本, 那么后果就是客户端有可能无法正确地解析该文件.所以需要 vary 响应
头部字段, vary 字段的值类似于这样: vary: user-agent, location. vary 字段是告诉中间实体如何正确判断有效的
缓存文件版本, 比如像上面的值, 那就是利用请求的 user-agent, location 两个头部的字段生成的 hash, 如果再有请
求过来并且请求的 ua 与 location 头部字段生成的 hash 有缓存, 那么就返回对应的缓存文件.
response.js
同样的, response 也是对 http 模块的 response 对象进行封装, 通过对 response 对象的某些属性或方法通过重写 getter/setter 函数进行代理, 请看下面的图帮助理解:
Content-disposition
在 response 对象的 attachment 方法中, 我们可以看到对 HTTP 头部的 Content-disposition 字段进行了处理, 那么究竟 Content-disposition 字段是做什么用的?
Content-disposition 是用于说明这个返回的信息是以什么形式展示的, 例如如果值为 inline, 那么就是以网页的一部分或者整个页面展示, 如果是 attachment 的话, 就是以下载附件的
形式展示:
当然, 在 Content-Type 为 multipart/form-data 格式中, Content-Disposition 也会发挥作用, 用于定义表单的键名:
缓存协商
在 request 中使用 fresh 字段来判断这个请求需要的内容是否是最新的, 其原理也就是我们熟知的 http 缓存机制, 内部通过 fresh 这个库, 判断请求头部中的 if-modify-since 与
if-match-since 对比于响应头部中的 last-Modified 字段与 ETag 字段.当然, 在检查这两个字段之前, 还需要检查一下请求头部的 Cache-Control 头部, 如果 Cache-Control 头部
是 no-cache, 那么就代表请求信息必须是最新的, 如果不是 no-cache, 接着就需要判断上面说的两个字段.而 last-modified 与 ETag 的检查有没有优先顺序呢? 答案是有的.
koa 中先检查 ETag 有没有过期, 手段是通过检查 if-match-since 字段与 Etag 字段是否相同, 然后会检查 last-modified 有没有过期, 手段是通过检查 if-modify-since 与 last-modified
的日期是不是 last-modified 日期时间戳小于 if-modified-since 日期时间戳, 如果是那么说明内容是新鲜的, 如果不是说明内容是旧的.
context.js
分析了上面的 request 与 response, context 的分析更为简单了, context 的核心就是通过 delegates 这一个库, 将 request, response 对象上的属性方法代理到 context 对象上.
也就是说例如 this.ctx.headersSent 相当于 this.response.headersSent. request 对象与 response 对象的所有方法与属性都能在 ctx 对象上找到. 这里我们来看一下 delegates 库
的属性代理函数的片段, 借此理解一下 context 是如何代理 request 与 response 上的属性与方法的:
错误处理
在 koa 中, 错误处理分为在 application.js 中的 onerror 处理函数与在 context.js 中的 onerror 处理函数.这两者绑定的位置是不一样的, context 的 onerror 函数是绑定在
中间函数数组生成的 Promise 的 catch 中与 res 对象的 onFinished 函数的回调的, 这里的意图显而易见, 就是为了处理请求或响应中出现的 error 事件的.
而 application.js 中的 onerror 函数是绑定在 koa 实例对象上的, 它监听的是整个对象的 error 事件.
context 中的错误处理
application 中的错误处理
application 中的错误处理是对 koa 实例对象中例如函数执行出错等等内部错误进行处理.
这个函数的主要作用就是处理出错函数的堆栈打印, 方便我们进行问题定位.
附录
1. koa 中 proxy 属性真正用途是什么?
要知道, 我们在实际运用中, 可能会使用很多的代理服务器, 包括我们常见的正向代理与反向代理, 虽然代理的用处很大, 但是无法避免地我们有时需要知晓真正的客户端的请求 ip,
而其实实际上, 服务器并不知道真正的客户端请求 ip, 即使你使用 socket.remoteAddrss 属性来查看, 因为这个请求是代理服务器转发给服务器的, 幸好代理服务器例如 nginx 提供了一个
HTTP 头部来记录每次代理服务器的源 IP 地址, 也就是 X-Forwarded-For 头部.形式如下:
如果一个请求跳转了很多代理服务器, 那么 X-Forwarded-For 头部的 ip 地址就会越多, 第一个就是原始的客户端请求 ip, 第二个就是第一个代理服务器 ip, 以此类推.
当然, X-Forwarded-For 并不完全可信, 因为中间的代理服务器可能会"使坏"更改某些 IP. 而 koa 中 proxy 属性的设置就是如果使用 true, 那么就是使用 X-Forwarded-For 头部的第一个
ip 地址, 如果使用 false, 则使用 server 中的 socket.remoteAddress 属性值.
除了 X-Forwarded-For 之外, proxy 还会影响 X-Forwarded-proto 的使用, 和 X-Forwarded-For 一样, X-Forwarded-proto 记录最开始的请求连接使用的协议类型(HTTP/HTTPS), 因为客户端与
服务端之间可能会存在很多层代理服务器, 而代理服务器与服务端之间可能只是使用 HTTP 协议, 并没有使用 HTTPS, 所以 proxy 属性为 true 的话, koa 的 protocol 属性会去取 X-Forwarded-proto 头部
的值(koa 中 protocol 属性会先使用 tlsSocket.encrypted 属性来判断是否是 https 协议, 如果是则直接返回 'https').
2. javascript 中的 ~ 运算符
~ 运算符是一元运算符, 它的运算逻辑是如下: 例如计算 ~1
用简略的表达式来说明就是 ~ X = -(X + 1).而我们可以看到在 koa 中, length 返回的结果使用了 ~~length 这样的形式, 两次二进制否运算, 这样的目的是为了值得安全输出, 如果 ~ 运算符后面的值
是 NaN, null, 空字符串, 空数组, 非数字字符串的话, 返回值为 -1, 而对于小数, ~ 运算符会向下取整.其实对于小数, ~ 运算会选择忽略小数部分, 对于非整数的值会先执行 Number 类型转化.
所以两次二进制否运算 ~~, 可以使小数向下取整, 让非整数值输出为 0(~-1 === 0).
3. Buffer.byteLength 计算长度
细心阅读源码会发现, 在 koa 中设置响应的 length 头部信息, 并不是使用字符串的 length 属性来设置的, 而是通过 Buffer.byteLength 方法来计算得到的. 为什么要这么做呢?
HTTP Content-length 头部的数值其实是字节数而不是字符数, 对于汉字来说, utf-8 编码模式下一个汉字字符需要 3 个字节, 所以不能使用字符串的 length 属性来赋值 Content-Length 头部.
4. Restful 中的幂等性
我们可以在 request 对象中找到, 有 idempotent 属性, 它用于判断请求方法 verb 是不是幂等的. 所谓幂等性, 就是无论这个相同的请求请求多少次, 得到的数据结果是一样的. 而在 HTTP 的方法中,
GET, HEAD, PUT, DELETE, TRACK, OPTIONS 请求都是幂等的. 对于 POST 与 PATCH 方法则是不幂等的.
这里特别讲解一下 PUT 的含义, PUT 的定义是 Replace(create or update), 如果存在那么就替换, 如果不存在那么就新增数据.
The text was updated successfully, but these errors were encountered: